mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
zh docs done & en docs refined
This commit is contained in:
@@ -22,7 +22,7 @@ Setting next step question suggestions allows the AI to generate 3 follow-up que
|
||||
|
||||
### Citation and Attribution
|
||||
|
||||
When this feature is enabled, when the large language model responds to a question by citing content from the knowledge base, you can view specific citation details below the response content, including **original segment text, segment number, matching degree**, etc.
|
||||
When this feature is enabled, if the AI references content from the knowledge base while answering a user question, the specific knowledge sources will be displayed below the response.
|
||||
|
||||
### Content Moderation
|
||||
|
||||
|
||||
@@ -17,23 +17,23 @@ The knowledge base offers two index methods: **High-Quality** and **Economical**
|
||||
<Tabs>
|
||||
<Tab title="High Quality">
|
||||
|
||||
The High Quality index method uses an embedding model to convert content chunks into numeric vectors.
|
||||
<Note>
|
||||
Once a knowledge base is created in the High Quality index method, it cannot switch to Economical later.
|
||||
</Note>
|
||||
|
||||
The High Quality index method uses an embedding model to convert content chunks into numeric vectors. This process is called embedding.
|
||||
|
||||
Think of these vectors as coordinates in a multi-dimensional space—the closer two points are, the more similar their meanings. This allows the system to find relevant information based on semantic similarity, not just exact keyword matches.
|
||||
|
||||
<Tip>
|
||||
Quick-created knowledge bases don't support image-based retrieval, because they do not allow selecting embedding models that support image vectorization (indicated by an **Image** icon).
|
||||
Quick-created knowledge bases don't allow selecting embedding models that support image embedding (indicated by an **Image** icon) and thus they don't support image-based retrieval.
|
||||
|
||||
But don't worry—you can easily convert a quick-created knowledge base into a pipeline-created one to enable this feature.
|
||||
|
||||
<img src="/images/convert_knowledge.png" alt="Convert Quick-created Knowledge to Pipeline-created Knowledge" width="300"/>
|
||||
</Tip>
|
||||
|
||||
Once chunked and vectorized, your content can be retrieved using one of three strategies: vector search, full-text search, or hybrid search. Learn more in [Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#retrieval-settings).
|
||||
|
||||
<Note>
|
||||
Once a knowledge base is created in the High Quality index method, it cannot switch to Economical later.
|
||||
</Note>
|
||||
Once chunked and vectorized, your content can be retrieved using one of three strategies: vector search, full-text search, or hybrid search. Learn more in [Retrieval Settings](#configure-the-retrieval-settings).
|
||||
|
||||
### Enable Q&A Mode (Optional, Community Edition Only)
|
||||
|
||||
|
||||
@@ -26,34 +26,6 @@ Here, you can modify the knowledge base's name, description, permissions, indexi
|
||||
* **Embedding Model**: Allows you to modify the embedding model for the knowledge base. Changing the embedding model will re-embed all documents in the knowledge base, and the original embeddings will be deleted.
|
||||
* **Retrieval Settings**: For detailed explanations, please refer to the [documentation](/en/learn-more/extended-reading/retrieval-augment/retrieval).
|
||||
|
||||
***
|
||||
|
||||
## View Linked Applications in the Knowledge Base
|
||||
|
||||
On the left side of the knowledge base, you can see all linked Apps. Hover over the circular icon to view the list of all linked apps. Click the jump button on the right to quickly browser them.
|
||||
|
||||
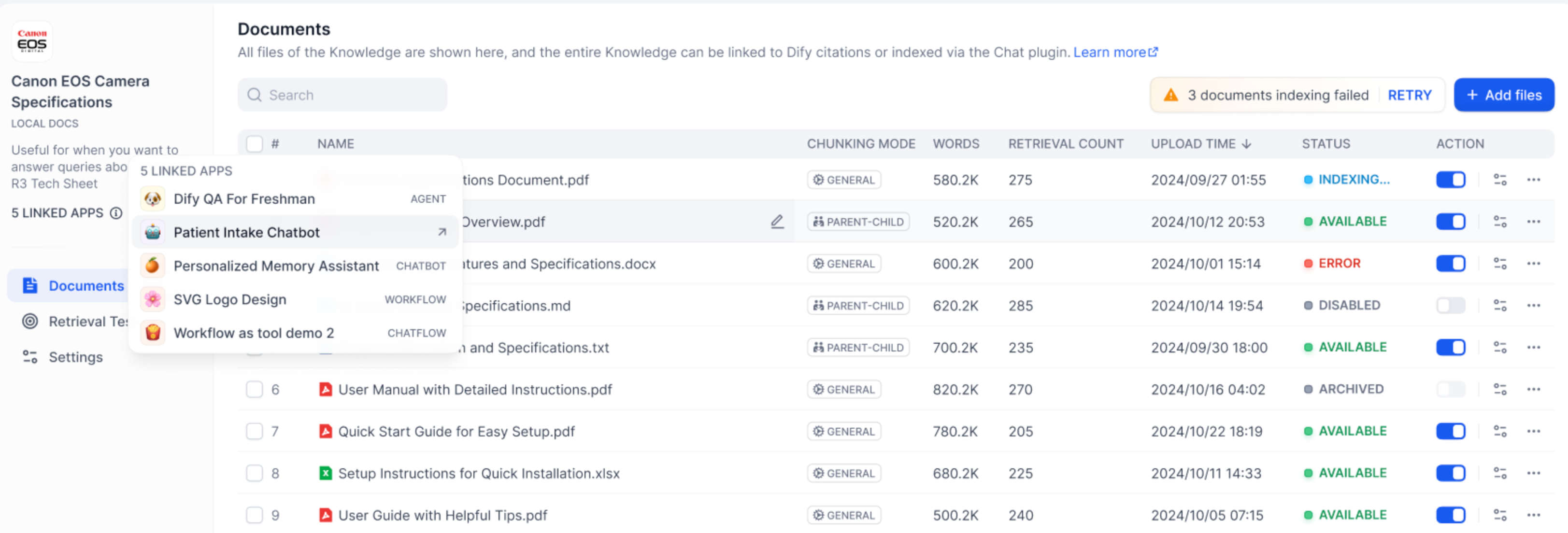
|
||||
|
||||
You can manage your knowledge base documents either through a web interface or via an API.
|
||||
|
||||
## Maintain Knowledge Documents
|
||||
|
||||
You can administer all documents and their corresponding chunks directly in the knowledge base. For more details, refer to the following documentation:
|
||||
|
||||
<Card title="Maintain Knowledge Documents" icon="link" href="/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents">
|
||||
Learn how to maintain knowledge documents
|
||||
</Card>
|
||||
|
||||
## Maintain Knowledge Base Via API
|
||||
|
||||
Dify Knowledge Base provides a comprehensive set of standard APIs. Developers can use these APIs to perform routine management and maintenance tasks, such as adding, deleting, updating, and retrieving documents and chunks. For more details, refer to the following documentation:
|
||||
|
||||
<Card title="Maintain Knowledge Base via API" icon="link" href="/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api">
|
||||
Learn how to maintain knowledge base via API
|
||||
</Card>
|
||||
|
||||
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
|
||||
@@ -25,7 +25,7 @@ In a knowledge base, each imported item—whether a local file, a Notion page, o
|
||||
|
||||
## Manage Chunks
|
||||
|
||||
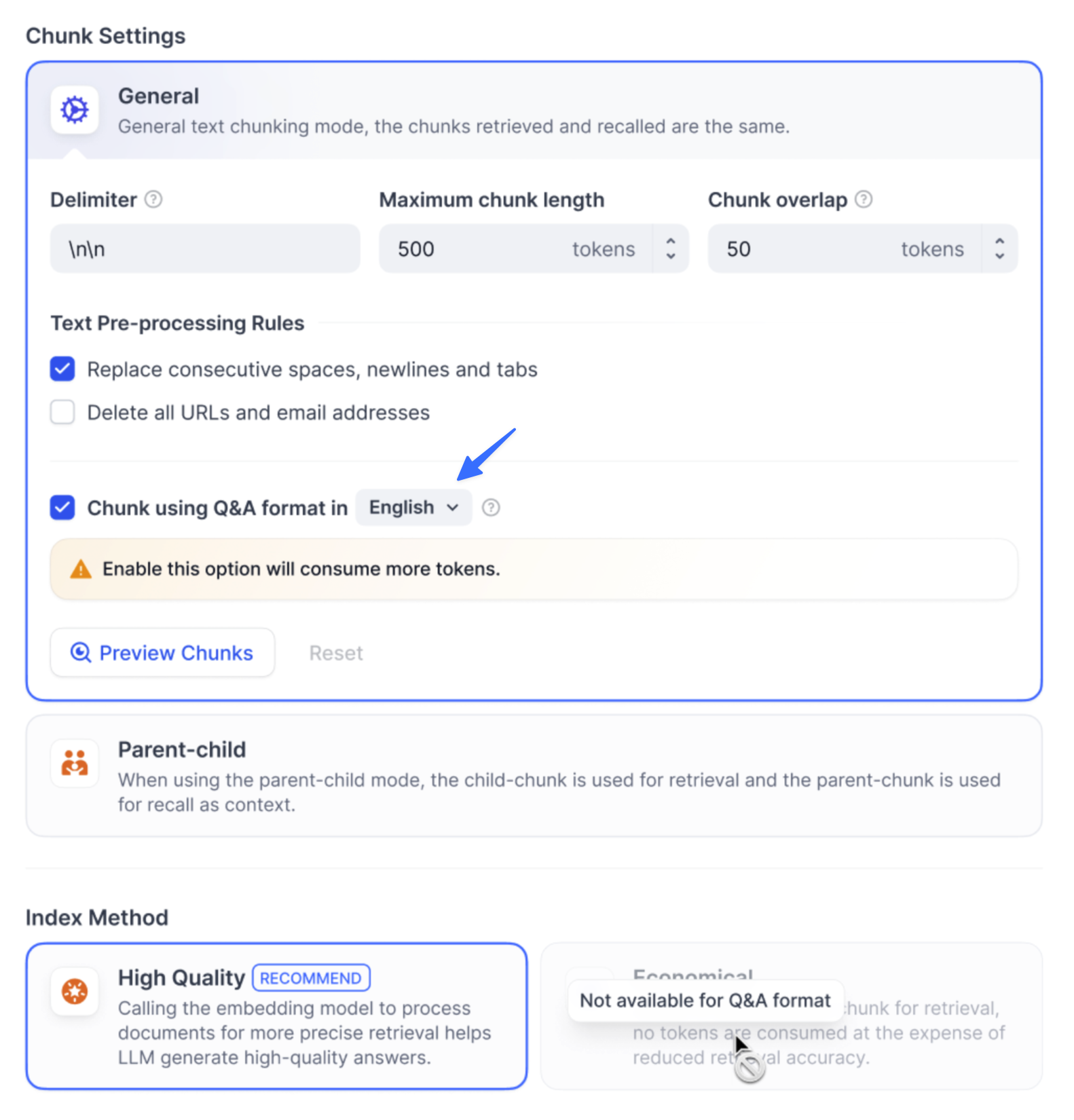
Every document is split into content chunks—the basic units for retrieval—according to its chunk settings. From the chunk list within a document, you can view and manage all its chunks to improve the retrieval efficiency and accuracy.
|
||||
According to its chunk settings, every document is split into content chunks—the basic units for retrieval. From the chunk list within a document, you can view and manage all its chunks to improve the retrieval efficiency and accuracy.
|
||||
|
||||
<Tip>
|
||||
Click the document name in the upper—left corner to quickly switch between documents.
|
||||
@@ -35,17 +35,15 @@ Every document is split into content chunks—the basic units for retrieval—ac
|
||||
|
||||
| Action | Description |
|
||||
|:-------- |:---------------------|
|
||||
| Add | Add one or batch add multiple new chunks. For documents chunked with Parent-child mode, both new parent and child chunks can be added. <Info>This is a paid feature on Dify Cloud. [Upgrade to Professional or Team](https://dify.ai/pricing) to use it.</Info>|
|
||||
| Add | Add one or batch add multiple new chunks. For documents chunked with Parent-child mode, both new parent and child chunks can be added. <Info>*Add chunks* is a paid feature on Dify Cloud. [Upgrade to Professional or Team](https://dify.ai/pricing) to use it.</Info>|
|
||||
| Delete | Permanently remove a chunk. **Deletion cannot be undone**.|
|
||||
| Enable / Disable | Temporarily include or exclude a chunk from retrieval. Disabled chunks cannot be edited.|
|
||||
| Edit | Modify the content of a chunk. Edited chunks are marked **Edited**.<br/><br/>For documents chunked with Parent-child mode: <ul><li>When editing a parent chunk, you can choose to regenerate its child chunks or keep them unchanged.</li><li>Editing a child chunk does not update its parent chunk. </li></ul>|
|
||||
| Add / Edit / Delete Keywords | In knowledge bases using the Economical index method, you can modify a chunk's keywords to improve its retrievability.|
|
||||
| Upload / Delete Images | In knowledge bases enabled with image-based retrieval, you can delete imported images or upload new ones to improve a chunk's visual context.<Tip>Choose an embedding model that supports image vectorization (indicated by an **Image** icon) for the knowledge base to enable image-based retrieval.</Tip>|
|
||||
| Add / Edit / Delete Keywords | In knowledge bases using the Economical index method, you can add or modify keywords for each chunk to improve its retrievability. Each chunk can have up to 10 keywords.|
|
||||
| Upload / Delete Images | In knowledge bases with image-based retrieval enabled, you can delete imported images or upload new ones within the corresponding chunk. <Tip>Choose an embedding model that supports image embedding (indicated by an **Image** icon) for the knowledge base to enable image-based retrieval.</Tip>|
|
||||
|
||||
## Best Practices
|
||||
|
||||
Follow these best practices to ensure your knowledge base delivers accurate and relevant results.
|
||||
|
||||
### Check Chunk Quality
|
||||
|
||||
After a document is chunked, carefully review each chunk to ensure it's semantically complete and appropriately sized for optimal retrieval accuracy and response relevance.
|
||||
|
||||
@@ -368,15 +368,15 @@ Think of it in this way: the index method determines how to organize your docume
|
||||
|
||||
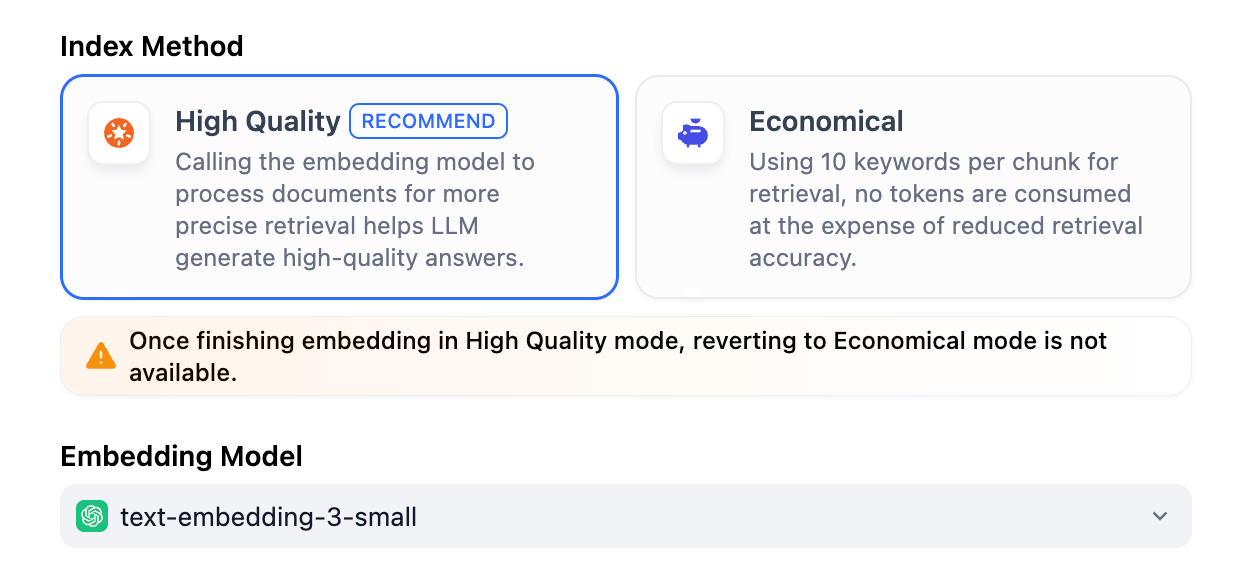
The knowledge base provides two index methods: **High Quality** and **Economical**, each offering different retrieval setting options.
|
||||
|
||||
The High Quality method uses embedding models to convent chunks into numerical vectors, helping to compress and store large amounts of information more effectively. This enables the system to find semantically relevant accurate answers even when the user's question wording doesn't exactly match the document.
|
||||
The High Quality method uses embedding models to convert chunks into numerical vectors, helping to compress and store large amounts of information more effectively. This enables the system to find semantically relevant accurate answers even when the user's question wording doesn't exactly match the document.
|
||||
|
||||
<Tip>
|
||||
|
||||
To enable image-based retrieval, choose an embedding model that supports image vectorization (indicated by an **Image** icon).
|
||||
To enable image-based retrieval, choose an embedding model that supports image embedding (indicated by an **Image** icon).
|
||||
|
||||
Knowledge bases with such embedding models are marked **Multimodal** on their cards.
|
||||
|
||||
![Knowledge Card]()
|
||||
![Knowledge Card]()
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
@@ -5,7 +5,7 @@ sidebarTitle: Overview
|
||||
|
||||
## Introduction
|
||||
|
||||
Knowledge in Dify is a collection of your own data that can be integrated into your Dify apps. It allows you to provide LLMs with domain-specific information as context, ensuring their responses are more accurate, relevant, and less prone to hallucinations.
|
||||
Knowledge in Dify is a collection of your own data that can be integrated into your AI apps. It allows you to provide LLMs with domain-specific information as context, ensuring their responses are more accurate, relevant, and less prone to hallucinations.
|
||||
|
||||
This is made possible through Retrieval-Augmented Generation (RAG). It means that instead of relying solely on its pre-trained public data, the LLM uses your custom knowledge as an additional source of truth:
|
||||
|
||||
@@ -29,7 +29,7 @@ With Dify knowledge, you can build AI apps that are grounded in your own data an
|
||||
|
||||
1. **Customer support chatbots**: Build smarter support bots that provide accurate answers from your up-to-date product documentation, FAQs, troubleshooting guides, and support ticket history.
|
||||
|
||||
2. **Internal knowledge portals**: Build AI-powered search and Q&A systems for employees to quickly access company policies, procedures, research reports, and institutional knowledge.
|
||||
2. **Internal knowledge portals**: Build AI-powered search and Q&A systems for employees to quickly access company policies and procedures.
|
||||
|
||||
3. **Content generation tools**: Build intelligent writing tools that generate reports, articles, or emails based on specific background materials.
|
||||
|
||||
@@ -49,7 +49,7 @@ With Dify knowledge, you can build AI apps that are grounded in your own data an
|
||||
|
||||
- **[Test and validate retrieval](/en/guides/knowledge-base/retrieval-test-and-citation#1-retrieval-testing)**: Simulate user queries to test how well your knowledge base retrieves relevant information.
|
||||
|
||||
- **[Enhance retrieval with metadata](/en/guides/knowledge-base/metadata)**: Add metadata to documents to enable filter-based searches during retrieval.
|
||||
- **[Enhance retrieval with metadata](/en/guides/knowledge-base/metadata)**: Add metadata to documents to enable filter-based searches and further improve retrieval precision.
|
||||
|
||||
- **[Fine-tune settings](/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)**: Adjust the index method, embedding model, and retrieval strategy at any time.
|
||||
|
||||
@@ -65,7 +65,7 @@ With Dify knowledge, you can build AI apps that are grounded in your own data an
|
||||
|
||||
- [Dify v0.15.0: Introducing Parent-child Retrieval for Enhanced Knowledge](https://dify.ai/blog/introducing-parent-child-retrieval-for-enhanced-knowledge)
|
||||
|
||||
- [Enhance Dify RAG with InfraNodus: Expand Your LLM’s Context](https://dify.ai/blog/enhance-dify-rag-with-infranodus-expand-your-llm-s-context)
|
||||
- [Enhance Dify RAG with InfraNodus: Expand Your LLM's Context](https://dify.ai/blog/enhance-dify-rag-with-infranodus-expand-your-llm-s-context)
|
||||
|
||||
- [Dify v1.1.0: Filtering Knowledge Retrieval with Customized Metadata](https://dify.ai/blog/dify-v1-1-0-filtering-knowledge-retrieval-with-customized-metadata)
|
||||
|
||||
|
||||
@@ -4,7 +4,7 @@ title: Knowledge Retrieval
|
||||
|
||||
## Introduction
|
||||
|
||||
The Knowledge Retrieval node allows you to embed existing knowledge bases into your Chatflows or Workflows. It searches specific knowledge for information relevant to queries and returns contextual content for use in downstream nodes (e.g., LLMs).
|
||||
You can use the Knowledge Retrieval node to integrate existing knowledge bases into your Chatflows or Workflows. The node searches specific knowledge for information relevant to queries and outputs results as contextual content for use in downstream nodes (e.g., LLMs).
|
||||
|
||||
Below is an example of using the Knowledge Retrieval node in a Chatflow:
|
||||
|
||||
@@ -30,7 +30,7 @@ To make the Knowledge Retrieval node work properly, you need to tell it *what* i
|
||||
|
||||
Provide the query content that the node should search for in the selected knowledge base(s).
|
||||
|
||||
- **Query Text**: Use `userinput.query` to reference user input in Chatflows, or select any text variables.
|
||||
- **Query Text**: Select a text variable. For example, use `userinput.query` to reference user input in Chatflows, or a custom text-type user input variable in Workflows.
|
||||
|
||||
- **Query Image**: Select an image variable to search by image, e.g., the image uploaded by the user through a User Input node. The image size limit is 10 MB.
|
||||
|
||||
@@ -41,7 +41,7 @@ Provide the query content that the node should search for in the selected knowle
|
||||
<Info>
|
||||
**Query Image** is available only when at least one added knowledge base supports image-based retrieval.
|
||||
|
||||
Such knowledge bases are marked with an **Image** icon, indicating that they use an embedding model that supports image vectorization.
|
||||
Such knowledge bases are marked with an **Image** icon, indicating that they use an embedding model that supports image embedding.
|
||||
</Info>
|
||||
|
||||
### Select Knowledge to Search
|
||||
@@ -98,7 +98,7 @@ With metadata filtering enabled, the Knowledge Retrieval node only searches docu
|
||||
|
||||
The Knowledge Retrieval node outputs the retrieval results as a variable named `result`, which is an array of retrieved document chunks containing their content, metadata, title, and other attributes.
|
||||
|
||||
If image-based retrieval is enabled and matching images are fetched, the `result` variable also includes an additional field named `files` containing the retrieved image information.
|
||||
If image-based retrieval is enabled and relevant images are fetched, the `result` variable also includes an additional field named `files` containing the retrieved image information.
|
||||
|
||||
![Knowledge Retrieval Node Output]()
|
||||
|
||||
@@ -110,7 +110,7 @@ To use the retrieval results to answer user questions in an LLM node:
|
||||
|
||||
2. In the prompt field, reference both the `Context` variable and the user input variable (e.g., `userinput.query` in Chatflows).
|
||||
|
||||
![LLM Node Configuration Example]()
|
||||
<img src="/images/llm_node_configuration_example.png" alt="LLM Node Configuration Example" width="400"/>
|
||||
|
||||
<Note>
|
||||
Knowledge retrieval operations are subject to rate limits based on your subscription plan. For more information, see [Knowledge Request Rate Limit](/en/guides/knowledge-base/knowledge-request-rate-limit).
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 110 KiB After Width: | Height: | Size: 129 KiB |
BIN
images/llm_node_configuration_example.png
Normal file
BIN
images/llm_node_configuration_example.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 78 KiB |
@@ -34,7 +34,7 @@ title: 应用工具箱
|
||||
|
||||
### 引用与归属
|
||||
|
||||
开启此功能后,当 AI 在回答问题时引用了知识库内容时,可在回复内容下方查看具体的引用来源,包括**原始分段内容、片段编号、匹配度**等信息。
|
||||
开启此功能后,若 AI 在回答问题时引用了知识库内容,具体的引用来源将展示在回复内容下方。
|
||||
|
||||
### 内容审查
|
||||
|
||||
|
||||
@@ -1,32 +1,39 @@
|
||||
---
|
||||
title: 3. 设定索引方法与检索设置
|
||||
title: 3. 指定索引方式与检索设置
|
||||
---
|
||||
|
||||
选定内容的分段模式后,接下来设定对于结构化内容的**索引方法**与**检索设置**。
|
||||
选定内容的分段模式后,接下来设定对于结构化内容的**索引方式**与**检索设置**。
|
||||
|
||||
## 设定索引方法
|
||||
## 选择索引方式
|
||||
|
||||
正如搜索引擎通过高效的索引算法匹配与用户问题最相关的网页内容,索引方式是否合理将直接影响 LLM 对知识库内容的检索效率以及回答的准确性。
|
||||
|
||||
提供 **高质量** 与 **经济** 两种索引方法,其中分别提供不同的检索设置选项:
|
||||
提供 **高质量** 与 **经济** 两种索引方式,其中分别提供不同的检索设置选项:
|
||||
|
||||
<Note>
|
||||
原 Q&A 模式(仅适用于社区版)已成为高质量索引方法下的一个可选项。
|
||||
原 Q&A 模式(仅适用于社区版)已成为高质量索引方式下的一个可选项。
|
||||
</Note>
|
||||
|
||||
<Tabs>
|
||||
<Tab title="高质量">
|
||||
**高质量**
|
||||
|
||||
在高质量模式下,使用 Embedding 嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息;**使得用户问题与文本之间的匹配能够更加精准**。
|
||||
<Note>
|
||||
一旦以高质量型索引方式创建知识库,后续无法切换为经济型索引。
|
||||
</Note>
|
||||
|
||||
将内容块向量化并录入至数据库后,需要通过有效的检索方式调取与用户问题相匹配的内容块。高质量模式提供向量检索、全文检索和混合检索三种检索设置。关于各个设置的详细说明,请继续阅读[检索设置](#指定检索方式)。
|
||||
高质量索引方式使用嵌入模型将内容分段转化为数字向量,这一过程称为嵌入或向量化。
|
||||
|
||||
这些向量可理解为多维空间中的坐标点——两个点越接近,它们的语义越相似。这使得系统能够基于语义相似度(而不仅仅是关键词匹配)找到相关信息。
|
||||
|
||||
选择高质量模式后,当前知识库的索引方式无法在后续降级为 **“经济”索引模式**。如需切换,建议重新创建知识库并重选索引方式。
|
||||
<Tip>
|
||||
快速创建的知识库无法选择支持图片向量化的嵌入模型(带有 **图片** 图标),因此不支持图片检索。
|
||||
|
||||
> 如需了解更多关于嵌入技术与向量的说明,请参考[《Embedding 技术与 Dify》](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)。
|
||||
不过,你可以轻松将快速创建的知识库转换为流水线创建的知识库,从而启用该功能。
|
||||
|
||||
|
||||
<img src="/images/convert_knowledge.png" alt="将快速创建知识库转换为流水线创建知识库" width="300"/>
|
||||
</Tip>
|
||||
|
||||
对内容进行分段和嵌入后,可通过三种检索策略进行检索:向量检索、全文检索或混合检索。详见 [指定检索方式](#指定检索方式)。
|
||||
|
||||
**启用 Q\&A 模式(可选,仅适用于[社区版](/zh-hans/getting-started/install-self-hosted/faq))**
|
||||
|
||||
@@ -34,7 +41,7 @@ title: 3. 设定索引方法与检索设置
|
||||
|
||||
这是因为 「常见问题」 文档里的文本**通常是具备完整语法结构的自然语言**,Q to Q 模式会令问题和答案的匹配更加清晰,并同时满足一些高频和高相似度问题的提问场景。
|
||||
|
||||
> **Q\&A 模式仅支持处理 「中英日」 三语。启用该模式后可能会消耗更多的 LLM Tokens,并且无法使用**[**经济型索引方法**](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)**。**
|
||||
> **Q\&A 模式仅支持处理 「中英日」 三语。启用该模式后可能会消耗更多的 LLM Tokens,并且无法使用**[**经济型索引方式**](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)**。**
|
||||
|
||||
|
||||
|
||||
@@ -45,7 +52,7 @@ title: 3. 设定索引方法与检索设置
|
||||
<Tab title="经济">
|
||||
**经济**
|
||||
|
||||
在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需产生费用。对于检索到的区块,仅提供倒排索引方式选择最相关的区块,详细说明请阅读[下文](#指定检索方式)。
|
||||
在经济模式下,每个区块内使用 10 个关键词进行检索,降低了准确度但无需产生费用。对于检索到的区块,仅提供倒排索引方式选择最相关的区块,详细说明请阅读[下文](#指定检索设置)。
|
||||
|
||||
选择经济型索引方式后,若感觉实际的效果不佳,可以在知识库设置页中升级为 **“高质量”索引方式**。
|
||||
|
||||
@@ -53,13 +60,13 @@ title: 3. 设定索引方法与检索设置
|
||||
</Tab>
|
||||
</Tabs>
|
||||
|
||||
## 指定检索方式 <a href="#retrieval_settings" id="retrieval_settings"></a>
|
||||
## 指定检索设置 <a href="#retrieval_settings" id="retrieval_settings"></a>
|
||||
|
||||
知识库在接收到用户查询问题后,按照预设的检索方式在已有的文档内查找相关内容,提取出高度相关的信息片段供语言模型生成高质量答案。这将决定 LLM 所能获取的背景信息,从而影响生成结果的准确性和可信度。
|
||||
|
||||
常见的检索方式包括基于向量相似度的语义检索,以及基于关键词的精准匹配:前者将文本内容块和问题查询转化为向量,通过计算向量相似度匹配更深层次的语义关联;后者通过倒排索引,即搜索引擎常用的检索方法,匹配问题与关键内容。
|
||||
|
||||
不同的索引方法对应差异化的检索设置。
|
||||
不同的索引方式对应差异化的检索设置。
|
||||
|
||||
<Tabs>
|
||||
<Tab title="高质量索引">
|
||||
|
||||
@@ -18,36 +18,6 @@ sidebarTitle: 调整设置
|
||||
* **Embedding 模型**, 修改知识库的嵌入模型,修改 Embedding 模型将对知识库内的所有文档重新嵌入,原先的嵌入将会被删除。
|
||||
* **检索设置**,详细说明请参考[检索设置文档](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)。
|
||||
|
||||
***
|
||||
|
||||
### 查看知识库内已关联的应用
|
||||
|
||||
知识库将会在左侧信息栏中显示已关联的应用数量。将鼠标悬停至圆形信息图标时将显示所有已关联的 Apps 列表,点击右侧的跳转按钮即可快速查看对应的应用。
|
||||
|
||||

|
||||
|
||||
***
|
||||
|
||||
你可以通过网页维护或 API 两种方式维护知识库内的文档。
|
||||
|
||||
#### 维护知识库内文档
|
||||
|
||||
支持管理知识库内的文档和对应的文档分段。详细说明请参考以下文档:
|
||||
|
||||
<Card title="维护知识库文档" icon="link" href="./maintain-knowledge-documents">
|
||||
详细说明请参考此文档
|
||||
</Card>
|
||||
|
||||
#### 使用 API 维护知识库
|
||||
|
||||
Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库内的文档、分段进行增删改查等日常管理维护操作,请参考以下文档:
|
||||
|
||||
<Card title="使用 API 维护知识库" icon="link" href="./maintain-dataset-via-api">
|
||||
详细说明请参考此文档
|
||||
</Card>
|
||||
|
||||
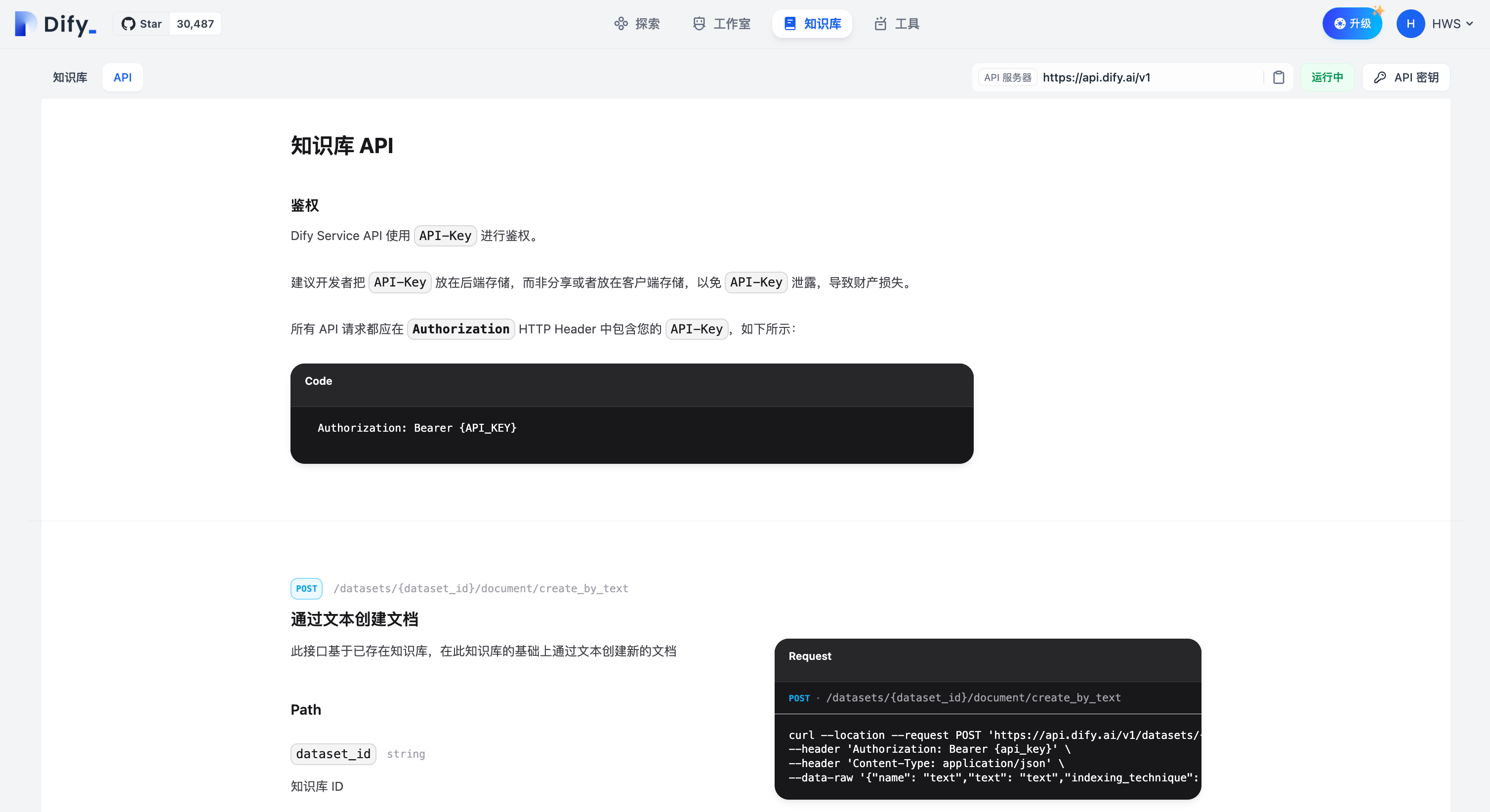
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
|
||||
@@ -4,7 +4,7 @@ sidebarTitle: 维护内容
|
||||
---
|
||||
## 管理文档
|
||||
|
||||
在知识库中,每个导入的项——无论是本地文件、Notion 页面还是网页——都会成为一个文档。你可以在文档列表中查看和管理所有文档,确保知识内容始终准确、相关且最新。
|
||||
在知识库中,每个导入的项——无论是本地文件、Notion 页面还是网页——都会成为一个文档。你可以在文档列表中查看和管理所有文档,确保知识库的内容始终准确、相关且最新。
|
||||
|
||||
<Tip>
|
||||
点击顶部的知识库名称,可快速切换不同知识库。
|
||||
@@ -24,7 +24,7 @@ sidebarTitle: 维护内容
|
||||
|
||||
## 管理分段
|
||||
|
||||
根据分段设置,每个文档会被拆分为一个或多个分段,而分段是检索的基本单元。你可以在文档的分段列表中查看和管理所有分段,以提升检索效率和准确性。
|
||||
根据其分段设置,每个文档被拆分为一个或多个分段,而分段是检索的基本单元。你可以在文档的分段列表中查看和管理所有分段,以提升检索效率与准确性。
|
||||
|
||||
<Tip>
|
||||
点击左上角的文档名称,可快速切换不同文档。
|
||||
@@ -34,17 +34,15 @@ sidebarTitle: 维护内容
|
||||
|
||||
| 操作 | 说明 |
|
||||
|:-------- |:---------------------|
|
||||
| 添加 | 新增或批量新增分段。对于采用父子分段模式的文档,可同时新增父分段和子分段。<Info>此功能为 Dify Cloud 付费功能,[升级至 Professional 或 Team 版](https://dify.ai/pricing) 即可解锁使用。</Info>|
|
||||
| 添加 | 新增或批量新增分段。对于采用父子分段模式的文档,可同时新增父分段和子分段。<Info>「添加分段」在 Dify Cloud 上为付费功能,[升级至 Professional 或 Team 版](https://dify.ai/pricing) 即可解锁使用。</Info>|
|
||||
| 删除 | 永久删除分段。**删除不可撤销**。|
|
||||
| 启用 / 禁用 | 临时将分段纳入或排除检索。已禁用的分段不可编辑。|
|
||||
| 编辑 | 修改分段内容。已编辑的分段会标记为 **已编辑**。<br/><br/>对于采用父子分段模式的文档:<ul><li>编辑父分段时,可选择重新生成子分段或保持原有的子分段不变。</li><li>编辑子分段不会影响父分段。</li></ul>|
|
||||
| 添加 / 编辑 / 删除关键词 | 在使用经济索引方式的知识库中,可修改分段关键词以提升检索精度。|
|
||||
| 上传 / 删除图片 | 在启用图片检索的知识库中,可删除已导入的图片或上传新图片,增强分段的视觉语境。<Tip>为知识库选择支持图片向量化的嵌入模型(带有 **图片** 图标)即可启用图片检索。</Tip>|
|
||||
| 编辑 | 修改分段内容。已编辑的分段将标记为 **已编辑**。<br/><br/>对于采用父子分段模式的文档:<ul><li>编辑父分段时,可选择重新生成其子分段或保持原有的子分段不变。</li><li>编辑子分段不会改变其父分段。</li></ul>|
|
||||
| 添加 / 编辑 / 删除关键词 | 在使用经济索引方式的知识库中,可为分段添加或修改关键词,以提升其可检索性。一个分段最多可添加 10 个关键词。|
|
||||
| 上传 / 删除图片 | 在启用图片检索的知识库中,可在对应分段中删除已导入的图片或上传新图片。<Tip>为知识库选择支持图片向量化的嵌入模型(带有 **图片** 图标)即可启用图片检索。</Tip>|
|
||||
|
||||
## 最佳实践
|
||||
|
||||
建议参考以下最佳实践,确保知识库的检索结果准确且相关。
|
||||
|
||||
### 检查分段质量
|
||||
|
||||
文档完成分段后,仔细检查每个分段,确保其语义完整、长度适中,以确保检索准确性和回复相关性。
|
||||
@@ -53,11 +51,11 @@ sidebarTitle: 维护内容
|
||||
|
||||
- 分段 **过短**:上下文不完整,易造成语义丢失和答案不准确。
|
||||
- 分段 **过长**:包含无关信息,易引入语义噪音、降低检索精度。
|
||||
- 分段 **语义不完整**:句子或段落被分段设置强制切断,导致检索结果存在内容缺失或误导。
|
||||
- 分段 **语义不完整**:句子或段落被分段设置强制切断,易导致检索结果存在内容缺失或误导。
|
||||
|
||||
### 将子分段用作父分段的检索钩子
|
||||
|
||||
对于采用父子分段模式的文档,系统会检索子分段,但返回父分段。由于编辑子分段不会影响父分段,可将子分段作为父分段的语义标签或检索提示。
|
||||
对于采用父子分段模式的文档,子分段用于检索,而返回的是父分段。由于编辑子分段不会改变其父分段,可将子分段作为父分段的语义标签或检索提示。
|
||||
|
||||
具体做法是将子分段改写为 **关键词**、**摘要** 或 **常见用户问题**。例如,若父分段的内容为*退货政策*,可将子分段改写为:
|
||||
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
---
|
||||
title: "步骤二:知识流水线编排"
|
||||
title: "步骤二:编排知识流水线"
|
||||
---
|
||||
|
||||
想象一下你正在搭建一条生产流水线,每个站点执行特定任务,你将不同它们连接起来将每个零部件组装最终成品。知识流水线编排与此类似,你组合不同节点,将原始文档数据通过每个节点逐步转化为可搜索的知识库。在 Dify 里,你通过可视化的方式,拖放和连接不同节点,对文档数据进行提取和分块处理,并配置索引方式和检索策略。
|
||||
@@ -341,14 +341,28 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
|
||||
|
||||
### 索引方式 (Index Method) 与检索设置 (Retrieval Setting)
|
||||
|
||||
索引方式决定了知识库如何建立内容索引,检索设置则基于所选的索引方式提供相应的检索策略。你可以这么理解,索引方式决定了整理文档的方式,而检索设置告知使用者可以用什么方法来查找文档。
|
||||
索引方式决定了知识库如何建立内容索引,检索设置则基于所选的索引方式提供相应的检索策略。可以这样理解:索引方式决定如何整理文档,而检索设置则决定如何查找文档。
|
||||
|
||||
知识库提供了两种索引方式:高质量和经济,分别提供不同的检索设置选项。 在高质量模式下,使用 Embedding 嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息。这使得即使用户的问题用词与文档不完全相同,系统也能找到语义相关的准确答案。
|
||||
知识库提供了两种索引方式:高质量和经济,分别提供不同的检索设置选项。
|
||||
|
||||
在高质量模式下,使用嵌入模型将已分段的文本块转换为数字向量,帮助更加有效地压缩与存储大量文本信息。这使得即使用户的问题用词与文档不完全相同,系统也能找到语义相关的准确答案。
|
||||
|
||||
<Tip>
|
||||
请查看[设定索引方法与检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods),了解更多详情。
|
||||
|
||||
若要启用图片检索,需选择支持图片向量化的嵌入模型(带有 **图片** 图标)。
|
||||
|
||||
采用此类嵌入模型的知识库,其卡片上将显示 **多模态** 图标。
|
||||
|
||||
![知识库卡片]()
|
||||
|
||||
</Tip>
|
||||
|
||||
<Info>
|
||||
了解更多细节,阅读 [指定索引方式与检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)。
|
||||
</Info>
|
||||
|
||||
在经济索引方式下,可为每个分段添加 10 个关键词用于检索,无需调用嵌入模型,且不消耗 token。
|
||||
|
||||
#### 索引方式和检索设置
|
||||
|
||||
| 索引方式 | 可用检索设置 | 说明 |
|
||||
|
||||
@@ -5,13 +5,13 @@ sidebarTitle: 概述
|
||||
|
||||
## 简介
|
||||
|
||||
知识是你自有数据的集合,可集成到 Dify 应用中。通过为大语言模型(LLM)提供特定领域的上下文信息,知识库能够让 LLM 的回复更加准确、相关,并显著减少幻觉。
|
||||
在 Dify 中,你可以将自有数据作为「知识」集成到 AI 应用中。通过为大语言模型(LLM)提供特定领域的上下文信息,知识能够让 LLM 的回复更加准确、相关,并显著减少幻觉。
|
||||
|
||||
这得益于检索增强生成(RAG)技术。其核心是:LLM 不再只依赖预训练的公开数据,还会将你的自定义知识作为额外的事实来源:
|
||||
这得益于检索增强生成(RAG)技术。其核心在于:LLM 不再只依赖预训练的公开数据,还会将你的自定义知识作为额外的事实来源:
|
||||
|
||||
1. (检索)用户提问时,系统会先从已集成的知识库中**检索最相关的信息**。
|
||||
2. (增强)检索到的信息会与用户原始问题打包,作为**增强的上下文**发送给 LLM。
|
||||
3. (生成)LLM 基于这些上下文**生成更精准的答案**。
|
||||
1. (检索)处理用户提问时,系统会先从已集成的知识库中 **检索最相关的信息**。
|
||||
2. (增强)检索到的信息会与用户的原始问题打包,作为 **增强的上下文** 发送给 LLM。
|
||||
3. (生成)LLM 基于这些上下文 **生成更精准的答案**。
|
||||
|
||||
<Tip>
|
||||
了解更多 [RAG 原理](/zh-hans/learn-more/extended-reading/retrieval-augment/README)。
|
||||
@@ -19,15 +19,14 @@ sidebarTitle: 概述
|
||||
|
||||
知识存储在知识库中。你可以创建多个知识库,分别适配不同领域、场景或数据源,并按需集成到应用中。
|
||||
|
||||
你可以通过多种方式将数据接入知识库:上传本地文件(支持多种格式)、导入在线文档(如 Notion)、同步网站内容,或连接外部知识库(如 AWS Bedrock)。
|
||||
知识库支持多种数据接入方式:上传本地文件、导入在线文档(如 Notion)、同步网站内容,或连接外部知识库(如 AWS Bedrock)。
|
||||
|
||||
|
||||
## 知识库应用场景
|
||||
## 应用场景
|
||||
|
||||
借助 Dify 知识库,你可以打造基于自有数据和特定领域知识的 AI 应用。常见场景包括:
|
||||
|
||||
1. **智能客服机器人**:让机器人基于最新产品文档、FAQ、故障排查指南和工单历史,智能回复客户问题。
|
||||
2. **企业内部知识门户**:为员工构建 AI 搜索与问答系统,快速访问公司政策、流程、研究报告和机构知识。
|
||||
1. **智能客服机器人**:让问答机器人基于最新产品文档、FAQ、故障排查指南和工单历史,智能回复客户问题。
|
||||
2. **企业内部知识门户**:为员工构建 AI 搜索与问答系统,快速查询公司政策与流程。
|
||||
3. **内容生成工具**:根据特定背景资料,智能生成报告、文章或邮件。
|
||||
4. **科研与分析应用**:检索和总结学术论文、市场报告、法律文档等专业知识,辅助研究与分析。
|
||||
|
||||
@@ -37,32 +36,31 @@ sidebarTitle: 概述
|
||||
- **[通过知识流水线创建](/zh-hans/guides/knowledge-base/knowledge-pipeline/readme)**:自定义步骤和插件,编排更复杂、灵活的数据处理流程。
|
||||
- **[连接外部知识库](/zh-hans/guides/knowledge-base/connect-external-knowledge-base)**:通过 API 直接同步外部知识库,无需迁移即可利用现有数据。
|
||||
|
||||
|
||||
## 管理与优化知识库
|
||||
|
||||
- **[维护知识库内容](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents)**:对文档和分段进行查看、添加、修改或删除等操作,保持知识库内容最新、准确、相关。
|
||||
- **[维护知识库内容](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents)**:对文档及其分段进行查看、添加、修改和删除等操作,使知识库内容保持最新、准确、相关。
|
||||
- **[测试召回效果](/zh-hans/guides/knowledge-base/test-retrieval)**:模拟用户提问,测试知识库召回效果。
|
||||
- **[利用元数据增强检索](/zh-hans/guides/knowledge-base/metadata)**:为文档添加元数据,实现基于筛选的检索。
|
||||
- **[调整知识库设置](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)**:随时调整索引方式、嵌入模型和检索策略。
|
||||
|
||||
- **[利用元数据增强检索](/zh-hans/guides/knowledge-base/metadata)**:为文档添加元数据,实现基于文档筛选的检索,进一步提升检索精度。
|
||||
- **[调整知识库设置](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)**:随时调整索引方式、嵌入模型和检索策略等设置。
|
||||
|
||||
## 使用知识库
|
||||
|
||||
- **[集成到应用](/zh-hans/guides/knowledge-base/integrate-knowledge-within-application)**:让应用真正基于自有数据。
|
||||
- **[显示知识来源](/zh-hans/guides/application-orchestrate/app-toolkits/readme#引用与归属)**:让应用展示每个答案的具体知识来源。
|
||||
- **[集成到应用](/zh-hans/guides/knowledge-base/integrate-knowledge-within-application)**:将自定义知识集成到你的 AI 应用中。
|
||||
- **[显示知识来源](/zh-hans/guides/application-orchestrate/app-toolkits/readme#引用与归属)**:让 AI 在基于知识库内容生成回复时,同时展现引用的知识来源。
|
||||
|
||||
---
|
||||
|
||||
|
||||
**延伸阅读**:
|
||||
|
||||
- [Dify v0.15.0:父子分块检索增强知识库](https://dify.ai/blog/introducing-parent-child-retrieval-for-enhanced-knowledge)
|
||||
- [结合 InfraNodus 扩展 Dify RAG 上下文](https://dify.ai/blog/enhance-dify-rag-with-infranodus-expand-your-llm-s-context)
|
||||
- [Dify v1.1.0:用自定义元数据筛选知识检索](https://dify.ai/blog/dify-v1-1-0-filtering-knowledge-retrieval-with-customized-metadata)
|
||||
- [Dify.AI x Jina AI:集成 Jina 嵌入模型](https://dify.ai/blog/integrating-jina-embeddings-v2-dify-enhancing-rag-applications)
|
||||
- [混合检索与重排序提升 RAG 检索准确率](https://dify.ai/blog/hybrid-search-rerank-rag-improvement)
|
||||
- [Dify.AI 新数据集功能:引用与溯源](https://dify.ai/blog/difyai-new-dataset-features)
|
||||
- [文本嵌入:基本概念与实现原理](https://dify.ai/blog/text-embedding-basic-concepts-and-implementation-principles)
|
||||
- [Dify v0.15.0:全新父子检索策略 - 更精准,更全面的知识检索](https://mp.weixin.qq.com/s/YCvxXVjKjIeOpTNf4NRkYQ)
|
||||
|
||||
- [Dify v1.1.0 发布:用元数据给知识库“贴标签”,RAG 检索效率翻倍](https://mp.weixin.qq.com/s/Zvyz9tS2jmPaLo7Bi9y5LA)
|
||||
|
||||
- [Dify.AI x Jina AI:Dify Embedding 模型新添助力 —— jina-embeddings-v2](https://mp.weixin.qq.com/s/k9-k1ONpRubRV4sKwuAhcg)
|
||||
|
||||
- [引入混合检索(Hybrid Search)和重排序(Rerank)改进 RAG 系统召回效果](https://mp.weixin.qq.com/s/57Wb0EcvgHzLO_XetTnRLg)
|
||||
|
||||
- [文本 Embedding 基本概念和应用实现原理](https://mp.weixin.qq.com/s/sYGxvx-qsu8xaIe2gb5haQ)
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
|
||||
@@ -14,10 +14,10 @@ title: 测试召回效果
|
||||
|
||||
![召回测试]()
|
||||
|
||||
**记录** 板块会记录与该知识库相关的所有检索事件,包括:
|
||||
**记录** 板块记录与该知识库相关的所有检索事件,包括:
|
||||
|
||||
- 在 **召回测试** 页面直接测试的查询
|
||||
- 任何关联应用发起的检索请求(无论是测试还是生产环境)
|
||||
- 在 **召回测试** 页面进行的测试检索
|
||||
- 由任何关联应用发起的常规检索请求(无论是测试还是生产环境)
|
||||
|
||||
<Info>
|
||||
召回测试与常规检索使用同一个 API 接口。
|
||||
|
||||
@@ -1,34 +1,34 @@
|
||||
---
|
||||
title: 知识检索节点
|
||||
title: 知识检索
|
||||
---
|
||||
|
||||
## 简介
|
||||
|
||||
知识检索节点可将已有知识库嵌入到 Chatflow 或 Workflow 中。它会在指定知识库中检索与查询相关的信息,然后将检索结果作为上下文传递给下游节点(如 LLM)。
|
||||
你可以通过知识检索节点将已有知识库集成到 Chatflow 或 Workflow 应用中。该节点在指定知识库中检索相关信息,其检索结果可传递给下游节点(如 LLM)用作上下文。
|
||||
|
||||
以下是知识检索节点在 Chatflow 中的典型用法:
|
||||
知识检索节点在 Chatflow 中的典型用例如下:
|
||||
|
||||
1. **开始** 节点收集用户问题。
|
||||
1. **用户输入** 节点收集用户问题。
|
||||
2. **知识检索** 节点在指定知识库中检索与用户问题相关的内容,并输出检索结果。
|
||||
3. **LLM** 节点基于用户问题和检索结果生成回复。
|
||||
4. **直接回答** 节点将 LLM 的回复返回给用户。
|
||||
4. **直接回答** 节点将 LLM 的回复输出给用户。
|
||||
|
||||

|
||||
|
||||
<Info>
|
||||
使用知识检索节点前,确保至少有一个可用的知识库。了解如何创建与管理知识库,阅读 [知识库](/zh-hans/guides/knowledge-base/readme)。
|
||||
使用知识检索节点前,确保至少有一个可用的知识库。了解如何创建知识库,阅读 [创建知识库](/zh-hans/guides/knowledge-base/readme#创建知识库)。
|
||||
</Info>
|
||||
|
||||
## 配置知识检索节点
|
||||
|
||||
要让知识检索节点正常工作,你需要告诉它 *检索什么*(查询内容)、*在哪里检索*(知识库),以及 *如何处理检索结果*(节点级检索设置)。你还可以利用文档元数据实现基于筛选的检索,进一步提升精准度。
|
||||
要使知识检索节点正常工作,你需要告诉它 *检索什么*(查询内容)、*在哪里检索*(知识库),以及 *如何处理检索结果*(节点级检索设置)。你还可以利用文档元数据实现基于筛选的检索,进一步提升检索精度。
|
||||
|
||||
### 指定查询内容
|
||||
|
||||
设置节点需要在选定知识库中检索的查询内容。
|
||||
设置节点需要在指定知识库中检索的查询内容。
|
||||
|
||||
- **文本查询**:在 Chatflow 中可用 `userinput.query` 引用用户输入,也可选择任意文本变量。
|
||||
- **图片查询**:选择图片变量进行图片检索,例如用户通过用户输入节点上传的图片。图片大小限制为 10MB。
|
||||
- **文本查询**:选择一个文本变量。例如,在 Chatflow 中可用 `userinput.query` 引用用户输入,而在 Workflow 中则可选择文本类型的用户输入变量。
|
||||
- **图片查询**:选择一个图片变量(如用户通过用户输入节点上传的图片),启用图片检索。图片大小限制为 10 MB。
|
||||
|
||||
<Info>
|
||||
自托管用户可通过环境变量 `UPLOAD_IMAGE_FILE_SIZE_LIMIT`(默认 10)调整图片大小限制。
|
||||
@@ -37,79 +37,85 @@ title: 知识检索节点
|
||||
<Info>
|
||||
仅当至少有一个已添加的知识库支持图片检索时,才可使用 **图片查询**。
|
||||
|
||||
支持图片检索的知识库会显示 **图片** 图标,表示其使用的嵌入模型可对图片进行向量化。
|
||||
支持图片检索的知识库带有 **图片** 图标,表示其使用的嵌入模型支持图片向量化。
|
||||
</Info>
|
||||
|
||||
|
||||
### 选择检索的知识库
|
||||
|
||||
为节点添加一个或多个已有知识库,用于检索与查询内容相关的信息。
|
||||
为节点添加一个或多个知识库,用于检索与查询内容相关的信息。
|
||||
|
||||
<Info>
|
||||
带有 **图片** 图标的知识库支持图片检索,可用文本和/或图片作为查询,同时检索语义相关的文本和图片。
|
||||
带有 **图片** 图标的知识库支持图片检索,可用文本和/或图片作为查询内容,同时检索语义相关的文本及图片。
|
||||
</Info>
|
||||
|
||||
<Tip>
|
||||
点击已添加知识库旁的 **编辑** 图标,可直接在知识检索节点内修改其设置。更多设置说明,阅读 [调整知识库设置](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)和[设定索引方式与检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)。
|
||||
点击已添加知识库对应的 **编辑** 图标,可直接在知识检索节点内修改其设置。了解更多设置说明,阅读 [调整知识库设置](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction) 和 [指定索引方式与检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)。
|
||||
</Tip>
|
||||
|
||||
|
||||
### 调整节点级检索设置
|
||||
### 调整节点级检索设置(召回设置)
|
||||
|
||||
进一步微调节点在获取知识库检索结果后的处理方式。
|
||||
设置节点在获取知识库检索结果后的处理方式。
|
||||
|
||||
<Info>
|
||||
检索设置分为知识库级和节点级两层。
|
||||
|
||||
可理解为两道筛选:知识库设置决定初步的检索结果池,而节点设置再对结果进行重排序或进一步筛选。
|
||||
可将其理解为先后两道筛选:知识库设置决定初步的检索结果池,而节点设置对结果进行重排序(Rerank)或进一步筛选。
|
||||
</Info>
|
||||
|
||||
- **重排序参数**
|
||||
- **加权分数**:语义相似度与关键词匹配的权重。语义权重高则更关注语义相关性,关键词权重高则更偏向精确匹配。
|
||||
- **Rerank 设置**
|
||||
|
||||
- **权重设置**:语义相似度与关键词匹配的权重。语义权重高则更注重语义相关性,关键词权重高则更偏向精确匹配。
|
||||
|
||||
<Info>
|
||||
仅当所有已添加的知识库均使用的是高质量索引方式时,才可设置 **加权分数**。
|
||||
仅当所有已添加的知识库使用的索引方式均为高质量时,才会出现 **权重设置** 的选项。
|
||||
</Info>
|
||||
- **重排序模型**:根据与查询的相关性,对所有结果重新评分和排序。
|
||||
- **Top K**:重排序后返回的最大结果数。选择重排序模型时,该值会根据模型的最大输入容量自动调整。
|
||||
- **分数阈值**:返回结果的最低相似度分数。低于阈值的结果会被过滤。阈值高则相关性更严格,阈值低则匹配更宽泛。
|
||||
|
||||
- **Rerank 模型**:根据与查询内容的相关性,对所有结果的相似度分数进行重新评定和排序。
|
||||
|
||||
- **Top K**:重排序后返回的最大结果数。选择 Rerank 模型时,该值将根据模型的最大输入容量自动调整。
|
||||
|
||||
- **Score 阈值**:返回结果的最低相似度分数。低于该阈值的结果会被过滤。阈值高表示对结果的相关性更严格,阈值低则更宽松。
|
||||
|
||||
<Info>
|
||||
添加多个知识库时,会同时检索所有知识库,合并结果并根据上述设置进行处理。
|
||||
</Info>
|
||||
|
||||
|
||||
### 启用元数据筛选
|
||||
### 启用元数据过滤
|
||||
|
||||
可利用已有的文档元数据,将检索范围限定在知识库的特定文档内,提升检索精度。
|
||||
可利用已有的文档元数据,将检索范围限定在知识库的特定文档内,以进一步提升检索精度。
|
||||
|
||||
启用元数据筛选后,知识检索节点只会检索符合指定元数据条件的文档,而非整个知识库。尤其适用于内容多样的大型知识库。
|
||||
启用元数据过滤后,知识检索节点仅会检索符合指定元数据条件的文档,而非整个知识库。尤其适用于内容多样的大型知识库。
|
||||
|
||||
<Info>
|
||||
了解如何创建与管理文档元数据,请阅读 [元数据](/zh-hans/guides/knowledge-base/metadata)。
|
||||
了解如何创建与管理文档元数据,阅读 [元数据](/zh-hans/guides/knowledge-base/metadata)。
|
||||
</Info>
|
||||
|
||||
## 输出变量
|
||||
|
||||
## 输出结果
|
||||
知识检索节点将检索结果输出为 `result` 变量——一个包含分段内容、分段标题、分段链接等属性的文档分段数组。
|
||||
|
||||
知识检索节点会将检索结果输出为 `result` 变量,是一个包含内容、元数据、标题等属性的文档分段数组。
|
||||
|
||||
若启用了图片检索且检索到图片,`result` 变量中还会包含名为 `files` 的字段,存储检索到的图片信息。
|
||||
若启用了图片检索且检索到相关图片,`result` 变量中将增加 `files` 字段,包含检索到的图片信息。
|
||||
|
||||
![知识检索节点输出]()
|
||||
|
||||
## 搭配 LLM 节点使用
|
||||
## 搭配 LLM 节点使用知识检索节点
|
||||
|
||||
如需在 LLM 节点中基于检索结果回答用户问题:
|
||||
|
||||
1. 在 **上下文** 字段选择知识检索节点的 `result` 变量。
|
||||
2. 在提示词字段同时引用 `Context` 变量和用户输入变量(如 Chatflow 中的 `userinput.query`)。
|
||||
1. 在 **上下文** 字段中,选择知识检索节点的 `result` 变量。
|
||||
2. 在提示词字段中,同时引用 `上下文` 变量和用户输入变量(如 Chatflow 中的 `userinput.query`)。
|
||||
|
||||
![LLM 节点配置示例]()
|
||||
<img src="/images/llm_node_configuration_example.png" alt="LLM 节点配置示例" width="400"/>
|
||||
|
||||
<Note>
|
||||
知识检索操作受订阅计划的频率限制。详见 [知识库请求频率限制](/zh-hans/guides/knowledge-base/knowledge-request-rate-limit)。
|
||||
</Note>
|
||||
|
||||
|
||||
|
||||
{/*
|
||||
Contributing Section
|
||||
DO NOT edit this section!
|
||||
|
||||
Reference in New Issue
Block a user