diff --git a/en/use-dify/nodes/llm.mdx b/en/use-dify/nodes/llm.mdx
index f91cb7ee..4fe85567 100644
--- a/en/use-dify/nodes/llm.mdx
+++ b/en/use-dify/nodes/llm.mdx
@@ -11,7 +11,7 @@ The LLM node invokes language models to process text, images, and documents. It
- Configure at least one model provider in **System Settings → Model Providers** before using LLM nodes. See [how to install model plugins](/en/use-dify/workspace/plugins) for setup instructions.
+ Configure at least one model provider in **System Settings → Model Providers** before using LLM nodes.
## Model Selection and Parameters
@@ -102,18 +102,12 @@ When processing images, you can control the detail level:
- **High detail** - Better accuracy for complex images but uses more tokens
- **Low detail** - Faster processing with fewer tokens for simple images
-The default variable selector for vision is `sys.files` which automatically picks up files from the Start node.
+The default variable selector for vision is `userinput.files` which automatically picks up files from the User Input node.
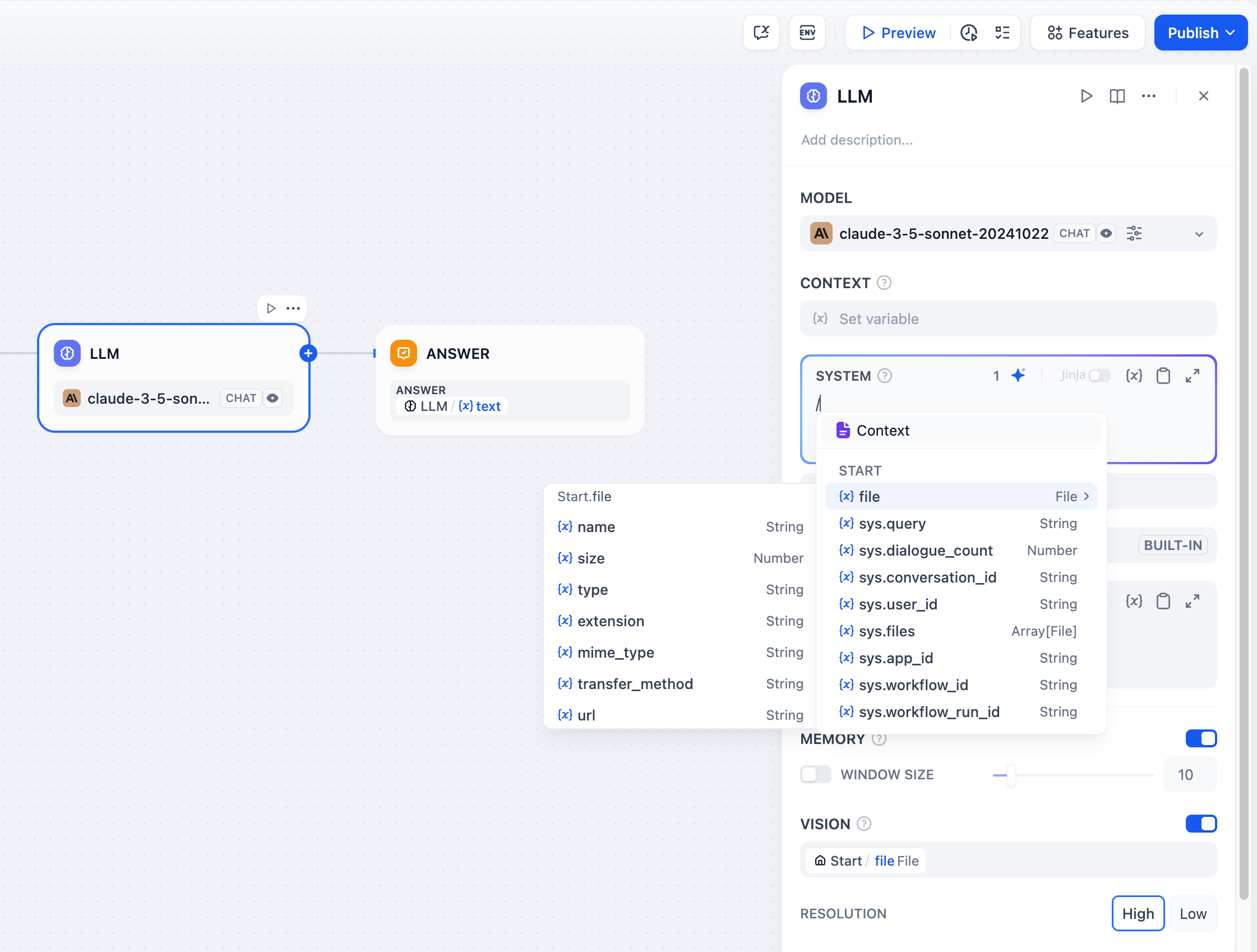 -For conversation history in completion models, insert conversation variables to maintain multi-turn context:
-
-
-
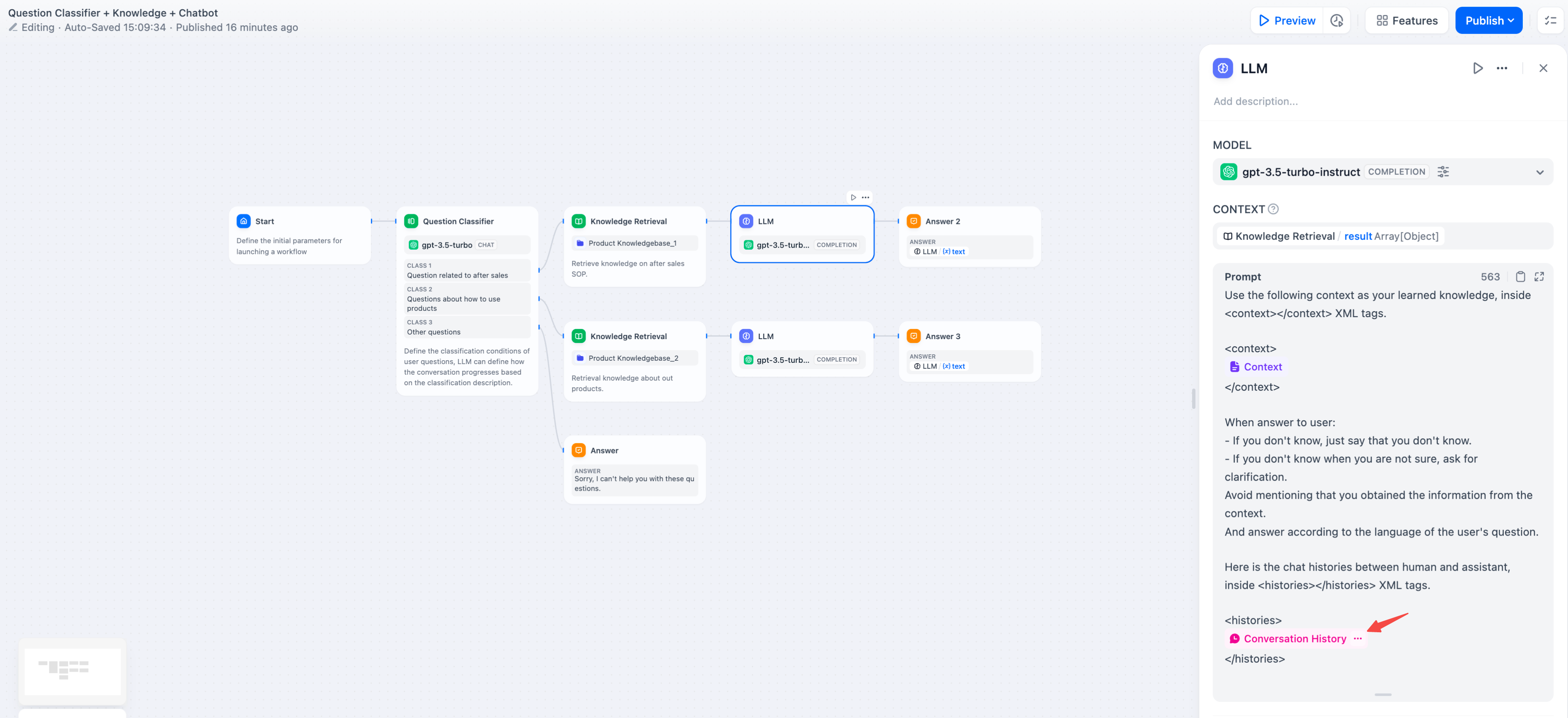
-For conversation history in completion models, insert conversation variables to maintain multi-turn context:
-
-
-  -
-
## Jinja2 Template Support
LLM prompts support Jinja2 templating for advanced variable handling. When you use Jinja2 mode (`edition_type: "jinja2"`), you can:
-
-
## Jinja2 Template Support
LLM prompts support Jinja2 templating for advanced variable handling. When you use Jinja2 mode (`edition_type: "jinja2"`), you can: