mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
docs: auto-translate documentation
This commit is contained in:
103
ja-jp/documentation/pages/build/additional-features.mdx
Normal file
103
ja-jp/documentation/pages/build/additional-features.mdx
Normal file
@@ -0,0 +1,103 @@
|
||||
> ⚠️ この文書は AI によって自動翻訳されています。不正確な箇所がある場合は、[英語版原文](../../../../en/documentation/pages/build/additional-features.mdx)を参照してください。
|
||||
|
||||
---
|
||||
title: "追加機能"
|
||||
icon: "circle-plus"
|
||||
---
|
||||
|
||||
機能を追加して、あなたのアプリケーションをより実用的にします。右上角の **機能** をクリックして機能を追加してください。
|
||||
|
||||
<iframe
|
||||
src="https://www.motionshot.app/walkthrough/6773d34ad27e58127b913945/embed?fullscreen=1&hideAsSteps=1&hideCopy=1&hideDownload=1&hideSteps=1"
|
||||
width="100%"
|
||||
height="400px"
|
||||
frameborder="0"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
## ワークフローアプリケーション
|
||||
|
||||
<Info>
|
||||
ワークフローアプリケーションでは、「機能」を通じてファイルをアップロードする方法は廃止されました。代わりに[開始ノードのファイル変数](/zh/guides/workflow/node/start)を使用してください。
|
||||
</Info>
|
||||
|
||||
ワークフローアプリケーションは「機能」を通じて**画像アップロード**のみをサポートします:
|
||||
|
||||
<iframe
|
||||
src="https://www.motionshot.app/walkthrough/6773d3d86a0c3ed534f24da9/embed?fullscreen=1&hideAsSteps=1&hideCopy=1&hideDownload=1&hideSteps=1"
|
||||
width="100%"
|
||||
height="400px"
|
||||
frameborder="0"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
**設定方法:**
|
||||
1. 「機能」で画像アップロードを有効にする
|
||||
2. ビジョン機能を持つ LLM ノードを追加する
|
||||
3. VISION を有効にして `sys.files` 変数を選択する
|
||||
4. 終了ノードに接続する
|
||||
|
||||
## チャットフローアプリケーション
|
||||
|
||||
チャットフローアプリケーションはより多くの機能をサポートします:
|
||||
|
||||
- **会話の開始挨拶** - AI が先に挨拶をする
|
||||
- **フォローアップ質問の提案** - 各回答後に次の質問を提案する
|
||||
- **テキスト音声変換** - 回答内容を読み上げる(モデルプロバイダーで TTS の設定が必要)
|
||||
- **ファイルアップロード** - ユーザーがファイルをアップロードできる
|
||||
- **引用と帰属** - 知識検索使用時に情報源を表示する
|
||||
- **コンテンツ審査** - 不適切なコンテンツをフィルタリングする
|
||||
|
||||
## ファイルアップロード
|
||||
|
||||
ほとんどの機能は有効にすると自動的に動作します。ファイルアップロードはより多くの設定が必要です。
|
||||
|
||||
**ユーザー向け**:クリップアイコンをクリックしてファイルをアップロード
|
||||
|
||||
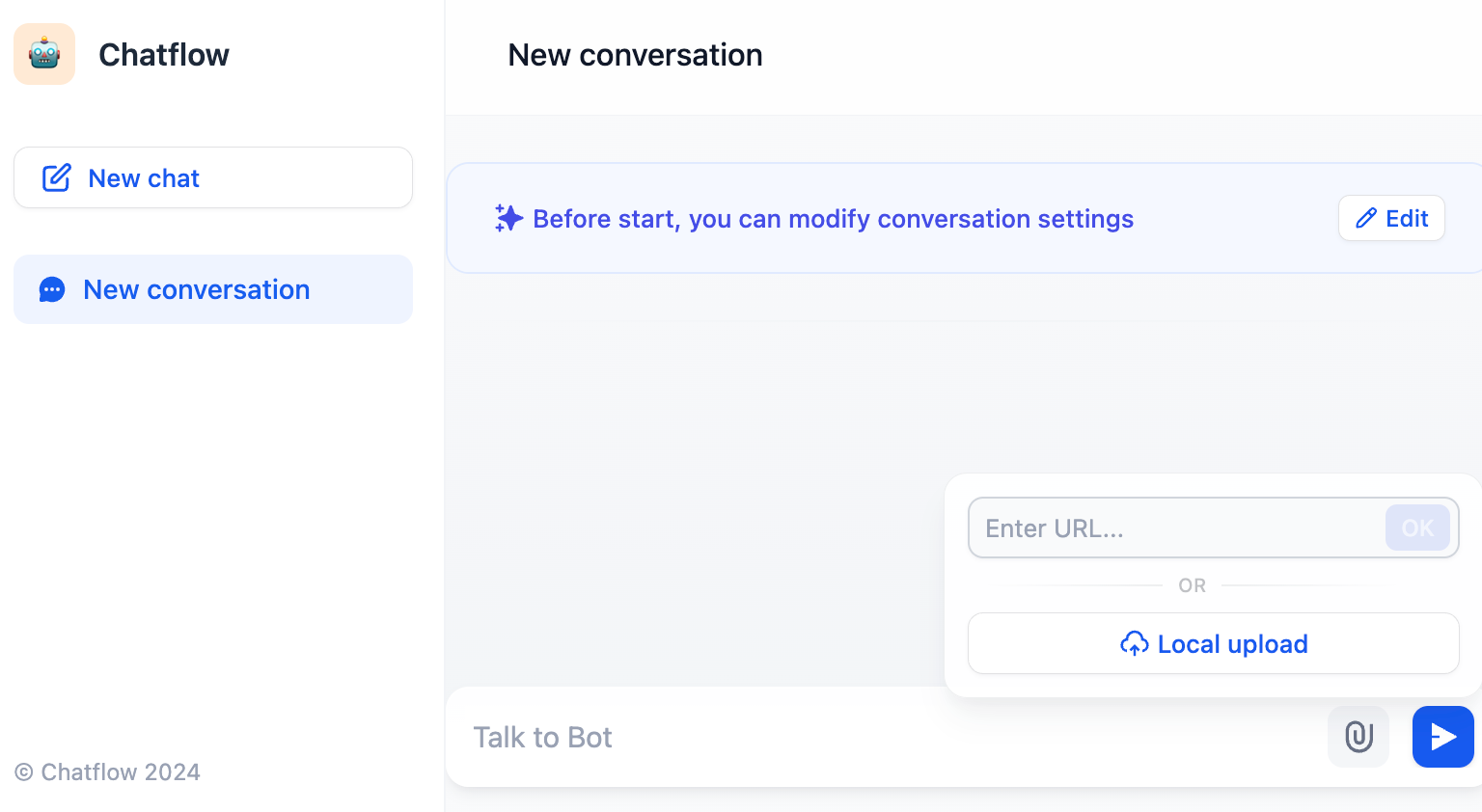
|
||||
|
||||
**開発者向け**:ファイルは `sys.files` 変数に表示されます。異なるファイル形式には異なる処理方法が必要です:
|
||||
|
||||
### 文書
|
||||
|
||||
大規模言語モデルはファイルを直接読み取ることができません。まず「文書抽出器」を使用してください。
|
||||
|
||||
1. ファイル形式で「文書」を有効にする
|
||||
2. 「文書抽出器」ノードを追加し、`sys.files` を入力として使用する
|
||||
3. LLM ノードを追加し、文書抽出器の出力を使用する
|
||||
4. 「回答」ノードを追加し、LLM の出力を使用する
|
||||
|
||||
<Warning>
|
||||
この方法では複数回の対話でファイルを記憶しません。ユーザーは毎回再アップロードする必要があります。永続化ファイルについては、[開始ノードのファイル変数](/zh/guides/workflow/node/start)を使用してください。
|
||||
</Warning>
|
||||
|
||||
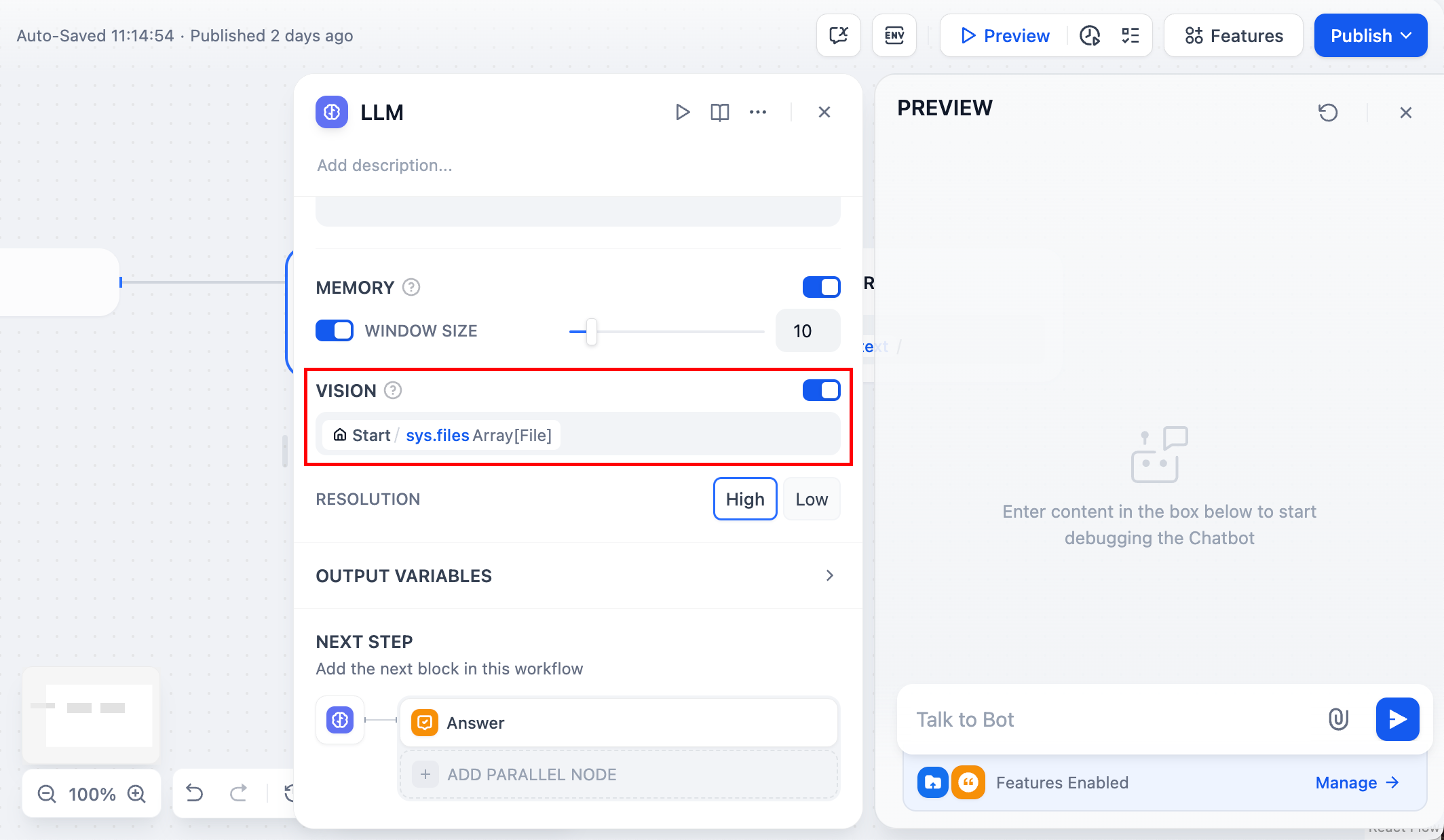
### 画像
|
||||
|
||||
一部の大規模言語モデルは画像を直接分析できます。
|
||||
|
||||
1. ファイル形式で「画像」を有効にする加する
|
||||
3. `sys.files` 変数を選択する
|
||||
4. 「回答」ノードを追加し、LLM の出力を使用する
|
||||
|
||||
|
||||
|
||||
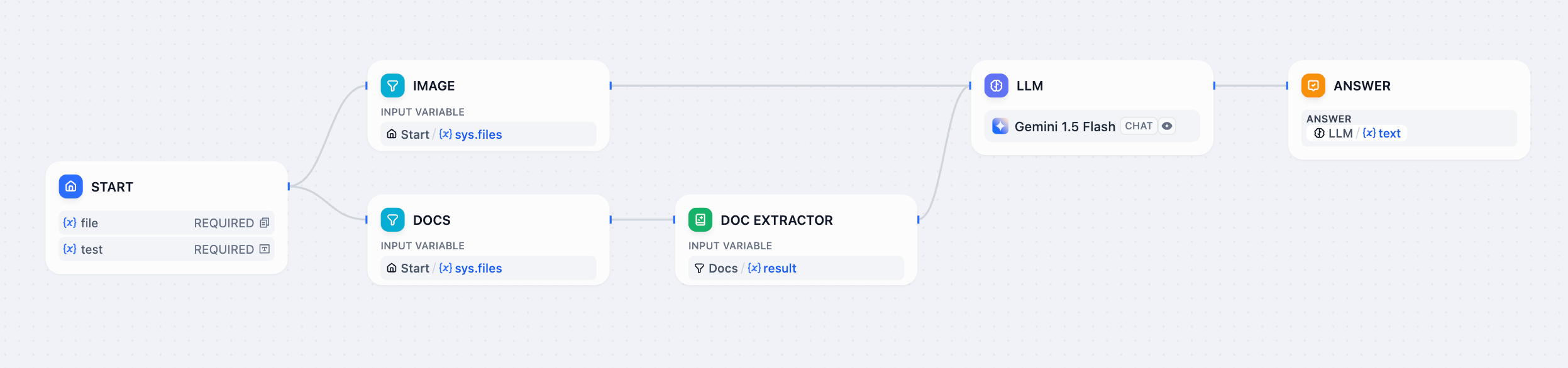
### 混合ファイル形式
|
||||
|
||||
文書と画像を同時に処理する:
|
||||
|
||||
1. 「画像」と「文書」を同時に有効にする
|
||||
2. 2つの「リスト操作」ノードを追加してファイル形式をフィルタリングする
|
||||
3. 画像をビジョン機能を持つ LLM に送信する
|
||||
4. 文書を「文書抽出器」に送信する
|
||||
5. 「回答」ノードで結果を統合する
|
||||
|
||||
|
||||
|
||||
### 音声と動画
|
||||
|
||||
大規模言語モデルはこれらのファイルを直接処理できません。音声/動画を処理するには[外部ツール](/zh/guides/extension/api-based-extension/external-data-tool)を使用する必要があります。
|
||||
|
||||
## 制限
|
||||
|
||||
- 各ファイル最大 15MB
|
||||
- 一度に最大 10 ファイル
|
||||
104
ja-jp/documja-jptation/pages/build/additional-features.mdx
Normal file
104
ja-jp/documja-jptation/pages/build/additional-features.mdx
Normal file
@@ -0,0 +1,104 @@
|
||||
```mdx
|
||||
---
|
||||
title: "追加機能"
|
||||
icon: "circle-plus"
|
||||
---
|
||||
|
||||
アプリをより便利にするために機能を追加します。右上の**Features**をクリックして機能を追加してください。
|
||||
|
||||
<iframe
|
||||
src="https://www.motionshot.app/walkthrough/6773d34ad27e58127b913945/embed?fullscreen=1&hideAsSteps=1&hideCopy=1&hideDownload=1&hideSteps=1"
|
||||
width="100%"
|
||||
height="400px"
|
||||
frameborder="0"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
## ワークフローアプリ
|
||||
|
||||
<Info>
|
||||
ワークフローアプリでのFeaturesを介したファイルアップロードは廃止されました。[Startノードのファイル変数](/en/guides/workflow/node/start)を代わりに使用してください。
|
||||
</Info>
|
||||
|
||||
ワークフローアプリでは、**画像アップロード**のみがFeatures経由でサポートされています:
|
||||
|
||||
<iframe
|
||||
src="https://www.motionshot.app/walkthrough/6773d3d86a0c3ed534f24da9/embed?fullscreen=1&hideAsSteps=1&hideCopy=1&hideDownload=1&hideSteps=1"
|
||||
width="100%"
|
||||
height="400px"
|
||||
frameborder="0"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
**設定方法:**
|
||||
1. Featuresで画像アップロードを有効にする
|
||||
2. 视觉能力があるLLMノードを追加する
|
||||
3. VISIONを有効にし、`sys.files`変数を選択する
|
||||
4. Endノードに接続する
|
||||
|
||||
## チャットフローアプリ
|
||||
|
||||
チャットフローアプリはより多くの機能を持っています:
|
||||
|
||||
- **会話の開始** - AIが最初に挨拶
|
||||
- **フォローアップ** - レスポンス後に次の質問を提案
|
||||
- **文本转语音** - レスポンスを音声で読み上げる(モデルプロバイダーでTTSの設定が必要)
|
||||
- **ファイルアップロード** - ユーザーがファイルをアップロード可能
|
||||
- **引用** - 知识检索を使用する際に情報源を表示
|
||||
- **コンテンツモデレーション** - 不適切なコンテンツをフィルタリング
|
||||
|
||||
## ファイルアップロード
|
||||
|
||||
大部分の機能は有効化すると自動的に動作しますが、ファイルアップロードには追加の設定が必要です。
|
||||
|
||||
**ユーザー向け**: クリップアイコンをクリックしてファイルをアップロード
|
||||
|
||||

|
||||
|
||||
**開発者向け**: ファイルは`sys.files`変数に表示されます。異なるファイルタイプには異なる処理が必要です:
|
||||
|
||||
### ドキュメント
|
||||
|
||||
LLMはファイルを直接読み取れません。最初にドキュメント抽出器を使用してください。
|
||||
|
||||
1. ファイルタイプで「ドキュメント」を有効にする
|
||||
2. `sys.files`を入力としてドキュメント抽出器ノードを追加する
|
||||
3. ドキュメント抽出器の出力を使用してLLMノードを追加する
|
||||
4. LLMの出力を持つ回答ノードを追加する
|
||||
|
||||
<Warning>
|
||||
これでは会話間でファイルを記憶しません。ユーザーは毎回再アップロードする必要があります。永続的なファイルには、[Startノードのファイル変数](/en/guides/workflow/node/start)を使用してください。
|
||||
</Warning>
|
||||
|
||||
### 画像
|
||||
|
||||
一部のLLMは画像を直接分析することができます。
|
||||
|
||||
1. ファイルタイプで「画像」を有効にする
|
||||
2. VISIONを有効にしたLLMノードを追加する
|
||||
3. `sys.files`変数を選択する
|
||||
4. LLMの出力を持つ回答ノードを追加する
|
||||
|
||||

|
||||
|
||||
### 混合ファイルタイプ
|
||||
|
||||
ドキュメントと画像の両方を処理します:
|
||||
|
||||
1. 「画像」と「ドキュメント」の両方を有効にする
|
||||
2. ファイルタイプをフィルタリングするための2つのリスト操作ノードを追加する
|
||||
3. 画像をビジョンを持つLLMに送る
|
||||
4. ドキュメントをドキュメント抽出器に送る
|
||||
5. 結果を回答ノードで結合する
|
||||
|
||||

|
||||
|
||||
### オーディオとビデオ
|
||||
|
||||
LLMはこれらを直接処理できません。オーディオ/ビデオ処理には[外部ツール](/en/guides/extension/api-based-extension/external-data-tool)が必要です。
|
||||
|
||||
## 制限
|
||||
|
||||
- ファイルあたり最大15MB
|
||||
- 一度に最大10ファイル
|
||||
```
|
||||
106
ja-jp/documja-jptation/pages/build/mcp.mdx
Normal file
106
ja-jp/documja-jptation/pages/build/mcp.mdx
Normal file
@@ -0,0 +1,106 @@
|
||||
---
|
||||
title: "MCPツールの使用"
|
||||
icon: "microchip"
|
||||
---
|
||||
|
||||
[MCPサーバー](https://modelcontextprotocol.io/introduction)から外部ツールをDifyアプリに接続します。組み込みツールだけでなく、成長する[MCPエコシステム](https://mcpservers.org/)のツールを使用できます。
|
||||
|
||||
<Note>
|
||||
これはDifyでMCPツールを使用することについて説明しています。DifyアプリをMCPサーバーとして公開するには、[こちら](/en/guides/application-publishing/publish-mcp)を参照してください。
|
||||
</Note>
|
||||
|
||||
<Info>
|
||||
現在は[HTTPトランスポート](https://modelcontextprotocol.io/docs/concepts/architecture#transport-layer)を持つMCPサーバーのみサポートしています。
|
||||
</Info>
|
||||
|
||||
## MCPサーバーの追加
|
||||
|
||||
ワークスペースで**ツール** → **MCP**に移動します。
|
||||
|
||||

|
||||
|
||||
**MCPサーバーを追加(HTTP)**をクリック:
|
||||
|
||||

|
||||
|
||||
**サーバーURL**: MCPサーバーの場所(例:`https://api.notion.com/mcp`)
|
||||
|
||||
**名前とアイコン**: 有用な名前を付けてください。Difyは自動的にアイコンを取得しようとします。
|
||||
|
||||
**サーバーID**: 一意の識別子(小文字、数字、アンダースコア、ハイフン、最大24文字)
|
||||
|
||||
<Warning>
|
||||
使用を開始したら、サーバーIDを変更しないでください。このサーバーのツールを使用するアプリが壊れます。
|
||||
</Warning>
|
||||
|
||||
## 次に何が起こるか
|
||||
|
||||
Difyが自動的に:
|
||||
1. サーバーに接続
|
||||
2. OAuth関連の処理を実行
|
||||
3. 利用可能なツールのリストを取得
|
||||
4. アプリビルダーで使用できるように設定
|
||||
|
||||
ツールが見つかるとサーバーカードが表示されます:
|
||||
|
||||

|
||||
|
||||
## サーバーの管理
|
||||
|
||||
任意のサーバーカードをクリックして:
|
||||
|
||||
**ツールを更新**: 外部サービスが新しいツールを追加したときに更新
|
||||
|
||||

|
||||
|
||||
**再認証**: トークンが期限切れになったときに認証を修正
|
||||
|
||||
**設定を編集**: サーバーの詳細を変更(ただしIDは除く!)
|
||||
|
||||
**削除**: サーバーを切断(そのツールを使用するアプリが壊れます)
|
||||
|
||||
## MCPツールの使用
|
||||
|
||||
接続されると、MCPツールは期待される場所すべてに表示されます:
|
||||
|
||||
**エージェント内**: ツールはサーバーごとにグループ化されて表示(「Notion MCP » ページを作成」)
|
||||
|
||||
**ワークフロー内**: MCPツールがノードとして利用可能
|
||||
|
||||
**エージェントノード内**: 通常のエージェントと同様
|
||||
|
||||
## ツールのカスタマイズ
|
||||
|
||||
MCPツールを追加するときにカスタマイズできます:
|
||||
|
||||

|
||||
|
||||
**説明**: デフォルトの説明をより具体的なものにオーバーライド
|
||||
|
||||
**パラメータ**: 各ツールパラメータに対して選択:
|
||||
- **自動**: AIに値を決定させる
|
||||
- **固定**: 変更されない特定の値を設定
|
||||
|
||||
**例**: 検索ツールの場合、`numResults`を5(ままにします。
|
||||
|
||||
## アプリの共有
|
||||
|
||||
MCPツールを使用するアプリをエクスポートするとき:
|
||||
- エクスポートにはサーバーIDが含まれます
|
||||
- 他の場所でアプリを使用するには、同じIDで同じサーバーを追加
|
||||
- アプリが必要とするMCPサーバーを文書化
|
||||
|
||||
## トラブルシューティング
|
||||
|
||||
**「未設定サーバー」**: URLを確認して再認証
|
||||
|
||||
**ツールが見つからない**: 「ツールを更新」をクリック
|
||||
|
||||
**アプリが壊れた**: おそらくサーバーIDを変更しました。元のIDで再度追加してください。
|
||||
|
||||
## ヒント
|
||||
|
||||
- `github-prod`や`crm-system`のような永続的で説明的なサーバーIDを使用
|
||||
- 開発/ステージング/本番環境で同じMCP設定を維持
|
||||
- 設定項目には固定値を、動的入力には自動を設定
|
||||
- デプロイ前にMCPインテグレーションをテスト
|
||||
36
ja-jp/documja-jptation/pages/build/orchestrate-node.mdx
Normal file
36
ja-jp/documja-jptation/pages/build/orchestrate-node.mdx
Normal file
@@ -0,0 +1,36 @@
|
||||
```mdx
|
||||
---
|
||||
title: "フローロジック"
|
||||
icon: "diagram-project"
|
||||
---
|
||||
|
||||
ノードは接続方法に応じて異なる方法で実行されます。
|
||||
|
||||
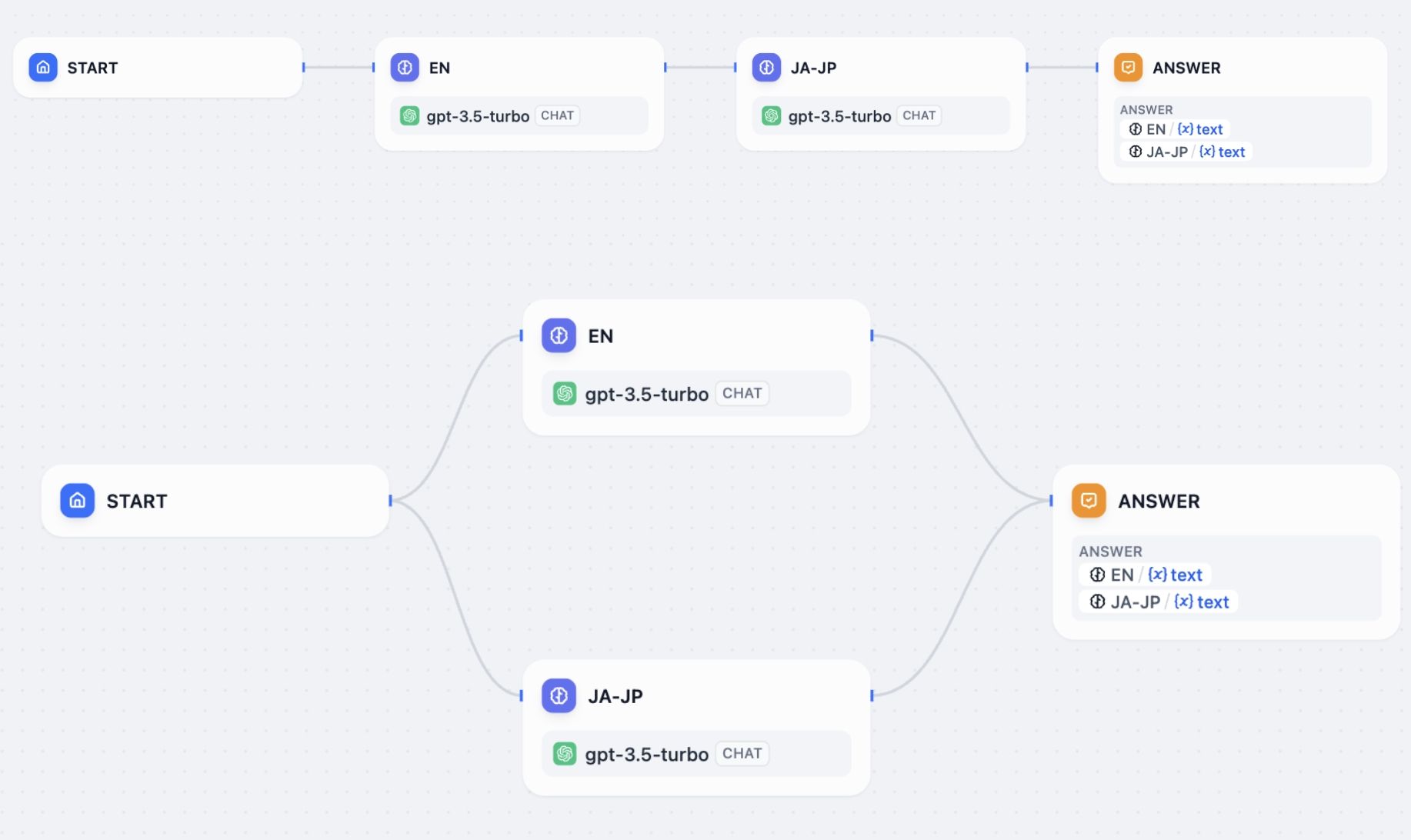
|
||||
|
||||
## 直列実行
|
||||
|
||||
ノードを次々と接続すると、それらは順番に実行されます。各ノードは、前のノードが終了するのを待ってから開始します。
|
||||
|
||||

|
||||
|
||||
各ノードは、チェーン内でそれ以前に実行された任意のノードから変数を使用できます。
|
||||
|
||||
## 並列実行
|
||||
|
||||
複数のノードを同じ開始ノードに接続すると、それらは同時に実行されます。
|
||||
|
||||
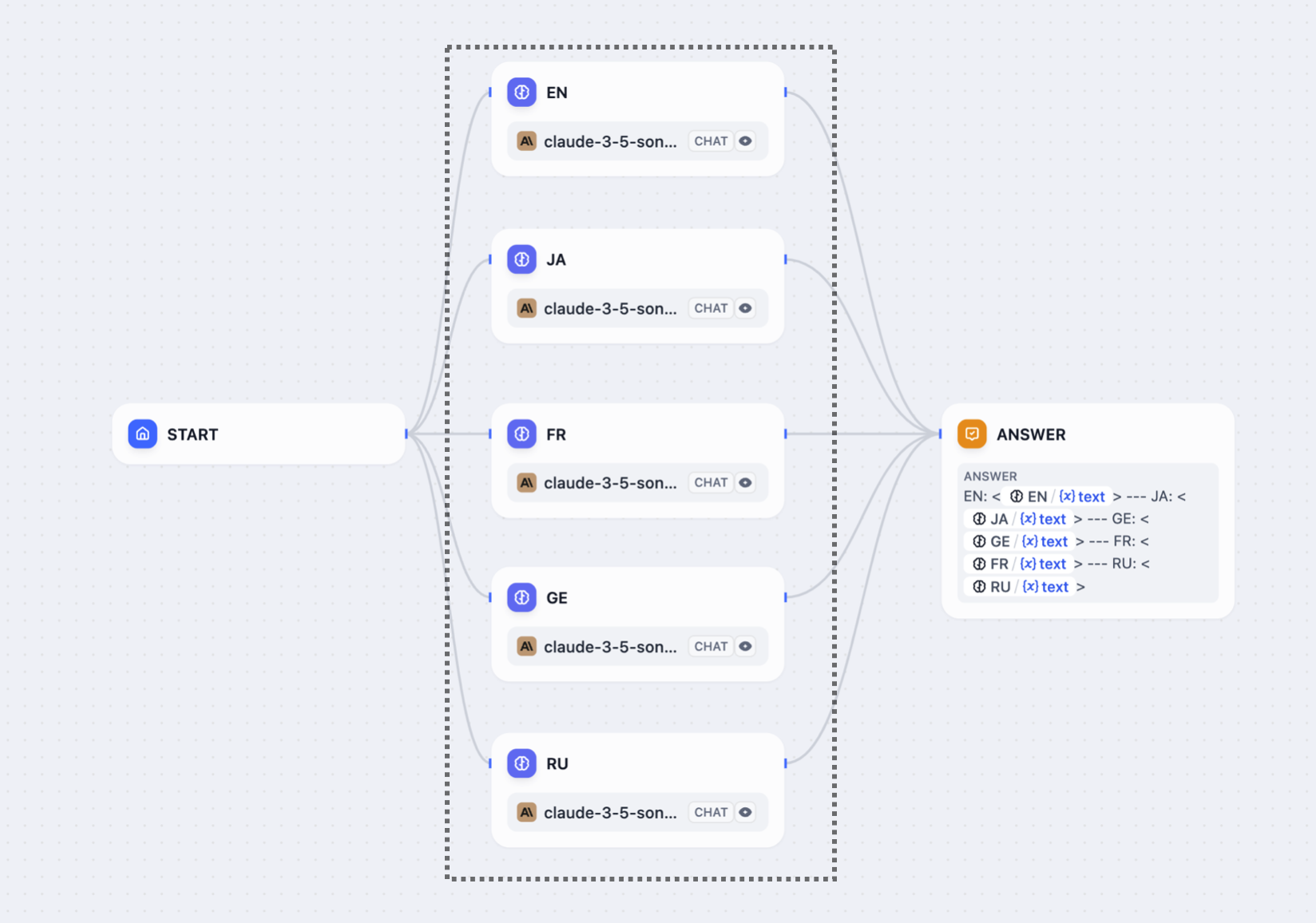
|
||||
|
||||
<Note>
|
||||
1つのノードから最大10個の並列ブランチを持つことができ、最大3レベルの入れ子になった並列構造を持つことができます。
|
||||
</Note>
|
||||
|
||||
## 変数アクセス
|
||||
|
||||
直列フローでは、ノードはチェーン内の任意の前のノードから変数にアクセスできます。
|
||||
|
||||
並列フローでは、ノードは並列分岐前に実行されたノードから変数にアクセスできますが、同時に実行されている他の並列ノードからは変数にアクセスできません。
|
||||
|
||||
並列ブランチが終了した後、下流のノードはすべての並列出力から変数にアクセスできます。
|
||||
```
|
||||
@@ -0,0 +1,88 @@
|
||||
```mdx
|
||||
---
|
||||
title: "エラーの処理"
|
||||
icon: "arrow-rotate-right"
|
||||
---
|
||||
|
||||
|
||||
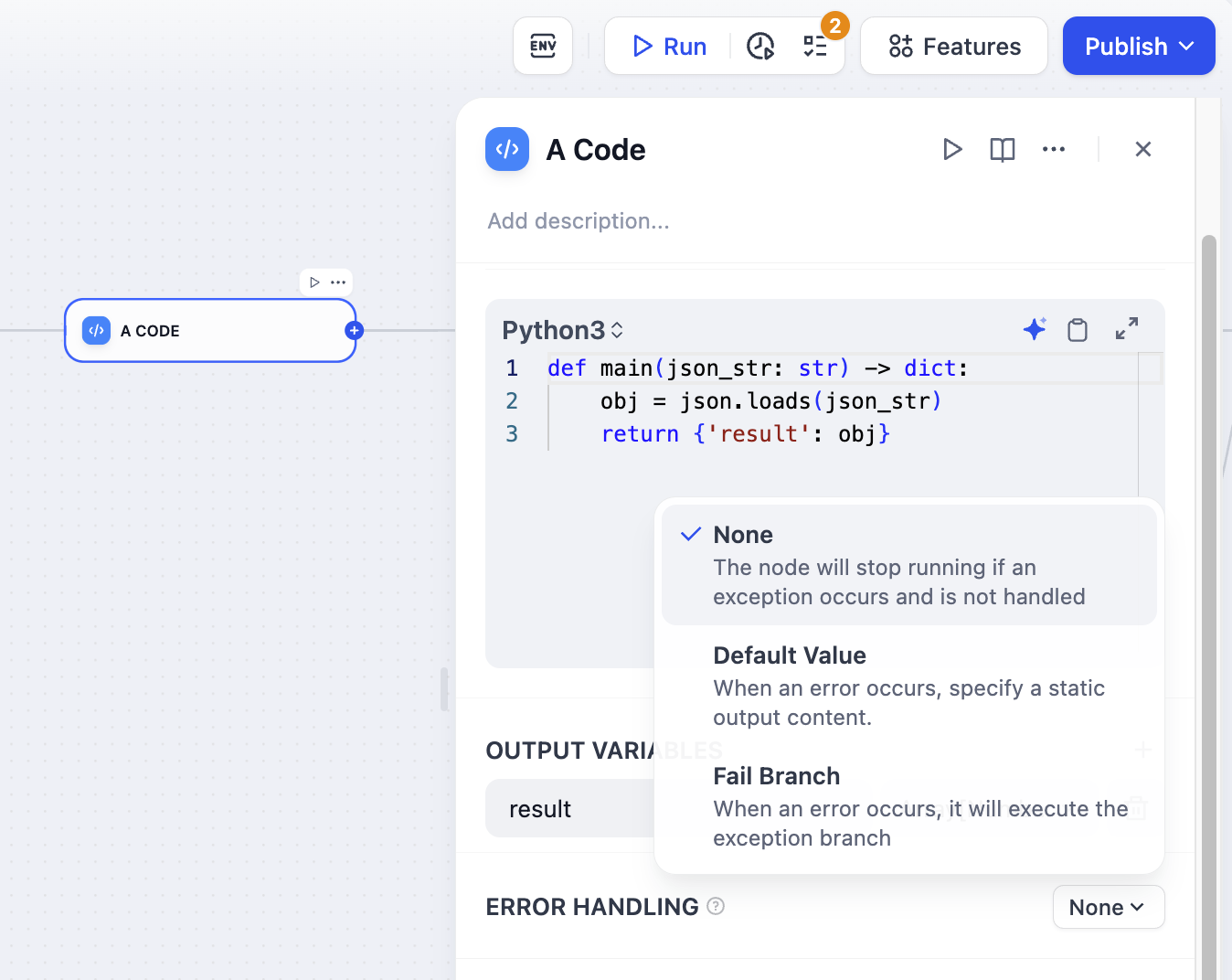
[大規模言語モデル](/en/guides/workflow/node/llm), [HTTP](/en/guides/workflow/node/http-request), [コード](/en/guides/workflow/node/code), および [ツール](/en/guides/workflow/node/tools) ノードは、エラー処理を標準でサポートしています。ノードが失敗した場合、以下の3つの動作のいずれかを取ることができます。
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="なし">
|
||||
デフォルトの動作です。ノードが失敗した場合、全体のワークフローが停止し、元のエラーメッセージが表示されます。
|
||||
|
||||
以下のような場合に使用します:
|
||||
- テスト中で何が壊れたのかを確認したい時
|
||||
- このステップなしではワークフローを続行できない時
|
||||
</Accordion>
|
||||
<Accordion title="デフォルト値">
|
||||
ノードが失敗した場合に、代替値を使用します。ワークフローは継続します。
|
||||
|
||||
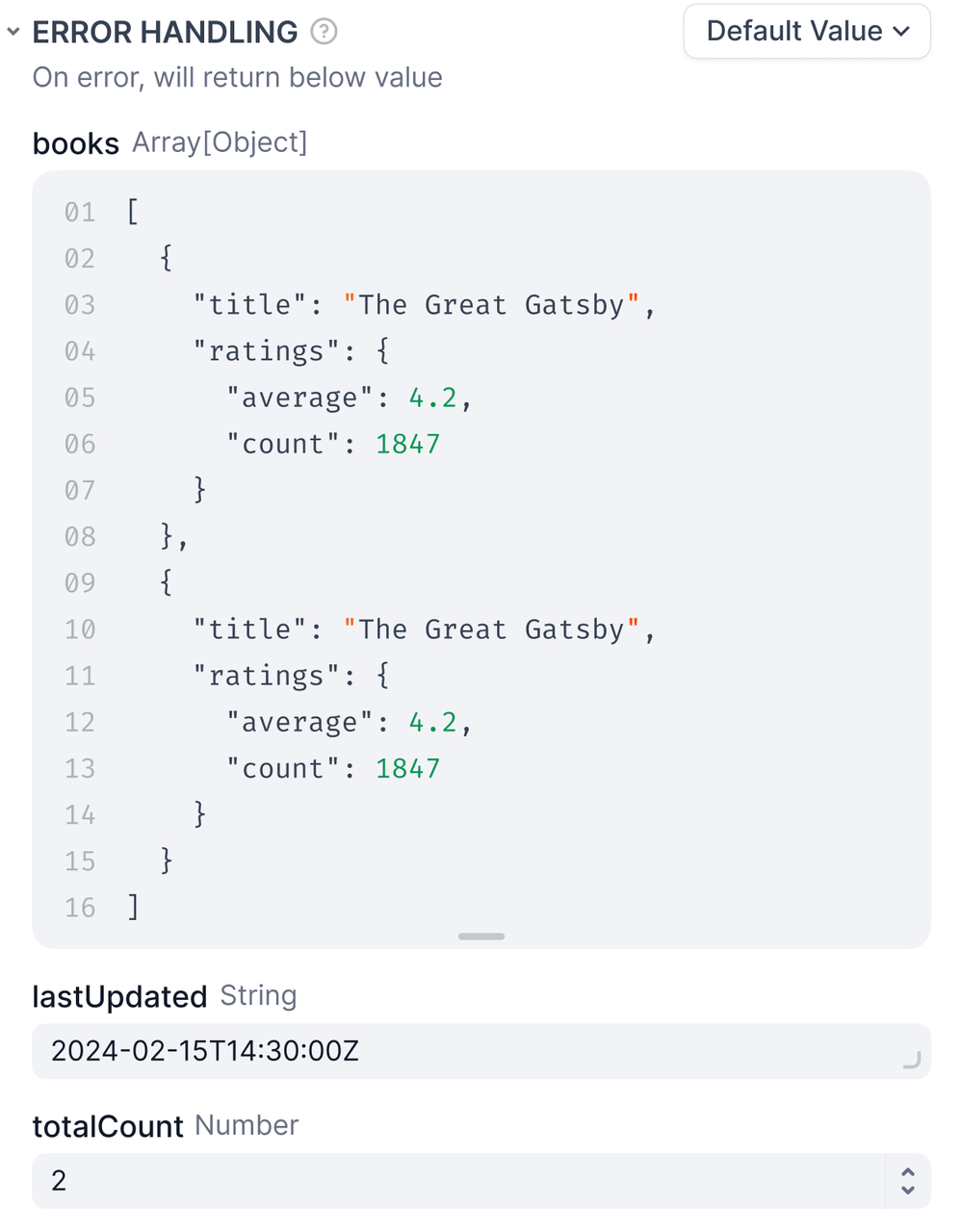
|
||||
|
||||
**要件**
|
||||
- デフォルト値はノードの出力タイプと一致している必要があります。文字列を出力する場合、デフォルトも文字列でなければなりません。
|
||||
|
||||
**例**
|
||||
|
||||
通常、あなたの大規模言語モデルノードは分析を返しますが、時折レート制限のために失敗します。このようなデフォルト値を設定します:
|
||||
|
||||
```
|
||||
"申し訳ありませんが、一時的に利用できません。数分後に再試行してください。"
|
||||
```
|
||||
|
||||
これにより、ユーザーは壊れたワークフローではなく、役立つメッセージを受け取ります。
|
||||
</Accordion>
|
||||
<Accordion title="失敗分岐">
|
||||
ノードが失敗した場合、エラーを処理するための別のフローをトリガーします。
|
||||
|
||||
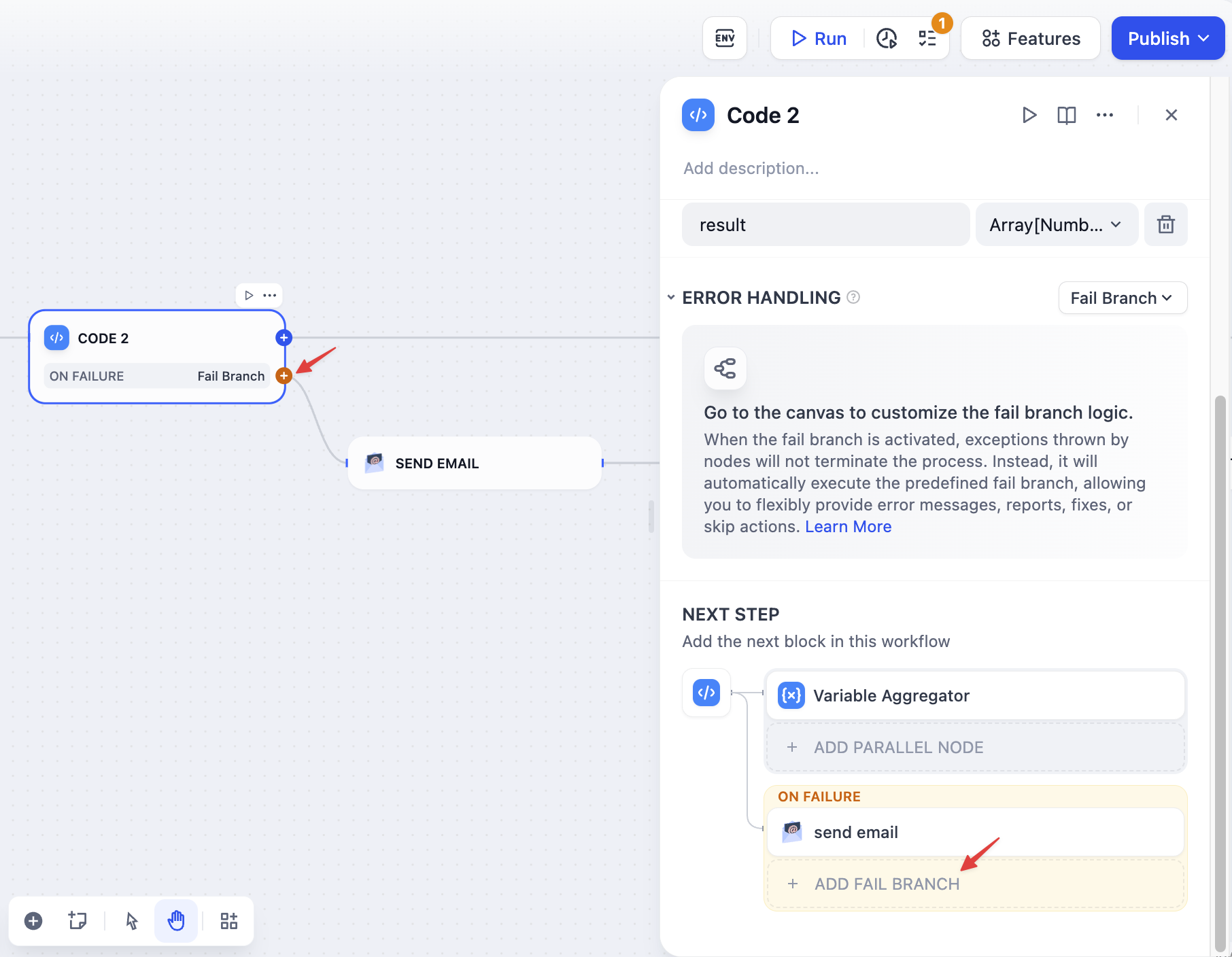
|
||||
|
||||
失敗分岐はオレンジ色で表示されます。以下のことができます:
|
||||
- エラーメッセージを送信する
|
||||
- 別のアプローチを試みる
|
||||
- デバッグのためにエラーをログに記録する
|
||||
- 代替サービスを使用する
|
||||
**例**
|
||||
|
||||
メインのAPIが失敗した場合、失敗分岐が代替APIを呼び出します。ユーザーは問題があったことを知りません。
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## ループ/イテレーションノードでのエラー
|
||||
|
||||
ループやイテレーション内で子ノードが失敗した場合、これらの制御フローノードには独自のエラー動作があります。
|
||||
|
||||
**ループノード**は、子ノードが失敗した場合、常に即座に停止します。ループ全体が終了し、エラーを返し、以降のイテレーションは実行されません。
|
||||
|
||||
**イテレーションノード**は、エラー処理モード設定を通じて子ノードの失敗をどのように処理するかを選択できます:
|
||||
|
||||
- `terminated` - いずれかの項目が失敗した場合、即座に処理を停止します(デフォルト)
|
||||
- `continue-on-error` - 失敗した項目をスキップし、次の項目を続行します
|
||||
- `remove-abnormal-output` - 処理を続行しますが、失敗した項目を最終出力から除外します
|
||||
|
||||
イテレーションを `continue-on-error` に設定すると、失敗した項目は出力配列で `null` を返します。 `remove-abnormal-output` を使用すると、出力配列には成功した結果のみが含まれるため、入力配列よりも短くなります。
|
||||
|
||||
## エラー変数
|
||||
|
||||
デフォルト値または失敗分岐を使用する場合、2つの特別な変数を取得します:
|
||||
|
||||
- `error_type` - どのような種類のエラーが発生したか([エラーの種類](en/guides/workflow/error-handling/error-type)を参照)
|
||||
- `error_message` - 実際のエラーの詳細
|
||||
|
||||
これを使用して:
|
||||
- ユーザーに役立つメッセージを表示する
|
||||
- チームに警告を送信する
|
||||
- 異なる回復戦略を選択する
|
||||
- デバッグのためにエラーを記録する
|
||||
|
||||
**例**
|
||||
|
||||
```
|
||||
{% if error_type == "rate_limit" %}
|
||||
リクエストが多すぎます。少し待ってから再試行してください。
|
||||
{% else %}
|
||||
何か問題が発生しました。私たちのチームが通知されました。
|
||||
{% endif %}
|
||||
```
|
||||
```
|
||||
150
ja-jp/documja-jptation/pages/build/shortcut-key.mdx
Normal file
150
ja-jp/documja-jptation/pages/build/shortcut-key.mdx
Normal file
@@ -0,0 +1,150 @@
|
||||
```mdx
|
||||
---
|
||||
title: "ホットキー"
|
||||
icon: "keyboard"
|
||||
---
|
||||
|
||||
キーボードショートカットでワークフローの構築をスピードアップします。
|
||||
|
||||
## ノード操作
|
||||
キャンバス上で選択されたノードに対して:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Windows</th>
|
||||
<th>macOS</th>
|
||||
<th>アクション</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>C</code></td>
|
||||
<td><code>Cmd</code> + <code>C</code></td>
|
||||
<td>ノードをコピー</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>V</code></td>
|
||||
<td><code>Cmd</code> + <code>V</code></td>
|
||||
<td>ノードをペースト</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>D</code></td>
|
||||
<td><code>Cmd</code> + <code>D</code></td>
|
||||
<td>ノードを複製</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Delete</code></td>
|
||||
<td><code>Delete</code></td>
|
||||
<td>選択したノードを削除</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>O</code></td>
|
||||
<td><code>Cmd</code> + <code>O</code></td>
|
||||
<td>ノードを自動配置</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Shift</code></td>
|
||||
<td><code>Shift</code></td>
|
||||
<td>変数の依存関係を可視化(単一ノードのみ)</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## キャンバスナビゲーション
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Windows</th>
|
||||
<th>macOS</th>
|
||||
<th>アクション</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>1</code></td>
|
||||
<td><code>Cmd</code> + <code>1</code></td>
|
||||
<td>表示に合わせる</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>-</code></td>
|
||||
<td><code>Cmd</code> + <code>-</code></td>
|
||||
<td>ズームアウト</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>=</code></td>
|
||||
<td><code>Cmd</code> + <code>=</code></td>
|
||||
<td>ズームイン</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Shift</code> + <code>1</code></td>
|
||||
<td><code>Shift</code> + <code>1</code></td>
|
||||
<td>100%にリセット</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Shift</code> + <code>5</code></td>
|
||||
<td><code>Shift</code> + <code>5</code></td>
|
||||
<td>50%に設定</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>H</code></td>
|
||||
<td><code>H</code></td>
|
||||
<td>手のひらツール(パン)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>V</code></td>
|
||||
<td><code>V</code></td>
|
||||
<td>選択ツール</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## 履歴
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Windows</th>
|
||||
<th>macOS</th>
|
||||
<th>アクション</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>Z</code></td>
|
||||
<td><code>Cmd</code> + <code>Z</code></td>
|
||||
<td>元に戻す</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>Y</code></td>
|
||||
<td><code>Cmd</code> + <code>Y</code></td>
|
||||
<td>やり直し</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>Shift</code> + <code>Z</code></td>
|
||||
<td><code>Cmd</code> + <code>Shift</code> + <code>Z</code></td>
|
||||
<td>やり直し</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## テスト
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Windows</th>
|
||||
<th>macOS</th>
|
||||
<th>アクション</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>Alt</code> + <code>R</code></td>
|
||||
<td><code>Option</code> + <code>R</code></td>
|
||||
<td>ワークフローを実行</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
```
|
||||
103
ja-jp/documja-jptation/pages/build/version-control.mdx
Normal file
103
ja-jp/documja-jptation/pages/build/version-control.mdx
Normal file
@@ -0,0 +1,103 @@
|
||||
```mdx
|
||||
---
|
||||
title: "バージョン管理"
|
||||
icon: "layer-group"
|
||||
---
|
||||
|
||||
ChatflowとWorkflowアプリで変更を追跡し、バージョンを管理します。
|
||||
|
||||
<Info>
|
||||
現在、ChatflowとWorkflowアプリでのみ利用可能です。
|
||||
</Info>
|
||||
|
||||
## 仕組み
|
||||
|
||||
**現在のドラフト**: あなたの作業バージョンです。ここで変更を行います。ユーザーには公開されません。
|
||||
|
||||

|
||||
|
||||
**最新バージョン**: ユーザーが見るライブバージョンです。
|
||||
|
||||
|
||||
|
||||
**以前のバージョン**: 以前に公開されたバージョンです。
|
||||
|
||||
|
||||
|
||||
## バージョンの公開
|
||||
|
||||
**公開** → **更新を公開**をクリックして、ドラフトをライブにします。
|
||||
|
||||
|
||||
|
||||
あなたのドラフトは新しい最新バージョンになり、新しいドラフトが作成されます。
|
||||
|
||||
|
||||
|
||||
## バージョンの表示
|
||||
|
||||
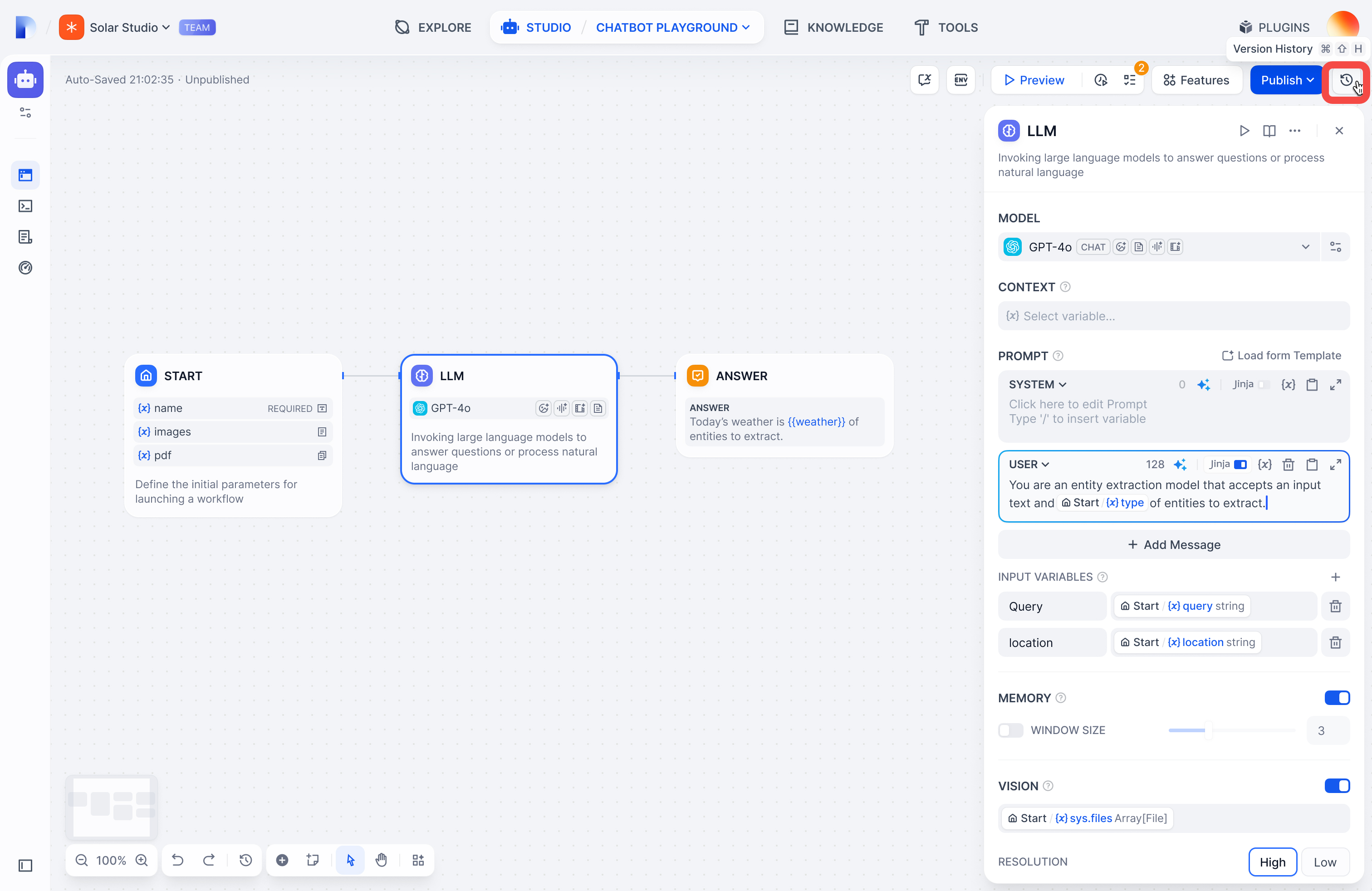
履歴アイコンをクリックしてすべてのバージョンを確認します:
|
||||
|
||||
|
||||
|
||||
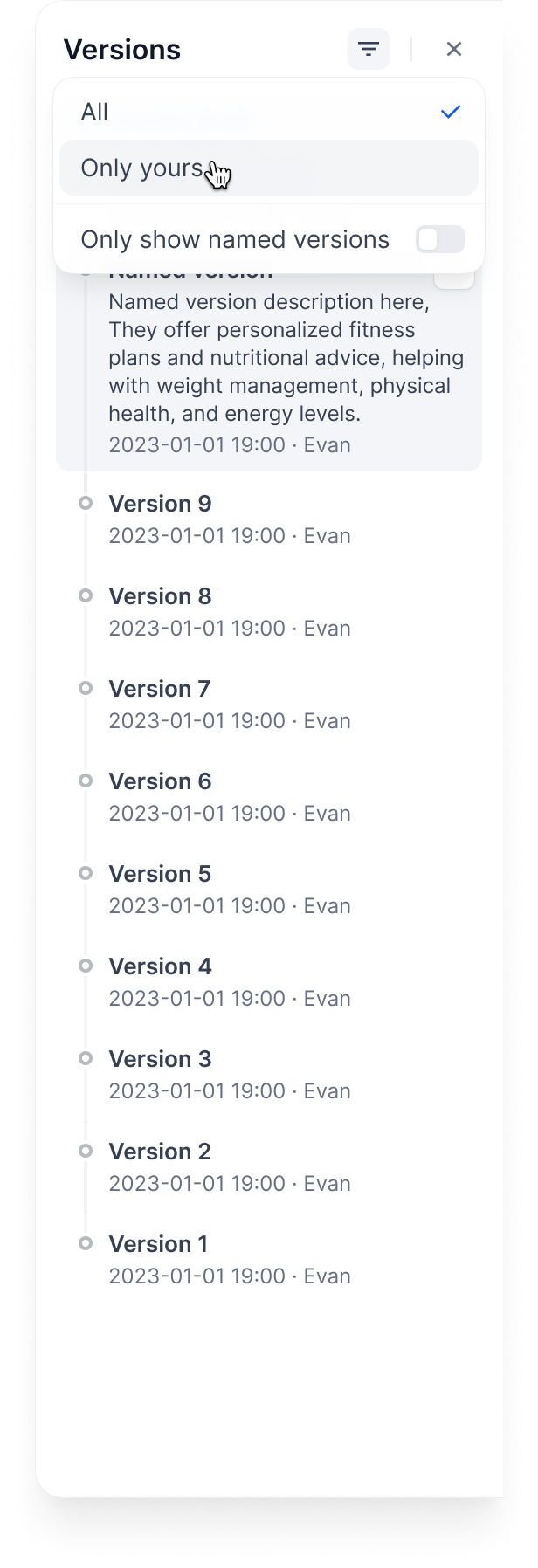
以下でフィルタリング:
|
||||
- **すべてのバージョン** または **自分のもののみ**
|
||||
- **名前付きバージョンのみ**(自動生成された名前は除外)
|
||||
|
||||
|
||||
|
||||
## バージョンの管理
|
||||
|
||||
**バージョンに名前を付ける**: 自動生成された名前の代わりに適切な名前を付けます
|
||||
|
||||
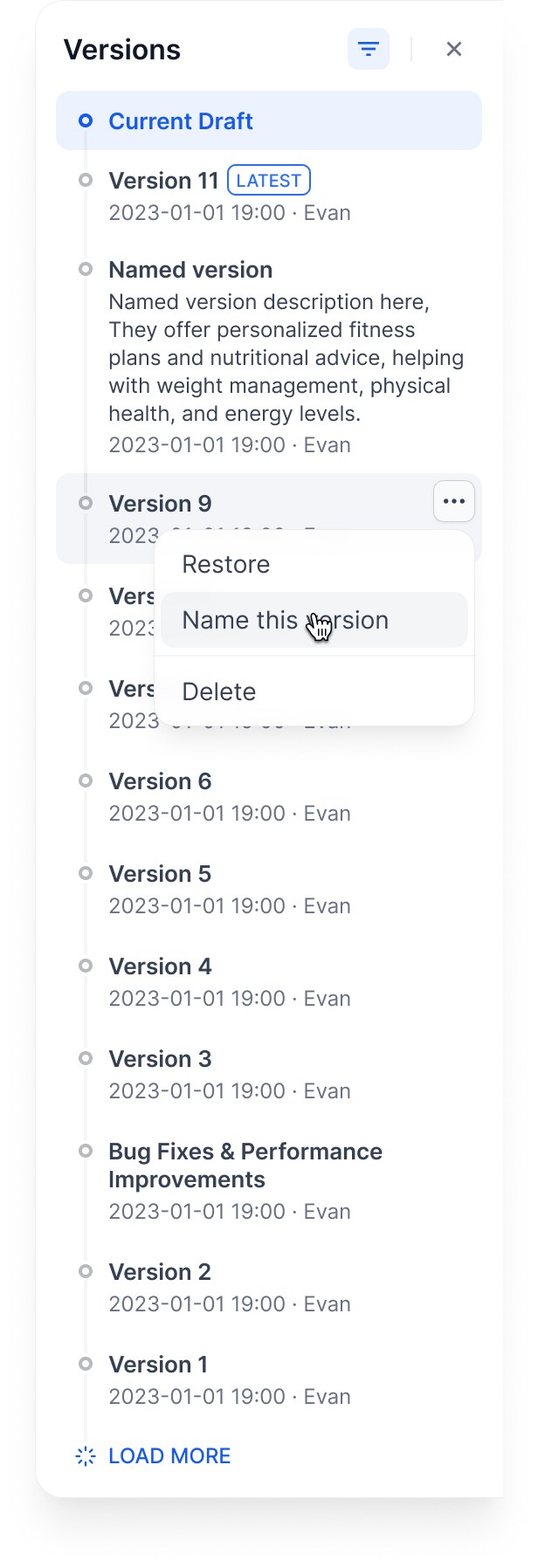
|
||||
|
||||
**バージョン情報を編集**: 名前を変更し、リリースノートを追加します
|
||||
|
||||
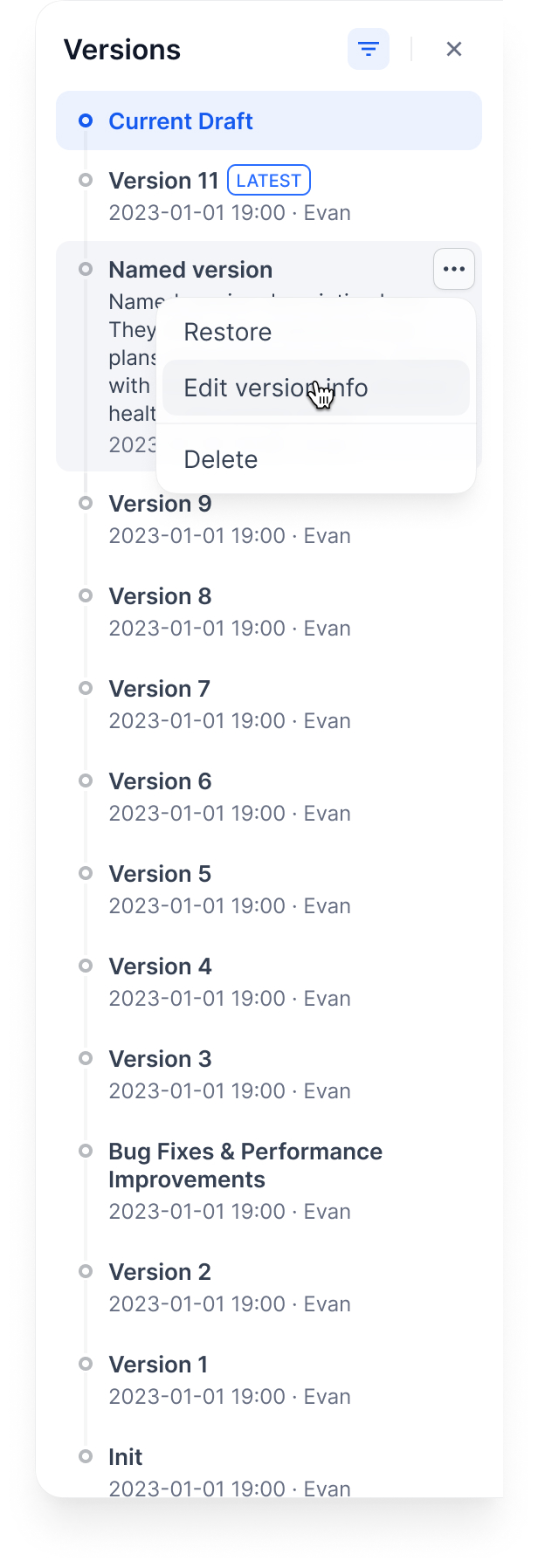
|
||||
|
||||
**古いバージョンを削除**: 不要なバージョンを整理します
|
||||
|
||||
|
||||
|
||||
<Warning>
|
||||
現在のドラフトや最新バージョンを削除することはできません。
|
||||
</Warning>
|
||||
|
||||
**バージョンを復元**: 古いバージョンをドラフトに戻します
|
||||
|
||||
|
||||
|
||||
<Warning>
|
||||
これにより現在のドラフトが完全に置き換えられます。未保存の作業がないことを確認してください。
|
||||
</Warning>
|
||||
|
||||
## 例示的なワークフロー
|
||||
|
||||
典型的な開発サイクルでバージョンがどのように機能するかを示します:
|
||||
|
||||
### 1. ドラフトから始める
|
||||

|
||||
|
||||
### 2. 最初のバージョンを公開
|
||||

|
||||
|
||||
### 3. 二番目のバージョンを公開
|
||||

|
||||
|
||||
### 4. 古いバージョンをドラフトに復元
|
||||

|
||||
|
||||
### 5. 復元したバージョンを公開
|
||||
|
||||
|
||||
完全なデモ:
|
||||

|
||||
|
||||
## ヒント
|
||||
|
||||
- 公開前に必ずドラフトでテストする
|
||||
- 重要なリリースには説明的なバージョン名を使用する
|
||||
- 迅速にロールバックする必要がある場合にバージョンを復元する
|
||||
- 参照用に古いバージョンを保持しておく
|
||||
```
|
||||
108
ja-jp/documja-jptation/pages/debug/error-type.mdx
Normal file
108
ja-jp/documja-jptation/pages/debug/error-type.mdx
Normal file
@@ -0,0 +1,108 @@
|
||||
```mdx
|
||||
---
|
||||
title: エラータイプ
|
||||
icon: "circle-xmark"
|
||||
---
|
||||
|
||||
各ノードタイプは、何が間違っていたのか、どのように修正するかを理解するのに役立つ特定のエラークラスをスローします。
|
||||
|
||||
## ノード固有のエラー
|
||||
|
||||
<Tabs>
|
||||
<Tab title="コード" icon="code">
|
||||
|
||||
`CodeNodeError`
|
||||
<Info>Python または JavaScript コードが実行中に例外をスローしました</Info>
|
||||
|
||||
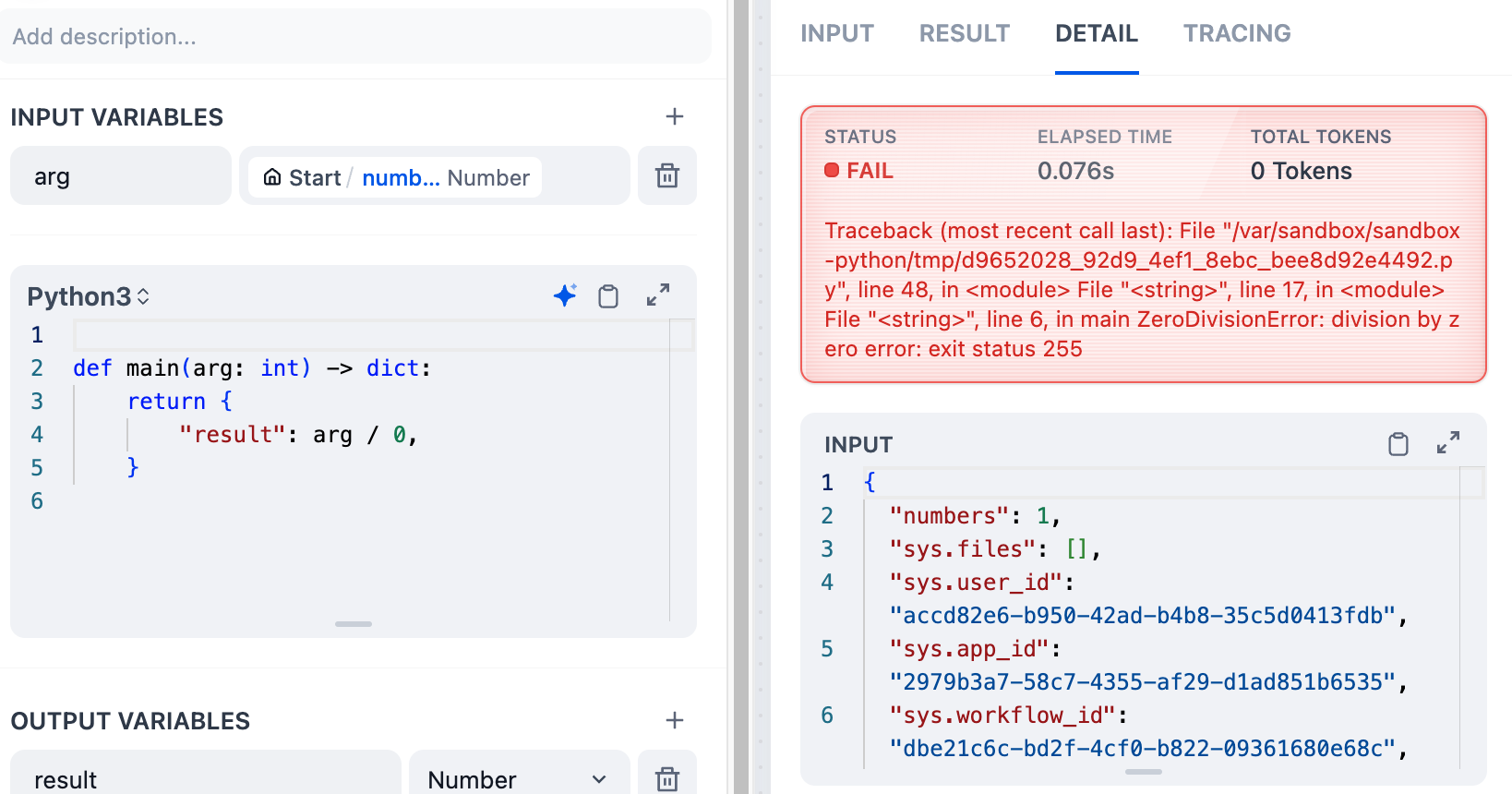
|
||||
|
||||
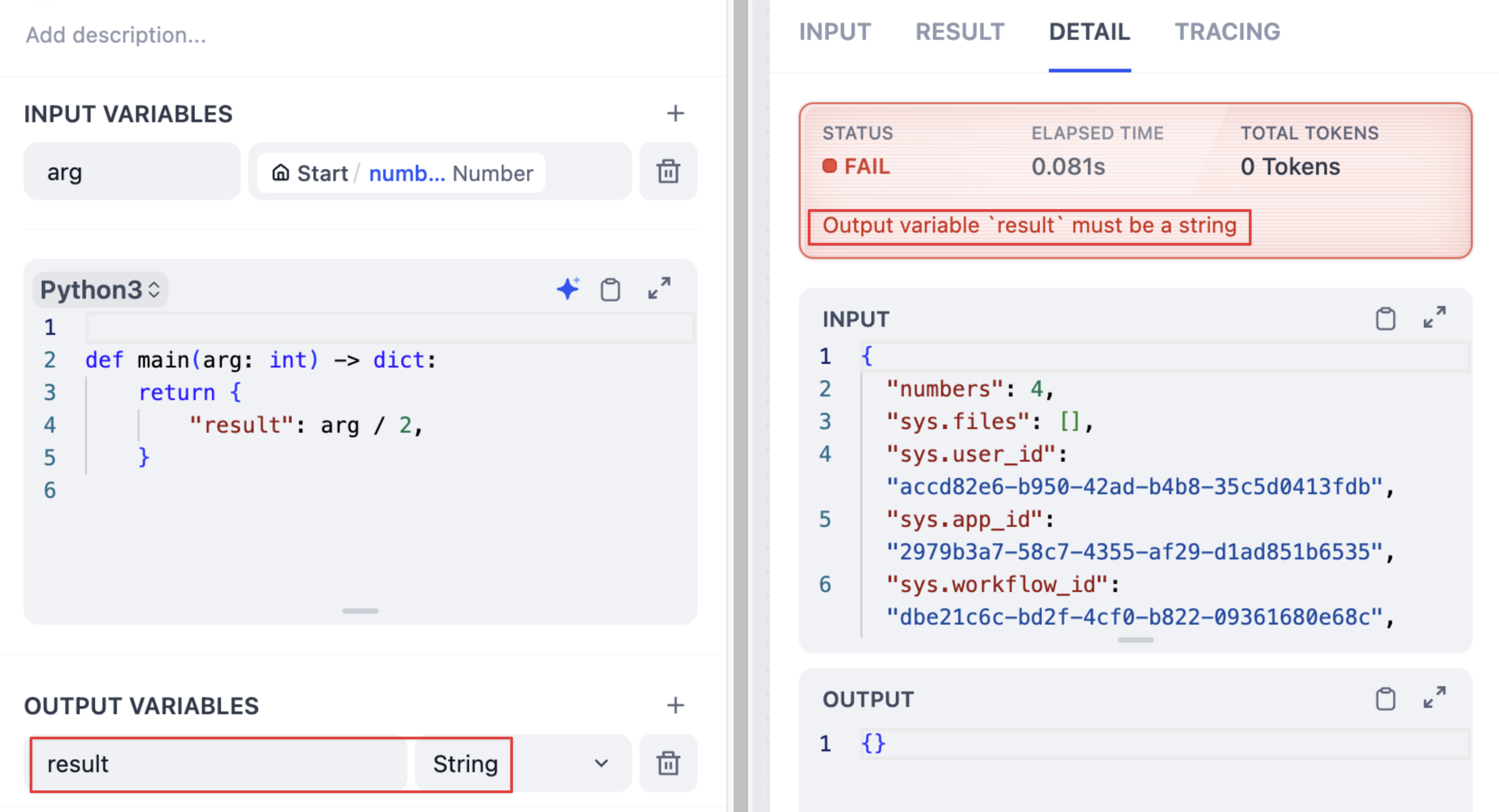
`OutputValidationError`
|
||||
<Info>コードが返したデータ型が設定された出力変数の型と一致しません</Info>
|
||||
|
||||
`DepthLimitError`
|
||||
<Info>コードが5レベル以上のネストされたデータ構造を作成しました</Info>
|
||||
|
||||
`CodeExecutionError`
|
||||
<Info>サンドボックスサービスがコードを実行できませんでした - 通常はサービスがダウンしていることを意味します</Info>
|
||||
|
||||
|
||||
|
||||
</Tab>
|
||||
<Tab title="LLM" icon="brain">
|
||||
|
||||
`VariableNotFoundError`
|
||||
<Info>プロンプトテンプレートが、ワークフローコンテキストに存在しない変数を参照しています</Info>
|
||||
|
||||
|
||||
|
||||
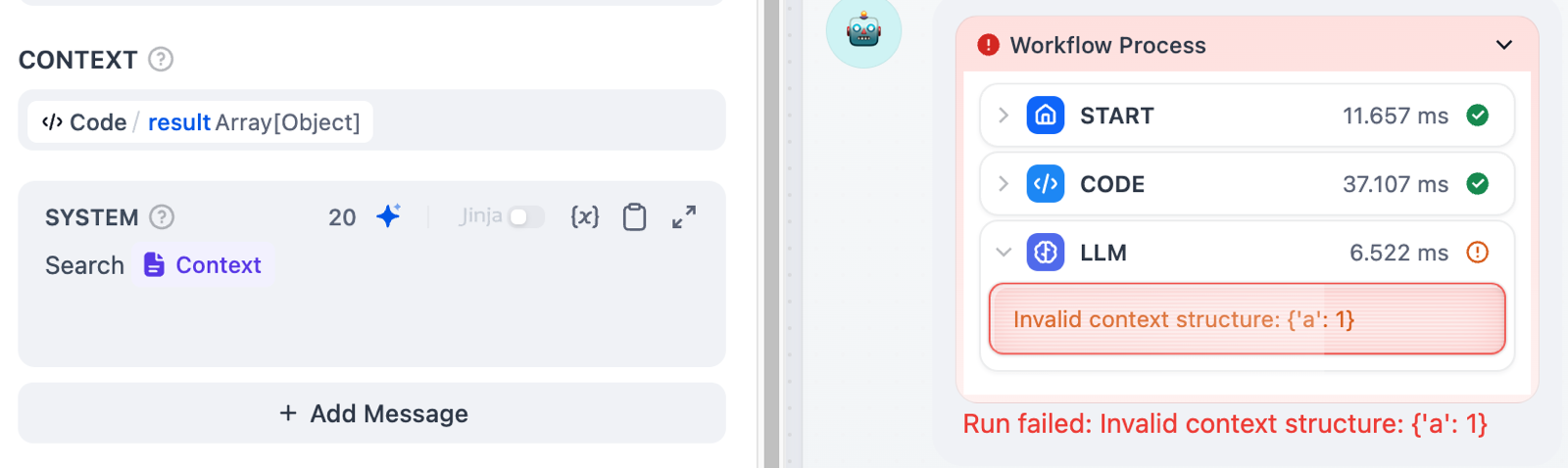
`InvalidContextStructureError`
|
||||
<Info>コンテキストフィールドに文字列のみを受け入れる配列またはオブジェクトを渡しました</Info>
|
||||
|
||||
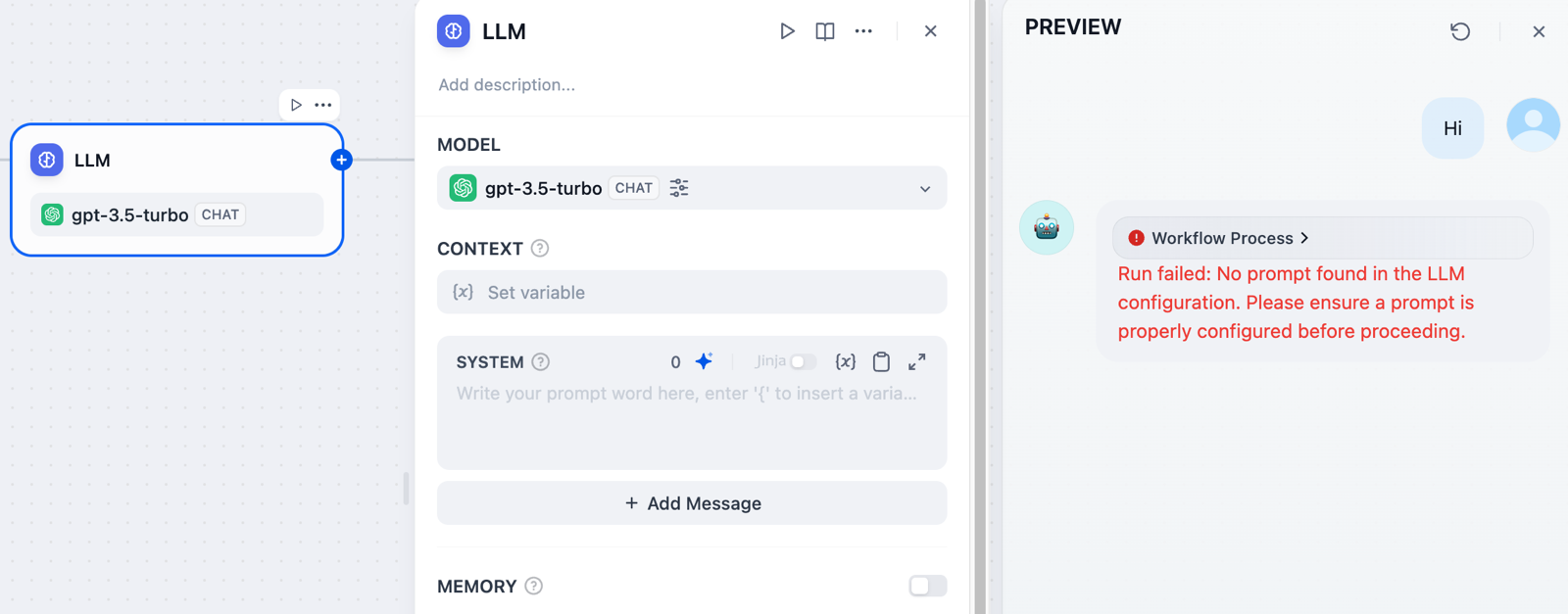
`NoPromptFoundError`
|
||||
<Info>プロンプトフィールドが完全に空です</Info>
|
||||
|
||||
`ModelNotExistError`
|
||||
<Info>LLMノード設定でモデルが選択されていません</Info>
|
||||
|
||||
`LLMModeRequiredError`
|
||||
<Info>選択されたモデルに有効なAPIクレデンシャルが設定されていません</Info>
|
||||
|
||||
`InvalidVariableTypeError`
|
||||
<Info>プロンプトテンプレートがJinja2の構文またはプレーンテキスト形式として有効ではありません</Info>
|
||||
|
||||
|
||||
|
||||
</Tab>
|
||||
<Tab title="HTTPリクエスト" icon="globe">
|
||||
|
||||
`AuthorizationConfigError`
|
||||
<Info>APIエンドポイントの認証設定が欠落しているか無効です</Info>
|
||||
|
||||
`InvalidHttpMethodError`
|
||||
<Info>HTTPメソッドはGET、HEAD、POST、PUT、PATCH、またはDELETEでなければなりません</Info>
|
||||
|
||||
`ResponseSizeError`
|
||||
<Info>API応答が10MBのサイズ制限を超えました</Info>
|
||||
|
||||
`FileFetchError`
|
||||
<Info>リクエストで参照されているファイル変数を取得できませんでした</Info>
|
||||
|
||||
`InvalidURLError`
|
||||
<Info>URL形式が正しくないか、到達不能です</Info>
|
||||
|
||||
</Tab>
|
||||
<Tab title="ツール" icon="wrench">
|
||||
|
||||
`ToolParameterError`
|
||||
<Info>ツールに渡されたパラメータが期待されるスキーマと一致しません</Info>
|
||||
|
||||
`ToolFileError`
|
||||
<Info>ツールが必要なファイルにアクセスできませんでした</Info>
|
||||
|
||||
`ToolInvokeError`
|
||||
<Info>外部ツールAPIが実行中にエラーを返しました</Info>
|
||||
|
||||
<p align="center">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/84af0831b7cb23e64159dfbba80e9b28.jpg" width="300" />
|
||||
</p>
|
||||
|
||||
`ToolProviderNotFoundError`
|
||||
<Info>ツールプロバイダーがインストールされていないか、正しく設定されていません</Info>
|
||||
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## システムレベルのエラー
|
||||
|
||||
`InvokeConnectionError`
|
||||
<Info>外部サービスへのネットワーク接続が失敗しました</Info>
|
||||
|
||||
`InvokeServerUnavailableError`
|
||||
<Info>外部サービスが503ステータスを返したか、一時的にダウンしています</Info>
|
||||
|
||||
`InvokeRateLimitError`
|
||||
<Info>APIまたはモデルプロバイダーのレート制限に達しました</Info>
|
||||
|
||||
`QuotaExceededError`
|
||||
<Info>このサービスの使用クォータを超えました</Info>
|
||||
```
|
||||
46
ja-jp/documja-jptation/pages/debug/history-and-logs.mdx
Normal file
46
ja-jp/documja-jptation/pages/debug/history-and-logs.mdx
Normal file
@@ -0,0 +1,46 @@
|
||||
```mdx
|
||||
---
|
||||
title: "ログ"
|
||||
icon: "memo"
|
||||
---
|
||||
|
||||
Difyは、あなたのワークフローが実行されるたびに詳細なログを記録します。アプリケーションレベルと個々のノードの両方で何が起こったかを見ることができます。
|
||||
|
||||
<Info>
|
||||
公開後のライブユーザーからのログについては、[ログとアノテーション](/en/guides/annotation/logs)を参照してください。
|
||||
</Info>
|
||||
|
||||
## アプリケーションログ
|
||||
|
||||
各ワークフロー実行は完全なログエントリを作成します。任意のエントリをクリックすると、次の3つのセクションが表示されます:
|
||||
|
||||
|
||||
|
||||
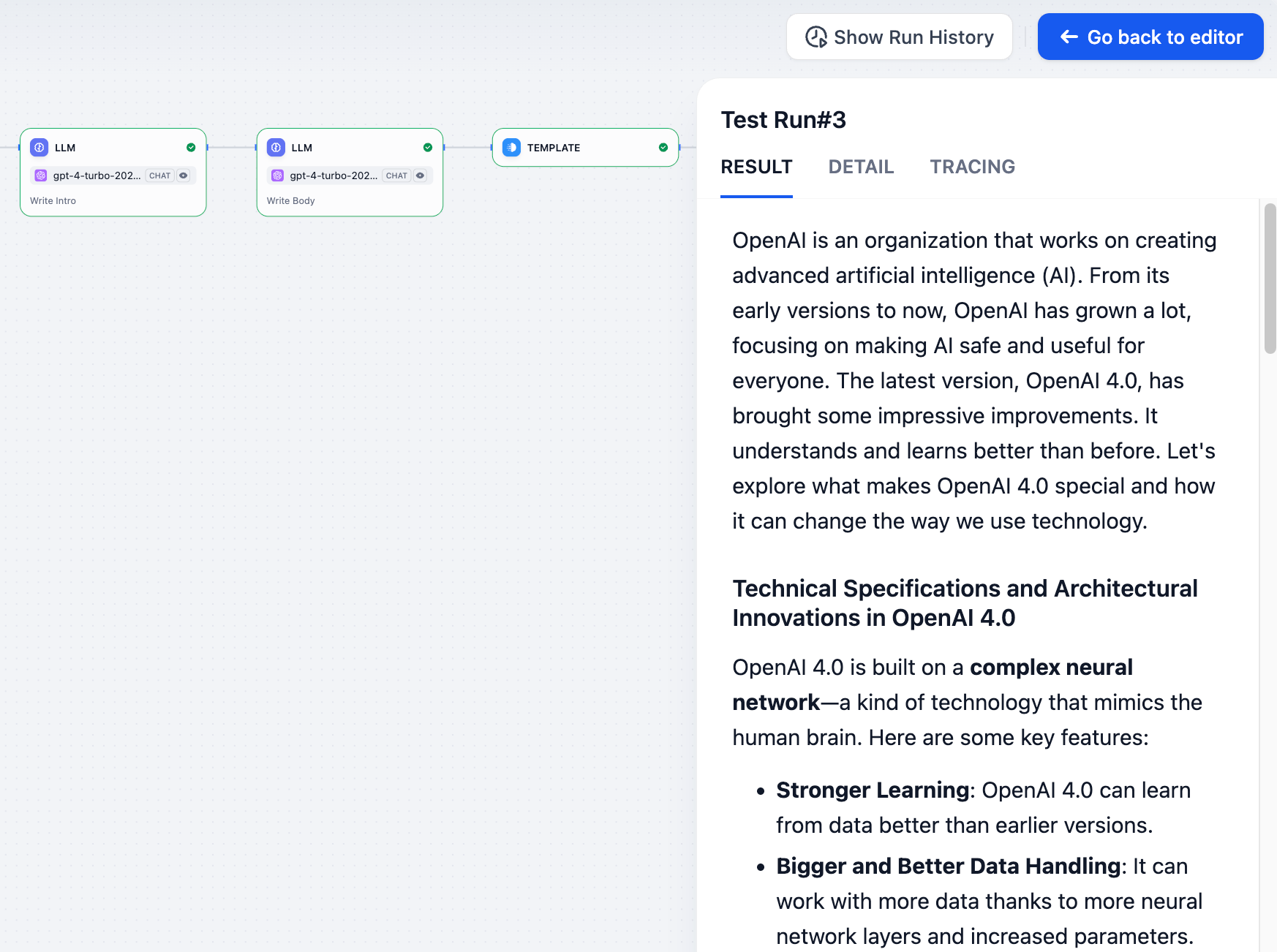
### 結果
|
||||
|
||||
ユーザーが見る最終的な出力を表示します。ワークフローが失敗した場合、ここにエラーメッセージが表示されます。
|
||||
|
||||
|
||||
|
||||
<Warning>
|
||||
ワークフローアプリケーションのみ利用可能です。
|
||||
</Warning>
|
||||
|
||||
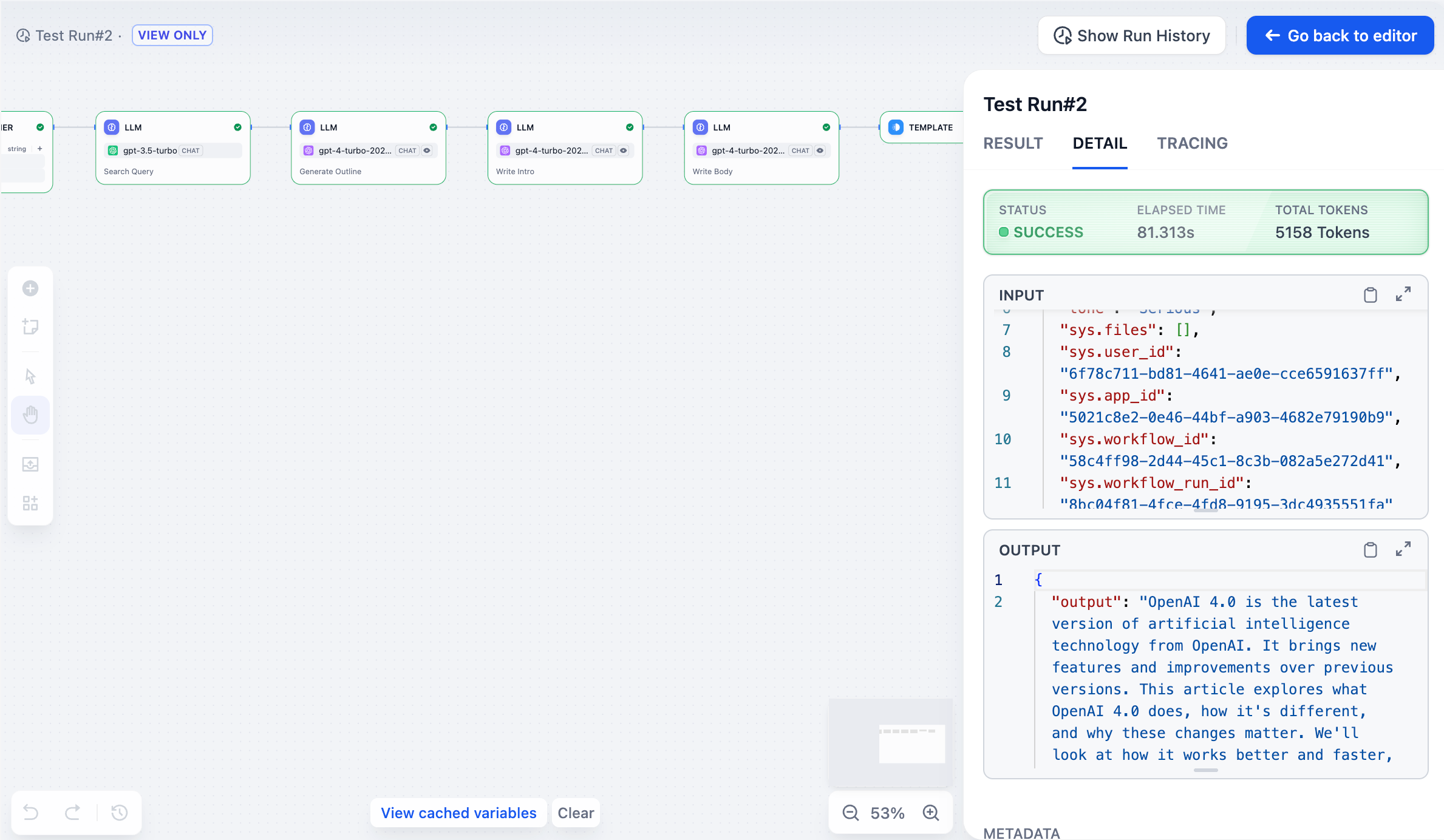
### 詳細
|
||||
|
||||
実行からの元の入力、最終出力、システムのメタデータを表示します。
|
||||
|
||||
|
||||
|
||||
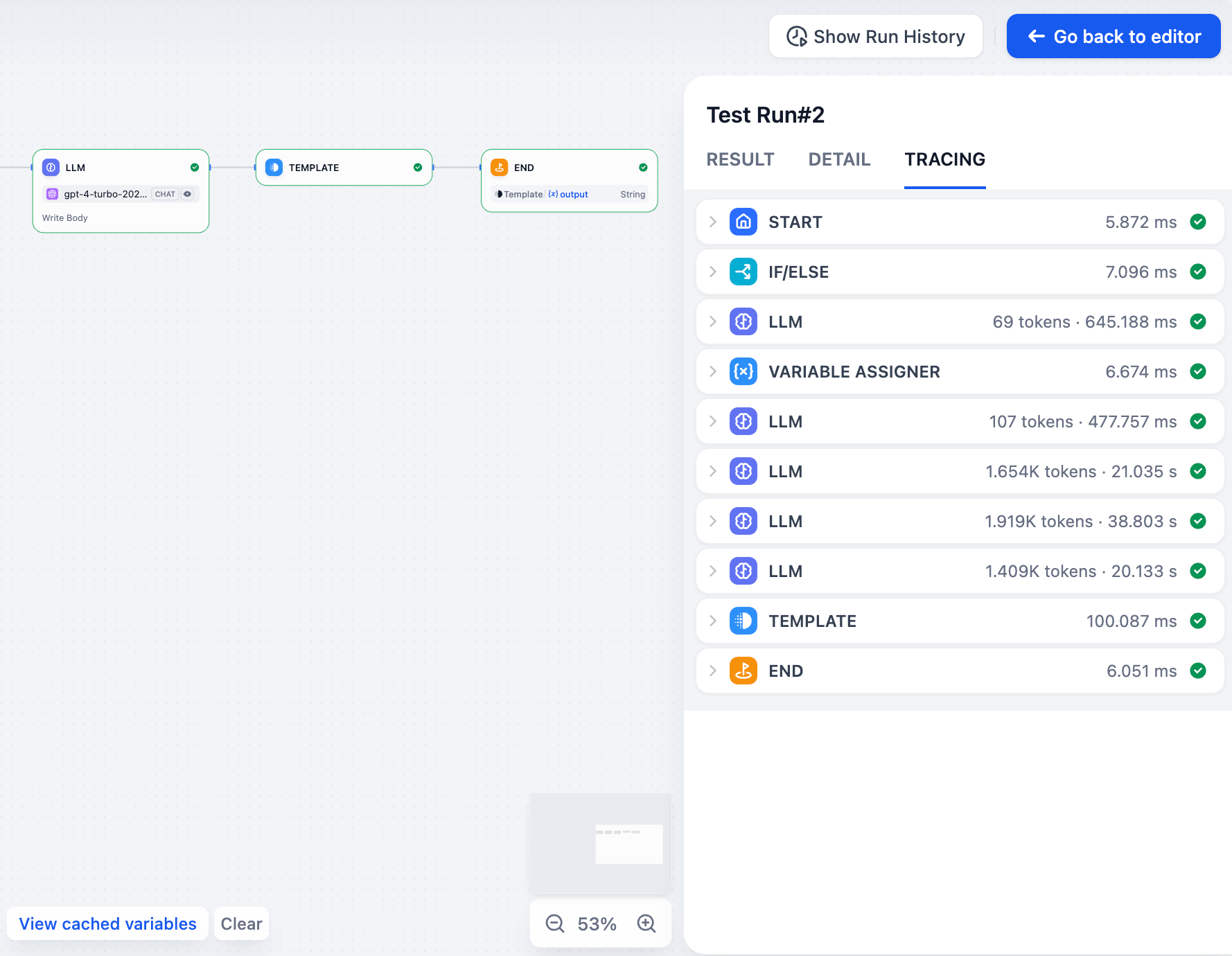
### トレース
|
||||
|
||||
ワークフローがどのように実行されたかを正確に示し、どのノードがどの順序で実行され、各ノードがどのくらいの時間を要したか、データがどのように流れたかを表示します。これは、ボトルネックを見つけたり、分岐やループを持つ複雑なワークフローを理解するのに役立ちます。
|
||||
|
||||
|
||||
|
||||
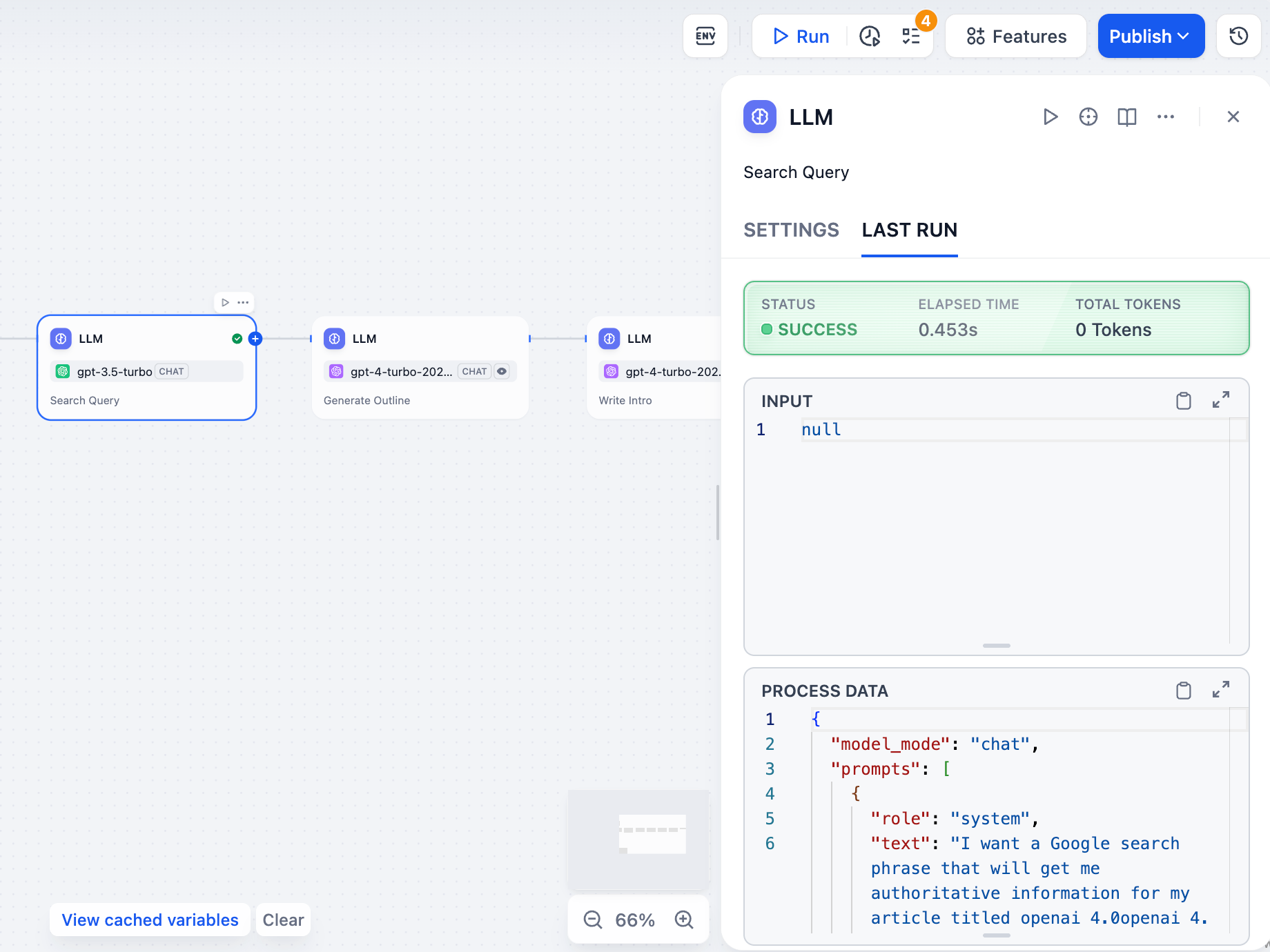
## ノードログ
|
||||
|
||||
個別のノードの最後の実行も確認できます。ノードの設定パネルで「最後の実行」をクリックすると、その最近の入力、出力、およびタイミングの詳細が表示されます。
|
||||
|
||||
|
||||
```
|
||||
34
ja-jp/documja-jptation/pages/debug/step-run.mdx
Normal file
34
ja-jp/documja-jptation/pages/debug/step-run.mdx
Normal file
@@ -0,0 +1,34 @@
|
||||
```mdx
|
||||
---
|
||||
title: "シングルノード"
|
||||
icon: "code-commit"
|
||||
---
|
||||
|
||||
個別のノードをテストするか、ワークフローをステップバイステップで実行して公開前に問題を見つけます。
|
||||
|
||||
## シングルノードテスト
|
||||
|
||||
ワークフロー全体を実行せずに任意のノードを個別にテストできます。ノードを選択し、設定パネルでテスト入力を行い、「実行」をクリックして出力を確認します。
|
||||
|
||||
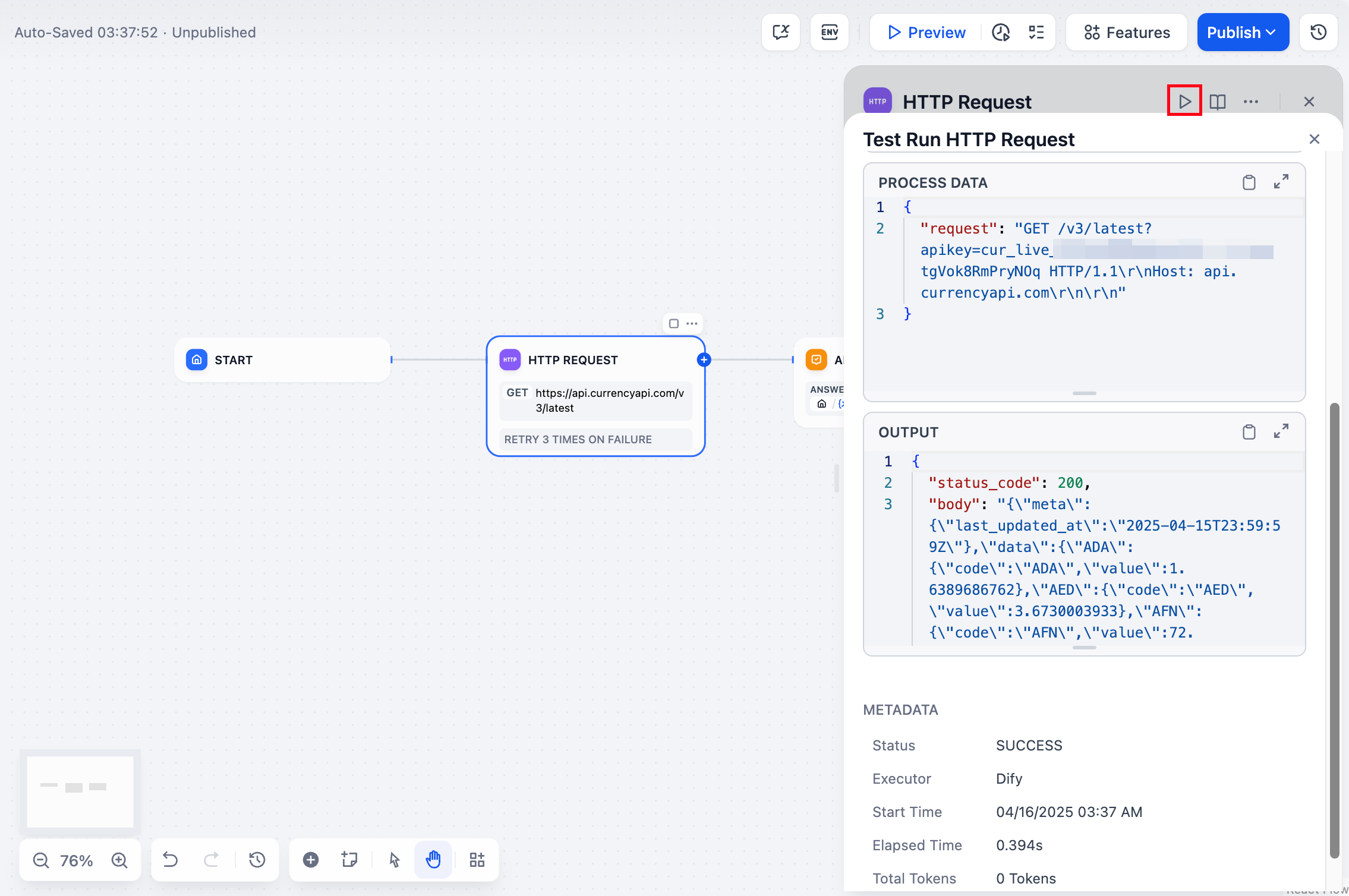
|
||||
|
||||
テスト後、「最終実行」をクリックして、入力、出力、タイミング、エラーメッセージなどの実行詳細を確認します。
|
||||
|
||||
<Warning>
|
||||
AnswerノードとEndノードはシングルノードテストをサポートしていません。
|
||||
</Warning>
|
||||
|
||||
## ステップバイステップの実行
|
||||
|
||||
ノードを一度に一つずつ実行する際、その出力は変数インスペクターにキャッシュされます。これらのキャッシュされた変数を編集して、上流のノードを再実行せずに異なるシナリオをテストできます。
|
||||
|
||||
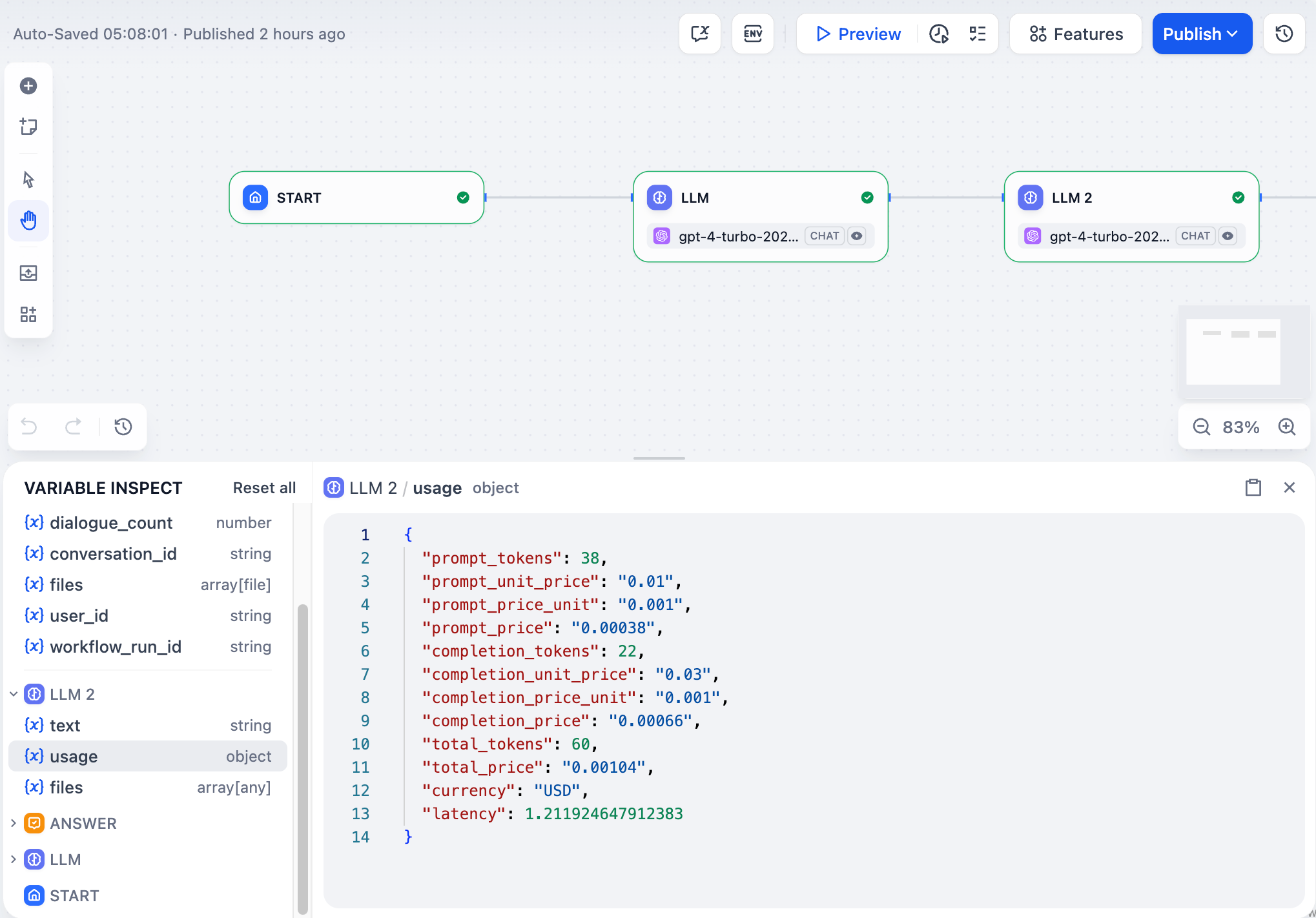
|
||||
|
||||
これは、ノードが異なるデータにどのように反応するかをテストしたいときに便利です。インスペクターで変数の値を変更し、再度ノードを実行するだけです。
|
||||
|
||||
## 実行履歴の表示
|
||||
|
||||
各ノードの実行は記録を作成します。任意のノードで「最終実行」をクリックして、最新の実行詳細を確認し、どのデータが入力され、何が出力され、どのくらい時間がかかったかを確認します。
|
||||
|
||||
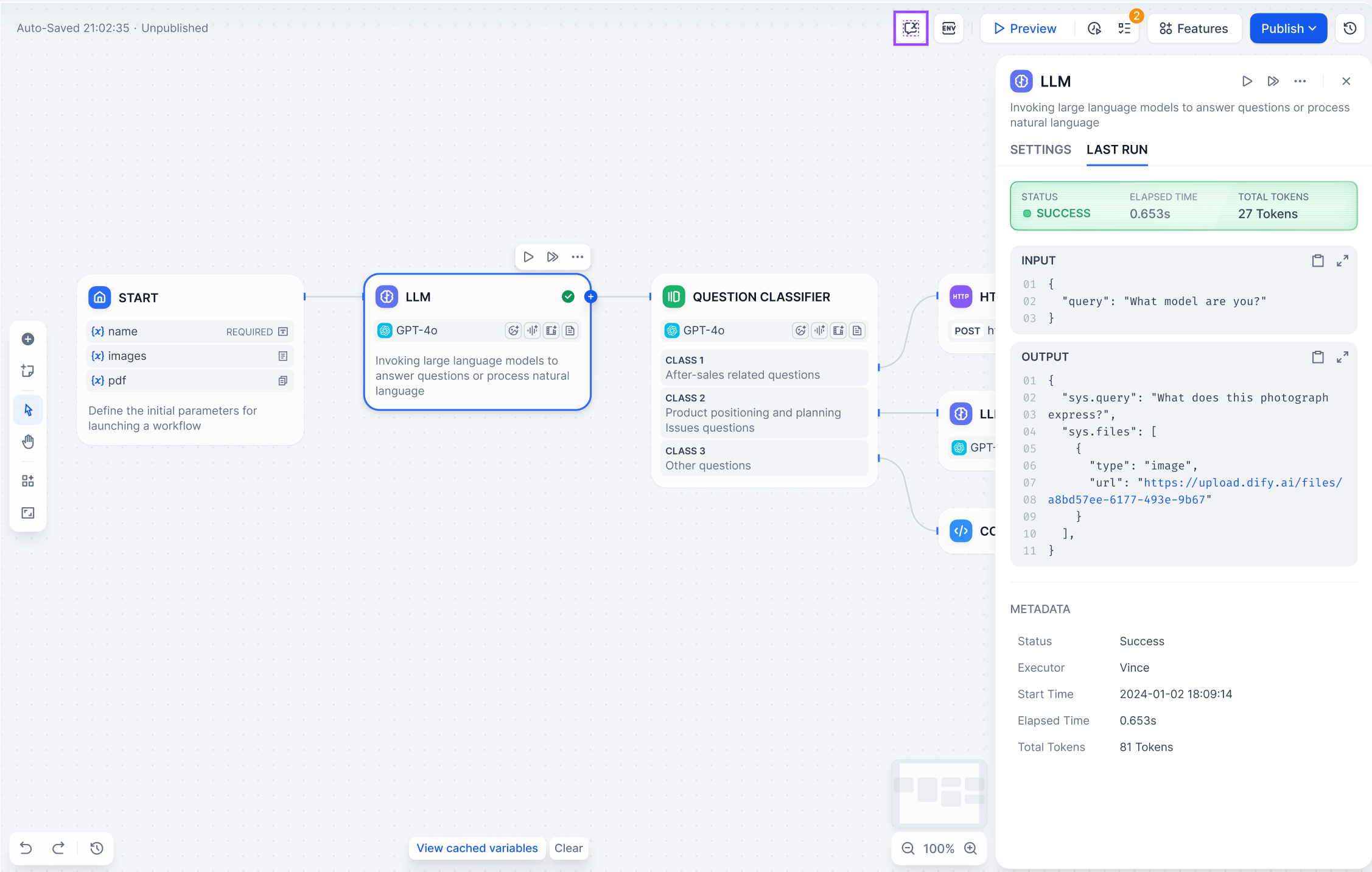
|
||||
```
|
||||
34
ja-jp/documja-jptation/pages/debug/variable-inspect.mdx
Normal file
34
ja-jp/documja-jptation/pages/debug/variable-inspect.mdx
Normal file
@@ -0,0 +1,34 @@
|
||||
```mdx
|
||||
---
|
||||
title: "ワークフロー"
|
||||
icon: "arrow-progress"
|
||||
---
|
||||
|
||||
Variable Inspectorは、ワークフローを通じて流れるすべてのデータを表示します。各ノードが実行された後の入力と出力をキャプチャし、何が起こっているのかを確認し、さまざまなシナリオをテストすることができます。
|
||||
|
||||
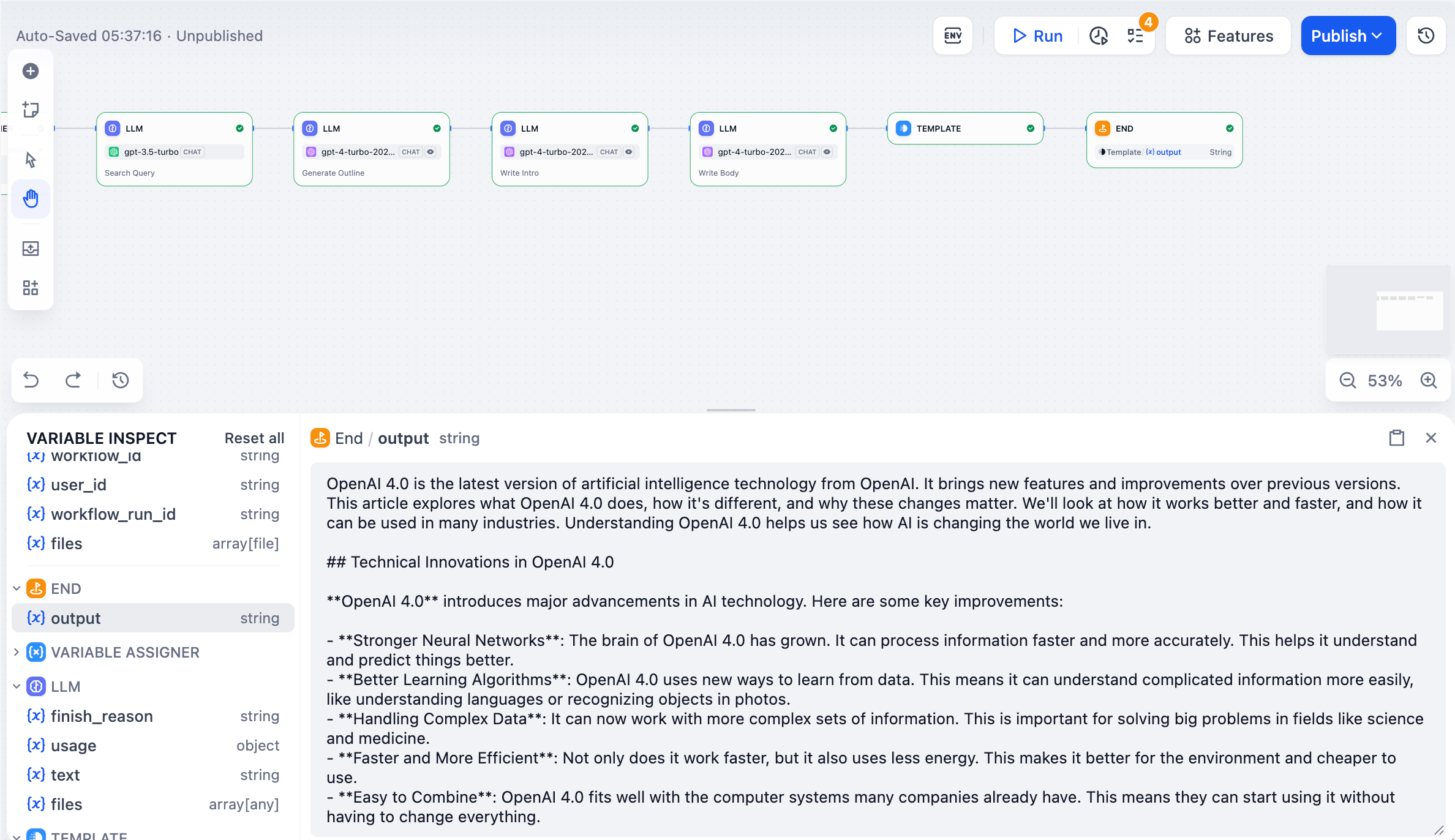
|
||||
|
||||
## 変数の表示
|
||||
|
||||
任意のノードが実行された後、その出力変数は画面下部のインスペクターパネルに表示されます。任意の変数をクリックすると、その全内容を確認できます。
|
||||
|
||||
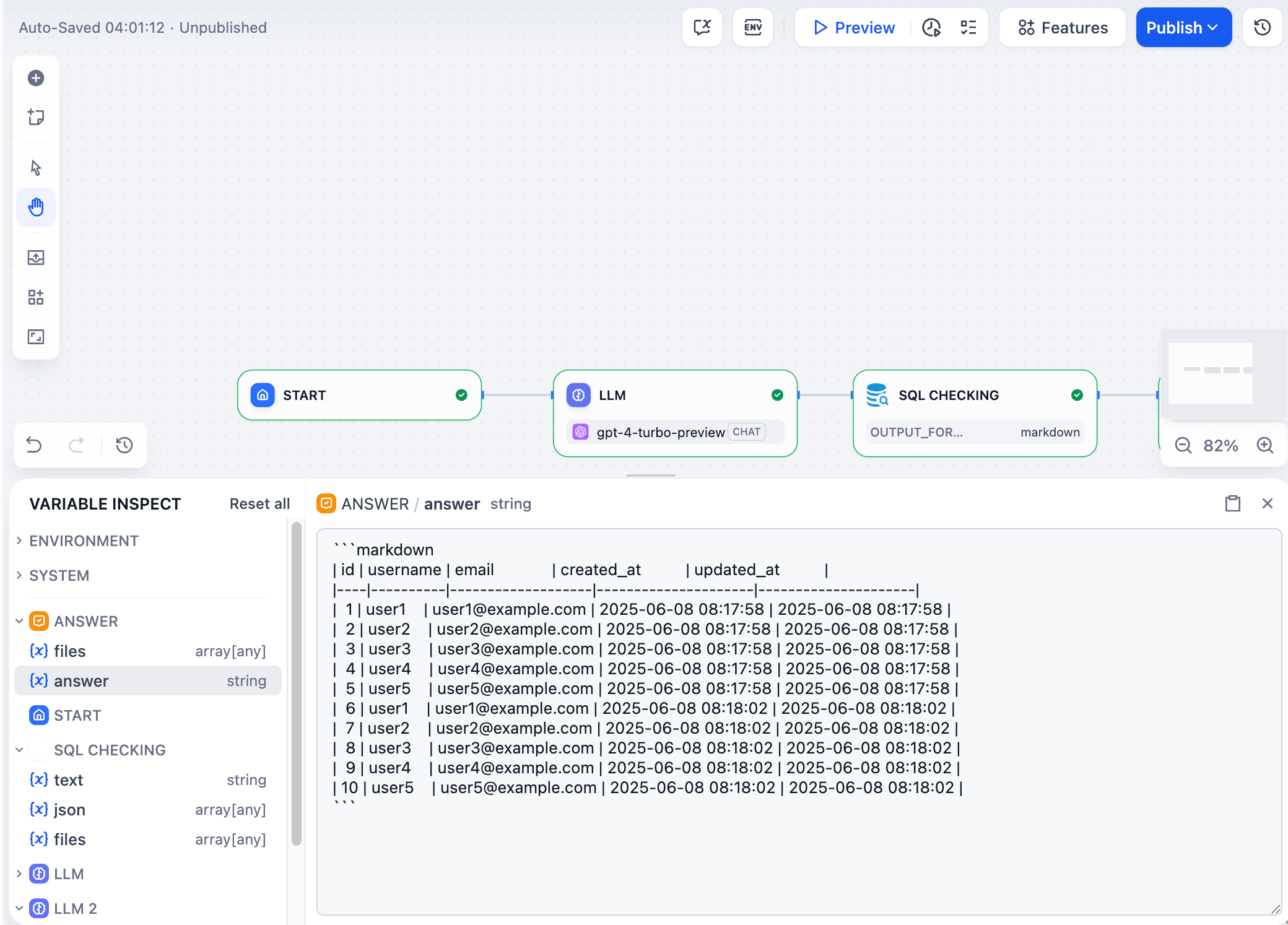
|
||||
|
||||
## 変数の編集
|
||||
|
||||
ほとんどの変数の値はクリックして編集できます。下流のノードを実行するとき、編集した値が元のものの代わりに使用されます。これにより、ワークフロー全体を再実行せずに異なるシナリオをテストすることができます。
|
||||
|
||||
<Info>
|
||||
ここで変数を編集しても、元のノードの「最後の実行」記録は変更されません。
|
||||
</Info>
|
||||
|
||||
例えば、大型言語モデル(LLM)ノードが `SELECT * FROM users` のようなSQLを生成する場合、インスペクターで `SELECT username FROM users` に編集して、データベースノードのみを再実行して異なる結果を見ることができます。
|
||||
|
||||
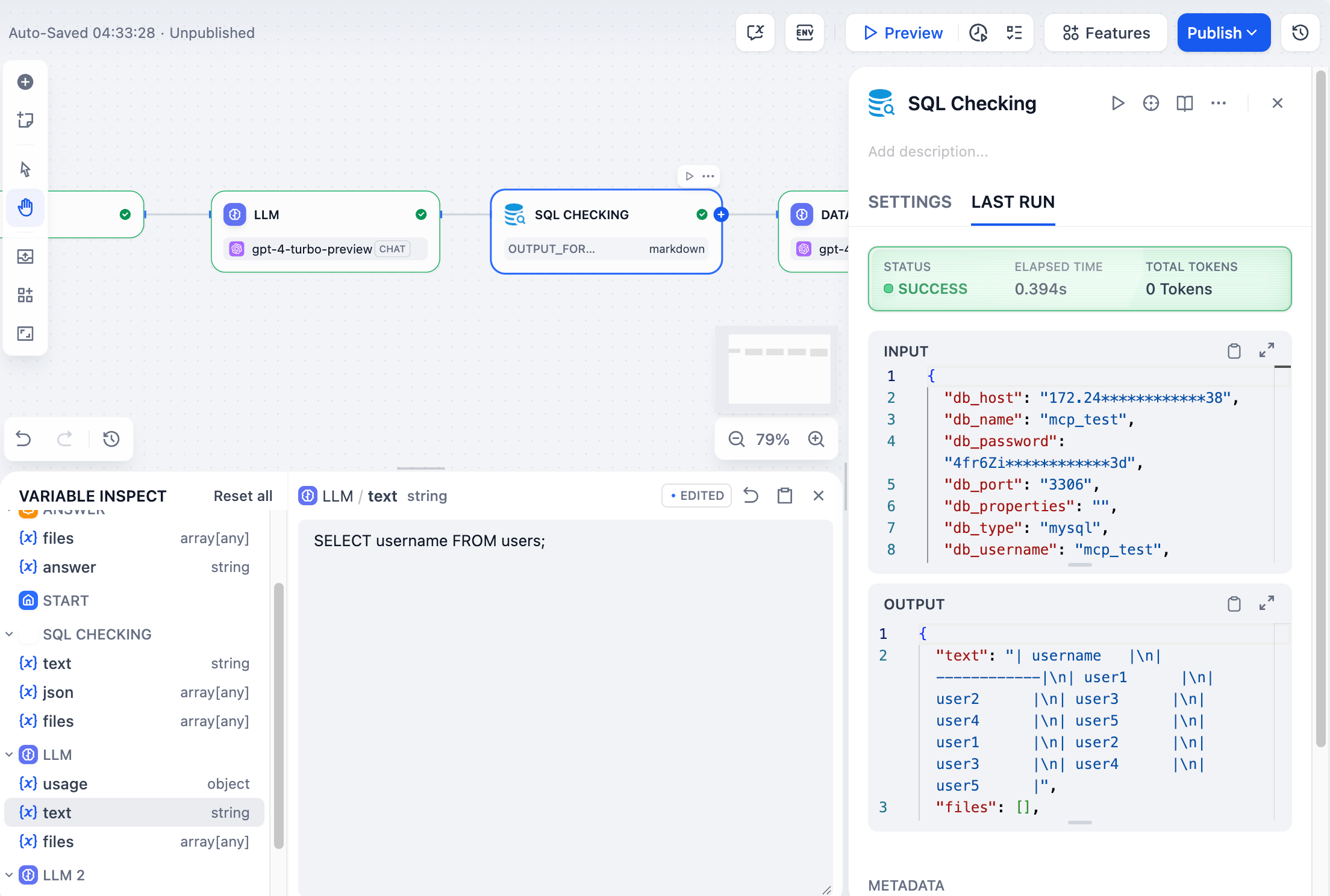
|
||||
|
||||
## 変数のリセット
|
||||
|
||||
任意の変数の横にあるリバートアイコンをクリックして元の値を復元するか、「すべてリセット」をクリックしてすべてのキャッシュされた変数を一度にクリアします。
|
||||
|
||||
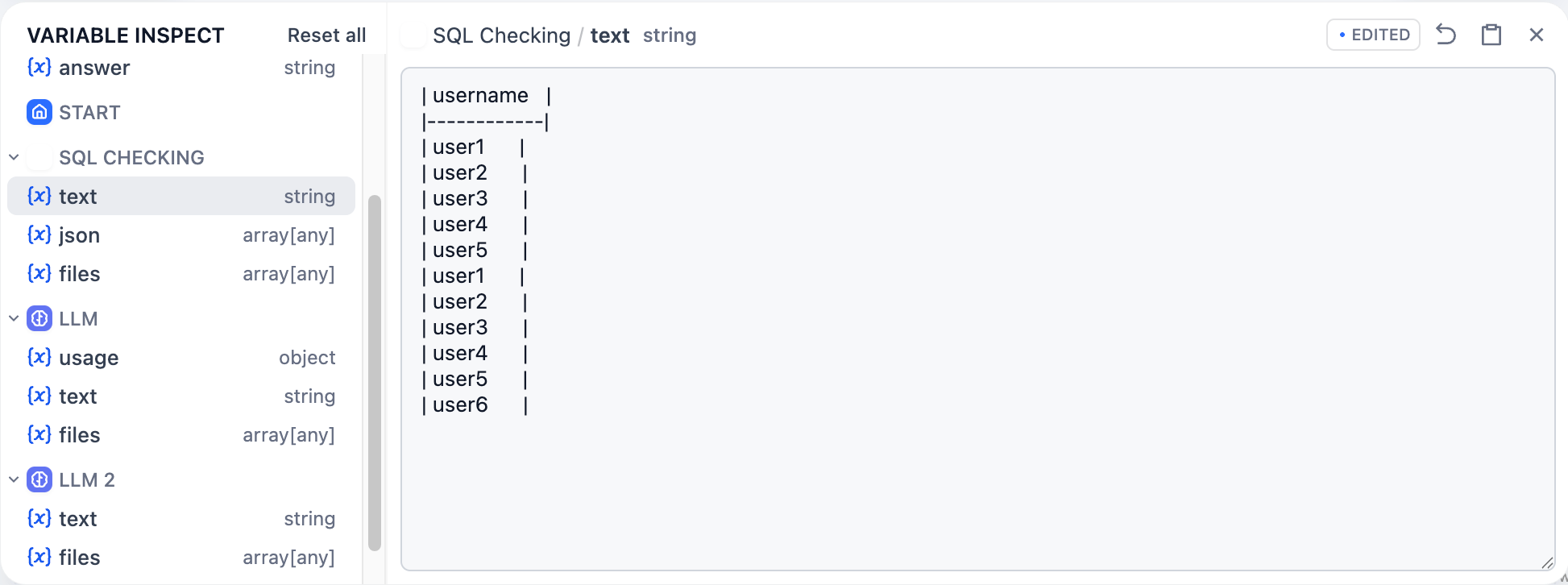
|
||||
```
|
||||
114
ja-jp/documja-jptation/pages/getting-started/faq.md
Normal file
114
ja-jp/documja-jptation/pages/getting-started/faq.md
Normal file
@@ -0,0 +1,114 @@
|
||||
```mdx
|
||||
# よくある質問
|
||||
|
||||
Dify の FAQ セクションへようこそ。ここでは、Dify の使用に関してよくある質問への回答を見つけることができます。
|
||||
|
||||
## 入門
|
||||
|
||||
### Dify とは何ですか?
|
||||
|
||||
Dify は、AI アプリケーションを構築するためのオープンソースプラットフォームです。広範なツールと機能を提供し、広範なコーディング知識がなくても AI アプリケーションを構築、デプロイ、管理するのを支援します。
|
||||
|
||||
### Dify の始め方は?
|
||||
|
||||
Dify を始めるには:
|
||||
|
||||
1. [dify.ai](https://dify.ai) で Dify アカウントに**サインアップ**します
|
||||
2. 直感的なインターフェイスを使用して**最初のアプリケーションを作成**します
|
||||
3. OpenAI、Anthropic、その他のプロバイダーに接続して**AI モデルを構成**します
|
||||
4. アプリケーションで**テストと反復**を行います
|
||||
5. AI アプリケーションを**本番環境にデプロイ**します
|
||||
|
||||
### Dify ではどのような種類のアプリケーションを構築できますか?
|
||||
|
||||
Dify を使用してさまざまな種類の AI アプリケーションを構築できます:
|
||||
|
||||
- カスタマーサービス用の**チャットボット**
|
||||
- ドキュメントに関する質問に回答できる**知識ベースアシスタント**
|
||||
- データをインテリジェントに処理する**ワークフロー自動化ツール**
|
||||
- マーケティングやライティングのための**コンテンツ生成ツール**
|
||||
- 複雑なタスクを実行できる**AI エージェント**
|
||||
|
||||
## 技術的な質問
|
||||
|
||||
### Dify はどの AI モデルをサポートしていますか?
|
||||
|
||||
Dify は以下を含む幅広い AI モデルをサポートしています:
|
||||
|
||||
- **OpenAI モデル**:GPT-4、GPT-3.5 など
|
||||
- **Anthropic モデル**:Claude 3 および Claude 2
|
||||
- **オープンソースモデル**:Hugging Face、Ollama などのプロバイダーを通じて
|
||||
- **ローカルモデル**:独自にホストできます
|
||||
|
||||
### Dify は私のデータをどのように処理しますか?
|
||||
|
||||
データのセキュリティとプライバシーは私たちの最優先事項です:
|
||||
|
||||
- **あなたのデータはあなたのもの** - 私たちはあなたのプライベートデータでトレーニングを行いません
|
||||
- **転送中および保存時の暗号化**
|
||||
- エンタープライズ顧客向けの**SOC2 準拠**
|
||||
- ヨーロッパのユーザー向けの**GDPR 準拠**
|
||||
|
||||
### Dify は商業目的で使用できますか?
|
||||
|
||||
はい! Dify は以下を提供しています:
|
||||
|
||||
- 自己ホスティング用の Apache 2.0 ライセンスを持つ**オープンソースバージョン**
|
||||
- マネージドホスティング用の商用プランを持つ**クラウドバージョン**
|
||||
- 高度な機能とサポートを備えた**エンタープライズプラン**
|
||||
|
||||
## トラブルシューティング
|
||||
|
||||
### 私の AI アプリケーションが誤った応答を返しています
|
||||
|
||||
これらのトラブルシューティング手順を試してください:
|
||||
|
||||
1. **プロンプトを確認** - 明確で具体的であることを確認します
|
||||
2. **知識ベースを確認** - 関連するドキュメントがアップロードされていることを確認します
|
||||
3. **モデルパラメータを調整** - 異なる温度または TopK 設定を試してください
|
||||
4. **異なるモデルでテスト** - 特定のタスクに対してより良いモデルが存在する場合があります
|
||||
|
||||
### 応答時間が遅くなっています
|
||||
|
||||
応答時間を改善するには:
|
||||
|
||||
1. **モデルの構成を確認** - 一部のモデルは他のモデルより高速です
|
||||
2. **知識ベースを最適化** - 不要なドキュメントを削除します
|
||||
3. **キャッシュを使用** - よくある質問に対して応答キャッシュを有効にします
|
||||
4. より良いパフォーマンスのために**プランのアップグレードを検討**
|
||||
|
||||
### サポートを受けるにはどうすればよいですか?
|
||||
|
||||
サポートを受ける方法:
|
||||
|
||||
- **コミュニティフォーラム** - 他の Dify ユーザーとつながる
|
||||
- **ドキュメント** - 包括的なガイドとチュートリアル
|
||||
- **GitHub の問題** - バグ報告と機能リクエスト
|
||||
- **メールサポート** - 有料プランの顧客向け
|
||||
- **エンタープライズサポート** - エンタープライズ顧客向けの専用サポート
|
||||
|
||||
## 請求とプラン
|
||||
|
||||
### 異なる料金プランは何ですか?
|
||||
|
||||
Dify はいくつかのプランを提供しています:
|
||||
|
||||
- **無料ティア** - 始めるのに最適で、小規模プロジェクト向け
|
||||
- **プロプラン** - 使用量の多い成長企業向け
|
||||
- **エンタープライズプラン** - 大規模組織向けのカスタムソリューション
|
||||
|
||||
### 使用量はどのように計算されますか?
|
||||
|
||||
使用量は通常、以下に基づいて計算されます:
|
||||
|
||||
- AI モデルへの**API コール**
|
||||
- ドキュメントとデータの**ストレージ**
|
||||
- アプリケーション上の**アクティブユーザー**
|
||||
- プランに応じた**カスタム機能**
|
||||
|
||||
詳細な料金情報については、[料金ページ](https://dify.ai/pricing)をご覧ください。
|
||||
|
||||
---
|
||||
|
||||
さらにサポートが必要ですか?サポートチームに連絡するか、[包括的なドキュメント](../../../guides/)をご覧ください。
|
||||
```
|
||||
128
ja-jp/documja-jptation/pages/getting-started/faq.mdx
Normal file
128
ja-jp/documja-jptation/pages/getting-started/faq.mdx
Normal file
@@ -0,0 +1,128 @@
|
||||
```mdx
|
||||
---
|
||||
title: "よくある質問"
|
||||
description: "Difyの使用に関する一般的な質問と回答"
|
||||
icon: "circle-question"
|
||||
---
|
||||
|
||||
DifyのFAQセクションへようこそ。ここでは、Difyの使用に関する最も一般的な質問への回答を見つけることができます。
|
||||
|
||||
## はじめに
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Difyとは何ですか?">
|
||||
DifyはAIアプリケーションを構築するためのオープンソースプラットフォームです。広範なツールと機能を提供し、広範なコーディング知識なしでAIアプリケーションを構築、展開、管理するのをサポートします。
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Difyの始め方は?">
|
||||
Difyを始めるには:
|
||||
|
||||
1. [dify.ai](https://dify.ai)でDifyアカウントに**サインアップ**します
|
||||
2. 直感的なインターフェースを使用して**最初のアプリケーションを作成**します
|
||||
3. OpenAI、Anthropic、その他のプロバイダに接続して**AIモデルを設定**します
|
||||
4. アプリケーションを**テストして反復**します
|
||||
5. AIアプリケーションを**本番環境に展開**します
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Difyでどのような種類のアプリケーションを構築できますか?">
|
||||
Difyを使用して構築できるAIアプリケーションの種類:
|
||||
|
||||
- カスタマーサービス用の**チャットボット**
|
||||
- ドキュメントに関する質問に答えられる**知識庫アシスタント**
|
||||
- データをインテリジェントに処理する**ワークフロー自動化ツール**
|
||||
- マーケティングやライティング向けの**コンテンツ生成ツール**
|
||||
- 複雑なタスクを実行できる**AIエージェント**
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## 技術的な質問
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="DifyはどのAIモデルをサポートしていますか?">
|
||||
Difyは幅広いAIモデルをサポートしています:
|
||||
|
||||
- **OpenAIモデル**: GPT-4、GPT-3.5など
|
||||
- **Anthropicモデル**: Claude 3およびClaude 2
|
||||
- **オープンソースモデル**: Hugging Face、Ollamaなどのプロバイダを通じて
|
||||
- **ローカルモデル**: 自分のモデルをホストすることができます
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Difyは私のデータをどのように扱いますか?">
|
||||
データのセキュリティとプライバシーは最優先事項です:
|
||||
|
||||
- **データはあなたのものです** - 私たちはあなたのプライベートデータを使って学習しません
|
||||
- **転送中および保存時の暗号化**
|
||||
- エンタープライズ顧客向けの**SOC2準拠**
|
||||
- ヨーロッパのユーザー向けの**GDPR準拠**
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Difyを商業目的で使用できますか?">
|
||||
はい!Difyは以下を提供しています:
|
||||
|
||||
- 自己ホスティング用のApache 2.0ライセンスを持つ**オープンソースバージョン**
|
||||
- マネージドホスティング用の商業プランを持つ**クラウドバージョン**
|
||||
- 高度な機能とサポートを備えた**エンタープライズプラン**
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## トラブルシューティング
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="私のAIアプリケーションが間違った応答を返す">
|
||||
次のトラブルシューティング手順を試してください:
|
||||
|
||||
1. **プロンプトを見直す** - 明確で具体的であることを確認してください
|
||||
2. **知識ベースを確認** - 関連するドキュメントがアップロードされていることを確認してください
|
||||
3. **モデルのパラメータを調整** - 異なる温度やTopK設定を試してください
|
||||
4. **異なるモデルでテスト** - 特定のタスクに対してはより良いモデルがあります
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="応答時間が遅いと感じる">
|
||||
応答時間を改善するには:
|
||||
|
||||
1. **モデル設定を確認** - いくつかのモデルは他のものよりも速いです
|
||||
2. **知識ベースを最適化** - 不必要なドキュメントを削除します
|
||||
3. **キャッシングを使用** - よくある質問の応答キャッシングを有効にします
|
||||
4. パフォーマンス向上のために**プランをアップグレード**を検討してください
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="サポートを受けるにはどうすればいいですか?">
|
||||
サポートを受けるには:
|
||||
|
||||
- **コミュニティフォーラム** - 他のDifyユーザーとの交流
|
||||
- **ドキュメント** - 包括的なガイドとチュートリアル
|
||||
- **GitHubの問題** - バグ報告や機能リクエスト
|
||||
- **メールサポート** - 有料プランの顧客向け
|
||||
- **エンタープライズサポート** - エンタープライズ顧客向けの専用サポート
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## 請求とプラン
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="異なる料金プランは何ですか?">
|
||||
Difyは以下のプランを提供しています:
|
||||
|
||||
- **無料ティア** - 始めるのに最適で、小規模プロジェクト向け
|
||||
- **プロプラン** - 高い使用量が必要な成長中のビジネス向け
|
||||
- **エンタープライズプラン** - 大規模組織向けのカスタムソリューション
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="使用量はどのように計算されますか?">
|
||||
使用量は通常以下に基づいて計算されます:
|
||||
|
||||
- AIモデルへの**APIコール**
|
||||
- ドキュメントとデータの**ストレージ**
|
||||
- アプリケーション上の**アクティブユーザー**
|
||||
- プランに応じた**カスタム機能**
|
||||
|
||||
詳細な料金情報については、[料金ページ](https://dify.ai/pricing)をご覧ください。
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
---
|
||||
|
||||
<Note>
|
||||
もっと助けが必要ですか? サポートチームに連絡するか、[包括的なドキュメント](../../../guides/)を確認してください。
|
||||
</Note>
|
||||
```
|
||||
165
ja-jp/documja-jptation/pages/getting-started/quick-start.mdx
Normal file
165
ja-jp/documja-jptation/pages/getting-started/quick-start.mdx
Normal file
@@ -0,0 +1,165 @@
|
||||
```mdx
|
||||
---
|
||||
title: "10分でクイックスタート"
|
||||
description: "Difyを使った簡単なアプリの作成"
|
||||
icon: "forward"
|
||||
---
|
||||
|
||||
Difyの本当の価値は、どんなに複雑なアイデアでも簡単に構築、展開、スケールできる点にあります。迅速なプロトタイピング、スムーズな反復、信頼性のある展開をあらゆるレベルで実現するために構築されています。
|
||||
|
||||
まずは、信頼できる大規模言語モデル(LLM)の統合を学びましょう。このガイドでは、ユーザーの質問を分類し、LLMを使用して直接応答し、国ごとの面白い事実で応答を強化するシンプルなチャットボットを構築します。
|
||||
|
||||
<iframe
|
||||
className="w-full aspect-video rounded-xl"
|
||||
src="https://www.youtube.com/embed/opKZRpfd80k?si=HEkyjRpiYheMyrZ0"
|
||||
title="Dify Quick Start Video"
|
||||
frameBorder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowFullScreen
|
||||
/>
|
||||
|
||||
## ステップ1: 新しいワークフローを作成する (2分)
|
||||
|
||||
1. **Studio** > **ワークフロー** > **空から作成** > **オーケストレート** > **新しい对话流** > **作成**に進みます。
|
||||
|
||||
## ステップ2: ワークフローノードを追加する (6分)
|
||||
|
||||
<Tip>
|
||||
変数を参照したい場合は、まず `{` または `/` を入力すると、ワークフロー内で使用可能なさまざまな変数が表示されます。
|
||||
</Tip>
|
||||
|
||||
### 1. LLMノードと出力: 質問を理解して回答する
|
||||
|
||||
<Info>
|
||||
`LLM` ノードは、ユーザー入力に基づいて応答を生成するために言語モデルにプロンプトを送信します。API呼び出し、レート制限、インフラストラクチャの複雑さを抽象化し、ロジックの設計に集中できます。
|
||||
</Info>
|
||||
|
||||
<Steps>
|
||||
<Step title="LLMノードを作成する">
|
||||
`ノードを追加` ボタンを使用してLLMノードを作成し、スタートノードに接続します。
|
||||
</Step>
|
||||
|
||||
<Step title="モデルを構成する">
|
||||
デフォルトのモデルを選択します。
|
||||
</Step>
|
||||
|
||||
<Step title="システムプロンプトを設定する">
|
||||
システムプロンプトフィールドに以下を貼り付けます:
|
||||
|
||||
```text
|
||||
ユーザーはある国について質問します。質問は {{sys.query}} です。
|
||||
タスク:
|
||||
1. 言及された国を特定する。
|
||||
2. 質問を明確に言い換える。
|
||||
3. 一般的な知識を使用して質問に答える。
|
||||
|
||||
以下のJSON形式で応答してください:
|
||||
{
|
||||
"country": "<country name>",
|
||||
"question": "<rephrased question>",
|
||||
"answer": "<direct answer to the question>"
|
||||
}
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="構造化出力を有効にする">
|
||||
**構造化出力を有効にする**ことで、LLMが返す内容を簡単に制御し、一貫性のある機械可読の出力を実現し、正確なデータ抽出や条件付きロジックに使用できます。
|
||||
|
||||
- 出力変数構造のトグルをONにし、`JSONからインポート`をクリックします。
|
||||
- 以下を貼り付けます:
|
||||
|
||||
```json
|
||||
{
|
||||
"country": "string",
|
||||
"question": "string",
|
||||
"answer": "string"
|
||||
}
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### 2. コードブロック: 面白い事実を取得する
|
||||
|
||||
<Info>
|
||||
`コード` ノードは、コードを使用してカスタムロジックを実行します。視覚的なワークフロー内で必要な場所にコードを挿入でき、バックエンド全体を配線する手間を省けます。
|
||||
</Info>
|
||||
|
||||
<Steps>
|
||||
<Step title="コードノードを作成する">
|
||||
`ノードを追加` ボタンを使用して `コード` ノードを作成し、LLMブロックに接続します。
|
||||
</Step>
|
||||
|
||||
<Step title="入力変数を構成する">
|
||||
1つの `入力変数` 名を "country" に変更し、変数を `structured_output` > `country` に設定します。
|
||||
</Step>
|
||||
|
||||
<Step title="Pythonコードを追加する">
|
||||
以下のコードを `PYTHON3` に貼り付けます:
|
||||
|
||||
```python
|
||||
def main(country: str) -> dict:
|
||||
country_name = country.lower()
|
||||
fun_facts = {
|
||||
"japan": "日本には500万台以上の自動販売機があります。",
|
||||
"france": "フランスは世界で最も訪問されている国です。",
|
||||
"italy": "イタリアには他のどの国よりも多くのユネスコ世界遺産があります。"
|
||||
}
|
||||
fun_fact = fun_facts.get(country_name, f"{country.title()}についての面白い事実はありません。")
|
||||
return {"fun_fact": fun_fact}
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="出力変数名を変更する">
|
||||
出力変数 `result` を `fun_fact` に変更して、よりラベルが明確な変数にします。
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### 3. アンサーノード: ユーザーへの最終回答
|
||||
|
||||
<Info>
|
||||
`アンサー` ノードは、返すためのクリーンな最終出力を作成します。
|
||||
</Info>
|
||||
|
||||
<Steps>
|
||||
<Step title="アンサーノードを作成する">
|
||||
`ノードを追加` ボタンを使用して `アンサー` ノードを作成します。
|
||||
</Step>
|
||||
|
||||
<Step title="回答フィールドを構成する">
|
||||
回答フィールドに以下を貼り付けます:
|
||||
|
||||
```text
|
||||
Q: {{ structured_output.question }}
|
||||
|
||||
A: {{ structured_output.answer }}
|
||||
|
||||
面白い事実: {{ fun_fact }}
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
ワークフローの終了:
|
||||
|
||||
<img
|
||||
src="/images/quick-start-workflow-overview.png"
|
||||
alt="LLM、コード、およびアンサーノードが接続された完全なワークフロー図"
|
||||
style={{ width: "100%" }}
|
||||
/>
|
||||
|
||||
---
|
||||
|
||||
## ステップ3: ボットをテストする (3分)
|
||||
|
||||
`プレビュー` をクリックして、次のように質問します:
|
||||
|
||||
- "フランスの首都はどこですか?"
|
||||
- "日本料理について教えて"
|
||||
- "イタリアの文化を説明してください"
|
||||
- その他の質問
|
||||
|
||||
ボットが予想通りに動作することを確認してください!
|
||||
|
||||
## ボットの完成!
|
||||
|
||||
このガイドでは、言語モデルを信頼性とスケーラビリティを持って統合する方法を示しました。Difyの視覚的なワークフローとモジュールノードを使用することで、ただ速く構築するだけでなく、LLMを活用したアプリのためのクリーンでプロダクション対応のアーキテクチャを採用しています。
|
||||
```
|
||||
@@ -0,0 +1,57 @@
|
||||
```mdx
|
||||
---
|
||||
title: "内部ワークフローのテスト"
|
||||
description: "内部貢献者のためのドキュメント同期テスト"
|
||||
icon: "flask"
|
||||
---
|
||||
|
||||
これは、内部貢献者のための自動ドキュメント同期を検証するためのテストドキュメントです。
|
||||
|
||||
## 機能のテスト
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="ワークフローテスト">
|
||||
このドキュメントは、2つのワークフローパターンをテストします:
|
||||
- 分析ワークフロー(読み取り専用)
|
||||
- 実行ワークフロー(権限あり)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="自動承認">
|
||||
内部貢献者は信頼リストに入っているため、自動承認されるべきです。
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="翻訳生成">
|
||||
このコンテンツは自動的に翻訳されるべきです:
|
||||
- 中国語(zh-hans)
|
||||
- 日本語(ja-jp)
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## 期待される結果
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="同期ブランチ" icon="code-branch">
|
||||
新しいブランチ `docs-sync-pr-XX` が作成されるべきです
|
||||
</Card>
|
||||
<Card title="PRコメント" icon="comment">
|
||||
翻訳結果を含む自動コメント
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
<Note>
|
||||
これは {{ new Date().toISOString() }} に作成されたテストファイルです。
|
||||
</Note>
|
||||
|
||||
## コード例
|
||||
|
||||
```python
|
||||
def test_workflow():
|
||||
"""Test the documentation sync workflow"""
|
||||
return "Testing internal contributor flow"
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
テスト実施者: 内部貢献者
|
||||
ブランチ: test/internal-docs-sync
|
||||
```
|
||||
117
ja-jp/documja-jptation/pages/nodes/agja-jpt.mdx
Normal file
117
ja-jp/documja-jptation/pages/nodes/agja-jpt.mdx
Normal file
@@ -0,0 +1,117 @@
|
||||
```mdx
|
||||
---
|
||||
title: "エージェント"
|
||||
description: "Give LLMs autonomous control over tools for complex task execution"
|
||||
icon: "robot"
|
||||
---
|
||||
|
||||
エージェントノードは、LLMにツールへの自律的な制御を与え、どのツールをいつ使用するかを反復的に決定できるようにします。すべてのステップを事前に計画する代わりに、エージェントは問題を動的に推論し、複雑なタスクを完了するために必要に応じてツールを呼び出します。
|
||||
|
||||
<Frame caption="エージェントノードの設定インターフェース">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/1f4d803ff68394d507abd3bcc13ba0f3.png" alt="Agent node interface" />
|
||||
</Frame>
|
||||
|
||||
## エージェント戦略
|
||||
|
||||
エージェント戦略は、エージェントがどのように考え、行動するかを定義します。モデルの能力とタスクの要件に最も合ったアプローチを選択してください。
|
||||
|
||||
<Frame caption="利用可能なエージェント戦略オプション">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/f14082c44462ac03955e41d66ffd4cca.png" alt="Agent strategies selection" />
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="関数呼び出し">
|
||||
LLMのネイティブな関数呼び出し機能を使用して、ツール定義をtoolsパラメータを通じて直接渡します。LLMは、いつどのようにツールを呼び出すかをその組み込みのメカニズムを使用して決定します。
|
||||
|
||||
GPT-4、Claude 3.5、および他の強力な関数呼び出しサポートを持つモデルに最適です。
|
||||
</Tab>
|
||||
|
||||
<Tab title="推理と行動 (ReAct)">
|
||||
明確な推論ステップを通じてLLMを導く構造化されたプロンプトを使用します。透明性のある意思決定のために**考え→行動→観察**サイクルをフォローします。
|
||||
|
||||
ネイティブの関数呼び出しがないモデルや、明確な推論の痕跡が必要な場合に適しています。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Info>
|
||||
**マーケットプレイス→エージェント戦略**から追加の戦略をインストールするか、[コミュニティリポジトリ](https://github.com/langgenius/dify-plugins)にカスタム戦略を投稿してください。
|
||||
</Info>
|
||||
|
||||
<Frame caption="関数呼び出し戦略の設定">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/10505cd7c6f0b3ba10161abb88d9e36b.png" alt="Function calling setup" />
|
||||
</Frame>
|
||||
|
||||
## 設定
|
||||
|
||||
### モデルの選択
|
||||
|
||||
選択したエージェント戦略をサポートするLLMを選んでください。より高性能なモデルは複雑な推論をよりよく処理しますが、1回のイテレーションごとにコストがかかります。関数呼び出しの戦略を使用する場合は、モデルが関数呼び出しをサポートしていることを確認してください。
|
||||
|
||||
### ツールの設定
|
||||
|
||||
エージェントがアクセスできるツールを設定します。各ツールには以下が必要です:
|
||||
|
||||
**認証** - ワークスペースで設定された外部サービスのAPIキーと資格情報
|
||||
|
||||
**説明** - ツールが何をするか、いつ使用するかの明確な説明(これはエージェントの意思決定を導きます)
|
||||
|
||||
**パラメータ** - 適切なバリデーションを伴うツールが受け入れる必須およびオプションの入力
|
||||
|
||||
### 指示とコンテキスト
|
||||
|
||||
エージェントの役割、目標、およびコンテキストを自然言語の指示を使って定義します。Jinja2構文を使用して、上流のワークフローノードから変数を参照します。
|
||||
|
||||
**クエリ**は、ユーザーの入力やエージェントが取り組むべきタスクを指定します。これは、前のワークフローノードからの動的な内容である可能性があります。
|
||||
|
||||
<Frame caption="エージェント設定パラメータ">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/54c8e4f0eaa7379bd8c1b5ac6305b326.png" alt="Agent configuration interface" />
|
||||
</Frame>
|
||||
|
||||
### 実行制御
|
||||
|
||||
**最大反復回数**は無限ループを防ぐための安全上の制限を設定します。タスクの複雑さに基づいて設定してください。単純なタスクには3~5回の反復が必要で、複雑な調査には10~15回が必要です。
|
||||
|
||||
**記憶**は、TokenBufferMemoryを使用してエージェントが覚えている以前のメッセージ数を制御します。大きなメモリウィンドウはより多くのコンテキストを提供しますが、トークンコストも増加します。これにより、ユーザーが以前のアクションを参照できる会話の連続性が可能になります。
|
||||
|
||||
### ツールパラメータの自動生成
|
||||
|
||||
ツールには**自動生成**または**手動入力**として設定されたパラメータが含まれることがあります。自動生成されたパラメータ(`auto: false`)はエージェントによって自動的に入力され、手動入力パラメータは明示的な値を必要とし、ツールの恒久的な設定の一部になります。
|
||||
|
||||
<video controls src="https://assets-docs.dify.ai/2025/04/1801b96763eb8f22f1e2158645897885.mp4" width="100%" />
|
||||
|
||||
## 出力変数
|
||||
|
||||
エージェントノードは包括的な出力を提供します:
|
||||
|
||||
**最終回答** - クエリに対するエージェントの最終的な応答
|
||||
|
||||
**ツール出力** - 実行中に各ツール呼び出しからの結果
|
||||
|
||||
**推論トレース** - ステップバイステップの意思決定プロセス(特にReAct戦略では詳細に)をJSON出力で利用可能
|
||||
|
||||
**反復回数** - 使用された推論サイクルの数
|
||||
|
||||
**成功ステータス** - エージェントがタスクを正常に完了したかどうか
|
||||
|
||||
**エージェントログ** - デバッグおよびツール呼び出しの監視のためのメタデータを含む構造化ログイベント
|
||||
|
||||
## 使用例
|
||||
|
||||
**調査と分析** - エージェントは複数のソースを自律的に検索し、情報を合成し、包括的な回答を提供できます。
|
||||
|
||||
**トラブルシューティング** - エージェントが情報を収集し、仮説をテストし、発見に基づいてアプローチを適応させる必要がある診断タスク。
|
||||
|
||||
**多段階データ処理** - 中間結果に依存する複雑なワークフロー。
|
||||
|
||||
**動的API統合** - API呼び出しのシーケンスが応答や条件に依存し、事前に決定できないシナリオ。
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**明確なツールの説明**は、エージェントが各ツールをいつどのように効果的に使用するかを理解するのに役立ちます。
|
||||
|
||||
**適切な反復制限**は、コストを抑制しながら複雑なタスクに十分な柔軟性を提供します。
|
||||
|
||||
**詳細な指示**は、エージェントの役割、目標、および制約や好みに関するコンテキストを提供します。
|
||||
|
||||
**メモリ管理**は、トークンの効率性とコンテキストの保持のバランスを、使用例の要件に基づいて調整します。
|
||||
```
|
||||
67
ja-jp/documja-jptation/pages/nodes/answer.mdx
Normal file
67
ja-jp/documja-jptation/pages/nodes/answer.mdx
Normal file
@@ -0,0 +1,67 @@
|
||||
```mdx
|
||||
---
|
||||
title: "回答"
|
||||
description: "チャットフローアプリケーションでの応答内容の定義"
|
||||
icon: "message"
|
||||
---
|
||||
|
||||
Answerノードは、チャットフローアプリケーションでユーザーに届けられるコンテンツを定義します。これを使用して、応答をフォーマットし、テキストと変数を組み合わせ、テキスト、画像、ファイルを含む多モーダルコンテンツをストリーミングします。
|
||||
|
||||
<Info>
|
||||
Answerノードはチャットフローアプリケーションでのみ利用可能です。ワークフローアプリケーションではEndノードが使用されます。
|
||||
</Info>
|
||||
|
||||
## コンテンツ構成
|
||||
|
||||
Answerノードは柔軟なテキストエディタを提供し、固定テキスト、前のノードからの変数、またはその両方を組み合わせた応答を作成できます。
|
||||
|
||||
`{{variable_name}}`の構文を使用して、前の任意のワークフローノードから変数を参照します。エディタはリッチコンテンツのフォーマットと変数の挿入をサポートし、動的でコンテキストに応じた応答を作成します。
|
||||
|
||||
<Frame caption="プレーンテキストの応答設定">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/42bb6bdef101bf79f959f4fc56a50ff3.png" alt="プレーンテキストの応答例" />
|
||||
</Frame>
|
||||
|
||||
## 多モーダル応答
|
||||
|
||||
Answerノードは、単一の応答ストリームでテキスト、画像、ファイルを含むリッチコンテンツの配信をサポートします。
|
||||
|
||||
<Frame caption="画像とテキストコンテンツを含む多モーダル応答">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/d2c901e821029756ebf95f4e099d833f.png" alt="多モーダル応答の例" />
|
||||
</Frame>
|
||||
|
||||
**テキストコンテンツ**には、変数の置換、マークダウン形式、およびワークフロープロセスの結果に基づく動的コンテンツを含めることができます。
|
||||
|
||||
**画像コンテンツ**は、ツールで生成された画像、ユーザーによってアップロードされた画像、またはワークフローノードで処理された画像を表示します。画像はテキストと並行してストリーミングされ、リッチなユーザー体験を提供します。
|
||||
|
||||
**ファイルコンテンツ**は、ワークフロー実行中に生成または処理されたドキュメント、スプレッドシート、その他のファイルを配信します。
|
||||
|
||||
<Frame caption="チャット内のAnswerノードユーザーインターフェース">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/5a70a5e568dded3975e54cfa84085c93.png" alt="Answerノードのチャットインターフェース" />
|
||||
</Frame>
|
||||
|
||||
## 複数のAnswerノード
|
||||
|
||||
チャットフロー内のさまざまな処理段階でコンテンツを配信するために、複数のAnswerノードを配置できます。これにより、以下が可能になります:
|
||||
|
||||
**進行中の応答** - 処理がバックグラウンドで続行されている間に即時の確認を提供します
|
||||
|
||||
**条件付き応答** - ワークフローブランチングロジックに基づいて異なるコンテンツを送信します
|
||||
|
||||
**ストリーミングアップデート** - 長時間実行されるプロセス中に利用可能になった部分的な結果を配信します
|
||||
|
||||
各Answerノードは独立して会話に貢献し、洗練された応答パターンとユーザー体験の設計を可能にします。
|
||||
|
||||
## 変数の統合
|
||||
|
||||
Answerノードは、すべてのワークフローノードタイプからの出力とシームレスに統合されます。一般的な変数のソースには以下が含まれます:
|
||||
|
||||
**LLM応答** - 生成されたテキスト、分析結果、または言語モデルからの構造化出力を表示します
|
||||
|
||||
**知識の検索** - 知識ベースで見つかった関連情報を、引用の追跡を自動で行い表示します
|
||||
|
||||
**ツールの結果** - 外部API、計算、またはサービス統合からのデータを表示します
|
||||
|
||||
**ファイル処理** - 抽出されたテキスト、分析結果、または処理されたドキュメントコンテンツを表示します
|
||||
|
||||
変数システムは型安全性を維持し、チャットインターフェースでの最適な表示のために異なるコンテンツタイプを自動的に処理します。
|
||||
```
|
||||
138
ja-jp/documja-jptation/pages/nodes/code.mdx
Normal file
138
ja-jp/documja-jptation/pages/nodes/code.mdx
Normal file
@@ -0,0 +1,138 @@
|
||||
```mdx
|
||||
---
|
||||
title: "コード"
|
||||
description: "データ処理のためにカスタムPythonまたはJavaScriptを実行"
|
||||
icon: "code"
|
||||
---
|
||||
|
||||
コードノードは、ワークフロー内で複雑なデータ変換、計算、およびロジックを処理するためにカスタムPythonまたはJavaScriptを実行します。プリセットノードでは特定の処理ニーズに十分でない場合に使用してください。
|
||||
|
||||
<Frame caption="コードノードの設定インターフェース">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/9969aa1bc1912aebe366f5d8f5dde296.png" alt="コードノードインターフェース" />
|
||||
</Frame>
|
||||
|
||||
## 設定
|
||||
|
||||
**入力変数**を定義して、ワークフロー内の他のノードからデータにアクセスし、その後これらの変数をコード内で参照します。関数は、宣言した**出力変数**を含む辞書を返さなければなりません。
|
||||
|
||||
```python
|
||||
def main(input_variable: str) -> dict:
|
||||
# 入力を処理
|
||||
result = input_variable.upper()
|
||||
return {
|
||||
'output_variable': result
|
||||
}
|
||||
```
|
||||
|
||||
## 言語サポート
|
||||
|
||||
ニーズと親しみやすさに基づいて、**Python**または**JavaScript**を選択してください。両方の言語はデータ処理のための一般的なライブラリにアクセスできる安全なサンドボックスで実行されます。
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Python">
|
||||
Pythonには`json`、`math`、`datetime`、`re`のような標準ライブラリが含まれています。データ分析、数学的操作、テキスト処理に最適です。
|
||||
|
||||
```python
|
||||
def main(data: list) -> dict:
|
||||
import json
|
||||
import math
|
||||
|
||||
average = sum(data) / len(data)
|
||||
return {'result': math.ceil(average)}
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="JavaScript">
|
||||
JavaScriptは標準の組み込みオブジェクトとメソッドを提供します。JSON操作や文字列操作に適しています。
|
||||
|
||||
```javascript
|
||||
function main(data) {
|
||||
const processed = data.map(item => item.toUpperCase());
|
||||
return { result: processed };
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## エラーハンドリングとリトライ
|
||||
|
||||
失敗したコード実行のための自動リトライ動作を設定し、コードがエラーに遭遇した際のフォールバック戦略を定義します。
|
||||
|
||||
<Frame caption="エラーハンドリング設定オプション">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/58f392734ce44b22cd8c160faf28cd14.png" alt="コードエラーハンドリング" />
|
||||
</Frame>
|
||||
|
||||
**リトライ設定**では、最大10回の自動リトライと最大5000msの間隔を設定できます。これは一時的な処理問題を扱うために有効にします。
|
||||
|
||||
**エラーハンドリング**では、コード実行が失敗した際のフォールバックパスを定義し、コードが問題に遭遇した場合でもワークフローを続行できるようにします。
|
||||
|
||||
<Frame caption="リトライ設定インターフェース">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/9fdd5525a91dc925b79b89272893becf.png" alt="リトライ設定" />
|
||||
</Frame>
|
||||
|
||||
## 出力の検証と制限
|
||||
|
||||
コード出力は厳格な制限で自動的に検証されます:
|
||||
- **文字列**: 最大80,000文字の長さ、ヌルバイトは削除されます
|
||||
- **数値**: -999999999から999999999までの範囲、浮動小数点数は小数点以下10桁に制限
|
||||
- **オブジェクト/配列**: 複雑なネスト構造を防ぐために最大5レベルの深さ
|
||||
|
||||
これらの制限は、パフォーマンスを確保し、ワークフローでのメモリ問題を防ぎます。
|
||||
|
||||
## セキュリティ考慮事項
|
||||
|
||||
コードはファイルシステムアクセス、ネットワーク要求、システムコマンドを防ぐ厳格なサンドボックスで実行されます。これにより、プログラミングの柔軟性を提供しながらセキュリティを維持します。
|
||||
|
||||
一部の操作はセキュリティ上の理由から自動的にブロックされます。システムファイルへのアクセスや潜在的に危険な操作を試みるのを避けてください:
|
||||
|
||||
<Frame caption="Cloudflare WAFによるセキュリティフィルタリング">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/ad4dc065c4c567c150ab7fa7bfd123a3.png" alt="Cloudflare WAFによるブロック" />
|
||||
</Frame>
|
||||
|
||||
コードが保存されない場合、ブラウザのネットワークタブを確認してください - セキュリティフィルターが潜在的に危険な操作をブロックしている可能性があります。
|
||||
|
||||
## 依存関係のサポート
|
||||
|
||||
コードノードはPythonとJavaScriptの両方で外部依存関係をサポートします:
|
||||
|
||||
```python
|
||||
# Python: numpy、pandas、requestsなどをインポート
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
def main(data: list) -> dict:
|
||||
df = pd.DataFrame(data)
|
||||
return {'mean': float(np.mean(df['values']))}
|
||||
```
|
||||
|
||||
```javascript
|
||||
// JavaScript: lodash、momentなどをインポート
|
||||
const _ = require('lodash');
|
||||
|
||||
function main(data) {
|
||||
return { unique: _.uniq(data) };
|
||||
}
|
||||
```
|
||||
|
||||
依存関係はサンドボックス環境に事前インストールされています。Difyインストールで利用可能なパッケージリストを確認してください。
|
||||
|
||||
## 自己ホスト型セットアップ
|
||||
|
||||
自己ホスト型Difyインストールの場合、安全なコード実行のためにサンドボックスサービスを開始します:
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.middleware.yaml up -d
|
||||
```
|
||||
|
||||
サンドボックスサービスはDockerを必要とし、セキュリティのためにコード実行をメインシステムから分離します。
|
||||
|
||||
## 一般的なユースケース
|
||||
|
||||
**データ解析** - APIや他のノードから返される複雑なJSON構造から特定の値を抽出します。
|
||||
|
||||
**数学的操作** - 計算、統計解析、またはプリセットノードでは対応できないデータ集計を行います。
|
||||
|
||||
**データ変換** - データ形式を変換し、複数のデータソースを結合するか、下流の処理のために情報を再構築します。
|
||||
|
||||
**条件付きロジック** - 単純なif-else条件を超えた複雑な意思決定ロジックを実装します。
|
||||
```
|
||||
112
ja-jp/documja-jptation/pages/nodes/doc-extractor.mdx
Normal file
112
ja-jp/documja-jptation/pages/nodes/doc-extractor.mdx
Normal file
@@ -0,0 +1,112 @@
|
||||
---
|
||||
title: "ドキュメント抽出器"
|
||||
description: "Extract text content from uploaded documents for AI processing"
|
||||
icon: "file-export"
|
||||
---
|
||||
|
||||
ドキュメント抽出器ノードは、アップロードされたファイルを大規模言語モデルが処理できるテキストに変換します。言語モデルはPDFやDOCXなどのドキュメント形式を直接読み取ることができないため、このノードはファイルアップロードとAI解析の間の重要な橋渡しとなります。
|
||||
|
||||
<Frame caption="ドキュメント抽出器ノードの設定">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/f3853b40904e275da895711107e9c72f.png" alt="ドキュメント抽出器インターフェース" />
|
||||
</Frame>
|
||||
|
||||
## サポートされているファイルタイプ
|
||||
|
||||
このノードは、ほとんどのテキストベースのドキュメント形式を処理します:
|
||||
|
||||
**テキストドキュメント** - TXT、Markdown、HTMLファイルなど、直接テキストコンテンツを含むファイル
|
||||
|
||||
**オフィス文書** - Microsoft WordおよびCompatible applicationsのDOCXファイル
|
||||
|
||||
**PDFドキュメント** - pypdfium2を使用して正確なテキスト抽出を行うテキストベースのPDF
|
||||
|
||||
**オフィスファイル** - DOCファイルはUnstructured APIが必要、DOCXファイルは直接解析をサポートし、テーブル抽出はMarkdown形式に変換される
|
||||
|
||||
**スプレッドシート** - Excel(.xls/.xlsx)およびCSVファイルをMarkdownテーブルに変換
|
||||
|
||||
**プレゼンテーション** - PowerPoint(.ppt/.pptx)ファイルをUnstructured API経由で処理
|
||||
|
||||
**メール形式** - EMLおよびMSGファイルによるメールコンテンツ抽出
|
||||
|
||||
**特殊形式** - EPUB書籍、VTT字幕、JSON/YAMLデータ、プロパティファイル
|
||||
|
||||
画像、音声、動画などの主にバイナリコンテンツを含むファイルは、専用の処理ツールまたは外部サービスが必要です。
|
||||
|
||||
## 入力と出力
|
||||
|
||||
### 入力設定
|
||||
|
||||
ノードを次のいずれかを受け入れるように設定します:
|
||||
|
||||
**単一ファイル**入力(通常はStartノードからのファイル変数)
|
||||
|
||||
**複数ファイル**をバッチドキュメント処理のための配列として
|
||||
|
||||
### 出力構造
|
||||
|
||||
ノードは抽出されたテキストコンテンツを出力します:
|
||||
|
||||
- 単一ファイル入力は、抽出されたテキストを含む`string`を生成
|
||||
- 複数ファイル入力は、各ファイルのコンテンツを含む`array[string]`を生成
|
||||
|
||||
出力変数は`text`という名前で、下流処理の準備が整った生のテキストコンテンツが含まれています。
|
||||
|
||||
## 実装例
|
||||
|
||||
以下は、ドキュメント抽出器を使用した完全なドキュメントQ&Aワークフローです:
|
||||
|
||||
<Frame caption="ChatPDFスタイルのワークフロー実装">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/f6ea094b30b240c999a4248d1fc21a1c.png" alt="ChatPDFワークフロー" />
|
||||
</Frame>
|
||||
|
||||
### ワークフロー設定
|
||||
|
||||
**ファイルアップロード設定** - Startノードでファイル入力を有効にして、ユーザーからのドキュメントアップロードを受け入れます。
|
||||
|
||||
**テキスト抽出** - ドキュメント抽出器を接続して、アップロードされたファイルを処理し、テキストコンテンツを抽出します。
|
||||
|
||||
**AI処理** - 抽出されたテキストを大規模言語モデルのプロンプトで使用して、分析、要約、または質問応答を行います。
|
||||
|
||||
<Frame caption="動作中のドキュメント処理ai/dify-enterprise-mintlify/en/guides/workflow/node/83bca46bcde07069660ff649e5c7cf4c.png" alt="ドキュメント処理設定" />
|
||||
</Frame>
|
||||
|
||||
<Frame caption="ドキュメントアップロード機能付きチャットインターフェース">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d05301438e8aab7393bb5863554f1009.png" alt="PDF付きチャットインターフェース" />
|
||||
</Frame>
|
||||
|
||||
## 一般的な使用例
|
||||
|
||||
**ドキュメントQ&Aアプリケーション** - ユーザーがドキュメントをアップロードし、そのコンテンツについて質問するChatPDFスタイルのアプリを構築します。
|
||||
|
||||
**コンテンツ分析** - 契約書、報告書、研究論文を処理して重要な情報や洞察を抽出します。
|
||||
|
||||
**バッチドキュメント処理** - 複数のドキュメントから同時にテキストを抽出して分析、インデックス化、移行を行います。
|
||||
|
||||
**ドキュメント変換** - さまざまなドキュメント形式をプレーンテキストに変換して、さらなる処理や保存を行います。
|
||||
|
||||
## 処理に関する考慮事項
|
||||
|
||||
ドキュメント抽出器は、異なるファイル形式に最適化された専用解析ライブラリを使用します。可能な限りテキスト構造と書式を保持し、抽出されたコンテンツを大規模言語モデル処理により有用にします。
|
||||
|
||||
### ファイル形式処理
|
||||
|
||||
**エンコーディング検出** - chardetライブラリを使用してファイルエンコーディングを自動検出し、テキストベースファイルにはUTF-8フォールバックを使用
|
||||
|
||||
**テーブル変換** - ExcelおよびCSVデータは、大規模言語モデルの理解を向上させるためのMarkdownテーブルになります
|
||||
|
||||
**ドキュメント構造** - DOCXファイルは、適切なテーブルからMarkdownへの変換により段落とテーブルの順序を維持
|
||||
|
||||
**複数行コンテンツ** - VTT字幕ファイルは、同じ話者による連続する発言をマージ
|
||||
|
||||
### 外部依存関係
|
||||
|
||||
一部のファイル形式では、`UNSTRUCTURED_API_URL`と`UNSTRUCTURED_API_KEY`経由で設定される**Unstructured API**サービスが必要です:
|
||||
- DOCファイル(レガシーWordドキュメント)
|
||||
- PowerPointプレゼンテーション(API処理を使用する場合)
|
||||
- EPUB書籍(API処理を使用する場合)
|
||||
|
||||
非常に大きなドキュメントの場合は、大規模言語モデルのコンテキスト制限を考慮し、必要に応じてチャンキング戦略を実装してください。抽出されたテキストは、意味とコンテキストを保持するために元のドキュメントの論理構造を維持します。
|
||||
|
||||
<Info>
|
||||
詳細なファイルアップロード設定と高度なドキュメント処理機能については、[ファイルアップロードガイド](/en/guides/workflow/additional-features)を参照してください。
|
||||
</Info>
|
||||
138
ja-jp/documja-jptation/pages/nodes/http-request.mdx
Normal file
138
ja-jp/documja-jptation/pages/nodes/http-request.mdx
Normal file
@@ -0,0 +1,138 @@
|
||||
---
|
||||
title: "HTTPリクエスト"
|
||||
description: "Connect to external APIs and web services"
|
||||
icon: "globe"
|
||||
---
|
||||
|
||||
HTTPリクエストノードは、ワークフローを外部APIやWebサービスに接続します。データの取得、Webhookの送信、ファイルのアップロード、またはHTTPリクエストを受け付ける任意のサービスとの統合に使用します。
|
||||
|
||||
<Frame caption="HTTPリクエストノードの設定">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/07c5e952eb4c9d6a32d0b7c2d855d4a5.png" alt="HTTPリクエストノードのインターフェース" />
|
||||
</Frame>
|
||||
|
||||
## HTTPメソッド
|
||||
|
||||
このノードは、さまざまなタイプの操作に対応するすべての標準的なHTTPメソッドをサポートしています:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="データ取得">
|
||||
**GET**は何も変更せずにサーバーからデータを取得します。ユーザープロフィールの取得、データベースの検索、現在のステータスの取得に使用します。
|
||||
|
||||
**HEAD**は完全なレスポンスボディなしでレスポンスヘッダーを取得します。リソースの存在確認やメタデータの取得に役立ちます。
|
||||
</Tab>
|
||||
|
||||
<Tab title="データ送信">
|
||||
**POST**は通常、新しいリソースを作成するためにサーバーにデータを送信します。フォーム送信、ファイルアップロード、JSONペイロードの送信に使用します。
|
||||
|
||||
**PUT**はリソースを作成または完全に置換します。リソースの状態全体を設定したい場合に使用します。
|
||||
|
||||
**PATCH**は既存のリソースに部分的な更新を行います。特定のフィールドのみを変更する必要がある場合に使用します。
|
||||
</Tab>
|
||||
|
||||
<Tab title="リソース管理">
|
||||
**DELETE**はサーバーからリソースを削除します。ファイル、ユーザーアカウント、または削除すべき任意のリソースの削除に使用します。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 設定
|
||||
|
||||
URL、ヘッダー、クエリパラメータ、リクエストボディ、認証など、HTTPリクエストのあらゆる側面を設定します。前のワークフローノードからの変数は、リクエスト設定のどこにでも動的に挿入できます。
|
||||
|
||||
### 変数置換
|
||||
|
||||
ワークフロー変数は二重中括弧を使用して参照します:`{{variable_name}}`。Difyは深いオブジェクトアクセスをサポートしているため、前のHTTPレスポンスから`{{api_response.data.items[0].id}}`のような入れ子の値を抽出できます。
|
||||
|
||||
### タイムアウト設定
|
||||
|
||||
HTTPリクエストには、ハングを防ぐための設定可能なタイムアウトがあります:
|
||||
- **接続タイムアウト**:接続を確立するための最大時間(デフォルトはデプロイメントによって異なります)
|
||||
- **読み取りタイムアウト**:レスポンスデータを読み取るための最大時間
|
||||
- **書き込みタイムアウト**:リクエストデータを送信するための最大時間
|
||||
|
||||
タイムアウトは、ワークフローのパフォーマンスを維持し、リソースの枯渇を防ぐために強制されます。
|
||||
|
||||
### 認証
|
||||
|
||||
このノードは複数の認証タイプをサポートしています:
|
||||
|
||||
**認証なし**(`type: "no-auth"`) - 認証ヘッダーは追加されません
|
||||
|
||||
**APIキー**(`type: "api-key"`)には3つのサブタイプがあります:
|
||||
- **Basic**(`type: "basic"`) - base64エンコーディングで加
|
||||
- **Bearer**(`type: "bearer"`) - `Authorization: Bearer <token>`ヘッダーを追加
|
||||
- **Custom**(`type: "custom"`) - 指定された名前と値でカスタムヘッダーを追加
|
||||
|
||||
### リクエストボディ
|
||||
|
||||
APIの要件に基づいて適切なボディタイプを選択します:
|
||||
|
||||
- **JSON**:構造化データ用
|
||||
- **フォームデータ**:従来のWebフォーム用
|
||||
- **バイナリ**:ファイルアップロード用
|
||||
- **生テキスト**:カスタムコンテンツタイプ用
|
||||
|
||||
## ファイル検出
|
||||
|
||||
HTTPリクエストノードは、高度なロジックを使用してファイルレスポンスを自動的に検出します:
|
||||
|
||||
1. **Content-Disposition分析** - `attachment`ディスポジションまたはファイル名パラメータをチェック
|
||||
2. **MIMEタイプ評価** - コンテンツタイプを分析してテキストとバイナリを区別
|
||||
3. **コンテンツサンプリング** - 曖昧なタイプについては、最初の1024バイトをサンプリングしてテキストパターンを検出
|
||||
|
||||
テキストベースのレスポンス(JSON、XML、HTMLなど)は通常のデータとして扱われ、バイナリコンテンツはファイル変数になります。
|
||||
|
||||
## ファイル操作
|
||||
|
||||
HTTPリクエストノードは、ファイルのアップロードとダウンロードをシームレスに処理します:
|
||||
|
||||
<Frame caption="ファイルアップロード設定の例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/1f2e33cf7bed33096b5aee145006193d.png" alt="HTTPノードファイルアップロード" />
|
||||
</Frame>
|
||||
|
||||
**ファイルアップロード**はバイナリリクエストボディオプションを使用します。前のノードからファイル変数を選択して、ドキュメントストレージ、メディア処理、またはバックアップのために外部サービスにファイルを送信します。
|
||||
|
||||
**ファイルダウンロード**は、レスポンスにファイルコンテンツが含まれている場合に自動的に処理されます。ダウンロードされたファイルは、下流ノードで使用するためのファイル変数として利用可能になります。
|
||||
|
||||
## エラーハンドリングとリトライ
|
||||
|
||||
外部サービスに依存する本番環境ワークフロー向けに、堅牢なエラーハンドリングを設定します:
|
||||
|
||||
<Frame caption="HTTPリトライ設定">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/2e7c6080c0875e31a074c2a9a4543797.png" alt="HTTPリトライ設定" />
|
||||
</Frame>
|
||||
|
||||
**リトライ設定**は、設定可能な間隔(最大5000ms)で失敗したリクエストを最大10回まで自動的にリトライします。これにより、一時的なネットワーク問題やサービスの利用不可を処理します。
|
||||
|
||||
<Frame caption="HTTPエラーハンドリングオプション">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/91daa86d9770390ab2a41d6d0b6ed1e7.png" alt="HTTPエラーハンドリング" />
|
||||
</Frame>
|
||||
|
||||
**エラーハンドリング**は、HTTPリクエストが失敗した際の代替ワークフローパスを定義し、外部APIが利用できない場合でもワークフローが実行を継続できるようにします。
|
||||
|
||||
## レスポンス処理
|
||||
|
||||
HTTPレスポンスは、後続のノードで構造化された変数となり、以下への個別のアクセスが可能です:
|
||||
|
||||
- **レスポンスボディ** - APIから返されるメインコンテンツ
|
||||
- **ステータスコード** - 条件ロジック用のHTTPステータス
|
||||
- **ヘッダー** - キー値ペアとしてのレスポンスメタデータ
|
||||
- **ファイル** - APIから返される任意のファイルコンテンツ
|
||||
- **サイズ情報** - 読みやすい形式(KB/MB)でのコンテンツサイズ(バイト)
|
||||
|
||||
### SSL検証
|
||||
|
||||
SSL証明書検証は、ノードごとに設定可能です(`ssl_verify`パラメータ)。これにより、外しながら、自己署名証明書を使用する内部サービスへの接続が可能になります。
|
||||
|
||||
<Frame caption="動的API統合のワークフロー例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/090975269f8998f906c5636dde8d9540.png" alt="顧客フィードバック分類ワークフロー" />
|
||||
</Frame>
|
||||
|
||||
## 一般的な統合パターン
|
||||
|
||||
**APIデータ取得** - ユーザープロフィール、製品情報、または外部データを取得して、ワークフロー処理を充実させます。
|
||||
|
||||
**Webhook配信** - 通知、ステータス更新、または処理結果を外部システムやサービスに送信します。
|
||||
|
||||
**ファイル処理** - 分析用のドキュメントをアップロード、さらなる処理用のリソースをダウンロード、またはクラウドストレージサービスと統合します。
|
||||
|
||||
**マルチステップAPIワークフロー** - 複数のAPI呼び出しを連携させ、1つのリクエストのレスポンスを使用して後続のリクエストを設定します。
|
||||
75
ja-jp/documja-jptation/pages/nodes/ifelse.mdx
Normal file
75
ja-jp/documja-jptation/pages/nodes/ifelse.mdx
Normal file
@@ -0,0 +1,75 @@
|
||||
```mdx
|
||||
---
|
||||
title: "If-Else"
|
||||
description: "Add conditional logic and branching to workflows"
|
||||
icon: "code-branch"
|
||||
---
|
||||
|
||||
If-Elseノードは、定義した条件に基づいて実行を異なるパスにルーティングすることで、ワークフローに意思決定ロジックを追加します。変数を評価し、ワークフローがどの分岐に従うべきかを決定します。
|
||||
|
||||
<Frame caption="If-Else条件分岐の例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d26ffff1b2ad0989d46e80d6812cf2e7.png" alt="条件ロジックを含むテキスト要約ワークフロー" />
|
||||
</Frame>
|
||||
|
||||
## 分岐ロジック
|
||||
|
||||
このノードは、複雑な決定木を処理するための複数の分岐パスをサポートします:
|
||||
|
||||
**IF Path** は、主要な条件がtrueと評価されたときに実行されます。
|
||||
|
||||
**ELIF Paths** は、IF条件がfalseのときに順番にチェックする追加の条件を提供します。複雑なロジックのために複数のELIF分岐を追加できます。
|
||||
|
||||
**ELSE Path** は、どの条件にも一致しないときのフォールバックとして機能し、常にワークフローに従うパスを提供します。
|
||||
|
||||
## 条件タイプ
|
||||
|
||||
さまざまな比較演算子を使用して変数をテストするために条件を設定します:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="テキスト操作">
|
||||
**Contains** / **Not contains** - テキストが特定の単語やフレーズを含むかどうかをチェック
|
||||
|
||||
**Starts with** / **Ends with** - パターンマッチングのためにテキストの始まりや終わりをテスト
|
||||
|
||||
**Is** / **Is not** - 正確なテキスト比較のための値一致
|
||||
</Tab>
|
||||
|
||||
<Tab title="値チェック">
|
||||
**Is empty** / **Is not empty** - 空白、null、または欠落した値をチェック
|
||||
|
||||
**Greater than** / **Less than** - 数字や日付のための数値比較
|
||||
|
||||
**Equals** / **Not equals** - 任意のデータ型のための正確な一致
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 複雑な条件
|
||||
|
||||
論理演算子を使用して複数の条件を組み合わせ、洗練された意思決定を可能にします:
|
||||
|
||||
<Frame caption="AND/ORロジックを使用した複雑な条件設定">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/0b71ee7363e07298348e0c81e63481b0.png" alt="複数条件の判断" />
|
||||
</Frame>
|
||||
|
||||
**AND Logic** は、すべての条件がtrueであることを要求します。複数の基準を同時に満たす必要があるときに使用します。
|
||||
|
||||
**OR Logic** は、いずれかの条件がtrueであることを要求します。異なるシナリオに対して同じアクションをトリガーしたいときに使用します。
|
||||
|
||||
## 変数参照
|
||||
|
||||
条件内で、前のワークフローノードからの任意の変数を参照します。変数はユーザー入力、LLMの応答、API呼び出し、または他のワークフローノードの出力から取得できます。
|
||||
|
||||
変数セレクターを使用して利用可能な変数から選択するか、`{{variable_name}}`の構文を使用して変数名を直接入力します。
|
||||
|
||||
## 共通パターン
|
||||
|
||||
**コンテンツルーティング** - カテゴリ、言語、または複雑さに基づいて、異なるタイプのコンテンツを専門的な処理ノードに直接送ります。
|
||||
|
||||
**ユーザーロール管理** - ユーザーの権限、サブスクリプションレベル、またはアカウントタイプに基づいて異なるワークフロービヘイビアを実装します。
|
||||
|
||||
**エラーハンドリング** - 応答ステータスコード、データの有効性、または処理結果をチェックして、ワークフローを適切にルーティングします。
|
||||
|
||||
**動的処理** - 入力特性、処理結果、または外部条件に基づいてワークフロービヘイビアを調整します。
|
||||
|
||||
**多パスワークフロー** - アプリケーション内のさまざまなシナリオやエッジケースを処理する高度な分岐ロジックを作成します。
|
||||
```
|
||||
164
ja-jp/documja-jptation/pages/nodes/iteration.mdx
Normal file
164
ja-jp/documja-jptation/pages/nodes/iteration.mdx
Normal file
@@ -0,0 +1,164 @@
|
||||
```mdx
|
||||
---
|
||||
title: "反復"
|
||||
description: "各要素にワークフローを適用して配列を処理する"
|
||||
icon: "arrows-rotate"
|
||||
---
|
||||
|
||||
反復ノードは、各要素に対して同じワークフローステップを順次または並行して実行することで配列を処理します。単一の操作としては制限に達したり非効率的であるバッチ処理タスクに使用します。
|
||||
|
||||
<Frame caption="反復ノードの処理ワークフロー">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/5f3f124c16b9e3565853f125f7db0e32.png" alt="反復ノードの概要" />
|
||||
</Frame>
|
||||
|
||||
## 反復の動作
|
||||
|
||||
ノードは配列入力を受け取り、各配列要素に対して一度実行されるサブワークフローを作成します。各反復の間、現在の項目とそのインデックスが内部ノードで参照可能な変数として利用できます。
|
||||
|
||||
**コアコンポーネント:**
|
||||
- **入力変数** - 上流ノードからの配列データ
|
||||
- **内部ワークフロー** - 各要素に対して実行する処理ステップ
|
||||
- **出力変数** - すべての反復から収集された結果(配列でもあります)
|
||||
|
||||
## 設定
|
||||
|
||||
### 配列入力
|
||||
|
||||
パラメータ抽出、コードノード、知識検索、またはHTTPリクエストの応答などの上流ノードから配列変数を接続します。
|
||||
|
||||
### 組み込み変数
|
||||
|
||||
各反復は以下にアクセスを提供します:
|
||||
- `items[object]` - 現在処理中の配列要素
|
||||
- `index[number]` - 現在の反復インデックス(0から開始)
|
||||
|
||||
### 処理モード
|
||||
|
||||
<Tabs>
|
||||
<Tab title="順次モード">
|
||||
**順次処理** - 項目が順番に処理される
|
||||
|
||||
**ストリーミングサポート** - Answerノードを使用して結果を段階的に出力可能
|
||||
|
||||
**リソース管理** - 低メモリ使用、予測可能な実行順序
|
||||
|
||||
**最適用途** - 順序が重要な場合やストリーミング出力を使用する場合
|
||||
</Tab>
|
||||
|
||||
<Tab title="並行モード">
|
||||
**同時処理** - 最大10項目が同時に処理される
|
||||
|
||||
**性能向上** - 独立した操作のための高速実行
|
||||
|
||||
**バッチ処理** - 大きな配列を効率的に処理
|
||||
|
||||
**最適用途** - 順序が重要でない独立した操作
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Frame caption="順次処理と並行処理の比較">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/2656dec26d6357556a280fcd69ccd9a7.png" alt="処理モードの比較" />
|
||||
</Frame>
|
||||
|
||||
<Frame caption="反復設定で並行モードを有効にする">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/516af5e7427fce9a58fa9d9b583230d4.png" alt="並行モードの設定" />
|
||||
</Frame>
|
||||
|
||||
## エラーハンドリング
|
||||
|
||||
個々の配列要素の処理失敗をどのように扱うかを設定します:
|
||||
|
||||
**停止** - エラーが発生したら処理を停止し、エラーメッセージを返す
|
||||
|
||||
**エラー時継続** - 失敗した項目をスキップし、処理を続行し、失敗した要素にはnullを出力
|
||||
|
||||
**失敗した結果を削除** - 失敗した項目をスキップし、成功した結果のみを返す
|
||||
|
||||
入力出力対応の例:
|
||||
- 入力: `[1, 2, 3]`
|
||||
- エラー時継続の出力: `[result-1, null, result-3]`
|
||||
- 失敗した結果を削除の出力: `[result-1, result-3]`
|
||||
|
||||
## 長文記事生成の例
|
||||
|
||||
章のアウトラインを個別に処理して長文コンテンツを生成する:
|
||||
|
||||
<Frame caption="長文記事生成ワークフロー">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/3a403551d48b178d0a41ce2a5748dd2d.png" alt="長文ストーリー生成器" />
|
||||
</Frame>
|
||||
|
||||
**ワークフローステップ:**
|
||||
|
||||
1. **開始ノード** - ユーザーがストーリーのタイトルとアウトラインを提供
|
||||
2. **LLMノード** - 詳細な章のブレイクダウンを生成
|
||||
3. **パラメータ抽出器** - 章リストを構造化配列に変換
|
||||
4. **反復ノード** - 各章を内部LLMで処理
|
||||
5. **Answerノード** - 生成された章コンテンツをストリーミング
|
||||
|
||||
<Frame caption="ストーリー入力用開始ノードの設定">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/3af1c2ed0df00f19e584bcf511302f55.png" alt="開始ノードの設定" />
|
||||
</Frame>
|
||||
|
||||
<Frame caption="章構造のパラメータ抽出">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d3beee536ff3c35f4e1eb1ab610f35d7.png" alt="パラメータ抽出の設定" />
|
||||
</Frame>
|
||||
|
||||
<Frame caption="LLM処理を伴う反復設定">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/ac91582998868004b298afe2f04e5589.png" alt="反復ノードの設定" />
|
||||
</Frame>
|
||||
|
||||
<Info>
|
||||
パラメータ抽出の効果はモデルの能力と指示の質に依存します。強力なモデルを使用し、指示に例を提供して結果を改善します。
|
||||
</Info>
|
||||
|
||||
## 出力処理
|
||||
|
||||
反復ノードは、最終的な使用のために変換が必要な配列を出力します:
|
||||
|
||||
### 配列をテキストに変換
|
||||
|
||||
<Tabs>
|
||||
<Tab title="コードノードを使用">
|
||||
```python
|
||||
def main(articleSections: list):
|
||||
return {
|
||||
"result": "\n".join(articleSections)
|
||||
}
|
||||
```
|
||||
|
||||
<Frame caption="コードノードの配列変換">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/8be2372b00a802e981efe6f0ceff815b.png" alt="コードノードの変換" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
|
||||
<Tab title="テンプレートノードを使用">
|
||||
```jinja2
|
||||
{{ articleSections | join("\n") }}
|
||||
```
|
||||
|
||||
<Frame caption="テンプレートノードの配列変換">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/8c0bcc5de453dea2776d2755449bd971.png" alt="テンプレートノードの変換" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 一般的な使用例
|
||||
|
||||
**トークン制限管理** - 大きなテキストを翻訳、要約、または分析のために分割し、LLMコンテキストウィンドウを超えたコンテンツを処理します。
|
||||
|
||||
**バッチ処理** - 複数の項目に効率的に同じ操作を適用し、複数のドキュメントやAPIコールの処理などを行います。
|
||||
|
||||
**品質管理** - 項目を個別に処理して品質を維持し、エラーを優雅に処理し、バッチ全体の失敗を避けます。
|
||||
|
||||
**進行中の出力** - すべての処理が完了するのを待つのではなく、完了次第結果をストリームします。
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**適切なモードを選択** - 順序処理やストリーミングには順次、速度を要する独立した操作には並行を使用します。
|
||||
|
||||
**エラーを優雅に処理** - 部分的な失敗が処理を停止するべきか、スキップするべきかに基づいてエラーハンドリングを設定します。
|
||||
|
||||
**内部ワークフローを最適化** - 反復サブワークフローは複数回実行されるため効率的に保ちます。
|
||||
|
||||
**リソース使用を監視** - 大きな配列に複雑な処理を行うと、特に並行モードでは多大なリソースを消費する可能性があります。
|
||||
```
|
||||
67
ja-jp/documja-jptation/pages/nodes/ja-jpd.mdx
Normal file
67
ja-jp/documja-jptation/pages/nodes/ja-jpd.mdx
Normal file
@@ -0,0 +1,67 @@
|
||||
```mdx
|
||||
---
|
||||
title: "終了"
|
||||
description: "ワークフローの出力と終了ポイントを定義する"
|
||||
icon: "flag-checkered"
|
||||
---
|
||||
|
||||
End ノードは、ワークフローが完了した際に何を出力するかを定義します。すべての工作流アプリケーションは、ユーザーに結果を返し、実行を終了するために少なくとも1つの End ノードが必要です。
|
||||
|
||||
<Info>
|
||||
End ノードは工作流アプリケーション専用です。对话流アプリケーションでは、会話の流れの中で応答を届けるために Answer ノードを使用します。
|
||||
</Info>
|
||||
|
||||
## 出力設定
|
||||
|
||||
End ノードは、前の工作流ノードからの出力を収集し、それらを最終的な応答にまとめます。上流のノードからのデータを変数セレクターや `{{variable_name}}` 構文を使用して参照し、どの変数を出力するかを設定します。
|
||||
|
||||
テキスト、数字、オブジェクト、配列、ファイルなど、さまざまなタイプの複数の変数を出力することができます。各出力変数は、工作流の最終結果構造の一部となります。
|
||||
|
||||
## 単一ノードと複数ノード
|
||||
|
||||
### 単一パス工作流
|
||||
|
||||
1つの実行パスを持つシンプルな工作流には、最終結果をキャプチャするための1つの End ノードだけが必要です:
|
||||
|
||||
<Frame caption="1つの End ノードを持つ単一パス工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/9e43961344d318e09af8d64464d81774.png" alt="単一パス工作流の例" />
|
||||
</Frame>
|
||||
|
||||
### 多路工作流
|
||||
|
||||
条件分岐を持つ工作流は、各実行パスに End ノードが必要です。各分岐は、工作流のロジックに応じて異なる変数を出力することができます:
|
||||
|
||||
<Frame caption="複数の End ノードを持つ多路工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/3cb3f5fea376265bede0a4ac5bcc1ddc.png" alt="多路工作流の例" />
|
||||
</Frame>
|
||||
|
||||
## 実行動作
|
||||
|
||||
工作流の実行が End ノードに到達すると、処理は即座に停止します。End ノードの後に接続されたノードは実行されません。これにより、End ノードは異なる工作流分岐の自然な終了ポイントになります。
|
||||
|
||||
もし工作流に複数の実行パスがある場合(例えば If-Else ノードを通じて)、各パスが End ノードに導かれるようにしてください。そうしないと、いくつかの実行分岐が結果を返さない可能性があります。
|
||||
|
||||
## 出力例
|
||||
|
||||
**テキスト処理結果** - 大規模言語モデルノードから処理されたテキスト、要約、または分析結果を出力します。
|
||||
|
||||
**構造化データ** - JSONオブジェクト、配列、またはさまざまな処理ノードから抽出されたパラメータを返します。
|
||||
|
||||
**ファイル出力** - ワークフロー実行中に生成された文書、画像、その他のファイルを提供します。
|
||||
|
||||
**ステータス情報** - 処理のメタデータ、成功指標、または診断情報を含めます。
|
||||
|
||||
<Frame caption="複雑な工作流出力の例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/a103792790447c1725c1da1176334cae.png" alt="End ノード - 長編ストーリー生成の例" />
|
||||
</Frame>
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**一貫した出力構造** - 同じ工作流内の異なる End ノードで、予測可能なAPI応答のために類似した変数名とデータ型を使用します。
|
||||
|
||||
**ステータス情報を含める** - 主な結果に加えて、成功指標や処理のメタデータを出力することを検討してください。
|
||||
|
||||
**すべてのパスを処理する** - 工作流のすべての可能な実行パスが End ノードに導かれるようにして、不完全な実行を防ぎます。
|
||||
|
||||
**出力スキーマの文書化** - 各 End ノードがAPI利用者および統合目的のために何を返すかを明確に文書化します。
|
||||
```
|
||||
93
ja-jp/documja-jptation/pages/nodes/knowledge-retrieval.mdx
Normal file
93
ja-jp/documja-jptation/pages/nodes/knowledge-retrieval.mdx
Normal file
@@ -0,0 +1,93 @@
|
||||
```mdx
|
||||
---
|
||||
title: "知識検索"
|
||||
description: "Search knowledge bases for relevant information"
|
||||
icon: "database"
|
||||
---
|
||||
|
||||
知識检索ノードは、知識ベースから関連情報を検索し、下流ノードで使用するためのコンテキストコンテンツを返します。これは、文書からの特定の情報を提供することによって、RAG(检索增强生成)アプリケーションを可能にします。
|
||||
|
||||
<Frame caption="知識検索ノードの設定">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d90961c6d794d425a8e11df177315188.png" alt="知識検索ノードインターフェース" />
|
||||
</Frame>
|
||||
|
||||
<Info>
|
||||
このノードを使用する前に知識ベースを作成して入力してください。セットアップ手順については、[知識ベース作成ガイド](/en/guides/knowledge-base/create-knowledge-and-upload-documents)を参照してください。
|
||||
</Info>
|
||||
|
||||
## 設定
|
||||
|
||||
### クエリと知識ベースの選択
|
||||
|
||||
**Query**は、知識ベースで何を検索するかを決定します。チャットフローアプリケーションでのユーザー入力には `sys.query` を使用するか、ワークフローから任意のテキスト変数を使用してください。クエリは200文字に制限されています。
|
||||
|
||||
検索する1つ以上の**知識ベース**を選択します。それぞれには、Difyにアップロードしたインデックス付き文書が含まれています。異なる戦略を使用して、複数の知識ベースを同時に検索できます。
|
||||
|
||||
### 検索戦略
|
||||
|
||||
コンテンツをどのように検索するかを選択します:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="セマンティック検索">
|
||||
ベクトル埋め込みを使用して、意味に基づいた概念的に類似したコンテンツを見つけます。自然言語クエリや異なる用語を使った関連概念に適しています。
|
||||
</Tab>
|
||||
|
||||
<Tab title="キーワード検索">
|
||||
特定の単語の正確な一致を対象とする従来の全文検索。特定の用語、コード、または名前に対しては迅速かつ予測可能です。
|
||||
</Tab>
|
||||
|
||||
<Tab title="ハイブリッド検索">
|
||||
セマンティックアプローチとキーワードアプローチを組み合わせます。結果は、特別なモデルを使用して再ランキングされ、より関連性の高いものになります。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 高度な設定
|
||||
|
||||
<Frame caption="高度な検索設定オプション">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/fbd43d558f83b355a1b18ac26a253b84.png" alt="知識検索設定インターフェース" />
|
||||
</Frame>
|
||||
|
||||
### 検索パラメータ
|
||||
|
||||
**Top K**は、検索する文書チャンクの数を制御します。焦点を絞った結果には3〜5チャンク、包括的なカバレッジには10〜15チャンクから始めてください。
|
||||
|
||||
**スコア閾値**は最低類似度スコアを設定します。より高い閾値(0.7以上)は関連性を保証し、低い閾値(0.5以下)はより多くの関連性の低いコンテンツを含みます。
|
||||
|
||||
**再ランキング**は、初期検索後に結果を再スコアリングします。ハイブリッド検索、多くのチャンク、または速度よりも精度が重要な場合に有効にします。
|
||||
|
||||
### メタデータフィルタリング
|
||||
|
||||
文書のタイプ、日付、部門などのメタデータを使用して結果をフィルタリングします。大規模な知識ベースでのターゲット検索を可能にするために、文書をアップロードする際にメタデータを設定してください。
|
||||
|
||||
### 複数知識ベース戦略
|
||||
|
||||
**N対1リコール**は、クエリを分析し、適切な知識ベースを選択して検索を最適化するために関数呼び出しを使用します。異なるドメインの専門知識ベースに最適です。
|
||||
|
||||
**多方向リコール**は、選択したすべての知識ベースを同時にクエリし、結果を組み合わせます。情報が複数のソースにまたがる場合や総合的なカバレッジを必要とする場合に使用します。
|
||||
|
||||
<Frame caption="複数知識ベースの検索戦略の比較">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/4a3007cda9dfa50ddac3711693725dce.png" alt="検索モードの比較" />
|
||||
</Frame>
|
||||
|
||||
## 出力と統合
|
||||
|
||||
ノードはテキストコンテンツとメタデータ(ソース、スコア、ドキュメントID)を含む取得された文書チャンクの配列を出力します。この構造化された出力は、引用に必要な情報を保持します。
|
||||
|
||||
### RAG統合
|
||||
|
||||
知識検索の出力をLLMノードのコンテキスト入力に接続してRAGアプリケーションに使用します。検索結果をコンテキスト変数として使用する場合、Difyはソースを自動的に追跡し、引用を可能にします。
|
||||
|
||||
```text
|
||||
System: 提供されたコンテキストに基づいて回答してください。
|
||||
Context: {{knowledge_retrieval.result}}
|
||||
User: {{user_question}}
|
||||
```
|
||||
|
||||
### レート制限
|
||||
|
||||
知識検索操作は、サブスクリプションプランに基づいてレート制限が課されます。システムは、リクエストを60秒のスライディングウィンドウを使用してRedisで追跡します。制限を超えると、`RateLimitExceeded`エラーが返されます。
|
||||
|
||||
### パフォーマンスの考慮事項
|
||||
|
||||
検索の質はインデックス作成の方法に依存します。小さいチャンク(200-500トークン)は正確な検索を可能にし、大きいチャンク(800-1500トークン)はコンテキストを維持します。知識ベースにはレート制限があります - ノードはスロットリングを処理し、同一クエリを自動的にキャッシュします。
|
||||
```
|
||||
124
ja-jp/documja-jptation/pages/nodes/list-operator.mdx
Normal file
124
ja-jp/documja-jptation/pages/nodes/list-operator.mdx
Normal file
@@ -0,0 +1,124 @@
|
||||
```mdx
|
||||
---
|
||||
title: "リストオペレーター"
|
||||
description: "配列から要素をフィルタリング、並べ替え、選択する"
|
||||
icon: "filter"
|
||||
---
|
||||
|
||||
リストオペレーターノードは、配列をフィルタリング、並べ替え、特定の要素を選択することで処理します。混合ファイルのアップロード、大規模なデータセット、または下流処理の前に分離や整理が必要な配列データを扱う必要がある場合に使用します。
|
||||
|
||||
<Frame caption="リストオペレーターノードインターフェース">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/522a0c932aab93d4f3970168412f759e.png" alt="リストオペレーターインターフェース" />
|
||||
</Frame>
|
||||
|
||||
## 配列処理の問題
|
||||
|
||||
ほとんどの工作流ノードは、配列ではなく単一の値を期待します。変数に `[image.png, document.pdf, audio.mp3]` のような混合コンテンツがある場合、これを下流ノードが効果的に処理できるようにフォーカスされたストリームに分離する必要があります。
|
||||
|
||||
リストオペレーターは、フィルターを使用して混合配列を分離し、専門的な処理の準備をするインテリジェントなルーターとして機能します。
|
||||
|
||||
<Frame caption="配列処理ワークフローの例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/812d1b2f167065e17df8392b2cb3cc8a.png" alt="配列処理の例" />
|
||||
</Frame>
|
||||
|
||||
## サポートされているデータタイプ
|
||||
|
||||
ノードは異なる配列タイプを適切なフィルタリングオプションで処理します:
|
||||
|
||||
**Array[string]** - テキストリスト、カテゴリ、名前、または任意の文字列コレクション
|
||||
|
||||
**Array[number]** - 数値データ、スコア、測定値、または計算
|
||||
|
||||
**Array[file]** - 豊富なメタデータフィルタリング機能を備えた混合ファイルアップロード
|
||||
|
||||
## 操作
|
||||
|
||||
### フィルタリング
|
||||
|
||||
属性に基づいて特定のアイテムを抽出します。ファイル配列の場合、以下でフィルタリング:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="コンテンツプロパティ">
|
||||
**Type** - コンテンツカテゴリでフィルター:画像、ドキュメント、音声、ビデオ
|
||||
|
||||
**MIME Type** - 正確なコンテンツタイプの識別(image/jpeg、application/pdf など)
|
||||
|
||||
**Extension** - ファイル拡張子(.pdf、.jpg、.mp3、.docx など)
|
||||
</Tab>
|
||||
|
||||
<Tab title="ファイルプロパティ">
|
||||
**Size** - 処理制限のためのファイルサイズ制約
|
||||
|
||||
**Name** - ファイル名のパターンまたは特定の名前
|
||||
|
||||
**Transfer Method** - ローカルアップロードとURLベースのファイルを区別
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 並べ替え
|
||||
|
||||
フィルタリングされた結果を任意の属性で整理:
|
||||
|
||||
**Ascending (ASC)** - 最小から最大の値、A-Z のアルファベット順
|
||||
|
||||
**Descending (DESC)** - 最大から最小の値、Z-A の逆順
|
||||
|
||||
### 選択
|
||||
|
||||
処理された配列から特定の要素を選択:
|
||||
|
||||
**Take First N** - フィルタリングと並べ替え後の最初の1-20アイテムを選択
|
||||
|
||||
**First Record** - 最初の一致する要素のみを単一の値として返す
|
||||
|
||||
**Last Record** - 最後の一致する要素のみを単一の値として返す
|
||||
|
||||
## 出力変数
|
||||
|
||||
**result** - バルク処理用の完全にフィルタリングおよび並べ替えられた配列
|
||||
|
||||
**first_record** - 始めからの単一要素、"主要"または"最新"アイテムの選択に最適
|
||||
|
||||
**last_record** - 終わりからの単一要素、"最も最近"または"最終"選択に便利
|
||||
|
||||
## 混合ファイル処理の例
|
||||
|
||||
ユーザーがドキュメントと画像の両方をアップロードするワークフローを処理:
|
||||
|
||||
<Frame caption="混合ファイル処理ワークフロー">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/610358293217e54b55b7e1d4d16bf83c.png" alt="混合ファイル処理の例" />
|
||||
</Frame>
|
||||
|
||||
**実装手順:**
|
||||
|
||||
1. **混合アップロードの設定** - 複数のファイルタイプを受け入れるファイルアップロード機能を有効にする
|
||||
2. **タイプ別に分割** - 異なるフィルターを持つ別々のリストオペレーターノードを使用:
|
||||
- `type = "image"` のフィルター → ビジョン能力を持つ LLM にルート
|
||||
- `type = "document"` のフィルター → ドキュメントエクストラクターにルート
|
||||
3. **適切に処理** - 画像は直接分析され、ドキュメントはテキスト抽出される
|
||||
4. **結果を統合** - 処理された出力を統合された応答にマージ
|
||||
|
||||
このパターンは、異なるファイルタイプを適切なプロセッサに自動的にルーティングし、シームレスなマルチモーダルユーザーエクスペリエンスを作成します。
|
||||
|
||||
## 一般的なユースケース
|
||||
|
||||
**ファイルタイプルーティング** - コンテンツタイプに基づいて混合アップロードを専門的な処理パイプラインに分離。
|
||||
|
||||
**データフィルタリング** - 特定の基準に基づいて大規模データセットから関連する部分集合を抽出。
|
||||
|
||||
**コンテンツの優先順位付け** - コレクションから最も重要または最近のアイテムを並べ替え選択。
|
||||
|
||||
**品質管理** - 処理前に無効な、過大な、またはサポートされていないコンテンツをフィルタリング。
|
||||
|
||||
**バッチ準備** - 下流の反復または並行処理のためにデータを管理可能なチャンクに整理。
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**フィルター基準を計画** - 下流処理要件に基づいて明確なフィルタリングルールを定義。
|
||||
|
||||
**適切な出力タイプを使用** - データをどのように使用するかに基づいて、完全な配列、最初のレコード、または最後のレコードを選択。
|
||||
|
||||
**空の結果を処理** - フィルターが一致しない場合の対応を考慮し、適切なフォールバックロジックを計画。
|
||||
|
||||
**実際のデータでテスト** - 本番環境での信頼性を確保するために、実際のユーザーアップロードでフィルタリング動作を検証。
|
||||
```
|
||||
131
ja-jp/documja-jptation/pages/nodes/llm.mdx
Normal file
131
ja-jp/documja-jptation/pages/nodes/llm.mdx
Normal file
@@ -0,0 +1,131 @@
|
||||
---
|
||||
title: "LLM"
|
||||
description: "Invoke language models for text generation and analysis"
|
||||
icon: "brain"
|
||||
---
|
||||
|
||||
LLMノードは、大規模言語モデルを呼び出してテキスト、画像、文書を処理します。設定されたモデルにプロンプトを送信し、その応答を取得します。構造化出力、コンテキスト管理、マルチモーダル入力をサポートしています。
|
||||
|
||||
<Frame caption="LLMノード設定インターフェース">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/85730fbfa1d441d12d969b89adf2670e.png" alt="LLM Node Overview" />
|
||||
</Frame>
|
||||
|
||||
<Info>
|
||||
LLMノードを使用する前に、**システム設定 → モデルプロバイダー**で少なくとも1つのモデルプロバイダーを設定してください。セットアップ手順については[モデル設定ガイド](/en/guides/model-configuration/readme)をご覧ください。
|
||||
</Info>
|
||||
|
||||
## モデル選択とパラメータ
|
||||
|
||||
設定済みの任意のモデルプロバイダーから選択できます。異なるモデルは異なるタスクに優れています。GPT-4とClaude 3.5は複雑な推論を上手く処理しますが、コストが高くなります。一方、GPT-3.5 Turboは性能と手頃な価格のバランスが取れています。ローカル配信には、Ollama、LocalAI、またはXinferenceを使用してください。
|
||||
|
||||
<Frame caption="モデル選択とパラメータ設定">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/43f81418ea70d4d79e3705505e777b1b.png" alt="LLM Node Configuration" />
|
||||
</Frame>
|
||||
|
||||
モデルパラメータは応答生成を制御します。**温度**は0(決定論的)から1(創造的)の範囲です。**核サンプリング**は確率により単語選択を制限します。**頻度ペナルティ**は繰り返しを減らします。**存在ペナルティ**は新しいトピックを促します。プリセットも使用できます:**精密**、**バランス**、または**創造的**。
|
||||
|
||||
## プロンプト設定
|
||||
|
||||
インターフェースはモデルタイプに応じて適応されます。チャットモデルはメッセージ役割(**システム**は動作用、**ユーザー**は入力用、**アシスタント**は例用)を使用し、完了モデルは単純なテキスト継続を使用します。
|
||||
|
||||
プロンプト内でワークフロー変数を参照するには、二重中括弧を使用します:`{{variable_name}}`。変数はモデルに到達する前に実際の値に置き換えられます。
|
||||
|
||||
```text
|
||||
System: あなたは技術文書の専門家です。
|
||||
User: {{user_input}}
|
||||
```
|
||||
|
||||
## コンテキスト変数
|
||||
|
||||
コンテキスト変数は、ソース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルが特定の文書を使用して質問に答えるRAGアプリケーションが可能になります。
|
||||
|
||||
<Frame caption="RAGアプリケーション用のコンテキスト変数の使用">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guidesed96962bd994f8f05bac96b11e22.png" alt="Context Variables" />
|
||||
</Frame>
|
||||
|
||||
知識検索ノードの出力をLLMノードのコンテキスト入力に接続し、それを参照します:
|
||||
|
||||
```text
|
||||
このコンテキストのみを使用して回答してください:
|
||||
{{knowledge_retrieval.result}}
|
||||
|
||||
質問:{{user_question}}
|
||||
```
|
||||
|
||||
知識検索からのコンテキスト変数を使用する場合、Difyは自動的に引用と帰属を追跡するため、ユーザーは情報源を確認できます。
|
||||
|
||||
## 構造化出力
|
||||
|
||||
プログラム用のJSONなど、特定のデータ形式を返すようモデルに強制します。3つの方法で設定できます:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="ビジュアルエディター">
|
||||
シンプルな構造のためのユーザーフレンドリーなインターフェース。名前とタイプでフィールドを追加し、必須フィールドにマークし、説明を設定します。エディターは自動的にJSONスキーマを生成します。
|
||||
</Tab>
|
||||
|
||||
<Tab title="JSON Schema">
|
||||
ネストされたオブジェクト、配列、検証ルールを持つ複雑な構造のために、スキーマを直接記述します。
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"sentiment": {
|
||||
"type": "string",
|
||||
"enum": ["positive", "negative", "neutral"]
|
||||
}
|
||||
},
|
||||
"required": ["sentiment"]
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="AI生成">
|
||||
平易な言葉でニーズを記述し、AIにスキーマを生成させます。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Warning>
|
||||
ネイティブJSONサポートを持つモデルは構造化出力を確実に処理します。その他のモデルについては、Difyはプロンプトにスキーマを含めますが、結果は変動する場合があります。
|
||||
</Warning>
|
||||
|
||||
## メモリとファイル処理
|
||||
|
||||
**メモリ**を有効にして、ワークフロー実行内の複数のLLM呼び出し間でコンテキストを維持します。ノードは以前のやり取りを後続のプロンプトに含めます。メモリはノード固有で、ワークフロー実行間では持続しません。
|
||||
|
||||
**ファイル処理**では、マルチモーダルモデル用のプロンプトにファイル変数を追加します。GPT-4Vは画像を処理し、ClaudeはPDFを直接処理しますが、他のモデルには前処理が必要な場合があります。
|
||||
|
||||
### ビジョン機能設定
|
||||
|
||||
画像を処理する際、詳細レベルを制御できます:
|
||||
- **高詳細** - 複雑な画像に対してより良い精度を提供しますが、より多くの最大トークン数を使用します
|
||||
- **低詳細** - シンプルな画像に対して少ない最大トークン数でより高速な処理を行います
|
||||
|
||||
ビジョン機能のデフォルト変数セレクタは`sys.files`で、開始ノードからファイルを自動的に取得します。
|
||||
|
||||
<Frame caption="マルチモーダル大規模言語モデルによるファイル処理">
|
||||
<img src="https://assets-docs.dify.ai/2024/11/05b3d4a78038bc7afbb157078e3b2b26.png" alt="File Processing" />
|
||||
</Frame>
|
||||
|
||||
完了モデルでの会話履歴については、会話変数を挿入してマルチターンコンテキストを維持します:
|
||||
|
||||
<Frame caption="会話履歴変数の使用">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/b8642f8c6e3f562fceeefae83628fd68.png" alt="Conversation History" />
|
||||
</Frame>
|
||||
|
||||
## Jinja2テンプレートサポート
|
||||
|
||||
LLMプロンプトは高度な変数処理のためのJinja2テンプレートをサポートします。Jinja2モード(`edition_type: "jinja2"`)を使用する場合:
|
||||
|
||||
```jinja2
|
||||
{% for item in search_results %}
|
||||
{{ loop.index }}. {{ item.title }}: {{ item.content }}
|
||||
{% endfor %}常の変数置換とは別に処理され、プロンプト内でのループ、条件分岐、複雑なデータ変換が可能です。
|
||||
|
||||
## ストリーミングレスポンス
|
||||
|
||||
LLMノードはデフォルトでストリーミングレスポンスをサポートします。各テキストチャンクは`RunStreamChunkEvent`として出力され、リアルタイム応答表示を可能にします。ファイル出力(画像、文書)は、ストリーミング中に自動的に処理され保存されます。
|
||||
|
||||
## エラーハンドリング
|
||||
|
||||
失敗したLLM呼び出しの再試行動作を設定します。最大再試行回数、再試行間隔、バックオフ乗数を設定します。再試行が十分でない場合のデフォルト値、エラールーティング、代替モデルなどのフォールバック戦略を定義します。
|
||||
119
ja-jp/documja-jptation/pages/nodes/loop.mdx
Normal file
119
ja-jp/documja-jptation/pages/nodes/loop.mdx
Normal file
@@ -0,0 +1,119 @@
|
||||
```mdx
|
||||
---
|
||||
title: "ループ"
|
||||
description: "進行的改善を伴う反復的なワークフローの実行"
|
||||
icon: "infinity"
|
||||
---
|
||||
|
||||
ループノードは、各サイクルが前の結果に基づいて構築される反復的なワークフローを実行します。配列要素を独立して処理するイテレーションとは異なり、ループは各反復で進化する進行的なワークフローを作成します。
|
||||
|
||||
## ループ vs イテレーション
|
||||
|
||||
各反復パターンを使用するタイミングの理解:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="ループ">
|
||||
**順次処理** - 各サイクルは前の結果に依存します
|
||||
|
||||
**進行的な改善** - 出力はイテレーションごとに改善または進化します
|
||||
|
||||
**状態管理** - 変数はサイクルを通じて持続し、蓄積されます
|
||||
|
||||
**ユースケース** - コンテンツの改善、問題解決、品質保証
|
||||
</Tab>
|
||||
|
||||
<Tab title="イテレーション">
|
||||
**独立した処理** - 各アイテムは個別に処理されます
|
||||
|
||||
**並列実行** - アイテムは同時に処理されることができます
|
||||
|
||||
**バッチ操作** - 同じ操作が複数のデータポイントに適用されます
|
||||
|
||||
**ユースケース** - データ変換、大量処理、並列分析
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 設定
|
||||
|
||||
### ループ変数
|
||||
|
||||
ループイテレーションを通じて持続し、ループ完了後もアクセス可能な変数を定義します。これらの変数は状態を維持し、進行的なワークフローを可能にします。
|
||||
|
||||
### 終了条件
|
||||
|
||||
ループの実行を停止するタイミングを設定:
|
||||
|
||||
**ループ終了条件** - 退出を決定する式(例: `quality_score > 0.9`)
|
||||
|
||||
**最大ループ回数** - 無限ループを防ぐための安全制限
|
||||
|
||||
**ループ終了ノード** - このノードに達したときに即時終了
|
||||
|
||||
<Info>
|
||||
ループは終了条件が満たされた場合、最大カウントに達した場合、またはループ終了ノードが実行された場合に終了します。条件が指定されていない場合、最大カウントまでループは続きます。
|
||||
</Info>
|
||||
|
||||
## 基本的なループ例
|
||||
|
||||
50未満のランダムな数が見つかるまで生成:
|
||||
|
||||
<Frame caption="ランダム数生成のための基本的なループワークフロー">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/282013c48b46d3cc4ebf99323da10a31.png" alt="基本的なループワークフロー" />
|
||||
</Frame>
|
||||
|
||||
**ワークフローステップ:**
|
||||
1. **コードノード** は1から100のランダムな整数を生成
|
||||
2. **If-Elseノード** は数が50未満かどうかをチェック
|
||||
3. **テンプレートノード** は数が50未満の場合「完了」を返し、ループ終了をトリガー
|
||||
4. 終了条件が満たされるまでループは続行
|
||||
|
||||
<Frame caption="ループ実行ステップと結果">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/9d9fb4db7093521000ac735a26f86962.png" alt="ループ実行ステップ" />
|
||||
</Frame>
|
||||
|
||||
## 高度なループ例
|
||||
|
||||
反復改善を通じて詩を作成し、各バージョンが前のものに基づいて構築されます:
|
||||
|
||||
<video controls src="https://assets-docs.dify.ai/2025/04/7ecfc04458aa38e721baaa5f6355486c.mp4" width="100%" />
|
||||
|
||||
**ループ変数:**
|
||||
- `num` - 各イテレーションでインクリメントされるカウンター(初期値0)
|
||||
- `verse` - 現在の詩のバージョンを保持するテキスト変数
|
||||
|
||||
**ワークフローロジック:**
|
||||
1. **If-Elseノード** は `num > 3` をチェックして終了時を決定
|
||||
2. **LLMノード** は前のバージョンに基づいた改良された詩を生成
|
||||
3. **変数アサイナー** はカウンターと詩の内容の両方を更新
|
||||
4. **ループ終了ノード** は4サイクルの改善後に終了
|
||||
|
||||
LLMプロンプトは現在の詩とイテレーションのコンテキストの両方を参照します:
|
||||
|
||||
```text
|
||||
あなたはヨーロッパの文学者として詩的な詩を作成しています。
|
||||
|
||||
現在の詩: {{verse}}
|
||||
|
||||
以前の作品に基づいてこの詩を改良してください。
|
||||
```
|
||||
|
||||
## 一般的なユースケース
|
||||
|
||||
**コンテンツの改善** - 複数のLLMレビューを通じてテキスト、コード、デザインを段階的に改善し、品質基準を満たすまで。
|
||||
|
||||
**問題解決** - 複雑な問題を反復的なステップに分解し、各サイクルが前の進捗に基づいて次の論理的な部分を解決。
|
||||
|
||||
**研究ワークフロー** - 各検索サイクルからの発見に基づいて研究クエリを反復的に検索、分析、改善。
|
||||
|
||||
**品質保証** - 出力を繰り返しテストおよび検証し、すべての基準を満たすまで改善。
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**明確な終了条件を定義** - 無限実行を防ぐために、ループに具体的で測定可能な終了条件を持たせる。
|
||||
|
||||
**適切な制限を設定** - 予想される複雑さと処理要件に基づいて適切な最大イテレーション数を使用。
|
||||
|
||||
**状態を効果的に管理** - ループ変数を使用してイテレーション間で必要な情報を維持し、不必要なデータの蓄積を避ける。
|
||||
|
||||
**進捗を監視** - 特に長時間実行されるプロセスの場合、ループ実行を追跡するためのログまたは進捗インジケーターを含める。
|
||||
```
|
||||
84
ja-jp/documja-jptation/pages/nodes/parameter-extractor.mdx
Normal file
84
ja-jp/documja-jptation/pages/nodes/parameter-extractor.mdx
Normal file
@@ -0,0 +1,84 @@
|
||||
```mdx
|
||||
---
|
||||
title: "パラメータ抽出器"
|
||||
description: "自然言語を構造化データに変換するLLMインテリジェンスを活用"
|
||||
icon: "crop-simple"
|
||||
---
|
||||
|
||||
Parameter Extractorノードは、LLMインテリジェンスを使用して非構造化テキストを構造化データに変換します。これは、自然言語入力とツール、API、およびその他のワークフローノードが必要とする構造化パラメータとのギャップを埋めます。
|
||||
|
||||
## 構成
|
||||
|
||||
### 入力とモデルの選択
|
||||
|
||||
パラメータを抽出したいテキストを含む**入力変数**を選択します。これは通常、ユーザー入力、LLMの応答、または他のワークフローノードから来ます。
|
||||
|
||||
強力な構造化出力能力を持つ**モデル**を選択します。Parameter Extractorは、文脈を理解し、構造化されたJSON応答を生成するLLMの能力に依存します。
|
||||
|
||||
### パラメータ定義
|
||||
|
||||
抽出したいパラメータを以下のように指定して定義します:
|
||||
|
||||
- **パラメータ名** - 出力JSONに表示されるキー
|
||||
- **データ型** - 文字列、数値、ブール値、配列、またはオブジェクト
|
||||
- **説明** - LLMが何を抽出するか理解するのに役立ちます
|
||||
- **必須ステータス** - パラメータが存在する必要があるかどうか
|
||||
|
||||
パラメータを手動で定義することも、**既存のツールから素早くインポート**して、下流のノードのパラメータ要件にマッチさせることもできます。
|
||||
|
||||
### 抽出指示
|
||||
|
||||
抽出する情報とそのフォーマット方法を説明する明確な指示を書きます。指示に例を含めることで、複雑なパラメータの抽出精度と一貫性が向上します。
|
||||
|
||||
<Frame caption="Arxiv論文取得のためのパラメータ抽出">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/a8bae4106a015c76ebb0a165f2409458.png" alt="Arxiv Paper Retrieval Tool" />
|
||||
</Frame>
|
||||
|
||||
## 高度な構成
|
||||
|
||||
### 推論モード
|
||||
|
||||
モデルの能力に基づいて、2つの抽出アプローチから選択します:
|
||||
|
||||
**関数呼び出し/工具呼び出し**は、モデルの構造化出力機能を利用して、強力な型準拠で信頼性の高いパラメータ抽出を行います。
|
||||
|
||||
**プロンプトベース**は、関数呼び出しをサポートしないモデルまたはプロンプトベースの抽出がより良い結果を出す場合に、純粋なプロンプトに依存します。
|
||||
|
||||
### メモリ
|
||||
|
||||
パラメータを抽出するときに会話履歴を含めるためにメモリを有効にします。これにより、LLMがインタラクティブな対話の文脈を理解し、会話型ワークフローの抽出精度を向上させます。
|
||||
|
||||
## 出力変数
|
||||
|
||||
ノードは、抽出されたパラメータと組み込みのステータス変数の両方を提供します:
|
||||
|
||||
**抽出されたパラメータ**は、下流のノードで使用するためのパラメータ定義に一致する個別の変数として表示されます。
|
||||
|
||||
**組み込み変数**には、ステータス情報が含まれます:
|
||||
- `__is_success` - 抽出の成功ステータス(成功の場合は1、失敗の場合は0)
|
||||
- `__reason` - 抽出が失敗した場合のエラー説明
|
||||
|
||||
<Frame caption="データフォーマット変換の例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/71d8e48d842342668f92e6dd84fc03c1.png" alt="Data format conversion workflow" />
|
||||
</Frame>
|
||||
|
||||
## 一般的な使用例
|
||||
|
||||
**ツールパラメータ準備**は、構造化入力を必要とするワークフローツールのために自然言語から特定のパラメータを抽出します。
|
||||
|
||||
**データフォーマット変換**は、リストを反復処理用の配列に変換するなど、他のノードが必要とするフォーマットにテキストを変換します。
|
||||
|
||||
**APIリクエスト準備**は、ユーザーの意図をAPI互換のパラメータに変換する際のHTTPリクエスト用にデータを構造化します。
|
||||
|
||||
**フォームデータ処理**は、データベースの保存やさらなる処理のために、自由形式のユーザー入力から構造化された情報を抽出します。
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**明確なパラメータ説明**は、LLMがどの情報をどの形式で抽出するかを正確に理解するのに役立ちます。
|
||||
|
||||
**例を提供する**ことで、特に複雑またはドメイン固有のパラメータにおいて、抽出精度が向上します。
|
||||
|
||||
**適切なデータ型を使用する**ことで、抽出されたパラメータが下流のノードの要件に一致することを保証します。
|
||||
|
||||
**抽出失敗を処理する**ために、`__is_success`変数を確認し、抽出が失敗した場合のフォールバックロジックを提供します。
|
||||
```
|
||||
83
ja-jp/documja-jptation/pages/nodes/question-classifier.mdx
Normal file
83
ja-jp/documja-jptation/pages/nodes/question-classifier.mdx
Normal file
@@ -0,0 +1,83 @@
|
||||
```mdx
|
||||
---
|
||||
title: "質問分類器"
|
||||
description: "ユーザー入力を知的に分類してワークフローパスをルート化する"
|
||||
icon: "sitemap"
|
||||
---
|
||||
|
||||
質問分類器ノードは、ユーザー入力を知的に分類して、異なるワークフローパスに会話をルート化します。複雑な条件ロジックを構築する代わりに、カテゴリを定義し、LLM が意味理解に基づいて最適なものを決定します。
|
||||
|
||||
## 設定
|
||||
|
||||
### 入力とモデルのセットアップ
|
||||
|
||||
**入力変数** - 分類する内容を選択します。通常はユーザーの質問に対する `sys.query` ですが、前のワークフローノードからの任意のテキスト変数も使用できます。
|
||||
|
||||
**モデル選択** - 分類のために LLM を選択します。シンプルなカテゴリには高速なモデルが適しており、より微妙な区別には強力なモデルが適しています。
|
||||
|
||||
<Frame caption="質問分類器の設定インターフェース">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/2f039c5ff3f095b0eed291101d9bff15.png" alt="質問分類器のセットアップ" />
|
||||
</Frame>
|
||||
|
||||
### カテゴリ定義
|
||||
|
||||
各カテゴリに対して、具体的な説明を伴う明確で記述的なラベルを作成します。カテゴリ間の境界を明確にすることで、LLM が正確な決定を下せるようにします。
|
||||
|
||||
各カテゴリは、専門的な知識ベース、応答テンプレート、または処理ワークフローのような異なる下流ノードに接続できる潜在的な出力パスとなります。
|
||||
|
||||
## 分類例
|
||||
|
||||
以下は、カスタマーサービスのシナリオにおける質問分類器の動作例です:
|
||||
|
||||
<Frame caption="カスタマーサービス分類ワークフロー">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/2f06ecce149c844c23be70a8fcff09bc.png" alt="カスタマーサービス分類" />
|
||||
</Frame>
|
||||
|
||||
**定義されたカテゴリ:**
|
||||
- **アフターサービス** - 保証請求、返品、修理、購入後のサポート
|
||||
- **製品使用** - セットアップ手順、トラブルシューティング、機能説明
|
||||
- **その他の質問** - 特定のカテゴリに該当しない一般的な問い合わせ
|
||||
|
||||
**分類結果:**
|
||||
- "iPhone 14で連絡先をセットアップする方法は?" → **製品使用**
|
||||
- "購入品の保証期間はどのくらいですか?" → **アフターサービス**
|
||||
- "今日の天気はどうですか?" → **その他の質問**
|
||||
|
||||
各分類結果は、異なる知識ベースや応答戦略にルート化され、ユーザーが関連する専門的な支援を受けられるようにします。
|
||||
|
||||
## 高度な設定
|
||||
|
||||
### 指示とガイドライン
|
||||
|
||||
**指示**フィールドに詳細な分類ガイドラインを追加して、エッジケース、不明瞭なシナリオ、または特定のビジネスルールを処理します。これにより、LLM はカテゴリ間の微妙な違いを理解できます。
|
||||
|
||||
### メモリ統合
|
||||
|
||||
**メモリ**を有効にして、分類時に会話履歴を含めます。これにより、現在の入力が前のコンテキストに依存するマルチターンの会話での精度が向上します。
|
||||
|
||||
**メモリウィンドウ**は、トークン効率と処理速度を考慮しつつ、どれだけの会話履歴を含めるかを制御します。
|
||||
|
||||
## 出力の使用
|
||||
|
||||
分類器は、一致したカテゴリラベルを含む `class_name` 変数を出力します。この変数を下流ノードで使用して:
|
||||
|
||||
**条件ルーティング** - 分類結果に基づいて異なるワークフローパスを接続
|
||||
|
||||
**知識ベース選択** - 各カテゴリに対応する専門知識ベースにルート化
|
||||
|
||||
**応答カスタマイズ** - 異なる応答テンプレートまたは処理ロジックを適用
|
||||
|
||||
**分析とログ** - カテゴリごとのユーザー問い合わせの分布を追跡
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**明確なカテゴリ境界** - 特定の説明を持つ、重複しない明確なカテゴリを定義して、分類精度を向上させます。
|
||||
|
||||
**適切なモデル選択** - 分類の複雑さに基づいてモデルを選択します。シンプルな二項分類には高速なモデルが適しており、微妙な多カテゴリ分類にはより能力のあるモデルが必要です。
|
||||
|
||||
**エッジケースのテスト** - 複数のカテゴリに適合する可能性がある曖昧な入力で分類動作を確認します。
|
||||
|
||||
**会話コンテキストを利用** - 分類が過去の対話に依存する会話型アプリケーションではメモリを有効にします。
|
||||
|
||||
**監視と反復** - 分類結果をレビューし、実際の使用パターンに基づいてカテゴリ説明を改善します。
|
||||
```
|
||||
89
ja-jp/documja-jptation/pages/nodes/start.mdx
Normal file
89
ja-jp/documja-jptation/pages/nodes/start.mdx
Normal file
@@ -0,0 +1,89 @@
|
||||
```mdx
|
||||
---
|
||||
title: "開始"
|
||||
description: "ワークフローとチャットフローアプリケーションのエントリーポイント"
|
||||
icon: "play"
|
||||
---
|
||||
|
||||
開始ノードは、すべてのワークフローとチャットフローアプリケーションのエントリーポイントです。エンドユーザーから受け入れる入力を定義し、ワークフロー全体で参照可能なシステム変数を提供します。
|
||||
|
||||
## 入力変数
|
||||
|
||||
開始ノードでカスタム入力フィールドを設定して、ユーザーから情報を収集できます。各入力フィールドはワークフローを通じて流れる変数になります。たとえば、`user_name`という入力フィールドを作成すると、ワークフローのどこでも`{{user_name}}`として参照できます。
|
||||
|
||||
### 入力タイプ
|
||||
|
||||
開始ノードは、さまざまな種類のユーザーデータを処理するために6つの入力タイプをサポートしています:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="テキスト入力">
|
||||
**テキスト** は256文字までの短い応答を受け入れます。名前、メールアドレス、タイトル、または1行に収まる簡単なテキスト入力に使用します。
|
||||
|
||||
**段落** は文字制限なしで長文のテキストを受け入れます。ユーザーに詳細な応答、説明、またはより多くのスペースが必要なコンテンツのための複数行のテキストエリアを提供します。
|
||||
</Tab>
|
||||
|
||||
<Tab title="構造化入力">
|
||||
**選択** は、ユーザーに事前に定義されたオプションのドロップダウンメニューを提示します。ユーザーは指定したオプションからのみ選択でき、データの一貫性を確保し、予期しない入力を防ぎます。
|
||||
|
||||
**数値** は数値のみの入力を制限します。これは数量、評価、ID、またはワークフローで数学的に処理する必要があるデータに不可欠です。
|
||||
</Tab>
|
||||
|
||||
<Tab title="ファイル入力">
|
||||
**単一ファイル** は、ユーザーが任意のサポートされるタイプのファイルを1つアップロードできるようにします。ユーザーはデバイスからアップロードするか、ファイルのURLを提供できます。ファイルはワークフロー内でファイル変数として利用可能になります。
|
||||
|
||||
**ファイルリスト** は、単一ファイルと同様に機能しますが、複数のファイルを一度にアップロードすることをサポートします。これは、ドキュメント、画像、またはその他のファイルを一緒に処理する際に便利です。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Info>
|
||||
ユーザーがファイルをアップロードすると、DifyのドキュメントエクストラクタがPDF、Wordドキュメント、およびほとんどのテキスト形式を自動的に処理できます。画像、音声、またはビデオファイルの場合、ワークフローに適切な処理ノードを接続する必要があります。
|
||||
</Info>
|
||||
|
||||
## システム変数
|
||||
|
||||
カスタム入力に加えて、開始ノードはワークフローのメタデータとコンテキストにアクセスできるシステム変数を提供します。これらの変数は自動的に利用可能で、変更することはできません。
|
||||
|
||||
<Frame caption="ワークフローとチャットフローアプリケーションで利用可能なシステム変数">
|
||||
<img src="/images/2bc13695bb7c41fe54b7362d4b7237a480524aa7c05b42c80649fd1e1209f091.png" alt="システム変数の比較" />
|
||||
</Frame>
|
||||
|
||||
利用可能なシステム変数は、アプリケーションの種類によって異なります。ワークフローアプリケーションは`sys.app_id`や`sys.workflow_id`のような基本的なメタデータを提供し、チャットフローアプリケーションは`sys.conversation_id`や`sys.dialogue_count`のような会話特有の追加変数を含みます。
|
||||
|
||||
システム変数は、実行コンテキストの追跡、ユーザー固有のロジックの実装、またはチャットフローアプリケーションで会話の状態を維持するのに特に便利です。
|
||||
|
||||
## 変数の参照
|
||||
|
||||
開始ノードからの変数は、下流の任意のノードで参照できます。ノードの入力フィールドを設定する際、ドロップダウンメニューから変数を選択するか、テキストフィールドに`/`を入力して変数の値を挿入できます。
|
||||
|
||||
<Frame caption="スラッシュコマンドを使用してテキスト入力に変数を挿入する">
|
||||
<img src="/images/image.png" alt="変数挿入インターフェイス" />
|
||||
</Frame>
|
||||
|
||||
変数はワークフロー全体でそのタイプを維持します。数値入力は数値のまま、ファイルアップロードはファイルオブジェクトのまま、テキスト入力は文字列のままです。このタイプの一貫性は、下流のノードがデータを正しく処理できるようにします。
|
||||
|
||||
## ファイル処理
|
||||
|
||||
開始ノードを通じてアップロードされたファイルは、ワークフロー内で適切に処理する必要があります。開始ノード自体はファイルを収集し、変数として利用可能にするだけです。コンテンツを抽出および処理するために特定のノードを接続する必要があります:
|
||||
|
||||
ドキュメントファイルは、テキストコンテンツを抽出するためにドキュメントエクストラクタノードにルーティングする必要があります。画像は、視覚能力を持つLLMノードや特殊な画像処理ツールに送信できます。CSVやJSONのような構造化データファイルは、データを解析および変換するためにコードノードで処理できます。
|
||||
|
||||
<Note>
|
||||
ファイル変数には、アップロードされたファイルの名前、サイズ、タイプなどのメタデータが含まれています。実際のファイルコンテンツは、下流のノードで抽出または処理する必要があります。
|
||||
</Note>
|
||||
|
||||
## 非表示変数
|
||||
|
||||
任意の入力変数を「非表示」に設定して、ユーザーインターフェースから除外しつつ、ワークフローで利用可能にすることができます。
|
||||
|
||||
## 設定のベストプラクティス
|
||||
|
||||
開始ノードの入力を設計する際、ワークフローの初めに必要な情報と、後で導出または収集できる情報を考慮してください。最初に多くの入力を必要とすると、ユーザーに摩擦を生じさせ、少なすぎるとワークフローの能力を制限する可能性があります。
|
||||
|
||||
変数が含むデータを明確に示す記述的な変数名を選択してください。変数名は一貫してアンダースコアまたはキャメルケースを使用し、解析問題を引き起こす可能性のある特殊文字を避けてください。変数名は大文字と小文字を区別するため、`userName`と`username`は異なる変数です。
|
||||
|
||||
ファイルアップロードの場合、適切なファイルタイプの制限やサイズ制限を設定することを検討してください。これにより、下流での処理エラーを防ぎ、ワークフローが期待される入力形式を受け取ることができます。
|
||||
|
||||
## 次のステップ
|
||||
|
||||
開始ノードを設定した後、通常は収集された入力を処理するノードに接続します。一般的なパターンには、ユーザー入力を処理するためにLLMノードに送信すること、入力に基づいて関連情報を見つけるために知識検索を使用すること、または入力値に基づいて条件付きロジックを使用して異なるワークフローブランチにルーティングすることが含まれます。
|
||||
```
|
||||
131
ja-jp/documja-jptation/pages/nodes/template.mdx
Normal file
131
ja-jp/documja-jptation/pages/nodes/template.mdx
Normal file
@@ -0,0 +1,131 @@
|
||||
```mdx
|
||||
---
|
||||
title: "テンプレート"
|
||||
description: "Jinja2 テンプレートを使用してデータを変換およびフォーマット"
|
||||
icon: "note-sticky"
|
||||
---
|
||||
|
||||
テンプレートノードは、Jinja2 テンプレートを使用して複数のソースからのデータを構造化テキストに変換およびフォーマットします。変数を組み合わせ、出力をフォーマットし、データを下流のノードやエンドユーザーのために準備するために使用します。
|
||||
|
||||
<Frame caption="テンプレートノードの設定インターフェース">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/0838bb5c7e1d1a58ed30fcd9fc48920f.png" alt="テンプレートノードインターフェース" />
|
||||
</Frame>
|
||||
|
||||
## Jinja2 テンプレート
|
||||
|
||||
テンプレートノードは、Jinja2 テンプレート構文を使用してワークフローデータに基づいた動的コンテンツを作成します。これにより、プログラミングのような機能が提供され、ループや条件分岐、フィルターを使用して高度なテキスト生成が可能になります。
|
||||
|
||||
### 変数の代入
|
||||
|
||||
ワークフローの変数を参照するには、二重中括弧を使います: `{{ variable_name }}`。ネストされたオブジェクトのプロパティや配列の要素には、ドット表記とブラケット構文を使用してアクセスできます。
|
||||
|
||||
```jinja2
|
||||
{{ user.name }}
|
||||
{{ items[0].title }}
|
||||
{{ data.metrics.score }}
|
||||
```
|
||||
|
||||
### 条件ロジック
|
||||
|
||||
if-else 文を使用してデータ値に基づいた異なるコンテンツを表示します:
|
||||
|
||||
```jinja2
|
||||
{% if user.subscription == 'premium' %}
|
||||
Welcome back, Premium Member! You have access to all features.
|
||||
{% else %}
|
||||
Consider upgrading to Premium for additional capabilities.
|
||||
{% endif %}
|
||||
```
|
||||
|
||||
### ループと反復
|
||||
|
||||
配列やオブジェクトを for ループで処理して、繰り返しのコンテンツを生成します:
|
||||
|
||||
```jinja2
|
||||
{% for item in search_results %}
|
||||
### Result {{ loop.index }}
|
||||
**Score**: {{ item.score | round(2) }}
|
||||
{{ item.content }}
|
||||
---
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
<Frame caption="テンプレート処理の知識検索結果">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/0ae3f13cf725cb2c52c72cc354e592ee.png" alt="テンプレートフォーマット例" />
|
||||
</Frame>
|
||||
|
||||
## データフォーマット
|
||||
|
||||
### フィルター
|
||||
|
||||
Jinja2 フィルターはテンプレートレンダリング中にデータを変換します:
|
||||
|
||||
```jinja2
|
||||
{{ name | upper }}
|
||||
{{ price | round(2) }}
|
||||
{{ content | replace('\n', '<br>') }}
|
||||
{{ timestamp | strftime('%B %d, %Y') }}
|
||||
{{ score | default('No score available') }}
|
||||
```
|
||||
|
||||
### エラーハンドリング
|
||||
|
||||
デフォルト値や条件チェックを使用して、不足または無効なデータを適切に処理します:
|
||||
|
||||
```jinja2
|
||||
{{ user.email | default('No email provided') }}
|
||||
{{ metrics.accuracy | round(2) if metrics.accuracy else 'Not calculated' }}
|
||||
```
|
||||
|
||||
## インタラクティブフォーム
|
||||
|
||||
テンプレートは、チャットインターフェースで構造化データ収集用のインタラクティブな HTML フォームを生成できます:
|
||||
|
||||
```html
|
||||
<form data-format="json">
|
||||
<label for="username">Username:</label>
|
||||
<input type="text" name="username" required />
|
||||
|
||||
<label for="priority">Priority:</label>
|
||||
<input type="select" name="priority" data-options='["low","medium","high"]'/>
|
||||
|
||||
<label for="message">Message:</label>
|
||||
<textarea name="message" placeholder="Enter your message"></textarea>
|
||||
|
||||
<input type="checkbox" name="urgent" data-tip="Mark as urgent"/>
|
||||
<button data-variant="primary">Submit</button>
|
||||
</form>
|
||||
```
|
||||
|
||||
<Frame caption="チャットインターフェースでレンダリングされたインタラクティブフォーム">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/9d24e9cfa3cdde00e4eee15bd4bbea76.png" alt="インタラクティブフォームのレンダリング" />
|
||||
</Frame>
|
||||
|
||||
ユーザーがフォームを送信すると、応答は構造化された JSON データとなり、即座に下流のワークフローノードで処理可能です。
|
||||
|
||||
## 出力制限
|
||||
|
||||
テンプレートの出力は **80,000 文字**(`TEMPLATE_TRANSFORM_MAX_LENGTH` で設定可能)に制限されています。これはメモリ問題を防ぎ、大規模なテンプレート出力の処理時間を合理的に保ちます。
|
||||
|
||||
## よくあるユースケース
|
||||
|
||||
**レポート生成** - 複数ソースからのデータを一貫した構造とスタイリングでフォーマットされたレポートに結合します。
|
||||
|
||||
**API 応答フォーマット** - 内部データ構造を外部消費向けにユーザーフレンドリーなフォーマットに変換します。
|
||||
|
||||
**LLM プロンプト準備** - 複雑なデータをよくフォーマットされたプロンプトに構造化し、LLM の処理精度を向上させます。
|
||||
|
||||
**メールと通知テンプレート** - ユーザーデータとワークフローの結果に基づいた動的コンテンツでパーソナライズされたメッセージを生成します。
|
||||
|
||||
**データ変換** - 外部システムとの統合のために異なるデータフォーマットや構造を変換します。
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**説明的な変数名を使用する**ことで、特に複雑なデータ構造を処理する際に、テンプレートを読みやすく、維持しやすくします。
|
||||
|
||||
**データの欠如を処理する**ために、デフォルト値や条件チェックを使用し、テンプレートレンダリングエラーを防ぎます。
|
||||
|
||||
**可読性のためのフォーマット**により、適切なスペースや改行、フォーマットを使用して、クリーンでプロフェッショナルな出力を作成します。
|
||||
|
||||
**サンプルデータでテストする**ことで、テンプレートがエッジケースを処理し、異なる入力シナリオで期待通りの結果を出すことを確認します。
|
||||
```
|
||||
91
ja-jp/documja-jptation/pages/nodes/tools.mdx
Normal file
91
ja-jp/documja-jptation/pages/nodes/tools.mdx
Normal file
@@ -0,0 +1,91 @@
|
||||
```mdx
|
||||
---
|
||||
title: "ツール"
|
||||
description: "事前に構築された統合機能を使って外部サービスやAPIに接続する"
|
||||
icon: "wrench"
|
||||
---
|
||||
|
||||
ツール ノードは、事前に構築された統合機能を通じて、ワークフローを外部サービスやAPIに接続します。HTTPリクエスト ノードとは異なり、ツールは構造化されたインターフェース、組み込みのエラー処理、および人気のあるサービスのための簡素化された設定を提供します。
|
||||
|
||||
<Frame caption="ツールノードの設定インターフェース">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/0f0255764a3f459f0b3c708db1cb32c9.png" alt="ツールノードインターフェース" />
|
||||
</Frame>
|
||||
|
||||
## ツールの種類
|
||||
|
||||
Difyは、さまざまな統合ニーズに対応する複数の種類のツールをサポートします:
|
||||
|
||||
<Frame caption="利用可能なツールカテゴリとオプション">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/f37cce4ccbb7456154cfa9eacda6b322.png" alt="ツールカテゴリ" />
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="組み込みツール">
|
||||
Google検索、天気API、生産性ツール、AIサービスなど、人気のあるサービス向けにDifyが維持するすぐに使える統合機能。これらのツールは最低限の設定で済み、信頼性のあるテスト済みの統合機能を提供します。
|
||||
</Tab>
|
||||
|
||||
<Tab title="カスタムツール">
|
||||
OpenAPI/Swagger仕様を使用して独自のツールをインポートします。内部API、専門サービス、または組み込みオプションでカバーされていないAPIに最適です。一度設定すれば、複数のワークフローで再利用できます。
|
||||
</Tab>
|
||||
|
||||
<Tab title="ワークフローツール">
|
||||
複雑なワークフローを再利用可能なツールとして公開します。これにより、異なるアプリケーション間で共有できるモジュール式のビルディングブロックが作成され、コードの再利用が促進され、メンテナンスが簡素化されます。
|
||||
</Tab>
|
||||
|
||||
<Tab title="MCPツール">
|
||||
専門的な機能を提供する外部MCP(モデルコンテキストプロトコル)サーバーからのツール。機能を拡張するために増え続けるMCPサーバーのエコシステムに接続します。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 設定
|
||||
|
||||
### 認証
|
||||
|
||||
多くのツールはAPIキーまたはOAuth認証を必要とします。これらの資格情報は、ワークスペースの**ツール**セクションでワークフローで使用する前に設定してください。一度設定されると、認証は自動的に処理されます。
|
||||
|
||||
### 入力パラメータ
|
||||
|
||||
ツールは入力設定のための検証付きの構造化フォームを提供します。前のワークフローノードからの変数を使用してパラメータを設定します。インターフェースはデータタイプの検証を自動的に処理し、各パラメータのための役立つ説明を提供します。
|
||||
|
||||
### 出力処理
|
||||
|
||||
ツールは、ダウンストリームノードのために変数として利用可能になる構造化データを返します。出力スキーマは事前に定義されており、互換性を確保し、統合の複雑さを軽減します。
|
||||
|
||||
## HTTPリクエストよりも優れた点
|
||||
|
||||
**構造化インターフェース**は、検証付きのフォームベースの設定を提供し、手動のHTTPリクエスト設定よりも簡単にセットアップできます。
|
||||
|
||||
**組み込みのエラー処理**は、自動リトライロジックとエラー管理を含み、API障害の処理の複雑さを軽減します。
|
||||
|
||||
**型安全性**は、ワークフローノード間でのデータ互換性を維持するために、入力および出力スキーマを保証します。
|
||||
|
||||
**ドキュメンテーション**は、各ツールに対する使用例と詳細なパラメータ説明を含みます。
|
||||
|
||||
## エラー処理とリトライ
|
||||
|
||||
外部サービスに依存するツールのための堅牢なエラー処理を設定します:
|
||||
|
||||
<Frame caption="ツールリトライ設定">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/34867b2d910d74d2671cd40287200480.png" alt="ツールリトライ設定" />
|
||||
</Frame>
|
||||
|
||||
**リトライ設定**は、最大10回まで失敗したツールの実行を自動的にリトライし、設定可能な間隔で(最大5000ms)行います。これにより、一時的なサービスの問題やネットワークの問題を処理します。
|
||||
|
||||
<Frame caption="ツールエラー処理オプション">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/39dc3b5881d9a5fe35b877971f70d3a6.png" alt="ツールエラー処理" />
|
||||
</Frame>
|
||||
|
||||
**エラー処理**は、ツールの実行が失敗した際に代替のワークフローパスを定義し、外部サービスが利用できない場合でもワークフローが継続されるようにします。
|
||||
|
||||
## カスタムツールの作成
|
||||
|
||||
**OpenAPI統合**により、OpenAPI/Swagger仕様を持つ任意のサービスをインポートできます。一度インポートされると、そのサービスは組み込みオプションと同じ使いやすさでツールとして利用可能になります。
|
||||
|
||||
**ワークフロー公開**は、複数ノードのワークフローを異なるアプリケーション間で再利用可能な単一ノードのツールに変換します。これにより、モジュール性が促進され、複雑なワークフロー管理が簡素化されます。
|
||||
|
||||
## ツール管理
|
||||
|
||||
ワークスペースのナビゲーションで**ツール**を通じてツール設定にアクセスします。ここで、認証資格情報を管理し、カスタムツールをインポートし、MCPサーバーを設定し、ワークフローをツールとして公開できます。
|
||||
|
||||
ツールの作成、管理、およびワークフローをツールとして公開するための詳細なガイダンスについては、[ツール設定ガイド](/en/guides/tools) を参照してください。
|
||||
```
|
||||
89
ja-jp/documja-jptation/pages/nodes/variable-aggregator.mdx
Normal file
89
ja-jp/documja-jptation/pages/nodes/variable-aggregator.mdx
Normal file
@@ -0,0 +1,89 @@
|
||||
```mdx
|
||||
---
|
||||
title: "変数アグリゲーター"
|
||||
description: "異なるワークフローブランチからの変数を統合された出力に結合"
|
||||
icon: "merge"
|
||||
---
|
||||
|
||||
Variable Aggregatorノードは、異なる実行パスからの変数を単一の統合された出力に結合します。複数のブランチが類似の出力を生成する場合、このノードは一貫した変数リファレンスを作成することにより、重複した下流処理の必要性を排除します。
|
||||
|
||||
## ブランチングの問題
|
||||
|
||||
条件付きワークフローは、同時に1つのブランチしか実行されない並列実行パスを作成します。集約がないと、各可能なブランチの結果に対応する重複した下流ノードが必要になり、複雑でメンテナンスが難しいワークフローが生じます。
|
||||
|
||||
Variable Aggregatorはマージポイントとして機能し、ブランチの出力を単一の変数に収集し、実際にどのブランチが実行されたかに関係なく下流ノードが一貫して参照できるようにします。
|
||||
|
||||
## 分類ワークフローの例
|
||||
|
||||
ユーザーの入力が分類され、各カテゴリが異なる知識検索を必要とする場合、Variable Aggregatorは結果を結合します:
|
||||
|
||||
**集約なし** - 重複した大型言語モデルノードを必要とする複雑なワークフロー:
|
||||
|
||||
<Frame caption="変数集約なしの複雑なワークフロー">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/7a7c91663c3799ce9d056b013d5df29c.png" alt="変数集約なしの課題分類" />
|
||||
</Frame>
|
||||
|
||||
**集約あり** - 単一の下流処理による簡素化されたワークフロー:
|
||||
|
||||
<Frame caption="変数集約を使用した簡素化されたワークフロー">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/2b1694936fdab4843f5edc3f2fd1e79a.png" alt="課題分類後のマルチブランチ集約" />
|
||||
</Frame>
|
||||
|
||||
集約されたワークフローは、各分類ブランチ用に大型言語モデルノードを重複させる代わりに1つのノードを使用し、同じ機能を維持しながら複雑さを大幅に削減します。
|
||||
|
||||
## 条件付き処理の例
|
||||
|
||||
類似した出力を生成するIf-Elseブランチにも同様の利点があります:
|
||||
|
||||
<Frame caption="条件分岐後の変数集約">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/ff0e5774a3eccc8a04c310ab9bae25e7.png" alt="条件分岐後のマルチブランチ集約" />
|
||||
</Frame>
|
||||
|
||||
## 設定
|
||||
|
||||
### 変数選択
|
||||
|
||||
結合したい異なるワークフローブランチからの変数を接続します。接続された各変数は、集約された出力への潜在的な入力になります。
|
||||
|
||||
### 型制約
|
||||
|
||||
**同型ルール** - すべての集約された変数は同じデータ型でなければなりません。最初の変数(例:文字列)を接続すると、そのノードは他のブランチから同じ型の変数のみを受け入れます。
|
||||
|
||||
**サポートされる型:**
|
||||
- **文字列** - 異なる処理ブランチからのテキスト出力
|
||||
- **数値** - 数値計算、スコア、または測定値
|
||||
- **オブジェクト** - 類似したスキーマを持つ構造化データオブジェクト
|
||||
- **配列** - リスト、コレクション、または複数の結果
|
||||
|
||||
### 出力の動作
|
||||
|
||||
Variable Aggregatorは、実際に実行されたブランチからの値を出力します。条件付きワークフローでは1つのブランチしか実行されないため、実行中は1つの入力変数のみが値を持ちます。
|
||||
|
||||
## 高度な機能
|
||||
|
||||
### 複数の集約グループ
|
||||
|
||||
高度なワークフロー(v0.6.10+)では、複数の変数グループを同時に集約できます。各グループは独自の型制約を維持し、同じノード内で異なるデータ型を並行して集約できます。
|
||||
|
||||
これは、ブランチが複数の関連する出力を生成し、それらを個別に結合する必要がある場合に便利です。例えば、異なる処理パスからのテキストの要約と数値のスコアの両方を集約する場合です。
|
||||
|
||||
## 一般的な使用例
|
||||
|
||||
**マルチカテゴリ処理** - 異なるコンテンツタイプは専門的な処理を必要としますが、共通の下流ロジックに供給される類似の出力を生成します。
|
||||
|
||||
**条件付きデータソース** - 異なる条件が異なる知識検索やAPI呼び出しをトリガーしますが、すべての結果は同じ最終処理を必要とします。
|
||||
|
||||
**ブランチ結果の統合** - 複雑なブランチロジックが様々な出力を生成し、それらを最終的に統一的に処理する必要があります。
|
||||
|
||||
**エラーハンドリング** - メインの処理とフォールバックブランチが異なるが互換性のある結果を生成し、それを下流ノードが一貫して処理できます。
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**データ型の計画** - すべてのブランチがVariable Aggregatorに接続する前に互換性のあるデータ型を生成することを確認します。
|
||||
|
||||
**一貫した出力構造** - オブジェクトや配列を集約する際、すべてのブランチで一貫した構造を維持し、予測可能な下流処理を可能にします。
|
||||
|
||||
**説明的な名前を使用** - 集約された変数に複数の可能なソースからの結果を含むことを示すように明確な名前を付けます。
|
||||
|
||||
**すべてのブランチをテスト** - 各可能な実行パスが、集約されたときに正しく機能する有効な出力を生成することを確認します。
|
||||
```
|
||||
125
ja-jp/documja-jptation/pages/nodes/variable-assigner.mdx
Normal file
125
ja-jp/documja-jptation/pages/nodes/variable-assigner.mdx
Normal file
@@ -0,0 +1,125 @@
|
||||
```mdx
|
||||
---
|
||||
title: "変数アサイナー"
|
||||
description: "チャットフローアプリケーションで永続的な会話変数を管理する"
|
||||
icon: "pen-to-square"
|
||||
---
|
||||
|
||||
Variable Assignerノードは、会話変数に書き込むことでチャットフローアプリケーション内の永続データを管理します。通常の工作流変数とは異なり、会話変数はチャットセッション全体を通じて持続します。
|
||||
|
||||
<Frame caption="変数アサイナーノードの設定">
|
||||
<img src="https://assets-docs.dify.ai/2024/11/83d0b9ef4c1fad947b124398d472d656.png" alt="変数アサイナのインターフェース" />
|
||||
</Frame>
|
||||
|
||||
## 会話変数と工作流変数の比較
|
||||
|
||||
**工作流変数**は、単一の工作流実行中のみ存在し、工作流が完了するとリセットされます。
|
||||
|
||||
**会話変数**は、同じチャットセッション内で複数の会話ターンにわたって持続し、ステートフルなインタラクションとコンテクストメモリを可能にします。
|
||||
|
||||
この持続性により、コンテクスト会話、ユーザーのパーソナライズ、ステートフル工作流、および複数のユーザーインタラクションにわたる進捗追跡が可能になります。
|
||||
|
||||
## 設定
|
||||
|
||||
更新する会話変数を設定し、そのソースデータを指定します。単一のノードで複数の変数をアサインできます。
|
||||
|
||||
<Frame caption="変数アサインの設定インターフェース">
|
||||
<img src="https://assets-docs.dify.ai/2024/11/ee15dee864107ba5a93b459ebdfc32cf.png" alt="変数アサインの設定" />
|
||||
</Frame>
|
||||
|
||||
**変数** - 書き込む会話変数を選択する
|
||||
|
||||
**変数を設定** - 上流の工作流ノードからソースデータを選択する
|
||||
|
||||
**操作モード** - 変数をどのように更新するかを決定する(上書き、追加、クリアなど)
|
||||
|
||||
## 操作モード
|
||||
|
||||
異なる変数タイプは、そのデータ構造に基づいて異なる操作をサポートします:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="文字列変数">
|
||||
**上書き** - 文字列値全体を新しいコンテンツで置き換える
|
||||
|
||||
**クリア** - 変数を空にし、nullまたは空白に設定する
|
||||
|
||||
**設定** - 固定値を手動で入力する
|
||||
</Tab>
|
||||
|
||||
<Tab title="数値変数">
|
||||
**上書き** - 数値値を完全に置き換える
|
||||
|
||||
**クリア** - nullまたは空の状態に設定する
|
||||
|
||||
**設定** - 特定の数値値を手動で入力する
|
||||
|
||||
**算術** - 現在の値に加算、減算、乗算、または除算を行う
|
||||
</Tab>
|
||||
|
||||
<Tab title="オブジェクト変数">
|
||||
**上書き** - オブジェクト全体を新しいデータで置き換える
|
||||
|
||||
**クリア** - オブジェクトを空にし、すべてのプロパティを削除する
|
||||
|
||||
**設定** - オブジェクトの構造と値を手動で定義する
|
||||
</Tab>
|
||||
|
||||
<Tab title="配列変数">
|
||||
**上書き** - 配列全体を新しいデータで置き換える
|
||||
|
||||
**クリア** - 配列を空にし、すべての要素を削除する
|
||||
|
||||
**追加** - 配列の末尾にアイテムを1つ追加する
|
||||
|
||||
**拡張** - 他の配列から複数のアイテムを追加する
|
||||
|
||||
**削除** - 最初または最後の位置からアイテムを削除する
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
配列操作は、時間とともに成長するメモリシステム、チェックリスト、および会話履歴を構築するのに特に強力です。
|
||||
|
||||
## 一般的な実装パターン
|
||||
|
||||
### スマートメモリシステム
|
||||
|
||||
会話から重要な情報を自動的に検出し保存するチャットボットを構築します:
|
||||
|
||||
<Frame caption="スマートメモリシステム工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/8d0492814b1515f50e87b2900ff400db.png" alt="スマートメモリの実装" />
|
||||
</Frame>
|
||||
|
||||
システムはユーザー入力を分析して記憶に残る事実を抽出し、構造化された情報を抽出して将来の会話で参照するための永続的なメモリ配列に追加します。
|
||||
|
||||
### ユーザー設定の保存
|
||||
|
||||
言語設定、通知設定、表示オプションなどのユーザー設定を保存します:
|
||||
|
||||
<Frame caption="ユーザー設定管理">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/1867d608a7d009431b73377ed65b427b.png" alt="ユーザー設定工作流" />
|
||||
</Frame>
|
||||
|
||||
ユーザー入力から初期設定をキャプチャするために**上書き**モードを使用し、その後のすべての大型语言模型(LLM)応答で参照してパーソナライズされたインタラクションを実現します。
|
||||
|
||||
### 進捗チェックリスト
|
||||
|
||||
複数の会話ターンにわたって完了状況を追跡するガイド付き工作流を構築します:
|
||||
|
||||
<Frame caption="進捗チェックリストの実装">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/c4362b01298b12e7d6fcd9e798f3165a.png" alt="進捗チェックリスト工作流" />
|
||||
</Frame>
|
||||
|
||||
配列会話変数を使用して完了した項目を追跡します。Variable Assignerは各ターンでチェックリストを更新し、LLMは残りのタスクをユーザーに案内するためにそれを参考にします。
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
**適切なデータ型を選択する** - 成長するコレクションには配列を、構造化データにはオブジェクトを、単一値には単純型を使用します。
|
||||
|
||||
**記述的な変数名を使用する** - 会話変数の目的と内容を示すために明確な名前を付けます。
|
||||
|
||||
**データの成長を管理する** - 長い会話での過剰なメモリ使用を防ぐために配列とオブジェクトのサイズを監視します。
|
||||
|
||||
**変数を初期化する** - 定義されていない動作を防ぐために会話変数に初期値を設定します。
|
||||
|
||||
**適切なタイミングでクリアする** - 新しいプロセスやセッションを開始する際に変数をリセットするためのクリア操作を使用します。
|
||||
```
|
||||
487
ja-jp/documja-jptation/pages/workspace/readme.mdx
Normal file
487
ja-jp/documja-jptation/pages/workspace/readme.mdx
Normal file
@@ -0,0 +1,487 @@
|
||||
```mdx
|
||||
---
|
||||
title: モデル
|
||||
description: Learn about the Different Models Supported by Dify.
|
||||
---
|
||||
|
||||
<Warning>
|
||||
「モデル」は「プラグイン」エコシステムに完全に統合されました。モデルプラグインの詳細な開発手順については、[プラグイン開発](/en/plugins/quick-start/develop-plugins/model-plugin/README)を参照してください。以下の内容はアーカイブされています。
|
||||
</Warning>
|
||||
|
||||
DifyはLLMアプリに基づくAIアプリケーションの開発プラットフォームであり、初めてDifyを使用する際には、**設定 --> モデルプロバイダー**に移動して、使用するLLMを追加および設定する必要があります。
|
||||
|
||||
|
||||
|
||||
Difyは、OpenAIのGPTシリーズやAnthropicのClaudeシリーズなどの主要なモデルプロバイダーをサポートしています。各モデルの能力とパラメーターは異なるため、アプリケーションのニーズに合ったモデルプロバイダーを選択してください。**Difyで使用する前に、モデルプロバイダーの公式ウェブサイトからAPIキーを取得してください。**
|
||||
|
||||
## Difyのモデルタイプ
|
||||
|
||||
Difyでは、モデルを4つのタイプに分類しており、それぞれ異なる用途に使用されます:
|
||||
|
||||
1. **システム推論モデル:** チャット、名前生成、フォローアップ質問の提案などのタスクにアプリケーションで使用されます。
|
||||
|
||||
> プロバイダーには、[OpenAI](https://platform.openai.com/account/api-keys)、[Azure OpenAI Service](https://azure.microsoft.com/en-us/products/ai-services/openai-service/)、[Anthropic](https://console.anthropic.com/account/keys)、Hugging Face Hub、Replicate、Xinference、OpenLLM、[iFLYTEK SPARK](https://www.xfyun.cn/solutions/xinghuoAPI)、[WENXINYIYAN](https://console.bce.baidu.com/qianfan/ais/console/applicationConsole/application)、[TONGYI](https://dashscope.console.aliyun.com/api-key\_management?spm=a2c4g.11186623.0.0.3bbc424dxZms9k)、[Minimax](https://api.minimax.chat/user-center/basic-information/interface-key)、ZHIPU(ChatGLM)、[Ollama](/en/development/models-integration/ollama)、[LocalAI](https://github.com/mudler/LocalAI)、[GPUStack](https://github.com/gpustack/gpustack)が含まれます。
|
||||
2. **Embeddingモデル:** 知識のセグメント化されたドキュメントを埋め込むために使用され、アプリケーション内のユーザークエリを処理します。
|
||||
|
||||
> プロバイダーには、OpenAI、ZHIPU (ChatGLM)、Jina AI([Jina Embeddings](https://jina.ai/embeddings/))が含まれます。
|
||||
3. [ReRankモデル](/en/learn-more/extended-reading/retrieval-augment/rerank)**:** LLMの検索機能を強化します。
|
||||
|
||||
> プロバイダーには、Cohere、Jina AI([Jina Reranker](https://jina.ai/reranker))が含まれます。
|
||||
4. **Speech-to-Textモデル:** 会話アプリケーションで話された言葉をテキストに変換します。
|
||||
|
||||
> プロバイダー: OpenAI。
|
||||
|
||||
Difyは、技術とユーザーのニーズが進化するにつれて、より多くのLLMプロバイダーを追加する予定です。
|
||||
|
||||
## ホストされたモデル試用サービス
|
||||
|
||||
Difyは、クラウドサービスユーザーがさまざまなモデルを試せる試用クォータを提供しています。試用期間が終了する前にモデルプロバイダーをセットアップして、アプリケーションの使用が途切れないようにしてください。
|
||||
|
||||
* OpenAIホストモデル試用: GPT3.5-turbo、GPT3.5-turbo-16k、text-davinci-003モデルなどの200回の呼び出しが含まれます。
|
||||
|
||||
## デフォルトモデルの設定
|
||||
|
||||
Difyは使用状況に基づいて自動的にデフォルトモデルを選択します。これを`設定 > モデルプロバイダー`で設定します。
|
||||
|
||||
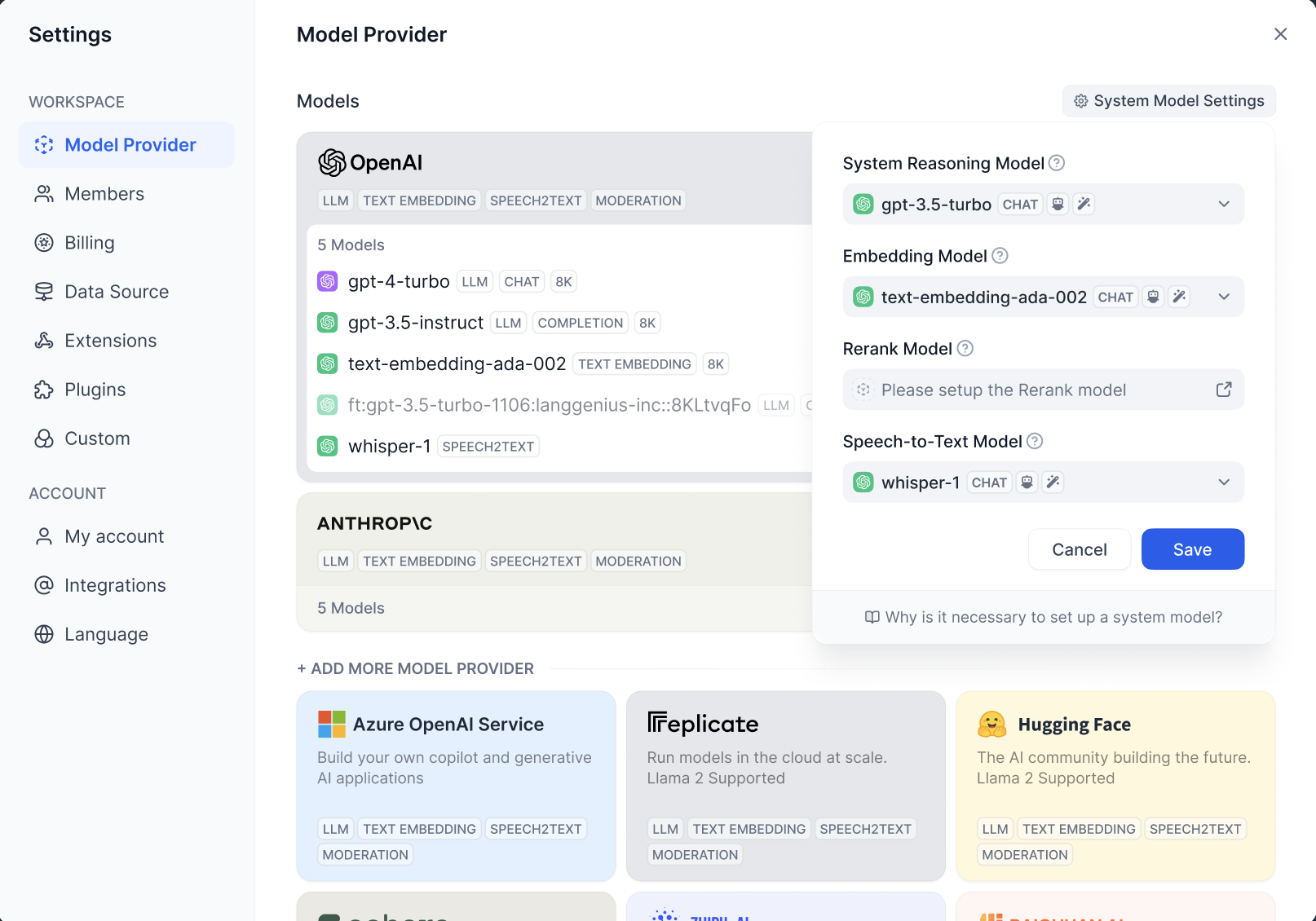
|
||||
|
||||
## モデル統合設定
|
||||
|
||||
Difyの`設定 > モデルプロバイダー`で使用するモデルを選択します。
|
||||
|
||||
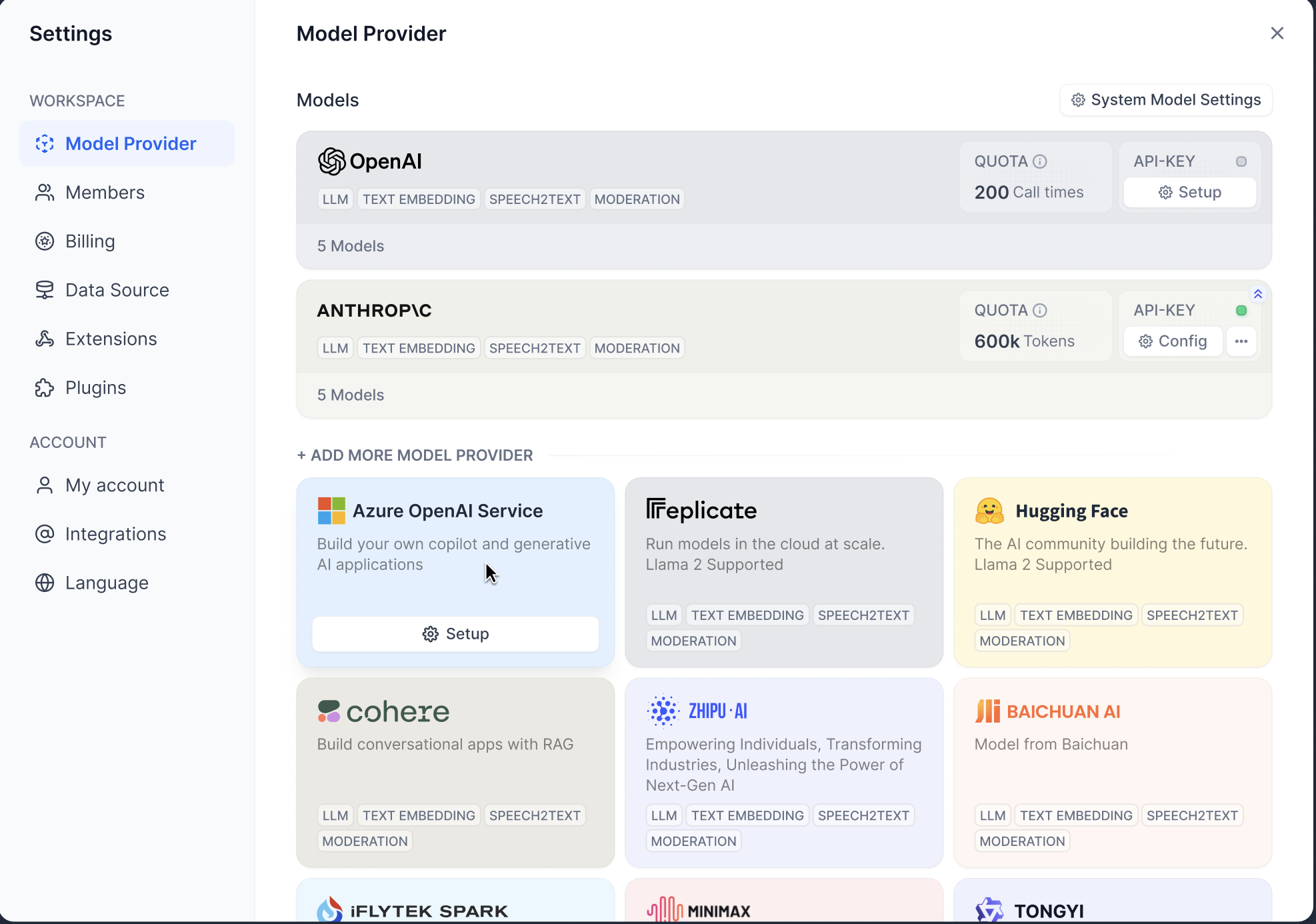
|
||||
|
||||
モデルプロバイダーは2つのカテゴリに分かれます:
|
||||
|
||||
1. 独自モデル: OpenAIやAnthropicなどのプロバイダーによって開発されたもの。
|
||||
2. ホストモデル: Hugging FaceやReplicateなどのサードパーティモデルを提供します。
|
||||
|
||||
これらのカテゴリ間で統合方法が異なります。
|
||||
|
||||
**独自モデルプロバイダー:** Difyは統合されたプロバイダーから全てのモデルに接続します。プロバイダーのAPIキーをDifyに設定して統合します。
|
||||
|
||||
<Info>
|
||||
Difyは[PKCS1\_OAEP](https://pycryptodome.readthedocs.io/en/latest/src/cipher/oaep.html)暗号化を使用してAPIキーを保護します。各ユーザー(テナント)には暗号化用のユニークな鍵ペアがあり、APIキーの機密性を確保します。
|
||||
</Info>
|
||||
|
||||
**ホストモデルプロバイダー:** サードパーティモデルを個別に統合します。
|
||||
|
||||
具体的な統合方法はここでは詳述されていません。
|
||||
|
||||
* [Hugging Face](/en/development/models-integration/hugging-face)
|
||||
* [Replicate](/en/development/models-integration/replicate)
|
||||
* [Xinference](/en/development/models-integration/xinference)
|
||||
* [OpenLLM](/en/development/models-integration/openllm)
|
||||
|
||||
## モデルの使用
|
||||
|
||||
設定が完了すると、これらのモデルはアプリケーションで使用可能になります。
|
||||
|
||||
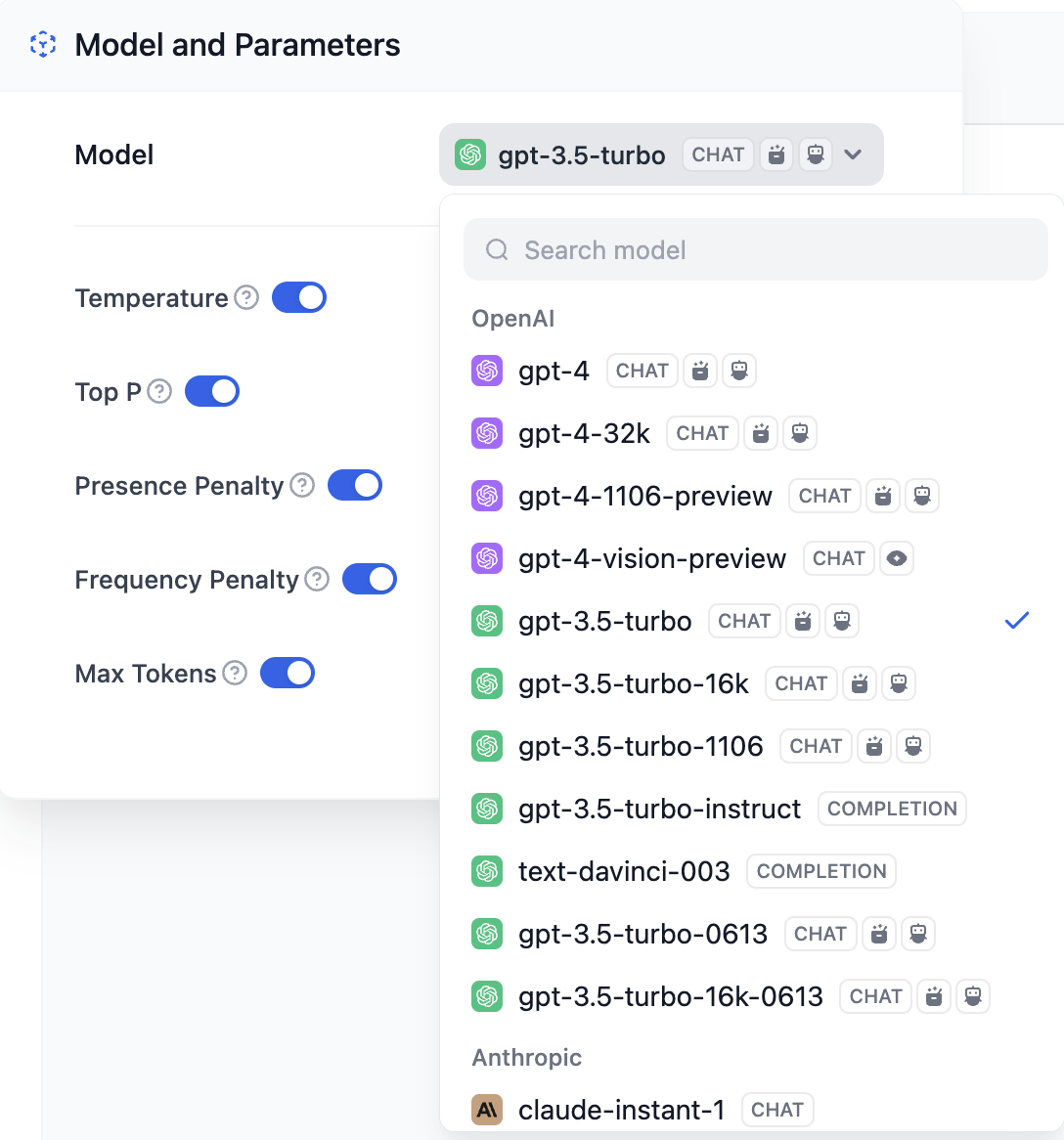
|
||||
|
||||
## サポートされているプロバイダー
|
||||
Difyは以下のモデルプロバイダーをアウトオブボックスでサポートしています:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>プロバイダー</th>
|
||||
<th>LLM</th>
|
||||
<th>テキスト埋め込み</th>
|
||||
<th>ReRank</th>
|
||||
<th>Speech to text</th>
|
||||
<th>TTS</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>OpenAI</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Anthropic</td>
|
||||
<td>✔️(🛠️)</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Azure OpenAI</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Gemini</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Google Cloud</td>
|
||||
<td>✔️(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Nvidia API Catalog</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Nvidia NIM</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Nvidia Triton Inference Server</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>AWS Bedrock</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>OpenRouter</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Cohere</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>together.ai</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Ollama</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Mistral AI</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>groqcloud</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Replicate</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Hugging Face</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Xorbits inference</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Zhipu AI</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Baichuan</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Spark</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Minimax</td>
|
||||
<td>✔️(🛠️)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Tongyi</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Wenxin</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Moonshot AI</td>
|
||||
<td>✔️(🛠️)</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Tencent Cloud</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Stepfun</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>VolcanoEngine</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>01.AI</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>360 Zhinao</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Azure AI Studio</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>deepseek</td>
|
||||
<td>✔️(🛠️)</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Tencent Hunyuan</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>SILICONFLOW</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Jina AI</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>ChatGLM</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Xinference</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>OpenLLM</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>LocalAI</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>OpenAI API-Compatible</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>PerfXCloud</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Lepton AI</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>novita.ai</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Amazon Sagemaker</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text Embedding Inference</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>GPUStack</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>GPUStack</td>
|
||||
<td>✔️(🔧️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
where (🛠️) ︎ denotes "function calling" and (👓) denotes "support for vision".
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[このページを編集](https://github.com/langgenius/dify-docs/edit/main/en/guides/model-configuration/readme.mdx) | [問題を報告](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
```
|
||||
59
ja-jp/guides/workflow/README.mdx
Normal file
59
ja-jp/guides/workflow/README.mdx
Normal file
@@ -0,0 +1,59 @@
|
||||
```mdx
|
||||
---
|
||||
title: はじめに
|
||||
---
|
||||
|
||||
### 基本的な紹介
|
||||
|
||||
ワークフローは、複雑なタスクを小さなステップ(ノード)に分解することでシステムの複雑性を軽減し、提示词工学と模型推理能力への依存を減らし、複雑なタスクに対する大型语言模型(LLM)アプリケーションの性能を向上させます。これにより、システムの解釈可能性、安定性、および耐障害性も向上します。
|
||||
|
||||
Difyのワークフローは2つのタイプに分かれています:
|
||||
|
||||
* **对话流**: 顧客サービス、语义检索、その他の会話型アプリケーションで、多段階のロジックを必要とする応答構築に設計されています。
|
||||
* **工作流**: 自動化およびバッチ処理のシナリオに向けられており、高品質な翻訳、データ分析、コンテンツ生成、メール自動化などに適しています。
|
||||
|
||||
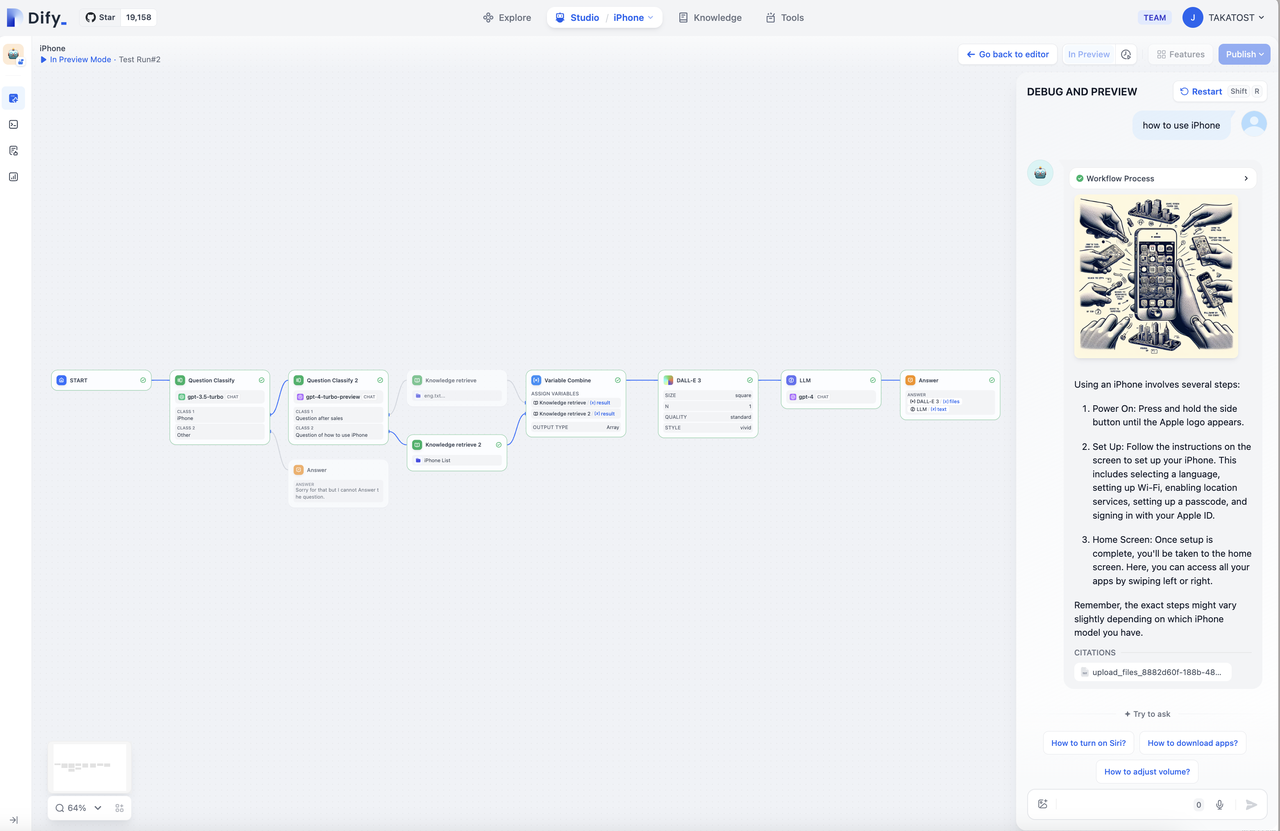
|
||||
|
||||
自然言語入力におけるユーザー意図認識の複雑性に対処するために,对话流は質問理解ノードを提供します。工作流と比較して、会話履歴(记忆)、注釈付き応答、回答ノードなどのチャットボット機能をサポートします。
|
||||
|
||||
自動化およびバッチ処理のシナリオにおける複雑なビジネスロジックを処理するために,工作流はコードノード、IF/ELSEノード、テンプレート変換、反復ノードなど、さまざまなロジックノードを提供します。さらに、タイミングやイベントトリガーアクションの機能を提供し、自動化プロセスの構築を容易にします。
|
||||
|
||||
### 共通のユースケース
|
||||
|
||||
* カスタマーサービス
|
||||
|
||||
LLMをカスタマーサービスシステムに統合することで、一般的な質問への応答を自動化し、サポートチームの負担を軽減できます。LLMは顧客の問い合わせの文脈と意図を理解し、リアルタイムで役立つ正確な回答を生成できます。
|
||||
|
||||
* コンテンツ生成
|
||||
|
||||
ブログ投稿、製品説明、マーケティング資料を作成する必要がある場合、LLMは高品質なコンテンツを生成するのを支援します。アウトラインやトピックを提供するだけで、LLMはその広範な知识库を活用して、魅力的で情報豊かで構造化されたコンテンツを作成します。
|
||||
|
||||
* タスク自動化
|
||||
|
||||
LLMはTrello、Slack、Larkなどのさまざまなタスク管理システムと統合して、プロジェクトとタスク管理を自動化できます。自然言語処理を使用して、LLMはユーザー入力を理解し解釈し、タスクを作成し、ステータスを更新し、優先順位を割り当てることができます。
|
||||
|
||||
* データ分析とレポート
|
||||
|
||||
LLMは大規模なデータセットを分析し、レポートや要約を生成できます。LLMに関連情報を提供することで、トレンド、パターン、洞察を特定し、生データを実用的なインテリジェンスに変換できます。これは、データに基づいた意思決定を求める企業にとって特に価値があります。
|
||||
|
||||
* メール自動化
|
||||
|
||||
LLMを使用して、メール、ソーシャルメディアの更新、その他の形式のコミュニケーションを作成できます。簡単なアウトラインや重要なポイントを提供することで、LLMは構造化され、一貫性があり、文脈に合ったメッセージを生成します。これにより、時間が大幅に節約され、応答が明確でプロフェッショナルになります。
|
||||
|
||||
### 始め方
|
||||
|
||||
* 新たにワークフローを構築するか、システムテンプレートを使用して始めましょう。
|
||||
* キャンバス上でノードを作成し、接続して設定する、ワークフローをデバッグする、実行履歴を見るなど、基本操作に慣れましょう。
|
||||
* ワークフローを保存し、公開します。
|
||||
* 公開されたアプリケーションを実行するか、APIを通じてワークフローを呼び出します。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[このページを編集](https://github.com/langgenius/dify-docs/edit/main/en/guides/workflow/README.mdx) | [問題を報告](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
```
|
||||
23
ja-jp/workshop/README.mdx
Normal file
23
ja-jp/workshop/README.mdx
Normal file
@@ -0,0 +1,23 @@
|
||||
```mdx
|
||||
---
|
||||
title: はじめに
|
||||
---
|
||||
|
||||
Difyワークショップへようこそ!これらのチュートリアルは、初心者がDifyをゼロから学び始めるために設計されています。プログラミングやAI関連の背景知識があるかどうかに関わらず、細部を省略せずにDifyの核心概念と使い方をマスターするためのステップを追ってガイドします。
|
||||
|
||||
一連の実験を通じてDifyを理解するお手伝いをします。各実験には、詳細な手順と説明が含まれており、簡単に従って内容を把握できるようにします。実験の中で知識を教え込み、実践の中で学びながら、Difyへの包括的な理解を徐々に構築できるようにします。
|
||||
|
||||
前提条件について心配する必要はありません!最も基本的な概念から始めて、徐々により高度なトピックへと導きます。完全な初心者であっても、ある程度のプログラミング経験がありAI技術を学びたい場合でも、このチュートリアルは必要なすべてを提供します。
|
||||
|
||||
一緒にこの学習の旅に出て、Difyの無限の可能性を探求しましょう!
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[このページを編集](https://github.com/langgenius/dify-docs/edit/main/en/workshop/README.mdx) | [問題を報告](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
```
|
||||
104
zh-hans/documzh-hanstation/pages/build/additional-features.mdx
Normal file
104
zh-hans/documzh-hanstation/pages/build/additional-features.mdx
Normal file
@@ -0,0 +1,104 @@
|
||||
```mdx
|
||||
---
|
||||
title: "附加功能"
|
||||
icon: "circle-plus"
|
||||
---
|
||||
|
||||
添加功能以使您的应用程序更有用。点击右上角的**功能**以添加功能。
|
||||
|
||||
<iframe
|
||||
src="https://www.motionshot.app/walkthrough/6773d34ad27e58127b913945/embed?fullscreen=1&hideAsSteps=1&hideCopy=1&hideDownload=1&hideSteps=1"
|
||||
width="100%"
|
||||
height="400px"
|
||||
frameborder="0"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
## 工作流应用
|
||||
|
||||
<Info>
|
||||
工作流应用中的功能文件上传已被弃用。请改用[启动节点上的文件变量](/en/guides/workflow/node/start)。
|
||||
</Info>
|
||||
|
||||
工作流应用仅支持通过功能进行**图像上传**:
|
||||
|
||||
<iframe
|
||||
src="https://www.motionshot.app/walkthrough/6773d3d86a0c3ed534f24da9/embed?fullscreen=1&hideAsSteps=1&hideCopy=1&hideDownload=1&hideSteps=1"
|
||||
width="100%"
|
||||
height="400px"
|
||||
frameborder="0"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
**设置方法:**
|
||||
1. 在功能中启用图像上传
|
||||
2. 添加具有视觉能力的LLM节点
|
||||
3. 启用视觉并选择`sys.files`变量
|
||||
4. 连接到结束节点
|
||||
|
||||
## 对话流应用
|
||||
|
||||
对话流应用获得更多功能:
|
||||
|
||||
- **对话开启者** - AI首先打招呼
|
||||
- **跟进** - 在响应后建议下一个问题
|
||||
- **文本转语音** - 大声朗读响应(需要在模型提供商中设置TTS)
|
||||
- **文件上传** - 用户可以上传文件
|
||||
- **引用** - 在使用知识检索时显示来源
|
||||
- **内容审核** - 过滤不当内容
|
||||
|
||||
## 文件上传
|
||||
|
||||
大多数功能在启用后会自动工作。文件上传需要更多设置。
|
||||
|
||||
**对于用户**:点击回形针图标上传文件
|
||||
|
||||

|
||||
|
||||
**对于开发者**:文件显示在`sys.files`变量中。不同的文件类型需要不同的处理方式:
|
||||
|
||||
### 文档
|
||||
|
||||
LLM不能直接读取文件。请先使用文档提取器。
|
||||
|
||||
1. 在文件类型中启用“文档”
|
||||
2. 添加文档提取器节点,将`sys.files`作为输入
|
||||
3. 添加使用文档提取器输出的LLM节点
|
||||
4. 添加答案节点,使用LLM输出
|
||||
|
||||
<Warning>
|
||||
这不会在对话之间记住文件。用户需要每次重新上传。对于持久文件,请使用[启动节点文件变量](/en/guides/workflow/node/start)。
|
||||
</Warning>
|
||||
|
||||
### 图像
|
||||
|
||||
某些LLM可以直接分析图像。
|
||||
|
||||
1. 在文件类型中启用“图像”
|
||||
2. 添加启用视觉的LLM节点
|
||||
3. 选择`sys.files`变量
|
||||
4. 添加答案节点,使用LLM输出
|
||||
|
||||

|
||||
|
||||
### 混合文件类型
|
||||
|
||||
同时处理文档和图像:
|
||||
|
||||
1. 启用“图像”和“文档”
|
||||
2. 添加两个列表操作节点以筛选文件类型
|
||||
3. 将图像发送到具有视觉的LLM
|
||||
4. 将文档发送到文档提取器
|
||||
5. 在答案节点中合并结果
|
||||
|
||||

|
||||
|
||||
### 音频和视频
|
||||
|
||||
LLM不能直接处理这些。您需要[外部工具](/en/guides/extension/api-based-extension/external-data-tool)来处理音频/视频。
|
||||
|
||||
## 限制
|
||||
|
||||
- 每个文件最大15MB
|
||||
- 一次最多10个文件
|
||||
```
|
||||
108
zh-hans/documzh-hanstation/pages/build/mcp.mdx
Normal file
108
zh-hans/documzh-hanstation/pages/build/mcp.mdx
Normal file
@@ -0,0 +1,108 @@
|
||||
```mdx
|
||||
---
|
||||
title: "使用 MCP 工具"
|
||||
icon: "microchip"
|
||||
---
|
||||
|
||||
将外部工具从 [MCP 服务器](https://modelcontextprotocol.io/introduction) 连接到您的 Dify 应用程序。除了内置工具外,您还可以使用不断增长的 [MCP 生态系统](https://mcpservers.org/)中的工具。
|
||||
|
||||
<Note>
|
||||
本文涵盖在 Dify 中使用 MCP 工具。要将 Dify 应用程序发布为 MCP 服务器,请参见[此处](/en/guides/application-publishing/publish-mcp)。
|
||||
</Note>
|
||||
|
||||
<Info>
|
||||
目前仅支持具有 [HTTP 传输](https://modelcontextprotocol.io/docs/concepts/architecture#transport-layer)的 MCP 服务器。
|
||||
</Info>
|
||||
|
||||
## 添加 MCP 服务器
|
||||
|
||||
前往您的工作区中的 **工具** → **MCP**。
|
||||
|
||||

|
||||
|
||||
点击 **添加 MCP 服务器 (HTTP)**:
|
||||
|
||||

|
||||
|
||||
**服务器 URL**:MCP 服务器所在位置(例如 `https://api.notion.com/mcp`)
|
||||
|
||||
**名称和图标**:将其命名为有用的名称。Dify 会尝试自动获取图标。
|
||||
|
||||
**服务器 ID**:唯一标识符(小写字母、数字、下划线、连字符,最多 24 个字符)
|
||||
|
||||
<Warning>
|
||||
一旦开始使用,切勿更改服务器 ID。这将导致使用该服务器工具的应用程序无法运行。
|
||||
</Warning>
|
||||
|
||||
## 接下来会发生什么
|
||||
|
||||
Dify 自动:
|
||||
1. 连接到服务器
|
||||
2. 处理任何 OAuth 相关问题
|
||||
3. 获取可用工具列表
|
||||
4. 在您的应用程序构建器中提供这些工具
|
||||
|
||||
一旦找到工具,您将看到一个服务器卡片:
|
||||
|
||||

|
||||
|
||||
## 管理服务器
|
||||
|
||||
点击任何服务器卡片以:
|
||||
|
||||
**更新工具**:当外部服务添加新工具时刷新
|
||||
|
||||

|
||||
|
||||
**重新授权**:在令牌过期时修复授权
|
||||
|
||||
**编辑设置**:更改服务器详细信息(但不能更改 ID!)
|
||||
|
||||
**移除**:断开与服务器的连接(这将导致使用其工具的应用程序无法运行)
|
||||
|
||||
## 使用 MCP 工具
|
||||
|
||||
连接后,MCP 工具将在您期望的地方出现:
|
||||
|
||||
**在智能代理中**:工具按服务器分组显示(例如“Notion MCP » 创建页面”)
|
||||
|
||||
**在工作流中**:MCP 工具可用作节点
|
||||
|
||||
**在智能代理节点中**:与常规智能代理相同
|
||||
|
||||
## 自定义工具
|
||||
|
||||
添加 MCP 工具时,您可以自定义它:
|
||||
|
||||

|
||||
|
||||
**描述**:覆盖默认描述以更具体
|
||||
|
||||
**参数**:对于每个工具参数,选择:
|
||||
- **自动**:让 AI 决定值
|
||||
- **固定**:设置一个永不改变的特定值
|
||||
|
||||
**示例**:对于搜索工具,将 `numResults` 设置为 5(固定),但将 `query` 保持为自动。
|
||||
|
||||
## 共享应用程序
|
||||
|
||||
当您导出使用 MCP 工具的应用程序时:
|
||||
- 导出包括服务器 ID
|
||||
- 要在其他地方使用应用程序,请添加具有相同 ID 的相同服务器
|
||||
- 记录您的应用程序需要哪些 MCP 服务器
|
||||
|
||||
## 疑难解答
|
||||
|
||||
**“未配置的服务器”**:检查 URL 并重新授权
|
||||
|
||||
**缺少工具**:点击“更新工具”
|
||||
|
||||
**应用程序损坏**:您可能更改了服务器 ID。使用原始 ID 添加回去。
|
||||
|
||||
## 提示
|
||||
|
||||
- 使用永久性、描述性的服务器 ID,如 `github-prod` 或 `crm-system`
|
||||
- 在开发/测试/生产环境中保持相同的 MCP 设置
|
||||
- 为配置项目设置固定值,为动态输入保持自动
|
||||
- 在部署前测试 MCP 集成
|
||||
```
|
||||
36
zh-hans/documzh-hanstation/pages/build/orchestrate-node.mdx
Normal file
36
zh-hans/documzh-hanstation/pages/build/orchestrate-node.mdx
Normal file
@@ -0,0 +1,36 @@
|
||||
```mdx
|
||||
---
|
||||
title: "流程逻辑"
|
||||
icon: "diagram-project"
|
||||
---
|
||||
|
||||
节点的执行方式取决于你如何连接它们。
|
||||
|
||||

|
||||
|
||||
## 串行执行
|
||||
|
||||
当你一个接一个地连接节点时,它们按顺序执行。每个节点在前一个节点完成后才开始。
|
||||
|
||||

|
||||
|
||||
每个节点可以使用链中之前运行的任何节点的变量。
|
||||
|
||||
## 并行执行
|
||||
|
||||
当你将多个节点连接到同一个起始节点时,它们会同时运行。
|
||||
|
||||

|
||||
|
||||
<Note>
|
||||
从一个节点最多可以有10个并行分支,以及最多3级嵌套的并行结构。
|
||||
</Note>
|
||||
|
||||
## 变量访问
|
||||
|
||||
在串行流程中,节点可以访问链中任何前面节点的变量。
|
||||
|
||||
在并行流程中,节点只能访问并行分支之前运行的节点的变量,因为它们是同时运行的,不能访问其他并行节点的变量。
|
||||
|
||||
在并行分支完成后,下游节点可以访问所有并行输出的变量。
|
||||
```
|
||||
@@ -0,0 +1,88 @@
|
||||
```
|
||||
---
|
||||
title: "处理错误"
|
||||
icon: "arrow-rotate-right"
|
||||
---
|
||||
|
||||

|
||||
[大型语言模型](/en/guides/workflow/node/llm), [HTTP](/en/guides/workflow/node/http-request), [代码](/en/guides/workflow/node/code), 和 [工具](/en/guides/workflow/node/tools) 节点支持开箱即用的错误处理。当一个节点失败时,它可以采取以下三种行为之一:
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="无">
|
||||
默认行为。当一个节点失败时,整个工作流停止。您将获得原始错误信息。
|
||||
|
||||
在以下情况下使用此选项:
|
||||
- 您正在测试并希望查看哪个部分出错
|
||||
- 工作流无法在没有此步骤的情况下继续
|
||||
</Accordion>
|
||||
<Accordion title="默认值">
|
||||
当一个节点失败时,使用备份值代替。工作流继续运行。
|
||||
|
||||

|
||||
|
||||
**要求**
|
||||
- 默认值必须与节点的输出类型匹配 —— 如果它输出一个字符串,您的默认值也必须是一个字符串。
|
||||
|
||||
**示例**
|
||||
|
||||
您的LLM节点通常返回分析结果,但有时由于速率限制而失败。设置一个默认值,例如:
|
||||
|
||||
```
|
||||
"抱歉,我暂时不可用。请稍后再试。"
|
||||
```
|
||||
|
||||
现在,用户将收到一条帮助信息,而不是一个中断的工作流。
|
||||
</Accordion>
|
||||
<Accordion title="失败分支">
|
||||
当一个节点失败时,触发一个单独的流程来处理错误。
|
||||
|
||||

|
||||
|
||||
失败分支用橙色高亮显示。您可以:
|
||||
- 发送错误通知
|
||||
- 尝试不同的方法
|
||||
- 记录错误以进行调试
|
||||
- 使用备份服务
|
||||
**示例**
|
||||
|
||||
您的主要API失败,因此失败分支调用备份API。用户永远不会知道有问题存在。
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## 循环/迭代节点中的错误
|
||||
|
||||
当子节点在循环和迭代中失败时,这些控制流节点有自己的错误行为。
|
||||
|
||||
**循环节点**总是在任何子节点失败时立即停止。整个循环终止并返回错误,防止运行任何进一步的迭代。
|
||||
|
||||
**迭代节点**允许您通过错误处理模式设置选择如何处理子节点失败:
|
||||
|
||||
- `terminated` - 当任何项目失败时立即停止处理(默认)
|
||||
- `continue-on-error` - 跳过失败的项目并继续下一个
|
||||
- `remove-abnormal-output` - 继续处理但从最终输出中过滤掉失败的项目
|
||||
|
||||
当您将迭代设置为`continue-on-error`时,失败的项目在输出数组中返回`null`。当您使用`remove-abnormal-output`时,输出数组仅包含成功的结果,使其比输入数组更短。
|
||||
|
||||
## 错误变量
|
||||
|
||||
使用默认值或失败分支时,您将获得两个特殊变量:
|
||||
|
||||
- `error_type` - 发生了什么类型的错误(参见[错误类型](en/guides/workflow/error-handling/error-type))
|
||||
- `error_message` - 实际的错误详情
|
||||
|
||||
使用这些变量来:
|
||||
- 向用户显示有帮助的信息
|
||||
- 向您的团队发送警报
|
||||
- 选择不同的恢复策略
|
||||
- 记录错误以进行调试
|
||||
|
||||
**示例**
|
||||
|
||||
```
|
||||
{% if error_type == "rate_limit" %}
|
||||
请求过多。请稍等片刻再试。
|
||||
{% else %}
|
||||
出现问题。我们的团队已收到通知。
|
||||
{% endif %}
|
||||
```
|
||||
```
|
||||
150
zh-hans/documzh-hanstation/pages/build/shortcut-key.mdx
Normal file
150
zh-hans/documzh-hanstation/pages/build/shortcut-key.mdx
Normal file
@@ -0,0 +1,150 @@
|
||||
```mdx
|
||||
---
|
||||
title: "快捷键"
|
||||
icon: "keyboard"
|
||||
---
|
||||
|
||||
使用键盘快捷键加速您的工作流构建。
|
||||
|
||||
## 节点操作
|
||||
在画布上选择任意节点时:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Windows</th>
|
||||
<th>macOS</th>
|
||||
<th>操作</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>C</code></td>
|
||||
<td><code>Cmd</code> + <code>C</code></td>
|
||||
<td>复制节点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>V</code></td>
|
||||
<td><code>Cmd</code> + <code>V</code></td>
|
||||
<td>粘贴节点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>D</code></td>
|
||||
<td><code>Cmd</code> + <code>D</code></td>
|
||||
<td>复制节点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Delete</code></td>
|
||||
<td><code>Delete</code></td>
|
||||
<td>删除选择的节点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>O</code></td>
|
||||
<td><code>Cmd</code> + <code>O</code></td>
|
||||
<td>自动排列节点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Shift</code></td>
|
||||
<td><code>Shift</code></td>
|
||||
<td>可视化变量依赖关系(仅限单个节点)</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## 画布导航
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Windows</th>
|
||||
<th>macOS</th>
|
||||
<th>操作</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>1</code></td>
|
||||
<td><code>Cmd</code> + <code>1</code></td>
|
||||
<td>适应视图</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>-</code></td>
|
||||
<td><code>Cmd</code> + <code>-</code></td>
|
||||
<td>缩小</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>=</code></td>
|
||||
<td><code>Cmd</code> + <code>=</code></td>
|
||||
<td>放大</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Shift</code> + <code>1</code></td>
|
||||
<td><code>Shift</code> + <code>1</code></td>
|
||||
<td>重置为100%</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Shift</code> + <code>5</code></td>
|
||||
<td><code>Shift</code> + <code>5</code></td>
|
||||
<td>设置为50%</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>H</code></td>
|
||||
<td><code>H</code></td>
|
||||
<td>手动工具(平移)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>V</code></td>
|
||||
<td><code>V</code></td>
|
||||
<td>选择工具</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## 历史记录
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Windows</th>
|
||||
<th>macOS</th>
|
||||
<th>操作</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>Z</code></td>
|
||||
<td><code>Cmd</code> + <code>Z</code></td>
|
||||
<td>撤销</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>Y</code></td>
|
||||
<td><code>Cmd</code> + <code>Y</code></td>
|
||||
<td>重做</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>Ctrl</code> + <code>Shift</code> + <code>Z</code></td>
|
||||
<td><code>Cmd</code> + <code>Shift</code> + <code>Z</code></td>
|
||||
<td>重做</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## 测试
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Windows</th>
|
||||
<th>macOS</th>
|
||||
<th>操作</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>Alt</code> + <code>R</code></td>
|
||||
<td><code>Option</code> + <code>R</code></td>
|
||||
<td>运行工作流</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
```
|
||||
103
zh-hans/documzh-hanstation/pages/build/version-control.mdx
Normal file
103
zh-hans/documzh-hanstation/pages/build/version-control.mdx
Normal file
@@ -0,0 +1,103 @@
|
||||
```mdx
|
||||
---
|
||||
title: "版本控制"
|
||||
icon: "layer-group"
|
||||
---
|
||||
|
||||
在对话流和工作流应用中跟踪更改和管理版本。
|
||||
|
||||
<Info>
|
||||
目前仅适用于对话流和工作流应用。
|
||||
</Info>
|
||||
|
||||
## 工作原理
|
||||
|
||||
**当前草稿**:您的工作版本。这是您进行更改的地方。用户不可见。
|
||||
|
||||

|
||||
|
||||
**最新版本**:用户可见的实时版本。
|
||||
|
||||

|
||||
|
||||
**以前版本**:已发布的旧版本。
|
||||
|
||||

|
||||
|
||||
## 发布版本
|
||||
|
||||
点击 **发布** → **发布更新** 以使您的草稿上线。
|
||||
|
||||

|
||||
|
||||
您的草稿将成为新的最新版本,并且您将获得一个新的草稿来进行工作。
|
||||
|
||||

|
||||
|
||||
## 查看版本
|
||||
|
||||
点击历史图标查看所有版本:
|
||||
|
||||

|
||||
|
||||
过滤条件:
|
||||
- **所有版本**或**仅您的版本**
|
||||
- **仅命名版本**(跳过自动生成的名称)
|
||||
|
||||

|
||||
|
||||
## 管理版本
|
||||
|
||||
**命名版本**:给它一个合适的名字,而不是自动生成的名字
|
||||
|
||||

|
||||
|
||||
**编辑版本信息**:更改名称并添加发布说明
|
||||
|
||||

|
||||
|
||||
**删除旧版本**:清理不需要的版本
|
||||
|
||||

|
||||
|
||||
<Warning>
|
||||
您无法删除当前草稿或最新版本。
|
||||
</Warning>
|
||||
|
||||
**恢复版本**:将旧版本加载回您的草稿
|
||||
|
||||

|
||||
|
||||
<Warning>
|
||||
这将完全替换您当前的草稿。确保您没有未保存的工作。
|
||||
</Warning>
|
||||
|
||||
## 示例工作流
|
||||
|
||||
以下是版本在典型开发周期中的工作方式:
|
||||
|
||||
### 1. 从草稿开始
|
||||

|
||||
|
||||
### 2. 发布第一个版本
|
||||

|
||||
|
||||
### 3. 发布第二个版本
|
||||

|
||||
|
||||
### 4. 将旧版本恢复为草稿
|
||||

|
||||
|
||||
### 5. 发布恢复的版本
|
||||

|
||||
|
||||
完整演示:
|
||||

|
||||
|
||||
## 提示
|
||||
|
||||
- 在发布前始终在草稿中测试
|
||||
- 对重要发布使用描述性版本名称
|
||||
- 需要快速回滚时恢复版本
|
||||
- 保留旧版本以供参考
|
||||
```
|
||||
108
zh-hans/documzh-hanstation/pages/debug/error-type.mdx
Normal file
108
zh-hans/documzh-hanstation/pages/debug/error-type.mdx
Normal file
@@ -0,0 +1,108 @@
|
||||
```mdx
|
||||
---
|
||||
title: 错误类型
|
||||
icon: "circle-xmark"
|
||||
---
|
||||
|
||||
每种节点类型都会抛出特定的错误类,帮助您了解问题所在及如何解决。
|
||||
|
||||
## 节点特定错误
|
||||
|
||||
<Tabs>
|
||||
<Tab title="代码" icon="code">
|
||||
|
||||
`CodeNodeError`
|
||||
<Info>您的 Python 或 JavaScript 代码在执行期间抛出了异常</Info>
|
||||
|
||||

|
||||
|
||||
`OutputValidationError`
|
||||
<Info>您的代码返回的数据类型与您配置的输出变量类型不匹配</Info>
|
||||
|
||||
`DepthLimitError`
|
||||
<Info>您的代码创建了超过 5 层深的嵌套数据结构</Info>
|
||||
|
||||
`CodeExecutionError`
|
||||
<Info>沙箱服务无法执行您的代码 - 通常意味着服务已宕机</Info>
|
||||
|
||||

|
||||
|
||||
</Tab>
|
||||
<Tab title="LLM" icon="brain">
|
||||
|
||||
`VariableNotFoundError`
|
||||
<Info>您的提示词模板引用了工作流上下文中不存在的变量</Info>
|
||||
|
||||

|
||||
|
||||
`InvalidContextStructureError`
|
||||
<Info>您向上下文字段传递了数组或对象,而该字段仅接受字符串</Info>
|
||||
|
||||
`NoPromptFoundError`
|
||||
<Info>提示词字段完全为空</Info>
|
||||
|
||||
`ModelNotExistError`
|
||||
<Info>在 LLM 节点配置中没有选择模型</Info>
|
||||
|
||||
`LLMModeRequiredError`
|
||||
<Info>所选模型未配置有效的 API 凭据</Info>
|
||||
|
||||
`InvalidVariableTypeError`
|
||||
<Info>您的提示词模板不是有效的 Jinja2 语法或纯文本格式</Info>
|
||||
|
||||

|
||||
|
||||
</Tab>
|
||||
<Tab title="HTTP 请求" icon="globe">
|
||||
|
||||
`AuthorizationConfigError`
|
||||
<Info>API 端点的身份验证配置缺失或无效</Info>
|
||||
|
||||
`InvalidHttpMethodError`
|
||||
<Info>HTTP 方法必须是 GET、HEAD、POST、PUT、PATCH 或 DELETE</Info>
|
||||
|
||||
`ResponseSizeError`
|
||||
<Info>API 响应超过 10MB 大小限制</Info>
|
||||
|
||||
`FileFetchError`
|
||||
<Info>无法检索请求中引用的文件变量</Info>
|
||||
|
||||
`InvalidURLError`
|
||||
<Info>URL 格式错误或无法访问</Info>
|
||||
|
||||
</Tab>
|
||||
<Tab title="工具" icon="wrench">
|
||||
|
||||
`ToolParameterError`
|
||||
<Info>传递给工具的参数与其预期的模式不匹配</Info>
|
||||
|
||||
`ToolFileError`
|
||||
<Info>工具无法访问所需的文件</Info>
|
||||
|
||||
`ToolInvokeError`
|
||||
<Info>外部工具 API 在执行期间返回了错误</Info>
|
||||
|
||||
<p align="center">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/84af0831b7cb23e64159dfbba80e9b28.jpg" width="300" />
|
||||
</p>
|
||||
|
||||
`ToolProviderNotFoundError`
|
||||
<Info>工具提供者未安装或配置不正确</Info>
|
||||
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 系统级错误
|
||||
|
||||
`InvokeConnectionError`
|
||||
<Info>与外部服务的网络连接失败</Info>
|
||||
|
||||
`InvokeServerUnavailableError`
|
||||
<Info>外部服务返回了 503 状态或暂时宕机</Info>
|
||||
|
||||
`InvokeRateLimitError`
|
||||
<Info>您已达到 API 或模型提供者的速率限制</Info>
|
||||
|
||||
`QuotaExceededError`
|
||||
<Info>您已超出此服务的使用配额</Info>
|
||||
```
|
||||
46
zh-hans/documzh-hanstation/pages/debug/history-and-logs.mdx
Normal file
46
zh-hans/documzh-hanstation/pages/debug/history-and-logs.mdx
Normal file
@@ -0,0 +1,46 @@
|
||||
```mdx
|
||||
---
|
||||
title: "日志"
|
||||
icon: "memo"
|
||||
---
|
||||
|
||||
Dify 记录了每次工作流运行时的详细日志。您可以看到应用程序级别和各个节点发生了什么。
|
||||
|
||||
<Info>
|
||||
有关发布后来自实时用户的日志,请参见[日志与注释](/en/guides/annotation/logs)。
|
||||
</Info>
|
||||
|
||||
## 应用程序日志
|
||||
|
||||
每次工作流运行都会创建一个完整的日志条目。点击任意条目查看三个部分:
|
||||
|
||||

|
||||
|
||||
### 结果
|
||||
|
||||
显示用户看到的最终输出。如果工作流失败,您将在此处看到错误信息。
|
||||
|
||||

|
||||
|
||||
<Warning>
|
||||
仅适用于工作流应用程序。
|
||||
</Warning>
|
||||
|
||||
### 详情
|
||||
|
||||
显示执行的原始输入、最终输出和系统元数据。
|
||||
|
||||

|
||||
|
||||
### 跟踪
|
||||
|
||||
准确显示您的工作流如何执行,包括哪些节点按什么顺序运行,每个节点花费的时间,以及数据在它们之间的流动情况。这对于查找瓶颈和理解具有分支或循环的复杂工作流非常有用。
|
||||
|
||||

|
||||
|
||||
## 节点日志
|
||||
|
||||
您还可以检查任何单个节点的最后一次执行。点击节点配置面板中的“最后运行”查看其最近的输入、输出和时间详情。
|
||||
|
||||

|
||||
```
|
||||
34
zh-hans/documzh-hanstation/pages/debug/step-run.mdx
Normal file
34
zh-hans/documzh-hanstation/pages/debug/step-run.mdx
Normal file
@@ -0,0 +1,34 @@
|
||||
```mdx
|
||||
---
|
||||
title: "单节点"
|
||||
icon: "code-commit"
|
||||
---
|
||||
|
||||
在发布之前,通过逐步运行您的工作流或测试单个节点来捕捉问题。
|
||||
|
||||
## 单节点测试
|
||||
|
||||
您可以在不运行整个工作流的情况下单独测试任何节点。选择节点,在其设置面板中提供测试输入,然后点击“运行”以查看输出。
|
||||
|
||||

|
||||
|
||||
测试后,点击“上次运行”查看执行详情,包括输入、输出、时间和任何错误信息。
|
||||
|
||||
<Warning>
|
||||
Answer 和 End 节点不支持单节点测试。
|
||||
</Warning>
|
||||
|
||||
## 逐步执行
|
||||
|
||||
当您一次运行一个节点时,其输出会缓存到变量检查器中。您可以编辑这些缓存的变量,以不同的场景进行测试,而无需重新运行上游节点。
|
||||
|
||||

|
||||
|
||||
当您想测试一个节点对不同数据的响应时,这非常有用,而无需修改并重新运行之前的所有节点。只需在检查器中更改变量值,然后再次运行该节点。
|
||||
|
||||
## 查看执行历史
|
||||
|
||||
每次节点执行都会创建一个记录。点击任何节点上的“上次运行”以查看其最近的执行详情,包括输入了哪些数据,输出了什么,以及所用时间。
|
||||
|
||||

|
||||
```
|
||||
32
zh-hans/documzh-hanstation/pages/debug/variable-inspect.mdx
Normal file
32
zh-hans/documzh-hanstation/pages/debug/variable-inspect.mdx
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
title: "工作流"
|
||||
icon: "arrow-progress"
|
||||
---
|
||||
|
||||
变量检查器显示流经工作流的所有数据。它会在每个节点运行后捕获输入和输出,这样你就能了解正在发生的情况并测试不同的场景。
|
||||
|
||||

|
||||
|
||||
## 查看变量
|
||||
|
||||
任何节点运行后,其输出变量都会出现在屏幕底部的检查器面板中。点击任何变量可以查看其完整内容。
|
||||
|
||||

|
||||
|
||||
## 编辑变量
|
||||
|
||||
你可以通过点击来编辑大多数变量值。当你运行下游节点时,它们将使用你编辑的值而不是原始值。这让你能够测试不同场景而无需重新运行整个工作流。
|
||||
|
||||
<Info>
|
||||
在此处编辑变量不会更改最初创建这些变量的节点的"最后运行"记录。
|
||||
</Info>
|
||||
|
||||
例如,如果一个大型语言模型节点生成了类似 `SELECT * FROM users` 的 SQL,你可以在检查器中将其编辑为 `SELECT username FROM users`,然后只重新运行数据库节点来查看不同的结果。
|
||||
|
||||

|
||||
|
||||
## 重置变量
|
||||
|
||||
点击任何变量旁边的还原图标来恢复其原始值,或者点击"全部重置"来一次性清除所有缓存的变量。
|
||||
|
||||

|
||||
114
zh-hans/documzh-hanstation/pages/getting-started/faq.md
Normal file
114
zh-hans/documzh-hanstation/pages/getting-started/faq.md
Normal file
@@ -0,0 +1,114 @@
|
||||
```mdx
|
||||
# 常见问题解答
|
||||
|
||||
欢迎来到 Dify 的常见问题解答部分。在这里,您将找到关于使用 Dify 的最常见问题的答案。
|
||||
|
||||
## 入门
|
||||
|
||||
### 什么是 Dify?
|
||||
|
||||
Dify 是一个用于构建 AI 应用的开源平台。它提供了一整套工具和功能,帮助您在无需广泛编程知识的情况下构建、部署和管理 AI 应用。
|
||||
|
||||
### 如何开始使用 Dify?
|
||||
|
||||
要开始使用 Dify:
|
||||
|
||||
1. **注册** 在 [dify.ai](https://dify.ai) 创建一个 Dify 账户
|
||||
2. 使用我们直观的界面 **创建您的第一个应用程序**
|
||||
3. **配置您的 AI 模型**,通过连接 OpenAI、Anthropic 或其他供应商
|
||||
4. **测试并迭代** 您的应用程序
|
||||
5. **部署** 您的 AI 应用程序到生产环境
|
||||
|
||||
### 我可以用 Dify 构建哪些类型的应用程序?
|
||||
|
||||
您可以使用 Dify 构建各种类型的 AI 应用程序:
|
||||
|
||||
- 用于客户服务的 **聊天机器人**
|
||||
- 可以回答文档问题的 **知识库助手**
|
||||
- 智能处理数据的 **工作流自动化工具**
|
||||
- 用于营销和写作的 **内容生成工具**
|
||||
- 能执行复杂任务的 **智能代理**
|
||||
|
||||
## 技术问题
|
||||
|
||||
### Dify 支持哪些 AI 模型?
|
||||
|
||||
Dify 支持多种 AI 模型,包括:
|
||||
|
||||
- **OpenAI 模型**:GPT-4、GPT-3.5 等
|
||||
- **Anthropic 模型**:Claude 3 和 Claude 2
|
||||
- **开源模型**:通过 Hugging Face、Ollama 等提供商
|
||||
- **本地模型**:您可以托管自己的模型
|
||||
|
||||
### Dify 如何处理我的数据?
|
||||
|
||||
数据安全和隐私是我们的首要任务:
|
||||
|
||||
- **您的数据仍然是您的** - 我们不会在您的私人数据上进行训练
|
||||
- **传输和静态加密**
|
||||
- **企业客户的 SOC2 合规性**
|
||||
- **欧洲用户的 GDPR 合规性**
|
||||
|
||||
### 我可以将 Dify 用于商业用途吗?
|
||||
|
||||
可以!Dify 提供:
|
||||
|
||||
- **开源版本**,使用 Apache 2.0 许可证进行自托管
|
||||
- **云版本**,提供商业计划用于托管
|
||||
- **企业计划**,提供高级功能和支持
|
||||
|
||||
## 故障排除
|
||||
|
||||
### 我的 AI 应用程序产生了错误的响应
|
||||
|
||||
尝试以下故障排除步骤:
|
||||
|
||||
1. **检查您的提示词** - 确保其清晰且具体
|
||||
2. **检查您的知识库** - 确保上传了相关文档
|
||||
3. **调整模型参数** - 尝试不同的温度或 TopK 设置
|
||||
4. **尝试不同的模型** - 一些模型在特定任务上表现更好
|
||||
|
||||
### 我遇到响应时间较慢的问题
|
||||
|
||||
要改善响应时间:
|
||||
|
||||
1. **检查您的模型配置** - 有些模型比其他模型更快
|
||||
2. **优化您的知识库** - 删除不必要的文档
|
||||
3. **使用缓存** - 为常见问题启用响应缓存
|
||||
4. **考虑升级** 您的计划以提高性能
|
||||
|
||||
### 我如何获得支持?
|
||||
|
||||
您可以通过以下方式获得支持:
|
||||
|
||||
- **社区论坛** - 与其他 Dify 用户交流
|
||||
- **文档** - 全面的指南和教程
|
||||
- **GitHub 问题** - 用于错误报告和功能请求
|
||||
- **电子邮件支持** - 针对付费计划客户
|
||||
- **企业支持** - 为企业客户提供专属支持
|
||||
|
||||
## 计费和计划
|
||||
|
||||
### 不同的定价计划有哪些?
|
||||
|
||||
Dify 提供多个计划:
|
||||
|
||||
- **免费层** - 适合入门和小型项目
|
||||
- **专业计划** - 适用于有较高使用需求的成长型企业
|
||||
- **企业计划** - 为大型组织提供定制解决方案
|
||||
|
||||
### 如何计算使用量?
|
||||
|
||||
使用量通常基于以下几点计算:
|
||||
|
||||
- 对 AI 模型的 **API 调用**
|
||||
- 文档和数据的 **存储**
|
||||
- 应用程序上的 **活跃用户**
|
||||
- 取决于您的计划的 **定制功能**
|
||||
|
||||
有关详细的定价信息,请访问我们的 [定价页面](https://dify.ai/pricing)。
|
||||
|
||||
---
|
||||
|
||||
需要更多帮助?请联系我们的支持团队或查看我们的 [全面文档](../../../guides/)。
|
||||
```
|
||||
128
zh-hans/documzh-hanstation/pages/getting-started/faq.mdx
Normal file
128
zh-hans/documzh-hanstation/pages/getting-started/faq.mdx
Normal file
@@ -0,0 +1,128 @@
|
||||
```mdx
|
||||
---
|
||||
title: "常见问题解答"
|
||||
description: "关于使用 Dify 的常见问题和答案"
|
||||
icon: "circle-question"
|
||||
---
|
||||
|
||||
欢迎来到 Dify 常见问题解答部分。在这里,您会找到关于如何使用 Dify 的一些常见问题的答案。
|
||||
|
||||
## 入门
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="什么是 Dify?">
|
||||
Dify 是一个用于构建 AI 应用程序的开源平台。它提供了一整套工具和功能,帮助您在不需要广泛编码知识的情况下,构建、部署和管理您的 AI 应用程序。
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="如何开始使用 Dify?">
|
||||
要开始使用 Dify:
|
||||
|
||||
1. **注册** 一个 Dify 账户,访问 [dify.ai](https://dify.ai)
|
||||
2. 使用我们的直观界面 **创建您的第一个应用程序**
|
||||
3. **配置您的 AI 模型**,通过连接 OpenAI、Anthropic 或其他提供商
|
||||
4. **测试和迭代** 您的应用程序
|
||||
5. **部署** 您的 AI 应用程序到生产环境
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="我可以用 Dify 构建哪种类型的应用程序?">
|
||||
您可以使用 Dify 构建各种类型的 AI 应用程序:
|
||||
|
||||
- 用于客户服务的 **聊天机器人**
|
||||
- 能够回答有关您文档问题的 **知识库助手**
|
||||
- 智能处理数据的 **工作流自动化工具**
|
||||
- 用于营销和写作的 **内容生成工具**
|
||||
- 能够执行复杂任务的 **智能代理**
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## 技术问题
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="Dify 支持哪些 AI 模型?">
|
||||
Dify 支持多种 AI 模型,包括:
|
||||
|
||||
- **OpenAI 模型**:GPT-4、GPT-3.5 等
|
||||
- **Anthropic 模型**:Claude 3 和 Claude 2
|
||||
- **开源模型**:通过 Hugging Face、Ollama 等提供商
|
||||
- **本地模型**:您可以托管自己的模型
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="Dify 如何处理我的数据?">
|
||||
数据安全和隐私是我们的首要任务:
|
||||
|
||||
- **您的数据仍然属于您** - 我们不会使用您的私人数据进行训练
|
||||
- **传输和存储加密**
|
||||
- **企业客户的 SOC2 合规性**
|
||||
- **欧洲用户的 GDPR 合规性**
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="我可以将 Dify 用于商业目的吗?">
|
||||
可以!Dify 提供以下版本:
|
||||
|
||||
- 适用于自托管的 Apache 2.0 许可证的 **开源版本**
|
||||
- 适用于托管服务的商业计划的 **云版本**
|
||||
- 提供高级功能和支持的 **企业计划**
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## 疑难解答
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="我的 AI 应用程序给出了错误的响应">
|
||||
尝试以下故障排除步骤:
|
||||
|
||||
1. **检查您的提示词** - 确保其清晰且具体
|
||||
2. **检查您的知识库** - 确保上传了相关文档
|
||||
3. **调整模型参数** - 尝试不同的温度或 TopK 设置
|
||||
4. **使用不同的模型进行测试** - 某些模型在特定任务上表现更好
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="我遇到了响应时间缓慢的问题">
|
||||
要提高响应时间:
|
||||
|
||||
1. **检查您的模型配置** - 某些模型速度更快
|
||||
2. **优化您的知识库** - 删除不必要的文档
|
||||
3. **使用缓存** - 启用常见问题的响应缓存
|
||||
4. **考虑升级** 您的计划以获得更好的性能
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="我如何获得支持?">
|
||||
您可以通过以下方式获得支持:
|
||||
|
||||
- **社区论坛** - 与其他 Dify 用户交流
|
||||
- **文档** - 全面的指南和教程
|
||||
- **GitHub 问题** - 用于错误报告和功能请求
|
||||
- **电子邮件支持** - 针对付费计划客户
|
||||
- **企业支持** - 为企业客户提供专门支持
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## 计费和计划
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="有哪些不同的定价计划?">
|
||||
Dify 提供多种计划:
|
||||
|
||||
- **免费层** - 适合入门和小型项目
|
||||
- **专业计划** - 适用于有更高使用需求的成长型企业
|
||||
- **企业计划** - 针对大型组织的定制解决方案
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="如何计算使用量?">
|
||||
使用量通常基于以下因素计算:
|
||||
|
||||
- 对 AI 模型的 **API 调用**
|
||||
- **文档和数据的存储**
|
||||
- 您应用程序的 **活跃用户**
|
||||
- **自定义功能** 视您的计划而定
|
||||
|
||||
有关详细的定价信息,请访问我们的 [定价页面](https://dify.ai/pricing)。
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
---
|
||||
|
||||
<Note>
|
||||
需要更多帮助?请联系支持团队或查看我们的 [全面文档](../../../guides/)。
|
||||
</Note>
|
||||
```
|
||||
165
zh-hans/documzh-hanstation/pages/getting-started/quick-start.mdx
Normal file
165
zh-hans/documzh-hanstation/pages/getting-started/quick-start.mdx
Normal file
@@ -0,0 +1,165 @@
|
||||
```mdx
|
||||
---
|
||||
title: "10分钟快速入门"
|
||||
description: "通过一个简单的应用程序快速进入Dify"
|
||||
icon: "forward"
|
||||
---
|
||||
|
||||
Dify的真正价值在于,无论想法多么复杂,都能轻松地构建、部署和扩展。它为快速原型设计、流畅迭代和任何级别的可靠部署而构建。
|
||||
|
||||
让我们开始学习如何将可靠的大型语言模型(LLM)集成到您的应用程序中。在本指南中,您将构建一个简单的聊天机器人,该机器人可以分类用户的问题,直接使用大型语言模型响应,并通过国家特定的趣味事实增强响应。
|
||||
|
||||
<iframe
|
||||
className="w-full aspect-video rounded-xl"
|
||||
src="https://www.youtube.com/embed/opKZRpfd80k?si=HEkyjRpiYheMyrZ0"
|
||||
title="Dify Quick Start Video"
|
||||
frameBorder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowFullScreen
|
||||
/>
|
||||
|
||||
## 第一步:创建一个新工作流(2分钟)
|
||||
|
||||
1. 前往 **Studio** > **工作流** > **从空白创建** > **编排** > **新建对话流** > **创建**
|
||||
|
||||
## 第二步:添加工作流节点(6分钟)
|
||||
|
||||
<Tip>
|
||||
当您想引用任何变量时,先输入 `{` 或 `/`,您就可以看到工作流中可用的不同变量。
|
||||
</Tip>
|
||||
|
||||
### 1. LLM节点和输出:理解并回答问题
|
||||
|
||||
<Info>
|
||||
`LLM` 节点向大型语言模型发送提示词,以根据用户输入生成响应。它抽象了API调用、速率限制和基础设施的复杂性,因此您只需专注于设计逻辑。
|
||||
</Info>
|
||||
|
||||
<Steps>
|
||||
<Step title="创建LLM节点">
|
||||
使用`添加节点`按钮创建一个LLM节点,并将其连接到您的开始节点
|
||||
</Step>
|
||||
|
||||
<Step title="配置模型">
|
||||
选择一个默认模型
|
||||
</Step>
|
||||
|
||||
<Step title="设置系统提示词">
|
||||
将以下内容粘贴到系统提示词字段中:
|
||||
|
||||
```text
|
||||
用户将询问有关某个国家的问题。问题是 {{sys.query}}
|
||||
任务:
|
||||
1. 确定提到的国家。
|
||||
2. 明确地重新表述问题。
|
||||
3. 使用一般知识回答问题。
|
||||
|
||||
以以下JSON格式响应:
|
||||
{
|
||||
"country": "<country name>",
|
||||
"question": "<rephrased question>",
|
||||
"answer": "<direct answer to the question>"
|
||||
}
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="启用结构化输出">
|
||||
**启用结构化输出** 允许您轻松控制LLM的返回内容,并确保下游使用时的输出一致且可机器读取,以进行精确的数据提取或条件逻辑。
|
||||
|
||||
- 切换输出变量结构化开关为ON > `配置`,然后点击`从JSON导入`
|
||||
- 粘贴:
|
||||
|
||||
```json
|
||||
{
|
||||
"country": "string",
|
||||
"question": "string",
|
||||
"answer": "string"
|
||||
}
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### 2. 代码块:获取趣味事实
|
||||
|
||||
<Info>
|
||||
`代码`节点使用代码执行自定义逻辑。它允许您在可视化工作流中恰当插入代码,避免搭建整个后端。
|
||||
</Info>
|
||||
|
||||
<Steps>
|
||||
<Step title="创建代码节点">
|
||||
使用`添加节点`按钮创建一个`代码`节点,并连接到LLM块
|
||||
</Step>
|
||||
|
||||
<Step title="配置输入变量">
|
||||
将一个`输入变量`名称更改为“country”,并将变量设置为`structured_output` > `country`
|
||||
</Step>
|
||||
|
||||
<Step title="添加Python代码">
|
||||
将以下代码粘贴到`PYTHON3`中:
|
||||
|
||||
```python
|
||||
def main(country: str) -> dict:
|
||||
country_name = country.lower()
|
||||
fun_facts = {
|
||||
"japan": "日本有超过500万台自动售货机。",
|
||||
"france": "法国是世界上访问量最大的国家。",
|
||||
"italy": "意大利拥有的联合国教科文组织世界遗产地比任何其他国家都多。"
|
||||
}
|
||||
fun_fact = fun_facts.get(country_name, f"No fun fact available for {country.title()}.")
|
||||
return {"fun_fact": fun_fact}
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="重命名输出变量">
|
||||
将输出变量`result`更改为`fun_fact`,使变量标签更清晰
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### 3. 答案节点:最终答复用户
|
||||
|
||||
<Info>
|
||||
`答案`节点创建一个干净的最终输出以返回。
|
||||
</Info>
|
||||
|
||||
<Steps>
|
||||
<Step title="创建答案节点">
|
||||
使用`添加节点`按钮创建一个`答案`节点
|
||||
</Step>
|
||||
|
||||
<Step title="配置答案字段">
|
||||
将以下内容粘贴到答案字段中:
|
||||
|
||||
```text
|
||||
Q: {{ structured_output.question }}
|
||||
|
||||
A: {{ structured_output.answer }}
|
||||
|
||||
趣味事实: {{ fun_fact }}
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
结束工作流:
|
||||
|
||||
<img
|
||||
src="/images/quick-start-workflow-overview.png"
|
||||
alt="完整的工作流图,显示连接的LLM、代码和答案节点"
|
||||
style={{ width: "100%" }}
|
||||
/>
|
||||
|
||||
---
|
||||
|
||||
## 第三步:测试机器人(3分钟)
|
||||
|
||||
点击`预览`,然后询问:
|
||||
|
||||
- "法国的首都是什么?"
|
||||
- "告诉我关于日本美食的信息"
|
||||
- "描述意大利的文化"
|
||||
- 任何其他问题
|
||||
|
||||
确保您的机器人按预期工作!
|
||||
|
||||
## 您已完成机器人!
|
||||
|
||||
本指南展示了如何在不重新构建基础设施的情况下可靠且可扩展地集成大型语言模型。借助Dify的可视化工作流和模块化节点,您不仅能更快地构建,还能采用干净、可投入生产的架构来构建由大型语言模型驱动的应用程序。
|
||||
```
|
||||
@@ -0,0 +1,57 @@
|
||||
```mdx
|
||||
---
|
||||
title: "测试内部工作流"
|
||||
description: "Testing documentation sync for internal contributors"
|
||||
icon: "flask"
|
||||
---
|
||||
|
||||
这是一个用于验证内部贡献者自动文档同步工作流的测试文档。
|
||||
|
||||
## 测试功能
|
||||
|
||||
<AccordionGroup>
|
||||
<Accordion title="工作流测试">
|
||||
此文档测试双工作流模式:
|
||||
- 分析工作流(只读)
|
||||
- 执行工作流(有权限)
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="自动审批">
|
||||
内部贡献者应被自动批准,因为他们在可信列表中。
|
||||
</Accordion>
|
||||
|
||||
<Accordion title="翻译生成">
|
||||
此内容应自动翻译为:
|
||||
- 中文(zh-hans)
|
||||
- 日语(ja-jp)
|
||||
</Accordion>
|
||||
</AccordionGroup>
|
||||
|
||||
## 预期结果
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card title="同步分支" icon="code-branch">
|
||||
应创建一个新的分支 `docs-sync-pr-XX`
|
||||
</Card>
|
||||
<Card title="PR 评论" icon="comment">
|
||||
包含翻译结果的自动评论
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
<Note>
|
||||
这是一个在 {{ new Date().toISOString() }} 创建的测试文件
|
||||
</Note>
|
||||
|
||||
## 代码示例
|
||||
|
||||
```python
|
||||
def test_workflow():
|
||||
"""Test the documentation sync workflow"""
|
||||
return "Testing internal contributor flow"
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
测试由:内部贡献者进行
|
||||
分支:test/internal-docs-sync
|
||||
```
|
||||
117
zh-hans/documzh-hanstation/pages/nodes/agzh-hanst.mdx
Normal file
117
zh-hans/documzh-hanstation/pages/nodes/agzh-hanst.mdx
Normal file
@@ -0,0 +1,117 @@
|
||||
```mdx
|
||||
---
|
||||
title: "智能代理"
|
||||
description: "Give LLMs autonomous control over tools for complex task execution"
|
||||
icon: "robot"
|
||||
---
|
||||
|
||||
智能代理节点赋予您的大型语言模型(LLM)对工具的自主控制,使其能够反复决定使用哪些工具以及何时使用这些工具。智能代理不是预先规划每一步,而是动态地通过问题进行推理,根据需要调用工具以完成复杂任务。
|
||||
|
||||
<Frame caption="智能代理节点配置界面">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/1f4d803ff68394d507abd3bcc13ba0f3.png" alt="Agent node interface" />
|
||||
</Frame>
|
||||
|
||||
## 智能代理策略
|
||||
|
||||
智能代理策略定义了您的智能代理如何思考和行动。选择最符合您的模型能力和任务需求的方法。
|
||||
|
||||
<Frame caption="可用的智能代理策略选项">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/f14082c44462ac03955e41d66ffd4cca.png" alt="Agent strategies selection" />
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="函数调用">
|
||||
使用LLM的本地函数调用能力,通过工具参数直接传递工具定义。LLM使用其内置机制决定何时以及如何调用工具。
|
||||
|
||||
最适合像GPT-4、Claude 3.5以及其他具有强大函数调用支持的模型。
|
||||
</Tab>
|
||||
|
||||
<Tab title="推理与行动 (ReAct)">
|
||||
使用结构化提示词指导LLM通过明确的推理步骤。遵循**思维 → 行动 → 观察**周期以实现透明的决策过程。
|
||||
|
||||
适用于可能没有本地函数调用的模型或当您需要明确的推理轨迹时。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Info>
|
||||
从**市场 → 智能代理策略**安装其他策略或向[社区仓库](https://github.com/langgenius/dify-plugins)贡献自定义策略。
|
||||
</Info>
|
||||
|
||||
<Frame caption="函数调用策略配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/10505cd7c6f0b3ba10161abb88d9e36b.png" alt="Function calling setup" />
|
||||
</Frame>
|
||||
|
||||
## 配置
|
||||
|
||||
### 模型选择
|
||||
|
||||
选择支持您所选智能代理策略的LLM。能力更强的模型能更好地处理复杂推理,但每次迭代的成本更高。如果使用该策略,请确保您的模型支持函数调用。
|
||||
|
||||
### 工具配置
|
||||
|
||||
配置您的智能代理可以访问的工具。每个工具需要:
|
||||
|
||||
**授权** - 在您的工作空间中配置的外部服务的API密钥和凭证
|
||||
|
||||
**描述** - 对工具的功能及使用时机的清晰解释(这将指导智能代理的决策过程)
|
||||
|
||||
**参数** - 工具接受的必需和可选输入,并进行适当验证
|
||||
|
||||
### 说明和上下文
|
||||
|
||||
使用自然语言说明定义智能代理的角色、目标和上下文。使用Jinja2语法引用上游工作流节点的变量。
|
||||
|
||||
**查询**指定智能代理应该处理的用户输入或任务。这可以是来自之前工作流节点的动态内容。
|
||||
|
||||
<Frame caption="智能代理配置参数">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/54c8e4f0eaa7379bd8c1b5ac6305b326.png" alt="Agent configuration interface" />
|
||||
</Frame>
|
||||
|
||||
### 执行控制
|
||||
|
||||
**最大迭代次数**设置一个安全限制以防止无限循环。根据任务复杂性进行配置——简单任务需要3-5次迭代,而复杂研究可能需要10-15次。
|
||||
|
||||
**记忆**控制智能代理使用TokenBufferMemory记住多少前面的消息。更大的记忆窗口提供更多的上下文,但增加了标记成本。这使得用户可以在多轮对话中引用先前的操作。
|
||||
|
||||
### 工具参数自动生成
|
||||
|
||||
工具可以配置为**自动生成**或**手动输入**参数。自动生成的参数(`auto: false`)由智能代理自动填充,而手动输入参数需要明确的值,并成为工具永久配置的一部分。
|
||||
|
||||
<video controls src="https://assets-docs.dify.ai/2025/04/1801b96763eb8f22f1e2158645897885.mp4" width="100%" />
|
||||
|
||||
## 输出变量
|
||||
|
||||
智能代理节点提供全面的输出,包括:
|
||||
|
||||
**最终答案** - 智能代理对查询的最终回应
|
||||
|
||||
**工具输出** - 执行过程中每次工具调用的结果
|
||||
|
||||
**推理轨迹** - 步骤决策过程(特别是在使用ReAct策略时详细)可在JSON输出中查看
|
||||
|
||||
**迭代次数** - 使用的推理循环次数
|
||||
|
||||
**成功状态** - 智能代理是否成功完成任务
|
||||
|
||||
**智能代理日志** - 结构化的日志事件和元数据,用于调试和监控工具调用
|
||||
|
||||
## 用例
|
||||
|
||||
**研究和分析** - 智能代理可以自主搜索多个来源,综合信息并提供全面答案。
|
||||
|
||||
**故障排除** - 诊断任务中,智能代理需要收集信息,测试假设,并根据发现调整其方法。
|
||||
|
||||
**多步数据处理** - 复杂的工作流中,下一步操作取决于中间结果。
|
||||
|
||||
**动态API集成** - 在响应和条件无法预先确定的情况下,API调用顺序可能依赖于场景。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**清晰的工具描述**帮助智能代理有效理解何时和如何使用每个工具。
|
||||
|
||||
**适当的迭代限制**防止费用失控,同时为复杂任务提供足够的灵活性。
|
||||
|
||||
**详细的说明**提供关于智能代理角色、目标以及任何限制或偏好的上下文。
|
||||
|
||||
**记忆管理**根据您的用例需求,在上下文保留和标记效率之间找到平衡。
|
||||
```
|
||||
67
zh-hans/documzh-hanstation/pages/nodes/answer.mdx
Normal file
67
zh-hans/documzh-hanstation/pages/nodes/answer.mdx
Normal file
@@ -0,0 +1,67 @@
|
||||
```mdx
|
||||
---
|
||||
title: "回答"
|
||||
description: "在对话流应用中定义响应内容"
|
||||
icon: "message"
|
||||
---
|
||||
|
||||
Answer 节点定义了在对话流应用中传递给用户的内容。使用它来格式化响应,将文本与变量结合,并流式传输包括文本、图像和文件在内的多模态内容。
|
||||
|
||||
<Info>
|
||||
Answer 节点仅适用于对话流应用。工作流应用使用 End 节点。
|
||||
</Info>
|
||||
|
||||
## 内容配置
|
||||
|
||||
Answer 节点提供了一个灵活的文本编辑器,您可以使用固定文本、来自先前节点的变量或两者的组合来编写响应。
|
||||
|
||||
使用 `{{variable_name}}` 语法引用任何先前工作流节点的变量。编辑器支持丰富的内容格式和变量插入,以创建动态的、上下文相关的响应。
|
||||
|
||||
<Frame caption="纯文本回答配置">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/42bb6bdef101bf79f959f4fc56a50ff3.png" alt="纯文本回答示例" />
|
||||
</Frame>
|
||||
|
||||
## 多模态响应
|
||||
|
||||
Answer 节点支持在单个响应流中传递包括文本、图像和文件在内的丰富内容。
|
||||
|
||||
<Frame caption="包含图像和文本内容的多模态回答">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/d2c901e821029756ebf95f4e099d833f.png" alt="多模态回答示例" />
|
||||
</Frame>
|
||||
|
||||
**文本内容** 可以包括变量替换、Markdown 格式和基于工作流处理结果的动态内容。
|
||||
|
||||
**图像内容** 显示由工具生成、用户上传或由工作流节点处理的图像。图像与文本一同流式传输,为用户提供丰富的体验。
|
||||
|
||||
**文件内容** 传递在工作流执行期间生成或处理的文档、电子表格或其他文件。
|
||||
|
||||
<Frame caption="对话中的 Answer 节点用户界面">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/5a70a5e568dded3975e54cfa84085c93.png" alt="Answer 节点对话界面" />
|
||||
</Frame>
|
||||
|
||||
## 多个 Answer 节点
|
||||
|
||||
您可以在整个对话流中放置多个 Answer 节点,以便在处理的不同阶段传递内容。这使得:
|
||||
|
||||
**渐进响应** - 在后台继续处理的同时提供即时确认
|
||||
|
||||
**条件响应** - 根据工作流分支逻辑发送不同的内容
|
||||
|
||||
**流式更新** - 在长时间运行的过程中,当部分结果可用时立即传递
|
||||
|
||||
每个 Answer 节点独立地为对话做出贡献,允许进行复杂的响应模式和用户体验设计。
|
||||
|
||||
## 变量集成
|
||||
|
||||
Answer 节点无缝集成来自所有工作流节点类型的输出。常见的变量来源包括:
|
||||
|
||||
**大型语言模型响应** - 显示生成的文本、分析结果或语言模型的结构化输出
|
||||
|
||||
**知识检索** - 显示知识库中找到的相关信息,并自动进行引用跟踪
|
||||
|
||||
**工具结果** - 显示来自外部 API、计算或服务集成的数据
|
||||
|
||||
**文件处理** - 显示提取的文本、分析结果或处理的文档内容
|
||||
|
||||
变量系统保持类型安全,并自动处理不同的内容类型,以便在聊天界面中进行最佳显示。
|
||||
```
|
||||
138
zh-hans/documzh-hanstation/pages/nodes/code.mdx
Normal file
138
zh-hans/documzh-hanstation/pages/nodes/code.mdx
Normal file
@@ -0,0 +1,138 @@
|
||||
```mdx
|
||||
---
|
||||
title: "代码"
|
||||
description: "执行自定义Python或JavaScript进行数据处理"
|
||||
icon: "code"
|
||||
---
|
||||
|
||||
代码节点执行自定义Python或JavaScript以处理工作流中的复杂数据转换、计算和逻辑。当预设节点不足以满足特定处理需求时使用此节点。
|
||||
|
||||
<Frame caption="代码节点配置界面">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/9969aa1bc1912aebe366f5d8f5dde296.png" alt="代码节点界面" />
|
||||
</Frame>
|
||||
|
||||
## 配置
|
||||
|
||||
定义**输入变量**以从工作流中的其他节点访问数据,然后在代码中引用这些变量。您的函数必须返回一个包含您声明的**输出变量**的字典。
|
||||
|
||||
```python
|
||||
def main(input_variable: str) -> dict:
|
||||
# 处理输入
|
||||
result = input_variable.upper()
|
||||
return {
|
||||
'output_variable': result
|
||||
}
|
||||
```
|
||||
|
||||
## 语言支持
|
||||
|
||||
根据您的需求和熟悉程度选择**Python**或**JavaScript**。两种语言都在安全的沙箱中运行,并可以访问常用的数据处理库。
|
||||
|
||||
<Tabs>
|
||||
<Tab title="Python">
|
||||
Python包括标准库,如`json`、`math`、`datetime`和`re`。非常适合数据分析、数学运算和文本处理。
|
||||
|
||||
```python
|
||||
def main(data: list) -> dict:
|
||||
import json
|
||||
import math
|
||||
|
||||
average = sum(data) / len(data)
|
||||
return {'result': math.ceil(average)}
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="JavaScript">
|
||||
JavaScript提供标准的内置对象和方法。适用于JSON操作和字符串处理。
|
||||
|
||||
```javascript
|
||||
function main(data) {
|
||||
const processed = data.map(item => item.toUpperCase());
|
||||
return { result: processed };
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 错误处理和重试
|
||||
|
||||
配置失败代码执行的自动重试行为,并在代码遇到错误时定义回退策略。
|
||||
|
||||
<Frame caption="错误处理配置选项">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/58f392734ce44b22cd8c160faf28cd14.png" alt="代码错误处理" />
|
||||
</Frame>
|
||||
|
||||
**重试设置**允许最多10次自动重试,具有可配置的间隔(最大5000ms)。启用此功能以处理临时处理问题。
|
||||
|
||||
**错误处理**允许您在代码执行失败时定义回退路径,使您的工作流即使在代码遇到问题时也能继续运行。
|
||||
|
||||
<Frame caption="重试配置界面">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/9fdd5525a91dc925b79b89272893becf.png" alt="重试设置" />
|
||||
</Frame>
|
||||
|
||||
## 输出验证和限制
|
||||
|
||||
代码输出会自动进行严格的限制验证:
|
||||
- **字符串**:最大长度为80,000字符,空字节被移除
|
||||
- **数字**:范围从-999999999到999999999,浮点数限制为10位小数
|
||||
- **对象/数组**:最大深度为5级,以防止复杂的嵌套结构
|
||||
|
||||
这些限制确保了工作流的性能并防止内存问题。
|
||||
|
||||
## 安全考虑
|
||||
|
||||
代码在严格的沙箱中执行,防止文件系统访问、网络请求和系统命令。这在提供编程灵活性的同时保持安全性。
|
||||
|
||||
出于安全原因,某些操作会被自动阻止。请避免尝试访问系统文件或执行潜在危险的操作:
|
||||
|
||||
<Frame caption="由Cloudflare WAF进行的安全过滤">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/ad4dc065c4c567c150ab7fa7bfd123a3.png" alt="Cloudflare WAF阻止" />
|
||||
</Frame>
|
||||
|
||||
如果您的代码未保存,请检查浏览器的网络选项卡——安全过滤器可能会阻止潜在危险的操作。
|
||||
|
||||
## 依赖支持
|
||||
|
||||
代码节点支持Python和JavaScript的外部依赖:
|
||||
|
||||
```python
|
||||
# Python:导入numpy、pandas、requests等
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
|
||||
def main(data: list) -> dict:
|
||||
df = pd.DataFrame(data)
|
||||
return {'mean': float(np.mean(df['values']))}
|
||||
```
|
||||
|
||||
```javascript
|
||||
// JavaScript:导入lodash、moment等
|
||||
const _ = require('lodash');
|
||||
|
||||
function main(data) {
|
||||
return { unique: _.uniq(data) };
|
||||
}
|
||||
```
|
||||
|
||||
依赖项已预安装在沙箱环境中。请在您的Dify安装中检查可用的软件包列表。
|
||||
|
||||
## 自托管设置
|
||||
|
||||
对于自托管的Dify安装,启动沙箱服务以进行安全的代码执行:
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.middleware.yaml up -d
|
||||
```
|
||||
|
||||
沙箱服务需要Docker,并将代码执行与您的主系统隔离以确保安全。
|
||||
|
||||
## 常见用例
|
||||
|
||||
**数据解析** - 从API或其他节点返回的复杂JSON结构中提取特定值。
|
||||
|
||||
**数学运算** - 执行计算、统计分析或数据聚合,而预设节点无法处理。
|
||||
|
||||
**数据转换** - 转换数据格式,合并多个数据源或重组信息以进行下游处理。
|
||||
|
||||
**条件逻辑** - 实现超出简单if-else条件的复杂决策逻辑。
|
||||
```
|
||||
113
zh-hans/documzh-hanstation/pages/nodes/doc-extractor.mdx
Normal file
113
zh-hans/documzh-hanstation/pages/nodes/doc-extractor.mdx
Normal file
@@ -0,0 +1,113 @@
|
||||
---
|
||||
title: "文档提取器"
|
||||
description: "从上传的文档中提取文本内容以进行AI处理"
|
||||
icon: "file-export"
|
||||
---
|
||||
|
||||
文档提取器节点将上传的文件转换为大型语言模型(LLM)可以处理的文本。由于语言模型无法直接读取PDF或DOCX等文档格式,此节点充当文件上传与AI分析之间的关键桥梁。
|
||||
|
||||
<Frame caption="文档提取器节点配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/f3853b40904e275da895711107e9c72f.png" alt="文档提取器界面" />
|
||||
</Frame>
|
||||
|
||||
## 支持的文件类型
|
||||
|
||||
节点处理大多数基于文本的文档格式:
|
||||
|
||||
**文本文件** - 含有直接文本内容的TXT、Markdown、HTML文件
|
||||
|
||||
**办公文档** - 来自Microsoft Word及兼容应用的DOCX文件
|
||||
|
||||
**PDF文档** - 使用pypdfium2进行准确文本提取的基于文本的PDF
|
||||
|
||||
**办公文件** - DOC文件需要Unstructured API,DOCX文件支持直接解析,并将表格提取为Markdown格式
|
||||
|
||||
**电子表格** - Excel (.xls/.xlsx)和CSV文件转换为Markdown表格
|
||||
|
||||
**演示文稿** - 通过Unstructured API处理的PowerPoint (.ppt/.pptx)文件
|
||||
|
||||
**电子邮件格式** - EML和MSG文件用于电子邮件内容提取
|
||||
|
||||
**专用格式** - EPUB电子书、VTT字幕、JSON/YAML数据和Properties文件
|
||||
|
||||
主要包含图像、音频或视频的文件需要专门的处理工具或外部服务。
|
||||
|
||||
## 输入和输出
|
||||
|
||||
### 输入配置
|
||||
|
||||
将节点配置为接受:
|
||||
|
||||
**单文件** 输入,来自文件变量(通常来自开始节点)
|
||||
|
||||
**多文件** 作为数组进行批量文档处理
|
||||
|
||||
### 输出结构
|
||||
|
||||
节点输出提取的文本内容:
|
||||
|
||||
- 单文件输入生成包含提取文本的`string`
|
||||
- 多文件输入生成`array[string]`,每个文件的内容分别存储
|
||||
|
||||
输出变量命名为`text`,其中包含准备好进行下游处理的原始文本内容。
|
||||
|
||||
## 实施示例
|
||||
|
||||
以下是使用文档提取器的完整文档问答工作流:
|
||||
|
||||
<Frame caption="ChatPDF风格的工作流实现">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/f6ea094b30b240c999a4248d1fc21a1c.png" alt="ChatPDF工作流" />
|
||||
</Frame>
|
||||
|
||||
### 工作流设置
|
||||
|
||||
**文件上传配置** - 在开始节点中启用文件输入,以接受用户上传的文档。
|
||||
|
||||
**文本提取** - 连接文档提取器以处理上传的文件并提取其文本内容。
|
||||
|
||||
**AI处理** - 在LLM提示词中使用提取的文本进行分析、总结或问答。
|
||||
|
||||
<Frame caption="文档处理操作">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/83bca46bcde07069660ff649e5c7cf4c.png" alt="文档处理设置" />
|
||||
</Frame>
|
||||
|
||||
<Frame caption="带文档上传的聊天界面">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d05301438e8aab7393bb5863554f1009.png" alt="带PDF的聊天界面" />
|
||||
</Frame>
|
||||
|
||||
## 常见用例
|
||||
|
||||
**文档问答应用** - 构建ChatPDF风格的应用程序,用户上传文档并询问其内容。
|
||||
|
||||
**内容分析** - 处理合同、报告或研究论文,提取关键信息和见解。
|
||||
|
||||
**批量文档处理** - 同时从多个文档中提取文本以进行分析、索引或迁移。
|
||||
|
||||
**文档转换** - 将各种文档格式转换为纯文本以供进一步处理或存储。
|
||||
|
||||
## 处理注意事项
|
||||
|
||||
文档提取器使用针对不同文件格式优化的专用解析库。它在可能的情况下保留文本结构和格式,使提取的内容在LLM处理时更有用。
|
||||
|
||||
### 文件格式处理
|
||||
|
||||
**编码检测** - 使用chardet库自动检测文件编码,文本文件默认为UTF-8
|
||||
|
||||
**表格转换** - Excel和CSV数据转换为Markdown表格以增强LLM理解
|
||||
|
||||
**文档结构** - DOCX文件保持段落和表格顺序,正确转换表格为Markdown
|
||||
|
||||
**多行内容** - VTT字幕文件合并同一说话者的连续话语
|
||||
|
||||
### 外部依赖
|
||||
|
||||
某些文件格式需要配置**Unstructured API**服务,通过`UNSTRUCTURED_API_URL`和`UNSTRUCTURED_API_KEY`:
|
||||
- DOC文件(旧版Word文档)
|
||||
- PowerPoint演示文稿(若使用API处理)
|
||||
- EPUB电子书(若使用API处理)
|
||||
|
||||
对于非常大的文档,请考虑LLM的上下文限制,并在需要时实施分段策略。提取的文本保持原始文档的逻辑结构,以保留意义和上下文。
|
||||
|
||||
<Info>
|
||||
有关详细的文件上传配置和高级文档处理功能,请参阅[文件上传指南](/en/guides/workflow/additional-features)。
|
||||
</Info>
|
||||
140
zh-hans/documzh-hanstation/pages/nodes/http-request.mdx
Normal file
140
zh-hans/documzh-hanstation/pages/nodes/http-request.mdx
Normal file
@@ -0,0 +1,140 @@
|
||||
```mdx
|
||||
---
|
||||
title: "HTTP请求"
|
||||
description: "连接到外部API和Web服务"
|
||||
icon: "globe"
|
||||
---
|
||||
|
||||
HTTP请求节点将您的工作流连接到外部API和Web服务。使用它来获取数据、发送webhooks、上传文件或与接受HTTP请求的任何服务集成。
|
||||
|
||||
<Frame caption="HTTP请求节点配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/07c5e952eb4c9d6a32d0b7c2d855d4a5.png" alt="HTTP请求节点界面" />
|
||||
</Frame>
|
||||
|
||||
## HTTP方法
|
||||
|
||||
该节点支持所有标准HTTP方法,用于不同类型的操作:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="数据检索">
|
||||
**GET** 从服务器检索数据而不修改任何内容。用于获取用户档案、搜索数据库或获取当前状态。
|
||||
|
||||
**HEAD** 获取响应头而不获取完整的响应体。用于检查资源是否存在或获取元数据。
|
||||
</Tab>
|
||||
|
||||
<Tab title="数据提交">
|
||||
**POST** 向服务器发送数据,通常用于创建新资源。用于表单提交、文件上传或发送JSON负载。
|
||||
|
||||
**PUT** 创建或完全替换资源。用于设置资源的整个状态。
|
||||
|
||||
**PATCH** 对现有资源进行部分更新。用于只需修改特定字段的情况。
|
||||
</Tab>
|
||||
|
||||
<Tab title="资源管理">
|
||||
**DELETE** 从服务器删除资源。用于删除文件、用户账户或任何应被移除的资源。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 配置
|
||||
|
||||
配置HTTP请求的各个方面,包括URL、头、查询参数、请求体和认证。可以在请求配置中的任何地方动态插入来自先前工作流节点的变量。
|
||||
|
||||
### 变量替换
|
||||
|
||||
使用双花括号引用工作流变量:`{{variable_name}}`。Dify支持深层对象访问,因此您可以从先前的HTTP响应中提取嵌套值,如`{{api_response.data.items[0].id}}`。
|
||||
|
||||
### 超时配置
|
||||
|
||||
HTTP请求具有可配置的超时,以防止挂起:
|
||||
- **连接超时**:建立连接的最长时间(默认值因部署而异)
|
||||
- **读取超时**:读取响应数据的最长时间
|
||||
- **写入超时**:发送请求数据的最长时间
|
||||
|
||||
强制执行超时以维护工作流性能并防止资源耗尽。
|
||||
|
||||
### 认证
|
||||
|
||||
该节点支持多种认证类型:
|
||||
|
||||
**无认证** (`type: "no-auth"`) - 不添加认证头
|
||||
|
||||
**API密钥** (`type: "api-key"`) 有三个子类型:
|
||||
- **Basic** (`type: "basic"`) - 使用base64编码添加Basic认证头
|
||||
- **Bearer** (`type: "bearer"`) - 添加`Authorization: Bearer <token>`头
|
||||
- **Custom** (`type: "custom"`) - 添加具有指定名称和值的自定义头
|
||||
|
||||
### 请求体
|
||||
|
||||
根据您的API需求选择适当的主体类型:
|
||||
|
||||
- **JSON** 用于结构化数据
|
||||
- **Form Data** 用于传统Web表单
|
||||
- **Binary** 用于文件上传
|
||||
- **Raw Text** 用于自定义内容类型
|
||||
|
||||
## 文件检测
|
||||
|
||||
HTTP请求节点使用复杂的逻辑自动检测文件响应:
|
||||
|
||||
1. **内容处置分析** - 检查`attachment`处置或文件名参数
|
||||
2. **MIME类型评估** - 分析内容类型以区分文本和二进制
|
||||
3. **内容采样** - 对于不明确的类型,采样前1024字节以检测文本模式
|
||||
|
||||
基于文本的响应(JSON、XML、HTML等)被视为常规数据,而二进制内容则成为文件变量。
|
||||
|
||||
## 文件操作
|
||||
|
||||
HTTP请求节点无缝处理文件上传和下载:
|
||||
|
||||
<Frame caption="文件上传配置示例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/1f2e33cf7bed33096b5aee145006193d.png" alt="HTTP节点文件上传" />
|
||||
</Frame>
|
||||
|
||||
**文件上传** 使用二进制请求体选项。从先前节点中选择文件变量,将文件发送到外部服务以进行文档存储、媒体处理或备份。
|
||||
|
||||
**文件下载** 在响应包含文件内容时自动处理。下载的文件作为文件变量可用于下游节点。
|
||||
|
||||
## 错误处理和重试
|
||||
|
||||
为依赖外部服务的生产工作流配置健壮的错误处理:
|
||||
|
||||
<Frame caption="HTTP重试配置">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/2e7c6080c0875e31a074c2a9a4543797.png" alt="HTTP重试设置" />
|
||||
</Frame>
|
||||
|
||||
**重试设置** 自动重试失败的请求最多10次,并具有可配置的间隔(最大5000毫秒)。这处理了临时网络问题或服务不可用的情况。
|
||||
|
||||
<Frame caption="HTTP错误处理选项">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/91daa86d9770390ab2a41d6d0b6ed1e7.png" alt="HTTP错误处理" />
|
||||
</Frame>
|
||||
|
||||
**错误处理** 定义HTTP请求失败时的替代工作流路径,确保即使外部API不可用,您的工作流也能继续执行。
|
||||
|
||||
## 响应处理
|
||||
|
||||
HTTP响应成为后续节点中的结构化变量,可单独访问:
|
||||
|
||||
- **响应体** - API返回的主要内容
|
||||
- **状态码** - 用于条件逻辑的HTTP状态
|
||||
- **头** - 作为键值对的响应元数据
|
||||
- **文件** - API返回的任何文件内容
|
||||
- **大小信息** - 以字节为单位的内容大小,并以可读格式显示(KB/MB)
|
||||
|
||||
### SSL验证
|
||||
|
||||
SSL证书验证可在每个节点上配置(`ssl_verify`参数)。这允许与自签名证书的内部服务连接,同时维护对外部API的安全性。
|
||||
|
||||
<Frame caption="动态API集成示例工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/090975269f8998f906c5636dde8d9540.png" alt="客户反馈分类工作流" />
|
||||
</Frame>
|
||||
|
||||
## 常见集成模式
|
||||
|
||||
**API数据获取** - 检索用户档案、产品信息或外部数据以丰富您的工作流处理。
|
||||
|
||||
**Webhook传递** - 发送通知、状态更新或处理结果到外部系统和服务。
|
||||
|
||||
**文件处理** - 上传文档以进行分析,下载资源以进行进一步处理,或与云存储服务集成。
|
||||
|
||||
**多步骤API工作流** - 将多个API调用链接在一起,使用一个请求的响应来配置后续请求。
|
||||
```
|
||||
73
zh-hans/documzh-hanstation/pages/nodes/ifelse.mdx
Normal file
73
zh-hans/documzh-hanstation/pages/nodes/ifelse.mdx
Normal file
@@ -0,0 +1,73 @@
|
||||
---
|
||||
title: "If-Else"
|
||||
description: "Add conditional logic and branching to workflows"
|
||||
icon: "code-branch"
|
||||
---
|
||||
|
||||
If-Else 节点通过根据您定义的条件将执行路由到不同路径,为您的工作流添加决策逻辑。它评估变量并确定您的工作流应该遵循哪个分支。
|
||||
|
||||
<Frame caption="If-Else 条件分支示例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d26ffff1b2ad0989d46e80d6812cf2e7.png" alt="带有条件逻辑的文本摘要工作流" />
|
||||
</Frame>
|
||||
|
||||
## 分支逻辑
|
||||
|
||||
该节点支持多个分支路径来处理复杂的决策树:
|
||||
|
||||
**IF 路径**在主要条件评估为真时执行。
|
||||
|
||||
**ELIF 路径**在 IF 条件为假时提供按顺序检查的附加条件。您可以为复杂逻辑添加多个 ELIF 分支。
|
||||
|
||||
**ELSE 路径**在没有条件匹配时作为后备,确保您的工作流始终有路径可遵循。
|
||||
|
||||
## 条件类型
|
||||
|
||||
配置条件以使用各种比较运算符测试变量:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="文本操作">
|
||||
**包含** / **不包含** - 检查文本是否包含特定单词或短语
|
||||
|
||||
**开头是** / **结尾是** - 测试文本开头或结尾的模式匹配
|
||||
|
||||
**是** / **不是** - 精确文本比较的精确值匹配
|
||||
</Tab>
|
||||
|
||||
<Tab title="值检查">
|
||||
**为空** / **不为空** - 检查空白、空值或缺失值
|
||||
|
||||
**大于** / **小于** - 数字和日期的数值比较
|
||||
|
||||
**等于** / **不等于** - 任何数据类型的精确匹配
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 复杂条件
|
||||
|
||||
使用逻辑运算符组合多个条件,实现复杂的决策:
|
||||
|
||||
<Frame caption="带有 AND/OR 逻辑的复杂条件配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/0b71ee7363e07298348e0c81e63481b0.png" alt="多条件判断" />
|
||||
</Frame>
|
||||
|
||||
**AND 逻辑**要求所有条件都为真。当您需要同时满足多个标准时使用此选项。
|
||||
|
||||
**OR 逻辑**要求任何条件为真。当您想要为不同场景触发相同操作时使用此选项。
|
||||
|
||||
## 变量引用
|
||||
|
||||
在条件中引用来自先前工作流节点的任何变量。变量可以来自用户输入、大型语言模型响应、API 调用或任何其他工作流节点输出。
|
||||
|
||||
使用变量选择器从可用变量中选择,或使用 `{{variable_name}}` 语法直接输入变量名。
|
||||
|
||||
## 常见模式
|
||||
|
||||
**内容路由** - 根据类别、语言或复杂性将不同类型的内容导向专门的处理节点。
|
||||
|
||||
**用户角色管理** - 根据用户权限、订阅级别或账户类型实现不同的工作流行为。
|
||||
|
||||
**错误处理** - 检查响应状态码、数据有效性或处理结果以适当地路由工作流。
|
||||
|
||||
**动态处理** - 根据输入特征、处理结果或外部条件调整工作流行为。
|
||||
|
||||
**多路径工作流** - 创建复杂的分支逻辑,处理应用程序中的各种场景和边缘情况。
|
||||
164
zh-hans/documzh-hanstation/pages/nodes/iteration.mdx
Normal file
164
zh-hans/documzh-hanstation/pages/nodes/iteration.mdx
Normal file
@@ -0,0 +1,164 @@
|
||||
```mdx
|
||||
---
|
||||
title: "迭代"
|
||||
description: "通过对每个元素应用工作流来处理数组"
|
||||
icon: "arrows-rotate"
|
||||
---
|
||||
|
||||
迭代节点通过在每个元素上顺序或并行运行相同的工作流步骤来处理数组。用于批处理任务,否则这些任务将达到限制或作为单一操作效率低下。
|
||||
|
||||
<Frame caption="迭代节点处理工作流">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/5f3f124c16b9e3565853f125f7db0e32.png" alt="迭代节点概览" />
|
||||
</Frame>
|
||||
|
||||
## 迭代如何工作
|
||||
|
||||
该节点接受一个数组输入,并创建一个子工作流,对每个数组元素运行一次。在每次迭代过程中,当前项目及其索引可作为变量供内部节点引用。
|
||||
|
||||
**核心组件:**
|
||||
- **输入变量** - 来自上游节点的数组数据
|
||||
- **内部工作流** - 对每个元素进行处理的步骤
|
||||
- **输出变量** - 从所有迭代中收集的结果(也是一个数组)
|
||||
|
||||
## 配置
|
||||
|
||||
### 数组输入
|
||||
|
||||
连接来自上游节点的数组变量,如参数提取器、代码节点、知识检索或 HTTP 请求响应。
|
||||
|
||||
### 内置变量
|
||||
|
||||
每次迭代提供访问:
|
||||
- `items[object]` - 当前正在处理的数组元素
|
||||
- `index[number]` - 当前迭代索引(从 0 开始)
|
||||
|
||||
### 处理模式
|
||||
|
||||
<Tabs>
|
||||
<Tab title="顺序模式">
|
||||
**顺序处理** - 按顺序逐个处理项目
|
||||
|
||||
**流式支持** - 可以使用答案节点逐步输出结果
|
||||
|
||||
**资源管理** - 较低的内存使用,预测执行顺序
|
||||
|
||||
**最佳适用** - 当顺序很重要或使用流式输出时
|
||||
</Tab>
|
||||
|
||||
<Tab title="并行模式">
|
||||
**并发处理** - 最多同时处理 10 个项目
|
||||
|
||||
**性能提升** - 独立操作的更快执行
|
||||
|
||||
**批处理** - 高效处理大型数组
|
||||
|
||||
**最佳适用** - 顺序不重要的独立操作
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Frame caption="顺序与并行处理对比">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/2656dec26d6357556a280fcd69ccd9a7.png" alt="处理模式比较" />
|
||||
</Frame>
|
||||
|
||||
<Frame caption="在迭代设置中启用并行模式">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/516af5e7427fce9a58fa9d9b583230d4.png" alt="并行模式设置" />
|
||||
</Frame>
|
||||
|
||||
## 错误处理
|
||||
|
||||
配置如何处理单个数组元素的处理失败:
|
||||
|
||||
**终止** - 发生任何错误时停止处理并返回错误信息
|
||||
|
||||
**继续错误** - 跳过失败的项目并继续处理,输出失败元素的 null
|
||||
|
||||
**移除失败结果** - 跳过失败的项目,仅返回成功的结果
|
||||
|
||||
输入输出对应示例:
|
||||
- 输入: `[1, 2, 3]`
|
||||
- 继续错误的输出: `[result-1, null, result-3]`
|
||||
- 移除失败的输出: `[result-1, result-3]`
|
||||
|
||||
## 长文生成示例
|
||||
|
||||
通过分别处理章节大纲生成长篇内容:
|
||||
|
||||
<Frame caption="长文生成工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/3a403551d48b178d0a41ce2a5748dd2d.png" alt="长篇故事生成器" />
|
||||
</Frame>
|
||||
|
||||
**工作流步骤:**
|
||||
|
||||
1. **起始节点** - 用户提供故事标题和大纲
|
||||
2. **大型语言模型 (LLM) 节点** - 生成详细的章节分解
|
||||
3. **参数提取器** - 将章节列表转换为结构化数组
|
||||
4. **迭代节点** - 使用内部大型语言模型处理每个章节
|
||||
5. **答案节点** - 在生成过程中流式输出章节内容
|
||||
|
||||
<Frame caption="故事输入的起始节点配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/3af1c2ed0df00f19e584bcf511302f55.png" alt="起始节点设置" />
|
||||
</Frame>
|
||||
|
||||
<Frame caption="章节结构的参数提取">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d3beee536ff3c35f4e1eb1ab610f35d7.png" alt="参数提取设置" />
|
||||
</Frame>
|
||||
|
||||
<Frame caption="LLM 处理的迭代配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/ac91582998868004b298afe2f04e5589.png" alt="迭代节点配置" />
|
||||
</Frame>
|
||||
|
||||
<Info>
|
||||
参数提取效果取决于模型能力和指令质量。使用更强的模型并在指令中提供示例以改善结果。
|
||||
</Info>
|
||||
|
||||
## 输出处理
|
||||
|
||||
迭代节点输出的数组通常需要转换以便最终使用:
|
||||
|
||||
### 将数组转换为文本
|
||||
|
||||
<Tabs>
|
||||
<Tab title="使用代码节点">
|
||||
```python
|
||||
def main(articleSections: list):
|
||||
return {
|
||||
"result": "\n".join(articleSections)
|
||||
}
|
||||
```
|
||||
|
||||
<Frame caption="代码节点数组转换">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/8be2372b00a802e981efe6f0ceff815b.png" alt="代码节点转换" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
|
||||
<Tab title="使用模板节点">
|
||||
```jinja2
|
||||
{{ articleSections | join("\n") }}
|
||||
```
|
||||
|
||||
<Frame caption="模板节点数组转换">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/8c0bcc5de453dea2776d2755449bd971.png" alt="模板节点转换" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 常见用例
|
||||
|
||||
**标记限制管理** - 在内容超过大型语言模型上下文窗口时,将大文本分段进行翻译、总结或分析。
|
||||
|
||||
**批处理** - 高效地对多个项目应用相同操作,如处理多个文档或 API 调用。
|
||||
|
||||
**质量控制** - 单独处理项目以保持质量,并优雅地处理错误,而不是冒整个批次失败的风险。
|
||||
|
||||
**渐进输出** - 结果完成时逐步流式输出,而不是等待所有处理完成。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**选择合适的模式** - 对于有序处理或流式输出使用顺序模式,对于需要速度的独立操作使用并行模式。
|
||||
|
||||
**优雅地处理错误** - 根据部分失败是否应停止处理或跳过,配置错误处理。
|
||||
|
||||
**优化内部工作流** - 保持迭代子工作流高效,因为它们会多次运行。
|
||||
|
||||
**监控资源使用** - 带有复杂处理的大型数组会消耗大量资源,尤其是在并行模式下。
|
||||
```
|
||||
@@ -0,0 +1,93 @@
|
||||
```mdx
|
||||
---
|
||||
title: "知识检索"
|
||||
description: "Search knowledge bases for relevant information"
|
||||
icon: "database"
|
||||
---
|
||||
|
||||
知识检索节点在您的知识库中搜索相关信息,并返回上下文内容以供下游节点使用。通过提供文档中的特定信息,它支持检索增强生成 (RAG) 应用。
|
||||
|
||||
<Frame caption="知识检索节点配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/d90961c6d794d425a8e11df177315188.png" alt="Knowledge Retrieval Node Interface" />
|
||||
</Frame>
|
||||
|
||||
<Info>
|
||||
在使用此节点之前,请创建并填充知识库。有关设置说明,请参阅[知识库创建指南](/en/guides/knowledge-base/create-knowledge-and-upload-documents)。
|
||||
</Info>
|
||||
|
||||
## 配置
|
||||
|
||||
### 查询和知识库选择
|
||||
|
||||
**查询**决定了在您的知识库中要搜索的内容。在对话流应用中使用 `sys.query` 进行用户输入,或使用工作流中的任何文本变量。查询限制为 200 个字符。
|
||||
|
||||
选择一个或多个**知识库**进行搜索。每个知识库包含您上传到 Dify 的索引文档。可以使用不同的策略同时搜索多个知识库。
|
||||
|
||||
### 检索策略
|
||||
|
||||
选择如何搜索您的内容:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="语义检索">
|
||||
使用向量嵌入来根据含义查找概念上相似的内容。适用于自然语言查询和使用不同术语的相关概念。
|
||||
</Tab>
|
||||
|
||||
<Tab title="关键词检索">
|
||||
传统的全文检索用于精确的词匹配。对于特定术语、代码或名称,速度更快且更可预测。
|
||||
</Tab>
|
||||
|
||||
<Tab title="混合检索">
|
||||
结合语义和关键词方法。结果使用专门的模型重新排序以提高相关性。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 高级设置
|
||||
|
||||
<Frame caption="高级检索配置选项">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/fbd43d558f83b355a1b18ac26a253b84.png" alt="Knowledge retrieval configuration interface" />
|
||||
</Frame>
|
||||
|
||||
### 检索参数
|
||||
|
||||
**Top K** 控制要检索的文档分段数量。开始时选择 3-5 个分段以获得集中结果,或选择 10-15 个分段以获得全面覆盖。
|
||||
|
||||
**分数阈值**设置最低相似度分数。较高的阈值(0.7+)确保相关性,较低的阈值(0.5-)包括更多边缘内容。
|
||||
|
||||
**重新排序**在初始检索后重新评分结果。启用于混合检索、多个分段,或当精度优先于速度时。
|
||||
|
||||
### 元数据筛选
|
||||
|
||||
使用文档的元数据(如类型、日期或部门)来筛选结果。上传文档时设置元数据,以便在大型知识库中实现有针对性的搜索。
|
||||
|
||||
### 多知识库策略
|
||||
|
||||
**N 对 1 召回**使用函数调用分析查询,选择合适的知识库并优化搜索。适用于不同领域的专业知识库。
|
||||
|
||||
**多路召回**同时查询所有选定的知识库并合并结果。当信息跨多个来源或需要全面覆盖时使用。
|
||||
|
||||
<Frame caption="多知识库检索策略比较">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/4a3007cda9dfa50ddac3711693725dce.png" alt="Retrieval Mode Comparison" />
|
||||
</Frame>
|
||||
|
||||
## 输出与集成
|
||||
|
||||
节点输出包含文本内容和元数据(来源、分数、文档 ID)的检索文档分段数组。此结构化输出保留了引用所需的信息。
|
||||
|
||||
### RAG 集成
|
||||
|
||||
将知识检索输出连接到 LLM 节点上下文输入以用于 RAG 应用。当使用检索结果作为上下文变量时,Dify 会自动跟踪来源并启用引用。
|
||||
|
||||
```text
|
||||
System: Answer based on the provided context.
|
||||
Context: {{knowledge_retrieval.result}}
|
||||
User: {{user_question}}
|
||||
```
|
||||
|
||||
### 速率限制
|
||||
|
||||
知识检索操作受限于您的订阅计划的速率限制。系统使用 Redis 通过 60 秒滑动窗口跟踪请求。当超过限额时,返回 `RateLimitExceeded` 错误。
|
||||
|
||||
### 性能考量
|
||||
|
||||
检索质量取决于索引实践。较小的分段(200-500 标记)实现精确检索,较大的分段(800-1500 标记)保持上下文。知识库有速率限制 - 节点自动处理节流并缓存相同的查询。
|
||||
```
|
||||
124
zh-hans/documzh-hanstation/pages/nodes/list-operator.mdx
Normal file
124
zh-hans/documzh-hanstation/pages/nodes/list-operator.mdx
Normal file
@@ -0,0 +1,124 @@
|
||||
```mdx
|
||||
---
|
||||
title: "列表运算符"
|
||||
description: "从数组中筛选、排序和选择元素"
|
||||
icon: "filter"
|
||||
---
|
||||
|
||||
列表运算符节点通过筛选、排序和选择特定元素来处理数组。当您需要处理混合文件上传、大型数据集或任何需要在下游处理前进行分离或组织的数组数据时,请使用它。
|
||||
|
||||
<Frame caption="列表运算符节点界面">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/522a0c932aab93d4f3970168412f759e.png" alt="列表运算符界面" />
|
||||
</Frame>
|
||||
|
||||
## 数组处理问题
|
||||
|
||||
大多数工作流节点期望单个值,而不是数组。当您在一个变量中拥有像 `[image.png, document.pdf, audio.mp3]` 这样的混合内容时,您需要将其分离成下游节点可以有效处理的专注流。
|
||||
|
||||
列表运算符充当智能路由器,使用过滤器分离混合数组并为专业处理做好准备。
|
||||
|
||||
<Frame caption="数组处理工作流示例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/812d1b2f167065e17df8392b2cb3cc8a.png" alt="数组处理示例" />
|
||||
</Frame>
|
||||
|
||||
## 支持的数据类型
|
||||
|
||||
该节点处理不同类型的数组,提供适当的过滤选项:
|
||||
|
||||
**Array[string]** - 文本列表、类别、名称或任何字符串集合
|
||||
|
||||
**Array[number]** - 数字数据、分数、测量或计算
|
||||
|
||||
**Array[file]** - 混合文件上传,具有丰富的元数据筛选功能
|
||||
|
||||
## 操作
|
||||
|
||||
### 筛选
|
||||
|
||||
根据属性提取特定项目。对于文件数组,可以根据以下进行筛选:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="内容属性">
|
||||
**类型** - 根据内容类别筛选:图像、文档、音频、视频
|
||||
|
||||
**MIME 类型** - 精确的内容类型识别(如 image/jpeg, application/pdf 等)
|
||||
|
||||
**扩展名** - 文件扩展名(如 .pdf, .jpg, .mp3, .docx 等)
|
||||
</Tab>
|
||||
|
||||
<Tab title="文件属性">
|
||||
**大小** - 处理限制的文件大小约束
|
||||
|
||||
**名称** - 文件名模式或特定名称
|
||||
|
||||
**传输方式** - 区分本地上传和基于 URL 的文件
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 排序
|
||||
|
||||
根据任何属性组织筛选结果:
|
||||
|
||||
**升序 (ASC)** - 从最小到最大值,A-Z 字母顺序
|
||||
|
||||
**降序 (DESC)** - 从最大到最小值,Z-A 反向顺序
|
||||
|
||||
### 选择
|
||||
|
||||
从处理过的数组中选择特定元素:
|
||||
|
||||
**取前 N 个** - 筛选和排序后选择前 1-20 个项目
|
||||
|
||||
**第一个记录** - 仅返回第一个匹配元素作为单个值
|
||||
|
||||
**最后一个记录** - 仅返回最后一个匹配元素作为单个值
|
||||
|
||||
## 输出变量
|
||||
|
||||
**result** - 用于批量处理的完整筛选和排序数组
|
||||
|
||||
**first_record** - 从开头的单个元素,适合用于“主要”或“最新”项目选择
|
||||
|
||||
**last_record** - 从末尾的单个元素,适用于“最近”或“最终”选择
|
||||
|
||||
## 混合文件处理示例
|
||||
|
||||
处理用户上传文档和图像的工作流:
|
||||
|
||||
<Frame caption="混合文件处理工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/610358293217e54b55b7e1d4d16bf83c.png" alt="混合文件处理示例" />
|
||||
</Frame>
|
||||
|
||||
**实施步骤:**
|
||||
|
||||
1. **配置混合上传** - 启用文件上传功能以接受多种文件类型
|
||||
2. **按类型拆分** - 使用不同的筛选器配置单独的列表运算符节点:
|
||||
- 筛选 `type = "image"` → 路由至具有视觉能力的LLM
|
||||
- 筛选 `type = "document"` → 路由至文档提取器
|
||||
3. **适当处理** - 图像直接分析,文档进行文本提取
|
||||
4. **合并结果** - 将处理过的输出合并为统一的响应
|
||||
|
||||
此模式自动将不同文件类型路由到适当的处理器,创造无缝的多模态用户体验。
|
||||
|
||||
## 常见用例
|
||||
|
||||
**文件类型路由** - 根据内容类型将混合上传分离到专业处理管道中。
|
||||
|
||||
**数据筛选** - 根据特定标准从大型数据集中提取相关子集。
|
||||
|
||||
**内容优先级** - 从集合中排序并选择最重要或最近的项目。
|
||||
|
||||
**质量控制** - 在处理之前筛选掉无效、超大的或不支持的内容。
|
||||
|
||||
**批处理准备** - 将数据组织成可管理的块,以便下游迭代或并行处理。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**规划过滤条件** - 根据您的下游处理需求定义清晰的过滤规则。
|
||||
|
||||
**使用适当的输出类型** - 根据下游节点如何使用数据,选择完整数组、第一个记录或最后一个记录。
|
||||
|
||||
**处理空结果** - 考虑当过滤器没有返回匹配项时会发生什么,并规划适当的备用逻辑。
|
||||
|
||||
**使用真实数据测试** - 使用实际用户上传验证过滤行为,确保在生产中可靠运行。
|
||||
```
|
||||
136
zh-hans/documzh-hanstation/pages/nodes/llm.mdx
Normal file
136
zh-hans/documzh-hanstation/pages/nodes/llm.mdx
Normal file
@@ -0,0 +1,136 @@
|
||||
```mdx
|
||||
---
|
||||
title: "大型语言模型 (LLM)"
|
||||
description: "Invoke language models for text generation and analysis"
|
||||
icon: "brain"
|
||||
---
|
||||
|
||||
LLM 节点调用大型语言模型来处理文本、图像和文档。它向您配置的模型发送提示词并捕获其响应,支持结构化输出、上下文管理和多模态输入。
|
||||
|
||||
<Frame caption="LLM 节点配置界面">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/85730fbfa1d441d12d969b89adf2670e.png" alt="LLM 节点概览" />
|
||||
</Frame>
|
||||
|
||||
<Info>
|
||||
在使用 LLM 节点之前,请在 **System Settings → Model Providers** 中配置至少一个模型提供商。设置说明请参阅[模型配置指南](/en/guides/model-configuration/readme)。
|
||||
</Info>
|
||||
|
||||
## 模型选择与参数
|
||||
|
||||
从您配置的任何模型提供商中选择。不同的模型擅长不同的任务 - GPT-4 和 Claude 3.5 能够很好地处理复杂推理但成本较高,而 GPT-3.5 Turbo 在性能和经济性之间取得了平衡。对于本地部署,请使用 Ollama、LocalAI 或 Xinference。
|
||||
|
||||
<Frame caption="模型选择与参数配置">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/43f81418ea70d4d79e3705505e777b1b.png" alt="LLM 节点配置" />
|
||||
</Frame>
|
||||
|
||||
模型参数控制响应生成。**温度**范围从 0(确定性)到 1(创意性)。**核采样**通过概率限制词汇选择。**频率惩罚**减少重复。**存在惩罚**鼓励新主题。您还可以使用预设:**精确**、**平衡**或**创意**。
|
||||
|
||||
## 提示词配置
|
||||
|
||||
您的界面会根据模型类型进行调整。聊天模型使用消息角色(**System** 用于行为,**User** 用于输入,**Assistant** 用于示例),而完成模型使用简单的文本续写。
|
||||
|
||||
在提示词中使用双花括号引用工作流变量:`{{variable_name}}`。变量会在到达模型之前被实际值替换。
|
||||
|
||||
```text
|
||||
System: 您是一位技术文档专家。
|
||||
User: {{user_input}}
|
||||
```
|
||||
|
||||
## 上下文变量
|
||||
|
||||
上下文变量在保留来源归属的同时注入外部知识。这使得通过检索增强生成 (RAG) 应用程序,LLM 能够使用您特定的文档回答问题。
|
||||
|
||||
<Frame caption="在 RAG 应用程序中使用上下文变量">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/5aefed96962bd994f8f05bac96b11e22.png" alt="上下文变量" />
|
||||
</Frame>
|
||||
|
||||
将知识检索节点的输出连接到您的 LLM 节点的上下文输入,然后引用它:
|
||||
|
||||
```text
|
||||
仅使用此上下文回答:
|
||||
{{knowledge_retrieval.result}}
|
||||
|
||||
问题: {{user_question}}
|
||||
```
|
||||
|
||||
使用知识检索的上下文变量时,Dify 会自动跟踪引用,以便用户查看信息来源。
|
||||
|
||||
## 结构化输出
|
||||
|
||||
强制模型返回特定的数据格式,如 JSON,以便程序使用。通过三种方法进行配置:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="可视化编辑器">
|
||||
用户友好的界面用于简单结构。添加具有名称和类型的字段,标记必填字段,设置描述。编辑器会自动生成 JSON Schema。
|
||||
</Tab>
|
||||
|
||||
<Tab title="JSON Schema">
|
||||
直接编写用于复杂结构的 Schema,包括嵌套对象、数组和验证规则。
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"sentiment": {
|
||||
"type": "string",
|
||||
"enum": ["positive", "negative", "neutral"]
|
||||
}
|
||||
},
|
||||
"required": ["sentiment"]
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
|
||||
<Tab title="AI 生成">
|
||||
用简单语言描述需求,让 AI 生成 Schema。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Warning>
|
||||
支持原生 JSON 的模型可以可靠地处理结构化输出。对于其他模型,Dify 会在提示词中包含 Schema,但结果可能有所不同。
|
||||
</Warning>
|
||||
|
||||
## 记忆与文件处理
|
||||
|
||||
启用**记忆**以在工作流运行中的多个 LLM 调用间保持上下文。节点在后续提示词中包含先前的交互。记忆是节点特定的,并且不会在工作流运行之间持久化。
|
||||
|
||||
对于**文件处理**,将文件变量添加到多模态模型的提示词中。GPT-4V 处理图像,Claude 直接处理 PDF,而其他模型可能需要预处理。
|
||||
|
||||
### 视觉配置
|
||||
|
||||
处理图像时,您可以控制细节级别:
|
||||
- **高细节** - 对复杂图像的准确性更高,但会使用更多标记
|
||||
- **低细节** - 对简单图像处理更快,标记更少
|
||||
|
||||
视觉的默认变量选择器是 `sys.files`,它会自动从起始节点接收文件。
|
||||
|
||||
<Frame caption="使用多模态 LLM 进行文件处理">
|
||||
<img src="https://assets-docs.dify.ai/2024/11/05b3d4a78038bc7afbb157078e3b2b26.png" alt="文件处理" />
|
||||
</Frame>
|
||||
|
||||
对于完成模型中的对话历史,将对话变量插入以保持多轮对话上下文:
|
||||
|
||||
<Frame caption="使用对话历史变量">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/b8642f8c6e3f562fceeefae83628fd68.png" alt="对话历史" />
|
||||
</Frame>
|
||||
|
||||
## Jinja2 模板支持
|
||||
|
||||
LLM 提示词支持 Jinja2 模板以进行高级变量处理。当您使用 Jinja2 模式(`edition_type: "jinja2"`)时,您可以:
|
||||
|
||||
```jinja2
|
||||
{% for item in search_results %}
|
||||
{{ loop.index }}. {{ item.title }}: {{ item.content }}
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
Jinja2 变量与常规变量替换分开处理,允许在提示词中进行循环、条件和复杂的数据转换。
|
||||
|
||||
## 流式输出
|
||||
|
||||
LLM 节点默认支持流式输出。每个文本块作为 `RunStreamChunkEvent` 被传递,启用实时响应显示。文件输出(图像、文档)在流式传输期间自动处理并保存。
|
||||
|
||||
## 错误处理
|
||||
|
||||
配置失败的 LLM 调用的重试行为。设置最大重试次数、重试间隔和回退倍数。当重试不足时,定义备用策略,如默认值、错误路由或备用模型。
|
||||
```
|
||||
117
zh-hans/documzh-hanstation/pages/nodes/loop.mdx
Normal file
117
zh-hans/documzh-hanstation/pages/nodes/loop.mdx
Normal file
@@ -0,0 +1,117 @@
|
||||
---
|
||||
title: "循环"
|
||||
description: "Execute repetitive workflows with progressive refinement"
|
||||
icon: "infinity"
|
||||
---
|
||||
|
||||
循环节点执行重复性工作流,每个周期都建立在前一个周期的结果基础上。与迭代独立处理数组元素不同,循环创建的是随每次重复而演进的渐进式工作流。
|
||||
|
||||
## 循环 vs 迭代
|
||||
|
||||
了解何时使用每种重复模式:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="循环">
|
||||
**顺序处理** - 每个周期依赖于之前的结果
|
||||
|
||||
**渐进式优化** - 输出在迭代过程中改进或演化
|
||||
|
||||
**状态管理** - 变量在周期间持续存在并累积
|
||||
|
||||
**使用场景** - 内容优化、问题解决、质量保证
|
||||
</Tab>
|
||||
|
||||
<Tab title="迭代">
|
||||
**独立处理** - 每个项目分别处理
|
||||
|
||||
**并行执行** - 项目可以同时处理
|
||||
|
||||
**批量操作** - 对多个数据点应用相同操作
|
||||
|
||||
**使用场景** - 数据转换、批量处理、并行分析
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 配置
|
||||
|
||||
### 循环变量
|
||||
|
||||
定义在循环迭代间持续存在并在循环完成后保持可访问的变量。这些变量维护状态并启用渐进式工作流。
|
||||
|
||||
### 终止条件
|
||||
|
||||
配置循环何时应停止执行:
|
||||
|
||||
**循环终止条件** - 确定何时退出的表达式(例如,`quality_score > 0.9`)
|
||||
|
||||
**最大循环次数** - 防止无限循环的安全限制
|
||||
|
||||
**退出循环节点** - 到达此节点时立即终止
|
||||
|
||||
<Info>
|
||||
当终止条件满足、达到最大次数或执行退出循环节点时,循环终止。如果未指定条件,循环将继续直到达到最大次数。
|
||||
</Info>
|
||||
|
||||
## 基础循环示例
|
||||
|
||||
生成随机数直到找到一个小于50的数:
|
||||
|
||||
<Frame caption="随机数生成的基础循环工作流">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/282013c48b46d3cc4ebf99323da10a31.png" alt="Basic loop workflow" />
|
||||
</Frame>
|
||||
|
||||
**工作流步骤:**
|
||||
1. **代码节点** 生成1-100之间的随机整数
|
||||
2. **条件分支节点** 检查数字是否小于50
|
||||
3. **模板节点** 为小于50的数字返回"done"以触发循环终止
|
||||
4. 循环继续直到满足终止条件
|
||||
|
||||
<Frame caption="循环执行步骤和结果">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/9d9fb4db7093521000ac735a26f86962.png" alt="Loop execution steps" />
|
||||
</Frame>
|
||||
|
||||
## 高级循环示例
|
||||
|
||||
通过迭代优化创建诗歌,每个版本都建立在前一个版本的基础上:
|
||||
|
||||
<video controls src="https://assets-docs.dify.ai/2025/04/7ecfc04458aa38e721baaa5f6355486c.mp4" width="100%" />
|
||||
|
||||
**循环变量:**
|
||||
- `num` - 从0开始的计数器,每次迭代递增
|
||||
- `verse` - 保存当前诗歌版本的文本变量
|
||||
|
||||
**工作流逻辑:**
|
||||
1. **条件分支节点** 检查`num > 3`以确定何时退出
|
||||
2. **大型语言模型节点** 基于前一版本生成改进的诗歌
|
||||
3. **变量分配器** 更新计数器和诗歌内容
|
||||
4. **退出循环节点** 在4次优化周期后终止
|
||||
|
||||
大型语言模型提示词同时引用当前诗句和迭代上下文:
|
||||
|
||||
```text
|
||||
You are a European literary figure creating poetic verses.
|
||||
|
||||
Current verse: {{verse}}
|
||||
|
||||
Refine and improve this poem based on your previous work.
|
||||
```
|
||||
|
||||
## 常见使用场景
|
||||
|
||||
**内容优化** - 通过多次大型语言模型审查逐步改进文本、代码或设计,直到达到质量标准。
|
||||
|
||||
**问题解决** - 将复杂问题分解为迭代步骤,每个周期基于之前的进展处理下一个逻辑部分。
|
||||
|
||||
**研究工作流** - 基于每个现,迭代搜索、分析和优化研究查询。
|
||||
|
||||
**质量保证** - 反复测试和验证输出,进行改进直到满足所有标准。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**定义清晰的退出条件** - 确保循环具有具体的、可测量的终止条件,以防止无限执行。
|
||||
|
||||
**设置合理限制** - 根据预期复杂性和处理要求使用适当的最大迭代次数。
|
||||
|
||||
**有效管理状态** - 使用循环变量在迭代间维护必要信息,同时避免不必要的数据累积。
|
||||
|
||||
**监控进度** - 包含日志记录或进度指示器来跟踪循环执行,特别是对于长时间运行的进程。
|
||||
@@ -0,0 +1,82 @@
|
||||
---
|
||||
title: "参数提取器"
|
||||
description: "Convert natural language to structured data using LLM intelligence"
|
||||
icon: "crop-simple"
|
||||
---
|
||||
|
||||
参数提取器节点使用大型语言模型智能将非结构化文本转换为结构化数据。它连接了自然语言输入与工具、API 和其他工作流节点所需的结构化参数之间的鸿沟。
|
||||
|
||||
## 配置
|
||||
|
||||
### 输入和模型选择
|
||||
|
||||
选择包含您想要提取参数的文本的**输入变量**。这通常来自用户输入、大型语言模型响应或其他工作流节点。
|
||||
|
||||
选择一个具有强大结构化输出能力的**模型**。参数提取器依赖于大型语言模型理解上下文并生成结构化 JSON 响应的能力。
|
||||
|
||||
### 参数定义
|
||||
|
||||
通过指定以下内容来定义您想要提取的参数:
|
||||
|
||||
- **参数名称** - 将出现在输出 JSON 中的键
|
||||
- **数据类型** - 字符串、数字、布尔值、数组或对象
|
||||
- **描述** - 帮助大型语言模型理解要提取什么
|
||||
- **必需状态** - 参数是否必须存在
|
||||
|
||||
您可以手动定义参数或**从现有工具快速导入**以匹配下游节点的参数要求。
|
||||
|
||||
### 提取指令
|
||||
|
||||
编写清晰的指令,描述要提取什么信息以及如何格式化。在指令中提供示例可以提高复杂参数的提取准确性和一致性。
|
||||
|
||||
<Frame caption="Arxiv 论文检索的参数提取">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/a8bae4106a015c76ebb0a165f2409458.png" alt="Arxiv Paper Retrieval Tool" />
|
||||
</Frame>
|
||||
|
||||
## 高级配置
|
||||
|
||||
### 推理模式
|
||||
|
||||
根据您的模型能力,在两种提取方法之间选择:
|
||||
|
||||
**函数调用/工具调用**使用模型的结构化输出功能进行可靠的参数提取,具有强大的类型合规性。
|
||||
|
||||
**基于提示词的**依靠纯提示词进行提取,适用于可能不支持函数调用的模型,或当基于提示词的提取表现更好时使用。
|
||||
|
||||
### 记忆
|
||||
|
||||
启用记忆功能,在提取参数时包含对话历史。这有助于大型语言模型理解交互式对话中的上下文,并提高对话式工作流的提取准确性。
|
||||
|
||||
## 输出变量
|
||||
|
||||
该节点提供提取的参数和内置状态变量:
|
||||
|
||||
**提取的参数**显示为与您的参数定义匹配的单个变量,可供下游节点使用。
|
||||
|
||||
**内置变量**包括状态信息:
|
||||
- `__is_success` - 提取成功状态(1 表示成功,0 表示失败)
|
||||
- `__reason` - 提取失败时的错误描述
|
||||
|
||||
<Frame caption="数据格式转换示例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/71d8e48d842342668f92e6dd84fc03c1.png" alt="Data format conversion workflow" />
|
||||
</Frame>
|
||||
|
||||
## 常见用例
|
||||
|
||||
**工具参数准备**从自然语言中提取特定参数,用于需要结构化输入的工作流工具。
|
||||
|
||||
**数据格式转换**将文本转换为其他节点所需的格式,例如将列表转换为数组以进行迭代处理。
|
||||
|
||||
**API 请求准备**为向外部服务发送的 HTTP 请求构造数据,处理从用户意图到 API 兼容参数的转换。
|
||||
|
||||
**表单数据处理**从自由形式的用户输入中提取结构化信息,用于数据库存储或进一步处理。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**清晰的参数描述**帮助大型语言模型准确理解要提取什么信息以及采用什么格式。
|
||||
|
||||
**在指令中提供示例**以提高提取准确性,特别是对于复杂或特定领域的参数。
|
||||
|
||||
**使用适当的数据类型**确保提取的参数匹配下游节点的要求。
|
||||
|
||||
**处理提取失败**通过检查 `__is_success` 变量并在提取失败时提供后备逻辑。
|
||||
@@ -0,0 +1,83 @@
|
||||
```mdx
|
||||
---
|
||||
title: "问题分类器"
|
||||
description: "智能地对用户输入进行分类以引导工作流路径"
|
||||
icon: "sitemap"
|
||||
---
|
||||
|
||||
问题分类器节点智能地对用户输入进行分类,从而将对话引导到不同的工作流路径。与其构建复杂的条件逻辑,不如定义类别,让大型语言模型(LLM)基于语义理解来确定最合适的类别。
|
||||
|
||||
## 配置
|
||||
|
||||
### 输入和模型设置
|
||||
|
||||
**输入变量** - 选择要分类的内容,通常为用户问题的`sys.query`,但也可以是来自先前工作流节点的任何文本变量。
|
||||
|
||||
**模型选择** - 选择用于分类的LLM。对于简单类别,速度较快的模型效果很好,而更强大的模型可以更好地处理细微的区别。
|
||||
|
||||
<Frame caption="问题分类器配置界面">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/2f039c5ff3f095b0eed291101d9bff15.png" alt="问题分类器设置" />
|
||||
</Frame>
|
||||
|
||||
### 类别定义
|
||||
|
||||
为每个类别创建明确的描述性标签,并对每个类别包含的内容进行具体描述。准确界定类别之间的界限,以帮助LLM做出准确的决策。
|
||||
|
||||
每个类别都成为一个潜在的输出路径,您可以将其连接到不同的下游节点,如专业知识库、响应模板或处理工作流。
|
||||
|
||||
## 分类示例
|
||||
|
||||
以下是在客户服务场景中问题分类器的工作方式:
|
||||
|
||||
<Frame caption="客户服务分类工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/2f06ecce149c844c23be70a8fcff09bc.png" alt="客户服务分类" />
|
||||
</Frame>
|
||||
|
||||
**定义的类别:**
|
||||
- **售后服务** - 保修索赔、退货、维修和购买后的支持
|
||||
- **产品使用** - 设置说明、故障排除、功能说明
|
||||
- **其他问题** - 不属于特定类别的常规咨询
|
||||
|
||||
**分类结果:**
|
||||
- “如何在iPhone 14上设置联系人?” → **产品使用**
|
||||
- “我的购买保修期是多久?” → **售后服务**
|
||||
- “今天的天气怎么样?” → **其他问题**
|
||||
|
||||
每个分类结果都会引导到不同的知识库和响应策略,确保用户获得相关的专业帮助。
|
||||
|
||||
## 高级配置
|
||||
|
||||
### 指导和准则
|
||||
|
||||
在**指导**字段中添加详细的分类指南,以处理边缘案例、模糊场景或特定的业务规则。这有助于LLM理解类别之间的细微区别。
|
||||
|
||||
### 记忆集成
|
||||
|
||||
启用**记忆**以在分类输入时包含对话历史。这改善了多轮对话中准确性,其中当前输入依赖于先前的上下文。
|
||||
|
||||
**记忆窗口**控制要包含多少对话历史,在上下文感知与标记效率和处理速度之间取得平衡。
|
||||
|
||||
## 输出使用
|
||||
|
||||
分类器输出一个包含匹配类别标签的`class_name`变量。使用此变量在下游节点中进行:
|
||||
|
||||
**条件路由** - 根据分类结果连接不同的工作流路径
|
||||
|
||||
**知识库选择** - 为每个类别路由到专业知识库
|
||||
|
||||
**响应定制** - 应用不同的响应模板或处理逻辑
|
||||
|
||||
**分析和日志记录** - 跟踪用户查询在各个类别中的分布
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**清晰的类别界限** - 定义明确的、不重叠的类别,并提供具体的描述以提高分类准确性。
|
||||
|
||||
**合适的模型选择** - 根据分类复杂性选择模型。简单的二元分类适合速度较快的模型,而复杂的多类别分类可能需要更强大的模型。
|
||||
|
||||
**测试边缘案例** - 使用可能适合多个类别的模糊输入验证分类行为。
|
||||
|
||||
**使用对话上下文** - 为需要依赖先前交互的分类应用启用记忆。
|
||||
|
||||
**监控和迭代** - 审核分类结果并根据实际使用模式优化类别描述。
|
||||
```
|
||||
89
zh-hans/documzh-hanstation/pages/nodes/start.mdx
Normal file
89
zh-hans/documzh-hanstation/pages/nodes/start.mdx
Normal file
@@ -0,0 +1,89 @@
|
||||
```mdx
|
||||
---
|
||||
title: "开始"
|
||||
description: "工作流和对话流应用程序的入口点"
|
||||
icon: "play"
|
||||
---
|
||||
|
||||
Start节点是每个工作流和对话流应用程序的入口点。它定义了您的应用程序从终端用户接受的输入,并提供您可以在整个工作流中引用的系统变量。
|
||||
|
||||
## 输入变量
|
||||
|
||||
您可以在Start节点中配置自定义输入字段以收集用户信息。每个输入字段都会成为流经您的工作流的变量。例如,如果您创建一个名为 `user_name` 的输入字段,您可以在工作流中的任何地方引用它,如 `{{user_name}}`。
|
||||
|
||||
### 输入类型
|
||||
|
||||
Start节点支持六种输入类型以处理不同类型的用户数据:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="文本输入">
|
||||
**Text** 接受最多256个字符的简短响应。适用于姓名、电子邮件地址、标题或任何适合单行的简短文本输入。
|
||||
|
||||
**Paragraph** 接受不限字符数的长文本。这为用户提供了一个多行文本区域,用于详细响应、描述或任何需要更多空间的内容。
|
||||
</Tab>
|
||||
|
||||
<Tab title="结构化输入">
|
||||
**Select** 向用户呈现一个预定义选项的下拉菜单。用户只能从您指定的选项中选择,确保数据一致性并防止出现意外输入。
|
||||
|
||||
**Number** 仅限输入数值。这对于数量、评分、ID或您需要在工作流中进行数学处理的任何数据都是必需的。
|
||||
</Tab>
|
||||
|
||||
<Tab title="文件输入">
|
||||
**Single File** 允许用户上传一个任何支持类型的文件。用户可以从他们的设备上传或提供文件的URL。该文件在您的工作流中作为文件变量可用。
|
||||
|
||||
**File List** 的工作方式与单个文件相似,但支持一次性上传多个文件。这在一起处理批量文档、图像或其他文件时非常有用。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
<Info>
|
||||
当用户上传文件时,Dify的文档提取器可以自动处理PDF、Word文档和大多数文本格式。对于图像、音频或视频文件,您需要在工作流中连接适当的处理节点。
|
||||
</Info>
|
||||
|
||||
## 系统变量
|
||||
|
||||
除了您的自定义输入外,Start节点提供的系统变量可以让您访问工作流元数据和上下文。这些变量是自动可用的,不能被修改。
|
||||
|
||||
<Frame caption="工作流和对话流应用程序中可用的系统变量">
|
||||
<img src="/images/2bc13695bb7c41fe54b7362d4b7237a480524aa7c05b42c80649fd1e1209f091.png" alt="系统变量比较" />
|
||||
</Frame>
|
||||
|
||||
可用的系统变量取决于您的应用程序类型。工作流应用程序提供基本的元数据,如 `sys.app_id` 和 `sys.workflow_id`,而对话流应用程序则包括附加的与对话相关的变量,如 `sys.conversation_id` 和 `sys.dialogue_count`。
|
||||
|
||||
系统变量特别有助于跟踪执行上下文、实现特定于用户的逻辑或在对话流应用程序中维护对话状态。
|
||||
|
||||
## 变量引用
|
||||
|
||||
从Start节点的变量可以在任何下游节点中引用。在配置节点的输入字段时,您可以从下拉菜单中选择变量或在文本字段中键入 `/` 以插入变量值。
|
||||
|
||||
<Frame caption="使用斜杠命令将变量插入文本输入中">
|
||||
<img src="/images/image.png" alt="变量插入界面" />
|
||||
</Frame>
|
||||
|
||||
变量在整个工作流中保持其类型。一种数字输入仍然是一个数字,文件上传仍然是一个文件对象,而文本输入仍然是字符串。这种类型一致性确保下游节点可以正确处理数据。
|
||||
|
||||
## 文件处理
|
||||
|
||||
通过Start节点上传的文件需要在您的工作流中进行适当处理。Start节点本身仅收集文件并使其作为变量可用。您需要连接特定的节点以提取和处理内容:
|
||||
|
||||
文档文件应路由到文档提取器节点以提取文本内容。图像可以发送到具有视觉能力的LLM节点或专门的图像处理工具。像CSV或JSON这样的结构化数据文件可以使用代码节点进行解析和转换。
|
||||
|
||||
<Note>
|
||||
文件变量包含有关上传文件的元数据,包括其名称、大小和类型。实际的文件内容需要由下游节点提取或处理。
|
||||
</Note>
|
||||
|
||||
## 隐藏变量
|
||||
|
||||
您可以将任何输入变量标记为“隐藏”以将其从用户界面中排除,同时仍然使其在您的工作流中可用。
|
||||
|
||||
## 配置最佳实践
|
||||
|
||||
在设计您的Start节点输入时,请考虑在开始时哪些信息是必要的,以及哪些信息可以在工作流的后续步骤中推导或收集。过多的初始输入要求会给用户带来阻力,而过少则可能限制您的工作流能力。
|
||||
|
||||
选择描述性变量名称,以清楚地指示它们包含的数据。变量名称应一致地使用下划线或驼峰命名法,并避免可能导致解析问题的特殊字符。请记住,变量名称是区分大小写的,因此 `userName` 和 `username` 是不同的变量。
|
||||
|
||||
对于文件上传,请考虑设置适当的文件类型限制和大小限制。这可以防止下游处理错误,并确保您的工作流接收到预期的输入格式。
|
||||
|
||||
## 接下来是什么
|
||||
|
||||
在配置您的Start节点后,您通常会将其连接到处理收集输入的节点。常见的模式包括将用户输入发送到LLM节点进行处理,使用知识检索根据输入查找相关信息,或使用基于输入值的条件逻辑路由到不同的工作流分支。
|
||||
```
|
||||
131
zh-hans/documzh-hanstation/pages/nodes/template.mdx
Normal file
131
zh-hans/documzh-hanstation/pages/nodes/template.mdx
Normal file
@@ -0,0 +1,131 @@
|
||||
```mdx
|
||||
---
|
||||
title: "模板"
|
||||
description: "使用 Jinja2 模板转换和格式化数据"
|
||||
icon: "note-sticky"
|
||||
---
|
||||
|
||||
The Template node transforms and formats data from multiple sources into structured text using Jinja2 templating. Use it to combine variables, format outputs, and prepare data for downstream nodes or end users.
|
||||
|
||||
<Frame caption="模板节点配置界面">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/0838bb5c7e1d1a58ed30fcd9fc48920f.png" alt="模板节点界面" />
|
||||
</Frame>
|
||||
|
||||
## Jinja2 模板
|
||||
|
||||
模板节点使用 Jinja2 模板语法创建基于工作流数据动态适应的内容。这提供了类似编程的功能,包括循环、条件和过滤器,用于复杂的文本生成。
|
||||
|
||||
### 变量替换
|
||||
|
||||
使用双大括号引用工作流变量:`{{ variable_name }}`。可以使用点符号和括号语法访问嵌套对象属性和数组元素。
|
||||
|
||||
```jinja2
|
||||
{{ user.name }}
|
||||
{{ items[0].title }}
|
||||
{{ data.metrics.score }}
|
||||
```
|
||||
|
||||
### 条件逻辑
|
||||
|
||||
使用 if-else 语句根据数据值显示不同内容:
|
||||
|
||||
```jinja2
|
||||
{% if user.subscription == 'premium' %}
|
||||
Welcome back, Premium Member! You have access to all features.
|
||||
{% else %}
|
||||
Consider upgrading to Premium for additional capabilities.
|
||||
{% endif %}
|
||||
```
|
||||
|
||||
### 循环和迭代
|
||||
|
||||
使用 for 循环处理数组和对象以生成重复内容:
|
||||
|
||||
```jinja2
|
||||
{% for item in search_results %}
|
||||
### Result {{ loop.index }}
|
||||
**Score**: {{ item.score | round(2) }}
|
||||
{{ item.content }}
|
||||
---
|
||||
{% endfor %}
|
||||
```
|
||||
|
||||
<Frame caption="模板处理知识检索结果">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/0ae3f13cf725cb2c52c72cc354e592ee.png" alt="模板格式化示例" />
|
||||
</Frame>
|
||||
|
||||
## 数据格式化
|
||||
|
||||
### 过滤器
|
||||
|
||||
Jinja2 过滤器在模板渲染期间转换数据:
|
||||
|
||||
```jinja2
|
||||
{{ name | upper }}
|
||||
{{ price | round(2) }}
|
||||
{{ content | replace('\n', '<br>') }}
|
||||
{{ timestamp | strftime('%B %d, %Y') }}
|
||||
{{ score | default('No score available') }}
|
||||
```
|
||||
|
||||
### 错误处理
|
||||
|
||||
使用默认值和条件检查优雅地处理缺失或无效数据:
|
||||
|
||||
```jinja2
|
||||
{{ user.email | default('No email provided') }}
|
||||
{{ metrics.accuracy | round(2) if metrics.accuracy else 'Not calculated' }}
|
||||
```
|
||||
|
||||
## 交互式表单
|
||||
|
||||
模板可以生成交互式 HTML 表单,用于在聊天界面中收集结构化数据:
|
||||
|
||||
```html
|
||||
<form data-format="json">
|
||||
<label for="username">Username:</label>
|
||||
<input type="text" name="username" required />
|
||||
|
||||
<label for="priority">Priority:</label>
|
||||
<input type="select" name="priority" data-options='["low","medium","high"]'/>
|
||||
|
||||
<label for="message">Message:</label>
|
||||
<textarea name="message" placeholder="Enter your message"></textarea>
|
||||
|
||||
<input type="checkbox" name="urgent" data-tip="Mark as urgent"/>
|
||||
<button data-variant="primary">Submit</button>
|
||||
</form>
|
||||
```
|
||||
|
||||
<Frame caption="在聊天界面中渲染的交互式表单">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/9d24e9cfa3cdde00e4eee15bd4bbea76.png" alt="交互式表单渲染" />
|
||||
</Frame>
|
||||
|
||||
当用户提交表单时,响应变为可在下游工作流节点中立即处理的结构化 JSON 数据。
|
||||
|
||||
## 输出限制
|
||||
|
||||
模板输出限制为**80,000 个字符**(可通过 `TEMPLATE_TRANSFORM_MAX_LENGTH` 配置)。这可以防止内存问题并确保大型模板输出的合理处理时间。
|
||||
|
||||
## 常见用例
|
||||
|
||||
**报告生成** - 将来自多个来源的数据组合成具有一致结构和样式的格式化报告。
|
||||
|
||||
**API 响应格式化** - 将内部数据结构转换为供外部使用的用户友好格式。
|
||||
|
||||
**LLM 提示词准备** - 将复杂数据结构化为格式良好的提示词,提高 LLM 的处理准确性。
|
||||
|
||||
**电子邮件和通知模板** - 根据用户数据和工作流结果生成带有动态内容的个性化消息。
|
||||
|
||||
**数据转换** - 在不同的数据格式和结构之间进行转换,以便与外部系统集成。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**使用描述性变量名**以使模板可读和可维护,特别是在处理复杂数据结构时。
|
||||
|
||||
**处理缺失数据**,通过默认值和条件检查,防止模板渲染错误。
|
||||
|
||||
**格式化以提高可读性**,通过使用适当的间距、换行和格式创建干净、专业的输出。
|
||||
|
||||
**使用示例数据进行测试**,确保模板处理边缘情况并在不同输入场景中产生预期结果。
|
||||
```
|
||||
91
zh-hans/documzh-hanstation/pages/nodes/tools.mdx
Normal file
91
zh-hans/documzh-hanstation/pages/nodes/tools.mdx
Normal file
@@ -0,0 +1,91 @@
|
||||
```mdx
|
||||
---
|
||||
title: "工具"
|
||||
description: "Connect to external services and APIs with pre-built integrations"
|
||||
icon: "wrench"
|
||||
---
|
||||
|
||||
工具节点通过预构建的集成将您的工作流连接到外部服务和API。与HTTP请求节点不同,工具提供结构化接口、内置错误处理和简化的流行服务配置。
|
||||
|
||||
<Frame caption="工具节点配置界面">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/0f0255764a3f459f0b3c708db1cb32c9.png" alt="Tools node interface" />
|
||||
</Frame>
|
||||
|
||||
## 工具类型
|
||||
|
||||
Dify支持多种类型的工具以应对不同的集成需求:
|
||||
|
||||
<Frame caption="可用工具类别和选项">
|
||||
<img src="https://assets-docs.dify.ai/2025/04/f37cce4ccbb7456154cfa9eacda6b322.png" alt="Tool categories" />
|
||||
</Frame>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="内置工具">
|
||||
Dify维护的即用型集成,适用于包括Google搜索、天气API、生产力工具和AI服务等流行服务。这些工具需要最少的配置,并提供可靠、经过测试的集成。
|
||||
</Tab>
|
||||
|
||||
<Tab title="自定义工具">
|
||||
使用OpenAPI/Swagger规范导入您自己的工具。非常适合内部API、专业化服务或未涵盖的内置选项的任何API。配置一次即可在多个工作流中重复使用。
|
||||
</Tab>
|
||||
|
||||
<Tab title="工作流工具">
|
||||
将复杂工作流发布为可重用的工具。这创建了可以在不同应用程序之间共享的模块化构建块,促进代码重用和简化维护。
|
||||
</Tab>
|
||||
|
||||
<Tab title="MCP工具">
|
||||
来自外部MCP(模型上下文协议)服务器的工具,提供专业功能。连接到不断增长的MCP服务器生态系统以扩展功能。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 配置
|
||||
|
||||
### 认证
|
||||
|
||||
许多工具需要API密钥或OAuth认证。在使用工具之前,在工作区的**工具**部分配置这些凭据。配置后,认证会自动处理。
|
||||
|
||||
### 输入参数
|
||||
|
||||
工具提供带有验证功能的结构化表单用于输入配置。使用来自先前工作流节点的变量设置参数。界面会自动处理数据类型验证,并为每个参数提供有用的说明。
|
||||
|
||||
### 输出处理
|
||||
|
||||
工具返回的结构化数据可作为下游节点的变量使用。输出模式是预定义的,确保兼容性并减少集成复杂性。
|
||||
|
||||
## 优于HTTP请求的优势
|
||||
|
||||
**结构化接口**提供基于表单的配置与内置验证,使设置比手动HTTP请求配置更简单。
|
||||
|
||||
**内置错误处理**包括自动重试逻辑和错误管理,降低了处理API故障的复杂性。
|
||||
|
||||
**类型安全**确保输入和输出模式在工作流节点之间保持数据兼容性。
|
||||
|
||||
**文档**包括每个工具的使用示例和详细参数描述。
|
||||
|
||||
## 错误处理和重试
|
||||
|
||||
为依赖外部服务的工具配置强大的错误处理:
|
||||
|
||||
<Frame caption="工具重试配置">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/34867b2d910d74d2671cd40287200480.png" alt="Tool retry settings" />
|
||||
</Frame>
|
||||
|
||||
**重试设置**自动重试失败的工具执行最多10次,并具有可配置的间隔(最大5000ms)。这处理临时服务问题或网络问题。
|
||||
|
||||
<Frame caption="工具错误处理选项">
|
||||
<img src="https://assets-docs.dify.ai/2024/12/39dc3b5881d9a5fe35b877971f70d3a6.png" alt="Tool error handling" />
|
||||
</Frame>
|
||||
|
||||
**错误处理**定义当工具执行失败时的替代工作流路径,确保即使外部服务不可用,您的工作流也能继续。
|
||||
|
||||
## 创建自定义工具
|
||||
|
||||
**OpenAPI集成**允许您导入任何具有OpenAPI/Swagger规范的服务。一旦导入,该服务即可作为工具使用,与内置选项一样易于使用。
|
||||
|
||||
**工作流发布**将多节点工作流转换为可在不同应用程序中重用的单节点工具。这促进了模块化和简化了复杂工作流管理。
|
||||
|
||||
## 工具管理
|
||||
|
||||
通过工作区导航中的**工具**访问工具配置。在这里,您可以管理认证凭据、导入自定义工具、配置MCP服务器,并将工作流发布为工具。
|
||||
|
||||
有关工具创建、管理和将工作流发布为工具的详细指南,请参阅[工具配置指南](/en/guides/tools)。
|
||||
```
|
||||
@@ -0,0 +1,89 @@
|
||||
```mdx
|
||||
---
|
||||
title: "变量聚合器"
|
||||
description: "将不同工作流分支的变量合并为统一的输出"
|
||||
icon: "merge"
|
||||
---
|
||||
|
||||
变量聚合器节点将不同执行路径的变量组合为一个统一的输出。当多个分支产生相似的输出时,此节点通过创建一个一致的变量引用,消除了重复下游处理的需要。
|
||||
|
||||
## 分支问题
|
||||
|
||||
条件工作流创建了并行执行路径,其中一次仅运行一个分支。如果没有聚合,你需要为每个可能的分支结果创建重复的下游节点,从而创建复杂且维护繁重的工作流。
|
||||
|
||||
变量聚合器作为一个合并点,将分支输出收集为一个单一的变量,无论哪个分支实际执行,下游节点都可以一致地引用这个变量。
|
||||
|
||||
## 分类工作流示例
|
||||
|
||||
当用户输入被分类且每个类别需要不同的知识检索时,变量聚合器将结果合并:
|
||||
|
||||
**无聚合** - 复杂的工作流需要重复的大型语言模型节点:
|
||||
|
||||
<Frame caption="没有变量聚合的复杂工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/7a7c91663c3799ce9d056b013d5df29c.png" alt="没有变量聚合的问题分类" />
|
||||
</Frame>
|
||||
|
||||
**有聚合** - 使用变量聚合的简化工作流:
|
||||
|
||||
<Frame caption="使用变量聚合的简化工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/2b1694936fdab4843f5edc3f2fd1e79a.png" alt="问题分类后的多分支聚合" />
|
||||
</Frame>
|
||||
|
||||
聚合后的工作流使用一个大型语言模型节点,而不是为每个分类分支重复它,从而显著减少复杂性,同时保持相同的功能。
|
||||
|
||||
## 条件处理示例
|
||||
|
||||
类似的好处也适用于产生相似输出的 If-Else 分支:
|
||||
|
||||
<Frame caption="条件分支后的变量聚合">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/ff0e5774a3eccc8a04c310ab9bae25e7.png" alt="条件分支后的多分支聚合" />
|
||||
</Frame>
|
||||
|
||||
## 配置
|
||||
|
||||
### 变量选择
|
||||
|
||||
连接您想要合并的不同工作流分支中的变量。每个连接的变量都会成为聚合输出的潜在输入。
|
||||
|
||||
### 类型约束
|
||||
|
||||
**同类型规则** - 所有聚合的变量必须是相同的数据类型。一旦连接第一个变量(例如,字符串),节点只接受来自其他分支的相同类型的变量。
|
||||
|
||||
**支持的类型:**
|
||||
- **字符串** - 来自不同处理分支的文本输出
|
||||
- **数字** - 数值计算、分数或测量值
|
||||
- **对象** - 具有相似模式的结构化数据对象
|
||||
- **数组** - 列表、集合或多个结果
|
||||
|
||||
### 输出行为
|
||||
|
||||
变量聚合器输出来自实际执行的分支的值。由于在条件工作流中只有一个分支运行,因此在执行期间只有一个输入变量将有值。
|
||||
|
||||
## 高级功能
|
||||
|
||||
### 多个聚合组
|
||||
|
||||
高级工作流(v0.6.10+)可以同时聚合多个变量组。每个组保持自己的类型约束,允许您在同一个节点内并行聚合不同的数据类型。
|
||||
|
||||
当分支产生多个相关输出需要分别合并时,这很有用 - 例如,聚合来自不同处理路径的文本摘要和数值分数。
|
||||
|
||||
## 常见用例
|
||||
|
||||
**多类别处理** - 不同内容类型需要专门处理,但产生相似的输出以供通用下游逻辑使用。
|
||||
|
||||
**条件数据源** - 不同条件触发不同的知识检索或 API 调用,但所有结果都需要相同的最终处理。
|
||||
|
||||
**分支结果合并** - 复杂的分支逻辑产生各种输出,最终需要统一处理。
|
||||
|
||||
**错误处理** - 主处理和回退分支产生不同但兼容的结果,下游节点可以一致地处理这些结果。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**规划数据类型** - 确保所有分支在连接到变量聚合器之前产生兼容的数据类型。
|
||||
|
||||
**一致的输出结构** - 聚合对象或数组时,保持所有分支的结构一致,以便下游处理可预测。
|
||||
|
||||
**使用描述性名称** - 清晰命名聚合变量,以指示它们包含来自多个可能来源的结果。
|
||||
|
||||
**测试所有分支** - 验证每个可能的执行路径产生的有效输出在聚合时正常工作。
|
||||
```
|
||||
125
zh-hans/documzh-hanstation/pages/nodes/variable-assigner.mdx
Normal file
125
zh-hans/documzh-hanstation/pages/nodes/variable-assigner.mdx
Normal file
@@ -0,0 +1,125 @@
|
||||
```mdx
|
||||
---
|
||||
title: "变量分配器"
|
||||
description: "管理对话流应用中的持久性会话变量"
|
||||
icon: "pen-to-square"
|
||||
---
|
||||
|
||||
变量分配器节点通过写入会话变量来管理对话流应用中的持久数据。与每次执行时重置的常规工作流变量不同,会话变量会在整个聊天会话中保持存在。
|
||||
|
||||
<Frame caption="变量分配器节点配置">
|
||||
<img src="https://assets-docs.dify.ai/2024/11/83d0b9ef4c1fad947b124398d472d656.png" alt="变量分配器界面" />
|
||||
</Frame>
|
||||
|
||||
## 会话变量与工作流变量
|
||||
|
||||
**工作流变量**仅在单次工作流执行期间存在,并在工作流完成后重置。
|
||||
|
||||
**会话变量**在同一聊天会话中的多个对话轮次中保持存在,使状态交互和上下文记忆成为可能。
|
||||
|
||||
这种持久性支持上下文对话、用户个性化、状态工作流以及跨多个用户交互的进度跟踪。
|
||||
|
||||
## 配置
|
||||
|
||||
配置要更新的会话变量并指定其源数据。您可以在单个节点中分配多个变量。
|
||||
|
||||
<Frame caption="变量分配配置界面">
|
||||
<img src="https://assets-docs.dify.ai/2024/11/ee15dee864107ba5a93b459ebdfc32cf.png" alt="变量分配配置" />
|
||||
</Frame>
|
||||
|
||||
**变量** - 选择要写入的会话变量
|
||||
|
||||
**设置变量** - 从上游工作流节点中选择源数据
|
||||
|
||||
**操作模式** - 确定如何更新变量(覆盖、追加、清除等)
|
||||
|
||||
## 操作模式
|
||||
|
||||
不同的变量类型根据其数据结构支持不同的操作:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="字符串变量">
|
||||
**覆盖** - 用新内容替换整个字符串值
|
||||
|
||||
**清除** - 清空变量,设为空或空白
|
||||
|
||||
**设置** - 手动输入固定值
|
||||
</Tab>
|
||||
|
||||
<Tab title="数字变量">
|
||||
**覆盖** - 完全替换数字值
|
||||
|
||||
**清除** - 设为空或空状态
|
||||
|
||||
**设置** - 手动输入特定数字值
|
||||
|
||||
**算术** - 加、减、乘或除当前值
|
||||
</Tab>
|
||||
|
||||
<Tab title="对象变量">
|
||||
**覆盖** - 用新数据替换整个对象
|
||||
|
||||
**清除** - 清空对象,移除所有属性
|
||||
|
||||
**设置** - 手动定义对象结构和值
|
||||
</Tab>
|
||||
|
||||
<Tab title="数组变量">
|
||||
**覆盖** - 用新数据替换整个数组
|
||||
|
||||
**清除** - 清空数组,移除所有元素
|
||||
|
||||
**追加** - 在数组末尾添加一个项目
|
||||
|
||||
**扩展** - 从另一个数组中添加多个项目
|
||||
|
||||
**移除** - 从首位或末位删除项目
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
数组操作在构建记忆系统、清单和随时间增长的对话历史记录中尤其强大。
|
||||
|
||||
## 常见实现模式
|
||||
|
||||
### 智能记忆系统
|
||||
|
||||
构建自动检测并存储对话中重要信息的聊天机器人:
|
||||
|
||||
<Frame caption="智能记忆系统工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/8d0492814b1515f50e87b2900ff400db.png" alt="智能记忆实现" />
|
||||
</Frame>
|
||||
|
||||
系统分析用户输入以获取可记忆的事实,提取结构化信息,并将其附加到持久记忆数组中,以便在未来的对话中引用。
|
||||
|
||||
### 用户偏好存储
|
||||
|
||||
存储用户偏好,如语言设置、通知偏好或显示选项:
|
||||
|
||||
<Frame caption="用户偏好管理">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/1867d608a7d009431b73377ed65b427b.png" alt="用户偏好工作流" />
|
||||
</Frame>
|
||||
|
||||
使用**覆盖**模式捕获用户输入的初始偏好,然后在所有后续的LLM响应中引用它们以进行个性化互动。
|
||||
|
||||
### 渐进式清单
|
||||
|
||||
构建跟踪多个对话轮次中的完成状态的引导式工作流:
|
||||
|
||||
<Frame caption="渐进式清单实现">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/c4362b01298b12e7d6fcd9e798f3165a.png" alt="渐进式清单工作流" />
|
||||
</Frame>
|
||||
|
||||
使用数组会话变量来跟踪已完成的项目。变量分配器在每一轮更新清单,而LLM引用它来引导用户完成剩余的任务。
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**选择合适的数据类型** - 对于不断增长的集合使用数组,对于结构化数据使用对象,对于单一值使用简单类型。
|
||||
|
||||
**使用描述性变量名** - 清晰命名会话变量以指示其用途和内容。
|
||||
|
||||
**处理数据增长** - 监控数组和对象的大小,以防止长时间对话中过度使用内存。
|
||||
|
||||
**初始化变量** - 设置会话变量的初始值,以防止未定义的行为。
|
||||
|
||||
**适时清除** - 在开始新流程或会话时使用清除操作重置变量。
|
||||
```
|
||||
67
zh-hans/documzh-hanstation/pages/nodes/zh-hansd.mdx
Normal file
67
zh-hans/documzh-hanstation/pages/nodes/zh-hansd.mdx
Normal file
@@ -0,0 +1,67 @@
|
||||
```mdx
|
||||
---
|
||||
title: "结束"
|
||||
description: "定义工作流输出和终止点"
|
||||
icon: "flag-checkered"
|
||||
---
|
||||
|
||||
End 节点定义了工作流完成时的输出。每个工作流应用程序至少需要一个 End 节点来向用户返回结果并终止执行。
|
||||
|
||||
<Info>
|
||||
End 节点仅适用于工作流应用程序。对话流应用程序使用 Answer 节点来在对话流中传递响应。
|
||||
</Info>
|
||||
|
||||
## 输出配置
|
||||
|
||||
End 节点从之前的工作流节点收集输出,并将它们打包成最终响应。通过使用变量选择器或 `{{variable_name}}` 语法引用上游节点的数据来配置要输出的变量。
|
||||
|
||||
您可以输出包括文本、数字、对象、数组和文件在内的多种类型的多个变量。每个输出变量都成为工作流最终结果结构的一部分。
|
||||
|
||||
## 单个与多个 End 节点
|
||||
|
||||
### 单路径工作流
|
||||
|
||||
具有一个执行路径的简单工作流只需要一个 End 节点来捕获最终结果:
|
||||
|
||||
<Frame caption="具有一个 End 节点的单路径工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/9e43961344d318e09af8d64464d81774.png" alt="单路径工作流示例" />
|
||||
</Frame>
|
||||
|
||||
### 多路径工作流
|
||||
|
||||
具有条件分支的工作流需要为每个可能的执行路径设置 End 节点。每个分支可以根据工作流逻辑输出不同的变量:
|
||||
|
||||
<Frame caption="具有多个 End 节点的多路径工作流">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/3cb3f5fea376265bede0a4ac5bcc1ddc.png" alt="多路径工作流示例" />
|
||||
</Frame>
|
||||
|
||||
## 执行行为
|
||||
|
||||
一旦工作流执行到达 End 节点,处理就会立即停止。连接在 End 节点之后的节点将不再执行。这使得 End 节点成为不同工作流分支的自然终止点。
|
||||
|
||||
如果您的工作流有多个可能的执行路径(例如通过 If-Else 节点),请确保每个路径都通向一个 End 节点。否则,一些执行分支可能不会返回结果。
|
||||
|
||||
## 输出示例
|
||||
|
||||
**文本处理结果** - 输出处理过的文本、摘要或大型语言模型节点的分析结果。
|
||||
|
||||
**结构化数据** - 返回 JSON 对象、数组或从各种处理节点中提取的参数。
|
||||
|
||||
**文件输出** - 传递在工作流执行期间生成的文档、图像或其他文件。
|
||||
|
||||
**状态信息** - 包含处理元数据、成功指示或诊断信息。
|
||||
|
||||
<Frame caption="复杂工作流输出示例">
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/en/guides/workflow/node/a103792790447c1725c1da1176334cae.png" alt="End 节点 - 长篇故事生成示例" />
|
||||
</Frame>
|
||||
|
||||
## 最佳实践
|
||||
|
||||
**一致的输出结构** - 在同一工作流的不同 End 节点中使用相似的变量名称和数据类型,以获得可预测的 API 响应。
|
||||
|
||||
**包含状态信息** - 考虑输出成功指示或处理元数据与主要结果一起。
|
||||
|
||||
**处理所有路径** - 确保工作流中的每个可能执行路径都通向一个 End 节点,以防止执行不完整。
|
||||
|
||||
**文档输出模式** - 清楚地记录每个 End 节点返回的内容,以便于 API 消费者和集成目的。
|
||||
```
|
||||
487
zh-hans/documzh-hanstation/pages/workspace/readme.mdx
Normal file
487
zh-hans/documzh-hanstation/pages/workspace/readme.mdx
Normal file
@@ -0,0 +1,487 @@
|
||||
```mdx
|
||||
---
|
||||
title: 模型
|
||||
description: Learn about the Different Models Supported by Dify.
|
||||
---
|
||||
|
||||
<Warning>
|
||||
"模型" 已完全集成到 "插件" 生态系统中。有关模型插件的详细开发说明,请参阅 [插件开发](/en/plugins/quick-start/develop-plugins/model-plugin/README)。以下内容已归档。
|
||||
</Warning>
|
||||
|
||||
Dify 是一个基于大型语言模型应用程序的 AI 应用开发平台,首次使用 Dify 时,您需要进入 **设置 --> 模型提供商** 添加和配置您将要使用的大型语言模型。
|
||||
|
||||

|
||||
|
||||
Dify 支持主流的模型提供商,如 OpenAI 的 GPT 系列和 Anthropic 的 Claude 系列。每个模型的能力和参数各不相同,因此选择适合您应用需求的模型提供商。在 Dify 中使用之前,请从模型提供商的官方网站获取 API 密钥。
|
||||
|
||||
## Dify 的模型类型
|
||||
|
||||
Dify 将模型分为 4 种类型,各自用于不同用途:
|
||||
|
||||
1. **系统推理模型:** 用于应用程序中执行聊天、名称生成和建议后续问题等任务。
|
||||
|
||||
> 提供商包括 [OpenAI](https://platform.openai.com/account/api-keys)、[Azure OpenAI Service](https://azure.microsoft.com/en-us/products/ai-services/openai-service/)、[Anthropic](https://console.anthropic.com/account/keys)、Hugging Face Hub、Replicate、Xinference、OpenLLM、[科大讯飞星火](https://www.xfyun.cn/solutions/xinghuoAPI)、[文心一言](https://console.bce.baidu.com/qianfan/ais/console/applicationConsole/application)、[通义](https://dashscope.console.aliyun.com/api-key\_management?spm=a2c4g.11186623.0.0.3bbc424dxZms9k)、[Minimax](https://api.minimax.chat/user-center/basic-information/interface-key)、智谱(ChatGLM)、[Ollama](/en/development/models-integration/ollama)、[LocalAI](https://github.com/mudler/LocalAI)、[GPUStack](https://github.com/gpustack/gpustack)。
|
||||
2. **嵌入模型:** 用于在知识中嵌入分段文档和处理应用程序中的用户查询。
|
||||
|
||||
> 提供商包括 OpenAI,智谱 (ChatGLM),Jina AI([Jina Embeddings](https://jina.ai/embeddings/))。
|
||||
3. [重新排序模型](/en/learn-more/extended-reading/retrieval-augment/rerank)**:** 增强大型语言模型的搜索能力。
|
||||
|
||||
> 提供商包括 Cohere,Jina AI([Jina Reranker](https://jina.ai/reranker))。
|
||||
4. **语音转文字模型:** 在对话应用中将口语转换为文字。
|
||||
|
||||
> 提供商:OpenAI。
|
||||
|
||||
Dify 计划随着技术和用户需求的发展,增加更多的大型语言模型提供商。
|
||||
|
||||
## 托管模型试用服务
|
||||
|
||||
Dify 为云服务用户提供试用配额,以便试验不同模型。在试用期结束前设置好您的模型提供商,以确保应用程序的持续使用。
|
||||
|
||||
* OpenAI 托管模型试用:包括 200 次调用,如 GPT3.5-turbo、GPT3.5-turbo-16k 和 text-davinci-003 模型。
|
||||
|
||||
## 设置默认模型
|
||||
|
||||
Dify 会根据使用情况自动选择默认模型。您可以在 `设置 > 模型提供商` 中进行配置。
|
||||
|
||||

|
||||
|
||||
## 模型集成设置
|
||||
|
||||
在 Dify 的 `设置 > 模型提供商` 中选择您的模型。
|
||||
|
||||

|
||||
|
||||
模型提供商分为两类:
|
||||
|
||||
1. 专有模型:由 OpenAI 和 Anthropic 等提供商开发。
|
||||
2. 托管模型:提供第三方模型,如 Hugging Face 和 Replicate。
|
||||
|
||||
这两种类别的集成方法有所不同。
|
||||
|
||||
**专有模型提供商:** Dify 连接到来自集成提供商的所有模型。在 Dify 中设置提供商的 API 密钥进行集成。
|
||||
|
||||
<Info>
|
||||
Dify 使用 [PKCS1\_OAEP](https://pycryptodome.readthedocs.io/en/latest/src/cipher/oaep.html) 加密保护您的 API 密钥。每位用户(租户)都有独特的密钥对进行加密,确保您的 API 密钥保密。
|
||||
</Info>
|
||||
|
||||
**托管模型提供商:** 单独集成第三方模型。
|
||||
|
||||
具体的集成方法未在此详细说明。
|
||||
|
||||
* [Hugging Face](/en/development/models-integration/hugging-face)
|
||||
* [Replicate](/en/development/models-integration/replicate)
|
||||
* [Xinference](/en/development/models-integration/xinference)
|
||||
* [OpenLLM](/en/development/models-integration/openllm)
|
||||
|
||||
## 使用模型
|
||||
|
||||
配置完成后,这些模型即可用于应用程序使用。
|
||||
|
||||

|
||||
|
||||
## 支持的提供商
|
||||
Dify 开箱即用地支持以下模型提供商:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>提供商</th>
|
||||
<th>大型语言模型</th>
|
||||
<th>文本嵌入</th>
|
||||
<th>重新排序</th>
|
||||
<th>语音转文字</th>
|
||||
<th>文本转语音</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>OpenAI</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Anthropic</td>
|
||||
<td>✔️(🛠️)</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Azure OpenAI</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Gemini</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Google Cloud</td>
|
||||
<td>✔️(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Nvidia API Catalog</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Nvidia NIM</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Nvidia Triton Inference Server</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>AWS Bedrock</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>OpenRouter</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Cohere</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>together.ai</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Ollama</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Mistral AI</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>groqcloud</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Replicate</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Hugging Face</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Xorbits inference</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>智谱 AI</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>百川</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Spark</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Minimax</td>
|
||||
<td>✔️(🛠️)</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>通义</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>文心</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Moonshot AI</td>
|
||||
<td>✔️(🛠️)</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>腾讯云</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Stepfun</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>火山引擎</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>01.AI</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>360 智脑</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Azure AI Studio</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>deepseek</td>
|
||||
<td>✔️(🛠️)</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>腾讯混元</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>SILICONFLOW</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Jina AI</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>ChatGLM</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Xinference</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>OpenLLM</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>LocalAI</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>OpenAI API-Compatible</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>PerfXCloud</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Lepton AI</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>novita.ai</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Amazon Sagemaker</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>文本嵌入推理</td>
|
||||
<td></td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>GPUStack</td>
|
||||
<td>✔️(🛠️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>GPUStack</td>
|
||||
<td>✔️(🔧️)(👓)</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
<td>✔️</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
其中 (🛠️) 表示“函数调用”,(👓) 表示“支持视觉”。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/model-configuration/readme.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
```
|
||||
57
zh-hans/guides/workflow/README.mdx
Normal file
57
zh-hans/guides/workflow/README.mdx
Normal file
@@ -0,0 +1,57 @@
|
||||
---
|
||||
title: 介绍
|
||||
---
|
||||
|
||||
### 基本介绍
|
||||
|
||||
工作流通过将复杂任务分解为更小的步骤(节点)来降低系统复杂性,减少对提示词工程和模型推理能力的依赖,并提升大型语言模型(LLM)在复杂任务中的表现。这也提高了系统的可解释性、稳定性和容错性。
|
||||
|
||||
Dify工作流分为两种类型:
|
||||
|
||||
* **对话流**:专为对话场景设计,包括客户服务、语义检索和其他需要多步逻辑的对话应用。
|
||||
* **工作流**:面向自动化和批处理场景,适用于高质量翻译、数据分析、内容生成、邮件自动化等。
|
||||
|
||||

|
||||
|
||||
为了解决自然语言输入中用户意图识别的复杂性,对话流提供了问题理解节点。与工作流相比,它增加了对聊天机器人功能的支持,如对话历史(记忆)、带注释的回复和回答节点。
|
||||
|
||||
在自动化和批处理场景中处理复杂业务逻辑时,工作流提供了多种逻辑节点,如代码节点、IF/ELSE节点、模板转换、迭代节点等。此外,它还提供了定时和事件触发操作的能力,方便构建自动化流程。
|
||||
|
||||
### 常见用例
|
||||
|
||||
* 客户服务
|
||||
|
||||
通过在客户服务系统中集成大型语言模型(LLM),可以自动响应常见问题,减轻支持团队的工作量。LLM可以理解客户查询的上下文和意图,并实时生成有用且准确的答案。
|
||||
|
||||
* 内容生成
|
||||
|
||||
无论是创建博客文章、产品描述还是营销材料,LLM都可以通过生成高质量的内容来提供帮助。只需提供大纲或主题,LLM就能利用其广泛的知识库生成引人入胜、信息丰富且结构良好的内容。
|
||||
|
||||
* 任务自动化
|
||||
|
||||
LLM可以与Trello、Slack、Lark等各种任务管理系统集成,以自动化项目和任务管理。通过自然语言处理,LLM可以理解和解释用户输入,创建任务、更新状态并分配优先级,无需人工干预。
|
||||
|
||||
* 数据分析和报告
|
||||
|
||||
LLM可以分析大型数据集并生成报告或摘要。通过向LLM提供相关信息,它可以识别趋势、模式和洞察力,将原始数据转化为可操作的情报。这对于希望做出数据驱动决策的企业特别有价值。
|
||||
|
||||
* 邮件自动化
|
||||
|
||||
LLM可以用于撰写电子邮件、社交媒体更新和其他形式的沟通。通过提供简要的大纲或关键点,LLM可以生成结构良好、连贯且上下文相关的消息。这大大节省了时间,并确保您的回复清晰且专业。
|
||||
|
||||
### 如何开始
|
||||
|
||||
* 从头开始构建工作流或使用系统模板来帮助您入门。
|
||||
* 熟悉基本操作,包括在画布上创建节点、连接和配置节点、调试工作流以及查看运行历史。
|
||||
* 保存并发布工作流。
|
||||
* 运行已发布的应用程序或通过API调用工作流。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/workflow/README.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
23
zh-hans/workshop/README.mdx
Normal file
23
zh-hans/workshop/README.mdx
Normal file
@@ -0,0 +1,23 @@
|
||||
```mdx
|
||||
---
|
||||
title: 介绍
|
||||
---
|
||||
|
||||
欢迎来到 Dify 研讨会!这些教程是为想要从头开始学习 Dify 的初学者设计的。无论您是否具备编程或 AI 相关背景知识,我们将一步步引导您掌握 Dify 的核心概念和用法,不会遗漏任何细节。
|
||||
|
||||
我们将通过一系列实验帮助您理解 Dify。每个实验都包含详细的步骤和解释,以确保您能够轻松跟随并掌握内容。我们将在实验中穿插知识教学,让您在实践中学习,并逐步建立对 Dify 的全面理解。
|
||||
|
||||
无需担心任何先决条件!我们将从最基本的概念开始,逐步引导您进入更高级的主题。无论您是完全的初学者,还是有一些编程经验但想学习 AI 技术,本教程都将为您提供所需的一切。
|
||||
|
||||
让我们一起踏上这段学习旅程,探索 Dify 的无限可能性!
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/en/workshop/README.mdx) | [报告问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
```
|
||||
Reference in New Issue
Block a user