mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-27 13:28:32 +07:00
Revise based on hands-on testing
This commit is contained in:
@@ -1,144 +0,0 @@
|
||||
---
|
||||
title: Configure the Chunk Settings
|
||||
---
|
||||
|
||||
After uploading content to the knowledge base, the next step is chunking and data cleaning. **This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.**
|
||||
|
||||
<Accordion title="What is the Chunking and Cleaning Strategy?">
|
||||
* **Chunking**
|
||||
|
||||
Due to the limited context window of LLMs, it is hard to process and transmit the entire knowledge base content at once. Instead, long texts in documents must be splited into content chunks. Even though some advanced models now support uploading complete documents, studies show that retrieval efficiency remains weaker compared to querying individual content chunks.
|
||||
|
||||
The ability of an LLM to accurately answer questions based on the knowledge base depends on the retrieval effectiveness of content chunks. This process is similar to finding key chapters in a manual for quick answers, without the need to analyze the entire document line by line. After chunking, the knowledge base uses a Top-K retrieval method to identify the most relevant content chunks based on user queries, supplementing key information to enhance the accuracy of responses.
|
||||
|
||||
The size of the content chunks is critical during semantic matching between queries and chunks. Properly sized chunks enable the model to locate the most relevant content accurately while minimizing noise. Overly large or small chunks can negatively impact retrieval effectiveness.
|
||||
|
||||
Dify offers two chunking modes: **General Mode** and **Parent-child Mode**, tailored to different document structures and application scenarios. These modes are designed to meet varying requirements for retrieval efficiency and accuracy in knowledge bases.
|
||||
|
||||
* **Cleaning**
|
||||
|
||||
To ensure effective text retrieval, it’s essential to clean the data before uploading it to the knowledge base. For instance, meaningless characters or empty lines can affect the quality of query responses and should be removed.
|
||||
</Accordion>
|
||||
|
||||
Whether an LLM can accurately answer knowledge base queries depends on how effectively the system retrieves relevant content chunks. High-relevance chunks are crucial for AI applications to produce precise and comprehensive responses.
|
||||
|
||||
In an AI customer chatbot scenario, for example, directing the LLM to the key content chunks in a tool manual is sufficient to quickly answer user questions—no need to repeatedly analyze the entire document. This approach saves tokens during the analysis phase while boosting the overall quality of the AI-generated answers.
|
||||
|
||||
### Chunk Mode
|
||||
|
||||
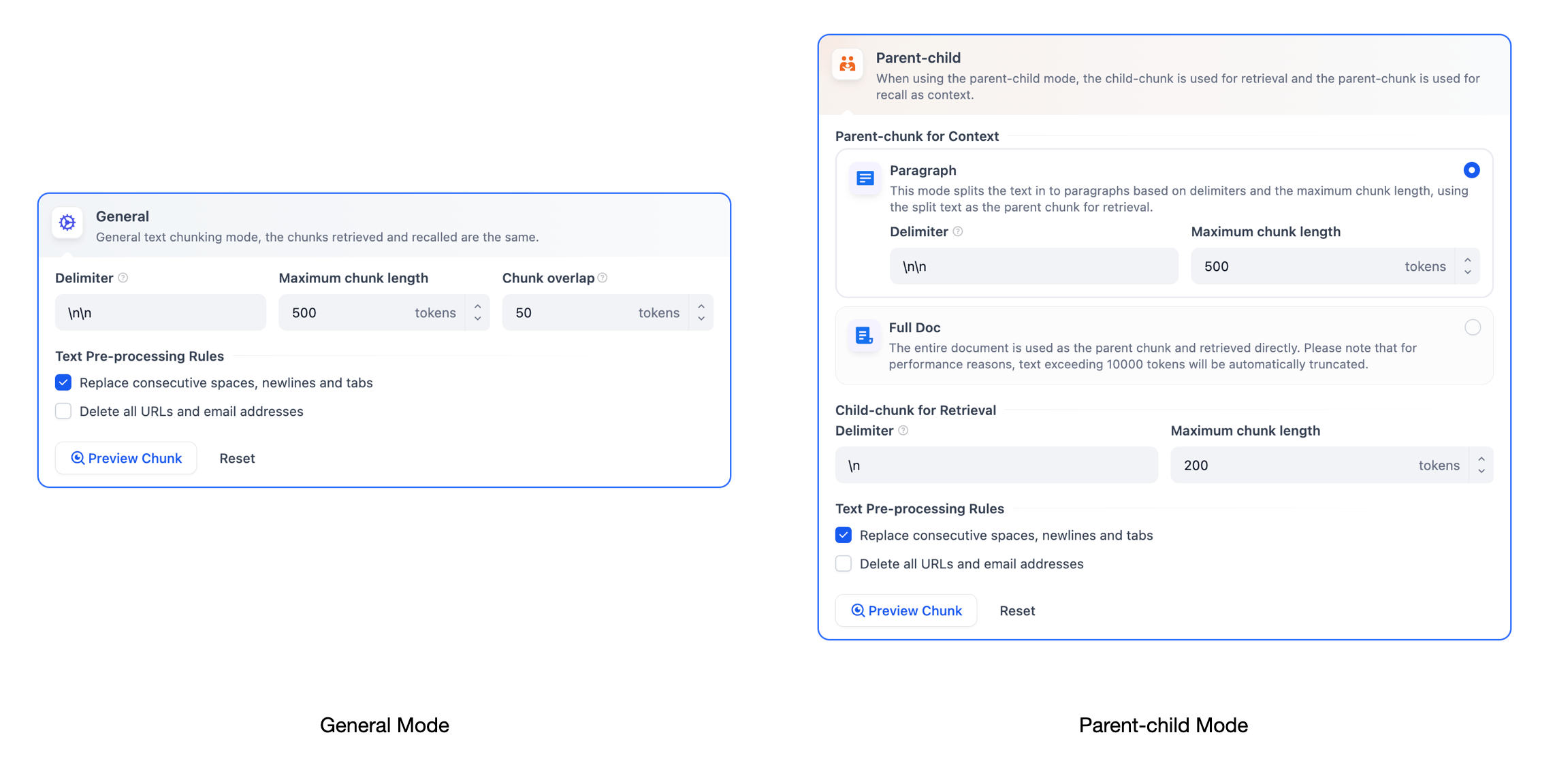
The knowledge base supports two chunking modes: **General Mode** and **Parent-child Mode**. If you are creating a knowledge base for the first time, it is recommended to choose Parent-Child Mode.
|
||||
|
||||
<Info>
|
||||
**Please note**: The original **“Automatic Chunking and Cleaning”** mode has been automatically updated to **“General”** mode. No changes are required, and you can continue to use the default setting.
|
||||
|
||||
Once the chunk mode is selected and the knowledge base is created, it cannot be changed later. Any new documents added to the knowledge base will follow the same chunking strategy.
|
||||
</Info>
|
||||
|
||||
|
||||
|
||||
#### General Mode
|
||||
|
||||
Content will be divided into independent chunks. When a user submits a query, the system automatically calculates the relevance between the chunks and the query keywords. The top-ranked chunks are then retrieved and sent to the LLM for processing the answers.
|
||||
|
||||
In this mode, you need to manually define text chunking rules based on different document formats or specific scenario requirements. Refer to the following configuration options for guidance:
|
||||
|
||||
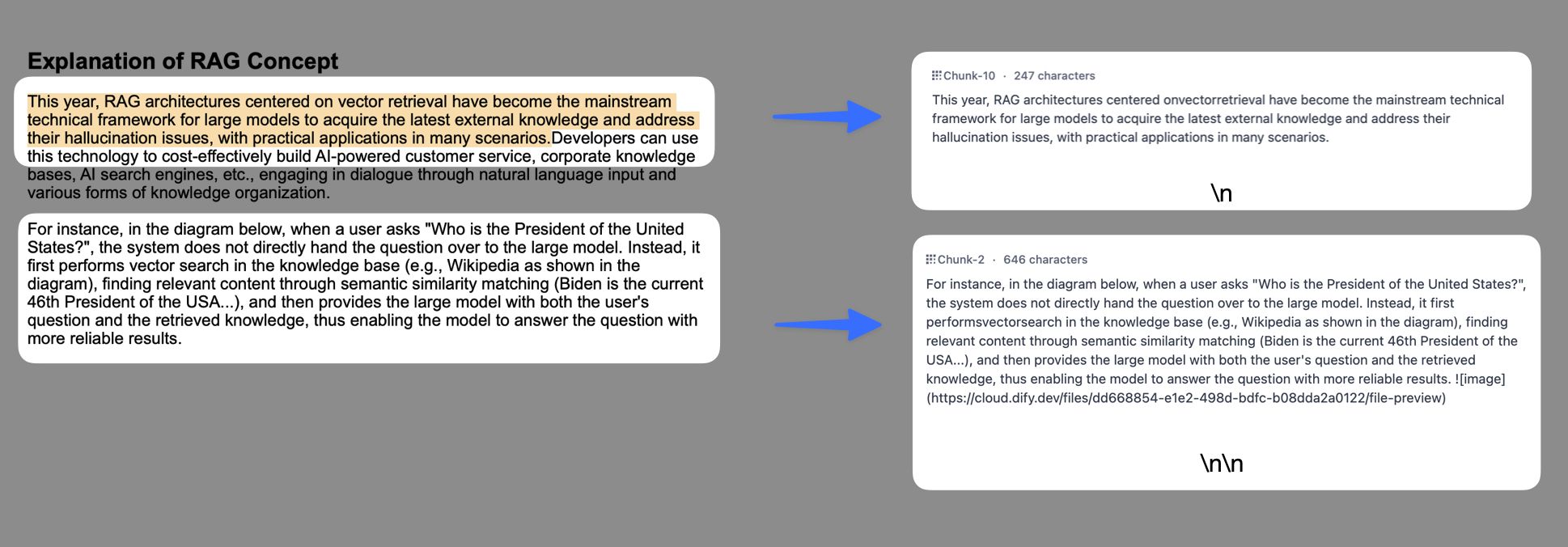
* **Chunk identifier**: The system will automatically execute chunking whenever it detects the specified delimiter. The default value is `\n\n`, which means the text will be chunked by paragraphs.
|
||||
|
||||
|
||||
* **Maximum chunk length:** Specifies the maximum number of text characters allowed per chunk. If this limit is exceeded, the system will automatically enforce chunking.
|
||||
* **Overlapping chunk length**: When data is chunked, there is a certain amount of overlap between chunks. This overlap can help to improve the retention of information and the accuracy of analysis, and enhance retrieval effects. It is recommended that the setting be 10-25% of the chunk length Tokens.
|
||||
|
||||
**Text Preprocessing Rules**, Text preprocessing rules help filter out irrelevant content from the knowledge base. The following options are available:
|
||||
|
||||
* Replace consecutive spaces, newline characters, and tabs
|
||||
* Remove all URLs and email addresses
|
||||
|
||||
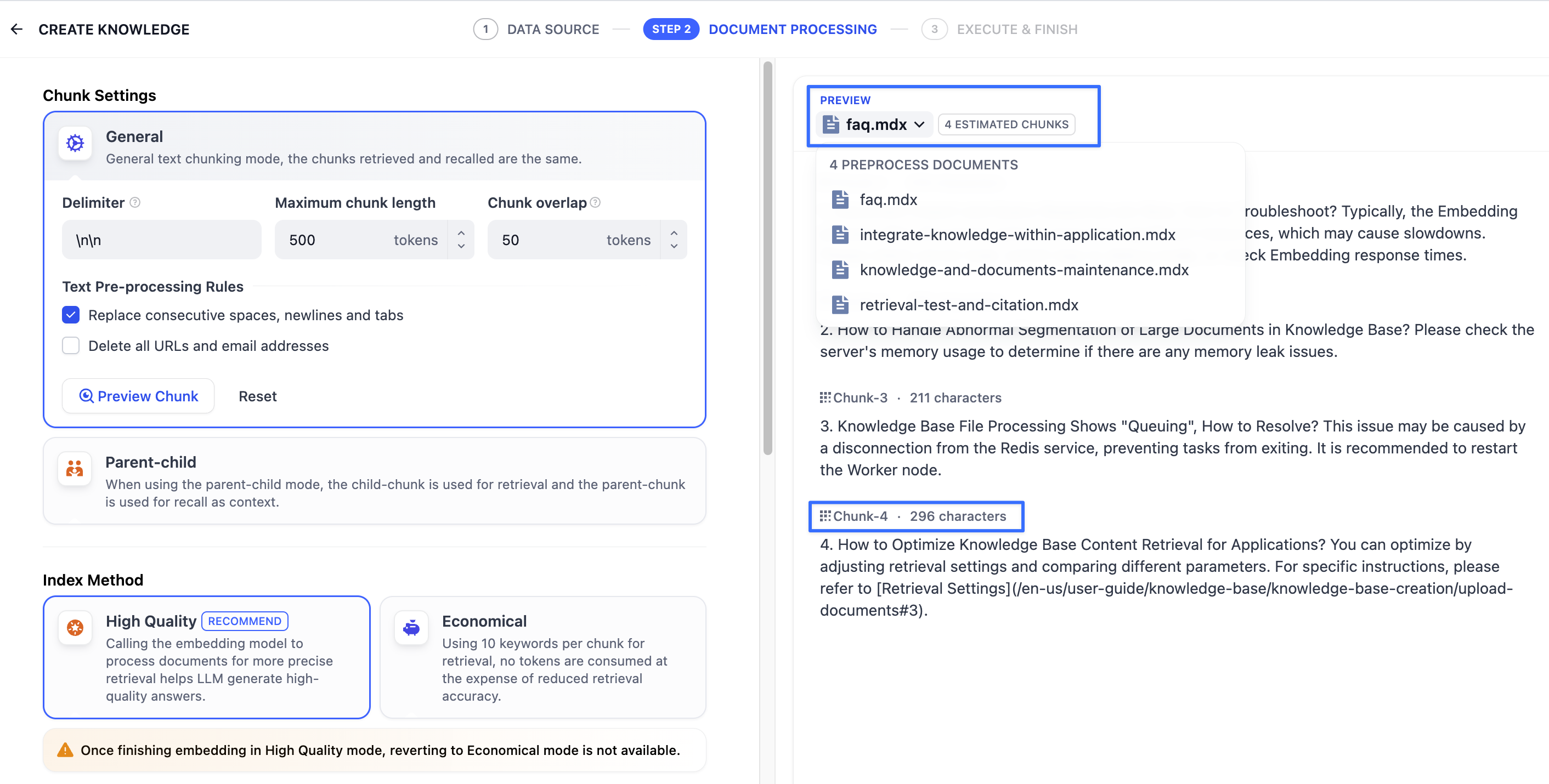
Once configured, click **“Preview Chunk”** to see the chunking results. You can view the character count for each chunk. If you modify the chunking rules, click the button again to view the latest generated text chunks.
|
||||
|
||||
If multiple documents are uploaded in bulk, you can switch between them by clicking the document titles at the top to review the chunk results for other documents.
|
||||
|
||||
|
||||
|
||||
After setting the chunking rules, the next step is to specify the indexing method. General mode supports **High-Quality Indexing** **Method** and **Economical Indexing Method**. For more details, please refer to [Set up the Indexing Method](/en/use-dify/knowledge/create-knowledge/setting-indexing-methods).
|
||||
|
||||
#### Parent-child Mode
|
||||
|
||||
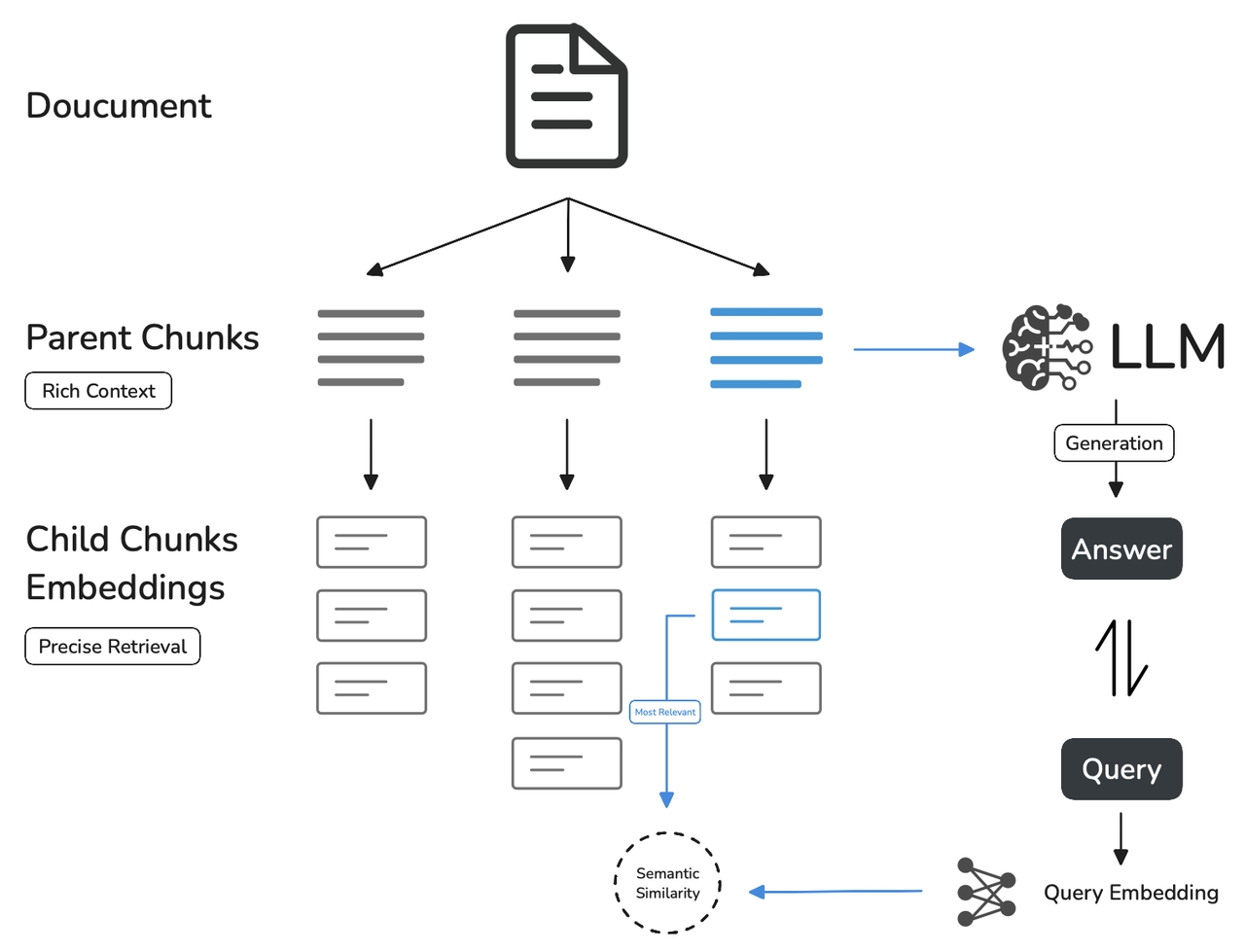
Compared to **General mode**, **Parent-child mode** uses a two-tier data structure that balances precise retrieval with comprehensive context, combining accurate matching and richer contextual information.
|
||||
|
||||
In this mode, parent chunks (e.g., paragraphs) serve as larger text units to provide context, while child chunks (e.g., sentences) focus on pinpoint retrieval. The system searches child chunks first to ensure relevance, then fetches the corresponding parent chunk to supply the full context—thereby guaranteeing both accuracy and a complete background in the final response. You can customize how parent and child chunks are split by configuring delimiters and maximum chunk lengths.
|
||||
|
||||
For example, in an AI-powered customer chatbot case, a user query can be mapped to a specific sentence within a support document. The paragraph or chapter containing that sentence is then provided to the LLM, filling in the overall context so the answer is more precise.
|
||||
|
||||
Its fundamental mechanism includes:
|
||||
|
||||
* **Query Matching with Child Chunks:**
|
||||
* Small, focused pieces of information, often as concise as a single sentence within a paragraph, are used to match the user's query.
|
||||
* These child chunks enable precise and relevant initial retrieval.
|
||||
* **Contextual Enrichment with Parent Chunks:**
|
||||
* Larger, encompassing sections—such as a paragraph, a section, or even an entire document—that include the matched child chunks are then retrieved.
|
||||
* These parent chunks provide comprehensive context for the Language Model (LLM).
|
||||
|
||||
|
||||
|
||||
In this mode, you need to manually configure separate chunking rules for both parent and child chunks based on different document formats or specific scenario requirements.
|
||||
|
||||
**Parent Chunk**
|
||||
|
||||
The parent chunk settings offer the following options:
|
||||
|
||||
* **Paragraph**
|
||||
|
||||
This mode splits the text in to paragraphs based on delimiters and the maximum chunk length, using the split text as the parent chunk for retrieval. Each paragraph is treated as a parent chunk, suitable for documents with large volumes of text, clear content, and relatively independent paragraphs. The following settings are supported:
|
||||
|
||||
* **Chunk Delimiter**: The system automatically chunks the text whenever the specified delimiter appears. The default value is `\n\n`, which chunks text by paragraphs.
|
||||
* **Maximum chunk length:** Specifies the maximum number of text characters allowed per chunk. If this limit is exceeded, the system will automatically enforce chunking.
|
||||
* **Full Doc**
|
||||
|
||||
Instead of splitting the text into paragraphs, the entire document is used as the parent chunk and retrieved directly. For performance reasons, only the first 10,000 tokens of the text are retained. This setting is ideal for smaller documents where paragraphs are interrelated, requiring full doc retrieval.
|
||||
|
||||

|
||||
|
||||
**Child Chunk**
|
||||
|
||||
Child chunks are derived from parent chunks by splitting them based on delimiter rules. They are used to identify and match the most relevant and direct information to the query keywords. When using the default child chunking rules, the segmentation typically results in the following:
|
||||
|
||||
* If the parent chunk is a paragraph, child chunks correspond to individual sentences within each paragraph.
|
||||
* If the parent chunk is the full document, child chunks correspond to the individual sentences within the document.
|
||||
|
||||
You can configure the following chunk settings:
|
||||
|
||||
* **Chunk Delimiter**: The system automatically chunks the text whenever the specified delimiter appears. The default value is `\n`, which chunks text by sentences.
|
||||
* **Maximum chunk length:** Specifies the maximum number of text characters allowed per chunk. If this limit is exceeded, the system will automatically enforce chunking.
|
||||
|
||||
You can also use **text preprocessing rules** to filter out irrelevant content from the knowledge base:
|
||||
|
||||
* Replace consecutive spaces, newline characters, and tabs
|
||||
* Remove all URLs and email addresses
|
||||
|
||||
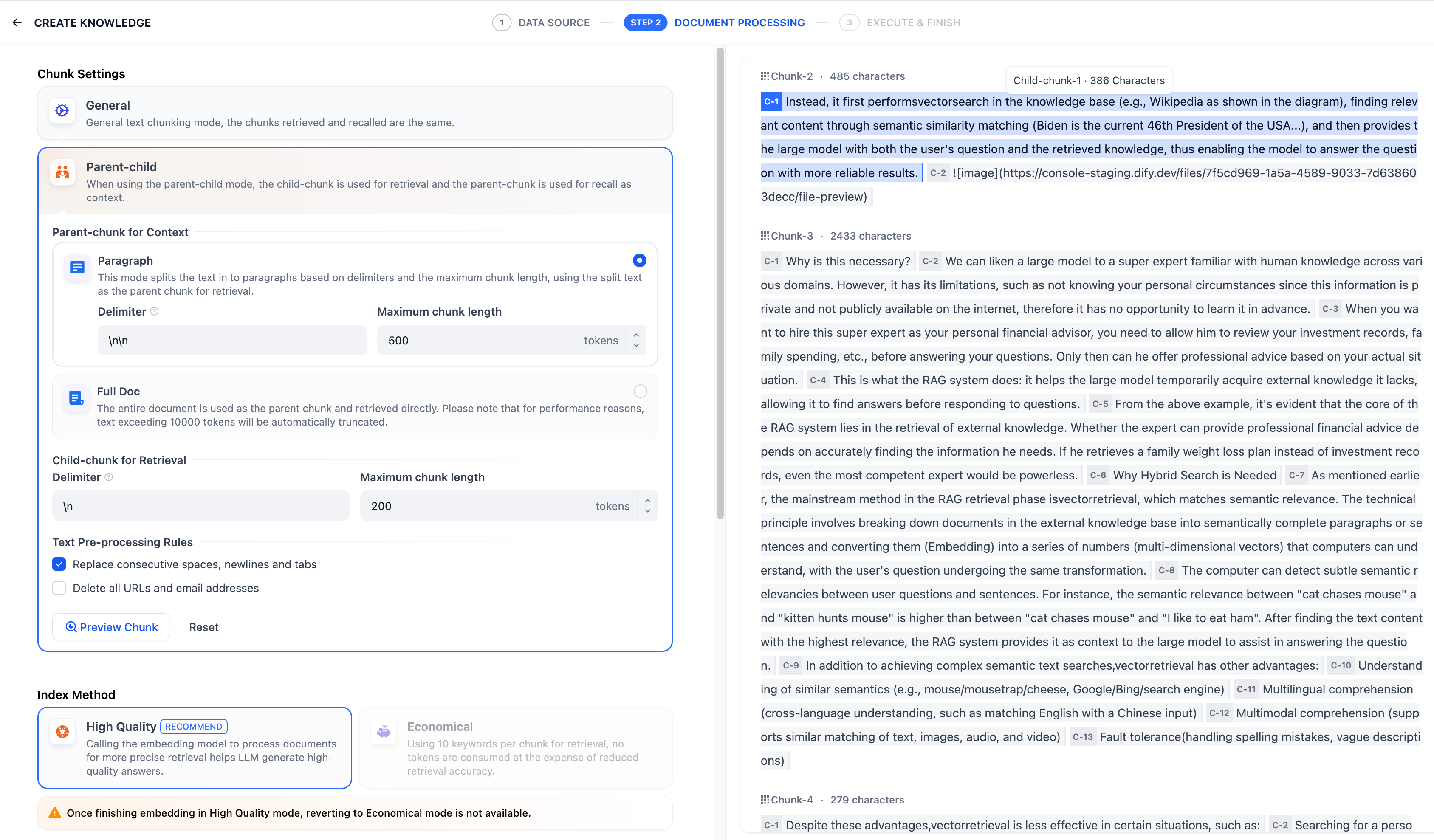
After completing the configuration, click **“Preview Chunks”** to view the results. You can see the total character count of the parent chunk.
|
||||
|
||||
Once configured, click **“Preview Chunk”** to see the chunking results. You can see the total character count of the parent chunk. Characters highlighted in blue represent child chunks, and the character count for the current child chunk is also displayed for reference.
|
||||
|
||||
If you modify the chunking rules, click the button again to view the latest generated text chunks.
|
||||
|
||||
If multiple documents are uploaded in bulk, you can switch between them by clicking the document titles at the top to review the chunk results for other documents.
|
||||
|
||||
|
||||
|
||||
To ensure accurate content retrieval, the Parent-child chunk mode only supports the [High-Quality Indexing](/en/use-dify/knowledge/create-knowledge/setting-indexing-methods#high-quality).
|
||||
|
||||
### What's the Difference Between Two Modes?
|
||||
|
||||
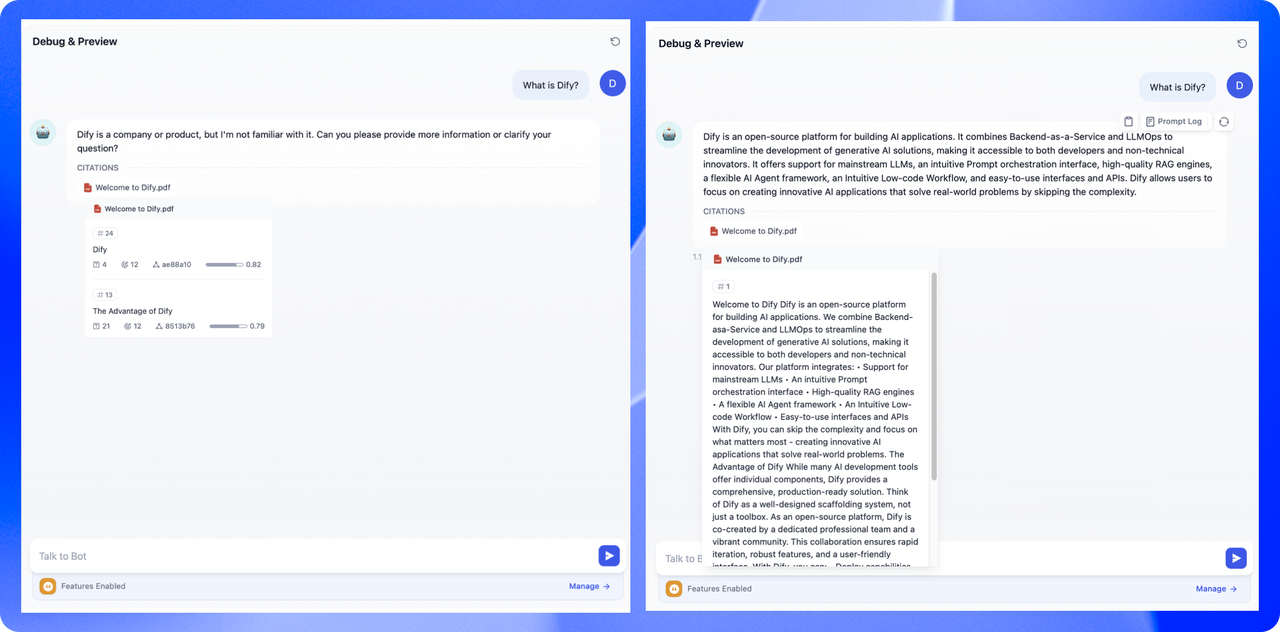
The difference between the two modes lies in the structure of the content chunks. **General Mode** produces multiple independent content chunks, whereas **Parent-child Mode** uses a two-layer chunking approach. In this way, a single parent chunk (e.g., the entire document or a paragraph) contains multiple child chunks (e.g., sentences).
|
||||
|
||||
Different chunking methods influence how effectively the LLM can search the knowledge base. When used on the same document, Parent-child Retrieval provides more comprehensive context while maintaining high precision, making it significantly more effective than the traditional single-layer approach.
|
||||
|
||||
|
||||
|
||||
### Summary Auto-Gen
|
||||
|
||||
<Info>Available for self-hosted deployments only.</Info>
|
||||
|
||||
Use an LLM to automatically generate summaries for document chunks, enhancing their retrievability.
|
||||
|
||||
Summaries are embedded and indexed for retrieval. When a summary matches the query, its corresponding chunk is returned as well.
|
||||
@@ -8,14 +8,14 @@ Documents imported into knowledge bases are split into smaller segments called *
|
||||
|
||||
When users ask questions, the system searches through these chunks for relevant information and provides it to the LLM as context. Without chunking, processing entire documents for every query would be slow and inefficient.
|
||||
|
||||
**Key Chunking Parameters**
|
||||
**Key Chunk Parameters**
|
||||
|
||||
- **Delimiter**: The character or sequence where text is split. For example, `\n\n` splits at paragraph breaks, `\n` at line breaks.
|
||||
|
||||
<Note>
|
||||
Delimiters are removed during chunking. To avoid information loss, use non-content characters that don't naturally appear in your documents.
|
||||
Delimiters are removed during chunking. For example, using `A` as the delimiter splits `CBACD` into `CB` and `CD`.
|
||||
|
||||
For example, using `A` as the delimiter splits `CBACD` into `CB` and `CD`.
|
||||
To avoid information loss, use non-content characters that don't naturally appear in your documents.
|
||||
</Note>
|
||||
|
||||
- **Maximum chunk length**: The maximum size of each chunk in characters. Text exceeding this limit is force-split regardless of delimiter settings.
|
||||
@@ -23,7 +23,7 @@ When users ask questions, the system searches through these chunks for relevant
|
||||
## General vs. Parent-child Chunking
|
||||
|
||||
<Note>
|
||||
The chunk mode cannot be changed once the knowledge base is created, while chunk settings (such as the delimiter and maximum chunk length) can be adjusted at any time.
|
||||
The chunk mode cannot be changed once the knowledge base is created. However, chunk settings like the delimiter and maximum chunk length can be adjusted at any time.
|
||||
</Note>
|
||||
|
||||
### Mode Overview
|
||||
@@ -31,20 +31,18 @@ When users ask questions, the system searches through these chunks for relevant
|
||||
<Tabs>
|
||||
<Tab title="General">
|
||||
|
||||
In General mode, all chunks share the same settings. When a query retrieves a relevant chunk, that chunk is directly sent to the LLM as context.
|
||||
In General mode, all chunks share the same settings. Matched chunks are returned directly as retrieval results.
|
||||
|
||||
**Chunk Settings**
|
||||
|
||||
In addition to the delimiter and maximum chunk length, General mode offers a unique parameter: **Chunk overlap**, which specifies how many characters overlap between adjacent chunks.
|
||||
Beyond delimiter and maximum chunk length, you can also configure **Chunk overlap** to specify how many characters overlap between adjacent chunks. This helps preserve semantic connections and prevents important information from being split across chunk boundaries.
|
||||
|
||||
For example, with a 50-character overlap, the last 50 characters of one chunk will also appear as the first 50 characters of the next chunk.
|
||||
|
||||
This helps preserve semantic connections and prevents important information from being split across chunk boundaries.
|
||||
|
||||
</Tab>
|
||||
<Tab title="Parent-child">
|
||||
|
||||
In Parent-child mode, text is split into two tiers: smaller **child chunks** are used for retrieval, while larger **parent chunks** provide context to the LLM. When a query matches a child chunk, the system returns its entire parent chunk as context.
|
||||
In Parent-child mode, text is split into two tiers: smaller **child chunks** and larger **parent chunks**. When a query matches a child chunk, its entire parent chunk is returned as the retrieval result.
|
||||
|
||||
This solves a common retrieval dilemma: smaller chunks enable precise query matching but lack context, while larger chunks provide rich context but reduce retrieval accuracy.
|
||||
|
||||
@@ -93,13 +91,13 @@ When users ask questions, the system searches through these chunks for relevant
|
||||
| Dimension | General Mode | Parent-child Mode |
|
||||
|:----------|:-------------|:------------------|
|
||||
| Chunking Strategy | Single-tier: all chunks use the same settings | Two-tier: separate settings for parent and child chunks |
|
||||
| Retrieval Workflow | Retrieved chunks are sent directly to the LLM | Child chunks match queries; parent chunks are returned to provide broader context |
|
||||
| Retrieval Workflow | Matched chunks are directly returned | Child chunks are used for matching queries; parent chunks are returned to provide broader context |
|
||||
| Compatible [Index Method](/en/use-dify/knowledge/create-knowledge/setting-indexing-methods) | High Quality, Economical | High Quality only |
|
||||
| Best For | Simple, self-contained content like glossaries or FAQs | Information-dense documents like technical manuals or research papers where context matters |
|
||||
|
||||
## Pre-process Text Before Chunking
|
||||
|
||||
Before splitting text into chunks, clean up irrelevant content to improve retrieval quality. Since chunks are directly used for matching queries, removing noise ensures more accurate results.
|
||||
Before splitting text into chunks, you can clean up irrelevant content to improve retrieval quality.
|
||||
|
||||
- **Replace consecutive spaces, newlines, and tabs**
|
||||
|
||||
@@ -112,9 +110,9 @@ Before splitting text into chunks, clean up irrelevant content to improve retrie
|
||||
- **Remove all URLs and email addresses**\
|
||||
Eliminates URLs and email addresses that rarely contribute to meaningful retrieval.
|
||||
|
||||
<Note>
|
||||
This is not applicable to **Full Doc** mode.
|
||||
</Note>
|
||||
<Info>
|
||||
This setting is ignored in **Full Doc** mode.
|
||||
</Info>
|
||||
|
||||
## Enable Summary Auto-Gen
|
||||
|
||||
@@ -122,9 +120,9 @@ Before splitting text into chunks, clean up irrelevant content to improve retrie
|
||||
|
||||
Automatically generate summaries for all chunks to enhance their retrievability.
|
||||
|
||||
Summaries are embedded and indexed for retrieval. When a summary matches the query, its corresponding chunk is returned as well.
|
||||
Summaries are embedded and indexed for retrieval as well. When a summary matches a query, its corresponding chunk is also returned.
|
||||
|
||||
You can manually edit these summaries or regenerate them for specific documents later. See [Manage Documents and Chunks](/en/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents) for details.
|
||||
You can manually edit auto-generated summaries or regenerate them for specific documents later. See [Manage Documents and Chunks](/en/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents) for details.
|
||||
|
||||
<Tip>
|
||||
If you select a vision-capable LLM, summaries will be generated based on both the chunk text and any attached images.
|
||||
|
||||
@@ -438,9 +438,9 @@ You can also refer to the table below for information on configuring chunk struc
|
||||
|
||||
Automatically generate summaries for all chunks to enhance their retrievability.
|
||||
|
||||
Summaries are embedded and indexed for retrieval. When a summary matches the query, its corresponding chunk is returned as well.
|
||||
Summaries are embedded and indexed for retrieval as well. When a summary matches a query, its corresponding chunk is also returned.
|
||||
|
||||
You can manually edit these summaries or regenerate them for specific documents later. See [Manage Documents and Chunks](/en/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents) for details.
|
||||
You can manually edit auto-generated summaries or regenerate them for specific documents later. See [Manage Documents and Chunks](/en/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents) for details.
|
||||
|
||||
<Tip>
|
||||
If you select a vision-capable LLM, summaries will be generated based on both the chunk text and any attached images.
|
||||
|
||||
@@ -16,9 +16,5 @@ In a knowledge base, click the **Settings** icon in the left sidebar to enter it
|
||||
| Permissions | Defines which workspace members can access the knowledge base.<Note>Members granted access to a knowledge base have all the permissions listed in [Manage Knowledge Content](/en/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents).</Note>|
|
||||
| Index Method | Defines how document chunks are processed and organized for retrieval. For more details, see [Select the Index Method](/en/use-dify/knowledge/create-knowledge/setting-indexing-methods#select-the-index-method).|
|
||||
| Embedding Model | Specifies the embedding model used to convert document chunks into vector representations.<Info>Changing the embedding model will re-embed all chunks.</Info>|
|
||||
| Summary Auto-Gen | Uses an LLM to automatically generate summaries for document chunks.<Tip>Once enabled, this only applies for newly added documents and chunks. For existing chunks, select the document(s) in the document list and click **Generate summary**.</Tip>|
|
||||
| Retrieval Settings | Defines how the knowledge base retrieves relevant content. For more details, see [Configure the Retrieval Settings](/en/use-dify/knowledge/create-knowledge/setting-indexing-methods#configure-the-retrieval-settings).|
|
||||
|
||||
<Info>
|
||||
Once a knowledge base is created, its chunk structure cannot be changed.
|
||||
</Info>
|
||||
| Summary Auto-Gen | Automatically generate summaries for document chunks.<Info>Once enabled, this only applies for newly added documents and chunks. For existing chunks, select the document(s) in the document list and click **Generate summary**.</Info>|
|
||||
| Retrieval Settings | Defines how the knowledge base retrieves relevant content. For more details, see [Configure the Retrieval Settings](/en/use-dify/knowledge/create-knowledge/setting-indexing-methods#configure-the-retrieval-settings).|
|
||||
@@ -21,7 +21,7 @@ From the document list, you can view and manage all these documents to keep your
|
||||
| Modify Chunk Settings | Modify a document's chunking settings (excluding the chunk structure).<Info>Each document can have its own chunking settings, while the chunk structure is shared across the knowledge base and cannot be changed once set.</Info>|
|
||||
| Delete | Permanently remove a document. **Deletion cannot be undone**.|
|
||||
| Enable / Disable | Temporarily include or exclude a document from retrieval. <Note>On Dify Cloud, documents that have not been updated or retrieved for a certain period are automatically disabled to optimize performance.<br/><br/>The inactivity period varies by subscription plan:<ul><li>Sandbox: 7 days</li><li>Professional & Team: 30 days</li></ul> For Professional and Team plans, these documents can be re-enabled **with one click**.</Note>|
|
||||
| Generate Summary | Automatically generates summaries for all chunks in a document. Only available for self-hosted deployments with **Summary Auto-Gen** enabled.<Note>Any existing summaries will be overwritten.</Note>|
|
||||
| Generate Summary | Automatically generates summaries for all chunks in a document. Only available for self-hosted deployments with **Summary Auto-Gen** enabled.<Note>Existing summaries will be overwritten.</Note>|
|
||||
| Archive / Unarchive | Archive a document that you no longer need for retrieval but still want to keep. Archived documents are read-only and can be unarchived at any time.|
|
||||
| Edit | Modify the content of a document by editing its chunks. See [Manage Chunks](#manage-chunks) for details.|
|
||||
| Rename | Change the name of a document.|
|
||||
@@ -46,7 +46,7 @@ From the chunk list within a document, you can view and manage all its chunks to
|
||||
| Edit | Modify the content of a chunk. Edited chunks are marked **Edited**.<br/><br/>For knowledge bases using the Parent-child chunk mode: <ul><li>When editing a parent chunk, you can choose to regenerate its child chunks or keep them unchanged.</li><li>Editing a child chunk does not update its parent chunk. </li></ul>|
|
||||
| Add / Edit / Delete Keywords | Add or modify keywords (up to 10) for a chunk to improve its retrievability. Only available for knowledge bases using the Economical index method.|
|
||||
| Add / Delete Image Attachments | Remove images extracted from documents or upload new ones within their corresponding chunk.<br/><br/>URLs of extracted images remain in the chunk text, but you can safely remove these URLs to keep the text clean—this won't affect the extracted images. <Note> Each chunk can have up to 10 image attachments, which are returned alongside it during retrieval; images beyond this limit will not be extracted.<br/><br/>For self-hosted deployments, you can adjust this limit via the environment variable `SINGLE_CHUNK_ATTACHMENT_LIMIT`.</Note><Tip>If you select a multimodal embedding model (marked with a **Vision** icon), the extracted images will also be embedded and indexed for retrieval.</Tip>|
|
||||
| Add / Edit / Delete Summary | Add, modify, or remove a summary for a chunk to improve its retrievability.<br/><br/>Summaries are embedded and indexed for retrieval. When a summary matches the query, its corresponding chunk is returned as well.<Tip>Add identical summaries to multiple chunks to enable grouped retrieval, allowing related chunks to be returned together (subject to the Top K limit).</Tip>|
|
||||
| Add / Edit / Delete Summary | Add, modify, or remove a summary for a chunk.<br/><br/>Summaries are embedded and indexed for retrieval as well. When a summary matches a query, its corresponding chunk is also returned.<Tip>Add identical summaries to multiple chunks to enable grouped retrieval, allowing related chunks to be returned together (subject to the Top K limit).</Tip>|
|
||||
|
||||
## Best Practices
|
||||
|
||||
@@ -80,15 +80,15 @@ While high-quality indexing enables semantic search, raw chunks can still be har
|
||||
|
||||
Summaries bridge this gap by providing a condensed semantic layer that makes the chunk's core intent explicit.
|
||||
|
||||
Consider using summaries when:
|
||||
Use summaries when:
|
||||
|
||||
- **User queries differ from document language**: For technical documentation written formally, add summaries in the way users actually ask questions—plain language or common question formats.
|
||||
- **User queries differ from document language**: For technical documentation written formally, add summaries in the way users actually ask questions.
|
||||
|
||||
- **Concepts are implicit or buried in details**: Add high-level, concise summaries that surface the core concepts and intent, so the chunk can be matched without relying on small details scattered across the text.
|
||||
- **Concepts are implicit or buried in details**: Add high-level summaries that surface the core concepts and intent, so the chunk can be matched without relying on small details scattered across the text.
|
||||
|
||||
- **Raw text is non-textual**: When a chunk is primarily code, tables, logs, transcripts, or otherwise hard to match semantically, add descriptive summaries that clearly label *what the chunk contains*.
|
||||
- **Raw text is non-textual**: When a chunk is primarily code, tables, logs, transcripts, or otherwise hard to match semantically, add descriptive summaries that clearly label what the chunk contains.
|
||||
|
||||
- **Related chunks should be retrieved together**: Apply identical summaries to a series of related chunks to enable grouped retrieval. This semantic glue allows multiple parts of a topic to be retrieved together to provide a comprehensive answer.
|
||||
- **Related chunks should be retrieved together**: Apply identical summaries to a series of related chunks to enable grouped retrieval. This semantic glue allows multiple parts of a topic to be retrieved together, providing richer context.
|
||||
|
||||
<Info>
|
||||
The number of returned related chunks is subject to the Top K limit defined in the retrieval settings.
|
||||
|
||||
Reference in New Issue
Block a user