mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
Merge pull request #419 from langgenius/code-fix-prompt-optimize-new
Code fix prompt optimize new
This commit is contained in:
@@ -1,14 +1,13 @@
|
||||
---
|
||||
title: Code Execution
|
||||
title: "Code Execution"
|
||||
---
|
||||
|
||||
|
||||
## Table of Contents
|
||||
|
||||
* [Introduction](#introduction)
|
||||
* [Usage Scenarios](#usage-scenarios)
|
||||
* [Local Deployment](#local-deployment)
|
||||
* [Security Policies](#security-policies)
|
||||
- [Introduction](#introduction)
|
||||
- [Usage Scenarios](#usage-scenarios)
|
||||
- [Local Deployment](#local-deployment)
|
||||
- [Security Policies](#security-policies)
|
||||
|
||||
## Introduction
|
||||
|
||||
@@ -16,7 +15,10 @@ The code node supports running Python/NodeJS code to perform data transformation
|
||||
|
||||
This node significantly enhances the flexibility for developers, allowing them to embed custom Python or JavaScript scripts within the workflow and manipulate variables in ways that preset nodes cannot achieve. Through configuration options, you can specify the required input and output variables and write the corresponding execution code:
|
||||
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/9969aa1bc1912aebe366f5d8f5dde296.png" width="400"/>
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/9969aa1bc1912aebe366f5d8f5dde296.png"
|
||||
width="400"
|
||||
/>
|
||||
|
||||
## Configuration
|
||||
|
||||
@@ -113,20 +115,59 @@ def main() -> dict:
|
||||
|
||||
This code snippet has the following issues:
|
||||
|
||||
* **Unauthorized file access:** The code attempts to read the "/etc/passwd" file, which is a critical system file in Unix/Linux systems that stores user account information.
|
||||
* **Sensitive information disclosure:** The "/etc/passwd" file contains important information about system users, such as usernames, user IDs, group IDs, home directory paths, etc. Direct access could lead to information leakage.
|
||||
- **Unauthorized file access:** The code attempts to read the "/etc/passwd" file, which is a critical system file in Unix/Linux systems that stores user account information.
|
||||
- **Sensitive information disclosure:** The "/etc/passwd" file contains important information about system users, such as usernames, user IDs, group IDs, home directory paths, etc. Direct access could lead to information leakage.
|
||||
|
||||
Dangerous code will be automatically blocked by Cloudflare WAF. You can check if it's been blocked by looking at the "Network" tab in your browser's "Web Developer Tools".
|
||||
|
||||
|
||||
|
||||
The **Code Fix** feature enables **automatic code correction** by leveraging the previous run’s `current_code` and `error_message` variables.
|
||||
|
||||
# When a Code Node fails:
|
||||
|
||||
- The system captures the code and error message.
|
||||
- These are passed into the prompt as context variables.
|
||||
- A new version of the code is generated for review and retry.
|
||||
|
||||
**Configuration:**
|
||||
|
||||
1. **Write Repair Prompt**:
|
||||
|
||||
In the prompt editor, use the variable insertion menu (`/` or `{`) to insert variables. You may customize a prompt like:
|
||||
|
||||
`Fix the following code based on this error message: Code: {{current_code}} Error: {{error_message}}`
|
||||
|
||||

|
||||
|
||||
2. **Using Context Variables (if needed later in workflow)**
|
||||
|
||||
To enable automatic code repair, reference the following **context variables** in your prompt:
|
||||
|
||||
- `{{current_code}}`: The code from the last run of this node.
|
||||
- `{{error_message}}`: The error message if the last run failed.
|
||||
|
||||
You can also reference output variables from any predecessor nodes.
|
||||
|
||||
These variables are automatically available when the Code Node is run and allow the model to use prior run information for iterative correction.
|
||||
|
||||
3. **Use Version Management**:
|
||||
1. Each correction attempt is saved as a separate version (e.g., Version 1, Version 2).
|
||||
2. Users can **switch between versions** via the dropdown in the result display area.
|
||||
|
||||
**Notes:**
|
||||
|
||||
- `error_message` is empty if the last run succeeds.
|
||||
- `last_run` can be used to reference previous input/output.
|
||||
|
||||
This reduces manual copy-paste and allows iterative debugging directly within the workflow.
|
||||
|
||||
---
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/workflow/node/code.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: LLM
|
||||
title: "LLM"
|
||||
---
|
||||
|
||||
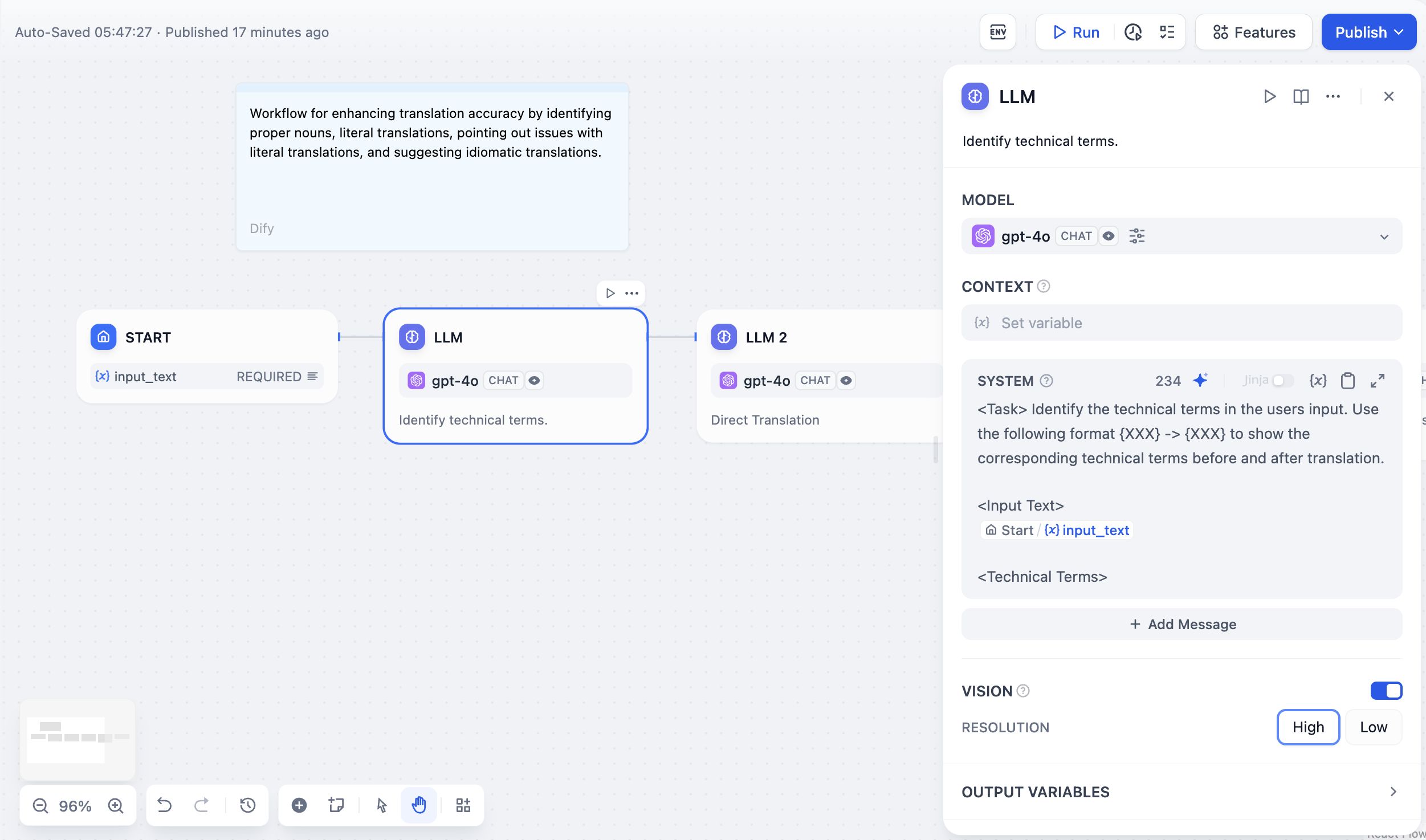
### Definition
|
||||
@@ -8,24 +8,24 @@ Invokes the capabilities of large language models to process information input b
|
||||
|
||||
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
### Scenarios
|
||||
|
||||
LLM is the core node of Chatflow/Workflow, utilizing the conversational/generative/classification/processing capabilities of large language models to handle a wide range of tasks based on given prompts and can be used in different stages of workflows.
|
||||
|
||||
* **Intent Recognition**: In customer service scenarios, identifying and classifying user inquiries to guide downstream processes.
|
||||
* **Text Generation**: In content creation scenarios, generating relevant text based on themes and keywords.
|
||||
* **Content Classification**: In email batch processing scenarios, automatically categorizing emails, such as inquiries/complaints/spam.
|
||||
* **Text Conversion**: In translation scenarios, translating user-provided text into a specified language.
|
||||
* **Code Generation**: In programming assistance scenarios, generating specific business code or writing test cases based on user requirements.
|
||||
* **RAG**: In knowledge base Q\&A scenarios, reorganizing retrieved relevant knowledge to respond to user questions.
|
||||
* **Image Understanding**: Using multimodal models with vision capabilities to understand and answer questions about the information within images.
|
||||
* **File Analysis**: In file processing scenarios, use LLMs to recognize and analyze the information contained within files.
|
||||
- **Intent Recognition**: In customer service scenarios, identifying and classifying user inquiries to guide downstream processes.
|
||||
- **Text Generation**: In content creation scenarios, generating relevant text based on themes and keywords.
|
||||
- **Content Classification**: In email batch processing scenarios, automatically categorizing emails, such as inquiries/complaints/spam.
|
||||
- **Text Conversion**: In translation scenarios, translating user-provided text into a specified language.
|
||||
- **Code Generation**: In programming assistance scenarios, generating specific business code or writing test cases based on user requirements.
|
||||
- **RAG**: In knowledge base Q&A scenarios, reorganizing retrieved relevant knowledge to respond to user questions.
|
||||
- **Image Understanding**: Using multimodal models with vision capabilities to understand and answer questions about the information within images.
|
||||
- **File Analysis**: In file processing scenarios, use LLMs to recognize and analyze the information contained within files.
|
||||
|
||||
By selecting the appropriate model and writing prompts, you can build powerful and reliable solutions within Chatflow/Workflow.
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
### How to Configure
|
||||
|
||||
@@ -39,7 +39,7 @@ By selecting the appropriate model and writing prompts, you can build powerful a
|
||||
4. **Advanced Settings**: You can enable memory, set memory windows, and use the Jinja-2 template language for more complex prompts.
|
||||
|
||||
<Info>
|
||||
If you are using Dify for the first time, you need to complete the [model configuration](/en/guides/model-configuration) in **System Settings-Model Providers** before selecting a model in the LLM node.
|
||||
If you are using Dify for the first time, you need to complete the [model configuration](/en/guides/model-configuration) in **System Settings-Model Providers** before selecting a model in the LLM node.
|
||||
</Info>
|
||||
|
||||
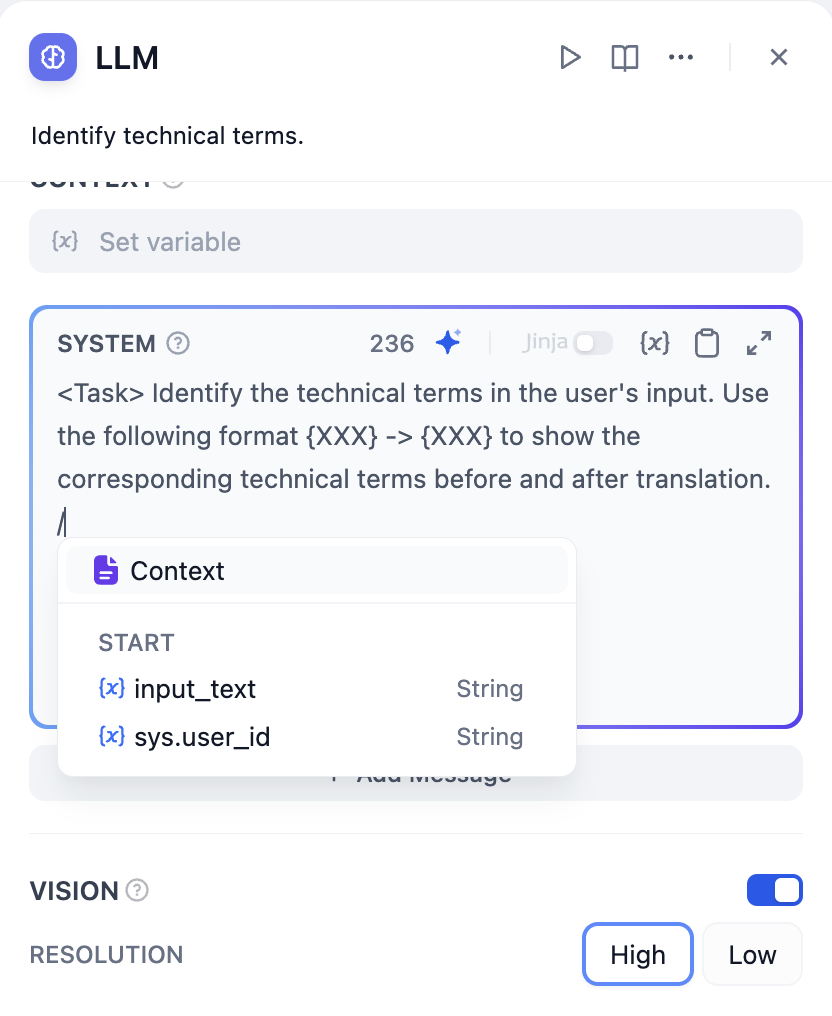
#### **Writing Prompts**
|
||||
@@ -56,7 +56,7 @@ In the prompt editor, you can call out the **variable insertion menu** by typing
|
||||
|
||||
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
### Explanation of Special Variables
|
||||
|
||||
@@ -66,12 +66,12 @@ Context variables are a special type of variable defined within the LLM node, us
|
||||
|
||||

|
||||
|
||||
In common knowledge base Q\&A applications, the downstream node of knowledge retrieval is typically the LLM node. The **output variable** `result` of knowledge retrieval needs to be configured in the **context variable** within the LLM node for association and assignment. After association, inserting the **context variable** at the appropriate position in the prompt can incorporate the externally retrieved knowledge into the prompt.
|
||||
In common knowledge base Q&A applications, the downstream node of knowledge retrieval is typically the LLM node. The **output variable** `result` of knowledge retrieval needs to be configured in the **context variable** within the LLM node for association and assignment. After association, inserting the **context variable** at the appropriate position in the prompt can incorporate the externally retrieved knowledge into the prompt.
|
||||
|
||||
This variable can be used not only as external knowledge introduced into the prompt context for LLM responses but also supports the application's [citation and attribution](/en/guides/knowledge-base/retrieval-test-and-citation#id-2-citation-and-attribution) feature due to its data structure containing segment reference information.
|
||||
|
||||
<Info>
|
||||
If the context variable is associated with a common variable from an upstream node, such as a string type variable from the start node, the context variable can still be used as external knowledge, but the **citation and attribution** feature will be disabled.
|
||||
If the context variable is associated with a common variable from an upstream node, such as a string type variable from the start node, the context variable can still be used as external knowledge, but the **citation and attribution** feature will be disabled.
|
||||
</Info>
|
||||
|
||||
**File Variables**
|
||||
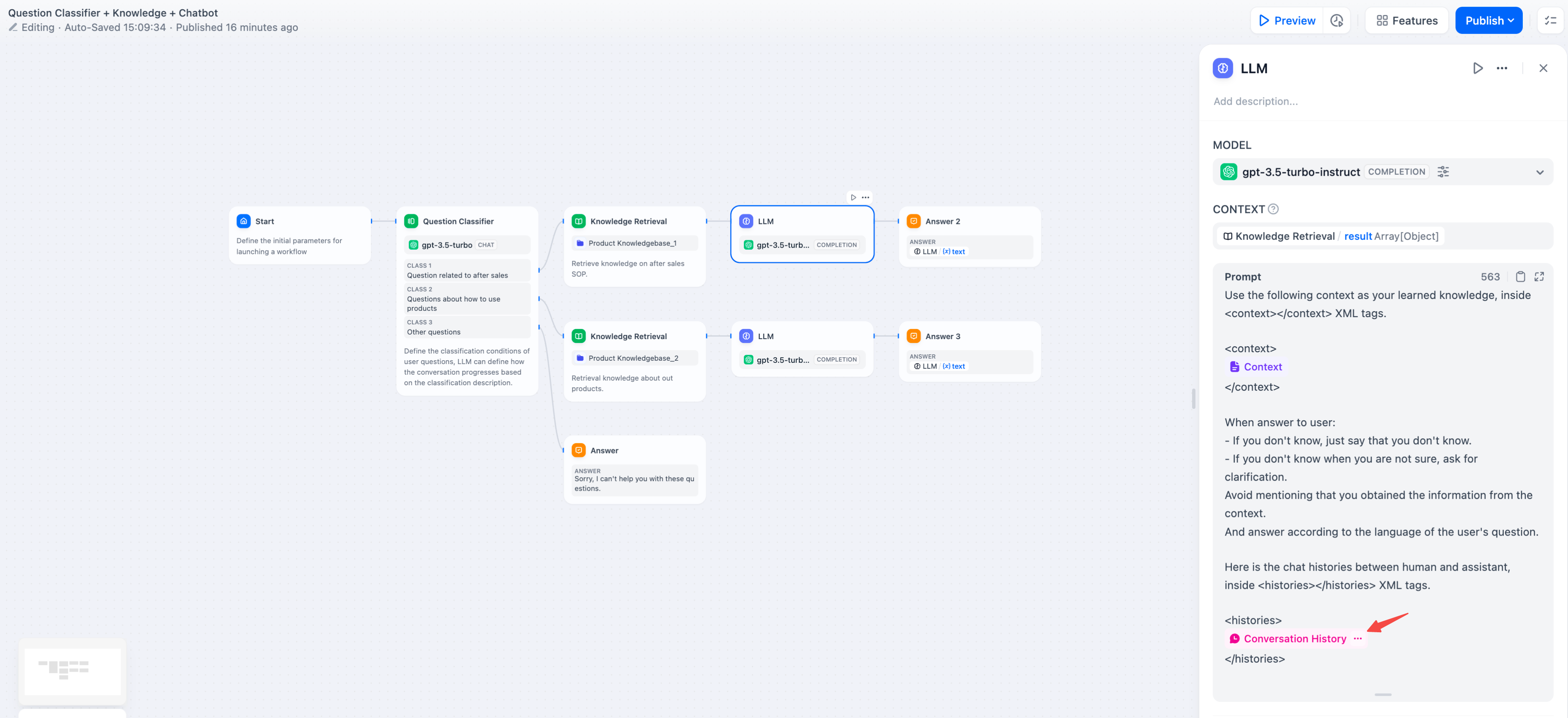
@@ -87,7 +87,7 @@ Some LLMs, such as [Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-
|
||||
To achieve conversational memory in text completion models (e.g., gpt-3.5-turbo-Instruct), Dify designed the conversation history variable in the original [Prompt Expert Mode (discontinued)](/en/learn-more/extended-reading/prompt-engineering/prompt-engineering-1). This variable is carried over to the LLM node in Chatflow, used to insert chat history between the AI and the user into the prompt, helping the LLM understand the context of the conversation.
|
||||
|
||||
<Info>
|
||||
The conversation history variable is not widely used and can only be inserted when selecting text completion models in Chatflow.
|
||||
The conversation history variable is not widely used and can only be inserted when selecting text completion models in Chatflow.
|
||||
</Info>
|
||||
|
||||
|
||||
@@ -110,9 +110,12 @@ The main parameter terms are explained as follows:
|
||||
|
||||
If you do not understand what these parameters are, you can choose to load presets and select from the three presets: Creative, Balanced, and Precise.
|
||||
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/b913f9cdf1f9b03e791a49836bc770dd.png" width="400" />
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/b913f9cdf1f9b03e791a49836bc770dd.png"
|
||||
width="400"
|
||||
/>
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
### Advanced Features
|
||||
|
||||
@@ -136,188 +139,174 @@ If you do not understand what these parameters are, you can choose to load prese
|
||||
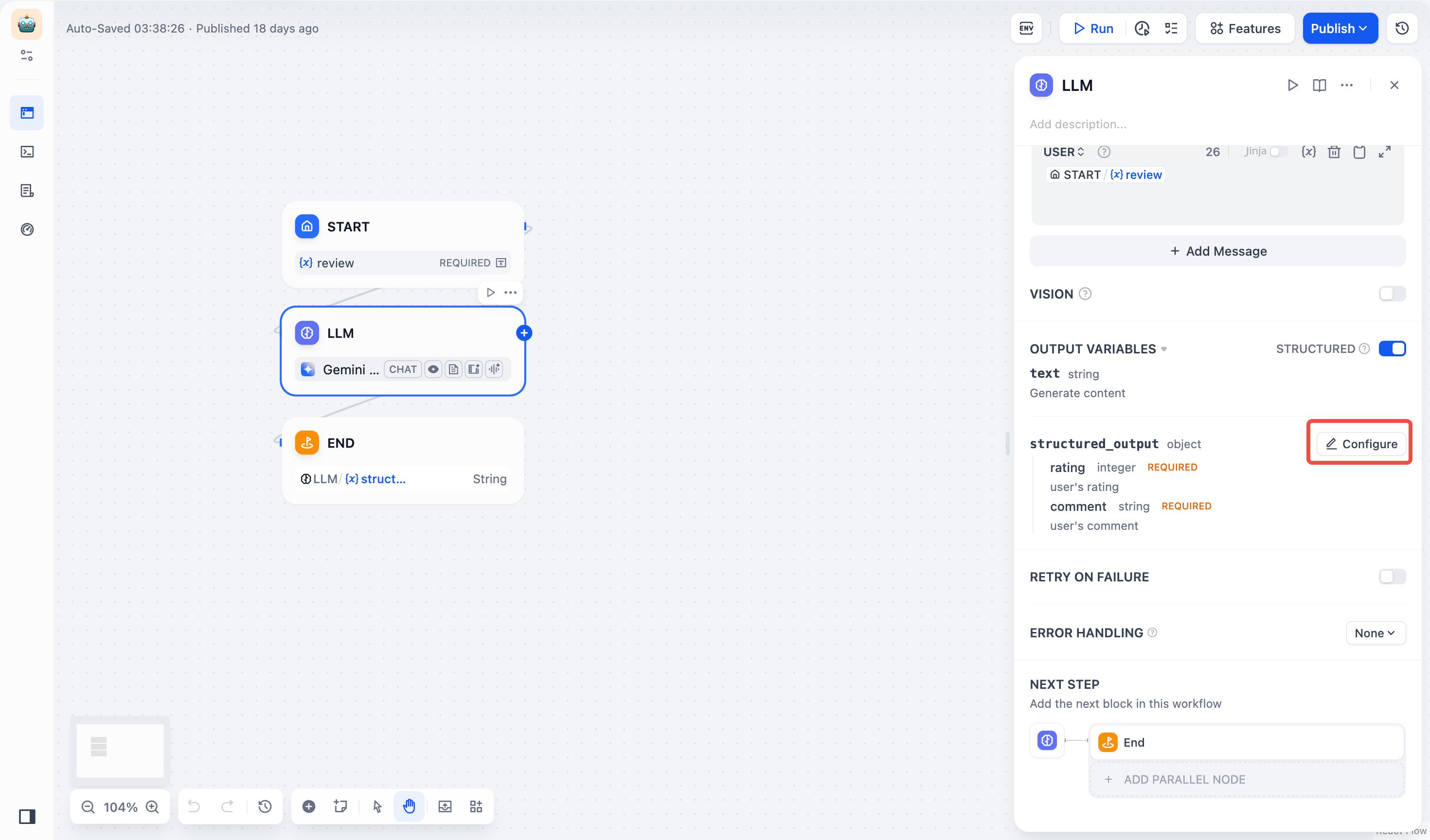
**Structured Outputs**: Ensures LLM returns data in a usable, stable, and predictable format, helping users to control exactly how their LLM nodes return data.
|
||||
|
||||
<Accordion title="JSON Schema Editor">
|
||||
The **JSON Schema Editor** in LLM nodes lets you define how you want your data structured. You can use either the **Visual Editor** for a user-friendly experience or the **JSON Schema** for more precise control.
|
||||
|
||||
The **JSON Schema Editor** in LLM nodes lets you define how you want your data structured. You can use either the **Visual Editor** for a user-friendly experience or the **JSON Schema** for more precise control.
|
||||
<Info>
|
||||
JSON Schema Editor supports structured outputs across all models:
|
||||
|
||||
<Info>
|
||||
JSON Schema Editor supports structured outputs across all models:
|
||||
- Models with Native Support: Can directly use JSON Schema definitions.
|
||||
- Models without Native Support: Not all models handle structured outputs reliably. We will include your schema in the prompt, but response formatting may vary by model.
|
||||
</Info>
|
||||
**Get Started**
|
||||
|
||||
- Models with Native Support: Can directly use JSON Schema definitions.
|
||||
Access the editor through **LLM Node \> Output Variables \> Structured \> Configure**. You can switch between visual and JSON Schema editing modes.
|
||||
|
||||
- Models without Native Support: Not all models handle structured outputs reliably. We will include your schema in the prompt, but response formatting may vary by model.
|
||||
</Info>
|
||||
|
||||
|
||||
**Get Started**
|
||||
**_Visual Editor_**
|
||||
|
||||
Access the editor through **LLM Node > Output Variables > Structured > Configure**. You can switch between visual and JSON Schema editing modes.
|
||||
**When to Use**
|
||||
|
||||

|
||||
- For simple fields such as `name`, `email`, `age` without nested structures
|
||||
- If you prefer a drag-and-drop way over writing JSON
|
||||
- When you need to quickly iterate on your schema structure
|
||||
|
||||
***Visual Editor***
|
||||
|
||||
|
||||
**When to Use**
|
||||
**Add Fields**
|
||||
|
||||
- For simple fields such as `name`, `email`, `age` without nested structures
|
||||
Click **Add Field** and set parameters below:
|
||||
|
||||
- If you prefer a drag-and-drop way over writing JSON
|
||||
- _(required)_ Field Name
|
||||
- _(required)_ Field Type: Choose from string, number, object, array, etc.
|
||||
|
||||
- When you need to quickly iterate on your schema structure
|
||||
> Note: Object and array type fields can contain child fields.
|
||||
- Description: Helps the LLM understand what the field means.
|
||||
- Required: Ensures the LLM always includes this field in its output.
|
||||
- Enum: Restricts possible values. For example, to allow only red, green, blue:
|
||||
|
||||

|
||||
```json
|
||||
{
|
||||
"type": "string",
|
||||
"enum": ["red", "green", "blue"]
|
||||
}
|
||||
```
|
||||
|
||||
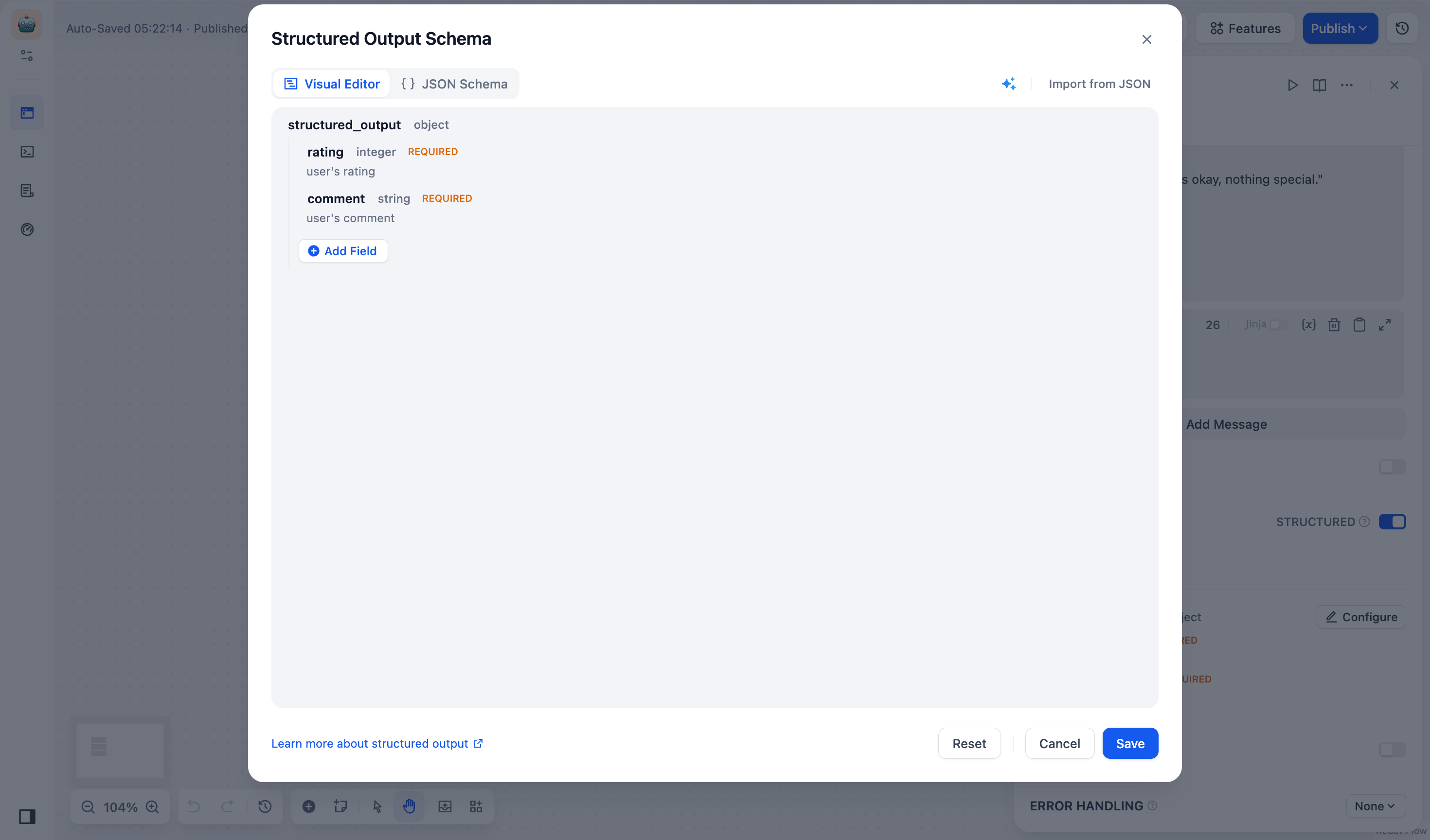
**Add Fields**
|
||||
**Manage Fields**
|
||||
|
||||
Click **Add Field** and set parameters below:
|
||||
- To Edit: Hover over a field and click the Edit icon.
|
||||
- To Delete: Hover over a field and click the Delete icon.
|
||||
|
||||
- *(required)* Field Name
|
||||
> Note: Deleting an object or array removes all its child fields.
|
||||
|
||||
- *(required)* Field Type: Choose from string, number, object, array, etc.
|
||||
**Import from JSON**
|
||||
|
||||
> Note: Object and array type fields can contain child fields.
|
||||
1. Click **Import from JSON** and paste your example:
|
||||
|
||||
- Description: Helps the LLM understand what the field means.
|
||||
```json
|
||||
{
|
||||
"comment": "This is great!",
|
||||
"rating": 5
|
||||
}
|
||||
```
|
||||
|
||||
- Required: Ensures the LLM always includes this field in its output.
|
||||
2. Click **Submit** to convert it into a schema.
|
||||
|
||||
- Enum: Restricts possible values. For example, to allow only red, green, blue:
|
||||
**Generate with AI**
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "string",
|
||||
"enum": ["red", "green", "blue"]
|
||||
}
|
||||
```
|
||||
|
||||
**Manage Fields**
|
||||
|
||||
- To Edit: Hover over a field and click the Edit icon.
|
||||
|
||||
- To Delete: Hover over a field and click the Delete icon.
|
||||
|
||||
> Note: Deleting an object or array removes all its child fields.
|
||||
|
||||
**Import from JSON**
|
||||
|
||||
1. Click **Import from JSON** and paste your example:
|
||||
|
||||
```json
|
||||
{
|
||||
"comment": "This is great!",
|
||||
"rating": 5
|
||||
}
|
||||
```
|
||||
|
||||
2. Click **Submit** to convert it into a schema.
|
||||
|
||||
**Generate with AI**
|
||||
|
||||
1. Click the AI Generate icon, select a model (like GPT-4o), and describe what you need:
|
||||
1. Click the AI Generate icon, select a model (like GPT-4o), and describe what you need:
|
||||
|
||||
> "I need a JSON Schema for user profiles with username (string), age (number), and interests (array)."
|
||||
|
||||
2. Click **Generate** to create a schema:
|
||||
2. Click **Generate** to create a schema:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"username": {
|
||||
"type": "string"
|
||||
},
|
||||
"age": {
|
||||
"type": "number"
|
||||
},
|
||||
"interests": {
|
||||
"type": "array",
|
||||
"items": {
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"username": {
|
||||
"type": "string"
|
||||
},
|
||||
"age": {
|
||||
"type": "number"
|
||||
},
|
||||
"interests": {
|
||||
"type": "array",
|
||||
"items": {
|
||||
"type": "string"
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"required": ["username", "age", "interests"]
|
||||
}
|
||||
```
|
||||
},
|
||||
"required": ["username", "age", "interests"]
|
||||
}
|
||||
```
|
||||
|
||||
***JSON Schema***
|
||||
**_JSON Schema_**
|
||||
|
||||
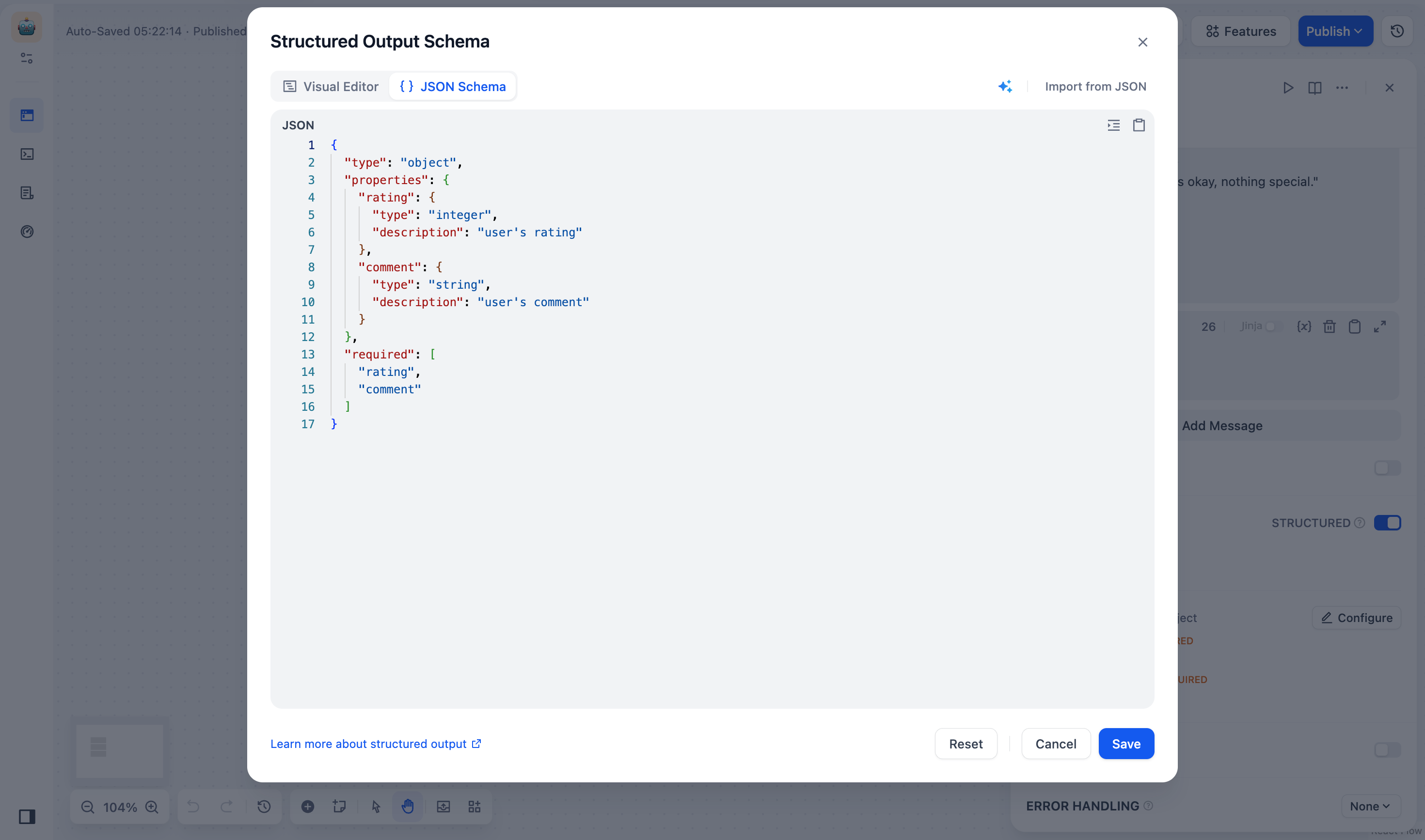
**When to Use**
|
||||
**When to Use**
|
||||
|
||||
- For complex fields that need nesting, (e.g., `order_details`, `product_lists`)
|
||||
- For complex fields that need nesting, (e.g., `order_details`, `product_lists`)
|
||||
- When you want to import and modify existing JSON Schemas or API examples
|
||||
- When you need advanced schema features, such as `pattern` (regex matching) or `oneOf` (multiple type support)
|
||||
- When you want to fine-tune an AI-generated schema to fit your exact requirements
|
||||
|
||||
- When you want to import and modify existing JSON Schemas or API examples
|
||||
|
||||
|
||||
- When you need advanced schema features, such as `pattern` (regex matching) or `oneOf` (multiple type support)
|
||||
**Add Fields**
|
||||
|
||||
- When you want to fine-tune an AI-generated schema to fit your exact requirements
|
||||
1. Click **Import from JSON** and add your field structure:
|
||||
|
||||

|
||||
```json
|
||||
{
|
||||
"name": "username",
|
||||
"type": "string",
|
||||
"description": "user's name",
|
||||
"required": true
|
||||
}
|
||||
```
|
||||
|
||||
**Add Fields**
|
||||
2. Click **Save**. Your schema will be validated automatically.
|
||||
|
||||
1. Click **Import from JSON** and add your field structure:
|
||||
**Manage Fields**: Edit field types, descriptions, default values, etc. in the JSON code box, and then click **Save**.
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "username",
|
||||
"type": "string",
|
||||
"description": "user's name",
|
||||
"required": true
|
||||
}
|
||||
```
|
||||
**Import from JSON**
|
||||
|
||||
2. Click **Save**. Your schema will be validated automatically.
|
||||
1. Click **Import from JSON** and paste your example:
|
||||
|
||||
**Manage Fields**: Edit field types, descriptions, default values, etc. in the JSON code box, and then click **Save**.
|
||||
```json
|
||||
{
|
||||
"comment": "This is great!",
|
||||
"rating": 5
|
||||
}
|
||||
```
|
||||
|
||||
**Import from JSON**
|
||||
2. Click **Submit** to convert it into a schema.
|
||||
|
||||
1. Click **Import from JSON** and paste your example:
|
||||
**Generate with AI**
|
||||
|
||||
```json
|
||||
{
|
||||
"comment": "This is great!",
|
||||
"rating": 5
|
||||
}
|
||||
```
|
||||
|
||||
2. Click **Submit** to convert it into a schema.
|
||||
|
||||
**Generate with AI**
|
||||
|
||||
1. Click the AI Generate icon, select a model (like GPT-4o), and describe what you need:
|
||||
1. Click the AI Generate icon, select a model (like GPT-4o), and describe what you need:
|
||||
|
||||
> "I need a JSON Schema for user profiles with username (string), age (number), and interests (array)."
|
||||
|
||||
2. Click **Generate** to create a schema:
|
||||
2. Click **Generate** to create a schema:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"username": {
|
||||
"type": "string"
|
||||
},
|
||||
"age": {
|
||||
"type": "number"
|
||||
},
|
||||
"interests": {
|
||||
"type": "array",
|
||||
"items": {
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"username": {
|
||||
"type": "string"
|
||||
},
|
||||
"age": {
|
||||
"type": "number"
|
||||
},
|
||||
"interests": {
|
||||
"type": "array",
|
||||
"items": {
|
||||
"type": "string"
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"required": ["username", "age", "interests"]
|
||||
}
|
||||
```
|
||||
|
||||
},
|
||||
"required": ["username", "age", "interests"]
|
||||
}
|
||||
```
|
||||
</Accordion>
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
#### Use Cases
|
||||
|
||||
* **Reading Knowledge Base Content**
|
||||
- **Reading Knowledge Base Content**
|
||||
|
||||
To enable workflow applications to read "[Knowledge Base](../../knowledge-base/)" content, such as building an intelligent customer service application, please follow these steps:
|
||||
|
||||
@@ -330,22 +319,22 @@ To enable workflow applications to read "[Knowledge Base](../../knowledge-base/)
|
||||
The `result` variable output by the Knowledge Retrieval Node also includes segmented reference information. You can view the source of information through the **Citation and Attribution** feature.
|
||||
|
||||
<Info>
|
||||
Regular variables from upstream nodes can also be filled into context variables, such as string-type variables from the start node, but the **Citation and Attribution** feature will be ineffective.
|
||||
Regular variables from upstream nodes can also be filled into context variables, such as string-type variables from the start node, but the **Citation and Attribution** feature will be ineffective.
|
||||
</Info>
|
||||
|
||||
* **Reading Document Files**
|
||||
- **Reading Document Files**
|
||||
|
||||
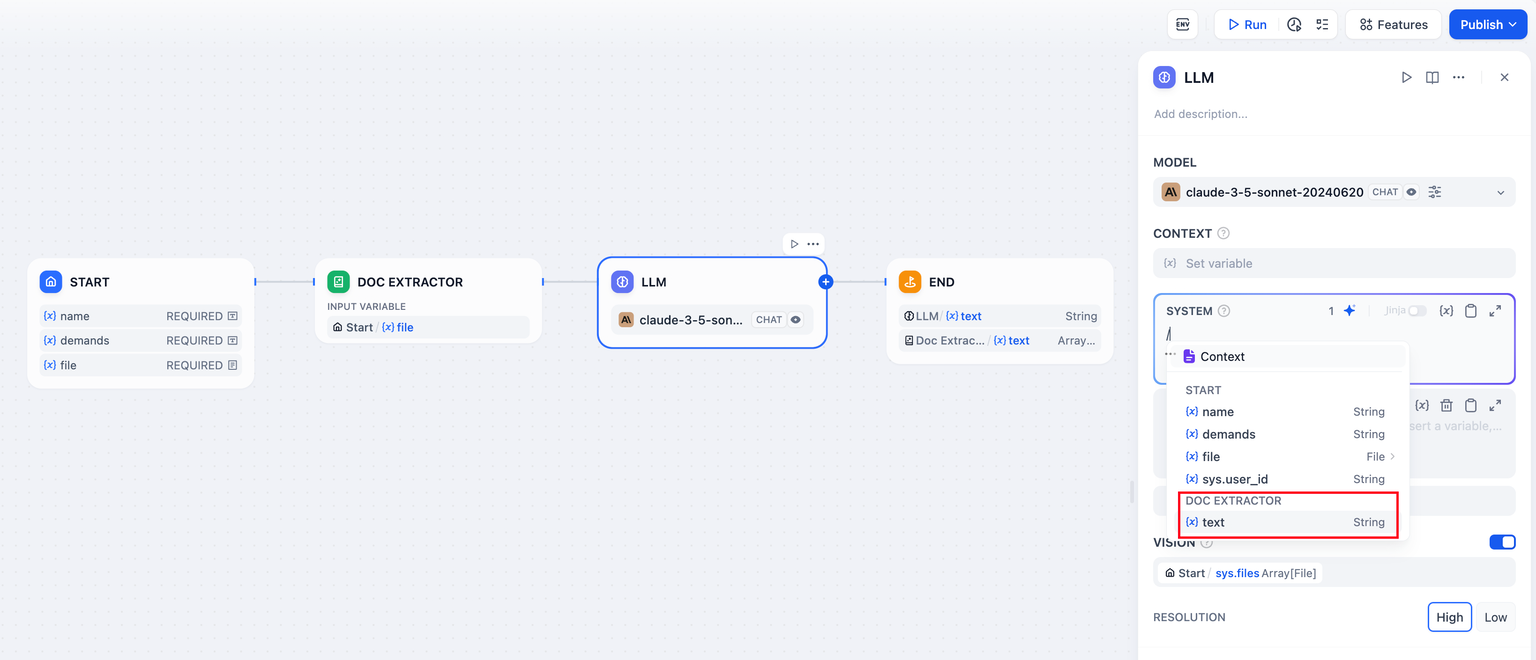
To enable workflow applications to read document contents, such as building a ChatPDF application, you can follow these steps:
|
||||
|
||||
* Add a file variable in the "Start" node;
|
||||
* Add a document extractor node upstream of the LLM node, using the file variable as an input variable;
|
||||
* Fill in the **output variable** `text` of the document extractor node into the prompt of the LLM node.
|
||||
- Add a file variable in the "Start" node;
|
||||
- Add a document extractor node upstream of the LLM node, using the file variable as an input variable;
|
||||
- Fill in the **output variable** `text` of the document extractor node into the prompt of the LLM node.
|
||||
|
||||
For more information, please refer to [File Upload](../file-upload).
|
||||
|
||||
|
||||
|
||||
* **Error Handling**
|
||||
- **Error Handling**
|
||||
|
||||
When processing information, LLM nodes may encounter errors such as input text exceeding token limits or missing key parameters. Developers can follow these steps to configure exception branches, enabling contingency plans when node errors occur to avoid interrupting the entire flow:
|
||||
|
||||
@@ -356,21 +345,94 @@ When processing information, LLM nodes may encounter errors such as input text e
|
||||
|
||||
For more information about exception handling methods, please refer to the [Error Handling](https://docs.dify.ai/guides/workflow/error-handling).
|
||||
|
||||
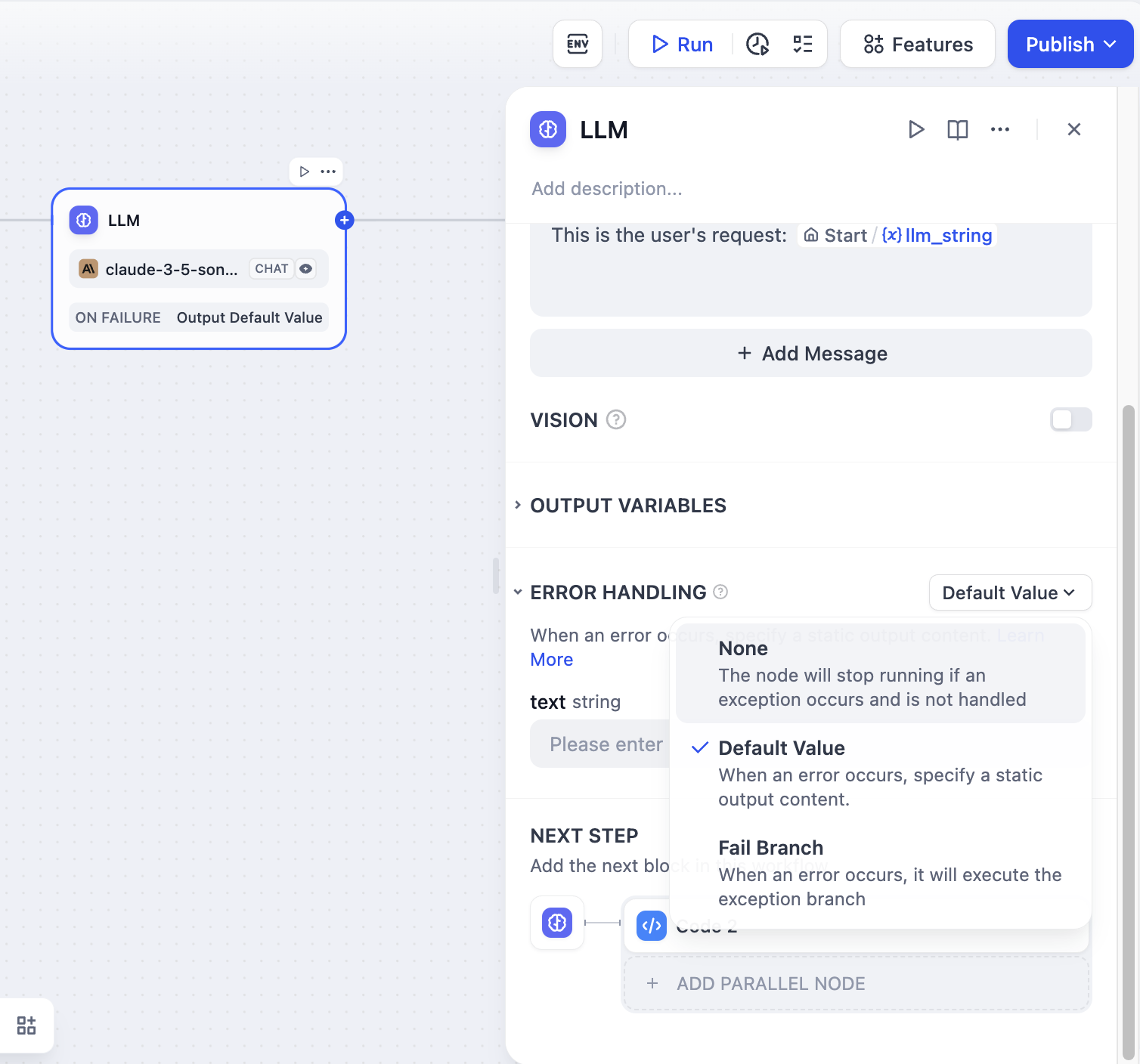
* **Structured Outputs**
|
||||
- **Structured Outputs**
|
||||
|
||||
**Case: Customer Information Intake Form**
|
||||
|
||||
Watch the following video to learn how to use JSON Schema Editor to collect customer information:
|
||||
|
||||
<iframe
|
||||
width="560"
|
||||
height="315"
|
||||
src="https://www.youtube.com/embed/u8NQFxrsaW0"
|
||||
title="Customer Information Intake Form Demo"
|
||||
frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/u8NQFxrsaW0" title="Customer Information Intake Form Demo" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen />
|
||||
|
||||
## Prompt Optimization
|
||||
|
||||
The **Prompt Optimization** feature enables iterative improvement of prompts based on unsatisfactory output. It allows users to refine their instructions with direct reference to the previous run’s result, closing the loop between prompt writing, model output, and feedback.
|
||||
|
||||
---
|
||||
|
||||
### Purpose
|
||||
|
||||
Previously, the LLM node was **stateless**—if a prompt underperformed, users had to manually guess how to improve it. With this feature, you can now:
|
||||
|
||||
- Reference the last output using context variables
|
||||
- Define an _ideal output_ for comparison
|
||||
- Use the Prompt Generator UI to regenerate an optimized prompt
|
||||
|
||||
---
|
||||
|
||||
### How It Works
|
||||
|
||||
After a prompt is executed in the LLM Node:
|
||||
|
||||
- The system captures both the **original prompt** and its **last output**
|
||||
- These are exposed as context variables:
|
||||
- `{{current_prompt}}`: the current prompt in this node
|
||||
- `{{last_run}}`: the previous input and output from this node
|
||||
|
||||
These variables can be inserted directly into the prompt editor using `/` or `{}` to provide the model with context for iterative improvement.
|
||||
|
||||
---
|
||||
|
||||
### Configuration Steps
|
||||
|
||||
1. Open the Prompt Generator
|
||||
|
||||
Click the wand icon to launch the Prompt Generator, which pre-fills a repair instruction like:
|
||||
|
||||
`The output of this prompt is not as expected: {{last_run}}. You should edit the prompt according to the IDEAL OUTPUT.`
|
||||
|
||||

|
||||
|
||||
2. Customize the Instruction
|
||||
|
||||
Edit the instruction in the left-hand prompt editor to reflect what should change or improve. This could be tone, structure, formatting, factuality, etc.
|
||||
|
||||
3. Use the Ideal Output Box
|
||||
|
||||
Click to expand the **Ideal Output** area and write a few-shot example or desired response format. This is used as a reference for the model during prompt regeneration.
|
||||
|
||||
_Note: You cannot insert variables into the Ideal Output box. It is for static examples only._
|
||||
|
||||
For example, if your task were to rewrite the prompt so that the model outputs a concise summary of a news article in exactly three bullet points, an ideal output could be:
|
||||
|
||||

|
||||
|
||||
4. Generate an Optimized Prompt
|
||||
|
||||
Click **Generate** to allow the system to rewrite the prompt using your instruction and reference output. You can test the new version immediately.
|
||||
|
||||
---
|
||||
|
||||
### Version Management
|
||||
|
||||
Each prompt regeneration is saved as a new version:
|
||||
|
||||
- The output area includes a dropdown labeled “Version 1,” “Version 2,” etc.
|
||||
- You can switch between versions to compare results
|
||||
- When only one version exists, the dropdown is hidden
|
||||
|
||||
---
|
||||
|
||||
### Notes
|
||||
|
||||
- `last_run` includes the previous input/output specific to this LLM node
|
||||
- This is not the same as the Code Node’s `current_code` or `error_message`
|
||||
- This feature improves prompt iteration without breaking workflow continuity
|
||||
|
||||
---
|
||||
|
||||
Prompt Optimization helps developers and low-code users fine-tune prompts _with context_—reducing guesswork and improving results through guided iteration.
|
||||
|
||||
---
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
@@ -378,7 +440,4 @@ DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/workflow/node/llm.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
|
||||
BIN
images/codefix.PNG
Normal file
BIN
images/codefix.PNG
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 135 KiB |
BIN
images/llm.PNG
Normal file
BIN
images/llm.PNG
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 129 KiB |
BIN
images/llm2.PNG
Normal file
BIN
images/llm2.PNG
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 41 KiB |
@@ -93,6 +93,49 @@ def main() -> dict:
|
||||
|
||||

|
||||
|
||||
## **コード修正**
|
||||
|
||||
この機能は、前回の実行時の`current_code`と`error_message`変数を活用し、**自動できにコードの修正**を実現できます。
|
||||
|
||||
コードノードが失敗した時:
|
||||
|
||||
- システムはコードとエラーメッセージを取得
|
||||
- それらをコンテキスト変数としてプロンプトに渡します
|
||||
- コードの新しいバージョンが生成され、レビューや再試行に提供されます。
|
||||
|
||||
**設定**
|
||||
|
||||
1. **修正プロンプトの作成**:
|
||||
|
||||
プロンプトエディタでは、変数挿入メニュー(`/` または `{`)を使用して変数を挿入可能です。例えば、次のようなプロンプトをカスタマイズできます。
|
||||
|
||||
`以下のエラーメッセージに基づいてコードを修正してください:
|
||||
Code: {{current_code}}
|
||||
Error: {{error_message}}`
|
||||
|
||||

|
||||
|
||||
2. **コンテキスト変数の使用(ワークフローで必要な場合)**
|
||||
自動コード修正を有効にするためには、プロンプト内で以下のコンテキスト変数を参照してください:
|
||||
|
||||
`{{current_code}}`: このノードの前回実行からのコード。
|
||||
`{{error_message}}`: 最後の実行が失敗した場合のエラーメッセージ。
|
||||
|
||||
また、前のノードからの出力変数も参照可能です。
|
||||
|
||||
これらの変数は、コードノードが実行された際に自動的に利用可能になり、モデルが前回の実行データを用いて反復的な修正を行えます。
|
||||
|
||||
3. **バージョン管理の利用**:
|
||||
1. 各修正試行は個別のバージョン(例:バージョン1、バージョン2)として保存されます。
|
||||
2. ユーザーは結果表示エリアのドロップダウンからバージョンを切り替えられます。
|
||||
|
||||
**注意点:**
|
||||
|
||||
- `error_message`は、最後の実行が成功した場合は空になります。
|
||||
- `last_run`は前回の入力/出力を参照するために使用できます。
|
||||
|
||||
これにより、手動でのコピー&ペーストが減少し、ワークフロー内で直接反復的なデバッグが可能になります。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
|
||||
@@ -387,6 +387,81 @@ LLMノードの出力変数をクリックし、構造化スイッチの設定
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
## プロンプト最適化
|
||||
|
||||
この機能は、満足のいかない出力に基づいてプロンプトを反復的に改善することを可能にします。この機能により、ユーザーは前回の実行結果を直接参照しながら指示を洗練でき、プロンプトの作成、モデルの出力、フィードバックの間に閉ループを実現します。
|
||||
|
||||
### 目的
|
||||
|
||||
以前、LLMノードは**ステートレス**でした。プロンプトの効果が期待ほどではないの場合、ユーザーは試行錯誤で改善方法を見つける必要がありました。本機能により、以下が可能になります:
|
||||
|
||||
- コンテキスト変数を使用して前回の出力を参照
|
||||
- 比較用のために、“理想的な出力”を定義
|
||||
- プロンプトジェネレーターUIを使用して最適化されたプロンプトを再生成
|
||||
|
||||
---
|
||||
|
||||
### 仕組み
|
||||
|
||||
LLMノードでプロンプトを実行後:
|
||||
|
||||
- システムは“オリジナルプロンプト”とその“最後の出力”を取得
|
||||
- これらはコンテキスト変数として提供されます:
|
||||
- `{{current_prompt}}`:このノード内の現在のプロンプト
|
||||
- `{{last_run}}`:このノードの前回の入力と出力
|
||||
|
||||
これらの変数は、反復的な改善のためにモデルに文脈を提供するため、プロンプトエディタに / や {} を使用して直接挿入できます。
|
||||
|
||||
---
|
||||
|
||||
### 設定手順
|
||||
|
||||
1. プロンプトジェネレーターを開く
|
||||
|
||||
最適化アイコンをクリックしてプロンプトジェネレーターを起動します。これにより、以下のような修正指示が自動的に入力されます:
|
||||
|
||||
`このプロンプトの出力は期待通りではありません:{{last_run}}。理想的な出力に基づいてプロンプトを編集してください。`
|
||||
|
||||

|
||||
|
||||
2. 指示をカスタマイズする
|
||||
|
||||
左側のプロンプトエディタで指示を編集し、変更・改善点(例: トーン、構造など)を反映させます。
|
||||
|
||||
3. 理想的な出力ボックスの使用
|
||||
|
||||
理想的な出力領域を展開し、サンプルや期待される出力形式を記述します。これはプロンプト再生成中にモデルの参考として使用されます。
|
||||
|
||||
注意:理想的な出力ボックスには変数を挿入することはできません。これは静的な例のためのものです。
|
||||
|
||||
例えば、タスクがモデルにニュース記事の簡潔な要約を正確に3つの箇条書きで出力するようにプロンプトを書き直すことであれば、理想的な出力は以下のようになります:
|
||||
|
||||

|
||||
|
||||
4. 最適化されたプロンプトを生成する
|
||||
|
||||
生成をクリックすると、システムがユーザーの指示と参照出力に基づいてプロンプトを書き換えます。新しいバージョンをすぐにテストできます。
|
||||
|
||||
---
|
||||
|
||||
### バージョン管理
|
||||
|
||||
プロンプト再生成は、新しいバージョンとしてそれぞれ保存されます:
|
||||
|
||||
- 出力エリアには「バージョン1」、「バージョン2」などのラベルの付いたドロップダウンが含まれています。
|
||||
- 結果を比較するためにバージョン間で切り替えて比較できます。
|
||||
- バージョンが1つだけ存在する場合、ドロップダウンは隠れます。
|
||||
|
||||
---
|
||||
|
||||
### メモ
|
||||
|
||||
- `last_run`には、このLLMノード特有の前回の入力/出力が含まれます。
|
||||
- これは、コードノードの`current_code`や`error_message`とは異なります。
|
||||
- この機能は、ワークフローの連続性を損なうことなく、プロンプトの反復を改善します。
|
||||
|
||||
プロンプト最適化は、開発者やローコードユーザーが文脈に基づいてプロンプトを微調整する手助けをし、推測を減らしてガイド付きの反復を通じて成果を向上させます。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
|
||||
@@ -1,13 +1,13 @@
|
||||
---
|
||||
title: 代码执行
|
||||
title: "代码执行"
|
||||
---
|
||||
|
||||
## 目录
|
||||
|
||||
* [介绍](#介绍)
|
||||
* [使用场景](#使用场景)
|
||||
* [本地部署](#本地部署)
|
||||
* [安全策略](#安全策略)
|
||||
- [介绍](#介绍)
|
||||
- [使用场景](#使用场景)
|
||||
- [本地部署](#本地部署)
|
||||
- [安全策略](#安全策略)
|
||||
|
||||
## 介绍
|
||||
|
||||
@@ -114,20 +114,68 @@ def main() -> dict:
|
||||
|
||||
这段代码包含以下问题:
|
||||
|
||||
* **未经授权的文件访问:** 代码试图读取 "/etc/passwd" 文件,这是 Unix/Linux 系统中存储用户账户信息的关键系统文件。
|
||||
* **敏感信息泄露:** "/etc/passwd" 文件包含系统用户的重要信息,如用户名、用户 ID、组 ID、home 目录路径等。直接访问可能会导致信息泄露。
|
||||
- **未经授权的文件访问:** 代码试图读取 "/etc/passwd" 文件,这是 Unix/Linux 系统中存储用户账户信息的关键系统文件。
|
||||
- **敏感信息泄露:** "/etc/passwd" 文件包含系统用户的重要信息,如用户名、用户 ID、组 ID、home 目录路径等。直接访问可能会导致信息泄露。
|
||||
|
||||
危险代码将会被 Cloudflare WAF 自动拦截,你可以通过 “网页调试工具” 中的 “网络” 查看是否被拦截。
|
||||
|
||||
|
||||
|
||||
## 代码修复
|
||||
|
||||
此功能通过利用上次运行`current_codeerror_message`变量实现自动代码纠正。
|
||||
|
||||
当代码节点运行失败时:
|
||||
|
||||
- 系统会捕获代码和错误信息。
|
||||
- 这些信息会作为上下文变量传递到提示中。
|
||||
- 系统会生成一个新版本的代码供审查和重试。
|
||||
|
||||
**配置:**
|
||||
|
||||
1. **编写修复提示:**
|
||||
|
||||
你可以自定义一个提示,例如:
|
||||
|
||||
在提示编辑器中,使用变量插入菜单(`/`或`{`)插入变量。
|
||||
|
||||
`根据以下错误信息修复代码:
|
||||
代码:
|
||||
{{current_code}}
|
||||
错误:
|
||||
{{error_message}}`
|
||||
|
||||

|
||||
|
||||
2. **使用上下文变量(如果在工作流程后续需要)**
|
||||
|
||||
要启用自动代码修复,请在提示中引用以下上下文变量:
|
||||
|
||||
- `{{current_code}}`:此节点上次运行的代码。
|
||||
- `{{error_message}}`:如果上次运行失败,则为错误消息。
|
||||
|
||||
你还可以引用任何前置节点的输出变量。
|
||||
|
||||
当代码节点运行时,这些变量会自动可用,并允许模型使用先前的运行信息进行迭代修正。
|
||||
|
||||
3. **版本管理**
|
||||
|
||||
- 每次修正尝试都会保存为一个单独的版本(例如,版本1、版本2)。
|
||||
- 用户可以通过结果显示区域的下拉菜单在不同版本间切换。
|
||||
|
||||
**注意事项:**
|
||||
|
||||
- 如果上次运行成功,error_message为空。
|
||||
- last_run可用于引用先前的输入/输出。
|
||||
|
||||
这减少了手动复制粘贴操作,并允许在工作流程中直接进行迭代调试。
|
||||
|
||||
---
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/zh-hans/guides/workflow/node/code.mdx) | [提交问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: LLM
|
||||
title: "LLM"
|
||||
---
|
||||
|
||||
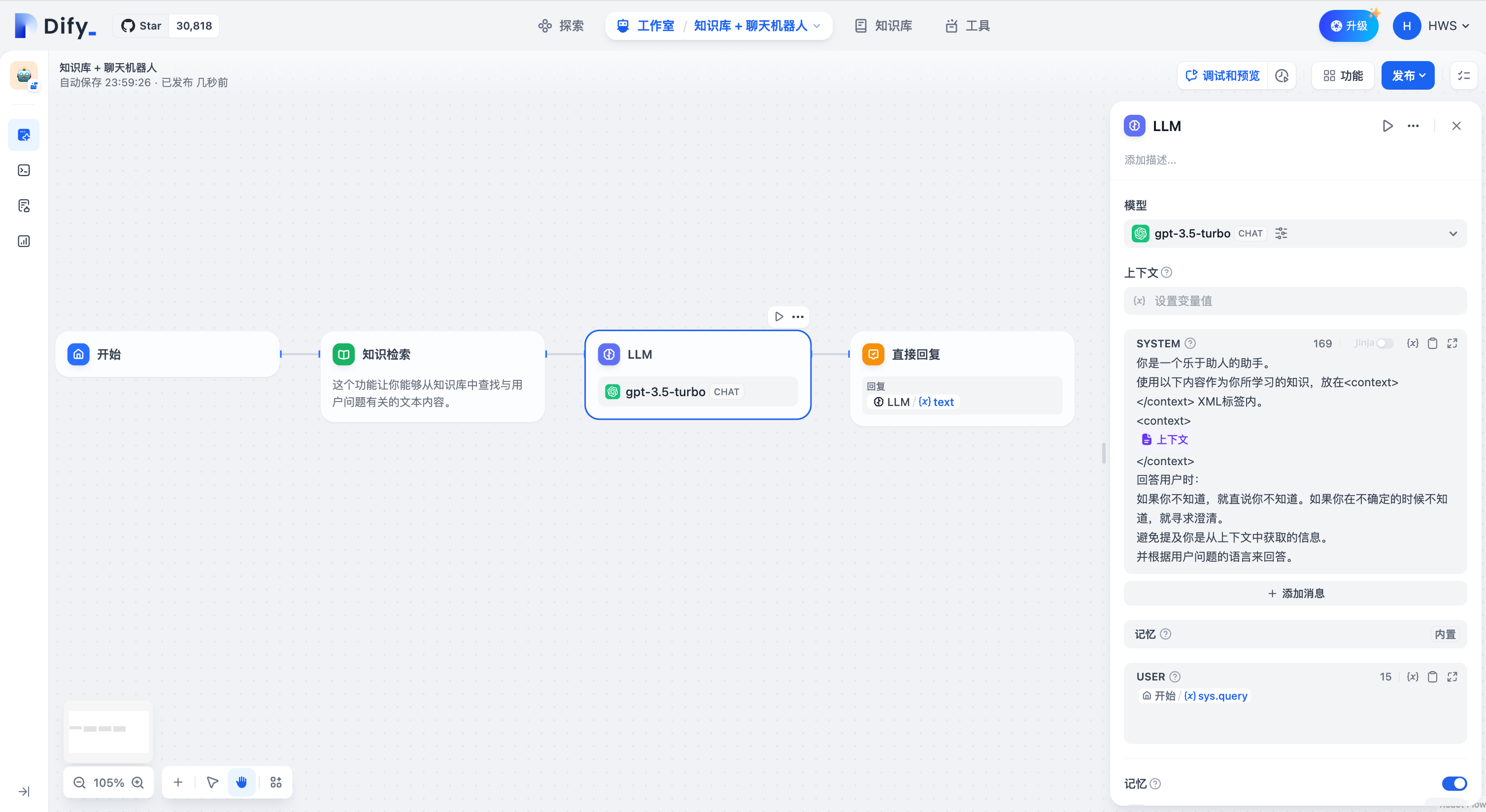
### 定义
|
||||
@@ -7,33 +7,33 @@ title: LLM
|
||||
调用大语言模型的能力,处理用户在 "开始" 节点中输入的信息(自然语言、上传的文件或图片),给出有效的回应信息。
|
||||
|
||||
<Frame caption="LLM 节点">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/0356bf3a8c46660181707da6f736386f.png" alt="LLM 节点" />
|
||||
|
||||
</Frame>
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
### 应用场景
|
||||
|
||||
LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
|
||||
|
||||
* **意图识别**,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
|
||||
* **文本生成**,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
|
||||
* **内容分类**,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
|
||||
* **文本转换**,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
|
||||
* **代码生成**,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
|
||||
* **RAG**,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
|
||||
* **图片理解**,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
|
||||
- **意图识别**,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
|
||||
- **文本生成**,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
|
||||
- **内容分类**,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
|
||||
- **文本转换**,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
|
||||
- **代码生成**,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
|
||||
- **RAG**,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
|
||||
- **图片理解**,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
|
||||
|
||||
选择合适的模型,编写提示词,你可以在 Chatflow/Workflow 中构建出强大、可靠的解决方案。
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
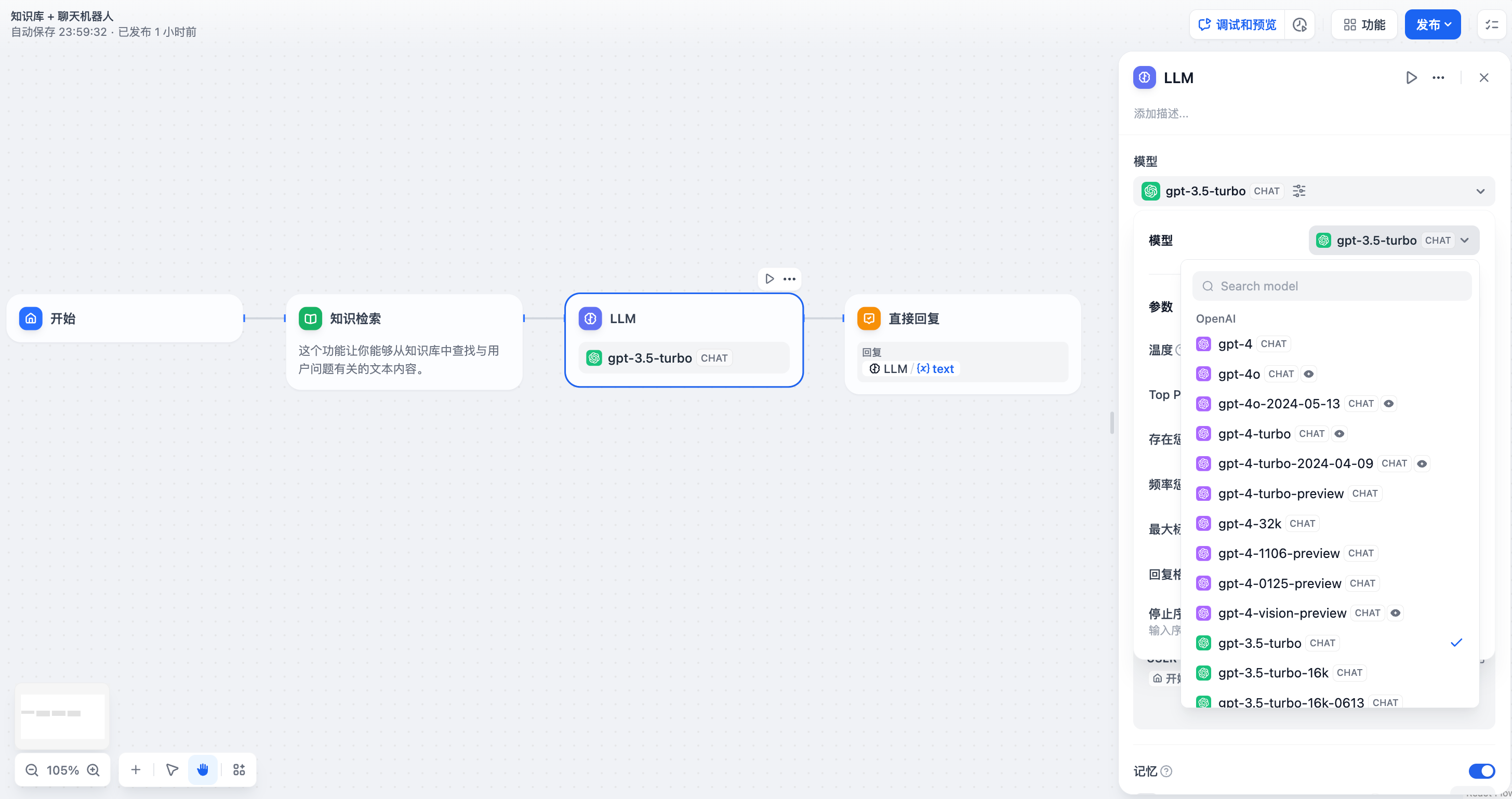
### 配置示例
|
||||
|
||||
在应用编辑页中,点击鼠标右键或轻点上一节点末尾的 + 号,添加节点并选择 LLM。
|
||||
在应用编辑页中,点击鼠标右键或轻点上一节点末尾的 \+ 号,添加节点并选择 LLM。
|
||||
|
||||
<Frame caption="LLM 节点配置-选择模型">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/778b40e25d203a5da9dddd9d8d7063a1.png" alt="LLM 节点配置-选择模型" />
|
||||
|
||||
</Frame>
|
||||
|
||||
**配置步骤:**
|
||||
@@ -55,18 +55,18 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
|
||||
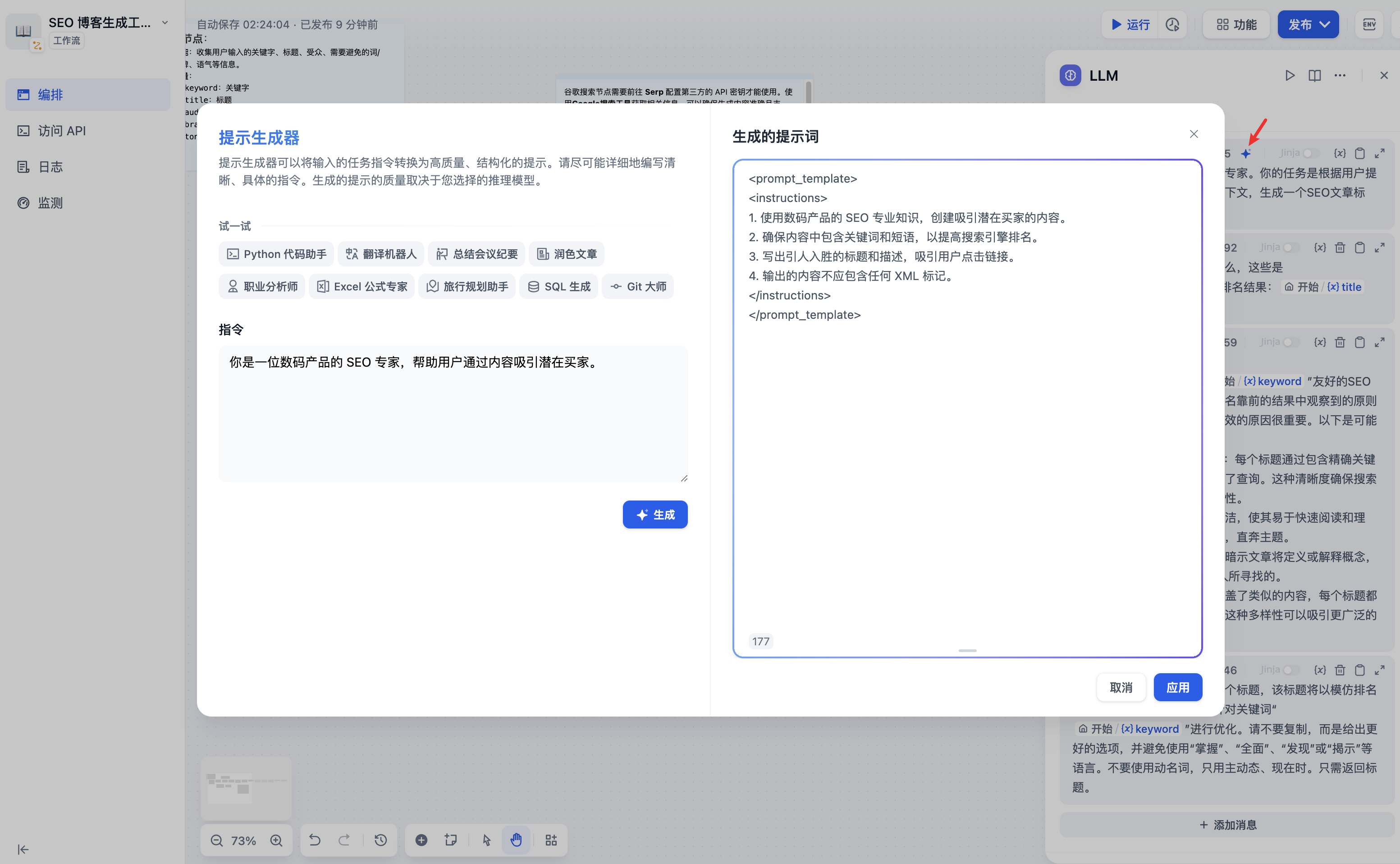
如果在编写系统提示词(SYSTEM)时没有好的思路,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
|
||||
|
||||
<Frame caption="提示生成器">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/727e40ef04a4df13d3bef82ad02e73f1.png" alt="提示生成器" />
|
||||
|
||||
</Frame>
|
||||
|
||||
在提示词编辑器中,你可以通过输入 **"/"** 呼出 **变量插入菜单**,将 **特殊变量块** 或者 **上游节点变量** 插入到提示词中作为上下文内容。
|
||||
|
||||
<Frame caption="呼出变量插入菜单">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/cc96ca72400fb81aca6936908d667478.png" alt="呼出变量插入菜单" />
|
||||
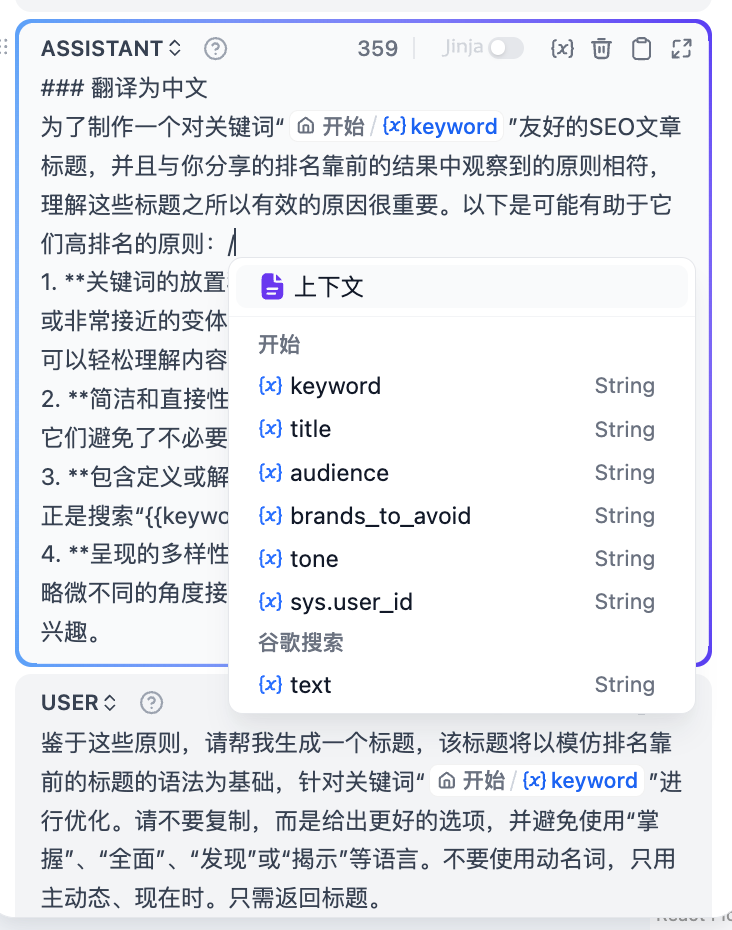
|
||||
</Frame>
|
||||
|
||||
5. **高级设置**,可以开关记忆功能并设置记忆窗口、开关 Vision 功能或者使用 Jinja-2 模板语言来进行更复杂的提示词等。
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
### 特殊变量说明
|
||||
|
||||
@@ -89,7 +89,7 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
|
||||
> 会话历史变量应用并不广泛,仅在 Chatflow 中选择文本补全类模型时可以插入使用。
|
||||
|
||||
<Frame caption="插入会话历史变量">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/b8642f8c6e3f562fceeefae83628fd68.png" alt="插入会话历史变量" />
|
||||
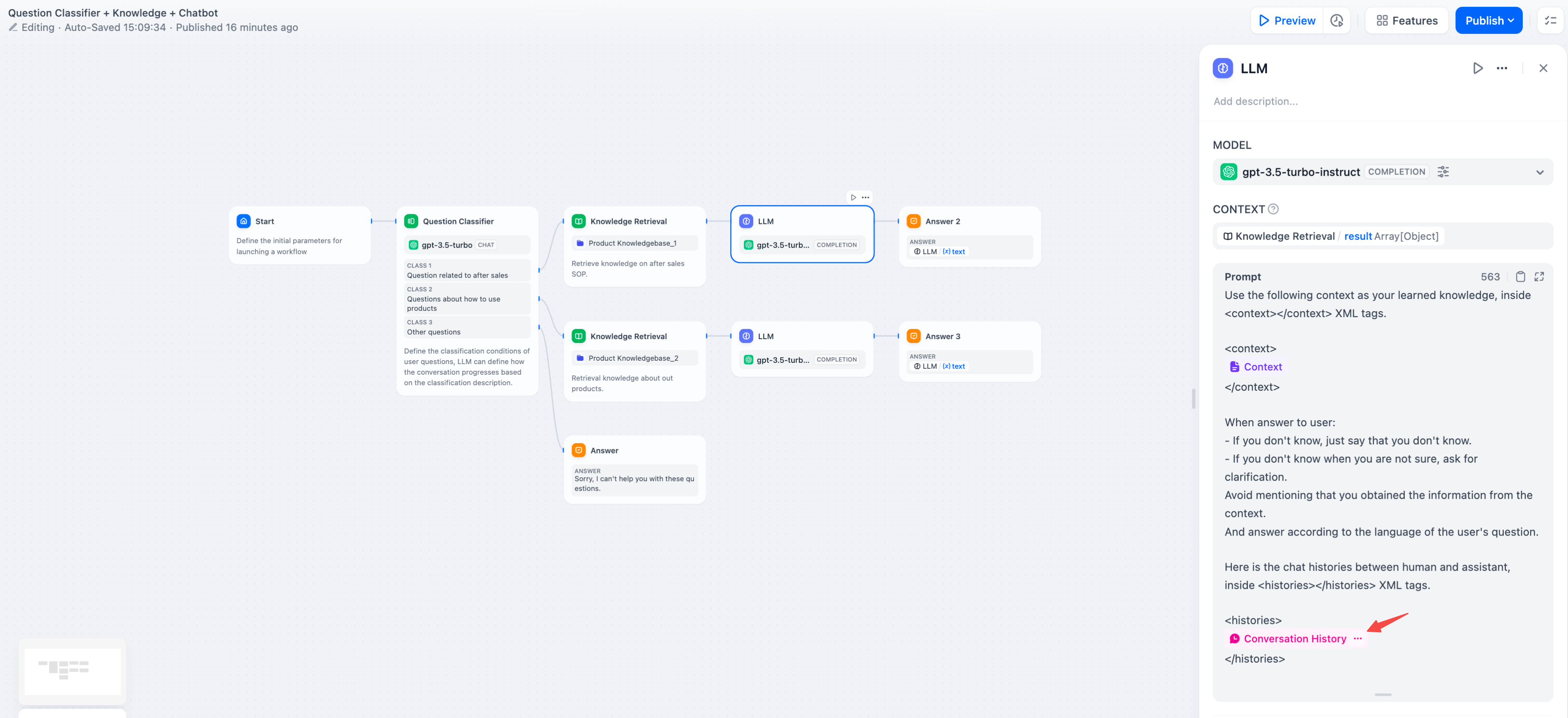
|
||||
</Frame>
|
||||
|
||||
**模型参数**
|
||||
@@ -97,23 +97,23 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
|
||||
模型的参数会影响模型的输出效果。不同模型的参数会有所区别。下图为`gpt-4`的参数列表。
|
||||
|
||||
<Frame caption="模型参数列表">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/74a93d9b4982a8ad4d046dc9fb290b2d.png" alt="模型参数列表" />
|
||||
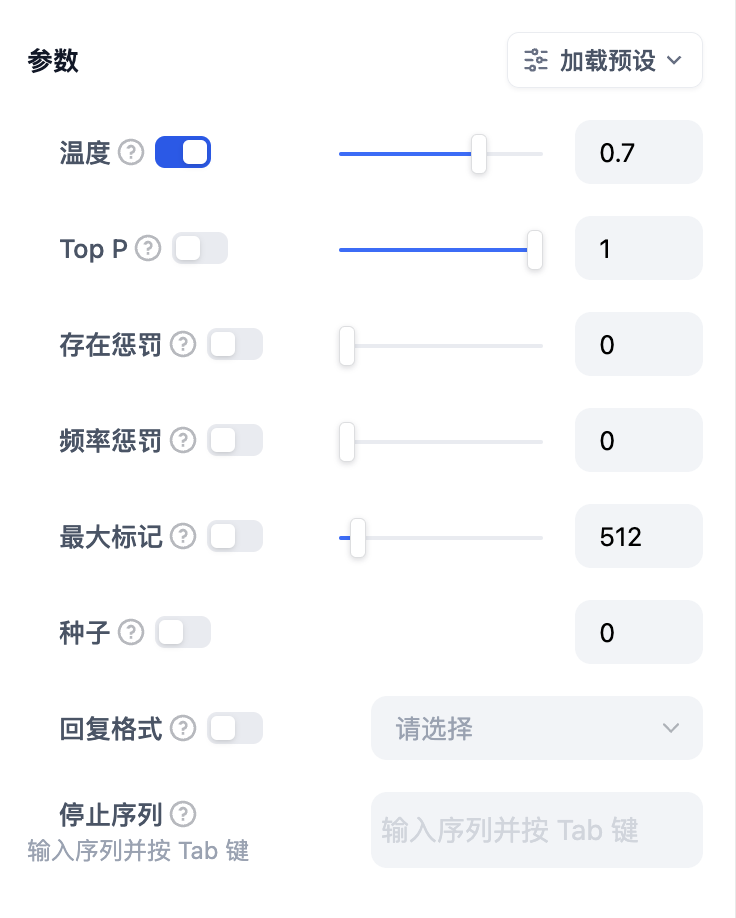
|
||||
</Frame>
|
||||
|
||||
主要的参数名词解释如下:
|
||||
|
||||
* **温度:** 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
|
||||
* **Top P:** 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
|
||||
* **存在惩罚:** 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
|
||||
* **频率惩罚:** 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
|
||||
- **温度:** 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
|
||||
- **Top P:** 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
|
||||
- **存在惩罚:** 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
|
||||
- **频率惩罚:** 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
|
||||
|
||||
如果你不理解这些参数是什么,可以选择**加载预设**,从创意、平衡、精确三种预设中选择。
|
||||
|
||||
<Frame caption="加载预设参数">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/a117606125cbc65573f201738cd0af6e.png" alt="加载预设参数" />
|
||||
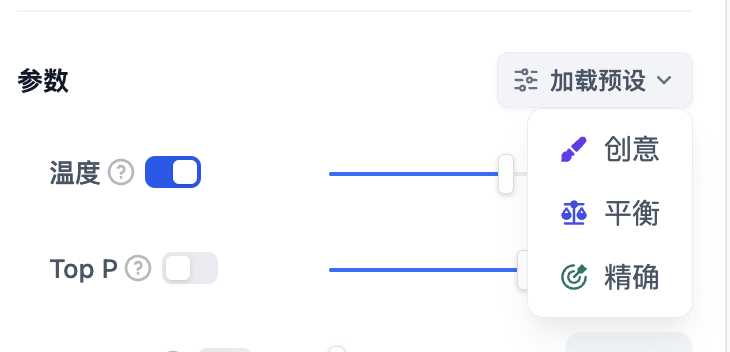
|
||||
</Frame>
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
### 高级功能
|
||||
|
||||
@@ -137,221 +137,207 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
|
||||
**结构化输出**:确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。
|
||||
|
||||
<Accordion title="JSON Schema 编辑器">
|
||||
LLM 节点中的 **JSON Schema 编辑器** 让你能够定义 LLM 返回的数据结构,确保输出可解析、可复用、可控。你可以使用**可视化编辑模式**直观编辑,或通过**代码编辑模式**精细调整,适配不同复杂度的需求。
|
||||
|
||||
LLM 节点中的 **JSON Schema 编辑器** 让你能够定义 LLM 返回的数据结构,确保输出可解析、可复用、可控。你可以使用**可视化编辑模式**直观编辑,或通过**代码编辑模式**精细调整,适配不同复杂度的需求。
|
||||
<Info>
|
||||
作为节点级能力,JSON Schema 适用于所有模型的结构化输出定义和约束。
|
||||
|
||||
<Info>
|
||||
作为节点级能力,JSON Schema 适用于所有模型的结构化输出定义和约束。
|
||||
- **原生支持结构化输出的模型**:可直接使用 JSON Schema 定义结构化变量。
|
||||
- **不支持结构化输出的模型**:系统会将 JSON Schema 以提示词方式输入。你可以尝试引导模型按结构生成内容,但这并不保证一定可以正确解析输出。
|
||||
</Info>
|
||||
**JSON Schema 编辑器入口**
|
||||
|
||||
- **原生支持结构化输出的模型**:可直接使用 JSON Schema 定义结构化变量。
|
||||
点击 **LLM 节点 \> 输出变量**,打开 **结构化开关 \> 配置**,即可进入 **JSON Schema 编辑器** 界面。JSON Schema 编辑器分为可视化编辑窗口与代码编辑窗口,两者可无缝切换。
|
||||
|
||||
- **不支持结构化输出的模型**:系统会将 JSON Schema 以提示词方式输入。你可以尝试引导模型按结构生成内容,但这并不保证一定可以正确解析输出。
|
||||
</Info>
|
||||

|
||||
|
||||
**JSON Schema 编辑器入口**
|
||||
<Tabs>
|
||||
<Tab title="可视化编辑">
|
||||
**适用场景**
|
||||
|
||||
点击 **LLM 节点 > 输出变量**,打开 **结构化开关 > 配置**,即可进入 **JSON Schema 编辑器** 界面。JSON Schema 编辑器分为可视化编辑窗口与代码编辑窗口,两者可无缝切换。
|
||||
- **你只需要定义几个简单的字段**,例如 `name`、`email`、`age` 等,并不涉及嵌套结构。
|
||||
- **你不熟悉 JSON Schema 语法**,希望不写代码,而是用直观的界面拖拽、添加字段。
|
||||
- **你希望快速迭代字段结构**,而不是每次修改都需要更新 JSON 代码。
|
||||
|
||||

|
||||

|
||||
|
||||
<Tabs>
|
||||
<Tab title="可视化编辑">
|
||||
**适用场景**
|
||||
**添加字段**
|
||||
|
||||
- **你只需要定义几个简单的字段**,例如 `name`、`email`、`age` 等,并不涉及嵌套结构。
|
||||
在 **结构化输出** 框中点击 **添加子字段** 按钮,并配置字段参数:
|
||||
|
||||
- **你不熟悉 JSON Schema 语法**,希望不写代码,而是用直观的界面拖拽、添加字段。
|
||||
- _(必填)_ **字段名**
|
||||
- _(必填)_ **字段类型**:支持 string、number、object、array 等字段类型等。
|
||||
|
||||
- **你希望快速迭代字段结构**,而不是每次修改都需要更新 JSON 代码。
|
||||
> 对象(object)或数组(array)字段可添加子字段。
|
||||
- **描述**:帮助 LLM 理解字段含义,提高输出准确性。
|
||||
- **必填**:开启后,LLM 将强制返回该字段值。
|
||||
- **枚举值**:用于限制字段值的可选范围,使模型仅能从预设的枚举值中返回值。例如,若只允许 `red`、`green`、`blue`:
|
||||
|
||||

|
||||
|
||||
**添加字段**
|
||||
|
||||
在 **结构化输出** 框中点击 **添加子字段** 按钮,并配置字段参数:
|
||||
|
||||
- *(必填)* **字段名**
|
||||
|
||||
- *(必填)* **字段类型**:支持 string、number、object、array 等字段类型等。
|
||||
|
||||
> 对象(object)或数组(array)字段可添加子字段。
|
||||
|
||||
- **描述**:帮助 LLM 理解字段含义,提高输出准确性。
|
||||
|
||||
- **必填**:开启后,LLM 将强制返回该字段值。
|
||||
|
||||
- **枚举值**:用于限制字段值的可选范围,使模型仅能从预设的枚举值中返回值。例如,若只允许 `red`、`green`、`blue`:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "string",
|
||||
"enum": ["red", "green", "blue"]
|
||||
}
|
||||
```
|
||||
|
||||
> 该规则要求输入值只能是 `red`、`green` 或 `blue`。
|
||||
|
||||
**删改字段**
|
||||
|
||||
- 编辑字段:鼠标悬停至字段卡片,点击 **编辑** 图标,修改字段类型、描述、默认值等参数。
|
||||
|
||||
- 删除字段:鼠标悬停至字段卡片,点击 **删除** 图标,字段将从列表中删除。
|
||||
|
||||
> 删除对象(object)或数组(array)字段时,其所有子字段也会被删除。
|
||||
|
||||
**导入现有 JSON 示例**
|
||||
|
||||
1. 点击 **从 JSON 导入** 按钮,在弹出的对话框中粘贴或上传 JSON 示例,例如:
|
||||
|
||||
```json
|
||||
{
|
||||
"comment": "This is great!",
|
||||
"rating": 5
|
||||
}
|
||||
```
|
||||
|
||||
2. 点击 **提交** 按钮,系统会自动解析 JSON 示例,并转换为 JSON Schema 如下:
|
||||
|
||||

|
||||
|
||||
**使用 AI 生成 JSON Schema**
|
||||
|
||||
1. 点击 **AI 生成** 图标,选择模型(如 GPT-4o)。在输入框中描述你的 JSON Schema,例如:
|
||||
|
||||
> “我需要一个包含用户名(string)、年龄(number)和兴趣爱好(array)的 JSON Schema。”
|
||||
|
||||
2. 点击 **生成** ,系统将自动生成 JSON Schema 如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"username": {
|
||||
"type": "string"
|
||||
},
|
||||
"age": {
|
||||
"type": "number"
|
||||
},
|
||||
"interests": {
|
||||
"type": "array",
|
||||
"items": {
|
||||
"type": "string"
|
||||
```json
|
||||
{
|
||||
"type": "string",
|
||||
"enum": ["red", "green", "blue"]
|
||||
}
|
||||
}
|
||||
},
|
||||
"required": [
|
||||
"username",
|
||||
"age",
|
||||
"interests"
|
||||
]
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="代码编辑">
|
||||
**适用场景**
|
||||
```
|
||||
|
||||
- **你的数据结构复杂,需要支持嵌套对象或数组**,例如 `订单详情`、`产品列表` 等。
|
||||
> 该规则要求输入值只能是 `red`、`green` 或 `blue`。
|
||||
|
||||
- **你已经有一个 JSON Schema(或者 API 响应示例)**,希望直接粘贴并手动调整。
|
||||
**删改字段**
|
||||
|
||||
- **你希望使用高级 Schema 特性**,如 `pattern`(正则表达式匹配)或 `oneOf`(多种类型支持)。
|
||||
- 编辑字段:鼠标悬停至字段卡片,点击 **编辑** 图标,修改字段类型、描述、默认值等参数。
|
||||
- 删除字段:鼠标悬停至字段卡片,点击 **删除** 图标,字段将从列表中删除。
|
||||
|
||||
- 你使用 LLM 生成了初步 Schema,但**希望修改某些字段的类型或结构**,使其更符合业务需求。
|
||||
> 删除对象(object)或数组(array)字段时,其所有子字段也会被删除。
|
||||
|
||||

|
||||
**导入现有 JSON 示例**
|
||||
|
||||
**添加字段**
|
||||
1. 点击 **从 JSON 导入** 按钮,在弹出的对话框中粘贴或上传 JSON 示例,例如:
|
||||
|
||||
1. 进入 JSON Schema 代码编辑器。
|
||||
|
||||
2. 点击 **从 JSON 导入**, 输入字段。例如:
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "username",
|
||||
"type": "string",
|
||||
"description": "user's name",
|
||||
"required": true
|
||||
}
|
||||
```
|
||||
|
||||
3. 点击 **保存**,系统会自动校验 JSON Schema 并保存。
|
||||
|
||||
**删改字段**:在 JSON 代码框直接删改字段类型、描述、默认值等参数,并点击 **保存**。
|
||||
|
||||
**导入现有 JSON 示例**
|
||||
|
||||
1. 点击 **从 JSON 导入** 按钮,在弹出的对话框中粘贴或上传 JSON 示例,例如:
|
||||
|
||||
```json
|
||||
{
|
||||
"comment": "This is great!",
|
||||
"rating": 5
|
||||
}
|
||||
```
|
||||
|
||||
2. 点击 **提交** 按钮,系统会自动解析 JSON 示例,并转换为 JSON Schema 如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"comment": {
|
||||
"type": "string"
|
||||
},
|
||||
"rating": {
|
||||
"type": "number"
|
||||
}
|
||||
},
|
||||
"required": [
|
||||
"comment",
|
||||
"rating"
|
||||
],
|
||||
"additionalProperties": false
|
||||
}
|
||||
```
|
||||
|
||||
**使用 AI 生成 JSON Schema**
|
||||
|
||||
1. 点击 **AI 生成** 图标,选择模型(如 GPT-4o)。在输入框中描述你的 JSON Schema,例如:
|
||||
|
||||
> “我需要一个包含用户名(string)、年龄(number)和兴趣爱好(array)的 JSON Schema。”
|
||||
|
||||
2. 点击 **生成** ,系统将自动生成 JSON Schema 如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"username": {
|
||||
"type": "string"
|
||||
},
|
||||
"age": {
|
||||
"type": "number"
|
||||
},
|
||||
"interests": {
|
||||
"type": "array",
|
||||
"items": {
|
||||
"type": "string"
|
||||
```json
|
||||
{
|
||||
"comment": "This is great!",
|
||||
"rating": 5
|
||||
}
|
||||
}
|
||||
},
|
||||
"required": [
|
||||
"username",
|
||||
"age",
|
||||
"interests"
|
||||
]
|
||||
}
|
||||
```
|
||||
```
|
||||
|
||||
2. 点击 **提交** 按钮,系统会自动解析 JSON 示例,并转换为 JSON Schema 如下:
|
||||
|
||||

|
||||
|
||||
**使用 AI 生成 JSON Schema**
|
||||
|
||||
1. 点击 **AI 生成** 图标,选择模型(如 GPT-4o)。在输入框中描述你的 JSON Schema,例如:
|
||||
|
||||
> “我需要一个包含用户名(string)、年龄(number)和兴趣爱好(array)的 JSON Schema。”
|
||||
|
||||
2. 点击 **生成** ,系统将自动生成 JSON Schema 如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"username": {
|
||||
"type": "string"
|
||||
},
|
||||
"age": {
|
||||
"type": "number"
|
||||
},
|
||||
"interests": {
|
||||
"type": "array",
|
||||
"items": {
|
||||
"type": "string"
|
||||
}
|
||||
}
|
||||
},
|
||||
"required": [
|
||||
"username",
|
||||
"age",
|
||||
"interests"
|
||||
]
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
<Tab title="代码编辑">
|
||||
**适用场景**
|
||||
|
||||
- **你的数据结构复杂,需要支持嵌套对象或数组**,例如 `订单详情`、`产品列表` 等。
|
||||
- **你已经有一个 JSON Schema(或者 API 响应示例)**,希望直接粘贴并手动调整。
|
||||
- **你希望使用高级 Schema 特性**,如 `pattern`(正则表达式匹配)或 `oneOf`(多种类型支持)。
|
||||
- 你使用 LLM 生成了初步 Schema,但**希望修改某些字段的类型或结构**,使其更符合业务需求。
|
||||
|
||||

|
||||
|
||||
**添加字段**
|
||||
|
||||
1. 进入 JSON Schema 代码编辑器。
|
||||
2. 点击 **从 JSON 导入**, 输入字段。例如:
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "username",
|
||||
"type": "string",
|
||||
"description": "user's name",
|
||||
"required": true
|
||||
}
|
||||
```
|
||||
|
||||
3. 点击 **保存**,系统会自动校验 JSON Schema 并保存。
|
||||
|
||||
**删改字段**:在 JSON 代码框直接删改字段类型、描述、默认值等参数,并点击 **保存**。
|
||||
|
||||
**导入现有 JSON 示例**
|
||||
|
||||
1. 点击 **从 JSON 导入** 按钮,在弹出的对话框中粘贴或上传 JSON 示例,例如:
|
||||
|
||||
```json
|
||||
{
|
||||
"comment": "This is great!",
|
||||
"rating": 5
|
||||
}
|
||||
```
|
||||
|
||||
2. 点击 **提交** 按钮,系统会自动解析 JSON 示例,并转换为 JSON Schema 如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"comment": {
|
||||
"type": "string"
|
||||
},
|
||||
"rating": {
|
||||
"type": "number"
|
||||
}
|
||||
},
|
||||
"required": [
|
||||
"comment",
|
||||
"rating"
|
||||
],
|
||||
"additionalProperties": false
|
||||
}
|
||||
```
|
||||
|
||||
**使用 AI 生成 JSON Schema**
|
||||
|
||||
1. 点击 **AI 生成** 图标,选择模型(如 GPT-4o)。在输入框中描述你的 JSON Schema,例如:
|
||||
|
||||
> “我需要一个包含用户名(string)、年龄(number)和兴趣爱好(array)的 JSON Schema。”
|
||||
|
||||
2. 点击 **生成** ,系统将自动生成 JSON Schema 如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"username": {
|
||||
"type": "string"
|
||||
},
|
||||
"age": {
|
||||
"type": "number"
|
||||
},
|
||||
"interests": {
|
||||
"type": "array",
|
||||
"items": {
|
||||
"type": "string"
|
||||
}
|
||||
}
|
||||
},
|
||||
"required": [
|
||||
"username",
|
||||
"age",
|
||||
"interests"
|
||||
]
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
</Accordion>
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
### 使用案例
|
||||
|
||||
* **读取知识库内容**
|
||||
- **读取知识库内容**
|
||||
|
||||
想要让工作流应用具备读取 [“知识库”](../../knowledge-base/) 内容的能力,例如搭建智能客服应用,请参考以下步骤:
|
||||
|
||||
@@ -364,22 +350,22 @@ LLM 节点中的 **JSON Schema 编辑器** 让你能够定义 LLM 返回的数
|
||||
[知识检索节点](knowledge-retrieval)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](../../knowledge-base/retrieval-test-and-citation#id-2-yin-yong-yu-gui-shu) 功能查看信息来源。
|
||||
|
||||
<Info>
|
||||
上游节点的普通变量同样可以填写至上下文变量内,例如开始节点的字符串类型变量,但 **引用与归属** 功能将会失效。
|
||||
上游节点的普通变量同样可以填写至上下文变量内,例如开始节点的字符串类型变量,但 **引用与归属** 功能将会失效。
|
||||
</Info>
|
||||
|
||||
* **读取文档文件**
|
||||
- **读取文档文件**
|
||||
|
||||
想要让工作流应用具备读取读取文档内容的能力,例如搭建 ChatPDF 应用,可以参考以下步骤:
|
||||
|
||||
* 在 “开始” 节点内添加文件变量;
|
||||
* 在 LLM 节点上游添加文档提取器节点,将文件变量作为输入变量;
|
||||
* 将文档提取器节点的 **输出变量** `text` 填写至 LLM 节点中的提示词内。
|
||||
- 在 “开始” 节点内添加文件变量;
|
||||
- 在 LLM 节点上游添加文档提取器节点,将文件变量作为输入变量;
|
||||
- 将文档提取器节点的 **输出变量** `text` 填写至 LLM 节点中的提示词内。
|
||||
|
||||
如需了解更多,请参考[文件上传](../file-upload)。
|
||||
|
||||

|
||||
|
||||
* **异常处理**
|
||||
- **异常处理**
|
||||
|
||||
LLM 节点处理信息时有可能会遇到输入文本超过 Token 限制,未填写关键参数等错误。应用开发者可以参考以下步骤配置异常分支,在节点出现异常时启用应对方案,而避免中断整个流程。
|
||||
|
||||
@@ -390,21 +376,86 @@ LLM 节点处理信息时有可能会遇到输入文本超过 Token 限制,未
|
||||
|
||||
|
||||
|
||||
* **结构化输出**
|
||||
- **结构化输出**
|
||||
|
||||
**案例:客户信息采集表单**
|
||||
|
||||
你可以通过以下视频,了解如何使用结构化输出功能采集客户信息:
|
||||
|
||||
<iframe
|
||||
width="560"
|
||||
height="315"
|
||||
src="https://www.youtube.com/embed/u8NQFxrsaW0"
|
||||
title="Customer Information Intake Form Demo"
|
||||
frameborder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/u8NQFxrsaW0" title="Customer Information Intake Form Demo" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen />
|
||||
|
||||
## 提示优化
|
||||
|
||||
提示优化功能可根据不尽人意的输出对提示进行迭代改进。它允许用户直接参考上一次运行的结果来完善其指令,从而在提示编写、模型输出和反馈之间形成闭环。
|
||||
|
||||
### 目的
|
||||
|
||||
此前,大语言模型(LLM)节点是无状态的——如果提示效果不佳,用户必须自行猜测如何改进。借助此功能,您现在可以:
|
||||
|
||||
- 使用上下文变量引用上一次输出
|
||||
- 定义一个理想输出用于比较
|
||||
- 使用提示生成器用户界面重新生成优化后的提示
|
||||
|
||||
### 原理
|
||||
|
||||
在大语言模型(LLM)节点中执行提示后:
|
||||
|
||||
- 系统会捕获原始提示及其最后输出。
|
||||
- 这些将作为上下文变量公开:
|
||||
- `{current_prompt}`:此节点中的当前提示。
|
||||
- `{last_run}`:此节点的上一次输入和输出。
|
||||
|
||||
这些变量可以使用 `/` 或 `{}` 直接插入到提示编辑器中,为模型提供迭代改进所需的上下文。
|
||||
|
||||
---
|
||||
|
||||
### 步骤
|
||||
|
||||
打开提示生成器
|
||||
|
||||
点击魔杖图标启动提示生成器,它会预先填充一条修复指令,例如:
|
||||
|
||||

|
||||
|
||||
1. 自定义指令
|
||||
|
||||
在左侧的提示编辑器中编辑指令,以反映应该做出哪些改变或改进。这可能涉及语气、结构、格式、真实性等方面。
|
||||
|
||||
2. 使用理想输出框
|
||||
|
||||
点击展开理想输出区域,并编写几个示例或期望的响应格式。这将在提示重新生成期间作为模型的参考。
|
||||
|
||||
注意:你不能在理想输出框中插入变量。它仅用于静态示例。
|
||||
|
||||
例如,如果你的任务是重写提示,以便模型以恰好三个项目符号点输出新闻文章的简洁摘要,一个理想的输出可能是:
|
||||
|
||||

|
||||
|
||||
3. 生成优化提示
|
||||
|
||||
点击“生成”,让系统根据你的指令和参考输出重写提示。你可以立即测试新版本。
|
||||
|
||||
---
|
||||
|
||||
### 版本管理
|
||||
|
||||
每次提示词重新生成都会保存为一个新版本:
|
||||
|
||||
- 输出区域包含一个下拉菜单,标签为“版本1”、“版本2”等。
|
||||
- 你可以在不同版本之间切换以比较结果。
|
||||
- 当只有一个版本时,下拉菜单将隐藏。
|
||||
|
||||
---
|
||||
|
||||
### 备注
|
||||
|
||||
- last_run包含此大语言模型节点特定的上一次输入/输出。
|
||||
- 这与代码节点的当前代码或错误消息不同。
|
||||
- 此功能在不破坏工作流程连续性的情况下改进提示迭代。
|
||||
|
||||
提示优化可帮助开发人员和低代码用户根据上下文微调提示——通过有指导的迭代减少猜测并提高结果。
|
||||
|
||||
---
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
@@ -412,7 +463,4 @@ DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/zh-hans/guides/workflow/node/llm.mdx) | [提交问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
|
||||
Reference in New Issue
Block a user