mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
Docs: update metadata content english
This commit is contained in:
44
docs.json
44
docs.json
@@ -140,21 +140,38 @@
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Knowledge Base",
|
||||
"group": "Knowledge",
|
||||
"pages": [
|
||||
"en-us/user-guide/knowledge-base/readme",
|
||||
{
|
||||
"group": "Create Knowledge Base",
|
||||
"group": "Create Knowledge",
|
||||
"pages": [
|
||||
"en-us/user-guide/knowledge-base/knowledge-base-creation/upload-documents",
|
||||
"en-us/user-guide/knowledge-base/knowledge-base-creation/sync-from-notion",
|
||||
"en-us/user-guide/knowledge-base/knowledge-base-creation/sync-from-website",
|
||||
"en-us/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge"
|
||||
"en-us/user-guide/knowledge-base/knowledge-base-creation/introduction",
|
||||
{
|
||||
"group": "1. Import Text Data",
|
||||
"pages": [
|
||||
"en-us/user-guide/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme",
|
||||
"en-us/user-guide/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion",
|
||||
"en-us/user-guide/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website"
|
||||
]
|
||||
},
|
||||
"en-us/user-guide/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text",
|
||||
"en-us/user-guide/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods"
|
||||
]
|
||||
},
|
||||
"en-us/user-guide/knowledge-base/retrieval-test-and-citation",
|
||||
"en-us/user-guide/knowledge-base/knowledge-and-documents-maintenance",
|
||||
{
|
||||
"group": "Manage Knowledge",
|
||||
"pages": [
|
||||
"en-us/user-guide/knowledge-base/knowledge-and-documents-maintenance/introduction",
|
||||
"en-us/user-guide/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents",
|
||||
"en-us/user-guide/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api"
|
||||
]
|
||||
},
|
||||
"en-us/user-guide/knowledge-base/metadata",
|
||||
"en-us/user-guide/knowledge-base/integrate-knowledge-within-application",
|
||||
"en-us/user-guide/knowledge-base/faq"
|
||||
"en-us/user-guide/knowledge-base/retrieval-test-and-citation",
|
||||
"en-us/user-guide/knowledge-base/connect-external-knowledge-base",
|
||||
"en-us/user-guide/knowledge-base/api-documentation/external-knowledge-api-documentation"
|
||||
]
|
||||
},
|
||||
{
|
||||
@@ -367,7 +384,7 @@
|
||||
"zh-cn/user-guide/knowledge-base/metadata",
|
||||
"zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application",
|
||||
"zh-cn/user-guide/knowledge-base/retrieval-test-and-citation",
|
||||
"zh-cn/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge-base",
|
||||
"zh-cn/user-guide/knowledge-base/connect-external-knowledge-base",
|
||||
"zh-cn/user-guide/knowledge-base/api-documentation/external-knowledge-api-documentation"
|
||||
]
|
||||
},
|
||||
@@ -677,7 +694,12 @@
|
||||
"label": "Support",
|
||||
"href": "mailto:support@dify.ai"
|
||||
}
|
||||
]
|
||||
],
|
||||
"primary": {
|
||||
"type": "button",
|
||||
"label": "Dify.AI",
|
||||
"href": "https://cloud.dify.ai"
|
||||
}
|
||||
},
|
||||
"footer": {
|
||||
"socials": {
|
||||
|
||||
@@ -1,46 +0,0 @@
|
||||
# Welcome to Dify
|
||||
|
||||
Dify is an open-source platform for building AI applications. We combine Backend-as-a-Service and LLMOps to streamline the development of generative AI solutions, making it accessible to both developers and non-technical innovators.
|
||||
|
||||
Our platform integrates:
|
||||
|
||||
- Support for mainstream LLMs
|
||||
- An intuitive Prompt orchestration interface
|
||||
- High-quality RAG engines
|
||||
- A flexible AI Agent framework
|
||||
- An Intuitive Low-code Workflow
|
||||
- Easy-to-use interfaces and APIs
|
||||
|
||||
With Dify, you can skip the complexity and focus on what matters most - creating innovative AI applications that solve real-world problems.
|
||||
|
||||
### The Advantage of Dify
|
||||
|
||||
While many AI development tools offer individual components, Dify provides a comprehensive, production-ready solution. Think of Dify as a well-designed scaffolding system, not just a toolbox.
|
||||
|
||||
As an open-source platform, Dify is co-created by a dedicated professional team and a vibrant community. This collaboration ensures rapid iteration, robust features, and a user-friendly interface.
|
||||
|
||||
With Dify, you can:
|
||||
|
||||
- Deploy capabilities similar to Assistants API and GPTs using any model
|
||||
- Maintain full control over your data with flexible security options
|
||||
- Leverage an intuitive interface for easy management and deployment
|
||||
|
||||
### Dify
|
||||
|
||||
{% hint style="info" %} The name Dify comes from "Define + Modify", referring to defining and continuously improving your AI applications. It's made for you. {% endhint %}
|
||||
|
||||
Here's how various groups are leveraging Dify:
|
||||
|
||||
1. **Startups**: Rapidly prototype and iterate on AI ideas, accelerating both successes and failures. Numerous teams have used Dify to build MVPs, secure funding, and win customer contracts.
|
||||
2. **Established Businesses**: Enhance existing applications with LLM capabilities. Use Dify's RESTful APIs to separate prompts from business logic, while utilizing our management interface to track data, costs, and usage.
|
||||
3. **Enterprise AI infrastructure**: Banks and tech companies are deploying Dify as an internal LLM gateway, facilitating GenAI adoption with centralized governance.
|
||||
4. **AI Enthusiasts and Learners**: Practice prompt engineering and explore agent technologies with ease. Over 60,000 developers built their first AI app on Dify even before GPTs were introduced. Since then, our community has grown significantly, now boasting over 180,000 developers and supporting 59,000+ end users.
|
||||
|
||||
Whether you're a startup founder, an enterprise developer, or an AI enthusiast, Dify is designed to meet your needs and accelerate your AI journey!
|
||||
|
||||
### Next Steps
|
||||
|
||||
- Read [**Quick Start**](https://docs.dify.ai/application/creating-an-application) for an overview of Dify’s application building workflow.
|
||||
- Learn how to [**self-deploy Dify** ](https://docs.dify.ai/getting-started/install-self-hosted)to your servers and [**integrate open source models**](https://docs.dify.ai/advanced/model-configuration)**.**
|
||||
- Understand Dify’s [**specifications and roadmap**](https://docs.dify.ai/getting-started/readme/features-and-specifications)**.**
|
||||
- [**Star us on GitHub**](https://github.com/langgenius/dify) and read our **Contributor Guidelines.**
|
||||
61
en-us/user-guide/build-app/agent.mdx
Normal file
61
en-us/user-guide/build-app/agent.mdx
Normal file
@@ -0,0 +1,61 @@
|
||||
---
|
||||
title: Agent
|
||||
---
|
||||
|
||||
## Definition
|
||||
|
||||
An Agent Assistant can leverage the reasoning abilities of large language models (LLMs). It independently sets goals, simplifies complex tasks, operates tools, and refines processes to complete tasks autonomously.
|
||||
|
||||
## Usage Instructions
|
||||
|
||||
To facilitate quick learning and use, application templates for the Agent Assistant are available in the 'Explore' section. You can integrate these templates into your workspace. The new Dify 'Studio' also allows the creation of a custom Agent Assistant to suit individual requirements. This assistant can assist in analyzing financial reports, composing reports, designing logos, and organizing travel plans.
|
||||
|
||||

|
||||
|
||||
The task completion ability of the Agent Assistant depends on the inference capabilities of the model selected. We recommend using a more powerful model series like GPT-4 when employing Agent Assistant to achieve more stable task completion results.
|
||||
|
||||

|
||||
|
||||
You can write prompts for the Agent Assistant in 'Instructions'. To achieve optimal results, you can clearly define its task objectives, workflow, resources, and limitations in the instructions.
|
||||
|
||||

|
||||
|
||||
## Adding Tools for the Agent Assistant
|
||||
|
||||
In the "Context" section, you can incorporate knowledge base tools that the Agent Assistant can utilize for information retrieval. This will assist in providing it with external background knowledge.
|
||||
|
||||
In the "Tools" section, you are able to add tools that are required for use. These tools can enhance the capabilities of LLMs, such as internet searches, scientific computations, or image creation, thereby enriching the LLM's ability to interact with the real world. Dify offers two types of tools: **built-in tools and custom tools.**
|
||||
|
||||
You have the option to directly use built-in tools in Dify, or you can easily import custom API tools (currently supporting OpenAPI/Swagger and OpenAI Plugin standards).
|
||||
|
||||

|
||||
|
||||
The **Tools** feature allows you to create more powerful AI applications on Dify. For example, you can orchestrate suitable tools for Agent Assistant, enabling it to complete complex tasks through reasoning, step decomposition, and tool invocation.
|
||||
|
||||
Additionally, the tool simplifies the integration of your application with other systems or services, enabling interactions with the external environment, such as executing code or accessing proprietary information sources. Simply mention the name of the tool you want to invoke in the chat box, and it will be automatically activated.
|
||||
|
||||

|
||||
|
||||
## Agent Settings
|
||||
|
||||
On Dify, two inference modes are provided for Agent Assistant: Function Calling and ReAct. Models like GPT-3.5 and GPT-4 that support Function Calling have demonstrated better and more stable performance. For model series that do not support Function Calling, we have implemented the ReAct inference framework to achieve similar effects.
|
||||
|
||||
In the Agent settings, you can modify the iteration limit of the Agent.
|
||||
|
||||

|
||||
|
||||
## Configuring the Conversation Opener
|
||||
|
||||
You can set up a conversation opener and initial questions for your Agent Assistant. The configured conversation opener will be displayed at the beginning of each user's first interaction, showcasing the types of tasks the Agent can perform, along with examples of questions that can be asked.
|
||||
|
||||

|
||||
|
||||
## Debugging and Preview
|
||||
|
||||
After orchestrating the intelligent assistant, you can debug and preview it before publishing as an application to verify the assistant's task completion effectiveness.
|
||||
|
||||

|
||||
|
||||
## Publish Application
|
||||
|
||||

|
||||
81
en-us/user-guide/build-app/chatbot.mdx
Normal file
81
en-us/user-guide/build-app/chatbot.mdx
Normal file
@@ -0,0 +1,81 @@
|
||||
---
|
||||
title: Chatbot Application
|
||||
---
|
||||
|
||||
Conversation applications use a one-question-one-answer mode to have a continuous conversation with the user.
|
||||
|
||||
### Applicable scenarios
|
||||
|
||||
Conversation applications can be used in fields such as customer service, online education, healthcare, financial services, etc. These applications can help organizations improve work efficiency, reduce labor costs, and provide a better user experience.
|
||||
|
||||
### How to compose
|
||||
|
||||
Conversation applications supports: prompts, variables, context, opening remarks, and suggestions for the next question.
|
||||
|
||||
Here, we use a interviewer application as an example to introduce the way to compose a conversation applications.
|
||||
|
||||
#### Step 1 Create an application
|
||||
|
||||
Click the "Create Application" button on the homepage to create an application. Fill in the application name, and select **"Chat App"** as the application type.
|
||||
|
||||

|
||||
|
||||
#### Step 2: Compose the Application
|
||||
|
||||
After the application is successfully created, it will automatically redirect to the application overview page. Click on the button on the left menu: **"Orchestrate"** to compose the application.
|
||||
|
||||

|
||||
|
||||
**2.1 Fill in Prompts**
|
||||
|
||||
Prompt phrases are used to guide AI in providing professional responses, making the replies more precise. You can utilize the built-in prompt generator to craft suitable prompts. Prompts support the insertion of form variables, such as `{{input}}`. The values in the prompt variables will be replaced with the values filled in by the user.
|
||||
|
||||
Example:
|
||||
|
||||
1. Enter the interview scenario command.
|
||||
2. The prompt will automatically generate on the right side content box.
|
||||
3. You can insert custom variables within the prompt to tailor it to specific needs or details.
|
||||
|
||||
For a better experience, we will add an opening dialogue: `"Hello, {{name}}. I'm your interviewer, Bob. Are you ready?"`
|
||||
|
||||
To add the opening dialogue, click the "Add Feature" button in the upper left corner, and enable the "Conversation remarkers" feature:
|
||||
|
||||

|
||||
|
||||
And then edit the opening remarks:
|
||||
|
||||

|
||||
|
||||
**2.2 Adding Context**
|
||||
|
||||
If an application wants to generate content based on private contextual conversations, it can use our [knowledge](/en-us/knowledge-base/introduction) feature. Click the "Add" button in the context to add a knowledge base.
|
||||
|
||||

|
||||
|
||||
**2.3 Debugging**
|
||||
|
||||
Enter user inputs on the right side and check the respond content.
|
||||
|
||||

|
||||
|
||||
If the results are not satisfactory, you can adjust the prompts and model parameters. Click on the model name in the upper right corner to set the parameters of the model:
|
||||
|
||||

|
||||
|
||||
**Debugging with multiple models:**
|
||||
|
||||
If debugging with a single model feels inefficient, you can utilize the **Debug as Multiple Models** feature to batch-test the models’ response effectiveness.
|
||||
|
||||

|
||||
|
||||
Supports adding up to 4 LLMs at the same time.
|
||||
|
||||

|
||||
|
||||
> ⚠️ When using the multi-model debugging feature, if only some large models are visible, it is because other large models’ keys have not been added yet. You can manually add multiple models’ keys in [“Add New Provider”](/en-us/user-guide/models/new-provider).
|
||||
|
||||
**2.4 Publish App**
|
||||
|
||||
After debugging your application, click the **"Publish"** button in the top right corner to create a standalone AI application. In addition to experiencing the application via a public URL, you can also perform secondary development based on APIs, embed it into websites, and more. For details, please refer to [Publishing](/en-us/user-guide/application-publishing/launch-your-webapp-quickly/web-app-settings).
|
||||
|
||||
If you want to customize the application that you share, you can Fork our open source [WebApp template](https://github.com/langgenius/webapp-conversation). Based on the template, you can modify the application to meet your specific needs and style requirements.
|
||||
130
en-us/user-guide/build-app/flow-app/additional-features.mdx
Normal file
130
en-us/user-guide/build-app/flow-app/additional-features.mdx
Normal file
@@ -0,0 +1,130 @@
|
||||
---
|
||||
title: Additional Features
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
Both Workflow and Chatflow applications support enabling additional features to enhance the user interaction experience. For example, adding a file upload entry, giving the LLM application a self-introduction, or using a welcome message can provide users with a richer interactive experience.
|
||||
|
||||
Click the **"Features"** button in the upper right corner of the application to add more functionality.
|
||||
|
||||
<iframe
|
||||
src="https://app.arcade.software/share/a0tbwuEIT5I3y5RdHsJp"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="500px"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
#### Workflow
|
||||
|
||||
Workflow type applications only support the **"Image Upload"** feature. When enabled, an image upload entry will appear on the usage page of the Workflow application.
|
||||
|
||||
<iframe
|
||||
src="https://app.arcade.software/share/DqlK9RV79K25ElxMq1BJ"
|
||||
frameborder="0"
|
||||
width="100%"
|
||||
height="500px"
|
||||
allowfullscreen
|
||||
></iframe>
|
||||
|
||||
**Usage:**
|
||||
|
||||
**For application users:** Applications with image upload enabled will display an upload button on the usage page. Click the button or paste a file link to complete the image upload. You will receive the LLM's response to the image.
|
||||
|
||||
**For application developers:** After enabling the image upload feature, the uploaded image files will be stored in the `sys.files` variable. Next, add an LLM node, select a large model with vision capabilities, and enable the VISION feature within it. Choose the `sys.files` variable to allow the LLM to read the image file.
|
||||
|
||||
Finally, select the output variable of the LLM node in the END node to complete the setup.
|
||||
|
||||
<Frame caption="Enabling visual analysis capabilities">
|
||||
<img src="/ja-jp/user-guide/.gitbook/assets/image (7).png" alt="Setting interface for enabling visual analysis capabilities in LLM nodes" />
|
||||
</Frame>
|
||||
|
||||
#### Chatflow
|
||||
|
||||
Chatflow type applications support the following features:
|
||||
|
||||
* **Conversation Opener**
|
||||
|
||||
Allow AI to proactively send a message, which can be a welcome message or AI self-introduction, to bring it closer to the user.
|
||||
* **Follow-up**
|
||||
|
||||
Automatically add suggestions for the next question after the conversation is complete, to increase the depth and frequency of dialogue topics.
|
||||
* **Text-to-Speech**
|
||||
|
||||
Add an audio playback button in the Q&A text box, using a TTS service (needs to be set up in Model Providers) to read out the text.
|
||||
* **File Upload**
|
||||
|
||||
Supports the following file types: documents, images, audio, video, and other file types. After enabling this feature, application users can upload and update files at any time during the application dialogue. A maximum of 10 files can be uploaded simultaneously, with a size limit of 15MB per file.
|
||||
|
||||
<Frame caption="ファイルのアップロード機能">
|
||||
<img src="/ja-jp/user-guide/.gitbook/assets/image (8).png" alt="Chatflow应用中文件上传功能的设置界面" />
|
||||
</Frame>
|
||||
|
||||
* **Citation and Attribution**
|
||||
|
||||
Commonly used in conjunction with the "Knowledge Retrieval" node to display the reference source documents and attribution parts of the LLM's responses.
|
||||
* **Content Moderation**
|
||||
|
||||
Supports using moderation APIs to maintain a sensitive word library, ensuring that the LLM can respond and output safe content. For detailed instructions, please refer to Sensitive Content Moderation.
|
||||
|
||||
**Usage:**
|
||||
|
||||
Except for the **File Upload** feature, the usage of other features in Chatflow applications is relatively simple. Once enabled, they can be intuitively used on the application interaction page.
|
||||
|
||||
This section will mainly introduce the specific usage of the **File Upload** feature:
|
||||
|
||||
**For application users:** Chatflow applications with file upload enabled will display a "paperclip" icon on the right side of the dialogue box. Click it to upload files and interact with the LLM.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-8.png" alt="Upload file" />
|
||||
</Frame>
|
||||
|
||||
**For application developers:**
|
||||
|
||||
After enabling the file upload feature, the files users send will be uploaded in the `sys.files` variable. It will be updated after the user sends a new message in the same conversation turn.
|
||||
|
||||
Different types of files correspond to different application orchestration methods based on the uploaded file differences.
|
||||
|
||||
* **Document Files**
|
||||
|
||||
LLMs do not have the ability to directly read document files, so a Document Extractor node is needed to preprocess the files in the `sys.files` variable. The orchestration steps are as follows:
|
||||
|
||||
1. Enable the Features function and only check "Documents" in the file types.
|
||||
2. Select the `sys.files` variable in the input variables of the Document Extractor node.
|
||||
3. Add an LLM node and select the output variable of the document extractor node in the system prompt.
|
||||
4. Add a "Direct Reply" node at the end, filling in the output variable of the LLM node.
|
||||
|
||||
Chatflow applications built using this method cannot remember the content of uploaded files. Application users need to upload document files in the chat box for each conversation. If you want the application to remember uploaded files, please refer to File Upload: Adding Variables in the Start Node.
|
||||
|
||||
* **Image Files**
|
||||
|
||||
Some LLMs support directly obtaining information from images, so no additional nodes are needed to process images.
|
||||
|
||||
The orchestration steps are as follows:
|
||||
|
||||
1. Enable the Features function and only check "Images" in the file types.
|
||||
2. Add an LLM node, enable the VISION feature, and select the `sys.files` variable.
|
||||
3. Add a "Answer" node at the end, filling in the output variable of the LLM node.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-9.png" alt="Enable vision" />
|
||||
</Frame>
|
||||
|
||||
* **Mixed File Types**
|
||||
|
||||
If you want the application to have the ability to process both document files and image files simultaneously, you need to use the List Operation node to preprocess the files in the `sys.files` variable, extract more refined variables, and send them to the corresponding processing nodes. The orchestration steps are as follows:
|
||||
|
||||
1. Enable the Features function and check both "Images" and "Document Files" types.
|
||||
2. Add two list operation nodes, extracting image and document variables in the "Filter" condition.
|
||||
3. Extract document file variables and pass them to the "Document Extractor" node; extract image file variables and pass them to the "LLM" node.
|
||||
4. Add a "Direct Reply" node at the end, filling in the output variable of the LLM node.
|
||||
|
||||
After the application user uploads both document files and images, document files are automatically diverted to the document extractor node, and image files are automatically diverted to the LLM node to achieve joint processing of files.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-10.png" alt="Mixed File Types" />
|
||||
</Frame>
|
||||
|
||||
* **Audio and Video Files**
|
||||
|
||||
LLMs do not yet support direct reading of audio and video files, and the Dify platform has not yet built-in related file processing tools. Application developers can refer to [External Data Tools](/extension/api-based-extension/external-data-tool) to integrate tools for processing file information themselves.
|
||||
38
en-us/user-guide/build-app/flow-app/concepts.mdx
Normal file
38
en-us/user-guide/build-app/flow-app/concepts.mdx
Normal file
@@ -0,0 +1,38 @@
|
||||
---
|
||||
title: Concepts
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
### Nodes
|
||||
|
||||
**Nodes are the key components of a workflow**. By connecting nodes with different functionalities, you can execute a series of operations within the workflow.
|
||||
|
||||
For core workflow nodes, please refer to [Node - Start](/en-us/user-guide/build-app/flow-app/nodes/start).
|
||||
|
||||
***
|
||||
|
||||
### Variables
|
||||
|
||||
**Variables are used to link the input and output of nodes within a workflow**, enabling complex processing logic throughout the process. Fore more details, please take refer to [Variables](/en-us/user-guide/build-app/flow-app/variables).
|
||||
|
||||
***
|
||||
|
||||
### Chatflow and Workflow
|
||||
|
||||
**Application Scenarios**
|
||||
|
||||
* **Chatflow**: Designed for conversational scenarios, including customer service, semantic search, and other conversational applications that require multi-step logic in response construction.
|
||||
* **Workflow**: Geared towards automation and batch processing scenarios, suitable for high-quality translation, data analysis, content generation, email automation, and more.
|
||||
|
||||
**Usage Entry Points**
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**Differences in Available Nodes**
|
||||
|
||||
1. The End node is an ending node for Workflow and can only be selected at the end of the process.
|
||||
2. The Answer node is specific to Chatflow, used for streaming text output, and can output at intermediate steps in the process.
|
||||
3. Chatflow has built-in chat memory (Memory) for storing and passing multi-turn conversation history, which can be enabled in nodes like LLM and question classifiers. Workflow does not have Memory-related configurations and cannot enable them.
|
||||
4. Built-in variables for Chatflow's start node include: `sys.query`, `sys.files`, `sys.conversation_id`, `sys.user_id`. Built-in variables for Workflow's start node include: `sys.files`, `sys_id`.
|
||||
35
en-us/user-guide/build-app/flow-app/create-flow-app.mdx
Normal file
35
en-us/user-guide/build-app/flow-app/create-flow-app.mdx
Normal file
@@ -0,0 +1,35 @@
|
||||
---
|
||||
title: Creating Applications
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
## Chatflow
|
||||
|
||||
**Use Cases:**
|
||||
|
||||
Suitable for conversational scenarios, including customer service, semantic search, and other dialogue-based applications that require multiple logical steps when constructing responses. The distinctive feature of this type of application is its support for multi-round conversational interactions with generated results, allowing for adjustment of the generated content.
|
||||
|
||||
Common interaction path: Give instructions → Generate content → Multiple discussions about the content → Regenerate results → End.
|
||||
|
||||
On the "Studio" page, click "Create Blank Application" on the left, then select "Workflow Orchestration" under "Chat Assistant."
|
||||
|
||||

|
||||
|
||||
## Workflow
|
||||
|
||||
**Use Cases:**
|
||||
|
||||
Suitable for automation and batch processing scenarios, ideal for high-quality translation, data analysis, content generation, email automation, and similar applications. This type of application does not support multi-round conversational interactions with generated results.
|
||||
|
||||
Common interaction path: Give instructions → Generate content → End
|
||||
|
||||
On the "Studio" page, click "Create Blank Application" on the left, then select "Workflow" to complete the creation.
|
||||
|
||||

|
||||
|
||||
## Differences Between the Two Application Type
|
||||
|
||||
1. The End node belongs to Workflow as a termination node and can only be selected at the end of the process.
|
||||
2. The Answer node belongs to Chatflow, used for streaming text content output and supports output during intermediate steps of the process.
|
||||
3. Chatflow has built-in chat memory (Memory) for storing and transmitting historical messages from multiple rounds of conversation, which can be enabled in LLM, question classification, and other nodes. Workflow has no Memory-related configuration and cannot be enabled.
|
||||
4. Chatflow's start node built-in variables include: `sys.query`, `sys.files`, `sys.conversation_id`, `sys.user_id`. Workflow's start node built-in variables include: `sys.files`, `sys.user_id`
|
||||
151
en-us/user-guide/build-app/flow-app/file-upload.mdx
Normal file
151
en-us/user-guide/build-app/flow-app/file-upload.mdx
Normal file
@@ -0,0 +1,151 @@
|
||||
---
|
||||
title: File Upload
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
Compared to chat text, document files can contain vast amounts of information, such as academic reports and legal contracts. However, Large Language Models (LLMs) are inherently limited to processing only text or images, making it challenging to extract the rich contextual information within these files. As a result, application users often resort to manually copying and pasting large amounts of information to converse with LLMs, significantly increasing unnecessary operational overhead.
|
||||
|
||||
The file upload feature addresses this limitation by allowing files to be uploaded, parsed, referenced, and downloaded as File variables within workflow applications. **This empowers developers to easily construct complex workflows capable of understanding and processing various media types, including images, audio, and video.**
|
||||
|
||||
## Application Scenarios
|
||||
|
||||
1. **Document Analysis**: Upload academic research reports for LLMs to quickly summarize key points and answer related questions based on the file content.
|
||||
2. **Code Review**: Developers can upload code files to receive optimization suggestions and bug detection.
|
||||
3. **Learning Assistance**: Students can upload assignments or study materials for personalized explanations and guidance.
|
||||
4. **Legal Aid**: Upload complete contract texts for LLMs to assist in reviewing clauses and identifying potential risks.
|
||||
|
||||
## Difference Between File Upload and Knowledge Base
|
||||
|
||||
Both file upload and knowledge base provide additional contextual information for LLMs, but they differ significantly in usage scenarios and functionality:
|
||||
|
||||
1. **Information Source**:
|
||||
* File Upload: Allows end-users to dynamically upload files during conversations, providing immediate, personalized contextual information.
|
||||
* Knowledge Base: Pre-set and managed by application developers, containing a relatively fixed set of information.
|
||||
2. **Usage Flexibility**:
|
||||
* File Upload: More flexible, users can upload different types of files based on specific needs.
|
||||
* Knowledge Base: Content is relatively fixed but can be reused across multiple sessions.
|
||||
3. **Information Processing**:
|
||||
* File Upload: Requires document extractors or other tools to convert file content into text that LLMs can understand.
|
||||
* Knowledge Base: Usually pre-processed and indexed, ready for direct retrieval.
|
||||
4. **Application Scenarios**:
|
||||
* File Upload: Suitable for scenarios that need to process user-specific documents, such as document analysis, personalized learning assistance, etc.
|
||||
* Knowledge Base: Suitable for scenarios that require access to a large amount of preset information, such as customer service, product inquiries, etc.
|
||||
5. **Data Persistence**:
|
||||
* File Upload: Typically for temporary use, not stored long-term in the system.
|
||||
* Knowledge Base: Exists as a long-term part of the application, can be continuously updated and maintained.
|
||||
|
||||
## Quick Start
|
||||
|
||||
Dify supports file uploads in both [ChatFlow](/en-us/user-guide/build-app/flow-app/create-flow-app#chatflow) and [WorkFlow](/en-us/user-guide/build-app/flow-app/create-flow-app#workflow) type applications, processing them through variables for LLMs. Application developers can refer to the following methods to enable file upload functionality:
|
||||
|
||||
* In Workflow applications:
|
||||
* Add file variables in the ["Start Node"](/en-us/user-guide/build-app/flow-app/nodes/start)
|
||||
* In ChatFlow applications:
|
||||
* Enable file upload in ["Additional Features"](/en-us/user-guide/build-app/flow-app/additional-features) to allow direct file uploads in the chat window
|
||||
* Add file variables in the "[Start Node"](/en-us/user-guide/build-app/flow-app/nodes/start)
|
||||
* Note: These two methods can be configured simultaneously and are independent of each other. The file upload settings in additional features (including upload method and quantity limit) do not affect the file variables in the start node. For example, if you only want to create file variables through the start node, you don't need to enable the file upload feature in additional features.
|
||||
|
||||
These two methods provide flexible file upload options for applications to meet the needs of different scenarios.
|
||||
|
||||
**File Types**
|
||||
|
||||
| File Type | Supported Formats |
|
||||
|-----------|------------------|
|
||||
| Documents | TXT, MARKDOWN, PDF, HTML, XLSX, XLS, DOCX, CSV, EML, MSG, PPTX, PPT, XML, EPUB |
|
||||
| Images | JPG, JPEG, PNG, GIF, WEBP, SVG |
|
||||
| Audio | MP3, M4A, WAV, WEBM, AMR |
|
||||
| Video | MP4, MOV, MPEG, MPGA |
|
||||
| Others | Custom file extension support |
|
||||
|
||||
**Method 1: Enable File Upload in Application Chat Box (Chatflow Only)**
|
||||
|
||||
1. Click the **"Features"** button in the upper right corner of the Chatflow application to add more functionality to the application. After enabling this feature, application users can upload and update files at any time during the application dialogue. A maximum of 10 files can be uploaded simultaneously, with a size limit of 15MB per file.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-1-3.png" alt="File upload feature" />
|
||||
</Frame>
|
||||
|
||||
Enabling this feature does not grant LLMs the ability to directly read files. A **Document Extractor** is still needed to parse documents into text for LLM comprehension.
|
||||
|
||||
* For audio files, models like `gpt-4o-audio-preview` that support multimodal input can process audio directly without additional extractors.
|
||||
* For video and other file types, there are currently no corresponding extractors. Application developers need to [integrate external tools](/en-us/user-guide/tools/extensions/api-based/external-data-tool) for processing.
|
||||
|
||||
2. Add a Document Extractor node, and select the `sys.files` variable in the input variables.
|
||||
3. Add an LLM node and select the output variable of the Document Extractor node in the system prompt.
|
||||
4. Add an "Answer" node at the end, filling in the output variable of the LLM node.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-2-4.png" alt="Document extractor workflow" />
|
||||
</Frame>
|
||||
|
||||
Once enabled, users can upload files and engage in conversations in the dialogue box. However, with this method, the LLM application does not have the ability to remember file contents, and files need to be uploaded for each conversation.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-3-3.png" alt="Chat interface" />
|
||||
</Frame>
|
||||
|
||||
If you want the LLM to remember file contents during conversations, please refer to Method 2.
|
||||
|
||||
**Method 2: Enable File Upload by Adding File Variables**
|
||||
|
||||
**1. Add File Variables in the "Start" Node**
|
||||
|
||||
Add input fields in the application's "Start" node, choosing either **"Single File"** or **"File List"** as the field type for the variable.
|
||||
|
||||
* **Single File**: Allows the application user to upload only one file.
|
||||
* **File List**: Allows the application user to batch upload multiple files at once.
|
||||
|
||||
> For ease of operation, we will use a single file variable as an example.
|
||||
|
||||
**File Parsing**
|
||||
|
||||
There are two main ways to use file variables:
|
||||
|
||||
1. Using tool nodes to convert file content:
|
||||
* For document-type files, you can use the "Document Extractor" node to convert file content into text form.
|
||||
* This method is suitable for cases where file content needs to be parsed into a format that the model can understand (such as string, array[string], etc.).
|
||||
2. Using file variables directly in LLM nodes:
|
||||
* For certain types of files (such as images), you can use file variables directly in LLM nodes.
|
||||
* For example, for file variables of image type, you can enable the vision feature in the LLM node and then directly reference the corresponding file variable in the variable selector.
|
||||
|
||||
**2. Add Document Extractor Node**
|
||||
|
||||
After uploading, files are stored in single file variables, which LLMs cannot directly read. Therefore, a **"Document Extractor"** node needs to be added first to extract content from uploaded document files and send it to the LLM node for information processing.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-4.png" alt="Document Extractor configuration" />
|
||||
</Frame>
|
||||
|
||||
Fill in the output variable of the "Document Extractor" node in the system prompt of the LLM node.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-5.png" alt="LLM node configuration" />
|
||||
</Frame>
|
||||
|
||||
**Referencing File Variables in LLM Nodes**
|
||||
|
||||
For certain file types (such as images), file variables can be directly used within LLM nodes. This method is particularly suitable for scenarios requiring visual analysis. Here are the specific steps:
|
||||
|
||||
1. In the LLM node, enable the vision functionality.
|
||||
2. In the variable selector of the LLM node, directly reference the previously created file variable.
|
||||
3. In the system prompt, guide the model on how to process the image input.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-6.png" alt="LLM node with vision" />
|
||||
</Frame>
|
||||
|
||||
**File Download**
|
||||
|
||||
Placing file variables in answer nodes or end nodes will provide a file download card in the conversation box when the application reaches that node.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image-7.png" alt="File download interface" />
|
||||
</Frame>
|
||||
|
||||
## Advanced Usage
|
||||
|
||||
If you want the application to support uploading multiple types of files, such as allowing users to upload document files, images, and audio/video files simultaneously, you need to add a "File List" variable in the "Start Node" and use the "List Operation" node to process different file types. For detailed instructions, please refer to the List Operation node.
|
||||
|
||||
<Frame caption="Handling multiple file types">
|
||||
<img src="/ja-jp/user-guide/.gitbook/assets/image (3).png" alt="Diagram of workflow for processing multiple file types" />
|
||||
</Frame>
|
||||
7
en-us/user-guide/build-app/flow-app/nodes/README.md
Normal file
7
en-us/user-guide/build-app/flow-app/nodes/README.md
Normal file
@@ -0,0 +1,7 @@
|
||||
# Node Description
|
||||
|
||||
**Nodes are the key components of a workflow**, enabling the execution of a series of operations by connecting nodes with different functionalities.
|
||||
|
||||
### Core Nodes
|
||||
|
||||
<table data-view="cards"><thead><tr><th></th><th></th><th></th></tr></thead><tbody><tr><td><a href="start.md"><strong>Start</strong></a></td><td>Defines the initial parameters for starting a workflow process.</td><td></td></tr><tr><td><a href="end.md"><strong>End</strong></a></td><td>Defines the final output content for ending a workflow process.</td><td></td></tr><tr><td><a href="answer.md"><strong>Answer</strong></a></td><td>Defines the response content in a Chatflow process.</td><td></td></tr><tr><td><a href="llm.md"><strong>Large Language Model (LLM)</strong></a></td><td>Calls a large language model to answer questions or process natural language.</td><td></td></tr><tr><td><a href="knowledge_retrieval.md"><strong>Knowledge Retrieval</strong></a></td><td>Retrieves text content related to user questions from a knowledge base, which can serve as context for downstream LLM nodes.</td><td></td></tr><tr><td><a href="question-classifier.md"><strong>Question Classifier</strong></a></td><td>By defining classification descriptions, the LLM can select the matching classification based on user input.</td><td></td></tr><tr><td><a href="ifelse.md"><strong>IF/ELSE</strong></a></td><td>Allows you to split the workflow into two branches based on if/else conditions.</td><td></td></tr><tr><td><a href="code.md"><strong>Code Execution</strong></a></td><td>Runs Python/NodeJS code to execute custom logic such as data transformation within the workflow.</td><td></td></tr><tr><td><a href="template.md"><strong>Template</strong></a></td><td>Enables flexible data transformation and text processing using Jinja2, a Python templating language.</td><td></td></tr><tr><td><a href="variable-assigner.md"><strong>Variable Aggregator</strong></a></td><td>Aggregates variables from multiple branches into one variable for unified configuration of downstream nodes.</td><td></td></tr><tr><td><a href="variable-assignment.md"><strong>Variable Assigner</strong></a></td><td>The variable assigner node is used to assign values to writable variables.</td><td></td></tr><tr><td><a href="parameter-extractor.md"><strong>Parameter Extractor</strong></a></td><td>Uses LLM to infer and extract structured parameters from natural language for subsequent tool calls or HTTP requests.</td><td></td></tr><tr><td><a href="iteration.md"><strong>Iteration</strong></a></td><td>Executes multiple steps on list objects until all results are output.</td><td></td></tr><tr><td><a href="http-request.md"><strong>HTTP Request</strong></a></td><td>Allows sending server requests via the HTTP protocol, suitable for retrieving external results, webhooks, generating images, and other scenarios.</td><td></td></tr><tr><td><a href="tools.md"><strong>Tools</strong></a></td><td>Enables calling built-in Dify tools, custom tools, sub-workflows, and more within the workflow.</td><td></td></tr></tbody></table>
|
||||
24
en-us/user-guide/build-app/flow-app/nodes/answer.mdx
Normal file
24
en-us/user-guide/build-app/flow-app/nodes/answer.mdx
Normal file
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: 'Answer'
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
# Direct Reply
|
||||
|
||||
Defining Reply Content in a Chatflow Process. In a text editor, you have the flexibility to determine the reply format. This includes crafting a fixed block of text, utilizing output variables from preceding steps as the reply content, or merging custom text with variables for the response.
|
||||
|
||||
Answer node can be seamlessly integrated at any point to dynamically deliver content into the dialogue responses. This setup supports a live-editing configuration mode, allowing for both text and image content to be arranged together. The configurations include:
|
||||
|
||||
1. Outputting the reply content from a Language Model (LLM) node.
|
||||
2. Outputting generated images.
|
||||
3. Outputting plain text.
|
||||
|
||||
Example 1: Output plain text.
|
||||
|
||||

|
||||
|
||||
Example 2: Output image and LLM reply.
|
||||
|
||||

|
||||
|
||||

|
||||
98
en-us/user-guide/build-app/flow-app/nodes/code.mdx
Normal file
98
en-us/user-guide/build-app/flow-app/nodes/code.mdx
Normal file
@@ -0,0 +1,98 @@
|
||||
---
|
||||
title: Code Execution
|
||||
---
|
||||
|
||||
## Table of Contents
|
||||
|
||||
* [Introduction](#introduction)
|
||||
* [Usage Scenarios](#usage-scenarios)
|
||||
* [Local Deployment](#local-deployment)
|
||||
* [Security Policies](#security-policies)
|
||||
|
||||
## Introduction
|
||||
|
||||
The code node supports running Python/NodeJS code to perform data transformations within a workflow. It can simplify your workflow and is suitable for scenarios such as arithmetic operations, JSON transformations, text processing, and more.
|
||||
|
||||
This node significantly enhances the flexibility for developers, allowing them to embed custom Python or JavaScript scripts within the workflow and manipulate variables in ways that preset nodes cannot achieve. Through configuration options, you can specify the required input and output variables and write the corresponding execution code:
|
||||
|
||||
.png)
|
||||
|
||||
## Configuration
|
||||
|
||||
If you need to use variables from other nodes in the code node, you must define the variable names in the `input variables` and reference these variables. You can refer to [Variable References](../key-concept.md#variables).
|
||||
|
||||
## Usage Scenarios
|
||||
|
||||
Using the code node, you can perform the following common operations:
|
||||
|
||||
### Structured Data Processing
|
||||
|
||||
In workflows, you often have to deal with unstructured data processing, such as parsing, extracting, and transforming JSON strings. A typical example is data processing from an HTTP node. In common API return structures, data may be nested within multiple layers of JSON objects, and you need to extract certain fields. The code node can help you perform these operations. Here is a simple example that extracts the `data.name` field from a JSON string returned by an HTTP node:
|
||||
|
||||
```python
|
||||
def main(http_response: str) -> str:
|
||||
import json
|
||||
data = json.loads(http_response)
|
||||
return {
|
||||
# Note to declare 'result' in the output variables
|
||||
'result': data['data']['name']
|
||||
}
|
||||
```
|
||||
|
||||
### Mathematical Calculations
|
||||
|
||||
When you need to perform complex mathematical calculations in a workflow, you can also use the code node. For example, calculating a complex mathematical formula or performing some statistical analysis on data. Here is a simple example that calculates the variance of an array:
|
||||
|
||||
```python
|
||||
def main(x: list) -> float:
|
||||
return {
|
||||
# Note to declare 'result' in the output variables
|
||||
'result': sum([(i - sum(x) / len(x)) ** 2 for i in x]) / len(x)
|
||||
}
|
||||
```
|
||||
|
||||
### Data Concatenation
|
||||
|
||||
Sometimes, you may need to concatenate multiple data sources, such as multiple knowledge retrievals, data searches, API calls, etc. The code node can help you integrate these data sources together. Here is a simple example that merges data from two knowledge bases:
|
||||
|
||||
```python
|
||||
def main(knowledge1: list, knowledge2: list) -> list:
|
||||
return {
|
||||
# Note to declare 'result' in the output variables
|
||||
'result': knowledge1 + knowledge2
|
||||
}
|
||||
```
|
||||
|
||||
## Local Deployment
|
||||
|
||||
If you are a local deployment user, you need to start a sandbox service to ensure that malicious code is not executed. This service requires the use of Docker. You can find specific information about the sandbox service [here](https://github.com/langgenius/dify/tree/main/docker/docker-compose.middleware.yaml). You can also start the service directly via `docker-compose`:
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.middleware.yaml up -d
|
||||
```
|
||||
|
||||
## Security Policies
|
||||
|
||||
Both Python and JavaScript execution environments are strictly isolated (sandboxed) to ensure security. This means that developers cannot use functions that consume large amounts of system resources or may pose security risks, such as direct file system access, making network requests, or executing operating system-level commands. These limitations ensure the safe execution of the code while avoiding excessive consumption of system resources.
|
||||
|
||||
### FAQ
|
||||
|
||||
**Why can't I save the code it in the code node?**
|
||||
|
||||
Please check if the code contains potentially dangerous behaviors. For example:
|
||||
|
||||
```python
|
||||
def main() -> dict:
|
||||
return {
|
||||
"result": open("/etc/passwd").read(),
|
||||
}
|
||||
```
|
||||
|
||||
This code snippet has the following issues:
|
||||
|
||||
* **Unauthorized file access:** The code attempts to read the "/etc/passwd" file, which is a critical system file in Unix/Linux systems that stores user account information.
|
||||
* **Sensitive information disclosure:** The "/etc/passwd" file contains important information about system users, such as usernames, user IDs, group IDs, home directory paths, etc. Direct access could lead to information leakage.
|
||||
|
||||
Dangerous code will be automatically blocked by Cloudflare WAF. You can check if it's been blocked by looking at the "Network" tab in your browser's "Web Developer Tools".
|
||||
|
||||
|
||||
62
en-us/user-guide/build-app/flow-app/nodes/doc-extractor.mdx
Normal file
62
en-us/user-guide/build-app/flow-app/nodes/doc-extractor.mdx
Normal file
@@ -0,0 +1,62 @@
|
||||
---
|
||||
title: Doc Extractor
|
||||
---
|
||||
|
||||
#### Definition
|
||||
|
||||
LLMs cannot directly read or interpret document contents. Therefore, it's necessary to parse and read information from user-uploaded documents through a document extractor node, convert it to text, and then pass the content to the LLM to process the file contents.
|
||||
|
||||
#### Application Scenarios
|
||||
|
||||
* Building LLM applications that can interact with files, such as ChatPDF or ChatWord;
|
||||
* Analyzing and examining the contents of user-uploaded files;
|
||||
|
||||
#### Node Functionality
|
||||
|
||||
The document extractor node can be understood as an information processing center. It recognizes and reads files in the input variables, extracts information, and converts it into string-type output variables for downstream nodes to call.
|
||||
|
||||
.png)
|
||||
|
||||
The document extractor node structure is divided into input variables and output variables.
|
||||
|
||||
**Input Variables**
|
||||
|
||||
The document extractor only accepts variables with the following data structures:
|
||||
|
||||
* `File`, a single file
|
||||
* `Array[File]`, multiple files
|
||||
|
||||
The document extractor can only extract information from document-type files, such as the contents of TXT, Markdown, PDF, HTML, DOCX format files. It cannot process image, audio, video, or other file formats.
|
||||
|
||||
**Output Variables**
|
||||
|
||||
The output variable is fixed and named as text. The type of output variable depends on the input variable:
|
||||
|
||||
* If the input variable is `File`, the output variable is `string`
|
||||
* If the input variable is `Array[File]`, the output variable is `array[string]`
|
||||
|
||||
> Array variables generally need to be used in conjunction with list operation nodes. For detailed instructions, please refer to list-operator.
|
||||
|
||||
#### Configuration Example
|
||||
|
||||
In a typical file interaction Q\&A scenario, the document extractor can serve as a preliminary step for the LLM node, extracting file information from the application and passing it to the downstream LLM node to answer user questions about the file.
|
||||
|
||||
This section will introduce the usage of the document extractor node through a typical ChatPDF example workflow template.
|
||||
|
||||
.png)
|
||||
|
||||
**Configuration Process:**
|
||||
|
||||
1. Enable file upload for the application. Add a **single file variable** in the "Start" node and name it `pdf`.
|
||||
2. Add a document extractor node and select the `pdf` variable in the input variables.
|
||||
3. Add an LLM node and select the output variable of the document extractor node in the system prompt. The LLM can read the contents of the file through this output variable.
|
||||
|
||||
.png)
|
||||
|
||||
Configure the end node by selecting the output variable of the LLM node in the end node.
|
||||
|
||||
.png)
|
||||
|
||||
After configuration, the application will have file upload functionality, allowing users to upload PDF files and engage in conversation.
|
||||
|
||||
<Note>To learn how to upload files in chat conversations and interact with the LLM, please refer to Additional Features.</Note>
|
||||
29
en-us/user-guide/build-app/flow-app/nodes/end.mdx
Normal file
29
en-us/user-guide/build-app/flow-app/nodes/end.mdx
Normal file
@@ -0,0 +1,29 @@
|
||||
---
|
||||
title: End
|
||||
---
|
||||
|
||||
### 1 Definition
|
||||
|
||||
Define the final output content of a workflow. Every workflow needs at least one end node after complete execution to output the final result.
|
||||
|
||||
The end node is a termination point in the process; no further nodes can be added after it. In a workflow application, results are only output when the end node is reached. If there are conditional branches in the process, multiple end nodes need to be defined.
|
||||
|
||||
The end node must declare one or more output variables, which can reference any upstream node's output variables.
|
||||
|
||||
<Note>End nodes are not supported within Chatflow.</Note>
|
||||
|
||||
***
|
||||
|
||||
### 2 Scenarios
|
||||
|
||||
In the following long story generation workflow, the variable `Output` declared by the end node is the output of the upstream code node. This means the workflow will end after the Code node completes execution and will output the execution result of Code.
|
||||
|
||||

|
||||
|
||||
**Single Path Execution Example:**
|
||||
|
||||

|
||||
|
||||
**Multi-Path Execution Example:**
|
||||
|
||||

|
||||
43
en-us/user-guide/build-app/flow-app/nodes/http-request.mdx
Normal file
43
en-us/user-guide/build-app/flow-app/nodes/http-request.mdx
Normal file
@@ -0,0 +1,43 @@
|
||||
---
|
||||
title: HTTP Request
|
||||
---
|
||||
|
||||
### Definition
|
||||
|
||||
Allows sending server requests via the HTTP protocol, suitable for scenarios such as retrieving external data, webhooks, generating images, and downloading files. It enables you to send customized HTTP requests to specified web addresses, achieving interconnectivity with various external services.
|
||||
|
||||
This node supports common HTTP request methods:
|
||||
|
||||
* **GET**: Used to request the server to send a specific resource.
|
||||
* **POST**: Used to submit data to the server, typically for submitting forms or uploading files.
|
||||
* **HEAD**: Similar to GET requests, but the server only returns the response headers without the resource body.
|
||||
* **PATCH**: Used to apply partial modifications to a resource.
|
||||
* **PUT**: Used to upload resources to the server, typically for updating an existing resource or creating a new one.
|
||||
* **DELETE**: Used to request the server to delete a specified resource.
|
||||
|
||||
You can configure various aspects of the HTTP request, including URL, request headers, query parameters, request body content, and authentication information.
|
||||
|
||||

|
||||
|
||||
***
|
||||
|
||||
### Scenarios
|
||||
|
||||
* **Send Application Interaction Content to a Specific Server**
|
||||
|
||||
One practical feature of this node is the ability to dynamically insert variables into different parts of the request based on the scenario. For example, when handling customer feedback requests, you can embed variables such as username or customer ID, feedback content, etc., into the request to customize automated reply messages or fetch specific customer information and send related resources to a designated server.
|
||||
|
||||

|
||||
|
||||
The return values of an HTTP request include the response body, status code, response headers, and files. Notably, if the response contains a file, this node can automatically save the file for use in subsequent steps of the workflow. This design not only improves processing efficiency but also makes handling responses with files straightforward and direct.
|
||||
|
||||
* **Send File**
|
||||
|
||||
You can use an HTTP PUT request to send files from the application to other API services. In the request body, you can select the file variable within the `binary`. This method is commonly used in scenarios such as file transfer, document storage, or media processing.
|
||||
|
||||
Example: Suppose you are developing a document management application and need to send a user-uploaded PDF file to a third-party service. You can use an HTTP request node to pass the file variable.
|
||||
|
||||
Here is a configuration example:
|
||||
|
||||
.png)
|
||||
|
||||
46
en-us/user-guide/build-app/flow-app/nodes/ifelse.mdx
Normal file
46
en-us/user-guide/build-app/flow-app/nodes/ifelse.mdx
Normal file
@@ -0,0 +1,46 @@
|
||||
---
|
||||
title: Conditional Branch IF/ELSE
|
||||
---
|
||||
|
||||
### Definition
|
||||
|
||||
Allows you to split the workflow into two branches based on if/else conditions.
|
||||
|
||||
A conditional branching node has three parts:
|
||||
|
||||
* IF Condition: Select a variable, set the condition, and specify the value that satisfies the condition.
|
||||
* IF condition evaluates to `True`, execute the IF path.
|
||||
* IF condition evaluates to `False`, execute the ELSE path.
|
||||
* If the ELIF condition evaluates to `True`, execute the ELIF path;
|
||||
* If the ELIF condition evaluates to `False`, continue to evaluate the next ELIF path or execute the final ELSE path.
|
||||
|
||||
**Condition Types**
|
||||
|
||||
* Contains
|
||||
* Not contains
|
||||
* Starts with
|
||||
* Ends with
|
||||
* Is
|
||||
* Is not
|
||||
* Is empty
|
||||
* Is not empty
|
||||
|
||||
***
|
||||
|
||||
### Scenario
|
||||
|
||||

|
||||
|
||||
Taking the above **Text Summary Workflow** as an example:
|
||||
|
||||
* IF Condition: Select the `summarystyle` variable from the start node, with the condition **Contains** `technical`.
|
||||
* IF condition evaluates to `True`, follow the IF path by querying technology-related knowledge through the knowledge retrieval node, then respond via the LLM node (as shown in the upper half of the diagram);
|
||||
* IF condition evaluates to `False`, but an `ELIF` condition is added, where the input for the `summarystyle` variable **does not include** `technology`, yet the `ELIF` condition includes `science`, check if the condition in `ELIF` is `True`, then execute the steps defined within that path;
|
||||
* If the condition within `ELIF` is `False`, meaning the input variable contains neither `technology` nor `science`, continue to evaluate the next `ELIF` condition or execute the final `ELSE` path;
|
||||
* IF condition evaluates to `False`, i.e., the `summarystyle` variable input **does not contain** `technical`, execute the ELSE path, responding via the LLM2 node (lower part of the diagram).
|
||||
|
||||
**Multiple Condition Judgments**
|
||||
|
||||
For complex condition judgments, you can set multiple condition judgments and configure **AND** or **OR** between conditions to take the **intersection** or **union** of the conditions, respectively.
|
||||
|
||||
.png)
|
||||
163
en-us/user-guide/build-app/flow-app/nodes/iteration.mdx
Normal file
163
en-us/user-guide/build-app/flow-app/nodes/iteration.mdx
Normal file
@@ -0,0 +1,163 @@
|
||||
---
|
||||
title: Iteration
|
||||
---
|
||||
|
||||
### Definition
|
||||
|
||||
Execute multiple steps on an array until all results are output.
|
||||
|
||||
The iteration step performs the same steps on each item in a list. To use iteration, ensure that the input value is formatted as a list object. The iteration node allows AI workflows to handle more complex processing logic. It is a user-friendly version of the loop node, making some compromises in customization to allow non-technical users to quickly get started.
|
||||
|
||||
***
|
||||
|
||||
### Scenarios
|
||||
|
||||
#### **Example 1: Long Article Iteration Generator**
|
||||
|
||||

|
||||
|
||||
1. Enter the story title and outline in the **Start Node**.
|
||||
2. Use a **Generate Subtitles and Outlines Node** to use LLM to generate the complete content from user input.
|
||||
3. Use a **Extract Subtitles and Outlines Node** to convert the complete content into an array format.
|
||||
4. Use an **Iteration Node** to wrap an **LLM Node** and generate content for each chapter through multiple iterations.
|
||||
5. Add a **Direct Answer Node** inside the iteration node to achieve streaming output after each iteration.
|
||||
|
||||
**Detailed Configuration Steps**
|
||||
|
||||
1. Configure the story title (title) and outline (outline) in the **Start Node**.
|
||||
|
||||

|
||||
|
||||
2. Use a **Generate Subtitles and Outlines Node** to convert the story title and outline into complete text.
|
||||
|
||||

|
||||
|
||||
3. Use a **Extract Subtitles and Outlines Node** to convert the story text into an array (Array) structure. The parameter to extract is `sections`, and the parameter type is `Array[Object]`.
|
||||
|
||||

|
||||
|
||||
<Note>
|
||||
The effectiveness of parameter extraction is influenced by the model's inference capability and the instructions given. Using a model with stronger inference capabilities and adding examples in the **instructions** can improve the parameter extraction results.
|
||||
</Note>
|
||||
|
||||
4. Use the array-formatted story outline as the input for the iteration node and process it within the iteration node using an **LLM Node**.
|
||||
|
||||

|
||||
|
||||
Configure the input variables `GenerateOverallOutline/output` and `Iteration/item` in the LLM Node.
|
||||
|
||||

|
||||
|
||||
<Note>
|
||||
Built-in variables for iteration: `items[object]` and `index[number]`.
|
||||
|
||||
`items[object]` represents the input item for each iteration;
|
||||
|
||||
`index[number]` represents the current iteration round;
|
||||
</Note>
|
||||
|
||||
1. Configure a **Direct Reply Node** inside the iteration node to achieve streaming output after each iteration.
|
||||
|
||||

|
||||
|
||||
6. Complete debugging and preview.
|
||||
|
||||

|
||||
|
||||
#### **Example 2: Long Article Iteration Generator (Another Arrangement)**
|
||||
|
||||

|
||||
|
||||
* Enter the story title and outline in the **Start Node**.
|
||||
* Use an **LLM Node** to generate subheadings and corresponding content for the article.
|
||||
* Use a **Code Node** to convert the complete content into an array format.
|
||||
* Use an **Iteration Node** to wrap an **LLM Node** and generate content for each chapter through multiple iterations.
|
||||
* Use a **Template Conversion** Node to convert the string array output from the iteration node back to a string.
|
||||
* Finally, add a **Direct Reply Node** to directly output the converted string.
|
||||
|
||||
### What is Array Content
|
||||
|
||||
A list is a specific data type where elements are separated by commas and enclosed in `[` and `]`. For example:
|
||||
|
||||
**Numeric:**
|
||||
|
||||
```
|
||||
[0,1,2,3,4,5]
|
||||
```
|
||||
|
||||
**String:**
|
||||
|
||||
```
|
||||
["Monday", "Tuesday", "Wednesday", "Thursday"]
|
||||
```
|
||||
|
||||
**JSON Object:**
|
||||
|
||||
```
|
||||
[
|
||||
{
|
||||
"name": "Alice",
|
||||
"age": 30,
|
||||
"email": "alice@example.com"
|
||||
},
|
||||
{
|
||||
"name": "Bob",
|
||||
"age": 25,
|
||||
"email": "bob@example.com"
|
||||
},
|
||||
{
|
||||
"name": "Charlie",
|
||||
"age": 35,
|
||||
"email": "charlie@example.com"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
***
|
||||
|
||||
### Nodes Supporting Array Return
|
||||
|
||||
* Code Node
|
||||
* Parameter Extraction
|
||||
* Knowledge Base Retrieval
|
||||
* Iteration
|
||||
* Tools
|
||||
* HTTP Request
|
||||
|
||||
### How to Obtain Array-Formatted Content
|
||||
|
||||
**Return Using the CODE Node**
|
||||
|
||||

|
||||
|
||||
**Return Using the Parameter Extraction Node**
|
||||
|
||||

|
||||
|
||||
### How to Convert an Array to Text
|
||||
|
||||
The output variable of the iteration node is in array format and cannot be directly output. You can use a simple step to convert the array back to text.
|
||||
|
||||
**Convert Using a Code Node**
|
||||
|
||||

|
||||
|
||||
CODE Example:
|
||||
|
||||
```python
|
||||
def main(articleSections: list):
|
||||
data = articleSections
|
||||
return {
|
||||
"result": "/n".join(data)
|
||||
}
|
||||
```
|
||||
|
||||
**Convert Using a Template Node**
|
||||
|
||||

|
||||
|
||||
CODE Example:
|
||||
|
||||
```django
|
||||
{{ articleSections | join("/n") }}
|
||||
```
|
||||
@@ -0,0 +1,36 @@
|
||||
---
|
||||
title: Knowledge Retrieval
|
||||
---
|
||||
|
||||
The Knowledge Base Retrieval Node is designed to query text content related to user questions from the Dify Knowledge Base, which can then be used as context for subsequent answers by the Large Language Model (LLM).
|
||||
|
||||

|
||||
|
||||
Configuring the Knowledge Base Retrieval Node involves four main steps:
|
||||
|
||||
1. **Selecting the Query Variable**
|
||||
2. **Choosing the Knowledge Base for Query**
|
||||
3. **Applying Metadata Filtering**
|
||||
4. **Configuring the Retrieval Strategy**
|
||||
|
||||
**Selecting the Query Variable**
|
||||
|
||||
In knowledge base retrieval scenarios, the query variable typically represents the user's input question. In the "Start" node of conversational applications, the system pre-sets "sys.query" as the user input variable. This variable can be used to query the knowledge base for text chunks most closely related to the user's question. The maximum query content sent to the knowledge base is 200 characters.
|
||||
|
||||
**Choosing the Knowledge Base for Query**
|
||||
|
||||
Within the knowledge base retrieval node, you can add an existing knowledge base from Dify. For instructions on creating a knowledge base within Dify, please refer to the knowledge base [documentation](/en-us/user-guide/knowledge-base/knowledge-base-creation/upload-documents).
|
||||
|
||||
**Applying Metadata Filtering**
|
||||
|
||||
Use **Metadata Filtering** to refine document search in your knowledge base. For details, see **Metadata Filtering** in *[Integrate Knowledge Base within Application](https://docs.dify.ai/guides/knowledge-base/integrate-knowledge-within-application)*.
|
||||
|
||||
**Configuring the Retrieval Strategy**
|
||||
|
||||
It's possible to modify the indexing strategy and retrieval mode for an individual knowledge base within the node. For a detailed explanation of these settings, refer to the knowledge base [documentation](/en-us/user-guide/knowledge-base/knowledge-base-creation/upload-documents).
|
||||
|
||||

|
||||
|
||||
Dify offers two recall strategies for different knowledge base retrieval scenarios: "N-to-1 Recall" and "Multi-way Recall". In the N-to-1 mode, knowledge base queries are executed through function calling, requiring the selection of a system reasoning model. In the multi-way recall mode, a Rerank model needs to be configured for result re-ranking. For a detailed explanation of these two recall strategies, refer to the retrieval mode explanation in the [help documentation](https://docs.dify.ai/guides/knowledge-base/create-knowledge-and-upload-documents#id-5-indexing-methods).
|
||||
|
||||

|
||||
79
en-us/user-guide/build-app/flow-app/nodes/list-operator.mdx
Normal file
79
en-us/user-guide/build-app/flow-app/nodes/list-operator.mdx
Normal file
@@ -0,0 +1,79 @@
|
||||
---
|
||||
title: List Operator
|
||||
---
|
||||
|
||||
File list variables support simultaneous uploading of multiple file types such as document files, images, audio, and video files. When application users upload files, all files are stored in the same `Array[File]` array-type variable, which **is not conducive to subsequent individual file processing.**
|
||||
|
||||
> The `Array` data type means that the actual value of the variable could be \[1.mp3, 2.png, 3.doc]. LLMs only support reading single values such as image files or text content as input variables and cannot directly read array variables.
|
||||
|
||||
#### Node Functionality
|
||||
|
||||
The list operator can filter and extract attributes such as file format type, file name, and size, passing different format files to corresponding processing nodes to achieve precise control over different file processing flows.
|
||||
|
||||
For example, in an application that allows users to upload both document files and image files simultaneously, different files need to be sorted through the **list operation node**, with different files being handled by different processes.
|
||||
|
||||
.png)
|
||||
|
||||
List operation nodes are generally used to extract information from array variables, converting them into variable types that can be accepted by downstream nodes through setting conditions. Its structure is divided into input variables, filter conditions, sorting, taking the first N items, and output variables.
|
||||
|
||||
.png)
|
||||
|
||||
**Input Variables**
|
||||
|
||||
The list operation node only accepts variables with the following data structures:
|
||||
|
||||
* Array\[string]
|
||||
* Array\[number]
|
||||
* Array\[file]
|
||||
|
||||
**Filter Conditions**
|
||||
|
||||
Process arrays in input variables by adding filter conditions. Sort out all array variables that meet the conditions from the array, which can be understood as filtering the attributes of variables.
|
||||
|
||||
Example: Files may contain multiple dimensions of attributes, such as file name, file type, file size, etc. Filter conditions allow setting screening conditions to select and extract specific files from array variables.
|
||||
|
||||
Supports extracting the following variables:
|
||||
|
||||
* type: File category, including image, document, audio, and video types
|
||||
* size: File size
|
||||
* name: File name
|
||||
* url: Refers to files uploaded by application users via URL, can fill in the complete URL for filtering
|
||||
* extension: File extension
|
||||
* mime\_type: [MIME types](https://datatracker.ietf.org/doc/html/rfc2046) are standardized strings used to identify file content types. Example: "text/html" indicates an HTML document.
|
||||
* transfer\_method: File upload method, divided into local upload or upload via URL
|
||||
|
||||
**Sorting**
|
||||
|
||||
Provides the ability to sort arrays in input variables, supporting sorting based on file attributes.
|
||||
|
||||
* Ascending order(ASC): Default sorting option, sorted from small to large. For letters and text, sorted in alphabetical order (A - Z)
|
||||
* Descending order(DESC): Sorted from large to small, for letters and text, sorted in reverse alphabetical order (Z - A)
|
||||
|
||||
This option is often used in conjunction with first\_record and last\_record in output variables.
|
||||
|
||||
**Take First N Items**
|
||||
|
||||
You can choose a value between 1-20, used to select the first n items of the array variable.
|
||||
|
||||
**Output Variables**
|
||||
|
||||
Array elements that meet all filter conditions. Filter conditions, sorting, and limitations can be enabled separately. If enabled simultaneously, array elements that meet all conditions are returned.
|
||||
|
||||
* Result: Filtering result, data type is array variable. If the array contains only 1 file, the output variable contains only 1 array element;
|
||||
* first\_record: The first element of the filtered array, i.e., result\[0];
|
||||
* last\_record: The last element of the filtered array, i.e., result\[array.length-1].
|
||||
|
||||
***
|
||||
|
||||
#### Configuration Example
|
||||
|
||||
In file interaction Q\&A scenarios, application users may upload document files or image files simultaneously. LLMs only support the ability to recognize image files and do not support reading document files. At this time, the List Operation node is needed to preprocess the array of file variables and send different file types to corresponding processing nodes. The orchestration steps are as follows:
|
||||
|
||||
1. Enable the [Features](/en-us/user-guide/build-app/flow-app/additional-features) function and check both "Images" and "Document" types in the file types.
|
||||
2. Add two list operation nodes, setting to extract image and document variables respectively in the "List Operator" conditions.
|
||||
3. Extract document file variables and pass them to the "Doc Extractor" node; extract image file variables and pass them to the "LLM" node.
|
||||
4. Add a "Answer" node at the end, filling in the output variable of the LLM node.
|
||||
|
||||
.png)
|
||||
|
||||
After the application user uploads both document files and images, document files are automatically diverted to the doc extractor node, and image files are automatically diverted to the LLM node to achieve joint processing of mixed files.
|
||||
152
en-us/user-guide/build-app/flow-app/nodes/llm.mdx
Normal file
152
en-us/user-guide/build-app/flow-app/nodes/llm.mdx
Normal file
@@ -0,0 +1,152 @@
|
||||
---
|
||||
title: LLM
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
### Definition
|
||||
|
||||
Invokes the capabilities of large language models to process information input by users in the "Start" node (natural language, uploaded files, or images) and provide effective response information.
|
||||
|
||||

|
||||
|
||||
***
|
||||
|
||||
### Scenarios
|
||||
|
||||
LLM is the core node of Chatflow/Workflow, utilizing the conversational/generative/classification/processing capabilities of large language models to handle a wide range of tasks based on given prompts and can be used in different stages of workflows.
|
||||
|
||||
* **Intent Recognition**: In customer service scenarios, identifying and classifying user inquiries to guide downstream processes.
|
||||
* **Text Generation**: In content creation scenarios, generating relevant text based on themes and keywords.
|
||||
* **Content Classification**: In email batch processing scenarios, automatically categorizing emails, such as inquiries/complaints/spam.
|
||||
* **Text Conversion**: In translation scenarios, translating user-provided text into a specified language.
|
||||
* **Code Generation**: In programming assistance scenarios, generating specific business code or writing test cases based on user requirements.
|
||||
* **RAG**: In knowledge base Q\&A scenarios, reorganizing retrieved relevant knowledge to respond to user questions.
|
||||
* **Image Understanding**: Using multimodal models with vision capabilities to understand and answer questions about the information within images.
|
||||
|
||||
By selecting the appropriate model and writing prompts, you can build powerful and reliable solutions within Chatflow/Workflow.
|
||||
|
||||
***
|
||||
|
||||
### How to Configure
|
||||
|
||||

|
||||
|
||||
**Configuration Steps:**
|
||||
|
||||
1. **Select a Model**: Dify supports major global models, including OpenAI's GPT series, Anthropic's Claude series, and Google's Gemini series. Choosing a model depends on its inference capability, cost, response speed, context window, etc. You need to select a suitable model based on the scenario requirements and task type.
|
||||
2. **Configure Model Parameters**: Model parameters control the generation results, such as temperature, TopP, maximum tokens, response format, etc. To facilitate selection, the system provides three preset parameter sets: Creative, Balanced, and Precise.
|
||||
3. **Write Prompts**: The LLM node offers an easy-to-use prompt composition page. Selecting a chat model or completion model will display different prompt composition structures.
|
||||
4. **Advanced Settings**: You can enable memory, set memory windows, and use the Jinja-2 template language for more complex prompts.
|
||||
|
||||
<Note>
|
||||
If you are using Dify for the first time, you need to complete the [model configuration](/en-us/user-guide/models/model-configuration) in **System Settings-Model Providers** before selecting a model in the LLM node.
|
||||
</Note>
|
||||
|
||||
#### **Writing Prompts**
|
||||
|
||||
In the LLM node, you can customize the model input prompts. If you select a chat model, you can customize the System/User/Assistant sections.
|
||||
|
||||
**Prompt Generator**
|
||||
|
||||
If you're struggling to come up with effective system prompts (System), you can use the Prompt Generator to quickly create prompts suitable for your specific business scenarios, leveraging AI capabilities.
|
||||
|
||||

|
||||
|
||||
In the prompt editor, you can call out the **variable insertion menu** by typing `/` or `{` to insert **special variable blocks** or **upstream node variables** into the prompt as context content.
|
||||
|
||||

|
||||
|
||||
***
|
||||
|
||||
### Explanation of Special Variables
|
||||
|
||||
**Context Variables**
|
||||
|
||||
Context variables are a special type of variable defined within the LLM node, used to insert externally retrieved text content into the prompt.
|
||||
|
||||

|
||||
|
||||
In common knowledge base Q\&A applications, the downstream node of knowledge retrieval is typically the LLM node. The **output variable** `result` of knowledge retrieval needs to be configured in the **context variable** within the LLM node for association and assignment. After association, inserting the **context variable** at the appropriate position in the prompt can incorporate the externally retrieved knowledge into the prompt.
|
||||
|
||||
This variable can be used not only as external knowledge introduced into the prompt context for LLM responses but also supports the application's **citation and attribution** feature due to its data structure containing segment reference information.
|
||||
|
||||
<Note>
|
||||
If the context variable is associated with a common variable from an upstream node, such as a string type variable from the start node, the context variable can still be used as external knowledge, but the **citation and attribution** feature will be disabled.
|
||||
</Note>
|
||||
|
||||
**Conversation History**
|
||||
|
||||
To achieve conversational memory in text completion models (e.g., gpt-3.5-turbo-Instruct), Dify designed the conversation history variable in the original Prompt Expert Mode (discontinued). This variable is carried over to the LLM node in Chatflow, used to insert chat history between the AI and the user into the prompt, helping the LLM understand the context of the conversation.
|
||||
|
||||
<Note>
|
||||
The conversation history variable is not widely used and can only be inserted when selecting text completion models in Chatflow.
|
||||
</Note>
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (204).png" alt="Inserting Conversation History Variable" />
|
||||
</Frame>
|
||||
|
||||
**Model Parameters**
|
||||
|
||||
The parameters of the model affect the output of the model. Different models have different parameters. The following figure shows the parameter list for `gpt-4`.
|
||||
|
||||

|
||||
|
||||
The main parameter terms are explained as follows:
|
||||
|
||||
**Temperature**: Usually a value between 0-1, it controls randomness. The closer the temperature is to 0, the more certain and repetitive the results; the closer it is to 1, the more random the results.
|
||||
|
||||
**Top P**: Controls the diversity of the results. The model selects from candidate words based on probability, ensuring that the cumulative probability does not exceed the preset threshold P.
|
||||
|
||||
**Presence Penalty**: Used to reduce the repetitive generation of the same entity or information by imposing penalties on content that has already been generated, making the model inclined to generate new or different content. As the parameter value increases, greater penalties are applied in subsequent generations to content that has already been generated, lowering the likelihood of repeating content.
|
||||
|
||||
**Frequency Penalty**: Imposes penalties on words or phrases that appear too frequently by reducing their probability of generation. With an increase in parameter value, greater penalties are imposed on frequently occurring words or phrases. Higher parameter values reduce the frequency of these words, thereby increasing the lexical diversity of the text.
|
||||
|
||||
If you do not understand what these parameters are, you can choose to load presets and select from the three presets: Creative, Balanced, and Precise.
|
||||
|
||||

|
||||
|
||||
***
|
||||
|
||||
### Advanced Features
|
||||
|
||||
**Memory**: When enabled, each input to the intent classifier will include chat history from the conversation to help the LLM understand the context and improve question comprehension in interactive dialogues.
|
||||
|
||||
**Memory Window**: When the memory window is closed, the system dynamically filters the amount of chat history passed based on the model's context window; when open, users can precisely control the amount of chat history passed (in terms of numbers).
|
||||
|
||||
**Conversation Role Name Settings**: Due to differences in model training stages, different models adhere to role name instructions differently, such as Human/Assistant, Human/AI, Human/Assistant, etc. To adapt to the prompt response effects of multiple models, the system provides conversation role name settings. Modifying the role name will change the role prefix in the conversation history.
|
||||
|
||||
**Jinja-2 Templates**: The LLM prompt editor supports Jinja-2 template language, allowing you to leverage this powerful Python template language for lightweight data transformation and logical processing. Refer to the [official documentation](https://jinja.palletsprojects.com/en/3.1.x/templates/).
|
||||
|
||||
***
|
||||
|
||||
#### Use Cases
|
||||
|
||||
* **Reading Knowledge Base Content**
|
||||
|
||||
To enable workflow applications to read "[Knowledge Base](/en-us/user-guide/knowledge-base/knowledge-base-creation/upload-documents)" content, such as building an intelligent customer service application, please follow these steps:
|
||||
|
||||
1. Add a knowledge base retrieval node upstream of the LLM node;
|
||||
2. Fill in the **output variable** `result` of the knowledge retrieval node into the **context variable** of the LLM node;
|
||||
3. Insert the **context variable** into the application prompt to give the LLM the ability to read text within the knowledge base.
|
||||
|
||||
.png)
|
||||
|
||||
The `result` variable output by the Knowledge Retrieval Node also includes segmented reference information. You can view the source of information through the **Citation and Attribution** feature.
|
||||
|
||||
<Note>
|
||||
Regular variables from upstream nodes can also be filled into context variables, such as string-type variables from the start node, but the **Citation and Attribution** feature will be ineffective.
|
||||
</Note>
|
||||
|
||||
* **Reading Document Files**
|
||||
|
||||
To enable workflow applications to read document contents, such as building a ChatPDF application, you can follow these steps:
|
||||
|
||||
* Add a file variable in the "Start" node;
|
||||
* Add a document extractor node upstream of the LLM node, using the file variable as an input variable;
|
||||
* Fill in the **output variable** `text` of the document extractor node into the prompt of the LLM node.
|
||||
|
||||
For more information, please refer to [File Upload](/en-us/user-guide/build-app/flow-app/file-upload).
|
||||
|
||||
.png)
|
||||
|
||||
@@ -0,0 +1,61 @@
|
||||
---
|
||||
title: Parameter Extraction
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
### 1 Definition
|
||||
|
||||
Utilize LLM to infer and extract structured parameters from natural language for subsequent tool invocation or HTTP requests.
|
||||
|
||||
Dify workflows provide a rich selection of [tools](/en-us/user-guide/build-app/flow-app/nodes/tools), most of which require structured parameters as input. The parameter extractor can convert user natural language into parameters recognizable by these tools, facilitating tool invocation.
|
||||
|
||||
Some nodes within the workflow require specific data formats as inputs, such as the [iteration](/en-us/user-guide/build-app/flow-app/nodes/iteration) node, which requires an array format. The parameter extractor can conveniently achieve structured parameter conversion.
|
||||
|
||||
***
|
||||
|
||||
### 2 Scenarios
|
||||
|
||||
1. **Extracting key parameters required by tools from natural language**, such as building a simple conversational Arxiv paper retrieval application.
|
||||
|
||||
In this example: The Arxiv paper retrieval tool requires **paper author** or **paper ID** as input parameters. The parameter extractor extracts the paper ID **2405.10739** from the query "What is the content of this paper: 2405.10739" and uses it as the tool parameter for precise querying.
|
||||
|
||||

|
||||
|
||||
2. **Converting text to structured data**, such as in the long story iteration generation application, where it serves as a pre-step for the [iteration node](/en-us/user-guide/build-app/flow-app/nodes/iteration), converting chapter content in text format to an array format, facilitating multi-round generation processing by the iteration node.
|
||||
|
||||

|
||||
|
||||
3. **Extracting structured data and using the** [**HTTP Request**](/en-us/user-guide/build-app/flow-app/nodes/http-request), which can request any accessible URL, suitable for obtaining external retrieval results, webhooks, generating images, and other scenarios.
|
||||
|
||||
***
|
||||
|
||||
### 3 How to Configure
|
||||
|
||||
**Configuration Steps**
|
||||
|
||||
1. Select the input variable, usually the variable input for parameter extraction.
|
||||
2. Choose the model, as the parameter extractor relies on the LLM's inference and structured generation capabilities.
|
||||
3. Define the parameters to extract, which can be manually added or **quickly imported from existing tools**.
|
||||
4. Write instructions, where providing examples can help the LLM improve the effectiveness and stability of extracting complex parameters.
|
||||
|
||||
**Advanced Settings**
|
||||
|
||||
**Inference Mode**
|
||||
|
||||
Some models support two inference modes, achieving parameter extraction through function/tool calls or pure prompt methods, with differences in instruction compliance. For instance, some models may perform better in prompt inference if function calling is less effective.
|
||||
|
||||
* Function Call/Tool Call
|
||||
* Prompt
|
||||
|
||||
**Memory**
|
||||
|
||||
When memory is enabled, each input to the question classifier will include the chat history in the conversation to help the LLM understand the context and improve question comprehension during interactive dialogues.
|
||||
|
||||
**Output Variables**
|
||||
|
||||
* Extracted defined variables
|
||||
* Node built-in variables
|
||||
|
||||
`__is_success Number` Extraction success status, with a value of 1 for success and 0 for failure.
|
||||
|
||||
`__reason String` Extraction error reason
|
||||
@@ -0,0 +1,59 @@
|
||||
---
|
||||
title: Question Classifier
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
### 1. Definition
|
||||
|
||||
By defining classification descriptions, the issue classifier can infer and match user inputs to the corresponding categories and output the classification results.
|
||||
|
||||
***
|
||||
|
||||
### 2. Scenarios
|
||||
|
||||
Common use cases include **customer service conversation intent classification, product review classification, and bulk email classification**.
|
||||
|
||||
In a typical product customer service Q\&A scenario, the issue classifier can serve as a preliminary step before knowledge base retrieval. It classifies the user's input question, directing it to different downstream knowledge base queries to accurately respond to the user's question.
|
||||
|
||||
The following diagram is an example workflow template for a product customer service scenario:
|
||||
|
||||

|
||||
|
||||
In this scenario, we set up three classification labels/descriptions:
|
||||
|
||||
* Category 1: **Questions related to after-sales service**
|
||||
* Category 2: **Questions related to product usage**
|
||||
* Category 3: **Other questions**
|
||||
|
||||
When users input different questions, the issue classifier will automatically classify them based on the set classification labels/descriptions:
|
||||
|
||||
* "**How to set up contacts on iPhone 14?**" —> "**Questions related to product usage**"
|
||||
* "**What is the warranty period?**" —> "**Questions related to after-sales service**"
|
||||
* "**How's the weather today?**" —> "**Other questions**"
|
||||
|
||||
***
|
||||
|
||||
### 3. How to Configure
|
||||
|
||||

|
||||
|
||||
**Configuration Steps:**
|
||||
|
||||
1. **Select Input Variable**: This refers to the content to be classified, usually the user's question in a customer service Q\&A scenario, e.g., `sys.query`.
|
||||
2. **Choose Inference Model**: The issue classifier leverages the natural language classification and inference capabilities of large language models. Selecting an appropriate model can enhance classification effectiveness.
|
||||
3. **Write Classification Labels/Descriptions**: You can manually add multiple classifications by writing keywords or descriptive statements for each category, helping the large language model better understand the classification criteria.
|
||||
4. **Choose Corresponding Downstream Nodes**: After classification, the issue classification node can direct the flow to different paths based on the relationship between the classification and downstream nodes.
|
||||
|
||||
#### Advanced Settings:
|
||||
|
||||
**Instructions**: In **Advanced Settings - Instructions**, you can add supplementary instructions, such as more detailed classification criteria, to enhance the classifier's capabilities.
|
||||
|
||||
**Memory**: When enabled, each input to the issue classifier will include chat history from the conversation to help the LLM understand the context and improve question comprehension in interactive dialogues.
|
||||
|
||||
**Memory Window**: When the memory window is closed, the system dynamically filters the amount of chat history passed based on the model's context window; when open, users can precisely control the amount of chat history passed (in terms of numbers).
|
||||
|
||||
**Output Variable**:
|
||||
|
||||
`class_name`
|
||||
|
||||
This is the classification name output after classification. You can use the classification result variable in downstream nodes as needed.
|
||||
68
en-us/user-guide/build-app/flow-app/nodes/start.mdx
Normal file
68
en-us/user-guide/build-app/flow-app/nodes/start.mdx
Normal file
@@ -0,0 +1,68 @@
|
||||
---
|
||||
title: Start
|
||||
---
|
||||
|
||||
#### Definition
|
||||
|
||||
The **“Start”** node is a critical preset node in the [Chatflow / Workflow](../) application. It provides essential initial information, such as user input and [uploaded files](/en-us/user-guide/build-app/flow-app/file-upload), to support the normal flow of the application and subsequent workflow nodes.
|
||||
|
||||
#### Configuring the Node
|
||||
|
||||
On the Start node's settings page, you'll find two sections: **"Input Fields"** and preset **[System Variables](/en-us/user-guide/build-app/flow-app/variables#system-variables)**.
|
||||
|
||||

|
||||
|
||||
#### Input Field
|
||||
|
||||
Input field is configured by application developers to prompt users for additional information.
|
||||
|
||||
For example, in a weekly report application, users might be required to provide background information such as name, work date range, and work details in a specific format. This preliminary information helps the LLM generate higher quality responses.
|
||||
|
||||
Six types of input variables are supported, all of which can be set as required:
|
||||
|
||||
* **Text:** Short text, filled in by the user, with a maximum length of 256 characters.
|
||||
* **Paragraph:** Long text, allowing users to input longer content.
|
||||
* **Select:** Fixed options set by the developer; users can only select from preset options and cannot input custom content.
|
||||
* **Number:** Only allows numerical input.
|
||||
* **Single File:** Allows users to upload a single file. Supports document types, images, audio, video, and other file types. Users can upload locally or paste a file URL. For detailed usage, refer to [File Upload](/en-us/user-guide/build-app/flow-app/file-upload).
|
||||
* **File List:** Allows users to batch upload files. Supports document types, images, audio, video, and other file types. Users can upload locally or paste file URLs. For detailed usage, refer to [File Upload](/en-us/user-guide/build-app/flow-app/file-upload).
|
||||
|
||||
|
||||
<Note>Dify's built-in document extractor node can only process certain document formats. For processing images, audio, or video files, refer to External Data Tools to set up corresponding file processing nodes.</Note>
|
||||
|
||||
Once configured, users will be guided to provide necessary information to the LLM before using the application. More information will help to improve the LLM's question-answering efficiency.
|
||||
|
||||
### System Variables
|
||||
|
||||
System variables are system-level parameters preset in Chatflow / Workflow applications that can be globally read by other nodes within the application. They are typically used in advanced development scenarios, such as building multi-round conversation applications, collecting application logs and monitoring, and recording usage behavior across different applications and users.
|
||||
|
||||
**Workflow**
|
||||
|
||||
Workflow type applications provide the following system variables:
|
||||
|
||||
| Variable Name | Data Type | Description | Notes |
|
||||
|---------|--------|------|------|
|
||||
| `sys.files` [LEGACY] | Array[File] | File parameter, stores images uploaded by users when initially using the application | Image upload feature needs to be enabled in "Features" at the top right of the application configuration page |
|
||||
| `sys.user_id` | String | User ID, system automatically assigns a unique identifier to each user when using the workflow application to distinguish different conversation users | |
|
||||
| `sys.app_id` | String | Application ID, system assigns a unique identifier to each Workflow application to distinguish different applications and record basic information of the current application through this parameter | For users with development capabilities to distinguish and locate different Workflow applications using this parameter |
|
||||
| `sys.workflow_id` | String | Workflow ID, used to record all node information contained in the current Workflow application | For users with development capabilities to track and record node information within the Workflow |
|
||||
| `sys.workflow_run_id` | String | Workflow application run ID, used to record the running status of the Workflow application | For users with development capabilities to track application run history |
|
||||
|
||||

|
||||
|
||||
**Chatflow**
|
||||
|
||||
Chatflow type applications provide the following system variables:
|
||||
|
||||
| Variable Name | Data Type | Description | Notes |
|
||||
|---------|--------|------|------|
|
||||
| `sys.query` | String | Initial content entered by users in the dialogue box | |
|
||||
| `sys.files` | Array[File] | Images uploaded by users in the dialogue box | Image upload feature needs to be enabled in "Features" at the top right of the application configuration page |
|
||||
| `sys.dialogue_count` | Number | Number of conversation rounds when users interact with Chatflow type applications. Count automatically increases by 1 after each round of dialogue, can be combined with if-else nodes for rich branching logic. For example, reviewing and analyzing conversation history at round X | |
|
||||
| `sys.conversation_id` | String | Unique identifier for dialogue interaction sessions, grouping all related messages into the same conversation, ensuring LLM maintains continuous dialogue on the same topic and context | |
|
||||
| `sys.user_id` | String | Unique identifier assigned to each application user to distinguish different conversation users | |
|
||||
| `sys.app_id` | String | Application ID, system assigns a unique identifier to each Workflow application to distinguish different applications and record basic information of the current application through this parameter | For users with development capabilities to distinguish and locate different Workflow applications using this parameter |
|
||||
| `sys.workflow_id` | String | Workflow ID, used to record all node information contained in the current Workflow application | For users with development capabilities to track and record node information within the Workflow |
|
||||
| `sys.workflow_run_id` | String | Workflow application run ID, used to record the running status of the Workflow application | For users with development capabilities to track application run history |
|
||||
|
||||

|
||||
31
en-us/user-guide/build-app/flow-app/nodes/template.mdx
Normal file
31
en-us/user-guide/build-app/flow-app/nodes/template.mdx
Normal file
@@ -0,0 +1,31 @@
|
||||
---
|
||||
title: Template
|
||||
---
|
||||
|
||||
Template lets you dynamically format and combine variables from previous nodes into a single text-based output using Jinja2, a powerful templating syntax for Python. It's useful for combining data from multiple sources into a specific structure required by subsequent nodes. The simple example below shows how to assemble an article by piecing together various previous outputs:
|
||||
|
||||
.png)
|
||||
|
||||
Beyond naive use cases, you can create more complex templates as per Jinja's [documentation](https://jinja.palletsprojects.com/en/3.1.x/templates/) for a variety of tasks. Here's one template that structures retrieved chunks and their relevant metadata from a knowledge retrieval node into a formatted markdown:
|
||||
|
||||
```Plain
|
||||
{% raw %}
|
||||
{% for item in chunks %}
|
||||
### Chunk {{ loop.index }}.
|
||||
### Similarity: {{ item.metadata.score | default('N/A') }}
|
||||
|
||||
#### {{ item.title }}
|
||||
|
||||
##### Content
|
||||
{{ item.content | replace('\n', '\n\n') }}
|
||||
|
||||
---
|
||||
{% endfor %}
|
||||
{% endraw %}
|
||||
```
|
||||
|
||||
.png)
|
||||
|
||||
This template node can then be used within a Chatflow to return intermediate outputs to the end user, before a LLM response is initiated.
|
||||
|
||||
> The `Answer` node in a Chatflow is non-terminal. It can be inserted anywhere to output responses at multiple points within the flow.
|
||||
28
en-us/user-guide/build-app/flow-app/nodes/tools.mdx
Normal file
28
en-us/user-guide/build-app/flow-app/nodes/tools.mdx
Normal file
@@ -0,0 +1,28 @@
|
||||
---
|
||||
title: Tools
|
||||
---
|
||||
|
||||
### Definition
|
||||
|
||||
The workflow provides a rich selection of tools, categorized into three types:
|
||||
|
||||
* **Built-in Tools**: Tools provided by Dify.
|
||||
* **Custom Tools**: Tools imported or configured via the OpenAPI/Swagger standard format.
|
||||
* **Workflows**: Workflows that have been published as tools.
|
||||
|
||||
Before using built-in tools, you may need to **authorize** the tools.
|
||||
|
||||
If built-in tools do not meet your needs, you can create custom tools in the **Dify menu navigation -- Tools** section.
|
||||
|
||||
You can also orchestrate a more complex workflow and publish it as a tool.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Configuring a tool node generally involves two steps:
|
||||
|
||||
1. Authorizing the tool/creating a custom tool/publishing a workflow as a tool.
|
||||
2. Configuring the tool's input and parameters.
|
||||
|
||||
For more information on how to create custom tools and configure them, please refer to the [Tool Configuration Guide](/en-us/user-guide/tools/introduction).
|
||||
@@ -0,0 +1,39 @@
|
||||
---
|
||||
title: Variable Aggregator
|
||||
---
|
||||
|
||||
### 1 Definition
|
||||
|
||||
Aggregate variables from multiple branches into a single variable to achieve unified configuration for downstream nodes.
|
||||
|
||||
The variable aggregation node (formerly the variable assignment node) is a key node in the workflow. It is responsible for integrating the output results from different branches, ensuring that regardless of which branch is executed, its results can be referenced and accessed through a unified variable. This is particularly useful in multi-branch scenarios, as it maps variables with the same function from different branches into a single output variable, avoiding the need for repeated definitions in downstream nodes.
|
||||
|
||||
***
|
||||
|
||||
### 2 Scenarios
|
||||
|
||||
Through variable aggregation, you can aggregate multiple outputs, such as from issue classification or conditional branching, into a single output for use and manipulation by downstream nodes, simplifying data flow management.
|
||||
|
||||
**Multi-Branch Aggregation after Issue Classification**
|
||||
|
||||
Without variable aggregation, the branches of Classification 1 and Classification 2, after different knowledge base retrievals, would require repeated definitions for downstream LLM and direct response nodes.
|
||||
|
||||
.png)
|
||||
|
||||
By adding variable aggregation, the outputs of the two knowledge retrieval nodes can be aggregated into a single variable.
|
||||
|
||||

|
||||
|
||||
**Multi-Branch Aggregation after IF/ELSE Conditional Branching**
|
||||
|
||||

|
||||
|
||||
### 3 Format Requirements
|
||||
|
||||
The variable aggregator supports aggregating various data types, including strings (`String`), numbers (`Number`), objects (`Object`), and arrays (`Array`).
|
||||
|
||||
**The variable aggregator can only aggregate variables of the same data type**. If the first variable added to the variable aggregation node is of the `String` data type, subsequent connections will automatically filter and allow only `String` type variables to be added.
|
||||
|
||||
**Aggregation Grouping**
|
||||
|
||||
When aggregation grouping is enabled, the variable aggregator can aggregate multiple groups of variables, with each group requiring the same data type for aggregation.
|
||||
161
en-us/user-guide/build-app/flow-app/nodes/variable-assigner.mdx
Normal file
161
en-us/user-guide/build-app/flow-app/nodes/variable-assigner.mdx
Normal file
@@ -0,0 +1,161 @@
|
||||
---
|
||||
title: Variable Assigner
|
||||
---
|
||||
|
||||
### Definition
|
||||
|
||||
The variable assigner node is used to assign values to writable variables. Currently supported writable variables include:
|
||||
|
||||
* [Conversation variables](/en-us/user-guide/build-app/flow-app/concepts#variables).
|
||||
|
||||
Usage: Through the variable assigner node, you can assign workflow variables to conversation variables for temporary storage, which can be continuously referenced in subsequent conversations.
|
||||
|
||||

|
||||
|
||||
***
|
||||
|
||||
### Usage Scenario Examples
|
||||
|
||||
Using the variable assigner node, you can write context from the conversation process, files uploaded to the dialog box (coming soon), and user preference information into conversation variables. These stored variables can then be referenced in subsequent conversations to direct different processing flows or formulate responses.
|
||||
|
||||
**Scenario 1**
|
||||
|
||||
You can write the **context during the conversation, the file uploaded to the chatting box (coming soon), the preference information entered by the user,etc.** into the conversation variable using **Variable Assigner** node. These stored information can be referenced in subsequent chats to guide different processing flows or provide responses.
|
||||
|
||||
**Scenario 1**
|
||||
|
||||
**Automatically judge and extract content**, store history in the conversation, record important user information through the session variable array within the conversation, and use this history content to personalize responses in subsequent chats.
|
||||
|
||||
Example: After the conversation starts, LLM will automatically determine whether the user's input contains facts, preferences, or chat history that need to be remembered. If it has, LLM will first extract and store those information, then use it as context to respond. If there is no new information to remember, LLM will directly use the previously relevant memories to answer questions.
|
||||
|
||||

|
||||
|
||||
**Configuration process:**
|
||||
|
||||
1. **Set Conversation Variables:**
|
||||
* First, set up a Conversation Variables array `memories`, of type array\[object] to store user information, preferences, and chat history.
|
||||
2. **Determine and Extract Memories:**
|
||||
* Add a Conditional Branching node, using LLM to determine whether the user's input contains new information that needs to be remembered.
|
||||
* If there's new information, follow the upper branch and use an LLM node to extract this information.
|
||||
* If there's no new information, go down the branch and directly use existing memories to answer.
|
||||
3. **Variable Assignment/Writing:**
|
||||
* In the upper branch, use the variable assigner node to append the newly extracted information to the `memories` array.
|
||||
* Use the escape function to convert the text string output by LLM into a format suitable for storage in an array\[object].
|
||||
4. **Variable Reading and Usage:**
|
||||
* In subsequent LLM nodes, convert the contents of the `memories` array to a string and insert it into the prompt of LLM as context.
|
||||
* Use these memories to generate personalized responses.
|
||||
|
||||
The code for the node in the upper diagram is as follows:
|
||||
|
||||
1. Escape the string to object
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: str) -> object:
|
||||
try:
|
||||
# Parse the input JSON string
|
||||
input_data = json.loads(arg1)
|
||||
|
||||
# Extract the memory object
|
||||
memory = input_data.get("memory", {})
|
||||
|
||||
# Construct the return object
|
||||
result = {
|
||||
"facts": memory.get("facts", []),
|
||||
"preferences": memory.get("preferences", []),
|
||||
"memories": memory.get("memories", [])
|
||||
}
|
||||
|
||||
return {
|
||||
"mem": result
|
||||
}
|
||||
except json.JSONDecodeError:
|
||||
return {
|
||||
"result": "Error: Invalid JSON string"
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"Error: {str(e)}"
|
||||
}
|
||||
```
|
||||
|
||||
2. Escape object as string
|
||||
|
||||
```python
|
||||
import json
|
||||
|
||||
def main(arg1: list) -> str:
|
||||
try:
|
||||
# Assume arg1[0] is the dictionary we need to process
|
||||
context = arg1[0] if arg1 else {}
|
||||
|
||||
# Construct the memory object
|
||||
memory = {"memory": context}
|
||||
|
||||
# Convert the object to a JSON string
|
||||
json_str = json.dumps(memory, ensure_ascii=False, indent=2)
|
||||
|
||||
# Wrap the JSON string in <answer> tags
|
||||
result = f"<answer>{json_str}</answer>"
|
||||
|
||||
return {
|
||||
"result": result
|
||||
}
|
||||
except Exception as e:
|
||||
return {
|
||||
"result": f"<answer>Error: {str(e)}</answer>"
|
||||
}
|
||||
```
|
||||
|
||||
**Scenario 2**
|
||||
|
||||
**Recording initial user preferences input**: Remember the user's language preference input during the conversation and continue to use this language for responses in subsequent chatting.
|
||||
|
||||
Example: Before the chatting, the user specifies "English" in the `language` input box. This language will be written to the conversation variable, and the LLM will reference this information when responding, continuing to use "English" in subsequent conversations.
|
||||
|
||||

|
||||
|
||||
**Configuration Guide:**
|
||||
|
||||
**Set conversation variable**: First, set a conversation variable `language`. Add a condition judgment node at the beginning of the conversation flow to check if the `language` variable is empty.
|
||||
|
||||
**Variable writing/assignment**: At the start of the first round of chatting, if the `language` variable is empty, use an LLM node to extract the user's input language, then use a variable assigner node to write this language type into the conversation variable `language`.
|
||||
|
||||
**Variable reading**: In subsequent conversation rounds, the `language` variable has stored the user's language preference. The LLM node references the language variable to respond using the user's preferred language type.
|
||||
|
||||
**Scenario 3**
|
||||
|
||||
**Assisting with Checklist checks**: Record user inputs within the conversation using conversation variables, update the contents of the Checklist, and check for missing items in subsequent conversations.
|
||||
|
||||
Example: After starting the conversation, the LLM will ask the user to input items related to the Checklist in the chatting box. Once the user mentions content from the Checklist, it will be updated and stored in the Conversation Variable. The LLM will remind the user to continue supplementing missing items after each round of dialogue.
|
||||
|
||||

|
||||
|
||||
**Configuration Process:**
|
||||
|
||||
* **Set conversation variable:** First, set a conversation variable `ai_checklist`, and reference this variable within the LLM as context for checking.
|
||||
* **variable assigner/writing**: During each round of dialogue, check the value in `ai_checklist` within the LLM node and compare it with user input. If the user provides new information, update the Checklist and write the output content to `ai_checklist` using the variable assigner node.
|
||||
* **Variable reading:** Read the value in `ai_checklist` and compare it with user input in each round of dialogue until all checklist items are completed.
|
||||
|
||||
***
|
||||
|
||||
### Using the Variable Assigner Node
|
||||
|
||||
Click the + sign on the right side of the node, select the "variable assigner" node, and fill in "Assigned Variable" and "Set Variable".
|
||||
|
||||

|
||||
|
||||
**Setting Variables:**
|
||||
|
||||
Assigned Variable: Select the variable to be assigned, i.e., specify the target conversation variable that needs to be assigned.
|
||||
|
||||
Set Variable: Select the variable to assign, i.e., specify the source variable that needs to be converted.
|
||||
|
||||
Taking the assignment logic in the above figure as an example: Assign the text output item `Language Recognition/text` from the previous node to the conversation variable `language`.
|
||||
|
||||
**Write Mode:**
|
||||
|
||||
* Overwrite: Overwrite the content of the source variable to the target conversation variable
|
||||
* Append: When the specified variable is of Array type
|
||||
* Clear: Clear the content in the target conversation variable
|
||||
101
en-us/user-guide/build-app/flow-app/orchestrate-node.mdx
Normal file
101
en-us/user-guide/build-app/flow-app/orchestrate-node.mdx
Normal file
@@ -0,0 +1,101 @@
|
||||
---
|
||||
title: Orchestrate Node
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
Both Chatflow and Workflow applications support node orchestration through visual drag-and-drop, with two orchestration design patterns: serial and parallel.
|
||||
|
||||

|
||||
|
||||
## Serial Node Design Pattern
|
||||
|
||||
In this pattern, nodes execute sequentially in a predefined order. Each node initiates its operation only after the preceding node has completed its task and generated output. This helps ensure tasks are executed in a logical sequence.
|
||||
|
||||
Consider a "Novel Generation" Workflow App implementing serial pattern: after the user inputs the novel style, rhythm, and characters, the LLM completes the novel outline, plot, and ending in sequence. Each node works based on the output of the previous node, ensuring consistency in the novel's style.
|
||||
|
||||
### Designing Serial Structure
|
||||
|
||||
1. Click the `+` icon between two nodes to insert a new serial node.
|
||||
2. Sequentially link the nodes.
|
||||
3. Converge all paths to the "End" node to finalize the workflow.
|
||||
|
||||

|
||||
|
||||
### Viewing Serial Structure Application Logs
|
||||
|
||||
In a serial structure application, logs display node operations sequentially. Click "View Logs - Tracing" in the upper right corner of the dialog box to see the complete workflow process, including input/output, token consumption, and runtime for each node.
|
||||
|
||||

|
||||
|
||||
## Designing Parallel Structure
|
||||
|
||||
This architectural pattern enables concurrent execution of multiple nodes. The preceding node can simultaneously trigger multiple nodes within the parallel structure. These parallel nodes operate independently, executing tasks concurrently and significantly enhancing overall workflow efficiency.
|
||||
|
||||
Consider a translation workflow application implementing parallel architecture: Once the user inputs the source text, triggering the workflow, all nodes within the parallel structure simultaneously receive instructions from the preceding node. This allows for concurrent translation into multiple languages, significantly reducing overall processing time.
|
||||
|
||||
### Parallel Structure Design Pattern
|
||||
|
||||
The following four methods demonstrate how to create a parallel structure through node addition or visual manipulation:
|
||||
|
||||
**Method 1** Hover over a node to reveal the `+` button. Click it to add multiple nodes, automatically forming a parallel structure.
|
||||
|
||||

|
||||
|
||||
**Method 2** Extend a connection from a node by dragging its `+` button, creating a parallel structure.
|
||||
|
||||

|
||||
|
||||
**Method 3** With multiple nodes on the canvas, visually drag and link them to form a parallel structure.
|
||||
|
||||

|
||||
|
||||
**Method 4** In addition to canvas-based methods, you can generate parallel structures by adding nodes through the "Next Step" section in a node's right-side panel. This approach automatically creates the parallel configuration.
|
||||
|
||||

|
||||
|
||||
**Notes:**
|
||||
|
||||
* Any node can serve as the downstream node of a parallel structure;
|
||||
* Workflow applications require a single, unique "end" node;
|
||||
* Chatflow applications support multiple "answer" nodes. Each parallel structure in these applications must terminate with an "answer" node to ensure proper output of content;
|
||||
* All parallel structures will run simultaneously; nodes within the parallel structure output results after completing their tasks, with no order relationship in output. The simpler the parallel structure, the faster the output of results.
|
||||
|
||||

|
||||
|
||||
### Designing Parallel Structure Patterns
|
||||
|
||||
The following four patterns demonstrate common parallel structure designs:
|
||||
|
||||
#### 1. Normal Parallel
|
||||
|
||||
Normal parallel refers to the `Start | Parallel Nodes | End three-layer` relationship, which is also the smallest unit of parallel structure. This structure is intuitive, allowing the workflow to execute multiple tasks simultaneously after user input.
|
||||
|
||||
The upper limit for parallel branches is 10.
|
||||
|
||||

|
||||
|
||||
#### 2. Nested Parallel
|
||||
|
||||
Nested parallel refers to the Start | Multiple Parallel Structures | End multi-layer relationship. It is suitable for more complex workflows, such as needing to request an external API within a certain node and simultaneously passing the returned results to downstream nodes for processing.
|
||||
|
||||
A workflow supports up to 3 layers of nesting relationships.
|
||||
|
||||

|
||||
|
||||
#### 3. Conditional Branch + Parallel
|
||||
|
||||
Parallel structures can also be used in conjunction with conditional branches.
|
||||
|
||||

|
||||
|
||||
#### 4. Iteration Branch + Parallel
|
||||
|
||||
This pattern integrates parallel structures within iteration branches, optimizing the execution efficiency of repetitive tasks.
|
||||
|
||||

|
||||
|
||||
### Viewing Parallel Structure Application Logs
|
||||
|
||||
Applications with parallel structures generate logs in a tree-like format. Collapsible parallel node groups facilitate easier viewing of individual node logs.
|
||||
|
||||

|
||||
26
en-us/user-guide/build-app/flow-app/shotcut-key.mdx
Normal file
26
en-us/user-guide/build-app/flow-app/shotcut-key.mdx
Normal file
@@ -0,0 +1,26 @@
|
||||
---
|
||||
title: Shotcut Key
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
The Chatflow / Workflow application orchestration page supports the following shortcut keys to help you improve the efficiency of orchestration nodes.
|
||||
|
||||
| Windows | macOS | Explanation |
|
||||
| ---------------- | ------------------- | ------------------------------ |
|
||||
| Ctrl + C | Command + C | Copy nodes |
|
||||
| Ctrl + V | Command + V | Paste nodes |
|
||||
| Ctrl + D | Command + D | Duplicate nodes |
|
||||
| Ctrl + O | Command + O | Organize nodes |
|
||||
| Ctrl + Z | Command + Z | Undo |
|
||||
| Ctrl + Y | Command + Y | Redo |
|
||||
| Ctrl + Shift + Z | Command + Shift + Z | Redo |
|
||||
| Ctrl + 1 | Command + 1 | Canvas fits view |
|
||||
| Ctrl + (-) | Command + (-) | Canvas zooms out |
|
||||
| Ctrl + (=) | Command + (=) | Canvas zooms in |
|
||||
| Shift + 1 | Shift + 1 | Resets canvas view to 100% |
|
||||
| Shift + 5 | Shift + 5 | Scales canvas to 50% |
|
||||
| H | H | Canvas toggles to Hand mode |
|
||||
| V | V | Canvas toggles to Pointer mode |
|
||||
| Delete/Backspace | Delete/Backspace | Delete selected nodes |
|
||||
| Alt + R | Option + R | Workflow starts to run |
|
||||
|
||||
178
en-us/user-guide/build-app/flow-app/variables.mdx
Normal file
178
en-us/user-guide/build-app/flow-app/variables.mdx
Normal file
@@ -0,0 +1,178 @@
|
||||
---
|
||||
title: Variables
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
Workflow and Chatflow type applications are composed of independent nodes. Most nodes have input and output items, but the input information for each node varies, and the outputs from different nodes also differ.
|
||||
|
||||
How can we use a fixed symbol to **represent dynamically changing content?** Variables, acting as dynamic data containers, can store and transmit variable content, being referenced across different nodes to achieve flexible communication of information between nodes.
|
||||
|
||||
### **System Variables**
|
||||
|
||||
System variables are system-level parameters preset in Chatflow / Workflow applications that can be globally read by other nodes. System-level variables all begin with `sys`.
|
||||
|
||||
#### Workflow
|
||||
|
||||
Workflow type applications provide the following system variables:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th width="193">Variable Name</th>
|
||||
<th width="116">Data Type</th>
|
||||
<th width="278">Description</th>
|
||||
<th>Notes</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><p><code>sys.files</code></p><p><code>[LEGACY]</code></p></td>
|
||||
<td>Array[File]</td>
|
||||
<td>File parameter, stores images uploaded by users when initially using the application</td>
|
||||
<td>Image upload feature needs to be enabled in "Features" at the top right of the application configuration page</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.user_id</code></td>
|
||||
<td>String</td>
|
||||
<td>User ID, system automatically assigns a unique identifier to each user when using the workflow application to distinguish different conversation users</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.app_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Application ID, system assigns a unique identifier to each Workflow application to distinguish different applications and record basic information of the current application through this parameter</td>
|
||||
<td>For users with development capabilities to distinguish and locate different Workflow applications using this parameter</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.workflow_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Workflow ID, used to record all node information contained in the current Workflow application</td>
|
||||
<td>For users with development capabilities to track and record node information within the Workflow</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.workflow_run_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Workflow application run ID, used to record the running status of the Workflow application</td>
|
||||
<td>For users with development capabilities to track application run history</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||

|
||||
|
||||
#### Chatflow
|
||||
|
||||
Chatflow type applications provide the following system variables:
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Variable Name</th>
|
||||
<th width="127">Data Type</th>
|
||||
<th width="283">Description</th>
|
||||
<th>Notes</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>sys.query</code></td>
|
||||
<td>String</td>
|
||||
<td>Initial content entered by users in the dialogue box</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.files</code></td>
|
||||
<td>Array[File]</td>
|
||||
<td>Images uploaded by users in the dialogue box</td>
|
||||
<td>Image upload feature needs to be enabled in "Features" at the top right of the application configuration page</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.dialogue_count</code></td>
|
||||
<td>Number</td>
|
||||
<td><p>Number of conversation rounds when users interact with Chatflow type applications. Count automatically increases by 1 after each round of dialogue, can be combined with if-else nodes for rich branching logic.</p><p>For example, reviewing and analyzing conversation history at round X</p></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.conversation_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Unique identifier for dialogue interaction sessions, grouping all related messages into the same conversation, ensuring LLM maintains continuous dialogue on the same topic and context</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.user_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Unique identifier assigned to each application user to distinguish different conversation users</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.app_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Application ID, system assigns a unique identifier to each Workflow application to distinguish different applications and record basic information of the current application through this parameter</td>
|
||||
<td>For users with development capabilities to distinguish and locate different Workflow applications using this parameter</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.workflow_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Workflow ID, used to record all node information contained in the current Workflow application</td>
|
||||
<td>For users with development capabilities to track and record node information within the Workflow</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>sys.workflow_run_id</code></td>
|
||||
<td>String</td>
|
||||
<td>Workflow application run ID, used to record the running status of the Workflow application</td>
|
||||
<td>For users with development capabilities to track application run history</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||

|
||||
|
||||
### Environment Variables
|
||||
|
||||
**Environment variables are used to protect sensitive information involved in workflows**, such as API keys and database passwords used when running workflows. They are stored in the workflow rather than in the code to facilitate sharing across different environments.
|
||||
|
||||

|
||||
|
||||
The following three data types are supported:
|
||||
|
||||
* String
|
||||
* Number
|
||||
* Secret
|
||||
|
||||
Environment variables have the following characteristics:
|
||||
|
||||
* Environment variables can be globally referenced in most nodes
|
||||
* Environment variable names cannot be duplicated
|
||||
* Environment variables are read-only and cannot be written to
|
||||
|
||||
### Conversation Variables
|
||||
|
||||
> Conversation variables are designed for multi-round conversation scenarios. Since Workflow type applications have linear and independent interactions without multiple conversation exchanges, conversation variables are only applicable to Chatflow type (Chat Assistant → Workflow Orchestration) applications.
|
||||
|
||||
**Conversation variables allow application developers to specify particular information that needs to be temporarily stored within the same Chatflow session, ensuring this information can be referenced across multiple rounds of dialogue within the current workflow**. This includes context, files uploaded to the dialogue box (coming soon), and user preferences input during conversations. It's like providing LLM with a "memo" that can be checked at any time, avoiding information discrepancies due to LLM memory errors.
|
||||
|
||||
For example, you can store the language preference input by users in the first round of conversation in conversation variables, and LLM will reference this information when responding and use the specified language to reply to users in subsequent conversations.
|
||||
|
||||

|
||||
|
||||
**Conversation variables** support the following six data types:
|
||||
|
||||
* String
|
||||
* Number
|
||||
* Object
|
||||
* Array[string]
|
||||
* Array[number]
|
||||
* Array[object]
|
||||
|
||||
**Conversation variables** have the following characteristics:
|
||||
|
||||
* Conversation variables can be globally referenced in most nodes
|
||||
* Writing to conversation variables requires using the [Variable Assigner](./nodes/variable-assigner) node
|
||||
* Conversation variables are readable and writable
|
||||
|
||||
For more details about how to use conversation variables with variable assigner nodes, please refer to the [Variable Assigner](./nodes/variable-assigner) node documentation.
|
||||
|
||||
### Notes
|
||||
|
||||
* To avoid variable name duplication, node names cannot be duplicated
|
||||
* Node output variables are generally fixed variables and cannot be edited
|
||||
81
en-us/user-guide/build-app/text-generator.mdx
Normal file
81
en-us/user-guide/build-app/text-generator.mdx
Normal file
@@ -0,0 +1,81 @@
|
||||
---
|
||||
title: Text Generation Application
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
A text generation application is a type of application specifically designed to produce content in specific formats. These applications allow users to input specific requirements or parameters and automatically generate text output that conforms to preset formats. Unlike chat assistants that can maintain continuous conversations, text generation applications primarily process single inputs to provide one-time content generation services, with "Prompt Generator" being a typical example.
|
||||
|
||||
## Use Cases
|
||||
|
||||
Text generation applications are particularly suitable for scenarios requiring quick, batch generation of standardized content, such as creative writing, marketing copy, or technical documentation.
|
||||
|
||||
## How to Configure
|
||||
|
||||
Text generation applications support configuration of: pre-conversation prompts, variables, context, opening messages, and suggested follow-up questions.
|
||||
|
||||
Let's take creating a **Weekly Report Generator** application as an example to explain how to configure a text generation application.
|
||||
|
||||
### Creating the Application
|
||||
|
||||
Click the "Create Application" button on the homepage to create an application. Enter the application name and select **Text Generation Application** as the application type.
|
||||
|
||||

|
||||
|
||||
### Configuring the Application
|
||||
|
||||
After creating the application, you'll automatically be redirected to the application overview page, where you can set variables, add context, and configure additional chat features for the application.
|
||||
|
||||

|
||||
|
||||
#### Application Configuration
|
||||
|
||||
**Writing Prompts**
|
||||
|
||||
Prompts are used to constrain AI responses to be professional and precise. You can use the built-in prompt generator to write appropriate prompts. Prompts support the insertion of form variables, such as `{{input}}`. The values of variables in the prompt will be replaced with user-entered values.
|
||||
|
||||
Example:
|
||||
1. Enter prompt instructions requesting a prompt for an interview scenario.
|
||||
2. The right content box will automatically generate the prompt.
|
||||
3. You can insert custom variables into the prompt.
|
||||
|
||||

|
||||
|
||||
#### Adding Context
|
||||
|
||||
If you want to limit AI conversations to within a knowledge base, such as enterprise customer service conversation standards, you can reference the knowledge base in the "Context" section.
|
||||
|
||||

|
||||
|
||||
### Debugging
|
||||
|
||||
Fill in the user input fields on the right side and enter content for debugging.
|
||||
|
||||

|
||||
|
||||
If the response results are not satisfactory, you can adjust the prompts and underlying model. You can also debug simultaneously with multiple models to find the most suitable configuration.
|
||||
|
||||

|
||||
|
||||
**Debugging with Multiple Models:**
|
||||
|
||||
If debugging with a single model feels inefficient, you can use the **"Debug with Multiple Models"** feature to batch review model response effects.
|
||||
|
||||

|
||||
|
||||
Supports adding up to 4 large models simultaneously.
|
||||
|
||||

|
||||
|
||||
⚠️ When using the multi-model debugging feature, if you only see some large models, this is because Keys for other large models haven't been added yet. You can manually add Keys for multiple models in "Add New Provider".
|
||||
|
||||
### Publishing the Application
|
||||
|
||||
After debugging the application, click the **"Publish"** button in the top right corner to generate a standalone AI application. In addition to experiencing the application through a public URL, you can also perform secondary development based on APIs or embed it into websites. For details, please refer to [Publishing Applications](/en-us/user-guide/application-publishing/launch-your-webapp-quickly/web-app-settings).
|
||||
|
||||
If you want to customize a published application, you can fork our open-source WebApp template and modify it to meet your scenario and style requirements.
|
||||
|
||||
## Frequently Asked Questions
|
||||
|
||||
**How to add custom tools in the text generator?**
|
||||
|
||||
Text generation applications do not support adding third-party tools.
|
||||
@@ -1,6 +1,5 @@
|
||||
---
|
||||
title: External Knowledge API
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
## Endpoint
|
||||
@@ -106,7 +105,7 @@ If the action fails, the service sends back the following error information in J
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| error_code | TRUE | int | Error code | 1001 |
|
||||
| error_msg | TRUE | string | The description of API exception | Invalid Authorization header format. Expected 'Bearer \<api-key\>' format. |
|
||||
| error_msg | TRUE | string | The description of API exception | Invalid Authorization header format. Expected 'Bearer `<api-key>`' format. |
|
||||
|
||||
The `error_code` property has the following types:
|
||||
|
||||
|
||||
@@ -0,0 +1,122 @@
|
||||
---
|
||||
title: Connect External Knowledge
|
||||
---
|
||||
|
||||
> To make a distinction, knowledge bases independent of the Dify platform are collectively referred to as **"external knowledge bases"** in this article.
|
||||
|
||||
## Functional Introduction
|
||||
|
||||
For developers with advanced content retrieval requirements, **the built-in knowledge base functionality and text retrieval mechanisms of the Dify platform may have limitations, particularly in terms of customizing recall results.**
|
||||
|
||||
Due to the requirement of higher accuracy of text retrieval and recall, as well as the need to manage internal materials, some developer teams choose to independently develop RAG algorithms and independently maintain text retrieval systems, or uniformly host content to cloud vendors' knowledge base services (such as [AWS Bedrock](https://aws.amazon.com/bedrock/)).
|
||||
|
||||
As a neutral platform for LLM application development, Dify is committed to providing developers with a wider range of options.
|
||||
|
||||
The **Connect to External Knowledge Base** feature enables integration between the Dify platform and external knowledge bases. Through API services, AI applications can access a broader range of information sources. This capability offers two key advantages:
|
||||
|
||||
* The Dify platform can directly obtain the text content hosted in the cloud service provider's knowledge base, so that developers do not need to repeatedly move the content to the knowledge base in Dify;
|
||||
* The Dify platform can directly obtain the text content processed by algorithms in the self-built knowledge base. Developers only need to focus on the information retrieval mechanism of the self-built knowledge base and continuously optimize and improve the accuracy of information retrieval.
|
||||
|
||||
<Frame caption="Principle of external knowledge base connection">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/f5fb91d18740c1e2d3938d4d106c4d3c.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
Here are the detailed steps for connecting to external knowledge:
|
||||
|
||||
<Steps>
|
||||
<Step title="建立符合要求的外部知识库 API" titleSize="h2" >
|
||||
为了确保你的外部知识库与 Dify 连接成功,请在建立 API 服务前仔细阅读由 Dify 编写的[外部知识库 API 规范](../knowledge-and-documents-maintenance/maintain-dataset-via-api)。
|
||||
</Step>
|
||||
<Step title="关联外部知识库">
|
||||
> 目前, Dify 连接外部知识库时仅具备检索权限,暂不支持对外部知识库进行优化与修改,开发者需自行维护外部知识库。
|
||||
|
||||
前往 **“知识库”** 页,点击右上角的 **“外部知识库 API”**,轻点 **“添加外部知识库 API”**。
|
||||
|
||||
按照页面提示,依次填写以下内容:
|
||||
|
||||
* 知识库的名称,允许自定义名称,用于区分所连接的不同外部知识 API;
|
||||
* API 接口地址,外部知识库的连接地址,示例 `api-endpoint/retrieval`;详细说明请参考[外部知识库 API](../knowledge-and-documents-maintenance/maintain-dataset-via-api);
|
||||
* API Key,外部知识库连接密钥,详细说明请参考[外部知识库 API](../knowledge-and-documents-maintenance/maintain-dataset-via-api);
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/727221d849615cd2e52b3fd1e6c10129.png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="连接外部知识库">
|
||||
前往 **“知识库”** 页,点击添加知识库卡片下方的 **“连接外部知识库”** 跳转至参数配置页面。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/efae240731f7fa9693da809c08878188.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
填写以下参数:
|
||||
|
||||
* **知识库名称与描述**
|
||||
* **外部知识库 API** 选择在第二步中关联的外部知识库 API;Dify 将通过 API 连接的方式,调用存储在外部知识库的文本内容;
|
||||
* **外部知识库 ID** 指定需要被关联的特定的外部知识库 ID,详细说明请参考[外部知识库 API](../knowledge-and-documents-maintenance/maintain-dataset-via-api)。
|
||||
* **调整召回设置**
|
||||
|
||||
**Top K:** 用户发起提问时,将请求外部知识 API 获取相关性较高的内容分段。该参数用于筛选与用户问题相似度较高的文本片段。默认值为 3,数值越高,召回存在相关性的文本分段也就越多。
|
||||
|
||||
**Score 阈值:** 文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少,结果也会相对而言更加精准。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/d6345c3af3c2b3befb25fba4dc553a73.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="测试外部知识库连接与召回">
|
||||
建立与外部知识库的连接后,开发者可以在 **“召回测试”** 中模拟可能的问题关键词,预览从外部知识库召回的文本分段。若对于召回结果不满意,可以尝试修改召回参数或自行调整外部知识库的检索设置。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/c5977a5d48dc116589cf2f99e67ccfaa.png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="在应用内集成外部知识库">
|
||||
- **Chatbot / Agent 类型应用**
|
||||
|
||||
在 Chatbot / Agent 类型应用内的编排页中的 **“上下文”** 内,选中带有 `EXTERNAL` 标签的外部知识库。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/e7df9d7360186ee0f0e156c166f84a3b.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
- **Chatflow / Workflow 类型应用**
|
||||
|
||||
在 Chatflow / Workflow 类型应用内添加 **“知识检索”** 节点,选中带有 `EXTERNAL` 标签的外部知识库。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="https://assets-docs.dify.ai/2025/03/4e1cbdcf4a9e6e7c2535a53e478054e3.png" alt="" /><figcaption></figcaption>
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="管理外部知识库" titleSize="p">
|
||||
在 **“知识库”** 页,外部知识库的卡片右上角会带有 **EXTERNAL** 标签。进入需要修改的知识库,点击 **“设置”** 修改以下内容:
|
||||
|
||||
* **知识库名称和描述**
|
||||
* **可见范围** 提供 「 只有我 」 、 「 所有团队成员 」 和 「部分团队成员」 三种权限范围。不具有权限的人将无法访问该知识库。若选择将知识库公开至其它成员,则意味着其它成员同样具备该知识库的查看、编辑和删除权限。
|
||||
* **召回设置**
|
||||
|
||||
**Top K:** 用户发起提问时,将请求外部知识 API 获取相关性较高的内容分段。该参数用于筛选与用户问题相似度较高的文本片段。默认值为 3,数值越高,召回存在相关性的文本分段也就越多。
|
||||
|
||||
**Score 阈值:** 文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少,结果也会相对而言更加精准。
|
||||
|
||||
外部知识库所关联的 **“外部知识库 API”** 和 **“外部知识 ID”** 不支持修改,如需修改请关联新的 “外部知识库 API” 并重新进行连接。
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## 连接示例
|
||||
|
||||
[如何连接 AWS Bedrock 知识库?](https://docs.dify.ai/zh-hans/learn-more/use-cases/how-to-connect-aws-bedrock)
|
||||
|
||||
## 常见问题
|
||||
|
||||
**连接外部知识库 API 时异常,出现报错如何处理?**
|
||||
|
||||
以下是返回信息各个错误码所对应的错误提示与解决办法:
|
||||
|
||||
| 错误码 | 错误提示 | 解决办法 |
|
||||
| ---- | --------------------------- | ------------------------------ |
|
||||
| 1001 | 无效的 Authorization header 格式 | 请检查请求的 Authorization header 格式 |
|
||||
| 1002 | 验证异常 | 请检查所填写的 API Key 是否正确 |
|
||||
| 2001 | 知识库不存在 | 请检查外部知识库 |
|
||||
@@ -0,0 +1,145 @@
|
||||
---
|
||||
title: 2. Choose a Chunk Mode
|
||||
---
|
||||
|
||||
After uploading content to the knowledge base, the next step is chunking and data cleaning. **This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.**
|
||||
|
||||
<Accordion title="What is the Chunking and Cleaning Strategy?">
|
||||
* **Chunking**
|
||||
|
||||
Due to the limited context window of LLMs, it is hard to process and transmit the entire knowledge base content at once. Instead, long texts in documents must be splited into content chunks. Even though some advanced models now support uploading complete documents, studies show that retrieval efficiency remains weaker compared to querying individual content chunks.
|
||||
|
||||
The ability of an LLM to accurately answer questions based on the knowledge base depends on the retrieval effectiveness of content chunks. This process is similar to finding key chapters in a manual for quick answers, without the need to analyze the entire document line by line. After chunking, the knowledge base uses a Top-K retrieval method to identify the most relevant content chunks based on user queries, supplementing key information to enhance the accuracy of responses.
|
||||
|
||||
The size of the content chunks is critical during semantic matching between queries and chunks. Properly sized chunks enable the model to locate the most relevant content accurately while minimizing noise. Overly large or small chunks can negatively impact retrieval effectiveness.
|
||||
|
||||
Dify offers two chunking modes: **General Mode** and **Parent-child Mode**, tailored to different document structures and application scenarios. These modes are designed to meet varying requirements for retrieval efficiency and accuracy in knowledge bases.
|
||||
|
||||
* **Cleaning**
|
||||
|
||||
To ensure effective text retrieval, it’s essential to clean the data before uploading it to the knowledge base. For instance, meaningless characters or empty lines can affect the quality of query responses and should be removed. Dify provides built-in automatic cleaning strategies. For more information, see [ETL](https://docs.dify.ai/guides/knowledge-base/create-knowledge-and-upload-documents#optional-etl-configuration).
|
||||
</Accordion>
|
||||
|
||||
Whether an LLM can accurately answer knowledge base queries depends on how effectively the system retrieves relevant content chunks. High-relevance chunks are crucial for AI applications to produce precise and comprehensive responses.
|
||||
|
||||
In an AI customer chatbot scenario, for example, directing the LLM to the key content chunks in a tool manual is sufficient to quickly answer user questions—no need to repeatedly analyze the entire document. This approach saves tokens during the analysis phase while boosting the overall quality of the AI-generated answers.
|
||||
|
||||
### Chunk Mode
|
||||
|
||||
The knowledge base supports two chunking modes: **General Mode** and **Parent-child Mode**. If you are creating a knowledge base for the first time, it is recommended to choose Parent-Child Mode.
|
||||
|
||||
<Info>
|
||||
**Please note**: The original **“Automatic Chunking and Cleaning”** mode has been automatically updated to **“General”** mode. No changes are required, and you can continue to use the default setting.
|
||||
|
||||
Once the chunk mode is selected and the knowledge base is created, it cannot be changed later. Any new documents added to the knowledge base will follow the same chunking strategy.
|
||||
</Info>
|
||||
|
||||
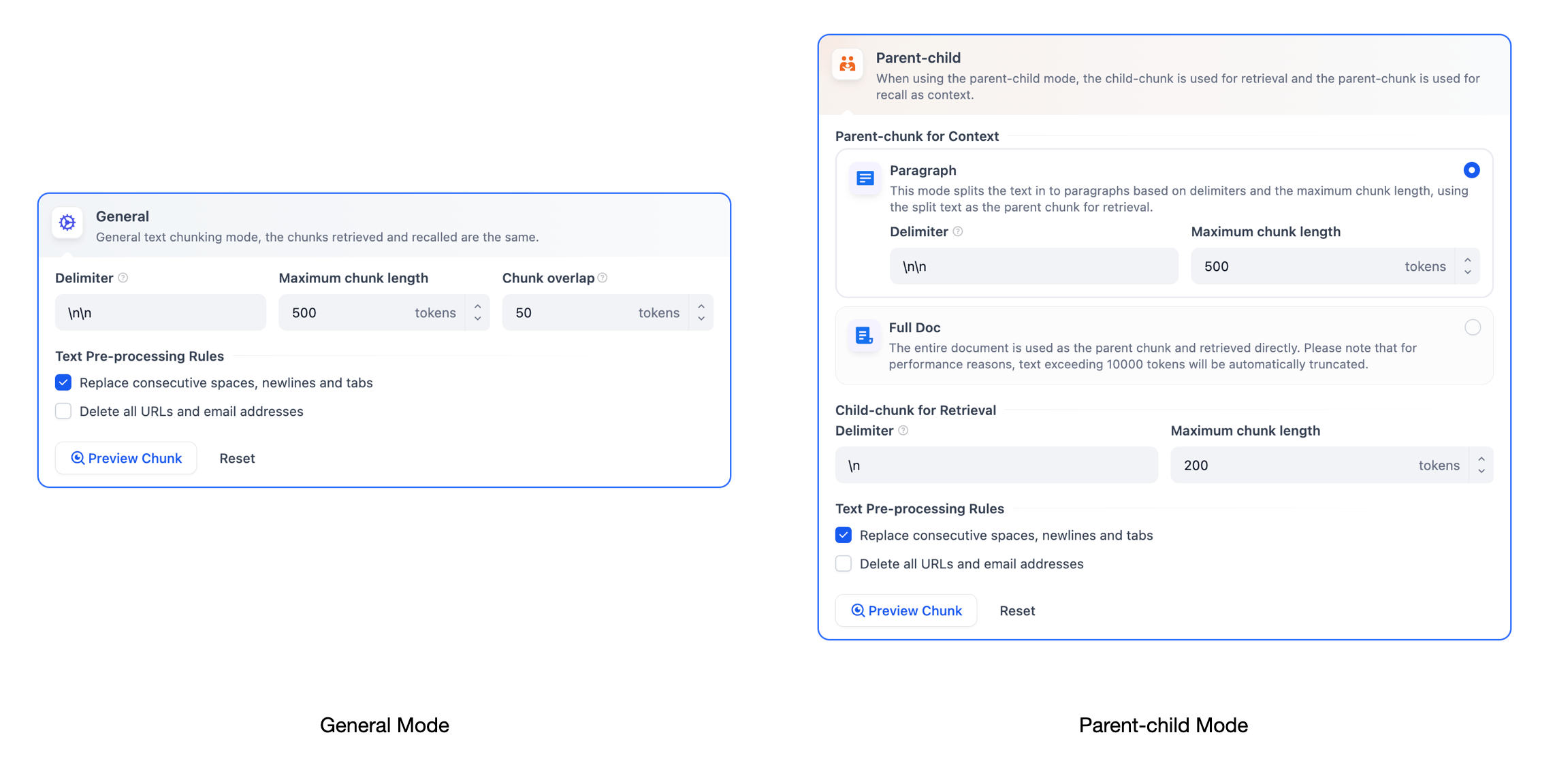
|
||||
|
||||
#### General Mode
|
||||
|
||||
Content will be divided into independent chunks. When a user submits a query, the system automatically calculates the relevance between the chunks and the query keywords. The top-ranked chunks are then retrieved and sent to the LLM for processing the answers.
|
||||
|
||||
In this mode, you need to manually define text chunking rules based on different document formats or specific scenario requirements. Refer to the following configuration options for guidance:
|
||||
|
||||
* **Chunk identifier**, The default value is `\n`, which means the text will be chunked by paragraphs. You can customize chunking rules using [regex](https://regexr.com/). The system will automatically execute chunking whenever it detects the specified delimiter. For example, means chunk the text by sentences.
|
||||
|
||||
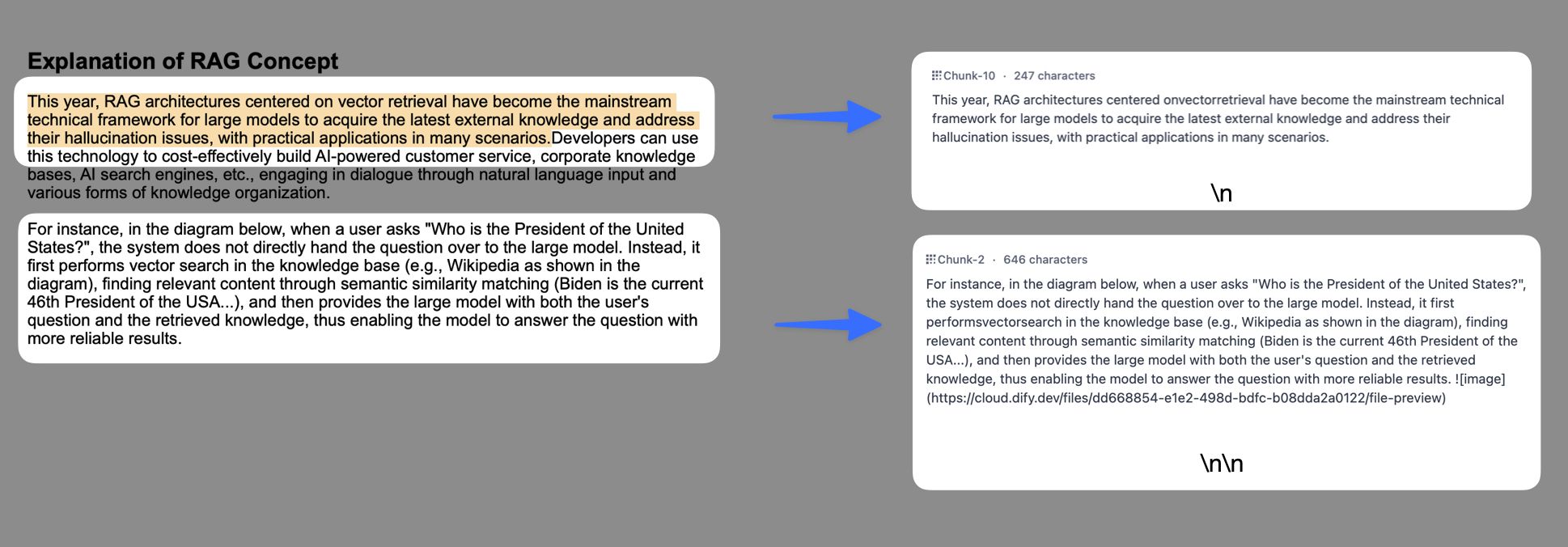
|
||||
* **Maximum chunk length:** Specifies the maximum number of text characters allowed per chunk. If this limit is exceeded, the system will automatically enforce chunking. The default value is 500 tokens, with a maximum chunk length of 4000 tokens.
|
||||
* **Overlapping chunk length**: When data is chunked, there is a certain amount of overlap between chunks. This overlap can help to improve the retention of information and the accuracy of analysis, and enhance retrieval effects. It is recommended that the setting be 10-25% of the chunk length Tokens.
|
||||
|
||||
**Text Preprocessing Rules**, Text preprocessing rules help filter out irrelevant content from the knowledge base. The following options are available:
|
||||
|
||||
* Replace consecutive spaces, newline characters, and tabs
|
||||
* Remove all URLs and email addresses
|
||||
|
||||
Once configured, click **“Preview Chunk”** to see the chunking results. You can view the character count for each chunk. If you modify the chunking rules, click the button again to view the latest generated text chunks.
|
||||
|
||||
If multiple documents are uploaded in bulk, you can switch between them by clicking the document titles at the top to review the chunk results for other documents.
|
||||
|
||||
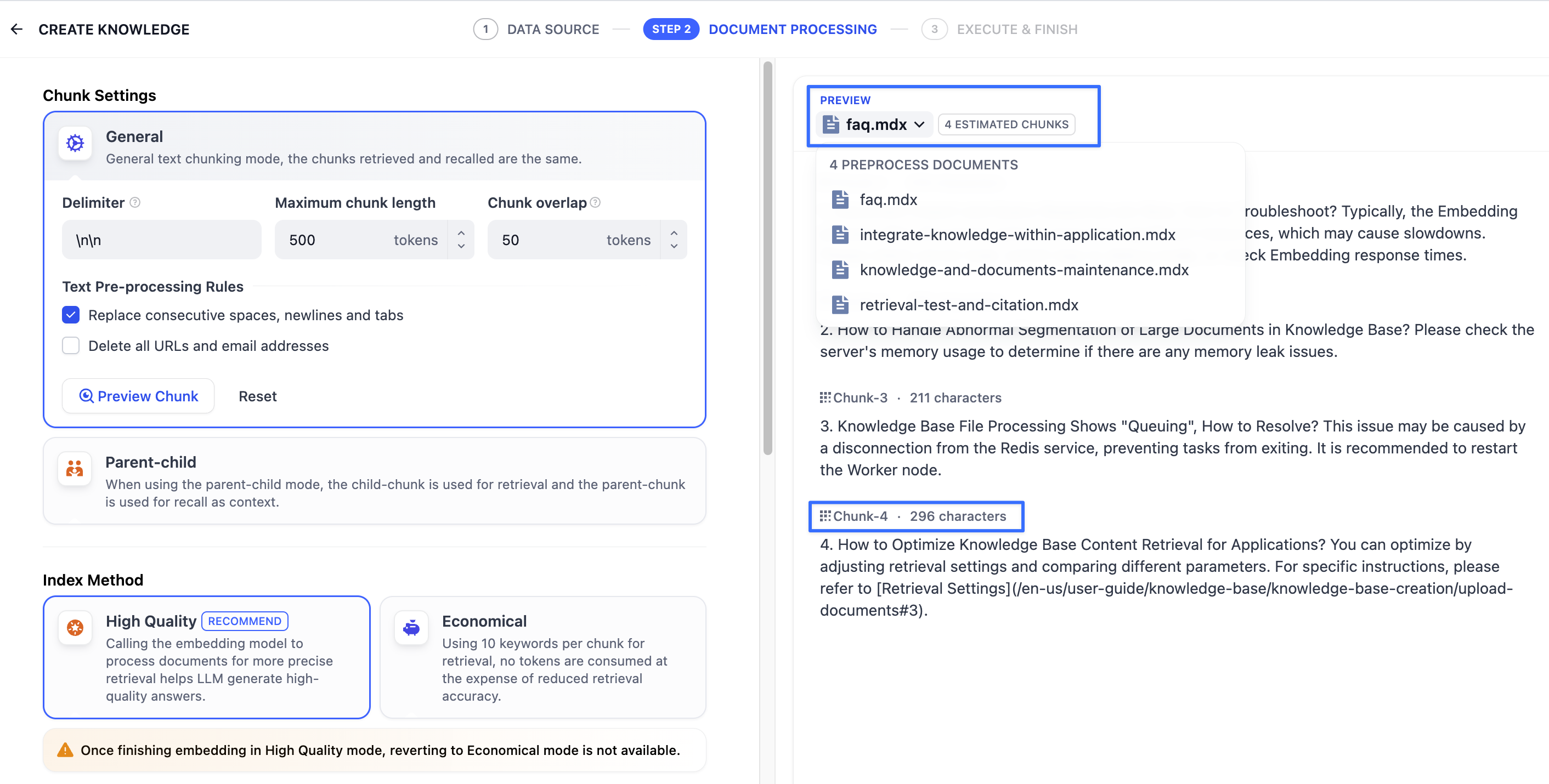
|
||||
|
||||
After setting the chunking rules, the next step is to specify the indexing method. General mode supports **High-Quality Indexing** **Method** and **Economical Indexing Method**. For more details, please refer to [Set up the Indexing Method](3.-select-the-indexing-method-and-retrieval-setting.md).
|
||||
|
||||
#### Parent-child Mode
|
||||
|
||||
Compared to **General mode**, **Parent-child mode** uses a two-tier data structure that balances precise retrieval with comprehensive context, combining accurate matching and richer contextual information.
|
||||
|
||||
In this mode, parent chunks (e.g., paragraphs) serve as larger text units to provide context, while child chunks (e.g., sentences) focus on pinpoint retrieval. The system searches child chunks first to ensure relevance, then fetches the corresponding parent chunk to supply the full context—thereby guaranteeing both accuracy and a complete background in the final response. You can customize how parent and child chunks are split by configuring delimiters and maximum chunk lengths.
|
||||
|
||||
For example, in an AI-powered customer chatbot case, a user query can be mapped to a specific sentence within a support document. The paragraph or chapter containing that sentence is then provided to the LLM, filling in the overall context so the answer is more precise.
|
||||
|
||||
Its fundamental mechanism includes:
|
||||
|
||||
* **Query Matching with Child Chunks:**
|
||||
* Small, focused pieces of information, often as concise as a single sentence within a paragraph, are used to match the user's query.
|
||||
* These child chunks enable precise and relevant initial retrieval.
|
||||
* **Contextual Enrichment with Parent Chunks:**
|
||||
* Larger, encompassing sections—such as a paragraph, a section, or even an entire document—that include the matched child chunks are then retrieved.
|
||||
* These parent chunks provide comprehensive context for the Language Model (LLM).
|
||||
|
||||
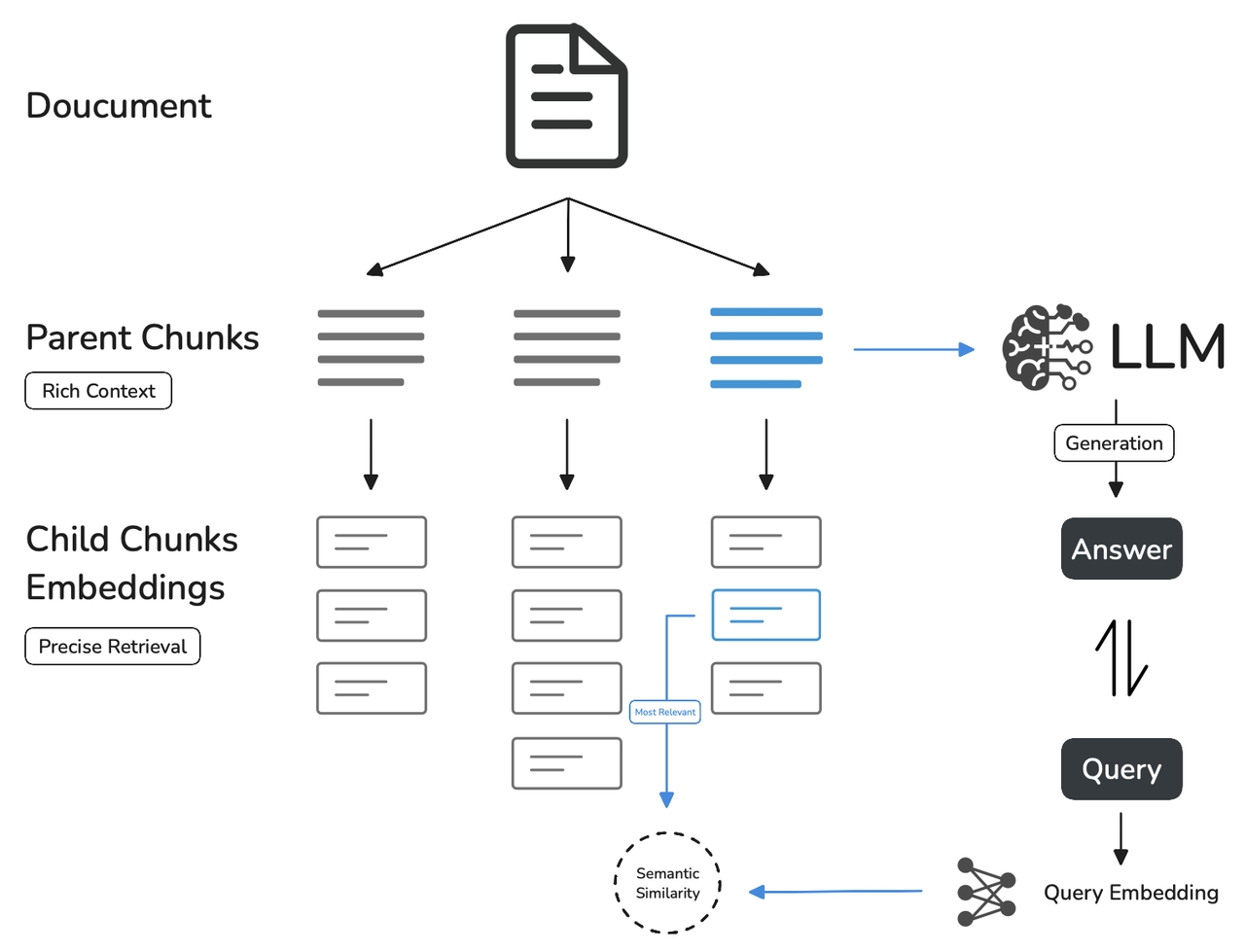
|
||||
|
||||
In this mode, you need to manually configure separate chunking rules for both parent and child chunks based on different document formats or specific scenario requirements.
|
||||
|
||||
**Parent Chunk**
|
||||
|
||||
The parent chunk settings offer the following options:
|
||||
|
||||
* **Paragraph**
|
||||
|
||||
This mode splits the text in to paragraphs based on delimiters and the maximum chunk length, using the split text as the parent chunk for retrieval. Each paragraph is treated as a parent chunk, suitable for documents with large volumes of text, clear content, and relatively independent paragraphs. The following settings are supported:
|
||||
|
||||
* **Chunk Delimiter**: The default value is `\n`, which chunks text by paragraphs. You can customize the chunking rules using [regex](https://regexr.com/). The system automatically chunks the text whenever the specified delimiter appears.
|
||||
* **Maximum chunk length:** Specifies the maximum number of text characters allowed per chunk. If this limit is exceeded, the system will automatically enforce chunking. The default value is 500 tokens, with a maximum chunk length of 4000 tokens.
|
||||
* **Full Doc**
|
||||
|
||||
Instead of splitting the text into paragraphs, the entire document is used as the parent chunk and retrieved directly. For performance reasons, only the first 10,000 tokens of the text are retained. This setting is ideal for smaller documents where paragraphs are interrelated, requiring full doc retrieval.
|
||||
|
||||

|
||||
|
||||
**Child Chunk**
|
||||
|
||||
Child chunks are derived from parent chunks by splitting them based on delimiter rules. They are used to identify and match the most relevant and direct information to the query keywords. When using the default child chunking rules, the segmentation typically results in the following:
|
||||
|
||||
* If the parent chunk is a paragraph, child chunks correspond to individual sentences within each paragraph.
|
||||
* If the parent chunk is the full document, child chunks correspond to the individual sentences within the document.
|
||||
|
||||
You can configure the following chunk settings:
|
||||
|
||||
* **Chunk Delimiter**: The default value is , which chunks text by sentences. You can customize the chunking rules using [regex](https://regexr.com/). The system automatically chunks the text whenever the specified delimiter appears.
|
||||
* **Maximum chunk length:** Specifies the maximum number of text characters allowed per chunk. If this limit is exceeded, the system will automatically enforce chunking. The default value is 200 tokens, with a maximum chunk length of 4000 tokens.
|
||||
|
||||
You can also use **text preprocessing rules** to filter out irrelevant content from the knowledge base:
|
||||
|
||||
* Replace consecutive spaces, newline characters, and tabs
|
||||
* Remove all URLs and email addresses
|
||||
|
||||
After completing the configuration, click **“Preview Chunks”** to view the results. You can see the total character count of the parent chunk.
|
||||
|
||||
Once configured, click **“Preview Chunk”** to see the chunking results. You can see the total character count of the parent chunk. Characters highlighted in blue represent child chunks, and the character count for the current child chunk is also displayed for reference.
|
||||
|
||||
If you modify the chunking rules, click the button again to view the latest generated text chunks.
|
||||
|
||||
If multiple documents are uploaded in bulk, you can switch between them by clicking the document titles at the top to review the chunk results for other documents.
|
||||
|
||||
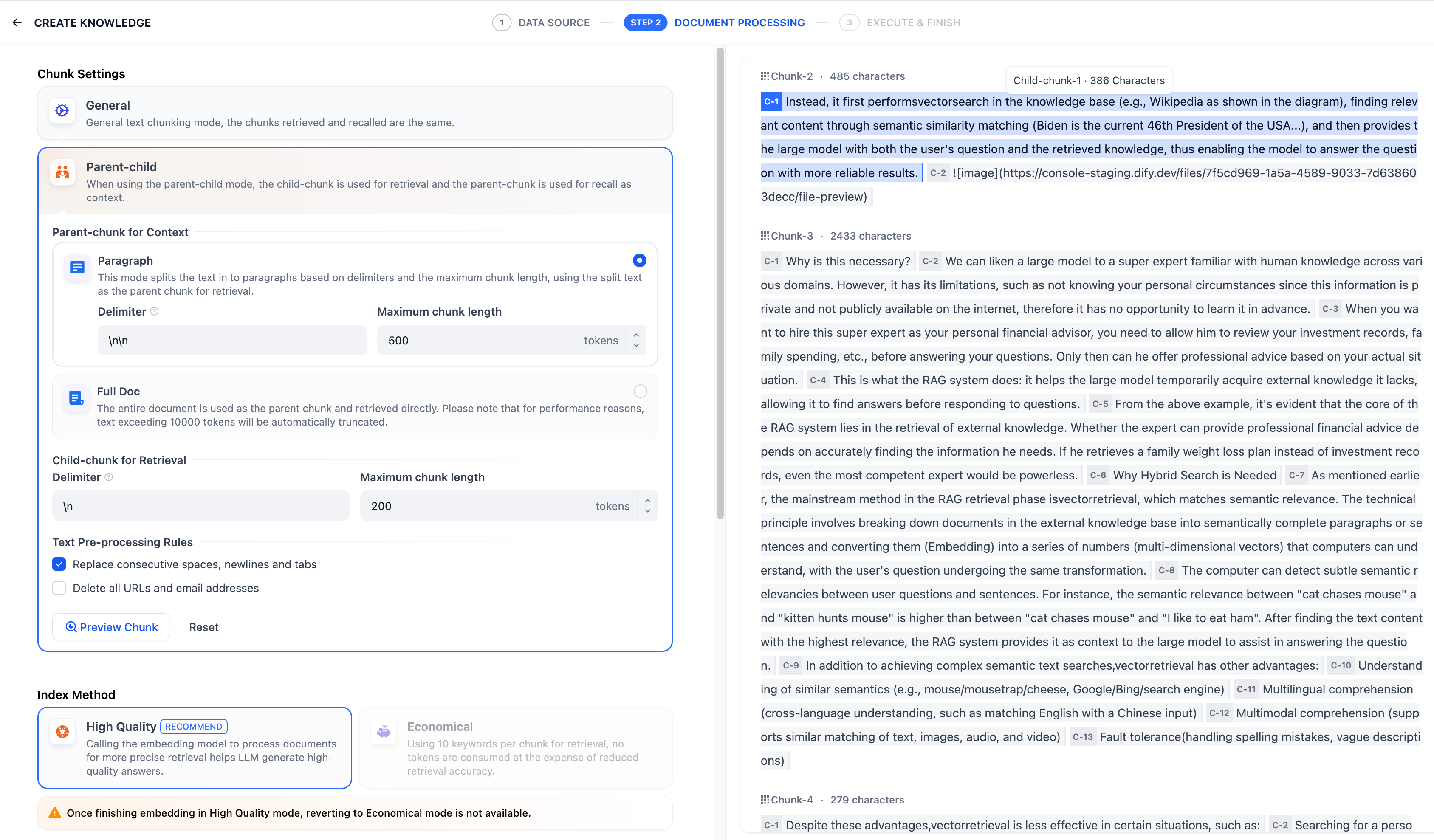
|
||||
|
||||
To ensure accurate content retrieval, the Parent-child chunk mode only supports the [High-Quality Indexing](3.-select-the-indexing-method-and-retrieval-setting.md#high-quality).
|
||||
|
||||
### What's the Difference Between Two Modes?
|
||||
|
||||
The difference between the two modes lies in the structure of the content chunks. **General Mode** produces multiple independent content chunks, whereas **Parent-child Mode** uses a two-layer chunking approach. In this way, a single parent chunk (e.g., the entire document or a paragraph) contains multiple child chunks (e.g., sentences).
|
||||
|
||||
Different chunking methods influence how effectively the LLM can search the knowledge base. When used on the same document, Parent-child Retrieval provides more comprehensive context while maintaining high precision, making it significantly more effective than the traditional single-layer approach.
|
||||
|
||||
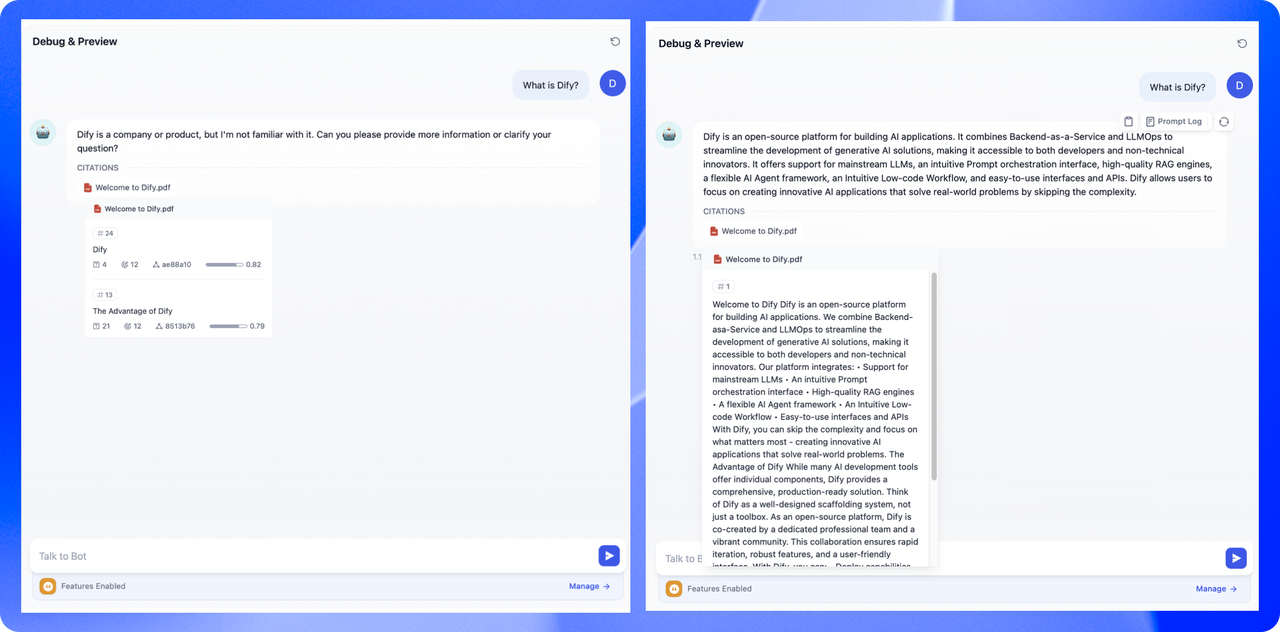
|
||||
|
||||
### Reference
|
||||
|
||||
After choosing the chunking mode, refer to the following documentation to configure the indexing method and retrieval method and finis the creation of your knowledge base.
|
||||
|
||||
|
||||
<Card title="3.-select-the-indexing-method-and-retrieval-setting" icon="link" href="setting-indexing-methods.md">
|
||||
texts
|
||||
</Card>
|
||||
@@ -0,0 +1,38 @@
|
||||
---
|
||||
title: 1. Import Text Data
|
||||
---
|
||||
|
||||
Click on Knowledge in the main navigation bar of Dify. On this page, you can see your existing knowledge bases. Click **Create Knowledge** to enter the setup wizard. The Knowledge supports the import of the following two online data:
|
||||
|
||||
Click **Knowledge** in the top navigation bar of the Dify, then select **Create Knowledge**. You can upload documents to the knowledge or importing online data to it.
|
||||
|
||||
## Upload Local Files
|
||||
|
||||
Drag and drop or select files to upload. The number of files allowed for **batch upload** depends on your [subscription plan](https://dify.ai/pricing).
|
||||
|
||||
**Limitations for uploading documents:**
|
||||
|
||||
* The upload size limit for a single document is 15MB;
|
||||
* Different [subscription plans](https://dify.ai/pricing) for the SaaS version limit **batch upload numbers, total document uploads, and vector storage**
|
||||
|
||||

|
||||
|
||||
## Import From Online Data Source
|
||||
|
||||
When creating a **Knowledge**, you can import data from online sources. The knowledge supports the following two types of online data:
|
||||
|
||||
<Card title="Import Data from Notion" icon="link" href="1.1-import-data-from-notion.md">
|
||||
Learn how to import data from Notion
|
||||
</Card>
|
||||
|
||||
<Card title="Sync from Website" icon="link" href="../../sync-from-website.md">
|
||||
Learn how to sync data from websites
|
||||
</Card>
|
||||
|
||||
<Info>
|
||||
If a knowledge base is set up to use online data, you won't be able to add local documents later or switch it to a local file-based mode. This prevents a single knowledge base from mixing multiple data sources, avoiding management complications.
|
||||
</Info>
|
||||
|
||||
## Adding Data Later
|
||||
|
||||
If you haven't prepared your documents or other content yet, simply create an empty knowledge first. You can then upload local files or import online data whenever you're ready.
|
||||
@@ -0,0 +1,80 @@
|
||||
---
|
||||
title: 1.1 Sync Data from Notion
|
||||
---
|
||||
|
||||
Dify datasets support importing from Notion and setting up **synchronization** so that data updates in Notion are automatically synced to Dify.
|
||||
|
||||
### Authorization Verification
|
||||
|
||||
1. When creating a dataset and selecting the data source, click **Sync from Notion Content -- Bind Now** and follow the prompts to complete the authorization verification.
|
||||
2. Alternatively, you can go to **Settings -- Data Sources -- Add Data Source**, click on the Notion source **Bind**, and complete the authorization verification.
|
||||
|
||||
|
||||
|
||||
### Importing Notion Data
|
||||
|
||||
After completing the authorization verification, go to the create dataset page, click **Sync from Notion Content**, and select the authorized pages you need to import.
|
||||
|
||||
### Segmentation and Cleaning
|
||||
|
||||
Next, choose your **segmentation settings** and **indexing method**, then **Save and Process**. Wait for Dify to process this data for you, which typically requires token consumption in the LLM provider. Dify supports importing not only standard page types but also aggregates and saves page properties under the database type.
|
||||
|
||||
_**Please note: Images and files are not currently supported for import, and tabular data will be converted to text display.**_
|
||||
|
||||
### Synchronizing Notion Data
|
||||
|
||||
If your Notion content is modified, you can directly click **Sync** in the Dify dataset **Document List Page** to perform a one-click data synchronization. This step requires token consumption.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/sync-notion (1).png" alt="Sync Notion Content" />
|
||||
</Frame>
|
||||
|
||||
### Integration Configuration Method for Community Edition Notion
|
||||
|
||||
Notion integration can be done in two ways: **internal integration** and **public integration**. You can configure them as needed in Dify. For specific differences between the two integration methods, please refer to [Notion Official Documentation](https://developers.notion.com/docs/authorization).
|
||||
|
||||
### 1. **Using Internal Integration**
|
||||
|
||||
First, create an integration in the integration settings page [Create Integration](https://www.notion.so/my-integrations). By default, all integrations start as internal integrations; internal integrations will be associated with the workspace you choose, so you need to be the workspace owner to create an integration.
|
||||
|
||||
Specific steps:
|
||||
|
||||
Click the **New integration** button. The type is **Internal** by default (cannot be modified). Select the associated space, enter the integration name, upload a logo, and click **Submit** to create the integration successfully.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/integrate-notion-1.png" alt="Create Internal Integration" />
|
||||
</Frame>
|
||||
|
||||
After creating the integration, you can update its settings as needed under the Capabilities tab and click the **Show** button under Secrets to copy the secrets.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/notion-secret.png" alt="Copy Notion Secret" />
|
||||
</Frame>
|
||||
|
||||
After copying, go back to the Dify source code, and configure the relevant environment variables in the **.env** file. The environment variables are as follows:
|
||||
|
||||
**NOTION_INTEGRATION_TYPE**=internal or **NOTION_INTEGRATION_TYPE**=public
|
||||
|
||||
**NOTION_INTERNAL_SECRET**=your-internal-secret
|
||||
|
||||
### 2. **Using Public Integration**
|
||||
|
||||
**You need to upgrade the internal integration to a public integration.** Navigate to the Distribution page of the integration, and toggle the switch to make the integration public. When switching to the public setting, you need to fill in additional information in the Organization Information form below, including your company name, website, and redirect URL, then click the **Submit** button.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/public-integration.png" alt="Public Integration Setup" />
|
||||
</Frame>
|
||||
|
||||
After successfully making the integration public on the integration settings page, you will be able to access the integration key in the Keys tab:
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/notion-public-secret.png" alt="Notion Public Secret" />
|
||||
</Frame>
|
||||
|
||||
Go back to the Dify source code, and configure the relevant environment variables in the **.env** file. The environment variables are as follows:
|
||||
|
||||
* **NOTION_INTEGRATION_TYPE**=public
|
||||
* **NOTION_CLIENT_SECRET**=your-client-secret
|
||||
* **NOTION_CLIENT_ID**=your-client-id
|
||||
|
||||
After configuration, you can operate the Notion data import and synchronization functions in the dataset.
|
||||
@@ -0,0 +1,63 @@
|
||||
---
|
||||
title: 1.2 Import Data from Website
|
||||
---
|
||||
|
||||
The knowledge base supports crawling content from public web pages using third-party tools such as [Jina Reader](https://jina.ai/reader/) and [Firecrawl](https://www.firecrawl.dev/), parsing it into Markdown content, and importing it into the knowledge base.
|
||||
|
||||
<Info>
|
||||
[Firecrawl](https://www.firecrawl.dev/) and [Jina Reader](https://jina.ai/reader/) are both open-source web parsing tools that can convert web pages into clean Markdown format text that is easy for LLMs to recognize, while providing easy-to-use API services.
|
||||
</Info>
|
||||
|
||||
The following sections will introduce the usage methods for Firecrawl and Jina Reader respectively.
|
||||
|
||||
## Firecrawl
|
||||
|
||||
### **1. Configure Firecrawl API credentials**
|
||||
|
||||
Click on the avatar in the upper right corner, then go to the **DataSource** page, and click the **Configure** button next to Firecrawl.
|
||||
|
||||

|
||||
|
||||
Log in to the [Firecrawl website](https://www.firecrawl.dev/) to complete registration, get your API Key, and then enter and save it in Dify.
|
||||
|
||||
|
||||
|
||||
### 2. Scrape target webpage
|
||||
|
||||
On the knowledge base creation page, select **Sync from website**, choose Firecrawl as the provider, and enter the target URL to be crawled.
|
||||
|
||||
The configuration options include: Whether to crawl sub-pages, Page crawling limit, Page scraping max depth, Excluded paths, Include only paths, and Content extraction scope. After completing the configuration, click **Run** to preview the parsed pages.
|
||||
|
||||
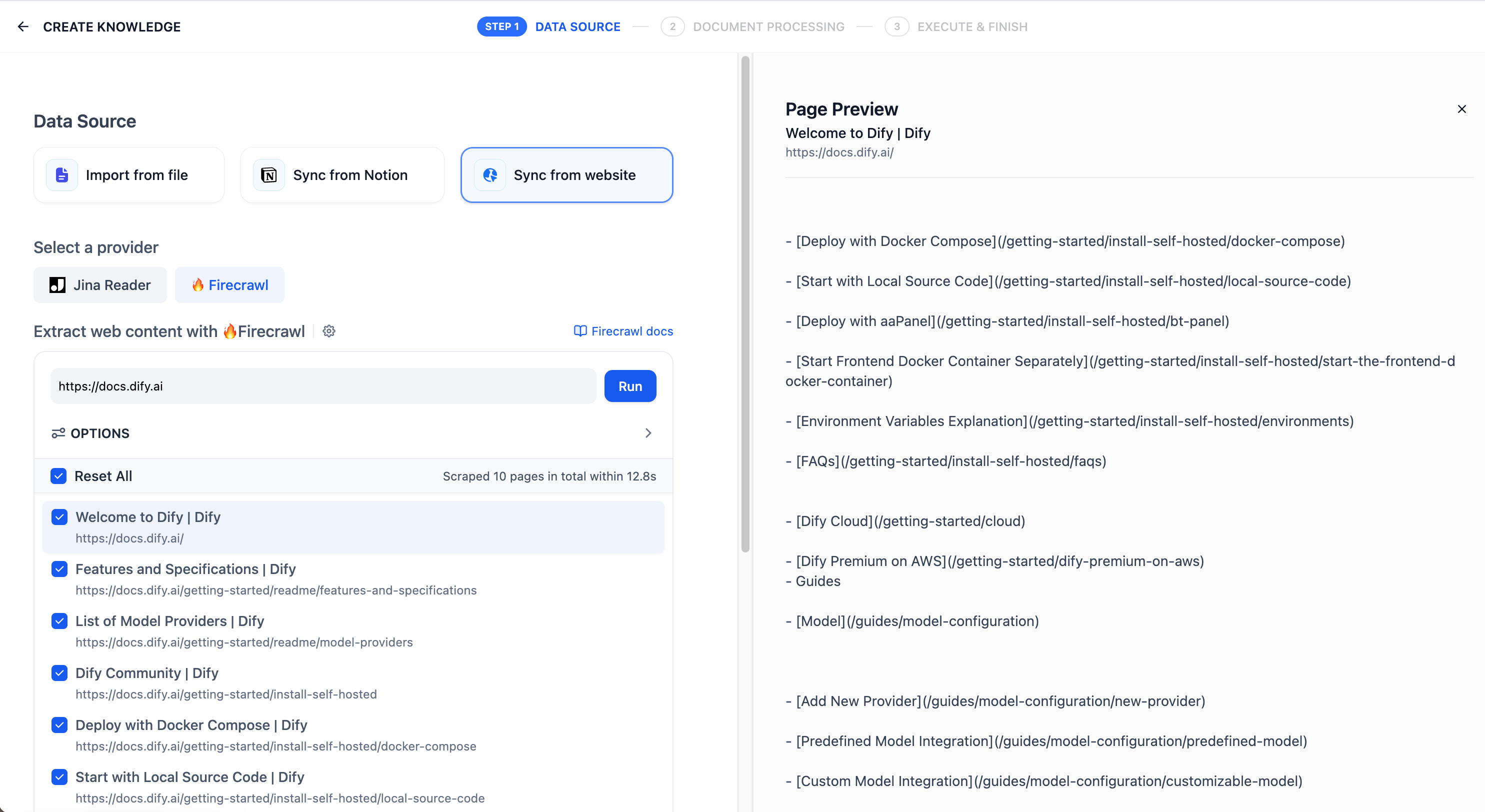
|
||||
|
||||
### 3. Review import results
|
||||
|
||||
After importing the parsed text from the webpage, it is stored in the knowledge base documents. View the import results and click **Add URL** to continue importing new web pages.
|
||||
|
||||
***
|
||||
|
||||
## Jina Reader
|
||||
|
||||
### 1. Configuring Jina Reader Credentials
|
||||
|
||||
Click on the avatar in the upper right corner, then go to the **DataSource** page, and click the **Configure** button next to Jina Reader.
|
||||
|
||||
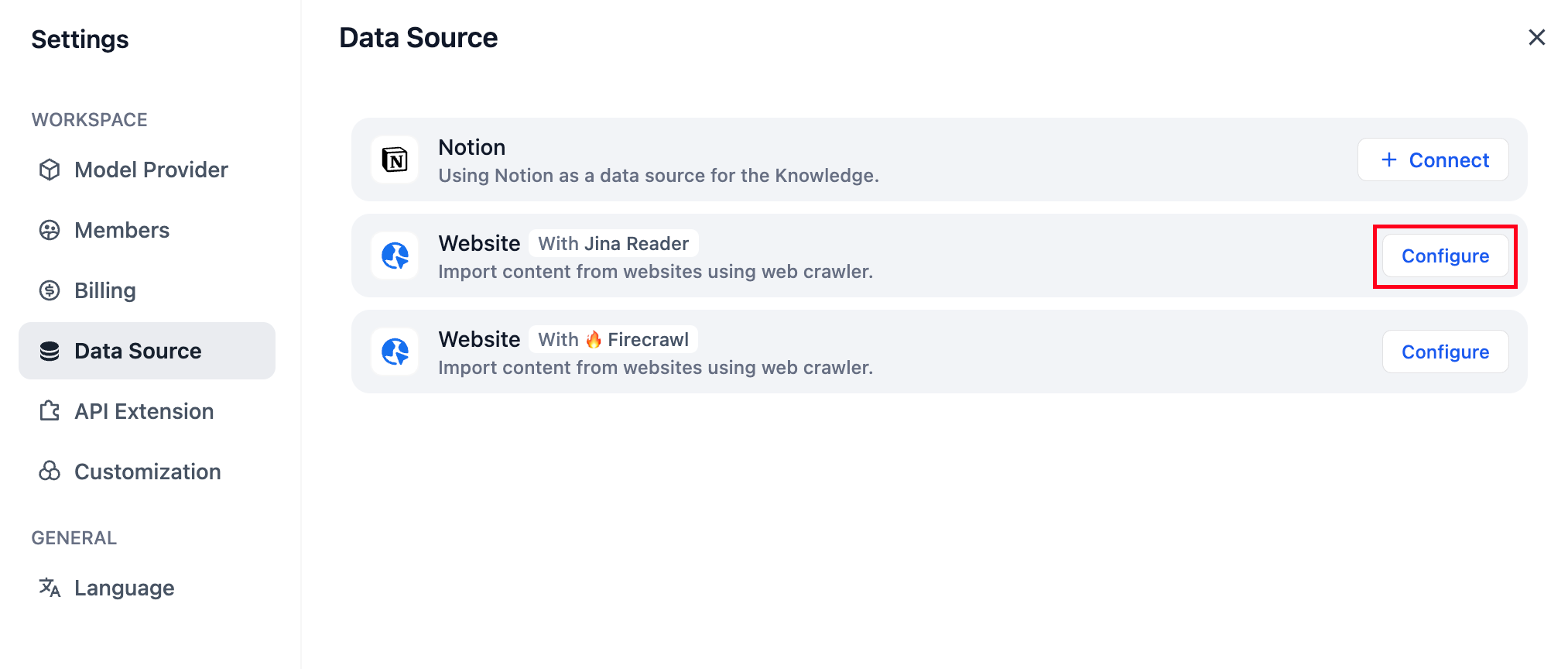
|
||||
|
||||
Log in to the [Jina Reader website](https://jina.ai/reader/), complete registration, obtain the API Key, then fill it in and save.
|
||||
|
||||
### 2. Using Jina Reader to Crawl Web Content
|
||||
|
||||
On the knowledge base creation page, select **Sync from website**, choose Jina Reader as the provider, and enter the target URL to be crawled.
|
||||
|
||||
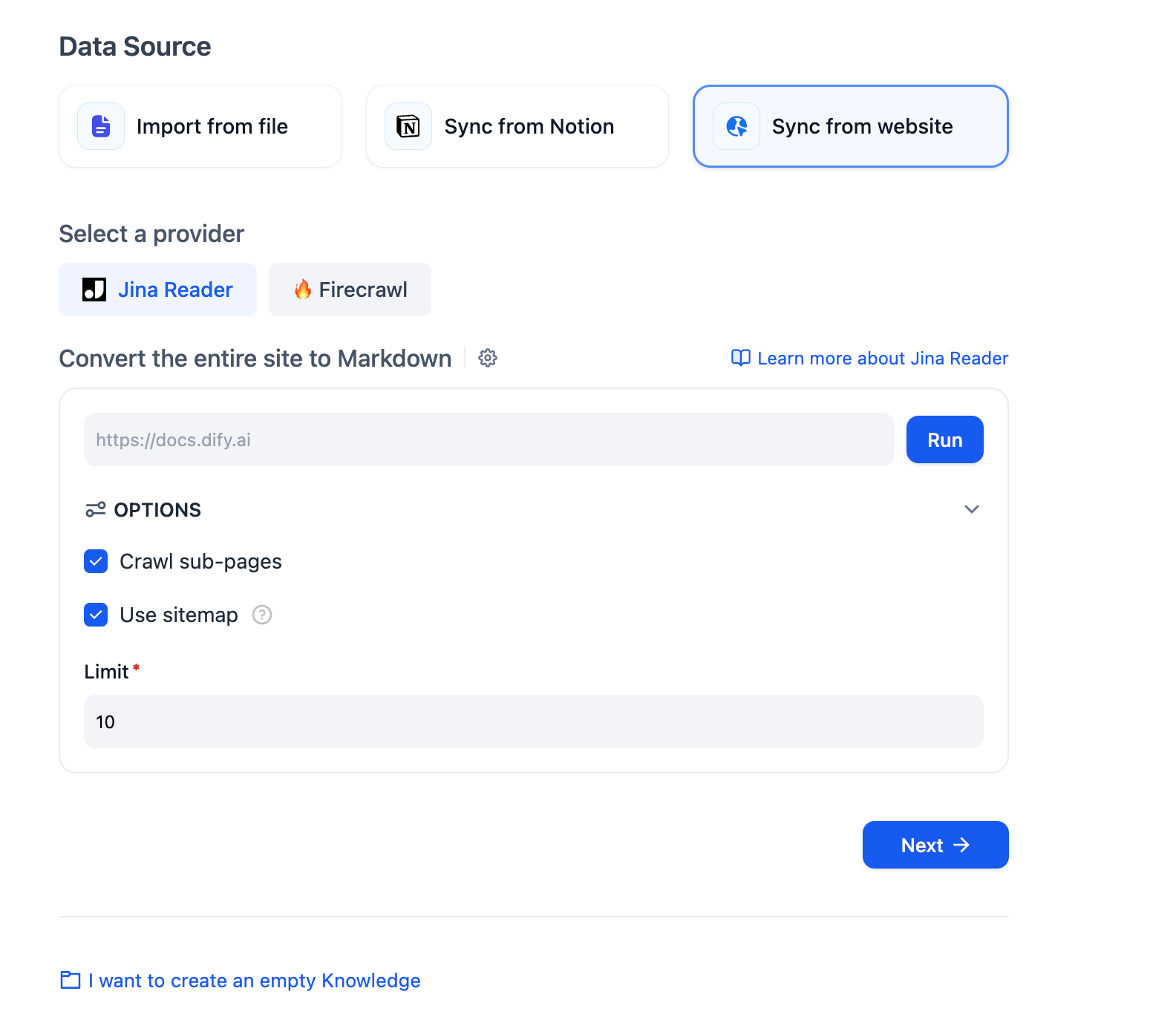
|
||||
|
||||
Configuration options include: whether to crawl subpages, maximum number of pages to crawl, and whether to use sitemap for crawling. After completing the configuration, click the **Run** button to preview the page links to be crawled.
|
||||
|
||||
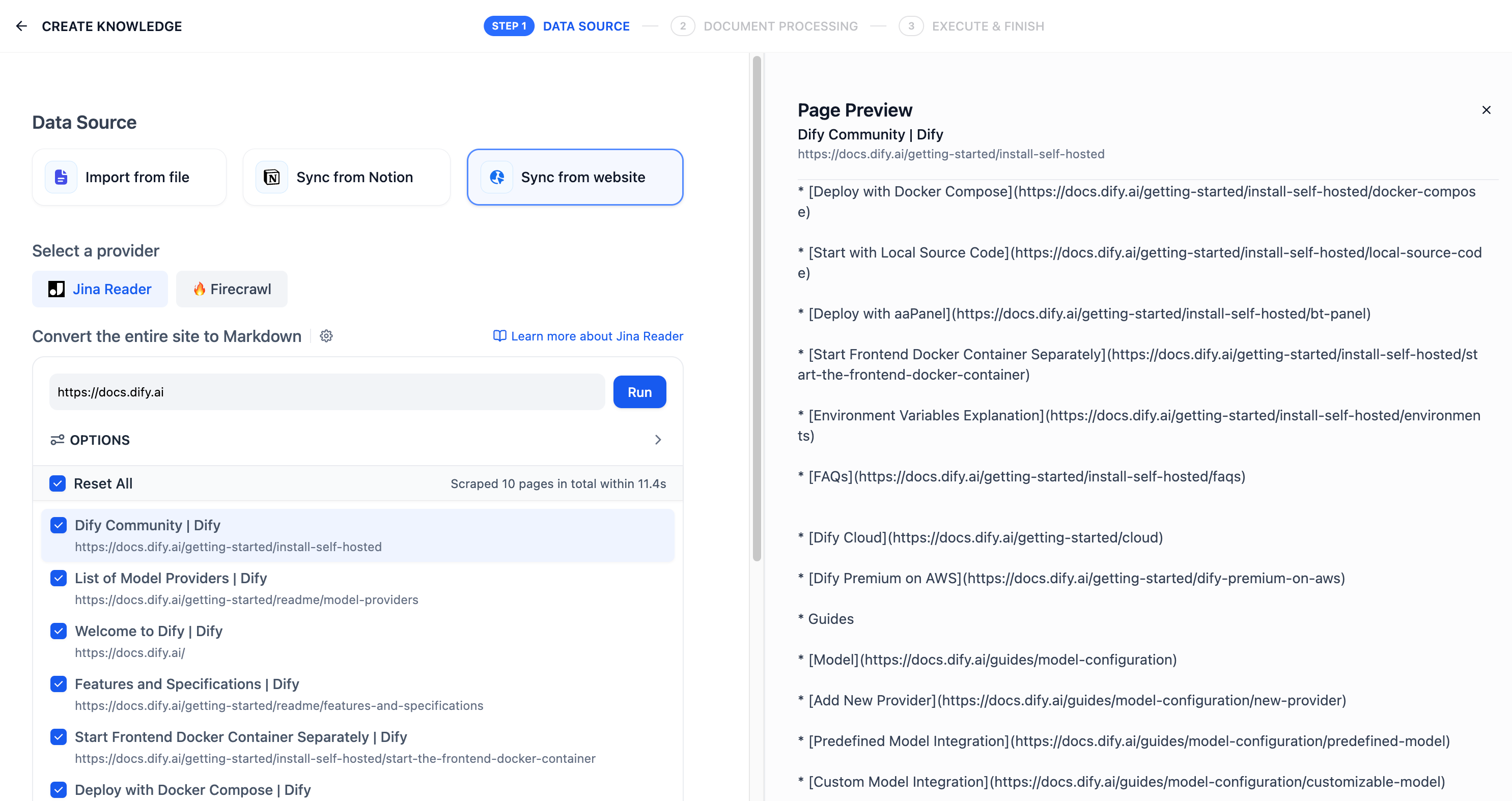
|
||||
|
||||
After importing the parsed text from web pages into the knowledge base, you can review the imported results in the documents section. To add more web pages, click the **Add URL** button on the right to continue importing new pages.
|
||||
|
||||
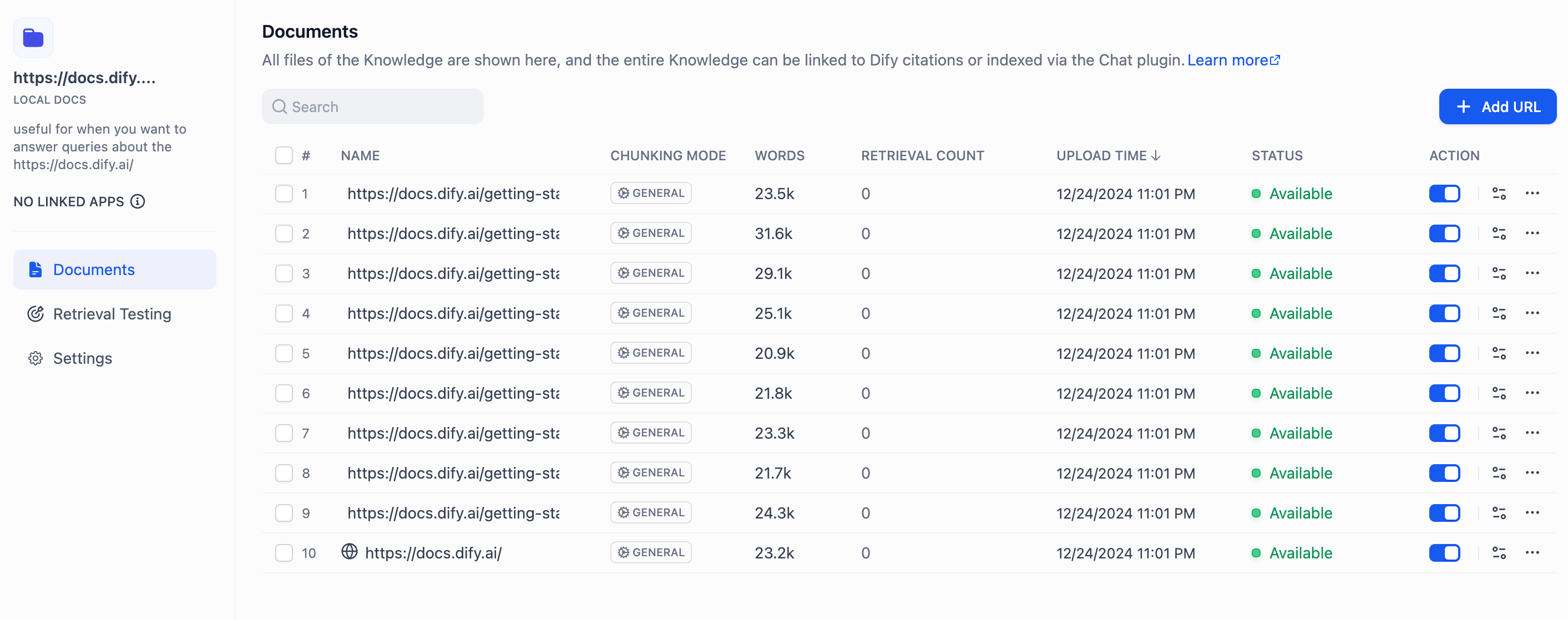
|
||||
|
||||
After crawling is complete, the content from the web pages will be incorporated into the knowledge base.
|
||||
@@ -0,0 +1,57 @@
|
||||
---
|
||||
title: 知识库创建步骤
|
||||
---
|
||||
|
||||
创建知识库并上传文档大致分为以下步骤:
|
||||
|
||||
1. 创建知识库。通过上传本地文件、导入在线数据或创建一个空的知识库。
|
||||
|
||||
<Card title="导入文本数据" icon="link" href="import-content-data">
|
||||
选择通过上传本地文件或导入在线数据的方式创建知识库
|
||||
</Card>
|
||||
|
||||
2. 指定分段模式。该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。你可以在此环节预览文本的分段效果。
|
||||
|
||||
<Card title="分段和清洗文本" icon="link" href="chunking-and-cleaning-text">
|
||||
了解如何设置文本分段和清洗规则
|
||||
</Card>
|
||||
|
||||
3. 设定索引方法和检索设置。知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。
|
||||
|
||||
<Card title="设置索引方法" icon="link" href="setting-indexing-methods">
|
||||
了解如何配置检索方式和相关设置
|
||||
</Card>
|
||||
|
||||
5. 等待分段嵌入
|
||||
6. 完成上传,在应用内关联知识库并使用。你可以参考[在应用内集成知识库](../integrate-knowledge-within-application.md),搭建出能够基于知识库进行问答的 LLM 应用。如需修改或管理知识库,请参考[知识库管理与文档维护](../knowledge-and-documents-maintenance/)。
|
||||
|
||||

|
||||
|
||||
### 参考阅读
|
||||
|
||||
#### ETL
|
||||
|
||||
在 RAG 的生产级应用中,为了获得更好的数据召回效果,需要对多源数据进行预处理和清洗,即 ETL (_extract, transform, load_)。为了增强非结构化/半结构化数据的预处理能力,Dify 支持了可选的 ETL 方案:**Dify ETL** 和[ ](https://docs.unstructured.io/welcome)[**Unstructured ETL** ](https://unstructured.io/)。Unstructured 能够高效地提取并转换你的数据为干净的数据用于后续的步骤。Dify 各版本的 ETL 方案选择:
|
||||
|
||||
* SaaS 版不可选,默认使用 Unstructured ETL;
|
||||
* 社区版可选,默认使用 Dify ETL ,可通过[环境变量](https://docs.dify.ai/v/zh-hans/getting-started/install-self-hosted/environments#zhi-shi-ku-pei-zhi)开启 Unstructured ETL;
|
||||
|
||||
文件解析支持格式的差异:
|
||||
|
||||
| DIFY ETL | Unstructured ETL |
|
||||
| --- | --- |
|
||||
| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
|
||||
|
||||
不同的 ETL 方案在文件提取效果的方面也会存在差异,想了解更多关于 Unstructured ETL 的数据处理方式,请参考[官方文档](https://docs.unstructured.io/open-source/core-functionality/partitioning)。
|
||||
|
||||
#### **Embedding**
|
||||
|
||||
**Embedding 嵌入**是一种将离散型变量(如单词、句子或者整个文档)转化为连续的向量表示的技术。它可以将高维数据(如单词、短语或图像)映射到低维空间,提供一种紧凑且有效的表示方式。这种表示不仅减少了数据的维度,还保留了重要的语义信息,使得后续的内容检索更加高效。
|
||||
|
||||
**Embedding 模型**是一种专门用于将文本向量化的大语言模型,它擅长将文本转换为密集的数值向量,有效捕捉语义信息。
|
||||
|
||||
> 如需了解更多,请参考:[《Dify:Embedding 技术与 Dify 知识库设计/规划》](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)。
|
||||
|
||||
#### **元数据**
|
||||
|
||||
如需使用元数据功能管理知识库,请参阅 [元数据](https://docs.dify.ai/zh-hans/guides/knowledge-base/metadata)。
|
||||
@@ -0,0 +1,163 @@
|
||||
---
|
||||
title: 3. Select the Indexing Method and Retrieval Setting
|
||||
---
|
||||
|
||||
After selecting the chunking mode, the next step is to define the indexing method for structured content.
|
||||
|
||||
## Setting the Indexing Method
|
||||
|
||||
Similar to the search engines use efficient indexing algorithms to match search results most relevant to user queries, the selected indexing method directly impacts the retrieval efficiency of the LLM and the accuracy of its responses to knowledge base content.
|
||||
|
||||
The knowledge base offers two indexing methods: **High-Quality** and **Economical**, each with different retrieval setting options:
|
||||
|
||||
<Note>
|
||||
**Note**: The original **Q\&A mode (Available only in the Community Edition)** is now an optional feature under the High-Quality Indexing Method.
|
||||
</Note>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="High Quality">
|
||||
|
||||
In High-Quality Mode, the Embedding model converts text chunks into numerical vectors, enabling efficient compression and storage of large volumes of textual information. **This allows for more precise matching between user queries and text.**
|
||||
|
||||
Once the text chunks are vectorized and stored in the database, an effective retrieval method is required to fetch the chunks that match user queries. The High-Quality indexing method offers three retrieval settings: vector retrieval, full-text retrieval, and hybrid retrieval. For more details on retrieval settings, please check ["Retrieval Settings"](3.-select-the-indexing-method-and-retrieval-setting.md#id-4-retrieval-settings).
|
||||
|
||||
After selecting **High Quality** mode, the indexing method for the knowledge base cannot be downgraded to **Economical** mode later. If you need to switch, it is recommended to create a new knowledge base and select the desired indexing method.
|
||||
|
||||
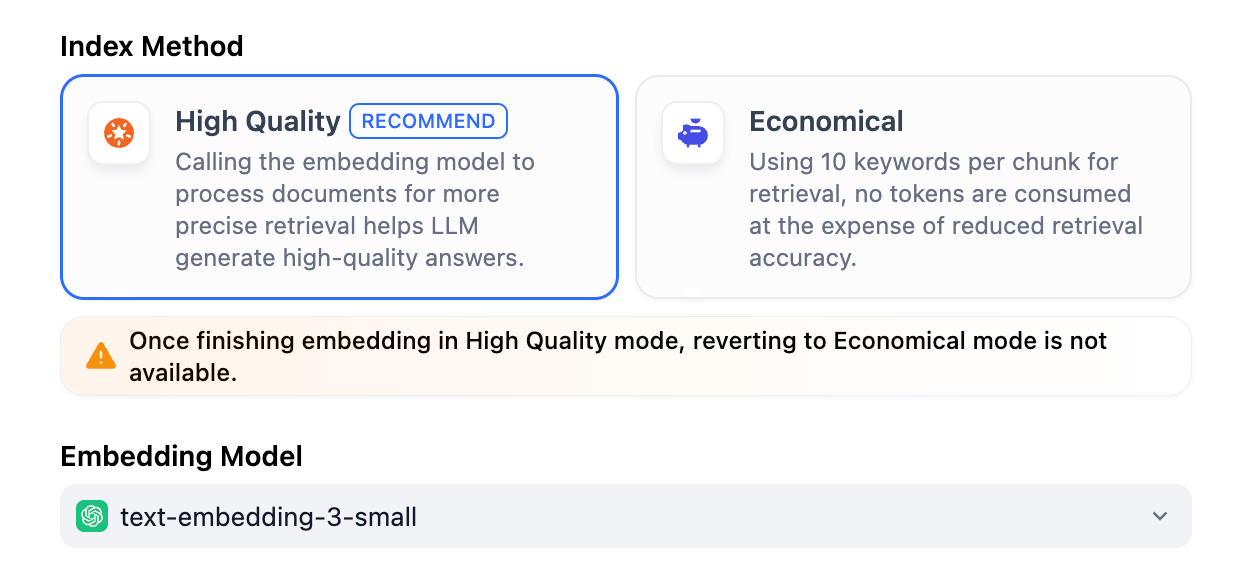
|
||||
|
||||
</Tab>
|
||||
<Tab title="Enable Q&A Mode (Optional, Community Edition Only)">
|
||||
When this mode is enabled, the system segments the uploaded text and automatically generates Q\&A pairs for each segment after summarizing its content.
|
||||
|
||||
Compared with the common **Q to P** strategy (user questions matched with text paragraphs), the Q\&A mode uses a **Q to Q** strategy (questions matched with questions).
|
||||
|
||||
This approach is particularly effective because the text in FAQ documents **is often written in natural language with complete grammatical structures**.
|
||||
|
||||
> The **Q to Q** strategy makes the matching between questions and answers clearer and better supports scenarios with high-frequency or highly similar questions.
|
||||
|
||||
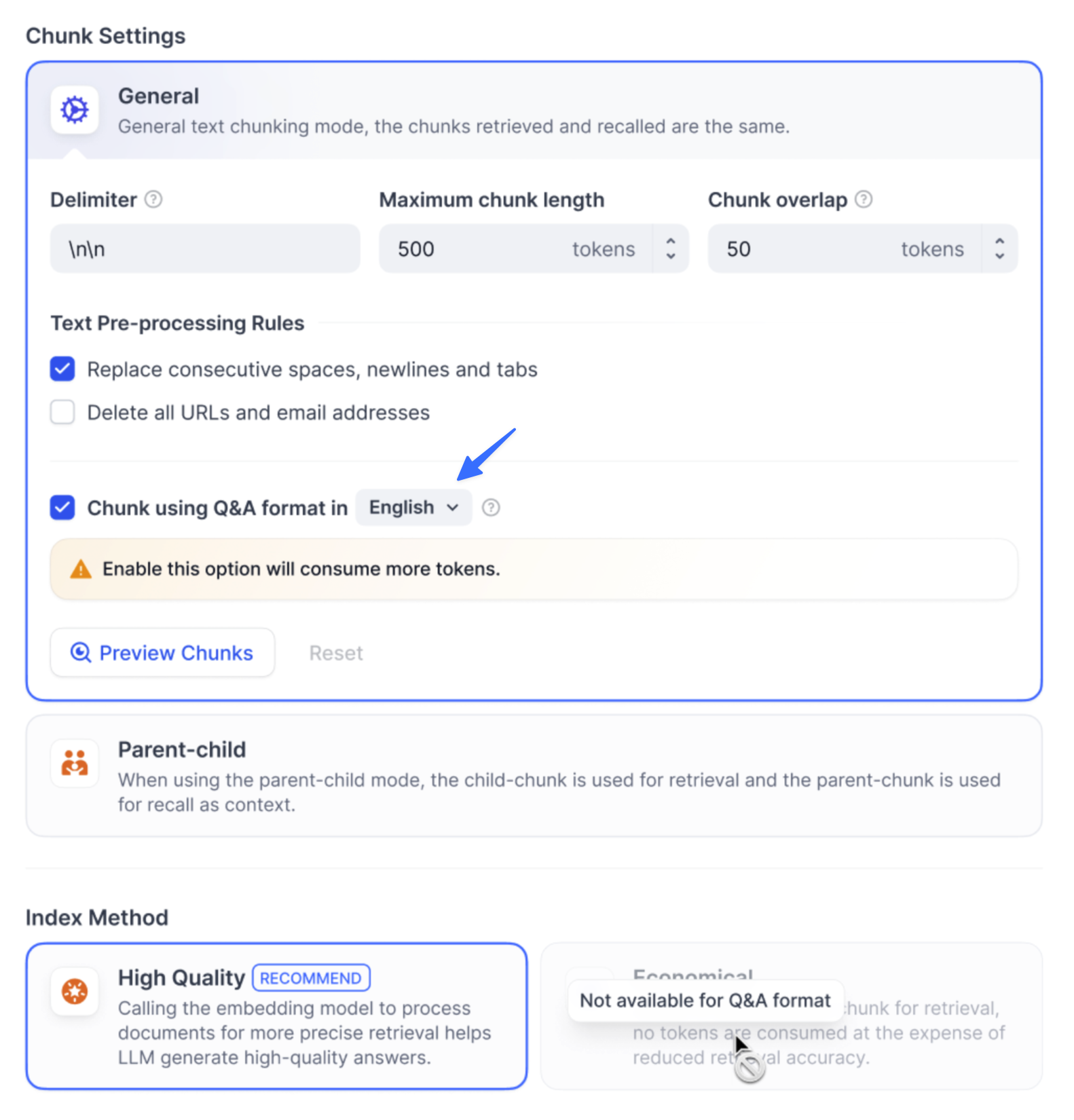
|
||||
|
||||
When a user asks a question, the system identifies the most similar question and returns the corresponding chunk as the answer. This approach is more precise, as it directly matches the user’s query, helping them retrieve the exact information they need.
|
||||
|
||||
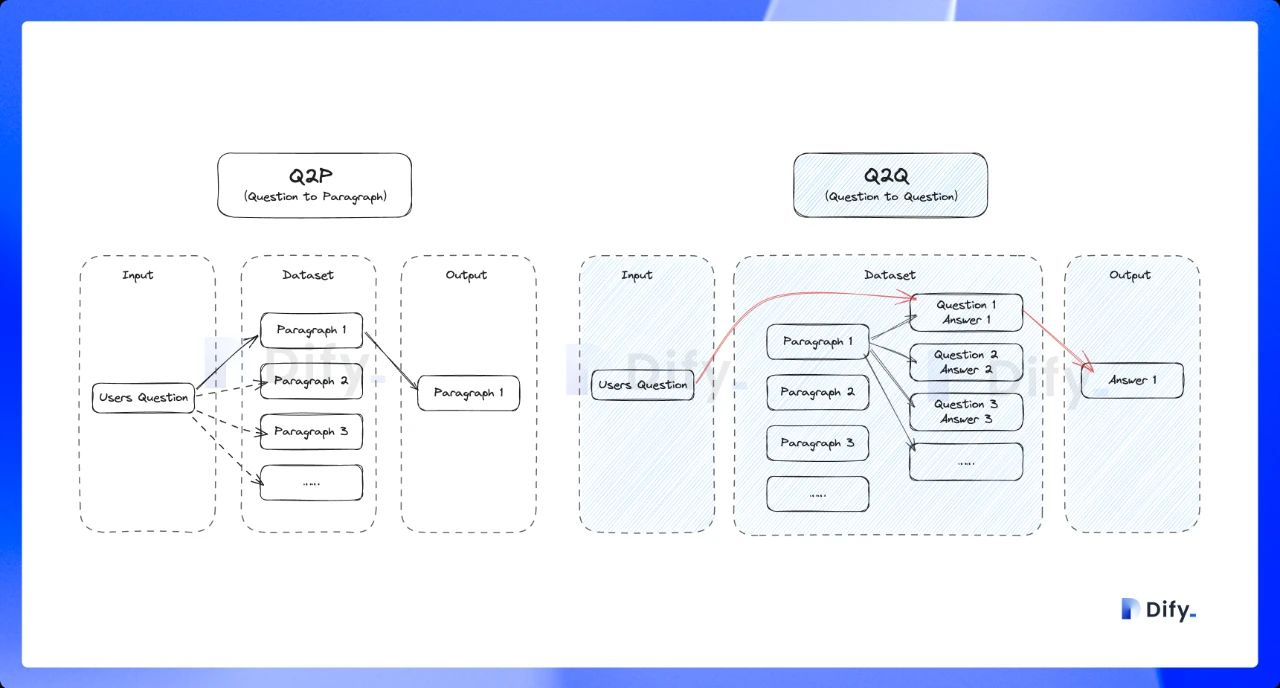
|
||||
|
||||
</Tab>
|
||||
|
||||
<Tab title="Economical">
|
||||
|
||||
Using 10 keywords per chunk for retrieval, no tokens are consumed at the expense of reduced retrieval accuracy. For the retrieved blocks, only the inverted index method is provided to select the most relevant blocks. For more details, please refer to [Inverted Index](3.-select-the-indexing-method-and-retrieval-setting.md#inverted-index).
|
||||
|
||||
If the performance of the economical indexing method does not meet your expectations, you can upgrade to the High-Quality indexing method in the Knowledge settings page.
|
||||
|
||||

|
||||
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## Setting the Retrieval Setting
|
||||
|
||||
Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks. These chunks provide essential contextual for the LLM, ultimately affecting the accuracy and credibility of its answers.
|
||||
|
||||
Common retrieval methods include:
|
||||
|
||||
1. Semantic Retrieval based on vector similarity—where text chunks and queries are converted into vectors and matched via similarity scoring.
|
||||
2. Keyword Matching using an inverted index (a standard search engine technique). Both methods are supported in Dify’s knowledge base.
|
||||
|
||||
Both retrieval methods are supported in Dify’s knowledge base. The specific retrieval options available depend on the chosen indexing method.
|
||||
|
||||
<Tabs>
|
||||
<Tab title="High Quality">
|
||||
**High Quality**
|
||||
|
||||
In the **High-Quality** Indexing Method, Dify offers three retrieval settings: **Vector Search, Full-Text Search, and Hybrid Search**.
|
||||
|
||||
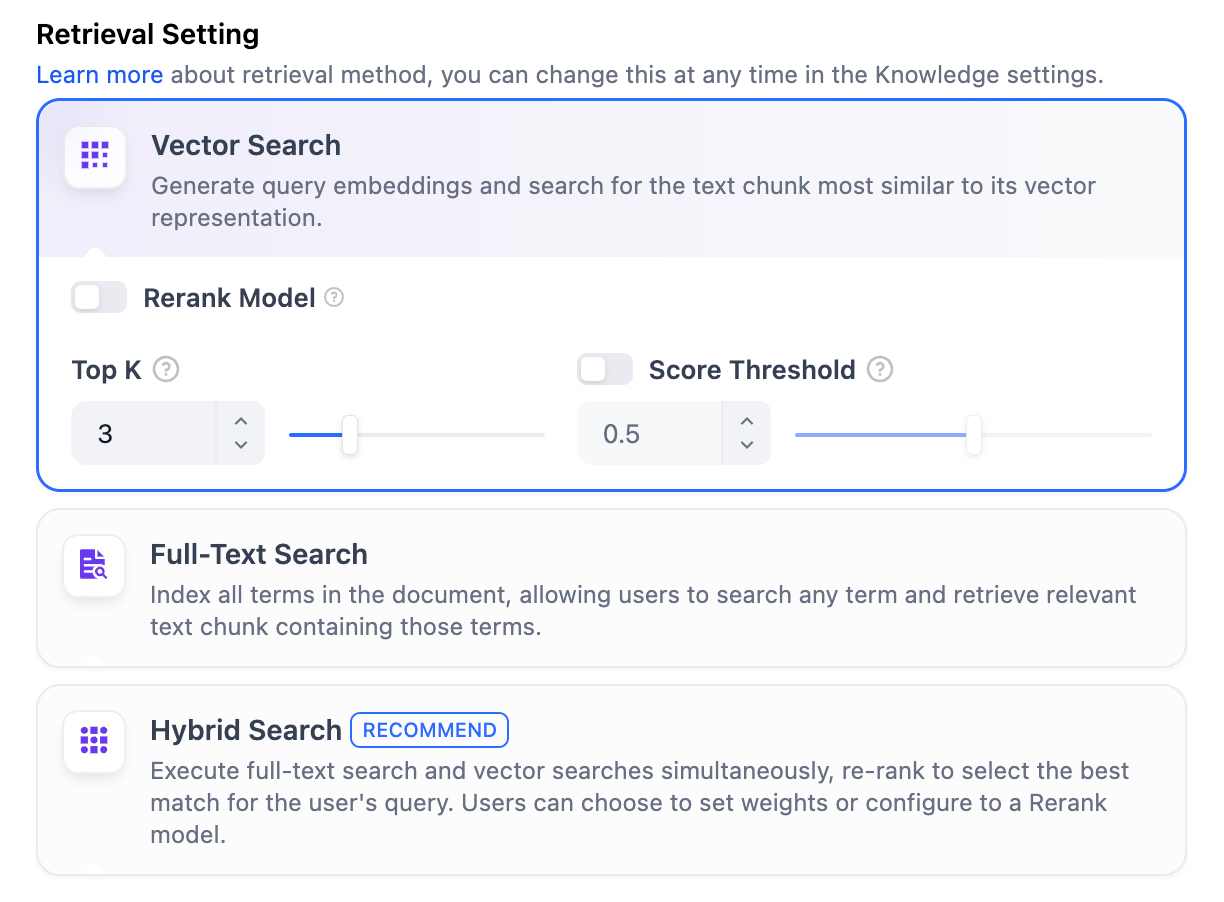
|
||||
|
||||
**Vector Search**
|
||||
|
||||
**Definition**: Vectorize the user’s question to generate a query vector, then compare it with the corresponding text vectors in the knowledge base to find the nearest chunks.
|
||||
|
||||
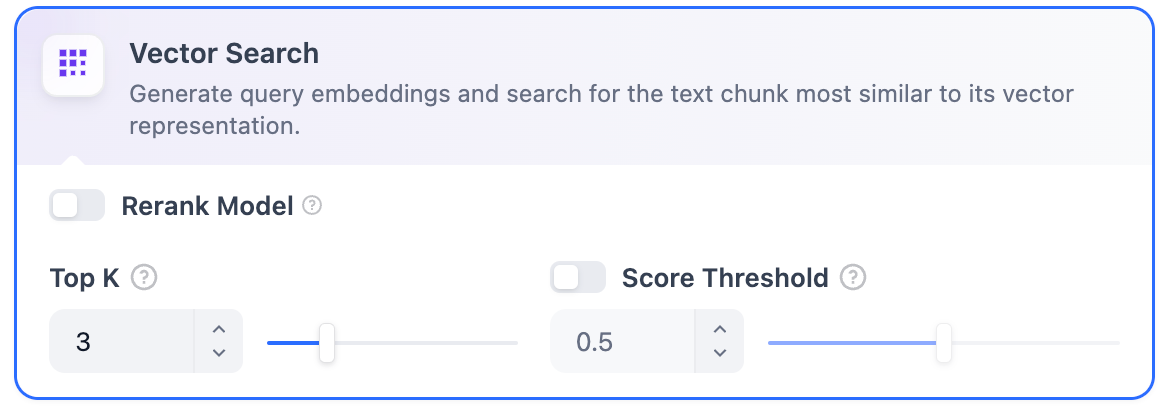
|
||||
|
||||
**Vector Search Settings:**
|
||||
|
||||
**Rerank Model**: Disabled by default. When enabled, a third-party Rerank model will sort the text chunks returned by Vector Search to optimize results. This helps the LLM access more precise information and improve output quality. Before enabling this option, go to **Settings** → **Model Providers** and configure the Rerank model’s API key.
|
||||
|
||||
> Enabling this feature will consume tokens from the Rerank model. For more details, refer to the associated model’s pricing page.
|
||||
|
||||
**TopK**: Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
**Score Threshold**: Sets the minimum similarity score required for a chunk to be retrieved. Only chunks exceeding this score are retrieved. The default value is **0.5**. Higher thresholds demand greater similarity and thus result in fewer chunks being retrieved.
|
||||
|
||||
> The TopK and Score configurations are only effective during the Rerank phase. Therefore, to apply either of these settings, it is necessary to add and enable a Rerank model.
|
||||
|
||||
***
|
||||
|
||||
**Full-Text Search**
|
||||
|
||||
**Definition:** Indexing all terms in the document, allowing users to query any terms and return text fragments containing those terms.
|
||||
|
||||
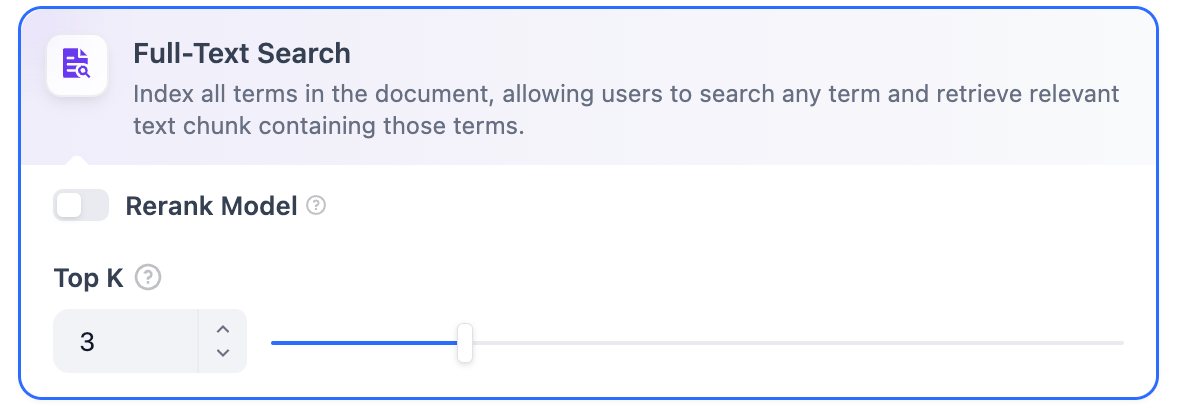
|
||||
|
||||
**Rerank Model**: Disabled by default. When enabled, a third-party Rerank model will sort the text chunks returned by Full-Text Search to optimize results. This helps the LLM access more precise information and improve output quality. Before enabling this option, go to **Settings** → **Model Providers** and configure the Rerank model’s API key.
|
||||
|
||||
> Enabling this feature will consume tokens from the Rerank model. For more details, refer to the associated model’s pricing page.
|
||||
|
||||
**TopK**: Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
**Score Threshold**: Sets the minimum similarity score required for a chunk to be retrieved. Only chunks exceeding this score are retrieved. The default value is **0.5**. Higher thresholds demand greater similarity and thus result in fewer chunks being retrieved.
|
||||
|
||||
> The TopK and Score configurations are only effective during the Rerank phase. Therefore, to apply either of these settings, it is necessary to add and enable a Rerank model.
|
||||
|
||||
***
|
||||
|
||||
**Hybrid Search**
|
||||
|
||||
**Definition**: This process combines full-text search and vector search, performing both simultaneously. It includes a reordering step to select the best-matching results from both search outcomes based on the user’s query.
|
||||
|
||||
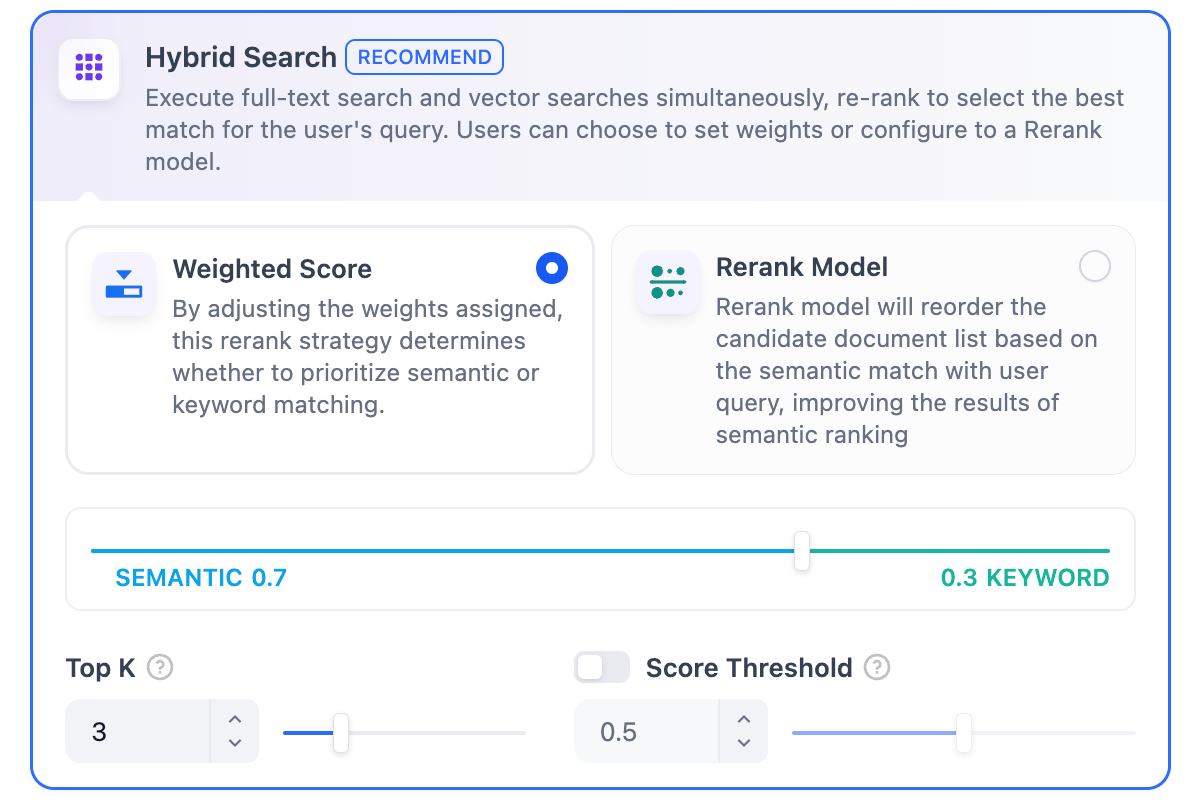
|
||||
|
||||
In this mode, you can specify **"Weight settings"** without needing to configure the Rerank model API, or enable **Rerank model** for retrieval.
|
||||
|
||||
* **Weight Settings**
|
||||
|
||||
This feature enables users to set custom weights for semantic priority and keyword priority. Keyword search refers to performing a full-text search within the knowledge base, while semantic search involves vector search within the knowledge base.
|
||||
|
||||
* **Semantic Value of 1**
|
||||
|
||||
This activates only the semantic search mode. Utilizing embedding models, even if the exact terms from the query do not appear in the knowledge base, the search can delve deeper by calculating vector distances, thus returning relevant content. Additionally, when dealing with multilingual content, semantic search can capture meaning across different languages, providing more accurate cross-language search results.
|
||||
* **Keyword Value of 1**
|
||||
|
||||
This activates only the keyword search mode. It performs a full match against the input text in the knowledge base, suitable for scenarios where the user knows the exact information or terminology. This approach consumes fewer computational resources and is ideal for quick searches within a large document knowledge base.
|
||||
* **Custom Keyword and Semantic Weights**
|
||||
|
||||
In addition to enabling only semantic search or keyword search, we provide flexible custom weight settings. You can continuously adjust the weights of the two methods to identify the optimal weight ratio that suits your business scenario.
|
||||
***
|
||||
|
||||
**Rerank Model**
|
||||
|
||||
Disabled by default. When enabled, a third-party Rerank model will sort the text chunks returned by Hybrid Search to optimize results. This helps the LLM access more precise information and improve output quality. Before enabling this option, go to **Settings** → **Model Providers** and configure the Rerank model’s API key.
|
||||
|
||||
> Enabling this feature will consume tokens from the Rerank model. For more details, refer to the associated model’s pricing page.
|
||||
|
||||
The **"Weight Settings"** and **"Rerank Model"** settings support the following options:
|
||||
|
||||
**TopK**: Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
|
||||
**Score Threshold**: Sets the minimum similarity score required for a chunk to be retrieved. Only chunks exceeding this score are retrieved. The default value is **0.5**. Higher thresholds demand greater similarity and thus result in fewer chunks being retrieved.
|
||||
</Tab>
|
||||
<Tab title="Economical">
|
||||
**Economical**
|
||||
|
||||
In **Economical Indexing** mode, only the inverted index approach is available. An inverted index is a data structure designed for fast keyword retrieval within documents, commonly used in online search engines. Inverted indexing supports only the **TopK** setting.
|
||||
|
||||
**TopK:** Determines how many text chunks, deemed most similar to the user’s query, are retrieved. It also automatically adjusts the number of chunks based on the chosen model’s context window. The default value is **3**, and higher numbers will recall more text chunks.
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### Reference
|
||||
|
||||
After specifying the retrieval settings, you can refer to the following documentation to review how keywords match with content chunks in different scenarios.
|
||||
|
||||
<Card title="retrieval-test-and-citation" icon="link" href="../retrieval-test-and-citation">
|
||||
</Card>
|
||||
@@ -1,142 +0,0 @@
|
||||
---
|
||||
title: Knowledge Base and Document Maintenance
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
## Knowledge Base Management
|
||||
|
||||
> The knowledge base page is accessible only to the team owner, team administrators, and users with editor permissions.
|
||||
|
||||
On the Dify team homepage, click the "Knowledge Base" tab at the top, select the knowledge base you want to manage, then click **Settings** in the left navigation panel to make adjustments. You can modify the knowledge base name, description, visibility permissions, indexing mode, embedding model, and retrieval settings.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/knowledge-settings-01.png" alt="Knowledge Base Settings" />
|
||||
</Frame>
|
||||
|
||||
**Knowledge Base Name**: Used to distinguish among different knowledge bases.
|
||||
|
||||
**Knowledge Description**: Used to describe the information represented by the documents in the knowledge base.
|
||||
|
||||
**Visibility Permissions**: Defines access control for the knowledge base with three levels:
|
||||
|
||||
1. **"Only Me"**: Restricts access to the knowledge base owner.
|
||||
2. **"All team members"**: Grants access to every member of the team.
|
||||
3. **"Partial team members"**: Allows selective access to specific team members.
|
||||
|
||||
Users without appropriate permissions cannot access the knowledge base. When granting access to team members (options 2 or 3), authorized users receive full permissions, including view, edit, and delete rights for the knowledge base content.
|
||||
|
||||
**Indexing Mode**: For detailed explanations, please [refer to the documentation](https://docs.dify.ai/guides/knowledge-base/create-knowledge-and-upload-documents#5-indexing-method).
|
||||
|
||||
**Embedding Model**: Allows you to modify the embedding model for the knowledge base. Changing the embedding model will re-embed all documents in the knowledge base, and the original embeddings will be deleted.
|
||||
|
||||
**Retrieval Settings**: For detailed explanations, please [refer to the documentation](https://docs.dify.ai/guides/knowledge-base/create-knowledge-and-upload-documents#6-retrieval-settings).
|
||||
|
||||
***
|
||||
|
||||
### Knowledge Base API Management
|
||||
|
||||
Dify Knowledge Base provides a complete set of standard APIs. Developers can use API calls to perform daily management and maintenance operations such as adding, deleting, modifying, and querying documents and chunks in the knowledge base. Please refer to the [Knowledge Base API Documentation](maintain-dataset-via-api.md).
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/knowledge-base-api.png" alt="Knowledge base API management" />
|
||||
</Frame>
|
||||
|
||||
## Maintaining Text in the Knowledge Base
|
||||
|
||||
### Viewing Text Chunks
|
||||
|
||||
Each document uploaded to the knowledge base is stored in the form of text chunks. You can view the specific text content of each chunks in the chunks list.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/viewing-uploaded-document-segments.png" alt="Viewing uploaded document chunks" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Checking Chunk Quality
|
||||
|
||||
The quality of document chunk significantly affects the Q&A performance of the knowledge base application. It is recommended to manually check the chunks quality before associating the knowledge base with the application.
|
||||
|
||||
Although automated chunk methods based on character length, identifiers, or NLP semantic chunk can significantly reduce the workload of large-scale text chunk, the quality of chunk is related to the text structure of different document formats and the semantic context. Manual checking and correction can effectively compensate for the shortcomings of machine chunk in semantic recognition.
|
||||
|
||||
When checking chunk quality, pay attention to the following situations:
|
||||
|
||||
* **Overly short text chunks**, leading to semantic loss;
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/short-text-segments.png" alt="Overly short text chunks" width="373" />
|
||||
</Frame>
|
||||
|
||||
* **Overly long text chunks**, leading to semantic noise affecting matching accuracy;
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/long-text-segments.png" alt="Overly long text chunks" width="375" />
|
||||
</Frame>
|
||||
|
||||
* **Obvious semantic truncation**, which occurs when using maximum segment length limits, leading to forced semantic truncation and missing content during recall;
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/semantic-truncation.png" alt="Obvious semantic truncation" width="357" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Adding Text Chunks
|
||||
|
||||
In the chunk list, click "Add Segment" to add one or multiple custom chunks to the document.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/add-a-chunk.png" alt="Add a chunk" />
|
||||
</Frame>
|
||||
|
||||
When adding chunks in bulk, you need to first download the CSV format chunk upload template, edit all the chunk content in Excel according to the template format, save the CSV file, and then upload it.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/bulk-add-custom-segment (1).png" alt="Bulk adding custom chunks" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Editing Text Chunks
|
||||
|
||||
In the chunk list, you can directly edit the content of the added chunks, including the text content and keywords of the chunks.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/edit-segment (1).png" alt="Editing document chunks" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Metadata Management
|
||||
|
||||
In addition to marking metadata information from different source documents, such as the title, URL, keywords, and description of web data, metadata will be used in the chunk recall process of the knowledge base as structured fields for recall filtering or displaying citation sources.
|
||||
|
||||
<Tip>
|
||||
The metadata filtering and citation source functions are not yet supported in the current version.
|
||||
</Tip>
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/metadata.png" alt="Add metadata" width="258" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Adding Documents
|
||||
|
||||
In "Knowledge Base > Document List," click "Add File" to upload new documents or [Notion pages](sync-from-notion.md) to the created knowledge base.
|
||||
|
||||
A knowledge base (Knowledge) is a collection of documents (Documents). Documents can be uploaded by developers or operators, or synchronized from other data sources (usually corresponding to a file unit in the data source).
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/en-knowledge-add-document.png" alt="Upload new document at Knowledge base" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Document Disable and Archive
|
||||
|
||||
**Disable**: The dataset supports disabling documents or chunks that are temporarily not to be indexed. In the dataset document list, click the disable button to disable the document. You can also disable an entire document or a specific chunk in the document details. Disabled documents will not be indexed. Click enable on the disabled documents to cancel the disable status.
|
||||
|
||||
**Archive**: Old document data that is no longer in use can be archived if you do not want to delete it. Archived data can only be viewed or deleted, not edited. In the dataset document list, click the archive button to archive the document. You can also archive documents in the document details. Archived documents will not be indexed. Archived documents can also be unarchived.
|
||||
|
||||
***
|
||||
@@ -0,0 +1,415 @@
|
||||
---
|
||||
title: Chatbot
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
## Overview
|
||||
Chat applications support session persistence, allowing previous chat history to be used as context for responses. This can be applicable for chatbots, customer service AI, etc.
|
||||
|
||||
## Base URL
|
||||
```
|
||||
https://api.dify.ai/v1
|
||||
```
|
||||
|
||||
## Authentication
|
||||
The Service API uses API-Key authentication.
|
||||
|
||||
> **Important**: Strongly recommend storing your API Key on the server-side, not shared or stored on the client-side, to avoid possible API-Key leakage that can lead to serious consequences.
|
||||
|
||||
For all API requests, include your API Key in the Authorization HTTP Header:
|
||||
```
|
||||
Authorization: Bearer {API_KEY}
|
||||
```
|
||||
|
||||
## API Endpoints
|
||||
|
||||
### Send Chat Message
|
||||
`POST /chat-messages`
|
||||
|
||||
Send a request to the chat application.
|
||||
|
||||
#### Request Body
|
||||
|
||||
- **query** (string) Required
|
||||
- User Input / Question Content
|
||||
|
||||
- **inputs** (object) Required
|
||||
- Allows the entry of various variable values defined by the App
|
||||
- Contains multiple key/value pairs, each key corresponding to a specific variable
|
||||
- At least one key/value pair required
|
||||
|
||||
- **response_mode** (string) Required
|
||||
- Modes supported:
|
||||
- `streaming`: Streaming mode (recommended), implements typewriter-like output through SSE
|
||||
- `blocking`: Blocking mode, returns result after execution completes
|
||||
- Note: Due to Cloudflare restrictions, requests will timeout after 100 seconds
|
||||
- Note: blocking mode is not supported in Agent Assistant mode
|
||||
|
||||
- **user** (string) Required
|
||||
- User identifier for retrieval and statistics
|
||||
- Should be uniquely defined within the application
|
||||
|
||||
- **conversation_id** (string) Optional
|
||||
- Conversation ID to continue based on previous chat records
|
||||
|
||||
- **files** (array[object]) Optional
|
||||
- File list for image input with text understanding
|
||||
- Available only when model supports Vision capability
|
||||
- Properties:
|
||||
- `type` (string): Supported type: image
|
||||
- `transfer_method` (string): 'remote_url' or 'local_file'
|
||||
- `url` (string): Image URL (for remote_url)
|
||||
- `upload_file_id` (string): Uploaded file ID (for local_file)
|
||||
|
||||
- **auto_generate_name** (bool) Optional
|
||||
- Auto-generate title, default is false
|
||||
- Can achieve async title generation via conversation rename API
|
||||
|
||||
#### Response Types
|
||||
|
||||
**Blocking Mode Response (ChatCompletionResponse)**
|
||||
Returns complete App result with Content-Type: application/json
|
||||
|
||||
```typescript
|
||||
interface ChatCompletionResponse {
|
||||
message_id: string;
|
||||
conversation_id: string;
|
||||
mode: string;
|
||||
answer: string;
|
||||
metadata: {
|
||||
usage: Usage;
|
||||
retriever_resources: RetrieverResource[];
|
||||
};
|
||||
created_at: number;
|
||||
}
|
||||
```
|
||||
|
||||
**Streaming Mode Response (ChunkChatCompletionResponse)**
|
||||
Returns stream chunks with Content-Type: text/event-stream
|
||||
|
||||
Events:
|
||||
- `message`: LLM text chunk event
|
||||
- `agent_message`: LLM text chunk event (Agent Assistant mode)
|
||||
- `agent_thought`: Agent reasoning process
|
||||
- `message_file`: New file created by tool
|
||||
- `message_end`: Stream end event
|
||||
- `message_replace`: Content replacement event
|
||||
- `workflow_started`: Workflow execution start
|
||||
- `node_started`: Node execution start
|
||||
- `node_finished`: Node execution completion
|
||||
- `workflow_finished`: Workflow execution completion
|
||||
- `parallel_branch_started`: Parallel branch start
|
||||
- `parallel_branch_finished`: Parallel branch completion
|
||||
- `iteration_started`: Iteration start
|
||||
- `iteration_next`: Next iteration
|
||||
- `iteration_completed`: Iteration completion
|
||||
- `error`: Exception event
|
||||
- `ping`: Keep-alive event (every 10s)
|
||||
|
||||
### File Upload
|
||||
`POST /files/upload`
|
||||
|
||||
Upload files (currently only images) for multimodal understanding.
|
||||
|
||||
#### Supported Formats
|
||||
- png
|
||||
- jpg
|
||||
- jpeg
|
||||
- webp
|
||||
- gif
|
||||
|
||||
#### Request Body
|
||||
Requires multipart/form-data:
|
||||
- `file` (File) Required
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface FileUploadResponse {
|
||||
id: string;
|
||||
name: string;
|
||||
size: number;
|
||||
extension: string;
|
||||
mime_type: string;
|
||||
created_by: string;
|
||||
created_at: number;
|
||||
}
|
||||
```
|
||||
|
||||
### Stop Generate
|
||||
`POST /chat-messages/:task_id/stop`
|
||||
|
||||
Stop ongoing generation (streaming mode only).
|
||||
|
||||
#### Request Body
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```json
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### Message Feedback
|
||||
`POST /messages/:message_id/feedbacks`
|
||||
|
||||
Submit user feedback on messages.
|
||||
|
||||
#### Request Body
|
||||
- `rating` (string) Required: "like" | "dislike" | null
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```json
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### Get Conversation History
|
||||
`GET /messages`
|
||||
|
||||
Returns historical chat records in reverse chronological order.
|
||||
|
||||
#### Query Parameters
|
||||
- `conversation_id` (string) Required
|
||||
- `user` (string) Required
|
||||
- `first_id` (string) Optional: First chat record ID
|
||||
- `limit` (int) Optional: Default 20
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface ConversationHistory {
|
||||
data: Array<{
|
||||
id: string;
|
||||
conversation_id: string;
|
||||
inputs: Record<string, any>;
|
||||
query: string;
|
||||
message_files: Array<{
|
||||
id: string;
|
||||
type: string;
|
||||
url: string;
|
||||
belongs_to: 'user' | 'assistant';
|
||||
}>;
|
||||
agent_thoughts: Array<{
|
||||
id: string;
|
||||
message_id: string;
|
||||
position: number;
|
||||
thought: string;
|
||||
observation: string;
|
||||
tool: string;
|
||||
tool_input: string;
|
||||
created_at: number;
|
||||
message_files: string[];
|
||||
}>;
|
||||
answer: string;
|
||||
created_at: number;
|
||||
feedback?: {
|
||||
rating: 'like' | 'dislike';
|
||||
};
|
||||
retriever_resources: RetrieverResource[];
|
||||
}>;
|
||||
has_more: boolean;
|
||||
limit: number;
|
||||
}
|
||||
```
|
||||
|
||||
### Get Conversations
|
||||
`GET /conversations`
|
||||
|
||||
Retrieve conversation list for current user.
|
||||
|
||||
#### Query Parameters
|
||||
- `user` (string) Required
|
||||
- `last_id` (string) Optional
|
||||
- `limit` (int) Optional: Default 20
|
||||
- `pinned` (boolean) Optional
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface ConversationList {
|
||||
data: Array<{
|
||||
id: string;
|
||||
name: string;
|
||||
inputs: Record<string, any>;
|
||||
introduction: string;
|
||||
created_at: number;
|
||||
}>;
|
||||
has_more: boolean;
|
||||
limit: number;
|
||||
}
|
||||
```
|
||||
|
||||
### Delete Conversation
|
||||
`DELETE /conversations/:conversation_id`
|
||||
|
||||
Delete a conversation.
|
||||
|
||||
#### Request Body
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```json
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### Rename Conversation
|
||||
`POST /conversations/{conversation_id}/name`
|
||||
|
||||
#### Request Body
|
||||
- `name` (string) Optional
|
||||
- `auto_generate` (boolean) Optional: Default false
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface RenamedConversation {
|
||||
id: string;
|
||||
name: string;
|
||||
inputs: Record<string, any>;
|
||||
introduction: string;
|
||||
created_at: number;
|
||||
}
|
||||
```
|
||||
|
||||
### Speech to Text
|
||||
`POST /audio-to-text`
|
||||
|
||||
Convert audio to text.
|
||||
|
||||
#### Request Body (multipart/form-data)
|
||||
- `file` (File) Required
|
||||
- Supported formats: mp3, mp4, mpeg, mpga, m4a, wav, webm
|
||||
- Size limit: 15MB
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface AudioToTextResponse {
|
||||
text: string;
|
||||
}
|
||||
```
|
||||
|
||||
### Get Application Parameters
|
||||
`GET /parameters`
|
||||
|
||||
Retrieve application configuration and settings.
|
||||
|
||||
#### Query Parameters
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface ApplicationParameters {
|
||||
opening_statement: string;
|
||||
suggested_questions_after_answer: {
|
||||
enabled: boolean;
|
||||
};
|
||||
speech_to_text: {
|
||||
enabled: boolean;
|
||||
};
|
||||
retriever_resource: {
|
||||
enabled: boolean;
|
||||
};
|
||||
annotation_reply: {
|
||||
enabled: boolean;
|
||||
};
|
||||
user_input_form: Array<{
|
||||
'text-input' | 'paragraph' | 'select': {
|
||||
label: string;
|
||||
variable: string;
|
||||
required: boolean;
|
||||
default: string;
|
||||
options?: string[];
|
||||
};
|
||||
}>;
|
||||
file_upload: {
|
||||
image: {
|
||||
enabled: boolean;
|
||||
number_limits: number;
|
||||
transfer_methods: string[];
|
||||
};
|
||||
};
|
||||
system_parameters: {
|
||||
image_file_size_limit: string;
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
### Get Application Meta Information
|
||||
`GET /meta`
|
||||
|
||||
Retrieve tool icons and metadata.
|
||||
|
||||
#### Query Parameters
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface ApplicationMeta {
|
||||
tool_icons: Record<string, string | {
|
||||
background: string;
|
||||
content: string;
|
||||
}>;
|
||||
}
|
||||
```
|
||||
|
||||
## Type Definitions
|
||||
|
||||
### Usage
|
||||
```typescript
|
||||
interface Usage {
|
||||
prompt_tokens: number;
|
||||
prompt_unit_price: string;
|
||||
prompt_price_unit: string;
|
||||
prompt_price: string;
|
||||
completion_tokens: number;
|
||||
completion_unit_price: string;
|
||||
completion_price_unit: string;
|
||||
completion_price: string;
|
||||
total_tokens: number;
|
||||
total_price: string;
|
||||
currency: string;
|
||||
latency: number;
|
||||
}
|
||||
```
|
||||
|
||||
### RetrieverResource
|
||||
```typescript
|
||||
interface RetrieverResource {
|
||||
position: number;
|
||||
content: string;
|
||||
score: string;
|
||||
dataset_id: string;
|
||||
dataset_name: string;
|
||||
document_id: string;
|
||||
document_name: string;
|
||||
segment_id: string;
|
||||
}
|
||||
```
|
||||
|
||||
## Error Codes
|
||||
|
||||
Common error codes you may encounter:
|
||||
- 404: Conversation does not exist
|
||||
- 400: invalid_param - Abnormal parameter input
|
||||
- 400: app_unavailable - App configuration unavailable
|
||||
- 400: provider_not_initialize - No available model credential configuration
|
||||
- 400: provider_quota_exceeded - Model invocation quota insufficient
|
||||
- 400: model_currently_not_support - Current model unavailable
|
||||
- 400: completion_request_error - Text generation failed
|
||||
- 500: Internal server error
|
||||
|
||||
For file uploads:
|
||||
- 400: no_file_uploaded - File must be provided
|
||||
- 400: too_many_files - Only one file accepted
|
||||
- 400: unsupported_preview - File does not support preview
|
||||
- 400: unsupported_estimate - File does not support estimation
|
||||
- 413: file_too_large - File is too large
|
||||
- 415: unsupported_file_type - Unsupported extension
|
||||
- 503: s3_connection_failed - Unable to connect to S3
|
||||
- 503: s3_permission_denied - No permission for S3
|
||||
- 503: s3_file_too_large - Exceeds S3 size limit
|
||||
@@ -0,0 +1,53 @@
|
||||
---
|
||||
title: Manage Knowledge
|
||||
---
|
||||
|
||||
<Info>
|
||||
The knowledge page is accessible only to the team owner, team administrators, and users with editor permissions.
|
||||
</Info>
|
||||
|
||||
Click the **Knowledge** button at the top of the Dify platform and select the knowledge you want to manage. Navigate to Settings in the left sidebar to configure it.
|
||||
|
||||
Here, you can modify the knowledge base's name, description, permissions, indexing method, embedding model and retrieval settings.
|
||||
|
||||
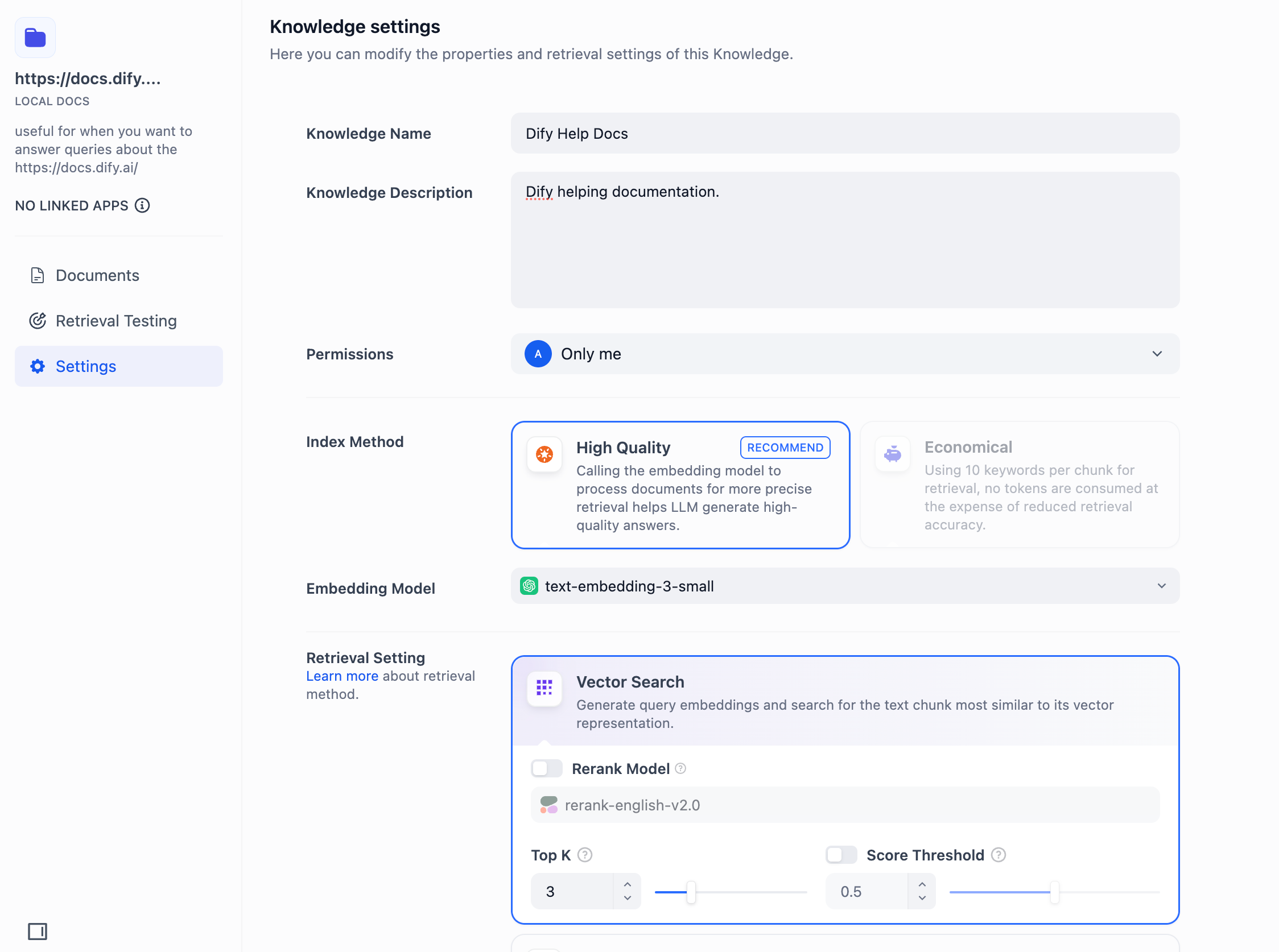
|
||||
|
||||
* **Knowledge Name**: Used to distinguish among different knowledge bases.
|
||||
* **Knowledge Description**: Used to describe the information represented by the documents in the knowledge base.
|
||||
* **Permission**: Defines access control for the knowledge base with three levels:
|
||||
* **"Only Me"**: Restricts access to the knowledge base owner.
|
||||
* **"All team members"**: Grants access to every member of the team.
|
||||
* **"Partial team members"**: Allows selective access to specific team members.
|
||||
|
||||
Users without appropriate permissions cannot access the knowledge base. When granting access to team members (Options 2 or 3), authorized users are granted full permissions, including the ability to view, edit, and delete knowledge base content.
|
||||
* **Indexing Mode**: For detailed explanations, please refer to the [documentation](create-knowledge-and-upload-documents/3.-select-the-indexing-method-and-retrieval-setting.md).
|
||||
* **Embedding Model**: Allows you to modify the embedding model for the knowledge base. Changing the embedding model will re-embed all documents in the knowledge base, and the original embeddings will be deleted.
|
||||
* **Retrieval Settings**: For detailed explanations, please refer to the [documentation](../../learn-more/extended-reading/retrieval-augment/retrieval.md).
|
||||
|
||||
***
|
||||
|
||||
## View Linked Applications in the Knowledge Base
|
||||
|
||||
On the left side of the knowledge base, you can see all linked Apps. Hover over the circular icon to view the list of all linked apps. Click the jump button on the right to quickly browser them.
|
||||
|
||||
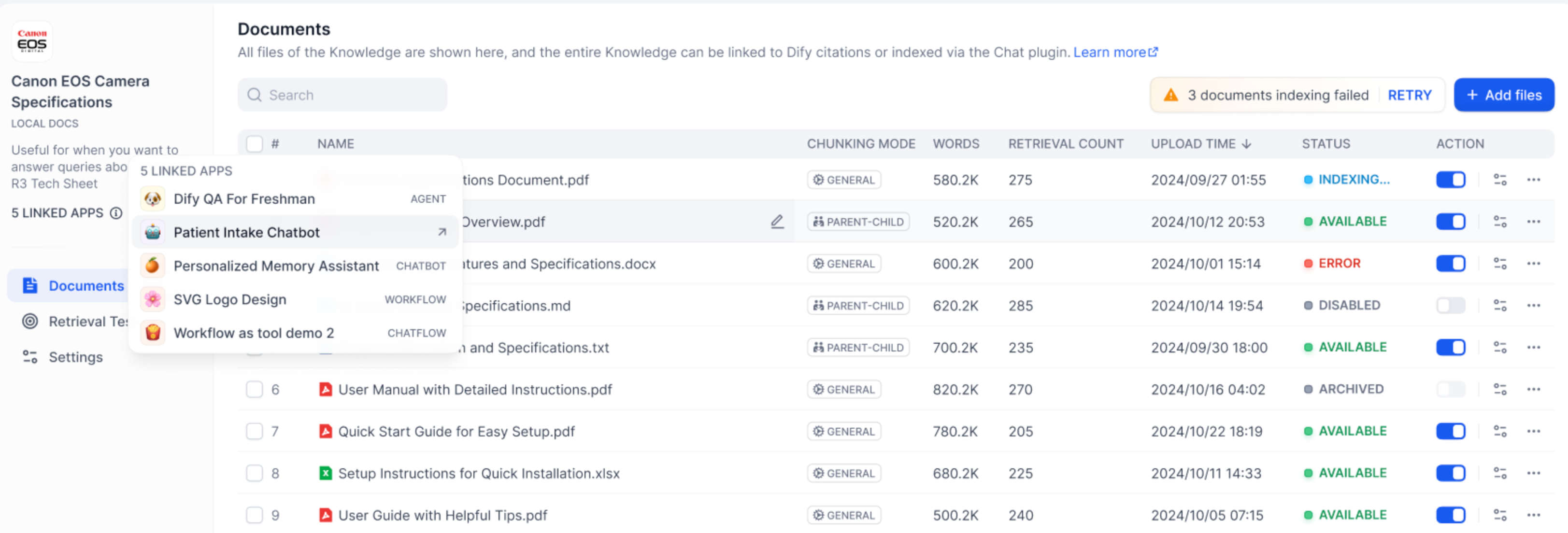
|
||||
|
||||
You can manage your knowledge base documents either through a web interface or via an API.
|
||||
|
||||
## Maintain Knowledge Documents
|
||||
|
||||
You can administer all documents and their corresponding chunks directly in the knowledge base. For more details, refer to the following documentation:
|
||||
|
||||
<Card title="Maintain Knowledge Documents" icon="link" href="knowledge-and-documents-maintenance/maintain-knowledge-documents.md">
|
||||
Learn how to maintain knowledge documents
|
||||
</Card>
|
||||
|
||||
## Maintain Knowledge Base Via API
|
||||
|
||||
Dify Knowledge Base provides a comprehensive set of standard APIs. Developers can use these APIs to perform routine management and maintenance tasks, such as adding, deleting, updating, and retrieving documents and chunks. For more details, refer to the following documentation:
|
||||
|
||||
<Card title="Maintain Knowledge Base via API" icon="link" href="knowledge-and-documents-maintenance/maintain-dataset-via-api.md">
|
||||
Learn how to maintain knowledge base via API
|
||||
</Card>
|
||||
|
||||
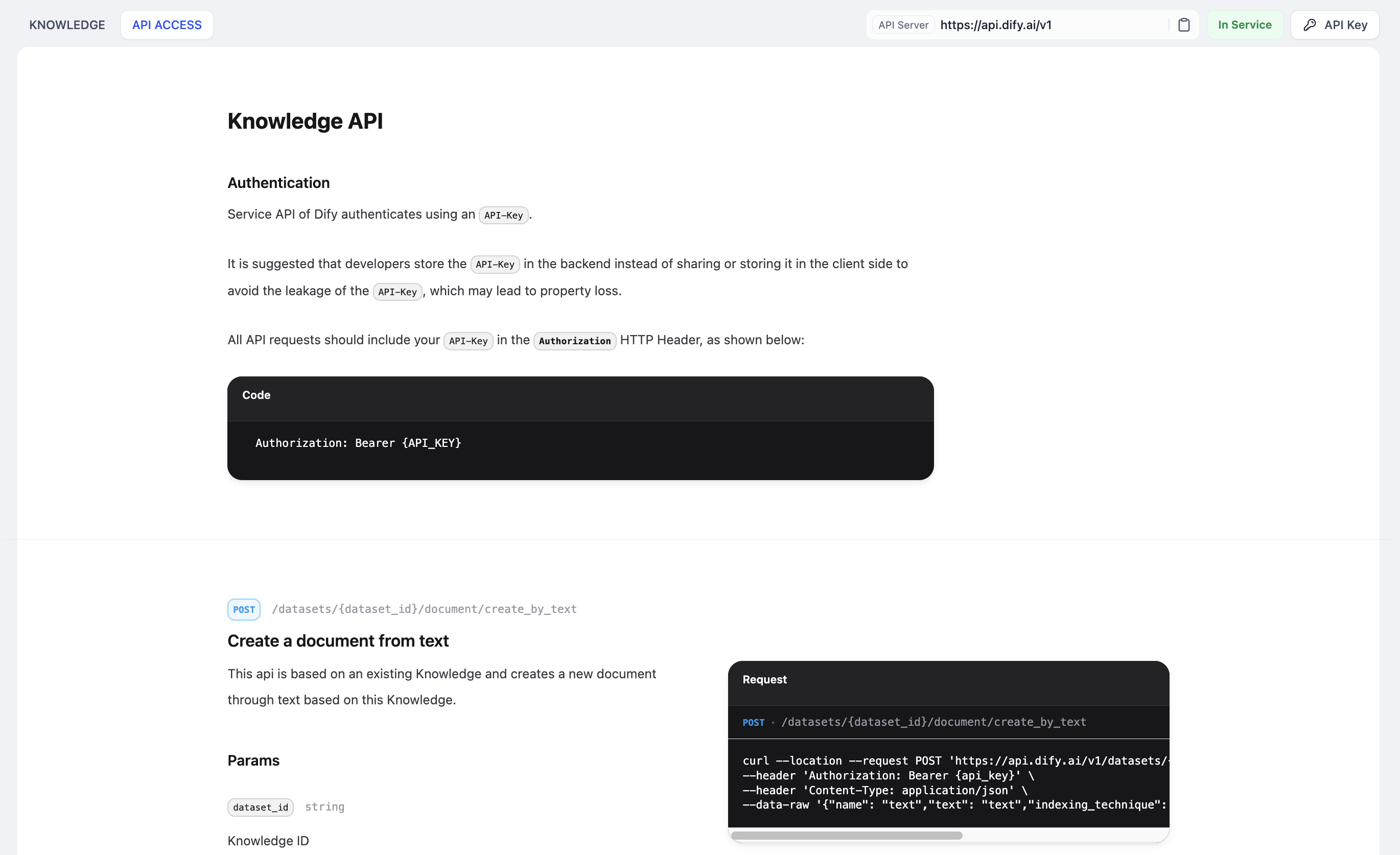
|
||||
@@ -0,0 +1,686 @@
|
||||
---
|
||||
title: Maintain Knowledge via API
|
||||
---
|
||||
|
||||
> The authentication and invocation methods for the Knowledge Base API are consistent with the Application Service API. However, a single Knowledge Base API token generated has the authority to operate on all visible knowledge bases under the same account. Please pay attention to data security.
|
||||
|
||||
### Advantages of Utilizing Knowledge Base API
|
||||
|
||||
Leveraging the API for knowledge base maintenance significantly enhances data processing efficiency. It enables seamless data synchronization via command-line interfaces, facilitating automated operations instead of manipulating the user interface.
|
||||
|
||||
Key advantages include:
|
||||
|
||||
* Automated Synchronization: Enables seamless integration between data systems and the Dify knowledge base, fostering efficient workflow construction.
|
||||
* Comprehensive Management: Offers functionalities such as knowledge base listing, document enumeration, and detailed querying, facilitating the development of custom data management interfaces.
|
||||
* Flexible Content Ingestion: Accommodates both plain text and file upload methodologies, supporting batch operations for addition and modification of content chunks.
|
||||
* Enhanced Productivity: Minimizes manual data handling requirements, thereby optimizing the overall user experience on the Dify platform.
|
||||
|
||||
### How to Use
|
||||
|
||||
Navigate to the knowledge base page, and you can switch to the **API ACCESS** page from the left navigation. On this page, you can view the dataset API documentation provided by Dify and manage the credentials for accessing the dataset API in **API Keys**.
|
||||
|
||||
|
||||
|
||||
### API Requesting Examples
|
||||
|
||||
#### **Create a document from text**
|
||||
|
||||
This api is based on an existing Knowledge and creates a new document through text based on this Knowledge.
|
||||
|
||||
Request example:
|
||||
|
||||
```json
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create_by_text' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"name": "text","text": "text","indexing_technique": "high_quality","process_rule": {"mode": "automatic"}}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "text.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695690280,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
```
|
||||
|
||||
#### Create a Document from a file
|
||||
|
||||
This API is based on an existing knowledge and creates a new document through a file based on this knowledge.
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create-by-file' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--form 'data="{"indexing_technique":"high_quality","process_rule":{"rules":{"pre_processing_rules":[{"id":"remove_extra_spaces","enabled":true},{"id":"remove_urls_emails","enabled":true}],"segmentation":{"separator":"###","max_tokens":500}},"mode":"custom"}}";type=text/plain' \
|
||||
--form 'file=@"/path/to/file"'
|
||||
```
|
||||
|
||||
```bash
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "Dify.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### Create Documents from a File
|
||||
|
||||
This api is based on an existing Knowledge and creates a new document through a file based on this Knowledge.
|
||||
|
||||
Request example:
|
||||
|
||||
```json
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create-by-file' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--form 'data="{"indexing_technique":"high_quality","process_rule":{"rules":{"pre_processing_rules":[{"id":"remove_extra_spaces","enabled":true},{"id":"remove_urls_emails","enabled":true}],"segmentation":{"separator":"###","max_tokens":500}},"mode":"custom"}}";type=text/plain' \
|
||||
--form 'file=@"/path/to/file"'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "Dify.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### Create an Empty Knowledge Base
|
||||
|
||||
<Warning>
|
||||
Only used to create an empty knowledge base.
|
||||
</Warning>
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"name": "name", "permission": "only_me"}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "",
|
||||
"name": "name",
|
||||
"description": null,
|
||||
"provider": "vendor",
|
||||
"permission": "only_me",
|
||||
"data_source_type": null,
|
||||
"indexing_technique": null,
|
||||
"app_count": 0,
|
||||
"document_count": 0,
|
||||
"word_count": 0,
|
||||
"created_by": "",
|
||||
"created_at": 1695636173,
|
||||
"updated_by": "",
|
||||
"updated_at": 1695636173,
|
||||
"embedding_model": null,
|
||||
"embedding_model_provider": null,
|
||||
"embedding_available": null
|
||||
}
|
||||
```
|
||||
|
||||
#### Get Knowledge Base List
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets?page=1&limit=20' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
{
|
||||
"data": [
|
||||
{
|
||||
"id": "",
|
||||
"name": "name",
|
||||
"description": "desc",
|
||||
"permission": "only_me",
|
||||
"data_source_type": "upload_file",
|
||||
"indexing_technique": "",
|
||||
"app_count": 2,
|
||||
"document_count": 10,
|
||||
"word_count": 1200,
|
||||
"created_by": "",
|
||||
"created_at": "",
|
||||
"updated_by": "",
|
||||
"updated_at": ""
|
||||
},
|
||||
...
|
||||
],
|
||||
"has_more": true,
|
||||
"limit": 20,
|
||||
"total": 50,
|
||||
"page": 1
|
||||
}
|
||||
```
|
||||
|
||||
#### Delete a Knowledge Base
|
||||
|
||||
Request example:
|
||||
|
||||
```json
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
204 No Content
|
||||
```
|
||||
|
||||
#### Update a Document with Text
|
||||
|
||||
This api is based on an existing Knowledge and updates the document through text based on this Knowledge
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/update_by_text' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"name": "name","text": "text"}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "name.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
```
|
||||
|
||||
#### Update a document with a file
|
||||
|
||||
This api is based on an existing Knowledge, and updates documents through files based on this Knowledge.
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/update-by-file' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--form 'data="{"name":"Dify","indexing_technique":"high_quality","process_rule":{"rules":{"pre_processing_rules":[{"id":"remove_extra_spaces","enabled":true},{"id":"remove_urls_emails","enabled":true}],"segmentation":{"separator":"###","max_tokens":500}},"mode":"custom"}}";type=text/plain' \
|
||||
--form 'file=@"/path/to/file"'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "Dify.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": "20230921150427533684"
|
||||
}
|
||||
```
|
||||
|
||||
#### Get Document Embedding Status (Progress)
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{batch}/indexing-status' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
{
|
||||
"data":[{
|
||||
"id": "",
|
||||
"indexing_status": "indexing",
|
||||
"processing_started_at": 1681623462.0,
|
||||
"parsing_completed_at": 1681623462.0,
|
||||
"cleaning_completed_at": 1681623462.0,
|
||||
"splitting_completed_at": 1681623462.0,
|
||||
"completed_at": null,
|
||||
"paused_at": null,
|
||||
"error": null,
|
||||
"stopped_at": null,
|
||||
"completed_segments": 24,
|
||||
"total_segments": 100
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
#### Delete a Document
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```bash
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
#### Get the Document List of a Knowledge Base
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
{
|
||||
"data": [
|
||||
{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "file_upload",
|
||||
"data_source_info": null,
|
||||
"dataset_process_rule_id": null,
|
||||
"name": "dify",
|
||||
"created_from": "",
|
||||
"created_by": "",
|
||||
"created_at": 1681623639,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false
|
||||
},
|
||||
],
|
||||
"has_more": false,
|
||||
"limit": 20,
|
||||
"total": 9,
|
||||
"page": 1
|
||||
}
|
||||
```
|
||||
|
||||
#### Add Chunks to a Document
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"segments": [{"content": "1","answer": "1","keywords": ["a"]}]}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```json
|
||||
{
|
||||
"data": [{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"document_id": "",
|
||||
"content": "1",
|
||||
"answer": "1",
|
||||
"word_count": 25,
|
||||
"tokens": 0,
|
||||
"keywords": [
|
||||
"a"
|
||||
],
|
||||
"index_node_id": "",
|
||||
"index_node_hash": "",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "",
|
||||
"created_at": 1695312007,
|
||||
"indexing_at": 1695312007,
|
||||
"completed_at": 1695312007,
|
||||
"error": null,
|
||||
"stopped_at": null
|
||||
}],
|
||||
"doc_form": "text_model"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### Get Chunks from a Document
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```bash
|
||||
{
|
||||
"data": [{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"document_id": "",
|
||||
"content": "1",
|
||||
"answer": "1",
|
||||
"word_count": 25,
|
||||
"tokens": 0,
|
||||
"keywords": [
|
||||
"a"
|
||||
],
|
||||
"index_node_id": "",
|
||||
"index_node_hash": "",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "",
|
||||
"created_at": 1695312007,
|
||||
"indexing_at": 1695312007,
|
||||
"completed_at": 1695312007,
|
||||
"error": null,
|
||||
"stopped_at": null
|
||||
}],
|
||||
"doc_form": "text_model"
|
||||
}
|
||||
```
|
||||
|
||||
#### Delete a Chunk in a Document
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments/{segment_id}' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```bash
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
#### Update a Chunk in a Document
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments/{segment_id}' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json'\
|
||||
--data-raw '{"segment": {"content": "1","answer": "1", "keywords": ["a"], "enabled": false}}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```bash
|
||||
{
|
||||
"data": [{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"document_id": "",
|
||||
"content": "1",
|
||||
"answer": "1",
|
||||
"word_count": 25,
|
||||
"tokens": 0,
|
||||
"keywords": [
|
||||
"a"
|
||||
],
|
||||
"index_node_id": "",
|
||||
"index_node_hash": "",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "",
|
||||
"created_at": 1695312007,
|
||||
"indexing_at": 1695312007,
|
||||
"completed_at": 1695312007,
|
||||
"error": null,
|
||||
"stopped_at": null
|
||||
}],
|
||||
"doc_form": "text_model"
|
||||
}
|
||||
```
|
||||
|
||||
#### Retrieve Chunks from a Knowledge Base
|
||||
|
||||
Request example:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/retrieve' \
|
||||
--header 'Authorization: Bearer {api_key}'\
|
||||
--header 'Content-Type: application/json'\
|
||||
--data-raw '{
|
||||
"query": "test",
|
||||
"retrieval_model": {
|
||||
"search_method": "keyword_search",
|
||||
"reranking_enable": false,
|
||||
"reranking_mode": null,
|
||||
"reranking_model": {
|
||||
"reranking_provider_name": "",
|
||||
"reranking_model_name": ""
|
||||
},
|
||||
"weights": null,
|
||||
"top_k": 1,
|
||||
"score_threshold_enabled": false,
|
||||
"score_threshold": null
|
||||
}
|
||||
}'
|
||||
```
|
||||
|
||||
Response example:
|
||||
|
||||
```bash
|
||||
{
|
||||
"query": {
|
||||
"content": "test"
|
||||
},
|
||||
"records": [
|
||||
{
|
||||
"segment": {
|
||||
"id": "7fa6f24f-8679-48b3-bc9d-bdf28d73f218",
|
||||
"position": 1,
|
||||
"document_id": "a8c6c36f-9f5d-4d7a-8472-f5d7b75d71d2",
|
||||
"content": "Operation guide",
|
||||
"answer": null,
|
||||
"word_count": 847,
|
||||
"tokens": 280,
|
||||
"keywords": [
|
||||
"install",
|
||||
"java",
|
||||
"base",
|
||||
"scripts",
|
||||
"jdk",
|
||||
"manual",
|
||||
"internal",
|
||||
"opens",
|
||||
"add",
|
||||
"vmoptions"
|
||||
],
|
||||
"index_node_id": "39dd8443-d960-45a8-bb46-7275ad7fbc8e",
|
||||
"index_node_hash": "0189157697b3c6a418ccf8264a09699f25858975578f3467c76d6bfc94df1d73",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "dbcb1ab5-90c8-41a7-8b78-73b235eb6f6f",
|
||||
"created_at": 1728734540,
|
||||
"indexing_at": 1728734552,
|
||||
"completed_at": 1728734584,
|
||||
"error": null,
|
||||
"stopped_at": null,
|
||||
"document": {
|
||||
"id": "a8c6c36f-9f5d-4d7a-8472-f5d7b75d71d2",
|
||||
"data_source_type": "upload_file",
|
||||
"name": "readme.txt",
|
||||
"doc_type": null
|
||||
}
|
||||
},
|
||||
"score": 3.730463140527718e-05,
|
||||
"tsne_position": null
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### Error message
|
||||
|
||||
Response example:
|
||||
|
||||
```bash
|
||||
{
|
||||
"code": "no_file_uploaded",
|
||||
"message": "Please upload your file.",
|
||||
"status": 400
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
| code | status | message |
|
||||
| ----------------------------- | ------ | -------------------------------------------------------------------------------------------- |
|
||||
| no\_file\_uploaded | 400 | Please upload your file. |
|
||||
| too\_many\_files | 400 | Only one file is allowed. |
|
||||
| file\_too\_large | 413 | File size exceeded. |
|
||||
| unsupported\_file\_type | 415 | File type not allowed. Supported format: txt, markdown, md, pdf, html, html, xlsx, docx, csv |
|
||||
| high\_quality\_dataset\_only | 400 | Current operation only supports 'high-quality' datasets. |
|
||||
| dataset\_not\_initialized | 400 | The dataset is still being initialized or indexing. Please wait a moment. |
|
||||
| archived\_document\_immutable | 403 | The archived document is not editable. |
|
||||
| dataset\_name\_duplicate | 409 | The dataset name already exists. Please modify your dataset name. |
|
||||
| invalid\_action | 400 | Invalid action. |
|
||||
| document\_already\_finished | 400 | The document has been processed. Please refresh the page or go to the document details. |
|
||||
| document\_indexing | 400 | The document is being processed and cannot be edited. |
|
||||
| invalid\_metadata | 400 | The metadata content is incorrect. Please check and verify. |
|
||||
@@ -0,0 +1,59 @@
|
||||
---
|
||||
title: Knowledge Base and Document Maintenance
|
||||
---
|
||||
|
||||
## Knowledge Base Management
|
||||
|
||||
> The knowledge base page is accessible only to the team owner, team administrators, and users with editor permissions.
|
||||
|
||||
On the Dify team homepage, click the "Knowledge Base" tab at the top, select the knowledge base you want to manage, then click **Settings** in the left navigation panel to make adjustments. You can modify the knowledge base name, description, visibility permissions, indexing mode, embedding model, and retrieval settings.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/knowledge-settings-01.png" alt="Knowledge Base Settings" />
|
||||
</Frame>
|
||||
|
||||
**Knowledge Base Name**: Used to distinguish among different knowledge bases.
|
||||
|
||||
**Knowledge Description**: Used to describe the information represented by the documents in the knowledge base.
|
||||
|
||||
**Visibility Permissions**: Defines access control for the knowledge base with three levels:
|
||||
|
||||
1. **"Only Me"**: Restricts access to the knowledge base owner.
|
||||
2. **"All team members"**: Grants access to every member of the team.
|
||||
3. **"Partial team members"**: Allows selective access to specific team members.
|
||||
|
||||
Users without appropriate permissions cannot access the knowledge base. When granting access to team members (options 2 or 3), authorized users receive full permissions, including view, edit, and delete rights for the knowledge base content.
|
||||
|
||||
**Indexing Mode**: For detailed explanations, please [refer to the documentation](https://docs.dify.ai/guides/knowledge-base/create-knowledge-and-upload-documents#5-indexing-method).
|
||||
|
||||
**Embedding Model**: Allows you to modify the embedding model for the knowledge base. Changing the embedding model will re-embed all documents in the knowledge base, and the original embeddings will be deleted.
|
||||
|
||||
**Retrieval Settings**: For detailed explanations, please [refer to the documentation](https://docs.dify.ai/guides/knowledge-base/create-knowledge-and-upload-documents#6-retrieval-settings).
|
||||
|
||||
***
|
||||
|
||||
#### View Linked Applications in the Knowledge Base
|
||||
|
||||
On the left side of the knowledge base, you can see all linked Apps. Hover over the circular icon to view the list of all linked apps. Click the jump button on the right to quickly browser them.
|
||||
|
||||

|
||||
|
||||
You can manage your knowledge base documents either through a web interface or via an API.
|
||||
|
||||
#### Maintain Knowledge Documents
|
||||
|
||||
You can administer all documents and their corresponding chunks directly in the knowledge base. For more details, refer to the following documentation:
|
||||
|
||||
<Card title="Maintain Knowledge Documents" icon="link" href="knowledge-and-documents-maintenance/maintain-knowledge-documents.md">
|
||||
Learn more about managing knowledge documents
|
||||
</Card>
|
||||
|
||||
#### Maintain Knowledge Base Via API
|
||||
|
||||
Dify Knowledge Base provides a comprehensive set of standard APIs. Developers can use these APIs to perform routine management and maintenance tasks, such as adding, deleting, updating, and retrieving documents and chunks. For more details, refer to the following documentaiton:
|
||||
|
||||
<Card title="Maintain Dataset via API" icon="link" href="knowledge-and-documents-maintenance/maintain-dataset-via-api.md">
|
||||
Learn more about maintaining knowledge base through API
|
||||
</Card>
|
||||
|
||||

|
||||
@@ -1,129 +0,0 @@
|
||||
---
|
||||
title: Connect External Knowledge
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
> To make a distinction, knowledge bases independent of the Dify platform are collectively referred to as **"external knowledge bases"** in this article.
|
||||
|
||||
## Functional Introduction
|
||||
|
||||
For developers with advanced content retrieval requirements, **the built-in knowledge base functionality and text retrieval mechanisms of the Dify platform may have limitations, particularly in terms of customizing recall results.**
|
||||
|
||||
Due to the requirement of higher accuracy of text retrieval and recall, as well as the need to manage internal materials, some developer teams choose to independently develop RAG algorithms and independently maintain text retrieval systems, or uniformly host content to cloud vendors' knowledge base services (such as [AWS Bedrock](https://aws.amazon.com/bedrock/)).
|
||||
|
||||
As a neutral platform for LLM application development, Dify is committed to providing developers with a wider range of options.
|
||||
|
||||
The **Connect to External Knowledge Base** feature enables integration between the Dify platform and external knowledge bases. Through API services, AI applications can access a broader range of information sources. This capability offers two key advantages:
|
||||
|
||||
* The Dify platform can directly obtain the text content hosted in the cloud service provider's knowledge base, so that developers do not need to repeatedly move the content to the knowledge base in Dify;
|
||||
* The Dify platform can directly obtain the text content processed by algorithms in the self-built knowledge base. Developers only need to focus on the information retrieval mechanism of the self-built knowledge base and continuously optimize and improve the accuracy of information retrieval.
|
||||
|
||||
<Frame caption="Principle of external knowledge base connection">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (1) (1).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
Here are the detailed steps for connecting to external knowledge:
|
||||
|
||||
<Steps>
|
||||
<Step title="Create a Compliant External Knowledge Base API" titleSize="h2" >
|
||||
Create a compliant External Knowledge Base API before setting up the API service, please refer to Dify's [External Knowledge Base API](external-knowledge-api-documentation.md) specifications to ensure successful integration between your external knowledge base and Dify.
|
||||
</Step>
|
||||
<Step title="Add External Knowledge API">
|
||||
> Currently, when connecting to external knowledge bases, Dify only supports retrieval permissions and does not support optimization or modification of external knowledge bases. Developers need to maintain external knowledge bases themselves.
|
||||
|
||||
Navigate to the **"Knowledge"** page, click **"External Knowledge API"** in the upper right corner, then click **"Add External Knowledge API"**. Follow the page prompts to fill in the following information:
|
||||
|
||||
* Name Customizable name to distinguish different external knowledge APIs;
|
||||
* API Endpoint The URL of the external knowledge base API endpoint, e.g., api-endpoint/retrieval; refer to the [External Knowledge API](external-knowledge-api-documentation.md) for detailed instructions;
|
||||
* API Key Connection key for the external knowledge, refer to the [External Knowledge API](external-knowledge-api-documentation.md) for detailed instructions.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (353).png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="Connect to the External Knowledge Base">
|
||||
Go to the **"Knowledge"** page, click **"Connect to an External Knowledge Base"** under the Add Knowledge Base card to direct to the parameter configuration page.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (354).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
Fill in the following parameters:
|
||||
|
||||
* **Knowledge base name & description**
|
||||
* **External Knowledge API**
|
||||
Select the external knowledge base API associated in step 2; Dify will call the text content stored in the external knowledge base through the API connection method.
|
||||
* **External knowledge ID**
|
||||
Specify the particular external knowledge base ID to be associated, refer to the external knowledge base API definition for detailed instructions.
|
||||
|
||||
* **Retrieval Setting**
|
||||
|
||||
**Top K:** When a user sends a question, it will request the external knowledge API to obtain highly relevant content chunks. This parameter is used to filter text chunks with high similarity to the user's question. The default value is 3; the higher the value, the more text chunks with relevant similarities will be retrieval.
|
||||
|
||||
**Score Threshold:** The similarity threshold for text chunk filtering, only retrievaling text chunks that exceed the set score. The default value is 0.5. A higher value indicates a higher requirement for similarity between the text and the question, expecting fewer retrievaled text chunks, and the results will be relatively more precise.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (355).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="Test External Knowledge Base and Retrieval Results">
|
||||
After connected with the external knowledge base, developers can simulate possible question keywords in the **"Retrieval Testing"** to preview text chunks that might be retrieval. If you are unsatisfied with the retrieval results, try modifying the **External Knowledge Base Settings** or adjusting the retrieval strategy of the external knowledge base.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (356).png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="Integrating External Knowledge base in Applications">
|
||||
* **Chatbot / Agent** type application
|
||||
|
||||
Associate the external knowledge base in the orchestration page within Chatbot / Agent type applications.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (357).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
* **Chatflow / Workflow** type application
|
||||
|
||||
Add a **"Knowledge Retrieval"** node and select the external knowledge base.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (358).png" alt="" /><figcaption></figcaption>
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="Manage External Knowledge" titleSize="p">
|
||||
Navigate to the **"Knowledge"** page, external knowledge base cards will list an **EXTERNAL** label in the upper right corner. Select the knowledge base needs to be modified, click **"Settings"** to modify the following information:
|
||||
|
||||
* **Knowledge base name and description**
|
||||
* **Permissions**
|
||||
|
||||
Provide **"Only me"**, **"All team members"**, and **"Partial team members"** permission scope. Those without permission will not be able to access the knowledge base. If you choose to make the knowledge base public to other members, it means that other members also have the rights to view, edit, and delete the knowledge base.
|
||||
* **Retrieval Setting**
|
||||
|
||||
**Top K:** When a user sends a question, it will request the external knowledge API to obtain highly relevant content segments. This parameter is used to filter text chunks with high similarity to the user's question. The default value is 3; the higher the value, the more text chunks with relevant similarities will be retrievaled.
|
||||
|
||||
**Score threshold:** The similarity threshold for text chunk filtering, only retrievaling text chunks that exceed the set score. The default value is 0.5. A higher value indicates a higher requirement for similarity between the text and the question, expecting fewer retrievaled text chunks, and the results will be relatively more precise.
|
||||
|
||||
The **"External Knowledge API"** and **"External Knowledge ID"** associated with the external knowledge base do not support modification. If modification is needed, please associate a new **"External Knowledge API"** and reset it.
|
||||
<Frame caption="create knowledge base">
|
||||
<img src="/ja-jp/img/connect-kb-7-en.webp" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Connection Example
|
||||
|
||||
[how-to-connect-aws-bedrock.md](/learn-more/use-cases/how-to-connect-aws-bedrock.md "mention")
|
||||
|
||||
## FAQ
|
||||
|
||||
**How to Fix the Errors Occurring When Connecting to External Knowledge API?**
|
||||
|
||||
Solutions corresponding to each error code in the return information:
|
||||
|
||||
| Error Code | Result | Solutions |
|
||||
| ---------- | ----------------------------------- | ----------------------------------------------------------- |
|
||||
| 1001 | Invalid Authorization header format | Please check the Authorization header format of the request |
|
||||
| 1002 | Authorization failed | Please check whether the API Key you entered is correct. |
|
||||
| 2001 | The knowledge is not exist | Please check the external repository |
|
||||
@@ -0,0 +1,64 @@
|
||||
---
|
||||
title: Create Knowledge Base
|
||||
---
|
||||
|
||||
Steps to upload documents to create a knowledge base:
|
||||
|
||||
1. Create a knowledge base and import either local document file or online data.
|
||||
|
||||
<Card title="1.-import-text-data" icon="link" href="import-content-data">
|
||||
Create a knowledge base and import either local document file or online data.
|
||||
</Card>
|
||||
|
||||
2. Choose a chunking mode and preview the spliting results. This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.
|
||||
|
||||
<Card title="2. choose-a-chunk-mode" icon="link" href="chunking-and-cleaning-text">
|
||||
Choose a chunking mode and preview the spliting results. This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.
|
||||
</Card>
|
||||
|
||||
3. Configure the indexing method and retrieval setting. Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks.
|
||||
|
||||
<Card title="select-the-indexing-method-and-retrieval-setting" icon="link" href="setting-indexing-methods">
|
||||
Configure the indexing method and retrieval setting. Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks.
|
||||
</Card>
|
||||
|
||||
4. Wait for the chunk embeddings to complete.
|
||||
|
||||
5. Once finished, link the knowledge base to your application and start using it. You can then [integrate it into your application](integrate-knowledge-within-application.md) to build an LLM that are capable of Q\&A based on knowledge-bases. If you want to modify and manage the knowledge base further, take refer to [Knowledge Base and Document Maintenance](knowledge-and-documents-maintenance.md).
|
||||
|
||||

|
||||
|
||||
***
|
||||
|
||||
### Reference
|
||||
|
||||
#### ETL
|
||||
|
||||
In production-level applications of RAG, to achieve better data retrieval, multi-source data needs to be preprocessed and cleaned, i.e., ETL (extract, transform, load). To enhance the preprocessing capabilities of unstructured/semi-structured data, Dify supports optional ETL solutions: **Dify ETL** and [**Unstructured ETL**](https://unstructured.io/).
|
||||
|
||||
> Unstructured can efficiently extract and transform your data into clean data for subsequent steps.
|
||||
|
||||
ETL solution choices in different versions of Dify:
|
||||
|
||||
* The SaaS version defaults to using Unstructured ETL and cannot be changed;
|
||||
* The community version defaults to using Dify ETL but can enable Unstructured ETL through [environment variables](../../getting-started/install-self-hosted/environments.md#zhi-shi-ku-pei-zhi);
|
||||
|
||||
Differences in supported file formats for parsing:
|
||||
|
||||
| DIFY ETL | Unstructured ETL |
|
||||
| ------------------------------------------------------- | --------------------------------------------------------------------------------------- |
|
||||
| txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv | txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv, eml, msg, pptx, ppt, xml, epub |
|
||||
|
||||
<Info>
|
||||
Different ETL solutions may have differences in file extraction effects. For more information on Unstructured ETL’s data processing methods, please refer to the [official documentation](https://docs.unstructured.io/open-source/core-functionality/partitioning).
|
||||
</Info>
|
||||
|
||||
#### **Embedding**
|
||||
|
||||
**Embedding** transforms discrete variables (words, sentences, documents) into continuous vector representations, mapping high-dimensional data to lower-dimensional spaces. This technique preserves crucial semantic information while reducing dimensionality, enhancing content retrieval efficiency.
|
||||
|
||||
**Embedding models**, specialized large language models, excel at converting text into dense numerical vectors, effectively capturing semantic nuances for improved data processing and analysis.
|
||||
|
||||
#### **Metadata**
|
||||
|
||||
For managing the knowledge base with metadata, see *[Metadata](https://docs.dify.ai/guides/knowledge-base/metadata)*.
|
||||
379
en-us/user-guide/knowledge-base/metadata.mdx
Normal file
379
en-us/user-guide/knowledge-base/metadata.mdx
Normal file
@@ -0,0 +1,379 @@
|
||||
---
|
||||
title: Metadata
|
||||
---
|
||||
|
||||
## What is Metadata?
|
||||
|
||||
### Overview
|
||||
|
||||
Metadata is information that describes your data - essentially “data about data”. Just as a book has a table of contents to help you understand its structure, metadata provides context about your data’s content, origin, purpose, etc., making it easier for you to find and manage information in your knowledge base.
|
||||
|
||||
This guide aims to help you understand metadata and effectively manage your knowledge base.
|
||||
|
||||
### Core Concepts
|
||||
|
||||
- **Metadata Field:** The container for specific information about a document. Think of it as a labeled box where you store particular details about your content.
|
||||
|
||||
- **Value Count:** The number of unique values contained in a metadata field.
|
||||
|
||||

|
||||
|
||||
- **Field Name:** The label of a metadata field (e.g., “author”, “language”).
|
||||
|
||||
- **Value:** The information stored in a metadata field (e.g., “Jack”, “English”).
|
||||
|
||||

|
||||
|
||||
- **Value Type:** The type of value a field can contain.
|
||||
- Dify supports three value types:
|
||||
- String: For text-based information
|
||||
- Number: For numerical data
|
||||
- Time: For dates/timestamps
|
||||
|
||||
|
||||
|
||||
## How to Manage My Metadata?
|
||||
|
||||
### Manage Metadata Fields in the Knowledge Base
|
||||
|
||||
You can create, modify, and delete metadata fields in the knowledge base.
|
||||
|
||||
> Any changes you make to metadata fields here affect your knowledge base globally.
|
||||
|
||||
#### Get Started with the Metadata Panel
|
||||
|
||||
##### Access the Metadata Panel
|
||||
|
||||
To access the Metadata Panel, go to **Knowledge Base** page and click **Metadata**.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
##### Work with the Metadata Panel
|
||||
|
||||
- **View Metadata:** Browse built-in and custom metadata. **Built-in Metadata** is system-generated; **Custom Metadata** is user-defined.
|
||||
|
||||
- **Add Metadata Fields:** Create new metadata fields by clicking **+Add Metadata**.
|
||||
|
||||
- **Edit Metadata Fields:** Modify field names by clicking the edit icon next to each field.
|
||||
|
||||
- **Delete Metadata Fields:** delete unwanted fields by clicking the the delete icon next to each field.
|
||||
|
||||
##### Benefits
|
||||
|
||||
**Metadata panel** centralizes field management, making it easy to organize and find documents through customizable labels.
|
||||
|
||||
##### Built-in vs Custom Metadata
|
||||
|
||||
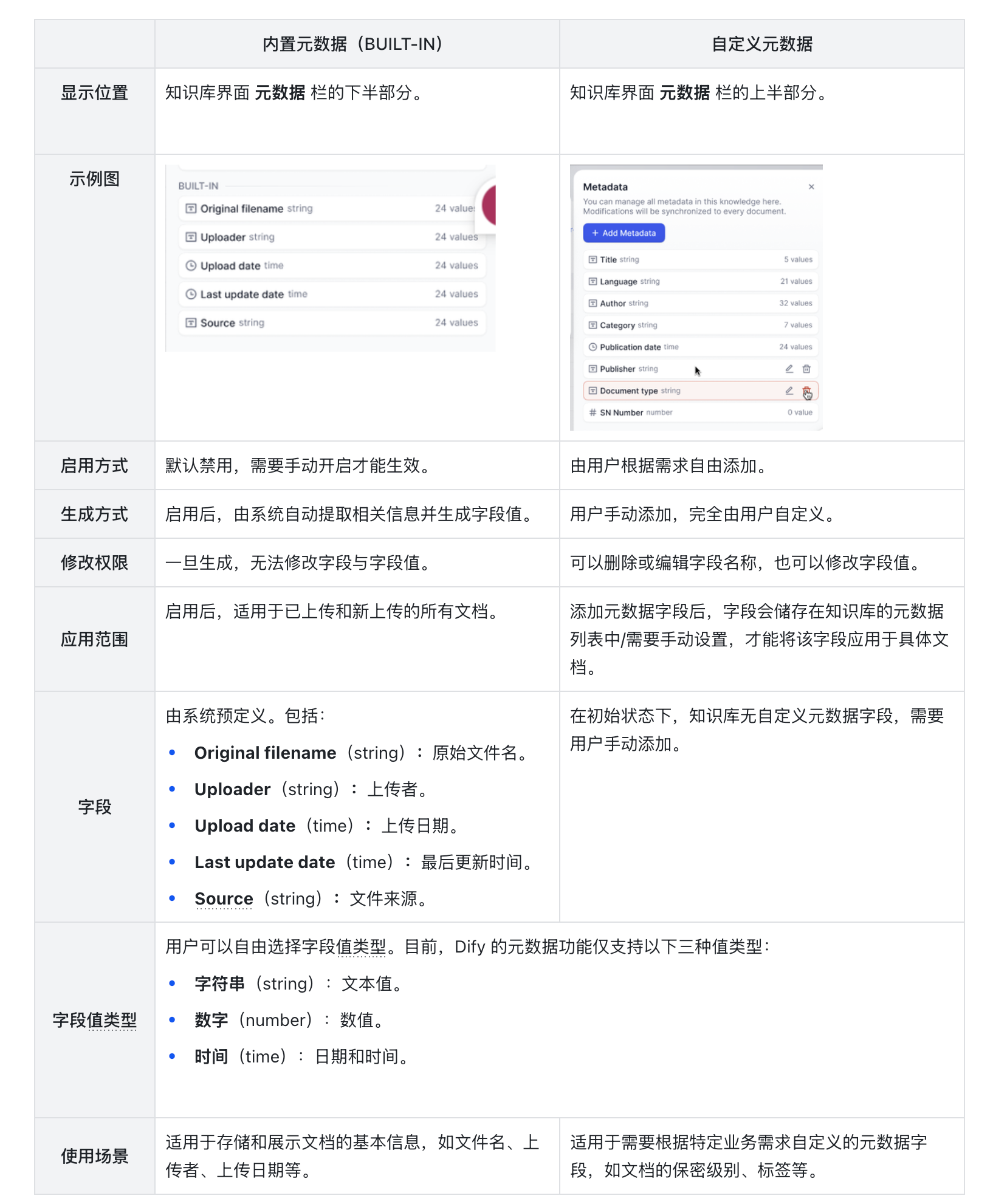
|
||||
|
||||
#### Create New Metadata Fields
|
||||
|
||||
To create a new metadata field:
|
||||
|
||||
1. Click **+Add Metadata** to open the **New Metadata** dialog.
|
||||
|
||||

|
||||
|
||||
2. Choose the value type:
|
||||
- String (for text)
|
||||
- Number (for numerical values)
|
||||
- Time (for dates/timestamps)
|
||||
|
||||
3. Name the field.
|
||||
|
||||
> Naming rules: Use lowercase letters, numbers, and underscores only.
|
||||
|
||||
|
||||
|
||||
4. Click **Save** to apply changes.
|
||||
|
||||
> Note: New fields are automatically available across all documents in your knowledge base.
|
||||
|
||||

|
||||
|
||||
#### Edit Metadata Fields
|
||||
|
||||
To edit a metadata field:
|
||||
|
||||
1. Click the edit icon next to a field to open the **Rename** dialog.
|
||||
|
||||

|
||||
|
||||
2. Enter the new name in the **Name** field.
|
||||
|
||||
> Note: You can only modify the field name, not the value type.
|
||||
|
||||
|
||||
|
||||
3. Click **Save** to apply changes.
|
||||
|
||||

|
||||
|
||||
#### Delete Metadata Fields
|
||||
|
||||
To delete a metadata field, click the delete icon next to a field to delete it.
|
||||
|
||||
> Note: Deleting a field deletes it and all its values from all documents in your knowledge base.
|
||||
|
||||

|
||||
|
||||
### Edit Metadata
|
||||
|
||||
#### Bulk Edit Metadata in the Metadata Editor
|
||||
|
||||
You can edit metadata in bulk in the knowledge base.
|
||||
|
||||
##### Get Started with the Metadata Editor
|
||||
|
||||
###### Access the Metadata Editor
|
||||
|
||||
To access the Metadata Editor:
|
||||
|
||||
1. In the knowledge base, select documents using the checkboxes on the left.
|
||||
|
||||
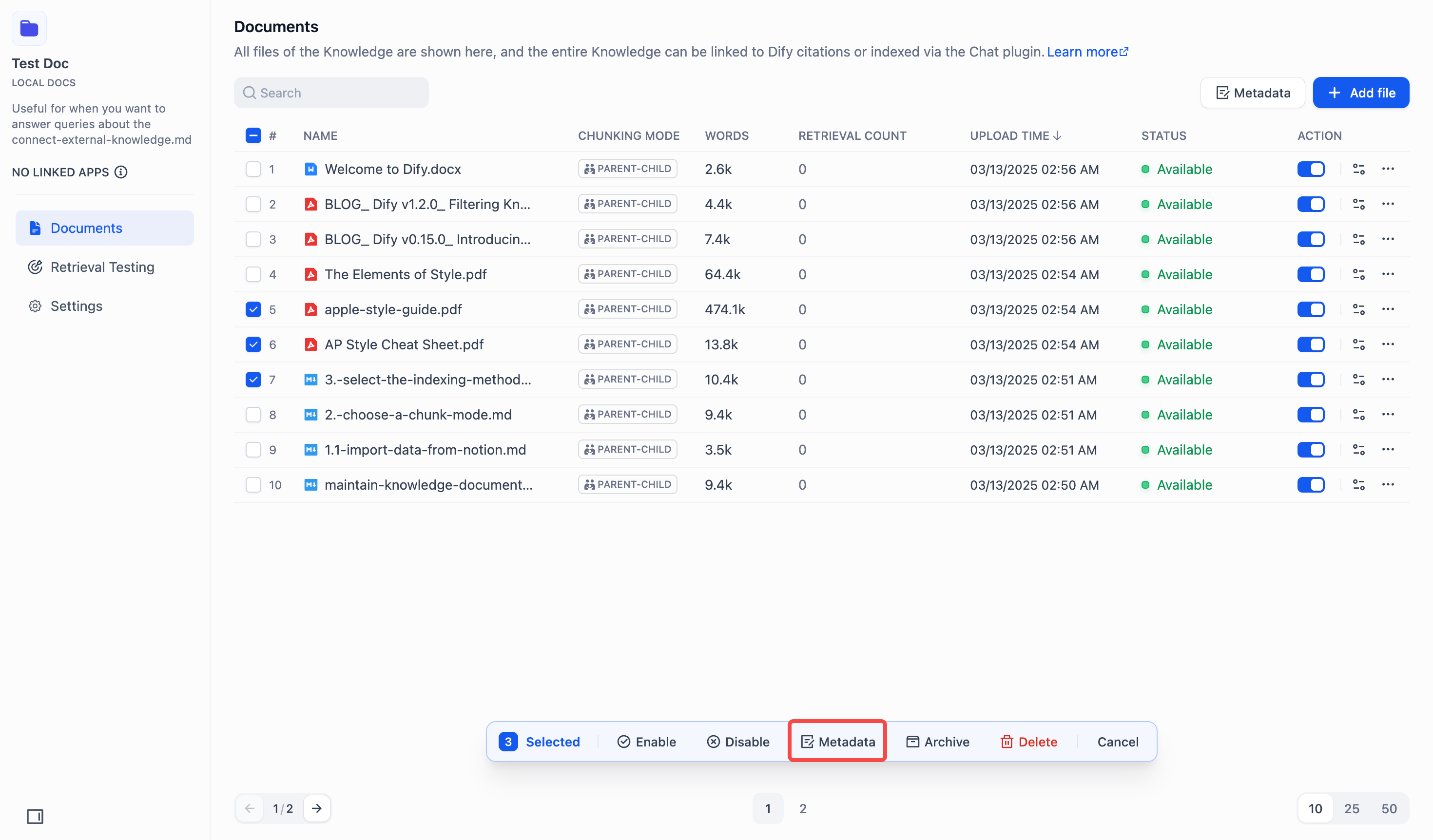
|
||||
|
||||
2. Click **Metadata** in the bottom action bar to open the Metadata Editor.
|
||||
|
||||

|
||||
|
||||
###### Work with the Metadata Editor
|
||||
|
||||
- **View Metadata:** The editor shows existing metadata in the upper section and new metadata in the lower section.
|
||||
|
||||
<Info>
|
||||
Field status is indicated by:
|
||||
No marker: Unchanged.
|
||||
Blue dot: Modified.
|
||||
Reset option: Appears on hover over the blue dot.
|
||||
</Info>
|
||||
|
||||
- **Edit Values:** Modify values in the field box.
|
||||
|
||||
<Info>
|
||||
Single values show directly in the field box.
|
||||
Multiple values show as a “Multiple Values” card. If you delete all values, the box will show “Empty”.
|
||||
</Info>
|
||||
|
||||
- **Add Fields:** Click **+Add Metadata** to **create new fields**, **add existing fields** and **manage all fields**.
|
||||
|
||||
- **Delete Fields:** Click the delete icon to delete a field from selected documents.
|
||||
|
||||
- **Set Update Scope:** Choose whether to apply changes to all selected documents.
|
||||
|
||||
##### Bulk Add Metadata
|
||||
|
||||
To add metadata in bulk:
|
||||
|
||||
1. Click **+Add Metadata** in the editor to:
|
||||
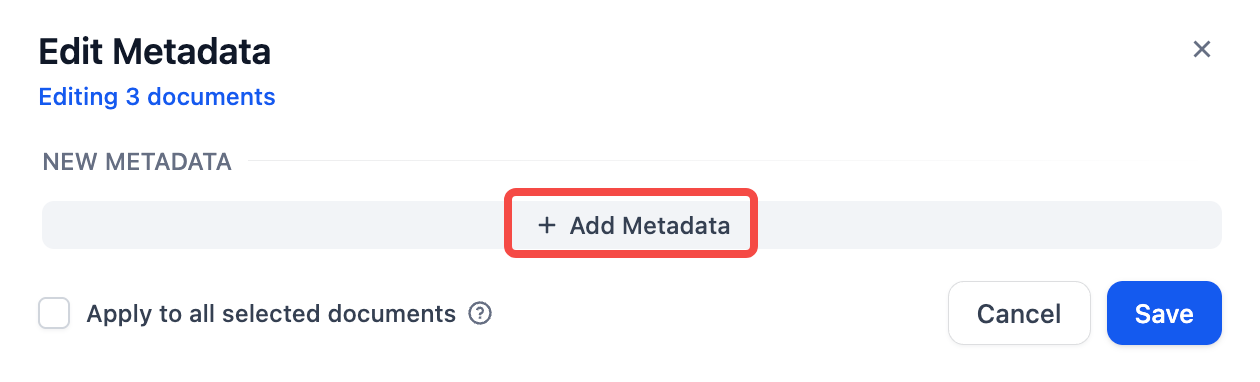
|
||||
|
||||
- Create new fields via **+New Metadata**.
|
||||
|
||||
> New fields are automatically added to the knowledge base.
|
||||
|
||||

|
||||
|
||||
- Add existing fields from the dropdown or from the search box.
|
||||
|
||||

|
||||
|
||||
- Access the Metadata Panel to manage metadata fields via **Manage**.
|
||||
|
||||

|
||||
|
||||
2. *(Optional)* Enter values for new fields.
|
||||
|
||||
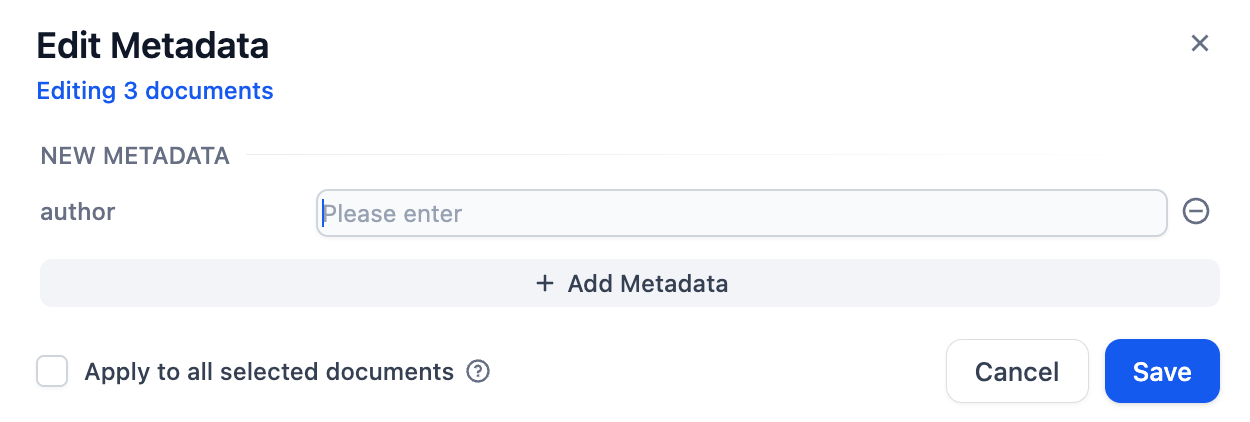
|
||||
|
||||
> The date picker is for time-type fields.
|
||||
|
||||
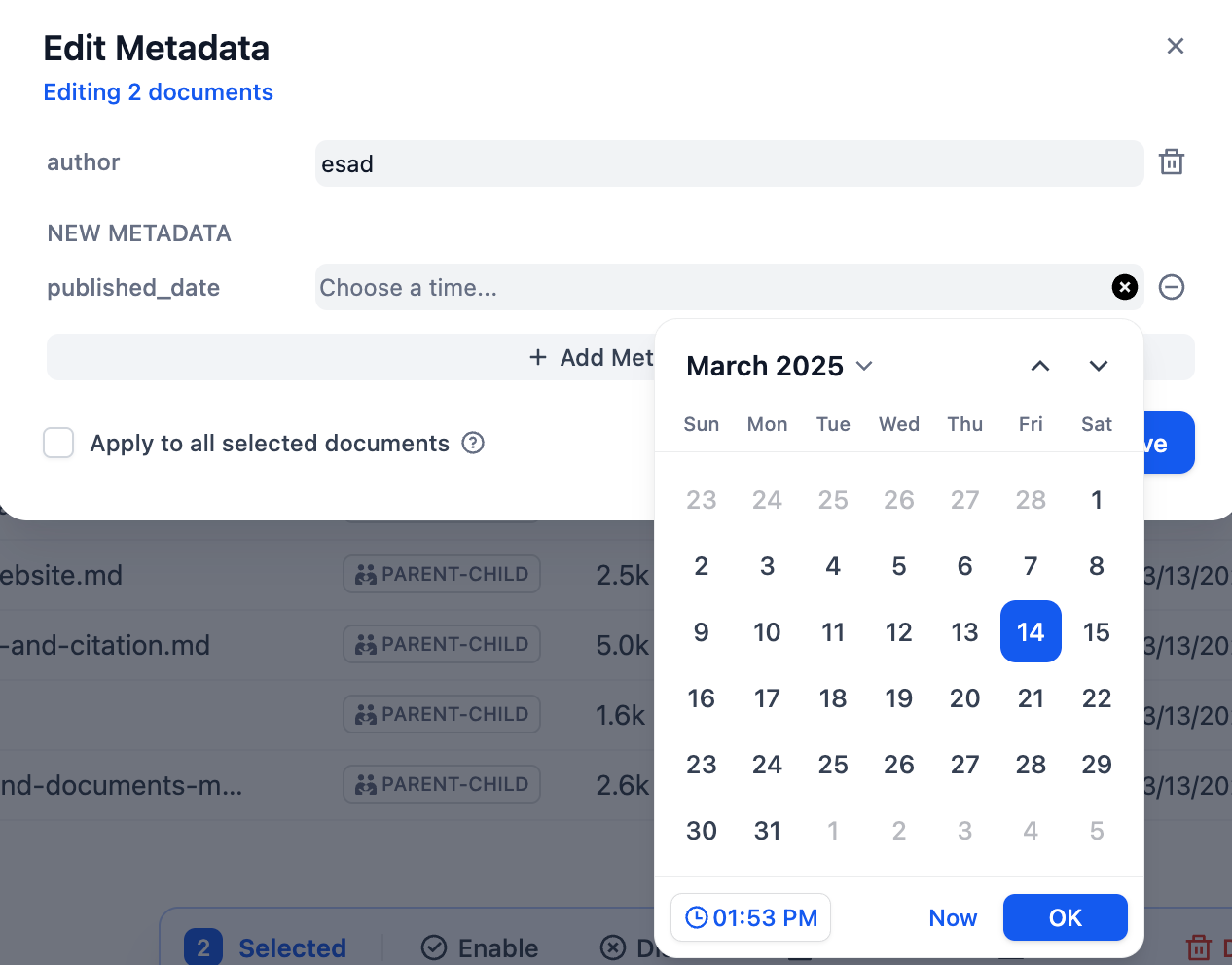
|
||||
|
||||
3. Click **Save** to apply changes.
|
||||
|
||||
##### Bulk Update Metadata
|
||||
|
||||
To update metadata in bulk:
|
||||
|
||||
1. In the editor:
|
||||
- **Add Values:** Type directly in the field boxes.
|
||||
|
||||
- **Reset Values:** Click the blue dot that appears on hover.
|
||||

|
||||
|
||||
- **Delete Values:** Clear the field or delete the **Multiple Value** card.
|
||||
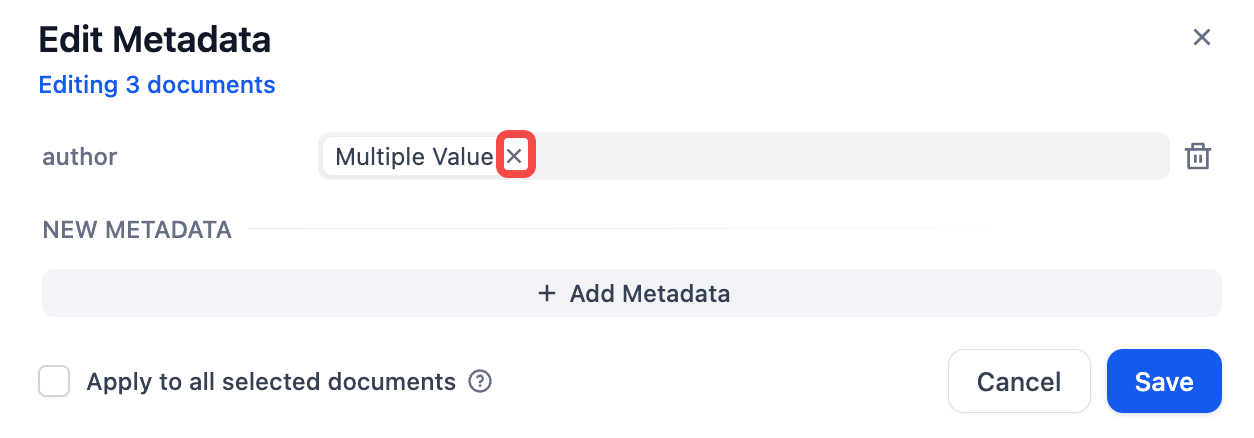
|
||||
|
||||
- **Delete fields:** Click the delete icon (fields appear struck through and grayed out).
|
||||
> Note: This only deletes the field from this document, not from your knowledge base.
|
||||
|
||||
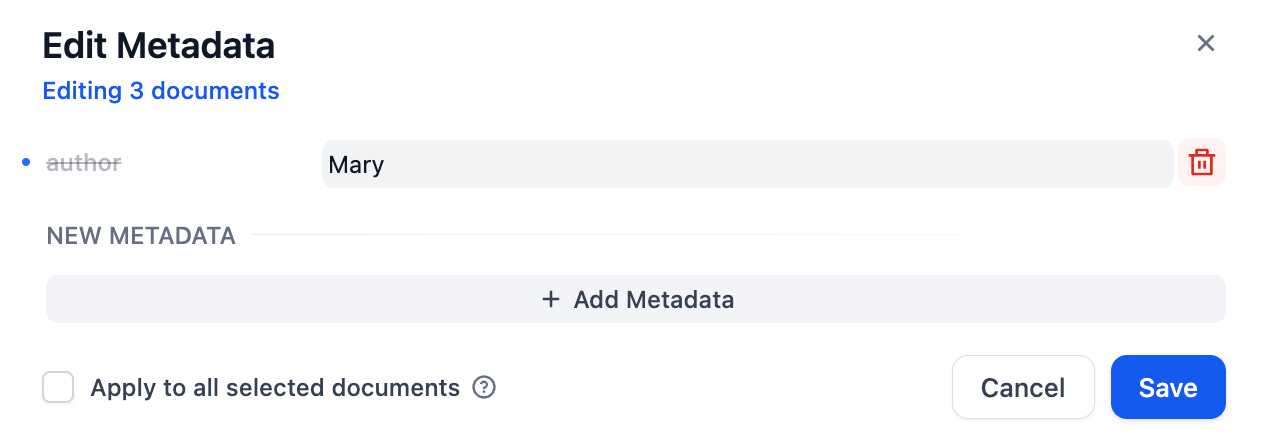
|
||||
|
||||
2. Click **Save** to apply changes.
|
||||
|
||||
##### Set Update Scope
|
||||
|
||||
Use **Apply to All Documents** to control changes:
|
||||
|
||||
- **Unchecked (Default)**: Updates only documents that already have the field.
|
||||
|
||||
- **Checked**: Adds or updates fields across all selected documents.
|
||||
|
||||
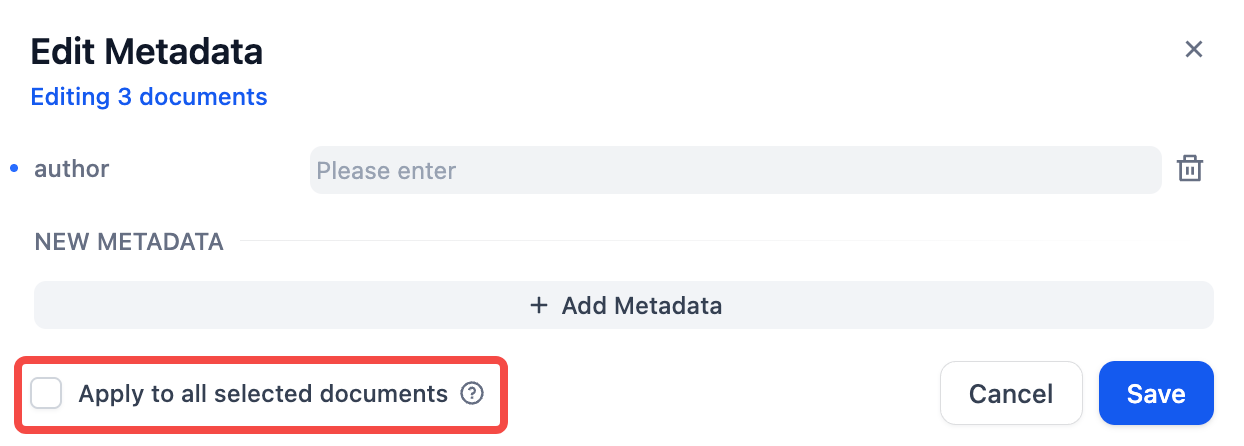
|
||||
|
||||
#### Edit Metadata on the Document Details Page
|
||||
|
||||
You can edit a single document’s metadata on its details page.
|
||||
|
||||
##### Access Metadata Edit Mode
|
||||
|
||||
To edit a single document’s metadata:
|
||||
|
||||
On the document details page, click **Start labeling** to begin editing.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
##### Add Metadata
|
||||
|
||||
To add a single document’s metadata fields and values:
|
||||
|
||||
1. Click **+Add Metadata** to:
|
||||

|
||||
|
||||
- Create new fields via **+New Metadata**.
|
||||
|
||||
> New fields are automatically added to the knowledge base.
|
||||
|
||||

|
||||
|
||||
- Add existing fields from the dropdown or from the search box.
|
||||
|
||||

|
||||
|
||||
- Access the Metadata Panel via **Manage**.
|
||||
|
||||

|
||||
|
||||
2. *(Optional)* Enter values for new fields.
|
||||
|
||||

|
||||
|
||||
3. Click **Save** to apply changes.
|
||||
|
||||
##### Edit Metadata
|
||||
|
||||
To update a single document’s metadata fields and values:
|
||||
|
||||
1. Click **Edit** in the top right to begin editing.
|
||||
|
||||

|
||||
|
||||
2. Edit metadata:
|
||||
- **Update Values:** Type directly in value fields or delete it.
|
||||
|
||||
> Note: You can only modify the value, not the value name.
|
||||
|
||||
- **Delete Fields:** Click the delete icon.
|
||||
|
||||
> Note: This only deletes the field from this document, not from your knowledge base.
|
||||
|
||||

|
||||
|
||||
3. Click **Save** to apply changes.
|
||||
|
||||
## How to Filter Documents with Metadata?
|
||||
|
||||
See **Metadata Filtering** in *[Integrate Knowledge Base within Application](https://docs.dify.ai/guides/knowledge-base/integrate-knowledge-within-application)*.
|
||||
|
||||
## API Documentation
|
||||
|
||||
See *[Maintaining Dataset via API](https://docs.dify.ai/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api)*.
|
||||
|
||||
## FAQ
|
||||
|
||||
- **What can I do with metadata?**
|
||||
|
||||
- Find information faster with smart filtering.
|
||||
|
||||
- Control access to sensitive content.
|
||||
|
||||
- Organize data more effectively.
|
||||
|
||||
- Automate workflows based on metadata rules.
|
||||
|
||||
- **Fields vs Values: What is the difference?**
|
||||
|
||||
| Concept | Definition | Characteristics | Examples |
|
||||
|---|---|---|---|
|
||||
| Metadata Fields in the Metadata Panel | System-defined attributes that describe document properties | Global fields accessible across all documents in the knowledge base | Author, Type, Date, etc. |
|
||||
| Metadata Value on a document's detail page | Custom metadata tagged according to individual document requirements | Unique metadata values assigned based on document content and context | The "Author" field in Document A is set to "Mary" value, while in Document B it is set to "John" value. |
|
||||
|
||||
- **How do different delete options work?**
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Action</th>
|
||||
<th>Steps</th>
|
||||
<th>Image</th>
|
||||
<th>Impact</th>
|
||||
<th>Outcome</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>Delete field in the Metadata Panel</td>
|
||||
<td>In the Metadata Panel, click delete icon next to field</td>
|
||||
<td align="center">
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2025/03/13367a865d589a29b7c4098526fad5dc.png"
|
||||
alt="knowledge_base_delete"
|
||||
width="150"
|
||||
/>
|
||||
</td>
|
||||
<td>Global - affects all documents</td>
|
||||
<td>Field and all values permanently deleted from the knowledge base</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Delete field in the Metadata Editor</td>
|
||||
<td>In the Metadata Editor, click delete icon next to field</td>
|
||||
<td align="center">
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2025/03/ed8c9143ba9a8eae6efcb76e309dbec1.png"
|
||||
alt="bulk_delete"
|
||||
width="150"
|
||||
/>
|
||||
</td>
|
||||
<td>Selected documents only</td>
|
||||
<td>Field deleted from selected documents; remains in the knowledge base</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Delete field on the document detail page</td>
|
||||
<td>In the Edit Mode, click delete icon next to field</td>
|
||||
<td align="center">
|
||||
<img
|
||||
src="https://assets-docs.dify.ai/2025/03/19d7fe886dd30a3f3322fa2a87f87203.png"
|
||||
alt="single_delete"
|
||||
width="150"
|
||||
/>
|
||||
</td>
|
||||
<td>Current document only</td>
|
||||
<td>Field deleted from current document; remains in the knowledge base</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
- **Can I see values in the Metadata Panel?**
|
||||
|
||||
The management panel only shows value counts (e.g., "24 values"). Please check the document details page to see specific values.
|
||||
|
||||
- **Can I delete a specific value in the Metadata Editor?**
|
||||
|
||||
No - bulk edit only deletes all values at once.
|
||||
|
||||
To delete a specific value, go to the document details page and follow the steps in **Edit Metadata on the Document Details Page > Edit Metadata**.
|
||||
49
en-us/user-guide/knowledge-base/readme.mdx
Normal file
49
en-us/user-guide/knowledge-base/readme.mdx
Normal file
@@ -0,0 +1,49 @@
|
||||
---
|
||||
title: Knowledge
|
||||
---
|
||||
|
||||
Dify’s Knowledge feature visualizes each stage of the RAG pipeline, providing a friendly UI for application builders to easily manage personal or team knowledge. It also allows for seamless integration into AI applications.
|
||||
|
||||
Developers can upload internal company documents, FAQs, and standard working guides, then process them into structured data that large language models (LLMs) can query.
|
||||
|
||||
Compared with the static pre-trained datasets built into AI models, the content in a knowledge base can be updated in real time, ensuring LLMs always have access to the latest information and helping avoid problems caused by outdated or missing data.
|
||||
|
||||
When an LLM receives a user query, it first uses keywords to search within the knowledge base. Based on those keywords, the knowledge base returns content chunks with high relevance rankings, giving the LLM crucial context to generate more precise answers.
|
||||
|
||||
This approach ensures LLMs don’t rely solely on pre-trained knowledge. Instead, they can also draw from real-time documents and databases, enhancing both the accuracy and relevance of responses.
|
||||
|
||||
**Key Advantages**
|
||||
|
||||
**• Real-Time Updates**: The knowledge base can be updated anytime, ensuring the model always has the latest information.
|
||||
|
||||
• **Precision**: By retrieving relevant documents, the LLM can ground its answers in actual information, minimizing hallucinations.
|
||||
|
||||
• **Flexibility**: Developers can customize the knowledge base content to match specific needs, defining the scope of knowledge as required.
|
||||
|
||||
***
|
||||
|
||||
You only need to prepare text content, such as:
|
||||
|
||||
* Long text content (TXT, Markdown, DOCX, HTML, JSONL, or even PDF files)
|
||||
* Structured data (CSV, Excel, etc.)
|
||||
* Online data source(Web pages, Notion, etc.)
|
||||
|
||||
By simply uploading files to the **Knowledge Base**, data processing is handled automatically.
|
||||
|
||||
> If your team already has an independent knowledge base, you can use the [“Connect to an External Knowledge Base”](connect-external-knowledge) feature to establish its connection with Dify.
|
||||
|
||||
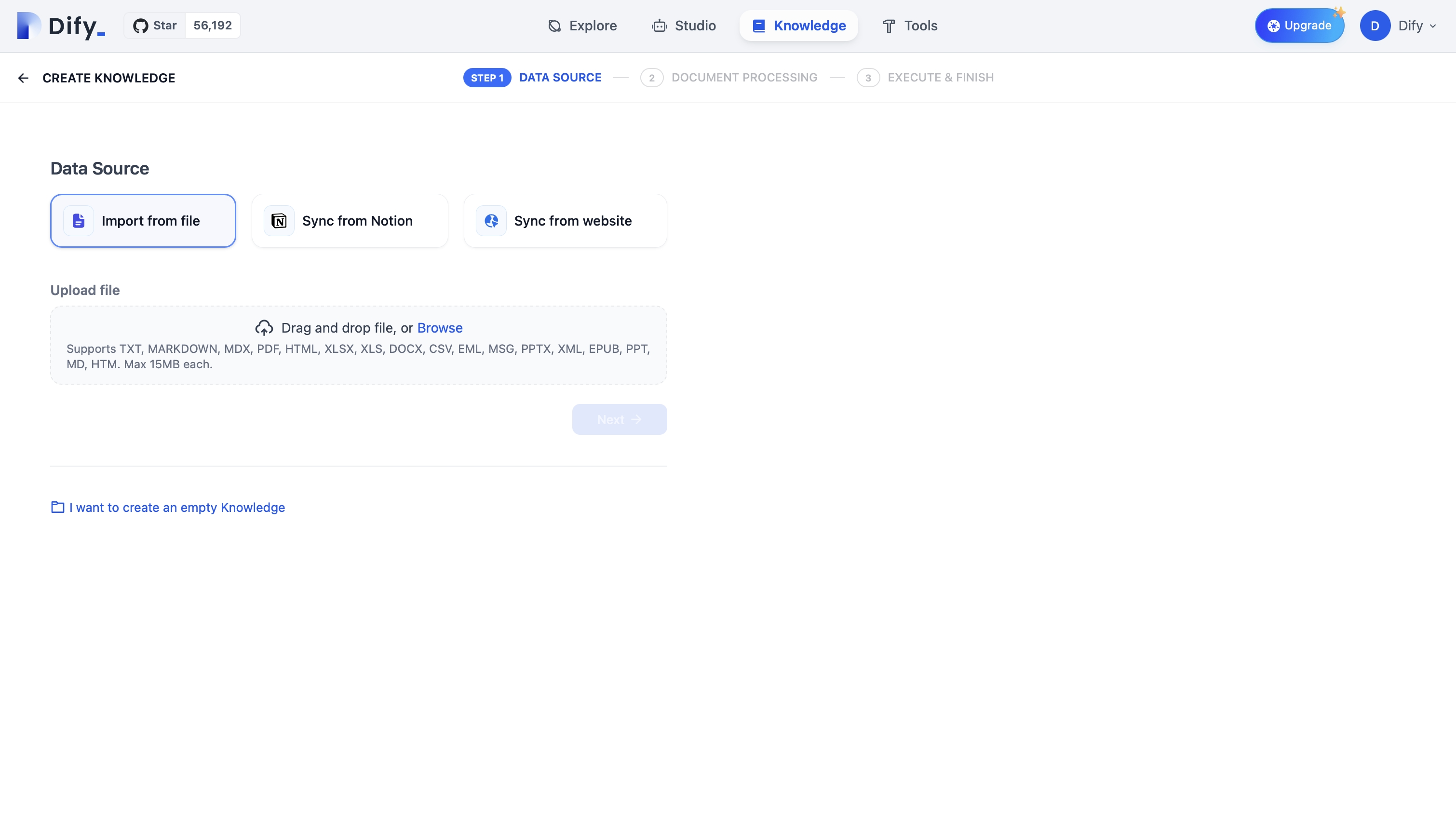
|
||||
|
||||
### **Use Case**
|
||||
|
||||
If you want to create an AI customer support assistant based on your existing knowledge base and product documentation, you can simply upload those files to the Knowledge Base in Dify and then set up a conversational application.
|
||||
|
||||
Traditionally, going from raw text training to a fully developed AI customer support chatbot could take weeks, plus it’s challenging to maintain and iterate effectively.
|
||||
|
||||
In Dify, the entire process takes just three minutes, after which you can immediately begin gathering user feedback.
|
||||
|
||||
### Knowledge Base and Documents
|
||||
|
||||
In Dify, a Knowledge Base is a collection of Documents, each of which can include multiple Chunks of content. You can integrate an entire knowledge base into an application to serve as a retrieval context, drawing from uploaded files or data synchronized from other sources.
|
||||
|
||||
If your team already has an independent, external knowledge that is separate from the Dify platform, you can link it using the [External Knowledge Base](external-knowledge-api-documentation.md) feature. This way, you don’t need to re-upload all your content to Dify. Your AI app can directly access and process information in real time from your team’s existing knowledge.
|
||||
Reference in New Issue
Block a user