mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
142 lines
10 KiB
Plaintext
142 lines
10 KiB
Plaintext
---
|
||
title: 2. 指定分段模式
|
||
---
|
||
|
||
将内容上传至知识库后,接下来需要对内容进行分段与数据清洗。**该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。**
|
||
|
||
|
||
<Accordion title="什么是分段与清洗策略?">
|
||
* **分段**
|
||
|
||
由于大语言模型的上下文窗口有限,无法一次性处理和传输整个知识库的内容,因此需要对文档中的长文本分段为内容块。即便部分大模型已支持上传完整的文档文件,但实验表明,检索效率依然弱于检索单个内容分段。
|
||
|
||
LLM 能否精准地回答出知识库中的内容,关键在于知识库对内容块的检索与召回效果。类似于在手册中查找关键章节即可快速得到答案,而无需逐字逐句分析整个文档。经过分段后,知识库能够基于用户问题,采用分段 TopK 召回模式,召回与问题高度相关的内容块,补全关键信息从而提高回答的精准性。
|
||
|
||
在进行问题与内容块的语义匹配时,合理的分段大小非常关键,它能够帮助模型准确地找到与问题最相关的内容,减少噪音信息。过大或过小的分段都可能影响召回的效果。
|
||
|
||
Dify 提供了 **"通用分段"** 和 **"父子分段"** 两种分段模式,分别适应不同类型的文档结构和应用场景,满足不同的知识库检索和召回的效率与准确性要求。
|
||
|
||
* **清洗**
|
||
|
||
为了保证文本召回的效果,通常需要在将数据录入知识库之前便对其进行清理。例如,文本内容中存在无意义的字符或者空行可能会影响问题回复的质量,需要对其清洗。Dify 已内置的自动清洗策略,详细说明请参考 [ETL](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)。
|
||
</Accordion>
|
||
|
||
LLM 收到用户问题后,能否精准地回答出知识库中的内容,取决于知识库对内容块的检索和召回效果。匹配与问题相关度高的文本分段对 AI 应用生成准确且全面的回应至关重要。
|
||
|
||
好比在智能客服场景下,仅需帮助 LLM 定位至工具手册的关键章节内容块即可快速得到用户问题的答案,而无需重复分析整个文档。在节省分析过程中所耗费的 Tokens 的同时,提高 AI 应用的问答质量。
|
||
|
||
### 分段模式
|
||
|
||
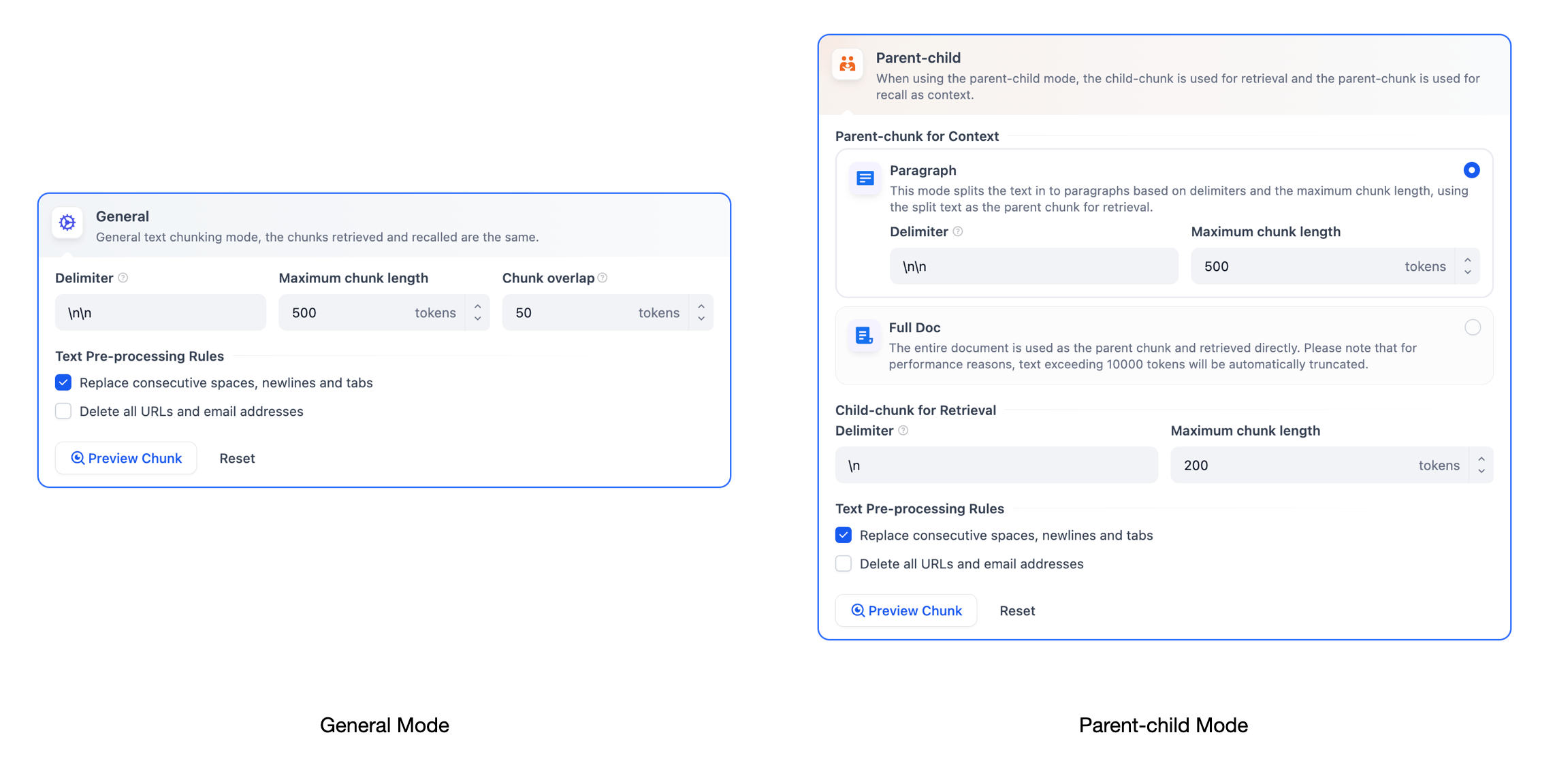
知识库支持两种分段模式:**通用模式**与**父子模式**。如果你是首次创建知识库,建议选择父子模式。
|
||
|
||
<Info>
|
||
**注意**:原 **"自动分段与清洗"** 模式已自动更新为 **"通用"** 模式。无需进行任何更改,原知识库保持默认设置即可继续使用。选定分段模式并完成知识库的创建后,后续无法变更。知识库内新增的文档也将遵循同样的分段模式。
|
||
</Info>
|
||
|
||
|
||
|
||
#### 通用模式
|
||
|
||
系统按照用户自定义的规则将内容拆分为独立的分段。当用户输入问题后,系统自动分析问题中的关键词,并计算关键词与知识库中各内容分段的相关度。根据相关度排序,选取最相关的内容分段并发送给 LLM,辅助其处理与更有效地回答。
|
||
|
||
在该模式下,你需要根据不同的文档格式或场景要求,参考以下设置项,手动设置文本的**分段规则**。
|
||
|
||
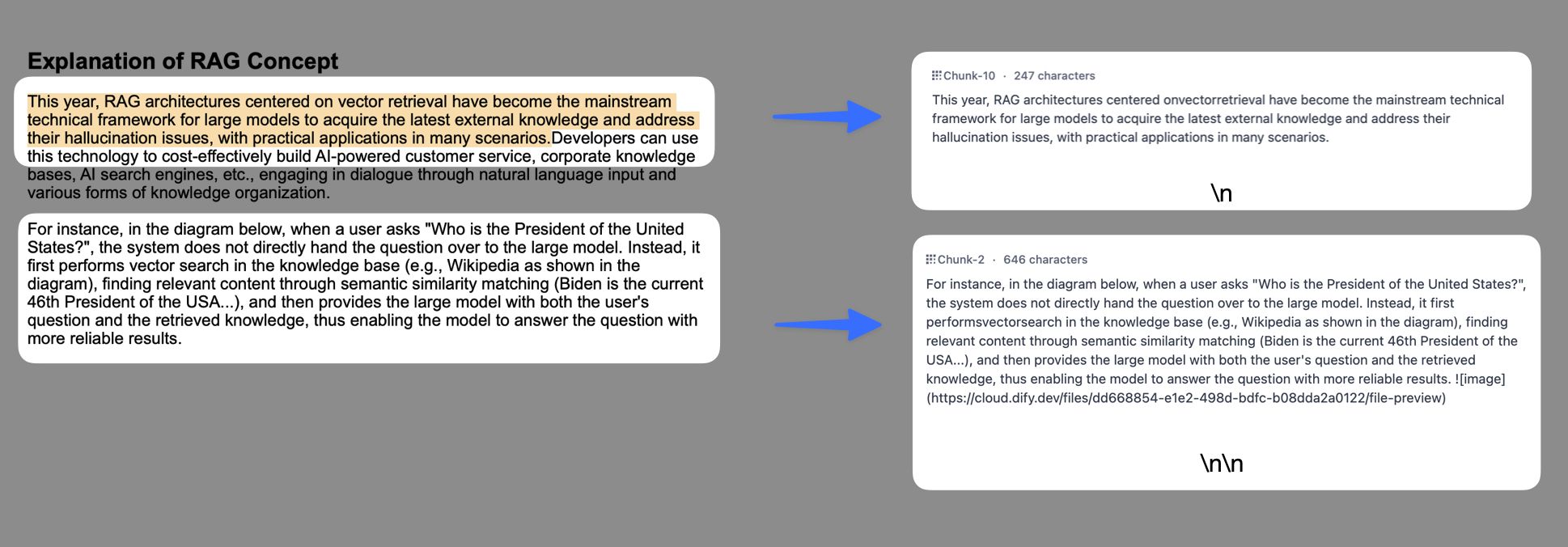
* **分段标识符**,默认值为 `\n`,即按照文章段落进行分块。你可以遵循[正则表达式语法](https://regexr.com/)自定义分块规则,系统将在文本出现分段标识符时自动执行分段。例如 的含义是按照句子进行分段。下图是不同语法的文本分段效果:
|
||
|
||
|
||
|
||
* **分段最大长度**,指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为 500 Tokens,分段长度的最大上限为 4000 Tokens;
|
||
* **分段重叠长度**,指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%;
|
||
|
||
**文本预处理规则,** 过滤知识库内部分无意义的内容。提供以下选项:
|
||
|
||
* 替换连续的空格、换行符和制表符
|
||
* 删除所有 URL 和电子邮件地址
|
||
|
||
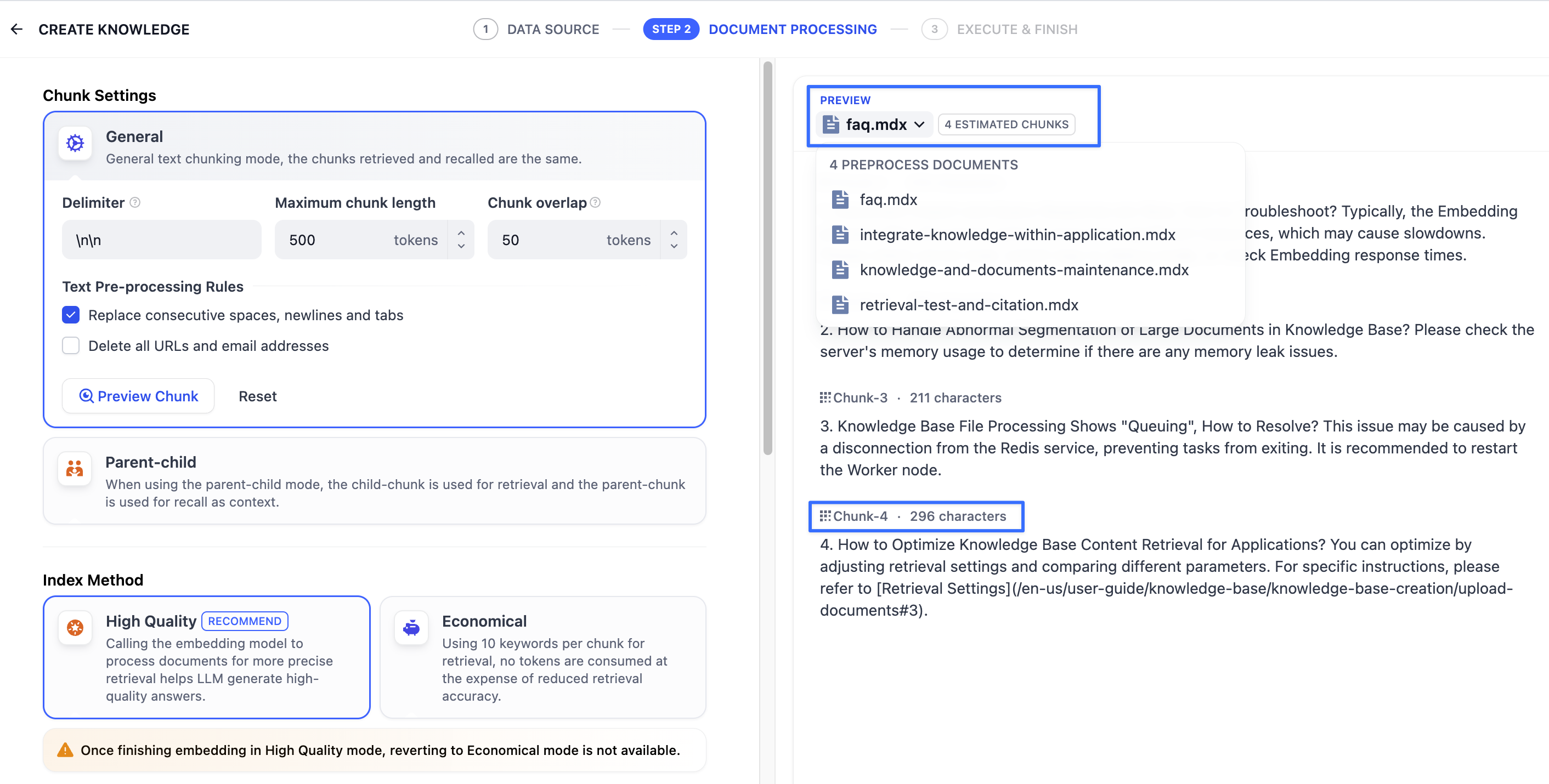
配置完成后,点击"预览区块"即可查看分段后的效果。你可以直观的看到每个区块的字符数。如果重新修改了分段规则,需要重新点击按钮以查看新的内容分段。
|
||
|
||
若同时批量上传了多个文档,轻点顶部的文档标题,快速切换并查看其它文档的分段效果。
|
||
|
||
|
||
|
||
分段规则设置完成后,接下来需指定索引方式。支持"高质量索引"和"经济索引",详细说明请参考[设定索引方法](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)。
|
||
|
||
#### **父子模式**
|
||
|
||
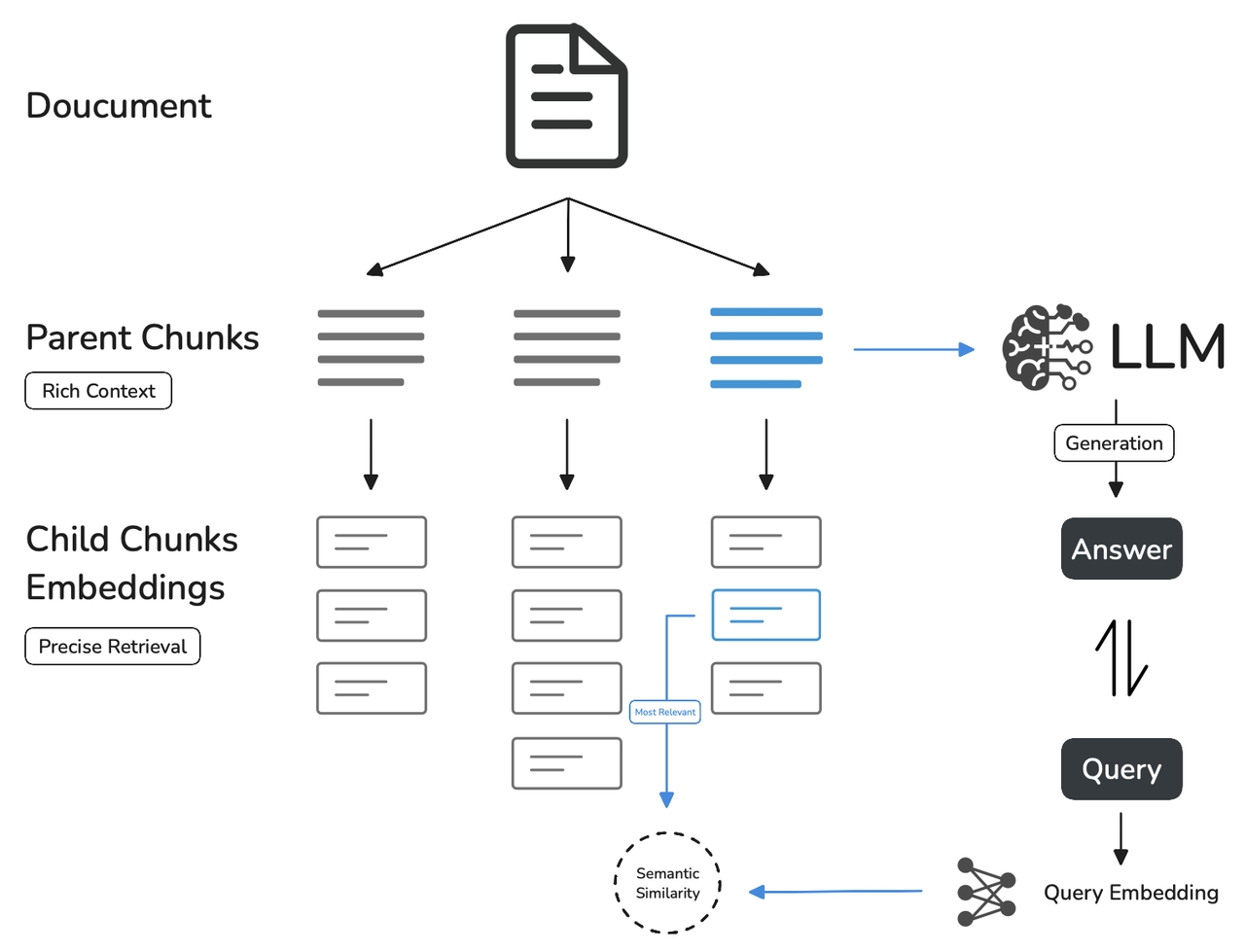
与**通用模式**相比,父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。
|
||
|
||
其中,父区块(Parent-chunk)保持较大的文本单位(如段落),提供丰富的上下文信息;子区块(Child-chunk)则是较小的文本单位(如句子),用于精确检索。系统首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息,从而在生成响应时既保证准确性又能提供完整的背景信息。你可以通过设置分隔符和最大长度来自定义父子区块的分段方式。
|
||
|
||
例如在 AI 智能客服场景下,用户输入的问题将定位至解决方案文档内某个具体的句子,随后将该句子所在的段落或章节,联同发送至 LLM,补全该问题的完整背景信息,给出更加精准的回答。
|
||
|
||
其基本机制包括:
|
||
|
||
* **子分段匹配查询**:
|
||
* 将文档拆分为较小、集中的信息单元(例如一句话),更加精准的匹配用户所输入的问题。
|
||
* 子分段能快速提供与用户需求最相关的初步结果。
|
||
* **父分段提供上下文**:
|
||
* 将包含匹配子分段的更大部分(如段落、章节甚至整个文档)视作父分段并提供给大语言模型(LLM)。
|
||
* 父分段能为 LLM 提供完整的背景信息,避免遗漏重要细节,帮助 LLM 输出更贴合知识库内容的回答。
|
||
|
||
|
||
|
||
在该模式下,你需要根据不同的文档格式或场景要求,手动分别设置父子分段的**分段规则**。
|
||
|
||
**父分段:**
|
||
|
||
父分段设置提供以下分段选项:
|
||
|
||
* **段落**
|
||
|
||
根据预设的分隔符规则和最大块长度将文本拆分为段落。每个段落视为父分段,适用于文本量较大,内容清晰且段落相对独立的文档。支持以下设置项:
|
||
|
||
* **分段标识符**,默认值为 `\n`,即按照文本段落分段。你可以遵循[正则表达式语法](https://regexr.com/)自定义分块规则,系统将在文本出现分段标识符时自动执行分段。
|
||
* **分段最大长度**,指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为 500 Tokens,分段长度的最大上限为 4000 Tokens;
|
||
|
||
* **全文**
|
||
|
||
不进行段落分段,而是直接将全文视为单一父分段。出于性能原因,仅保留文本内的前 10000 Tokens 字符,适用于文本量较小,但段落间互有关联,需要完整检索全文的场景。
|
||
|
||

|
||
|
||
**子分段:**
|
||
|
||
子分段文本是在父文本分段基础上,由分隔符规则切分而成,用于查找和匹配与问题关键词最相关和直接的信息。如果使用默认的子分段规则,通常呈现以下分段效果:
|
||
|
||
* 当父分段为段落时,子分段对应各个段落中的单个句子。
|
||
* 父分段为全文时,子分段对应全文中各个单独的句子。
|
||
|
||
在子分段内填写以下分段设置:
|
||
|
||
* **分段标识符**,默认值为 ,即按照句子进行分段。你可以遵循[正则表达式语法](https://regexr.com/)自定义分块规则,系统将在文本出现分段标识符时自动执行分段。
|
||
* **分段最大长度**,指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为 200 Tokens,分段长度的最大上限为 4000 Tokens;
|
||
|
||
你还可以使用**文本预处理规则**过滤知识库内部分无意义的内容:
|
||
|
||
* 替换连续的空格、换行符和制表符
|
||
* 删除所有 URL 和电子邮件地址
|
||
|
||
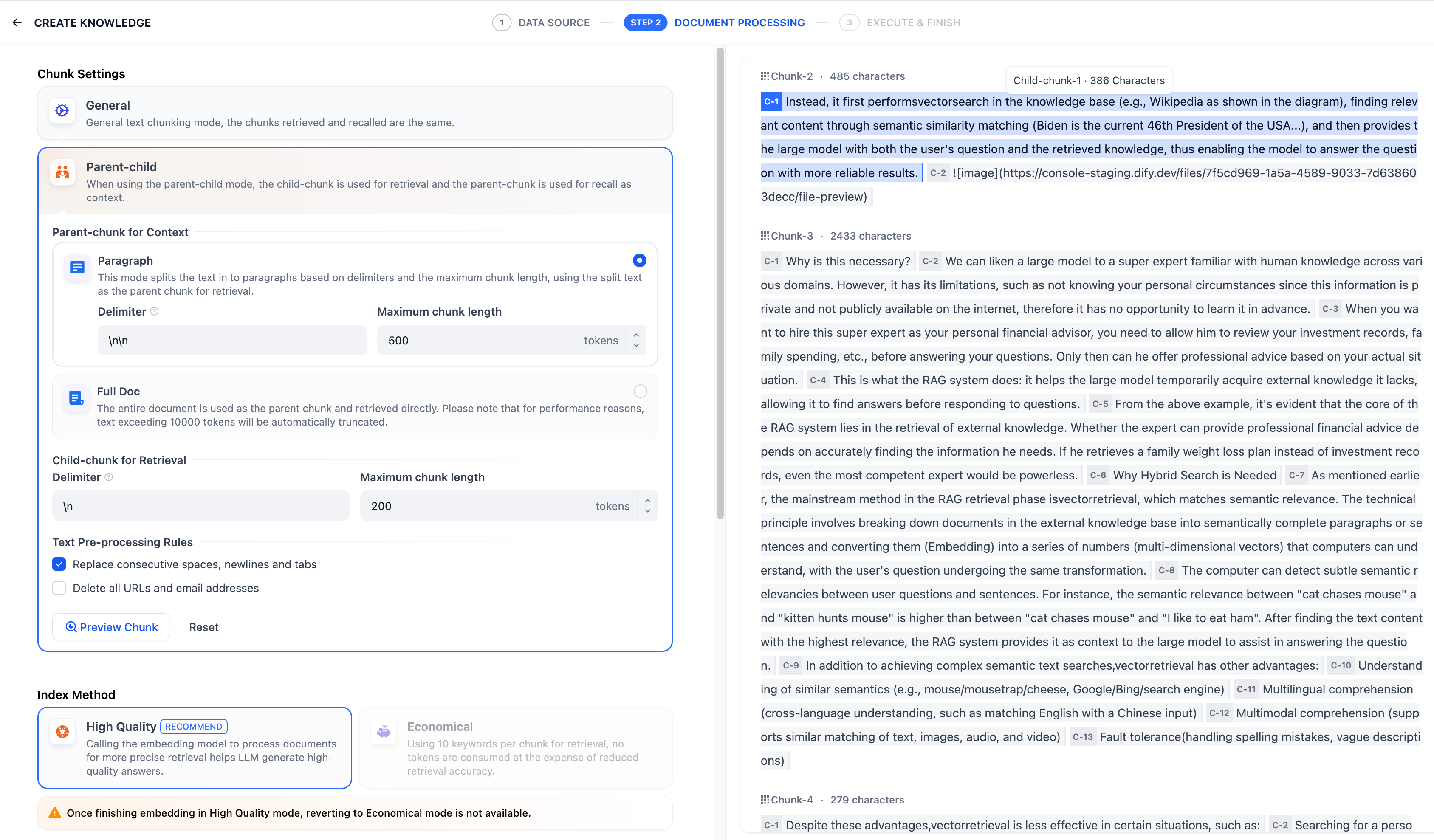
配置完成后,点击"预览区块"即可查看分段后的效果。你可以查看父分段的整体字符数。背景标蓝的字符为子分块,同时显示当前子段的字符数。
|
||
|
||
如果重新修改了分段规则,需要重新点击"预览区块"按钮以查看新的内容分段。若同时批量上传了多个文档,轻点顶部的文档标题,快速切换至其它文档并预览内容的分段效果。
|
||
|
||
|
||
|
||
为了确保内容检索的准确性,父子分段模式仅支持使用["高质量索引"](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)。
|
||
|
||
### 两种模式的区别是什么?
|
||
|
||
两者的主要区别在于内容区块的分段形式。**通用模式**的分段结果为多个独立的内容分段,而**父子模式**采用双层结构进行内容分段,即单个父分段的内容(文档全文或段落)内包含多个子分段内容(句子)。
|
||
|
||
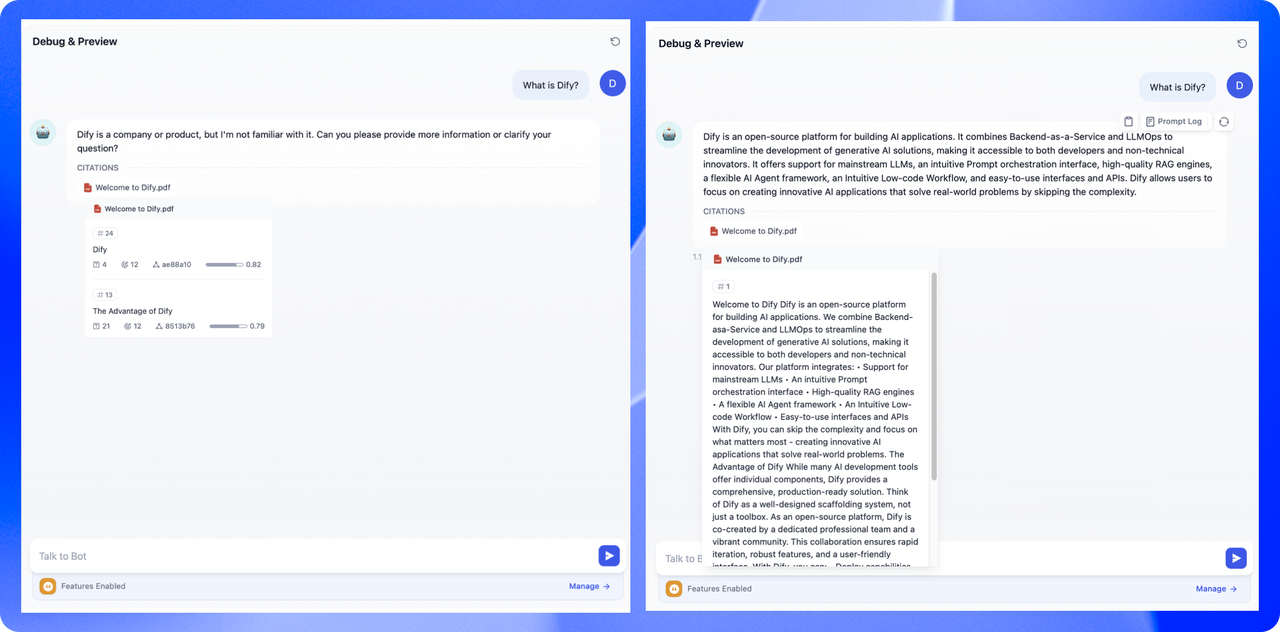
不同的分段方式将影响 LLM 对于知识库内容的检索效果。在相同文档中,采用父子检索所提供的上下文信息会更全面,且在精准度方面也能保持较高水平,大大优于传统的单层通用检索方式。
|
||
|
||
|
||
|
||
### 阅读更多
|
||
|
||
选定分段模式后,接下来你可以参考以下文档分别设定索引方式和检索方式,完成知识库的创建。
|
||
|
||
<Card title="设定索引方法" icon="link" href="setting-indexing-methods">
|
||
了解更多高质量索引和经济索引的详细信息
|
||
</Card>
|