mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
changed a sea of things...
This commit is contained in:
77
docs.json
77
docs.json
@@ -146,30 +146,36 @@
|
||||
{
|
||||
"group": "Create Knowledge",
|
||||
"pages": [
|
||||
"en/guides/knowledge-base/knowledge-base-creation/introduction",
|
||||
{
|
||||
"group": "1. Import Text Data",
|
||||
{"group": "Quick Create",
|
||||
"pages": [
|
||||
"en/guides/knowledge-base/knowledge-base-creation/introduction",
|
||||
{
|
||||
"group": "Import Data",
|
||||
"pages": [
|
||||
"en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme",
|
||||
"en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion",
|
||||
"en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website"
|
||||
]
|
||||
"en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website"]
|
||||
},
|
||||
"en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text",
|
||||
"en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods"]
|
||||
},
|
||||
"en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text",
|
||||
"en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Create from Knowledge Pipeline",
|
||||
"pages": [
|
||||
"en/guides/knowledge-base/knowledge-pipeline/readme",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/create-knowledge-pipeline",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/publish-knowledge-pipeline",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/upload-files",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/manage-knowledge-base",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/authorize-data-source"
|
||||
]
|
||||
{
|
||||
"group": "Create from Knowledge Pipeline",
|
||||
"pages": [
|
||||
"en/guides/knowledge-base/knowledge-pipeline/readme",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/create-knowledge-pipeline",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/publish-knowledge-pipeline",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/upload-files",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/manage-knowledge-base",
|
||||
"en/guides/knowledge-base/knowledge-pipeline/authorize-data-source"]
|
||||
},
|
||||
{
|
||||
"group": "Connect External Knowledge",
|
||||
"pages": [
|
||||
"en/guides/knowledge-base/connect-external-knowledge-base",
|
||||
"en/guides/knowledge-base/external-knowledge-api"]
|
||||
}]
|
||||
},
|
||||
{
|
||||
"group": "Manage Knowledge",
|
||||
@@ -180,11 +186,9 @@
|
||||
"en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api"
|
||||
]
|
||||
},
|
||||
"en/guides/knowledge-base/integrate-knowledge-within-application",
|
||||
"en/guides/knowledge-base/test-retrieval",
|
||||
"en/guides/knowledge-base/knowledge-request-rate-limit",
|
||||
"en/guides/knowledge-base/connect-external-knowledge-base",
|
||||
"en/guides/knowledge-base/external-knowledge-api"
|
||||
"en/guides/knowledge-base/integrate-knowledge-within-application",
|
||||
"en/guides/knowledge-base/knowledge-request-rate-limit"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -785,7 +789,8 @@
|
||||
{
|
||||
"group": "创建知识库",
|
||||
"pages": [
|
||||
{"group": "快速创建知识库", "pages": [
|
||||
{"group": "快速创建",
|
||||
"pages": [
|
||||
"zh-hans/guides/knowledge-base/knowledge-base-creation/introduction",
|
||||
{
|
||||
"group": "导入数据",
|
||||
@@ -795,10 +800,10 @@
|
||||
"zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website"]
|
||||
},
|
||||
"zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text",
|
||||
"zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods"]
|
||||
"zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods"]
|
||||
},
|
||||
{
|
||||
"group": "通过知识流水线创建知识库",
|
||||
"group": "通过知识流水线创建",
|
||||
"pages": [
|
||||
"zh-hans/guides/knowledge-base/knowledge-pipeline/readme",
|
||||
"zh-hans/guides/knowledge-base/knowledge-pipeline/create-knowledge-pipeline",
|
||||
@@ -807,6 +812,12 @@
|
||||
"zh-hans/guides/knowledge-base/knowledge-pipeline/upload-files",
|
||||
"zh-hans/guides/knowledge-base/knowledge-pipeline/manage-knowledge-base",
|
||||
"zh-hans/guides/knowledge-base/knowledge-pipeline/authorize-data-source"]
|
||||
},
|
||||
{
|
||||
"group": "连接外部知识库",
|
||||
"pages": [
|
||||
"zh-hans/guides/knowledge-base/connect-external-knowledge-base",
|
||||
"zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation"]
|
||||
}]
|
||||
},
|
||||
{
|
||||
@@ -818,11 +829,9 @@
|
||||
"zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api"
|
||||
]
|
||||
},
|
||||
"zh-hans/guides/knowledge-base/test-retrieval",
|
||||
"zh-hans/guides/knowledge-base/integrate-knowledge-within-application",
|
||||
"zh-hans/guides/knowledge-base/test-retrieval",
|
||||
"zh-hans/guides/knowledge-base/knowledge-request-rate-limit",
|
||||
"zh-hans/guides/knowledge-base/connect-external-knowledge-base",
|
||||
"zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation"
|
||||
"zh-hans/guides/knowledge-base/knowledge-request-rate-limit"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -1505,8 +1514,8 @@
|
||||
]
|
||||
},
|
||||
"ja-jp/guides/knowledge-base/metadata",
|
||||
"ja-jp/guides/knowledge-base/test-retrieval",
|
||||
"ja-jp/guides/knowledge-base/integrate-knowledge-within-application",
|
||||
"ja-jp/guides/knowledge-base/retrieval-test-and-citation",
|
||||
"ja-jp/guides/knowledge-base/knowledge-request-rate-limit",
|
||||
"ja-jp/guides/knowledge-base/connect-external-knowledge-base",
|
||||
"ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api-documentation"
|
||||
@@ -2520,8 +2529,8 @@
|
||||
"destination": "/en/guides/knowledge-base/integrate-knowledge-within-application"
|
||||
},
|
||||
{
|
||||
"source": "/guides/knowledge-base/retrieval-test-and-citation",
|
||||
"destination": "/en/guides/knowledge-base/retrieval-test-and-citation"
|
||||
"source": "/guides/knowledge-base/test-retrieval",
|
||||
"destination": "/en/guides/knowledge-base/test-retrieval"
|
||||
},
|
||||
{
|
||||
"source": "/guides/knowledge-base/knowledge-request-rate-limit",
|
||||
|
||||
@@ -50,9 +50,9 @@ _Please ensure that your device environment is authorized to use the microphone.
|
||||
|
||||
|
||||
|
||||
### References and Attributions
|
||||
### Citation and Attribution
|
||||
|
||||
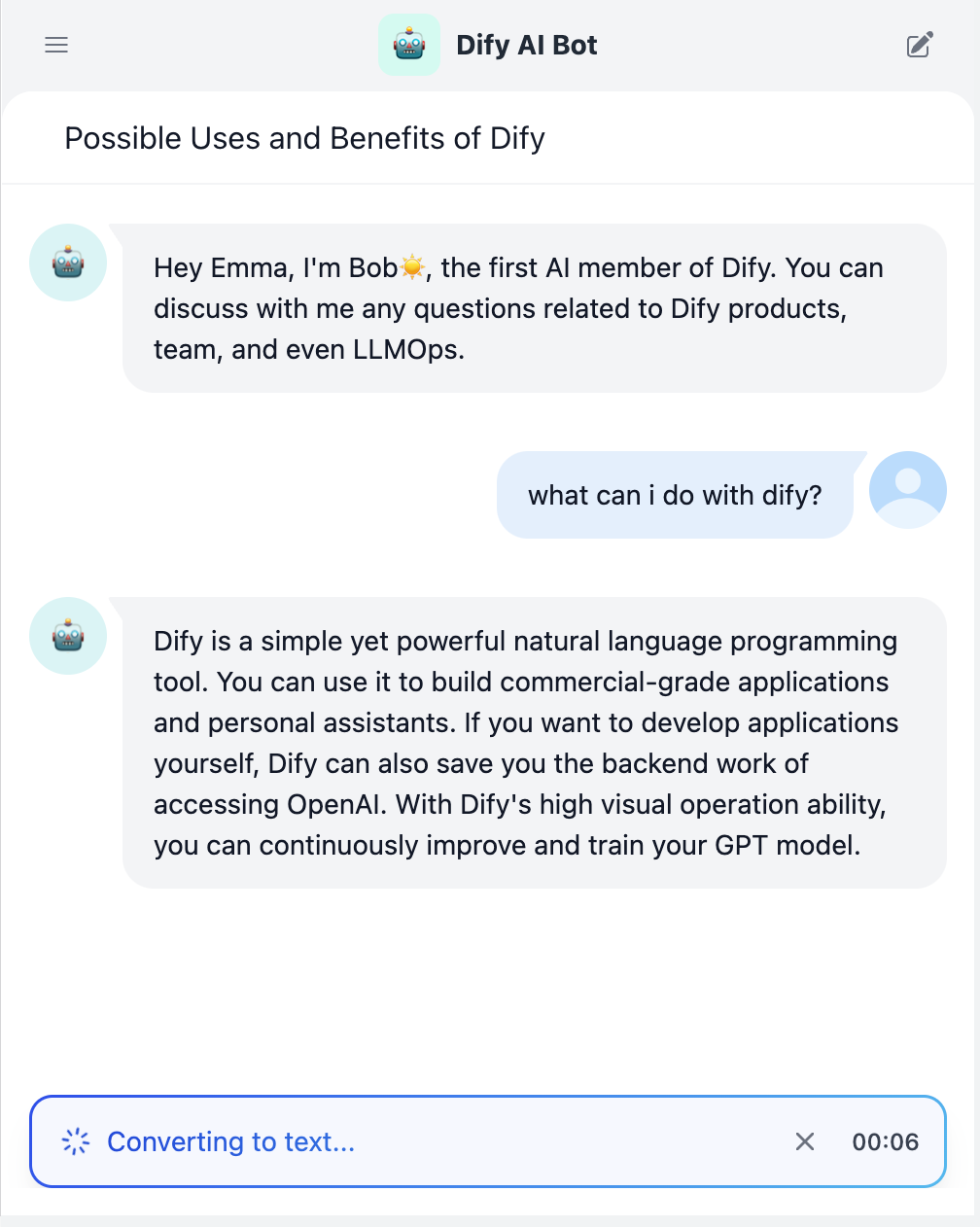
When testing the knowledge base effect within the application, you can go to **Workspace -- Add Function -- Citation and Attribution** to enable the citation attribution feature. For detailed instructions, please refer to [Citation and Attribution](/en/guides/knowledge-base/retrieval-test-and-citation).
|
||||
When this feature is enabled, if the AI references content from the knowledge base while answering a user question, the specific knowledge sources will be displayed below the response.
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 2. Choose a Chunk Mode
|
||||
title: Specify the Chunk Mode
|
||||
---
|
||||
|
||||
After uploading content to the knowledge base, the next step is chunking and data cleaning. **This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.**
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 1. Import Text Data
|
||||
title: Upload Local Files
|
||||
---
|
||||
|
||||
Click on Knowledge in the main navigation bar of Dify. On this page, you can see your existing knowledge bases. Click **Create Knowledge** to enter the setup wizard. The Knowledge supports the import of the following two online data:
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 1.1 Sync Data from Notion
|
||||
title: Sync Data from Notion
|
||||
---
|
||||
|
||||
Dify datasets support importing from Notion and setting up **synchronization** so that data updates in Notion are automatically synced to Dify.
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 1.2 Import Data from Website
|
||||
title: Import Data from Website
|
||||
---
|
||||
|
||||
The knowledge base supports crawling content from public web pages using third-party tools such as [Jina Reader](https://jina.ai/reader/) and [Firecrawl](https://www.firecrawl.dev/), parsing it into Markdown content, and importing it into the knowledge base.
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 3. Specify the Index Method and Retrieval Settings
|
||||
title: Specify the Index Method and Retrieval Settings
|
||||
---
|
||||
|
||||
After selecting the chunking mode, the next step is to define the index method for structured content.
|
||||
@@ -175,7 +175,7 @@ In **Economical Indexing** mode, only the inverted index approach is available.
|
||||
|
||||
After specifying the retrieval settings, you can refer to the following documentation to review how keywords match with content chunks in different scenarios.
|
||||
|
||||
<Card title="Retrieval Test and Citation" icon="link" href="/en/guides/knowledge-base/retrieval-test-and-citation">
|
||||
<Card title="Test Knowledge Retrieval" icon="link" href="/en/guides/knowledge-base/test-retrieval">
|
||||
Learn how to test and cite your knowledge base retrieval
|
||||
</Card>
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: Maintain Knowledge via API
|
||||
title: Manage Knowledge via API
|
||||
---
|
||||
|
||||
> The authentication and invocation methods for the Knowledge Base API are consistent with the Application Service API. However, a single Knowledge Base API token generated has the authority to operate on all visible knowledge bases under the same account. Please pay attention to data security.
|
||||
|
||||
@@ -1,66 +1,18 @@
|
||||
---
|
||||
title: Quick-Create Knowledge Base
|
||||
title: Quick Create Knowledge
|
||||
sidebarTitle: Overview
|
||||
---
|
||||
|
||||
## Procedure
|
||||
1. Click **Knowledge** > **Create Knowledge**, then [upload local files](/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme), [sync data from Notion](/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion), or [webpages](/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website), or create an empty knowledge base.
|
||||
|
||||
1. Create a knowledge base and import either local document file or online data.
|
||||
2. [Specify the chunk mode](/en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text) and preview the splitting results. This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.
|
||||
|
||||
<Card title="Import text data" icon="link" href=".././import-content-data">
|
||||
Create a knowledge base and import either local document file or online data.
|
||||
</Card>
|
||||
3. [Specify the index method and retrieval settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods). Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks.
|
||||
|
||||
2. Choose a chunking mode and preview the spliting results. This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.
|
||||
|
||||
<Card title="Choose a chunk mode" icon="link" href=".././chunking-and-cleaning-text">
|
||||
Choose a chunking mode and preview the spliting results. This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.
|
||||
</Card>
|
||||
|
||||
3. Configure the indexing method and retrieval setting. Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks.
|
||||
|
||||
<Card title="Select the indexing method and retrieval setting" icon="link" href=".././setting-indexing-methods">
|
||||
Configure the indexing method and retrieval setting. Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks.
|
||||
</Card>
|
||||
|
||||
4. Wait for the chunk embeddings to complete.
|
||||
|
||||
5. Once finished, link the knowledge base to your application and start using it. You can then [integrate it into your application](../integrate-knowledge-within-application) to build an LLM that are capable of Q\&A based on knowledge-bases. If you want to modify and manage the knowledge base further, take refer to [Knowledge Base and Document Maintenance]([knowledge-and-documents-maintenance](/en/guides/knowledge-base/knowledge-and-documents-maintenance)).
|
||||
4. Wait for the data processing to complete.
|
||||
|
||||

|
||||
|
||||
## Read More
|
||||
|
||||
**ETL**
|
||||
|
||||
In production-level applications of RAG, to achieve better data retrieval, multi-source data needs to be preprocessed and cleaned, i.e., ETL (extract, transform, load). To enhance the preprocessing capabilities of unstructured/semi-structured data, Dify supports optional ETL solutions: **Dify ETL** and [**Unstructured ETL**](https://unstructured.io/).
|
||||
|
||||
> Unstructured can efficiently extract and transform your data into clean data for subsequent steps.
|
||||
|
||||
ETL solution choices in different versions of Dify:
|
||||
|
||||
* The SaaS version defaults to using Unstructured ETL and cannot be changed;
|
||||
* The community version defaults to using Dify ETL but can enable Unstructured ETL through [environment variables](/en/getting-started/install-self-hosted/environments#zhi-shi-ku-pei-zhi);
|
||||
|
||||
Differences in supported file formats for parsing:
|
||||
|
||||
| DIFY ETL | Unstructured ETL |
|
||||
| ------------------------------------------------------- | --------------------------------------------------------------------------------------- |
|
||||
| txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv | txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv, eml, msg, pptx, ppt, xml, epub |
|
||||
|
||||
<Info>
|
||||
Different ETL solutions may have differences in file extraction effects. For more information on Unstructured ETL’s data processing methods, please refer to the [official documentation](https://docs.unstructured.io/open-source/core-functionality/partitioning).
|
||||
</Info>
|
||||
|
||||
#### **Embedding**
|
||||
|
||||
**Embedding** transforms discrete variables (words, sentences, documents) into continuous vector representations, mapping high-dimensional data to lower-dimensional spaces. This technique preserves crucial semantic information while reducing dimensionality, enhancing content retrieval efficiency.
|
||||
|
||||
**Embedding models**, specialized large language models, excel at converting text into dense numerical vectors, effectively capturing semantic nuances for improved data processing and analysis.
|
||||
|
||||
#### **Metadata**
|
||||
|
||||
For managing the knowledge base with metadata, see *[Metadata](../metadata)*.
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
|
||||
@@ -213,7 +213,7 @@ An inverted index is an index structure designed for rapid keyword retrieval in
|
||||
<img src="/zh-hans/images/en-upload-files-8.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
After specifying the retrieval settings, you can refer to [Retrieval Test/Citation Attribution](/en/guides/knowledge-base/retrieval-test-and-citation) to check the matching between keywords and content chunks.
|
||||
After specifying the retrieval settings, you can refer to [Test Knowledge Retrieval](/en/guides/knowledge-base/test-retrieval) to check the matching between keywords and content chunks.
|
||||
|
||||
## 5. Complete Upload
|
||||
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
---
|
||||
title: Create from Knowledge Pipeline
|
||||
title: Create Knowledge from a Knowledge Pipeline
|
||||
sidebarTitle: Overview
|
||||
---
|
||||
|
||||
A knowledge pipeline is a document processing workflow that transforms raw data into searchable knowledge bases. Think of orchestrating a workflow, now you can visually combine and configure different processing nodes and tools to optimize data processing for better accuracy and relevance.
|
||||
|
||||
@@ -37,7 +37,7 @@ With Dify knowledge, you can build AI apps that are grounded in your own data an
|
||||
|
||||
## Create Knowledge
|
||||
|
||||
- **[Quick-create](/en/guides/knowledge-base/knowledge-base-creation/introduction)**: Import data, define processing rules, and let Dify handle the rest. Fast and beginner-friendly.
|
||||
- **[Quick create](/en/guides/knowledge-base/knowledge-base-creation/introduction)**: Import data, define processing rules, and let Dify handle the rest. Fast and beginner-friendly.
|
||||
|
||||
- **[Create from a knowledge pipeline](/en/guides/knowledge-base/knowledge-pipeline/readme)**: Orchestrate more complex, flexible data processing workflows with custom steps and various plugins.
|
||||
|
||||
@@ -47,17 +47,17 @@ With Dify knowledge, you can build AI apps that are grounded in your own data an
|
||||
|
||||
- **[Manage content](/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents)**: View, add, modify, or delete documents and text chunks to keep your knowledge current, accurate, and retrieval-ready.
|
||||
|
||||
- **[Test and validate retrieval](/en/guides/knowledge-base/retrieval-test-and-citation#1-retrieval-testing)**: Simulate user queries to test how well your knowledge base retrieves relevant information.
|
||||
- **[Test and validate retrieval](/en/guides/knowledge-base/test-retrieval)**: Simulate user queries to test how well your knowledge base retrieves relevant information.
|
||||
|
||||
- **[Enhance retrieval with metadata](/en/guides/knowledge-base/metadata)**: Add metadata to documents to enable filter-based searches and further improve retrieval precision.
|
||||
|
||||
- **[Fine-tune settings](/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)**: Adjust the index method, embedding model, and retrieval strategy at any time.
|
||||
- **[Adjust settings](/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)**: Modify the index method, embedding model, and retrieval strategy at any time.
|
||||
|
||||
## Use Knowledge
|
||||
|
||||
- **[Integrate into applications](/en/guides/knowledge-base/integrate-knowledge-within-application)**: Ground your AI applications in your own data.
|
||||
- **[Integrate into applications](/en/guides/knowledge-base/integrate-knowledge-within-application)**: Ground your AI app in your own data.
|
||||
|
||||
- **[Provide source citations](/en/guides/knowledge-base/test-retrieval)**: Enable your app to display the specific knowledge source for each answer.
|
||||
- **[Provide source citations](/en/guides/application-orchestrate/app-toolkits/readme#citation-and-attribution)**: Enable your app to display the specific knowledge source when generating responses based on knowledge base content.
|
||||
|
||||
---
|
||||
|
||||
|
||||
@@ -33,6 +33,6 @@ It will be automatically generated by the script.
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/knowledge-base/retrieval-test-and-citation.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/knowledge-base/test-retrieval.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
entire
|
||||
@@ -68,7 +68,7 @@ Context variables are a special type of variable defined within the LLM node, us
|
||||
|
||||
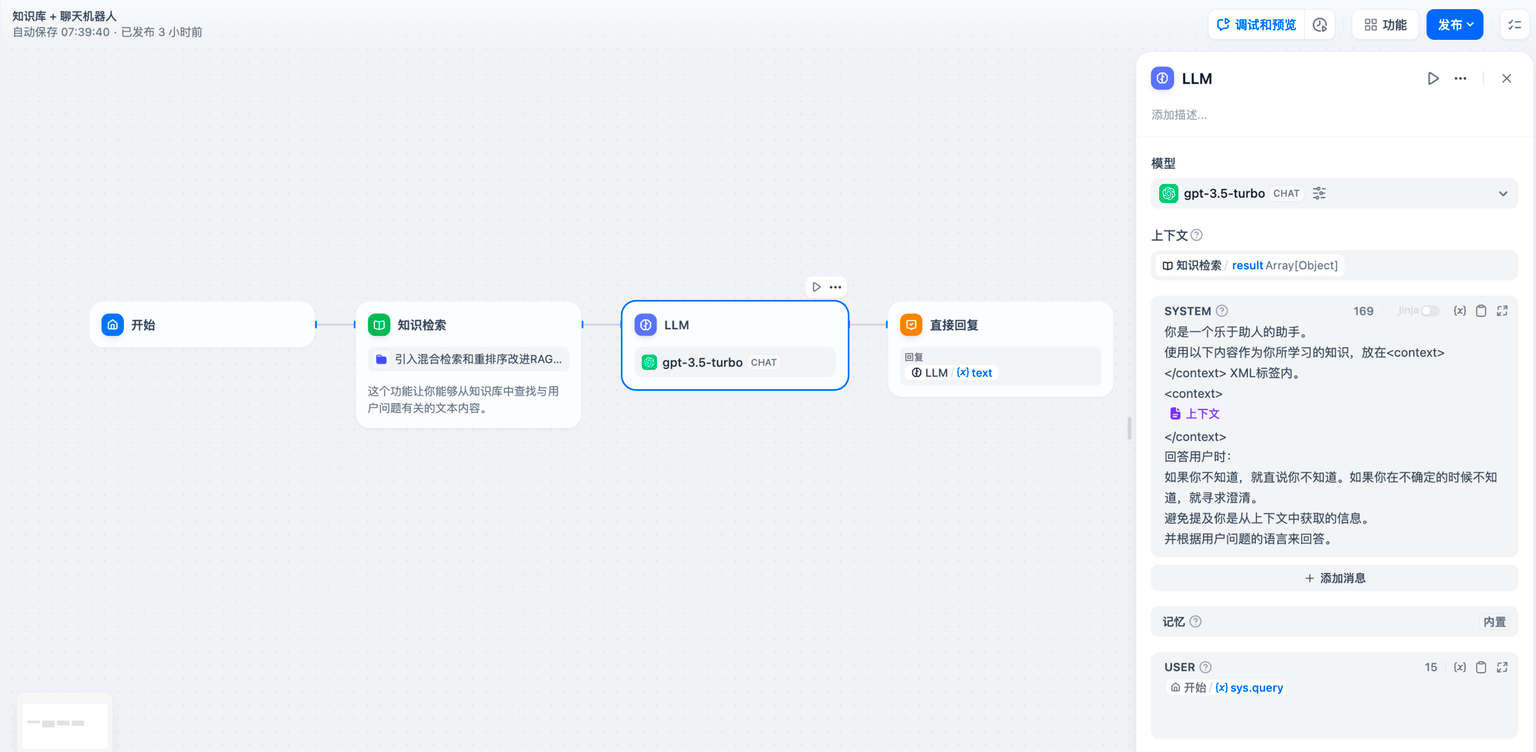
In common knowledge base Q&A applications, the downstream node of knowledge retrieval is typically the LLM node. The **output variable** `result` of knowledge retrieval needs to be configured in the **context variable** within the LLM node for association and assignment. After association, inserting the **context variable** at the appropriate position in the prompt can incorporate the externally retrieved knowledge into the prompt.
|
||||
|
||||
This variable can be used not only as external knowledge introduced into the prompt context for LLM responses but also supports the application's [citation and attribution](/en/guides/knowledge-base/retrieval-test-and-citation#id-2-citation-and-attribution) feature due to its data structure containing segment reference information.
|
||||
This variable can be used not only as external knowledge introduced into the prompt context for LLM responses but also supports the application's [citation and attribution](/en/guides/application-orchestrate/app-toolkits/readme#citation-and-attribution) feature due to its data structure containing segment reference information.
|
||||
|
||||
<Info>
|
||||
If the context variable is associated with a common variable from an upstream node, such as a string type variable from the start node, the context variable can still be used as external knowledge, but the **citation and attribution** feature will be disabled.
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 129 KiB After Width: | Height: | Size: 113 KiB |
@@ -46,9 +46,7 @@ alt=""
|
||||
|
||||
### 引用と帰属
|
||||
|
||||
この機能をオンにすると、大規模言語モデルがナレッジベースからの内容を引用して回答する際に、返信内容の下に具体的な引用段落情報(元の段落テキスト、段落番号、マッチ度など)を表示できます。
|
||||
|
||||
詳しい説明は[引用と帰属](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)をご覧ください。
|
||||
この機能を有効にすると、AIがユーザーの質問に回答する際にナレッジベースの内容を参照した場合、その参照元の具体的な情報源が回答の下に表示されます。
|
||||
|
||||
### コンテンツレビュー
|
||||
|
||||
|
||||
@@ -50,7 +50,7 @@ _使用するデバイス環境がマイクロフォンの使用を許可して
|
||||
|
||||
### 引用と帰属
|
||||
|
||||
アプリ内でナレッジベースの効果をテストする際、**ワークスペース -- 機能の追加 -- 引用と帰属** に移動し、引用と帰属機能をオンにすることができます。詳細については[「引用と帰属」](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)を参照してください。
|
||||
この機能を有効にすると、AI がユーザーの質問に回答する際にナレッジベースの内容を参照した場合、該当するナレッジソースが回答の下に表示されます。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
|
||||
@@ -198,7 +198,7 @@ title: 3. インデックス方法と検索設定を指定
|
||||
|
||||
検索設定を指定した後、以下のドキュメントを参照して、実際のシナリオでのキーワードとコンテンツブロックのマッチング状況を確認できます。
|
||||
|
||||
<Card title="リコールテスト/引用と帰属" icon="link" href="../retrieval-test-and-citation">
|
||||
<Card title="リコールテスト" icon="link" href="/ja-jp/guides/knowledge-base/test-retrieval">
|
||||
実際のシナリオでのキーワードとコンテンツブロックのマッチング状況を確認する
|
||||
</Card>
|
||||
|
||||
|
||||
@@ -221,7 +221,7 @@ version: '简体中文'
|
||||
<img src="/zh-hans/images/en-upload-files-8.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
指定检索设置后,你可以参考[召回测试/引用归属](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
|
||||
指定检索设置后,你可以参考[测试召回效果](/zh-hans/guides/knowledge-base/test-retrieval)查看关键词与内容块的匹配情况。
|
||||
|
||||
## 5 完成上传
|
||||
|
||||
|
||||
@@ -76,5 +76,5 @@ It will be automatically generated by the script.
|
||||
|
||||
---
|
||||
|
||||
[このページを編集する](https://github.com/langgenius/dify-docs/edit/main/ja-jp/guides/knowledge-base/retrieval-test-and-citation.mdx) | [問題を報告する](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
[このページを編集する](https://github.com/langgenius/dify-docs/edit/main/ja-jp/guides/knowledge-base/test-retrieval.mdx) | [問題を報告する](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
@@ -56,7 +56,7 @@ version: '日本語'
|
||||
<img src="https://assets-docs.dify.ai/dify-enterprise-mintlify/jp/guides/workflow/node/4d6388a3cc7b23a6a0e8b511a46faa99.png" alt="配置下游LLM节点" />
|
||||
</Frame>
|
||||
|
||||
この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)機能もサポートします。
|
||||
この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](/ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属)機能もサポートします。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
|
||||
@@ -344,7 +344,7 @@ LLMノードの出力変数をクリックし、構造化スイッチの設定
|
||||
|
||||
.png)
|
||||
|
||||
[知識検索ノード](knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](../../knowledge-base/retrieval-test-and-citation.md#id-2-yin-yong-yu-gui-shu) 機能を使用して情報の出所を確認できます。
|
||||
[知識検索ノード](knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](../ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属) 機能を使用して情報の出所を確認できます。
|
||||
|
||||
<Info>
|
||||
通常のノードの変数もコンテキスト変数に入力可能ですが、例えば開始ノードの文字列型変数など、**引用と帰属** 機能は機能しません。
|
||||
|
||||
@@ -64,9 +64,7 @@ _请注意确保你使用的设备环境已经授权使用麦克风。_
|
||||
|
||||
### 引用与归属
|
||||
|
||||
开启该功能后,当 LLM 回复问题来自知识库的内容时,可以在回复内容下面查看到具体的引用段落信息,包括原始分段文本、分段序号、匹配度等。
|
||||
|
||||
详细说明请参考[《引用与归属》](/zh-hans/guides/knowledge-base/retrieval-test-and-citation)。
|
||||
开启此功能后,若 AI 在回答问题时引用了知识库内容,具体的引用来源将展示在回复内容下方。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
|
||||
@@ -169,7 +169,7 @@ title: 指定索引方式与检索设置
|
||||
|
||||
指定检索设置后,你可以参考以下文档查看在实际场景下,关键词与内容块的匹配情况。
|
||||
|
||||
<Card title="召回测试/引用归属" icon="link" href="../retrieval-test-and-citation">
|
||||
<Card title="测试召回效果" icon="link" href="/zh-hans/guides/knowledge-base/test-retrieval">
|
||||
查看实际场景下的关键词与内容块匹配情况
|
||||
</Card>
|
||||
|
||||
|
||||
@@ -19,7 +19,7 @@ sidebarTitle: 维护内容
|
||||
| 删除 | 永久删除文档。**删除不可撤销**。|
|
||||
| 启用 / 禁用 | 临时将文档纳入或排除检索。<Note>在 Dify Cloud 上,长时间未更新或未被检索的文档会自动禁用以优化性能。<br/><br/>不同订阅计划的未活跃时长如下:<ul><li>Sandbox:7 天</li><li>Professional & Team:30 天</li></ul>Professional 和 Team 用户可一键重新启用这些文档。</Note>|
|
||||
| 归档 / 取消归档 | 将不再需要检索但仍需保留的文档归档。归档文档为只读,可随时取消归档。|
|
||||
| 编辑 | 通过编辑分段内容修改文档。详见 [管理分段](#manage-chunks)。|
|
||||
| 编辑 | 通过编辑分段内容修改文档。详见 [管理分段](#管理分段)。|
|
||||
| 重命名 | 修改文档名称。|
|
||||
|
||||
## 管理分段
|
||||
|
||||
@@ -3,49 +3,16 @@ title: 快速创建知识库
|
||||
sidebarTitle: 概述
|
||||
---
|
||||
|
||||
## 步骤
|
||||
1. 点击 **知识库** > **创建知识库**。然后,[上传本地文件](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme)、[从 Notion 导入数据](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion)、[从网页导入数据](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website),或创建一个空的知识库。
|
||||
|
||||
1. 创建知识库。通过上传本地文件、导入在线数据或创建一个空的知识库。
|
||||
2. [指定分段模式](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)。该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。你可以在此环节预览文本的分段效果。
|
||||
|
||||
<Card title="导入内容数据" icon="link" href=".././create-knowledge-and-upload-documents/import-content-data/readme">
|
||||
通过上传本地文件、导入在线数据或创建一个空的知识库。
|
||||
</Card>
|
||||
3. [设定索引方法和检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)。知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。
|
||||
|
||||
2. 指定分段模式。该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。你可以在此环节预览文本的分段效果。
|
||||
|
||||
<Card title="文本分段和清洗" icon="link" href=".././create-knowledge-and-upload-documents/chunking-and-cleaning-text">
|
||||
了解文本分段和数据清洗流程
|
||||
</Card>
|
||||
|
||||
3. 设定索引方法和检索设置。知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。
|
||||
|
||||
<Card title="设置索引方法" icon="link" href=".././create-knowledge-and-upload-documents/setting-indexing-methods">
|
||||
了解如何设置索引方法和检索参数
|
||||
</Card>
|
||||
|
||||
4. 等待分段嵌入。
|
||||
5. 完成上传,在应用内关联知识库并使用。你可以参考[在应用内集成知识库](/zh-hans/guides/knowledge-base/integrate-knowledge-within-application),搭建出能够基于知识库进行问答的 LLM 应用。如需修改或管理知识库,请参考[知识库管理与文档维护](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)。
|
||||
4. 等待数据处理完成,完成知识库的创建。
|
||||
|
||||

|
||||
|
||||
## 延伸阅读
|
||||
|
||||
**ETL**
|
||||
|
||||
在 RAG 的生产级应用中,为了获得更好的数据召回效果,需要对多源数据进行预处理和清洗,即 ETL (_extract, transform, load_)。为了增强非结构化/半结构化数据的预处理能力,Dify 支持了可选的 ETL 方案:**Dify ETL** 和[**Unstructured ETL**](https://docs.unstructured.io/welcome)。Unstructured 能够高效地提取并转换你的数据为干净的数据用于后续的步骤。Dify 各版本的 ETL 方案选择:
|
||||
|
||||
* SaaS 版不可选,默认使用 Unstructured ETL;
|
||||
* 社区版可选,默认使用 Dify ETL ,可通过[环境变量](/zh-hans/getting-started/install-self-hosted/environments)开启 Unstructured ETL;
|
||||
|
||||
文件解析支持格式的差异:
|
||||
|
||||
| DIFY ETL | Unstructured ETL |
|
||||
| ---------------------------------------------- | ------------------------------------------------------------------------ |
|
||||
| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
|
||||
|
||||
不同的 ETL 方案在文件提取效果的方面也会存在差异,想了解更多关于 Unstructured ETL 的数据处理方式,请参考[官方文档](https://docs.unstructured.io/open-source/core-functionality/partitioning)。
|
||||
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
|
||||
@@ -221,7 +221,7 @@ version: '简体中文'
|
||||
<img src="/zh-hans/images/en-upload-files-8.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
指定检索设置后,你可以参考[召回测试/引用归属](/zh-hans/guides/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
|
||||
指定检索设置后,你可以参考[召回测试效果](/zh-hans/guides/knowledge-base/test-retrieval)查看关键词与内容块的匹配情况。
|
||||
|
||||
## 5 完成上传
|
||||
|
||||
|
||||
@@ -31,5 +31,5 @@ It will be automatically generated by the script.
|
||||
|
||||
---
|
||||
|
||||
[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/zh-hans/guides/knowledge-base/retrieval-test-and-citation.mdx) | [提交问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/zh-hans/guides/knowledge-base/test-retrieval.mdx) | [提交问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
|
||||
@@ -87,7 +87,7 @@ title: 知识检索
|
||||
|
||||
可利用已有的文档元数据,将检索范围限定在知识库的特定文档内,以进一步提升检索精度。
|
||||
|
||||
启用元数据过滤后,知识检索节点仅会检索符合指定元数据条件的文档,而非整个知识库。尤其适用于内容多样的大型知识库。
|
||||
启用元数据过滤后,知识检索节点仅会检索符合指定元数据过滤条件的文档,而非整个知识库。尤其适用于内容多样的大型知识库。
|
||||
|
||||
<Info>
|
||||
了解如何创建与管理文档元数据,阅读 [元数据](/zh-hans/guides/knowledge-base/metadata)。
|
||||
|
||||
@@ -347,7 +347,7 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
|
||||
|
||||
|
||||
|
||||
[知识检索节点](knowledge-retrieval)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](../../knowledge-base/retrieval-test-and-citation#id-2-yin-yong-yu-gui-shu) 功能查看信息来源。
|
||||
[知识检索节点](knowledge-retrieval)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](/zh-hans/guides/application-orchestrate/app-toolkits/readme#引用与归属) 功能查看信息来源。
|
||||
|
||||
<Info>
|
||||
上游节点的普通变量同样可以填写至上下文变量内,例如开始节点的字符串类型变量,但 **引用与归属** 功能将会失效。
|
||||
|
||||
Reference in New Issue
Block a user