mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
* fix redirect language code prefixes * rename: cn -> zh, jp -> ja * remove hardcoded ja / zh references * remove hardcoded 'english' references * renamed variable names and dict keys to language agnostic names * fix: add missing language helper methods to PRAnalyzer - Add get_language_directory() method - Initialize source_language and target_languages from config - Fixes AttributeError when generating mixed PR errors 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * test: kitchen sink workflow validation v2 This PR validates the translation workflow after config-driven refactoring: Changes: - Add new test file: test-workflow-validation.mdx - Modify existing file: introduction.mdx - Update docs.json navigation Tests: - New file translation (add workflow) - Existing file translation (update workflow) - Navigation sync across languages - Config-driven language codes (zh/ja instead of cn/jp) - Source language abstraction (no hardcoded "English") Expected workflow behavior: 1. Detect changes in en/ directory 2. Translate new file to zh and ja 3. Update modified file translations 4. Sync docs.json for all language sections 5. Commit translated files automatically 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * fix: update workflow paths to use zh/ja instead of cn/jp Aligns workflow trigger paths with the zh/ja language directory rename. 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * Revert "fix: update workflow paths to use zh/ja instead of cn/jp" This reverts commit9587b7cc5d. * Revert "test: kitchen sink workflow validation v2" This reverts commit4abdd69fd2. * fix: update workflow paths in doc analyze workflow to use zh/ja instead of cn/jp * Refactor/language codes (#240) * test: kitchen sink workflow validation v2 This PR validates the translation workflow after config-driven refactoring: Changes: - Add new test file: test-workflow-validation.mdx - Modify existing file: introduction.mdx - Update docs.json navigation Tests: - New file translation (add workflow) - Existing file translation (update workflow) - Navigation sync across languages - Config-driven language codes (zh/ja instead of cn/jp) - Source language abstraction (no hardcoded "English") Expected workflow behavior: 1. Detect changes in en/ directory 2. Translate new file to zh and ja 3. Update modified file translations 4. Sync docs.json for all language sections 5. Commit translated files automatically 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * fix: update workflow paths to use zh/ja instead of cn/jp Aligns workflow trigger paths with the zh/ja language directory rename. 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * Revert "fix: update workflow paths to use zh/ja instead of cn/jp" This reverts commit9587b7cc5d. * Revert "test: kitchen sink workflow validation v2" This reverts commit4abdd69fd2. * fix: update workflow paths in doc analyze workflow to use zh/ja instead of cn/jp --------- Co-authored-by: Claude <noreply@anthropic.com> * fix: update workflow files to use 'source' instead of 'english' After refactoring the PR analyzer to use 'source' for source language PRs (instead of hardcoded 'english'), the workflow files need to match. Changes: - sync_docs_analyze.yml: pr_type == 'source' (was 'english') - sync_docs_update.yml: PR_TYPE != 'source' check - Updated all comments from "English" to "source language" - Updated all pr_type values in JSON from "english" to "source" This ensures the workflows trigger correctly with the refactored config-driven language system. Related: language code refactoring (cn/jp → zh/ja) 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * Fix/workflow source language references (#245) * test: kitchen sink workflow validation v2 This PR validates the translation workflow after config-driven refactoring: Changes: - Add new test file: test-workflow-validation.mdx - Modify existing file: introduction.mdx - Update docs.json navigation Tests: - New file translation (add workflow) - Existing file translation (update workflow) - Navigation sync across languages - Config-driven language codes (zh/ja instead of cn/jp) - Source language abstraction (no hardcoded "English") Expected workflow behavior: 1. Detect changes in en/ directory 2. Translate new file to zh and ja 3. Update modified file translations 4. Sync docs.json for all language sections 5. Commit translated files automatically 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * fix: update workflow paths to use zh/ja instead of cn/jp Aligns workflow trigger paths with the zh/ja language directory rename. 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> * Revert "fix: update workflow paths to use zh/ja instead of cn/jp" This reverts commit9587b7cc5d. * Revert "test: kitchen sink workflow validation v2" This reverts commit4abdd69fd2. * fix: update workflow paths in doc analyze workflow to use zh/ja instead of cn/jp * fix: update workflow files to use 'source' instead of 'english' After refactoring the PR analyzer to use 'source' for source language PRs (instead of hardcoded 'english'), the workflow files need to match. Changes: - sync_docs_analyze.yml: pr_type == 'source' (was 'english') - sync_docs_update.yml: PR_TYPE != 'source' check - Updated all comments from "English" to "source language" - Updated all pr_type values in JSON from "english" to "source" This ensures the workflows trigger correctly with the refactored config-driven language system. Related: language code refactoring (cn/jp → zh/ja) 🤖 Generated with [Claude Code](https://claude.com/claude-code) Co-Authored-By: Claude <noreply@anthropic.com> --------- Co-authored-by: Claude <noreply@anthropic.com> * fix * fix docs.json language codes * rename previous version docs: cn -> zh, jp -> ja * rm duplicate redirect entires --------- Co-authored-by: Claude <noreply@anthropic.com>
170 lines
10 KiB
Plaintext
170 lines
10 KiB
Plaintext
---
|
||
title: ファイルアップロードを使用した記事理解アシスタントの構築方法
|
||
---
|
||
|
||
Difyでは、ナレッジベースツールを利用して、エージェントが大量のテキストコンテンツから正確な情報を取得することが可能です。しかし、多くの場合、理解する必要があるローカルファイルはそれほど大きくないため、ナレッジベースを使用する必要はありません。このような場合には、ファイルアップロード機能を活用して、LLMがローカルファイルをコンテキストとして理解できるようにします。
|
||
|
||
本実験では、資料理解アシスタントを例に取り上げます。このアシスタントは、アップロードされたドキュメントに基づいてユーザーに質問を行い、論文などの資料を読みながらの理解をサポートします。
|
||
|
||
### 今回の学ぶポイント
|
||
|
||
* ファイルアップロード機能
|
||
* Chatflowの基本操作
|
||
* プロンプトの作成
|
||
* イテレーションの使用
|
||
* 文書抽出器とリスト操作ノード
|
||
|
||
### **前提条件**
|
||
|
||
DifyでChatflowを作成し、モデルプロバイダーを追加して、十分な残高があることを確認してください。
|
||
|
||
### **ノードの追加**
|
||
|
||
この実験では、以下の4つのノードが必要です:開始ノード、文書抽出器ノード、LLMノード、返信ノード。
|
||
|
||
### **開始ノード**
|
||
|
||
開始ノードでは、ファイル変数を追加する必要があります。Difyの0.10.0バージョンでは、ファイルのアップロード機能をサポートしており、ファイルを変数として追加できます。
|
||
|
||
開始ノードにファイル変数を追加し、サポートされているファイルタイプの中でドキュメントにチェックを入れる必要があります。
|
||
|
||
一部の読者は、システム変数に`sys.files`が存在することに気づくかもしれません。この変数は、ユーザーがダイアログボックスでアップロードしたファイルやファイルリストを示します。
|
||
|
||
自分でファイル変数を作成することとの違いは、この機能がファイルのアップロードを行い、アップロードされたファイルのタイプを設定し、対話中に新しいファイルをアップロードするたびにこの変数が上書きされる点です。
|
||
|
||
ビジネスシーンに応じて、適切なファイルアップロード方法を選択してください。
|
||
|
||
### **テキスト抽出ツール**
|
||
|
||
LLMはファイルを直接読み取ることができません。これは、多くのユーザーがファイルアップロード機能を初めて使用する際に抱く誤解であり、ファイルを変数としてLLMノードに適用すればよいと考えがちですが、実際にはLLMが読み取る内容は何もありません。
|
||
|
||
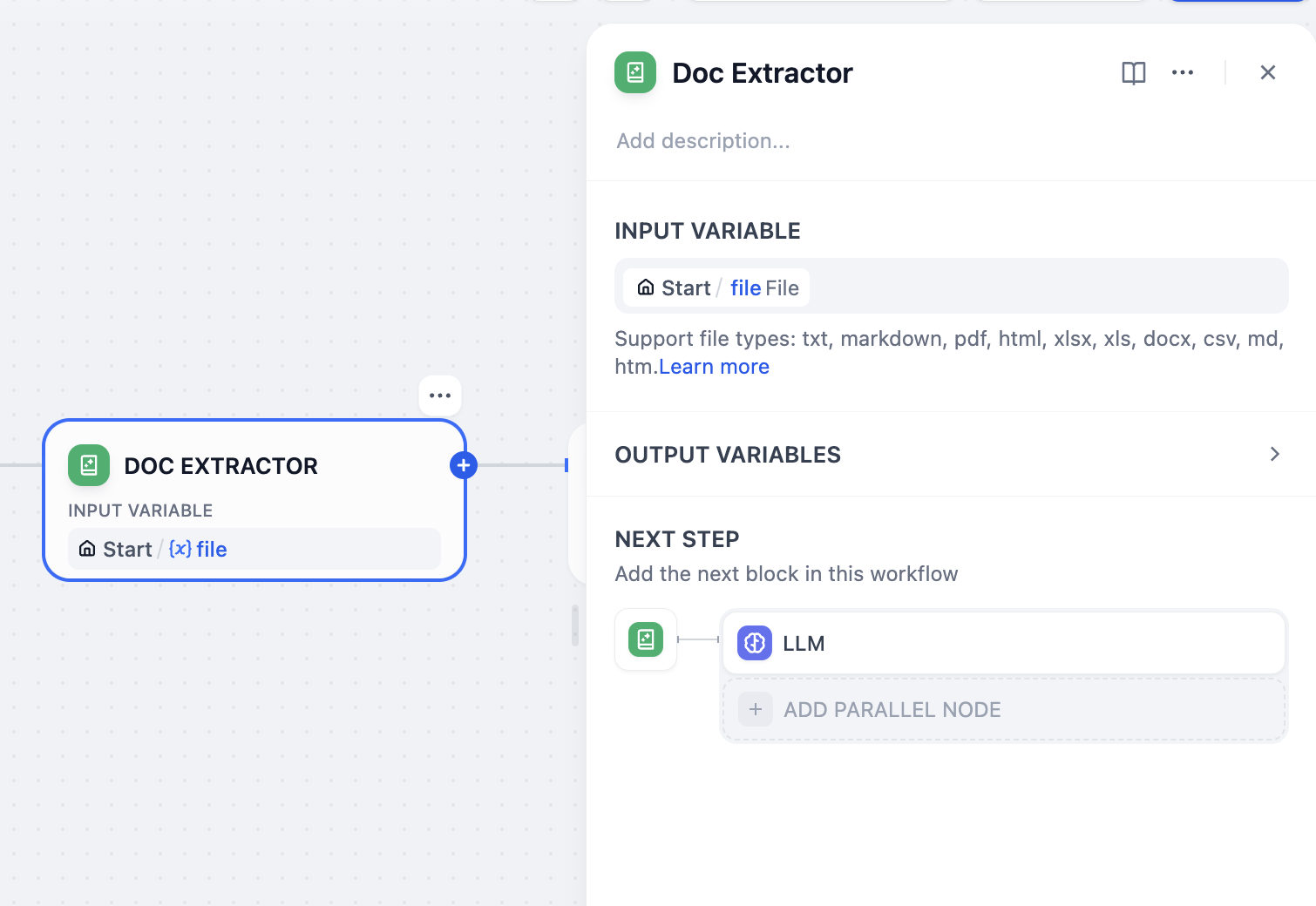
そのため、Difyではテキスト抽出ツールを導入しており、このノードはファイル変数からテキストを抽出し、テキスト形式の変数を出力します。
|
||
|
||
開始ノードのファイル変数を入力として、テキスト抽出ツールはドキュメント形式のファイルをテキスト形式の変数に変換します。
|
||
|
||
|
||
|
||
### **LLM**
|
||
|
||
この実験では、構造抽出ノードと問題提起ノードの2つのLLMノードを設計する必要があります。
|
||
|
||
#### 構造抽出
|
||
|
||
構造抽出ノードは、元文書から文章の構造を抽出し、重要な内容を要約することができます。
|
||
|
||
ヒントの内容は以下の通りです:
|
||
|
||
```
|
||
以下の記事を読み、タスクを実行してください
|
||
{{文書抽出器の結果の変数}}
|
||
|
||
#### タスク
|
||
|
||
- **主要目標**:記事の構造を包括的に解析すること。
|
||
- **目標**:各部分の内容を詳細に説明すること。
|
||
- **要求**:可能な限り詳細に分析すること。
|
||
- **制限**:特定の形式の制限はないが、解析の整理と論理性を維持する必要があります。
|
||
- **期待される出力**:各部分の主要な内容と役割を含む、記事の構造の詳細な解析。
|
||
|
||
# 推論の手順
|
||
|
||
- **推論部分**:記事を注意深く読み、その構造を識別し解析します。
|
||
- **結論部分**:各部分の具体的な内容と役割を提供します。
|
||
|
||
# 出力形式
|
||
|
||
- **解析形式**:各部分は見出し形式でリストアップされ、その後に詳細な説明が続きます。
|
||
- **構造形式**:Markdownを使用し、可読性を向上させます。
|
||
- **具体的な説明**:導入、本文、結論、引用など、各部分の内容と役割について。
|
||
|
||
# サンプル出力
|
||
|
||
## サンプル記事の解析
|
||
|
||
### 導入
|
||
- **内容**:研究の背景、目的、重要性を紹介します。
|
||
- **役割**:読者の注意を引き、記事のコンテキストを提供します。
|
||
|
||
### 方法
|
||
- **内容**:研究の具体的な方法や手順、実験設計、データ収集、分析技術を説明します。
|
||
- **役割**:読者に研究の科学性と再現性を理解させます。
|
||
|
||
### 結果
|
||
- **内容**:研究の主な発見とデータを示します。
|
||
- **役割**:研究結論の根拠を提供します。
|
||
|
||
### 議論
|
||
- **内容**:結果の意義を説明し、他の研究と比較し、改善の可能性を提案します。
|
||
- **役割**:読者に結果の広範な影響と将来の研究の可能性を理解させます。
|
||
|
||
### 結論
|
||
- **内容**:研究の主な発見と貢献を要約します。
|
||
- **役割**:記事の中核情報を強調し、明確な結論を提供します。
|
||
|
||
### 引用
|
||
- **内容**:記事で引用されているすべての文献をリストアップします。
|
||
- **役割**:さらなる読書のリソースを提供し、学術的誠実性を確保します。
|
||
|
||
# 備考
|
||
|
||
- **境界条件**:記事の構造が典型的でない場合(たとえば、特定の部分が欠落している場合や余分な部分がある場合など)、解析でこれらの特殊な状況を明示する必要があります。
|
||
- **重要な考慮事項**:解析時には記事の論理性と整合性に注意し、各部分の内容が記事全体の目標と一致していることを確認してください。
|
||
```
|
||
|
||
#### 問題提起
|
||
問題提起ノードは、構造抽出ノードが要約した内容から記事の問題を抽出し、読者が読む中で問いかけるのを支援します。
|
||
|
||
ヒントは以下の通りです:
|
||
|
||
```
|
||
以下の記事を読み、タスクを実行してください
|
||
{{構造抽出の出力}}
|
||
|
||
# タスク
|
||
|
||
- **主要目標**:上記の内容を包括的に読み、各部分に可能な限り多くの問題を提起すること。
|
||
- **要求**:意義深く、価値のある問題を提起すること。
|
||
- **制限**:特定の制限はありません。
|
||
- **期待される出力**:各部分に関連する一連の問題、それぞれが深い考察と価値を持つ必要があります。
|
||
|
||
# 推論手順
|
||
|
||
- **推論部分**:記事全体を網羅的に読み、各部分の内容を分析し、各部分が引き起こす潜在的な問題を考えます。
|
||
- **結論部分**:意義深く、価値のある問題を提起し、深い考察を促します。
|
||
|
||
# 出力形式
|
||
|
||
- **形式**:それぞれの問題を個別の行にし、番号でリストアップします。
|
||
- **内容**:導入、背景、方法、結果、議論、結論など、記事の各部分に関連する問題を提起します。
|
||
- **数量**:可能な限り多く、ただし各問題は意義深く、価値のあるものである必要があります。
|
||
|
||
# 備考
|
||
|
||
- **境界条件**:記事の特定の部分の内容が少ない場合、問題の数量や深さを適宜調整することができますが、各問題は考察に値するものである必要があります。
|
||
- **重要な考慮事項**:問題が読者を記事の内容を深く理解し、表面的な疑問にとどまらず、深い考察を促すことを確実にしてください。
|
||
```
|
||
|
||
## **問題1:複数のアップロードファイルの処理**
|
||
|
||
複数のアップロードファイルを処理するためには、イテレーションノードを使用する必要があります。
|
||
|
||
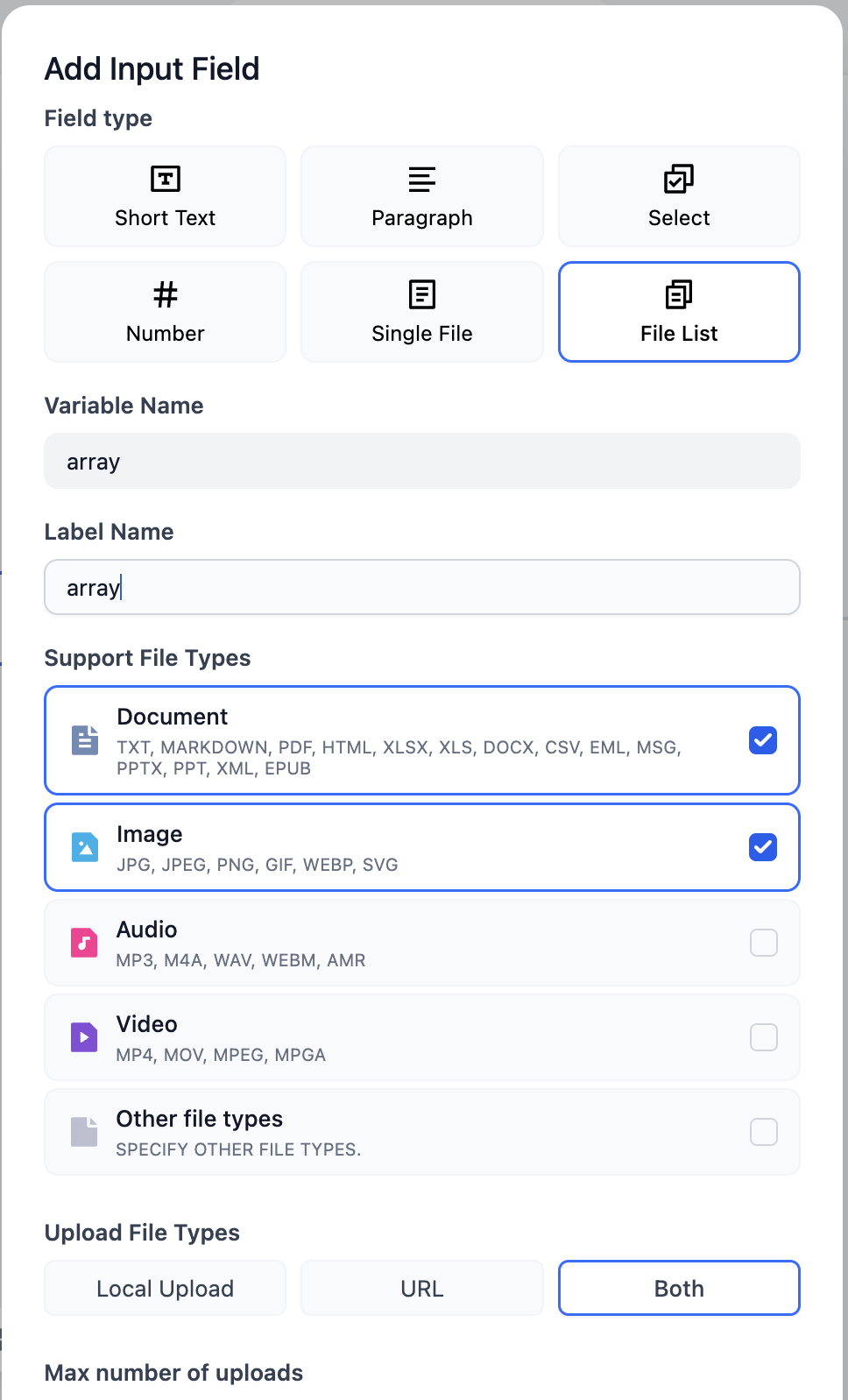
イテレーションノードは、一般的なプログラミング言語のwhileループに似ていますが、Difyでは条件制限がなく、**入力変数は`array`型(リスト)のみ使用できます**。これは、Difyがリスト内のすべての項目を実行するからです。
|
||
|
||
そのため、開始ノードのファイル変数を`array`型に調整する必要があります。つまり、ファイルリストに変更します。
|
||
|
||
|
||
|
||
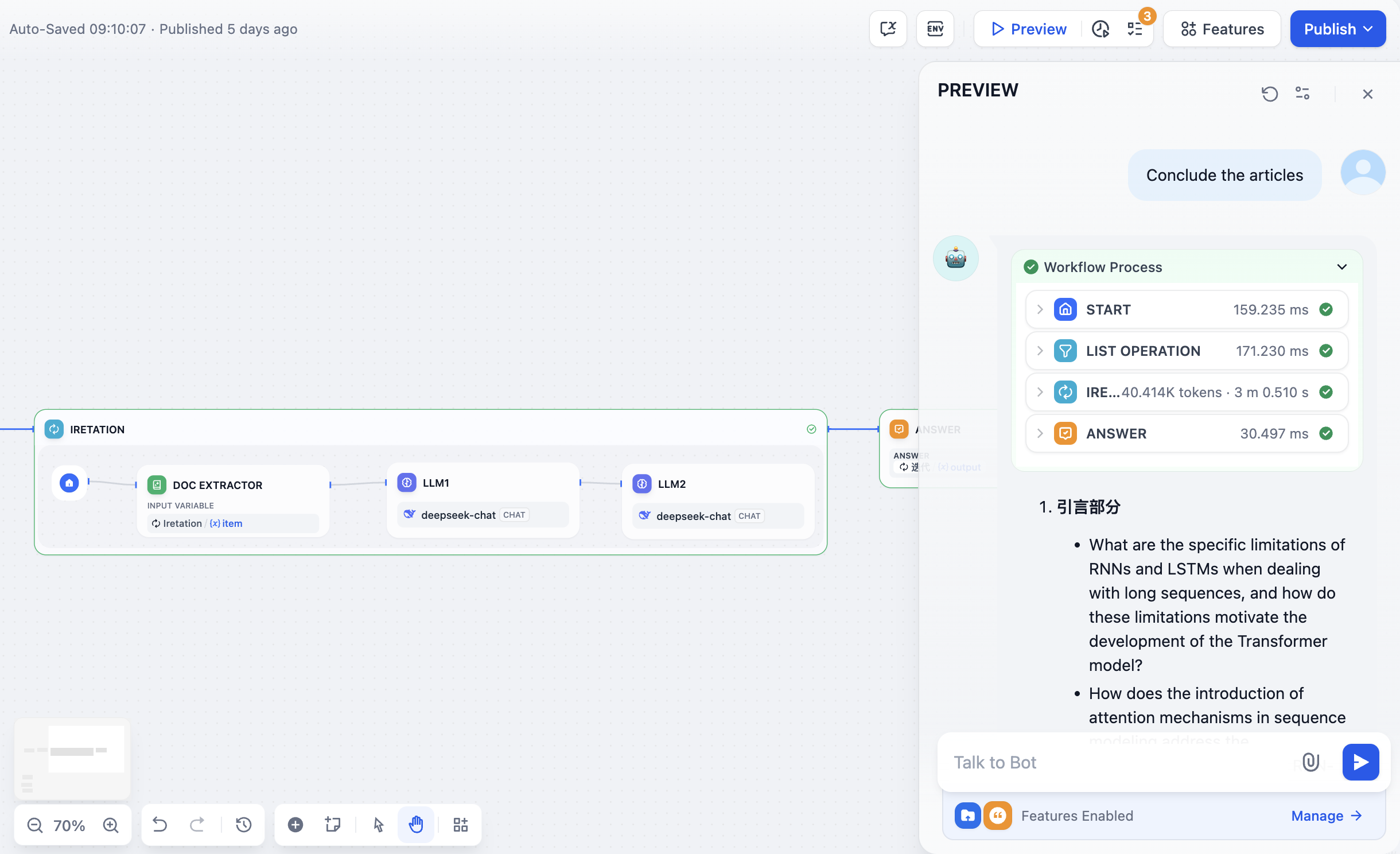
開始ノードの後にイテレーションノードを追加し、入力変数と出力変数を設定します。イテレーションノード内では、各ループで実行する内容を設定します。この部分は前述の内容と完全に一致します。
|
||
|
||
|
||
|
||
## **問題2:特定のファイルのみを処理する**
|
||
|
||
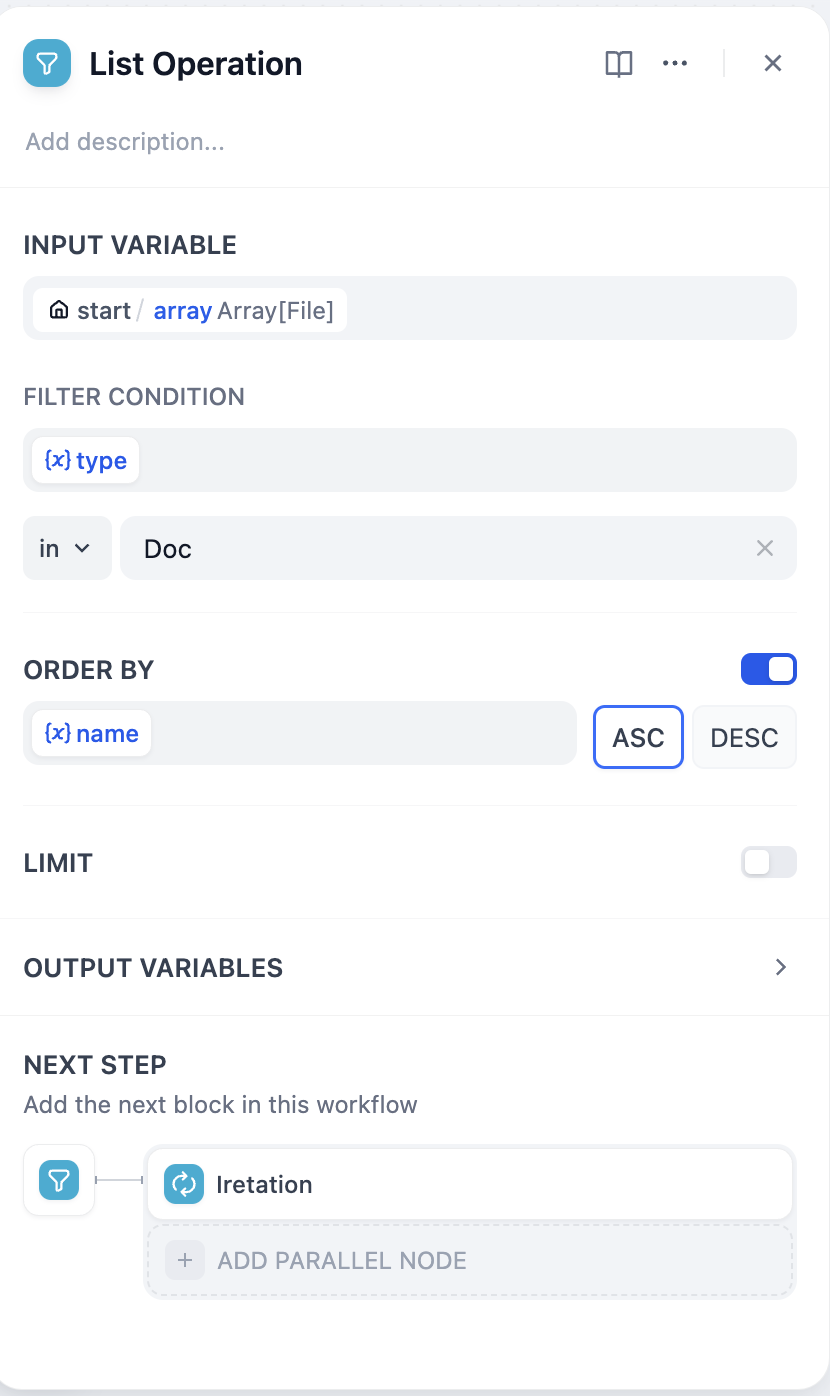
問題1において、Difyはすべてのファイルを処理してからループを終了するため、一部のファイルだけを操作したい場合があります。この問題に対処するために、ファイルリストをフィルタリングする必要があります。Difyでは、リストに対して操作を行うノードを **「リスト操作」** と呼びます。リスト操作は、ファイルリストだけでなく、すべての`array`型変数に対して適用できます。
|
||
|
||
例えば、ドキュメントタイプのファイルのみを分析し、処理するファイルをファイル名でソートすることができます。
|
||
|
||
イテレーションノードの前にリスト操作を追加し、**フィルタ条件**や**ソート**を調整し、その後、イテレーションノードの入力をリスト操作ノードの出力に変更します。
|
||
|
||
|