diff --git a/docs.json b/docs.json
index b544c50d..c73675ce 100644
--- a/docs.json
+++ b/docs.json
@@ -213,7 +213,7 @@
"en/use-dify/workspace/subscription-management",
{
"group": "API Extension",
- "icon":"puzzle-piece-simple",
+ "icon": "puzzle-piece-simple",
"pages": [
"en/use-dify/workspace/api-extension/api-extension",
"en/use-dify/workspace/api-extension/external-data-tool-api-extension",
@@ -598,7 +598,7 @@
"zh/use-dify/workspace/subscription-management",
{
"group": "API 扩展",
- "icon":"puzzle-piece-simple",
+ "icon": "puzzle-piece-simple",
"pages": [
"zh/use-dify/workspace/api-extension/api-extension",
"zh/use-dify/workspace/api-extension/external-data-tool-api-extension",
@@ -983,7 +983,7 @@
"ja/use-dify/workspace/subscription-management",
{
"group": "API 拡張",
- "icon":"puzzle-piece-simple",
+ "icon": "puzzle-piece-simple",
"pages": [
"ja/use-dify/workspace/api-extension/api-extension",
"ja/use-dify/workspace/api-extension/external-data-tool-api-extension",
diff --git a/ja/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text.mdx b/ja/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text.mdx
index 329e4a33..32d427d8 100644
--- a/ja/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text.mdx
+++ b/ja/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text.mdx
@@ -1,164 +1,138 @@
---
-title: セグメント分割設定
+title: チャンク設定
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text)を参照してください。
-コンテンツをナレッジベースにアップロードした後、次に行うべき作業は、コンテンツの分割とデータのクリーニングです。この段階では、コンテンツの前処理と構造化を行い、長いテキストを複数の小さなブロックに分割します。
+## チャンクとは?
-
+ナレッジベースにインポートされたドキュメントは、**チャンク**と呼ばれる小さなセグメントに分割されます。チャンクとは、大きな本を章や段落に整理するようなものです。大きなテキストブロックから特定の情報をすぐに見つけることはできませんが、適切に整理されたセクションなら効率的に検索できます。
-* 分割
+ユーザーが質問すると、システムはこれらのチャンクから関連情報を検索し、LLMにコンテキストとして提供します。チャンク化がなければ、クエリごとにドキュメント全体を処理することになり、遅くて非効率的です。
- 大規模な言語モデルが処理できる情報量には限界があるため、知識データベースのコンテンツを一度にすべて処理することはできません。このため、長い文書をより小さいコンテンツブロックに分割する必要があります。一部のモデルでは、文書全体をアップロードする機能をサポートしていますが、実験により、コンテンツをブロックごとに検索した方が効率的であることが分かっています。
+**主要なチャンクパラメータ**
- 言語モデルが知識データベース内の情報に基づいて正確な回答を提供できるかどうかは、コンテンツブロックの検索と選択の効果に依存します。マニュアルから必要な章を探すように、文書全体を詳細に分析することなく迅速に答えを見つけられます。分割された知識データベースでは、ユーザーの質問に基づいて、関連性が高いコンテンツブロックを選択し、重要な情報を提供することで、回答の精度を向上させます。
+- **区切り文字**:テキストを分割する文字またはシーケンス。例えば、`\n\n`は段落区切りで分割し、`\n`は改行で分割します。
- 質問とコンテンツブロックの意味的なマッチングを行う際、適切な分割サイズが非常に重要です。これにより、モデルが問題に最も関連性が高いコンテンツを正確に特定し、無関係な情報を減らすことができます。分割が大きすぎるか小さすぎると、選択の効果に悪影響を及ぼす可能性があります。
+
+ 区切り文字はチャンク化の際に削除されます。例えば、`A`を区切り文字として使用すると、`CBACD`は`CB`と`CD`に分割されます。
+
+ 情報の損失を避けるために、ドキュメント内に自然に出現しない非コンテンツ文字を使用してください。
+
- Difyは、「汎用分割」と「階層分割」の2種類の分割モードを提供しており、それぞれ異なる文書の構造と用途に適応し、異なる検索と選択の効率と精度の要件を満たします。
+- **最大チャンク長**:各チャンクの最大サイズ(文字数)。この制限を超えるテキストは、区切り文字の設定に関係なく強制的に分割されます。
-* クリーニング
+## 汎用モード vs 親子モード
- テキストの選択効果を保証するためには、通常、データを知識データベースに入力する前にクリーニングが必要です。例えば、意味のない文字や空行が含まれている可能性があり、これらは応答の品質に影響を与えるため、クリーニングが必要です。
-
+
+ チャンクモードは、ナレッジベースを作成した後は変更できません。ただし、区切り文字や最大チャンク長などのチャンク設定はいつでも調整できます。
+
+### モードの概要
-ユーザーが質問した後、LLMがその質問に基づいたナレッジベースからの正確な回答を提供できるかどうかは、関連する情報ブロックを効率的に検索し取り出せるかにかかっています。AIアプリケーションが正確かつ包括的な回答を出すためには、その問題に直接関わる情報ブロックの特定が非常に重要です。
+
+
-例えば、スマートカスタマーサービスの場合、LLMがツールマニュアル内の重要な章の情報ブロックをすぐに見つけ出せれば、ユーザーの問いに素早く答えられます。これにより、文書全体を何度も分析する手間が省けます。結果として、AIアプリケーションの質問応答(Q&A)機能の品質を、トークン使用量を節約しつつ向上させることができます。
+ 汎用モードでは、すべてのチャンクが同じ設定を共有します。マッチしたチャンクは検索結果として直接返されます。
-## ナレッジベースのセグメント分類方法の選択
+ **チャンク設定**
-私たちのナレッジベースでは、以下の2つのセグメント分類方法を提供しています。
+ 区切り文字と最大チャンク長に加えて、**チャンクのオーバーラップ**を設定して、隣接するチャンク間で重複する文字数を指定できます。これにより、意味的なつながりが保持され、重要な情報がチャンクの境界で分断されることを防ぎます。
-* **汎用分割**
+ 例えば、50文字のオーバーラップを設定すると、あるチャンクの最後の50文字が次のチャンクの最初の50文字としても表示されます。
+
+
+
-
- 注意:以前の「自動セグメント分割&クリーニング」モードは、自動で汎用分割へとアップデートされました。何も手を加える必要はありません。既定の設定でそのまま利用可能です。
-
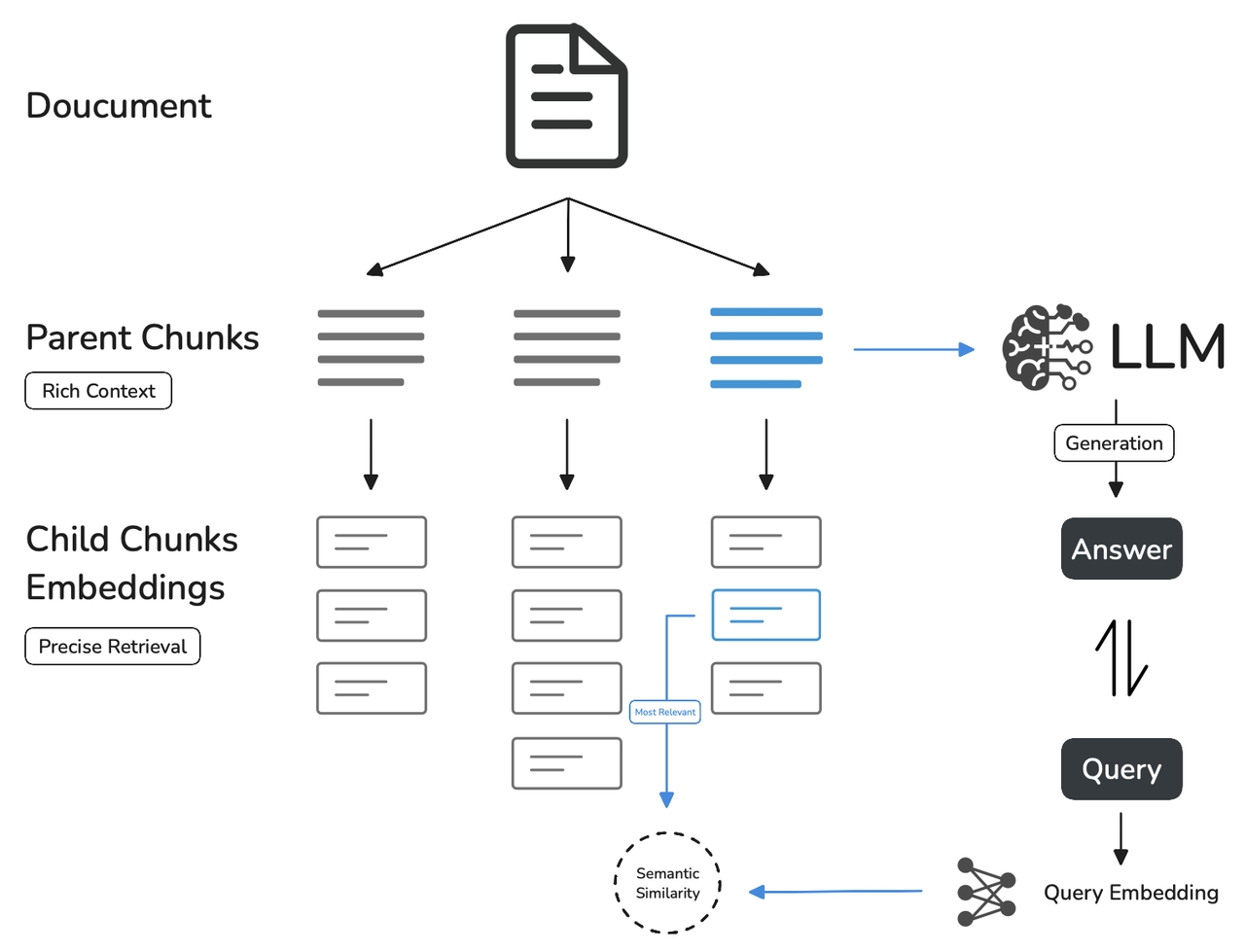
+ 親子モードでは、テキストは2つの階層に分割されます:小さな**子チャンク**と大きな**親チャンク**です。クエリが子チャンクにマッチすると、その親チャンク全体が検索結果として返されます。
-* **親子分割(階層分割)**
+ これは一般的な検索のジレンマを解決します:小さなチャンクは正確なクエリマッチングを可能にしますがコンテキストが不足し、大きなチャンクは豊富なコンテキストを提供しますが検索精度が低下します。
-
- セグメント分類方法を選んでナレッジベースを作成した後での変更は不可能です。ナレッジベースに新たに追加される文書も、選択した同じセグメント分類方法に従います。
-
+ 親子モードは両方のバランスを取り、精度の高い検索とコンテキストのある回答を実現します。
-### 汎用分割モード
+ **親チャンク設定**
-汎用分割では、システムはユーザーが設定したルールに沿ってコンテンツを独立したセグメントに分割します。ユーザーが検索クエリを入力すると、システムは自動的にそのクエリのキーワードを分析し、それらのキーワードとナレッジベース内の各コンテンツセグメントとの関連性を評価します。その後、関連性が高いものから順に並べ、最も関連性の高いコンテンツセグメントを選択し、大規模言語モデル(LLM)による処理と回答を行います。
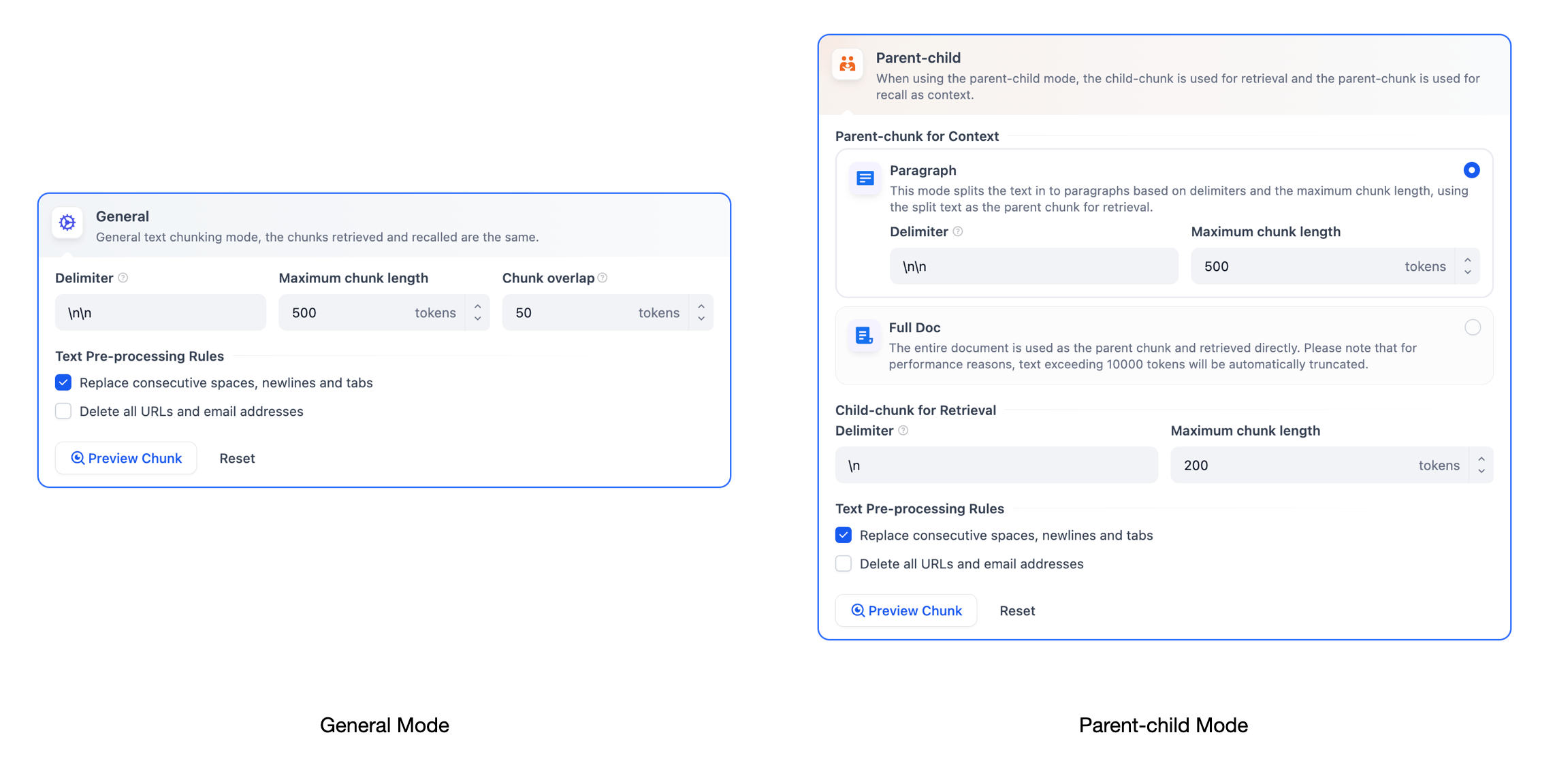
+ 親チャンクは**段落**モードまたは**全文**モードで作成できます。
-このモードでは、異なる文書形式やシナリオの要件に応じて、以下の設定項目を参考にしながら、テキストのセグメント**分割ルール**を手動で調整することが必要です。
+
+
+ ドキュメントは、指定された区切り文字と最大チャンク長に基づいて複数の親チャンクに分割されます。
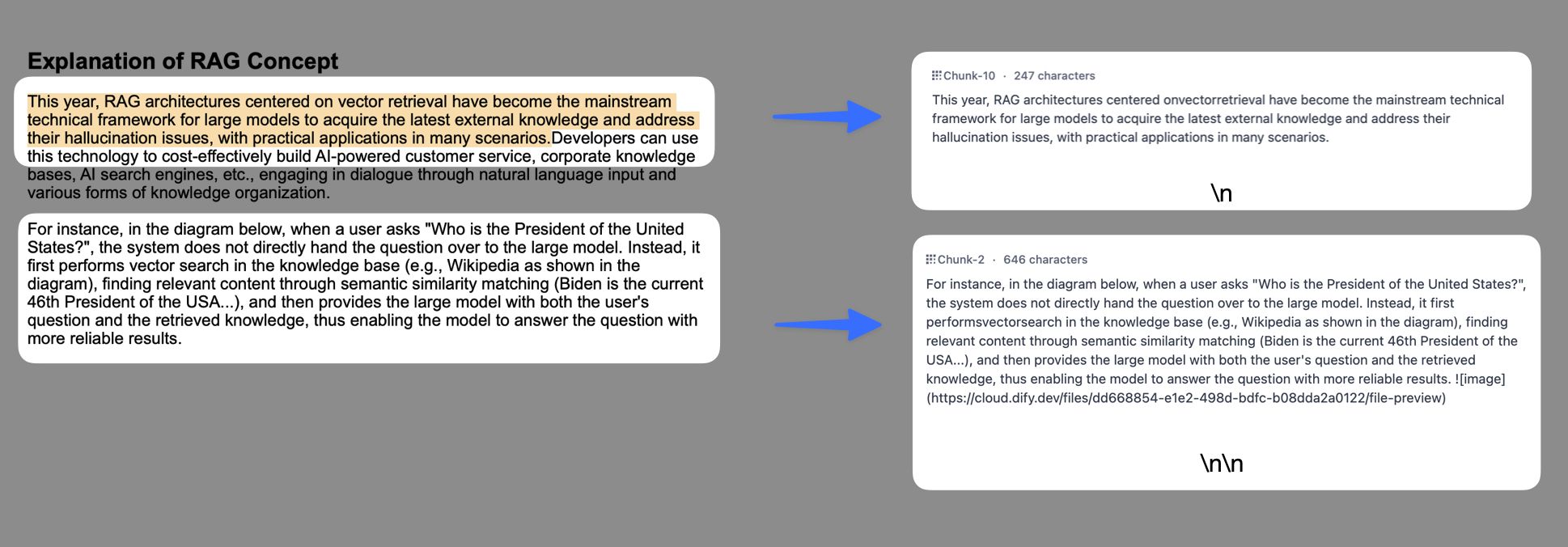
-* **チャンク識別子**:システムは、テキストにチャンク識別子が出現した際に自動的に分割を実行します。デフォルト値は `\n\n` で、文章の段落に従って分割されます。下図は異なる構文によるテキスト分割効果を示しています。
+ セクションが適切に構造化された長いドキュメントで、各セクションが独立して意味のあるコンテキストを提供する場合に適しています。
+
+
+ ドキュメント全体が単一の親チャンクとして扱われます。
- + 特定の詳細を理解するために完全なコンテキストが不可欠な、小さくまとまりのあるドキュメントに適しています。
-* **最大チャンク長**:セグメント内のテキスト文字数の最大値を設定します。この長さを超えると、強制的にセグメントが分割されます。
+
+ **全文**モードでは:
-* **チャンクのオーバーラップ**:データをセグメントに分割する際、セグメント間で一定量の重複が生じます。この重複は情報の損失を防ぎ、分析の精度を向上させ、情報のリコール効率を高めるのに役立ちます。セグメント長の10%から25%を重複させることを推奨します。
+ - 最初の10,000トークンのみが処理されます。この制限を超えるコンテンツは切り捨てられます。
-**テキストの前処理ルール**:ナレッジベース内の不要な内容をフィルタリングするための設定です。
+ - 親チャンクは作成後に編集できません。変更するには、新しいドキュメントをアップロードする必要があります。
-* 連続する空白、改行、タブを置換
-* すべてのURLと電子メールアドレスを削除
+
+
+
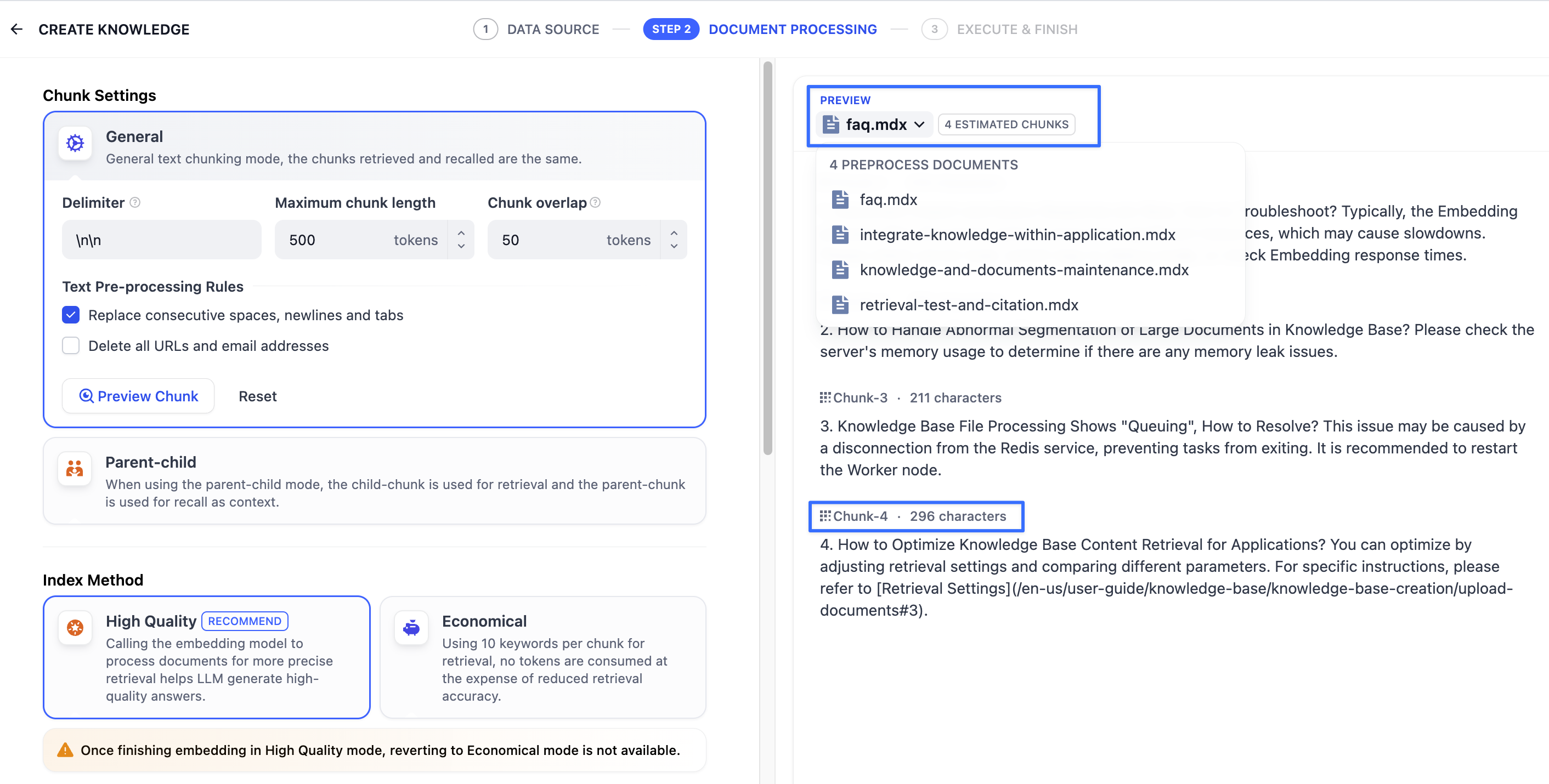
-設定完了後、「プレビューブロック」をクリックすることで、セグメント分割後の効果を確認できます。各セグメントの文字数が直感的に理解可能です。
+ **子チャンク設定**
-複数の文書を一括でアップロードした場合、文書のタイトルをクリックすることで、他の文書のセグメント分割効果を素早く確認できます。
+ 各親チャンクは、独自の区切り文字と最大チャンク長設定を使用してさらに子チャンクに分割されます。
-
+ 特定の詳細を理解するために完全なコンテキストが不可欠な、小さくまとまりのあるドキュメントに適しています。
-* **最大チャンク長**:セグメント内のテキスト文字数の最大値を設定します。この長さを超えると、強制的にセグメントが分割されます。
+
+ **全文**モードでは:
-* **チャンクのオーバーラップ**:データをセグメントに分割する際、セグメント間で一定量の重複が生じます。この重複は情報の損失を防ぎ、分析の精度を向上させ、情報のリコール効率を高めるのに役立ちます。セグメント長の10%から25%を重複させることを推奨します。
+ - 最初の10,000トークンのみが処理されます。この制限を超えるコンテンツは切り捨てられます。
-**テキストの前処理ルール**:ナレッジベース内の不要な内容をフィルタリングするための設定です。
+ - 親チャンクは作成後に編集できません。変更するには、新しいドキュメントをアップロードする必要があります。
-* 連続する空白、改行、タブを置換
-* すべてのURLと電子メールアドレスを削除
+
+
+
-設定完了後、「プレビューブロック」をクリックすることで、セグメント分割後の効果を確認できます。各セグメントの文字数が直感的に理解可能です。
+ **子チャンク設定**
-複数の文書を一括でアップロードした場合、文書のタイトルをクリックすることで、他の文書のセグメント分割効果を素早く確認できます。
+ 各親チャンクは、独自の区切り文字と最大チャンク長設定を使用してさらに子チャンクに分割されます。
- +
+ 親チャンクと子チャンクで互いのサブセットとなる区切り文字を使用しないでください。予期しないチャンク動作を引き起こす可能性があります。
-セグメント分割ルールの設定が完了したら、次にインデックス方式を選択する必要があります。「高品質インデックス」と「経済インデックス」が利用可能で、詳細は[インデックス方法の設定](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#インデックス方法の設定)をご覧ください。
+ 例えば、`??`と`?`よりも`??`と`##`の使用を推奨します。
+
+
+
-### 親子分割モード(階層分割モード)
+### 比較表
-汎用分割モードと比べると、親子分割モードは、データを二層構造で扱うことで、詳細なマッチングと文脈情報の提供の両方を可能にします。例として、AIを活用したカスタマーサポートでは、このモードを用いてユーザーの質問を解決策のドキュメント内の特定の文へと紐づけ、その文が含まれる段落や章をLLMへと送信します。これにより、質問の背景情報を完全に把握し、より適切な回答を提供することができます。
+| 項目 | 汎用モード | 親子モード |
+|:----------|:-------------|:------------------|
+| チャンク戦略 | 単一階層:すべてのチャンクが同じ設定を使用 | 二階層:親チャンクと子チャンクで別々の設定 |
+| 検索ワークフロー | マッチしたチャンクが直接返される | 子チャンクがクエリのマッチングに使用され、親チャンクがより広いコンテキストを提供するために返される |
+| 対応する[インデックス方式](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods) | 高品質、経済的 | 高品質のみ |
+| 最適な用途 | 用語集やFAQなどのシンプルで自己完結したコンテンツ | 技術マニュアルや研究論文などコンテキストが重要な情報密度の高いドキュメント |
-基本的な動作は以下の通りです:
+## チャンク化前のテキスト前処理
-* サブセグメントマッチングクエリ:
- * ドキュメントを小さな情報単位(例えば、一文)に分割し、ユーザーの質問により精密にマッチングします。
- * サブセグメントは、ユーザーのニーズに最も適した初期結果を素早く提供します。
-* メインセグメントによる文脈を提供:
- * マッチングしたサブセグメントを含むより大きな単位(段落、章、または文書全体)をメインブロックとして扱い、LLMへと送信します。
- * メインセグメントは、LLMが情報を逃さず、ナレッジベースに基づいた適切な回答を導くための完全な背景情報を提供します。
+テキストをチャンクに分割する前に、不要なコンテンツをクリーンアップして検索品質を向上させることができます。
-
+
+ 親チャンクと子チャンクで互いのサブセットとなる区切り文字を使用しないでください。予期しないチャンク動作を引き起こす可能性があります。
-セグメント分割ルールの設定が完了したら、次にインデックス方式を選択する必要があります。「高品質インデックス」と「経済インデックス」が利用可能で、詳細は[インデックス方法の設定](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#インデックス方法の設定)をご覧ください。
+ 例えば、`??`と`?`よりも`??`と`##`の使用を推奨します。
+
+
+
-### 親子分割モード(階層分割モード)
+### 比較表
-汎用分割モードと比べると、親子分割モードは、データを二層構造で扱うことで、詳細なマッチングと文脈情報の提供の両方を可能にします。例として、AIを活用したカスタマーサポートでは、このモードを用いてユーザーの質問を解決策のドキュメント内の特定の文へと紐づけ、その文が含まれる段落や章をLLMへと送信します。これにより、質問の背景情報を完全に把握し、より適切な回答を提供することができます。
+| 項目 | 汎用モード | 親子モード |
+|:----------|:-------------|:------------------|
+| チャンク戦略 | 単一階層:すべてのチャンクが同じ設定を使用 | 二階層:親チャンクと子チャンクで別々の設定 |
+| 検索ワークフロー | マッチしたチャンクが直接返される | 子チャンクがクエリのマッチングに使用され、親チャンクがより広いコンテキストを提供するために返される |
+| 対応する[インデックス方式](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods) | 高品質、経済的 | 高品質のみ |
+| 最適な用途 | 用語集やFAQなどのシンプルで自己完結したコンテンツ | 技術マニュアルや研究論文などコンテキストが重要な情報密度の高いドキュメント |
-基本的な動作は以下の通りです:
+## チャンク化前のテキスト前処理
-* サブセグメントマッチングクエリ:
- * ドキュメントを小さな情報単位(例えば、一文)に分割し、ユーザーの質問により精密にマッチングします。
- * サブセグメントは、ユーザーのニーズに最も適した初期結果を素早く提供します。
-* メインセグメントによる文脈を提供:
- * マッチングしたサブセグメントを含むより大きな単位(段落、章、または文書全体)をメインブロックとして扱い、LLMへと送信します。
- * メインセグメントは、LLMが情報を逃さず、ナレッジベースに基づいた適切な回答を導くための完全な背景情報を提供します。
+テキストをチャンクに分割する前に、不要なコンテンツをクリーンアップして検索品質を向上させることができます。
- -
-このモードでは、文書の形式やシナリオの要求に応じて、手動で階層型セグメンテーションのルールを設定する必要があります。
+- **連続する空白、改行、タブを置換**
-**メインセグメント(親セグメント)**:
+ - 3つ以上の連続した改行 → 2つの改行
-メインセグメントの設定では、以下のオプションを提供します:
+ - 複数の空白 → 単一の空白
-* 段落
- あらかじめ設定された区切り記号ルールと最大ブロック長を基にテキストを段落に分割します。各段落はメインブロックとして扱われ、テキスト量が多く、内容が明確で段落が独立している文書に適しています。以下の設定オプションがあります:
+ - タブ、フォームフィード、特殊なUnicode空白 → 通常の空白
- * **チャンク識別子**、システムは、テキストにチャンク識別子が出現した際に自動的に分割を実行します。デフォルト値は `\n\n` で、文章の段落に従って分割されます。
+- **すべてのURLとメールアドレスを削除**
- * **最大チャンク長**、分割内のテキストの最大文字数を指定し、超えると自動的に分割します。
+
+ この設定は**全文**モードでは無視されます。
+
-* 全文
- 段落に分けずに、全文を単一のメインブロックとして扱います。パフォーマンスの観点から、テキスト内の最初の10000トークンの文字のみが保持され、テキスト量が少なく、段落間に関連性があり、全文を完全に検索する必要があるシナリオに適しています。
+## サマリー自動生成を有効にする
-
-
-このモードでは、文書の形式やシナリオの要求に応じて、手動で階層型セグメンテーションのルールを設定する必要があります。
+- **連続する空白、改行、タブを置換**
-**メインセグメント(親セグメント)**:
+ - 3つ以上の連続した改行 → 2つの改行
-メインセグメントの設定では、以下のオプションを提供します:
+ - 複数の空白 → 単一の空白
-* 段落
- あらかじめ設定された区切り記号ルールと最大ブロック長を基にテキストを段落に分割します。各段落はメインブロックとして扱われ、テキスト量が多く、内容が明確で段落が独立している文書に適しています。以下の設定オプションがあります:
+ - タブ、フォームフィード、特殊なUnicode空白 → 通常の空白
- * **チャンク識別子**、システムは、テキストにチャンク識別子が出現した際に自動的に分割を実行します。デフォルト値は `\n\n` で、文章の段落に従って分割されます。
+- **すべてのURLとメールアドレスを削除**
- * **最大チャンク長**、分割内のテキストの最大文字数を指定し、超えると自動的に分割します。
+
+ この設定は**全文**モードでは無視されます。
+
-* 全文
- 段落に分けずに、全文を単一のメインブロックとして扱います。パフォーマンスの観点から、テキスト内の最初の10000トークンの文字のみが保持され、テキスト量が少なく、段落間に関連性があり、全文を完全に検索する必要があるシナリオに適しています。
+## サマリー自動生成を有効にする
- +セルフホスト環境でのみ利用可能です。
-**サブセグメント(子セグメント)**:
+すべてのチャンクのサマリーを自動生成し、検索性を向上させます。
-サブセグメントのテキストは、メインテキストのセグメントに基づいて、区切り記号ルールに従って分割されます。これは、クエリのキーワードに最も関連し、直接的な情報を検索しマッチングするために使用されます。
+サマリーも埋め込まれ、検索用にインデックス化されます。サマリーがクエリにマッチすると、対応するチャンクも返されます。
-メインセグメントが段落の場合、サブセグメントはその段落内の個別の文です;メインセグメントが全文の場合、サブセグメントは全文中の各個別の文です。
+自動生成されたサマリーを手動で編集したり、後で特定のドキュメントのサマリーを再生成することができます。詳細は[ナレッジコンテンツの管理](/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents)を参照してください。
-* **チャンク識別子**、システムは、テキストにチャンク識別子が出現した際に自動的に分割を実行します。デフォルト値は `\n` で、文に従って分割されます。
+
+ ビジョン対応のLLMを選択すると、チャンクテキストと添付画像の両方に基づいてサマリーが生成されます。
+
-* **最大チャンク長**、分割内のテキストの最大文字数を指定し、超えると自動的に分割します。
+## チャンクをプレビュー
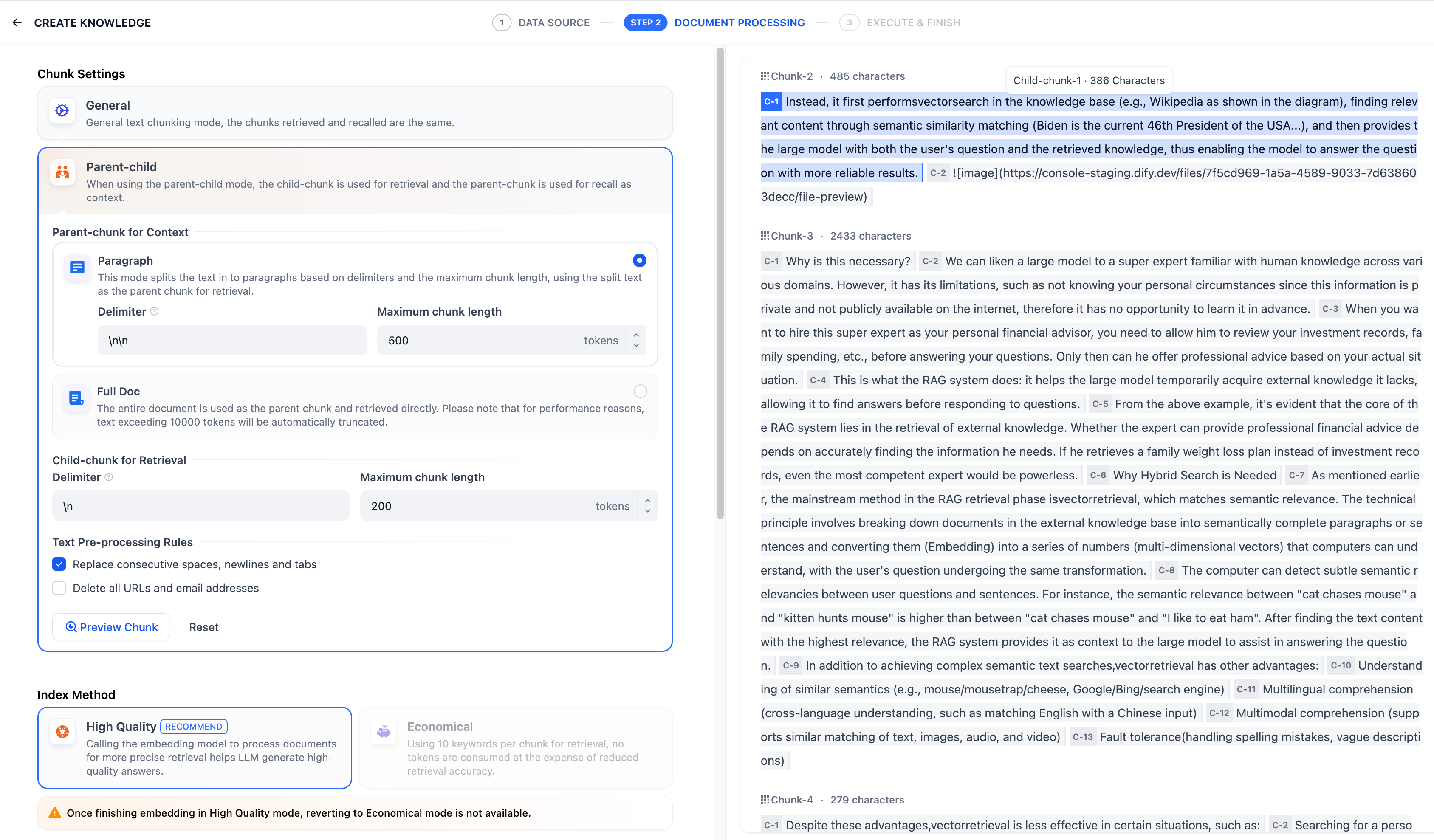
-設定完了後、「プレビュー」ボタンをクリックすると、分割された結果を確認できます。メインブロック全体の文字数が確認でき、背景が青色で表示された部分がサブブロックであり、現在のサブセグメントの文字数も表示されます。
+**プレビュー**をクリックして、コンテンツがどのようにチャンク化されるかを確認できます。クイックレビュー用に限られた数のチャンクが表示されます。
-分割ルールを変更した場合は、「プレビュー」ボタンを再度クリックして、新しい内容の分割結果を確認する必要があります。
+結果が期待と完全に一致しない場合は、最も近い設定を選択してください。後で手動でチャンクを微調整できます。詳細は[ナレッジコンテンツの管理](/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents)を参照してください。
-複数の文書を同時にアップロードした場合、ページ上部の文書タイトルをタップして、他の文書へ素早く切り替えて分割結果をプレビューできます。
-
-
+セルフホスト環境でのみ利用可能です。
-**サブセグメント(子セグメント)**:
+すべてのチャンクのサマリーを自動生成し、検索性を向上させます。
-サブセグメントのテキストは、メインテキストのセグメントに基づいて、区切り記号ルールに従って分割されます。これは、クエリのキーワードに最も関連し、直接的な情報を検索しマッチングするために使用されます。
+サマリーも埋め込まれ、検索用にインデックス化されます。サマリーがクエリにマッチすると、対応するチャンクも返されます。
-メインセグメントが段落の場合、サブセグメントはその段落内の個別の文です;メインセグメントが全文の場合、サブセグメントは全文中の各個別の文です。
+自動生成されたサマリーを手動で編集したり、後で特定のドキュメントのサマリーを再生成することができます。詳細は[ナレッジコンテンツの管理](/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents)を参照してください。
-* **チャンク識別子**、システムは、テキストにチャンク識別子が出現した際に自動的に分割を実行します。デフォルト値は `\n` で、文に従って分割されます。
+
+ ビジョン対応のLLMを選択すると、チャンクテキストと添付画像の両方に基づいてサマリーが生成されます。
+
-* **最大チャンク長**、分割内のテキストの最大文字数を指定し、超えると自動的に分割します。
+## チャンクをプレビュー
-設定完了後、「プレビュー」ボタンをクリックすると、分割された結果を確認できます。メインブロック全体の文字数が確認でき、背景が青色で表示された部分がサブブロックであり、現在のサブセグメントの文字数も表示されます。
+**プレビュー**をクリックして、コンテンツがどのようにチャンク化されるかを確認できます。クイックレビュー用に限られた数のチャンクが表示されます。
-分割ルールを変更した場合は、「プレビュー」ボタンを再度クリックして、新しい内容の分割結果を確認する必要があります。
+結果が期待と完全に一致しない場合は、最も近い設定を選択してください。後で手動でチャンクを微調整できます。詳細は[ナレッジコンテンツの管理](/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents)を参照してください。
-複数の文書を同時にアップロードした場合、ページ上部の文書タイトルをタップして、他の文書へ素早く切り替えて分割結果をプレビューできます。
-
- -
-コンテンツ検索の精度を確保するため、親子分割モードは[「高品質インデックス」](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#高品質インデックス)の使用のみをサポートしています。
-
-### 二つのモードの主な違いは何ですか?
-
-主な違いは、コンテンツをどのように分割するかにあります。汎用モードでは、複数の独立したブロックにコンテンツが分けられますが、親子モードでは二層構造を使ってコンテンツを分割します。つまり、一つの親ブロック(文書全体や段落)が、複数の子ブロック(文)を含む構造になっています。
-
-この分割方法の違いが、LLMがナレッジベースを検索する際の効率に大きな影響を与えます。特に、親子検索では、より包括的なコンテキスト情報が提供されるため、精度も向上し、従来の単層の汎用検索方法と比べて格段に優れた性能を発揮します。
-
-
-
-コンテンツ検索の精度を確保するため、親子分割モードは[「高品質インデックス」](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#高品質インデックス)の使用のみをサポートしています。
-
-### 二つのモードの主な違いは何ですか?
-
-主な違いは、コンテンツをどのように分割するかにあります。汎用モードでは、複数の独立したブロックにコンテンツが分けられますが、親子モードでは二層構造を使ってコンテンツを分割します。つまり、一つの親ブロック(文書全体や段落)が、複数の子ブロック(文)を含む構造になっています。
-
-この分割方法の違いが、LLMがナレッジベースを検索する際の効率に大きな影響を与えます。特に、親子検索では、より包括的なコンテキスト情報が提供されるため、精度も向上し、従来の単層の汎用検索方法と比べて格段に優れた性能を発揮します。
-
- -
-### もっと読む
-
-分割モードを選んだら、次にインデックスの設定や検索方法の調整を行い、ナレッジベースの構築を進めましょう。
-
-* [インデックス方式](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#インデックス方法の設定)
-* [検索オプションの設定](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#検索方法の指定)
\ No newline at end of file
+複数のドキュメントの場合、プレビューパネル上部のファイル名をクリックして、ドキュメントを切り替えることができます。
diff --git a/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx b/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
index 0eeabdc6..3a2227e5 100644
--- a/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
+++ b/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
@@ -434,6 +434,20 @@ Q&AモードはHQ(高品質)モードのみ対応です。
| 親子モード | 高品質のみ | 埋め込みモデル | ベクトル検索
-
-### もっと読む
-
-分割モードを選んだら、次にインデックスの設定や検索方法の調整を行い、ナレッジベースの構築を進めましょう。
-
-* [インデックス方式](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#インデックス方法の設定)
-* [検索オプションの設定](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#検索方法の指定)
\ No newline at end of file
+複数のドキュメントの場合、プレビューパネル上部のファイル名をクリックして、ドキュメントを切り替えることができます。
diff --git a/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx b/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
index 0eeabdc6..3a2227e5 100644
--- a/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
+++ b/ja/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
@@ -434,6 +434,20 @@ Q&AモードはHQ(高品質)モードのみ対応です。
| 親子モード | 高品質のみ | 埋め込みモデル | ベクトル検索
全文検索
ハイブリッド検索 |
| Q&Aモード | 高品質のみ | 埋め込みモデル | ベクトル検索
全文検索
ハイブリッド検索 |
+### サマリー自動生成
+
+セルフホスト環境でのみ利用可能です。
+
+すべてのチャンクに対してサマリーを自動生成し、検索性を向上させます。
+
+サマリーも埋め込み・インデックス化され、検索対象となります。サマリーがクエリにマッチした場合、対応するチャンクも返されます。
+
+自動生成されたサマリーは後から手動で編集したり、特定のドキュメントに対して再生成することができます。詳細は[ナレッジコンテンツの管理](/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents)をご参照ください。
+
+
+ ビジョン対応のLLMを選択した場合、サマリーはチャンクテキストと添付画像の両方に基づいて生成されます。
+
+
---
## ステップ4:ユーザー入力フォームの作成
diff --git a/ja/use-dify/knowledge/manage-knowledge/introduction.mdx b/ja/use-dify/knowledge/manage-knowledge/introduction.mdx
index f6d0321d..a9b861b3 100644
--- a/ja/use-dify/knowledge/manage-knowledge/introduction.mdx
+++ b/ja/use-dify/knowledge/manage-knowledge/introduction.mdx
@@ -13,13 +13,10 @@ sidebarTitle: 設定の管理
| 設定項目 | 説明 |
|:---------------- |:-------------|
-| 名前とアイコン | ナレッジベースを識別・区別するために使用します。|
-| 説明 | ナレッジベースの目的と内容を示す簡潔な説明文です。|
-| 権限 | このナレッジベースへアクセスできるワークスペースメンバーを定義します。ナレッジベースへのアクセス権を付与されたメンバーは、[ナレッジコンテンツの管理](/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents) に記載されたすべての操作権限を持ちます。 |
-| インデックス方法 | ドキュメントチャンクがどのように処理・整理され検索に使用されるかを定義します。詳細については、[インデックス方法の設定](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#インデックス方法の設定) を参照してください。 |
-| 埋め込みモデル | ドキュメントチャンクをベクトル表現に変換する際に使用する埋め込みモデルを指定します。埋め込みモデルを変更すると、すべてのチャンクが再度ベクトル化され、ベクトルインデックスが再構築されます。 |
-| 検索設定 | ナレッジベースが関連するコンテンツをどのように検索するかを定義します。詳細については、[検索方法の指定 ](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#検索方法の指定) を参照してください。 |
-
-
- ナレッジベースを作成した後は、チャンク構造を変更することはできません。
-
\ No newline at end of file
+| 名前とアイコン | ナレッジベースを識別します。|
+| 説明 | ナレッジベースの目的と内容を示します。|
+| 権限 | このナレッジベースへアクセスできるワークスペースメンバーを定義します。ナレッジベースへのアクセス権を付与されたメンバーは、[ナレッジコンテンツの管理](/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents) に記載されたすべての権限を持ちます。|
+| インデックス方法 | ドキュメントチャンクがどのように処理・整理され検索に使用されるかを定義します。詳細については、[インデックス方法の選択](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#インデックス方法の選択) を参照してください。|
+| 埋め込みモデル | ドキュメントチャンクをベクトル表現に変換する際に使用する埋め込みモデルを指定します。埋め込みモデルを変更すると、すべてのチャンクが再度埋め込み処理されます。|
+| 要約の自動生成 | ドキュメントチャンクの要約を自動的に生成します。有効にすると、新しく追加されたドキュメントとチャンクにのみ適用されます。既存のチャンクについては、ドキュメントリストでドキュメントを選択し、**要約を生成** をクリックしてください。|
+| 検索設定 | ナレッジベースが関連するコンテンツをどのように検索するかを定義します。詳細については、[検索設定の構成](/ja/use-dify/knowledge/create-knowledge/setting-indexing-methods#検索設定の指定) を参照してください。|
diff --git a/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx b/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx
index 9574965c..98772a54 100644
--- a/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx
+++ b/ja/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx
@@ -22,7 +22,8 @@ sidebarTitle: コンテンツの管理
| 追加 | 新しいドキュメントをインポートします。|
| チャンク設定の変更 | ドキュメントのチャンク設定を変更します(チャンク構造を除く)。各ドキュメントには個別のチャンク設定を持たせることができますが、チャンク構造はナレッジベース全体で共通であり、一度設定すると変更できません。|
| 削除 | ドキュメントを完全に削除します。**削除は元に戻せません。**|
-| 有効/無効 | 一時的にドキュメントを検索対象に含める/除外します。Dify Cloud では、一定期間更新または検索に使用されていないドキュメントは、自動的に無効化されパフォーマンスが最適化されます。
非アクティブ期間はプランごとに異なります:- Sandbox:7日
- Professional/Team:30日
Professional および Team プランのユーザーは、**ワンクリックで**これらのドキュメントを再有効化できます。|
+| 有効/無効 | 一時的にドキュメントを検索対象に含める/除外します。Dify Cloud では、一定期間更新または検索に使用されていないドキュメントは、自動的に無効化されパフォーマンスが最適化されます。
非アクティブ期間はプランごとに異なります:- Sandbox:7日
- Professional/Team:30日
Professional および Team プランでは、これらのドキュメントを**ワンクリックで**再有効化できます。|
+| 要約を生成 | ドキュメント内のすべてのチャンクの要約を自動生成します。**Summary Auto-Gen** が有効になっているセルフホスティング環境でのみ利用可能です。既存の要約は上書きされます。|
| アーカイブ/アーカイブ解除 | 検索には不要だが保持しておきたいドキュメントをアーカイブします。アーカイブ済みドキュメントは読み取り専用で、いつでもアーカイブ解除可能です。|
| 編集 | ドキュメント内のチャンクを編集して、コンテンツを修正します。詳細は [チャンクの管理](#チャンクの管理) を参照してください。|
| 名前を変更 | ドキュメントの名前を変更します。|
@@ -44,9 +45,10 @@ sidebarTitle: コンテンツの管理
| 追加 | 新しいチャンクを1つまたは複数まとめて追加します。
親子分割モードのドキュメントでは、親チャンクと子チャンクの両方を追加可能です。「チャンクを追加」は Dify Cloud の有料機能です。利用するには [Professional または Team プラン](https://dify.ai/pricing) へのアップグレードが必要です。|
| 削除 | チャンクを完全に削除します。**削除は元に戻せません。**|
| 有効/無効 | 一時的にチャンクを検索対象に含める/除外します。無効化されたチャンクは編集できません。|
-| 編集 | チャンクの内容を修正します。編集されたチャンクには **Edited** マークが付きます。
親子分割モードのドキュメントでは:- 親チャンクを編集するとき、子チャンクを再生成するか変更せずに保持するかを選択できます。
- 子チャンクを編集しても、親チャンクは更新されません。
|
-| キーワードの追加/編集/削除 | 経済的インデックス方式を使用するナレッジベースでは、各チャンクに対してキーワードを追加・編集して検索精度を向上させることができます。
1つのチャンクにつき最大10個のキーワードを設定可能です。|
+| 編集 | チャンクの内容を修正します。編集されたチャンクには **Edited** マークが付きます。
親子分割モードを使用するナレッジベースでは:- 親チャンクを編集するとき、子チャンクを再生成するか変更せずに保持するかを選択できます。
- 子チャンクを編集しても、親チャンクは更新されません。
|
+| キーワードの追加/編集/削除 | チャンクにキーワード(最大10個)を追加・編集して検索精度を向上させます。経済的インデックス方式を使用するナレッジベースでのみ利用可能です。|
| 画像添付ファイルの追加/削除 | ドキュメントから抽出された画像を削除したり、対応するチャンク内に新しい画像をアップロードしたりできます。
抽出された画像のURLはチャンクテキスト内に残りますが、テキストをきれいに保つためにこれらのURLを安全に削除できます。抽出された画像には影響しません。各チャンクには最大10枚まで画像の添付が可能で、検索時にチャンクと一緒に返されます。この制限を超える画像は抽出されません。
セルフホスティング環境では、環境変数 `SINGLE_CHUNK_ATTACHMENT_LIMIT` でこの制限を調整できます。マルチモーダル埋め込みモデル(**Vision** アイコン付き)を選択すると、抽出された画像も埋め込み・インデックス化され、検索に利用されます。|
+| 要約の追加/編集/削除 | チャンクに要約を追加、編集、または削除します。
要約も埋め込み・インデックス化され、検索に利用されます。要約がクエリにマッチすると、対応するチャンクも返されます。複数のチャンクに同一の要約を追加することで、グループ検索が可能になり、関連するチャンクをまとめて取得できます(Top K の制限に従います)。|
## ベストプラクティス
@@ -67,10 +69,30 @@ sidebarTitle: コンテンツの管理
親子分割モードで分割されたドキュメントでは、システムは子チャンクを検索し、結果として親チャンクを返します。子チャンクを編集しても親チャンクは更新されないため、子チャンクを親チャンクの **セマンティックタグ(意味的タグ)** や **検索ヒント** として活用できます。
そのためには、子チャンクを **キーワード**・**要約**・**ユーザーの一般的な質問** のいずれかに書き換えることを推奨します。
-たとえば、親チャンクが *返品ポリシー* 全体を扱う場合、子チャンクを次のように設定できます:
+たとえば、親チャンクが技術的な「LEDステータスインジケーター」を扱う場合、子チャンクを次のように設定できます:
-- 「商品を返品するにはどうすればいいですか?」
+- *点滅、電源が入らない、赤いライト、接続エラー、フリーズ*(キーワード)
-- 「返金期間はどのくらいですか?」
+- *LEDの色の解釈とハードウェアの電源やペアリング問題のトラブルシューティングガイド*(要約)
-- 「返品時の送料はかかりますか?」
\ No newline at end of file
+- *赤いライトが点灯し続けるのはどういう意味ですか?*(クエリ)
+
+### 要約を使用してクエリとコンテンツのギャップを埋める
+
+高品質なインデックス化によりセマンティック検索が可能になりますが、生のチャンクが具体的すぎたり、ノイズが多かったり、構造が複雑すぎてユーザーのクエリとうまく一致しない場合、検索が困難になることがあります。
+
+要約は、チャンクの核心的な意図を明確にする凝縮されたセマンティックレイヤーを提供することで、このギャップを埋めます。
+
+以下の場合に要約を使用してください:
+
+- **ユーザーのクエリがドキュメントの言語と異なる場合**:フォーマルに書かれた技術文書に対して、ユーザーが実際に質問する方法で要約を追加します。
+
+- **コンセプトが暗黙的または詳細に埋もれている場合**:核心的なコンセプトと意図を表面化する高レベルな要約を追加し、テキスト全体に散らばった細かい詳細に頼らずにチャンクをマッチできるようにします。
+
+- **生のテキストが非テキスト的な場合**:チャンクが主にコード、テーブル、ログ、トランスクリプト、またはその他セマンティックにマッチしにくいものである場合、チャンクの内容を明確にラベル付けする説明的な要約を追加します。
+
+- **関連するチャンクをまとめて検索する必要がある場合**:一連の関連チャンクに同一の要約を適用してグループ検索を有効にします。このセマンティックな接着剤により、トピックの複数の部分をまとめて検索でき、より豊富なコンテキストを提供できます。
+
+
+ 返される関連チャンクの数は、検索設定で定義された Top K の制限に従います。
+
\ No newline at end of file
diff --git a/zh/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text.mdx b/zh/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text.mdx
index e22878cf..ae022317 100644
--- a/zh/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text.mdx
+++ b/zh/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text.mdx
@@ -4,141 +4,135 @@ title: 指定分段设置
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考[英文原版](/en/use-dify/knowledge/create-knowledge/chunking-and-cleaning-text)。
+## 什么是分段?
-将内容上传至知识库后,接下来需要对内容进行分段与数据清洗。**该阶段是内容的预处理与数据结构化过程,长文本将会被划分为多个内容分段。**
+导入知识库的文档会被拆分为较小的片段,称为**分段**。分段的概念类似于将一本大书整理成章节和段落——你无法在一大块文本中快速找到特定信息,但组织良好的章节能使检索变得高效。
+当用户提出问题时,系统会在这些分段中搜索相关信息,并将其作为上下文提供给 LLM。如果没有分段,每次查询都需要处理整个文档,这将既缓慢又低效。
-
-* **分段**
+**关键分段参数**
-由于大语言模型的上下文窗口有限,无法一次性处理和传输整个知识库的内容,因此需要对文档中的长文本分段为内容块。即便部分大模型已支持上传完整的文档文件,但实验表明,检索效率依然弱于检索单个内容分段。
+- **分隔符**:文本被拆分的字符或字符序列。例如,`\n\n` 在段落换行处拆分,`\n` 在行换行处拆分。
-LLM 能否精准地回答出知识库中的内容,关键在于知识库对内容块的检索与召回效果。类似于在手册中查找关键章节即可快速得到答案,而无需逐字逐句分析整个文档。经过分段后,知识库能够基于用户问题,采用分段 TopK 召回模式,召回与问题高度相关的内容块,补全关键信息从而提高回答的精准性。
+
+ 分隔符在分段过程中会被移除。例如,使用 `A` 作为分隔符会将 `CBACD` 拆分为 `CB` 和 `CD`。
+
+ 为避免信息丢失,请使用文档中不会自然出现的非内容字符。
+
-在进行问题与内容块的语义匹配时,合理的分段大小非常关键,它能够帮助模型准确地找到与问题最相关的内容,减少噪音信息。过大或过小的分段都可能影响召回的效果。
+- **分段最大长度**:每个分段的最大字符数。超过此限制的文本将被强制拆分,无论分隔符设置如何。
-Dify 提供了 **"通用分段"** 和 **"父子分段"** 两种分段模式,分别适应不同类型的文档结构和应用场景,满足不同的知识库检索和召回的效率与准确性要求。
+## 通用模式与父子模式
-* **清洗**
+
+ 知识库创建后,分段模式无法更改。但分隔符和分段最大长度等分段设置可以随时调整。
+
-为了保证文本召回的效果,通常需要在将数据录入知识库之前便对其进行清理。例如,文本内容中存在无意义的字符或者空行可能会影响问题回复的质量,需要对其清洗。
-
+### 模式概述
-LLM 收到用户问题后,能否精准地回答出知识库中的内容,取决于知识库对内容块的检索和召回效果。匹配与问题相关度高的文本分段对 AI 应用生成准确且全面的回应至关重要。
+
+
-好比在智能客服场景下,仅需帮助 LLM 定位至工具手册的关键章节内容块即可快速得到用户问题的答案,而无需重复分析整个文档。在节省分析过程中所耗费的 Tokens 的同时,提高 AI 应用的问答质量。
+ 在通用模式下,所有分段共享相同的设置。匹配的分段将直接作为检索结果返回。
-### 分段模式
+ **分段设置**
-知识库支持两种分段模式:**通用模式**与**父子模式**。如果你是首次创建知识库,建议选择父子模式。
+ 除了分隔符和分段最大长度外,你还可以配置**分段重叠长度**来指定相邻分段之间重叠的字符数。这有助于保持语义连接,防止重要信息被拆分到不同的分段边界。
-
-**注意**:原 **"自动分段与清洗"** 模式已自动更新为 **"通用"** 模式。无需进行任何更改,原知识库保持默认设置即可继续使用。选定分段模式并完成知识库的创建后,后续无法变更。知识库内新增的文档也将遵循同样的分段模式。
-
+ 例如,设置 50 个字符的重叠,一个分段的最后 50 个字符也会出现在下一个分段的前 50 个字符中。
+
+
+
-
+ 在父子模式下,文本被拆分为两层:较小的**子分段**和较大的**父分段**。当查询匹配到子分段时,其整个父分段将作为检索结果返回。
-#### 通用模式
+ 这解决了一个常见的检索困境:较小的分段能够实现精确的查询匹配但缺乏上下文,而较大的分段提供丰富的上下文但降低了检索准确性。
-系统按照用户自定义的规则将内容拆分为独立的分段。当用户输入问题后,系统自动分析问题中的关键词,并计算关键词与知识库中各内容分段的相关度。根据相关度排序,选取最相关的内容分段并发送给 LLM,辅助其处理与更有效地回答。
+ 父子模式兼顾两者——以精准检索,以上下文响应。
-在该模式下,你需要根据不同的文档格式或场景要求,参考以下设置项,手动设置文本的**分段规则**。
+ **父分段设置**
-* **分段标识符**:系统将在文本出现分段标识符时自动执行分段。默认值为 `\n\n`,即按照文章段落进行分块。下图是不同语法的文本分段效果:
+ 父分段可以在**段落**或**全文**模式下创建。
-
+
+
+ 文档根据指定的分隔符和分段最大长度被拆分为多个父分段。
-* **分段最大长度**:指定分段内的文本字符数最大上限,超出该长度时将强制分段。
-* **分段重叠长度**:指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%。
+ 适用于结构良好的长文档,其中每个部分都能独立提供有意义的上下文。
+
+
+ 整个文档作为单个父分段。
-**文本预处理规则**:过滤知识库内部分无意义的内容。提供以下选项:
+ 适用于小型、内容紧密的文档,其中完整的上下文对于理解任何具体细节都是必要的。
-* 替换连续的空格、换行符和制表符
-* 删除所有 URL 和电子邮件地址
+
+ 在**全文**模式下:
-配置完成后,点击"预览区块"即可查看分段后的效果。你可以直观的看到每个区块的字符数。如果重新修改了分段规则,需要重新点击按钮以查看新的内容分段。
+ - 仅处理前 10,000 个 token。超出此限制的内容将被截断。
-若同时批量上传了多个文档,轻点顶部的文档标题,快速切换并查看其它文档的分段效果。
+ - 父分段创建后无法编辑。如需修改,必须上传新文档。
-
+
+
+
-分段规则设置完成后,接下来需指定索引方式。支持"高质量索引"和"经济索引",详细说明请参考[选择索引方法](/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods#选择索引方式)。
+ **子分段设置**
-#### **父子模式**
+ 每个父分段会使用其自己的分隔符和分段最大长度设置进一步拆分为子分段。
-与**通用模式**相比,父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。
+
+ 避免为父分段和子分段使用互为子集的分隔符,因为这可能导致意外的分段行为。
-其中,父区块(Parent-chunk)保持较大的文本单位(如段落),提供丰富的上下文信息;子区块(Child-chunk)则是较小的文本单位(如句子),用于精确检索。系统首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息,从而在生成响应时既保证准确性又能提供完整的背景信息。你可以通过设置分隔符和最大长度来自定义父子区块的分段方式。
+ 例如,推荐使用 `??` 和 `##`,而不是 `??` 和 `?`。
+
+
+
-例如在 AI 智能客服场景下,用户输入的问题将定位至解决方案文档内某个具体的句子,随后将该句子所在的段落或章节,联同发送至 LLM,补全该问题的完整背景信息,给出更加精准的回答。
+### 快速对比
-其基本机制包括:
+| 维度 | 通用模式 | 父子模式 |
+|:----------|:-------------|:------------------|
+| 分段策略 | 单层:所有分段使用相同设置 | 双层:父分段和子分段分别设置 |
+| 检索流程 | 匹配的分段直接返回 | 子分段用于匹配查询;父分段返回以提供更广泛的上下文 |
+| 兼容的[索引方式](/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods) | 高质量、经济 | 仅高质量 |
+| 最佳适用场景 | 简单、独立的内容,如术语表或常见问题 | 信息密集型文档,如技术手册或研究论文,上下文很重要 |
-* **子分段匹配查询**:
- * 将文档拆分为较小、集中的信息单元(例如一句话),更加精准的匹配用户所输入的问题。
- * 子分段能快速提供与用户需求最相关的初步结果。
-* **父分段提供上下文**:
- * 将包含匹配子分段的更大部分(如段落、章节甚至整个文档)视作父分段并提供给大语言模型(LLM)。
- * 父分段能为 LLM 提供完整的背景信息,避免遗漏重要细节,帮助 LLM 输出更贴合知识库内容的回答。
+## 分段前的文本预处理
-
+在将文本拆分为分段之前,你可以清理无关内容以提高检索质量。
-在该模式下,你需要根据不同的文档格式或场景要求,手动分别设置父子分段的**分段规则**。
+- **替换连续的空格、换行符和制表符**
-**父分段:**
+ - 三个或更多连续换行符 → 两个换行符
-父分段设置提供以下分段选项:
+ - 多个空格 → 单个空格
-* **段落**
+ - 制表符、换页符和特殊 Unicode 空格 → 普通空格
-根据预设的分隔符规则和最大块长度将文本拆分为段落。每个段落视为父分段,适用于文本量较大,内容清晰且段落相对独立的文档。支持以下设置项:
+- **删除所有 URL 和电子邮件地址**
-* **分段标识符**:系统将在文本出现分段标识符时自动执行分段。默认值为 `\n\n`,即按照文本段落分段。
-* **分段最大长度**:指定分段内的文本字符数最大上限,超出该长度时将强制分段。
+
+ 此设置在**全文**模式下被忽略。
+
-* **全文**
+## 启用摘要自动生成
-不进行段落分段,而是直接将全文视为单一父分段。出于性能原因,仅保留文本内的前 10000 Tokens 字符,适用于文本量较小,但段落间互有关联,需要完整检索全文的场景。
+仅适用于自托管部署。
-
+自动为所有分段生成摘要以增强其可检索性。
-**子分段:**
+摘要也会被嵌入和索引以用于检索。当摘要匹配查询时,其对应的分段也会被返回。
-子分段文本是在父文本分段基础上,由分隔符规则切分而成,用于查找和匹配与问题关键词最相关和直接的信息。如果使用默认的子分段规则,通常呈现以下分段效果:
+你可以稍后手动编辑自动生成的摘要或为特定文档重新生成摘要。详情请参阅[维护知识库内容](/zh/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents)。
-* 当父分段为段落时,子分段对应各个段落中的单个句子。
-* 父分段为全文时,子分段对应全文中各个单独的句子。
+
+ 如果你选择具有视觉能力的 LLM,摘要将基于分段文本和任何附加图像生成。
+
-在子分段内填写以下分段设置:
+## 预览分段
-* **分段标识符**:系统将在文本出现分段标识符时自动执行分段。默认值为 `\n`,即按照句子进行分段。
-* **分段最大长度**:指定分段内的文本字符数最大上限,超出该长度时将强制分段。
+点击**预览**查看你的内容将如何被分段。将显示有限数量的分段供快速审阅。
-你还可以使用**文本预处理规则**过滤知识库内部分无意义的内容:
+如果结果与你的预期不完全匹配,请选择最接近的配置——你可以稍后手动微调分段。详情请参阅[维护知识库内容](/zh/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents)。
-* 替换连续的空格、换行符和制表符
-* 删除所有 URL 和电子邮件地址
-
-配置完成后,点击"预览区块"即可查看分段后的效果。你可以查看父分段的整体字符数。背景标蓝的字符为子分块,同时显示当前子段的字符数。
-
-如果重新修改了分段规则,需要重新点击"预览区块"按钮以查看新的内容分段。若同时批量上传了多个文档,轻点顶部的文档标题,快速切换至其它文档并预览内容的分段效果。
-
-
-
-为了确保内容检索的准确性,父子分段模式仅支持使用["高质量索引"](/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods#高质量)。
-
-### 两种模式的区别是什么?
-
-两者的主要区别在于内容区块的分段形式。**通用模式**的分段结果为多个独立的内容分段,而**父子模式**采用双层结构进行内容分段,即单个父分段的内容(文档全文或段落)内包含多个子分段内容(句子)。
-
-不同的分段方式将影响 LLM 对于知识库内容的检索效果。在相同文档中,采用父子检索所提供的上下文信息会更全面,且在精准度方面也能保持较高水平,大大优于传统的单层通用检索方式。
-
-
-
-### 阅读更多
-
-选定分段模式后,接下来你可以参考以下文档分别设定索引方式和检索方式,完成知识库的创建。
-
-
- 了解更多高质量索引和经济索引的详细信息
-
\ No newline at end of file
+对于多个文档,点击预览面板顶部的文件名以在它们之间切换。
diff --git a/zh/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx b/zh/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
index e7815a19..196b23df 100644
--- a/zh/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
+++ b/zh/use-dify/knowledge/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
@@ -425,6 +425,20 @@ Dify Extractor 是 Dify 开发的一款内置文档解析器。它支持多种
| 父子模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索
全文检索
混合检索 |
| 问答模式 | 高质量(仅支持) | Embedding Model 嵌入模型 | 向量检索
全文检索
混合检索 |
+### 摘要自动生成
+
+仅适用于自托管部署。
+
+自动为所有分段生成摘要,以增强其可检索性。
+
+摘要同样会被向量化并参与检索。当摘要匹配查询时,其对应的分段也会被返回。
+
+你可以稍后手动编辑自动生成的摘要,或为特定文档重新生成摘要。详情请参阅[维护知识库内容](/zh/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents)。
+
+
+ 如果你选择了支持视觉的 LLM,摘要将基于分段文本和任何附加的图片一起生成。
+
+
---
## 步骤四:配置用户输入表单
diff --git a/zh/use-dify/knowledge/manage-knowledge/introduction.mdx b/zh/use-dify/knowledge/manage-knowledge/introduction.mdx
index 9eac3f88..4f9ad3ff 100644
--- a/zh/use-dify/knowledge/manage-knowledge/introduction.mdx
+++ b/zh/use-dify/knowledge/manage-knowledge/introduction.mdx
@@ -17,9 +17,6 @@ sidebarTitle: 调整设置
| 描述 | 简要说明知识库的用途和内容。|
| 权限 | 定义哪些工作区成员可访问该知识库。被授予访问权限的成员将拥有 [维护知识库内容](/zh/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents) 中列出的全部权限。|
| 索引方式 | 决定文档分段的处理和组织方式。详见 [选择索引方式](/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods#选择索引方式)。|
-| 嵌入模型 | 选择用于将文档分段转化为向量的嵌入模型。更换嵌入模型将对所有分段重新进行向量化、重建向量索引。|
+| 嵌入模型 | 选择用于将文档分段转化为向量的嵌入模型。更换嵌入模型将对所有分段重新进行向量化。|
+| 摘要自动生成 | 自动为文档分段生成摘要。启用后,仅对新添加的文档和分段生效。对于已有分段,请在文档列表中选择文档,然后点击 **生成摘要**。|
| 检索设置 | 决定知识库如何检索相关内容。详见 [指定检索设置](/zh/use-dify/knowledge/create-knowledge/setting-indexing-methods#指定检索设置)。|
-
-
- 知识库创建后,其分段结构不可更改。
-
diff --git a/zh/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx b/zh/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx
index fcbeddd9..116aa26b 100644
--- a/zh/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx
+++ b/zh/use-dify/knowledge/manage-knowledge/maintain-knowledge-documents.mdx
@@ -23,6 +23,7 @@ sidebarTitle: 维护内容
| 修改分段设置 | 修改文档的分段设置(不包括分段结构)。每个文档可拥有独立的分段设置,但分段结构在整个知识库中共享,且一旦设置无法更改。|
| 删除 | 永久删除文档。**删除不可撤销**。|
| 启用 / 禁用 | 临时将文档纳入或排除检索。在 Dify Cloud 上,长时间未更新或未被检索的文档会自动禁用以优化性能。
不同订阅计划的未活跃时长如下:- Sandbox:7 天
- Professional & Team:30 天
Professional 和 Team 用户可**一键**重新启用这些文档。|
+| 生成摘要 | 自动为文档中的所有分段生成摘要。仅适用于启用了**摘要自动生成**功能的自托管部署。已有的摘要将被覆盖。|
| 归档 / 取消归档 | 将不再需要检索但仍需保留的文档归档。归档文档为只读,可随时取消归档。|
| 编辑 | 通过编辑分段内容修改文档。详见 [管理分段](#管理分段)。|
| 重命名 | 修改文档名称。|
@@ -44,9 +45,10 @@ sidebarTitle: 维护内容
| 添加 | 新增或批量新增分段。
对于采用父子分段模式的文档,可同时新增父分段和子分段。「添加分段」在 Dify Cloud 上为付费功能,[升级至 Professional 或 Team 版](https://dify.ai/pricing) 即可解锁使用。|
| 删除 | 永久删除分段。**删除不可撤销**。|
| 启用 / 禁用 | 临时将分段纳入或排除检索。已禁用的分段不可编辑。|
-| 编辑 | 修改分段内容。已编辑的分段将标记为 **已编辑**。
对于采用父子分段模式的文档:- 编辑父分段时,可选择重新生成其子分段或保持原有的子分段不变。
- 编辑子分段不会改变其父分段。
|
-| 添加 / 编辑 / 删除关键词 | 在使用经济索引方式的知识库中,可为分段添加或修改关键词,以提升其可检索性。
一个分段最多可添加 10 个关键词。|
+| 编辑 | 修改分段内容。已编辑的分段将标记为 **已编辑**。
对于采用父子分段模式的知识库:- 编辑父分段时,可选择重新生成其子分段或保持原有的子分段不变。
- 编辑子分段不会改变其父分段。
|
+| 添加 / 编辑 / 删除关键词 | 为分段添加或修改关键词(最多 10 个),以提升其可检索性。仅适用于使用经济索引方式的知识库。|
| 添加 / 删除图片附件 | 在对应分段中,删除从文档中提取的图片或上传新图片。
提取的图片 URL 会保留在分段文本中,你可以安全地删除这些 URL 以保持文本简洁——这不会影响已提取的图片。 每个分段最多支持 10 张图片附件,在检索中将被一同返回;超过数量的图片不会被提取。
对于自托管部署,可通过修改环境变量 `SINGLE_CHUNK_ATTACHMENT_LIMIT` 调整此数量限制。若选择多模态嵌入模型(带有 **Vision** 图标),提取的图片也将被向量化并索引以供检索。|
+| 添加 / 编辑 / 删除摘要 | 为分段添加、修改或删除摘要。
摘要同样会被向量化并索引以供检索。当摘要与查询匹配时,其对应的分段也会被返回。为多个分段添加相同的摘要,可实现分组检索,使相关分段能够一同返回(受 Top K 限制)。|
## 最佳实践
@@ -66,10 +68,30 @@ sidebarTitle: 维护内容
对于采用父子分段模式的文档,系统会在子分段中进行搜索,但返回的是父分段。由于编辑子分段不会改变其父分段,可将子分段作为父分段的语义标签或检索提示。
-具体做法是将子分段改写为 **关键词**、**摘要** 或 **常见用户问题**。例如,若父分段的内容为*退货政策*,可将子分段改写为:
+具体做法是将子分段改写为 **关键词**、**摘要** 或 **常见用户问题**。例如,若父分段的内容涉及技术性的"LED 状态指示灯",可将子分段改写为:
-- *如何退货?*
+- *闪烁灯、无法开机、红灯、连接错误、卡死*(关键词)
-- *退款周期是多少?*
+- *LED 颜色解读及硬件电源或配对问题排查指南*(摘要)
-- *退货需要支付运费吗?*
\ No newline at end of file
+- *常亮红灯是什么意思?*(问题)
+
+### 使用摘要弥合查询与内容之间的差距
+
+虽然高质量的索引可以实现语义搜索,但当原始分段过于具体、包含噪音或结构复杂时,仍然难以与用户查询良好匹配。
+
+摘要通过提供一个精简的语义层来弥合这一差距,使分段的核心意图更加明确。
+
+在以下情况下使用摘要:
+
+- **用户查询与文档语言不同**:对于正式书写的技术文档,按照用户实际提问的方式添加摘要。
+
+- **概念隐含或埋没在细节中**:添加高层次的摘要,提炼核心概念和意图,使分段能够被匹配,而不依赖于分散在文本中的细枝末节。
+
+- **原始文本是非文本内容**:当分段主要是代码、表格、日志、记录稿或其他难以进行语义匹配的内容时,添加描述性摘要,清楚标注分段包含的内容。
+
+- **相关分段需要一起检索**:为一系列相关分段应用相同的摘要,以实现分组检索。这种语义粘合剂使一个主题的多个部分能够一起被检索,提供更丰富的上下文。
+
+
+ 返回的相关分段数量受检索设置中定义的 Top K 限制。
+
\ No newline at end of file