.
8
.github/ISSUE_TEMPLATE/config.yml
vendored
Normal file
@@ -0,0 +1,8 @@
|
||||
blank_issues_enabled: false
|
||||
contact_links:
|
||||
- name: "\U0001F4A1 Model Providers & Plugins"
|
||||
url: "https://github.com/langgenius/dify-official-plugins/issues/new/choose"
|
||||
about: Report issues with official plugins or model providers, you will need to provide the plugin version and other relevant details.
|
||||
- name: "\U0001F4E7 Discussions"
|
||||
url: https://github.com/langgenius/dify/discussions/categories/general
|
||||
about: General discussions and seek help from the community
|
||||
68
.github/ISSUE_TEMPLATE/docs.yml
vendored
Normal file
@@ -0,0 +1,68 @@
|
||||
name: Documentation Change Request
|
||||
description: Suggest changes or improvements to the documentation
|
||||
title: "[DOCS]: "
|
||||
labels: ["documentation"]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to help us improve our documentation!
|
||||
|
||||
- type: dropdown
|
||||
id: type
|
||||
attributes:
|
||||
label: Type of Documentation Change
|
||||
options:
|
||||
- Error/Typo fix
|
||||
- Content update
|
||||
- New documentation
|
||||
- Translation
|
||||
- Reorganization
|
||||
- Other
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: input
|
||||
id: page
|
||||
attributes:
|
||||
label: Documentation Page URL or Path
|
||||
description: Please provide the URL or file path of the documentation page you're referring to.
|
||||
placeholder: e.g., https://docs.dify.ai/getting-started or /getting-started.md
|
||||
validations:
|
||||
required: false
|
||||
|
||||
- type: textarea
|
||||
id: current
|
||||
attributes:
|
||||
label: Current Content
|
||||
description: What does the documentation currently say?
|
||||
placeholder: Paste the current content here...
|
||||
validations:
|
||||
required: false
|
||||
|
||||
- type: textarea
|
||||
id: suggestion
|
||||
attributes:
|
||||
label: Suggested Changes
|
||||
description: What would you like to be changed or added?
|
||||
placeholder: Describe your suggested changes...
|
||||
validations:
|
||||
required: true
|
||||
|
||||
- type: textarea
|
||||
id: reason
|
||||
attributes:
|
||||
label: Reason for Change
|
||||
description: Why do you think this change would improve the documentation?
|
||||
placeholder: Explain why this change would be helpful...
|
||||
validations:
|
||||
required: false
|
||||
|
||||
- type: checkboxes
|
||||
id: terms
|
||||
attributes:
|
||||
label: Code of Conduct
|
||||
description: By submitting this issue, you agree to follow our contribution guidelines
|
||||
options:
|
||||
- label: I agree to follow Dify's documentation [contribution guidelines](https://github.com/langgenius/dify/blob/0277a37fcad5ad86aeb239485c27fffd5cd90043/CONTRIBUTING.md)
|
||||
required: true
|
||||
157
.github/workflows/translate.yml
vendored
Normal file
@@ -0,0 +1,157 @@
|
||||
name: Auto Translate Docs
|
||||
|
||||
on:
|
||||
workflow_run:
|
||||
workflows: ["Process Documentation"]
|
||||
types:
|
||||
- completed
|
||||
branches-ignore:
|
||||
- 'main'
|
||||
push:
|
||||
branches-ignore:
|
||||
- 'main'
|
||||
paths-ignore:
|
||||
- '.github/workflows/**'
|
||||
|
||||
jobs:
|
||||
translate:
|
||||
runs-on: ubuntu-latest
|
||||
# Only run if the workflow_run event was successful, or if it's a direct push
|
||||
if: github.event_name == 'push' || github.event.workflow_run.conclusion == 'success'
|
||||
permissions:
|
||||
contents: write
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0 # Fetches all history for git diff
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
# For workflow_run events, checkout the head of the triggering workflow
|
||||
ref: ${{ github.event_name == 'workflow_run' && github.event.workflow_run.head_sha || github.sha }}
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '3.9'
|
||||
|
||||
- name: Install dependencies
|
||||
run: pip install httpx aiofiles python-dotenv
|
||||
|
||||
- name: Get changed markdown files
|
||||
id: changed-files
|
||||
run: |
|
||||
# Get the list of newly added files between the current and previous commit
|
||||
# We filter for .md and .mdx files that are inside the language directories
|
||||
# Only include added (A) files, skip modified (M) and deleted (D) files
|
||||
|
||||
# Determine the commit SHA to use based on event type
|
||||
if [[ "${{ github.event_name }}" == "workflow_run" ]]; then
|
||||
current_sha="${{ github.event.workflow_run.head_sha }}"
|
||||
echo "Using workflow_run head_sha: $current_sha"
|
||||
else
|
||||
current_sha="${{ github.sha }}"
|
||||
echo "Using github.sha: $current_sha"
|
||||
fi
|
||||
|
||||
# Try different approaches to get the diff
|
||||
if [[ -n "${{ github.event.before }}" && "${{ github.event_name }}" == "push" ]]; then
|
||||
echo "Using github.event.before: ${{ github.event.before }}"
|
||||
files=$(git diff --name-status ${{ github.event.before }} $current_sha | grep -E '^A\s+' | cut -f2 | grep -E '^(en|en-us|zh-hans|ja-jp|plugin-dev-en|plugin-dev-zh|plugin-dev-ja|versions)/.*(\.md|\.mdx)$' || true)
|
||||
else
|
||||
echo "Using HEAD~1 for comparison"
|
||||
files=$(git diff --name-status HEAD~1 $current_sha | grep -E '^A\s+' | cut -f2 | grep -E '^(en|en-us|zh-hans|ja-jp|plugin-dev-en|plugin-dev-zh|plugin-dev-ja|versions)/.*(\.md|\.mdx)$' || true)
|
||||
fi
|
||||
|
||||
echo "Detected files (Added only):"
|
||||
echo "$files"
|
||||
|
||||
# Filter out files that don't actually exist
|
||||
existing_files=""
|
||||
if [[ -n "$files" ]]; then
|
||||
while IFS= read -r file; do
|
||||
if [[ -n "$file" && -f "$file" ]]; then
|
||||
if [[ -z "$existing_files" ]]; then
|
||||
existing_files="$file"
|
||||
else
|
||||
existing_files="$existing_files"$'\n'"$file"
|
||||
fi
|
||||
else
|
||||
echo "Skipping non-existent file: $file"
|
||||
fi
|
||||
done <<< "$files"
|
||||
fi
|
||||
|
||||
echo "Final files to translate:"
|
||||
echo "$existing_files"
|
||||
|
||||
if [[ -z "$existing_files" ]]; then
|
||||
echo "No new markdown files to translate."
|
||||
echo "files=" >> $GITHUB_OUTPUT
|
||||
else
|
||||
# The script expects absolute paths, but we run it from the root, so relative is fine.
|
||||
echo "files<<EOF" >> $GITHUB_OUTPUT
|
||||
echo "$existing_files" >> $GITHUB_OUTPUT
|
||||
echo "EOF" >> $GITHUB_OUTPUT
|
||||
fi
|
||||
|
||||
- name: Run translation script
|
||||
if: steps.changed-files.outputs.files
|
||||
env:
|
||||
DIFY_API_KEY: ${{ secrets.DIFY_API_KEY }}
|
||||
run: |
|
||||
echo "Files to translate:"
|
||||
echo "${{ steps.changed-files.outputs.files }}"
|
||||
|
||||
# Create temporary file list
|
||||
echo "${{ steps.changed-files.outputs.files }}" > /tmp/files_to_translate.txt
|
||||
|
||||
# Start all translation processes in parallel
|
||||
pids=()
|
||||
while IFS= read -r file; do
|
||||
if [[ -n "$file" ]]; then
|
||||
echo "Starting translation for $file..."
|
||||
python tools/translate/main.py "$file" "$DIFY_API_KEY" &
|
||||
pids+=($!)
|
||||
fi
|
||||
done < /tmp/files_to_translate.txt
|
||||
|
||||
# Wait for all background processes to complete
|
||||
echo "Waiting for ${#pids[@]} translation processes to complete..."
|
||||
failed=0
|
||||
for pid in "${pids[@]}"; do
|
||||
if ! wait "$pid"; then
|
||||
echo "Translation process $pid failed"
|
||||
failed=1
|
||||
fi
|
||||
done
|
||||
|
||||
if [ $failed -eq 1 ]; then
|
||||
echo "Some translations failed"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
echo "All translations completed successfully"
|
||||
|
||||
- name: Commit and push changes
|
||||
run: |
|
||||
git config --global user.name 'github-actions[bot]'
|
||||
git config --global user.email 'github-actions[bot]@users.noreply.github.com'
|
||||
# Check if there are any changes to commit
|
||||
if [[ -n $(git status --porcelain) ]]; then
|
||||
git add .
|
||||
git commit -m "docs: auto-translate documentation"
|
||||
# Push to the appropriate branch based on event type
|
||||
if [[ "${{ github.event_name }}" == "workflow_run" ]]; then
|
||||
# For workflow_run events, push to the head branch of the triggering workflow
|
||||
branch_ref="${{ github.event.workflow_run.head_branch }}"
|
||||
echo "Pushing to workflow_run head branch: $branch_ref"
|
||||
git push origin HEAD:$branch_ref
|
||||
else
|
||||
# For push events, push to the same branch the workflow was triggered from
|
||||
echo "Pushing to current branch: ${{ github.ref_name }}"
|
||||
git push origin HEAD:${{ github.ref_name }}
|
||||
fi
|
||||
echo "Translated files have been pushed to the branch."
|
||||
else
|
||||
echo "No new translations to commit."
|
||||
fi
|
||||
BIN
dify-logo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.0 KiB |
@@ -3,20 +3,27 @@ title: "10-Minute Quick Start"
|
||||
description: "Dive into Dify through a quick example app"
|
||||
---
|
||||
|
||||
The real value of Dify lies in how easily you can build, deploy, and scale an idea no matter how complex. It’s built for fast prototyping, smooth iteration, and reliable deployment at any level.
|
||||
The real value of Dify lies in how easily you can build, deploy, and scale an idea no matter how complex. It's built for fast prototyping, smooth iteration, and reliable deployment at any level.
|
||||
|
||||
Let's start by learning reliable LLM integration into your applications. In this guide, you'll build a simple chatbot that classifies the user’s question, respond directly using the LLM, and enhance the response with a country-specific fun fact.
|
||||
Let's start by learning reliable LLM integration into your applications. In this guide, you'll build a simple chatbot that classifies the user's question, respond directly using the LLM, and enhance the response with a country-specific fun fact.
|
||||
|
||||
<iframe className="w-full aspect-video rounded-xl" src="https://www.youtube.com/embed/opKZRpfd80k?si=HEkyjRpiYheMyrZ0" title="Dify Quick Start Video" frameBorder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowFullScreen />
|
||||
<iframe
|
||||
className="w-full aspect-video rounded-xl"
|
||||
src="https://www.youtube.com/embed/opKZRpfd80k?si=HEkyjRpiYheMyrZ0"
|
||||
title="Dify Quick Start Video"
|
||||
frameBorder="0"
|
||||
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
|
||||
allowFullScreen
|
||||
/>
|
||||
|
||||
## Step 1: Create a New Workflow (2 min)
|
||||
|
||||
1. Go to `Studio`**\> ** `Workflow`**\> ** `Create from Blank`**\> ** `Orchestrate`**\> ** `New Chatflow`**\> ** `Create`
|
||||
1. Go to **Studio** > **Workflow** > **Create from Blank** > **Orchestrate** > **New Chatflow** > **Create**
|
||||
|
||||
## Step 2: Add Workflow Nodes (6 min)
|
||||
|
||||
<Tip>
|
||||
IMPORTANT: When you want to reference any variable, type `{` or `/`first and you can see the different variables available in your workflow.
|
||||
When you want to reference any variable, type `{` or `/` first and you can see the different variables available in your workflow.
|
||||
</Tip>
|
||||
|
||||
### 1. LLM Node and Output: Understand and Answer the Question
|
||||
@@ -25,43 +32,85 @@ Let's start by learning reliable LLM integration into your applications. In this
|
||||
`LLM` node sends a prompt to a language model to generate a response based on user input. It abstracts away the complexity of API calls, rate limits, and infrastructure, so you can just focus on designing logic.
|
||||
</Info>
|
||||
|
||||
- Create an LLM node using the `Add Node` button and connect it to your Start node
|
||||
- Choose a default model
|
||||
- Paste this into `System Prompt`**:**
|
||||
<Steps>
|
||||
<Step title="Create LLM Node">
|
||||
Create an LLM node using the `Add Node` button and connect it to your Start node
|
||||
</Step>
|
||||
|
||||
<Step title="Configure Model">
|
||||
Choose a default model
|
||||
</Step>
|
||||
|
||||
<Step title="Set System Prompt">
|
||||
Paste this into the System Prompt field:
|
||||
|
||||
> The user will ask a question about a country. The question is {{sys.query}} Tasks: 1. Identify the country mentioned. 2. Rephrase the question clearly. 3. Answer the question using general knowledge. \
|
||||
> \
|
||||
> Respond in the following JSON format: { "country": "\<country name\>","question": "\<rephrased question\>","answer": "\<direct answer to the question\>" }
|
||||
- **_Enable Structured Output_** allows you to easily control what the LLM will return and ensure consistent, machine-readable outputs for downstream use in precise data extraction or conditional logic.\_
|
||||
- Toggle Output Variables Structured ON \> `Configure` and click `Import from JSON`
|
||||
- Paste:
|
||||
|
||||
> { "country": "string", "question": "string", "answer": "string" }
|
||||
```text
|
||||
The user will ask a question about a country. The question is {{sys.query}}
|
||||
Tasks:
|
||||
1. Identify the country mentioned.
|
||||
2. Rephrase the question clearly.
|
||||
3. Answer the question using general knowledge.
|
||||
|
||||
Respond in the following JSON format:
|
||||
{
|
||||
"country": "<country name>",
|
||||
"question": "<rephrased question>",
|
||||
"answer": "<direct answer to the question>"
|
||||
}
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Enable Structured Output">
|
||||
**Enable Structured Output** allows you to easily control what the LLM will return and ensure consistent, machine-readable outputs for downstream use in precise data extraction or conditional logic.
|
||||
|
||||
- Toggle Output Variables Structured ON > `Configure` and click `Import from JSON`
|
||||
- Paste:
|
||||
|
||||
```json
|
||||
{
|
||||
"country": "string",
|
||||
"question": "string",
|
||||
"answer": "string"
|
||||
}
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### 2. Code Block: Get Fun Fact
|
||||
|
||||
<Info>
|
||||
`Code` node _executes custom logic using code. It lets you inject code exactly where needed—within a visual workflow—saving you from wiring up an entire backend._
|
||||
`Code` node executes custom logic using code. It lets you inject code exactly where needed—within a visual workflow—saving you from wiring up an entire backend.
|
||||
</Info>
|
||||
|
||||
- Create a `Code` Node using the `Add Node` button and connect to LLM block
|
||||
- Change one `Input Variable` name to "country" and set the variable to `structured_output`**\>** `country`
|
||||
<Steps>
|
||||
<Step title="Create Code Node">
|
||||
Create a `Code` Node using the `Add Node` button and connect to LLM block
|
||||
</Step>
|
||||
|
||||
<Step title="Configure Input Variable">
|
||||
Change one `Input Variable` name to "country" and set the variable to `structured_output` > `country`
|
||||
</Step>
|
||||
|
||||
<Step title="Add Python Code">
|
||||
Paste this code into `PYTHON3`:
|
||||
|
||||
Paste this code into `PYTHON3`:
|
||||
|
||||
```python expandable
|
||||
def main(country: str) -> dict:
|
||||
country_name = country.lower()
|
||||
fun_facts = {
|
||||
"japan": "Japan has more than 5 million vending machines.",
|
||||
"france": "France is the most visited country in the world.",
|
||||
"italy": "Italy has more UNESCO World Heritage sites than any other country."
|
||||
}
|
||||
fun_fact = fun_facts.get(country_name, f"No fun fact available for {country.title()}.")
|
||||
return {"fun_fact": fun_fact}
|
||||
```
|
||||
|
||||
- Change output variable`result`into `fun_fact` to have a better labeled variable
|
||||
```python
|
||||
def main(country: str) -> dict:
|
||||
country_name = country.lower()
|
||||
fun_facts = {
|
||||
"japan": "Japan has more than 5 million vending machines.",
|
||||
"france": "France is the most visited country in the world.",
|
||||
"italy": "Italy has more UNESCO World Heritage sites than any other country."
|
||||
}
|
||||
fun_fact = fun_facts.get(country_name, f"No fun fact available for {country.title()}.")
|
||||
return {"fun_fact": fun_fact}
|
||||
```
|
||||
</Step>
|
||||
|
||||
<Step title="Rename Output Variable">
|
||||
Change output variable `result` to `fun_fact` to have a better labeled variable
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
### 3. Answer Node: Final Answer to User
|
||||
|
||||
@@ -69,19 +118,30 @@ def main(country: str) -> dict:
|
||||
`Answer` Node creates a clean final output to return.
|
||||
</Info>
|
||||
|
||||
- Create an`Answer`Node using the `Add Node` button.
|
||||
- Paste into the `Answer Field`**:**
|
||||
<Steps>
|
||||
<Step title="Create Answer Node">
|
||||
Create an `Answer` Node using the `Add Node` button
|
||||
</Step>
|
||||
|
||||
<Step title="Configure Answer Field">
|
||||
Paste into the Answer Field:
|
||||
|
||||
> Q: {{ structured_output.question }}
|
||||
>
|
||||
> A: {{ structured_output.answer }}
|
||||
>
|
||||
> Fun Fact: {{ fun_fact }}
|
||||
```text
|
||||
Q: {{ structured_output.question }}
|
||||
|
||||
A: {{ structured_output.answer }}
|
||||
|
||||
Fun Fact: {{ fun_fact }}
|
||||
```
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
End Workflow:
|
||||
|
||||
<img
|
||||
style={{ width:"1850%" }}
|
||||
src="/images/quick-start-workflow-overview.png"
|
||||
alt="Complete workflow diagram showing LLM, Code, and Answer nodes connected"
|
||||
style={{ width: "100%" }}
|
||||
/>
|
||||
|
||||
---
|
||||
@@ -90,13 +150,13 @@ End Workflow:
|
||||
|
||||
Click `Preview`, then ask:
|
||||
|
||||
- “What is the capital of France?”
|
||||
- “Tell me about Japanese cuisine”
|
||||
- “Describe the culture in Italy”
|
||||
- "What is the capital of France?"
|
||||
- "Tell me about Japanese cuisine"
|
||||
- "Describe the culture in Italy"
|
||||
- Any other questions
|
||||
|
||||
Make sure your Bot works as expected\!
|
||||
Make sure your Bot works as expected!
|
||||
|
||||
## You’ve Completed the Bot\!
|
||||
## You've Completed the Bot!
|
||||
|
||||
This guide showed how to integrate language models reliably and scalably without reinventing infrastructure. With Dify’s visual workflows and modular nodes, you’re not just building faster, you’re adopting a clean, production-ready architecture for LLM-powered apps.
|
||||
This guide showed how to integrate language models reliably and scalably without reinventing infrastructure. With Dify's visual workflows and modular nodes, you're not just building faster, you're adopting a clean, production-ready architecture for LLM-powered apps.
|
||||
221
en/getting-started/readme/features-and-specifications.mdx
Normal file
@@ -0,0 +1,221 @@
|
||||
---
|
||||
title: Features and Specifications
|
||||
description: For those already familiar with LLM application tech stacks, this document serves as a shortcut to understand Dify's unique advantages
|
||||
---
|
||||
|
||||
|
||||
We adopt transparent policies around product specifications to ensure decisions are made based on complete understanding. Such transparency not only benefits your technical selection, but also promotes deeper comprehension within the community for active contributions.
|
||||
|
||||
### Project Basics
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Attribute</th>
|
||||
<th>Details</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>Established</td>
|
||||
<td>March 2023</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Open Source License</td>
|
||||
<td>[Apache License 2.0 with commercial licensing](../../policies/open-source)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Official R&D Team</td>
|
||||
<td>Over 15 full-time employees</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Community Contributors</td>
|
||||
<td>Over [290](https://ossinsight.io/analyze/langgenius/dify#overview) people (As of Q2 2024)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Backend Technology</td>
|
||||
<td>Python/Flask/PostgreSQL</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Frontend Technology</td>
|
||||
<td>Next.js</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Codebase Size</td>
|
||||
<td>Over 130,000 lines</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Release Frequency</td>
|
||||
<td>Average once per week</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Technical Features
|
||||
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Feature</th>
|
||||
<th>Details</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>LLM Inference Engines</td>
|
||||
<td>Dify Runtime (LangChain removed since v0.4)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Commercial Models Supported</td>
|
||||
<td>
|
||||
<p><strong>10+</strong>, including OpenAI and Anthropic</p>
|
||||
<p>Onboard new mainstream models within 48 hours</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>MaaS Vendor Supported</td>
|
||||
<td><strong>7</strong>, Hugging Face, Replicate, AWS Bedrock, NVIDIA, GroqCloud, together.ai, OpenRouter</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Local Model Inference Runtimes Supported</td>
|
||||
<td><strong>6</strong>, Xoribits (recommended), OpenLLM, LocalAI, ChatGLM, Ollama, NVIDIA TIS</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>OpenAI Interface Standard Model Integration Supported</td>
|
||||
<td><strong>∞</strong></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Multimodal Capabilities</td>
|
||||
<td>
|
||||
<p>ASR Models</p>
|
||||
<p>Rich-text models up to GPT-4o specs</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Built-in App Types</td>
|
||||
<td>Text generation, Chatbot, Agent, Workflow, Chatflow</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Prompt-as-a-Service Orchestration</td>
|
||||
<td>
|
||||
<p>Visual orchestration interface widely praised, modify Prompts and preview effects in one place.</p>
|
||||
<p><strong>Orchestration Modes</strong></p>
|
||||
<ul>
|
||||
<li>Simple orchestration</li>
|
||||
<li>Assistant orchestration</li>
|
||||
<li>Flow orchestration</li>
|
||||
</ul>
|
||||
<p><strong>Prompt Variable Types</strong></p>
|
||||
<ul>
|
||||
<li>String</li>
|
||||
<li>Radio enum</li>
|
||||
<li>External API</li>
|
||||
<li>File (Q3 2024)</li>
|
||||
</ul>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Agentic Workflow Features</td>
|
||||
<td>
|
||||
<p>Industry-leading visual workflow orchestration interface, live-editing node debugging, modular DSL, and native code runtime, designed for building more complex, reliable, and stable LLM applications.</p>
|
||||
<p><strong>Supported Nodes</strong></p>
|
||||
<ul>
|
||||
<li>LLM</li>
|
||||
<li>Knowledge Retrieval</li>
|
||||
<li>Question Classifier</li>
|
||||
<li>IF/ELSE</li>
|
||||
<li>CODE</li>
|
||||
<li>Template</li>
|
||||
<li>HTTP Request</li>
|
||||
<li>Tool</li>
|
||||
</ul>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>RAG Features</td>
|
||||
<td>
|
||||
<p>Industry-first visual knowledge base management interface, supporting snippet previews and recall testing.</p>
|
||||
<p><strong>Indexing Methods</strong></p>
|
||||
<ul>
|
||||
<li>Keywords</li>
|
||||
<li>Text vectors</li>
|
||||
<li>LLM-assisted question-snippet model</li>
|
||||
</ul>
|
||||
<p><strong>Retrieval Methods</strong></p>
|
||||
<ul>
|
||||
<li>Keywords</li>
|
||||
<li>Text similarity matching</li>
|
||||
<li>Hybrid Search</li>
|
||||
<li>N choose 1 (Legacy)</li>
|
||||
<li>Multi-path retrieval</li>
|
||||
</ul>
|
||||
<p><strong>Recall Optimization</strong></p>
|
||||
<ul>
|
||||
<li>Rerank models</li>
|
||||
</ul>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>ETL Capabilities</td>
|
||||
<td>
|
||||
<p>Automated cleaning for TXT, Markdown, PDF, HTML, DOC, CSV formats. Unstructured service enables maximum support.</p>
|
||||
<p>Sync Notion docs as knowledge bases.</p>
|
||||
<p>Sync Webpages as knowledge bases.</p>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Vector Databases Supported</td>
|
||||
<td>Qdrant (recommended), Weaviate, Zilliz/Milvus, Pgvector, Pgvector-rs, Chroma, OpenSearch, TiDB, Tencent Cloud VectorDB, Oracle, Relyt, Analyticdb, Couchbase, OceanBase, Tablestore, Lindorm, OpenGauss, Matrixone</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Agent Technologies</td>
|
||||
<td>
|
||||
<p>ReAct, Function Call.</p>
|
||||
<p><strong>Tooling Support</strong></p>
|
||||
<ul>
|
||||
<li>Invoke OpenAI Plugin standard tools</li>
|
||||
<li>Directly load OpenAPI Specification APIs as tools</li>
|
||||
</ul>
|
||||
<p><strong>Built-in Tools</strong></p>
|
||||
<ul>
|
||||
<li>40+ tools (As of Q2 2024)</li>
|
||||
</ul>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Logging</td>
|
||||
<td>Supported, annotations based on logs</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Annotation Reply</td>
|
||||
<td>Based on human-annotated Q&As, used for similarity-based replies. Exportable as data format for model fine-tuning.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Content Moderation</td>
|
||||
<td>OpenAI Moderation or external APIs</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Team Collaboration</td>
|
||||
<td>Workspaces, multi-member management</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>API Specs</td>
|
||||
<td>RESTful, most features covered</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Deployment Methods</td>
|
||||
<td>Docker, Helm</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/getting-started/readme/features-and-specifications.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
58
en/guides/workflow/README.mdx
Normal file
@@ -0,0 +1,58 @@
|
||||
---
|
||||
title: Introduction
|
||||
---
|
||||
|
||||
### Basic Introduction
|
||||
|
||||
Workflows reduce system complexity by breaking down complex tasks into smaller steps (nodes), reducing reliance on prompt engineering and model inference capabilities, and enhancing the performance of LLM applications for complex tasks. This also improves the system's interpretability, stability, and fault tolerance.
|
||||
|
||||
Dify workflows are divided into two types:
|
||||
|
||||
* **Chatflow**: Designed for conversational scenarios, including customer service, semantic search, and other conversational applications that require multi-step logic in response construction.
|
||||
* **Workflow**: Geared towards automation and batch processing scenarios, suitable for high-quality translation, data analysis, content generation, email automation, and more.
|
||||
|
||||
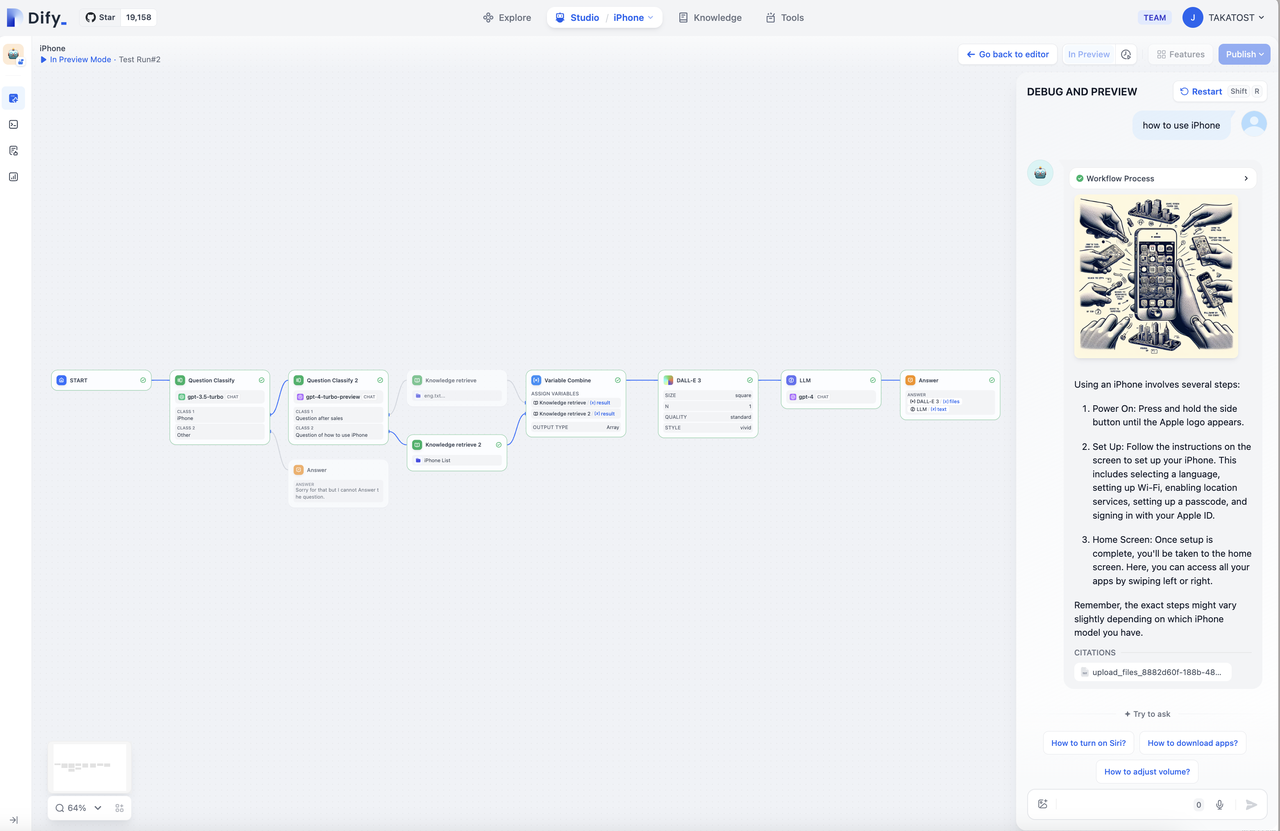
|
||||
|
||||
To address the complexity of user intent recognition in natural language input, Chatflow provides question understanding nodes. Compared to Workflow, it adds support for Chatbot features such as conversation history (Memory), annotated replies, and Answer nodes.
|
||||
|
||||
To handle complex business logic in automation and batch processing scenarios, Workflow offers a variety of logic nodes, such as code nodes, IF/ELSE nodes, template transformation, iteration nodes, and more. Additionally, it provides capabilities for timed and event-triggered actions, facilitating the construction of automated processes.
|
||||
|
||||
### Common Use Cases
|
||||
|
||||
* Customer Service
|
||||
|
||||
By integrating LLM into your customer service system, you can automate responses to common questions, reducing the workload of your support team. LLM can understand the context and intent of customer queries and generate helpful and accurate answers in real-time.
|
||||
|
||||
* Content Generation
|
||||
|
||||
Whether you need to create blog posts, product descriptions, or marketing materials, LLM can assist by generating high-quality content. Simply provide an outline or topic, and LLM will use its extensive knowledge base to produce engaging, informative, and well-structured content.
|
||||
|
||||
* Task Automation
|
||||
|
||||
LLM can be integrated with various task management systems like Trello, Slack, and Lark to automate project and task management. Using natural language processing, LLM can understand and interpret user input, create tasks, update statuses, and assign priorities without manual intervention.
|
||||
|
||||
* Data Analysis and Reporting
|
||||
|
||||
LLM can analyze large datasets and generate reports or summaries. By providing relevant information to LLM, it can identify trends, patterns, and insights, transforming raw data into actionable intelligence. This is particularly valuable for businesses looking to make data-driven decisions.
|
||||
|
||||
* Email Automation
|
||||
|
||||
LLM can be used to draft emails, social media updates, and other forms of communication. By providing a brief outline or key points, LLM can generate well-structured, coherent, and contextually relevant messages. This saves significant time and ensures your responses are clear and professional.
|
||||
|
||||
### How to Get Started
|
||||
|
||||
* Start by building a workflow from scratch or use system templates to help you get started.
|
||||
* Get familiar with basic operations, including creating nodes on the canvas, connecting and configuring nodes, debugging workflows, and viewing run history.
|
||||
* Save and publish a workflow.
|
||||
* Run the published application or call the workflow through an API.
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/workflow/README.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
127
en/resources/about-dify/dify-brand-guidelines.mdx
Normal file
@@ -0,0 +1,127 @@
|
||||
---
|
||||
title: Dify Brand Guidelines
|
||||
---
|
||||
|
||||
The Dify identity is more than a logo—it's a statement of thoughtful construction, system-level clarity, and open collaboration.
|
||||
When you are authorized or recognized as part of the Dify ecosystem, you represent the values we stand for.
|
||||
By using Dify Brand Assets in an official or affiliate capacity, you share in the responsibility of upholding our design system and product philosophy.
|
||||
Use of Dify Brand Assets must comply with our Brand Guidelines and be consistent with the principles outlined in the Dify Brand Usage Terms.
|
||||
Any use that implies endorsement, partnership, or certification without explicit permission is not allowed.
|
||||
Dify may revoke usage rights at any time if misuse occurs.
|
||||
|
||||
Refer to: [Dify Brand Usage Terms](/en/resources/about-dify/dify-brand-usage-terms).
|
||||
|
||||
## Our Logo
|
||||
|
||||

|
||||
|
||||
## Using Our Logo
|
||||
|
||||
The Dify logo signifies more than product—it signals trust, clarity, and technical credibility.
|
||||
To maintain brand integrity, it must be used in accordance with our guidelines.
|
||||
Misuse or casual placement may imply endorsement or affiliation where none exists.
|
||||
Please use thoughtfully and only in approved contexts.
|
||||
|
||||
### Examples of appropriate logo usage
|
||||
|
||||
- In co-branded visuals with official partners
|
||||
- In event materials or pages where Dify is a sponsor or participant
|
||||
- In a group of logos alongside other tools (“logo garden”)
|
||||
- In documentation, presentations, or integrations referencing Dify technologies
|
||||
|
||||
## Use the Right Color
|
||||
|
||||
Whenever possible, use the official two-tone Dify logo.
|
||||
|
||||
This version best represents the balance between clarity and structure in our brand.
|
||||
|
||||
Alternative color variations may be used when:
|
||||
|
||||
- Background colors limit contrast
|
||||
- Specific print or digital limitations apply
|
||||
- Layout demands mono or reversed options
|
||||
|
||||

|
||||
|
||||
## Keep It Legible
|
||||
|
||||
To ensure visibility and clarity, the Dify logo must always be surrounded by a minimum area of clear space.This prevents visual interference from nearby text, images, or other graphic elements.
|
||||
- More space is recommended wherever possible to enhance legibility.
|
||||
- Do not crowd the logo. Respecting this spacing is essential to maintain its impact and recognizability across all applications.
|
||||
|
||||

|
||||
|
||||
## Co-Branding Guidance
|
||||
|
||||
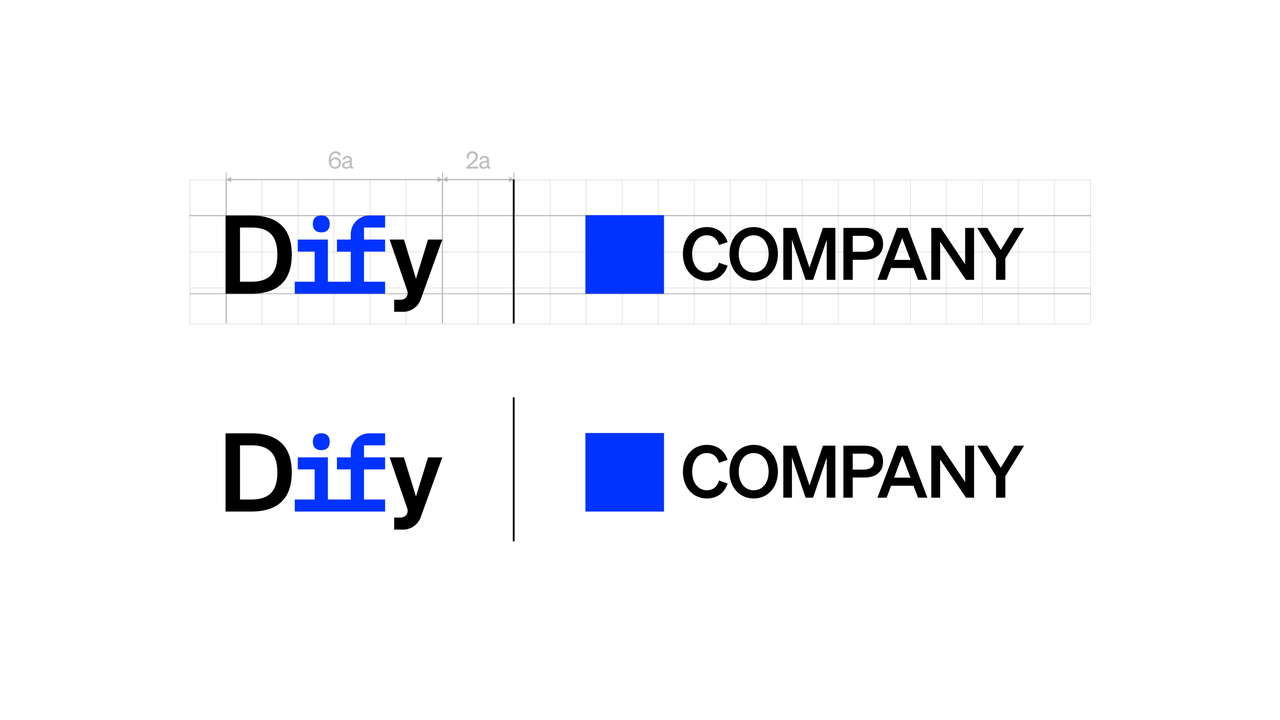
|
||||
|
||||
When pairing the Dify logo with another brand, always follow the co-branding layout shown here to maintain clarity and balance.
|
||||
- Use a thin vertical divider to separate the Dify logo from the partner brand.
|
||||
- Always maintain the relative positioning and proportions between the Dify and partner logos.
|
||||
- Do not rearrange the layout, change alignment, or scale elements independently.
|
||||
|
||||
## Multiple Logo Lockup Guidelines
|
||||
|
||||

|
||||
|
||||
When Dify appears alongside two or more partner logos, follow these rules to ensure clarity and visual order:
|
||||
|
||||
- Do not use dividers between logos.
|
||||
- Maintain consistent and equal spacing between all logos.
|
||||
- If the initiative is partner-led, the partner’s logo should appear first. All other logos, including Dify, should follow in alphabetical order.
|
||||
- All logos must be visually aligned to the same height. Do not scale or distort individual marks.
|
||||
- Preserve each brand’s official colors, adequate whitespace, and consistent spacing throughout.
|
||||
|
||||
## Dify Partner Badge
|
||||
|
||||

|
||||
|
||||
The Dify Partner Badge is used to indicate an official relationship with Dify.
|
||||
It can be included in marketing materials, presentations, documentation, and event assets owned by the partner, as long as the content refers to Dify’s products, integrations, or support.
|
||||
- Ensure minimum clear space so the design doesn't appear cluttered.
|
||||
- Do not change the badge color.
|
||||
- Do not change the proportions of the logo.
|
||||
- Do not alter or replace the text in the badge.
|
||||
- Do not make the badge bigger than the partner logo.
|
||||
|
||||
## Powered by Dify Badge
|
||||
|
||||

|
||||
|
||||
The “Powered by Dify” badge indicates that your project, product, or content integrates Dify’s open-source capabilities or platform services.
|
||||
|
||||
It is a lightweight attribution that highlights the origin of the tooling—not an endorsement or partnership.
|
||||
|
||||
### Where You Can Use It
|
||||
|
||||
- On websites, applications, or systems that include Dify-powered features
|
||||
- In open-source project documentation, README files, demos, or footers
|
||||
- In educational materials, presentations, blog posts, or talks that showcase Dify's technology stack
|
||||
|
||||
### Badge Usage Rules
|
||||
|
||||
- Use the official “Powered by Dify” badge provided by Dify
|
||||
- Do not alter the badge’s color, typography, proportions, or wording
|
||||
- The badge must be clearly visible and not distorted, compressed, or placed on visually disruptive backgrounds
|
||||
|
||||
### Usage Restrictions
|
||||
|
||||
- Do not imply endorsement, certification, or official partnership with Dify
|
||||
- Do not use the badge in commercial marketing, paid training, or monetized courses without prior written permission
|
||||
|
||||
[Download Dify Design Kit](https://assets-docs.dify.ai/2025/05/5f547d3718bf32067849d9a83d9c92cf.zip)
|
||||
|
||||
---
|
||||
|
||||
© LangGenius, Inc. All rights reserved. Unauthorized use of Dify brand assets is strictly prohibited.
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/resources/about-dify/dify-brand-guidelines.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
123
en/resources/about-dify/dify-brand-usage-terms.mdx
Normal file
@@ -0,0 +1,123 @@
|
||||
---
|
||||
title: Dify Brand Usage Terms
|
||||
---
|
||||
|
||||
These Brand Usage Terms ("Terms") govern the proper use of trademarks, logos, names, designs, and other brand elements (collectively, "Brand Assets") owned by LangGenius, Inc. ("Dify," "we," "our," or "us"). By using Dify Brand Assets, you agree to comply with these Terms.
|
||||
|
||||
---
|
||||
## 1. Permitted Uses (No Prior Approval Required)
|
||||
|
||||
You may use Dify Brand Assets without prior approval in the following cases, provided you adhere to the Dify Brand Guidelines:
|
||||
|
||||
### Community & Content Creation
|
||||
|
||||
- In blog posts, articles, documentation, social media, forums, and presentations to reference or discuss Dify.
|
||||
- In open-source projects (e.g., GitHub repositories, README files, and code examples) to indicate integration or support for Dify, as long as it is clear that your project is not officially affiliated with or endorsed by Dify.
|
||||
- In YouTube videos, podcasts, and developer talks for educational or informational purposes.
|
||||
|
||||
### Open-Source Projects
|
||||
|
||||
- You may display "Powered by Dify" in non-commercial open-source projects to acknowledge the use of Dify.
|
||||
- Linking to the official Dify website or GitHub repository is encouraged.
|
||||
|
||||
### Media & News Coverage
|
||||
|
||||
- Journalists, bloggers, and media outlets may use Dify Brand Assets in news articles or reports, provided the content is factually accurate and does not imply endorsement or sponsorship by Dify.
|
||||
|
||||
---
|
||||
|
||||
## 2. Restricted Uses (Approval Required)
|
||||
|
||||
The following uses require prior written approval from Dify:
|
||||
|
||||
### Commercial Use & Marketing
|
||||
|
||||
- Resellers, partners, and SaaS platforms integrating Dify into commercial products or services.
|
||||
- Using Dify Brand Assets in advertisements, promotional materials, or sales collateral.
|
||||
- Using Dify Brand Assets in paid training, consulting, or courses that suggest official endorsement.
|
||||
|
||||
### Official Partnership & Endorsement
|
||||
|
||||
- You may not use any Dify Brand Assets in a way that implies endorsement, certification, sponsorship, or partnership with Dify without explicit written authorization.
|
||||
|
||||
- Dify Partner badges are exclusively available to officially contracted partners. Each badge tier (e.g., Partner, Preferred Partner, Elite Partner) requires separate written approval and may only be used by partners who have been expressly granted that specific designation. Unauthorized use of any badge, or use of a badge outside your approved tier, is strictly prohibited.
|
||||
|
||||
### Merchandise & Physical Goods
|
||||
|
||||
- You may not use Dify Brand Assets on T-shirts, stickers, posters, or any merchandise without written permission.
|
||||
|
||||
### Modifications & Brand Combinations
|
||||
|
||||
- You may not alter the Dify Logo, including changes to colors, fonts, proportions, or effects.
|
||||
- You may not combine the Dify Logo with other logos or symbols to create a new or composite mark.
|
||||
|
||||
---
|
||||
|
||||
## 3. Brand Usage Guidelines
|
||||
|
||||
When using Dify Brand Assets, you must comply with our Brand Guidelines, which include:
|
||||
|
||||
- Maintain logo integrity: Do not distort, stretch, or rotate the logo.
|
||||
- Use official logo versions: Do not use unofficial or outdated versions.
|
||||
- Provide sufficient spacing: Ensure clear visual separation around the logo.
|
||||
- Do not alter colors: The logo must be used in the official Dify color scheme.
|
||||
|
||||
---
|
||||
|
||||
## 4. Trademark & Copyright Notice
|
||||
|
||||
- "Dify" and all related logos and brand elements are trademarks or registered trademarks of LangGenius, Inc.
|
||||
- These Terms do not grant any ownership or licensing rights to you. Dify retains all rights to its Brand Assets.
|
||||
|
||||
---
|
||||
|
||||
## 5. Misuse & Enforcement
|
||||
|
||||
- Dify reserves the right to revoke usage rights at any time and may require you to cease using the Brand Assets if they are used improperly.
|
||||
- Unauthorized or misleading use of the Brand Assets may result in legal action.
|
||||
|
||||
---
|
||||
|
||||
## 6. How to Request Permission?
|
||||
|
||||
If your use case requires approval (e.g., commercial use, partnerships, merchandising), please submit a request to: [business@dify.ai](mailto:business@dify.ai)
|
||||
|
||||
Your request should include:
|
||||
|
||||
- Your name / company name
|
||||
- A detailed description of how you intend to use the Dify Brand Assets
|
||||
- Relevant materials (e.g., mockups, website links)
|
||||
|
||||
---
|
||||
## 7. Reporting Brand Misuse
|
||||
|
||||
If you believe that Dify Brand Assets are being misused in violation of these Terms—such as unauthorized commercial use, misleading endorsements, or counterfeit merchandise—you may report it to us.
|
||||
|
||||
To submit a report, contact [brand@dify.ai](mailto:brand@dify.ai) with the following details:
|
||||
|
||||
- A description of the issue (e.g., unauthorized commercial use, misleading branding, counterfeit products)
|
||||
- Relevant evidence (e.g., screenshots, links, documents)
|
||||
- Your contact information (optional, in case we need further details)
|
||||
|
||||
Dify will review all reports and take appropriate action as necessary, which may include legal enforcement or requiring the violating party to cease unauthorized use. We appreciate your support in protecting the Dify brand.
|
||||
|
||||
---
|
||||
## 8. Updates to These Terms
|
||||
|
||||
Dify may update these Brand Usage Terms periodically. Any changes will be published on this page, and by continuing to use the Brand Assets, you agree to the latest version.
|
||||
|
||||
Latest Version: 2025/03/04
|
||||
|
||||
---
|
||||
© LangGenius, Inc. All rights reserved. Unauthorized use of Dify Brand Assets is strictly prohibited.
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/resources/about-dify/dify-brand-usage-terms.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
201
en/resources/termbase.mdx
Normal file
@@ -0,0 +1,201 @@
|
||||
---
|
||||
title: Termbase
|
||||
---
|
||||
|
||||
## A
|
||||
### Agent
|
||||
An autonomous AI system capable of making decisions and executing tasks based on environmental information. In the Dify platform, agents combine the comprehension capabilities of large language models with the ability to interact with external tools, automatically completing a series of operations ranging from simple to complex, such as searching for information, calling APIs, or generating content.
|
||||
|
||||
### Agentic Workflow
|
||||
A task orchestration method that allows AI systems to autonomously solve complex problems through multiple steps. For example, an agentic workflow can first understand a user's question, then query a knowledge base, call computational tools, and finally integrate information to generate a complete answer, all without human intervention.
|
||||
|
||||
### Automatic Speech Recognition (ASR)
|
||||
Technology that converts human speech into text and serves as the foundation for voice interaction applications. This technology allows users to interact with AI systems by speaking rather than typing, and is widely used in scenarios such as voice assistants, meeting transcription, and accessibility services.
|
||||
|
||||
## B
|
||||
### Backbone of Thought (BoT)
|
||||
A structured thinking framework that provides the main structure for reasoning in large language models. It helps models maintain a clear thinking path when processing complex problems, similar to the outline of an academic paper or the skeleton of a decision tree.
|
||||
|
||||
## C
|
||||
### Chunking
|
||||
A processing technique that splits long text into smaller content blocks, enabling retrieval systems to find relevant information more precisely. A good chunking strategy considers both the semantic integrity of the content and the context window limitations of language models, thereby improving the quality of retrieval and generation.
|
||||
|
||||
### Citation and Attribution
|
||||
Features that allow AI systems to clearly indicate the sources of information, increasing the credibility and transparency of responses. When the system generates answers based on knowledge base content, it can automatically annotate the referenced document name, page number, or URL, enabling users to understand the origin of the information.
|
||||
|
||||
### Chain of Thought (CoT)
|
||||
A prompting technique that guides large language models to display their step-by-step thinking process. For example, when solving a math problem, the model first lists the known conditions, then follows reasoning steps to solve it one by one, and finally reaches a conclusion. The entire process resembles human thinking.
|
||||
|
||||
## D
|
||||
### Domain-Specific Language (DSL)
|
||||
A programming language or configuration format designed for a specific application domain. Dify DSL is an application engineering file standard based on YAML format, used to define various configurations of AI applications, including model parameters, prompt design, and workflow orchestration, allowing non-professional developers to build complex AI applications.
|
||||
|
||||
## E
|
||||
### Extract, Transform, Load (ETL)
|
||||
A classic data processing workflow: extracting raw data, transforming it into a format suitable for analysis, and then loading it into the target system. In AI document processing, ETL may include extracting text from PDFs, cleaning formats, splitting content, calculating embedding vectors, and finally loading into a vector database, preparing for RAG systems.
|
||||
|
||||
## F
|
||||
### Frequency Penalty
|
||||
A text generation control parameter that increases output diversity by reducing the probability of generating frequently occurring vocabulary. The higher the value, the more the model tends to use diverse vocabulary and expressions; at a value of 0, the model will not specifically avoid reusing the same vocabulary.
|
||||
|
||||
### Function Calling
|
||||
The capability of large language models to recognize when to call specific functions and provide the required parameters. For example, when a user asks about the weather, the model can automatically call a weather API, construct the correct parameter format (city, date), and then generate a response based on the API's returned results.
|
||||
|
||||
## G
|
||||
### General Chunking Pattern
|
||||
A simple text splitting strategy that divides documents into mutually independent content blocks. This pattern is suitable for documents with clear structures and relatively independent paragraphs, such as product manuals or encyclopedia entries, where each chunk can be understood independently without heavily relying on context.
|
||||
|
||||
### Graph of Thought (GoT)
|
||||
A method of representing the thinking process as a network structure, capturing complex relationships between concepts. Unlike the linear Chain of Thought, the Graph of Thought can express branching, cyclical, and multi-path thinking patterns, suitable for dealing with complex problems that have multiple interrelated factors.
|
||||
|
||||
## H
|
||||
### Hybrid Search
|
||||
A search method that combines the advantages of keyword matching and semantic search to provide more comprehensive retrieval results. For example, when searching for "apple nutritional components," hybrid search can find both documents containing the keywords "apple" and "nutrition," as well as content discussing related semantic concepts like "fruit health value," selecting the optimal results through weight adjustment or reranking.
|
||||
|
||||
## I
|
||||
### Inverted Index
|
||||
A core data structure of search engines that records which documents each word appears in. Unlike traditional indexes that find content from documents, inverted indexes find documents from vocabulary, greatly improving full-text retrieval speed. For example, the index entry for the term "artificial intelligence" would list all document IDs and positions containing this term.
|
||||
|
||||
## K
|
||||
### Keyword Search
|
||||
A search method based on exact matching that finds documents containing specific vocabulary. This method is computationally efficient and suitable for scenarios where users clearly know the terms they want to find, such as product models, proper nouns, or specific commands, but may miss content expressed using synonyms or related concepts.
|
||||
|
||||
### Knowledge Base
|
||||
A database that stores structured information in AI applications, providing a source of professional knowledge for models. In the Dify platform, knowledge bases can contain various documents (PDF, Word, web pages, etc.), which are processed for AI retrieval and used to generate accurate, well-founded answers, particularly suitable for building domain expert applications.
|
||||
|
||||
### Knowledge Retrieval
|
||||
The process of finding information from a knowledge base that is most relevant to a user's question, and is a key component of RAG systems. Effective knowledge retrieval not only finds relevant content but also controls the amount of information returned, avoiding irrelevant content that could interfere with the model, while providing sufficient background to ensure accurate and complete answers.
|
||||
|
||||
## L
|
||||
### Large Language Model (LLM)
|
||||
An AI model trained on massive amounts of text that can understand and generate human language. Modern LLMs (such as the GPT series, Claude, etc.) can write articles, answer questions, write code, and even conduct reasoning. They are the core engines of various AI applications, especially suitable for scenarios requiring language understanding and generation.
|
||||
|
||||
### Local Model Inference
|
||||
The process of running AI models on a user's own device rather than relying on cloud services. This approach provides better privacy protection (data does not leave the local environment) and lower latency (no network transmission required), making it suitable for processing sensitive data or scenarios requiring offline work, though it is typically limited by the computational capacity of local devices.
|
||||
|
||||
## M
|
||||
### Model-as-a-Service (MaaS)
|
||||
A cloud service model where providers offer access to pre-trained models through APIs. Users don't need to worry about training, deploying, or maintaining models; they simply call the API and pay for usage, significantly lowering the development threshold and infrastructure costs of AI applications. It's suitable for quickly validating ideas or building prototypes.
|
||||
|
||||
### Max_tokens
|
||||
A parameter that controls the maximum number of characters the model generates in a single response. One token is approximately equivalent to 4 characters or 3/4 of an English word. Setting a reasonable maximum token count can control the length of the answer, avoid overly verbose output, and ensure complete expression of necessary information. For example, a brief summary might be set to 200 tokens, while a detailed report might require 2000 tokens.
|
||||
|
||||
### Memory
|
||||
The ability of AI systems to save and use historical interaction information, keeping multi-turn conversations coherent. Effective memory mechanisms enable AI to understand contextual references, remember user preferences, and track long-term goals, thereby providing personalized and continuous user experiences, avoiding repeatedly asking for information that has already been provided.
|
||||
|
||||
### Metadata Filtering
|
||||
A technique that utilizes document attribute information (such as title, author, date, classification tags) for content filtering. For example, users can restrict retrieval to technical documents within a specific date range, or only query reports from a specific department, thereby narrowing the scope before retrieval, improving search efficiency and result relevance.
|
||||
|
||||
### Multimodal Model
|
||||
A model capable of processing multiple types of input data, such as text, images, audio, etc. These models break the single-perception limitations of traditional AI and can understand image content, analyze video scenes, recognize voice emotions, creating possibilities for more comprehensive information understanding, suitable for complex application scenarios requiring cross-media understanding.
|
||||
|
||||
### Multi-tool-call
|
||||
The ability of a model to call multiple different tools in a single response. For example, when processing a request like "Compare tomorrow's weather in Beijing and Shanghai and recommend suitable clothing," the model can simultaneously call weather APIs for both cities, then provide reasonable suggestions based on the returned results, improving the efficiency of handling complex tasks.
|
||||
|
||||
### Multi-path Retrieval
|
||||
A strategy for obtaining information in parallel through multiple retrieval methods. For example, the system can simultaneously use keyword search, semantic matching, and knowledge graph queries, then merge and filter the results, improving the coverage and accuracy of information retrieval, particularly suitable for handling complex or ambiguous user queries.
|
||||
|
||||
## P
|
||||
### Parent-Child Chunking
|
||||
An advanced text splitting strategy that creates two levels of content blocks: parent blocks retain the complete context, while child blocks provide precise matching points. The system first uses child blocks to determine the location of relevant content, then retrieves the corresponding parent blocks to provide complete background, balancing retrieval precision and context completeness, suitable for processing complex documents such as research papers or technical manuals.
|
||||
|
||||
### Presence Penalty
|
||||
A parameter setting that prevents language models from repeating content. It encourages models to explore new expressions by reducing the probability of generating vocabulary that has already appeared. The higher the parameter value, the less likely the model is to repeat previously generated content, helping to avoid common circular arguments or repetitive problem statements in AI responses.
|
||||
|
||||
### Predefined Model
|
||||
A ready-made model trained and provided by AI vendors that users can directly call without training themselves. These closed-source models (such as GPT-4, Claude, etc.) are typically trained and optimized on a large scale, powerful and easy to use, suitable for rapid application development or teams lacking independent training resources.
|
||||
|
||||
### Prompt
|
||||
Input text that guides AI models to generate specific responses. Well-designed prompts can significantly improve output quality, including elements such as clear instructions, providing examples, setting format requirements, etc. For example, different prompts can guide the same model to generate academic articles, creative stories, or technical analysis, making them one of the most critical factors affecting AI output.
|
||||
|
||||
## Q
|
||||
### Q&A Mode
|
||||
A special indexing strategy that automatically generates question-answer pairs for document content, implementing "question-to-question" matching. When a user asks a question, the system looks for semantically similar pre-generated questions and returns the corresponding answers. This mode is particularly suitable for FAQ content or structured knowledge points, providing a more precise question-answering experience.
|
||||
|
||||
## R
|
||||
### Retrieval-Augmented Generation (RAG)
|
||||
A technical architecture that combines external knowledge retrieval and language generation. The system first retrieves information from a knowledge base related to the user's question, then provides this information as context to the language model, generating well-founded, accurate answers. RAG overcomes the limited knowledge and hallucination problems of language models, particularly suitable for application scenarios requiring the latest or specialized knowledge.
|
||||
|
||||
### Reasoning and Acting (ReAct)
|
||||
An AI agent framework that enables models to alternate between thinking and executing operations. In the problem-solving process, the model first analyzes the current state, formulates a plan, then calls appropriate tools (such as search engines, calculators), and thinks about the next step based on the tool's returned results, forming a thinking-action-thinking cycle until the problem is solved. It is suitable for complex tasks requiring multiple steps and external tools.
|
||||
|
||||
### ReRank
|
||||
A technique for secondary sorting of preliminary retrieval results to improve the relevance of final results. For example, the system might first quickly retrieve a large number of candidate content through efficient algorithms, then use more complex but precise models to reevaluate and sort these results, placing the most relevant content first, balancing retrieval efficiency and result quality.
|
||||
|
||||
### Rerank Model
|
||||
A model specifically designed to evaluate the relevance of retrieval results to queries and reorder them. Unlike preliminary retrieval, these models typically use more complex algorithms, consider more semantic factors, and can more accurately determine how well content matches user intent. For example, models like Cohere Rerank and BGE Reranker can significantly improve the quality of search and recommendation system results.
|
||||
|
||||
### Response_format
|
||||
A specification of the structure type for model output, such as plain text, JSON, or HTML. Setting a specific response format can make AI output easier to process by programs or integrate into other systems. For example, requiring the model to answer in JSON format ensures the output has a consistent structure, facilitating direct parsing and display by frontend applications.
|
||||
|
||||
### Reverse Calling
|
||||
A bidirectional mechanism for plugins to interact with platforms, allowing plugins to actively call platform functionality. In Dify, this means third-party plugins can not only be called by AI but can also use Dify's core features in return, such as triggering workflows or calling other plugins, greatly enhancing the system's extensibility and flexibility.
|
||||
|
||||
### Retrieval Test
|
||||
A functionality for verifying the effectiveness of knowledge base retrieval, allowing developers to simulate user queries and evaluate system return results. This testing helps developers understand the boundaries of the system's retrieval capabilities, discover and fix potential issues such as missed detection, false detection, or poor relevance, and is an indispensable tool for optimizing RAG systems.
|
||||
|
||||
## S
|
||||
### Score Threshold
|
||||
A similarity threshold for filtering retrieval results, where only content with scores exceeding the set value is returned. Setting a reasonable threshold can avoid irrelevant information interfering with model generation, improving the accuracy of answers. For example, if the threshold is set to 0.8 (out of 1.0), only highly relevant content will be adopted, but it may result in incomplete information; lowering the threshold will include more content but may introduce noise.
|
||||
|
||||
### Semantic Search
|
||||
A retrieval method based on understanding and matching text meaning rather than simple keyword matching. It uses vector embedding technology to convert text into mathematical representations, then calculates the semantic similarity between queries and documents. This method can find content that is expressed differently but has similar meanings, understand synonyms and contextual relationships, and even support cross-language retrieval, particularly suitable for complex or natural language form queries.
|
||||
|
||||
### Session Variables
|
||||
A mechanism for storing multi-turn dialogue context information, allowing AI to maintain coherent interactions. For example, the system can remember user preferences (such as "concise answers"), identity information, or interaction history status, avoiding repeated inquiries and providing personalized experiences. In Dify, developers can define and manage these variables to build applications that truly remember users.
|
||||
|
||||
### Speech-to-Text (STT)
|
||||
Technology that converts users' voice input into text data. This technology allows users to interact with AI systems by speaking rather than typing, improving the naturalness and convenience of interaction, particularly suitable for mobile devices, driving scenarios, or accessibility applications, and is the foundation for voice assistants and real-time transcription applications.
|
||||
|
||||
### Stream-tool-call
|
||||
A real-time processing mode that allows AI systems to call external tools while generating responses, without waiting until the complete answer is generated before processing. This approach greatly improves the response speed for complex tasks, making the user experience more smooth, suitable for interactive scenarios requiring multiple tool calls.
|
||||
|
||||
### Streaming Response
|
||||
A real-time response mechanism where AI systems return content to users as it is generated, rather than waiting until all content is generated before displaying it at once. This approach significantly improves the user waiting experience, especially for long answers, allowing users to immediately see partial content and begin reading, providing a more natural interaction experience similar to immediate feedback in human conversations.
|
||||
|
||||
## T
|
||||
### Temperature
|
||||
A parameter controlling the randomness of language model output, typically between 0-1. Lower temperature (close to 0) makes model output more deterministic and conservative, favoring high-probability vocabulary, suitable for factual answers; higher temperature (close to 1) makes output more diverse and creative, suitable for creative writing. For example, weather forecasts might use a low temperature of 0.1, while story creation might use a high temperature of 0.8.
|
||||
|
||||
### Text Embedding
|
||||
The process of converting text into numerical vectors, enabling AI systems to understand and process language. These vectors capture the semantic features of vocabulary and sentences, allowing computers to measure similarity between texts, cluster related content, or retrieve matching information. Different embedding models (such as OpenAI's text-embedding-ada-002 or Cohere's embed-multilingual) are optimized for different languages and application scenarios.
|
||||
|
||||
### Tool Calling
|
||||
The ability of AI systems to identify and use external functionality, greatly expanding the model's capability boundaries. For example, language models themselves cannot access real-time data, but by calling a weather API, they can provide current weather information; by calling database query tools, they can retrieve the latest product inventory; by calling calculators, they can perform complex calculations, enabling AI to solve problems beyond their training data range.
|
||||
|
||||
### TopK
|
||||
A parameter controlling the number of retrieval results returned, specifying to retain the top K text fragments with the highest similarity. Setting an appropriate TopK value is crucial for RAG system performance: too small a value may lose key information, while too large a value may introduce noise and increase the language model's processing burden. For example, simple questions might only need TopK=3, while complex questions might require TopK=10 to obtain sufficient background.
|
||||
|
||||
### TopP (Nucleus Sampling)
|
||||
A text generation control method that selects the next word only from the most likely vocabulary with cumulative probability reaching threshold P. Unlike fixed selection of the highest-probability word or completely random selection, TopP balances determinism and creativity. For example, TopP=0.9 means the model only considers vocabulary accounting for 90% of the probability and ignores low-probability options, avoiding both completely predictable output and excessively random content.
|
||||
|
||||
### Tree of Thought (ToT)
|
||||
A thinking method for exploring multiple reasoning paths, allowing models to analyze problems from different perspectives. Similar to human "if...then..." thinking patterns, Tree of Thought lets models generate multiple possible thinking branches, evaluate the feasibility of each branch, and then select the optimal path to continue, particularly suitable for solving complex problems requiring trial and error or consideration of multiple possibilities.
|
||||
|
||||
### Text-to-Speech (TTS)
|
||||
Technology that converts written text into natural speech, enabling AI systems to communicate with users through voice. Modern TTS systems can generate natural speech close to human quality, supporting multiple languages, tones, and emotional expressions, widely used in audiobooks, navigation systems, voice assistants, and accessibility services, providing more natural interaction experiences for different scenarios and users.
|
||||
|
||||
## V
|
||||
### Vector Database
|
||||
A database system specialized in storing and searching vector embeddings, serving as the infrastructure for efficient semantic retrieval. Unlike traditional databases, vector databases are optimized for high-dimensional vector similarity search, capable of quickly finding semantically similar content from millions of documents. Common vector databases include Pinecone, Milvus, Qdrant, etc., which play key roles in RAG systems, recommendation engines, and content analysis.
|
||||
|
||||
### Vector Retrieval
|
||||
A search method based on text vector embedding similarity, forming the technical core of semantic search. The system first converts user queries into vectors, then finds the most similar content in pre-calculated document vectors. This method can capture deep semantic relationships, find content expressed differently but with similar meanings, overcoming the limitations of keyword search, particularly suitable for processing natural language queries and conceptual problems.
|
||||
|
||||
### Vision
|
||||
The functionality of multimodal LLMs to understand and process images, allowing models to analyze user-uploaded pictures and generate responses combining text. For example, users can upload product photos to inquire about usage methods, upload menu photos requesting translation, or upload charts asking for data trend analysis. This capability greatly expands AI application scenarios, making interaction more intuitive and diverse.
|
||||
|
||||
## W
|
||||
### Workflow
|
||||
A task orchestration method that breaks down complex AI applications into multiple independent nodes executed in a specific order. In the Dify platform, developers can visually design workflows, combining multiple processing steps (such as user input processing, knowledge retrieval, multi-model collaboration, conditional branching) to build AI applications capable of handling complex business logic, making application development both flexible and intuitive.
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/resources/termbase.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
22
en/workshop/README.mdx
Normal file
@@ -0,0 +1,22 @@
|
||||
---
|
||||
title: Introduction
|
||||
---
|
||||
|
||||
Welcome to the Dify Workshop! These tutorials are designed for beginners who want to start learning Dify from scratch. Whether you have programming or AI-related background knowledge or not, we will guide you step by step to master the core concepts and usage of Dify without skipping any details.
|
||||
|
||||
We will help you understand Dify through a series of experiments. Each experiment will include detailed steps and explanations to ensure you can easily follow and grasp the content. We will interweave knowledge teaching in the experiments, allowing you to learn in practice and gradually build a comprehensive understanding of Dify.
|
||||
|
||||
No need to worry about any prerequisites! We will start from the most basic concepts and gradually guide you into more advanced topics. Whether you are a complete beginner or have some programming experience but want to learn AI technology, this tutorial will provide you with everything you need.
|
||||
|
||||
Let's embark on this learning journey together and explore the endless possibilities of Dify!
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/workshop/README.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
249
en/workshop/basic/the-right-way-of-markdown.mdx
Normal file
@@ -0,0 +1,249 @@
|
||||
---
|
||||
title: "The Right Way of Markdown"
|
||||
---
|
||||
|
||||
[Markdown](https://www.markdownguide.org/basic-syntax/) transforms your Dify app outputs from plain text dumps into properly formatted, professional responses. Use it in Answer and End nodes to render headers, lists, code blocks, tables, and more to create clear visual hierarchies for the end user.
|
||||
|
||||
## Basic Markdown Syntax in Dify
|
||||
|
||||
Use Markdown in your Answer / End nodes to render things like:
|
||||
|
||||
- Headings
|
||||
- Bold and Italic text, strike-through text
|
||||
- Lists
|
||||
- Tables
|
||||
- Fenced Code Blocks
|
||||
- Audio and Video
|
||||
|
||||
<img
|
||||
src="/images/CleanShot2025-07-14at00.34.54.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
### Headings
|
||||
|
||||
Use `#` for headings, with the number of `#` symbols indicating the heading level:
|
||||
|
||||
```markdown
|
||||
# Heading 1
|
||||
## Heading 2
|
||||
### Heading 3
|
||||
```
|
||||
|
||||
### Bold, Italic, and Strikethrough
|
||||
|
||||
You can format text as bold, italic, or strikethrough:
|
||||
|
||||
```markdown
|
||||
**Bold Text**
|
||||
*Italic Text*
|
||||
~~Strikethrough Text~~
|
||||
```
|
||||
|
||||
|
||||
### Lists
|
||||
|
||||
You can create ordered and unordered lists:
|
||||
|
||||
```markdown
|
||||
- Unordered List Item 1
|
||||
- Unordered List Item 2
|
||||
- Nested Unordered Item
|
||||
1. Ordered List Item 1
|
||||
2. Ordered List Item 2
|
||||
1. Nested Ordered Item
|
||||
```
|
||||
|
||||
### Tables
|
||||
|
||||
You can create tables using pipes and dashes:
|
||||
|
||||
```markdown
|
||||
| Header 1 | Header 2 |
|
||||
|----------|----------|
|
||||
| Row 1 Col 1 | Row 1 Col 2 |
|
||||
| Row 2 Col 1 | Row 2 Col 2 |
|
||||
```
|
||||
|
||||
### Fenced Code Blocks
|
||||
|
||||
Use triple backticks to create fenced code blocks:
|
||||
|
||||
```python
|
||||
def hello_world():
|
||||
print("Hello, World!")
|
||||
```
|
||||
|
||||
### Audio and Video
|
||||
|
||||
You can embed audio and video files using the following syntax:
|
||||
|
||||
```markdown
|
||||
<video controls>
|
||||
<source src="https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerBlazes.mp4" type="video/mp4">
|
||||
</video>
|
||||
<audio controls>
|
||||
<source src="https://www.soundhelix.com/examples/mp3/SoundHelix-Song-1.mp3" type="audio/mpeg">
|
||||
</audio>
|
||||
```
|
||||
|
||||
## Advanced Markdown Features in Dify
|
||||
|
||||
### Button & Links
|
||||
|
||||
You might not be happy with the default follow-up questions generated by the LLM. In this case, you can use buttons and links to guide the conversation in a specific direction.
|
||||
|
||||
<img
|
||||
src="/images/screenshot-20250714-134035.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
You can use the following syntax to create buttons and links:
|
||||
|
||||
```
|
||||
<button data-message="Hello Dify" data-variant="primary">Hello Dify</button>
|
||||
<button data-message="Hello Dify" data-variant="danger">Hello Dify</button>
|
||||
```
|
||||
|
||||
For buttons, we need to define two attributes `data-variant` and `data-message`.
|
||||
|
||||
- `data-variant`: The style of the button, can be `primary`, `secondary`, `warning`, `secondary-accent`, `ghost`, `ghost-accent`, `tertiary`.
|
||||
- `data-message`: The message that will be sent when the button is clicked.
|
||||
|
||||
For links, it's more straightforward:
|
||||
|
||||
```
|
||||
<a href="https://dify.ai" target="_blank">Dify</a>
|
||||
```
|
||||
|
||||
Or you can use the `abbr` syntax to create an abbreviation link, this is useful for create interactive links that can be used in the conversation:
|
||||
|
||||
```
|
||||
[Special Link](abbr:special-link)
|
||||
```
|
||||
|
||||
### Form
|
||||
|
||||
For forms, we need to define the `data-format` attribute, which can be `json` or `text`. If not specified, it defaults to `text`. The form will be submitted as a JSON object if `data-format="json"` is set.
|
||||
|
||||
<img
|
||||
src="/images/screenshot-20250714-134150.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
#### Supported Input Types
|
||||
|
||||
Dify supports a variety of input types for forms, including:
|
||||
|
||||
- text
|
||||
- textarea
|
||||
- password
|
||||
- time
|
||||
- date
|
||||
- datetime
|
||||
- select
|
||||
- checkbox
|
||||
- hidden
|
||||
|
||||
If you want to render a form during the conversation, you can use the following syntax:
|
||||
|
||||
```
|
||||
<form data-format="json"> // Default to text
|
||||
<label for="username">Username:</label>
|
||||
<input type="text" name="username" />
|
||||
<label for="hidden_input">Hidden input:</label>
|
||||
<input type="hidden" name="hidden_input" value="hidden_value" />
|
||||
<label for="password">Password:</label>
|
||||
<input type="password" name="password" />
|
||||
<label for="content">Content:</label>
|
||||
<textarea name="content"></textarea>
|
||||
<label for="date">Date:</label>
|
||||
<input type="date" name="date" />
|
||||
<label for="time">Time:</label>
|
||||
<input type="time" name="time" />
|
||||
<label for="datetime">Datetime:</label>
|
||||
<input type="datetime" name="datetime" />
|
||||
<label for="select">Select:</label>
|
||||
<input type="select" name="select" data-options='["hello","world"]'/>
|
||||
<input type="checkbox" name="check" data-tip="By checking this means you agreed"/>
|
||||
<button data-variant="primary">Login</button>
|
||||
</form>
|
||||
```
|
||||
|
||||
<Note>
|
||||
Hidden is not visible to users, you can set the value to pass data without user input.
|
||||
</Note>
|
||||
|
||||
### Chart
|
||||
|
||||
We support rendering [echarts](https://dify.ai/docs/guides/tools/chart) in markdown. You can use the following syntax to render a chart:
|
||||
|
||||
<img
|
||||
src="/images/screenshot-20250714-134238.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
<Note>
|
||||
To render a chart, start a fenced code block with <code>\`\`\`echarts</code> and place your chart configuration inside.
|
||||
</Note>
|
||||
|
||||
```echarts
|
||||
{
|
||||
"title": {
|
||||
"text": "ECharts Entry Example"
|
||||
},
|
||||
"tooltip": {},
|
||||
"legend": {
|
||||
"data": ["Sales"]
|
||||
},
|
||||
"xAxis": {
|
||||
"data": ["Shirts", "Cardigans", "Chiffons", "Pants", "Heels", "Socks"]
|
||||
},
|
||||
"yAxis": {},
|
||||
"series": [{
|
||||
"name": "Sales",
|
||||
"type": "bar",
|
||||
"data": [5, 20, 36, 10, 10, 20]
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
### Music
|
||||
|
||||
Not only can you render charts, but also music sheets in markdown. We support rendering [ABC notation](https://paulrosen.github.io/abcjs/) in markdown. You can use the following syntax to render a music sheet:
|
||||
|
||||
<img
|
||||
src="/images/screenshot-20250714-134431.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
<Note>
|
||||
To render a music sheet, start a fenced code block with <code>\`\`\`abc</code> and place your ABC notation inside.
|
||||
</Note>
|
||||
|
||||
```abc
|
||||
X: 1
|
||||
T: Cooley's
|
||||
M: 4/4
|
||||
L: 1/8
|
||||
K: Emin
|
||||
|:D2|EB{c}BA B2 EB|~B2 AB dBAG|FDAD BDAD|FDAD dAFD|
|
||||
EBBA B2 EB|B2 AB defg|afe^c dBAF|DEFD E2:|
|
||||
|:gf|eB B2 efge|eB B2 gedB|A2 FA DAFA|A2 FA defg|
|
||||
eB B2 eBgB|eB B2 defg|afe^c dBAF|DEFD E2:|
|
||||
```
|
||||
|
||||
## Best Practices
|
||||
|
||||
If you want to predefine the markdown content, you can use the [template](/en/guides/workflow/node/template) feature in Dify. This allows you to use template content in downstream nodes.
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/workshop/basic/the-right-way-of-markdown.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
BIN
images/CleanShot2025-07-14at00.34.54.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 403 KiB |
BIN
images/quick-start-workflow-overview.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 96 KiB |
BIN
images/screenshot-20250714-134035.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 188 KiB |
BIN
images/screenshot-20250714-134150.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 177 KiB |
BIN
images/screenshot-20250714-134238.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 211 KiB |
BIN
images/screenshot-20250714-134431.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 266 KiB |
250
ja-jp/workshop/basic/the-right-way-of-markdown.mdx
Normal file
@@ -0,0 +1,250 @@
|
||||
---
|
||||
title: Markdown の正しい使い方
|
||||
---
|
||||
|
||||
[Markdown](https://www.markdownguide.org/basic-syntax/) は、Dify アプリの出力をプレーンテキストから、適切に整形されたプロフェッショナルなレスポンスに変換することができます。Answer や End ノードで Markdown を使うことで、見出し・リスト・コードブロック・表などをレンダリングし、エンドユーザーにとって分かりやすい視覚的階層を構築できます。
|
||||
|
||||
## Dify における基本的な Markdown 構文
|
||||
|
||||
Answer / End ノード内で以下のような要素を Markdown で描画できます:
|
||||
|
||||
* 見出し
|
||||
* 太字、斜体、取り消し線
|
||||
* リスト
|
||||
* 表
|
||||
* 複数行のコードブロック
|
||||
* オーディオとビデオ
|
||||
|
||||
<img
|
||||
src="/images/CleanShot2025-07-14at00.34.54.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
### 見出し
|
||||
|
||||
`#` を使って見出しを作成します。`#` の数が見出しの階層を表します:
|
||||
|
||||
```markdown
|
||||
# 見出し 1
|
||||
## 見出し 2
|
||||
### 見出し 3
|
||||
```
|
||||
|
||||
### 太字・斜体・取り消し線
|
||||
|
||||
以下のような構文でテキストのスタイルを変更できます:
|
||||
|
||||
```markdown
|
||||
**太字テキスト**
|
||||
*斜体テキスト*
|
||||
~~取り消し線テキスト~~
|
||||
```
|
||||
|
||||
### リスト
|
||||
|
||||
順序付きおよび順序なしリストを作成できます:
|
||||
|
||||
```markdown
|
||||
- 順序なし項目 1
|
||||
- 順序なし項目 2
|
||||
- ネストされた項目
|
||||
1. 順序付き項目 1
|
||||
2. 順序付き項目 2
|
||||
1. ネストされた項目
|
||||
```
|
||||
|
||||
### 表
|
||||
|
||||
パイプ(|)とハイフン(-)を使って表を作成します:
|
||||
|
||||
```markdown
|
||||
| ヘッダー 1 | ヘッダー 2 |
|
||||
|------------|------------|
|
||||
| 行 1 列 1 | 行 1 列 2 |
|
||||
| 行 2 列 1 | 行 2 列 2 |
|
||||
```
|
||||
|
||||
### 複数行のコードブロック
|
||||
|
||||
3つのバッククォート(\`\`\`)を使ってコードブロックを作成します:
|
||||
|
||||
```python
|
||||
def hello_world():
|
||||
print("Hello, World!")
|
||||
```
|
||||
|
||||
### オーディオとビデオ
|
||||
|
||||
以下の構文を使用して、音声および動画を埋め込むことができます:
|
||||
|
||||
```markdown
|
||||
<video controls>
|
||||
<source src="https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerBlazes.mp4" type="video/mp4">
|
||||
</video>
|
||||
<audio controls>
|
||||
<source src="https://www.soundhelix.com/examples/mp3/SoundHelix-Song-1.mp3" type="audio/mpeg">
|
||||
</audio>
|
||||
```
|
||||
|
||||
<Note>
|
||||
Markdown の使い方についてさらに詳しく知りたい場合は、[Markdown Guide](https://www.markdownguide.org/basic-syntax/) をご参照ください。
|
||||
</Note>
|
||||
|
||||
---
|
||||
|
||||
## Dify における高度な Markdown 機能
|
||||
|
||||
### ボタンとリンク
|
||||
|
||||
LLM が自動生成したフォローアップ質問が不満な場合、Markdown のボタンやリンクを使って会話の流れをコントロールすることができます。
|
||||
|
||||
<img src="/images/screenshot-20250714-134035.png" className="mr-auto"/>
|
||||
|
||||
以下の構文でボタンとリンクを作成できます:
|
||||
|
||||
```
|
||||
<button data-message="Hello Dify" data-variant="primary">Hello Dify</button>
|
||||
<button data-message="Hello Dify" data-variant="danger">Hello Dify</button>
|
||||
```
|
||||
|
||||
ボタンには次の2つの属性が必要です:
|
||||
|
||||
* `data-variant`: ボタンのスタイル。`primary`、`secondary`、`warning`、`secondary-accent`、`ghost`、`ghost-accent`、`tertiary` など
|
||||
* `data-message`: ボタンがクリックされたときに送信されるメッセージ
|
||||
|
||||
リンクの構文はよりシンプルです:
|
||||
|
||||
```
|
||||
<a href="https://dify.ai" target="_blank">Dify</a>
|
||||
```
|
||||
|
||||
会話内で特定のアクションをトリガーする省略リンク (`abbr`) も使えます:
|
||||
|
||||
```
|
||||
[特別リンク](abbr:special-link)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### フォーム(Form)
|
||||
|
||||
フォームを使用する際には `data-format` 属性を設定する必要があります。`json` または `text` を指定でき、デフォルトは `text` です。`data-format="json"` に設定すると JSON 形式で送信されます。
|
||||
|
||||
<img src="/images/screenshot-20250714-134150.png" className="mr-auto"/>
|
||||
|
||||
#### サポートされている入力タイプ
|
||||
|
||||
Dify では以下の入力タイプをフォームで利用できます:
|
||||
|
||||
* text(テキスト)
|
||||
* textarea(複数行テキスト)
|
||||
* password(パスワード)
|
||||
* time(時間)
|
||||
* date(日付)
|
||||
* datetime(日付と時間)
|
||||
* select(セレクトボックス)
|
||||
* checkbox(チェックボックス)
|
||||
* hidden(非表示フィールド)
|
||||
|
||||
以下のような構文で会話中にフォームを描画できます:
|
||||
|
||||
```
|
||||
<form data-format="json"> // デフォルトは text
|
||||
<label for="username">ユーザー名:</label>
|
||||
<input type="text" name="username" />
|
||||
<label for="hidden_input">非表示項目:</label>
|
||||
<input type="hidden" name="hidden_input" value="hidden_value" />
|
||||
<label for="password">パスワード:</label>
|
||||
<input type="password" name="password" />
|
||||
<label for="content">内容:</label>
|
||||
<textarea name="content"></textarea>
|
||||
<label for="date">日付:</label>
|
||||
<input type="date" name="date" />
|
||||
<label for="time">時間:</label>
|
||||
<input type="time" name="time" />
|
||||
<label for="datetime">日時:</label>
|
||||
<input type="datetime" name="datetime" />
|
||||
<label for="select">選択:</label>
|
||||
<input type="select" name="select" data-options='["hello","world"]'/>
|
||||
<input type="checkbox" name="check" data-tip="チェックすることで同意と見なされます"/>
|
||||
<button data-variant="primary">ログイン</button>
|
||||
</form>
|
||||
```
|
||||
|
||||
<Note>
|
||||
`hidden` タイプの入力はユーザーに表示されず、ユーザーの操作なしにデータを渡すのに使用されます。
|
||||
</Note>
|
||||
|
||||
---
|
||||
|
||||
### グラフ(Chart)
|
||||
|
||||
Markdown 内で [echarts](https://dify.ai/docs/guides/tools/chart) を使ってグラフを描画できます。以下のような構文を使用します:
|
||||
|
||||
<img src="/images/screenshot-20250714-134238.png" className="mr-auto"/>
|
||||
|
||||
<Note>
|
||||
グラフを描画するには、<code>\`\`\`echarts</code> でコードブロックを開始し、その中に設定を記述してください。
|
||||
</Note>
|
||||
|
||||
```echarts
|
||||
{
|
||||
"title": {
|
||||
"text": "ECharts 入門例"
|
||||
},
|
||||
"tooltip": {},
|
||||
"legend": {
|
||||
"data": ["売上"]
|
||||
},
|
||||
"xAxis": {
|
||||
"data": ["シャツ", "カーディガン", "シフォン", "ズボン", "ヒール", "靴下"]
|
||||
},
|
||||
"yAxis": {},
|
||||
"series": [{
|
||||
"name": "売上",
|
||||
"type": "bar",
|
||||
"data": [5, 20, 36, 10, 10, 20]
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 音楽(譜面)
|
||||
|
||||
Markdown では譜面も描画できます。[ABC 記譜法](https://paulrosen.github.io/abcjs/) に対応しており、以下のような構文で利用します:
|
||||
|
||||
<img src="/images/screenshot-20250714-134431.png" className="mr-auto"/>
|
||||
|
||||
<Note>
|
||||
譜面を描画するには、<code>\`\`\`abc</code> でコードブロックを開始し、ABC 記譜内容を記述してください。
|
||||
</Note>
|
||||
|
||||
```abc
|
||||
X: 1
|
||||
T: Cooley's
|
||||
M: 4/4
|
||||
L: 1/8
|
||||
K: Emin
|
||||
|:D2|EB{c}BA B2 EB|~B2 AB dBAG|FDAD BDAD|FDAD dAFD|
|
||||
EBBA B2 EB|B2 AB defg|afe^c dBAF|DEFD E2:|
|
||||
|:gf|eB B2 efge|eB B2 gedB|A2 FA DAFA|A2 FA defg|
|
||||
eB B2 eBgB|eB B2 defg|afe^c dBAF|DEFD E2:|
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## ベストプラクティス
|
||||
|
||||
Markdown コンテンツを事前に定義しておきたい場合は、Dify の [テンプレート機能](/en/guides/workflow/node/template) を活用しましょう。これにより、下流のノードでもテンプレート内容を再利用でき、効率と一貫性を高めることができます。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[このページを編集する](https://github.com/langgenius/dify-docs/edit/main/ja-jp/workshop/basic/the-right-way-of-markdown.mdx) | [問題を報告する](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||
1
tools/translate/.env.example
Normal file
@@ -0,0 +1 @@
|
||||
dify_api_key=your_dify_api_key_here
|
||||
1
tools/translate/.gitignore
vendored
Normal file
@@ -0,0 +1 @@
|
||||
.env
|
||||
125
tools/translate/README.md
Normal file
@@ -0,0 +1,125 @@
|
||||
# Automatic Document Translation
|
||||
|
||||
Multi-language document auto-translation system based on GitHub Actions and Dify AI, supporting English, Chinese, and Japanese trilingual translation.
|
||||
|
||||
> **Other Languages**: [中文](README.md) | [日本語](README_JA.md)
|
||||
|
||||
## How It Works
|
||||
|
||||
1. **Trigger Condition**: Automatically runs when pushing to non-main branches
|
||||
2. **Smart Detection**: Automatically identifies modified `.md/.mdx` files and determines source language
|
||||
3. **Translation Logic**:
|
||||
- ✅ Translates new documents to other languages
|
||||
- ❌ Skips existing translation files (avoids overwriting manual edits)
|
||||
4. **Auto Commit**: Translation results are automatically pushed to the current branch
|
||||
|
||||
## System Features
|
||||
|
||||
- 🌐 **Multi-language Support**: Configuration-based language mapping, theoretically supports any language extension
|
||||
- 📚 **Terminology Consistency**: Built-in professional terminology database, LLM intelligently follows terminology to ensure unified technical vocabulary translation
|
||||
- 🔄 **Concurrent Processing**: Smart concurrency control, translates multiple target languages simultaneously
|
||||
- 🛡️ **Fault Tolerance**: 3-retry mechanism with exponential backoff strategy
|
||||
- ⚡ **Incremental Translation**: Only processes changed files, avoids redundant work
|
||||
- 🧠 **High-Performance Models**: Uses high-performance LLM models to ensure translation quality
|
||||
|
||||
## Usage
|
||||
|
||||
### For Document Writers
|
||||
|
||||
1. Write/modify documents in any language directory
|
||||
2. Push to branch (non-main)
|
||||
3. Wait 0.5-1 minute for automatic translation completion
|
||||
4. **View Translation Results**:
|
||||
- Create Pull Request for local viewing and subsequent editing
|
||||
- Or view Actions push commit details on GitHub to directly review translation quality
|
||||
|
||||
### Supported Language Directories
|
||||
|
||||
- **General Documentation**: `en/` ↔ `zh-hans/` ↔ `ja-jp/`
|
||||
- **Plugin Development Documentation**: `plugin-dev-en/` ↔ `plugin-dev-zh/` ↔ `plugin-dev-ja/`
|
||||
|
||||
Note: System architecture supports extending more languages, just modify configuration files
|
||||
|
||||
## Important Notes
|
||||
|
||||
- System only translates new documents, won't overwrite existing translations
|
||||
- To update existing translations, manually delete target files then retrigger
|
||||
- Terminology translation follows professional vocabulary in `termbase_i18n.md`, LLM has intelligent terminology recognition capabilities
|
||||
- Translation quality depends on configured high-performance models, recommend using high-performance base models in Dify Studio
|
||||
|
||||
### System Configuration
|
||||
|
||||
#### Terminology Database
|
||||
|
||||
Edit `tools/translate/termbase_i18n.md` to update professional terminology translation reference table.
|
||||
|
||||
#### Translation Model
|
||||
|
||||
Visit Dify Studio to adjust translation prompts or change base models.
|
||||
|
||||
---
|
||||
|
||||
## 🔧 Development and Deployment Configuration
|
||||
|
||||
### Local Development Environment
|
||||
|
||||
#### 1. Create Virtual Environment
|
||||
|
||||
```bash
|
||||
# Create virtual environment
|
||||
python -m venv venv
|
||||
|
||||
# Activate virtual environment
|
||||
# macOS/Linux:
|
||||
source venv/bin/activate
|
||||
# Windows:
|
||||
# venv\Scripts\activate
|
||||
```
|
||||
|
||||
#### 2. Install Dependencies
|
||||
|
||||
```bash
|
||||
pip install -r tools/translate/requirements.txt
|
||||
```
|
||||
|
||||
#### 3. Configure API Key
|
||||
|
||||
Create `.env` file in `tools/translate/` directory:
|
||||
|
||||
```bash
|
||||
DIFY_API_KEY=your_dify_api_key_here
|
||||
```
|
||||
|
||||
#### 4. Run Translation
|
||||
|
||||
```bash
|
||||
# Interactive mode (recommended for beginners)
|
||||
python tools/translate/main.py
|
||||
|
||||
# Command line mode (specify file)
|
||||
python tools/translate/main.py path/to/file.mdx [DIFY_API_KEY]
|
||||
```
|
||||
|
||||
> **Tip**: Right-click in IDE and select "Copy Relative Path" to use as parameter
|
||||
|
||||
### Deploy to Other Repositories
|
||||
|
||||
1. **Copy Files**:
|
||||
- `.github/workflows/translate.yml`
|
||||
- `tools/translate/` entire directory
|
||||
|
||||
2. **Configure GitHub Secrets**:
|
||||
- Repository Settings → Secrets and variables → Actions
|
||||
- Add `DIFY_API_KEY` secret
|
||||
|
||||
3. **Test**: Modify documents in branch to verify automatic translation functionality
|
||||
|
||||
### Technical Details
|
||||
|
||||
- Concurrent translation limited to 2 tasks to avoid excessive API pressure
|
||||
- Supports `.md` and `.mdx` file formats
|
||||
- Based on Dify API workflow mode
|
||||
|
||||
## TODO
|
||||
|
||||
- [ ] Support updating existing translations
|
||||
131
tools/translate/README_CN.md
Normal file
@@ -0,0 +1,131 @@
|
||||
# 自动翻译文档
|
||||
|
||||
基于 GitHub Actions 和 Dify AI 的文档自动翻译系统,支持英文、中文、日文三语互译。
|
||||
|
||||
> **其他语言**: [English](README_EN.md) | [日本語](README_JA.md)
|
||||
|
||||
## 工作原理
|
||||
|
||||
1. **触发条件**: 推送到非 main 分支时自动运行
|
||||
2. **智能检测**: 自动识别修改的 `.md/.mdx` 文件并判断源语言
|
||||
3. **翻译逻辑**:
|
||||
- ✅ 翻译新增文档到其他语言
|
||||
- ❌ 跳过已存在的翻译文件(避免覆盖手动修改)
|
||||
4. **自动提交**: 翻译结果自动推送到当前分支
|
||||
|
||||
## 系统特性
|
||||
|
||||
- 🌐 **多语言支持**: 基于配置的语言映射,理论上支持任意语言扩展
|
||||
- 📚 **术语表一致性**: 内置专业术语库,LLM 智能遵循术语表确保技术词汇翻译统一
|
||||
- 🔄 **并发处理**: 智能并发控制,同时翻译多个目标语言
|
||||
- 🛡️ **容错机制**: 3 次重试机制,指数退避策略
|
||||
- ⚡ **增量翻译**: 只处理变更文件,避免重复工作
|
||||
- 🧠 **高性能模型**: 使用性能较强的 LLM 模型确保翻译质量
|
||||
|
||||
## 使用方法
|
||||
|
||||
### 文档编写者
|
||||
|
||||
1. 在任意语言目录下编写/修改文档
|
||||
2. 推送到分支(非 main)
|
||||
3. 等待 0.5-1 分钟自动翻译完成
|
||||
4. **查看翻译结果**:
|
||||
- 创建 Pull Request 进行本地查看和后续编辑
|
||||
- 或在 GitHub 查看 Actions 推送的 commit 详情,直接审查翻译质量
|
||||
|
||||
### 支持的语言目录
|
||||
|
||||
- **通用文档**: `en/` ↔ `zh-hans/` ↔ `ja-jp/`
|
||||
- **插件开发文档**: `plugin-dev-en/` ↔ `plugin-dev-zh/` ↔ `plugin-dev-ja/`
|
||||
|
||||
注:系统架构支持扩展更多语言,只需修改配置文件
|
||||
|
||||
## 注意事项
|
||||
|
||||
- 系统只翻译新文档,不会覆盖已存在的翻译
|
||||
- 如需更新现有翻译,请手动删除目标文件后重新触发
|
||||
- 术语翻译遵循 `termbase_i18n.md` 中的专业词汇表,LLM 具备智能术语识别能力
|
||||
- 翻译质量依赖于配置的高性能模型,建议在 Dify Studio 中使用性能较强的基座模型
|
||||
|
||||
### 系统配置
|
||||
|
||||
#### 术语表
|
||||
|
||||
编辑 `tools/translate/termbase_i18n.md` 更新专业术语翻译对照表。
|
||||
|
||||
#### 翻译模型
|
||||
|
||||
访问 Dify Studio 调整翻译 prompt 或更换基座模型。
|
||||
|
||||
---
|
||||
|
||||
---
|
||||
|
||||
---
|
||||
|
||||
## 🔧 开发和部署配置
|
||||
|
||||
### 本地开发环境
|
||||
|
||||
#### 1. 创建虚拟环境
|
||||
|
||||
```bash
|
||||
# 创建虚拟环境
|
||||
python -m venv venv
|
||||
|
||||
# 激活虚拟环境
|
||||
# macOS/Linux:
|
||||
source venv/bin/activate
|
||||
# Windows:
|
||||
# venv\Scripts\activate
|
||||
```
|
||||
|
||||
#### 2. 安装依赖
|
||||
|
||||
```bash
|
||||
pip install -r tools/translate/requirements.txt
|
||||
```
|
||||
|
||||
#### 3. 配置 API 密钥
|
||||
|
||||
在 `tools/translate/` 目录下创建 `.env` 文件:
|
||||
|
||||
```bash
|
||||
DIFY_API_KEY=your_dify_api_key_here
|
||||
```
|
||||
|
||||
#### 4. 运行翻译
|
||||
|
||||
```bash
|
||||
# 交互模式(推荐新手使用)
|
||||
python tools/translate/main.py
|
||||
|
||||
# 命令行模式(指定文件)
|
||||
python tools/translate/main.py path/to/file.mdx [DIFY_API_KEY]
|
||||
```
|
||||
|
||||
> **提示**: 在 IDE 中右键选择"复制相对路径"作为参数传入
|
||||
|
||||
### 部署到其他仓库
|
||||
|
||||
1. **复制文件**:
|
||||
|
||||
- `.github/workflows/translate.yml`
|
||||
- `tools/translate/` 整个目录
|
||||
|
||||
2. **配置 GitHub Secrets**:
|
||||
|
||||
- Repository Settings → Secrets and variables → Actions
|
||||
- 添加 `DIFY_API_KEY` 密钥
|
||||
|
||||
3. **测试**: 在分支中修改文档,验证自动翻译功能
|
||||
|
||||
### 技术细节
|
||||
|
||||
- 并发翻译限制为 2 个任务,避免 API 压力过大
|
||||
- 支持 `.md` 和 `.mdx` 文件格式
|
||||
- 基于 Dify API 的 workflow 模式
|
||||
|
||||
## TODO
|
||||
|
||||
- [ ] 支持更新现有翻译
|
||||
125
tools/translate/README_JA.md
Normal file
@@ -0,0 +1,125 @@
|
||||
# 自動ドキュメント翻訳
|
||||
|
||||
GitHub Actions と Dify AI に基づく多言語ドキュメント自動翻訳システム。英語、中国語、日本語の三言語相互翻訳をサポートします。
|
||||
|
||||
> **他の言語**: [中文](README.md) | [English](README_EN.md)
|
||||
|
||||
## 動作原理
|
||||
|
||||
1. **トリガー条件**: main以外のブランチにプッシュすると自動実行
|
||||
2. **スマート検出**: 変更された `.md/.mdx` ファイルを自動識別し、元言語を判定
|
||||
3. **翻訳ロジック**:
|
||||
- ✅ 新規ドキュメントを他の言語に翻訳
|
||||
- ❌ 既存の翻訳ファイルはスキップ(手動編集の上書きを回避)
|
||||
4. **自動コミット**: 翻訳結果を現在のブランチに自動プッシュ
|
||||
|
||||
## システム特徴
|
||||
|
||||
- 🌐 **多言語サポート**: 設定ベースの言語マッピング、理論的には任意の言語拡張をサポート
|
||||
- 📚 **用語の一貫性**: 内蔵専門用語データベース、LLMが用語表を賢く遵守し技術用語翻訳の統一を確保
|
||||
- 🔄 **並行処理**: スマート並行制御、複数のターゲット言語を同時翻訳
|
||||
- 🛡️ **フォールトトレランス**: 3回再試行メカニズム、指数バックオフ戦略
|
||||
- ⚡ **増分翻訳**: 変更ファイルのみ処理、重複作業を回避
|
||||
- 🧠 **高性能モデル**: 高性能LLMモデルを使用し翻訳品質を確保
|
||||
|
||||
## 使用方法
|
||||
|
||||
### ドキュメント作成者向け
|
||||
|
||||
1. 任意の言語ディレクトリでドキュメントを作成/修正
|
||||
2. ブランチ(main以外)にプッシュ
|
||||
3. 0.5-1分待って自動翻訳完了
|
||||
4. **翻訳結果の確認**:
|
||||
- Pull Requestを作成してローカル確認と後続編集
|
||||
- またはGitHubでActionsプッシュコミット詳細を確認し、翻訳品質を直接レビュー
|
||||
|
||||
### サポート言語ディレクトリ
|
||||
|
||||
- **一般ドキュメント**: `en/` ↔ `zh-hans/` ↔ `ja-jp/`
|
||||
- **プラグイン開発ドキュメント**: `plugin-dev-en/` ↔ `plugin-dev-zh/` ↔ `plugin-dev-ja/`
|
||||
|
||||
注:システムアーキテクチャはより多くの言語拡張をサポート、設定ファイルの修正のみで可能
|
||||
|
||||
## 注意事項
|
||||
|
||||
- システムは新規ドキュメントのみ翻訳、既存翻訳は上書きしません
|
||||
- 既存翻訳を更新する場合、対象ファイルを手動削除してから再トリガー
|
||||
- 用語翻訳は `termbase_i18n.md` の専門用語表に従い、LLMはスマート用語認識機能を持つ
|
||||
- 翻訳品質は設定された高性能モデルに依存、Dify Studioで高性能ベースモデル使用を推奨
|
||||
|
||||
### システム設定
|
||||
|
||||
#### 用語データベース
|
||||
|
||||
`tools/translate/termbase_i18n.md` を編集して専門用語翻訳対照表を更新。
|
||||
|
||||
#### 翻訳モデル
|
||||
|
||||
Dify Studio で翻訳プロンプトの調整やベースモデルの変更。
|
||||
|
||||
---
|
||||
|
||||
## 🔧 開発とデプロイ設定
|
||||
|
||||
### ローカル開発環境
|
||||
|
||||
#### 1. 仮想環境作成
|
||||
|
||||
```bash
|
||||
# 仮想環境作成
|
||||
python -m venv venv
|
||||
|
||||
# 仮想環境アクティベート
|
||||
# macOS/Linux:
|
||||
source venv/bin/activate
|
||||
# Windows:
|
||||
# venv\Scripts\activate
|
||||
```
|
||||
|
||||
#### 2. 依存関係インストール
|
||||
|
||||
```bash
|
||||
pip install -r tools/translate/requirements.txt
|
||||
```
|
||||
|
||||
#### 3. APIキー設定
|
||||
|
||||
`tools/translate/` ディレクトリに `.env` ファイルを作成:
|
||||
|
||||
```bash
|
||||
DIFY_API_KEY=your_dify_api_key_here
|
||||
```
|
||||
|
||||
#### 4. 翻訳実行
|
||||
|
||||
```bash
|
||||
# インタラクティブモード(初心者推奨)
|
||||
python tools/translate/main.py
|
||||
|
||||
# コマンドラインモード(ファイル指定)
|
||||
python tools/translate/main.py path/to/file.mdx [DIFY_API_KEY]
|
||||
```
|
||||
|
||||
> **ヒント**: IDEで右クリック「相対パスをコピー」をパラメータとして使用
|
||||
|
||||
### 他のリポジトリへのデプロイ
|
||||
|
||||
1. **ファイルコピー**:
|
||||
- `.github/workflows/translate.yml`
|
||||
- `tools/translate/` ディレクトリ全体
|
||||
|
||||
2. **GitHub Secrets設定**:
|
||||
- Repository Settings → Secrets and variables → Actions
|
||||
- `DIFY_API_KEY` シークレットを追加
|
||||
|
||||
3. **テスト**: ブランチでドキュメント修正し、自動翻訳機能を検証
|
||||
|
||||
### 技術詳細
|
||||
|
||||
- 並行翻訳は2タスクに制限、過度なAPI圧迫を回避
|
||||
- `.md` と `.mdx` ファイル形式をサポート
|
||||
- Dify API ワークフローモードベース
|
||||
|
||||
## TODO
|
||||
|
||||
- [ ] 既存翻訳の更新サポート
|
||||
455
tools/translate/main.py
Normal file
@@ -0,0 +1,455 @@
|
||||
import httpx
|
||||
import os
|
||||
import sys
|
||||
import asyncio
|
||||
import aiofiles
|
||||
|
||||
docs_structure = {
|
||||
"general_help": {
|
||||
"English": "en",
|
||||
"Chinese": "zh-hans",
|
||||
"Japanese": "ja-jp"
|
||||
},
|
||||
"plugin_dev": {
|
||||
"English": "plugin-dev-en",
|
||||
"Chinese": "plugin-dev-zh",
|
||||
"Japanese": "plugin-dev-ja"
|
||||
},
|
||||
"version_28x": {
|
||||
"English": "versions/2-8-x/en-us",
|
||||
"Chinese": "versions/2-8-x/zh-cn",
|
||||
"Japanese": "versions/2-8-x/ja-jp"
|
||||
},
|
||||
"version_30x": {
|
||||
"English": "versions/3-0-x/en-us",
|
||||
"Chinese": "versions/3-0-x/zh-cn",
|
||||
"Japanese": "versions/3-0-x/ja-jp"
|
||||
},
|
||||
"version_31x": {
|
||||
"English": "versions/3-1-x/en-us",
|
||||
"Chinese": "versions/3-1-x/zh-cn",
|
||||
"Japanese": "versions/3-1-x/ja-jp"
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
async def translate_text(file_path, dify_api_key, original_language, target_language1, termbase_path=None, max_retries=3):
|
||||
"""
|
||||
Translate text using Dify API with termbase from `tools/translate/termbase_i18n.md`
|
||||
"""
|
||||
if termbase_path is None:
|
||||
# Get project root directory
|
||||
script_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
base_dir = os.path.dirname(os.path.dirname(script_dir)) # Two levels up
|
||||
termbase_path = os.path.join(base_dir, "tools", "translate", "termbase_i18n.md")
|
||||
|
||||
url = "https://api.dify.ai/v1/workflows/run"
|
||||
|
||||
termbase = await load_md_mdx(termbase_path)
|
||||
the_doc = await load_md_mdx(file_path)
|
||||
payload = {
|
||||
"response_mode": "blocking",
|
||||
"user": "Dify",
|
||||
"inputs": {
|
||||
"original_language": original_language,
|
||||
"output_language1": target_language1,
|
||||
"the_doc": the_doc,
|
||||
"termbase": termbase
|
||||
}
|
||||
}
|
||||
|
||||
headers = {
|
||||
"Authorization": "Bearer " + dify_api_key,
|
||||
"Content-Type": "application/json"
|
||||
}
|
||||
|
||||
# Retry mechanism
|
||||
for attempt in range(max_retries):
|
||||
try:
|
||||
# Add delay to avoid concurrent pressure
|
||||
if attempt > 0:
|
||||
delay = attempt * 2 # Incremental delay: 2s, 4s, 6s
|
||||
print(f"Retrying in {delay} seconds... (attempt {attempt + 1}/{max_retries})")
|
||||
await asyncio.sleep(delay)
|
||||
|
||||
async with httpx.AsyncClient(timeout=120.0) as client: # Increase timeout to 120 seconds
|
||||
response = await client.post(url, json=payload, headers=headers)
|
||||
|
||||
# Check HTTP status code
|
||||
if response.status_code != 200:
|
||||
print(f"HTTP Error: {response.status_code}")
|
||||
print(f"Response: {response.text}")
|
||||
if attempt == max_retries - 1: # Last attempt
|
||||
return ""
|
||||
continue
|
||||
|
||||
try:
|
||||
response_data = response.json()
|
||||
print(f"API Response: {response_data}") # Debug info
|
||||
|
||||
# Extract output1
|
||||
output1 = response_data.get("data", {}).get("outputs", {}).get("output1", "")
|
||||
if not output1:
|
||||
print("Warning: No output1 found in response")
|
||||
print(f"Full response: {response_data}")
|
||||
return output1
|
||||
except Exception as e:
|
||||
print(f"Error parsing response: {e}")
|
||||
print(f"Response text: {response.text}")
|
||||
if attempt == max_retries - 1: # Last attempt
|
||||
return ""
|
||||
continue
|
||||
|
||||
except httpx.ReadTimeout as e:
|
||||
print(f"Request timeout (attempt {attempt + 1}/{max_retries}): {str(e)}")
|
||||
if attempt == max_retries - 1: # Last attempt
|
||||
print(f"All {max_retries} attempts failed due to timeout")
|
||||
return ""
|
||||
except Exception as e:
|
||||
print(f"Unexpected error (attempt {attempt + 1}/{max_retries}): {str(e)}")
|
||||
if attempt == max_retries - 1: # Last attempt
|
||||
return ""
|
||||
|
||||
return ""
|
||||
|
||||
|
||||
async def load_md_mdx(file_path):
|
||||
async with aiofiles.open(file_path, "r", encoding="utf-8") as f:
|
||||
content = await f.read()
|
||||
return content
|
||||
|
||||
|
||||
def determine_doc_type_and_language(file_path):
|
||||
"""
|
||||
Determine document type and current language based on file path
|
||||
Returns (doc_type, current_language, language_name)
|
||||
"""
|
||||
# Normalize path separators
|
||||
normalized_path = file_path.replace(os.sep, '/')
|
||||
|
||||
# Collect all possible matches and find the longest one
|
||||
matches = []
|
||||
for doc_type, languages in docs_structure.items():
|
||||
for lang_name, lang_code in languages.items():
|
||||
# Normalize lang_code path separators too
|
||||
normalized_lang_code = lang_code.replace(os.sep, '/')
|
||||
if normalized_lang_code in normalized_path:
|
||||
matches.append((len(normalized_lang_code), doc_type, lang_code, lang_name))
|
||||
|
||||
# Return the match with the longest lang_code (most specific)
|
||||
if matches:
|
||||
matches.sort(reverse=True) # Sort by length descending
|
||||
_, doc_type, lang_code, lang_name = matches[0]
|
||||
return doc_type, lang_code, lang_name
|
||||
|
||||
return None, None, None
|
||||
|
||||
|
||||
def get_language_code_name_map(doc_type):
|
||||
"""
|
||||
Get mapping from language code to language name
|
||||
"""
|
||||
code_to_name = {}
|
||||
for lang_name, lang_code in docs_structure[doc_type].items():
|
||||
code_to_name[lang_code] = lang_name
|
||||
return code_to_name
|
||||
|
||||
|
||||
def generate_target_path(file_path, current_lang_code, target_lang_code):
|
||||
"""
|
||||
Generate target language file path
|
||||
"""
|
||||
return file_path.replace(current_lang_code, target_lang_code)
|
||||
|
||||
|
||||
async def save_translated_content(content, file_path):
|
||||
"""
|
||||
Save translated content to file
|
||||
"""
|
||||
try:
|
||||
print(f"Attempting to save to: {file_path}")
|
||||
print(f"Content length: {len(content)} characters")
|
||||
|
||||
# Ensure directory exists
|
||||
os.makedirs(os.path.dirname(file_path), exist_ok=True)
|
||||
|
||||
# Save file
|
||||
async with aiofiles.open(file_path, "w", encoding="utf-8") as f:
|
||||
await f.write(content)
|
||||
|
||||
# Verify file was saved successfully
|
||||
if os.path.exists(file_path):
|
||||
file_size = os.path.getsize(file_path)
|
||||
print(f"✓ Translated content saved to {file_path} (size: {file_size} bytes)")
|
||||
else:
|
||||
print(f"✗ Failed to save file: {file_path}")
|
||||
except Exception as e:
|
||||
print(f"Error saving file {file_path}: {str(e)}")
|
||||
|
||||
|
||||
async def translate_single_file(file_path, dify_api_key, current_lang_name, target_lang_code, target_lang_name, current_lang_code, semaphore):
|
||||
"""
|
||||
Async translate single file (using semaphore to control concurrency)
|
||||
"""
|
||||
async with semaphore: # Control concurrency
|
||||
# Generate target file path
|
||||
target_file_path = generate_target_path(file_path, current_lang_code, target_lang_code)
|
||||
|
||||
print(f"Source: {file_path}")
|
||||
print(f"Target: {target_file_path}")
|
||||
|
||||
# Check if target file exists
|
||||
if os.path.exists(target_file_path):
|
||||
print(f"Target file already exists: {target_file_path}")
|
||||
return
|
||||
|
||||
print(f"Translating from {current_lang_name} to {target_lang_name}...")
|
||||
|
||||
try:
|
||||
# Call translation function
|
||||
translated_content = await translate_text(
|
||||
file_path,
|
||||
dify_api_key,
|
||||
current_lang_name,
|
||||
target_lang_name
|
||||
)
|
||||
|
||||
print(f"Translation result length: {len(translated_content)} characters")
|
||||
|
||||
if translated_content and translated_content.strip():
|
||||
# Save translation result
|
||||
await save_translated_content(translated_content, target_file_path)
|
||||
else:
|
||||
print(f"Error: Translation failed for {target_lang_name} - empty or no content returned")
|
||||
except Exception as e:
|
||||
print(f"Error translating to {target_lang_name}: {str(e)}")
|
||||
import traceback
|
||||
traceback.print_exc()
|
||||
|
||||
|
||||
async def main_async(file_path, dify_api_key=None):
|
||||
"""
|
||||
Async main function
|
||||
"""
|
||||
# Get script directory
|
||||
script_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
# Try to load API key from .env file
|
||||
env_path = os.path.join(script_dir, '.env')
|
||||
if os.path.exists(env_path) and dify_api_key is None:
|
||||
try:
|
||||
# Import dotenv only when needed
|
||||
import importlib.util
|
||||
dotenv_spec = importlib.util.find_spec("dotenv")
|
||||
if dotenv_spec is not None:
|
||||
from dotenv import load_dotenv
|
||||
load_dotenv(env_path)
|
||||
dify_api_key = os.getenv('DIFY_API_KEY') or os.getenv('dify_api_key')
|
||||
else:
|
||||
raise ImportError
|
||||
except ImportError:
|
||||
# Manual parsing of .env file if dotenv is not available
|
||||
with open(env_path, 'r') as f:
|
||||
for line in f:
|
||||
if line.strip().startswith('DIFY_API_KEY=') or line.strip().startswith('dify_api_key='):
|
||||
dify_api_key = line.strip().split('=', 1)[1].strip('"\'')
|
||||
break
|
||||
|
||||
if not dify_api_key:
|
||||
print("Error: DIFY_API_KEY not found. Please provide it as parameter or in .env file.")
|
||||
return
|
||||
|
||||
# Determine document type and current language
|
||||
doc_type, current_lang_code, current_lang_name = determine_doc_type_and_language(file_path)
|
||||
|
||||
if not doc_type:
|
||||
print(f"Error: Unable to determine document type and language for {file_path}")
|
||||
return
|
||||
|
||||
print(f"Document type: {doc_type}, Current language: {current_lang_name} ({current_lang_code})")
|
||||
|
||||
# Get all languages for current document type
|
||||
code_to_name = get_language_code_name_map(doc_type)
|
||||
|
||||
# Create semaphore to limit concurrency (avoid excessive API pressure)
|
||||
semaphore = asyncio.Semaphore(2)
|
||||
|
||||
# Create all translation tasks
|
||||
tasks = []
|
||||
for target_lang_code, target_lang_name in code_to_name.items():
|
||||
# Skip current language
|
||||
if target_lang_code == current_lang_code:
|
||||
continue
|
||||
|
||||
task = translate_single_file(
|
||||
file_path,
|
||||
dify_api_key,
|
||||
current_lang_name,
|
||||
target_lang_code,
|
||||
target_lang_name,
|
||||
current_lang_code,
|
||||
semaphore
|
||||
)
|
||||
tasks.append(task)
|
||||
|
||||
# Execute all translation tasks
|
||||
if tasks:
|
||||
print("Running translations concurrently...")
|
||||
await asyncio.gather(*tasks)
|
||||
print("All translations completed!")
|
||||
else:
|
||||
print("No translations needed.")
|
||||
|
||||
|
||||
def get_file_path_interactive():
|
||||
"""
|
||||
Interactive file path input
|
||||
"""
|
||||
while True:
|
||||
print("Please enter the file path to translate:")
|
||||
print("请输入要翻译的文件路径:")
|
||||
print("翻訳するファイルパスを入力してください:")
|
||||
file_path = input("File path / 文件路径 / ファイルパス: ").strip()
|
||||
|
||||
if not file_path:
|
||||
print("File path cannot be empty. Please try again.")
|
||||
print("文件路径不能为空,请重新输入。")
|
||||
print("ファイルパスは空にできません。再度入力してください。")
|
||||
continue
|
||||
|
||||
# Remove quotes if user copy-pasted with quotes
|
||||
file_path = file_path.strip('\'"')
|
||||
|
||||
# Check if file exists
|
||||
if not os.path.exists(file_path):
|
||||
print(f"File does not exist: {file_path}")
|
||||
print(f"文件不存在: {file_path}")
|
||||
print(f"ファイルが存在しません: {file_path}")
|
||||
print("Please check if the path is correct.")
|
||||
print("请检查路径是否正确。")
|
||||
print("パスが正しいか確認してください。")
|
||||
continue
|
||||
|
||||
# Check if it's a file
|
||||
if not os.path.isfile(file_path):
|
||||
print(f"The specified path is not a file: {file_path}")
|
||||
print(f"指定的路径不是文件: {file_path}")
|
||||
print(f"指定されたパスはファイルではありません: {file_path}")
|
||||
continue
|
||||
|
||||
# Check file extension
|
||||
if not (file_path.endswith('.md') or file_path.endswith('.mdx')):
|
||||
print(f"Warning: File is not .md or .mdx format: {file_path}")
|
||||
print(f"警告: 文件不是 .md 或 .mdx 格式: {file_path}")
|
||||
print(f"警告: ファイルは .md または .mdx 形式ではありません: {file_path}")
|
||||
confirm = input("Continue anyway? (y/n) / 是否继续? (y/n) / 続行しますか? (y/n): ").strip().lower()
|
||||
if confirm not in ['y', 'yes', 'Y', 'YES']:
|
||||
continue
|
||||
|
||||
return file_path
|
||||
|
||||
|
||||
def load_local_api_key():
|
||||
"""
|
||||
Load API key from local .env file
|
||||
"""
|
||||
script_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
env_path = os.path.join(script_dir, '.env')
|
||||
|
||||
if not os.path.exists(env_path):
|
||||
print(f"Error: .env file not found: {env_path}")
|
||||
print(f"错误: 未找到 .env 文件: {env_path}")
|
||||
print(f"エラー: .env ファイルが見つかりません: {env_path}")
|
||||
print("Please create .env file and add: DIFY_API_KEY=your_api_key")
|
||||
print("请在当前目录创建 .env 文件并添加: DIFY_API_KEY=your_api_key")
|
||||
print(".env ファイルを作成し、DIFY_API_KEY=your_api_key を追加してください")
|
||||
return None
|
||||
|
||||
try:
|
||||
# Try using dotenv
|
||||
import importlib.util
|
||||
dotenv_spec = importlib.util.find_spec("dotenv")
|
||||
if dotenv_spec is not None:
|
||||
from dotenv import load_dotenv
|
||||
load_dotenv(env_path)
|
||||
api_key = os.getenv('DIFY_API_KEY') or os.getenv('dify_api_key')
|
||||
else:
|
||||
# Manual parsing of .env file
|
||||
api_key = None
|
||||
with open(env_path, 'r') as f:
|
||||
for line in f:
|
||||
line = line.strip()
|
||||
if line.startswith('DIFY_API_KEY=') or line.startswith('dify_api_key='):
|
||||
api_key = line.split('=', 1)[1].strip('"\'')
|
||||
break
|
||||
except Exception as e:
|
||||
print(f"Error reading .env file: {e}")
|
||||
print(f"读取 .env 文件时出错: {e}")
|
||||
print(f".env ファイルの読み取りエラー: {e}")
|
||||
return None
|
||||
|
||||
if not api_key:
|
||||
print("Error: DIFY_API_KEY not found in .env file")
|
||||
print("错误: 在 .env 文件中未找到 DIFY_API_KEY")
|
||||
print("エラー: .env ファイルに DIFY_API_KEY が見つかりません")
|
||||
print("Please ensure .env file contains: DIFY_API_KEY=your_api_key")
|
||||
print("请确保 .env 文件包含: DIFY_API_KEY=your_api_key")
|
||||
print(".env ファイルに DIFY_API_KEY=your_api_key が含まれていることを確認してください")
|
||||
return None
|
||||
|
||||
print("✓ Successfully loaded local API key")
|
||||
print("✓ 成功加载本地 API key")
|
||||
print("✓ ローカル API キーの読み込みに成功しました")
|
||||
return api_key
|
||||
|
||||
|
||||
def main(file_path, dify_api_key=None):
|
||||
"""
|
||||
Sync wrapper function to run async main function
|
||||
"""
|
||||
asyncio.run(main_async(file_path, dify_api_key))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# If no parameters provided, enter interactive mode
|
||||
if len(sys.argv) == 1:
|
||||
print("=== Dify Documentation Translation Tool ===")
|
||||
print("=== Dify 文档翻译工具 ===")
|
||||
print("=== Dify ドキュメント翻訳ツール ===")
|
||||
print()
|
||||
|
||||
# Interactive file path input
|
||||
file_path = get_file_path_interactive()
|
||||
|
||||
# Load local API key
|
||||
dify_api_key = load_local_api_key()
|
||||
if not dify_api_key:
|
||||
sys.exit(1)
|
||||
|
||||
print()
|
||||
print(f"Starting translation for file: {file_path}")
|
||||
print(f"开始翻译文件: {file_path}")
|
||||
print(f"ファイルの翻訳を開始: {file_path}")
|
||||
main(file_path, dify_api_key)
|
||||
|
||||
# Command line argument mode
|
||||
elif len(sys.argv) >= 2:
|
||||
file_path = sys.argv[1]
|
||||
dify_api_key = None
|
||||
|
||||
# Parse command line arguments
|
||||
for i, arg in enumerate(sys.argv[2:], 2):
|
||||
if dify_api_key is None:
|
||||
dify_api_key = arg
|
||||
|
||||
main(file_path, dify_api_key)
|
||||
|
||||
else:
|
||||
print("Usage: python main.py [file_path] [dify_api_key]")
|
||||
print(" No arguments: Enter interactive mode")
|
||||
print(" file_path: File path to translate")
|
||||
print(" dify_api_key: (Optional) Dify API key")
|
||||
sys.exit(1)
|
||||
|
||||
|
||||
|
||||
3
tools/translate/requirements.txt
Normal file
@@ -0,0 +1,3 @@
|
||||
python-dotenv>=1.0.0
|
||||
httpx>=0.25.0
|
||||
aiofiles>=23.0.0
|
||||
64
tools/translate/termbase_i18n.md
Normal file
@@ -0,0 +1,64 @@
|
||||
# Dify Termbase (EN/CN/JP)
|
||||
|
||||
| English Term | 中文 (简体) | 日本語 | Definition |
|
||||
| :--------------------------------------- | :--------------- | :----------------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| **Agent** | 智能代理 | エージェント | An autonomous AI system capable of making decisions and executing tasks based on environmental information. |
|
||||
| **Agentic Workflow** | 智能体工作流 | エージェンティックワークフロー | A task orchestration method that allows AI systems to autonomously solve complex problems through multiple steps. |
|
||||
| **Automatic Speech Recognition (ASR)** | 自动语音识别 | 自動音声認識 | Technology that converts human speech into text and serves as the foundation for voice interaction applications. |
|
||||
| **Backbone of Thought (BoT)** | 思维骨架 | 思考の骨格 | A structured thinking framework that provides the main structure for reasoning in large language models. |
|
||||
| **Chain of Thought (CoT)** | 思维链 | 思考の連鎖 | A prompting technique that guides large language models to display their step-by-step thinking process. |
|
||||
| **Chatflow** | 对话流 | チャットフロー | 一种面向对话场景的工作流编排模式,专为需要多步逻辑处理的交互式应用设计。(CN) |
|
||||
| **Chunking** | 分段 | チャンキング | A processing technique that splits long text into smaller content blocks, enabling retrieval systems to find relevant information more precisely. |
|
||||
| **Citation and Attribution** | 引用与归属 | 引用と帰属 | Features that allow AI systems to clearly indicate the sources of information, increasing the credibility and transparency of responses. |
|
||||
| **Domain-Specific Language (DSL)** | 领域特定语言 | ドメイン固有言語 | A programming language or configuration format designed for a specific application domain. |
|
||||
| **Extract, Transform, Load (ETL)** | 提取、转换、加载 | 抽出・変換・読み込み | A classic data processing workflow: extracting raw data, transforming it into a format suitable for analysis, and then loading it into the target system. |
|
||||
| **Frequency Penalty** | 频率惩罚 | 頻度ペナルティ | A text generation control parameter that increases output diversity by reducing the probability of generating frequently occurring vocabulary. |
|
||||
| **Full-text Search** | 全文检索 | 全文検索 | 索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。(CN) |
|
||||
| **Function Calling** | 函数调用 | 関数呼び出し | The capability of large language models to recognize when to call specific functions and provide the required parameters. |
|
||||
| **General Chunking Pattern** | 通用分段模式 | 一般的なチャンキングパターン | A simple text splitting strategy that divides documents into mutually independent content blocks. |
|
||||
| **Graph of Thought (GoT)** | 思维图 | 思考のグラフ | A method of representing the thinking process as a network structure, capturing complex relationships between concepts. |
|
||||
| **Hybrid Search** | 混合检索 | ハイブリッド検索 | A search method that combines the advantages of keyword matching and semantic search to provide more comprehensive retrieval results. |
|
||||
| **Inverted Index** | 倒排索引 | 転置インデックス | A core data structure of search engines that records which documents each word appears in. |
|
||||
| **Keyword Search** | 关键词检索 | キーワード検索 | A search method based on exact matching that finds documents containing specific vocabulary. |
|
||||
| **Knowledge Base** | 知识库 | 知識ベース | A database that stores structured information in AI applications, providing a source of professional knowledge for models. |
|
||||
| **Knowledge Retrieval** | 知识检索 | 知識検索 | The process of finding information from a knowledge base that is most relevant to a user's question. |
|
||||
| **Large Language Model (LLM)** | 大型语言模型 | 大規模言語モデル | An AI model trained on massive amounts of text that can understand and generate human language. |
|
||||
| **Local Model Inference** | 本地模型推理 | ローカルモデル推論 | The process of running AI models on a user's own device rather than relying on cloud services. |
|
||||
| **Max_tokens** | 最大标记数 | 最大トークン数 | A parameter that controls the maximum number of characters the model generates in a single response. |
|
||||
| **Memory** | 记忆 | メモリ | The ability of AI systems to save and use historical interaction information, keeping multi-turn conversations coherent. |
|
||||
| **Metadata** | 元数据 | メタデータ | 描述数据的数据,提供关于内容的结构化信息,如文档的创建时间、作者、标题、标签、文件格式等属性信息等。(CN) |
|
||||
| **Metadata Filtering** | 元数据筛选 | メタデータフィルタリング | A technique that utilizes document attribute information for content filtering. |
|
||||
| **Model-as-a-Service (MaaS)** | 模型即服务 | サービスとしてのモデル | A cloud service model where providers offer access to pre-trained models through APIs. |
|
||||
| **Multimodal Model** | 多模态模型 | マルチモーダルモデル | A model capable of processing multiple types of input data, such as text, images, audio, etc. |
|
||||
| **Multi-path Retrieval** | 多路召回 | マルチパス検索 | A strategy for obtaining information in parallel through multiple retrieval methods. |
|
||||
| **Multi-tool-call** | 多工具调用 | マルチツール呼び出し | The ability of a model to call multiple different tools in a single response. |
|
||||
| **Parent-Child Chunking** | 父子分段模式 | 親子チャンキング | An advanced text splitting strategy that creates two levels of content blocks. |
|
||||
| **Predefined Model** | 预定义模型 | 事前定義モデル | A ready-made model trained and provided by AI vendors that users can directly call without training themselves. |
|
||||
| **Presence Penalty** | 存在惩罚 | 存在ペナルティ | A parameter setting that prevents language models from repeating content. |
|
||||
| **Prompt** | 提示词 | プロンプト | Input text that guides AI models to generate specific responses. |
|
||||
| **Q\&A Mode** | 问答模式 | Q\&A モード | A special indexing strategy that automatically generates question-answer pairs for document content. |
|
||||
| **Reasoning and Acting (ReAct)** | 推理与行动 | 推論と行動 | An AI agent framework that enables models to alternate between thinking and executing operations. |
|
||||
| **ReRank** | 重排序 | 再ランキング | A technique for secondary sorting of preliminary retrieval results to improve the relevance of final results. |
|
||||
| **Rerank Model** | 重新排序模型 | 再ランキングモデル | A model specifically designed to evaluate the relevance of retrieval results to queries and reorder them. |
|
||||
| **Response_format** | 响应格式 | レスポンス形式 | A specification of the structure type for model output, such as plain text, JSON, or HTML. |
|
||||
| **Retrieval Test** | 召回测试 | 検索テスト | A functionality for verifying the effectiveness of knowledge base retrieval. |
|
||||
| **Retrieval-Augmented Generation (RAG)** | 检索增强生成 | 検索拡張生成 | A technical architecture that combines external knowledge retrieval and language generation. |
|
||||
| **Reverse Calling** | 反向调用 | リバースコーリング | A bidirectional mechanism for plugins to interact with platforms, allowing plugins to actively call platform functionality. |
|
||||
| **Score Threshold** | 分数阈值 | スコア閾値 | A similarity threshold for filtering retrieval results. |
|
||||
| **Software Development Kit (SDK)** | 软件开发工具包 | (N/A) | 一组用于开发特定平台或服务应用程序的工具集合。(CN) |
|
||||
| **Semantic Search** | 语义检索 | セマンティック検索 | A retrieval method based on understanding and matching text meaning rather than simple keyword matching. |
|
||||
| **Session Variables** | 会话变量 | セッション変数 | A mechanism for storing multi-turn dialogue context information. |
|
||||
| **Speech-to-Text (STT)** | 语音转文字 | 音声からテキスト変換 | Technology that converts users' voice input into text data. |
|
||||
| **Stream-tool-call** | 流式工具调用 | ストリームツール呼び出し | A real-time processing mode that allows AI systems to call external tools while generating responses. |
|
||||
| **Streaming Response** | 流式结果返回 | ストリーミングレスポンス | A real-time response mechanism where AI systems return content to users as it is generated. |
|
||||
| **Temperature** | 温度 | 温度 | A parameter controlling the randomness of language model output. |
|
||||
| **Text Embedding** | 文本嵌入 | テキスト埋め込み | The process of converting text into numerical vectors. |
|
||||
| **Text-to-Speech (TTS)** | 文本转语音 | テキスト音声変換 | Technology that converts written text into natural speech. |
|
||||
| **Tool Calling** | 工具调用 | ツール呼び出し | The ability of AI systems to identify and use external functionality. |
|
||||
| **TopK** | TopK | TopK | A parameter controlling the number of retrieval results returned. |
|
||||
| **TopP (Nucleus Sampling)** | 核采样 | 核サンプリング | A text generation control method that selects the next word from a probability-weighted subset of vocabulary. |
|
||||
| **Tree of Thought (ToT)** | 思维树 | 思考の木 | A thinking method for exploring multiple reasoning paths. |
|
||||
| **Vector Database** | 向量数据库 | ベクトルデータベース | A database system specialized in storing and searching vector embeddings. |
|
||||
| **Vector Retrieval** | 向量检索 | ベクトル検索 | A search method based on text vector embedding similarity. |
|
||||
| **Vision** | 视觉能力 | ビジョン機能 | The functionality of multimodal LLMs to understand and process images. |
|
||||
| **Workflow** | 工作流 | ワークフロー | A task orchestration method that breaks down complex AI applications into multiple independent nodes. |
|
||||
259
zh-hans/workshop/basic/the-right-way-of-markdown.mdx
Normal file
@@ -0,0 +1,259 @@
|
||||
---
|
||||
title: Markdown 的正确使用方式
|
||||
---
|
||||
|
||||
[Markdown](https://www.markdownguide.org/basic-syntax/) 可以将你在 Dify 应用中的输出从纯文本转化为格式良好、专业美观的响应内容。在 Answer 和 End 节点中使用 Markdown,可以渲染标题、列表、代码块、表格等元素,为终端用户创造清晰的视觉层次结构。
|
||||
|
||||
## Dify 中的基本 Markdown 语法
|
||||
|
||||
你可以在 Answer / End 节点中使用 Markdown 渲染以下内容:
|
||||
|
||||
* 标题
|
||||
* 加粗、斜体、删除线
|
||||
* 列表
|
||||
* 表格
|
||||
* 多行代码块
|
||||
* 音频和视频
|
||||
|
||||
<img
|
||||
src="/images/CleanShot2025-07-14at00.34.54.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
### 标题
|
||||
|
||||
使用 `#` 来表示标题,`#` 的数量表示标题级别:
|
||||
|
||||
```markdown
|
||||
# 一级标题
|
||||
## 二级标题
|
||||
### 三级标题
|
||||
```
|
||||
|
||||
### 加粗、斜体、删除线
|
||||
|
||||
你可以使用以下方式设置文本样式:
|
||||
|
||||
```markdown
|
||||
**加粗文本**
|
||||
*斜体文本*
|
||||
~~删除线文本~~
|
||||
```
|
||||
|
||||
### 列表
|
||||
|
||||
可以创建有序和无序列表:
|
||||
|
||||
```markdown
|
||||
- 无序列表项 1
|
||||
- 无序列表项 2
|
||||
- 嵌套无序项
|
||||
1. 有序列表项 1
|
||||
2. 有序列表项 2
|
||||
1. 嵌套有序项
|
||||
```
|
||||
|
||||
### 表格
|
||||
|
||||
使用竖线和短横线创建表格:
|
||||
|
||||
```markdown
|
||||
| 表头 1 | 表头 2 |
|
||||
|--------|--------|
|
||||
| 第 1 行第 1 列 | 第 1 行第 2 列 |
|
||||
| 第 2 行第 1 列 | 第 2 行第 2 列 |
|
||||
```
|
||||
|
||||
### 多行代码块
|
||||
|
||||
使用三个反引号 <code>\`\`\`python</code> 创建多行代码块:
|
||||
|
||||
```python
|
||||
def hello_world():
|
||||
print("Hello, World!")
|
||||
```
|
||||
|
||||
### 音频和视频
|
||||
|
||||
可以通过以下语法插入音频和视频:
|
||||
|
||||
```markdown
|
||||
<video controls>
|
||||
<source src="https://commondatastorage.googleapis.com/gtv-videos-bucket/sample/ForBiggerBlazes.mp4" type="video/mp4">
|
||||
</video>
|
||||
<audio controls>
|
||||
<source src="https://www.soundhelix.com/examples/mp3/SoundHelix-Song-1.mp3" type="audio/mpeg">
|
||||
</audio>
|
||||
```
|
||||
<Note>
|
||||
如果你希望了解更多关于 Markdown 的使用方式,可以参考 [Markdown Guide](https://www.markdownguide.org/basic-syntax/)。
|
||||
</Note>
|
||||
|
||||
## Dify 中的高级 Markdown 功能
|
||||
|
||||
### 按钮和链接
|
||||
|
||||
你可能不喜欢默认由大模型生成的后续问题,此时你可以使用按钮和链接,引导对话朝特定方向发展。
|
||||
|
||||
<img
|
||||
src="/images/screenshot-20250714-134035.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
你可以使用以下语法创建按钮和链接:
|
||||
|
||||
```
|
||||
<button data-message="Hello Dify" data-variant="primary">Hello Dify</button>
|
||||
<button data-message="Hello Dify" data-variant="danger">Hello Dify</button>
|
||||
```
|
||||
|
||||
按钮需要定义两个属性:
|
||||
|
||||
* `data-variant`:按钮样式,可选值包括 `primary`、`secondary`、`warning`、`secondary-accent`、`ghost`、`ghost-accent`、`tertiary`
|
||||
* `data-message`:点击按钮时发送的消息内容
|
||||
|
||||
链接的用法更为简单:
|
||||
|
||||
```
|
||||
<a href="https://dify.ai" target="_blank">Dify</a>
|
||||
```
|
||||
|
||||
你也可以使用 `abbr` 语法创建交互链接,用于对话中触发特定交互:
|
||||
|
||||
```
|
||||
[特殊链接](abbr:special-link)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 表单(Form)
|
||||
|
||||
表单需要设置 `data-format` 属性,支持 `json` 和 `text` 两种格式,默认是 `text`。当设置为 `data-format="json"` 时,表单会以 JSON 对象提交。
|
||||
|
||||
<img
|
||||
src="/images/screenshot-20250714-134150.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
#### 支持的输入类型
|
||||
|
||||
Dify 支持多种表单输入类型:
|
||||
|
||||
* text(文本)
|
||||
* textarea(多行文本)
|
||||
* password(密码)
|
||||
* time(时间)
|
||||
* date(日期)
|
||||
* datetime(日期时间)
|
||||
* select(下拉选择)
|
||||
* checkbox(复选框)
|
||||
* hidden(隐藏字段)
|
||||
|
||||
如果你想在对话中渲染一个表单,可以使用如下语法:
|
||||
|
||||
```
|
||||
<form data-format="json"> // 默认为 text
|
||||
<label for="username">用户名:</label>
|
||||
<input type="text" name="username" />
|
||||
<label for="hidden_input">隐藏字段:</label>
|
||||
<input type="hidden" name="hidden_input" value="hidden_value" />
|
||||
<label for="password">密码:</label>
|
||||
<input type="password" name="password" />
|
||||
<label for="content">内容:</label>
|
||||
<textarea name="content"></textarea>
|
||||
<label for="date">日期:</label>
|
||||
<input type="date" name="date" />
|
||||
<label for="time">时间:</label>
|
||||
<input type="time" name="time" />
|
||||
<label for="datetime">日期时间:</label>
|
||||
<input type="datetime" name="datetime" />
|
||||
<label for="select">选择:</label>
|
||||
<input type="select" name="select" data-options='["hello","world"]'/>
|
||||
<input type="checkbox" name="check" data-tip="勾选表示你已同意"/>
|
||||
<button data-variant="primary">登录</button>
|
||||
</form>
|
||||
```
|
||||
|
||||
<Note>
|
||||
Hidden 隐藏字段不会显示给用户,可以用来在不经用户输入的情况下传递数据。
|
||||
</Note>
|
||||
|
||||
---
|
||||
|
||||
### 图表(Chart)
|
||||
|
||||
你可以在 Markdown 中使用 [echarts](https://dify.ai/docs/guides/tools/chart) 渲染图表。语法如下:
|
||||
|
||||
<img
|
||||
src="/images/screenshot-20250714-134238.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
<Note>
|
||||
要渲染图表,使用以 <code>\`\`\`echarts</code> 开头的代码块,并将配置写入其中。
|
||||
</Note>
|
||||
|
||||
```echarts
|
||||
{
|
||||
"title": {
|
||||
"text": "ECharts 入门示例"
|
||||
},
|
||||
"tooltip": {},
|
||||
"legend": {
|
||||
"data": ["销量"]
|
||||
},
|
||||
"xAxis": {
|
||||
"data": ["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"]
|
||||
},
|
||||
"yAxis": {},
|
||||
"series": [{
|
||||
"name": "销量",
|
||||
"type": "bar",
|
||||
"data": [5, 20, 36, 10, 10, 20]
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 音乐(乐谱)
|
||||
|
||||
除了图表,你还可以在 Markdown 中渲染乐谱。我们支持 [ABC notation](https://paulrosen.github.io/abcjs/) 乐谱标准,使用以下语法:
|
||||
|
||||
<img
|
||||
src="/images/screenshot-20250714-134431.png"
|
||||
className="mr-auto"
|
||||
/>
|
||||
|
||||
<Note>
|
||||
要渲染乐谱,使用以 <code>\`\`\`abc</code> 开头的代码块,并将 ABC 记谱内容写入其中。
|
||||
</Note>
|
||||
|
||||
```abc
|
||||
X: 1
|
||||
T: Cooley's
|
||||
M: 4/4
|
||||
L: 1/8
|
||||
K: Emin
|
||||
|:D2|EB{c}BA B2 EB|~B2 AB dBAG|FDAD BDAD|FDAD dAFD|
|
||||
EBBA B2 EB|B2 AB defg|afe^c dBAF|DEFD E2:|
|
||||
|:gf|eB B2 efge|eB B2 gedB|A2 FA DAFA|A2 FA defg|
|
||||
eB B2 eBgB|eB B2 defg|afe^c dBAF|DEFD E2:|
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 最佳实践
|
||||
|
||||
如果你希望提前定义 Markdown 内容,可以使用 Dify 的 [模板功能](/en/guides/workflow/node/template)。这可以让你在后续节点中复用模板内容,提高效率与一致性。
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
It will be automatically generated by the script.
|
||||
*/}
|
||||
|
||||
---
|
||||
|
||||
[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/zh-hans/workshop/basic/the-right-way-of-markdown.mdx) | [提交问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
|
||||
|
||||