mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-26 13:18:34 +07:00
Docs: update knowledge docs
This commit is contained in:
BIN
dify-logo.png
Normal file
BIN
dify-logo.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 6.0 KiB |
731
docs.json
731
docs.json
@@ -1,102 +1,689 @@
|
||||
{
|
||||
"$schema": "https://mintlify.com/docs.json",
|
||||
"theme": "mint",
|
||||
"name": "Mint Starter Kit",
|
||||
"name": "Dify Enterprise Docs",
|
||||
"colors": {
|
||||
"primary": "#16A34A",
|
||||
"light": "#07C983",
|
||||
"dark": "#15803D"
|
||||
"primary": "#346DDB",
|
||||
"light": "#688FE8",
|
||||
"dark": "#346DDB"
|
||||
},
|
||||
"favicon": "/dify-logo.png",
|
||||
"logo": {
|
||||
"light": "/logo/dify-logo.svg",
|
||||
"dark": "/logo/dify-logo.svg"
|
||||
},
|
||||
"favicon": "/favicon.svg",
|
||||
"navigation": {
|
||||
"tabs": [
|
||||
"languages": [
|
||||
{
|
||||
"tab": "Guides",
|
||||
"groups": [
|
||||
"language": "en",
|
||||
"href": "/en-us/introduction",
|
||||
"tabs": [
|
||||
{
|
||||
"group": "Get Started",
|
||||
"pages": [
|
||||
"introduction",
|
||||
"quickstart",
|
||||
"development"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Essentials",
|
||||
"pages": [
|
||||
"essentials/markdown",
|
||||
"essentials/code",
|
||||
"essentials/images",
|
||||
"essentials/settings",
|
||||
"essentials/navigation",
|
||||
"essentials/reusable-snippets"
|
||||
"tab": "Documentation",
|
||||
"groups": [
|
||||
{
|
||||
"group": "Introduction",
|
||||
"pages": [
|
||||
"introduction"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "User Guide",
|
||||
"pages": [
|
||||
"en-us/user-guide/welcome",
|
||||
{
|
||||
"group": "Model",
|
||||
"pages": [
|
||||
"en-us/user-guide/models/model-configuration",
|
||||
"en-us/user-guide/models/new-provider",
|
||||
"en-us/user-guide/models/predefined-model",
|
||||
"en-us/user-guide/models/customizable-model",
|
||||
"en-us/user-guide/models/interfaces",
|
||||
"en-us/user-guide/models/schema",
|
||||
"en-us/user-guide/models/load-balancing"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Application Orchestration",
|
||||
"pages": [
|
||||
"en-us/user-guide/build-app/chatbot",
|
||||
"en-us/user-guide/build-app/text-generator",
|
||||
"en-us/user-guide/build-app/agent",
|
||||
{
|
||||
"group": "Chatflow & Workflow",
|
||||
"pages": [
|
||||
"en-us/user-guide/build-app/flow-app/concepts",
|
||||
"en-us/user-guide/build-app/flow-app/create-flow-app",
|
||||
"en-us/user-guide/build-app/flow-app/variables",
|
||||
{
|
||||
"group": "Nodes",
|
||||
"pages": [
|
||||
"en-us/user-guide/build-app/flow-app/nodes/start",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/end",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/answer",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/llm",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/knowledge-retrieval",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/question-classifier",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/ifelse",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/code",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/template",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/doc-extractor",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/list-operator",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/variable-aggregator",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/variable-assigner",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/iteration",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/parameter-extractor",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/http-request",
|
||||
"en-us/user-guide/build-app/flow-app/nodes/tools"
|
||||
]
|
||||
},
|
||||
"en-us/user-guide/build-app/flow-app/shotcut-key",
|
||||
"en-us/user-guide/build-app/flow-app/orchestrate-node",
|
||||
"en-us/user-guide/build-app/flow-app/file-upload",
|
||||
"en-us/user-guide/build-app/flow-app/additional-features"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Debug and Preview",
|
||||
"pages": [
|
||||
{
|
||||
"group": "Chatflow & Workflow",
|
||||
"pages": [
|
||||
"en-us/user-guide/debug-app/chatflow-and-workflow/preview-and-run",
|
||||
"en-us/user-guide/debug-app/chatflow-and-workflow/step-run",
|
||||
"en-us/user-guide/debug-app/chatflow-and-workflow/log",
|
||||
"en-us/user-guide/debug-app/chatflow-and-workflow/checklist",
|
||||
"en-us/user-guide/debug-app/chatflow-and-workflow/history"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Application Publishing",
|
||||
"pages": [
|
||||
{
|
||||
"group": "Publish as a Single-page Web App",
|
||||
"pages": [
|
||||
"en-us/user-guide/application-publishing/launch-your-webapp-quickly/web-app-settings",
|
||||
"en-us/user-guide/application-publishing/launch-your-webapp-quickly/text-generator",
|
||||
"en-us/user-guide/application-publishing/launch-your-webapp-quickly/conversation-application"
|
||||
]
|
||||
},
|
||||
"en-us/user-guide/application-publishing/embedding-in-websites",
|
||||
"en-us/user-guide/application-publishing/developing-with-apis",
|
||||
"en-us/user-guide/application-publishing/based-on-frontend-templates"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Management",
|
||||
"pages": [
|
||||
"en-us/user-guide/management/app-management",
|
||||
"en-us/user-guide/management/team-members-management",
|
||||
"en-us/user-guide/management/personal-account-management"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Monitoring",
|
||||
"pages": [
|
||||
"en-us/user-guide/monitoring/analysis",
|
||||
"en-us/user-guide/monitoring/logs",
|
||||
"en-us/user-guide/monitoring/annotation-reply",
|
||||
{
|
||||
"group": "Integrate External Ops Tools",
|
||||
"pages": [
|
||||
"en-us/user-guide/monitoring/integrate-external-ops-tools/integrate-langfuse",
|
||||
"en-us/user-guide/monitoring/integrate-external-ops-tools/integrate-langsmith"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Knowledge Base",
|
||||
"pages": [
|
||||
{
|
||||
"group": "Create Knowledge Base",
|
||||
"pages": [
|
||||
"en-us/user-guide/knowledge-base/knowledge-base-creation/upload-documents",
|
||||
"en-us/user-guide/knowledge-base/knowledge-base-creation/sync-from-notion",
|
||||
"en-us/user-guide/knowledge-base/knowledge-base-creation/sync-from-website",
|
||||
"en-us/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge"
|
||||
]
|
||||
},
|
||||
"en-us/user-guide/knowledge-base/retrieval-test-and-citation",
|
||||
"en-us/user-guide/knowledge-base/knowledge-and-documents-maintenance",
|
||||
"en-us/user-guide/knowledge-base/integrate-knowledge-within-application",
|
||||
"en-us/user-guide/knowledge-base/faq"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Tools",
|
||||
"pages": [
|
||||
"en-us/user-guide/tools/introduction",
|
||||
{
|
||||
"group": "Tool Configuration",
|
||||
"pages": [
|
||||
{
|
||||
"group": "Dify Official Tools",
|
||||
"pages": [
|
||||
"en-us/user-guide/tools/dify/google",
|
||||
"en-us/user-guide/tools/dify/bing",
|
||||
"en-us/user-guide/tools/dify/perplexity",
|
||||
"en-us/user-guide/tools/dify/stable-diffusion"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Community Tools",
|
||||
"pages": [
|
||||
"en-us/user-guide/tools/community/searchapi",
|
||||
"en-us/user-guide/tools/community/alphavantage",
|
||||
"en-us/user-guide/tools/community/comfyui",
|
||||
"en-us/user-guide/tools/community/searxng",
|
||||
"en-us/user-guide/tools/community/serper",
|
||||
"en-us/user-guide/tools/community/siliconflow"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
"en-us/user-guide/tools/quick-tool-integration",
|
||||
"en-us/user-guide/tools/advanced-tool-integration"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "API",
|
||||
"pages": [
|
||||
"en-us/user-guide/api-documentation/text-generator",
|
||||
"en-us/user-guide/api-documentation/chatbot",
|
||||
"en-us/user-guide/api-documentation/workflow",
|
||||
"en-us/user-guide/api-documentation/maintain-dataset-via-api",
|
||||
"en-us/user-guide/api-documentation/external-knowledge-api-documentation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "FAQ",
|
||||
"pages": [
|
||||
"en-us/faq/llm-using"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"tab": "API Reference",
|
||||
"groups": [
|
||||
"language": "cn",
|
||||
"href": "/zh-cn/introduction",
|
||||
"tabs": [
|
||||
{
|
||||
"group": "API Documentation",
|
||||
"pages": [
|
||||
"api-reference/introduction"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "Endpoint Examples",
|
||||
"pages": [
|
||||
"api-reference/endpoint/get",
|
||||
"api-reference/endpoint/create",
|
||||
"api-reference/endpoint/delete",
|
||||
"api-reference/endpoint/webhook"
|
||||
"tab": "使用文档",
|
||||
"groups": [
|
||||
{
|
||||
"group": "简介",
|
||||
"pages": [
|
||||
"zh-cn/readme"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "用户手册",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/readme",
|
||||
{
|
||||
"group": "接入模型",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/models/model-configuration",
|
||||
"zh-cn/user-guide/models/new-provider",
|
||||
"zh-cn/user-guide/models/predefined-model",
|
||||
"zh-cn/user-guide/models/customizable-model",
|
||||
"zh-cn/user-guide/models/interfaces",
|
||||
"zh-cn/user-guide/models/schema",
|
||||
"zh-cn/user-guide/models/load-balancing"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "构建应用",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/build-app/chatbot",
|
||||
"zh-cn/user-guide/build-app/text-generator",
|
||||
"zh-cn/user-guide/build-app/agent",
|
||||
{
|
||||
"group": "Chatflow & Workflow",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/build-app/flow-app/concepts",
|
||||
"zh-cn/user-guide/build-app/flow-app/create-flow-app",
|
||||
"zh-cn/user-guide/build-app/flow-app/variables",
|
||||
{
|
||||
"group": "节点说明",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/start",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/end",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/answer",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/llm",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/knowledge-retrieval",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/question-classifier",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/ifelse",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/code",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/template",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/doc-extractor",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/list-operator",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/variable-aggregation",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/variable-assigner",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/iteration",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/parameter-extractor",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/http-request",
|
||||
"zh-cn/user-guide/build-app/flow-app/nodes/tools"
|
||||
]
|
||||
},
|
||||
"zh-cn/user-guide/build-app/flow-app/orchestrate-node",
|
||||
"zh-cn/user-guide/build-app/flow-app/file-upload",
|
||||
"zh-cn/user-guide/build-app/flow-app/additional-feature"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "调试应用",
|
||||
"pages": [
|
||||
{
|
||||
"group": "Chatflow & Workflow",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/debug-app/chatflow-and-workflow/preview-and-run",
|
||||
"zh-cn/user-guide/debug-app/chatflow-and-workflow/step-run",
|
||||
"zh-cn/user-guide/debug-app/chatflow-and-workflow/log",
|
||||
"zh-cn/user-guide/debug-app/chatflow-and-workflow/checklist",
|
||||
"zh-cn/user-guide/debug-app/chatflow-and-workflow/history"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "发布应用",
|
||||
"pages": [
|
||||
{
|
||||
"group": "发布为公开 Web 站点",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/application-publishing/launch-your-webapp-quickly/web-app-settings",
|
||||
"zh-cn/user-guide/application-publishing/launch-your-webapp-quickly/text-generator",
|
||||
"zh-cn/user-guide/application-publishing/launch-your-webapp-quickly/conversation-application"
|
||||
]
|
||||
},
|
||||
"zh-cn/user-guide/application-publishing/embedding-in-websites",
|
||||
"zh-cn/user-guide/application-publishing/developing-with-apis",
|
||||
"zh-cn/user-guide/application-publishing/based-on-frontend-templates"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "管理",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/management/app-management",
|
||||
"zh-cn/user-guide/management/team-members-management",
|
||||
"zh-cn/user-guide/management/personal-account-management"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "应用监测",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/monitoring/analysis",
|
||||
"zh-cn/user-guide/monitoring/logs",
|
||||
"zh-cn/user-guide/monitoring/annotation-reply",
|
||||
{
|
||||
"group": "集成外部与 Ops 工具",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/monitoring/integrate-external-ops-tools/integrate-langfuse",
|
||||
"zh-cn/user-guide/monitoring/integrate-external-ops-tools/integrate-langsmith"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "知识库",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/knowledge-base/readme",
|
||||
{
|
||||
"group": "创建知识库",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/knowledge-base/knowledge-base-creation/introduction",
|
||||
{
|
||||
"group": "1. 导入文本数据",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme",
|
||||
"zh-cn/user-guide/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion",
|
||||
"zh-cn/user-guide/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website"
|
||||
]
|
||||
},
|
||||
"zh-cn/user-guide/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text",
|
||||
"zh-cn/user-guide/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "管理知识库",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/knowledge-base/knowledge-and-documents-maintenance/introduction",
|
||||
"zh-cn/user-guide/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents",
|
||||
"zh-cn/user-guide/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api"
|
||||
]
|
||||
},
|
||||
"zh-cn/user-guide/knowledge-base/metadata",
|
||||
"zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application",
|
||||
"zh-cn/user-guide/knowledge-base/retrieval-test-and-citation",
|
||||
"zh-cn/user-guide/knowledge-base/connect-external-knowledge-base",
|
||||
"zh-cn/user-guide/knowledge-base/external-knowledge-api-documentation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "工具扩展",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/tools/introduction",
|
||||
{
|
||||
"group": "工具配置",
|
||||
"pages": [
|
||||
{
|
||||
"group": "Dify 官方工具",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/tools/dify/google",
|
||||
"zh-cn/user-guide/tools/dify/bing",
|
||||
"zh-cn/user-guide/tools/dify/perplexity",
|
||||
"zh-cn/user-guide/tools/dify/stable-diffusion"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "社区工具",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/tools/community/searchapi",
|
||||
"zh-cn/user-guide/tools/community/alphavantage",
|
||||
"zh-cn/user-guide/tools/community/comfyui",
|
||||
"zh-cn/user-guide/tools/community/searxng",
|
||||
"zh-cn/user-guide/tools/community/serper",
|
||||
"zh-cn/user-guide/tools/community/siliconflow"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
"zh-cn/user-guide/tools/quick-tool-integration",
|
||||
"zh-cn/user-guide/tools/advanced-tool-integration",
|
||||
{
|
||||
"group": "API 扩展",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/tools/extensions/api-based/api-based-extension",
|
||||
"zh-cn/user-guide/tools/extensions/api-based/external-data-tool",
|
||||
"zh-cn/user-guide/tools/extensions/api-based/cloudflare-workers",
|
||||
"zh-cn/user-guide/tools/extensions/api-based/moderation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "代码扩展",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/tools/extensions/code-based/external-data-tool",
|
||||
"zh-cn/user-guide/tools/extensions/code-based/moderation"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "API 文档",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/api-documentation/text-generator",
|
||||
"zh-cn/user-guide/api-documentation/chatbot",
|
||||
"zh-cn/user-guide/api-documentation/workflow",
|
||||
"zh-cn/user-guide/api-documentation/knowledge-base",
|
||||
"zh-cn/user-guide/api-documentation/external-knowledge-api-documentation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "常见问题",
|
||||
"pages": [
|
||||
"zh-cn/user-guide/faq/llm-using"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"language": "ja",
|
||||
"href": "/ja-jp/introduction",
|
||||
"tabs": [
|
||||
{
|
||||
"tab": "ドキュメント",
|
||||
"groups": [
|
||||
{
|
||||
"group": "はじめに",
|
||||
"pages": [
|
||||
"ja-jp/introduction"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "ユーザーマニュアル",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/welcome",
|
||||
{
|
||||
"group": "モデルの接続",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/models/model-configuration",
|
||||
"ja-jp/user-guide/models/new-provider",
|
||||
"ja-jp/user-guide/models/predefined-model",
|
||||
"ja-jp/user-guide/models/customizable-model",
|
||||
"ja-jp/user-guide/models/interfaces",
|
||||
"ja-jp/user-guide/models/schema",
|
||||
"ja-jp/user-guide/models/load-balancing"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "アプリの構築",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/build-app/chatbot",
|
||||
"ja-jp/user-guide/build-app/text-generator",
|
||||
"ja-jp/user-guide/build-app/agent",
|
||||
{
|
||||
"group": "チャットフロー & ワークフロー",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/build-app/flow-app/concepts",
|
||||
"ja-jp/user-guide/build-app/flow-app/create-flow-app",
|
||||
"ja-jp/user-guide/build-app/flow-app/variables",
|
||||
{
|
||||
"group": "ノードの説明",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/start",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/end",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/answer",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/llm",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/knowledge-retrieval",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/question-classifier",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/ifelse",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/code",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/template",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/doc-extractor",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/list-operator",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/variable-aggregation",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/variable-assigner",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/iteration",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/parameter-extractor",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/http-request",
|
||||
"ja-jp/user-guide/build-app/flow-app/nodes/tools"
|
||||
]
|
||||
},
|
||||
"ja-jp/user-guide/build-app/flow-app/orchestrate-node",
|
||||
"ja-jp/user-guide/build-app/flow-app/file-upload",
|
||||
"ja-jp/user-guide/build-app/flow-app/additional-feature"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "アプリのデバッグ",
|
||||
"pages": [
|
||||
{
|
||||
"group": "チャットフロー & ワークフロー",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/debug-app/chatflow-and-workflow/preview-and-run",
|
||||
"ja-jp/user-guide/debug-app/chatflow-and-workflow/step-run",
|
||||
"ja-jp/user-guide/debug-app/chatflow-and-workflow/log",
|
||||
"ja-jp/user-guide/debug-app/chatflow-and-workflow/checklist",
|
||||
"ja-jp/user-guide/debug-app/chatflow-and-workflow/history"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "アプリの発表",
|
||||
"pages": [
|
||||
{
|
||||
"group": "公開Webアプリとしてのリリース",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/application-publishing/launch-your-webapp-quickly/web-app-settings",
|
||||
"ja-jp/user-guide/application-publishing/launch-your-webapp-quickly/text-generator",
|
||||
"ja-jp/user-guide/application-publishing/launch-your-webapp-quickly/conversation-application"
|
||||
]
|
||||
},
|
||||
"ja-jp/user-guide/application-publishing/embedding-in-websites",
|
||||
"ja-jp/user-guide/application-publishing/developing-with-apis",
|
||||
"ja-jp/user-guide/application-publishing/based-on-frontend-templates"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "管理",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/management/app-management",
|
||||
"ja-jp/user-guide/management/team-members-management",
|
||||
"ja-jp/user-guide/management/personal-account-management"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "アプリのモニタリング",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/monitoring/analysis",
|
||||
"ja-jp/user-guide/monitoring/logs",
|
||||
"ja-jp/user-guide/monitoring/annotation-reply",
|
||||
{
|
||||
"group": "外部ツールとOpsツールの統合",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/monitoring/integrate-external-ops-tools/integrate-langfuse",
|
||||
"ja-jp/user-guide/monitoring/integrate-external-ops-tools/integrate-langsmith"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "ナレッジベース",
|
||||
"pages": [
|
||||
{
|
||||
"group": "ナレッジベースの作成",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/knowledge-base/knowledge-base-creation/upload-documents",
|
||||
"ja-jp/user-guide/knowledge-base/knowledge-base-creation/sync-from-notion",
|
||||
"ja-jp/user-guide/knowledge-base/knowledge-base-creation/sync-from-website",
|
||||
"ja-jp/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge-base"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "インデックスと検索",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/knowledge-base/indexing-and-retrieval/retrieval-augment",
|
||||
"ja-jp/user-guide/knowledge-base/indexing-and-retrieval/hybrid-search",
|
||||
"ja-jp/user-guide/knowledge-base/indexing-and-retrieval/rerank",
|
||||
"ja-jp/user-guide/knowledge-base/indexing-and-retrieval/retrieval"
|
||||
]
|
||||
},
|
||||
"ja-jp/user-guide/knowledge-base/retrieval-test-and-citation",
|
||||
"ja-jp/user-guide/knowledge-base/knowledge-and-documents-maintenance",
|
||||
"ja-jp/user-guide/knowledge-base/integrate-knowledge-within-application",
|
||||
"ja-jp/user-guide/knowledge-base/faq"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "ツール拡張",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/tools/introduction",
|
||||
{
|
||||
"group": "ツールの構成",
|
||||
"pages": [
|
||||
{
|
||||
"group": "Difyオフィシャルツール",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/tools/dify/google",
|
||||
"ja-jp/user-guide/tools/dify/bing",
|
||||
"ja-jp/user-guide/tools/dify/dall-e",
|
||||
"ja-jp/user-guide/tools/dify/perplexity",
|
||||
"ja-jp/user-guide/tools/dify/stable-diffusion"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "コミュニティツール",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/tools/community/searchapi",
|
||||
"ja-jp/user-guide/tools/community/alphavantage",
|
||||
"ja-jp/user-guide/tools/community/comfyui",
|
||||
"ja-jp/user-guide/tools/community/searxng",
|
||||
"ja-jp/user-guide/tools/community/serper",
|
||||
"ja-jp/user-guide/tools/community/siliconflow"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
"ja-jp/user-guide/tools/quick-tool-integration",
|
||||
"ja-jp/user-guide/tools/advanced-tool-integration",
|
||||
{
|
||||
"group": "API 拡張子",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/tools/extensions/api-based/api-based-extension",
|
||||
"ja-jp/user-guide/tools/extensions/api-based/external-data-tool",
|
||||
"ja-jp/user-guide/tools/extensions/api-based/cloudflare-workers",
|
||||
"ja-jp/user-guide/tools/extensions/api-based/moderation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "コード拡張子",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/tools/extensions/code-based/external-data-tool",
|
||||
"ja-jp/user-guide/tools/extensions/code-based/moderation"
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "API ドキュメント",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/api-documentation/text-generator",
|
||||
"ja-jp/user-guide/api-documentation/chatbot",
|
||||
"ja-jp/user-guide/api-documentation/workflow",
|
||||
"ja-jp/user-guide/api-documentation/knowledge-base",
|
||||
"ja-jp/user-guide/api-documentation/external-knowledge-api-documentation"
|
||||
]
|
||||
},
|
||||
{
|
||||
"group": "FAQ",
|
||||
"pages": [
|
||||
"ja-jp/user-guide/faq/llm-using"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
},
|
||||
{
|
||||
"tab": "API リファレンス",
|
||||
"openapi": "https://assets-docs.dify.ai/2025/03/d497c10fe2c248a01ac93f6cfdf210b1.json"
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"global": {
|
||||
"anchors": [
|
||||
{
|
||||
"anchor": "Documentation",
|
||||
"href": "https://mintlify.com/docs",
|
||||
"icon": "book-open-cover"
|
||||
},
|
||||
{
|
||||
"anchor": "Community",
|
||||
"href": "https://mintlify.com/community",
|
||||
"icon": "slack"
|
||||
},
|
||||
{
|
||||
"anchor": "Blog",
|
||||
"href": "https://mintlify.com/blog",
|
||||
"icon": "newspaper"
|
||||
}
|
||||
]
|
||||
}
|
||||
},
|
||||
"logo": {
|
||||
"light": "/logo/light.svg",
|
||||
"dark": "/logo/dark.svg"
|
||||
]
|
||||
},
|
||||
"navbar": {
|
||||
"links": [
|
||||
{
|
||||
"label": "Support",
|
||||
"href": "mailto:hi@mintlify.com"
|
||||
"href": "mailto:support@dify.ai"
|
||||
}
|
||||
],
|
||||
"primary": {
|
||||
"type": "button",
|
||||
"label": "Dashboard",
|
||||
"href": "https://dashboard.mintlify.com"
|
||||
}
|
||||
]
|
||||
},
|
||||
"footer": {
|
||||
"socials": {
|
||||
"x": "https://x.com/mintlify",
|
||||
"github": "https://github.com/mintlify",
|
||||
"linkedin": "https://linkedin.com/company/mintlify"
|
||||
"x": "https://x.com/dify_ai",
|
||||
"github": "https://github.com/langgenius/dify",
|
||||
"linkedin": "https://www.linkedin.com/company/langgenius"
|
||||
}
|
||||
}
|
||||
}
|
||||
46
en-us/README.md
Normal file
46
en-us/README.md
Normal file
@@ -0,0 +1,46 @@
|
||||
# Welcome to Dify
|
||||
|
||||
Dify is an open-source platform for building AI applications. We combine Backend-as-a-Service and LLMOps to streamline the development of generative AI solutions, making it accessible to both developers and non-technical innovators.
|
||||
|
||||
Our platform integrates:
|
||||
|
||||
- Support for mainstream LLMs
|
||||
- An intuitive Prompt orchestration interface
|
||||
- High-quality RAG engines
|
||||
- A flexible AI Agent framework
|
||||
- An Intuitive Low-code Workflow
|
||||
- Easy-to-use interfaces and APIs
|
||||
|
||||
With Dify, you can skip the complexity and focus on what matters most - creating innovative AI applications that solve real-world problems.
|
||||
|
||||
### The Advantage of Dify
|
||||
|
||||
While many AI development tools offer individual components, Dify provides a comprehensive, production-ready solution. Think of Dify as a well-designed scaffolding system, not just a toolbox.
|
||||
|
||||
As an open-source platform, Dify is co-created by a dedicated professional team and a vibrant community. This collaboration ensures rapid iteration, robust features, and a user-friendly interface.
|
||||
|
||||
With Dify, you can:
|
||||
|
||||
- Deploy capabilities similar to Assistants API and GPTs using any model
|
||||
- Maintain full control over your data with flexible security options
|
||||
- Leverage an intuitive interface for easy management and deployment
|
||||
|
||||
### Dify
|
||||
|
||||
{% hint style="info" %} The name Dify comes from "Define + Modify", referring to defining and continuously improving your AI applications. It's made for you. {% endhint %}
|
||||
|
||||
Here's how various groups are leveraging Dify:
|
||||
|
||||
1. **Startups**: Rapidly prototype and iterate on AI ideas, accelerating both successes and failures. Numerous teams have used Dify to build MVPs, secure funding, and win customer contracts.
|
||||
2. **Established Businesses**: Enhance existing applications with LLM capabilities. Use Dify's RESTful APIs to separate prompts from business logic, while utilizing our management interface to track data, costs, and usage.
|
||||
3. **Enterprise AI infrastructure**: Banks and tech companies are deploying Dify as an internal LLM gateway, facilitating GenAI adoption with centralized governance.
|
||||
4. **AI Enthusiasts and Learners**: Practice prompt engineering and explore agent technologies with ease. Over 60,000 developers built their first AI app on Dify even before GPTs were introduced. Since then, our community has grown significantly, now boasting over 180,000 developers and supporting 59,000+ end users.
|
||||
|
||||
Whether you're a startup founder, an enterprise developer, or an AI enthusiast, Dify is designed to meet your needs and accelerate your AI journey!
|
||||
|
||||
### Next Steps
|
||||
|
||||
- Read [**Quick Start**](https://docs.dify.ai/application/creating-an-application) for an overview of Dify’s application building workflow.
|
||||
- Learn how to [**self-deploy Dify** ](https://docs.dify.ai/getting-started/install-self-hosted)to your servers and [**integrate open source models**](https://docs.dify.ai/advanced/model-configuration)**.**
|
||||
- Understand Dify’s [**specifications and roadmap**](https://docs.dify.ai/getting-started/readme/features-and-specifications)**.**
|
||||
- [**Star us on GitHub**](https://github.com/langgenius/dify) and read our **Contributor Guidelines.**
|
||||
@@ -0,0 +1,127 @@
|
||||
---
|
||||
title: External Knowledge API
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
## Endpoint
|
||||
|
||||
```
|
||||
POST <your-endpoint>/retrieval
|
||||
```
|
||||
|
||||
## Header
|
||||
|
||||
This API is used to connect to a knowledge base that is independent of the Dify and maintained by developers. For more details, please refer to [Connecting to an External Knowledge Base](https://docs.dify.ai/guides/knowledge-base/connect-external-knowledge-base). You can use `API-Key` in the `Authorization` HTTP Header to verify permissions. The authentication logic is defined by you in the retrieval API, as shown below:
|
||||
|
||||
```
|
||||
Authorization: Bearer {API_KEY}
|
||||
```
|
||||
|
||||
## Request Body Elements
|
||||
|
||||
The request accepts the following data in JSON format.
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| knowledge_id | TRUE | string | Your knowledge's unique ID | AAA-BBB-CCC |
|
||||
| query | TRUE | string | User's query | What is Dify? |
|
||||
| retrieval_setting | TRUE | object | Knowledge's retrieval parameters | See below |
|
||||
|
||||
The `retrieval_setting` property is an object containing the following keys:
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| top_k | TRUE | int | Maximum number of retrieved results | 5 |
|
||||
| score_threshold | TRUE | float | The score limit of relevance of the result to the query, scope: 0~1 | 0.5 |
|
||||
|
||||
## Request Syntax
|
||||
|
||||
```json
|
||||
POST <your-endpoint>/retrieval HTTP/1.1
|
||||
-- header
|
||||
Content-Type: application/json
|
||||
Authorization: Bearer your-api-key
|
||||
-- data
|
||||
{
|
||||
"knowledge_id": "your-knowledge-id",
|
||||
"query": "your question",
|
||||
"retrieval_setting":{
|
||||
"top_k": 2,
|
||||
"score_threshold": 0.5
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Response Elements
|
||||
|
||||
If the action is successful, the service sends back an HTTP 200 response.
|
||||
|
||||
The following data is returned in JSON format by the service.
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| records | TRUE | List[Object] | A list of records from querying the knowledge base. | See below |
|
||||
|
||||
The `records` property is a list object containing the following keys:
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| content | TRUE | string | Contains a chunk of text from a data source in the knowledge base. | Dify:The Innovation Engine for GenAI Applications |
|
||||
| score | TRUE | float | The score of relevance of the result to the query, scope: 0~1 | 0.5 |
|
||||
| title | TRUE | string | Document title | Dify Introduction |
|
||||
| metadata | FALSE | json | Contains metadata attributes and their values for the document in the data source. | See example |
|
||||
|
||||
## Response Syntax
|
||||
|
||||
```json
|
||||
HTTP/1.1 200
|
||||
Content-type: application/json
|
||||
{
|
||||
"records": [{
|
||||
"metadata": {
|
||||
"path": "s3://dify/knowledge.txt",
|
||||
"description": "dify knowledge document"
|
||||
},
|
||||
"score": 0.98,
|
||||
"title": "knowledge.txt",
|
||||
"content": "This is the document for external knowledge."
|
||||
},
|
||||
{
|
||||
"metadata": {
|
||||
"path": "s3://dify/introduce.txt",
|
||||
"description": "dify introduce"
|
||||
},
|
||||
"score": 0.66,
|
||||
"title": "introduce.txt",
|
||||
"content": "The Innovation Engine for GenAI Applications"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Errors
|
||||
|
||||
If the action fails, the service sends back the following error information in JSON format:
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| error_code | TRUE | int | Error code | 1001 |
|
||||
| error_msg | TRUE | string | The description of API exception | Invalid Authorization header format. Expected 'Bearer \<api-key\>' format. |
|
||||
|
||||
The `error_code` property has the following types:
|
||||
|
||||
| Code | Description |
|
||||
|------|-------------|
|
||||
| 1001 | Invalid Authorization header format. |
|
||||
| 1002 | Authorization failed |
|
||||
| 2001 | The knowledge does not exist |
|
||||
|
||||
### HTTP Status Codes
|
||||
|
||||
**AccessDeniedException**
|
||||
The request is denied because of missing access permissions. Check your permissions and retry your request.
|
||||
HTTP Status Code: 403
|
||||
|
||||
**InternalServerException**
|
||||
An internal server error occurred. Retry your request.
|
||||
HTTP Status Code: 500
|
||||
@@ -0,0 +1,415 @@
|
||||
---
|
||||
title: Chatbot
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
## Overview
|
||||
Chat applications support session persistence, allowing previous chat history to be used as context for responses. This can be applicable for chatbots, customer service AI, etc.
|
||||
|
||||
## Base URL
|
||||
```
|
||||
https://api.dify.ai/v1
|
||||
```
|
||||
|
||||
## Authentication
|
||||
The Service API uses API-Key authentication.
|
||||
|
||||
> **Important**: Strongly recommend storing your API Key on the server-side, not shared or stored on the client-side, to avoid possible API-Key leakage that can lead to serious consequences.
|
||||
|
||||
For all API requests, include your API Key in the Authorization HTTP Header:
|
||||
```
|
||||
Authorization: Bearer {API_KEY}
|
||||
```
|
||||
|
||||
## API Endpoints
|
||||
|
||||
### Send Chat Message
|
||||
`POST /chat-messages`
|
||||
|
||||
Send a request to the chat application.
|
||||
|
||||
#### Request Body
|
||||
|
||||
- **query** (string) Required
|
||||
- User Input / Question Content
|
||||
|
||||
- **inputs** (object) Required
|
||||
- Allows the entry of various variable values defined by the App
|
||||
- Contains multiple key/value pairs, each key corresponding to a specific variable
|
||||
- At least one key/value pair required
|
||||
|
||||
- **response_mode** (string) Required
|
||||
- Modes supported:
|
||||
- `streaming`: Streaming mode (recommended), implements typewriter-like output through SSE
|
||||
- `blocking`: Blocking mode, returns result after execution completes
|
||||
- Note: Due to Cloudflare restrictions, requests will timeout after 100 seconds
|
||||
- Note: blocking mode is not supported in Agent Assistant mode
|
||||
|
||||
- **user** (string) Required
|
||||
- User identifier for retrieval and statistics
|
||||
- Should be uniquely defined within the application
|
||||
|
||||
- **conversation_id** (string) Optional
|
||||
- Conversation ID to continue based on previous chat records
|
||||
|
||||
- **files** (array[object]) Optional
|
||||
- File list for image input with text understanding
|
||||
- Available only when model supports Vision capability
|
||||
- Properties:
|
||||
- `type` (string): Supported type: image
|
||||
- `transfer_method` (string): 'remote_url' or 'local_file'
|
||||
- `url` (string): Image URL (for remote_url)
|
||||
- `upload_file_id` (string): Uploaded file ID (for local_file)
|
||||
|
||||
- **auto_generate_name** (bool) Optional
|
||||
- Auto-generate title, default is false
|
||||
- Can achieve async title generation via conversation rename API
|
||||
|
||||
#### Response Types
|
||||
|
||||
**Blocking Mode Response (ChatCompletionResponse)**
|
||||
Returns complete App result with Content-Type: application/json
|
||||
|
||||
```typescript
|
||||
interface ChatCompletionResponse {
|
||||
message_id: string;
|
||||
conversation_id: string;
|
||||
mode: string;
|
||||
answer: string;
|
||||
metadata: {
|
||||
usage: Usage;
|
||||
retriever_resources: RetrieverResource[];
|
||||
};
|
||||
created_at: number;
|
||||
}
|
||||
```
|
||||
|
||||
**Streaming Mode Response (ChunkChatCompletionResponse)**
|
||||
Returns stream chunks with Content-Type: text/event-stream
|
||||
|
||||
Events:
|
||||
- `message`: LLM text chunk event
|
||||
- `agent_message`: LLM text chunk event (Agent Assistant mode)
|
||||
- `agent_thought`: Agent reasoning process
|
||||
- `message_file`: New file created by tool
|
||||
- `message_end`: Stream end event
|
||||
- `message_replace`: Content replacement event
|
||||
- `workflow_started`: Workflow execution start
|
||||
- `node_started`: Node execution start
|
||||
- `node_finished`: Node execution completion
|
||||
- `workflow_finished`: Workflow execution completion
|
||||
- `parallel_branch_started`: Parallel branch start
|
||||
- `parallel_branch_finished`: Parallel branch completion
|
||||
- `iteration_started`: Iteration start
|
||||
- `iteration_next`: Next iteration
|
||||
- `iteration_completed`: Iteration completion
|
||||
- `error`: Exception event
|
||||
- `ping`: Keep-alive event (every 10s)
|
||||
|
||||
### File Upload
|
||||
`POST /files/upload`
|
||||
|
||||
Upload files (currently only images) for multimodal understanding.
|
||||
|
||||
#### Supported Formats
|
||||
- png
|
||||
- jpg
|
||||
- jpeg
|
||||
- webp
|
||||
- gif
|
||||
|
||||
#### Request Body
|
||||
Requires multipart/form-data:
|
||||
- `file` (File) Required
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface FileUploadResponse {
|
||||
id: string;
|
||||
name: string;
|
||||
size: number;
|
||||
extension: string;
|
||||
mime_type: string;
|
||||
created_by: string;
|
||||
created_at: number;
|
||||
}
|
||||
```
|
||||
|
||||
### Stop Generate
|
||||
`POST /chat-messages/:task_id/stop`
|
||||
|
||||
Stop ongoing generation (streaming mode only).
|
||||
|
||||
#### Request Body
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```json
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### Message Feedback
|
||||
`POST /messages/:message_id/feedbacks`
|
||||
|
||||
Submit user feedback on messages.
|
||||
|
||||
#### Request Body
|
||||
- `rating` (string) Required: "like" | "dislike" | null
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```json
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### Get Conversation History
|
||||
`GET /messages`
|
||||
|
||||
Returns historical chat records in reverse chronological order.
|
||||
|
||||
#### Query Parameters
|
||||
- `conversation_id` (string) Required
|
||||
- `user` (string) Required
|
||||
- `first_id` (string) Optional: First chat record ID
|
||||
- `limit` (int) Optional: Default 20
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface ConversationHistory {
|
||||
data: Array<{
|
||||
id: string;
|
||||
conversation_id: string;
|
||||
inputs: Record<string, any>;
|
||||
query: string;
|
||||
message_files: Array<{
|
||||
id: string;
|
||||
type: string;
|
||||
url: string;
|
||||
belongs_to: 'user' | 'assistant';
|
||||
}>;
|
||||
agent_thoughts: Array<{
|
||||
id: string;
|
||||
message_id: string;
|
||||
position: number;
|
||||
thought: string;
|
||||
observation: string;
|
||||
tool: string;
|
||||
tool_input: string;
|
||||
created_at: number;
|
||||
message_files: string[];
|
||||
}>;
|
||||
answer: string;
|
||||
created_at: number;
|
||||
feedback?: {
|
||||
rating: 'like' | 'dislike';
|
||||
};
|
||||
retriever_resources: RetrieverResource[];
|
||||
}>;
|
||||
has_more: boolean;
|
||||
limit: number;
|
||||
}
|
||||
```
|
||||
|
||||
### Get Conversations
|
||||
`GET /conversations`
|
||||
|
||||
Retrieve conversation list for current user.
|
||||
|
||||
#### Query Parameters
|
||||
- `user` (string) Required
|
||||
- `last_id` (string) Optional
|
||||
- `limit` (int) Optional: Default 20
|
||||
- `pinned` (boolean) Optional
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface ConversationList {
|
||||
data: Array<{
|
||||
id: string;
|
||||
name: string;
|
||||
inputs: Record<string, any>;
|
||||
introduction: string;
|
||||
created_at: number;
|
||||
}>;
|
||||
has_more: boolean;
|
||||
limit: number;
|
||||
}
|
||||
```
|
||||
|
||||
### Delete Conversation
|
||||
`DELETE /conversations/:conversation_id`
|
||||
|
||||
Delete a conversation.
|
||||
|
||||
#### Request Body
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```json
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### Rename Conversation
|
||||
`POST /conversations/{conversation_id}/name`
|
||||
|
||||
#### Request Body
|
||||
- `name` (string) Optional
|
||||
- `auto_generate` (boolean) Optional: Default false
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface RenamedConversation {
|
||||
id: string;
|
||||
name: string;
|
||||
inputs: Record<string, any>;
|
||||
introduction: string;
|
||||
created_at: number;
|
||||
}
|
||||
```
|
||||
|
||||
### Speech to Text
|
||||
`POST /audio-to-text`
|
||||
|
||||
Convert audio to text.
|
||||
|
||||
#### Request Body (multipart/form-data)
|
||||
- `file` (File) Required
|
||||
- Supported formats: mp3, mp4, mpeg, mpga, m4a, wav, webm
|
||||
- Size limit: 15MB
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface AudioToTextResponse {
|
||||
text: string;
|
||||
}
|
||||
```
|
||||
|
||||
### Get Application Parameters
|
||||
`GET /parameters`
|
||||
|
||||
Retrieve application configuration and settings.
|
||||
|
||||
#### Query Parameters
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface ApplicationParameters {
|
||||
opening_statement: string;
|
||||
suggested_questions_after_answer: {
|
||||
enabled: boolean;
|
||||
};
|
||||
speech_to_text: {
|
||||
enabled: boolean;
|
||||
};
|
||||
retriever_resource: {
|
||||
enabled: boolean;
|
||||
};
|
||||
annotation_reply: {
|
||||
enabled: boolean;
|
||||
};
|
||||
user_input_form: Array<{
|
||||
'text-input' | 'paragraph' | 'select': {
|
||||
label: string;
|
||||
variable: string;
|
||||
required: boolean;
|
||||
default: string;
|
||||
options?: string[];
|
||||
};
|
||||
}>;
|
||||
file_upload: {
|
||||
image: {
|
||||
enabled: boolean;
|
||||
number_limits: number;
|
||||
transfer_methods: string[];
|
||||
};
|
||||
};
|
||||
system_parameters: {
|
||||
image_file_size_limit: string;
|
||||
};
|
||||
}
|
||||
```
|
||||
|
||||
### Get Application Meta Information
|
||||
`GET /meta`
|
||||
|
||||
Retrieve tool icons and metadata.
|
||||
|
||||
#### Query Parameters
|
||||
- `user` (string) Required
|
||||
|
||||
#### Response
|
||||
```typescript
|
||||
interface ApplicationMeta {
|
||||
tool_icons: Record<string, string | {
|
||||
background: string;
|
||||
content: string;
|
||||
}>;
|
||||
}
|
||||
```
|
||||
|
||||
## Type Definitions
|
||||
|
||||
### Usage
|
||||
```typescript
|
||||
interface Usage {
|
||||
prompt_tokens: number;
|
||||
prompt_unit_price: string;
|
||||
prompt_price_unit: string;
|
||||
prompt_price: string;
|
||||
completion_tokens: number;
|
||||
completion_unit_price: string;
|
||||
completion_price_unit: string;
|
||||
completion_price: string;
|
||||
total_tokens: number;
|
||||
total_price: string;
|
||||
currency: string;
|
||||
latency: number;
|
||||
}
|
||||
```
|
||||
|
||||
### RetrieverResource
|
||||
```typescript
|
||||
interface RetrieverResource {
|
||||
position: number;
|
||||
content: string;
|
||||
score: string;
|
||||
dataset_id: string;
|
||||
dataset_name: string;
|
||||
document_id: string;
|
||||
document_name: string;
|
||||
segment_id: string;
|
||||
}
|
||||
```
|
||||
|
||||
## Error Codes
|
||||
|
||||
Common error codes you may encounter:
|
||||
- 404: Conversation does not exist
|
||||
- 400: invalid_param - Abnormal parameter input
|
||||
- 400: app_unavailable - App configuration unavailable
|
||||
- 400: provider_not_initialize - No available model credential configuration
|
||||
- 400: provider_quota_exceeded - Model invocation quota insufficient
|
||||
- 400: model_currently_not_support - Current model unavailable
|
||||
- 400: completion_request_error - Text generation failed
|
||||
- 500: Internal server error
|
||||
|
||||
For file uploads:
|
||||
- 400: no_file_uploaded - File must be provided
|
||||
- 400: too_many_files - Only one file accepted
|
||||
- 400: unsupported_preview - File does not support preview
|
||||
- 400: unsupported_estimate - File does not support estimation
|
||||
- 413: file_too_large - File is too large
|
||||
- 415: unsupported_file_type - Unsupported extension
|
||||
- 503: s3_connection_failed - Unable to connect to S3
|
||||
- 503: s3_permission_denied - No permission for S3
|
||||
- 503: s3_file_too_large - Exceeds S3 size limit
|
||||
20
en-us/user-guide/knowledge-base/faq.mdx
Normal file
20
en-us/user-guide/knowledge-base/faq.mdx
Normal file
@@ -0,0 +1,20 @@
|
||||
---
|
||||
title: FAQ
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
## 1. Document Import and Query Response are Slow, How to Troubleshoot?
|
||||
|
||||
Typically, the Embedding process after document upload consumes significant resources, which may cause slowdowns. Please check server load, switch logs to debug mode, or check Embedding response times.
|
||||
|
||||
## 2. How to Handle Abnormal Segmentation of Large Documents in Knowledge Base?
|
||||
|
||||
Please check the server's memory usage to determine if there are any memory leak issues.
|
||||
|
||||
## 3. Knowledge Base File Processing Shows "Queuing", How to Resolve?
|
||||
|
||||
This issue may be caused by a disconnection from the Redis service, preventing tasks from exiting. It is recommended to restart the Worker node.
|
||||
|
||||
## 4. How to Optimize Knowledge Base Content Retrieval for Applications?
|
||||
|
||||
You can optimize by adjusting retrieval settings and comparing different parameters. For specific instructions, please refer to [Retrieval Settings](/en-us/user-guide/knowledge-base/knowledge-base-creation/upload-documents#3).
|
||||
@@ -0,0 +1,103 @@
|
||||
---
|
||||
title: Hybrid Search
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
### Why is Hybrid Search Needed?
|
||||
|
||||
The mainstream method in the retrieval phase of RAG (Retrieval-Augmented Generation) is vector search, which matches based on semantic relevance. The technical principle involves splitting the documents in the external knowledge base into semantically complete paragraphs or sentences, converting them into a series of numbers (multi-dimensional vectors) that the computer can understand, and performing the same conversion on the user's query.
|
||||
|
||||
The computer can detect subtle semantic relationships between the user's query and the sentences. For example, "cats chase mice" and "kittens hunt mice" will have a higher semantic relevance than "cats chase mice" and "I like eating ham." After finding the most relevant text content, the RAG system provides it as context for the user's query to the large model, helping it answer the question.
|
||||
|
||||
In addition to enabling complex semantic text retrieval, vector search has other advantages:
|
||||
|
||||
* Understanding similar semantics (e.g., mouse/mousetrap/cheese, Google/Bing/search engine)
|
||||
* Multilingual understanding (cross-language understanding, such as matching English input with Chinese)
|
||||
* Multimodal understanding (support for similar matching of text, images, audio, video, etc.)
|
||||
* Fault tolerance (handling spelling errors and vague descriptions)
|
||||
|
||||
While vector search has clear advantages in the above scenarios, it performs poorly in certain situations, such as:
|
||||
|
||||
* Searching for names of people or objects (e.g., Elon Musk, iPhone 15)
|
||||
* Searching for abbreviations or phrases (e.g., RAG, RLHF)
|
||||
* Searching for IDs (e.g., `gpt-3.5-turbo`, `titan-xlarge-v1.01`)
|
||||
|
||||
These weaknesses are precisely the strengths of traditional keyword search, which excels in:
|
||||
|
||||
* Exact matching (e.g., product names, personal names, product numbers)
|
||||
* Matching with a few characters (vector search performs poorly with few characters, but many users tend to input only a few keywords)
|
||||
* Matching low-frequency words (low-frequency words often carry significant meaning in language, such as "Would you like to have coffee with me?" where "have" and "coffee" carry more importance than "you" and "like")
|
||||
|
||||
For most text search scenarios, the primary goal is to ensure that the most relevant potential results appear in the candidate results. Vector search and keyword search each have their advantages in the retrieval field. Hybrid search combines the strengths of both search technologies and compensates for their weaknesses.
|
||||
|
||||
In hybrid search, you need to establish vector indexes and keyword indexes in the database in advance. When a user query is input, the most relevant texts are retrieved from the documents using both retrieval methods.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (127).png" alt="Hybrid Search" width="563" />
|
||||
</Frame>
|
||||
|
||||
"Hybrid search" does not have a precise definition. This article uses the combination of vector search and keyword search as an example. If we use other combinations of search algorithms, it can also be called "hybrid search." For instance, we can combine knowledge graph techniques for retrieving entity relationships with vector search techniques.
|
||||
|
||||
Different retrieval systems excel at finding various subtle relationships between texts (paragraphs, sentences, words), including exact relationships, semantic relationships, thematic relationships, structural relationships, entity relationships, temporal relationships, event relationships, etc. No single retrieval mode can be suitable for all scenarios. **Hybrid search achieves complementarity between multiple retrieval technologies through the combination of multiple retrieval systems.**
|
||||
|
||||
### Vector Search
|
||||
|
||||
Definition: Generating query embeddings and querying the text segments most similar to their vector representations.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (116).png" alt="Vector Search Settings" width="563" />
|
||||
</Frame>
|
||||
|
||||
**TopK:** Used to filter the text fragments most similar to the user's query. The system will dynamically adjust the number of fragments based on the context window size of the selected model. The default value is 3.
|
||||
|
||||
**Score Threshold:** Used to set the similarity threshold for filtering text fragments, i.e., only recalling text fragments that exceed the set score. The system's default is to turn off this setting, meaning it does not filter the similarity values of recalled text fragments. When enabled, the default value is 0.5.
|
||||
|
||||
**Rerank Model:** After configuring the Rerank model's API key on the "Model Providers" page, you can enable the "Rerank Model" in the retrieval settings. The system will perform semantic re-ranking on the recalled document results after semantic retrieval to optimize the ranking results. When the Rerank model is set, the TopK and Score Threshold settings only take effect in the Rerank step.
|
||||
|
||||
### Full-Text Search
|
||||
|
||||
Definition: Indexing all words in the document, allowing users to query any word and return text fragments containing those words.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (122).png" alt="Full-Text Search Settings" width="563" />
|
||||
</Frame>
|
||||
|
||||
**TopK:** Used to filter the text fragments most similar to the user's query. The system will dynamically adjust the number of fragments based on the context window size of the selected model. The default value is 3.
|
||||
|
||||
**Rerank Model:** After configuring the Rerank model's API key on the "Model Providers" page, you can enable the "Rerank Model" in the retrieval settings. The system will perform semantic re-ranking on the recalled document results after full-text retrieval to optimize the ranking results. When the Rerank model is set, the TopK and Score Threshold settings only take effect in the Rerank step.
|
||||
|
||||
### Hybrid Search
|
||||
|
||||
Simultaneously performs full-text search and vector search, applying a re-ranking step to select the best results matching the user's query from both types of query results. Requires configuring the Rerank model API.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (118).png" alt="Hybrid Search Settings" width="563" />
|
||||
</Frame>
|
||||
|
||||
**TopK:** Used to filter the text fragments most similar to the user's query. The system will dynamically adjust the number of fragments based on the context window size of the selected model. The default value is 3.
|
||||
|
||||
**Rerank Model:** After configuring the Rerank model's API key on the "Model Providers" page, you can enable the "Rerank Model" in the retrieval settings. The system will perform semantic re-ranking on the recalled document results after hybrid retrieval to optimize the ranking results. When the Rerank model is set, the TopK and Score Threshold settings only take effect in the Rerank step.
|
||||
|
||||
### Setting Retrieval Mode When Creating a Dataset
|
||||
|
||||
Set different retrieval modes by entering the "Dataset -> Create Dataset" page and configuring the retrieval settings.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (119).png" alt="Setting Retrieval Mode When Creating a Dataset" width="563" />
|
||||
</Frame>
|
||||
|
||||
### Modifying Retrieval Mode in Dataset Settings
|
||||
|
||||
Modify the retrieval mode of an existing dataset by entering the "Dataset -> Select Dataset -> Settings" page.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (120).png" alt="Modifying Retrieval Mode in Dataset Settings" width="563" />
|
||||
</Frame>
|
||||
|
||||
### Modifying Retrieval Mode in Prompt Arrangement
|
||||
|
||||
Modify the retrieval mode when creating an application by entering the "Prompt Arrangement -> Context -> Select Dataset -> Settings" page.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (121).png" alt="Modifying Retrieval Mode in Prompt Arrangement" />
|
||||
</Frame>
|
||||
@@ -0,0 +1,64 @@
|
||||
---
|
||||
title: 重排序
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
### 为什么需要重排序?
|
||||
|
||||
混合检索能够结合不同检索技术的优势获得更好的召回结果,但在不同检索模式下的查询结果需要进行合并和归一化(将数据转换为统一的标准范围或分布,以便更好地进行比较、分析和处理),然后再一起提供给大模型。这时候我们需要引入一个评分系统:重排序模型(Rerank Model)。
|
||||
|
||||
**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
|
||||
|
||||
<Frame title="混合检索+重排序">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (179).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
|
||||
|
||||
不过,重排序并不是只适用于不同检索系统的结果合并,即使是在单一检索模式下,引入重排序步骤也能有效帮助改进文档的召回效果,比如我们可以在关键词检索之后加入语义重排序。
|
||||
|
||||
在具体实践过程中,除了将多路查询结果进行归一化之外,在将相关的文本分段交给大模型之前,我们一般会限制传递给大模型的分段个数(即 TopK,可以在重排序模型参数中设置),这样做的原因是大模型的输入窗口存在大小限制(一般为 4K、8K、16K、128K 的 Token 数量),你需要根据选用的模型输入窗口的大小限制,选择合适的分段策略和 TopK 值。
|
||||
|
||||
需要注意的是,即使模型上下文窗口很足够大,过多的召回分段会可能会引入相关度较低的内容,导致回答的质量降低,所以重排序的 TopK 参数并不是越大越好。
|
||||
|
||||
重排序并不是搜索技术的替代品,而是一种用于增强现有检索系统的辅助工具。**它最大的优势是不仅提供了一种简单且低复杂度的方法来改善搜索结果,允许用户将语义相关性纳入现有的搜索系统中,而且无需进行重大的基础设施修改。**
|
||||
|
||||
以 Cohere Rerank 为例,你只需要注册账户和申请 API ,接入只需要两行代码。另外,他们也提供了多语言模型,也就是说你可以将不同语言的文本查询结果进行一次性排序。\\
|
||||
|
||||
### 如何配置 Rerank 模型?
|
||||
|
||||
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
|
||||
|
||||
<Frame title="在模型供应商内配置 Cohere Rerank 模型">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (163).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
###
|
||||
|
||||
### 如何获取 Cohere Rerank 模型?
|
||||
|
||||
登录:[https://cohere.com/rerank](https://cohere.com/rerank),在页内注册并申请 Rerank 模型的使用资格,获取 API 秘钥。
|
||||
|
||||
###
|
||||
|
||||
### 数据集检索模式中设置 Rerank 模型
|
||||
|
||||
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
|
||||
|
||||
<Frame title="数据集检索模式中设置 Rerank 模型">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (132).png" alt="" width="563" />
|
||||
</Frame>
|
||||
|
||||
**TopK:** 用于设置 Rerank 后返回相关文档的数量。
|
||||
|
||||
**Score 阈值:** 用于设置 Rerank 后返回相关文档的最低分值。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
|
||||
|
||||
### 数据集多路召回模式中设置 Rerank 模型
|
||||
|
||||
进入“提示词编排->上下文->设置”页面中设置为多路召回模式时需开启 Rerank 模型。
|
||||
|
||||
查看更多关于多路召回模式的说明,[《多路召回》](/zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application)。
|
||||
|
||||
<Frame title="数据集多路召回模式中设置 Rerank 模型">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (133).png" alt="" />
|
||||
</Frame>
|
||||
@@ -0,0 +1,26 @@
|
||||
---
|
||||
title: 检索增强生成(RAG)
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
### RAG 的概念解释
|
||||
|
||||
向量检索为核心的 RAG 架构已成为解决大模型获取最新外部知识,同时解决其生成幻觉问题时的主流技术框架,并且已在相当多的应用场景中落地实践。
|
||||
|
||||
开发者可以利用该技术低成本地构建一个 AI 智能客服、企业智能知识库、AI 搜索引擎等,通过自然语言输入与各类知识组织形式进行对话。以一个有代表性的 RAG 应用为例:
|
||||
|
||||
在下图中,当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统…),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
|
||||
|
||||
<Frame title="RAG 基本架构">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (180).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**为什么需要这样做呢?**
|
||||
|
||||
我们可以把大模型比做是一个超级专家,他熟悉人类各个领域的知识,但他也有自己的局限性,比如他不知道你个人的一些状况,因为这些信息是你私人的,不会在互联网上公开,所以他没有提前学习的机会。
|
||||
|
||||
当你想雇佣这个超级专家来充当你的家庭财务顾问时,需要允许他在接受你的提问时先翻看一下你的投资理财记录、家庭消费支出等数据。这样他才能根据你个人的实际情况提供专业的建议。
|
||||
|
||||
**这就是 RAG 系统所做的事情:帮助大模型临时性地获得他所不具备的外部知识,允许它在回答问题之前先找答案。**
|
||||
|
||||
根据上面这个例子,我们很容易发现 RAG 系统中最核心是外部知识的检索环节。专家能不能向你提供专业的家庭财务建议,取决于能不能精确找到他需要的信息,如果他找到的不是投资理财记录,而是家庭减肥计划,那再厉害的专家都会无能为力。
|
||||
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: 召回模式
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
|
||||
|
||||
<Frame title="召回模式设置">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/zh-rag-multiple.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### 召回设置
|
||||
|
||||
根据用户意图同时匹配所有知识库,从多路知识库查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
|
||||
|
||||
在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
|
||||
|
||||
以下是多路召回模式的技术流程图:
|
||||
|
||||
<Frame title="多路召回">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (134).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
|
||||
@@ -0,0 +1,106 @@
|
||||
---
|
||||
title: Integrate Knowledge Base within Application
|
||||
---
|
||||
|
||||
### Creating an Application Integrated with Knowledge Base
|
||||
|
||||
A **"Knowledge Base"** can be used as an external information source to provide precise answers to user questions via LLM. You can associate an existing knowledge base with any [application type](https://docs.dify.ai/guides/application-orchestrate#application\_type) in Dify.
|
||||
|
||||
Taking a chat assistant as an example, the process is as follows:
|
||||
|
||||
1. Go to **Knowledge -- Create Knowledge -- Upload file**
|
||||
2. Go to **Studio -- Create Application -- Select Chatbot**
|
||||
3. Enter **Context**, click **Add**, and select one of the knowledge base created
|
||||
4. In **Context Settings -- Retrieval Setting**, configure the **Retrieval Setting**
|
||||
5. Enable **Citation and Attribution** in **Add Features**
|
||||
6. In **Debug and Preview**, input user questions related to the knowledge base for debugging
|
||||
7. After debugging, click **Publish** button to make an AI application based on your own knowledge!
|
||||
|
||||
***
|
||||
|
||||
### Connecting Knowledge and Setting Retrieval Mode
|
||||
|
||||
In applications that utilize multiple knowledge bases, it is essential to configure the retrieval mode to enhance the precision of retrieved content. To set the retrieval mode for the knowledge bases, navigate to **Context -- Retrieval Settings -- Rerank Setting**.
|
||||
|
||||
#### Retrieval Setting
|
||||
|
||||
The retriever scans all knowledge bases linked to the application for text content relevant to the user's question. The results are then consolidated. Below is the technical flowchart for the Multi-path Retrieval mode:
|
||||
|
||||

|
||||
|
||||
This method simultaneously queries all knowledge bases connected in **"Context"**, seeking relevant text chucks across multiple knowledge bases, collecting all content that aligns with the user's question, and ultimately applying the Rerank strategy to identify the most appropriate content to respond to the user. This retrieval approach offers more comprehensive and accurate results by leveraging multiple knowledge bases simultaneously.
|
||||
|
||||

|
||||
|
||||
For instance, in application A, with three knowledge bases K1, K2, and K3. When a user send a question, multiple relevant pieces of content will be retrieved and combined from these knowledge bases. To ensure the most pertinent content is identified, the Rerank strategy is employed to find the content that best relates to the user's query, enhancing the precision and reliability of the results.
|
||||
|
||||
In practical Q\&A scenarios, the sources of content and retrieval methods for each knowledge base may differ. To manage the mixed content returned from retrieval, the [Rerank strategy](https://docs.dify.ai/learn-more/extended-reading/retrieval-augment/rerank) acts as a refined sorting mechanism. It ensures that the candidate content aligns well with the user's question, optimizing the ranking of results across multiple knowledge bases to identify the most suitable content, thereby improving answer quality and overall user experience.
|
||||
|
||||
Considering the costs associated with using Rerank and the needs of the business, the multi-path retrieval mode provides two Rerank settings:
|
||||
|
||||
**Weighted Score**
|
||||
|
||||
This setting uses internal scoring mechanisms and does not require an external Rerank model, thus **avoiding any additional processing costs**. You can select the most appropriate content matching strategy by adjusting the weight ratio sliders for semantics or keywords.
|
||||
|
||||
* **Semantic Value of 1**
|
||||
|
||||
This mode activates semantic retrieval only. By utilizing the Embedding model, the search depth can be enhanced even if the exact words from the query do not appear in the knowledge base, as it calculates vector distances to return the relevant content. Furthermore, when dealing with multilingual content, semantic retrieval can capture meanings across different languages, yielding more accurate cross-language search results.
|
||||
* **Keyword Value of 1**
|
||||
|
||||
This mode activates keyword retrieval only. It matches the user's input text against the full text of the knowledge base, making it ideal for scenarios where the user knows the exact information or terminology. This method is resource-efficient, making it suitable for quickly retrieving information from large document repositories.
|
||||
* **Custom Keyword and Semantic Weights**
|
||||
|
||||
In addition to enabling only semantic or keyword retrieval modes, we offer flexible custom Weight Score. You can determine the best weight ratio for your business scenario by continuously adjusting the weights of both.
|
||||
|
||||
**Rerank Model**
|
||||
|
||||
The Rerank model is an external scoring system that calculates the relevance score between the user's question and each candidate document provided, improving the results of semantic ranking and returning a list of documents sorted by relevance from high to low.
|
||||
|
||||
While this method incurs some additional costs, it is more adept at handling complex knowledge base content, such as content that combines semantic queries and keyword matches, or cases involving multilingual returned content.
|
||||
|
||||
> Click here to learn more about the [Re-ranking](https://docs.dify.ai/learn-more/extended-reading/retrieval-augment/rerank).
|
||||
|
||||
Dify currently supports multiple Rerank models. To use external Rerank models, you'll need to provide an API Key. Enter the API Key for the Rerank model (such as Cohere, Jina AI, etc.) on the "Model Provider" page.
|
||||
|
||||

|
||||
|
||||
**Adjustable Parameters**
|
||||
|
||||
* **TopK**
|
||||
|
||||
This parameter filters the text segments that are most similar to the user's question. The system dynamically adjusts the number of segments based on the context window size of the selected model. A higher value results in more text segments being recalled.
|
||||
* **Score Threshold**
|
||||
|
||||
This parameter establishes the similarity threshold for filtering text segments. Only those segments with a vector retrieval similarity score exceeding the set threshold will be recalled. A higher threshold value results in fewer texts being recalled, but those recalled are likely to be more relevant. Adjust this parameter based on your specific needs for precision versus recall.
|
||||
|
||||
The multi-recall mode can achieve higher quality recall results when retrieving from multiple knowledge bases; therefore, it is **recommended to set the recall mode to multi-recall**.
|
||||
|
||||
### Frequently Asked Questions
|
||||
|
||||
Here's the translation of the provided content:
|
||||
|
||||
1. **How should I choose Rerank settings in multi-recall mode?**
|
||||
|
||||
If users know the exact information or terminology, and keyword retrieval can accurately deliver matching results, set the **Keyword to 1** in the "Weight Score".
|
||||
|
||||
If the exact vocabulary does not appear in the knowledge base, or if there are cross-language queries, it's recommended to set the **Semantic setting to 1** in the "Weight Score".
|
||||
|
||||
If business personnel are familiar with the actual questioning scenarios of users and wish to actively adjust the ratio of semantics or keywords, it's recommended to adjust the ratio in the "Weight Score" themselves.
|
||||
|
||||
If the content in the knowledge base is complex and cannot be matched by simple conditions such as semantics or keywords, while requiring precise answers, and if you are willing to incur additional costs, it's recommended to use the **Rerank model** for content retrieval.
|
||||
|
||||
2. **What should I do if I encounter issues finding the “Weight Score” or the requirement to configure a Rerank model?**
|
||||
|
||||
Here's how the knowledge base retrieval method affects Multi-path Retrieval:
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (101).png" alt="Knowledge Base Integration" />
|
||||
</Frame>
|
||||
|
||||
3. **What should I do if I cannot adjust the “Weight Score” when referencing multiple knowledge bases and an error message appears?**
|
||||
|
||||
This issue occurs because the embedding models used in the multiple referenced knowledge bases are inconsistent, prompting this notification to avoid conflicts in retrieval content. It is advisable to set and enable the Rerank model in the "Model Provider" or unify the retrieval settings of the knowledge bases.
|
||||
|
||||
4. **Why can't I find the “Weight Score” option in multi-recall mode, and only see the Rerank model?**
|
||||
|
||||
Please check whether your knowledge base is using the “Economical” index mode. If so, switch it to the “High Quality” index mode.
|
||||
@@ -0,0 +1,142 @@
|
||||
---
|
||||
title: Knowledge Base and Document Maintenance
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
## Knowledge Base Management
|
||||
|
||||
> The knowledge base page is accessible only to the team owner, team administrators, and users with editor permissions.
|
||||
|
||||
On the Dify team homepage, click the "Knowledge Base" tab at the top, select the knowledge base you want to manage, then click **Settings** in the left navigation panel to make adjustments. You can modify the knowledge base name, description, visibility permissions, indexing mode, embedding model, and retrieval settings.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/knowledge-settings-01.png" alt="Knowledge Base Settings" />
|
||||
</Frame>
|
||||
|
||||
**Knowledge Base Name**: Used to distinguish among different knowledge bases.
|
||||
|
||||
**Knowledge Description**: Used to describe the information represented by the documents in the knowledge base.
|
||||
|
||||
**Visibility Permissions**: Defines access control for the knowledge base with three levels:
|
||||
|
||||
1. **"Only Me"**: Restricts access to the knowledge base owner.
|
||||
2. **"All team members"**: Grants access to every member of the team.
|
||||
3. **"Partial team members"**: Allows selective access to specific team members.
|
||||
|
||||
Users without appropriate permissions cannot access the knowledge base. When granting access to team members (options 2 or 3), authorized users receive full permissions, including view, edit, and delete rights for the knowledge base content.
|
||||
|
||||
**Indexing Mode**: For detailed explanations, please [refer to the documentation](https://docs.dify.ai/guides/knowledge-base/create-knowledge-and-upload-documents#5-indexing-method).
|
||||
|
||||
**Embedding Model**: Allows you to modify the embedding model for the knowledge base. Changing the embedding model will re-embed all documents in the knowledge base, and the original embeddings will be deleted.
|
||||
|
||||
**Retrieval Settings**: For detailed explanations, please [refer to the documentation](https://docs.dify.ai/guides/knowledge-base/create-knowledge-and-upload-documents#6-retrieval-settings).
|
||||
|
||||
***
|
||||
|
||||
### Knowledge Base API Management
|
||||
|
||||
Dify Knowledge Base provides a complete set of standard APIs. Developers can use API calls to perform daily management and maintenance operations such as adding, deleting, modifying, and querying documents and chunks in the knowledge base. Please refer to the [Knowledge Base API Documentation](maintain-dataset-via-api.md).
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/knowledge-base-api.png" alt="Knowledge base API management" />
|
||||
</Frame>
|
||||
|
||||
## Maintaining Text in the Knowledge Base
|
||||
|
||||
### Viewing Text Chunks
|
||||
|
||||
Each document uploaded to the knowledge base is stored in the form of text chunks. You can view the specific text content of each chunks in the chunks list.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/viewing-uploaded-document-segments.png" alt="Viewing uploaded document chunks" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Checking Chunk Quality
|
||||
|
||||
The quality of document chunk significantly affects the Q&A performance of the knowledge base application. It is recommended to manually check the chunks quality before associating the knowledge base with the application.
|
||||
|
||||
Although automated chunk methods based on character length, identifiers, or NLP semantic chunk can significantly reduce the workload of large-scale text chunk, the quality of chunk is related to the text structure of different document formats and the semantic context. Manual checking and correction can effectively compensate for the shortcomings of machine chunk in semantic recognition.
|
||||
|
||||
When checking chunk quality, pay attention to the following situations:
|
||||
|
||||
* **Overly short text chunks**, leading to semantic loss;
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/short-text-segments.png" alt="Overly short text chunks" width="373" />
|
||||
</Frame>
|
||||
|
||||
* **Overly long text chunks**, leading to semantic noise affecting matching accuracy;
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/long-text-segments.png" alt="Overly long text chunks" width="375" />
|
||||
</Frame>
|
||||
|
||||
* **Obvious semantic truncation**, which occurs when using maximum segment length limits, leading to forced semantic truncation and missing content during recall;
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/semantic-truncation.png" alt="Obvious semantic truncation" width="357" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Adding Text Chunks
|
||||
|
||||
In the chunk list, click "Add Segment" to add one or multiple custom chunks to the document.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/add-a-chunk.png" alt="Add a chunk" />
|
||||
</Frame>
|
||||
|
||||
When adding chunks in bulk, you need to first download the CSV format chunk upload template, edit all the chunk content in Excel according to the template format, save the CSV file, and then upload it.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/bulk-add-custom-segment (1).png" alt="Bulk adding custom chunks" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Editing Text Chunks
|
||||
|
||||
In the chunk list, you can directly edit the content of the added chunks, including the text content and keywords of the chunks.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/edit-segment (1).png" alt="Editing document chunks" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Metadata Management
|
||||
|
||||
In addition to marking metadata information from different source documents, such as the title, URL, keywords, and description of web data, metadata will be used in the chunk recall process of the knowledge base as structured fields for recall filtering or displaying citation sources.
|
||||
|
||||
<Tip>
|
||||
The metadata filtering and citation source functions are not yet supported in the current version.
|
||||
</Tip>
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/metadata.png" alt="Add metadata" width="258" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Adding Documents
|
||||
|
||||
In "Knowledge Base > Document List," click "Add File" to upload new documents or [Notion pages](sync-from-notion.md) to the created knowledge base.
|
||||
|
||||
A knowledge base (Knowledge) is a collection of documents (Documents). Documents can be uploaded by developers or operators, or synchronized from other data sources (usually corresponding to a file unit in the data source).
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/en-knowledge-add-document.png" alt="Upload new document at Knowledge base" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Document Disable and Archive
|
||||
|
||||
**Disable**: The dataset supports disabling documents or chunks that are temporarily not to be indexed. In the dataset document list, click the disable button to disable the document. You can also disable an entire document or a specific chunk in the document details. Disabled documents will not be indexed. Click enable on the disabled documents to cancel the disable status.
|
||||
|
||||
**Archive**: Old document data that is no longer in use can be archived if you do not want to delete it. Archived data can only be viewed or deleted, not edited. In the dataset document list, click the archive button to archive the document. You can also archive documents in the document details. Archived documents will not be indexed. Archived documents can also be unarchived.
|
||||
|
||||
***
|
||||
@@ -0,0 +1,129 @@
|
||||
---
|
||||
title: Connect External Knowledge
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
> To make a distinction, knowledge bases independent of the Dify platform are collectively referred to as **"external knowledge bases"** in this article.
|
||||
|
||||
## Functional Introduction
|
||||
|
||||
For developers with advanced content retrieval requirements, **the built-in knowledge base functionality and text retrieval mechanisms of the Dify platform may have limitations, particularly in terms of customizing recall results.**
|
||||
|
||||
Due to the requirement of higher accuracy of text retrieval and recall, as well as the need to manage internal materials, some developer teams choose to independently develop RAG algorithms and independently maintain text retrieval systems, or uniformly host content to cloud vendors' knowledge base services (such as [AWS Bedrock](https://aws.amazon.com/bedrock/)).
|
||||
|
||||
As a neutral platform for LLM application development, Dify is committed to providing developers with a wider range of options.
|
||||
|
||||
The **Connect to External Knowledge Base** feature enables integration between the Dify platform and external knowledge bases. Through API services, AI applications can access a broader range of information sources. This capability offers two key advantages:
|
||||
|
||||
* The Dify platform can directly obtain the text content hosted in the cloud service provider's knowledge base, so that developers do not need to repeatedly move the content to the knowledge base in Dify;
|
||||
* The Dify platform can directly obtain the text content processed by algorithms in the self-built knowledge base. Developers only need to focus on the information retrieval mechanism of the self-built knowledge base and continuously optimize and improve the accuracy of information retrieval.
|
||||
|
||||
<Frame caption="Principle of external knowledge base connection">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (1) (1).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
Here are the detailed steps for connecting to external knowledge:
|
||||
|
||||
<Steps>
|
||||
<Step title="Create a Compliant External Knowledge Base API" titleSize="h2" >
|
||||
Create a compliant External Knowledge Base API before setting up the API service, please refer to Dify's [External Knowledge Base API](external-knowledge-api-documentation.md) specifications to ensure successful integration between your external knowledge base and Dify.
|
||||
</Step>
|
||||
<Step title="Add External Knowledge API">
|
||||
> Currently, when connecting to external knowledge bases, Dify only supports retrieval permissions and does not support optimization or modification of external knowledge bases. Developers need to maintain external knowledge bases themselves.
|
||||
|
||||
Navigate to the **"Knowledge"** page, click **"External Knowledge API"** in the upper right corner, then click **"Add External Knowledge API"**. Follow the page prompts to fill in the following information:
|
||||
|
||||
* Name Customizable name to distinguish different external knowledge APIs;
|
||||
* API Endpoint The URL of the external knowledge base API endpoint, e.g., api-endpoint/retrieval; refer to the [External Knowledge API](external-knowledge-api-documentation.md) for detailed instructions;
|
||||
* API Key Connection key for the external knowledge, refer to the [External Knowledge API](external-knowledge-api-documentation.md) for detailed instructions.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (353).png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="Connect to the External Knowledge Base">
|
||||
Go to the **"Knowledge"** page, click **"Connect to an External Knowledge Base"** under the Add Knowledge Base card to direct to the parameter configuration page.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (354).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
Fill in the following parameters:
|
||||
|
||||
* **Knowledge base name & description**
|
||||
* **External Knowledge API**
|
||||
Select the external knowledge base API associated in step 2; Dify will call the text content stored in the external knowledge base through the API connection method.
|
||||
* **External knowledge ID**
|
||||
Specify the particular external knowledge base ID to be associated, refer to the external knowledge base API definition for detailed instructions.
|
||||
|
||||
* **Retrieval Setting**
|
||||
|
||||
**Top K:** When a user sends a question, it will request the external knowledge API to obtain highly relevant content chunks. This parameter is used to filter text chunks with high similarity to the user's question. The default value is 3; the higher the value, the more text chunks with relevant similarities will be retrieval.
|
||||
|
||||
**Score Threshold:** The similarity threshold for text chunk filtering, only retrievaling text chunks that exceed the set score. The default value is 0.5. A higher value indicates a higher requirement for similarity between the text and the question, expecting fewer retrievaled text chunks, and the results will be relatively more precise.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (355).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="Test External Knowledge Base and Retrieval Results">
|
||||
After connected with the external knowledge base, developers can simulate possible question keywords in the **"Retrieval Testing"** to preview text chunks that might be retrieval. If you are unsatisfied with the retrieval results, try modifying the **External Knowledge Base Settings** or adjusting the retrieval strategy of the external knowledge base.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (356).png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="Integrating External Knowledge base in Applications">
|
||||
* **Chatbot / Agent** type application
|
||||
|
||||
Associate the external knowledge base in the orchestration page within Chatbot / Agent type applications.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (357).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
* **Chatflow / Workflow** type application
|
||||
|
||||
Add a **"Knowledge Retrieval"** node and select the external knowledge base.
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (358).png" alt="" /><figcaption></figcaption>
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="Manage External Knowledge" titleSize="p">
|
||||
Navigate to the **"Knowledge"** page, external knowledge base cards will list an **EXTERNAL** label in the upper right corner. Select the knowledge base needs to be modified, click **"Settings"** to modify the following information:
|
||||
|
||||
* **Knowledge base name and description**
|
||||
* **Permissions**
|
||||
|
||||
Provide **"Only me"**, **"All team members"**, and **"Partial team members"** permission scope. Those without permission will not be able to access the knowledge base. If you choose to make the knowledge base public to other members, it means that other members also have the rights to view, edit, and delete the knowledge base.
|
||||
* **Retrieval Setting**
|
||||
|
||||
**Top K:** When a user sends a question, it will request the external knowledge API to obtain highly relevant content segments. This parameter is used to filter text chunks with high similarity to the user's question. The default value is 3; the higher the value, the more text chunks with relevant similarities will be retrievaled.
|
||||
|
||||
**Score threshold:** The similarity threshold for text chunk filtering, only retrievaling text chunks that exceed the set score. The default value is 0.5. A higher value indicates a higher requirement for similarity between the text and the question, expecting fewer retrievaled text chunks, and the results will be relatively more precise.
|
||||
|
||||
The **"External Knowledge API"** and **"External Knowledge ID"** associated with the external knowledge base do not support modification. If modification is needed, please associate a new **"External Knowledge API"** and reset it.
|
||||
<Frame caption="create knowledge base">
|
||||
<img src="/ja-jp/img/connect-kb-7-en.webp" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## Connection Example
|
||||
|
||||
[how-to-connect-aws-bedrock.md](/learn-more/use-cases/how-to-connect-aws-bedrock.md "mention")
|
||||
|
||||
## FAQ
|
||||
|
||||
**How to Fix the Errors Occurring When Connecting to External Knowledge API?**
|
||||
|
||||
Solutions corresponding to each error code in the return information:
|
||||
|
||||
| Error Code | Result | Solutions |
|
||||
| ---------- | ----------------------------------- | ----------------------------------------------------------- |
|
||||
| 1001 | Invalid Authorization header format | Please check the Authorization header format of the request |
|
||||
| 1002 | Authorization failed | Please check whether the API Key you entered is correct. |
|
||||
| 2001 | The knowledge is not exist | Please check the external repository |
|
||||
@@ -0,0 +1,127 @@
|
||||
---
|
||||
title: 'External Knowledge API'
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
## Endpoint
|
||||
|
||||
```
|
||||
POST <your-endpoint>/retrieval
|
||||
```
|
||||
|
||||
## Header
|
||||
|
||||
This API is used to connect to a knowledge base that is independent of the Dify and maintained by developers. For more details, please refer to [Connecting to an External Knowledge Base](https://docs.dify.ai/guides/knowledge-base/connect-external-knowledge-base). You can use `API-Key` in the `Authorization` HTTP Header to verify permissions. The authentication logic is defined by you in the retrieval API, as shown below:
|
||||
|
||||
```
|
||||
Authorization: Bearer {API_KEY}
|
||||
```
|
||||
|
||||
## Request Body Elements
|
||||
|
||||
The request accepts the following data in JSON format.
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| knowledge_id | TRUE | string | Your knowledge's unique ID | AAA-BBB-CCC |
|
||||
| query | TRUE | string | User's query | What is Dify? |
|
||||
| retrieval_setting | TRUE | object | Knowledge's retrieval parameters | See below |
|
||||
|
||||
The `retrieval_setting` property is an object containing the following keys:
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| top_k | TRUE | int | Maximum number of retrieved results | 5 |
|
||||
| score_threshold | TRUE | float | The score limit of relevance of the result to the query, scope: 0~1 | 0.5 |
|
||||
|
||||
## Request Syntax
|
||||
|
||||
```json
|
||||
POST <your-endpoint>/retrieval HTTP/1.1
|
||||
-- header
|
||||
Content-Type: application/json
|
||||
Authorization: Bearer your-api-key
|
||||
-- data
|
||||
{
|
||||
"knowledge_id": "your-knowledge-id",
|
||||
"query": "your question",
|
||||
"retrieval_setting":{
|
||||
"top_k": 2,
|
||||
"score_threshold": 0.5
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Response Elements
|
||||
|
||||
If the action is successful, the service sends back an HTTP 200 response.
|
||||
|
||||
The following data is returned in JSON format by the service.
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| records | TRUE | List[Object] | A list of records from querying the knowledge base. | See below |
|
||||
|
||||
The `records` property is a list object containing the following keys:
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| content | TRUE | string | Contains a chunk of text from a data source in the knowledge base. | Dify:The Innovation Engine for GenAI Applications |
|
||||
| score | TRUE | float | The score of relevance of the result to the query, scope: 0~1 | 0.5 |
|
||||
| title | TRUE | string | Document title | Dify Introduction |
|
||||
| metadata | FALSE | json | Contains metadata attributes and their values for the document in the data source. | See example |
|
||||
|
||||
## Response Syntax
|
||||
|
||||
```json
|
||||
HTTP/1.1 200
|
||||
Content-type: application/json
|
||||
{
|
||||
"records": [{
|
||||
"metadata": {
|
||||
"path": "s3://dify/knowledge.txt",
|
||||
"description": "dify knowledge document"
|
||||
},
|
||||
"score": 0.98,
|
||||
"title": "knowledge.txt",
|
||||
"content": "This is the document for external knowledge."
|
||||
},
|
||||
{
|
||||
"metadata": {
|
||||
"path": "s3://dify/introduce.txt",
|
||||
"description": "dify introduce"
|
||||
},
|
||||
"score": 0.66,
|
||||
"title": "introduce.txt",
|
||||
"content": "The Innovation Engine for GenAI Applications"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Errors
|
||||
|
||||
If the action fails, the service sends back the following error information in JSON format:
|
||||
|
||||
| Property | Required | Type | Description | Example value |
|
||||
|----------|----------|------|-------------|---------------|
|
||||
| error_code | TRUE | int | Error code | 1001 |
|
||||
| error_msg | TRUE | string | The description of API exception | Invalid Authorization header format. Expected 'Bearer `<api-key>`' format. |
|
||||
|
||||
The `error_code` property has the following types:
|
||||
|
||||
| Code | Description |
|
||||
|------|-------------|
|
||||
| 1001 | Invalid Authorization header format. |
|
||||
| 1002 | Authorization failed |
|
||||
| 2001 | The knowledge does not exist |
|
||||
|
||||
### HTTP Status Codes
|
||||
|
||||
**AccessDeniedException**
|
||||
The request is denied because of missing access permissions. Check your permissions and retry your request.
|
||||
HTTP Status Code: 403
|
||||
|
||||
**InternalServerException**
|
||||
An internal server error occurred. Retry your request.
|
||||
HTTP Status Code: 500
|
||||
@@ -0,0 +1,83 @@
|
||||
---
|
||||
title: Sync Data from Notion
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
Dify datasets support importing from Notion and setting up **synchronization** so that data updates in Notion are automatically synced to Dify.
|
||||
|
||||
### Authorization Verification
|
||||
|
||||
1. When creating a dataset and selecting the data source, click **Sync from Notion Content -- Bind Now** and follow the prompts to complete the authorization verification.
|
||||
2. Alternatively, you can go to **Settings -- Data Sources -- Add Data Source**, click on the Notion source **Bind**, and complete the authorization verification.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/binding-notion (1).png" alt="Binding Notion" />
|
||||
</Frame>
|
||||
|
||||
### Importing Notion Data
|
||||
|
||||
After completing the authorization verification, go to the create dataset page, click **Sync from Notion Content**, and select the authorized pages you need to import.
|
||||
|
||||
### Segmentation and Cleaning
|
||||
|
||||
Next, choose your **segmentation settings** and **indexing method**, then **Save and Process**. Wait for Dify to process this data for you, which typically requires token consumption in the LLM provider. Dify supports importing not only standard page types but also aggregates and saves page properties under the database type.
|
||||
|
||||
_**Please note: Images and files are not currently supported for import, and tabular data will be converted to text display.**_
|
||||
|
||||
### Synchronizing Notion Data
|
||||
|
||||
If your Notion content is modified, you can directly click **Sync** in the Dify dataset **Document List Page** to perform a one-click data synchronization. This step requires token consumption.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/sync-notion (1).png" alt="Sync Notion Content" />
|
||||
</Frame>
|
||||
|
||||
### Integration Configuration Method for Community Edition Notion
|
||||
|
||||
Notion integration can be done in two ways: **internal integration** and **public integration**. You can configure them as needed in Dify. For specific differences between the two integration methods, please refer to [Notion Official Documentation](https://developers.notion.com/docs/authorization).
|
||||
|
||||
### 1. **Using Internal Integration**
|
||||
|
||||
First, create an integration in the integration settings page [Create Integration](https://www.notion.so/my-integrations). By default, all integrations start as internal integrations; internal integrations will be associated with the workspace you choose, so you need to be the workspace owner to create an integration.
|
||||
|
||||
Specific steps:
|
||||
|
||||
Click the **New integration** button. The type is **Internal** by default (cannot be modified). Select the associated space, enter the integration name, upload a logo, and click **Submit** to create the integration successfully.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/integrate-notion-1.png" alt="Create Internal Integration" />
|
||||
</Frame>
|
||||
|
||||
After creating the integration, you can update its settings as needed under the Capabilities tab and click the **Show** button under Secrets to copy the secrets.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/notion-secret.png" alt="Copy Notion Secret" />
|
||||
</Frame>
|
||||
|
||||
After copying, go back to the Dify source code, and configure the relevant environment variables in the **.env** file. The environment variables are as follows:
|
||||
|
||||
**NOTION_INTEGRATION_TYPE**=internal or **NOTION_INTEGRATION_TYPE**=public
|
||||
|
||||
**NOTION_INTERNAL_SECRET**=your-internal-secret
|
||||
|
||||
### 2. **Using Public Integration**
|
||||
|
||||
**You need to upgrade the internal integration to a public integration.** Navigate to the Distribution page of the integration, and toggle the switch to make the integration public. When switching to the public setting, you need to fill in additional information in the Organization Information form below, including your company name, website, and redirect URL, then click the **Submit** button.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/public-integration.png" alt="Public Integration Setup" />
|
||||
</Frame>
|
||||
|
||||
After successfully making the integration public on the integration settings page, you will be able to access the integration key in the Keys tab:
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/notion-public-secret.png" alt="Notion Public Secret" />
|
||||
</Frame>
|
||||
|
||||
Go back to the Dify source code, and configure the relevant environment variables in the **.env** file. The environment variables are as follows:
|
||||
|
||||
* **NOTION_INTEGRATION_TYPE**=public
|
||||
* **NOTION_CLIENT_SECRET**=your-client-secret
|
||||
* **NOTION_CLIENT_ID**=your-client-id
|
||||
|
||||
After configuration, you can operate the Notion data import and synchronization functions in the dataset.
|
||||
@@ -0,0 +1,90 @@
|
||||
---
|
||||
title: Sync Data from Website
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
Dify knowledge base supports crawling content from public web pages using third-party tools such as [Jina Reader](https://jina.ai/reader/) and [Firecrawl](https://www.firecrawl.dev/), parsing it into Markdown content, and importing it into the knowledge base.
|
||||
|
||||
<Note>
|
||||
[Firecrawl](https://www.firecrawl.dev/) and [Jina Reader](https://jina.ai/reader/) are both open-source web parsing tools that can convert web pages into clean Markdown format text that is easy for LLMs to recognize, while providing easy-to-use API services.Comment
|
||||
</Note>
|
||||
|
||||
The following sections will introduce the usage methods for Firecrawl and Jina Reader respectively.
|
||||
|
||||
### Firecrawl <a href="#how-to-configure" id="how-to-configure"></a>
|
||||
|
||||
#### **1. Configure Firecrawl API credentials**
|
||||
|
||||
Click on the avatar in the upper right corner, then go to the **DataSource** page, and click the **Configure** button next to Firecrawl.
|
||||
|
||||
<Frame caption="Firecrawlの設定">
|
||||
<img src="/ja-jp/img/image (6) (2).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
Log in to the [Firecrawl website](https://www.firecrawl.dev/) to complete registration, get your API Key, and then enter and save it in Dify.
|
||||
|
||||
<Frame caption="">
|
||||

|
||||
</Frame>
|
||||
|
||||
#### 2. Scrape target webpage
|
||||
|
||||
On the knowledge base creation page, select **Sync from website**, choose Firecrawl as the provider, and enter the target URL to be crawled.
|
||||
|
||||
<Frame caption="Webページの取得設定">
|
||||
<img src="/ja-jp/img/image (102).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
The configuration options include: Whether to crawl sub-pages, Page crawling limit, Page scraping max depth, Excluded paths, Include only paths, and Content extraction scope. After completing the configuration, click **Run** to preview the parsed pages.
|
||||
|
||||
<Frame caption="取得実行">
|
||||
<img src="/ja-jp/img/image (103).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
#### 3. Review import results
|
||||
|
||||
After importing the parsed text from the webpage, it is stored in the knowledge base documents. View the import results and click **Add URL** to continue importing new web pages.
|
||||
|
||||
<Frame caption="Webページ解析テキストのインポート">
|
||||
<img src="/ja-jp/img/image (104).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### Jina Reader
|
||||
|
||||
#### 1. Configuring Jina Reader Credentials 
|
||||
|
||||
Click on the avatar in the upper right corner, then go to the **DataSource** page, and click the **Configure** button next to Jina Reader.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (105).png" alt="Configuring Jina Reader" />
|
||||
</Frame>
|
||||
|
||||
Log in to the [Jina Reader website](https://jina.ai/reader/), complete registration, obtain the API Key, then fill it in and save.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (106).png" alt="Fill in Jina configuration" />
|
||||
</Frame>
|
||||
|
||||
#### 2. Using Jina Reader to Crawl Web Content 
|
||||
|
||||
On the knowledge base creation page, select Sync from website, choose Jina Reader as the provider, and enter the target URL to be crawled.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (107).png" alt="Web Crawling Configuration" />
|
||||
</Frame>
|
||||
|
||||
Configuration options include: whether to crawl subpages, maximum number of pages to crawl, and whether to use sitemap for crawling. After completing the configuration, click the **Run** button to preview the page links to be crawled.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (109).png" alt="Executing the Crawl" />
|
||||
</Frame>
|
||||
|
||||
Import the parsed text from web pages and store it in the knowledge base documents, then view the import results. To continue adding web pages, click the Add URL button on the right to import new web pages.
|
||||
|
||||
<Frame>
|
||||
<img src="/images/assets/image (110).png" alt="Importing parsed web text into the knowledge base" />
|
||||
</Frame>
|
||||
|
||||
After crawling is complete, the content from the web pages will be incorporated into the knowledge base.
|
||||
@@ -0,0 +1,245 @@
|
||||
---
|
||||
title: Create Knowledge Base & Upload Documents
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
**Steps to upload documents into Knowledge:**
|
||||
|
||||
1. Select the document you need to upload from your local files;
|
||||
2. Segment and clean the document, and preview the effect;
|
||||
3. Choose and configure Index Mode and Retrieval Settings;
|
||||
4. Wait for the chunks to be embedded;
|
||||
5. Upload completed, now you can use it in your applications 🎉
|
||||
|
||||
### 1 Creating a Knowledge Base
|
||||
|
||||
Click on Knowledge in the main navigation bar of Dify. On this page, you can see your existing knowledge bases. Click **Create Knowledge** to enter the setup wizard:
|
||||
|
||||
* If you have not prepared any documents yet, you can first create an empty knowledge base;
|
||||
* When creating a knowledge base with an external data source (such as Notion or Sync from website), the knowledge base type becomes immutable. This restriction prevents management complexities that could arise from multiple data sources within a single knowledge base.
|
||||
|
||||
For scenarios requiring multiple data sources, we recommend creating separate knowledge bases for each source. You can then utilize the Multiple-Retrieval feature to reference multiple knowledge bases within the same application.
|
||||
|
||||
**Limitations for uploading documents:**
|
||||
|
||||
* The upload size limit for a single document is 15MB;
|
||||
|
||||
<Frame caption="Create Knowledge base">
|
||||
<img src="/zh-cn/images/en-upload-files-1.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 2 Text Preprocessing and Cleaning
|
||||
|
||||
After uploading content to the knowledge base, it needs to undergo chunking and data cleaning. This stage can be understood as content preprocessing and structuring.
|
||||
|
||||
<Accordion title="What is text chunking and cleaning?">
|
||||
|
||||
* **Chunking**
|
||||
|
||||
LLMs have a limited context window, usually requiring the entire text to be segmented and then recalling the most relevant segments to the user’s question, known as the segment TopK recall mode. Additionally, appropriate segment sizes help match the most relevant text content and reduce information noise when semantically matching user questions with text segments.
|
||||
|
||||
* **Cleaning**
|
||||
|
||||
To ensure the quality of text recall, it is usually necessary to clean the data before passing it into the model. For example, unwanted characters or blank lines in the output may affect the quality of the response. To help users solve this problem, Dify provides various cleaning methods to help clean the output before sending it to downstream applications, check [ETL](create-knowledge-and-upload-documents.md#optional-etl-configuration) to know more details.
|
||||
|
||||
</Accordion>
|
||||
|
||||
Two strategies are supported:
|
||||
|
||||
* Automatic mode
|
||||
* Custom mode
|
||||
|
||||
<Tabs>
|
||||
|
||||
<Tab title="Automatic" >
|
||||
|
||||
#### Automatic
|
||||
|
||||
The Automated mode is designed for users unfamiliar with segmentation and preprocessing techniques. In this mode, Dify automatically segments and sanitizes content files, streamlining the document preparation process.
|
||||
|
||||
<Frame caption="Automatic mode">
|
||||
<img src="/zh-cn/images/en-upload-files-2.avif" alt="Automatic segmentation and cleaning" />
|
||||
</Frame>
|
||||
|
||||
</Tab>
|
||||
|
||||
<Tab title="Custom" >
|
||||
#### Custom
|
||||
|
||||
Custom mode is tailored for advanced users with specific text processing requirements. This mode allows manual configuration of chunking rules and cleaning strategies based on different document formats and scenario demands.
|
||||
|
||||
**Chunking Rules:**
|
||||
|
||||
1. **Delimiter**: Specify a delimiter for text segmentation. For example, `\n` (newline character in [regex](https://regexr.com/)) will chunk text at each line break.
|
||||
2. **Maximum chunk length**: Set the maximum character count per segment. Chunk exceeding this limit will be forcibly divided. The maximum length for a segment is 4000 tokens.
|
||||
3. **Chunk overlap**: Define the overlap between adjacent chunks. This overlap enhances information retention and analysis accuracy, improving recall effectiveness. Recommended setting is 10-25% of the segment length in tokens.
|
||||
|
||||
**Text Preprocessing Rules**: These rules help filter out insignificant content from the knowledge base.
|
||||
|
||||
* Replace consecutive spaces, newlines, and tabs.
|
||||
* Delete all URLs and email addresses.
|
||||
|
||||
<Frame caption="Custom mode">
|
||||
<img src="/zh-cn/images/en-upload-files-3.webp" alt="" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 3 Indexing Mode
|
||||
|
||||
You need to choose the **indexing method** for the text to specify the data matching method. The indexing strategy is often related to the retrieval method, and you need to choose the appropriate retrieval settings according to the scenario.
|
||||
|
||||
* **High-Quality Mode**
|
||||
* **Economical Mode**
|
||||
|
||||
<Tabs>
|
||||
<Tab title="High Quality" >
|
||||
In High-Quality mode, the system first leverages an configurable Embedding model (which can be switched) to convert chunk text into numerical vectors. This process facilitates efficient compression and persistent storage of large-scale textual data, while simultaneously enhancing the accuracy of LLM-user interactions.
|
||||
|
||||
The High-Quality indexing method offers three retrieval settings: vector retrieval, full-text retrieval, and hybrid retrieval. For more details on retrieval settings, please check ["Retrieval Settings"](#4-retrieval-settings).
|
||||
<Frame caption="High Quality">
|
||||
<img src="/zh-cn/images/en-upload-files-4.webp" alt="" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
|
||||
<Tab title="Economical" >
|
||||
This mode employs an offline vector engine and keyword indexing, which reduces accuracy but eliminates additional token consumption and associated costs. The indexing method is limited to inverted indexing. For detailed specifications, please refer to the section below.
|
||||
<Frame caption="Economical mode">
|
||||
<img src="/zh-cn/images/en-upload-files-5.webp" alt="" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
|
||||
</Tabs>
|
||||
|
||||
***
|
||||
|
||||
## 4 Retrieval Settings
|
||||
|
||||
In high-quality indexing mode, Dify offers three retrieval settings:
|
||||
|
||||
* **Vector Search**
|
||||
* **Full-Text Search**
|
||||
* **Hybrid Search**
|
||||
|
||||
<Tabs>
|
||||
|
||||
<Tab title="Vector Search" >
|
||||
|
||||
**Definition**: The system vectorizes the user's input query to generate a query vector. It then computes the distance between this query vector and the text vectors in the knowledge base to identify the most semantically proximate text chunks.
|
||||
|
||||
<Frame caption="Vector Search Settings">
|
||||
<img src="/zh-cn/images/en-upload-files-8.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**Vector Search Settings:**
|
||||
|
||||
**Rerank Model**: After configuring the API key for the Rerank model on the "Model Provider" page, you can enable the “Rerank Model” in the retrieval settings. The system will then perform semantic reordering of the retrieved document results after hybrid retrieval, optimizing the ranking results. Once the Rerank model is established, the TopK and Score Threshold settings will only take effect during the reranking step.
|
||||
|
||||
**TopK**: This parameter filters the text chucks that are most similar to the user's question. The system dynamically adjusts the number of snippets based on the context window size of the selected model. The default value is 3, meaning a higher value results in more text segments being retrieved.
|
||||
|
||||
**Score Threshold**: This parameter sets the similarity threshold for filtering text chucks. Only text chucks that exceed the specified score will be recalled. By default, this setting is off, meaning there will be no filtering of similarity values for recalled text chucks. When enabled, the default value is 0.5. A higher value
|
||||
|
||||
> The TopK and Score configurations are only effective during the Rerank phase. Therefore, to apply either of these settings, it is necessary to add and enable a Rerank model.
|
||||
|
||||
</Tab>
|
||||
|
||||
<Tab title="Full-Text Search" >
|
||||
|
||||
**Definition:** Indexing all terms in the document, allowing users to query any terms and return text fragments containing those terms.
|
||||
|
||||
<Frame caption="Full-Text Search Settings">
|
||||
<img src="/zh-cn/images/en-upload-files-9.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**Rerank Model**: After configuring the API key for the Rerank model on the "Model Provider" page, you can enable the “Rerank Model” in the retrieval settings. The system will then perform semantic reordering of the retrieved document results after hybrid retrieval, optimizing the ranking results. Once the Rerank model is established, the TopK and Score Threshold settings will only take effect during the reranking step.
|
||||
|
||||
**TopK**: This parameter filters the text chucks that are most similar to the user's question. The system dynamically adjusts the number of snippets based on the context window size of the selected model. The default value is 3, meaning a higher value results in more text segments being retrieved.
|
||||
|
||||
**Score Threshold**: This parameter sets the similarity threshold for filtering text chucks. Only text chucks that exceed the specified score will be recalled. By default, this setting is off, meaning there will be no filtering of similarity values for recalled text chucks. When enabled, the default value is 0.5. A higher value is likely to yield fewer recalled texts.
|
||||
|
||||
> The TopK and Score configurations are only effective during the Rerank phase. Therefore, to apply either of these settings, it is necessary to add and enable a Rerank model.
|
||||
|
||||
</Tab>
|
||||
|
||||
<Tab title="Hybrid Search" >
|
||||
**Definition:** This process performs both full-text search and vector search simultaneously, incorporating a reordering step to select the best results that match the user's query from both types of search outcomes. In this mode, users can specify "weight settings" without needing to configure the Rerank model API, or they can opt for a Rerank model for retrieval.
|
||||
|
||||
<Frame caption="Hybrid Retrieval Setting">
|
||||
<img src="/zh-cn/images/en-upload-files-10.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**Weight Settings:** This feature enables users to set custom weights for semantic priority and keyword priority. Keyword search refers to performing a full-text search within the knowledge base, while semantic search involves vector search within the knowledge base.
|
||||
|
||||
* **Semantic Value of 1**
|
||||
|
||||
This activates only the semantic search mode. Utilizing embedding models, even if the exact terms from the query do not appear in the knowledge base, the search can delve deeper by calculating vector distances, thus returning relevant content. Additionally, when dealing with multilingual content, semantic search can capture meaning across different languages, providing more accurate cross-language search results.
|
||||
|
||||
* **Keyword Value of 1**
|
||||
|
||||
This activates only the keyword search mode. It performs a full match against the input text in the knowledge base, suitable for scenarios where the user knows the exact information or terminology. This approach consumes fewer computational resources and is ideal for quick searches within a large document knowledge base.
|
||||
|
||||
* **Custom Keyword and Semantic Weights**
|
||||
|
||||
In addition to enabling only semantic search or keyword search, we provide flexible custom weight settings. You can continuously adjust the weights of the two methods to identify the optimal weight ratio that suits your business scenario.
|
||||
|
||||
***
|
||||
|
||||
**Rerank Model**: After configuring the API key for the Rerank model on the "Model Provider" page, you can enable the “Rerank Model” in the retrieval settings. The system will then perform semantic reordering of the retrieved document results after hybrid retrieval, optimizing the ranking results. Once the Rerank model is established, the TopK and Score Threshold settings will only take effect during the reranking step.
|
||||
|
||||
***
|
||||
|
||||
The **"Weight Settings"** and **"Rerank Model"** settings support the following options:
|
||||
|
||||
**TopK**: This parameter filters the text chucks that are most similar to the user's question. The system dynamically adjusts the number of snippets based on the context window size of the selected model. The default value is 3, meaning a higher value results in more text segments being retrieved.
|
||||
|
||||
**Score Threshold**: This parameter sets the similarity threshold for filtering text chucks. Only text chucks that exceed the specified score will be recalled. By default, this setting is off, meaning there will be no filtering of similarity values for recalled text chucks. When enabled, the default value is 0.5. A higher value is likely to yield fewer recalled texts.
|
||||
|
||||
</Tab>
|
||||
|
||||
</Tabs>
|
||||
|
||||
***
|
||||
|
||||
In the **Economical indexing** mode, Dify offers a single retrieval setting:
|
||||
|
||||
#### **Inverted Index**
|
||||
|
||||
An inverted index is an index structure designed for rapid keyword retrieval in documents. Its fundamental principle involves mapping keywords from documents to lists of documents containing those keywords, thereby enhancing search efficiency. For a detailed explanation of the underlying mechanism, please refer to the ["Inverted Index"](https://en.wikipedia.org/wiki/Inverted\_index).
|
||||
|
||||
**TopK:** This parameter filters the text chucks that are most similar to the user's question. The system dynamically adjusts the number of snippets based on the context window size of the selected model. The default value is 3, meaning a higher value results in more text segments being retrieved.
|
||||
|
||||
<Frame caption="Inverted Index">
|
||||
<img src="/zh-cn/images/en-upload-files-8.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
After specifying the retrieval settings, you can refer to [Retrieval Test/Citation Attribution](/en-us/user-guide/knowledge-base/retrieval-test-and-citation) to check the matching between keywords and content chunks.
|
||||
|
||||
## 5. Complete Upload
|
||||
|
||||
After configuring all the settings mentioned above, simply click "Save and Process" to complete the creation of your knowledge base. You can refer to [Integrate Knowledge Base Within Application](integrate-knowledge-within-application.md) to build an LLM application that can answer questions based on the knowledge base.
|
||||
|
||||
***
|
||||
|
||||
## Reference
|
||||
|
||||
#### Optional ETL Configuration
|
||||
|
||||
In production-level applications of RAG, to achieve better data recall, multi-source data needs to be preprocessed and cleaned, i.e., ETL (extract, transform, load). To enhance the preprocessing capabilities of unstructured/semi-structured data, Dify supports optional ETL solutions: **Dify ETL** and [**Unstructured ETL**](https://unstructured.io/).
|
||||
|
||||
> Unstructured can efficiently extract and transform your data into clean data for subsequent steps.
|
||||
|
||||
| DIFY ETL | Unstructured ETL |
|
||||
| ------------------------------------------------------- | --------------------------------------------------------------------------------------- |
|
||||
| txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv | txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv, eml, msg, pptx, ppt, xml, epub |
|
||||
|
||||
<Info>
|
||||
Different ETL solutions may have differences in file extraction effects. For more information on Unstructured ETL’s data processing methods, please refer to the [official documentation](https://docs.unstructured.io/open-source/core-functionality/partitioning).
|
||||
</Info>
|
||||
|
||||
**Embedding Model**
|
||||
|
||||
**Embedding** transforms discrete variables (words, sentences, documents) into continuous vector representations, mapping high-dimensional data to lower-dimensional spaces. This technique preserves crucial semantic information while reducing dimensionality, enhancing content retrieval efficiency.
|
||||
|
||||
**Embedding models**, specialized large language models, excel at converting text into dense numerical vectors, effectively capturing semantic nuances for improved data processing and analysis.
|
||||
@@ -0,0 +1,37 @@
|
||||
---
|
||||
title: Retrieval Test/Citation
|
||||
version: 'English'
|
||||
---
|
||||
|
||||
### 1. Retrieval Testing
|
||||
|
||||
The Dify Knowledge Base provides a text retrieval testing feature to debug the recall effects under different retrieval methods and parameter configurations. You can enter common user questions in the **Source Text** input box, click **Test**, and view the recall results in the **Recalled Paragraph** section on the right. The **Recent Queries** section allows you to view the history of query records; if the knowledge base is linked to an application, queries triggered from within the application can also be viewed here.
|
||||
|
||||

|
||||
|
||||
Clicking the icon in the upper right corner of the source text input box allows you to change the retrieval method and specific parameters of the current knowledge base. **Changes will only take effect during the recall testing process.** After completing the recall test and confirming changes to the retrieval parameters of the knowledge base, you need to make changes in [Knowledge Base Settings > Retrieval Settings](/en-us/user-guide/knowledge-base/knowledge-base-creation/upload-documents#4-retrieval-settings).
|
||||
|
||||

|
||||
|
||||
**Suggested Steps for Recall Testing:**
|
||||
|
||||
1. Design and organize test cases/test question sets covering common user questions.
|
||||
2. Choose an appropriate retrieval strategy: vector search/full-text search/hybrid search. For the pros and cons of different retrieval methods, please refer to the extended [reference](/en-us/user-guide/knowledge-base/knowledge-base-creation/upload-documents#inverted-index).
|
||||
3. Debug the number of recall segments (TopK) and the recall score threshold (Score). Choose appropriate parameter combinations based on the application scenario, including the quality of the documents themselves.
|
||||
|
||||
**How to Configure TopK Value and Recall Threshold (Score)**
|
||||
|
||||
* **TopK represents the maximum number of recall segments when sorted in descending order of similarity scores.** A smaller TopK value will recall fewer segments, which may result in incomplete recall of relevant texts; a larger TopK value will recall more segments, which may result in recalling segments with lower semantic relevance, reducing the quality of LLM responses.
|
||||
* **The recall threshold (Score) represents the minimum similarity score allowed for recall segments.** A smaller recall score will recall more segments, which may result in recalling less relevant segments; a larger recall score threshold will recall fewer segments, and if too large, may result in missing relevant segments.
|
||||
|
||||
***
|
||||
|
||||
### 2. Citation and Attribution
|
||||
|
||||
When testing the knowledge base effect within the application, you can go to **Workspace -- Add Function -- Citation Attribution** to enable the citation attribution feature.
|
||||
|
||||

|
||||
|
||||
After enabling the feature, when the large language model responds to a question by citing content from the knowledge base, you can view specific citation paragraph information below the response content, including **original segment text, segment number, matching degree**, etc. Clicking **Jump to Knowledge Base** above the cited segment allows quick access to the segment list in the knowledge base, facilitating developers in debugging and editing.
|
||||
|
||||

|
||||
19
logo/dify-logo.svg
Normal file
19
logo/dify-logo.svg
Normal file
{kind=link}
File diff suppressed because one or more lines are too long
|
After Width: | Height: | Size: 141 KiB |
BIN
logo/dify.png
Normal file
BIN
logo/dify.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 6.0 KiB |
2
robots.txt
Normal file
2
robots.txt
Normal file
@@ -0,0 +1,2 @@
|
||||
User-agent: *
|
||||
Disallow: /
|
||||
71
zh-cn/introduction.mdx
Normal file
71
zh-cn/introduction.mdx
Normal file
@@ -0,0 +1,71 @@
|
||||
---
|
||||
title: Introduction
|
||||
description: "Welcome to the home of your new documentation"
|
||||
---
|
||||
|
||||
<img
|
||||
className="block dark:hidden"
|
||||
src="/images/hero-light.png"
|
||||
alt="Hero Light"
|
||||
/>
|
||||
<img
|
||||
className="hidden dark:block"
|
||||
src="/images/hero-dark.png"
|
||||
alt="Hero Dark"
|
||||
/>
|
||||
|
||||
## Setting up
|
||||
|
||||
The first step to world-class documentation is setting up your editing environments.
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card
|
||||
title="Edit Your Docs"
|
||||
icon="pen-to-square"
|
||||
href="https://mintlify.com/docs/quickstart"
|
||||
>
|
||||
Get your docs set up locally for easy development
|
||||
</Card>
|
||||
<Card
|
||||
title="Preview Changes"
|
||||
icon="image"
|
||||
href="https://mintlify.com/docs/development"
|
||||
>
|
||||
Preview your changes before you push to make sure they're perfect
|
||||
</Card>
|
||||
</CardGroup>
|
||||
|
||||
## Make it yours
|
||||
|
||||
Update your docs to your brand and add valuable content for the best user conversion.
|
||||
|
||||
<CardGroup cols={2}>
|
||||
<Card
|
||||
title="Customize Style"
|
||||
icon="palette"
|
||||
href="https://mintlify.com/docs/settings/global"
|
||||
>
|
||||
Customize your docs to your company's colors and brands
|
||||
</Card>
|
||||
<Card
|
||||
title="Reference APIs"
|
||||
icon="code"
|
||||
href="https://mintlify.com/docs/api-playground/openapi"
|
||||
>
|
||||
Automatically generate endpoints from an OpenAPI spec
|
||||
</Card>
|
||||
<Card
|
||||
title="Add Components"
|
||||
icon="screwdriver-wrench"
|
||||
href="https://mintlify.com/docs/content/components/accordions"
|
||||
>
|
||||
Build interactive features and designs to guide your users
|
||||
</Card>
|
||||
<Card
|
||||
title="Get Inspiration"
|
||||
icon="stars"
|
||||
href="https://mintlify.com/customers"
|
||||
>
|
||||
Check out our showcase of our favorite documentation
|
||||
</Card>
|
||||
</CardGroup>
|
||||
36
zh-cn/readme.mdx
Normal file
36
zh-cn/readme.mdx
Normal file
@@ -0,0 +1,36 @@
|
||||
---
|
||||
title: 欢迎使用 Dify
|
||||
---
|
||||
|
||||
**Dify** 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 [LLMOps](learn-more/extended-reading/what-is-llmops.md) 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
|
||||
|
||||
由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
|
||||
|
||||
### 为什么使用 Dify?
|
||||
|
||||
你或许可以把 LangChain 这类的开发库(Library)想象为有着锤子、钉子的工具箱。与之相比,Dify 提供了更接近生产需要的完整方案,Dify 好比是一套脚手架,并且经过了精良的工程设计和软件测试。
|
||||
|
||||
重要的是,Dify 是**开源**的,它由一个专业的全职团队和社区共同打造。你可以基于任何模型自部署类似 Assistants API 和 GPTs 的能力,在灵活和安全的基础上,同时保持对数据的完全控制。
|
||||
|
||||
> 我们的社区用户对 Dify 的产品评价可以归结为简单、克制、迭代迅速。\
|
||||
> ——路宇,Dify.AI CEO
|
||||
|
||||
希望以上信息和这份指南可以帮助你了解这款产品,我们相信 Dify 是为你而做的。
|
||||
|
||||
### Dify 能做什么?
|
||||
|
||||
<Info>
|
||||
Dify 一词源自 Define + Modify,意指定义并且持续的改进你的 AI 应用,它是为你而做的(Do it for you)。
|
||||
</Info>
|
||||
|
||||
* **创业**,快速的将你的 AI 应用创意变成现实,无论成功和失败都需要加速。在真实世界,已经有几十个团队通过 Dify 构建 MVP(最小可用产品)获得投资,或通过 POC(概念验证)赢得了客户的订单。
|
||||
* **将 LLM 集成至已有业务**,通过引入 LLM 增强现有应用的能力,接入 Dify 的 RESTful API 从而实现 Prompt 与业务代码的解耦,在 Dify 的管理界面是跟踪数据、成本和用量,持续改进应用效果。
|
||||
* **作为企业级 LLM 基础设施**,一些银行和大型互联网公司正在将 Dify 部署为企业内的 LLM 网关,加速 GenAI 技术在企业内的推广,并实现中心化的监管。
|
||||
* **探索 LLM 的能力边界**,即使你是一个技术爱好者,通过 Dify 也可以轻松的实践 Prompt 工程和 Agent 技术,在 GPTs 推出以前就已经有超过 60,000 开发者在 Dify 上创建了自己的第一个应用。
|
||||
|
||||
### 下一步行动
|
||||
|
||||
* 阅读[**快速开始**](guides/application-orchestrate/creating-an-application.md),速览 Dify 的应用构建流程
|
||||
* 了解如何[**自部署 Dify 到服务器**](getting-started/install-self-hosted/)上,并[**接入开源模型**](guides/model-configuration/)
|
||||
* 了解 Dify 的[**特性规格**](getting-started/readme/features-and-specifications.md)和 **Roadmap**
|
||||
* 在 [**GitHub**](https://github.com/langgenius/dify) 上为我们点亮一颗星,并阅读我们的**贡献指南**
|
||||
@@ -0,0 +1,126 @@
|
||||
---
|
||||
title: 外部知识库 API
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
## 端点
|
||||
|
||||
```
|
||||
POST <your-endpoint>/retrieval
|
||||
```
|
||||
|
||||
## 请求头
|
||||
|
||||
该 API 用于连接团队内独立维护的知识库,如需了解更多操作指引,请参考阅读 [连接外部知识库](/zh-cn/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge-base)。你可以在 HTTP 请求头的 `Authorization` 字段中使用 `API-Key` 来验证权限。身份验证逻辑由您在检索 API 中定义,如下所示:
|
||||
|
||||
```
|
||||
Authorization: Bearer {API_KEY}
|
||||
```
|
||||
|
||||
## 请求体元素
|
||||
|
||||
请求接受以下 JSON 格式的数据。
|
||||
|
||||
| 属性 | 是否必需 | 类型 | 描述 | 示例值 |
|
||||
|------|----------|------|------|--------|
|
||||
| knowledge_id | 是 | 字符串 | 知识库唯一 ID | AAA-BBB-CCC |
|
||||
| query | 是 | 字符串 | 用户的查询 | Dify 是什么? |
|
||||
| retrieval_setting | 是 | 对象 | 知识检索参数 | 见下文 |
|
||||
|
||||
`retrieval_setting` 属性是一个包含以下键的对象:
|
||||
|
||||
| 属性 | 是否必需 | 类型 | 描述 | 示例值 |
|
||||
|------|----------|------|------|--------|
|
||||
| top_k | 是 | 整数 | 检索结果的最大数量 | 5 |
|
||||
| score_threshold | 是 | 浮点数 | 结果与查询相关性的分数限制,范围:0~1 | 0.5 |
|
||||
|
||||
## 请求语法
|
||||
|
||||
```json
|
||||
POST <your-endpoint>/retrieval HTTP/1.1
|
||||
-- 请求头
|
||||
Content-Type: application/json
|
||||
Authorization: Bearer your-api-key
|
||||
-- 数据
|
||||
{
|
||||
"knowledge_id": "your-knowledge-id",
|
||||
"query": "你的问题",
|
||||
"retrieval_setting":{
|
||||
"top_k": 2,
|
||||
"score_threshold": 0.5
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 响应元素
|
||||
|
||||
如果操作成功,服务将返回 HTTP 200 响应。服务以 JSON 格式返回以下数据。
|
||||
|
||||
| 属性 | 是否必需 | 类型 | 描述 | 示例值 |
|
||||
|------|----------|------|------|--------|
|
||||
| records | 是 | 对象列表 | 从知识库查询的记录列表 | 见下文 |
|
||||
|
||||
`records` 属性是一个包含以下键的对象列表:
|
||||
|
||||
| 属性 | 是否必需 | 类型 | 描述 | 示例值 |
|
||||
|------|----------|------|------|--------|
|
||||
| content | 是 | 字符串 | 包含知识库中数据源的文本块 | Dify:GenAI 应用程序的创新引擎 |
|
||||
| score | 是 | 浮点数 | 结果与查询的相关性分数,范围:0~1 | 0.5 |
|
||||
| title | 是 | 字符串 | 文档标题 | Dify 简介 |
|
||||
| metadata | 否 | json | 包含数据源中文档的元数据属性及其值 | 见示例 |
|
||||
|
||||
## 响应语法
|
||||
|
||||
```json
|
||||
HTTP/1.1 200
|
||||
Content-type: application/json
|
||||
{
|
||||
"records": [{
|
||||
"metadata": {
|
||||
"path": "s3://dify/knowledge.txt",
|
||||
"description": "dify 知识文档"
|
||||
},
|
||||
"score": 0.98,
|
||||
"title": "knowledge.txt",
|
||||
"content": "这是外部知识的文档。"
|
||||
},
|
||||
{
|
||||
"metadata": {
|
||||
"path": "s3://dify/introduce.txt",
|
||||
"description": "dify 介绍"
|
||||
},
|
||||
"score": 0.66,
|
||||
"title": "introduce.txt",
|
||||
"content": "GenAI 应用程序的创新引擎"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## 错误
|
||||
|
||||
如果操作失败,服务将返回以下错误信息(JSON 格式):
|
||||
|
||||
| 属性 | 是否必需 | 类型 | 描述 | 示例值 |
|
||||
|------|----------|------|------|--------|
|
||||
| error_code | 是 | 整数 | 错误代码 | 1001 |
|
||||
| error_msg | 是 | 字符串 | API 异常描述 | 无效的 Authorization 头格式。预期格式为 `Bearer <api-key>`'。 |
|
||||
|
||||
`error_code` 属性有以下类型:
|
||||
|
||||
| 代码 | 描述 |
|
||||
|------|------|
|
||||
| 1001 | 无效的 Authorization 头格式 |
|
||||
| 1002 | 授权失败 |
|
||||
| 2001 | 知识库不存在 |
|
||||
|
||||
### HTTP 状态码
|
||||
|
||||
**AccessDeniedException**
|
||||
由于缺少访问权限,请求被拒绝。请检查您的权限并重试。
|
||||
HTTP 状态码:403
|
||||
|
||||
**InternalServerException**
|
||||
发生内部服务器错误。请重试您的请求。
|
||||
HTTP 状态码:500
|
||||
|
||||
@@ -0,0 +1,192 @@
|
||||
{
|
||||
"openapi": "3.0.1",
|
||||
"info": { "title": "Dify-test", "description": "", "version": "1.0.0" },
|
||||
"tags": [],
|
||||
"paths": {
|
||||
"/retrieval": {
|
||||
"post": {
|
||||
"summary": "知识召回 API",
|
||||
"deprecated": false,
|
||||
"description": "该 API 用于连接团队内独立维护的知识库,如需了解更多操作指引,请参考阅读[连接外部知识库](/zh-cn/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge-base)。你可以在 Authorization HTTP 头部中使用 API-Key 来验证权限,认证逻辑由开发者在检索 API 中定义,如下所示:\n\n```text\nAuthorization: Bearer {API_KEY}\n```",
|
||||
"tags": [],
|
||||
"requestBody": {
|
||||
"content": {
|
||||
"application/json": {
|
||||
"schema": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"knowledge_id": {
|
||||
"type": "string",
|
||||
"description": "你的知识库唯一 ID"
|
||||
},
|
||||
"query": { "type": "string", "description": "用户的提问" },
|
||||
"retrival_setting": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"top_k": {
|
||||
"type": "integer",
|
||||
"description": "检索结果的最大数量"
|
||||
},
|
||||
"score_threshold": {
|
||||
"type": "number",
|
||||
"description": "结果与查询相关性的分数限制,范围 0~1",
|
||||
"format": "float",
|
||||
"minimum": 0,
|
||||
"maximum": 1
|
||||
}
|
||||
},
|
||||
"description": "知识库的检索参数",
|
||||
"required": ["top_k", "score_threshold"]
|
||||
}
|
||||
},
|
||||
"required": ["knowledge_id", "query", "retrival_setting"]
|
||||
},
|
||||
"example": {
|
||||
"knowledge_id": "your-knowledge-id",
|
||||
"query": "your question",
|
||||
"retrival_setting": { "top_k": 2, "score_threshold": 0.5 }
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"responses": {
|
||||
"200": {
|
||||
"description": "如果操作成功,服务将发回 HTTP 200 响应。",
|
||||
"content": {
|
||||
"application/json": {
|
||||
"schema": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"records": {
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"content": {
|
||||
"type": "string",
|
||||
"description": "包含知识库中数据源的一段文本。"
|
||||
},
|
||||
"score": {
|
||||
"type": "number",
|
||||
"format": "float",
|
||||
"description": "结果与查询相关性的分数,范围: 0~1"
|
||||
},
|
||||
"title": {
|
||||
"type": "string",
|
||||
"description": " 文档标题"
|
||||
},
|
||||
"metadata": {
|
||||
"type": "string",
|
||||
"description": "包含数据源中文档的元数据属性及其值。"
|
||||
}
|
||||
},
|
||||
"title": "从知识库查询的记录列表",
|
||||
"required": ["content", "score", "title"]
|
||||
}
|
||||
},
|
||||
"required": ["records"]
|
||||
},
|
||||
"examples": {
|
||||
"1": {
|
||||
"summary": "Success",
|
||||
"value": {
|
||||
"records": [
|
||||
{
|
||||
"metadata": {
|
||||
"path": "s3://dify/knowledge.txt",
|
||||
"description": "dify 知识文档"
|
||||
},
|
||||
"score": 0.98,
|
||||
"title": "knowledge.txt",
|
||||
"content": "外部知识的文件"
|
||||
},
|
||||
{
|
||||
"metadata": {
|
||||
"path": "s3://dify/introduce.txt",
|
||||
"description": "Dify 介绍"
|
||||
},
|
||||
"score": 0.66,
|
||||
"title": "introduce.txt",
|
||||
"content": "The Innovation Engine for GenAI Applications"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"headers": {}
|
||||
},
|
||||
"403": {
|
||||
"description": "请求被拒绝因为缺失访问权限。请检查你的权限并在此发起请求。",
|
||||
"content": {
|
||||
"application/json": {
|
||||
"schema": {
|
||||
"title": "",
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"error_code": {
|
||||
"type": "integer",
|
||||
"description": "错误码"
|
||||
},
|
||||
"error_msg": {
|
||||
"type": "string",
|
||||
"description": "API 异常描述"
|
||||
}
|
||||
},
|
||||
"required": ["error_code", "error_msg"]
|
||||
},
|
||||
"examples": {
|
||||
"1": {
|
||||
"summary": "Erros",
|
||||
"value": {
|
||||
"error_code": 1001,
|
||||
"error_msg": "无效的鉴权头格式,预期应为 'Bearer <api-key>' 格式。"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"headers": {}
|
||||
},
|
||||
"500": {
|
||||
"description": "发生了内部服务器错误,请再次连接。",
|
||||
"content": {
|
||||
"application/json": {
|
||||
"schema": {
|
||||
"title": "",
|
||||
"type": "object",
|
||||
"properties": {
|
||||
"error_code": {
|
||||
"type": "integer",
|
||||
"description": "错误码"
|
||||
},
|
||||
"error_msg": {
|
||||
"type": "string",
|
||||
"description": " API 异常描述"
|
||||
}
|
||||
},
|
||||
"required": ["error_code", "error_msg"]
|
||||
},
|
||||
"examples": {
|
||||
"1": {
|
||||
"summary": "Erros",
|
||||
"value": {
|
||||
"error_code": 1001,
|
||||
"error_msg": "Invalid Authorization header format. Expected 'Bearer <api-key>' format."
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"headers": {}
|
||||
}
|
||||
},
|
||||
"security": [{ "bearer": [] }]
|
||||
}
|
||||
}
|
||||
},
|
||||
"components": {
|
||||
"schemas": {},
|
||||
"securitySchemes": { "bearer": { "type": "http", "scheme": "bearer" } }
|
||||
},
|
||||
"servers": [{ "url": "your-endpoint", "description": "test-environment" }]
|
||||
}
|
||||
@@ -0,0 +1,552 @@
|
||||
---
|
||||
title: 通过 API 维护知识库
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
> 鉴权、调用方式与应用 Service API 保持一致,不同之处在于,所生成的单个知识库 API token 具备操作当前账号下所有可见知识库的权限,请注意数据安全。
|
||||
|
||||
### 使用知识库 API 的优势
|
||||
|
||||
通过 API 维护知识库可大幅提升数据处理效率,你可以通过命令行轻松同步数据,实现自动化操作,而无需在用户界面进行繁琐操作。
|
||||
|
||||
主要优势包括:
|
||||
|
||||
* 自动同步: 将数据系统与 Dify 知识库无缝对接,构建高效工作流程;
|
||||
* 全面管理: 提供知识库列表,文档列表及详情查询等功能,方便你自建数据管理界面;
|
||||
* 灵活上传: 支持纯文本和文件上传方式,可针对分段(Chunks)内容的批量新增和修改操作;
|
||||
* 提高效率: 减少手动处理时间,提升 Dify 平台使用体验。
|
||||
|
||||
### 如何使用
|
||||
|
||||
进入知识库页面,在左侧的导航中切换至 **API** 页面。在该页面中你可以查看 Dify 提供的知识库 API 文档,并可以在 **API 密钥** 中管理可访问知识库 API 的凭据。
|
||||
|
||||
<Frame caption="Knowledge API Document">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/dataset-api-token.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### API 调用示例
|
||||
|
||||
#### 通过文本创建文档
|
||||
|
||||
输入示例:
|
||||
|
||||
```json
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create_by_text' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"name": "text","text": "text","indexing_technique": "high_quality","process_rule": {"mode": "automatic"}}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "text.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695690280,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
```
|
||||
|
||||
#### 通过文件创建文档
|
||||
|
||||
输入示例:
|
||||
|
||||
```json
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create_by_file' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--form 'data="{"indexing_technique":"high_quality","process_rule":{"rules":{"pre_processing_rules":[{"id":"remove_extra_spaces","enabled":true},{"id":"remove_urls_emails","enabled":true}],"segmentation":{"separator":"###","max_tokens":500}},"mode":"custom"}}";type=text/plain' \
|
||||
--form 'file=@"/path/to/file"'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "Dify.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### **创建空知识库**
|
||||
|
||||
<Info>
|
||||
仅用来创建空知识库
|
||||
</Info>
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"name": "name", "permission": "only_me"}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "",
|
||||
"name": "name",
|
||||
"description": null,
|
||||
"provider": "vendor",
|
||||
"permission": "only_me",
|
||||
"data_source_type": null,
|
||||
"indexing_technique": null,
|
||||
"app_count": 0,
|
||||
"document_count": 0,
|
||||
"word_count": 0,
|
||||
"created_by": "",
|
||||
"created_at": 1695636173,
|
||||
"updated_by": "",
|
||||
"updated_at": 1695636173,
|
||||
"embedding_model": null,
|
||||
"embedding_model_provider": null,
|
||||
"embedding_available": null
|
||||
}
|
||||
```
|
||||
|
||||
#### **知识库列表**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets?page=1&limit=20' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"data": [
|
||||
{
|
||||
"id": "",
|
||||
"name": "知识库名称",
|
||||
"description": "描述信息",
|
||||
"permission": "only_me",
|
||||
"data_source_type": "upload_file",
|
||||
"indexing_technique": "",
|
||||
"app_count": 2,
|
||||
"document_count": 10,
|
||||
"word_count": 1200,
|
||||
"created_by": "",
|
||||
"created_at": "",
|
||||
"updated_by": "",
|
||||
"updated_at": ""
|
||||
},
|
||||
...
|
||||
],
|
||||
"has_more": true,
|
||||
"limit": 20,
|
||||
"total": 50,
|
||||
"page": 1
|
||||
}
|
||||
```
|
||||
|
||||
#### 删除知识库
|
||||
|
||||
输入示例:
|
||||
|
||||
```json
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
204 No Content
|
||||
```
|
||||
|
||||
#### 通过文本更新文档
|
||||
|
||||
此接口基于已存在知识库,在此知识库的基础上通过文本更新文档
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/update_by_text' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"name": "name","text": "text"}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "name.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
```
|
||||
|
||||
#### 通过文件更新文档
|
||||
|
||||
此接口基于已存在知识库,在此知识库的基础上通过文件更新文档的操作。
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/update_by_file' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--form 'data="{"name":"Dify","indexing_technique":"high_quality","process_rule":{"rules":{"pre_processing_rules":[{"id":"remove_extra_spaces","enabled":true},{"id":"remove_urls_emails","enabled":true}],"segmentation":{"separator":"###","max_tokens":500}},"mode":"custom"}}";type=text/plain' \
|
||||
--form 'file=@"/path/to/file"'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "Dify.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": "20230921150427533684"
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
#### **获取文档嵌入状态(进度)**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{batch}/indexing-status' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"data":[{
|
||||
"id": "",
|
||||
"indexing_status": "indexing",
|
||||
"processing_started_at": 1681623462.0,
|
||||
"parsing_completed_at": 1681623462.0,
|
||||
"cleaning_completed_at": 1681623462.0,
|
||||
"splitting_completed_at": 1681623462.0,
|
||||
"completed_at": null,
|
||||
"paused_at": null,
|
||||
"error": null,
|
||||
"stopped_at": null,
|
||||
"completed_segments": 24,
|
||||
"total_segments": 100
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
#### **删除文档**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```bash
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
#### **知识库文档列表**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"data": [
|
||||
{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "file_upload",
|
||||
"data_source_info": null,
|
||||
"dataset_process_rule_id": null,
|
||||
"name": "dify",
|
||||
"created_from": "",
|
||||
"created_by": "",
|
||||
"created_at": 1681623639,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false
|
||||
},
|
||||
],
|
||||
"has_more": false,
|
||||
"limit": 20,
|
||||
"total": 9,
|
||||
"page": 1
|
||||
}
|
||||
```
|
||||
|
||||
#### **新增分段**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"segments": [{"content": "1","answer": "1","keywords": ["a"]}]}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"data": [{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"document_id": "",
|
||||
"content": "1",
|
||||
"answer": "1",
|
||||
"word_count": 25,
|
||||
"tokens": 0,
|
||||
"keywords": [
|
||||
"a"
|
||||
],
|
||||
"index_node_id": "",
|
||||
"index_node_hash": "",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "",
|
||||
"created_at": 1695312007,
|
||||
"indexing_at": 1695312007,
|
||||
"completed_at": 1695312007,
|
||||
"error": null,
|
||||
"stopped_at": null
|
||||
}],
|
||||
"doc_form": "text_model"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 查询文档分段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```bash
|
||||
{
|
||||
"data": [{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"document_id": "",
|
||||
"content": "1",
|
||||
"answer": "1",
|
||||
"word_count": 25,
|
||||
"tokens": 0,
|
||||
"keywords": [
|
||||
"a"
|
||||
],
|
||||
"index_node_id": "",
|
||||
"index_node_hash": "",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "",
|
||||
"created_at": 1695312007,
|
||||
"indexing_at": 1695312007,
|
||||
"completed_at": 1695312007,
|
||||
"error": null,
|
||||
"stopped_at": null
|
||||
}],
|
||||
"doc_form": "text_model"
|
||||
}
|
||||
```
|
||||
|
||||
### 删除文档分段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments/{segment_id}' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```bash
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### 更新文档分段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments/{segment_id}' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json'\
|
||||
--data-raw '{"segment": {"content": "1","answer": "1", "keywords": ["a"], "enabled": false}}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```bash
|
||||
{
|
||||
"data": [{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"document_id": "",
|
||||
"content": "1",
|
||||
"answer": "1",
|
||||
"word_count": 25,
|
||||
"tokens": 0,
|
||||
"keywords": [
|
||||
"a"
|
||||
],
|
||||
"index_node_id": "",
|
||||
"index_node_hash": "",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "",
|
||||
"created_at": 1695312007,
|
||||
"indexing_at": 1695312007,
|
||||
"completed_at": 1695312007,
|
||||
"error": null,
|
||||
"stopped_at": null
|
||||
}],
|
||||
"doc_form": "text_model"
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 错误信息
|
||||
|
||||
| 错误信息 | 错误码 | 原因描述 |
|
||||
|------|--------|---------|
|
||||
| no_file_uploaded | 400 | 请上传你的文件 |
|
||||
| too_many_files | 400 | 只允许上传一个文件 |
|
||||
| file_too_large | 413 | 文件大小超出限制 |
|
||||
| unsupported_file_type | 415 | 不支持的文件类型。目前只支持以下内容格式:`txt`, `markdown`, `md`, `pdf`, `html`, `html`, `xlsx`, `docx`, `csv` |
|
||||
| high_quality_dataset_only | 400 | 当前操作仅支持"高质量"知识库 |
|
||||
| dataset_not_initialized | 400 | 知识库仍在初始化或索引中。请稍候 |
|
||||
| archived_document_immutable | 403 | 归档文档不可编辑 |
|
||||
| dataset_name_duplicate | 409 | 知识库名称已存在,请修改你的知识库名称 |
|
||||
| invalid_action | 400 | 无效操作 |
|
||||
| document_already_finished | 400 | 文档已处理完成。请刷新页面或查看文档详情 |
|
||||
| document_indexing | 400 | 文档正在处理中,无法编辑 |
|
||||
| invalid_metadata | 400 | 元数据内容不正确。请检查并验证 |
|
||||
@@ -0,0 +1,141 @@
|
||||
---
|
||||
title: 2. 指定分段模式
|
||||
---
|
||||
|
||||
将内容上传至知识库后,接下来需要对内容进行分段与数据清洗。**该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。**
|
||||
|
||||
|
||||
<Accordion title="什么是分段与清洗策略?">
|
||||
* **分段**
|
||||
|
||||
由于大语言模型的上下文窗口有限,无法一次性处理和传输整个知识库的内容,因此需要对文档中的长文本分段为内容块。即便部分大模型已支持上传完整的文档文件,但实验表明,检索效率依然弱于检索单个内容分段。
|
||||
|
||||
LLM 能否精准地回答出知识库中的内容,关键在于知识库对内容块的检索与召回效果。类似于在手册中查找关键章节即可快速得到答案,而无需逐字逐句分析整个文档。经过分段后,知识库能够基于用户问题,采用分段 TopK 召回模式,召回与问题高度相关的内容块,补全关键信息从而提高回答的精准性。
|
||||
|
||||
在进行问题与内容块的语义匹配时,合理的分段大小非常关键,它能够帮助模型准确地找到与问题最相关的内容,减少噪音信息。过大或过小的分段都可能影响召回的效果。
|
||||
|
||||
Dify 提供了 **"通用分段"** 和 **"父子分段"** 两种分段模式,分别适应不同类型的文档结构和应用场景,满足不同的知识库检索和召回的效率与准确性要求。
|
||||
|
||||
* **清洗**
|
||||
|
||||
为了保证文本召回的效果,通常需要在将数据录入知识库之前便对其进行清理。例如,文本内容中存在无意义的字符或者空行可能会影响问题回复的质量,需要对其清洗。Dify 已内置的自动清洗策略,详细说明请参考 [ETL](chunking-and-cleaning-text.md#etl)。
|
||||
</Accordion>
|
||||
|
||||
LLM 收到用户问题后,能否精准地回答出知识库中的内容,取决于知识库对内容块的检索和召回效果。匹配与问题相关度高的文本分段对 AI 应用生成准确且全面的回应至关重要。
|
||||
|
||||
好比在智能客服场景下,仅需帮助 LLM 定位至工具手册的关键章节内容块即可快速得到用户问题的答案,而无需重复分析整个文档。在节省分析过程中所耗费的 Tokens 的同时,提高 AI 应用的问答质量。
|
||||
|
||||
### 分段模式
|
||||
|
||||
知识库支持两种分段模式:**通用模式**与**父子模式**。如果你是首次创建知识库,建议选择父子模式。
|
||||
|
||||
<Info>
|
||||
**注意**:原 **"自动分段与清洗"** 模式已自动更新为 **"通用"** 模式。无需进行任何更改,原知识库保持默认设置即可继续使用。选定分段模式并完成知识库的创建后,后续无法变更。知识库内新增的文档也将遵循同样的分段模式。
|
||||
</Info>
|
||||
|
||||
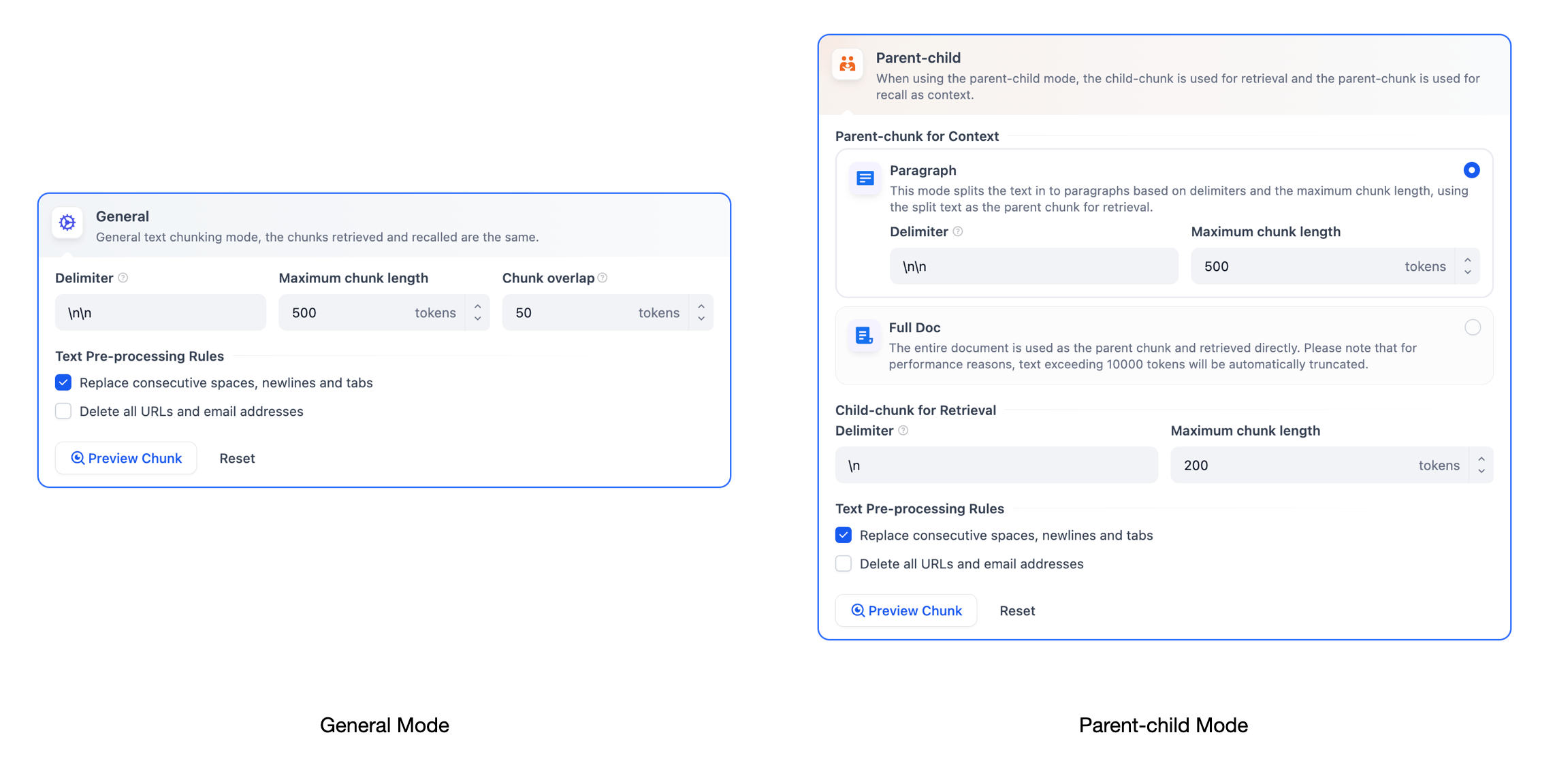
|
||||
|
||||
#### 通用模式
|
||||
|
||||
系统按照用户自定义的规则将内容拆分为独立的分段。当用户输入问题后,系统自动分析问题中的关键词,并计算关键词与知识库中各内容分段的相关度。根据相关度排序,选取最相关的内容分段并发送给 LLM,辅助其处理与更有效地回答。
|
||||
|
||||
在该模式下,你需要根据不同的文档格式或场景要求,参考以下设置项,手动设置文本的**分段规则**。
|
||||
|
||||
* **分段标识符**,默认值为 `\n`,即按照文章段落进行分块。你可以遵循[正则表达式语法](https://regexr.com/)自定义分块规则,系统将在文本出现分段标识符时自动执行分段。例如 的含义是按照句子进行分段。下图是不同语法的文本分段效果:
|
||||
|
||||
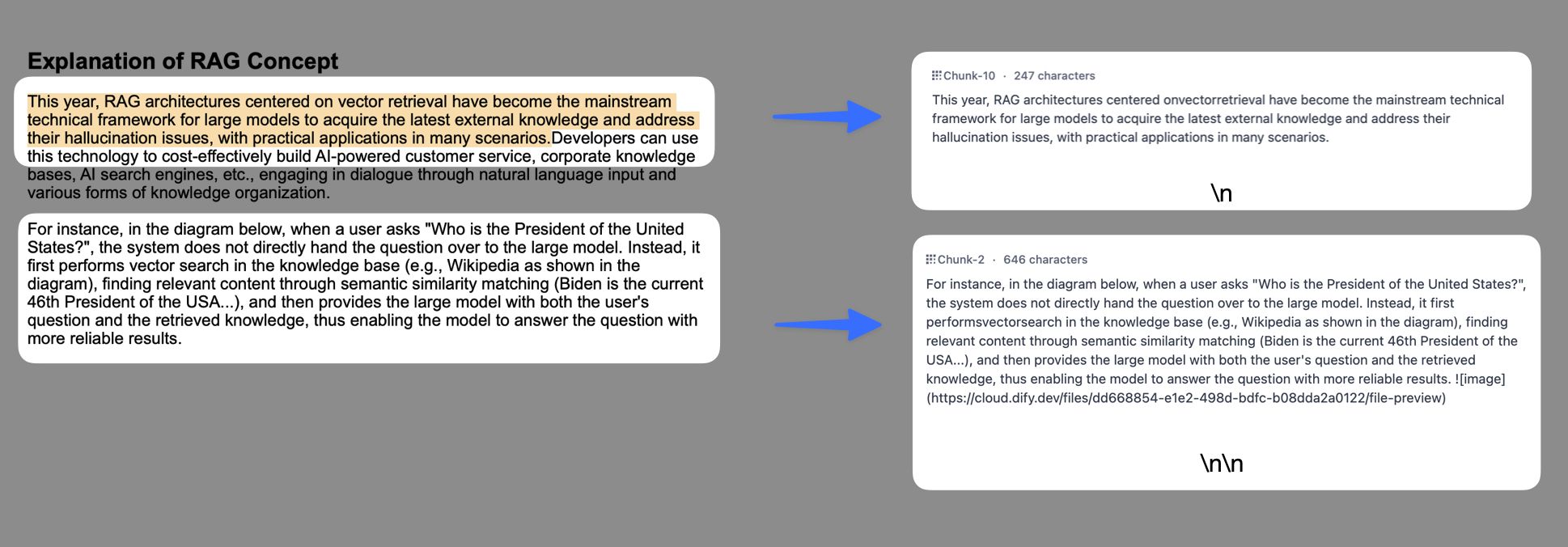
|
||||
|
||||
* **分段最大长度**,指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为 500 Tokens,分段长度的最大上限为 4000 Tokens;
|
||||
* **分段重叠长度**,指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%;
|
||||
|
||||
**文本预处理规则,** 过滤知识库内部分无意义的内容。提供以下选项:
|
||||
|
||||
* 替换连续的空格、换行符和制表符
|
||||
* 删除所有 URL 和电子邮件地址
|
||||
|
||||
配置完成后,点击"预览区块"即可查看分段后的效果。你可以直观的看到每个区块的字符数。如果重新修改了分段规则,需要重新点击按钮以查看新的内容分段。
|
||||
|
||||
若同时批量上传了多个文档,轻点顶部的文档标题,快速切换并查看其它文档的分段效果。
|
||||
|
||||
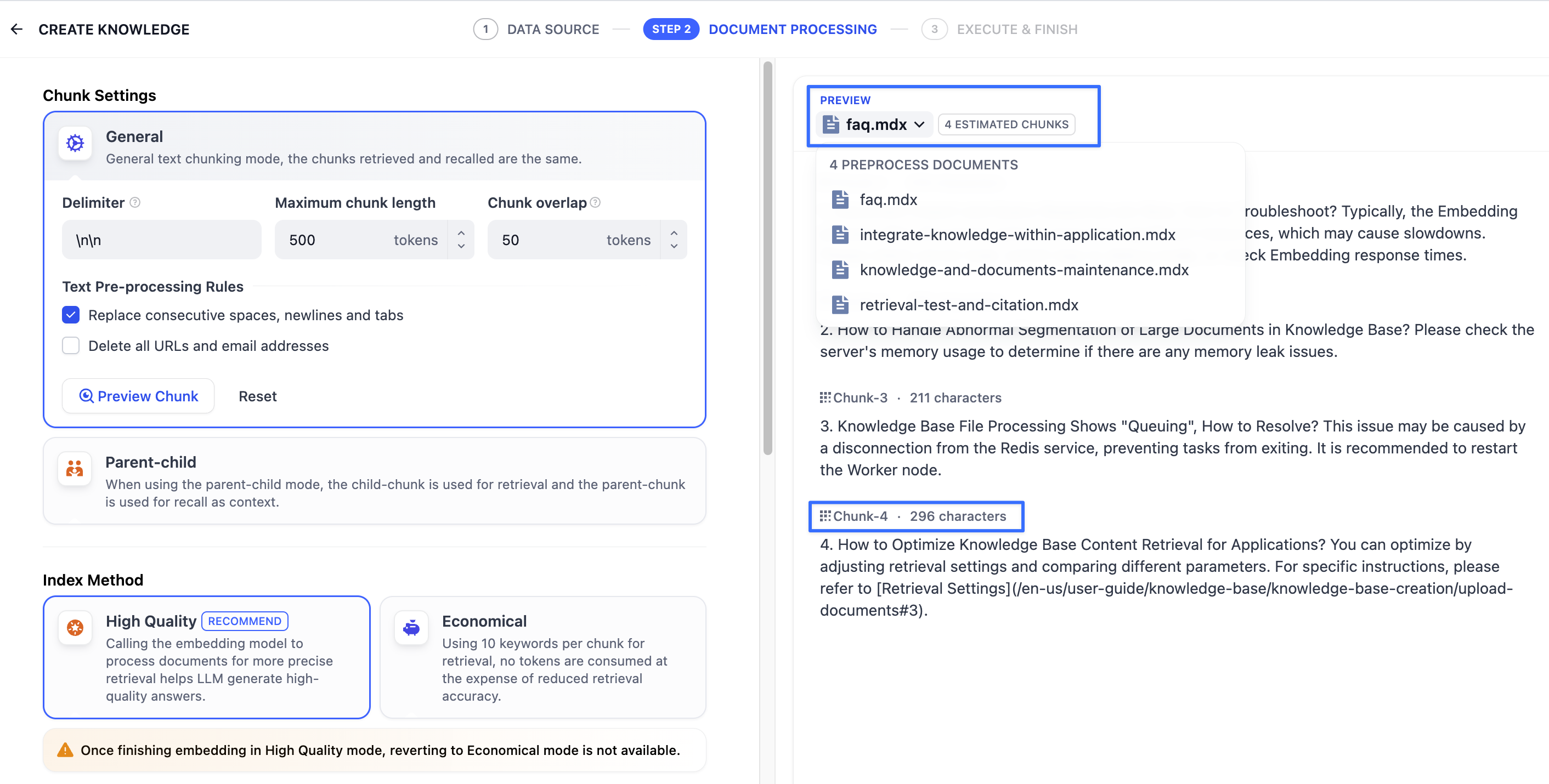
|
||||
|
||||
分段规则设置完成后,接下来需指定索引方式。支持"高质量索引"和"经济索引",详细说明请参考[设定索引方法](setting-indexing-methods.md)。
|
||||
|
||||
#### **父子模式**
|
||||
|
||||
与**通用模式**相比,父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。
|
||||
|
||||
其中,父区块(Parent-chunk)保持较大的文本单位(如段落),提供丰富的上下文信息;子区块(Child-chunk)则是较小的文本单位(如句子),用于精确检索。系统首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息,从而在生成响应时既保证准确性又能提供完整的背景信息。你可以通过设置分隔符和最大长度来自定义父子区块的分段方式。
|
||||
|
||||
例如在 AI 智能客服场景下,用户输入的问题将定位至解决方案文档内某个具体的句子,随后将该句子所在的段落或章节,联同发送至 LLM,补全该问题的完整背景信息,给出更加精准的回答。
|
||||
|
||||
其基本机制包括:
|
||||
|
||||
* **子分段匹配查询**:
|
||||
* 将文档拆分为较小、集中的信息单元(例如一句话),更加精准的匹配用户所输入的问题。
|
||||
* 子分段能快速提供与用户需求最相关的初步结果。
|
||||
* **父分段提供上下文**:
|
||||
* 将包含匹配子分段的更大部分(如段落、章节甚至整个文档)视作父分段并提供给大语言模型(LLM)。
|
||||
* 父分段能为 LLM 提供完整的背景信息,避免遗漏重要细节,帮助 LLM 输出更贴合知识库内容的回答。
|
||||
|
||||
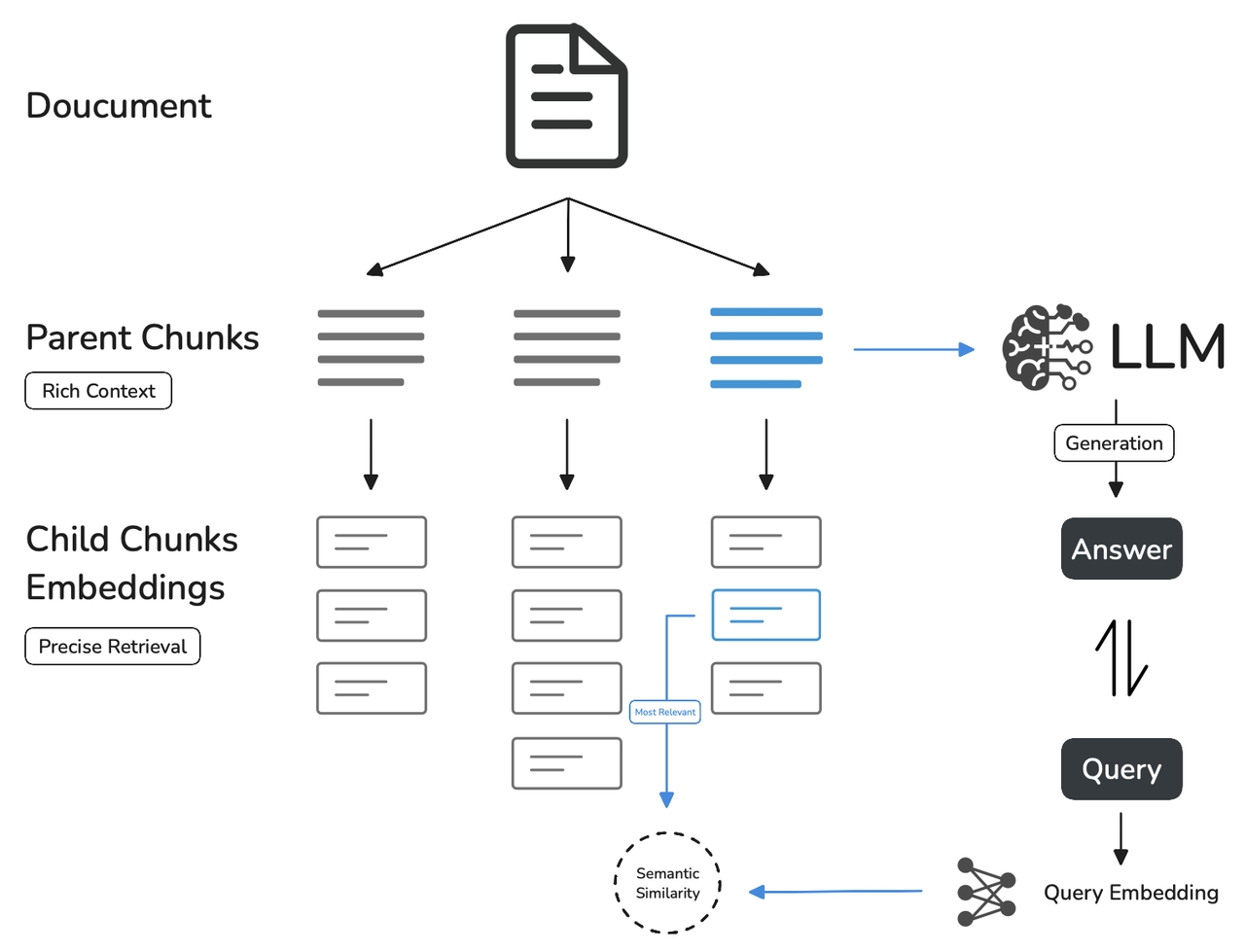
|
||||
|
||||
在该模式下,你需要根据不同的文档格式或场景要求,手动分别设置父子分段的**分段规则**。
|
||||
|
||||
**父分段:**
|
||||
|
||||
父分段设置提供以下分段选项:
|
||||
|
||||
* **段落**
|
||||
|
||||
根据预设的分隔符规则和最大块长度将文本拆分为段落。每个段落视为父分段,适用于文本量较大,内容清晰且段落相对独立的文档。支持以下设置项:
|
||||
|
||||
* **分段标识符**,默认值为 `\n`,即按照文本段落分段。你可以遵循[正则表达式语法](https://regexr.com/)自定义分块规则,系统将在文本出现分段标识符时自动执行分段。
|
||||
* **分段最大长度**,指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为 500 Tokens,分段长度的最大上限为 4000 Tokens;
|
||||
|
||||
* **全文**
|
||||
|
||||
不进行段落分段,而是直接将全文视为单一父分段。出于性能原因,仅保留文本内的前 10000 Tokens 字符,适用于文本量较小,但段落间互有关联,需要完整检索全文的场景。
|
||||
|
||||

|
||||
|
||||
**子分段:**
|
||||
|
||||
子分段文本是在父文本分段基础上,由分隔符规则切分而成,用于查找和匹配与问题关键词最相关和直接的信息。如果使用默认的子分段规则,通常呈现以下分段效果:
|
||||
|
||||
* 当父分段为段落时,子分段对应各个段落中的单个句子。
|
||||
* 父分段为全文时,子分段对应全文中各个单独的句子。
|
||||
|
||||
在子分段内填写以下分段设置:
|
||||
|
||||
* **分段标识符**,默认值为 ,即按照句子进行分段。你可以遵循[正则表达式语法](https://regexr.com/)自定义分块规则,系统将在文本出现分段标识符时自动执行分段。
|
||||
* **分段最大长度**,指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为 200 Tokens,分段长度的最大上限为 4000 Tokens;
|
||||
|
||||
你还可以使用**文本预处理规则**过滤知识库内部分无意义的内容:
|
||||
|
||||
* 替换连续的空格、换行符和制表符
|
||||
* 删除所有 URL 和电子邮件地址
|
||||
|
||||
配置完成后,点击"预览区块"即可查看分段后的效果。你可以查看父分段的整体字符数。背景标蓝的字符为子分块,同时显示当前子段的字符数。
|
||||
|
||||
如果重新修改了分段规则,需要重新点击"预览区块"按钮以查看新的内容分段。若同时批量上传了多个文档,轻点顶部的文档标题,快速切换至其它文档并预览内容的分段效果。
|
||||
|
||||
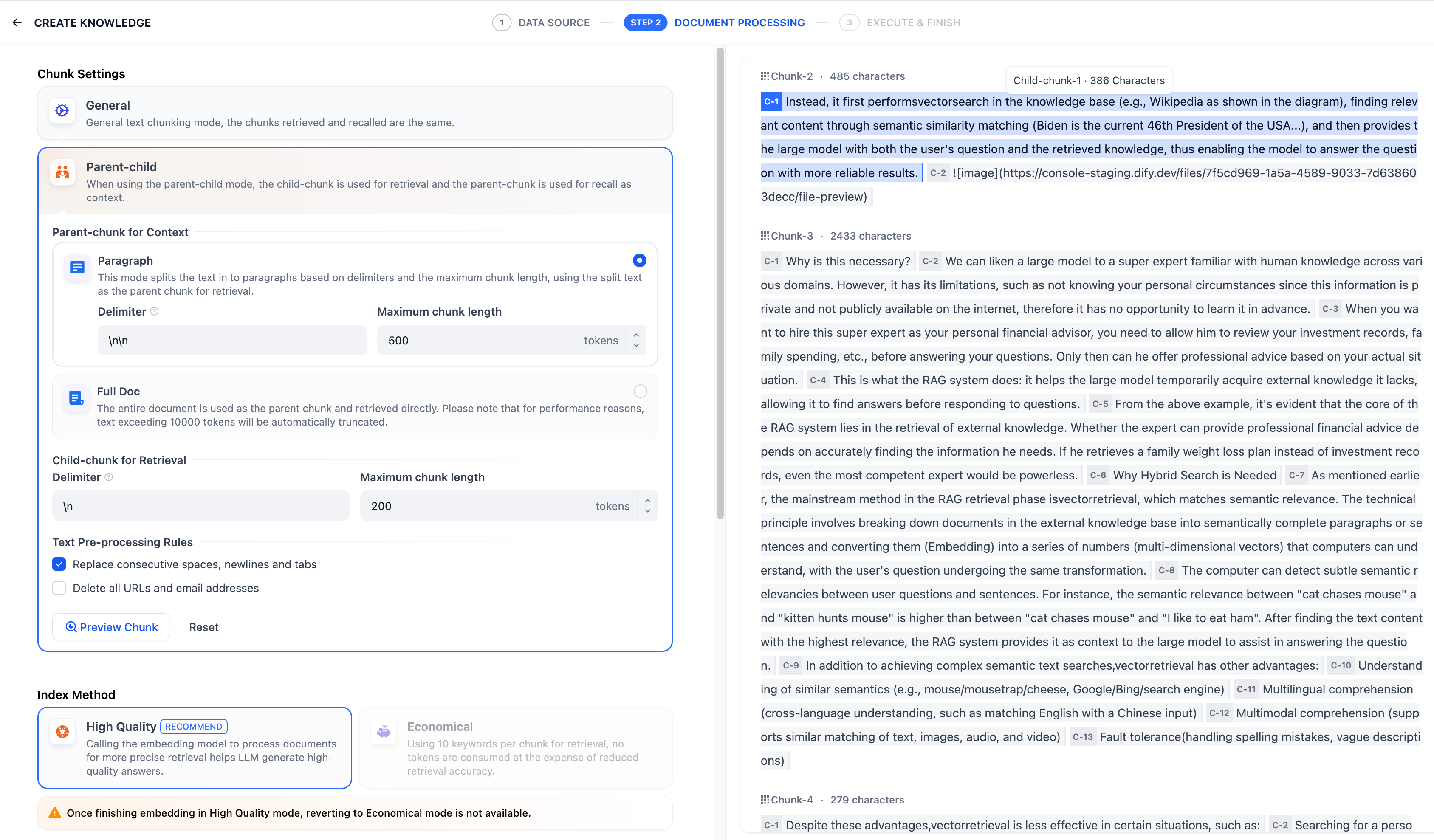
|
||||
|
||||
为了确保内容检索的准确性,父子分段模式仅支持使用["高质量索引"](chunking-and-cleaning-text.md#gao-zhi-liang-suo-yin)。
|
||||
|
||||
### 两种模式的区别是什么?
|
||||
|
||||
两者的主要区别在于内容区块的分段形式。**通用模式**的分段结果为多个独立的内容分段,而**父子模式**采用双层结构进行内容分段,即单个父分段的内容(文档全文或段落)内包含多个子分段内容(句子)。
|
||||
|
||||
不同的分段方式将影响 LLM 对于知识库内容的检索效果。在相同文档中,采用父子检索所提供的上下文信息会更全面,且在精准度方面也能保持较高水平,大大优于传统的单层通用检索方式。
|
||||
|
||||
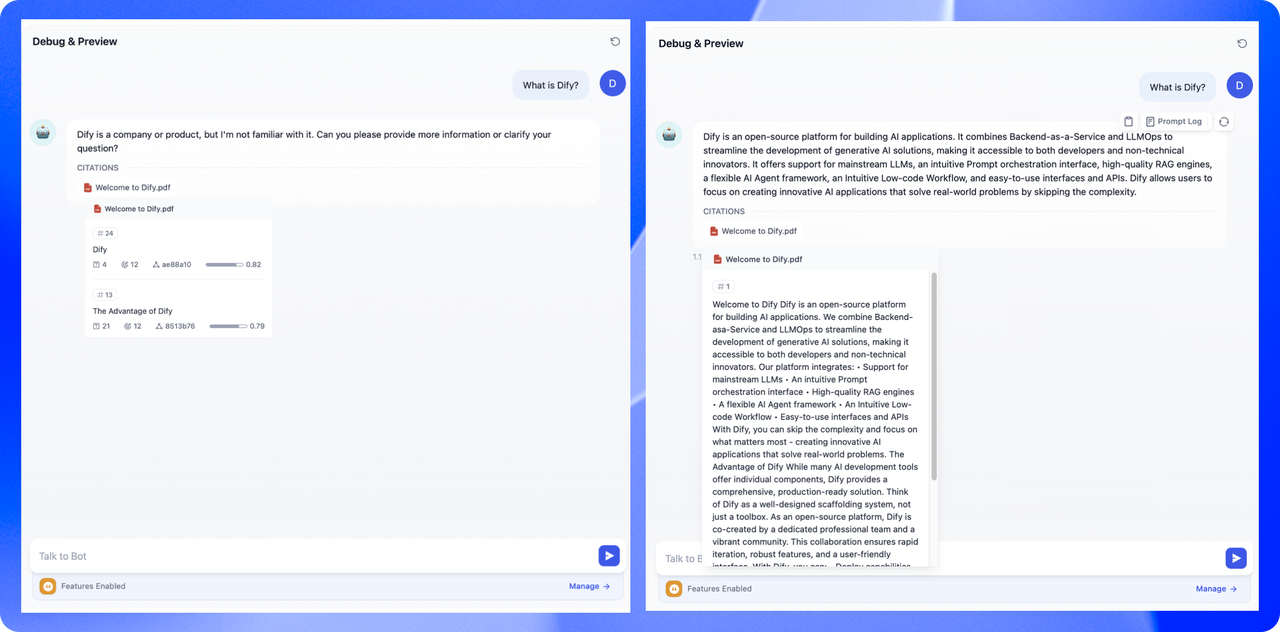
|
||||
|
||||
### 阅读更多
|
||||
|
||||
选定分段模式后,接下来你可以参考以下文档分别设定索引方式和检索方式,完成知识库的创建。
|
||||
|
||||
<Card title="设定索引方法" icon="link" href="setting-indexing-methods.md">
|
||||
了解更多高质量索引和经济索引的详细信息
|
||||
</Card>
|
||||
@@ -0,0 +1,34 @@
|
||||
---
|
||||
title: 导入文本数据简介
|
||||
---
|
||||
|
||||
轻点 Dify 平台顶部导航中 **"知识库"** → "**创建知识库"**。你可以通过上传本地文件或导入在线数据两种方式上传文档至知识库内。
|
||||
|
||||
### **上传本地文件**
|
||||
|
||||
拖拽或选中文件进行上传,**支持批量上传**,同时上传的文件数量限制取决于[订阅计划](https://dify.ai/pricing)。
|
||||
|
||||
**本地上传文档文件存在以下限制:**
|
||||
|
||||
* 单文档的上传大小限制为 **15MB**
|
||||
* 不同 SaaS 版本的[订阅计划](https://dify.ai/pricing)限定了**批量上传个数、文档上传总数、向量存储空间**
|
||||
|
||||

|
||||
|
||||
### **导入在线数据**
|
||||
|
||||
创建知识库时支持通过在线数据导入。知识库支持导入以下两种在线数据:
|
||||
|
||||
<Card title="从 Notion 导入" icon="link" href="/guides/knowledge-base/sync-from-notion">
|
||||
了解如何从 Notion 导入数据
|
||||
</Card>
|
||||
|
||||
<Card title="从网站导入" icon="link" href="/guides/knowledge-base/sync-from-website">
|
||||
了解如何从网站导入数据
|
||||
</Card>
|
||||
|
||||
引用在线数据的知识库后续无法新增本地文档,也无法变更为本地文件类型的知识库,以防止单一知识库存在多种数据来源而造成管理困难。
|
||||
|
||||
### 后续导入
|
||||
|
||||
如果还没有准备好文档或其它内容数据,可以先创建一个空知识库,在后续上传本地文档或导入在线数据。
|
||||
@@ -0,0 +1,56 @@
|
||||
---
|
||||
title: 1.1 从 Notion 导入数据
|
||||
---
|
||||
|
||||
Dify 知识库支持从 Notion 导入,并支持后续的数据自动同步。
|
||||
|
||||
### 授权验证
|
||||
|
||||
1. 在创建知识库,选择数据源时,点击 **同步自 Notion 内容-- 去绑定,根据提示完成授权验证。**
|
||||
2. 你也可以:进入 **设置 -- 数据来源 -- 添加数据源** 中点击 Notion 来源 **绑定** ,完成授权验证。
|
||||
|
||||
|
||||
|
||||
### 导入 Notion 数据
|
||||
|
||||
完成验证授权后,进入创建知识库页面,点击**同步自 Notion 内容**,选择需要的授权页面进行导入。
|
||||
|
||||
|
||||
|
||||
### 进行分段和清洗
|
||||
|
||||
接下来,选择知识库的**分段设置**和**索引方式**,**保存并处理**。等待 Dify 自动处理数据。Dify 不仅可以导入 Notion 的普通类型页面,同时也支持导入并汇总保存 database 类型下的页面属性。
|
||||
|
||||
_**请注意:暂不支持导入图片和文件,表格类数据会被转换为文本展示。**_
|
||||
|
||||
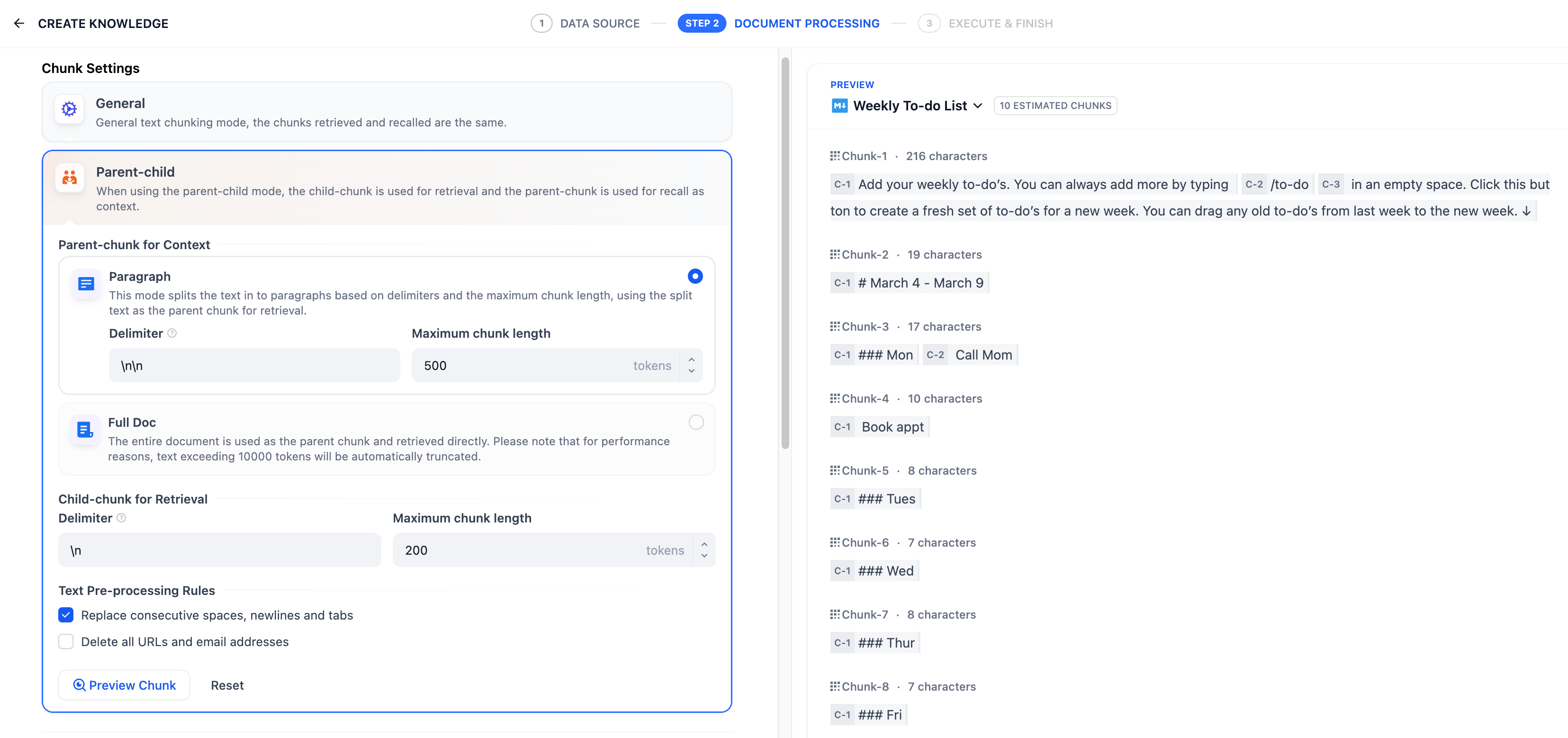
|
||||
|
||||
### 同步 Notion 数据
|
||||
|
||||
如果你的 Notion 内容有更新,可以在知识库的 **文档列表页**中点击对应内容页的 **同步** 按钮进行数据同步。同步文档涉及嵌入过程,因此将消耗嵌入模型的 Tokens。
|
||||
|
||||
|
||||
|
||||
### 社区版 Notion 的集成配置方法
|
||||
|
||||
Notion 分为**内部集成**(internal integration)和**外部集成**(public integration)两种方式,两种集成方式的具体区别请参阅 [Notion 官方文档](https://developers.notion.com/docs/authorization)。
|
||||
|
||||
### 1、**使用 internal 集成方式**
|
||||
|
||||
首先,在集成的设置页面中[创建集成](https://www.notion.so/my-integrations)。默认情况下,所有集成都以内部集成开始;内部集成将与你选择的工作区相关联,因此你需要是工作区所有者才能创建集成。
|
||||
|
||||
具体操作步骤:
|
||||
|
||||
点击"**New integration**"按钮,类型默认是 **Internal**(不可修改),选择关联的空间,输入集成名称并上传 logo 后,点击"Submit",集成创建成功。
|
||||
|
||||
创建集成后,你可以根据需要在 Capabilities 选项卡下更新其设置,并在 Secrets 下点击 "Show" 按钮然后复制 Secrets。
|
||||
|
||||
复制后回到 Dify 源代码下,在 **.env** 文件里配置相关环境变量,环境变量如下:
|
||||
|
||||
```
|
||||
NOTION_INTEGRATION_TYPE=public
|
||||
NOTION_CLIENT_SECRET=you-client-secret
|
||||
NOTION_CLIENT_ID=you-client-id
|
||||
```
|
||||
|
||||
配置完成后,即可在知识库中操作 Notion 的数据导入及同步功能。
|
||||
@@ -0,0 +1,59 @@
|
||||
---
|
||||
title: 1.2 从网页导入数据
|
||||
---
|
||||
|
||||
知识库支持通过第三方工具如 [Jina Reader](https://jina.ai/reader), [Firecrawl ](https://www.firecrawl.dev/)抓取公开网页中的内容,解析为 Markdown 内容并导入至知识库。
|
||||
|
||||
<Info>
|
||||
Jina Reader 和 Firecrawl 均是开源的网页解析工具,能将网页将其转换为干净并且方便 LLM 识别的 Markdown 格式文本,同时提供了易于使用的 API 服务。
|
||||
</Info>
|
||||
|
||||
下文将分别介绍 Firecrawl 和 Jina Reader 的使用方法。
|
||||
|
||||
## Firecrawl
|
||||
|
||||
### 配置 Firecrawl 凭据
|
||||
|
||||
点击右上角头像,然后前往 **DataSource** 页面,点击 Firecrawl 右侧的 Configure 按钮。
|
||||
|
||||

|
||||
|
||||
登录 [Firecrawl 官网](https://www.firecrawl.dev/) 完成注册,获取 API Key 后按照页面提示填入并点击保存。
|
||||
|
||||
### 使用 Firecrawl 抓取网页内容
|
||||
|
||||
在知识库创建页选择 **Sync from website**,provider 选中 Firecrawl,填入需要抓取的目标 URL。
|
||||
|
||||
设置中的配置项包括:是否抓取子页面、抓取页面数量上限、页面抓取深度、排除页面、仅抓取页面、提取内容。完成配置后点击 **Run**,预览将要被抓取的目标页面链接。
|
||||
|
||||
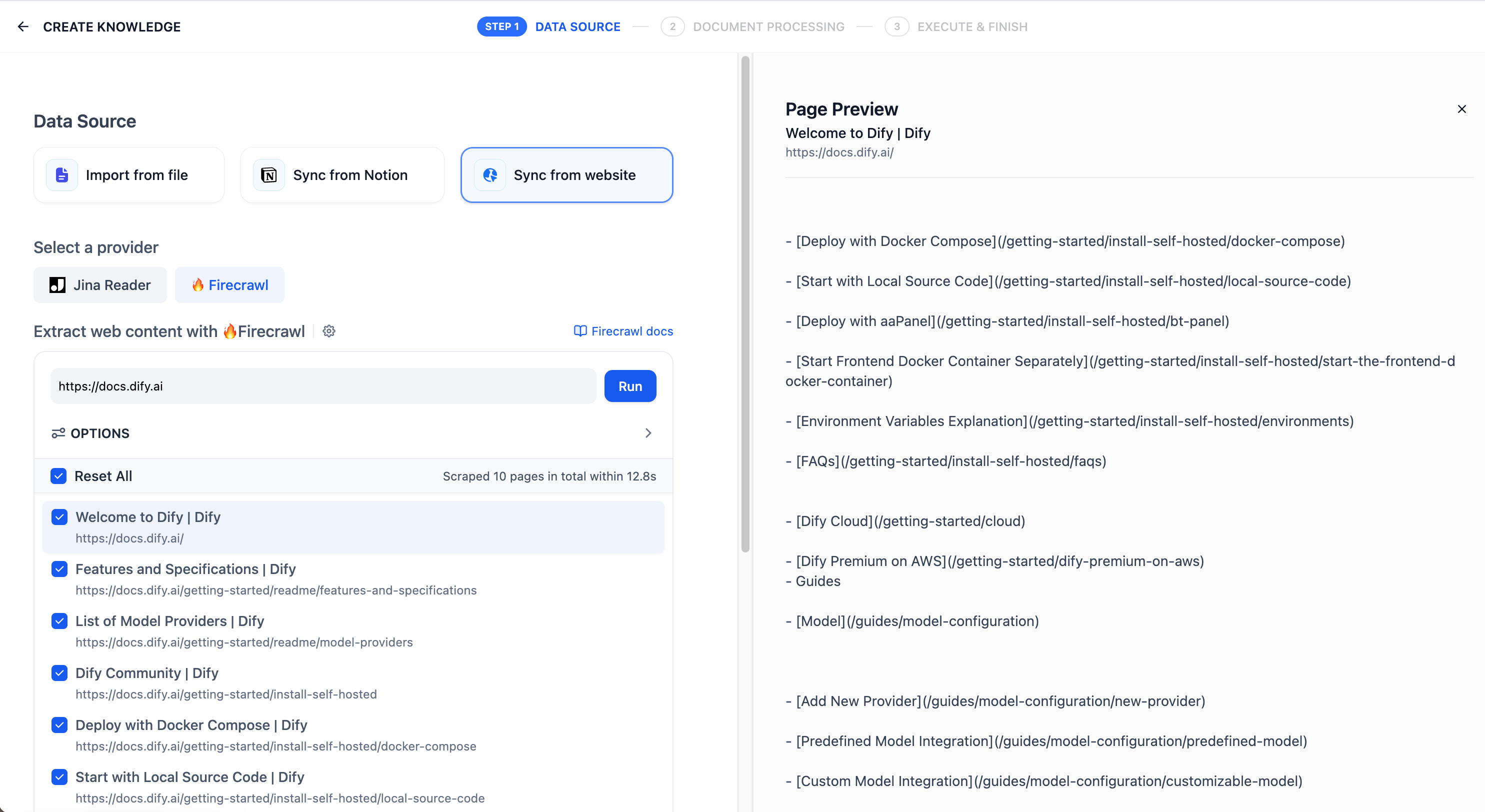
|
||||
|
||||
导入网页解析的文本后存储至知识库的文档中,查看导入结果。点击 **Add URL** 可以继续导入新的网页。抓取完成后,网页中的内容将会被收录至知识库内。
|
||||
|
||||
---
|
||||
|
||||
## Jina Reader
|
||||
|
||||
### 配置 Jina Reader 凭据
|
||||
|
||||
点击右上角头像,然后前往 **DataSource** 页面,点击 Jina Reader 右侧的 Configure 按钮。
|
||||
|
||||
|
||||
|
||||
登录[ Jina Reader 官网](https://jina.ai/reader) 完成注册,获取 API Key 后并按照页面提示填入并保存。
|
||||
|
||||
### 使用 Jina Reader 抓取网页内容
|
||||
|
||||
在知识库创建页选择 **Sync from website**,provider 选中 Jina Reader,填写需要抓取的目标 URL。
|
||||
|
||||
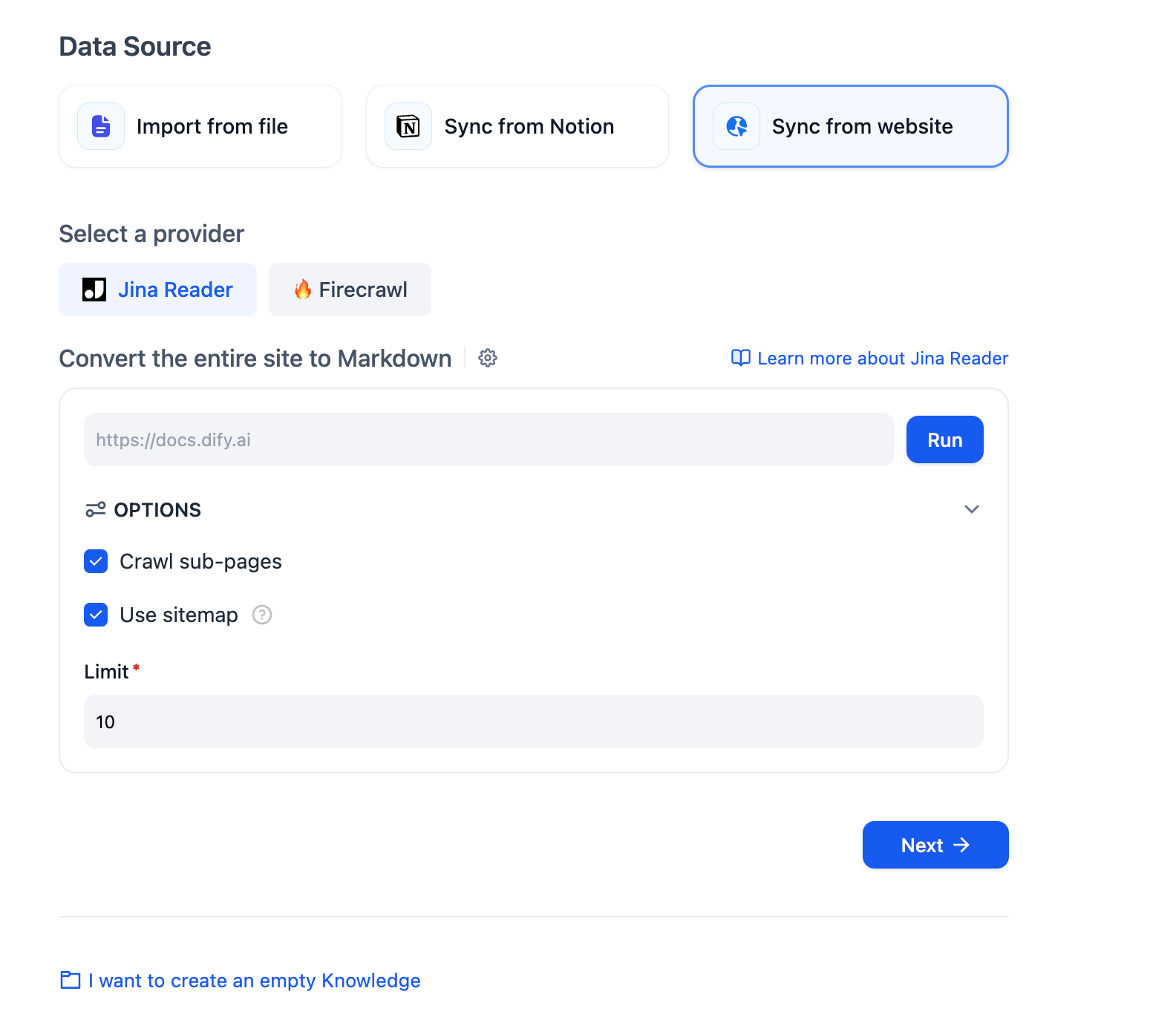
|
||||
|
||||
设置中的配置项包括:是否抓取子页面、抓取页面数量上限、是否使用 sitemap 抓取。完成配置后点击 **Run** 按钮,预览将要被抓取的页面链接。
|
||||
|
||||
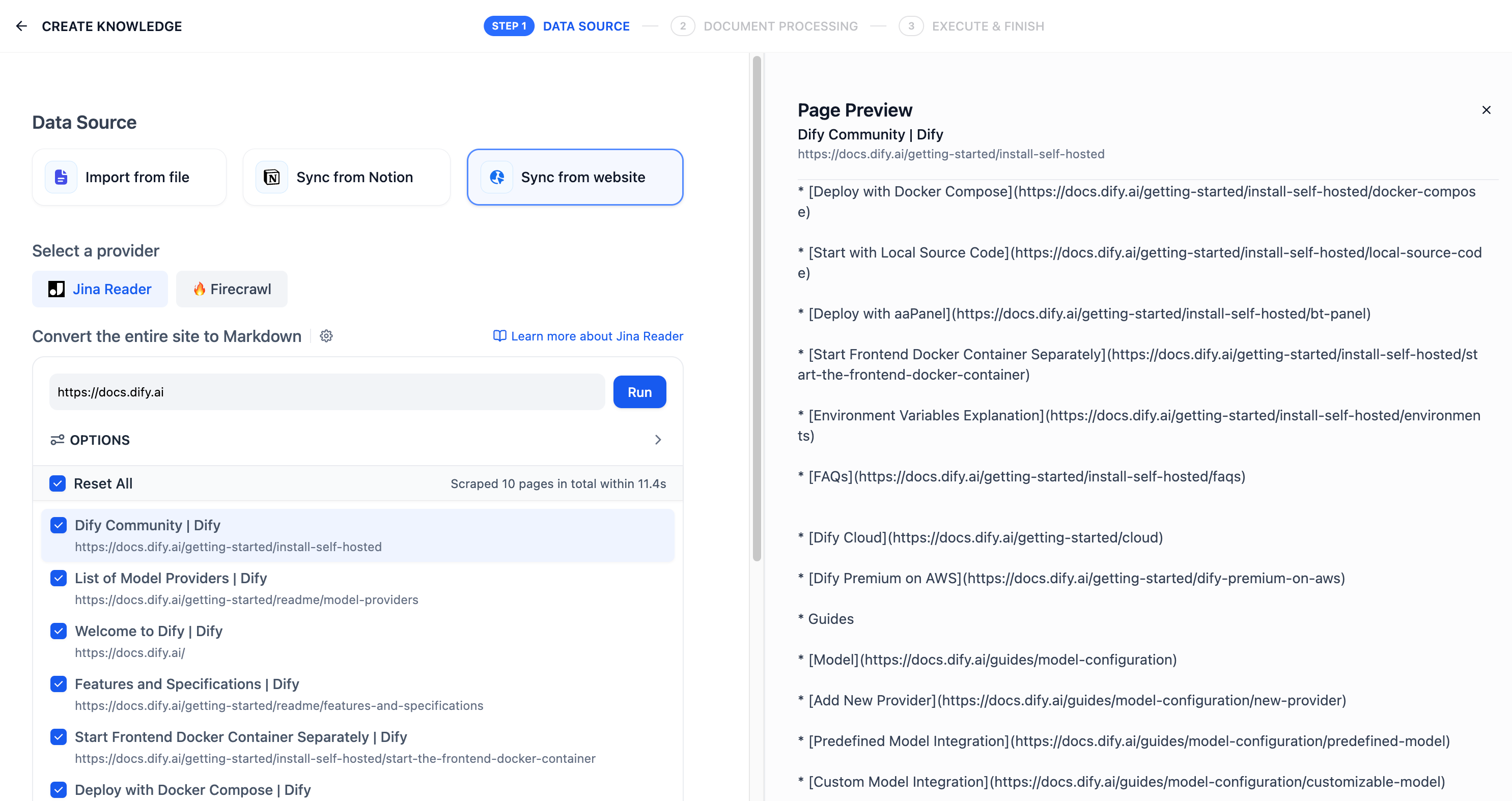
|
||||
|
||||
导入网页解析的文本后存储至知识库的文档中,查看导入结果。如需继续添加网页,轻点右侧 **Add URL** 按钮继续导入新的网页。
|
||||
|
||||
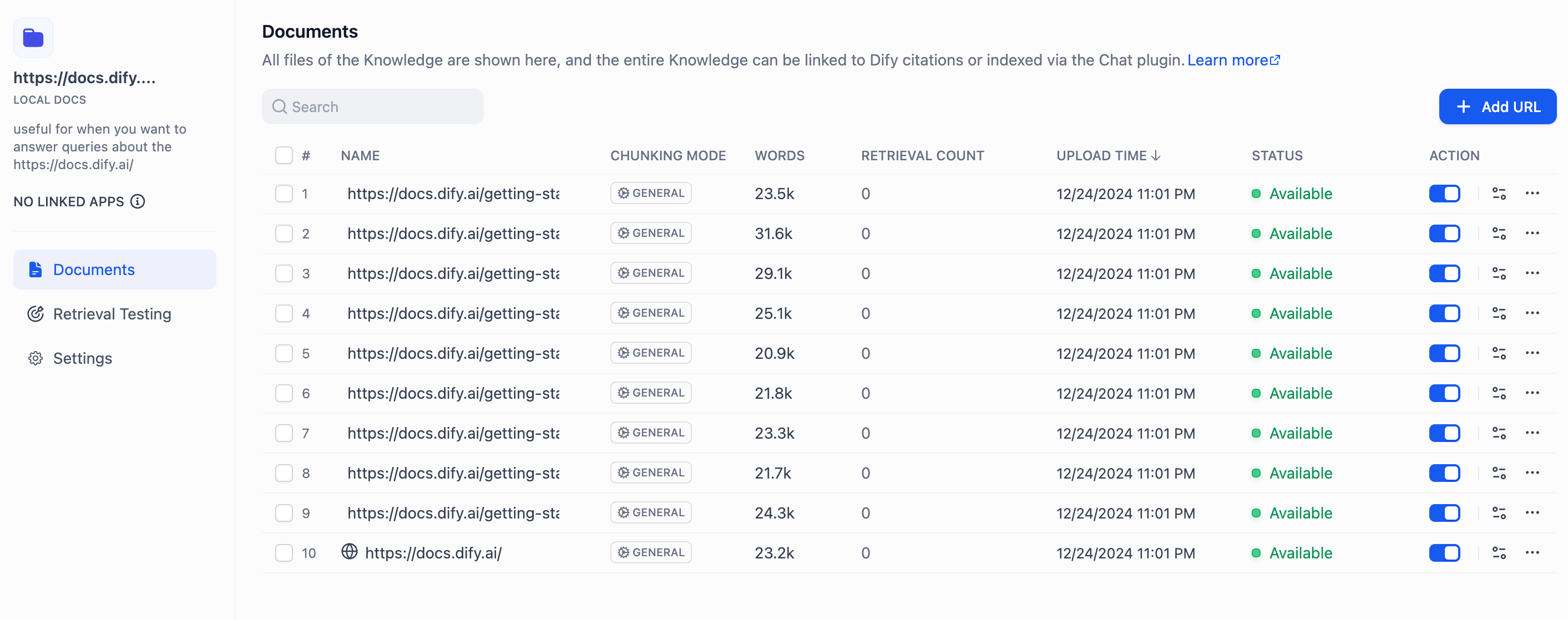
|
||||
|
||||
抓取完成后,网页中的内容将会被收录至知识库内。
|
||||
@@ -0,0 +1,57 @@
|
||||
---
|
||||
title: 知识库创建步骤
|
||||
---
|
||||
|
||||
创建知识库并上传文档大致分为以下步骤:
|
||||
|
||||
1. 创建知识库。通过上传本地文件、导入在线数据或创建一个空的知识库。
|
||||
|
||||
<Card title="导入文本数据" icon="link" href="import-content-data">
|
||||
选择通过上传本地文件或导入在线数据的方式创建知识库
|
||||
</Card>
|
||||
|
||||
2. 指定分段模式。该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。你可以在此环节预览文本的分段效果。
|
||||
|
||||
<Card title="分段和清洗文本" icon="link" href="chunking-and-cleaning-text">
|
||||
了解如何设置文本分段和清洗规则
|
||||
</Card>
|
||||
|
||||
3. 设定索引方法和检索设置。知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。
|
||||
|
||||
<Card title="设置索引方法" icon="link" href="setting-indexing-methods">
|
||||
了解如何配置检索方式和相关设置
|
||||
</Card>
|
||||
|
||||
5. 等待分段嵌入
|
||||
6. 完成上传,在应用内关联知识库并使用。你可以参考[在应用内集成知识库](../integrate-knowledge-within-application.md),搭建出能够基于知识库进行问答的 LLM 应用。如需修改或管理知识库,请参考[知识库管理与文档维护](../knowledge-and-documents-maintenance/)。
|
||||
|
||||

|
||||
|
||||
### 参考阅读
|
||||
|
||||
#### ETL
|
||||
|
||||
在 RAG 的生产级应用中,为了获得更好的数据召回效果,需要对多源数据进行预处理和清洗,即 ETL (_extract, transform, load_)。为了增强非结构化/半结构化数据的预处理能力,Dify 支持了可选的 ETL 方案:**Dify ETL** 和[ ](https://docs.unstructured.io/welcome)[**Unstructured ETL** ](https://unstructured.io/)。Unstructured 能够高效地提取并转换你的数据为干净的数据用于后续的步骤。Dify 各版本的 ETL 方案选择:
|
||||
|
||||
* SaaS 版不可选,默认使用 Unstructured ETL;
|
||||
* 社区版可选,默认使用 Dify ETL ,可通过[环境变量](https://docs.dify.ai/v/zh-hans/getting-started/install-self-hosted/environments#zhi-shi-ku-pei-zhi)开启 Unstructured ETL;
|
||||
|
||||
文件解析支持格式的差异:
|
||||
|
||||
| DIFY ETL | Unstructured ETL |
|
||||
| --- | --- |
|
||||
| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
|
||||
|
||||
不同的 ETL 方案在文件提取效果的方面也会存在差异,想了解更多关于 Unstructured ETL 的数据处理方式,请参考[官方文档](https://docs.unstructured.io/open-source/core-functionality/partitioning)。
|
||||
|
||||
#### **Embedding**
|
||||
|
||||
**Embedding 嵌入**是一种将离散型变量(如单词、句子或者整个文档)转化为连续的向量表示的技术。它可以将高维数据(如单词、短语或图像)映射到低维空间,提供一种紧凑且有效的表示方式。这种表示不仅减少了数据的维度,还保留了重要的语义信息,使得后续的内容检索更加高效。
|
||||
|
||||
**Embedding 模型**是一种专门用于将文本向量化的大语言模型,它擅长将文本转换为密集的数值向量,有效捕捉语义信息。
|
||||
|
||||
> 如需了解更多,请参考:[《Dify:Embedding 技术与 Dify 知识库设计/规划》](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)。
|
||||
|
||||
#### **元数据**
|
||||
|
||||
如需使用元数据功能管理知识库,请参阅 [元数据](https://docs.dify.ai/zh-hans/guides/knowledge-base/metadata)。
|
||||
@@ -0,0 +1,167 @@
|
||||
---
|
||||
title: 3. 设定索引方法与检索设置
|
||||
---
|
||||
|
||||
选定内容的分段模式后,接下来设定对于结构化内容的**索引方法**与**检索设置**。
|
||||
|
||||
## 设定索引方法
|
||||
|
||||
正如搜索引擎通过高效的索引算法匹配与用户问题最相关的网页内容,索引方式是否合理将直接影响 LLM 对知识库内容的检索效率以及回答的准确性。
|
||||
|
||||
提供 **高质量** 与 **经济** 两种索引方法,其中分别提供不同的检索设置选项:
|
||||
|
||||
<Tip>
|
||||
**注意:** 原 **Q\&A 模式(仅适用于社区版)**已成为高质量索引方法下的一个可选项。
|
||||
</Tip>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="高质量">
|
||||
**高质量**
|
||||
|
||||
在高质量模式下,使用 Embedding 嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息;**使得用户问题与文本之间的匹配能够更加精准**。
|
||||
|
||||
将内容块向量化并录入至数据库后,需要通过有效的检索方式调取与用户问题相匹配的内容块。高质量模式提供向量检索、全文检索和混合检索三种检索设置。关于各个设置的详细说明,请继续阅读[检索设置](setting-indexing-methods.md#retrieval_settings)。
|
||||
|
||||
选择高质量模式后,当前知识库的索引方式无法在后续降级为 **“经济”索引模式**。如需切换,建议重新创建知识库并重选索引方式。
|
||||
|
||||
> 如需了解更多关于嵌入技术与向量的说明,请参考[《Embedding 技术与 Dify》](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)。
|
||||
|
||||
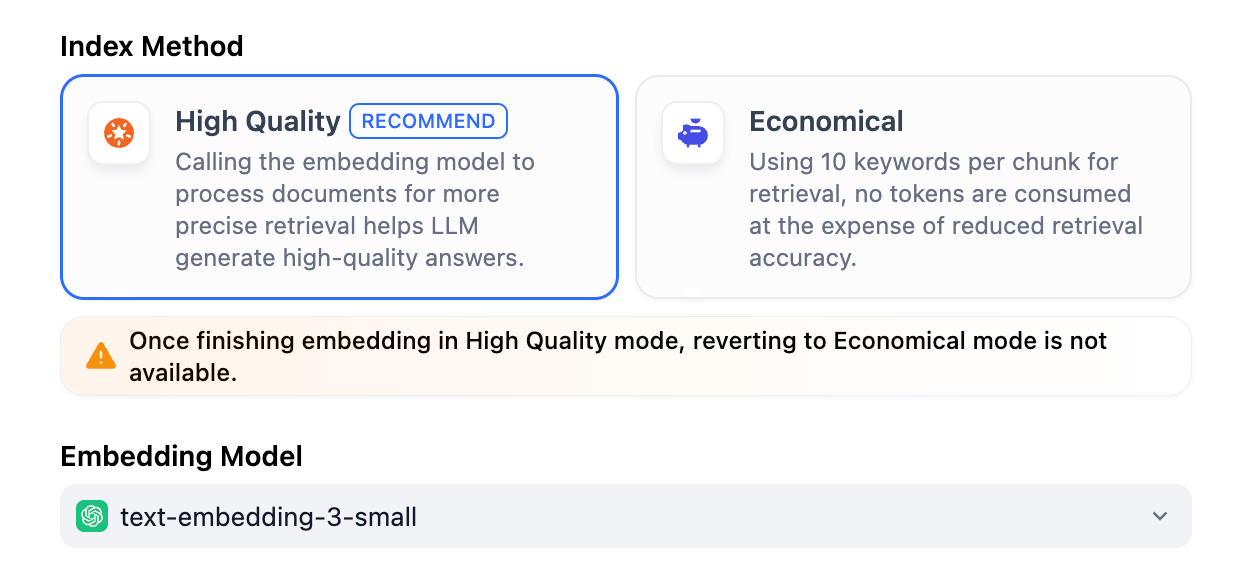
|
||||
|
||||
**启用 Q\&A 模式(可选,仅适用于[社区版](../../../getting-started/install-self-hosted/))**
|
||||
|
||||
开启该模式后,系统将对已上传的文本进行分段。总结内容后为每个分段自动生成 Q\&A 匹配对。与常见的 「Q to P」(用户问题匹配文本段落)策略不同,QA 模式采用 「Q to Q」(问题匹配问题)策略。
|
||||
|
||||
这是因为 「常见问题」 文档里的文本**通常是具备完整语法结构的自然语言**,Q to Q 模式会令问题和答案的匹配更加清晰,并同时满足一些高频和高相似度问题的提问场景。
|
||||
|
||||
> **Q\&A 模式仅支持处理 「中英日」 三语。启用该模式后可能会消耗更多的 LLM Tokens,并且无法使用**[**经济型索引方法**](setting-indexing-methods.md#jing-ji)**。**
|
||||
|
||||
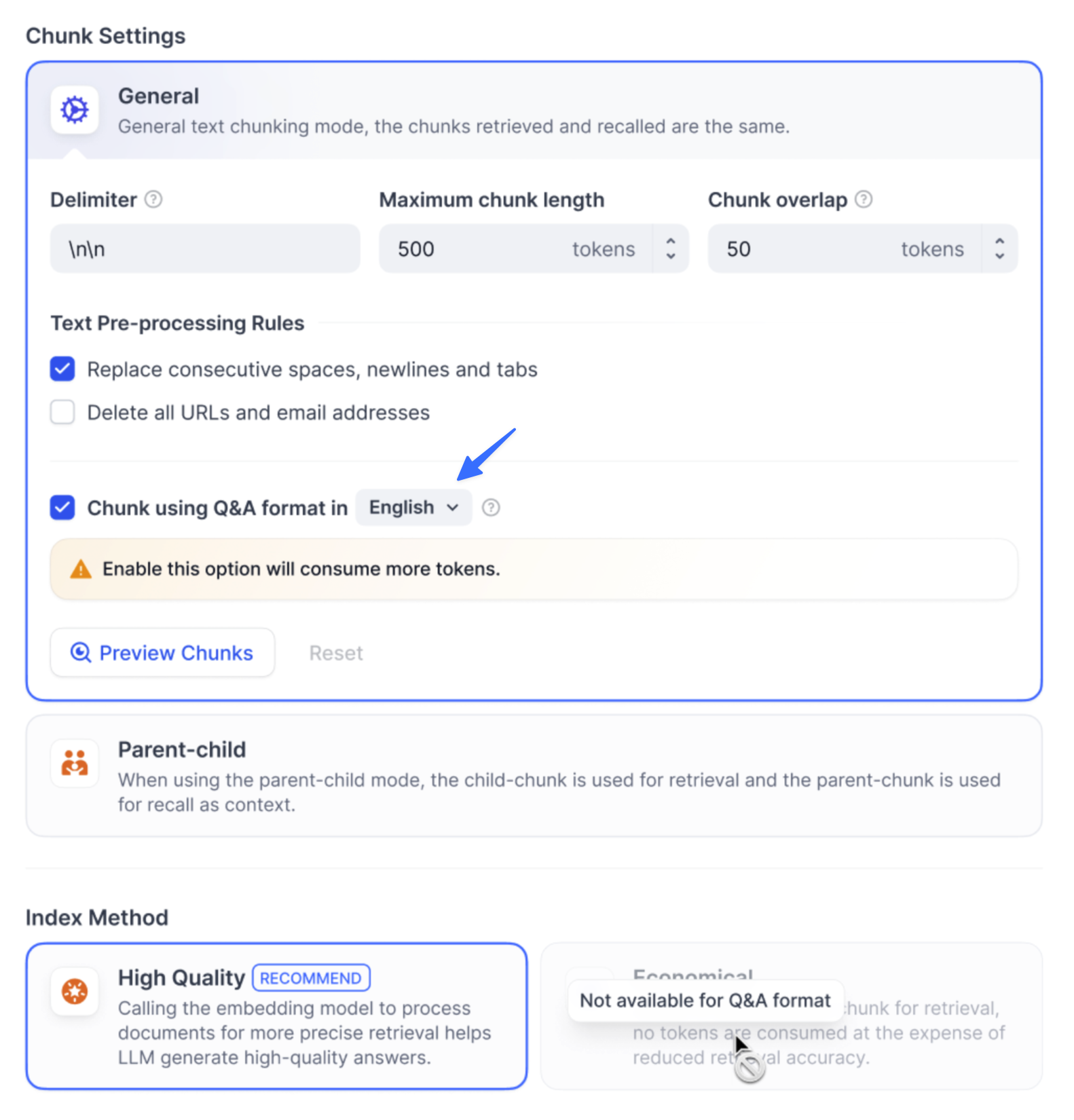
|
||||
|
||||
当用户提问时,系统会找出与之最相似的问题,然后返回对应的分段作为答案。这种方式更加精确,因为它直接针对用户问题进行匹配,可以更准确地帮助用户检索真正需要的信息。
|
||||
|
||||
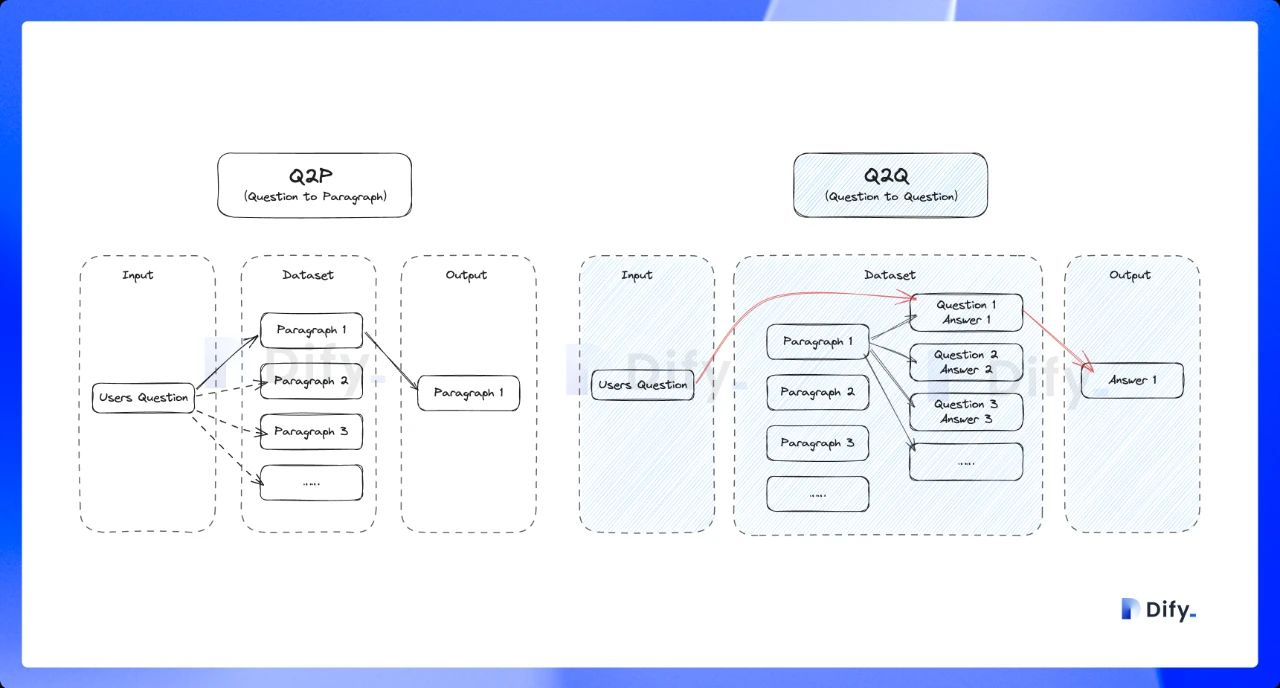
|
||||
</Tab>
|
||||
<Tab title="经济">
|
||||
**经济**
|
||||
|
||||
在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需产生费用。对于检索到的区块,仅提供倒排索引方式选择最相关的区块,详细说明请阅读[下文](setting-indexing-methods.md#dao-pai-suo-yin)。
|
||||
|
||||
选择经济型索引方式后,若感觉实际的效果不佳,可以在知识库设置页中升级为 **“高质量”索引方式**。
|
||||
|
||||

|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 指定检索方式 <a href="#retrieval_settings" id="retrieval_settings"></a>
|
||||
|
||||
知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。这将决定 LLM 所能获取的背景信息,从而影响生成结果的准确性和可信度。
|
||||
|
||||
常见的检索方式包括基于向量相似度的语义检索,以及基于关键词的精准匹配:前者将文本内容块和问题查询转化为向量,通过计算向量相似度匹配更深层次的语义关联;后者通过倒排索引,即搜索引擎常用的检索方法,匹配问题与关键内容。
|
||||
|
||||
不同的索引方法对应差异化的检索设置。
|
||||
|
||||
<Tabs>
|
||||
<Tab title="高质量索引">
|
||||
**高质量索引**
|
||||
|
||||
在高质量索引方式下,Dify 提供向量检索、全文检索与混合检索设置:
|
||||
|
||||
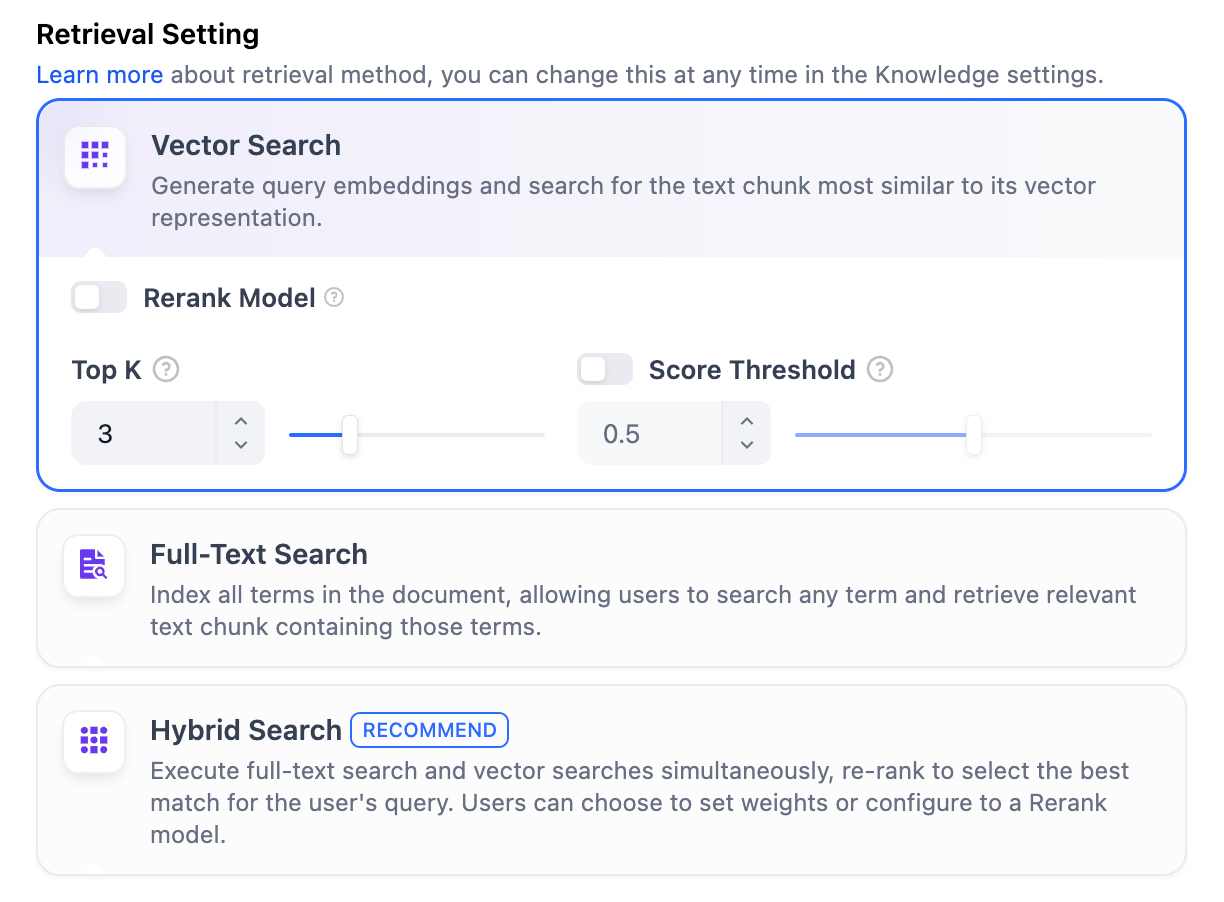
|
||||
|
||||
**向量检索**
|
||||
|
||||
**定义:** 向量化用户输入的问题并生成查询文本的数学向量,比较查询向量与知识库内对应的文本向量间的距离,寻找相邻的分段内容。
|
||||
|
||||
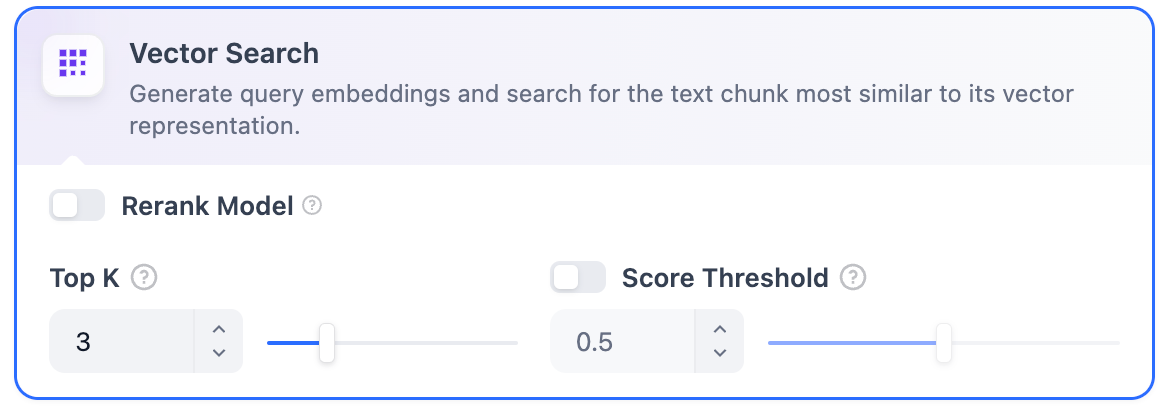
|
||||
|
||||
**向量检索设置:**
|
||||
|
||||
**Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由向量检索召回的内容分段,以优化排序结果。帮助 LLM 获取更加精确的内容,辅助其提升输出的质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
|
||||
|
||||
> 开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
**Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
|
||||
|
||||
> TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置参数。
|
||||
|
||||
***
|
||||
|
||||
**全文检索**
|
||||
|
||||
**定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
|
||||
|
||||
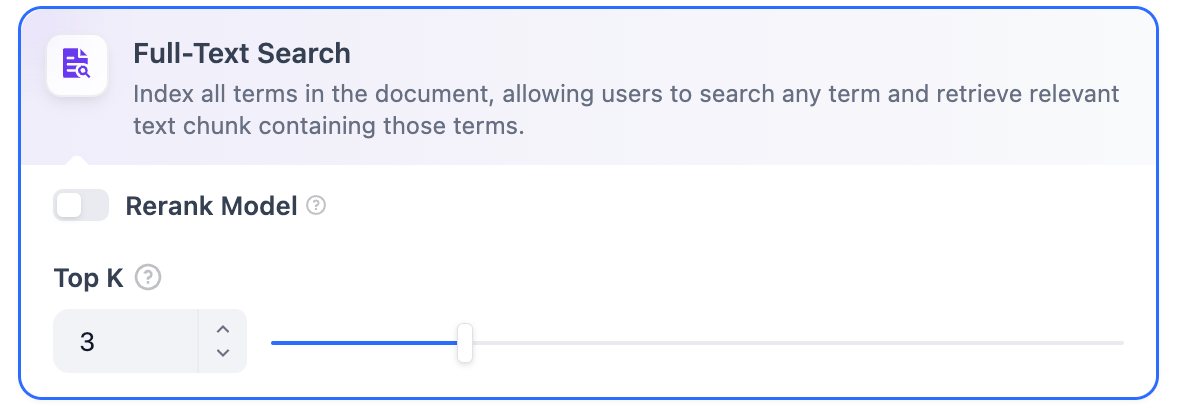
|
||||
|
||||
**Rerank 模型:** 默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由全文检索召回的内容分段,以优化排序结果。向 LLM 发送经过重排序的分段,辅助其提升输出的内容质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
|
||||
|
||||
> 开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
**Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
|
||||
|
||||
> TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置参数。
|
||||
|
||||
***
|
||||
|
||||
**混合检索**
|
||||
|
||||
**定义:** 同时执行全文检索和向量检索,或 Rerank 模型,从查询结果中选择匹配用户问题的最佳结果。
|
||||
|
||||
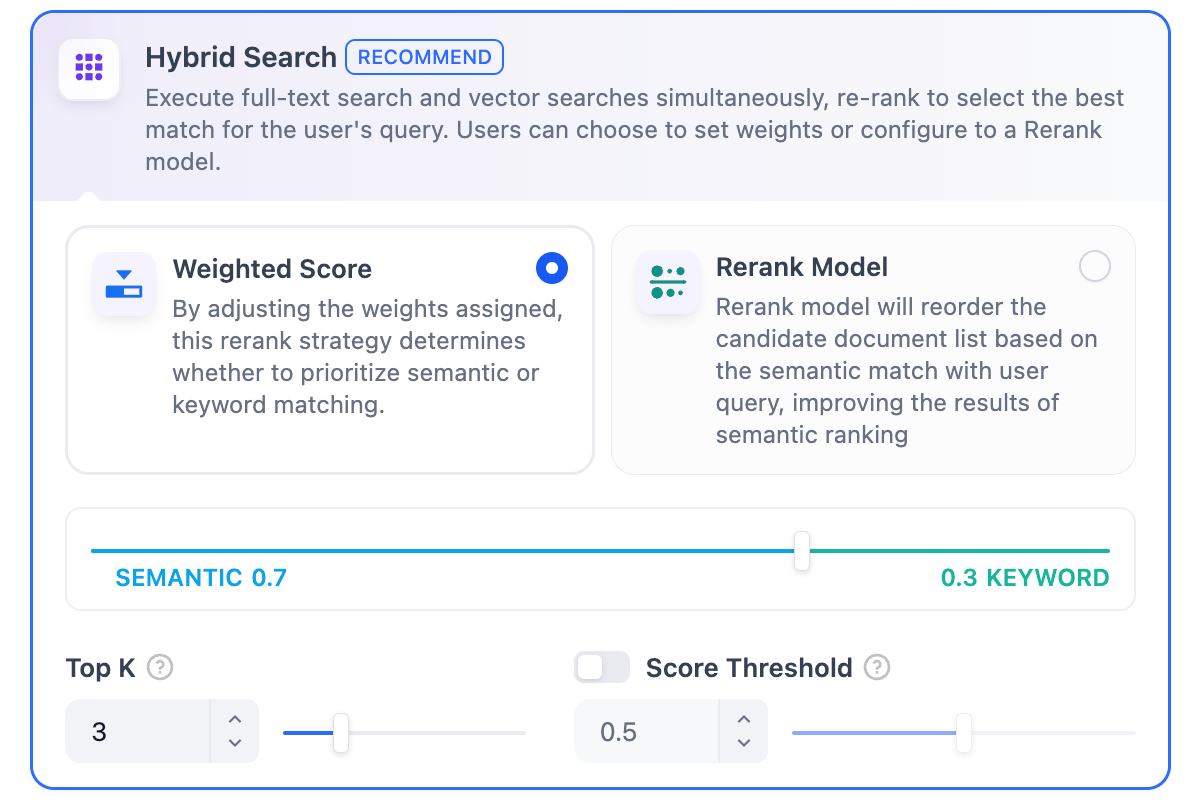
|
||||
|
||||
在混合检索设置内可以选择启用 **“权重设置”** 或 **“Rerank 模型”**。
|
||||
|
||||
* **权重设置**
|
||||
|
||||
允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。
|
||||
|
||||
* **将语义值拉至 1**
|
||||
|
||||
**仅启用语义检索模式**。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
|
||||
* **将关键词的值拉至 1**
|
||||
|
||||
**仅启用关键词检索模式**。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
|
||||
* **自定义关键词和语义权重**
|
||||
|
||||
除了将不同的数值拉至 1,你还可以不断调试二者的权重,找到符合业务场景的最佳权重比例。
|
||||
|
||||
> 语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:[《Dify:Embedding 技术与 Dify 知识库设计/规划》](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)。
|
||||
|
||||
***
|
||||
|
||||
* **Rerank 模型**
|
||||
|
||||
默认关闭。开启后将使用第三方 Rerank 模型再一次重排序由混合检索召回的内容分段,以优化排序结果。向 LLM 发送经过重排序的分段,辅助其提升输出的内容质量。开启该选项前,需前往“设置” → “模型供应商”,提前配置 Rerank 模型的 API 秘钥。
|
||||
|
||||
> 开启该功能后,将消耗 Rerank 模型的 Tokens,详情请参考对应模型的价格说明。
|
||||
|
||||
**“权重设置”** 和 **“Rerank 模型”** 设置内支持启用以下选项:
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
**Score 阈值:** 用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5。数值越高,预期被召回的文本数量越少。
|
||||
</Tab>
|
||||
<Tab title="经济索引">
|
||||
**倒排索引**
|
||||
|
||||
在经济索引方式下,仅提供**倒排索引方式**。这是一种用于快速检索文档中关键词的索引结构,常用于在线搜索引擎。倒排索引仅支持 **TopK** 设置项。
|
||||
|
||||
**TopK:**
|
||||
|
||||
用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
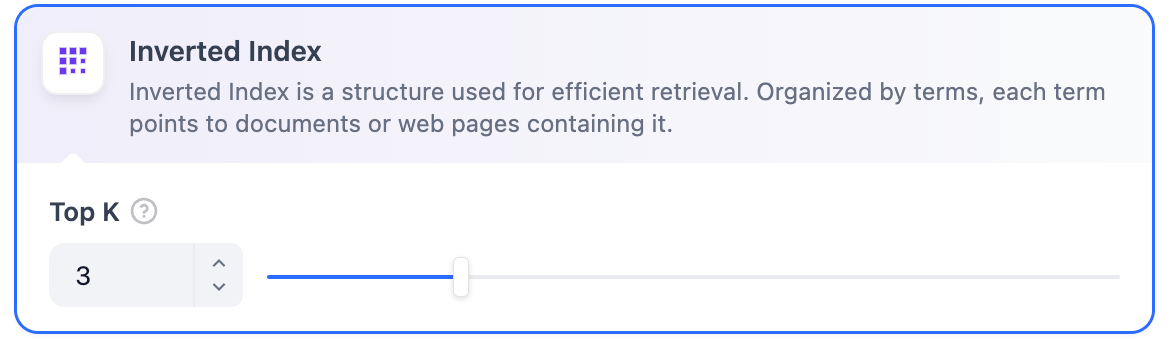
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 阅读更多
|
||||
|
||||
指定检索设置后,你可以参考以下文档查看在实际场景下,关键词与内容块的匹配情况。
|
||||
|
||||
<Card title="检索测试与引文示例" icon="link" href="../retrieval-test-and-citation.md">
|
||||
查看实际场景下的关键词与内容块匹配情况
|
||||
</Card>
|
||||
20
zh-cn/user-guide/knowledge-base/faq.mdx
Normal file
20
zh-cn/user-guide/knowledge-base/faq.mdx
Normal file
@@ -0,0 +1,20 @@
|
||||
---
|
||||
title: 常见问题
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
## 1. 导入文档与查询响应速度缓慢,如何排查原因?
|
||||
|
||||
通常情况下,上传文档后的 Embedding 过程将耗费大量资源,有可能造成速度缓慢。请检查服务器负载,将日志切换为 debug 模式或检查 Embedding 的返回时间。
|
||||
|
||||
## 2. 上传至知识库的文档内容较多,分段后内容异常,如何处理?
|
||||
|
||||
请检查服务器负载的内存占用情况,查看是否出现内存泄漏问题。
|
||||
|
||||
## 3. 知识库的文件处理一直显示为“排队中”,如何处理?
|
||||
|
||||
此问题有可能是由于与 redis 服务的连接中断,导致任务无法退出。建议重启 Worker 节点。
|
||||
|
||||
## 4. 如何优化应用对知识库内容的检索结果?
|
||||
|
||||
你可以通过调整检索设置,比较不同的参数进行优化。具体操作请参考[检索设置](/zh-cn/user-guide/knowledge-base/knowledge-base-creation/upload-documents#3)。
|
||||
@@ -0,0 +1,103 @@
|
||||
---
|
||||
title: 混合检索
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
### 为什么需要混合检索?
|
||||
|
||||
RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的方式。技术原理是通过将外部知识库的文档先拆分为语义完整的段落或句子,并将其转换(Embedding)为计算机能够理解的一串数字表达(多维向量),同时对用户问题进行同样的转换操作。
|
||||
|
||||
计算机能够发现用户问题与句子之间细微的语义相关性,比如 “猫追逐老鼠” 和 “小猫捕猎老鼠” 的语义相关度会高于 “猫追逐老鼠” 和 “我喜欢吃火腿” 之间的相关度。在将相关度最高的文本内容查找到后,RAG 系统会将其作为用户问题的上下文一起提供给大模型,帮助大模型回答问题。
|
||||
|
||||
除了能够实现复杂语义的文本查找,向量检索还有其他的优势:
|
||||
|
||||
* 相近语义理解(如老鼠/捕鼠器/奶酪,谷歌/必应/搜索引擎)
|
||||
* 多语言理解(跨语言理解,如输入中文匹配英文)
|
||||
* 多模态理解(支持文本、图像、音视频等的相似匹配)
|
||||
* 容错性(处理拼写错误、模糊的描述)
|
||||
|
||||
虽然向量检索在以上情景中具有明显优势,但有某些情况效果不佳。比如:
|
||||
|
||||
* 搜索一个人或物体的名字(例如,伊隆·马斯克,iPhone 15)
|
||||
* 搜索缩写词或短语(例如,RAG,RLHF)
|
||||
* 搜索 ID(例如, `gpt-3.5-turbo` , `titan-xlarge-v1.01` )
|
||||
|
||||
而上面这些的缺点恰恰都是传统关键词搜索的优势所在,传统关键词搜索擅长:
|
||||
|
||||
* 精确匹配(如产品名称、姓名、产品编号)
|
||||
* 少量字符的匹配(通过少量字符进行向量检索时效果非常不好,但很多用户恰恰习惯只输入几个关键词)
|
||||
* 倾向低频词汇的匹配(低频词汇往往承载了语言中的重要意义,比如“你想跟我去喝咖啡吗?”这句话中的分词,“喝”“咖啡”会比“你”“想”“吗”在句子中承载更重要的含义)
|
||||
|
||||
对于大多数文本搜索的情景,首要的是确保潜在最相关结果能够出现在候选结果中。向量检索和关键词检索在检索领域各有其优势。混合搜索正是结合了这两种搜索技术的优点,同时弥补了两方的缺点。
|
||||
|
||||
在混合检索中,你需要在数据库中提前建立向量索引和关键词索引,在用户问题输入时,分别通过两种检索器在文档中检索出最相关的文本。
|
||||
|
||||
<Frame title="混合检索">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (178).png" alt="" width="563" />
|
||||
</Frame>
|
||||
|
||||
“混合检索”实际上并没有明确的定义,本文以向量检索和关键词检索的组合为示例。如果我们使用其他搜索算法的组合,也可以被称为“混合检索”。比如,我们可以将用于检索实体关系的知识图谱技术与向量检索技术结合。
|
||||
|
||||
不同的检索系统各自擅长寻找文本(段落、语句、词汇)之间不同的细微联系,这包括了精确关系、语义关系、主题关系、结构关系、实体关系、时间关系、事件关系等。可以说没有任何一种检索模式能够适用全部的情景。**混合检索通过多个检索系统的组合,实现了多个检索技术之间的互补。**
|
||||
|
||||
### **向量检索**
|
||||
|
||||
定义:通过生成查询嵌入并查询与其向量表示最相似的文本分段。
|
||||
|
||||
<Frame title="向量检索设置">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (167).png" alt="" width="563" />
|
||||
</Frame>
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
|
||||
|
||||
**Score 阈值:** 用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5 。
|
||||
|
||||
**Rerank 模型:** 你可以在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”,系统会在语义检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
|
||||
|
||||
### **全文检索**
|
||||
|
||||
定义:索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。
|
||||
|
||||
<Frame title="全文检索设置">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (173).png" alt="" width="563" />
|
||||
</Frame>
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
|
||||
|
||||
**Rerank 模型:** 你可以在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”,系统会在全文检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
|
||||
|
||||
### **混合检索**
|
||||
|
||||
同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。
|
||||
|
||||
<Frame title="混合检索设置">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (169).png" alt="" width="563" />
|
||||
</Frame>
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
|
||||
|
||||
**Rerank 模型:** 你可以在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”,系统会在混合检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
|
||||
|
||||
### 创建数据集时设置检索模式
|
||||
|
||||
进入“数据集->创建数据集”页面并在检索设置中设置不同的检索模式:
|
||||
|
||||
<Frame title="创建数据集时设置检索模式">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (170).png" alt="" width="563" />
|
||||
</Frame>
|
||||
|
||||
### 数据集设置中修改检索模式
|
||||
|
||||
进入“数据集->选择数据集->设置”页面中可以对已创建的数据集修改不同的检索模式。
|
||||
|
||||
<Frame title="数据集设置中修改检索模式">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (171).png" alt="" width="563" />
|
||||
</Frame>
|
||||
|
||||
### 提示词编排中修改检索模式
|
||||
|
||||
进入“提示词编排->上下文->选择数据集->设置”页面中可以在创建应用时修改不同的检索模式。
|
||||
|
||||
<Frame title="提示词编排中修改检索模式">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (172).png" alt="" />
|
||||
</Frame>
|
||||
@@ -0,0 +1,64 @@
|
||||
---
|
||||
title: 重排序
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
### 为什么需要重排序?
|
||||
|
||||
混合检索能够结合不同检索技术的优势获得更好的召回结果,但在不同检索模式下的查询结果需要进行合并和归一化(将数据转换为统一的标准范围或分布,以便更好地进行比较、分析和处理),然后再一起提供给大模型。这时候我们需要引入一个评分系统:重排序模型(Rerank Model)。
|
||||
|
||||
**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
|
||||
|
||||
<Frame title="混合检索+重排序">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (179).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
|
||||
|
||||
不过,重排序并不是只适用于不同检索系统的结果合并,即使是在单一检索模式下,引入重排序步骤也能有效帮助改进文档的召回效果,比如我们可以在关键词检索之后加入语义重排序。
|
||||
|
||||
在具体实践过程中,除了将多路查询结果进行归一化之外,在将相关的文本分段交给大模型之前,我们一般会限制传递给大模型的分段个数(即 TopK,可以在重排序模型参数中设置),这样做的原因是大模型的输入窗口存在大小限制(一般为 4K、8K、16K、128K 的 Token 数量),你需要根据选用的模型输入窗口的大小限制,选择合适的分段策略和 TopK 值。
|
||||
|
||||
需要注意的是,即使模型上下文窗口很足够大,过多的召回分段会可能会引入相关度较低的内容,导致回答的质量降低,所以重排序的 TopK 参数并不是越大越好。
|
||||
|
||||
重排序并不是搜索技术的替代品,而是一种用于增强现有检索系统的辅助工具。**它最大的优势是不仅提供了一种简单且低复杂度的方法来改善搜索结果,允许用户将语义相关性纳入现有的搜索系统中,而且无需进行重大的基础设施修改。**
|
||||
|
||||
以 Cohere Rerank 为例,你只需要注册账户和申请 API ,接入只需要两行代码。另外,他们也提供了多语言模型,也就是说你可以将不同语言的文本查询结果进行一次性排序。\\
|
||||
|
||||
### 如何配置 Rerank 模型?
|
||||
|
||||
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
|
||||
|
||||
<Frame title="在模型供应商内配置 Cohere Rerank 模型">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (163).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
###
|
||||
|
||||
### 如何获取 Cohere Rerank 模型?
|
||||
|
||||
登录:[https://cohere.com/rerank](https://cohere.com/rerank),在页内注册并申请 Rerank 模型的使用资格,获取 API 秘钥。
|
||||
|
||||
###
|
||||
|
||||
### 数据集检索模式中设置 Rerank 模型
|
||||
|
||||
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
|
||||
|
||||
<Frame title="数据集检索模式中设置 Rerank 模型">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (132).png" alt="" width="563" />
|
||||
</Frame>
|
||||
|
||||
**TopK:** 用于设置 Rerank 后返回相关文档的数量。
|
||||
|
||||
**Score 阈值:** 用于设置 Rerank 后返回相关文档的最低分值。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
|
||||
|
||||
### 数据集多路召回模式中设置 Rerank 模型
|
||||
|
||||
进入“提示词编排->上下文->设置”页面中设置为多路召回模式时需开启 Rerank 模型。
|
||||
|
||||
查看更多关于多路召回模式的说明,[《多路召回》](/zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application)。
|
||||
|
||||
<Frame title="数据集多路召回模式中设置 Rerank 模型">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (133).png" alt="" />
|
||||
</Frame>
|
||||
@@ -0,0 +1,26 @@
|
||||
---
|
||||
title: 检索增强生成(RAG)
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
### RAG 的概念解释
|
||||
|
||||
向量检索为核心的 RAG 架构已成为解决大模型获取最新外部知识,同时解决其生成幻觉问题时的主流技术框架,并且已在相当多的应用场景中落地实践。
|
||||
|
||||
开发者可以利用该技术低成本地构建一个 AI 智能客服、企业智能知识库、AI 搜索引擎等,通过自然语言输入与各类知识组织形式进行对话。以一个有代表性的 RAG 应用为例:
|
||||
|
||||
在下图中,当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统…),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
|
||||
|
||||
<Frame title="RAG 基本架构">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (180).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**为什么需要这样做呢?**
|
||||
|
||||
我们可以把大模型比做是一个超级专家,他熟悉人类各个领域的知识,但他也有自己的局限性,比如他不知道你个人的一些状况,因为这些信息是你私人的,不会在互联网上公开,所以他没有提前学习的机会。
|
||||
|
||||
当你想雇佣这个超级专家来充当你的家庭财务顾问时,需要允许他在接受你的提问时先翻看一下你的投资理财记录、家庭消费支出等数据。这样他才能根据你个人的实际情况提供专业的建议。
|
||||
|
||||
**这就是 RAG 系统所做的事情:帮助大模型临时性地获得他所不具备的外部知识,允许它在回答问题之前先找答案。**
|
||||
|
||||
根据上面这个例子,我们很容易发现 RAG 系统中最核心是外部知识的检索环节。专家能不能向你提供专业的家庭财务建议,取决于能不能精确找到他需要的信息,如果他找到的不是投资理财记录,而是家庭减肥计划,那再厉害的专家都会无能为力。
|
||||
@@ -0,0 +1,24 @@
|
||||
---
|
||||
title: 召回模式
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
|
||||
|
||||
<Frame title="召回模式设置">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/zh-rag-multiple.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### 召回设置
|
||||
|
||||
根据用户意图同时匹配所有知识库,从多路知识库查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
|
||||
|
||||
在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
|
||||
|
||||
以下是多路召回模式的技术流程图:
|
||||
|
||||
<Frame title="多路召回">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (134).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
|
||||
@@ -0,0 +1,104 @@
|
||||
---
|
||||
title: 在应用内集成知识库
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
知识库可以作为外部知识提供给大语言模型用于精确回复用户问题,你可以在 Dify 的[所有应用类型](user-guide/application-orchestrate/#application\_type)内关联已创建的知识库。
|
||||
|
||||
以聊天助手为例,使用流程如下:
|
||||
|
||||
1. 进入 **工作室 -- 创建应用 --创建聊天助手**
|
||||
2. 进入 **上下文设置** 点击 **添加** 选择已创建的知识库
|
||||
3. 在 **上下文设置 -- 参数设置** 内配置**召回策略**
|
||||
4. 在 **添加功能** 内打开 **引用和归属**
|
||||
5. 在 **调试与预览** 内输入与知识库相关的用户问题进行调试
|
||||
6. 调试完成之后**保存并发布**为一个 AI 知识库问答类应用
|
||||
|
||||
***
|
||||
|
||||
### 关联知识库并指定召回模式
|
||||
|
||||
如果当前应用的上下文涉及多个知识库,需要设置召回模式以使得检索的内容更加精确。进入 **上下文 -- 参数设置 -- 召回设置**。
|
||||
|
||||
#### 召回设置
|
||||
|
||||
检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,以下是召回策略的技术流程图:
|
||||
|
||||
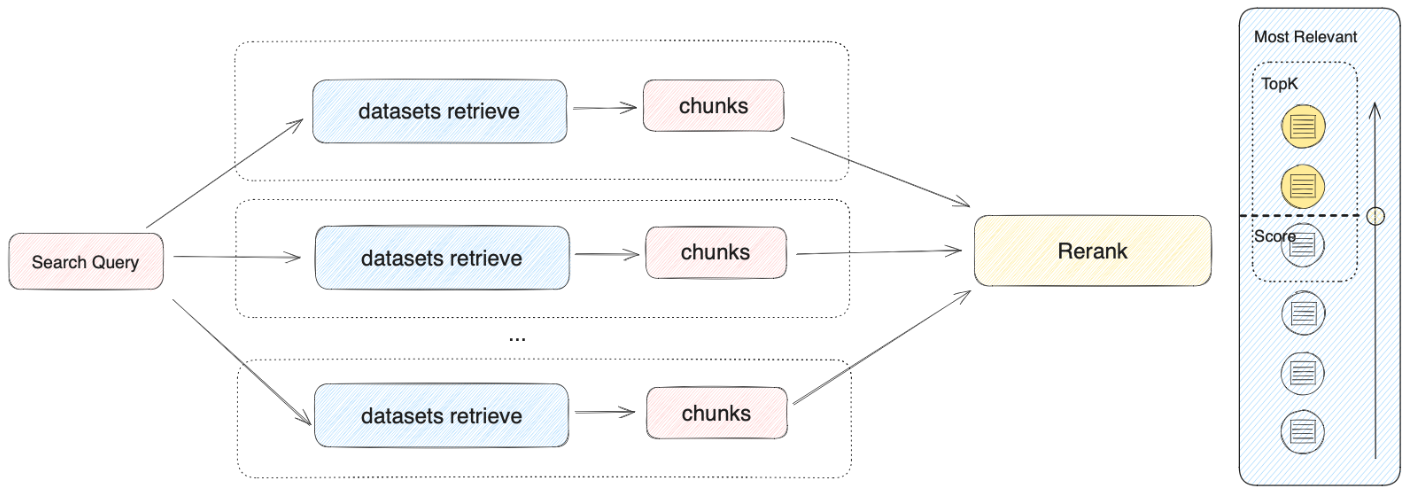
|
||||
|
||||
根据用户意图同时检索所有添加至 **“上下文”** 的知识库,在多个知识库内查询相关文本片段,选择所有和用户问题相匹配的内容,最后通过 Rerank 策略找到最适合的内容并回答用户。该方法的检索原理更为科学。
|
||||
|
||||
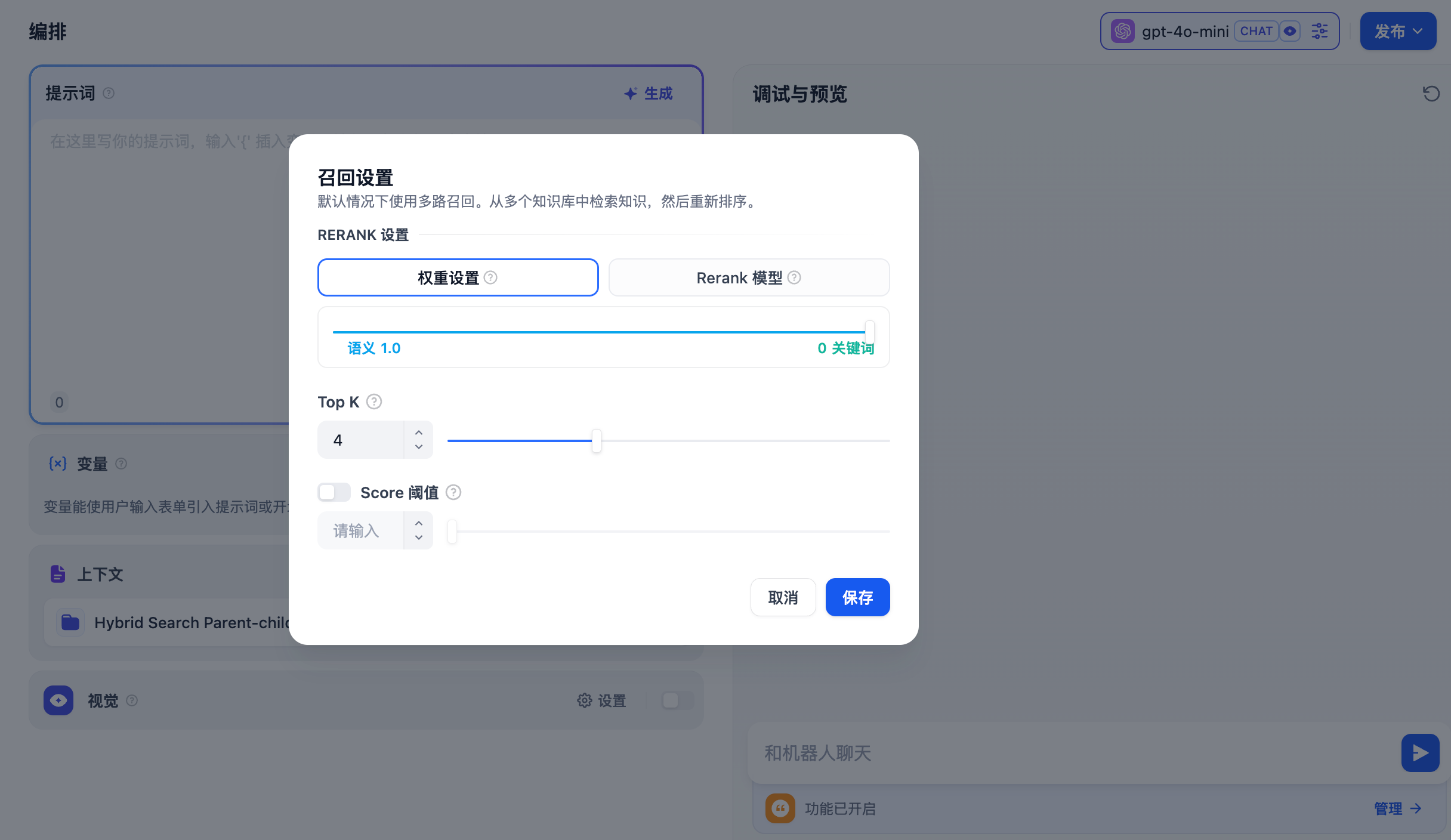
|
||||
|
||||
举例:A 应用的上下文关联了 K1、K2、K3 三个知识库,当用户输入问题后,将在三个知识库内检索并汇总多条内容。为确保能找到最匹配的内容,需要通过 Rerank 策略确定与用户问题最相关的内容,确保结果更加精准与可信。
|
||||
|
||||
在实际问答场景中,每个知识库的内容来源和检索方式可能都有所差异。针对检索返回的多条混合内容,[Rerank 策略](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank)是一个更加科学的内容排序机制。它可以帮助确认候选内容列表与用户问题的匹配度,改进多个知识间排序的结果以找到最匹配的内容,提高回答质量和用户体验。
|
||||
|
||||
考虑到 Rerank 的使用成本和业务需求,多路召回模式提供了以下两种 Rerank 设置:
|
||||
|
||||
**权重设置**
|
||||
|
||||
该设置无需配置外部 Rerank 模型,重排序内容**无需额外花费**。可以通过调整语义或关键词的权重比例条,选择最适合的内容匹配策略。
|
||||
|
||||
* **语义值为 1**
|
||||
|
||||
仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
|
||||
|
||||
> 语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:[《Dify:Embedding 技术与 Dify 数据集设计/规划》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
|
||||
* **关键词值为 1**
|
||||
|
||||
仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
|
||||
* **自定义关键词和语义权重**
|
||||
|
||||
除了仅启用语义检索或关键词检索模式,我们还提供了灵活的自定义权重设置。你可以通过不断调试二者的权重,找到符合业务场景的最佳权重比例。
|
||||
|
||||
**Rerank 模型**
|
||||
|
||||
Rerank 模型是一种外部评分系统,它会计算用户问题与给定的每个候选文档之间的相关性分数,从而改进语义排序的结果,并按相关性返回从高到低排序的文档列表。
|
||||
|
||||
虽然此方法会产生一定的额外花费,但是更加擅长处理知识库内容来源复杂的情况,例如混合了语义查询和关键词匹配的内容,或返回内容存在多语言的情况。
|
||||
|
||||
> 点击了解更多[重排序](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank)机制。
|
||||
|
||||
Dify 目前支持多个 Rerank 模型,进入 “模型供应商” 页填入 Rerank 模型(例如 Cohere、Jina AI 等模型)的 API Key。
|
||||
|
||||
<Frame caption="在模型供应商内配置 Rerank 模型">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/zh-rerank-model-api.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**可调参数**
|
||||
|
||||
* **TopK**
|
||||
|
||||
用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小,动态调整分段数量。数值越高,预期被召回的文本分段数量越多。
|
||||
* **Score 阈值**
|
||||
|
||||
用于设置文本片段筛选的相似度阈值。向量检索的相似度分数需要超过设置的分数后才会被召回,数值越高,预期被召回的文本数量越少。
|
||||
|
||||
多路召回模式在多知识库检索时能够获得质量更高的召回效果,因此更**推荐将召回模式设置为多路召回**。
|
||||
|
||||
### 常见问题
|
||||
|
||||
1. **如何选择多路召回中的 Rerank 设置?**
|
||||
|
||||
如果用户知道确切的信息或术语,可以通过关键词检索精确发挥匹配结果,那么请将 “权重设置” 中的**关键词设置为 1**。
|
||||
|
||||
如果知识库内并未出现确切词汇,或者存在跨语言查询的情况,那么推荐使用 “权重设置” 中的**语义设置为 1**。
|
||||
|
||||
如果业务人员对于用户的实际提问场景比较熟悉,想要主动调整语义或关键词的比值,那么推荐自行调整 “权重设置” 里的比值。
|
||||
|
||||
如果知识库内容较为复杂,无法通过语义或关键词等简单条件进行匹配,同时要求较为精准的回答,愿意支付额外的费用,那么推荐使用 **Rerank 模型** 进行内容检索。
|
||||
|
||||
2. **为什么会出现找不到 “权重设置” 或要求必须配置 Rerank 模型等情况,应该如何处理?**
|
||||
|
||||
以下是知识库检索方式对文本召回的影响情况:
|
||||
|
||||
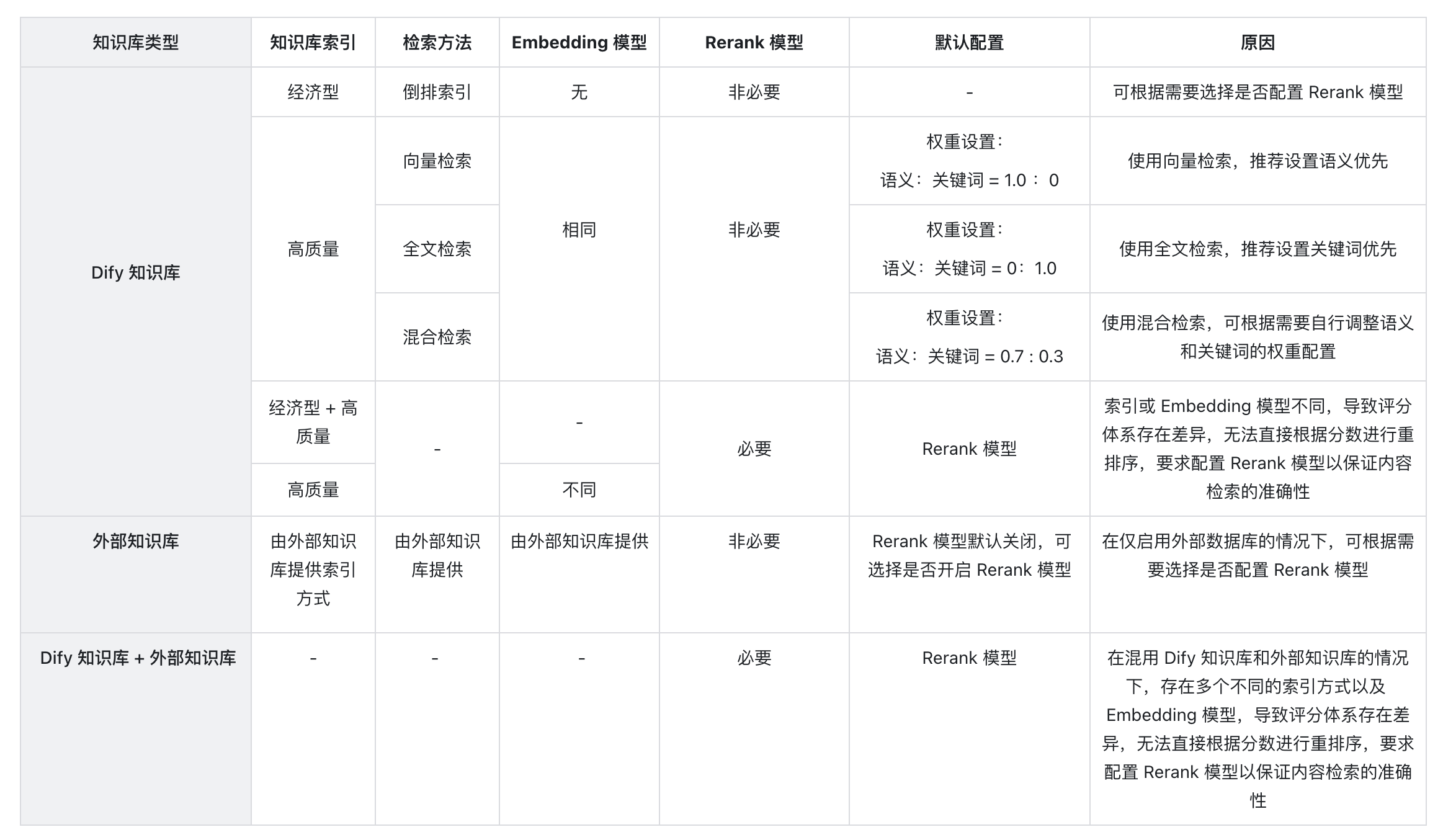
|
||||
|
||||
3. **引用多个知识库时,无法调整 “权重设置”,提示错误应如何处理?**
|
||||
|
||||
出现此问题是因为上下文内所引用的多个知识库内所使用的嵌入模型(Embedding)不一致,为避免检索内容冲突而出现此提示。推荐设置在“模型供应商”内设置并启用 Rerank 模型,或者统一知识库的检索设置。
|
||||
|
||||
4. **为什么在多路召回模式下找不到“权重设置”选项,只能看到 Rerank 模型?**
|
||||
|
||||
请检查你的知识库是否使用了“经济”型索引模式。如果是,那么将其切换为“高质量”索引模式。
|
||||
@@ -0,0 +1,134 @@
|
||||
---
|
||||
title: 知识库管理与文档维护
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
## 知识库管理
|
||||
|
||||
> 知识库管理页仅面向团队所有者、团队管理员、编辑权限角色开放。
|
||||
|
||||
在 Dify 团队首页中,点击顶部的 “知识库” tab 页,选择需要管理的知识库,轻点左侧导航中的**设置**进行调整。你可以调整知识库名称、描述、可见权限、索引模式、Embedding 模型和检索设置。
|
||||
|
||||
<Frame caption="知识库设置">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (8).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**知识库名称**,用于区分不同的知识库。
|
||||
|
||||
**知识库描述**,用于描述知识库内文档代表的信息。
|
||||
|
||||
**可见权限**,提供 **「 只有我 」** 、 **「 所有团队成员 」** 和 **「部分团队成员」** 三种权限范围。不具有权限的人将无法访问该知识库。若选择将知识库公开至其它成员,则意味着其它成员同样具备该知识库的查看、编辑和删除权限。
|
||||
|
||||
**索引模式**,详细说明请[参考文档](/zh-cn/user-guide/knowledge-base/knowledge-base-creation/upload-documents#3)。
|
||||
|
||||
**Embedding 模型**, 修改知识库的嵌入模型,修改 Embedding 模型将对知识库内的所有文档重新嵌入,原先的嵌入将会被删除。
|
||||
|
||||
**检索设置**,详细说明请[参考文档](/zh-cn/user-guide/knowledge-base/knowledge-base-creation/upload-documents#4)。
|
||||
|
||||
***
|
||||
|
||||
### 使用 API 维护知识库
|
||||
|
||||
Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库内的文档、分段进行增删改查等日常管理维护操作,请参考[知识库 API 文档](maintain-dataset-via-api.md)。
|
||||
|
||||
<Frame caption="知识库 API 管理">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (231).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
## 维护知识库中的文本
|
||||
|
||||
### 添加文档
|
||||
|
||||
知识库(Knowledge)是一些文档(Documents)的集合。文档可以由开发者或运营人员上传,或由同步其它数据源(对应数据源中的一个文件单位,例如 Notion 库内的一篇文档或新的在线文档网页)。
|
||||
|
||||
点击 「知识库」 > 「文档列表 ,然后轻点 「 添加文件 」,即可在已创建的知识库内上传新的文档。
|
||||
|
||||
<Frame caption="在知识库内上传新文档">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (10).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 禁用或归档文档
|
||||
|
||||
**禁用**:数据集支持将暂时不想被索引的文档或分段进行禁用,在数据集文档列表,点击禁用按钮,则文档被禁用;也可以在文档详情,点击禁用按钮,禁用整个文档或某个分段,禁用的文档将不会被索引。禁用的文档点击启用,可以取消禁用。
|
||||
|
||||
**归档**:一些不再使用的旧文档数据,如果不想删除可以将它进行归档,归档后的数据就只能查看或删除,不可以进行编辑。在数据集文档列表,点击归档按钮,则文档被归档,也可以在文档详情,归档文档。归档的文档将不会被索引。归档的文档也可以点击撤销归档。
|
||||
|
||||
***
|
||||
|
||||
### 查看文本分段
|
||||
|
||||
知识库内已上传的每个文档都会以文本分段(Chunks)的形式进行存储,你可以在分段列表内查看每一个分段的具体文本内容。
|
||||
|
||||
<Frame caption="查看已上传的文档分段">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (88).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 检查分段质量
|
||||
|
||||
文档分段对于知识库应用的问答效果有明显影响,在将知识库与应用关联之前,建议人工检查分段质量。
|
||||
|
||||
通过字符长度、标识符或者 NLP 语义分段等机器自动化的分段方式虽然能够显著减少大规模文本分段的工作量,但分段质量与不同文档格式的文本结构、前后文的语义联系都有关系,通过人工检查和订正可以有效弥补机器分段在语义识别方面的缺点。
|
||||
|
||||
检查分段质量时,一般需要关注以下几种情况:
|
||||
|
||||
* **过短的文本分段**,导致语义缺失;
|
||||
|
||||
<Frame caption="过短的文本分段">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (234).png" alt="" width="373" />
|
||||
</Frame>
|
||||
|
||||
* **过长的文本分段**,导致语义噪音影响匹配准确性;
|
||||
|
||||
<Frame caption="过长的文本分段">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (237).png" alt="" width="375" />
|
||||
</Frame>
|
||||
|
||||
* **明显的语义截断**,在使用最大分段长度限制时会出现强制性的语义截断,导致召回时缺失内容;
|
||||
|
||||
<Frame caption="明显的语义截断">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (236).png" alt="" width="357" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 添加文本分段
|
||||
|
||||
在分段列表内点击 「 添加分段 」 ,可以在文档内自行添加一个或批量添加多个自定义分段。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (90).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
批量添加分段时,你需要先下载 CSV 格式的分段上传模板,并按照模板格式在 Excel 内编辑所有的分段内容,再将 CSV 文件保存后上传。
|
||||
|
||||
<Frame caption="批量添加自定义分段">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (92).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### .png>)编辑文本分段
|
||||
|
||||
在分段列表内,你可以对已添加的分段内容直接进行编辑修改。包括分段的文本内容和关键词。
|
||||
|
||||
<Frame caption="编辑文档分段">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (93).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
### 元数据管理
|
||||
|
||||
除了用于标记不同来源文档的元数据信息,例如网页数据的标题、网址、关键词、描述等。元数据将被用于知识库的分段召回过程中,作为结构化字段参与召回过滤或者显示引用来源。
|
||||
|
||||
<Info>
|
||||
元数据过滤及引用来源功能当前版本尚未支持。
|
||||
</Info>
|
||||
|
||||
<Frame caption="元数据管理">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (230).png" alt="" />
|
||||
</Frame>
|
||||
@@ -0,0 +1,48 @@
|
||||
---
|
||||
title: 管理方式简介
|
||||
---
|
||||
|
||||
> 知识库管理页仅面向团队所有者、团队管理员、拥有编辑权限的角色开放。
|
||||
|
||||
点击 Dify 平台顶部的“知识库”按钮,选择需要管理的知识库。轻点左侧导航中的**设置**进行调整。
|
||||
|
||||
你可以在此处调整知识库名称、描述、可见权限、索引模式、Embedding 模型和检索设置。
|
||||
|
||||
|
||||
|
||||
* **知识库名称**,用于区分不同的知识库。
|
||||
* **知识库描述**,用于描述知识库内文档代表的信息。
|
||||
* **可见权限**,提供 **“只有我”** 、**“所有团队成员”** 和 **“部分团队成员”** 三种权限范围。不具有权限的人将无法访问该知识库。若选择将知识库公开至其它成员,则意味着其它成员同样具备该知识库的查看、编辑和删除权限。
|
||||
* **索引方法**,详细说明请参考[索引方法文档](../create-knowledge-and-upload-documents/setting-indexing-methods.md)。
|
||||
* **Embedding 模型**, 修改知识库的嵌入模型,修改 Embedding 模型将对知识库内的所有文档重新嵌入,原先的嵌入将会被删除。
|
||||
* **检索设置**,详细说明请参考[检索设置文档](../create-knowledge-and-upload-documents/setting-indexing-methods.md)。
|
||||
|
||||
***
|
||||
|
||||
#### 查看知识库内已关联的应用
|
||||
|
||||
知识库将会在左侧信息栏中显示已关联的应用数量。将鼠标悬停至圆形信息图标时将显示所有已关联的 Apps 列表,点击右侧的跳转按钮即可快速查看对应的应用。
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
你可以通过网页维护或 API 两种方式维护知识库内的文档。
|
||||
|
||||
#### 维护知识库内文档
|
||||
|
||||
支持管理知识库内的文档和对应的文档分段。详细说明请参考以下文档:
|
||||
|
||||
<Card title="维护知识库文档" icon="link" href="maintain-knowledge-documents.md">
|
||||
详细说明请参考此文档
|
||||
</Card>
|
||||
|
||||
#### 使用 API 维护知识库
|
||||
|
||||
Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库内的文档、分段进行增删改查等日常管理维护操作,请参考以下文档:
|
||||
|
||||
<Card title="使用 API 维护知识库" icon="link" href="maintain-dataset-via-api.md">
|
||||
详细说明请参考此文档
|
||||
</Card>
|
||||
|
||||
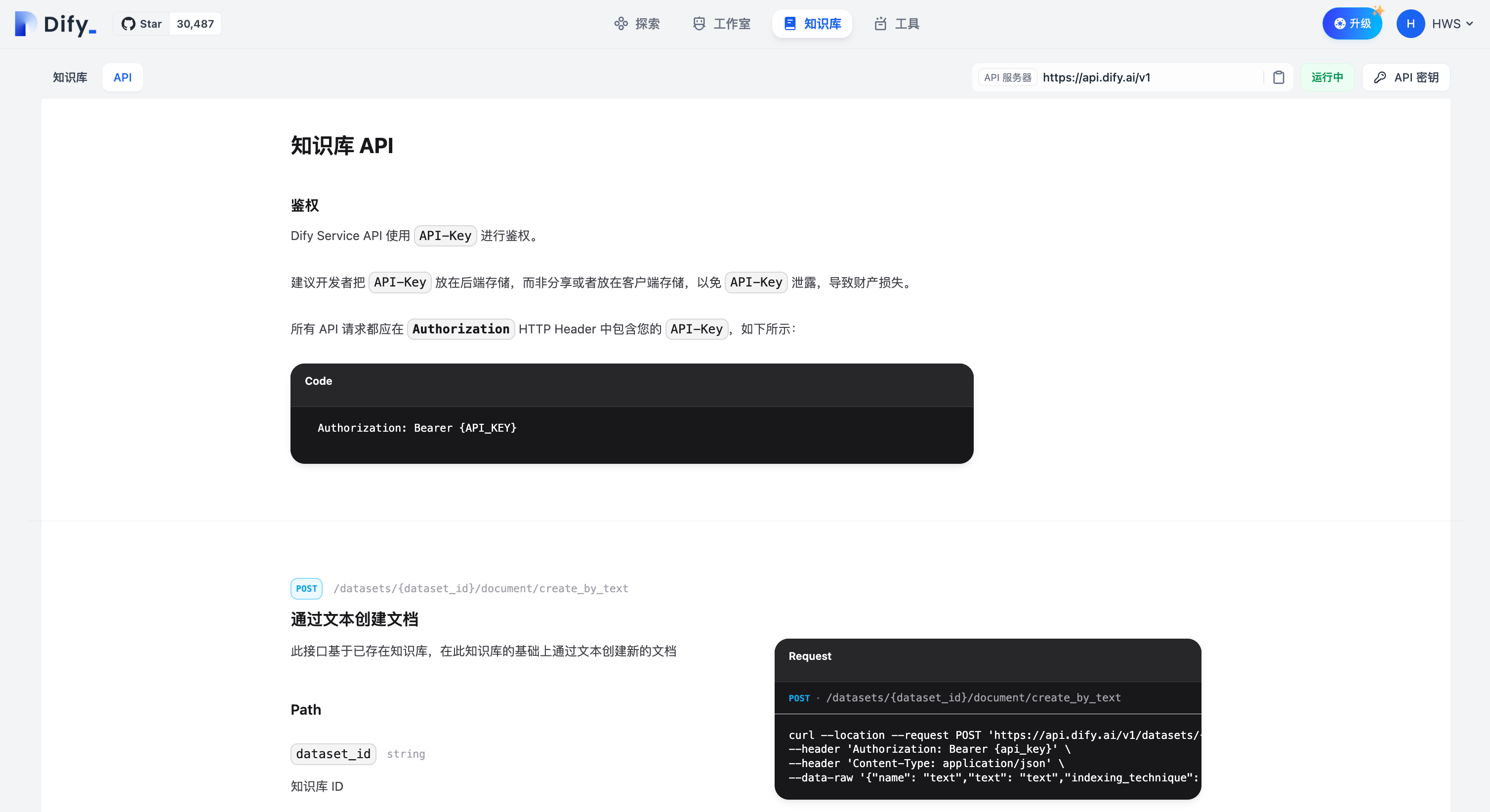
|
||||
@@ -0,0 +1,696 @@
|
||||
---
|
||||
title: 通过 API 维护知识库
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
> 鉴权、调用方式与应用 Service API 保持一致,不同之处在于,所生成的单个知识库 API token 具备操作当前账号下所有可见知识库的权限,请注意数据安全。
|
||||
|
||||
### 使用知识库 API 的优势
|
||||
|
||||
通过 API 维护知识库可大幅提升数据处理效率,你可以通过命令行轻松同步数据,实现自动化操作,而无需在用户界面进行繁琐操作。
|
||||
|
||||
主要优势包括:
|
||||
|
||||
* 自动同步: 将数据系统与 Dify 知识库无缝对接,构建高效工作流程;
|
||||
* 全面管理: 提供知识库列表,文档列表及详情查询等功能,方便你自建数据管理界面;
|
||||
* 灵活上传: 支持纯文本和文件上传方式,可针对分段(Chunks)内容的批量新增和修改操作;
|
||||
* 提高效率: 减少手动处理时间,提升 Dify 平台使用体验。
|
||||
|
||||
### 如何使用
|
||||
|
||||
进入知识库页面,在左侧的导航中切换至 **API** 页面。在该页面中你可以查看 Dify 提供的知识库 API 文档,并可以在 **API 密钥** 中管理可访问知识库 API 的凭据。
|
||||
|
||||
<Frame caption="Knowledge API Document">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/dataset-api-token.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
### API 调用示例
|
||||
|
||||
#### 通过文本创建文档
|
||||
|
||||
输入示例:
|
||||
|
||||
```json
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create_by_text' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"name": "text","text": "text","indexing_technique": "high_quality","process_rule": {"mode": "automatic"}}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "text.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695690280,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
```
|
||||
|
||||
#### 通过文件创建文档
|
||||
|
||||
输入示例:
|
||||
|
||||
```json
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create_by_file' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--form 'data="{"indexing_technique":"high_quality","process_rule":{"rules":{"pre_processing_rules":[{"id":"remove_extra_spaces","enabled":true},{"id":"remove_urls_emails","enabled":true}],"segmentation":{"separator":"###","max_tokens":500}},"mode":"custom"}}";type=text/plain' \
|
||||
--form 'file=@"/path/to/file"'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "Dify.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### **创建空知识库**
|
||||
|
||||
<Info>
|
||||
仅用来创建空知识库
|
||||
</Info>
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"name": "name", "permission": "only_me"}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "",
|
||||
"name": "name",
|
||||
"description": null,
|
||||
"provider": "vendor",
|
||||
"permission": "only_me",
|
||||
"data_source_type": null,
|
||||
"indexing_technique": null,
|
||||
"app_count": 0,
|
||||
"document_count": 0,
|
||||
"word_count": 0,
|
||||
"created_by": "",
|
||||
"created_at": 1695636173,
|
||||
"updated_by": "",
|
||||
"updated_at": 1695636173,
|
||||
"embedding_model": null,
|
||||
"embedding_model_provider": null,
|
||||
"embedding_available": null
|
||||
}
|
||||
```
|
||||
|
||||
#### **知识库列表**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets?page=1&limit=20' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"data": [
|
||||
{
|
||||
"id": "",
|
||||
"name": "知识库名称",
|
||||
"description": "描述信息",
|
||||
"permission": "only_me",
|
||||
"data_source_type": "upload_file",
|
||||
"indexing_technique": "",
|
||||
"app_count": 2,
|
||||
"document_count": 10,
|
||||
"word_count": 1200,
|
||||
"created_by": "",
|
||||
"created_at": "",
|
||||
"updated_by": "",
|
||||
"updated_at": ""
|
||||
},
|
||||
...
|
||||
],
|
||||
"has_more": true,
|
||||
"limit": 20,
|
||||
"total": 50,
|
||||
"page": 1
|
||||
}
|
||||
```
|
||||
|
||||
#### 删除知识库
|
||||
|
||||
输入示例:
|
||||
|
||||
```json
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
204 No Content
|
||||
```
|
||||
|
||||
#### 通过文本更新文档
|
||||
|
||||
此接口基于已存在知识库,在此知识库的基础上通过文本更新文档
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/update_by_text' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"name": "name","text": "text"}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "name.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": ""
|
||||
}
|
||||
```
|
||||
|
||||
#### 通过文件更新文档
|
||||
|
||||
此接口基于已存在知识库,在此知识库的基础上通过文件更新文档的操作。
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/update_by_file' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--form 'data="{"name":"Dify","indexing_technique":"high_quality","process_rule":{"rules":{"pre_processing_rules":[{"id":"remove_extra_spaces","enabled":true},{"id":"remove_urls_emails","enabled":true}],"segmentation":{"separator":"###","max_tokens":500}},"mode":"custom"}}";type=text/plain' \
|
||||
--form 'file=@"/path/to/file"'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"document": {
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "upload_file",
|
||||
"data_source_info": {
|
||||
"upload_file_id": ""
|
||||
},
|
||||
"dataset_process_rule_id": "",
|
||||
"name": "Dify.txt",
|
||||
"created_from": "api",
|
||||
"created_by": "",
|
||||
"created_at": 1695308667,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false,
|
||||
"display_status": "queuing",
|
||||
"word_count": 0,
|
||||
"hit_count": 0,
|
||||
"doc_form": "text_model"
|
||||
},
|
||||
"batch": "20230921150427533684"
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
#### **获取文档嵌入状态(进度)**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{batch}/indexing-status' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"data":[{
|
||||
"id": "",
|
||||
"indexing_status": "indexing",
|
||||
"processing_started_at": 1681623462.0,
|
||||
"parsing_completed_at": 1681623462.0,
|
||||
"cleaning_completed_at": 1681623462.0,
|
||||
"splitting_completed_at": 1681623462.0,
|
||||
"completed_at": null,
|
||||
"paused_at": null,
|
||||
"error": null,
|
||||
"stopped_at": null,
|
||||
"completed_segments": 24,
|
||||
"total_segments": 100
|
||||
}]
|
||||
}
|
||||
```
|
||||
|
||||
#### **删除文档**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```bash
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
#### **知识库文档列表**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"data": [
|
||||
{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"data_source_type": "file_upload",
|
||||
"data_source_info": null,
|
||||
"dataset_process_rule_id": null,
|
||||
"name": "dify",
|
||||
"created_from": "",
|
||||
"created_by": "",
|
||||
"created_at": 1681623639,
|
||||
"tokens": 0,
|
||||
"indexing_status": "waiting",
|
||||
"error": null,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"archived": false
|
||||
},
|
||||
],
|
||||
"has_more": false,
|
||||
"limit": 20,
|
||||
"total": 9,
|
||||
"page": 1
|
||||
}
|
||||
```
|
||||
|
||||
#### **新增分段**
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{"segments": [{"content": "1","answer": "1","keywords": ["a"]}]}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"data": [{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"document_id": "",
|
||||
"content": "1",
|
||||
"answer": "1",
|
||||
"word_count": 25,
|
||||
"tokens": 0,
|
||||
"keywords": [
|
||||
"a"
|
||||
],
|
||||
"index_node_id": "",
|
||||
"index_node_hash": "",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "",
|
||||
"created_at": 1695312007,
|
||||
"indexing_at": 1695312007,
|
||||
"completed_at": 1695312007,
|
||||
"error": null,
|
||||
"stopped_at": null
|
||||
}],
|
||||
"doc_form": "text_model"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 查询文档分段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```bash
|
||||
{
|
||||
"data": [{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"document_id": "",
|
||||
"content": "1",
|
||||
"answer": "1",
|
||||
"word_count": 25,
|
||||
"tokens": 0,
|
||||
"keywords": [
|
||||
"a"
|
||||
],
|
||||
"index_node_id": "",
|
||||
"index_node_hash": "",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "",
|
||||
"created_at": 1695312007,
|
||||
"indexing_at": 1695312007,
|
||||
"completed_at": 1695312007,
|
||||
"error": null,
|
||||
"stopped_at": null
|
||||
}],
|
||||
"doc_form": "text_model"
|
||||
}
|
||||
```
|
||||
|
||||
### 删除文档分段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments/{segment_id}' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```bash
|
||||
{
|
||||
"result": "success"
|
||||
}
|
||||
```
|
||||
|
||||
### 更新文档分段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments/{segment_id}' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--header 'Content-Type: application/json'\
|
||||
--data-raw '{"segment": {"content": "1","answer": "1", "keywords": ["a"], "enabled": false}}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```bash
|
||||
{
|
||||
"data": [{
|
||||
"id": "",
|
||||
"position": 1,
|
||||
"document_id": "",
|
||||
"content": "1",
|
||||
"answer": "1",
|
||||
"word_count": 25,
|
||||
"tokens": 0,
|
||||
"keywords": [
|
||||
"a"
|
||||
],
|
||||
"index_node_id": "",
|
||||
"index_node_hash": "",
|
||||
"hit_count": 0,
|
||||
"enabled": true,
|
||||
"disabled_at": null,
|
||||
"disabled_by": null,
|
||||
"status": "completed",
|
||||
"created_by": "",
|
||||
"created_at": 1695312007,
|
||||
"indexing_at": 1695312007,
|
||||
"completed_at": 1695312007,
|
||||
"error": null,
|
||||
"stopped_at": null
|
||||
}],
|
||||
"doc_form": "text_model"
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 错误信息
|
||||
|
||||
| 错误信息 | 错误码 | 原因描述 |
|
||||
|------|--------|---------|
|
||||
| no_file_uploaded | 400 | 请上传你的文件 |
|
||||
| too_many_files | 400 | 只允许上传一个文件 |
|
||||
| file_too_large | 413 | 文件大小超出限制 |
|
||||
| unsupported_file_type | 415 | 不支持的文件类型。目前只支持以下内容格式:`txt`, `markdown`, `md`, `pdf`, `html`, `html`, `xlsx`, `docx`, `csv` |
|
||||
| high_quality_dataset_only | 400 | 当前操作仅支持"高质量"知识库 |
|
||||
| dataset_not_initialized | 400 | 知识库仍在初始化或索引中。请稍候 |
|
||||
| archived_document_immutable | 403 | 归档文档不可编辑 |
|
||||
| dataset_name_duplicate | 409 | 知识库名称已存在,请修改你的知识库名称 |
|
||||
| invalid_action | 400 | 无效操作 |
|
||||
| document_already_finished | 400 | 文档已处理完成。请刷新页面或查看文档详情 |
|
||||
| document_indexing | 400 | 文档正在处理中,无法编辑 |
|
||||
| invalid_metadata | 400 | 元数据内容不正确。请检查并验证 |
|
||||
|
||||
#### 新增知识库元数据字段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location 'https://api.dify.ai/v1/datasets/{dataset_id}/metadata' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--data '{
|
||||
"type":"string",
|
||||
"name":"test"
|
||||
}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "9f63c91b-d60e-4142-bb0c-c81a54dc2db5",
|
||||
"type": "string",
|
||||
"name": "test"
|
||||
}
|
||||
```
|
||||
|
||||
#### 修改知识库元数据字段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request PATCH 'https://api.dify.ai/v1/datasets/{dataset_id}/metadata/{metadata_id}' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--header 'Authorization: Bearer {api_key}' \
|
||||
--data '{
|
||||
"name":"test"
|
||||
}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"id": "9f63c91b-d60e-4142-bb0c-c81a54dc2db5",
|
||||
"type": "string",
|
||||
"name": "test"
|
||||
}
|
||||
```
|
||||
|
||||
#### 删除知识库元数据字段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}/document/metadata/{metadata_id}' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```bash
|
||||
200 success
|
||||
```
|
||||
|
||||
#### 启用/禁用知识库元数据中的内置字段
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}/document/metadata/built-in/{action}' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
200 success
|
||||
```
|
||||
|
||||
#### 修改文档的元数据(赋值)
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/metadata' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
--data '{
|
||||
"operation_data":[
|
||||
{
|
||||
"document_id": "3e928bc4-65ea-4201-87c8-cbcc5871f525",
|
||||
"metadata_list": [
|
||||
{
|
||||
"id": "1887f5ec-966f-4c93-8c99-5ad386022f46",
|
||||
"value": "dify",
|
||||
"name": "test"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
200 success
|
||||
```
|
||||
|
||||
#### 数据集的元数据列表
|
||||
|
||||
输入示例:
|
||||
|
||||
```bash
|
||||
curl --location 'https://api.dify.ai/v1/datasets/{dataset_id}/metadata' \
|
||||
--header 'Authorization: Bearer {api_key}'
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
```json
|
||||
{
|
||||
"doc_metadata": [
|
||||
{
|
||||
"id": "550e8400-e29b-41d4-a716-446655440000",
|
||||
"type": "string",
|
||||
"name": "title",
|
||||
"use_count": 42
|
||||
},
|
||||
{
|
||||
"id": "6ba7b810-9dad-11d1-80b4-00c04fd430c8",
|
||||
"type": "number",
|
||||
"name": "price",
|
||||
"use_count": 28
|
||||
},
|
||||
{
|
||||
"id": "7ba7b810-9dad-11d1-80b4-00c04fd430c9",
|
||||
"type": "time",
|
||||
"name": "created_at",
|
||||
"use_count": 35
|
||||
}
|
||||
],
|
||||
"built_in_field_enabled": true
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,135 @@
|
||||
---
|
||||
title: 管理知识库
|
||||
---
|
||||
|
||||
## 管理知识库中的文档
|
||||
|
||||
### 添加文档
|
||||
|
||||
知识库是文档的集合。文档支持本地上传,或导入其它在线数据源。知识库内的文档对应数据源中的一个文件单位,例如 Notion 库内的一篇文档或新的在线文档网页。
|
||||
|
||||
点击“知识库” → “文档列表” → “添加文件”,在已创建的知识库内上传新的文档。
|
||||
|
||||

|
||||
|
||||
### 启用 / 禁用 / 归档 / 删除文档
|
||||
|
||||
**启用**:处于正常使用状态的文档,支持编辑内容与被知识库检索。对于已被禁用的文档,允许重新启用。已归档的文档需撤销归档状态后才能重新启用。
|
||||
|
||||
**禁用**:对于不希望在使用 AI 应用时被检索的文档,可以关闭文档右侧的蓝色开关按钮以禁用文档。禁用文档后,仍然可以编辑当前内容。
|
||||
|
||||
**归档**:对于一些不再使用的旧文档数据,如果不想删除可以将其归档。归档后的数据就只能查看或删除,无法重新编辑。你可以在知识库文档列表,点击归档按钮;或在文档详情页内进行归档。**归档操作支持撤销。**
|
||||
|
||||
**删除**:⚠️ 危险操作。对于一些错误文档或明显有歧义的内容,可以点击文档右侧菜单按钮中的删除。删除后的内容将无法被找回,请进行谨慎操作。
|
||||
|
||||
> 以上选项均支持选中多个文档后批量操作。
|
||||
|
||||
|
||||
|
||||
### 注意事项
|
||||
|
||||
* 对于 Sandbox/Free 版本用户,未使用知识库的将在 **7 天** 后自动禁用;
|
||||
* 对于 Professional/Team 版本用户,未使用知识库的将在 **30 天** 后自动禁用。
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
## 管理文本分段
|
||||
|
||||
### 查看文本分段
|
||||
|
||||
知识库内已上传的每个文档都会以文本分段(Chunks)形式进行存储。点击文档标题,在详情页中查看当前文档的分段列表,每页默认展示 10 个区块,你可以在网页底部调整每页的展示数量。
|
||||
|
||||
每个内容区块展示前 2 行的预览内容。若需要查看更加分段内的完整内容,轻点“展开分段”按钮即可查看。
|
||||
|
||||
|
||||
|
||||
你可以通过筛选栏快速查看所有已启用 / 未启用的文档。
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
### 检查分段质量
|
||||
|
||||
文档分段对于知识库应用的问答效果有明显影响,在将知识库与应用关联之前,建议人工检查分段质量。
|
||||
|
||||
检查分段质量时,一般需要关注以下几种情况:
|
||||
|
||||
* **过短的文本分段**,导致语义缺失;
|
||||
* **过长的文本分段**,导致语义噪音影响匹配准确性;
|
||||
* **明显的语义截断**,在使用最大分段长度限制时会出现强制性的语义截断,导致召回时缺失内容;
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
***
|
||||
|
||||
### 添加文本分段
|
||||
|
||||
知识库中的文档支持单独添加文本分段,不同的分段模式对应不同的分段添加方法。
|
||||
|
||||
<Card title="添加文本分段" icon="info" href="#">
|
||||
添加文本分段为付费功能,请前往[此处](https://dify.ai/pricing)升级账号以使用功能。
|
||||
</Card>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="通用模式">
|
||||
点击分段列表顶部的“添加分段”按钮,可以在文档内自行添加一个或批量添加多个自定义分段。
|
||||
|
||||
|
||||
</Tab>
|
||||
<Tab title="父子模式">
|
||||
点击分段列表顶部的「 添加分段 」按钮,可以在文档内自行添加一个或批量添加多个自定义**父分段。**
|
||||
|
||||

|
||||
|
||||
填写内容后,勾选尾部“连续新增”钮后,可以继续添加文本。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
***
|
||||
|
||||
### 编辑文本分段
|
||||
|
||||
<Tabs>
|
||||
<Tab title="通用模式">
|
||||
你可以对已添加的分段内容直接进行编辑或修改,包括修改分段内的文本内容或关键词。
|
||||
|
||||
|
||||
</Tab>
|
||||
<Tab title="父子模式">
|
||||
父分段包含其本身所包含的子分段内容,两者相互独立。你可以单独修改父分段或子分段的内容。
|
||||
|
||||
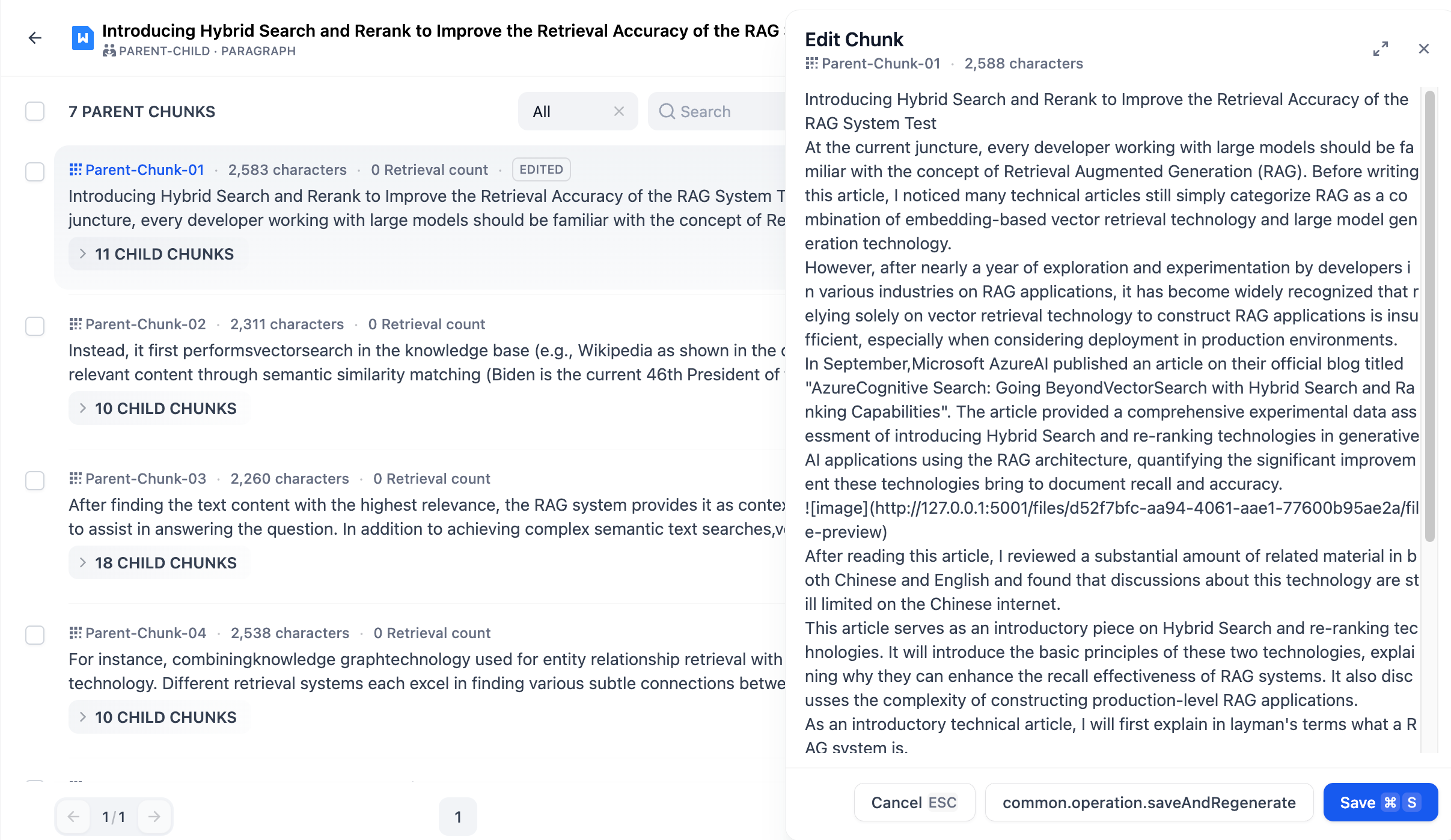
|
||||
|
||||
修改父分段后,点击 **“保存”** 后将不会影响子分段的内容。如需重新生成子分段内容,轻点 **“保存并重新生成子分段”**。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
### 修改已上传文档的文本分段
|
||||
|
||||
已创建的知识库支持重新配置文档分段。
|
||||
|
||||
<Tabs>
|
||||
<Tab title="较大分段">
|
||||
- 可在单个分段内保留更多上下文,适合需要处理复杂或上下文相关任务的场景。
|
||||
- 分段数量减少,从而降低处理时间和存储需求。
|
||||
</Tab>
|
||||
<Tab title="较小分段">
|
||||
- 提供更高的粒度,适合精确提取或总结文本内容。
|
||||
- 减少超出模型 token 限制的风险,更适配限制严格的模型。
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
你可以访问 **分段设置**,点击 **保存并处理** 按钮以保存对分段设置的修改,并重新触发当前文档的分段流程。当你保存设置并完成嵌入处理后,文档的分段列表将自动更新。
|
||||
|
||||
|
||||
|
||||
***
|
||||
|
||||
### 元数据管理
|
||||
|
||||
如需了解元数据的相关信息,请参阅 [元数据](https://docs.dify.ai/zh-hans/guides/knowledge-base/metadata)。
|
||||
@@ -0,0 +1,123 @@
|
||||
---
|
||||
title: 连接外部知识库
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
> 为做出区别,独立于 Dify 平台之外的知识库在本文内均被统称为 **“外部知识库”** 。
|
||||
|
||||
## 功能简介
|
||||
|
||||
对于内容检索有着更高要求的进阶开发者而言,Dify 平台内置的知识库功能和文本检索和召回机制**存在限制,无法轻易变更文本召回结果。**
|
||||
|
||||
出于对文本检索和召回的精确度有着更高追求,以及对内部资料的管理需求,部分团队选择自主研发 RAG 算法并独立维护文本召回系统、或将内容统一托管至云厂商的知识库服务(例如 [AWS Bedrock](https://aws.amazon.com/bedrock/))。
|
||||
|
||||
作为中立的 LLM 应用开发平台,Dify 致力于给予开发者更多选择权。
|
||||
|
||||
**连接外部知识库**功能可以将 Dify 平台与外部知识库建立连接。通过 API 服务,AI 应用能够获取更多信息来源。这意味着:
|
||||
|
||||
* Dify 平台能够直接获取托管在云服务提供商知识库内的文本内容,开发者无需将内容重复搬运至 Dify 中的知识库;
|
||||
* Dify 平台能够直接获取自建知识库内经算法处理后的文本内容,开发者仅需关注自建知识库的信息检索机制,并不断优化与提升信息召回的准确度。
|
||||
|
||||
<Frame caption="外部知识库连接原理">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (1) (1).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
以下是连接外部知识的详细步骤:
|
||||
|
||||
<Steps>
|
||||
<Step title="建立符合要求的外部知识库 API" titleSize="h2" >
|
||||
为了确保你的外部知识库与 Dify 连接成功,请在建立 API 服务前仔细阅读由 Dify 编写的[外部知识库 API 规范。](external-knowledge-api-documentation.md)
|
||||
</Step>
|
||||
<Step title="关联外部知识库">
|
||||
> 目前, Dify 连接外部知识库时仅具备检索权限,暂不支持对外部知识库进行优化与修改,开发者需自行维护外部知识库。
|
||||
|
||||
前往 **“知识库”** 页,点击右上角的 **“外部知识库 API”**,轻点 **“添加外部知识库 API”**。
|
||||
|
||||
按照页面提示,依次填写以下内容:
|
||||
|
||||
* 知识库的名称,允许自定义名称,用于区分所连接的不同外部知识 API;
|
||||
* API 接口地址,外部知识库的连接地址,示例 `api-endpoint/retrieval`;详细说明请参考[外部知识库 API](/zh-cn/user-guide/knowledge-base/api-connection/external-knowledge-api-documentation);
|
||||
* API Key,外部知识库连接密钥,详细说明请参考[外部知识库 API](/zh-cn/user-guide/knowledge-base/api-connection/external-knowledge-api-documentation);
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (353).png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="连接外部知识库">
|
||||
前往 **“知识库”** 页,点击添加知识库卡片下方的 **“连接外部知识库”** 跳转至参数配置页面。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (354).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
填写以下参数:
|
||||
|
||||
* **知识库名称与描述**
|
||||
* **外部知识库 API** 选择在第二步中关联的外部知识库 API;Dify 将通过 API 连接的方式,调用存储在外部知识库的文本内容;
|
||||
* **外部知识库 ID** 指定需要被关联的特定的外部知识库 ID,详细说明请参考[外部知识库 API](/zh-cn/user-guide/knowledge-base/api-connection/external-knowledge-api-documentation)。
|
||||
* **调整召回设置**
|
||||
|
||||
**Top K:** 用户发起提问时,将请求外部知识 API 获取相关性较高的内容分段。该参数用于筛选与用户问题相似度较高的文本片段。默认值为 3,数值越高,召回存在相关性的文本分段也就越多。
|
||||
|
||||
**Score 阈值:** 文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少,结果也会相对而言更加精准。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (355).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="测试外部知识库连接与召回">
|
||||
建立与外部知识库的连接后,开发者可以在 **“召回测试”** 中模拟可能的问题关键词,预览从外部知识库召回的文本分段。若对于召回结果不满意,可以尝试修改召回参数或自行调整外部知识库的检索设置。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (356).png" alt="" />
|
||||
</Frame>
|
||||
</Step>
|
||||
<Step title="在应用内集成外部知识库">
|
||||
- **Chatbot / Agent 类型应用**
|
||||
|
||||
在 Chatbot / Agent 类型应用内的编排页中的 **“上下文”** 内,选中带有 `EXTERNAL` 标签的外部知识库。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (357).png" alt="" />
|
||||
</Frame>
|
||||
|
||||
- **Chatflow / Workflow 类型应用**
|
||||
|
||||
在 Chatflow / Workflow 类型应用内添加 **“知识检索”** 节点,选中带有 `EXTERNAL` 标签的外部知识库。
|
||||
|
||||
<Frame caption="">
|
||||
<img src="/zh-cn/user-guide/.gitbook/assets/image (358).png" alt="" /><figcaption></figcaption>
|
||||
</Frame>
|
||||
|
||||
</Step>
|
||||
<Step title="管理外部知识库" titleSize="p">
|
||||
在 **“知识库”** 页,外部知识库的卡片右上角会带有 **EXTERNAL** 标签。进入需要修改的知识库,点击 **“设置”** 修改以下内容:
|
||||
|
||||
* **知识库名称和描述**
|
||||
* **可见范围** 提供 「 只有我 」 、 「 所有团队成员 」 和 「部分团队成员」 三种权限范围。不具有权限的人将无法访问该知识库。若选择将知识库公开至其它成员,则意味着其它成员同样具备该知识库的查看、编辑和删除权限。
|
||||
* **召回设置**
|
||||
|
||||
**Top K:** 用户发起提问时,将请求外部知识 API 获取相关性较高的内容分段。该参数用于筛选与用户问题相似度较高的文本片段。默认值为 3,数值越高,召回存在相关性的文本分段也就越多。
|
||||
|
||||
**Score 阈值:** 文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少,结果也会相对而言更加精准。
|
||||
|
||||
外部知识库所关联的 **“外部知识库 API”** 和 **“外部知识 ID”** 不支持修改,如需修改请关联新的 “外部知识库 API” 并重新进行连接。
|
||||
</Step>
|
||||
</Steps>
|
||||
|
||||
## 连接示例
|
||||
|
||||
[如何连接 AWS Bedrock 知识库?](user-guide/learn-more/use-cases/how-to-connect-aws-bedrock.md "mention")
|
||||
|
||||
## 常见问题
|
||||
|
||||
**连接外部知识库 API 时异常,出现报错如何处理?**
|
||||
|
||||
以下是返回信息各个错误码所对应的错误提示与解决办法:
|
||||
|
||||
| 错误码 | 错误提示 | 解决办法 |
|
||||
| ---- | --------------------------- | ------------------------------ |
|
||||
| 1001 | 无效的 Authorization header 格式 | 请检查请求的 Authorization header 格式 |
|
||||
| 1002 | 验证异常 | 请检查所填写的 API Key 是否正确 |
|
||||
| 2001 | 知识库不存在 | 请检查外部知识库 |
|
||||
@@ -0,0 +1,63 @@
|
||||
---
|
||||
title: 创建步骤
|
||||
---
|
||||
|
||||
创建知识库并上传文档大致分为以下步骤:
|
||||
|
||||
1. 创建知识库。通过上传本地文件、导入在线数据或创建一个空的知识库。
|
||||
|
||||
<Card title="导入内容数据" icon="link" href="/guides/knowledge-base/import-content-data">
|
||||
通过上传本地文件、导入在线数据或创建一个空的知识库。
|
||||
</Card>
|
||||
|
||||
2. 指定分段模式。该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。你可以在此环节预览文本的分段效果。
|
||||
|
||||
<Card title="文本分段和清洗" icon="link" href="/guides/knowledge-base/chunking-and-cleaning-text">
|
||||
了解文本分段和数据清洗流程
|
||||
</Card>
|
||||
|
||||
3. 设定索引方法和检索设置。知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。
|
||||
|
||||
<Card title="设置索引方法" icon="link" href="/guides/knowledge-base/setting-indexing-methods">
|
||||
了解如何设置索引方法和检索参数
|
||||
</Card>
|
||||
|
||||
5. 等待分段嵌入
|
||||
6. 完成上传,在应用内关联知识库并使用。你可以参考[在应用内集成知识库](/guides/knowledge-base/integrate-knowledge-within-application),搭建出能够基于知识库进行问答的 LLM 应用。如需修改或管理知识库,请参考[知识库管理与文档维护](/guides/knowledge-base/knowledge-and-documents-maintenance/)。
|
||||
|
||||

|
||||
|
||||
***
|
||||
|
||||
### 参考阅读
|
||||
|
||||
#### ETL
|
||||
|
||||
在 RAG 的生产级应用中,为了获得更好的数据召回效果,需要对多源数据进行预处理和清洗,即 ETL (_extract, transform, load_)。为了增强非结构化/半结构化数据的预处理能力,Dify 支持了可选的 ETL 方案:**Dify ETL** 和[ ](https://docs.unstructured.io/welcome)[**Unstructured ETL** ](https://unstructured.io/)。Unstructured 能够高效地提取并转换你的数据为干净的数据用于后续的步骤。Dify 各版本的 ETL 方案选择:
|
||||
|
||||
* SaaS 版不可选,默认使用 Unstructured ETL;
|
||||
* 社区版可选,默认使用 Dify ETL ,可通过[环境变量](https://docs.dify.ai/v/zh-hans/getting-started/install-self-hosted/environments#zhi-shi-ku-pei-zhi)开启 Unstructured ETL;
|
||||
|
||||
文件解析支持格式的差异:
|
||||
|
||||
| DIFY ETL | Unstructured ETL |
|
||||
| ---------------------------------------------- | ------------------------------------------------------------------------ |
|
||||
| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
|
||||
|
||||
不同的 ETL 方案在文件提取效果的方面也会存在差异,想了解更多关于 Unstructured ETL 的数据处理方式,请参考[官方文档](https://docs.unstructured.io/open-source/core-functionality/partitioning)。
|
||||
|
||||
***
|
||||
|
||||
#### **Embedding**
|
||||
|
||||
**Embedding 嵌入**是一种将离散型变量(如单词、句子或者整个文档)转化为连续的向量表示的技术。它可以将高维数据(如单词、短语或图像)映射到低维空间,提供一种紧凑且有效的表示方式。这种表示不仅减少了数据的维度,还保留了重要的语义信息,使得后续的内容检索更加高效。
|
||||
|
||||
**Embedding 模型**是一种专门用于将文本向量化的大语言模型,它擅长将文本转换为密集的数值向量,有效捕捉语义信息。
|
||||
|
||||
> 如需了解更多,请参考:[《Dify:Embedding 技术与 Dify 知识库设计/规划》](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)。
|
||||
|
||||
***
|
||||
|
||||
#### **元数据**
|
||||
|
||||
如需使用元数据功能管理知识库,请参阅 [元数据](https://docs.dify.ai/zh-hans/guides/knowledge-base/metadata)。
|
||||
@@ -0,0 +1,254 @@
|
||||
---
|
||||
title: 创建知识库 & 上传文档
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
创建知识库并上传文档大致分为以下步骤:
|
||||
|
||||
1. 在 Dify 团队内创建知识库,从本地选择你需要上传的文档;
|
||||
2. 选择分段与清洗模式,预览效果;
|
||||
3. 配置索引方式和检索设置;
|
||||
4. 等待分段嵌入;
|
||||
5. 完成上传,在应用内关联并使用 🎉
|
||||
|
||||
以下是各个步骤的详细说明:
|
||||
|
||||
## 1 创建知识库
|
||||
|
||||
在 Dify 主导航栏中点击知识库,在该页面你可以看到团队内的知识库,点击“**创建知识库”** 进入创建向导。
|
||||
|
||||
- 拖拽或选中文件进行上传,批量上传的文件数量取决于[订阅计划](https://dify.ai/pricing);
|
||||
- 如果还没有准备好文档,可以先创建一个空知识库;
|
||||
- 如果你在创建知识库时选择了使用外部数据源(Notion 或同步 Web 站点),该知识库的类型不可更改;此举是为了防止单一知识库存在多数据源而造成的管理困难。如果你需要使用多个数据源,建议创建多个知识库并使用 [多路召回](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 模式在同一个应用内引用多个知识库。
|
||||
|
||||
**上传文档存在以下限制:**
|
||||
|
||||
- 单文档的上传大小限制为 15MB;
|
||||
|
||||
<Frame caption="创建知识库">
|
||||
<img src="/zh-cn/images/en-upload-files-1.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
***
|
||||
|
||||
## 2 选择分段与清洗策略
|
||||
|
||||
将内容上传至知识库后,需要先对内容进行分段与数据清洗,该阶段可以被理解为是对内容预处理与结构化。
|
||||
|
||||
<Accordion title="什么是分段与清洗?">
|
||||
|
||||
* **分段**
|
||||
|
||||
大语言模型存在有限的上下文窗口,无法将知识库中的所有内容发送至 LLM。因此可以将整段长文本分段处理,再基于用户问题,召回与关联度最高的段落内容,即采用分段 TopK 召回模式。此外,将用户问题与文本分段进行语义匹配时,合适的分段大小有助于找到知识库内关联性最高的文本内容,减少信息噪音。
|
||||
|
||||
* **清洗**
|
||||
|
||||
为了保证文本召回的效果,通常需要在将数据录入知识库之前便对其进行清理。例如,如果文本内容中存在无意义的字符或者空行,可能会影响问题回复的质量。关于 Dify 内置的清洗策略,详细说明请参考 [ETL](create-knowledge-and-upload-documents.md#etl)。
|
||||
|
||||
</Accordion>
|
||||
|
||||
支持以下两种策略:
|
||||
|
||||
* **自动分段与清洗**
|
||||
* **自定义**
|
||||
|
||||
<Tabs>
|
||||
|
||||
<Tab title="自动分段与清洗" >
|
||||
|
||||
#### 自动分段与清洗
|
||||
|
||||
自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,Dify 将为你自动分段与清洗内容文件。
|
||||
|
||||
<Frame caption="自动分段与清洗">
|
||||
<img src="/zh-cn/images/en-upload-files-2.avif" alt="Automatic segmentation and cleaning" />
|
||||
</Frame>
|
||||
|
||||
</Tab>
|
||||
|
||||
<Tab title="自定义" >
|
||||
#### 自定义
|
||||
|
||||
自定义模式适合对于文本处理有明确需求的进阶用户。在自定义模式下,你可以根据不同的文档格式和场景要求,手动配置文本的分段规则和清洗策略。
|
||||
|
||||
**分段规则:**
|
||||
|
||||
* **分段标识符**,指定标识符,系统将在文本中出现该标识符时分段。例如填写 `\n`([正则表达式](https://regexr.com/)中的换行符),文本换行时将自动分段;
|
||||
* **分段最大长度**,根据分段的文本字符数最大上限来进行分段,超出该长度时将强制分段。一个分段的最大长度为 4000 Tokens;
|
||||
* **分段重叠长度**,分段重叠指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%;
|
||||
|
||||
**文本预处理规则:** 文本预处理规则可以帮助过滤知识库内部分无意义的内容。
|
||||
|
||||
* 替换连续的空格、换行符和制表符;
|
||||
* 删除所有 URL 和电子邮件地址;
|
||||
|
||||
<Frame caption="自定义">
|
||||
<img src="/zh-cn/images/en-upload-files-3.webp" alt="" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 3 索引方式
|
||||
|
||||
指定内容的预处理方法(分段与清洗)后,接下来需要指定对结构化内容的索引方式。索引方式将直接影响 LLM 对知识库内容的检索效率以及回答的准确性。
|
||||
|
||||
系统提供以下三种索引方式,你可以根据实际需求调整每种方式内的[检索设置](create-knowledge-and-upload-documents.md#id-4-jian-suo-she-zhi):
|
||||
|
||||
* 高质量
|
||||
* 经济
|
||||
|
||||
<Tabs>
|
||||
<Tab title="高质量" >
|
||||
在高质量模式下,将首先调用 Embedding 嵌入模型(支持切换)将已分段的文本转换为数字向量,帮助开发者更有效地实现大量文本信息的压缩与存储;同时还能够在用户与 LLM 对话时提供更高的准确度。
|
||||
> 如需了解更多,请参考[《Embedding 技术与 Dify》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
|
||||
高质量索引方式提供向量检索、全文检索和混合检索三种检索设置。关于更多检索设置的说明,请阅读 [检索设置](create-knowledge-and-upload-documents.md#id-4-jian-suo-she-zhi)。
|
||||
<Frame caption="高质量模式">
|
||||
<img src="/zh-cn/images/en-upload-files-4.webp" alt="" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
|
||||
<Tab title="经济" >
|
||||
使用离线的向量引擎与关键词索引方式,降低了准确度但无需额外花费 Token,产生费用。检索方式仅提供倒排索引,详细说明请阅读[下文](create-knowledge-and-upload-documents.md#dao-pai-suo-yin)。
|
||||
<Frame caption="经济模式">
|
||||
<img src="/zh-cn/images/en-upload-files-5.webp" alt="" />
|
||||
</Frame>
|
||||
</Tab>
|
||||
|
||||
</Tabs>
|
||||
|
||||
***
|
||||
|
||||
## 4 检索设置
|
||||
|
||||
在**高质量索引方式**下,Dify 提供以下 3 种检索方案:
|
||||
|
||||
* **向量检索**
|
||||
* **全文检索**
|
||||
* **混合检索**
|
||||
|
||||
<Tabs>
|
||||
|
||||
<Tab title="向量检索" >
|
||||
|
||||
**定义:** 向量化用户输入的问题并生成查询向量,比较查询向量与知识库内对应的文本向量距离,寻找最近的分段内容。
|
||||
|
||||
<Frame caption="向量检索">
|
||||
<img src="/zh-cn/images/en-upload-files-8.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**向量检索设置:**
|
||||
|
||||
**Rerank 模型:** 使用第三方 Rerank 模型对向量检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
**Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
|
||||
|
||||
> TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置。
|
||||
|
||||
</Tab>
|
||||
|
||||
<Tab title="全文检索" >
|
||||
|
||||
**定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
|
||||
|
||||
<Frame caption="全文检索">
|
||||
<img src="/zh-cn/images/en-upload-files-9.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
**Rerank 模型:** 使用第三方 Rerank 模型对全文检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
**Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
|
||||
|
||||
> TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置。
|
||||
|
||||
</Tab>
|
||||
|
||||
<Tab title="混合检索" >
|
||||
**定义:** 同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。在此模式下可以指定“权重设置”(无需配置 Rerank 模型 API)或选择 Rerank 模型进行检索。
|
||||
|
||||
<Frame caption="混合检索">
|
||||
<img src="/zh-cn/images/en-upload-files-10.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
在混合检索设置内可以选择启用**“权重设置”**或**“Rerank 模型”**。
|
||||
|
||||
**权重设置:** 允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。
|
||||
|
||||
* **语义值为 1**
|
||||
|
||||
仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
|
||||
|
||||
> 语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:[《Dify:Embedding 技术与 Dify 数据集设计/规划》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
|
||||
|
||||
* **关键词值为 1**
|
||||
|
||||
仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
|
||||
|
||||
* **自定义关键词和语义权重**
|
||||
|
||||
除了仅启用语义检索或关键词检索模式,我们还提供了灵活的自定义权重设置。你可以通过不断调试二者的权重,找到符合业务场景的最佳权重比例。
|
||||
|
||||
***
|
||||
|
||||
**Rerank 模型:** 你可以在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”,系统会在混合检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。
|
||||
|
||||
***
|
||||
|
||||
**“权重设置”** 和 **“Rerank 模型”** 设置内支持启用以下选项:
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
**Score 阈值:**用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5。数值越高,预期被召回的文本数量越少。
|
||||
|
||||
</Tab>
|
||||
|
||||
</Tabs>
|
||||
|
||||
***
|
||||
|
||||
在**经济索引方式**下,Dify 仅提供 1 种检索设置:
|
||||
|
||||
#### **倒排索引**
|
||||
|
||||
倒排索引是一种用于快速检索文档中关键词的索引结构,它的基本原理是将文档中的关键词映射到包含这些关键词的文档列表,从而提高搜索效率。具体原理请参考[《倒排索引》](https://zh.wikipedia.org/wiki/%E5%80%92%E6%8E%92%E7%B4%A2%E5%BC%95)。
|
||||
|
||||
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
|
||||
|
||||
<Frame caption="倒排索引">
|
||||
<img src="/zh-cn/images/en-upload-files-8.png" alt="" />
|
||||
</Frame>
|
||||
|
||||
指定检索设置后,你可以参考[召回测试/引用归属](/zh-cn/user-guide/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
|
||||
|
||||
## 5 完成上传
|
||||
|
||||
配置完上文所述的各项配置后,轻点“保存并处理”即可完成知识库的创建。你可以参考 [在应用内集成知识库](integrate-knowledge-within-application.md),搭建出能够基于知识库进行问答的 LLM 应用。
|
||||
|
||||
***
|
||||
|
||||
## 参考阅读
|
||||
|
||||
#### ETL
|
||||
|
||||
在 RAG 的生产级应用中,为了获得更好的数据召回效果,需要对多源数据进行预处理和清洗,即 ETL (_extract, transform, load_)。为了增强非结构化/半结构化数据的预处理能力,Dify 支持了可选的 ETL 方案:**Dify ETL** 和[ ](https://docs.unstructured.io/welcome)[**Unstructured ETL** ](https://unstructured.io/)。
|
||||
|
||||
> Unstructured 能够高效地提取并转换您的数据为干净的数据用于后续的步骤。Dify 各版本的 ETL 方案选择:
|
||||
|
||||
文件解析支持格式的差异:
|
||||
|
||||
| DIFY ETL | Unstructured ETL |
|
||||
| ---------------------------------------------- | ------------------------------------------------------------------------ |
|
||||
| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
|
||||
|
||||
<Info>不同的 ETL 方案在文件提取效果的方面也会存在差异,想了解更多关于 Unstructured ETL 的数据处理方式,请参考[官方文档](https://docs.unstructured.io/open-source/core-functionality/partitioning)。</Info>
|
||||
|
||||
**Embedding 模型**
|
||||
|
||||
**Embedding 嵌入**是一种将离散型变量(如单词、句子或者整个文档)转化为连续的向量表示的技术。它可以将高维数据(如单词、短语或图像)映射到低维空间,提供一种紧凑且有效的表示方式。这种表示不仅减少了数据的维度,还保留了重要的语义信息,使得后续的内容检索更加高效。
|
||||
|
||||
**Embedding 模型**是一种专门用于将文本向量化的大语言模型,它擅长将文本转换为密集的数值向量,有效捕捉语义信息。
|
||||
|
||||
> 如需了解更多,请参考:[《Dify:Embedding 技术与 Dify 数据集设计/规划》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
|
||||
354
zh-cn/user-guide/knowledge-base/metadata.mdx
Normal file
354
zh-cn/user-guide/knowledge-base/metadata.mdx
Normal file
@@ -0,0 +1,354 @@
|
||||
---
|
||||
title: 元数据
|
||||
---
|
||||
|
||||
## 什么是元数据?
|
||||
|
||||
### 定义
|
||||
|
||||
元数据是用于描述其他数据的信息。简单来说,它是"关于数据的数据"。它就像一本书的目录或标签,可以为你介绍数据的内容、来源和用途。
|
||||
通过提供数据的上下文,元数据能帮助你在知识库内快速查找和管理数据。
|
||||
|
||||
### 其他相关定义
|
||||
|
||||
- **元数据字段(Metadata Field)**:元数据字段是用于描述文档特定属性的标识项,每个字段代表文档的某个特征或信息。例如,"author"字段用于描述该文档的作者。
|
||||
|
||||
- **字段值计数(Value Count)**:字段值计数是指在某条元数据字段中不同字段值的数量。例如,此处的"3"是字段值计数,指该字段中有 3 个独特的字段值。
|
||||
|
||||

|
||||
|
||||
- **字段名(Field Name)**:字段名是对该元数据的简短描述,它表示该字段所代表的内容。例如"author""language"等。
|
||||
|
||||
- **字段值(Value)**:字段值是该字段的具体信息或属性,例如"Jack""English"。
|
||||
|
||||

|
||||
|
||||
- **值类型(Value Type)**:值类型指字段值的类型。
|
||||
- 目前,Dify 的元数据功能仅支持以下三种值类型:
|
||||
- **字符串**(String):文本值。
|
||||
- **数字**(Number):数值。
|
||||
- **时间**(Time):日期和时间。
|
||||
|
||||
|
||||
|
||||
## 如何管理知识库元数据?
|
||||
|
||||
### 管理知识库元数据字段
|
||||
|
||||
在知识库管理界面,你可以创建、修改和删除元数据字段。
|
||||
|
||||
> 注意:所有在此界面进行的更新均为**全局更新**,这意味着对元数据字段列表的任何更改都会影响整个知识库,包括所有文档中标记的元数据。
|
||||
|
||||
#### 元数据管理界面简介
|
||||
|
||||
##### 入口
|
||||
|
||||
在知识库管理界面,点击右上方的 **元数据** 按钮,进入元数据管理界面。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
##### 功能
|
||||
|
||||
- **查看元数据字段**:你可以查看知识库的内置元数据和自定义元数据。**内置元数据(Built-in)** 是系统自动生成的字段;**自定义元数据** 是用户根据需求手动添加的字段。
|
||||
|
||||
- **新增元数据字段**:通过点击 **+添加元数据** 按钮,你可以添加新的元数据字段并选择字段值类型与填写字段名。
|
||||
|
||||
- **编辑元数据字段**:通过点击每条元数据字段旁的编辑图标,你可以修改字段的名称。
|
||||
|
||||
- **删除元数据字段**:通过点击每条元数据字段旁的删除图标,你可以移除不再需要的字段。
|
||||
|
||||
##### 价值
|
||||
|
||||
**元数据管理界面支持用户集中管理知识库中的元数据字段。** 这一界面能帮助用户灵活地调整文档的标识属性,使得文档在检索和访问时更加高效、准确。
|
||||
|
||||
##### 知识库元数据字段的类型
|
||||
|
||||
在知识库中,元数据字段分为两类:**内置元数据(Built-in)** 和 **自定义元数据**。
|
||||
|
||||
| | 内置元数据(Built-in) | 自定义元数据 |
|
||||
|---|---|---|
|
||||
| 显示位置 | 知识库界面 元数据 栏的下半部分。 | 知识库界面 元数据 栏的上半部分。 |
|
||||
| 示例图 |  |  |
|
||||
| 启用方式 | 默认禁用,需要手动开启才能生效。 | 由用户根据需求自由添加。 |
|
||||
| 生成方式 | 启用后,由系统自动提取相关信息并生成字段值。 | 用户手动添加,完全由用户自定义。 |
|
||||
| 修改权限 | 一旦生成,无法修改字段与字段值。 | 可以删除或编辑字段名称,也可以修改字段值。 |
|
||||
| 应用范围 | 启用后,适用于已上传和新上传的所有文档。 | 添加元数据字段后,字段会储存在知识库的元数据列表中/需要手动设置,才能将该字段应用于具体文档。 |
|
||||
| 字段 | 由系统预定义,包括:
|
||||
• Original filename (string):原始文件名
|
||||
• Uploader (string):上传者
|
||||
• Upload date (time):上传日期
|
||||
• Last update date (time):最后更新时间
|
||||
• Source (string):文件来源 | 在初始状态下,知识库无自定义元数据字段,需要用户手动添加。 |
|
||||
| 字段值类型 | 用户可以自由选择字段值类型,目前,Dify的元数据功能仅支持以下三种值类型:
|
||||
• 字符串 (string):文本值
|
||||
• 数字 (number):数值
|
||||
• 时间 (time):日期和时间 ||
|
||||
| 使用场景 | 适用于存储和展示文档的基本信息,如文件名、上传者、上传日期等。 | 适用于需要根据特定业务需求自定义的元数据字段,如文档的保密级别、标签等。 |
|
||||
|
||||
#### 新建元数据字段
|
||||
|
||||
1. 点击 **+添加元数据** 按钮,弹出 **新建元数据** 弹窗。
|
||||
|
||||

|
||||
|
||||
2. 在 **字段值类型** 中选择元数据字段的值类型。
|
||||
- **字符串**(String):文本值。
|
||||
- **数字**(Number):数值。
|
||||
- **时间**(Time):日期和时间。
|
||||
|
||||
3. 在 **名称** 框中填写字段的名称。
|
||||
|
||||
> 字段名仅支持小写字母、数字和下划线(_)字符,不支持空格和大写字母。
|
||||
|
||||
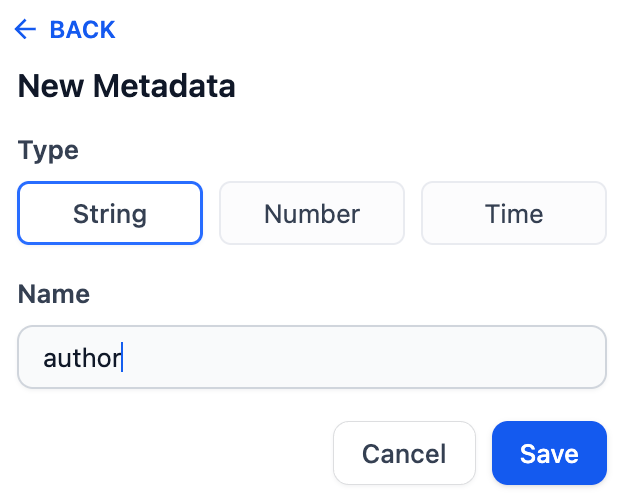
|
||||
|
||||
4. 点击 **保存** 按钮,保存字段。
|
||||
|
||||
> 如果新建单条字段,该字段将在知识库的所有文档中同步更新。
|
||||
|
||||

|
||||
|
||||
#### 修改元数据字段
|
||||
|
||||
1. 点击单条元数据字段右侧的编辑按钮,弹出 **重命名** 弹窗。
|
||||
|
||||

|
||||
|
||||
2. 在 **名称** 框中修改字段名称。
|
||||
|
||||
> 此弹窗仅支持修改字段名称,不支持修改字段值类型。
|
||||
|
||||
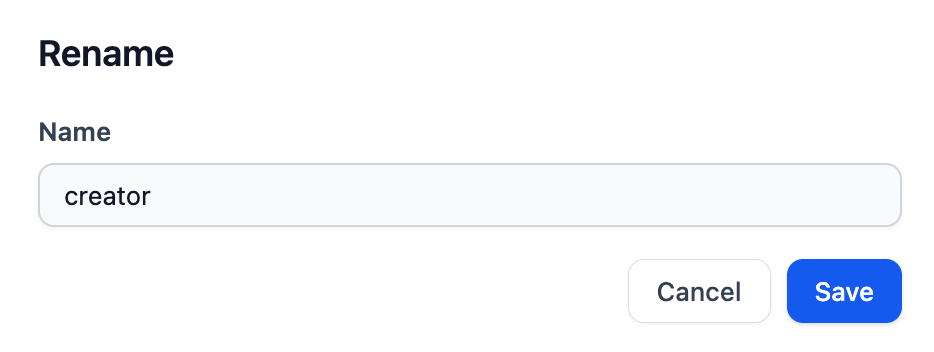
|
||||
|
||||
3. 点击 **保存** 按钮,保存修改后的字段。
|
||||
|
||||

|
||||
|
||||
#### 删除元数据字段
|
||||
|
||||
点击单条元数据字段右侧的删除按钮,可以删除该字段。
|
||||
|
||||
> 如果删除单条字段,该字段及该字段下包含的字段值将从知识库的所有文档中删除。
|
||||
|
||||

|
||||
|
||||
### 编辑文档元数据信息
|
||||
|
||||
#### 批量编辑文档元数据信息
|
||||
|
||||
你可以在知识库管理界面批量编辑文档的元数据信息。
|
||||
|
||||
##### 编辑元数据弹窗简介
|
||||
|
||||
###### 入口
|
||||
|
||||
1. 打开知识库管理界面,在文档列表左侧的白色方框中勾选你希望批量操作的文档。勾选后,页面下方会弹出操作选项。
|
||||
|
||||
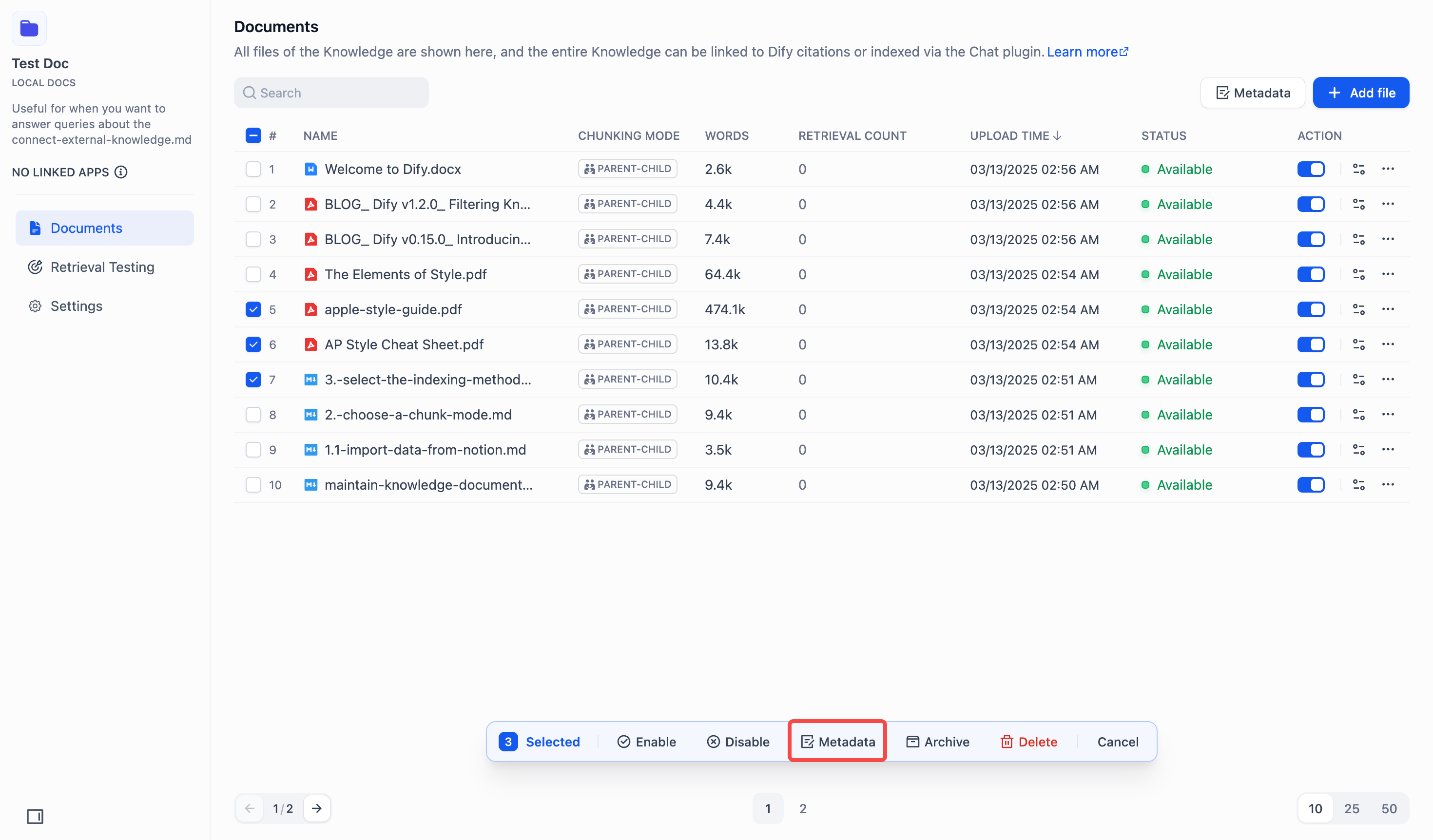
|
||||
|
||||
2. 点击操作选项中的 **元数据**,弹出 **编辑元数据** 弹窗。
|
||||
|
||||

|
||||
|
||||
###### 功能
|
||||
|
||||
- **查看选中文档的元数据信息:** 在弹窗的上半部分的 **已有元数据** 区和下半部分的 **新增元数据** 区,你会看到所有选中文档的元数据字段和此次操作新增的元数据字段。
|
||||
|
||||
<Info>
|
||||
每个字段的左侧会显示该字段的编辑状态:
|
||||
未编辑:字段左侧为空白,表示该字段未进行修改。
|
||||
已编辑:字段左侧显示蓝色圆点,表示该字段已经被编辑。
|
||||
重置:将光标悬停在蓝色圆点上时,圆点会变为 **重置** 按钮。点击后,该字段的内容会恢复到未编辑时的状态。
|
||||
</Info>
|
||||
|
||||
- **删改字段值:** 你可以在每条字段右侧的矩形框中删改其字段值。
|
||||
|
||||
<Info>
|
||||
如果某个字段只有一个值,你会看到该字段的值直接显示在字段右侧的矩形框中,可以直接修改或删除。
|
||||
如果某个字段有多个值,矩形框内会显示 **多个值** 卡片。如果删除该卡片,所有选中文档的该字段值将被清空,矩形框内会显示 **空** 标识。
|
||||
</Info>
|
||||
|
||||
- **新增元数据字段:** 如果你需要为选中的文档添加新的元数据字段,可以点击弹窗正下方的 **+添加元数据** 按钮,在弹出的弹窗中 **新建字段、添加已创建的字段** 或 **管理已创建的字段**。
|
||||
|
||||
- **删除元数据字段:** 通过点击每条元数据字段旁边的 **删除** 标识,你可以删除所有选中文档的该字段。
|
||||
|
||||
- **选择是否将操作应用于所有选中的文档:** 通过界面底部的选框,你可以选择是否将编辑后的元数据内容应用于所有选中的文档。
|
||||
|
||||
##### 批量新增元数据信息
|
||||
|
||||
1. 在 **编辑元数据** 弹窗中点击底部的 **+添加元数据** 按钮,弹出操作弹窗。
|
||||
|
||||
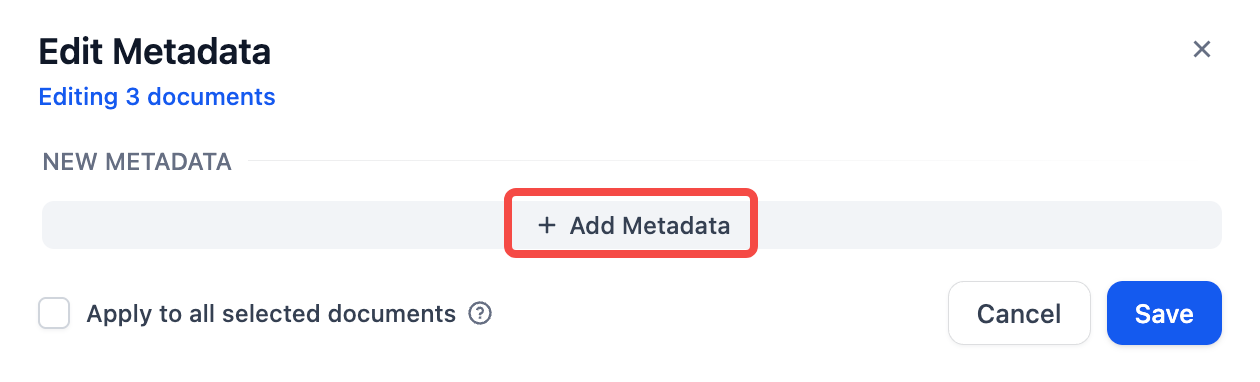
|
||||
|
||||
- 如需为选中文档新建字段,可以点击弹窗下方的 **+新建元数据** 按钮,并参考前文的 **新建元数据字段** 章节新建字段。
|
||||
|
||||
> 在 **编辑元数据** 弹窗中新建的元数据字段,将自动同步至知识库字段列表中。
|
||||
|
||||

|
||||
|
||||
- 如需为选中文档添加已创建的字段:
|
||||
|
||||
- 可以从下拉列表中选择已有的字段,添加到字段列表中。
|
||||
|
||||
- 可以在 **搜索元数据** 搜索框中搜索你需要的字段,添加到该文档的字段列表中。
|
||||
|
||||

|
||||
|
||||
- 如需管理已创建的字段,可以点击该弹窗右下角的 **管理** 按钮,跳转到知识库的管理界面。
|
||||
|
||||

|
||||
|
||||
2. *(可选)* 新增字段后,在字段值框内填写该字段相应的字段值。
|
||||
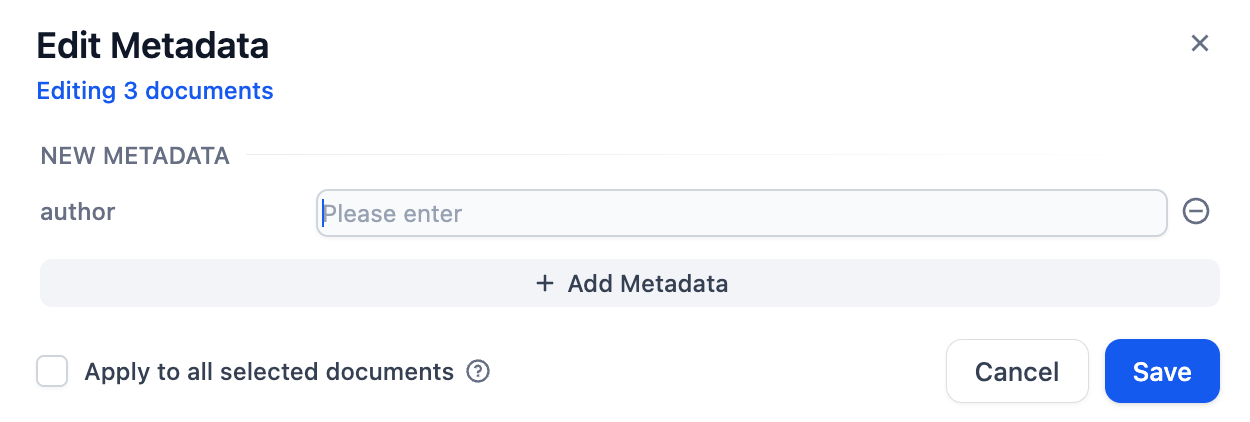
|
||||
|
||||
- 如果值类型为 **时间**,在填写字段值时会弹出时间选择器,供你选择具体时间。
|
||||
|
||||
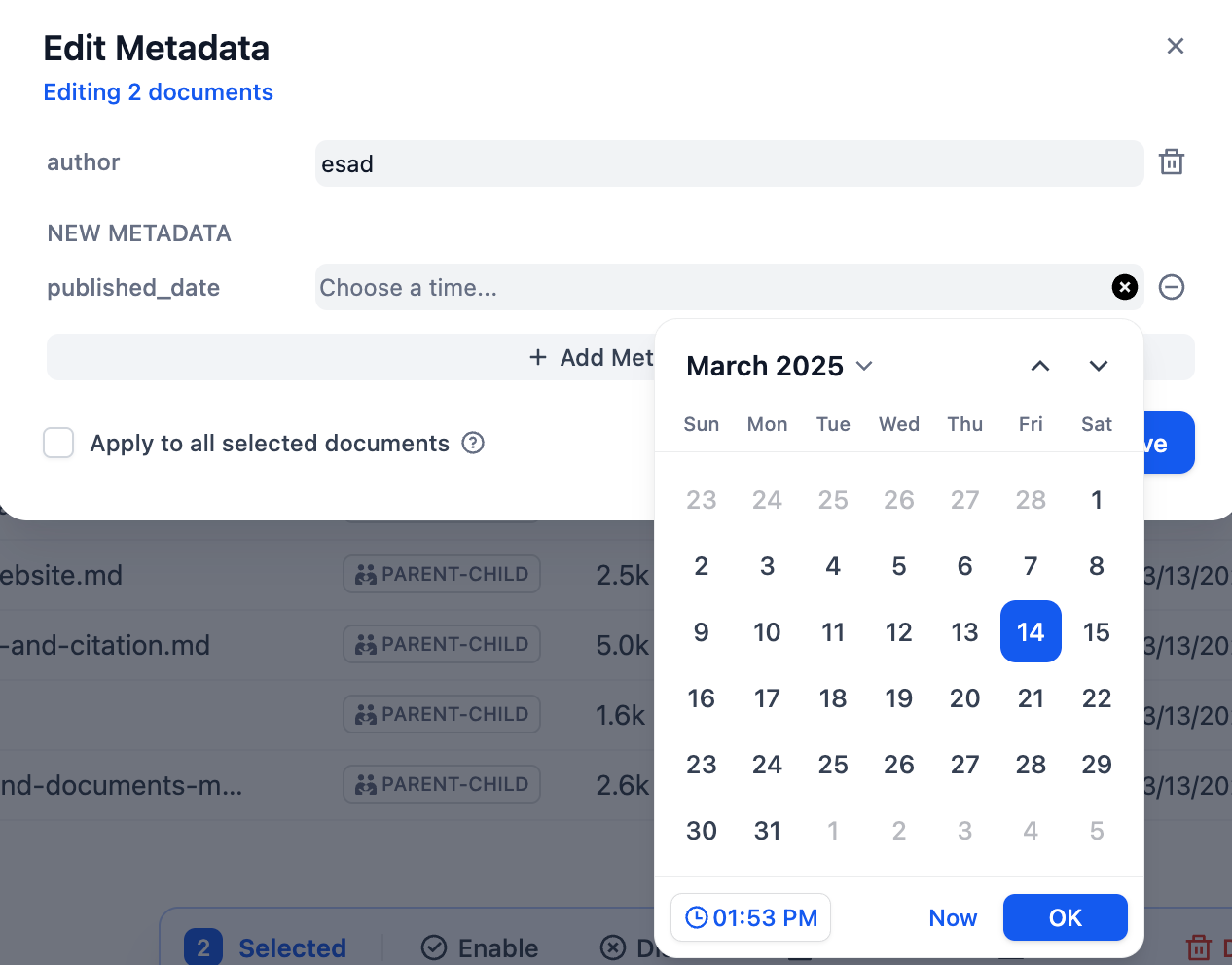
|
||||
|
||||
3. 点击 **保存** 按钮,保存操作。
|
||||
|
||||
##### 批量删改元数据信息
|
||||
|
||||
1. 在 **编辑元数据** 弹窗中删改元数据信息:
|
||||
|
||||
- **添加字段值:** 在需要添加元数据值的字段框内直接输入所需值。
|
||||
|
||||
- **重置字段值:** 将光标悬停在字段名左侧的蓝色圆点上,蓝点将变为 **重置** 按钮。点击蓝点,将字段框内修改后的内容重置为原始元数据值。
|
||||

|
||||
|
||||
- **删除字段值:**
|
||||
- 删除一个字段值:在需要删除字段值的字段框内直接删除该字段值。
|
||||
|
||||
- 删除多个字段值:点击 **多个值** 卡片的删除图标,清空所有选中文档的该元数据字段的值。
|
||||
|
||||
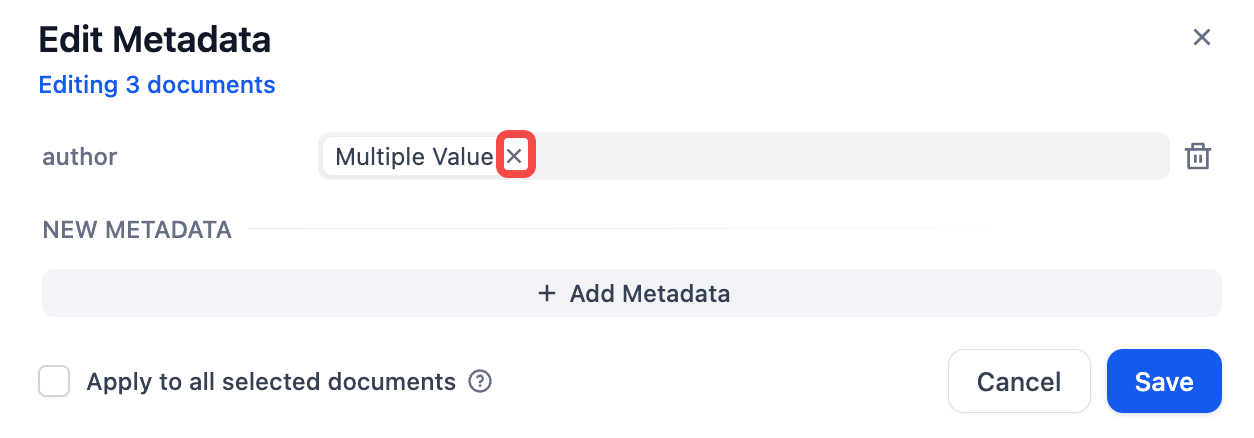
|
||||
|
||||
- **删除单条元数据字段:** 点击字段最右侧的删除符号,删除该字段。删除后,该字段会被横线划掉且置灰。
|
||||
|
||||
> 此操作仅会删除已选文档的该字段与字段值,字段本身依然保留在知识库中。
|
||||
|
||||
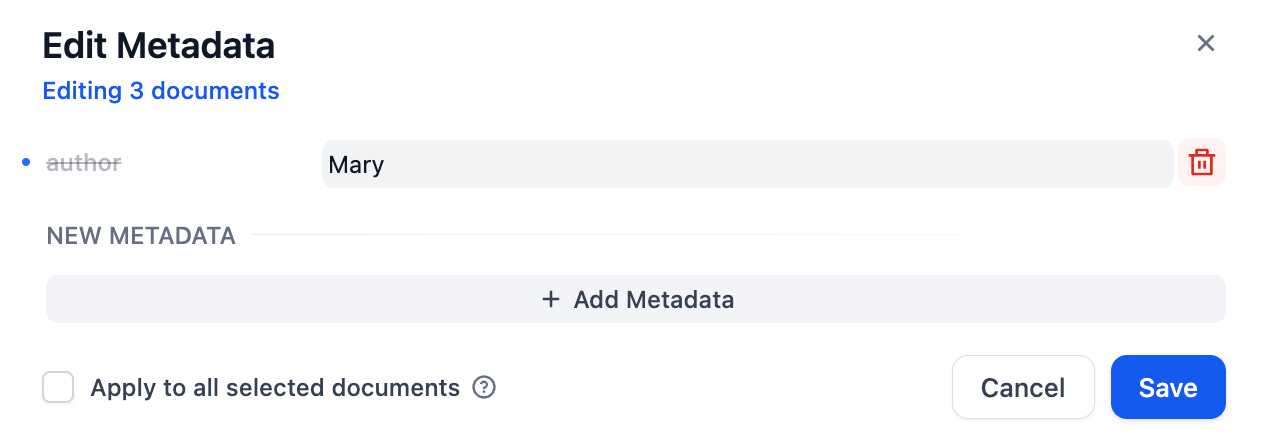
|
||||
|
||||
2. 点击 **保存** 按钮,保存操作。
|
||||
|
||||
##### 调整批量操作的应用范围
|
||||
|
||||
你可以使用 **编辑元数据** 弹窗左下角的 **应用于所有文档** 选框来调整编辑模式中改动的应用范围。
|
||||
|
||||
- **否(默认):** 如果不选中该选项,编辑模式中的改动仅对原本已有该元数据字段的文档生效,其他文档不会受到影响。
|
||||
|
||||
- **是:** 如果选中该选项,编辑模式中的改动会对所有选中的文档生效。原本没有该字段的文档,会自动添加该字段。
|
||||
|
||||
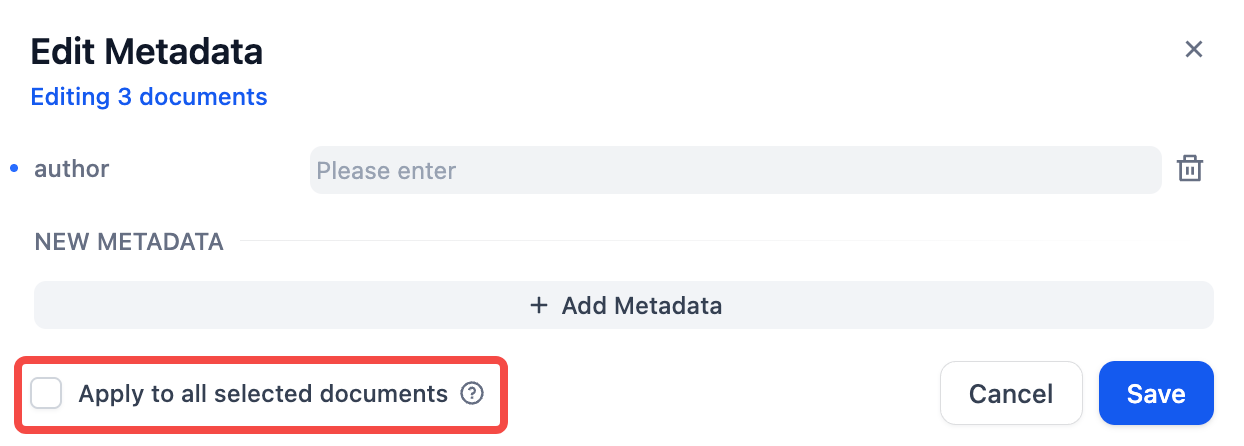
|
||||
|
||||
#### 编辑单篇文档元数据信息
|
||||
|
||||
你可以在文档详情界面中编辑单篇文档的元数据信息。
|
||||
|
||||
##### 进入文档元数据编辑模式
|
||||
|
||||
1. 在文档详情界面,点击信息栏上方的 **开始标记** 按钮。
|
||||
|
||||

|
||||
|
||||
2. 进入文档元数据编辑模式。
|
||||
|
||||

|
||||
|
||||
##### 新增文档元数据信息
|
||||
|
||||
1. 在文档的元数据编辑模式中,点击 **+添加元数据** 按钮,弹出操作弹窗。
|
||||

|
||||
|
||||
- 如需使用新建字段为该文档标记字段值,可以点击弹窗左下角的 **+ 新建元数据** 按钮,并参考前文的 **新建元数据字段** 章节新建字段。
|
||||
|
||||
> 在文档页面新建的元数据字段,将自动同步至知识库字段列表中。
|
||||
|
||||

|
||||
|
||||
- 如需使用知识库已有的字段为该文档标记字段值,可以选择下列任意一种方式使用已有的字段:
|
||||
|
||||
- 从下拉列表中选择知识库已有的字段,添加到该文档的字段列表中。
|
||||
|
||||
- 在 **搜索元数据** 搜索框中搜索你需要的字段,添加到该文档的字段列表中。
|
||||
|
||||

|
||||
|
||||
- 如需管理知识库已有的字段,可以点击弹窗右下角的 **管理** 按钮,跳转到知识库的管理界面。
|
||||
|
||||

|
||||
|
||||
|
||||
2. *(可选)* 添加字段后,在字段名右侧的元数据栏中填写字段值。
|
||||
|
||||

|
||||
|
||||
3. 点击右上角的 **保存** 按钮,保存字段值。
|
||||
|
||||
##### 删改文档元数据信息
|
||||
|
||||
1. 在文档的元数据编辑模式中,点击右上角的 **编辑** 按钮,进入编辑模式。
|
||||
|
||||

|
||||
|
||||
2. 删改文档元数据信息:
|
||||
- **删改字段值:** 在字段名右侧的字段值框内,删除或修改字段值。
|
||||
|
||||
> 此模式仅支持修改字段值,不支持修改字段名。
|
||||
|
||||
- **删除字段:** 点击字段值框右侧的删除按钮,删除字段。
|
||||
|
||||
> 此操作仅会删除该文档的该字段与字段值,字段本身依然保留在知识库中。
|
||||
|
||||

|
||||
|
||||
3. 点击右上角的 **保存** 按钮,保存修改后的字段信息。
|
||||
|
||||
## 如何使用元数据功能在知识库中筛选文档?
|
||||
|
||||
请参阅 [在应用内集成知识库](https://docs.dify.ai/zh-hans/guides/knowledge-base/integrate-knowledge-within-application) 中的 **使用元数据筛选知识** 章节。
|
||||
|
||||
## API 信息
|
||||
|
||||
请参阅 [通过 API 维护知识库](https://docs.dify.ai/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api)。
|
||||
|
||||
## FAQ
|
||||
|
||||
- **元数据有什么作用?**
|
||||
|
||||
- 提升搜索效率:用户可以根据元数据标签快速筛选和查找相关信息,节省时间并提高工作效率。
|
||||
|
||||
- 增强数据安全性:通过元数据设置访问权限,确保只有授权用户能访问敏感信息,保障数据的安全性。
|
||||
|
||||
- 优化数据管理能力:元数据帮助企业或组织有效分类和存储数据,提高数据的管理和检索能力,增强数据的可用性和一致性。
|
||||
|
||||
- 支持自动化流程:元数据在文档管理、数据分析等场景中可以自动触发任务或操作,简化流程并提高整体效率。
|
||||
|
||||
- **知识库元数据管理列表中的元数据字段和某篇文档中的元数据值有什么区别?**
|
||||
|
||||
| | 定义 | 性质 | 举例 |
|
||||
|---|---|---|---|
|
||||
| 元数据管理列表中的元数据字段 | 预定义的字段,用于描述文档的某些属性。 | 全局性字段。所有文档都可以使用这些字段。 | 作者、文档类型、上传日期。 |
|
||||
| 某篇文档中的元数据值 | 每个文档按需标记的针对特定文档的信息。 | 文档特定的值。每个文档根据其内容会标记不同的元数据值。 | 文档 A 的"作者"字段值为"张三",文档 B 的"作者"字段值为"李四"。 |
|
||||
|
||||
- **“在知识库管理界面删除某条元数据字段”“在编辑元数据弹窗中删除已选文档的某条元数据字段”和“在文档详情界面删除某条元数据字段”有什么区别?**
|
||||
|
||||
| 操作方式 | 操作方法 | 示例图 | 影响范围 | 结果 |
|
||||
|---|---|---|---|---|
|
||||
| 在知识库管理界面删除某条元数据字段 | 在知识库管理界面,点击某条元数据字段右侧的删除图标,删除该字段。 | 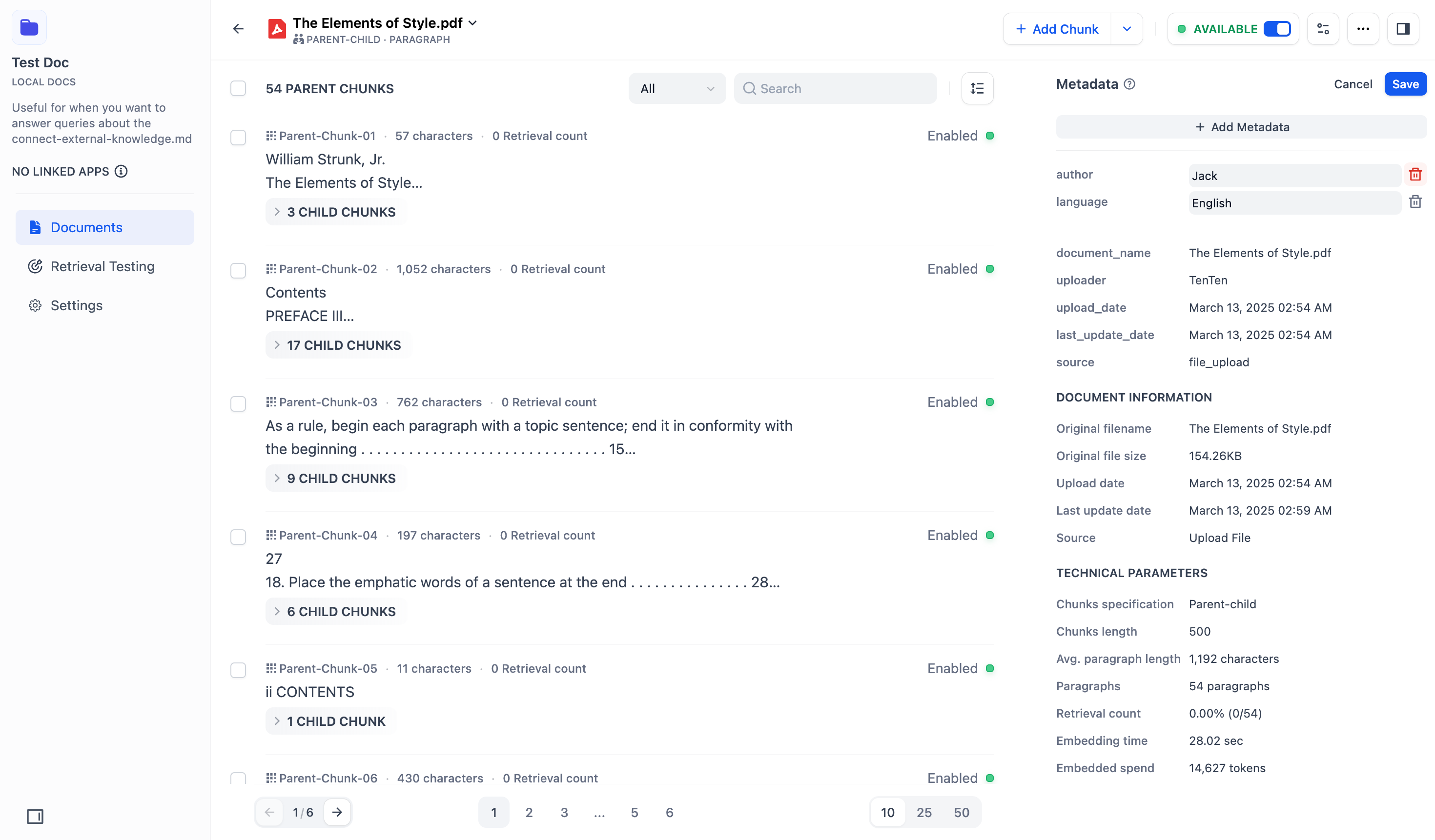 | 从知识库管理列表中完全删除该元数据字段及其所有字段值。 | 该字段从知识库中移除,所有文档中的该字段及包含的所有字段值也会消失。 |
|
||||
| 在编辑元数据弹窗中删除已选文档的某条元数据字段 | 在编辑元数据弹窗中,点击某条元数据字段右侧的删除图标,删除该字段。 |  | 仅删除已选文档的该字段与字段值,字段本身依然保留在知识库管理列表中。 | 选中文档中的字段与字段值被移除,但字段仍保留在知识库内,字段值计数会发生数值上的变化。 |
|
||||
| 在文档详情界面删除某条元数据字段 | 在文档详情界面中的元数据编辑模式里,点击某条元数据字段右侧的删除图标,删除该字段。 | 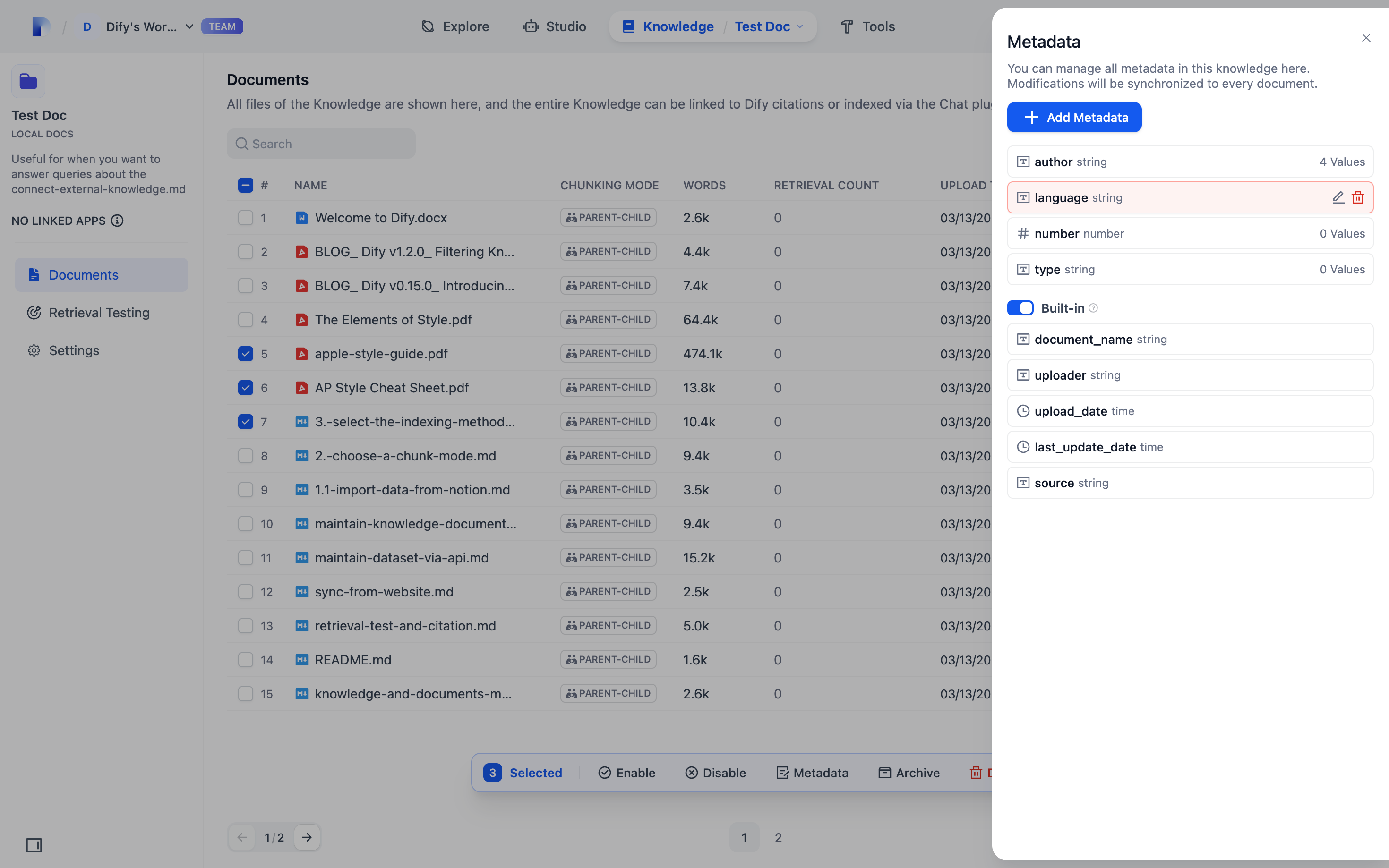 | 仅删除该文档的该字段与字段值,字段本身依然保留在知识库管理列表中。 | 该文档中的字段与字段值被移除,但字段仍保留在知识库内,字段值计数会发生数值上的变化。 |
|
||||
|
||||
- **我可以在知识库管理界面查看我设置的元数据值吗?**
|
||||
|
||||
目前,在知识库管理界面,你只能看到每条元数据字段的字段值计数(如“3 values”),无法查看字段值的具体内容。
|
||||
|
||||
如果你需要查看字段值的具体内容,可以在单个文档的详情界面中查看。
|
||||
|
||||
- **我可以在编辑元数据弹窗中删除单个元数据值吗?**
|
||||
|
||||
在 **编辑元数据弹窗** 中,你只能删除 **多个值** 卡片。删除该卡片将清空所有选中文档的该元数据字段的值。
|
||||
|
||||
如果你想删除单个元数据值,你需要进入对应文档的详情界面,并参照前文的 **编辑单篇文档的元数据值 > 删改文档元数据信息值** 章节进行操作。
|
||||
47
zh-cn/user-guide/knowledge-base/readme.mdx
Normal file
47
zh-cn/user-guide/knowledge-base/readme.mdx
Normal file
@@ -0,0 +1,47 @@
|
||||
---
|
||||
title: 功能简介
|
||||
---
|
||||
|
||||
知识库功能将 [RAG 管线](../../learn-more/extended-reading/retrieval-augment/)上的各环节可视化,提供了一套简单易用的用户界面来方便应用构建者管理个人或者团队的知识库,并能够快速集成至 AI 应用中。
|
||||
|
||||
开发者可以将企业内部文档、FAQ、规范信息等内容上传至知识库进行结构化处理,供后续 LLM 查询。
|
||||
|
||||
相比于 AI 大模型内置的静态预训练数据,知识库中的内容能够实时更新,确保 LLM 可以访问到最新的信息,避免因信息过时或遗漏而产生的问题。
|
||||
|
||||
LLM 接收到用户的问题后,将首先基于关键词在知识库内检索内容。知识库将根据关键词,召回相关度排名较高的内容区块,向 LLM 提供关键上下文以辅助其生成更加精准的回答。
|
||||
|
||||
开发者可以通过此方式确保 LLM 不仅仅依赖于训练数据中的知识,还能够处理来自实时文档和数据库的动态数据,从而提高回答的准确性和相关性。
|
||||
|
||||
**核心优势:**
|
||||
|
||||
• **实时性**:知识库中的数据可随时更新,确保模型获得最新的上下文。
|
||||
|
||||
• **精准性**:通过检索相关文档,LLM 能够基于实际内容生成高质量的回答,减少幻觉现象。
|
||||
|
||||
• **灵活性**:开发者可自定义知识库内容,根据实际需求调整知识的覆盖范围。
|
||||
|
||||
***
|
||||
|
||||
准备文本文件,例如:
|
||||
|
||||
* 长文本内容(TXT、Markdown、DOCX、HTML、JSON 甚至是 PDF)
|
||||
* 结构化数据(CSV、Excel 等)
|
||||
* 在线数据源(网页爬虫、Notion 等)
|
||||
|
||||
将文件上传至“知识库”即可自动完成数据处理。
|
||||
|
||||
> 如果你的团队内部已建有独立知识库,可以通过[连接外部知识库](connect-external-knowledge-base.md)与 Dify 建立连接。
|
||||
>
|
||||
> 可以通过“连接外部知识库”功能,建立与 Dify 平台的连接。
|
||||
|
||||
|
||||
|
||||
### 使用情景
|
||||
|
||||
例如你希望基于现有知识库和产品文档建立一个 AI 客服助手,可以在 Dify 中将文档上传至知识库,并建立一个对话型应用。如果使用传统方式,从文本训练到 AI 客服助手开发,可能需要花费数周的时间,且难以持续维护并进行有效迭代。在 Dify 内,仅需三分钟即可完成上述过程并开始获取用户反馈。
|
||||
|
||||
### 知识库与文档
|
||||
|
||||
在 Dify 中,知识库(Knowledge)是一系列文档(Documents)的集合,一个文档内可能包含多组内容分段(Chunks),知识库可以被整体集成至一个应用中作为检索上下文使用。文档可以由开发者或运营人员上传,或由其它数据源同步。
|
||||
|
||||
如果你已自建文档库,可以通过[连接外部知识库](connect-external-knowledge-base)功能将自有知识库与 Dify 平台相关联。无需重复将内容上传至 Dify 平台内的知识库即可让 AI 应用实时读取自建知识库中的内容。
|
||||
@@ -0,0 +1,44 @@
|
||||
---
|
||||
title: 召回测试/引用归属
|
||||
version: '简体中文'
|
||||
---
|
||||
|
||||
## 1 召回测试
|
||||
|
||||
Dify 知识库内提供了文本召回测试的功能,用于调试不同检索方式及参数配置下的召回效果。你可以在 **源文本** 输入框输入常见的用户问题,点击 **测试** 并在右侧的 **召回段落** 查看召回结果。在 **最近查询** 内可以查看到历史的查询记录;若知识库已关联至应用内,由应用内触发的知识库查询也可以在此查看记录。
|
||||
|
||||
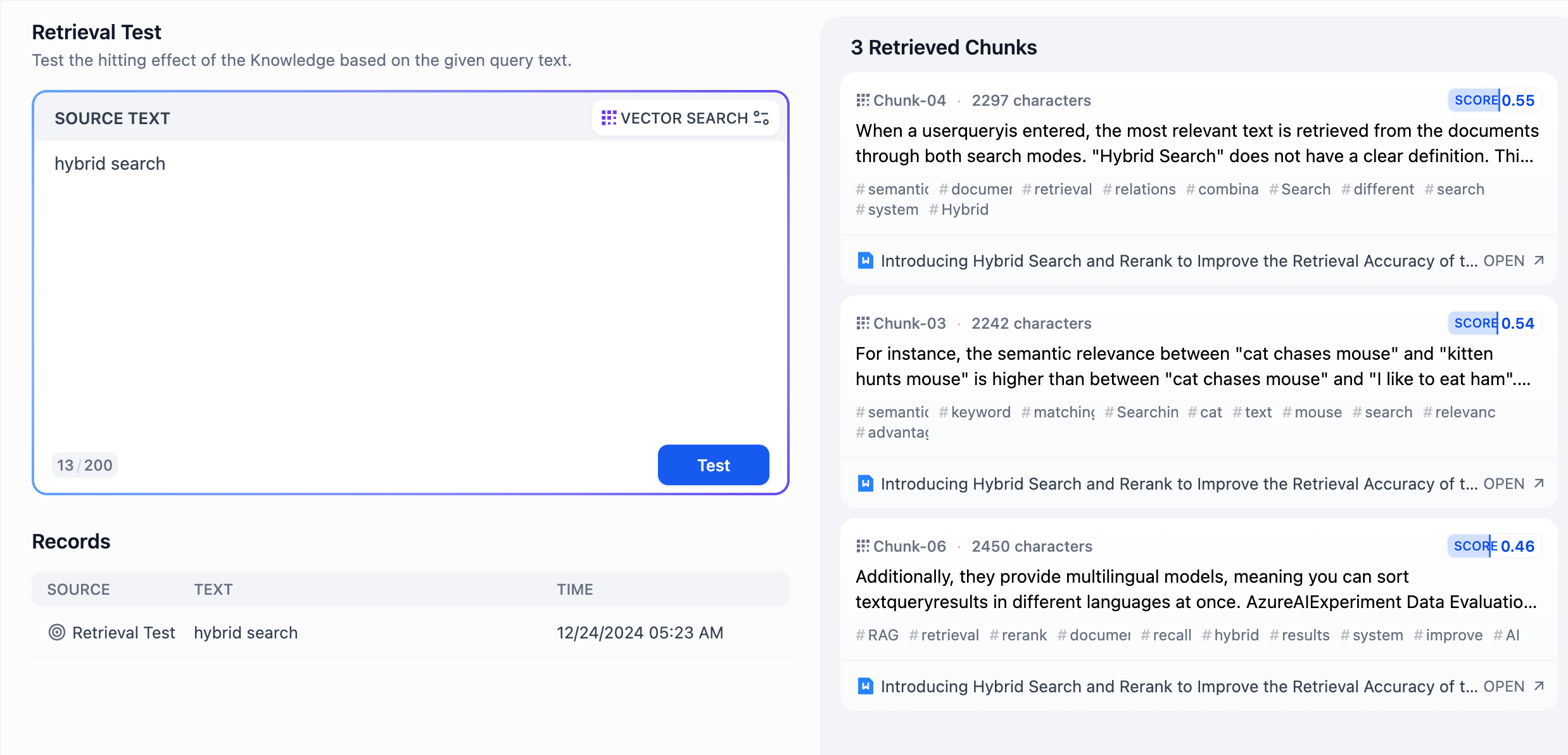
|
||||
|
||||
点击源文本输入框右上角的图标可以更换当前知识库的检索方式和具体参数,**保存之后仅在召回测试的调试过程中生效**。在召回测试完成调试并确认更改知识库的检索参数时,需要在 [知识库设置 > 检索设置](create-knowledge-and-upload-documents/#id-6-jian-suo-she-zhi) 中进行更改。
|
||||
|
||||
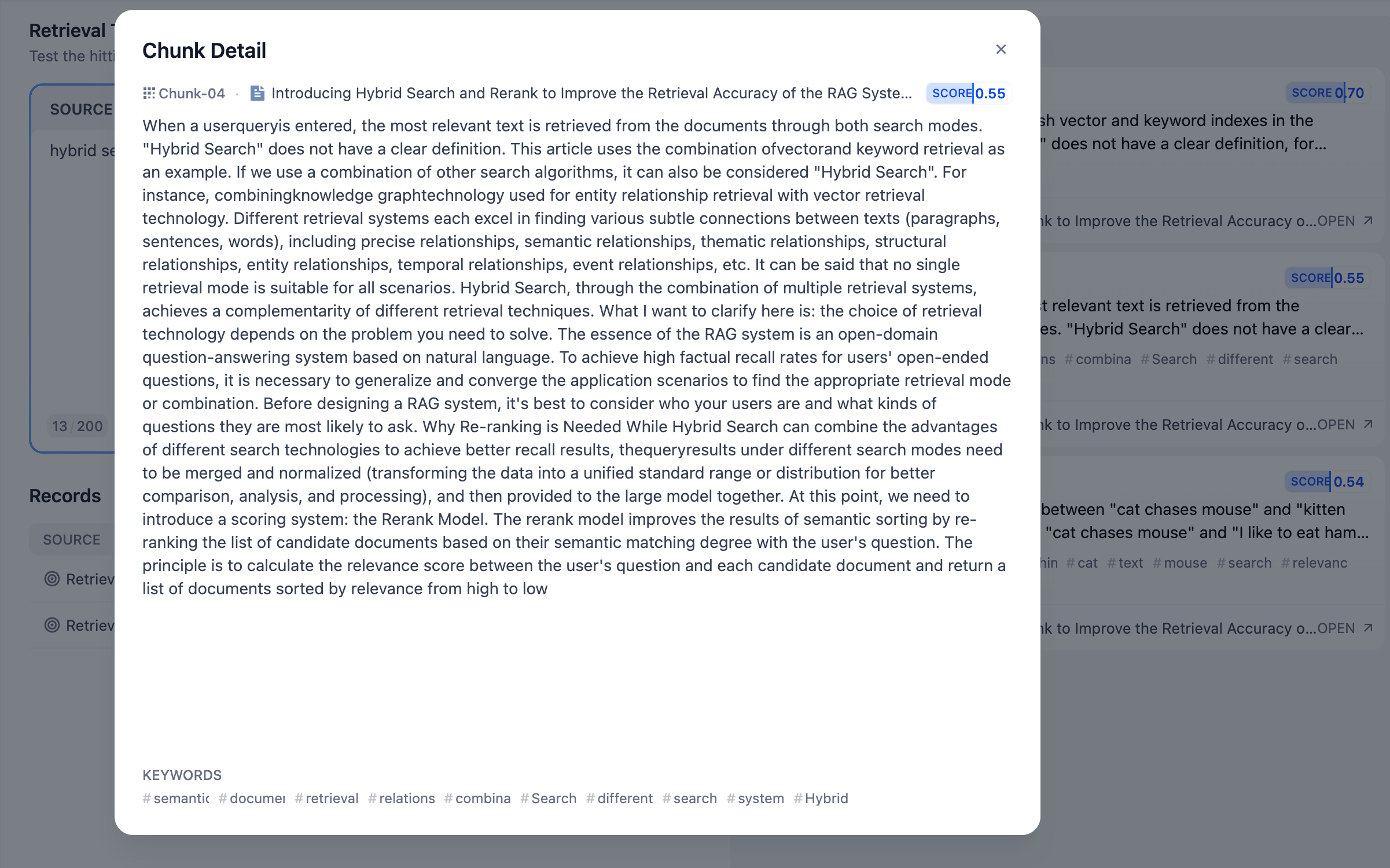
|
||||
|
||||
**召回测试建议步骤:**
|
||||
|
||||
1. 设计和整理覆盖常见用户问题的测试用例/测试问题集;
|
||||
2. 选择合适的检索策略:向量检索/全文检索/混合检索,不同检索方式的优缺点,请参考扩展阅读[检索增强生成(RAG)](user-guide/zh-cn/user-guide/learn-more/extended-reading/retrieval-augment/);
|
||||
3. 调试召回分段数量(TopK)和召回分数阈值(Score),需根据应用场景、包括文档本身的质量来选择合适的参数组合。
|
||||
|
||||
**TopK 值和召回阈值(Score )如何配置**
|
||||
|
||||
* **TopK 代表按相似分数倒排时召回分段的最大个数**。TopK 值调小,将会召回更少分段,可能导致召回的相关文本不全;TopK 值调大,将召回更多分段,可能导致召回语义相关性较低的分段使得 LLM 回复质量降低。
|
||||
* **召回阈值(Score)代表允许召回分段的最低相似分数。** 召回分数调小,将会召回更多分段,可能导致召回相关度较低的分段;召回分数阈值调大,将会召回更少分段,过大时将会导致丢失相关分段。
|
||||
|
||||
***
|
||||
|
||||
## 2 引用与归属
|
||||
|
||||
在应用内测试知识库效果时,你可以进入 **工作室 -- 添加功能 -- 引用归属**,打开引用归属功能。
|
||||
|
||||
|
||||
|
||||
开启功能后,当 LLM 引用知识库内容来回答问题时,可以在回复内容下面查看到具体的引用段落信息,包括**原始分段文本、分段序号、匹配度**等。点击引用分段上方的 **跳转至知识库**,可以快捷访问该分段所在的知识库分段列表,方便开发者进行调试编辑。
|
||||
|
||||
|
||||
|
||||
#### 查看知识库内已关联的应用
|
||||
|
||||
知识库将会在左侧信息栏中显示已关联的应用数量。将鼠标悬停至圆形信息图标时将显示所有已关联的 Apps 列表,点击右侧的跳转按钮即可快速查看对应的应用。
|
||||
|
||||

|
||||
|
||||
Reference in New Issue
Block a user