mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
66 lines
3.0 KiB
Plaintext
66 lines
3.0 KiB
Plaintext
---
|
||
title: 参数提取
|
||
---
|
||
|
||
### 定义
|
||
|
||
利用 LLM 从自然语言推理并提取结构化参数,用于后置的工具调用或 HTTP 请求。
|
||
|
||
Dify 工作流内提供了丰富的[工具](https://docs.dify.ai/v/zh-hans/guides/tools)选择,其中大多数工具的输入为结构化参数,参数提取器可以将用户的自然语言转换为工具可识别的参数,方便工具调用。
|
||
|
||
工作流内的部分节点有特定的数据格式传入要求,如[迭代](/zh-hans/guides/workflow/node/iteration)节点的输入要求为数组格式,参数提取器可以方便的实现结构化参数的转换。
|
||
|
||
***
|
||
|
||
### 场景
|
||
|
||
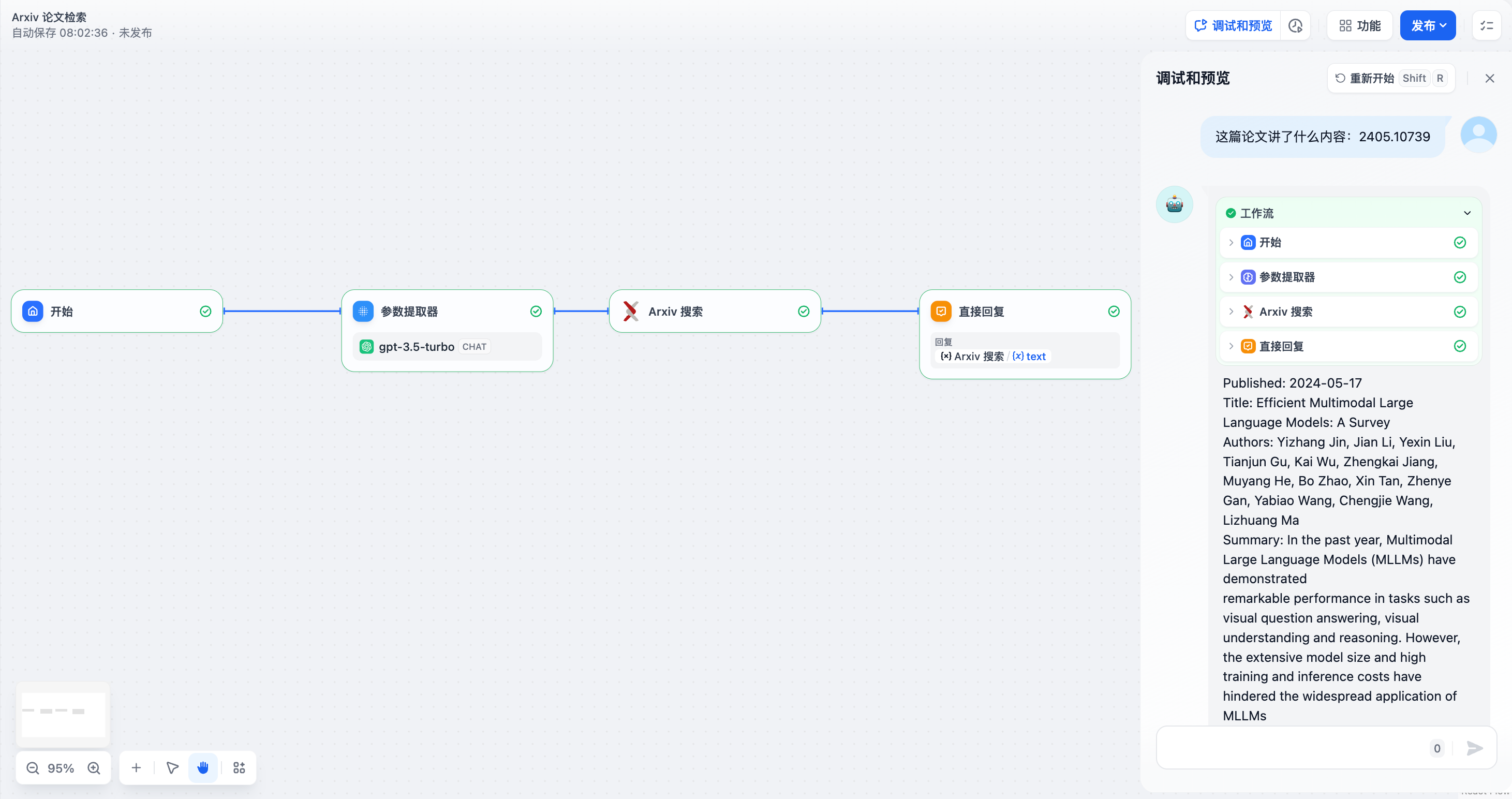
1. **从自然语言中提供工具所需的关键参数提取**,如构建一个简单的对话式 Arxiv 论文检索应用。
|
||
|
||
在该示例中:Arxiv 论文检索工具的输入参数要求为 **论文作者** 或 **论文编号**,参数提取器从问题"这篇论文中讲了什么内容:2405.10739"中提取出论文编号 **2405.10739**,并作为工具参数进行精确查询。
|
||
|
||
|
||
|
||
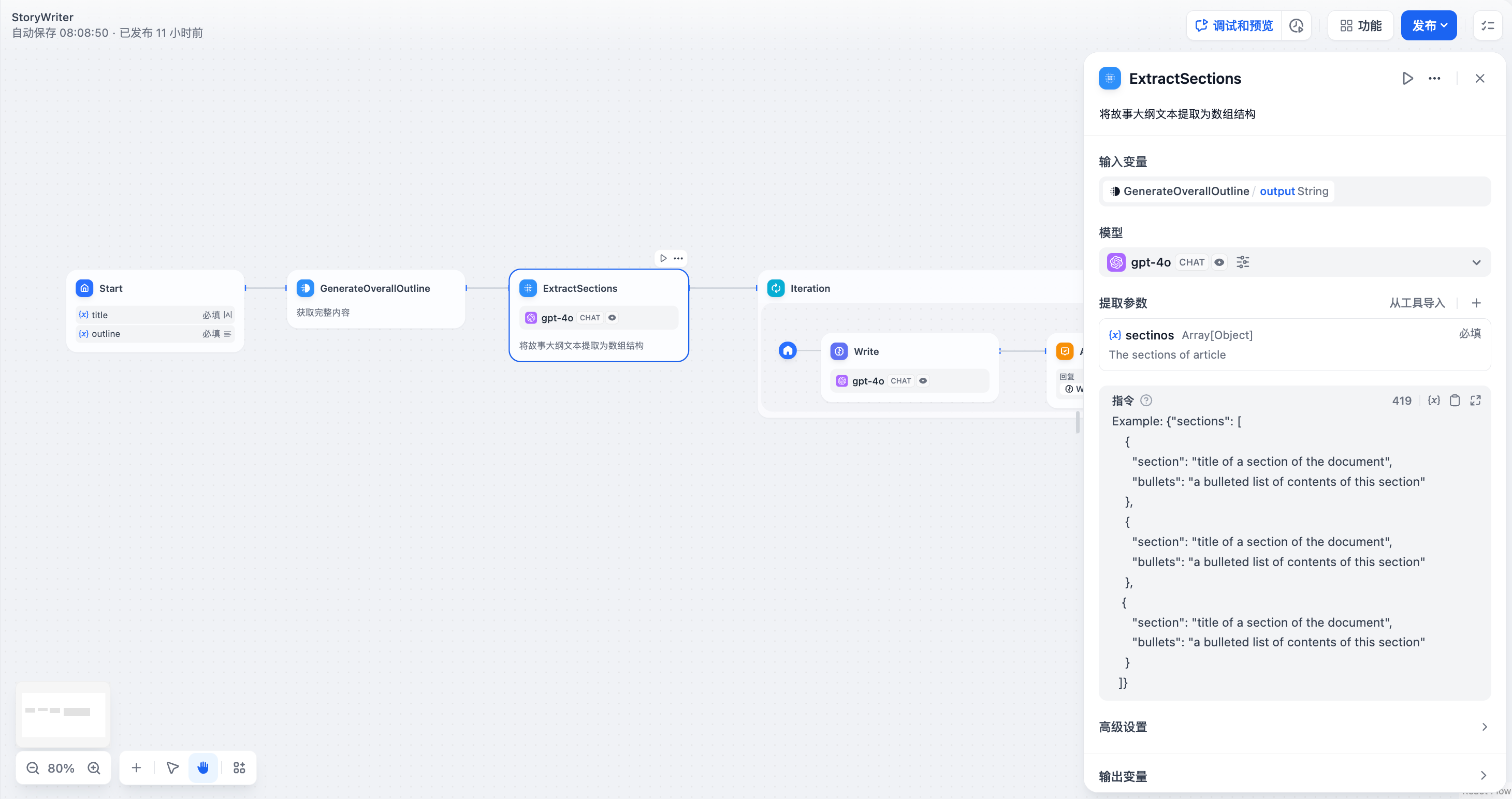
2. **将文本转换为结构化数据**,如长故事迭代生成应用中,作为[迭代节点](/zh-hans/guides/workflow/node/iteration)的前置步骤,将文本格式的章节内容转换为数组格式,方便迭代节点进行多轮生成处理。
|
||
|
||
|
||
|
||
3. **提取结构化数据并使用** [**HTTP 请求**](/zh-hans/guides/workflow/node/http-request) ,可请求任意可访问的 URL ,适用于获取外部检索结果、webhook、生成图片等情景。
|
||
|
||
***
|
||
|
||
### 如何配置
|
||
|
||
|
||
|
||
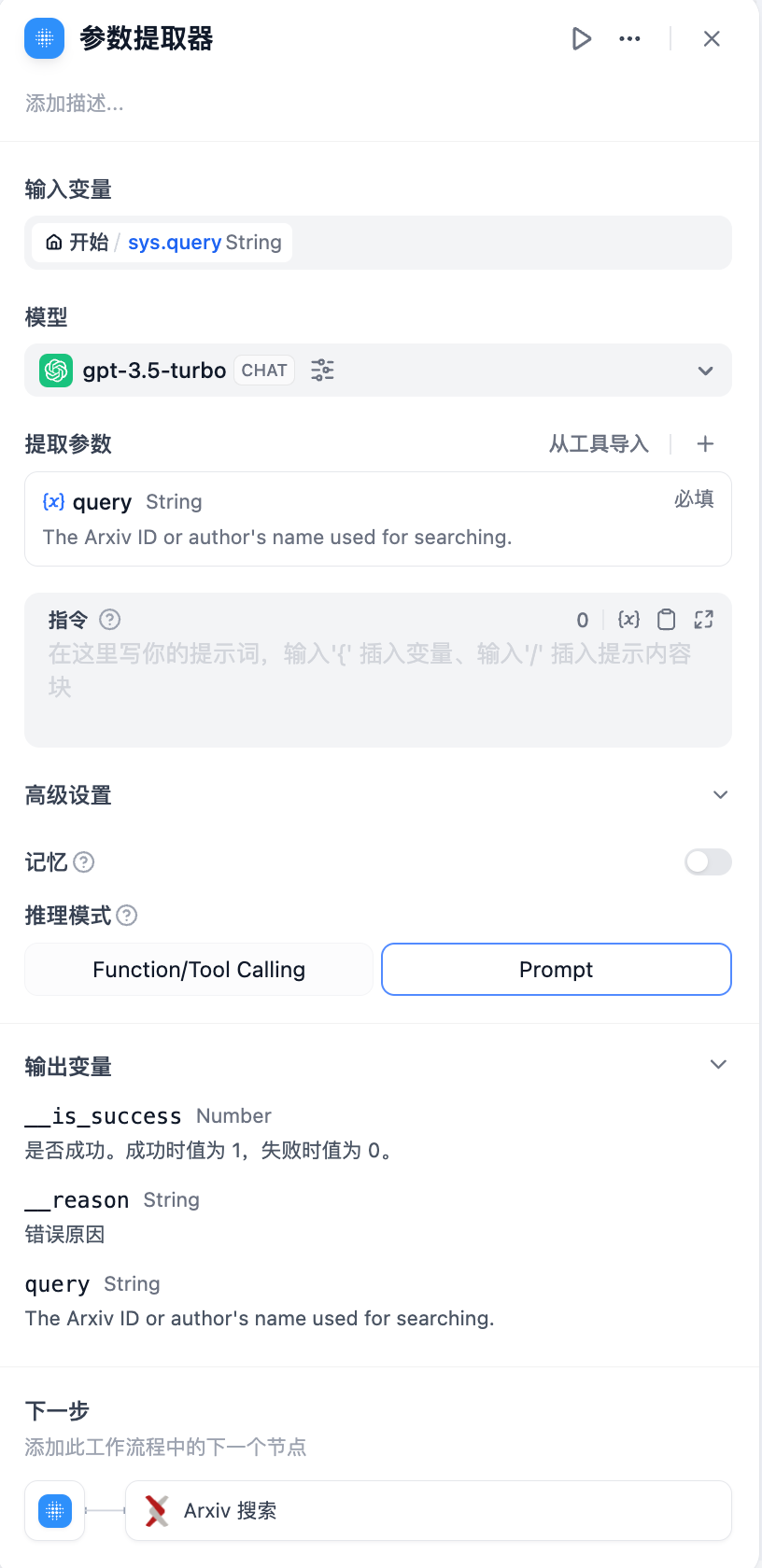
**配置步骤**
|
||
|
||
1. 选择输入变量,一般为用于提取参数的变量输入。输入变量支持 file
|
||
2. 选择模型,参数提取器的提取依靠的是 LLM 的推理和结构化生成能力
|
||
3. 定义提取参数,可以手动添加需要提取的参数,也可以**从已有工具中快捷导入**
|
||
4. 编写指令,在提取复杂的参数时,编写示例可以帮助 LLM 提升生成的效果和稳定性
|
||
|
||
**高级设置**
|
||
|
||
**推理模式**
|
||
|
||
部分模型同时支持两种推理模式,通过函数/工具调用或是纯提示词的方式实现参数提取,在指令遵循能力上有所差别。例如某些模型在函数调用效果欠佳的情况下可以切换成提示词推理。
|
||
|
||
* Function Call/Tool Call
|
||
* Prompt
|
||
|
||
**记忆**
|
||
|
||
开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
|
||
|
||
**图片**
|
||
|
||
开启图片
|
||
|
||
**输出变量**
|
||
|
||
* 提取定义的变量
|
||
* 节点内置变量
|
||
|
||
`__is_success Number 提取是否成功` 成功时值为 1,失败时值为 0。
|
||
|
||
`__reason String` 提取错误原因 |