mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
Fix/update introduction links (#661)
* fix the broken link for the en user input node * replace the legacy link prefix for ja and zh introduction * remove the redundant zh pages --------- Co-authored-by: Riskey <riskey47@dify.ai>
This commit is contained in:
@@ -16,7 +16,7 @@ Add features to make your apps more useful. Click **Features** in the top right
|
||||
## Workflow apps
|
||||
|
||||
<Info>
|
||||
File upload through Features is deprecated for Workflow apps. Use [file variables on the Start node](/en/ducmentation/pages/nodes/start) instead.
|
||||
File upload through Features is deprecated for Workflow apps. Use [file variables on the User Input node](/en/use-dify/nodes/user-input) instead.
|
||||
</Info>
|
||||
|
||||
Workflow apps only support **Image Upload** via Features:
|
||||
@@ -66,7 +66,7 @@ LLMs can't read files directly. Use Document Extractor first.
|
||||
4. Add Answer node with LLM output
|
||||
|
||||
<Warning>
|
||||
This doesn't remember files between conversations. Users need to re-upload each time. For persistent files, use [Start node file variables](/en/ducmentation/pages/nodes/start).
|
||||
This doesn't remember files between conversations. Users need to re-upload each time. For persistent files, use [file variables on the User Input node](/en/use-dify/nodes/user-input) instead.
|
||||
</Warning>
|
||||
|
||||
### Images
|
||||
|
||||
@@ -11,13 +11,13 @@ Difyは、AIワークフローを構築するためのオープンソースプ
|
||||

|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="クイックスタート" icon="play" href="/jp/use-dify/getting-started/quick-start">
|
||||
<Card title="クイックスタート" icon="play" href="/ja/use-dify/getting-started/quick-start">
|
||||
数分で強力なアプリの構築を開始
|
||||
</Card>
|
||||
<Card title="概念" icon="highlighter" iconType="regular" href="/jp/use-dify/getting-started/key-concepts">
|
||||
<Card title="概念" icon="highlighter" iconType="regular" href="/ja/use-dify/getting-started/key-concepts">
|
||||
Difyの核となる構成要素の説明
|
||||
</Card>
|
||||
<Card title="セルフホスティング" icon="arrow-down-to-line" href="/jp/self-host/quick-start/docker-compose">
|
||||
<Card title="セルフホスティング" icon="arrow-down-to-line" href="/ja/self-host/quick-start/docker-compose">
|
||||
自分のノートパソコン/サーバーにDifyをインストールするガイド
|
||||
</Card>
|
||||
<Card title="フォーラム" icon="message" href="https://forum.dify.ai">
|
||||
@@ -26,7 +26,7 @@ Difyは、AIワークフローを構築するためのオープンソースプ
|
||||
<Card title="変更履歴" icon="bell" href="https://github.com/langgenius/dify/releases">
|
||||
過去のリリースでの変更内容
|
||||
</Card>
|
||||
<Card title="チュートリアル" icon="lightbulb" href="/jp/use-dify/tutorials/customer-service-bot">
|
||||
<Card title="チュートリアル" icon="lightbulb" href="/ja/use-dify/tutorials/customer-service-bot">
|
||||
Difyのユースケース例のウォークスルー
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
@@ -11,13 +11,13 @@ Dify 是一个用于构建 AI 工作流的开源平台。通过在可视化画
|
||||

|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="快速开始" icon="play" href="/cn/use-dify/getting-started/quick-start">
|
||||
<Card title="快速开始" icon="play" href="/zh/use-dify/getting-started/quick-start">
|
||||
数分钟内开始构建强大的应用
|
||||
</Card>
|
||||
<Card title="概念" icon="highlighter" iconType="regular" href="/cn/use-dify/getting-started/key-concepts">
|
||||
<Card title="概念" icon="highlighter" iconType="regular" href="/zh/use-dify/getting-started/key-concepts">
|
||||
核心 Dify 构建模块解释
|
||||
</Card>
|
||||
<Card title="自部署" icon="arrow-down-to-line" href="/cn/self-host/quick-start/docker-compose">
|
||||
<Card title="自部署" icon="arrow-down-to-line" href="/zh/self-host/quick-start/docker-compose">
|
||||
在你的笔记本电脑/服务器上安装 Dify
|
||||
</Card>
|
||||
<Card title="论坛" icon="message" href="https://forum.dify.ai">
|
||||
@@ -26,7 +26,7 @@ Dify 是一个用于构建 AI 工作流的开源平台。通过在可视化画
|
||||
<Card title="更新日志" icon="bell" href="https://github.com/langgenius/dify/releases">
|
||||
查看过往版本的更新内容
|
||||
</Card>
|
||||
<Card title="教程" icon="lightbulb" href="/cn/use-dify/tutorials/customer-service-bot">
|
||||
<Card title="教程" icon="lightbulb" href="/zh/use-dify/tutorials/customer-service-bot">
|
||||
Dify 用例示例演练
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
@@ -1,108 +0,0 @@
|
||||
---
|
||||
title: "使用 MCP 工具"
|
||||
icon: "microchip"
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/build/mcp)。</Note>
|
||||
|
||||
|
||||
将来自 [MCP 服务器](https://modelcontextprotocol.io/introduction) 的外部工具连接到你的 Dify 应用程序。你可以使用不断增长的 [MCP 生态系统](https://mcpservers.org/) 中的工具,而不仅仅是内置工具。
|
||||
|
||||
<Note>
|
||||
本内容涵盖在 Dify 中使用 MCP 工具。要将 Dify 应用程序发布为 MCP 服务器,请参阅[这里](/zh/use-dify/publish/publish-mcp)。
|
||||
</Note>
|
||||
|
||||
<Info>
|
||||
目前仅支持使用 [HTTP 传输](https://modelcontextprotocol.io/docs/concepts/architecture#transport-layer) 的 MCP 服务器。
|
||||
</Info>
|
||||
|
||||
## 添加 MCP 服务器
|
||||
|
||||
在你的工作空间中转到**工具** → **MCP**。
|
||||
|
||||

|
||||
|
||||
点击**添加 MCP 服务器 (HTTP)**:
|
||||
|
||||

|
||||
|
||||
**服务器 URL**:MCP 服务器的位置(如 `https://api.notion.com/mcp`)
|
||||
|
||||
**名称和图标**:给它一个有用的名称。Dify 会尝试自动获取图标。
|
||||
|
||||
**服务器 ID**:唯一标识符(小写字母、数字、下划线、连字符,最多 24 个字符)
|
||||
|
||||
<Warning>
|
||||
一旦开始使用服务器 ID,就不要更改它。这将破坏任何使用该服务器工具的应用程序。
|
||||
</Warning>
|
||||
|
||||
## 接下来会发生什么
|
||||
|
||||
Dify 会自动:
|
||||
1. 连接到服务器
|
||||
2. 处理任何 OAuth 认证
|
||||
3. 获取可用工具列表
|
||||
4. 使它们在你的应用程序构建器中可用
|
||||
|
||||
一旦找到工具,你将看到服务器卡片:
|
||||
|
||||

|
||||
|
||||
## 管理服务器
|
||||
|
||||
点击任何服务器卡片可以:
|
||||
|
||||
**更新工具**:当外部服务添加新工具时刷新
|
||||
|
||||

|
||||
|
||||
**重新授权**:当令牌过期时修复认证
|
||||
|
||||
**编辑设置**:更改服务器详细信息(但不能更改 ID!)
|
||||
|
||||
**移除**:断开服务器连接(这会破坏使用其工具的应用程序)
|
||||
|
||||
## 使用 MCP 工具
|
||||
|
||||
连接后,MCP 工具会出现在你期望的所有地方:
|
||||
|
||||
**在智能代理中**:工具按服务器分组显示("Notion MCP » Create Page")
|
||||
|
||||
**在工作流中**:MCP 工具作为节点可用
|
||||
|
||||
**在智能代理节点中**:与常规智能代理相同
|
||||
|
||||
## 自定义工具
|
||||
|
||||
添加 MCP 工具时,你可以自定义它:
|
||||
|
||||

|
||||
|
||||
**描述**:覆盖默认描述以使其更具体
|
||||
|
||||
**参数**:对于每个工具参数,选择:
|
||||
- **自动**:让 AI 决定值
|
||||
- **固定**:设置一个永不改变的特定值
|
||||
|
||||
**示例**:对于搜索工具,将 `numResults` 设置为 5(固定),但保持 `query` 为自动。
|
||||
|
||||
## 分享应用程序
|
||||
|
||||
当你导出使用 MCP 工具的应用程序时:
|
||||
- 导出内容包含服务器 ID
|
||||
- 要在其他地方使用该应用程序,需要添加具有相同 ID 的相同服务器
|
||||
- 记录你的应用程序需要哪些 MCP 服务器
|
||||
|
||||
## 故障排除
|
||||
|
||||
**"未配置的服务器"**:检查 URL 并重新授权
|
||||
|
||||
**缺少工具**:点击"更新工具"
|
||||
|
||||
**应用程序损坏**:你可能更改了服务器 ID。使用原始 ID 重新添加它。
|
||||
|
||||
## 提示
|
||||
|
||||
- 使用永久的、描述性的服务器 ID,如 `github-prod` 或 `crm-system`
|
||||
- 在开发/测试/生产环境中保持相同的 MCP 设置
|
||||
- 为配置项设置固定值,为部署前测试 MCP 集成
|
||||
@@ -1,91 +0,0 @@
|
||||
---
|
||||
title: "处理错误"
|
||||
icon: "arrow-rotate-right"
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/build/predefined-error-handling-logic)。</Note>
|
||||
|
||||
|
||||
|
||||
[大型语言模型](/en/use-dify/nodes/llm)、[HTTP](/en/use-dify/nodes/http-request)、[代码](/en/use-dify/nodes/code) 和 [工具](/en/use-dify/nodes/tools)
|
||||
节点支持开箱即用的错误处理。当节点失败时,可以采用以下三种行为之一:
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="无">
|
||||
默认行为。当节点失败时,整个工作流停止。你会收到原始错误消息。
|
||||
|
||||
适用于以下情况:
|
||||
- 正在测试并希望查看哪里出了问题
|
||||
- 工作流无法在没有此步骤的情况下继续
|
||||
</Accordion>
|
||||
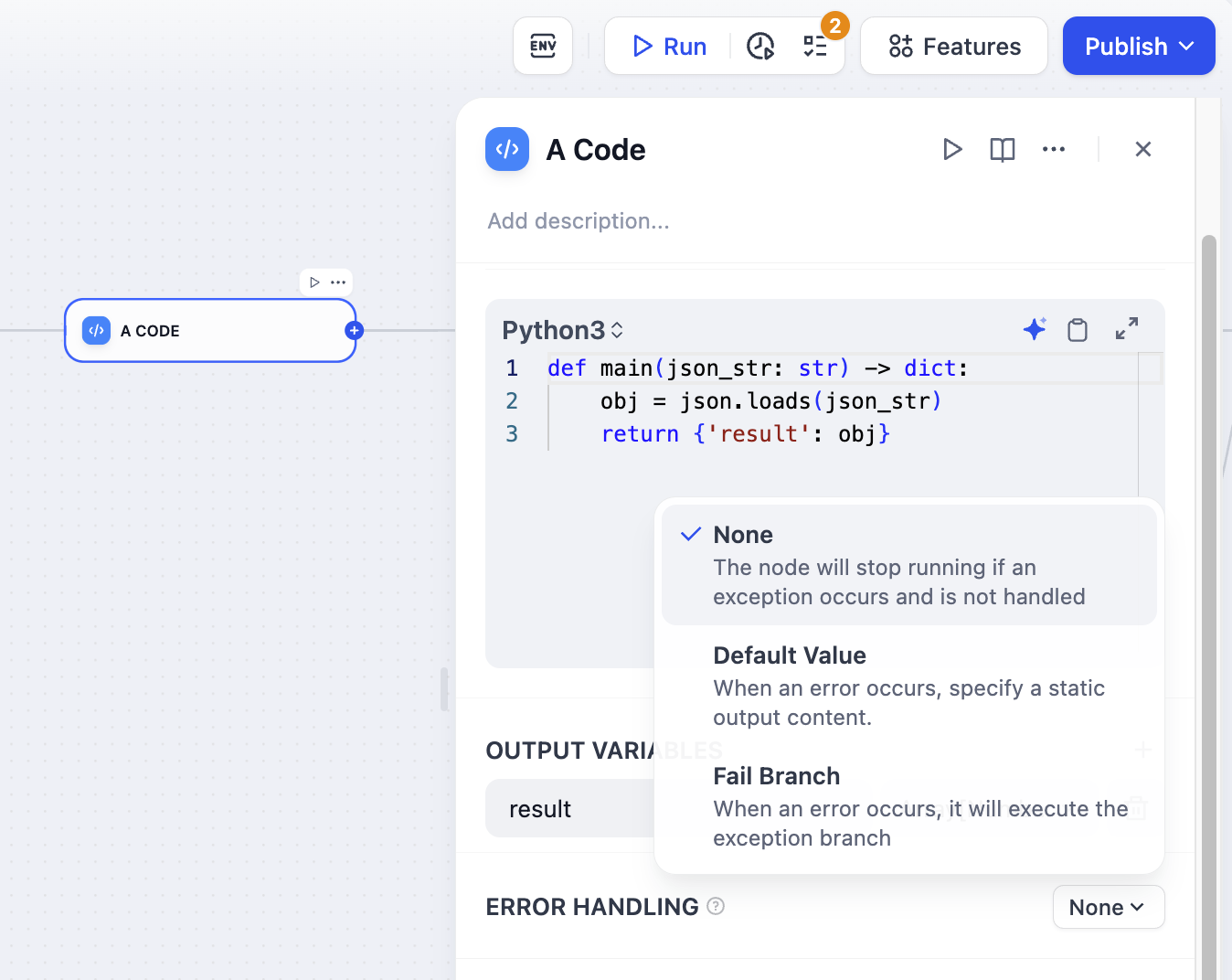
<Accordion title="默认值">
|
||||
当节点失败时,使用备用值代替。工作流继续运行。
|
||||
|
||||
|
||||
|
||||
**要求**
|
||||
- 默认值必须与节点的输出类型匹配——如果输出字符串,你的默认值也必须是字符串。
|
||||
|
||||
**示例**
|
||||
|
||||
你的大型语言模型节点通常返回分析结果,但有时由于速率限制而失败。设置一个默认值,如:
|
||||
|
||||
```
|
||||
"抱歉,我暂时不可用。请几分钟后再试。"
|
||||
```
|
||||
|
||||
现在用户会收到有用的消息,而不是损坏的工作流。
|
||||
</Accordion>
|
||||
<Accordion title="失败分支">
|
||||
当节点失败时,触发一个单独的流程来处理错误。
|
||||
|
||||
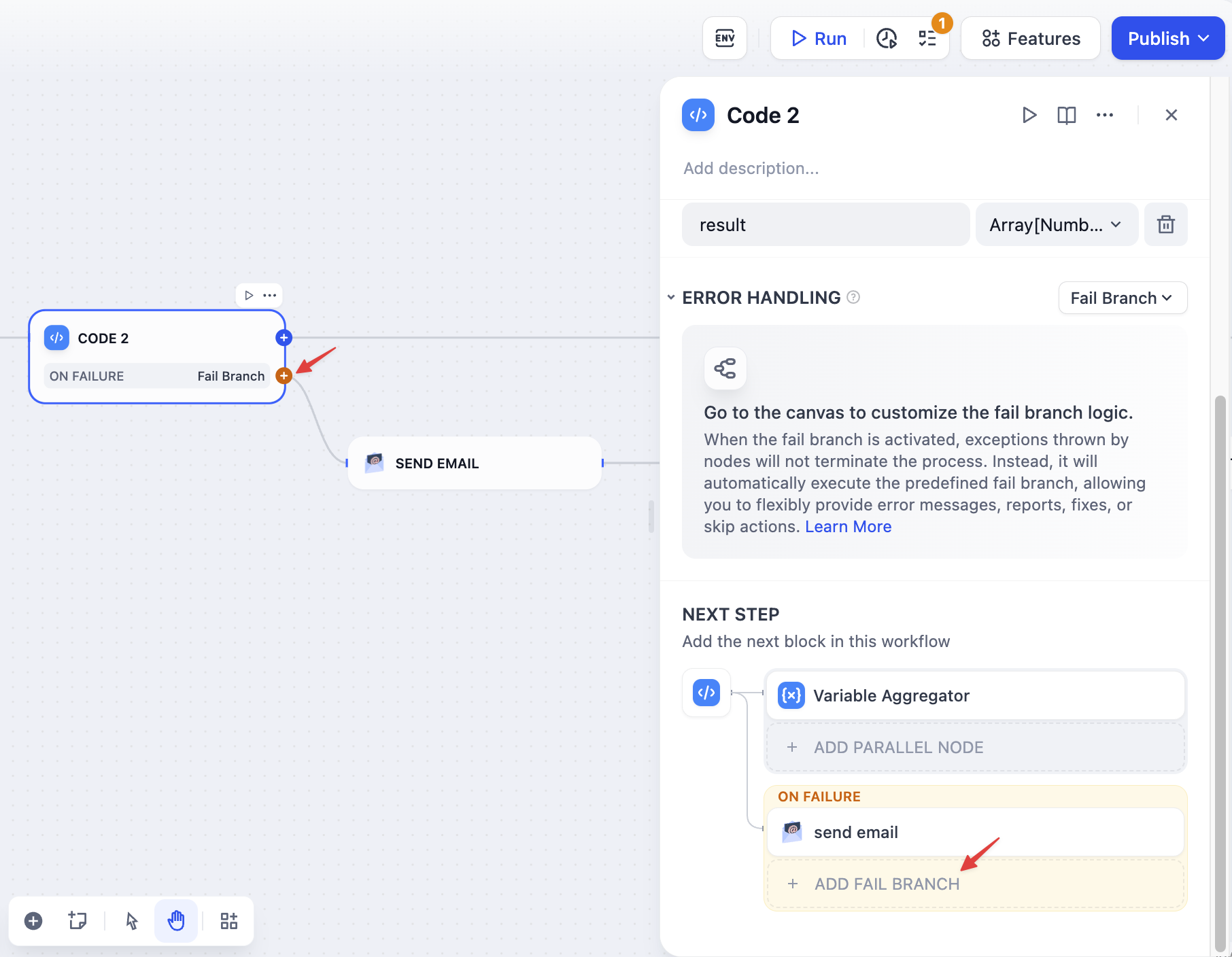
|
||||
|
||||
失败分支用橙色高亮显示。你可以:
|
||||
- 发送错误通知
|
||||
- 尝试不同的方法
|
||||
- 记录错误以进行调试
|
||||
- 使用备用服务
|
||||
|
||||
**示例**
|
||||
|
||||
你的主 API 失败,因此失败分支调用备用 API。用户永远不会知道出现了问题。
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## 循环/迭代节点中的错误
|
||||
|
||||
当子节点在循环和迭代中失败时,这些控制流节点有自己的错误行为。
|
||||
|
||||
**循环节点** 总是在任何子节点失败时立即停止。整个循环终止并返回错误,阻止任何进一步的迭代运行。
|
||||
|
||||
**迭代节点** 让你通过错误处理模式设置选择如何处理子节点失败:
|
||||
|
||||
- `terminated` - 当任何项目失败时立即停止处理(默认)
|
||||
- `continue-on-error` - 跳过失败的项目并继续下一个
|
||||
- `remove-abnormal-output` - 继续处理但从最终输出中过滤掉失败的项目
|
||||
|
||||
当你将迭代设置为 `continue-on-error` 时,失败的项目在输出数组中返回 `null`。当你使用 `remove-abnormal-output` 时,输出数组仅包含成功的结果,使其比输入数组更短。
|
||||
|
||||
## 错误变量
|
||||
|
||||
使用默认值或失败分支时,你会得到两个特殊变量:
|
||||
|
||||
- `error_type` - 发生了什么类型的错误(参见 [错误类型](cn/use-dify/debug/error-type))
|
||||
- `error_message` - 实际的错误详细信息
|
||||
|
||||
使用这些来:
|
||||
- 向用户显示有用的消息
|
||||
- 向你的团队发送警报
|
||||
- 选择不同的恢复策略
|
||||
- 记录错误以进行调试
|
||||
|
||||
**示例**
|
||||
|
||||
```text
|
||||
{% if error_type == "rate_limit" %}
|
||||
请求过多。请稍等片刻再试。
|
||||
{% else %}
|
||||
出了点问题。我们的团队已收到通知。
|
||||
{% endif %}
|
||||
```
|
||||
@@ -1,47 +0,0 @@
|
||||
---
|
||||
title: "运行历史"
|
||||
icon: "timer"
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/debug/history-and-logs)。</Note>
|
||||
|
||||
|
||||
Dify 会在每次工作流运行时记录详细的运行历史。你可以查看应用级别和各个节点的运行情况。
|
||||
|
||||
<Info>
|
||||
对于发布后来自真实用户的运行历史,请参阅[运行历史和标注](/zh/use-dify/monitor/logs)。
|
||||
</Info>
|
||||
|
||||
## 应用运行历史
|
||||
|
||||
每次工作流运行都会创建一个完整的日志条目。点击任何条目可以查看三个部分:
|
||||
|
||||
|
||||
|
||||
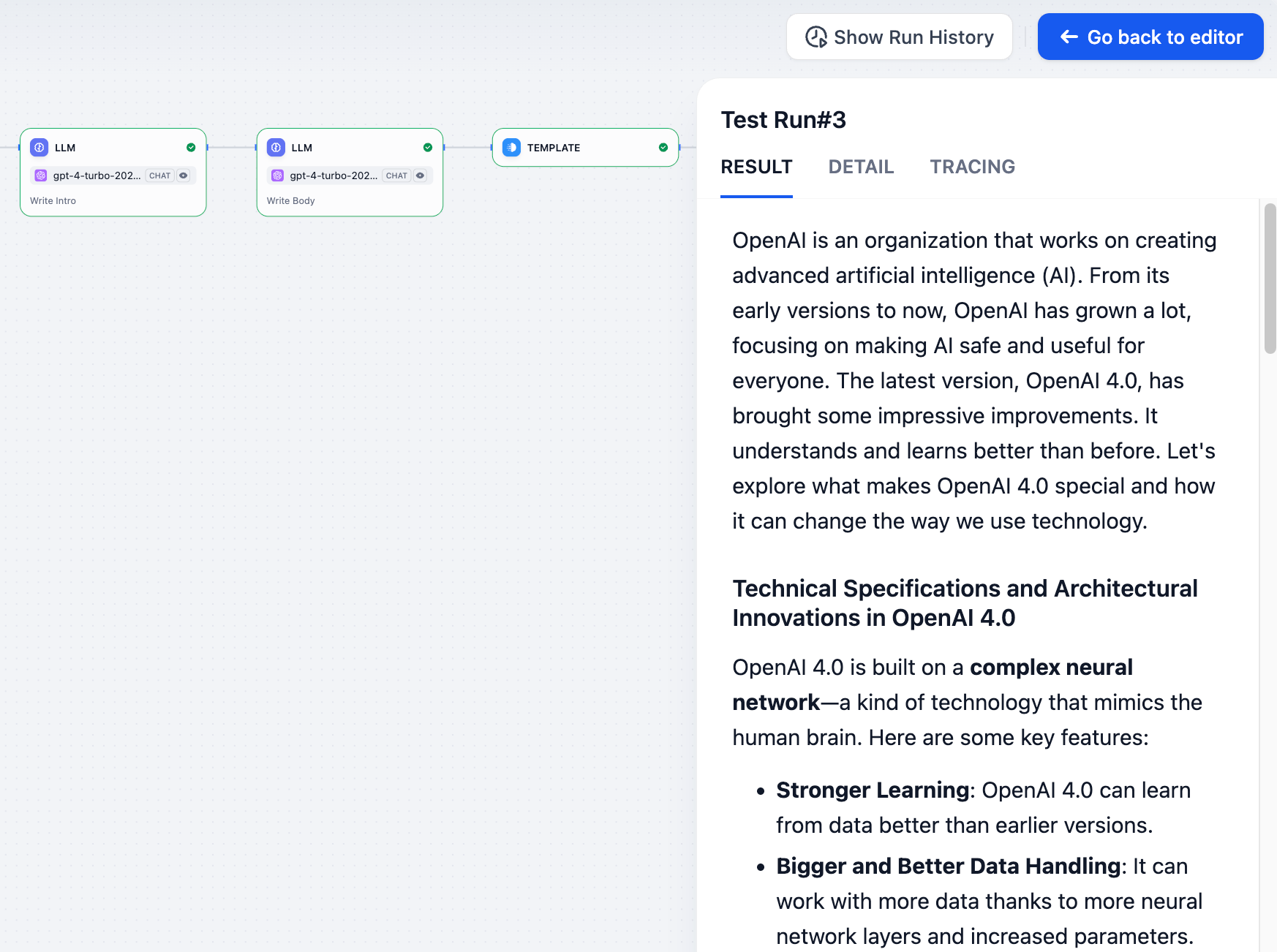
### 结果
|
||||
|
||||
显示用户看到的最终输出。如果工作流失败,你将在这里看到错误消息。
|
||||
|
||||
|
||||
|
||||
<Warning>
|
||||
仅适用于工作流应用。
|
||||
</Warning>
|
||||
|
||||
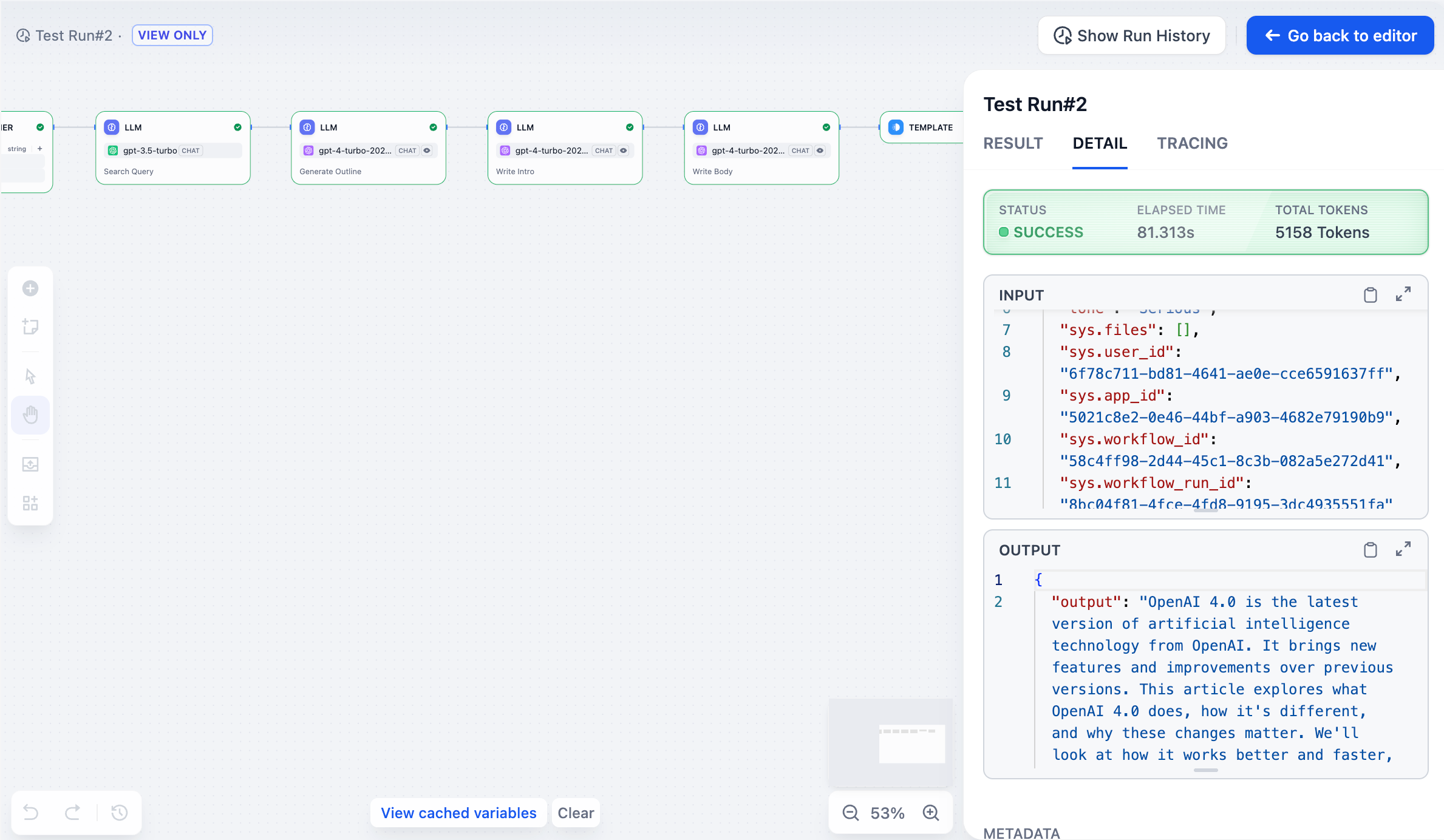
### 详情
|
||||
|
||||
显示原始输入、最终输出和执行过程中的系统元数据。
|
||||
|
||||
|
||||
|
||||
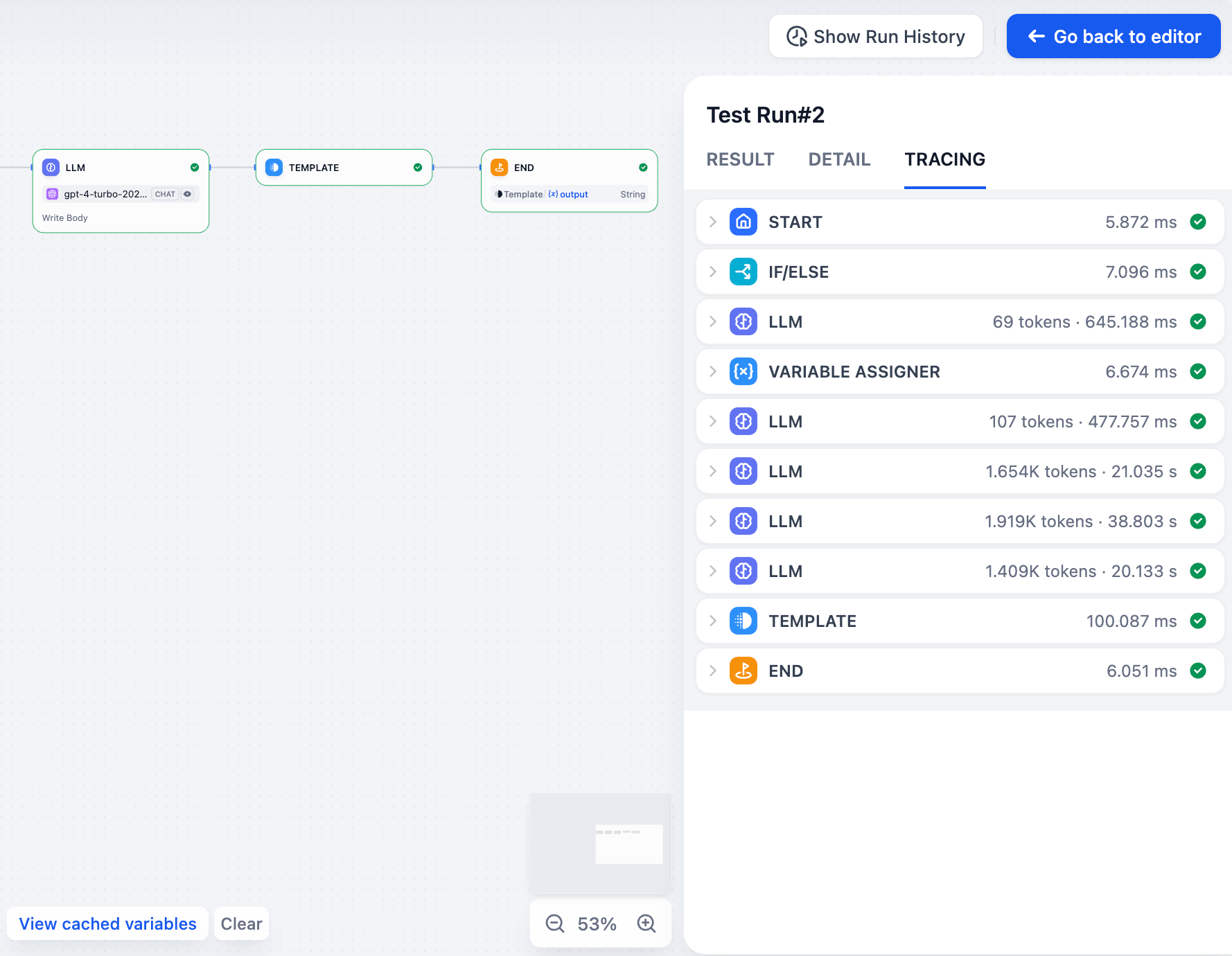
### 追踪
|
||||
|
||||
准确显示工作流的执行过程,包括哪些节点按什么顺序运行、每个节点耗时多长,以及数据在节点间如何流动。这对于找出瓶颈和理解具有分支或循环的复杂工作流很有用。
|
||||
|
||||
|
||||
|
||||
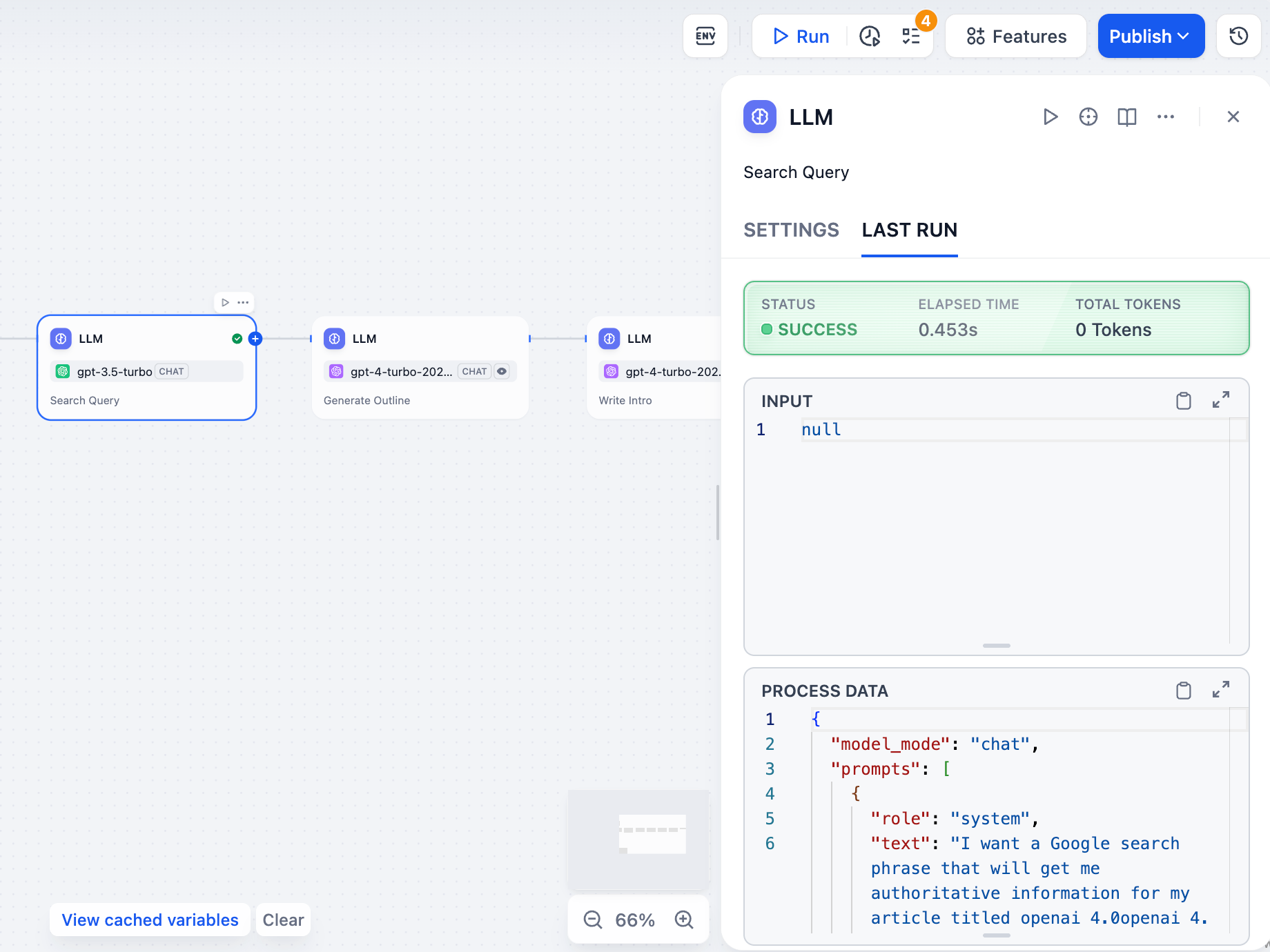
## 节点运行历史
|
||||
|
||||
你也可以检查任何单个节点的最后一次执行。在节点配置面板中点击"最后运行",查看其最近的输入、输出和时间详情。
|
||||
|
||||
|
||||
@@ -1,36 +0,0 @@
|
||||
---
|
||||
title: "介绍"
|
||||
mode: "wide"
|
||||
icon: "key"
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/getting-started/introduction)。</Note>
|
||||
|
||||
Dify 是一个用于构建 AI 工作流的开源平台。通过在可视化画布上编排 AI 模型、连接数据源、定义处理流程,直接将你的领域知识转化为可运行的软件。
|
||||
|
||||

|
||||
|
||||
<CardGroup cols={3}>
|
||||
<Card title="快速开始" icon="play" href="/cn/use-dify/getting-started/quick-start">
|
||||
数分钟内开始构建强大的应用
|
||||
</Card>
|
||||
<Card title="概念" icon="highlighter" iconType="regular" href="/cn/use-dify/getting-started/key-concepts">
|
||||
核心 Dify 构建模块解释
|
||||
</Card>
|
||||
<Card title="自部署" icon="arrow-down-to-line" href="/cn/self-host/quick-start/docker-compose">
|
||||
在你的笔记本电脑/服务器上安装 Dify
|
||||
</Card>
|
||||
<Card title="论坛" icon="message" href="https://forum.dify.ai">
|
||||
与社区交流心得
|
||||
</Card>
|
||||
<Card title="更新日志" icon="bell" href="https://github.com/langgenius/dify/releases">
|
||||
查看过往版本的更新内容
|
||||
</Card>
|
||||
<Card title="教程" icon="lightbulb" href="/cn/use-dify/tutorials/customer-service-bot">
|
||||
Dify 用例示例演练
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
<Info>
|
||||
Dify 这个名字来自 **D**o **I**t **F**or **Y**ou。
|
||||
</Info>
|
||||
@@ -1,151 +0,0 @@
|
||||
---
|
||||
title: "核心概念"
|
||||
description: "Dify 核心概念快速概览"
|
||||
icon: "circle-info"
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/getting-started/key-concepts)。</Note>
|
||||
|
||||
|
||||
### Dify 应用
|
||||
|
||||
Dify 专为智能体应用构建而设计。在 **Studio** 中,你可以通过拖拽界面快速构建智能体工作流并将其发布为应用。你可以通过 API、Web 或作为 [MCP 服务器](/zh/use-dify/publish/publish-mcp)访问已发布的应用。Dify 提供两种主要的应用类型:工作流和对话流。在创建新应用时,你需要选择一种应用类型。
|
||||
|
||||
<Info>
|
||||
我们推荐选择工作流或对话流作为你的应用类型。但除了这些之外,Dify 还提供 3 种更基础的应用类型:聊天机器人、智能代理和文本生成器。
|
||||
<img
|
||||
src="/images/22087830d0a6478d42d0c60e6eb88d19bca27be3c645f2bb0968d51330b7da72.png"
|
||||
alt="22087830d0a6478d42d0c60e6eb88d19bca27be3c645f2bb0968d51330b7da72.png"
|
||||
title="22087830d0a6478d42d0c60e6eb88d19bca27be3c645f2bb0968d51330b7da72.png"
|
||||
className="mt-1"
|
||||
style={{ width:"100%" }}
|
||||
/>
|
||||
这些应用类型在底层运行相同的工作流引擎,但提供了更简单的传统界面:
|
||||
<img
|
||||
src="/images/chatbot-interface.png"
|
||||
alt="chatbot-interface.png"
|
||||
title="chatbot-interface.png"
|
||||
className="mt-1"
|
||||
style={{ width:"100%" }}
|
||||
/>
|
||||
</Info>
|
||||
### 工作流
|
||||
|
||||
构建工作流应用来处理单轮任务。Web 应用界面和 API 提供了便捷的批量执行多个任务的访问方式。
|
||||
|
||||
<Info>
|
||||
在底层,工作流构成了 Dify 中所有其他应用类型的基础。
|
||||
</Info>
|
||||
|
||||
你可以指定如何以及何时启动工作流。有两种类型的开始节点:
|
||||
|
||||
- **[用户输入](/zh/use-dify/nodes/user-input)**:通过直接用户交互或 API 调用触发应用程序。
|
||||
|
||||
- **[触发器](/zh/use-dify/nodes/trigger/overview)**:应用程序按计划自动运行或响应特定的第三方事件。
|
||||
|
||||
用户输入和触发器开始节点是互斥的——它们不能在同一画布上使用。要在它们之间切换,请右键单击当前开始节点 > **更改节点**。或者,删除当前开始节点并添加一个新节点。
|
||||
|
||||
<Note>
|
||||
只有由用户输入启动的工作流才能发布为独立的 Web 应用程序或 MCP 服务器,通过后端服务 API 公开,或在其他 Dify 应用程序中用作工具。
|
||||
</Note>
|
||||
|
||||
|
||||
### 对话流
|
||||
|
||||
对话流是一种特殊类型的工作流应用,在对话的每一轮都会被触发。除了工作流功能外,对话流还具有存储和更新自定义对话特定变量的能力,在大型语言模型节点中启用记忆功能,并在对话流运行的不同节点流式传输格式化的文本、图像和文件。
|
||||
|
||||
与工作流不同,对话流不能使用[触发器](/zh/use-dify/nodes/trigger/overview)来启动。
|
||||
|
||||
### Dify 领域特定语言
|
||||
|
||||
所有 Dify 应用都可以导出为 Dify 自有领域特定语言的 YAML 文件,你也可以直接从这些领域特定语言文件创建 Dify 应用。这使得将应用移植到其他 Dify 实例并与他人分享变得容易。
|
||||
|
||||
### 变量
|
||||
|
||||
变量是存储信息的标记容器,因此你可以通过引用其名称来查找和使用该信息。在构建 Dify 应用时,你会遇到不同类型的变量:
|
||||
|
||||
**输入**:你可以在[用户输入](/zh/use-dify/nodes/user-input)节点为你的应用最终用户指定任意数量的输入变量来填写。
|
||||
|
||||
<img
|
||||
src="/images/CleanShot2025-08-04at14.34.04@2x.png"
|
||||
alt="CleanShot 2025-08-04 at 14.34.04@2x.png"
|
||||
title="CleanShot 2025-08-04 at 14.34.04@2x.png"
|
||||
className="mx-auto"
|
||||
style={{ width:"51%" }}
|
||||
/>
|
||||
|
||||
此外,用户输入节点还带有一组输入变量,你可以在流程中稍后引用。根据应用程序类型(工作流或对话流),会提供不同的变量。
|
||||
|
||||
<Tabs>
|
||||
<Tab title="工作流">
|
||||
|
||||
| 变量名 | <div style={{width: '70px'}}>数据类型</div> | 描述 | 注释 |
|
||||
|:----------------|:-----------|:-------------|:--------|
|
||||
| `sys.user_id` | String | 用户 ID:系统在用户使用工作流应用程序时自动分配给每个用户的唯一标识符。用于区分不同的用户。 | |
|
||||
| `sys.app_id` | String | 应用程序 ID:系统自动分配给每个应用程序的唯一标识符。此参数用于记录当前应用程序的基本信息。 | 此参数用于具有开发能力的用户区分和定位不同的工作流应用程序。 |
|
||||
| `sys.workflow_id` | String | 工作流 ID:此参数记录当前工作流应用程序中所有节点的信息。 | 此参数可供具有开发能力的用户用于跟踪和记录工作流中包含的节点信息。 |
|
||||
| `sys.workflow_run_id` | String | 工作流运行 ID:用于记录工作流应用程序的运行时状态和执行日志。 | 此参数可供具有开发能力的用户用于跟踪应用程序的历史执行记录。 |
|
||||
| `sys.timestamp` | String | 每次工作流执行的开始时间。 | |
|
||||
|
||||
</Tab>
|
||||
<Tab title="对话流">
|
||||
|
||||
| 变量名 | <div style={{width: '70px'}}>数据类型</div> | 描述 | 注释 |
|
||||
|:----------------|:-----------|:-------------|:--------|
|
||||
| `sys.conversation_id` | String | 聊天框交互会话的唯一 ID,将所有相关消息分组到同一对话中,确保 LLM 在相同的主题和上下文中继续聊天。 | |
|
||||
| `sys.dialogue_count` | Number | 用户与对话流应用程序交互期间的对话轮次数。每次聊天轮次后计数自动增加 1,可与 if-else 节点结合使用以创建丰富的分支逻辑。<br /><br />例如,LLM 将在第 X 个对话轮次时审查对话历史并自动提供分析。 | |
|
||||
| `sys.user_id` | String | 为每个应用程序用户分配一个唯一 ID,以区分不同的对话用户。 | 服务 API 不共享 WebApp 创建的对话。这意味着具有相同 ID 的用户将在 API 和 WebApp 界面之间具有单独的对话历史记录。 |
|
||||
| `sys.app_id` | String | 应用程序 ID:系统自动分配给每个应用程序的唯一标识符。此参数用于记录当前应用程序的基本信息。 | 此参数用于具有开发能力的用户区分和定位不同的工作流应用程序。 |
|
||||
| `sys.workflow_id` | String | 工作流 ID:此参数记录当前工作流应用程序中所有节点的信息。 | 此参数可供具有开发能力的用户用于跟踪和记录工作流中包含的节点信息。 |
|
||||
| `sys.workflow_run_id` | String | 工作流运行 ID:用于记录工作流应用程序的运行时状态和执行日志。 | 此参数可供具有开发能力的用户用于跟踪应用程序的历史执行记录。 |
|
||||
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
用户输入在每次工作流运行开始时设置,无法更新。
|
||||
|
||||
**输出**:每个节点产生一个或多个输出,可以在后续节点中引用。例如,大型语言模型节点有以下输出:
|
||||
|
||||
<img
|
||||
src="/images/CleanShot2025-08-04at14.28.57@2x.png"
|
||||
alt="Cl.57@2x.png"
|
||||
title="CleanShot 2025-08-04 at 14.28.57@2x.png"
|
||||
className="mx-auto"
|
||||
style={{ width:"45%" }}
|
||||
/>
|
||||
|
||||
与输入一样,节点输出也无法更新。
|
||||
|
||||
**环境变量**:使用环境变量来存储你应用特定的敏感信息,如 API 密钥。这允许在密钥和 Dify 应用本身之间进行清晰分离,因此在分享你的应用领域特定语言时,你不必承担暴露密码和密钥的风险。环境变量也是常量,无法更新。
|
||||
|
||||
**会话变量(仅对话流)**:这些变量是对话特定的——意味着它们在单个对话的多轮对话流运行中持续存在,因此你可以存储和访问动态信息,如待办事项列表和令牌成本。你可以通过变量分配器节点更新会话变量的值:
|
||||
|
||||
<img
|
||||
src="/images/2935cb58851e5c5407a08dde49f7d9738bb13aa0e64df24278e2104b316f6af6.png"
|
||||
alt="2935cb58851e5c5407a08dde49f7d9738bb13aa0e64df24278e2104b316f6af6.png"
|
||||
title="2935cb58851e5c5407a08dde49f7d9738bb13aa0e64df24278e2104b316f6af6.png"
|
||||
className="mx-auto"
|
||||
style={{ width:"70%" }}
|
||||
/>
|
||||
|
||||
### 变量引用
|
||||
|
||||
在配置输入字段时,你可以通过从下拉菜单中选择,轻松将变量传递给任何节点:
|
||||
|
||||
<img
|
||||
src="/images/CleanShot2025-08-04at15.13.33@2x.png"
|
||||
alt="CleanShot 2025-08-04 at 15.13.33@2x.png"
|
||||
title="CleanShot 2025-08-04 at 15.13.33@2x.png"
|
||||
className="mx-auto"
|
||||
style={{ width:"70%" }}
|
||||
/>
|
||||
|
||||
你还可以通过键入 `/` 斜杠并从下拉菜单中选择所需变量,将变量值插入到复杂的文本输入中。
|
||||
|
||||
<img
|
||||
src="/images/image.png"
|
||||
alt="image.png"
|
||||
title="image.png"
|
||||
className="mx-auto"
|
||||
style={{ width:"73%" }}
|
||||
/>
|
||||
@@ -1,143 +0,0 @@
|
||||
---
|
||||
title: 连接外部知识库
|
||||
icon: "link"
|
||||
---
|
||||
|
||||
> 为做出区别,独立于 Dify 平台之外的知识库在本文内均被统称为 **“外部知识库”** 。
|
||||
|
||||
## 功能简介
|
||||
|
||||
对于内容检索有着更高要求的进阶开发者而言,Dify 平台内置的知识库功能和文本检索和召回机制**存在限制,无法轻易变更文本召回结果。**
|
||||
|
||||
出于对文本检索和召回的精确度有着更高追求,以及对内部资料的管理需求,部分团队选择自主研发 RAG 算法并独立维护文本召回系统、或将内容统一托管至云厂商的知识库服务(例如 [AWS Bedrock](https://aws.amazon.com/bedrock/))。
|
||||
|
||||
作为中立的 LLM 应用开发平台,Dify 致力于给予开发者更多选择权。
|
||||
|
||||
**连接外部知识库**功能可以将 Dify 平台与外部知识库建立连接。通过 API 服务,AI 应用能够获取更多信息来源。这意味着:
|
||||
|
||||
* Dify 平台能够直接获取托管在云服务提供商知识库内的文本内容,开发者无需将内容重复搬运至 Dify 中的知识库;
|
||||
* Dify 平台能够直接获取自建知识库内经算法处理后的文本内容,开发者仅需关注自建知识库的信息检索机制,并不断优化与提升信息召回的准确度。
|
||||
|
||||
<Frame caption="外部知识库连接原理">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/f5fb91d18740c1e2d3938d4d106c4d3c.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
以下是连接外部知识的详细步骤:
|
||||
|
||||
<Steps>
|
||||
<Step title="建立符合要求的外部知识库 API" titleSize="h2" >
|
||||
为了确保你的外部知识库与 Dify 连接成功,请在建立 API 服务前仔细阅读由 Dify 编写的[外部知识库 API 规范](/zh/use-dify/knowledge/knowledge-and-documents-maintenance/maintain-dataset-via-api)。
|
||||
</Step>
|
||||
<Step title="关联外部知识库">
|
||||
> 目前, Dify 连接外部知识库时仅具备检索权限,暂不支持对外部知识库进行优化与修改,开发者需自行维护外部知识库。
|
||||
|
||||
前往 **“知识库”** 页,点击右上角的 **“外部知识库 API”**,轻点 **“添加外部知识库 API”**。
|
||||
|
||||
按照页面提示,依次填写以下内容:
|
||||
|
||||
* 知识库的名称,允许自定义名称,用于区分所连接的不同外部知识 API;
|
||||
* API 接口地址,外部知识库的连接地址,示例 `api-endpoint/retrieval`;详细说明请参考[外部知识库 API](/zh/use-dify/knowledge/knowledge-and-documents-maintenance/maintain-dataset-via-api);
|
||||
* API Key,外部知识库连接密钥,详细说明请参考[外部知识库 API](/zh/use-dify/knowledge/knowledge-and-documents-maintenance/maintain-dataset-via-api);
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/727221d849615cd2e52b3fd1e6c10129.png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="连接外部知识库">
|
||||
前往 **“知识库”** 页,点击添加知识库卡片下方的 **“连接外部知识库”** 跳转至参数配置页面。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/efae240731f7fa9693da809c08878188.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
填写以下参数:
|
||||
|
||||
* **知识库名称与描述**
|
||||
* **外部知识库 API** 选择在第二步中关联的外部知识库 API;Dify 将通过 API 连接的方式,调用存储在外部知识库的文本内容;
|
||||
* **外部知识库 ID** 指定需要被关联的特定的外部知识库 ID,详细说明请参考[外部知识库 API](/zh/use-dify/knowledge/knowledge-and-documents-maintenance/maintain-dataset-via-api)。
|
||||
* **调整召回设置**
|
||||
|
||||
**Top K:** 用户发起提问时,将请求外部知识 API 获取相关性较高的内容分段。该参数用于筛选与用户问题相似度较高的文本片段。默认值为 3,数值越高,召回存在相关性的文本分段也就越多。
|
||||
|
||||
**Score 阈值:** 文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少,结果也会相对而言更加精准。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/d6345c3af3c2b3befb25fba4dc553a73.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="测试外部知识库连接与召回">
|
||||
建立与外部知识库的连接后,开发者可以在 **“召回测试”** 中模拟可能的问题关键词,预览从外部知识库召回的文本分段。若对于召回结果不满意,可以尝试修改召回参数或自行调整外部知识库的检索设置。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/c5977a5d48dc116589cf2f99e67ccfaa.png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="在应用内集成外部知识库">
|
||||
- **Chatbot / Agent 类型应用**
|
||||
|
||||
在 Chatbot / Agent 类型应用内的编排页中的 **“上下文”** 内,选中带有 `EXTERNAL` 标签的外部知识库。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/e7df9d7360186ee0f0e156c166f84a3b.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
- **Chatflow / Workflow 类型应用**
|
||||
|
||||
在 Chatflow / Workflow 类型应用内添加 **“知识检索”** 节点,选中带有 `EXTERNAL` 标签的外部知识库。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/4e1cbdcf4a9e6e7c2535a53e478054e3.png" alt="" /><figcaption></figcaption>
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="管理外部知识库" titleSize="p">
|
||||
在 **“知识库”** 页,外部知识库的卡片右上角会带有 **EXTERNAL** 标签。进入需要修改的知识库,点击 **“设置”** 修改以下内容:
|
||||
|
||||
* **知识库名称和描述**
|
||||
* **可见范围** 提供 「 只有我 」 、 「 所有团队成员 」 和 「部分团队成员」 三种权限范围。不具有权限的人将无法访问该知识库。若选择将知识库公开至其它成员,则意味着其它成员同样具备该知识库的查看、编辑和删除权限。
|
||||
* **召回设置**
|
||||
|
||||
**Top K:** 用户发起提问时,将请求外部知识 API 获取相关性较高的内容分段。该参数用于筛选与用户问题相似度较高的文本片段。默认值为 3,数值越高,召回存在相关性的文本分段也就越多。
|
||||
|
||||
**Score 阈值:** 文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少,结果也会相对而言更加精准。
|
||||
|
||||
外部知识库所关联的 **“外部知识库 API”** 和 **“外部知识 ID”** 不支持修改,如需修改请关联新的 “外部知识库 API” 并重新进行连接。
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### 外部知识库连接示例
|
||||
|
||||
#### LlamaCloud
|
||||
|
||||
[Dify 插件市场](https://marketplace.dify.ai/)内提供了 LlamaCloud 插件,可以帮助你快速连接 LlamaCloud 知识库,在 Dify 平台中使用由 LlamaCloud 提供的检索功能,而无需编写自定义 API。
|
||||
|
||||
插件市场中搜索 `LlamaCloud` 即可快速安装插件。
|
||||
|
||||
按照插件配置向导,填写 LlamaCloud 的 API 密钥和其他必要信息。完成配置后,你可以在知识库列表中看到连接的外部知识库。
|
||||
|
||||
**视频教程**
|
||||
|
||||
以下视频详细展示了如何使用 LlamaCloud 插件连接外部知识库:
|
||||
|
||||
<iframe
|
||||
src="https://www.youtube.com/embed/FaOzKZRS-2E"
|
||||
width="100%"
|
||||
height="315"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowFullScreen
|
||||
/>
|
||||
|
||||
如需了解功能原理,请参考插件 [GitHub 地址](https://github.com/langgenius/dify-official-plugins/tree/main/extensions/llamacloud)。
|
||||
|
||||
## 常见问题
|
||||
|
||||
**连接外部知识库 API 时异常,出现报错如何处理?**
|
||||
|
||||
以下是返回信息各个错误码所对应的错误提示与解决办法:
|
||||
|
||||
| 错误码 | 错误提示 | 解决办法 |
|
||||
| ---- | --------------------------- | ------------------------------ |
|
||||
| 1001 | 无效的 Authorization header 格式 | 请检查请求的 Authorization header 格式 |
|
||||
| 1002 | 验证异常 | 请检查所填写的 API Key 是否正确 |
|
||||
| 2001 | 知识库不存在 | 请检查外部知识库 |
|
||||
@@ -1,204 +0,0 @@
|
||||
---
|
||||
title: 在应用内集成知识库
|
||||
icon: "puzzle-piece-simple"
|
||||
---
|
||||
|
||||
知识库可以作为外部知识提供给大语言模型用于精确回复用户问题,你可以在 Dify 的[所有应用类型](/zh/use-dify/getting-started/key-concepts)内关联已创建的知识库。
|
||||
|
||||
以聊天助手为例,使用流程如下:
|
||||
|
||||
1. 进入 **工作室 -- 创建应用 --创建聊天助手**
|
||||
2. 进入 **上下文设置** 点击 **添加** 选择已创建的知识库
|
||||
3. 在 **上下文设置 -- 参数设置** 内配置**召回策略**
|
||||
4. 在 **元数据筛选** 板块中配置元数据的筛选条件,使用元数据功能筛选知识库内的文档
|
||||
5. 在 **添加功能** 内打开 **引用和归属**
|
||||
6. 在 **调试与预览** 内输入与知识库相关的用户问题进行调试
|
||||
7. 调试完成之后**保存并发布**为一个 AI 知识库问答类应用
|
||||
|
||||
***
|
||||
|
||||
### 关联知识库并指定召回模式
|
||||
|
||||
如果当前应用的上下文涉及多个知识库,需要设置召回模式以使得检索的内容更加精确。进入 **上下文 -- 参数设置 -- 召回设置**。
|
||||
|
||||
#### 召回设置
|
||||
|
||||
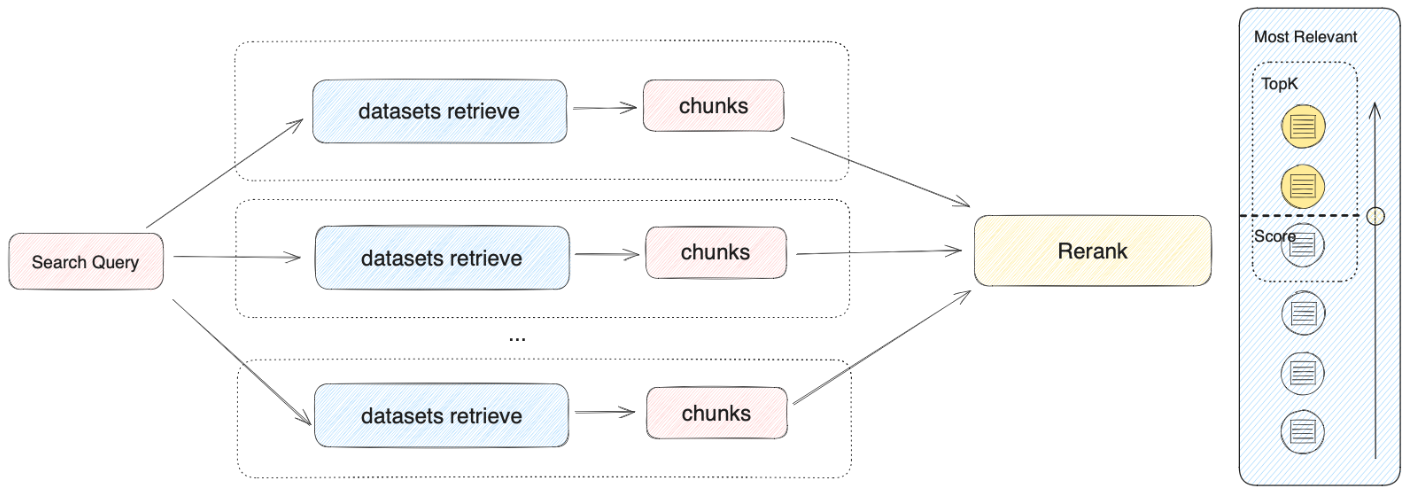
检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,以下是召回策略的技术流程图:
|
||||
|
||||
|
||||
|
||||
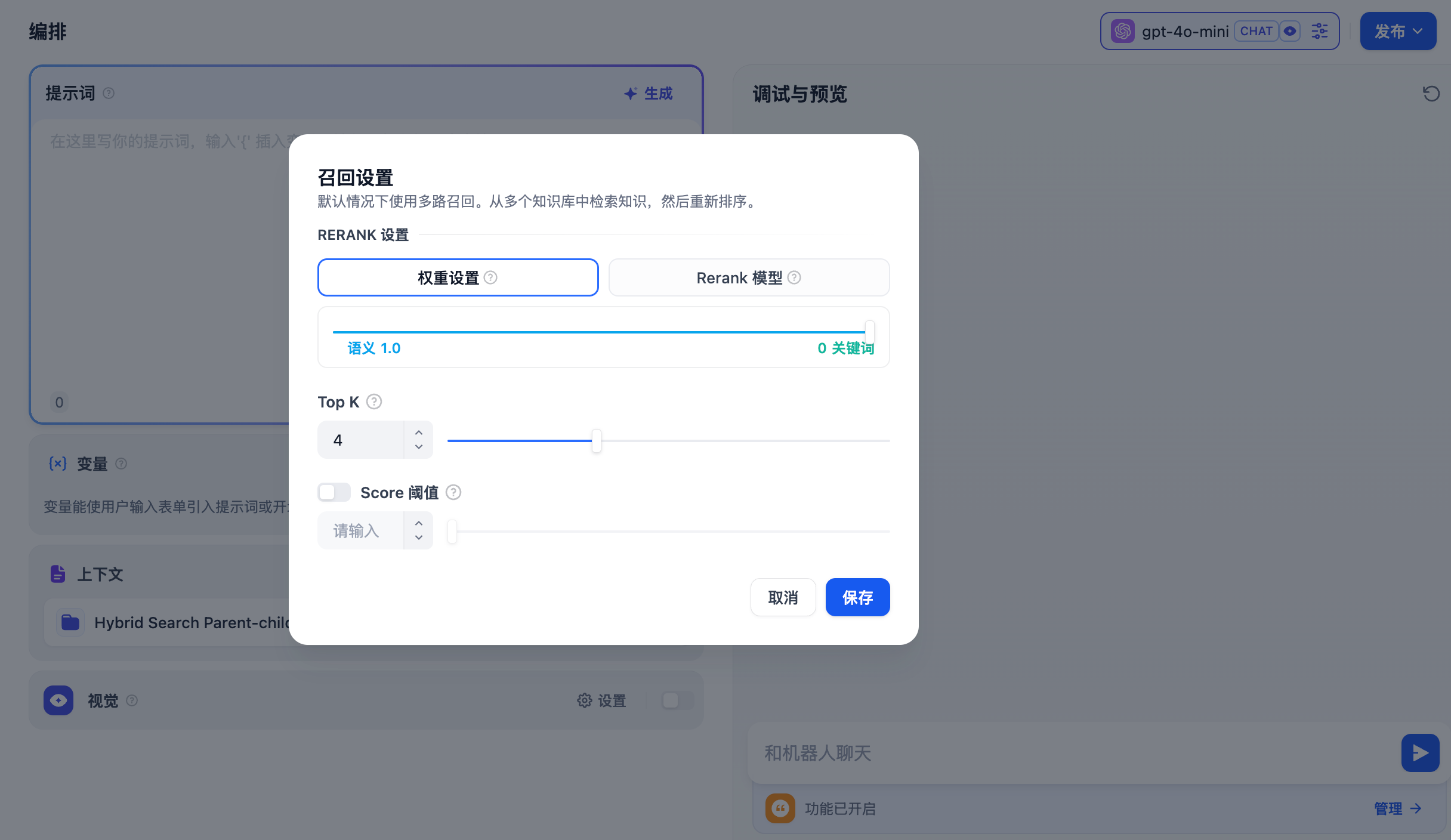
根据用户意图同时检索所有添加至 **“上下文”** 的知识库,在多个知识库内查询相关文本片段,选择所有和用户问题相匹配的内容,最后通过 Rerank 策略找到最适合的内容并回答用户。该方法的检索原理更为科学。
|
||||
|
||||
|
||||
|
||||
举例:A 应用的上下文关联了 K1、K2、K3 三个知识库,当用户输入问题后,将在三个知识库内检索并汇总多条内容。为确保能找到最匹配的内容,需要通过 Rerank 策略确定与用户问题最相关的内容,确保结果更加精准与可信。
|
||||
|
||||
在实际问答场景中,每个知识库的内容来源和检索方式可能都有所差异。针对检索返回的多条混合内容,Rerank 策略是一个更加科学的内容排序机制。它可以帮助确认候选内容列表与用户问题的匹配度,改进多个知识间排序的结果以找到最匹配的内容,提高回答质量和用户体验。
|
||||
|
||||
考虑到 Rerank 的使用成本和业务需求,多路召回模式提供了以下两种 Rerank 设置:
|
||||
|
||||
**权重设置**
|
||||
|
||||
该设置无需配置外部 Rerank 模型,重排序内容**无需额外花费**。可以通过调整语义或关键词的权重比例条,选择最适合的内容匹配策略。
|
||||
|
||||
* **语义值为 1**
|
||||
|
||||
仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
|
||||
|
||||
> 语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:[《Dify:Embedding 技术与 Dify 数据集设计/规划》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
|
||||
* **关键词值为 1**
|
||||
|
||||
仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
|
||||
* **自定义关键词和语义权重**
|
||||
|
||||
除了仅启用语义检索或关键词检索模式,我们还提供了灵活的自定义权重设置。你可以通过不断调试二者的权重,找到符合业务场景的最佳权重比例。
|
||||
|
||||
**Rerank 模型**
|
||||
|
||||
Rerank 模型是一种外部评分系统,它会计算用户问题与给定的每个候选文档之间的相关性分数,从而改进语义排序的结果,并按相关性返回从高到低排序的文档列表。
|
||||
|
||||
虽然此方法会产生一定的额外花费,但是更加擅长处理知识库内容来源复杂的情况,例如混合了语义查询和关键词匹配的内容,或返回内容存在多语言的情况。
|
||||
|
||||
Dify 目前支持多个 Rerank 模型,进入 “模型供应商” 页填入 Rerank 模型(例如 Cohere、Jina AI 等模型)的 API Key。
|
||||
|
||||
<Frame caption="在模型供应商内配置 Rerank 模型">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/07094b0052fd058e4c31856365feb1ca.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**可调参数**
|
||||
|
||||
* **TopK**
|
||||
|
||||
用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小,动态调整分段数量。数值越高,预期被召回的文本分段数量越多。
|
||||
* **Score 阈值**
|
||||
|
||||
用于设置文本片段筛选的相似度阈值。向量检索的相似度分数需要超过设置的分数后才会被召回,数值越高,预期被召回的文本数量越少。
|
||||
|
||||
### 使用元数据筛选知识
|
||||
|
||||
#### 聊天流/工作流
|
||||
|
||||
在 **聊天流/工作流** 的 **知识检索** 节点中,你可以使用 **元数据筛选** 功能精确检索文档。该功能有助于你根据文档的元数据字段(如标签、类别或访问权限)优化检索结果。
|
||||
|
||||
##### 配置步骤
|
||||
|
||||
1. 选择筛选模式
|
||||
|
||||
- **禁用模式**(默认):禁用 **元数据筛选** 功能,不配置任何筛选条件。
|
||||
|
||||
- **自动模式**:系统会根据传输给该 **知识检索** 节点的 **查询变量** 自动配置筛选条件,适用于简单的筛选需求。
|
||||
|
||||
> 启用自动模式后,你依然需要在 **模型** 栏中选择合适的大模型以执行文档检索任务。
|
||||
|
||||
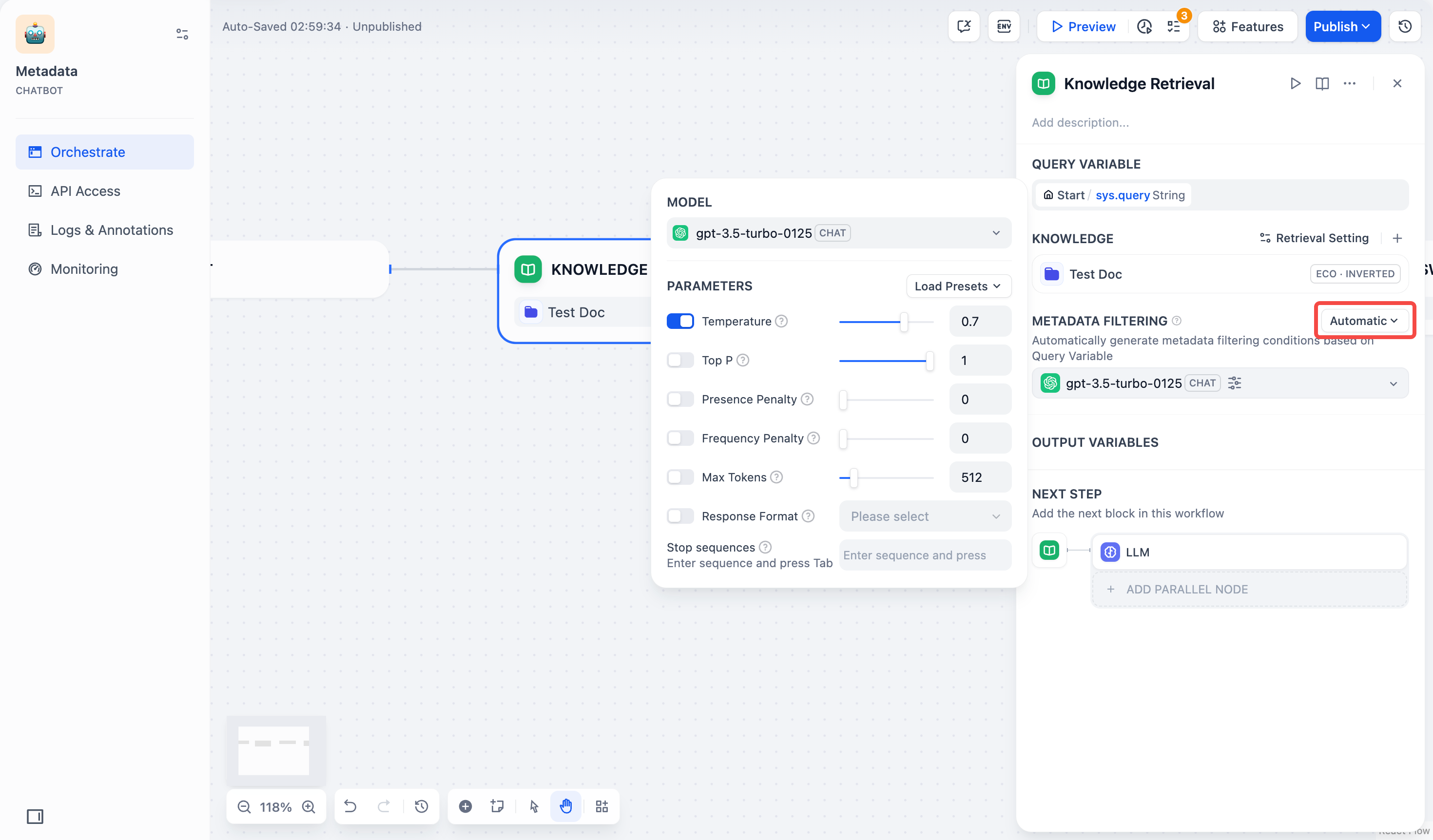
|
||||
|
||||
- **手动模式**:用户可以手动配置筛选条件,自由设置筛选规则,适用于复杂的筛选需求。
|
||||
|
||||
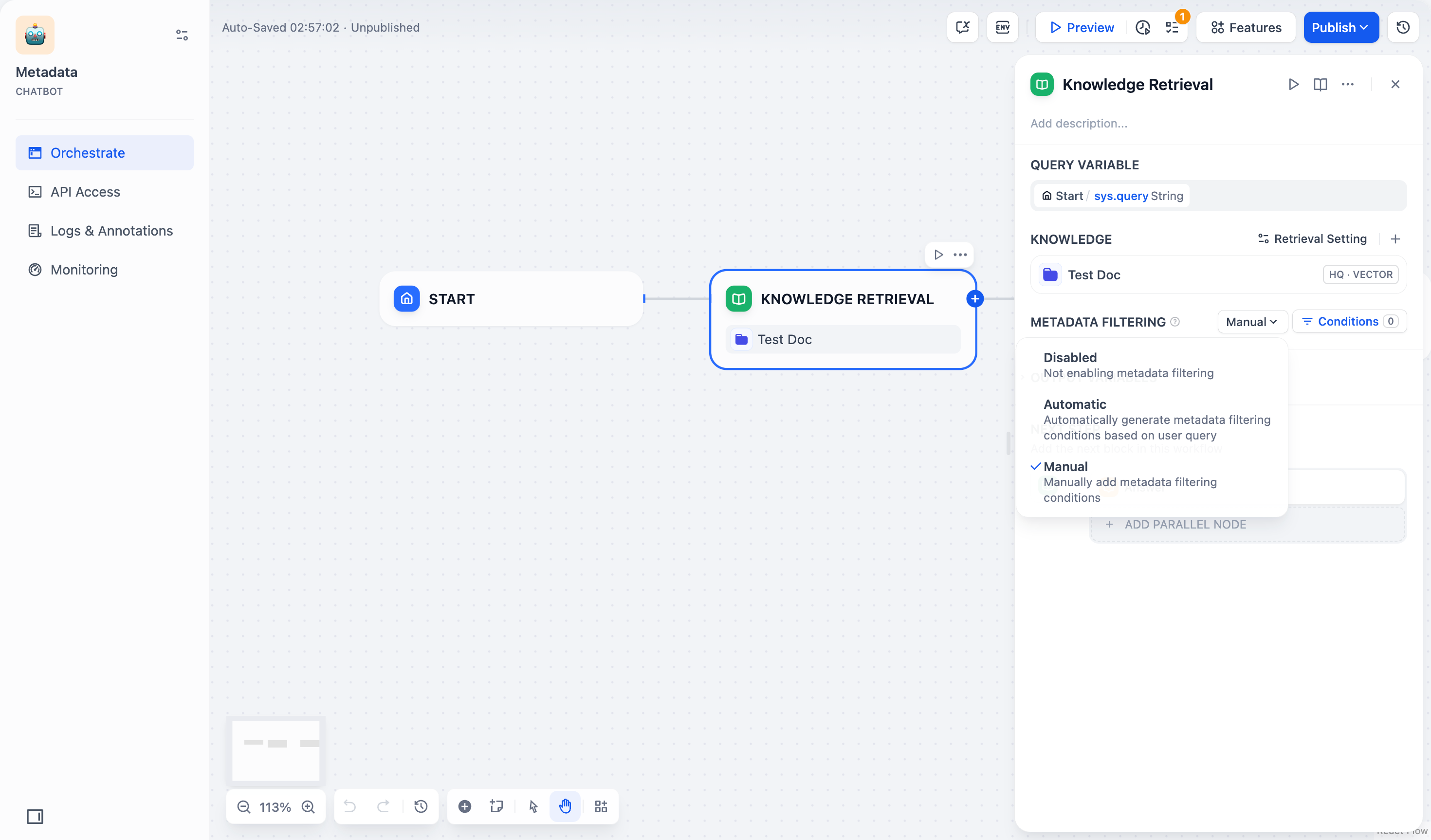
|
||||
|
||||
2. 如果你选择了 **手动模式**,请参照以下步骤配置筛选条件:
|
||||
|
||||
1. 点击 **条件** 按钮,弹出配置框。
|
||||
|
||||
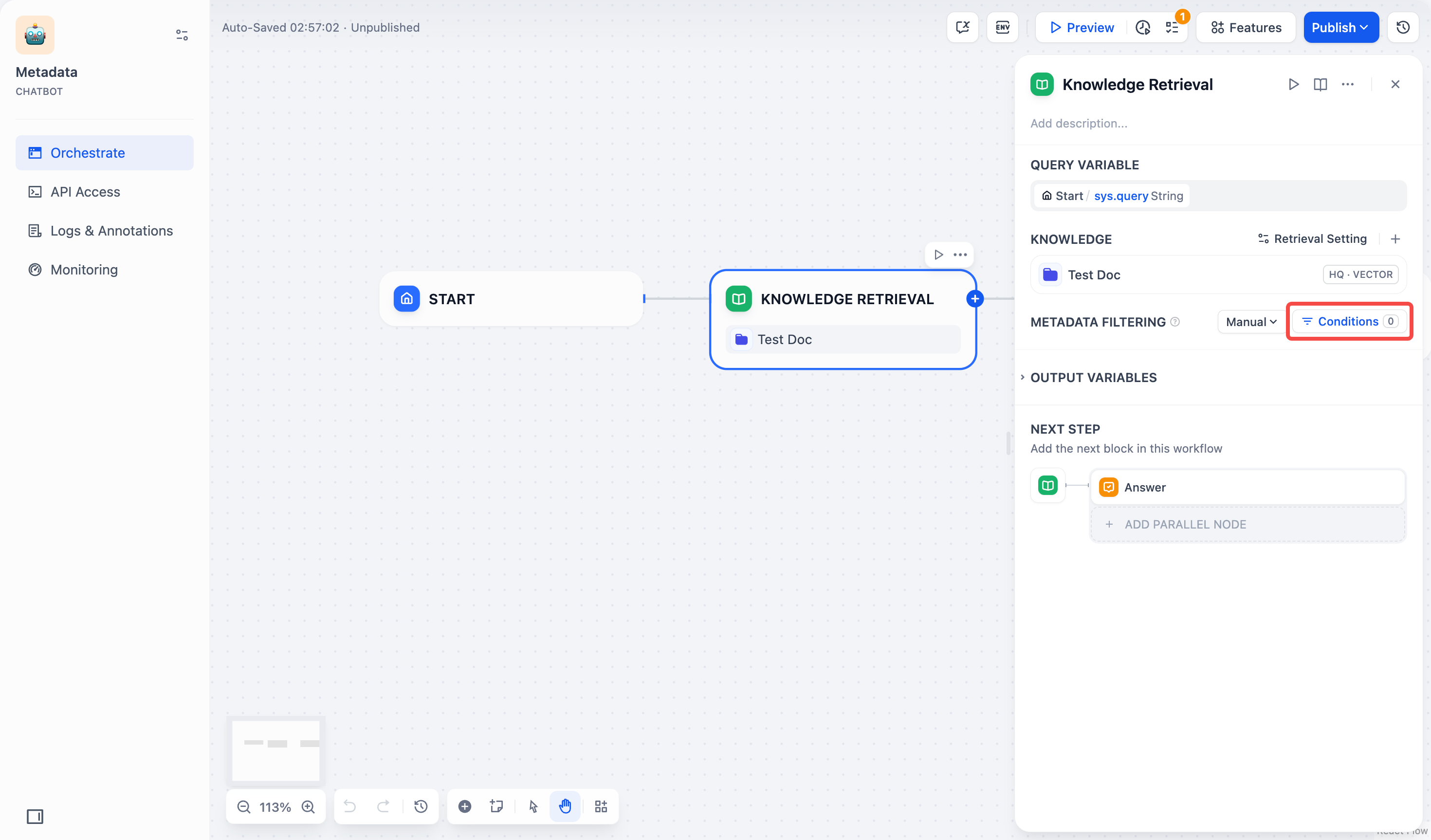
|
||||
|
||||
2. 点击配置框中的 **+添加条件** 按钮:
|
||||
|
||||
- 可以从下拉列表中选择一个已选中知识库内的元数据字段,添加到筛选条件列表中。
|
||||
|
||||
> 如果你同时选择了多个知识库,下拉列表只会显示这些知识库共有的元数据字段。
|
||||
|
||||
- 可以在 **搜索元数据** 搜索框中搜索你需要的字段,添加到筛选条件列表中。
|
||||
|
||||
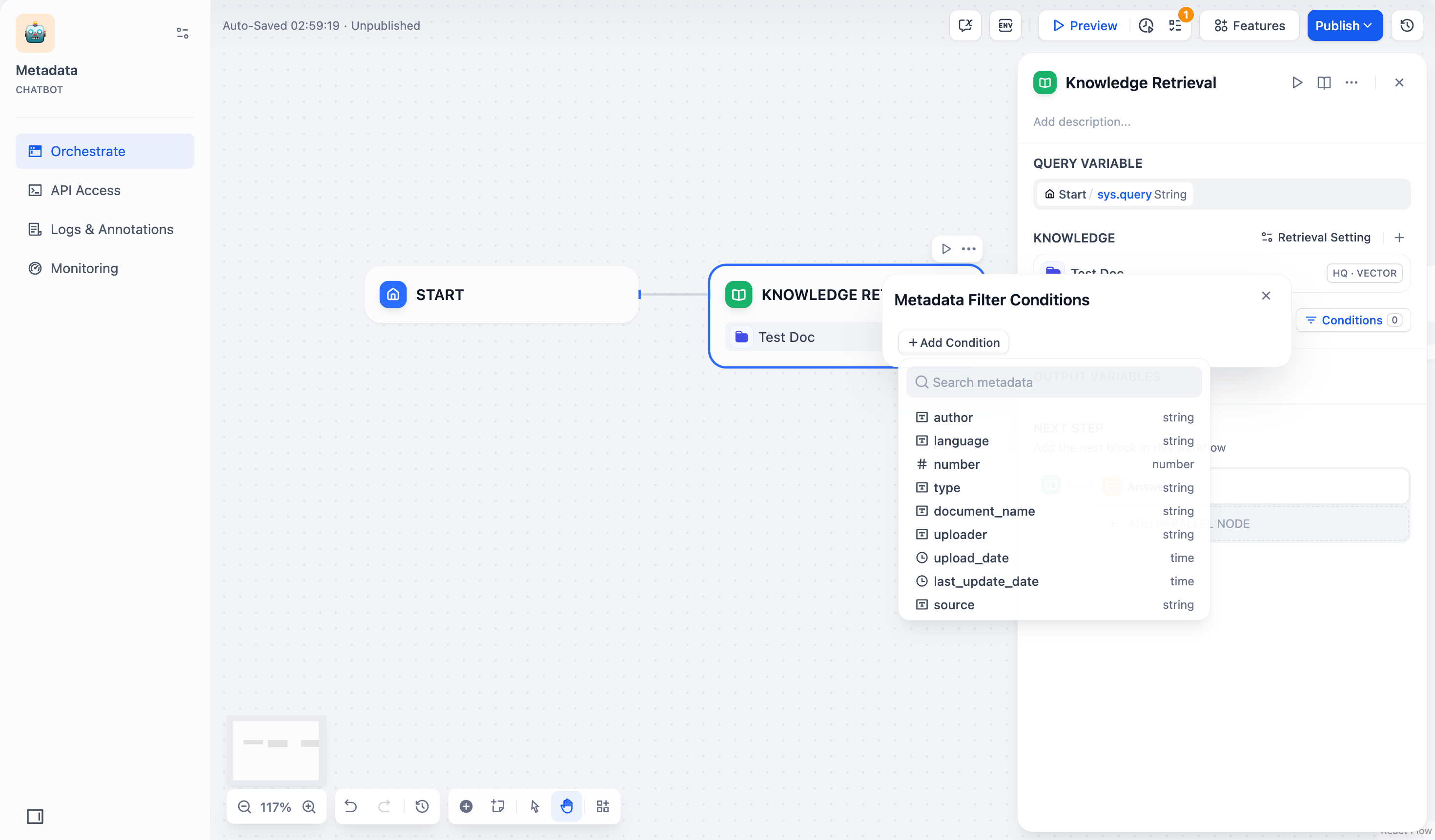
|
||||
|
||||
3. 如果需要添加多条字段,可以重复点击 **+添加条件** 按钮。
|
||||
|
||||
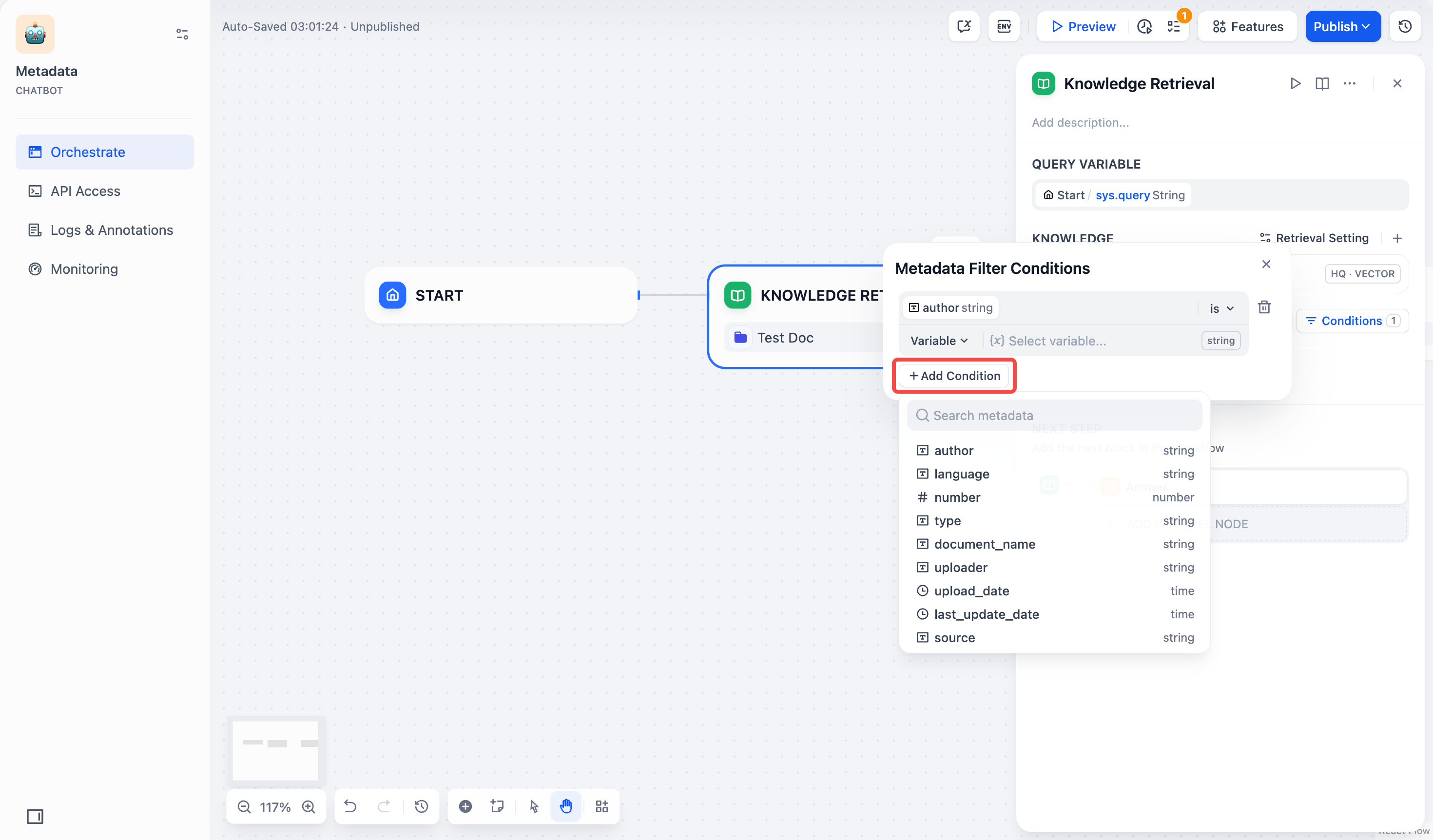
|
||||
|
||||
4. 配置字段类型的筛选条件:
|
||||
|
||||
| 字段类型 | 筛选条件 | 筛选条件说明与示例 |
|
||||
| --- | --- | --- |
|
||||
| 字符串 | is | 字段的值必须与你输入的值完全匹配。例如,如果你设置筛选条件为 `is "Published"`,则只会返回标记为 "Published" 的文档。 |
|
||||
| | is not | 字段的值不能与你输入的值匹配。例如,如果你设置筛选条件为 `is not "Draft"`,则会返回所有未标记为 "Draft" 的文档。 |
|
||||
| | is empty | 字段的值为空。如果你配置了此条件,可以检索到未标记该字符串的文档。 |
|
||||
| | is not empty | 字段的值不为空。如果你配置了此条件,可以检索到标记了该字符串的文档。 |
|
||||
| | contains | 字段的值包含你输入的文本。例如,如果你设置筛选条件为 `contains "Report"`,则会返回所有包含"Report"的文档,如"Monthly Report" 或 "Annual Report"。 |
|
||||
| | not contains | 字段的值不包含你输入的文本。例如,如果你设置筛选条件为 `not contains "Draft"`,则会返回所有不包含 "Draft" 的文档。 |
|
||||
| | starts with | 字段的值以你输入的文本开头。例如,如果你设置筛选条件为 `starts with "Doc"`,则会返回所有以"Doc"开头的文档,如 "Doc1"、"Document"等。 |
|
||||
| | ends with | 字段的值以你输入的文本结尾。例如,如果你设置筛选条件为 `ends with "2024"`,则会返回所有以"2024"结尾的文档,如"Report 2024"、"Summary 2024"等。 |
|
||||
| 数字 | = | 字段的值必须等于你输入的数字。例如,`= 10` 会匹配所有数字标记为 10 的文档。 |
|
||||
| | ≠ | 字段的值不能等于你输入的数字。例如,`≠ 5` 会返回所有数字未标记为 5 的文档。 |
|
||||
| | > | 字段的值必须大于你输入的数字。例如,`100` 会返回所有数字标记为大于 100 的文档。 |
|
||||
| | < | 字段的值必须小于你输入的数字。例如,`< 50` 会返回所有数字标记为小于 50 的文档。 |
|
||||
| | ≥ | 字段的值必须大于或等于你输入的数字。例如,`≥ 20` 会返回所有数字标记为大于或等于 20 的文档。 |
|
||||
| | ≤ | 字段的值必须小于或等于你输入的数字。例如,`≤ 200` 会返回所有数字标记为小于或等于 200 的文档。 |
|
||||
| | is empty | 字段未设置值。例如,`is empty` 会返回所有该字段未标记数字的文档。 |
|
||||
| | is not empty | 字段已设置值。例如,`is not empty` 会返回所有该字段已标记数字的文档。 |
|
||||
| 时间 | is | 字段的时间值必须与你选择的时间完全匹配。例如,`is "2024-01-01"` 只会返回标记为 2024 年 1 月 1 日的文档。 |
|
||||
| | before | 字段的时间值必须早于你选择的时间。例如,`before "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之前的文档。 |
|
||||
| | after | 字段的时间值必须晚于你选择的时间。例如,`after "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之后的文档。 |
|
||||
| | is empty | 字段的时间值为空。如果你配置了此条件,可以检索到未标记该时间信息的文档。 |
|
||||
| | is not empty | 字段的时间值不为空。如果你配置了此条件,可以检索到标记了该时间信息的文档。 |
|
||||
|
||||
5. 选择并添加元数据筛选值:
|
||||
- **变量**:选择 **变量(Variable)**,并选择该**聊天流/工作流**中需要用于筛选文档的变量。
|
||||
|
||||
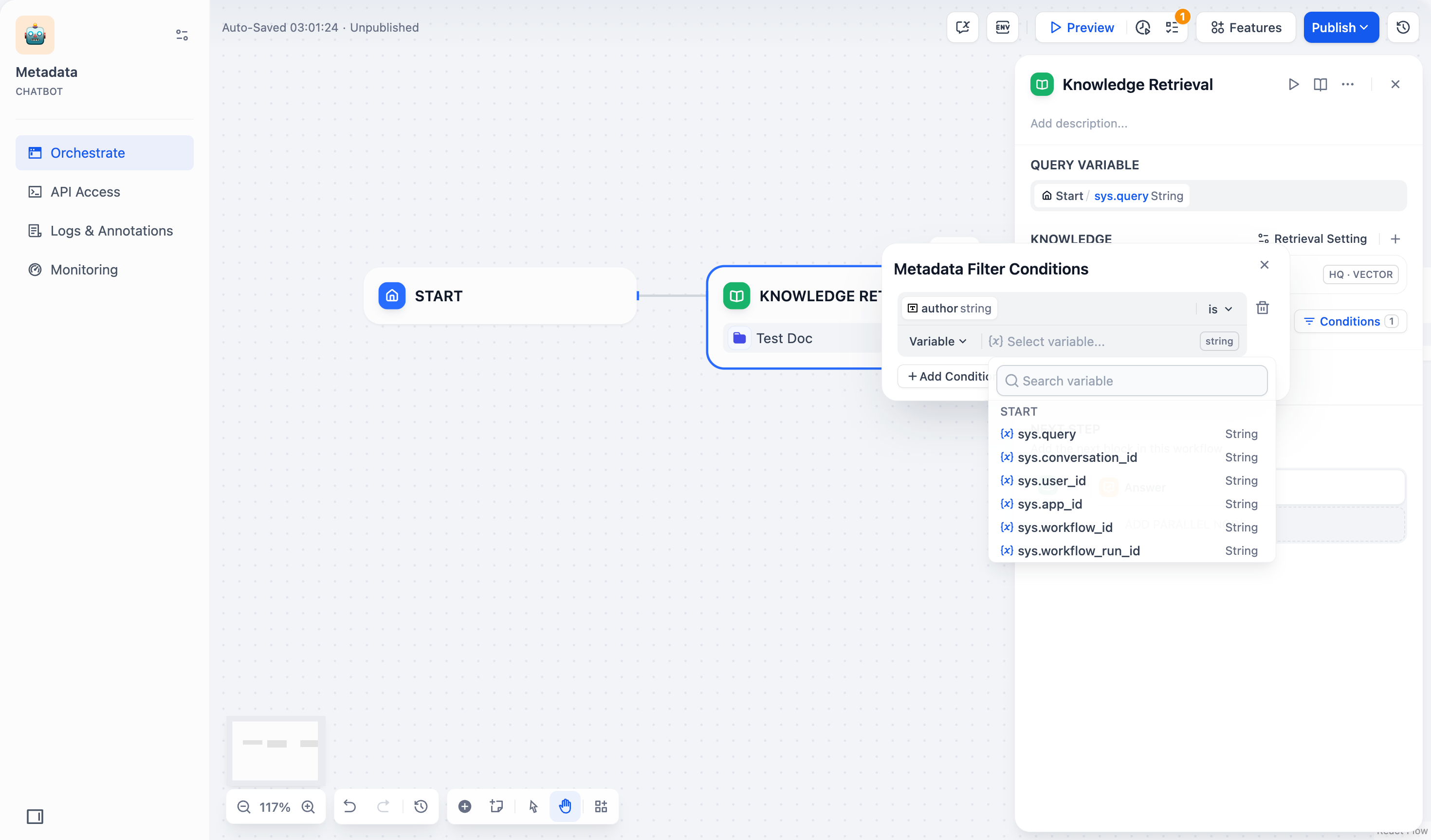
|
||||
|
||||
- **常量**:选择 **常量(Constant)**,并手动输入你需要的常量值。
|
||||
|
||||
> **时间** 字段类型仅支持使用常量筛选文档。如果你选用时间字段筛选文档,系统会弹出时间选择器,供你选择具体的时间节点。
|
||||
|
||||
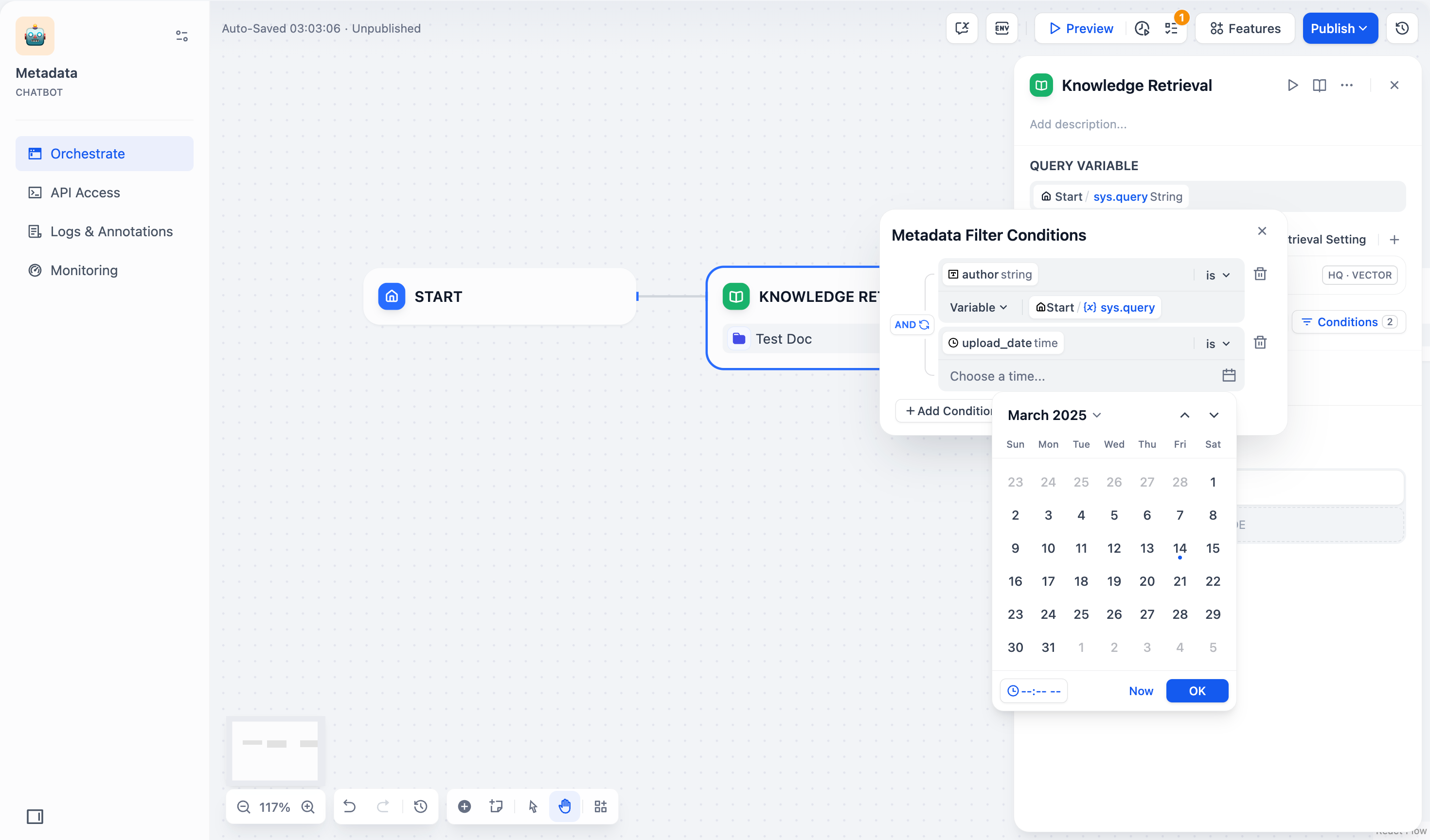
|
||||
|
||||
<Warning>
|
||||
当你输入常量筛选值时,该筛选值必须与该元数据字段值的文本完全一致,系统才能返回该文档。例如,当你设置筛选条件为 `starts with "App"` 或 `contains "App"` 时,系统会返回标记为 “Apple” 的文档,但不会返回标记为 “apple” 或 “APPLE” 的文档。
|
||||
</Warning>
|
||||
|
||||
6. 配置筛选条件之间的逻辑关系 `AND` 或 `OR`。
|
||||
- `AND`:当一个文档满足所有筛选条件时,才能检索到该文档。
|
||||
- `OR`:只要一个文档满足其中任意一个筛选条件,就可以检索到该文档。
|
||||
|
||||
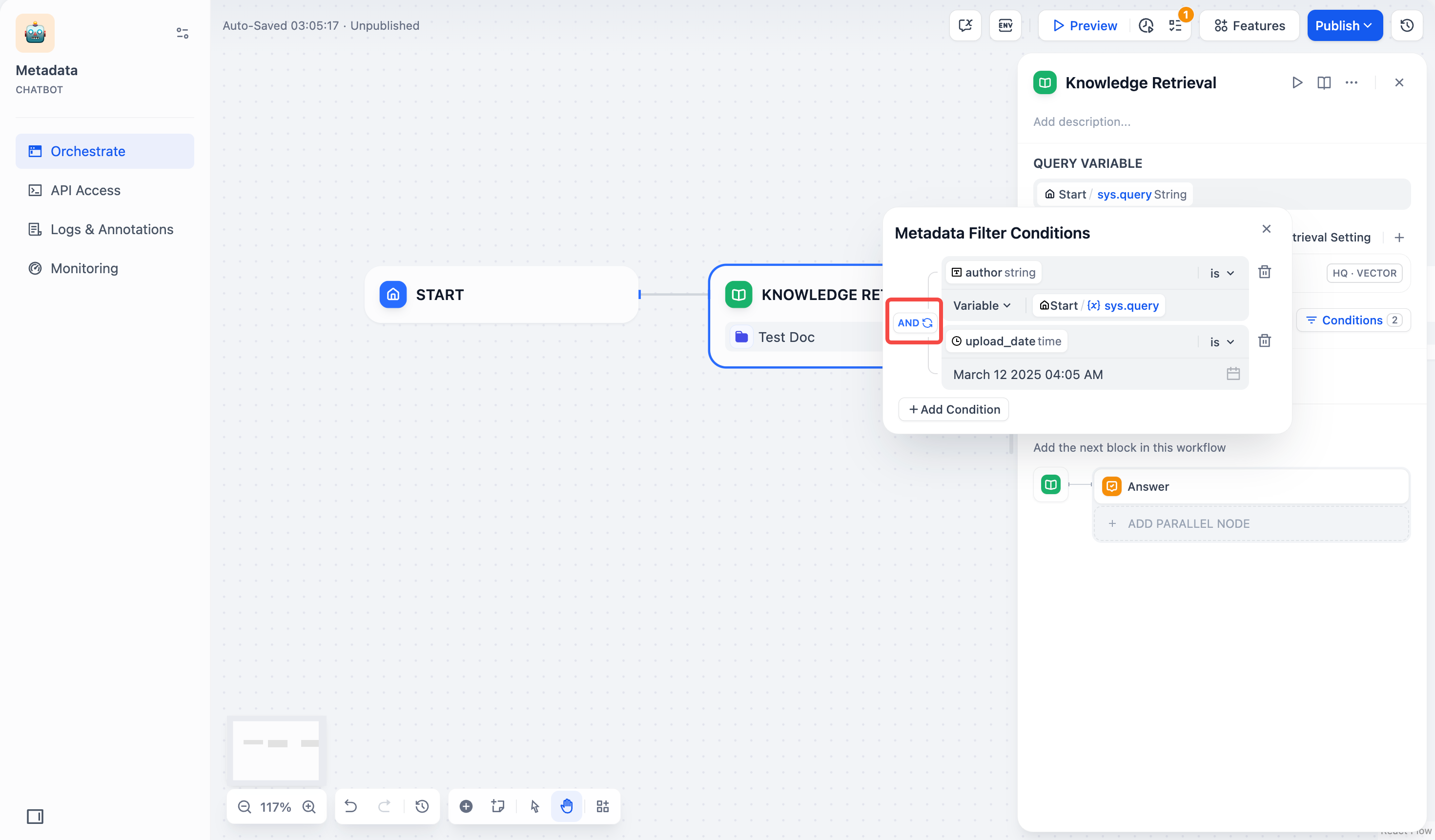
|
||||
|
||||
7. 关闭弹窗,系统将自动保存你的选择。
|
||||
|
||||
#### 聊天助手
|
||||
|
||||
在**聊天助手**中,**元数据筛选** 功能位于界面左下方的 **上下文** 板块下方,配置方法与**聊天流/工作流**中的操作一致。你可以按照相同的步骤配置元数据筛选条件。
|
||||
|
||||
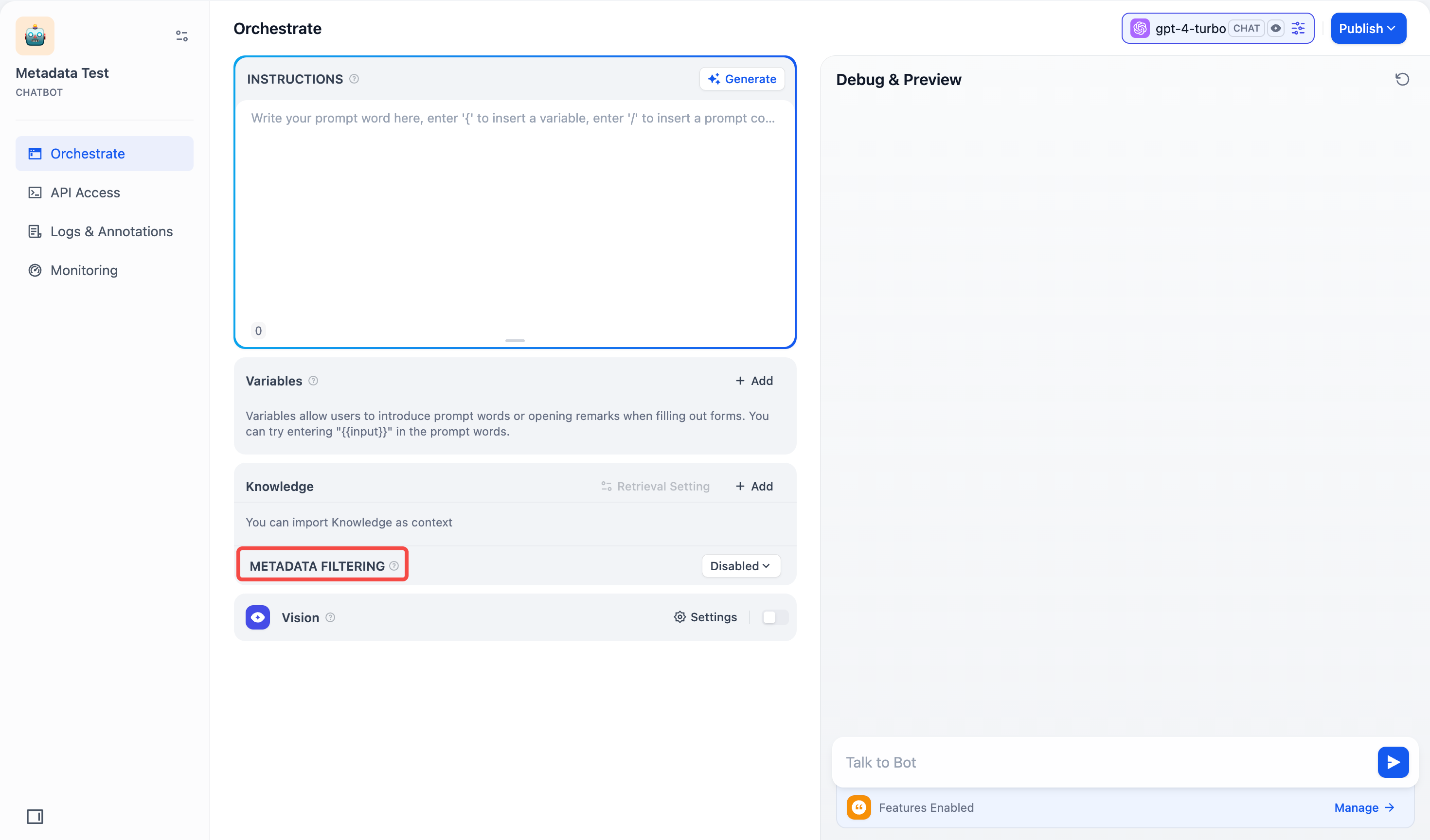
|
||||
|
||||
### 在知识库内查看已关联的应用
|
||||
|
||||
知识库将会在左侧信息栏中显示已关联的应用数量。将鼠标悬停至圆形信息图标时将显示所有已关联的 Apps 列表,点击右侧的跳转按钮即可快速查看对应的应用。
|
||||
|
||||
|
||||
|
||||
### 常见问题
|
||||
|
||||
1. **如何选择多路召回中的 Rerank 设置?**
|
||||
|
||||
如果用户知道确切的信息或术语,可以通过关键词检索精确发挥匹配结果,那么请将 “权重设置” 中的**关键词设置为 1**。
|
||||
|
||||
如果知识库内并未出现确切词汇,或者存在跨语言查询的情况,那么推荐使用 “权重设置” 中的**语义设置为 1**。
|
||||
|
||||
如果业务人员对于用户的实际提问场景比较熟悉,想要主动调整语义或关键词的比值,那么推荐自行调整 “权重设置” 里的比值。
|
||||
|
||||
如果知识库内容较为复杂,无法通过语义或关键词等简单条件进行匹配,同时要求较为精准的回答,愿意支付额外的费用,那么推荐使用 **Rerank 模型** 进行内容检索。
|
||||
|
||||
2. **为什么会出现找不到 “权重设置” 或要求必须配置 Rerank 模型等情况,应该如何处理?**
|
||||
|
||||
以下是知识库检索方式对文本召回的影响情况:
|
||||
|
||||
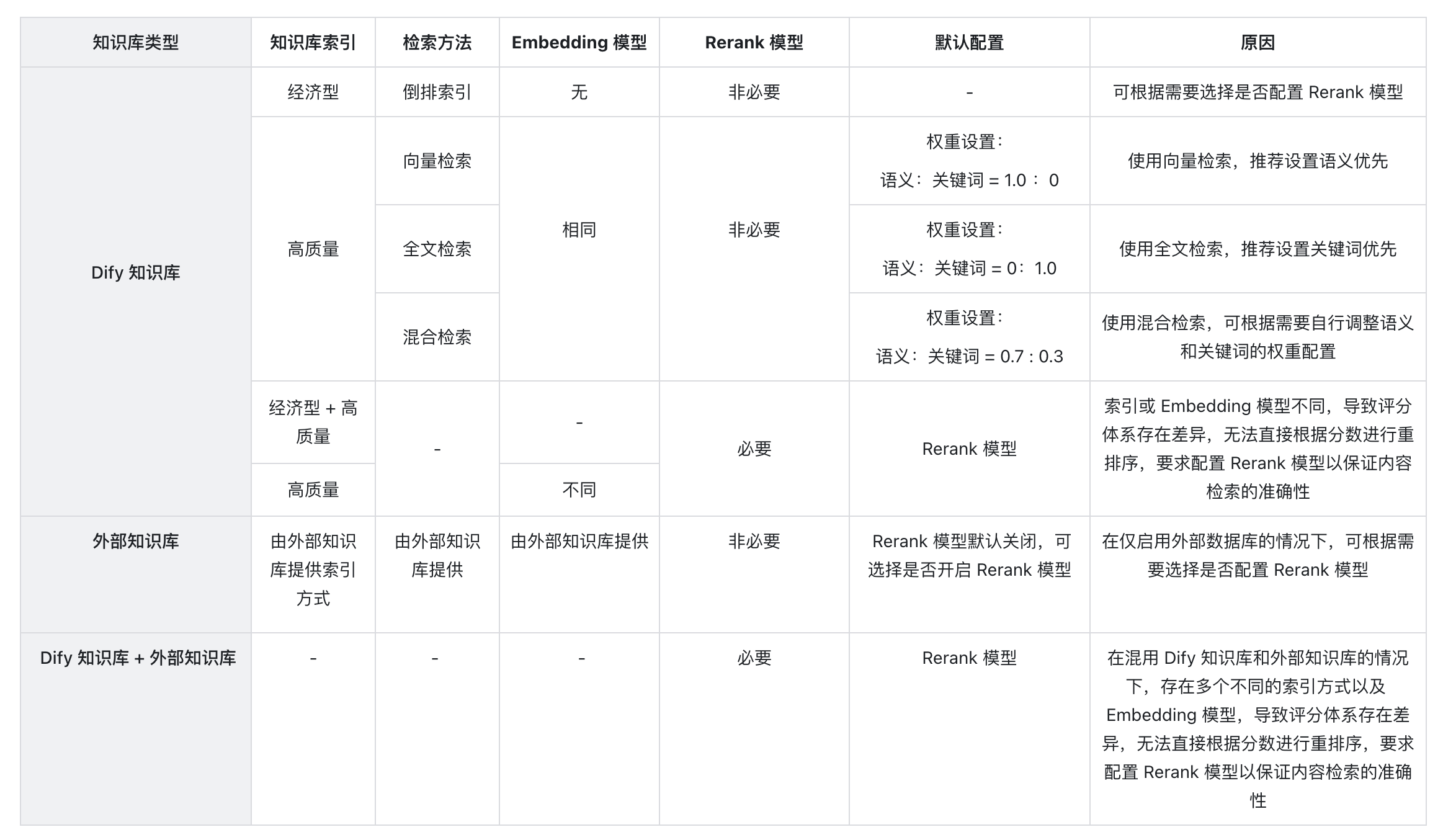
|
||||
|
||||
3. **引用多个知识库时,无法调整 “权重设置”,提示错误应如何处理?**
|
||||
|
||||
出现此问题是因为上下文内所引用的多个知识库内所使用的嵌入模型(Embedding)不一致,为避免检索内容冲突而出现此提示。推荐设置在“模型供应商”内设置并启用 Rerank 模型,或者统一知识库的检索设置。
|
||||
|
||||
4. **为什么在多路召回模式下找不到“权重设置”选项,只能看到 Rerank 模型?**
|
||||
|
||||
请检查你的知识库是否使用了“经济”型索引模式。如果是,那么将其切换为“高质量”索引模式。
|
||||
@@ -1,484 +0,0 @@
|
||||
---
|
||||
title: "步骤二:知识流水线编排"
|
||||
---
|
||||
|
||||
想象一下你正在搭建一条生产流水线,每个站点执行特定任务,你将不同它们连接起来将每个零部件组装最终成品。知识流水线编排与此类似,你组合不同节点,将原始文档数据通过每个节点逐步转化为可搜索的知识库。在 Dify 里,你通过可视化的方式,拖放和连接不同节点,对文档数据进行提取和分块处理,并配置索引方式和检索策略。
|
||||
|
||||
在这个章节,你将了解知识流水线的过程,理解不同节点的含义和配置,如何自定义构建数据处理流程,从而高效地管理和优化知识库。
|
||||
|
||||
### 界面状态
|
||||
进入知识流水线编排界面时,你会看到:
|
||||
- **标签页状态**:Documents(文档)、Retrieval Test(召回测试)和 Settings(设置)标签页将显示为置灰且不可用状态
|
||||
- **必要步骤**:你必须完成知识流水线的配置、调试和发布后,才能上传文件或使用其他功能
|
||||
|
||||
如果你选择了**空白知识流水线**,你将看到仅包含知识库节点的画布。你可以跟随该节点旁的指引,逐步完成流水线创建。
|
||||
|
||||

|
||||
|
||||
如果选择**特定的流水线模版**,编排界面将直接显示该流水线模版。
|
||||
|
||||

|
||||
|
||||
## 知识流水线处理流程
|
||||
|
||||
在开始之前,我们先拆解知识流水线的处理流程,你可以更好地理解数据是如何一步步转化为可用的知识库。
|
||||
|
||||
<Tip>
|
||||
**数据源配置 → 数据处理节点(文档提取器 + 分块器)→ 知识库节点(分块结构+索引配置) → 配置用户输入表单 → 测试发布**
|
||||
</Tip>
|
||||
|
||||
1. **数据源配置**:来自各种数据源的原始内容(本地文件、Notion、网页等)
|
||||
2. **数据处理节点配置**:处理和转换数据内容
|
||||
- 提取器 (Extractor) → 解析和结构化原始文档内容
|
||||
- 分块器 (Chunker) → 将结构化内容分割为适合处理的片段
|
||||
3. **知识库节点配置**:设置知识库的分段结构和检索策略
|
||||
4. **用户输入表单配置**:定义流水线使用者需要输入的参数
|
||||
5. **测试与发布**:验证并正式启用知识库
|
||||
|
||||
## 步骤一:数据源配置
|
||||
|
||||
在一个知识库里,你可以选择单一或多个数据源。每个数据源可以被多次选中,并包含不同配置。目前,Dify 支持 5 种数据源:文件上传、在线网盘、在线数据和 Web Crawler。
|
||||
|
||||
你也可以前往 [Dify Marketplace](https://marketplace.dify.ai),获得更多数据源。
|
||||
|
||||
### 文件上传
|
||||
|
||||
用户可以直接选择本地文件进行上传,以下是配置选项和限制。
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
**配置选择**
|
||||
|
||||
| 配置项 | 说明 |
|
||||
|--------|------|
|
||||
| 文件格式 | 支持 pdf, xlxs, docs 等,用户可自定义选择 |
|
||||
| 上传方式 | 通过拖拽或选择文件或文件夹上传本地文件,支持批量上传 |
|
||||
|
||||
**限制**
|
||||
|
||||
| 限制项 | 说明 |
|
||||
|--------|------|
|
||||
| 文件数量 | 每次最多上传 50 个文件 |
|
||||
| 文件大小 | 每个文件大小不超过 15MB |
|
||||
| 储存限制 | 不同 SaaS 版本的订阅计划对文档上传总数和向量存储空间有所限制 |
|
||||
|
||||
**输出变量**
|
||||
|
||||
| 输出变量 | 变量格式 |
|
||||
|----------|----------|
|
||||
| `{x} Document` | 单个文档 |
|
||||
</div>
|
||||
</div>
|
||||
---
|
||||
|
||||
### 在线数据
|
||||
|
||||
#### Notion
|
||||
|
||||
将知识库连接 Notion 工作区,可直接导入 Notion 页面和数据库内容,支持后续的数据自动同步。
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
**配置选项说明**
|
||||
|
||||
| 配置项 | 选项 | 输出变量 | 说明 |
|
||||
|--------|------|----------|------|
|
||||
| Extractor | 开启 | `{x} Content` | 输出结构化处理的页面信息 |
|
||||
| | 关闭 | `{x} Document` | 输出页面的原始文本信息 |
|
||||
</div>
|
||||
</div>
|
||||
|
||||
### 网页爬虫
|
||||
|
||||
将网页内容转化为大型语言模型容易识别的格式,知识库支持 Jina Reader 和 Firecrawl,提供灵活的网页解析能力。
|
||||
|
||||
#### Jina Reader
|
||||
|
||||
开源网页解析工具,提供简洁易用的 API 服务,适合快速抓取和处理网页内容。
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
**参数配置和说明**
|
||||
|
||||
| 参数 | 类型 | 说明 |
|
||||
|------|------|------|
|
||||
| URL | 必填 | 目标网页地址 |
|
||||
| 爬取子页面 (Crawl sub-page) | 可选 | 是否抓取链接页面 |
|
||||
| 使用站点地图 (Use sitemap) | 可选 | 利用网站地图进行爬取 |
|
||||
| 爬取页数限制 (Limit) | 必填 | 设置最大抓取页面数量 |
|
||||
| 启用内容提取器 (Enable Extractor) | 可选 | 选择数据提取方式 |
|
||||
</div>
|
||||
</div>
|
||||
|
||||
#### Firecrawl
|
||||
|
||||
开源网页解析工具,提供更精细的爬取控制选项和 API 服务,支持复杂网站结构的深度爬取,适合需要批量处理和精确控制的场景。
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
**参数配置和说明**
|
||||
|
||||
| 参数 | 类型 | 说明 |
|
||||
|------|------|------|
|
||||
| URL | 必填 | 目标网页地址 |
|
||||
| 爬取页数限制 (Limit) | 必填 | 设置最大抓取页面数量 |
|
||||
| 爬取子页面 (Crawl sub-page) | 可选 | 是否抓取链接页面 |
|
||||
| 最大爬取深度 (Max depth) | 可选 | 控制爬取层级深度 |
|
||||
| 排除路径 (Exclude paths) | 可选 | 设置不爬取的页面路径 |
|
||||
| 仅包含路径 (Include only paths) | 可选 | 限制只爬取指定路径 |
|
||||
| 启用内容提取器 (Enable Extractor) | 可选 | 选择数据处理方式 |
|
||||
| 只提取主要内容 | 可选 | 过滤页面辅助信息 |
|
||||
</div>
|
||||
</div>
|
||||
|
||||
### 在线网盘 (Online Drive)
|
||||
|
||||
连接你的在线云储存服务(例如 Google Drive、Dropbox、OneDrive),Dify 将自动检索云储存中的文件,你可以勾选并导入相应文档进行下一步处理,无需手动下载文件再进行上传。
|
||||
|
||||
<Tip>
|
||||
关于第三方数据源授权,请前往[数据源授权](/zh/use-dify/knowledge/knowledge-pipeline/authorize-data-source)。
|
||||
</Tip>
|
||||
|
||||
---
|
||||
|
||||
## 步骤二:配置数据处理节点
|
||||
|
||||
该阶段是内容的预处理与数据结构化过程,这一部分将会把数据源进行提取、分段并转换为适合知识库存储和检索的格式。你可以将这一步想象成备餐过程——处理原材料、进行清理、切分成小块,并整理好一切,以便在有人需要时能迅速"烹制"出这道"菜肴"。
|
||||
|
||||
### 文档处理
|
||||
|
||||
由于知识库无法直接理解 PDF、Word 等各种文档格式,提取器负责将这些文档"解读"成系统可以处理的文本内容。它支持多种常见文件格式,确保你的文档内容能够被正确提取和处理,并转换为大型语言模型可以有效使用的格式。 你可以选择 Dify 文档提取器来处理文件,也可以根据你的需求从 Dify Marketplace 中选择更多工具。Marketplace 提供了如 Dify Extractor 以及 MinerU、Unstructured 等第三方工具。
|
||||
|
||||
#### 文档提取器 (Doc Extractor)
|
||||
|
||||

|
||||
|
||||
文档提取器节点可以理解为一个信息处理中心,通过识别并读取输入变量中的文件,提取信息后转化为下一个节点可使用的格式。
|
||||
|
||||
<Tip>
|
||||
关于文档提取器的详细功能和配置方法,请参考[文档提取器](/zh/use-dify/nodes/doc-extractor)。
|
||||
</Tip>
|
||||
|
||||
#### Dify 提取器 (Dify Extractor)
|
||||
|
||||
Dify Extractor 是 Dify 开发的一款内置文档解析器。它支持多种常见文件格式,并针对 Doc 文件进行了专门优化。它能够从文档中提取图片,进行存储并返回图片的 URL。
|
||||
|
||||

|
||||
|
||||
#### MinerU
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
MinerU 是一款高质量文档解析器,可将文档转换为机器可读格式(Markdown、JSON),专注于保留复杂结构和数学符号。
|
||||
|
||||
与基础 PDF 提取器相比,MinerU 会移除页眉、页脚和页码,同时保持语义连贯性。它还能自动检测扫描 PDF 和乱码文档,支持 84 种语言的 OCR 功能。建议使用 MinerU 处理包含复杂公式的科学论文(自动转换为 LaTex)、多栏布局、包含混合内容(文本+图片+表格)的学术出版物文档。
|
||||
</div>
|
||||
</div>
|
||||
|
||||
#### Unstructured
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
Unstructured 将文档转换为结构化的机器可读格式,具有高度可定制的处理策略。它提供多种提取策略(auto、hi_res、fast、OCR-only)和分块方法(by_title、by_page、by_similarity)来处理各种文档类型,提供详细的元素级元数据,包括坐标、置信度分数和布局信息。推荐用于企业文档工作流、混合文件类型处理以及需要精确控制文档处理参数的场景。
|
||||
</div>
|
||||
</div>
|
||||
|
||||
你可前往 [Dify Marketplace](https://marketplace.dify.ai) 探索更多工具。
|
||||
|
||||
### 分块器 (Chunker)
|
||||
|
||||
在构建 AI 应用时,我们需要处理大量和不同种类的文档内容,比如产品手册、技术文档或论文等。和人类有限的注意力相似,大型语言模型无法同时处理过多的信息。因此,在信息提取后,分块器将大段的文档内容拆分成更小、更易于管理的片段(称为"块")。这就好比一本很厚的书,被分成了许多章节,你可以通过阅读目录快速定位到相关内容所在章节。
|
||||
|
||||
当 AI 应用需要回答问题时,良好的分块策略能够提供足够的上下文信息,并包含完整的语义。这样,当检索到对应的片段时,大型语言模型能够基于这个片段中的信息生成较为准确的答案。
|
||||
|
||||
不同类型的文档需要不同的分块策略,比如产品手册可能需要按照产品型号进行分块,确保产品功能介绍的完整性;论文则需要根据逻辑结构进行分块,确保论点叙述的流畅性。基于这样的多样性,Dify 提供了 3 种分块器,帮助你根据不同文档类型和使用场景进行选择和使用。
|
||||
|
||||
#### 分块器类型概述
|
||||
|
||||
| 类型 | 特点 | 使用场景 |
|
||||
|------|------|----------|
|
||||
| 通用分块器 | 固定大小分块,支持自定义分隔符 | 结构简单的基础文档 |
|
||||
| 父子分块器 | 双层分段结构,平衡匹配精准度和上下文 | 需要较多上下文信息的复杂文档结构 |
|
||||
| 问答处理器 | 处理表格中的问答组合 | CSV 和 Excel 的结构化问答数据 |
|
||||
|
||||
#### 通用文本预处理规则
|
||||
|
||||
| 处理选项 | 说明 |
|
||||
|----------|------|
|
||||
| 替换连续空格、换行符和制表符 | 将文档中的连续空格、换行符和制表符替换为单个空格 |
|
||||
| 移除所有 URL 和邮箱地址 | 自动识别并移除文本中的网址链接和邮箱地址 |
|
||||
|
||||
#### 通用分块器 (General Chunker)
|
||||
|
||||
基础文档分块处理,适用于结构相对简单的文档,你可以参考下面的配置对文本的分块、文本预处理规则进行配置。
|
||||
|
||||
**输入输出变量**
|
||||
|
||||
| 类型 | 变量 | 说明 |
|
||||
|------|------|------|
|
||||
| 输入变量 | `{x} Content` | 完整的文档内容块,通用分块器将其拆分为若干小段 |
|
||||
| 输出变量 | `{x} Array[Chunk]` | 分块后的内容数组,每个片段适合进行检索和分析 |
|
||||
|
||||
**分块设置 (Chunk Settings)**
|
||||
|
||||
| 配置项 | 说明 |
|
||||
|--------|------|
|
||||
| 分段标识符 (Delimiter) | 默认值为 `\n`,即按照文本段落分段。你可以遵循正则表达式语法自定义分块规则,系统将在文本出现分段标识符时自动执行分段。 |
|
||||
| 分段最大长度 (Maximum Chunk Length) | 指定分段内的文本字符数最大上限,超出该长度时将强制分段。 |
|
||||
| 分段重叠长度 (Chunk Overlap) | 对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。 |
|
||||
|
||||
#### 父子分块器 (Parent-child Chunker)
|
||||
|
||||
父子分块器采用双层分段结构解决了上下文与准确度之间的矛盾,在检索增强生成(RAG)系统中实现了准确匹配与全面的上下文信息的平衡。
|
||||
|
||||
**父子检索的工作机制**
|
||||
|
||||
- **使用子分块匹配查询**:使用小而精准的信息片段(通常简洁到段落中的单个句子)来匹配用户查询。这些子分块能够实现精确且相关的初始检索。
|
||||
- **父分块提供丰富的上下文**:检索包含匹配子分块的更大范围内容(如段落、章节甚至整个文档)。这些父分块为大语言模型(LLM)提供全面的上下文信息。
|
||||
|
||||
**输入输出变量**
|
||||
|
||||
| 类型 | 变量 | 说明 |
|
||||
|------|------|------|
|
||||
| 输入变量 | `{x} Content` | 完整的文档内容块,通用分块器将其拆分为若干小段 |
|
||||
| 输出变量 | `{x} Array[ParentChunk]` | 父分块数组 |
|
||||
|
||||
**分块设置 (Chunk Settings)**
|
||||
|
||||
| 配置项 | 说明 |
|
||||
|--------|------|
|
||||
| 父分块分隔符 (Parent Delimiter) | 设置父分块的分割标识符 |
|
||||
| 父分块最大长度 (Parent Maximum Chunk Length) | 控制父分块的最大字符数 |
|
||||
| 子分块分隔符 (Child Delimiter) | 设置子分块的分割标识符 |
|
||||
| 子分块最大长度 (Child Maximum Chunk Length) | 控制子分块的最大字符数 |
|
||||
| 父块模式 (Parent Mode) | 选择"段落"(将文本分割为段落)或"完整文档"(使用整个文档作为父分块)进行直接检索 |
|
||||
|
||||
#### 问答处理器 Q&A Processor (Extractor+Chunker)
|
||||
|
||||
问答处理器结合了提取和分块功能,专门用于处理 CSV 和 Excel 文件的结构化问答数据集,比如常见问题(FAQ)列表、排班表等。
|
||||
|
||||
**输入输出变量**
|
||||
|
||||
| 类型 | 变量 | 说明 |
|
||||
|------|------|------|
|
||||
| 输入变量 | `{x} Document` | 单个文档 |
|
||||
| 输出变量 | `{x} Array[QAChunk]` | 问答分块数组 |
|
||||
|
||||
**变量配置**
|
||||
|
||||
| 名称 | 说明 |
|
||||
|------|------|
|
||||
| 问题所在的列 | 将内容所在的列设置为问题 |
|
||||
| 答案所在的列 | 将内容所在的列设置为答案 |
|
||||
|
||||
## 步骤三:配置知识库节点
|
||||
|
||||
在完成数据处理后,我们将进入知识流水线的最后一个环节 — 知识库节点。你可以根据实际需求,在这个节点选择不同的索引方法和检索策略,以获得最适合的检索效果和成本控制。
|
||||
|
||||
知识库节点配置分为以下部分:输入变量、分段结构、索引方式以及检索设置。
|
||||
|
||||
### 分段结构 (Chunk Structure)
|
||||
|
||||

|
||||
|
||||
分段结构决定了知识库如何组织和索引你的文档内容。你可以根据文档类型、使用场景和成本考虑来选择最适合的结构模式。
|
||||
|
||||
知识库支持两种分段模式:通用模式与父子模式。如果你是首次创建知识库,建议选择父子模式。
|
||||
|
||||
<Warning>
|
||||
**重要提醒**:分段结构一旦保存发布后无法修改,请根据实际需求进行选择。
|
||||
</Warning>
|
||||
|
||||
#### 通用模式
|
||||
|
||||
适用于大多数标准文档处理场景。
|
||||
通用模式提供灵活的索引选项,你可以根据对质量和成本的不同要求选择合适的索引方法。通用模式支持高质量和经济的索引方式,以及多种检索设置。
|
||||
|
||||
#### 父子模式
|
||||
|
||||
父子模式能够在检索时,提供精确匹配和对应的上下文信息,适用于需要保持完整上下文的专业文档。父子模式仅支持 HQ (高质量)模式,检索时提供子分块匹配和父分块上下文。
|
||||
|
||||
#### 问答模式 (Question-Answer)
|
||||
|
||||
在使用结构化问答数据时,你可以创建问题与答案配对的文档。这些文档会根据问题部分进行索引,从而使系统能够根据查询相似性检索到相关的答案。问答模式仅支持 HQ(高质量)模式。
|
||||
|
||||
### 输入变量 (Input Variable)
|
||||
|
||||
输入变量用于接收来自数据处理节点的处理结果,用作知识库构建的数据源。你需要将前面配置的分块器节点的输出,连接到知识库节点并作为输入。
|
||||
|
||||
该节点根据所选的分段结构,支持不同类型的标准输入:
|
||||
- **通用模式**:`{x} Array[Chunk]` - 通用分块数组
|
||||
- **父子模式**:`{x} Array[ParentChunk]` - 父分块数组
|
||||
- **问答模式**:`{x} Array[QAChunk]` - 问答分块数组
|
||||
|
||||
### 索引方式 (Index Method) 与检索设置 (Retrieval Setting)
|
||||
|
||||
索引方式决定了知识库如何建立内容索引,检索设置则基于所选的索引方式提供相应的检索策略。你可以这么理解,索引方式决定了整理文档的方式,而检索设置告知使用者可以用什么方法来查找文档。
|
||||
|
||||
知识库提供了两种索引方式:高质量和经济,分别提供不同的检索设置选项。
|
||||
在高质量模式下,使用 Embedding 嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息。这使得即使用户的问题用词与文档不完全相同,系统也能找到语义相关的准确答案。
|
||||
|
||||
<Tip>
|
||||
请查看[设定索引方法与检索设置](/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods),了解更多详情。
|
||||
</Tip>
|
||||
|
||||
#### 索引方式和检索设置
|
||||
|
||||
| 索引方式 | 可用检索设置 | 说明 |
|
||||
|----------|--------------|------|
|
||||
| 高质量 | 向量搜索 | 基于语义相似度,理解查询深层含义。 |
|
||||
| | 全文检索 | 基于关键词匹配的检索方式,提供全面的检索能力。 |
|
||||
| | 混合检索 | 结合语义和关键词 |
|
||||
| 经济 | 倒排索引 | 搜索引擎常用的检索方法,匹配问题与关键内容。 |
|
||||
|
||||
关于配置分段结构、索引方法、配置参数和检索设置,你也可以参考下方表格。
|
||||
|
||||
| 分段结构 | 可选索引方式 | 可配置参数 | 可用检索设置 |
|
||||
|----------|--------------|------------|--------------|
|
||||
| 通用模式 | 高质量 <br /> <br /> <br /> 经济 | Embedding 嵌入模型 <br /> <br /> <br /> 关键词数量 | 向量检索 <br /> 全文检索 <br /> 混合检索 <br /> 倒排索引 |
|
||||
| 父子模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索 <br /> 全文检索 <br /> 混合检索 |
|
||||
| 问答模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索 <br /> 全文检索 <br /> 混合检索 |
|
||||
|
||||
## 步骤四:配置用户输入表单
|
||||
|
||||
用户输入表单对于收集流水线运行所需的有效初始信息非常重要。类似于工作流中的[开始节点](/zh/use-dify/nodes/start),这个表单从用户那里收集必要的相信信息,比如:需要上传的文件、文档处理的特定参数等,确保流水线拥有提供准确结果所需要的所有信息。
|
||||
|
||||
通过这种方式,你可以为不同的使用场景创建特定的的输入表单,提高流水线对于不同数据源和文档处理流程的灵活性和易用性。
|
||||
|
||||
### 创建用户输入表单
|
||||
|
||||
你可以通过下面两种方式,创建用户输入表单。
|
||||
|
||||
1. **知识流水线编排界面**
|
||||
点击输入字段(Input Field)开始创建和配置输入表单。
|
||||
|
||||

|
||||
|
||||
2. **节点参数面板**
|
||||
选中节点,在右侧的面板需要填写的参数内,点击最下方的`+ 创建用户输入字段`(+ Create user input)来创建新的输入项。新增的输入项将会汇总到输入字段(Input Field)的表单内。
|
||||
|
||||

|
||||
|
||||
### 输入类型
|
||||
|
||||
#### 非共享输入 (Unique Inputs for Each Entrance)
|
||||
|
||||

|
||||
|
||||
这类输入适用于每个数据源及其下游节点,用户只需在选择对应数据源时填写这些字段,比如不同数据源的URL。
|
||||
|
||||
在数据源右侧点击"+"按钮,为该数据源添加字段。这个字段只能被该数据源及其后续连接的节点引用。
|
||||
|
||||

|
||||
|
||||
#### 全局共享输入 (Global Inputs for All Entrance)
|
||||
|
||||

|
||||
|
||||
全局共享输入可以被所有节点引用。这类输入适用于通用处理参数,比如分隔符、最大分块长度、文档处理配置等。无论用户选择哪个数据源,都需要填写这些字段。
|
||||
|
||||
在全局共享输入右侧点击"+"按钮,添加的字段将被任意节点引用。
|
||||
|
||||
### 支持字段类型和填写说明
|
||||
|
||||
知识流水线支持以下七种类型的输入变量。
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
| 字段类型 | 说明 |
|
||||
|----------|------|
|
||||
| 文本 | 短文本,由知识库使用者自行填写,最大长度为 256 字符 |
|
||||
| 段落 | 长文本,知识库使用者可以输入较长字符 |
|
||||
| 下拉选项 | 由编排者预设的固定选项供使用者选择,使用者无法自行填写内容 |
|
||||
| 布尔值 | 只有真/假两个取值 |
|
||||
| 数字 | 只能输入数字 |
|
||||
| 单文件 | 上传单个文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
|
||||
| 文件列表 | 批量上传文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<Tip>
|
||||
请前往[输入字段](/zh/use-dify/nodes/start#%E8%BE%93%E5%85%A5%E5%AD%97%E6%AE%B5),了解关于支持字段的更多说明。
|
||||
</Tip>
|
||||
|
||||
所有类型的输入项包含:必填项、非必填项和更多设置,可以通过勾选设置为是否为必填。
|
||||
|
||||
| 名称 | 说明 | 示例 |
|
||||
|------|------|------|
|
||||
| **必填项** | | |
|
||||
| 变量名称 Variable Name | 系统内部标识名称,通常使用英文和下划线进行命名 | `user_email` |
|
||||
| 显示名称 Display Name | 界面展示的名称,通常是简洁易读的文字 | 用户邮箱 |
|
||||
| **类型特定设置** | 不同字段类型的特殊要求 | 文本的最大长度为 100 字符 |
|
||||
| **更多设置** | | |
|
||||
| 默认值 Default Value | 用户未输入时的默认值 | 数字字段默认为0, 文本字段默认为空 |
|
||||
| 占位符 Placeholder | 输入框空白时的提示文字 | 请输入你的邮箱 |
|
||||
| 提示 Tooltip | 解释或指引用户进行填写的文字,通常在用户鼠标悬停时显示 | 请输入有效的邮箱地址 |
|
||||
| **特殊非必填信息** | 根据不同字段类型的额外设置选项 | 邮箱格式验证 |
|
||||
|
||||
配置完成后,点击右上角的预览按钮,你可以在弹出的表单预览界面中浏览。你可以拖拽调整字段的分组,如果出现感叹号,则表明移动后引用失效。
|
||||
|
||||

|
||||
|
||||
## 步骤五:为知识库命名
|
||||
|
||||

|
||||
|
||||
默认情况下,知识库名称为"Untitled + 序号”,权限设置为"仅自己可见”,图表为橙色书本。如果你使用 DSL文件导入,则将使用其保存的图标。
|
||||
|
||||
点击左侧面板中的设置并填写以下信息:
|
||||
- **名称和图标**
|
||||
为你的知识库命名。你还可以选择一个 emoji、上传图片或粘贴图片 URL 作为知识库的图标。
|
||||
- **知识库描述**
|
||||
简要描述你的知识库。这有助于 AI 更好地理解和检索你的数据。如果留空,Dify 将应用默认的检索策略。
|
||||
- **权限**
|
||||
从下拉菜单中选择适当的访问权限。
|
||||
|
||||
## 步骤六:测试
|
||||
|
||||
在完成编排后,你需要先验证配置的完整性,然后测试流水线运行效果,确认各项设置正确无误,最后发布知识库。
|
||||
|
||||
### 检查配置完成度
|
||||
|
||||
在进行测试前,建议先检查配置的完整性,避免因遗漏配置而导致测试失败。
|
||||
|
||||
点击右上角的检查清单按钮,系统会显示遗漏部分。
|
||||
|
||||

|
||||
|
||||
完成所有的配置后,可以通过测试运行来预览知识流水线的运行效果,确认各项设置准确无误,再进行发布。
|
||||
|
||||
### 测试运行 (Test Run)
|
||||
|
||||

|
||||
|
||||
1. **开始测试**:点击右上角的测试运行(Test Run)按钮。
|
||||
2. **导入测试文件**:在右侧弹出的数据源窗口中,导入文件。
|
||||
<Warning>
|
||||
**重要提醒**:为了便于调试和观测,在测试运行状态下,每次仅允许上传一个文件。
|
||||
</Warning>
|
||||
3. **填写参数**:导入成功后,根据你之前配置的用户输入表单填写对应参数
|
||||
4. **开始试运行**:点击下一步,开始测试整个流水线。
|
||||
|
||||
在测试期间,你可以访问[运行历史](/zh/use-dify/monitor/logs)(记录所有运行记录,包括运行时间、执行状态和输入/输出参数概要)和[变量检查](/zh/use-dify/debug/variable-inspect)(位于底部面板,它显示每个节点的输入/输出数据,帮助你识别问题和验证数据流),以实现高效的故障排除和错误修复。
|
||||
|
||||

|
||||
@@ -1,46 +0,0 @@
|
||||
---
|
||||
title: 功能简介
|
||||
icon: "book"
|
||||
---
|
||||
|
||||
知识库功能将RAG 管线上的各环节可视化,提供了一套简单易用的用户界面来方便应用构建者管理个人或者团队的知识库,并能够快速集成至 AI 应用中。
|
||||
|
||||
开发者可以将企业内部文档、FAQ、规范信息等内容上传至知识库进行结构化处理,供后续 LLM 查询。
|
||||
|
||||
相比于 AI 大模型内置的静态预训练数据,知识库中的内容能够实时更新,确保 LLM 可以访问到最新的信息,避免因信息过时或遗漏而产生的问题。
|
||||
|
||||
LLM 接收到用户的问题后,将首先基于关键词在知识库内检索内容。知识库将根据关键词,召回相关度排名较高的内容区块,向 LLM 提供关键上下文以辅助其生成更加精准的回答。
|
||||
|
||||
开发者可以通过此方式确保 LLM 不仅仅依赖于训练数据中的知识,还能够处理来自实时文档和数据库的动态数据,从而提高回答的准确性和相关性。
|
||||
|
||||
**核心优势:**
|
||||
|
||||
• **实时性**:知识库中的数据可随时更新,确保模型获得最新的上下文。
|
||||
|
||||
• **精准性**:通过检索相关文档,LLM 能够基于实际内容生成高质量的回答,减少幻觉现象。
|
||||
|
||||
• **灵活性**:开发者可自定义知识库内容,根据实际需求调整知识的覆盖范围。
|
||||
|
||||
***
|
||||
|
||||
准备文本文件,例如:
|
||||
|
||||
* 长文本内容(TXT、Markdown、DOCX、HTML、JSON 甚至是 PDF)
|
||||
* 结构化数据(CSV、Excel 等)
|
||||
* 在线数据源(网页爬虫、Notion 等)
|
||||
|
||||
将文件上传至“知识库”即可自动完成数据处理。
|
||||
|
||||
> 如果你的团队内部已建有独立知识库,可以通过[连接外部知识库](/zh/use-dify/knowledge/connect-external-knowledge-base)与 Dify 建立连接。
|
||||
|
||||
|
||||
|
||||
### 使用情景
|
||||
|
||||
例如你希望基于现有知识库和产品文档建立一个 AI 客服助手,可以在 Dify 中将文档上传至知识库,并建立一个对话型应用。如果使用传统方式,从文本训练到 AI 客服助手开发,可能需要花费数周的时间,且难以持续维护并进行有效迭代。在 Dify 内,仅需三分钟即可完成上述过程并开始获取用户反馈。
|
||||
|
||||
### 知识库与文档
|
||||
|
||||
在 Dify 中,知识库(Knowledge)是一系列文档(Documents)的集合,一个文档内可能包含多组内容分段(Chunks),知识库可以被整体集成至一个应用中作为检索上下文使用。文档可以由开发者或运营人员上传,或由其它数据源同步。
|
||||
|
||||
如果你已自建文档库,可以通过[连接外部知识库](/zh/use-dify/knowledge/connect-external-knowledge-base)功能将自有知识库与 Dify 平台相关联。无需重复将内容上传至 Dify 平台内的知识库即可让 AI 应用实时读取自建知识库中的内容。
|
||||
@@ -1,93 +0,0 @@
|
||||
---
|
||||
title: "知识检索"
|
||||
icon: "database"
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/knowledge-retrieval)。</Note>
|
||||
|
||||
|
||||
知识检索节点从你的知识库中搜索相关信息,并返回上下文内容供下游节点使用。它通过从你的文档中提供特定信息来实现RAG(检索增强生成)应用。
|
||||
|
||||
<Frame caption="知识检索节点配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d90961c6d794d425a8e11df177315188.png" alt="Knowledge Retrieval Node Interface" />
|
||||
</Frame>
|
||||
|
||||
<Info>
|
||||
在使用此节点之前,请先创建并填充知识库。请参阅[知识库创建指南](/zh/use-dify/knowledge/create-knowledge)获取设置说明。
|
||||
</Info>
|
||||
|
||||
## 配置
|
||||
|
||||
### 查询和知识库选择
|
||||
|
||||
**查询**决定在你的知识库中搜索什么内容。对于对话流应用中的用户输入使用`sys.query`,或者使用工作流中的任何文本变量。查询限制为200个字符。
|
||||
|
||||
选择一个或多个**知识库**进行搜索。每个知识库都包含你上传到Dify的索引文档。可以使用不同策略同时搜索多个知识库。
|
||||
|
||||
### 检索策略
|
||||
|
||||
选择如何搜索你的内容:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="语义检索">
|
||||
使用向量嵌入根据含义查找概念上相似的内容。适用于自然语言查询和使用不同术语的相关概念。
|
||||
</Tab>
|
||||
|
||||
<Tab title="关键词检索">
|
||||
传统的全文检索,用于精确单词匹配。对于特定术语、代码或名称更快速且更可预测。
|
||||
</Tab>
|
||||
|
||||
<Tab title="混合检索">
|
||||
结合语义和关键词方法。使用专门的模型对结果进行重新排序以获得更好的相关性。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 高级设置
|
||||
|
||||
<Frame caption="高级检索配置选项">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/fbd43d558f83b355a1b18ac26a253b84.png" alt="Knowledge retrieval configuration interface" />
|
||||
</Frame>
|
||||
|
||||
### 检索参数
|
||||
|
||||
**TopK**控制要检索的文档块数量。从3-5个块开始以获得聚焦结果,或使用10-15个块以获得全面覆盖。
|
||||
|
||||
**分数阈值**设置最小相似度分数。更高的阈值(0.7+)确保相关性,较低的阈值(0.5-)包含更多相关的内容。
|
||||
|
||||
**重排序**在初始检索后重新评分结果。对于混合检索、大量块,或当精度比速度更重要时启用。
|
||||
|
||||
### 元数据筛选
|
||||
|
||||
使用文档元数据(如类型、日期或部门)筛选结果。上传文档时设置元数据,以在大型知识库中启用有针对性的搜索。
|
||||
|
||||
### 多知识库策略
|
||||
|
||||
**N对1召回**使用函数调用来分析查询、选择适当的知识库并优化搜索。最适用于不同领域的专业知识库。
|
||||
|
||||
**多路召回**同时查询所有选定的知识库并合并结果。当信息跨越多个来源或你需要全面覆盖时使用。
|
||||
|
||||
<Frame caption="多个知识库检索策略比较">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/4a3007cda9dfa50ddac3711693725dce.png" alt="Retrieval Mode Comparison" />
|
||||
</Frame>
|
||||
|
||||
## 输出和集成
|
||||
|
||||
该节点输出包含文本内容和元数据(来源、分数、文档ID)的检索文档块数组。这种结构化输出保留了引用所需的信息。
|
||||
|
||||
### RAG集成
|
||||
|
||||
将知识检索输出连接到大型语言模型节点上下文输入,用于RAG应用。当使用检索结果作为上下文变量时,Dify会自动跟踪来源并启用引用功能。
|
||||
|
||||
```text
|
||||
System: 根据提供的上下文回答。
|
||||
Context: {{knowledge_retrieval.result}}
|
||||
User: {{user_question}}
|
||||
```
|
||||
|
||||
### 速率限制
|
||||
|
||||
知识检索操作受到基于你订统使用Redis以60秒滑动窗口跟踪请求。当超出限制时,会返回`RateLimitExceeded`错误。
|
||||
|
||||
### 性能考虑
|
||||
|
||||
检索质量取决于索引实践。较小的块(200-500个标记)能够实现精确检索,较大的块(800-1500个标记)保持上下文。知识库有速率限制——该节点处理限制并自动缓存相同的查询。
|
||||
@@ -1,136 +0,0 @@
|
||||
---
|
||||
title: "大语言模型"
|
||||
icon: "brain"
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/llm)。</Note>
|
||||
|
||||
|
||||
大型语言模型节点调用语言模型来处理文本、图像和文档。它向你配置的模型发送提示词并捕获其响应,支持结构化输出、上下文管理和多模态输入。
|
||||
|
||||
<Frame caption="大型语言模型节点配置界面">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/85730fbfa1d441d12d969b89adf2670e.png" alt="LLM Node Overview" />
|
||||
</Frame>
|
||||
|
||||
<Info>
|
||||
在使用大型语言模型节点之前,请先在**系统设置 → 模型供应商**中配置至少一个模型供应商。请参阅[模型配置指南](/zh/use-dify/workspace/model-providers)了解设置说明。
|
||||
</Info>
|
||||
|
||||
## 模型选择和参数
|
||||
|
||||
从你已配置的任何模型供应商中进行选择。不同模型擅长不同任务 - GPT-4 和 Claude 3.5 在复杂推理方面表现良好但成本较高,而 GPT-3.5 Turbo 在能力和经济性之间取得平衡。对于本地部署,使用 Ollama、LocalAI 或 Xinference。
|
||||
|
||||
<Frame caption="模型选择和参数配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/43f81418ea70d4d79e3705505e777b1b.png" alt="LLM Node Configuration" />
|
||||
</Frame>
|
||||
|
||||
模型参数控制响应生成。**温度**范围从 0(确定性)到 1(创造性)。**核采样**通过概率限制词汇选择。**频率惩罚**减少重复。**存在惩罚**鼓励新话题。你也可以使用预设:**精确**、**平衡**或**创意**。
|
||||
|
||||
## 提示词配置
|
||||
|
||||
你的界面根据模型类型自适应。聊天模型使用消息角色(**系统**用于行为,**用户**用于输入,**助手**用于示例),而完成模型使用简单的文本续写。
|
||||
|
||||
在提示词中使用双花括号引用工作流变量:`{{variable_name}}`。变量在到达模型之前会被实际值替换。
|
||||
|
||||
```text
|
||||
System: You are a technical documentation expert.
|
||||
User: {{user_input}}
|
||||
```
|
||||
|
||||
## 上下文变量
|
||||
|
||||
上下文变量在保持来源归属的同时注入外部知识。这使得大型语言模型可以使用你的特定文档回答问题的检索增强生成应用成为可能。
|
||||
|
||||
<Frame caption="在检索增强生成应用中使用上下文变量">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/5aefed96962bd994f8f05bac96b11e22.png" alt="Context Variables" />
|
||||
</Frame>
|
||||
|
||||
将知识检索节点的输出连接到你的大型语言模型节点的上下文输入,然后引用它:
|
||||
|
||||
```text
|
||||
Answer using only this context:
|
||||
{{knowledge_retrieval.result}}
|
||||
|
||||
Question: {{user_question}}
|
||||
```
|
||||
|
||||
当使用来自知识检索的上下文变量时,Dify 会自动跟踪引用与归属,以便用户看到信息来源。
|
||||
|
||||
## 结构化输出
|
||||
|
||||
强制模型返回特定数据格式(如 JSON)以便程序化使用。通过三种方法配置:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="可视化编辑器">
|
||||
用户友好的界面适用于简单结构。添加具有名称和类型的字段,标记必需字段,设置描述。编辑器自动生成 JSON Schema。
|
||||
</Tab>
|
||||
|
||||
<Tab title="JSON Schema">
|
||||
直接编写 Schema,适用于具有嵌套对象、数组和验证规则的复杂结构。
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"sentiment": {
|
||||
"type": "string",
|
||||
"enum": ["positive", "negative", "neutral"]
|
||||
}
|
||||
},
|
||||
"required": ["sentiment"]
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="AI 生成">
|
||||
用自然语言描述需求,让 AI 生成 Schema
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Warning>
|
||||
具有原生 JSON 支持的模型可以可靠地处理结构化输出。对于其他模型,Dify 在提示词中包含 Schema,但结果可能有所不同。
|
||||
</Warning>
|
||||
|
||||
## 记忆和文件处理
|
||||
|
||||
启用**记忆**以在工作流运行中的多个大型语言模型调用之间维护上下文。该节点在后续提示词中包含之前的交互。记忆是节点特定的,不会在工作流运行之间持续存在。
|
||||
|
||||
对于**文件处理**,将文件变量添加到多模态模型的提示词中。GPT-4V 处理图像,Claude 直接处理 PDF,而其他模型可能需要预处理。
|
||||
|
||||
### 视觉能力配置
|
||||
|
||||
处理图像时,你可以控制细节级别:
|
||||
- **高细节** - 对复杂图像具有更好的准确性但使用更多标记数
|
||||
- **低细节** - 对简单图像进行更快处理,使用较少标记数
|
||||
|
||||
视觉能力的默认变量选择器是 `sys.files`,它会自动从开始节点获取文件。
|
||||
|
||||
<Frame caption="多模态模型的文件处理">
|
||||
<img src="https://assets-docs.dify.ai/2024/11/05b3d4a78038bc7afbb157078e3b2b26.png" alt="File Processing" />
|
||||
</Frame>
|
||||
|
||||
对于完成模型中的对话历史,插入对话变量以维护多轮对话上下文:
|
||||
|
||||
<Frame caption="使用对话历史变量">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/b8642f8c6e3f562fceeefae83628fd68.png" alt="Conversation History" />
|
||||
</Frame>
|
||||
|
||||
## Jinja2 模板支持
|
||||
|
||||
大型语言模型提示词支持 Jinja2 模板以进行高级变量处理。当你使用 Jinja2 模式(`edition_type: "jinja2"`)时,你可以:
|
||||
|
||||
```jinja2
|
||||
{% for item in search_results %}
|
||||
{{ loop.index }}. {{ item.title }}: {{ item.content }}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
Jinja2 变量与常规变量替换分别处理,允许在提示词中进行循环、条件和复杂数据转换。
|
||||
|
||||
## 流式结果返回
|
||||
|
||||
大型语言模型节点默认支持流式结果返回。每个文本块都作为 `RunStreamChunkEvent` 产生,实现实时响应显示。文件输出(图像、文档)在流式传输期间自动处理和保存。
|
||||
|
||||
## 错误处理
|
||||
|
||||
为失败的大型语言模型调用配置重试行为。设置最大重试次数、重试间隔和退避乘数。当重试不足时,定义回退策略,如默认值、错误路由或替代模型。
|
||||
@@ -1,91 +0,0 @@
|
||||
---
|
||||
title: "工具"
|
||||
icon: "wrench"
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/nodes/tools)。</Note>
|
||||
|
||||
|
||||
工具节点通过预构建的集成将你的工作流连接到外部服务和API。与HTTP请求节点不同,工具提供结构化接口、内置错误处理以及为流行服务简化的配置。
|
||||
|
||||
<Frame caption="工具节点配置界面">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/0f0255764a3f459f0b3c708db1cb32c9.png" alt="Tools node interface" />
|
||||
</Frame>
|
||||
|
||||
## 工具类型
|
||||
|
||||
Dify支持多种类型的工具来处理不同的集成需求:
|
||||
|
||||
<Frame caption="可用的工具类别和选项">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/f37cce4ccbb7456154cfa9eacda6b322.png" alt="Tool categories" />
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="内置工具">
|
||||
由Dify维护的即用型集成,适用于包括Google Search、天气API、生产力工具和AI服务在内的流行服务。这些工具需要最少的配置,并提供可靠、经过测试的集成。
|
||||
</Tab>
|
||||
|
||||
<Tab title="自定义工具">
|
||||
使用OpenAPI/Swagger规范导入你自己的工具。非常适合内部API、专业服务或内置选项未涵盖的任何API。配置一次即可在多个工作流中重复使用。
|
||||
</Tab>
|
||||
|
||||
<Tab title="工作流工具">
|
||||
将复杂的工作流发布为可重用的工具。这创建了可在不同应用程序间共享的模块化构建块,促进代码重用并简化维护。
|
||||
</Tab>
|
||||
|
||||
<Tab title="MCP工具">
|
||||
来自提供专业能力的外部MCP(模型上下文协议)服务器的工具。连接到不断增长的MCP服务器生态系统以获得扩展功能。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 配置
|
||||
|
||||
### 身份验证
|
||||
|
||||
许多工具需要API密钥或OAuth身份验证。在工作流中使用这些工具之前,请在你工作空间的**工具**部分配置这些凭据。配置完成后,身份验证将自动处理。
|
||||
|
||||
### 输入参数
|
||||
|
||||
工具提供带有验证的结构化表单用于输入配置。使用来自之前工作流节点的变量设置参数。界面自动处理数据类型验证,并为每个参数提供有用的描述。
|
||||
|
||||
### 输出处理
|
||||
|
||||
工具返回结构化数据,这些数据作为变量可用于下游节点。输出模式是预定义的,确保兼容性并降低集成复杂性。
|
||||
|
||||
## 相比HTTP请求的优势
|
||||
|
||||
**结构化接口**提供基于表单的配置和内置验证,使设置比手动HTTP请求配置更容易。
|
||||
|
||||
**内置错误处理**包括自动重试逻辑和错误管理,降低了处理API故障的复杂性。
|
||||
|
||||
**类型安全**确保输入和输出模式在工作流节点之间保持数据兼容性。
|
||||
|
||||
**文档**为每个工具包含使用示例和详细的参数描述。
|
||||
|
||||
## 错误处理和重试
|
||||
|
||||
为依赖外部服务的工具配置强大的错误处理:
|
||||
|
||||
<Frame caption="工具重试配置">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/34867b2d910d74d2671cd40287200480.png" alt="Tool retry settings" />
|
||||
</Frame>
|
||||
|
||||
**重试设置**自动重试失败的工具执行,最多10次,带有可配置的间隔(最大5000毫秒)。这可以处理临时服务问题或网络问题。
|
||||
|
||||
<Frame caption="工具错误处理选项">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/39dc3b5881d9a5fe35b877971f70d3a6.png" alt="Tool error handling" />
|
||||
</Frame>
|
||||
|
||||
**错误处理**定义当工具执行失败时的替代工作流路径,确保即使外部服务不可用时你的工作流也能继续。
|
||||
|
||||
## 创建自定义工具
|
||||
|
||||
**OpenAPI集成**允许你导入任何带有OpenAPI/Swagger规范的服务。导入后,该服务将作为工具可用,具有与内置选项相同的易用性。
|
||||
|
||||
**工作流发布**将多节点工作流转换为可在工具。这促进了模块化并简化了复杂的工作流管理。
|
||||
|
||||
## 工具管理
|
||||
|
||||
通过你工作空间导航中的**工具**访问工具配置。在这里你可以管理身份验证凭据、导入自定义工具、配置MCP服务器以及将工作流发布为工具。
|
||||
|
||||
有关工具创建、管理和将工作流发布为工具的详细指导,请参阅[工具配置指南](/zh/use-dify/nodes/tools)。
|
||||
@@ -1,58 +0,0 @@
|
||||
---
|
||||
title: "MCP 服务器"
|
||||
icon: "network-wired"
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/publish/publish-mcp)。</Note>
|
||||
|
||||
|
||||
Dify 现在支持将你的应用程序作为 [MCP](https://modelcontextprotocol.io/introduction)(Model Context Protocol)服务器公开,实现与 Claude Desktop 等 AI 助手和 Cursor 等开发环境的无缝集成。这使得这些工具可以直接与你的 Dify 应用程序交互,就像它们是原生扩展一样。
|
||||
|
||||
<Note>
|
||||
如果你希望在 Dify 工作流和智能代理中使用 MCP 工具,请参阅[此处](/zh/use-dify/build/mcp)。
|
||||
</Note>
|
||||
|
||||
## 将你的 Dify 应用程序配置为 MCP 服务器
|
||||
|
||||
导航到 Dify 中应用程序的配置界面,你会找到一个 MCP 服务器配置模块。该功能默认处于禁用状态。当你开启它时,Dify 会为你的应用程序生成一个唯一的 MCP 服务器地址。该地址作为外部工具的连接点。
|
||||
|
||||
<Danger>
|
||||
你的 MCP 服务器 URL 包含身份验证凭据,因此请像对待 API 密钥一样对待它。如果你怀疑它已被泄露,请使用重新生成按钮创建新的 URL。旧的 URL 将立即停止工作。
|
||||
</Danger>
|
||||
|
||||
<img
|
||||
src="/images/CleanShot2025-07-07at08.18.02.png"
|
||||
alt="CleanShot 2025-07-07 at 08.18.02.png"
|
||||
title="CleanShot 2025-07-07 at 08.18.02.png"
|
||||
className="mx-auto"
|
||||
style={{ width:"46%" }}
|
||||
/>
|
||||
|
||||
## 与 Claude Desktop 集成
|
||||
|
||||
要将你的 Dify 应用程序连接到 Claude Desktop,你需要添加一个 Claude 集成。转到你的 Claude Profile > Settings > Integrations > Add integration。用你的 Dify 应用程序的服务器 URL 替换集成 URL。
|
||||
|
||||
## 与 Cursor 集成
|
||||
|
||||
对于 Cursor,在你的项目根目录中创建或编辑 `.cursor/mcp.json` 文件:
|
||||
|
||||
```json
|
||||
{
|
||||
"mcpServers": {
|
||||
"your-server-name": {
|
||||
"url": "your-server-url"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
只需用你的 Dify 应用程序的 MCP 服务器地址替换 URL。Cursor 会自动检测此配置并将你的 Dify 应用程序作为工具提供。你可以通过在 `mcpServers` 对象中添加其他条目来添加多个 Dify 应用程序。
|
||||
|
||||
## 实用注意事项
|
||||
|
||||
- 描述性
|
||||
|
||||
在为你的工具及其输入参数设计描述时,考虑 AI 如何解释它们。清晰、具体的描述能带来更好的调用效果。不要使用"输入数据",而是指定"包含用户配置文件的 JSON 对象,必需字段:姓名、邮箱、偏好设置"。
|
||||
- 延迟
|
||||
|
||||
MCP 协议处理通信层,但你的 Dify 应用程序的性能仍然很重要。如果你的应用程序通常需要 30 秒来处理,那么这种延迟在客户端应用程序中会被感受到。考虑添加进度指示器或将复杂的工作流分解为更小、更快的操作。
|
||||
@@ -1,170 +0,0 @@
|
||||
---
|
||||
title: "聊天 Web App "
|
||||
---
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/publish/webappwebapp/chatflow-webapp)。</Note>
|
||||
|
||||
|
||||
聊天 Web App 将你的对话流转变为完整的对话体验。用户可获得持续的聊天会话、智能交互以及你配置的所有功能——无需安装任何软件。
|
||||
|
||||
## 聊天 Web App 的工作原理
|
||||
|
||||
当你发布对话流时,它会自动变成网页应用。系统会创建一个响应式界面,具备以下特点:
|
||||
|
||||
- **在用户会话间保持对话上下文**
|
||||
- **继承对话流配置的所有编排设置**
|
||||
- **适应从移动设备到桌面的任何屏幕尺寸**
|
||||
- **处理用户身份验证**(如果你启用了访问控制)
|
||||
|
||||
<Tip>
|
||||
与一次性文本生成器不同,聊天 Web App 保持对话记忆,让用户可以基于之前的交流继续构建对话。
|
||||
</Tip>
|
||||
|
||||
## 交互功能
|
||||
|
||||
你的网页应用会根据对话流设置自动包含以下功能:
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="对话前表单" icon="clipboard-list">
|
||||
在聊天开始前收集上下文信息——比在对话中途询问更好
|
||||
</Card>
|
||||
<Card title="AI 对话开场白" icon="message">
|
||||
通过有用的开场消息消除空白页面问题
|
||||
</Card>
|
||||
<Card title="智能后续问题" icon="arrow-right">
|
||||
系统在每次回应后生成3个与上下文相关的后续问题
|
||||
</Card>
|
||||
<Card title="语音输入" icon="microphone">
|
||||
语音转文字让用户可以说话而不必打字
|
||||
</Card>
|
||||
<Card title="来源引用" icon="quote">
|
||||
参考资料显示信息的准确来源
|
||||
</Card>
|
||||
<Card title="回应反馈" icon="thumbs-up">
|
||||
用户可以对回应进行评价以帮助改进你的应用
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## 对话前设置
|
||||
|
||||
当你的对话流使用变量时,用户在开始聊天前需要完成一个表单。这种做法将上下文收集前置,而不是中断对话流程。
|
||||
|
||||
<Frame>
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/application-publishing/launch-your-webapp-quickly/8decae00eeea24622e1f2ef73d4c447e.png" alt="对话前变量表单" />
|
||||
</Frame>
|
||||
|
||||
用户体验流程如下:
|
||||
|
||||
<Steps>
|
||||
<Step title="用户访问你的应用">
|
||||
他们会看到一个简洁的表单,要求提供必要的上下文信息。
|
||||
</Step>
|
||||
<Step title="完成表单后解锁聊天">
|
||||
只有在填写完必填字段后,"开始对话"按钮才会激活。
|
||||
</Step>
|
||||
<Step title="AI 获得完整上下文">
|
||||
对话开始时就具备所有需要的背景信息。
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
<Warning>
|
||||
每个表单字段都会增加摩擦。只询问能够显著改善回应的信息。
|
||||
</Warning>
|
||||
|
||||
## 对话体验
|
||||
|
||||
一旦开始聊天,用户会获得专为自然交互设计的界面:
|
||||
|
||||
<Frame>
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/application-publishing/launch-your-webapp-quickly/5b7a6f950ed8a2ce3a705f362b4813fe.png" alt="带有回应选项的聊天界面" />
|
||||
</Frame>
|
||||
|
||||
每个AI回应都包含这些操作:
|
||||
|
||||
- **复制按钮** - 一键复制,便于分享或记录笔记
|
||||
- **反馈按钮** - 点的应用持续改进
|
||||
- **后续建议** - AI生成3个与上下文相关的后续问题
|
||||
|
||||
## 会话管理
|
||||
|
||||
用户可以像现代消息应用一样管理多个对话线程:
|
||||
|
||||
<Frame>
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/application-publishing/launch-your-webapp-quickly/46372ad4d79a3ea943d43f9434974956.png" width="300" alt="对话管理侧边栏" />
|
||||
</Frame>
|
||||
|
||||
**对话控制功能:**
|
||||
- **新建** - 开始新的对话而不丢失之前对话的上下文
|
||||
- **置顶重要对话** - 将重要对话保持在列表顶部,便于访问
|
||||
- **删除已完成对话** - 清理不再相关的对话
|
||||
|
||||
<Info>
|
||||
每个对话线程都维护自己的记忆和上下文。用户可以在不同主题或项目间无缝切换。
|
||||
</Info>
|
||||
|
||||
## 对话开场白
|
||||
|
||||
启用对话开场白来消除令人生畏的空白聊天屏幕:
|
||||
|
||||
<Frame>
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/application-publishing/launch-your-webapp-quickly/22e59e509296d25eb85cbd541e161c6d.png" alt="AI 对话开场白消息" />
|
||||
</Frame>
|
||||
|
||||
当用户开始新对话时,AI会主动介绍自己并解释其功能。这立即向用户展示他们可以完成什么任务,并提高参与度。
|
||||
|
||||
<Tip>
|
||||
对话开场白在专业应用中特别有效,因为用户可能不知道所有可用功能。
|
||||
</Tip>
|
||||
|
||||
## 后续问题
|
||||
|
||||
系统在每次AI回应后自动生成与上下文相关的后续问题:
|
||||
|
||||
<Frame>
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/application-publishing/launch-your-webapp-quickly/f88a7ffd777d51299f8b604249c044b3.png" alt="后续问题建议" />
|
||||
</Frame>
|
||||
|
||||
这些建议具有以下特点:
|
||||
- **与当前对话主题相关**
|
||||
- **基于AI的回应动态生成**
|
||||
- **可点击的快捷方式**,帮助用户深入探索或转向相关主题
|
||||
|
||||
## 语音输入
|
||||
|
||||
语音转文字将你的聊天 Web App 转变为语音优先的体验:
|
||||
|
||||
<Frame>
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/application-publishing/launch-your-webapp-quickly/3a64c79792f1166301403f6c44cf4c85.png" alt="语音转文字麦克风按钮" />
|
||||
</Frame>
|
||||
|
||||
**工作原理:**
|
||||
1. 当你在对话流中启用语音转文字时,会出现麦克风按钮
|
||||
2. 用户点击开始录制他们的问题
|
||||
3. 语音在说话时实时转换为文本
|
||||
4. 他们可以在发送前编辑文本或立即发送
|
||||
|
||||
<Warning>
|
||||
用户必须在浏览器中授予麦克风权限。当他们首次尝试使用语音输入时,应用会提示此权限。
|
||||
</Warning>
|
||||
|
||||
## 来源引用
|
||||
|
||||
当你的应用引用知识库或外部内容时,引用与归属会向用户显示信息的确切来源:
|
||||
|
||||
<Steps>
|
||||
<Step title="启用引用">
|
||||
在你的工作空间中,前往**添加功能 → 引用与归属**。
|
||||
</Step>
|
||||
<Step title="配置来源">
|
||||
选择引用时应显示引用与归属的知识库。
|
||||
</Step>
|
||||
<Step title="自动显示">
|
||||
引用与归属会自动与相关的AI回应一起显示。
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
引用与归属通过提供信息来源的透明度来建立用户信任。用户可以点击验证详情或进一步探索源材料。
|
||||
|
||||
<Info>
|
||||
有关详细的引用与归属设置,请参阅[引用与归属](/zh/use-dify/knowledge/retrieval-test-and-citation)。
|
||||
</Info>
|
||||
@@ -1,174 +0,0 @@
|
||||
---
|
||||
title: 使用知识库搭建智能客服机器人
|
||||
---
|
||||
|
||||
上一个实验中,我们学习了文件上传的基本用法。然而,当我们需要读取的文本超出 LLM 的上下文窗口时,就需要用到知识库了。
|
||||
|
||||
> **什么是上下文?**
|
||||
>
|
||||
> 上下文窗口是指 LLM 在处理文本时能够“看到”和“记住”的文字范围。它决定了模型在生成回答或继续文本时,能够参考多少之前的文字信息。窗口越大,模型能利用的上下文信息越多,生成的内容通常更准确和连贯。
|
||||
|
||||
在之前,我们了解到 LLM 的幻觉的概念,很多情况下 LLM 知识库可以让 Agent 从中定位到准确的信息,从而准确地回答问题。在一些特定领域,比如客服、检索工具等有应用。
|
||||
|
||||
传统的客服机器人往往是基于关键词检索的,当用户输入了关键词以外的问题,机器人就无法解决。知识库正是为了解决这样一个问题,能够做到语义级别上的检索,降低人工的负担。
|
||||
|
||||
在实验开始之前,请记住知识库的核心是检索而非 LLM,是 LLM 增强了输出的过程,但真正的需求仍然是生成答案。
|
||||
|
||||
## 本实验中你将掌握的知识点
|
||||
|
||||
* Chatflow 的基础使用
|
||||
* 知识库、外部知识库的使用
|
||||
* embedding 的概念
|
||||
|
||||
## 前提条件
|
||||
|
||||
### 创建应用
|
||||
|
||||
在 Dify 中选择**创建空白应用 - 工作流编排。**
|
||||
|
||||
### 添加模型供应商
|
||||
|
||||
本次实验中需要涉及使用 embedding 模型,目前支持 embedding 的模型提供商中有 OpenAI、Cohere 等,在 Dify 的模型供应商中有标注 `TEXT EMBEDDING` ,请确保至少添加了一个并且有充足余额。
|
||||
|
||||
|
||||
|
||||
> **什么是 embedding?**
|
||||
>
|
||||
> " Embedding "是一种将离散型变量(如单词、句子或者整个文档)转化为连续的向量表示的技术。
|
||||
>
|
||||
> 直白地说,在我们将自然语言处理为数据时会将文本转为向量,这个过程被称作 embedding。语义相似的文本的向量会位置相近,语义相反的文本的向量位置相反。LLM 使用这样的数据做训练,预测出后续的向量,从而生成文本。
|
||||
|
||||
## 创建知识库
|
||||
|
||||
登录 Dify -> 知识库 -> 选择数据源
|
||||
|
||||
Dify 支持三种数据源:上传文本文件、Notion、网页。
|
||||
|
||||
其中,本地文本文件需要注意文件类型的限制以及文件大小的限制;同步 Notion 内容需要绑定 Notion 账号;同步 Web 站点需要使用 Jina 或者 Firecrawl 的 API。
|
||||
|
||||
下面将先以本地文件为例。
|
||||
|
||||
### 分段设置
|
||||
|
||||
上传文档后,会进入以下页面:
|
||||
|
||||
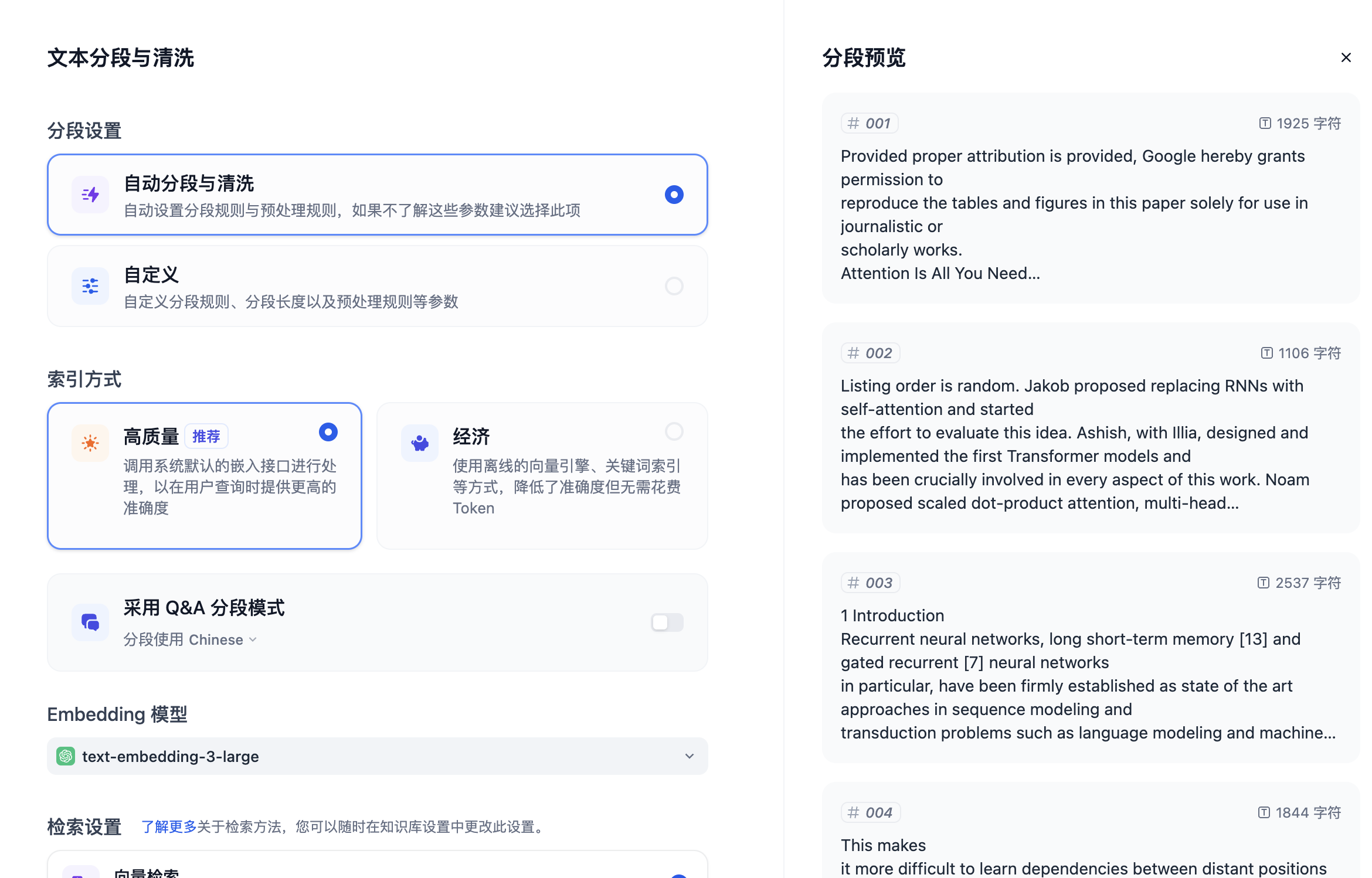
|
||||
|
||||
可以看到右侧有分段预览。当前默认选择的是自动分段与清洗,Dify 会根据文本内容的不同自动将文章切分为许多个段落。你也可以在自定义中设置其他的切分规则。
|
||||
|
||||
### 索引方式
|
||||
|
||||
通常情况下选择 **高质量**,但是需要额外消耗 token。选择 **经济** 无需消耗 token。
|
||||
|
||||
在社区版 Dify 里有采用 Q\&A 分段模式,选择对应的语言可以将文本内容整理为问答格式,需要额外消耗 token。
|
||||
|
||||
### Embedding 模型
|
||||
|
||||
请在使用前查阅模型供应商的使用文档、模型定价等信息。
|
||||
|
||||
不同的 embedding 模型适用场景不同。例如 Cohere 的 `embed-english` 适用于英语文档,`embed-multilingual` 适用于多语言文档。
|
||||
|
||||
### 检索设置
|
||||
|
||||
Dify 提供了向量检索、全文检索、混合检索三种检索功能,其中常用的检索是混合检索。
|
||||
|
||||
混合检索中可以设置权重或者使用重新排序(Rerank)模型。使用权重设置时,可以设置检索更侧重语义还是关键词,例如下图中语义占 70% 的权重,关键词占30%的权重。
|
||||
|
||||
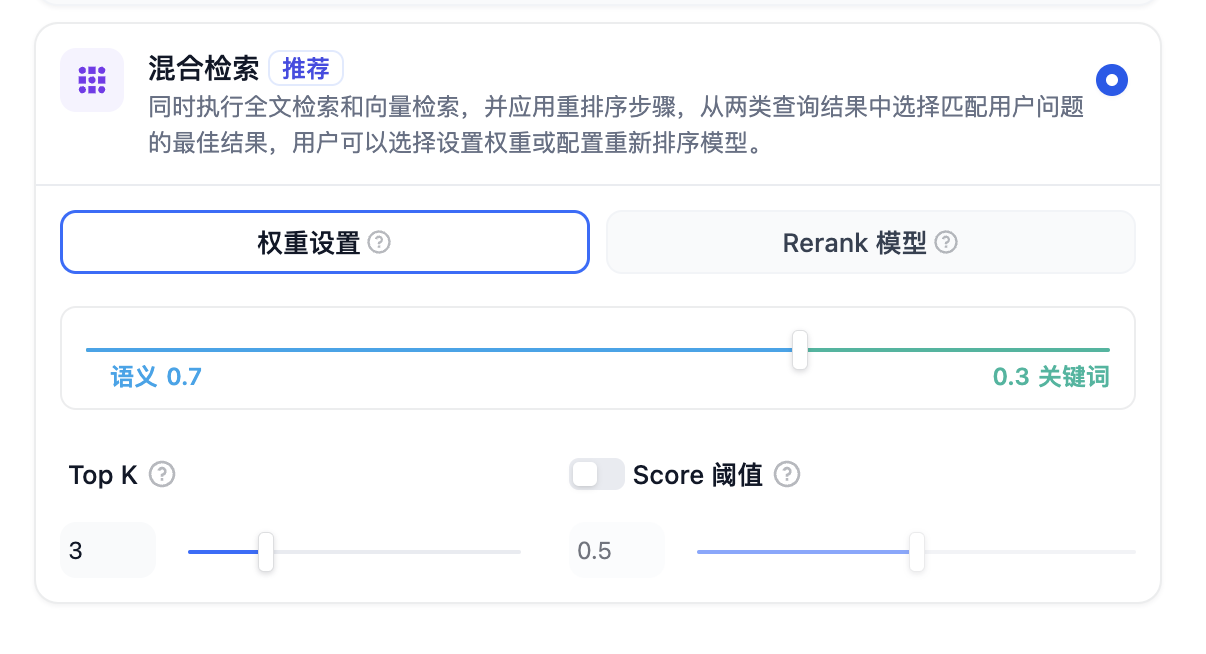
|
||||
|
||||
点击**保存并处理**将会处理文档,完成处理后文档就可以在应用中使用了。
|
||||
|
||||
|
||||
|
||||
### 同步自 Web 站点
|
||||
|
||||
很多情况下,我们需要根据帮助文档构建智能客服,以 Dify 为例,我们可以将 [Dify 的帮助文档](https://docs.dify.ai)转为知识库。
|
||||
|
||||
目前 Dify 支持最多 50 个页面的处理,请注意限制数量的设置。如果超出,可以再创建新的知识库。
|
||||
|
||||

|
||||
|
||||
### 调整知识库内容
|
||||
|
||||
在知识库处理完所有文档后,最好前往知识库确认分段的连贯性。如果不连贯将会影响检索的效果,需要手动调整。
|
||||
|
||||
点击文档内容,对分段内容进行浏览,如果有无关的内容可以禁用或删除。
|
||||
|
||||
如果有内容被分段到了另外一个段落,也需要调整回来。
|
||||
|
||||
### 召回测试
|
||||
|
||||
在知识库的文档页,左侧边栏中点击召回测试,可以输入关键词来测试检索结果的准确性。
|
||||
|
||||
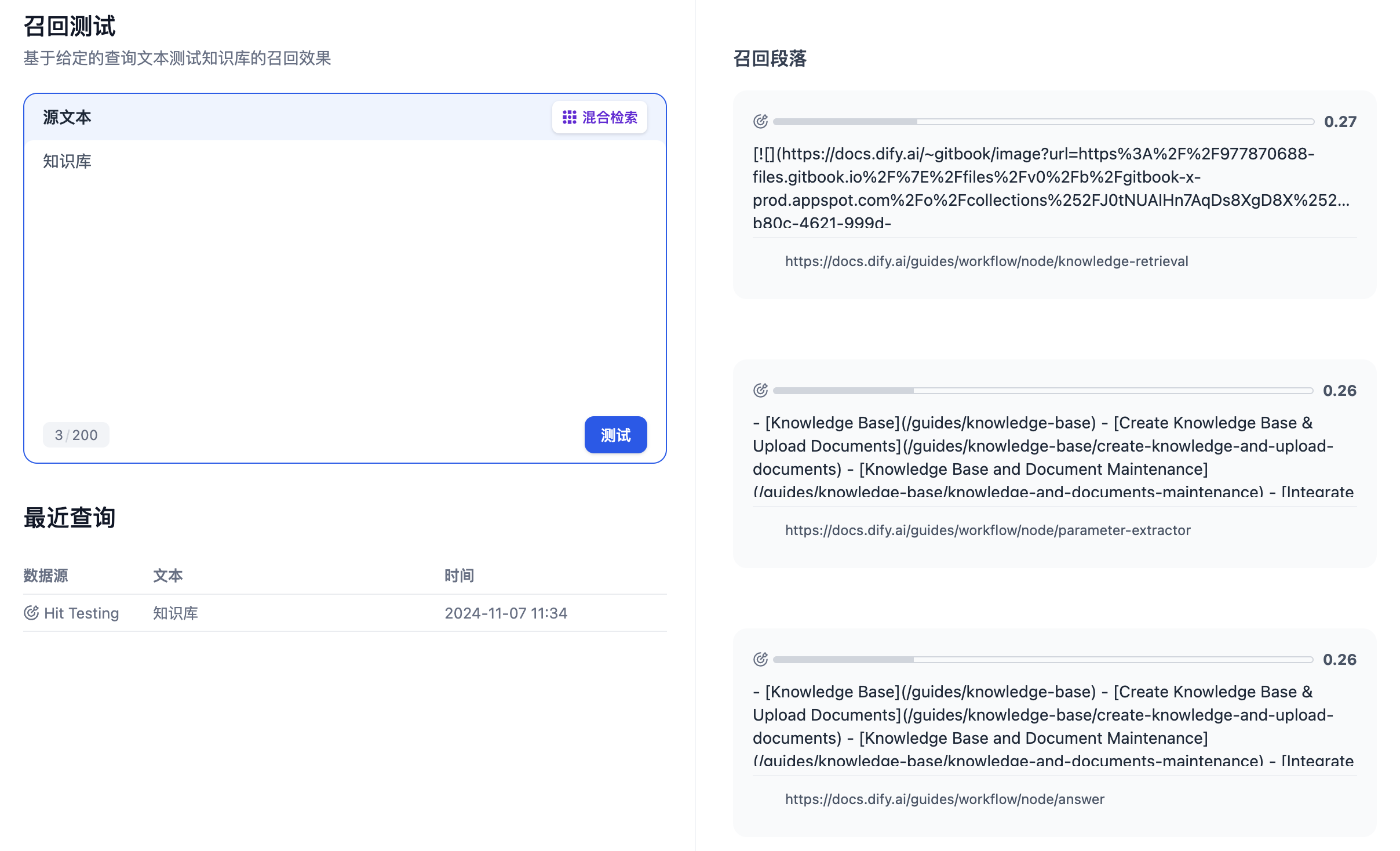
|
||||
|
||||
## 添加节点
|
||||
|
||||
进入创建好的 APP ,下面开始构建智能客服机器人。
|
||||
|
||||
### 问题分类节点
|
||||
|
||||
你需要使用问题分类节点将用户的不同需求分离开。有的情况下用户甚至会聊无关的话题,对此也需要设置一个分类。
|
||||
|
||||
为了让分类更准确,你需要选择更优秀的 LLM,分类需要写的足够具体、区分度足够大。
|
||||
|
||||
以下是一个参考分类:
|
||||
|
||||
* 用户询问无关问题
|
||||
* 用户询问和 Dify 相关问题
|
||||
* 用户请求对技术名词的解释
|
||||
* 用户询问社群加入方式
|
||||
|
||||
|
||||
|
||||
### 直接回复节点
|
||||
|
||||
问题分类中,“用户询问无关问题” 和 “用户询问社群加入方式” 这两个问题是不需要经过 LLM 的处理就能回复的。因此你可以直接在这两个问题后面连接直接回复节点。
|
||||
|
||||
“用户询问无关问题”:
|
||||
|
||||
可以将用户引导到帮助文档,让用户先尝试自己解决,例如:
|
||||
|
||||
```text
|
||||
很抱歉,我不能回答你的问题。如果你需要更多帮助,请查看[帮助文档](https://docs.dify.ai)。
|
||||
```
|
||||
|
||||
Dify 支持 Markdown 格式的文本的输出。你可以在输出中用 Markdown 来丰富文本的格式。甚至可以用 Markdown 格式在文中插入图片,效果如下:
|
||||
|
||||

|
||||
|
||||
### 知识检索节点
|
||||
|
||||
在 “用户询问和 Dify 相关问题”后增加知识检索节点,勾选需要使用的知识库。
|
||||
|
||||
### LLM 节点
|
||||
|
||||
在知识检索节点的下一个节点,你需要选择 LLM 节点来整理知识库召回的内容。
|
||||
|
||||
LLM 需要根据用户的提问,调整回复,使得回复内容更加得体。
|
||||
|
||||
上下文:需要将知识检索节点的输出作为 LLM 节点的上下文。
|
||||
|
||||
你可以在提示词书写区域输入 `/` 或者 `{` 来引用变量。在变量中,`sys.` 开头的变量是系统变量,请查询[帮助文档](/zh/use-dify/getting-started/key-concepts)相关说明。
|
||||
|
||||
此外,你可以打开 LLM 记忆让用户的对话体验更加连贯。
|
||||
|
||||
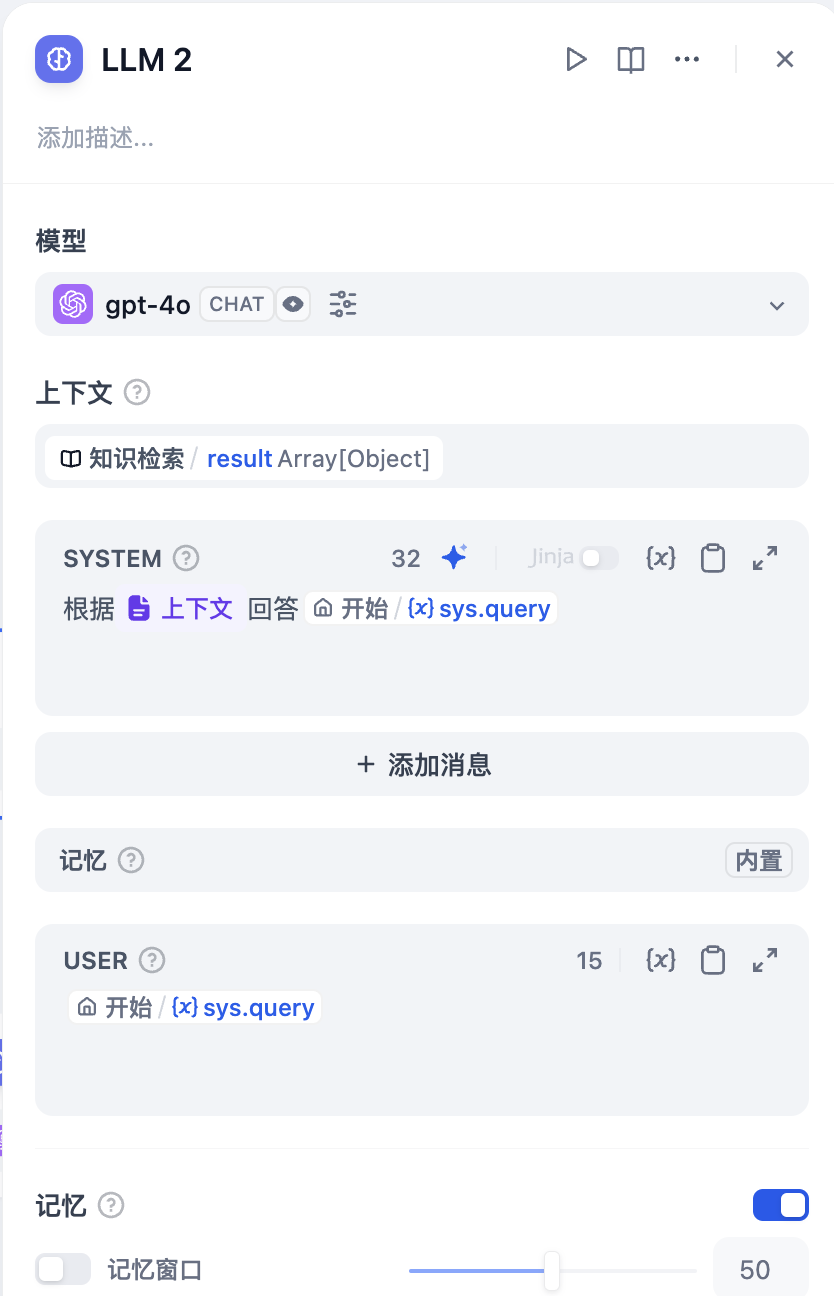
|
||||
|
||||
## 思考题 1: 如何连接外部知识库
|
||||
|
||||
在知识库功能中,你可以通过外部知识库 API 来连接外部知识库,例如 AWS Bedrock 知识库。
|
||||
|
||||
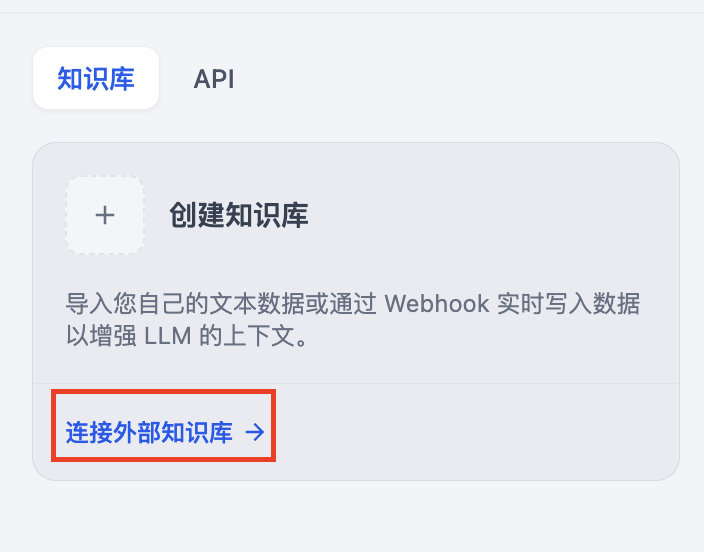
|
||||
|
||||
## 思考题 2: 如何通过 API 管理知识库
|
||||
|
||||
无论是社区版还是 SaaS 版 Dify,你都可以通过知识库 API 增加、删除、查询状态等。
|
||||
|
||||
在搭载知识库的实例中,进入 **知识库 -> API**,并且创建 API 密钥。请妥善保管 API 密钥。
|
||||
|
||||
|
||||
|
||||
## 思考题 3: 如何将客服机器人嵌入网页
|
||||
|
||||
应用发布后,选择嵌入网页,选择一种合适的嵌入形式,将代码粘贴到网页的合适位置即可。
|
||||
Reference in New Issue
Block a user