mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-26 13:18:34 +07:00
Merge pull request #398 from NanSike/today-docs
Add Japanese and English versions of gpt-oss deployment doc.
This commit is contained in:
10
docs.json
10
docs.json
@@ -12,6 +12,7 @@
|
||||
"light": "https://assets-docs.dify.ai/2025/05/d05cfc6ebe48f725d171dc71c64a5d16.svg",
|
||||
"dark": "https://assets-docs.dify.ai/2025/05/c51f1cda47c1d9a4a162d7736f6e4c53.svg"
|
||||
},
|
||||
|
||||
"navigation": {
|
||||
"versions": [
|
||||
{
|
||||
@@ -388,7 +389,8 @@
|
||||
"en/development/models-integration/ollama",
|
||||
"en/development/models-integration/litellm",
|
||||
"en/development/models-integration/gpustack",
|
||||
"en/development/models-integration/aws-bedrock-deepseek"
|
||||
"en/development/models-integration/aws-bedrock-deepseek",
|
||||
"en/development/models-integration/gpt-oss-local-deployment"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -1048,7 +1050,8 @@
|
||||
"zh-hans/development/models-integration/ollama",
|
||||
"zh-hans/development/models-integration/litellm",
|
||||
"zh-hans/development/models-integration/gpustack",
|
||||
"zh-hans/development/models-integration/aws-bedrock-deepseek"
|
||||
"zh-hans/development/models-integration/aws-bedrock-deepseek",
|
||||
"zh-hans/development/models-integration/gpt-oss-local-deployment"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -1691,7 +1694,8 @@
|
||||
"ja-jp/development/models-integration/ollama",
|
||||
"ja-jp/development/models-integration/litellm",
|
||||
"ja-jp/development/models-integration/gpustack",
|
||||
"ja-jp/development/models-integration/aws-bedrock-deepseek"
|
||||
"ja-jp/development/models-integration/aws-bedrock-deepseek",
|
||||
"ja-jp/development/models-integration/gpt-oss-local-deployment"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@@ -0,0 +1,130 @@
|
||||
---
|
||||
title: " gpt-oss Local Deployment with Ollama and Dify "
|
||||
---
|
||||
# I. Introduction
|
||||
|
||||
The gpt-oss series is an open-source model first released by OpenAI in August 2025.
|
||||
|
||||
> gpt-oss:20b (fits systems with ~16 GB memory)
|
||||
>
|
||||
> gpt-oss:120b (designed for ≥ 60 GB memory)
|
||||
|
||||
You can run it locally with Ollama. No cloud calls. Data stays on your machine, which helps with privacy and latency.
|
||||
|
||||
Dify is an open-source platform for building AI Agents and Workflows. This guide shows how to run gpt-oss with Ollama and plug it into Dify for a private, high-performance setup.
|
||||
|
||||
* * *
|
||||
|
||||
# II. Environment Setup
|
||||
|
||||
## Step 1: Run gpt-oss with Ollama
|
||||
|
||||
1. Install Ollama
|
||||
|
||||
|
||||
[Download](https://ollama.com/) and install for macOS, Windows, or Linux. If anything is unclear, see the [official docs](https://docs.dify.ai/en/development/models-integration/ollama#integrate-local-models-deployed-by-ollama).
|
||||
|
||||
|
||||
|
||||
2. Pull a model
|
||||
|
||||
|
||||
```Bash
|
||||
# Recommended for most dev machines
|
||||
ollama pull gpt-oss:20b
|
||||
|
||||
# For large GPUs or multi-GPU hosts
|
||||
ollama pull gpt-oss:120b
|
||||
```
|
||||
|
||||
Both models are pre‑quantized in **MXFP4** , suitable for local deployment.
|
||||
|
||||
|
||||
|
||||
3. Start Ollama
|
||||
|
||||
|
||||
The default endpoint is http://localhost:11434.
|
||||
|
||||
## Step 2: Install Dify locally
|
||||
|
||||
See the [Dify docs](https://docs.dify.ai/en/getting-started/install-self-hosted/readme) for full instructions. Or follow the quick tutorial below.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Install [Docker](https://www.docker.com/products/docker-desktop/) and make sure Docker Engine is running.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### Install steps
|
||||
|
||||
```Bash
|
||||
git clone https://github.com/langgenius/Dify.git
|
||||
cd Dify/docker
|
||||
cp .env.example .env
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
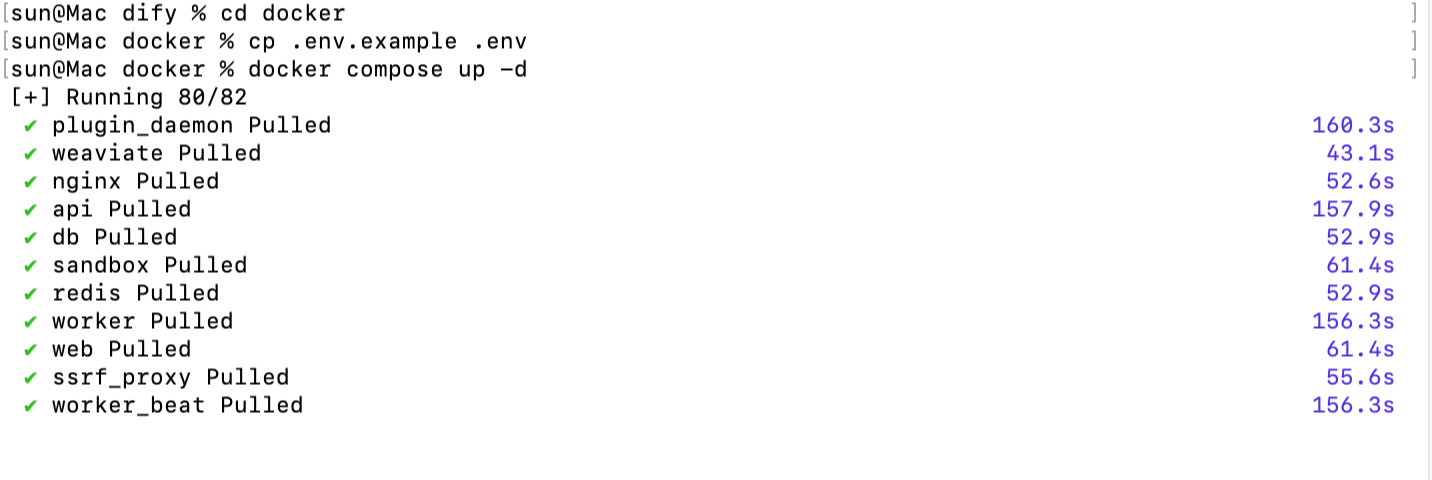
|
||||
|
||||
Open your local Dify instance and complete the initial setup.
|
||||
|
||||
|
||||
|
||||
# III. Add the model and test chat
|
||||
|
||||
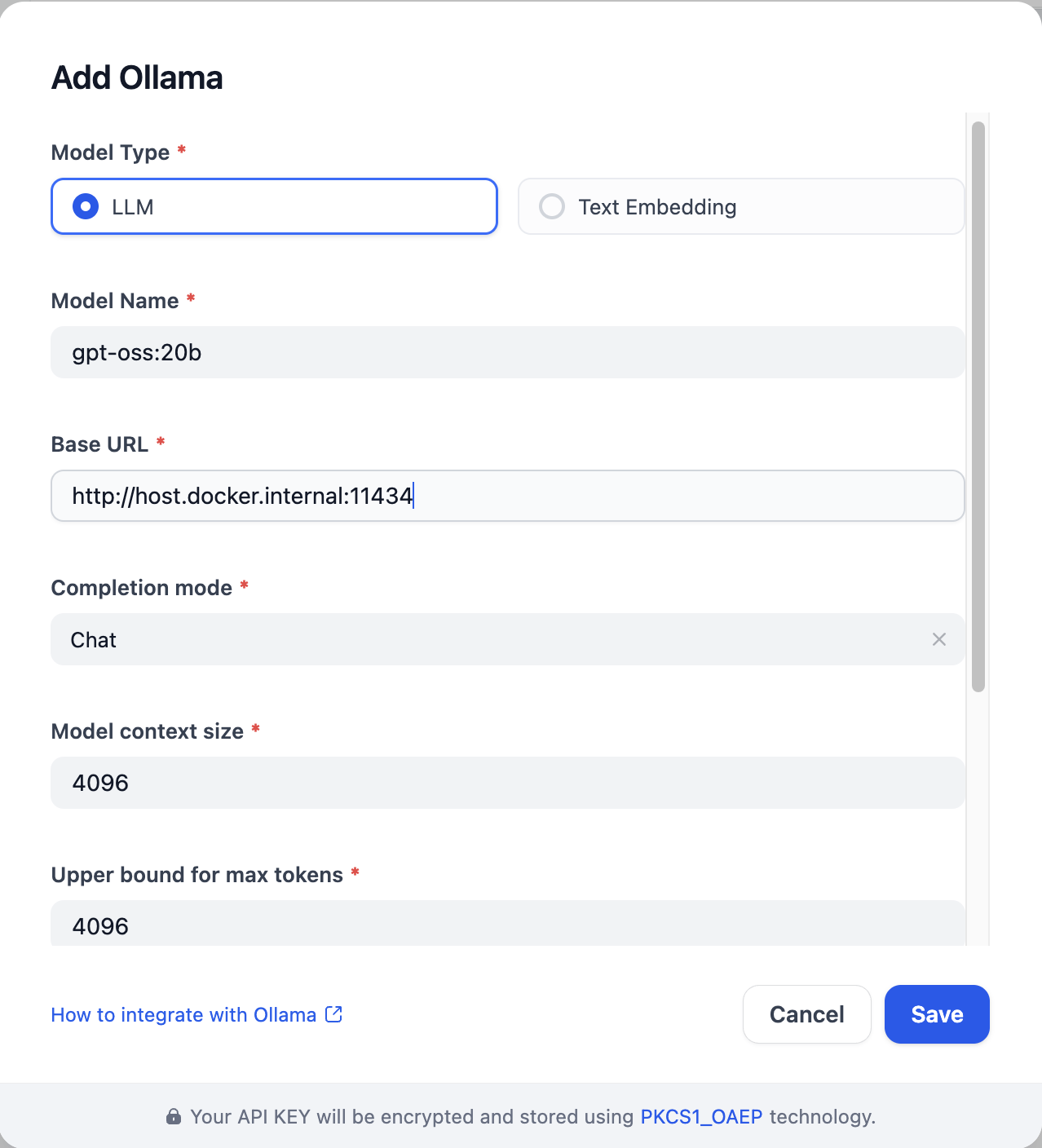
1. In **Settings → Model Providers → Ollama** , click **Add Ollama model type** .
|
||||
|
||||
|
||||
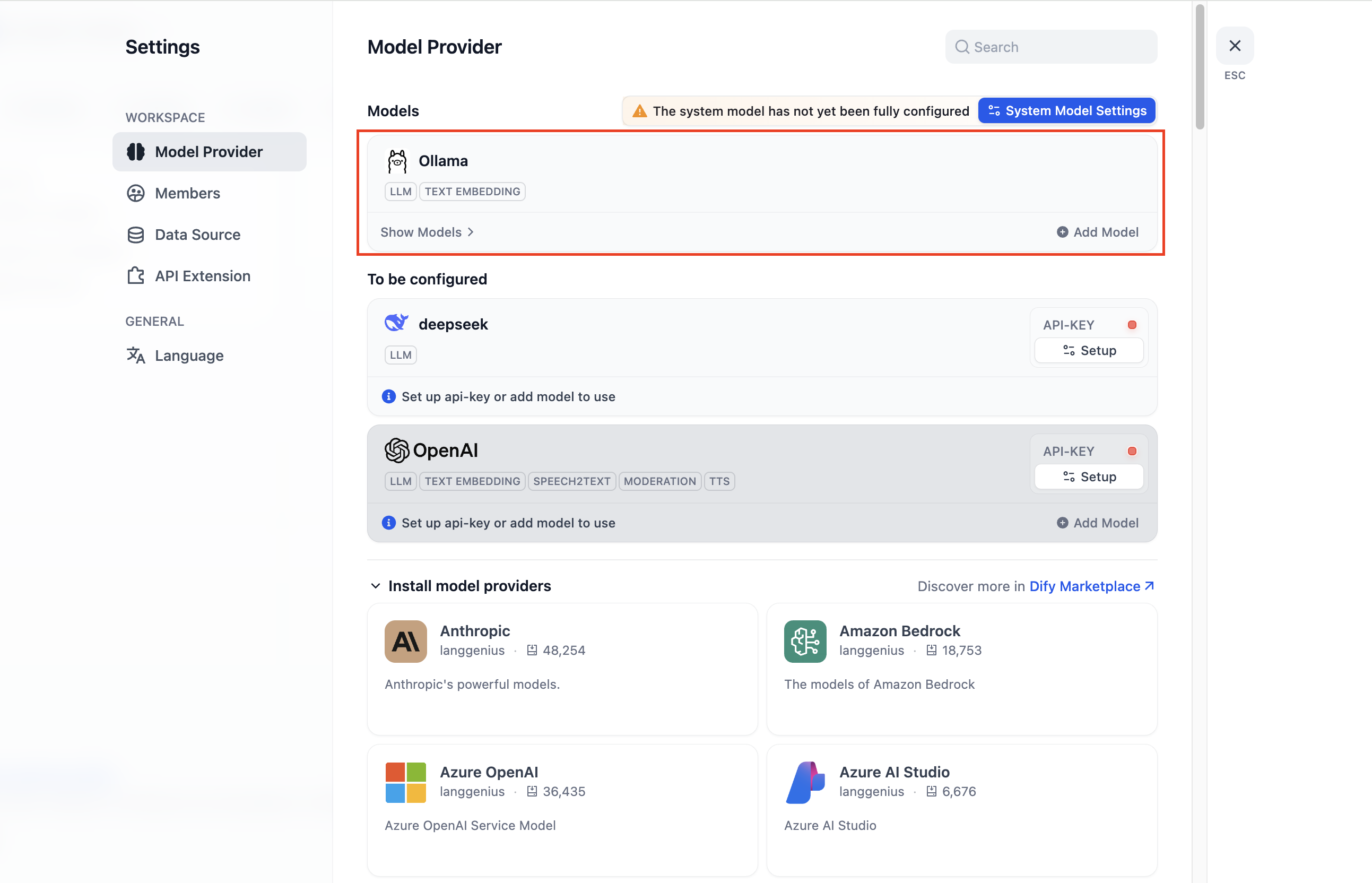
|
||||
|
||||
2. Set **Base URL** to `http://localhost:11434`, select **Model name** `gpt-oss:20b`, and fill in the required fields.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
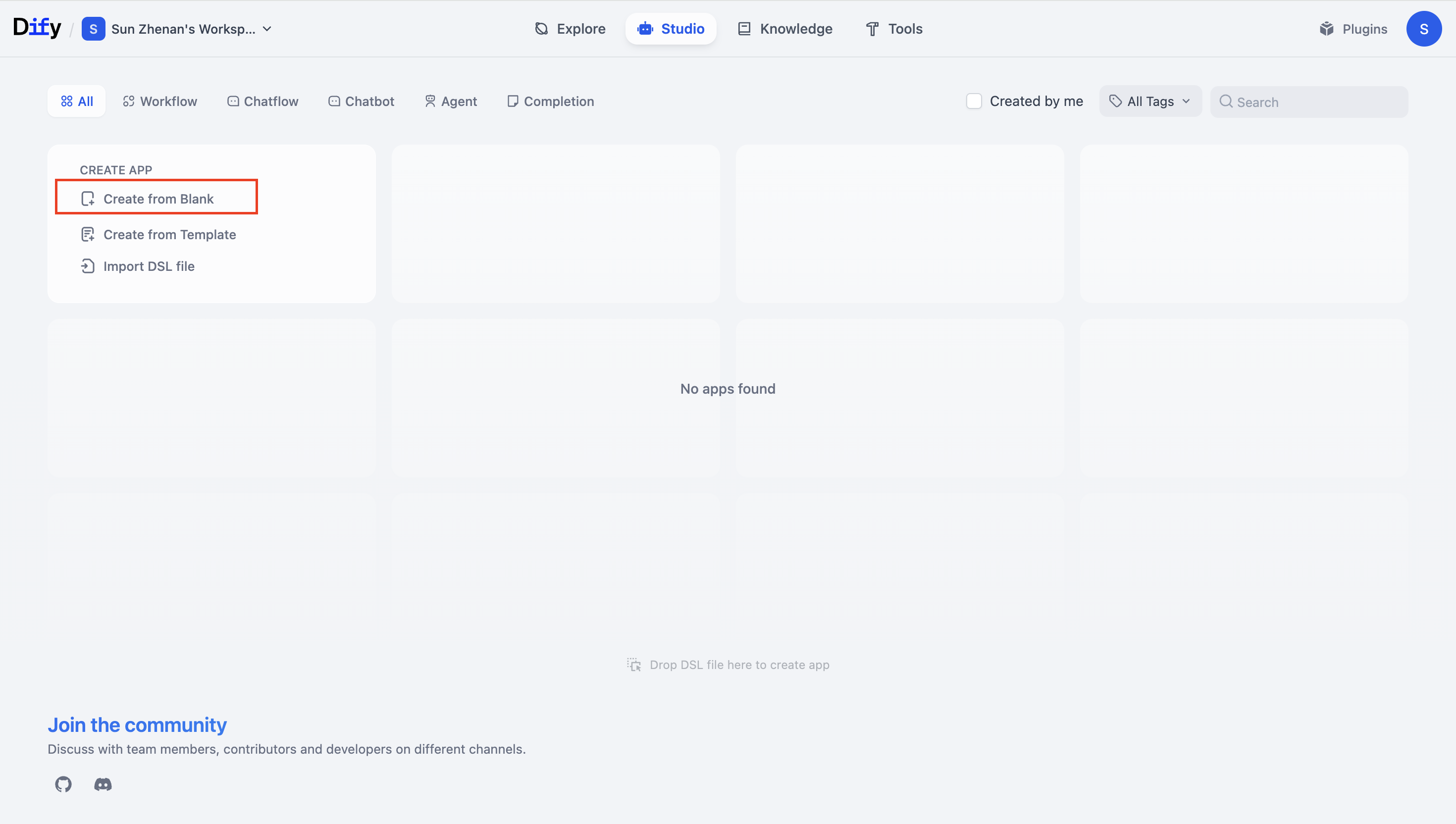
3. Create a blank template
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
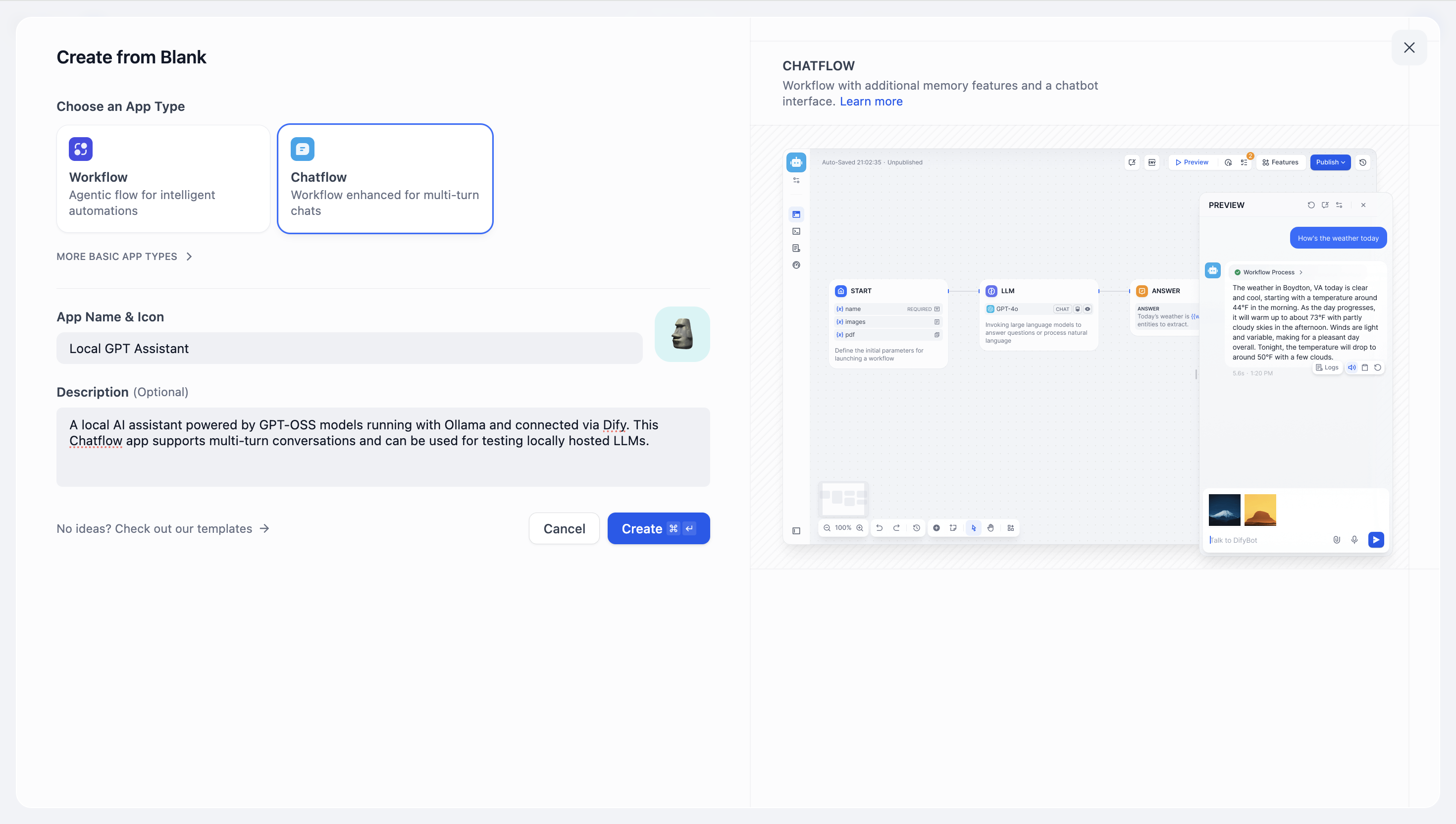
4. Select the app or workflow type you want to build.
|
||||
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
# IV. Verification and Usage
|
||||
|
||||
* On Dify’s **model testing** page, send a prompt and check that the response looks correct.
|
||||
|
||||
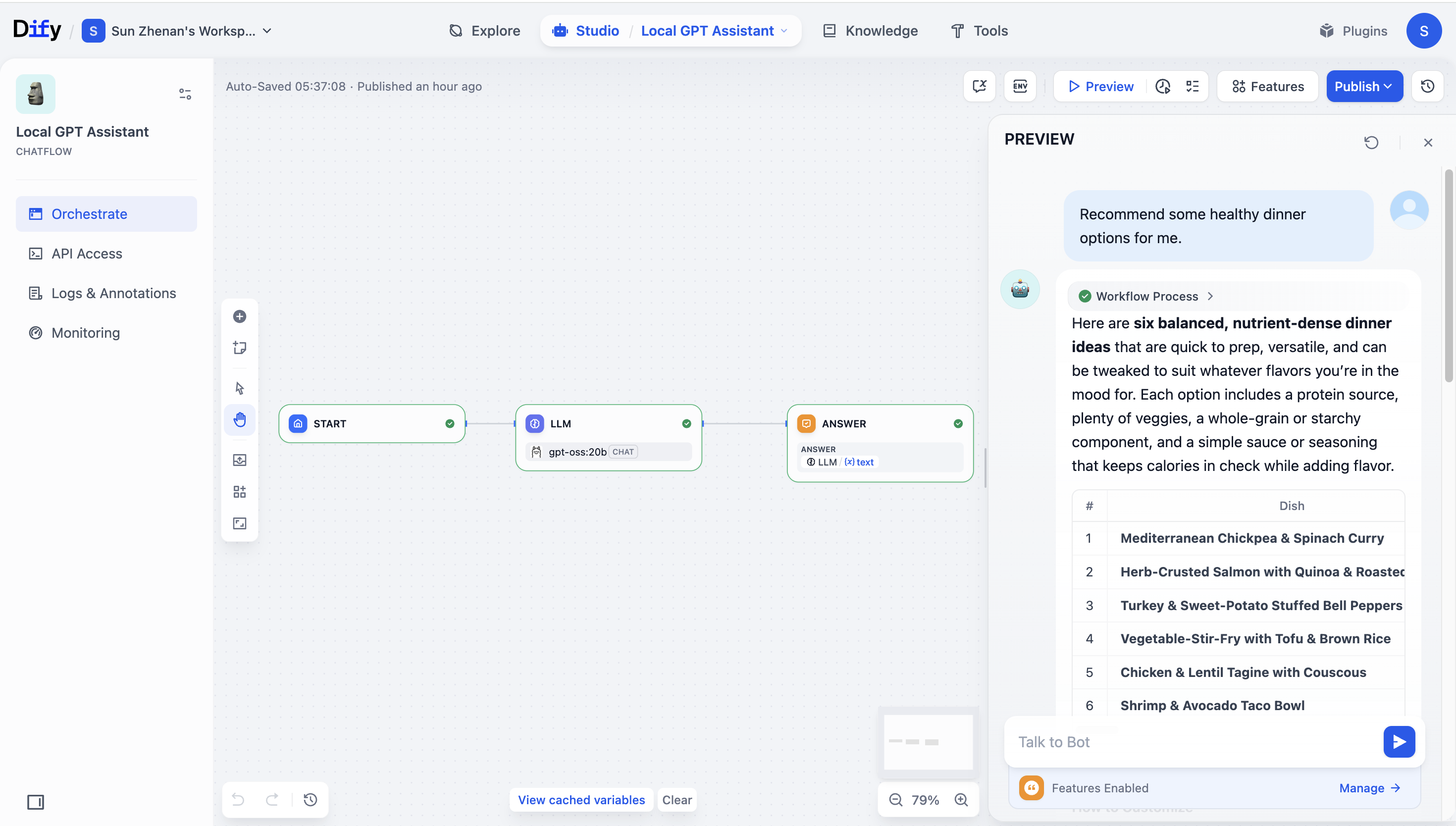
* In a workflow, add an **LLM** node, select `gpt-oss:20b`, and connect the nodes end to end.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
# V. Appendix — FAQ and tips
|
||||
|
||||
**Model Pull Is Slow**
|
||||
|
||||
* *Configure a Docker proxy or use an image mirror to speed up downloads.*
|
||||
|
||||
|
||||
**Insufficient GPU Memory**
|
||||
|
||||
* *Use* *`gpt-oss:20b`*. You can enable CPU offloading, but responses will be slower.*
|
||||
|
||||
**Port Access Issues**
|
||||
|
||||
* *Check firewall rules, port bindings, and Docker network settings to ensure connectivity.*
|
||||
@@ -0,0 +1,99 @@
|
||||
---
|
||||
title: " Ollama+Dify による gpt-oss のローカルデプロイ"
|
||||
---
|
||||
|
||||
## はじめに
|
||||
|
||||
gpt-ossシリーズは、2025年8月にOpenAIからリリースされたオープンソースモデルです。
|
||||
- gpt-oss:20b(約16GBのメモリを持つシステム向け)
|
||||
- gpt-oss:120b(60GB以上のメモリに対応)
|
||||
|
||||
ローカルでOllamaを使用して実行できます。クラウド呼び出しは不要で、データは常にローカルに保存され、プライバシー保護と低遅延に貢献します。
|
||||
|
||||
DifyはAIエージェントやワークフローを構築するためのオープンソースプラットフォームです。このガイドでは、Ollamaを使ってgpt-ossを実行し、Difyに接続してプライベートかつ高性能な設定を行う方法を示します。
|
||||
|
||||
## 環境のセットアップ
|
||||
|
||||
### ステップ1:Ollamaでgpt-ossを実行する
|
||||
|
||||
**1. Ollamaをインストール**
|
||||
|
||||
[Ollamaの公式サイト](https://ollama.com/)を通してmacOS、Windows、またはLinux用にダウンロードしてインストールしてください。
|
||||
|
||||
**2. gpt-ossモデルをインストール**
|
||||
|
||||
```Bash
|
||||
# 開発マシン用におすすめ
|
||||
ollama pull gpt-oss:20b
|
||||
|
||||
# 大規模GPUまたはマルチGPUホスト用におすすめ
|
||||
ollama pull gpt-oss:120b
|
||||
```
|
||||
|
||||
これらのモデルはすでに混合精度フォーマット(MXFP4)で量子化されており、ローカルデプロイに適しています。
|
||||
|
||||
**3. Ollamaの起動**
|
||||
|
||||
デフォルトのエンドポイントはhttp://localhost:11434です。
|
||||
|
||||
### ステップ2:Difyをローカルにインストール
|
||||
|
||||
Difyの[公式ドキュメント](https://docs.dify.ai/ja-jp/getting-started/install-self-hosted/readme)に完全な手順があります。もしくはこちらのシンプルなチュートリアルをご覧ください。
|
||||
|
||||
**前提条件**
|
||||
[Docker](https://www.docker.com/products/docker-desktop/)をインストールし、Dockerエンジンが正常に動作していることを確認してください。
|
||||
|
||||

|
||||
|
||||
**インストール手順**
|
||||
|
||||
```Bash
|
||||
git clone https://github.com/langgenius/Dify.git
|
||||
cd Dify/docker
|
||||
cp .env.example .env
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
|
||||
|
||||
ローカルDifyインスタンスを開き、初期設定を完了させてください。
|
||||
|
||||

|
||||
|
||||
## モデルの追加とチャットのテスト
|
||||
|
||||
1. **設定 > モデルプロバイダー > Ollama** に移動し、**「Ollamaモデルタイプを追加」**をクリックしてください。
|
||||
|
||||

|
||||
|
||||
2. 基本URLを`http://localhost:11434`に設定し、モデル名に`gpt-oss`を選択し、必要なフィールドを埋めてください。
|
||||
|
||||

|
||||
|
||||
3. 空のテンプレートを作成します。
|
||||
|
||||

|
||||
|
||||
4. 構築したいアプリのタイプを選択してください。
|
||||
|
||||

|
||||
|
||||
## 検証と使用
|
||||
|
||||
- Difyの**モデルテスト**ページでプロンプトを送信し、応答が期待通りであることを確認してください。
|
||||
- ワークフローに**LLMノード**を追加し、`gpt-oss:20b`を選択してノードをエンドツーエンドで接続してください。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## よくある質問
|
||||
|
||||
1. モデルのダウンロードが遅い
|
||||
ダウンロードを高速化するために、Dockerプロキシを設定するか、イメージミラーを使用してください。
|
||||
|
||||
2. GPUメモリ不足
|
||||
`gpt-oss:20b`を使用してください。CPUオフローディングを有効にすることもできますが、その場合は応答が遅くなります。
|
||||
|
||||
3. ポートアクセスの問題
|
||||
接続を確認するために、ファイアウォールのルール、ポートのバインディング、およびDockerネットワーク設定を確認してください。
|
||||
152
zh-hans/development/models-integration/gpt-oss + Ollama.md
Normal file
152
zh-hans/development/models-integration/gpt-oss + Ollama.md
Normal file
@@ -0,0 +1,152 @@
|
||||
---
|
||||
title: " gpt-oss + Ollama 本地化部署指南 "
|
||||
---
|
||||
# 一、引言
|
||||
|
||||
* gpt-oss 系列是 OpenAI 于 2025 年 8 月首次发布的开源模型。
|
||||
|
||||
|
||||
> gpt-oss:20b(适用于约 16GB 的内存)
|
||||
>
|
||||
> gpt-oss:120b(适用于≥ 60GB 的内存)
|
||||
|
||||
* 使用 Ollama 在本地部署,无需向云端发送 API 请求。数据始终在本地运行,适用于对隐私和响应速度有要求的场景。
|
||||
|
||||
* Dify 是一个开源的 LLM 应用平台,支持集成本地模型、快速构建 AI 应用程序和 RAG 流程。
|
||||
|
||||
|
||||
**目标:** 展示如何使用 Ollama 在本地部署 gpt-oss 并将其集成到 Dify 中,以构建一个私有且安全的 LLM 服务。
|
||||
|
||||
* * *
|
||||
|
||||
# **二、环境准备**
|
||||
|
||||
## **第一步:使用 Ollama 本地部署 gpt-oss 模型**
|
||||
|
||||
1. 安装 Ollama
|
||||
|
||||
|
||||
访问 [Ollama 官网](https://ollama.com)下载安装,根据操作系统选择 macOS、Windows 或 Linux 版本。
|
||||
|
||||
|
||||
|
||||
2. 拉取 gpt-oss 模型
|
||||
|
||||
|
||||
* gpt-oss:20b(推荐日常开发机器,需 ≥ 16 GB 显存或统一内存) `ollama pull gpt-oss:20b`
|
||||
|
||||
|
||||
|
||||
|
||||
* gpt-oss:120b(需 ≥ 60 GB 显存或多 GPU 支持) `ollama pull gpt-oss:120b`
|
||||
|
||||
|
||||
这两个模型均默认已量化为 MXFP4 格式,适合大多数本地部署场景
|
||||
|
||||
|
||||
|
||||
3. 启动 Ollama 服务
|
||||
|
||||
|
||||
服务默认监听在: http://localhost:11434。
|
||||
|
||||
|
||||
|
||||
## **第二步:本地部署 Dify 并准备接入**
|
||||
|
||||
详细内容参考Dify[官方文档](https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/readme),也可以参考如下简易教程。
|
||||
|
||||
### 前置条件
|
||||
|
||||
下载安装[Docker](https://www.docker.com/products/docker-desktop/) 环境,安装完毕后确认 Docker Engine 能正常运行。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
### 本地部署Dify
|
||||
|
||||
1. 使用Git克隆
|
||||
|
||||
|
||||
`git clone` `https://github.com/langgenius/Dify.git`
|
||||
|
||||
|
||||
|
||||
2. 进入 Dify 源代码的 docker 目录,执行一键启动命令:
|
||||
|
||||
|
||||
`cd Dify/docker` `cp .env.example .env` `d`ouyin
|
||||
|
||||
|
||||
|
||||
3. 进入本地 Dify,填写相关信息
|
||||
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
# **三、添加模型并测试聊天接口**
|
||||
|
||||
1. 点击页面右上角的设置,进入后选择模型提供商,点击添加 Ollama 模型类型: **Settings > Model Providers > Ollama**
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
2. 请填写 ollama 的相关信息。将 **“gpt-oss:20b”** 选作模型名称。如有任何不清楚的地方,您可以参考官方详细的[部署文档](https://docs.dify.ai/en/development/models-integration/ollama#integrate-local-models-deployed-by-ollama)来操作 ollama。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
3. 新建空白模板
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
4. 选择您想创建的类型
|
||||
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
# **四、验证与使用**
|
||||
|
||||
* 在 Dify 的模型测试页面中,输入适当的提示语,并确认模型的响应符合您的预期。
|
||||
|
||||
* 在您的应用流程中添加一个简单的 LLM 节点,选择 gpt-oss:20b 作为模型,并确保整个工作流程连接无误。
|
||||
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
* * *
|
||||
|
||||
# **五、附录**
|
||||
|
||||
**常见问题及建议**
|
||||
|
||||
* **模型下载速度慢**
|
||||
|
||||
|
||||
提示:配置 Docker 代理或使用图像加速服务以加快下载速度。
|
||||
|
||||
* **GPU 内存不足**
|
||||
|
||||
|
||||
提示:对于 GPU 内存有限的设备,请使用 gpt-oss:20b。您还可以启用 CPU 转发功能,但这样会导致响应速度变慢。
|
||||
|
||||
* **端口访问问题**
|
||||
|
||||
|
||||
提示:检查防火墙规则、端口绑定和 Docker 网络设置,以确保连接正常。
|
||||
Reference in New Issue
Block a user