diff --git a/docs.json b/docs.json
index 454ecfea..d1f13532 100644
--- a/docs.json
+++ b/docs.json
@@ -174,7 +174,7 @@
{
"group": "Manage Knowledge",
"pages": [
- "en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents-new",
+ "en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents",
"en/guides/knowledge-base/metadata",
"en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction",
"en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api"
@@ -813,14 +813,14 @@
{
"group": "管理知识库",
"pages": [
- "zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction",
"zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents",
+ "zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction",
+ "zh-hans/guides/knowledge-base/metadata",
"zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api"
]
},
- "zh-hans/guides/knowledge-base/metadata",
"zh-hans/guides/knowledge-base/integrate-knowledge-within-application",
- "zh-hans/guides/knowledge-base/retrieval-test-and-citation",
+ "zh-hans/guides/knowledge-base/test-retrieval",
"zh-hans/guides/knowledge-base/knowledge-request-rate-limit",
"zh-hans/guides/knowledge-base/connect-external-knowledge-base",
"zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation"
diff --git a/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents-new.mdx b/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents-new.mdx
deleted file mode 100644
index 0f7794f9..00000000
--- a/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents-new.mdx
+++ /dev/null
@@ -1,71 +0,0 @@
----
-title: Manage Knowledge Content
-sidebarTitle: Manage Content
----
-
-## Manage Documents
-
-In a knowledge base, each imported item—whether a local file, a Notion page, or a web page—becomes a document. From the document list, you can view and manage all these documents to keep your knowledge accurate, relevant, and up-to-date.
-
-
- Click the knowledge base name at the top to quickly switch between knowledge bases.
-
-
-
-
-| Action | Description |
-|:------------------- |:---------------------|
-| Add | Import a new document.|
-| Modify Chunk Settings | Modify a document's chunking settings (excluding the chunk mode).
Each document can have its own chunking settings, while the chunk mode is shared across the knowledge base and cannot be changed once set.|
-| Delete | Permanently remove a document. **Deletion cannot be undone**.|
-| Enable / Disable | Temporarily include or exclude a document from retrieval. On Dify Cloud, documents that have not been updated or retrieved for a certain period are automatically disabled to optimize performance.
The inactivity period varies by subscription plan:- Sandbox: 7 days
- Professional & Team: 30 days
Professional and Team users can re-enable these documents **with one click**.|
-| Archive / Unarchive | Archive a document that you no longer need for retrieval but still want to keep. Archived documents are read-only and can be unarchived at any time.|
-| Edit | Modify the content of a document by editing its chunks. See [Manage Chunks](#manage-chunks) for details.|
-| Rename | Change the name of a document.|
-
-## Manage Chunks
-
-Every document is split into content chunks—the basic units for retrieval—according to its chunk settings. From the chunk list within a document, you can view and manage all its chunks to improve the retrieval efficiency and accuracy.
-
-
- Click the document name in the upper—right corner to quickly switch between documents.
-
-
-
-
-| Action | Description |
-|:-------- |:---------------------|
-| Add | Add one or batch add multiple new chunks. For documents chunked with Parent-child mode, both new parent and child chunks can be added. This is a paid feature on Dify Cloud. [Upgrade to Professional or Team](https://dify.ai/pricing) to use it.|
-| Delete | Permanently remove a chunk. **Deletion cannot be undone**.|
-| Enable / Disable | Temporarily include or exclude a chunk from retrieval. Disabled chunks cannot be edited.|
-| Edit | Modify the content of a chunk. Edited chunks are marked **Edited**.
For documents chunked with Parent-child mode: - When editing a parent chunk, you can choose to regenerate its child chunks or keep them unchanged.
- Editing a child chunk does not update its parent chunk.
|
-| Add / Edit / Delete Keywords | For knowledge bases using the Economical index method, you can modify a chunk's keywords to improve its retrievability.|
-| Upload / Delete Images | For knowledge bases enabled with image-based retrieval, you can delete imported images or upload new ones to improve a chunk's visual context.Choose an embedding model that supports image vectorization (indicated by an **Image** icon) to enable image-based retrieval.|
-
-## Best Practices
-
-Follow these best practices to ensure your knowledge base delivers accurate and relevant results.
-
-### Check Chunk Quality
-
-After a document is chunked, carefully review each chunk to ensure it's semantically complete and appropriately sized for optimal retrieval accuracy and response relevance.
-
-Common issues to watch for:
-
-- Chunks are **too short**—may lack sufficient context, leading to semantic loss and inaccurate answers.
-
-- Chunks are **too long**—may include irrelevant information, introducing semantic noise and lowering retrieval precision.
-
-- Chunks are **semantically incomplete**—caused by forced chunking that cuts through sentences or paragraphs, resulting in missing or misleading content during retrieval.
-
-### Use Child Chunks as Retrieval Hooks
-
-For documents chunked with Parent-child mode, the system searches across child chunks but returns the parent chunks. Since editing a child chunk does not update its parent, you can treat child chunks as semantic tags or retrieval hints for their parent chunks.
-
-To do this, rewrite child chunks into **keywords**, **summaries**, or **common user queries**. For example, if a parent chunk covers the full *Return Policy*, you could rephrase its child chunks as:
-
-- *How do I return an item?*
-
-- *What's the refund period?*
-
-- *Are there any return shipping fees?*
\ No newline at end of file
diff --git a/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx b/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
index f8bdc242..a3306dd1 100644
--- a/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
+++ b/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
@@ -1,251 +1,71 @@
---
-title: Maintain Documents
+title: Manage Knowledge Content
+sidebarTitle: Manage Content
---
-## Manage Documentations in the Knowledge Base
+## Manage Documents
-### Adding Documentations
+In a knowledge base, each imported item—whether a local file, a Notion page, or a web page—becomes a document. From the document list, you can view and manage all these documents to keep your knowledge accurate, relevant, and up-to-date.
-A knowledge base is a collection of documents. Documents can be uploaded by developers or operators, or synchronized from other data sources. Each document in the knowledge base corresponds to a file in its data source—for example, a Notion document or an online webpage.
+
+ Click the knowledge base name at the top to quickly switch between knowledge bases.
+
-To upload a new document to an existing knowledge base, go to **Knowledge Base** > **Documents** and click **Add File**.
+
-
+| Action | Description |
+|:------------------- |:---------------------|
+| Add | Import a new document.|
+| Modify Chunk Settings | Modify a document's chunking settings (excluding the chunk mode).
Each document can have its own chunking settings, while the chunk mode is shared across the knowledge base and cannot be changed once set.|
+| Delete | Permanently remove a document. **Deletion cannot be undone**.|
+| Enable / Disable | Temporarily include or exclude a document from retrieval. On Dify Cloud, documents that have not been updated or retrieved for a certain period are automatically disabled to optimize performance.
The inactivity period varies by subscription plan:- Sandbox: 7 days
- Professional & Team: 30 days
Professional and Team users can re-enable these documents **with one click**.|
+| Archive / Unarchive | Archive a document that you no longer need for retrieval but still want to keep. Archived documents are read-only and can be unarchived at any time.|
+| Edit | Modify the content of a document by editing its chunks. See [Manage Chunks](#manage-chunks) for details.|
+| Rename | Change the name of a document.|
-### Disable / Archive / Delete document
+## Manage Chunks
-**Enable**: Documents that are currently in normal status can be edited and retrieved in the knowledge base. If a document has been disabled, you can re-enable it. For archived documents, you must first unarchive them before re-enabling.
+Every document is split into content chunks—the basic units for retrieval—according to its chunk settings. From the chunk list within a document, you can view and manage all its chunks to improve the retrieval efficiency and accuracy.
-**Disable**: If you don't want a document to be indexed during use, toggle off the blue switch on the right side of the document to disable it. A disabled document can still be edited or modified.
+
+ Click the document name in the upper—left corner to quickly switch between documents.
+
-**Archive**: For older documents that are no longer in use but you don't want to delete, you can archive them. Archived documents can only be viewed or deleted and cannot be edited. You can archive a document from the Knowledge Base's **Document List** by clicking the **Archive** button, or within the document's details page. Archiving can be undone.
+
-**Delete**: ⚠️ Dangerous Option. For incorrect documents or clearly ambiguous content, select Delete from the menu on the right side of the document. Deleted content cannot be restored, so proceed with caution.
+| Action | Description |
+|:-------- |:---------------------|
+| Add | Add one or batch add multiple new chunks. For documents chunked with Parent-child mode, both new parent and child chunks can be added. This is a paid feature on Dify Cloud. [Upgrade to Professional or Team](https://dify.ai/pricing) to use it.|
+| Delete | Permanently remove a chunk. **Deletion cannot be undone**.|
+| Enable / Disable | Temporarily include or exclude a chunk from retrieval. Disabled chunks cannot be edited.|
+| Edit | Modify the content of a chunk. Edited chunks are marked **Edited**.
For documents chunked with Parent-child mode: - When editing a parent chunk, you can choose to regenerate its child chunks or keep them unchanged.
- Editing a child chunk does not update its parent chunk.
|
+| Add / Edit / Delete Keywords | In knowledge bases using the Economical index method, you can modify a chunk's keywords to improve its retrievability.|
+| Upload / Delete Images | In knowledge bases enabled with image-based retrieval, you can delete imported images or upload new ones to improve a chunk's visual context.Choose an embedding model that supports image vectorization (indicated by an **Image** icon) for the knowledge base to enable image-based retrieval.|
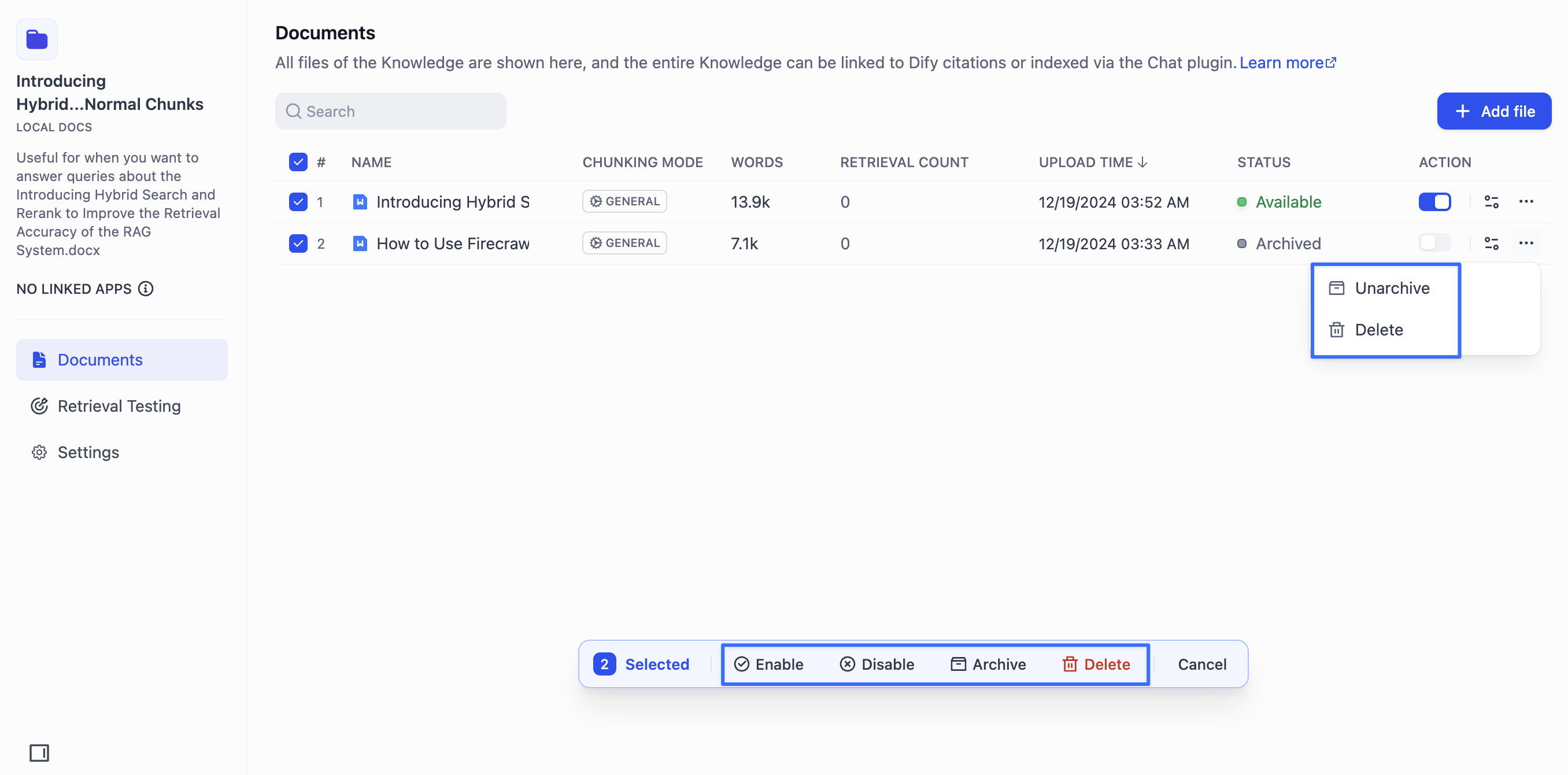
-> The above options all support batch operations after multiple documents are selected.
+## Best Practices
-
+Follow these best practices to ensure your knowledge base delivers accurate and relevant results.
-**Note:**
+### Check Chunk Quality
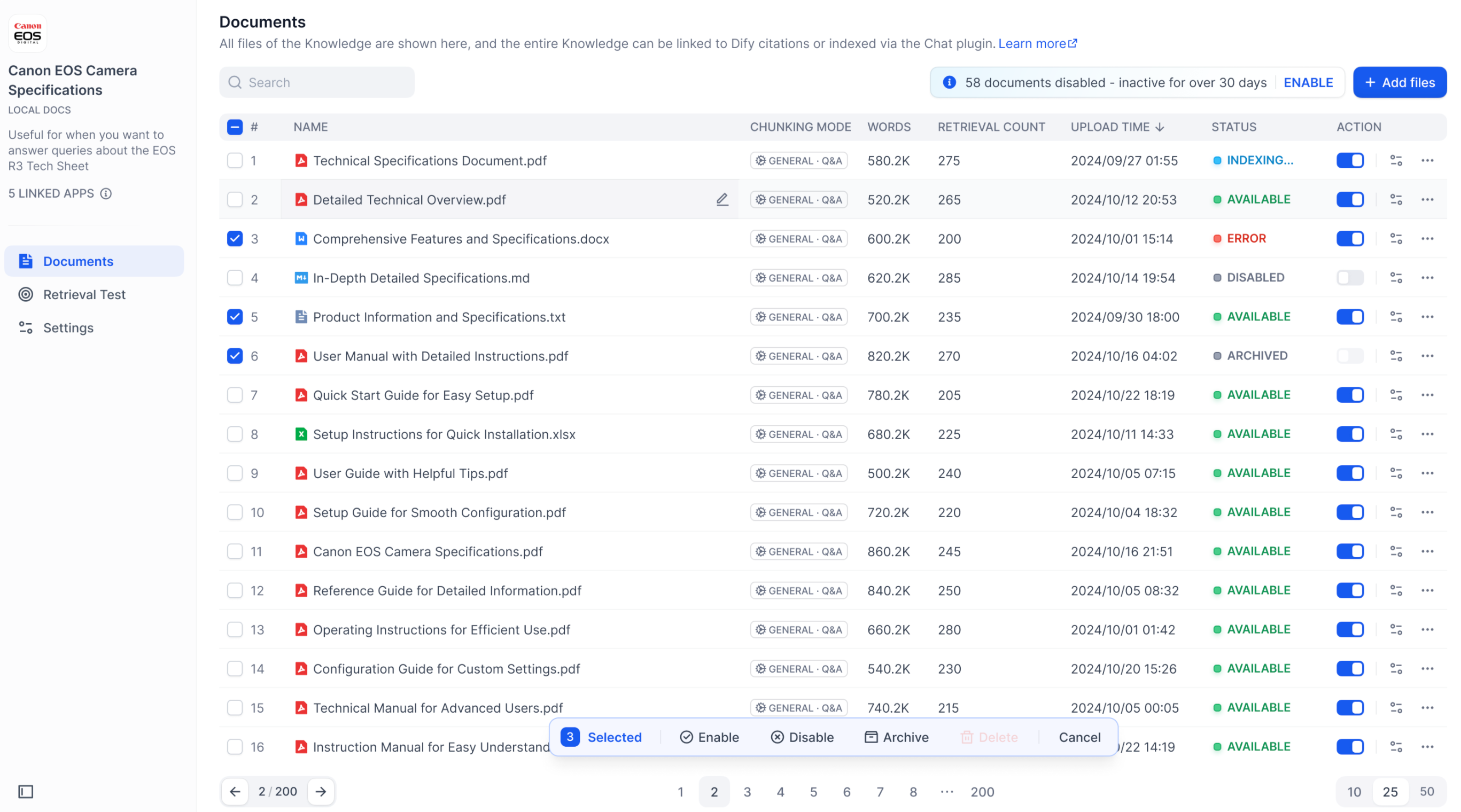
-If there are some documents in your knowledge base that haven't been updated or retrieved for a while, the system will disable inactive documents to ensure optimal performance.
+After a document is chunked, carefully review each chunk to ensure it's semantically complete and appropriately sized for optimal retrieval accuracy and response relevance.
-* For Sandbox users, the "inactive document disable period" is **after 7 days**.
-* For Professional and Team users, it is **after 30 days**. You can revert these documents and continue using them at any time by clicking the "Enable" button in the knowledge base.
+Common issues to watch for:
-You can revert these disable documents and continue using them at any time by clicking the "Enable" button in the knowledge base. Paid users are provided with **one-click revert** function.
+- Chunks are **too short**—may lack sufficient context, leading to semantic loss and inaccurate answers.
-
+- Chunks are **too long**—may include irrelevant information, introducing semantic noise and lowering retrieval precision.
-***
+- Chunks are **semantically incomplete**—caused by forced chunking that cuts through sentences or paragraphs, resulting in missing or misleading content during retrieval.
-## Managing Text Chunks
+### Use Child Chunks as Retrieval Hooks for Parent Chunks
-### Viewing Text Chunks
+For documents chunked with Parent-child mode, the system searches across child chunks but returns the parent chunks. Since editing a child chunk does not update its parent, you can treat child chunks as semantic tags or retrieval hints for their parent chunks.
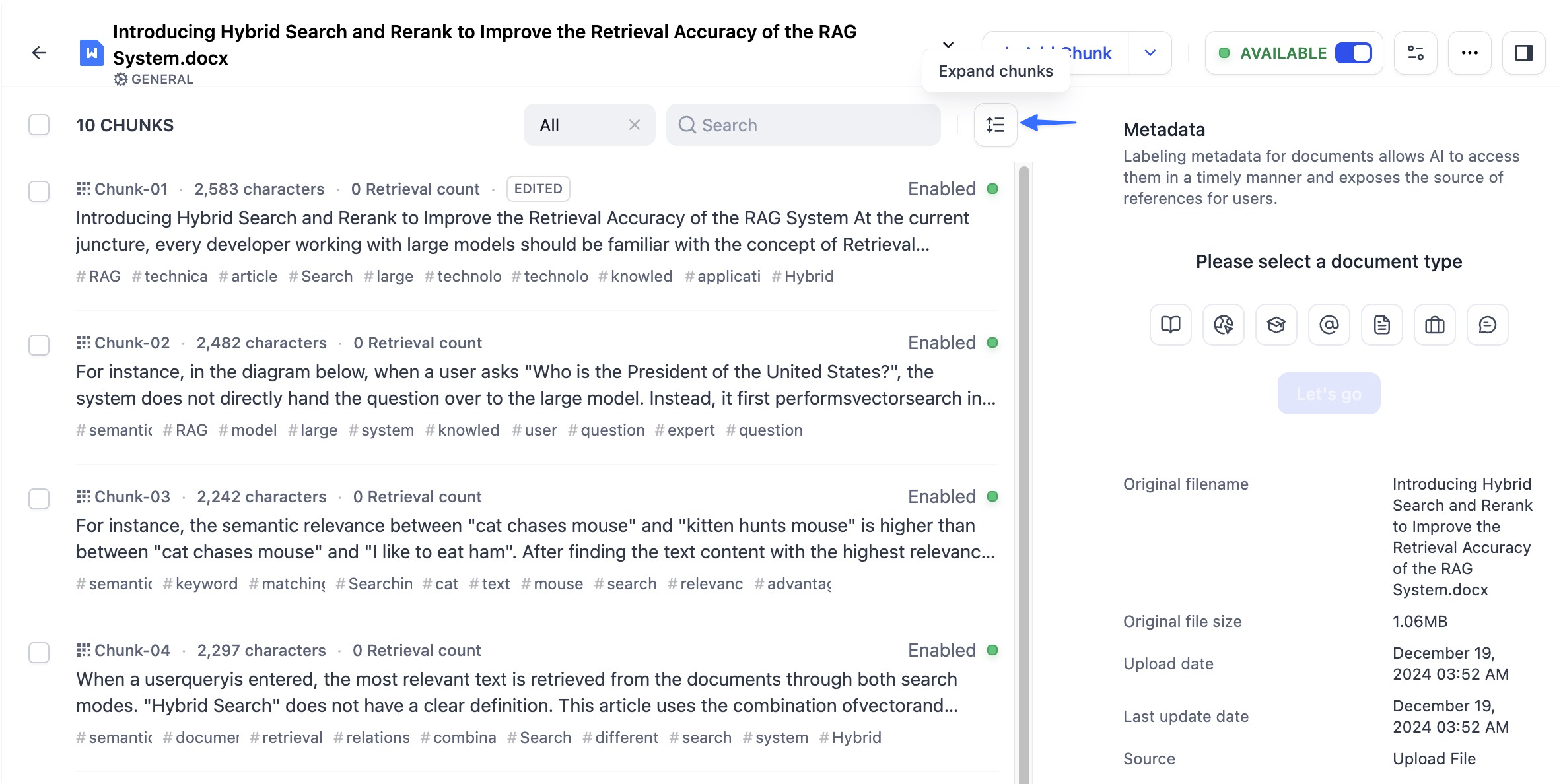
-In the knowledge base, each uploaded document is stored as text chunks. By clicking on the document title, you can view the list of chunks and their specific text content on the details page. Each page displays 10 chunks by default, but you can change the number of chunks shown per page at the bottom of the web.
+To do this, rewrite child chunks into **keywords**, **summaries**, or **common user queries**. For example, if a parent chunk covers the full *Return Policy*, you could rephrase its child chunks as:
-Only the first two lines of each content chunk are visible in the preview. If you need to see the full text within a chunk, click the "Expand Chunk" button for a complete view.
+- *How do I return an item?*
-
-
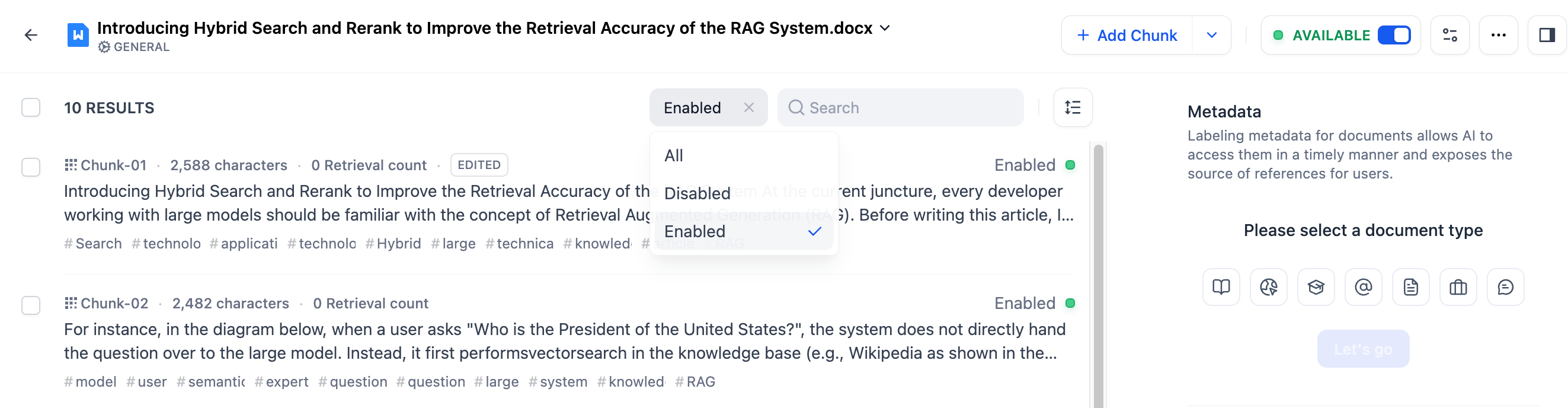
-You can quickly view all enabled or disabled documents using the filter.
-
-
-
-Different [chunking modes](/en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text) correspond to different text chunking preview methods:
-
-
-
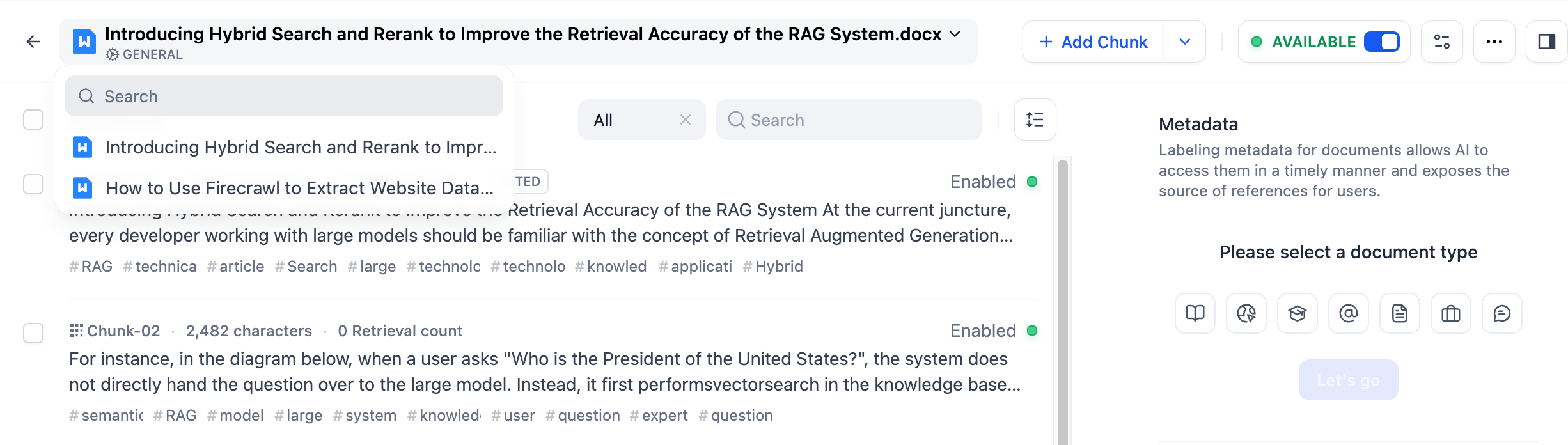
- **General Mode**
-
- Chunks of text in [General mode](/en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text#general-mode) are independent blocks. If you want to view the complete content of a chunk, click the **full-screen** icon.
-
- 
-
- Tap the document title at the top to quickly switch to other documents in the knowledge base.
-
- 
-
-
- **Parent-child Mode**
-
- In [Parent-child](/en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text#parent-child-mode) mode, content is divided into parent chunks and child chunks.
-
- * **Parent chunks**
-
- After selecting a document in the knowledge base, you'll first see the parent chunk content. Parent chunks can be split by **Paragraph** or **Full Doc**, offering a more comprehensive context. The illustration below shows how the text preview differs between these split modes.
-
- 
-
- * **Child chunks**
-
- Child chunks are usually sentences (smaller text blocks) within a paragraph, containing more detailed information. Each chunk displays its character count and the number of times it has been retrieved. Tapping **"Child Chunks"** reveals more details. If you want to see the full content of a chunk, click the full-screen icon in the top-right corner of that chunk to enter full-screen reading mode.
-
- 
-
-
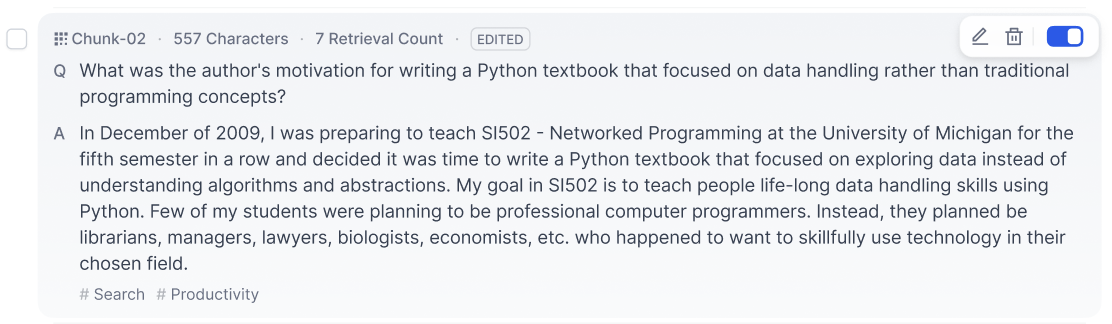
- **Q\&A Mode**
-
- In Q\&A Mode, a content chunk consists of a question and an answer. Click on any document title to view the text chunks.
-
- 
-
-
-
-***
-
-### Checking Chunk Quality
-
-Document chunking significantly influences the Q\&A performance of knowledge-base applications. It's recommended to perform a manual review of chunking quality before integrating the knowledge base with your application.
-
-Although automated chunk methods based on character length, identifiers, or NLP semantic system can significantly reduce the workload of large-scale text chunk, the quality of chunk is related to the text structure of different document formats and the semantic context. Manual checking and correction can effectively compensate for the shortcomings of machine chunk in semantic recognition.
-
-When checking chunk quality, pay attention to the following situations:
-
-* **Overly short text chunks**, leading to semantic loss;
-
-
-
-* **Overly long text chunks**, leading to semantic noise affecting matching accuracy;
-
-
-
-* **Obvious semantic truncation**, which occurs when using maximum segment length limits, leading to forced semantic truncation and missing content during recall;
-
-
-
-***
-
-### Adding Text Chunks
-
-You can add text chunks individually to the knowledge base, and different chunking modes correspond to different ways of adding those chunks.
-
-
-Adding text chunks is a paid feature. Please upgrade your account [here](https://dify.ai/pricing) to access this functionality.
-
-
-
-
- **General Mode**
-
- Click **Add Chunks** in the chunks list page to add one or multiple custom chunks to the document.
-
- 
-
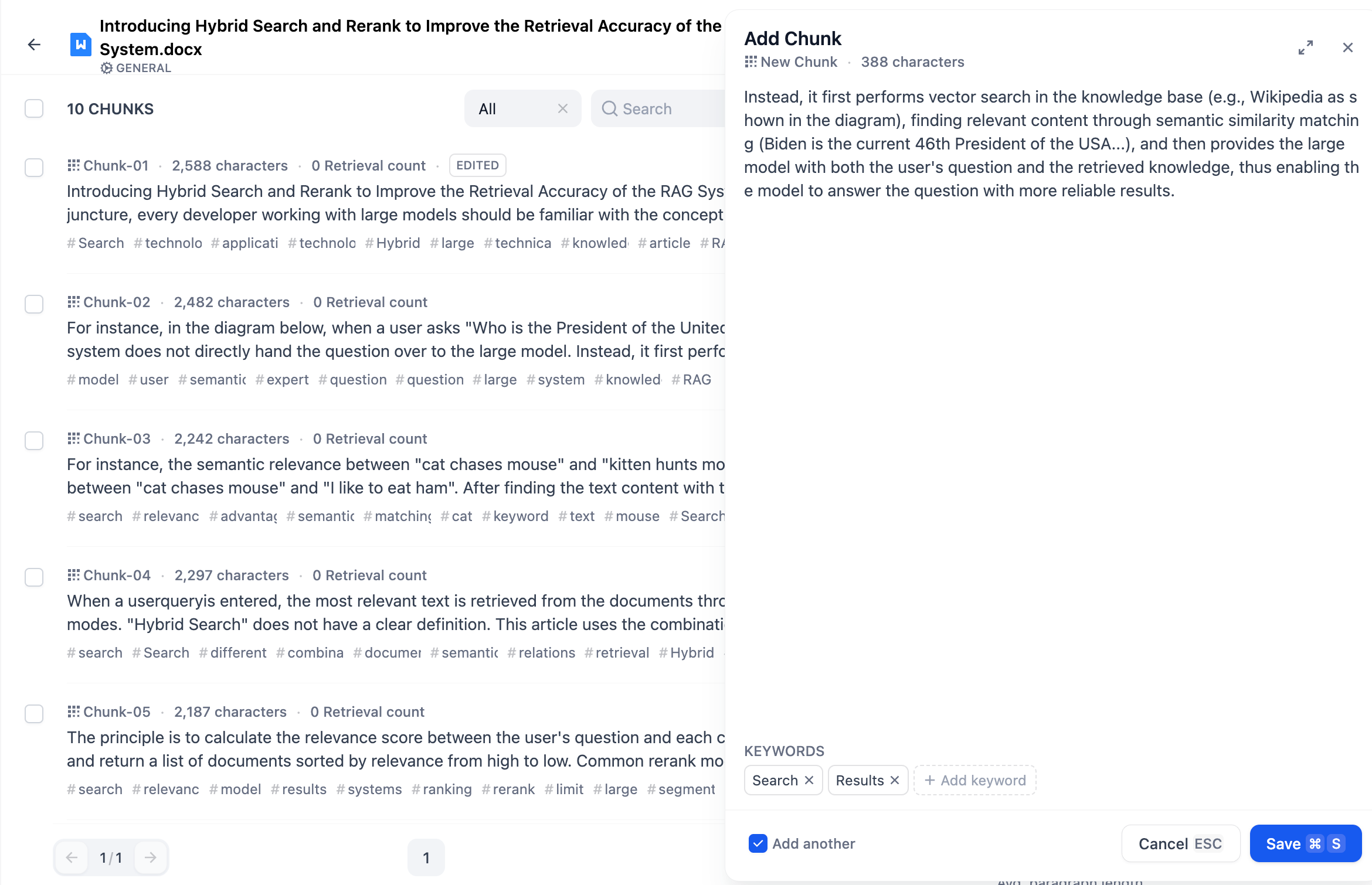
- When manually adding text chunks, you can choose to add both the main content and keywords. After entering the content, select the **"Add another"** checkbox at the bottom to continue adding more text chunks seamlessly.
-
- 
-
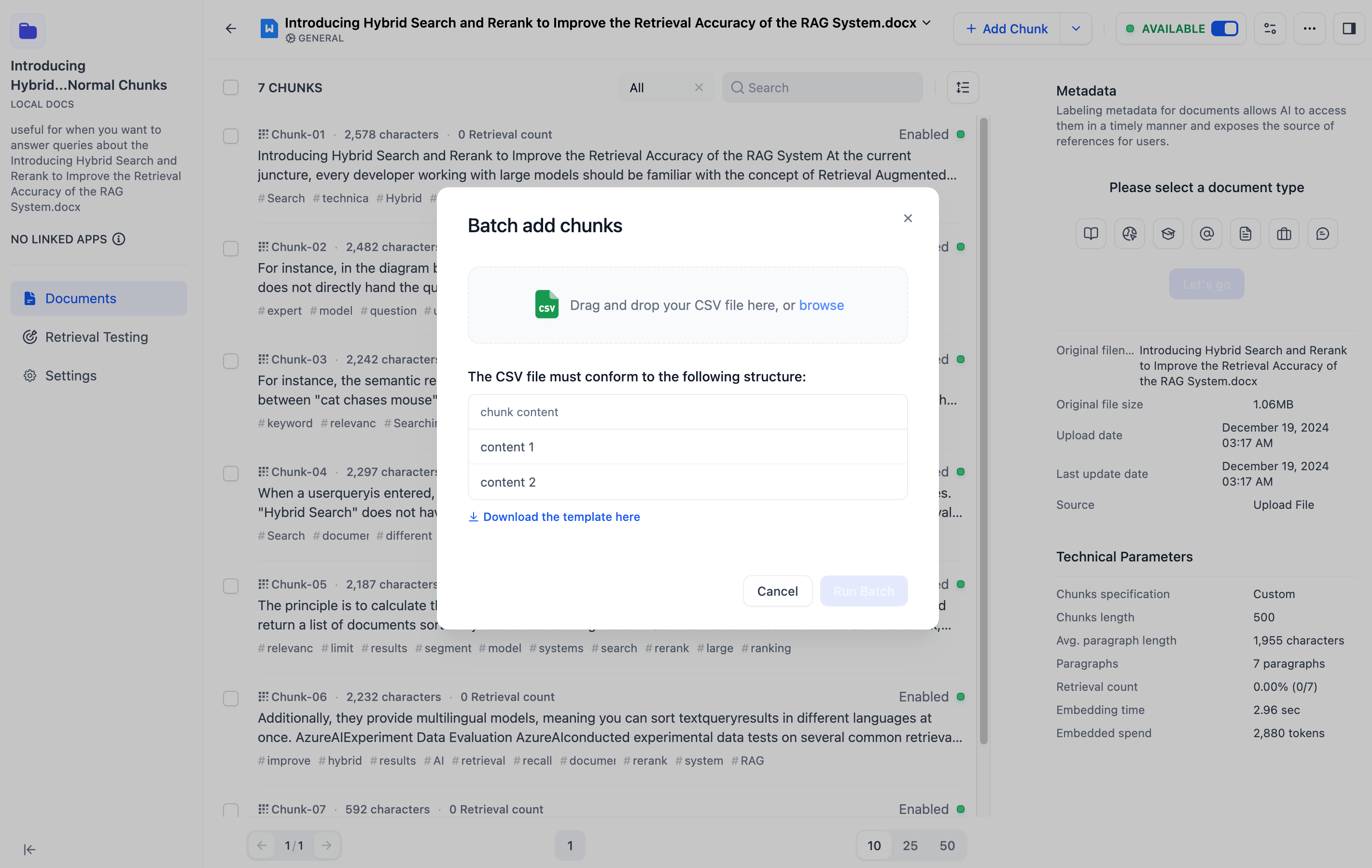
- To add chunks in bulk, you need to download the upload template in CSV format first and edit all the chunk contents in Excel according to the template format, then save the CSV file and upload it.
-
- 
-
-
- **Parent Child Chunks Mode**
-
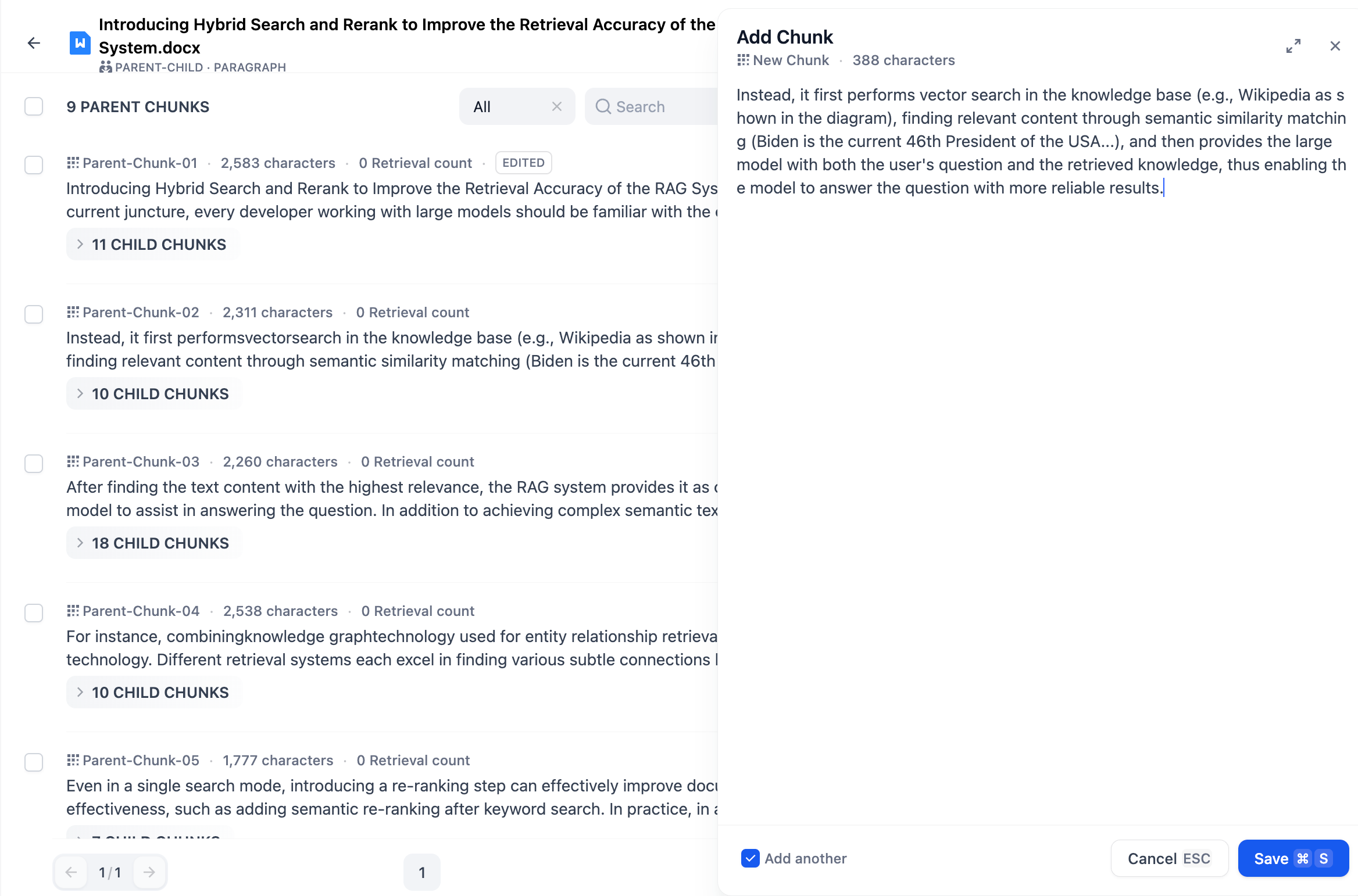
- Click Add Chunks in the Chunk list to add one or multiple custom **parent chunks** to the document.
-
- 
-
- After entering the content, select the **"Add another"** checkbox at the bottom to keep adding more text chunks.
-
- 
-
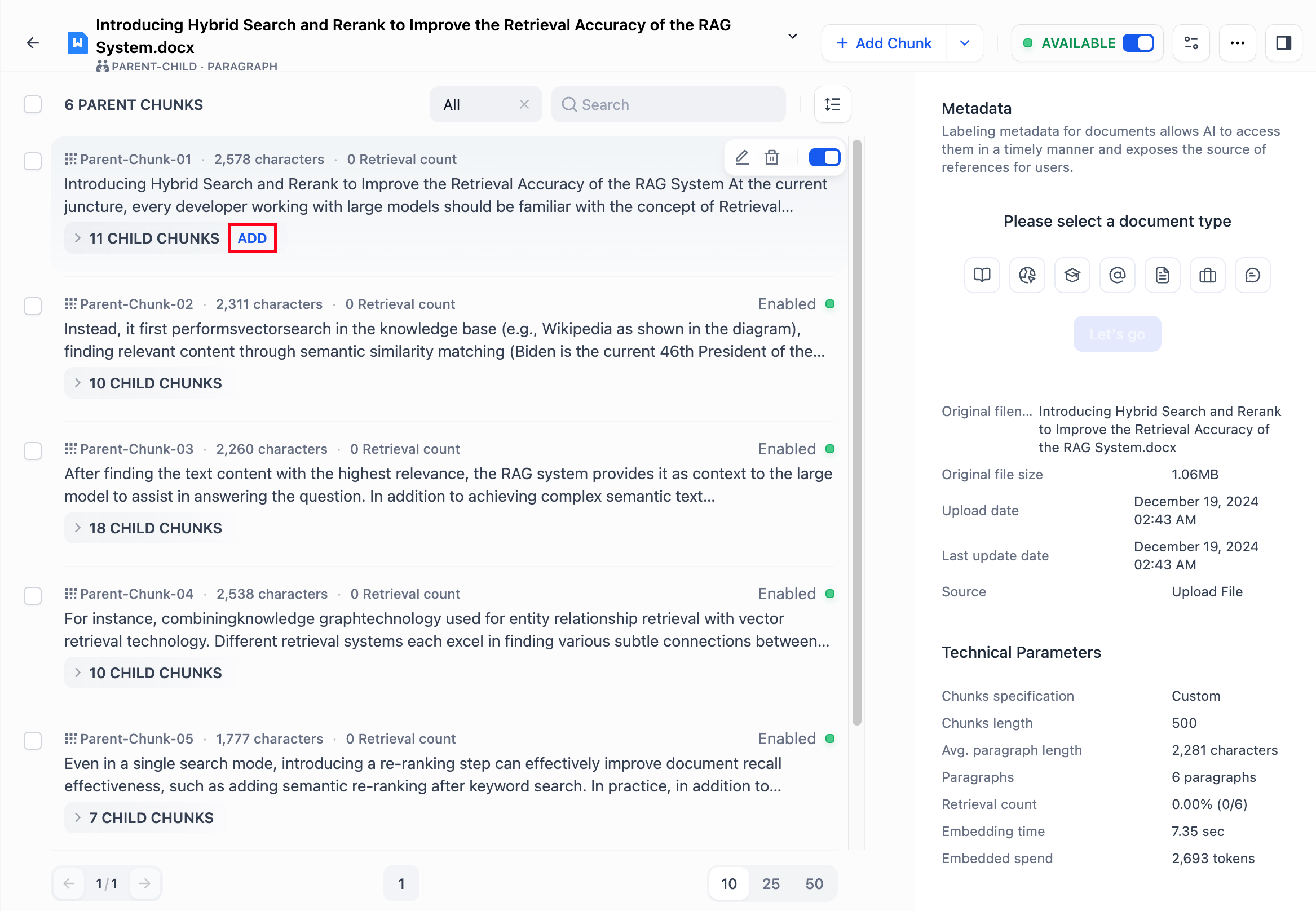
- You can add child chunks individually under a parent chunk. Click "Add" on the right side of the child chunk within the parent chunk to add it.
-
- 
-
-
- **Q\&A Mode**
-
- Click the "Add Chunk" button at the top of the chunk list to manually add a single or multiple question-answer pairs chunk to the document.
-
-
-
-***
-
-### Editing Text Chunks
-
-
-
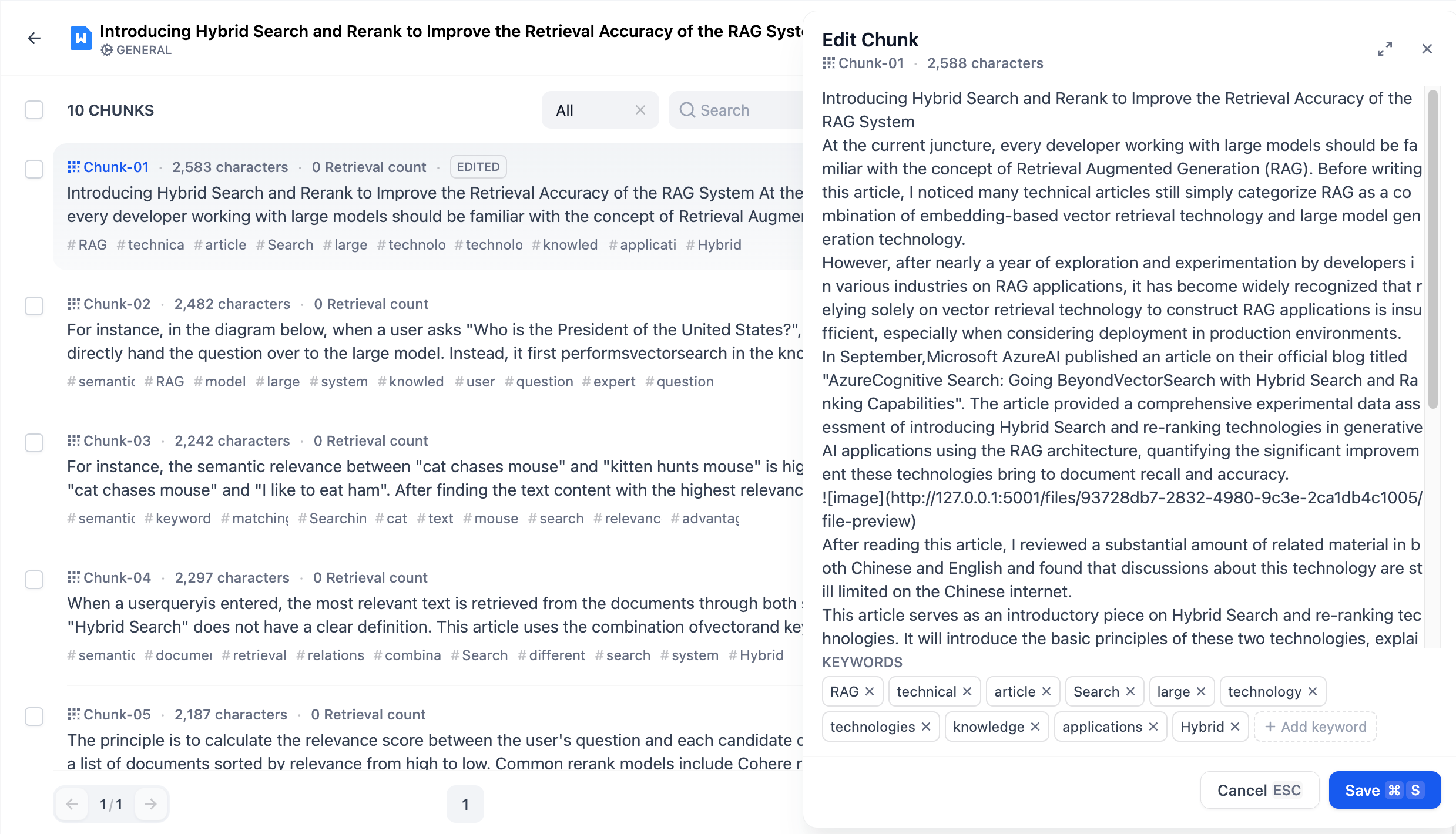
- **General Mode**
-
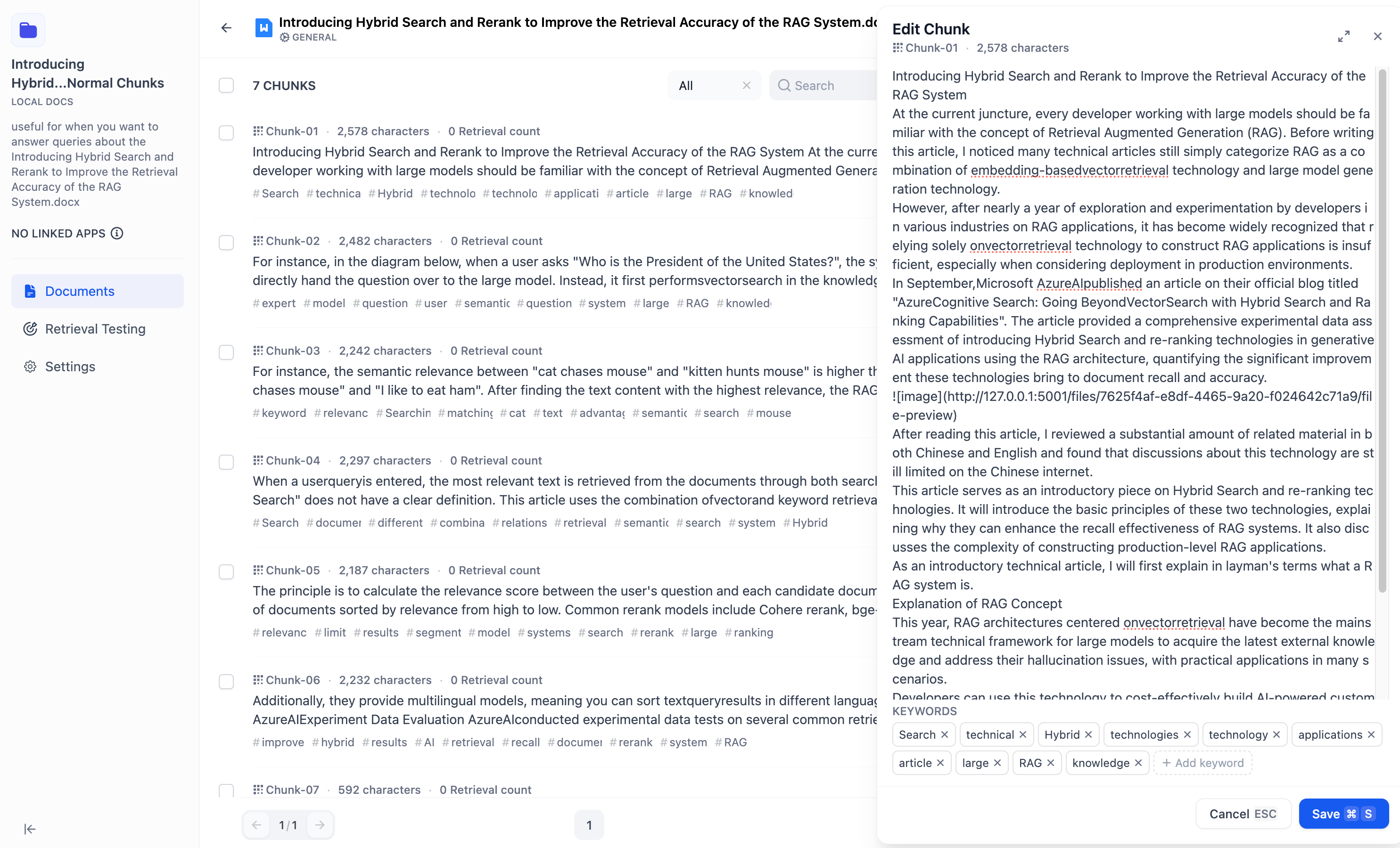
- You can directly edit or modify the added chunks content, including modifying the **text content or keywords within the chunks.**
-
- To prevent duplicate edits, an "Edited" tag will appear on the content chunk after it has been modified.
-
- 
-
-
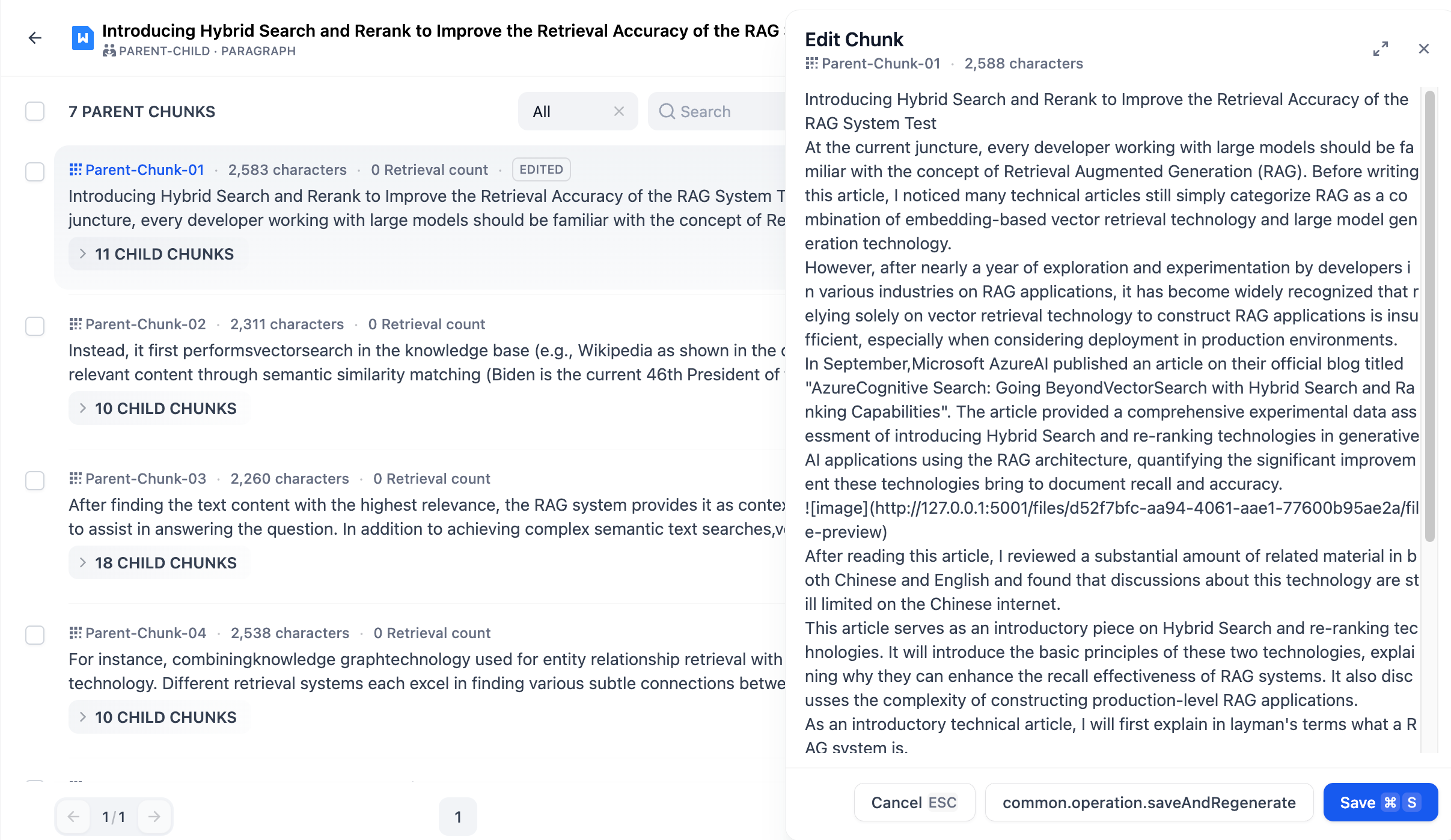
- **Parent-child Mode**
-
- A parent chunk contains the content of its child chunks, but they remain independent. You can edit the parent chunk or child chunks separately. Below is a diagram explaining the process of modifying parent and child chunks:
-
- 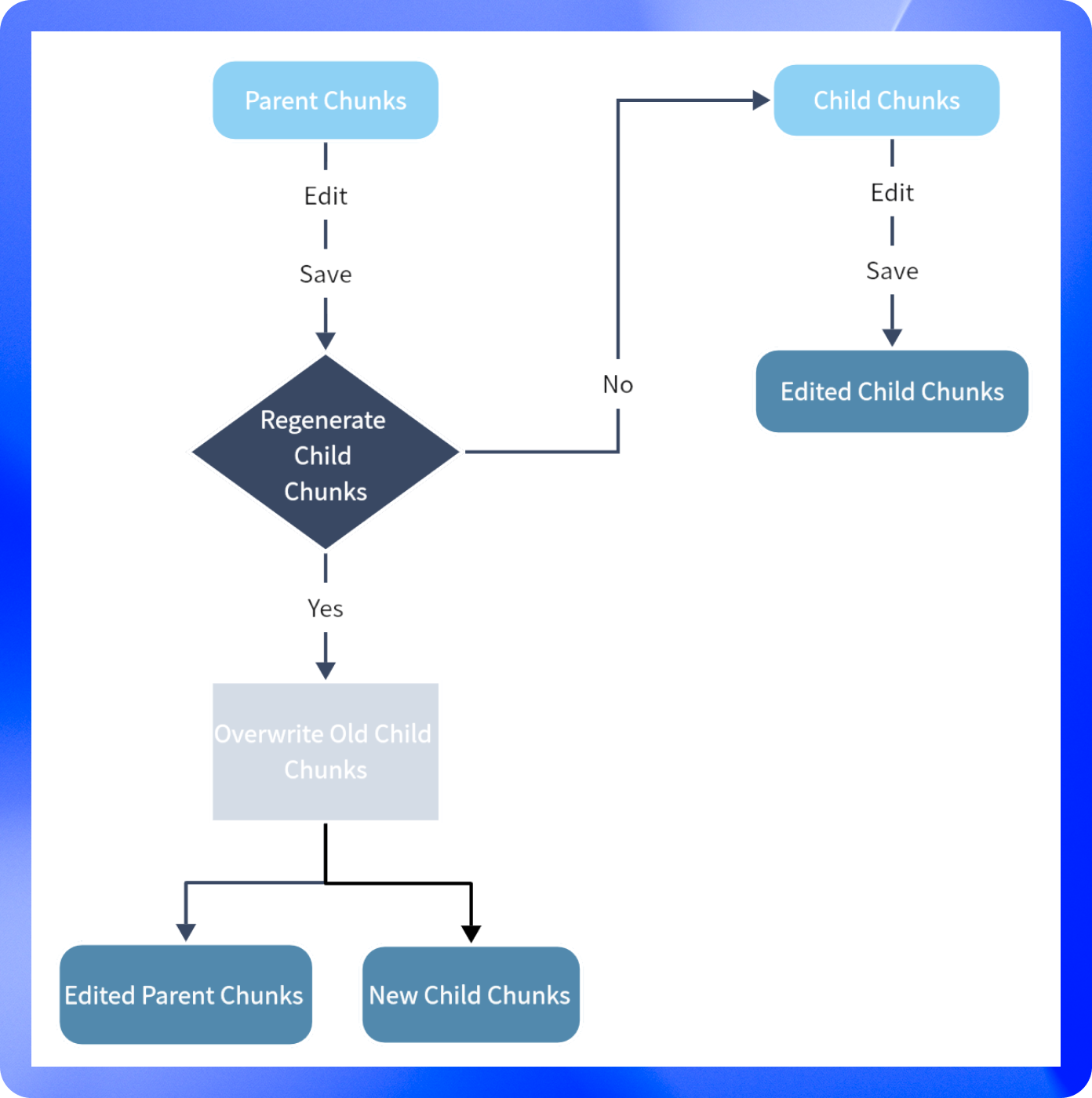
-
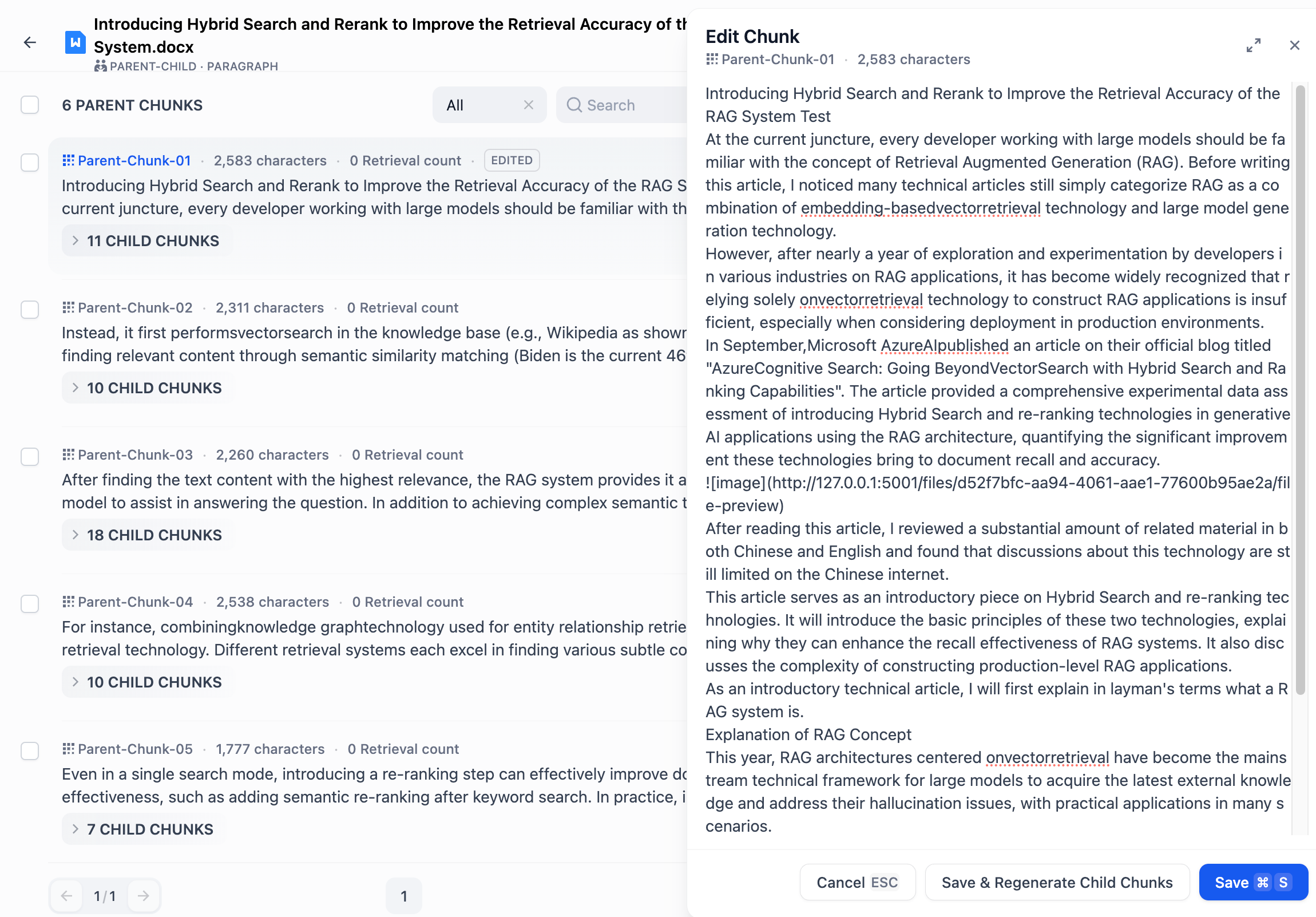
- **To edit a parent chunk:**
-
- 1\. Click the Edit button on the right side of the parent chunk.
-
- 2\. Enter your changes and then click **Save**—this won't affect the content of the child chunks.
-
- 3\. If you want to regenerate the child chunks after editing, click Save and Re-generate Child Chunks.
-
- To prevent duplicate edits, an "Edited" tag will appear on the content chunk after it has been modified.
-
- 
-
- **Modify child chunks**: select any child chunks and enter edit mode and save it after modification. The modification will not affect the contents of the parent chunks. Child chunks that have been edited or newly added will be marked with a deep blue label, `C-NUMBER-EDITED`.
-
- You can also treat child chunks as tags for the current parent text block.
-
- 
-
-
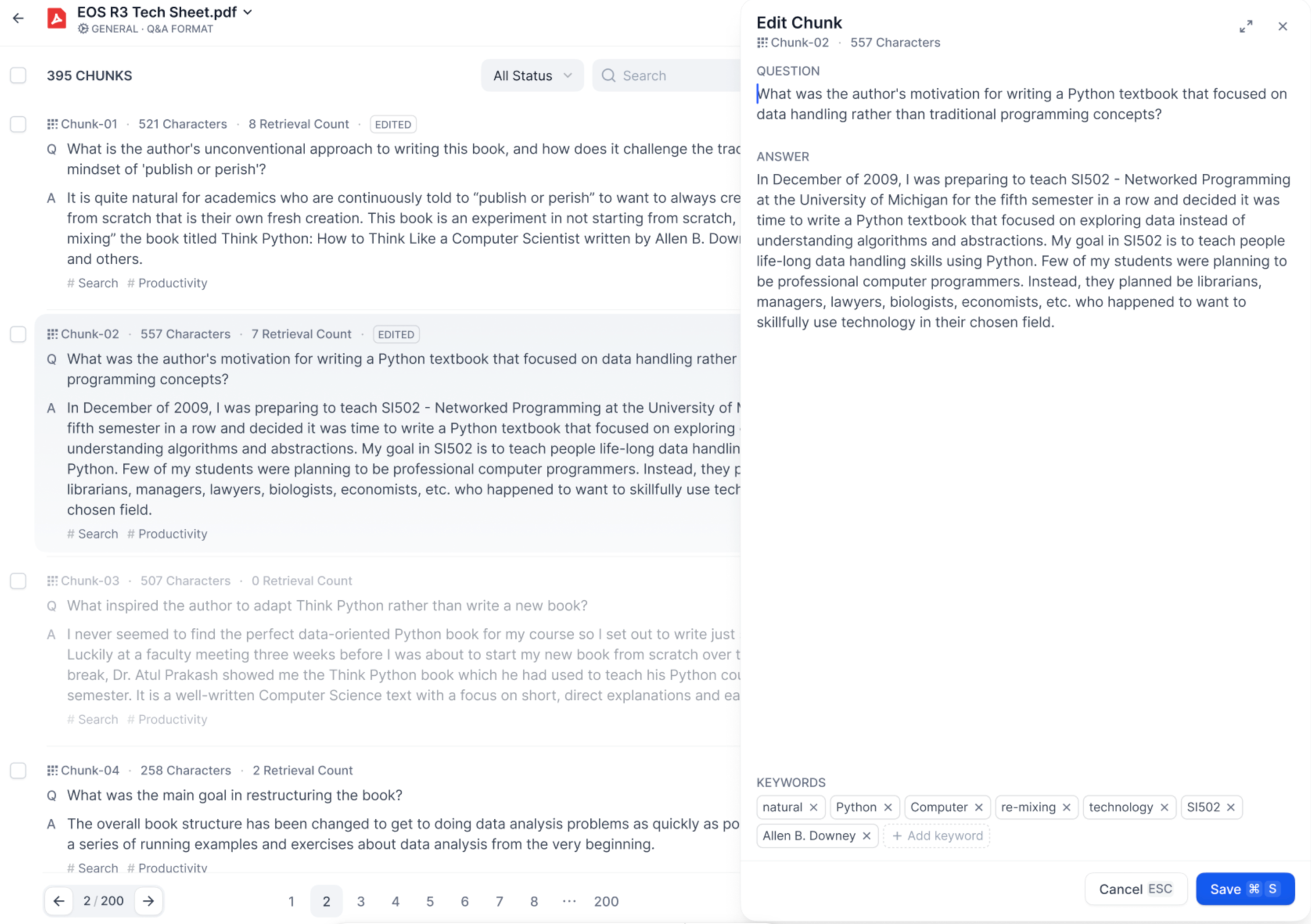
- **Q\&A Mode**
-
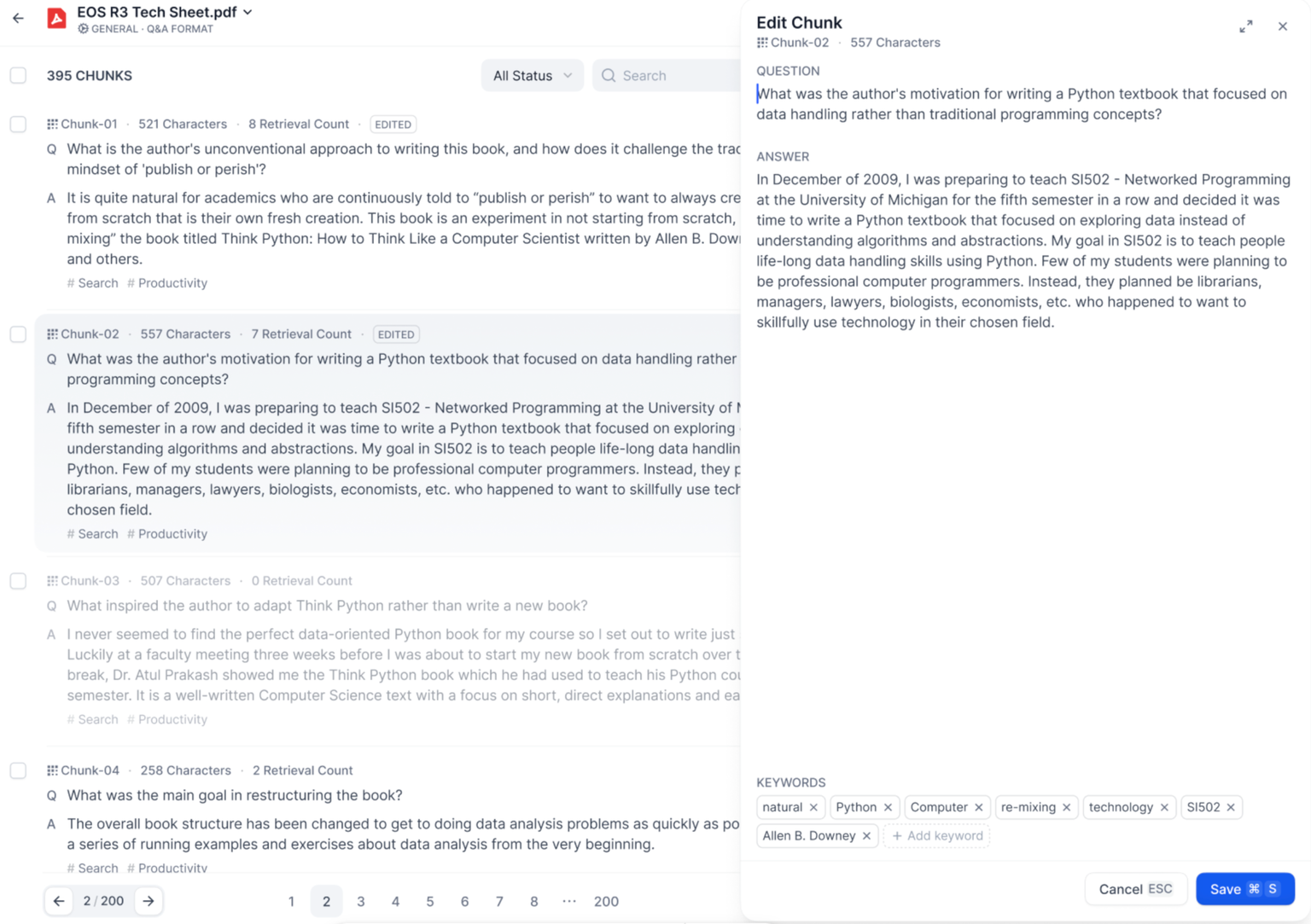
- In Q\&A chunking mode, each content chunk consists of a question and an answer. Click on the text chunk you wish to edit to modify the question and answer individually. Additionally, you can edit the keywords for the current chunk.
-
- 
-
-
-
-### Modify Text Chunks for Uploaded Documents
-
-Knowledge Base supports reconfiguring document segmentation.
-
-**Larger Chunks**
-
-* Retain more context within each chunk, ideal for tasks requiring a broader understanding of the text.
-* Reduce the total number of chunks, lowering processing time and storage overhead.
-
-**Smaller Chunks**
-
-* Provide finer granularity, improving accuracy for tasks like extraction or summarization.
-* Reduce the risk of exceeding model token limits, making it safer for models with stricter constraints.
-
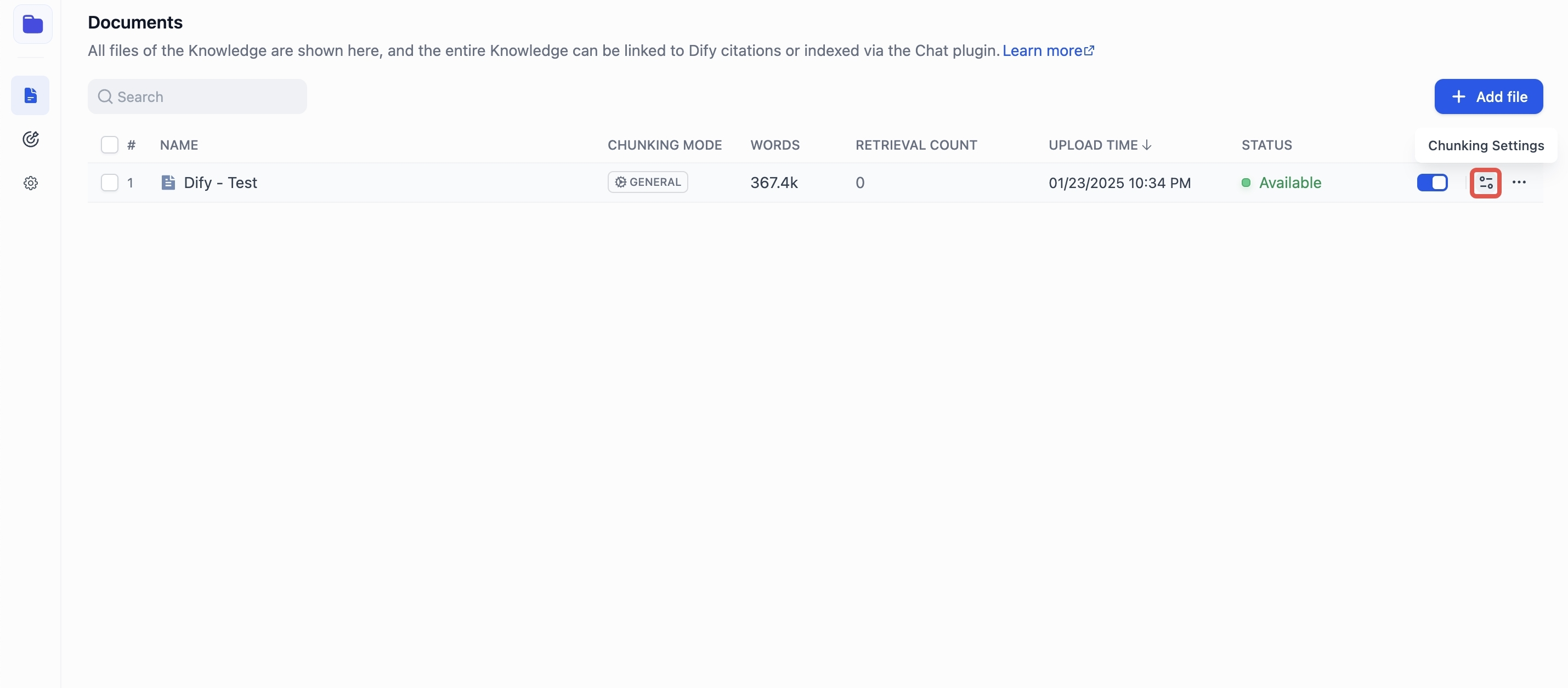
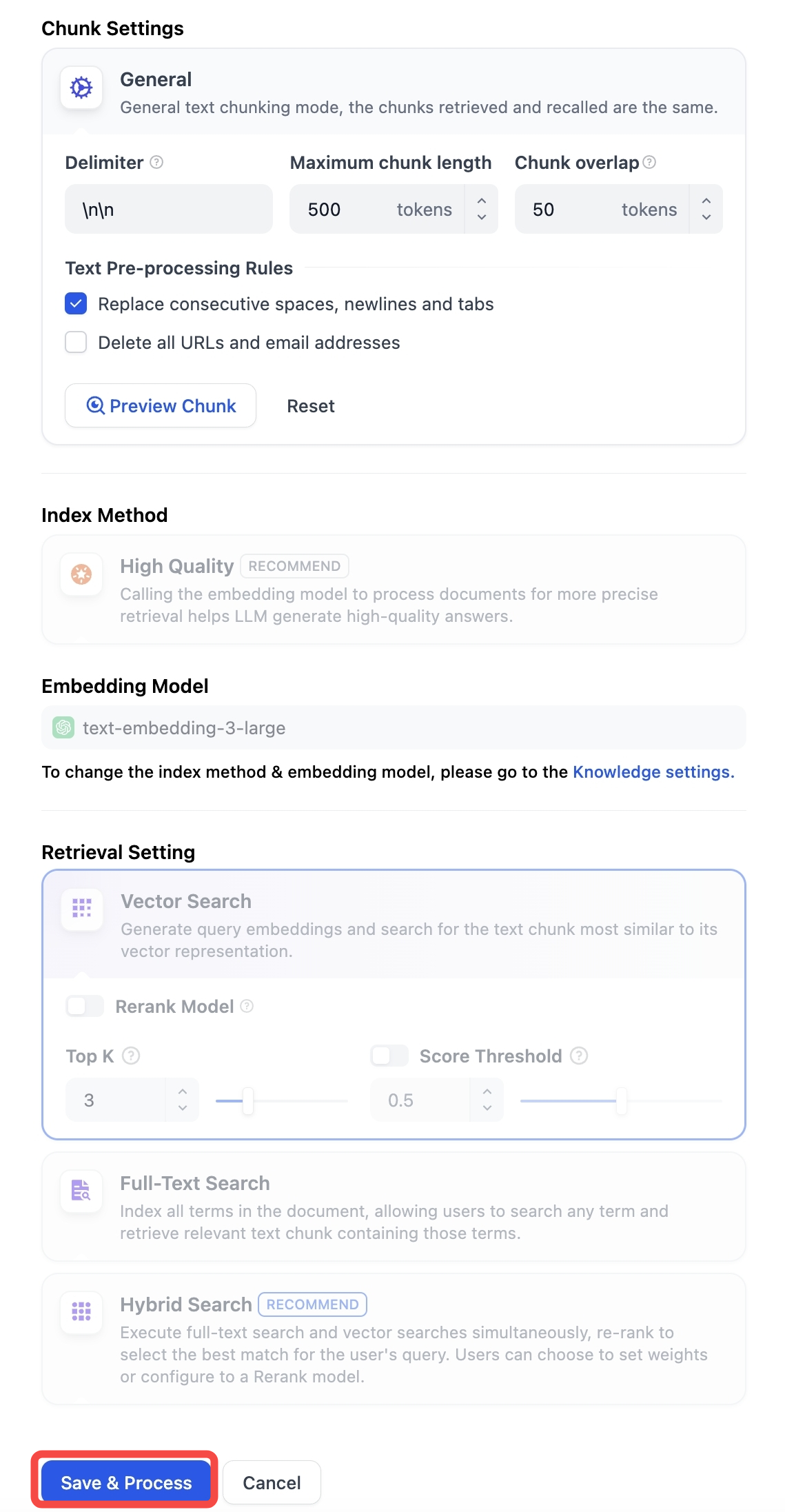
-Go to **Chunk Settings**, adjust the settings, and click **Save & Process** to save changes and reprocess the document. The chunk list will update automatically once processing is complete—no page refresh needed.
-
-
-
-
-
-***
-
-### Metadata
-
-For more details on metadata, see [_Metadata_](/en/guides/knowledge-base/metadata).
-
-***
-
-{/*
-Contributing Section
-DO NOT edit this section!
-It will be automatically generated by the script.
-*/}
-
----
-
-[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
+- *What's the refund period?*
+- *Are there any return shipping fees?*
\ No newline at end of file
diff --git a/en/guides/knowledge-base/readme.mdx b/en/guides/knowledge-base/readme.mdx
index 05823ac0..cc3b2184 100644
--- a/en/guides/knowledge-base/readme.mdx
+++ b/en/guides/knowledge-base/readme.mdx
@@ -19,7 +19,7 @@ This is made possible through Retrieval-Augmented Generation (RAG). It means tha
Learn more about [RAG](/en/learn-more/extended-reading/retrieval-augment/README).
-Knowledge is stored and organized in knowledge bases. You can create multiple knowledge bases, each tailored to different domains, use cases, or data sources, and selectively integrate them into your application as needed.
+Knowledge is stored and managed in knowledge bases. You can create multiple knowledge bases, each tailored to different domains, use cases, or data sources, and selectively integrate them into your application as needed.
To populate a knowledge base, you can upload local files in various formats, import pages directly from online documents like Notion, sync content from websites, or connect to external knowledge bases such as AWS Bedrock.
@@ -47,7 +47,7 @@ With Dify knowledge, you can build AI apps that are grounded in your own data an
- **[Manage content](/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents)**: View, add, modify, or delete documents and text chunks to keep your knowledge current, accurate, and retrieval-ready.
-- **[Test and validate retrieval](/en/guides/knowledge-base/retrieval-test-and-citation#1-retrieval-testing)**: Simulate user queries to test how well your knowledge base retrieves relevant information before deploying to production.
+- **[Test and validate retrieval](/en/guides/knowledge-base/retrieval-test-and-citation#1-retrieval-testing)**: Simulate user queries to test how well your knowledge base retrieves relevant information.
- **[Enhance retrieval with metadata](/en/guides/knowledge-base/metadata)**: Add metadata to documents to enable filter-based searches during retrieval.
@@ -57,7 +57,7 @@ With Dify knowledge, you can build AI apps that are grounded in your own data an
- **[Integrate into applications](/en/guides/knowledge-base/integrate-knowledge-within-application)**: Ground your AI applications in your own data.
-- **[Provide source citations](/en/guides/knowledge-base/retrieval-test-and-citation#2-citation-and-attribution)**: Enable your chatbot or chatflow applications to display the specific knowledge source for each answer.
+- **[Provide source citations](/en/guides/knowledge-base/test-retrieval)**: Enable your app to display the specific knowledge source for each answer.
---
@@ -75,4 +75,15 @@ With Dify knowledge, you can build AI apps that are grounded in your own data an
- [Dify.AI's New Dataset Feature Enhancements: Citations and Attributions](https://dify.ai/blog/difyai-new-dataset-features)
-- [Text Embedding: Basic Concepts and Implementation Principles](https://dify.ai/blog/text-embedding-basic-concepts-and-implementation-principles)
\ No newline at end of file
+- [Text Embedding: Basic Concepts and Implementation Principles](https://dify.ai/blog/text-embedding-basic-concepts-and-implementation-principles)
+
+
+{/*
+Contributing Section
+DO NOT edit this section!
+It will be automatically generated by the script.
+*/}
+
+---
+
+[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/knowledge-base/readme.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
\ No newline at end of file
diff --git a/en/guides/workflow/node/knowledge-retrieval.mdx b/en/guides/workflow/node/knowledge-retrieval.mdx
index 58396f0a..981095b7 100644
--- a/en/guides/workflow/node/knowledge-retrieval.mdx
+++ b/en/guides/workflow/node/knowledge-retrieval.mdx
@@ -8,7 +8,7 @@ The Knowledge Retrieval node allows you to embed existing knowledge bases into y
Below is an example of using the Knowledge Retrieval node in a Chatflow:
-1. The **Start** node collects the user query.
+1. The **User Input** node collects the user query.
2. The **Knowledge Retrieval** node searches the selected knowledge base(s) for content related to the user query and outputs the retrieval results.
@@ -24,7 +24,7 @@ Below is an example of using the Knowledge Retrieval node in a Chatflow:
## Configure a Knowledge Retrieval Node
-To make the Knowledge Retrieval node work properly, you need to tell it *what* it should search for (the query), *where* it should search (the knowledge base), and *how* to process the retrieval results (the node-level retrieval settings). You can also use document metadata to enable filer-based searches and improve retrieval precision.
+To make the Knowledge Retrieval node work properly, you need to tell it *what* it should search for (the query), *where* it should search (the knowledge base), and *how* to process the retrieval results (the node-level retrieval settings). You can also use document metadata to enable filter-based searches and further improve retrieval precision.
### Specify the Query
@@ -49,7 +49,7 @@ Provide the query content that the node should search for in the selected knowle
Add one or more existing knowledge bases for the node to search for content relevant to the query content.
- Knowledge bases marked with an **Image** icon support image-based retrieval, which means that you can use text and/or images as queries and retrieve semantically related text and images.
+ Knowledge bases marked with an **Image** icon support image-based retrieval, which means that you can use text and/or images as queries and retrieve both semantically related text and images.
@@ -115,3 +115,13 @@ To use the retrieval results to answer user questions in an LLM node:
Knowledge retrieval operations are subject to rate limits based on your subscription plan. For more information, see [Knowledge Request Rate Limit](/en/guides/knowledge-base/knowledge-request-rate-limit).
+
+{/*
+Contributing Section
+DO NOT edit this section!
+It will be automatically generated by the script.
+*/}
+
+---
+
+[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/workflow/node/knowledge-retrieval.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
\ No newline at end of file
diff --git a/zh-hans/guides/application-orchestrate/app-toolkits/readme.mdx b/zh-hans/guides/application-orchestrate/app-toolkits/readme.mdx
index fdf50394..d3044409 100644
--- a/zh-hans/guides/application-orchestrate/app-toolkits/readme.mdx
+++ b/zh-hans/guides/application-orchestrate/app-toolkits/readme.mdx
@@ -34,9 +34,7 @@ title: 应用工具箱
### 引用与归属
-开启功能后,当 LLM 引用知识库内容来回答问题时,可以在回复内容下面查看到具体的引用段落信息,包括原始分段文本、分段序号、匹配度等。
-
-具体介绍请查看[引用与归属](/zh-hans/guides/knowledge-base/retrieval-test-and-citation#id-2-yin-yong-yu-gui-shu)。
+开启此功能后,当 AI 在回答问题时引用了知识库内容时,可在回复内容下方查看具体的引用来源,包括**原始分段内容、片段编号、匹配度**等信息。
### 内容审查
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
index cebcae4b..669f220a 100644
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
@@ -1,5 +1,6 @@
---
-title: 管理知识库
+title: 调整知识库设置
+sidebarTitle: 调整设置
---
> 知识库管理页仅面向团队所有者、团队管理员、拥有编辑权限的角色开放。
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
index ed159fc7..b7c3bd66 100644
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
@@ -1,191 +1,69 @@
---
-title: 维护知识库内文档
+title: 维护知识库内容
+sidebarTitle: 维护内容
---
+## 管理文档
-### 添加文档
+在知识库中,每个导入的项——无论是本地文件、Notion 页面还是网页——都会成为一个文档。你可以在文档列表中查看和管理所有文档,确保知识内容始终准确、相关且最新。
-知识库是文档的集合。文档支持本地上传,或导入其它在线数据源。知识库内的文档对应数据源中的一个文件单位,例如 Notion 库内的一篇文档或新的在线文档网页。
+
+ 点击顶部的知识库名称,可快速切换不同知识库。
+
-点击“知识库” → “文档列表” → “添加文件”,在已创建的知识库内上传新的文档。
+
-
+| 操作 | 说明 |
+|:------------------- |:---------------------|
+| 添加 | 导入新文档。|
+| 修改分段设置 | 修改文档的分段设置(不包括分段模式)。
每个文档可拥有独立的分段设置,但分段模式在整个知识库中共享,且一旦设置无法更改。|
+| 删除 | 永久删除文档。**删除不可撤销**。|
+| 启用 / 禁用 | 临时将文档纳入或排除检索。在 Dify Cloud 上,长时间未更新或未被检索的文档会自动禁用以优化性能。
不同订阅计划的未活跃时长如下:- Sandbox:7 天
- Professional & Team:30 天
Professional 和 Team 用户可一键重新启用这些文档。|
+| 归档 / 取消归档 | 将不再需要检索但仍需保留的文档归档。归档文档为只读,可随时取消归档。|
+| 编辑 | 通过编辑分段内容修改文档。详见 [管理分段](#manage-chunks)。|
+| 重命名 | 修改文档名称。|
-### 启用 / 禁用 / 归档 / 删除文档
+## 管理分段
-**启用**:处于正常使用状态的文档,支持编辑内容与被知识库检索。对于已被禁用的文档,允许重新启用。已归档的文档需撤销归档状态后才能重新启用。
+根据分段设置,每个文档会被拆分为一个或多个分段,而分段是检索的基本单元。你可以在文档的分段列表中查看和管理所有分段,以提升检索效率和准确性。
-**禁用**:对于不希望在使用 AI 应用时被检索的文档,可以关闭文档右侧的蓝色开关按钮以禁用文档。禁用文档后,仍然可以编辑当前内容。
+
+ 点击左上角的文档名称,可快速切换不同文档。
+
-**归档**:对于一些不再使用的旧文档数据,如果不想删除可以将其归档。归档后的数据就只能查看或删除,无法重新编辑。你可以在知识库文档列表,点击归档按钮;或在文档详情页内进行归档。**归档操作支持撤销。**
+
-**删除**:⚠️ 危险操作。对于一些错误文档或明显有歧义的内容,可以点击文档右侧菜单按钮中的删除。删除后的内容将无法被找回,请进行谨慎操作。
+| 操作 | 说明 |
+|:-------- |:---------------------|
+| 添加 | 新增或批量新增分段。对于采用父子分段模式的文档,可同时新增父分段和子分段。此功能为 Dify Cloud 付费功能,[升级至 Professional 或 Team 版](https://dify.ai/pricing) 即可解锁使用。|
+| 删除 | 永久删除分段。**删除不可撤销**。|
+| 启用 / 禁用 | 临时将分段纳入或排除检索。已禁用的分段不可编辑。|
+| 编辑 | 修改分段内容。已编辑的分段会标记为 **已编辑**。
对于采用父子分段模式的文档:- 编辑父分段时,可选择重新生成子分段或保持原有的子分段不变。
- 编辑子分段不会影响父分段。
|
+| 添加 / 编辑 / 删除关键词 | 在使用经济索引方式的知识库中,可修改分段关键词以提升检索精度。|
+| 上传 / 删除图片 | 在启用图片检索的知识库中,可删除已导入的图片或上传新图片,增强分段的视觉语境。为知识库选择支持图片向量化的嵌入模型(带有 **图片** 图标)即可启用图片检索。|
-> 以上选项均支持选中多个文档后批量操作。
+## 最佳实践
-
-
-### 注意事项
-
-如果你的知识库中有部分文档长时间未更新或未检索时,为了确保知识库的高效运行,系统会暂时禁用这部分不活跃的文档。
-
-* 对于 Sandbox/Free 版本用户,未使用知识库的将在 **7 天** 后自动禁用;
-* 对于 Professional/Team 版本用户,未使用知识库的将在 **30 天** 后自动禁用。
-
-你随时可以前往知识库中重新启用它们以恢复正常使用。付费用户可以使用 **“一键恢复”** 功能快速启用所有被禁用的文档。
-
-
-
-***
-
-## 管理文本分段
-
-### 查看文本分段
-
-知识库内已上传的每个文档都会以文本分段(Chunks)形式进行存储。点击文档标题,在详情页中查看当前文档的分段列表,每页默认展示 10 个区块,你可以在网页底部调整每页的展示数量。
-
-每个内容区块展示前 2 行的预览内容。若需要查看更加分段内的完整内容,轻点“展开分段”按钮即可查看。
-
-
-
-你可以通过筛选栏快速查看所有已启用 / 未启用的文档。
-
-
-
-不同的[文本分段模式](../create-knowledge-and-upload-documents/chunking-and-cleaning-text)对应不同的文本分段查看方式:
-
-
-
- **通用模式**
-
- [通用模式](../create-knowledge-and-upload-documents/#tong-yong)下的文本分段为独立的区块。若希望查看区块内的完整内容,轻点右上角的全屏 icon 进入全屏阅读模式。
-
- 
-
- 点击顶部文档标题即可快速切换至当前知识库内的其它文档。
-
- 
-
-
-
- **父子模式**
-
- [父子模式](../create-knowledge-and-upload-documents/#fu-zi-fen-duan)下的内容分为父分段和子分段。
-
- * **父分段**
-
- 选择知识库内的文档后,你将会首先看到父分段的内容。父分段存在 **“段落”** 分段与 **“全文”** 分段两种模式,提供更加完整的上下文信息。下图为不同分段模式的文本预览差异。
-
- 
-
- * **子分段**
-
- 子分段一般为段落中的某个句子(较小的文本块),包含细节信息。各个分块均会展示字符数以及被检索召回的次数。轻点“子分段”即可查看更多详细内容。若希望查看区块内的完整内容,轻点区块右上角的全屏 icon 进入全屏阅读模式。
-
- 
-
-
-
- **Q&A 模式**
-
- 在 Q&A 模式下,一个内容区块包含问题与答案,轻点任意文档标题即可查看文本分段。
-
- 
-
-
-
-***
+建议参考以下最佳实践,确保知识库的检索结果准确且相关。
### 检查分段质量
-文档分段对于知识库应用的问答效果有明显影响,在将知识库与应用关联之前,建议人工检查分段质量。
+文档完成分段后,仔细检查每个分段,确保其语义完整、长度适中,以确保检索准确性和回复相关性。
-检查分段质量时,一般需要关注以下几种情况:
+常见问题包括:
-* **过短的文本分段**,导致语义缺失;
-* **过长的文本分段**,导致语义噪音影响匹配准确性;
-* **明显的语义截断**,在使用最大分段长度限制时会出现强制性的语义截断,导致召回时缺失内容;
+- 分段 **过短**:上下文不完整,易造成语义丢失和答案不准确。
+- 分段 **过长**:包含无关信息,易引入语义噪音、降低检索精度。
+- 分段 **语义不完整**:句子或段落被分段设置强制切断,导致检索结果存在内容缺失或误导。
-
-
-
+### 将子分段用作父分段的检索钩子
-***
+对于采用父子分段模式的文档,系统会检索子分段,但返回父分段。由于编辑子分段不会影响父分段,可将子分段作为父分段的语义标签或检索提示。
-### 添加文本分段
+具体做法是将子分段改写为 **关键词**、**摘要** 或 **常见用户问题**。例如,若父分段的内容为*退货政策*,可将子分段改写为:
-知识库中的文档支持单独添加文本分段,不同的分段模式对应不同的分段添加方法。
-
-
-添加文本分段为付费功能,请前往[此处](https://dify.ai/pricing)升级账号以使用功能。
-
-
-
-
- 点击分段列表顶部的“添加分段”按钮,可以在文档内自行添加一个或批量添加多个自定义分段。
-
- 
-
-
- 点击分段列表顶部的「 添加分段 」按钮,可以在文档内自行添加一个或批量添加多个自定义**父分段。**
-
- 
-
- 填写内容后,勾选尾部“连续新增”钮后,可以继续添加文本。
-
-
- 点击分段列表顶部的 「 添加分段 」 按钮,可以在文档内自行添加一个或批量添加多个问题-答案内容对区块。
-
-
-
-***
-
-### 编辑文本分段
-
-
-
- 你可以对已添加的分段内容直接进行编辑或修改,包括修改分段内的文本内容或关键词。
-
- 
-
-
- 父分段包含其本身所包含的子分段内容,两者相互独立。你可以单独修改父分段或子分段的内容。
-
- 
-
- 修改父分段后,点击 **“保存”** 后将不会影响子分段的内容。如需重新生成子分段内容,轻点 **“保存并重新生成子分段”**。
-
-
- 在 Q&A 分段模式下,一个内容区块包含问题与答案。点击需要编辑的文本分段,可以分别对问题和答案内容做出修改;同时也支持修改当前区块的关键词。
- 
-
-
-
-### 修改已上传文档的文本分段
-
-已创建的知识库支持重新配置文档分段。
-
-
-
- - 可在单个分段内保留更多上下文,适合需要处理复杂或上下文相关任务的场景。
- - 分段数量减少,从而降低处理时间和存储需求。
-
-
- - 提供更高的粒度,适合精确提取或总结文本内容。
- - 减少超出模型 token 限制的风险,更适配限制严格的模型。
-
-
-
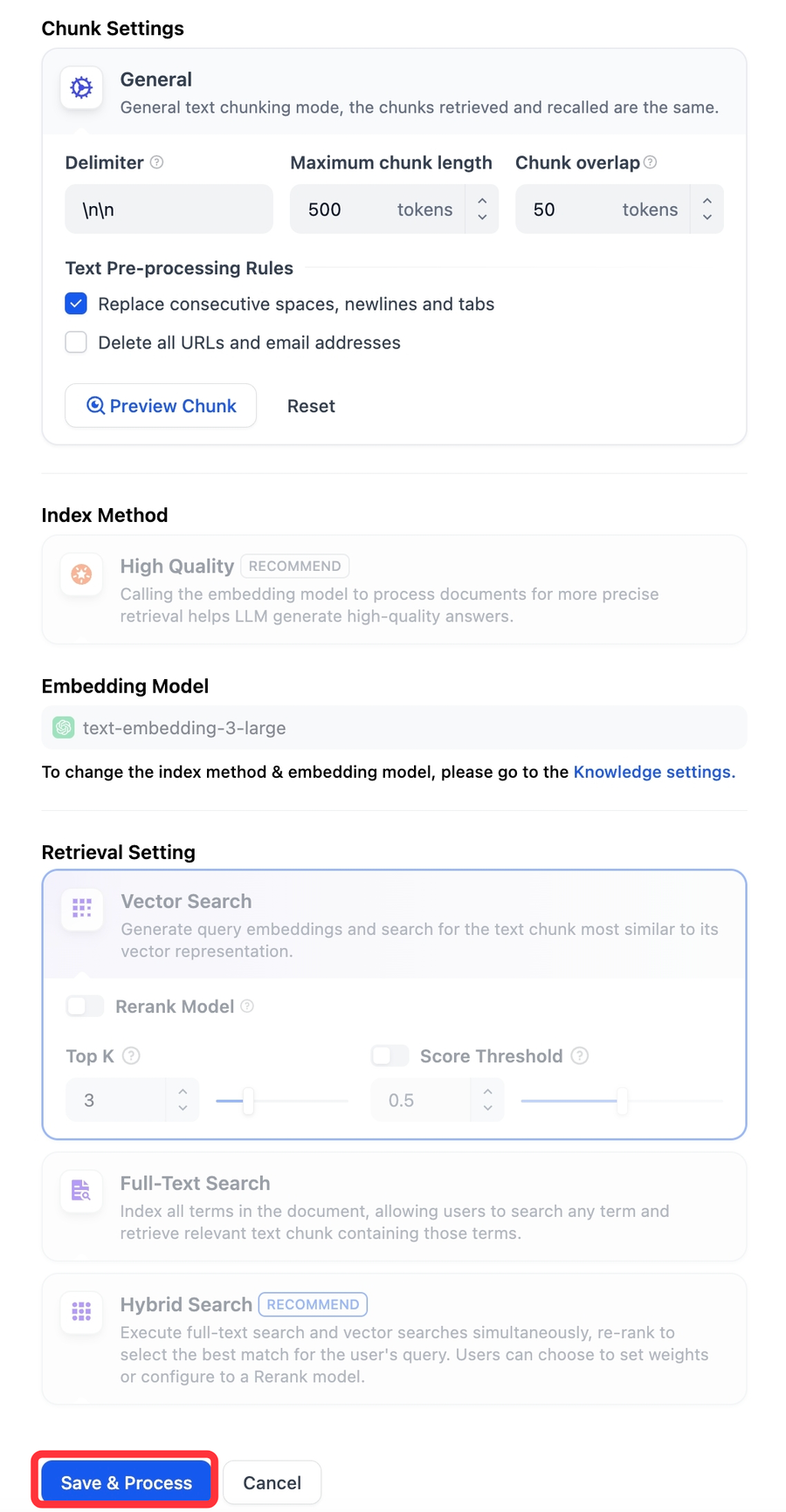
-你可以访问 **分段设置**,点击 **保存并处理** 按钮以保存对分段设置的修改,并重新触发当前文档的分段流程。当你保存设置并完成嵌入处理后,文档的分段列表将自动更新。
-
-
-
-
-
-***
-
-### 元数据管理
-
-如需了解元数据的相关信息,请参阅 [元数据](/zh-hans/guides/knowledge-base/metadata)。
+- *如何退货?*
+- *退款周期是多少?*
+- *退货需要支付运费吗?*
{/*
Contributing Section
diff --git a/zh-hans/guides/knowledge-base/metadata.mdx b/zh-hans/guides/knowledge-base/metadata.mdx
index f1f43900..b4692b79 100644
--- a/zh-hans/guides/knowledge-base/metadata.mdx
+++ b/zh-hans/guides/knowledge-base/metadata.mdx
@@ -1,5 +1,6 @@
---
-title: 元数据
+title: 管理文档元数据
+sidebarTitle: 管理元数据
---
## 什么是元数据?
diff --git a/zh-hans/guides/knowledge-base/readme.mdx b/zh-hans/guides/knowledge-base/readme.mdx
index d7a170db..3a68953e 100644
--- a/zh-hans/guides/knowledge-base/readme.mdx
+++ b/zh-hans/guides/knowledge-base/readme.mdx
@@ -1,48 +1,68 @@
---
-title: 功能简介
+title: 知识库
+sidebarTitle: 概述
---
-知识库功能将 [RAG 管线](/zh-hans/learn-more/extended-reading/retrieval-augment/rerank)上的各环节可视化,提供了一套简单易用的用户界面来方便应用构建者管理个人或者团队的知识库,并能够快速集成至 AI 应用中。
+## 简介
-开发者可以将企业内部文档、FAQ、规范信息等内容上传至知识库进行结构化处理,供后续 LLM 查询。
+知识是你自有数据的集合,可集成到 Dify 应用中。通过为大语言模型(LLM)提供特定领域的上下文信息,知识库能够让 LLM 的回复更加准确、相关,并显著减少幻觉。
-相比于 AI 大模型内置的静态预训练数据,知识库中的内容能够实时更新,确保 LLM 可以访问到最新的信息,避免因信息过时或遗漏而产生的问题。
+这得益于检索增强生成(RAG)技术。其核心是:LLM 不再只依赖预训练的公开数据,还会将你的自定义知识作为额外的事实来源:
-LLM 接收到用户的问题后,将首先基于关键词在知识库内检索内容。知识库将根据关键词,召回相关度排名较高的内容区块,向 LLM 提供关键上下文以辅助其生成更加精准的回答。
+1. (检索)用户提问时,系统会先从已集成的知识库中**检索最相关的信息**。
+2. (增强)检索到的信息会与用户原始问题打包,作为**增强的上下文**发送给 LLM。
+3. (生成)LLM 基于这些上下文**生成更精准的答案**。
-开发者可以通过此方式确保 LLM 不仅仅依赖于训练数据中的知识,还能够处理来自实时文档和数据库的动态数据,从而提高回答的准确性和相关性。
+
+ 了解更多 [RAG 原理](/zh-hans/learn-more/extended-reading/retrieval-augment/README)。
+
-**核心优势:**
+知识存储在知识库中。你可以创建多个知识库,分别适配不同领域、场景或数据源,并按需集成到应用中。
-• **实时性**:知识库中的数据可随时更新,确保模型获得最新的上下文。
+你可以通过多种方式将数据接入知识库:上传本地文件(支持多种格式)、导入在线文档(如 Notion)、同步网站内容,或连接外部知识库(如 AWS Bedrock)。
-• **精准性**:通过检索相关文档,LLM 能够基于实际内容生成高质量的回答,减少幻觉现象。
-• **灵活性**:开发者可自定义知识库内容,根据实际需求调整知识的覆盖范围。
+## 知识库应用场景
-***
+借助 Dify 知识库,你可以打造基于自有数据和特定领域知识的 AI 应用。常见场景包括:
-准备文本文件,例如:
+1. **智能客服机器人**:让机器人基于最新产品文档、FAQ、故障排查指南和工单历史,智能回复客户问题。
+2. **企业内部知识门户**:为员工构建 AI 搜索与问答系统,快速访问公司政策、流程、研究报告和机构知识。
+3. **内容生成工具**:根据特定背景资料,智能生成报告、文章或邮件。
+4. **科研与分析应用**:检索和总结学术论文、市场报告、法律文档等专业知识,辅助研究与分析。
-* 长文本内容(TXT、Markdown、DOCX、HTML、JSON 甚至是 PDF)
-* 结构化数据(CSV、Excel 等)
-* 在线数据源(网页爬虫、Notion 等)
+## 创建知识库
-将文件上传至“知识库”即可自动完成数据处理。
+- **[快速创建](/zh-hans/guides/knowledge-base/knowledge-base-creation/introduction)**:导入数据,设置处理规则,其余一切交给 Dify。简单高效,新手友好。
+- **[通过知识流水线创建](/zh-hans/guides/knowledge-base/knowledge-pipeline/readme)**:自定义步骤和插件,编排更复杂、灵活的数据处理流程。
+- **[连接外部知识库](/zh-hans/guides/knowledge-base/connect-external-knowledge-base)**:通过 API 直接同步外部知识库,无需迁移即可利用现有数据。
-> 如果你的团队内部已建有独立知识库,可以通过[连接外部知识库](/zh-hans/guides/knowledge-base/connect-external-knowledge-base)与 Dify 建立连接。
-
+## 管理与优化知识库
-### 使用情景
+- **[维护知识库内容](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents)**:对文档和分段进行查看、添加、修改或删除等操作,保持知识库内容最新、准确、相关。
+- **[测试召回效果](/zh-hans/guides/knowledge-base/test-retrieval)**:模拟用户提问,测试知识库召回效果。
+- **[利用元数据增强检索](/zh-hans/guides/knowledge-base/metadata)**:为文档添加元数据,实现基于筛选的检索。
+- **[调整知识库设置](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)**:随时调整索引方式、嵌入模型和检索策略。
-例如你希望基于现有知识库和产品文档建立一个 AI 客服助手,可以在 Dify 中将文档上传至知识库,并建立一个对话型应用。如果使用传统方式,从文本训练到 AI 客服助手开发,可能需要花费数周的时间,且难以持续维护并进行有效迭代。在 Dify 内,仅需三分钟即可完成上述过程并开始获取用户反馈。
-### 知识库与文档
+## 使用知识库
-在 Dify 中,知识库(Knowledge)是一系列文档(Documents)的集合,一个文档内可能包含多组内容分段(Chunks),知识库可以被整体集成至一个应用中作为检索上下文使用。文档可以由开发者或运营人员上传,或由其它数据源同步。
+- **[集成到应用](/zh-hans/guides/knowledge-base/integrate-knowledge-within-application)**:让应用真正基于自有数据。
+- **[显示知识来源](/zh-hans/guides/application-orchestrate/app-toolkits/readme#引用与归属)**:让应用展示每个答案的具体知识来源。
-如果你已自建文档库,可以通过[连接外部知识库](/zh-hans/guides/knowledge-base/connect-external-knowledge-base)功能将自有知识库与 Dify 平台相关联。无需重复将内容上传至 Dify 平台内的知识库即可让 AI 应用实时读取自建知识库中的内容。
+---
+
+
+**延伸阅读**:
+
+- [Dify v0.15.0:父子分块检索增强知识库](https://dify.ai/blog/introducing-parent-child-retrieval-for-enhanced-knowledge)
+- [结合 InfraNodus 扩展 Dify RAG 上下文](https://dify.ai/blog/enhance-dify-rag-with-infranodus-expand-your-llm-s-context)
+- [Dify v1.1.0:用自定义元数据筛选知识检索](https://dify.ai/blog/dify-v1-1-0-filtering-knowledge-retrieval-with-customized-metadata)
+- [Dify.AI x Jina AI:集成 Jina 嵌入模型](https://dify.ai/blog/integrating-jina-embeddings-v2-dify-enhancing-rag-applications)
+- [混合检索与重排序提升 RAG 检索准确率](https://dify.ai/blog/hybrid-search-rerank-rag-improvement)
+- [Dify.AI 新数据集功能:引用与溯源](https://dify.ai/blog/difyai-new-dataset-features)
+- [文本嵌入:基本概念与实现原理](https://dify.ai/blog/text-embedding-basic-concepts-and-implementation-principles)
{/*
Contributing Section
diff --git a/zh-hans/guides/knowledge-base/retrieval-test-and-citation.mdx b/zh-hans/guides/knowledge-base/retrieval-test-and-citation.mdx
deleted file mode 100644
index 1d597b09..00000000
--- a/zh-hans/guides/knowledge-base/retrieval-test-and-citation.mdx
+++ /dev/null
@@ -1,85 +0,0 @@
----
-title: 召回测试/引用归属
-version: '简体中文'
----
-
-### 1 召回测试
-
-Dify 知识库内提供了文本召回测试的功能,用于模拟用户输入关键词后调用知识库内容区块。召回的区块将按照分数高低进行排序并发送至 LLM。一般而言,问题与内容块的匹配度越高,LLM 所输出的答案也就更加贴近源文档,文本“训练效果”越好。
-
-你可以使用不同的检索方式及参数配置,查看召回的内容区块质量与效果。不同的知识库分段模式对应不同的召回测试方法。
-
-
-
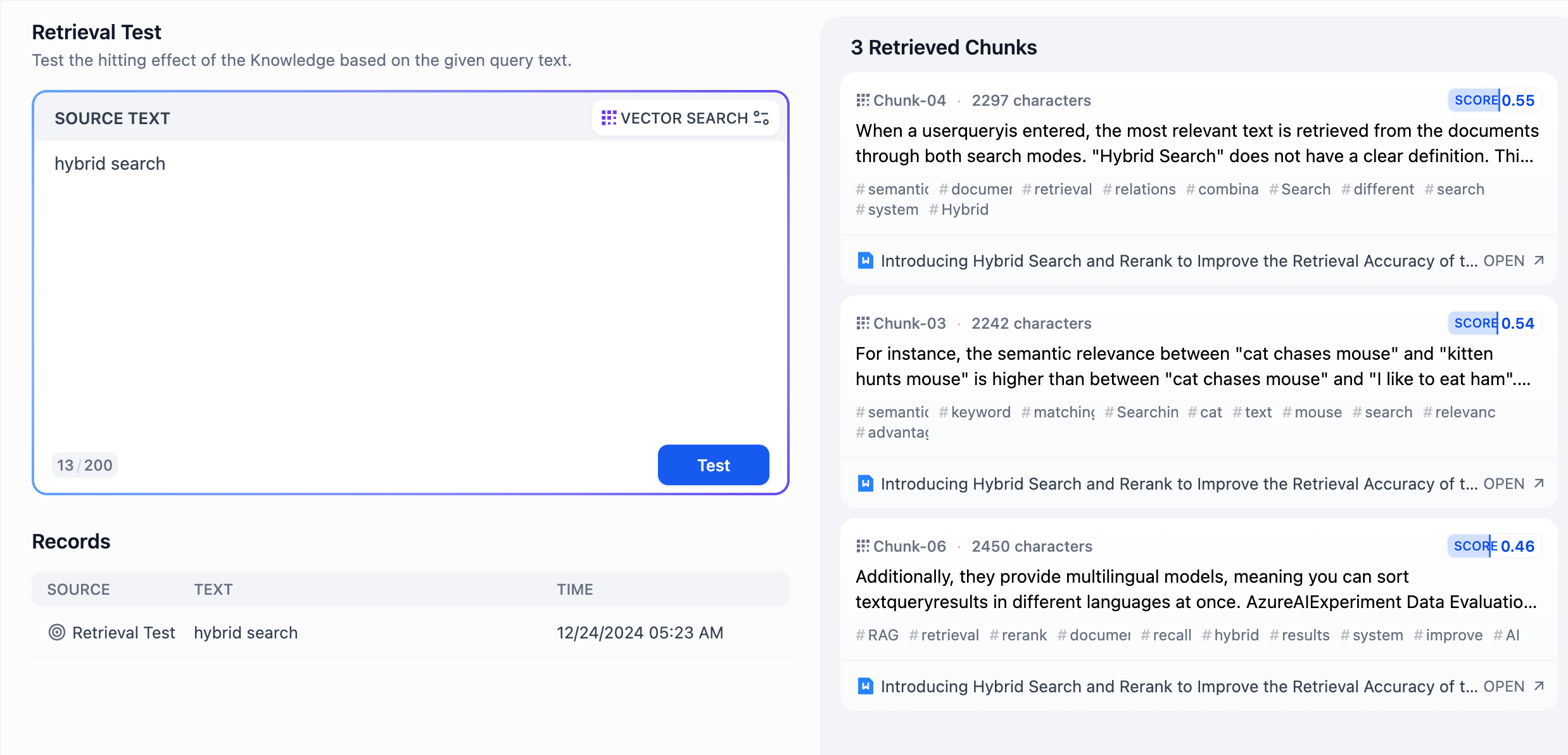
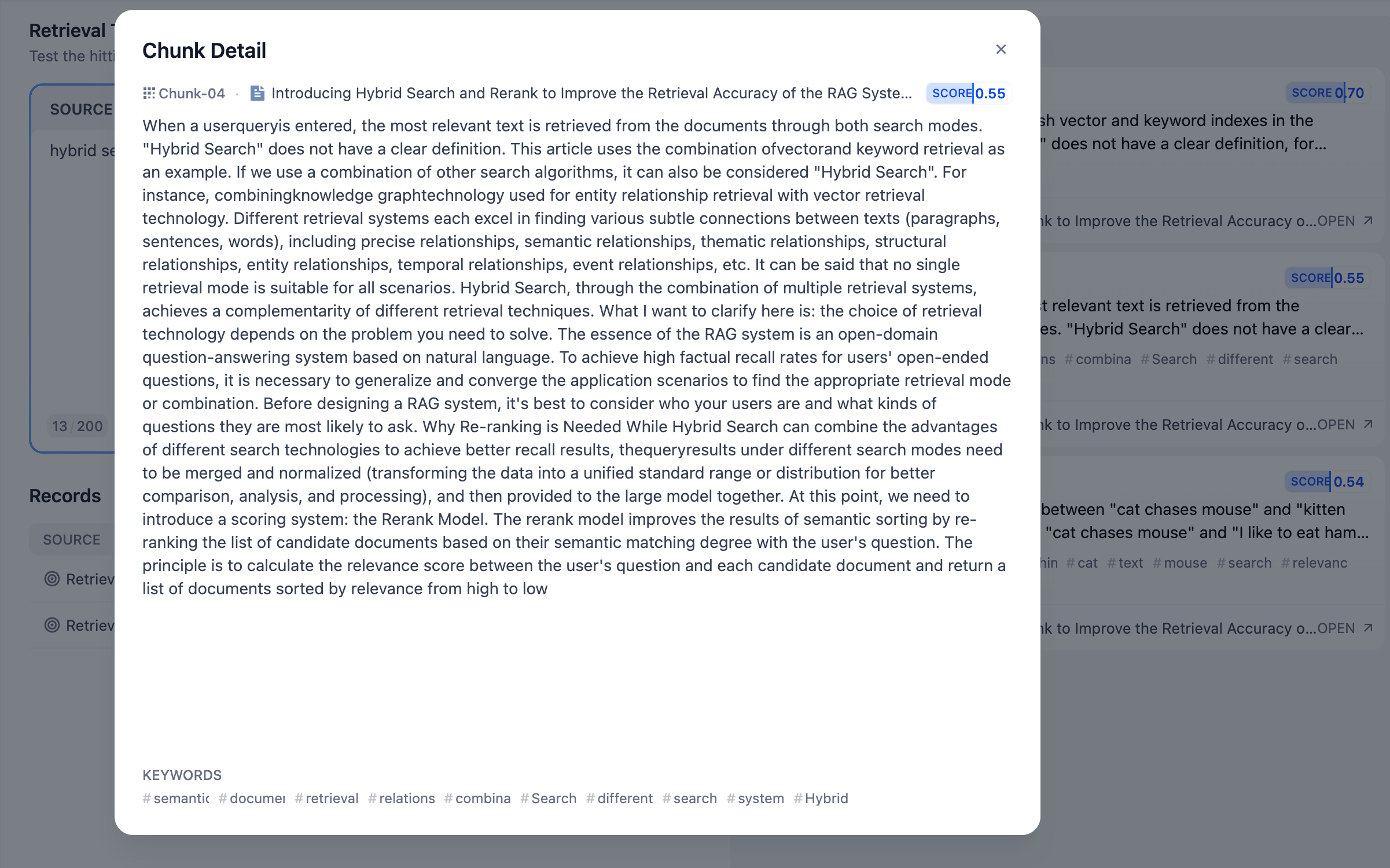
- 在 **源文本** 输入框输入常见的用户问题,点击 **测试** 按钮即可在右侧的 **召回段落** 内查看召回结果。
-
- 在通用模式下,内容区块相互独立;内容块右上角的分数为内容与关键词的匹配分数。得分越高,说明问题关键词与内容块的的匹配度越高。
-
- 
-
- 轻点内容块即可查看所引用的内容详情。每个内容块底部将展示所引用的文档信息源,你可以借此判断该内容分段是否合理。
-
- 
-
-
- 在 **源文本** 输入框输入常见的用户问题,点击 **测试** 并在右侧的 **召回段落** 查看召回结果。在父子分段模式下,问题的关键词将命中子分段中的内容块,以取得更加精准的匹配效果。区块右上角的得分指的是子区块与关键词之间的匹配得分。
-
- 你可以在预览区内查看具体的命中段落内容;匹配后将召回子分段所在父分段的完整上下文,向 AI 应用提供更加完整的信息。
-
- 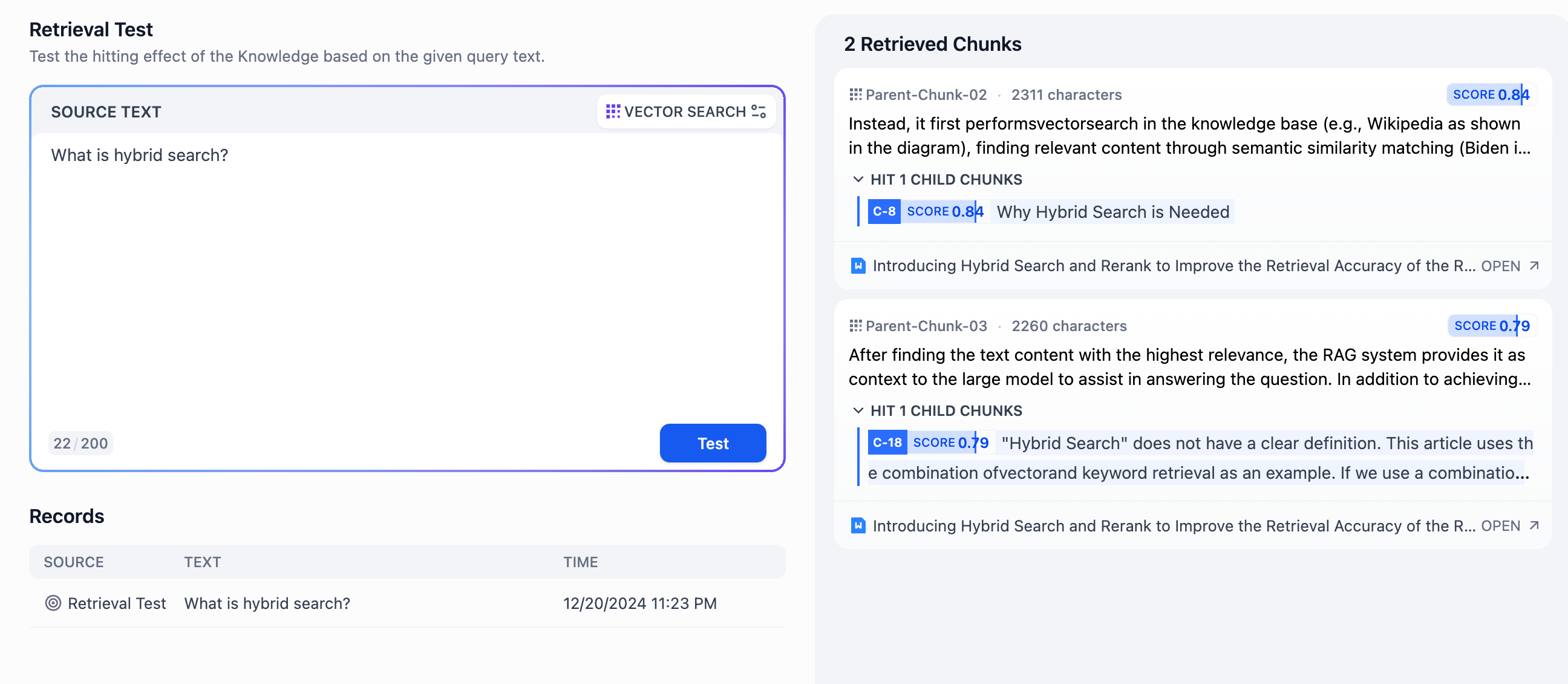
-
- 每个内容块底部将展示所引用的文档源,通常是文档中的某个段落或句子。轻点引用源右侧的“打开”按钮即可查看被引用的内容。
-
- 分段详情页的左侧为父分段信息,右侧为被命中的子分段。关键词可能命中多个子分段,同时在开头显示与关键词的匹配分数。你可以基于详情信息判断当前的内容分段是否合理。
-
- 
-
-
-
-在 **记录** 内可以查看到历史的查询记录;若知识库已关联至应用内,由应用内发起的知识库查询记录也可以在此查看。
-
-### 修改文本检索方式
-
-点击源文本输入框右上角的图标即可更换当前知识库的检索方式与具体参数,保存之后仅在当前召回测试的调试过程中生效,你可以借此比较不同检索设置的效果。如果你想要修改当前知识库的检索方式,前往“知识库设置” > “检索设置”中进行设置。
-
-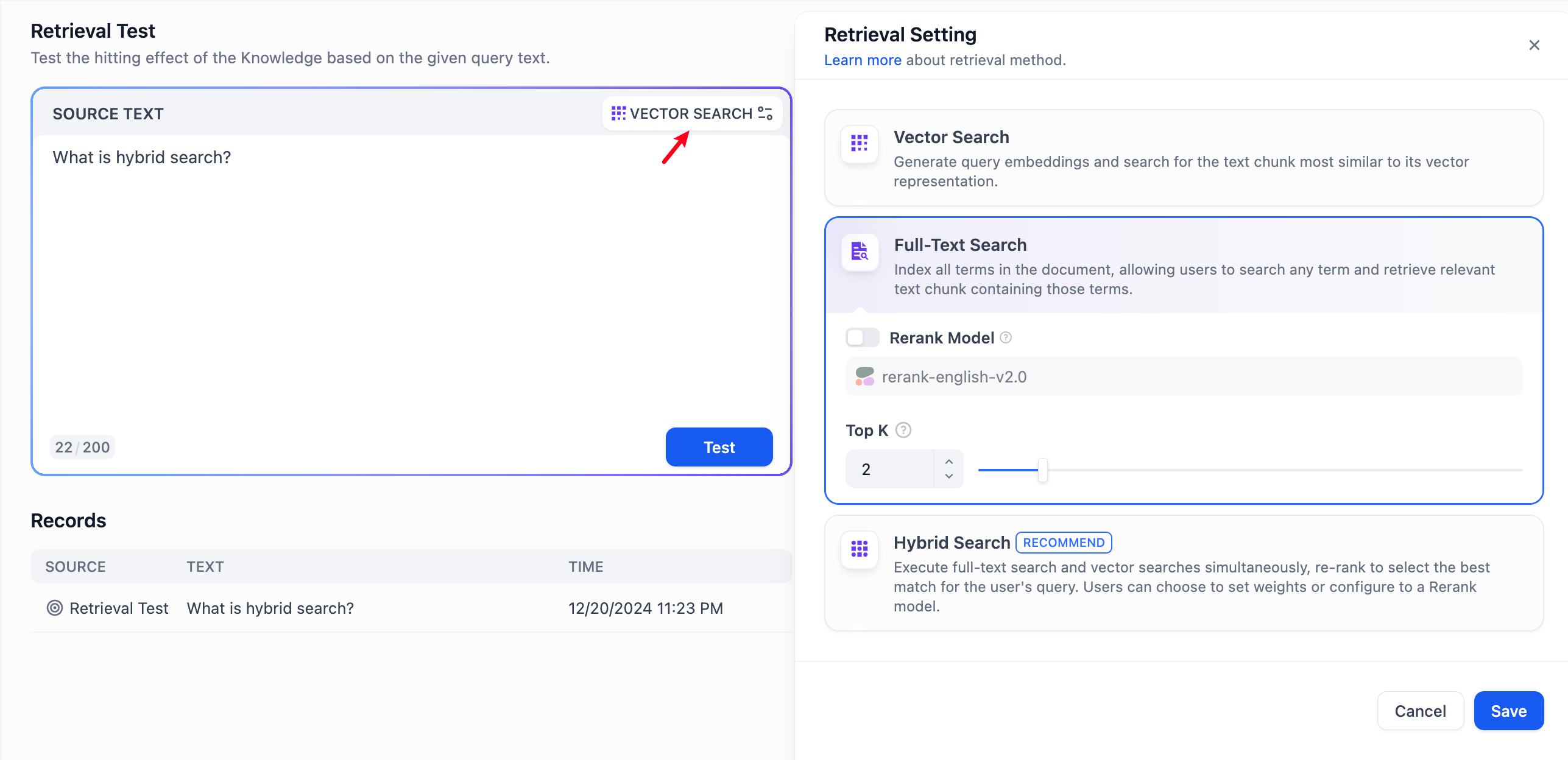
-
-**召回测试建议步骤:**
-
-1. 设计和整理能够覆盖用户常见问题的测试用例/测试问题集/指引内容;
-2. 根据内容特点和使用场景(是否为问答内容、是否涉及多语言问答等),选择合适的检索策略。
-3. 调整召回分段数量(TopK)和召回分数阈值(Score),根据实际的应用场景、包括文档本身的质量来选择合适的参数组合。
-
-**TopK 值和召回阈值(Score )如何配置**
-
-* **TopK 代表按相似分数倒排时召回分段的最大个数**。TopK 值调小,将会召回更少分段,可能导致召回的相关文本不全;TopK 值调大,将召回更多分段,可能导致召回语义相关性较低的分段使得 LLM 回复质量降低。
-* **召回阈值(Score)代表允许召回分段的最低相似分数。** 召回分数调小,将会召回更多分段,可能导致召回相关度较低的分段;召回分数阈值调大,将会召回更少分段,过大时将会导致丢失相关分段。
-
-***
-
-### 2 引用与归属
-
-在应用内的“上下文”添加知识库后,可以在 **“添加功能”** 内开启 **“引用与归属”**。在应用内输入问题后,若涉及已关联的知识库文档,将标注内容的引用来源。你可以通过此方式检查知识库所召回的内容分段是否符合预期。
-
-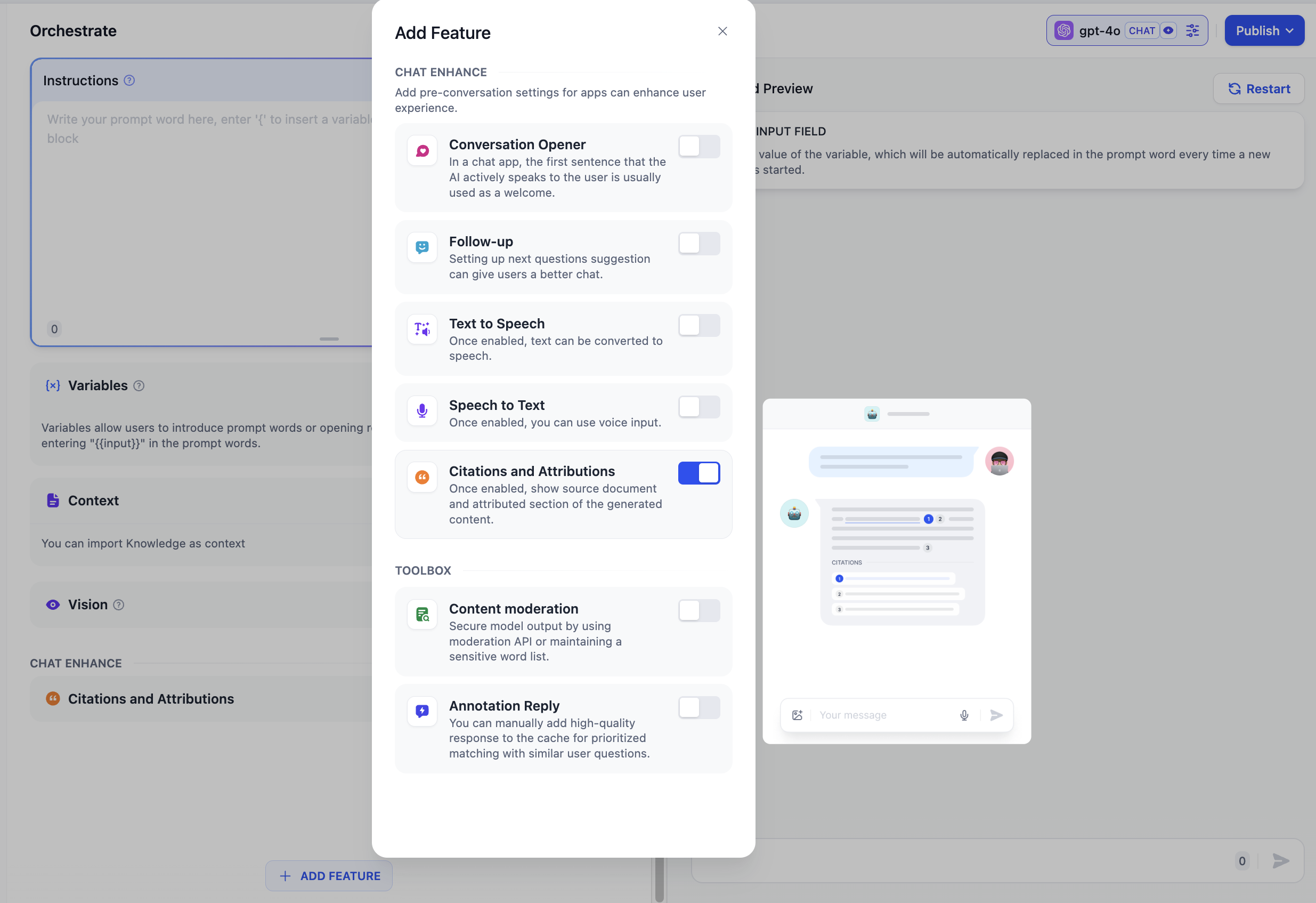
-
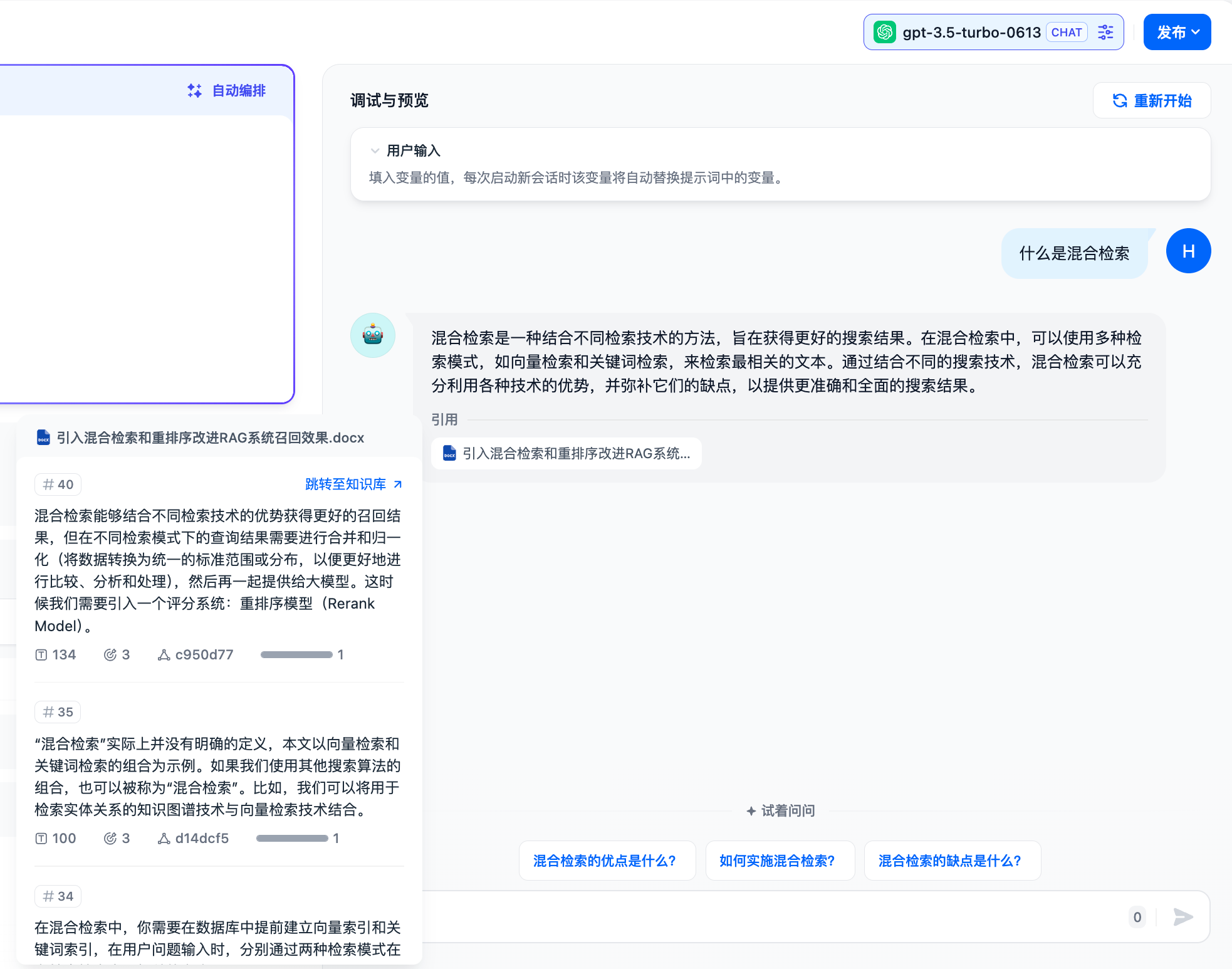
-开启功能后,当 LLM 引用知识库内容来回答问题时,可以在回复内容下面查看到具体的引用段落信息,包括**原始分段文本、分段序号、匹配度**等。点击引用分段上方的 **跳转至知识库**,可以快捷访问该分段所在的知识库分段列表,方便开发者进行调试编辑。
-
-
-
-### 查看知识库内已关联的应用
-
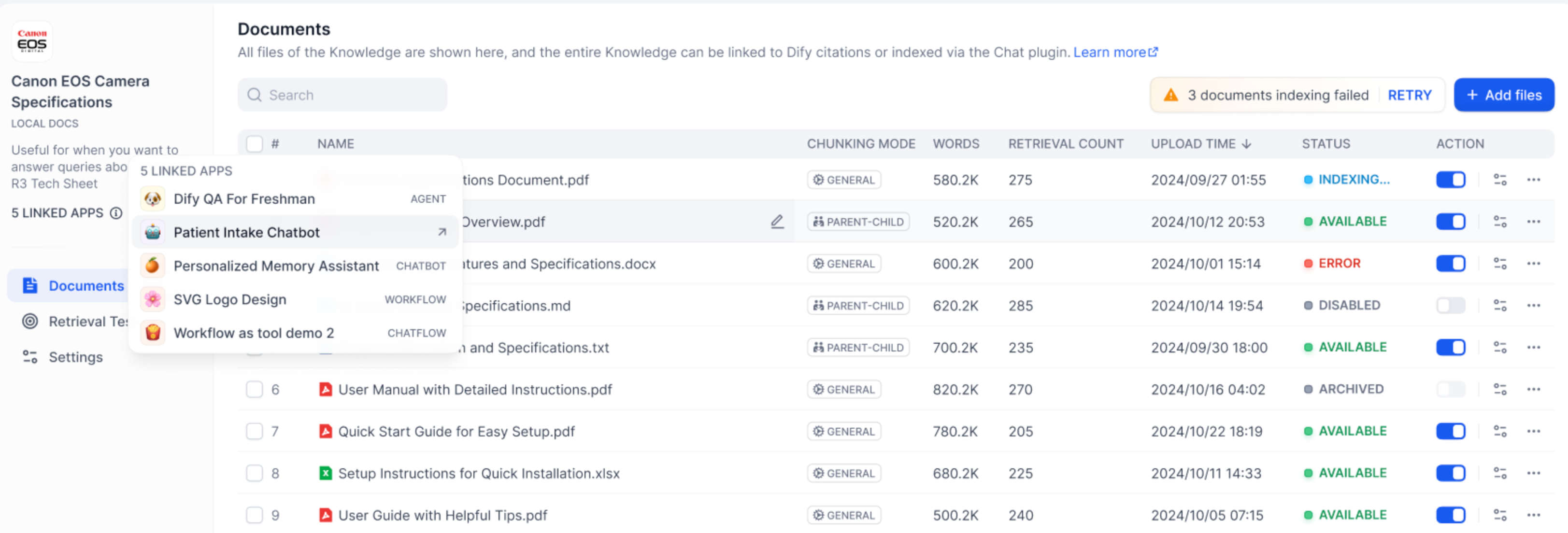
-知识库将会在左侧信息栏中显示已关联的应用数量。将鼠标悬停至圆形信息图标时将显示所有已关联的 Apps 列表,点击右侧的跳转按钮即可快速查看对应的应用。
-
-
-
-{/*
-Contributing Section
-DO NOT edit this section!
-It will be automatically generated by the script.
-*/}
-
----
-
-[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/zh-hans/guides/knowledge-base/retrieval-test-and-citation.mdx) | [提交问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
-
diff --git a/zh-hans/guides/knowledge-base/test-retrieval.mdx b/zh-hans/guides/knowledge-base/test-retrieval.mdx
new file mode 100644
index 00000000..e241332a
--- /dev/null
+++ b/zh-hans/guides/knowledge-base/test-retrieval.mdx
@@ -0,0 +1,35 @@
+---
+title: 测试召回效果
+---
+
+在 **召回测试** 中,你可以模拟用户提问、测试知识库的召回效果,并尝试不同的检索设置以获得最佳结果。
+
+
+ 在召回测试中调整的检索设置,仅在当前测试会话中临时生效。
+
+
+
+ 关于检索参数的更多说明,阅读 [指定检索方式](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#指定检索方式)。
+
+
+![召回测试]()
+
+**记录** 板块会记录与该知识库相关的所有检索事件,包括:
+
+- 在 **召回测试** 页面直接测试的查询
+- 任何关联应用发起的检索请求(无论是测试还是生产环境)
+
+
+ 召回测试与常规检索使用同一个 API 接口。
+
+
+{/*
+Contributing Section
+DO NOT edit this section!
+It will be automatically generated by the script.
+*/}
+
+---
+
+[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/zh-hans/guides/knowledge-base/retrieval-test-and-citation.mdx) | [提交问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
+
diff --git a/zh-hans/guides/workflow/node/knowledge-retrieval.mdx b/zh-hans/guides/workflow/node/knowledge-retrieval.mdx
index 3aa52a11..4c486852 100644
--- a/zh-hans/guides/workflow/node/knowledge-retrieval.mdx
+++ b/zh-hans/guides/workflow/node/knowledge-retrieval.mdx
@@ -1,56 +1,114 @@
---
-title: 知识检索
-version: '简体中文'
+title: 知识检索节点
---
+## 简介
-### 定义
+知识检索节点可将已有知识库嵌入到 Chatflow 或 Workflow 中。它会在指定知识库中检索与查询相关的信息,然后将检索结果作为上下文传递给下游节点(如 LLM)。
-从知识库中检索与用户问题相关的文本内容,可作为下游 LLM 节点的上下文来使用。
+以下是知识检索节点在 Chatflow 中的典型用法:
-***
+1. **开始** 节点收集用户问题。
+2. **知识检索** 节点在指定知识库中检索与用户问题相关的内容,并输出检索结果。
+3. **LLM** 节点基于用户问题和检索结果生成回复。
+4. **直接回答** 节点将 LLM 的回复返回给用户。
-### 应用场景
-
-常见情景:构建基于外部数据/知识的 AI 问答系统(RAG)。了解更多关于 RAG 的[基本概念](../../../learn-more/extended-reading/retrieval-augment/)。
-
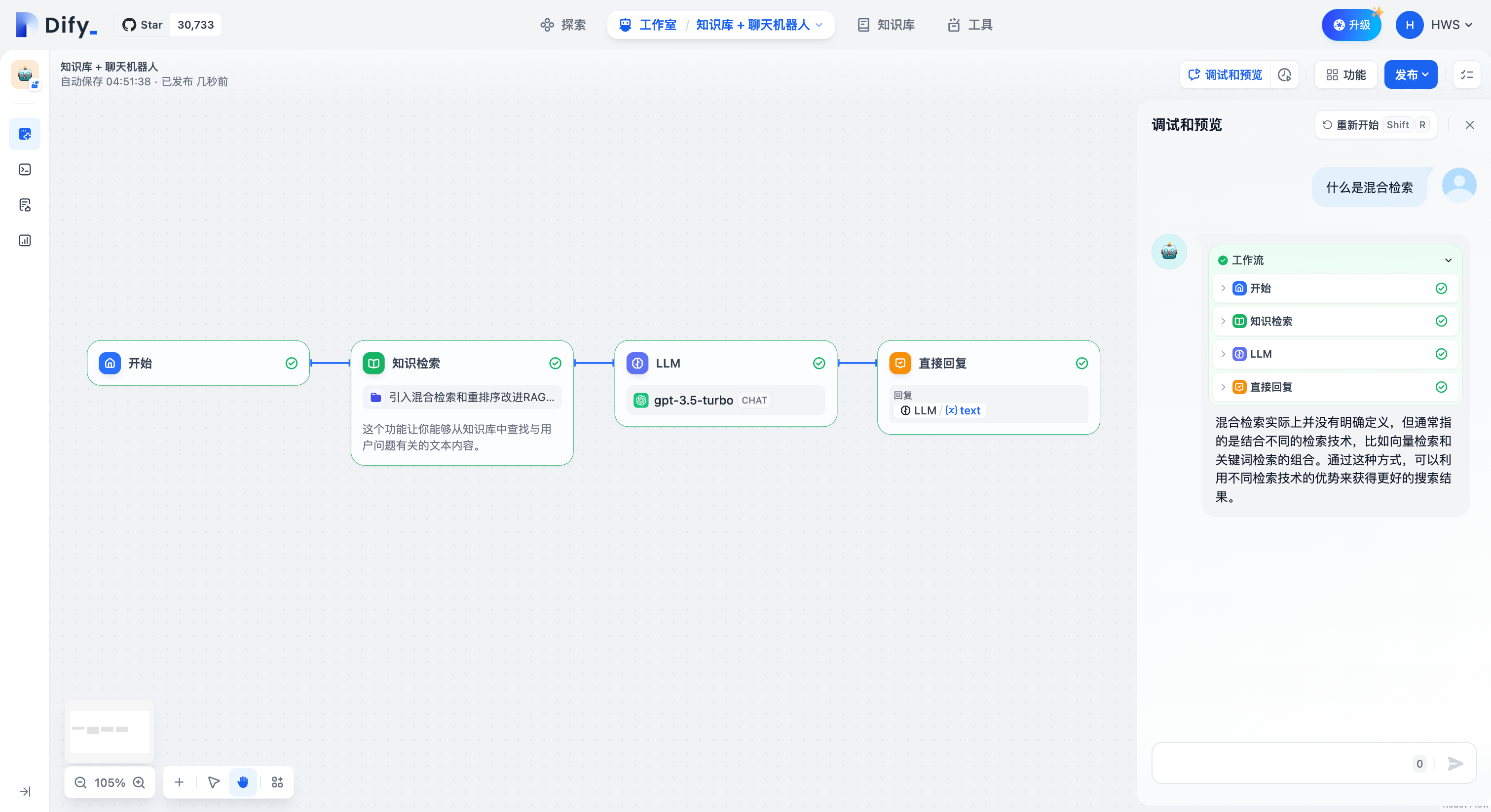
-下图为一个最基础的知识库问答应用示例,该流程的执行逻辑为:知识库检索作为 LLM 节点的前置步骤,在用户问题传递至 LLM 节点之前,先在知识检索节点内将匹配用户问题最相关的文本内容并召回,随后在 LLM 节点内将用户问题与检索到的上下文一同作为输入,让 LLM 根据检索内容来回复问题。
-
-
-
-***
-
-### 配置指引
-
-**配置流程:**
-
-1. 选择查询变量。查询变量通常代表用户输入的问题,该变量可以作为输入项并检索知识库中的相关文本分段。在常见的对话类应用中一般将开始节点的 `sys.query` 作为查询变量,知识库所能接受的最大查询内容为 200 字符;
-2. 选择需要查询的知识库,可选知识库需要在 Dify 知识库内预先[创建](../../knowledge-base/create-knowledge-and-upload-documents/);
-3. 在 元数据筛选 板块中配置元数据的筛选条件,使用元数据功能筛选知识库内的文档。详情请参阅[在应用内集成知识库](/zh-hans/guides/knowledge-base/integrate-knowledge-within-application)中的 **使用元数据筛选知识** 章节。
-4. 指定[召回模式](../../../learn-more/extended-reading/retrieval-augment/retrieval)。自 9 月 1 日后,知识库的召回模式将自动切换为多路召回,不再建议使用 N 选 1 召回模式;
-5. 连接并配置下游节点,一般为 LLM 节点;
-
-
-
-**输出变量**
-
-
-
-知识检索的输出变量 `result` 为从知识库中检索到的相关文本分段。其变量数据结构中包含了分段内容、标题、链接、图标、元数据信息。
-
-**配置下游节点**
-
-在常见的对话类应用中,知识库检索的下游节点一般为 LLM 节点,知识检索的**输出变量** `result` 需要配置在 LLM 节点中的 **上下文变量** 内关联赋值。关联后你可以在提示词的合适位置插入 **上下文变量**。
+
-上下文变量是 LLM 节点内定义的特殊变量类型,用于在提示词内插入外部检索的文本内容。
+ 使用知识检索节点前,确保至少有一个可用的知识库。了解如何创建与管理知识库,阅读 [知识库](/zh-hans/guides/knowledge-base/readme)。
-当用户提问时,若在知识检索中召回了相关文本,文本内容会作为上下文变量中的值填入提示词,提供 LLM 回复问题;若未在知识库检索中召回相关的文本,上下文变量值为空,LLM 则会直接回复用户问题。
+## 配置知识检索节点
-
+要让知识检索节点正常工作,你需要告诉它 *检索什么*(查询内容)、*在哪里检索*(知识库),以及 *如何处理检索结果*(节点级检索设置)。你还可以利用文档元数据实现基于筛选的检索,进一步提升精准度。
-该变量除了可以作为 LLM 回复问题时的提示词上下文作为外部知识参考引用,另外由于其数据结构中包含了分段引用信息,同时可以支持应用端的 [**引用与归属**](/zh-hans/guides/knowledge-base/retrieval-test-and-citation) 功能。
+### 指定查询内容
+
+设置节点需要在选定知识库中检索的查询内容。
+
+- **文本查询**:在 Chatflow 中可用 `userinput.query` 引用用户输入,也可选择任意文本变量。
+- **图片查询**:选择图片变量进行图片检索,例如用户通过用户输入节点上传的图片。图片大小限制为 10MB。
+
+
+ 自托管用户可通过环境变量 `UPLOAD_IMAGE_FILE_SIZE_LIMIT`(默认 10)调整图片大小限制。
+
+
+
+ 仅当至少有一个已添加的知识库支持图片检索时,才可使用 **图片查询**。
+
+ 支持图片检索的知识库会显示 **图片** 图标,表示其使用的嵌入模型可对图片进行向量化。
+
+
+
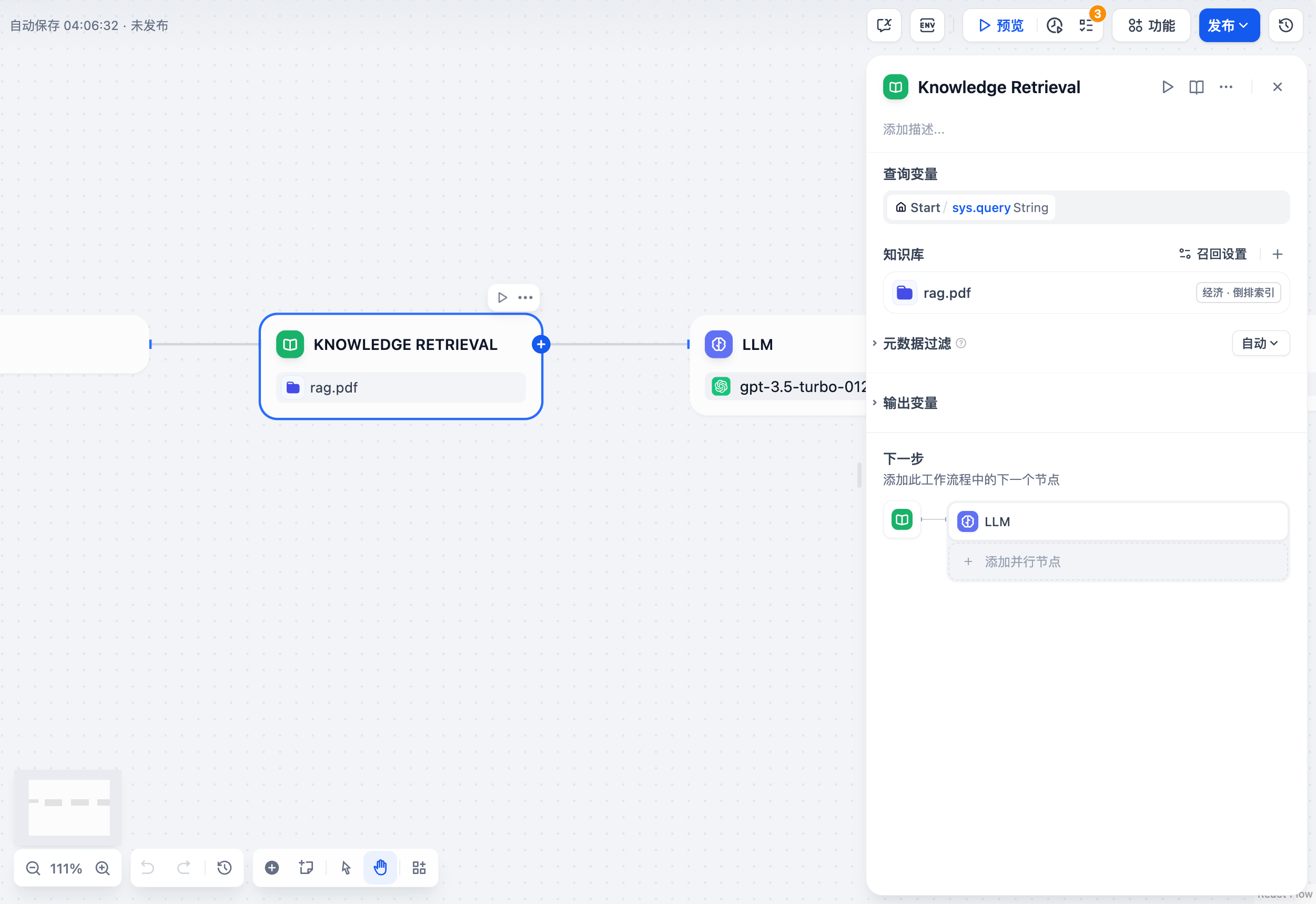
+### 选择检索的知识库
+
+为节点添加一个或多个已有知识库,用于检索与查询内容相关的信息。
+
+
+ 带有 **图片** 图标的知识库支持图片检索,可用文本和/或图片作为查询,同时检索语义相关的文本和图片。
+
+
+
+ 点击已添加知识库旁的 **编辑** 图标,可直接在知识检索节点内修改其设置。更多设置说明,阅读 [调整知识库设置](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)和[设定索引方式与检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)。
+
+
+
+### 调整节点级检索设置
+
+进一步微调节点在获取知识库检索结果后的处理方式。
+
+
+ 检索设置分为知识库级和节点级两层。
+
+ 可理解为两道筛选:知识库设置决定初步的检索结果池,而节点设置再对结果进行重排序或进一步筛选。
+
+
+- **重排序参数**
+ - **加权分数**:语义相似度与关键词匹配的权重。语义权重高则更关注语义相关性,关键词权重高则更偏向精确匹配。
+
+ 仅当所有已添加的知识库均使用的是高质量索引方式时,才可设置 **加权分数**。
+
+ - **重排序模型**:根据与查询的相关性,对所有结果重新评分和排序。
+- **Top K**:重排序后返回的最大结果数。选择重排序模型时,该值会根据模型的最大输入容量自动调整。
+- **分数阈值**:返回结果的最低相似度分数。低于阈值的结果会被过滤。阈值高则相关性更严格,阈值低则匹配更宽泛。
+
+
+ 添加多个知识库时,会同时检索所有知识库,合并结果并根据上述设置进行处理。
+
+
+
+### 启用元数据筛选
+
+可利用已有的文档元数据,将检索范围限定在知识库的特定文档内,提升检索精度。
+
+启用元数据筛选后,知识检索节点只会检索符合指定元数据条件的文档,而非整个知识库。尤其适用于内容多样的大型知识库。
+
+
+ 了解如何创建与管理文档元数据,请阅读 [元数据](/zh-hans/guides/knowledge-base/metadata)。
+
+
+
+## 输出结果
+
+知识检索节点会将检索结果输出为 `result` 变量,是一个包含内容、元数据、标题等属性的文档分段数组。
+
+若启用了图片检索且检索到图片,`result` 变量中还会包含名为 `files` 的字段,存储检索到的图片信息。
+
+![知识检索节点输出]()
+
+## 搭配 LLM 节点使用
+
+如需在 LLM 节点中基于检索结果回答用户问题:
+
+1. 在 **上下文** 字段选择知识检索节点的 `result` 变量。
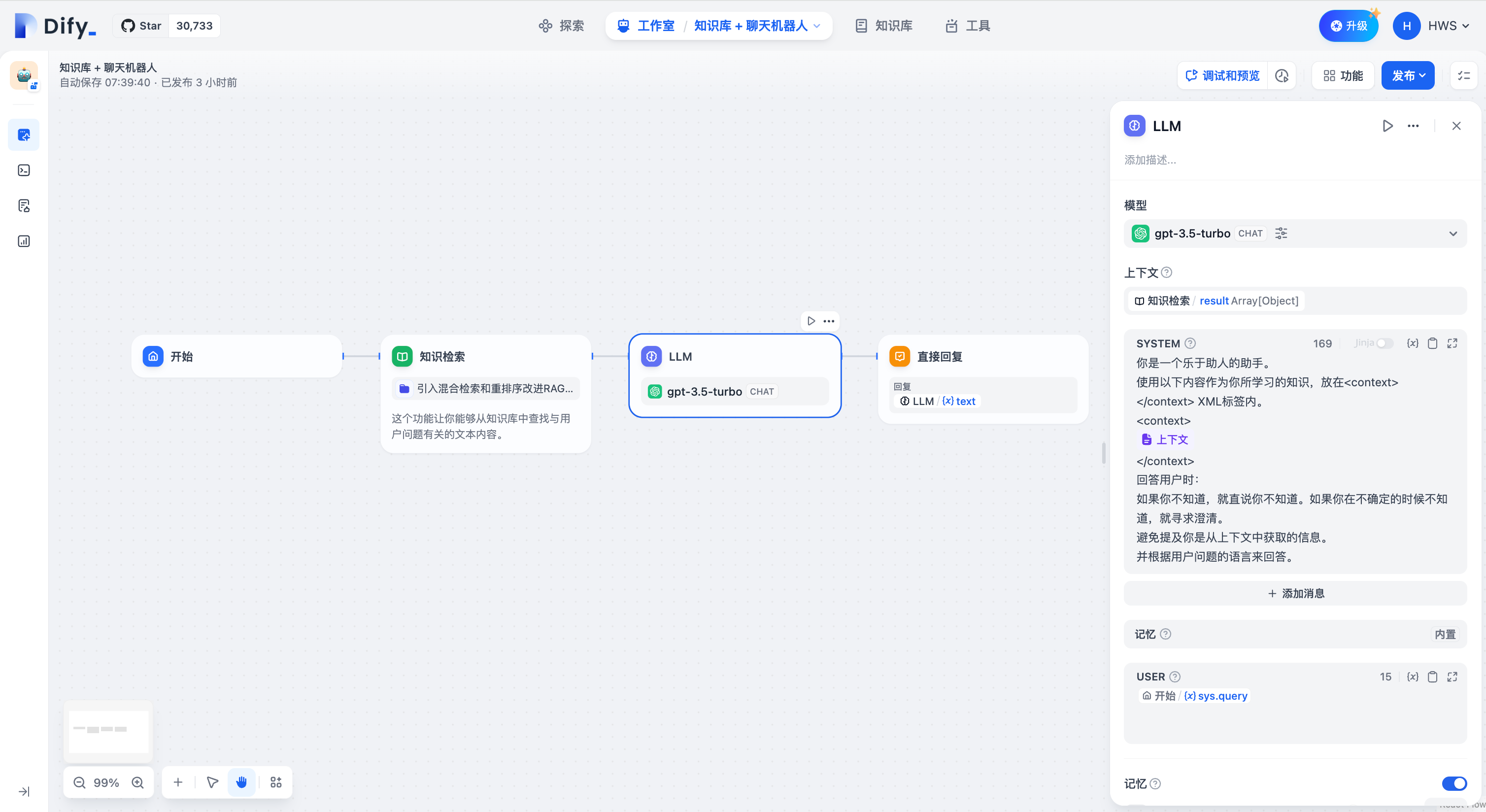
+2. 在提示词字段同时引用 `Context` 变量和用户输入变量(如 Chatflow 中的 `userinput.query`)。
+
+![LLM 节点配置示例]()
+
+
+ 知识检索操作受订阅计划的频率限制。详见 [知识库请求频率限制](/zh-hans/guides/knowledge-base/knowledge-request-rate-limit)。
+
{/*
Contributing Section