4.0 KiB
title
| title |
|---|
| gpt-oss + Ollama 本地化部署指南 |
一、引言
- gpt-oss 系列是 OpenAI 于 2025 年 8 月首次发布的开源模型。
gpt-oss:20b(适用于约 16GB 的内存)
gpt-oss:120b(适用于≥ 60GB 的内存)
-
使用 Ollama 在本地部署,无需向云端发送 API 请求。数据始终在本地运行,适用于对隐私和响应速度有要求的场景。
-
Dify 是一个开源的 LLM 应用平台,支持集成本地模型、快速构建 AI 应用程序和 RAG 流程。
目标: 展示如何使用 Ollama 在本地部署 gpt-oss 并将其集成到 Dify 中,以构建一个私有且安全的 LLM 服务。
二、环境准备
第一步:使用 Ollama 本地部署 gpt-oss 模型
- 安装 Ollama
访问 Ollama 官网下载安装,根据操作系统选择 macOS、Windows 或 Linux 版本。
- 拉取 gpt-oss 模型
-
gpt-oss:20b(推荐日常开发机器,需 ≥ 16 GB 显存或统一内存)
ollama pull gpt-oss:20b -
gpt-oss:120b(需 ≥ 60 GB 显存或多 GPU 支持)
ollama pull gpt-oss:120b
这两个模型均默认已量化为 MXFP4 格式,适合大多数本地部署场景
- 启动 Ollama 服务
服务默认监听在: http://localhost:11434。
第二步:本地部署 Dify 并准备接入
详细内容参考Dify官方文档,也可以参考如下简易教程。
前置条件
下载安装Docker 环境,安装完毕后确认 Docker Engine 能正常运行。
本地部署Dify
- 使用Git克隆
git clone https://github.com/langgenius/Dify.git
- 进入 Dify 源代码的 docker 目录,执行一键启动命令:
cd Dify/docker cp .env.example .env douyin
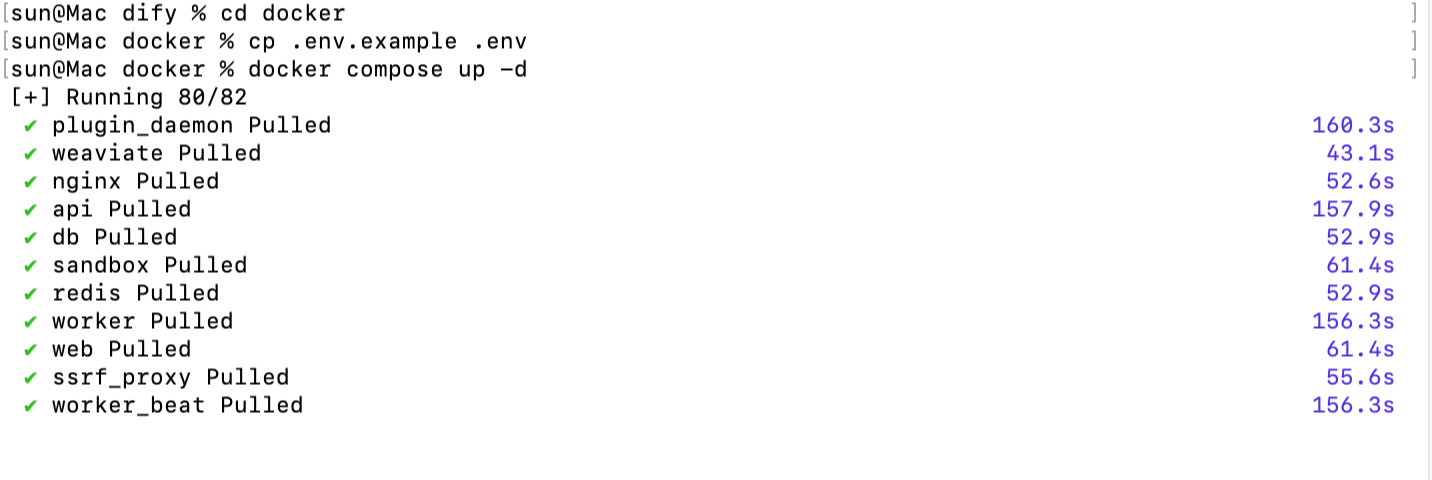
- 进入本地 Dify,填写相关信息
三、添加模型并测试聊天接口
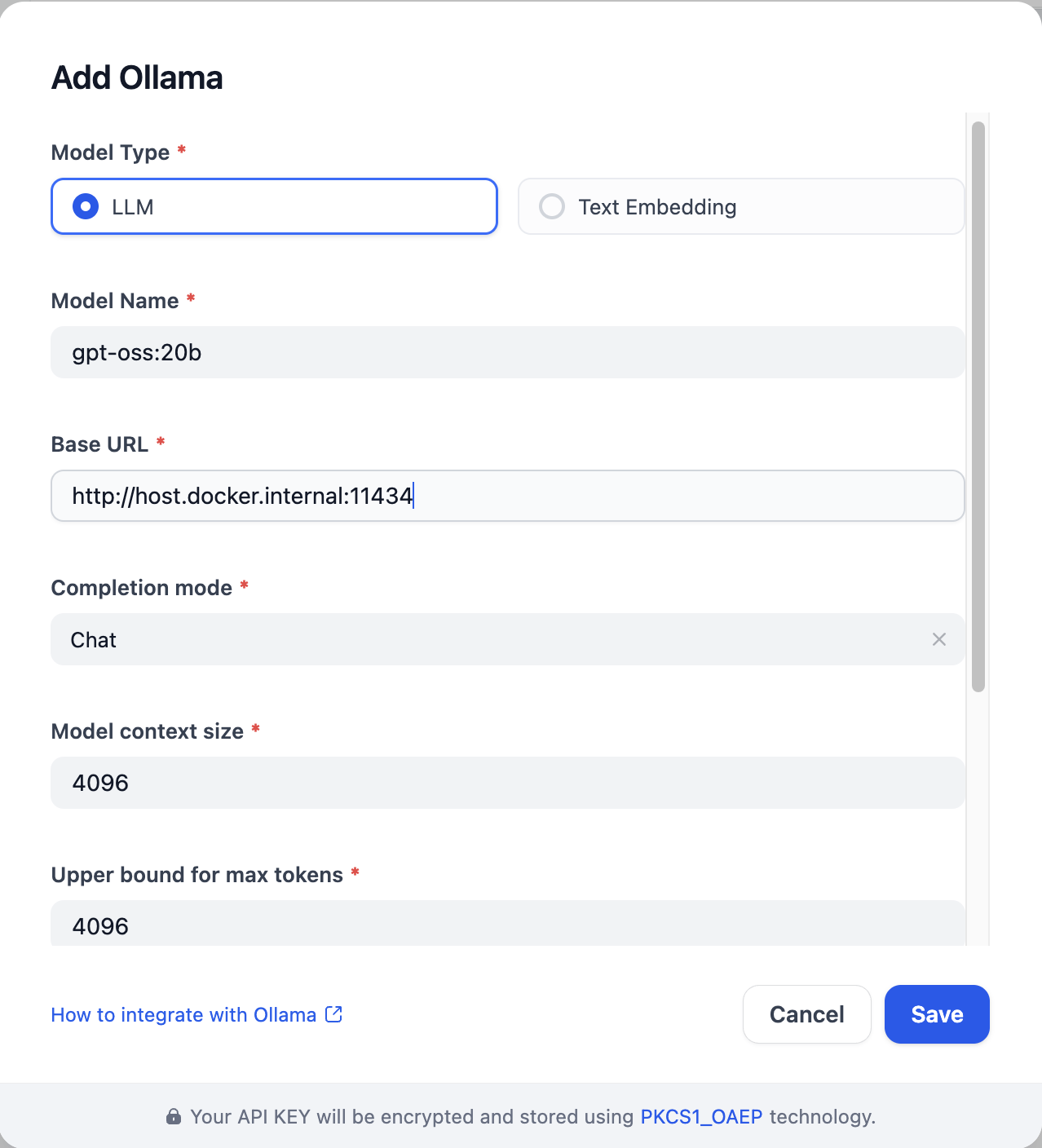
- 点击页面右上角的设置,进入后选择模型提供商,点击添加 Ollama 模型类型: Settings > Model Providers > Ollama
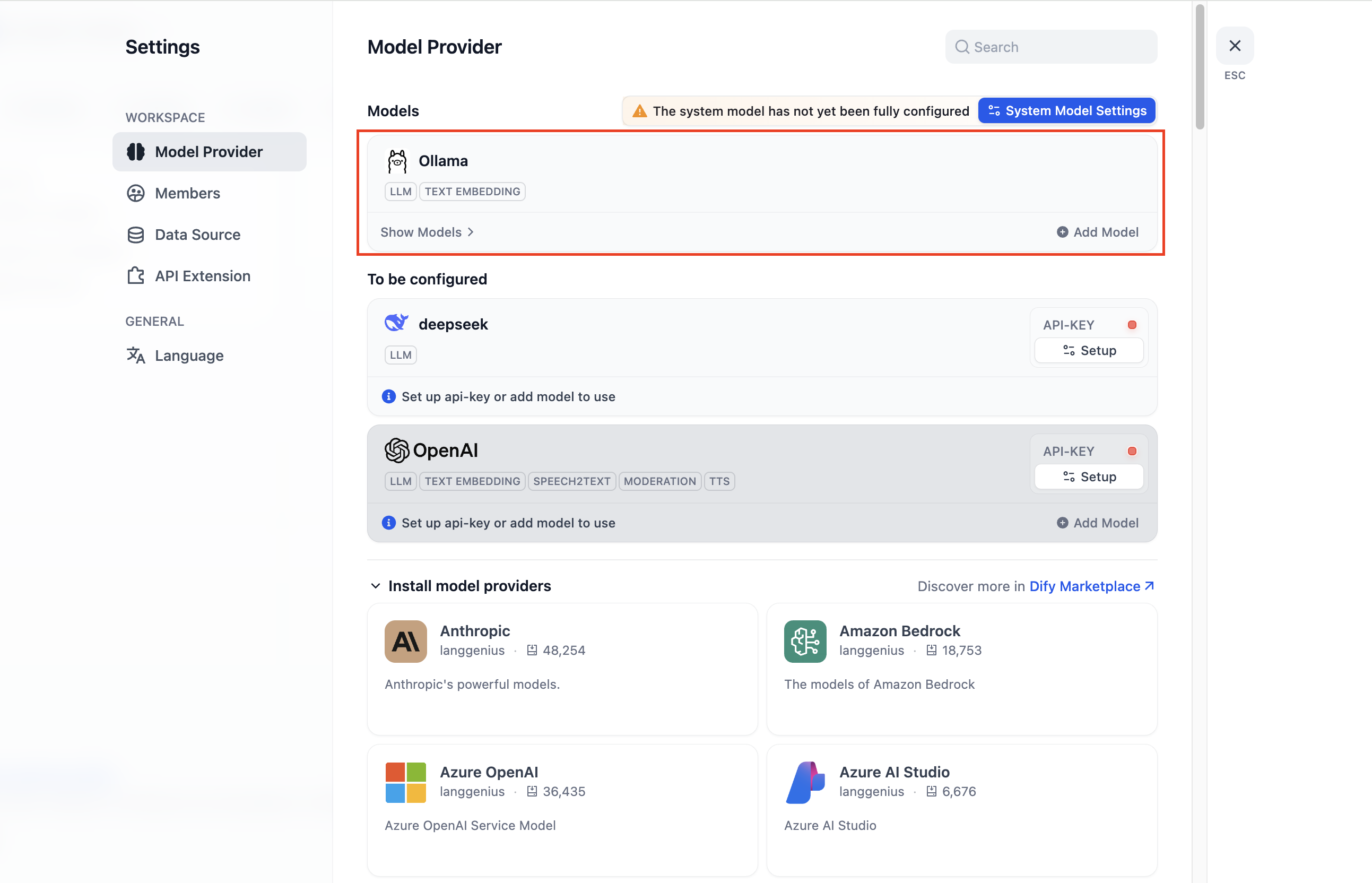
- 请填写 ollama 的相关信息。将 “gpt-oss:20b” 选作模型名称。如有任何不清楚的地方,您可以参考官方详细的部署文档来操作 ollama。
- 新建空白模板
- 选择您想创建的类型
四、验证与使用
-
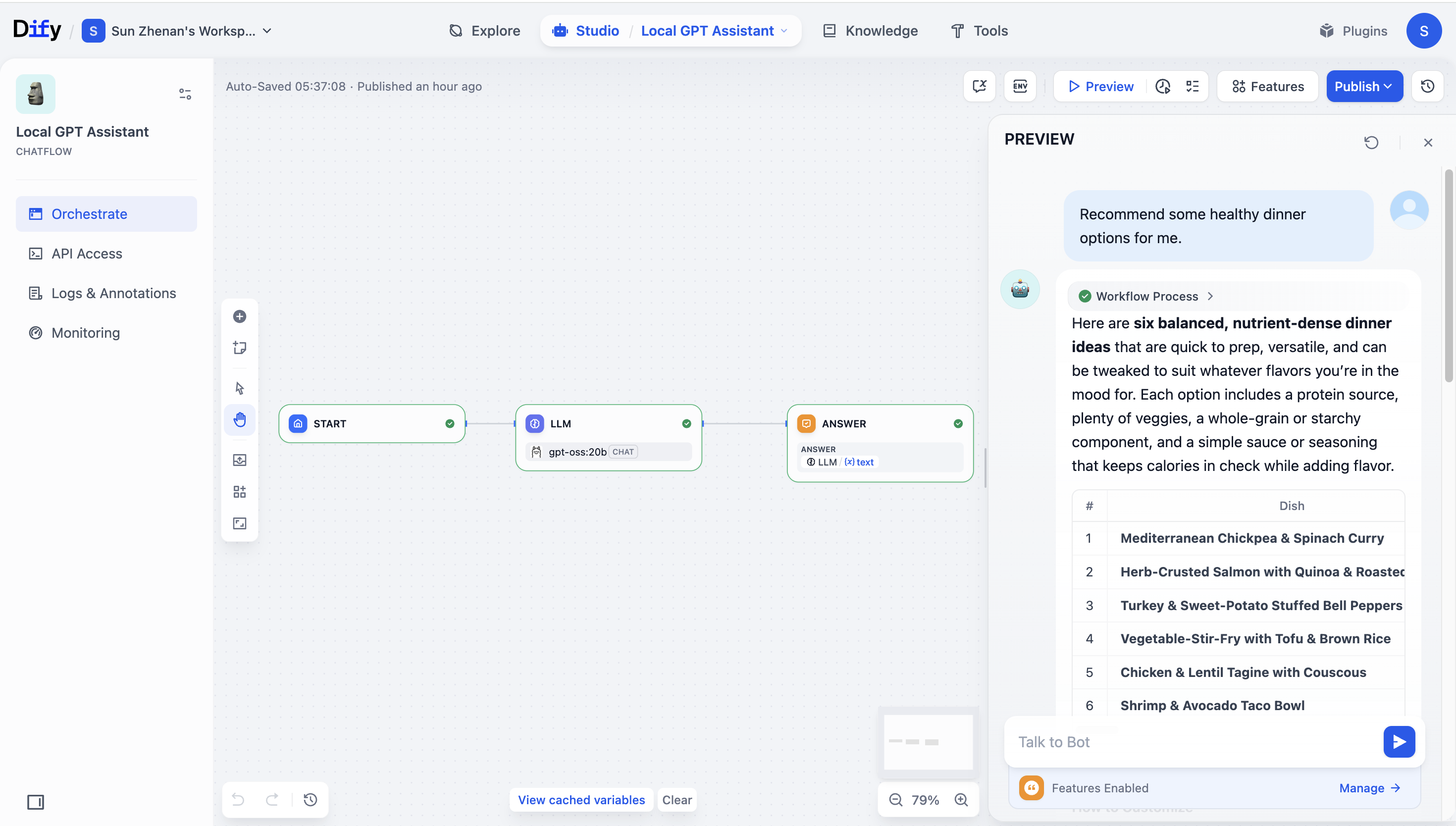
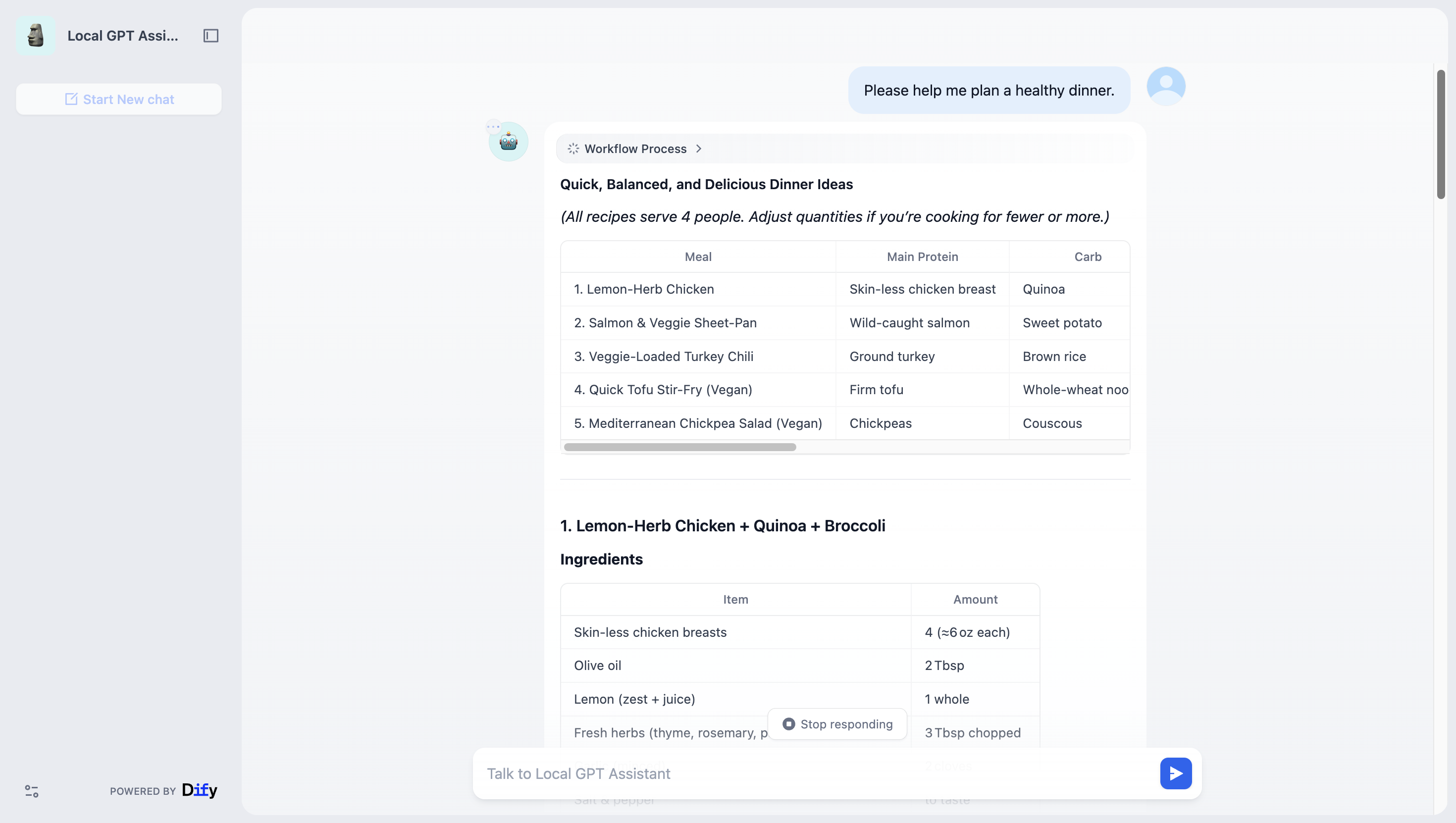
在 Dify 的模型测试页面中,输入适当的提示语,并确认模型的响应符合您的预期。
-
在您的应用流程中添加一个简单的 LLM 节点,选择 gpt-oss:20b 作为模型,并确保整个工作流程连接无误。
五、附录
常见问题及建议
- 模型下载速度慢
提示:配置 Docker 代理或使用图像加速服务以加快下载速度。
- GPU 内存不足
提示:对于 GPU 内存有限的设备,请使用 gpt-oss:20b。您还可以启用 CPU 转发功能,但这样会导致响应速度变慢。
- 端口访问问题
提示:检查防火墙规则、端口绑定和 Docker 网络设置,以确保连接正常。