mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-26 13:18:34 +07:00
* 🌐 Initial translations for PR #636 Auto-generated translations for documentation changes in PR #636. Last-Processed-Commit:3f204fbd9dOriginal-PR: #636 Languages: Chinese (zh), Japanese (ja) 🤖 Generated with GitHub Actions * 🔄 Update translations for commit623b346aAuto-generated translations for changes in commit623b346a77. Last-Processed-Commit:623b346a77Original-PR: #636 Languages: Chinese (zh), Japanese (ja) 🤖 Generated with GitHub Actions * Fix pricing link for batch upload information Updated the link for the paid plan pricing page. * Update maintain-knowledge-documents.mdx * Update link text for knowledge base creation * Update pricing link in readme for batch upload * Update setting-indexing-methods.mdx * Update knowledge-retrieval.mdx --------- Co-authored-by: github-actions[bot] <github-actions[bot]@users.noreply.github.com> Co-authored-by: Riskey <36894937+RiskeyL@users.noreply.github.com>
This commit is contained in:
committed by
 GitHub
GitHub
parent
59a18c8968
commit
688fd5756f
@@ -359,7 +359,6 @@
|
||||
"en/develop-plugin/dev-guides-and-walkthroughs/develop-a-slack-bot-plugin",
|
||||
"en/develop-plugin/dev-guides-and-walkthroughs/develop-md-exporter",
|
||||
"en/develop-plugin/dev-guides-and-walkthroughs/develop-multimodal-data-processing-tool"
|
||||
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -31,7 +31,7 @@ title: ローカルファイルをアップロード
|
||||
**アップロードファイル内の画像について**
|
||||
|
||||
JPG、JPEG、PNG、GIF形式で2MB未満の画像は、該当するチャンクの添付ファイルとして自動抽出されます。これらの画像は個別に管理でき、検索時にチャンクと一緒に返されます。
|
||||
|
||||
|
||||
1チャンクにつき最大10枚まで画像添付が可能です。超過分は抽出されません。
|
||||
|
||||
<Tip>
|
||||
@@ -56,6 +56,5 @@ title: ローカルファイルをアップロード
|
||||
- ``
|
||||
|
||||
<Tip>
|
||||
その後のインデックス設定で**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択した場合、抽出された画像もベクトル化され、検索用にインデックス化されます。
|
||||
その後のインデックス設定でマルチモーダル埋め込みモデル(**Vision**アイコン付き)を選択した場合、抽出された画像は埋め込まれ、検索用にインデックス化されます。
|
||||
</Tip>
|
||||
|
||||
|
||||
@@ -4,219 +4,191 @@ title: インデックス方法と検索設定を指定
|
||||
|
||||
<Note> ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/knowledge/create-knowledge/setting-indexing-methods)を参照してください。</Note>
|
||||
|
||||
コンテンツの分割モードを選択した後、構造化されたコンテンツの**インデックス方法**と**検索設定**を行います。
|
||||
チャンキングモードを選択した後、次のステップは構造化されたコンテンツのインデックス方法を定義することです。
|
||||
|
||||
## インデックス方法の設定
|
||||
## インデックス方法の選択
|
||||
|
||||
検索エンジンが効率的なインデックスアルゴリズムを通じてユーザーの質問に最も関連するウェブページコンテンツをマッチングするように、インデックス方法の適切さはLLMがナレッジベース内のコンテンツを検索する効率と回答の正確性に直接影響します。
|
||||
検索エンジンが効率的なインデックスアルゴリズムを使用してユーザーのクエリに最も関連する検索結果をマッチングするのと同様に、選択したインデックス方法はLLMの検索効率とナレッジベースコンテンツに対する回答の正確性に直接影響します。
|
||||
|
||||
**高品質**と**エコノミー**の2種類のインデックス方法を提供しており、それぞれ異なる検索設定オプションがあります。
|
||||
|
||||
<Note>
|
||||
元のQ&Aモード(コミュニティ版のみ対応)は、高品質インデックス方法のオプションになりました。
|
||||
</Note>
|
||||
ナレッジベースでは、**高品質**と**エコノミー**の2種類のインデックス方法を提供しており、それぞれ異なる検索設定オプションがあります。
|
||||
|
||||
<Tabs>
|
||||
<Tab title="高品質">
|
||||
|
||||
|
||||
<Note>
|
||||
**高品質インデックス方式** で作成されたナレッジベースは、後から **経済的インデックス方式** に切り替えることはできません。
|
||||
高品質インデックス方法で作成されたナレッジベースは、後からエコノミーに切り替えることはできません。
|
||||
</Note>
|
||||
|
||||
**高品質インデックス方式** では、埋め込みモデル(Embedding モデル)を使ってコンテンツチャンクをベクトル表現に変換します。この処理を「埋め込み(embedding)」と呼びます。
|
||||
|
||||
これらのベクトルは、多次元空間上の座標のようなものです。2つの点の距離が近いほど、それらの意味が近いことを示しています。このしくみにより、システムは単なるキーワード一致ではなく、意味的な類似性(セマンティック類似度)に基づいて関連情報を検索できます。
|
||||
高品質インデックス方法では、埋め込みモデルを使用してコンテンツチャンクをベクトル表現に変換します。この処理を埋め込み(embedding)と呼びます。
|
||||
|
||||
これらのベクトルは多次元空間上の座標のようなものです。2つの点の距離が近いほど、それらの意味が近いことを示しています。このしくみにより、システムは単なるキーワード一致ではなく、意味的な類似性に基づいて関連情報を検索できます。
|
||||
|
||||
<Tip>
|
||||
クロスモーダル検索(テキストと画像を意味的関連性に基づいて取得)を有効にするには、マルチモーダル埋め込みモデル(**Vision**アイコン付き)を選択してください。ドキュメントから抽出された画像もベクトル化され、検索用にインデックス化されます。
|
||||
|
||||
クロスモーダル検索(テキストと画像を意味的関連性に基づいて取得)を有効にするには、**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択してください。ドキュメントから抽出された画像もベクトル化され、検索用にインデックス化されます。
|
||||
|
||||
このような埋め込みモデルを使用するナレッジベースは、カード上で**Multimodal**と表示されます。
|
||||
このような埋め込みモデルを使用するナレッジベースは、カード上で**Multimodal**とラベル付けされます。
|
||||
|
||||
<img src="/images/multimodal_knowledge_base.png" alt="Multimodal Knowledge Base" width="300" />
|
||||
|
||||
</Tip>
|
||||
|
||||
高品質インデックス方法では、ベクトル検索、全文検索、ハイブリッド検索の3つの検索戦略がサポートされています。詳細は[検索設定の指定](#検索設定の指定)をご覧ください。
|
||||
|
||||
### Q&Aモード
|
||||
|
||||
<Info>
|
||||
Q&Aモードはセルフホスト環境でのみ利用可能です。
|
||||
</Info>
|
||||
|
||||
高品質インデックス方式では、ベクトル検索・全文検索・ハイブリッド検索の3つの検索戦略がサポートされています。詳細は[検索設定の指定](#検索方法の指定)をご覧ください。
|
||||
このモードを有効にすると、システムはアップロードされたテキストを分割し、各分割のコンテンツを要約して自動的にQ&Aペアを生成します。
|
||||
|
||||
**Q\&Aモードの有効化(セルフホスト環境のみ対応)**
|
||||
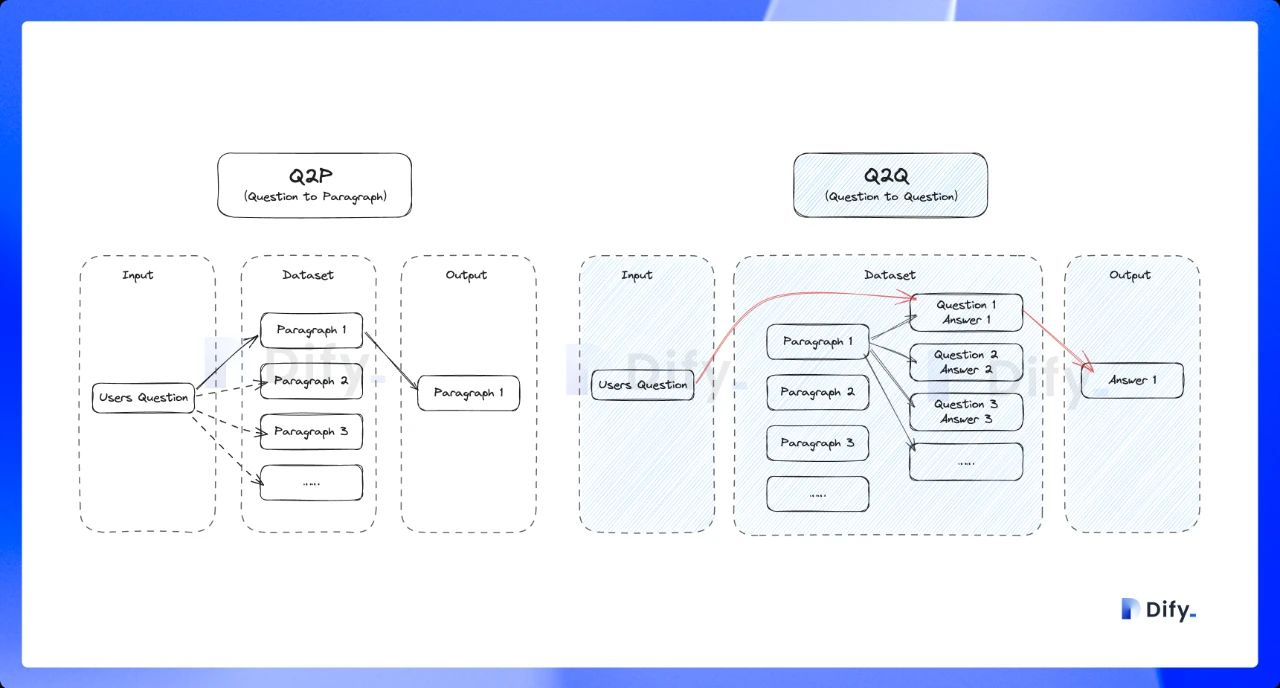
一般的な**Q to P**戦略(ユーザーの質問がテキスト段落にマッチング)とは異なり、Q&Aモードでは**Q to Q**戦略(質問が質問にマッチング)を採用しています。
|
||||
|
||||
このモードを有効にすると、システムはアップロードされたテキストを分割し、各分割のコンテンツを要約して自動的にQ\&Aマッチングペアを生成します。一般的な「Q to P」(ユーザーの質問がテキスト段落にマッチング)戦略とは異なり、QAモードでは「Q to Q」(質問が質問にマッチング)戦略を採用しています。
|
||||
このアプローチは、FAQ文書内のテキストが**通常、完全な文法構造を持つ自然言語で書かれている**ため、特に効果的です。
|
||||
|
||||
これは「よくある質問」文書内のテキストが**通常、完全な文法構造を持つ自然言語**であるため、Q to Qモードによって質問と回答のマッチングがより明確になり、同時に高頻度で類似度の高い質問のシナリオにも対応できるからです。
|
||||
> **Q to Q**戦略により、質問と回答のマッチングがより明確になり、高頻度または類似度の高い質問のシナリオにも適切に対応できます。
|
||||
|
||||
> **Q\&Aモードは「中国語、英語、日本語」の3言語のみサポートしています。このモードを有効にするとより多くのLLM Tokensを消費する可能性があり、**[**エコノミーインデックス方法**](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#エコノミーインデックス)**は使用できません。**
|
||||
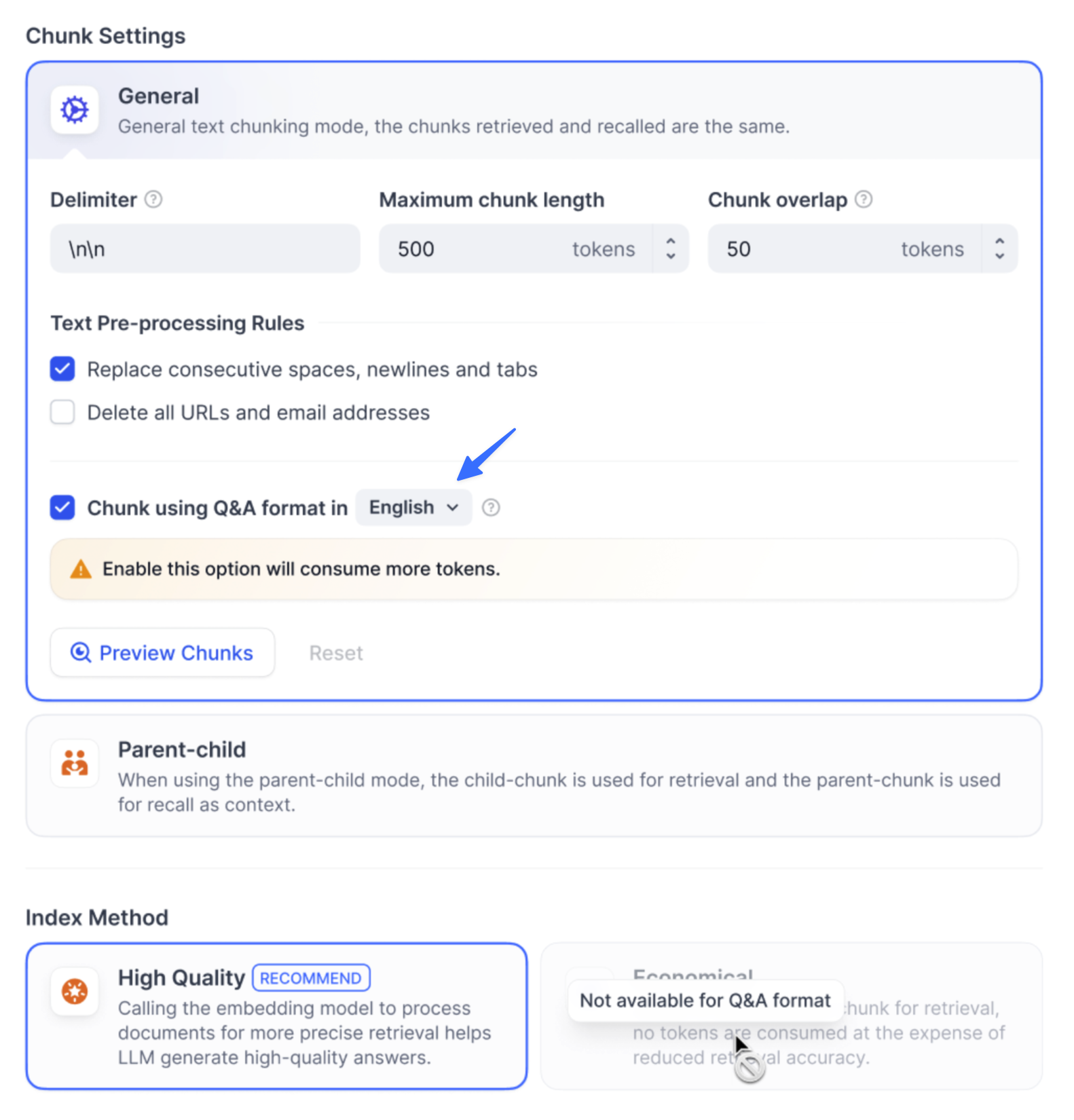
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2024/12/70960a237d4f5eaed2dbf46a2cca2bf7.png"
|
||||
className="mx-auto"
|
||||
alt="Q\&A チャンキング"
|
||||
/>
|
||||
ユーザーが質問すると、システムは最も類似した質問を特定し、対応するチャンクを回答として返します。この方法はより精密で、ユーザーのクエリに直接マッチングするため、ユーザーが必要とする正確な情報を検索できます。
|
||||
|
||||
ユーザーが質問すると、システムは最も類似した質問を見つけ、対応する分割を回答として返します。この方法はより精密で、ユーザーの質問に直接マッチングするため、ユーザーが本当に必要とする情報をより正確に検索できます。
|
||||
|
||||
|
||||
</Tab>
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2024/12/8745ccabff56290eae329a9d3592f745.png"
|
||||
className="mx-auto"
|
||||
alt="Q to P と Q to Q のインデックスモードの違い"
|
||||
/>
|
||||
</Tab>
|
||||
<Tab title="エコノミー">
|
||||
**エコノミー**
|
||||
|
||||
エコノミーモードでは、各ブロック内で10個のキーワードを使用して検索し、精度は下がりますが費用は発生しません。検索されたブロックに対しては、逆引きインデックス方式のみで最も関連性の高いブロックを選択します。詳細は[以下](#検索方法の指定)をお読みください。
|
||||
各チャンクで10個のキーワードを使用して検索し、検索精度は下がりますがトークンを消費しません。検索されたブロックに対しては、逆引きインデックス方式のみで最も関連性の高いブロックを選択します。
|
||||
|
||||
エコノミータイプのインデックス方法を選択した後、実際の効果が良くないと感じる場合は、ナレッジベース設定ページで**「高品質」インデックス方法**にアップグレードできます。
|
||||
エコノミーインデックス方法のパフォーマンスが期待に沿わない場合は、ナレッジ設定ページで高品質インデックス方法にアップグレードできます。
|
||||
|
||||

|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2024/12/3b86e6b484da39452c164cb6372a7242.png"
|
||||
className="mx-auto"
|
||||
alt="エコノミーモード"
|
||||
/>
|
||||
</Tab>
|
||||
|
||||
</Tabs>
|
||||
|
||||
## 検索方法の指定 <a href="#retrieval_settings" id="retrieval_settings"></a>
|
||||
## 検索設定の指定
|
||||
|
||||
ナレッジベースはユーザーのクエリを受け取った後、事前設定された検索方法に従って既存の文書内で関連コンテンツを検索し、言語モデルが高品質な回答を生成するために高度に関連する情報の断片を抽出します。これはLLMが取得できる背景情報を決定し、生成結果の正確性と信頼性に影響を与えます。
|
||||
ナレッジベースはユーザーのクエリを受け取った後、事前設定された検索方法に従って既存のドキュメントを検索し、高度に関連するコンテンツチャンクを抽出します。これらのチャンクはLLMに不可欠なコンテキストを提供し、最終的に回答の正確性と信頼性に影響を与えます。
|
||||
|
||||
一般的な検索方法には、ベクトル類似度に基づく意味検索と、キーワードに基づく精密マッチングがあります。前者はテキストコンテンツブロックと質問クエリをベクトルに変換し、ベクトル類似度の計算によってより深いレベルの意味的関連性をマッチングします。後者は検索エンジンでよく使われる検索方法である逆引きインデックスを通じて、質問と重要なコンテンツをマッチングします。
|
||||
一般的な検索方法には以下があります:
|
||||
|
||||
異なるインデックス方法には異なる検索設定があります。
|
||||
1. ベクトル類似度に基づく意味検索 - テキストチャンクとクエリをベクトルに変換し、類似度スコアリングでマッチングします。
|
||||
2. 逆引きインデックス(標準的な検索エンジン技術)を使用したキーワードマッチング。両方の方法がDifyのナレッジベースでサポートされています。
|
||||
|
||||
両方の検索方法がDifyのナレッジベースでサポートされています。利用可能な具体的な検索オプションは、選択したインデックス方法によって異なります。
|
||||
|
||||
<Tabs>
|
||||
<Tab title="高品質インデックス">
|
||||
**高品質インデックス**
|
||||
<Tab title="高品質">
|
||||
**高品質**
|
||||
|
||||
高品質インデックス方法では、Difyはベクトル検索、全文検索、ハイブリッド検索の設定を提供しています:
|
||||
**高品質**インデックス方法では、Difyは**ベクトル検索、全文検索、ハイブリッド検索**の3つの検索設定を提供しています。
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2024/12/9b02fc353324221cc91f185a350775b6.png"
|
||||
className="mx-auto"
|
||||
alt="検索設定"
|
||||
/>
|
||||
|
||||
|
||||
**ベクトル検索**
|
||||
**ベクトル検索**
|
||||
|
||||
**定義:** ユーザーが入力した質問をベクトル化し、クエリテキストの数学ベクトルを生成し、クエリベクトルとナレッジベース内の対応するテキストベクトル間の距離を比較し、隣接する分割コンテンツを探します。
|
||||
**定義**: ユーザーの質問をベクトル化してクエリベクトルを生成し、ナレッジベース内の対応するテキストベクトルと比較して、最も近いチャンクを見つけます。
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2024/12/620044faa47a5037f85b32a27a56fce5.png"
|
||||
className="mx-auto"
|
||||
alt="ベクトル検索"
|
||||
/>
|
||||
|
||||
|
||||
**ベクトル検索設定:**
|
||||
**ベクトル検索設定:**
|
||||
|
||||
**Rerankモデル:** デフォルトでは無効です。有効にすると、ベクトル検索によって呼び出されたコンテンツセグメントを第三者のRerankモデルを使用して再度並べ替え、並べ替え結果を最適化します。LLMがより正確なコンテンツを取得し、出力の品質を向上させるのを助けます。このオプションを有効にする前に、「設定」→「モデルプロバイダー」に移動し、RerankモデルのAPIキーを事前に設定する必要があります。
|
||||
**Rerankモデル**: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルがベクトル検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、**設定** → **モデルプロバイダー**に移動してRerankモデルのAPIキーを設定してください。
|
||||
|
||||
<Note>
|
||||
選択した埋め込みモデルがマルチモーダルの場合は、**Vision**アイコンが表示されたマルチモーダルリランキングモデルも選択してください。そうでない場合、検索された画像は再ランクおよび最終出力から除外されます。
|
||||
</Note>
|
||||
<Note>
|
||||
選択した埋め込みモデルがマルチモーダルの場合は、マルチモーダルRerankモデル(**Vision**アイコン付き)も選択してください。そうでない場合、検索された画像はリランキングと検索結果から除外されます。
|
||||
</Note>
|
||||
|
||||
> この機能を有効にすると、Rerankモデルのトークンが消費されます。詳細については、対応するモデルの価格説明を参照してください。
|
||||
> この機能を有効にすると、Rerankモデルのトークンが消費されます。詳細については、関連するモデルの価格ページを参照してください。
|
||||
|
||||
**TopK:** ユーザーの質問との類似度が最も高いテキスト断片をフィルタリングするために使用されます。システムは同時に使用するモデルのコンテキストウィンドウサイズに基づいて断片の数を動的に調整します。デフォルト値は3です。値が高いほど、呼び出されるテキストセグメントの予想数が多くなります。
|
||||
**TopK**: ユーザーのクエリに最も類似していると判断されたテキストチャンクの取得数を決定します。選択したモデルのコンテキストウィンドウに基づいてチャンク数を自動的に調整します。デフォルト値は**3**で、値が高いほど多くのテキストチャンクが呼び出されます。
|
||||
|
||||
**Scoreしきい値:** テキスト断片をフィルタリングする類似度のしきい値を設定するために使用され、設定されたスコアを超えるテキスト断片のみを呼び出します。デフォルト値は0.5です。値が高いほど、テキストと質問の類似度の要求が高くなり、呼び出されるテキストの予想数も少なくなります。
|
||||
**Scoreしきい値**: チャンクが取得されるために必要な最小類似度スコアを設定します。このスコアを超えるチャンクのみが取得されます。デフォルト値は**0.5**です。しきい値が高いほど類似度の要求が高くなり、取得されるチャンク数が少なくなります。
|
||||
|
||||
> TopKとScore設定はRerankステップでのみ有効であるため、RerankモデルをRerankモデルを追加して有効にする必要があります。
|
||||
> TopKとScore設定はRerankフェーズでのみ有効です。したがって、これらの設定を適用するには、Rerankモデルを追加して有効にする必要があります。
|
||||
|
||||
***
|
||||
|
||||
**全文検索**
|
||||
|
||||
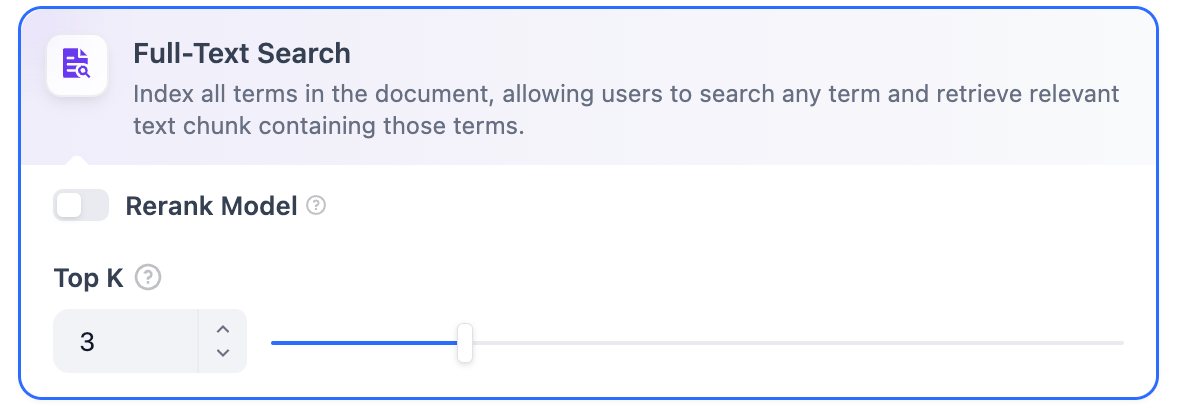
**定義:** キーワード検索、つまり文書内のすべての語彙のインデックス作成です。ユーザーが質問を入力した後、明示的なキーワードによってナレッジベース内の対応するテキスト断片をマッチングし、キーワードに合致するテキスト断片を返します。検索エンジンの明示的な検索と類似しています。
|
||||
**定義**: ドキュメント内のすべての用語をインデックス化し、ユーザーが任意の用語をクエリして、それらの用語を含むテキストフラグメントを返すことができます。
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2024/12/513bff1ca38ec746b3246502b0311b39.png"
|
||||
className="mx-auto"
|
||||
alt="全文検索"
|
||||
/>
|
||||
|
||||
|
||||
**Rerankモデル:** デフォルトでは無効です。有効にすると、全文検索によって呼び出されたコンテンツセグメントを第三者のRerankモデルを使用して再度並べ替え、並べ替え結果を最適化します。LLMに再並べ替えされたセグメントを送信し、出力コンテンツの品質を向上させます。このオプションを有効にする前に、「設定」→「モデルプロバイダー」に移動し、RerankモデルのAPIキーを事前に設定する必要があります。
|
||||
**Rerankモデル**: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルが全文検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、**設定** → **モデルプロバイダー**に移動してRerankモデルのAPIキーを設定してください。
|
||||
|
||||
<Note>
|
||||
選択した埋め込みモデルがマルチモーダルの場合は、**Vision**アイコンが表示されたマルチモーダルリランキングモデルも選択してください。そうでない場合、検索された画像は再ランクおよび最終出力から除外されます。
|
||||
</Note>
|
||||
<Note>
|
||||
選択した埋め込みモデルがマルチモーダルの場合は、マルチモーダルRerankモデル(**Vision**アイコン付き)も選択してください。そうでない場合、検索された画像はリランキングと検索結果から除外されます。
|
||||
</Note>
|
||||
|
||||
> この機能を有効にすると、Rerankモデルのトークンが消費されます。詳細については、対応するモデルの価格説明を参照してください。
|
||||
> この機能を有効にすると、Rerankモデルのトークンが消費されます。詳細については、関連するモデルの価格ページを参照してください。
|
||||
|
||||
**TopK:** ユーザーの質問との類似度が最も高いテキスト断片をフィルタリングするために使用されます。システムは同時に使用するモデルのコンテキストウィンドウサイズに基づいて断片の数を動的に調整します。システムのデフォルト値は3です。値が高いほど、呼び出されるテキストセグメントの予想数が多くなります。
|
||||
**TopK**: ユーザーのクエリに最も類似していると判断されたテキストチャンクの取得数を決定します。選択したモデルのコンテキストウィンドウに基づいてチャンク数を自動的に調整します。デフォルト値は**3**で、値が高いほど多くのテキストチャンクが呼び出されます。
|
||||
|
||||
**Scoreしきい値:** テキスト断片をフィルタリングする類似度のしきい値を設定するために使用され、設定されたスコアを超えるテキスト断片のみを呼び出します。デフォルト値は0.5です。値が高いほど、テキストと質問の類似度の要求が高くなり、呼び出されるテキストの予想数も少なくなります。
|
||||
**Scoreしきい値**: チャンクが取得されるために必要な最小類似度スコアを設定します。このスコアを超えるチャンクのみが取得されます。デフォルト値は**0.5**です。しきい値が高いほど類似度の要求が高くなり、取得されるチャンク数が少なくなります。
|
||||
|
||||
> TopKとScore設定はRerankステップでのみ有効であるため、RerankモデルをRerankモデルを追加して有効にする必要があります。
|
||||
> TopKとScore設定はRerankフェーズでのみ有効です。したがって、これらの設定を適用するには、Rerankモデルを追加して有効にする必要があります。
|
||||
|
||||
***
|
||||
|
||||
**ハイブリッド検索**
|
||||
**ハイブリッド検索**
|
||||
|
||||
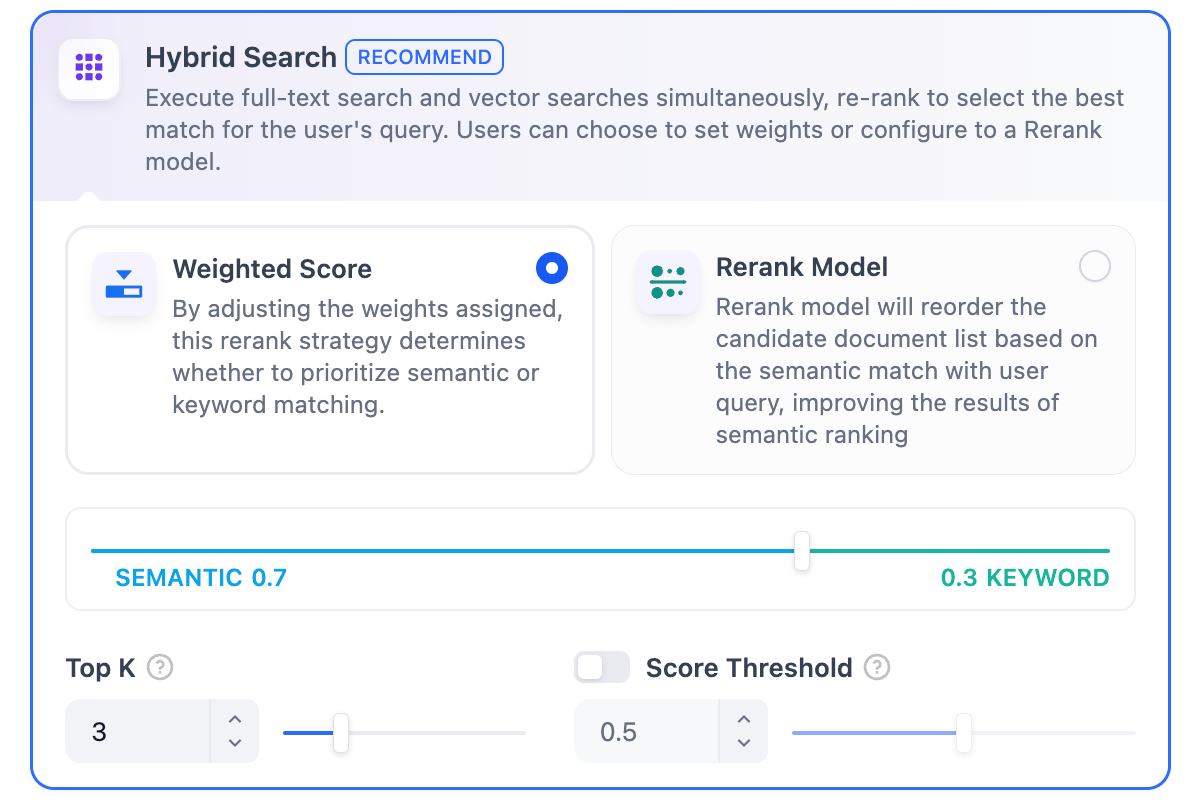
**定義:** 全文検索とベクトル検索、またはRerankモデルを同時に実行し、クエリ結果からユーザーの質問に最もマッチする最良の結果を選択します。
|
||||
**定義**: 全文検索とベクトル検索を同時に実行し、リオーダリングステップを含めて、ユーザーのクエリに基づいて両方の検索結果から最もマッチする結果を選択します。
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2024/12/bd2621bfe8a1a8e21fca0743ec495a9e.png"
|
||||
className="mx-auto"
|
||||
alt="ハイブリッド検索"
|
||||
/>
|
||||
|
||||
|
||||
ハイブリッド検索設定では、**「重み付け設定」**または**「Rerankモデル」**の有効化を選択できます。
|
||||
このモードでは、RerankモデルAPIを設定せずに**「重み付け設定」**を指定するか、**Rerankモデル**を有効にして検索を行うことができます。
|
||||
|
||||
* **重み付け設定**
|
||||
* **重み付け設定**
|
||||
|
||||
ユーザーが意味的優先度とキーワード優先度にカスタム重みを付けることができます。キーワード検索はナレッジベース内での全文検索(Full Text Search)を指し、意味検索はナレッジベース内でのベクトル検索(Vector Search)を指します。
|
||||
この機能により、ユーザーは意味優先度とキーワード優先度にカスタム重みを設定できます。キーワード検索はナレッジベース内での全文検索を指し、意味検索はナレッジベース内でのベクトル検索を指します。
|
||||
|
||||
* **意味値を1にする**
|
||||
* **意味値を1にする**
|
||||
|
||||
**意味検索モードのみを有効にします**。Embeddingモデルを活用することで、クエリに含まれる正確な単語がナレッジベースになくても、ベクトル距離を計算することで検索の深度を高め、正確なコンテンツを返すことができます。また、多言語コンテンツを処理する必要がある場合、意味検索は異なる言語間の意味変換をキャプチャし、より正確なクロス言語検索結果を提供できます。
|
||||
* **キーワード値を1にする**
|
||||
意味検索モードのみを有効にします。埋め込みモデルを活用することで、クエリに含まれる正確な用語がナレッジベースになくても、ベクトル距離を計算することで検索の深度を高め、関連コンテンツを返すことができます。また、多言語コンテンツを処理する場合、意味検索は異なる言語間の意味をキャプチャし、より正確なクロス言語検索結果を提供できます。
|
||||
* **キーワード値を1にする**
|
||||
|
||||
**キーワード検索モードのみを有効にします**。ユーザーが入力した情報テキストをナレッジベース全体でマッチングし、ユーザーが正確な情報や用語を知っているシナリオに適しています。この方法は消費する計算リソースが比較的少なく、大量の文書を含むナレッジベース内での迅速な検索に適しています。
|
||||
* **キーワードと意味の重みをカスタマイズする**
|
||||
|
||||
異なる値を1に引き上げるだけでなく、両者の重みを継続的に調整して、ビジネスシナリオに合った最適な重み比率を見つけることができます。
|
||||
|
||||
> 意味検索とは、ユーザーの質問とナレッジベースコンテンツ内のベクトル間の距離を比較することを指します。距離が近いほど、マッチングの確率が高くなります。
|
||||
キーワード検索モードのみを有効にします。ナレッジベース内で入力テキストとの完全一致を実行し、ユーザーが正確な情報や用語を知っているシナリオに適しています。この方法は消費する計算リソースが比較的少なく、大量のドキュメントを含むナレッジベース内での迅速な検索に適しています。
|
||||
* **キーワードと意味の重みをカスタマイズする**
|
||||
|
||||
意味検索またはキーワード検索のみを有効にするだけでなく、柔軟なカスタム重み設定を提供しています。両方の方法の重みを継続的に調整して、ビジネスシナリオに合った最適な重み比率を見つけることができます。
|
||||
***
|
||||
|
||||
* **Rerankモデル**
|
||||
**Rerankモデル**
|
||||
|
||||
デフォルトでは無効です。有効にすると、ハイブリッド検索によって呼び出されたコンテンツセグメントを第三者のRerankモデルを使用して再度並べ替え、並べ替え結果を最適化します。LLMに再並べ替えされたセグメントを送信し、出力コンテンツの品質を向上させます。このオプションを有効にする前に、「設定」→「モデルプロバイダー」に移動し、RerankモデルのAPIキーを事前に設定する必要があります。
|
||||
デフォルトでは無効です。有効にすると、サードパーティのRerankモデルがハイブリッド検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、**設定** → **モデルプロバイダー**に移動してRerankモデルのAPIキーを設定してください。
|
||||
|
||||
<Note>
|
||||
選択した埋め込みモデルがマルチモーダルの場合は、**Vision**アイコンが表示されたマルチモーダルリランキングモデルも選択してください。そうでない場合、検索された画像は再ランクおよび最終出力から除外されます。
|
||||
</Note>
|
||||
<Note>
|
||||
選択した埋め込みモデルがマルチモーダルの場合は、マルチモーダルRerankモデル(**Vision**アイコン付き)も選択してください。そうでない場合、検索された画像はリランキングと検索結果から除外されます。
|
||||
</Note>
|
||||
|
||||
> この機能を有効にすると、Rerankモデルのトークンが消費されます。詳細については、対応するモデルの価格説明を参照してください。
|
||||
> この機能を有効にすると、Rerankモデルのトークンが消費されます。詳細については、関連するモデルの価格ページを参照してください。
|
||||
|
||||
**「重み付け設定」**と**「Rerankモデル」**設定では、以下のオプションを有効にすることができます:
|
||||
**「重み付け設定」**と**「Rerankモデル」**設定では、以下のオプションがサポートされています:
|
||||
|
||||
**TopK:** ユーザーの質問との類似度が最も高いテキスト断片をフィルタリングするために使用されます。システムは同時に使用するモデルのコンテキストウィンドウサイズに基づいて断片の数を動的に調整します。システムのデフォルト値は3です。値が高いほど、呼び出されるテキストセグメントの予想数が多くなります。
|
||||
**TopK**: ユーザーのクエリに最も類似していると判断されたテキストチャンクの取得数を決定します。選択したモデルのコンテキストウィンドウに基づいてチャンク数を自動的に調整します。デフォルト値は**3**で、値が高いほど多くのテキストチャンクが呼び出されます。
|
||||
|
||||
**Scoreしきい値:** テキスト断片をフィルタリングする類似度のしきい値を設定するために使用されます。つまり、設定されたスコアを超えるテキスト断片のみを呼び出します。システムはデフォルトでこの設定を無効にしています。つまり、呼び出されたテキスト断片の類似値をフィルタリングしません。有効にするとデフォルト値は0.5です。値が高いほど、呼び出されるテキストの予想数は少なくなります。
|
||||
**Scoreしきい値**: チャンクが取得されるために必要な最小類似度スコアを設定します。このスコアを超えるチャンクのみが取得されます。デフォルト値は**0.5**です。しきい値が高いほど類似度の要求が高くなり、取得されるチャンク数が少なくなります。
|
||||
</Tab>
|
||||
<Tab title="エコノミーインデックス">
|
||||
**逆引きインデックス**
|
||||
<Tab title="エコノミー">
|
||||
**エコノミー**
|
||||
|
||||
エコノミーインデックス方法では、**逆引きインデックス方式**のみが提供されます。これは文書内のキーワードを迅速に検索するためのインデックス構造で、オンライン検索エンジンでよく使用されています。逆引きインデックスは**TopK**設定項目のみをサポートしています。
|
||||
**エコノミーインデックス**モードでは、逆引きインデックスアプローチのみが利用可能です。逆引きインデックスはドキュメント内のキーワードを高速に検索するために設計されたデータ構造で、オンライン検索エンジンでよく使用されています。逆引きインデックスは**TopK**設定のみをサポートしています。
|
||||
|
||||
**TopK:**
|
||||
**TopK:** ユーザーのクエリに最も類似していると判断されたテキストチャンクの取得数を決定します。選択したモデルのコンテキストウィンドウに基づいてチャンク数を自動的に調整します。デフォルト値は**3**で、値が高いほど多くのテキストチャンクが呼び出されます。
|
||||
|
||||
ユーザーの質問との類似度が最も高いテキスト断片をフィルタリングするために使用されます。システムは同時に使用するモデルのコンテキストウィンドウサイズに基づいて断片の数を動的に調整します。システムのデフォルト値は3です。値が高いほど、呼び出されるテキストセグメントの予想数が多くなります。
|
||||
<p align="center">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/b417cd028131d34779993fbcbb8dbdd7.png" width="300" />
|
||||
</p>
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2024/12/b417cd028131d34779993fbcbb8dbdd7.png"
|
||||
className="mx-auto"
|
||||
alt="逆引きインデックス"
|
||||
/>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## もっと読む
|
||||
### リファレンス
|
||||
|
||||
検索設定を指定した後、以下のドキュメントを参照して、実際のシナリオでのキーワードとコンテンツブロックのマッチング状況を確認できます。
|
||||
検索設定を指定した後、以下のドキュメントを参照して、さまざまなシナリオでのキーワードとコンテンツチャンクのマッチング状況を確認できます。
|
||||
|
||||
<Card title="ナレッジ検索テスト" icon="link" href="/ja/use-dify/knowledge/test-retrieval">
|
||||
実際のシナリオでのキーワードとコンテンツブロックのマッチング状況を確認する
|
||||
ナレッジベース検索のテストと引用方法を学ぶ
|
||||
</Card>
|
||||
@@ -4,8 +4,6 @@ title: ステップ2:ナレッジパイプラインをオーケストレーシ
|
||||
|
||||
<Note> ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration)を参照してください。</Note>
|
||||
|
||||
# ナレッジパイプラインの構築
|
||||
|
||||
工場の生産ラインを例に考えてみましょう。各ステーション(ノード)が特定の作業を担当し、それらを連携させて部品を組み立て、最終製品を完成させます。ナレッジパイプラインの構築も同様のプロセスです。視覚的なワークフロー設計ツールを使用し、ドラッグ&ドロップ操作だけで容易にデータ処理の流れを設計できます。これにより、ドキュメントの取り込み、処理、分割、インデックス化、検索戦略を自在に管理できます。
|
||||
|
||||
本ステップでは、ナレッジパイプライン全体のプロセス、各ノードの役割や設定方法について学び、独自のデータ処理フローをカスタマイズして、効率的にナレッジベースを管理・最適化する方法を解説します。
|
||||
@@ -56,32 +54,36 @@ title: ステップ2:ナレッジパイプラインをオーケストレーシ
|
||||
|
||||
ローカルファイルはドラッグ&ドロップまたはファイル選択でアップロードできます。
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
**設定オプション**
|
||||
<div style={{ display:"flex",flexWrap:"wrap",gap:"30px" }}>
|
||||
<div style={{ flex:1,minWidth:"200px" }}>
|
||||

|
||||
|
||||
| 項目 | 説明 |
|
||||
|----------------|------------------------------------|
|
||||
| ファイル形式 | PDF、XLSX、DOCXなどに対応 |
|
||||
| アップロード方法 | ドラッグ&ドロップまたは選択、バッチ対応 |
|
||||
</div>
|
||||
|
||||
**制限事項**
|
||||
<div style={{ flex:2,minWidth:"300px" }}>
|
||||
**設定オプション**
|
||||
|
||||
| 項目 | 説明 |
|
||||
|--------------|-------------------------------------------------|
|
||||
| ファイル数 | 1回あたり最大50ファイルまで |
|
||||
| ファイルサイズ | 1ファイルあたり最大15MB |
|
||||
| ストレージ | サブスクリプションプランによりアップロード上限が異なります |
|
||||
| 項目 | 説明 |
|
||||
|----------------|------------------------------------|
|
||||
| ファイル形式 | PDF、XLSX、DOCXなどに対応。ユーザーは選択をカスタマイズできます |
|
||||
| アップロード方法 | ドラッグ&ドロップまたはファイル選択でローカルファイルやフォルダをアップロード。バッチアップロード対応 |
|
||||
|
||||
**出力変数**
|
||||
**制限事項**
|
||||
|
||||
| 項目 | 説明 |
|
||||
|--------------|-------------------------------------------------|
|
||||
| ファイル数 | 1回あたり最大50ファイルまで |
|
||||
| ファイルサイズ | 1ファイルあたり最大15MB |
|
||||
| ストレージ | SaaSサブスクリプションプランによりアップロード上限やストレージ容量が異なる場合があります |
|
||||
|
||||
**出力変数**
|
||||
|
||||
| 出力変数 | 形式 |
|
||||
|----------------|-----------------|
|
||||
| `{x} Document` | 単一ドキュメント |
|
||||
|
||||
</div>
|
||||
|
||||
| 出力変数 | 形式 |
|
||||
|----------------|-----------------|
|
||||
| `{x} Document` | 単一ドキュメント |
|
||||
</div>
|
||||
</div>
|
||||
|
||||
---
|
||||
@@ -92,18 +94,22 @@ title: ステップ2:ナレッジパイプラインをオーケストレーシ
|
||||
|
||||
Notionワークスペースと連携し、ページやデータベースをシームレスにインポート可能です。ナレッジベースは常に自動で最新状態に保たれます。
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
**設定オプション**
|
||||
<div style={{ display:"flex",flexWrap:"wrap",gap:"30px" }}>
|
||||
<div style={{ flex:1,minWidth:"200px" }}>
|
||||

|
||||
|
||||
</div>
|
||||
|
||||
<div style={{ flex:2,minWidth:"300px" }}>
|
||||
**設定オプション**
|
||||
|
||||
| 項目 | オプション | 出力変数 | 説明 |
|
||||
|------------|------------|-----------------|------------------------|
|
||||
| Extractor | 有効 | `{x} Content` | 構造化・処理済み情報 |
|
||||
| | 無効 | `{x} Document` | オリジナルテキスト |
|
||||
|
||||
</div>
|
||||
|
||||
| 項目 | オプション | 出力変数 | 説明 |
|
||||
|------------|------------|-----------------|------------------------|
|
||||
| Extractor | 有効 | `{x} Content` | 構造化・処理済み情報 |
|
||||
| | 無効 | `{x} Document` | オリジナルテキスト |
|
||||
</div>
|
||||
</div>
|
||||
|
||||
---
|
||||
@@ -116,45 +122,53 @@ Webコンテンツを大規模言語モデルでも読みやすい形式に変
|
||||
|
||||
シンプルかつ使いやすいAPIを提供するオープンソースのWeb解析ツールです。Webコンテンツの高速クロールと処理に適しています。
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
**パラメータ設定**
|
||||
<div style={{ display:"flex",flexWrap:"wrap",gap:"30px" }}>
|
||||
<div style={{ flex:1,minWidth:"200px" }}>
|
||||

|
||||
|
||||
</div>
|
||||
|
||||
<div style={{ flex:2,minWidth:"300px" }}>
|
||||
**パラメータ設定**
|
||||
|
||||
| パラメータ | 種類 | 説明 |
|
||||
|--------------------|--------|------------------------------------------------|
|
||||
| URL | 必須 | 対象Webページのアドレス |
|
||||
| サブページのクロール | 任意 | リンク先ページもクロールするか |
|
||||
| サイトマップ使用 | 任意 | サイトマップを利用してクロール |
|
||||
| 制限 | 必須 | クロールする最大ページ数 |
|
||||
| Extractor有効化 | 任意 | データ抽出方式の選択 |
|
||||
|
||||
</div>
|
||||
|
||||
| パラメータ | 種類 | 説明 |
|
||||
|--------------------|--------|------------------------------------------------|
|
||||
| URL | 必須 | 対象Webページのアドレス |
|
||||
| サブページのクロール | 任意 | リンク先ページもクロールするか |
|
||||
| サイトマップ使用 | 任意 | サイトマップを利用してクロール |
|
||||
| 制限 | 必須 | クロールする最大ページ数 |
|
||||
| Extractor有効化 | 任意 | データ抽出方式の選択 |
|
||||
</div>
|
||||
</div>
|
||||
|
||||
#### Firecrawl
|
||||
|
||||
きめ細かなクロール制御オプションとAPIサービスを持つオープンソースのWeb解析ツールです。複雑なサイトの深層クロールやバッチ処理に適しています。
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
**パラメータ設定**
|
||||
<div style={{ display:"flex",flexWrap:"wrap",gap:"30px" }}>
|
||||
<div style={{ flex:1,minWidth:"200px" }}>
|
||||

|
||||
|
||||
</div>
|
||||
|
||||
<div style={{ flex:2,minWidth:"300px" }}>
|
||||
**パラメータ設定**
|
||||
|
||||
| パラメータ | 種類 | 説明 |
|
||||
|-----------------------|--------|------------------------------------------------|
|
||||
| URL | 必須 | 対象Webページのアドレス |
|
||||
| 制限 | 必須 | クロールする最大ページ数 |
|
||||
| サブページクロール | 任意 | リンク先ページもクロールするか |
|
||||
| 最大深度 | 任意 | 開始URLからクロールする階層の深さ |
|
||||
| 除外パス | 任意 | クロール対象から除外したいURLパターン |
|
||||
| 限定パス | 任意 | 指定したパスのみクロール |
|
||||
| Extractor | 任意 | データ処理方式の選択 |
|
||||
| 主要コンテンツのみ抽出 | 任意 | ページの主要テキストやメディアのみ抽出 |
|
||||
|
||||
</div>
|
||||
|
||||
| パラメータ | 種類 | 説明 |
|
||||
|-----------------------|--------|------------------------------------------------|
|
||||
| URL | 必須 | 対象Webページのアドレス |
|
||||
| 制限 | 必須 | クロールする最大ページ数 |
|
||||
| サブページクロール | 任意 | リンク先ページもクロールするか |
|
||||
| 最大深度 | 任意 | 開始URLからクロールする階層の深さ |
|
||||
| 除外パス | 任意 | クロール対象から除外したいURLパターン |
|
||||
| 限定パス | 任意 | 指定したパスのみクロール |
|
||||
| Extractor | 任意 | データ抽出方式の選択 |
|
||||
| 主要コンテンツのみ抽出 | 任意 | ページの主要テキストやメディアのみ抽出 |
|
||||
</div>
|
||||
</div>
|
||||
|
||||
---
|
||||
@@ -179,41 +193,41 @@ Google Drive、Dropbox、OneDriveなどのクラウドストレージサービ
|
||||
|
||||
### ドキュメントプロセッサ
|
||||
|
||||
PDF, XLSX, DOCXなど多様な形式のドキュメントが存在しますが、LLMはこれらをそのまま扱えません。そのため、抽出器(Extractor)が各種ファイルを解析・変換し、LLMが扱いやすい形式に変換します。
|
||||
PDF、XLSX、DOCXなど多様な形式のドキュメントが存在しますが、LLMはこれらをそのまま扱えません。そのため、抽出器(Extractor)が各種ファイルを解析・変換し、LLMが扱いやすい形式に変換します。
|
||||
|
||||
Difyのドキュメント抽出器、あるいはMarketplaceから「Dify Extractor」「Unstructured」等のツールを選択できます。
|
||||
|
||||
<Accordion title="ドキュメント内の画像">
|
||||
|
||||
ドキュメント内の画像は、適切なドキュメントプロセッサを使用して抽出できます。抽出された画像は対応するチャンクに添付され、個別に管理でき、検索時にはそのチャンクと一緒に返されます。
|
||||
|
||||
各チャンクには最大10枚まで画像を添付できます。これを超える画像は抽出されません。
|
||||
ドキュメント内の画像は、適切なドキュメントプロセッサを使用して抽出できます。抽出された画像は対応するチャンクに添付され、個別に管理でき、検索時にはそのチャンクと一緒に返されます。
|
||||
|
||||
選択したプロセッサで画像が抽出されなかった場合、Difyは以下のMarkdown記法でアクセス可能なURLが参照されている2MB未満のJPG、PNG、GIF画像を自動的に抽出します:
|
||||
各チャンクには最大10枚まで画像を添付できます。これを超える画像は抽出されません。
|
||||
|
||||
- ``
|
||||
- ``
|
||||
選択したプロセッサで画像が抽出されなかった場合、Difyは以下のMarkdown記法でアクセス可能なURLが参照されている2MB未満のJPG、JPEG、PNG、GIF画像を自動的に抽出します:
|
||||
|
||||
<Tip>
|
||||
セルフホスト環境では、以下の上限を環境変数で調整できます:
|
||||
|
||||
- 画像サイズの上限:`ATTACHMENT_IMAGE_FILE_SIZE_LIMIT`
|
||||
|
||||
- 1チャンクあたりの添付画像数上限:`SINGLE_CHUNK_ATTACHMENT_LIMIT`
|
||||
</Tip>
|
||||
- ``
|
||||
- ``
|
||||
|
||||
その後のインデックス設定で**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択した場合、抽出された画像も埋め込み・インデックス化され、検索対象となります。
|
||||
<Tip>
|
||||
セルフホスト環境では、以下の上限を環境変数で調整できます:
|
||||
|
||||
- 画像サイズの上限:`ATTACHMENT_IMAGE_FILE_SIZE_LIMIT`
|
||||
|
||||
- 1チャンクあたりの添付画像数上限:`SINGLE_CHUNK_ATTACHMENT_LIMIT`
|
||||
</Tip>
|
||||
|
||||
その後のインデックス設定で**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択した場合、抽出された画像も埋め込み・インデックス化され、検索対象となります。
|
||||
|
||||
</Accordion>
|
||||
|
||||
#### Doc Extractor(ドキュメント抽出器)
|
||||
|
||||

|
||||

|
||||
|
||||
情報処理の中核となり、入力ファイルを識別・読取・情報抽出を行い、次のノードで利用できる形式へ変換します。
|
||||
情報処理の中核となり、入力変数からファイルを識別・読取・情報抽出を行い、次のノードで利用できる形式へ変換します。
|
||||
|
||||
<Tip>
|
||||
詳細は[ドキュメント抽出器](/ja-jp/use-dify/nodes/doc-extractor)をご参照ください。
|
||||
詳細は[ドキュメント抽出器](/ja/use-dify/nodes/doc-extractor)をご参照ください。
|
||||
</Tip>
|
||||
|
||||
#### Dify Extractor
|
||||
@@ -224,15 +238,18 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
|
||||
|
||||
#### Unstructured
|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
[Unstructured](https://marketplace.dify.ai/plugins/langgenius/unstructured)は、高度なカスタマイズ可能性を備えた抽出戦略でドキュメントを機械可読形式へ変換します。
|
||||
抽出戦略(auto, hi_res, fast, OCR-only)や分割方法(by_title, by_page, by_similarity)に柔軟に対応。要素ごとの座標や信頼度、レイアウトなどリッチなメタデータも出力し、企業のドキュメントワークフローや混合タイプファイルの精密な処理に適しています。
|
||||
</div>
|
||||
</div>
|
||||
<div style={{ display:"flex",flexWrap:"wrap",gap:"30px" }}>
|
||||
<div style={{ flex:1,minWidth:"200px" }}>
|
||||

|
||||
|
||||
</div>
|
||||
|
||||
<div style={{ flex:2,minWidth:"300px" }}>
|
||||
[Unstructured](https://marketplace-staging.dify.dev/plugins/langgenius/unstructured)は、高度なカスタマイズ可能性を備えた抽出戦略でドキュメントを機械可読形式へ変換します。抽出戦略(auto、hi_res、fast、OCR-only)や分割方法(by_title、by_page、by_similarity)に柔軟に対応。要素ごとの座標や信頼度、レイアウトなどリッチなメタデータも出力し、企業のドキュメントワークフローや混合タイプファイルの精密な処理に適しています。
|
||||
|
||||
</div>
|
||||
|
||||
</div>
|
||||
|
||||
<Tip>
|
||||
他のツールについては[Dify Marketplace](https://marketplace.dify.ai)をご覧ください。
|
||||
@@ -278,22 +295,22 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
|
||||
|
||||
| 設定項目 | 説明 |
|
||||
|-------------------|--------------------------------------------------------------------------|
|
||||
| 区切り文字 | デフォルトは`\n`(段落区切り用改行)。正規表現も利用可。 |
|
||||
| 最大チャンク長 | 各セグメントの最大文字数(上限超過時は自動分割) |
|
||||
| 区切り文字 | デフォルトは`\n`(段落区切り用改行)。正規表現によるカスタム分割ルールも利用可。テキスト内に区切り文字が出現すると自動的に分割されます。 |
|
||||
| 最大チャンク長 | 各セグメントの最大文字数。上限超過時は強制分割されます。 |
|
||||
| チャンク重複 | 分割時にセグメント間で部分重複させることで情報保持・検索精度を向上 |
|
||||
|
||||
#### 親子分割器(Parent-child Chunker)
|
||||
|
||||
クエリマッチング精度と豊富なコンテキスト両立のため、二層チャンク構造を採用しています。
|
||||
クエリマッチング精度と豊富なコンテキスト両立のため、二層チャンク構造を採用し、RAGシステムにおけるコンテキストと精度の矛盾を解決します。
|
||||
|
||||
**親子分割器の仕組み**
|
||||
|
||||
- **子チャンク(高精度マッチング用)**:通常、1文ごとの細かなセグメント
|
||||
- **親チャンク(豊富なコンテキスト)**:該当する子チャンクを含む広い範囲(段落やセクション単位)
|
||||
- **子チャンク(高精度マッチング用)**:ユーザーのクエリに高精度でマッチングするための小さく精密な情報セグメント(通常、1文ごと)
|
||||
- **親チャンク(豊富なコンテキスト)**:該当する子チャンクを含む広い範囲のコンテンツブロック(段落、セクション、またはドキュメント全体)で、大規模言語モデル(LLM)に包括的な背景情報を提供
|
||||
|
||||
| タイプ | 変数 | 説明 |
|
||||
|------------|---------------------------|------------------------------|
|
||||
| 入力変数 | `{x} Content` | 原文テキスト |
|
||||
| 入力変数 | `{x} Content` | 分割対象となる文書コンテンツ |
|
||||
| 出力変数 | `{x} Array[ParentChunk]` | 親チャンク配列 |
|
||||
|
||||
**分割設定**
|
||||
@@ -304,7 +321,7 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
|
||||
| 親チャンク最大長 | 親チャンクの最大文字数 |
|
||||
| 子チャンク区切り文字 | 子チャンク分割ルール |
|
||||
| 子チャンク最大長 | 子チャンクの最大文字数 |
|
||||
| 親モード | 「段落」または「全文書」いずれか選択 |
|
||||
| 親モード | 「段落」(テキストを段落に分割)または「全文書」(ドキュメント全体を親チャンクとして直接検索に使用)いずれか選択 |
|
||||
|
||||
#### Q&Aプロセッサ
|
||||
|
||||
@@ -315,14 +332,14 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
|
||||
| タイプ | 変数 | 説明 |
|
||||
|-----------|------------------------|---------------------------------------|
|
||||
| 入力変数 | `{x} Document` | 単一ファイル |
|
||||
| 出力変数 | `{x} Array[QAChunk]` | Q&Aチャンク配列 |
|
||||
| 出力変数 | `{x} Array[QAChunk]` | Q&Aチャンク |
|
||||
|
||||
**変数設定**
|
||||
|
||||
| 設定項目 | 説明 |
|
||||
|-----------------|------------------|
|
||||
| 質問用カラム番号 | 質問内容の列番号 |
|
||||
| 回答用カラム番号 | 回答内容の列番号 |
|
||||
| 質問用カラム番号 | 質問として設定するコンテンツ列 |
|
||||
| 回答用カラム番号 | 回答として設定する列 |
|
||||
|
||||
---
|
||||
|
||||
@@ -336,9 +353,9 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
|
||||
|
||||

|
||||
|
||||
チャンク構造は、ナレッジベースが文書コンテンツをどう整理・インデックス化するかを定めます。用途やコストに適したモードを選択してください。
|
||||
チャンク構造は、ナレッジベースが文書コンテンツをどう整理・インデックス化するかを定めます。ドキュメントタイプ、用途、コストに適したモードを選択してください。
|
||||
|
||||
ナレッジベースは3つのチャンクモードをサポートします:**汎用モード**、**親子モード**、**Q&Aモード**。初めて設定する場合は親子モードが推奨されます。
|
||||
ナレッジベースは3つのチャンクモードをサポートします:**汎用モード**、**親子モード**、**Q&Aモード**。初めてナレッジベースを作成する場合は親子モードが推奨されます。
|
||||
|
||||
<Warning>
|
||||
**重要:** チャンク構造は一度保存・公開すると変更できません。慎重にご選択ください。
|
||||
@@ -346,146 +363,157 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
|
||||
|
||||
#### 汎用モード
|
||||
|
||||
標準的なドキュメント処理に最適です。ニーズに応じ、柔軟なインデックスと検索設定が選択可能です。
|
||||
標準的なドキュメント処理に最適です。柔軟なインデックスオプションを提供し、品質やコストの異なる要件に応じて適切なインデックス方法を選択できます。
|
||||
|
||||
汎用モードは高品質とコスト効率の両方のインデックス方法、および各種検索設定をサポートします。
|
||||
|
||||
#### 親子モード
|
||||
|
||||
検索時の高精度マッチングと文脈提供が必要なエンタープライズ向け専門ドキュメントに最適です。HQ(高品質)インデックスのみ対応です。
|
||||
検索時の高精度マッチングと対応するコンテキスト情報を提供し、完全なコンテキストを維持する必要がある専門ドキュメントに適しています。
|
||||
|
||||
親子モードはHQ(高品質)モードのみ対応で、クエリマッチング用の子チャンクと検索時のコンテキスト情報用の親チャンクを提供します。
|
||||
|
||||
#### Q&Aモード
|
||||
|
||||
構造化された質問回答データ向けです。Q&Aペアが質問部に基づいてインデックス化され、関連回答が検索できます。こちらもHQモードのみ対応です。
|
||||
構造化された質問回答データを使用する際に、質問と回答をペアにしたドキュメントを作成します。これらのドキュメントは質問部分に基づいてインデックス化され、クエリの類似性に基づいて関連する回答を検索できます。
|
||||
|
||||
Q&AモードはHQ(高品質)モードのみ対応です。
|
||||
|
||||
### 入力変数
|
||||
|
||||
入力変数はデータ処理ノードからの出力をナレッジベースのデータソースとして受け取ります。分割器の出力をナレッジベースノードへ接続します。
|
||||
入力変数はデータ処理ノードからの処理結果をナレッジベースのデータソースとして受け取ります。分割器の出力をナレッジベースノードへ入力として接続する必要があります。
|
||||
|
||||
- **汎用モード**:`{x} Array[Chunk]`(汎用チャンク配列)
|
||||
- **親子モード**:`{x} Array[ParentChunk]`(親チャンク配列)
|
||||
- **Q&Aモード**:`{x} Array[QAChunk]`(Q&Aチャンク配列)
|
||||
ノードは選択したチャンク構造に基づいて異なるタイプの標準入力をサポートします:
|
||||
|
||||
- **汎用モード**:x Array[Chunk] - 汎用チャンク配列
|
||||
- **親子モード**:x Array[ParentChunk] - 親チャンク配列
|
||||
- **Q&Aモード**:x Array[QAChunk] - Q&Aチャンク配列
|
||||
|
||||
### インデックス方法と検索設定
|
||||
|
||||
インデックス方法はナレッジベース内のコンテンツ整理法を決定し、検索設定はそれに基づいた検索戦略を指定します。
|
||||
ナレッジベースでは**高品質**と**コスト効率**の2方式があり、それぞれ検索方法が異なります。
|
||||
インデックス方法はナレッジベース内のコンテンツインデックスの構築方法を決定し、検索設定は選択したインデックス方法に基づいた対応する検索戦略を提供します。
|
||||
|
||||
**高品質モード**では、埋め込みモデル(Embedding)によりテキストをベクトル化し、意味的な関連性検索が可能です(完全一致でなくても適切な回答に辿り着けます)。
|
||||
つまり、インデックス方法はドキュメントの整理方法を決定し、検索設定はユーザーがドキュメントを見つけるために使用できる方法を指定します。
|
||||
|
||||
ナレッジベースでは**高品質**と**コスト効率**の2つのインデックス方法があり、それぞれ異なる検索設定オプションを提供します。
|
||||
|
||||
**高品質モード**では、埋め込みモデルを使用してチャンクを数値ベクトルに変換し、大量の情報をより効果的に圧縮・保存できます。これにより、ユーザーの質問の言い回しがドキュメントと完全に一致しなくても、意味的に関連する正確な回答をシステムが見つけることができます。
|
||||
|
||||
<Tip>
|
||||
|
||||
クロスモーダル検索(テキストと画像を意味的関連性に基づいて取得)を有効にするには、**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択してください。ドキュメントから抽出された画像もベクトル化され、検索用にインデックス化されます。
|
||||
クロスモーダル検索(テキストと画像を意味的関連性に基づいて取得)を有効にするには、**Vision**アイコン付きのマルチモーダル埋め込みモデルを選択してください。ドキュメントから抽出された画像も埋め込み・インデックス化され、検索対象となります。
|
||||
|
||||
このような埋め込みモデルを使用するナレッジベースは、カード上で**Multimodal**と表示されます。
|
||||
|
||||
<img src="/images/multimodal_knowledge_base.png" alt="Multimodal Knowledge Base" width="300" />
|
||||
|
||||
</Tip>
|
||||
|
||||
**コスト効率モード**では、各ブロックは10個のキーワードでインデックス化され、埋め込みモデルのコストは発生しません。
|
||||
**コスト効率モード**では、各ブロックは10個のキーワードで検索用にインデックス化され、埋め込みモデルを呼び出さないためコストは発生しません。
|
||||
|
||||
<Tip>
|
||||
詳細は[インデックス方法と検索設定を指定](/ja/use-dify/knowledge/create-knowledge-and-upload-documents/setting-indexing-methods)もご参照ください。
|
||||
</Tip>
|
||||
<Info>
|
||||
詳細は[インデックス方法と検索設定を指定](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods)をご参照ください。
|
||||
</Info>
|
||||
|
||||
#### インデックス方法と検索設定概要
|
||||
|
||||
| インデックス方法 | 検索設定 | 説明 |
|
||||
| インデックス方法 | 利用可能な検索設定 | 説明 |
|
||||
|----------------|----------------|-----------------------------------------------------|
|
||||
| 高品質 | ベクトル検索 | 意味的類似性(自然言語での深い検索) |
|
||||
| | 全文検索 | キーワードベースの包括的検索 |
|
||||
| | ハイブリッド検索| 意味検索+キーワード検索の組合せ |
|
||||
| コスト効率 | 逆引きインデックス| 一般的な検索エンジン型方式 |
|
||||
| 高品質 | ベクトル検索 | 意味的類似性に基づいてクエリの深い意味を理解 |
|
||||
| | 全文検索 | キーワードベースの包括的検索機能を提供 |
|
||||
| | ハイブリッド検索| 意味検索とキーワード検索を組み合わせ |
|
||||
| コスト効率 | 逆引きインデックス| 一般的な検索エンジン検索方式で、クエリを主要コンテンツとマッチング |
|
||||
|
||||
<Note>
|
||||
選択した埋め込みモデルがマルチモーダルの場合は、**Vision**アイコンが表示されたマルチモーダルリランキングモデルも選択してください。そうでない場合、検索された画像は再ランクおよび最終出力から除外されます。
|
||||
選択した埋め込みモデルがマルチモーダルの場合は、**Vision**アイコンが表示されたマルチモーダルリランキングモデルも選択してください。そうでない場合、検索された画像は再ランクおよび検索結果から除外されます。
|
||||
</Note>
|
||||
|
||||
詳細は以下の表をご参照ください。
|
||||
チャンク構造、インデックス方法、パラメータ、検索設定の構成については、以下の表もご参照ください。
|
||||
|
||||
| チャンク構造 | インデックス方法 | パラメータ | 検索設定 |
|
||||
|-------------|----------------|-------------------|----------------------|
|
||||
| 汎用モード | 高品質 <br /> <br /> <br /> コスト効率 | 埋め込みモデル <br /> <br /> <br /> キーワード数 | ベクトル<br/>全文<br/>ハイブリッド検索<br/>逆引きインデックス |
|
||||
| 親子モード | 高品質のみ | 埋め込みモデル | ベクトル<br/>全文<br/>ハイブリッド検索 |
|
||||
| Q&Aモード | 高品質のみ | 埋め込みモデル | ベクトル<br/>全文<br/>ハイブリッド検索 |
|
||||
| 汎用モード | 高品質 <br /> <br /> <br /> コスト効率 | 埋め込みモデル <br /> <br /> <br /> キーワード数 | ベクトル検索<br/>全文検索<br/>ハイブリッド検索<br/>逆引きインデックス |
|
||||
| 親子モード | 高品質のみ | 埋め込みモデル | ベクトル検索<br/>全文検索<br/>ハイブリッド検索 |
|
||||
| Q&Aモード | 高品質のみ | 埋め込みモデル | ベクトル検索<br/>全文検索<br/>ハイブリッド検索 |
|
||||
|
||||
---
|
||||
|
||||
## ステップ4:ユーザー入力フォームの作成
|
||||
|
||||
ユーザー入力フォームは、パイプライン実行時に必要な初期情報をユーザーから収集します。ワークフローの開始ノードと同様に、必要な设置情報(アップロードファイル、特定パラメータなど)を収集し、パイプラインの柔軟性・利便性を高めます。
|
||||
ユーザー入力フォームは、パイプラインを効果的に実行するために必要な初期情報を収集するために不可欠です。ワークフローの[ユーザー入力ノード](/ja/use-dify/nodes/user-input)と同様に、このフォームはユーザーから必要な詳細情報(アップロードするファイル、ドキュメント処理の特定パラメータなど)を収集し、パイプラインが正確な結果を提供するために必要なすべての情報を確保します。
|
||||
|
||||
これにより、さまざまなユースケースシナリオに特化した入力フォームを作成でき、さまざまなデータソースやドキュメント処理ステップに対するパイプラインの柔軟性と使いやすさを向上できます。
|
||||
|
||||
### フォームの作成方法
|
||||
|
||||
1. **パイプライン構築UI**
|
||||
- 「入力フィールド」をクリックして作成・設定を開始
|
||||

|
||||
ユーザー入力フィールドを作成する方法は2つあります:
|
||||
|
||||
2. **ノードパラメータパネル**
|
||||
- ノード選択後、パラメータ入力欄の「+ ユーザー入力を作成」をクリック
|
||||

|
||||
1. **パイプライン構築インターフェース**\
|
||||
**入力フィールド**をクリックして入力フォームの作成と設定を開始します。\
|
||||
<img src="/images/knowledge-base/knowledge-pipeline-orchestration-9.png" alt="" />
|
||||
2. **ノードパラメータパネル**\
|
||||
ノードを選択します。次に、右側パネルのパラメータ入力で、新しい入力項目のために「+ ユーザー入力を作成」をクリックします。新しい入力項目は入力フィールドにも収集されます。<img src="/images/knowledge-base/knowledge-pipeline-orchestration-10.png" alt="" />
|
||||
|
||||
### ユーザー入力フィールドの追加
|
||||
|
||||
#### 各エントランス固有入力
|
||||
#### 各エントランス固有の入力
|
||||
|
||||

|
||||

|
||||
|
||||
これは各データソースや下流ノードに固有です。該当データソース選択時のみ入力対象となります(例:異なるURLの指定等)。
|
||||
これらの入力は各データソースとその下流ノードに固有です。ユーザーは対応するデータソースを選択した場合にのみ、これらのフィールドに入力する必要があります(例:異なるデータソース用の異なるURL)。
|
||||
|
||||
**作成方法**:データソース横の`+`ボタンからそのソース専用フィールドを追加できます。選択したソースからのみアクセス可能です。
|
||||
**作成方法**:データソースの右側にある`+`ボタンをクリックして、その特定のデータソース用のフィールドを追加します。これらのフィールドは、そのデータソースとその後続の接続ノードからのみ参照できます。<img src="/images/knowledge-base/knowledge-pipeline-orchestration-12.png" alt="" />
|
||||
|
||||

|
||||
#### すべてのエントランス用のグローバル入力
|
||||
|
||||
#### すべてのエントランス共通入力
|
||||

|
||||
|
||||

|
||||
グローバル共有入力はすべてのノードから参照できます。これらの入力は、区切り文字、最大チャンク長、ドキュメント処理設定など、汎用的な処理パラメータに適しています。ユーザーはどのデータソースを選択しても、これらのフィールドに入力する必要があります。
|
||||
|
||||
全ノードから参照できるグローバル共有入力です。チャンク区切りや最大長等、汎用パラメータの入力に適します。
|
||||
|
||||
**作成方法**:グローバル入力の`+`ボタンから追加できます。
|
||||
**作成方法**:グローバル入力の右側にある`+`ボタンをクリックして、任意のノードから参照できるフィールドを追加します。
|
||||
|
||||
### サポートされる入力フィールドタイプ
|
||||
|
||||
ナレッジパイプラインでは7種の入力変数をサポートします:
|
||||
ナレッジパイプラインは7種類の入力変数をサポートします:
|
||||
|
||||
<div style={{ display:"flex",flexWrap:"wrap",gap:"30px" }}>
|
||||
<div style={{ flex:1,minWidth:"200px" }}>
|
||||

|
||||
|
||||
<div style={{display: 'flex', flexWrap: 'wrap', gap: '30px'}}>
|
||||
<div style={{flex: 1, minWidth: '200px'}}>
|
||||

|
||||
</div>
|
||||
<div style={{flex: 2, minWidth: '300px'}}>
|
||||
| フィールドタイプ | 説明 |
|
||||
|---------------|-----------------------------------------------------------------------|
|
||||
| テキスト | 256文字以内の短文の入力欄 |
|
||||
| 段落 | 長文テキストの入力欄 |
|
||||
| セレクト | 設定済み候補リストから選択(カスタム不可) |
|
||||
| ブール値 | 真偽値 |
|
||||
| 数値 | 数値のみ入力 |
|
||||
| 単一ファイル | 単一ファイルアップロード(各ファイルタイプ対応) |
|
||||
| ファイルリスト | 複数ファイルの一括アップロード(各ファイルタイプ対応) |
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<Warning>
|
||||
詳細は[入力フィールドのドキュメント](/ja/use-dify/nodes/user-input)をご参照ください。
|
||||
</Warning>
|
||||
<div style={{ flex:2,minWidth:"300px" }}>
|
||||
| フィールドタイプ | 説明 |
|
||||
|---------------|-----------------------------------------------------------------------|
|
||||
| テキスト | ナレッジベースユーザーが入力する短文、最大256文字 |
|
||||
| 段落 | 長い文字列用の長文テキスト入力欄 |
|
||||
| セレクト | オーケストレーターが事前設定した固定オプションから選択、ユーザーはカスタムコンテンツを追加不可 |
|
||||
| ブール値 | true/false値のみ |
|
||||
| 数値 | 数値入力のみ受付 |
|
||||
| 単一ファイル | 単一ファイルアップロード、複数のファイルタイプ(ドキュメント、画像、音声、その他のファイルタイプ)をサポート |
|
||||
| ファイルリスト | 複数ファイルの一括アップロード、複数のファイルタイプ(ドキュメント、画像、音声、その他のファイルタイプ)をサポート |
|
||||
|
||||
</div>
|
||||
|
||||
</div>
|
||||
|
||||
<Tip>
|
||||
サポートされるフィールドタイプの詳細については、[ユーザー入力](/ja/use-dify/nodes/user-input)をご参照ください。
|
||||
</Tip>
|
||||
|
||||
### フィールド設定オプション
|
||||
|
||||
全入力フィールドには必須/任意および追加設定があります。適切なチェックで必須化等を指定します。
|
||||
すべての入力フィールドタイプには、必須、任意、および追加設定があります。適切なオプションをチェックしてフィールドを必須にするかどうかを設定できます。
|
||||
|
||||
| 設定 | 名称 | 説明 | 例 |
|
||||
|-------------------|---------------|--------------------------------------------------|--------------------------|
|
||||
| 必須設定 | 変数名 | 内部識別用(英数字・アンダースコア推奨) | `user_email` |
|
||||
| | 表示名 | UI上に表示される名称 | ユーザーメール |
|
||||
| タイプ固有設定 | | タイプごとの条件 | テキストの最大長制限等 |
|
||||
| 追加設定 | デフォルト値 | 未入力時の既定値 | 数値は0、テキストは空文字 |
|
||||
| | プレースホルダー | 入力欄が空のときのヒント表示 | 「メールアドレス入力」 |
|
||||
| | ツールチップ | 補足説明(マウスホバー時表示) | 「有効なメールアドレスを…」 |
|
||||
| 特殊任意設定 | | タイプごとの特殊バリデーション | メール形式チェック等 |
|
||||
| 必須設定 | 変数名 | 内部システム識別子、通常は英語とアンダースコアで命名 | `user_email` |
|
||||
| | 表示名 | インターフェース表示名、通常は簡潔で読みやすいテキスト | ユーザーメール |
|
||||
| タイプ固有設定 | | 異なるフィールドタイプの特別な要件 | テキストフィールドの最大長100文字 |
|
||||
| 追加設定 | デフォルト値 | ユーザーが入力していない場合のデフォルト値 | 数値フィールドのデフォルトは0、テキストフィールドのデフォルトは空 |
|
||||
| | プレースホルダー | 入力ボックスが空のときに表示されるヒントテキスト | 「メールアドレスを入力してください」 |
|
||||
| | ツールチップ | ユーザー入力をガイドする説明テキスト、通常はマウスホバー時に表示 | 「有効なメールアドレスを入力してください」 |
|
||||
| 特殊任意設定 | | 異なるフィールドタイプに基づく追加設定オプション | メール形式のバリデーション |
|
||||
|
||||
設定後、右上のプレビューボタンで実際のフォーム動作確認やフィールド並び替えが可能です。「!」マーク表示時は参照無効を示します。
|
||||
設定完了後、右上のプレビューボタンをクリックしてフォームプレビューインターフェースを閲覧できます。フィールドのグループ化をドラッグして調整できます。感嘆符が表示された場合は、移動後に参照が無効になっていることを示します。
|
||||
|
||||

|
||||

|
||||
|
||||
---
|
||||
|
||||
@@ -493,40 +521,50 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
|
||||
|
||||

|
||||
|
||||
デフォルトのナレッジベース名は「Untitled+番号」、権限は「自分のみ」、アイコンはオレンジ色の書籍です。DSLファイルからインポートした場合は元のアイコンが適用されます。
|
||||
デフォルトのナレッジベース名は「Untitled+番号」、権限は「自分のみ」、アイコンはオレンジ色の書籍です。DSLファイルからインポートした場合は保存されたアイコンが使用されます。
|
||||
|
||||
左パネルの「設定」をクリックし、以下を設定してください。
|
||||
- **名前とアイコン**
|
||||
ナレッジベース名を決定します。絵文字選択、画像アップロード、画像URLによるアイコン設定が可能です。
|
||||
- **ナレッジベース説明**
|
||||
簡単な説明を記入してください。AIがデータをより適切に理解し検索できるようになります。未入力の場合はDifyのデフォルト検索戦略が使われます。
|
||||
- **権限**
|
||||
ドロップダウンから適切なアクセス権限を選択してください。
|
||||
左パネルの**設定**をクリックし、以下の情報を入力してください:
|
||||
|
||||
- **名前とアイコン**\
|
||||
ナレッジベースの名前を決定します。\
|
||||
絵文字を選択、画像をアップロード、または画像URLを貼り付けてこのナレッジベースのアイコンとして設定できます。
|
||||
- **ナレッジベース説明**\
|
||||
ナレッジベースの簡単な説明を入力してください。これによりAIがデータをより適切に理解し検索できるようになります。空のままにすると、Difyはデフォルトの検索戦略を適用します。
|
||||
- **権限**\
|
||||
ドロップダウンメニューから適切なアクセス権限を選択してください。
|
||||
|
||||
---
|
||||
|
||||
## ステップ6:テスト
|
||||
|
||||
いよいよ最終工程です!
|
||||
いよいよ最終工程です!これがナレッジパイプラインオーケストレーションの最終ステップです。
|
||||
|
||||
設定が整ったら、まずは全設定の完全性チェックを行いましょう。チェックは右上のチェックリストボタンで行え、不足項目があると通知されます。
|
||||
オーケストレーションが完了したら、まずすべての設定を検証する必要があります。次に、いくつかの実行テストを行い、すべての設定を確認します。最後に、ナレッジパイプラインを公開します。
|
||||
|
||||

|
||||
### 設定完全性チェック
|
||||
|
||||
全設定完了後、テスト実行でパイプライン全体の動作確認を行い、不備がないことを確認した上で公開します。
|
||||
テスト前に、設定の不備によるテスト失敗を避けるため、設定の完全性をチェックすることをお勧めします。
|
||||
|
||||
右上のチェックリストボタンをクリックすると、システムが不足している部分を表示します。
|
||||
|
||||

|
||||
|
||||
すべての設定が完了したら、テスト実行を通じてナレッジベースパイプラインの動作をプレビューし、すべての設定が正確であることを確認してから、公開に進みます。
|
||||
|
||||
### テスト実行
|
||||
|
||||

|
||||

|
||||
|
||||
1. **テスト開始**:**テスト実行**をクリック
|
||||
2. **テストファイルインポート**:右側ウィンドウからファイル選択
|
||||
<Warning>
|
||||
**注意:** デバッグのため、1回につき1ファイルのみアップロード可能です。
|
||||
</Warning>
|
||||
3. **パラメータ入力**:設定した入力フォームに従い必要なパラメータを入力
|
||||
4. **パイプライン実行**:**次へ**をクリックしテスト開始
|
||||
1. **テスト開始**:右上の「テスト実行」ボタンをクリック
|
||||
2. **テストファイルインポート**:右側にポップアップするデータソースウィンドウでファイルをインポート
|
||||
|
||||
テスト時は、[履歴ログ](/ja/use-dify/monitor/logs)(実行記録の確認)や[変数インスペクタ](/ja/use-dify/debug/variable-inspect)(ノード入出力内容の可視化)が問題特定に役立ちます。
|
||||
<Warning>
|
||||
**重要:** デバッグと観察を容易にするため、テスト実行ごとに1ファイルのみアップロード可能です。
|
||||
</Warning>
|
||||
|
||||
3. **パラメータ入力**:インポート成功後、先に設定したユーザー入力フォームに従って対応するパラメータを入力
|
||||
4. **テスト実行開始**:次のステップをクリックしてパイプライン全体のテストを開始
|
||||
|
||||
テスト中は、[履歴ログ](/ja/use-dify/monitor/logs)(タイムスタンプ、実行ステータス、入出力サマリーを含むすべての実行記録を追跡)と[変数インスペクタ](/ja/use-dify/debug/variable-inspect)(各ノードの入出力データを表示し、問題の特定とデータフローの検証を支援するダッシュボード)にアクセスして、効率的なトラブルシューティングとエラー修正を行えます。
|
||||
|
||||

|
||||
@@ -7,7 +7,9 @@ sidebarTitle: コンテンツの管理
|
||||
|
||||
## ドキュメントの管理
|
||||
|
||||
ナレッジベース内では、インポートされたすべてのアイテム(ローカルファイル、Notion ページ、またはウェブページなど)がドキュメントとして扱われます。ドキュメント一覧から、すべてのドキュメントを閲覧・管理し、ナレッジの正確性、関連性、最新性を維持できます。
|
||||
ナレッジベース内では、インポートされたすべてのアイテム(ローカルファイル、Notion ページ、またはウェブページなど)がドキュメントとして扱われます。
|
||||
|
||||
ドキュメント一覧から、すべてのドキュメントを閲覧・管理し、ナレッジの正確性、関連性、最新性を維持できます。
|
||||
|
||||
<Tip>
|
||||
画面上部のナレッジベース名をクリックすると、他のナレッジベースへ素早く切り替えできます。
|
||||
@@ -20,14 +22,16 @@ sidebarTitle: コンテンツの管理
|
||||
| 追加 | 新しいドキュメントをインポートします。|
|
||||
| チャンク設定の変更 | ドキュメントのチャンク設定を変更します(チャンク構造を除く)。<Info>各ドキュメントには個別のチャンク設定を持たせることができますが、チャンク構造はナレッジベース全体で共通であり、一度設定すると変更できません。</Info>|
|
||||
| 削除 | ドキュメントを完全に削除します。**削除は元に戻せません。**|
|
||||
| 有効/無効 | 一時的にドキュメントを検索対象に含める/除外します。<Note>Dify Cloud では、一定期間更新または検索に使用されていないドキュメントは、自動的に無効化されパフォーマンスが最適化されます。<br/><br/>非アクティブ期間はプランごとに異なります:<ul><li>Sandbox:7日</li><li>Professional/Team:30日</li></ul> Professional および Team プランのユーザーは、**ワンクリックで**これらのドキュメントを再有効化できます。</Note> |
|
||||
| 有効/無効 | 一時的にドキュメントを検索対象に含める/除外します。<Note>Dify Cloud では、一定期間更新または検索に使用されていないドキュメントは、自動的に無効化されパフォーマンスが最適化されます。<br/><br/>非アクティブ期間はプランごとに異なります:<ul><li>Sandbox:7日</li><li>Professional/Team:30日</li></ul> Professional および Team プランのユーザーは、**ワンクリックで**これらのドキュメントを再有効化できます。</Note>|
|
||||
| アーカイブ/アーカイブ解除 | 検索には不要だが保持しておきたいドキュメントをアーカイブします。アーカイブ済みドキュメントは読み取り専用で、いつでもアーカイブ解除可能です。|
|
||||
| 編集 | ドキュメント内のチャンクを編集して、コンテンツを修正します。詳細は [チャンクの管理](#チャンクの管理) を参照してください。|
|
||||
| 名前を変更 | ドキュメントの名前を変更します。|
|
||||
|
||||
## チャンクの管理
|
||||
|
||||
チャンク設定に基づき、すべてのドキュメントは検索の基本単位であるコンテンツチャンクに分割されます。各ドキュメント内のチャンク一覧からそれらを閲覧・管理し、検索の効率と精度を最適化できます。
|
||||
チャンク設定に基づき、すべてのドキュメントは検索の基本単位であるコンテンツチャンクに分割されます。
|
||||
|
||||
各ドキュメント内のチャンク一覧からそれらを閲覧・管理し、検索の効率と精度を最適化できます。
|
||||
|
||||
<Tip>
|
||||
左上のドキュメント名をクリックして、別のドキュメントに素早く切り替えられます。
|
||||
@@ -37,12 +41,12 @@ sidebarTitle: コンテンツの管理
|
||||
|
||||
| 操作 | 説明 |
|
||||
|:-------- |:---------------------|
|
||||
| 追加 | 新しいチャンクを1つまたは複数まとめて追加します。<br/><br/>親子分割モード(階層分割モード)のドキュメントでは、親チャンクと子チャンクの両方を追加可能です。<Info>「チャンクを追加」は有料機能です。Dify Cloud で利用するには [Professional または Team プラン](https://dify.ai/jp/pricing) へのアップグレードが必要です。</Info>|
|
||||
| 追加 | 新しいチャンクを1つまたは複数まとめて追加します。<br/><br/>親子分割モードのドキュメントでは、親チャンクと子チャンクの両方を追加可能です。<Info>「チャンクを追加」は Dify Cloud の有料機能です。利用するには [Professional または Team プラン](https://dify.ai/pricing) へのアップグレードが必要です。</Info>|
|
||||
| 削除 | チャンクを完全に削除します。**削除は元に戻せません。**|
|
||||
| 有効/無効 | 一時的にチャンクを検索対象に含める/除外します。無効化されたチャンクは編集できません。|
|
||||
| 編集 | チャンクの内容を修正します。編集されたチャンクは **「編集済み」** と表示されます。<br/><br/>親子分割モード(階層分割モード)のドキュメントでは:<ul><li>親チャンクを編集するとき、子チャンクを再生成するか保持するかを選択できます。</li><li>子チャンクを編集しても、親チャンクには影響しません。</li></ul><Tip>ドキュメント内の画像が添付ファイルとして抽出される場合、そのURLはチャンクテキスト内に残ります。これらのURLを削除しても、抽出された画像の添付ファイルには影響しません。</Tip>|
|
||||
| キーワードの追加/編集/削除 | 経済的インデックス方式を使用するナレッジベースでは、各チャンクに対してキーワードを追加・編集して検索精度を向上させることができます。<br/><br/>1つのチャンクにつき最大10個のキーワードを設定可能です。 |
|
||||
| 画像の追加/削除 | ドキュメントから抽出された画像を削除したり、対応するチャンク内に新しい画像をアップロードしたりできます。<br/><br/>画像の添付ファイルとチャンクは独立して編集でき、互いに影響しません。<Note> 各チャンクには最大10枚まで画像の添付が可能で、検索時に一緒に返されます。これを超える画像は抽出されません。<br/><br/>セルフホスティング環境では、環境変数 `SINGLE_CHUNK_ATTACHMENT_LIMIT` を変更してこの制限を調整できます。</Note><Tip>クロスモーダル検索(テキストと画像の両方を意味的関連性に基づいて検索)を有効にするには、ナレッジベースに多モーダル埋め込みモデル(**Vision** アイコン付き)を選択してください。画像の添付ファイルは埋め込み・インデックス化され、検索に利用されます。</Tip>|
|
||||
| 編集 | チャンクの内容を修正します。編集されたチャンクは **「編集済み」** と表示されます。<br/><br/>親子分割モードのドキュメントでは:<ul><li>親チャンクを編集するとき、子チャンクを再生成するか保持するかを選択できます。</li><li>子チャンクを編集しても、親チャンクには影響しません。</li></ul><Tip>ドキュメント内の画像がチャンクの添付ファイルとして抽出される場合、そのURLはチャンクテキスト内に残ります。これらのURLを削除しても、抽出された画像の添付ファイルには影響しません。</Tip>|
|
||||
| キーワードの追加/編集/削除 | 経済的インデックス方式を使用するナレッジベースでは、各チャンクに対してキーワードを追加・編集して検索精度を向上させることができます。<br/><br/>1つのチャンクにつき最大10個のキーワードを設定可能です。|
|
||||
| 画像添付ファイルの追加/削除 | ドキュメントから抽出された画像を削除したり、対応するチャンク内に新しい画像をアップロードしたりできます。<br/><br/>画像の添付ファイルとチャンクは独立して編集でき、互いに影響しません。<Note>各チャンクには最大10枚まで画像の添付が可能で、検索時に一緒に返されます。これを超える画像は抽出されません。<br/><br/>セルフホスティング環境では、環境変数 `SINGLE_CHUNK_ATTACHMENT_LIMIT` を変更してこの制限を調整できます。</Note><Tip>クロスモーダル検索(テキストと画像の両方を意味的関連性に基づいて検索)を有効にするには、ナレッジベースにマルチモーダル埋め込みモデル(**Vision** アイコン付き)を選択してください。<br/><br/>画像の添付ファイルは埋め込み・インデックス化され、検索に利用されます。</Tip>|
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
@@ -60,7 +64,7 @@ sidebarTitle: コンテンツの管理
|
||||
|
||||
### 子チャンクを親チャンクの検索フックとして使用
|
||||
|
||||
親子分割モード(階層分割モード)で分割されたドキュメントでは、システムは子チャンクを検索し、結果として親チャンクを返します。子チャンクを編集しても親チャンクは更新されないため、子チャンクを親チャンクの **セマンティックタグ(意味的タグ)** や **検索ヒント** として活用できます。
|
||||
親子分割モードで分割されたドキュメントでは、システムは子チャンクを検索し、結果として親チャンクを返します。子チャンクを編集しても親チャンクは更新されないため、子チャンクを親チャンクの **セマンティックタグ(意味的タグ)** や **検索ヒント** として活用できます。
|
||||
|
||||
そのためには、子チャンクを **キーワード**・**要約**・**ユーザーの一般的な質問** のいずれかに書き換えることを推奨します。
|
||||
たとえば、親チャンクが *返品ポリシー* 全体を扱う場合、子チャンクを次のように設定できます:
|
||||
|
||||
@@ -7,48 +7,50 @@ icon: "database"
|
||||
|
||||
## はじめに
|
||||
|
||||
知識検索ノードを使用すると、既存のナレッジベースを Chatflow や Workflow に統合できます。
|
||||
知識検索ノードを使用すると、既存のナレッジベースをChatflowやワークフローに統合できます。このノードは指定されたナレッジからクエリに関連する情報を検索し、その結果を下流ノード(例:LLM)で利用できるコンテキスト情報として出力します。
|
||||
|
||||
このノードは指定されたナレッジからクエリに関連する情報を検索し、その結果を下流ノード(例:LLM)で利用できるコンテキスト情報として出力します。
|
||||
|
||||
以下は Chatflow における 知識検索ノード の利用例です:
|
||||
以下はChatflowにおける知識検索ノードの利用例です:
|
||||
|
||||
1. **ユーザー入力** ノードがユーザーの質問を収集します。
|
||||
|
||||
2. **知識検索** ノードが選択されたナレッジベースから関連情報を検索し、結果を出力します。
|
||||
2. **知識検索** ノードが選択されたナレッジベースからユーザーの質問に関連するコンテンツを検索し、検索結果を出力します。
|
||||
|
||||
3. **LLM** ノードがユーザー質問と検索結果の両方をもとに回答を生成します。
|
||||
3. **LLM** ノードがユーザーの質問と検索されたナレッジの両方をもとに回答を生成します。
|
||||
|
||||
4. **回答** ノードが LLM の出力をユーザーへ返します。
|
||||
4. **回答** ノードがLLMの応答をユーザーへ返します。
|
||||
|
||||

|
||||
|
||||
<Info>
|
||||
知識検索ノードを使用する前に、少なくとも1つの利用可能なナレッジベースが存在することを確認してください。
|
||||
|
||||
ナレッジベースの作成方法については、[ナレッジ](/ja/use-dify/knowledge/readme#ナレッジの作成) を参照してください。
|
||||
知識検索ノードを使用する前に、少なくとも1つのナレッジベースが利用可能であることを確認してください。ナレッジベースの作成方法については、[ナレッジ](/ja/use-dify/knowledge/readme#ナレッジの作成)を参照してください。
|
||||
</Info>
|
||||
|
||||
## 知識検索ノードの設定
|
||||
<Note>
|
||||
Dify Cloudでは、知識検索の操作は契約プランに応じたレートリミットが適用されます。詳細は[ナレッジベースの要求頻度制限](/ja/use-dify/knowledge/knowledge-request-rate-limit)を参照してください。
|
||||
</Note>
|
||||
|
||||
知識検索ノードを正常に機能させるには、次の3点を指定する必要があります:
|
||||
## 設定
|
||||
|
||||
- **何を検索するか**(クエリ)
|
||||
- **どこを検索するか**(ナレッジベース)
|
||||
- **どのように検索結果を処理するか**(ノードレベルの検索設定)
|
||||
知識検索ノードを正常に機能させるには、次の点を指定する必要があります:
|
||||
|
||||
- **何を**検索するか(クエリ)
|
||||
|
||||
- **どこを**検索するか(ナレッジベース)
|
||||
|
||||
- **どのように**検索結果を処理するか(ノードレベルの検索設定)
|
||||
|
||||
また、ドキュメントのメタデータを利用してフィルタベースの検索を有効化し、検索精度をさらに向上させることもできます。
|
||||
|
||||
### クエリの指定
|
||||
|
||||
ノードが選択されたナレッジベースで検索する対象を指定します。
|
||||
ノードが選択されたナレッジベースで検索するクエリ内容を指定します。
|
||||
|
||||
- **クエリテキスト**:テキスト変数を選択します。たとえば、Chatflow では `userinput.query`(ユーザー入力ノードの入力)を指定できます。Workflow ではテキスト型のユーザー入力変数を利用します。
|
||||
- **クエリテキスト**:テキスト変数を選択します。たとえば、Chatflowでは`userinput.query`を使用してユーザー入力を参照したり、ワークフローではカスタムのテキスト型ユーザー入力変数を使用したりできます。
|
||||
|
||||
**クエリ画像**:画像検索を行う場合は、ユーザー入力ノードを通じてアップロードされた画像など、画像変数を選択してください。最大サイズは 2 MB です。
|
||||
- **クエリ画像**:画像変数を選択します。例えば、ユーザー入力ノードを通じてユーザーがアップロードした画像を使用して画像検索を行います。画像サイズの上限は2 MBです。
|
||||
|
||||
<Tip>
|
||||
自己ホスティング環境では、環境変数 `ATTACHMENT_IMAGE_FILE_SIZE_LIMIT` を変更することで画像サイズ上限を調整できます。
|
||||
セルフホスト環境では、環境変数`ATTACHMENT_IMAGE_FILE_SIZE_LIMIT`を変更することで画像サイズ上限を調整できます。
|
||||
</Tip>
|
||||
|
||||
<Info>
|
||||
@@ -59,82 +61,76 @@ icon: "database"
|
||||
|
||||
### 検索対象ナレッジベースの選択
|
||||
|
||||
ノードで検索対象とするナレッジベースを1つ以上追加します。
|
||||
ノードでクエリ内容に関連するコンテンツを検索するためのナレッジベースを1つ以上追加します。
|
||||
|
||||
複数のナレッジベースを追加した場合、すべてのナレッジベースから同時に検索を行い、その結果を統合して[ノードレベルの検索設定](#ノードレベルの検索設定)に従って処理します。
|
||||
複数のナレッジベースを追加した場合、まずすべてのナレッジベースから同時に検索を行い、その後[ノードレベルの検索設定](#ノードレベルの検索設定)に従って結果を統合・処理します。
|
||||
|
||||
<Info>
|
||||
**Vision**アイコンが付いたナレッジベースは、セマンティックな関連性に基づいてテキストと画像の両方をクロスモーダルで検索できます。
|
||||
**Vision**アイコンが付いたナレッジベースはクロスモーダル検索をサポートしており、セマンティックな関連性に基づいてテキストと画像の両方を検索できます。
|
||||
</Info>
|
||||
|
||||
<Tip>
|
||||
ノード内で任意のナレッジベースの **編集** アイコンをクリックすると、直接その設定を変更できます。
|
||||
|
||||
詳細な設定方法については、[ナレッジ設定の管理](/ja/use-dify/knowledge/manage-knowledge/introduction)をご覧ください。
|
||||
追加したナレッジベースの横にある**編集**アイコンをクリックすると、知識検索ノード内で直接その設定を変更できます。
|
||||
|
||||
これらの設定の詳細については、[ナレッジ設定の管理](/ja/use-dify/knowledge/manage-knowledge/introduction)をご覧ください。
|
||||
</Tip>
|
||||
|
||||
### ノードレベルの検索設定
|
||||
|
||||
ナレッジベースから取得した検索結果を、ノード内でどのように絞り込み・再ランク付けするかを調整できます。
|
||||
ナレッジベースから取得した検索結果を、ノード内でどのように処理するかを微調整できます。
|
||||
|
||||
<Info>
|
||||
検索設定には2つのレイヤー(階層)があります。
|
||||
|
||||
ナレッジベースレベルの設定が最初の検索プールを決定し、ノードレベルの設定がその結果を再スコアリングまたは絞り込みします。
|
||||
検索設定には2つのレイヤーがあります—ナレッジベースレベルと知識検索ノードレベルです。
|
||||
|
||||
これらは2つの連続したフィルターと考えてください:ナレッジベースの設定が最初の結果プールを決定し、ノードの設定がさらに結果を再ランク付けまたは絞り込みます。
|
||||
</Info>
|
||||
|
||||
- **Rerank 設定**
|
||||
- **Rerank設定**
|
||||
|
||||
- **ウェイト設定**: 再ランク付け時におけるセマンティック類似度(意味の近さ)とキーワード一致の比重を調整します。セマンティックの比重を高くすると意味的関連性を重視し、キーワードの比重を高くすると正確な一致を重視します。
|
||||
- **ウェイト設定**:再ランク付け時におけるセマンティック類似度とキーワード一致の相対的な比重です。セマンティックの比重を高くすると意味的関連性を重視し、キーワードの比重を高くすると正確な一致を重視します。
|
||||
|
||||
<Info>
|
||||
**ウェイト設定** は、追加したナレッジベースがすべて「高品質」タイプである場合に利用できます。
|
||||
**ウェイト設定**は、追加したナレッジベースがすべて高品質タイプである場合のみ利用できます。
|
||||
</Info>
|
||||
|
||||
- **Rerank モデル**: クエリとの関連度に基づいてすべての検索結果を再スコアリング・並べ替えします。
|
||||
|
||||
<Note>
|
||||
選択したナレッジベースの中にマルチモーダル対応のものが含まれている場合は、**Vision**アイコンが表示されたマルチモーダル再ランクモデルを選択してください。そうでない場合、検索された画像は再ランクおよび最終出力から除外されます。
|
||||
</Note>
|
||||
|
||||
- **トップ K**: 再ランク後に返す最大件数を指定します。 Rerank モデルを選択している場合、この値はモデルが処理可能な最大入力サイズ(トークン上限)に応じて自動的に調整されます。
|
||||
- **Rerankモデル**:クエリとの関連度に基づいてすべての結果を再スコアリング・並べ替えするRerankモデルです。
|
||||
|
||||
<Note>
|
||||
選択したナレッジベースの中にマルチモーダル対応のものが含まれている場合は、**Vision**アイコンが表示されたマルチモーダル再ランクモデルを選択してください。そうでない場合、検索された画像は再ランクおよび最終出力から除外されます。
|
||||
マルチモーダルナレッジベースが追加されている場合は、マルチモーダルRerankモデル(**Vision**アイコン付き)も選択してください。そうでない場合、検索された画像は再ランク付けおよび最終出力から除外されます。
|
||||
</Note>
|
||||
|
||||
- **スコア閾値**: 結果を返す際の最低スコア(類似度)を指定します。この閾値未満の結果は除外されます。高めに設定すると関連性の厳密な検索が行われ、低めにするとより広範なマッチを含めることができます。
|
||||
- **トップK**:再ランク後に返す結果の最大件数です。Rerankモデルを選択している場合、この値はモデルの最大入力容量(モデルが一度に処理できるテキスト量)に基づいて自動的に調整されます。
|
||||
|
||||
- **スコア閾値**:返される結果の最低類似度スコアです。この閾値未満の結果は除外されます。高めに設定すると関連性の厳密な検索が行われ、低めにするとより広範なマッチを含めることができます。
|
||||
|
||||
### メタデータフィルタの有効化
|
||||
|
||||
ナレッジベース内のドキュメントメタデータを利用して、特定の条件に合致するドキュメントのみを検索対象とすることができます。これにより、大規模または多様なナレッジベース内での検索精度が向上します。
|
||||
既存のドキュメントメタデータを使用して、ナレッジベース内の特定のドキュメントに検索を制限し、検索精度を向上させます。
|
||||
|
||||
メタデータフィルタを有効にすると、知識検索ノードはナレッジベース全体を検索するのではなく、指定されたメタデータ条件に一致するドキュメントのみを検索します。これは、大規模で多様なナレッジベースでのターゲット検索に特に有用です。
|
||||
|
||||
<Info>
|
||||
ドキュメントメタデータの作成と管理については、[メタデータ](/ja/use-dify/knowledge/metadata) を参照してください。
|
||||
ドキュメントメタデータの作成と管理については、[メタデータ](/ja/use-dify/knowledge/metadata)を参照してください。
|
||||
</Info>
|
||||
|
||||
## 出力
|
||||
|
||||
知識検索ノードの出力は `result` という変数として返されます。この変数は検索されたドキュメントチャンクの配列で、各チャンクには内容・メタデータ・タイトルなどの情報が含まれます。
|
||||
知識検索ノードの出力は`result`という変数として返されます。この変数は検索されたドキュメントチャンクの配列で、各チャンクにはコンテンツ、メタデータ、タイトル、その他の属性が含まれます。
|
||||
|
||||
検索結果に画像が含まれる場合、`result` 変数には画像の詳細が格納された `files` フィールドも含まれます。
|
||||
検索結果に画像添付が含まれる場合、`result`変数には画像メタデータを含む`files`というフィールドも含まれます。
|
||||
|
||||
## LLM ノードとの連携
|
||||
## LLMノードとの連携
|
||||
|
||||
検索結果を活用して LLM ノードで質問応答を行うには:
|
||||
LLMノードでユーザーの質問に回答するためのコンテキストとして検索結果を使用するには:
|
||||
|
||||
1. **コンテキスト** フィールドで、知識検索ノードの `result` 変数を選択します。
|
||||
1. **コンテキスト**フィールドで、知識検索ノードの`result`変数を選択します。
|
||||
|
||||
2. LLM のプロンプト入力欄では、`コンテキスト` 変数とユーザー入力変数(例:Chatflow の `userinput.query`)の両方を参照してください。
|
||||
2. プロンプトフィールドで、`Context`変数とユーザー入力変数(例:Chatflowの`userinput.query`)の両方を参照します。
|
||||
|
||||
3. (任意)LLMがVision機能に対応している場合は、**Vision**を有効にすると、`コンテキスト`変数内の画像添付を解釈できるようになります。
|
||||
3. (任意)LLMがVision機能に対応している場合(**Vision**アイコン付き)、**Vision**を有効にして検索された画像を解釈させることができます。
|
||||
|
||||
<Info>
|
||||
**Vision**を有効にすると、LLMは`コンテキスト`変数内の画像を直接理解できます。別途**Vision**入力変数を設定する必要はありません。
|
||||
**Vision**を有効にすると、LLMは検索された画像を自動的に処理します。**Vision**入力フィールドで`Context`変数を再度手動で参照する必要はありません。
|
||||
</Info>
|
||||
|
||||
<img src="/images/llm_node_configuration_example.png" alt="LLM ノード設定の例" width="400"/>
|
||||
|
||||
<Note>
|
||||
Dify Cloud では、知識検索の操作は契約プランに応じたレートリミット(リクエスト上限)が適用されます。詳細は [ナレッジベースの要求頻度制限](/ja/use-dify/knowledge/knowledge-request-rate-limit) を参照してください。
|
||||
</Note>
|
||||
<img src="/images/llm_node_configuration_example.png" alt="LLMノード設定の例" width="400"/>
|
||||
|
||||
@@ -17,7 +17,7 @@ title: 上传本地文件
|
||||
- 单次最多可上传 5 个文件
|
||||
|
||||
<Info>
|
||||
在 Dify Cloud 上,仅 [**Professional** 和 **Team** 套餐](https://dify.ai/zh/pricing) 支持 **批量上传**(单次最多 50 个文件)。
|
||||
在 Dify Cloud 上,仅[付费套餐](https://dify.ai/zh/pricing)支持**批量上传**(单次最多 50 个文件)。
|
||||
</Info>
|
||||
|
||||
- 单个文件最大支持 15 MB
|
||||
@@ -47,7 +47,7 @@ title: 上传本地文件
|
||||
- DOCX 文件中嵌入的图片
|
||||
|
||||
<Note>
|
||||
更多文件类型(如 PDF)中嵌入的图片,只能通过在 [知识流水线](/zh/use-dify/knowledge/knowledge-pipeline/readme) 中使用合适的文档提取器插件(如 MinerU)进行提取。
|
||||
其他文件类型(如 PDF)中嵌入的图片,只能通过在[知识流水线](/zh/use-dify/knowledge/knowledge-pipeline/readme)中使用合适的文档提取器插件进行提取。
|
||||
</Note>
|
||||
|
||||
- 在任何文件类型中,通过以下 Markdown 语法引用、URL 可访问的图片:
|
||||
@@ -57,4 +57,4 @@ title: 上传本地文件
|
||||
|
||||
<Tip>
|
||||
若在后续的索引设置中选择多模态嵌入模型(带有 **Vision** 图标),则提取出的图片将被向量化并参与检索。
|
||||
</Tip>
|
||||
</Tip>
|
||||
|
||||
@@ -4,7 +4,7 @@ title: 指定索引方式与检索设置
|
||||
|
||||
<Note> ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/knowledge/create-knowledge/setting-indexing-methods)。</Note>
|
||||
|
||||
选定内容的分段模式后,接下来设定对于结构化内容的**索引方式**与**检索设置**。
|
||||
选定内容的分段模式后,接下来设定对于结构化内容的**索引方式**。
|
||||
|
||||
## 选择索引方式
|
||||
|
||||
@@ -23,162 +23,172 @@ title: 指定索引方式与检索设置
|
||||
|
||||
这些向量可理解为多维空间中的坐标点——两个点越接近,它们的语义越相似。这使得系统能够基于语义相似度(而不仅仅是关键词匹配)找到相关信息。
|
||||
|
||||
<Tip>
|
||||
若要启用跨模态检索——即基于语义相关性同时检索文本和图片,需选择多模态嵌入模型(带有 **Vision** 图标)。从文档中提取的图片将被向量化并参与检索。
|
||||
<Tip>
|
||||
若要启用跨模态检索——即基于语义相关性同时检索文本和图片——需选择多模态嵌入模型(带有 **Vision** 图标)。从文档中提取的图片将被嵌入并索引以供检索。
|
||||
|
||||
使用此类嵌入模型的知识库,其卡片上标有 **Multimodal**。
|
||||
使用此类嵌入模型的知识库,其卡片上标有 **Multimodal**。
|
||||
|
||||
<img src="/images/multimodal_knowledge_base.png" alt="Multimodal Knowledge Base" width="300" />
|
||||
</Tip>
|
||||
<img src="/images/multimodal_knowledge_base.png" alt="Multimodal Knowledge Base" width="300" />
|
||||
</Tip>
|
||||
|
||||
高质量索引方式支持三种检索策略:向量检索、全文检索或混合检索。详见 [指定检索设置](#指定检索设置)。
|
||||
|
||||
**启用 Q\&A 模式(仅适用于自托管部署)**
|
||||
### Q&A 模式
|
||||
|
||||
开启该模式后,系统将对已上传的文本进行分段。总结内容后为每个分段自动生成 Q\&A 匹配对。与常见的 「Q to P」(用户问题匹配文本段落)策略不同,QA 模式采用 「Q to Q」(问题匹配问题)策略。
|
||||
<Info>
|
||||
Q&A 模式仅适用于自托管部署。
|
||||
</Info>
|
||||
|
||||
开启该模式后,系统将对已上传的文本进行分段。总结内容后为每个分段自动生成 Q&A 匹配对。
|
||||
|
||||
这是因为 「常见问题」 文档里的文本**通常是具备完整语法结构的自然语言**,Q to Q 模式会令问题和答案的匹配更加清晰,并同时满足一些高频和高相似度问题的提问场景。
|
||||
与常见的 「Q to P」(用户问题匹配文本段落)策略不同,Q&A 模式采用 「Q to Q」(问题匹配问题)策略。
|
||||
|
||||
> **Q\&A 模式仅支持处理 「中英日」 三语。启用该模式后可能会消耗更多的 LLM Tokens,并且无法使用**[**经济型索引方式**](/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods#经济)**。**
|
||||
这种方法特别有效,因为常见问题文档中的文本**通常是具备完整语法结构的自然语言**。
|
||||
|
||||

|
||||
> **Q to Q** 策略使问题和答案的匹配更加清晰,并能更好地支持高频或高相似度问题的场景。
|
||||
|
||||

|
||||
|
||||
当用户提问时,系统会找出与之最相似的问题,然后返回对应的分段作为答案。这种方式更加精确,因为它直接针对用户问题进行匹配,可以更准确地帮助用户检索真正需要的信息。
|
||||
|
||||

|
||||
</Tab>
|
||||
|
||||
</Tab>
|
||||
|
||||
<Tab title="经济">
|
||||
**经济**
|
||||
|
||||
在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需产生费用。对于检索到的区块,仅提供倒排索引方式选择最相关的区块,详细说明请阅读[下文](#指定检索设置)。
|
||||
在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需消耗 Token。对于检索到的区块,仅提供倒排索引方式选择最相关的区块。
|
||||
|
||||
选择经济型索引方式后,若感觉实际的效果不佳,可以在知识库设置页中升级为 **“高质量”索引方式**。
|
||||
如果经济型索引方式的效果不符合预期,可以在知识库设置页中升级为高质量索引方式。
|
||||
|
||||

|
||||
|
||||

|
||||
</Tab>
|
||||
|
||||
</Tabs>
|
||||
|
||||
## 指定检索设置 <a href="#retrieval_settings" id="retrieval_settings"></a>
|
||||
## 指定检索设置
|
||||
|
||||
知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。这将决定 LLM 所能获取的背景信息,从而影响生成结果的准确性和可信度。
|
||||
知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段。这些片段为 LLM 提供必要的上下文,最终影响其回答的准确性和可信度。
|
||||
|
||||
常见的检索方式包括基于向量相似度的语义检索,以及基于关键词的精准匹配:前者将文本内容块和问题查询转化为向量,通过计算向量相似度匹配更深层次的语义关联;后者通过倒排索引,即搜索引擎常用的检索方法,匹配问题与关键内容。
|
||||
常见的检索方式包括:
|
||||
|
||||
不同的索引方式对应差异化的检索设置。
|
||||
1. 基于向量相似度的语义检索——将文本块和查询转化为向量,通过相似度评分进行匹配。
|
||||
2. 使用倒排索引的关键词匹配(一种标准的搜索引擎技术)。
|
||||
|
||||
Dify 的知识库支持这两种检索方式。具体可用的检索选项取决于所选的索引方式。
|
||||
|
||||
<Tabs>
|
||||
<Tab title="高质量索引">
|
||||
**高质量索引**
|
||||
<Tab title="高质量">
|
||||
**高质量**
|
||||
|
||||
在高质量索引方式下,Dify 提供向量检索、全文检索与混合检索设置:
|
||||
在**高质量**索引方式下,Dify 提供三种检索设置:**向量检索、全文检索和混合检索**。
|
||||
|
||||

|
||||

|
||||
|
||||
**向量检索**
|
||||
**向量检索**
|
||||
|
||||
**定义:** 向量化用户输入的问题并生成查询文本的数学向量,比较查询向量与知识库内对应的文本向量间的距离,寻找相邻的分段内容。
|
||||
**定义:** 向量化用户输入的问题并生成查询向量,然后将其与知识库中对应的文本向量进行比较,找到最相邻的分段。
|
||||
|
||||

|
||||

|
||||
|
||||
**向量检索设置:**
|
||||
**向量检索设置:**
|
||||
|
||||
**Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由向量检索召回的内容分段,以优化排序结果。帮助 LLM 获取更加精确的内容,辅助其提升输出的质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
|
||||
**Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型对向量检索返回的文本分段进行重新排序,以优化结果。这有助于 LLM 获取更精确的信息并提升输出质量。开启该选项前,需前往**设置** → **模型供应商**,提前配置 Rerank 模型的 API 密钥。
|
||||
|
||||
<Note>
|
||||
若选择的嵌入模型支持多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
|
||||
</Note>
|
||||
<Note>
|
||||
若选择的嵌入模型为多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
|
||||
</Note>
|
||||
|
||||
> 开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
|
||||
> 开启该功能后,将消耗 Rerank 模型的 Token。详情请参考对应模型的价格说明。
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
|
||||
**TopK:** 用于确定检索与用户问题相似度最高的文本分段数量。系统同时会根据选用模型上下文窗口大小动态调整分段数量。默认值为 **3**,数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
**Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
|
||||
**Score 阈值:** 用于设置文本分段被检索所需的最低相似度分数。只有超过该分数的分段才会被检索。默认值为 **0.5**。阈值越高,对相似度要求越高,因此被检索的分段数量越少。
|
||||
|
||||
> TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置参数。
|
||||
> TopK 和 Score 设置仅在 Rerank 阶段生效。因此,要应用这些设置中的任何一项,需要添加并启用 Rerank 模型。
|
||||
|
||||
***
|
||||
|
||||
**全文检索**
|
||||
|
||||
**定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
|
||||
**定义:** 索引文档中的所有词汇,允许用户查询任意词汇并返回包含这些词汇的文本片段。
|
||||
|
||||

|
||||

|
||||
|
||||
**Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由全文检索召回的内容分段,以优化排序结果。向 LLM 发送经过重排序的分段,辅助其提升输出的内容质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
|
||||
**Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型对全文检索返回的文本分段进行重新排序,以优化结果。这有助于 LLM 获取更精确的信息并提升输出质量。开启该选项前,需前往**设置** → **模型供应商**,提前配置 Rerank 模型的 API 密钥。
|
||||
|
||||
<Note>
|
||||
若选择的嵌入模型支持多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
|
||||
</Note>
|
||||
<Note>
|
||||
若选择的嵌入模型为多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
|
||||
</Note>
|
||||
|
||||
> 开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
|
||||
> 开启该功能后,将消耗 Rerank 模型的 Token。详情请参考对应模型的价格说明。
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
|
||||
**TopK:** 用于确定检索与用户问题相似度最高的文本分段数量。系统同时会根据选用模型上下文窗口大小动态调整分段数量。默认值为 **3**,数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
**Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
|
||||
**Score 阈值:** 用于设置文本分段被检索所需的最低相似度分数。只有超过该分数的分段才会被检索。默认值为 **0.5**。阈值越高,对相似度要求越高,因此被检索的分段数量越少。
|
||||
|
||||
> TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置参数。
|
||||
> TopK 和 Score 设置仅在 Rerank 阶段生效。因此,要应用这些设置中的任何一项,需要添加并启用 Rerank 模型。
|
||||
|
||||
***
|
||||
|
||||
**混合检索**
|
||||
**混合检索**
|
||||
|
||||
**定义:** 同时执行全文检索和向量检索,或 Rerank 模型,从查询结果中选择匹配用户问题的最佳结果。
|
||||
**定义:** 同时执行全文检索和向量检索。它包含一个重排序步骤,根据用户的查询从两种搜索结果中选择最佳匹配结果。
|
||||
|
||||

|
||||

|
||||
|
||||
在混合检索设置内可以选择启用 **“权重设置”** 或 **“Rerank 模型”**。
|
||||
在此模式下,你可以指定**"权重设置"**而无需配置 Rerank 模型 API,或启用 **Rerank 模型**进行检索。
|
||||
|
||||
* **权重设置**
|
||||
* **权重设置**
|
||||
|
||||
允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。
|
||||
此功能允许用户为语义优先和关键词优先设置自定义权重。关键词检索指的是在知识库内进行全文检索,语义检索指的是在知识库内进行向量检索。
|
||||
|
||||
* **将语义值拉至 1**
|
||||
* **语义值设为 1**
|
||||
|
||||
**仅启用语义检索模式**。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
|
||||
* **将关键词的值拉至 1**
|
||||
仅启用语义检索模式。借助嵌入模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回相关内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
|
||||
* **关键词值设为 1**
|
||||
|
||||
**仅启用关键词检索模式**。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
|
||||
* **自定义关键词和语义权重**
|
||||
|
||||
除了将不同的数值拉至 1,你还可以不断调试二者的权重,找到符合业务场景的最佳权重比例。
|
||||
|
||||
> 语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:[《Dify:Embedding 技术与 Dify 知识库设计/规划》](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)。
|
||||
仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
|
||||
* **自定义关键词和语义权重**
|
||||
|
||||
除了仅启用语义检索或关键词检索外,还提供灵活的自定义权重设置。你可以不断调整两种方法的权重,找到符合业务场景的最佳权重比例。
|
||||
***
|
||||
|
||||
* **Rerank 模型**
|
||||
**Rerank 模型**
|
||||
|
||||
默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由混合检索召回的内容分段,以优化排序结果。向 LLM 发送经过重排序的分段,辅助其提升输出的内容质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
|
||||
默认关闭。开启后将使用第三方 Rerank 模型对混合检索返回的文本分段进行重新排序,以优化结果。这有助于 LLM 获取更精确的信息并提升输出质量。开启该选项前,需前往**设置** → **模型供应商**,提前配置 Rerank 模型的 API 密钥。
|
||||
|
||||
<Note>
|
||||
若选择的嵌入模型支持多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
|
||||
</Note>
|
||||
<Note>
|
||||
若选择的嵌入模型为多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
|
||||
</Note>
|
||||
|
||||
> 开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
|
||||
> 开启该功能后,将消耗 Rerank 模型的 Token。详情请参考对应模型的价格说明。
|
||||
|
||||
**“权重设置”** 和 **“Rerank 模型”** 设置内支持启用以下选项:
|
||||
**"权重设置"**和**"Rerank 模型"**设置支持以下选项:
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
|
||||
**TopK:** 用于确定检索与用户问题相似度最高的文本分段数量。系统同时会根据选用模型上下文窗口大小动态调整分段数量。默认值为 **3**,数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
**Score 阈值:** 用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5。数值越高,预期被召回的文本数量越少。
|
||||
**Score 阈值:** 用于设置文本分段被检索所需的最低相似度分数。只有超过该分数的分段才会被检索。默认值为 **0.5**。阈值越高,对相似度要求越高,因此被检索的分段数量越少。
|
||||
</Tab>
|
||||
<Tab title="经济索引">
|
||||
**倒排索引**
|
||||
<Tab title="经济">
|
||||
**经济**
|
||||
|
||||
在经济索引方式下,仅提供**倒排索引方式**。这是一种用于快速检索文档中关键词的索引结构,常用于在线搜索引擎。倒排索引仅支持 **TopK** 设置项。
|
||||
在**经济索引**模式下,仅提供倒排索引方式。倒排索引是一种用于快速检索文档中关键词的数据结构,常用于在线搜索引擎。倒排索引仅支持 **TopK** 设置。
|
||||
|
||||
**TopK:**
|
||||
**TopK:** 用于确定检索与用户问题相似度最高的文本分段数量。系统同时会根据选用模型上下文窗口大小动态调整分段数量。默认值为 **3**,数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
|
||||
<p align="center">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/b417cd028131d34779993fbcbb8dbdd7.png" width="300" />
|
||||
</p>
|
||||
|
||||
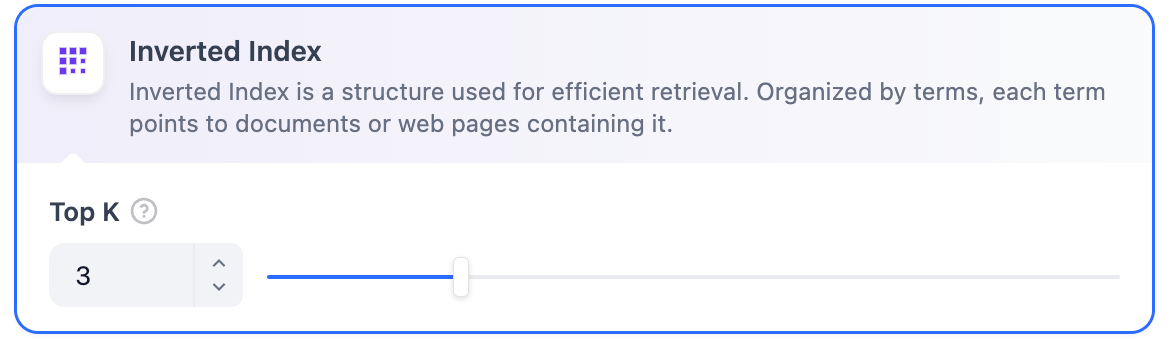
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 阅读更多
|
||||
### 参考
|
||||
|
||||
指定检索设置后,你可以参考以下文档查看在实际场景下,关键词与内容块的匹配情况。
|
||||
指定检索设置后,你可以参考以下文档查看在不同场景下关键词与内容块的匹配情况。
|
||||
|
||||
<Card title="测试召回效果" icon="link" href="/zh/use-dify/knowledge/test-retrieval">
|
||||
查看实际场景下的关键词与内容块匹配情况
|
||||
</Card>
|
||||
<Card title="测试知识检索" icon="link" href="/zh/use-dify/knowledge/test-retrieval">
|
||||
了解如何测试和引用知识库检索
|
||||
</Card>
|
||||
|
||||
@@ -41,7 +41,7 @@ title: "步骤二:编排知识流水线"
|
||||
|
||||
## 步骤一:数据源配置
|
||||
|
||||
在一个知识库里,你可以选择单一或多个数据源。每个数据源可以被多次选中,并包含不同配置。目前,Dify 支持 4 种数据源:文件上传、在线网盘、在线文档和网页爬虫。
|
||||
在一个知识库里,你可以选择单一或多个数据源。目前,Dify 支持 4 种数据源:**文件上传、在线网盘、在线文档和网页爬虫**。
|
||||
|
||||
你也可以前往 [Dify Marketplace](https://marketplace.dify.ai),获得更多数据源。
|
||||
|
||||
@@ -107,6 +107,8 @@ title: "步骤二:编排知识流水线"
|
||||
|
||||
</div>
|
||||
|
||||
---
|
||||
|
||||
### 网页爬虫
|
||||
|
||||
将网页内容转化为大型语言模型容易识别的格式,知识库支持 Jina Reader 和 Firecrawl,提供灵活的网页解析能力。
|
||||
@@ -157,13 +159,15 @@ title: "步骤二:编排知识流水线"
|
||||
| 最大爬取深度 (Max depth) | 可选 | 控制爬取层级深度 |
|
||||
| 排除路径 (Exclude paths) | 可选 | 设置不爬取的页面路径 |
|
||||
| 仅包含路径 (Include only paths) | 可选 | 限制只爬取指定路径 |
|
||||
| 启用内容提取器 (Enable Extractor) | 可选 | 选择数据处理方式 |
|
||||
| 启用内容提取器 (Extractor) | 可选 | 选择数据处理方式 |
|
||||
| 只提取主要内容 | 可选 | 过滤页面辅助信息 |
|
||||
|
||||
</div>
|
||||
|
||||
</div>
|
||||
|
||||
---
|
||||
|
||||
### 在线网盘
|
||||
|
||||
连接你的在线云储存服务(例如 Google Drive、Dropbox、OneDrive),Dify 将自动检索云储存中的文件,你可以勾选并导入相应文档进行下一步处理,无需手动下载文件再进行上传。
|
||||
@@ -232,21 +236,23 @@ Dify Extractor 是 Dify 开发的一款内置文档解析器。它支持多种
|
||||
</div>
|
||||
|
||||
<div style={{ flex:2,minWidth:"300px" }}>
|
||||
Unstructured 将文档转换为结构化的机器可读格式,具有高度可定制的处理策略。它提供多种提取策略(auto、hi_res、fast、OCR-only)和分块方法(by_title、by_page、by_similarity)来处理各种文档类型,提供详细的元素级元数据,包括坐标、置信度分数和布局信息。推荐用于企业文档工作流、混合文件类型处理以及需要精确控制文档处理参数的场景。
|
||||
[Unstructured](https://marketplace-staging.dify.dev/plugins/langgenius/unstructured) 将文档转换为结构化的机器可读格式,具有高度可定制的处理策略。它提供多种提取策略(auto、hi_res、fast、OCR-only)和分块方法(by_title、by_page、by_similarity)来处理各种文档类型,提供详细的元素级元数据,包括坐标、置信度分数和布局信息。推荐用于企业文档工作流、混合文件类型处理以及需要精确控制文档处理参数的场景。
|
||||
|
||||
</div>
|
||||
|
||||
</div>
|
||||
|
||||
你可前往 [Dify Marketplace](https://marketplace.dify.ai) 探索更多工具。
|
||||
<Tip>
|
||||
你可前往 [Dify Marketplace](https://marketplace.dify.ai) 探索更多工具。
|
||||
</Tip>
|
||||
|
||||
---
|
||||
|
||||
### 分块器 (Chunker)
|
||||
|
||||
在构建 AI 应用时,我们需要处理大量和不同种类的文档内容,比如产品手册、技术文档或论文等。和人类有限的注意力相似,大型语言模型无法同时处理过多的信息。因此,在信息提取后,分块器将大段的文档内容拆分成更小、更易于管理的片段(称为"块")。这就好比一本很厚的书,被分成了许多章节,你可以通过阅读目录快速定位到相关内容所在章节。
|
||||
在构建 AI 应用时,我们需要处理大量和不同种类的文档内容,比如产品手册、技术文档或论文等。和人类有限的注意力相似,大型语言模型无法同时处理过多的信息。因此,在信息提取后,分块器将大段的文档内容拆分成更小、更易于管理的片段(称为"块")。
|
||||
|
||||
当 AI 应用需要回答问题时,良好的分块策略能够提供足够的上下文信息,并包含完整的语义。这样,当检索到对应的片段时,大型语言模型能够基于这个片段中的信息生成较为准确的答案。
|
||||
|
||||
不同类型的文档需要不同的分块策略,比如产品手册可能需要按照产品型号进行分块,确保产品功能介绍的完整性;论文则需要根据逻辑结构进行分块,确保论点叙述的流畅性。基于这样的多样性,Dify 提供了 3 种分块器,帮助你根据不同文档类型和使用场景进行选择和使用。
|
||||
不同类型的文档需要不同的分块策略,比如产品手册可能需要按照产品特性进行分块,而论文则需要根据逻辑结构进行分块。Dify 提供了 3 种分块器,帮助你根据不同文档类型和使用场景进行选择和使用。
|
||||
|
||||
#### 分块器类型概述
|
||||
|
||||
@@ -258,6 +264,8 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
|
||||
#### 通用文本预处理规则
|
||||
|
||||
所有分块器都支持以下文本清理选项:
|
||||
|
||||
| 处理选项 | 说明 |
|
||||
| -------------- | ------------------------ |
|
||||
| 替换连续空格、换行符和制表符 | 将文档中的连续空格、换行符和制表符替换为单个空格 |
|
||||
@@ -326,6 +334,8 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
| 问题所在的列 | 将内容所在的列设置为问题 |
|
||||
| 答案所在的列 | 将内容所在的列设置为答案 |
|
||||
|
||||
---
|
||||
|
||||
## 步骤三:配置知识库节点
|
||||
|
||||
在完成数据处理后,我们将进入知识流水线的最后一个环节 — 知识库节点。你可以根据实际需求,在这个节点选择不同的索引方法和检索策略,以获得最适合的检索效果和成本控制。
|
||||
@@ -338,7 +348,7 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
|
||||
分段结构决定了知识库如何组织和索引你的文档内容。你可以根据文档类型、使用场景和成本考虑来选择最适合的结构模式。
|
||||
|
||||
知识库支持两种分段模式:通用模式与父子模式。如果你是首次创建知识库,建议选择父子模式。
|
||||
知识库支持三种分段模式:**通用模式、父子模式和问答模式**。如果你是首次创建知识库,建议选择父子模式。
|
||||
|
||||
<Warning>
|
||||
**重要提醒**:分段结构一旦保存发布后无法修改,请根据实际需求进行选择。
|
||||
@@ -370,7 +380,7 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
|
||||
索引方式决定了知识库如何建立内容索引,检索设置则基于所选的索引方式提供相应的检索策略。可以这样理解:索引方式决定如何整理文档,而检索设置则决定如何查找文档。
|
||||
|
||||
知识库提供了两种索引方式:高质量和经济,分别提供不同的检索设置选项。
|
||||
知识库提供了两种索引方式:**高质量**和**经济**,分别提供不同的检索设置选项。
|
||||
|
||||
在高质量模式下,使用嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息。这使得即使用户的问题用词与文档不完全相同,系统也能找到语义相关的准确答案。
|
||||
|
||||
@@ -384,20 +394,18 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
|
||||
</Tip>
|
||||
|
||||
在经济索引方式下,每个分段使用 10 个关键词用于检索,无需调用嵌入模型,且不消耗 token。
|
||||
|
||||
<Info>
|
||||
了解更多细节,阅读 [指定索引方式与检索设置](/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods)。
|
||||
</Info>
|
||||
|
||||
在经济索引方式下,可为每个分段添加 10 个关键词用于检索,无需调用嵌入模型,且不消耗 token。
|
||||
|
||||
#### 索引方式和检索设置
|
||||
|
||||
| 索引方式 | 可用检索设置 | 说明 |
|
||||
| ---- | ------ | ----------------------- |
|
||||
| 高质量 | 向量搜索 | 基于语义相似度,理解查询深层含义。 |
|
||||
| | 全文检索 | 基于关键词匹配的检索方式,提供全面的检索能力。 |
|
||||
| 高质量 | 向量检索 | 基于语义相似度,理解查询深层含义 |
|
||||
| | 全文检索 | 基于关键词匹配的检索方式,提供全面的检索能力 |
|
||||
| | 混合检索 | 结合语义和关键词 |
|
||||
| 经济 | 倒排索引 | 搜索引擎常用的检索方法,匹配问题与关键内容。 |
|
||||
| 经济 | 倒排索引 | 搜索引擎常用的检索方法,匹配问题与关键内容 |
|
||||
|
||||
<Note>
|
||||
若选择的嵌入模型支持多模态,需同样选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和检索结果中被排除。
|
||||
@@ -411,24 +419,25 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
| 父子模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索 <br /> 全文检索 <br /> 混合检索 |
|
||||
| 问答模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索 <br /> 全文检索 <br /> 混合检索 |
|
||||
|
||||
---
|
||||
|
||||
## 步骤四:配置用户输入表单
|
||||
|
||||
用户输入表单对于收集流水线运行所需的有效初始信息非常重要。类似于工作流中的[用户输入节点](/zh/use-dify/nodes/user-input),这个表单从用户那里收集必要的相信信息,比如:需要上传的文件、文档处理的特定参数等,确保流水线拥有提供准确结果所需要的所有信息。
|
||||
用户输入表单对于收集流水线运行所需的有效初始信息非常重要。类似于工作流中的[用户输入节点](/zh/use-dify/nodes/user-input),这个表单从用户那里收集必要的详细信息,比如:需要上传的文件、文档处理的特定参数等,确保流水线拥有提供准确结果所需要的所有信息。
|
||||
|
||||
通过这种方式,你可以为不同的使用场景创建特定的的输入表单,提高流水线对于不同数据源和文档处理流程的灵活性和易用性。
|
||||
通过这种方式,你可以为不同的使用场景创建特定的输入表单,提高流水线对于不同数据源和文档处理流程的灵活性和易用性。
|
||||
|
||||
### 创建用户输入表单
|
||||
|
||||
你可以通过下面两种方式,创建用户输入表单。
|
||||
|
||||
1. **知识流水线编排界面** 点击输入字段(Input Field)开始创建和配置输入表单。
|
||||
1. **知识流水线编排界面**\
|
||||
点击输入字段(Input Field)开始创建和配置输入表单。\
|
||||
<img src="/images/knowledge-base/knowledge-pipeline-orchestration-9.png" alt="" />
|
||||
2. **节点参数面板**\
|
||||
选中节点,在右侧的面板需要填写的参数内,点击最下方的`+ 创建用户输入字段`(+ Create user input)来创建新的输入项。新增的输入项将会汇总到输入字段(Input Field)的表单内。<img src="/images/knowledge-base/knowledge-pipeline-orchestration-10.png" alt="" />
|
||||
|
||||

|
||||
2. **节点参数面板** 选中节点,在右侧的面板需要填写的参数内,点击最下方的`+ 创建用户输入字段`(+ Create user input)来创建新的输入项。新增的输入项将会汇总到输入字段(Input Field)的表单内。
|
||||
|
||||

|
||||
|
||||
### 输入类型
|
||||
### 添加用户输入字段
|
||||
|
||||
#### 非共享输入 (Unique Inputs for Each Entrance)
|
||||
|
||||
@@ -436,17 +445,15 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
|
||||
这类输入适用于每个数据源及其下游节点,用户只需在选择对应数据源时填写这些字段,比如不同数据源的URL。
|
||||
|
||||
在数据源右侧点击"+"按钮,为该数据源添加字段。这个字段只能被该数据源及其后续连接的节点引用。
|
||||
**创建方式**:在数据源右侧点击"+"按钮,为该数据源添加字段。这个字段只能被该数据源及其后续连接的节点引用。<img src="/images/knowledge-base/knowledge-pipeline-orchestration-12.png" alt="" />
|
||||
|
||||

|
||||
|
||||
#### 全局共享输入 (Global Inputs for All Entrance)
|
||||
#### 全局共享输入 (Global Inputs for All Entrances)
|
||||
|
||||

|
||||
|
||||
全局共享输入可以被所有节点引用。这类输入适用于通用处理参数,比如分隔符、最大分块长度、文档处理配置等。无论用户选择哪个数据源,都需要填写这些字段。
|
||||
|
||||
在全局共享输入右侧点击"+"按钮,添加的字段将被任意节点引用。
|
||||
**创建方式**:在全局共享输入右侧点击"+"按钮,添加的字段将被任意节点引用。
|
||||
|
||||
### 支持字段类型和填写说明
|
||||
|
||||
@@ -466,8 +473,8 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
| 下拉选项 | 由编排者预设的固定选项供使用者选择,使用者无法自行填写内容 |
|
||||
| 布尔值 | 只有真/假两个取值 |
|
||||
| 数字 | 只能输入数字 |
|
||||
| 单文件 | 上传单个文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
|
||||
| 文件列表 | 批量上传文件,支持多种文件类型(文档、图片、音频、视频和其他文件类型) |
|
||||
| 单文件 | 上传单个文件,支持多种文件类型(文档、图片、音频和其他文件类型) |
|
||||
| 文件列表 | 批量上传文件,支持多种文件类型(文档、图片、音频和其他文件类型) |
|
||||
|
||||
</div>
|
||||
|
||||
@@ -477,38 +484,48 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
请阅读[用户输入节点](/zh/use-dify/nodes/user-input),了解关于支持字段的更多说明。
|
||||
</Tip>
|
||||
|
||||
### 字段配置选项
|
||||
|
||||
所有类型的输入项包含:必填项、非必填项和更多设置,可以通过勾选设置为是否为必填。
|
||||
|
||||
| 名称 | 说明 | 示例 |
|
||||
| ------------------ | --------------------------- | ------------------ |
|
||||
| **必填项** | | |
|
||||
| 变量名称 Variable Name | 系统内部标识名称,通常使用英文和下划线进行命名 | `user_email` |
|
||||
| 显示名称 Display Name | 界面展示的名称,通常是简洁易读的文字 | 用户邮箱 |
|
||||
| **类型特定设置** | 不同字段类型的特殊要求 | 文本的最大长度为 100 字符 |
|
||||
| **更多设置** | | |
|
||||
| 默认值 Default Value | 用户未输入时的默认值 | 数字字段默认为0, 文本字段默认为空 |
|
||||
| 占位符 Placeholder | 输入框空白时的提示文字 | 请输入您的邮箱 |
|
||||
| 提示 Tooltip | 解释或指引用户进行填写的文字,通常在用户鼠标悬停时显示 | 请输入有效的邮箱地址 |
|
||||
| **特殊非必填信息** | 根据不同字段类型的额外设置选项 | 邮箱格式验证 |
|
||||
| 设置类型 | 名称 | 说明 | 示例 |
|
||||
| ---------- | ----------- | --------------------------- | ------------------ |
|
||||
| 必填项 | 变量名称 | 系统内部标识名称,通常使用英文和下划线进行命名 | `user_email` |
|
||||
| | 显示名称 | 界面展示的名称,通常是简洁易读的文字 | 用户邮箱 |
|
||||
| 类型特定设置 | | 不同字段类型的特殊要求 | 文本的最大长度为 100 字符 |
|
||||
| 更多设置 | 默认值 | 用户未输入时的默认值 | 数字字段默认为0, 文本字段默认为空 |
|
||||
| | 占位符 | 输入框空白时的提示文字 | 请输入您的邮箱 |
|
||||
| | 提示 | 解释或指引用户进行填写的文字,通常在用户鼠标悬停时显示 | 请输入有效的邮箱地址 |
|
||||
| 特殊非必填信息 | | 根据不同字段类型的额外设置选项 | 邮箱格式验证 |
|
||||
|
||||
配置完成后,点击右上角的预览按钮,你可以在弹出的表单预览界面中浏览。你可以拖拽调整字段的分组,如果出现感叹号,则表明移动后引用失效。
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
## 步骤五:为知识库命名
|
||||
|
||||

|
||||
|
||||
默认情况下,知识库名称为"Untitled + 序号”,权限设置为"仅自己可见”,图表为橙色书本。如果你使用 DSL文件导入,则将使用其保存的图标。
|
||||
默认情况下,知识库名称为"Untitled + 序号",权限设置为"仅自己可见",图标为橙色书本。如果你使用 DSL文件导入,则将使用其保存的图标。
|
||||
|
||||
点击左侧面板中的设置并填写以下信息:
|
||||
点击左侧面板中的**设置**并填写以下信息:
|
||||
|
||||
- **名称和图标** 为你的知识库命名。你还可以选择一个 emoji、上传图片或粘贴图片 URL 作为知识库的图标。
|
||||
- **知识库描述** 简要描述您的知识库。这有助于 AI 更好地理解和检索您的数据。如果留空,Dify 将应用默认的检索策略。
|
||||
- **权限** 从下拉菜单中选择适当的访问权限。
|
||||
- **名称和图标**\
|
||||
为你的知识库命名。\
|
||||
你还可以选择一个 emoji、上传图片或粘贴图片 URL 作为知识库的图标。
|
||||
- **知识库描述**\
|
||||
简要描述您的知识库。这有助于 AI 更好地理解和检索您的数据。如果留空,Dify 将应用默认的检索策略。
|
||||
- **权限**\
|
||||
从下拉菜单中选择适当的访问权限。
|
||||
|
||||
---
|
||||
|
||||
## 步骤六:测试
|
||||
|
||||
你马上就要完成了!这是知识流水线编排的最后一步。
|
||||
|
||||
在完成编排后,你需要先验证配置的完整性,然后测试流水线运行效果,确认各项设置正确无误,最后发布知识库。
|
||||
|
||||
### 检查配置完成度
|
||||
@@ -525,14 +542,15 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
|
||||

|
||||
|
||||
1. **开始测试**:点击右上角的测试运行(Test Run)按钮。
|
||||
2. **导入测试文件**:在右侧弹出的数据源窗口中,导入文件。
|
||||
1. **开始测试**:点击右上角的测试运行(Test Run)按钮
|
||||
2. **导入测试文件**:在右侧弹出的数据源窗口中,导入文件
|
||||
|
||||
<Warning>
|
||||
**重要提醒**:为了便于调试和观测,在测试运行状态下,每次仅允许上传一个文件。
|
||||
</Warning>
|
||||
|
||||
<Warning>
|
||||
**重要提醒**:为了便于调试和观测,在测试运行状态下,每次仅允许上传一个文件。
|
||||
</Warning>
|
||||
3. **填写参数**:导入成功后,根据你之前配置的用户输入表单填写对应参数
|
||||
4. **开始试运行**:点击下一步,开始测试整个流水线。
|
||||
4. **开始试运行**:点击下一步,开始测试整个流水线
|
||||
|
||||
在测试期间,你可以访问[运行历史](/zh/use-dify/monitor/logs)(记录所有运行记录,包括运行时间、执行状态和输入/输出参数概要)和[变量检查](/zh/use-dify/debug/variable-inspect)(位于底部面板,它显示每个节点的输入/输出数据,帮助你识别问题和验证数据流),以实现高效的故障排除和错误修复。
|
||||
|
||||
|
||||
@@ -7,7 +7,9 @@ sidebarTitle: 维护内容
|
||||
|
||||
## 管理文档
|
||||
|
||||
在知识库中,每个导入的项——无论是本地文件、Notion 页面还是网页——都会成为一个文档。你可以在文档列表中查看和管理所有文档,确保知识库的内容始终准确、相关且最新。
|
||||
在知识库中,每个导入的项——无论是本地文件、Notion 页面还是网页——都会成为一个文档。
|
||||
|
||||
你可以在文档列表中查看和管理所有文档,确保知识库的内容始终准确、相关且最新。
|
||||
|
||||
<Tip>
|
||||
点击顶部的知识库名称,可快速切换不同知识库。
|
||||
@@ -20,14 +22,16 @@ sidebarTitle: 维护内容
|
||||
| 添加 | 导入新文档。|
|
||||
| 修改分段设置 | 修改文档的分段设置(不包括分段结构)。<Info>每个文档可拥有独立的分段设置,但分段结构在整个知识库中共享,且一旦设置无法更改。</Info>|
|
||||
| 删除 | 永久删除文档。**删除不可撤销**。|
|
||||
| 启用 / 禁用 | 临时将文档纳入或排除检索。<Note>在 Dify Cloud 上,长时间未更新或未被检索的文档会自动禁用以优化性能。<br/><br/>不同订阅计划的未活跃时长如下:<ul><li>Sandbox:7 天</li><li>Professional & Team:30 天</li></ul>Professional 和 Team 用户可一键重新启用这些文档。</Note>|
|
||||
| 启用 / 禁用 | 临时将文档纳入或排除检索。<Note>在 Dify Cloud 上,长时间未更新或未被检索的文档会自动禁用以优化性能。<br/><br/>不同订阅计划的未活跃时长如下:<ul><li>Sandbox:7 天</li><li>Professional & Team:30 天</li></ul>Professional 和 Team 用户可**一键**重新启用这些文档。</Note>|
|
||||
| 归档 / 取消归档 | 将不再需要检索但仍需保留的文档归档。归档文档为只读,可随时取消归档。|
|
||||
| 编辑 | 通过编辑分段内容修改文档。详见 [管理分段](#管理分段)。|
|
||||
| 重命名 | 修改文档名称。|
|
||||
|
||||
## 管理分段
|
||||
|
||||
根据其分段设置,每个文档被拆分为一个或多个分段,而分段是检索的基本单元。你可以在文档的分段列表中查看和管理所有分段,以提升检索效率与准确性。
|
||||
根据其分段设置,每个文档被拆分为一个或多个分段,而分段是检索的基本单元。
|
||||
|
||||
你可以在文档的分段列表中查看和管理所有分段,以提升检索效率与准确性。
|
||||
|
||||
<Tip>
|
||||
点击左上角的文档名称,可快速切换不同文档。
|
||||
@@ -42,7 +46,7 @@ sidebarTitle: 维护内容
|
||||
| 启用 / 禁用 | 临时将分段纳入或排除检索。已禁用的分段不可编辑。|
|
||||
| 编辑 | 修改分段内容。已编辑的分段将标记为 **已编辑**。<br/><br/>对于采用父子分段模式的文档:<ul><li>编辑父分段时,可选择重新生成其子分段或保持原有的子分段不变。</li><li>编辑子分段不会改变其父分段。</li></ul><Tip>当文档中的图片被提取为分段附件时,其 URL 会保留在分段文本中。删除 URL 不会影响已提取的图片附件。</Tip>|
|
||||
| 添加 / 编辑 / 删除关键词 | 在使用经济索引方式的知识库中,可为分段添加或修改关键词,以提升其可检索性。<br/><br/>一个分段最多可添加 10 个关键词。|
|
||||
| 添加 / 删除图片附件 | 在对应分段中,删除从文档中提取的图片或上传新图片。<br/><br/>图片附件和分段内容可独立编辑,互不影响。<Note> 每个分段最多支持 10 张图片附件,在检索中将被一同返回;超过数量的图片不会被提取。<br/><br/>对于自托管部署,可通过修改环境变量 `SINGLE_CHUNK_ATTACHMENT_LIMIT`(默认值:10)调整此数量限制。</Note><Tip>若要启用跨模态检索——即基于语义相关性同时检索文本和图片,需为知识库选择多模态嵌入模型(带有 **Vision** 图标)。被提取的图片附件将被向量化并参与检索。</Tip>|
|
||||
| 添加 / 删除图片附件 | 在对应分段中,删除从文档中提取的图片或上传新图片。<br/><br/>图片附件和分段内容可独立编辑,互不影响。<Note> 每个分段最多支持 10 张图片附件,在检索中将被一同返回;超过数量的图片不会被提取。<br/><br/>对于自托管部署,可通过修改环境变量 `SINGLE_CHUNK_ATTACHMENT_LIMIT` 调整此数量限制。</Note><Tip>若要启用跨模态检索——即基于语义相关性同时检索文本和图片,需为知识库选择多模态嵌入模型(带有 **Vision** 图标)。<br/><br/>被提取的图片附件将被向量化并参与检索。</Tip>|
|
||||
|
||||
## 最佳实践
|
||||
|
||||
@@ -53,15 +57,19 @@ sidebarTitle: 维护内容
|
||||
常见问题包括:
|
||||
|
||||
- 分段 **过短**:上下文不完整,易造成语义丢失和答案不准确。
|
||||
|
||||
- 分段 **过长**:包含无关信息,易引入语义噪音、降低检索精度。
|
||||
|
||||
- 分段 **语义不完整**:句子或段落被分段设置强制切断,易导致检索结果存在内容缺失或误导。
|
||||
|
||||
### 将子分段用作父分段的检索钩子
|
||||
|
||||
对于采用父子分段模式的文档,子分段用于检索,而返回的是父分段。由于编辑子分段不会改变其父分段,可将子分段作为父分段的语义标签或检索提示。
|
||||
对于采用父子分段模式的文档,系统会在子分段中进行搜索,但返回的是父分段。由于编辑子分段不会改变其父分段,可将子分段作为父分段的语义标签或检索提示。
|
||||
|
||||
具体做法是将子分段改写为 **关键词**、**摘要** 或 **常见用户问题**。例如,若父分段的内容为*退货政策*,可将子分段改写为:
|
||||
|
||||
- *如何退货?*
|
||||
|
||||
- *退款周期是多少?*
|
||||
|
||||
- *退货需要支付运费吗?*
|
||||
@@ -7,21 +7,28 @@ icon: "database"
|
||||
|
||||
## 简介
|
||||
|
||||
你可以通过知识检索节点将已有知识库集成到 Chatflow 或 Workflow 应用中。该节点在指定知识库中检索相关信息,其检索结果可传递给下游节点(如 LLM)用作上下文。
|
||||
你可以通过知识检索节点将已有知识库集成到 Chatflow 或 Workflow 应用中。该节点在指定知识库中检索与查询相关的信息,并将检索结果作为上下文内容传递给下游节点(如 LLM)使用。
|
||||
|
||||
知识检索节点在 Chatflow 中的典型用例如下:
|
||||
|
||||
1. **用户输入** 节点收集用户问题。
|
||||
|
||||
2. **知识检索** 节点在指定知识库中检索与用户问题相关的内容,并输出检索结果。
|
||||
|
||||
3. **LLM** 节点基于用户问题和检索结果生成回复。
|
||||
|
||||
4. **直接回答** 节点将 LLM 的回复输出给用户。
|
||||
|
||||

|
||||
|
||||
<Info>
|
||||
使用知识检索节点前,确保至少有一个可用的知识库。了解如何创建知识库,阅读 [创建知识库](/zh/use-dify/knowledge/readme#创建知识库)。
|
||||
使用知识检索节点前,确保至少有一个可用的知识库。了解如何创建知识库,阅读 [知识库](/zh/use-dify/knowledge/readme#创建知识库)。
|
||||
</Info>
|
||||
|
||||
<Note>
|
||||
在 Dify Cloud 上,知识检索操作受订阅计划的频率限制。详见 [知识库请求频率限制](/zh/use-dify/knowledge/knowledge-request-rate-limit)。
|
||||
</Note>
|
||||
|
||||
## 配置知识检索节点
|
||||
|
||||
要使知识检索节点正常工作,你需要指定:
|
||||
@@ -49,10 +56,9 @@ icon: "database"
|
||||
<Info>
|
||||
当添加了至少一个多模态知识库时,才会出现 **查询图片** 选项。
|
||||
|
||||
此类知识库带有 **Vision** 图标,表示其使用的是多模态嵌入模型。
|
||||
此类知识库会带有 **Vision** 图标,表示其使用的是多模态嵌入模型。
|
||||
</Info>
|
||||
|
||||
|
||||
### 选择检索的知识库
|
||||
|
||||
为节点添加一个或多个知识库,用于检索与查询内容相关的信息。
|
||||
@@ -60,14 +66,13 @@ icon: "database"
|
||||
添加了多个知识库时,会同时检索所有知识库,合并结果并根据 [节点级检索设置](#调整节点级检索设置) 进行处理。
|
||||
|
||||
<Info>
|
||||
带有 **Vision** 图标的知识库支持跨模态检索,即基于语义相关性同时检索文本和图片。
|
||||
带有 **Vision** 图标的知识库支持跨模态检索——基于语义相关性同时检索文本和图片。
|
||||
</Info>
|
||||
|
||||
<Tip>
|
||||
点击已添加知识库对应的 **编辑** 图标,可直接在知识检索节点内修改其设置。了解更多设置说明,阅读 [调整知识库设置](/zh/use-dify/knowledge/manage-knowledge/introduction)。
|
||||
</Tip>
|
||||
|
||||
|
||||
### 调整节点级检索设置
|
||||
|
||||
设置节点在获取知识库检索结果后的处理方式。
|
||||
@@ -88,9 +93,9 @@ icon: "database"
|
||||
|
||||
- **Rerank 模型**:根据与查询内容的相关性,对所有结果的相似度分数进行重新评定和排序。
|
||||
|
||||
<Note>
|
||||
若添加了多模态知识库,需选择多模态 Rerank 模型(带有 Vision 图标)。否则,检索到的图片将在重排序和最终的检索结果中被排除。
|
||||
</Note>
|
||||
<Note>
|
||||
若添加了多模态知识库,需同时选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和最终输出中被排除。
|
||||
</Note>
|
||||
|
||||
- **Top K**:重排序后返回的最大结果数。选择 Rerank 模型时,该值将根据模型的最大输入容量自动调整。
|
||||
|
||||
@@ -108,9 +113,9 @@ icon: "database"
|
||||
|
||||
## 输出变量
|
||||
|
||||
知识检索节点将检索结果输出为 `result` 变量——一个包含分段内容、分段标题、分段链接等属性的文档分段数组。
|
||||
知识检索节点将检索结果输出为 `result` 变量——一个包含分段内容、元数据、标题等属性的文档分段数组。
|
||||
|
||||
若检索结果中包含图片附件,`result` 变量中将增加包含图片信息的 `files` 字段。
|
||||
若检索结果中包含图片附件,`result` 变量中将增加包含图片元数据的 `files` 字段。
|
||||
|
||||
## 搭配 LLM 节点使用知识检索节点
|
||||
|
||||
@@ -118,16 +123,12 @@ icon: "database"
|
||||
|
||||
1. 在 **上下文** 字段中,选择知识检索节点的 `result` 变量。
|
||||
|
||||
2. 在 LLM 提示词字段中,同时引用 `上下文` 变量和用户输入变量(如 Chatflow 中的 `userinput.query`)。
|
||||
2. 在提示词字段中,同时引用 `上下文` 变量和用户输入变量(如 Chatflow 中的 `userinput.query`)。
|
||||
|
||||
3. (可选)若 LLM 支持 Vision 功能,可启用 **Vision**,以便其理解 `上下文` 变量中的图片附件。
|
||||
3. (可选)若 LLM 支持视觉能力(带有 **Vision** 图标),可启用 **Vision**,以便其理解检索到的图片。
|
||||
|
||||
<Info>
|
||||
启用 **Vision** 后,LLM 可直接理解 `上下文` 变量中的图片;无需额外设置 **Vision** 的输入变量。
|
||||
启用 **Vision** 后,LLM 会自动处理检索到的图片。无需在 **Vision** 输入字段中再次手动引用 `上下文` 变量。
|
||||
</Info>
|
||||
|
||||
<img src="/images/llm_node_configuration_example.png" alt="LLM 节点配置示例" width="400"/>
|
||||
|
||||
<Note>
|
||||
在 Dify Cloud 上,知识检索操作受订阅计划的频率限制。详见 [知识库请求频率限制](/zh/use-dify/knowledge/knowledge-request-rate-limit)。
|
||||
</Note>
|
||||
Reference in New Issue
Block a user