mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
* fix redirect language code prefixes * rename: cn -> zh, jp -> ja * remove hardcoded ja / zh references * remove hardcoded 'english' references * renamed variable names and dict keys to language agnostic names * fix: add missing language helper methods to PRAnalyzer - Add get_language_directory() method - Initialize source_language and target_languages from config - Fixes AttributeError when generating mixed PR errors 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * test: kitchen sink workflow validation v2 This PR validates the translation workflow after config-driven refactoring: Changes: - Add new test file: test-workflow-validation.mdx - Modify existing file: introduction.mdx - Update docs.json navigation Tests: - New file translation (add workflow) - Existing file translation (update workflow) - Navigation sync across languages - Config-driven language codes (zh/ja instead of cn/jp) - Source language abstraction (no hardcoded "English") Expected workflow behavior: 1. Detect changes in en/ directory 2. Translate new file to zh and ja 3. Update modified file translations 4. Sync docs.json for all language sections 5. Commit translated files automatically 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * fix: update workflow paths to use zh/ja instead of cn/jp Aligns workflow trigger paths with the zh/ja language directory rename. 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * Revert "fix: update workflow paths to use zh/ja instead of cn/jp" This reverts commit9587b7cc5d. * Revert "test: kitchen sink workflow validation v2" This reverts commit4abdd69fd2. * fix: update workflow paths in doc analyze workflow to use zh/ja instead of cn/jp * Refactor/language codes (#240) * test: kitchen sink workflow validation v2 This PR validates the translation workflow after config-driven refactoring: Changes: - Add new test file: test-workflow-validation.mdx - Modify existing file: introduction.mdx - Update docs.json navigation Tests: - New file translation (add workflow) - Existing file translation (update workflow) - Navigation sync across languages - Config-driven language codes (zh/ja instead of cn/jp) - Source language abstraction (no hardcoded "English") Expected workflow behavior: 1. Detect changes in en/ directory 2. Translate new file to zh and ja 3. Update modified file translations 4. Sync docs.json for all language sections 5. Commit translated files automatically 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * fix: update workflow paths to use zh/ja instead of cn/jp Aligns workflow trigger paths with the zh/ja language directory rename. 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * Revert "fix: update workflow paths to use zh/ja instead of cn/jp" This reverts commit9587b7cc5d. * Revert "test: kitchen sink workflow validation v2" This reverts commit4abdd69fd2. * fix: update workflow paths in doc analyze workflow to use zh/ja instead of cn/jp --------- Co-authored-by: Claude <noreply@anthropic.com> * fix: update workflow files to use 'source' instead of 'english' After refactoring the PR analyzer to use 'source' for source language PRs (instead of hardcoded 'english'), the workflow files need to match. Changes: - sync_docs_analyze.yml: pr_type == 'source' (was 'english') - sync_docs_update.yml: PR_TYPE != 'source' check - Updated all comments from "English" to "source language" - Updated all pr_type values in JSON from "english" to "source" This ensures the workflows trigger correctly with the refactored config-driven language system. Related: language code refactoring (cn/jp → zh/ja) 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * Fix/workflow source language references (#245) * test: kitchen sink workflow validation v2 This PR validates the translation workflow after config-driven refactoring: Changes: - Add new test file: test-workflow-validation.mdx - Modify existing file: introduction.mdx - Update docs.json navigation Tests: - New file translation (add workflow) - Existing file translation (update workflow) - Navigation sync across languages - Config-driven language codes (zh/ja instead of cn/jp) - Source language abstraction (no hardcoded "English") Expected workflow behavior: 1. Detect changes in en/ directory 2. Translate new file to zh and ja 3. Update modified file translations 4. Sync docs.json for all language sections 5. Commit translated files automatically 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * fix: update workflow paths to use zh/ja instead of cn/jp Aligns workflow trigger paths with the zh/ja language directory rename. 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * Revert "fix: update workflow paths to use zh/ja instead of cn/jp" This reverts commit9587b7cc5d. * Revert "test: kitchen sink workflow validation v2" This reverts commit4abdd69fd2. * fix: update workflow paths in doc analyze workflow to use zh/ja instead of cn/jp * fix: update workflow files to use 'source' instead of 'english' After refactoring the PR analyzer to use 'source' for source language PRs (instead of hardcoded 'english'), the workflow files need to match. Changes: - sync_docs_analyze.yml: pr_type == 'source' (was 'english') - sync_docs_update.yml: PR_TYPE != 'source' check - Updated all comments from "English" to "source language" - Updated all pr_type values in JSON from "english" to "source" This ensures the workflows trigger correctly with the refactored config-driven language system. Related: language code refactoring (cn/jp → zh/ja) 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> --------- Co-authored-by: Claude <noreply@anthropic.com> * fix * fix docs.json language codes * rename previous version docs: cn -> zh, jp -> ja * rm duplicate redirect entires --------- Co-authored-by: Claude <noreply@anthropic.com>
179 lines
12 KiB
Plaintext
179 lines
12 KiB
Plaintext
---
|
||
title: 知識ベースを使用したカスタマーサービスボット
|
||
---
|
||
|
||
前回の実験では、ファイルアップロードの基本的な使い方を学びました。しかし、読み込む必要のあるテキストがLLMのコンテキストウィンドウを超える場合、知識ベースを使用する必要があります。
|
||
|
||
> **コンテキストとは?**
|
||
>
|
||
> コンテキストウィンドウとは、LLMがテキストを処理する際に「見る」ことができ、「記憶」できるテキストの範囲を指します。これは、モデルが応答を生成したりテキストを続ける際に、どれだけの過去のテキスト情報を参照できるかを決定します。ウィンドウが大きいほど、モデルはより多くの文脈情報を利用でき、生成されるコンテンツは通常より正確で一貫性があります。
|
||
|
||
以前、LLMの幻覚の概念について学びました。多くの場合、LLM知識ベースによりエージェントは正確な情報を見つけることができ、質問に正確に答えることができます。カスタマーサービスや検索ツールなどの特定分野での応用があります。
|
||
|
||
従来のカスタマーサービスボットは、多くの場合キーワード検索に基づいています。ユーザーがキーワード外の質問を入力すると、ボットは問題を解決できません。知識ベースはこの問題を解決するために設計されており、セマンティックレベルの検索を可能にし、人間のエージェントの負担を軽減します。
|
||
|
||
実験を始める前に、知識ベースの核心は検索であり、LLMではないことを覚えておいてください。LLMは出力プロセスを強化しますが、本当の必要性は依然として回答を生成することです。
|
||
|
||
### この実験で学ぶこと
|
||
|
||
* チャットフローの基本的な使い方
|
||
* 知識ベースと外部知識ベースの使用方法
|
||
* 埋め込みの概念
|
||
|
||
### 前提条件
|
||
|
||
#### アプリケーションの作成
|
||
|
||
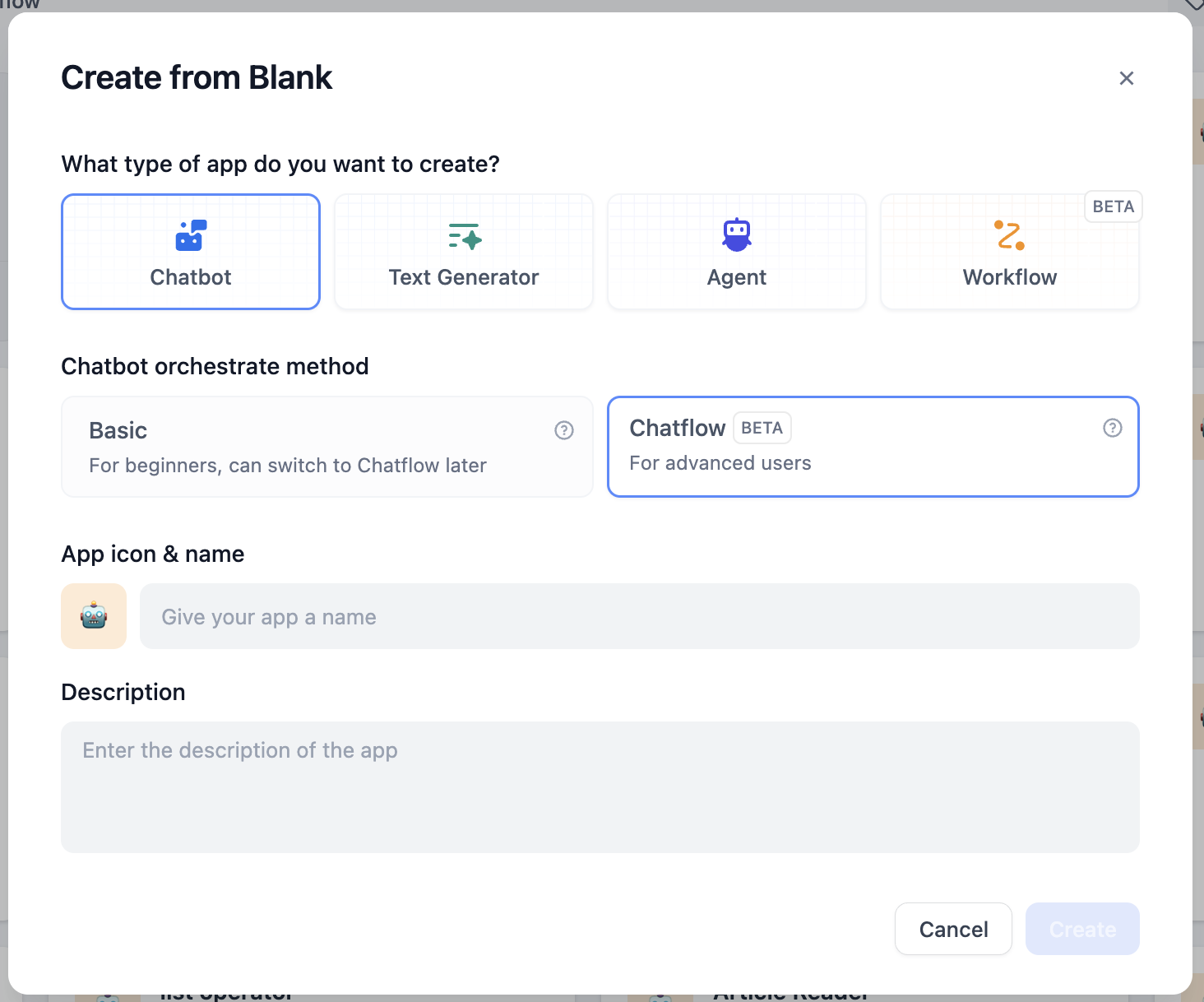
Difyで、**空白から作成 - チャットフロー**を選択します。
|
||
|
||
|
||
|
||
#### モデルプロバイダーの追加
|
||
|
||
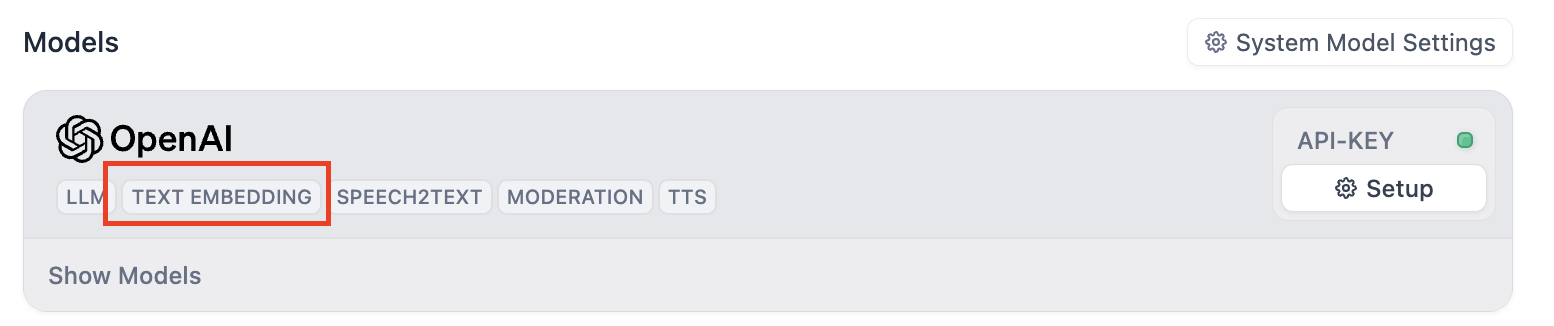
この実験では埋め込みモデルを使用します。現在サポートされている埋め込みモデルプロバイダーには、OpenAIとCohereが含まれます。Difyのモデルプロバイダーで、`TEXT EMBEDDING`ラベルがあるものがサポートされています。少なくとも1つを追加し、十分な残高があることを確認してください。
|
||
|
||
|
||
|
||
> **埋め込みとは?**
|
||
>
|
||
> 「埋め込み」は、離散変数(単語、文、または文書全体など)を連続ベクトル表現に変換する技術です。
|
||
>
|
||
> 簡単に言えば、自然言語をデータに処理する際、テキストをベクトルに変換します。このプロセスを埋め込みと呼びます。意味的に類似したテキストのベクトルは近くになり、意味的に反対のテキストのベクトルは離れます。LLMはこのデータを使用してトレーニングを行い、後続のベクトルを予測し、テキストを生成します。
|
||
|
||
### 知識ベースの作成
|
||
|
||
Difyにログイン -> 知識 -> 知識を作成
|
||
|
||
|
||
Difyは3つのデータソースをサポートしています:ドキュメント、Notion、ウェブページ。
|
||
|
||
ローカルテキストファイルの場合、ファイルの種類とサイズ制限に注意してください。Notionコンテンツの同期にはNotionアカウントのバインドが必要です。ウェブサイトの同期には**Jina**または**Firecrawl API**を使用する必要があります。
|
||
|
||
まずローカルドキュメントのアップロードを例として始めます。
|
||
|
||
#### チャンク設定
|
||
|
||
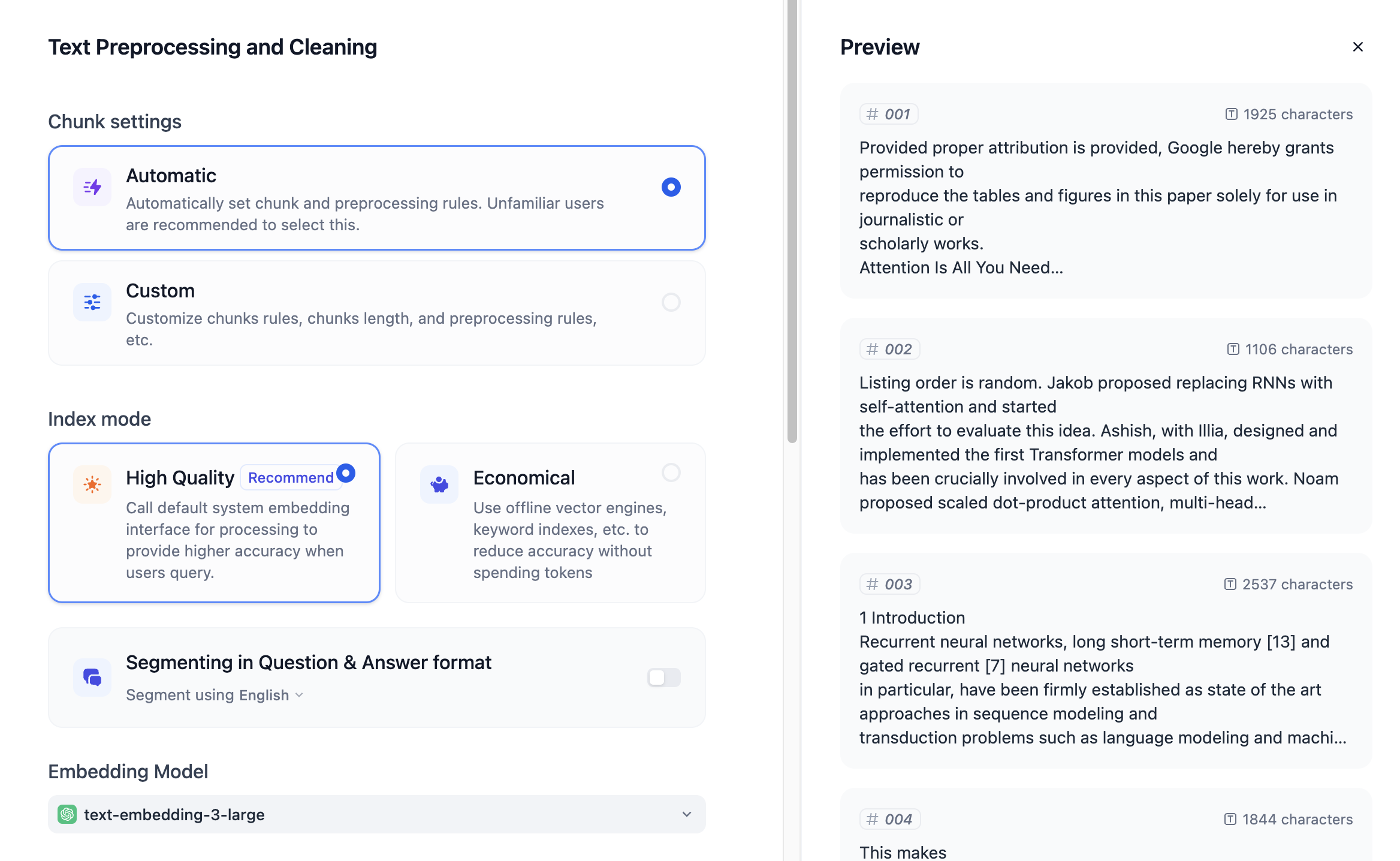
ドキュメントをアップロードすると、次のページが表示されます:
|
||
|
||
|
||
|
||
右側にセグメンテーションプレビューが表示されます。デフォルトでは自動セグメンテーションとクリーニングが選択されています。Difyはコンテンツに基づいて記事を自動的に多くの段落に分割します。カスタム設定で他のセグメンテーションルールを設定することもできます。
|
||
|
||
#### インデックス方法
|
||
|
||
通常は**高品質**を選択することが好まれますが、これは追加のトークンを消費します。**経済的**を選択するとトークンを消費しません。
|
||
|
||
Difyのコミュニティ版はQ&Aセグメンテーションモードを使用します。対応する言語を選択すると、テキストコンテンツをQ&A形式に整理でき、追加のトークン消費が必要です。
|
||
|
||
#### 埋め込みモデル
|
||
|
||
使用前にモデルプロバイダーのドキュメントと価格情報を参照してください。
|
||
|
||
異なる埋め込みモデルは異なるシナリオに適しています。例えば、Cohereの`embed-english`は英語ドキュメントに適しており、`embed-multilingual`は多言語ドキュメントに適しています。
|
||
|
||
#### 検索設定
|
||
|
||
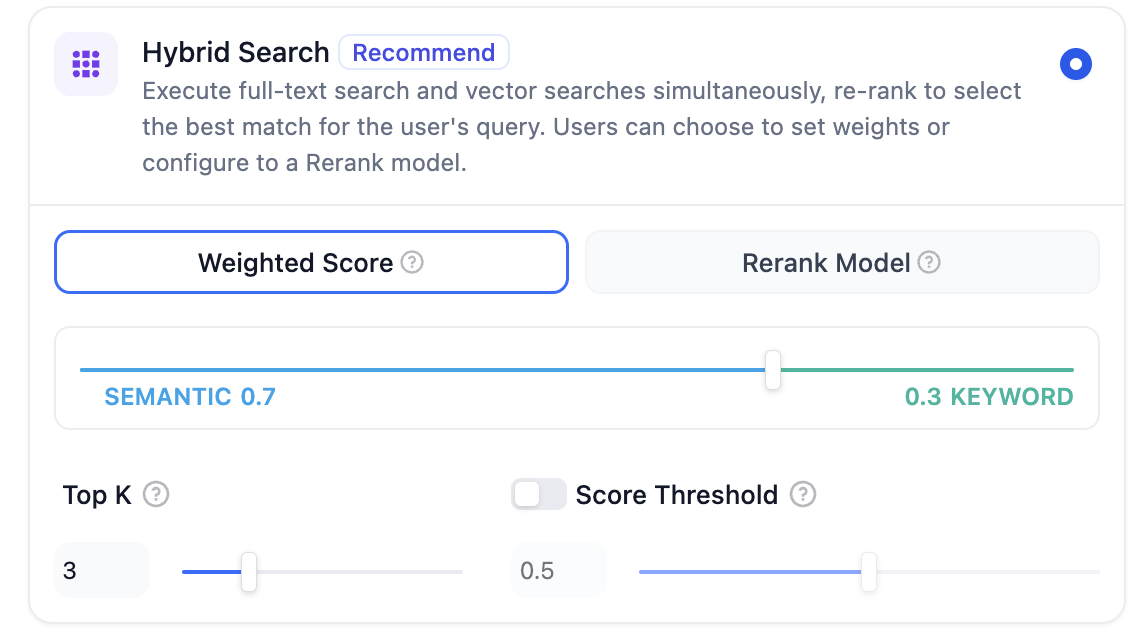
Difyは3つの検索機能を提供しています:ベクトル検索、全文検索、ハイブリッド検索。ハイブリッド検索が最もよく使用されます。
|
||
|
||
ハイブリッド検索では、重みを設定したり、再ランキングモデルを使用したりできます。重みを設定する際、検索がセマンティクスとキーワードのどちらをより重視すべきかを設定できます。例えば、下の画像では、セマンティクスが重みの70%を占め、キーワードが30%を占めています。
|
||
|
||
|
||
|
||
**保存して処理**をクリックするとドキュメントが処理されます。処理後、ドキュメントはアプリケーションで使用できます。
|
||
|
||
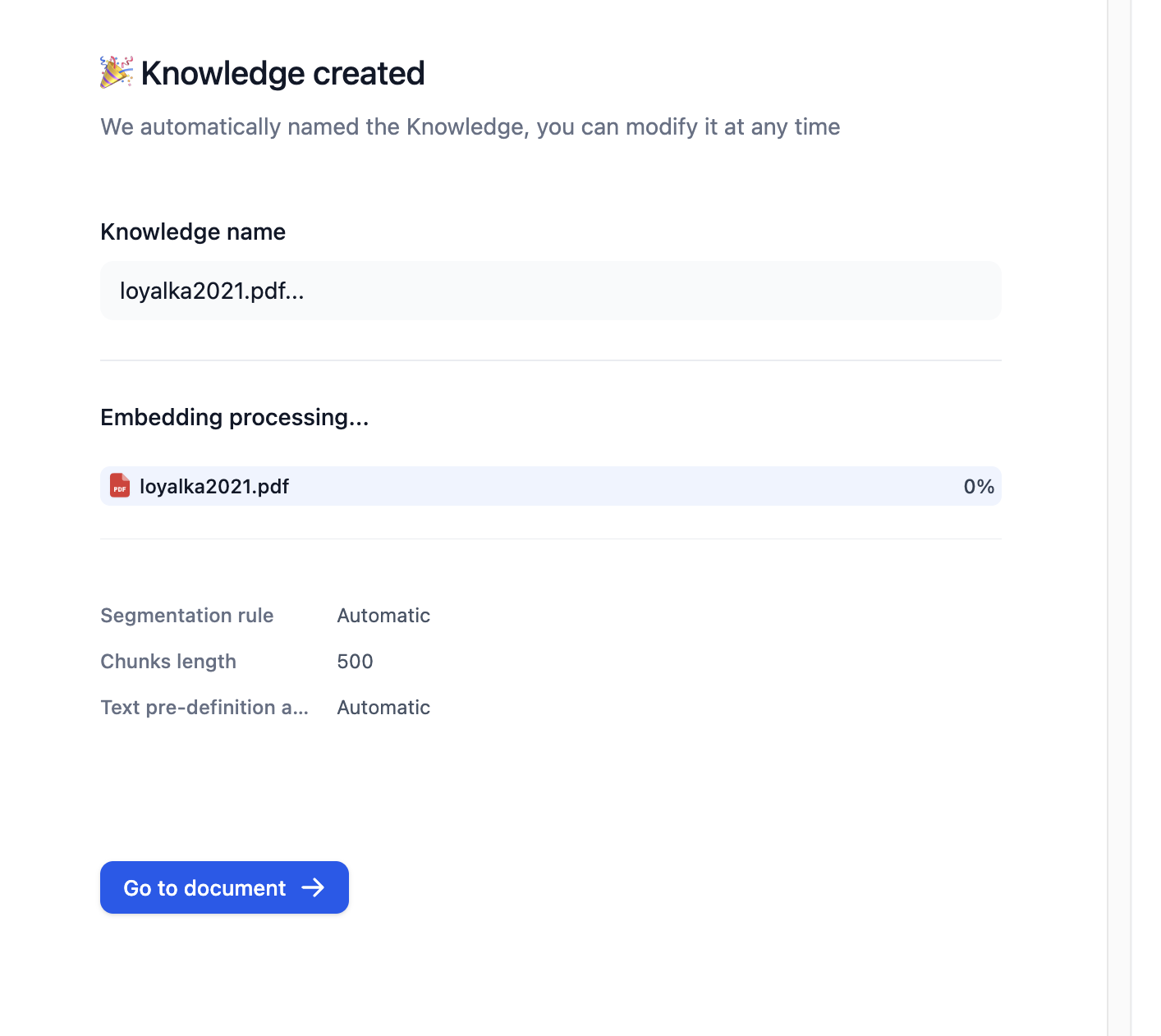
|
||
|
||
#### ウェブサイトからの同期
|
||
|
||
多くの場合、ヘルプドキュメンテーションに基づいてスマートカスタマーサービスボットを構築する必要があります。Difyを例として、[Difyヘルプドキュメンテーション](https://docs.dify.ai)を知識ベースに変換できます。
|
||
|
||
現在、Difyは最大50ページの処理をサポートしています。数量制限に注意してください。超過した場合は、新しい知識ベースを作成できます。
|
||
|
||
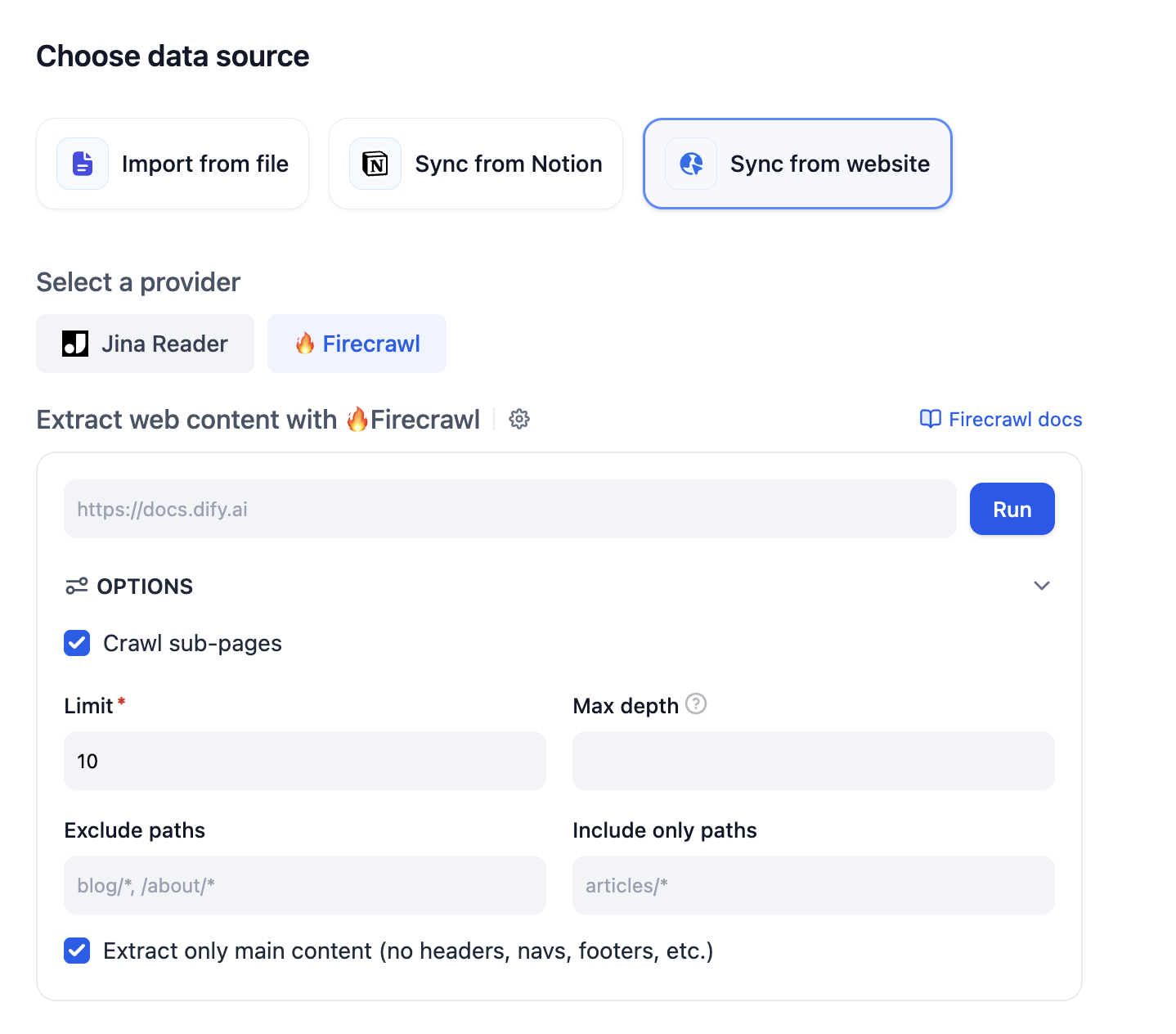
|
||
|
||
#### 知識ベースコンテンツの調整
|
||
|
||
知識ベースがすべてのドキュメントを処理した後、知識ベース内のセグメンテーションの一貫性を確認することが最善です。不一致は検索効果に影響し、手動で調整する必要があります。
|
||
|
||
ドキュメントコンテンツをクリックして、セグメント化されたコンテンツを閲覧します。無関係なコンテンツがある場合は、無効化または削除できます。
|
||
|
||
|
||
コンテンツが別の段落にセグメント化されている場合も、元に戻す必要があります。
|
||
|
||
#### 召回テスト
|
||
|
||
知識ベースのドキュメントページで、左サイドバーの召回テストをクリックしてキーワードを入力し、検索結果の精度をテストします。
|
||
|
||
### ノードの追加
|
||
|
||
作成したAPPに入り、スマートカスタマーサービスボットの構築を始めましょう。
|
||
|
||
#### 質問分類ノード
|
||
|
||
異なるユーザーニーズを分離するために質問分類ノードを使用する必要があります。場合によっては、ユーザーが無関係な話題についてチャットすることもあるため、これに対しても分類を設定する必要があります。
|
||
|
||
分類をより正確にするために、より良いLLMを選択する必要があり、分類は十分に具体的で十分な区別がある必要があります。
|
||
|
||
参考分類は以下の通りです:
|
||
|
||
* ユーザーが無関係な質問をする
|
||
* ユーザーがDify関連の質問をする
|
||
* ユーザーが技術用語の説明を求める
|
||
* ユーザーがコミュニティへの参加について尋ねる
|
||
|
||
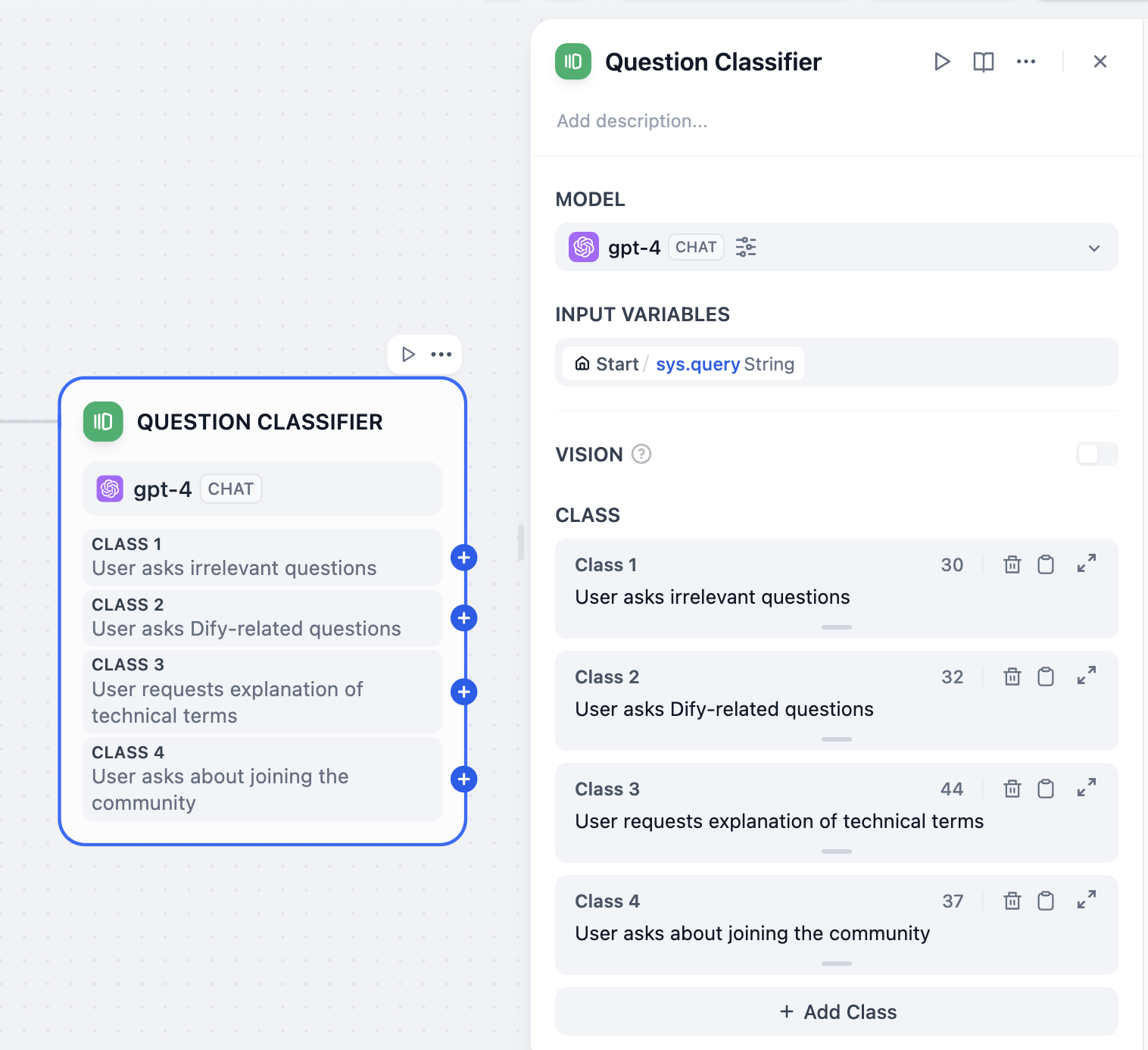
|
||
|
||
#### 直接返信ノード
|
||
|
||
質問分類では、「ユーザーが無関係な質問をする」と「ユーザーがコミュニティへの参加について尋ねる」はLLM処理を必要とせず返信できます。したがって、これら2つの質問の後に直接返信ノードを直接接続できます。
|
||
|
||
「ユーザーが無関係な質問をする」:
|
||
|
||
ユーザーをヘルプドキュメンテーションに誘導し、自分で問題を解決しようとしてもらうことができます。例えば:
|
||
|
||
```
|
||
申し訳ございませんが、ご質問にお答えできません。さらにヘルプが必要な場合は、[ヘルプドキュメンテーション](https://docs.dify.ai)をご確認ください。
|
||
```
|
||
|
||
DifyはMarkdown形式のテキスト出力をサポートしています。Markdownを使用して出力のテキスト形式を豊かにできます。Markdownを使用してテキスト内に画像を挿入することもできます。
|
||
|
||
#### 知識検索ノード
|
||
|
||
「ユーザーがDify関連の質問をする」の後に知識検索ノードを追加し、使用する知識ベースをチェックします。
|
||
|
||
|
||
|
||
#### LLMノード
|
||
|
||
知識検索ノードの次のノードでは、知識ベースから取得したコンテンツを整理するためのLLMノードを選択する必要があります。
|
||
|
||
LLMはユーザーの質問に基づいて返信を調整し、返信をより適切にする必要があります。
|
||
|
||
コンテキスト:知識検索ノードの出力をLLMノードのコンテキストとして使用する必要があります。
|
||
|
||
システムプロンプト:`{{context}}`に基づいて、`{{user question}}`に答えてください。
|
||
|
||
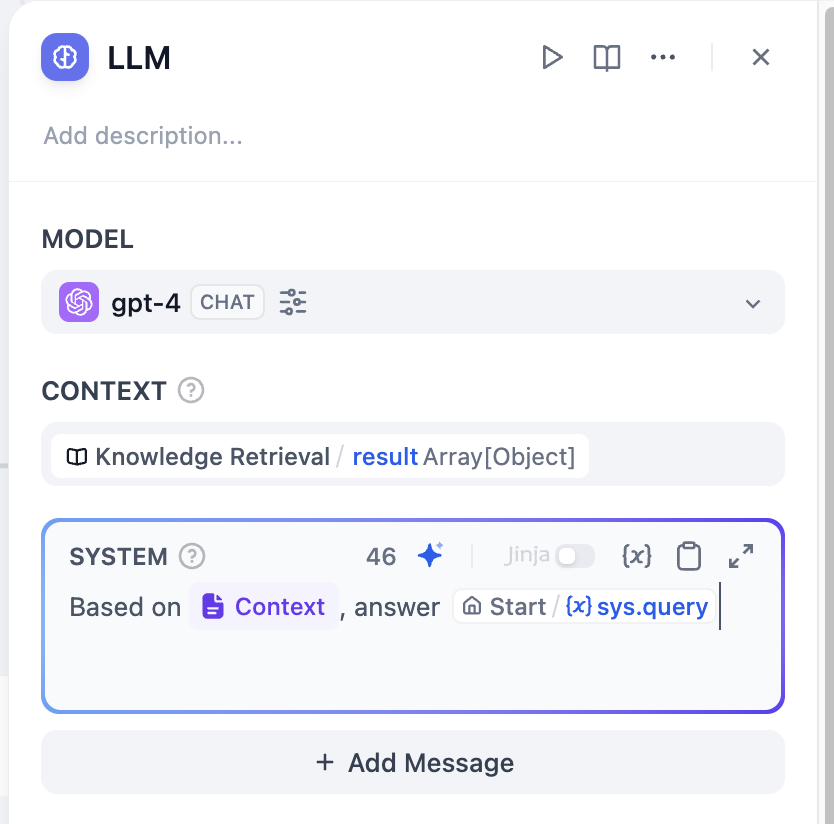
|
||
|
||
プロンプト作成エリアで`/`または`{`を使用して変数を参照できます。変数では、`sys.`で始まる変数はシステム変数です。詳細はヘルプドキュメンテーションを参照してください。
|
||
|
||
さらに、LLMメモリを有効にして、ユーザーの会話体験をより一貫性のあるものにすることができます。
|
||
|
||
### 質問1:外部知識ベースの接続方法
|
||
|
||
知識ベース機能では、AWS Bedrock知識ベースなどの外部知識ベースAPIを通じて外部知識ベースに接続できます。
|
||
|
||
|
||
|
||
### 質問2:APIを通じて知識ベースを管理する方法
|
||
|
||
Difyのコミュニティ版とSaaS版の両方で、知識ベースAPIを通じて知識ベースの追加、削除、ステータスのクエリができます。
|
||
|
||
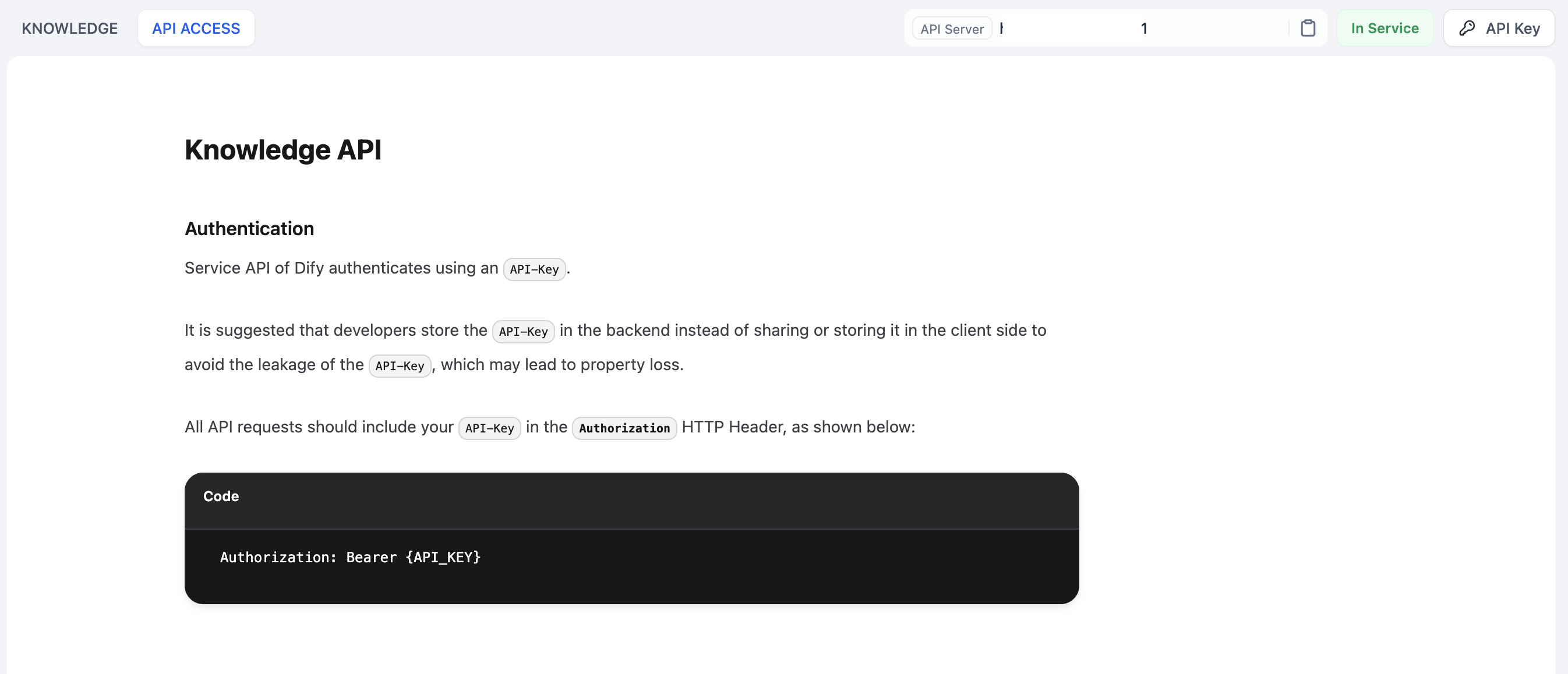
|
||
|
||
知識ベースがデプロイされているインスタンスで、**知識ベース -> API**に移動し、APIキーを作成します。APIキーは安全に保管してください。
|
||
|
||
### 質問3:カスタマーサービスボットをウェブページに埋め込む方法
|
||
|
||
アプリケーションのデプロイ後、ウェブページ埋め込みを選択し、適切な埋め込み方法を選択して、コードをウェブページの適切な場所に貼り付けます。
|