mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
refactor index method docs
This commit is contained in:
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: Choose a Chunk Mode
|
||||
title: Configure the Chunk Settings
|
||||
---
|
||||
|
||||
After uploading content to the knowledge base, the next step is chunking and data cleaning. **This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.**
|
||||
|
||||
@@ -1,3 +1,115 @@
|
||||
---
|
||||
title: Configure Retrieval Settings
|
||||
---
|
||||
---
|
||||
|
||||
Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks. These chunks provide essential contextual for the LLM, ultimately affecting the accuracy and credibility of its answers.
|
||||
|
||||
Common retrieval methods include:
|
||||
|
||||
1. Semantic Retrieval based on vector similarity—where text chunks and queries are converted into vectors and matched via similarity scoring.
|
||||
2. Keyword Matching using an inverted index (a standard search engine technique). Both methods are supported in Dify’s knowledge base.
|
||||
|
||||
Both retrieval methods are supported in Dify’s knowledge base. The specific retrieval options available depend on the chosen indexing method.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="High Quality">
|
||||
**High Quality**
|
||||
|
||||
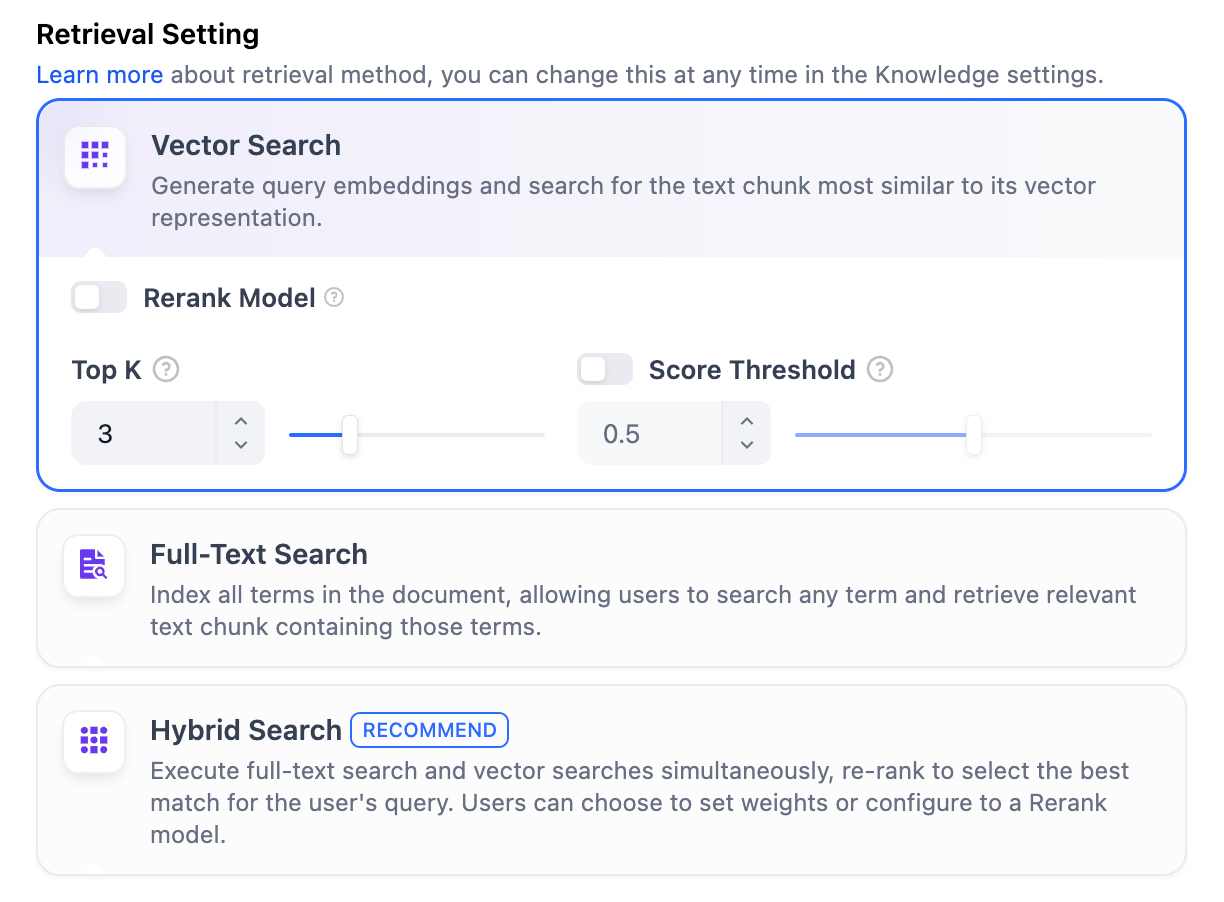
In the **High-Quality** Indexing Method, Dify offers three retrieval settings: **Vector Search, Full-Text Search, and Hybrid Search**.
|
||||
|
||||
|
||||
|
||||
**Vector Search**
|
||||
|
||||
**Definition**: Vectorize the user’s question to generate a query vector, then compare it with the corresponding text vectors in the knowledge base to find the nearest chunks.
|
||||
|
||||
|
||||
|
||||
**Vector Search Settings:**
|
||||
|
||||
**Rerank Model**: Disabled by default. When enabled, a third-party Rerank model will sort the text chunks returned by Vector Search to optimize results. This helps the LLM access more precise information and improve output quality. Before enabling this option, go to **Settings** → **Model Providers** and configure the Rerank model’s API key.
|
||||
|
||||
> Enabling this feature will consume tokens from the Rerank model. For more details, refer to the associated model’s pricing page.
|
||||
|
||||
**TopK**: Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
**Score Threshold**: Sets the minimum similarity score required for a chunk to be retrieved. Only chunks exceeding this score are retrieved. The default value is **0.5**. Higher thresholds demand greater similarity and thus result in fewer chunks being retrieved.
|
||||
|
||||
> The TopK and Score configurations are only effective during the Rerank phase. Therefore, to apply either of these settings, it is necessary to add and enable a Rerank model.
|
||||
|
||||
***
|
||||
|
||||
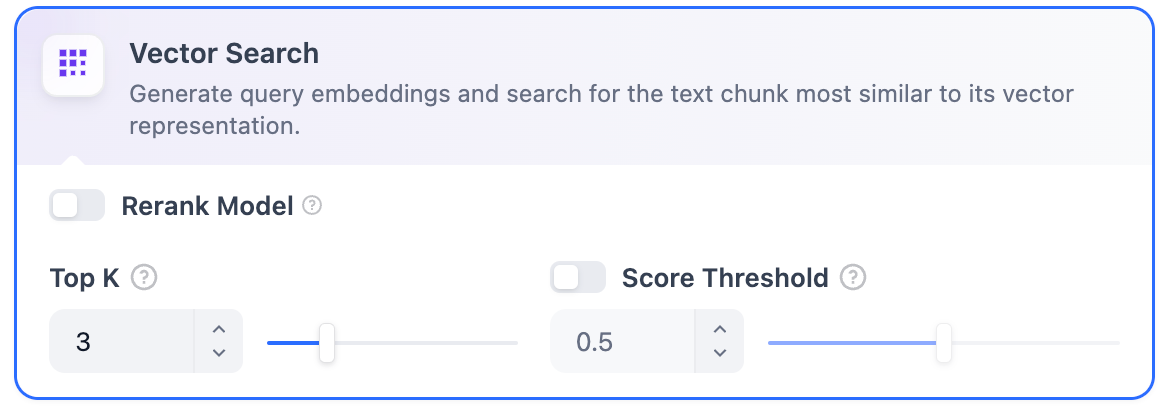
**Full-Text Search**
|
||||
|
||||
**Definition:** Indexing all terms in the document, allowing users to query any terms and return text fragments containing those terms.
|
||||
|
||||
|
||||
|
||||
**Rerank Model**: Disabled by default. When enabled, a third-party Rerank model will sort the text chunks returned by Full-Text Search to optimize results. This helps the LLM access more precise information and improve output quality. Before enabling this option, go to **Settings** → **Model Providers** and configure the Rerank model’s API key.
|
||||
|
||||
> Enabling this feature will consume tokens from the Rerank model. For more details, refer to the associated model’s pricing page.
|
||||
|
||||
**TopK**: Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
**Score Threshold**: Sets the minimum similarity score required for a chunk to be retrieved. Only chunks exceeding this score are retrieved. The default value is **0.5**. Higher thresholds demand greater similarity and thus result in fewer chunks being retrieved.
|
||||
|
||||
> The TopK and Score configurations are only effective during the Rerank phase. Therefore, to apply either of these settings, it is necessary to add and enable a Rerank model.
|
||||
|
||||
***
|
||||
|
||||
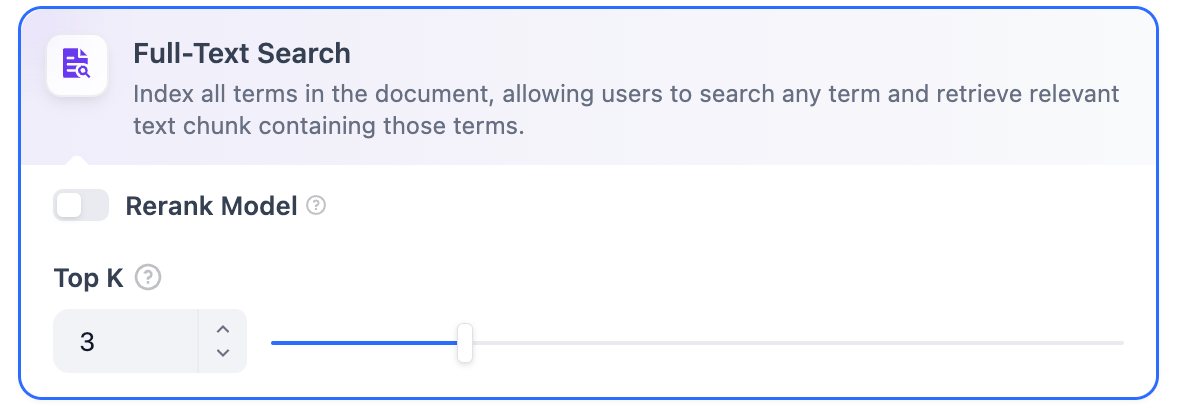
**Hybrid Search**
|
||||
|
||||
**Definition**: This process combines full-text search and vector search, performing both simultaneously. It includes a reordering step to select the best-matching results from both search outcomes based on the user’s query.
|
||||
|
||||
|
||||
|
||||
In this mode, you can specify **"Weight settings"** without needing to configure the Rerank model API, or enable **Rerank model** for retrieval.
|
||||
|
||||
* **Weight Settings**
|
||||
|
||||
This feature enables users to set custom weights for semantic priority and keyword priority. Keyword search refers to performing a full-text search within the knowledge base, while semantic search involves vector search within the knowledge base.
|
||||
|
||||
* **Semantic Value of 1**
|
||||
|
||||
This activates only the semantic search mode. Utilizing embedding models, even if the exact terms from the query do not appear in the knowledge base, the search can delve deeper by calculating vector distances, thus returning relevant content. Additionally, when dealing with multilingual content, semantic search can capture meaning across different languages, providing more accurate cross-language search results.
|
||||
* **Keyword Value of 1**
|
||||
|
||||
This activates only the keyword search mode. It performs a full match against the input text in the knowledge base, suitable for scenarios where the user knows the exact information or terminology. This approach consumes fewer computational resources and is ideal for quick searches within a large document knowledge base.
|
||||
* **Custom Keyword and Semantic Weights**
|
||||
|
||||
In addition to enabling only semantic search or keyword search, we provide flexible custom weight settings. You can continuously adjust the weights of the two methods to identify the optimal weight ratio that suits your business scenario.
|
||||
***
|
||||
|
||||
**Rerank Model**
|
||||
|
||||
Disabled by default. When enabled, a third-party Rerank model will sort the text chunks returned by Hybrid Search to optimize results. This helps the LLM access more precise information and improve output quality. Before enabling this option, go to **Settings** → **Model Providers** and configure the Rerank model’s API key.
|
||||
|
||||
> Enabling this feature will consume tokens from the Rerank model. For more details, refer to the associated model’s pricing page.
|
||||
|
||||
The **"Weight Settings"** and **"Rerank Model"** settings support the following options:
|
||||
|
||||
**TopK**: Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
**Score Threshold**: Sets the minimum similarity score required for a chunk to be retrieved. Only chunks exceeding this score are retrieved. The default value is **0.5**. Higher thresholds demand greater similarity and thus result in fewer chunks being retrieved.
|
||||
</Tab>
|
||||
<Tab title="Economical">
|
||||
**Economical**
|
||||
|
||||
In **Economical Indexing** mode, only the inverted index approach is available. An inverted index is a data structure designed for fast keyword retrieval within documents, commonly used in online search engines. Inverted indexing supports only the **TopK** setting.
|
||||
|
||||
**TopK:** Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
<p align="center">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/b417cd028131d34779993fbcbb8dbdd7.png" width="300" />
|
||||
</p>
|
||||
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### Reference
|
||||
|
||||
After specifying the retrieval settings, you can refer to the following documentation to review how keywords match with content chunks in different scenarios.
|
||||
|
||||
<Card title="Retrieval Test and Citation" icon="link" href="/en/guides/knowledge-base/retrieval-test-and-citation">
|
||||
Learn how to test and cite your knowledge base retrieval
|
||||
</Card>
|
||||
@@ -1,173 +1,68 @@
|
||||
---
|
||||
title: 3. Select the Indexing Method and Retrieval Setting
|
||||
title: Choose an Index Method
|
||||
---
|
||||
|
||||
After selecting the chunking mode, the next step is to define the indexing method for structured content.
|
||||
After configuring the chunk settings, you need to specify the index method for chunks.
|
||||
|
||||
## Setting the Indexing Method
|
||||
## What Does the Index Method Do in Knowledge Retrieval?
|
||||
|
||||
Similar to the search engines use efficient indexing algorithms to match search results most relevant to user queries, the selected indexing method directly impacts the retrieval efficiency of the LLM and the accuracy of its responses to knowledge base content.
|
||||
When you import files, webpages, or other content into a knowledge base, they are first split—according to the chunk settings—into smaller pieces called chunks.
|
||||
|
||||
The knowledge base offers two indexing methods: **High-Quality** and **Economical**, each with different retrieval setting options:
|
||||
**The index method defines how these chunks are turned into searchable representations**, so they can be quickly and accurately retrieved to match a query. These representations are stored and form the **index** of the knowledge base.
|
||||
|
||||
When a user asks a question, it is converted into a compatible representation using the same index method, and then used to search the index and find the most relevant chunks.
|
||||
|
||||
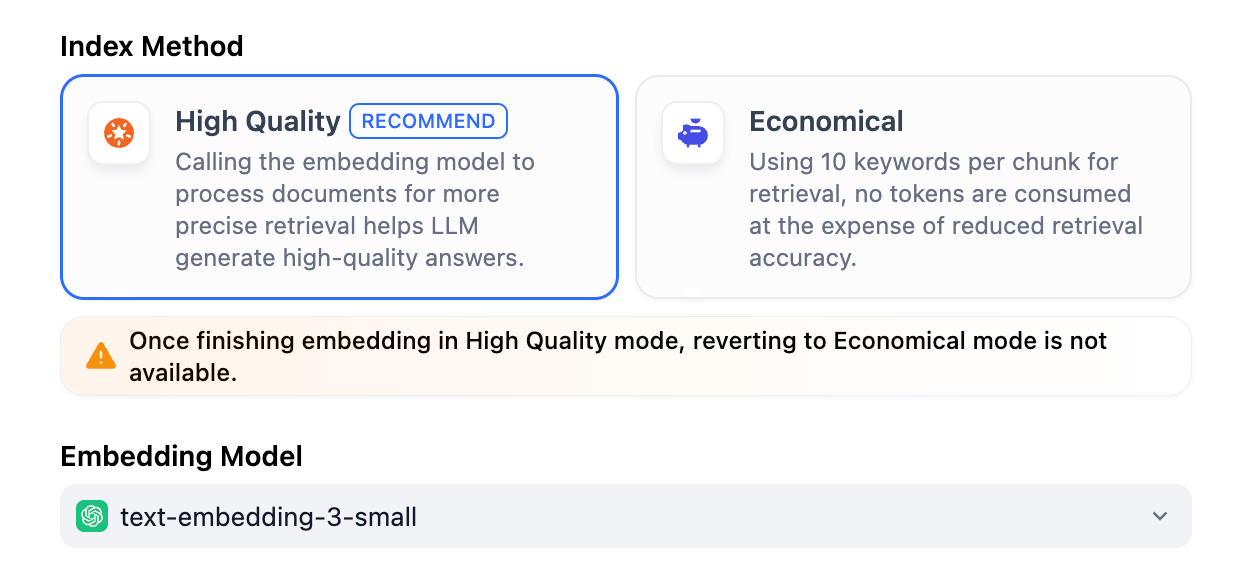
## High Quality vs. Economical
|
||||
|
||||
Dify supports two index methods: **High Quality** and **Economical**. Choosing between them means choosing how a chunk is represented and made searchable—either a vector or a set of keywords.
|
||||
|
||||
<Note>
|
||||
**Note**: The original **Q\&A mode (Available only in the Community Edition)** is now an optional feature under the High-Quality Indexing Method.
|
||||
Once created, a knowledge base can be upgraded from **Economical** to **High Quality**, but not the other way around.
|
||||
</Note>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="High Quality">
|
||||
|
||||
In High-Quality Mode, the Embedding model converts text chunks into numerical vectors, enabling efficient compression and storage of large volumes of textual information. **This allows for more precise matching between user queries and text.**
|
||||
With the **High Quality** index method, each chunk is converted into a vector representation by an embedding model (which consumes tokens). This process is called embedding.
|
||||
|
||||
Once the text chunks are vectorized and stored in the database, an effective retrieval method is required to fetch the chunks that match user queries. The High-Quality indexing method offers three retrieval settings: vector retrieval, full-text retrieval, and hybrid retrieval. For more details on retrieval settings, please check ["Retrieval Settings"](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#retrieval-settings).
|
||||
Think of these vectors as coordinates in a multi-dimensional space—the closer two points are, the more similar their meanings. This allows the system to find relevant information based on semantic similarity, not just exact keyword matches.
|
||||
|
||||
After selecting **High Quality** mode, the indexing method for the knowledge base cannot be downgraded to **Economical** mode later. If you need to switch, it is recommended to create a new knowledge base and select the desired indexing method.
|
||||
|
||||
|
||||
|
||||
### Enable Q&A Mode (Optional, Community Edition Only)
|
||||
<Tip>
|
||||
Quick-created knowledge bases don't allow selecting embedding models that support image embedding (indicated by the **Vision** icon) and thus don't support image-based retrieval.
|
||||
|
||||
When this mode is enabled, the system segments the uploaded text and automatically generates Q\&A pairs for each segment after summarizing its content.
|
||||
But don't worry—you can easily convert a quick-created knowledge base into a pipeline-created one to enable this feature.
|
||||
|
||||
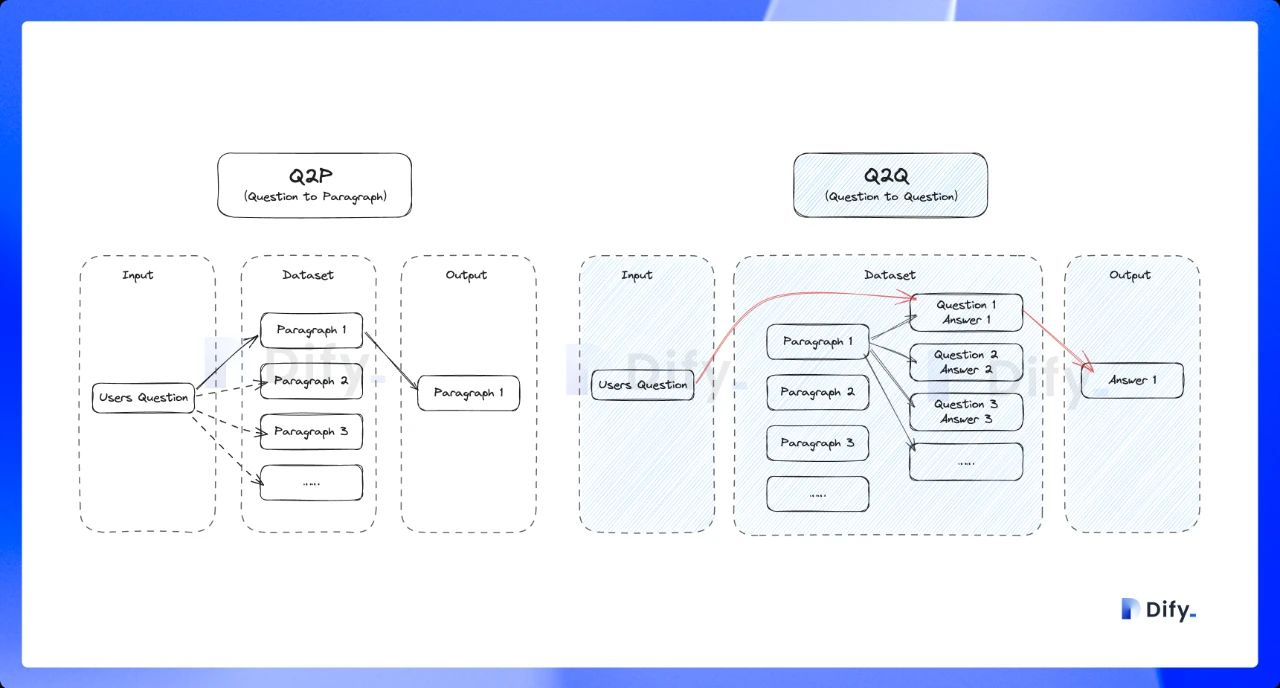
Compared with the common **Q to P** strategy (user questions matched with text paragraphs), the Q\&A mode uses a **Q to Q** strategy (questions matched with questions).
|
||||
<img src="/images/convert_knowledge.png" alt="Convert Quick-created Knowledge to Pipeline-created Knowledge" width="300"/>
|
||||
</Tip>
|
||||
|
||||
This approach is particularly effective because the text in FAQ documents **is often written in natural language with complete grammatical structures**.
|
||||
|
||||
> The **Q to Q** strategy makes the matching between questions and answers clearer and better supports scenarios with high-frequency or highly similar questions.
|
||||
|
||||
|
||||
|
||||
When a user asks a question, the system identifies the most similar question and returns the corresponding chunk as the answer. This approach is more precise, as it directly matches the user’s query, helping them retrieve the exact information they need.
|
||||
|
||||
|
||||
|
||||
</Tab>
|
||||
|
||||
<Tab title="Economical">
|
||||
|
||||
Using 10 keywords per chunk for retrieval, no tokens are consumed at the expense of reduced retrieval accuracy. For the retrieved blocks, only the inverted index method is provided to select the most relevant blocks. For more details, please refer to [Inverted Index](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#inverted-index).
|
||||
|
||||
If the performance of the economical indexing method does not meet your expectations, you can upgrade to the High-Quality indexing method in the Knowledge settings page.
|
||||
|
||||

|
||||
Once embedded, chunks can be retrieved using one of three strategies: **Vector Search**, **Full-Text Search**, or **Hybrid Search**. Learn more in [Configure the Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/configure-retrieval-settings).
|
||||
|
||||
</Tab>
|
||||
|
||||
</Tabs>
|
||||
|
||||
## Setting the Retrieval Setting
|
||||
|
||||
Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks. These chunks provide essential contextual for the LLM, ultimately affecting the accuracy and credibility of its answers.
|
||||
|
||||
Common retrieval methods include:
|
||||
|
||||
1. Semantic Retrieval based on vector similarity—where text chunks and queries are converted into vectors and matched via similarity scoring.
|
||||
2. Keyword Matching using an inverted index (a standard search engine technique). Both methods are supported in Dify’s knowledge base.
|
||||
|
||||
Both retrieval methods are supported in Dify’s knowledge base. The specific retrieval options available depend on the chosen indexing method.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="High Quality">
|
||||
**High Quality**
|
||||
|
||||
In the **High-Quality** Indexing Method, Dify offers three retrieval settings: **Vector Search, Full-Text Search, and Hybrid Search**.
|
||||
|
||||

|
||||
|
||||
**Vector Search**
|
||||
|
||||
**Definition**: Vectorize the user’s question to generate a query vector, then compare it with the corresponding text vectors in the knowledge base to find the nearest chunks.
|
||||
|
||||

|
||||
|
||||
**Vector Search Settings:**
|
||||
|
||||
**Rerank Model**: Disabled by default. When enabled, a third-party Rerank model will sort the text chunks returned by Vector Search to optimize results. This helps the LLM access more precise information and improve output quality. Before enabling this option, go to **Settings** → **Model Providers** and configure the Rerank model’s API key.
|
||||
|
||||
> Enabling this feature will consume tokens from the Rerank model. For more details, refer to the associated model’s pricing page.
|
||||
|
||||
**TopK**: Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
**Score Threshold**: Sets the minimum similarity score required for a chunk to be retrieved. Only chunks exceeding this score are retrieved. The default value is **0.5**. Higher thresholds demand greater similarity and thus result in fewer chunks being retrieved.
|
||||
|
||||
> The TopK and Score configurations are only effective during the Rerank phase. Therefore, to apply either of these settings, it is necessary to add and enable a Rerank model.
|
||||
|
||||
***
|
||||
|
||||
**Full-Text Search**
|
||||
|
||||
**Definition:** Indexing all terms in the document, allowing users to query any terms and return text fragments containing those terms.
|
||||
|
||||

|
||||
|
||||
**Rerank Model**: Disabled by default. When enabled, a third-party Rerank model will sort the text chunks returned by Full-Text Search to optimize results. This helps the LLM access more precise information and improve output quality. Before enabling this option, go to **Settings** → **Model Providers** and configure the Rerank model’s API key.
|
||||
|
||||
> Enabling this feature will consume tokens from the Rerank model. For more details, refer to the associated model’s pricing page.
|
||||
|
||||
**TopK**: Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
**Score Threshold**: Sets the minimum similarity score required for a chunk to be retrieved. Only chunks exceeding this score are retrieved. The default value is **0.5**. Higher thresholds demand greater similarity and thus result in fewer chunks being retrieved.
|
||||
|
||||
> The TopK and Score configurations are only effective during the Rerank phase. Therefore, to apply either of these settings, it is necessary to add and enable a Rerank model.
|
||||
|
||||
***
|
||||
|
||||
**Hybrid Search**
|
||||
|
||||
**Definition**: This process combines full-text search and vector search, performing both simultaneously. It includes a reordering step to select the best-matching results from both search outcomes based on the user’s query.
|
||||
|
||||

|
||||
|
||||
In this mode, you can specify **"Weight settings"** without needing to configure the Rerank model API, or enable **Rerank model** for retrieval.
|
||||
|
||||
* **Weight Settings**
|
||||
|
||||
This feature enables users to set custom weights for semantic priority and keyword priority. Keyword search refers to performing a full-text search within the knowledge base, while semantic search involves vector search within the knowledge base.
|
||||
|
||||
* **Semantic Value of 1**
|
||||
|
||||
This activates only the semantic search mode. Utilizing embedding models, even if the exact terms from the query do not appear in the knowledge base, the search can delve deeper by calculating vector distances, thus returning relevant content. Additionally, when dealing with multilingual content, semantic search can capture meaning across different languages, providing more accurate cross-language search results.
|
||||
* **Keyword Value of 1**
|
||||
|
||||
This activates only the keyword search mode. It performs a full match against the input text in the knowledge base, suitable for scenarios where the user knows the exact information or terminology. This approach consumes fewer computational resources and is ideal for quick searches within a large document knowledge base.
|
||||
* **Custom Keyword and Semantic Weights**
|
||||
|
||||
In addition to enabling only semantic search or keyword search, we provide flexible custom weight settings. You can continuously adjust the weights of the two methods to identify the optimal weight ratio that suits your business scenario.
|
||||
***
|
||||
|
||||
**Rerank Model**
|
||||
|
||||
Disabled by default. When enabled, a third-party Rerank model will sort the text chunks returned by Hybrid Search to optimize results. This helps the LLM access more precise information and improve output quality. Before enabling this option, go to **Settings** → **Model Providers** and configure the Rerank model’s API key.
|
||||
|
||||
> Enabling this feature will consume tokens from the Rerank model. For more details, refer to the associated model’s pricing page.
|
||||
|
||||
The **"Weight Settings"** and **"Rerank Model"** settings support the following options:
|
||||
|
||||
**TopK**: Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
**Score Threshold**: Sets the minimum similarity score required for a chunk to be retrieved. Only chunks exceeding this score are retrieved. The default value is **0.5**. Higher thresholds demand greater similarity and thus result in fewer chunks being retrieved.
|
||||
</Tab>
|
||||
<Tab title="Economical">
|
||||
**Economical**
|
||||
|
||||
In **Economical Indexing** mode, only the inverted index approach is available. An inverted index is a data structure designed for fast keyword retrieval within documents, commonly used in online search engines. Inverted indexing supports only the **TopK** setting.
|
||||
With the **Economical** index method, each chunk is represented by 10 keywords extracted from its content—no tokens are consumed, but matching is more surface-level.
|
||||
|
||||
**TopK:** Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
<p align="center">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/b417cd028131d34779993fbcbb8dbdd7.png" width="300" />
|
||||
</p>
|
||||
This index method only supports the **Inverted Index** retrieval strategy. Learn more in [Configure the Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/configure-retrieval-settings).
|
||||
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### Reference
|
||||
---
|
||||
|
||||
After specifying the retrieval settings, you can refer to the following documentation to review how keywords match with content chunks in different scenarios.
|
||||
When choosing the index method, you are mainly making two trade-offs:
|
||||
|
||||
- **Retrieval Quality vs. Cost**
|
||||
|
||||
- **High Quality**: better semantic recall, suitable when answer relevance is critical.
|
||||
|
||||
- **Economical**: no token usage and lower cost, suitable for scenarios with less strict recall requirements.
|
||||
|
||||
- **Semantic Understanding vs. Keyword-based Matching**
|
||||
|
||||
- **High Quality** is better at understanding synonyms, paraphrases, and long or fuzzy questions.
|
||||
|
||||
- **Economical** is better when users rely on clear keywords, terms, or exact phrases present in the content.
|
||||
|
||||
<Card title="Retrieval Test and Citation" icon="link" href="/en/guides/knowledge-base/retrieval-test-and-citation">
|
||||
Learn how to test and cite your knowledge base retrieval
|
||||
</Card>
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
|
||||
Reference in New Issue
Block a user