4.3 KiB
title
| title |
|---|
| Ollama+Dify による gpt-oss のローカルデプロイ |
はじめに
gpt-ossシリーズは、2025年8月にOpenAIからリリースされたオープンソースモデルです。
- gpt-oss:20b(約16GBのメモリを持つシステム向け)
- gpt-oss:120b(60GB以上のメモリに対応)
ローカルでOllamaを使用して実行できます。クラウド呼び出しは不要で、データは常にローカルに保存され、プライバシー保護と低遅延に貢献します。
DifyはAIエージェントやワークフローを構築するためのオープンソースプラットフォームです。このガイドでは、Ollamaを使ってgpt-ossを実行し、Difyに接続してプライベートかつ高性能な設定を行う方法を示します。
環境のセットアップ
ステップ1:Ollamaでgpt-ossを実行する
1. Ollamaをインストール
Ollamaの公式サイトを通してmacOS、Windows、またはLinux用にダウンロードしてインストールしてください。
2. gpt-ossモデルをインストール
# 開発マシン用におすすめ
ollama pull gpt-oss:20b
# 大規模GPUまたはマルチGPUホスト用におすすめ
ollama pull gpt-oss:120b
これらのモデルはすでに混合精度フォーマット(MXFP4)で量子化されており、ローカルデプロイに適しています。
3. Ollamaの起動
デフォルトのエンドポイントはhttp://localhost:11434です。
ステップ2:Difyをローカルにインストール
Difyの公式ドキュメントに完全な手順があります。もしくはこちらのシンプルなチュートリアルをご覧ください。
前提条件 Dockerをインストールし、Dockerエンジンが正常に動作していることを確認してください。
インストール手順
git clone https://github.com/langgenius/Dify.git
cd Dify/docker
cp .env.example .env
docker compose up -d
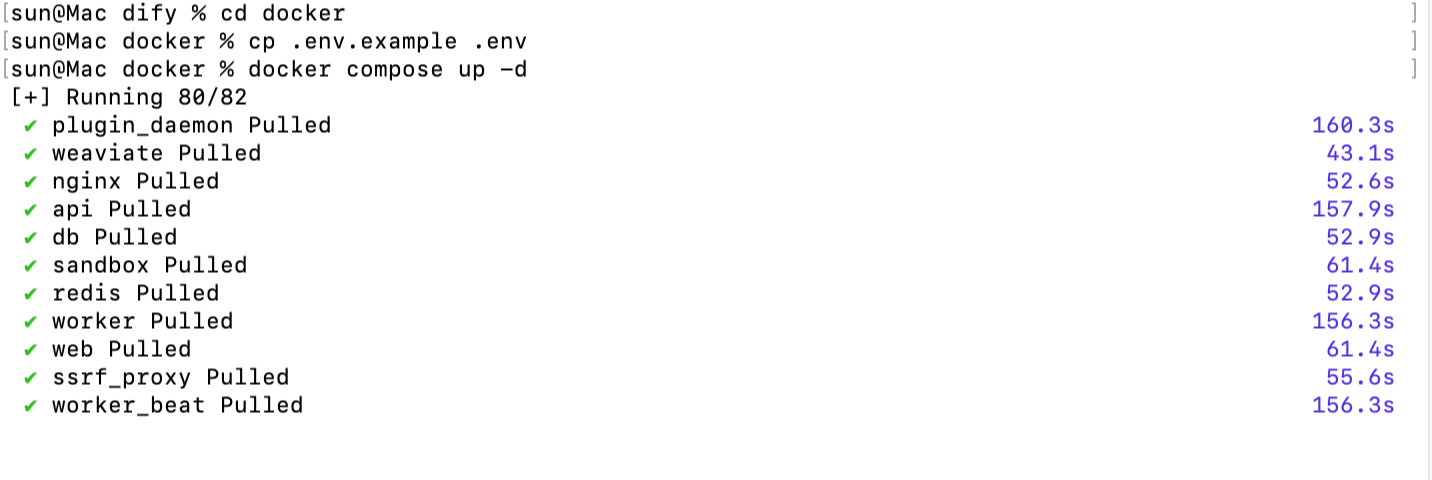
ローカルDifyインスタンスを開き、初期設定を完了させてください。
モデルの追加とチャットのテスト
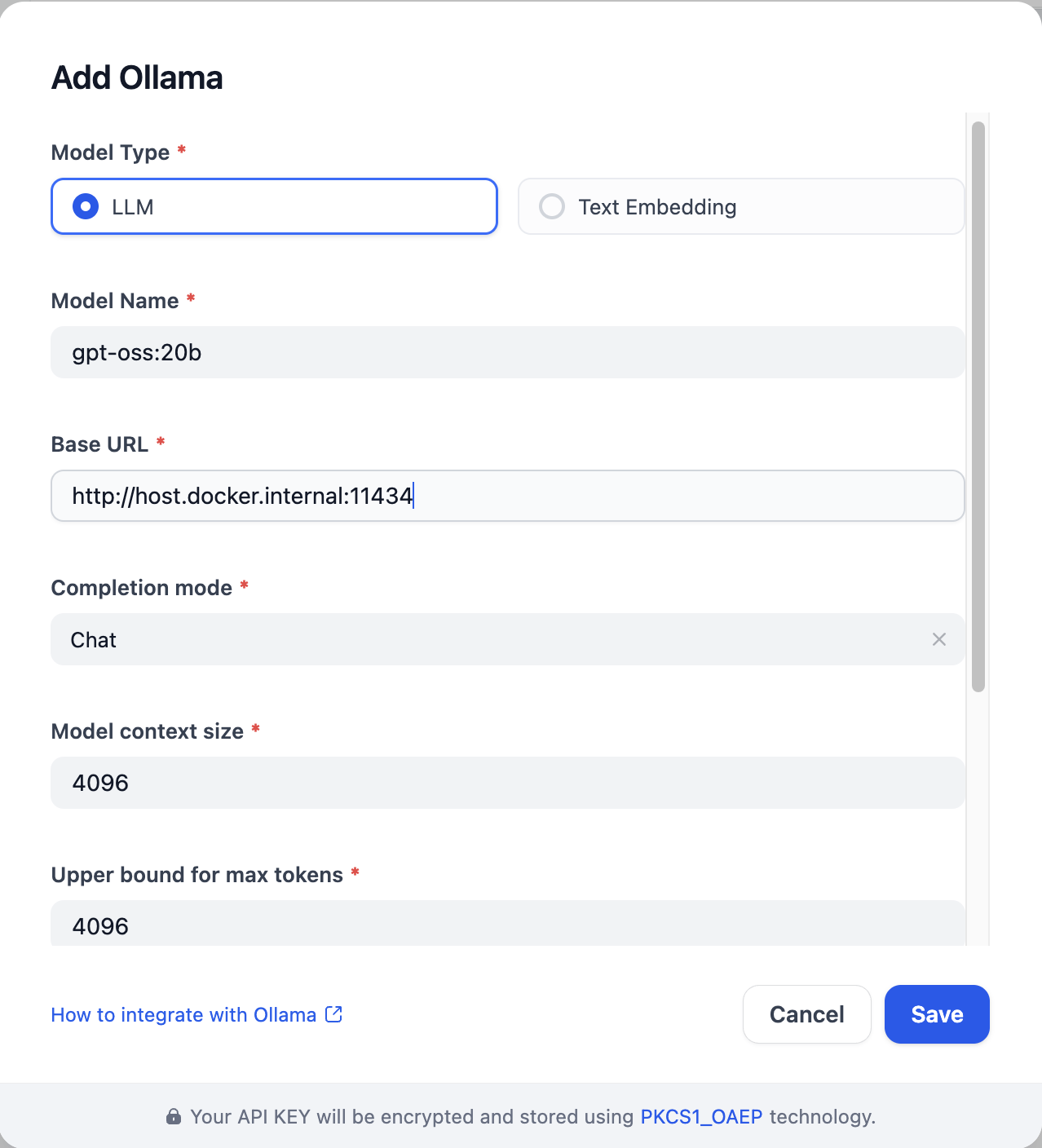
- 設定 > モデルプロバイダー > Ollama に移動し、**「Ollamaモデルタイプを追加」**をクリックしてください。
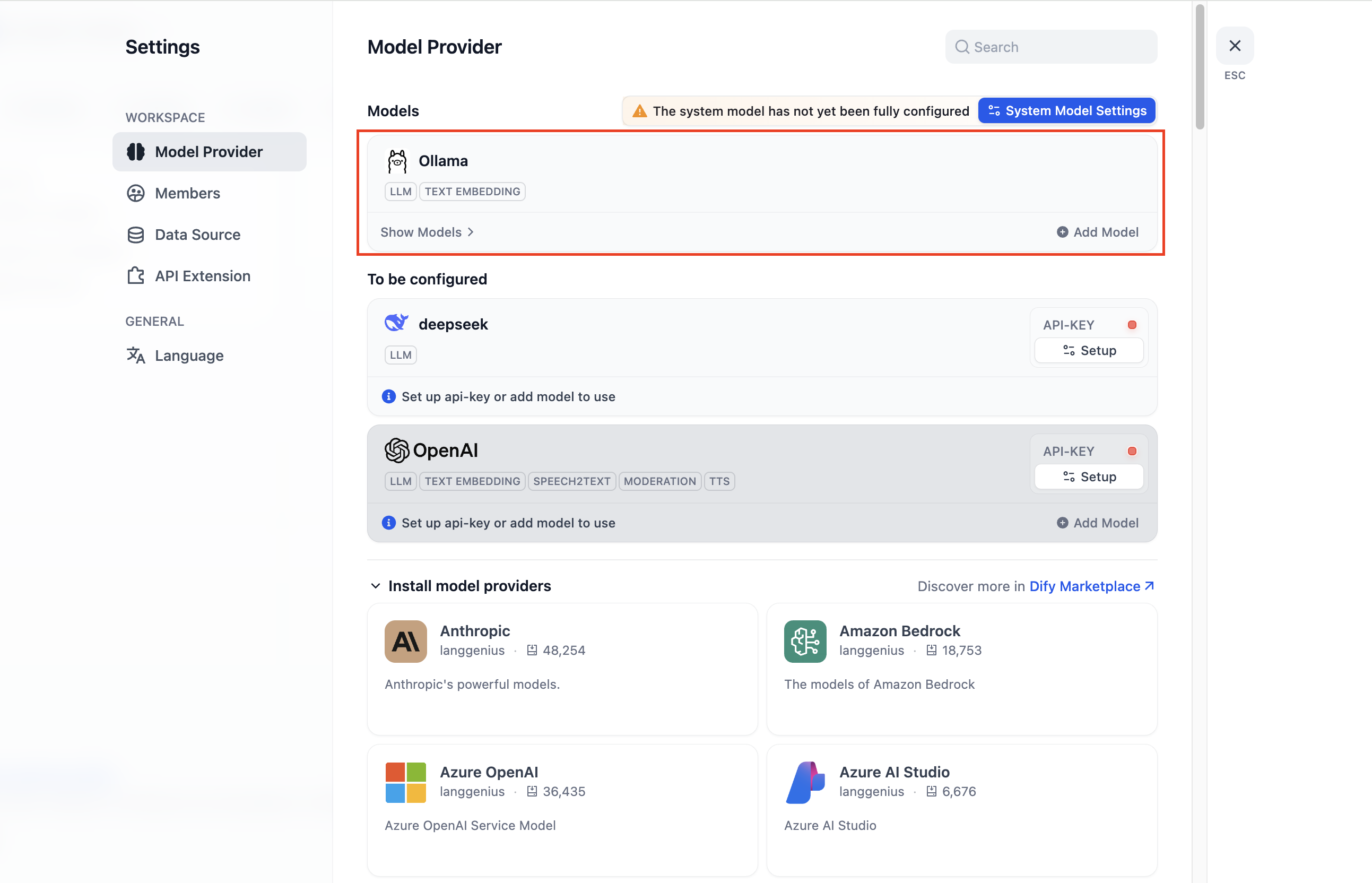
- 基本URLを
http://localhost:11434に設定し、モデル名にgpt-ossを選択し、必要なフィールドを埋めてください。
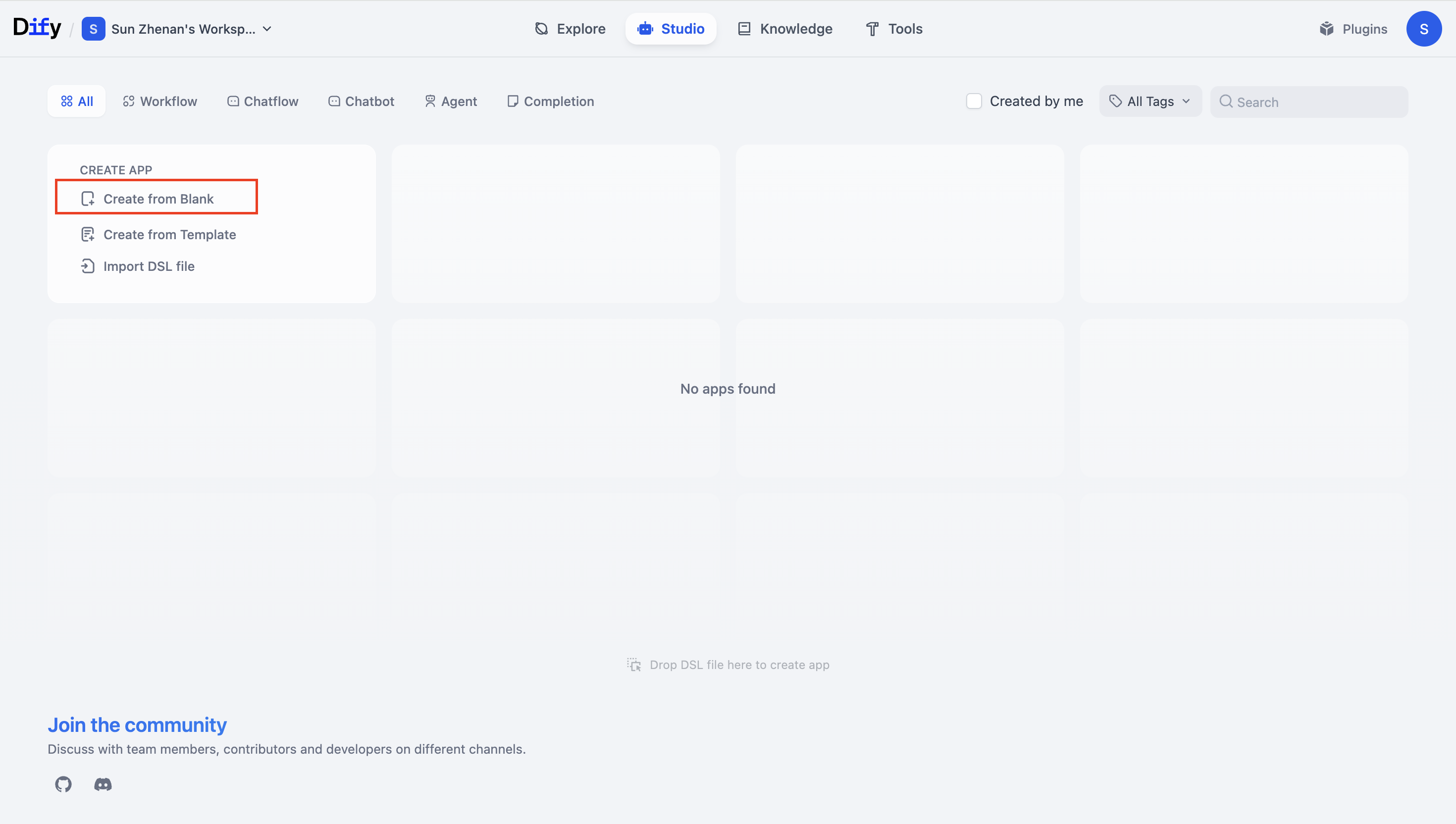
- 空のテンプレートを作成します。
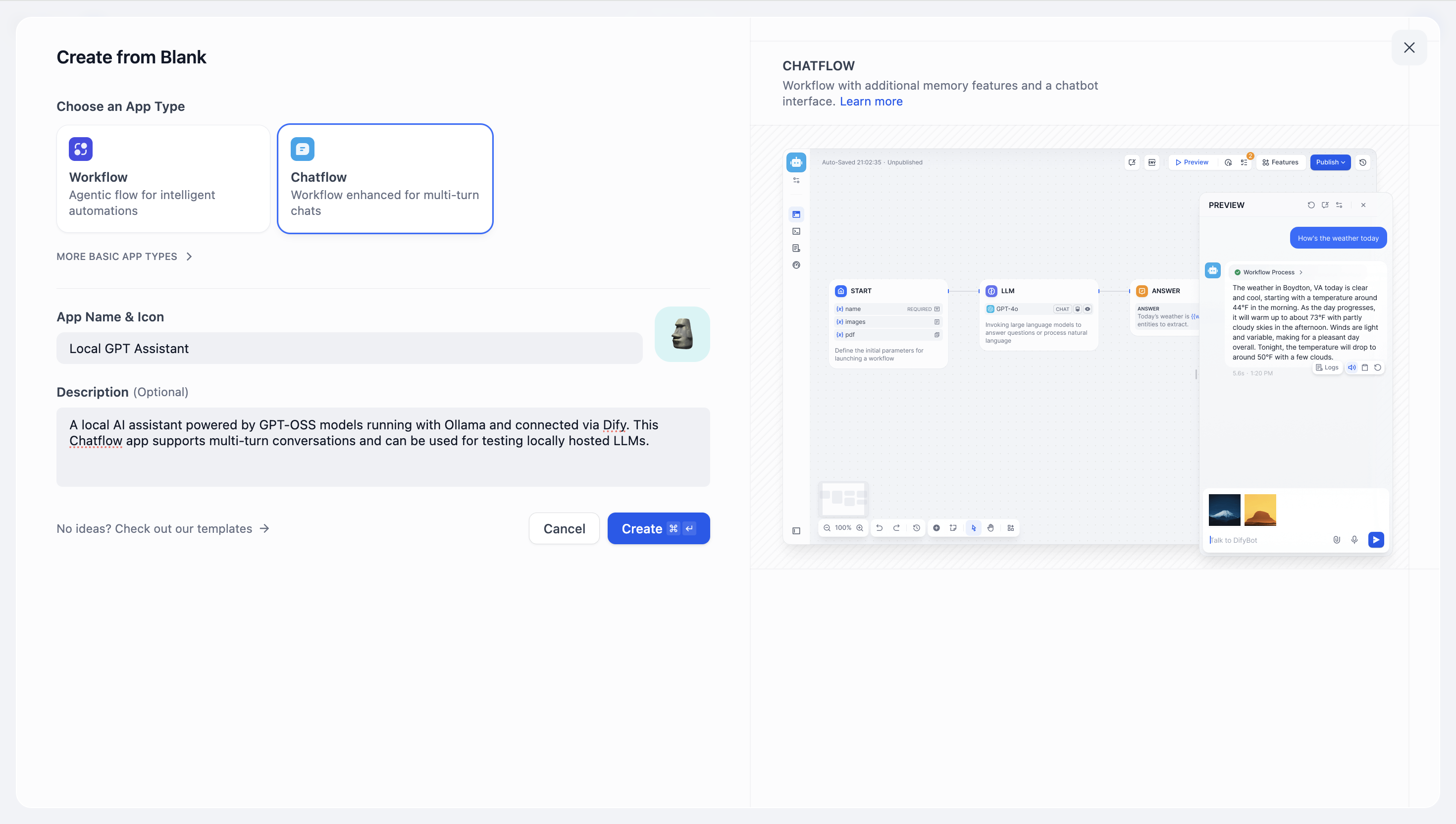
- 構築したいアプリのタイプを選択してください。
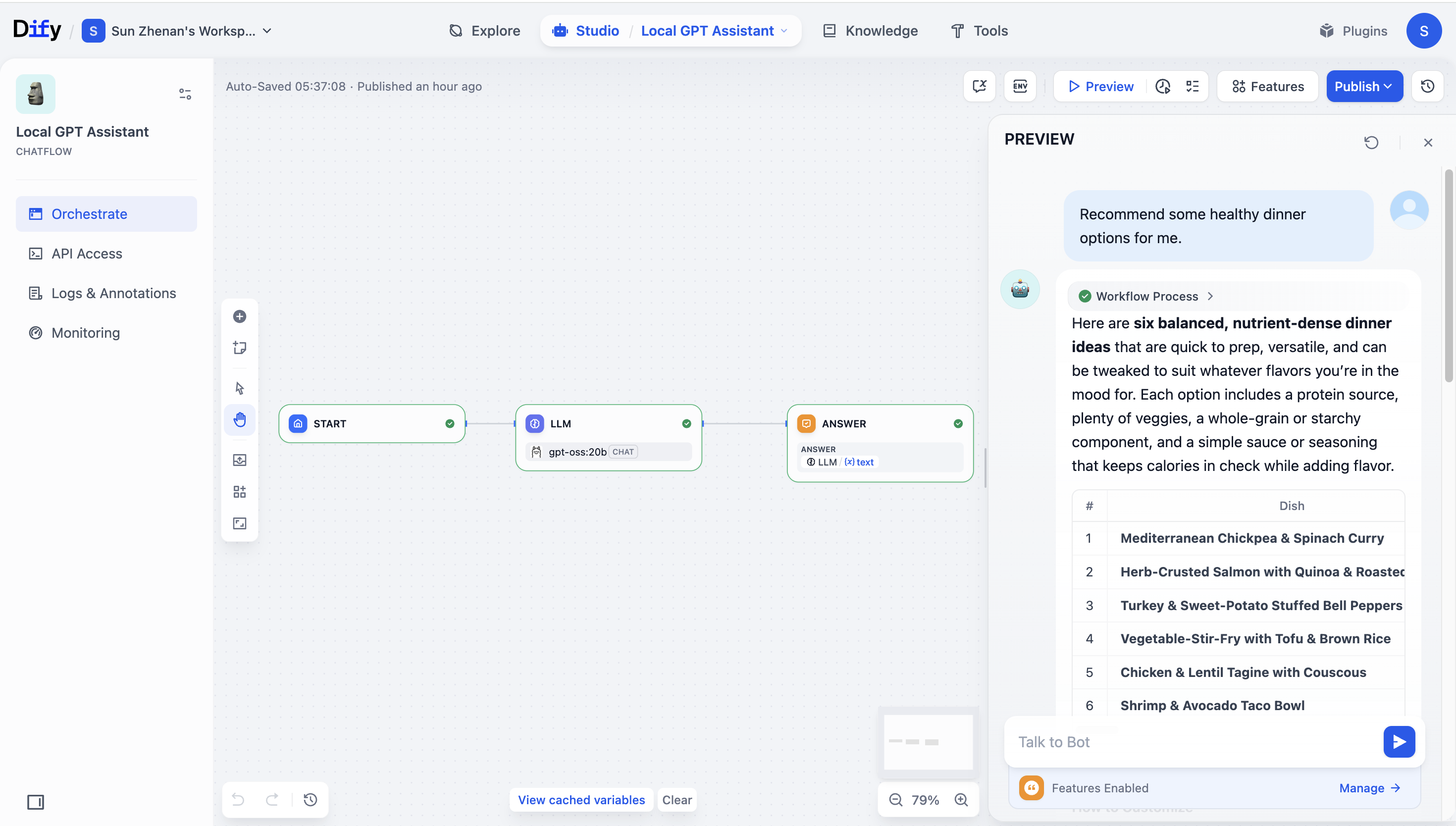
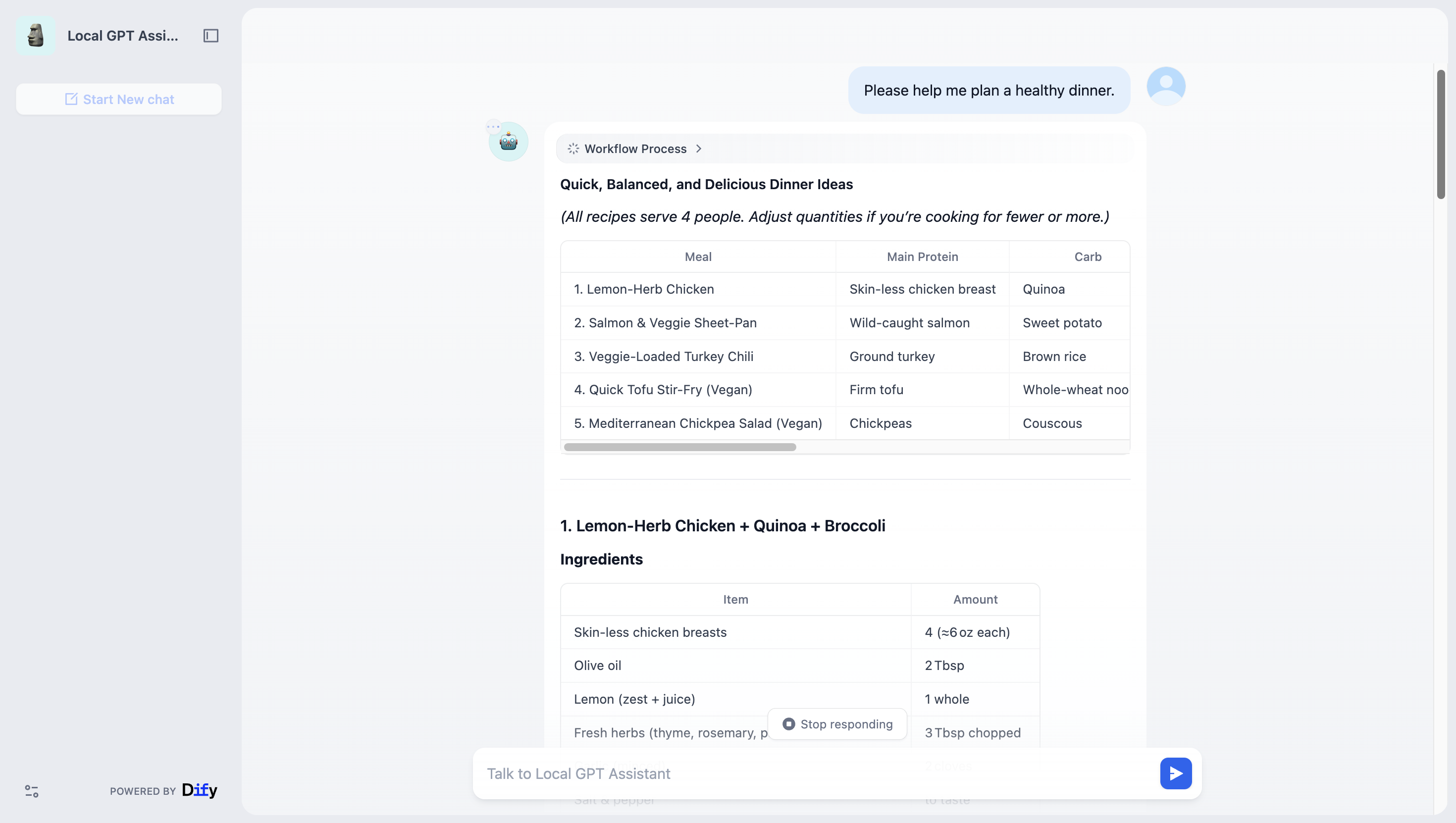
検証と使用
- Difyのモデルテストページでプロンプトを送信し、応答が期待通りであることを確認してください。
- ワークフローにLLMノードを追加し、
gpt-oss:20bを選択してノードをエンドツーエンドで接続してください。
よくある質問
-
モデルのダウンロードが遅い ダウンロードを高速化するために、Dockerプロキシを設定するか、イメージミラーを使用してください。
-
GPUメモリ不足
gpt-oss:20bを使用してください。CPUオフローディングを有効にすることもできますが、その場合は応答が遅くなります。 -
ポートアクセスの問題 接続を確認するために、ファイアウォールのルール、ポートのバインディング、およびDockerネットワーク設定を確認してください。