g-tH}cJTZ(ComvT$g}{5
zLdZZ}{nv$f$IUFf#O^$W76x+W&o~xN?+*pQA;xG@VJ-%SE>AMbAlH_S)wP8Ac@H?`
zdYb*@fukX=I>B+o^LOXr`658nMd4`gP|u&RH;TC53ctO?$}+m(=bUwYc6KLjcjyPn
zW`PsOrg2V1*=j-S-RziE$`hv`wYjFIrdu&F|A_+mKSJ?_a5R9BA}b*|+b+gXSzT4t
zjO(>@Bx%9mP5R8rvIG8mXxDID$rJ=VDi1Jz!F+-h-KU4eJ-IGzcUfQy55jXLmU
z002%UN*MnE)HN^NH`J6wK53~Na}l*Ub~5^zYR7&_*>KC!2ZYMV-<4xEFa+e0XYB&
z2%}V8;+N8(!EK%aShI-(V_ZW(RE4{an_uWcQC_48N1_{%H2~@bdLzi6Rv*Fo*??=y
zRcuC$qgz=piQCNXd1L4kxY5vHZm~qT==Z%}VW@EW!Q54)3DoAgpcu1*3|TnTcJk?QSr(Ud&uV-09^!yI4H9C9b{379B<$5`;xh{wK
zSvrGw+yTEPmQDkk86`hA6)U)<^}y?8!0|IGX^t#-&Sp#Skxtz(w*|
z99c*knXi3D!0Hq4;DK#8l;R;3W|MhHU(vpJ-U
zHujR6@CR}@qF*d6&Byop^7!~~eu6rSRh>U(FYSGc3S(kmi9AVC*32^?P_w0gq>M{XFWD8%nKjagCY}D|4<8Y3>ddf9;BU&9Unthfili
z-N;7SMUykwRS22x-=JDfsQsB7Gh)3bxpXx
z@CgAe=u5uD%j|8l{geo+5L(!wjwgnnq|9_!oFie8|5dGQT&X>&?H~&(LcY4jw;x{!
zFJ%ZU8WKVhih^W=n(YYI!}Kx43x4RdFx_O7e~opM%liltkAs{8n{kwu1oT#OD){b3
ztN(J<{#R|nGh!r1V$H99BNrC|5?96%{kcr3EM6o_{|jg$Xq%myq9kYKeA2^M7=(@D
z@qPS{5&t`4BIHAob;wIZ`caHhi>~Zc)M-w6cM6nr#vu4L0bg?J@JprlPj(HBb(c-J
zbS~4Wp5L6hSxxYrq(z+;!>XIO|3?N6`!`g7ED92GrQwGXKi_#GQy$o8>&1s
zT6J>y3KnKgouTZKmfi20>KdLV8!?T4c4I^(HBz4cf#%`7kbM;m4NY}yMjfJeaLDxS
zY?
zqkmE!Hlm#uzeq#hN8C=USGPHuP4fgMh%SVp>=;SfZKWMg~8{I
z!}80U(yz_cNK)fU?dY|V@d*pZ*
zRr~l}cLr)AEl$5**YWHQK19Qw8ddEz{Ea!g6RE~5<300rT{rYtLxiBY74kvOW^Ab`
zYr=D1kaE&V4M+vd2?u8{<3PfBE9cCy|IUvE-Q&s-hL~^g6}6a08(#Xt{Uz*Ck`d7I
z=l{mj(c0Dkp#DQ#wBDM`GLSmdi^%zG06d~|tt?4w%kAchRh=J{@_4Uiry;Pj_!N99
zG<4E|c4@WM&j4m;)yd*5$9FlXA6_PnvfL;TK==N-x3#-}&gJPdqo;m_=~Z6X@EjCV
zGsDQo>M^(7LozFW_a9jWPj-pj_NXXqAD)S~IolEPKYZLKYjz3&PCXk`0bS!w9&gHJ!E(#tft
zOXizu>^Pfy1}^KU)i76N|HL7&u9|bY2y0&0mN#&a3vb(T^4Hf4?-1lW*d2$Kl(s@z
zbLU}P=u~?tbHl^+EYP;3lj4gI)l{c~(LLw>>bM^c^II>koc5e@in4S}Oq`&BvMZ%U
zjji?NId*9E4O^-6cf!7d|8ZPnoXQtLc{=aRch9yjnB08tS#GSib1v>Q$(H^uM#b~g
zCxt6B&tU=|>?4?r+TE}B`v}V~-pAK}xW7hwgK+KxFgAM<5>ZbC0Ib(#O(o~-oysG&0de6SKQ}&V)dFRU#Pz+cp!@&*=-_6B0BZ
z_KFE%WPB`g1HI7tVRb{)@>g(YhXSyM{q4tOWmoZHTh3-9s}R=|<%i?fsG>x?9+I$I9l>asMSJKNE6
zlDlLCz@KXP?cJNSN`a1hPGyTic)i>ae)F9wIQ0Gp9%RG0l7HkB%0nj#1sL9k>0BDiUx;b^zNp
z-wOn`ln79BK1#3FiX;U>922HjU!#?VMwaKEkOr-Y?D5e&1^TeAXdy
zv7hC0pLf$p|5&!ar*RKOlvII>{4-v0-z8sTd%&^Uyn&tFySr_I`+EvIa&F_8u1?Q3
z4S|NaCTP1I?FtTqx8V|H@o>2iPFCxWP8QvZuM-o#kIQ?^y8%HvO^W)K2j8`p0N0|Jqp0Cw4COs1QBM^W&%TaS*em8D#R!@h^SME$Mcr14_
z{0aNzlwMrd#lo5dQ`|G3@5a+RWN!Di@-u|AZnvARcJgRrHH?7cfUrjmc0w5hU(L4%;P>
z!|!?AnhL~uJ@vLXNO@&XnJ`VIjbTw@5`U`wjNz!JpjEB?m@??jrw1I$#0V14>|Pp9
zphON^Z$Av^+?&}K+y|%ua66^^?x(d=WL7Z6J68M=raJ*8!ue5=-{DwzcE>xQmz0^}
zz*%WnSn5}`UKSm;S5#Um+81{VY1Y`%epAi1N8_V0l<-I|7^|yk@Hn*MyJuGi0B9~X
ze^XUe(Iz9tO*K@$I}SAri~GX!dZtu|lmxCTG23>syKQ%UbDM%jLuXGat)BZeaR}Oe
zr%3x{)X%5Hu7%j7v~VK;L@pRt@NPd(#GowtKA#sV3Dne>>Ftx`=HltN-lnU=iZsh}
zID+(?IjArc(?yXEpVlNRZ4n@&Xq_}){HPo?l2lo~x4$Sp6a=m*V45qWaNWuKoFy5a
zTwc`R;U_&__F2Kb09*&xN-~z&>|&`TNo%O!)5`2O_Pd>$3f30Wr=qpM_5~MO7q)*D{J=I~N#XBF~mP)Hurw
zVe2gvJ{qbz=m0IYllkI!X$fHaT)o}QGF*)p{@nmp11>Z`jLZ2@0c(AK^~;x}mHX2q
zSB#}AxZ0Y_9?us6zf>d67E|KQ^#l;a?fGag1}nfIS?X?y6CIcEDa*O`3nK#`bU(_D
zN-klZ^UNu^8pSQ2t1H`}vG`|?tDGyaSCzZ@mk+z8d#?r=AuDb>6J}}Nv#VcJ5<*@m
zwwn#i7G`;GOq*gFo4k=!@i_K9DQh#ST3VaG*=u;xlv9!EVI^;CX_~v<*CmmZ!N$RA
z1|KXXYdq4)DTApxDzBonjX8d+XJhu6{$ir44(&
zosm?2@bnj;*udGVEbl9_d@d%g-D80yt-7-sxapup|CA0wf!~pV0ojGlcXtayp4WxS
zvW1G|P8V1;-os;XXSP`LOrLLL^c;jQSI$ec*kTlcO|B^5%oVuN_;&*EdHxAI-%lg4
zvLpfc$=PNK*j_4oJMVQI?57!c-pAkF^}?+k@Yzd#^TB;));eltWlr5dh5B@njFAxQ
zb+X%y#a(OyQ+U>U-U@oY(dTl3q@WPwcVTxUA*|I-m>_Z96*kZDpjdd|ps-yuuG4WG
z!4s~1!j{xn@p;Bf8l(mON?ouE`v&y9DpLZ|LfbBv*Cn0aMp0Bs4wXAV`9|({6I^8tv-;;MutUh%5!fPf~Av8hNV{2d8V!E*htCI83hk
z%dob#ejX+Zmk2<5{W@*M3pUYm?A(DX{B*fc8sC&K?qCwa-1arobqjqvrhCuh;1PPF
z<o{-`ojg{m@W%B4TYl
zp6`DpEe5zI=er)BZo~6~^Y6I9i`HC3Kw1i~2N#{~z1_bB$>5pHdQqUrt@Xj!hBm$Q|#>|~~Rd>Rz|_j(uMglHwj
zkl8Kxt4zsSz;+{p`IPiHl7Bpl8`i4Ln)dRh-5NqDbW*k32j`Xf0c1XiscWc#F6)am
zJJ?_^io4ZZ9#a}CzOJ=Oyt$u6x$|mqkeq;q+Omiq_lj5S!wau-v%wWDA)3)PaS^jty@lG54ey
zxczh>w_+mdU
zSK<4CLF0?*bI#&Qo1{wtRwVhq0BNeSwL*EKE|
zJBkZ!P-c$_4n@1UdKlbN7ky!2LieiJ6vF^O>)mwk*LdmYeL9#?lz=nM(m@CYl^3`>
z2_-lmTw%arcRh(kVaLKyMqg3t^LV6WW+1S)TsN4Oc2v=R_1(4(PJFsaR*{%qsd*z%
zXn#Kv*d6*Jna$SC;^XT6f-Srl87!HP6*&y>BQ#iEwY%~>U0w(XL~LL1){5R_ddC9(
z9w!V43umN}(Zt*OQzb7VGPnd@7FR$2HFy$D!FgzoQ?}*)RM)^O25dMHtOffHqzc$(
z@|x>d&NGbfN0x3leh-Z{``s(G+~PVHyP=)sRdob+&Suc$2l%3;vsAU_-c2>|7zns5
zwpk^;&w!J+yk1ZV+S6YxoLpDvxOWE}ln)EWQir_}Ki#b=wGqHxtnt|M23O3s!FF?~
z_fpXn*@=QuQ{hsuHf>f@%s6Eod5yJicq=~g9;wN~p-e%qUBAlFRgH$_KNpLG72cc9
zVX&n(uU_sA1MiKE@oHJainLEFiywj7zR&?5^eO>YGRx`Qa6{i6HF)ajZ84nCpJ(W^
zVWJX8BQxjAS7+#T8F*l8V_W5Y*W(K4>`QBBc*o#-SqRAeN>-m%jb&GQV+yJ=i{(-NdGL<{-
zsQu##jirYcAD9!6JKp-Reg!MlYuW!n)`Fce&`*eL02M2PY|8tf=NOG$aWWH3xYQIz
zk#TdqeYZXu>zpJvp6QgY^~eOITH+=7e^k8%P+aTM1v(H26LgT^?(VL^8C(JccXxLQ
zA-Dv0IJiS_w-DUjAq01Kd;8pb|5xu-QAHIA%$ELI)>_>ycE7xmVQq7?P^rc4ci7Cc
z@zh?_DBShWb{2}kc#g-3kWF&3=I5@L*FA8L-NuQCC+|y@fPI>fiK_OlRZ_EvHIR?&
zJIeMy`e;J!z_DnPMBP<3C+Zn@#gpThy3|UJ@-S`^`eQjJF};8@rxQ2k(Z0~
z*P)B*j*btYpDq(|YD*7YzSr4(JY#Df=gpK*x`DcX|15AAPW9T3+peRU)p}dE=r|ez4erUv`aamZe@m%_QB)rj1L3INsMJv$6%G2e!Q+u>G
zmVG%zvoSl*q}IaKfRg@1GPfo>W{!Drk+d){d2s9tx0%(nhD$=wU_Yh`jhB;UU}tv;
zL6*%Ha+wa?4qi!SfeXBZ%}I9}CItgJF+D#uTlwwHe7y9v2{ovk3RYxag$^uW-7_@V
zz6Y9JKD$8rHOIq=lah#rKUocUEoSQ4+S;P}_K4o*0O#lDmYKiC6nmrT6$s+QN{g%Ow(o&}>U-&$U4{X-`OG)dA4^1xL0Dp-=to|qlp-`qAdNsd4KjgA&=I~)Qlxl#P9dduN0vunIazP
zv_qZmq9ExI93hYS?XT}1ZmoJTqC+ylCjbtIK{Vg=6NLng*IO4Bsgs3PCLPPO8?>}r3U=vp$Y#q41
z+~VBD;&Ll@T`u2nzDIz^MG-TVurx7|GlKT%d924naQxOXtzHuT#ujEzMyEl3r7wqE
zMjX1?B;Uw|rSbR-@5g;3bIy4xJ#GiCQe9&%u+PJAqmr+1pV*Fb(tMg6;kJ~uHvDx{BRJUl$6*=bY0c!X)?3JAXbZ&yGl@Oye;
z0Ww+*jrrmD<4*jGsU~KfMWq#VQA~oUM2f{DA942$H1v0#
z4vaX#;GVE^$k#m+6Y??htrGNaQSW=xp2@W|hKI|6u(iFmXkNGXF>%#xFTTLv$;Cp+
z>)7H5Pzk?^Tjfh3rwiNZIvcM7uAeVUjWlBV;(CUMC0)qY@@d}uQ3If`*;RqNEb&R;`!lIE!Mdk%nw
z(4*%0W4pYroI+&Ghj(56pCG|6q0<U`>4j1DDTbGh45@E{D-u?&p_-8=!!srv5#i#YM%*35aE?#O1mEgF8o!
zV3v&i;EP%=zO`KWBdGfio+id)0RhEtr!ORMU~`KX*XEn7A|>XsL-624W6SILGQqi9r8H)Jey3OFN=c?#ScO0Sd|K1R!`j~<
z+YeHv2e71ziINz3&H9iy@9^)EL-hb+mtg|RiJHk#jd+NA!
zJTCMULr;Ifkr9GMG+9*z17}_bgyK5n2$Z96
zFqv8|{@9MHAe2;j2U}6YhOXa4p0PIMl9`jE72B#57W*E=$<+V{|8SJ^9=q;?@}Xn1
zM5!C{CkT)tOJ(zLa-OXFBr5;w%OwcjY5Ud|bM%P9JPOQqu#lC>3a{R~Sw9{$H_J$B
zz=12?fQ3q+Y_njl*z*Xk1TE4#s-{F5}A6%1x$%w_q@EY?Mm@vCFX^6^F
z|Ir9VQmVn06&L@;D%QkgfQ!4229lW=y={8*l52^=b>m$8Pf|0Wx%ne3=M%
zJJTz7!26MS{wi&-FwX@*1WB5}K=7vD15#XEE1k==ayivGqvI~Ey5OFYFjf(fD{&hdPGnwW-*EFDXmJR9RI_w|?!Ek*PeL!$j5d3+sdvQdP#fQigo7MJ6ih
zrAUHwN0DuqAU%2aA&>83H;@7&fK2zWf`j1>&Gq%Hu#yr5d*>#Uvf*(5Csr^n)
z_w}nEhm51J)KNa5!X?^28b6Ii?wXorkMqX~_#d#!2nN=gt0;Yd;`-PPZ
z{)`&U^r|a@1+gn_D<5_?8s&;gecSBuaexOUYJP5$fKCWna^eC+iH_~9G;up7=zL@#
zXUXT!V&w>S{Cs;ba1AODu}z~M=9JU~HD0G@u)4ZZ_PCDojIM)F<@vc`K>5zM*se~$
zJ`{jy0(963m|Mv2drUdU+ui>TZoY#7;b|?A^}twM!d&uEhygmA_up8p@BewYD)N#}
z@v$W>pwTR;c37KainWT4<{471K!G(bK-9
z1?@F8c4YU;$IS)b?>~kVF|FJJ_1|-LhcwVoi1PkxJ)&YqieRXu3cet#(|NbVnO|vH
zX?3LyEhF<04vCt&9-uDizp{VXb!;U>r9nihDk*X2)s@P>07}MzK8gL5JDz~&*mb%y
z$7zJrZ1`y9vOBxwZ8iso`@DjBH99x&*-_chFwpJhgy*315#klEf9Ob<5|`xH
zd&6<rEZo4YD!U82<<6^eD}Vora98
zs5h_+S2Fj%e6FtT_4b!^1JkxMCtxa&qOE)A_Ex*~-NVeLD|gf4OJy=$f|Stf-dhH%
z{e9_iP#~y_>|1<$k{J0faSg^6{fT$m7Bz%?$#I#uBBXqxe;zJOLSIFEEMTamlWtyo
zMwWdFe2NCvxG+7$Fjn2-zQbz>ue+sq7@g=DX%WK0eSm`vh7e+e`LHKAdE6bGTBX!J
z3F&do9K?OXz)0?X5fW_Unp3}9=XYyUd*k2BzPdwLz`-%s)Zk&(;-wMPHBilbIvDQ-
zI6bxS3pOIX4me;h*21rc?>=aWYj;gF?9=hGBQ~0qUr5bPMV%RKytSv3QuNOU6Idn~
z=>D++C{AG>n#uy+*u23=4VIS$@d+kv<<%LU!H1Tv^*dlfw4SOP-csa|s}~5gpx@xW
z_PEg2`eb%-wI}kdj1{LVi48K0VE>(-m+kAWmdI9HRii-0$JC%5EjA>0{d?qY)$3&$
z2`5F9>-kD#LQ*PNeSs_BOn_%t-C8Rd1z*8i1q5VXVKCln`du*fNgBJ
z6MUTQpTl7!#wQ+`fTE$zRCgLqi4g0)RflHt;8Otibk_N@9LzhjTe-6S=IP+C=&fV1
zv8*0hs6nHOqZe?qyr;jsEW&GCvsl4BV1`qfDpKt@@jBi0>Y}G=e0(wdm{HaB*?rch
zaIU>}VRq|6cF0z%$>J9&ajfS0LmkQ5#W9jjnRR+R<`z3g{Azqs1Y)iJ;{9!q7yO#g
zJJezwEXiz~0?JQc*-Q(lK5m;o@5Z8~j1E;++Cb&QnCQkkj`KdE2{&$T(&%fHCMqxy
z0plz%9SQg1wUgU!m6%!G+k}{#EKW05^`2s0A99YS&3an_cIsNr>MLc~OCeCGnr0$9U4R>iO&c=fz{
zTcw}8v&`>(`n1+TDcYQg8G6u=KD!-^!_%1sv4{`agHPUZ)sB{`^gb@t^mm+4z(LqO
zzk2g@^ott$qOI>U5}jgEKm|_}MqHf}jOnjgJ;4$QO&Qs`c&x|2iS>6p0(!=pJOZ?|
zt;L*GGux9_4xE*e6~s`7E*RRrd@CEp`q*M>bnz|LK2?Cm!O=32^1}faTvB>`^JxoD
z1X7*Oa;u-e$bgeegtNiM4bC`&
zJTzvZWG-vX@6P{BC)b7?46E-kx2&lj&{di5A>$qCbdqF~!jk24F4MO`?AecHS5jf$
ze${9L0;N>xy-s4Xh&;|pg%lBF@E2@P|2bq}_PxJI8BKOdl2uWkaXs^JfXarUtczyj
zct3_@dzxbg|E%h~p}AYH`b@7HzoqZ>@{+iHUsQxDG7=9rwIK5RM~6V8@{6HM^Ry~P
zRDW1QdGhmC&&`|vbzd0k3t+xJr_Ib%e6PPgMgk{qraj&_a?ad^cgJl?6za1!XR}Zl
zU@~j##wV0-e&li1uAe=PX@y?U)_b*AhRX3D8B40mhXR>+q-O#DJQO?%z(c8(fDERMls&2rxgIun(gp&T%PBP4zb~(t-l(?ZP6X
z--8m97jAFR22!KsaK_>atPW<|3iE-tnAO74laYl+yinCs5WpnpvlKnt%_9im@vRZTMrv{vdg2Tt7fWe$NW0jX
zxW0C3(iWel8TB}&a}7g62BZcm`o90W`iY&JpTA~pjYC;|<~Qp#;QmzlWsaIV^6MP*
zq1m<_Y;`x5TG85tqvNtf9I+F0qtswyN6Y%MqLva?0k(D1I)RwvInVajzd;pI^^{AS
zR$<6!D3^&m{R2eOBV}YTbsTDT+|o`es8C454U-*FhmrT%w4}>6EH`%fiKQ0G#D(Pd
zB`dlQFb{_p#7vd$yn1N|Lzmj~%F6;iHb**c+Bfl%F7@~giH;*4`<8{ho5MqjBNG5H
z?do>-q{U6cps;@Xu(Wzy-}%+3ZH+FYzOj=_7g65sXg?|0Ue&tckmOCP%Tx3sT|M%J
zQOCP|-WD%MEm1)DbZ|^@$1}IE(#9Y9wc@KJIuTtZJ~10j{{Ulpdxqajuh~a8mHx2n
zS;{&y-Nr`Sh$%K3gSSb*T0oz~)!MWR1hdk|bB*{Hmdu)a!4Qe56=y4F?%jKA`f(6Y}F8*dL&0tKJv1{er-
zvG?e)q89e5D;?6*QZaQ?h;6aST<C%>A2}DNmQ%(Ywj7
zs?8K;ENUOpXU#xASVUV}(~{rPAeXPfr1gbS`cG_H7Jf?j8bXsS{dH0(wJw%4qMfuGiV_8Xo-&X^7udzik>jf5
zzr81dHEw%idXi(@#c`RDb7(m+d|)y8hm*n2KDL;PGI(+Zm_5CJtXJ!(=)B;(c;^b(6oD1R%WKlEzk#rFdn)4k
zoFdY~K*0o6)Wvze#@c&082_46Zk*YvA6HB~Mv1?zU{<4Uyz0kAPIK|}T1M*CCH-R`QUo;q=So%!-$4_w
zlqd6*>6$qh)uhO5d-Mdqfu4#_zj{WNZ@MVf$Fl2m#pw#^UY6VshhYIkOHG
z3tx5%weK<~>I)ZG|7j0+&`gmDTB~9!X>-Rp7YdoT1iU9@;?>5xbTm(6f{`+tUoi2O
z{}tI?-Mkm`+?Pok+x^FizQoJI@A;Jl`7{Ft?o+C~sJA!qAC4LG%Pqvt{Jj(eTo?T-
zNumG)flkh*^@WeN-F2w9|9geUFs~8aPVKg*GcrL`>X0HheTY&WDV!ua1cNsm{N6?J
zgN7|4we@R=i!eUre&{oKFDifD#PAPFj$c;(w*Qrgrd}a|VGsppGiw3e?BlclQ;Ayj
z0(}zVgPmlF90w;at1C_Lq`AlA%WK#hU8jB+2`ySNPXjf>(dFL8Ik{~Ae`}!UuRg>Yot_v*N^{w#9l~v>ea*@
zh$2`fo{*S}r^)q@^RRK;zG)yKA&EJnq@}^d)HI582*~f6za)@OEw6K#H>zT#r9v`r
zNfuU@*~}YhljOC`?6hT##e9(mF81Vj$#;=8D13Vwf^xkq$EP^s^f%zl`n|AM!n^o$
zgnEK8I|BN^P+cfYm-99=b>YSdbb_o&(d+DD)ynw{Ia&Ej|;6!J6
zxKlLeBfu>}+25pN?$D6wu;ktJ)ZFy)KfjxA^Eunh?u1c+XeB2MTX|~543v6}3-F#^
zV><-&(A-Z#l(TWhzl%qak~+cCdh{TPIS%b>rlmE#BXc!JI+naZR(k$>F8GEwpKMT=
zbv!eXZ79exctJ-vkTblEE*ZC1eC^hH`~0`uPFzW3t(xF}I^bQbxI@v*AW-rw3keC1
zP%-Vq(GAYFIkS%7f^`E|gS%-#VTFFnHjtxnS-Xk55R5pR*GU%7VQ-rO)yx5v4a;PS
z`a?_Fhl?6PmI~cQRwk;rE#Bk5ydGhy7Z_dyWR&vukqQ3{^{wQF4z1*c1xYKkLPeF%
z{y3caSenifS~8KM)5P#iY6v&gp*b6!S0K{s*+r`|2d961aY6>Fkl!fYo$YF<0K
zi3FpdWCXZuhH*;)_RjEr}xaq?SCjrSg
z_qL-r8lKZc&fD`6uhrc|X|6i-rPN%#?@_+3T;@#Pj668Y$D`OqFVGO=z&u*8k+t*l
zjb^1fYrUXML>@TEP|M!X(KTIYXSyiY1gwt(g*fx`S1*XLx=v$?GkZOrhvD@ZD!Ehg
z^%;MCxn#u0=Wf%@PU}smw)9;!s#!Mgz=0EO2i`^Ft$q;cwphdVtf-#X61*h*QeIey
z^r&!7!0^ux)*RO1qNpKY;)Q2F?-G?#p-h8-V?~dJM0u~PZU&VcN|CH(}5luiXi2ipB&FPC9
z-+SUyLRF{ha!J9|32an!U$=OJNDD*x*k~A-n5n%@X9al$wYBw699xo^(<8UDOS-)l
z6`W#zaLEIC@W_r<{Xbw3tG!F2=DfjAV=~}px5Ot$B!JjayUvRFY
zkdb3t-S4Wu@K;ymDnNqcRO(2>QVeQU?IE)0zvz>k4K3@d1HP0Rmf2(^B>ZLmB5dIQ
zhnb<;#`ZKU3c1a5j6G-K?c(-ji+ccoE|~S}R&8sRiI_uscP<{2nV3r}ZM14^g`pVO
zk(E_7c74+=l+atWC_-LUR7k1_j|c-rA&|4>wTeQ50U3vGyEz_dP-$P!`ny6Qzi(_)
z{aoeP9LPfa=2mCNGe?{s=c0>fdk>MY*^p5{w7`J2*=Z}zU<1z{@@Q?YBX5=TJm3Oc
z^`XKbQj>t`TOtJJR>$z5T(dcaI8!YzJ#jUkM7FU_sCAu1Aq|WE7i6-E3j1IPDr)pJ
zvfssFVUHG%z00wH@~*3obKNxdD8mmaopOzGg!iGL(oAyL*cN65AkdfOjfT6y!Bn%0
zXYvNw58(&&kCs+$;%d@H{?w9jK{C)TZV59569qjvQ_scaIXO=2xz29`PYBZPCjy5z
z57(1<;J+P(Pju4FF@3cG#;!hynyX#7{(h2N@#q{oskg4##nuMmSa5~sHs
z=!PyBN9dB|_hrBs!*Ta+(RQ#bi$vq&r>|apUO@2)>^dE2v)EvZoXbwgYV;IUk+ad%
zk_3ppvw-%y+Q{UE*`^Zp;r^nSsB6j&eVc}5;LhMcoDHt6YuOJjNTk6)T|3t>rd{bh
zcL^UCx0!RwFDPjJaG&r3%>SYt90MaO)kgImtaqHHuAKs9v|jB`T+rn5`iX0+RrabUsdhFb21mcRF|w(j>_f{&MLSF$p=
z1NN_;U_ha<>L<%SiA95Z1_0PIAeyDvarfz9W}*WIw10T`GhGl$Ozeum>U~U(S!jqTO26c}MNjJ7%L2czfE9i}w
zDA^?v{{9iD3_%y|PH&wbSm@B!TdA0_2B3%aSHogLSXM#y#+wcz$gi(GaR?-SPQI(B
zcTXgq_uq#PrKB$H6g@M@R-fk^TSK@(-65LmuZ~Z`SsER0$`5K2oiPx09ovb{pI%Qf
z;=m>3E8RLQKa+tBfz#m7)kQ(w|3z!&dYdCd@wO43>^Bl7Nm?FC0$Z!H@M}UAg2CGJ
zSE+pZ>I#FqX995U>(@90V*j33rx*H^i_Z&d*20{2rq-_>a|p%PL=
z7JOu|TI&K#W7X&|xr@7D>4e5_ufH<`3|Ja`|8iV3M$#&@-uarV;NS}a?Vl3)o=>3=
z#|D_rJ_FFbEW^>}pYz3DrS{_sPe0)|3Z;%|5mw|)2|X=vPxedU5l=f*#Z=B_!Qkzt
zeq<-tQWlkq1PF}Jzen8L6863i%y&%B2!uf%C-Mob3ADMa=NKG(&xgjvL4n_-=>aHB
z&BCKgwiH}u&@}MWO~C>35m7
zQ1I*(_=B(*SzI9N6o6yJlr~5uRVKRHZ!E32K!zg%IT{OGn9~IOOMQ>Cb=B&#oYu3$
z(EyHVbH)ZXa56@^qjk&osz~18a
z$47)Sf86_4E^ZIO%kBQhe)sP|UblTbv4rKYpnqd~M0$U7YDwkU>Eh)r%}n0#|Bd}r
z6D{6`Nlq}73=ZwaEXtP#-$u<0S4RAK|r|bT~
z%BlJp2}wN{y1u%jlY@(K(-AF_4}Fp?{vwfP=UND2u%MroMi)TM&E4RdgthbeGncO0
z!*}ksy7n?)IMbt5BHLwr!$`nevGh){OSBYI&fp}lLNKnw4&EzGb-}kY*O6Z?f`&9Zl3vU|FG?4mtp&}
zlvm3^*W-a+ErLAF4LJh(e!X=Nsr#{TW_J30KFR8P5P-IMw5|fN>Eo`&64AKaJmWi%
zCD$Qq$NZ)%Np;2B5lH}{3A?`k1$??4q`(l?D80^bbx&9+aZ%)9YrO
z61uhKONBNmBS>`bFf671as`ok1NsvF=#djIm!sSEOjoaZtdIBnwi{mi^BGlNS}kMT
zR$m9Ygx9B*a7@_O?^fP$aBxsSmPh;cXZz7H5yz)^_wy(zKw+WZYz)H^W@2t5slHVm
z;IHItY-^-HpD@wk|3Jmid#z15w^C#!+rtXA7kIXor$T&_-?aDgN8
z8lyS{93dXgCSbFv2+GV6pxwF*?GofSC+@l(<|47*@BrZD6#<`*0F1F3^cd3klhyB&
z(J7y5V$MzP*#;~~nf9aEjvM5CfsdHj=-pZ82hjQC7R%Y9%XYRv6^^7zO#A(Q!b?-Y
z5&aVMejGtyjkp@Cfk6z~h)3Rg_Ojjt0>xOYk_5EA1$24OIbc)x-OI@btvpyOq)p~W-
zH3M5uy#~aU4z_KE4?%!804TICs+mU@kN&qJO*FE4D}>{hW&KoTv*-p*25sriU!s($%g
z2}2oyALCQgQvfW8c5pm4vqFPaUe@^;cuOko&+}aMOnSQ0^HXik5ADFg=yKf2
zn_@#^UWxoqVgAr3F-e6SB9u2XRz=5hj<^J4h67G*M0!Vk7@TPht|vrjGd_TA>y@0r
z8gXW$-lDS6SUyG#3Pj&Dk}ZtiY7T0z*!~R{Is=WDknqIqW%U;!Ai(S}pHppGDW58F
zLMd>83nnFX1Cz7RbQCr632{xCyNt37IanV=g>y^cQFw_?T5$nlpe(%??JVs~c^!D_
znJY)a90&muRT~Cf1ac!|7nReBRb`=fvRUEFdpBjz`~z
z4b*+$`VMZ@zFNC-+iM*c4}G-wJ2ecZXp5!kXsf4aT;heME+f1buvjH|k2f0!E`kzX
zB@m8~m^hMMLP8qPQ&hP;>BB`4kb2E-dv+)ipyvWcT|PHhwM9_fa^Dy2@OFuYmY#>q
zqvrv2Oxmrl<;IdEVyd*VI>A6s7is$QSiUg)1dYFb(#nZlYq;A7VxaP}i3=|#riuHR
z$o%qpzA`ICK6bD~rIg>*O^Wc_v<5&Tsb+f2xZy0!av=qs1EJb0TN*@**UxXC0>}Ep
zmf)wpSbI1QT%l@QBJRo>2LunjXr?4dRtl>xI~&Ht6fl4RBr%C#VbY&I2!KHutX$TN
zomN!YjgKiJ4HCyBg!1!pwi+)9F6C!u#i^>VVL_}kp8ibki;#Guk{JR<8+s7rAZ5!<
z1BGZE(6y6(0#$WAlJh<4VauTw+gN%Y=e&8Lf>_Oom6Q~MA@1%sUH8KRi0MwPt140t
z!Vxt^C6jnTkbmfEJ9AGSQX1($j+QK?C&e)q8^>@-hLZ>$_CE9kd&X0nJ+qdW$U9v
zT<*bPYw`_CN1-Zh$N=NRbY#>ILK7Ie#SM|}+SS&Z>Z|tdi%ivA$JSNF6afY`Zg>Dn
z=c7I7C+*o*ZzrYvEj^OJ%`P~4bR!P7Z+nQi6JG7G8|Zn?tk0-wgCpC%s`CYX&682V
z0yMCa!G`w%geO9aL8NQSo$
zAHt|#DIsFc-j%fCzx}#87WnNqI?fh>B*%CA>&D1K8Yli-@SS@4wKFV5%obkASIAF7
zmb-BXnQ7}MX&mB9)HjTA3=p@&*2TrC`;%f7LM1CGg
z3kE*4KkUihqk7I7NOkrDh&Rs9-k#J`^#x|+2?y33Pb5dMQ-b{o3O|d7<AF6KOI+g4v8PyON1`
zT-W0%QKtt1?N7-#OT$Ne(D-@*J^gAHd5l8r@-fRW@SrBGAJT_kmSK*q9hZovDp*;H
zO|qo`;LJebwRcJZP;LvlE&TQ7HTu;=M0LZFU;hQ=kZFz5ix4l_9iHZsU|H_9xIJ}X
zK-!h*TV6-aW2Wpf{>Rz4YM&jG7)2p1OI98mPFbX3&doDBeMG4Qz(=i_r%1_JKU4St8>)y&%iH%KOto!h1XKO(O}qfKz2LgR@u#p);g
zfj7;o1bFDty>HqJsL9Wc4}Er`(f-v;O!#{uh-Z2w?ZTv#8n0<=r(9T&Bo^0Ug5$Q3pgUf>MvUi8g}2Qv2~DGi>CCfAl+!t^!(%
z^~`pl+8EPms@8eye|z0USbP`t-w*{0jqjz{1z6OWq%1;KaptC93nqkY_jxXjV_kA(mg5udGcz_RYf+AxN*cTEg*
z)DjMiXktvt
 +
+ +
+ + 
-***
+---
### 应用场景
LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
-* **意图识别**,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
-* **文本生成**,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
-* **内容分类**,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
-* **文本转换**,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
-* **代码生成**,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
-* **RAG**,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
-* **图片理解**,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
+- **意图识别**,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
+- **文本生成**,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
+- **内容分类**,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
+- **文本转换**,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
+- **代码生成**,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
+- **RAG**,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
+- **图片理解**,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
选择合适的模型,编写提示词,你可以在 Chatflow/Workflow 中构建出强大、可靠的解决方案。
-***
+---
### 配置示例
-在应用编辑页中,点击鼠标右键或轻点上一节点末尾的 + 号,添加节点并选择 LLM。
+在应用编辑页中,点击鼠标右键或轻点上一节点末尾的 \+ 号,添加节点并选择 LLM。
-
+ 
-***
+---
### 应用场景
LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
-* **意图识别**,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
-* **文本生成**,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
-* **内容分类**,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
-* **文本转换**,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
-* **代码生成**,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
-* **RAG**,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
-* **图片理解**,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
+- **意图识别**,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
+- **文本生成**,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
+- **内容分类**,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
+- **文本转换**,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
+- **代码生成**,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
+- **RAG**,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
+- **图片理解**,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
选择合适的模型,编写提示词,你可以在 Chatflow/Workflow 中构建出强大、可靠的解决方案。
-***
+---
### 配置示例
-在应用编辑页中,点击鼠标右键或轻点上一节点末尾的 + 号,添加节点并选择 LLM。
+在应用编辑页中,点击鼠标右键或轻点上一节点末尾的 \+ 号,添加节点并选择 LLM。
-  + 
**配置步骤:**
@@ -55,18 +55,18 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
如果在编写系统提示词(SYSTEM)时没有好的思路,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
-
+ 
**配置步骤:**
@@ -55,18 +55,18 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
如果在编写系统提示词(SYSTEM)时没有好的思路,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
- 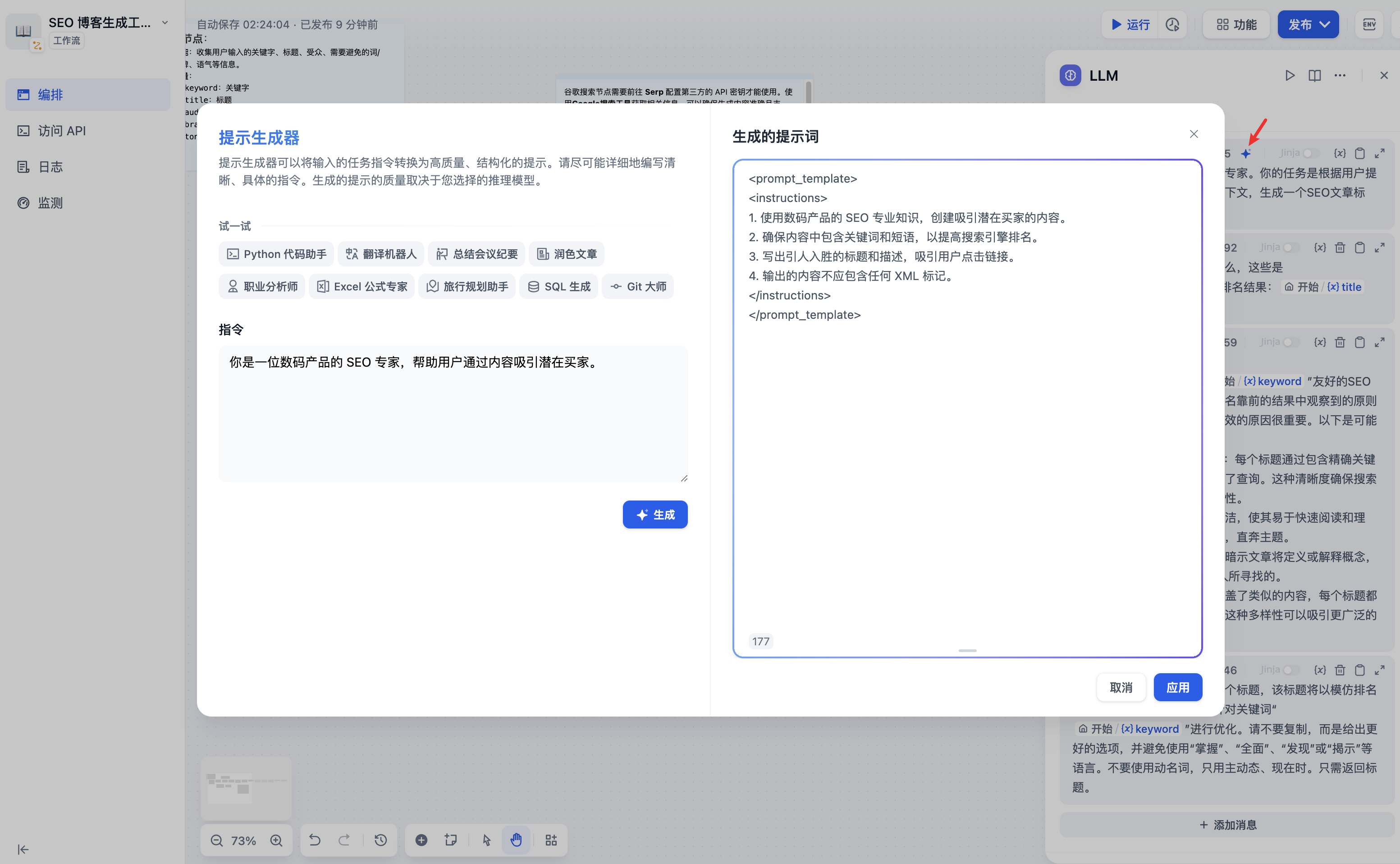 + 
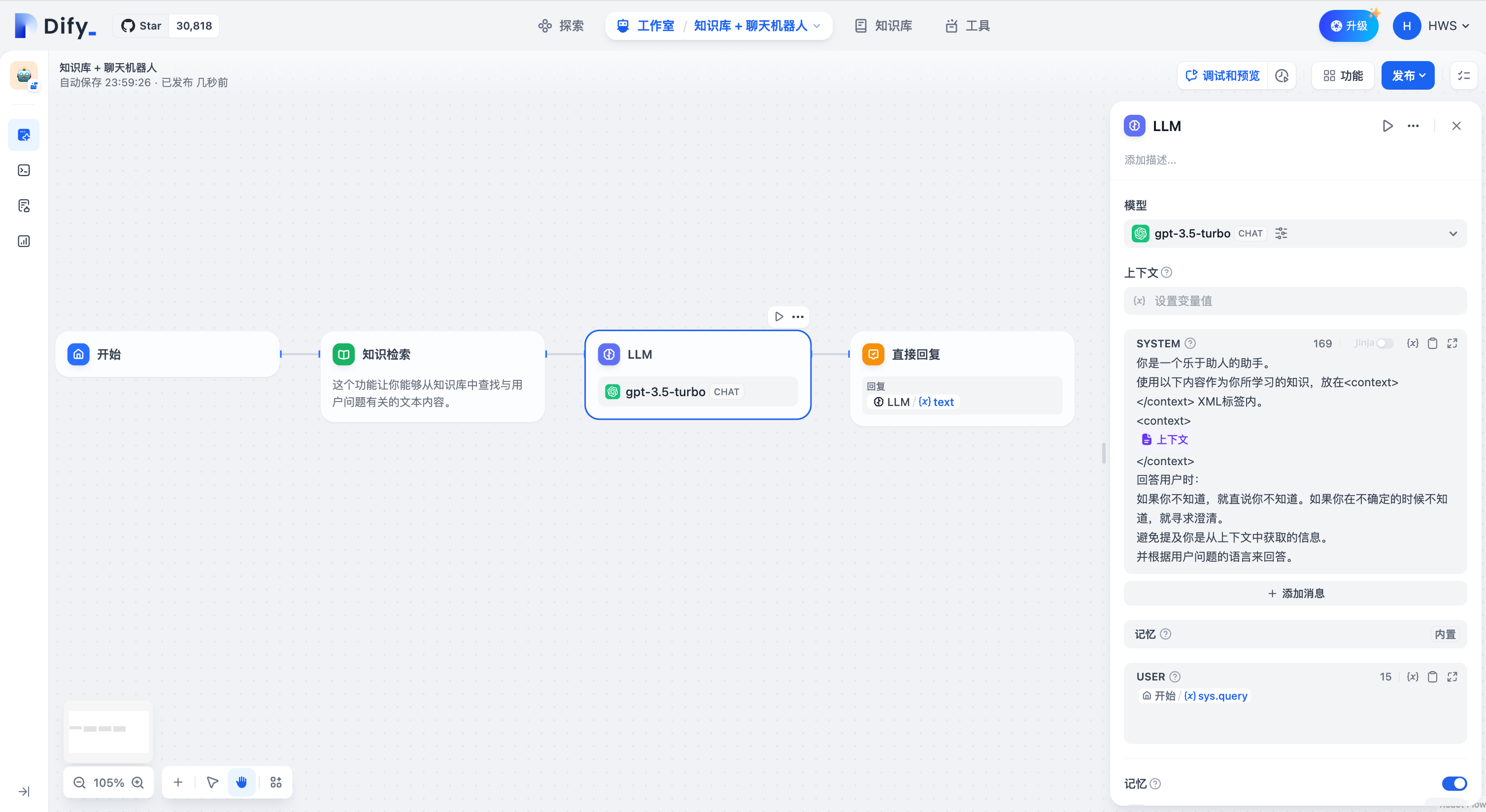
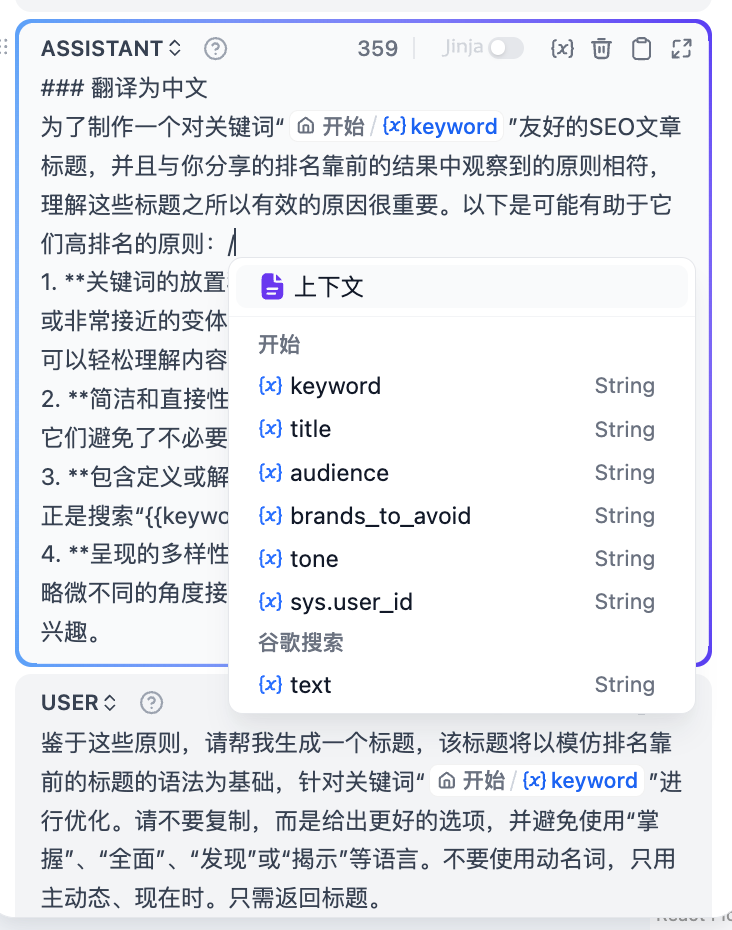
在提示词编辑器中,你可以通过输入 **"/"** 呼出 **变量插入菜单**,将 **特殊变量块** 或者 **上游节点变量** 插入到提示词中作为上下文内容。
-
+ 
在提示词编辑器中,你可以通过输入 **"/"** 呼出 **变量插入菜单**,将 **特殊变量块** 或者 **上游节点变量** 插入到提示词中作为上下文内容。
-  + 
5. **高级设置**,可以开关记忆功能并设置记忆窗口、开关 Vision 功能或者使用 Jinja-2 模板语言来进行更复杂的提示词等。
-***
+---
### 特殊变量说明
@@ -89,7 +89,7 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
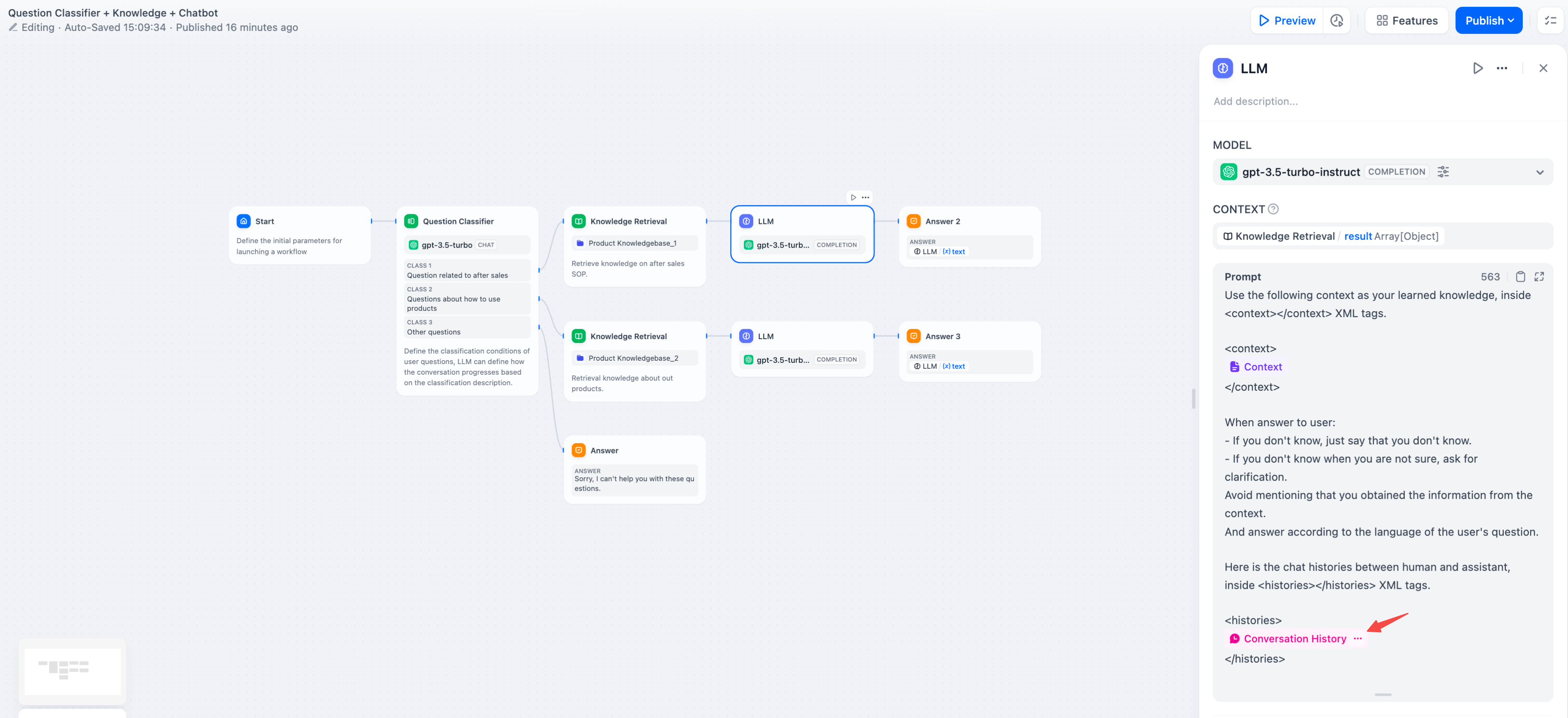
> 会话历史变量应用并不广泛,仅在 Chatflow 中选择文本补全类模型时可以插入使用。
-
+ 
5. **高级设置**,可以开关记忆功能并设置记忆窗口、开关 Vision 功能或者使用 Jinja-2 模板语言来进行更复杂的提示词等。
-***
+---
### 特殊变量说明
@@ -89,7 +89,7 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
> 会话历史变量应用并不广泛,仅在 Chatflow 中选择文本补全类模型时可以插入使用。
-  + 
**模型参数**
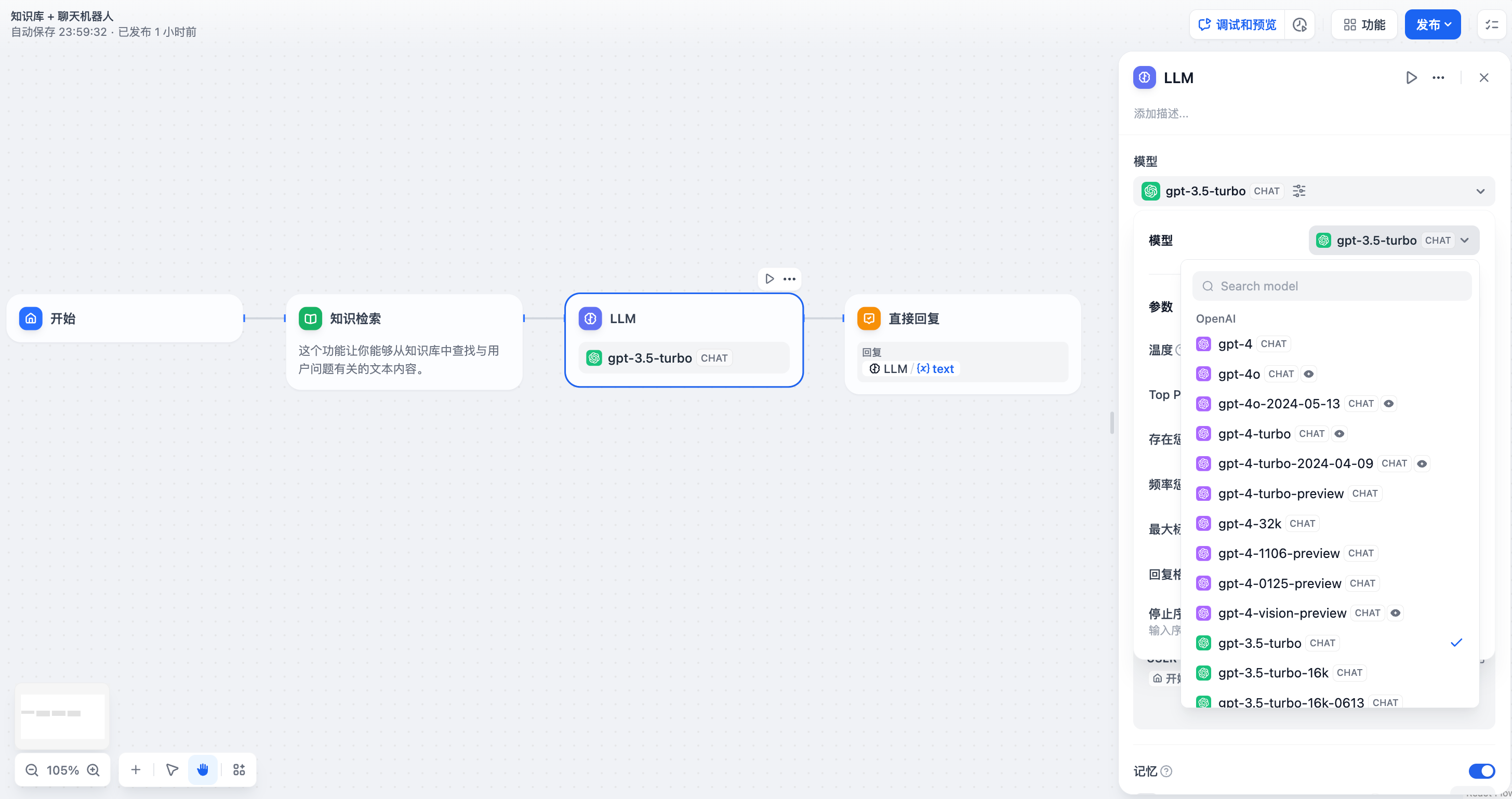
@@ -97,23 +97,23 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
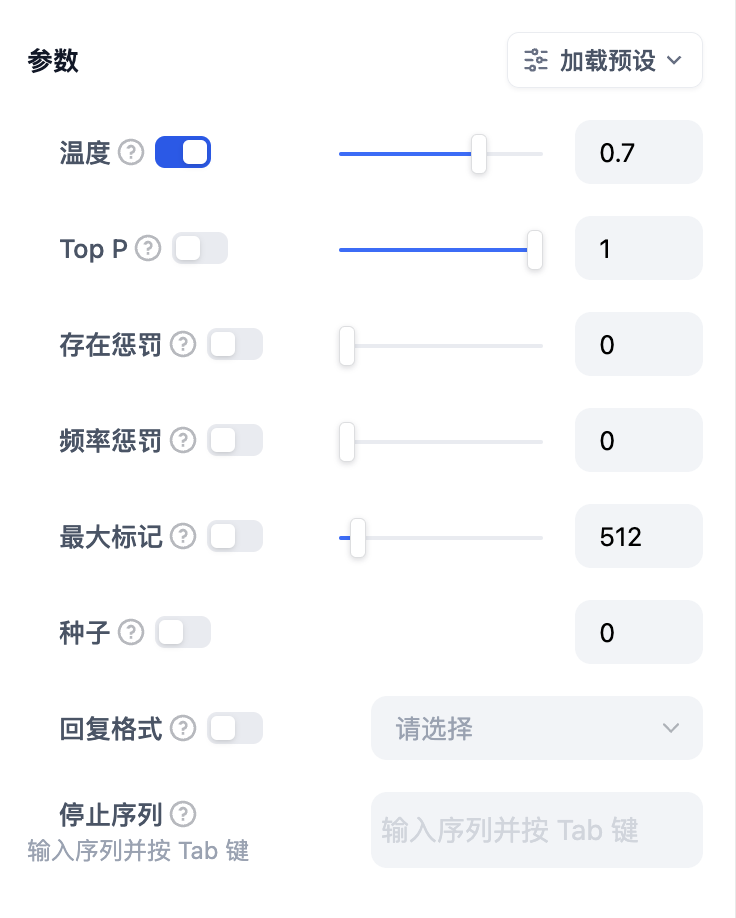
模型的参数会影响模型的输出效果。不同模型的参数会有所区别。下图为`gpt-4`的参数列表。
-
+ 
**模型参数**
@@ -97,23 +97,23 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
模型的参数会影响模型的输出效果。不同模型的参数会有所区别。下图为`gpt-4`的参数列表。
-  + 
主要的参数名词解释如下:
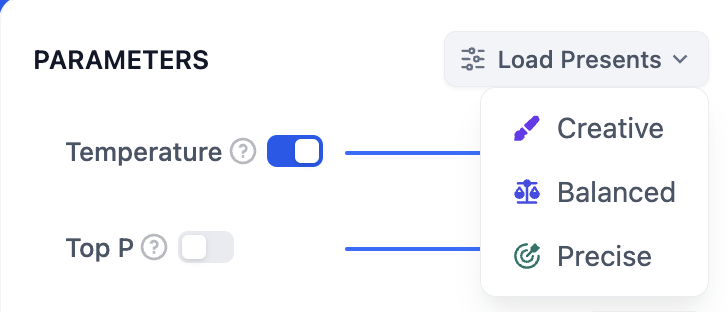
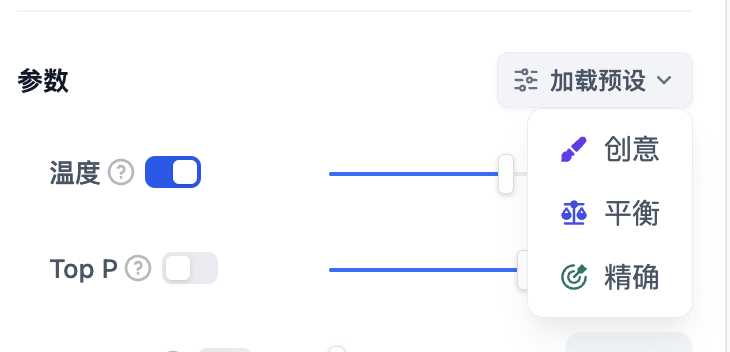
-* **温度:** 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
-* **Top P:** 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
-* **存在惩罚:** 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
-* **频率惩罚:** 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
+- **温度:** 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
+- **Top P:** 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
+- **存在惩罚:** 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
+- **频率惩罚:** 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
如果你不理解这些参数是什么,可以选择**加载预设**,从创意、平衡、精确三种预设中选择。
-
+ 
主要的参数名词解释如下:
-* **温度:** 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
-* **Top P:** 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
-* **存在惩罚:** 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
-* **频率惩罚:** 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
+- **温度:** 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
+- **Top P:** 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
+- **存在惩罚:** 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
+- **频率惩罚:** 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
如果你不理解这些参数是什么,可以选择**加载预设**,从创意、平衡、精确三种预设中选择。
-  + 
-***
+---
### 高级功能
@@ -137,221 +137,207 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
**结构化输出**:确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。
+ 
-***
+---
### 高级功能
@@ -137,221 +137,207 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
**结构化输出**:确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。