mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
Feat: update redirect links
This commit is contained in:
10
en/guides/workflow/node/README.mdx
Normal file
10
en/guides/workflow/node/README.mdx
Normal file
@@ -0,0 +1,10 @@
|
||||
---
|
||||
title: Node Description
|
||||
---
|
||||
|
||||
|
||||
**Nodes are the key components of a workflow**, enabling the execution of a series of operations by connecting nodes with different functionalities.
|
||||
|
||||
### Core Nodes
|
||||
|
||||
<table data-view="cards"><thead><tr><th></th><th></th><th></th></tr></thead><tbody><tr><td><a href="/en/guides/workflow/nodes/start"><strong>Start</strong></a></td><td>Defines the initial parameters for starting a workflow process.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/end"><strong>End</strong></a></td><td>Defines the final output content for ending a workflow process.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/answer"><strong>Answer</strong></a></td><td>Defines the response content in a Chatflow process.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/llm"><strong>Large Language Model (LLM)</strong></a></td><td>Calls a large language model to answer questions or process natural language.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/knowledge-retrieval"><strong>Knowledge Retrieval</strong></a></td><td>Retrieves text content related to user questions from a knowledge base, which can serve as context for downstream LLM nodes.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/question-classifier"><strong>Question Classifier</strong></a></td><td>By defining classification descriptions, the LLM can select the matching classification based on user input.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/ifelse"><strong>IF/ELSE</strong></a></td><td>Allows you to split the workflow into two branches based on if/else conditions.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/code"><strong>Code Execution</strong></a></td><td>Runs Python/NodeJS code to execute custom logic such as data transformation within the workflow.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/template"><strong>Template</strong></a></td><td>Enables flexible data transformation and text processing using Jinja2, a Python templating language.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/variable-aggregator"><strong>Variable Aggregator</strong></a></td><td>Aggregates variables from multiple branches into one variable for unified configuration of downstream nodes.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/variable-assigner"><strong>Variable Assigner</strong></a></td><td>The variable assigner node is used to assign values to writable variables.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/parameter-extractor"><strong>Parameter Extractor</strong></a></td><td>Uses LLM to infer and extract structured parameters from natural language for subsequent tool calls or HTTP requests.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/iteration"><strong>Iteration</strong></a></td><td>Executes multiple steps on list objects until all results are output.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/http-request"><strong>HTTP Request</strong></a></td><td>Allows sending server requests via the HTTP protocol, suitable for retrieving external results, webhooks, generating images, and other scenarios.</td><td></td></tr><tr><td><a href="/en/guides/workflow/nodes/tools"><strong>Tools</strong></a></td><td>Enables calling built-in Dify tools, custom tools, sub-workflows, and more within the workflow.</td><tr><td><a href="/en/guides/workflow/nodes/loop"><strong>Loop</strong></a></td><td>A Loop node executes repetitive tasks that depend on previous iteration results until exit conditions are met or the maximum loop count is reached.</td><td></td></tr></tbody></table>
|
||||
78
en/guides/workflow/node/agent.mdx
Normal file
78
en/guides/workflow/node/agent.mdx
Normal file
@@ -0,0 +1,78 @@
|
||||
---
|
||||
title: Agent
|
||||
---
|
||||
|
||||
|
||||
## Definition
|
||||
|
||||
An Agent Node is a component in Dify Chatflow/Workflow that enables autonomous tool invocation. By integrating different Agent reasoning strategies, LLMs can dynamically select and execute tools at runtime, thereby performing multi-step reasoning.
|
||||
|
||||
## Configuration Steps
|
||||
|
||||
### Add the Node
|
||||
|
||||
In the Dify Chatflow/Workflow editor, drag the Agent node from the components panel onto the canvas.
|
||||
|
||||
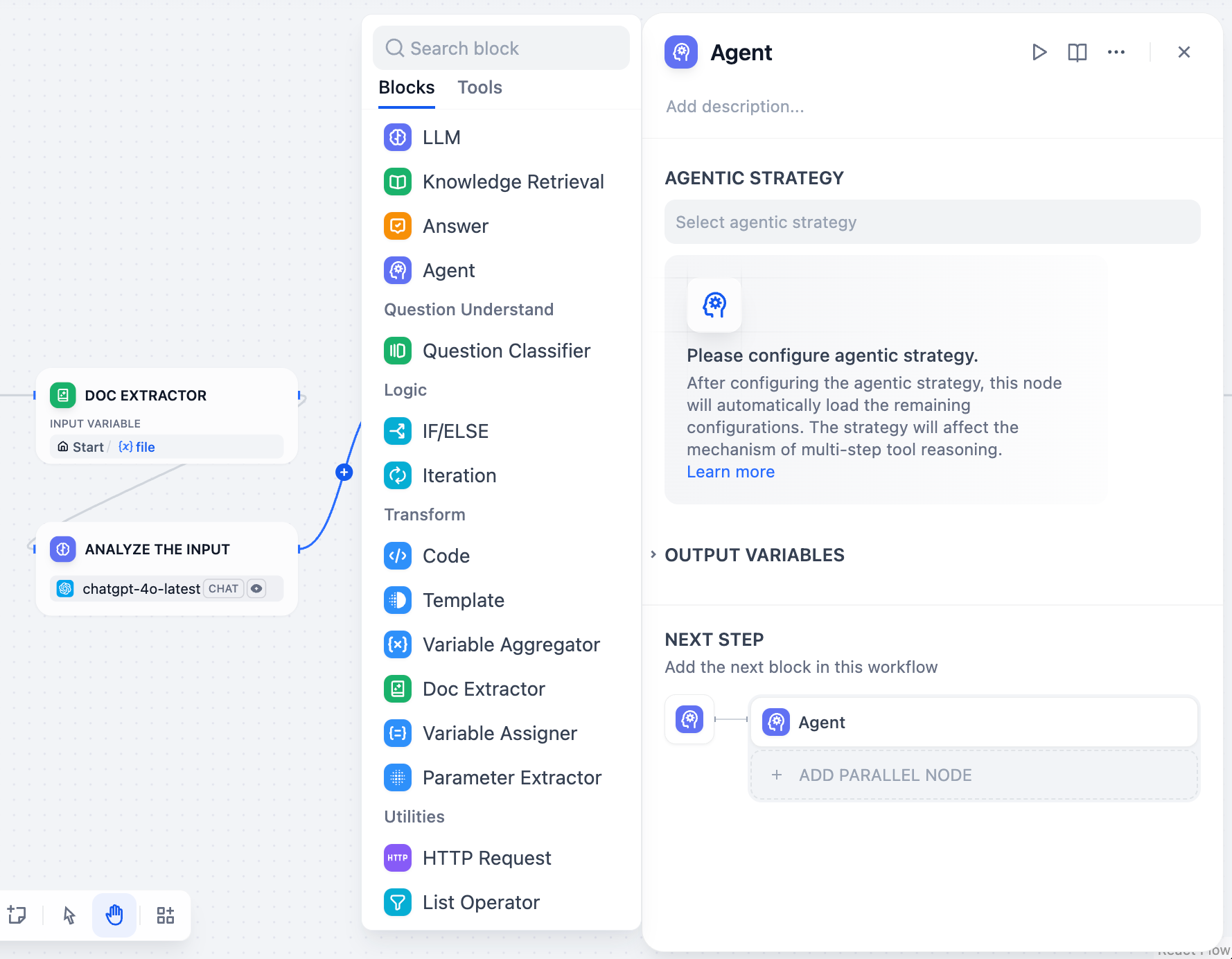
|
||||
|
||||
### Select an Agent Strategy
|
||||
|
||||
In the node configuration panel, click Agent Strategy.
|
||||
|
||||
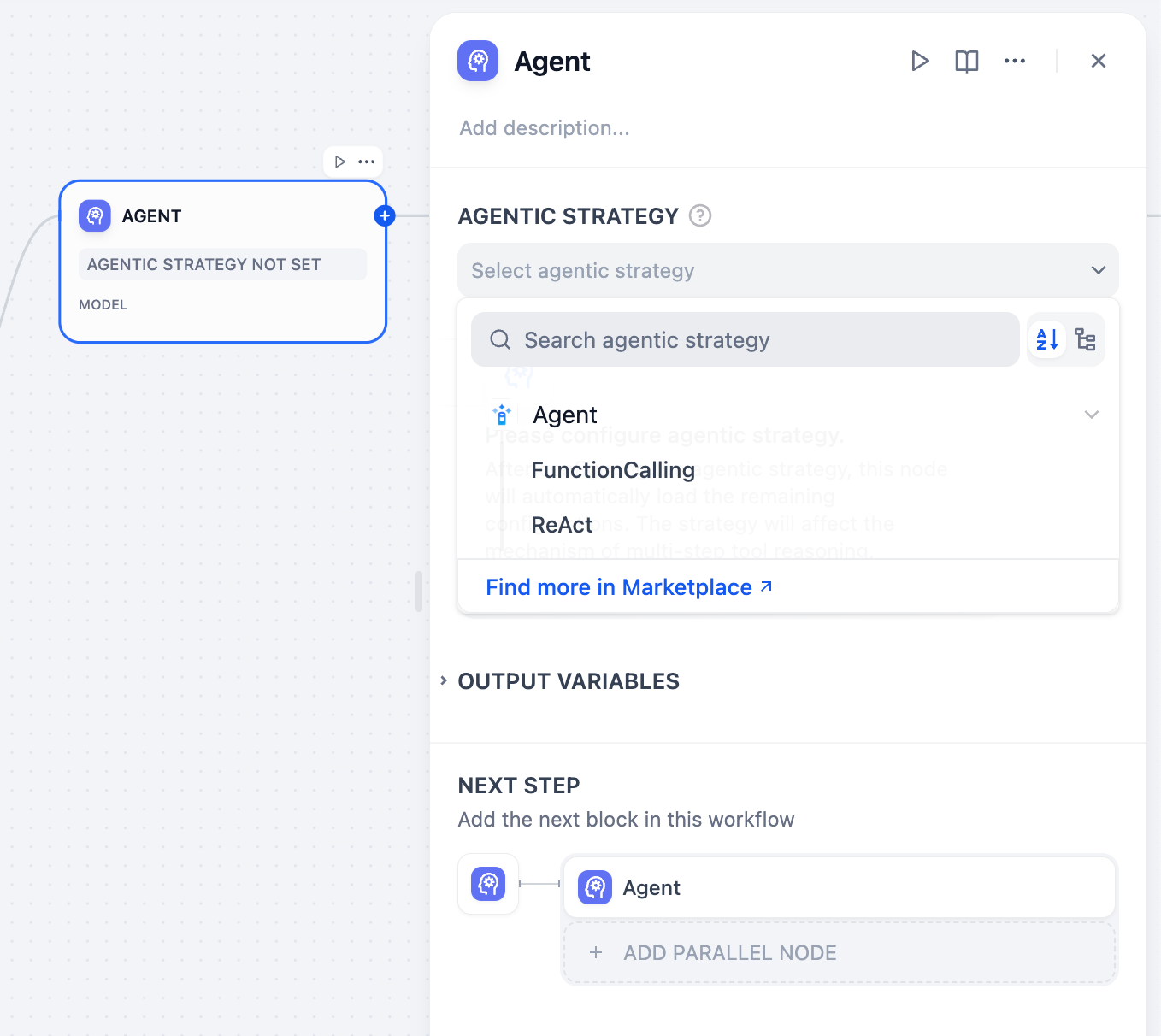
|
||||
|
||||
From the dropdown menu, select the desired Agent reasoning strategy. Dify provides two built-in strategies, **Function Calling and ReAct**, which can be installed from the **Marketplace → Agent Strategies category**.
|
||||
|
||||
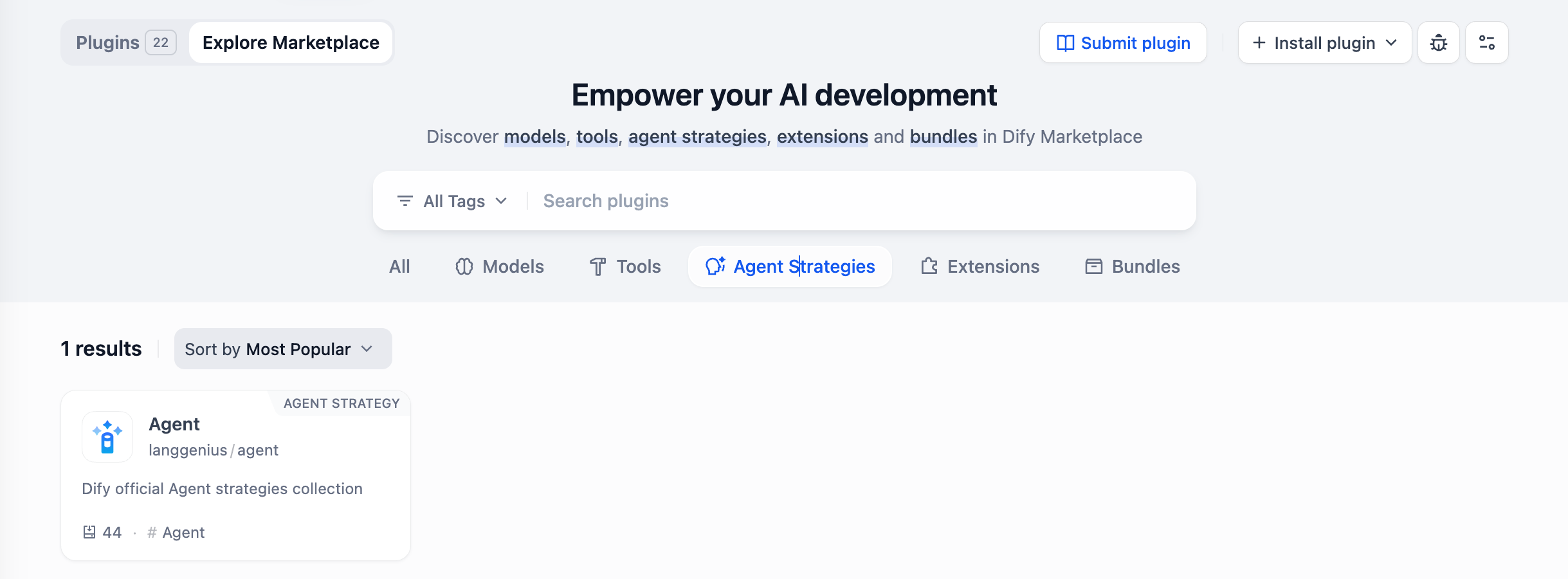
|
||||
|
||||
#### 1. Function Calling
|
||||
|
||||
Function Calling maps user commands to predefined functions or tools. The LLM first identifies user intent, then decides which function to call and extracts the required parameters. Its core mechanism involves explicitly calling external functions or tools.
|
||||
|
||||
Pros:
|
||||
|
||||
**• Precision:** For well-defined tasks, it can call the corresponding tool directly without requiring complex reasoning.
|
||||
|
||||
**• Easier external feature integration:** Various external APIs or tools can be wrapped into functions for the model to call.
|
||||
|
||||
**• Structured output:** The model outputs structured information about function calls, facilitating processing by downstream nodes.
|
||||
|
||||
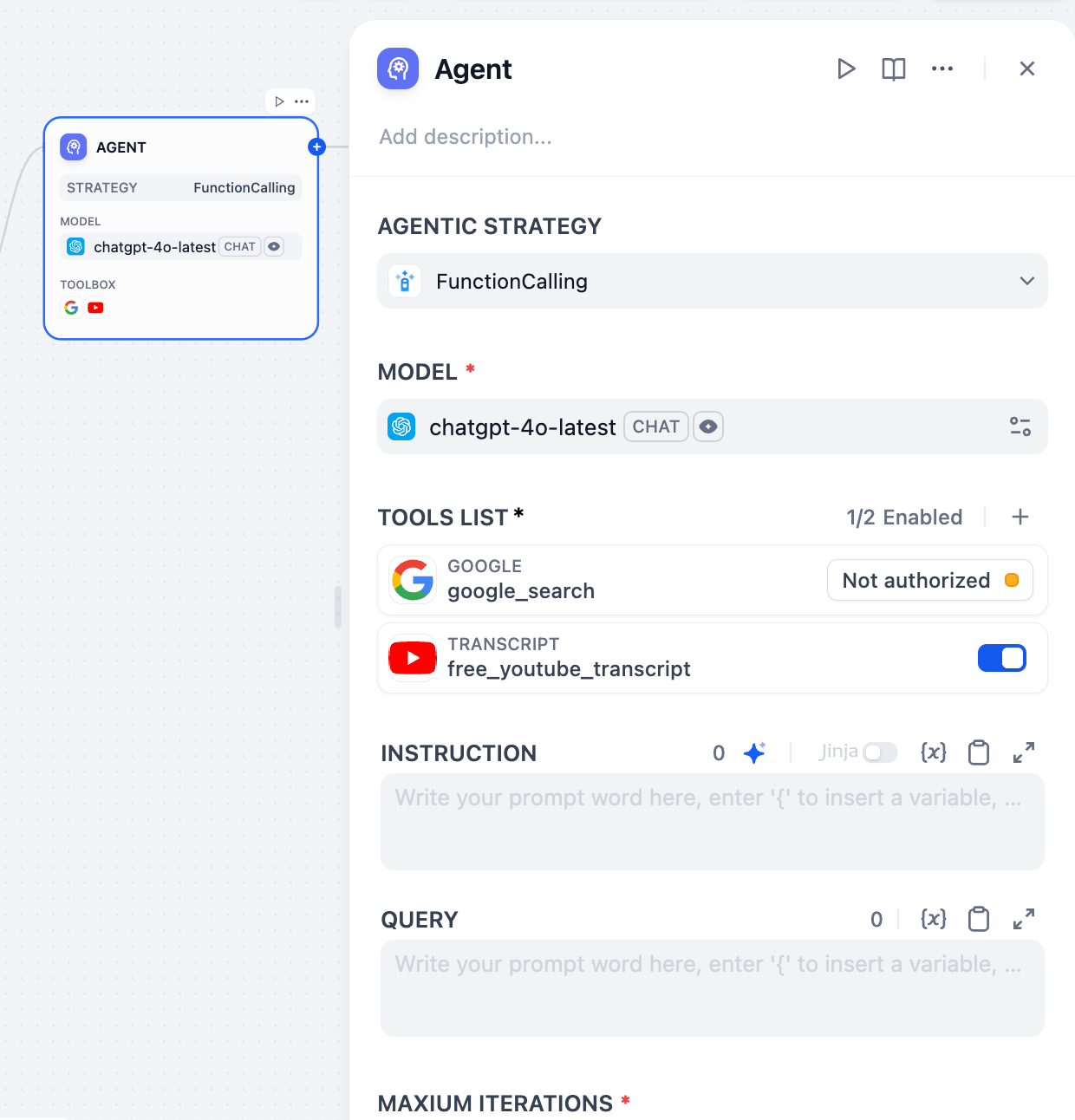
|
||||
|
||||
#### 2. ReAct (Reason + Act)
|
||||
|
||||
ReAct enables the Agent to alternate between reasoning and taking action: the LLM first thinks about the current state and goal, then selects and calls the appropriate tool. The tool’s output in turn informs the LLM’s next step of reasoning and action. This cycle continues until the problem is resolved.
|
||||
|
||||
Pros:
|
||||
|
||||
**• Effective external information use:** It can leverage external tools to retrieve information and handle tasks that the model alone cannot accomplish.
|
||||
|
||||
**• Improved explainability:** Because reasoning and actions are interwoven, there is a certain level of traceability in the Agent’s thought process.
|
||||
|
||||
**• Wide applicability:** Suitable for scenarios that require external knowledge or need to perform specific actions, such as Q\&A, information retrieval, and task execution.
|
||||
|
||||
|
||||
|
||||
Developers can contribute Agent strategy plugins to the public [repository](https://github.com/langgenius/dify-plugins). After review, these plugins will be listed in the Marketplace for others to install.
|
||||
|
||||
### Configure Node Parameters
|
||||
|
||||
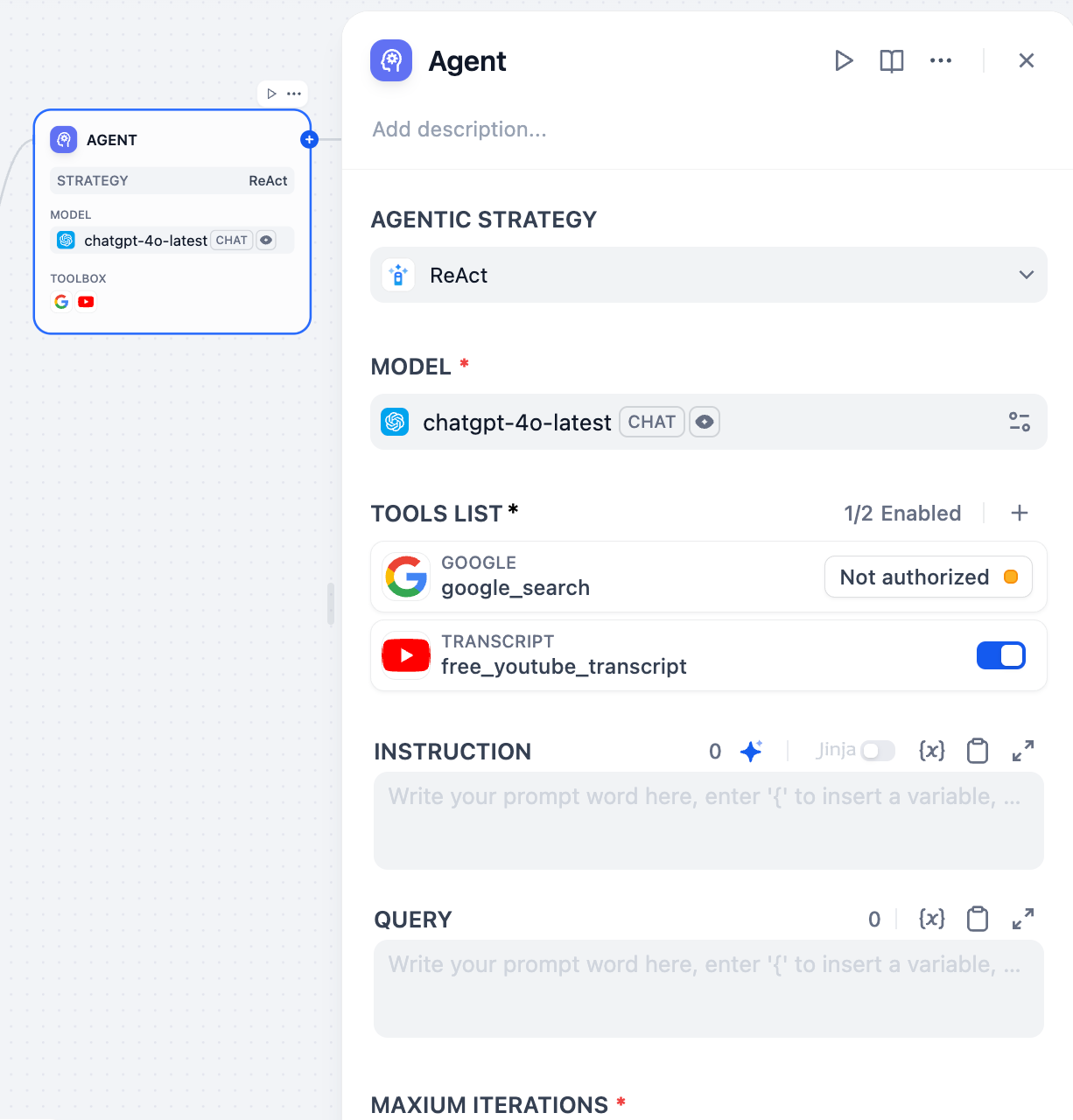
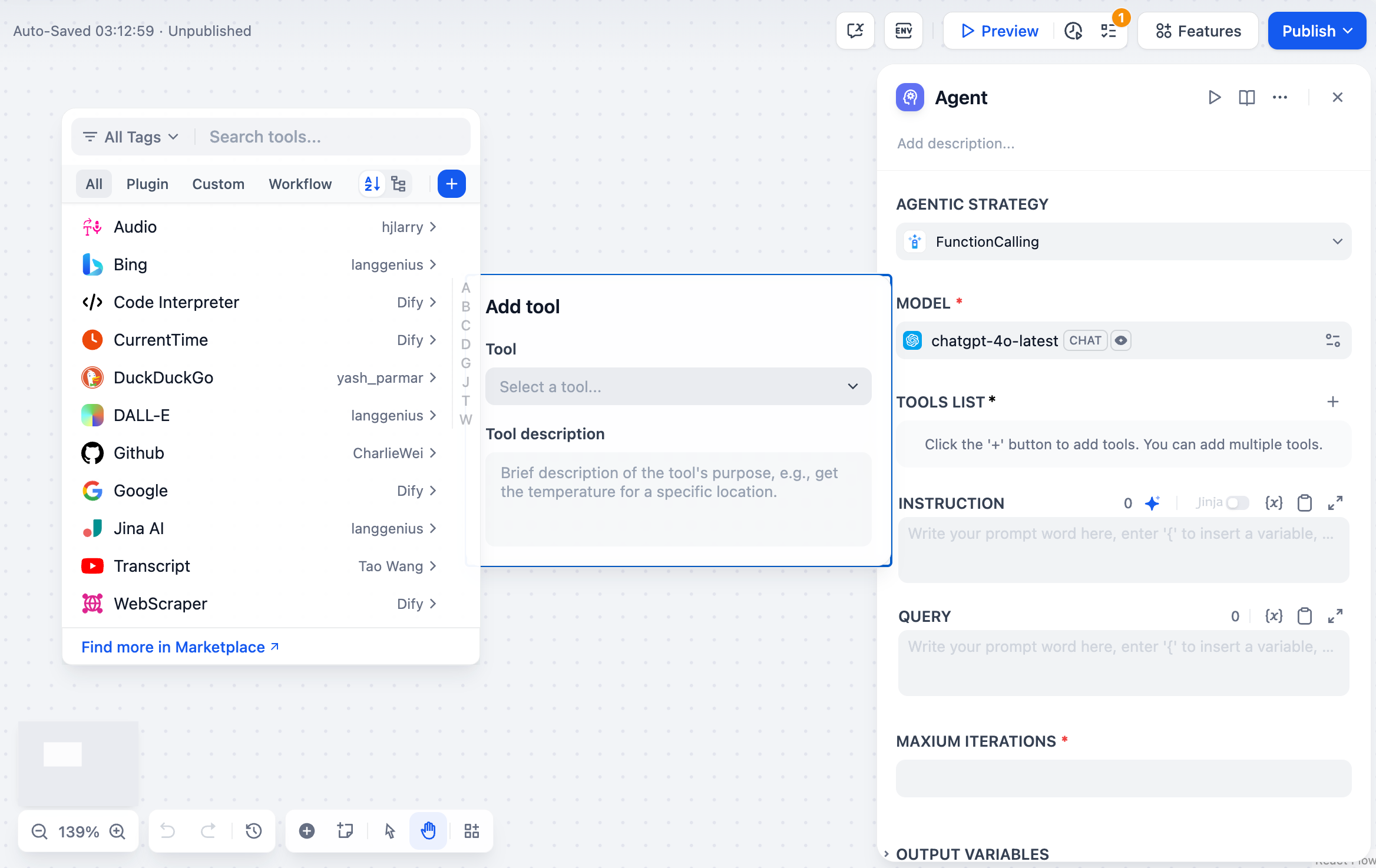
After choosing the Agent strategy, the configuration panel will display the relevant options. For the Function Calling and ReAct strategies that ship with Dify, the available configuration items include:
|
||||
|
||||
1. **Model:** Select the large language model that drives the Agent.
|
||||
2. **Tools List:** The approach to using tools is defined by the Agent strategy. Click + to add and configure tools the Agent can call.
|
||||
* Search: Select an installed tool plugin from the dropdown.
|
||||
* Authorization: Provide API keys and other credentials to enable the tool.
|
||||
* Tool Description and Parameter Settings: Provide a description to help the LLM understand when and why to use the tool, and configure any functional parameters.
|
||||
3. **Instruction**: Define the Agent’s task goals and context. Jinja syntax is supported to reference upstream node variables.
|
||||
4. **Query**: Receives user input.
|
||||
5. **Maximum Iterations:** Set the maximum number of execution steps for the Agent.
|
||||
6. **Output Variables:** Indicates the data structure output by the node.
|
||||
|
||||
|
||||
|
||||
## Logs
|
||||
|
||||
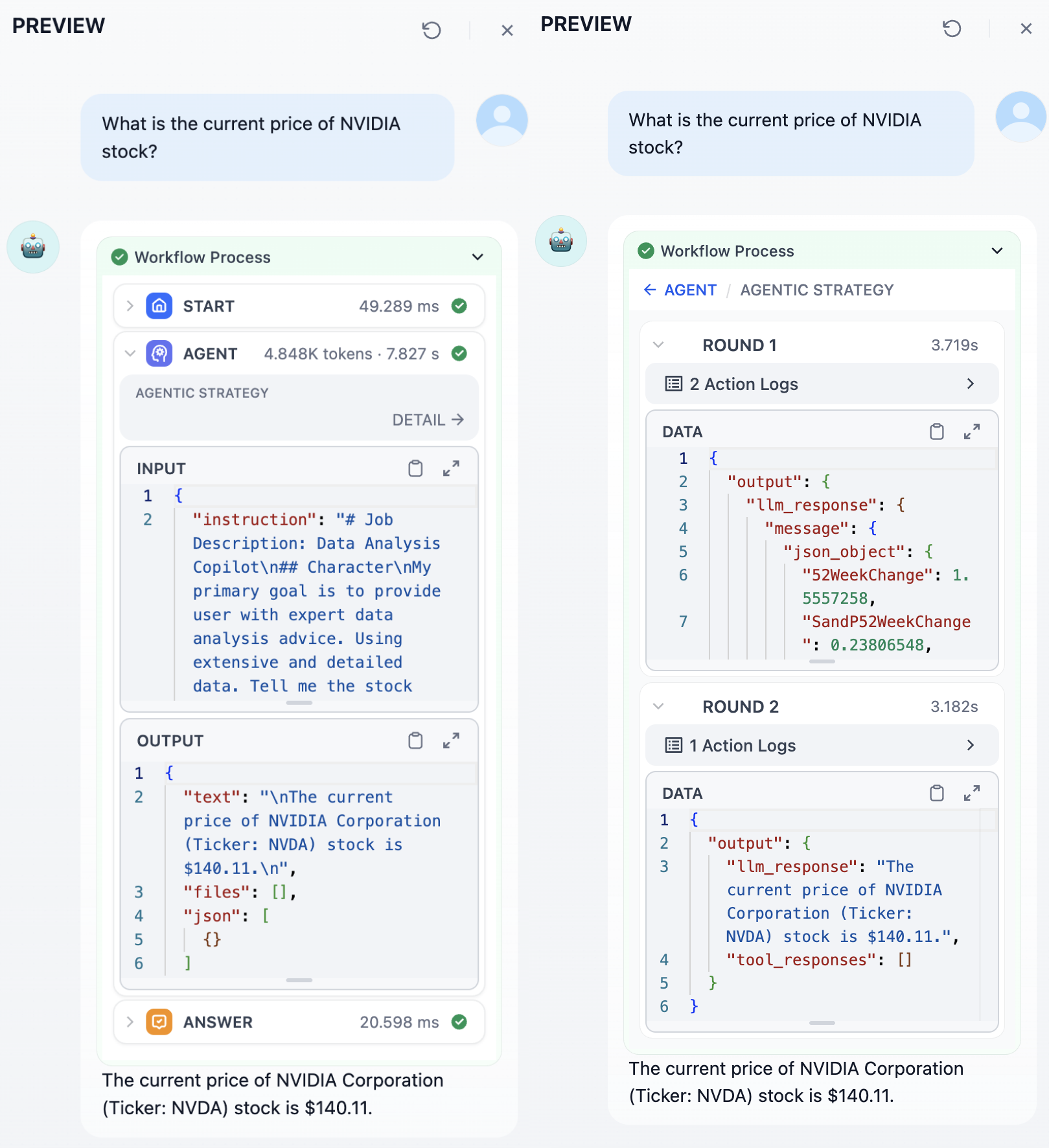
During execution, the Agent node generates detailed logs. You can see overall node execution information—including inputs and outputs, token usage, time spent, and status. Click Details to view the output from each round of Agent strategy execution.
|
||||
|
||||
|
||||
31
en/guides/workflow/node/answer.mdx
Normal file
31
en/guides/workflow/node/answer.mdx
Normal file
@@ -0,0 +1,31 @@
|
||||
---
|
||||
title: Answer
|
||||
---
|
||||
|
||||
|
||||
Defining Reply Content in a Chatflow Process. In a text editor, you have the flexibility to determine the reply format. This includes crafting a fixed block of text, utilizing output variables from preceding steps as the reply content, or merging custom text with variables for the response.
|
||||
|
||||
Answer node can be seamlessly integrated at any point to dynamically deliver content into the dialogue responses. This setup supports a live-editing configuration mode, allowing for both text and image content to be arranged together. The configurations include:
|
||||
|
||||
1. Outputting the reply content from a Language Model (LLM) node.
|
||||
2. Outputting generated images.
|
||||
3. Outputting plain text.
|
||||
|
||||
Example 1: Output plain text.
|
||||
|
||||
<div class="image-side-by-side">
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/1b1fadb8f838963134fc5c9eb14b5632.png)
|
||||
|
||||
Example 2: Output image and LLM reply.
|
||||
|
||||

|
||||
* [Usage Scenarios](#usage-scenarios)
|
||||
* [Local Deployment](#local-deployment)
|
||||
* [Security Policies](#security-policies)
|
||||
|
||||
## Introduction
|
||||
|
||||
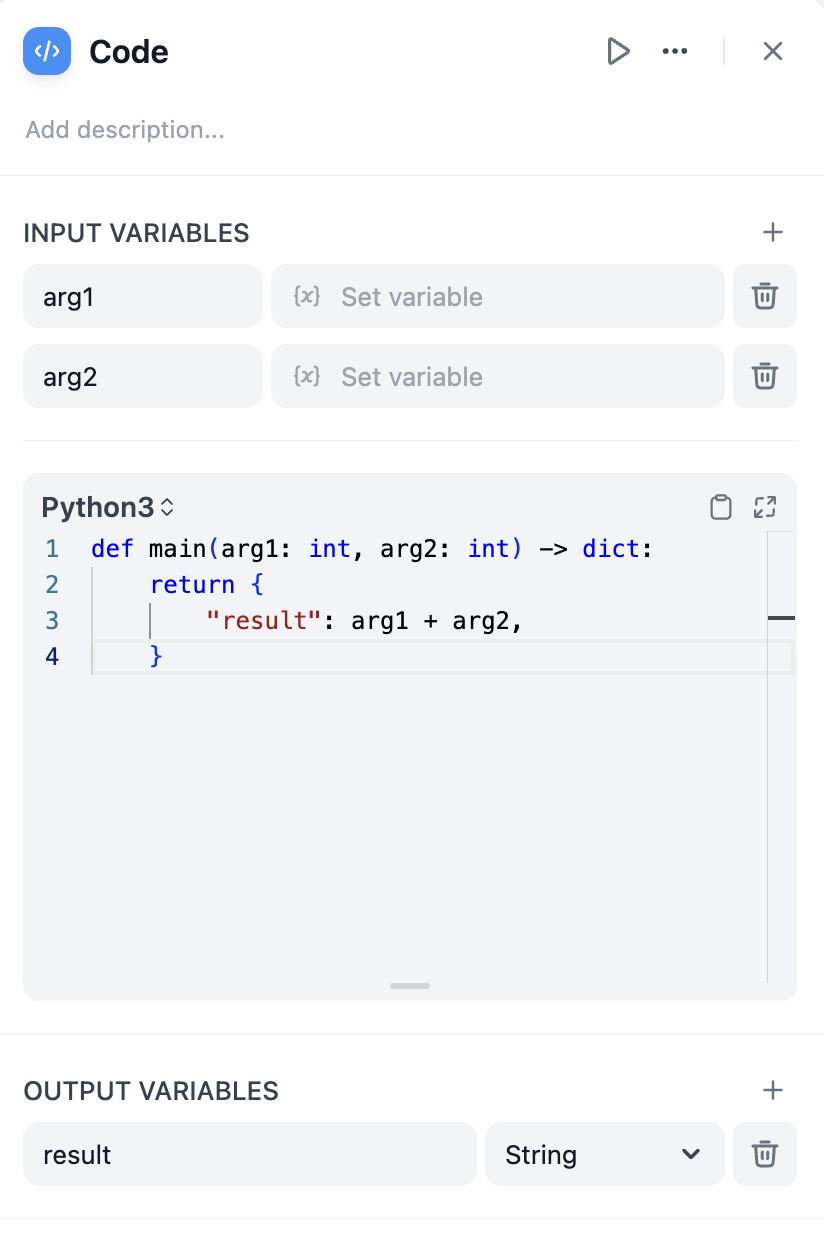
The code node supports running Python/NodeJS code to perform data transformations within a workflow. It can simplify your workflow and is suitable for scenarios such as arithmetic operations, JSON transformations, text processing, and more.
|
||||
|
||||
This node significantly enhances the flexibility for developers, allowing them to embed custom Python or JavaScript scripts within the workflow and manipulate variables in ways that preset nodes cannot achieve. Through configuration options, you can specify the required input and output variables and write the corresponding execution code:
|
||||
|
||||
|
||||
|
||||
## Configuration
|
||||
|
||||
If you need to use variables from other nodes in the code node, you must define the variable names in the `input variables` and reference these variables. You can refer to [Variable References](/en/guides/workflow/variables).
|
||||
|
||||
## Usage Scenarios
|
||||
|
||||
Using the code node, you can perform the following common operations:
|
||||
|
||||
### Structured Data Processing
|
||||
|
||||
In workflows, you often have to deal with unstructured data processing, such as parsing, extracting, and transforming JSON strings. A typical example is data processing from an HTTP node. In common API return structures, data may be nested within multiple layers of JSON objects, and you need to extract certain fields. The code node can help you perform these operations. Here is a simple example that extracts the `data.name` field from a JSON string returned by an HTTP node:
|
||||
|
||||
```python
|
||||
def main(http_response: str) -> str:
|
||||
import json
|
||||
data = json.loads(http_response)
|
||||
return {
|
||||
# Note to declare 'result' in the output variables
|
||||
'result': data['data']['name']
|
||||
}
|
||||
```
|
||||
|
||||
### Mathematical Calculations
|
||||
|
||||
When you need to perform complex mathematical calculations in a workflow, you can also use the code node. For example, calculating a complex mathematical formula or performing some statistical analysis on data. Here is a simple example that calculates the variance of an array:
|
||||
|
||||
```python
|
||||
def main(x: list) -> float:
|
||||
return {
|
||||
# Note to declare 'result' in the output variables
|
||||
'result': sum([(i - sum(x) / len(x)) ** 2 for i in x]) / len(x)
|
||||
}
|
||||
```
|
||||
|
||||
### Data Concatenation
|
||||
|
||||
Sometimes, you may need to concatenate multiple data sources, such as multiple knowledge retrievals, data searches, API calls, etc. The code node can help you integrate these data sources together. Here is a simple example that merges data from two knowledge bases:
|
||||
|
||||
```python
|
||||
def main(knowledge1: list, knowledge2: list) -> list:
|
||||
return {
|
||||
# Note to declare 'result' in the output variables
|
||||
'result': knowledge1 + knowledge2
|
||||
}
|
||||
```
|
||||
|
||||
## Local Deployment
|
||||
|
||||
If you are a local deployment user, you need to start a sandbox service to ensure that malicious code is not executed. This service requires the use of Docker. You can find specific information about the sandbox service [here](https://github.com/langgenius/dify/tree/main/docker/docker-compose.middleware.yaml). You can also start the service directly via `docker-compose`:
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.middleware.yaml up -d
|
||||
```
|
||||
|
||||
## Security Policies
|
||||
|
||||
Both Python and JavaScript execution environments are strictly isolated (sandboxed) to ensure security. This means that developers cannot use functions that consume large amounts of system resources or may pose security risks, such as direct file system access, making network requests, or executing operating system-level commands. These limitations ensure the safe execution of the code while avoiding excessive consumption of system resources.
|
||||
|
||||
### Advanced Features
|
||||
|
||||
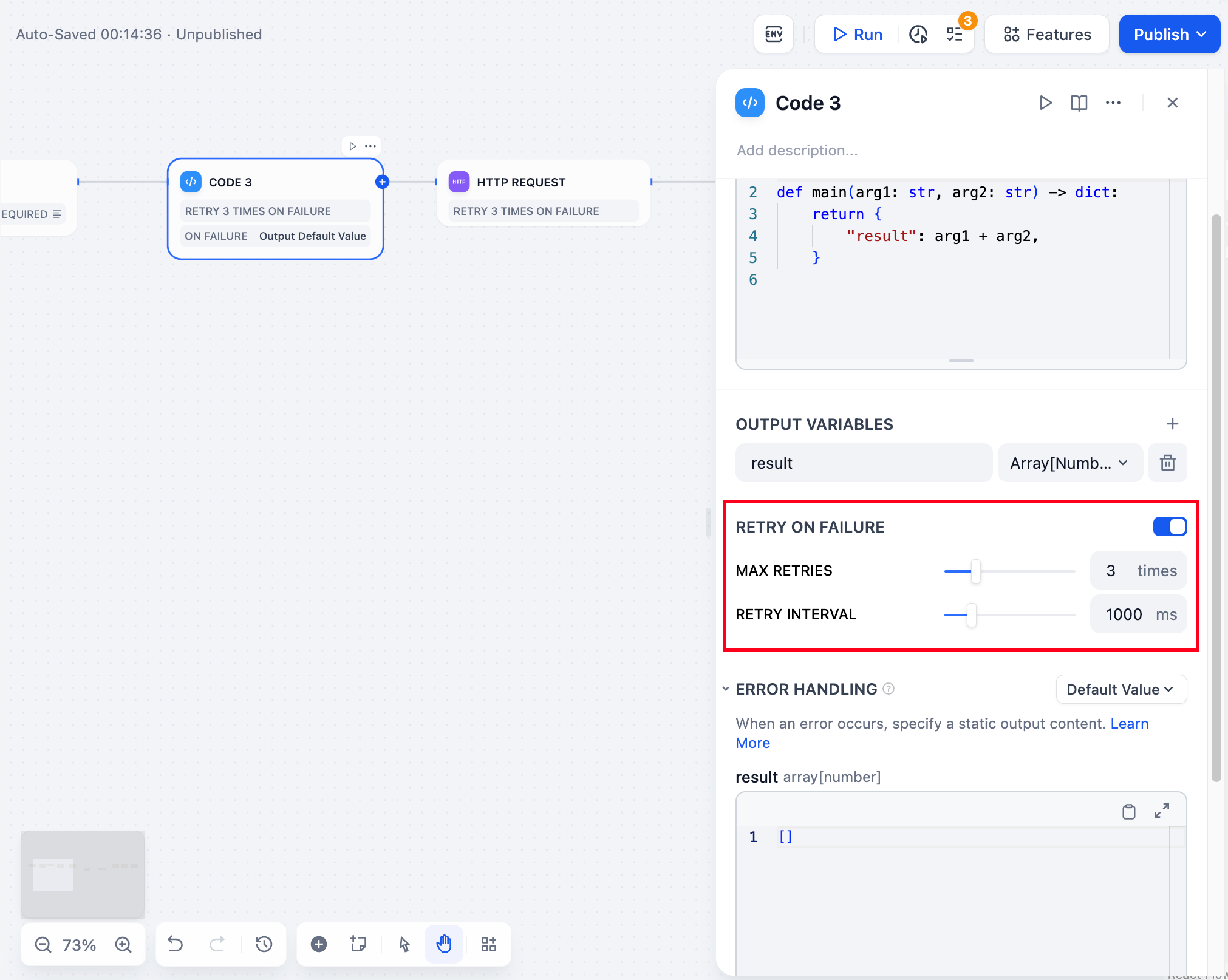
**Retry on Failure**
|
||||
|
||||
For some exceptions that occur in the node, it is usually sufficient to retry the node again. When the error retry function is enabled, the node will automatically retry according to the preset strategy when an error occurs. You can adjust the maximum number of retries and the interval between each retry to set the retry strategy.
|
||||
|
||||
- The maximum number of retries is 10
|
||||
- The maximum retry interval is 5000 ms
|
||||
|
||||
|
||||
|
||||
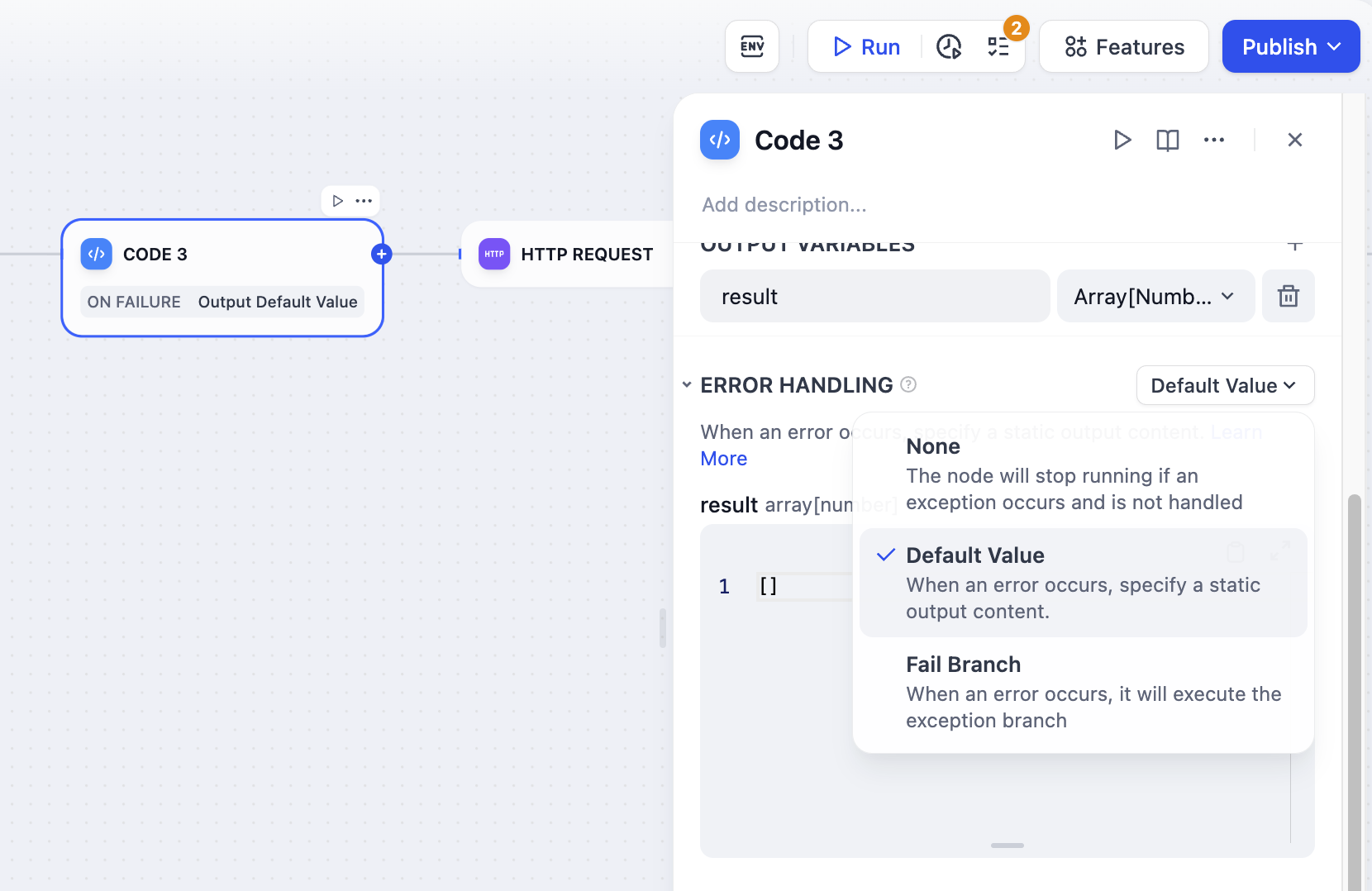
**Error Handling**
|
||||
|
||||
When processing information, code nodes may encounter code execution exceptions. Developers can follow these steps to configure fail branches, enabling contingency plans when nodes encounter exceptions, thus avoiding workflow interruptions.
|
||||
|
||||
1. Enable "Error Handling" in the code node
|
||||
2. Select and configure an error handling strategy
|
||||
|
||||
|
||||
|
||||
For more information about exception handling approaches, please refer to [Error Handling](/en/guides/workflow/error-handling).
|
||||
|
||||
### FAQ
|
||||
|
||||
**Why can't I save the code it in the code node?**
|
||||
|
||||
Please check if the code contains potentially dangerous behaviors. For example:
|
||||
|
||||
```python
|
||||
def main() -> dict:
|
||||
return {
|
||||
"result": open("/etc/passwd").read(),
|
||||
}
|
||||
```
|
||||
|
||||
This code snippet has the following issues:
|
||||
|
||||
* **Unauthorized file access:** The code attempts to read the "/etc/passwd" file, which is a critical system file in Unix/Linux systems that stores user account information.
|
||||
* **Sensitive information disclosure:** The "/etc/passwd" file contains important information about system users, such as usernames, user IDs, group IDs, home directory paths, etc. Direct access could lead to information leakage.
|
||||
|
||||
Dangerous code will be automatically blocked by Cloudflare WAF. You can check if it's been blocked by looking at the "Network" tab in your browser's "Web Developer Tools".
|
||||
|
||||
|
||||
|
||||
65
en/guides/workflow/node/doc-extractor.mdx
Normal file
65
en/guides/workflow/node/doc-extractor.mdx
Normal file
@@ -0,0 +1,65 @@
|
||||
---
|
||||
title: Doc Extractor
|
||||
---
|
||||
|
||||
|
||||
#### Definition
|
||||
|
||||
LLMs cannot directly read or interpret document contents. Therefore, it's necessary to parse and read information from user-uploaded documents through a document extractor node, convert it to text, and then pass the content to the LLM to process the file contents.
|
||||
|
||||
#### Application Scenarios
|
||||
|
||||
* Building LLM applications that can interact with files, such as ChatPDF or ChatWord;
|
||||
* Analyzing and examining the contents of user-uploaded files;
|
||||
|
||||
#### Node Functionality
|
||||
|
||||
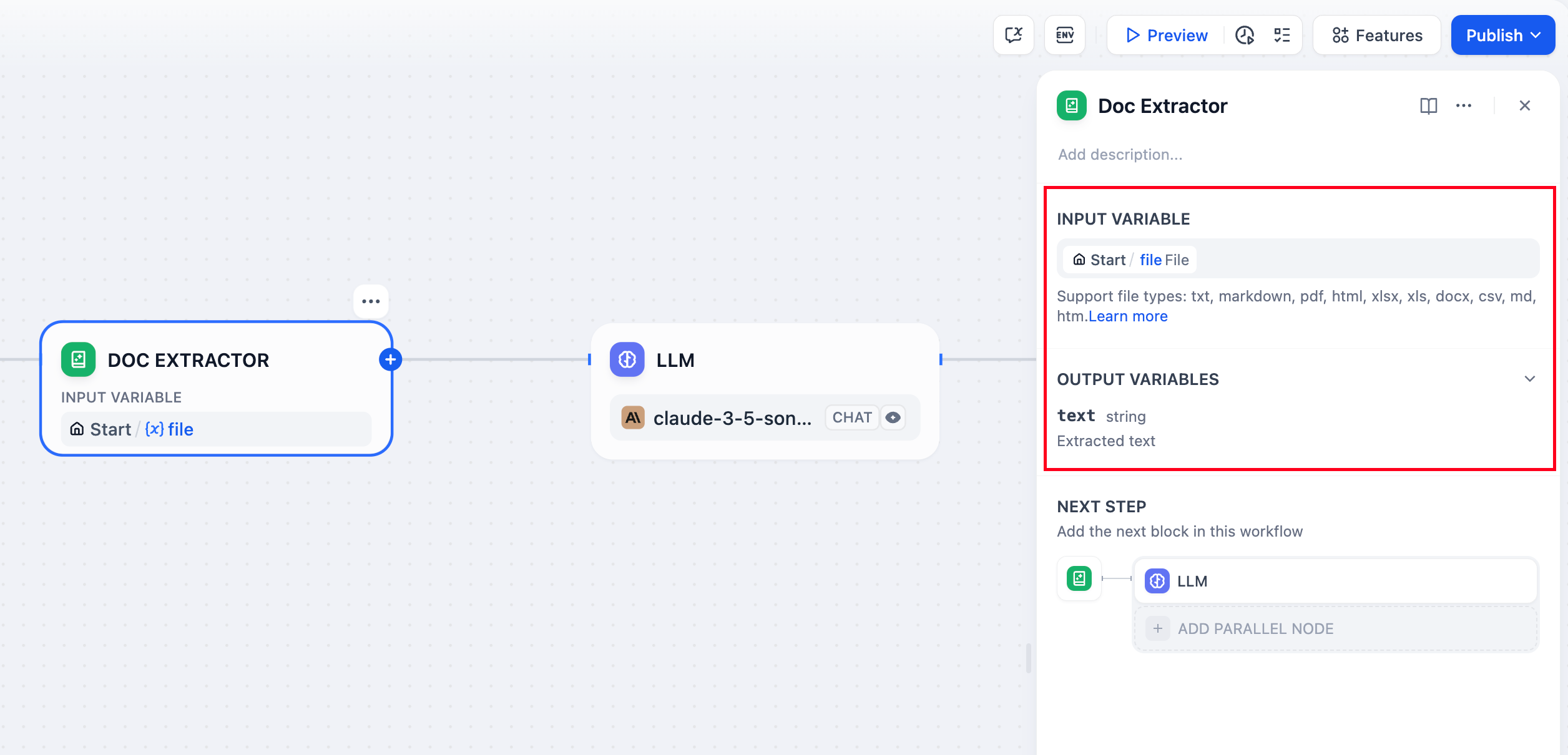
The document extractor node can be understood as an information processing center. It recognizes and reads files in the input variables, extracts information, and converts it into string-type output variables for downstream nodes to call.
|
||||
|
||||
|
||||
|
||||
The document extractor node structure is divided into input variables and output variables.
|
||||
|
||||
**Input Variables**
|
||||
|
||||
The document extractor only accepts variables with the following data structures:
|
||||
|
||||
* `File`, a single file
|
||||
* `Array[File]`, multiple files
|
||||
|
||||
The document extractor can only extract information from document-type files, such as the contents of TXT, Markdown, PDF, HTML, DOCX format files. It cannot process image, audio, video, or other file formats.
|
||||
|
||||
**Output Variables**
|
||||
|
||||
The output variable is fixed and named as text. The type of output variable depends on the input variable:
|
||||
|
||||
* If the input variable is `File`, the output variable is `string`
|
||||
* If the input variable is `Array[File]`, the output variable is `array[string]`
|
||||
|
||||
> Array variables generally need to be used in conjunction with list operation nodes. For details, please refer to [List Operator](/en/guides/workflow/nodes/list-operator).
|
||||
|
||||
#### Configuration Example
|
||||
|
||||
In a typical file interaction Q\&A scenario, the document extractor can serve as a preliminary step for the LLM node, extracting file information from the application and passing it to the downstream LLM node to answer user questions about the file.
|
||||
|
||||
This section will introduce the usage of the document extractor node through a typical ChatPDF example workflow template.
|
||||
|
||||
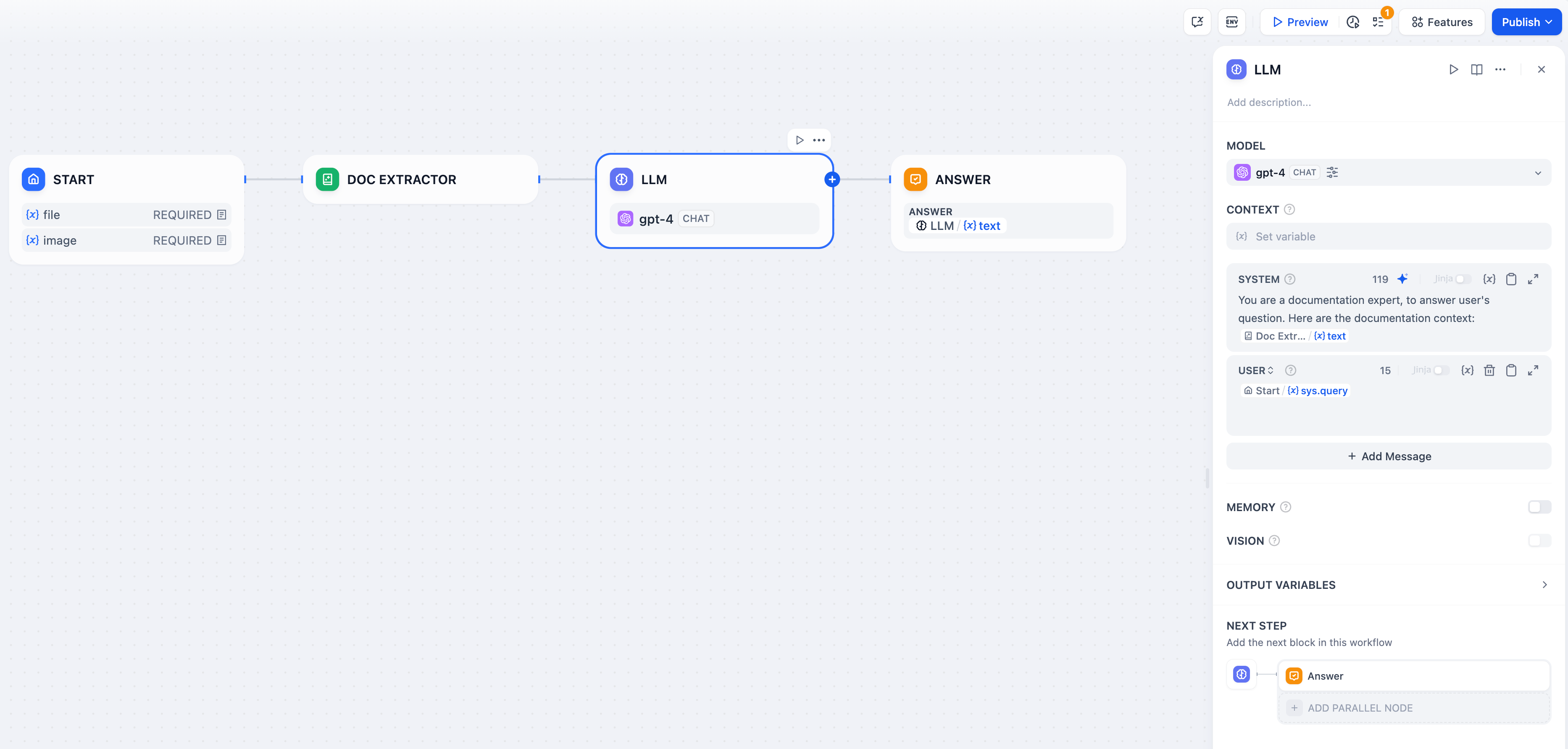
|
||||
|
||||
**Configuration Process:**
|
||||
|
||||
1. Enable file upload for the application. Add a **single file variable** in the "Start" node and name it `pdf`.
|
||||
2. Add a document extractor node and select the `pdf` variable in the input variables.
|
||||
3. Add an LLM node and select the output variable of the document extractor node in the system prompt. The LLM can read the contents of the file through this output variable.
|
||||
|
||||
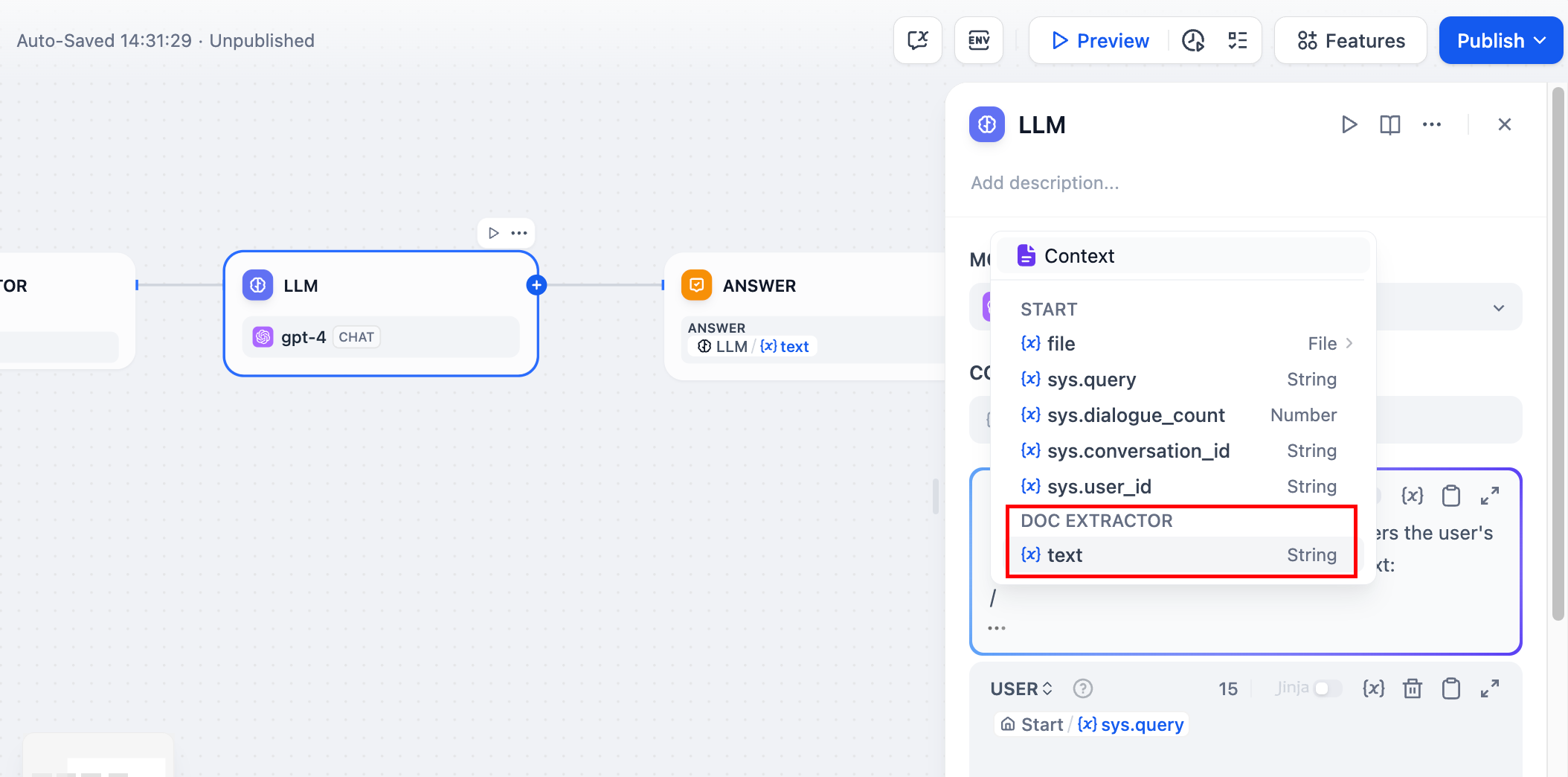
|
||||
|
||||
Configure the end node by selecting the output variable of the LLM node in the end node.
|
||||
|
||||
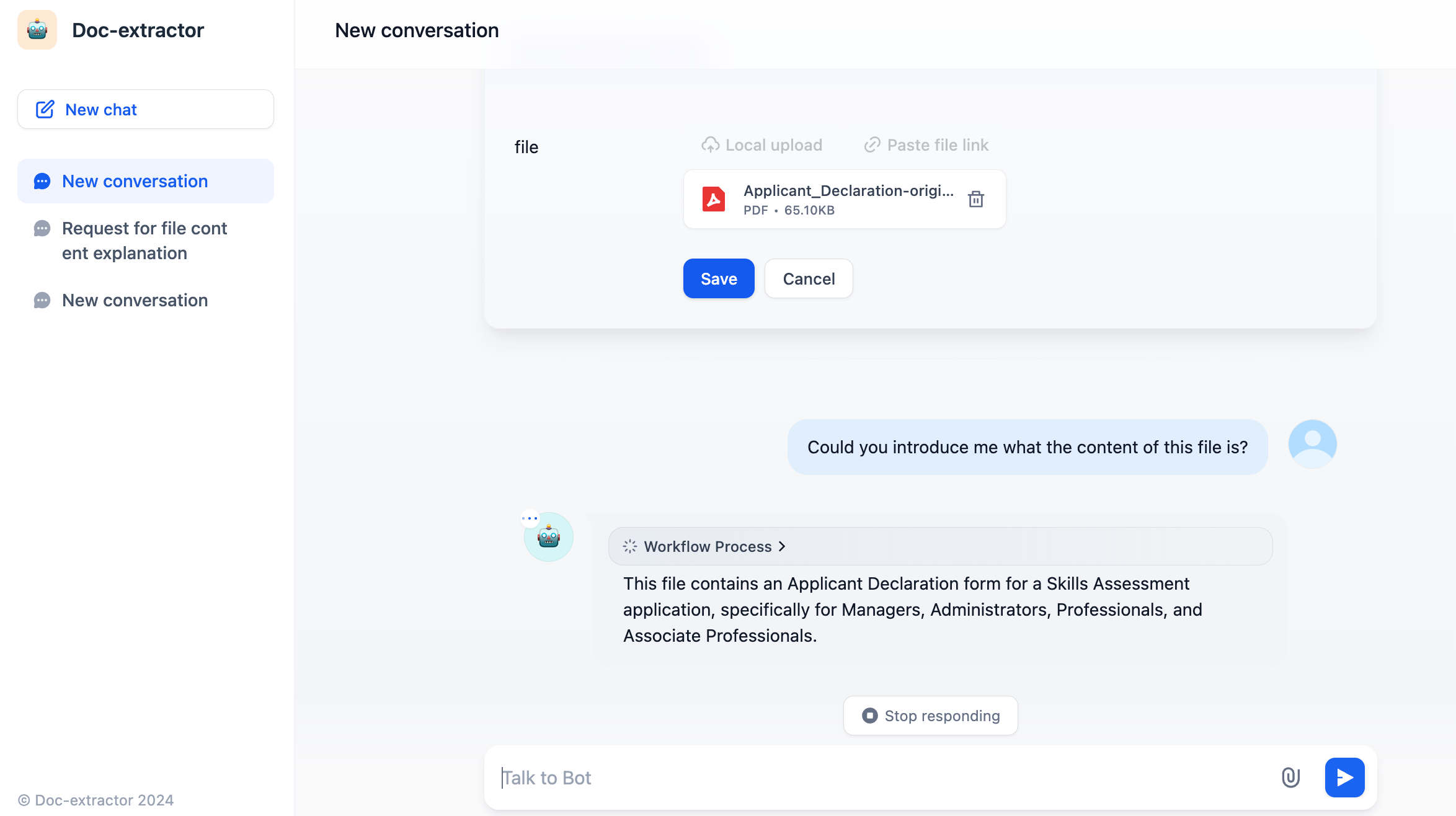
|
||||
|
||||
After configuration, the application will have file upload functionality, allowing users to upload PDF files and engage in conversation.
|
||||
|
||||
<Info>
|
||||
For how to upload files in chat conversations and interact with the LLM, please refer to [Additional Features](/en/guides/workflow/additional-features).
|
||||
</Info>
|
||||
32
en/guides/workflow/node/end.mdx
Normal file
32
en/guides/workflow/node/end.mdx
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
title: End
|
||||
---
|
||||
|
||||
|
||||
### 1 Definition
|
||||
|
||||
Define the final output content of a workflow. Every workflow needs at least one end node after complete execution to output the final result.
|
||||
|
||||
The end node is a termination point in the process; no further nodes can be added after it. In a workflow application, results are only output when the end node is reached. If there are conditional branches in the process, multiple end nodes need to be defined.
|
||||
|
||||
The end node must declare one or more output variables, which can reference any upstream node's output variables.
|
||||
|
||||
<Info>
|
||||
End nodes are not supported within Chatflow.
|
||||
</Info>
|
||||
|
||||
***
|
||||
|
||||
### 2 Scenarios
|
||||
|
||||
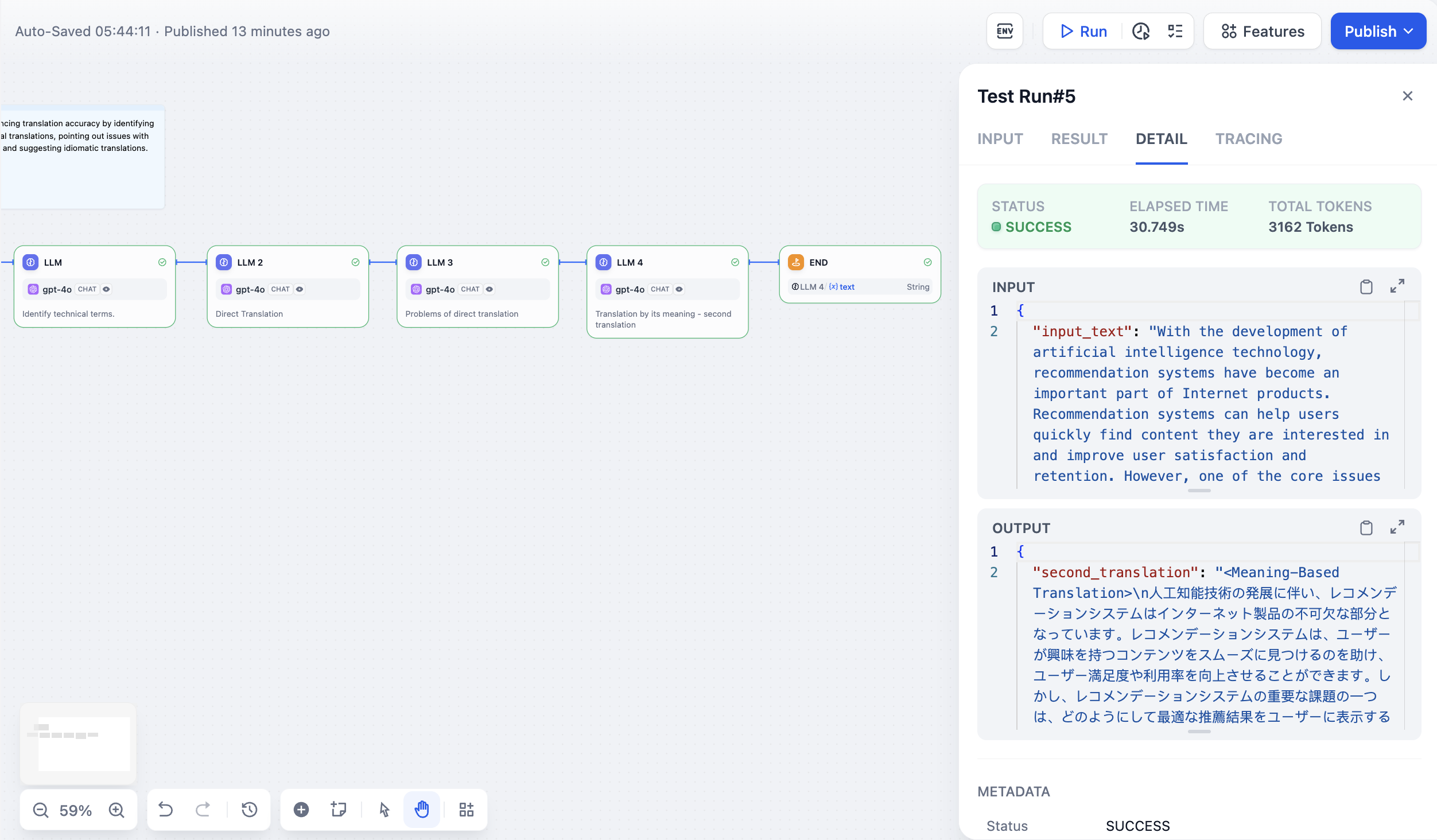
In the following [long story generation workflow](/en/guides/workflow/nodes/iteration#example-2-long-article-iterative-generation-another-scheduling-method), the variable `Output` declared by the end node is the output of the upstream code node. This means the workflow will end after the Code node completes execution and will output the execution result of Code.
|
||||
|
||||
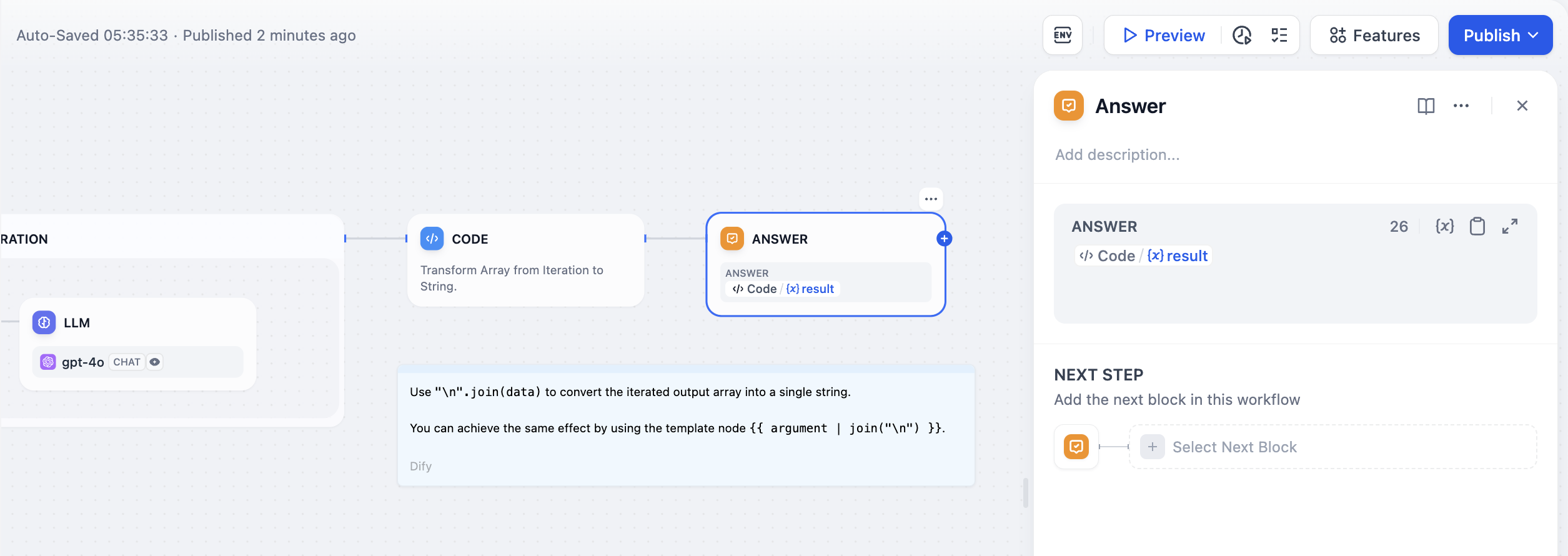
|
||||
|
||||
**Single Path Execution Example:**
|
||||
|
||||
|
||||
|
||||
**Multi-Path Execution Example:**
|
||||
|
||||
|
||||
65
en/guides/workflow/node/http-request.mdx
Normal file
65
en/guides/workflow/node/http-request.mdx
Normal file
@@ -0,0 +1,65 @@
|
||||
---
|
||||
title: HTTP Request
|
||||
---
|
||||
|
||||
|
||||
### Definition
|
||||
|
||||
Allows sending server requests via the HTTP protocol, suitable for scenarios such as retrieving external data, webhooks, generating images, and downloading files. It enables you to send customized HTTP requests to specified web addresses, achieving interconnectivity with various external services.
|
||||
|
||||
This node supports common HTTP request methods:
|
||||
|
||||
* **GET**: Used to request the server to send a specific resource.
|
||||
* **POST**: Used to submit data to the server, typically for submitting forms or uploading files.
|
||||
* **HEAD**: Similar to GET requests, but the server only returns the response headers without the resource body.
|
||||
* **PATCH**: Used to apply partial modifications to a resource.
|
||||
* **PUT**: Used to upload resources to the server, typically for updating an existing resource or creating a new one.
|
||||
* **DELETE**: Used to request the server to delete a specified resource.
|
||||
|
||||
You can configure various aspects of the HTTP request, including URL, request headers, query parameters, request body content, and authentication information.
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
### Scenarios
|
||||
|
||||
* **Send Application Interaction Content to a Specific Server**
|
||||
|
||||
One practical feature of this node is the ability to dynamically insert variables into different parts of the request based on the scenario. For example, when handling customer feedback requests, you can embed variables such as username or customer ID, feedback content, etc., into the request to customize automated reply messages or fetch specific customer information and send related resources to a designated server.
|
||||
|
||||
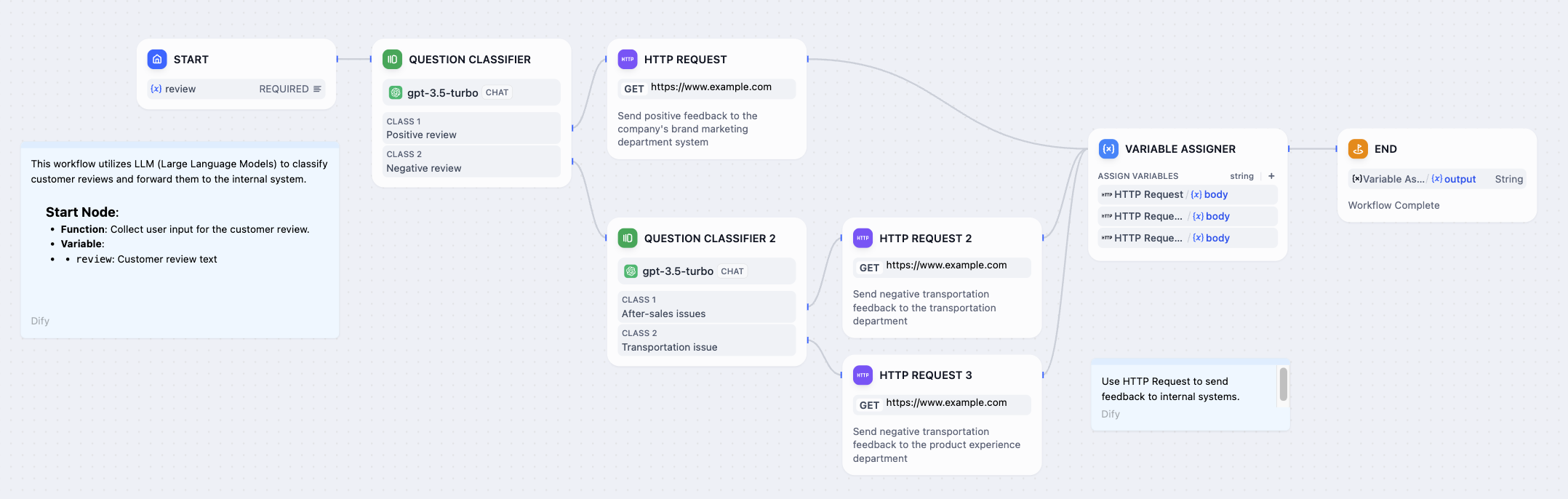
|
||||
|
||||
The return values of an HTTP request include the response body, status code, response headers, and files. Notably, if the response contains a file, this node can automatically save the file for use in subsequent steps of the workflow. This design not only improves processing efficiency but also makes handling responses with files straightforward and direct.
|
||||
|
||||
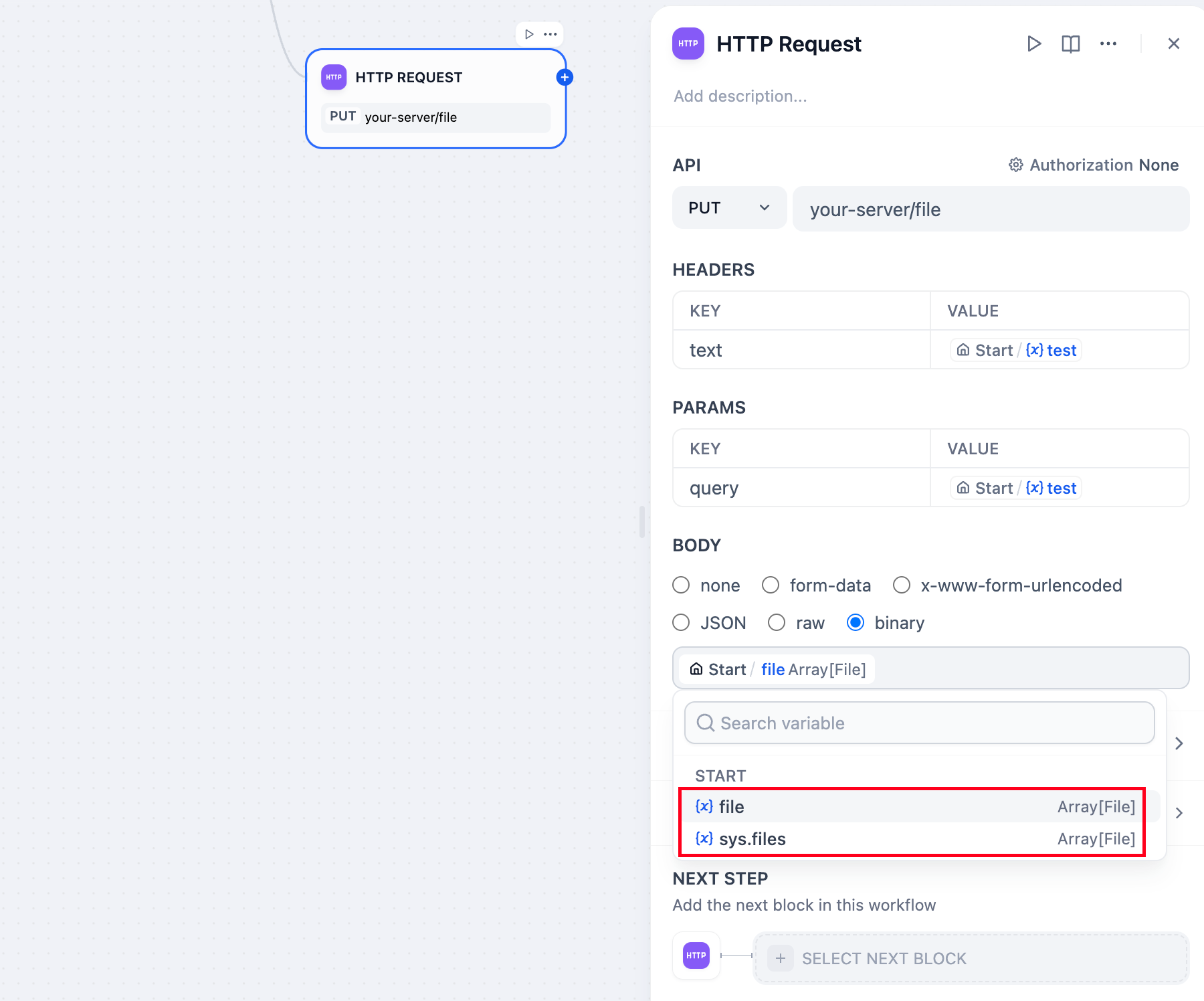
* **Send File**
|
||||
|
||||
You can use an HTTP PUT request to send files from the application to other API services. In the request body, you can select the file variable within the `binary`. This method is commonly used in scenarios such as file transfer, document storage, or media processing.
|
||||
|
||||
Example: Suppose you are developing a document management application and need to send a user-uploaded PDF file to a third-party service. You can use an HTTP request node to pass the file variable.
|
||||
|
||||
Here is a configuration example:
|
||||
|
||||
|
||||
|
||||
### Advanced Features
|
||||
|
||||
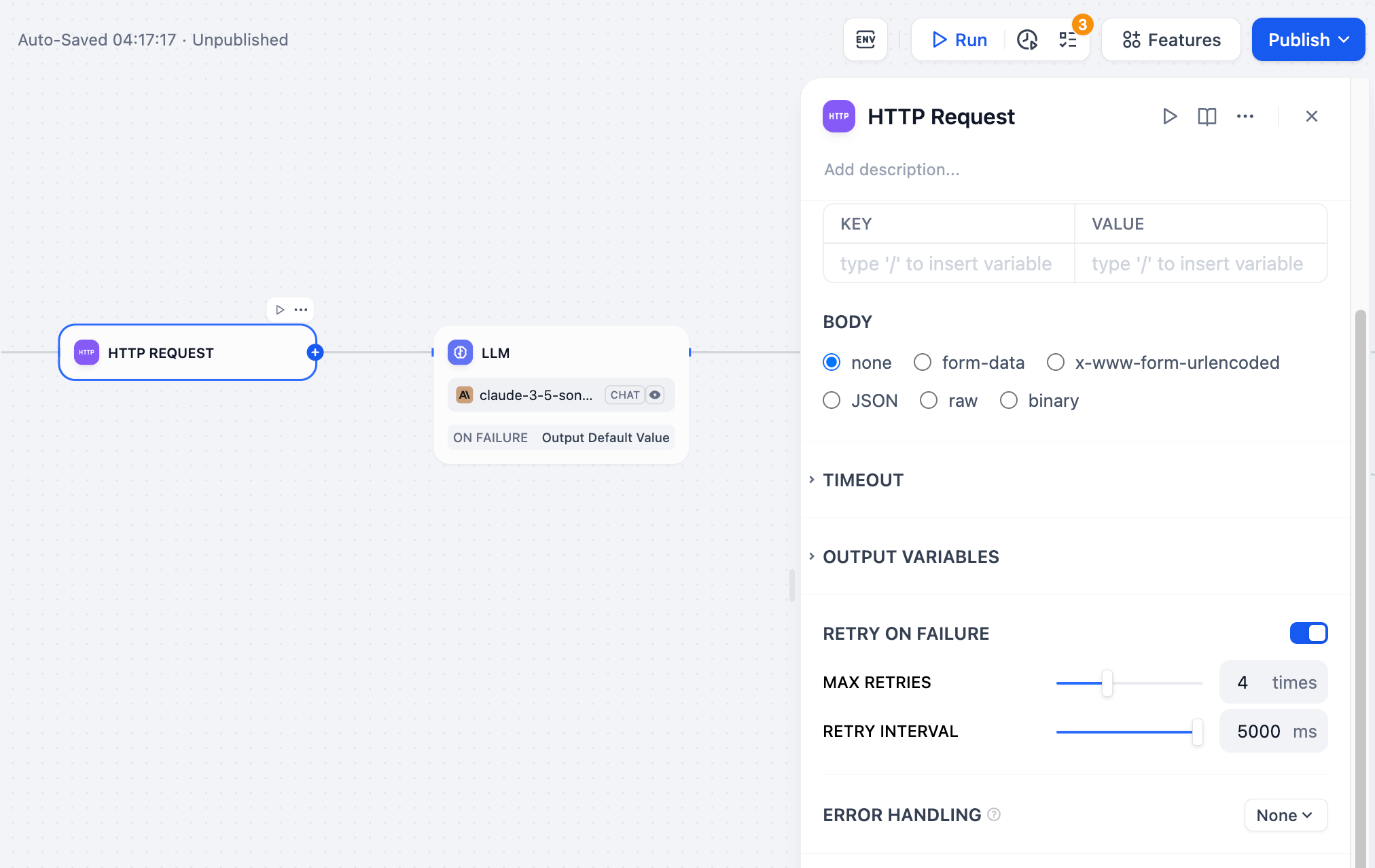
**Retry on Failure**
|
||||
|
||||
For some exceptions that occur in the node, it is usually sufficient to retry the node again. When the error retry function is enabled, the node will automatically retry according to the preset strategy when an error occurs. You can adjust the maximum number of retries and the interval between each retry to set the retry strategy.
|
||||
|
||||
- The maximum number of retries is 10
|
||||
- The maximum retry interval is 5000 ms
|
||||
|
||||
|
||||
|
||||
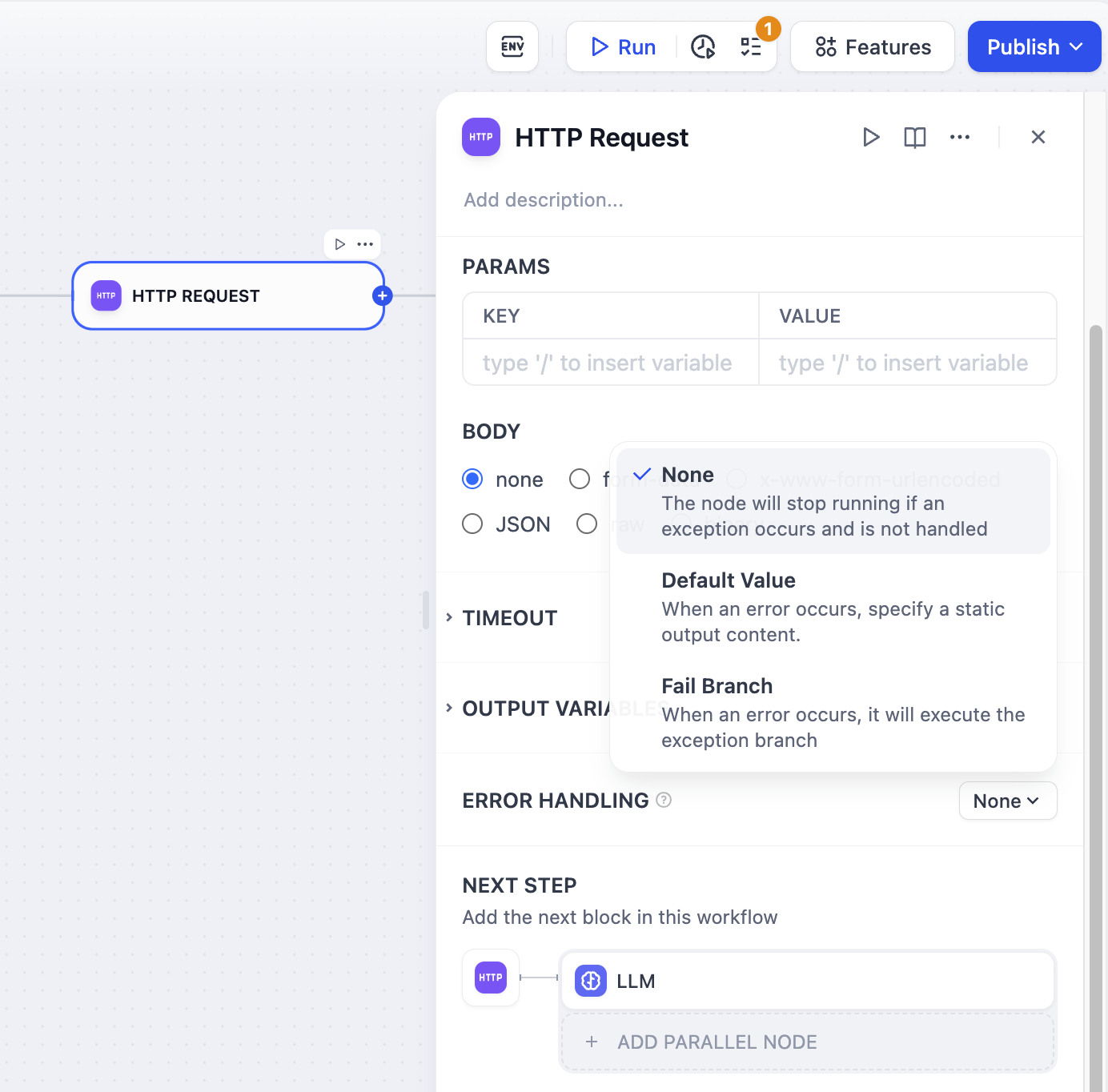
**Error Handling**
|
||||
|
||||
When processing information, HTTP nodes may encounter exceptional situations such as network request timeouts or request limits. Application developers can follow these steps to configure fail branches, enabling contingency plans when nodes encounter exceptions and avoiding workflow interruptions.
|
||||
|
||||
1. Enable "Error Handling" in the HTTP node
|
||||
2. Select and configure an error handling strategy
|
||||
|
||||
For more information about exception handling approaches, please refer to [Error Handling](/en/guides/workflow/error-handling).
|
||||
|
||||
|
||||
47
en/guides/workflow/node/ifelse.mdx
Normal file
47
en/guides/workflow/node/ifelse.mdx
Normal file
@@ -0,0 +1,47 @@
|
||||
---
|
||||
title: Conditional Branch IF/ELSE
|
||||
---
|
||||
|
||||
|
||||
### Definition
|
||||
|
||||
Allows you to split the workflow into two branches based on if/else conditions.
|
||||
|
||||
A conditional branching node has three parts:
|
||||
|
||||
* IF Condition: Select a variable, set the condition, and specify the value that satisfies the condition.
|
||||
* IF condition evaluates to `True`, execute the IF path.
|
||||
* IF condition evaluates to `False`, execute the ELSE path.
|
||||
* If the ELIF condition evaluates to `True`, execute the ELIF path;
|
||||
* If the ELIF condition evaluates to `False`, continue to evaluate the next ELIF path or execute the final ELSE path.
|
||||
|
||||
**Condition Types**
|
||||
|
||||
* Contains
|
||||
* Not contains
|
||||
* Starts with
|
||||
* Ends with
|
||||
* Is
|
||||
* Is not
|
||||
* Is empty
|
||||
* Is not empty
|
||||
|
||||
***
|
||||
|
||||
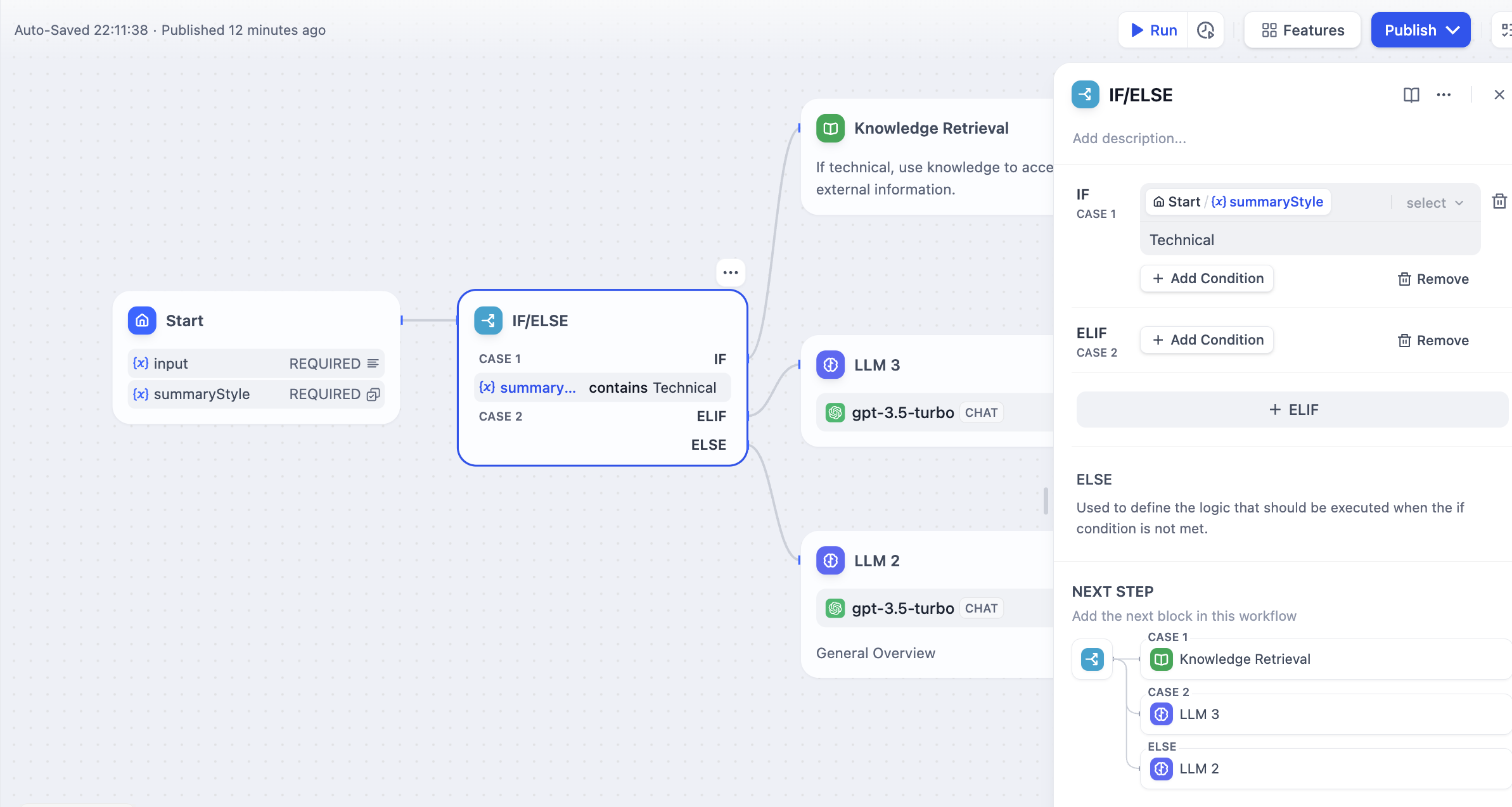
### Scenario
|
||||
|
||||
|
||||
|
||||
Taking the above **Text Summary Workflow** as an example:
|
||||
|
||||
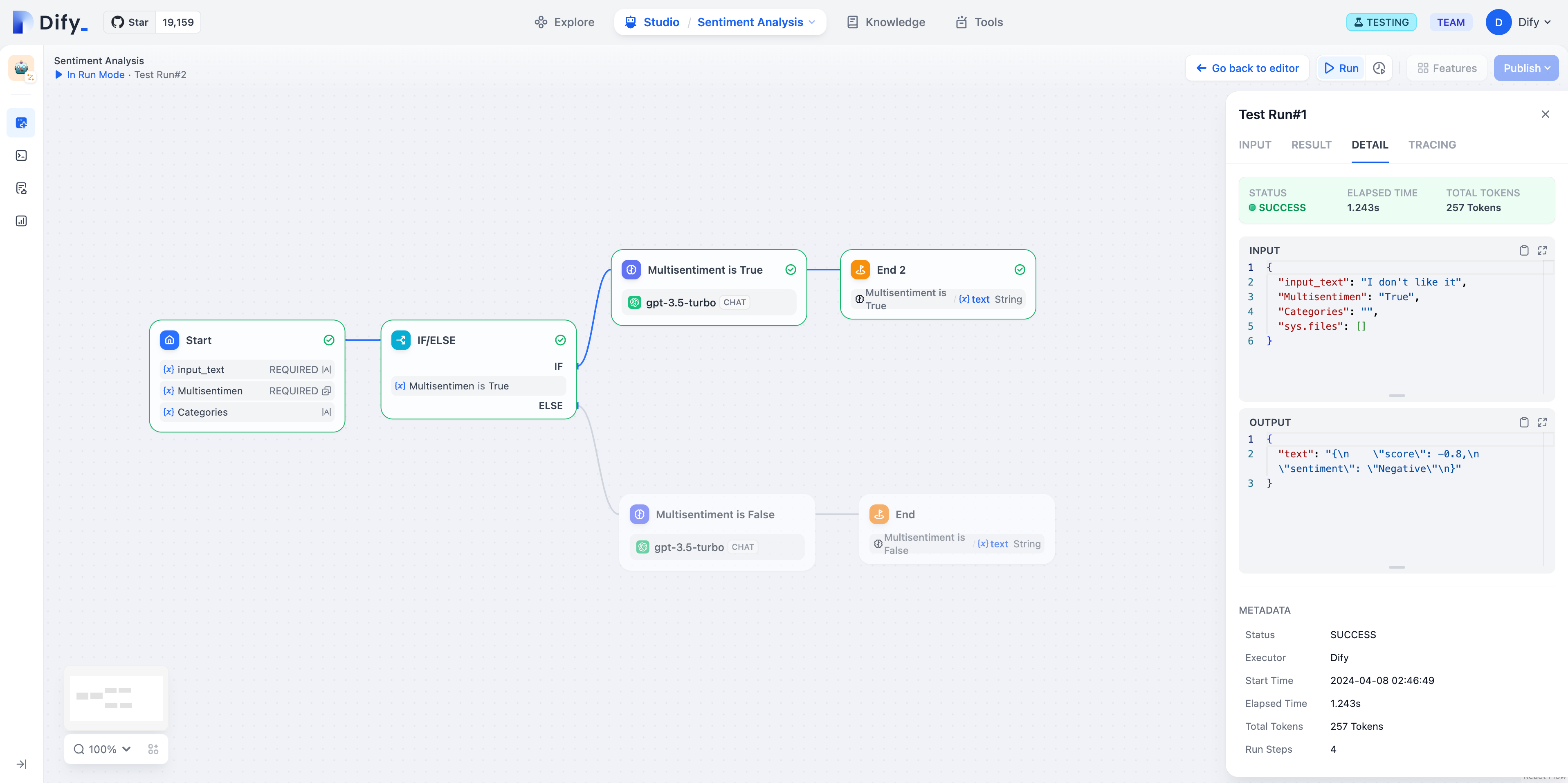
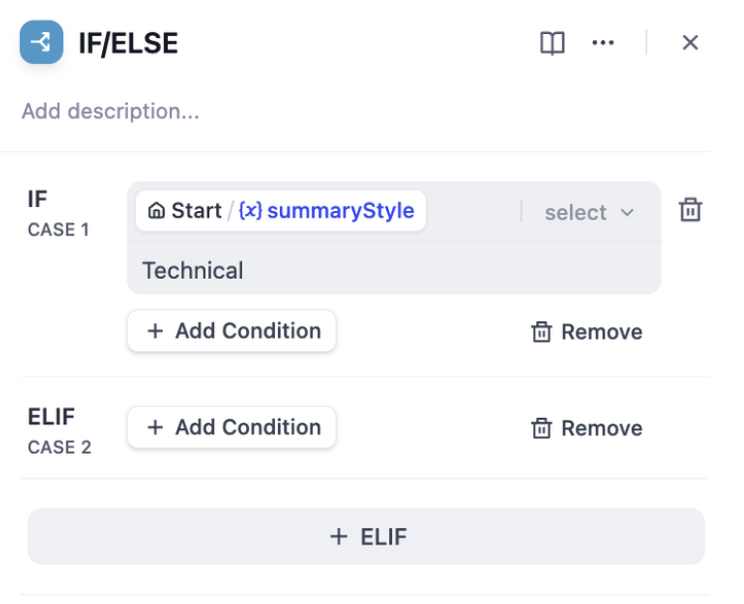
* IF Condition: Select the `summarystyle` variable from the start node, with the condition **Contains** `technical`.
|
||||
* IF condition evaluates to `True`, follow the IF path by querying technology-related knowledge through the knowledge retrieval node, then respond via the LLM node (as shown in the upper half of the diagram);
|
||||
* IF condition evaluates to `False`, but an `ELIF` condition is added, where the input for the `summarystyle` variable **does not include** `technology`, yet the `ELIF` condition includes `science`, check if the condition in `ELIF` is `True`, then execute the steps defined within that path;
|
||||
* If the condition within `ELIF` is `False`, meaning the input variable contains neither `technology` nor `science`, continue to evaluate the next `ELIF` condition or execute the final `ELSE` path;
|
||||
* IF condition evaluates to `False`, i.e., the `summarystyle` variable input **does not contain** `technical`, execute the ELSE path, responding via the LLM2 node (lower part of the diagram).
|
||||
|
||||
**Multiple Condition Judgments**
|
||||
|
||||
For complex condition judgments, you can set multiple condition judgments and configure **AND** or **OR** between conditions to take the **intersection** or **union** of the conditions, respectively.
|
||||
|
||||
|
||||
186
en/guides/workflow/node/iteration.mdx
Normal file
186
en/guides/workflow/node/iteration.mdx
Normal file
@@ -0,0 +1,186 @@
|
||||
---
|
||||
title: Iteration
|
||||
---
|
||||
|
||||
|
||||
### Definition
|
||||
|
||||
Sequentially performs the same operations on array elements until all results are outputted, functioning as a task batch processor. Iteration nodes typically work in conjunction with array variables.
|
||||
|
||||
For example, when processing long text translations, inputting all content directly into an LLM node may reach the single conversation limit. To address the issue, upstream nodes first split the long text into multiple chunks, then use iteration nodes to perform batch translations, thus avoiding the message limit of a single LLM conversation.
|
||||
|
||||
***
|
||||
|
||||
### Functional Description
|
||||
|
||||
Using iteration nodes requires input values to be formatted as list objects. The node sequentially processes all elements in the array variable from the iteration start node, applying identical processing steps to each element. Each processing cycle is called an iteration, culminating in the final output.
|
||||
|
||||
An iteration node consists of three core components: **Input Variables**, **Iteration Workflow**, and **Output Variables**.
|
||||
|
||||
**Input Variables:** Accepts only Array type data.
|
||||
|
||||
**Iteration Workflow:** Supports multiple workflow nodes to orchestrate task sequences within the iteration node.
|
||||
|
||||
**Output Variables:** Outputs only array variables (`Array[List]`).
|
||||
|
||||
<div class="image-side-by-side">
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2024/12/7c94bccbb6f8dc4570c69c2bf02ec6d3.png"
|
||||
className="mx-auto"
|
||||
alt=""
|
||||
/>
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d3beee536ff3c35f4e1eb1ab610f35d7.png"
|
||||
className="mx-auto"
|
||||
alt=""
|
||||
/>
|
||||
</div>
|
||||
|
||||
### Scenarios
|
||||
|
||||
#### **Example 1: Long Article Iteration Generator**
|
||||
|
||||
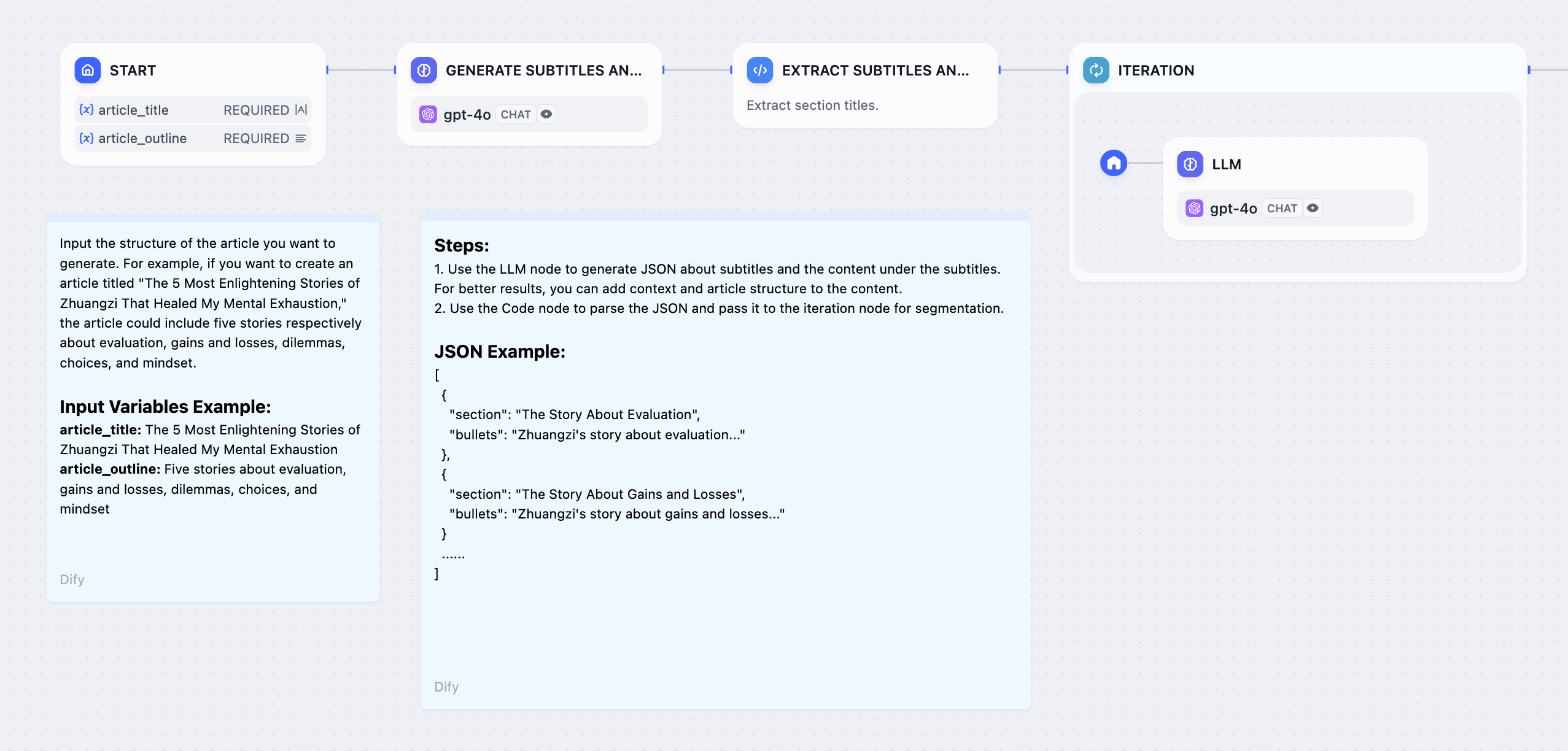
|
||||
|
||||
1. Enter the story title and outline in the **Start Node**.
|
||||
2. Use a **Generate Subtitles and Outlines Node** to use LLM to generate the complete content from user input.
|
||||
3. Use a **Extract Subtitles and Outlines Node** to convert the complete content into an array format.
|
||||
4. Use an **Iteration Node** to wrap an **LLM Node** and generate content for each chapter through multiple iterations.
|
||||
5. Add a **Direct Answer Node** inside the iteration node to achieve streaming output after each iteration.
|
||||
|
||||
**Detailed Configuration Steps**
|
||||
|
||||
1. Configure the story title (title) and outline (outline) in the **Start Node**.
|
||||
|
||||
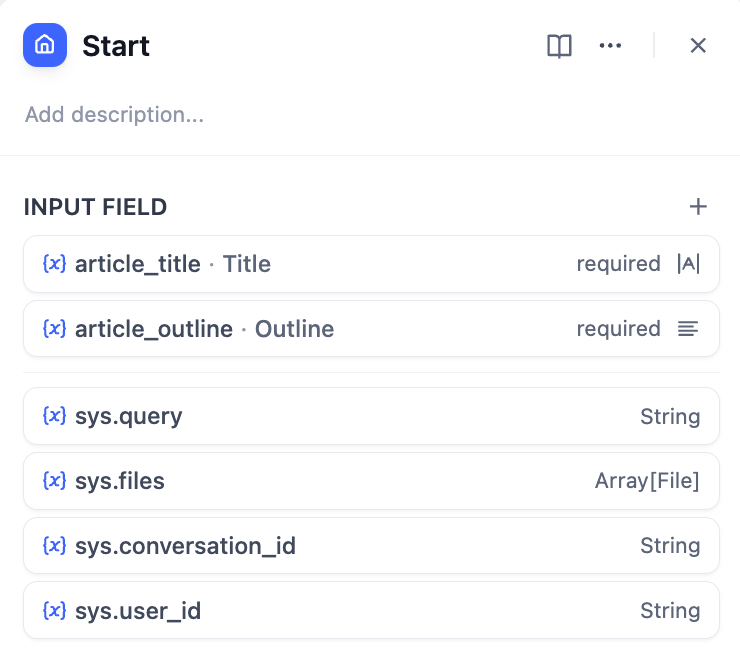
|
||||
|
||||
2. Use a **Generate Subtitles and Outlines Node** to convert the story title and outline into complete text.
|
||||
|
||||
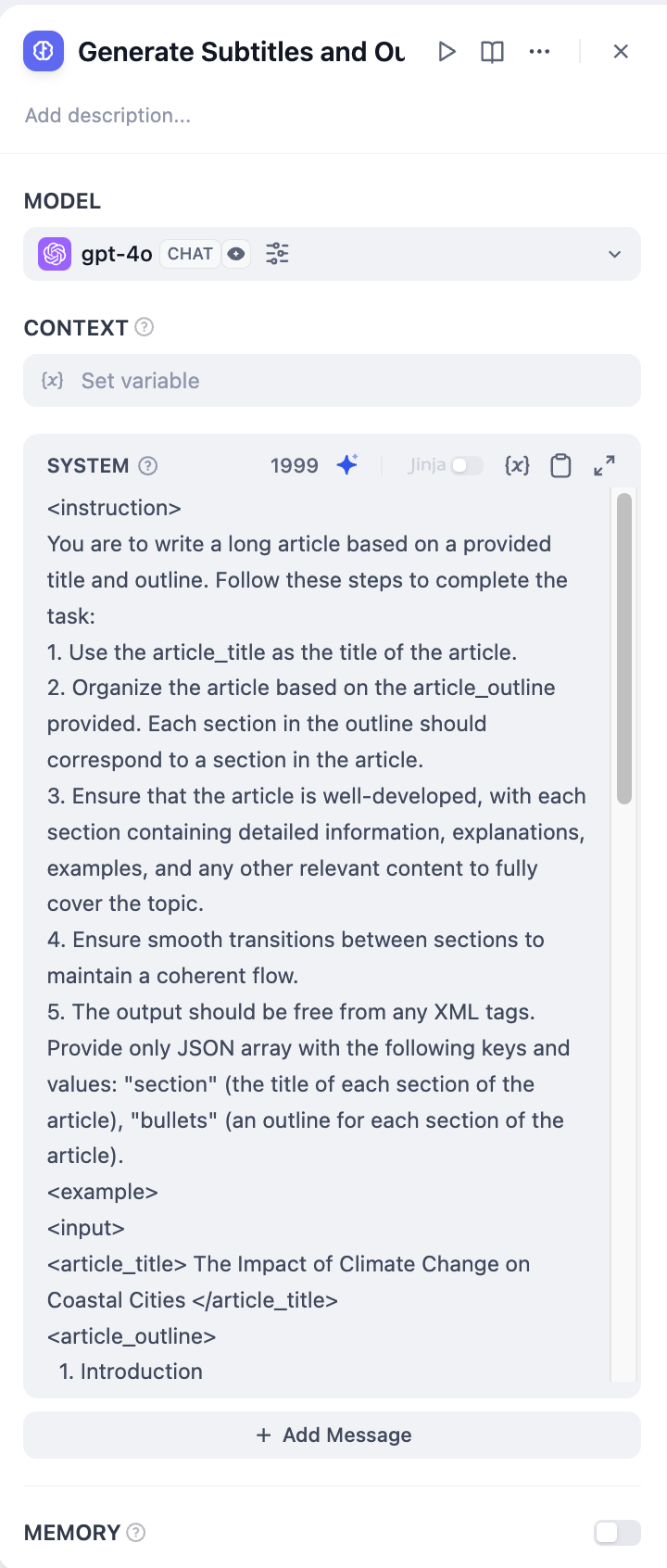
|
||||
|
||||
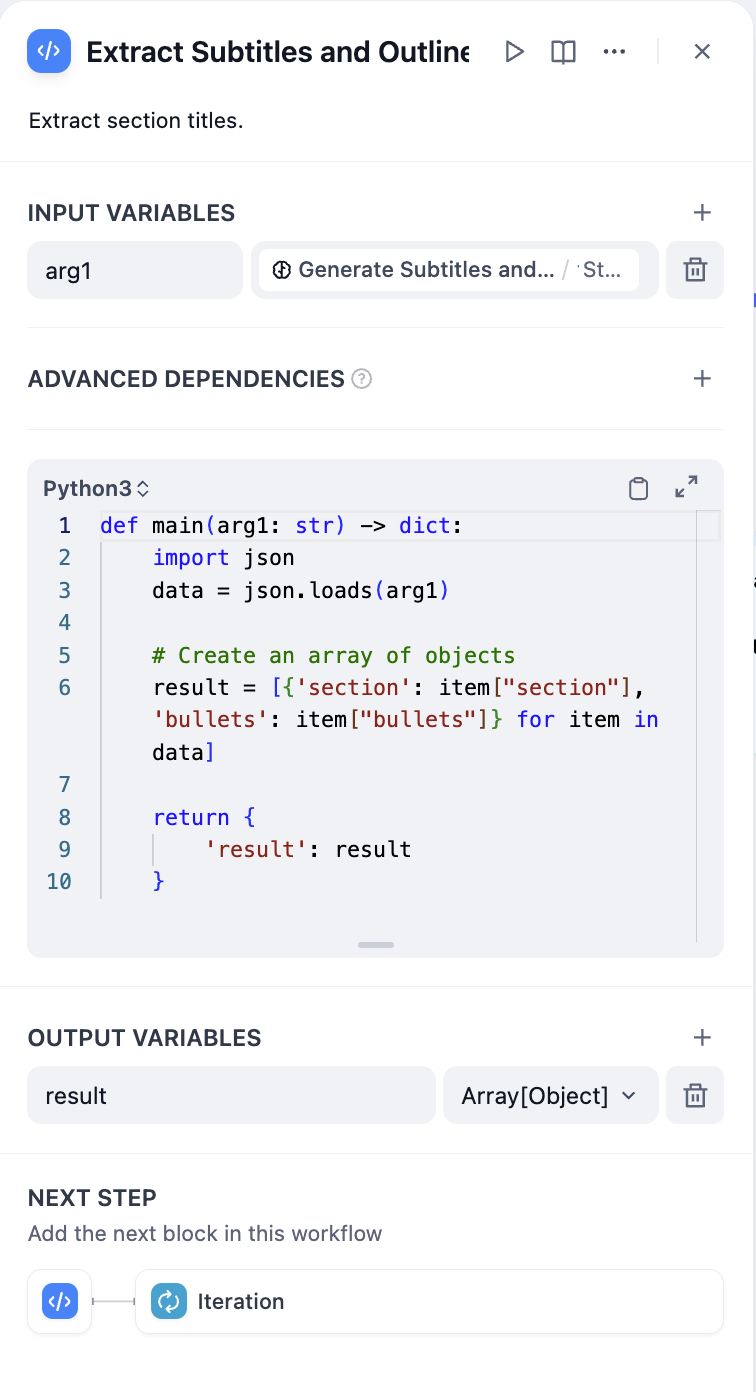
3. Use a **Extract Subtitles and Outlines Node** to convert the story text into an array (Array) structure. The parameter to extract is `sections`, and the parameter type is `Array[Object]`.
|
||||
|
||||
|
||||
|
||||
<Info>
|
||||
The effectiveness of parameter extraction is influenced by the model's inference capability and the instructions given. Using a model with stronger inference capabilities and adding examples in the **instructions** can improve the parameter extraction results.
|
||||
</Info>
|
||||
|
||||
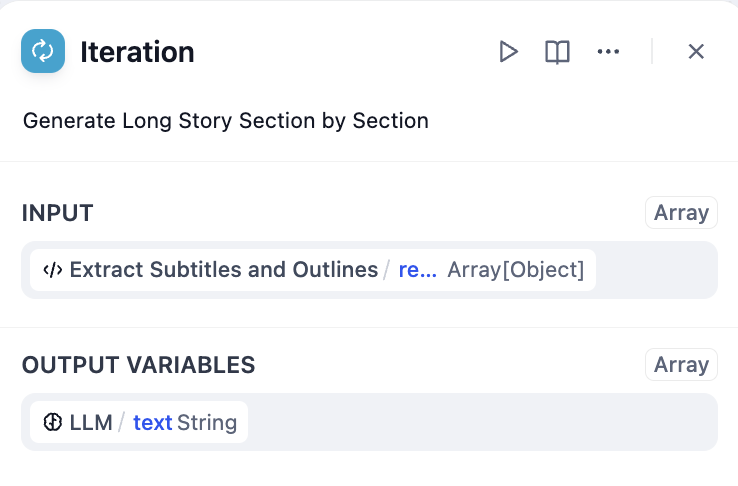
4. Use the array-formatted story outline as the input for the iteration node and process it within the iteration node using an **LLM Node**.
|
||||
|
||||
|
||||
|
||||
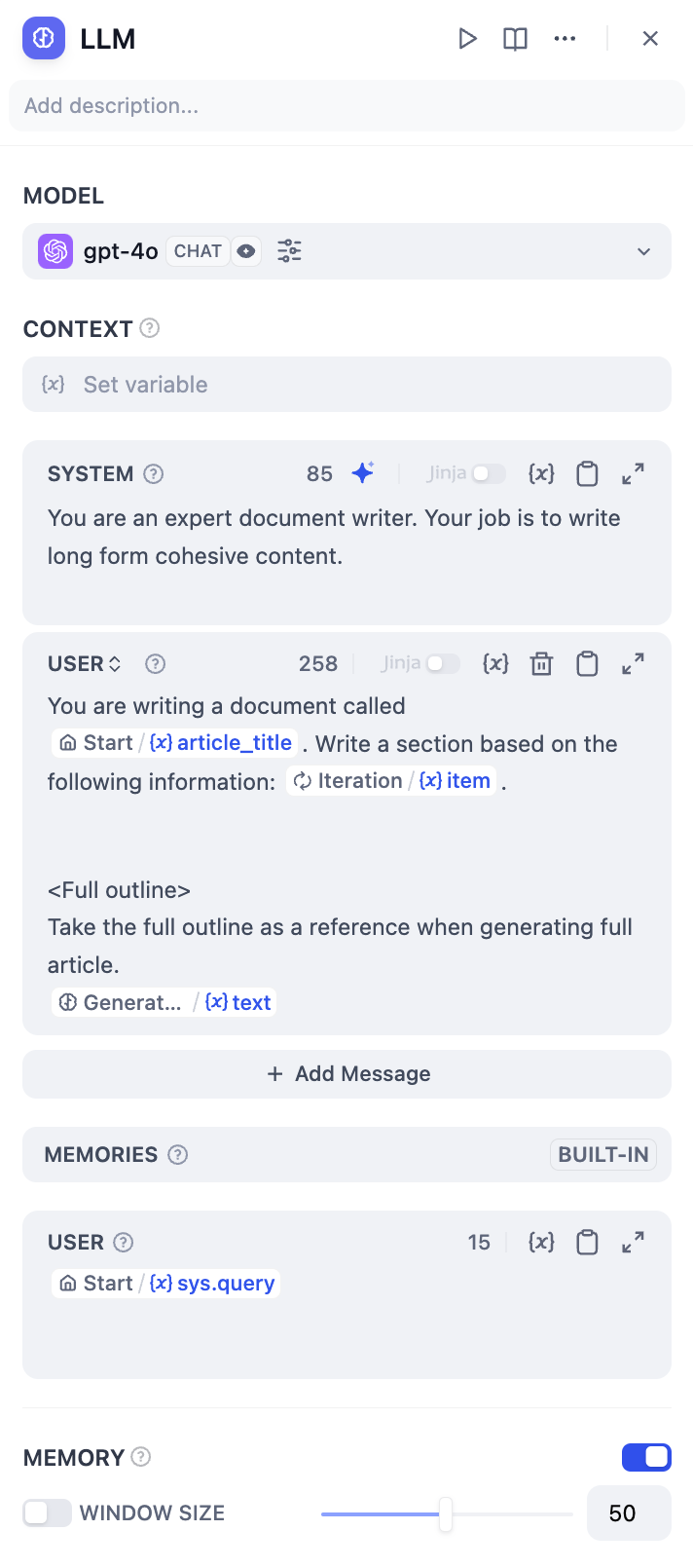
Configure the input variables `GenerateOverallOutline/output` and `Iteration/item` in the LLM Node.
|
||||
|
||||
|
||||
|
||||
<Info>
|
||||
Built-in variables for iteration: `items[object]` and `index[number]`.
|
||||
|
||||
`items[object]` represents the input item for each iteration;
|
||||
|
||||
`index[number]` represents the current iteration round;
|
||||
</Info>
|
||||
|
||||
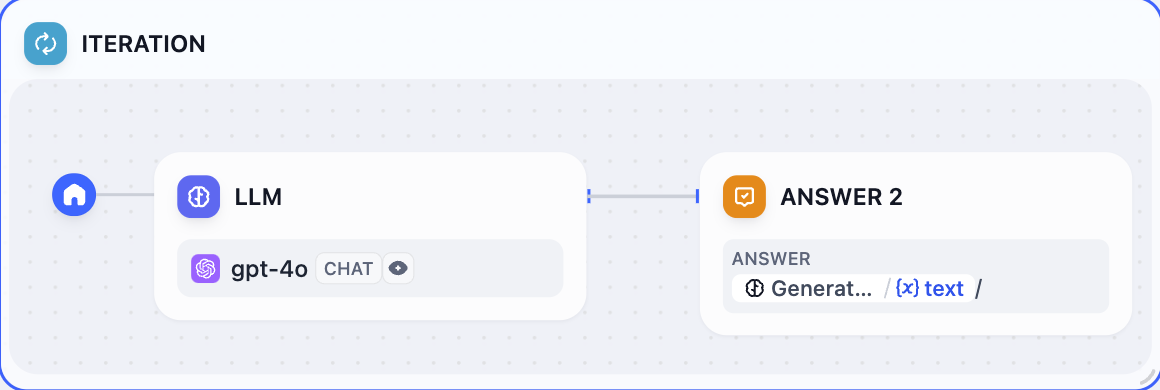
5. Configure a **Direct Reply Node** inside the iteration node to achieve streaming output after each iteration.
|
||||
|
||||
|
||||
|
||||
6. Complete debugging and preview.
|
||||
|
||||
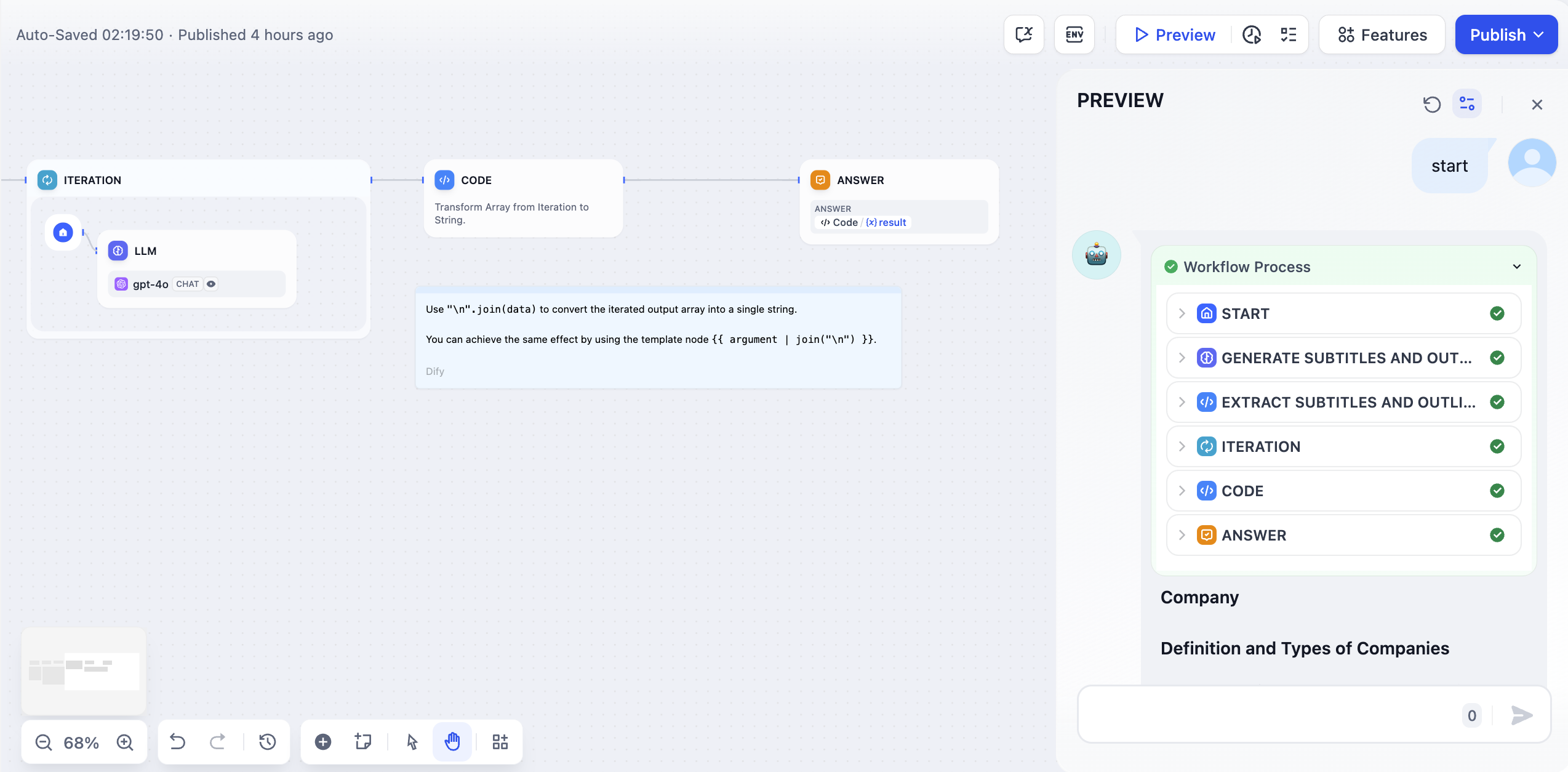
|
||||
|
||||
#### **Example 2: Long Article Iteration Generator (Another Arrangement)**
|
||||
|
||||

|
||||
|
||||
* Enter the story title and outline in the **Start Node**.
|
||||
* Use an **LLM Node** to generate subheadings and corresponding content for the article.
|
||||
* Use a **Code Node** to convert the complete content into an array format.
|
||||
* Use an **Iteration Node** to wrap an **LLM Node** and generate content for each chapter through multiple iterations.
|
||||
* Use a **Template Conversion** Node to convert the string array output from the iteration node back to a string.
|
||||
* Finally, add a **Direct Reply Node** to directly output the converted string.
|
||||
|
||||
***
|
||||
|
||||
### Advanced Feature
|
||||
|
||||
#### Parallel Mode
|
||||
|
||||
The iteration node supports parallel processing, improving execution efficiency when enabled.
|
||||
|
||||
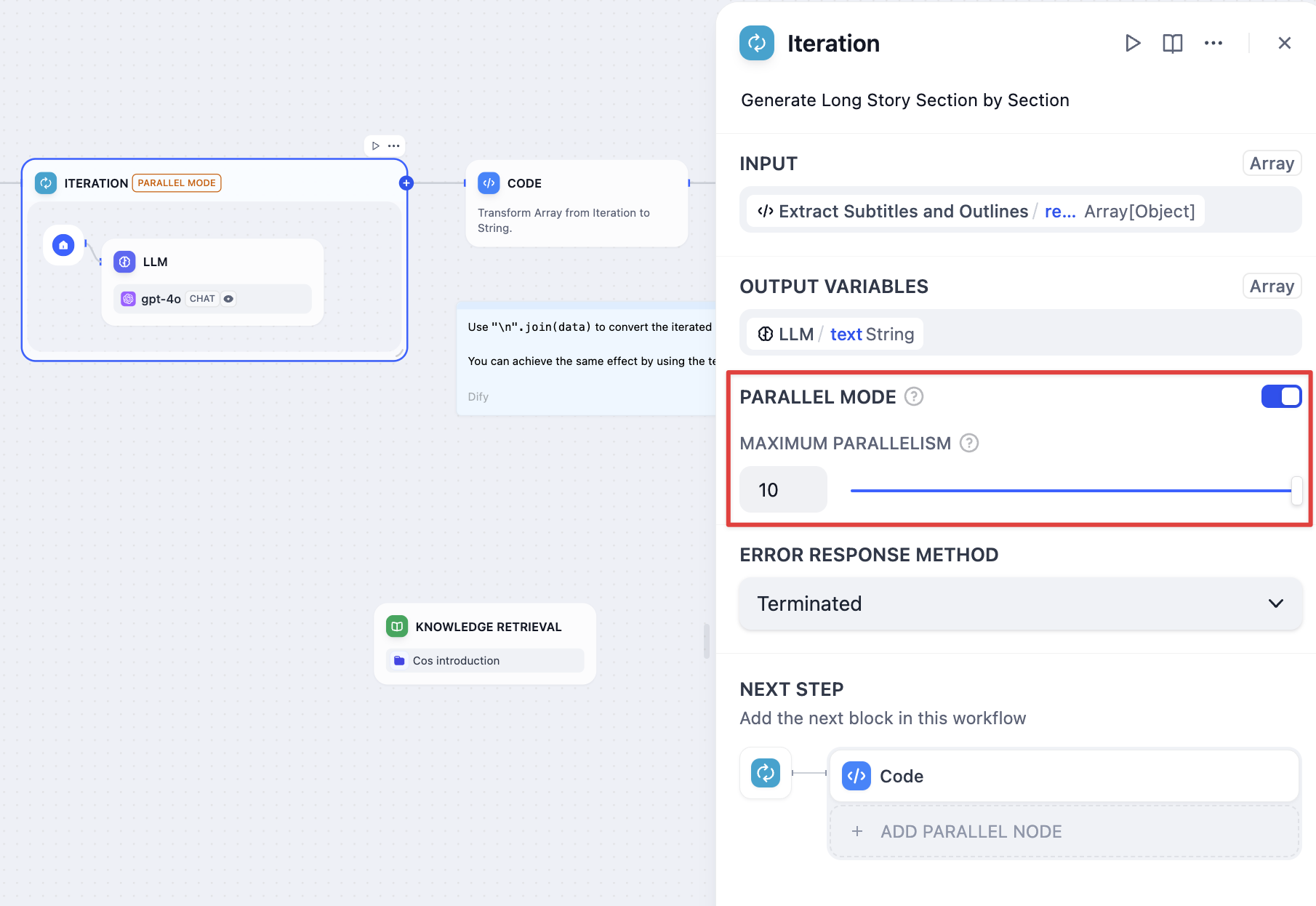
|
||||
|
||||
Below illustrates the comparison between parallel and sequential execution in the iteration node.
|
||||
|
||||
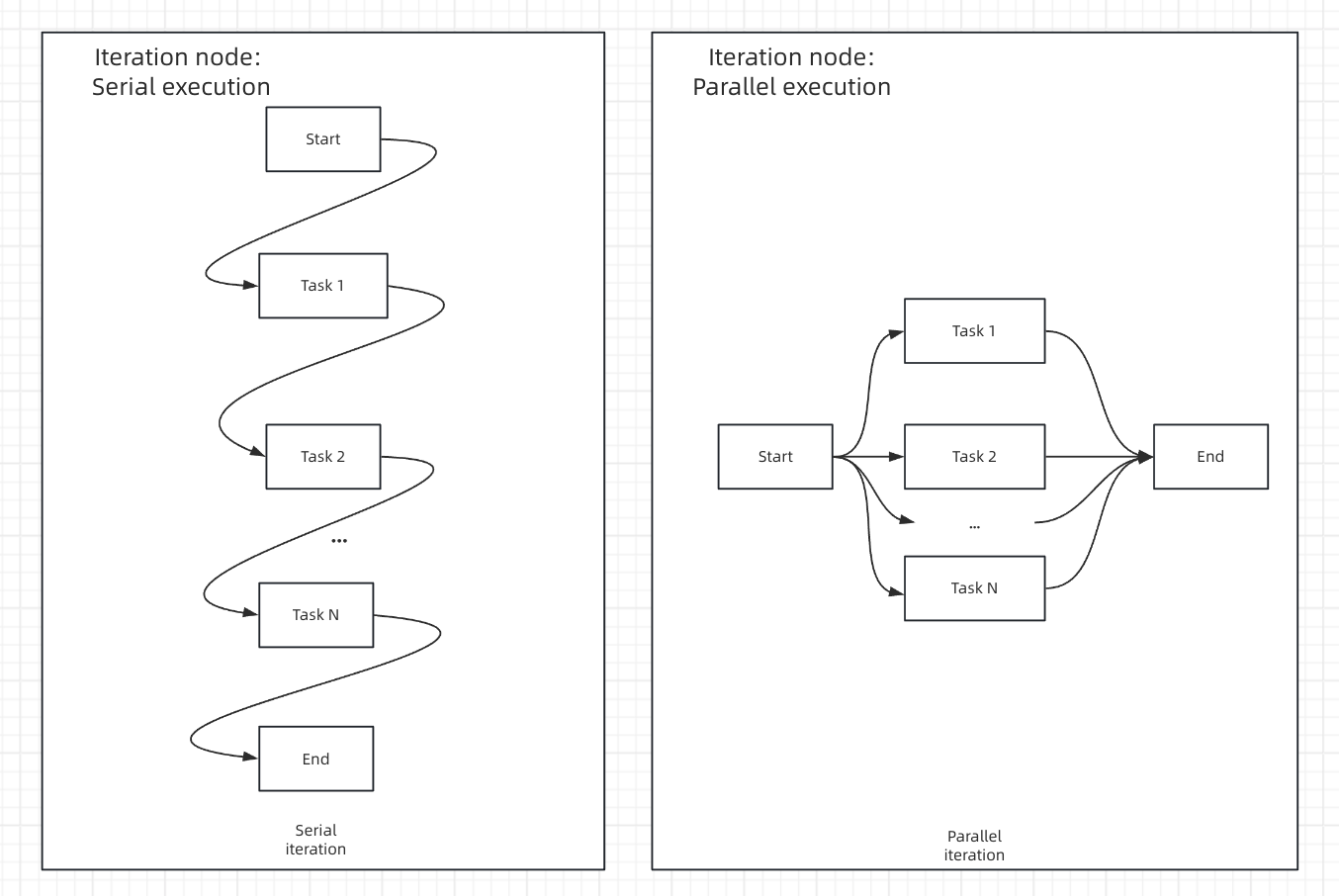
|
||||
|
||||
Parallel mode supports up to 10 concurrent iterations. When processing more than 10 tasks, the first 10 elements execute simultaneously, with remaining tasks processed after the completion of the initial batch.
|
||||
|
||||
<Info>
|
||||
Avoid placing Direct Answer, Variable Assignment, or Tool nodes within the iteration node to prevent potential errors.
|
||||
</Info>
|
||||
|
||||
* **Error response method**
|
||||
|
||||
Iteration nodes process multiple tasks and may encounter errors during element processing. To prevent a single error from interrupting all tasks, configure the **Error Response Method**:
|
||||
|
||||
* **Terminated**: Terminates the iteration node and outputs error messages when an exception is detected.
|
||||
* **Continue on error**: Ignores error messages and continues processing remaining elements. The output contains successful results with null values for errors.
|
||||
* **Remove abnormal output**: Ignores error messages and continues processing remaining elements. The output contains only successful results.
|
||||
|
||||
Input and output variables maintain a one-to-one correspondence. For example:
|
||||
|
||||
* Input: \[1, 2, 3]
|
||||
* Output: \[result-1, result-2, result-3]
|
||||
|
||||
Error handling examples:
|
||||
|
||||
* With **Continue on error**: \[result-1, null, result-3]
|
||||
* With **Remove abnormal output**: \[result-1, result-3]
|
||||
|
||||
***
|
||||
|
||||
### Reference
|
||||
|
||||
#### How to Obtain Array-Formatted Content
|
||||
|
||||
Array variables can be generated via the following nodes as iteration node inputs:
|
||||
|
||||
* [Code Node](/en/guides/workflow/nodes/code)
|
||||
* [Parameter Extraction](/en/guides/workflow/nodes/parameter-extractor)
|
||||
* [Knowledge Base Retrieval](/en/guides/workflow/nodes/knowledge-retrieval)
|
||||
* [Iteration](/en/guides/workflow/nodes/iteration)
|
||||
* [Tools](/en/guides/workflow/nodes/tools)
|
||||
* [HTTP Request](/en/guides/workflow/nodes/http-request)
|
||||
|
||||
***
|
||||
|
||||
#### How to Convert an Array to Text
|
||||
|
||||
The output variable of the iteration node is in array format and cannot be directly output. You can use a simple step to convert the array back to text.
|
||||
|
||||
**Convert Using a Code Node**
|
||||
|
||||
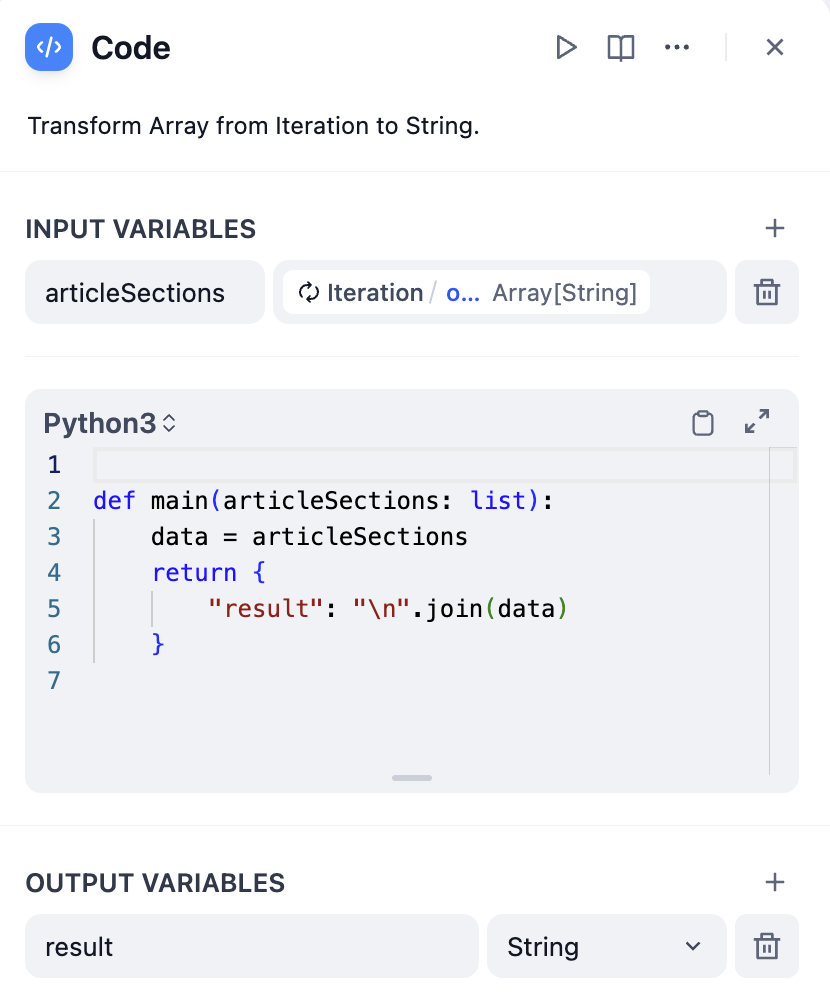
|
||||
|
||||
CODE Example:
|
||||
|
||||
```python
|
||||
def main(articleSections: list):
|
||||
data = articleSections
|
||||
return {
|
||||
"result": "/n".join(data)
|
||||
}
|
||||
```
|
||||
|
||||
**Convert Using a Template Node**
|
||||
|
||||
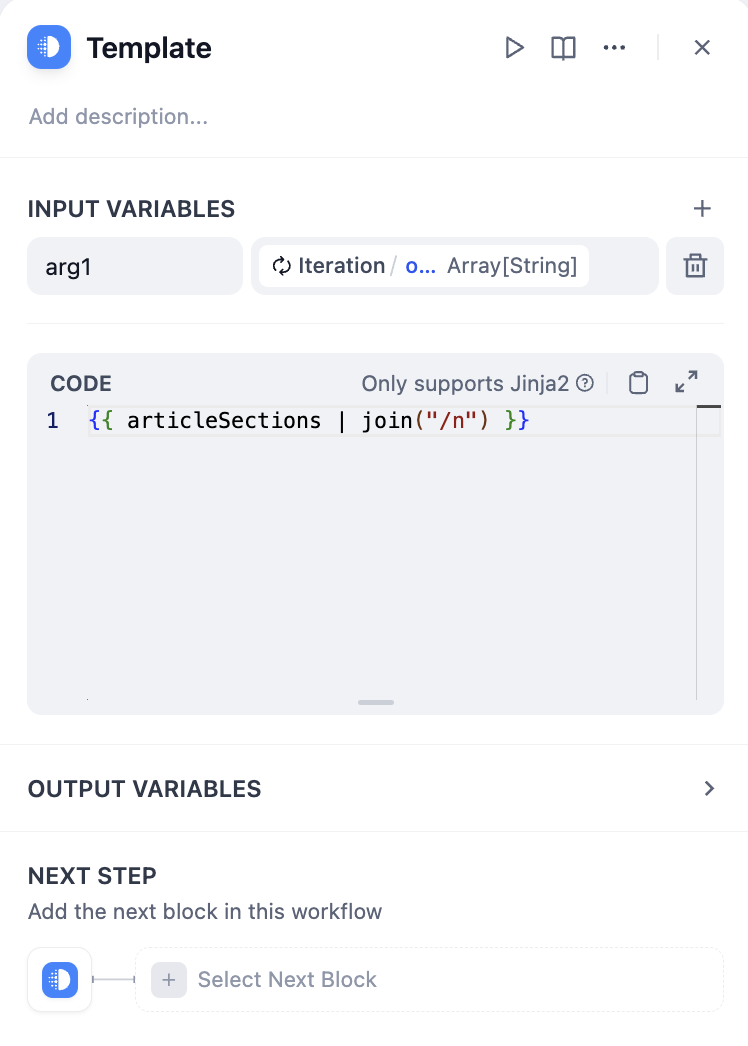
|
||||
|
||||
CODE Example:
|
||||
|
||||
```django
|
||||
{{ articleSections | join("/n") }}
|
||||
```
|
||||
41
en/guides/workflow/node/knowledge-retrieval.mdx
Normal file
41
en/guides/workflow/node/knowledge-retrieval.mdx
Normal file
@@ -0,0 +1,41 @@
|
||||
---
|
||||
title: Knowledge Retrieval
|
||||
---
|
||||
|
||||
|
||||
The Knowledge Base Retrieval Node is designed to query text content related to user questions from the Dify Knowledge Base, which can then be used as context for subsequent answers by the Large Language Model (LLM).
|
||||
|
||||
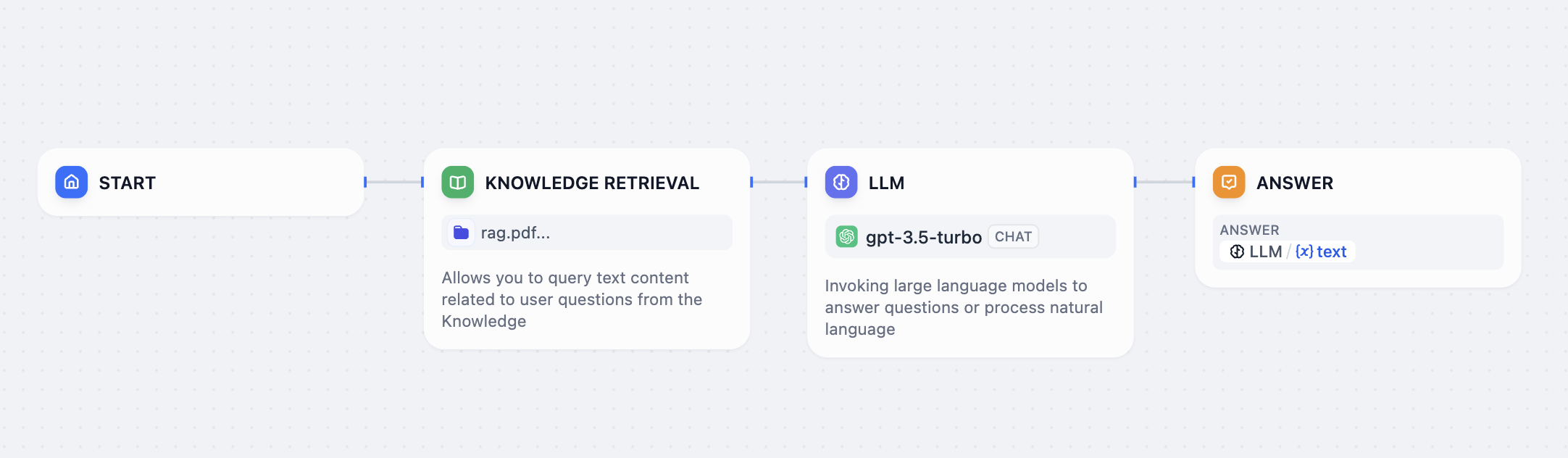
|
||||
|
||||
Configuring the Knowledge Base Retrieval Node involves four main steps:
|
||||
|
||||
1. **Selecting the Query Variable**
|
||||
2. **Choosing the Knowledge Base for Query**
|
||||
3. **Applying Metadata Filtering**
|
||||
4. **Configuring the Retrieval Strategy**
|
||||
|
||||
**Selecting the Query Variable**
|
||||
|
||||
In knowledge base retrieval scenarios, the query variable typically represents the user's input question. In the "Start" node of conversational applications, the system pre-sets "sys.query" as the user input variable. This variable can be used to query the knowledge base for text chunks most closely related to the user's question. The maximum query content sent to the knowledge base is 200 characters.
|
||||
|
||||
**Choosing the Knowledge Base for Query**
|
||||
|
||||
Within the knowledge base retrieval node, you can add an existing knowledge base from Dify. For instructions on creating a knowledge base within Dify, please refer to the knowledge base [help documentation](/en/guides/knowledge-base/create-knowledge-and-upload-documents).
|
||||
|
||||
**Applying Metadata Filtering**
|
||||
|
||||
Use **Metadata Filtering** to refine document search in your knowledge base. For details, see **Metadata Filtering** in *[Integrate Knowledge Base within Application](/en/guides/knowledge-base/integrate-knowledge-within-application)*.
|
||||
|
||||
**Configuring the Retrieval Strategy**
|
||||
|
||||
It's possible to modify the indexing strategy and retrieval mode for an individual knowledge base within the node. For a detailed explanation of these settings, refer to the knowledge base [help documentation](/en/guides/knowledge-base/retrieval-test-and-citation).
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2025/03/fbd43d558f83b355a1b18ac26a253b84.png"
|
||||
className="mx-auto"
|
||||
alt=""
|
||||
/>
|
||||
|
||||
Dify offers two recall strategies for different knowledge base retrieval scenarios: "N-to-1 Recall" and "Multi-way Recall". In the N-to-1 mode, knowledge base queries are executed through function calling, requiring the selection of a system reasoning model. In the multi-way recall mode, a Rerank model needs to be configured for result re-ranking. For a detailed explanation of these two recall strategies, refer to the retrieval mode explanation in the [help documentation](/en/guides/knowledge-base/create-knowledge-and-upload-documents#id-5-indexing-methods).
|
||||
|
||||
|
||||
80
en/guides/workflow/node/list-operator.mdx
Normal file
80
en/guides/workflow/node/list-operator.mdx
Normal file
@@ -0,0 +1,80 @@
|
||||
---
|
||||
title: List Operator
|
||||
---
|
||||
|
||||
|
||||
File list variables support simultaneous uploading of multiple file types such as document files, images, audio, and video files. When application users upload files, all files are stored in the same `Array[File]` array-type variable, which **is not conducive to subsequent individual file processing.**
|
||||
|
||||
> The `Array` data type means that the actual value of the variable could be \[1.mp3, 2.png, 3.doc]. LLMs only support reading single values such as image files or text content as input variables and cannot directly read array variables.
|
||||
|
||||
#### Node Functionality
|
||||
|
||||
The list operator can filter and extract attributes such as file format type, file name, and size, passing different format files to corresponding processing nodes to achieve precise control over different file processing flows.
|
||||
|
||||
For example, in an application that allows users to upload both document files and image files simultaneously, different files need to be sorted through the **list operation node**, with different files being handled by different processes.
|
||||
|
||||
|
||||
|
||||
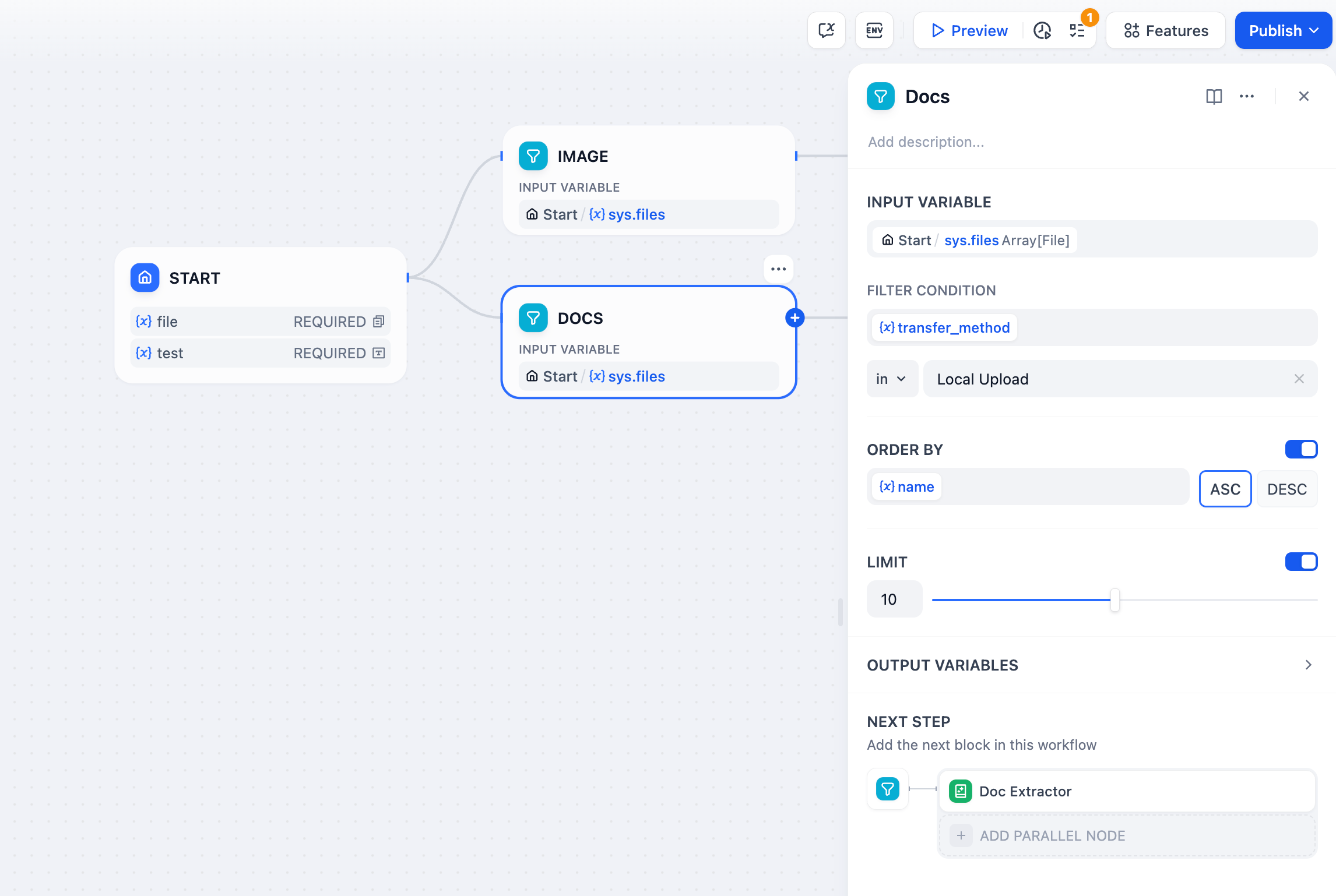
List operation nodes are generally used to extract information from array variables, converting them into variable types that can be accepted by downstream nodes through setting conditions. Its structure is divided into input variables, filter conditions, sorting, taking the first N items, and output variables.
|
||||
|
||||
|
||||
|
||||
**Input Variables**
|
||||
|
||||
The list operation node only accepts variables with the following data structures:
|
||||
|
||||
* Array\[string]
|
||||
* Array\[number]
|
||||
* Array\[file]
|
||||
|
||||
**Filter Conditions**
|
||||
|
||||
Process arrays in input variables by adding filter conditions. Sort out all array variables that meet the conditions from the array, which can be understood as filtering the attributes of variables.
|
||||
|
||||
Example: Files may contain multiple dimensions of attributes, such as file name, file type, file size, etc. Filter conditions allow setting screening conditions to select and extract specific files from array variables.
|
||||
|
||||
Supports extracting the following variables:
|
||||
|
||||
* type: File category, including image, document, audio, and video types
|
||||
* size: File size
|
||||
* name: File name
|
||||
* url: Refers to files uploaded by application users via URL, can fill in the complete URL for filtering
|
||||
* extension: File extension
|
||||
* mime\_type: [MIME types](https://datatracker.ietf.org/doc/html/rfc2046) are standardized strings used to identify file content types. Example: "text/html" indicates an HTML document.
|
||||
* transfer\_method: File upload method, divided into local upload or upload via URL
|
||||
|
||||
**Sorting**
|
||||
|
||||
Provides the ability to sort arrays in input variables, supporting sorting based on file attributes.
|
||||
|
||||
* Ascending order(ASC): Default sorting option, sorted from small to large. For letters and text, sorted in alphabetical order (A - Z)
|
||||
* Descending order(DESC): Sorted from large to small, for letters and text, sorted in reverse alphabetical order (Z - A)
|
||||
|
||||
This option is often used in conjunction with first\_record and last\_record in output variables.
|
||||
|
||||
**Take First N Items**
|
||||
|
||||
You can choose a value between 1-20, used to select the first n items of the array variable.
|
||||
|
||||
**Output Variables**
|
||||
|
||||
Array elements that meet all filter conditions. Filter conditions, sorting, and limitations can be enabled separately. If enabled simultaneously, array elements that meet all conditions are returned.
|
||||
|
||||
* Result: Filtering result, data type is array variable. If the array contains only 1 file, the output variable contains only 1 array element;
|
||||
* first\_record: The first element of the filtered array, i.e., result\[0];
|
||||
* last\_record: The last element of the filtered array, i.e., result\[array.length-1].
|
||||
|
||||
***
|
||||
|
||||
#### Configuration Example
|
||||
|
||||
In file interaction Q\&A scenarios, application users may upload document files or image files simultaneously. LLMs only support the ability to recognize image files and do not support reading document files. At this time, the List Operation node is needed to preprocess the array of file variables and send different file types to corresponding processing nodes. The orchestration steps are as follows:
|
||||
|
||||
1. Enable the [Features](/en/guides/workflow/additional-features) function and check both "Images" and "Document" types in the file types.
|
||||
2. Add two list operation nodes, setting to extract image and document variables respectively in the "List Operator" conditions.
|
||||
3. Extract document file variables and pass them to the "Doc Extractor" node; extract image file variables and pass them to the "LLM" node.
|
||||
4. Add a "Answer" node at the end, filling in the output variable of the LLM node.
|
||||
|
||||

|
||||
|
||||
After the application user uploads both document files and images, document files are automatically diverted to the doc extractor node, and image files are automatically diverted to the LLM node to achieve joint processing of mixed files.
|
||||
177
en/guides/workflow/node/llm.mdx
Normal file
177
en/guides/workflow/node/llm.mdx
Normal file
@@ -0,0 +1,177 @@
|
||||
---
|
||||
title: LLM
|
||||
---
|
||||
|
||||
### Definition
|
||||
|
||||
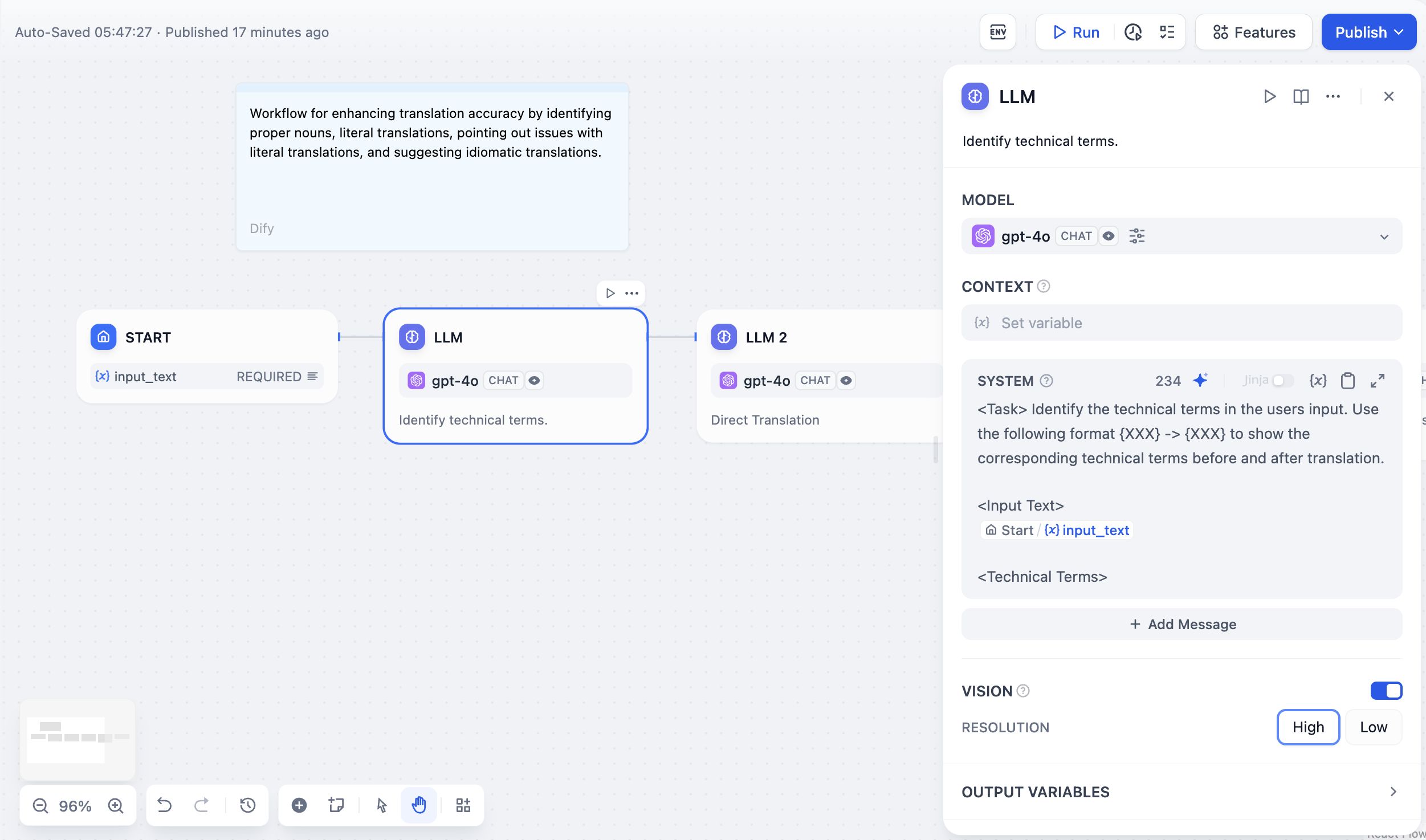
Invokes the capabilities of large language models to process information input by users in the "Start" node (natural language, uploaded files, or images) and provide effective response information.
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
### Scenarios
|
||||
|
||||
LLM is the core node of Chatflow/Workflow, utilizing the conversational/generative/classification/processing capabilities of large language models to handle a wide range of tasks based on given prompts and can be used in different stages of workflows.
|
||||
|
||||
* **Intent Recognition**: In customer service scenarios, identifying and classifying user inquiries to guide downstream processes.
|
||||
* **Text Generation**: In content creation scenarios, generating relevant text based on themes and keywords.
|
||||
* **Content Classification**: In email batch processing scenarios, automatically categorizing emails, such as inquiries/complaints/spam.
|
||||
* **Text Conversion**: In translation scenarios, translating user-provided text into a specified language.
|
||||
* **Code Generation**: In programming assistance scenarios, generating specific business code or writing test cases based on user requirements.
|
||||
* **RAG**: In knowledge base Q\&A scenarios, reorganizing retrieved relevant knowledge to respond to user questions.
|
||||
* **Image Understanding**: Using multimodal models with vision capabilities to understand and answer questions about the information within images.
|
||||
* **File Analysis**: In file processing scenarios, use LLMs to recognize and analyze the information contained within files.
|
||||
|
||||
By selecting the appropriate model and writing prompts, you can build powerful and reliable solutions within Chatflow/Workflow.
|
||||
|
||||
***
|
||||
|
||||
### How to Configure
|
||||
|
||||
|
||||
|
||||
**Configuration Steps:**
|
||||
|
||||
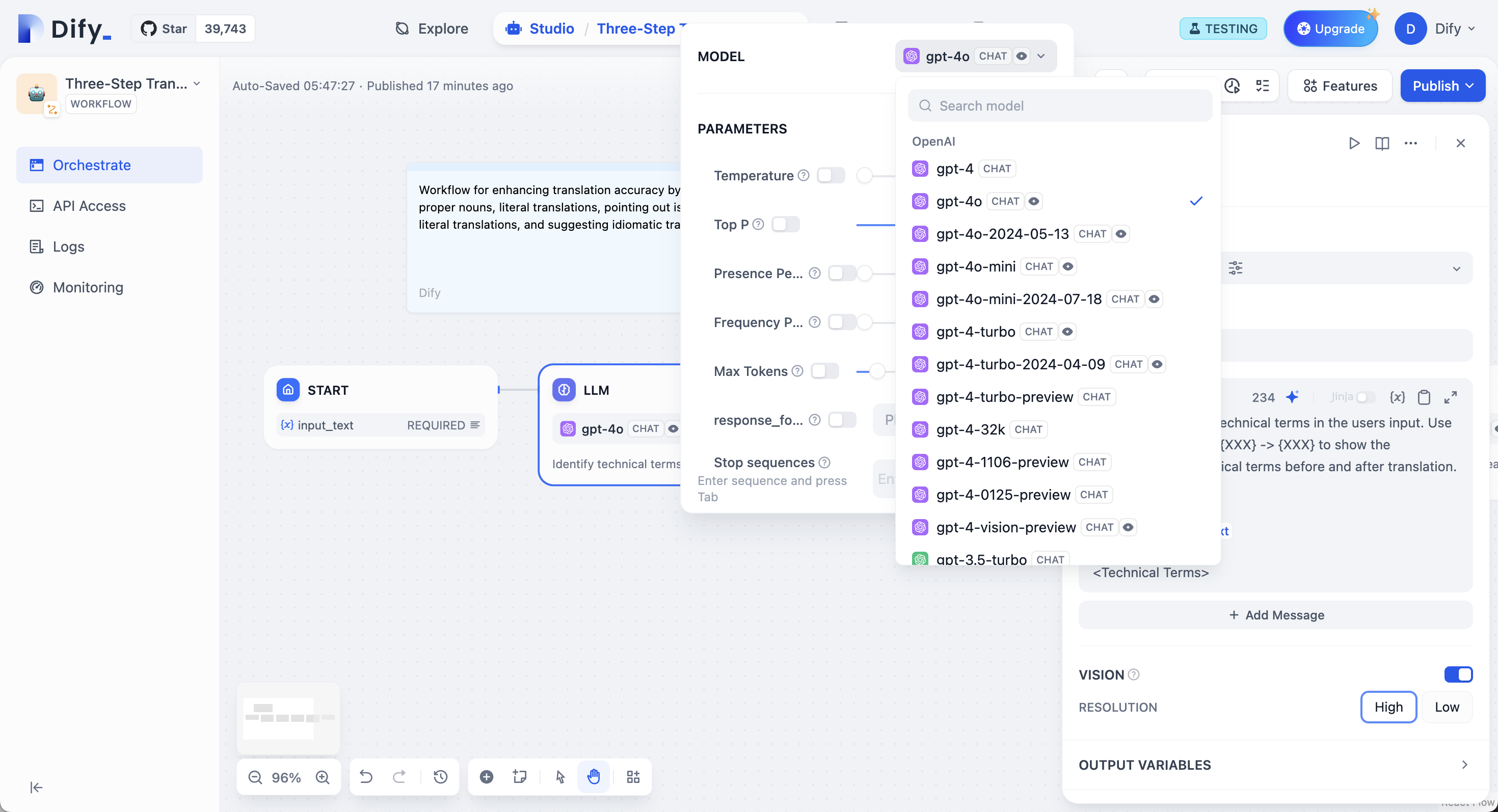
1. **Select a Model**: Dify supports major global models, including OpenAI's GPT series, Anthropic's Claude series, and Google's Gemini series. Choosing a model depends on its inference capability, cost, response speed, context window, etc. You need to select a suitable model based on the scenario requirements and task type.
|
||||
2. **Configure Model Parameters**: Model parameters control the generation results, such as temperature, TopP, maximum tokens, response format, etc. To facilitate selection, the system provides three preset parameter sets: Creative, Balanced, and Precise.
|
||||
3. **Write Prompts**: The LLM node offers an easy-to-use prompt composition page. Selecting a chat model or completion model will display different prompt composition structures.
|
||||
4. **Advanced Settings**: You can enable memory, set memory windows, and use the Jinja-2 template language for more complex prompts.
|
||||
|
||||
<Info>
|
||||
If you are using Dify for the first time, you need to complete the [model configuration](/en/guides/model-configuration) in **System Settings-Model Providers** before selecting a model in the LLM node.
|
||||
</Info>
|
||||
|
||||
#### **Writing Prompts**
|
||||
|
||||
In the LLM node, you can customize the model input prompts. If you select a chat model, you can customize the System/User/Assistant sections.
|
||||
|
||||
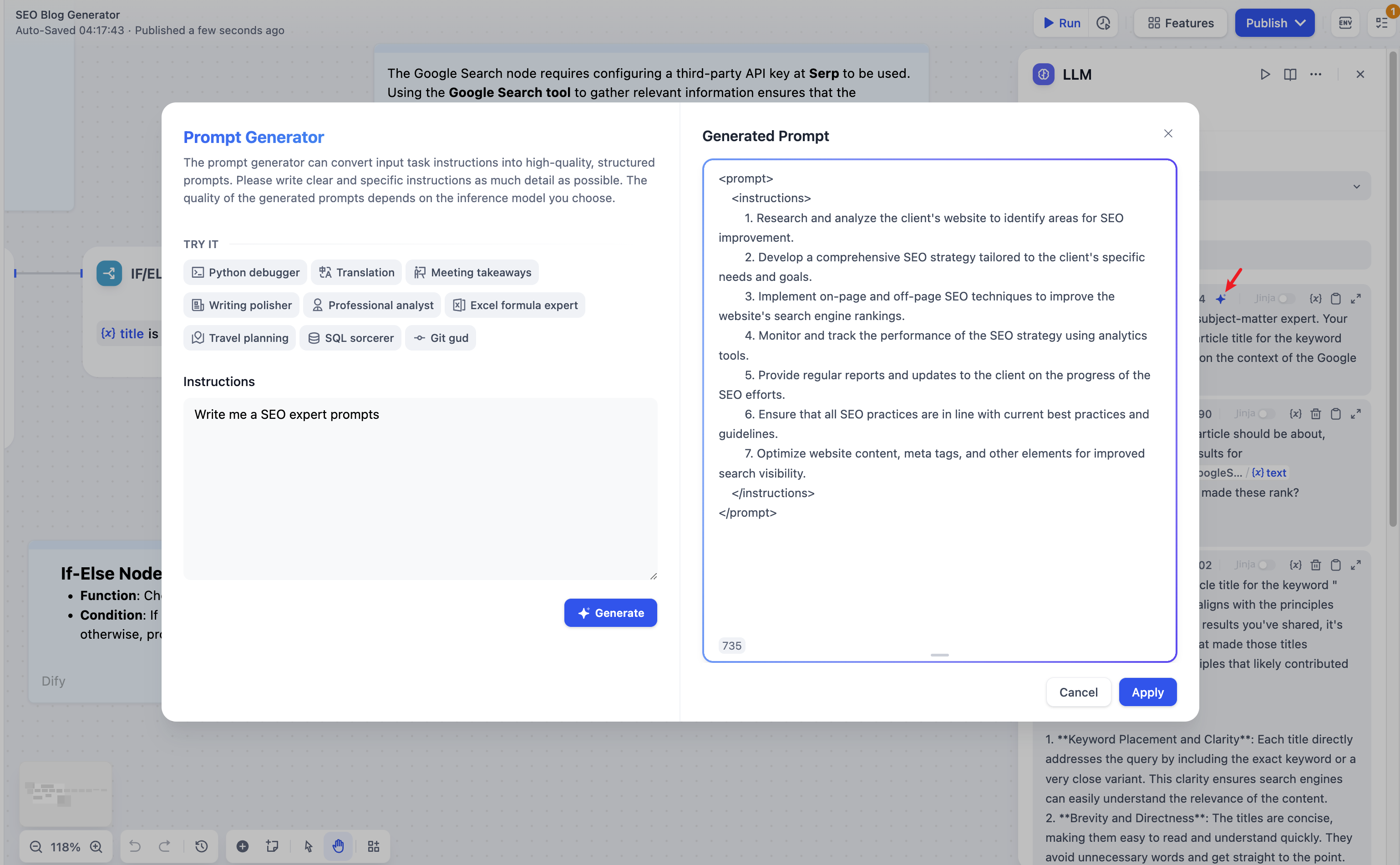
**Prompt Generator**
|
||||
|
||||
If you're struggling to come up with effective system prompts (System), you can use the Prompt Generator to quickly create prompts suitable for your specific business scenarios, leveraging AI capabilities.
|
||||
|
||||
|
||||
|
||||
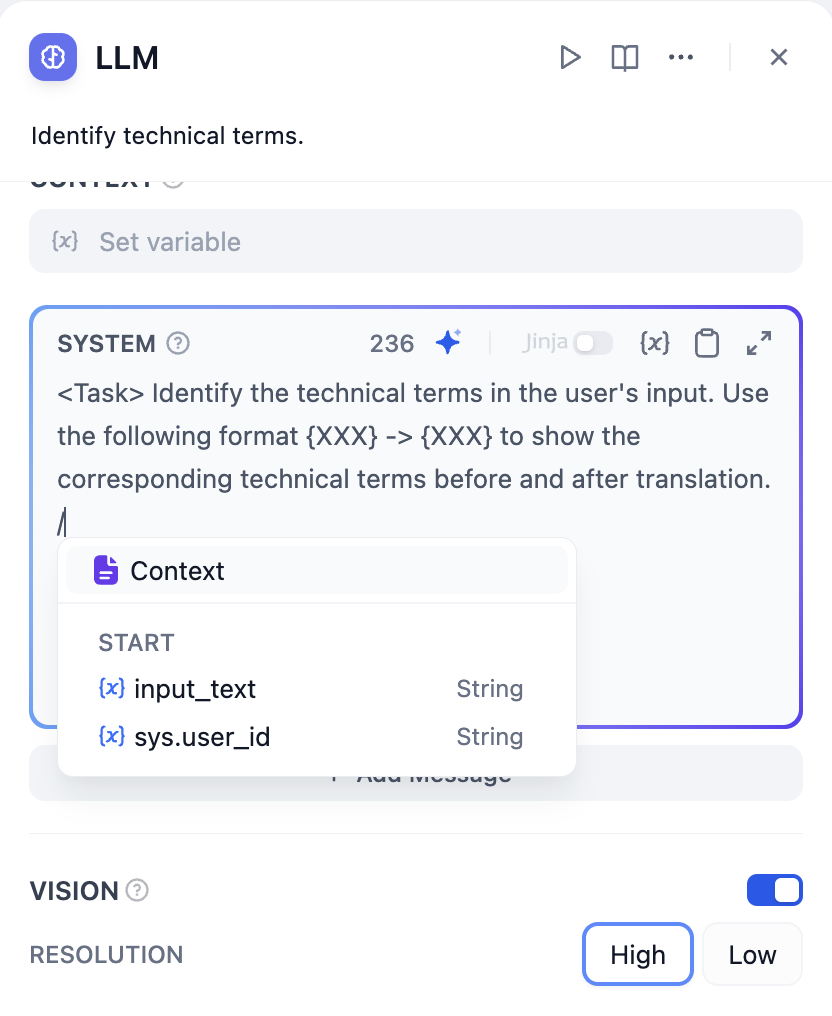
In the prompt editor, you can call out the **variable insertion menu** by typing `/` or `{` to insert **special variable blocks** or **upstream node variables** into the prompt as context content.
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
### Explanation of Special Variables
|
||||
|
||||
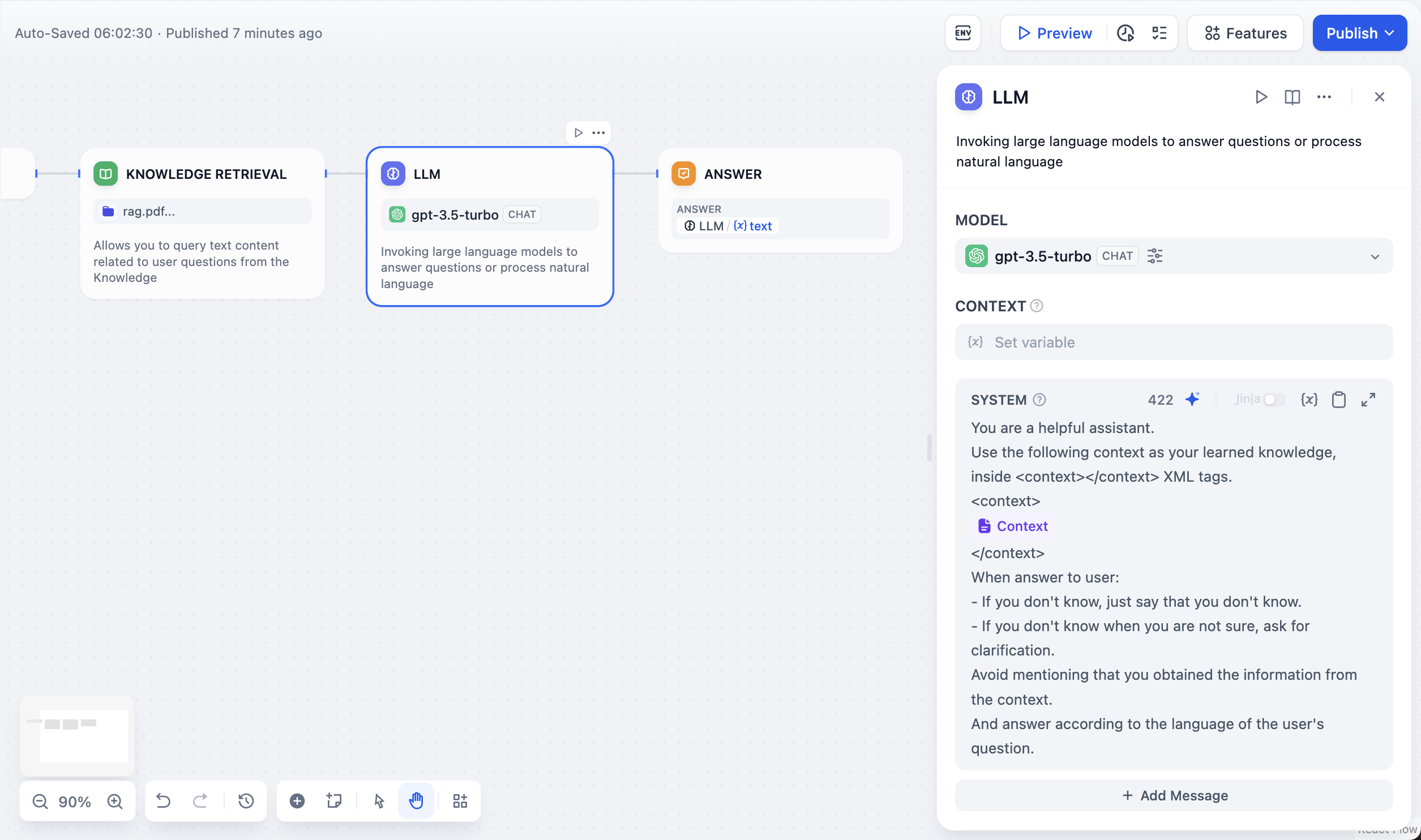
**Context Variables**
|
||||
|
||||
Context variables are a special type of variable defined within the LLM node, used to insert externally retrieved text content into the prompt.
|
||||
|
||||

|
||||
|
||||
In common knowledge base Q\&A applications, the downstream node of knowledge retrieval is typically the LLM node. The **output variable** `result` of knowledge retrieval needs to be configured in the **context variable** within the LLM node for association and assignment. After association, inserting the **context variable** at the appropriate position in the prompt can incorporate the externally retrieved knowledge into the prompt.
|
||||
|
||||
This variable can be used not only as external knowledge introduced into the prompt context for LLM responses but also supports the application's [citation and attribution](/en/guides/knowledge-base/retrieval-test-and-citation#id-2-citation-and-attribution) feature due to its data structure containing segment reference information.
|
||||
|
||||
<Info>
|
||||
If the context variable is associated with a common variable from an upstream node, such as a string type variable from the start node, the context variable can still be used as external knowledge, but the **citation and attribution** feature will be disabled.
|
||||
</Info>
|
||||
|
||||
**File Variables**
|
||||
|
||||
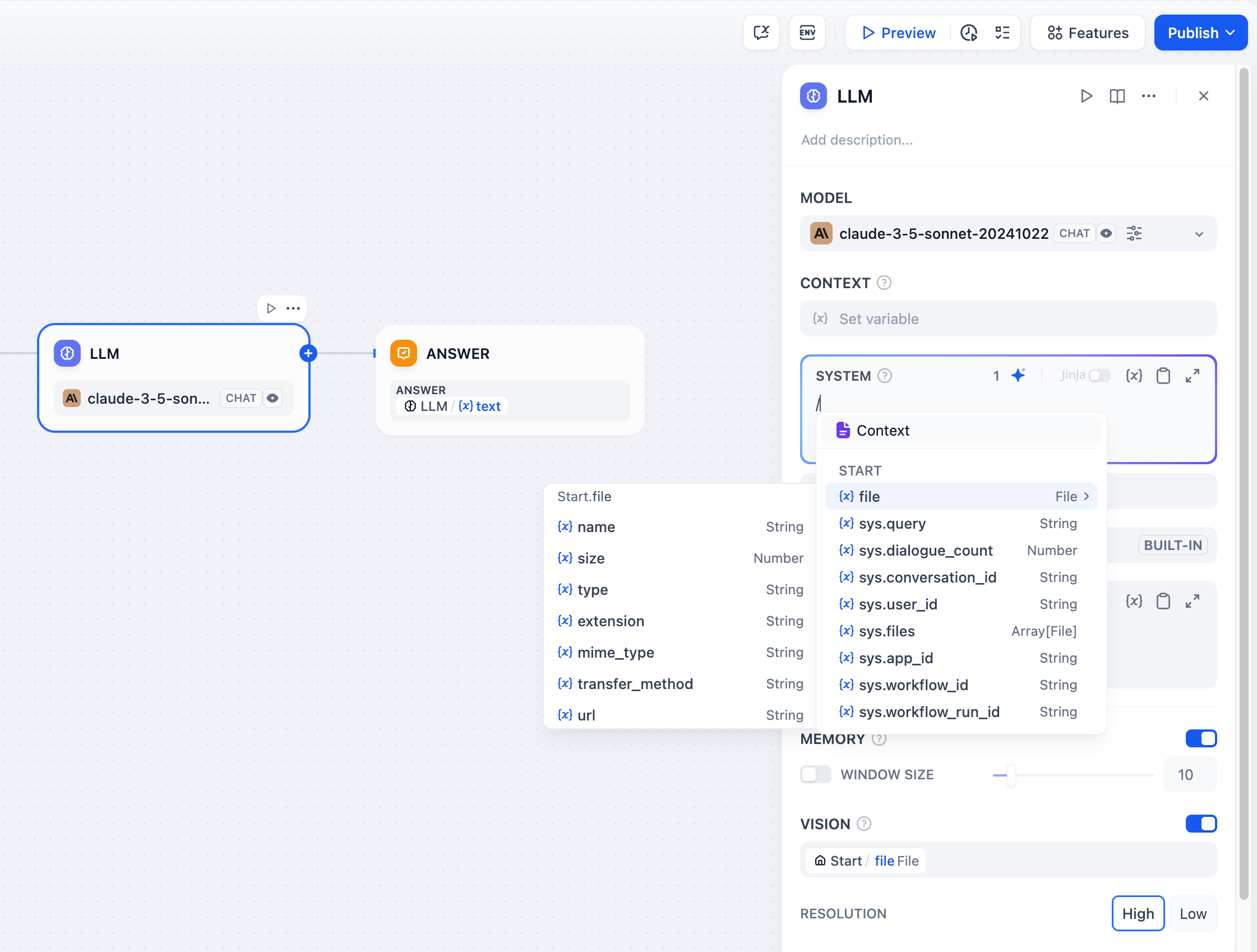
Some LLMs, such as [Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support), now support direct processing of file content, enabling the use of file variables in prompts. To prevent potential issues, application developers should verify the supported file types on the LLM's official website before utilizing the file variable.
|
||||
|
||||
|
||||
|
||||
> Refer to [File Upload](/en/guides/workflow/file-upload) for guidance on building a Chatflow/Workflow application with file upload functionality.
|
||||
|
||||
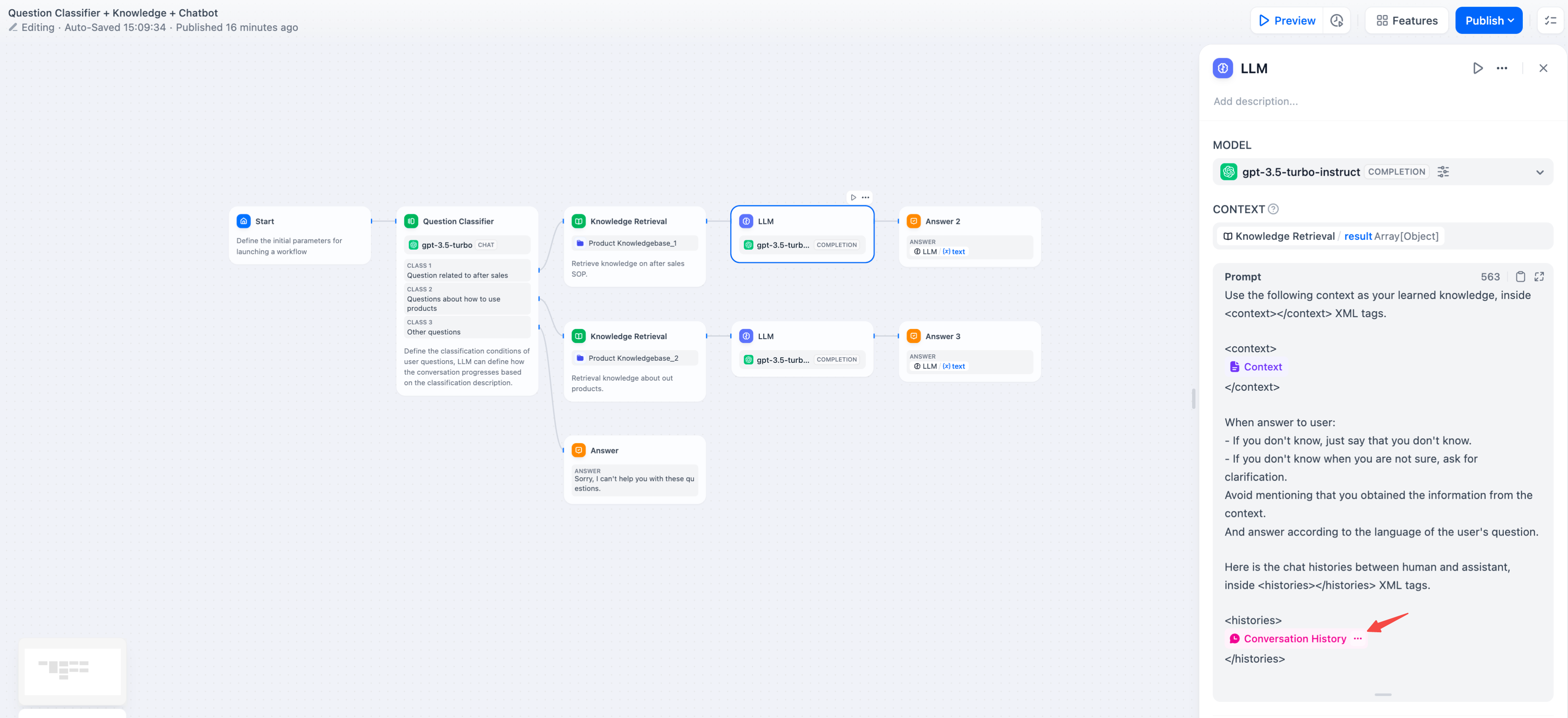
**Conversation History**
|
||||
|
||||
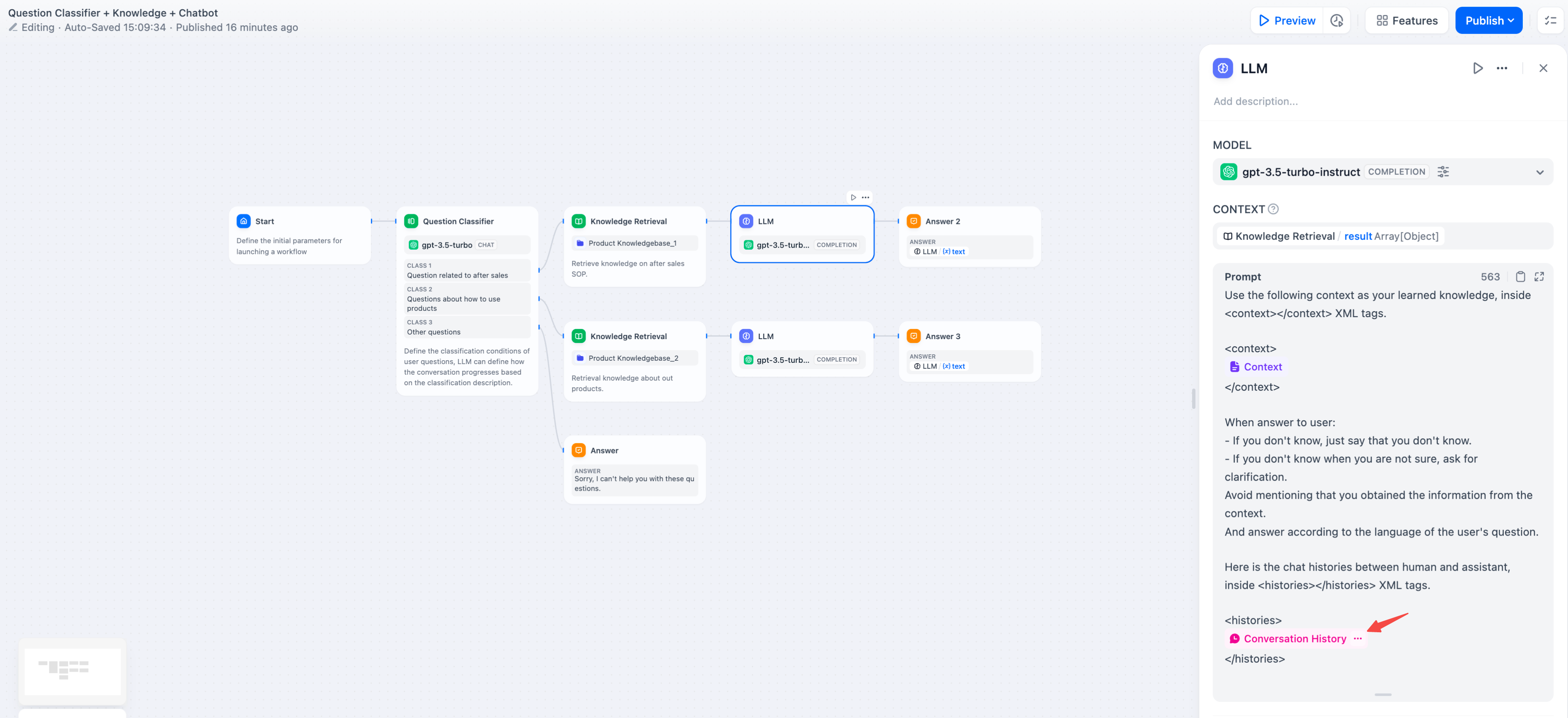
To achieve conversational memory in text completion models (e.g., gpt-3.5-turbo-Instruct), Dify designed the conversation history variable in the original [Prompt Expert Mode (discontinued)](/en/learn-more/extended-reading/prompt-engineering/prompt-engineering-1). This variable is carried over to the LLM node in Chatflow, used to insert chat history between the AI and the user into the prompt, helping the LLM understand the context of the conversation.
|
||||
|
||||
<Info>
|
||||
The conversation history variable is not widely used and can only be inserted when selecting text completion models in Chatflow.
|
||||
</Info>
|
||||
|
||||
|
||||
|
||||
**Model Parameters**
|
||||
|
||||
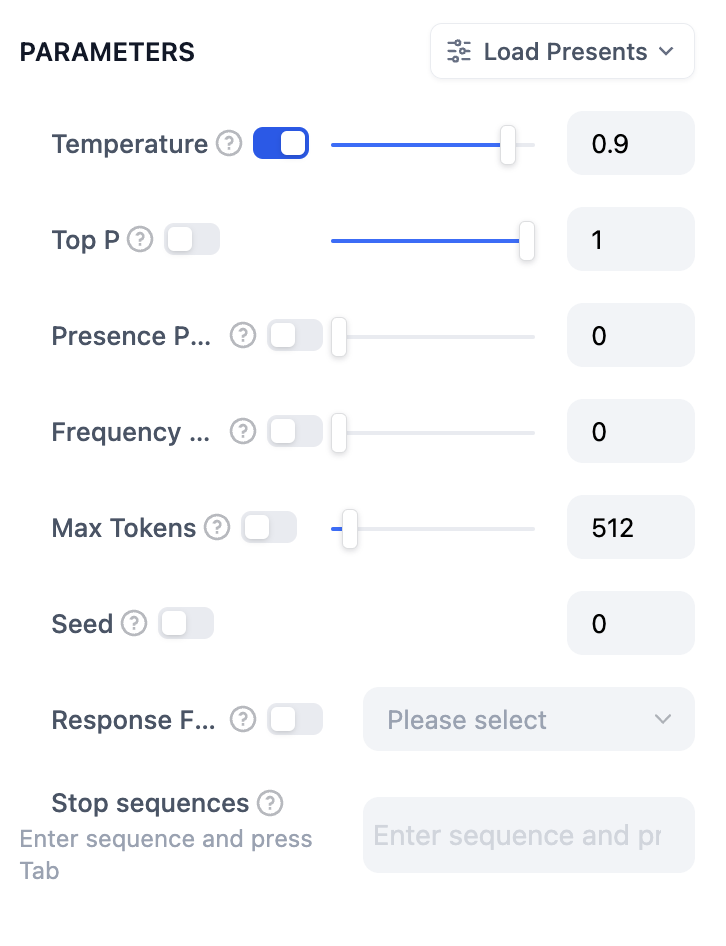
The parameters of the model affect the output of the model. Different models have different parameters. The following figure shows the parameter list for `gpt-4`.
|
||||
|
||||
|
||||
|
||||
The main parameter terms are explained as follows:
|
||||
|
||||
**Temperature**: Usually a value between 0-1, it controls randomness. The closer the temperature is to 0, the more certain and repetitive the results; the closer it is to 1, the more random the results.
|
||||
|
||||
**Top P**: Controls the diversity of the results. The model selects from candidate words based on probability, ensuring that the cumulative probability does not exceed the preset threshold P.
|
||||
|
||||
**Presence Penalty**: Used to reduce the repetitive generation of the same entity or information by imposing penalties on content that has already been generated, making the model inclined to generate new or different content. As the parameter value increases, greater penalties are applied in subsequent generations to content that has already been generated, lowering the likelihood of repeating content.
|
||||
|
||||
**Frequency Penalty**: Imposes penalties on words or phrases that appear too frequently by reducing their probability of generation. With an increase in parameter value, greater penalties are imposed on frequently occurring words or phrases. Higher parameter values reduce the frequency of these words, thereby increasing the lexical diversity of the text.
|
||||
|
||||
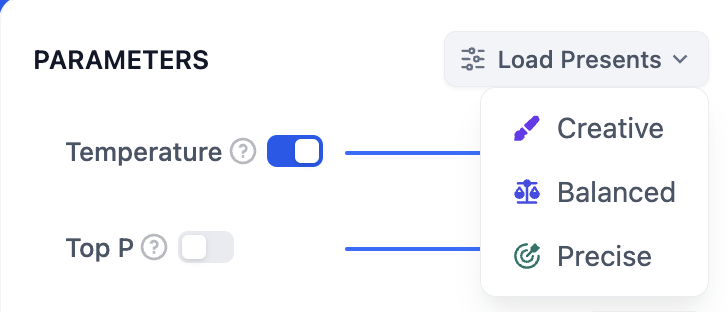
If you do not understand what these parameters are, you can choose to load presets and select from the three presets: Creative, Balanced, and Precise.
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
### Advanced Features
|
||||
|
||||
**Memory**: When enabled, each input to the intent classifier will include chat history from the conversation to help the LLM understand the context and improve question comprehension in interactive dialogues.
|
||||
|
||||
**Memory Window**: When the memory window is closed, the system dynamically filters the amount of chat history passed based on the model's context window; when open, users can precisely control the amount of chat history passed (in terms of numbers).
|
||||
|
||||
**Conversation Role Name Settings**: Due to differences in model training stages, different models adhere to role name instructions differently, such as Human/Assistant, Human/AI, Human/Assistant, etc. To adapt to the prompt response effects of multiple models, the system provides conversation role name settings. Modifying the role name will change the role prefix in the conversation history.
|
||||
|
||||
**Jinja-2 Templates**: The LLM prompt editor supports Jinja-2 template language, allowing you to leverage this powerful Python template language for lightweight data transformation and logical processing. Refer to the [official documentation](https://jinja.palletsprojects.com/en/3.1.x/templates/).
|
||||
|
||||
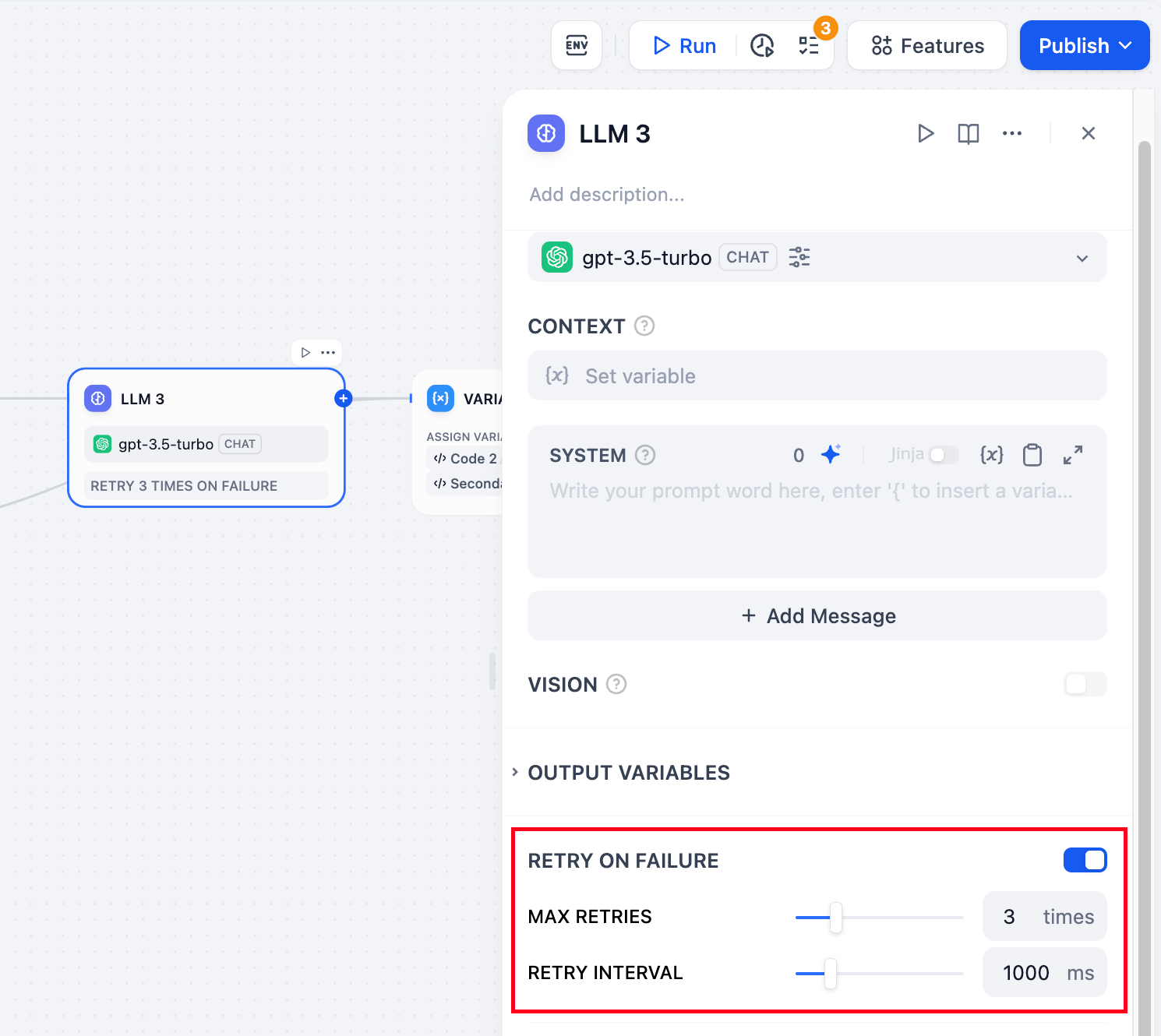
**Retry on Failure**: For some exceptions that occur in the node, it is usually sufficient to retry the node again. When the error retry function is enabled, the node will automatically retry according to the preset strategy when an error occurs. You can adjust the maximum number of retries and the interval between each retry to set the retry strategy.
|
||||
|
||||
- The maximum number of retries is 10
|
||||
- The maximum retry interval is 5000 ms
|
||||
|
||||
|
||||
|
||||
**Error Handling**: Provides diverse node error handling strategies that can throw error messages when the current node fails without interrupting the main process, or continue completing tasks through backup paths. For detailed information, please refer to the [Error Handling](/en/guides/workflow/error-handling).
|
||||
|
||||
***
|
||||
|
||||
#### Use Cases
|
||||
|
||||
* **Reading Knowledge Base Content**
|
||||
|
||||
To enable workflow applications to read [Knowledge Base](/en/guides/knowledge-base) content, such as building an intelligent customer service application, please follow these steps:
|
||||
|
||||
1. Add a knowledge base retrieval node upstream of the LLM node;
|
||||
2. Fill in the **output variable** `result` of the knowledge retrieval node into the **context variable** of the LLM node;
|
||||
3. Insert the **context variable** into the application prompt to give the LLM the ability to read text within the knowledge base.
|
||||
|
||||
|
||||
|
||||
The `result` variable output by the Knowledge Retrieval Node also includes segmented reference information. You can view the source of information through the **Citation and Attribution** feature.
|
||||
|
||||
<Info>
|
||||
Regular variables from upstream nodes can also be filled into context variables, such as string-type variables from the start node, but the **Citation and Attribution** feature will be ineffective.
|
||||
</Info>
|
||||
|
||||
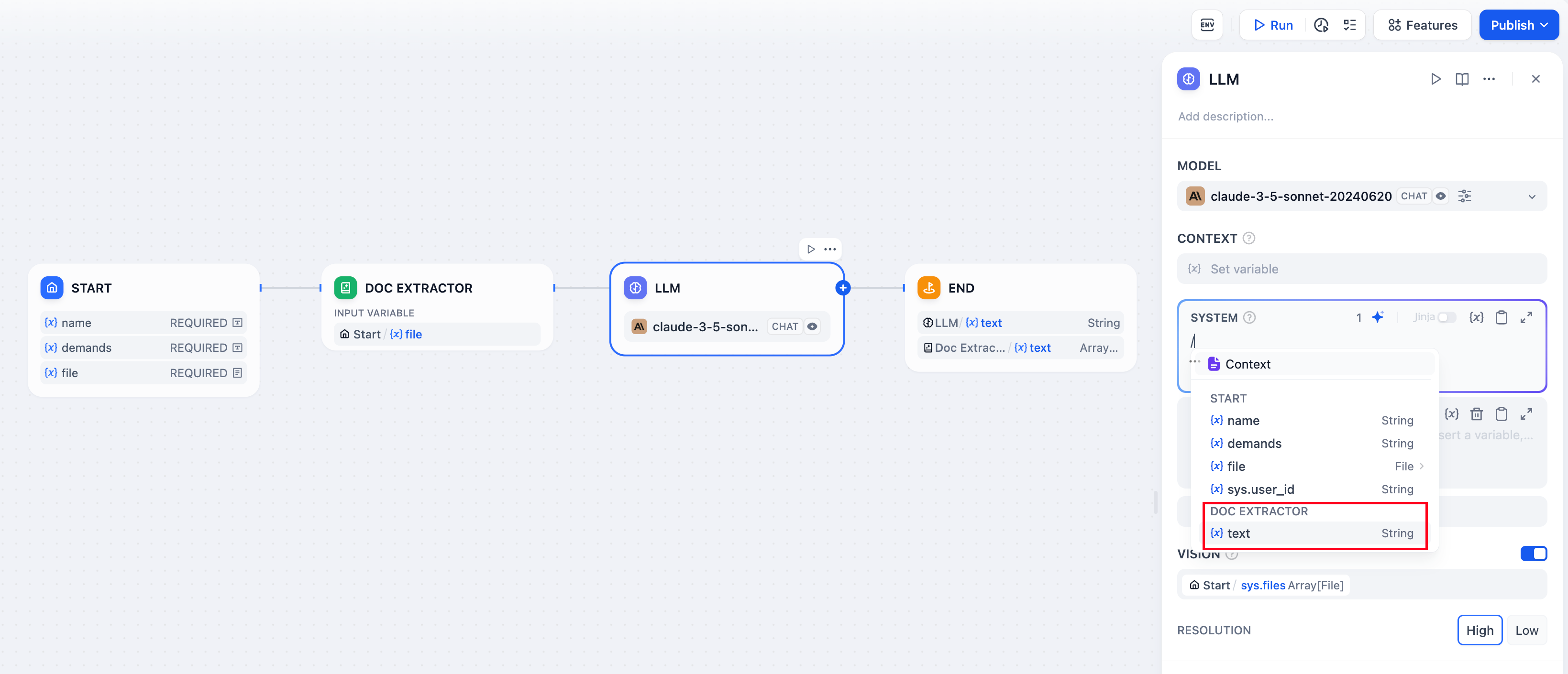
* **Reading Document Files**
|
||||
|
||||
To enable workflow applications to read document contents, such as building a ChatPDF application, you can follow these steps:
|
||||
|
||||
* Add a file variable in the "Start" node;
|
||||
* Add a document extractor node upstream of the LLM node, using the file variable as an input variable;
|
||||
* Fill in the **output variable** `text` of the document extractor node into the prompt of the LLM node.
|
||||
|
||||
For more information, please refer to [File Upload](/en/guides/workflow/file-upload).
|
||||
|
||||
|
||||
|
||||
* **Error Handling**
|
||||
|
||||
When processing information, LLM nodes may encounter errors such as input text exceeding token limits or missing key parameters. Developers can follow these steps to configure exception branches, enabling contingency plans when node errors occur to avoid interrupting the entire flow:
|
||||
|
||||
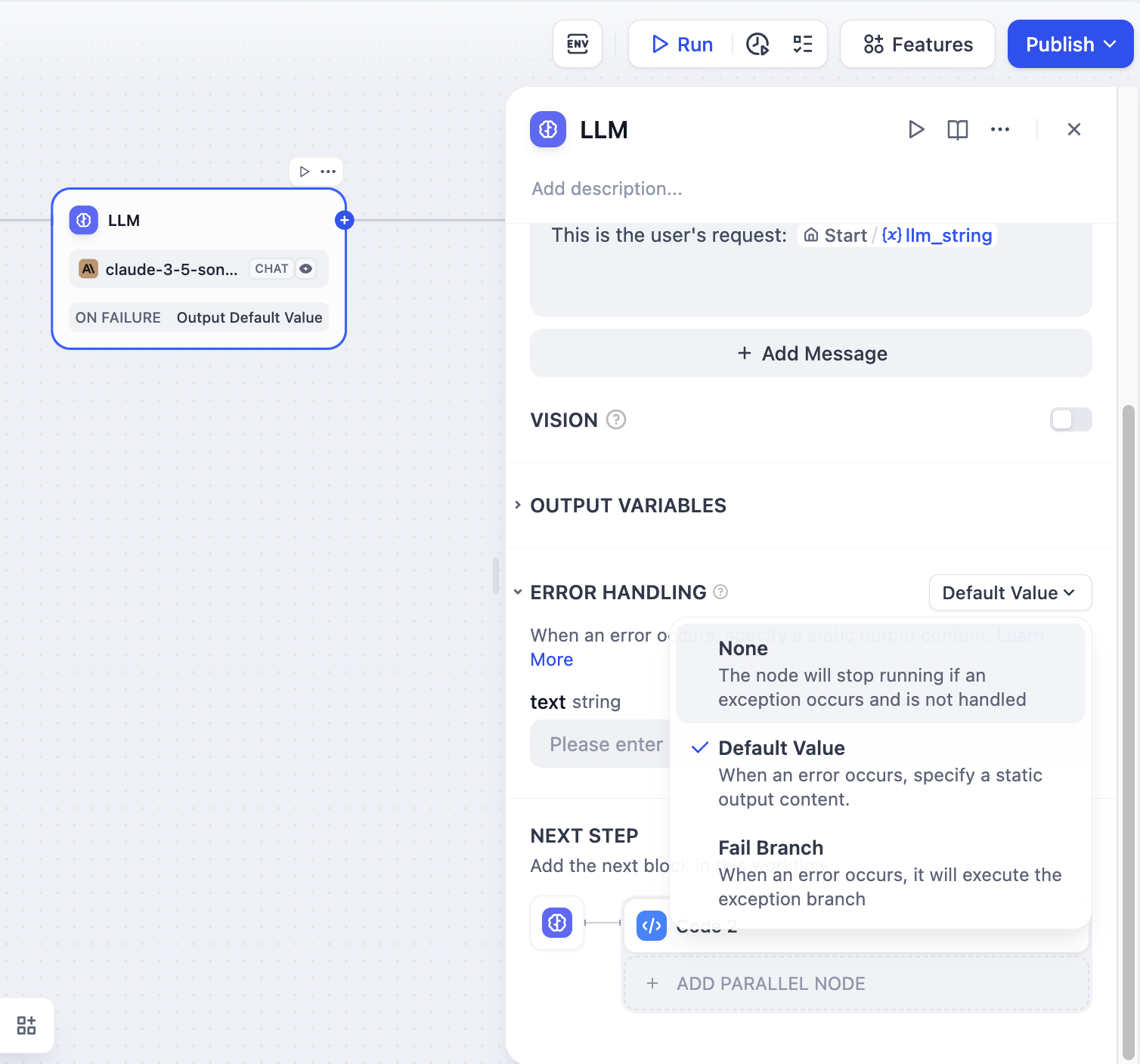
1. Enable "Error Handling" in the LLM node
|
||||
2. Select and configure an error handling strategy
|
||||
|
||||
|
||||
|
||||
For more information about exception handling methods, please refer to the [Error Handling](/en/guides/workflow/error-handling).
|
||||
85
en/guides/workflow/node/loop.mdx
Normal file
85
en/guides/workflow/node/loop.mdx
Normal file
@@ -0,0 +1,85 @@
|
||||
---
|
||||
title: Loop
|
||||
---
|
||||
|
||||
## What is Loop Node?
|
||||
|
||||
A **Loop** node executes repetitive tasks that depend on previous iteration results until exit conditions are met or the maximum loop count is reached.
|
||||
|
||||
## Loop vs. Iteration
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Type</th>
|
||||
<th>Dependencies</th>
|
||||
<th>Use Cases</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><strong>Loop</strong></td>
|
||||
<td>Each iteration depends on previous results</td>
|
||||
<td>Recursive operations, optimization problems</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><strong>Iteration</strong></td>
|
||||
<td>Iterations execute independently</td>
|
||||
<td>Batch processing, parallel data handling</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## Configuration
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Parameter</th>
|
||||
<th>Description</th>
|
||||
<th>Example</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
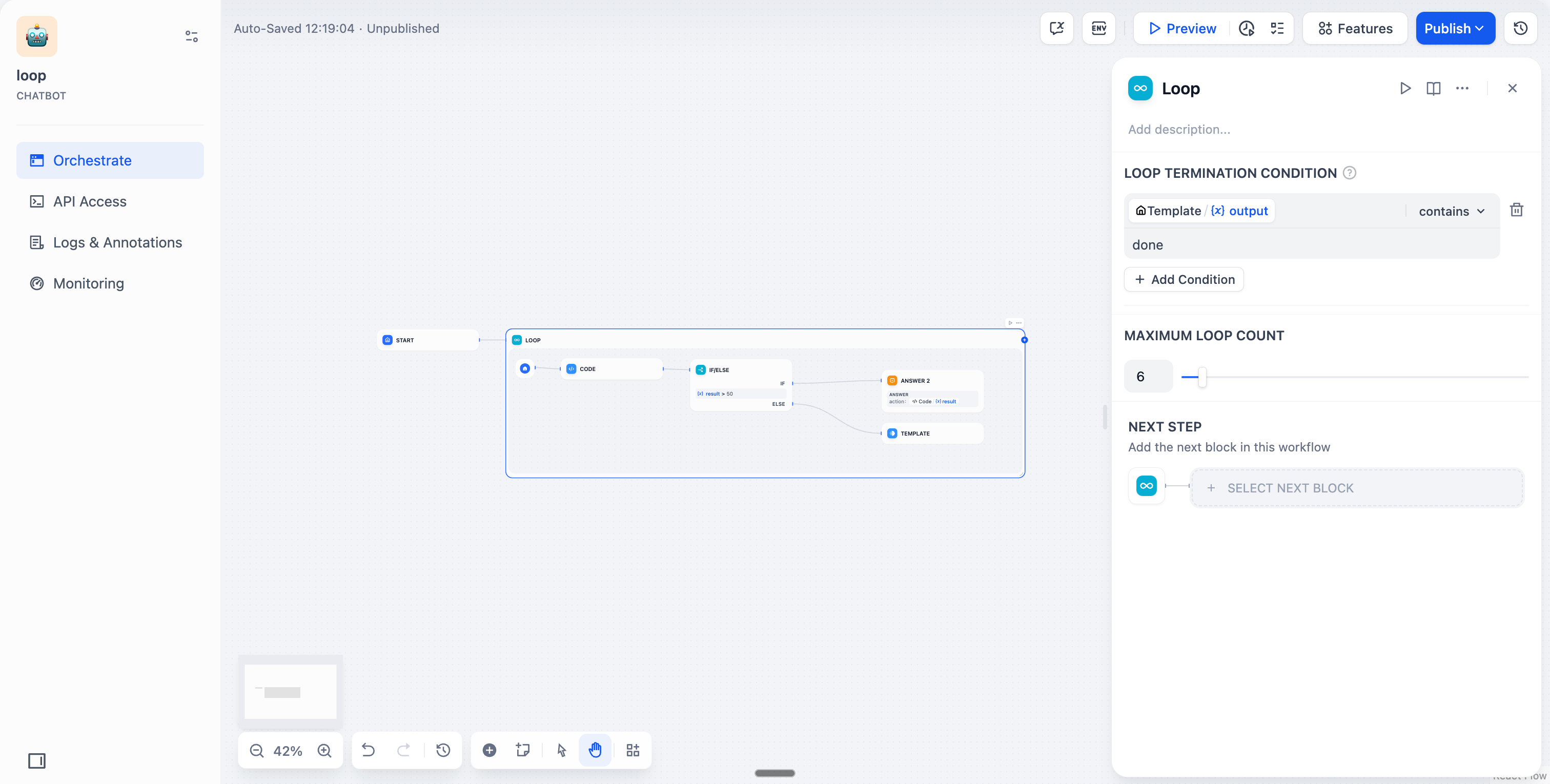
<td>Loop Termination Condition</td>
|
||||
<td>Expression that determines when to exit the loop</td>
|
||||
<td><code>x < 50</code>, <code>error_rate < 0.01</code></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Maximum Loop Count</td>
|
||||
<td>Upper limit on iterations to prevent infinite loops</td>
|
||||
<td>10, 100, 1000</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
|
||||
## Usage Example
|
||||
|
||||
**Goal: Generate random numbers (1-100) until a value below 50 appears.**
|
||||
|
||||
**Steps**:
|
||||
|
||||
1. Use `node` to generate a random number between 1-100.
|
||||
|
||||
2. Use `if` to evaluate the number:
|
||||
|
||||
- If < 50: Output `done` and terminate loop.
|
||||
|
||||
- If ≥ 50: Continue loop and generate another random number.
|
||||
|
||||
3. Set the exit criterion to random_number < 50.
|
||||
|
||||
4. Loop ends when a number below 50 appears.
|
||||
|
||||

|
||||
|
||||
## Planned Enhancements
|
||||
|
||||
**Future releases will include:**
|
||||
|
||||
- Loop variables: Store and reference values across iterations for improved state management and conditional logic.
|
||||
|
||||
- `break` node: Terminate loops from within the execution path, enabling more sophisticated control flow patterns.
|
||||
61
en/guides/workflow/node/parameter-extractor.mdx
Normal file
61
en/guides/workflow/node/parameter-extractor.mdx
Normal file
@@ -0,0 +1,61 @@
|
||||
---
|
||||
title: Parameter Extraction
|
||||
---
|
||||
|
||||
|
||||
### 1 Definition
|
||||
|
||||
Utilize LLM to infer and extract structured parameters from natural language for subsequent tool invocation or HTTP requests.
|
||||
|
||||
Dify workflows provide a rich selection of [tools](/en/tools), most of which require structured parameters as input. The parameter extractor can convert user natural language into parameters recognizable by these tools, facilitating tool invocation.
|
||||
|
||||
Some nodes within the workflow require specific data formats as inputs, such as the [iteration](/en/guides/workflow/nodes/iteration#definition) node, which requires an array format. The parameter extractor can conveniently achieve [structured parameter conversion](/en/guides/workflow/nodes/iteration#example-1-long-article-iteration-generator).
|
||||
|
||||
***
|
||||
|
||||
### 2 Scenarios
|
||||
|
||||
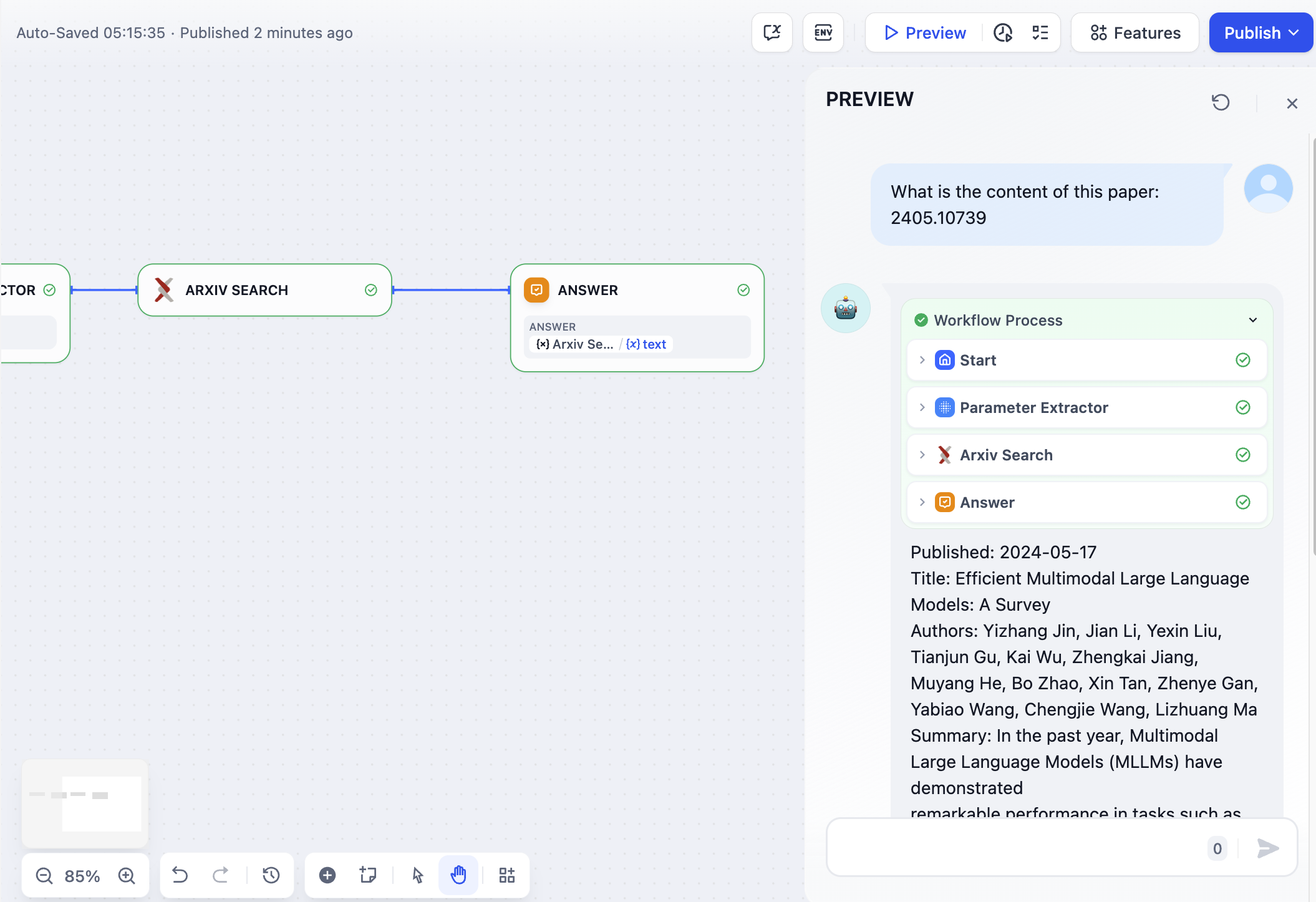
1. **Extracting key parameters required by tools from natural language**, such as building a simple conversational Arxiv paper retrieval application.
|
||||
|
||||
In this example: The Arxiv paper retrieval tool requires **paper author** or **paper ID** as input parameters. The parameter extractor extracts the paper ID **2405.10739** from the query "What is the content of this paper: 2405.10739" and uses it as the tool parameter for precise querying.
|
||||
|
||||
|
||||
|
||||
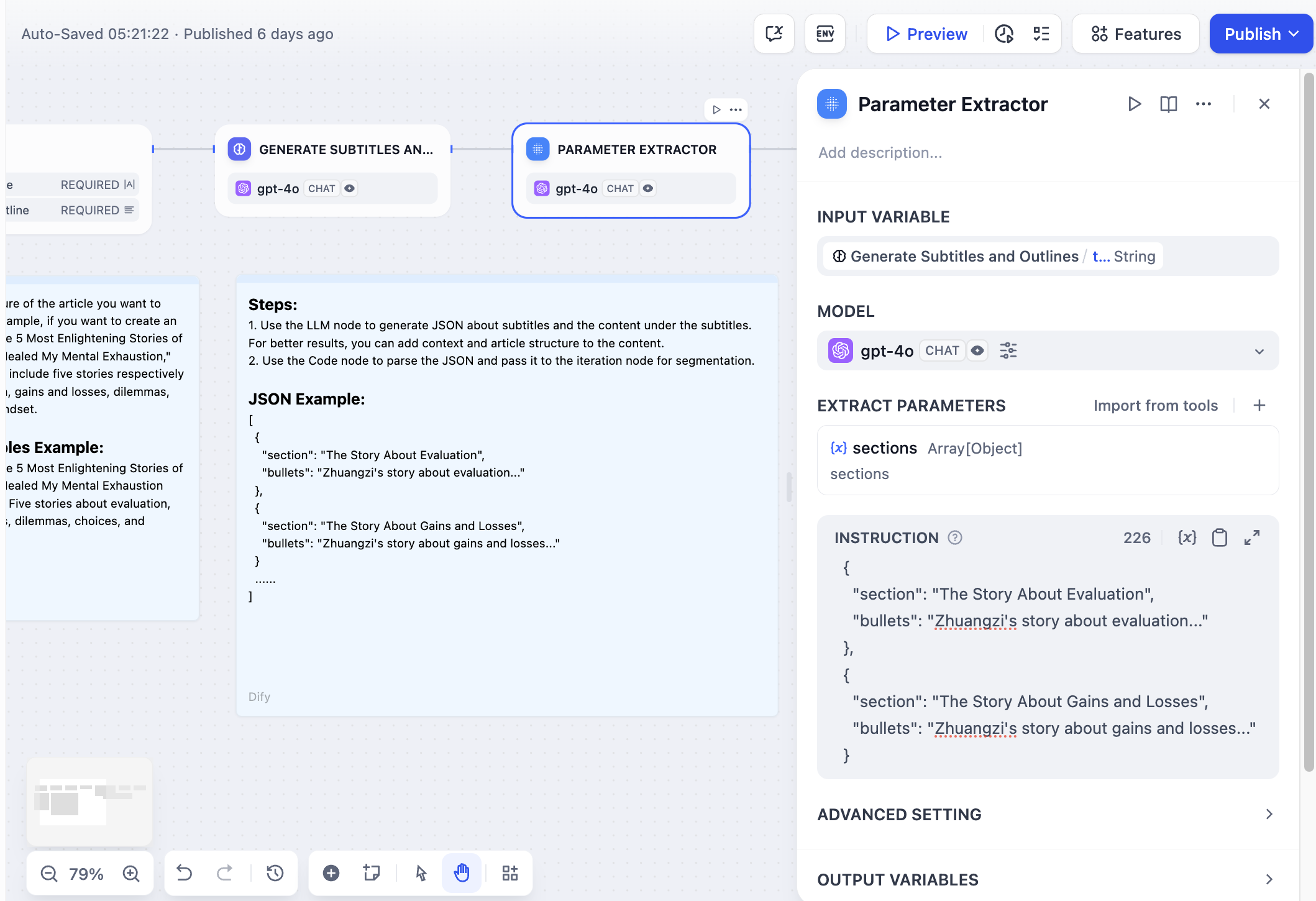
2. **Converting text to structured data**, such as in the long story iteration generation application, where it serves as a pre-step for the [iteration node](/en/guides/workflow/nodes/iteration), converting chapter content in text format to an array format, facilitating multi-round generation processing by the iteration node.
|
||||
|
||||
|
||||
|
||||
1. **Extracting structured data and using the** [**HTTP Request**](/en/guides/workflow/nodes/http-request), which can request any accessible URL, suitable for obtaining external retrieval results, webhooks, generating images, and other scenarios.
|
||||
|
||||
***
|
||||
|
||||
### 3 How to Configure
|
||||
|
||||
**Configuration Steps**
|
||||
|
||||
1. Select the input variable, usually the variable input for parameter extraction.
|
||||
2. Choose the model, as the parameter extractor relies on the LLM's inference and structured generation capabilities.
|
||||
3. Define the parameters to extract, which can be manually added or **quickly imported from existing tools**.
|
||||
4. Write instructions, where providing examples can help the LLM improve the effectiveness and stability of extracting complex parameters.
|
||||
|
||||
**Advanced Settings**
|
||||
|
||||
**Inference Mode**
|
||||
|
||||
Some models support two inference modes, achieving parameter extraction through function/tool calls or pure prompt methods, with differences in instruction compliance. For instance, some models may perform better in prompt inference if function calling is less effective.
|
||||
|
||||
* Function Call/Tool Call
|
||||
* Prompt
|
||||
|
||||
**Memory**
|
||||
|
||||
When memory is enabled, each input to the question classifier will include the chat history in the conversation to help the LLM understand the context and improve question comprehension during interactive dialogues.
|
||||
|
||||
**Output Variables**
|
||||
|
||||
* Extracted defined variables
|
||||
* Node built-in variables
|
||||
|
||||
`__is_success Number` Extraction success status, with a value of 1 for success and 0 for failure.
|
||||
|
||||
`__reason String` Extraction error reason
|
||||
57
en/guides/workflow/node/question-classifier.mdx
Normal file
57
en/guides/workflow/node/question-classifier.mdx
Normal file
@@ -0,0 +1,57 @@
|
||||
---
|
||||
title: Question Classifier
|
||||
---
|
||||
|
||||
|
||||
### 1. Definition
|
||||
|
||||
By defining classification descriptions, the issue classifier can infer and match user inputs to the corresponding categories and output the classification results.
|
||||
|
||||
***
|
||||
|
||||
### 2. Scenarios
|
||||
|
||||
Common use cases include **customer service conversation intent classification, product review classification, and bulk email classification**.
|
||||
|
||||
In a typical product customer service Q\&A scenario, the issue classifier can serve as a preliminary step before knowledge base retrieval. It classifies the user's input question, directing it to different downstream knowledge base queries to accurately respond to the user's question.
|
||||
|
||||
The following diagram is an example workflow template for a product customer service scenario:
|
||||
|
||||
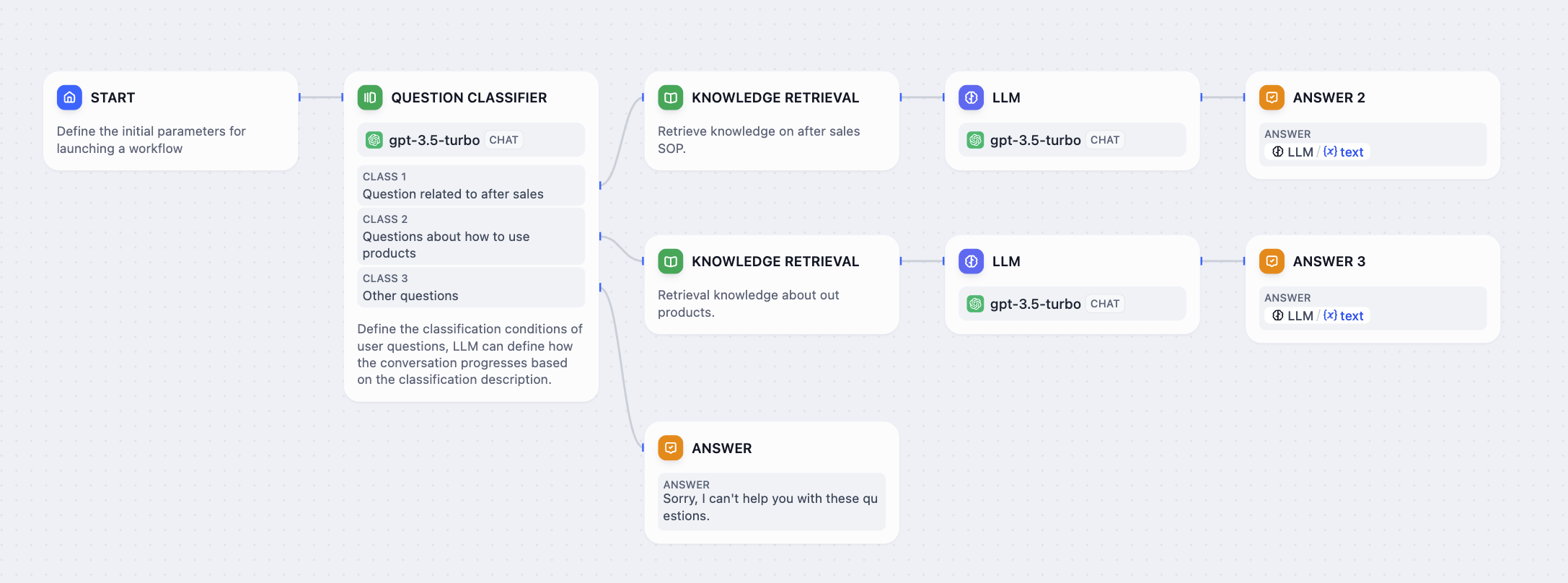
|
||||
|
||||
In this scenario, we set up three classification labels/descriptions:
|
||||
|
||||
* Category 1: **Questions related to after-sales service**
|
||||
* Category 2: **Questions related to product usage**
|
||||
* Category 3: **Other questions**
|
||||
|
||||
When users input different questions, the issue classifier will automatically classify them based on the set classification labels/descriptions:
|
||||
|
||||
* "**How to set up contacts on iPhone 14?**" —> "**Questions related to product usage**"
|
||||
* "**What is the warranty period?**" —> "**Questions related to after-sales service**"
|
||||
* "**How's the weather today?**" —> "**Other questions**"
|
||||
|
||||
***
|
||||
|
||||
### 3. How to Configure
|
||||
|
||||
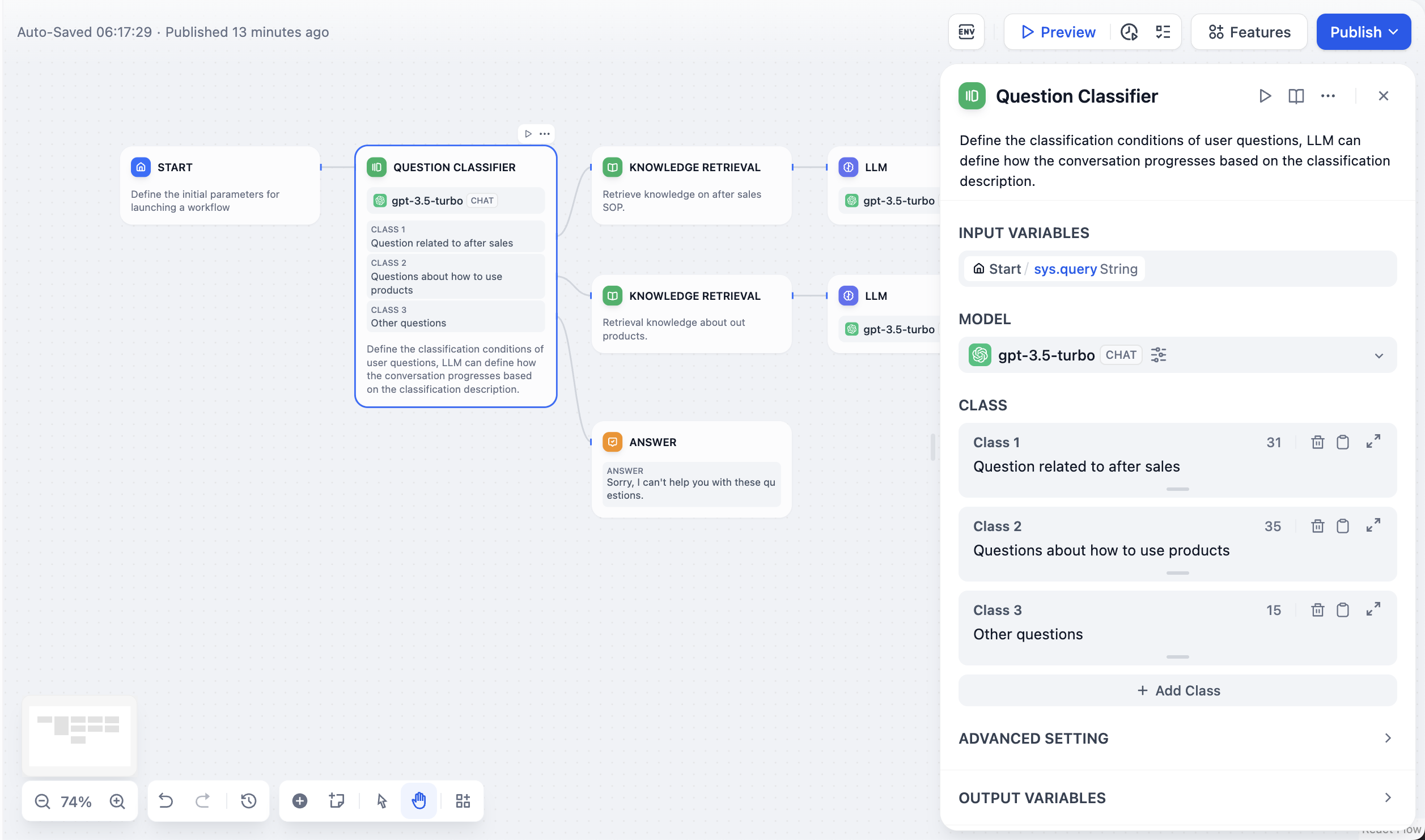
|
||||
|
||||
**Configuration Steps:**
|
||||
|
||||
1. **Select Input Variable**: This refers to the content to be classified, usually the user's question in a customer service Q\&A scenario, e.g., `sys.query`.
|
||||
2. **Choose Inference Model**: The issue classifier leverages the natural language classification and inference capabilities of large language models. Selecting an appropriate model can enhance classification effectiveness.
|
||||
3. **Write Classification Labels/Descriptions**: You can manually add multiple classifications by writing keywords or descriptive statements for each category, helping the large language model better understand the classification criteria.
|
||||
4. **Choose Corresponding Downstream Nodes**: After classification, the issue classification node can direct the flow to different paths based on the relationship between the classification and downstream nodes.
|
||||
|
||||
#### Advanced Settings:
|
||||
|
||||
**Instructions**: In **Advanced Settings - Instructions**, you can add supplementary instructions, such as more detailed classification criteria, to enhance the classifier's capabilities.
|
||||
|
||||
**Memory**: When enabled, each input to the issue classifier will include chat history from the conversation to help the LLM understand the context and improve question comprehension in interactive dialogues.
|
||||
|
||||
**Memory Window**: When the memory window is closed, the system dynamically filters the amount of chat history passed based on the model's context window; when open, users can precisely control the amount of chat history passed (in terms of numbers).
|
||||
|
||||
**Output Variable**:
|
||||
|
||||
`class_name` stores the classification output label. You can reference this classification result in downstream nodes when needed.
|
||||
150
en/guides/workflow/node/start.mdx
Normal file
150
en/guides/workflow/node/start.mdx
Normal file
@@ -0,0 +1,150 @@
|
||||
---
|
||||
title: Start
|
||||
---
|
||||
|
||||
### Definition
|
||||
|
||||
The **“Start”** node is a critical preset node in the Chatflow / Workflow application. It provides essential initial information, such as user input and [uploaded files](/en/guides/workflow/file-upload), to support the normal flow of the application and subsequent workflow nodes.
|
||||
|
||||
### Configuring the Node
|
||||
|
||||
On the Start node's settings page, you'll find two sections: **"Input Fields"** and preset **System Variables**.
|
||||
|
||||
|
||||
|
||||
### Input Field
|
||||
|
||||
Input field is configured by application developers to prompt users for additional information.
|
||||
|
||||
For example, in a weekly report application, users might be required to provide background information such as name, work date range, and work details in a specific format. This preliminary information helps the LLM generate higher quality responses.
|
||||
|
||||
Six types of input variables are supported, all of which can be set as required:
|
||||
|
||||
* **Text:** Short text, filled in by the user, with a maximum length of 256 characters.
|
||||
* **Paragraph:** Long text, allowing users to input longer content.
|
||||
* **Select:** Fixed options set by the developer; users can only select from preset options and cannot input custom content.
|
||||
* **Number:** Only allows numerical input.
|
||||
* **Single File:** Allows users to upload a single file. Supports document types, images, audio, video, and other file types. Users can upload locally or paste a file URL. For detailed usage, refer to File Upload.
|
||||
* **File List:** Allows users to batch upload files. Supports document types, images, audio, video, and other file types. Users can upload locally or paste file URLs. For detailed usage, refer to File Upload.
|
||||
|
||||
<Info>
|
||||
Dify's built-in document extractor node can only process certain document formats. For processing images, audio, or video files, refer to External Data Tools to set up corresponding file processing nodes.
|
||||
</Info>
|
||||
|
||||
Once configured, users will be guided to provide necessary information to the LLM before using the application. More information will help to improve the LLM's question-answering efficiency.
|
||||
|
||||
### System Variables
|
||||
|
||||
System variables are preset system-level parameters in Chatflow / Workflow applications that can be globally accessed by other nodes in the application. They are typically used in advanced development scenarios, such as building multi-turn dialogue applications, collecting application logs and monitoring data, or recording usage behavior across different applications and users.
|
||||
|
||||
**Workflow**
|
||||
|
||||
Workflow application provides the following system variables:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Variable Name</th>
|
||||
<th>Data Type</th>
|
||||
<th>Description</th>
|
||||
<th>Notes</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>sys.files</code><br />[LEGACY]</td>
|
||||
<td>Array[File]</td>
|
||||
<td>File parameter, stores images uploaded by users when initially using the application</td>
|
||||
<td>Image upload feature needs to be enabled in the "Features" section at the top right of the application orchestration page</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.user_id</code></td>
|
||||
<td>String</td>
|
||||
<td>User ID, a unique identifier automatically assigned to each user when using the workflow application, used to distinguish different conversation users</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.app_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Application ID, a unique identifier assigned to each Workflow application by the system, used to distinguish different applications and record basic information of the current application</td>
|
||||
<td>For users with development capabilities, this parameter can be used to differentiate and locate different Workflow applications</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.workflow_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Workflow ID, used to record all node information contained in the current Workflow application</td>
|
||||
<td>For users with development capabilities, this parameter can be used to track and record node information within the Workflow</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.workflow_run_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Workflow application run ID, used to record the running status of the Workflow application</td>
|
||||
<td>For users with development capabilities, this parameter can be used to track the application's run history</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
**Chatflow**
|
||||
|
||||
Chatflow application provides the following system variables:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Variable Name</th>
|
||||
<th>Data Type</th>
|
||||
<th>Description</th>
|
||||
<th>Notes</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>sys.query</code></td>
|
||||
<td>String</td>
|
||||
<td>The initial content input by the user in the dialogue box</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.files</code></td>
|
||||
<td>Array[File]</td>
|
||||
<td>Images uploaded by the user in the dialogue box</td>
|
||||
<td>Image upload feature needs to be enabled in the "Features" section at the top right of the application orchestration page</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.dialogue_count</code></td>
|
||||
<td>Number</td>
|
||||
<td>The number of dialogue turns during user interaction with the Chatflow application. Automatically increments by 1 after each turn. Can be used with if-else nodes to create rich branching logic. For example, at the Xth turn of dialogue, review the conversation history and provide analysis</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.conversation_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Unique identifier for the dialogue interaction session, grouping all related messages into the same conversation, ensuring the LLM continues the dialogue on the same topic and context</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.user_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Unique identifier assigned to each application user, used to distinguish different conversation users</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.app_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Application ID, a unique identifier assigned to each Workflow application by the system, used to distinguish different applications and record basic information of the current application</td>
|
||||
<td>For users with development capabilities, this parameter can be used to differentiate and locate different Workflow applications</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.workflow_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Workflow ID, used to record all node information contained in the current Workflow application</td>
|
||||
<td>For users with development capabilities, this parameter can be used to track and record node information within the Workflow</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.workflow_run_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Workflow application run ID, used to record the running status of the Workflow application</td>
|
||||
<td>For users with development capabilities, this parameter can be used to track the application's run history</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
32
en/guides/workflow/node/template.mdx
Normal file
32
en/guides/workflow/node/template.mdx
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
title: Template
|
||||
---
|
||||
|
||||
|
||||
Template lets you dynamically format and combine variables from previous nodes into a single text-based output using Jinja2, a powerful templating syntax for Python. It's useful for combining data from multiple sources into a specific structure required by subsequent nodes. The simple example below shows how to assemble an article by piecing together various previous outputs:
|
||||
|
||||
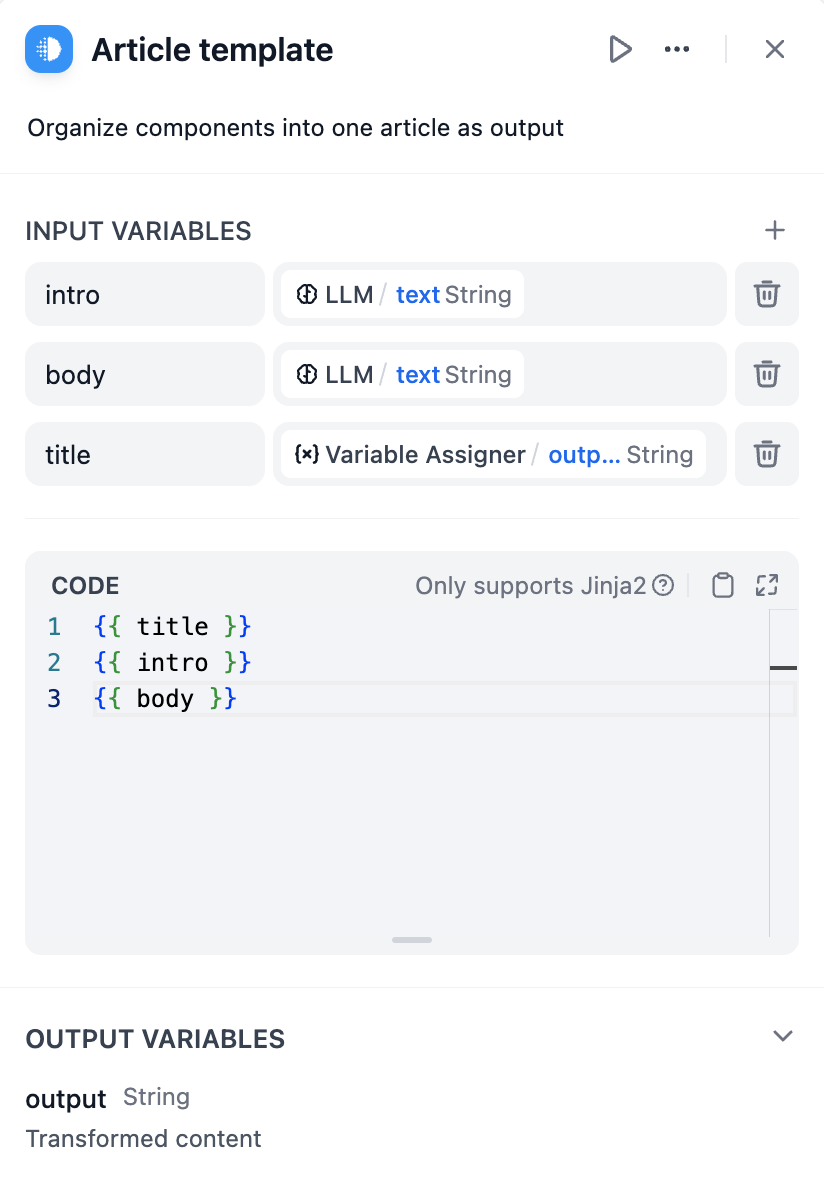
|
||||
|
||||
Beyond naive use cases, you can create more complex templates as per Jinja's [documentation](https://jinja.palletsprojects.com/en/3.1.x/templates/) for a variety of tasks. Here's one template that structures retrieved chunks and their relevant metadata from a knowledge retrieval node into a formatted markdown:
|
||||
|
||||
```Plain
|
||||
{% raw %}
|
||||
{% for item in chunks %}
|
||||
### Chunk {{ loop.index }}.
|
||||
### Similarity: {{ item.metadata.score | default('N/A') }}
|
||||
|
||||
#### {{ item.title }}
|
||||
|
||||
##### Content
|
||||
{{ item.content | replace('\n', '\n\n') }}
|
||||
|
||||
---
|
||||
{% endfor %}
|
||||
{% endraw %}
|
||||
```
|
||||
|
||||

|
||||
|
||||
This template node can then be used within a Chatflow to return intermediate outputs to the end user, before a LLM response is initiated.
|
||||
|
||||
> The `Answer` node in a Chatflow is non-terminal. It can be inserted anywhere to output responses at multiple points within the flow.
|
||||
64
en/guides/workflow/node/tools.mdx
Normal file
64
en/guides/workflow/node/tools.mdx
Normal file
@@ -0,0 +1,64 @@
|
||||
---
|
||||
title: Tools
|
||||
---
|
||||
|
||||
|
||||
The workflow provides a rich selection of tools, categorized into three types:
|
||||
|
||||
* **Built-in Tools**: Tools provided by Dify.
|
||||
* **Custom Tools**: Tools imported or configured via the OpenAPI/Swagger standard format.
|
||||
* **Workflows**: Workflows that have been published as tools.
|
||||
|
||||
## Add and Use the Tool Node
|
||||
|
||||
Before using built-in tools, you may need to **authorize** the tools.
|
||||
|
||||
If built-in tools do not meet your needs, you can create custom tools in the **Dify menu navigation -- Tools** section.
|
||||
|
||||
You can also orchestrate a more complex workflow and publish it as a tool.
|
||||
|
||||
<div class="image-side-by-side">
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/0f0255764a3f459f0b3c708db1cb32c9.png"
|
||||
className="mx-auto"
|
||||
alt=""
|
||||
/>
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/c7b52209e7ad4e15ce42b882cf646d1b.png"
|
||||
className="mx-auto"
|
||||
alt=""
|
||||
/>
|
||||
</div>
|
||||
|
||||
Configuring a tool node generally involves two steps:
|
||||
|
||||
1. Authorizing the tool/creating a custom tool/publishing a workflow as a tool.
|
||||
2. Configuring the tool's input and parameters.
|
||||
|
||||
For more information on how to create custom tools and configure them, please refer to the [Tool Configuration Guide](/en/guides/tools).
|
||||
|
||||
### Advanced Features
|
||||
|
||||
**Retry on Failure**
|
||||
|
||||
For some exceptions that occur in the node, it is usually sufficient to retry the node again. When the error retry function is enabled, the node will automatically retry according to the preset strategy when an error occurs. You can adjust the maximum number of retries and the interval between each retry to set the retry strategy.
|
||||
|
||||
- The maximum number of retries is 10
|
||||
- The maximum retry interval is 5000 ms
|
||||
|
||||
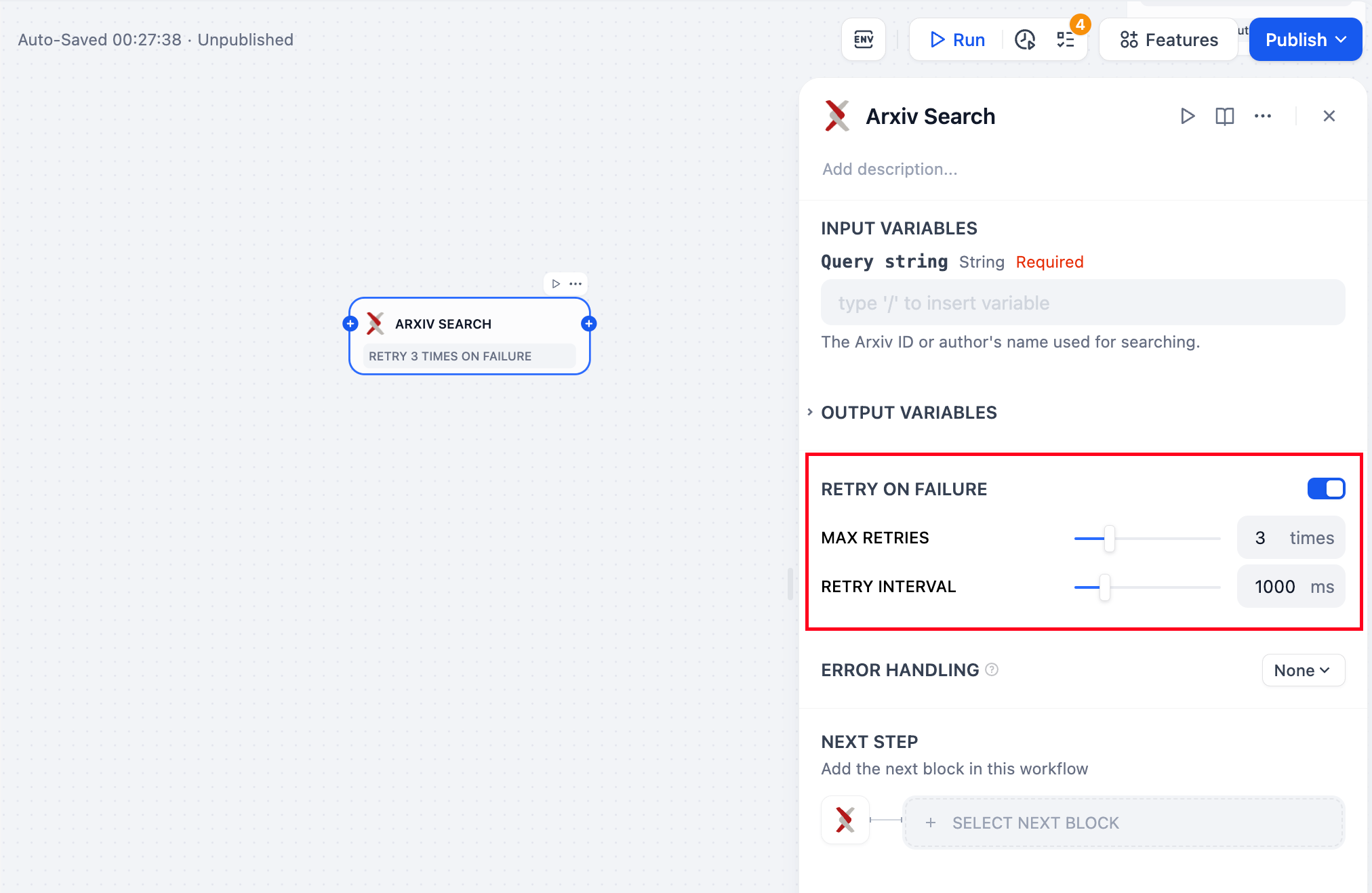
|
||||
|
||||
**Error Handling**
|
||||
|
||||
Tool nodes may encounter errors during information processing that could interrupt the workflow. Developers can follow these steps to configure fail branches, enabling contingency plans when nodes encounter exceptions, avoiding workflow interruptions.
|
||||
|
||||
1. Enable "Error Handling" in the tool node
|
||||
2. Select and configure an error-handling strategy
|
||||
|
||||
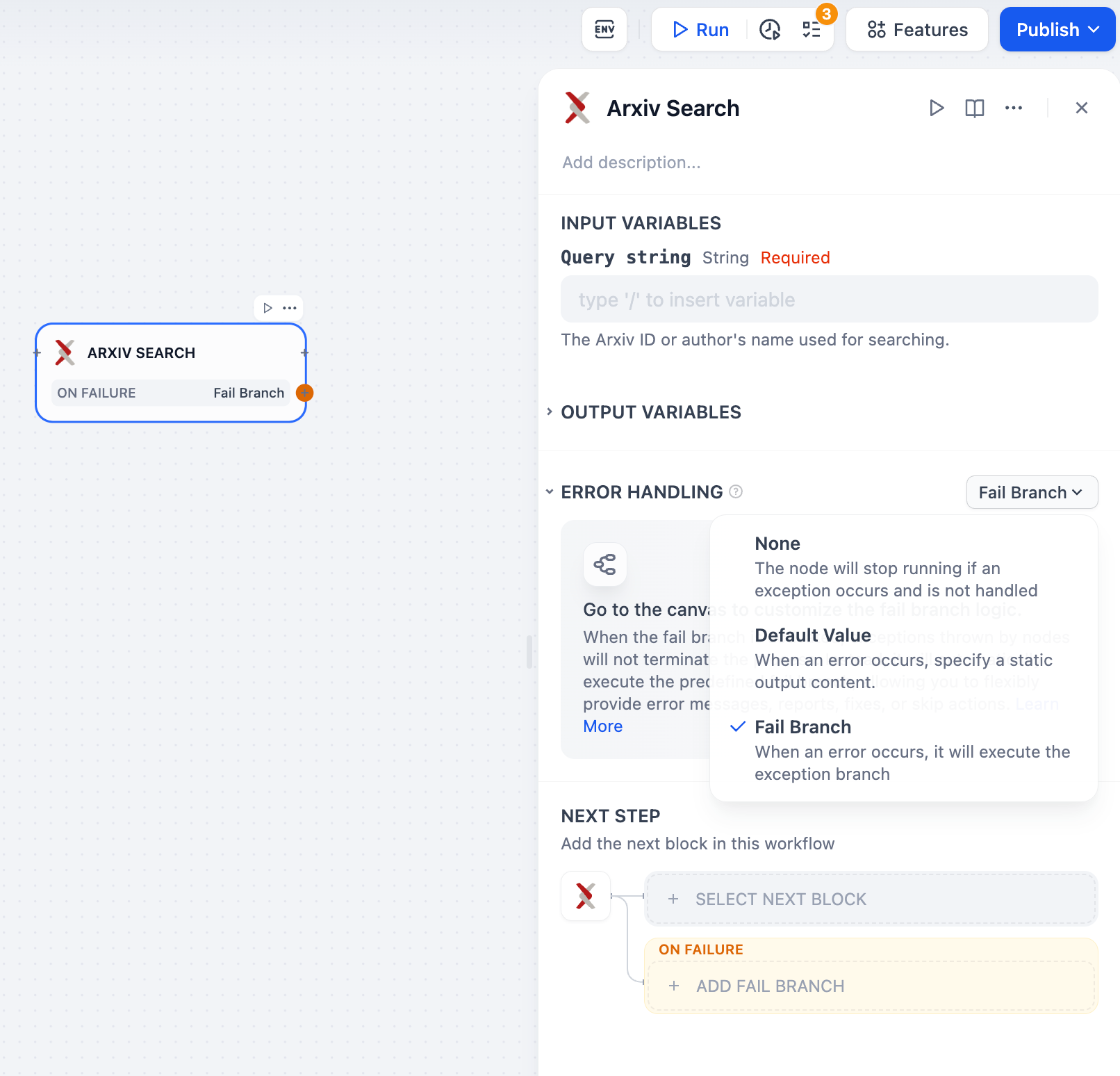
|
||||
|
||||
For more information about exception handling approaches, please refer to [Error Handling](/en/guides/workflow/error-handling).
|
||||
|
||||
## Publishing Workflow Applications as Tools
|
||||
|
||||
Workflow applications can be published as tools and used by nodes in other workflows. For information about creating custom tools and tool configuration, please refer to the [Tool Configuration Guide](/en/guides/tools).
|
||||
42
en/guides/workflow/node/variable-aggregator.mdx
Normal file
42
en/guides/workflow/node/variable-aggregator.mdx
Normal file
@@ -0,0 +1,42 @@
|
||||
---
|
||||
title: Variable Aggregator
|
||||
---
|
||||
|
||||
|
||||
### 1 Definition
|
||||
|
||||
Aggregate variables from multiple branches into a single variable to achieve unified configuration for downstream nodes.
|
||||
|
||||
The variable aggregation node (formerly the variable assignment node) is a key node in the workflow. It is responsible for integrating the output results from different branches, ensuring that regardless of which branch is executed, its results can be referenced and accessed through a unified variable. This is particularly useful in multi-branch scenarios, as it maps variables with the same function from different branches into a single output variable, avoiding the need for repeated definitions in downstream nodes.
|
||||
|
||||
***
|
||||
|
||||
### 2 Scenarios
|
||||
|
||||
Through variable aggregation, you can aggregate multiple outputs, such as from issue classification or conditional branching, into a single output for use and manipulation by downstream nodes, simplifying data flow management.
|
||||
|
||||
**Multi-Branch Aggregation after Issue Classification**
|
||||
|
||||
Without variable aggregation, the branches of Classification 1 and Classification 2, after different knowledge base retrievals, would require repeated definitions for downstream LLM and direct response nodes.
|
||||
|
||||
|
||||
|
||||
By adding variable aggregation, the outputs of the two knowledge retrieval nodes can be aggregated into a single variable.
|
||||
|
||||
|
||||
|
||||
**Multi-Branch Aggregation after IF/ELSE Conditional Branching**
|
||||
|
||||
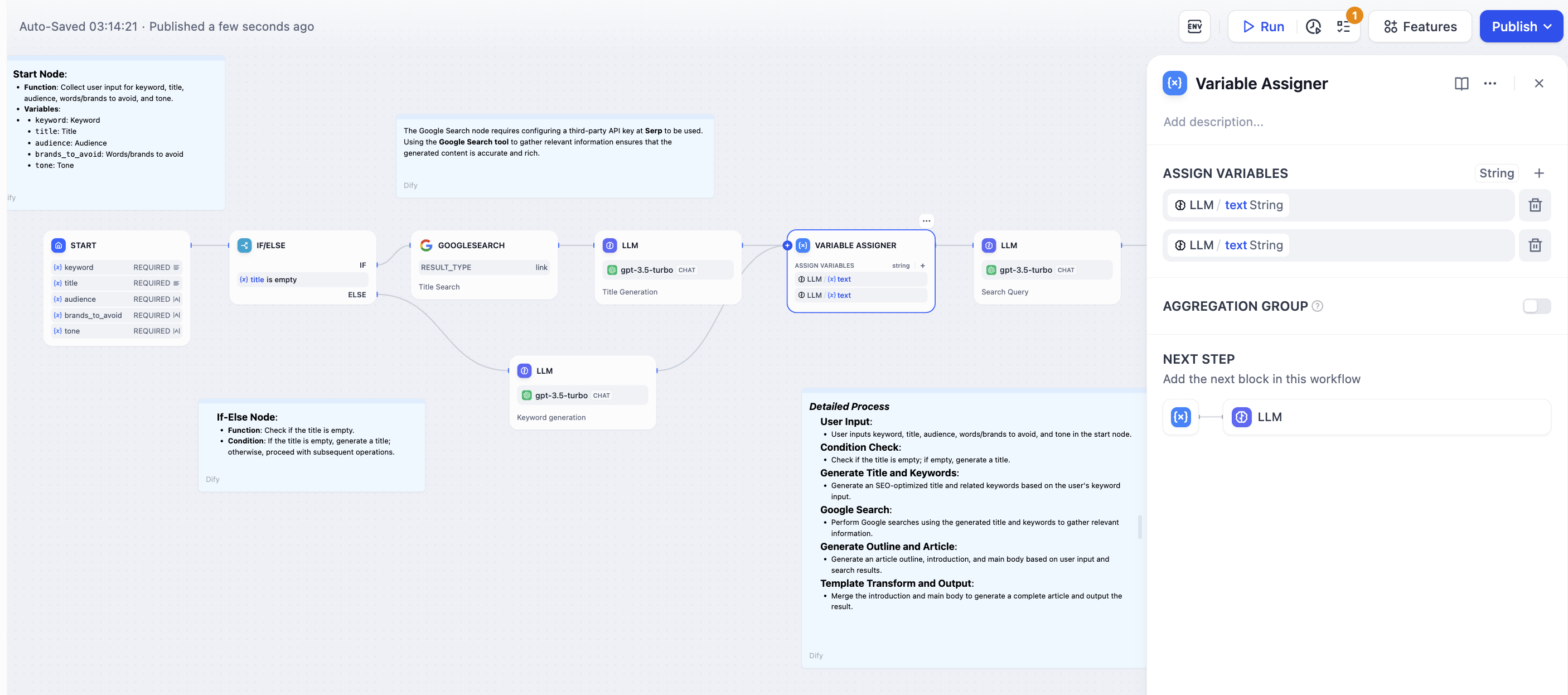
|
||||
|
||||
### 3 Format Requirements
|
||||
|
||||
The variable aggregator supports aggregating various data types, including strings (`String`), numbers (`Number`), objects (`Object`), and arrays (`Array`).
|
||||
|
||||
**The variable aggregator can only aggregate variables of the same data type**. If the first variable added to the variable aggregation node is of the `String` data type, subsequent connections will automatically filter and allow only `String` type variables to be added.
|
||||
|
||||
**Aggregation Grouping**
|
||||
|
||||
Starting from version v0.6.10, aggregation grouping is supported.
|
||||
|
||||
When aggregation grouping is enabled, the variable aggregator can aggregate multiple groups of variables, with each group requiring the same data type for aggregation.
|
||||
183
en/guides/workflow/node/variable-assigner.mdx
Normal file
183
en/guides/workflow/node/variable-assigner.mdx
Normal file
@@ -0,0 +1,183 @@
|
||||
---
|
||||
title: Variable Assigner
|
||||
---
|
||||
|
||||
|
||||
### Definition
|
||||
|
||||
The variable assigner node is used to assign values to writable variables. Currently supported writable variables include:
|
||||
|
||||
* [conversation variables](/en/guides/workflow/key-concepts#conversation-variables).
|
||||
|
||||
Usage: Through the variable assigner node, you can assign workflow variables to conversation variables for temporary storage, which can be continuously referenced in subsequent conversations.
|
||||
|
||||
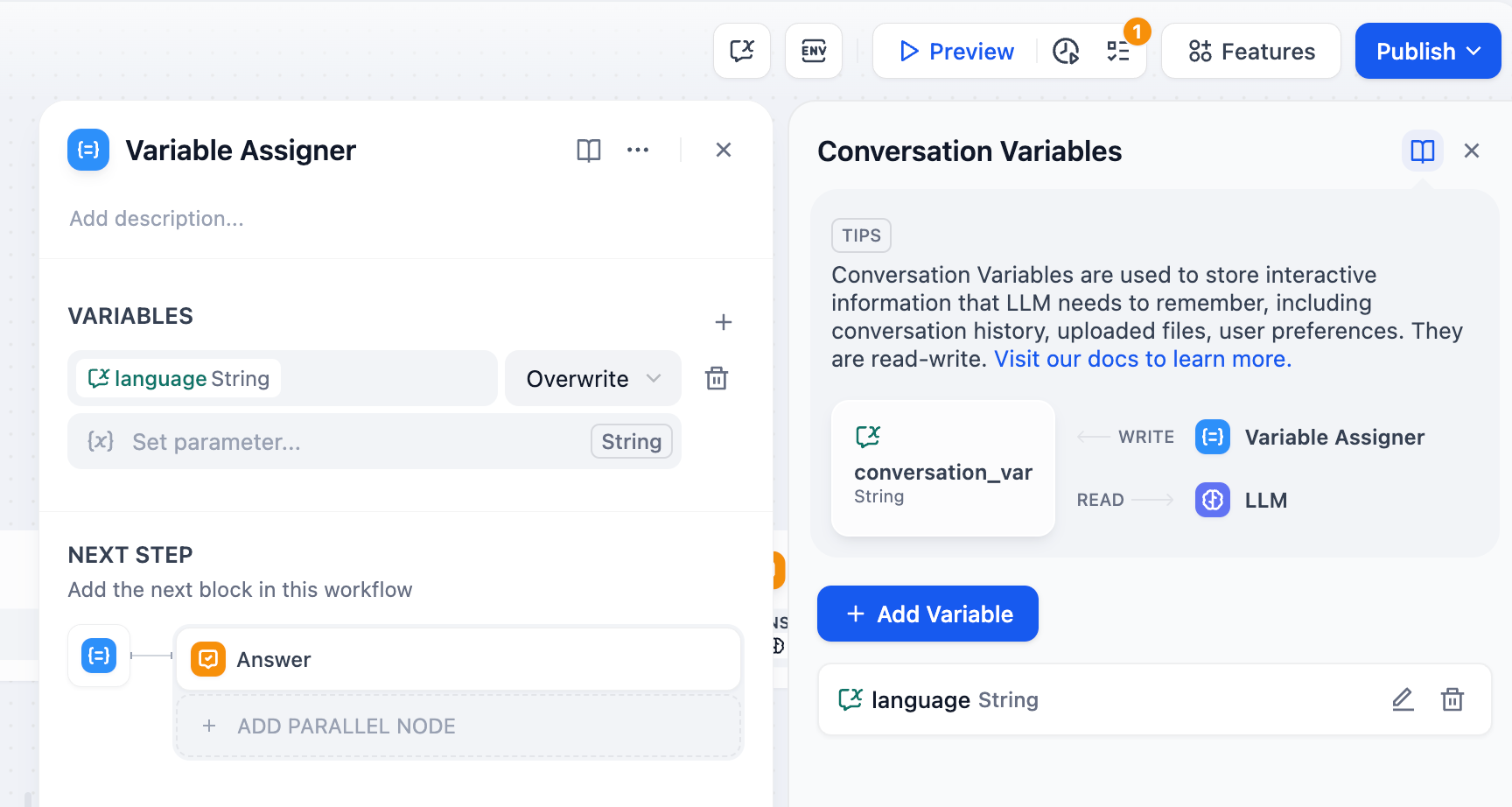
|
||||
|
||||
***
|
||||
|
||||
### Usage Scenario Examples
|
||||
|
||||
Using the variable assigner node, you can write context from the conversation process, files uploaded to the dialog box, and user preference information into conversation variables. These stored variables can then be referenced in subsequent conversations to direct different processing flows or formulate responses.
|
||||
|
||||
**Scenario 1**
|
||||
|
||||
**Automatically judge and extract content**, store history in the conversation, record important user information through the session variable array within the conversation, and use this history content to personalize responses in subsequent chats.
|
||||
|
||||
Example: After the conversation starts, LLM will automatically determine whether the user's input contains facts, preferences, or chat history that need to be remembered. If it has, LLM will first extract and store those information, then use it as context to respond. If there is no new information to remember, LLM will directly use the previously relevant memories to answer questions.
|
||||
|
||||
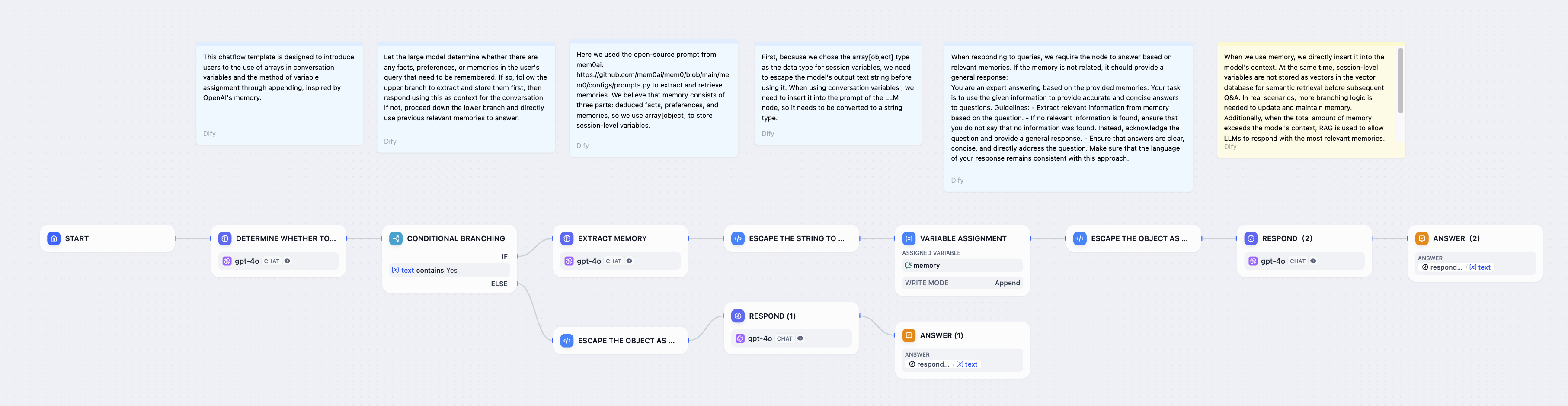
|
||||
|
||||
**Configuration process:**
|
||||
|
||||
1. **Set Conversation Variables:**
|
||||
* First, set up a Conversation Variables array `memories`, of type array\[object] to store user information, preferences, and chat history.
|
||||
2. **Determine and Extract Memories:**
|
||||
* Add a Conditional Branching node, using LLM to determine whether the user's input contains new information that needs to be remembered.
|
||||
* If there's new information, follow the upper branch and use an LLM node to extract this information.
|
||||
* If there's no new information, go down the branch and directly use existing memories to answer.
|
||||
3. **Variable Assignment/Writing:**
|
||||
* In the upper branch, use the variable assigner node to append the newly extracted information to the `memories` array.
|
||||
* Use the escape function to convert the text string output by LLM into a format suitable for storage in an array\[object].
|
||||
4. **Variable Reading and Usage:**
|
||||
* In subsequent LLM nodes, convert the contents of the `memories` array to a string and insert it into the prompt of LLM as context.
|
||||
* Use these memories to generate personalized responses.
|
||||
|
||||
The code for the node in the upper diagram is as follows:
|
||||
|
||||
1. Escape the string to object
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: str) -> object:
|
||||
try:
|
||||
# Parse the input JSON string
|
||||
input_data = json.loads(arg1)
|
||||
|
||||
# Extract the memory object
|
||||
memory = input_data.get("memory", {})
|
||||
|
||||
# Construct the return object
|
||||
result = {
|
||||
"facts": memory.get("facts", []),
|
||||
"preferences": memory.get("preferences", []),
|
||||
"memories": memory.get("memories", [])
|
||||
}
|
||||
|
||||
return {
|
||||
"mem": result
|
||||
}
|
||||
except json.JSONDecodeError:
|
||||
return {
|
||||
"result": "Error: Invalid JSON string"
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"Error: {str(e)}"
|
||||
}
|
||||
```
|
||||
|
||||
2. Escape object as string
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: list) -> str:
|
||||
try:
|
||||
# Assume arg1[0] is the dictionary we need to process
|
||||
context = arg1[0] if arg1 else {}
|
||||
|
||||
# Construct the memory object
|
||||
memory = {"memory": context}
|
||||
|
||||
# Convert the object to a JSON string
|
||||
json_str = json.dumps(memory, ensure_ascii=False, indent=2)
|
||||
|
||||
# Wrap the JSON string in <answer> tags
|
||||
result = f"<answer>{json_str}</answer>"
|
||||
|
||||
return {
|
||||
"result": result
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"<answer>Error: {str(e)}</answer>"
|
||||
}
|
||||
```
|
||||
|
||||
**Scenario 2**
|
||||
|
||||
**Recording initial user preferences input**: Remember the user's language preference input during the conversation and continue to use this language for responses in subsequent chatting.
|
||||
|
||||
Example: Before the chatting, the user specifies "English" in the `language` input box. This language will be written to the conversation variable, and the LLM will reference this information when responding, continuing to use "English" in subsequent conversations.
|
||||
|
||||
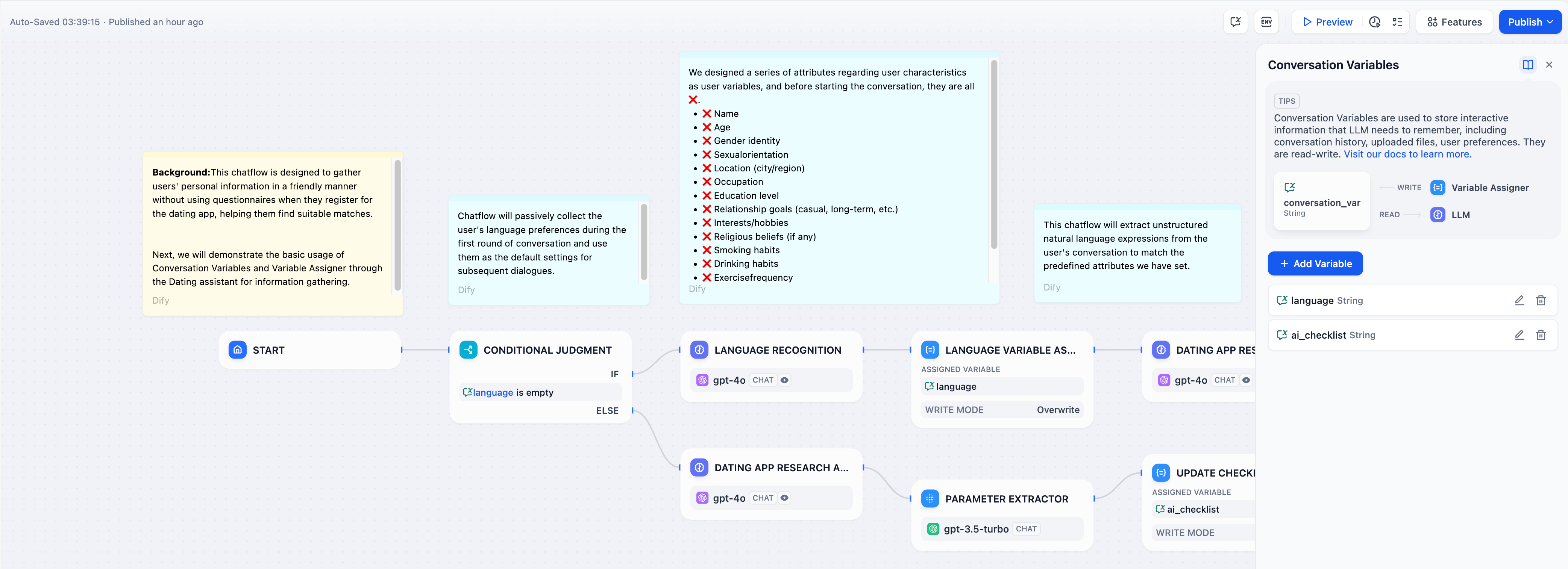
|
||||
|
||||
**Configuration Guide:**
|
||||
|
||||
**Set conversation variable**: First, set a conversation variable `language`. Add a condition judgment node at the beginning of the conversation flow to check if the `language` variable is empty.
|
||||
|
||||
**Variable writing/assignment**: At the start of the first round of chatting, if the `language` variable is empty, use an LLM node to extract the user's input language, then use a variable assigner node to write this language type into the conversation variable `language`.
|
||||
|
||||
**Variable reading**: In subsequent conversation rounds, the `language` variable has stored the user's language preference. The LLM node references the language variable to respond using the user's preferred language type.
|
||||
|
||||
**Scenario 3**
|
||||
|
||||
**Assisting with Checklist checks**: Record user inputs within the conversation using conversation variables, update the contents of the Checklist, and check for missing items in subsequent conversations.
|
||||
|
||||
Example: After starting the conversation, the LLM will ask the user to input items related to the Checklist in the chatting box. Once the user mentions content from the Checklist, it will be updated and stored in the Conversation Variable. The LLM will remind the user to continue supplementing missing items after each round of dialogue.
|
||||
|
||||
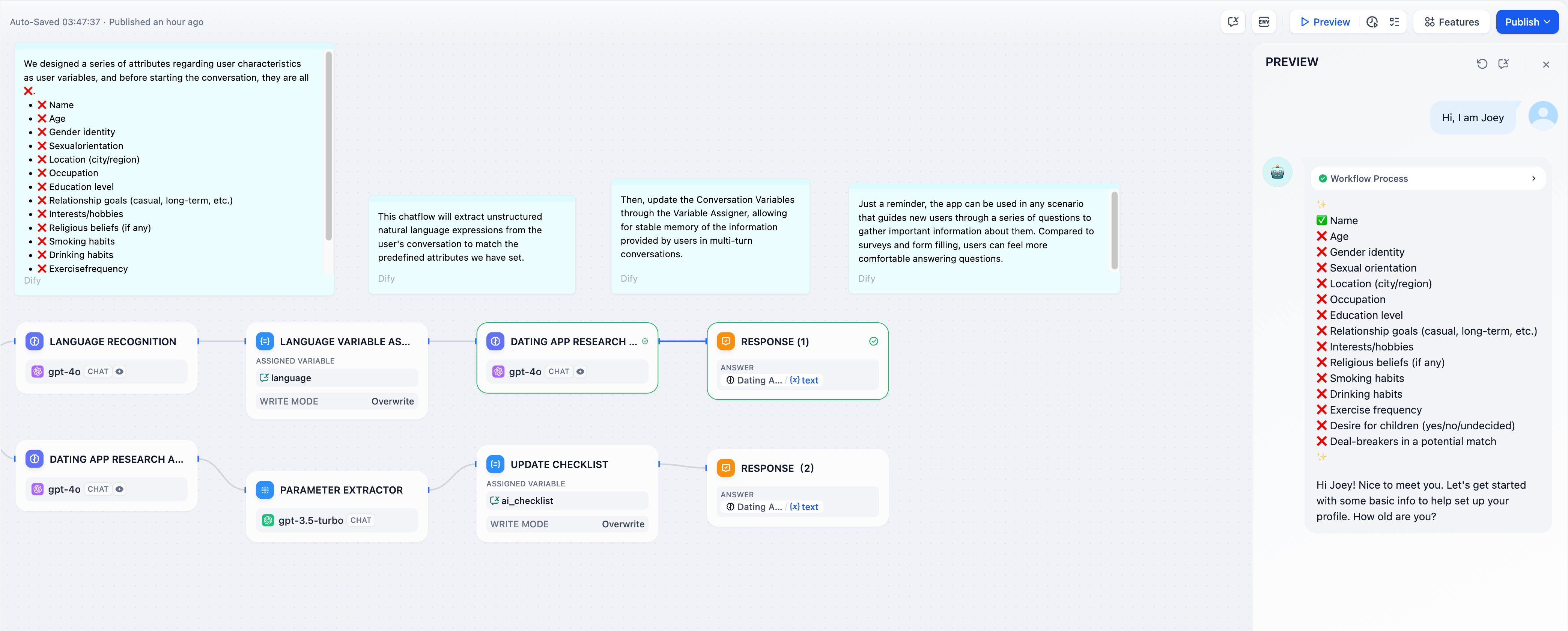
|
||||
|
||||
**Configuration Process:**
|
||||
|
||||
* **Set conversation variable:** First, set a conversation variable `ai_checklist`, and reference this variable within the LLM as context for checking.
|
||||
* **variable assigner/writing**: During each round of dialogue, check the value in `ai_checklist` within the LLM node and compare it with user input. If the user provides new information, update the Checklist and write the output content to `ai_checklist` using the variable assigner node.
|
||||
* **Variable reading:** Read the value in `ai_checklist` and compare it with user input in each round of dialogue until all checklist items are completed.
|
||||
|
||||
***
|
||||
|
||||
### Using the Variable Assigner Node
|
||||
|
||||
Click the `+` icon on the right side of the node and select the **“Variable Assignment”** node. Configure the target variables and their corresponding source variables. This node allows you to assign values to multiple variables simultaneously.
|
||||
|
||||
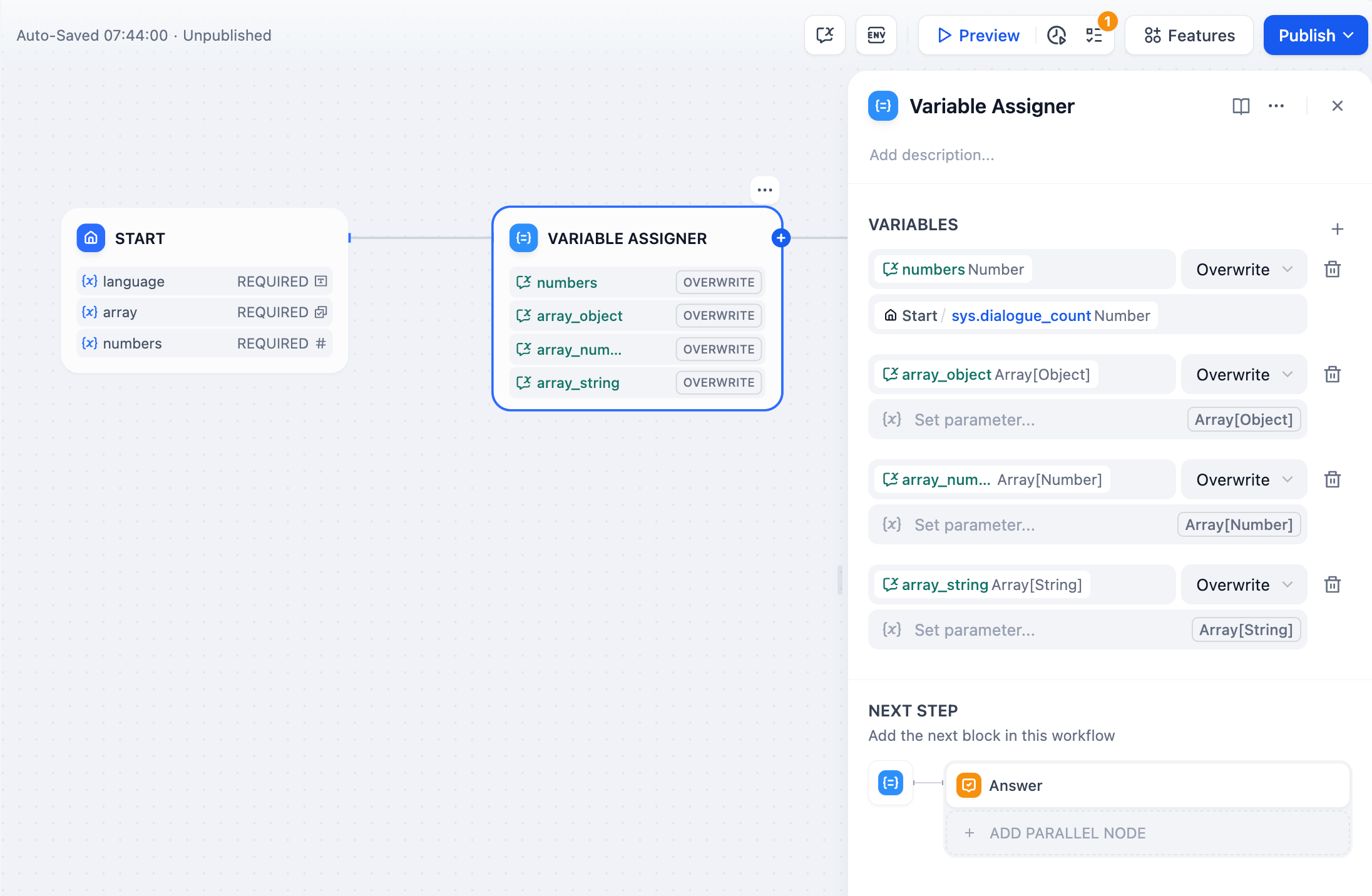
|
||||
|
||||
**Setting Variables:**
|
||||
|
||||
Variable: Select the variable to be assigned, i.e., specify the target conversation variable that needs to be assigned.
|
||||
|
||||
Set Variable: Select the variable to assign, i.e., specify the source variable that needs to be converted.
|
||||
|
||||
The variable assignment logic illustrated in the image above assigns the user’s language preference, specified on the initial page `Start/language`, to the system-level conversation variable `language`.
|
||||
|
||||
### **Operation Modes for Specifying Variables**
|
||||
|
||||
The data type of the target variable determines its operation method. Below are the operation modes for different variable types:
|
||||
|
||||
1. Target variable data type: `String`
|
||||
|
||||
• **Overwrite**: Directly overwrite the target variable with the source variable.
|
||||
• **Clear**: Clear the contents of the selected target variable.
|
||||
• **Set**: Manually assign a value without requiring a source variable.
|
||||
|
||||
2. Target variable data type: `Number`
|
||||
|
||||
• **Overwrite**: Directly overwrite the target variable with the source variable.
|
||||
• **Clear**: Clear the contents of the selected target variable.
|
||||
• **Set**: Manually assign a value without requiring a source variable.
|
||||
• **Arithmetic**: Perform addition, subtraction, multiplication, or division on the target variable.
|
||||
|
||||
3. Target variable data type: `Object`
|
||||
|
||||
• **Overwrite**: Directly overwrite the target variable with the source variable.
|
||||
• **Clear**: Clear the contents of the selected target variable.
|
||||
• **Set**: Manually assign a value without requiring a source variable.
|
||||
|
||||
4. Target variable data type: `Array`
|
||||
|
||||
• **Overwrite**: Directly overwrite the target variable with the source variable.
|
||||
• **Clear**: Clear the contents of the selected target variable.
|
||||
• **Append**: Add a new element to the array in the target variable.
|
||||
• **Extend**: Add a new array to the target variable, effectively adding multiple elements at once.
|
||||
|
||||
7
ja-jp/guides/workflow/node/README.mdx
Normal file
7
ja-jp/guides/workflow/node/README.mdx
Normal file
@@ -0,0 +1,7 @@
|
||||
# 节点说明
|
||||
|
||||
**节点是工作流中的关键构成**,通过连接不同功能的节点,执行工作流的一系列操作。
|
||||
|
||||
### 核心节点
|
||||
|
||||
<table data-view="cards"><thead><tr><th></th><th></th><th></th></tr></thead><tbody><tr><td><a href="start.md"><strong>开始(Start)</strong></a></td><td>定义一个 workflow 流程启动的初始参数。</td><td></td></tr><tr><td><a href="end.md"><strong>结束(End)</strong></a></td><td>定义一个 workflow 流程结束的最终输出内容。</td><td></td></tr><tr><td><a href="answer.md"><strong>回复(Answer)</strong></a></td><td>定义一个 Chatflow 流程中的回复内容。</td><td></td></tr><tr><td><a href="llm.md"><strong>大语言模型(LLM)</strong></a></td><td>调用大语言模型回答问题或者对自然语言进行处理。</td><td></td></tr><tr><td><a href="knowledge-retrieval.md"><strong>知识检索(Knowledge Retrieval)</strong></a></td><td>从知识库中检索与用户问题相关的文本内容,可作为下游 LLM 节点的上下文。</td><td></td></tr><tr><td><a href="question-classifier.md"><strong>问题分类(Question Classifier)</strong></a></td><td>通过定义分类描述,LLM 能够根据用户输入选择与之相匹配的分类。</td><td></td></tr><tr><td><a href="ifelse.md"><strong>条件分支(IF/ELSE)</strong></a></td><td>允许你根据 if/else 条件将 workflow 拆分成两个分支。</td><td></td></tr><tr><td><a href="code.md"><strong>代码执行(Code)</strong></a></td><td>运行 Python / NodeJS 代码以在工作流程中执行数据转换等自定义逻辑。</td><td></td></tr><tr><td><a href="template.md"><strong>模板转换(Template)</strong></a></td><td>允许借助 Jinja2 的 Python 模板语言灵活地进行数据转换、文本处理等。</td><td></td></tr><tr><td><a href="variable-assigner.md"><strong>变量聚合(Variable Aggregator)</strong></a></td><td>将多路分支的变量聚合为一个变量,以实现下游节点统一配置。</td><td></td></tr><tr><td><a href="parameter-extractor.md"><strong>参数提取器(Parameter Extractor)</strong></a></td><td>利用 LLM 从自然语言推理并提取结构化参数,用于后置的工具调用或 HTTP 请求。</td><td></td></tr><tr><td><a href="iteration.md"><strong>迭代(Iteration)</strong></a></td><td>对列表对象执行多次步骤直至输出所有结果。</td><td></td></tr><tr><td><a href="http-request.md"><strong>HTTP 请求(HTTP Request)</strong></a></td><td>允许通过 HTTP 协议发送服务器请求,适用于获取外部检索结果、webhook、生成图片等情景。</td><td></td></tr><tr><td><a href="tools.md"><strong>工具(Tools)</strong></a></td><td>允许在工作流内调用 Dify 内置工具、自定义工具、子工作流等。</td><td></td></tr><tr><td><a href="variable-assignment.md"><strong>变量赋值(Variable Assigner)</strong></a></td><td>变量赋值节点用于向可写入变量(例如会话变量)进行变量赋值。</td><td></td></tr></tbody></table>
|
||||
99
ja-jp/guides/workflow/node/agent.mdx
Normal file
99
ja-jp/guides/workflow/node/agent.mdx
Normal file
@@ -0,0 +1,99 @@
|
||||
---
|
||||
title: エージェント
|
||||
---
|
||||
|
||||
## 定義
|
||||
|
||||
エージェントノードは、Difyチャットフローやワークフローにおいて自律的なツール呼び出しを実現するコンポーネントです。異なるエージェント推論戦略を統合することで、大規模言語モデル(LLM)が実行時に動的にツールを選択・実行し、多段階推論を可能にします。
|
||||
|
||||
## 設定手順
|
||||
|
||||
### ノードの追加
|
||||
|
||||
チャットフローやワークフローのエディタで、コンポーネントパネルからエージェントノードをキャンバスにドラッグします。
|
||||
|
||||
<img
|
||||
src="../../../.gitbook/assets/en-1-9-1.png"
|
||||
className="mx-auto"
|
||||
alt="エージェントノードの追加"
|
||||
/>
|
||||
|
||||
### エージェント戦略の選択
|
||||
|
||||
ノード設定パネルで **エージェント戦略** をクリックします。
|
||||
|
||||
<img
|
||||
src="../../../.gitbook/assets/en-1-9-0.png"
|
||||
className="mx-auto"
|
||||
alt="エージェント戦略設定"
|
||||
/>
|
||||
|
||||
ドロップダウンメニューから推論戦略を選択します。Difyは **Function Calling と ReAct** を標準装備しており、**Marketplace → エージェント戦略** カテゴリから追加インストール可能です。
|
||||
|
||||
<img
|
||||
src="../../../.gitbook/assets/en-1-9-2.png"
|
||||
className="mx-auto"
|
||||
alt="推論戦略選択"
|
||||
/>
|
||||
|
||||
#### 1. Function Calling
|
||||
|
||||
ユーザー指示を事前定義された関数/ツールにマッピングし、LLMが意図を識別→適切な関数を選択→パラメータ抽出という明確なツール呼び出しメカニズムです。
|
||||
|
||||
特徴:
|
||||
|
||||
**• 高精度**: 明確なタスクに直結するツールを直接呼び出し
|
||||
|
||||
**• 外部連携容易**: API/ツールを関数化して統合可能
|
||||
|
||||
**• 構造化出力**: 下流ノード処理向けの定型化された情報出力
|
||||
|
||||
<img
|
||||
src="../../../.gitbook/assets/en-agent-1.png"
|
||||
className="mx-auto"
|
||||
alt="Function Calling"
|
||||
/>
|
||||
|
||||
#### 2. ReAct(Reason + Act)
|
||||
|
||||
思考(Reason)と行動(Act)を交互に繰り返す戦略です。LLMが現状分析→ツール選択→実行→結果評価のサイクルを問題解決まで継続します。
|
||||
|
||||
特徴:
|
||||
|
||||
**• 外部リソース活用**: モデル単体では困難なタスクを実行可能
|
||||
|
||||
**• 処理追跡性**: 思考プロセスが可視化され説明性が向上
|
||||
|
||||
**• 広範な適用**: Q&A/情報検索/タスク実行など多様なシナリオに対応
|
||||
|
||||
<img
|
||||
src="../../../.gitbook/assets/en-agent-2.png"
|
||||
className="mx-auto"
|
||||
alt="ReAct戦略"
|
||||
/>
|
||||
|
||||
開発者は公開[リポジトリ](https://github.com/langgenius/dify-plugins)へ戦略プラグインを提供可能で、審査後Marketplaceで公開されます。
|
||||
|
||||
### ノードパラメータ設定
|
||||
|
||||
選択した戦略に応じた設定項目が表示されます。標準装備のFunction Calling/ReActでは以下を設定:
|
||||
|
||||
1. **モデル**: エージェントを駆動するLLMを選択
|
||||
2. **ツールリスト**: 「+」で呼び出し可能ツールを追加
|
||||
* 検索: インストール済みツールから選択
|
||||
* 認証: APIキーなどの認証情報を入力
|
||||
* 説明とパラメータ: ツールの用途説明とパラメータ設定
|
||||
3. **指示文**: タスク目標とコンテキストを定義(Jinja構文で上位ノード変数参照可)
|
||||
4. **クエリ**: ユーザー入力を受け取る変数
|
||||
5. **最大実行ステップ数**: 処理サイクルの上限値
|
||||
6. **出力変数**: ノードが出力するデータ構造
|
||||
|
||||
## ログ確認
|
||||
|
||||
実行時には詳細なログが生成されます。基本情報(入出力/トークン使用量/処理時間/状態)に加え、「詳細」から各処理ステップの出力を確認可能です。
|
||||
|
||||
<img
|
||||
src="../../../.gitbook/assets/en-1-9-6.png"
|
||||
className="mx-auto"
|
||||
alt="ログ確認"
|
||||
/>
|
||||
19
ja-jp/guides/workflow/node/answer.mdx
Normal file
19
ja-jp/guides/workflow/node/answer.mdx
Normal file
@@ -0,0 +1,19 @@
|
||||
---
|
||||
title: 回答
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
チャットフローアプリのプロセス内で返信内容を定義します。
|
||||
|
||||
テキストエディタを使用して返信フォーマットを自由に定義できます。固定のテキスト内容をカスタマイズしたり、前のステップで出力された変数を返信内容として使用したり、カスタマイズしたテキストと変数を組み合わせて返信することができます。
|
||||
|
||||
ノードを随時追加して内容をストリーミング形式で会話に返信し、所見即所得の設定モードをサポートし、テキストと画像の混在も可能です。例えば:
|
||||
|
||||
1. LLMノードの返信内容を出力
|
||||
2. 生成された画像を出力
|
||||
3. 純テキストを出力
|
||||
|
||||
<Info>
|
||||
直接返信ノードは最終出力ノードとして使用しなくてもよく、プロセスの中間ステップでストリーミング出力結果を出力することができます。
|
||||
</Info>
|
||||
94
ja-jp/guides/workflow/node/code.mdx
Normal file
94
ja-jp/guides/workflow/node/code.mdx
Normal file
@@ -0,0 +1,94 @@
|
||||
---
|
||||
title: コード
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
## 紹介
|
||||
|
||||
コードノードは、Python / NodeJSコードを実行してワークフロー内でデータ変換を行うことをサポートします。これにより、Arithmetic、JSON変換、テキスト処理などのシナリオでワークフローが簡素化されます。
|
||||
|
||||
このノードは開発者の柔軟性を大幅に向上させ、ワークフロー内にカスタムPythonまたはJavascriptスクリプトを埋め込んで、事前設定されたノードでは達成できない方法で変数を操作することができます。設定オプションを使用して、必要な入力変数と出力変数を指定し、対応する実行コードを記述できます。
|
||||
|
||||

|
||||
|
||||
## 設定
|
||||
|
||||
他のノードの変数をコードノードで使用する必要がある場合は、`入力変数`で変数名を定義し、これらの変数を参照する必要があります。[変数参照](/ja-jp/guides/workflow/concepts)を参考にしてください。
|
||||
|
||||
## 使用シナリオ
|
||||
|
||||
コードノードを使用して、以下の一般的な操作を実行できます:
|
||||
|
||||
### 構造化データ処理
|
||||
|
||||
ワークフローでは、しばしば非構造化データの処理が必要です。例えば、JSON文字列の解析、抽出、変換などです。典型的な例として、HTTPノードのデータ処理があります。一般的なAPI応答構造では、データが多層のJSONオブジェクトにネストされていることがあり、特定のフィールドを抽出する必要があります。コードノードはこれらの操作を支援します。以下は、HTTPノードから返されたJSON文字列から`data.name`フィールドを抽出する簡単な例です:
|
||||
|
||||
```python
|
||||
def main(http_response: str) -> str:
|
||||
import json
|
||||
data = json.loads(http_response)
|
||||
return {
|
||||
# 出力変数にresultを宣言することに注意
|
||||
'result': data['data']['name']
|
||||
}
|
||||
```
|
||||
|
||||
### 数学計算
|
||||
|
||||
ワークフロー内で複雑な数学計算を行う必要がある場合、コードノードを使用できます。例えば、複雑な数学公式の計算やデータの統計分析です。以下は、配列の平方差を計算する簡単な例です:
|
||||
|
||||
```python
|
||||
def main(x: list) -> float:
|
||||
return {
|
||||
# 出力変数にresultを宣言することに注意
|
||||
'result' : sum([(i - sum(x) / len(x)) ** 2 for i in x]) / len(x)
|
||||
}
|
||||
```
|
||||
|
||||
### データの結合
|
||||
|
||||
時には、複数のデータソースを結合する必要がある場合があります。例えば、複数の知識検索、データサーチ、API呼び出しなどです。コードノードはこれらのデータソースを統合するのに役立ちます。以下は、2つのナレッジベースのデータを結合する簡単な例です:
|
||||
|
||||
```python
|
||||
def main(knowledge1: list, knowledge2: list) -> list:
|
||||
return {
|
||||
# 出力変数にresultを宣言することに注意
|
||||
'result': knowledge1 + knowledge2
|
||||
}
|
||||
```
|
||||
|
||||
## ローカルデプロイ
|
||||
|
||||
ローカルデプロイのユーザーである場合、悪意のあるコードが実行されないようにするためのサンドボックスサービスを起動する必要があります。このサービスを起動するにはDockerサービスを使用します。サンドボックスサービスの詳細は[こちら](https://github.com/langgenius/dify/tree/main/docker/docker-compose.middleware.yaml)から確認できます。また、`docker-compose`を使用してサービスを直接起動することもできます:
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.middleware.yaml up -d
|
||||
```
|
||||
|
||||
> システムにDocker Compose V2がインストールされている場合は、`docker compose`を使用し;V1の場合、`docker-compose`を使用しください。`$docker compose version` でこれに該当するかどうかを確認してください。詳細は[こちら](https://docs.docker.com/compose/#compose-v2-and-the-new-docker-compose-command)をご覧ください。
|
||||
|
||||
## セキュリティポリシー
|
||||
|
||||
Python3とJavascriptのいずれであっても、その実行環境は安全性を確保するために厳密に隔離(サンドボックス化)されています。これにより、ファイルシステムへの直接アクセス、ネットワークリクエストの実行、OSレベルのコマンドの実行など、システムリソースを大量に消費する可能性がある機能を使用することはできません。これらの制限により、コードの安全な実行が保証され、システムリソースの過剰消費が防止されます。
|
||||
|
||||
### よくある質問
|
||||
|
||||
**コード ノードにコードを入力した後にコードを保存できないのはなぜですか?**
|
||||
|
||||
コードに危険な動作がないか確認してください。例えば:
|
||||
|
||||
```python
|
||||
def main() -> dict:
|
||||
return {
|
||||
"result": open("/etc/passwd").read(),
|
||||
}
|
||||
```
|
||||
|
||||
このコードには次の問題が含まれています。
|
||||
|
||||
* **不正なファイル アクセス:** コードは、ユーザー アカウント情報を保存する Unix/Linux システムの重要なシステム ファイルである`/etc/passwd`ファイルを読み取ろうとしました。
|
||||
* **機密情報の漏洩:** `/etc/passwd`ファイルには、ユーザー名、ユーザー ID、グループ ID、ホーム ディレクトリのパスなど、システム ユーザーの重要な情報が含まれています。直接アクセスすると情報が漏洩する可能性があります。
|
||||
|
||||
危険なコードはCloudflare WAFによって自動的にブロックされます。ブロックされているかどうかは、「Webデバッグツール」の「ネットワーク」から確認できます。
|
||||
|
||||

|
||||
94
ja-jp/guides/workflow/node/code.mdx.bak
Normal file
94
ja-jp/guides/workflow/node/code.mdx.bak
Normal file
@@ -0,0 +1,94 @@
|
||||
---
|
||||
title: コード
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
## 紹介
|
||||
|
||||
コードノードは、Python / NodeJSコードを実行してワークフロー内でデータ変換を行うことをサポートします。これにより、Arithmetic、JSON変換、テキスト処理などのシナリオでワークフローが簡素化されます。
|
||||
|
||||
このノードは開発者の柔軟性を大幅に向上させ、ワークフロー内にカスタムPythonまたはJavascriptスクリプトを埋め込んで、事前設定されたノードでは達成できない方法で変数を操作することができます。設定オプションを使用して、必要な入力変数と出力変数を指定し、対応する実行コードを記述できます。
|
||||
|
||||

|
||||
|
||||
## 設定
|
||||
|
||||
他のノードの変数をコードノードで使用する必要がある場合は、`入力変数`で変数名を定義し、これらの変数を参照する必要があります。[変数参照](../key-concept#変数)を参考にしてください。
|
||||
|
||||
## 使用シナリオ
|
||||
|
||||
コードノードを使用して、以下の一般的な操作を実行できます:
|
||||
|
||||
### 構造化データ処理
|
||||
|
||||
ワークフローでは、しばしば非構造化データの処理が必要です。例えば、JSON文字列の解析、抽出、変換などです。典型的な例として、HTTPノードのデータ処理があります。一般的なAPI応答構造では、データが多層のJSONオブジェクトにネストされていることがあり、特定のフィールドを抽出する必要があります。コードノードはこれらの操作を支援します。以下は、HTTPノードから返されたJSON文字列から`data.name`フィールドを抽出する簡単な例です:
|
||||
|
||||
```python
|
||||
def main(http_response: str) -> str:
|
||||
import json
|
||||
data = json.loads(http_response)
|
||||
return {
|
||||
# 出力変数にresultを宣言することに注意
|
||||
'result': data['data']['name']
|
||||
}
|
||||
```
|
||||
|
||||
### 数学計算
|
||||
|
||||
ワークフロー内で複雑な数学計算を行う必要がある場合、コードノードを使用できます。例えば、複雑な数学公式の計算やデータの統計分析です。以下は、配列の平方差を計算する簡単な例です:
|
||||
|
||||
```python
|
||||
def main(x: list) -> float:
|
||||
return {
|
||||
# 出力変数にresultを宣言することに注意
|
||||
'result' : sum([(i - sum(x) / len(x)) ** 2 for i in x]) / len(x)
|
||||
}
|
||||
```
|
||||
|
||||
### データの結合
|
||||
|
||||
時には、複数のデータソースを結合する必要がある場合があります。例えば、複数の知識検索、データサーチ、API呼び出しなどです。コードノードはこれらのデータソースを統合するのに役立ちます。以下は、2つのナレッジベースのデータを結合する簡単な例です:
|
||||
|
||||
```python
|
||||
def main(knowledge1: list, knowledge2: list) -> list:
|
||||
return {
|
||||
# 出力変数にresultを宣言することに注意
|
||||
'result': knowledge1 + knowledge2
|
||||
}
|
||||
```
|
||||
|
||||
## ローカルデプロイ
|
||||
|
||||
ローカルデプロイのユーザーである場合、悪意のあるコードが実行されないようにするためのサンドボックスサービスを起動する必要があります。このサービスを起動するにはDockerサービスを使用します。サンドボックスサービスの詳細は[こちら](https://github.com/langgenius/dify/tree/main/docker/docker-compose.middleware.yaml)から確認できます。また、`docker-compose`を使用してサービスを直接起動することもできます:
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.middleware.yaml up -d
|
||||
```
|
||||
|
||||
> システムにDocker Compose V2がインストールされている場合は、`docker compose`を使用し;V1の場合、`docker-compose`を使用しください。`$docker compose version` でこれに該当するかどうかを確認してください。詳細は[こちら](https://docs.docker.com/compose/#compose-v2-and-the-new-docker-compose-command)をご覧ください。
|
||||
|
||||
## セキュリティポリシー
|
||||
|
||||
Python3とJavascriptのいずれであっても、その実行環境は安全性を確保するために厳密に隔離(サンドボックス化)されています。これにより、ファイルシステムへの直接アクセス、ネットワークリクエストの実行、OSレベルのコマンドの実行など、システムリソースを大量に消費する可能性がある機能を使用することはできません。これらの制限により、コードの安全な実行が保証され、システムリソースの過剰消費が防止されます。
|
||||
|
||||
### よくある質問
|
||||
|
||||
**コード ノードにコードを入力した後にコードを保存できないのはなぜですか?**
|
||||
|
||||
コードに危険な動作がないか確認してください。例えば:
|
||||
|
||||
```python
|
||||
def main() -> dict:
|
||||
return {
|
||||
"result": open("/etc/passwd").read(),
|
||||
}
|
||||
```
|
||||
|
||||
このコードには次の問題が含まれています。
|
||||
|
||||
* **不正なファイル アクセス:** コードは、ユーザー アカウント情報を保存する Unix/Linux システムの重要なシステム ファイルである`/etc/passwd`ファイルを読み取ろうとしました。
|
||||
* **機密情報の漏洩:** `/etc/passwd`ファイルには、ユーザー名、ユーザー ID、グループ ID、ホーム ディレクトリのパスなど、システム ユーザーの重要な情報が含まれています。直接アクセスすると情報が漏洩する可能性があります。
|
||||
|
||||
危険なコードはCloudflare WAFによって自動的にブロックされます。ブロックされているかどうかは、「Webデバッグツール」の「ネットワーク」から確認できます。
|
||||
|
||||

|
||||
67
ja-jp/guides/workflow/node/doc-extractor.mdx
Normal file
67
ja-jp/guides/workflow/node/doc-extractor.mdx
Normal file
@@ -0,0 +1,67 @@
|
||||
---
|
||||
title: テキスト抽出ツール
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
LLM(大規模言語モデル)は文書の内容を直接読み取ることができません。そのため、ユーザーがアップロードした文書を”テキスト抽出ツールノード”を介して解析し、文書ファイルの情報を読み取り、テキストに変換して内容をLLMに送信する必要があります。
|
||||
|
||||
### 適用シナリオ
|
||||
|
||||
* ファイルに対話できるLLMアプリを構築する、例えばChatPDFやChatWord;
|
||||
* ユーザーがアップロードしたファイルの内容を分析およびチェックする;
|
||||
|
||||
### ノードの機能
|
||||
|
||||
テキスト抽出ツールノードは、情報を処理する中心的な役割を果たします。入力変数内のファイルを識別して読み取り、情報を抽出し、string型の出力変数に変換して、下流のノードが呼び出すために提供します。
|
||||
|
||||

|
||||
|
||||
テキスト抽出ツールノードは、入力変数と出力変数に分かれています。
|
||||
|
||||
#### 入力変数
|
||||
|
||||
テキスト抽出ツールは以下のデータ構造の変数のみを受け入れます:
|
||||
|
||||
* `File`,1つのファイル
|
||||
* `Array[File]`,複数のファイル
|
||||
|
||||
テキスト抽出ツールは、テキスト、Markdown、PDF、HTML、DOCX形式のファイルなどの文書タイプから情報を抽出できますが、画像、音声、映像などの形式のファイルは処理できません。
|
||||
|
||||
#### 出力変数
|
||||
|
||||
出力変数は`text`という固定の名前です。出力変数の型は入力変数に依存します:
|
||||
|
||||
* 入力変数が`File`の場合、出力変数は`string`です。
|
||||
* 入力変数が`Array[File]`の場合、出力変数は`array[string]`です。
|
||||
|
||||
> Array配列変数は通常、リスト操作ノードと組み合わせて使用されます。詳細については、[リスト操作](./list-operator)を参照してください。
|
||||
|
||||
### 設定例
|
||||
|
||||
典型的なファイルインタラクションの質疑応答シナリオでは、テキスト抽出ツールはLLMノードの前段階として機能し、アプリのファイル情報を抽出し、LLMノードに渡してユーザーのファイルに関する質問に回答します。
|
||||
|
||||
このセクションでは、典型的なChatPDFサンプルワークフローテンプレートを用いて、テキスト抽出ツールノードの使用方法を説明します。
|
||||
|
||||

|
||||
|
||||
**設定手順:**
|
||||
|
||||
1. アプリでファイルアップロード機能を有効にします。 [“スタート”](./start) ノードで**単一ファイル変数**を追加し、`pdf`と名付けます。
|
||||
2. テキスト抽出ツールノードを追加し、入力変数で`pdf`変数を選択します。
|
||||
3. LLMノードを追加し、システムプロンプトでテキスト抽出ツールノードの出力変数を選択します。LLMはこの出力変数を使用してファイルの内容を読み取ることができます。
|
||||
|
||||

|
||||
|
||||
4. エンドノードを設定し、LLMノードの出力変数を選択します。
|
||||
|
||||
設定が完了すると、アプリケーションはファイルアップロード機能を持ち、ユーザーはPDFファイルをアップロードして対話を展開できるようになります。
|
||||
|
||||
<Frame>
|
||||
<img src="/ja-jp/img/0ae3f13cf725cb2c52c72cc354e592ee.png" alt="ドキュメント抽出ノードの設定" />
|
||||
</Frame>
|
||||
|
||||
<Tip>
|
||||
チャット対話でファイルをアップロードしLLMと対話する方法については、[追加機能](/ja-jp/guides/workflow/additional-feature)を参照してください。
|
||||
</Tip>
|
||||
67
ja-jp/guides/workflow/node/doc-extractor.mdx.bak
Normal file
67
ja-jp/guides/workflow/node/doc-extractor.mdx.bak
Normal file
@@ -0,0 +1,67 @@
|
||||
---
|
||||
title: テキスト抽出ツール
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
LLM(大規模言語モデル)は文書の内容を直接読み取ることができません。そのため、ユーザーがアップロードした文書を”テキスト抽出ツールノード”を介して解析し、文書ファイルの情報を読み取り、テキストに変換して内容をLLMに送信する必要があります。
|
||||
|
||||
### 適用シナリオ
|
||||
|
||||
* ファイルに対話できるLLMアプリを構築する、例えばChatPDFやChatWord;
|
||||
* ユーザーがアップロードしたファイルの内容を分析およびチェックする;
|
||||
|
||||
### ノードの機能
|
||||
|
||||
テキスト抽出ツールノードは、情報を処理する中心的な役割を果たします。入力変数内のファイルを識別して読み取り、情報を抽出し、string型の出力変数に変換して、下流のノードが呼び出すために提供します。
|
||||
|
||||

|
||||
|
||||
テキスト抽出ツールノードは、入力変数と出力変数に分かれています。
|
||||
|
||||
#### 入力変数
|
||||
|
||||
テキスト抽出ツールは以下のデータ構造の変数のみを受け入れます:
|
||||
|
||||
* `File`,1つのファイル
|
||||
* `Array[File]`,複数のファイル
|
||||
|
||||
テキスト抽出ツールは、テキスト、Markdown、PDF、HTML、DOCX形式のファイルなどの文書タイプから情報を抽出できますが、画像、音声、映像などの形式のファイルは処理できません。
|
||||
|
||||
#### 出力変数
|
||||
|
||||
出力変数は`text`という固定の名前です。出力変数の型は入力変数に依存します:
|
||||
|
||||
* 入力変数が`File`の場合、出力変数は`string`です。
|
||||
* 入力変数が`Array[File]`の場合、出力変数は`array[string]`です。
|
||||
|
||||
> Array配列変数は通常、リスト操作ノードと組み合わせて使用されます。詳細については、[リスト操作](./list-operator)を参照してください。
|
||||
|
||||
### 設定例
|
||||
|
||||
典型的なファイルインタラクションの質疑応答シナリオでは、テキスト抽出ツールはLLMノードの前段階として機能し、アプリのファイル情報を抽出し、LLMノードに渡してユーザーのファイルに関する質問に回答します。
|
||||
|
||||
このセクションでは、典型的なChatPDFサンプルワークフローテンプレートを用いて、テキスト抽出ツールノードの使用方法を説明します。
|
||||
|
||||

|
||||
|
||||
**設定手順:**
|
||||
|
||||
1. アプリでファイルアップロード機能を有効にします。 [“スタート”](./start) ノードで**単一ファイル変数**を追加し、`pdf`と名付けます。
|
||||
2. テキスト抽出ツールノードを追加し、入力変数で`pdf`変数を選択します。
|
||||
3. LLMノードを追加し、システムプロンプトでテキスト抽出ツールノードの出力変数を選択します。LLMはこの出力変数を使用してファイルの内容を読み取ることができます。
|
||||
|
||||

|
||||
|
||||
4. エンドノードを設定し、LLMノードの出力変数を選択します。
|
||||
|
||||
設定が完了すると、アプリケーションはファイルアップロード機能を持ち、ユーザーはPDFファイルをアップロードして対話を展開できるようになります。
|
||||
|
||||
<Frame>
|
||||
<img src="/ja-jp/img/0ae3f13cf725cb2c52c72cc354e592ee.png" alt="ドキュメント抽出ノードの設定" />
|
||||
</Frame>
|
||||
|
||||
<Tip>
|
||||
チャット対話でファイルをアップロードしLLMと対話する方法については、[追加機能](../additional-feature)を参照してください。
|
||||
</Tip>
|
||||
30
ja-jp/guides/workflow/node/end.mdx
Normal file
30
ja-jp/guides/workflow/node/end.mdx
Normal file
@@ -0,0 +1,30 @@
|
||||
---
|
||||
title: 終了
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
ワークフローの最終出力内容を定義します。すべてのワークフローは、完全に実行された後、最終結果を出力するための少なくとも1つの終了ノードを必要とします。
|
||||
|
||||
終了ノードはプロセスの終了ノードであり、その後に他のノードを追加することはできません。ワークフローアプリケーションでは、終了ノードに到達して初めて実行結果が出力されます。プロセスに条件分岐がある場合、複数の終了ノードを定義する必要があります。
|
||||
|
||||
終了ノードは1つ以上の出力変数を宣言する必要があります。この宣言の際、任意の上流ノードの出力変数を参照することができます。
|
||||
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
以下の[長編ストーリー生成ワークフロー](./iteration#1)では、終了ノードで宣言された変数 `Output` は上流のコードノードの出力です。つまり、このワークフローはCode3ノードが実行された後に終了し、Code3の実行結果を出力します。
|
||||
|
||||

|
||||
|
||||
**単一ルートの実行例:**
|
||||
|
||||

|
||||
|
||||
**複数ルートの実行例:**
|
||||
|
||||

|
||||
|
||||
30
ja-jp/guides/workflow/node/end.mdx.bak
Normal file
30
ja-jp/guides/workflow/node/end.mdx.bak
Normal file
@@ -0,0 +1,30 @@
|
||||
---
|
||||
title: 終了
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
ワークフローの最終出力内容を定義します。すべてのワークフローは、完全に実行された後、最終結果を出力するための少なくとも1つの終了ノードを必要とします。
|
||||
|
||||
終了ノードはプロセスの終了ノードであり、その後に他のノードを追加することはできません。ワークフローアプリケーションでは、終了ノードに到達して初めて実行結果が出力されます。プロセスに条件分岐がある場合、複数の終了ノードを定義する必要があります。
|
||||
|
||||
終了ノードは1つ以上の出力変数を宣言する必要があります。この宣言の際、任意の上流ノードの出力変数を参照することができます。
|
||||
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
以下の[長編ストーリー生成ワークフロー](./iteration#1)では、終了ノードで宣言された変数 `Output` は上流のコードノードの出力です。つまり、このワークフローはCode3ノードが実行された後に終了し、Code3の実行結果を出力します。
|
||||
|
||||

|
||||
|
||||
**単一ルートの実行例:**
|
||||
|
||||

|
||||
|
||||
**複数ルートの実行例:**
|
||||
|
||||

|
||||
|
||||
36
ja-jp/guides/workflow/node/http-request.mdx
Normal file
36
ja-jp/guides/workflow/node/http-request.mdx
Normal file
@@ -0,0 +1,36 @@
|
||||
---
|
||||
title: HTTPリクエスト
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
HTTP プロトコルを介してサーバーにリクエストを送信することを可能にし、外部データの取得、ウェブフック、画像生成、ファイルのダウンロードなどのシナリオに適用されます。指定されたネットワークアドレスにカスタマイズされたHTTPリクエストを送信し、さまざまな外部サービスとの連携を実現します。
|
||||
|
||||
このノードは一般的なHTTPリクエストメソッドをサポートしています:
|
||||
|
||||
* **GET**、リソースをサーバーにリクエストするために使用されます。
|
||||
* **POST**、データをサーバーに送信するために使用され、通常はフォームの送信やファイルのアップロードに使用されます。
|
||||
* **HEAD**、GETリクエストに似ていますが、サーバーはリソースの本体を返さず、レスポンスヘッダーのみを返します。
|
||||
* **PATCH**、リクエスト-レスポンスチェーンの各ノードで伝送経路を取得するために使用されます。
|
||||
* **PUT**、リソースをサーバーにアップロードするために使用され、通常は既存のリソースの更新や新しいリソースの作成に使用されます。
|
||||
* **DELETE**、指定されたリソースをサーバーに削除するようにリクエストするために使用されます。
|
||||
|
||||
HTTPリクエストのURL、リクエストヘッダー、クエリパラメータ、リクエストボディの内容、および認証情報などを設定することができます。
|
||||
|
||||
<Frame caption="HTTP リクエスト設定">
|
||||
<img src="/ja-jp/img/jp-http-request.png" alt="长故事迭代生成应用流程图" />
|
||||
</Frame>
|
||||
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
このノードの便利な特性の一つは、シナリオに応じてリクエストの異なる部分に動的に変数を挿入できることです。例えば、カスタマーレビュープロセスを処理する際に、ユーザー名や顧客ID、レビュー内容などの変数をリクエストに埋め込むことで、カスタマイズされた自動返信情報を作成したり、特定の顧客情報を取得して関連リソースを特定のサーバーに送信したりすることができます。
|
||||
|
||||
<Frame caption="カスタマーレビューの分類">
|
||||
<img src="/ja-jp/img/customer-feedback-classification.png" alt="长故事迭代生成应用流程图" />
|
||||
</Frame>
|
||||
|
||||
HTTP HTTPリクエストの戻り値には、レスポンスボディ、ステータスコード、レスポンスヘッダー、ファイルが含まれます。特に、レスポンスにファイル(現在は画像タイプのみ)が含まれている場合、このノードはファイルを自動的に保存し、後続のプロセスで使用できるようにします。この設計により、処理効率が向上し、ファイルを含むレスポンスの処理がシンプルで直接的になります。
|
||||
55
ja-jp/guides/workflow/node/ifelse.mdx
Normal file
55
ja-jp/guides/workflow/node/ifelse.mdx
Normal file
@@ -0,0 +1,55 @@
|
||||
---
|
||||
title: 条件分岐
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
if/else 条件に基づいてチャットフローとワークフローを2つの分岐に分けることができます。
|
||||
|
||||
### ノードの機能
|
||||
|
||||
条件分岐の動作メカニズムには、次の6つのパスが含まれます:
|
||||
|
||||
* IFの条件:変数を選び、条件と満たすべき値を設定します;
|
||||
* IFの条件が `True` と判断された場合、IFパスを実行します;
|
||||
* IFの条件が `False` と判断された場合、ELSEパスを実行します;
|
||||
* ELIFの条件が `True` と判断された場合, ELIFパスを実行します;
|
||||
* ELIFの条件が `False` と判断された場合, 次のELIFパスを判断します、もしくは最後のELIFパスを実行します;
|
||||
|
||||
**条件の種類**
|
||||
|
||||
次の条件タイプの設定をサポートします:
|
||||
|
||||
* 含む(Contains)
|
||||
* 含まない(Not contains)
|
||||
* ..から始まる(Start with)
|
||||
* ..から終わる(End with)
|
||||
* である(Is)
|
||||
* ではない(Is not)
|
||||
* 空である(Is empty)
|
||||
* 空ではない(Is not empty)
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
<Frame>
|
||||
<img src="/ja-jp/img/jp-ifelse.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**テキスト要約ワークフロー**を例に、各条件を説明します。
|
||||
|
||||
* IFの条件:開始ノードの`summarystyle`変数を選び、条件を **含む** として `技術` を設定します;
|
||||
* IFの条件が `True` と判断された場合、IFパスを実行し、技術関連の知識をナレッジ検索ノードを通じて問い合わせ、その後大規模言語モデル(LLM)ノードを介して応答します。(上図の下半部分に示されるように);
|
||||
* IFの条件が `False` と判断され、さらにELIF条件が加えられた場合、`summarystyle` 変数の入力に `技術` は含まれず、ELIFの条件に `科学` が含まれている場合は、ELIFの条件が `True` であるかどうかを確認し、該当する手順を実行します。
|
||||
* ELIFの条件が `False` で、かつ入力変数に `技術` や `科学` が含まれていない場合は、次のELIFの条件の評価を続けるか、もしくはELSEパスを実行します。
|
||||
* IFの条件が `False` と判断された場合、つまり`summarystyle`変数の入力が **含まない** として `技術` を設定し、ELSEパスを実行し、LLM2ノードで返信します(上図の下半部分に示されるように);
|
||||
|
||||
**複数条件の判断**
|
||||
|
||||
複雑な条件判断が必要な場合、複数条件を設定し、条件間に **AND** または **OR** を設定することができます。これは条件間に**交集**または**并集**を取ることを意味します。
|
||||
|
||||
<Frame caption="複数条件の判断" width="369">
|
||||
<img src="/ja-jp/img/jp-ifelse-setting.png" alt="" />
|
||||
</Frame>
|
||||
189
ja-jp/guides/workflow/node/iteration.mdx
Normal file
189
ja-jp/guides/workflow/node/iteration.mdx
Normal file
@@ -0,0 +1,189 @@
|
||||
---
|
||||
title: 反復処理(イテレーション)
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
配列に対して複数のステップを実行し、すべての結果を出力すること。
|
||||
|
||||
イテレーションステップはリスト中の各項目に対して同じステップを実行します。イテレーションを使用する条件は、入力値がリストオブジェクトとしてフォーマットされていることを確認することです。イテレーションノードは、AIワークフローにより複雑な処理ロジックを取り入れることを可能にします。イテレーションノードはループノードの親しみやすいバージョンであり、非技術ユーザーが迅速に始められるようにカスタマイズの程度を調整しています。
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
#### **例1:長文イテレーション生成器**
|
||||
|
||||
<Frame caption="长故事生成器">
|
||||
<img src="/ja-jp/user-guide/.gitbook/assets/iteration-story-generator.png" alt="长故事生成器流程图" />
|
||||
</Frame>
|
||||
|
||||
1. **開始ノード** 内にタイトルとアウトラインを入力
|
||||
2. **コードノード** を使用してユーザー入力から完全な内容を抽出
|
||||
3. **パラメータ抽出ノード** を使用して完全な内容を配列形式に変換
|
||||
4. **イテレーションノード** でラップされた **LLM ノード** を通じて各章の内容を複数回生成
|
||||
5. イテレーションノード内に **直接応答ノード** を追加して、各イテレーション生成の後にストリーム出力を行う
|
||||
|
||||
**具体的な設定ステップ**
|
||||
|
||||
1. **開始ノード** にタイトル(title)とアウトライン(outline)を設定;
|
||||
|
||||
<Frame caption="開始ノードの設定" width="375">
|
||||
<img src="/ja-jp/img/jp-iteration-start.png" alt="开始节点配置界面" />
|
||||
</Frame>
|
||||
|
||||
2. **Jinja-2 テンプレートノード** を使用してタイトルとアウトラインを完全なテキストに変換;
|
||||
|
||||
<Frame caption="テンプレートノード" width="375">
|
||||
<img src="/ja-jp/img/jp-iteration-outline.png" alt="LLM节点配置界面" />
|
||||
</Frame>
|
||||
|
||||
3. **パラメータ抽出ノード** を使用して、ストーリーテキストを配列(Array)構造に変換。抽出パラメータは `sections`、パラメータタイプは `Array[Object]`
|
||||
|
||||
<Frame caption="パラメータ抽出" width="375">
|
||||
<img src="/ja-jp/img/workflow-extract-subtitles-and-outlines.png" alt="参数提取节点配置界面" />
|
||||
</Frame>
|
||||
|
||||
<Note>
|
||||
パラメータ抽出の効果はモデル推論能力と指示に影響されます。推論能力が高いモデルを使用し、**指示** 内に例を追加することでパラメータ抽出の効果を向上させることができます。
|
||||
</Note>
|
||||
|
||||
4. ストーリーアウトラインの配列形式をイテレーションノードの入力として使用し、イテレーションノード内で **LLM ノード** を使用して処理
|
||||
|
||||
<Frame caption="イテレーションノードの設定" width="375">
|
||||
<img src="/ja-jp/img/workflow-iteration-node.png" alt="迭代节点配置界面" />
|
||||
</Frame>
|
||||
|
||||
LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/item` を設定
|
||||
|
||||
<Frame caption="LLMノードの設定" width="375">
|
||||
<img src="/ja-jp/img/workflow-iteration-llm-node.png" alt="LLM节点内部配置界面" />
|
||||
</Frame>
|
||||
|
||||
<Note>
|
||||
イテレーションの組み込み変数:`items[object]` と `index[number]`
|
||||
|
||||
`items[object]` は各イテレーションの入力項目を表します;
|
||||
|
||||
`index[number]` は現在のイテレーションのラウンドを表します;
|
||||
</Note>
|
||||
|
||||
5. イテレーションノード内に **直接応答ノード** を設定して、各イテレーション生成の後にストリーム出力を実現。
|
||||
|
||||
<Frame caption="Answerノードの設定" width="375">
|
||||
<img src="/ja-jp/img/workflow-configure-anwer-node.png" alt="直接回复节点配置界面" />
|
||||
</Frame>
|
||||
|
||||
6. 完全なデバッグとプレビュー
|
||||
|
||||
<Frame caption="ストーリー章ごとの多段イテレーション生成">
|
||||
<img src="/ja-jp/img/iteration-node-iteration-through-story-chapters.png" alt="完整调试和预览界面" />
|
||||
</Frame>
|
||||
|
||||
#### **例2:長文イテレーション生成器(別の編成方法)**
|
||||
|
||||
<Frame caption="長文イテレーション生成器(別の編成方法)">
|
||||
<img src="/ja-jp/img/iteration-node-iteration-long-article-iteration-generator.png" alt="长文章迭代生成器另一种编排方式流程图" />
|
||||
</Frame>
|
||||
|
||||
* **開始ノード** にタイトルとアウトラインを入力
|
||||
* **LLM ノード** を使用して小見出しと対応する内容を生成
|
||||
* **コードノード** を使用して完全な内容を配列形式に変換
|
||||
* **イテレーションノード** でラップされた **LLM ノード** を通じて各章の内容を複数回生成
|
||||
* **テンプレート変換ノード** を使用してイテレーションノードが出力する文字列配列を文字列に変換
|
||||
* 最後に **直接応答ノード** を追加して変換後の文字列を直接出力
|
||||
|
||||
### 配列の内容とは
|
||||
|
||||
リストは特定のデータ型であり、要素はコンマで区切られ、 `[` で始まり `]` で終わります。例えば:
|
||||
|
||||
**数値型:**
|
||||
|
||||
```
|
||||
[0,1,2,3,4,5]
|
||||
```
|
||||
|
||||
**文字列型:**
|
||||
|
||||
```
|
||||
["monday", "Tuesday", "Wednesday", "Thursday"]
|
||||
```
|
||||
|
||||
**JSON オブジェクト:**
|
||||
|
||||
```
|
||||
[
|
||||
{
|
||||
"name": "Alice",
|
||||
"age": 30,
|
||||
"email": "alice@example.com"
|
||||
},
|
||||
{
|
||||
"name": "Bob",
|
||||
"age": 25,
|
||||
"email": "bob@example.com"
|
||||
},
|
||||
{
|
||||
"name": "Charlie",
|
||||
"age": 35,
|
||||
"email": "charlie@example.com"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
***
|
||||
|
||||
### 配列を返すノード
|
||||
|
||||
* コードノード
|
||||
* パラメータ抽出
|
||||
* ナレッジベース検索
|
||||
* イテレーション
|
||||
* ツール
|
||||
* HTTPリクエスト
|
||||
|
||||
### 配列形式の内容を取得する方法
|
||||
|
||||
**CODE ノードを使用して返す**
|
||||
|
||||
<Frame caption="コードノード出力Array" width="375">
|
||||
<img src="/ja-jp/img/workflow-extract-subtitles-and-outlines.png" alt="CODE节点返回数组格式内容界面" />
|
||||
</Frame>
|
||||
|
||||
**パラメータ抽出ノードを使用して返す**
|
||||
|
||||
<Frame caption="パラメータ抽出ノード出力array" width="375">
|
||||
<img src="/ja-jp/img/workflow-parameter-extraction-node.png" alt="参数提取节点返回数组格式内容界面" />
|
||||
</Frame>
|
||||
|
||||
### 配列をテキストに変換する方法
|
||||
|
||||
イテレーションノードの出力変数は配列形式であり、直接出力することはできません。配列をテキストに戻すための簡単なステップを実行することができます。
|
||||
|
||||
**コードノードを使用した変換**
|
||||
|
||||
<Frame caption="コードノード変換" width="334">
|
||||
<img src="/ja-jp/img/iteration-code-node-convert.png" alt="使用代码节点将数组转换为文本界面" />
|
||||
</Frame>
|
||||
|
||||
コード例:
|
||||
|
||||
```python
|
||||
def main(articleSections: list):
|
||||
data = articleSections
|
||||
return {
|
||||
"result": "\n".join(data)
|
||||
}
|
||||
```
|
||||
|
||||
**テンプレートノードを使用した変換**
|
||||
|
||||
<Frame caption="テンプレートノード変換" width="332">
|
||||
<img src="/ja-jp/img/workflow-template-node.png" alt="使用模板节点将数组转换为文本界面" />
|
||||
</Frame>
|
||||
|
||||
コード例:
|
||||
|
||||
```django
|
||||
{{ articleSections | join("\n") }}
|
||||
```
|
||||
59
ja-jp/guides/workflow/node/knowledge-retrieval.mdx
Normal file
59
ja-jp/guides/workflow/node/knowledge-retrieval.mdx
Normal file
@@ -0,0 +1,59 @@
|
||||
---
|
||||
title: 知識検索
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
ナレッジベースからユーザーの質問に関連するテキスト内容を検索し、それを下流のLLMノードのコンテキストとして使用することができます。
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
一般的なシナリオ:外部データ/ナレッジに基づくAI質問応答システム(RAG)を構築。RAGの[基本概念](/ja-jp/learn-more/extended-reading/retrieval-augment/README)についてもっと知る。
|
||||
|
||||
下図は最も基本的なナレッジベース質問応答アプリケーションの例です。このプロセスの実行ロジックは、ユーザーの質問がLLMノードに渡される前に、ナレッジ検索ノードでユーザーの質問に最も関連するテキスト内容を検索し、召喚することです。その後、LLMノード内でユーザーの質問と検索されたコンテキストを一緒に入力し、LLMが検索内容に基づいて質問に答えるようにします。
|
||||
|
||||
<Frame caption="ナレッジベース質問応答アプリケーションの例">
|
||||
<img src="/ja-jp/img/jp-knowledge-retrieval.png" alt="知识库问答应用示例" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 設定方法
|
||||
|
||||
**設定プロセス:**
|
||||
|
||||
1. クエリ変数を選択し、ナレッジベース内の関連するテキストセグメントを検索するための入力として使用します。一般的な対話型アプリケーションでは、開始ノードの`sys.query`をクエリ変数として使用します。ナレッジ ベースが受け入れることができる最大クエリ コンテンツは 200 文字です。
|
||||
2. 検索するナレッジベースを選択します。オプションとして選択可能なナレッジベースは、Difyナレッジベース内で事前に[作成](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)する必要があります。
|
||||
3. [リコールモード](/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval)と[ナレッジベース設定](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)を設定します。
|
||||
4. 下流ノードを接続し設定します。一般的にはLLMノードです。
|
||||
|
||||
<Frame caption="ナレッジ検索の設定">
|
||||
<img src="/ja-jp/img/jp-knowledge-retrieval-setting.png" alt="知识检索配置" />
|
||||
</Frame>
|
||||
|
||||
**出力変数**
|
||||
|
||||
<Frame caption="出力変数">
|
||||
<img src="/ja-jp/img/jp-knowledge-retrieval-output.png" alt="输出变量" width="272" />
|
||||
</Frame>
|
||||
|
||||
ナレッジ検索の出力変数`result`は、ナレッジベースから検索された関連テキストセグメントです。この変数のデータ構造には、セグメント内容、タイトル、リンク、アイコン、メタデータ情報が含まれています。
|
||||
|
||||
**下流ノードの設定**
|
||||
|
||||
一般的な対話型アプリケーションでは、ナレッジベース検索の下流ノードは通常LLMノードであり、ナレッジ検索の**出力変数**`result`はLLMノード内の**コンテキスト変数**に関連付けられて設定されます。関連付け後、プロンプトの適切な位置に**コンテキスト変数**を挿入することができます。
|
||||
|
||||
<Note>
|
||||
コンテキスト変数は、LLMノード内で定義された特殊な変数タイプで、プロンプト内に外部検索されたテキスト内容を挿入するために使用されます。
|
||||
</Note>
|
||||
|
||||
ユーザーが質問すると、関連するテキストがナレッジ検索で召喚された場合、そのテキスト内容がコンテキスト変数の値としてプロンプトに挿入され、LLMが質問に答えます。関連するテキストが検索されなかった場合、コンテキスト変数の値は空となり、LLMは直接ユーザーの質問に答えます。
|
||||
|
||||
<Frame caption="下流LLMノードの設定">
|
||||
<img src="/ja-jp/img/jp-knowledge-retrieval-llm.png" alt="配置下游LLM节点" />
|
||||
</Frame>
|
||||
|
||||
この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)機能もサポートします。
|
||||
59
ja-jp/guides/workflow/node/knowledge-retrieval.mdx.bak
Normal file
59
ja-jp/guides/workflow/node/knowledge-retrieval.mdx.bak
Normal file
@@ -0,0 +1,59 @@
|
||||
---
|
||||
title: 知識検索
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
ナレッジベースからユーザーの質問に関連するテキスト内容を検索し、それを下流のLLMノードのコンテキストとして使用することができます。
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
一般的なシナリオ:外部データ/ナレッジに基づくAI質問応答システム(RAG)を構築。RAGの[基本概念](../../../knowledge-base/indexing-and-retrieval/retrieval-augment)についてもっと知る。
|
||||
|
||||
下図は最も基本的なナレッジベース質問応答アプリケーションの例です。このプロセスの実行ロジックは、ユーザーの質問がLLMノードに渡される前に、ナレッジ検索ノードでユーザーの質問に最も関連するテキスト内容を検索し、召喚することです。その後、LLMノード内でユーザーの質問と検索されたコンテキストを一緒に入力し、LLMが検索内容に基づいて質問に答えるようにします。
|
||||
|
||||
<Frame caption="ナレッジベース質問応答アプリケーションの例">
|
||||
<img src="/ja-jp/img/jp-knowledge-retrieval.png" alt="知识库问答应用示例" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 設定方法
|
||||
|
||||
**設定プロセス:**
|
||||
|
||||
1. クエリ変数を選択し、ナレッジベース内の関連するテキストセグメントを検索するための入力として使用します。一般的な対話型アプリケーションでは、開始ノードの`sys.query`をクエリ変数として使用します。ナレッジ ベースが受け入れることができる最大クエリ コンテンツは 200 文字です。
|
||||
2. 検索するナレッジベースを選択します。オプションとして選択可能なナレッジベースは、Difyナレッジベース内で事前に[作成](../../knowledge-base/create-knowledge-and-upload-documents#id-1-chuang-jian-zhi-shi-ku)する必要があります。
|
||||
3. [リコールモード](../../../learn-more/extended-reading/retrieval-augment/retrieval)と[ナレッジベース設定](../../knowledge-base/knowledge-and-documents-maintenance#id-8-zhi-shi-ku-she-zhi)を設定します。
|
||||
4. 下流ノードを接続し設定します。一般的にはLLMノードです。
|
||||
|
||||
<Frame caption="ナレッジ検索の設定">
|
||||
<img src="/ja-jp/img/jp-knowledge-retrieval-setting.png" alt="知识检索配置" />
|
||||
</Frame>
|
||||
|
||||
**出力変数**
|
||||
|
||||
<Frame caption="出力変数">
|
||||
<img src="/ja-jp/img/jp-knowledge-retrieval-output.png" alt="输出变量" width="272" />
|
||||
</Frame>
|
||||
|
||||
ナレッジ検索の出力変数`result`は、ナレッジベースから検索された関連テキストセグメントです。この変数のデータ構造には、セグメント内容、タイトル、リンク、アイコン、メタデータ情報が含まれています。
|
||||
|
||||
**下流ノードの設定**
|
||||
|
||||
一般的な対話型アプリケーションでは、ナレッジベース検索の下流ノードは通常LLMノードであり、ナレッジ検索の**出力変数**`result`はLLMノード内の**コンテキスト変数**に関連付けられて設定されます。関連付け後、プロンプトの適切な位置に**コンテキスト変数**を挿入することができます。
|
||||
|
||||
<Note>
|
||||
コンテキスト変数は、LLMノード内で定義された特殊な変数タイプで、プロンプト内に外部検索されたテキスト内容を挿入するために使用されます。
|
||||
</Note>
|
||||
|
||||
ユーザーが質問すると、関連するテキストがナレッジ検索で召喚された場合、そのテキスト内容がコンテキスト変数の値としてプロンプトに挿入され、LLMが質問に答えます。関連するテキストが検索されなかった場合、コンテキスト変数の値は空となり、LLMは直接ユーザーの質問に答えます。
|
||||
|
||||
<Frame caption="下流LLMノードの設定">
|
||||
<img src="/ja-jp/img/jp-knowledge-retrieval-llm.png" alt="配置下游LLM节点" />
|
||||
</Frame>
|
||||
|
||||
この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](../../knowledge-base/retrieval-test-and-citation#id-2-yin-yong-yu-gui-shu)機能もサポートします。
|
||||
93
ja-jp/guides/workflow/node/list-operator.mdx
Normal file
93
ja-jp/guides/workflow/node/list-operator.mdx
Normal file
@@ -0,0 +1,93 @@
|
||||
---
|
||||
title: リスト処理
|
||||
---
|
||||
|
||||
リスト変数は、文章、画像、音声、映像など、さまざまなファイルを同時にアップロードすることができます。ユーザーがファイルをアップロードすると、すべてのファイルが同じ `Array[File]` 配列変数に保存されますが、**その後の個別ファイルの処理が難しくなります。**
|
||||
|
||||
> `Array` データ型は、変数の実際の値が \[1.mp3、2.png、3.doc] である可能性があることを意味します。LLM は、入力変数として画像やテキストなどの単一の値の読み取りのみをサポートしており、配列変数を直接読み取ることはできません。
|
||||
|
||||
### ノード機能
|
||||
|
||||
リストフィルタは、ファイルの形式のタイプ、名、サイズなどの属性に基づいてフィルターして抽出し、異なる形式のファイルをそれぞれの処理ノードに渡すことで、ファイル処理の流れを正確に制御します。
|
||||
|
||||
例えば、あるアプリでは、ユーザーが文章と画像を同時にアップロードすることを許可しています。異なるファイルは**リスト操作ノード**を通じて分類され、異なる処理フローに引き渡されます。
|
||||
|
||||
<Frame caption="異なるファイルタイプのフロー分岐">
|
||||
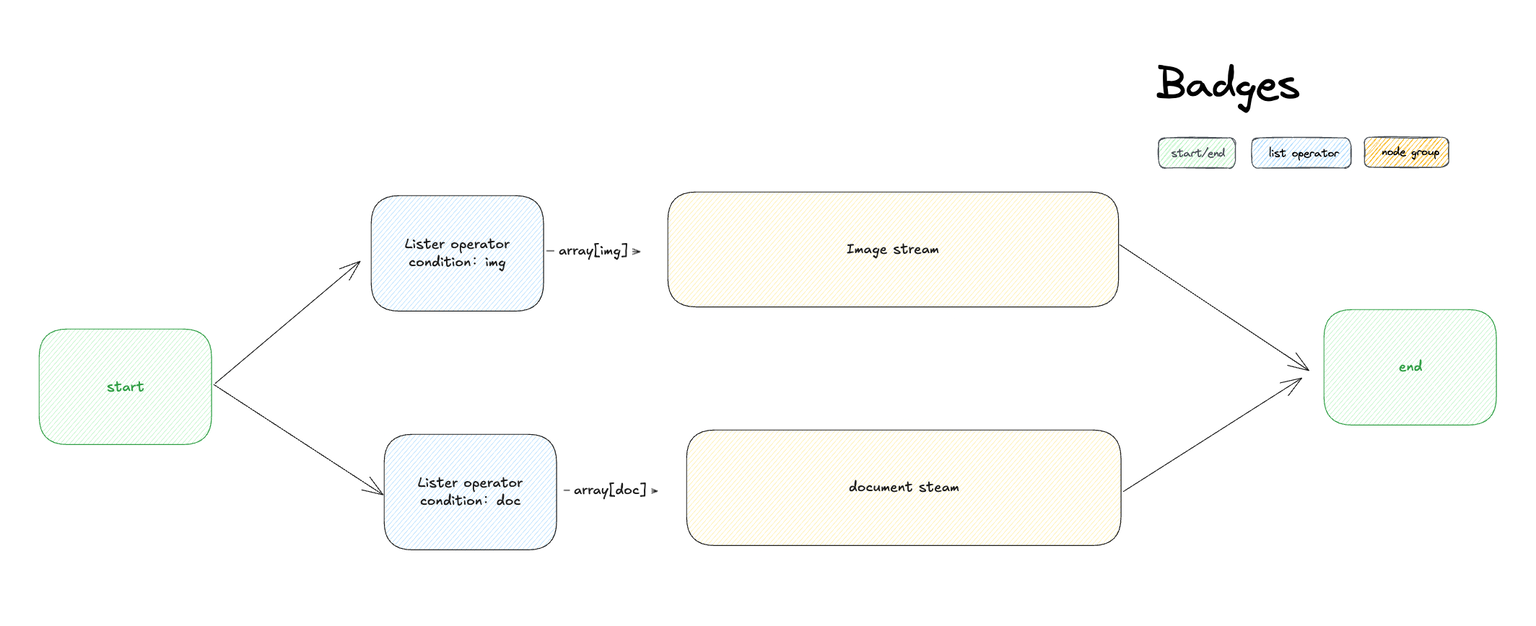
|
||||
</Frame>
|
||||
|
||||
リスト操作ノードは通常、配列変数から情報を抽出するために使用され、条件を設定して、下流ノードが受け入れることのできる変数タイプに変換します。その構造は、入力変数、フィルタ条件、ソート、上位 N 項目、および出力変数に分かれています。
|
||||
|
||||
<Frame caption="リスト操作ノード">
|
||||
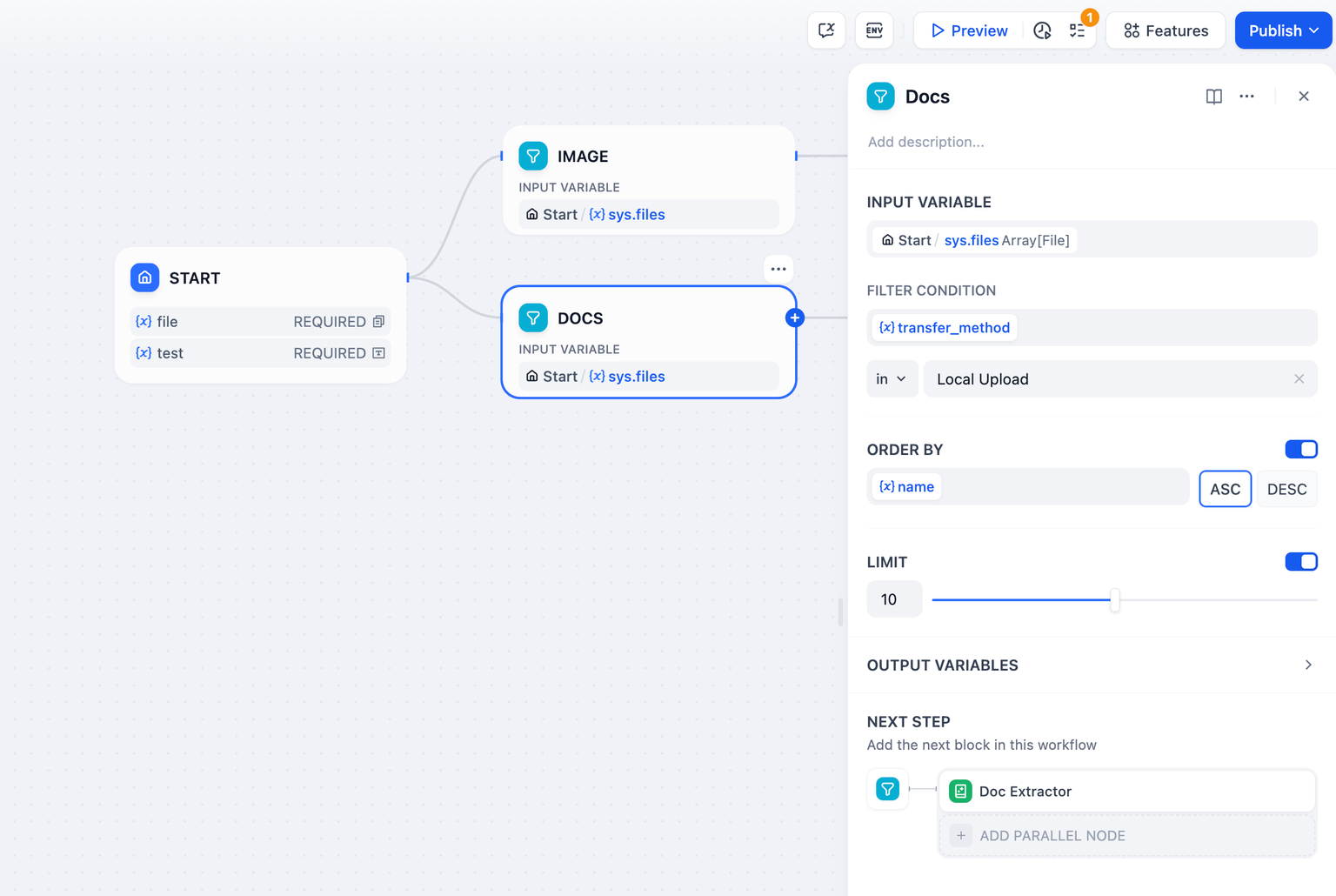
|
||||
</Frame>
|
||||
|
||||
#### 入力変数
|
||||
|
||||
リスト操作ノードは以下のデータ構造変数のみを受け入れます:
|
||||
|
||||
* Array[string]
|
||||
* Array[number]
|
||||
* Array[file]
|
||||
|
||||
#### フィルタ条件
|
||||
|
||||
入力変数の配列を処理し、フィルタ条件を追加します。条件に合致するすべての配列変数を選択し、その属性をフィルタリングします。
|
||||
|
||||
例:ファイルにはファイル名、ファイルタイプ、ファイルサイズなど、複数の属性が含まれる可能性があります。フィルタ条件では、特定のファイルを配列変数から選択し抽出するための条件を設定します。
|
||||
|
||||
以下の変数を抽出できます:
|
||||
|
||||
* type:ファイルのタイプ(画像、文章、音声、映像など)
|
||||
* size:ファイルサイズ
|
||||
* name:ファイル名
|
||||
* url:ユーザーがURL経由でアップロードしたファイルを指し、完全なURLを入力してフィルタリングできます。
|
||||
* extension:ファイルの拡張子
|
||||
* mime_type:
|
||||
|
||||
[MIMEタイプ](https://datatracker.ietf.org/doc/html/rfc2046)は、ファイルのコンテンツタイプを識別するための標準化された文字列です。例: "text/html" はHTMLドキュメントを示します。
|
||||
|
||||
* transfer_method:
|
||||
|
||||
ファイルのアップロード方法(ローカルアップロードまたはURL経由でのアップロード)を示します。
|
||||
|
||||
#### ソート
|
||||
|
||||
入力変数の配列をファイルの属性に基づいて並べ替える機能を提供します。
|
||||
|
||||
- 昇順ソート:
|
||||
|
||||
デフォルトの並べ替えオプションで、値が小さい順に並べ替えます。文字やテキストの場合はアルファベット順(A - Z)に並べ替えます。
|
||||
|
||||
- 降順ソート:
|
||||
|
||||
値が大きい順に並べ替えます。文字やテキストの場合は逆アルファベット順(Z - A)に並べ替えます。
|
||||
|
||||
このオプションは通常、出力変数の first_record および last_record と組み合わせて使用されます。
|
||||
|
||||
#### 上位 N 項目
|
||||
|
||||
1から20の値を選択し、配列変数の上位 n 項目を選択します。
|
||||
|
||||
#### 出力変数
|
||||
|
||||
すべてのフィルタ条件を満たす配列要素。フィルタ条件、ソート、制限は個別に有効にできます。すべての条件を同時に有効にした場合、すべての条件を満たす配列要素が返されます。
|
||||
|
||||
* Result:フィルタリング結果で、データ型は配列変数です。配列に1つのファイルしか含まれていない場合、出力変数には1つの要素のみが含まれます。
|
||||
* first_record:フィルタリングされた配列の最初の要素、すなわち result[0];
|
||||
* last_record:フィルタリングされた配列の最後の要素、すなわち result[array.length-1]。
|
||||
|
||||
***
|
||||
|
||||
### 設定例
|
||||
|
||||
ファイルのインタラクティブな質疑応答シナリオでは、アプリのユーザーが文章や画像ファイルを同時にアップロードする可能性があります。LLMは画像ファイルを認識できる能力しか持たず、文章を読み取ることができません。その場合、[リスト操作](/ja-jp/guides/workflow/nodes/list-operator)ノードを使用して、ファイル変数の配列を事前処理し、異なるファイルタイプをそれぞれの処理ノードに送信する必要があります。手順は以下の通りです:
|
||||
|
||||
1. [機能](/en/guides/workflow/additional-features)を有効にし、ファイルタイプで「画像」および「文章」を選択します。
|
||||
2. フィルタ条件で、画像変数とドキュメント変数をそれぞれ抽出するための2つのリスト操作ノードを追加します。
|
||||
3. 文章変数を抽出し、「ドキュメントエクストラクタ」ノードに渡し、画像ファイル変数を抽出してLLMノードに渡します。
|
||||
4. 最後に「直接返信」ノードを追加し、LLMノードの出力変数を記入します。
|
||||
|
||||

|
||||
|
||||
アプリのユーザーが文章と画像ファイルを同時にアップロードした場合、文章は自動的にドキュメントエクストラクタノードに、画像ファイルは自動的にLLMノードに分流され、混合ファイルの共通処理が実現されます。
|
||||
93
ja-jp/guides/workflow/node/list-operator.mdx.bak
Normal file
93
ja-jp/guides/workflow/node/list-operator.mdx.bak
Normal file
@@ -0,0 +1,93 @@
|
||||
---
|
||||
title: リスト処理
|
||||
---
|
||||
|
||||
リスト変数は、文章、画像、音声、映像など、さまざまなファイルを同時にアップロードすることができます。ユーザーがファイルをアップロードすると、すべてのファイルが同じ `Array[File]` 配列変数に保存されますが、**その後の個別ファイルの処理が難しくなります。**
|
||||
|
||||
> `Array` データ型は、変数の実際の値が \[1.mp3、2.png、3.doc] である可能性があることを意味します。LLM は、入力変数として画像やテキストなどの単一の値の読み取りのみをサポートしており、配列変数を直接読み取ることはできません。
|
||||
|
||||
### ノード機能
|
||||
|
||||
リストフィルタは、ファイルの形式のタイプ、名、サイズなどの属性に基づいてフィルターして抽出し、異なる形式のファイルをそれぞれの処理ノードに渡すことで、ファイル処理の流れを正確に制御します。
|
||||
|
||||
例えば、あるアプリでは、ユーザーが文章と画像を同時にアップロードすることを許可しています。異なるファイルは**リスト操作ノード**を通じて分類され、異なる処理フローに引き渡されます。
|
||||
|
||||
<Frame caption="異なるファイルタイプのフロー分岐">
|
||||

|
||||
</Frame>
|
||||
|
||||
リスト操作ノードは通常、配列変数から情報を抽出するために使用され、条件を設定して、下流ノードが受け入れることのできる変数タイプに変換します。その構造は、入力変数、フィルタ条件、ソート、上位 N 項目、および出力変数に分かれています。
|
||||
|
||||
<Frame caption="リスト操作ノード">
|
||||

|
||||
</Frame>
|
||||
|
||||
#### 入力変数
|
||||
|
||||
リスト操作ノードは以下のデータ構造変数のみを受け入れます:
|
||||
|
||||
* Array[string]
|
||||
* Array[number]
|
||||
* Array[file]
|
||||
|
||||
#### フィルタ条件
|
||||
|
||||
入力変数の配列を処理し、フィルタ条件を追加します。条件に合致するすべての配列変数を選択し、その属性をフィルタリングします。
|
||||
|
||||
例:ファイルにはファイル名、ファイルタイプ、ファイルサイズなど、複数の属性が含まれる可能性があります。フィルタ条件では、特定のファイルを配列変数から選択し抽出するための条件を設定します。
|
||||
|
||||
以下の変数を抽出できます:
|
||||
|
||||
* type:ファイルのタイプ(画像、文章、音声、映像など)
|
||||
* size:ファイルサイズ
|
||||
* name:ファイル名
|
||||
* url:ユーザーがURL経由でアップロードしたファイルを指し、完全なURLを入力してフィルタリングできます。
|
||||
* extension:ファイルの拡張子
|
||||
* mime_type:
|
||||
|
||||
[MIMEタイプ](https://datatracker.ietf.org/doc/html/rfc2046)は、ファイルのコンテンツタイプを識別するための標準化された文字列です。例: "text/html" はHTMLドキュメントを示します。
|
||||
|
||||
* transfer_method:
|
||||
|
||||
ファイルのアップロード方法(ローカルアップロードまたはURL経由でのアップロード)を示します。
|
||||
|
||||
#### ソート
|
||||
|
||||
入力変数の配列をファイルの属性に基づいて並べ替える機能を提供します。
|
||||
|
||||
- 昇順ソート:
|
||||
|
||||
デフォルトの並べ替えオプションで、値が小さい順に並べ替えます。文字やテキストの場合はアルファベット順(A - Z)に並べ替えます。
|
||||
|
||||
- 降順ソート:
|
||||
|
||||
値が大きい順に並べ替えます。文字やテキストの場合は逆アルファベット順(Z - A)に並べ替えます。
|
||||
|
||||
このオプションは通常、出力変数の first_record および last_record と組み合わせて使用されます。
|
||||
|
||||
#### 上位 N 項目
|
||||
|
||||
1から20の値を選択し、配列変数の上位 n 項目を選択します。
|
||||
|
||||
#### 出力変数
|
||||
|
||||
すべてのフィルタ条件を満たす配列要素。フィルタ条件、ソート、制限は個別に有効にできます。すべての条件を同時に有効にした場合、すべての条件を満たす配列要素が返されます。
|
||||
|
||||
* Result:フィルタリング結果で、データ型は配列変数です。配列に1つのファイルしか含まれていない場合、出力変数には1つの要素のみが含まれます。
|
||||
* first_record:フィルタリングされた配列の最初の要素、すなわち result[0];
|
||||
* last_record:フィルタリングされた配列の最後の要素、すなわち result[array.length-1]。
|
||||
|
||||
***
|
||||
|
||||
### 設定例
|
||||
|
||||
ファイルのインタラクティブな質疑応答シナリオでは、アプリのユーザーが文章や画像ファイルを同時にアップロードする可能性があります。LLMは画像ファイルを認識できる能力しか持たず、文章を読み取ることができません。その場合、[リスト操作](list-operator)ノードを使用して、ファイル変数の配列を事前処理し、異なるファイルタイプをそれぞれの処理ノードに送信する必要があります。手順は以下の通りです:
|
||||
|
||||
1. [機能](../additional-features)を有効にし、ファイルタイプで「画像」および「文章」を選択します。
|
||||
2. フィルタ条件で、画像変数とドキュメント変数をそれぞれ抽出するための2つのリスト操作ノードを追加します。
|
||||
3. 文章変数を抽出し、「ドキュメントエクストラクタ」ノードに渡し、画像ファイル変数を抽出してLLMノードに渡します。
|
||||
4. 最後に「直接返信」ノードを追加し、LLMノードの出力変数を記入します。
|
||||
|
||||

|
||||
|
||||
アプリのユーザーが文章と画像ファイルを同時にアップロードした場合、文章は自動的にドキュメントエクストラクタノードに、画像ファイルは自動的にLLMノードに分流され、混合ファイルの共通処理が実現されます。
|
||||
156
ja-jp/guides/workflow/node/llm.mdx
Normal file
156
ja-jp/guides/workflow/node/llm.mdx
Normal file
@@ -0,0 +1,156 @@
|
||||
---
|
||||
title: LLM
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
大規模言語モデルを活用して質問に回答したり、自然言語を処理したりします。
|
||||
|
||||
<Frame caption="LLMノード">
|
||||
<img src="/ja-jp/img/jp-llm-detail.png" alt="LLM 节点" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
LLM は チャットフロー/ワークフロー の中心的なノードであり、大規模言語モデルの会話/生成/分類/処理などの能力を活用して、多様なタスクを提示されたプロンプトに基づいて処理し、ワークフローのさまざまな段階で使用することができます。
|
||||
|
||||
* **意図識別**:カスタマーサービスの対話シナリオにおいて、ユーザーの質問を意図識別および分類し、異なるフローに誘導します。
|
||||
* **テキスト生成**:記事生成シナリオにおいて、テーマやキーワードに基づいて適切なテキスト内容を生成するノードとして機能します。
|
||||
* **内容分類**:メールのバッチ処理シナリオにおいて、メールの種類を自動的に分類します(例:問い合わせ/苦情/スパム)。
|
||||
* **テキスト変換**:テキスト翻訳シナリオにおいて、ユーザーが提供したテキスト内容を指定された言語に翻訳します。
|
||||
* **コード生成**:プログラミング支援シナリオにおいて、ユーザーの要求に基づいて指定のビジネスコードやテストケースを生成します。
|
||||
* **RAG**:ナレッジベースの質問応答シナリオにおいて、検索した関連知識とユーザーの質問を再構成して回答します。
|
||||
* **画像理解**:ビジョン能力を持つマルチモーダルモデルを使用し、画像内の情報を理解して質問に回答します。
|
||||
|
||||
適切なモデルを選択し、プロンプトを記述することで、チャットフロー/ワークフロー で強力で信頼性の高いソリューションを構築できます。
|
||||
|
||||
***
|
||||
|
||||
### 設定方法
|
||||
|
||||
エディットページで、前のノードの末尾を右クリックするか、+ボタンを軽くタップして新しいノードを追加し、LLM(大規模言語モデル)を選択します。
|
||||
|
||||
<Frame caption="LLM ノード設定 - モデル選択">
|
||||
<img src="/ja-jp/img/jp-llm-model.png" alt="LLM ノード設定 - モデル選択" />
|
||||
</Frame>
|
||||
|
||||
**設定手順:**
|
||||
|
||||
1. **モデルの選択**:Difyでは、OpenAIのGPTシリーズ、AnthropicのClaudeシリーズ、GoogleのGeminiシリーズなど、世界中で広く使用されているさまざまなモデルを[サポート](/ja-jp/getting-started/readme/model-providers)しています。モデルの選択は、推論能力、コスト、応答速度、コンテキストウィンドウのサイズなどの要因に基づいて行います。使用するシーンやタスクの種類に応じて、適切なモデルを選ぶことが重要です。
|
||||
|
||||
<Note>
|
||||
Difyを初めて使用する場合は、LLMノードでモデルを選択する前に、**システム設定 - モデルプロバイダ**で[モデルの設定](/ja-jp/guides/model-configuration/readme)を事前に行う必要があります。
|
||||
</Note>
|
||||
|
||||
2. **モデルパラメータの設定**:モデルパラメータは、生成される結果を調整するために使用されます。これには、温度、TopP、最大トークン数、応答形式などが含まれます。選択肢を簡素化するために、3つの事前設定されたパラメータ(クリエイティブ、バランス、精密)が用意されています。これらのパラメータに不慣れな場合は、デフォルト設定を選択することをお勧めします。画像解析機能を利用したい場合は、視覚能力を持つモデルを選んでください。
|
||||
3. **コンテキストの入力(オプション)**:コンテキストとは、LLMに提供される背景情報のことを指します。通常は、[知識検索](./knowledge-retrieval)の出力変数を記入するために使用されます。
|
||||
4. **プロンプトの作成**:LLMノードには使いやすいプロンプト編集ページがあり、チャットモデルまたはコンプリートモデルを選択することで異なるプロンプト編集構造が表示されます。チャットモデル(Chat model)を選択した場合、システムプロンプト(SYSTEM)、ユーザー(USER)、アシスタント(ASSISTANT)の3つのセクションをカスタマイズできます。
|
||||
|
||||
<Frame caption="プロンプトの作成">
|
||||
<img src="/ja-jp/img/jp-llm-customize.png" alt="编写提示词" width="352" />
|
||||
</Frame>
|
||||
|
||||
システムプロンプト(SYSTEM)を作成する際にアイデアが浮かばない場合は、プロンプトジェネレーター機能を使用して、実際のビジネスシナリオに適したプロンプトを迅速に生成することができます。
|
||||
|
||||
<Frame caption="プロンプトジェネレーター">
|
||||
<img src="/ja-jp/img/jp-node-llm-prompt-generator.png" alt="プロンプトジェネレーター" />
|
||||
</Frame>
|
||||
|
||||
プロンプトエディターでは、**“/”** を入力することで **変数挿入メニュー** を呼び出し、**特殊変数ブロック**や **上流ノードの変数**をプロンプトに挿入してコンテキスト内容として使用できます。
|
||||
|
||||
<Frame caption="変数挿入メニューを呼び出す">
|
||||
<img src="/ja-jp/img/jp-llm-variable.png" alt="呼出变量插入菜单" width="366" />
|
||||
</Frame>
|
||||
|
||||
5. **上級的な設定**:メモリ機能をオンにしたり、メモリウィンドウを設定したり、ビジョン機能を有効にしたり、Jinja-2テンプレート言語を使ってより複雑なプロンプトを作成したりできます。
|
||||
|
||||
***
|
||||
|
||||
### **特殊変数の説明**
|
||||
|
||||
**コンテキスト変数**
|
||||
|
||||
コンテキスト変数とは、言語モデル(LLM)に背景情報を提供するための特別な変数の一種で、特に知識検索のシナリオでよく利用されます。詳細については、[知識検索ノード](/ja-jp/guides/workflow/nodes/knowledge-retrieval)を参照してください。
|
||||
|
||||
**画像ファイル変数**
|
||||
|
||||
視覚機能を備えた言語モデル(LLM)は、アプリケーションユーザーがアップロードした画像をこの変数を通じて読み取ることができます。VISION機能を有効にした後、画像ファイルの出力変数を選択して設定を完了させてください。
|
||||
|
||||
<Frame caption="ビジョンアップロード機能">
|
||||
{/* <img src="/ja-jp/user-guide/.gitbook/assets/image (371).png" alt="ビジョンアップロード機能" /> */}
|
||||

|
||||
</Frame>
|
||||
|
||||
**会話履歴**
|
||||
|
||||
テキスト補完モデル(例:gpt-3.5-turbo-Instruct)内でチャット型アプリケーションの対話記憶を実現するために、Dify は元の[プロンプト専門モード(廃止)](/zh-hans/learn-more/extended-reading/prompt-engineering)内で会話履歴変数を設計しました。この変数はチャットフローのLLMノード内でも使用され、プロンプト内に AI とユーザーの対話履歴を挿入して、LLM が対話の文脈を理解するのを助けます。
|
||||
|
||||
<Note>
|
||||
会話履歴変数の使用は広範ではなく、チャットフロー内でテキスト補完モデルを選択した場合にのみ使用できます。
|
||||
</Note>
|
||||
|
||||
<Frame caption="会話履歴変数の挿入">
|
||||
<img src="/ja-jp/img/jp-llm-with-histories.png" alt="会話履歴変数の挿入" />
|
||||
</Frame>
|
||||
|
||||
**モデルパラメーター**
|
||||
|
||||
モデルのパラメータはモデルの出力に影響を与えます。異なるモデルには異なるパラメータがあります。以下の図は`gpt-4`のパラメータリストです。
|
||||
|
||||
<Frame caption="モデルパラメータリスト">
|
||||
<img src="/ja-jp/img/jp-llm-model-provider-1.png" alt="模型参数列表" width="368" />
|
||||
</Frame>
|
||||
|
||||
主要なパラメータ用語は以下のように説明されています:
|
||||
|
||||
* **Temperature(温度)**: 通常は0-1の値で、ランダム性を制御します。温度が0に近いほど、結果はより確定的で繰り返しになり、温度が1に近いほど、結果はよりランダムになります。
|
||||
* **Top P**: 結果の多様性を制御します。モデルは確率に基づいて候補語から選択し、累積確率が設定された閾値Pを超えないようにします。
|
||||
* **Presence Penalty(存在ペナルティ)**: 既に生成された内容にペナルティを課すことにより、同じエンティティや情報の繰り返し生成を減少させるために使用されます。パラメータ値が増加するにつれて、既に生成された内容に対して後続の生成でより大きなペナルティが課され、内容の繰り返しの可能性が低くなります。
|
||||
* **Frequency Penalty(頻度ペナルティ)**: 頻繁に出現する単語やフレーズにペナルティを課し、これらの単語の生成確率を低下させます。パラメータ値が増加すると、頻繁に出現する単語やフレーズにより大きなペナルティが課されます。パラメータ値が高いほど、これらの単語の出現頻度が減少し、テキストの語彙の多様性が増加します。
|
||||
|
||||
これらのパラメータが何であるか理解できない場合は、プリセットを読み込んで、「クリエイティブ」、「バランス」、「正確」の3つのプリセットから選択することができます。
|
||||
|
||||
<Frame caption="加载预设参数">
|
||||
<img src="/ja-jp/img/jp-llm-model-provider-2.png" alt="加载预设参数" width="367" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 高度な機能
|
||||
|
||||
**記憶**:記憶をオンにすると、問題分類器の各入力に対話履歴が含まれ、LLM が文脈を理解しやすくなり、対話の理解能力が向上します。
|
||||
|
||||
**記憶ウィンドウ**:記憶ウィンドウが閉じている場合、システムはモデルのコンテキストウィンドウに基づいて対話履歴の伝達数を動的にフィルタリングします。開いている場合、ユーザーは対話履歴の伝達数を正確に制御できます(対数)。
|
||||
|
||||
**対話役割名の設定**:モデルのトレーニング段階の違いにより、異なるモデルは役割名のプロンプト遵守度が異なります(例:Human/Assistant、Human/AI、人間/助手など)。複数のモデルに対応するために、システムは対話役割名の設定を提供しており、対話役割名を変更すると会話履歴の役割プレフィックスも変更されます。
|
||||
|
||||
**Jinja-2 テンプレート**:LLM のプロンプトエディター内で Jinja-2 テンプレート言語をサポートしており、Jinja2 の強力な Python テンプレート言語を使用して軽量なデータ変換やロジック処理を実現できます。詳細は[公式ドキュメント](https://jinja.palletsprojects.com/en/3.1.x/templates/)を参照してください。
|
||||
|
||||
***
|
||||
|
||||
### ユースケース
|
||||
|
||||
* **ナレッジベースの内容を検索する**
|
||||
|
||||
ワークフローアプリケーションが[「ナレッジベース」](/ja-jp/guides/knowledge-base/readme)の内容を検索できるようにしたい場合、例えばインテリジェントカスタマーサービスアプリケーションを構築する場合は、以下の手順を参考にしてください。
|
||||
|
||||
1. LLMノードの上流に知識検索ノードを追加します;
|
||||
2. 知識検索ノードの **出力変数** `result` をLLMノードの **コンテキスト変数** に入力します;
|
||||
3. **コンテキスト変数** をアプリケーションのプロンプトに挿入し、LLMがナレッジベース内のテキスト内容を読み取れるようにします。
|
||||
|
||||
<Frame caption="コンテキスト変数">
|
||||
<img src="/ja-jp/img/jp-llm-use-case.png" alt="コンテキスト変数" />
|
||||
</Frame>
|
||||
|
||||
[知識検索ノード](./knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](/ja-jp/guides/knowledge-base/retrieval-test-and-citation) 機能を使用して情報の出所を確認できます。
|
||||
|
||||
<Note>
|
||||
通常のノードの変数もコンテキスト変数に入力可能ですが、例えば開始ノードの文字列型変数など、**引用と帰属** 機能は機能しません。
|
||||
</Note>
|
||||
|
||||
* **文書ファイルの読み取り**
|
||||
|
||||
ChatPDF アプリケーションの構築など、ワークフロー アプリケーションにドキュメントのコンテンツを読み取る機能を提供する場合は、次を参照してください。
|
||||
156
ja-jp/guides/workflow/node/llm.mdx.bak
Normal file
156
ja-jp/guides/workflow/node/llm.mdx.bak
Normal file
@@ -0,0 +1,156 @@
|
||||
---
|
||||
title: LLM
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
大規模言語モデルを活用して質問に回答したり、自然言語を処理したりします。
|
||||
|
||||
<Frame caption="LLMノード">
|
||||
<img src="/ja-jp/img/jp-llm-detail.png" alt="LLM 节点" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
LLM は チャットフロー/ワークフロー の中心的なノードであり、大規模言語モデルの会話/生成/分類/処理などの能力を活用して、多様なタスクを提示されたプロンプトに基づいて処理し、ワークフローのさまざまな段階で使用することができます。
|
||||
|
||||
* **意図識別**:カスタマーサービスの対話シナリオにおいて、ユーザーの質問を意図識別および分類し、異なるフローに誘導します。
|
||||
* **テキスト生成**:記事生成シナリオにおいて、テーマやキーワードに基づいて適切なテキスト内容を生成するノードとして機能します。
|
||||
* **内容分類**:メールのバッチ処理シナリオにおいて、メールの種類を自動的に分類します(例:問い合わせ/苦情/スパム)。
|
||||
* **テキスト変換**:テキスト翻訳シナリオにおいて、ユーザーが提供したテキスト内容を指定された言語に翻訳します。
|
||||
* **コード生成**:プログラミング支援シナリオにおいて、ユーザーの要求に基づいて指定のビジネスコードやテストケースを生成します。
|
||||
* **RAG**:ナレッジベースの質問応答シナリオにおいて、検索した関連知識とユーザーの質問を再構成して回答します。
|
||||
* **画像理解**:ビジョン能力を持つマルチモーダルモデルを使用し、画像内の情報を理解して質問に回答します。
|
||||
|
||||
適切なモデルを選択し、プロンプトを記述することで、チャットフロー/ワークフロー で強力で信頼性の高いソリューションを構築できます。
|
||||
|
||||
***
|
||||
|
||||
### 設定方法
|
||||
|
||||
エディットページで、前のノードの末尾を右クリックするか、+ボタンを軽くタップして新しいノードを追加し、LLM(大規模言語モデル)を選択します。
|
||||
|
||||
<Frame caption="LLM ノード設定 - モデル選択">
|
||||
<img src="/ja-jp/img/jp-llm-model.png" alt="LLM ノード設定 - モデル選択" />
|
||||
</Frame>
|
||||
|
||||
**設定手順:**
|
||||
|
||||
1. **モデルの選択**:Difyでは、OpenAIのGPTシリーズ、AnthropicのClaudeシリーズ、GoogleのGeminiシリーズなど、世界中で広く使用されているさまざまなモデルを[サポート](../../../getting-started/readme/model-providers)しています。モデルの選択は、推論能力、コスト、応答速度、コンテキストウィンドウのサイズなどの要因に基づいて行います。使用するシーンやタスクの種類に応じて、適切なモデルを選ぶことが重要です。
|
||||
|
||||
<Note>
|
||||
Difyを初めて使用する場合は、LLMノードでモデルを選択する前に、**システム設定 - モデルプロバイダ**で[モデルの設定](../../model-configuration/)を事前に行う必要があります。
|
||||
</Note>
|
||||
|
||||
2. **モデルパラメータの設定**:モデルパラメータは、生成される結果を調整するために使用されます。これには、温度、TopP、最大トークン数、応答形式などが含まれます。選択肢を簡素化するために、3つの事前設定されたパラメータ(クリエイティブ、バランス、精密)が用意されています。これらのパラメータに不慣れな場合は、デフォルト設定を選択することをお勧めします。画像解析機能を利用したい場合は、視覚能力を持つモデルを選んでください。
|
||||
3. **コンテキストの入力(オプション)**:コンテキストとは、LLMに提供される背景情報のことを指します。通常は、[知識検索](./knowledge-retrieval)の出力変数を記入するために使用されます。
|
||||
4. **プロンプトの作成**:LLMノードには使いやすいプロンプト編集ページがあり、チャットモデルまたはコンプリートモデルを選択することで異なるプロンプト編集構造が表示されます。チャットモデル(Chat model)を選択した場合、システムプロンプト(SYSTEM)、ユーザー(USER)、アシスタント(ASSISTANT)の3つのセクションをカスタマイズできます。
|
||||
|
||||
<Frame caption="プロンプトの作成">
|
||||
<img src="/ja-jp/img/jp-llm-customize.png" alt="编写提示词" width="352" />
|
||||
</Frame>
|
||||
|
||||
システムプロンプト(SYSTEM)を作成する際にアイデアが浮かばない場合は、プロンプトジェネレーター機能を使用して、実際のビジネスシナリオに適したプロンプトを迅速に生成することができます。
|
||||
|
||||
<Frame caption="プロンプトジェネレーター">
|
||||
<img src="/ja-jp/img/jp-node-llm-prompt-generator.png" alt="プロンプトジェネレーター" />
|
||||
</Frame>
|
||||
|
||||
プロンプトエディターでは、**“/”** を入力することで **変数挿入メニュー** を呼び出し、**特殊変数ブロック**や **上流ノードの変数**をプロンプトに挿入してコンテキスト内容として使用できます。
|
||||
|
||||
<Frame caption="変数挿入メニューを呼び出す">
|
||||
<img src="/ja-jp/img/jp-llm-variable.png" alt="呼出变量插入菜单" width="366" />
|
||||
</Frame>
|
||||
|
||||
5. **上級的な設定**:メモリ機能をオンにしたり、メモリウィンドウを設定したり、ビジョン機能を有効にしたり、Jinja-2テンプレート言語を使ってより複雑なプロンプトを作成したりできます。
|
||||
|
||||
***
|
||||
|
||||
### **特殊変数の説明**
|
||||
|
||||
**コンテキスト変数**
|
||||
|
||||
コンテキスト変数とは、言語モデル(LLM)に背景情報を提供するための特別な変数の一種で、特に知識検索のシナリオでよく利用されます。詳細については、[知識検索ノード](knowledge-retrieval)を参照してください。
|
||||
|
||||
**画像ファイル変数**
|
||||
|
||||
視覚機能を備えた言語モデル(LLM)は、アプリケーションユーザーがアップロードした画像をこの変数を通じて読み取ることができます。VISION機能を有効にした後、画像ファイルの出力変数を選択して設定を完了させてください。
|
||||
|
||||
<Frame caption="ビジョンアップロード機能">
|
||||
{/* <img src="/ja-jp/user-guide/.gitbook/assets/image (371).png" alt="ビジョンアップロード機能" /> */}
|
||||

|
||||
</Frame>
|
||||
|
||||
**会話履歴**
|
||||
|
||||
テキスト補完モデル(例:gpt-3.5-turbo-Instruct)内でチャット型アプリケーションの対話記憶を実現するために、Dify は元の[プロンプト専門モード(廃止)](https://docs.dify.ai/v/ja-jp/learn-more/extended-reading/prompt-engineering/prompt-engineering)内で会話履歴変数を設計しました。この変数はチャットフローのLLMノード内でも使用され、プロンプト内に AI とユーザーの対話履歴を挿入して、LLM が対話の文脈を理解するのを助けます。
|
||||
|
||||
<Note>
|
||||
会話履歴変数の使用は広範ではなく、チャットフロー内でテキスト補完モデルを選択した場合にのみ使用できます。
|
||||
</Note>
|
||||
|
||||
<Frame caption="会話履歴変数の挿入">
|
||||
<img src="/ja-jp/img/jp-llm-with-histories.png" alt="会話履歴変数の挿入" />
|
||||
</Frame>
|
||||
|
||||
**モデルパラメーター**
|
||||
|
||||
モデルのパラメータはモデルの出力に影響を与えます。異なるモデルには異なるパラメータがあります。以下の図は`gpt-4`のパラメータリストです。
|
||||
|
||||
<Frame caption="モデルパラメータリスト">
|
||||
<img src="/ja-jp/img/jp-llm-model-provider-1.png" alt="模型参数列表" width="368" />
|
||||
</Frame>
|
||||
|
||||
主要なパラメータ用語は以下のように説明されています:
|
||||
|
||||
* **Temperature(温度)**: 通常は0-1の値で、ランダム性を制御します。温度が0に近いほど、結果はより確定的で繰り返しになり、温度が1に近いほど、結果はよりランダムになります。
|
||||
* **Top P**: 結果の多様性を制御します。モデルは確率に基づいて候補語から選択し、累積確率が設定された閾値Pを超えないようにします。
|
||||
* **Presence Penalty(存在ペナルティ)**: 既に生成された内容にペナルティを課すことにより、同じエンティティや情報の繰り返し生成を減少させるために使用されます。パラメータ値が増加するにつれて、既に生成された内容に対して後続の生成でより大きなペナルティが課され、内容の繰り返しの可能性が低くなります。
|
||||
* **Frequency Penalty(頻度ペナルティ)**: 頻繁に出現する単語やフレーズにペナルティを課し、これらの単語の生成確率を低下させます。パラメータ値が増加すると、頻繁に出現する単語やフレーズにより大きなペナルティが課されます。パラメータ値が高いほど、これらの単語の出現頻度が減少し、テキストの語彙の多様性が増加します。
|
||||
|
||||
これらのパラメータが何であるか理解できない場合は、プリセットを読み込んで、「クリエイティブ」、「バランス」、「正確」の3つのプリセットから選択することができます。
|
||||
|
||||
<Frame caption="加载预设参数">
|
||||
<img src="/ja-jp/img/jp-llm-model-provider-2.png" alt="加载预设参数" width="367" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 高度な機能
|
||||
|
||||
**記憶**:記憶をオンにすると、問題分類器の各入力に対話履歴が含まれ、LLM が文脈を理解しやすくなり、対話の理解能力が向上します。
|
||||
|
||||
**記憶ウィンドウ**:記憶ウィンドウが閉じている場合、システムはモデルのコンテキストウィンドウに基づいて対話履歴の伝達数を動的にフィルタリングします。開いている場合、ユーザーは対話履歴の伝達数を正確に制御できます(対数)。
|
||||
|
||||
**対話役割名の設定**:モデルのトレーニング段階の違いにより、異なるモデルは役割名のプロンプト遵守度が異なります(例:Human/Assistant、Human/AI、人間/助手など)。複数のモデルに対応するために、システムは対話役割名の設定を提供しており、対話役割名を変更すると会話履歴の役割プレフィックスも変更されます。
|
||||
|
||||
**Jinja-2 テンプレート**:LLM のプロンプトエディター内で Jinja-2 テンプレート言語をサポートしており、Jinja2 の強力な Python テンプレート言語を使用して軽量なデータ変換やロジック処理を実現できます。詳細は[公式ドキュメント](https://jinja.palletsprojects.com/en/3.1.x/templates/)を参照してください。
|
||||
|
||||
***
|
||||
|
||||
### ユースケース
|
||||
|
||||
* **ナレッジベースの内容を検索する**
|
||||
|
||||
ワークフローアプリケーションが[「ナレッジベース」](../../knowledge-base/)の内容を検索できるようにしたい場合、例えばインテリジェントカスタマーサービスアプリケーションを構築する場合は、以下の手順を参考にしてください。
|
||||
|
||||
1. LLMノードの上流に知識検索ノードを追加します;
|
||||
2. 知識検索ノードの **出力変数** `result` をLLMノードの **コンテキスト変数** に入力します;
|
||||
3. **コンテキスト変数** をアプリケーションのプロンプトに挿入し、LLMがナレッジベース内のテキスト内容を読み取れるようにします。
|
||||
|
||||
<Frame caption="コンテキスト変数">
|
||||
<img src="/ja-jp/img/jp-llm-use-case.png" alt="コンテキスト変数" />
|
||||
</Frame>
|
||||
|
||||
[知識検索ノード](./knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](../../knowledge-base/retrieval-test-and-citation) 機能を使用して情報の出所を確認できます。
|
||||
|
||||
<Note>
|
||||
通常のノードの変数もコンテキスト変数に入力可能ですが、例えば開始ノードの文字列型変数など、**引用と帰属** 機能は機能しません。
|
||||
</Note>
|
||||
|
||||
* **文書ファイルの読み取り**
|
||||
|
||||
ChatPDF アプリケーションの構築など、ワークフロー アプリケーションにドキュメントのコンテンツを読み取る機能を提供する場合は、次を参照してください。
|
||||
91
ja-jp/guides/workflow/node/loop.mdx
Normal file
91
ja-jp/guides/workflow/node/loop.mdx
Normal file
@@ -0,0 +1,91 @@
|
||||
---
|
||||
title: 繰り返し処理(ループ)
|
||||
---
|
||||
|
||||
## 概要
|
||||
|
||||
繰り返し処理(ループ)ノードは、前回の結果に依存する反復タスクを実行し、終了条件を満たすか最大繰り返し回数に達するまで継続します。
|
||||
|
||||
## 繰り返し処理ノードと反復処理ノードの違い
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>タイプ</th>
|
||||
<th>特徴</th>
|
||||
<th>用途</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><strong>繰り返し処理(ループ)</strong></td>
|
||||
<td>各回の処理が前回の結果に依存する。</td>
|
||||
<td>再帰処理や最適化問題など、前回の計算結果を必要とする処理に適している。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><strong>反復処理(イテレーション)</strong></td>
|
||||
<td>各回の処理は独立しており、前回の結果に依存しない。</td>
|
||||
<td>データの一括処理など、各処理を独立して実行できるタスクに適している。</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## 繰り返し処理(ループ)ノードの設定方法
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>パラメータ</th>
|
||||
<th>説明</th>
|
||||
<th>例</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>ループ終了条件</td>
|
||||
<td>ループを終了するタイミングを決定する式</td>
|
||||
<td><code>x < 50</code>、<code>error_rate < 0.01</code></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>最大繰り返し回数(Maximum Loop Count)</td>
|
||||
<td>無限ループを防ぐための繰り返し回数の上限</td>
|
||||
<td>10、100、1000</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2025/03/13853bfaaa068cdbdeba1b1f75d482f2.png"
|
||||
className="mx-auto"
|
||||
alt="ループノードの設定画面"
|
||||
/>
|
||||
|
||||
## 使用例
|
||||
|
||||
**目標:50未満の値が出るまで、1から100までのランダムな数値を生成する。**
|
||||
|
||||
**実装手順**:
|
||||
|
||||
1. `code`ノードを使用して1-100の間のランダムな数値を生成します。
|
||||
|
||||
2. `if`ノードを使用して数値を評価します:
|
||||
- 50未満の場合:`done`を出力してループを終了します。
|
||||
- 50以上の場合:ループを継続し、別のランダムな数値を生成します。
|
||||
|
||||
3. ループ終了条件を「ランダム数値 < 50」に設定します。
|
||||
|
||||
4. 50未満の数値が出現したらループは自動的に終了します。
|
||||
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2025/03/b1c277001fc3cb1fbb85fe7c22a6d0fc.png"
|
||||
className="mx-auto"
|
||||
alt="ループノードの使用例"
|
||||
/>
|
||||
|
||||
## 今後の拡張
|
||||
|
||||
**今後のリリースには以下の機能が追加される予定です:**
|
||||
|
||||
- ループ変数:繰り返し間で値を保存・参照できるようにし、状態管理と条件付きロジックを強化します。
|
||||
|
||||
- `break`ノード:実行パス内からループを直接終了できるようにし、より高度な制御フローパターンを実現します。
|
||||
73
ja-jp/guides/workflow/node/parameter-extractor.mdx
Normal file
73
ja-jp/guides/workflow/node/parameter-extractor.mdx
Normal file
@@ -0,0 +1,73 @@
|
||||
---
|
||||
title: パラメータ抽出
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
大規模言語モデル(LLM)を利用して自然言語から推論し、構造化パラメータを抽出し、ツール呼び出しやHTTPリクエストに用いる。
|
||||
|
||||
Difyワークフロー内には豊富な[ツール](/ja-jp/introduction)が用意されており、その多くは構造化パラメータを入力として要求します。パラメータ抽出器は、ユーザーの自然言語をツールが認識できるパラメータに変換し、ツールの呼び出しを容易にします。
|
||||
|
||||
ワークフロー内の一部のノードは特定のデータ形式を入力として要求します。例えば[イテレーション](./iteration)ノードの入力は配列形式である必要があり、パラメータ抽出器は[構造化パラメータの変換](./iteration#1)を容易に実現します。
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
1. **自然言語からツールが必要とするキー・パラメーターを抽出する**例として、簡単な対話形式のArxiv論文検索アプリを構築する場合を考えます。
|
||||
|
||||
この例では、Arxiv論文検索ツールの入力パラメータとして「論文の著者」または「論文番号」が要求されます。パラメータ抽出器は「この論文の内容は何ですか:2405.10739」という質問から論文番号**2405.10739**を抽出し、ツールのパラメータとして正確に検索します。
|
||||
|
||||
<Frame caption="Arxiv論文検索ツール">
|
||||
<img src="/ja-jp/img/jp-parameter-extractor1.png" alt="Arxiv 论文检索工具流程图" />
|
||||
</Frame>
|
||||
|
||||
2. **テキストを構造化データに変換する**例として、長い物語のイテレーション生成アプリの前工程として、テキスト形式の章内容を配列形式に変換し、[イテレーションノード](./iteration)でのマルチラウンド生成処理を容易にします。
|
||||
|
||||
<Frame caption="テキストを構造化データに変換する">
|
||||
<img src="/ja-jp/img/jp-parameter-extractor2.png" alt="长故事迭代生成应用流程图" />
|
||||
</Frame>
|
||||
|
||||
3. **構造化データを抽出して**[**HTTPリクエスト**](./http-request)**を使用する**ことで、任意のアクセス可能なURLにリクエストを送信し、外部検索結果の取得やウェブフック、画像生成などのシナリオに適用できます。
|
||||
|
||||
***
|
||||
|
||||
### 設定方法
|
||||
|
||||
<Frame caption="パラメータ抽出の設定" width="375">
|
||||
<img src="/ja-jp/img/jp-parameter-extractor-setting.png" alt="参数提取配置界面" />
|
||||
</Frame>
|
||||
|
||||
**設定手順**
|
||||
|
||||
1. 入力変数を選択。通常はパラメータ抽出のための変数入力を選びます。ファイルタイプもサポートします。
|
||||
2. モデルを選択。パラメータ抽出器の抽出はLLMの推論と構造化生成能力に依存します。
|
||||
3. 抽出パラメータを定義。必要なパラメータを手動で追加するか、**既存のツールから簡単にインポート**できます。
|
||||
4. コマンド作成。複雑なパラメータの抽出時には、例を作成することでLLMの生成効果と安定性を向上させることができます。
|
||||
|
||||
**高度な設定**
|
||||
|
||||
**推論モード**
|
||||
|
||||
一部のモデルは関数/ツール呼び出しや純プロンプトの方法でパラメータ抽出を実現する2つの推論モードをサポートしており、コマンドの遵守能力に違いがあります。例えば、あるモデルが関数呼び出しに不向きな場合、プロンプト推論に切り替えることができます。
|
||||
|
||||
* Function Call/Tool Call
|
||||
* プロンプト
|
||||
|
||||
**メモリ**
|
||||
|
||||
メモリを有効にすると、問題分類器の各入力にチャット履歴が含まれ、LLMが前文を理解し、対話の中での問題理解能力を向上させます。
|
||||
|
||||
**画像**
|
||||
|
||||
画像をオープンする。
|
||||
|
||||
**出力変数**
|
||||
|
||||
* 定義された変数を抽出
|
||||
* ノード組み込み変数
|
||||
|
||||
`__is_success 数値` 抽出が成功した場合は1、失敗した場合は0となります。
|
||||
|
||||
`__reason 文字列` 抽出エラーの原因
|
||||
73
ja-jp/guides/workflow/node/parameter-extractor.mdx.bak
Normal file
73
ja-jp/guides/workflow/node/parameter-extractor.mdx.bak
Normal file
@@ -0,0 +1,73 @@
|
||||
---
|
||||
title: パラメータ抽出
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
大規模言語モデル(LLM)を利用して自然言語から推論し、構造化パラメータを抽出し、ツール呼び出しやHTTPリクエストに用いる。
|
||||
|
||||
Difyワークフロー内には豊富な[ツール](/ja-jp/tools/introduction)が用意されており、その多くは構造化パラメータを入力として要求します。パラメータ抽出器は、ユーザーの自然言語をツールが認識できるパラメータに変換し、ツールの呼び出しを容易にします。
|
||||
|
||||
ワークフロー内の一部のノードは特定のデータ形式を入力として要求します。例えば[イテレーション](./iteration)ノードの入力は配列形式である必要があり、パラメータ抽出器は[構造化パラメータの変換](./iteration#1)を容易に実現します。
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
1. **自然言語からツールが必要とするキー・パラメーターを抽出する**例として、簡単な対話形式のArxiv論文検索アプリを構築する場合を考えます。
|
||||
|
||||
この例では、Arxiv論文検索ツールの入力パラメータとして「論文の著者」または「論文番号」が要求されます。パラメータ抽出器は「この論文の内容は何ですか:2405.10739」という質問から論文番号**2405.10739**を抽出し、ツールのパラメータとして正確に検索します。
|
||||
|
||||
<Frame caption="Arxiv論文検索ツール">
|
||||
<img src="/ja-jp/img/jp-parameter-extractor1.png" alt="Arxiv 论文检索工具流程图" />
|
||||
</Frame>
|
||||
|
||||
2. **テキストを構造化データに変換する**例として、長い物語のイテレーション生成アプリの前工程として、テキスト形式の章内容を配列形式に変換し、[イテレーションノード](./iteration)でのマルチラウンド生成処理を容易にします。
|
||||
|
||||
<Frame caption="テキストを構造化データに変換する">
|
||||
<img src="/ja-jp/img/jp-parameter-extractor2.png" alt="长故事迭代生成应用流程图" />
|
||||
</Frame>
|
||||
|
||||
3. **構造化データを抽出して**[**HTTPリクエスト**](./http-request)**を使用する**ことで、任意のアクセス可能なURLにリクエストを送信し、外部検索結果の取得やウェブフック、画像生成などのシナリオに適用できます。
|
||||
|
||||
***
|
||||
|
||||
### 設定方法
|
||||
|
||||
<Frame caption="パラメータ抽出の設定" width="375">
|
||||
<img src="/ja-jp/img/jp-parameter-extractor-setting.png" alt="参数提取配置界面" />
|
||||
</Frame>
|
||||
|
||||
**設定手順**
|
||||
|
||||
1. 入力変数を選択。通常はパラメータ抽出のための変数入力を選びます。ファイルタイプもサポートします。
|
||||
2. モデルを選択。パラメータ抽出器の抽出はLLMの推論と構造化生成能力に依存します。
|
||||
3. 抽出パラメータを定義。必要なパラメータを手動で追加するか、**既存のツールから簡単にインポート**できます。
|
||||
4. コマンド作成。複雑なパラメータの抽出時には、例を作成することでLLMの生成効果と安定性を向上させることができます。
|
||||
|
||||
**高度な設定**
|
||||
|
||||
**推論モード**
|
||||
|
||||
一部のモデルは関数/ツール呼び出しや純プロンプトの方法でパラメータ抽出を実現する2つの推論モードをサポートしており、コマンドの遵守能力に違いがあります。例えば、あるモデルが関数呼び出しに不向きな場合、プロンプト推論に切り替えることができます。
|
||||
|
||||
* Function Call/Tool Call
|
||||
* プロンプト
|
||||
|
||||
**メモリ**
|
||||
|
||||
メモリを有効にすると、問題分類器の各入力にチャット履歴が含まれ、LLMが前文を理解し、対話の中での問題理解能力を向上させます。
|
||||
|
||||
**画像**
|
||||
|
||||
画像をオープンする。
|
||||
|
||||
**出力変数**
|
||||
|
||||
* 定義された変数を抽出
|
||||
* ノード組み込み変数
|
||||
|
||||
`__is_success 数値` 抽出が成功した場合は1、失敗した場合は0となります。
|
||||
|
||||
`__reason 文字列` 抽出エラーの原因
|
||||
65
ja-jp/guides/workflow/node/question-classifier.mdx
Normal file
65
ja-jp/guides/workflow/node/question-classifier.mdx
Normal file
@@ -0,0 +1,65 @@
|
||||
---
|
||||
title: 質問分類
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### **定義**
|
||||
|
||||
分類記述を定義することにより、問題分類子は LLM を使用してユーザー入力に基づいて一致する分類を推測し、分類結果を出力し、より正確な情報を下流ノードに提供できます。
|
||||
|
||||
***
|
||||
|
||||
### **シナリオ**
|
||||
|
||||
よくある使用シナリオには、**カスタマーサービス対話意図分類、製品評価分類、メールのバッチ分類**などがあります。
|
||||
|
||||
典型的な製品カスタマーサービスのシナリオでは、問題分類器はナレッジベース検索の前段階として機能し、ユーザーの質問の意図を分類します。分類後、異なるナレッジベースに誘導され、ユーザーの質問に正確に回答します。
|
||||
|
||||
以下の図は製品カスタマーサービスシナリオのサンプルワークフローテンプレートです:
|
||||
|
||||
<Frame>
|
||||
<img src="/ja-jp/img/jp-question.png" alt="質問分類のシナレオ" />
|
||||
</Frame>
|
||||
|
||||
このシナリオでは、3つの分類ラベル/説明を設定しています:
|
||||
|
||||
* 分類 1:**アフターサービスに関する問題**
|
||||
* 分類 2:**製品の操作に関する問題**
|
||||
* 分類 3:**その他の問題**
|
||||
|
||||
ユーザーが異なる質問を入力すると、問題分類器は設定された分類ラベル/説明に基づいて自動的に分類を行います:
|
||||
|
||||
* “**iPhone 14で連絡先を設定する方法は?**” —> “**製品の操作に関する問題**”
|
||||
* “**保証期間はどれくらいですか?**” —> “**アフターサービスに関する問題**”
|
||||
* “**今日の天気はどうですか?**” —> “**その他の問題**”
|
||||
|
||||
***
|
||||
|
||||
### 設定方法
|
||||
|
||||
<Frame caption="質問分類器の設定">
|
||||
<img src="/ja-jp/img/jp-question-setting.png" alt="質問分類器の設定" />
|
||||
</Frame>
|
||||
|
||||
**設定手順:**
|
||||
|
||||
1. **入力変数を選択する**、分類に使用する入力内容を指します、[ファイルのアップロード](/ja-jp/guides/workflow/file-upload)もサポートします。カスタマーサービスのシナリオでは一般的にユーザーの質問 `sys.query` が対象です。
|
||||
2. **推論モデルを選択する**、問題分類器は大規模言語モデル (LLM) の自然言語分類と推論能力に基づいており、適切なモデルを選ぶことで分類効果を向上させることができます。
|
||||
3. **分類ラベル/説明を作成する**、複数の分類を手動で追加し、分類のキーワードや説明文を作成することで、大規模言語モデルが分類基準をよりよく理解できるようにします。
|
||||
4. **分類に対応する下流ノードを選択する**、問題分類ノードが分類を完了した後、分類と下流ノードの関係に基づいて後続のプロセスパスを選択します。
|
||||
|
||||
#### **高度な設定:**
|
||||
|
||||
**指示:** **高度な設定-指示** では、例えばより豊富な分類基準など、追加の指示を補足することができます。これにより問題分類器の分類能力が強化されます。
|
||||
|
||||
**メモリー:** メモリーをオンにすると、問題分類器の各入力には対話のチャット履歴が含まれ、LLM が前文を理解しやすくなり、対話の中での問題理解能力が向上します。
|
||||
|
||||
**画像分析:** 画像認識機能を備えた LLM でのみ利用可能で、画像変数の入力が可能です。
|
||||
|
||||
**メモリウィンドウ:** メモリウィンドウがオフの時、システムはモデルのコンテキストウィンドウに基づいてチャット履歴の伝達量を動的にフィルタリングします。オンの時、ユーザーはチャット履歴の伝達量を正確に制御できます(対数表示)。
|
||||
|
||||
**出力変数:**
|
||||
|
||||
`class_name`
|
||||
|
||||
分類後に出力される分類名です。必要に応じて下流ノードで分類結果変数を使用することができます。
|
||||
65
ja-jp/guides/workflow/node/question-classifier.mdx.bak
Normal file
65
ja-jp/guides/workflow/node/question-classifier.mdx.bak
Normal file
@@ -0,0 +1,65 @@
|
||||
---
|
||||
title: 質問分類
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### **定義**
|
||||
|
||||
分類記述を定義することにより、問題分類子は LLM を使用してユーザー入力に基づいて一致する分類を推測し、分類結果を出力し、より正確な情報を下流ノードに提供できます。
|
||||
|
||||
***
|
||||
|
||||
### **シナリオ**
|
||||
|
||||
よくある使用シナリオには、**カスタマーサービス対話意図分類、製品評価分類、メールのバッチ分類**などがあります。
|
||||
|
||||
典型的な製品カスタマーサービスのシナリオでは、問題分類器はナレッジベース検索の前段階として機能し、ユーザーの質問の意図を分類します。分類後、異なるナレッジベースに誘導され、ユーザーの質問に正確に回答します。
|
||||
|
||||
以下の図は製品カスタマーサービスシナリオのサンプルワークフローテンプレートです:
|
||||
|
||||
<Frame>
|
||||
<img src="/ja-jp/img/jp-question.png" alt="質問分類のシナレオ" />
|
||||
</Frame>
|
||||
|
||||
このシナリオでは、3つの分類ラベル/説明を設定しています:
|
||||
|
||||
* 分類 1:**アフターサービスに関する問題**
|
||||
* 分類 2:**製品の操作に関する問題**
|
||||
* 分類 3:**その他の問題**
|
||||
|
||||
ユーザーが異なる質問を入力すると、問題分類器は設定された分類ラベル/説明に基づいて自動的に分類を行います:
|
||||
|
||||
* “**iPhone 14で連絡先を設定する方法は?**” —> “**製品の操作に関する問題**”
|
||||
* “**保証期間はどれくらいですか?**” —> “**アフターサービスに関する問題**”
|
||||
* “**今日の天気はどうですか?**” —> “**その他の問題**”
|
||||
|
||||
***
|
||||
|
||||
### 設定方法
|
||||
|
||||
<Frame caption="質問分類器の設定">
|
||||
<img src="/ja-jp/img/jp-question-setting.png" alt="質問分類器の設定" />
|
||||
</Frame>
|
||||
|
||||
**設定手順:**
|
||||
|
||||
1. **入力変数を選択する**、分類に使用する入力内容を指します、[ファイルのアップロード](/ja-jp/user-guide/build-app/flow-app/file-upload)もサポートします。カスタマーサービスのシナリオでは一般的にユーザーの質問 `sys.query` が対象です。
|
||||
2. **推論モデルを選択する**、問題分類器は大規模言語モデル (LLM) の自然言語分類と推論能力に基づいており、適切なモデルを選ぶことで分類効果を向上させることができます。
|
||||
3. **分類ラベル/説明を作成する**、複数の分類を手動で追加し、分類のキーワードや説明文を作成することで、大規模言語モデルが分類基準をよりよく理解できるようにします。
|
||||
4. **分類に対応する下流ノードを選択する**、問題分類ノードが分類を完了した後、分類と下流ノードの関係に基づいて後続のプロセスパスを選択します。
|
||||
|
||||
#### **高度な設定:**
|
||||
|
||||
**指示:** **高度な設定-指示** では、例えばより豊富な分類基準など、追加の指示を補足することができます。これにより問題分類器の分類能力が強化されます。
|
||||
|
||||
**メモリー:** メモリーをオンにすると、問題分類器の各入力には対話のチャット履歴が含まれ、LLM が前文を理解しやすくなり、対話の中での問題理解能力が向上します。
|
||||
|
||||
**画像分析:** 画像認識機能を備えた LLM でのみ利用可能で、画像変数の入力が可能です。
|
||||
|
||||
**メモリウィンドウ:** メモリウィンドウがオフの時、システムはモデルのコンテキストウィンドウに基づいてチャット履歴の伝達量を動的にフィルタリングします。オンの時、ユーザーはチャット履歴の伝達量を正確に制御できます(対数表示)。
|
||||
|
||||
**出力変数:**
|
||||
|
||||
`class_name`
|
||||
|
||||
分類後に出力される分類名です。必要に応じて下流ノードで分類結果変数を使用することができます。
|
||||
88
ja-jp/guides/workflow/node/start.mdx
Normal file
88
ja-jp/guides/workflow/node/start.mdx
Normal file
@@ -0,0 +1,88 @@
|
||||
---
|
||||
title: 開始
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
## 定義
|
||||
|
||||
**“開始”** ノードは、すべてのワークフローアプリ(チャットフロー / ワークフロー)に必須のデフォルトノードであり、後続のワークフローノードやアプリの正常なプロセスに必要な初期情報を提供します。これには、アプリの使用者が入力した内容や、[アップロードされたファイル](/ja-jp/guides/workflow/file-upload)などが含まれます。
|
||||
|
||||
### ノードの設定
|
||||
|
||||
開始ノードの設定ページでは、**“入力フィールド”**とデフォルトの[**システム変数**](/ja-jp/guides/workflow/variables)という二つの設定部分が見られます。
|
||||
|
||||
<Frame caption="チャットフローとワークフロー">
|
||||
<img src="/ja-jp/img/jp-start-setup.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### 入力フィールド
|
||||
|
||||
入力フィールドの機能はアプリ開発者によって設定され、通常はアプリの使用者がさらに情報を提供するために使用されます。例えば、週次報告アプリでは、使用者に対して名前、作業期間、作業内容などの背景情報をあらかじめフォーマットに従って提供するよう求めることがあります。これらの前提情報は、LLM(大規模言語モデル)がより質の高い回答を生成するのに役立ちます。
|
||||
|
||||
以下の6種類の入力変数をサポートしており、すべての変数は必須項目として設定可能です:
|
||||
|
||||
* **テキスト**
|
||||
|
||||
短いテキストで、アプリ使用者が自分で内容を入力します。最大文字数は256文字です。
|
||||
* **段落**
|
||||
|
||||
長文で、アプリ使用者が長いテキストを入力することができます。
|
||||
* **ドロップダウンオプション**
|
||||
|
||||
アプリ開発者によって固定された選択肢で、アプリ使用者は設定された選択肢の中からのみ選ぶことができ、自由に内容を入力することはできません。
|
||||
* **数字**
|
||||
|
||||
数字のみの入力を許可します。
|
||||
* **単一ファイル**
|
||||
|
||||
アプリ使用者が単独でファイルをアップロードできる機能で、サポートされるファイルタイプは文書、画像、音声、動画、その他のファイルです。ローカルからのファイルアップロードやファイルのURLを貼り付けてのアップロードが可能です。詳細な使い方については[ファイルアップロード](/ja-jp/guides/workflow/file-upload)を参照してください。
|
||||
* **ファイルリスト**
|
||||
|
||||
アプリ使用者が複数のファイルを一括でアップロードできる機能で、サポートされるファイルタイプは文書、画像、音声、動画、その他のファイルです。ローカルからのファイルアップロードやファイルのURLを貼り付けてのアップロードが可能です。詳細な使い方については[ファイルアップロード](/ja-jp/guides/workflow/file-upload)を参照してください。
|
||||
|
||||
<Note>
|
||||
Difyに組み込まれているファイル抽出ノードは、特定のフォーマットファイルのみを処理できます。画像、音声、動画ファイルを処理する必要がある場合は、[外部データツール](/ja-jp/guides/extension/code-based-extension/external-data-tool)を参照し、対応するファイル処理ノードを構築してください。
|
||||
</Note>
|
||||
|
||||
設定が完了した後、使用者はアプリを使用する前に、入力項目に従ってLLMに必要な情報を提供します。より多くの情報がLLMの質問応答効率を向上させるのに役立ちます。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/ja-jp/user-guide/.gitbook/assets/image (4).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### システム変数
|
||||
|
||||
システム変数は、チャットフロー / ワークフローアプリ内であらかじめ設定されたシステムレベルのパラメータであり、アプリ内の他のノードからグローバルに読み取ることができます。通常は、高度な開発シナリオで使用され、たとえば多段階対話アプリの構築、アプリのログ収集と監視、異なるアプリや使用者の使用行動の記録などに利用されます。
|
||||
|
||||
**ワークフロー**
|
||||
|
||||
ワークフロータイプのアプリは以下のシステム変数を提供します:
|
||||
|
||||
| 変数名 | データタイプ | 説明 | メモ |
|
||||
| ---------------------- | ------------ | ----------------------------------------------------------------------------------------------------- | ------------------------- |
|
||||
| `sys.files` | Array[File] | ファイルパラメータで、ユーザーがアプリを使用する際にアップロードした画像を保存します。複数の画像をアップロードできます。このパラメータは今後廃止予定であり、「入力フィールド」内のファイル変数の使用を推奨します。 | 画像アップロード機能は、アプリの編成ページの右上にある「機能」で有効にする必要があります。 |
|
||||
| `sys.user_id` | String | ユーザーIDで、各ユーザーがワークフローアプリを使用する際に、システムが自動的に一意の識別子を割り当てて、異なる対話ユーザーを区別します。 | |
|
||||
| `sys.app_id` | String | アプリIDで、システムが各ワークフローアプリに一意の識別子を割り当て、異なるアプリを区別し、このパラメータを通じて現在のアプリの基本情報を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じて異なるワークフローアプリを区別・特定できます。 |
|
||||
| `sys.workflow_id` | String | ワークフローIDで、現在のワークフローアプリに含まれるすべてのノード情報を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じてワークフロー内のノード情報を追跡・記録できます。 |
|
||||
| `sys.workflow_run_id` | String | ワークフローアプリの実行IDで、ワークフローアプリの運用状況を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じてアプリの過去の実行状況を追跡できます。 |
|
||||
|
||||
<Frame caption="ワークフロータイプアプリのシステム変数">
|
||||

|
||||
</Frame>
|
||||
|
||||
**チャットフロー**
|
||||
|
||||
チャットフロータイプのアプリケーションは、以下のシステム変数を提供しています:
|
||||
|
||||
| 変数名 | データ型 | 説明 | メモ |
|
||||
|---------|--------|------|------|
|
||||
| `sys.query` | String | ユーザーが最初に入力した内容 | |
|
||||
| `sys.files` | Array[File] | ユーザーがアップロードした画像 | 画像のアップロード機能は、アプリケーションの編成ページ右上の「機能」で有効化する必要があります |
|
||||
| `sys.dialogue_count` | Number | チャットフロータイプのアプリケーションとの対話中にユーザーが行った対話のラウンド数です。各対話の後に自動的に数が増加し、if-elseノードと組み合わせて複雑な分岐ロジックを構築できます。たとえば、Xラウンド目に達したときに、対話履歴を振り返って分析が可能です | |
|
||||
| `sys.conversation_id` | String | ダイアログの対話セッションの一意の識別子で、関連するすべてのメッセージを同じ対話にグループ化し、LLMが同じトピックとコンテキストで継続的に対話できるようにします | |
|
||||
| `sys.user_id` | String | 各アプリケーションユーザーに割り当てられた一意の識別子で、異なる対話ユーザーを区別するために使用されます | |
|
||||
| `sys.app_id` | String | アプリケーションのIDで、システムは各ワークフローアプリケーションに一意の識別子を割り当て、異なるアプリケーションを識別します。このパラメータを使用して現在のアプリケーションの基本情報を記録します | 開発者向けで、このパラメータを使用して異なるワークフローアプリケーションを区別します |
|
||||
| `sys.workflow_id` | String | ワークフローIDで、現在のワークフローアプリケーションに含まれるすべてのノード情報を記録するために使用されます | 開発者向けで、このパラメータを使用してワークフロー内のノード情報を追跡および記録できます |
|
||||
| `sys.workflow_run_id` | String | ワークフローアプリケーションの実行IDで、アプリケーションの実行状況を記録するために使用されます | 開発者向けで、このパラメータを使用してアプリケーションの過去の実行状況を追跡できます |
|
||||
|
||||

|
||||
88
ja-jp/guides/workflow/node/start.mdx.bak
Normal file
88
ja-jp/guides/workflow/node/start.mdx.bak
Normal file
@@ -0,0 +1,88 @@
|
||||
---
|
||||
title: 開始
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
## 定義
|
||||
|
||||
**“開始”** ノードは、すべてのワークフローアプリ(チャットフロー / ワークフロー)に必須のデフォルトノードであり、後続のワークフローノードやアプリの正常なプロセスに必要な初期情報を提供します。これには、アプリの使用者が入力した内容や、[アップロードされたファイル](../file-upload)などが含まれます。
|
||||
|
||||
### ノードの設定
|
||||
|
||||
開始ノードの設定ページでは、**“入力フィールド”**とデフォルトの[**システム変数**](../variables)という二つの設定部分が見られます。
|
||||
|
||||
<Frame caption="チャットフローとワークフロー">
|
||||
<img src="/ja-jp/img/jp-start-setup.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### 入力フィールド
|
||||
|
||||
入力フィールドの機能はアプリ開発者によって設定され、通常はアプリの使用者がさらに情報を提供するために使用されます。例えば、週次報告アプリでは、使用者に対して名前、作業期間、作業内容などの背景情報をあらかじめフォーマットに従って提供するよう求めることがあります。これらの前提情報は、LLM(大規模言語モデル)がより質の高い回答を生成するのに役立ちます。
|
||||
|
||||
以下の6種類の入力変数をサポートしており、すべての変数は必須項目として設定可能です:
|
||||
|
||||
* **テキスト**
|
||||
|
||||
短いテキストで、アプリ使用者が自分で内容を入力します。最大文字数は256文字です。
|
||||
* **段落**
|
||||
|
||||
長文で、アプリ使用者が長いテキストを入力することができます。
|
||||
* **ドロップダウンオプション**
|
||||
|
||||
アプリ開発者によって固定された選択肢で、アプリ使用者は設定された選択肢の中からのみ選ぶことができ、自由に内容を入力することはできません。
|
||||
* **数字**
|
||||
|
||||
数字のみの入力を許可します。
|
||||
* **単一ファイル**
|
||||
|
||||
アプリ使用者が単独でファイルをアップロードできる機能で、サポートされるファイルタイプは文書、画像、音声、動画、その他のファイルです。ローカルからのファイルアップロードやファイルのURLを貼り付けてのアップロードが可能です。詳細な使い方については[ファイルアップロード](../file-upload)を参照してください。
|
||||
* **ファイルリスト**
|
||||
|
||||
アプリ使用者が複数のファイルを一括でアップロードできる機能で、サポートされるファイルタイプは文書、画像、音声、動画、その他のファイルです。ローカルからのファイルアップロードやファイルのURLを貼り付けてのアップロードが可能です。詳細な使い方については[ファイルアップロード](../file-upload)を参照してください。
|
||||
|
||||
<Note>
|
||||
Difyに組み込まれているファイル抽出ノードは、特定のフォーマットファイルのみを処理できます。画像、音声、動画ファイルを処理する必要がある場合は、[外部データツール](../../extension/api-based-extension/external-data-tool.md)を参照し、対応するファイル処理ノードを構築してください。
|
||||
</Note>
|
||||
|
||||
設定が完了した後、使用者はアプリを使用する前に、入力項目に従ってLLMに必要な情報を提供します。より多くの情報がLLMの質問応答効率を向上させるのに役立ちます。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/ja-jp/user-guide/.gitbook/assets/image (4).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### システム変数
|
||||
|
||||
システム変数は、チャットフロー / ワークフローアプリ内であらかじめ設定されたシステムレベルのパラメータであり、アプリ内の他のノードからグローバルに読み取ることができます。通常は、高度な開発シナリオで使用され、たとえば多段階対話アプリの構築、アプリのログ収集と監視、異なるアプリや使用者の使用行動の記録などに利用されます。
|
||||
|
||||
**ワークフロー**
|
||||
|
||||
ワークフロータイプのアプリは以下のシステム変数を提供します:
|
||||
|
||||
| 変数名 | データタイプ | 説明 | メモ |
|
||||
| ---------------------- | ------------ | ----------------------------------------------------------------------------------------------------- | ------------------------- |
|
||||
| `sys.files` | Array[File] | ファイルパラメータで、ユーザーがアプリを使用する際にアップロードした画像を保存します。複数の画像をアップロードできます。このパラメータは今後廃止予定であり、「入力フィールド」内のファイル変数の使用を推奨します。 | 画像アップロード機能は、アプリの編成ページの右上にある「機能」で有効にする必要があります。 |
|
||||
| `sys.user_id` | String | ユーザーIDで、各ユーザーがワークフローアプリを使用する際に、システムが自動的に一意の識別子を割り当てて、異なる対話ユーザーを区別します。 | |
|
||||
| `sys.app_id` | String | アプリIDで、システムが各ワークフローアプリに一意の識別子を割り当て、異なるアプリを区別し、このパラメータを通じて現在のアプリの基本情報を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じて異なるワークフローアプリを区別・特定できます。 |
|
||||
| `sys.workflow_id` | String | ワークフローIDで、現在のワークフローアプリに含まれるすべてのノード情報を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じてワークフロー内のノード情報を追跡・記録できます。 |
|
||||
| `sys.workflow_run_id` | String | ワークフローアプリの実行IDで、ワークフローアプリの運用状況を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じてアプリの過去の実行状況を追跡できます。 |
|
||||
|
||||
<Frame caption="ワークフロータイプアプリのシステム変数">
|
||||

|
||||
</Frame>
|
||||
|
||||
**チャットフロー**
|
||||
|
||||
チャットフロータイプのアプリケーションは、以下のシステム変数を提供しています:
|
||||
|
||||
| 変数名 | データ型 | 説明 | メモ |
|
||||
|---------|--------|------|------|
|
||||
| `sys.query` | String | ユーザーが最初に入力した内容 | |
|
||||
| `sys.files` | Array[File] | ユーザーがアップロードした画像 | 画像のアップロード機能は、アプリケーションの編成ページ右上の「機能」で有効化する必要があります |
|
||||
| `sys.dialogue_count` | Number | チャットフロータイプのアプリケーションとの対話中にユーザーが行った対話のラウンド数です。各対話の後に自動的に数が増加し、if-elseノードと組み合わせて複雑な分岐ロジックを構築できます。たとえば、Xラウンド目に達したときに、対話履歴を振り返って分析が可能です | |
|
||||
| `sys.conversation_id` | String | ダイアログの対話セッションの一意の識別子で、関連するすべてのメッセージを同じ対話にグループ化し、LLMが同じトピックとコンテキストで継続的に対話できるようにします | |
|
||||
| `sys.user_id` | String | 各アプリケーションユーザーに割り当てられた一意の識別子で、異なる対話ユーザーを区別するために使用されます | |
|
||||
| `sys.app_id` | String | アプリケーションのIDで、システムは各ワークフローアプリケーションに一意の識別子を割り当て、異なるアプリケーションを識別します。このパラメータを使用して現在のアプリケーションの基本情報を記録します | 開発者向けで、このパラメータを使用して異なるワークフローアプリケーションを区別します |
|
||||
| `sys.workflow_id` | String | ワークフローIDで、現在のワークフローアプリケーションに含まれるすべてのノード情報を記録するために使用されます | 開発者向けで、このパラメータを使用してワークフロー内のノード情報を追跡および記録できます |
|
||||
| `sys.workflow_run_id` | String | ワークフローアプリケーションの実行IDで、アプリケーションの実行状況を記録するために使用されます | 開発者向けで、このパラメータを使用してアプリケーションの過去の実行状況を追跡できます |
|
||||
|
||||

|
||||
48
ja-jp/guides/workflow/node/template.mdx
Normal file
48
ja-jp/guides/workflow/node/template.mdx
Normal file
@@ -0,0 +1,48 @@
|
||||
---
|
||||
title: テンプレート
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
Jinja2のPythonテンプレート言語を使って、データ変換やテキスト処理などを柔軟に行うことができます。
|
||||
|
||||
### Jinjaとは?
|
||||
|
||||
> Jinjaは、高速で表現力豊かで拡張可能なテンプレートエンジンです。
|
||||
>
|
||||
> Jinja は、速く、表現力があり、拡張可能なテンプレートエンジンです。
|
||||
|
||||
—— [https://jinja.palletsprojects.com/en/3.1.x/](https://jinja.palletsprojects.com/en/3.1.x/)
|
||||
|
||||
### シーン
|
||||
|
||||
テンプレートノードを使うことで、強力なPythonテンプレート言語であるJinja2を用いて、ワークフロー内で軽量かつ柔軟なデータ変換が可能になります。これは、テキスト処理やJSON変換などのシナリオに適しています。例えば、前のステップからの変数を柔軟にフォーマットして結合し、単一のテキスト出力を作成することができます。これは、複数のデータソースの情報を特定のフォーマットにまとめ、後続のステップの要件を満たすのに非常に適しています。
|
||||
|
||||
**例1:** 複数の入力(記事のタイトル、紹介、内容)を一つの完全なテキストに結合する
|
||||
|
||||
<Frame caption="テキストの結合" width="375">
|
||||
<img src="/ja-jp/img/jp-template.png" alt="テキストの結合" />
|
||||
</Frame>
|
||||
|
||||
**例2:** ナレッジリトリーバルノードで取得した情報およびその関連メタデータを、構造化されたMarkdown形式にまとめる
|
||||
|
||||
```Plain
|
||||
{% for item in chunks %}
|
||||
### Chunk {{ loop.index }}.
|
||||
### Similarity: {{ item.metadata.score | default('N/A') }}
|
||||
|
||||
#### {{ item.title }}
|
||||
|
||||
##### Content
|
||||
{{ item.content | replace('\n', '\n\n') }}
|
||||
|
||||
---
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
<Frame caption="ナレッジリトリーバルノードの出力をMarkdownに変換">
|
||||
<img src="/ja-jp/user-guide/.gitbook/assets/image (210).png" alt="ナレッジリトリーバルノードの出力をMarkdownに変換" />
|
||||
</Frame>
|
||||
|
||||
Jinjaの[公式ドキュメント](https://jinja.palletsprojects.com/en/3.1.x/templates/)を参考にして、さまざまなタスクを実行するためのより複雑なテンプレートを作成することができます。
|
||||
32
ja-jp/guides/workflow/node/tools.mdx
Normal file
32
ja-jp/guides/workflow/node/tools.mdx
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
title: ツール
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
ワークフロー内で豊富なツール選択が提供されており、ツールは3つのタイプに分かれています:
|
||||
|
||||
* **ビルトインツール**、Difyファーストパーティが提供するツール
|
||||
* **カスタムツール**、OpenAPI/Swagger標準フォーマットでインポートまたは設定されたツール
|
||||
* **ワークフロー**、ツールとして公開されたワークフロー
|
||||
|
||||
ビルトインツールを使用する前に、ツールに **認可** を行う必要があるかもしれません。
|
||||
|
||||
ビルトインツールが使用要求を満たさない場合は、**Dify メニュー ナビゲーション --ツール** でカスタムツールを作成できます。
|
||||
|
||||
また、より複雑なワークフローを編成し、それをツールとして公開することもできます。
|
||||
|
||||
<Frame caption="ツール選択">
|
||||
<img src="/ja-jp/img/jp-tool-list.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
ツールノードは他のノードと接続でき、[変数](/ja-jp/guides/workflow/variables)を通じてデータを処理および受け渡しすることができます。
|
||||
|
||||
<Frame caption="Google 検索ツールで外部知識を検索">
|
||||
<img src="/ja-jp/img/jp-tool-google-search.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### 将工作流应用发布为工具
|
||||
|
||||
カスタムツールの作成とツールの設定方法については[ツール設定説明](/ja-jp/introduction)を参照してください。
|
||||
32
ja-jp/guides/workflow/node/tools.mdx.bak
Normal file
32
ja-jp/guides/workflow/node/tools.mdx.bak
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
title: ツール
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
ワークフロー内で豊富なツール選択が提供されており、ツールは3つのタイプに分かれています:
|
||||
|
||||
* **ビルトインツール**、Difyファーストパーティが提供するツール
|
||||
* **カスタムツール**、OpenAPI/Swagger標準フォーマットでインポートまたは設定されたツール
|
||||
* **ワークフロー**、ツールとして公開されたワークフロー
|
||||
|
||||
ビルトインツールを使用する前に、ツールに **認可** を行う必要があるかもしれません。
|
||||
|
||||
ビルトインツールが使用要求を満たさない場合は、**Dify メニュー ナビゲーション --ツール** でカスタムツールを作成できます。
|
||||
|
||||
また、より複雑なワークフローを編成し、それをツールとして公開することもできます。
|
||||
|
||||
<Frame caption="ツール選択">
|
||||
<img src="/ja-jp/img/jp-tool-list.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
ツールノードは他のノードと接続でき、[変数](../variables)を通じてデータを処理および受け渡しすることができます。
|
||||
|
||||
<Frame caption="Google 検索ツールで外部知識を検索">
|
||||
<img src="/ja-jp/img/jp-tool-google-search.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### 将工作流应用发布为工具
|
||||
|
||||
カスタムツールの作成とツールの設定方法については[ツール設定説明](../../../tools/introduction)を参照してください。
|
||||
45
ja-jp/guides/workflow/node/variable-aggregator.mdx
Normal file
45
ja-jp/guides/workflow/node/variable-aggregator.mdx
Normal file
@@ -0,0 +1,45 @@
|
||||
---
|
||||
title: 変数集約
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
マルチブランチの変数を一つの変数に集約し、ダウンズトリームノードの統一設定を実現します。
|
||||
|
||||
変数集約ノード(元変数割り当てノード)はワークフローの重要なノードであり、異なるブランチの出力結果を統合し、どのブランチが実行されても、その結果を一つの統一された変数を通じて参照およびアクセスできるようにします。これはマルチブランチの状況で非常に有用で、異なるブランチで同じ役割を果たす変数を一つの出力変数にマッピングし、ダウンズトリームノードでの重複定義を避けます。
|
||||
|
||||
***
|
||||
|
||||
### シナリオ
|
||||
|
||||
変数集約を通じて、問題分類や条件ブランチなどのマルチ出力をシングル出力に集約し、プロセスのダウンズトリームノードが使用および操作できるようにします。これによりデータフローの管理が簡素化されます。
|
||||
|
||||
**問題分類後のマルチ集約**
|
||||
|
||||
変数集約を追加しない場合、分類1と分類2のブランチは異なるナレッジベース検索を経て、ダウンズトリームの大規模言語モデルおよび直接返信ノードを繰り返し定義する必要があります。
|
||||
|
||||
<Frame caption="問題分類(変数集約なし)">
|
||||
<img src="/ja-jp/img/image (227).png" alt="问题分类无变量聚合的流程图" />
|
||||
</Frame>
|
||||
|
||||
変数集約を追加することで、二つのナレッジベース検索ノードの出力を一つの変数に集約できます。
|
||||
|
||||
<Frame caption="問題分類後のマルチ集約">
|
||||
<img src="/ja-jp/img/variable-aggregation.png" alt="问题分类后添加变量聚合的流程图" />
|
||||
</Frame>
|
||||
|
||||
**IF/ELSE 条件ブランチ後のマルチ集約**
|
||||
|
||||
<Frame caption="IF/ELSE 問題分類後のマルチ集約">
|
||||
<img src="/ja-jp/img/if-else-conditional.png" alt="IF/ELSE 条件分支后添加变量聚合的流程图" />
|
||||
</Frame>
|
||||
|
||||
### フォーマットに要求
|
||||
|
||||
変数集約器は文字列(`String`)、数値(`Number`)、ファイル(`File`)、オブジェクト(`Object`)、および配列(`Array`)など、さまざまなデータ型の集約をサポートします。
|
||||
|
||||
**変数集約器は同一データ型の変数しか集約できません**。最初に変数集約ノードに追加された変数データ形式が `String` である場合、後続の接続では追加可能な変数が `String` タイプに自動的にフィルタリングされます。
|
||||
|
||||
**アグリゲートグループ**
|
||||
|
||||
アグリゲートグループを有効にすると、変数集約器は複数のグループの変数を集約でき、各グループ内の集約時には同一データ型が求められます。
|
||||
169
ja-jp/guides/workflow/node/variable-assigner.mdx
Normal file
169
ja-jp/guides/workflow/node/variable-assigner.mdx
Normal file
@@ -0,0 +1,169 @@
|
||||
---
|
||||
title: 変数代入
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
変数代入ノードは、書き込み可能な変数に他の変数を代入するために使用されます。現在、サポートされている可書き入れの変数は:
|
||||
|
||||
* [会話変数](/ja-jp/guides/workflow/concepts)
|
||||
|
||||
使用方法:このノードを使用することで、ワークフローの中で変数の値を会話変数に一時的に保存し、後続の会話でその値を参照することができます。
|
||||
|
||||
<Frame caption="変数代入の例" width="375">
|
||||
<img src="/ja-jp/user-guide/.gitbook/assets/variable-assigner.png" alt="変数代入の例" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 使用シナリオの例
|
||||
|
||||
変数代入ノードを活用することで、会話中の**コンテキスト、ダイアログにアップロードされたファイル(近々配布予定)、ユーザーの好みの情報**などを会話変数に書き込み、保存された情報は後続の会話で参照され、異なる処理フローに誘導したり、返答を行ったりすることができます。
|
||||
|
||||
**シナリオ 1**
|
||||
|
||||
**会話中の記録を自動的に抽出し保存します**、会話変数配列を使用してユーザーの重要な情報を記録します。その後の会話ではこれらの記録を活用し、個別の返信を行います。
|
||||
|
||||
例えば:会話が始まると、LLMはユーザーの入力に必要な情報や好み、またはチャット履歴が含まれているかを自動的に判断します。情報が存在する場合、LLMはそれを先に抽出して保存し、コンテキストとして利用して応答します。もし新しい情報を覚える必要がない場合、LLMは以前の関連する記録を用いて個性化な応答を出します。
|
||||
|
||||
<Frame caption="会話から情報を自動的に判断、抽出、保存します">
|
||||
<img src="/ja-jp/img/conversational-variables-scenario-01.png" alt="会話から情報を自動的に判断、抽出、保存のフローチャート" />
|
||||
</Frame>
|
||||
|
||||
**設定手順:**
|
||||
|
||||
1. **会話変数を設定**:まず、会話変数配列 `memories` を設定し、array\[object]型を持たせてユーザーの事実、好み、会話記録を保存します。
|
||||
2. **記録の判断と抽出**:
|
||||
* 条件判断ノードを追加し、LLMを使用してユーザーの入力に新しい情報が含まれているかを判断します。
|
||||
* 新しい情報がある場合は上流に進み、LLMノードを使用してこれらの情報を抽出します。
|
||||
* 新しい情報がない場合は下流に進み、既存の記憶を直接使用して返答します。
|
||||
3. **変数の代入と書き込み**:
|
||||
* 上流に進んだ後、変数代入ノードを用いて抽出した新しい情報を `memories` 配列に追加(append)します。
|
||||
* LLMの出力テキスト文字列を適切な array\[object] 形式に変換するためにエスケープ機能を使用します。
|
||||
4. **変数の読み取りと利用**:
|
||||
* 後続のLLMノードで、`memories` 配列の内容を文字列に変換し、LLMのプロンプトにコンテキストとして挿入します。
|
||||
* LLMはこれらの記憶を使用して個別の返信を生成します。
|
||||
|
||||
図中のcodeノードのコードは以下の通りです:
|
||||
|
||||
1. 文字列をオブジェクトに変換する
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: str) -> object:
|
||||
try:
|
||||
# Parse the input JSON string
|
||||
input_data = json.loads(arg1)
|
||||
|
||||
# Extract the memory object
|
||||
memory = input_data.get("memory", {})
|
||||
|
||||
# Construct the return object
|
||||
result = {
|
||||
"facts": memory.get("facts", []),
|
||||
"preferences": memory.get("preferences", []),
|
||||
"memories": memory.get("memories", [])
|
||||
}
|
||||
|
||||
return {
|
||||
"mem": result
|
||||
}
|
||||
except json.JSONDecodeError:
|
||||
return {
|
||||
"result": "Error: Invalid JSON string"
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"Error: {str(e)}"
|
||||
}
|
||||
```
|
||||
|
||||
2. オブジェクトを文字列に変換する
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: list) -> str:
|
||||
try:
|
||||
# Assume arg1[0] is the dictionary we need to process
|
||||
context = arg1[0] if arg1 else {}
|
||||
|
||||
# Construct the memory object
|
||||
memory = {"memory": context}
|
||||
|
||||
# Convert the object to a JSON string
|
||||
json_str = json.dumps(memory, ensure_ascii=False, indent=2)
|
||||
|
||||
# Wrap the JSON string in <answer> tags
|
||||
result = f"<answer>{json_str}</answer>"
|
||||
|
||||
return {
|
||||
"result": result
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"<answer>Error: {str(e)}</answer>"
|
||||
}
|
||||
```
|
||||
|
||||
**シナリオ 2**
|
||||
|
||||
**ユーザーの初期の好み情報を記録**し,会話中にユーザーが入力した言語の好みを記憶し、後続の会話でその言語を使用して返信します。
|
||||
|
||||
例:ユーザーが会話を始める前に、`language`入力欄に「日本語」と指定した場合、その言語は会話変数に書き込まれ、LLMは後続の返信時に会話変数の情報を参照し、継続的に「日本語」を使用して返信します。
|
||||
|
||||
<Frame caption="ユーザーの初期設定情報を記録する">
|
||||
<img src="/ja-jp/img/conversation-var-scenario-1.png" alt="ユーザーの初期嗜好情報を記録するフローチャート" />
|
||||
</Frame>
|
||||
|
||||
**設定手順:**
|
||||
|
||||
**会話変数の設定**:まず、会話変数 `language` を設定し、会話の開始時にこの変数の値が空かどうかを判断する条件分岐ノードを追加します。
|
||||
|
||||
**変数の書き込み/代入**:最初の会話が開始された際、 `language` 変数の値が空であれば、LLMノードを使用してユーザーの言語入力を抽出し、その言語タイプを会話変数 `language` に書き込みます。
|
||||
|
||||
**変数の読み取り**:後続の会話ラウンドでは、`language` 変数にユーザーの好みの言語が保存されています。以降の会話では、LLMノードがこの変数を参照し、ユーザーの好みの言語タイプを用いて返信します。
|
||||
|
||||
**シナリオ 3**
|
||||
|
||||
**Checklistのチェックを補助**し、会話中に会話変数にユーザーの入力項目を記録し、Checklistの内容を更新し、後続の会話で抜け漏れ項目を確認します。
|
||||
|
||||
例:会話を始める際、LLMはユーザーにチェックリストに関連するアイテムの入力を求めます。ユーザーがチェックリストの内容を一度述べると、その内容は会話変数に更新され、及び保存されます。LLMは各会話の後に、ユーザーに不足しているアイテムの追加を促します。
|
||||
|
||||
<Frame caption="Checklistのチェックを補助">
|
||||
<img src="/ja-jp/img/conversation-var-scenario-2-1.png" alt="Checklistのチェックを補助のフローチャート" />
|
||||
</Frame>
|
||||
|
||||
**配置流程:**
|
||||
|
||||
* **会話変数の設定**:最初に会話変数 `ai_checklist` を設定し、これをLLM内でチェックのコンテクストとして参照します。
|
||||
* **変数の書き込み/代入**:各会話のラウンドごとに、LLMノード内の `ai_checklist` の値を確認し、ユーザーの入力と比較します。ユーザーが新しい情報を提供した場合、チェックリストを更新し、変数代入ノードを使用して出力内容を `ai_checklist` に書き込みます。
|
||||
* **変数の読み取り**:`ai_checklist`の値を読み取り、すべてのチェックリストアイテムが完了するまで、各会話のラウンドでユーザーの入力と比較します。
|
||||
|
||||
***
|
||||
|
||||
### 3 操作方法
|
||||
|
||||
**変数代入の使用:**
|
||||
|
||||
ノードの右側の `+` マークをクリックし、「変数代入」 ノードを選択し、「代入られた変数」 と 「設定する変数」 を入力します。
|
||||
|
||||
<Frame caption="変数代入ノードの設定">
|
||||
<img src="/ja-jp/img/language-variable-assigner.png" width="375px" alt="変数代入ノードの設定画面" />
|
||||
</Frame>
|
||||
|
||||
**変数の設定:**
|
||||
|
||||
代入られた変数:代入された変数を選択し、対象の会話変数を指定します
|
||||
|
||||
設定する変数:変換する必要のあるソース変数を選択します
|
||||
|
||||
上図の代入ロジック:`Language Recognition/text` を `language` に代入します。
|
||||
|
||||
**書き込みモード:**
|
||||
|
||||
* Overwrite (上書き): ソース変数の内容を対象の会話変数に上書きします
|
||||
* Append (追加):指定された変数が配列型の場合に使用します
|
||||
* Clear (クリア): 対象の会話変数内の内容をクリアします
|
||||
169
ja-jp/guides/workflow/node/variable-assigner.mdx.bak
Normal file
169
ja-jp/guides/workflow/node/variable-assigner.mdx.bak
Normal file
@@ -0,0 +1,169 @@
|
||||
---
|
||||
title: 変数代入
|
||||
version: '日本語'
|
||||
---
|
||||
|
||||
### 定義
|
||||
|
||||
変数代入ノードは、書き込み可能な変数に他の変数を代入するために使用されます。現在、サポートされている可書き入れの変数は:
|
||||
|
||||
* [会話変数](../concepts)
|
||||
|
||||
使用方法:このノードを使用することで、ワークフローの中で変数の値を会話変数に一時的に保存し、後続の会話でその値を参照することができます。
|
||||
|
||||
<Frame caption="変数代入の例" width="375">
|
||||
<img src="/ja-jp/user-guide/.gitbook/assets/variable-assigner.png" alt="変数代入の例" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 使用シナリオの例
|
||||
|
||||
変数代入ノードを活用することで、会話中の**コンテキスト、ダイアログにアップロードされたファイル(近々配布予定)、ユーザーの好みの情報**などを会話変数に書き込み、保存された情報は後続の会話で参照され、異なる処理フローに誘導したり、返答を行ったりすることができます。
|
||||
|
||||
**シナリオ 1**
|
||||
|
||||
**会話中の記録を自動的に抽出し保存します**、会話変数配列を使用してユーザーの重要な情報を記録します。その後の会話ではこれらの記録を活用し、個別の返信を行います。
|
||||
|
||||
例えば:会話が始まると、LLMはユーザーの入力に必要な情報や好み、またはチャット履歴が含まれているかを自動的に判断します。情報が存在する場合、LLMはそれを先に抽出して保存し、コンテキストとして利用して応答します。もし新しい情報を覚える必要がない場合、LLMは以前の関連する記録を用いて個性化な応答を出します。
|
||||
|
||||
<Frame caption="会話から情報を自動的に判断、抽出、保存します">
|
||||
<img src="/ja-jp/img/conversational-variables-scenario-01.png" alt="会話から情報を自動的に判断、抽出、保存のフローチャート" />
|
||||
</Frame>
|
||||
|
||||
**設定手順:**
|
||||
|
||||
1. **会話変数を設定**:まず、会話変数配列 `memories` を設定し、array\[object]型を持たせてユーザーの事実、好み、会話記録を保存します。
|
||||
2. **記録の判断と抽出**:
|
||||
* 条件判断ノードを追加し、LLMを使用してユーザーの入力に新しい情報が含まれているかを判断します。
|
||||
* 新しい情報がある場合は上流に進み、LLMノードを使用してこれらの情報を抽出します。
|
||||
* 新しい情報がない場合は下流に進み、既存の記憶を直接使用して返答します。
|
||||
3. **変数の代入と書き込み**:
|
||||
* 上流に進んだ後、変数代入ノードを用いて抽出した新しい情報を `memories` 配列に追加(append)します。
|
||||
* LLMの出力テキスト文字列を適切な array\[object] 形式に変換するためにエスケープ機能を使用します。
|
||||
4. **変数の読み取りと利用**:
|
||||
* 後続のLLMノードで、`memories` 配列の内容を文字列に変換し、LLMのプロンプトにコンテキストとして挿入します。
|
||||
* LLMはこれらの記憶を使用して個別の返信を生成します。
|
||||
|
||||
図中のcodeノードのコードは以下の通りです:
|
||||
|
||||
1. 文字列をオブジェクトに変換する
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: str) -> object:
|
||||
try:
|
||||
# Parse the input JSON string
|
||||
input_data = json.loads(arg1)
|
||||
|
||||
# Extract the memory object
|
||||
memory = input_data.get("memory", {})
|
||||
|
||||
# Construct the return object
|
||||
result = {
|
||||
"facts": memory.get("facts", []),
|
||||
"preferences": memory.get("preferences", []),
|
||||
"memories": memory.get("memories", [])
|
||||
}
|
||||
|
||||
return {
|
||||
"mem": result
|
||||
}
|
||||
except json.JSONDecodeError:
|
||||
return {
|
||||
"result": "Error: Invalid JSON string"
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"Error: {str(e)}"
|
||||
}
|
||||
```
|
||||
|
||||
2. オブジェクトを文字列に変換する
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: list) -> str:
|
||||
try:
|
||||
# Assume arg1[0] is the dictionary we need to process
|
||||
context = arg1[0] if arg1 else {}
|
||||
|
||||
# Construct the memory object
|
||||
memory = {"memory": context}
|
||||
|
||||
# Convert the object to a JSON string
|
||||
json_str = json.dumps(memory, ensure_ascii=False, indent=2)
|
||||
|
||||
# Wrap the JSON string in <answer> tags
|
||||
result = f"<answer>{json_str}</answer>"
|
||||
|
||||
return {
|
||||
"result": result
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"<answer>Error: {str(e)}</answer>"
|
||||
}
|
||||
```
|
||||
|
||||
**シナリオ 2**
|
||||
|
||||
**ユーザーの初期の好み情報を記録**し,会話中にユーザーが入力した言語の好みを記憶し、後続の会話でその言語を使用して返信します。
|
||||
|
||||
例:ユーザーが会話を始める前に、`language`入力欄に「日本語」と指定した場合、その言語は会話変数に書き込まれ、LLMは後続の返信時に会話変数の情報を参照し、継続的に「日本語」を使用して返信します。
|
||||
|
||||
<Frame caption="ユーザーの初期設定情報を記録する">
|
||||
<img src="/ja-jp/img/conversation-var-scenario-1.png" alt="ユーザーの初期嗜好情報を記録するフローチャート" />
|
||||
</Frame>
|
||||
|
||||
**設定手順:**
|
||||
|
||||
**会話変数の設定**:まず、会話変数 `language` を設定し、会話の開始時にこの変数の値が空かどうかを判断する条件分岐ノードを追加します。
|
||||
|
||||
**変数の書き込み/代入**:最初の会話が開始された際、 `language` 変数の値が空であれば、LLMノードを使用してユーザーの言語入力を抽出し、その言語タイプを会話変数 `language` に書き込みます。
|
||||
|
||||
**変数の読み取り**:後続の会話ラウンドでは、`language` 変数にユーザーの好みの言語が保存されています。以降の会話では、LLMノードがこの変数を参照し、ユーザーの好みの言語タイプを用いて返信します。
|
||||
|
||||
**シナリオ 3**
|
||||
|
||||
**Checklistのチェックを補助**し、会話中に会話変数にユーザーの入力項目を記録し、Checklistの内容を更新し、後続の会話で抜け漏れ項目を確認します。
|
||||
|
||||
例:会話を始める際、LLMはユーザーにチェックリストに関連するアイテムの入力を求めます。ユーザーがチェックリストの内容を一度述べると、その内容は会話変数に更新され、及び保存されます。LLMは各会話の後に、ユーザーに不足しているアイテムの追加を促します。
|
||||
|
||||
<Frame caption="Checklistのチェックを補助">
|
||||
<img src="/ja-jp/img/conversation-var-scenario-2-1.png" alt="Checklistのチェックを補助のフローチャート" />
|
||||
</Frame>
|
||||
|
||||
**配置流程:**
|
||||
|
||||
* **会話変数の設定**:最初に会話変数 `ai_checklist` を設定し、これをLLM内でチェックのコンテクストとして参照します。
|
||||
* **変数の書き込み/代入**:各会話のラウンドごとに、LLMノード内の `ai_checklist` の値を確認し、ユーザーの入力と比較します。ユーザーが新しい情報を提供した場合、チェックリストを更新し、変数代入ノードを使用して出力内容を `ai_checklist` に書き込みます。
|
||||
* **変数の読み取り**:`ai_checklist`の値を読み取り、すべてのチェックリストアイテムが完了するまで、各会話のラウンドでユーザーの入力と比較します。
|
||||
|
||||
***
|
||||
|
||||
### 3 操作方法
|
||||
|
||||
**変数代入の使用:**
|
||||
|
||||
ノードの右側の `+` マークをクリックし、「変数代入」 ノードを選択し、「代入られた変数」 と 「設定する変数」 を入力します。
|
||||
|
||||
<Frame caption="変数代入ノードの設定">
|
||||
<img src="/ja-jp/img/language-variable-assigner.png" width="375px" alt="変数代入ノードの設定画面" />
|
||||
</Frame>
|
||||
|
||||
**変数の設定:**
|
||||
|
||||
代入られた変数:代入された変数を選択し、対象の会話変数を指定します
|
||||
|
||||
設定する変数:変換する必要のあるソース変数を選択します
|
||||
|
||||
上図の代入ロジック:`Language Recognition/text` を `language` に代入します。
|
||||
|
||||
**書き込みモード:**
|
||||
|
||||
* Overwrite (上書き): ソース変数の内容を対象の会話変数に上書きします
|
||||
* Append (追加):指定された変数が配列型の場合に使用します
|
||||
* Clear (クリア): 対象の会話変数内の内容をクリアします
|
||||
7
zh-hans/guides/workflow/node/README.mdx
Normal file
7
zh-hans/guides/workflow/node/README.mdx
Normal file
@@ -0,0 +1,7 @@
|
||||
# 节点说明
|
||||
|
||||
**节点是工作流中的关键构成**,通过连接不同功能的节点,执行工作流的一系列操作。
|
||||
|
||||
### 核心节点
|
||||
|
||||
<table data-view="cards"><thead><tr><th></th><th></th><th></th></tr></thead><tbody><tr><td><a href="start.md"><strong>开始(Start)</strong></a></td><td>定义一个 workflow 流程启动的初始参数。</td><td></td></tr><tr><td><a href="end.md"><strong>结束(End)</strong></a></td><td>定义一个 workflow 流程结束的最终输出内容。</td><td></td></tr><tr><td><a href="answer.md"><strong>回复(Answer)</strong></a></td><td>定义一个 Chatflow 流程中的回复内容。</td><td></td></tr><tr><td><a href="llm.md"><strong>大语言模型(LLM)</strong></a></td><td>调用大语言模型回答问题或者对自然语言进行处理。</td><td></td></tr><tr><td><a href="knowledge-retrieval.md"><strong>知识检索(Knowledge Retrieval)</strong></a></td><td>从知识库中检索与用户问题相关的文本内容,可作为下游 LLM 节点的上下文。</td><td></td></tr><tr><td><a href="question-classifier.md"><strong>问题分类(Question Classifier)</strong></a></td><td>通过定义分类描述,LLM 能够根据用户输入选择与之相匹配的分类。</td><td></td></tr><tr><td><a href="ifelse.md"><strong>条件分支(IF/ELSE)</strong></a></td><td>允许你根据 if/else 条件将 workflow 拆分成两个分支。</td><td></td></tr><tr><td><a href="code.md"><strong>代码执行(Code)</strong></a></td><td>运行 Python / NodeJS 代码以在工作流程中执行数据转换等自定义逻辑。</td><td></td></tr><tr><td><a href="template.md"><strong>模板转换(Template)</strong></a></td><td>允许借助 Jinja2 的 Python 模板语言灵活地进行数据转换、文本处理等。</td><td></td></tr><tr><td><a href="variable-assigner.md"><strong>变量聚合(Variable Aggregator)</strong></a></td><td>将多路分支的变量聚合为一个变量,以实现下游节点统一配置。</td><td></td></tr><tr><td><a href="parameter-extractor.md"><strong>参数提取器(Parameter Extractor)</strong></a></td><td>利用 LLM 从自然语言推理并提取结构化参数,用于后置的工具调用或 HTTP 请求。</td><td></td></tr><tr><td><a href="iteration.md"><strong>迭代(Iteration)</strong></a></td><td>对列表对象执行多次步骤直至输出所有结果。</td><td></td></tr><tr><td><a href="http-request.md"><strong>HTTP 请求(HTTP Request)</strong></a></td><td>允许通过 HTTP 协议发送服务器请求,适用于获取外部检索结果、webhook、生成图片等情景。</td><td></td></tr><tr><td><a href="tools.md"><strong>工具(Tools)</strong></a></td><td>允许在工作流内调用 Dify 内置工具、自定义工具、子工作流等。</td><td></td></tr><tr><td><a href="variable-assignment.md"><strong>变量赋值(Variable Assigner)</strong></a></td><td>变量赋值节点用于向可写入变量(例如会话变量)进行变量赋值。</td><td></td></tr></tbody></table>
|
||||
73
zh-hans/guides/workflow/node/agent.mdx
Normal file
73
zh-hans/guides/workflow/node/agent.mdx
Normal file
@@ -0,0 +1,73 @@
|
||||
---
|
||||
title: Agent
|
||||
---
|
||||
|
||||
## 定义
|
||||
|
||||
Agent 节点是 Dify Chatflow/Workflow 中用于实现自主工具调用的组件。它通过集成不同的 Agent 推理策略,使大语言模型能够在运行时动态选择并执行工具,从而实现多步推理。
|
||||
|
||||
## 配置步骤
|
||||
|
||||
### 添加节点
|
||||
|
||||
在 Dify Chatflow/Workflow 编辑器中,从组件栏拖拽 Agent 节点至画布。
|
||||
|
||||
|
||||
|
||||
### 选择 Agent 策略
|
||||
|
||||
在节点配置面板中,点击 **Agent 策略**。
|
||||
|
||||
|
||||
|
||||
从下拉菜单选择所需的 Agent 推理策略。Dify 内置了 **Function Calling 和 ReAct** 两种策略,可在 **Marketplace** → **Agent 策略**分类中安装使用。
|
||||
|
||||
|
||||
|
||||
#### 1. Function Calling
|
||||
|
||||
通过将用户指令映射到预定义函数或工具,LLM 先识别用户意图,再决定调用哪个函数并提取所需参数。它的核心是调用外部函数或工具,属于一种明确的工具调用机制。
|
||||
|
||||
**优点:**
|
||||
|
||||
* **精确:** 对于明确的任务,可以直接调用相应的工具,无需复杂的推理过程。
|
||||
* **易于集成外部功能:** 可以将各种外部 API 或工具封装成函数供模型调用。
|
||||
* **结构化输出:** 模型输出的是结构化的函数调用信息,方便下游节点处理。
|
||||
|
||||
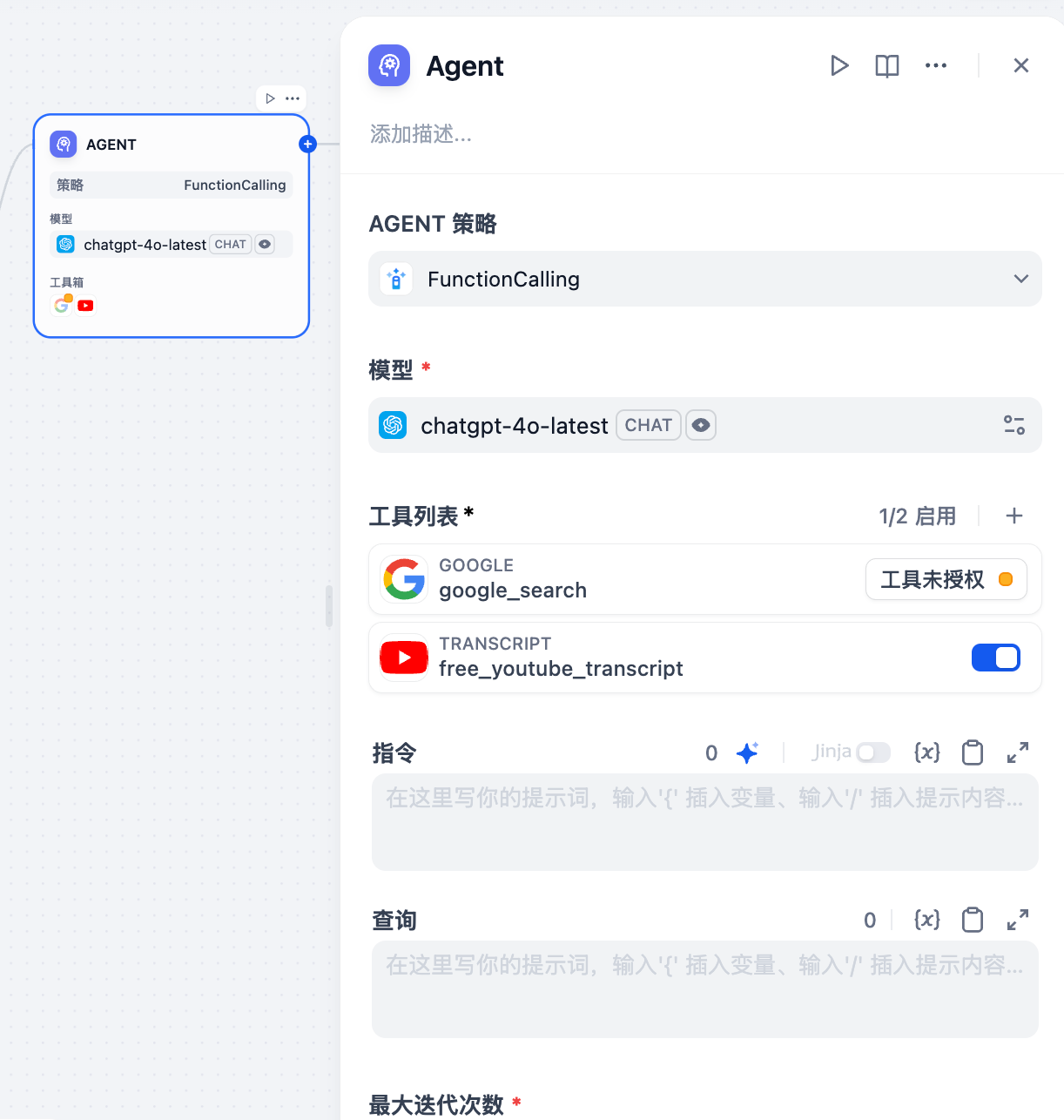
|
||||
|
||||
2. **ReAct (Reason + Act)**
|
||||
|
||||
ReAct 策略使 Agent 交替进行思考和行动:LLM 首先思考当前状态和目标,然后选择并调用合适的工具,工具的输出结果又将引导 LLM 进行下一步的思考和行动,如此循环,直到问题解决。
|
||||
|
||||
**优点:**
|
||||
|
||||
* **有效利用外部信息:** 能够有效地利用外部工具获取信息,解决仅靠模型自身无法完成的任务。
|
||||
* **可解释性较好:** 思考和行动的过程是交织的,可以一定程度上追踪 Agent 的推理路径。
|
||||
* **适用范围广:** 适用于需要外部知识或需要执行特定操作的场景,例如问答、信息检索、任务执行等。
|
||||
|
||||
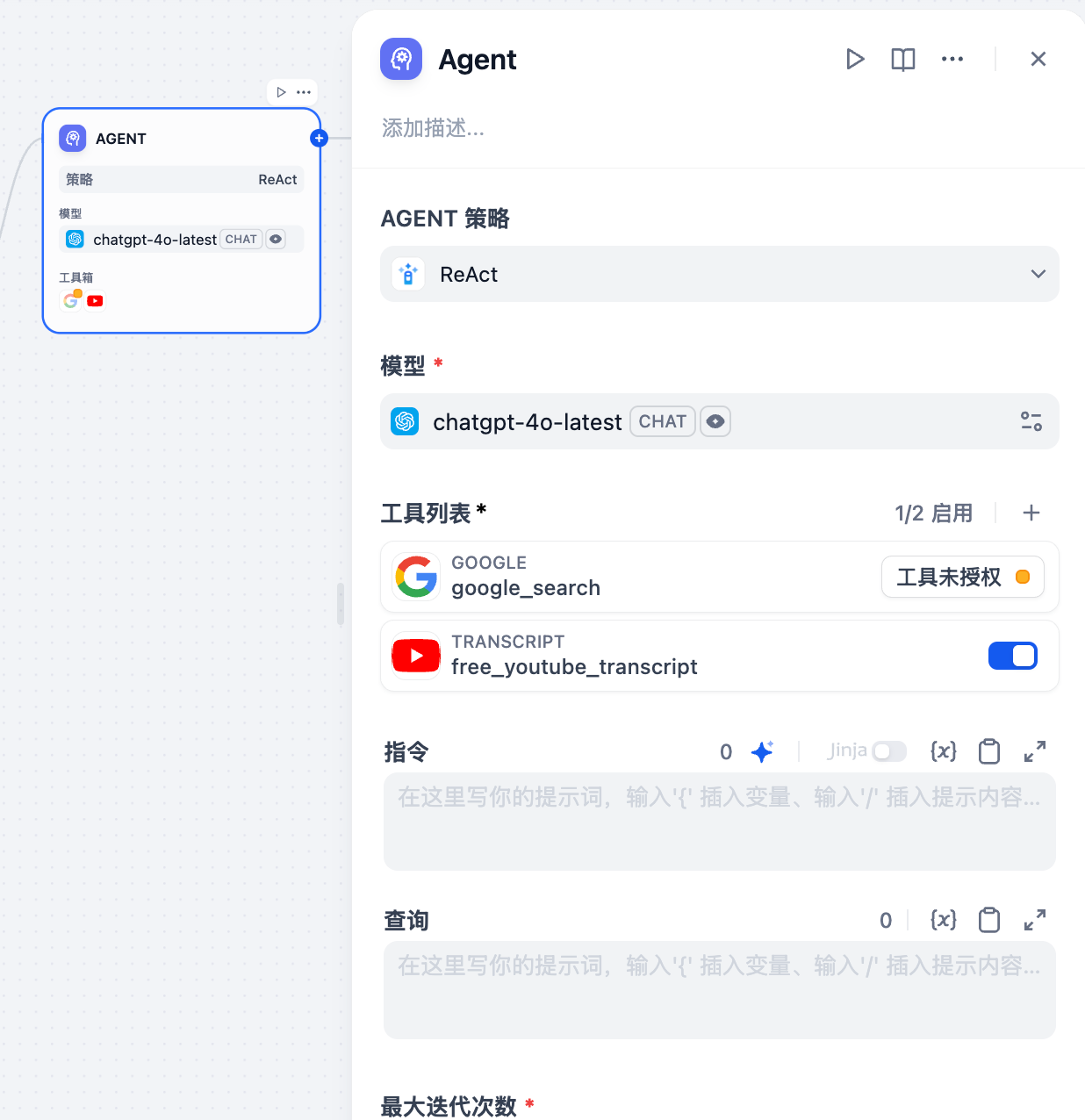
|
||||
|
||||
开发者可以向[公开仓库](https://github.com/langgenius/dify-plugins)贡献 Agent 策略插件,经过审核后将在 Marketplace 上架,供其他用户安装使用。
|
||||
|
||||
### **配置节点参数**
|
||||
|
||||
选择 Agent 策略后,配置面板会显示对应的配置项。Dify 官方内置的 Function Calling 和 ReAct 策略的配置项包括:
|
||||
|
||||
1. **模型:** 选择驱动 Agent 的大语言模型。
|
||||
2. **工具:** 工具的使用方式由 Agent 策略定义,点击 "+" 添加并配置 Agent 可调用的工具。
|
||||
* **搜索:** 在下拉框中选择已安装的工具插件。
|
||||
* **授权:** 填写 API 密钥等授权信息后启用工具。
|
||||
* **工具描述和参数设置:** 提供工具描述,帮助 LLM 理解工具用途并选择调用,同时设置工具的功能参数。
|
||||
3. **指令:** 定义 Agent 的任务目标和上下文。支持使用 Jinja 语法引用上游节点变量。
|
||||
4. **查询:** 接收用户输入。
|
||||
5. **最大迭代次数:** 设定 Agent 的最大执行步数。
|
||||
6. **输出变量:** 提示节点输出的数据结构。
|
||||
|
||||
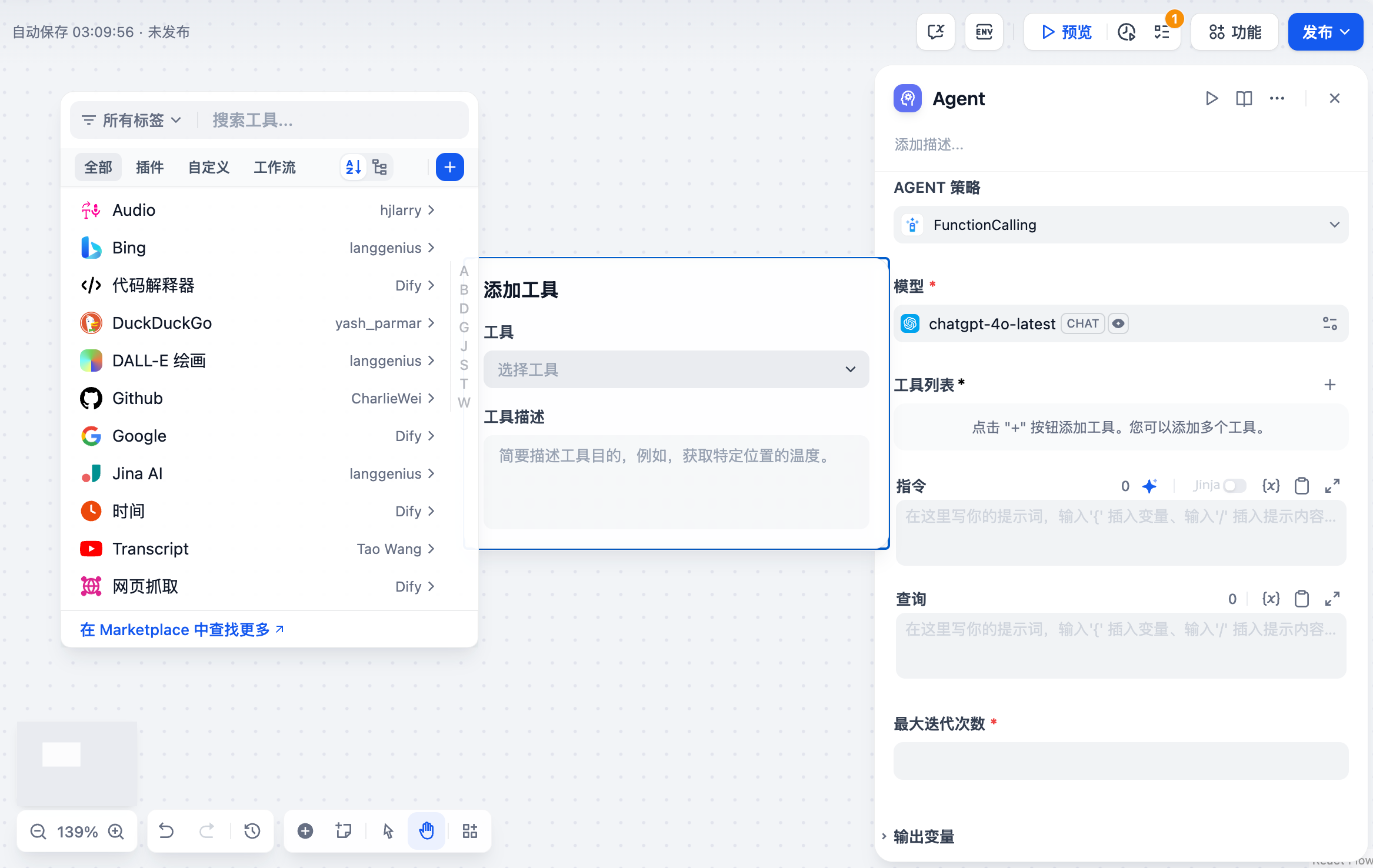
|
||||
|
||||
## **查看日志**
|
||||
|
||||
Agent 节点执行过程中将生成详细日志。显示节点执行的总体信息,包括输入和输出、token 开销、耗时和状态。点击 "详情" 查看 Agent 策略执行的每一轮输出信息。
|
||||
|
||||
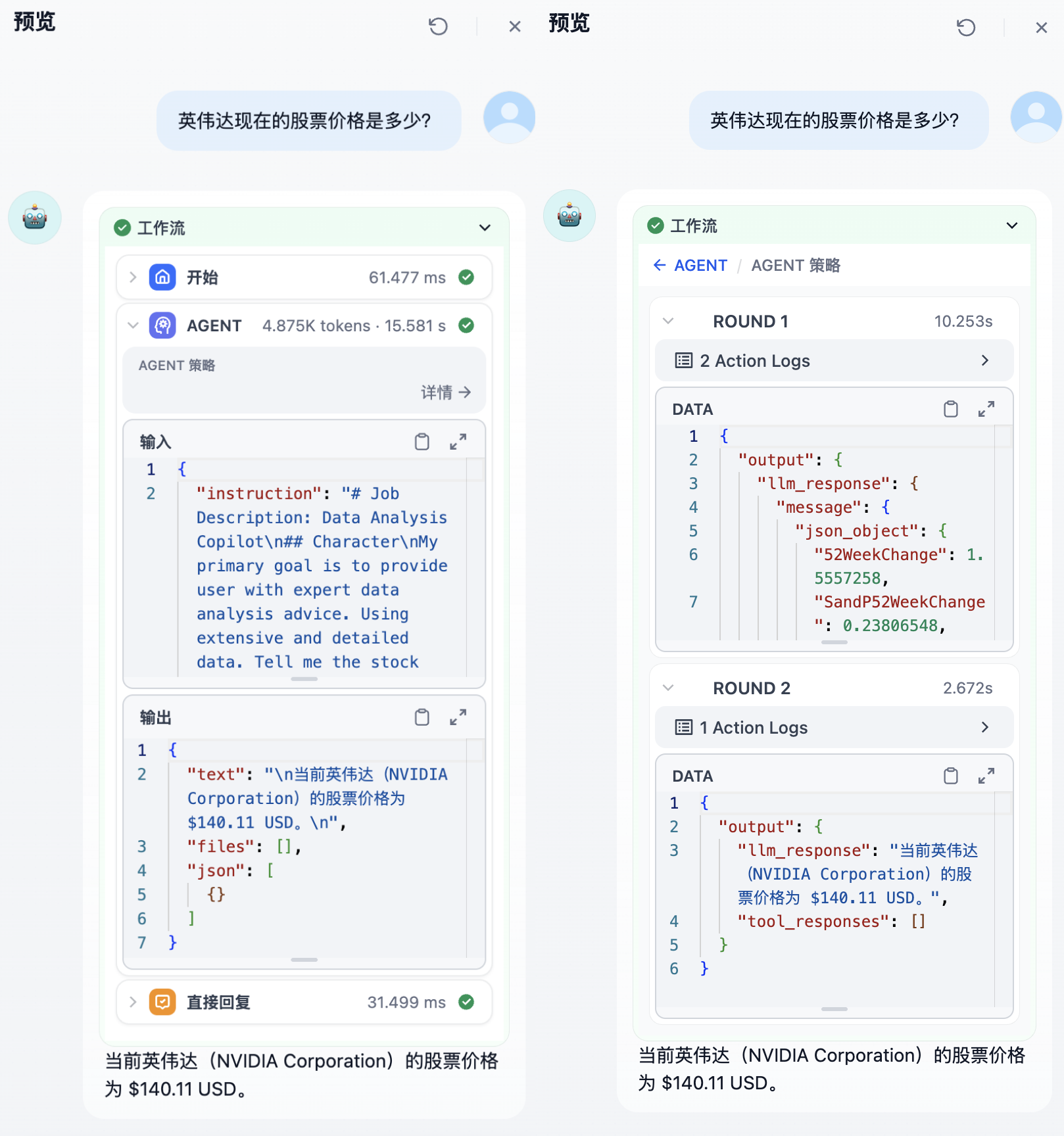
|
||||
21
zh-hans/guides/workflow/node/answer.mdx
Normal file
21
zh-hans/guides/workflow/node/answer.mdx
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
title: 直接回复
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
定义一个 Chatflow 流程中的回复内容。
|
||||
|
||||
你可以在文本编辑器中自由定义回复格式,包括自定义一段固定的文本内容、使用前置步骤中的输出变量作为回复内容、或者将自定义文本与变量组合后回复。
|
||||
|
||||
可随时加入节点将内容流式输出至对话回复,支持所见即所得配置模式并支持图文混排,如:
|
||||
|
||||
1. 输出 LLM 节点回复内容
|
||||
2. 输出生成图片
|
||||
3. 输出纯文本
|
||||
|
||||
<Info>
|
||||
直接回复节点可以不作为最终的输出节点,作为流程过程节点时,可以在中间步骤流式输出结果。
|
||||
</Info>
|
||||
|
||||
122
zh-hans/guides/workflow/node/code.mdx
Normal file
122
zh-hans/guides/workflow/node/code.mdx
Normal file
@@ -0,0 +1,122 @@
|
||||
---
|
||||
title: 代码执行
|
||||
---
|
||||
|
||||
## 目录
|
||||
|
||||
* [介绍](#介绍)
|
||||
* [使用场景](#使用场景)
|
||||
* [本地部署](#本地部署)
|
||||
* [安全策略](#安全策略)
|
||||
|
||||
## 介绍
|
||||
|
||||
代码节点支持运行 Python / NodeJS 代码以在工作流程中执行数据转换。它可以简化你的工作流程,适用于Arithmetic、JSON transform、文本处理等情景。
|
||||
|
||||
该节点极大地增强了开发人员的灵活性,使他们能够在工作流程中嵌入自定义的 Python 或 Javascript 脚本,并以预设节点无法达到的方式操作变量。通过配置选项,你可以指明所需的输入和输出变量,并撰写相应的执行代码:
|
||||
|
||||
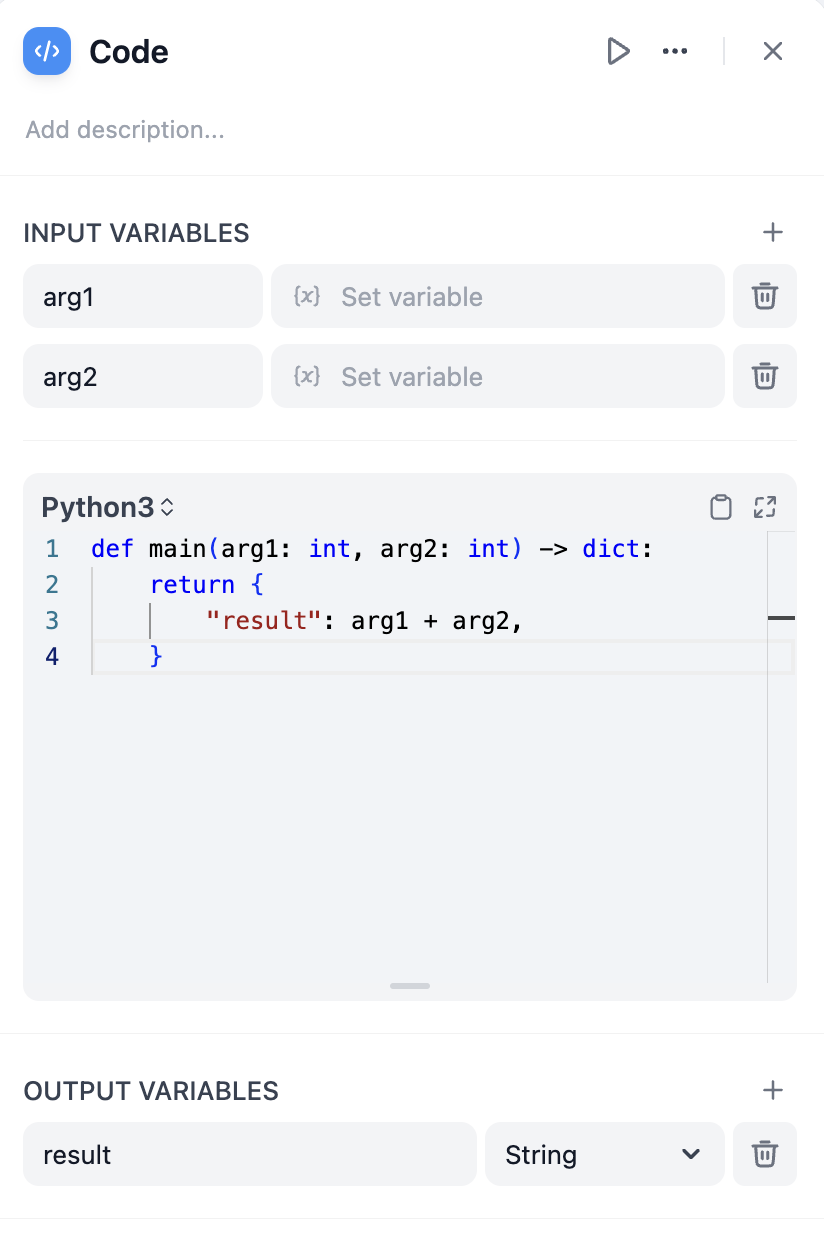
|
||||
|
||||
## 配置
|
||||
|
||||
如果你需要在代码节点中使用其他节点的变量,你需要在`输入变量`中定义变量名,并引用这些变量,可以参考[变量引用](../concepts#变量)。
|
||||
|
||||
## 使用场景
|
||||
|
||||
使用代码节点,你可以完成以下常见的操作:
|
||||
|
||||
### 结构化数据处理
|
||||
|
||||
在工作流中,经常要面对非结构化的数据处理,如JSON字符串的解析、提取、转换等。最典型的例子就是HTTP节点的数据处理,在常见的API返回结构中,数据可能会被嵌套在多层JSON对象中,而我们需要提取其中的某些字段。代码节点可以帮助你完成这些操作,下面是一个简单的例子,它从HTTP节点返回的JSON字符串中提取了`data.name`字段:
|
||||
|
||||
```python
|
||||
def main(http_response: str) -> str:
|
||||
import json
|
||||
data = json.loads(http_response)
|
||||
return {
|
||||
# 注意在输出变量中声明result
|
||||
'result': data['data']['name']
|
||||
}
|
||||
```
|
||||
|
||||
### 数学计算
|
||||
|
||||
当工作流中需要进行一些复杂的数学计算时,也可以使用代码节点。例如,计算一个复杂的数学公式,或者对数据进行一些统计分析。下面是一个简单的例子,它计算了一个数组的平方差:
|
||||
|
||||
```python
|
||||
def main(x: list) -> float:
|
||||
return {
|
||||
# 注意在输出变量中声明result
|
||||
'result' : sum([(i - sum(x) / len(x)) ** 2 for i in x]) / len(x)
|
||||
}
|
||||
```
|
||||
|
||||
### 拼接数据
|
||||
|
||||
有时,也许你需要拼接多个数据源,如多个知识检索、数据搜索、API调用等,代码节点可以帮助你将这些数据源整合在一起。下面是一个简单的例子,它将两个知识库的数据合并在一起:
|
||||
|
||||
```python
|
||||
def main(knowledge1: list, knowledge2: list) -> list:
|
||||
return {
|
||||
# 注意在输出变量中声明result
|
||||
'result': knowledge1 + knowledge2
|
||||
}
|
||||
```
|
||||
|
||||
## 本地部署
|
||||
|
||||
如果你是本地部署的用户,你需要启动一个沙盒服务,它会确保恶意代码不会被执行,同时,启动该服务需要使用Docker服务,你可以在[这里](https://github.com/langgenius/dify/tree/main/docker/docker-compose.middleware.yaml)找到Sandbox服务的具体信息,你也可以直接通过`docker-compose`启动服务:
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.middleware.yaml up -d
|
||||
```
|
||||
|
||||
> 如果你的系统安装了 Docker Compose V2 而不是 V1,请使用 `docker compose` 而不是 `docker-compose`。通过`$ docker compose version`检查这是否为情况。在[这里](https://docs.docker.com/compose/#compose-v2-and-the-new-docker-compose-command)阅读更多信息。
|
||||
|
||||
## 安全策略
|
||||
|
||||
无论是 Python3 还是 Javascript 代码执行器,它们的执行环境都被严格隔离(沙箱化),以确保安全性。这意味着开发者不能使用那些消耗大量系统资源或可能引发安全问题的功能,例如直接访问文件系统、进行网络请求或执行操作系统级别的命令。这些限制保证了代码的安全执行,同时避免了对系统资源的过度消耗。
|
||||
|
||||
### 高级功能
|
||||
|
||||
**错误重试**
|
||||
|
||||
针对节点发生的部分异常情况,通常情况下再次重试运行节点即可解决。开启错误重试功能后,节点将在发生错误的时候按照预设策略进行自动重试。你可以调整最大重试次数和每次重试间隔以设置重试策略。
|
||||
|
||||
- 最大重试次数为 10 次
|
||||
- 最大重试间隔时间为 5000 ms
|
||||
|
||||

|
||||
|
||||
**异常处理**
|
||||
|
||||
代码节点处理信息时有可能会遇到代码执行异常的情况。应用开发者可以参考以下步骤配置异常分支,在节点出现异常时启用应对方案,而避免中断整个流程。
|
||||
|
||||
1. 在代码节点启用 “异常处理”
|
||||
2. 选择异常处理方案并进行配置
|
||||
|
||||

|
||||
|
||||
需了解更多应对异常的处理办法,请参考[异常处理](../error-handling/readme)。
|
||||
|
||||
### 常见问题
|
||||
|
||||
**在代码节点内填写代码后为什么无法保存?**
|
||||
|
||||
请检查代码是否包含危险行为。例如:
|
||||
|
||||
```python
|
||||
def main() -> dict:
|
||||
return {
|
||||
"result": open("/etc/passwd").read(),
|
||||
}
|
||||
```
|
||||
|
||||
这段代码包含以下问题:
|
||||
|
||||
* **未经授权的文件访问:** 代码试图读取 "/etc/passwd" 文件,这是 Unix/Linux 系统中存储用户账户信息的关键系统文件。
|
||||
* **敏感信息泄露:** "/etc/passwd" 文件包含系统用户的重要信息,如用户名、用户 ID、组 ID、home 目录路径等。直接访问可能会导致信息泄露。
|
||||
|
||||
危险代码将会被 Cloudflare WAF 自动拦截,你可以通过 “网页调试工具” 中的 “网络” 查看是否被拦截。
|
||||
|
||||
|
||||
65
zh-hans/guides/workflow/node/doc-extractor.mdx
Normal file
65
zh-hans/guides/workflow/node/doc-extractor.mdx
Normal file
@@ -0,0 +1,65 @@
|
||||
---
|
||||
title: 文档提取器
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
LLM 自身无法直接读取或解释文档的内容。因此需要将用户上传的文档,通过文档提取器节点解析并读取文档文件中的信息,转化文本之后再将内容传给 LLM 以实现对于文件内容的处理。
|
||||
|
||||
### 应用场景
|
||||
|
||||
* 构建能够与文件进行互动的 LLM 应用,例如 ChatPDF 或 ChatWord;
|
||||
* 分析并检查用户上传的文件内容;
|
||||
|
||||
### 节点功能
|
||||
|
||||
文档提取器节点可以理解为一个信息处理中心,通过识别并读取输入变量中的文件,提取信息后并转化为 string 类型输出变量,供下游节点调用。
|
||||
|
||||
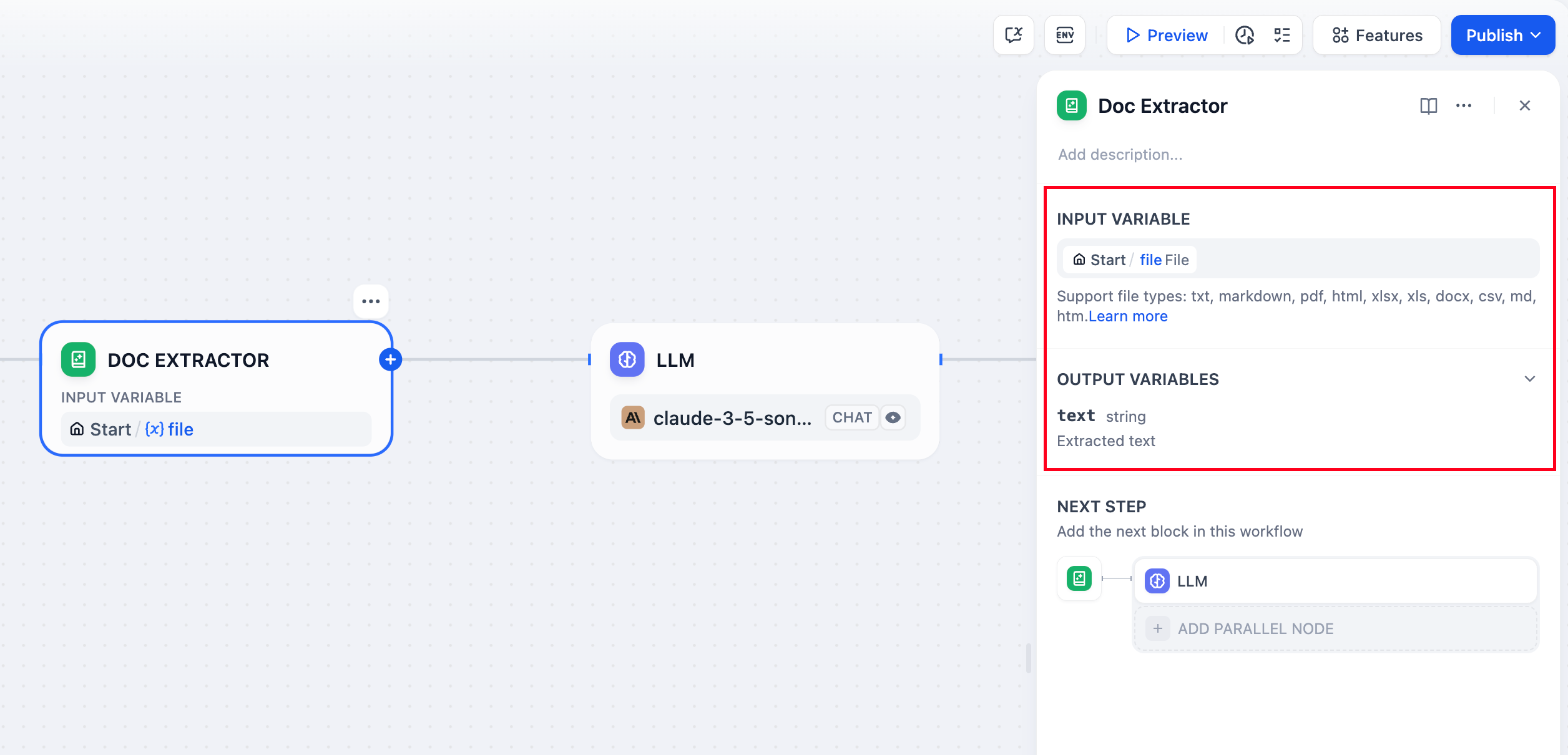
|
||||
|
||||
文档提取器节点结构分为输入变量、输出变量。
|
||||
|
||||
#### 输入变量
|
||||
|
||||
文档提取器仅接受以下数据结构的变量:
|
||||
|
||||
* `File`,单独一个文件
|
||||
* `Array[File]`,多个文件
|
||||
|
||||
文档提取器仅能够提取文档类型文件中的信息,例如 TXT、Markdown、PDF、HTML、DOCX 格式文件的内容,无法处理图片、音频、视频等格式文件。
|
||||
|
||||
#### 输出变量
|
||||
|
||||
输出变量固定命名为 text。输出的变量类型取决于输入变量:
|
||||
|
||||
* 输入变量为 `File`,输出变量为 `string`
|
||||
* 输入变量为 `Array[File]`,输出变量为 `array[string]`
|
||||
|
||||
> Array 数组变量一般需配合列表操作节点使用,详细说明请参考 [list-operator.md](list-operator "mention")。
|
||||
|
||||
### 配置示例
|
||||
|
||||
在一个典型的文件交互问答场景中,文档提取器可以作为 LLM 节点的前置步骤,提取应用的文件信息并传递至下游的 LLM 节点,回答用户关于文件的问题。
|
||||
|
||||
本章节将通过一个典型的 ChatPDF 示例工作流模板,介绍文档提取器节点的使用方法。
|
||||
|
||||
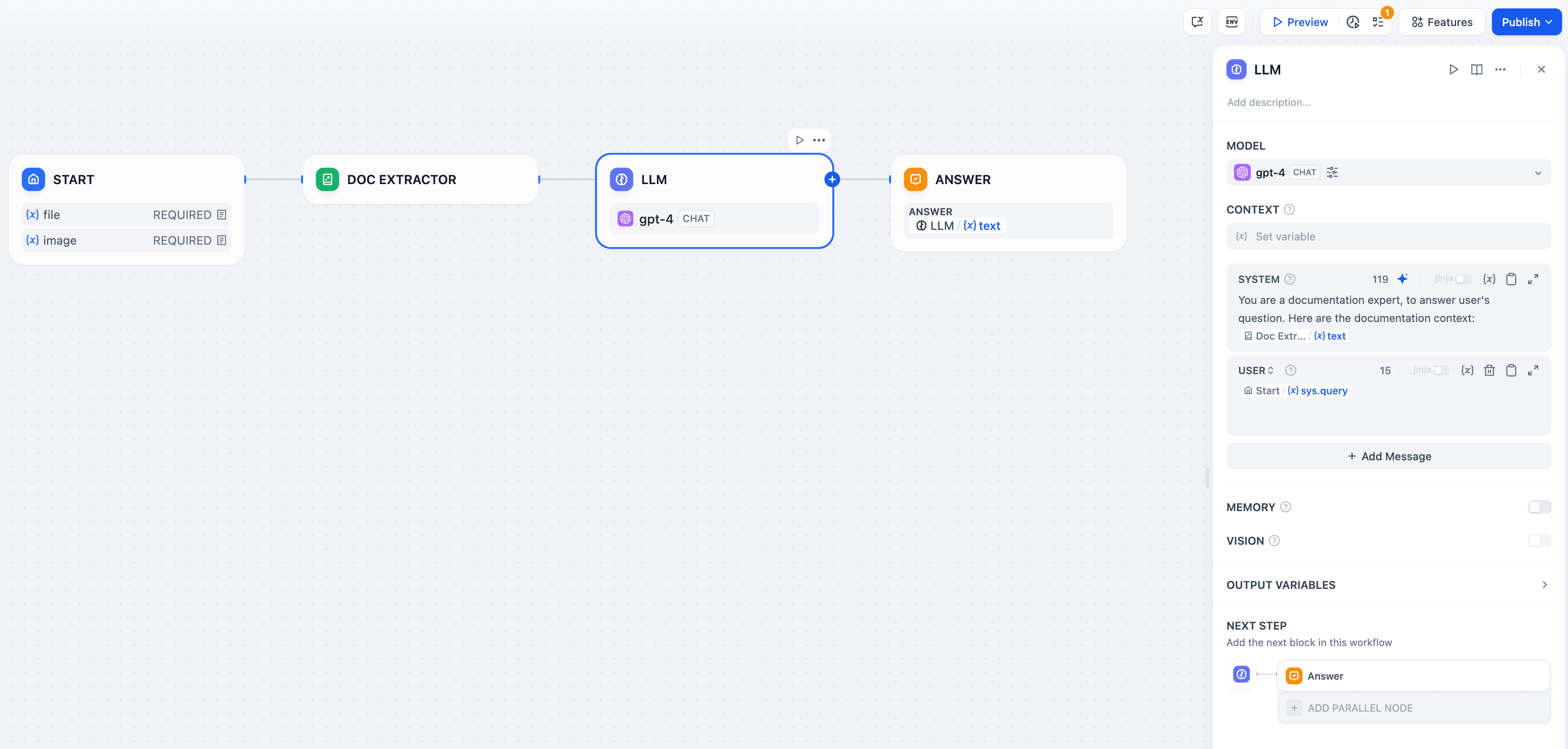
|
||||
|
||||
**配置流程:**
|
||||
|
||||
1. 为应用开启文件上传功能。在 ["开始"](start) 节点中添加**单文件变量**并命名为 `pdf`。
|
||||
2. 添加文档提取节点,并在输入变量内选中 `pdf` 变量。
|
||||
3. 添加 LLM 节点,在系统提示词内选中文档提取器节点的输出变量。LLM 可以通过该输出变量读取文件中的内容。
|
||||
|
||||
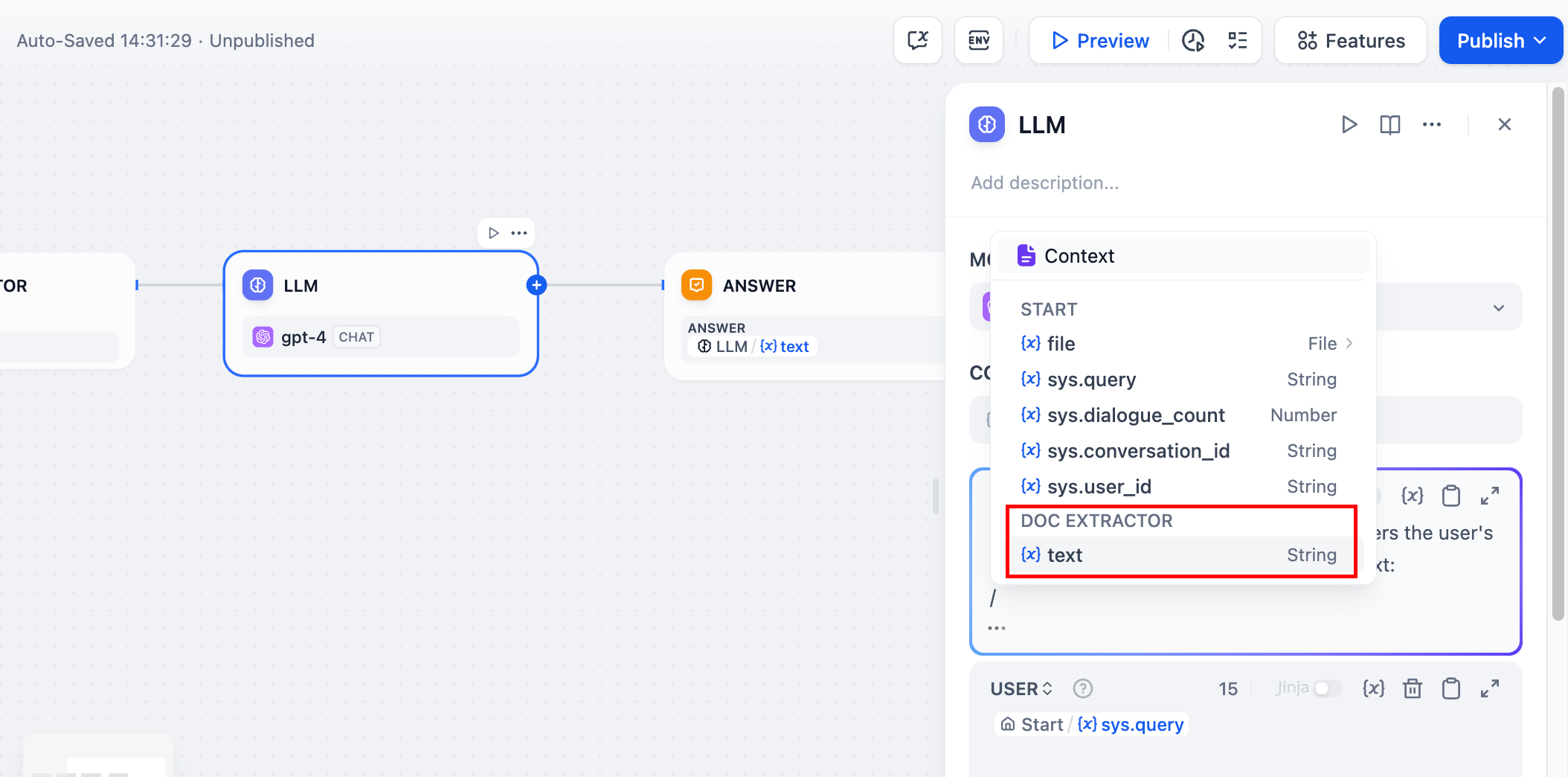
|
||||
|
||||
4\. 配置结束节点,在结束节点中选择 LLM 节点的输出变量。
|
||||
|
||||
配置完成后,应用将具备文件上传功能,使用者可以上传 PDF 文件并展开对话。
|
||||
|
||||
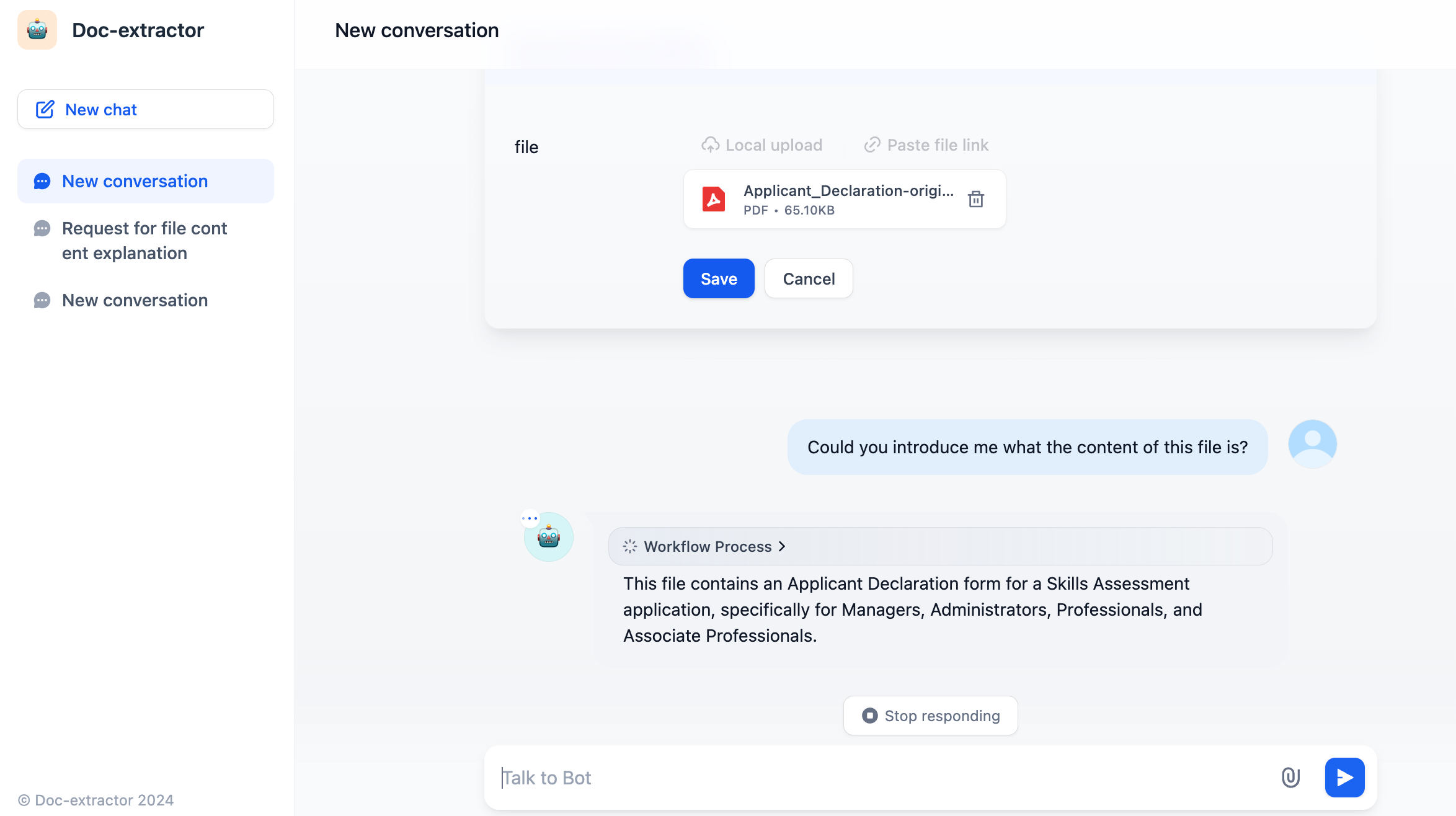
|
||||
|
||||
<Tip>
|
||||
如需了解如何在聊天对话中上传文件并与 LLM 互动,请参考 [附加功能](/zh-hans/guides/workflow/additional-feature)。
|
||||
</Tip>
|
||||
31
zh-hans/guides/workflow/node/end.mdx
Normal file
31
zh-hans/guides/workflow/node/end.mdx
Normal file
@@ -0,0 +1,31 @@
|
||||
---
|
||||
title: 结束
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
定义一个工作流程结束的最终输出内容。每一个工作流在完整执行后都需要至少一个结束节点,用于输出完整执行的最终结果。
|
||||
|
||||
结束节点为流程终止节点,后面无法再添加其他节点,工作流应用中只有运行到结束节点才会输出执行结果。若流程中出现条件分叉,则需要定义多个结束节点。
|
||||
|
||||
结束节点需要声明一个或多个输出变量,声明时可以引用任意上游节点的输出变量。
|
||||
|
||||
> **注意**
|
||||
> Chatflow 内不支持结束节点
|
||||
|
||||
***
|
||||
|
||||
### 场景
|
||||
|
||||
在以下[长故事生成工作流](/zh-hans/guides/workflow/nodes/iteration#示例-2:长文章迭代生成器(另一种编排方式))中,结束节点声明的变量 `Output` 为上游代码节点的输出,即该工作流会在 Code3 节点执行完成之后结束,并输出 Code3 的执行结果。
|
||||
|
||||
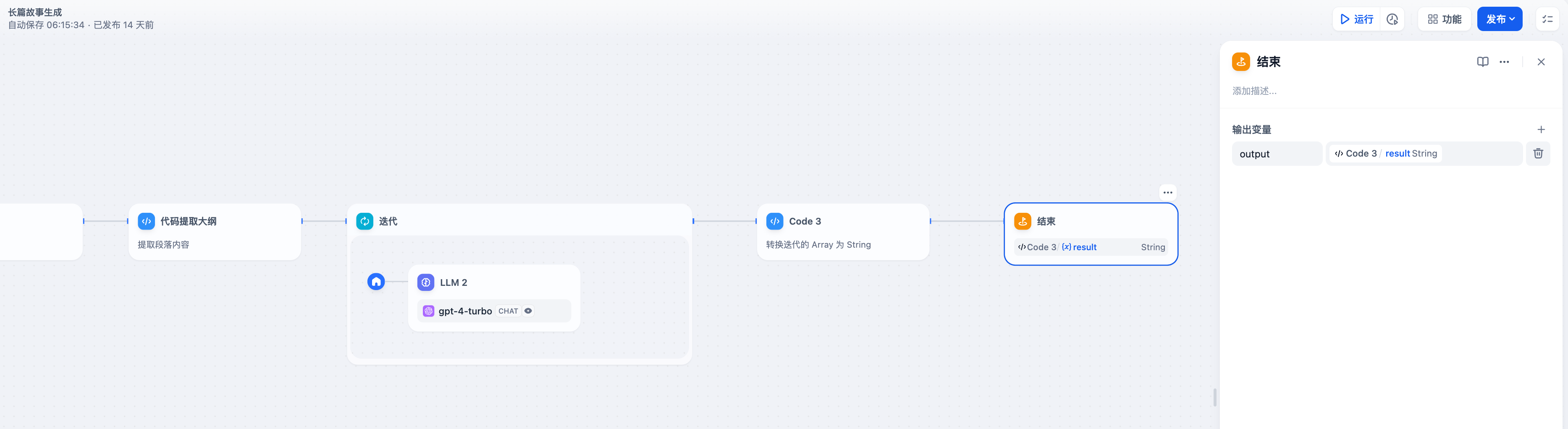
|
||||
|
||||
**单路执行示例:**
|
||||
|
||||
|
||||
|
||||
**多路执行示例:**
|
||||
|
||||
|
||||
|
||||
63
zh-hans/guides/workflow/node/http-request.mdx
Normal file
63
zh-hans/guides/workflow/node/http-request.mdx
Normal file
@@ -0,0 +1,63 @@
|
||||
---
|
||||
title: HTTP 请求
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
允许通过 HTTP 协议发送服务器请求,适用于获取外部数据、webhook、生成图片、下载文件等情景。它让你能够向指定的网络地址发送定制化的 HTTP 请求,实现与各种外部服务的互联互通。
|
||||
|
||||
该节点支持常见的 HTTP 请求方法:
|
||||
|
||||
* **GET**,用于请求服务器发送某个资源。
|
||||
* **POST**,用于向服务器提交数据,通常用于提交表单或上传文件。
|
||||
* **HEAD**,类似于 GET 请求,但服务器不返回请求的资源主体,只返回响应头。
|
||||
* **PATCH**,用于在请求-响应链上的每个节点获取传输路径。
|
||||
* **PUT**,用于向服务器上传资源,通常用于更新已存在的资源或创建新的资源。
|
||||
* **DELETE**,用于请求服务器删除指定的资源。
|
||||
|
||||
你可以通过配置 HTTP 请求的包括 URL、请求头、查询参数、请求体内容以及认证信息等。
|
||||
|
||||
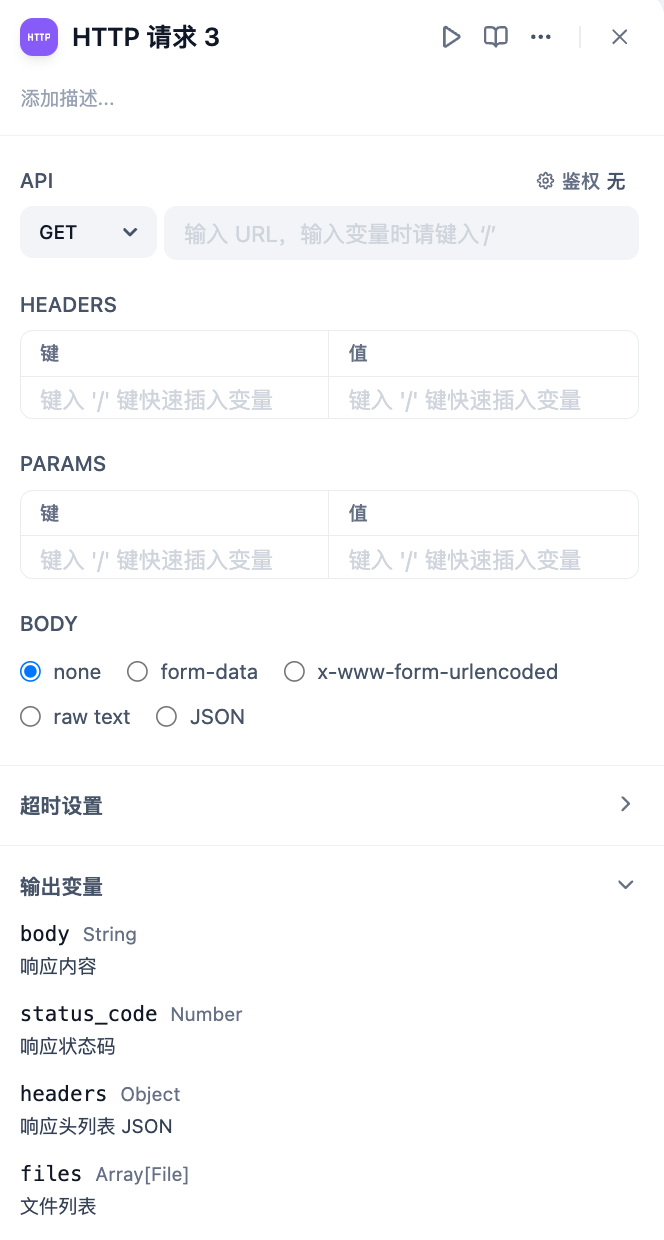
|
||||
|
||||
|
||||
***
|
||||
|
||||
### 场景
|
||||
|
||||
这个节点的一个实用特性是能够根据场景需要,在请求的不同部分动态插入变量。比如在处理客户评价请求时,你可以将用户名或客户ID、评价内容等变量嵌入到请求中,以定制化自动回复信息或获取特定客户信息并发送相关资源至特定的服务器。
|
||||
|
||||
|
||||
|
||||
HTTP 请求的返回值包括响应体、状态码、响应头和文件。值得注意的是,如果响应中包含了文件,这个节点能够自动保存文件,供流程后续步骤使用。这样不仅能提高处理效率,也可以更加简单直接地处理带有文件的响应。
|
||||
|
||||
* **发送文件**
|
||||
|
||||
你可以使用 HTTP PUT 请求将应用内的文件发送至其它 API 服务。在请求的 Body 中,可以在 `binary` 内选中文件变量。这种方式常用于文件传输、文档存储或媒体处理等场景。
|
||||
|
||||
示例: 假设你正在开发一个文档管理应用,需要将用户上传的 PDF 文件同步发送第三方服务,可以通过 HTTP 请求节点通过文件变量进行传递。
|
||||
|
||||
配置示例如下:
|
||||
|
||||
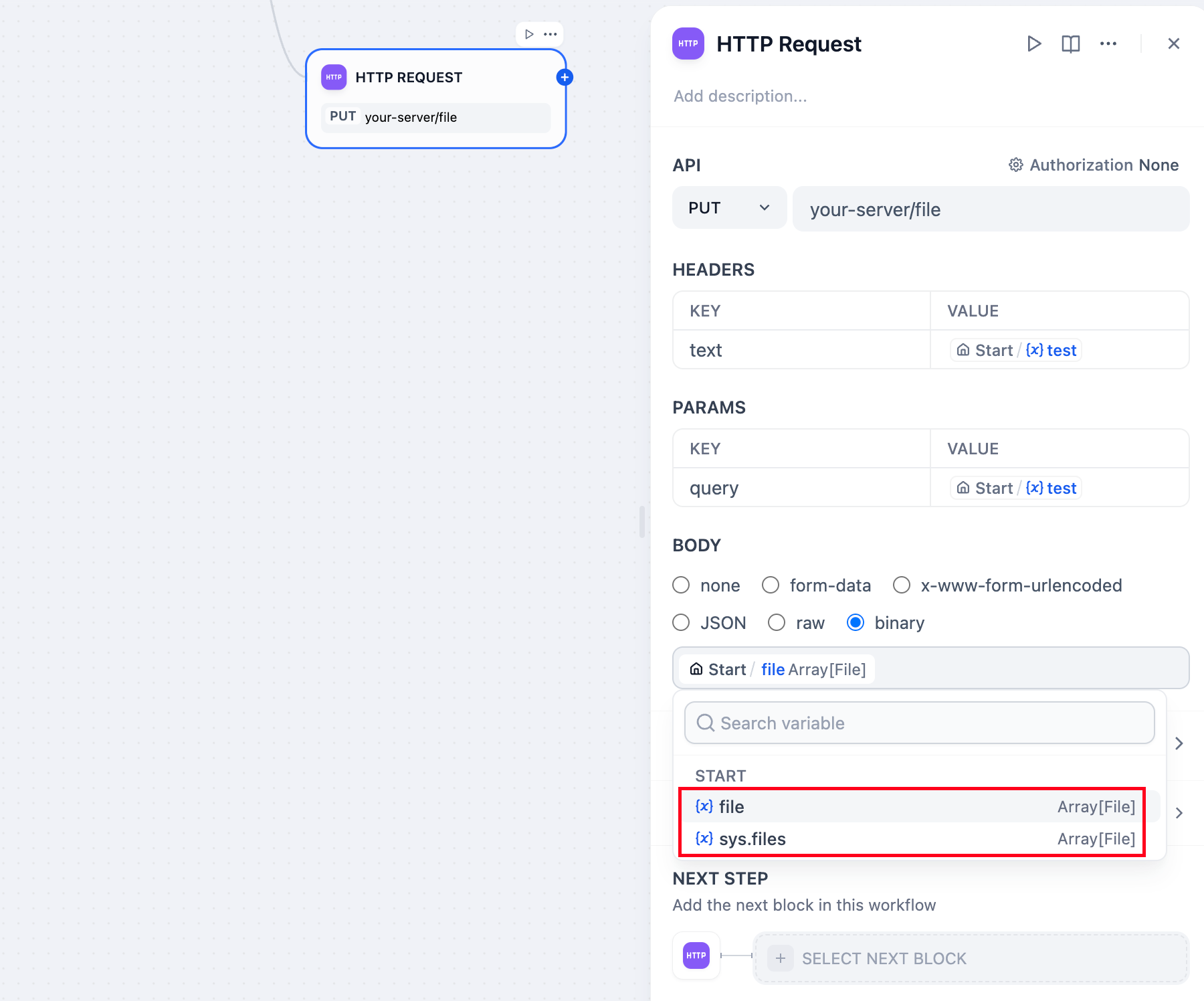
|
||||
|
||||
### 高级功能
|
||||
|
||||
**错误重试**
|
||||
|
||||
针对节点发生的部分异常情况,通常情况下再次重试运行节点即可解决。开启错误重试功能后,节点将在发生错误的时候按照预设策略进行自动重试。你可以调整最大重试次数和每次重试间隔以设置重试策略。
|
||||
|
||||
- 最大重试次数为 10 次
|
||||
- 最大重试间隔时间为 5000 ms
|
||||
|
||||

|
||||
|
||||
**异常处理**
|
||||
|
||||
HTTP 节点处理信息时有可能会遇到网络请求超时、请求限制等异常情况。应用开发者可以参考以下步骤配置异常分支,在节点出现异常时启用应对方案,而避免中断整个流程。
|
||||
|
||||
1. 在 HTTP 节点启用 “异常处理”
|
||||
2. 选择异常处理方案并进行配置
|
||||
|
||||
需了解更多应对异常的处理办法,请参考[异常处理](/zh-hans/guides/workflow/error-handling/readme)。
|
||||
|
||||

|
||||
50
zh-hans/guides/workflow/node/ifelse.mdx
Normal file
50
zh-hans/guides/workflow/node/ifelse.mdx
Normal file
@@ -0,0 +1,50 @@
|
||||
---
|
||||
title: 条件分支
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
根据 If/else/elif 条件将 Chatflow / Workflow 流程拆分成多个分支。
|
||||
|
||||
### 节点功能
|
||||
|
||||
条件分支的运行机制包含以下六个路径:
|
||||
|
||||
* IF 条件:选择变量,设置条件和满足条件的值;
|
||||
* IF 条件判断为 `True`,执行 IF 路径;
|
||||
* IF 条件判断为 `False`,执行 ELSE 路径;
|
||||
* ELIF 条件判断为 `True`,执行 ELIF 路径;
|
||||
* ELIF 条件判断为 `False`,继续判断下一个 ELIF 路径或执行最后的 ELSE 路径;
|
||||
|
||||
**条件类型**
|
||||
|
||||
支持设置以下条件类型:
|
||||
|
||||
* 包含(Contains)
|
||||
* 不包含(Not contains)
|
||||
* 开始是(Start with)
|
||||
* 结束是(End with)
|
||||
* 是(Is)
|
||||
* 不是(Is not)
|
||||
* 为空(Is empty)
|
||||
* 不为空(Is not empty)
|
||||
|
||||
***
|
||||
|
||||
### 场景
|
||||
|
||||
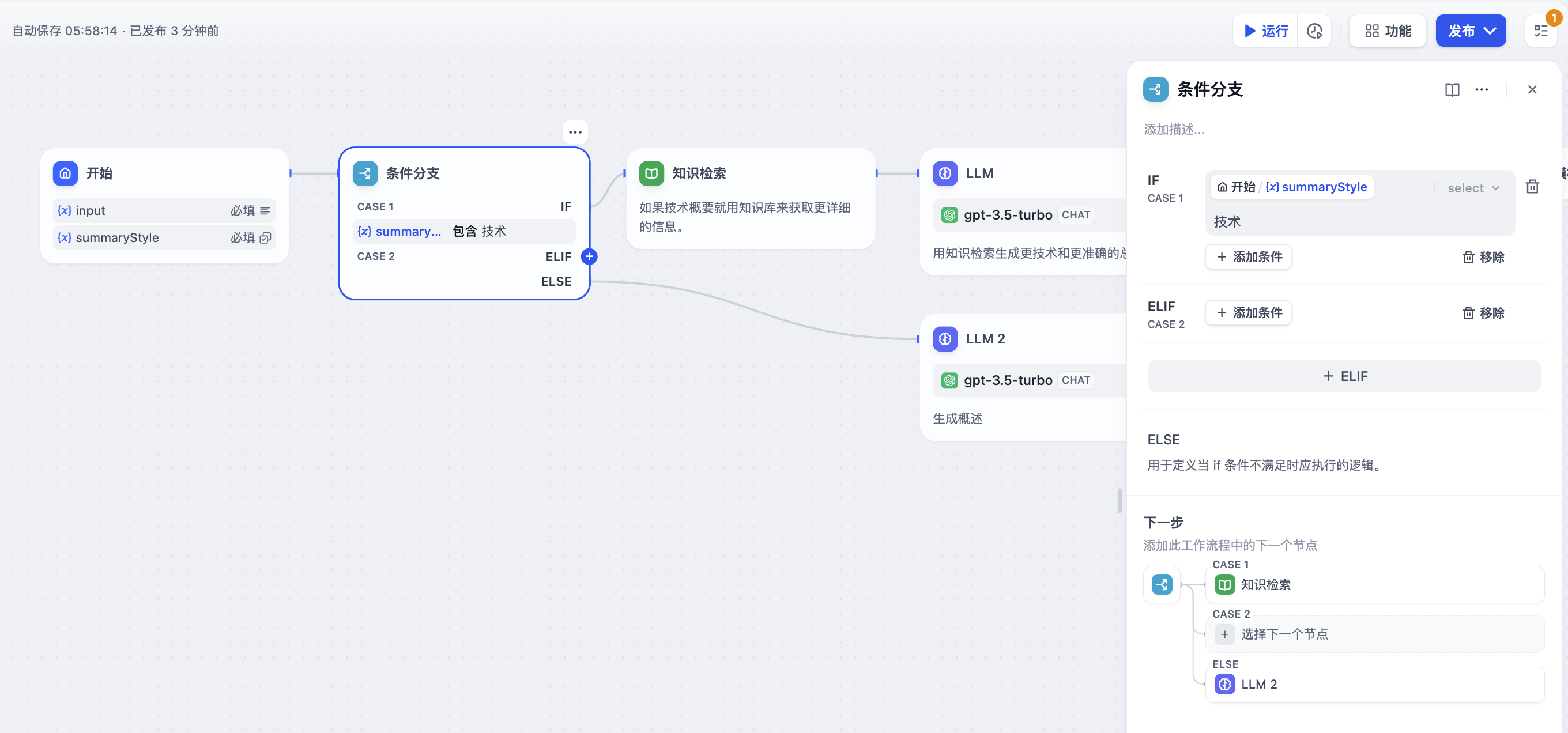
|
||||
|
||||
以**文本总结工作流**作为示例说明各个条件:
|
||||
|
||||
* IF 条件: 选择开始节点中的 `summarystyle` 变量,条件为**包含** `技术`;
|
||||
* IF 条件判断为 `True`,执行 IF 路径,通过知识检索节点查询技术相关知识再到 LLM 节点回复(图中上半部分);
|
||||
* IF 条件判断为 `False`,但添加了 `ELIF` 条件,即 `summarystyle` 变量输入**不包含**`技术`,但 `ELIF` 条件内包含 `科技`,会检查 `ELIF` 内的条件是否为 `True`,然后执行路径内定义的步骤;
|
||||
* `ELIF` 内的条件为 `False`,即输入变量既不不包含 `技术`,也不包含 `科技`,继续判断下一个 ELIF 路径或执行最后的 ELSE 路径;
|
||||
* IF 条件判断为 `False`,即 `summarystyle` 变量输入**不包含** `技术`,执行 ELSE 路径,通过 LLM2 节点进行回复(图中下半部分);
|
||||
|
||||
**多重条件判断**
|
||||
|
||||
涉及复杂的条件判断时,可以设置多重条件判断,在条件之间设置 **AND** 或者 **OR**,即在条件之间取**交集**或者**并集**。
|
||||
|
||||
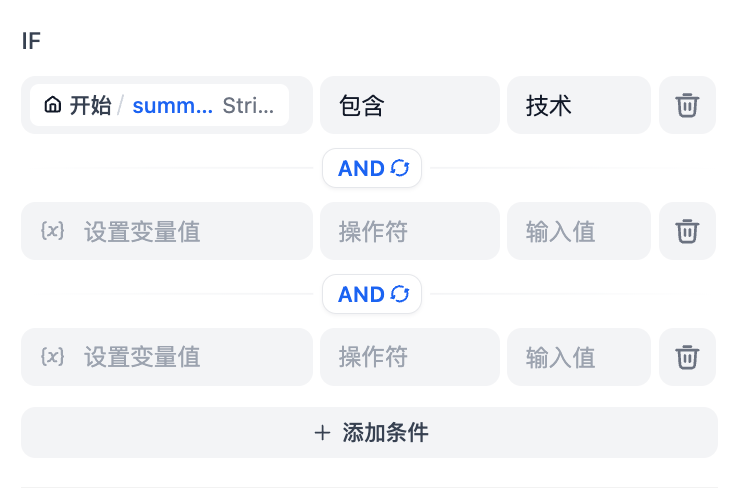
|
||||
175
zh-hans/guides/workflow/node/iteration.mdx
Normal file
175
zh-hans/guides/workflow/node/iteration.mdx
Normal file
@@ -0,0 +1,175 @@
|
||||
---
|
||||
title: 迭代
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
对数组中的元素依次执行相同的操作步骤,直至输出所有结果,可以理解为任务批处理器。迭代节点通常配合数组变量使用。
|
||||
|
||||
例如在长文翻译迭代节点内,如果将所有内容输入至 LLM 节点,有可能会达到单次对话限制。上游节点可以先将长文拆分为了多个片段,配合迭代节点对各个片段执行批量翻译,以避免达到 LLM 单次对话的消息限制。
|
||||
|
||||
***
|
||||
|
||||
### 功能简介
|
||||
|
||||
使用迭代的条件是确保输入值已格式化为列表对象;迭代节点将依次处理迭代开始节点数组变量内的所有元素,每个元素遵循相同的处理步骤,每轮处理被称为一个迭代,最终输出处理结果。
|
||||
|
||||
迭代节点的结构通常包含**输入变量**、**迭代工作流**、**输出变量**三个功能单元。
|
||||
|
||||
**输入变量:** 仅接受 Array 数组变量类型数据。如果你不了解什么是数组变量,请阅读 [扩展阅读:数组](../../../learn-more/extended-reading/what-is-array-variable)。
|
||||
|
||||
**迭代工作流:** 你可以在迭代节点中使用多个工作流节点,编排不同的任务步骤。
|
||||
|
||||
**输出变量:** 仅支持输出数组变量 `Array[List]`。如果你想要输出其它变量格式,请阅读 [扩展阅读:如何将数组转换为文本](#如何将数组转换为文本)。
|
||||
|
||||
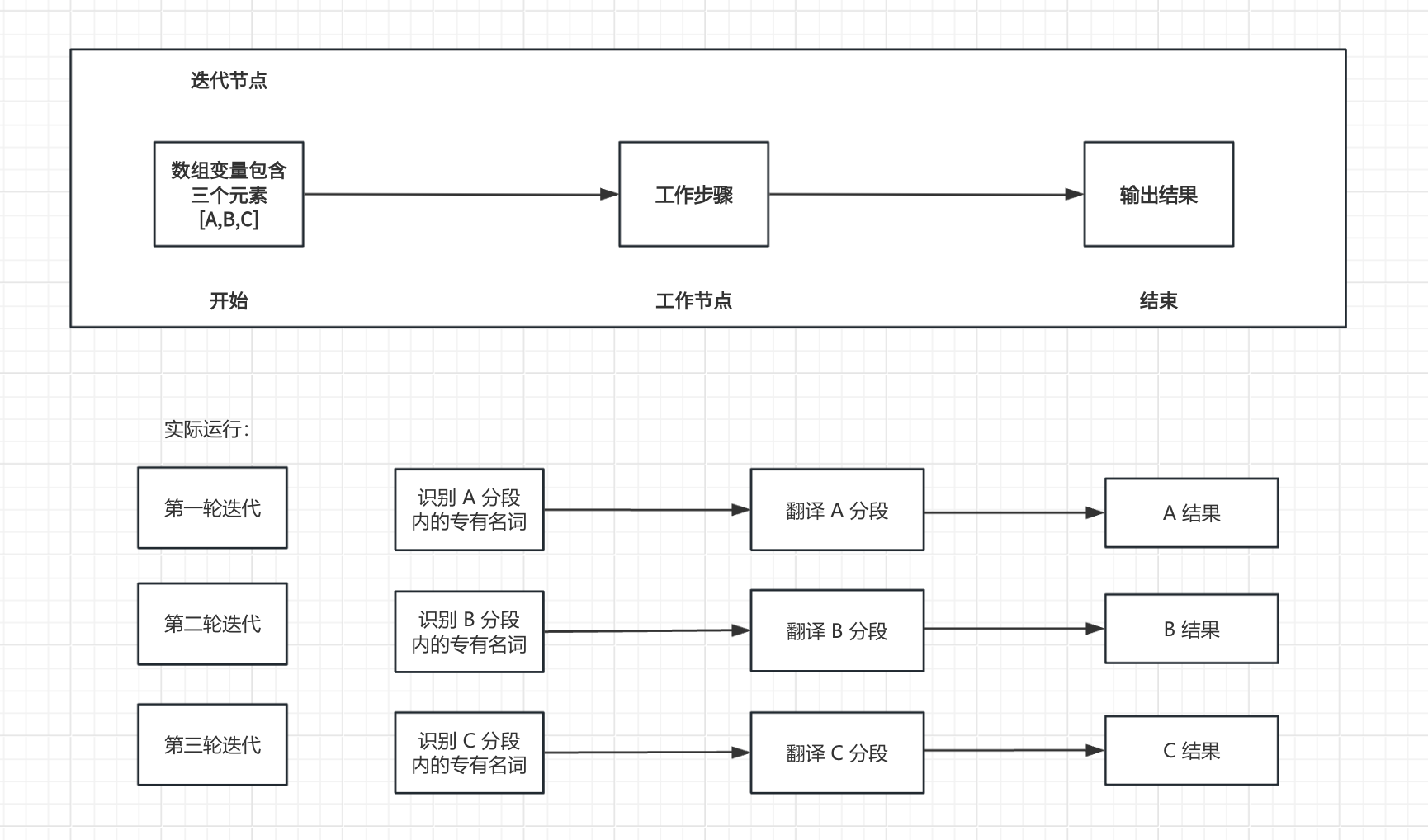
|
||||
|
||||
### 场景
|
||||
|
||||
#### **示例1:长文章迭代生成器**
|
||||
|
||||
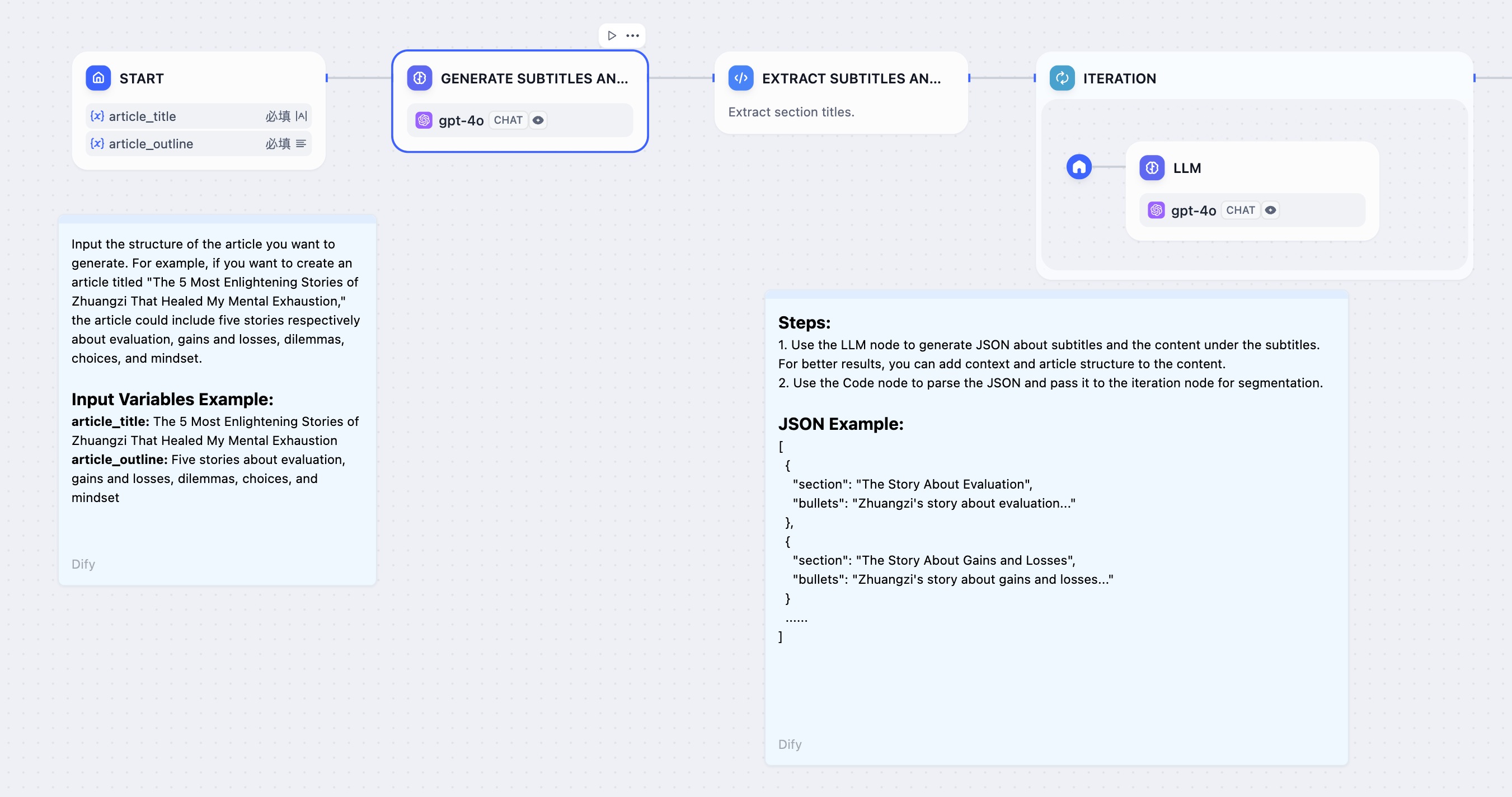
|
||||
|
||||
1. 在 **开始节点** 内添加输入故事标题、大纲变量,提示用户手动输入初始信息
|
||||
2. 使用 **LLM 节点** 基于用户输入的故事标题和大纲,让 LLM 开始编写内容
|
||||
3. 使用 **参数提取节点** 将 LLM 输出的完整内容转换成数组格式
|
||||
4. 通过 **迭代节点** 包裹的 **LLM 节点** 循环多次生成各章节内容
|
||||
5. 将 **直接回复** 节点添加在迭代节点内部,实现在每轮迭代生成之后流式输出
|
||||
|
||||
**具体配置步骤**
|
||||
|
||||
1. 在 **开始节点** 配置故事标题(title)和大纲(outline);
|
||||
|
||||
|
||||
|
||||
2. 选择 **LLM 节点** 基于用户输入的故事标题和大纲,让 LLM 开始编写文本;
|
||||
|
||||
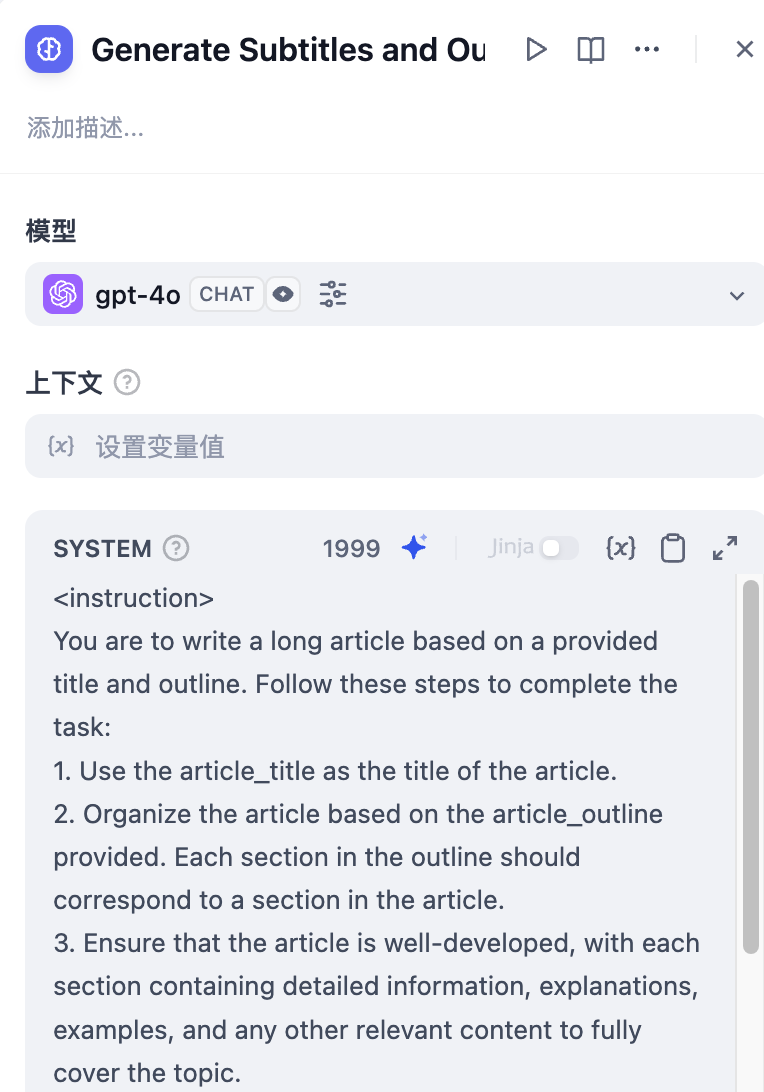
|
||||
|
||||
3. 选择 **参数提取节点**,将故事文本转换成为数组(Array)结构。提取参数为 `sections` ,参数类型为 `Array[Object]`
|
||||
|
||||
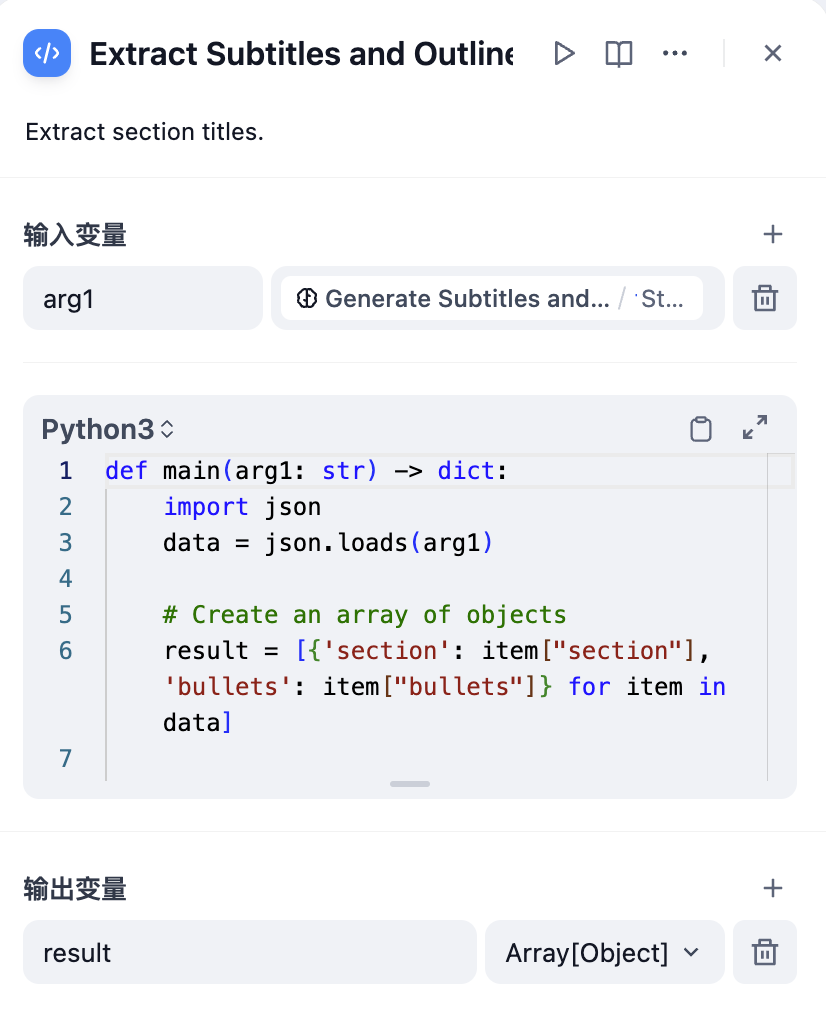
|
||||
|
||||
<Info>
|
||||
参数提取效果受模型推理能力和指令影响,使用推理能力更强的模型,在**指令**内增加示例可以提高参数提取的效果。
|
||||
</Info>
|
||||
|
||||
4. 将数组格式的故事大纲作为迭代节点的输入,在迭代节点内部使用 **LLM 节点** 进行处理
|
||||
|
||||
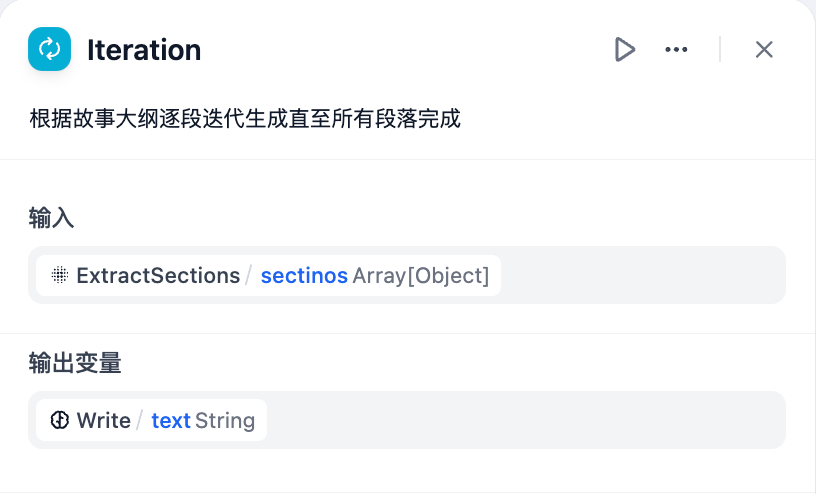
|
||||
|
||||
在 LLM 节点内配置输入变量 `GenerateOverallOutline/output` 和 `Iteration/item`
|
||||
|
||||
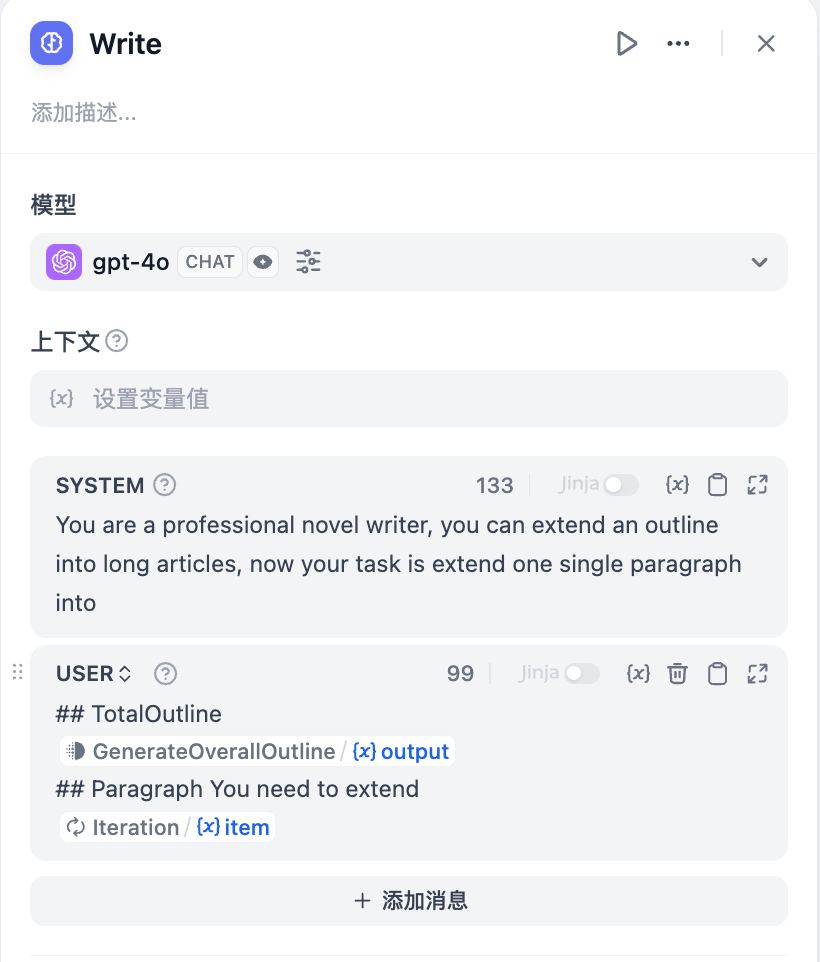
|
||||
|
||||
<Info>
|
||||
迭代的内置变量:`items[object]` 和 `index[number]`
|
||||
|
||||
`items[object] 代表以每轮迭代的输入条目;`
|
||||
|
||||
`index[number] 代表当前迭代的轮次;`
|
||||
</Info>
|
||||
|
||||
5. 在迭代节点内部配置 **直接回复节点** ,可以实现在每轮迭代生成之后流式输出。
|
||||
|
||||
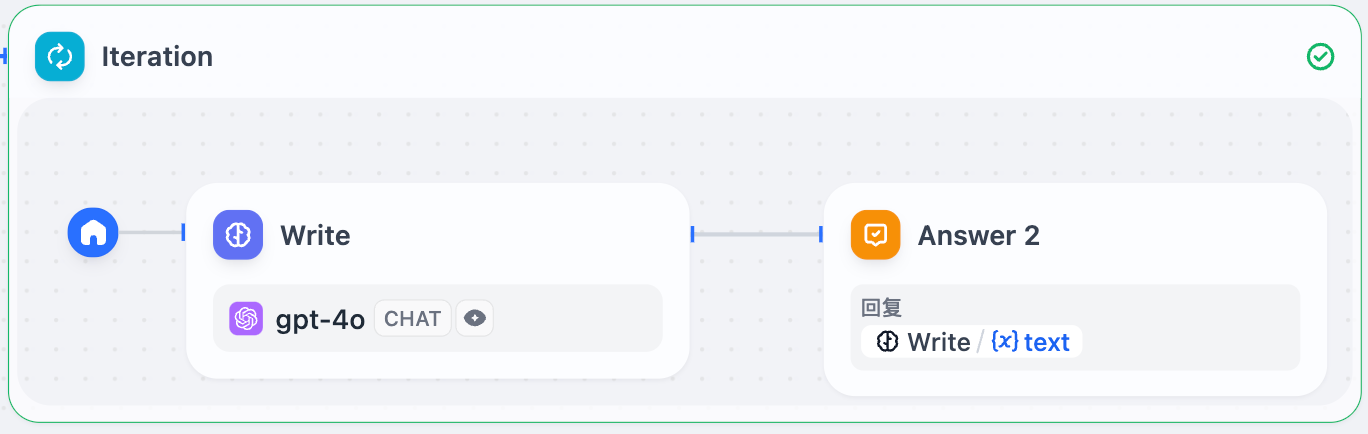
|
||||
|
||||
6. 完整调试和预览
|
||||
|
||||
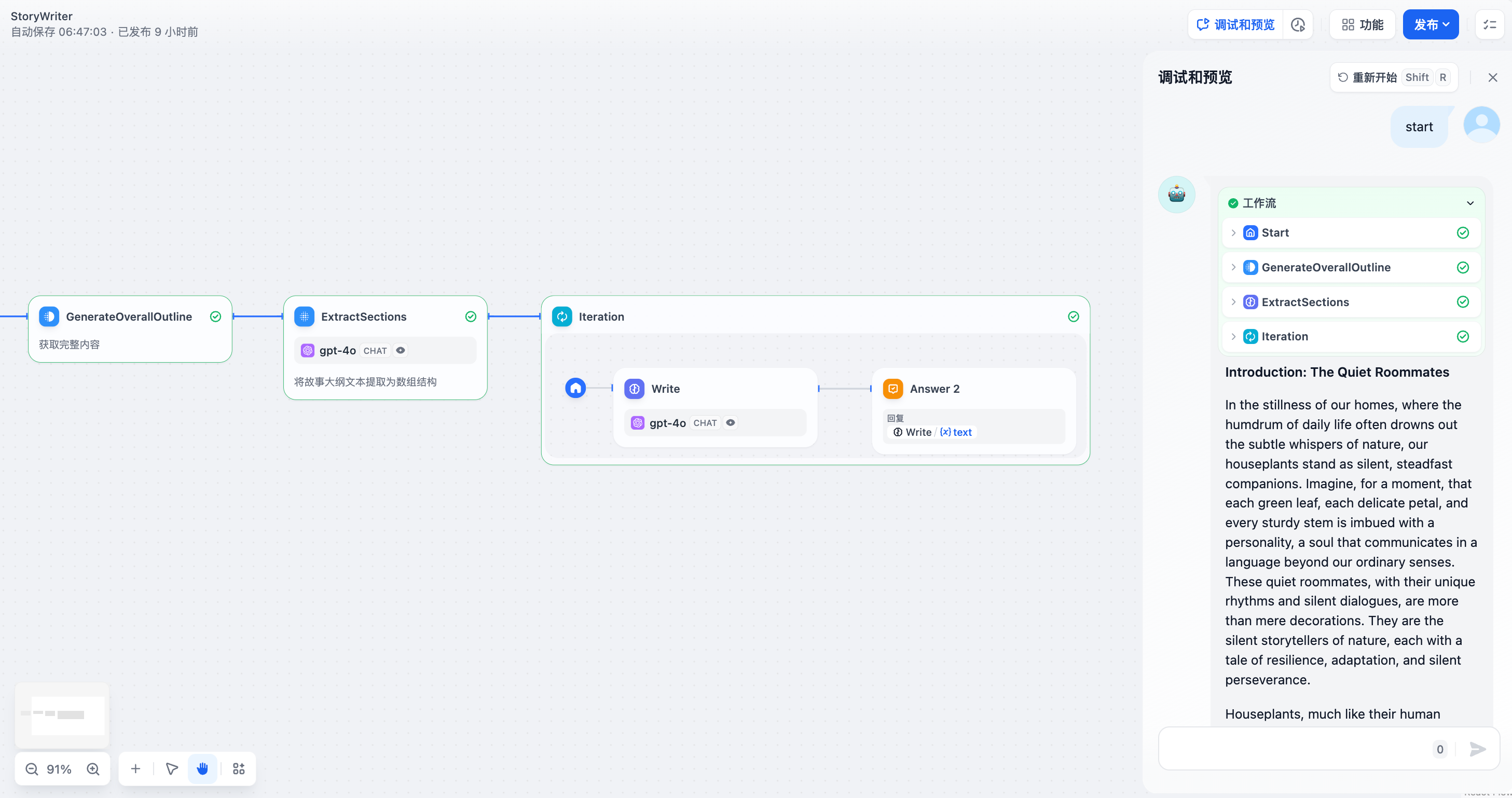
|
||||
|
||||
#### **示例 2:长文章迭代生成器(另一种编排方式)**
|
||||
|
||||
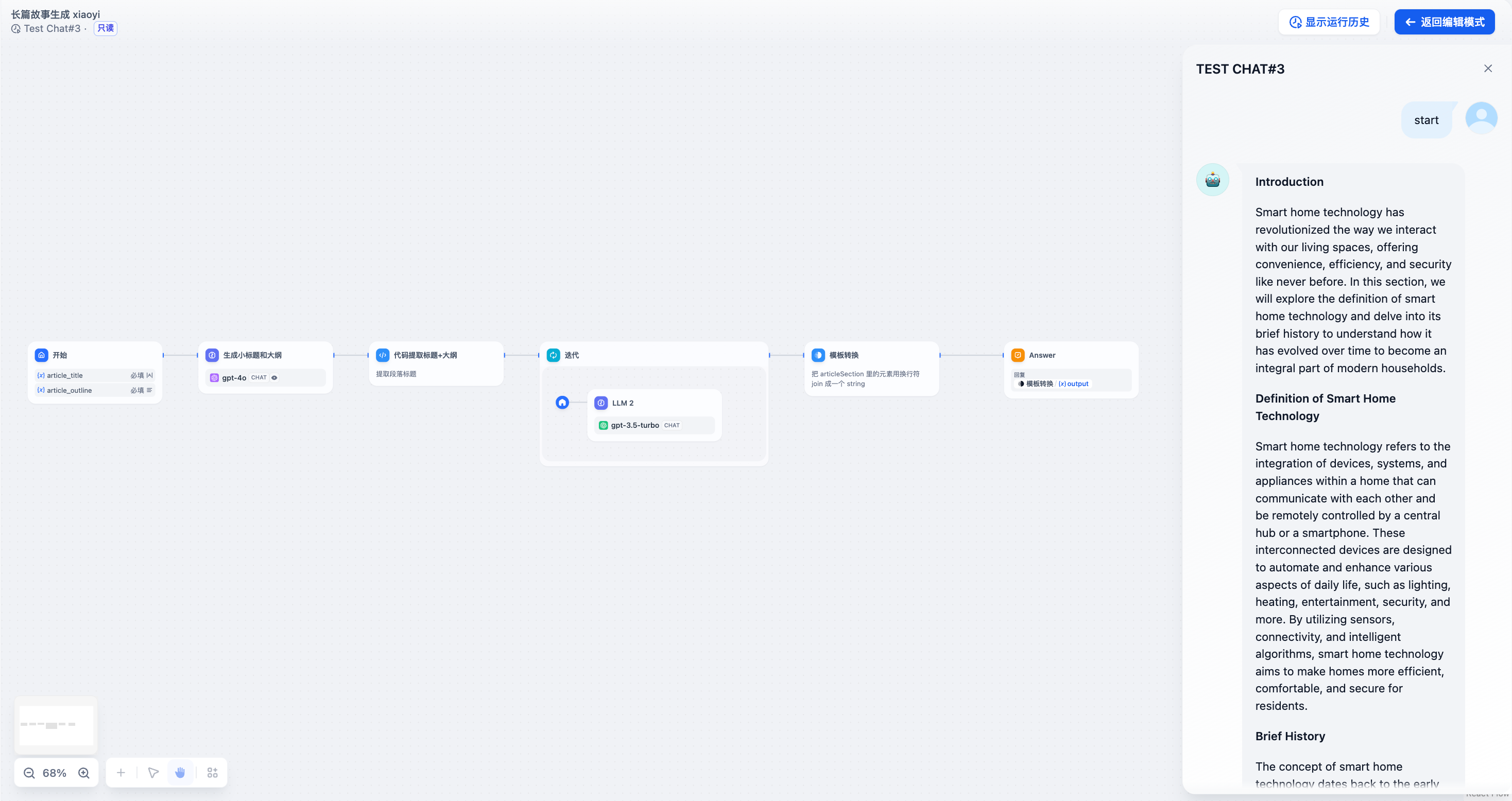
|
||||
|
||||
* 在 **开始节点** 内输入故事标题和大纲
|
||||
* 使用 **LLM 节点** 生成文章小标题,以及小标题对应的内容
|
||||
* 使用 **代码节点** 将完整内容转换成数组格式
|
||||
* 通过 **迭代节点** 包裹的 **LLM 节点** 循环多次生成各章节内容
|
||||
* 使用 **模板转换** 节点将迭代节点输出的字符串数组转换为字符串
|
||||
* 在最后添加 **直接回复节点** 将转换后的字符串直接输出
|
||||
|
||||
***
|
||||
|
||||
### 高级功能
|
||||
|
||||
**并行模式**
|
||||
|
||||
迭代节点支持并行模式,开启后将有效提升迭代节点的整体运行效率。
|
||||
|
||||
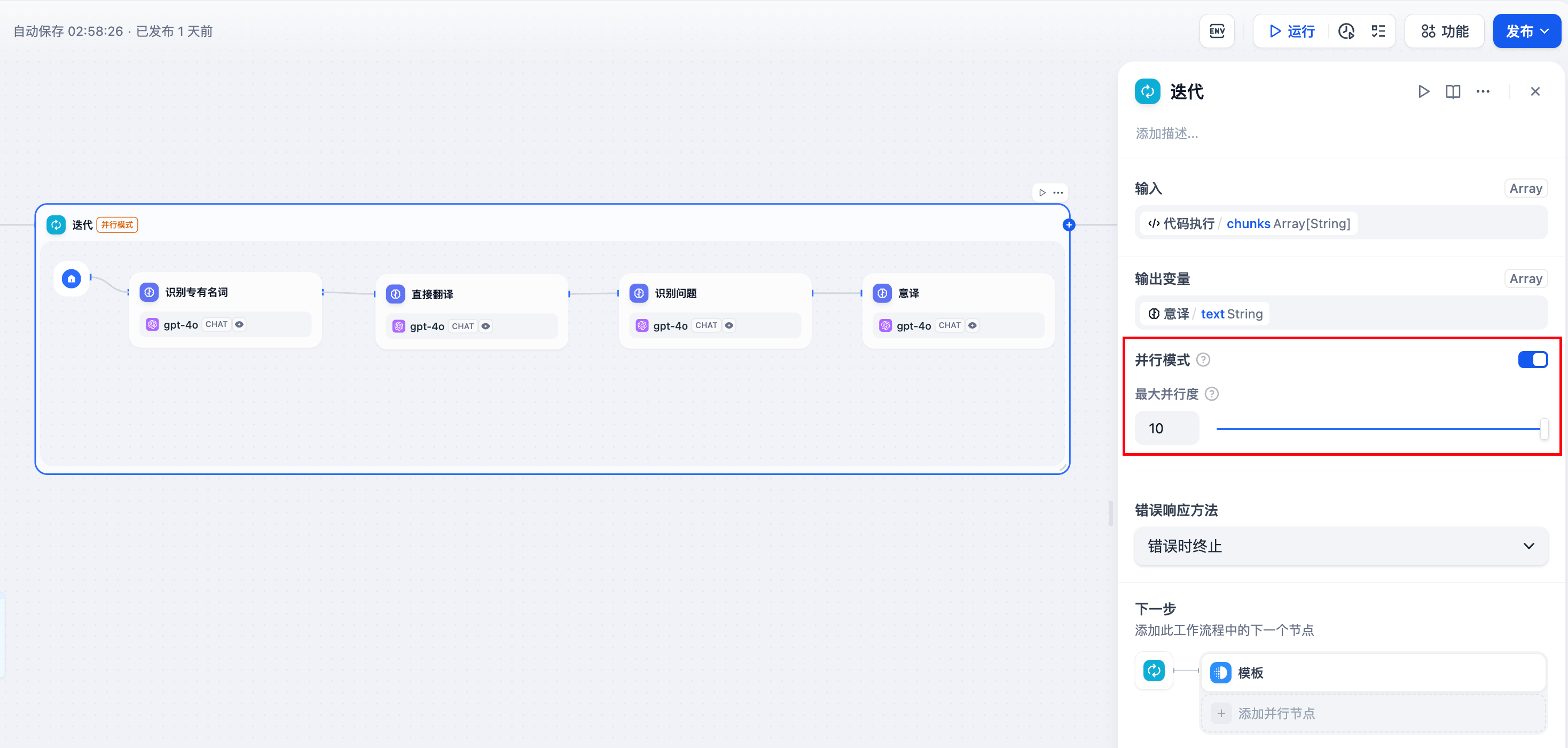
|
||||
|
||||
下图是迭代节点开启或关闭并行模式的运行效果对比。
|
||||
|
||||
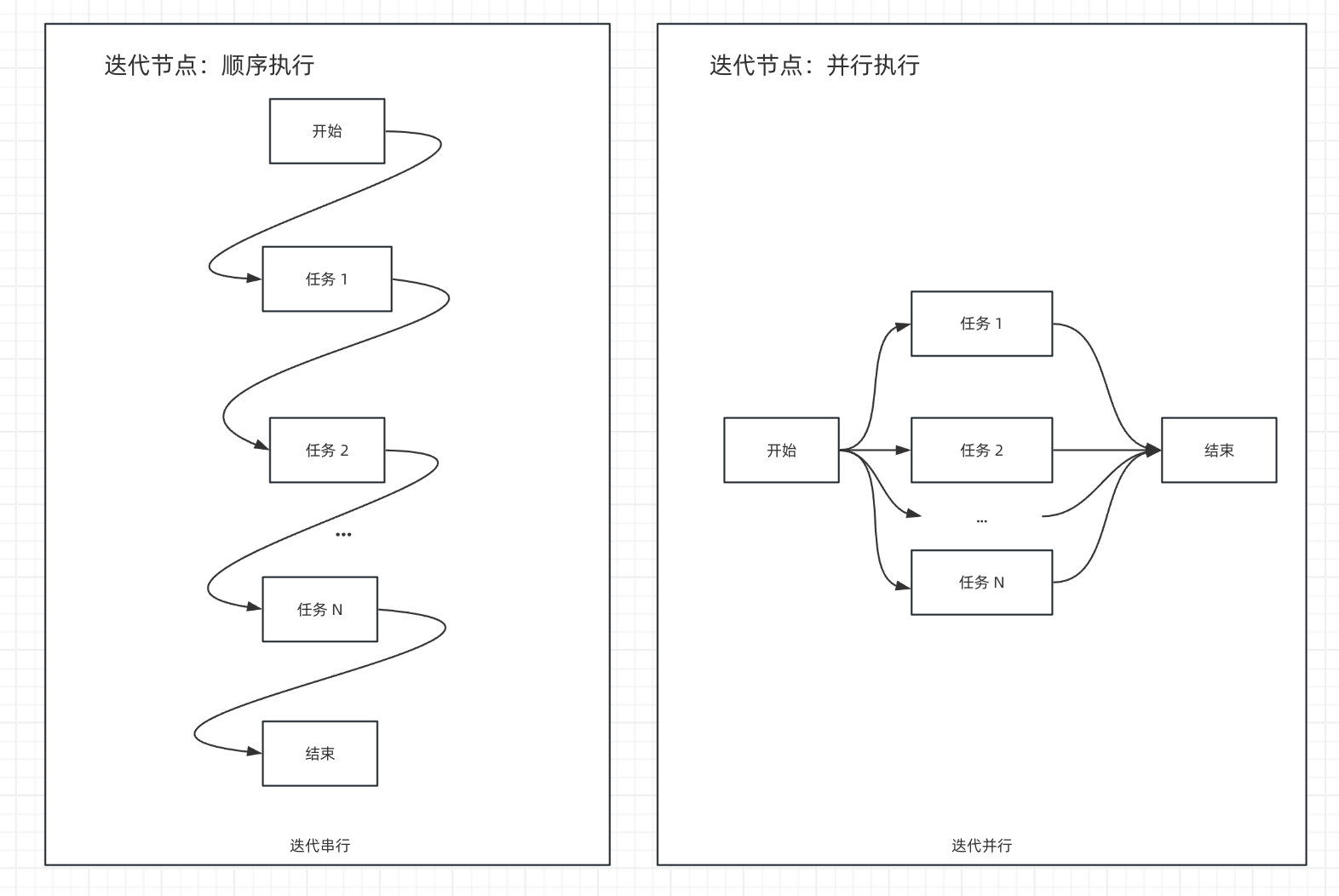
|
||||
|
||||
并行模式下的最高并行轮数为 10,这意味着单位时间内最多可以同时运行 10 个任务。如果需要处理超过 10 个任务,前 10 个元素将率先同时运行,前排任务处理完成后将继续处理剩余任务。
|
||||
|
||||
<Info>
|
||||
开启并行模式后,不再建议在迭代节点内放置直接回答、变量赋值和工具节点。此举可能会造成异常情况。
|
||||
</Info>
|
||||
|
||||
* **错误响应方法**
|
||||
|
||||
迭代节点通常需要处理大量任务,有时会在处理某个元素时发生错误。为了避免某个元素异常而中断所有任务,你可以在**错误响应方法**中设置异常的应对方法:
|
||||
|
||||
* 错误时终止。如果发现异常输出,终止迭代节点,输出错误信息。
|
||||
* 忽略错误并继续。忽略异常信息,继续处理剩余元素。输出的信息中包含正确信息,异常信息为空值。
|
||||
* 移除错误输出。忽略异常信息,继续处理剩余元素。输出的信息中仅包含正确信息。
|
||||
|
||||
迭代节点的输入变量与输出变量相对应。例如输入变量为 \[1,2,3] ,则输出变量同样为 \[result-1, result-2, result-3]。
|
||||
|
||||
如果选择了**忽略错误并继续,** 异常情况的输出值为 null 值,例如 \[result-1, null, result-3];
|
||||
|
||||
如果选择了**移除错误输出,** 将不会输出异常变量,例如 \[result-1, result-3]。
|
||||
|
||||
### 扩展阅读
|
||||
|
||||
[**什么是数组变量?**](../../../learn-more/extended-reading/what-is-array-variable)
|
||||
|
||||
***
|
||||
|
||||
#### 如何生成数组变量?
|
||||
|
||||
你可以通过以下节点生成数组变量,用以充当迭代节点的输入变量:
|
||||
|
||||
* [代码节点](code)
|
||||
|
||||
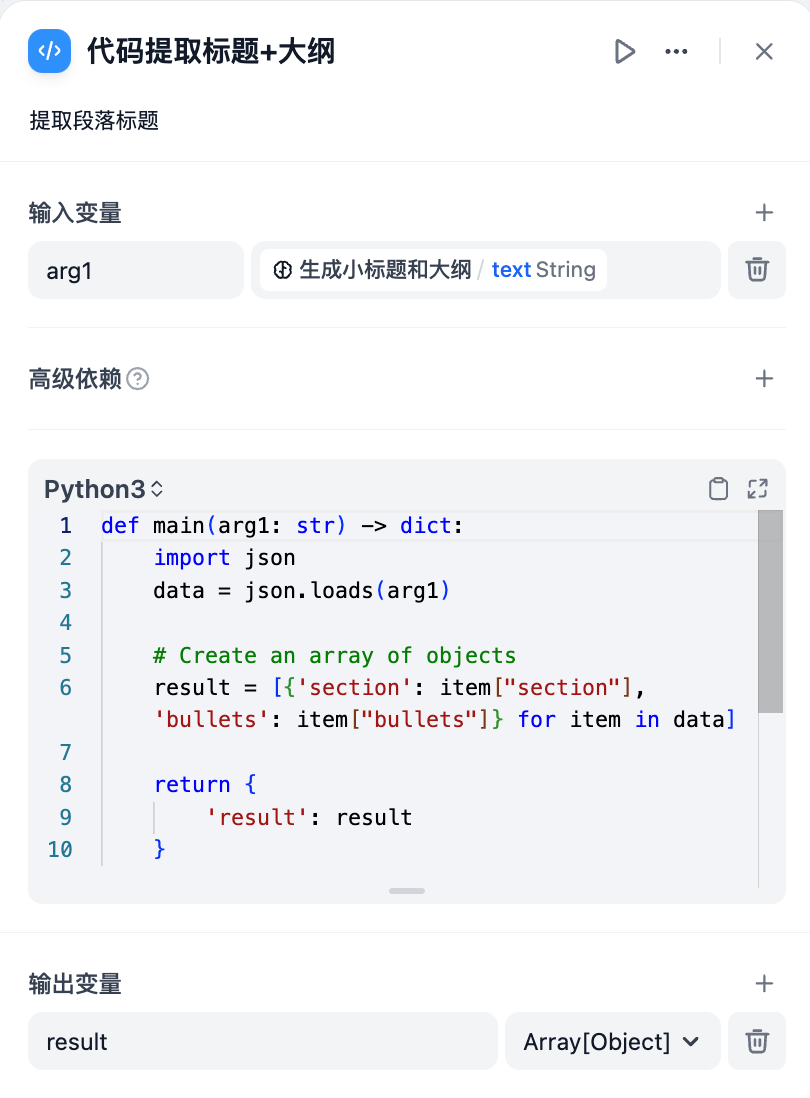
|
||||
* [参数提取](parameter-extractor)
|
||||
|
||||

|
||||
* [知识库检索](knowledge-retrieval)
|
||||
* [迭代](iteration)
|
||||
* [工具](tools)
|
||||
* [HTTP 请求](http-request)
|
||||
|
||||
***
|
||||
|
||||
#### 如何将数组转换为文本
|
||||
|
||||
迭代节点的输出变量为数组格式,无法直接输出 String 字符串内容。你可以使用一个简单的步骤将数组转换回文本。
|
||||
|
||||
**使用代码节点转换**
|
||||
|
||||
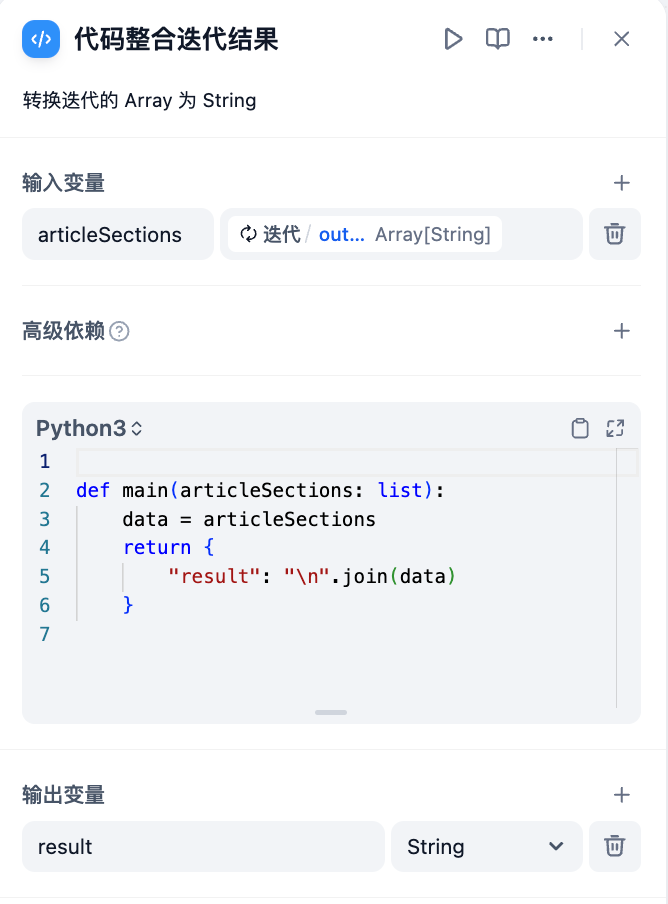
|
||||
|
||||
代码示例:
|
||||
|
||||
```python
|
||||
def main(articleSections: list):
|
||||
data = articleSections
|
||||
return {
|
||||
"result": "\n".join(data)
|
||||
}
|
||||
```
|
||||
|
||||
**使用模板节点转换**
|
||||
|
||||
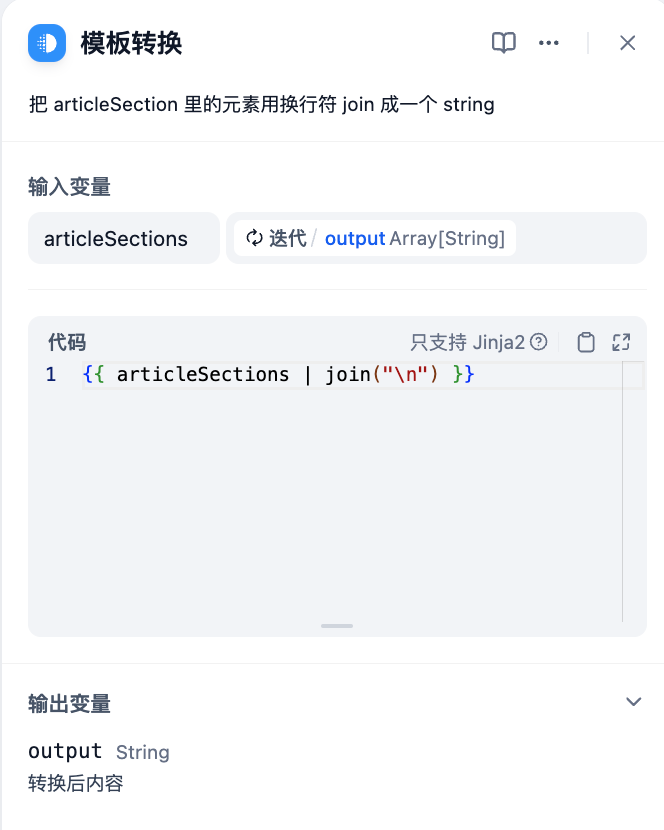
|
||||
|
||||
代码示例:
|
||||
|
||||
```django
|
||||
{{ articleSections | join("\n") }}
|
||||
```
|
||||
53
zh-hans/guides/workflow/node/knowledge-retrieval.mdx
Normal file
53
zh-hans/guides/workflow/node/knowledge-retrieval.mdx
Normal file
@@ -0,0 +1,53 @@
|
||||
---
|
||||
title: 知识检索
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
|
||||
### 定义
|
||||
|
||||
从知识库中检索与用户问题相关的文本内容,可作为下游 LLM 节点的上下文来使用。
|
||||
|
||||
***
|
||||
|
||||
### 应用场景
|
||||
|
||||
常见情景:构建基于外部数据/知识的 AI 问答系统(RAG)。了解更多关于 RAG 的[基本概念](../../../learn-more/extended-reading/retrieval-augment/)。
|
||||
|
||||
下图为一个最基础的知识库问答应用示例,该流程的执行逻辑为:知识库检索作为 LLM 节点的前置步骤,在用户问题传递至 LLM 节点之前,先在知识检索节点内将匹配用户问题最相关的文本内容并召回,随后在 LLM 节点内将用户问题与检索到的上下文一同作为输入,让 LLM 根据检索内容来回复问题。
|
||||
|
||||
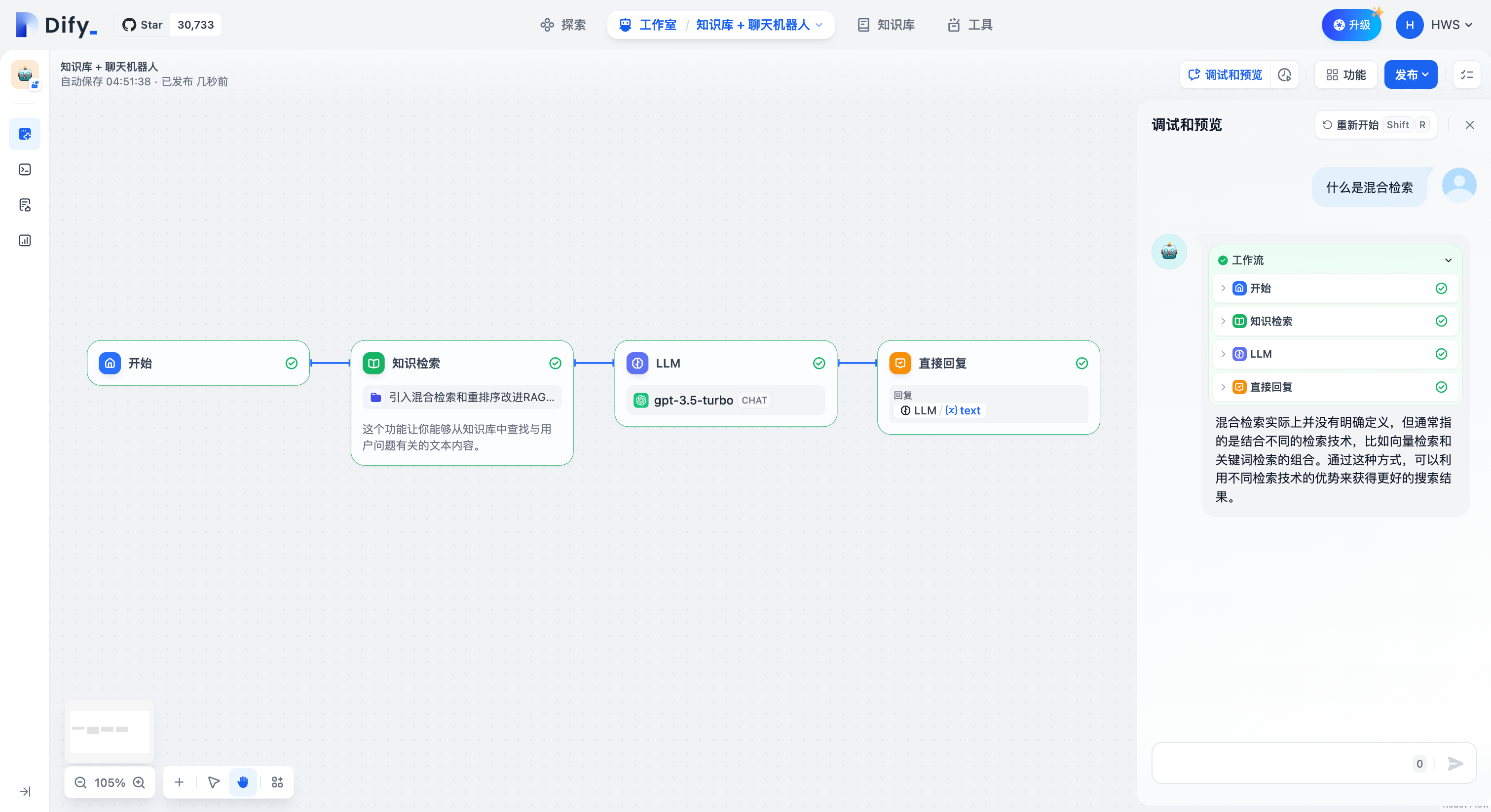
|
||||
|
||||
***
|
||||
|
||||
### 配置指引
|
||||
|
||||
**配置流程:**
|
||||
|
||||
1. 选择查询变量。查询变量通常代表用户输入的问题,该变量可以作为输入项并检索知识库中的相关文本分段。在常见的对话类应用中一般将开始节点的 `sys.query` 作为查询变量,知识库所能接受的最大查询内容为 200 字符;
|
||||
2. 选择需要查询的知识库,可选知识库需要在 Dify 知识库内预先[创建](../../knowledge-base/create-knowledge-and-upload-documents/);
|
||||
3. 在 元数据筛选 板块中配置元数据的筛选条件,使用元数据功能筛选知识库内的文档。详情请参阅[在应用内集成知识库](/zh-hans/guides/knowledge-base/integrate-knowledge-within-application)中的 **使用元数据筛选知识** 章节。
|
||||
4. 指定[召回模式](../../../learn-more/extended-reading/retrieval-augment/retrieval)。自 9 月 1 日后,知识库的召回模式将自动切换为多路召回,不再建议使用 N 选 1 召回模式;
|
||||
5. 连接并配置下游节点,一般为 LLM 节点;
|
||||
|
||||
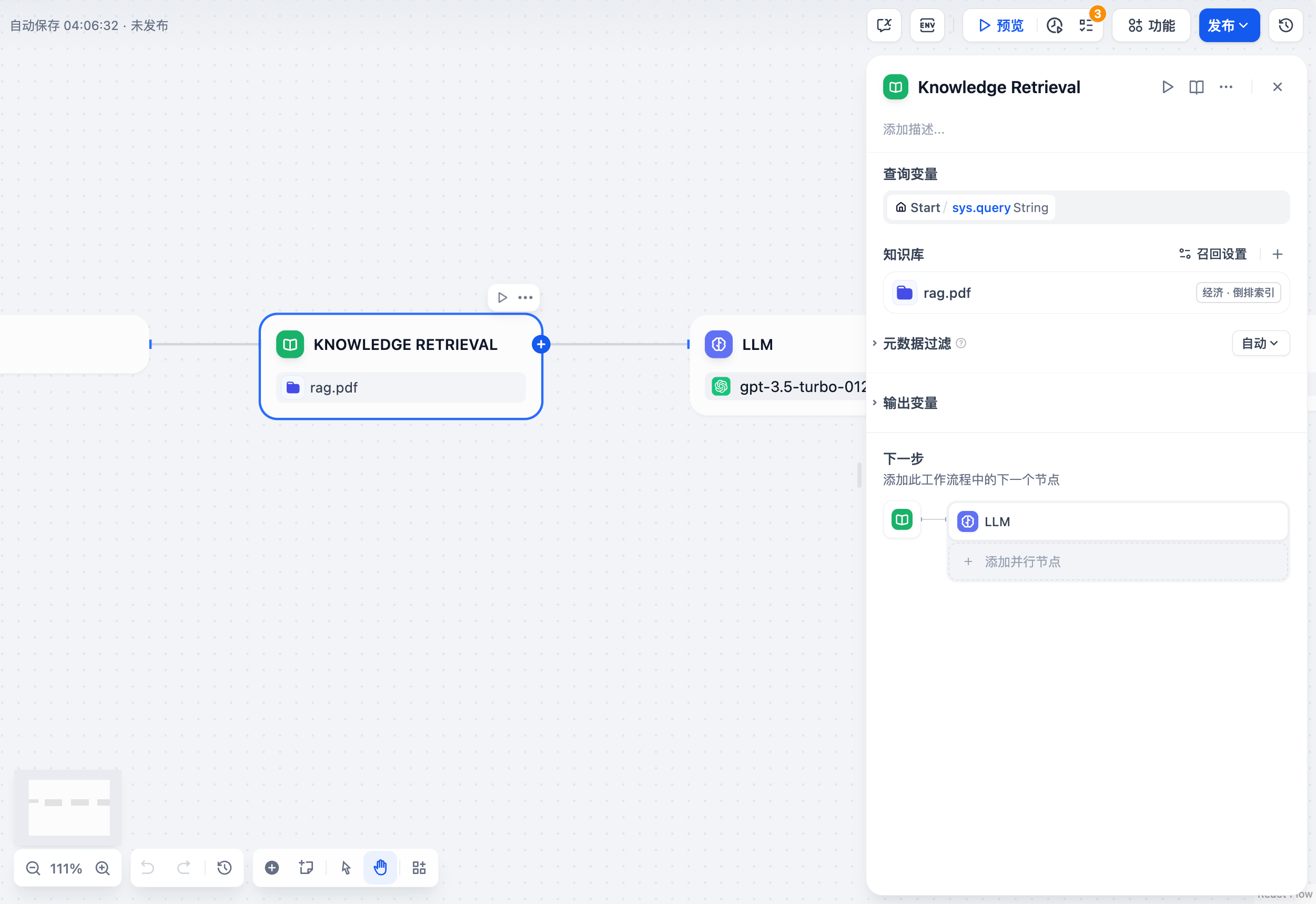
|
||||
|
||||
**输出变量**
|
||||
|
||||

|
||||
|
||||
知识检索的输出变量 `result` 为从知识库中检索到的相关文本分段。其变量数据结构中包含了分段内容、标题、链接、图标、元数据信息。
|
||||
|
||||
**配置下游节点**
|
||||
|
||||
在常见的对话类应用中,知识库检索的下游节点一般为 LLM 节点,知识检索的**输出变量** `result` 需要配置在 LLM 节点中的 **上下文变量** 内关联赋值。关联后你可以在提示词的合适位置插入 **上下文变量**。
|
||||
|
||||
<Info>
|
||||
上下文变量是 LLM 节点内定义的特殊变量类型,用于在提示词内插入外部检索的文本内容。
|
||||
</Info>
|
||||
|
||||
当用户提问时,若在知识检索中召回了相关文本,文本内容会作为上下文变量中的值填入提示词,提供 LLM 回复问题;若未在知识库检索中召回相关的文本,上下文变量值为空,LLM 则会直接回复用户问题。
|
||||
|
||||
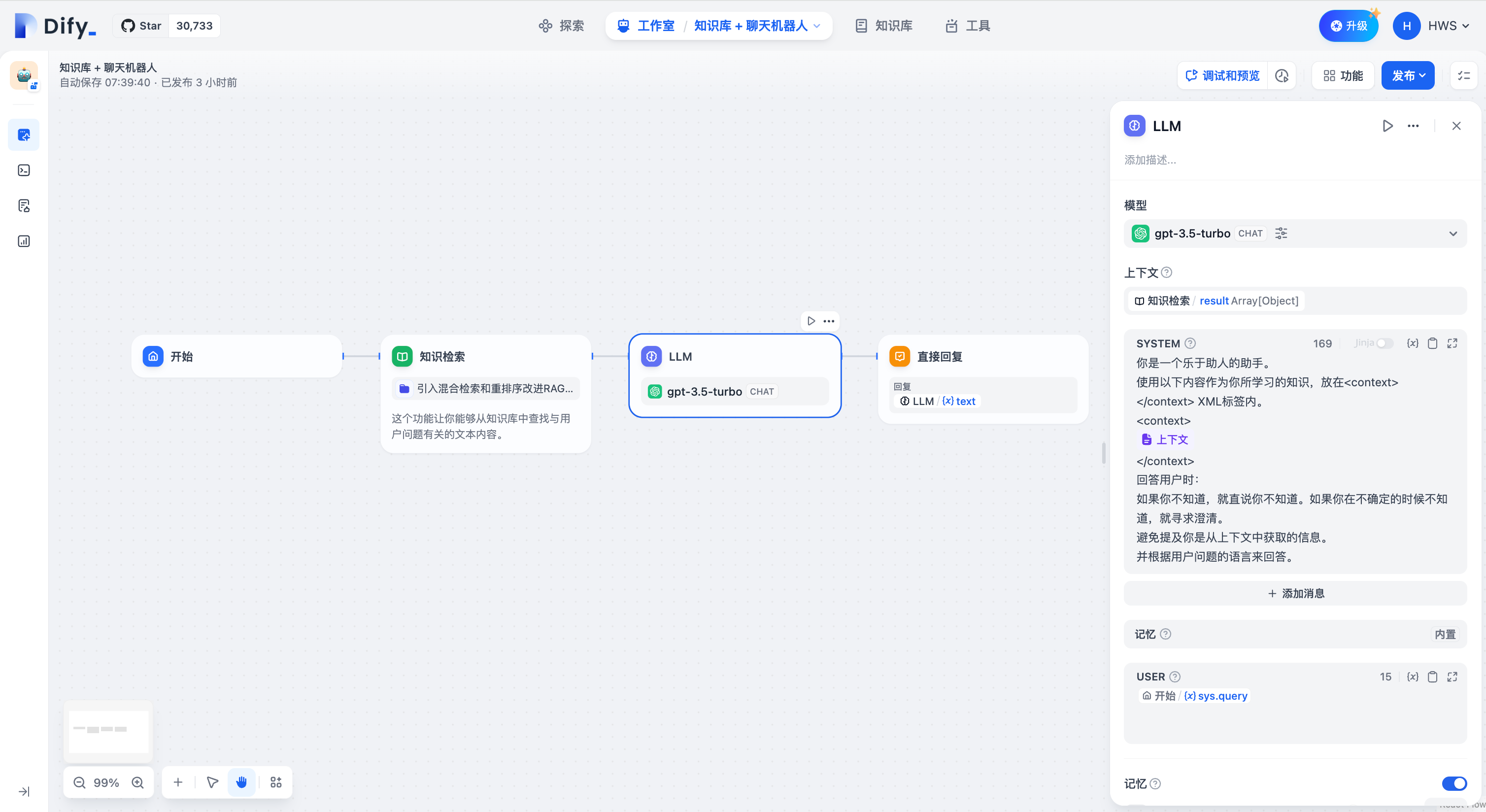
|
||||
|
||||
该变量除了可以作为 LLM 回复问题时的提示词上下文作为外部知识参考引用,另外由于其数据结构中包含了分段引用信息,同时可以支持应用端的 [**引用与归属**](/zh-hans/guides/knowledge-base/retrieval-test-and-citation) 功能。
|
||||
88
zh-hans/guides/workflow/node/list-operator.mdx
Normal file
88
zh-hans/guides/workflow/node/list-operator.mdx
Normal file
@@ -0,0 +1,88 @@
|
||||
---
|
||||
title: 列表操作
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
文件列表变量支持同时上传文档文件、图片、音频与视频文件等多种文件。应用使用者在上传文件时,所有文件都存储在同一个 `Array[File]` 数组类型变量内,**不利于后续单独处理文件。** 列表操作节点可以在数组变量内提取单独的元素,便于后续节点处理。
|
||||
|
||||
> `Array`数据类型意味着该变量的实际值可能为 \[1.mp3, 2.png, 3.doc],大语言模型(LLM)仅支持读取图片文件或文本内容等单一值作为输入变量,无法直接读取数组变量,通常需要配合列表操作节点一起使用。
|
||||
|
||||
### 节点功能
|
||||
|
||||
列表操作节点可以对文件的格式类型、文件名、大小等属性进行过滤与提取,将不同格式的文件传递给对应的处理节点,以实现对不同文件处理流的精确控制。
|
||||
|
||||
例如在一个应用中,允许用户同时上传文档文件和图片文件两种不同类型的文件。需要使用**列表操作节点**进行分拣,将不同的文件类型交由不同流程处理。
|
||||
|
||||
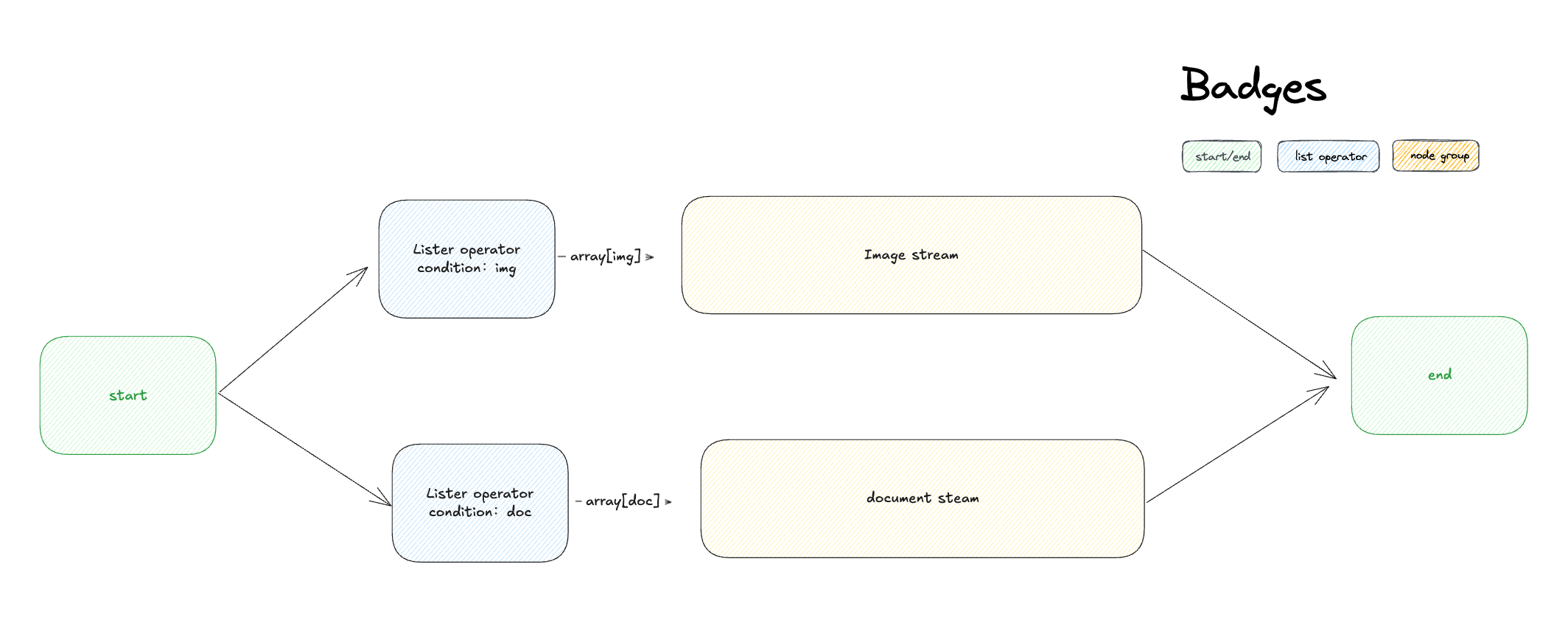
|
||||
|
||||
列表操作节点一般用于提取数组变量中的信息,通过设置条件将其转化为能够被下游节点所接受的变量类型。它的结构分为**输入变量**、**过滤条件**、**排序(可选)**、**取前 N 项(可选)**、**输出变量**。
|
||||
|
||||
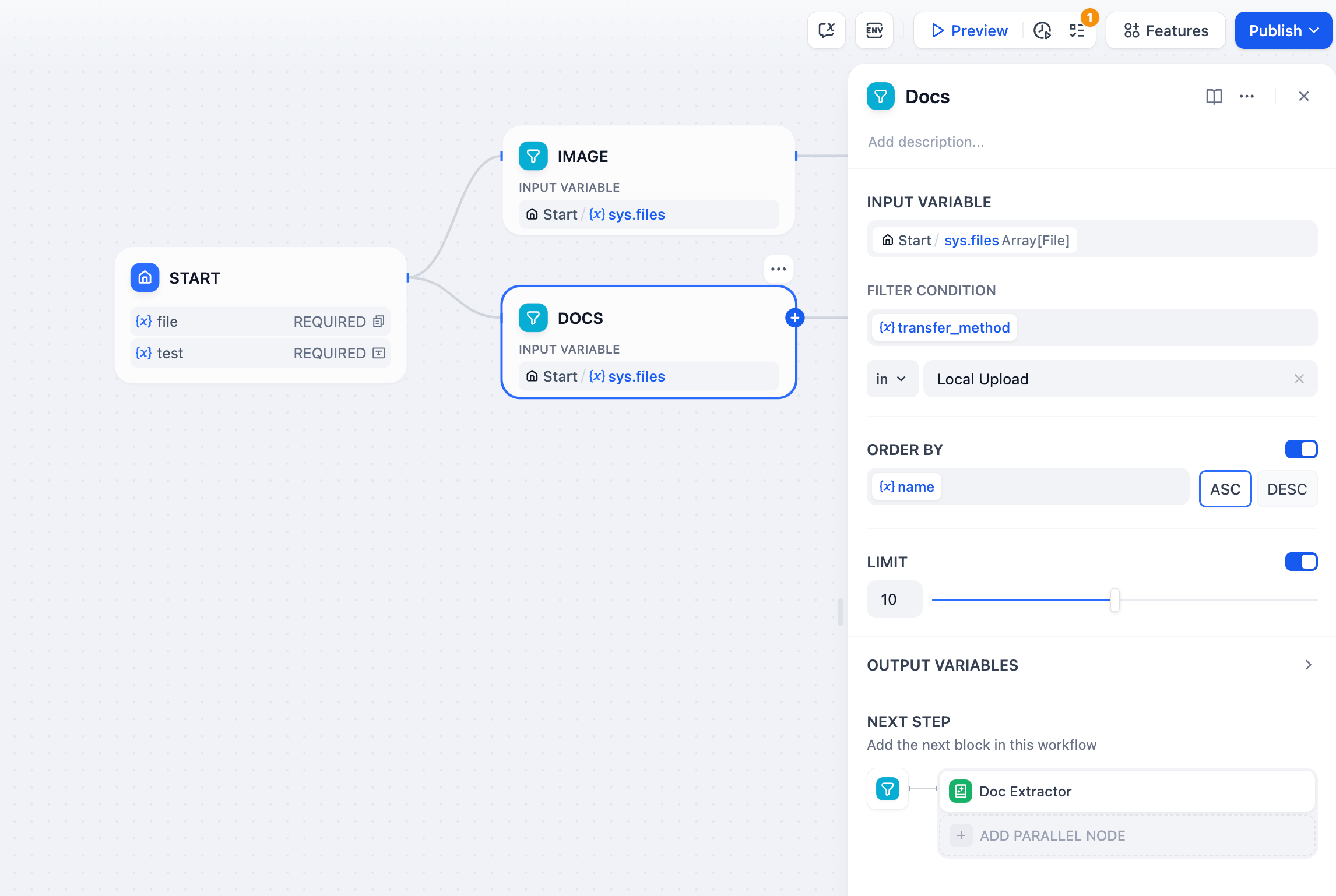
|
||||
|
||||
#### 输入变量
|
||||
|
||||
列表操作节点仅接受以下数据结构变量:
|
||||
|
||||
* Array\[string]
|
||||
* Array\[number]
|
||||
* Array\[file]
|
||||
|
||||
#### 过滤条件
|
||||
|
||||
处理输入变量中的数组,添加过滤条件。从数组中分拣所有满足条件的数组变量,可以理解为对变量的属性进行过滤。
|
||||
|
||||
举例:文件中可能包含多重维度的属性,例如文件名、文件类型、文件大小等属性。过滤条件允许设置筛选条件,选择并提取数组变量中的特定文件。
|
||||
|
||||
支持提取以下变量:
|
||||
|
||||
* type 文件类别,包含图片,文档,音频和视频类型
|
||||
* size 文件大小
|
||||
* name 文件名
|
||||
* url 指的是应用使用者通过 URL 上传的文件,可填写完整 URL 进行筛选
|
||||
* extension 文件拓展名
|
||||
* mime\_type
|
||||
|
||||
[MIME 类型](https://datatracker.ietf.org/doc/html/rfc2046)是用来标识文件内容类型的标准化字符串。示例: "text/html" 表示 HTML 文档。
|
||||
* transfer\_method
|
||||
|
||||
文件上传方式,分为本地上传或通过 URL 上传
|
||||
|
||||
#### 排序
|
||||
|
||||
提供对于输入变量中数组的排序能力,支持根据文件属性进行排序。
|
||||
|
||||
* 升序排列
|
||||
|
||||
默认排序选项,按照从小到大排序。对于字母和文本,按字母表顺序排列(A - Z)
|
||||
* 降序排列
|
||||
|
||||
由大到小排序,对于字母和文本,按字母表倒序排列(Z - A)
|
||||
|
||||
该选项常用于配合输出变量中的 first\_record 及 last\_record 使用。
|
||||
|
||||
#### 取前 N 项
|
||||
|
||||
可以在 1-20 中选值,用途是为了选中数组变量的前 n 项。
|
||||
|
||||
#### 输出变量
|
||||
|
||||
满足各项过滤条件的数组元素。过滤条件、排序和限制可以单独开启。如果同时开启,则返回符合所有条件的数组元素。
|
||||
|
||||
* Result,过滤结果,数据类型为数组变量。若数组中仅包含 1 个文件,则输出变量仅包含 1 个数组元素;
|
||||
* first\_record,筛选完的数组的首元素,即 result\[0];
|
||||
* last\_record,筛选完的数组的尾元素,即 result\[array.length-1]。
|
||||
|
||||
***
|
||||
|
||||
### 配置案例
|
||||
|
||||
在文件交互问答场景中,应用使用者可能会同时上传文档文件或图片文件。LLM 仅支持识别图片文件的能力,不支持读取文档文件。此时需要用到 [列表操作](list-operator) 节点预处理文件变量的数组,将不同的文件类型并发送至对应的处理节点。编排步骤如下:
|
||||
|
||||
1. 开启 [Features](../additional-feature) 功能,并在文件类型中勾选 "图片" + "文档文件" 类型。
|
||||
2. 添加两个列表操作节点,在 "过滤" 条件中分别设置提取图片与文档变量。
|
||||
3. 提取文档文件变量,传递至 "文档提取器" 节点;提取图片文件变量,传递至 "LLM" 节点。
|
||||
4. 在末尾添加 "直接回复" 节点,填写 LLM 节点的输出变量。
|
||||
|
||||

|
||||
|
||||
应用使用者同时上传文档文件和图片后,文档文件自动分流至文档提取器节点,图片文件自动分流至 LLM 节点以实现对于混合文件的共同处理。
|
||||
158
zh-hans/guides/workflow/node/llm.mdx
Normal file
158
zh-hans/guides/workflow/node/llm.mdx
Normal file
@@ -0,0 +1,158 @@
|
||||
---
|
||||
title: LLM
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
调用大语言模型的能力,处理用户在 "开始" 节点中输入的信息(自然语言、上传的文件或图片),给出有效的回应信息。
|
||||
|
||||
<Frame caption="LLM 节点">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/0356bf3a8c46660181707da6f736386f.png" alt="LLM 节点" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 应用场景
|
||||
|
||||
LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
|
||||
|
||||
* **意图识别**,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
|
||||
* **文本生成**,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
|
||||
* **内容分类**,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
|
||||
* **文本转换**,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
|
||||
* **代码生成**,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
|
||||
* **RAG**,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
|
||||
* **图片理解**,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
|
||||
|
||||
选择合适的模型,编写提示词,你可以在 Chatflow/Workflow 中构建出强大、可靠的解决方案。
|
||||
|
||||
***
|
||||
|
||||
### 配置示例
|
||||
|
||||
在应用编辑页中,点击鼠标右键或轻点上一节点末尾的 + 号,添加节点并选择 LLM。
|
||||
|
||||
<Frame caption="LLM 节点配置-选择模型">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/778b40e25d203a5da9dddd9d8d7063a1.png" alt="LLM 节点配置-选择模型" />
|
||||
</Frame>
|
||||
|
||||
**配置步骤:**
|
||||
|
||||
1. **选择模型**,Dify 提供了全球主流模型的[支持](user-guide/getting-started/readme/model-providers),包括 OpenAI 的 GPT 系列、Anthropic 的 Claude 系列、Google 的 Gemini 系列等,选择一个模型取决于其推理能力、成本、响应速度、上下文窗口等因素,你需要根据场景需求和任务类型选择合适的模型。
|
||||
|
||||
> 如果你是初次使用 Dify ,在 LLM 节点选择模型之前,需要在 **系统设置—模型供应商** 内提前完成[模型配置](../../model-configuration/)。
|
||||
|
||||
2. **配置模型参数**,模型参数用于控制模型的生成结果,例如温度、TopP,最大标记、回复格式等,为了方便选择系统同时提供了 3 套预设参数:创意,平衡和精确。如果你对以上参数并不熟悉,建议选择默认设置。若希望应用具备图片分析能力,请选择具备视觉能力的模型。
|
||||
3. **填写上下文(可选)**,上下文可以理解为向 LLM 提供的背景信息,常用于填写[知识检索](knowledge-retrieval)的输出变量。
|
||||
4. **编写提示词**,LLM 节点提供了一个易用的提示词编排页面,选择聊天模型或补全模型,会显示不同的提示词编排结构。如果选择聊天模型(Chat model),你可以自定义系统提示词(SYSTEM)/用户(USER)/ 助手(ASSISTANT)三部分内容。
|
||||
|
||||
<Frame caption="编写提示词">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/a986b3bb34a57a9440bcbf7a54c2467e.png" alt="编写提示词" />
|
||||
</Frame>
|
||||
|
||||
如果在编写系统提示词(SYSTEM)时没有好的思路,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
|
||||
|
||||
<Frame caption="提示生成器">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/727e40ef04a4df13d3bef82ad02e73f1.png" alt="提示生成器" />
|
||||
</Frame>
|
||||
|
||||
在提示词编辑器中,你可以通过输入 **"/"** 呼出 **变量插入菜单**,将 **特殊变量块** 或者 **上游节点变量** 插入到提示词中作为上下文内容。
|
||||
|
||||
<Frame caption="呼出变量插入菜单">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/cc96ca72400fb81aca6936908d667478.png" alt="呼出变量插入菜单" />
|
||||
</Frame>
|
||||
|
||||
5. **高级设置**,可以开关记忆功能并设置记忆窗口、开关 Vision 功能或者使用 Jinja-2 模版语言来进行更复杂的提示词等。
|
||||
|
||||
***
|
||||
|
||||
### 特殊变量说明
|
||||
|
||||
**上下文变量**
|
||||
|
||||
上下文变量是一种特殊变量类型,用于向 LLM 提供背景信息,常用于在知识检索场景下使用。详细说明请参考[知识检索节点](knowledge-retrieval)。
|
||||
|
||||
**图片文件变量**
|
||||
|
||||
具备视觉能力的 LLM 可以通过变量读取应用使用者所上传的图片。开启 VISION 后,选择图片文件的输出变量完成设置。
|
||||
|
||||
<Frame caption="视觉上传功能">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/2b2a9dac18c8b723ccdb620d7c003bd3.png" alt="视觉上传功能" />
|
||||
</Frame>
|
||||
|
||||
**会话历史**
|
||||
|
||||
为了在文本补全类模型(例如 gpt-3.5-turbo-Instruct)内实现聊天型应用的对话记忆,Dify 在原[提示词专家模式(已下线)](user-guide/learn-more/extended-reading/prompt-engineering/prompt-engineering-1/)内设计了会话历史变量,该变量沿用至 Chatflow 的 LLM 节点内,用于在提示词中插入 AI 与用户之间的聊天历史,帮助 LLM 理解对话上文。
|
||||
|
||||
> 会话历史变量应用并不广泛,仅在 Chatflow 中选择文本补全类模型时可以插入使用。
|
||||
|
||||
<Frame caption="插入会话历史变量">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/b8642f8c6e3f562fceeefae83628fd68.png" alt="插入会话历史变量" />
|
||||
</Frame>
|
||||
|
||||
**模型参数**
|
||||
|
||||
模型的参数会影响模型的输出效果。不同模型的参数会有所区别。下图为`gpt-4`的参数列表。
|
||||
|
||||
<Frame caption="模型参数列表">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/74a93d9b4982a8ad4d046dc9fb290b2d.png" alt="模型参数列表" />
|
||||
</Frame>
|
||||
|
||||
主要的参数名词解释如下:
|
||||
|
||||
* **温度:** 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
|
||||
* **Top P:** 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
|
||||
* **存在惩罚:** 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
|
||||
* **频率惩罚:** 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
|
||||
|
||||
如果你不理解这些参数是什么,可以选择**加载预设**,从创意、平衡、精确三种预设中选择。
|
||||
|
||||
<Frame caption="加载预设参数">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/a117606125cbc65573f201738cd0af6e.png" alt="加载预设参数" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 高级功能
|
||||
|
||||
**记忆:** 开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
|
||||
|
||||
**记忆窗口:** 记忆窗口关闭时,系统会根据模型上下文窗口动态过滤聊天历史的传递数量;打开时用户可以精确控制聊天历史的传递数量(对数)。
|
||||
|
||||
**对话角色名设置:** 由于模型在训练阶段的差异,不同模型对于角色名的指令遵循程度不同,如 Human/Assistant,Human/AI,人类/助手等等。为适配多模型的提示响应效果,系统提供了对话角色名的设置,修改对话角色名将会修改会话历史的角色前缀。
|
||||
|
||||
**Jinja-2 模板:** LLM 的提示词编辑器内支持 Jinja-2 模板语言,允许你借助 Jinja2 这一强大的 Python 模板语言,实现轻量级数据转换和逻辑处理,参考[官方文档](https://jinja.palletsprojects.com/en/3.1.x/templates/)。
|
||||
|
||||
***
|
||||
|
||||
### 使用案例
|
||||
|
||||
* **读取知识库内容**
|
||||
|
||||
想要让工作流应用具备读取 ["知识库"](/zh-cn/user-guide/knowledge-base/) 内容的能力,例如搭建智能客服应用,请参考以下步骤:
|
||||
|
||||
1. 在 LLM 节点上游添加知识库检索节点;
|
||||
2. 将知识检索节点的 **输出变量** `result` 填写至 LLM 节点中的 **上下文变量** 内;
|
||||
3. 将 **上下文变量** 插入至应用提示词内,赋予 LLM 读取知识库内的文本能力。
|
||||
|
||||
<Frame caption="上下文变量">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/1251058e2c87948a2015f4b74d9fc935.png" alt="上下文变量" />
|
||||
</Frame>
|
||||
|
||||
[知识检索节点](knowledge-retrieval)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](/zh-hans/guides/knowledge-base/retrieval-test-and-citation) 功能查看信息来源。
|
||||
|
||||
> 上游节点的普通变量同样可以填写至上下文变量内,例如开始节点的字符串类型变量,但 **引用与归属** 功能将会失效。
|
||||
|
||||
* **读取文档文件**
|
||||
|
||||
想要让工作流应用具备读取读取文档内容的能力,例如搭建 ChatPDF 应用,可以参考以下步骤:
|
||||
|
||||
* 在 “开始” 节点内添加文件变量;
|
||||
* 在 LLM 节点上游添加文档提取器节点,将文件变量作为输入变量;
|
||||
* 将文档提取器节点的 **输出变量** `text` 填写至 LLM 节点中的提示词内。
|
||||
|
||||
如需了解更多,请参考[文件上传](/zh-hans/guides/workflow/file-upload)。
|
||||
|
||||
<Frame caption="填写系统提示词">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/f64735b701bc77133391a5b7d55ff7d1.png" alt="填写系统提示词" />
|
||||
</Frame>
|
||||
89
zh-hans/guides/workflow/node/loop.mdx
Normal file
89
zh-hans/guides/workflow/node/loop.mdx
Normal file
@@ -0,0 +1,89 @@
|
||||
---
|
||||
title: Loop
|
||||
---
|
||||
|
||||
循环(Loop)节点用于执行依赖前一轮结果的重复任务,直到满足退出条件或达到最大循环次数。
|
||||
|
||||
## 循环节点与迭代节点有什么区别?
|
||||
|
||||
循环节点和迭代节点在任务处理上的定位不同:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>类型</th>
|
||||
<th>特点</th>
|
||||
<th>适用场景</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><strong>循环</strong>(Loop)</td>
|
||||
<td>轮次之间存在依赖关系的优化型任务。即任务的每一轮执行都依赖上一轮的结果。</td>
|
||||
<td>需要前一轮的计算结果,适用于递归、优化问题等。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><strong>迭代</strong>(Iteration)</td>
|
||||
<td>轮次之间无依赖关系的批处理任务。即每一轮任务可以独立运行,无需依赖前一轮。</td>
|
||||
<td>每轮独立执行,可用于数据批量处理等。</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## 如何配置循环节点?
|
||||
|
||||
循环节点包含以下两个关键配置项:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>配置项</th>
|
||||
<th>作用</th>
|
||||
<th>示例</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><strong>循环退出条件</strong>(Loop Termination Condition)</td>
|
||||
<td>设置循环何时停止</td>
|
||||
<td>例:当变量 <code>x < 50</code> 时,停止循环。</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><strong>最大循环次数</strong>(Maximum Loop Count)</td>
|
||||
<td>限制最多执行的轮次,避免无限循环</td>
|
||||
<td>例:最多执行 10 轮,不管是否满足退出条件。</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
你可以在 **循环退出条件** 中使用循环体内的变量或会话中的全局变量,让循环按照你的需求停止。
|
||||
|
||||

|
||||
|
||||
## 示例:如何使用循环节点?
|
||||
|
||||
**需求:生成 1-100 的随机数,直到随机数小于 50 时停止。**
|
||||
|
||||
**实现步骤**:
|
||||
|
||||
1. 使用 `code` 节点生成 `1-100` 的随机数。
|
||||
|
||||
2. 使用 `if` 节点判断随机数是否小于 `50`:
|
||||
|
||||
- 如果小于 50,输出 `done` 并结束循环。
|
||||
|
||||
- 如果不小于 50,继续循环,生成新的随机数。
|
||||
|
||||
3. 设置循环退出标准:随机数 `< 50`。
|
||||
|
||||
4. 循环将在随机数小于 `50` 时自动停止。
|
||||
|
||||

|
||||
|
||||
## 未来扩展
|
||||
|
||||
**后续版本将提供:**
|
||||
|
||||
- 循环变量:支持在循环过程中存储和引用变量,增强逻辑控制能力。
|
||||
|
||||
- `break` 节点:允许在循环体内部直接终止循环,适用于更复杂的流程控制。
|
||||
66
zh-hans/guides/workflow/node/parameter-extractor.mdx
Normal file
66
zh-hans/guides/workflow/node/parameter-extractor.mdx
Normal file
@@ -0,0 +1,66 @@
|
||||
---
|
||||
title: 参数提取
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
利用 LLM 从自然语言推理并提取结构化参数,用于后置的工具调用或 HTTP 请求。
|
||||
|
||||
Dify 工作流内提供了丰富的[工具](https://docs.dify.ai/v/zh-hans/guides/tools)选择,其中大多数工具的输入为结构化参数,参数提取器可以将用户的自然语言转换为工具可识别的参数,方便工具调用。
|
||||
|
||||
工作流内的部分节点有特定的数据格式传入要求,如[迭代](/zh-hans/guides/workflow/nodes/iteration)节点的输入要求为数组格式,参数提取器可以方便的实现结构化参数的转换。
|
||||
|
||||
***
|
||||
|
||||
### 场景
|
||||
|
||||
1. **从自然语言中提供工具所需的关键参数提取**,如构建一个简单的对话式 Arxiv 论文检索应用。
|
||||
|
||||
在该示例中:Arxiv 论文检索工具的输入参数要求为 **论文作者** 或 **论文编号**,参数提取器从问题"这篇论文中讲了什么内容:2405.10739"中提取出论文编号 **2405.10739**,并作为工具参数进行精确查询。
|
||||
|
||||
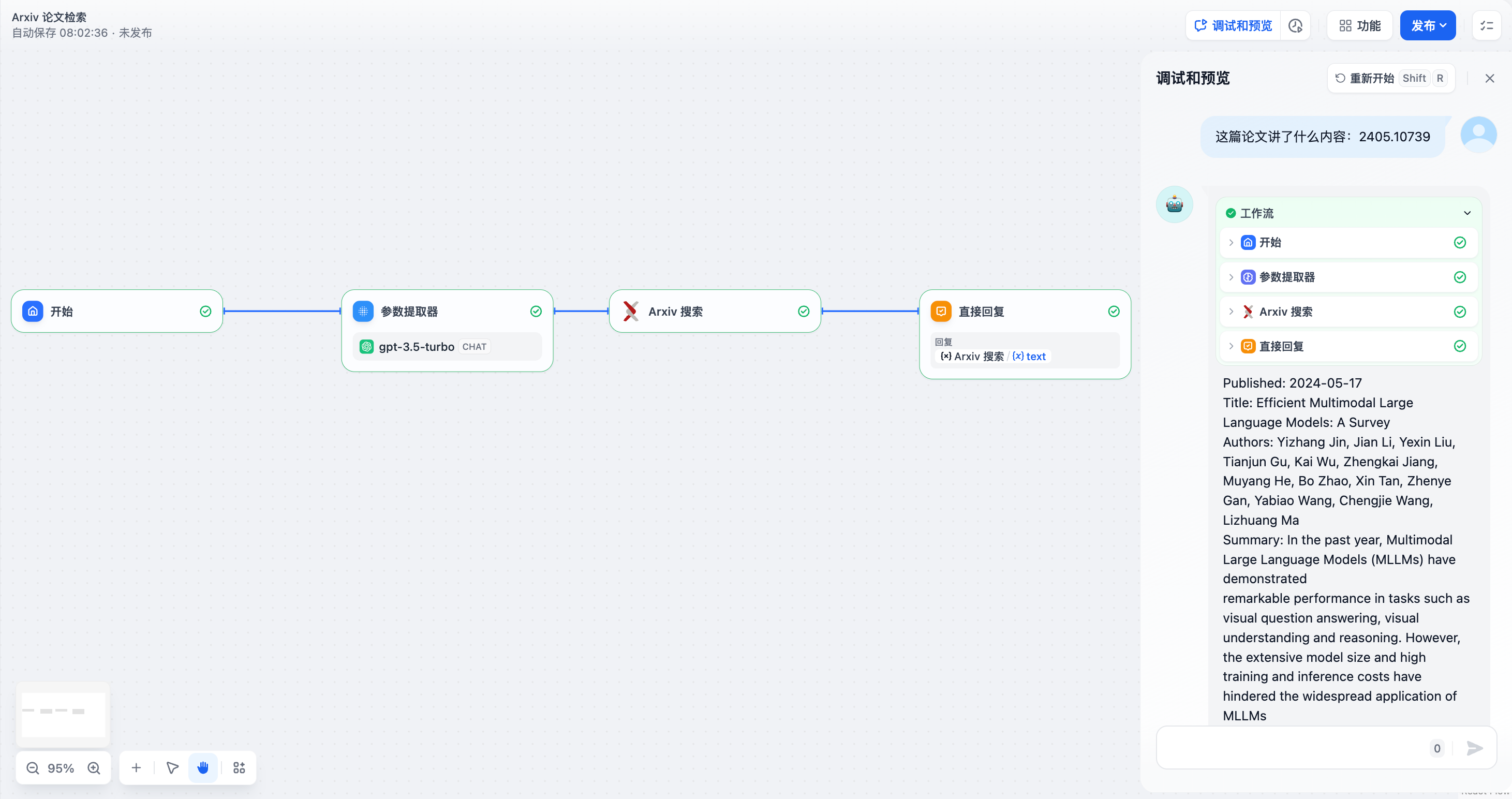
|
||||
|
||||
2. **将文本转换为结构化数据**,如长故事迭代生成应用中,作为[迭代节点](/zh-hans/guides/workflow/nodes/iteration)的前置步骤,将文本格式的章节内容转换为数组格式,方便迭代节点进行多轮生成处理。
|
||||
|
||||
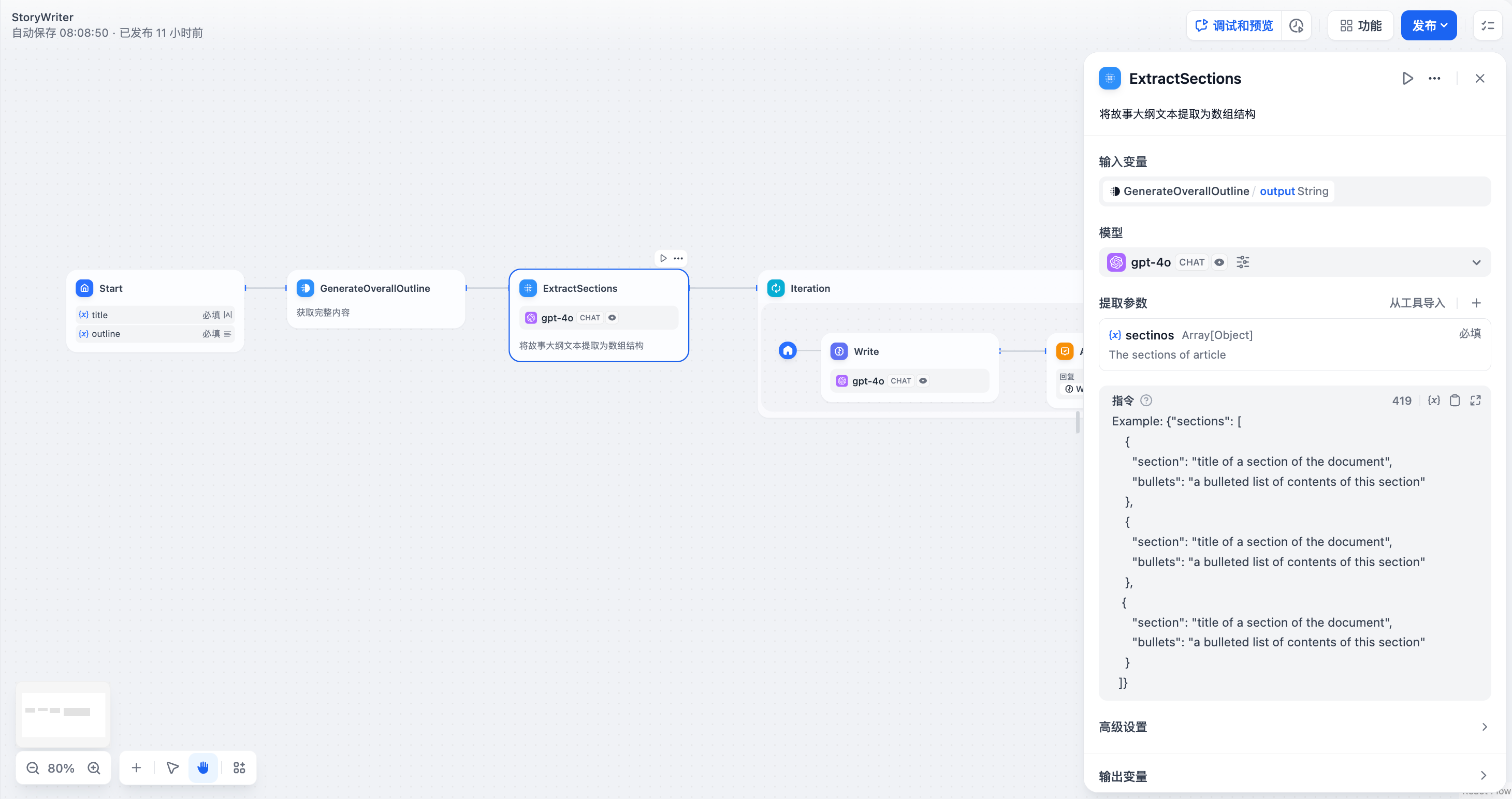
|
||||
|
||||
3. **提取结构化数据并使用** [**HTTP 请求**](/zh-hans/guides/workflow/nodes/http-request) ,可请求任意可访问的 URL ,适用于获取外部检索结果、webhook、生成图片等情景。
|
||||
|
||||
***
|
||||
|
||||
### 3 如何配置
|
||||
|
||||
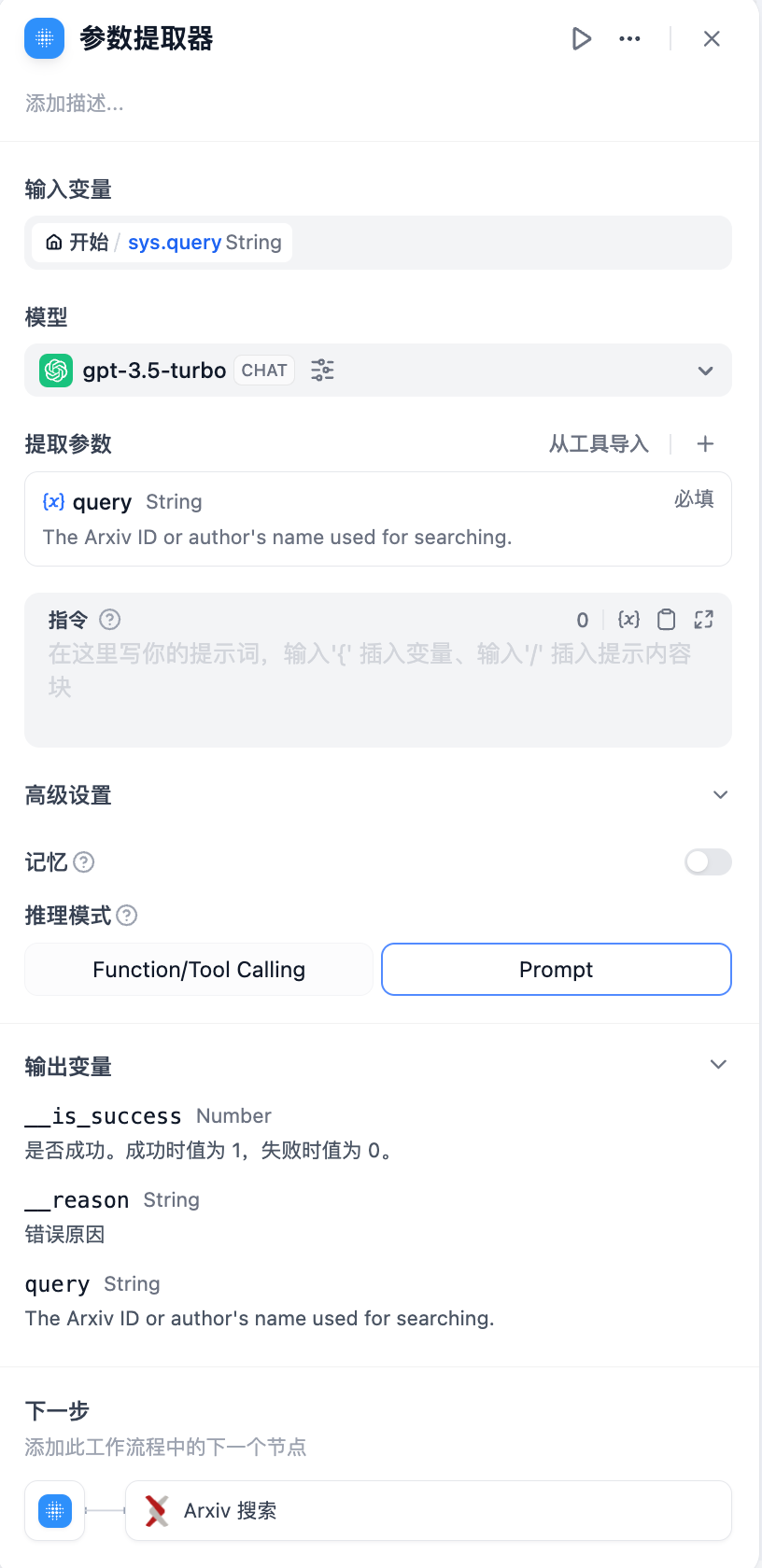
|
||||
|
||||
**配置步骤**
|
||||
|
||||
1. 选择输入变量,一般为用于提取参数的变量输入。输入变量支持 file
|
||||
2. 选择模型,参数提取器的提取依靠的是 LLM 的推理和结构化生成能力
|
||||
3. 定义提取参数,可以手动添加需要提取的参数,也可以**从已有工具中快捷导入**
|
||||
4. 编写指令,在提取复杂的参数时,编写示例可以帮助 LLM 提升生成的效果和稳定性
|
||||
|
||||
**高级设置**
|
||||
|
||||
**推理模式**
|
||||
|
||||
部分模型同时支持两种推理模式,通过函数/工具调用或是纯提示词的方式实现参数提取,在指令遵循能力上有所差别。例如某些模型在函数调用效果欠佳的情况下可以切换成提示词推理。
|
||||
|
||||
* Function Call/Tool Call
|
||||
* Prompt
|
||||
|
||||
**记忆**
|
||||
|
||||
开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
|
||||
|
||||
**图片**
|
||||
|
||||
开启图片
|
||||
|
||||
**输出变量**
|
||||
|
||||
* 提取定义的变量
|
||||
* 节点内置变量
|
||||
|
||||
`__is_success Number 提取是否成功` 成功时值为 1,失败时值为 0。
|
||||
|
||||
`__reason String` 提取错误原因
|
||||
58
zh-hans/guides/workflow/node/question-classifier.mdx
Normal file
58
zh-hans/guides/workflow/node/question-classifier.mdx
Normal file
@@ -0,0 +1,58 @@
|
||||
---
|
||||
title: 问题分类
|
||||
---
|
||||
|
||||
### **定义**
|
||||
|
||||
通过定义分类描述,问题分类器能够根据用户输入,使用 LLM 推理与之相匹配的分类并输出分类结果,向下游节点提供更加精确的信息。
|
||||
|
||||
***
|
||||
|
||||
### **场景**
|
||||
|
||||
常见的使用情景包括**客服对话意图分类、产品评价分类、邮件批量分类**等。
|
||||
|
||||
在一个典型的产品客服问答场景中,问题分类器可以作为知识库检索的前置步骤,对用户输入问题意图进行分类处理,分类后导向下游不同的知识库查询相关的内容,以精确回复用户的问题。
|
||||
|
||||
下图为产品客服场景的示例工作流模板:
|
||||
|
||||
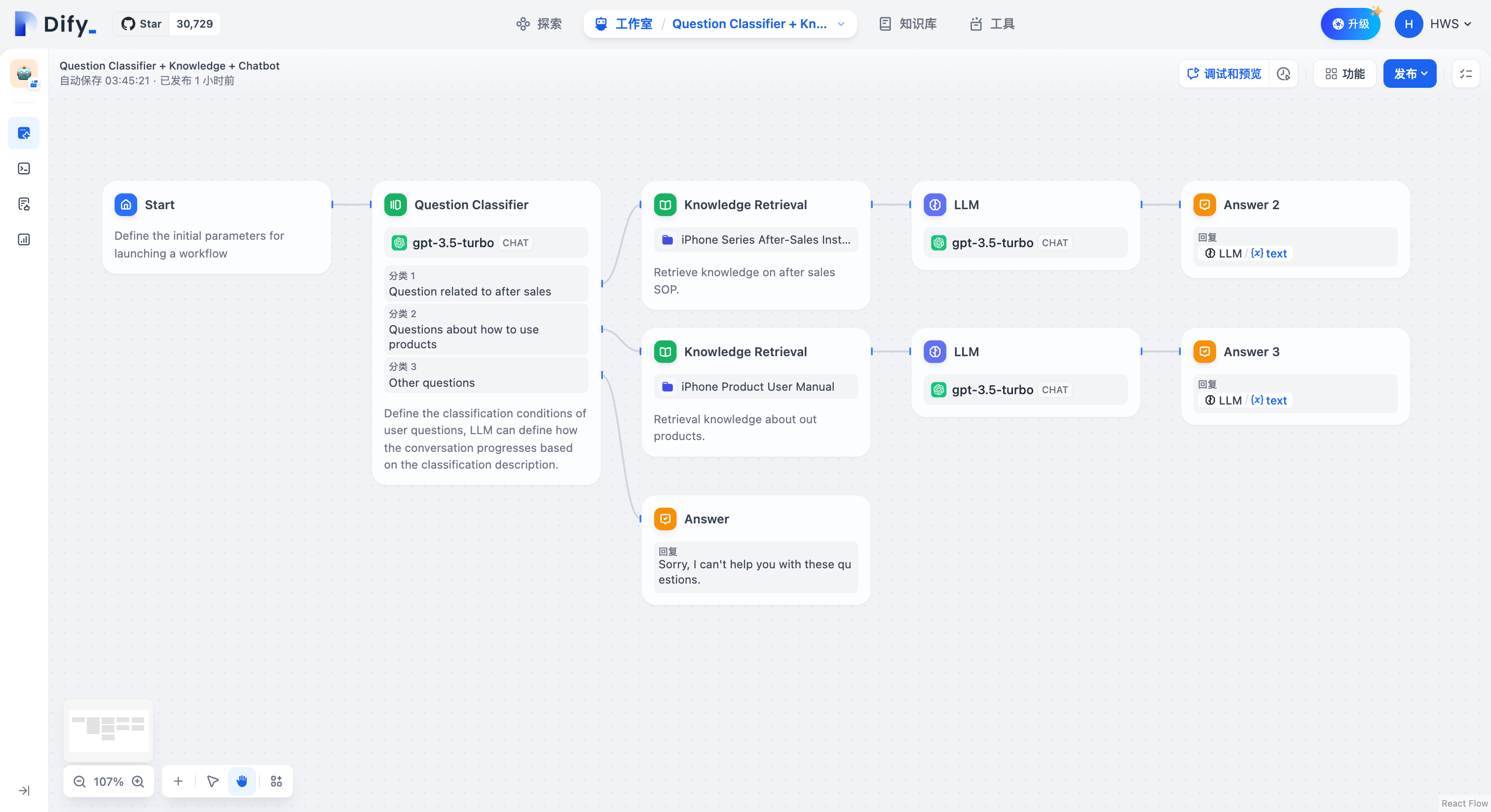
|
||||
|
||||
在该场景中我们设置了 3 个分类标签/描述:
|
||||
|
||||
* 分类 1 :**与售后相关的问题**
|
||||
* 分类 2:**与产品操作使用相关的问题**
|
||||
* 分类 3 :**其他问题**
|
||||
|
||||
当用户输入不同的问题时,问题分类器会根据已设置的分类标签 / 描述自动完成分类:
|
||||
|
||||
* "**iPhone 14 如何设置通讯录联系人?**" —> "**与产品操作使用相关的问题**"
|
||||
* "**保修期限是多久?**" —> "**与售后相关的问题**"
|
||||
* "**今天天气怎么样?**" —> "**其他问题**"
|
||||
|
||||
***
|
||||
|
||||
### 如何配置
|
||||
|
||||
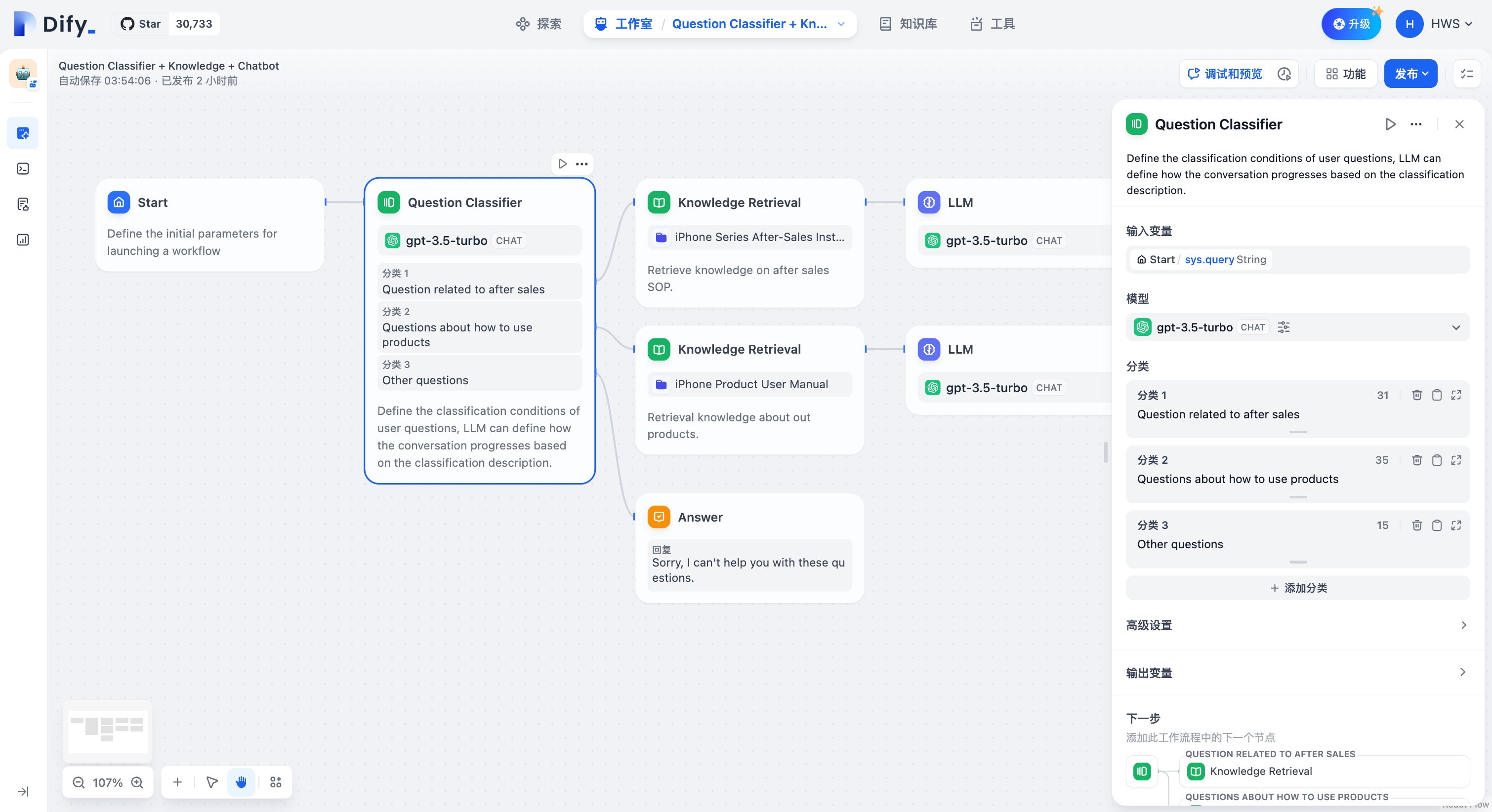
|
||||
|
||||
**配置步骤:**
|
||||
|
||||
1. **选择输入变量**,指用于分类的输入内容,支持输入[文件变量](/zh-hans/guides/workflow/variables)。客服问答场景下一般为用户输入的问题 `sys.query`;
|
||||
2. **选择推理模型**,问题分类器基于大语言模型的自然语言分类和推理能力,选择合适的模型将有助于提升分类效果;
|
||||
3. **编写分类标签/描述**,你可以手动添加多个分类,通过编写分类的关键词或者描述语句,让大语言模型更好的理解分类依据。
|
||||
4. **选择分类对应的下游节点,** 问题分类节点完成分类之后,可以根据分类与下游节点的关系选择后续的流程路径。
|
||||
|
||||
#### **高级设置:**
|
||||
|
||||
**指令:** 你可以在 **高级设置-指令** 里补充附加指令,比如更丰富的分类依据,以增强问题分类器的分类能力。
|
||||
|
||||
**记忆:** 开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
|
||||
|
||||
**图片分析:** 仅适用于具备图片识别能力的 LLM,允许输入图片变量。
|
||||
|
||||
**记忆窗口:** 记忆窗口关闭时,系统会根据模型上下文窗口动态过滤聊天历史的传递数量;打开时用户可以精确控制聊天历史的传递数量(对数)。
|
||||
|
||||
**输出变量:**
|
||||
|
||||
`class_name` 存储了分类模型的预测结果。当分类完成后,这个变量会包含具体的类别标签,你可以在后续的处理节点中引用这个分类结果来执行相应的逻辑。
|
||||
70
zh-hans/guides/workflow/node/start.mdx
Normal file
70
zh-hans/guides/workflow/node/start.mdx
Normal file
@@ -0,0 +1,70 @@
|
||||
---
|
||||
title: 开始
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
## 定义
|
||||
|
||||
**"开始"** 节点是每个工作流应用(Chatflow / Workflow)必备的预设节点,为后续工作流节点以及应用的正常流转提供必要的初始信息,例如应用使用者所输入的内容、以及[上传的文件](/zh-hans/guides/workflow/file-upload)等。
|
||||
|
||||
### 配置节点
|
||||
|
||||
在开始节点的设置页,你可以看到两部分设置,分别是 **"输入字段"** 和预设的[**系统变量**](/zh-hans/guides/workflow/variables#系统变量)。
|
||||
|
||||
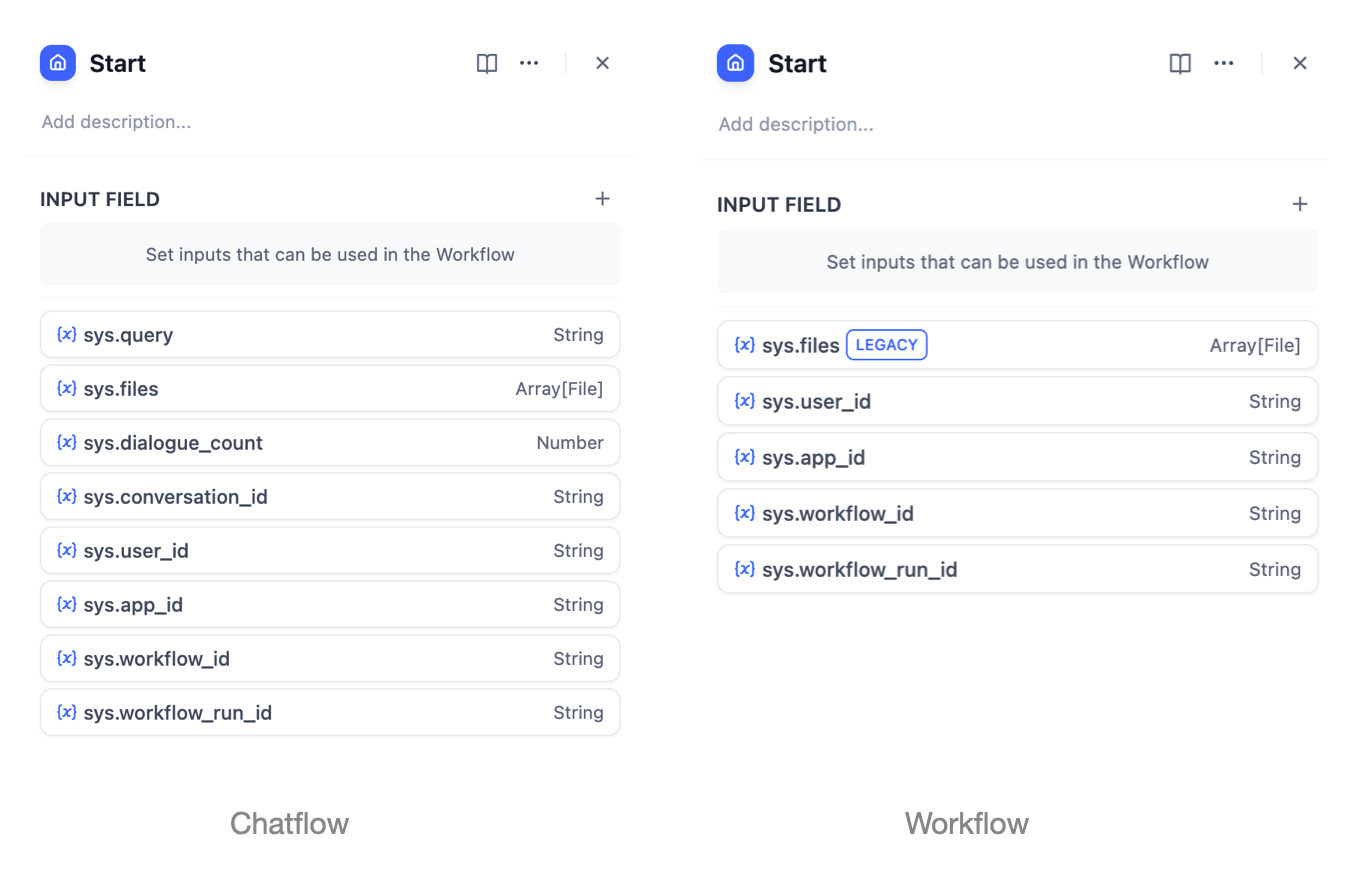
|
||||
|
||||
### 输入字段
|
||||
|
||||
输入字段功能由应用开发者设置,通常用于让应用使用者主动补全更多信息。例如在周报应用中要求使用者按照格式预先提供更多背景信息,如姓名、工作日期区间、工作详情等。这些前置信息将有助于 LLM 生成质量更高的答复。
|
||||
|
||||
支持以下六种类型输入变量,所有变量均可设置为必填项:
|
||||
|
||||
* **文本**:短文本,由应用使用者自行填写内容,最大长度 256 字符。
|
||||
* **段落**:长文本,允许应用使用者输入较长字符。
|
||||
* **下拉选项**:由应用开发者固定选项,应用使用者仅能选择预设选项,无法自行填写内容。
|
||||
* **数字**:仅允许用户输入数字。
|
||||
* **单文件**:允许应用使用者单独上传文件,支持文档类型文件、图片、音频、视频和其它文件类型。支持通过本地上传文件或粘贴文件 URL。详细用法请参考[文件上传](/zh-hans/guides/workflow/file-upload)。
|
||||
* **文件列表**:允许应用使用者批量上传文件,支持文档类型文件、图片、音频、视频和其它文件类型。支持通过本地上传文件或粘贴文件 URL。详细用法请参考[文件上传](/zh-hans/guides/workflow/file-upload)。
|
||||
|
||||
<Info>
|
||||
Dify 内置的文档提取器节点只能够处理部分格式的文档文件。如需处理图片、音频或视频类型文件,请参考[外部数据工具](/zh-hans/guides/tools/extensions/code-based/external-data-tool)搭建对应文件的处理节点。
|
||||
</Info>
|
||||
|
||||
配置完成后,用户在使用应用前将按照输入项指引,向 LLM 提供必要信息。更多的信息将有助于 LLM 提升问答效率。
|
||||
|
||||
|
||||
|
||||
### 系统变量
|
||||
|
||||
系统变量指的是在 Chatflow / Workflow 应用内预设的系统级参数,可以被应用内的其它节点全局读取。通常用于进阶开发场景,例如搭建多轮次对话应用、收集应用日志与监控、记录不同应用和用户的使用行为等。
|
||||
|
||||
**Workflow**
|
||||
|
||||
Workflow 类型应用提供以下系统变量:
|
||||
|
||||
| 变量名称 | 数据类型 | 说明 | 备注 |
|
||||
|---------|--------|------|------|
|
||||
| `sys.files` [LEGACY] | Array[File] | 文件参数,存储用户初始使用应用时上传的图片 | 图片上传功能需在应用编排页右上角的 "功能" 处开启 |
|
||||
| `sys.user_id` | String | 用户 ID,每个用户在使用工作流应用时,系统会自动向用户分配唯一标识符,用以区分不同的对话用户 | |
|
||||
| `sys.app_id` | String | 应用 ID,系统会向每个 Workflow 应用分配一个唯一的标识符,用以区分不同的应用,并通过此参数记录当前应用的基本信息 | 面向具备开发能力的用户,通过此参数区分并定位不同的 Workflow 应用 |
|
||||
| `sys.workflow_id` | String | Workflow ID,用于记录当前 Workflow 应用内所包含的所有节点信息 | 面向具备开发能力的用户,可以通过此参数追踪并记录 Workflow 内的包含节点信息 |
|
||||
| `sys.workflow_run_id` | String | Workflow 应用运行 ID,用于记录 Workflow 应用中的运行情况 | 面向具备开发能力的用户,可以通过此参数追踪应用的历次运行情况 |
|
||||
|
||||

|
||||
|
||||
**Chatflow**
|
||||
|
||||
Chatflow 类型应用提供以下系统变量:
|
||||
|
||||
| 变量名称 | 数据类型 | 说明 | 备注 |
|
||||
|---------|--------|------|------|
|
||||
| `sys.query` | String | 用户在对话框中初始输入的内容 | |
|
||||
| `sys.files` | Array[File] | 用户在对话框内上传的图片 | 图片上传功能需在应用编排页右上角的 "功能" 处开启 |
|
||||
| `sys.dialogue_count` | Number | 用户在与 Chatflow 类型应用交互时的对话轮数。每轮对话后自动计数增加 1,可以和 if-else 节点搭配出丰富的分支逻辑。例如到第 X 轮对话时,回顾历史对话并给出分析 | |
|
||||
| `sys.conversation_id` | String | 对话框交互会话的唯一标识符,将所有相关的消息分组到同一个对话中,确保 LLM 针对同一个主题和上下文持续对话 | |
|
||||
| `sys.user_id` | String | 分配给每个应用用户的唯一标识符,用以区分不同的对话用户 | |
|
||||
| `sys.app_id` | String | 应用 ID,系统会向每个 Workflow 应用分配一个唯一的标识符,用以区分不同的应用,并通过此参数记录当前应用的基本信息 | 面向具备开发能力的用户,通过此参数区分并定位不同的 Workflow 应用 |
|
||||
| `sys.workflow_id` | String | Workflow ID,用于记录当前 Workflow 应用内所包含的所有节点信息 | 面向具备开发能力的用户,可以通过此参数追踪并记录 Workflow 内的包含节点信息 |
|
||||
| `sys.workflow_run_id` | String | Workflow 应用运行 ID,用于记录 Workflow 应用中的运行情况 | 面向具备开发能力的用户,可以通过此参数追踪应用的历次运行情况 |
|
||||
|
||||

|
||||
48
zh-hans/guides/workflow/node/template.mdx
Normal file
48
zh-hans/guides/workflow/node/template.mdx
Normal file
@@ -0,0 +1,48 @@
|
||||
---
|
||||
title: 模板转换
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
允许借助 Jinja2 的 Python 模板语言灵活地进行数据转换、文本处理等。
|
||||
|
||||
### 什么是 Jinja?
|
||||
|
||||
> Jinja is a fast, expressive, extensible templating engine.
|
||||
>
|
||||
> Jinja 是一个快速、表达力强、可扩展的模板引擎。
|
||||
|
||||
—— [https://jinja.palletsprojects.com/en/3.1.x/](https://jinja.palletsprojects.com/en/3.1.x/)
|
||||
|
||||
### 场景
|
||||
|
||||
模板节点允许你借助 Jinja2 这一强大的 Python 模板语言,在工作流内实现轻量、灵活的数据转换,适用于文本处理、JSON 转换等情景。例如灵活地格式化并合并来自前面步骤的变量,创建出单一的文本输出。这非常适合于将多个数据源的信息汇总成一个特定格式,满足后续步骤的需求。
|
||||
|
||||
**示例1:** 将多个输入(文章标题、介绍、内容)拼接为完整文本
|
||||
|
||||
<Frame caption="拼接文本">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/549bd41e839ba2689d7ff286f77f7489.png" alt="拼接文本示例" />
|
||||
</Frame>
|
||||
|
||||
**示例2:** 将知识检索节点获取的信息及其相关的元数据,整理成一个结构化的 Markdown 格式
|
||||
|
||||
```Plain
|
||||
{% for item in chunks %}
|
||||
### Chunk {{ loop.index }}.
|
||||
### Similarity: {{ item.metadata.score | default('N/A') }}
|
||||
|
||||
#### {{ item.title }}
|
||||
|
||||
##### Content
|
||||
{{ item.content | replace('\n', '\n\n') }}
|
||||
|
||||
---
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
<Frame caption="知识检索节点输出转换为 Markdown">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/51f80c553d979e947a9749a9f820b6ab.png" alt="知识检索节点输出转换为 Markdown示例" />
|
||||
</Frame>
|
||||
|
||||
你可以参考 Jinja 的[官方文档](https://jinja.palletsprojects.com/en/3.1.x/templates/),创建更为复杂的模板来执行各种任务。
|
||||
56
zh-hans/guides/workflow/node/tools.mdx
Normal file
56
zh-hans/guides/workflow/node/tools.mdx
Normal file
@@ -0,0 +1,56 @@
|
||||
---
|
||||
title: 工具
|
||||
---
|
||||
|
||||
"工具"节点可以为工作流提供强大的第三方能力支持,分为以下三种类型:
|
||||
|
||||
* **内置工具**,Dify 第一方提供的工具,使用该工具前可能需要先给工具进行 **授权**。
|
||||
* **自定义工具**,通过 [OpenAPI/Swagger 标准格式](https://swagger.io/specification/)导入或配置的工具。如果内置工具无法满足使用需求,你可以在 **Dify 菜单导航 --工具** 内创建自定义工具。
|
||||
* **工作流**,你可以编排一个更复杂的工作流,并将其发布为工具。详细说明请参考[工具配置说明](/zh-hans/guides/tools/extensions/api-based/api-based-extension)。
|
||||
|
||||
### 添加并使用工具节点
|
||||
|
||||
添加节点时,选择右侧的 "工具" tab 页。配置工具节点一般分为两个步骤:
|
||||
|
||||
1. 对工具授权/创建自定义工具/将工作流发布为工具
|
||||
2. 配置工具输入和参数
|
||||
|
||||
<Frame caption="工具选择">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/736875fbb1b73f0b027d9f2b9063db32.png" alt="工具选择" />
|
||||
</Frame>
|
||||
|
||||
工具节点可以连接其它节点,通过[变量](/zh-hans/guides/workflow/variables)处理和传递数据。
|
||||
|
||||
<Frame caption="配置 Google 搜索工具检索外部知识">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/84a6ab75de95d2362d88cda8995c2d45.png" alt="配置 Google 搜索工具检索外部知识" />
|
||||
</Frame>
|
||||
|
||||
### 高级功能
|
||||
|
||||
**错误重试**
|
||||
|
||||
针对节点发生的部分异常情况,通常情况下再次重试运行节点即可解决。开启错误重试功能后,节点将在发生错误的时候按照预设策略进行自动重试。你可以调整最大重试次数和每次重试间隔以设置重试策略。
|
||||
|
||||
- 最大重试次数为 10 次
|
||||
- 最大重试间隔时间为 5000 ms
|
||||
|
||||
<Frame caption="错误重试配置">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/34867b2d910d74d2671cd40287200480.png" alt="错误重试配置" />
|
||||
</Frame>
|
||||
|
||||
**异常处理**
|
||||
|
||||
工具节点处理信息时有可能会遇到异常情况,导致流程中断。应用开发者可以参考以下步骤配置异常分支,在节点出现异常时启用应对方案,而避免中断整个流程。
|
||||
|
||||
1. 在工具节点启用 "异常处理"
|
||||
2. 选择异常处理方案并进行配置
|
||||
|
||||
<Frame caption="异常处理配置">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/39dc3b5881d9a5fe35b877971f70d3a6.png" alt="异常处理配置" />
|
||||
</Frame>
|
||||
|
||||
需了解更多应对异常的处理办法,请参考[异常处理](/zh-hans/guides/workflow/error-handling/readme)。
|
||||
|
||||
### 将工作流应用发布为工具
|
||||
|
||||
工作流应用可以被发布为工具,并被其它工作流内的节点所应用。关于如何创建自定义工具和配置工具,请参考[工具配置说明](/zh-hans/guides/tools/extensions/api-based/api-based-extension)。
|
||||
45
zh-hans/guides/workflow/node/variable-aggregator.mdx
Normal file
45
zh-hans/guides/workflow/node/variable-aggregator.mdx
Normal file
@@ -0,0 +1,45 @@
|
||||
---
|
||||
title: 变量聚合
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
将多路分支的变量聚合为一个变量,以实现下游节点统一配置。
|
||||
|
||||
变量聚合节点(原变量赋值节点)是工作流程中的一个关键节点,它负责整合不同分支的输出结果,确保无论哪个分支被执行,其结果都能通过一个统一的变量来引用和访问。这在多分支的情况下非常有用,可将不同分支下相同作用的变量映射为一个输出变量,避免下游节点重复定义。
|
||||
|
||||
***
|
||||
|
||||
### 场景
|
||||
|
||||
通过变量聚合,可以将诸如问题分类或条件分支等多路输出聚合为单路,供流程下游的节点使用和操作,简化了数据流的管理。
|
||||
|
||||
**问题分类后的多路聚合**
|
||||
|
||||
未添加变量聚合,分类1 和 分类 2 分支经不同的知识库检索后需要重复定义下游的 LLM 和直接回复节点。
|
||||
|
||||
<Frame caption="问题分类(无变量聚合)">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/7a7c91663c3799ce9d056b013d5df29c.png" alt="问题分类无变量聚合的流程图" />
|
||||
</Frame>
|
||||
|
||||
添加变量聚合,可以将两个知识检索节点的输出聚合为一个变量。
|
||||
|
||||
<Frame caption="问题分类后的多路聚合">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/78e088e16a409cc18552b21bec98bc01.png" alt="问题分类后添加变量聚合的流程图" />
|
||||
</Frame>
|
||||
|
||||
**IF/ELSE 条件分支后的多路聚合**
|
||||
|
||||
<Frame caption="IF/ELSE 条件分支后的多路聚合">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/da33064c784fc44c19b532a6d873cfaf.png" alt="IF/ELSE 条件分支后添加变量聚合的流程图" />
|
||||
</Frame>
|
||||
|
||||
### 格式要求
|
||||
|
||||
变量聚合器支持聚合多种数据类型,包括字符串(`String`)、数字(`Number`)、文件(`File`)对象(`Object`)以及数组(`Array`)
|
||||
|
||||
**变量聚合器只能聚合同一种数据类型的变量**。若第一个添加至变量聚合节点内的变量数据格式为 `String`,后续连线时会自动过滤可添加变量为 `String` 类型。
|
||||
|
||||
**聚合分组**
|
||||
|
||||
开启聚合分组后,变量聚合器可以聚合多组变量,各组内聚合时要求同一种数据类型。
|
||||
167
zh-hans/guides/workflow/node/variable-assigner.mdx
Normal file
167
zh-hans/guides/workflow/node/variable-assigner.mdx
Normal file
@@ -0,0 +1,167 @@
|
||||
---
|
||||
title: 变量赋值
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
### 定义
|
||||
|
||||
变量赋值节点用于向可写入变量进行变量赋值,已支持以下可写入变量:
|
||||
|
||||
* [会话变量](../variables#会话变量)。
|
||||
|
||||
用法:通过变量赋值节点,你可以将工作流内的变量赋值到会话变量中用于临时存储,并可以在后续对话中持续引用。
|
||||
|
||||
<Frame caption="会话变量示例">
|
||||
<img src="https://assets-docs.dify.ai/2024/11/83d0b9ef4c1fad947b124398d472d656.png" alt="会话变量示例图" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 使用场景示例
|
||||
|
||||
通过变量赋值节点,你可以将会话过程中的**上下文、上传至对话框的文件(即将上线)、用户所输入的偏好信息**等写入至会话变量,并在后续对话中引用已存储的信息导向不同的处理流程或者进行回复。
|
||||
|
||||
**场景 1**
|
||||
|
||||
**自动判断提取并存储对话中的信息**,在会话内通过会话变量数组记录用户输入的重要信息,并在后续对话中让 LLM 基于会话变量中存储的历史信息进行个性化回复。
|
||||
|
||||
示例:开始对话后,LLM 会自动判断用户输入是否包含需要记住的事实、偏好或历史记录。如果有,LLM 会先提取并存储这些信息,然后再用这些信息作为上下文来回答。如果没有新的信息需要保存,LLM 会直接使用自身的相关记忆知识来回答问题。
|
||||
|
||||
<Frame caption="自动判断提取并存储对话中的信息">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/f687e6837515fda2be3e18f656bd2a67.jpeg" alt="自动判断提取并存储对话中的信息流程图" />
|
||||
</Frame>
|
||||
|
||||
**配置流程:**
|
||||
|
||||
1. **设置会话变量**:首先设置一个会话变量数组 `memories`,类型为 array\[object],用于存储用户的事实、偏好和历史记录。
|
||||
2. **判断和提取记忆**:
|
||||
* 添加一个条件判断节点,使用 LLM 来判断用户输入是否包含需要记住的新信息。
|
||||
* 如果有新信息,走上分支,使用 LLM 节点提取这些信息。
|
||||
* 如果没有新信息,走下分支,直接使用现有记忆回答。
|
||||
3. **变量赋值/写入**:
|
||||
* 在上分支中,使用变量赋值节点,将提取出的新信息追加(append)到 `memories` 数组中。
|
||||
* 使用转义功能将 LLM 输出的文本字符串转换为适合存储在 array\[object] 中的格式。
|
||||
4. **变量读取和使用**:
|
||||
* 在后续的 LLM 节点中,将 `memories` 数组中的内容转换为字符串,并插入到 LLM 的提示词 Prompts 中作为上下文。
|
||||
* LLM 使用这些历史信息来生成个性化回复。
|
||||
|
||||
图中的 code 节点代码如下:
|
||||
|
||||
1. 将字符串转义为 object
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: str) -> object:
|
||||
try:
|
||||
# Parse the input JSON string
|
||||
input_data = json.loads(arg1)
|
||||
|
||||
# Extract the memory object
|
||||
memory = input_data.get("memory", {})
|
||||
|
||||
# Construct the return object
|
||||
result = {
|
||||
"facts": memory.get("facts", []),
|
||||
"preferences": memory.get("preferences", []),
|
||||
"memories": memory.get("memories", [])
|
||||
}
|
||||
|
||||
return {
|
||||
"mem": result
|
||||
}
|
||||
except json.JSONDecodeError:
|
||||
return {
|
||||
"result": "Error: Invalid JSON string"
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"Error: {str(e)}"
|
||||
}
|
||||
```
|
||||
|
||||
2. 将 object 转义为字符串
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: list) -> str:
|
||||
try:
|
||||
# Assume arg1[0] is the dictionary we need to process
|
||||
context = arg1[0] if arg1 else {}
|
||||
|
||||
# Construct the memory object
|
||||
memory = {"memory": context}
|
||||
|
||||
# Convert the object to a JSON string
|
||||
json_str = json.dumps(memory, ensure_ascii=False, indent=2)
|
||||
|
||||
# Wrap the JSON string in <answer> tags
|
||||
result = f"<answer>{json_str}</answer>"
|
||||
|
||||
return {
|
||||
"result": result
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"<answer>Error: {str(e)}</answer>"
|
||||
}
|
||||
```
|
||||
|
||||
**场景 2**
|
||||
|
||||
**记录用户的初始偏好信息**,在会话内记住用户输入的语言偏好,在后续对话中持续使用该语言类型进行回复。
|
||||
|
||||
示例:用户在对话开始前,在 `language` 输入框内指定了 "中文",该语言将会被写入会话变量,LLM 在后续进行答复时会参考会话变量中的信息,在后续对话中持续使用"中文"进行回复。
|
||||
|
||||
<Frame caption="记录用户的初始偏好信息">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/8ce622d50bd947d829fff85f36bbfa45.png" alt="记录用户的初始偏好信息流程图" />
|
||||
</Frame>
|
||||
|
||||
**配置流程:**
|
||||
|
||||
**设置会话变量**:首先设置一个会话变量 `language`,在会话流程开始时添加一个条件判断节点,用来判断 `language` 变量的值是否为空。
|
||||
|
||||
**变量写入/赋值**:首轮对话开始时,若 `language` 变量值为空,则使用 LLM 节点来提取用户输入的语言,再通过变量赋值节点将该语言类型写入到会话变量 `language` 中。
|
||||
|
||||
**变量读取**:在后续对话轮次中 `language` 变量已存储用户语言偏好。在后续对话中,LLM 节点通过引用 language 变量,使用用户的偏好语言类型进行回复。
|
||||
|
||||
**场景 3**
|
||||
|
||||
**辅助 Checklist 检查**,在会话内通过会话变量记录用户的输入项,更新 Checklist 中的内容,并在后续对话中检查遗漏项。
|
||||
|
||||
示例:开始对话后,LLM 会要求用户在对话框内输入 Checklist 所涉及的事项,用户一旦提及了 Checklist 中的内容,将会更新并存储至会话变量内。LLM 会在每轮对话后提醒用户继续补充遗漏项。
|
||||
|
||||
<Frame caption="辅助 Checklist 检查">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/zh_CN/guides/workflow/node/c4362b01298b12e7d6fcd9e798f3165a.png" alt="辅助 Checklist 检查流程图" />
|
||||
</Frame>
|
||||
|
||||
**配置流程:**
|
||||
|
||||
* **设置会话变量:** 首先设置一个会话变量 `ai_checklist`,在 LLM 内引用该变量作为上下文进行检查。
|
||||
* **变量赋值/写入:** 每一轮对话时,在 LLM 节点内检查 `ai_checklist` 内的值并比对用户输入,若用户提供了新的信息,则更新 Checklist 并将输出内容通过变量赋值节点写入到 `ai_checklist` 内。
|
||||
* **变量读取:** 每一轮对话读取 `ai_cheklist` 内的值并比对用户输入直至所有 checklist 完成。
|
||||
|
||||
***
|
||||
|
||||
### 使用变量赋值节点
|
||||
|
||||
点击节点右侧 + 号,选择"变量赋值"节点,填写"赋值的变量"和"设置变量"。
|
||||
|
||||
<Frame caption="变量赋值节点设置">
|
||||
<img src="https://assets-docs.dify.ai/2024/11/ee15dee864107ba5a93b459ebdfc32cf.png" alt="变量赋值节点设置界面" />
|
||||
</Frame>
|
||||
|
||||
**设置变量:**
|
||||
|
||||
赋值的变量:选择被赋值变量,即指定需要被赋值的目标会话变量。
|
||||
|
||||
设置变量:选择需要赋值的变量,即指定需要被转换的源变量。
|
||||
|
||||
以上图赋值逻辑为例:将上一个节点的文本输出项 `Language Recognition/text` 赋值到会话变量 `language` 内。
|
||||
|
||||
**写入模式:**
|
||||
|
||||
* 覆盖,将源变量的内容覆盖至目标会话变量
|
||||
* 追加,指定变量为 Array 类型时
|
||||
* 清空,清空目标会话变量中的内容
|
||||
Reference in New Issue
Block a user