.png) +
+
+### Integrations
+
+You can link your GitHub and Google accounts as login methods for your Dify team. Click on your avatar in the upper right corner of the Dify team homepage, then click **"Integrations"** to set up these links.
+
+### Changing Display Language
+
+To change the display language, click on your avatar in the upper right corner of the Dify team homepage, then click **"Language"**. Dify supports the following languages:
+
+* English
+* Simplified Chinese
+* Traditional Chinese
+* Portuguese (Brazil)
+* French (France)
+* Japanese (Japan)
+* Korean (South Korea)
+* Russian (Russia)
+* Italian (Italy)
+* Thai (Thailand)
+* Indonesian
+* Ukrainian (Ukraine)
+
+Dify welcomes community volunteers to contribute additional language versions. Visit the [GitHub repository](https://github.com/langgenius/dify/blob/main/CONTRIBUTING.md) to contribute!
+
+### Deleting Personal Account
+
+For team data security considerations, self-service online deletion of personal account information is not currently supported. If you need to completely delete your account, please include the following information in an email and send it to support@dify.ai.
+
+```
+Delete account: your-email
+```
+
+
+
+
+
+### Integrations
+
+You can link your GitHub and Google accounts as login methods for your Dify team. Click on your avatar in the upper right corner of the Dify team homepage, then click **"Integrations"** to set up these links.
+
+### Changing Display Language
+
+To change the display language, click on your avatar in the upper right corner of the Dify team homepage, then click **"Language"**. Dify supports the following languages:
+
+* English
+* Simplified Chinese
+* Traditional Chinese
+* Portuguese (Brazil)
+* French (France)
+* Japanese (Japan)
+* Korean (South Korea)
+* Russian (Russia)
+* Italian (Italy)
+* Thai (Thailand)
+* Indonesian
+* Ukrainian (Ukraine)
+
+Dify welcomes community volunteers to contribute additional language versions. Visit the [GitHub repository](https://github.com/langgenius/dify/blob/main/CONTRIBUTING.md) to contribute!
+
+### Deleting Personal Account
+
+For team data security considerations, self-service online deletion of personal account information is not currently supported. If you need to completely delete your account, please include the following information in an email and send it to support@dify.ai.
+
+```
+Delete account: your-email
+```
+
+
+ .png) +
diff --git a/en-us/management/subscription-management.mdx b/en-us/management/subscription-management.mdx
new file mode 100644
index 00000000..9c3824c4
--- /dev/null
+++ b/en-us/management/subscription-management.mdx
@@ -0,0 +1,61 @@
+---
+title: Subscription Management
+---
+
+### Upgrading Dify Team Subscription
+
+Team owners and administrators can upgrade the team subscription plan. Click the **"Upgrade"** button in the upper right corner of the Dify team homepage, select an appropriate package, and complete the payment to upgrade the team's subscription.
+
+### Managing Dify Team Subscription
+
+After subscribing to Dify's paid services (Professional or Team plan), team owners and administrators can navigate to **"Settings"** → **"Billing"** to manage the team's billing and subscription details.
+
+On the billing page, you can view the usage statistics for various team resources.
+
+
+
+### Frequently Asked Questions
+
+#### 1. How to upgrade/downgrade the team plan or cancel a subscription?
+
+Team owners and administrators can navigate to **Settings** → **Billing**, then click on **Manage billing and subscription** to change the subscription plan.
+
+* Upgrading from Professional to Team plan requires paying the difference for the current month and takes effect immediately.
+* Downgrading from Team to Professional plan takes effect immediately.
+
+
+
+Upon cancellation of the subscription plan, **the team will automatically transition to the Sandbox/Free plan at the end of the current billing cycle**. Subsequently, any team members and resources exceeding the Sandbox/Free plan limitations will become inaccessible.
+
+#### 2. What changes will occur to the team's available resources after upgrading the subscription plan?
+
+| Resource | Free | Professional | Team |
+| ---------------------------------------------------------------------------- | --------- | -------------- | --------------- |
+| Team member limit | 1 | 3 | Unlimited |
+| Application limit | 10 | 50 | Unlimited |
+| Vector space capacity | 5MB | 200MB | 1GB |
+| [Marked replies](https://docs.dify.ai/guides/biao-zhu/logs) for applications | 10 | 2000 | 5000 |
+| Document uploads for knowledge base | 50 | 500 | 1000 |
+| OpenAI conversation quota | 200 total | 5000 per month | 10000 per month |
+
+Note:
+
+* When upgrading from Free to Professional, all resources are increased as shown in the table.
+* When upgrading from Professional to Team, resources are further expanded, with some becoming unlimited.
+
+After upgrading the subscription plan:
+
+* The OpenAI conversation quota will be reset to the new limit for the current billing cycle.
+* Previously used computational resources (e.g., vector space usage, document uploads) will not be reset or removed.
+
+#### 3. What if I forget to renew subscription on time?
+
+If you forget to renew your subscription, the team will automatically downgrade to the Sandbox/Free version. Except for the team owner, others will not be able to continue accessing the team. Excess computational resources within the team (such as documents, vector space, etc.) will also be locked.
+
+#### 4. Will deleting the team owner's account affect the team?
+
+A team needs to be bound to one team owner. If the team ownership is not transferred to another team member in time, all data of the current team will be deleted along with the owner's account.
+
+#### 5. What are the differences between the subscription versions?
+
+For a detailed feature comparison, please refer to the [Dify pricing](https://dify.ai/pricing).
diff --git a/en-us/management/team-members-management.mdx b/en-us/management/team-members-management.mdx
new file mode 100644
index 00000000..1c479c81
--- /dev/null
+++ b/en-us/management/team-members-management.mdx
@@ -0,0 +1,58 @@
+---
+title: Team Members Management
+---
+
+This guide explains how to manage members within a Dify team. The team member limits for different Dify versions are below.
+
+### Adding Members
+
+
+
diff --git a/en-us/management/subscription-management.mdx b/en-us/management/subscription-management.mdx
new file mode 100644
index 00000000..9c3824c4
--- /dev/null
+++ b/en-us/management/subscription-management.mdx
@@ -0,0 +1,61 @@
+---
+title: Subscription Management
+---
+
+### Upgrading Dify Team Subscription
+
+Team owners and administrators can upgrade the team subscription plan. Click the **"Upgrade"** button in the upper right corner of the Dify team homepage, select an appropriate package, and complete the payment to upgrade the team's subscription.
+
+### Managing Dify Team Subscription
+
+After subscribing to Dify's paid services (Professional or Team plan), team owners and administrators can navigate to **"Settings"** → **"Billing"** to manage the team's billing and subscription details.
+
+On the billing page, you can view the usage statistics for various team resources.
+
+
+
+### Frequently Asked Questions
+
+#### 1. How to upgrade/downgrade the team plan or cancel a subscription?
+
+Team owners and administrators can navigate to **Settings** → **Billing**, then click on **Manage billing and subscription** to change the subscription plan.
+
+* Upgrading from Professional to Team plan requires paying the difference for the current month and takes effect immediately.
+* Downgrading from Team to Professional plan takes effect immediately.
+
+
+
+Upon cancellation of the subscription plan, **the team will automatically transition to the Sandbox/Free plan at the end of the current billing cycle**. Subsequently, any team members and resources exceeding the Sandbox/Free plan limitations will become inaccessible.
+
+#### 2. What changes will occur to the team's available resources after upgrading the subscription plan?
+
+| Resource | Free | Professional | Team |
+| ---------------------------------------------------------------------------- | --------- | -------------- | --------------- |
+| Team member limit | 1 | 3 | Unlimited |
+| Application limit | 10 | 50 | Unlimited |
+| Vector space capacity | 5MB | 200MB | 1GB |
+| [Marked replies](https://docs.dify.ai/guides/biao-zhu/logs) for applications | 10 | 2000 | 5000 |
+| Document uploads for knowledge base | 50 | 500 | 1000 |
+| OpenAI conversation quota | 200 total | 5000 per month | 10000 per month |
+
+Note:
+
+* When upgrading from Free to Professional, all resources are increased as shown in the table.
+* When upgrading from Professional to Team, resources are further expanded, with some becoming unlimited.
+
+After upgrading the subscription plan:
+
+* The OpenAI conversation quota will be reset to the new limit for the current billing cycle.
+* Previously used computational resources (e.g., vector space usage, document uploads) will not be reset or removed.
+
+#### 3. What if I forget to renew subscription on time?
+
+If you forget to renew your subscription, the team will automatically downgrade to the Sandbox/Free version. Except for the team owner, others will not be able to continue accessing the team. Excess computational resources within the team (such as documents, vector space, etc.) will also be locked.
+
+#### 4. Will deleting the team owner's account affect the team?
+
+A team needs to be bound to one team owner. If the team ownership is not transferred to another team member in time, all data of the current team will be deleted along with the owner's account.
+
+#### 5. What are the differences between the subscription versions?
+
+For a detailed feature comparison, please refer to the [Dify pricing](https://dify.ai/pricing).
diff --git a/en-us/management/team-members-management.mdx b/en-us/management/team-members-management.mdx
new file mode 100644
index 00000000..1c479c81
--- /dev/null
+++ b/en-us/management/team-members-management.mdx
@@ -0,0 +1,58 @@
+---
+title: Team Members Management
+---
+
+This guide explains how to manage members within a Dify team. The team member limits for different Dify versions are below.
+
+### Adding Members
+
+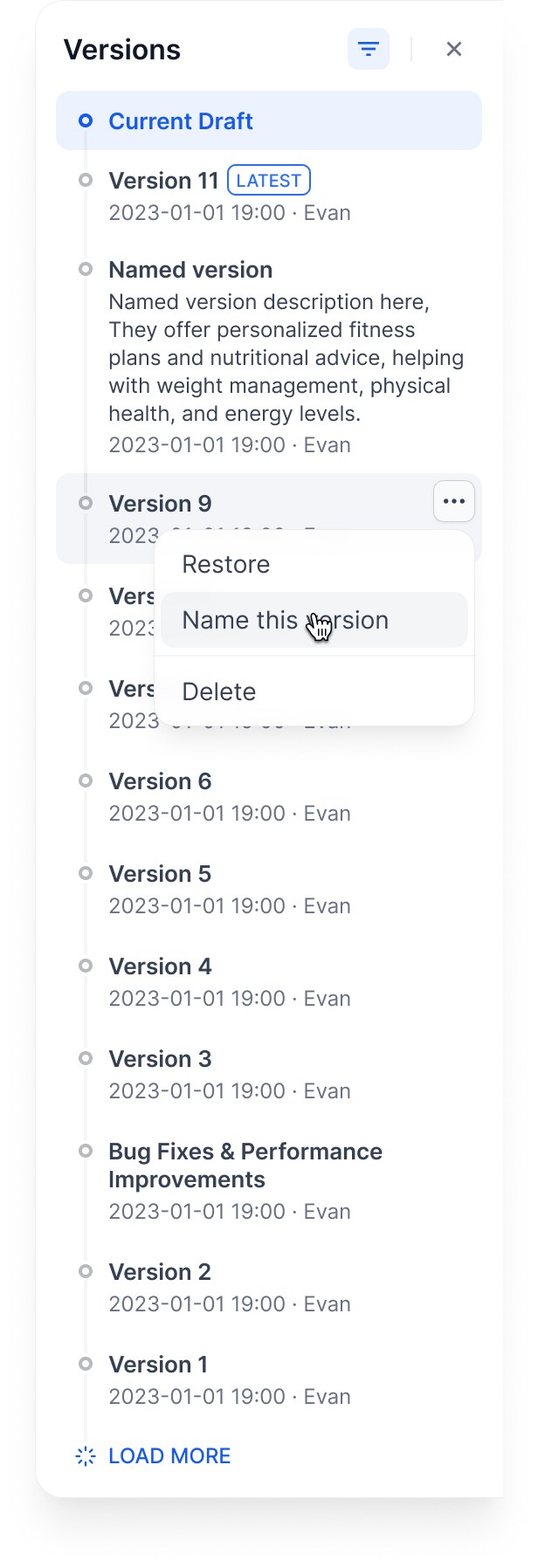 +
+- **Edit version info** for versions with custom names.
+
+
+
+- **Edit version info** for versions with custom names.
+
+.png) +
+## [アプリの複製](#copy-app)
+
+すべてのアプリは複製が可能です。アプリの左上隅にある「複製」をクリックしてください。
+
+## [アプリのエクスポート](#export-app)
+
+Difyで作成されたアプリはDSL形式でエクスポートをサポートしており、設定ファイルを任意のDifyチームに自由にインポートできます。
+
+DSLファイルは次の2つの方法でエクスポートできます:
+
+* シナリオページ中のアプリカードの右下隅の"DSLをエクスポート"をクリックする。
+* アプリ内のオーケストレートページに入れるあど、左上隅の"DSLをエクスポート"のボタンをクリックする。
+
+
+
+DSLファイルは以下の機密情報を含まれません:
+
+* APIキーなどの第三者ツールの認証情報
+* 環境変数に`Secret`が含まれる場合、DSLをエクスポートするときに機密情報のエクスポートを許可するかどうかを尋ねるメッセージが表示されます。
+
+
+
+
+
+## [アプリの複製](#copy-app)
+
+すべてのアプリは複製が可能です。アプリの左上隅にある「複製」をクリックしてください。
+
+## [アプリのエクスポート](#export-app)
+
+Difyで作成されたアプリはDSL形式でエクスポートをサポートしており、設定ファイルを任意のDifyチームに自由にインポートできます。
+
+DSLファイルは次の2つの方法でエクスポートできます:
+
+* シナリオページ中のアプリカードの右下隅の"DSLをエクスポート"をクリックする。
+* アプリ内のオーケストレートページに入れるあど、左上隅の"DSLをエクスポート"のボタンをクリックする。
+
+
+
+DSLファイルは以下の機密情報を含まれません:
+
+* APIキーなどの第三者ツールの認証情報
+* 環境変数に`Secret`が含まれる場合、DSLをエクスポートするときに機密情報のエクスポートを許可するかどうかを尋ねるメッセージが表示されます。
+
+
+
+.png) +
+### ログインをバインドする方法
+
+GitHubやGoogleアカウントのアカウントを利用しDifyチームにログインができます。これらを設定するには、Difyチームのホームページで右上隅のアバターをクリックし、**「統合」** を選択してください。
+
+### 表示言語の変更
+
+表示言語を変更するには、Difyチームのホームページで右上隅のアバターをクリックし、**「言語」** を選択します。Difyは以下の言語をサポートしています:
+
+* 英語
+* 中国語(簡体字)
+* 中国語(繁体字)
+* ポルトガル語(ブラジル)
+* フランス語(フランス)
+* 日本語(日本)
+* 韓国語(韓国)
+* ロシア語(ロシア)
+* イタリア語(イタリア)
+* タイ語(タイ)
+* インドネシア語
+* ウクライナ語(ウクライナ)
+
+Difyはコミュニティのボランティアによる追加の言語バージョンの提供を歓迎しています。貢献をご希望の方は、[GitHubリポジトリ](https://github.com/langgenius/dify/blob/main/CONTRIBUTING.md)をご覧ください。
diff --git a/ja-jp/management/team-members-management.mdx b/ja-jp/management/team-members-management.mdx
new file mode 100644
index 00000000..7d0e4590
--- /dev/null
+++ b/ja-jp/management/team-members-management.mdx
@@ -0,0 +1,63 @@
+---
+title: チームメンバーの管理
+version: '日本語'
+---
+
+このガイドでは、Difyチーム内のメンバーを管理する方法について説明します。
+
+### メンバーの追加
+
+
+
+### ログインをバインドする方法
+
+GitHubやGoogleアカウントのアカウントを利用しDifyチームにログインができます。これらを設定するには、Difyチームのホームページで右上隅のアバターをクリックし、**「統合」** を選択してください。
+
+### 表示言語の変更
+
+表示言語を変更するには、Difyチームのホームページで右上隅のアバターをクリックし、**「言語」** を選択します。Difyは以下の言語をサポートしています:
+
+* 英語
+* 中国語(簡体字)
+* 中国語(繁体字)
+* ポルトガル語(ブラジル)
+* フランス語(フランス)
+* 日本語(日本)
+* 韓国語(韓国)
+* ロシア語(ロシア)
+* イタリア語(イタリア)
+* タイ語(タイ)
+* インドネシア語
+* ウクライナ語(ウクライナ)
+
+Difyはコミュニティのボランティアによる追加の言語バージョンの提供を歓迎しています。貢献をご希望の方は、[GitHubリポジトリ](https://github.com/langgenius/dify/blob/main/CONTRIBUTING.md)をご覧ください。
diff --git a/ja-jp/management/team-members-management.mdx b/ja-jp/management/team-members-management.mdx
new file mode 100644
index 00000000..7d0e4590
--- /dev/null
+++ b/ja-jp/management/team-members-management.mdx
@@ -0,0 +1,63 @@
+---
+title: チームメンバーの管理
+version: '日本語'
+---
+
+このガイドでは、Difyチーム内のメンバーを管理する方法について説明します。
+
+### メンバーの追加
+
+ +
+
+追加されたメンバーは、URLリンクまたはメール招待を通じて登録を完了することができます。
+
+### メンバーの権限
+
+チームメンバーは、所有者、管理人、編集者、メンバーに分類されます。
+
+* **所有者**
+ * ロールの説明: チームの最初のメンバーで、最も高いレベルの権限を持ち、チーム全体の運営と管理を担当します。
+ * 権限の概要: チームメンバーの管理、メンバー権限の調整、モデルプロバイダーの設定、アプリケーションの作成と削除、ナレッジベースの作成、ツールライブラリの設定などの権限を持ちます。
+* **管理人**
+ * ロールの説明: チームの管理人で、チームメンバーとモデルプロバイダーの管理を担当します。
+ * 権限の概要: メンバー権限を調整することはできませんが、チームメンバーの追加や削除、モデルプロバイダーの設定、アプリケーションの作成、編集、削除、ナレッジベースの作成、ツールライブラリの設定などの権限を持ちます。
+* **編集者**
+ * ロールの説明: 通常のチームメンバーで、共同でアプリケーションの作成と編集を担当します。
+ * 権限の概要: チームメンバーの管理、モデルプロバイダーの設定、ツールライブラリの設定はできません。アプリケーションの作成、編集、削除、ナレッジベースの作成などの権限を持ちます。
+* **メンバー**
+ * ロールの説明: 通常のチームメンバーで、チーム内で作成されたアプリケーションの閲覧と使用のみが許可されます。
+ * 権限の概要: チーム内でのアプリケーションの使用とツールの使用のみが許可されます。
+
+### メンバーの削除
+
+
+
+
+追加されたメンバーは、URLリンクまたはメール招待を通じて登録を完了することができます。
+
+### メンバーの権限
+
+チームメンバーは、所有者、管理人、編集者、メンバーに分類されます。
+
+* **所有者**
+ * ロールの説明: チームの最初のメンバーで、最も高いレベルの権限を持ち、チーム全体の運営と管理を担当します。
+ * 権限の概要: チームメンバーの管理、メンバー権限の調整、モデルプロバイダーの設定、アプリケーションの作成と削除、ナレッジベースの作成、ツールライブラリの設定などの権限を持ちます。
+* **管理人**
+ * ロールの説明: チームの管理人で、チームメンバーとモデルプロバイダーの管理を担当します。
+ * 権限の概要: メンバー権限を調整することはできませんが、チームメンバーの追加や削除、モデルプロバイダーの設定、アプリケーションの作成、編集、削除、ナレッジベースの作成、ツールライブラリの設定などの権限を持ちます。
+* **編集者**
+ * ロールの説明: 通常のチームメンバーで、共同でアプリケーションの作成と編集を担当します。
+ * 権限の概要: チームメンバーの管理、モデルプロバイダーの設定、ツールライブラリの設定はできません。アプリケーションの作成、編集、削除、ナレッジベースの作成などの権限を持ちます。
+* **メンバー**
+ * ロールの説明: 通常のチームメンバーで、チーム内で作成されたアプリケーションの閲覧と使用のみが許可されます。
+ * 権限の概要: チーム内でのアプリケーションの使用とツールの使用のみが許可されます。
+
+### メンバーの削除
+
+ +
+
+### よくある質問
+
+#### 1. チームオーナーを変更するにはどうすればよいですか?
+
+チームオーナーは最高権限を持ち、チーム構造の安定性を維持するため、一度設定されたチームオーナーは手動で変更することができません。
+
+#### 2. チームを削除するにはどうすればよいですか?
+
+チームデータのセキュリティ上の理由から、チームオーナーは自身のチームを自己削除することはできません。
+
+#### 3. チームメンバーのアカウントを削除するにはどうすればよいですか?
+
+チームオーナー/管理者はチームメンバーのアカウントを削除することはできません。アカウントの削除はアカウント所有者自身が申請する必要があり、他者が削除することはできません。アカウントを削除する代わりに、メンバーをチームから削除することで、そのユーザーのチームへのアクセス権限を無効にすることができます。
diff --git a/ja-jp/management/version-control.mdx b/ja-jp/management/version-control.mdx
new file mode 100644
index 00000000..91df9860
--- /dev/null
+++ b/ja-jp/management/version-control.mdx
@@ -0,0 +1,189 @@
+---
+title: バージョン管理
+---
+
+## はじめに
+
+バージョン管理とは、**Difyのチャットフローやワークフロー管理インターフェース**の核となる機能です。この機能により、ユーザーはアプリの複数バージョンを効率的に管理および公開することができます。
+
+バージョン管理機能を使用することで、ユーザーは**下書きバージョン**と**公開バージョン**を明確に区別し、必要に応じて**過去のバージョン**にロールバックすることが可能です。これにより、アプリの改良と管理がより簡単で直感的になり、継続的な更新と安定性が確保されます。
+
+## 関連用語の説明
+
+- **下書きバージョン(Current Draft)**: Difyのチャットフローやワークフロー管理インターフェースにおいて、**現在の作業状態を示す唯一のバージョン**です。ユーザーはこのバージョンでチャットフローやワークフローの編集、修正、プレビューを行うことができます。
+
+
+
+
+### よくある質問
+
+#### 1. チームオーナーを変更するにはどうすればよいですか?
+
+チームオーナーは最高権限を持ち、チーム構造の安定性を維持するため、一度設定されたチームオーナーは手動で変更することができません。
+
+#### 2. チームを削除するにはどうすればよいですか?
+
+チームデータのセキュリティ上の理由から、チームオーナーは自身のチームを自己削除することはできません。
+
+#### 3. チームメンバーのアカウントを削除するにはどうすればよいですか?
+
+チームオーナー/管理者はチームメンバーのアカウントを削除することはできません。アカウントの削除はアカウント所有者自身が申請する必要があり、他者が削除することはできません。アカウントを削除する代わりに、メンバーをチームから削除することで、そのユーザーのチームへのアクセス権限を無効にすることができます。
diff --git a/ja-jp/management/version-control.mdx b/ja-jp/management/version-control.mdx
new file mode 100644
index 00000000..91df9860
--- /dev/null
+++ b/ja-jp/management/version-control.mdx
@@ -0,0 +1,189 @@
+---
+title: バージョン管理
+---
+
+## はじめに
+
+バージョン管理とは、**Difyのチャットフローやワークフロー管理インターフェース**の核となる機能です。この機能により、ユーザーはアプリの複数バージョンを効率的に管理および公開することができます。
+
+バージョン管理機能を使用することで、ユーザーは**下書きバージョン**と**公開バージョン**を明確に区別し、必要に応じて**過去のバージョン**にロールバックすることが可能です。これにより、アプリの改良と管理がより簡単で直感的になり、継続的な更新と安定性が確保されます。
+
+## 関連用語の説明
+
+- **下書きバージョン(Current Draft)**: Difyのチャットフローやワークフロー管理インターフェースにおいて、**現在の作業状態を示す唯一のバージョン**です。ユーザーはこのバージョンでチャットフローやワークフローの編集、修正、プレビューを行うことができます。
+
+ +
+
+エージェントアシスタントの推論モデルを選択します。エージェントアシスタントのタスク完了能力はモデルの推論能力に依存しますので、より強力な推論能力を持つモデルシリーズ、例えばgpt-4を選択することをお勧めします。これにより、より安定したタスク完了効果が得られます。
+
+
+
+
+
+エージェントアシスタントの推論モデルを選択します。エージェントアシスタントのタスク完了能力はモデルの推論能力に依存しますので、より強力な推論能力を持つモデルシリーズ、例えばgpt-4を選択することをお勧めします。これにより、より安定したタスク完了効果が得られます。
+
+
+  +
+
+「プロンプト」でエージェントアシスタントの指示を作成できます。より良い結果を得るために、指示の中でタスクの目標、ワークフロー、リソース、制約などを明確にすることが重要です。
+
+
+
+
+
+「プロンプト」でエージェントアシスタントの指示を作成できます。より良い結果を得るために、指示の中でタスクの目標、ワークフロー、リソース、制約などを明確にすることが重要です。
+
+
+  +
+
+### アシスタントに必要なツールを追加
+
+「コンテキスト」では、エージェントアシスタントが参照できるナレッジベースツールを追加できます。これにより、外部の背景知識を取得することができます。
+
+「ツール」では、使用する必要があるツールを追加できます。ツールはLLMの能力を拡張し、例えばネット検索、科学計算、画像の作成などが可能になります。これにより、LLMは外部世界と接続する能力を持つようになります。Difyは2種類のツールタイプを提供しています:**ファーストパーティツール**と**カスタムツール**です。
+
+Difyエコシステムが提供するファーストパーティ内蔵ツールを直接使用するか、カスタムAPIツール(現在はOpenAPI / SwaggerおよびOpenAIプラグイン規格をサポート)を簡単にインポートすることができます。
+
+
+
+
+
+### アシスタントに必要なツールを追加
+
+「コンテキスト」では、エージェントアシスタントが参照できるナレッジベースツールを追加できます。これにより、外部の背景知識を取得することができます。
+
+「ツール」では、使用する必要があるツールを追加できます。ツールはLLMの能力を拡張し、例えばネット検索、科学計算、画像の作成などが可能になります。これにより、LLMは外部世界と接続する能力を持つようになります。Difyは2種類のツールタイプを提供しています:**ファーストパーティツール**と**カスタムツール**です。
+
+Difyエコシステムが提供するファーストパーティ内蔵ツールを直接使用するか、カスタムAPIツール(現在はOpenAPI / SwaggerおよびOpenAIプラグイン規格をサポート)を簡単にインポートすることができます。
+
+
+  +
+
+**ツール** 機能を使用すると、Dify でより強力な AIアプリを作成できます。たとえば、エージェントアシスタントに適したツールを編成して、推論、ステップ分解、ツール呼び出しを通じて複雑なタスクを完了できるようにすることができます。
+
+さらに、このツールにより、アプリと他のシステムやサービスの統合が簡素化され、コードの実行や独自の情報ソースへのアクセスなど、外部環境とのやり取りが可能になります。チャット ボックスで呼び出したいツールの名前を言うだけで、自動的にアクティブ化されます。
+
+
+
+### エージェントの設定
+
+DifyではエージェントアシスタントにFunction Calling(関数呼び出し)とReActの2つの推論モードを提供しています。関数呼び出しをサポートするモデルシリーズ(例:gpt-3.5/gpt-4)はより良い、安定したパフォーマンスを持っています。関数呼び出しをサポートしていないモデルシリーズには、ReAct推論フレームワークで類似の効果を実現しています。
+
+エージェント設定では、アシスタントのイテレーション制限を変更できます。
+
+
+
+
+
+**ツール** 機能を使用すると、Dify でより強力な AIアプリを作成できます。たとえば、エージェントアシスタントに適したツールを編成して、推論、ステップ分解、ツール呼び出しを通じて複雑なタスクを完了できるようにすることができます。
+
+さらに、このツールにより、アプリと他のシステムやサービスの統合が簡素化され、コードの実行や独自の情報ソースへのアクセスなど、外部環境とのやり取りが可能になります。チャット ボックスで呼び出したいツールの名前を言うだけで、自動的にアクティブ化されます。
+
+
+
+### エージェントの設定
+
+DifyではエージェントアシスタントにFunction Calling(関数呼び出し)とReActの2つの推論モードを提供しています。関数呼び出しをサポートするモデルシリーズ(例:gpt-3.5/gpt-4)はより良い、安定したパフォーマンスを持っています。関数呼び出しをサポートしていないモデルシリーズには、ReAct推論フレームワークで類似の効果を実現しています。
+
+エージェント設定では、アシスタントのイテレーション制限を変更できます。
+
+
+  +
+
+
+
+
+
+
+  +
+
+### 会話のオープニング設定
+
+エージェントアシスタントの会話オープニングとオープニング質問を設定できます。設定された会話オープニングは、ユーザーが初めて対話を開始する際に、アシスタントが完了できるタスクや提案される質問の例を表示します。
+
+
+
+
+
+### 会話のオープニング設定
+
+エージェントアシスタントの会話オープニングとオープニング質問を設定できます。設定された会話オープニングは、ユーザーが初めて対話を開始する際に、アシスタントが完了できるタスクや提案される質問の例を表示します。
+
+
+  +
+
+### デバッグとプレビュー
+
+エージェントアシスタントの編成が完了したら、アプリとして公開する前にデバッグとプレビューを行い、アシスタントのタスク完了効果を確認できます。
+
+
+
+
+
+### デバッグとプレビュー
+
+エージェントアシスタントの編成が完了したら、アプリとして公開する前にデバッグとプレビューを行い、アシスタントのタスク完了効果を確認できます。
+
+
+  +
+
+### アプリの公開
+
+
+
+
+
+### アプリの公開
+
+
+  +
diff --git a/ja-jp/user-guide/build-app/chatbot.mdx b/ja-jp/user-guide/build-app/chatbot.mdx
new file mode 100644
index 00000000..1d3711f7
--- /dev/null
+++ b/ja-jp/user-guide/build-app/chatbot.mdx
@@ -0,0 +1,87 @@
+---
+title: 会話型アプリケーション
+version: '日本語'
+---
+
+会話型アプリケーションは、ユーザーとの継続的な対話を一問一答形式で行います。
+
+## 適用シーン
+
+会話型アプリケーションは、カスタマーサービス、オンライン教育、医療、金融サービスなどの分野で利用されることがあります。これらのアプリケーションは、組織の業務の効率を向上させたり、人件費を削減したり、ユーザーエクスペリエンスを高めるのに寄与します。
+
+## 編成方法
+
+会話型アプリケーションの作成には、プロンプト、変数、コンテキスト、オープニングダイアログ、次の質問の提案などが含まれています。
+
+ここでは、**面接官**用のアプリケーションを例に使って、会話型アプリケーションの編成方法を紹介します。
+
+### アプリケーションの作成
+
+ホームページで「最初から作成」をクリックしてアプリケーションを作成します。アプリケーション名を入力し、アプリタイプは**チャットボット**を選択します。
+
+
+
diff --git a/ja-jp/user-guide/build-app/chatbot.mdx b/ja-jp/user-guide/build-app/chatbot.mdx
new file mode 100644
index 00000000..1d3711f7
--- /dev/null
+++ b/ja-jp/user-guide/build-app/chatbot.mdx
@@ -0,0 +1,87 @@
+---
+title: 会話型アプリケーション
+version: '日本語'
+---
+
+会話型アプリケーションは、ユーザーとの継続的な対話を一問一答形式で行います。
+
+## 適用シーン
+
+会話型アプリケーションは、カスタマーサービス、オンライン教育、医療、金融サービスなどの分野で利用されることがあります。これらのアプリケーションは、組織の業務の効率を向上させたり、人件費を削減したり、ユーザーエクスペリエンスを高めるのに寄与します。
+
+## 編成方法
+
+会話型アプリケーションの作成には、プロンプト、変数、コンテキスト、オープニングダイアログ、次の質問の提案などが含まれています。
+
+ここでは、**面接官**用のアプリケーションを例に使って、会話型アプリケーションの編成方法を紹介します。
+
+### アプリケーションの作成
+
+ホームページで「最初から作成」をクリックしてアプリケーションを作成します。アプリケーション名を入力し、アプリタイプは**チャットボット**を選択します。
+
+ +
+### アプリケーションの編成
+
+アプリケーションを作成すると、自動的にアプリケーションの監視ページに移動します。左側のメニューから編成をクリックしてアプリケーションを編成します。
+
+
+
+### アプリケーションの編成
+
+アプリケーションを作成すると、自動的にアプリケーションの監視ページに移動します。左側のメニューから編成をクリックしてアプリケーションを編成します。
+
+ +
+**プロンプトの記入**
+
+プロンプトは、AIが専門的な回答を行う範囲を制限し、回答をより正確にします。組み込みのプロンプトジェネレータを使用して、適切なプロンプトを作成することができます。プロンプト内には、たとえば `{{input}}` のようなフォーム変数を挿入することができます。変数内の値は、ユーザーが入力した値に置き換えられます。
+
+例:
+1. インタビューシナリオの指示を入力します。
+2. プロンプトが自動的に右側の内容欄に生成されます。
+3. カスタム変数をプロンプトに挿入することで、特定の要望や詳細に応じてカスタマイズが可能です。
+
+ユーザーエクスペリエンスを向上させるために、オープニングダイアログを追加することができます:`こんにちは、{{name}}さん。私はあなたの面接官、Bobです。準備はできていますか?`。ページ下部の「機能の追加」ボタンをクリックして、「オープニングダイアログ」機能を開きます
+
+オープニングダイアログを追加する方法は、底の「機能を追加」ボタンをクリックして、「会話の開始」機能を開きます:
+
+
+
+**プロンプトの記入**
+
+プロンプトは、AIが専門的な回答を行う範囲を制限し、回答をより正確にします。組み込みのプロンプトジェネレータを使用して、適切なプロンプトを作成することができます。プロンプト内には、たとえば `{{input}}` のようなフォーム変数を挿入することができます。変数内の値は、ユーザーが入力した値に置き換えられます。
+
+例:
+1. インタビューシナリオの指示を入力します。
+2. プロンプトが自動的に右側の内容欄に生成されます。
+3. カスタム変数をプロンプトに挿入することで、特定の要望や詳細に応じてカスタマイズが可能です。
+
+ユーザーエクスペリエンスを向上させるために、オープニングダイアログを追加することができます:`こんにちは、{{name}}さん。私はあなたの面接官、Bobです。準備はできていますか?`。ページ下部の「機能の追加」ボタンをクリックして、「オープニングダイアログ」機能を開きます
+
+オープニングダイアログを追加する方法は、底の「機能を追加」ボタンをクリックして、「会話の開始」機能を開きます:
+
+ +
+オープニングステートメントを編集する際に、いくつかのオープニング質問を追加することもできます:
+
+
+
+#### コンテキストの追加
+
+AIの対話範囲を[ナレッジベース](/knowledge-base/)内に制限したい場合、企業内のカスタマーサービス用語規準などを「コンテキスト」で参照することができます。
+
+
+
+#### デバッグ
+
+右側にユーザー入力項目を入力し、内容を入力してデバッグします。
+
+
+
+回答結果が望ましくない場合は、プロンプトやモデルを調整することができます。また、複数のモデルを同期してデバッグすることもでき、適切な構成を組み合わせることができます。
+
+
+
+**複数のモデルでのデバッグ:**
+
+単一モデルでのデバッグが効率的ではない場合、**「複数のモデルでのデバッグ」**機能を使用して、複数のモデルの回答効果を一括確認することもできます。
+
+
+
+最大4つの大きなモデルを同時に追加できます。
+
+
+
+> ⚠️ 複数モデルでデバッグ機能を使用する際に、一部の大きなモデルしか表示されない場合は、他の大きなモデルのキーが追加されていないためです。["新しいプロバイダーの追加"](../models/new-provider)で、複数のモデルのキーを手動で追加できます。
+
+#### アプリケーションの公開
+
+アプリケーションのデバッグが完了したら、右上の**公開**ボタンをクリックして独立したAIアプリケーションを生成します。公開URLを使用してアプリケーションを体験するだけでなく、APIベースの開発やWebサイトへの組み込みなども行うことができます。詳細については[公開](../application-publishing/based-on-frontend-templates)を参照してください。
+
+公開されたアプリケーションをカスタマイズしたい場合は、当社のオープンソースの[WebAppテンプレート](https://github.com/langgenius/webapp-conversation)をForkしてください。テンプレートをベースに、シチュエーションやスタイルに合わせたアプリケーションを作成できます。
+
+### よくある質問
+
+**チャットアシスタント内にサードパーティツールを追加するにはどうすればよいですか?**
+
+チャット アシスタント タイプのアプリケーションは、サードパーティ ツールの追加をサポートしていません。[エージェント](../build-app/agent) 内でサードパーティ ツールを追加できます。アプリケーション。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/additional-feature.mdx b/ja-jp/user-guide/build-app/flow-app/additional-feature.mdx
new file mode 100644
index 00000000..74896981
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/additional-feature.mdx
@@ -0,0 +1,134 @@
+---
+title: 追加機能
+version: '日本語'
+---
+
+ワークフローとチャットフローアプリは、ユーザーのインタラクション体験を向上させるためにさまざまな機能を追加しています。たとえば、ファイルのアップロード機能を追加したり、LLMアプリに自己紹介セクションを組み込んだり、ウェルカムメッセージを活用することで、ユーザはより充実したインタラクションを楽しむことができます。
+
+アプリの右上隅にある **「機能」** ボタンをクリックすると、追加機能を利用できます。
+
+
+
+### ワークフロー
+
+> ワークフロー アプリにファイル アップロード機能を追加するこの方法は推奨されなくなりました
+
+ワークフロータイプのアプリは、**「画像のアップロを選択し、設定を完了ード」**機能のみをサポートしています。この機能を有効にすると、ワークフローアプリの使用ページに画像のアップロードエントリが表示されます。
+
+
+
+**使用方法:**
+
+**ユーザー向け:** 画像のアップロード機能が有効化されたアプリの使用ページには、アップロードボタンが表示されます。このボタンをクリックするか、ファイルのリンクを貼り付けることで画像をアップロードし、LLMから画像に関する回答を受け取ることができます。
+
+**開発者向け:** 画像のアップロード機能を有効化すると、ユーザーがアップロードした画像ファイルは`sys.files`変数に保存されます。次に、LLMノードを追加し、視覚能力を持つ大規模モデルを選択してVISION機能を有効化し、`sys.files`変数を選択することで、LLMがその画像ファイルを読み取れるようになります。
+
+最後に、ENDノードでLLMノードの出力変数を選択し、設定を完了させます。
+
+
+
+
+オープニングステートメントを編集する際に、いくつかのオープニング質問を追加することもできます:
+
+
+
+#### コンテキストの追加
+
+AIの対話範囲を[ナレッジベース](/knowledge-base/)内に制限したい場合、企業内のカスタマーサービス用語規準などを「コンテキスト」で参照することができます。
+
+
+
+#### デバッグ
+
+右側にユーザー入力項目を入力し、内容を入力してデバッグします。
+
+
+
+回答結果が望ましくない場合は、プロンプトやモデルを調整することができます。また、複数のモデルを同期してデバッグすることもでき、適切な構成を組み合わせることができます。
+
+
+
+**複数のモデルでのデバッグ:**
+
+単一モデルでのデバッグが効率的ではない場合、**「複数のモデルでのデバッグ」**機能を使用して、複数のモデルの回答効果を一括確認することもできます。
+
+
+
+最大4つの大きなモデルを同時に追加できます。
+
+
+
+> ⚠️ 複数モデルでデバッグ機能を使用する際に、一部の大きなモデルしか表示されない場合は、他の大きなモデルのキーが追加されていないためです。["新しいプロバイダーの追加"](../models/new-provider)で、複数のモデルのキーを手動で追加できます。
+
+#### アプリケーションの公開
+
+アプリケーションのデバッグが完了したら、右上の**公開**ボタンをクリックして独立したAIアプリケーションを生成します。公開URLを使用してアプリケーションを体験するだけでなく、APIベースの開発やWebサイトへの組み込みなども行うことができます。詳細については[公開](../application-publishing/based-on-frontend-templates)を参照してください。
+
+公開されたアプリケーションをカスタマイズしたい場合は、当社のオープンソースの[WebAppテンプレート](https://github.com/langgenius/webapp-conversation)をForkしてください。テンプレートをベースに、シチュエーションやスタイルに合わせたアプリケーションを作成できます。
+
+### よくある質問
+
+**チャットアシスタント内にサードパーティツールを追加するにはどうすればよいですか?**
+
+チャット アシスタント タイプのアプリケーションは、サードパーティ ツールの追加をサポートしていません。[エージェント](../build-app/agent) 内でサードパーティ ツールを追加できます。アプリケーション。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/additional-feature.mdx b/ja-jp/user-guide/build-app/flow-app/additional-feature.mdx
new file mode 100644
index 00000000..74896981
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/additional-feature.mdx
@@ -0,0 +1,134 @@
+---
+title: 追加機能
+version: '日本語'
+---
+
+ワークフローとチャットフローアプリは、ユーザーのインタラクション体験を向上させるためにさまざまな機能を追加しています。たとえば、ファイルのアップロード機能を追加したり、LLMアプリに自己紹介セクションを組み込んだり、ウェルカムメッセージを活用することで、ユーザはより充実したインタラクションを楽しむことができます。
+
+アプリの右上隅にある **「機能」** ボタンをクリックすると、追加機能を利用できます。
+
+
+
+### ワークフロー
+
+> ワークフロー アプリにファイル アップロード機能を追加するこの方法は推奨されなくなりました
+
+ワークフロータイプのアプリは、**「画像のアップロを選択し、設定を完了ード」**機能のみをサポートしています。この機能を有効にすると、ワークフローアプリの使用ページに画像のアップロードエントリが表示されます。
+
+
+
+**使用方法:**
+
+**ユーザー向け:** 画像のアップロード機能が有効化されたアプリの使用ページには、アップロードボタンが表示されます。このボタンをクリックするか、ファイルのリンクを貼り付けることで画像をアップロードし、LLMから画像に関する回答を受け取ることができます。
+
+**開発者向け:** 画像のアップロード機能を有効化すると、ユーザーがアップロードした画像ファイルは`sys.files`変数に保存されます。次に、LLMノードを追加し、視覚能力を持つ大規模モデルを選択してVISION機能を有効化し、`sys.files`変数を選択することで、LLMがその画像ファイルを読み取れるようになります。
+
+最後に、ENDノードでLLMノードの出力変数を選択し、設定を完了させます。
+
+
+ .png) +
+
+### チャットフロー
+
+チャットフロータイプのアプリは、以下の機能をサポートしています:
+
+* **冒頭の対話**
+
+ AIが自動的に一文を送信し、歓迎メッセージやAIの自己紹介などでユーザーとの距離を縮めます。
+* **次の質問の提案**
+
+ 対話が完了した後に、自動的に次の質問の提案を追加することで、対話のトピックの深さと頻度を向上させます。
+* **テキストから音声への変換**
+
+ テキストボックスに音声再生ボタンを追加し、TTSサービスを利用してテキストを読み上げます。
+* **ファイルのアップロード**
+
+ ドキュメント、画像、音声、映像、その他のファイル形式をサポートしています。この機能を有効にすると、アプリのユーザーは対話の過程でいつでもファイルをアップロードおよび更新できます。最大10個のファイルを同時にアップロードでき、各ファイルのサイズ上限は15MBです。
+
+
+
+
+
+### チャットフロー
+
+チャットフロータイプのアプリは、以下の機能をサポートしています:
+
+* **冒頭の対話**
+
+ AIが自動的に一文を送信し、歓迎メッセージやAIの自己紹介などでユーザーとの距離を縮めます。
+* **次の質問の提案**
+
+ 対話が完了した後に、自動的に次の質問の提案を追加することで、対話のトピックの深さと頻度を向上させます。
+* **テキストから音声への変換**
+
+ テキストボックスに音声再生ボタンを追加し、TTSサービスを利用してテキストを読み上げます。
+* **ファイルのアップロード**
+
+ ドキュメント、画像、音声、映像、その他のファイル形式をサポートしています。この機能を有効にすると、アプリのユーザーは対話の過程でいつでもファイルをアップロードおよび更新できます。最大10個のファイルを同時にアップロードでき、各ファイルのサイズ上限は15MBです。
+
+
+ .png) +
+
+* **引用と帰属**
+
+ [「知識検索」](node/knowledge-retrieval)ノードと組み合わせることで、LLMが応答した際の参照元ドキュメントと帰属部分を表示します。
+
+* **コンテンツの審査**
+
+ 審査APIを利用して適切な単語リストを維持し、LLMが安全なコンテンツを応答および出力できるようにします。詳細については[適切なコンテンツの審査](../application-orchestrate/app-toolkits/moderation-tool)を参照してください。
+
+**使用方法:**
+
+**ファイルのアップロード**機能以外のチャットフローアプリ内の機能は比較的簡単に使用できます。有効化すると、直感的にアプリのインタラクションページで利用可能です。
+
+このセクションでは、主に**ファイルのアップロード**機能の具体的な使用方法に焦点を当てます:
+
+**ユーザー向け:** ファイルのアップロード機能が有効化されたチャットフローアプリでは、対話ボックスの右側に「クリップ」アイコンが表示されます。このアイコンをクリックすることでファイルをアップロードし、LLMと対話できます。
+
+
+
+
+
+* **引用と帰属**
+
+ [「知識検索」](node/knowledge-retrieval)ノードと組み合わせることで、LLMが応答した際の参照元ドキュメントと帰属部分を表示します。
+
+* **コンテンツの審査**
+
+ 審査APIを利用して適切な単語リストを維持し、LLMが安全なコンテンツを応答および出力できるようにします。詳細については[適切なコンテンツの審査](../application-orchestrate/app-toolkits/moderation-tool)を参照してください。
+
+**使用方法:**
+
+**ファイルのアップロード**機能以外のチャットフローアプリ内の機能は比較的簡単に使用できます。有効化すると、直感的にアプリのインタラクションページで利用可能です。
+
+このセクションでは、主に**ファイルのアップロード**機能の具体的な使用方法に焦点を当てます:
+
+**ユーザー向け:** ファイルのアップロード機能が有効化されたチャットフローアプリでは、対話ボックスの右側に「クリップ」アイコンが表示されます。このアイコンをクリックすることでファイルをアップロードし、LLMと対話できます。
+
+
+ .png) +
+
+**アプリ開発者向け:**
+
+ファイルアップロード機能を有効にすると、ユーザーがアップロードしたファイルは `sys.files` 変数に保存されます。この変数は、ユーザーが同じ会話ラウンドで新しいメッセージを送信した後に更新されます。
+
+アップロードされるファイルの種類に応じて、アプリケーションの設定方法が異なります。
+
+* **ドキュメントファイル**
+
+LLMは直接ドキュメントファイルを読み取る機能を持っていないため、[ドキュメント抽出機](node/doc-extractor) ノードを使用して `sys.files` 変数内のファイルを前処理する必要があります。設定手順は以下の通りです:
+
+1. Features 機能を有効にし、ファイルタイプで "ドキュメント" のみを選択します。
+2. [ドキュメント抽出機](node/doc-extractor) ノードの入力変数で `sys.files` 変数を選択します。
+3. LLM ノードを追加し、システムプロンプトでドキュメント抽出機ノードの出力変数を選択します。
+4. 最後に "直接返信" ノードを追加し、LLM ノードの出力変数を記入します。
+
+この方法で構築された チャットフロー アプリは、アップロードされたファイルの内容を記憶しません。アプリのユーザーは毎回チャットボックスでドキュメントファイルをアップロードする必要があります。アプリがアップロードされたファイルを記憶する場合は、[「ファイルアップロード:開始ノードに変数を追加」](./file-upload#1-2)を参照してください。
+
+
+
+
+
+**アプリ開発者向け:**
+
+ファイルアップロード機能を有効にすると、ユーザーがアップロードしたファイルは `sys.files` 変数に保存されます。この変数は、ユーザーが同じ会話ラウンドで新しいメッセージを送信した後に更新されます。
+
+アップロードされるファイルの種類に応じて、アプリケーションの設定方法が異なります。
+
+* **ドキュメントファイル**
+
+LLMは直接ドキュメントファイルを読み取る機能を持っていないため、[ドキュメント抽出機](node/doc-extractor) ノードを使用して `sys.files` 変数内のファイルを前処理する必要があります。設定手順は以下の通りです:
+
+1. Features 機能を有効にし、ファイルタイプで "ドキュメント" のみを選択します。
+2. [ドキュメント抽出機](node/doc-extractor) ノードの入力変数で `sys.files` 変数を選択します。
+3. LLM ノードを追加し、システムプロンプトでドキュメント抽出機ノードの出力変数を選択します。
+4. 最後に "直接返信" ノードを追加し、LLM ノードの出力変数を記入します。
+
+この方法で構築された チャットフロー アプリは、アップロードされたファイルの内容を記憶しません。アプリのユーザーは毎回チャットボックスでドキュメントファイルをアップロードする必要があります。アプリがアップロードされたファイルを記憶する場合は、[「ファイルアップロード:開始ノードに変数を追加」](./file-upload#1-2)を参照してください。
+
+
+ .png) +
+
+* **画像ファイル**
+
+一部のLLMは画像から情報を直接取得できるため、画像を処理するための追加ノードは不要です。
+
+設定手順は以下の通りです:
+
+1. Features 機能を有効にし、ファイルタイプで "画像" のみを選択します。
+2. LLM ノードを追加し、VISION 機能を有効にして `sys.files` 変数を選択します。
+3. 最後に "直接返信" ノードを追加し、LLM ノードの出力変数を記入します。
+
+
+
+
+
+* **画像ファイル**
+
+一部のLLMは画像から情報を直接取得できるため、画像を処理するための追加ノードは不要です。
+
+設定手順は以下の通りです:
+
+1. Features 機能を有効にし、ファイルタイプで "画像" のみを選択します。
+2. LLM ノードを追加し、VISION 機能を有効にして `sys.files` 変数を選択します。
+3. 最後に "直接返信" ノードを追加し、LLM ノードの出力変数を記入します。
+
+
+  (2).png) +
+
+* **複合ファイルタイプ**
+
+ドキュメントファイルと画像ファイルを同時に処理したい場合は、[リスト操作](node/list-operator) ノードを使用して `sys.files` 変数内のファイルを前処理し、より詳細な変数を抽出して対応する処理ノードに送信する必要があります。設定手順は以下の通りです:
+
+1. Features 機能を有効にし、ファイルタイプで "画像" および "ドキュメントファイル" を選択します。
+2. 二つのリスト操作ノードを追加し、"フィルタリング" 条件で画像とドキュメント変数を抽出します。
+3. ドキュメントファイル変数を抽出し、"ドキュメント抽出機" ノードに渡し、画像ファイル変数を抽出し、LLM ノードに渡します。
+4. 最後に "直接返信" ノードを追加し、LLM ノードの出力変数を記入します。
+
+アプリユーザーが文書ファイルと画像を同時にアップロードした場合、文書ファイルは自動的に文書抽出機ノードに送られ、画像ファイルはLLMノードに送られて、ファイルを共同で処理することができます。
+
+* **音声・動画ファイル**
+
+LLMは音声・動画ファイルを直接読み取る機能をサポートしておらず、Difyプラットフォームにも関連するファイル処理ツールは組み込まれていません。アプリ開発者は[外部データツール](../extension/api-based-extension/external-data-tool)を参照して、ファイル情報を自分で処理することができます。
+
diff --git a/ja-jp/user-guide/build-app/flow-app/application-publishing.mdx b/ja-jp/user-guide/build-app/flow-app/application-publishing.mdx
new file mode 100644
index 00000000..81ed517f
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/application-publishing.mdx
@@ -0,0 +1,25 @@
+---
+title: アプリケーション公開
+version: '日本語'
+---
+
+デバッグが完了したら、右上の「公開する」をクリックして、このワークフローを保存し、さまざまなタイプのアプリとして素早く公開することができます。
+
+
+
+対話型アプリは以下の形式で公開できます:
+
+* 直接実行
+* Webサイトに埋め込む
+* APIアクセス
+
+ワークフローアプリは以下の形式で公開できます:
+
+* 直接実行
+* バッチ処理
+* APIアクセス
+* ツールとして公開
+
+
+
+
+* **複合ファイルタイプ**
+
+ドキュメントファイルと画像ファイルを同時に処理したい場合は、[リスト操作](node/list-operator) ノードを使用して `sys.files` 変数内のファイルを前処理し、より詳細な変数を抽出して対応する処理ノードに送信する必要があります。設定手順は以下の通りです:
+
+1. Features 機能を有効にし、ファイルタイプで "画像" および "ドキュメントファイル" を選択します。
+2. 二つのリスト操作ノードを追加し、"フィルタリング" 条件で画像とドキュメント変数を抽出します。
+3. ドキュメントファイル変数を抽出し、"ドキュメント抽出機" ノードに渡し、画像ファイル変数を抽出し、LLM ノードに渡します。
+4. 最後に "直接返信" ノードを追加し、LLM ノードの出力変数を記入します。
+
+アプリユーザーが文書ファイルと画像を同時にアップロードした場合、文書ファイルは自動的に文書抽出機ノードに送られ、画像ファイルはLLMノードに送られて、ファイルを共同で処理することができます。
+
+* **音声・動画ファイル**
+
+LLMは音声・動画ファイルを直接読み取る機能をサポートしておらず、Difyプラットフォームにも関連するファイル処理ツールは組み込まれていません。アプリ開発者は[外部データツール](../extension/api-based-extension/external-data-tool)を参照して、ファイル情報を自分で処理することができます。
+
diff --git a/ja-jp/user-guide/build-app/flow-app/application-publishing.mdx b/ja-jp/user-guide/build-app/flow-app/application-publishing.mdx
new file mode 100644
index 00000000..81ed517f
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/application-publishing.mdx
@@ -0,0 +1,25 @@
+---
+title: アプリケーション公開
+version: '日本語'
+---
+
+デバッグが完了したら、右上の「公開する」をクリックして、このワークフローを保存し、さまざまなタイプのアプリとして素早く公開することができます。
+
+
+
+対話型アプリは以下の形式で公開できます:
+
+* 直接実行
+* Webサイトに埋め込む
+* APIアクセス
+
+ワークフローアプリは以下の形式で公開できます:
+
+* 直接実行
+* バッチ処理
+* APIアクセス
+* ツールとして公開
+
+.png) +
+
+機能を有効にしても、LLM(大規模言語モデル)がファイルを直接読み取ることはできません。ファイルをLLMが理解できるテキスト形式に変換するには、が必要です。
+
+* 音声ファイルについては、`gpt-4o-audio-preview`などのマルチモーダル入力に対応したモデルを使用することで、音声を直接処理できます。この場合、追加のエクストラクタは必要ありません。
+* 映像やその他のファイルタイプについては、対応するエクストラクタがまだ用意されておらず、外部ツールを統合するためには開発者が外部ツールにアクセスする必要があります。[外部ツール](../tools/advanced-tool-integration)を接続して処理する必要があります。
+
+2. [テキスト抽出ツール](node/doc-extractor)ノードを追加し、入力変数で `sys.files` 変数を選択します。
+3. LLMノードを追加し、システムプロンプトでテキスト抽出ツールノードの出力変数を選択します。
+4. 最後に「直接応答」ノードを追加し、LLMノードの出力変数を入力します。
+
+
+
+
+
+機能を有効にしても、LLM(大規模言語モデル)がファイルを直接読み取ることはできません。ファイルをLLMが理解できるテキスト形式に変換するには、が必要です。
+
+* 音声ファイルについては、`gpt-4o-audio-preview`などのマルチモーダル入力に対応したモデルを使用することで、音声を直接処理できます。この場合、追加のエクストラクタは必要ありません。
+* 映像やその他のファイルタイプについては、対応するエクストラクタがまだ用意されておらず、外部ツールを統合するためには開発者が外部ツールにアクセスする必要があります。[外部ツール](../tools/advanced-tool-integration)を接続して処理する必要があります。
+
+2. [テキスト抽出ツール](node/doc-extractor)ノードを追加し、入力変数で `sys.files` 変数を選択します。
+3. LLMノードを追加し、システムプロンプトでテキスト抽出ツールノードの出力変数を選択します。
+4. 最後に「直接応答」ノードを追加し、LLMノードの出力変数を入力します。
+
+
+ .png) +
+
+有効にすると、ユーザーは対話ボックスでファイルをアップロードして対話できます。ただし、この方法では、LLMアプリはファイルの内容を記憶する能力を持ちません。各対話ごとにファイルをアップロードする必要があります。
+
+
+
+
+
+有効にすると、ユーザーは対話ボックスでファイルをアップロードして対話できます。ただし、この方法では、LLMアプリはファイルの内容を記憶する能力を持ちません。各対話ごとにファイルをアップロードする必要があります。
+
+
+ .png) +
+
+LLMが対話中にファイル内容を記憶する機能を追加したい場合は、方法2を参照してください。
+
+#### 方法2:ファイル変数を追加してファイルアップロード機能を有効にする
+
+#### 1. 「開始」ノードにファイル変数を追加する
+
+アプリの[「開始」](node/start)ノードに、**「単一ファイル」**または **「ファイルリスト」** といったフィールドタイプの変数を追加します。
+
+* **単一ファイル**
+
+ ユーザーが1つのファイルだけをアップロードできるようにします。
+
+* **ファイルリスト**
+
+ ユーザーが複数のファイルを一度にアップロードできるようにします。
+
+> 操作を簡単にするため、ここでは「単一ファイル」変数の例を用います。
+
+#### ファイルの解析方法
+
+ファイル変数の使用方法には主に2つのアプローチがあります:
+
+1. ツールノードを利用してファイルの内容を変換する:
+ * ドキュメント形式のファイルの場合、「ドキュメントエクストラクタ」ノードを使ってファイルの内容をテキスト形式に変換できます。
+ * この方法は、ファイルの内容をモデルが理解できる形式(例: string、array[string]など)に変換する必要がある場合に適しています。
+2. LLMノード内でファイル変数を直接使用する:
+ * 特定の種類のファイル(例: 画像)の場合、LLMノード内でファイル変数を直接使用することができます。
+ * たとえば、画像形式のファイル変数を使用する場合、LLMノードで視覚機能を有効にし、変数セレクターで該当するファイル変数を直接参照できます。
+
+どちらの方法を選ぶかは、ファイルの種類と具体的な要件によります。以下で、これら2つの方法の具体的な手順について詳しく説明します。
+
+#### 2. テキスト抽出ツールノードの追加
+
+ファイルをアップロードすると、そのファイルは「単一ファイル」変数に保存されます。しかし、LLMは変数内のファイルを直接読み込むことができないため、まず[**「テキスト抽出ツール」**](node/doc-extractor)ノードを追加する必要があります。
+
+「開始」ノード内のファイル変数を **「テキスト抽出ツール」** ノードの入力変数として使用します。
+
+
+
+
+
+LLMが対話中にファイル内容を記憶する機能を追加したい場合は、方法2を参照してください。
+
+#### 方法2:ファイル変数を追加してファイルアップロード機能を有効にする
+
+#### 1. 「開始」ノードにファイル変数を追加する
+
+アプリの[「開始」](node/start)ノードに、**「単一ファイル」**または **「ファイルリスト」** といったフィールドタイプの変数を追加します。
+
+* **単一ファイル**
+
+ ユーザーが1つのファイルだけをアップロードできるようにします。
+
+* **ファイルリスト**
+
+ ユーザーが複数のファイルを一度にアップロードできるようにします。
+
+> 操作を簡単にするため、ここでは「単一ファイル」変数の例を用います。
+
+#### ファイルの解析方法
+
+ファイル変数の使用方法には主に2つのアプローチがあります:
+
+1. ツールノードを利用してファイルの内容を変換する:
+ * ドキュメント形式のファイルの場合、「ドキュメントエクストラクタ」ノードを使ってファイルの内容をテキスト形式に変換できます。
+ * この方法は、ファイルの内容をモデルが理解できる形式(例: string、array[string]など)に変換する必要がある場合に適しています。
+2. LLMノード内でファイル変数を直接使用する:
+ * 特定の種類のファイル(例: 画像)の場合、LLMノード内でファイル変数を直接使用することができます。
+ * たとえば、画像形式のファイル変数を使用する場合、LLMノードで視覚機能を有効にし、変数セレクターで該当するファイル変数を直接参照できます。
+
+どちらの方法を選ぶかは、ファイルの種類と具体的な要件によります。以下で、これら2つの方法の具体的な手順について詳しく説明します。
+
+#### 2. テキスト抽出ツールノードの追加
+
+ファイルをアップロードすると、そのファイルは「単一ファイル」変数に保存されます。しかし、LLMは変数内のファイルを直接読み込むことができないため、まず[**「テキスト抽出ツール」**](node/doc-extractor)ノードを追加する必要があります。
+
+「開始」ノード内のファイル変数を **「テキスト抽出ツール」** ノードの入力変数として使用します。
+
+
+  +
+
+「テキスト抽出ツール」ノードの出力変数をLLMノードのシステムプロンプトに貼り付けます。
+
+
+
+
+
+「テキスト抽出ツール」ノードの出力変数をLLMノードのシステムプロンプトに貼り付けます。
+
+
+  +
+
+これらの設定が完了すると、ユーザーはWebApp内でファイルのURLを貼り付けるか、ローカルファイルをアップロードでき、その後、ドキュメントの内容に基づいてLLMとの対話が可能になります。ユーザーは対話の過程でいつでもファイルを置き換えることができ、LLMは常に最新のファイル内容を取得します。
+
+
+
+
+
+これらの設定が完了すると、ユーザーはWebApp内でファイルのURLを貼り付けるか、ローカルファイルをアップロードでき、その後、ドキュメントの内容に基づいてLLMとの対話が可能になります。ユーザーは対話の過程でいつでもファイルを置き換えることができ、LLMは常に最新のファイル内容を取得します。
+
+
+  +
+
+**LLMノードでファイル変数を参照する方法**
+
+特定の種類のファイル(例: 画像)の場合、LLMノード内でファイル変数を直接使用できます。この方法は、視覚的解析が必要な場面に特に適しています。具体的な手順は以下の通りです:
+
+1. LLMノードで視覚機能を有効にします。これにより、モデルが画像入力を処理できるようになります(モデルが視覚機能をサポートしている必要があります)。
+2. LLMノードの変数セレクターで、以前に作成したファイル変数を直接参照します。ファイルのアップロードによって作成されたファイル変数を選択する場合は、sys.files変数を選択します。
+3. システムプロンプトで、モデルに画像入力の処理方法を指示します。たとえば、モデルに画像の内容を説明させたり、画像に関する質問に答えさせたりできます。
+
+以下は設定の例です:
+
+
+
+
+
+**LLMノードでファイル変数を参照する方法**
+
+特定の種類のファイル(例: 画像)の場合、LLMノード内でファイル変数を直接使用できます。この方法は、視覚的解析が必要な場面に特に適しています。具体的な手順は以下の通りです:
+
+1. LLMノードで視覚機能を有効にします。これにより、モデルが画像入力を処理できるようになります(モデルが視覚機能をサポートしている必要があります)。
+2. LLMノードの変数セレクターで、以前に作成したファイル変数を直接参照します。ファイルのアップロードによって作成されたファイル変数を選択する場合は、sys.files変数を選択します。
+3. システムプロンプトで、モデルに画像入力の処理方法を指示します。たとえば、モデルに画像の内容を説明させたり、画像に関する質問に答えさせたりできます。
+
+以下は設定の例です:
+
+
+  +
+
+LLMノード内でファイル変数を直接使用する際は、そのファイル変数が画像ファイルのみを含むようにする必要があります。それ以外の場合、エラーが発生する可能性があります。ユーザーが異なる種類のファイルをアップロードする可能性がある場合は、フィルタリングを行うためにリスト操作を使用することが重要です。
+
+#### ファイルのダウンロード方法
+
+ファイル変数をanswerノードまたはendノードに配置すると、アプリケーションがそのノードに到達した際に、セッションボックスにファイルダウンロードカードが表示されます。このカードをクリックすることで、ファイルをダウンロードできます。
+
+
+
+
+
+LLMノード内でファイル変数を直接使用する際は、そのファイル変数が画像ファイルのみを含むようにする必要があります。それ以外の場合、エラーが発生する可能性があります。ユーザーが異なる種類のファイルをアップロードする可能性がある場合は、フィルタリングを行うためにリスト操作を使用することが重要です。
+
+#### ファイルのダウンロード方法
+
+ファイル変数をanswerノードまたはendノードに配置すると、アプリケーションがそのノードに到達した際に、セッションボックスにファイルダウンロードカードが表示されます。このカードをクリックすることで、ファイルをダウンロードできます。
+
+
+  +
+
+### 上級者向けの使用方法
+
+アプリが複数のファイル形式に対応できるようにしたい場合、例えば、ユーザーがドキュメントファイル、画像、音声、動画ファイルを同時にアップロードできるようにするには、「開始」ノードに「ファイルリスト」変数を追加し、「リスト操作」ノードを使用して異なるファイルタイプを処理する必要があります。詳細については、[リスト操作](node/list-operator)ノードを参照してください。
+
+
+
+
+
+### 上級者向けの使用方法
+
+アプリが複数のファイル形式に対応できるようにしたい場合、例えば、ユーザーがドキュメントファイル、画像、音声、動画ファイルを同時にアップロードできるようにするには、「開始」ノードに「ファイルリスト」変数を追加し、「リスト操作」ノードを使用して異なるファイルタイプを処理する必要があります。詳細については、[リスト操作](node/list-operator)ノードを参照してください。
+
+
+ .png) +
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/README.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/README.mdx
new file mode 100644
index 00000000..836abd41
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/README.mdx
@@ -0,0 +1,7 @@
+# 节点说明
+
+**节点是工作流中的关键构成**,通过连接不同功能的节点,执行工作流的一系列操作。
+
+### 核心节点
+
+
+
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/README.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/README.mdx
new file mode 100644
index 00000000..836abd41
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/README.mdx
@@ -0,0 +1,7 @@
+# 节点说明
+
+**节点是工作流中的关键构成**,通过连接不同功能的节点,执行工作流的一系列操作。
+
+### 核心节点
+
+ +
+
+
+
+
+ +
+
+
+***
+
+### シナリオ
+
+このノードの便利な特性の一つは、シナリオに応じてリクエストの異なる部分に動的に変数を挿入できることです。例えば、カスタマーレビュープロセスを処理する際に、ユーザー名や顧客ID、レビュー内容などの変数をリクエストに埋め込むことで、カスタマイズされた自動返信情報を作成したり、特定の顧客情報を取得して関連リソースを特定のサーバーに送信したりすることができます。
+
+
+
+
+
+
+***
+
+### シナリオ
+
+このノードの便利な特性の一つは、シナリオに応じてリクエストの異なる部分に動的に変数を挿入できることです。例えば、カスタマーレビュープロセスを処理する際に、ユーザー名や顧客ID、レビュー内容などの変数をリクエストに埋め込むことで、カスタマイズされた自動返信情報を作成したり、特定の顧客情報を取得して関連リソースを特定のサーバーに送信したりすることができます。
+
+
+  +
+
+HTTP HTTPリクエストの戻り値には、レスポンスボディ、ステータスコード、レスポンスヘッダー、ファイルが含まれます。特に、レスポンスにファイル(現在は画像タイプのみ)が含まれている場合、このノードはファイルを自動的に保存し、後続のプロセスで使用できるようにします。この設計により、処理効率が向上し、ファイルを含むレスポンスの処理がシンプルで直接的になります。
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/ifelse.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/ifelse.mdx
new file mode 100644
index 00000000..d18502af
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/ifelse.mdx
@@ -0,0 +1,55 @@
+---
+title: 条件分岐
+version: '日本語'
+---
+
+### 定義
+
+if/else 条件に基づいてチャットフローとワークフローを2つの分岐に分けることができます。
+
+### ノードの機能
+
+条件分岐の動作メカニズムには、次の6つのパスが含まれます:
+
+* IFの条件:変数を選び、条件と満たすべき値を設定します;
+* IFの条件が `True` と判断された場合、IFパスを実行します;
+* IFの条件が `False` と判断された場合、ELSEパスを実行します;
+* ELIFの条件が `True` と判断された場合, ELIFパスを実行します;
+* ELIFの条件が `False` と判断された場合, 次のELIFパスを判断します、もしくは最後のELIFパスを実行します;
+
+**条件の種類**
+
+次の条件タイプの設定をサポートします:
+
+* 含む(Contains)
+* 含まない(Not contains)
+* ..から始まる(Start with)
+* ..から終わる(End with)
+* である(Is)
+* ではない(Is not)
+* 空である(Is empty)
+* 空ではない(Is not empty)
+
+***
+
+### シナリオ
+
+
+
+
+
+HTTP HTTPリクエストの戻り値には、レスポンスボディ、ステータスコード、レスポンスヘッダー、ファイルが含まれます。特に、レスポンスにファイル(現在は画像タイプのみ)が含まれている場合、このノードはファイルを自動的に保存し、後続のプロセスで使用できるようにします。この設計により、処理効率が向上し、ファイルを含むレスポンスの処理がシンプルで直接的になります。
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/ifelse.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/ifelse.mdx
new file mode 100644
index 00000000..d18502af
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/ifelse.mdx
@@ -0,0 +1,55 @@
+---
+title: 条件分岐
+version: '日本語'
+---
+
+### 定義
+
+if/else 条件に基づいてチャットフローとワークフローを2つの分岐に分けることができます。
+
+### ノードの機能
+
+条件分岐の動作メカニズムには、次の6つのパスが含まれます:
+
+* IFの条件:変数を選び、条件と満たすべき値を設定します;
+* IFの条件が `True` と判断された場合、IFパスを実行します;
+* IFの条件が `False` と判断された場合、ELSEパスを実行します;
+* ELIFの条件が `True` と判断された場合, ELIFパスを実行します;
+* ELIFの条件が `False` と判断された場合, 次のELIFパスを判断します、もしくは最後のELIFパスを実行します;
+
+**条件の種類**
+
+次の条件タイプの設定をサポートします:
+
+* 含む(Contains)
+* 含まない(Not contains)
+* ..から始まる(Start with)
+* ..から終わる(End with)
+* である(Is)
+* ではない(Is not)
+* 空である(Is empty)
+* 空ではない(Is not empty)
+
+***
+
+### シナリオ
+
+
+  +
+
+**テキスト要約ワークフロー**を例に、各条件を説明します。
+
+* IFの条件:開始ノードの`summarystyle`変数を選び、条件を **含む** として `技術` を設定します;
+* IFの条件が `True` と判断された場合、IFパスを実行し、技術関連の知識をナレッジ検索ノードを通じて問い合わせ、その後大規模言語モデル(LLM)ノードを介して応答します。(上図の下半部分に示されるように);
+* IFの条件が `False` と判断され、さらにELIF条件が加えられた場合、`summarystyle` 変数の入力に `技術` は含まれず、ELIFの条件に `科学` が含まれている場合は、ELIFの条件が `True` であるかどうかを確認し、該当する手順を実行します。
+* ELIFの条件が `False` で、かつ入力変数に `技術` や `科学` が含まれていない場合は、次のELIFの条件の評価を続けるか、もしくはELSEパスを実行します。
+* IFの条件が `False` と判断された場合、つまり`summarystyle`変数の入力が **含まない** として `技術` を設定し、ELSEパスを実行し、LLM2ノードで返信します(上図の下半部分に示されるように);
+
+**複数条件の判断**
+
+複雑な条件判断が必要な場合、複数条件を設定し、条件間に **AND** または **OR** を設定することができます。これは条件間に**交集**または**并集**を取ることを意味します。
+
+
+
+
+
+**テキスト要約ワークフロー**を例に、各条件を説明します。
+
+* IFの条件:開始ノードの`summarystyle`変数を選び、条件を **含む** として `技術` を設定します;
+* IFの条件が `True` と判断された場合、IFパスを実行し、技術関連の知識をナレッジ検索ノードを通じて問い合わせ、その後大規模言語モデル(LLM)ノードを介して応答します。(上図の下半部分に示されるように);
+* IFの条件が `False` と判断され、さらにELIF条件が加えられた場合、`summarystyle` 変数の入力に `技術` は含まれず、ELIFの条件に `科学` が含まれている場合は、ELIFの条件が `True` であるかどうかを確認し、該当する手順を実行します。
+* ELIFの条件が `False` で、かつ入力変数に `技術` や `科学` が含まれていない場合は、次のELIFの条件の評価を続けるか、もしくはELSEパスを実行します。
+* IFの条件が `False` と判断された場合、つまり`summarystyle`変数の入力が **含まない** として `技術` を設定し、ELSEパスを実行し、LLM2ノードで返信します(上図の下半部分に示されるように);
+
+**複数条件の判断**
+
+複雑な条件判断が必要な場合、複数条件を設定し、条件間に **AND** または **OR** を設定することができます。これは条件間に**交集**または**并集**を取ることを意味します。
+
+
+  +
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/iteration.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/iteration.mdx
new file mode 100644
index 00000000..10d6e97a
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/iteration.mdx
@@ -0,0 +1,190 @@
+---
+title: イテレーション
+version: '日本語'
+---
+
+### 定義
+
+配列に対して複数のステップを実行し、すべての結果を出力すること。
+
+イテレーションステップはリスト中の各項目に対して同じステップを実行します。イテレーションを使用する条件は、入力値がリストオブジェクトとしてフォーマットされていることを確認することです。イテレーションノードは、AIワークフローにより複雑な処理ロジックを取り入れることを可能にします。イテレーションノードはループノードの親しみやすいバージョンであり、非技術ユーザーが迅速に始められるようにカスタマイズの程度を調整しています。
+
+***
+
+### シナリオ
+
+#### **例1:長文イテレーション生成器**
+
+
+
+
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/iteration.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/iteration.mdx
new file mode 100644
index 00000000..10d6e97a
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/iteration.mdx
@@ -0,0 +1,190 @@
+---
+title: イテレーション
+version: '日本語'
+---
+
+### 定義
+
+配列に対して複数のステップを実行し、すべての結果を出力すること。
+
+イテレーションステップはリスト中の各項目に対して同じステップを実行します。イテレーションを使用する条件は、入力値がリストオブジェクトとしてフォーマットされていることを確認することです。イテレーションノードは、AIワークフローにより複雑な処理ロジックを取り入れることを可能にします。イテレーションノードはループノードの親しみやすいバージョンであり、非技術ユーザーが迅速に始められるようにカスタマイズの程度を調整しています。
+
+***
+
+### シナリオ
+
+#### **例1:長文イテレーション生成器**
+
+
+  +
+
+1. **開始ノード** 内にタイトルとアウトラインを入力
+2. **コードノード** を使用してユーザー入力から完全な内容を抽出
+3. **パラメータ抽出ノード** を使用して完全な内容を配列形式に変換
+4. **イテレーションノード** でラップされた **LLM ノード** を通じて各章の内容を複数回生成
+5. イテレーションノード内に **直接応答ノード** を追加して、各イテレーション生成の後にストリーム出力を行う
+
+**具体的な設定ステップ**
+
+1. **開始ノード** にタイトル(title)とアウトライン(outline)を設定;
+
+
+
+
+
+1. **開始ノード** 内にタイトルとアウトラインを入力
+2. **コードノード** を使用してユーザー入力から完全な内容を抽出
+3. **パラメータ抽出ノード** を使用して完全な内容を配列形式に変換
+4. **イテレーションノード** でラップされた **LLM ノード** を通じて各章の内容を複数回生成
+5. イテレーションノード内に **直接応答ノード** を追加して、各イテレーション生成の後にストリーム出力を行う
+
+**具体的な設定ステップ**
+
+1. **開始ノード** にタイトル(title)とアウトライン(outline)を設定;
+
+
+  +
+
+2. **Jinja-2 テンプレートノード** を使用してタイトルとアウトラインを完全なテキストに変換;
+
+
+
+
+
+2. **Jinja-2 テンプレートノード** を使用してタイトルとアウトラインを完全なテキストに変換;
+
+
+  +
+
+3. **パラメータ抽出ノード** を使用して、ストーリーテキストを配列(Array)構造に変換。抽出パラメータは `sections`、パラメータタイプは `Array[Object]`
+
+
+
+
+
+3. **パラメータ抽出ノード** を使用して、ストーリーテキストを配列(Array)構造に変換。抽出パラメータは `sections`、パラメータタイプは `Array[Object]`
+
+
+  +
+
+
+
+
+ +
+
+LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/item` を設定
+
+
+
+
+
+LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/item` を設定
+
+
+  +
+
+
+
+
+ +
+
+6. 完全なデバッグとプレビュー
+
+
+
+
+
+6. 完全なデバッグとプレビュー
+
+
+  +
+
+#### **例2:長文イテレーション生成器(別の編成方法)**
+
+
+
+
+
+#### **例2:長文イテレーション生成器(別の編成方法)**
+
+
+  +
+
+* **開始ノード** にタイトルとアウトラインを入力
+* **LLM ノード** を使用して小見出しと対応する内容を生成
+* **コードノード** を使用して完全な内容を配列形式に変換
+* **イテレーションノード** でラップされた **LLM ノード** を通じて各章の内容を複数回生成
+* **テンプレート変換ノード** を使用してイテレーションノードが出力する文字列配列を文字列に変換
+* 最後に **直接応答ノード** を追加して変換後の文字列を直接出力
+
+### 配列の内容とは
+
+リストは特定のデータ型であり、要素はコンマで区切られ、 `[` で始まり `]` で終わります。例えば:
+
+**数値型:**
+
+```
+[0,1,2,3,4,5]
+```
+
+**文字列型:**
+
+```
+["monday", "Tuesday", "Wednesday", "Thursday"]
+```
+
+**JSON オブジェクト:**
+
+```
+[
+ {
+ "name": "Alice",
+ "age": 30,
+ "email": "alice@example.com"
+ },
+ {
+ "name": "Bob",
+ "age": 25,
+ "email": "bob@example.com"
+ },
+ {
+ "name": "Charlie",
+ "age": 35,
+ "email": "charlie@example.com"
+ }
+]
+```
+
+***
+
+### 配列を返すノード
+
+* コードノード
+* パラメータ抽出
+* ナレッジベース検索
+* イテレーション
+* ツール
+* HTTPリクエスト
+
+### 配列形式の内容を取得する方法
+
+**CODE ノードを使用して返す**
+
+
+
+
+
+* **開始ノード** にタイトルとアウトラインを入力
+* **LLM ノード** を使用して小見出しと対応する内容を生成
+* **コードノード** を使用して完全な内容を配列形式に変換
+* **イテレーションノード** でラップされた **LLM ノード** を通じて各章の内容を複数回生成
+* **テンプレート変換ノード** を使用してイテレーションノードが出力する文字列配列を文字列に変換
+* 最後に **直接応答ノード** を追加して変換後の文字列を直接出力
+
+### 配列の内容とは
+
+リストは特定のデータ型であり、要素はコンマで区切られ、 `[` で始まり `]` で終わります。例えば:
+
+**数値型:**
+
+```
+[0,1,2,3,4,5]
+```
+
+**文字列型:**
+
+```
+["monday", "Tuesday", "Wednesday", "Thursday"]
+```
+
+**JSON オブジェクト:**
+
+```
+[
+ {
+ "name": "Alice",
+ "age": 30,
+ "email": "alice@example.com"
+ },
+ {
+ "name": "Bob",
+ "age": 25,
+ "email": "bob@example.com"
+ },
+ {
+ "name": "Charlie",
+ "age": 35,
+ "email": "charlie@example.com"
+ }
+]
+```
+
+***
+
+### 配列を返すノード
+
+* コードノード
+* パラメータ抽出
+* ナレッジベース検索
+* イテレーション
+* ツール
+* HTTPリクエスト
+
+### 配列形式の内容を取得する方法
+
+**CODE ノードを使用して返す**
+
+
+  +
+
+### 配列をテキストに変換する方法
+
+イテレーションノードの出力変数は配列形式であり、直接出力することはできません。配列をテキストに戻すための簡単なステップを実行することができます。
+
+**コードノードを使用した変換**
+
+
+
+
+
+### 配列をテキストに変換する方法
+
+イテレーションノードの出力変数は配列形式であり、直接出力することはできません。配列をテキストに戻すための簡単なステップを実行することができます。
+
+**コードノードを使用した変換**
+
+
+  +
+
+コード例:
+
+```python
+def main(articleSections: list):
+ data = articleSections
+ return {
+ "result": "\n".join(data)
+ }
+```
+
+**テンプレートノードを使用した変換**
+
+
+
+
+
+コード例:
+
+```python
+def main(articleSections: list):
+ data = articleSections
+ return {
+ "result": "\n".join(data)
+ }
+```
+
+**テンプレートノードを使用した変換**
+
+
+  +
+
+コード例:
+
+```django
+{{ articleSections | join("\n") }}
+```
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/knowledge-retrieval.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/knowledge-retrieval.mdx
new file mode 100644
index 00000000..970de663
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/knowledge-retrieval.mdx
@@ -0,0 +1,59 @@
+---
+title: 知識検索
+version: '日本語'
+---
+
+### 定義
+
+ナレッジベースからユーザーの質問に関連するテキスト内容を検索し、それを下流のLLMノードのコンテキストとして使用することができます。
+
+***
+
+### シナリオ
+
+一般的なシナリオ:外部データ/ナレッジに基づくAI質問応答システム(RAG)を構築。RAGの[基本概念](../../../knowledge-base/indexing-and-retrieval/retrieval-augment)についてもっと知る。
+
+下図は最も基本的なナレッジベース質問応答アプリケーションの例です。このプロセスの実行ロジックは、ユーザーの質問がLLMノードに渡される前に、ナレッジ検索ノードでユーザーの質問に最も関連するテキスト内容を検索し、召喚することです。その後、LLMノード内でユーザーの質問と検索されたコンテキストを一緒に入力し、LLMが検索内容に基づいて質問に答えるようにします。
+
+
+
+
+
+コード例:
+
+```django
+{{ articleSections | join("\n") }}
+```
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/knowledge-retrieval.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/knowledge-retrieval.mdx
new file mode 100644
index 00000000..970de663
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/knowledge-retrieval.mdx
@@ -0,0 +1,59 @@
+---
+title: 知識検索
+version: '日本語'
+---
+
+### 定義
+
+ナレッジベースからユーザーの質問に関連するテキスト内容を検索し、それを下流のLLMノードのコンテキストとして使用することができます。
+
+***
+
+### シナリオ
+
+一般的なシナリオ:外部データ/ナレッジに基づくAI質問応答システム(RAG)を構築。RAGの[基本概念](../../../knowledge-base/indexing-and-retrieval/retrieval-augment)についてもっと知る。
+
+下図は最も基本的なナレッジベース質問応答アプリケーションの例です。このプロセスの実行ロジックは、ユーザーの質問がLLMノードに渡される前に、ナレッジ検索ノードでユーザーの質問に最も関連するテキスト内容を検索し、召喚することです。その後、LLMノード内でユーザーの質問と検索されたコンテキストを一緒に入力し、LLMが検索内容に基づいて質問に答えるようにします。
+
+
+  +
+
+***
+
+### 設定方法
+
+**設定プロセス:**
+
+1. クエリ変数を選択し、ナレッジベース内の関連するテキストセグメントを検索するための入力として使用します。一般的な対話型アプリケーションでは、開始ノードの`sys.query`をクエリ変数として使用します。ナレッジ ベースが受け入れることができる最大クエリ コンテンツは 200 文字です。
+2. 検索するナレッジベースを選択します。オプションとして選択可能なナレッジベースは、Difyナレッジベース内で事前に[作成](../../knowledge-base/create-knowledge-and-upload-documents#id-1-chuang-jian-zhi-shi-ku)する必要があります。
+3. [リコールモード](../../../learn-more/extended-reading/retrieval-augment/retrieval)と[ナレッジベース設定](../../knowledge-base/knowledge-and-documents-maintenance#id-8-zhi-shi-ku-she-zhi)を設定します。
+4. 下流ノードを接続し設定します。一般的にはLLMノードです。
+
+
+
+
+
+***
+
+### 設定方法
+
+**設定プロセス:**
+
+1. クエリ変数を選択し、ナレッジベース内の関連するテキストセグメントを検索するための入力として使用します。一般的な対話型アプリケーションでは、開始ノードの`sys.query`をクエリ変数として使用します。ナレッジ ベースが受け入れることができる最大クエリ コンテンツは 200 文字です。
+2. 検索するナレッジベースを選択します。オプションとして選択可能なナレッジベースは、Difyナレッジベース内で事前に[作成](../../knowledge-base/create-knowledge-and-upload-documents#id-1-chuang-jian-zhi-shi-ku)する必要があります。
+3. [リコールモード](../../../learn-more/extended-reading/retrieval-augment/retrieval)と[ナレッジベース設定](../../knowledge-base/knowledge-and-documents-maintenance#id-8-zhi-shi-ku-she-zhi)を設定します。
+4. 下流ノードを接続し設定します。一般的にはLLMノードです。
+
+
+  +
+
+**出力変数**
+
+
+
+
+
+**出力変数**
+
+
+  +
+
+ナレッジ検索の出力変数`result`は、ナレッジベースから検索された関連テキストセグメントです。この変数のデータ構造には、セグメント内容、タイトル、リンク、アイコン、メタデータ情報が含まれています。
+
+**下流ノードの設定**
+
+一般的な対話型アプリケーションでは、ナレッジベース検索の下流ノードは通常LLMノードであり、ナレッジ検索の**出力変数**`result`はLLMノード内の**コンテキスト変数**に関連付けられて設定されます。関連付け後、プロンプトの適切な位置に**コンテキスト変数**を挿入することができます。
+
+
+
+
+ナレッジ検索の出力変数`result`は、ナレッジベースから検索された関連テキストセグメントです。この変数のデータ構造には、セグメント内容、タイトル、リンク、アイコン、メタデータ情報が含まれています。
+
+**下流ノードの設定**
+
+一般的な対話型アプリケーションでは、ナレッジベース検索の下流ノードは通常LLMノードであり、ナレッジ検索の**出力変数**`result`はLLMノード内の**コンテキスト変数**に関連付けられて設定されます。関連付け後、プロンプトの適切な位置に**コンテキスト変数**を挿入することができます。
+
+ +
+
+この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](../../knowledge-base/retrieval-test-and-citation#id-2-yin-yong-yu-gui-shu)機能もサポートします。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/list-operator.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/list-operator.mdx
new file mode 100644
index 00000000..da2e6a9d
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/list-operator.mdx
@@ -0,0 +1,94 @@
+---
+title: リスト操作
+version: '日本語'
+---
+
+リスト変数は、文章、画像、音声、映像など、さまざまなファイルを同時にアップロードすることができます。ユーザーがファイルをアップロードすると、すべてのファイルが同じ `Array[File]` 配列変数に保存されますが、**その後の個別ファイルの処理が難しくなります。**
+
+> `Array` データ型は、変数の実際の値が \[1.mp3、2.png、3.doc] である可能性があることを意味します。LLM は、入力変数として画像やテキストなどの単一の値の読み取りのみをサポートしており、配列変数を直接読み取ることはできません。
+
+### ノード機能
+
+リストフィルタは、ファイルの形式のタイプ、名、サイズなどの属性に基づいてフィルターして抽出し、異なる形式のファイルをそれぞれの処理ノードに渡すことで、ファイル処理の流れを正確に制御します。
+
+例えば、あるアプリでは、ユーザーが文章と画像を同時にアップロードすることを許可しています。異なるファイルは**リスト操作ノード**を通じて分類され、異なる処理フローに引き渡されます。
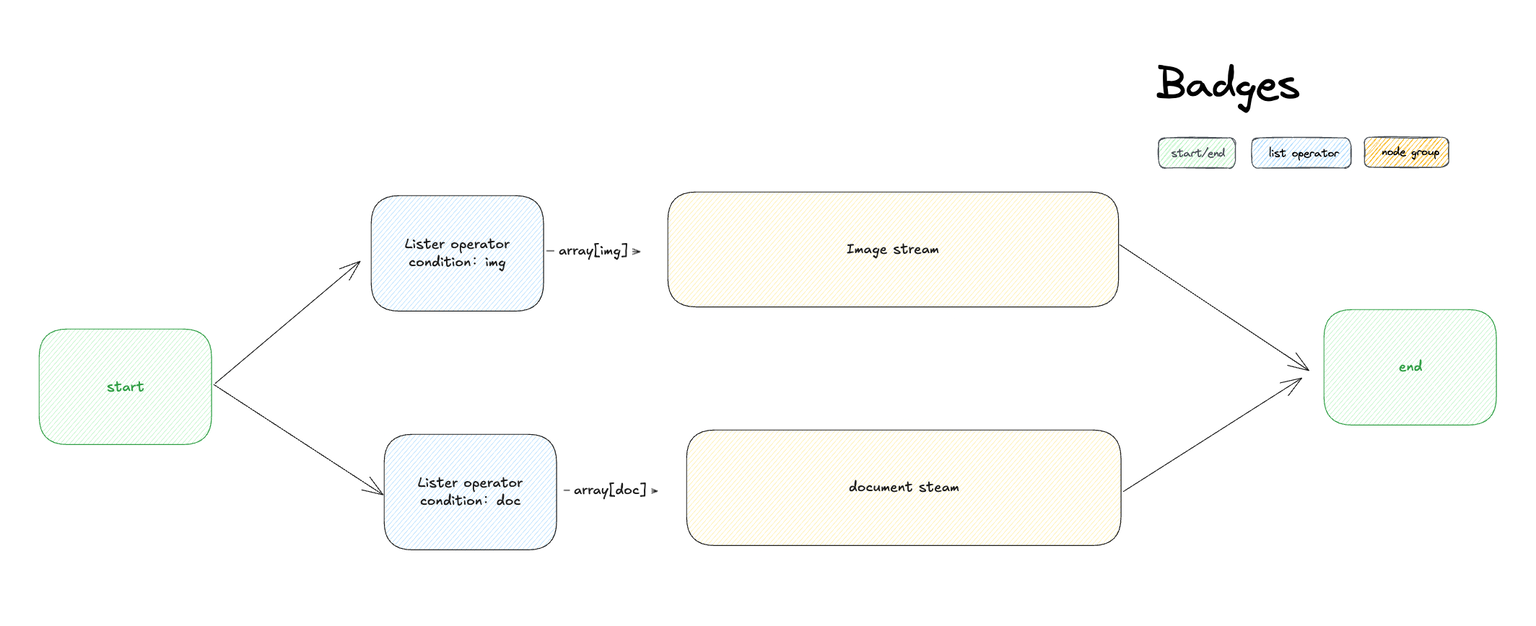
+
+
+
+
+
+リスト操作ノードは通常、配列変数から情報を抽出するために使用され、条件を設定して、下流ノードが受け入れることのできる変数タイプに変換します。その構造は、入力変数、フィルタ条件、ソート、上位 N 項目、および出力変数に分かれています。
+
+
+
+
+
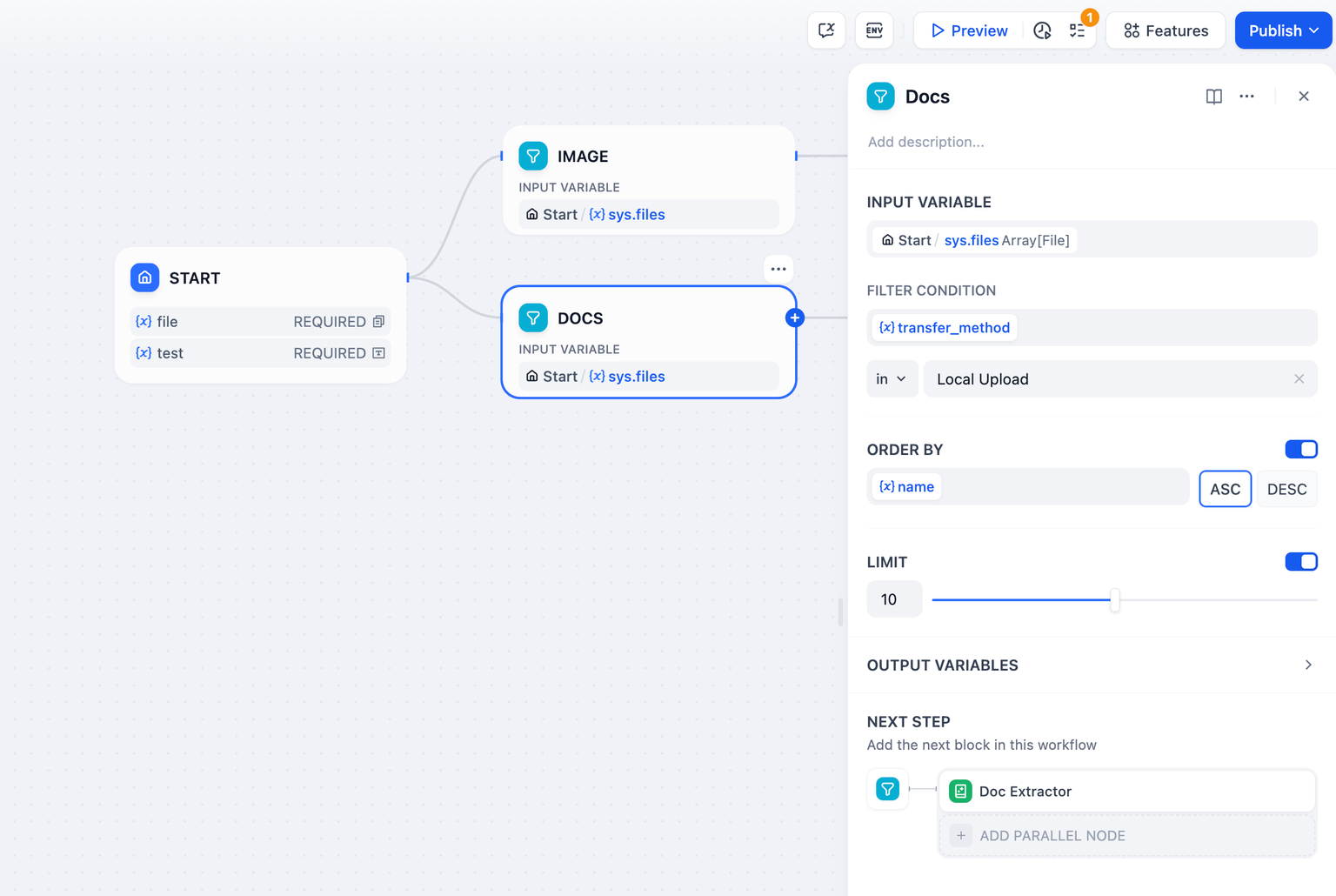
+#### 入力変数
+
+リスト操作ノードは以下のデータ構造変数のみを受け入れます:
+
+* Array[string]
+* Array[number]
+* Array[file]
+
+#### フィルタ条件
+
+入力変数の配列を処理し、フィルタ条件を追加します。条件に合致するすべての配列変数を選択し、その属性をフィルタリングします。
+
+例:ファイルにはファイル名、ファイルタイプ、ファイルサイズなど、複数の属性が含まれる可能性があります。フィルタ条件では、特定のファイルを配列変数から選択し抽出するための条件を設定します。
+
+以下の変数を抽出できます:
+
+* type:ファイルのタイプ(画像、文章、音声、映像など)
+* size:ファイルサイズ
+* name:ファイル名
+* url:ユーザーがURL経由でアップロードしたファイルを指し、完全なURLを入力してフィルタリングできます。
+* extension:ファイルの拡張子
+* mime_type:
+
+ [MIMEタイプ](https://datatracker.ietf.org/doc/html/rfc2046)は、ファイルのコンテンツタイプを識別するための標準化された文字列です。例: "text/html" はHTMLドキュメントを示します。
+
+* transfer_method:
+
+ ファイルのアップロード方法(ローカルアップロードまたはURL経由でのアップロード)を示します。
+
+#### ソート
+
+入力変数の配列をファイルの属性に基づいて並べ替える機能を提供します。
+
+- 昇順ソート:
+
+ デフォルトの並べ替えオプションで、値が小さい順に並べ替えます。文字やテキストの場合はアルファベット順(A - Z)に並べ替えます。
+
+- 降順ソート:
+
+ 値が大きい順に並べ替えます。文字やテキストの場合は逆アルファベット順(Z - A)に並べ替えます。
+
+このオプションは通常、出力変数の first_record および last_record と組み合わせて使用されます。
+
+#### 上位 N 項目
+
+1から20の値を選択し、配列変数の上位 n 項目を選択します。
+
+#### 出力変数
+
+すべてのフィルタ条件を満たす配列要素。フィルタ条件、ソート、制限は個別に有効にできます。すべての条件を同時に有効にした場合、すべての条件を満たす配列要素が返されます。
+
+* Result:フィルタリング結果で、データ型は配列変数です。配列に1つのファイルしか含まれていない場合、出力変数には1つの要素のみが含まれます。
+* first_record:フィルタリングされた配列の最初の要素、すなわち result[0];
+* last_record:フィルタリングされた配列の最後の要素、すなわち result[array.length-1]。
+
+***
+
+### 設定例
+
+ファイルのインタラクティブな質疑応答シナリオでは、アプリのユーザーが文章や画像ファイルを同時にアップロードする可能性があります。LLMは画像ファイルを認識できる能力しか持たず、文章を読み取ることができません。その場合、[リスト操作](list-operator)ノードを使用して、ファイル変数の配列を事前処理し、異なるファイルタイプをそれぞれの処理ノードに送信する必要があります。手順は以下の通りです:
+
+1. [機能](../additional-features)を有効にし、ファイルタイプで「画像」および「文章」を選択します。
+2. フィルタ条件で、画像変数とドキュメント変数をそれぞれ抽出するための2つのリスト操作ノードを追加します。
+3. 文章変数を抽出し、「ドキュメントエクストラクタ」ノードに渡し、画像ファイル変数を抽出してLLMノードに渡します。
+4. 最後に「直接返信」ノードを追加し、LLMノードの出力変数を記入します。
+
+
+
+アプリのユーザーが文章と画像ファイルを同時にアップロードした場合、文章は自動的にドキュメントエクストラクタノードに、画像ファイルは自動的にLLMノードに分流され、混合ファイルの共通処理が実現されます。
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/llm.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/llm.mdx
new file mode 100644
index 00000000..9ef53b0a
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/llm.mdx
@@ -0,0 +1,156 @@
+---
+title: LLM
+version: '日本語'
+---
+
+### 定義
+
+大規模言語モデルを活用して質問に回答したり、自然言語を処理したりします。
+
+
+
+
+
+この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](../../knowledge-base/retrieval-test-and-citation#id-2-yin-yong-yu-gui-shu)機能もサポートします。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/list-operator.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/list-operator.mdx
new file mode 100644
index 00000000..da2e6a9d
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/list-operator.mdx
@@ -0,0 +1,94 @@
+---
+title: リスト操作
+version: '日本語'
+---
+
+リスト変数は、文章、画像、音声、映像など、さまざまなファイルを同時にアップロードすることができます。ユーザーがファイルをアップロードすると、すべてのファイルが同じ `Array[File]` 配列変数に保存されますが、**その後の個別ファイルの処理が難しくなります。**
+
+> `Array` データ型は、変数の実際の値が \[1.mp3、2.png、3.doc] である可能性があることを意味します。LLM は、入力変数として画像やテキストなどの単一の値の読み取りのみをサポートしており、配列変数を直接読み取ることはできません。
+
+### ノード機能
+
+リストフィルタは、ファイルの形式のタイプ、名、サイズなどの属性に基づいてフィルターして抽出し、異なる形式のファイルをそれぞれの処理ノードに渡すことで、ファイル処理の流れを正確に制御します。
+
+例えば、あるアプリでは、ユーザーが文章と画像を同時にアップロードすることを許可しています。異なるファイルは**リスト操作ノード**を通じて分類され、異なる処理フローに引き渡されます。
+
+
+
+
+
+リスト操作ノードは通常、配列変数から情報を抽出するために使用され、条件を設定して、下流ノードが受け入れることのできる変数タイプに変換します。その構造は、入力変数、フィルタ条件、ソート、上位 N 項目、および出力変数に分かれています。
+
+
+
+
+
+#### 入力変数
+
+リスト操作ノードは以下のデータ構造変数のみを受け入れます:
+
+* Array[string]
+* Array[number]
+* Array[file]
+
+#### フィルタ条件
+
+入力変数の配列を処理し、フィルタ条件を追加します。条件に合致するすべての配列変数を選択し、その属性をフィルタリングします。
+
+例:ファイルにはファイル名、ファイルタイプ、ファイルサイズなど、複数の属性が含まれる可能性があります。フィルタ条件では、特定のファイルを配列変数から選択し抽出するための条件を設定します。
+
+以下の変数を抽出できます:
+
+* type:ファイルのタイプ(画像、文章、音声、映像など)
+* size:ファイルサイズ
+* name:ファイル名
+* url:ユーザーがURL経由でアップロードしたファイルを指し、完全なURLを入力してフィルタリングできます。
+* extension:ファイルの拡張子
+* mime_type:
+
+ [MIMEタイプ](https://datatracker.ietf.org/doc/html/rfc2046)は、ファイルのコンテンツタイプを識別するための標準化された文字列です。例: "text/html" はHTMLドキュメントを示します。
+
+* transfer_method:
+
+ ファイルのアップロード方法(ローカルアップロードまたはURL経由でのアップロード)を示します。
+
+#### ソート
+
+入力変数の配列をファイルの属性に基づいて並べ替える機能を提供します。
+
+- 昇順ソート:
+
+ デフォルトの並べ替えオプションで、値が小さい順に並べ替えます。文字やテキストの場合はアルファベット順(A - Z)に並べ替えます。
+
+- 降順ソート:
+
+ 値が大きい順に並べ替えます。文字やテキストの場合は逆アルファベット順(Z - A)に並べ替えます。
+
+このオプションは通常、出力変数の first_record および last_record と組み合わせて使用されます。
+
+#### 上位 N 項目
+
+1から20の値を選択し、配列変数の上位 n 項目を選択します。
+
+#### 出力変数
+
+すべてのフィルタ条件を満たす配列要素。フィルタ条件、ソート、制限は個別に有効にできます。すべての条件を同時に有効にした場合、すべての条件を満たす配列要素が返されます。
+
+* Result:フィルタリング結果で、データ型は配列変数です。配列に1つのファイルしか含まれていない場合、出力変数には1つの要素のみが含まれます。
+* first_record:フィルタリングされた配列の最初の要素、すなわち result[0];
+* last_record:フィルタリングされた配列の最後の要素、すなわち result[array.length-1]。
+
+***
+
+### 設定例
+
+ファイルのインタラクティブな質疑応答シナリオでは、アプリのユーザーが文章や画像ファイルを同時にアップロードする可能性があります。LLMは画像ファイルを認識できる能力しか持たず、文章を読み取ることができません。その場合、[リスト操作](list-operator)ノードを使用して、ファイル変数の配列を事前処理し、異なるファイルタイプをそれぞれの処理ノードに送信する必要があります。手順は以下の通りです:
+
+1. [機能](../additional-features)を有効にし、ファイルタイプで「画像」および「文章」を選択します。
+2. フィルタ条件で、画像変数とドキュメント変数をそれぞれ抽出するための2つのリスト操作ノードを追加します。
+3. 文章変数を抽出し、「ドキュメントエクストラクタ」ノードに渡し、画像ファイル変数を抽出してLLMノードに渡します。
+4. 最後に「直接返信」ノードを追加し、LLMノードの出力変数を記入します。
+
+
+
+アプリのユーザーが文章と画像ファイルを同時にアップロードした場合、文章は自動的にドキュメントエクストラクタノードに、画像ファイルは自動的にLLMノードに分流され、混合ファイルの共通処理が実現されます。
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/llm.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/llm.mdx
new file mode 100644
index 00000000..9ef53b0a
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/llm.mdx
@@ -0,0 +1,156 @@
+---
+title: LLM
+version: '日本語'
+---
+
+### 定義
+
+大規模言語モデルを活用して質問に回答したり、自然言語を処理したりします。
+
+
+  +
+
+***
+
+### シナリオ
+
+LLM は チャットフロー/ワークフロー の中心的なノードであり、大規模言語モデルの会話/生成/分類/処理などの能力を活用して、多様なタスクを提示されたプロンプトに基づいて処理し、ワークフローのさまざまな段階で使用することができます。
+
+* **意図識別**:カスタマーサービスの対話シナリオにおいて、ユーザーの質問を意図識別および分類し、異なるフローに誘導します。
+* **テキスト生成**:記事生成シナリオにおいて、テーマやキーワードに基づいて適切なテキスト内容を生成するノードとして機能します。
+* **内容分類**:メールのバッチ処理シナリオにおいて、メールの種類を自動的に分類します(例:問い合わせ/苦情/スパム)。
+* **テキスト変換**:テキスト翻訳シナリオにおいて、ユーザーが提供したテキスト内容を指定された言語に翻訳します。
+* **コード生成**:プログラミング支援シナリオにおいて、ユーザーの要求に基づいて指定のビジネスコードやテストケースを生成します。
+* **RAG**:ナレッジベースの質問応答シナリオにおいて、検索した関連知識とユーザーの質問を再構成して回答します。
+* **画像理解**:ビジョン能力を持つマルチモーダルモデルを使用し、画像内の情報を理解して質問に回答します。
+
+適切なモデルを選択し、プロンプトを記述することで、チャットフロー/ワークフロー で強力で信頼性の高いソリューションを構築できます。
+
+***
+
+### 設定方法
+
+エディットページで、前のノードの末尾を右クリックするか、+ボタンを軽くタップして新しいノードを追加し、LLM(大規模言語モデル)を選択します。
+
+
+
+
+
+***
+
+### シナリオ
+
+LLM は チャットフロー/ワークフロー の中心的なノードであり、大規模言語モデルの会話/生成/分類/処理などの能力を活用して、多様なタスクを提示されたプロンプトに基づいて処理し、ワークフローのさまざまな段階で使用することができます。
+
+* **意図識別**:カスタマーサービスの対話シナリオにおいて、ユーザーの質問を意図識別および分類し、異なるフローに誘導します。
+* **テキスト生成**:記事生成シナリオにおいて、テーマやキーワードに基づいて適切なテキスト内容を生成するノードとして機能します。
+* **内容分類**:メールのバッチ処理シナリオにおいて、メールの種類を自動的に分類します(例:問い合わせ/苦情/スパム)。
+* **テキスト変換**:テキスト翻訳シナリオにおいて、ユーザーが提供したテキスト内容を指定された言語に翻訳します。
+* **コード生成**:プログラミング支援シナリオにおいて、ユーザーの要求に基づいて指定のビジネスコードやテストケースを生成します。
+* **RAG**:ナレッジベースの質問応答シナリオにおいて、検索した関連知識とユーザーの質問を再構成して回答します。
+* **画像理解**:ビジョン能力を持つマルチモーダルモデルを使用し、画像内の情報を理解して質問に回答します。
+
+適切なモデルを選択し、プロンプトを記述することで、チャットフロー/ワークフロー で強力で信頼性の高いソリューションを構築できます。
+
+***
+
+### 設定方法
+
+エディットページで、前のノードの末尾を右クリックするか、+ボタンを軽くタップして新しいノードを追加し、LLM(大規模言語モデル)を選択します。
+
+
+  +
+
+**設定手順:**
+
+1. **モデルの選択**:Difyでは、OpenAIのGPTシリーズ、AnthropicのClaudeシリーズ、GoogleのGeminiシリーズなど、世界中で広く使用されているさまざまなモデルを[サポート](../../../getting-started/readme/model-providers)しています。モデルの選択は、推論能力、コスト、応答速度、コンテキストウィンドウのサイズなどの要因に基づいて行います。使用するシーンやタスクの種類に応じて、適切なモデルを選ぶことが重要です。
+
+
+
+
+**設定手順:**
+
+1. **モデルの選択**:Difyでは、OpenAIのGPTシリーズ、AnthropicのClaudeシリーズ、GoogleのGeminiシリーズなど、世界中で広く使用されているさまざまなモデルを[サポート](../../../getting-started/readme/model-providers)しています。モデルの選択は、推論能力、コスト、応答速度、コンテキストウィンドウのサイズなどの要因に基づいて行います。使用するシーンやタスクの種類に応じて、適切なモデルを選ぶことが重要です。
+
+ +
+
+システムプロンプト(SYSTEM)を作成する際にアイデアが浮かばない場合は、プロンプトジェネレーター機能を使用して、実際のビジネスシナリオに適したプロンプトを迅速に生成することができます。
+
+
+
+
+
+システムプロンプト(SYSTEM)を作成する際にアイデアが浮かばない場合は、プロンプトジェネレーター機能を使用して、実際のビジネスシナリオに適したプロンプトを迅速に生成することができます。
+
+
+  +
+
+プロンプトエディターでは、**“/”** を入力することで **変数挿入メニュー** を呼び出し、**特殊変数ブロック**や **上流ノードの変数**をプロンプトに挿入してコンテキスト内容として使用できます。
+
+
+
+
+
+プロンプトエディターでは、**“/”** を入力することで **変数挿入メニュー** を呼び出し、**特殊変数ブロック**や **上流ノードの変数**をプロンプトに挿入してコンテキスト内容として使用できます。
+
+
+  +
+
+5. **上級的な設定**:メモリ機能をオンにしたり、メモリウィンドウを設定したり、ビジョン機能を有効にしたり、Jinja-2テンプレート言語を使ってより複雑なプロンプトを作成したりできます。
+
+***
+
+### **特殊変数の説明**
+
+**コンテキスト変数**
+
+コンテキスト変数とは、言語モデル(LLM)に背景情報を提供するための特別な変数の一種で、特に知識検索のシナリオでよく利用されます。詳細については、[知識検索ノード](knowledge-retrieval)を参照してください。
+
+**画像ファイル変数**
+
+視覚機能を備えた言語モデル(LLM)は、アプリケーションユーザーがアップロードした画像をこの変数を通じて読み取ることができます。VISION機能を有効にした後、画像ファイルの出力変数を選択して設定を完了させてください。
+
+
+ {/*
+
+
+5. **上級的な設定**:メモリ機能をオンにしたり、メモリウィンドウを設定したり、ビジョン機能を有効にしたり、Jinja-2テンプレート言語を使ってより複雑なプロンプトを作成したりできます。
+
+***
+
+### **特殊変数の説明**
+
+**コンテキスト変数**
+
+コンテキスト変数とは、言語モデル(LLM)に背景情報を提供するための特別な変数の一種で、特に知識検索のシナリオでよく利用されます。詳細については、[知識検索ノード](knowledge-retrieval)を参照してください。
+
+**画像ファイル変数**
+
+視覚機能を備えた言語モデル(LLM)は、アプリケーションユーザーがアップロードした画像をこの変数を通じて読み取ることができます。VISION機能を有効にした後、画像ファイルの出力変数を選択して設定を完了させてください。
+
+
+ {/* .png) */}
+ 
+
+
+**会話履歴**
+
+テキスト補完モデル(例:gpt-3.5-turbo-Instruct)内でチャット型アプリケーションの対話記憶を実現するために、Dify は元の[プロンプト専門モード(廃止)](https://docs.dify.ai/v/ja-jp/learn-more/extended-reading/prompt-engineering/prompt-engineering)内で会話履歴変数を設計しました。この変数はチャットフローのLLMノード内でも使用され、プロンプト内に AI とユーザーの対話履歴を挿入して、LLM が対話の文脈を理解するのを助けます。
+
+
*/}
+ 
+
+
+**会話履歴**
+
+テキスト補完モデル(例:gpt-3.5-turbo-Instruct)内でチャット型アプリケーションの対話記憶を実現するために、Dify は元の[プロンプト専門モード(廃止)](https://docs.dify.ai/v/ja-jp/learn-more/extended-reading/prompt-engineering/prompt-engineering)内で会話履歴変数を設計しました。この変数はチャットフローのLLMノード内でも使用され、プロンプト内に AI とユーザーの対話履歴を挿入して、LLM が対話の文脈を理解するのを助けます。
+
+ +
+
+**モデルパラメーター**
+
+モデルのパラメータはモデルの出力に影響を与えます。異なるモデルには異なるパラメータがあります。以下の図は`gpt-4`のパラメータリストです。
+
+
+
+
+
+**モデルパラメーター**
+
+モデルのパラメータはモデルの出力に影響を与えます。異なるモデルには異なるパラメータがあります。以下の図は`gpt-4`のパラメータリストです。
+
+
+  +
+
+主要なパラメータ用語は以下のように説明されています:
+
+* **Temperature(温度)**: 通常は0-1の値で、ランダム性を制御します。温度が0に近いほど、結果はより確定的で繰り返しになり、温度が1に近いほど、結果はよりランダムになります。
+* **Top P**: 結果の多様性を制御します。モデルは確率に基づいて候補語から選択し、累積確率が設定された閾値Pを超えないようにします。
+* **Presence Penalty(存在ペナルティ)**: 既に生成された内容にペナルティを課すことにより、同じエンティティや情報の繰り返し生成を減少させるために使用されます。パラメータ値が増加するにつれて、既に生成された内容に対して後続の生成でより大きなペナルティが課され、内容の繰り返しの可能性が低くなります。
+* **Frequency Penalty(頻度ペナルティ)**: 頻繁に出現する単語やフレーズにペナルティを課し、これらの単語の生成確率を低下させます。パラメータ値が増加すると、頻繁に出現する単語やフレーズにより大きなペナルティが課されます。パラメータ値が高いほど、これらの単語の出現頻度が減少し、テキストの語彙の多様性が増加します。
+
+これらのパラメータが何であるか理解できない場合は、プリセットを読み込んで、「クリエイティブ」、「バランス」、「正確」の3つのプリセットから選択することができます。
+
+
+
+
+
+主要なパラメータ用語は以下のように説明されています:
+
+* **Temperature(温度)**: 通常は0-1の値で、ランダム性を制御します。温度が0に近いほど、結果はより確定的で繰り返しになり、温度が1に近いほど、結果はよりランダムになります。
+* **Top P**: 結果の多様性を制御します。モデルは確率に基づいて候補語から選択し、累積確率が設定された閾値Pを超えないようにします。
+* **Presence Penalty(存在ペナルティ)**: 既に生成された内容にペナルティを課すことにより、同じエンティティや情報の繰り返し生成を減少させるために使用されます。パラメータ値が増加するにつれて、既に生成された内容に対して後続の生成でより大きなペナルティが課され、内容の繰り返しの可能性が低くなります。
+* **Frequency Penalty(頻度ペナルティ)**: 頻繁に出現する単語やフレーズにペナルティを課し、これらの単語の生成確率を低下させます。パラメータ値が増加すると、頻繁に出現する単語やフレーズにより大きなペナルティが課されます。パラメータ値が高いほど、これらの単語の出現頻度が減少し、テキストの語彙の多様性が増加します。
+
+これらのパラメータが何であるか理解できない場合は、プリセットを読み込んで、「クリエイティブ」、「バランス」、「正確」の3つのプリセットから選択することができます。
+
+
+  +
+
+***
+
+### 高度な機能
+
+**記憶**:記憶をオンにすると、問題分類器の各入力に対話履歴が含まれ、LLM が文脈を理解しやすくなり、対話の理解能力が向上します。
+
+**記憶ウィンドウ**:記憶ウィンドウが閉じている場合、システムはモデルのコンテキストウィンドウに基づいて対話履歴の伝達数を動的にフィルタリングします。開いている場合、ユーザーは対話履歴の伝達数を正確に制御できます(対数)。
+
+**対話役割名の設定**:モデルのトレーニング段階の違いにより、異なるモデルは役割名のプロンプト遵守度が異なります(例:Human/Assistant、Human/AI、人間/助手など)。複数のモデルに対応するために、システムは対話役割名の設定を提供しており、対話役割名を変更すると会話履歴の役割プレフィックスも変更されます。
+
+**Jinja-2 テンプレート**:LLM のプロンプトエディター内で Jinja-2 テンプレート言語をサポートしており、Jinja2 の強力な Python テンプレート言語を使用して軽量なデータ変換やロジック処理を実現できます。詳細は[公式ドキュメント](https://jinja.palletsprojects.com/en/3.1.x/templates/)を参照してください。
+
+***
+
+### ユースケース
+
+* **ナレッジベースの内容を検索する**
+
+ワークフローアプリケーションが[「ナレッジベース」](../../knowledge-base/)の内容を検索できるようにしたい場合、例えばインテリジェントカスタマーサービスアプリケーションを構築する場合は、以下の手順を参考にしてください。
+
+1. LLMノードの上流に知識検索ノードを追加します;
+2. 知識検索ノードの **出力変数** `result` をLLMノードの **コンテキスト変数** に入力します;
+3. **コンテキスト変数** をアプリケーションのプロンプトに挿入し、LLMがナレッジベース内のテキスト内容を読み取れるようにします。
+
+
+
+
+
+***
+
+### 高度な機能
+
+**記憶**:記憶をオンにすると、問題分類器の各入力に対話履歴が含まれ、LLM が文脈を理解しやすくなり、対話の理解能力が向上します。
+
+**記憶ウィンドウ**:記憶ウィンドウが閉じている場合、システムはモデルのコンテキストウィンドウに基づいて対話履歴の伝達数を動的にフィルタリングします。開いている場合、ユーザーは対話履歴の伝達数を正確に制御できます(対数)。
+
+**対話役割名の設定**:モデルのトレーニング段階の違いにより、異なるモデルは役割名のプロンプト遵守度が異なります(例:Human/Assistant、Human/AI、人間/助手など)。複数のモデルに対応するために、システムは対話役割名の設定を提供しており、対話役割名を変更すると会話履歴の役割プレフィックスも変更されます。
+
+**Jinja-2 テンプレート**:LLM のプロンプトエディター内で Jinja-2 テンプレート言語をサポートしており、Jinja2 の強力な Python テンプレート言語を使用して軽量なデータ変換やロジック処理を実現できます。詳細は[公式ドキュメント](https://jinja.palletsprojects.com/en/3.1.x/templates/)を参照してください。
+
+***
+
+### ユースケース
+
+* **ナレッジベースの内容を検索する**
+
+ワークフローアプリケーションが[「ナレッジベース」](../../knowledge-base/)の内容を検索できるようにしたい場合、例えばインテリジェントカスタマーサービスアプリケーションを構築する場合は、以下の手順を参考にしてください。
+
+1. LLMノードの上流に知識検索ノードを追加します;
+2. 知識検索ノードの **出力変数** `result` をLLMノードの **コンテキスト変数** に入力します;
+3. **コンテキスト変数** をアプリケーションのプロンプトに挿入し、LLMがナレッジベース内のテキスト内容を読み取れるようにします。
+
+
+  +
+
+[知識検索ノード](./knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](../../knowledge-base/retrieval-test-and-citation) 機能を使用して情報の出所を確認できます。
+
+
+
+
+[知識検索ノード](./knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](../../knowledge-base/retrieval-test-and-citation) 機能を使用して情報の出所を確認できます。
+
+ +
+
+2. **テキストを構造化データに変換する**例として、長い物語のイテレーション生成アプリの前工程として、テキスト形式の章内容を配列形式に変換し、[イテレーションノード](./iteration)でのマルチラウンド生成処理を容易にします。
+
+
+
+
+
+2. **テキストを構造化データに変換する**例として、長い物語のイテレーション生成アプリの前工程として、テキスト形式の章内容を配列形式に変換し、[イテレーションノード](./iteration)でのマルチラウンド生成処理を容易にします。
+
+
+  +
+
+3. **構造化データを抽出して**[**HTTPリクエスト**](./http-request)**を使用する**ことで、任意のアクセス可能なURLにリクエストを送信し、外部検索結果の取得やウェブフック、画像生成などのシナリオに適用できます。
+
+***
+
+### 設定方法
+
+
+
+
+
+3. **構造化データを抽出して**[**HTTPリクエスト**](./http-request)**を使用する**ことで、任意のアクセス可能なURLにリクエストを送信し、外部検索結果の取得やウェブフック、画像生成などのシナリオに適用できます。
+
+***
+
+### 設定方法
+
+
+  +
+
+**設定手順**
+
+1. 入力変数を選択。通常はパラメータ抽出のための変数入力を選びます。ファイルタイプもサポートします。
+2. モデルを選択。パラメータ抽出器の抽出はLLMの推論と構造化生成能力に依存します。
+3. 抽出パラメータを定義。必要なパラメータを手動で追加するか、**既存のツールから簡単にインポート**できます。
+4. コマンド作成。複雑なパラメータの抽出時には、例を作成することでLLMの生成効果と安定性を向上させることができます。
+
+**高度な設定**
+
+**推論モード**
+
+一部のモデルは関数/ツール呼び出しや純プロンプトの方法でパラメータ抽出を実現する2つの推論モードをサポートしており、コマンドの遵守能力に違いがあります。例えば、あるモデルが関数呼び出しに不向きな場合、プロンプト推論に切り替えることができます。
+
+* Function Call/Tool Call
+* プロンプト
+
+**メモリ**
+
+メモリを有効にすると、問題分類器の各入力にチャット履歴が含まれ、LLMが前文を理解し、対話の中での問題理解能力を向上させます。
+
+**画像**
+
+画像をオープンする。
+
+**出力変数**
+
+* 定義された変数を抽出
+* ノード組み込み変数
+
+`__is_success 数値` 抽出が成功した場合は1、失敗した場合は0となります。
+
+`__reason 文字列` 抽出エラーの原因
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/question-classifier.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/question-classifier.mdx
new file mode 100644
index 00000000..2c1de316
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/question-classifier.mdx
@@ -0,0 +1,65 @@
+---
+title: 質問分類
+version: '日本語'
+---
+
+### **定義**
+
+分類記述を定義することにより、問題分類子は LLM を使用してユーザー入力に基づいて一致する分類を推測し、分類結果を出力し、より正確な情報を下流ノードに提供できます。
+
+***
+
+### **シナリオ**
+
+よくある使用シナリオには、**カスタマーサービス対話意図分類、製品評価分類、メールのバッチ分類**などがあります。
+
+典型的な製品カスタマーサービスのシナリオでは、問題分類器はナレッジベース検索の前段階として機能し、ユーザーの質問の意図を分類します。分類後、異なるナレッジベースに誘導され、ユーザーの質問に正確に回答します。
+
+以下の図は製品カスタマーサービスシナリオのサンプルワークフローテンプレートです:
+
+
+
+
+
+**設定手順**
+
+1. 入力変数を選択。通常はパラメータ抽出のための変数入力を選びます。ファイルタイプもサポートします。
+2. モデルを選択。パラメータ抽出器の抽出はLLMの推論と構造化生成能力に依存します。
+3. 抽出パラメータを定義。必要なパラメータを手動で追加するか、**既存のツールから簡単にインポート**できます。
+4. コマンド作成。複雑なパラメータの抽出時には、例を作成することでLLMの生成効果と安定性を向上させることができます。
+
+**高度な設定**
+
+**推論モード**
+
+一部のモデルは関数/ツール呼び出しや純プロンプトの方法でパラメータ抽出を実現する2つの推論モードをサポートしており、コマンドの遵守能力に違いがあります。例えば、あるモデルが関数呼び出しに不向きな場合、プロンプト推論に切り替えることができます。
+
+* Function Call/Tool Call
+* プロンプト
+
+**メモリ**
+
+メモリを有効にすると、問題分類器の各入力にチャット履歴が含まれ、LLMが前文を理解し、対話の中での問題理解能力を向上させます。
+
+**画像**
+
+画像をオープンする。
+
+**出力変数**
+
+* 定義された変数を抽出
+* ノード組み込み変数
+
+`__is_success 数値` 抽出が成功した場合は1、失敗した場合は0となります。
+
+`__reason 文字列` 抽出エラーの原因
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/question-classifier.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/question-classifier.mdx
new file mode 100644
index 00000000..2c1de316
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/question-classifier.mdx
@@ -0,0 +1,65 @@
+---
+title: 質問分類
+version: '日本語'
+---
+
+### **定義**
+
+分類記述を定義することにより、問題分類子は LLM を使用してユーザー入力に基づいて一致する分類を推測し、分類結果を出力し、より正確な情報を下流ノードに提供できます。
+
+***
+
+### **シナリオ**
+
+よくある使用シナリオには、**カスタマーサービス対話意図分類、製品評価分類、メールのバッチ分類**などがあります。
+
+典型的な製品カスタマーサービスのシナリオでは、問題分類器はナレッジベース検索の前段階として機能し、ユーザーの質問の意図を分類します。分類後、異なるナレッジベースに誘導され、ユーザーの質問に正確に回答します。
+
+以下の図は製品カスタマーサービスシナリオのサンプルワークフローテンプレートです:
+
+
+  +
+
+このシナリオでは、3つの分類ラベル/説明を設定しています:
+
+* 分類 1:**アフターサービスに関する問題**
+* 分類 2:**製品の操作に関する問題**
+* 分類 3:**その他の問題**
+
+ユーザーが異なる質問を入力すると、問題分類器は設定された分類ラベル/説明に基づいて自動的に分類を行います:
+
+* “**iPhone 14で連絡先を設定する方法は?**” —> “**製品の操作に関する問題**”
+* “**保証期間はどれくらいですか?**” —> “**アフターサービスに関する問題**”
+* “**今日の天気はどうですか?**” —> “**その他の問題**”
+
+***
+
+### 設定方法
+
+
+
+
+
+このシナリオでは、3つの分類ラベル/説明を設定しています:
+
+* 分類 1:**アフターサービスに関する問題**
+* 分類 2:**製品の操作に関する問題**
+* 分類 3:**その他の問題**
+
+ユーザーが異なる質問を入力すると、問題分類器は設定された分類ラベル/説明に基づいて自動的に分類を行います:
+
+* “**iPhone 14で連絡先を設定する方法は?**” —> “**製品の操作に関する問題**”
+* “**保証期間はどれくらいですか?**” —> “**アフターサービスに関する問題**”
+* “**今日の天気はどうですか?**” —> “**その他の問題**”
+
+***
+
+### 設定方法
+
+
+  +
+
+**設定手順:**
+
+1. **入力変数を選択する**、分類に使用する入力内容を指します、[ファイルのアップロード](/ja-jp/user-guide/build-app/flow-app/file-upload)もサポートします。カスタマーサービスのシナリオでは一般的にユーザーの質問 `sys.query` が対象です。
+2. **推論モデルを選択する**、問題分類器は大規模言語モデル (LLM) の自然言語分類と推論能力に基づいており、適切なモデルを選ぶことで分類効果を向上させることができます。
+3. **分類ラベル/説明を作成する**、複数の分類を手動で追加し、分類のキーワードや説明文を作成することで、大規模言語モデルが分類基準をよりよく理解できるようにします。
+4. **分類に対応する下流ノードを選択する**、問題分類ノードが分類を完了した後、分類と下流ノードの関係に基づいて後続のプロセスパスを選択します。
+
+#### **高度な設定:**
+
+**指示:** **高度な設定-指示** では、例えばより豊富な分類基準など、追加の指示を補足することができます。これにより問題分類器の分類能力が強化されます。
+
+**メモリー:** メモリーをオンにすると、問題分類器の各入力には対話のチャット履歴が含まれ、LLM が前文を理解しやすくなり、対話の中での問題理解能力が向上します。
+
+**画像分析:** 画像認識機能を備えた LLM でのみ利用可能で、画像変数の入力が可能です。
+
+**メモリウィンドウ:** メモリウィンドウがオフの時、システムはモデルのコンテキストウィンドウに基づいてチャット履歴の伝達量を動的にフィルタリングします。オンの時、ユーザーはチャット履歴の伝達量を正確に制御できます(対数表示)。
+
+**出力変数:**
+
+`class_name`
+
+分類後に出力される分類名です。必要に応じて下流ノードで分類結果変数を使用することができます。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/start.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/start.mdx
new file mode 100644
index 00000000..fb4aec69
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/start.mdx
@@ -0,0 +1,88 @@
+---
+title: 開始
+version: '日本語'
+---
+
+## 定義
+
+**“開始”** ノードは、すべてのワークフローアプリ(チャットフロー / ワークフロー)に必須のデフォルトノードであり、後続のワークフローノードやアプリの正常なプロセスに必要な初期情報を提供します。これには、アプリの使用者が入力した内容や、[アップロードされたファイル](../file-upload)などが含まれます。
+
+### ノードの設定
+
+開始ノードの設定ページでは、**“入力フィールド”**とデフォルトの[**システム変数**](../variables)という二つの設定部分が見られます。
+
+
+
+
+
+**設定手順:**
+
+1. **入力変数を選択する**、分類に使用する入力内容を指します、[ファイルのアップロード](/ja-jp/user-guide/build-app/flow-app/file-upload)もサポートします。カスタマーサービスのシナリオでは一般的にユーザーの質問 `sys.query` が対象です。
+2. **推論モデルを選択する**、問題分類器は大規模言語モデル (LLM) の自然言語分類と推論能力に基づいており、適切なモデルを選ぶことで分類効果を向上させることができます。
+3. **分類ラベル/説明を作成する**、複数の分類を手動で追加し、分類のキーワードや説明文を作成することで、大規模言語モデルが分類基準をよりよく理解できるようにします。
+4. **分類に対応する下流ノードを選択する**、問題分類ノードが分類を完了した後、分類と下流ノードの関係に基づいて後続のプロセスパスを選択します。
+
+#### **高度な設定:**
+
+**指示:** **高度な設定-指示** では、例えばより豊富な分類基準など、追加の指示を補足することができます。これにより問題分類器の分類能力が強化されます。
+
+**メモリー:** メモリーをオンにすると、問題分類器の各入力には対話のチャット履歴が含まれ、LLM が前文を理解しやすくなり、対話の中での問題理解能力が向上します。
+
+**画像分析:** 画像認識機能を備えた LLM でのみ利用可能で、画像変数の入力が可能です。
+
+**メモリウィンドウ:** メモリウィンドウがオフの時、システムはモデルのコンテキストウィンドウに基づいてチャット履歴の伝達量を動的にフィルタリングします。オンの時、ユーザーはチャット履歴の伝達量を正確に制御できます(対数表示)。
+
+**出力変数:**
+
+`class_name`
+
+分類後に出力される分類名です。必要に応じて下流ノードで分類結果変数を使用することができます。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/start.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/start.mdx
new file mode 100644
index 00000000..fb4aec69
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/start.mdx
@@ -0,0 +1,88 @@
+---
+title: 開始
+version: '日本語'
+---
+
+## 定義
+
+**“開始”** ノードは、すべてのワークフローアプリ(チャットフロー / ワークフロー)に必須のデフォルトノードであり、後続のワークフローノードやアプリの正常なプロセスに必要な初期情報を提供します。これには、アプリの使用者が入力した内容や、[アップロードされたファイル](../file-upload)などが含まれます。
+
+### ノードの設定
+
+開始ノードの設定ページでは、**“入力フィールド”**とデフォルトの[**システム変数**](../variables)という二つの設定部分が見られます。
+
+
+  +
+
+### 入力フィールド
+
+入力フィールドの機能はアプリ開発者によって設定され、通常はアプリの使用者がさらに情報を提供するために使用されます。例えば、週次報告アプリでは、使用者に対して名前、作業期間、作業内容などの背景情報をあらかじめフォーマットに従って提供するよう求めることがあります。これらの前提情報は、LLM(大規模言語モデル)がより質の高い回答を生成するのに役立ちます。
+
+以下の6種類の入力変数をサポートしており、すべての変数は必須項目として設定可能です:
+
+* **テキスト**
+
+ 短いテキストで、アプリ使用者が自分で内容を入力します。最大文字数は256文字です。
+* **段落**
+
+ 長文で、アプリ使用者が長いテキストを入力することができます。
+* **ドロップダウンオプション**
+
+ アプリ開発者によって固定された選択肢で、アプリ使用者は設定された選択肢の中からのみ選ぶことができ、自由に内容を入力することはできません。
+* **数字**
+
+ 数字のみの入力を許可します。
+* **単一ファイル**
+
+ アプリ使用者が単独でファイルをアップロードできる機能で、サポートされるファイルタイプは文書、画像、音声、動画、その他のファイルです。ローカルからのファイルアップロードやファイルのURLを貼り付けてのアップロードが可能です。詳細な使い方については[ファイルアップロード](../file-upload)を参照してください。
+* **ファイルリスト**
+
+ アプリ使用者が複数のファイルを一括でアップロードできる機能で、サポートされるファイルタイプは文書、画像、音声、動画、その他のファイルです。ローカルからのファイルアップロードやファイルのURLを貼り付けてのアップロードが可能です。詳細な使い方については[ファイルアップロード](../file-upload)を参照してください。
+
+
+
+
+### 入力フィールド
+
+入力フィールドの機能はアプリ開発者によって設定され、通常はアプリの使用者がさらに情報を提供するために使用されます。例えば、週次報告アプリでは、使用者に対して名前、作業期間、作業内容などの背景情報をあらかじめフォーマットに従って提供するよう求めることがあります。これらの前提情報は、LLM(大規模言語モデル)がより質の高い回答を生成するのに役立ちます。
+
+以下の6種類の入力変数をサポートしており、すべての変数は必須項目として設定可能です:
+
+* **テキスト**
+
+ 短いテキストで、アプリ使用者が自分で内容を入力します。最大文字数は256文字です。
+* **段落**
+
+ 長文で、アプリ使用者が長いテキストを入力することができます。
+* **ドロップダウンオプション**
+
+ アプリ開発者によって固定された選択肢で、アプリ使用者は設定された選択肢の中からのみ選ぶことができ、自由に内容を入力することはできません。
+* **数字**
+
+ 数字のみの入力を許可します。
+* **単一ファイル**
+
+ アプリ使用者が単独でファイルをアップロードできる機能で、サポートされるファイルタイプは文書、画像、音声、動画、その他のファイルです。ローカルからのファイルアップロードやファイルのURLを貼り付けてのアップロードが可能です。詳細な使い方については[ファイルアップロード](../file-upload)を参照してください。
+* **ファイルリスト**
+
+ アプリ使用者が複数のファイルを一括でアップロードできる機能で、サポートされるファイルタイプは文書、画像、音声、動画、その他のファイルです。ローカルからのファイルアップロードやファイルのURLを貼り付けてのアップロードが可能です。詳細な使い方については[ファイルアップロード](../file-upload)を参照してください。
+
+.png) +
+
+### システム変数
+
+システム変数は、チャットフロー / ワークフローアプリ内であらかじめ設定されたシステムレベルのパラメータであり、アプリ内の他のノードからグローバルに読み取ることができます。通常は、高度な開発シナリオで使用され、たとえば多段階対話アプリの構築、アプリのログ収集と監視、異なるアプリや使用者の使用行動の記録などに利用されます。
+
+**ワークフロー**
+
+ワークフロータイプのアプリは以下のシステム変数を提供します:
+
+| 変数名 | データタイプ | 説明 | メモ |
+| ---------------------- | ------------ | ----------------------------------------------------------------------------------------------------- | ------------------------- |
+| `sys.files` | Array[File] | ファイルパラメータで、ユーザーがアプリを使用する際にアップロードした画像を保存します。複数の画像をアップロードできます。このパラメータは今後廃止予定であり、「入力フィールド」内のファイル変数の使用を推奨します。 | 画像アップロード機能は、アプリの編成ページの右上にある「機能」で有効にする必要があります。 |
+| `sys.user_id` | String | ユーザーIDで、各ユーザーがワークフローアプリを使用する際に、システムが自動的に一意の識別子を割り当てて、異なる対話ユーザーを区別します。 | |
+| `sys.app_id` | String | アプリIDで、システムが各ワークフローアプリに一意の識別子を割り当て、異なるアプリを区別し、このパラメータを通じて現在のアプリの基本情報を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じて異なるワークフローアプリを区別・特定できます。 |
+| `sys.workflow_id` | String | ワークフローIDで、現在のワークフローアプリに含まれるすべてのノード情報を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じてワークフロー内のノード情報を追跡・記録できます。 |
+| `sys.workflow_run_id` | String | ワークフローアプリの実行IDで、ワークフローアプリの運用状況を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じてアプリの過去の実行状況を追跡できます。 |
+
+
+
+
+
+**チャットフロー**
+
+チャットフロータイプのアプリケーションは、以下のシステム変数を提供しています:
+
+| 変数名 | データ型 | 説明 | メモ |
+|---------|--------|------|------|
+| `sys.query` | String | ユーザーが最初に入力した内容 | |
+| `sys.files` | Array[File] | ユーザーがアップロードした画像 | 画像のアップロード機能は、アプリケーションの編成ページ右上の「機能」で有効化する必要があります |
+| `sys.dialogue_count` | Number | チャットフロータイプのアプリケーションとの対話中にユーザーが行った対話のラウンド数です。各対話の後に自動的に数が増加し、if-elseノードと組み合わせて複雑な分岐ロジックを構築できます。たとえば、Xラウンド目に達したときに、対話履歴を振り返って分析が可能です | |
+| `sys.conversation_id` | String | ダイアログの対話セッションの一意の識別子で、関連するすべてのメッセージを同じ対話にグループ化し、LLMが同じトピックとコンテキストで継続的に対話できるようにします | |
+| `sys.user_id` | String | 各アプリケーションユーザーに割り当てられた一意の識別子で、異なる対話ユーザーを区別するために使用されます | |
+| `sys.app_id` | String | アプリケーションのIDで、システムは各ワークフローアプリケーションに一意の識別子を割り当て、異なるアプリケーションを識別します。このパラメータを使用して現在のアプリケーションの基本情報を記録します | 開発者向けで、このパラメータを使用して異なるワークフローアプリケーションを区別します |
+| `sys.workflow_id` | String | ワークフローIDで、現在のワークフローアプリケーションに含まれるすべてのノード情報を記録するために使用されます | 開発者向けで、このパラメータを使用してワークフロー内のノード情報を追跡および記録できます |
+| `sys.workflow_run_id` | String | ワークフローアプリケーションの実行IDで、アプリケーションの実行状況を記録するために使用されます | 開発者向けで、このパラメータを使用してアプリケーションの過去の実行状況を追跡できます |
+
+
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/template.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/template.mdx
new file mode 100644
index 00000000..8b5a40e9
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/template.mdx
@@ -0,0 +1,48 @@
+---
+title: テンプレート
+version: '日本語'
+---
+
+### 定義
+
+Jinja2のPythonテンプレート言語を使って、データ変換やテキスト処理などを柔軟に行うことができます。
+
+### Jinjaとは?
+
+> Jinjaは、高速で表現力豊かで拡張可能なテンプレートエンジンです。
+>
+> Jinja は、速く、表現力があり、拡張可能なテンプレートエンジンです。
+
+—— [https://jinja.palletsprojects.com/en/3.1.x/](https://jinja.palletsprojects.com/en/3.1.x/)
+
+### シーン
+
+テンプレートノードを使うことで、強力なPythonテンプレート言語であるJinja2を用いて、ワークフロー内で軽量かつ柔軟なデータ変換が可能になります。これは、テキスト処理やJSON変換などのシナリオに適しています。例えば、前のステップからの変数を柔軟にフォーマットして結合し、単一のテキスト出力を作成することができます。これは、複数のデータソースの情報を特定のフォーマットにまとめ、後続のステップの要件を満たすのに非常に適しています。
+
+**例1:** 複数の入力(記事のタイトル、紹介、内容)を一つの完全なテキストに結合する
+
+
+
+
+
+### システム変数
+
+システム変数は、チャットフロー / ワークフローアプリ内であらかじめ設定されたシステムレベルのパラメータであり、アプリ内の他のノードからグローバルに読み取ることができます。通常は、高度な開発シナリオで使用され、たとえば多段階対話アプリの構築、アプリのログ収集と監視、異なるアプリや使用者の使用行動の記録などに利用されます。
+
+**ワークフロー**
+
+ワークフロータイプのアプリは以下のシステム変数を提供します:
+
+| 変数名 | データタイプ | 説明 | メモ |
+| ---------------------- | ------------ | ----------------------------------------------------------------------------------------------------- | ------------------------- |
+| `sys.files` | Array[File] | ファイルパラメータで、ユーザーがアプリを使用する際にアップロードした画像を保存します。複数の画像をアップロードできます。このパラメータは今後廃止予定であり、「入力フィールド」内のファイル変数の使用を推奨します。 | 画像アップロード機能は、アプリの編成ページの右上にある「機能」で有効にする必要があります。 |
+| `sys.user_id` | String | ユーザーIDで、各ユーザーがワークフローアプリを使用する際に、システムが自動的に一意の識別子を割り当てて、異なる対話ユーザーを区別します。 | |
+| `sys.app_id` | String | アプリIDで、システムが各ワークフローアプリに一意の識別子を割り当て、異なるアプリを区別し、このパラメータを通じて現在のアプリの基本情報を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じて異なるワークフローアプリを区別・特定できます。 |
+| `sys.workflow_id` | String | ワークフローIDで、現在のワークフローアプリに含まれるすべてのノード情報を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じてワークフロー内のノード情報を追跡・記録できます。 |
+| `sys.workflow_run_id` | String | ワークフローアプリの実行IDで、ワークフローアプリの運用状況を記録します。 | 開発能力のあるユーザー向けで、このパラメータを通じてアプリの過去の実行状況を追跡できます。 |
+
+
+
+
+
+**チャットフロー**
+
+チャットフロータイプのアプリケーションは、以下のシステム変数を提供しています:
+
+| 変数名 | データ型 | 説明 | メモ |
+|---------|--------|------|------|
+| `sys.query` | String | ユーザーが最初に入力した内容 | |
+| `sys.files` | Array[File] | ユーザーがアップロードした画像 | 画像のアップロード機能は、アプリケーションの編成ページ右上の「機能」で有効化する必要があります |
+| `sys.dialogue_count` | Number | チャットフロータイプのアプリケーションとの対話中にユーザーが行った対話のラウンド数です。各対話の後に自動的に数が増加し、if-elseノードと組み合わせて複雑な分岐ロジックを構築できます。たとえば、Xラウンド目に達したときに、対話履歴を振り返って分析が可能です | |
+| `sys.conversation_id` | String | ダイアログの対話セッションの一意の識別子で、関連するすべてのメッセージを同じ対話にグループ化し、LLMが同じトピックとコンテキストで継続的に対話できるようにします | |
+| `sys.user_id` | String | 各アプリケーションユーザーに割り当てられた一意の識別子で、異なる対話ユーザーを区別するために使用されます | |
+| `sys.app_id` | String | アプリケーションのIDで、システムは各ワークフローアプリケーションに一意の識別子を割り当て、異なるアプリケーションを識別します。このパラメータを使用して現在のアプリケーションの基本情報を記録します | 開発者向けで、このパラメータを使用して異なるワークフローアプリケーションを区別します |
+| `sys.workflow_id` | String | ワークフローIDで、現在のワークフローアプリケーションに含まれるすべてのノード情報を記録するために使用されます | 開発者向けで、このパラメータを使用してワークフロー内のノード情報を追跡および記録できます |
+| `sys.workflow_run_id` | String | ワークフローアプリケーションの実行IDで、アプリケーションの実行状況を記録するために使用されます | 開発者向けで、このパラメータを使用してアプリケーションの過去の実行状況を追跡できます |
+
+
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/template.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/template.mdx
new file mode 100644
index 00000000..8b5a40e9
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/template.mdx
@@ -0,0 +1,48 @@
+---
+title: テンプレート
+version: '日本語'
+---
+
+### 定義
+
+Jinja2のPythonテンプレート言語を使って、データ変換やテキスト処理などを柔軟に行うことができます。
+
+### Jinjaとは?
+
+> Jinjaは、高速で表現力豊かで拡張可能なテンプレートエンジンです。
+>
+> Jinja は、速く、表現力があり、拡張可能なテンプレートエンジンです。
+
+—— [https://jinja.palletsprojects.com/en/3.1.x/](https://jinja.palletsprojects.com/en/3.1.x/)
+
+### シーン
+
+テンプレートノードを使うことで、強力なPythonテンプレート言語であるJinja2を用いて、ワークフロー内で軽量かつ柔軟なデータ変換が可能になります。これは、テキスト処理やJSON変換などのシナリオに適しています。例えば、前のステップからの変数を柔軟にフォーマットして結合し、単一のテキスト出力を作成することができます。これは、複数のデータソースの情報を特定のフォーマットにまとめ、後続のステップの要件を満たすのに非常に適しています。
+
+**例1:** 複数の入力(記事のタイトル、紹介、内容)を一つの完全なテキストに結合する
+
+
+  +
+
+**例2:** ナレッジリトリーバルノードで取得した情報およびその関連メタデータを、構造化されたMarkdown形式にまとめる
+
+```Plain
+{% for item in chunks %}
+### Chunk {{ loop.index }}.
+### Similarity: {{ item.metadata.score | default('N/A') }}
+
+#### {{ item.title }}
+
+##### Content
+{{ item.content | replace('\n', '\n\n') }}
+
+---
+{% endfor %}
+```
+
+
+
+
+
+**例2:** ナレッジリトリーバルノードで取得した情報およびその関連メタデータを、構造化されたMarkdown形式にまとめる
+
+```Plain
+{% for item in chunks %}
+### Chunk {{ loop.index }}.
+### Similarity: {{ item.metadata.score | default('N/A') }}
+
+#### {{ item.title }}
+
+##### Content
+{{ item.content | replace('\n', '\n\n') }}
+
+---
+{% endfor %}
+```
+
+
+ .png) +
+
+Jinjaの[公式ドキュメント](https://jinja.palletsprojects.com/en/3.1.x/templates/)を参考にして、さまざまなタスクを実行するためのより複雑なテンプレートを作成することができます。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/tools.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/tools.mdx
new file mode 100644
index 00000000..cafbbb6c
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/tools.mdx
@@ -0,0 +1,32 @@
+---
+title: ツール
+version: '日本語'
+---
+
+### 定義
+
+ワークフロー内で豊富なツール選択が提供されており、ツールは3つのタイプに分かれています:
+
+* **ビルトインツール**、Difyファーストパーティが提供するツール
+* **カスタムツール**、OpenAPI/Swagger標準フォーマットでインポートまたは設定されたツール
+* **ワークフロー**、ツールとして公開されたワークフロー
+
+ビルトインツールを使用する前に、ツールに **認可** を行う必要があるかもしれません。
+
+ビルトインツールが使用要求を満たさない場合は、**Dify メニュー ナビゲーション --ツール** でカスタムツールを作成できます。
+
+また、より複雑なワークフローを編成し、それをツールとして公開することもできます。
+
+
+
+
+
+Jinjaの[公式ドキュメント](https://jinja.palletsprojects.com/en/3.1.x/templates/)を参考にして、さまざまなタスクを実行するためのより複雑なテンプレートを作成することができます。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/tools.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/tools.mdx
new file mode 100644
index 00000000..cafbbb6c
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/tools.mdx
@@ -0,0 +1,32 @@
+---
+title: ツール
+version: '日本語'
+---
+
+### 定義
+
+ワークフロー内で豊富なツール選択が提供されており、ツールは3つのタイプに分かれています:
+
+* **ビルトインツール**、Difyファーストパーティが提供するツール
+* **カスタムツール**、OpenAPI/Swagger標準フォーマットでインポートまたは設定されたツール
+* **ワークフロー**、ツールとして公開されたワークフロー
+
+ビルトインツールを使用する前に、ツールに **認可** を行う必要があるかもしれません。
+
+ビルトインツールが使用要求を満たさない場合は、**Dify メニュー ナビゲーション --ツール** でカスタムツールを作成できます。
+
+また、より複雑なワークフローを編成し、それをツールとして公開することもできます。
+
+
+  +
+
+ツールノードは他のノードと接続でき、[変数](../variables)を通じてデータを処理および受け渡しすることができます。
+
+
+
+
+
+ツールノードは他のノードと接続でき、[変数](../variables)を通じてデータを処理および受け渡しすることができます。
+
+
+  +
+
+### 将工作流应用发布为工具
+
+カスタムツールの作成とツールの設定方法については[ツール設定説明](../../../tools/introduction)を参照してください。
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/variable-aggregation.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/variable-aggregation.mdx
new file mode 100644
index 00000000..53bbb854
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/variable-aggregation.mdx
@@ -0,0 +1,46 @@
+---
+title: 变量聚合
+version: '日本語'
+---
+
+### 定義
+
+マルチブランチの変数を一つの変数に集約し、ダウンズトリームノードの統一設定を実現します。
+
+変数集約ノード(元変数割り当てノード)はワークフローの重要なノードであり、異なるブランチの出力結果を統合し、どのブランチが実行されても、その結果を一つの統一された変数を通じて参照およびアクセスできるようにします。これはマルチブランチの状況で非常に有用で、異なるブランチで同じ役割を果たす変数を一つの出力変数にマッピングし、ダウンズトリームノードでの重複定義を避けます。
+
+***
+
+### シナリオ
+
+変数集約を通じて、問題分類や条件ブランチなどのマルチ出力をシングル出力に集約し、プロセスのダウンズトリームノードが使用および操作できるようにします。これによりデータフローの管理が簡素化されます。
+
+**問題分類後のマルチ集約**
+
+変数集約を追加しない場合、分類1と分類2のブランチは異なるナレッジベース検索を経て、ダウンズトリームの大規模言語モデルおよび直接返信ノードを繰り返し定義する必要があります。
+
+
+
+
+
+### 将工作流应用发布为工具
+
+カスタムツールの作成とツールの設定方法については[ツール設定説明](../../../tools/introduction)を参照してください。
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/variable-aggregation.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/variable-aggregation.mdx
new file mode 100644
index 00000000..53bbb854
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/variable-aggregation.mdx
@@ -0,0 +1,46 @@
+---
+title: 变量聚合
+version: '日本語'
+---
+
+### 定義
+
+マルチブランチの変数を一つの変数に集約し、ダウンズトリームノードの統一設定を実現します。
+
+変数集約ノード(元変数割り当てノード)はワークフローの重要なノードであり、異なるブランチの出力結果を統合し、どのブランチが実行されても、その結果を一つの統一された変数を通じて参照およびアクセスできるようにします。これはマルチブランチの状況で非常に有用で、異なるブランチで同じ役割を果たす変数を一つの出力変数にマッピングし、ダウンズトリームノードでの重複定義を避けます。
+
+***
+
+### シナリオ
+
+変数集約を通じて、問題分類や条件ブランチなどのマルチ出力をシングル出力に集約し、プロセスのダウンズトリームノードが使用および操作できるようにします。これによりデータフローの管理が簡素化されます。
+
+**問題分類後のマルチ集約**
+
+変数集約を追加しない場合、分類1と分類2のブランチは異なるナレッジベース検索を経て、ダウンズトリームの大規模言語モデルおよび直接返信ノードを繰り返し定義する必要があります。
+
+
+ .png) +
+
+変数集約を追加することで、二つのナレッジベース検索ノードの出力を一つの変数に集約できます。
+
+
+
+
+
+変数集約を追加することで、二つのナレッジベース検索ノードの出力を一つの変数に集約できます。
+
+
+  +
+
+**IF/ELSE 条件ブランチ後のマルチ集約**
+
+
+
+
+
+**IF/ELSE 条件ブランチ後のマルチ集約**
+
+
+  +
+
+### フォーマットに要求
+
+変数集約器は文字列(`String`)、数値(`Number`)、ファイル(`File`)、オブジェクト(`Object`)、および配列(`Array`)など、さまざまなデータ型の集約をサポートします。
+
+**変数集約器は同一データ型の変数しか集約できません**。最初に変数集約ノードに追加された変数データ形式が `String` である場合、後続の接続では追加可能な変数が `String` タイプに自動的にフィルタリングされます。
+
+**アグリゲートグループ**
+
+アグリゲートグループを有効にすると、変数集約器は複数のグループの変数を集約でき、各グループ内の集約時には同一データ型が求められます。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/variable-assigner.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/variable-assigner.mdx
new file mode 100644
index 00000000..bedc9615
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/variable-assigner.mdx
@@ -0,0 +1,169 @@
+---
+title: 変数代入
+version: '日本語'
+---
+
+### 定義
+
+変数代入ノードは、書き込み可能な変数に他の変数を代入するために使用されます。現在、サポートされている可書き入れの変数は:
+
+* [会話変数](../concepts)
+
+使用方法:このノードを使用することで、ワークフローの中で変数の値を会話変数に一時的に保存し、後続の会話でその値を参照することができます。
+
+
+
+
+
+### フォーマットに要求
+
+変数集約器は文字列(`String`)、数値(`Number`)、ファイル(`File`)、オブジェクト(`Object`)、および配列(`Array`)など、さまざまなデータ型の集約をサポートします。
+
+**変数集約器は同一データ型の変数しか集約できません**。最初に変数集約ノードに追加された変数データ形式が `String` である場合、後続の接続では追加可能な変数が `String` タイプに自動的にフィルタリングされます。
+
+**アグリゲートグループ**
+
+アグリゲートグループを有効にすると、変数集約器は複数のグループの変数を集約でき、各グループ内の集約時には同一データ型が求められます。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/nodes/variable-assigner.mdx b/ja-jp/user-guide/build-app/flow-app/nodes/variable-assigner.mdx
new file mode 100644
index 00000000..bedc9615
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/nodes/variable-assigner.mdx
@@ -0,0 +1,169 @@
+---
+title: 変数代入
+version: '日本語'
+---
+
+### 定義
+
+変数代入ノードは、書き込み可能な変数に他の変数を代入するために使用されます。現在、サポートされている可書き入れの変数は:
+
+* [会話変数](../concepts)
+
+使用方法:このノードを使用することで、ワークフローの中で変数の値を会話変数に一時的に保存し、後続の会話でその値を参照することができます。
+
+
+  +
+
+***
+
+### 使用シナリオの例
+
+変数代入ノードを活用することで、会話中の**コンテキスト、ダイアログにアップロードされたファイル(近々配布予定)、ユーザーの好みの情報**などを会話変数に書き込み、保存された情報は後続の会話で参照され、異なる処理フローに誘導したり、返答を行ったりすることができます。
+
+**シナリオ 1**
+
+**会話中の記録を自動的に抽出し保存します**、会話変数配列を使用してユーザーの重要な情報を記録します。その後の会話ではこれらの記録を活用し、個別の返信を行います。
+
+例えば:会話が始まると、LLMはユーザーの入力に必要な情報や好み、またはチャット履歴が含まれているかを自動的に判断します。情報が存在する場合、LLMはそれを先に抽出して保存し、コンテキストとして利用して応答します。もし新しい情報を覚える必要がない場合、LLMは以前の関連する記録を用いて個性化な応答を出します。
+
+
+
+
+
+***
+
+### 使用シナリオの例
+
+変数代入ノードを活用することで、会話中の**コンテキスト、ダイアログにアップロードされたファイル(近々配布予定)、ユーザーの好みの情報**などを会話変数に書き込み、保存された情報は後続の会話で参照され、異なる処理フローに誘導したり、返答を行ったりすることができます。
+
+**シナリオ 1**
+
+**会話中の記録を自動的に抽出し保存します**、会話変数配列を使用してユーザーの重要な情報を記録します。その後の会話ではこれらの記録を活用し、個別の返信を行います。
+
+例えば:会話が始まると、LLMはユーザーの入力に必要な情報や好み、またはチャット履歴が含まれているかを自動的に判断します。情報が存在する場合、LLMはそれを先に抽出して保存し、コンテキストとして利用して応答します。もし新しい情報を覚える必要がない場合、LLMは以前の関連する記録を用いて個性化な応答を出します。
+
+
+  +
+
+**設定手順:**
+
+1. **会話変数を設定**:まず、会話変数配列 `memories` を設定し、array\[object]型を持たせてユーザーの事実、好み、会話記録を保存します。
+2. **記録の判断と抽出**:
+ * 条件判断ノードを追加し、LLMを使用してユーザーの入力に新しい情報が含まれているかを判断します。
+ * 新しい情報がある場合は上流に進み、LLMノードを使用してこれらの情報を抽出します。
+ * 新しい情報がない場合は下流に進み、既存の記憶を直接使用して返答します。
+3. **変数の代入と書き込み**:
+ * 上流に進んだ後、変数代入ノードを用いて抽出した新しい情報を `memories` 配列に追加(append)します。
+ * LLMの出力テキスト文字列を適切な array\[object] 形式に変換するためにエスケープ機能を使用します。
+4. **変数の読み取りと利用**:
+ * 後続のLLMノードで、`memories` 配列の内容を文字列に変換し、LLMのプロンプトにコンテキストとして挿入します。
+ * LLMはこれらの記憶を使用して個別の返信を生成します。
+
+図中のcodeノードのコードは以下の通りです:
+
+1. 文字列をオブジェクトに変換する
+
+```python
+import json
+
+def main(arg1: str) -> object:
+ try:
+ # Parse the input JSON string
+ input_data = json.loads(arg1)
+
+ # Extract the memory object
+ memory = input_data.get("memory", {})
+
+ # Construct the return object
+ result = {
+ "facts": memory.get("facts", []),
+ "preferences": memory.get("preferences", []),
+ "memories": memory.get("memories", [])
+ }
+
+ return {
+ "mem": result
+ }
+ except json.JSONDecodeError:
+ return {
+ "result": "Error: Invalid JSON string"
+ }
+ except Exception as e:
+ return {
+ "result": f"Error: {str(e)}"
+ }
+```
+
+2. オブジェクトを文字列に変換する
+
+```python
+import json
+
+def main(arg1: list) -> str:
+ try:
+ # Assume arg1[0] is the dictionary we need to process
+ context = arg1[0] if arg1 else {}
+
+ # Construct the memory object
+ memory = {"memory": context}
+
+ # Convert the object to a JSON string
+ json_str = json.dumps(memory, ensure_ascii=False, indent=2)
+
+ # Wrap the JSON string in
+
+
+**設定手順:**
+
+1. **会話変数を設定**:まず、会話変数配列 `memories` を設定し、array\[object]型を持たせてユーザーの事実、好み、会話記録を保存します。
+2. **記録の判断と抽出**:
+ * 条件判断ノードを追加し、LLMを使用してユーザーの入力に新しい情報が含まれているかを判断します。
+ * 新しい情報がある場合は上流に進み、LLMノードを使用してこれらの情報を抽出します。
+ * 新しい情報がない場合は下流に進み、既存の記憶を直接使用して返答します。
+3. **変数の代入と書き込み**:
+ * 上流に進んだ後、変数代入ノードを用いて抽出した新しい情報を `memories` 配列に追加(append)します。
+ * LLMの出力テキスト文字列を適切な array\[object] 形式に変換するためにエスケープ機能を使用します。
+4. **変数の読み取りと利用**:
+ * 後続のLLMノードで、`memories` 配列の内容を文字列に変換し、LLMのプロンプトにコンテキストとして挿入します。
+ * LLMはこれらの記憶を使用して個別の返信を生成します。
+
+図中のcodeノードのコードは以下の通りです:
+
+1. 文字列をオブジェクトに変換する
+
+```python
+import json
+
+def main(arg1: str) -> object:
+ try:
+ # Parse the input JSON string
+ input_data = json.loads(arg1)
+
+ # Extract the memory object
+ memory = input_data.get("memory", {})
+
+ # Construct the return object
+ result = {
+ "facts": memory.get("facts", []),
+ "preferences": memory.get("preferences", []),
+ "memories": memory.get("memories", [])
+ }
+
+ return {
+ "mem": result
+ }
+ except json.JSONDecodeError:
+ return {
+ "result": "Error: Invalid JSON string"
+ }
+ except Exception as e:
+ return {
+ "result": f"Error: {str(e)}"
+ }
+```
+
+2. オブジェクトを文字列に変換する
+
+```python
+import json
+
+def main(arg1: list) -> str:
+ try:
+ # Assume arg1[0] is the dictionary we need to process
+ context = arg1[0] if arg1 else {}
+
+ # Construct the memory object
+ memory = {"memory": context}
+
+ # Convert the object to a JSON string
+ json_str = json.dumps(memory, ensure_ascii=False, indent=2)
+
+ # Wrap the JSON string in  +
+
+**設定手順:**
+
+**会話変数の設定**:まず、会話変数 `language` を設定し、会話の開始時にこの変数の値が空かどうかを判断する条件分岐ノードを追加します。
+
+**変数の書き込み/代入**:最初の会話が開始された際、 `language` 変数の値が空であれば、LLMノードを使用してユーザーの言語入力を抽出し、その言語タイプを会話変数 `language` に書き込みます。
+
+**変数の読み取り**:後続の会話ラウンドでは、`language` 変数にユーザーの好みの言語が保存されています。以降の会話では、LLMノードがこの変数を参照し、ユーザーの好みの言語タイプを用いて返信します。
+
+**シナリオ 3**
+
+**Checklistのチェックを補助**し、会話中に会話変数にユーザーの入力項目を記録し、Checklistの内容を更新し、後続の会話で抜け漏れ項目を確認します。
+
+例:会話を始める際、LLMはユーザーにチェックリストに関連するアイテムの入力を求めます。ユーザーがチェックリストの内容を一度述べると、その内容は会話変数に更新され、及び保存されます。LLMは各会話の後に、ユーザーに不足しているアイテムの追加を促します。
+
+
+
+
+
+**設定手順:**
+
+**会話変数の設定**:まず、会話変数 `language` を設定し、会話の開始時にこの変数の値が空かどうかを判断する条件分岐ノードを追加します。
+
+**変数の書き込み/代入**:最初の会話が開始された際、 `language` 変数の値が空であれば、LLMノードを使用してユーザーの言語入力を抽出し、その言語タイプを会話変数 `language` に書き込みます。
+
+**変数の読み取り**:後続の会話ラウンドでは、`language` 変数にユーザーの好みの言語が保存されています。以降の会話では、LLMノードがこの変数を参照し、ユーザーの好みの言語タイプを用いて返信します。
+
+**シナリオ 3**
+
+**Checklistのチェックを補助**し、会話中に会話変数にユーザーの入力項目を記録し、Checklistの内容を更新し、後続の会話で抜け漏れ項目を確認します。
+
+例:会話を始める際、LLMはユーザーにチェックリストに関連するアイテムの入力を求めます。ユーザーがチェックリストの内容を一度述べると、その内容は会話変数に更新され、及び保存されます。LLMは各会話の後に、ユーザーに不足しているアイテムの追加を促します。
+
+
+  +
+
+**配置流程:**
+
+* **会話変数の設定**:最初に会話変数 `ai_checklist` を設定し、これをLLM内でチェックのコンテクストとして参照します。
+* **変数の書き込み/代入**:各会話のラウンドごとに、LLMノード内の `ai_checklist` の値を確認し、ユーザーの入力と比較します。ユーザーが新しい情報を提供した場合、チェックリストを更新し、変数代入ノードを使用して出力内容を `ai_checklist` に書き込みます。
+* **変数の読み取り**:`ai_checklist`の値を読み取り、すべてのチェックリストアイテムが完了するまで、各会話のラウンドでユーザーの入力と比較します。
+
+***
+
+### 3 操作方法
+
+**変数代入の使用:**
+
+ノードの右側の `+` マークをクリックし、「変数代入」 ノードを選択し、「代入られた変数」 と 「設定する変数」 を入力します。
+
+
+
+
+
+**配置流程:**
+
+* **会話変数の設定**:最初に会話変数 `ai_checklist` を設定し、これをLLM内でチェックのコンテクストとして参照します。
+* **変数の書き込み/代入**:各会話のラウンドごとに、LLMノード内の `ai_checklist` の値を確認し、ユーザーの入力と比較します。ユーザーが新しい情報を提供した場合、チェックリストを更新し、変数代入ノードを使用して出力内容を `ai_checklist` に書き込みます。
+* **変数の読み取り**:`ai_checklist`の値を読み取り、すべてのチェックリストアイテムが完了するまで、各会話のラウンドでユーザーの入力と比較します。
+
+***
+
+### 3 操作方法
+
+**変数代入の使用:**
+
+ノードの右側の `+` マークをクリックし、「変数代入」 ノードを選択し、「代入られた変数」 と 「設定する変数」 を入力します。
+
+
+  +
+
+**変数の設定:**
+
+代入られた変数:代入された変数を選択し、対象の会話変数を指定します
+
+設定する変数:変換する必要のあるソース変数を選択します
+
+上図の代入ロジック:`Language Recognition/text` を `language` に代入します。
+
+**書き込みモード:**
+
+* Overwrite (上書き): ソース変数の内容を対象の会話変数に上書きします
+* Append (追加):指定された変数が配列型の場合に使用します
+* Clear (クリア): 対象の会話変数内の内容をクリアします
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/orchestrate-node.mdx b/ja-jp/user-guide/build-app/flow-app/orchestrate-node.mdx
new file mode 100644
index 00000000..bbac1471
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/orchestrate-node.mdx
@@ -0,0 +1,141 @@
+---
+title: オーケストレートノード
+version: '日本語'
+---
+
+チャットフローおよびワークフローアプリケーションは、ビジュアルなドラッグアンドドロップ機能を通じてノードのオーケストレーションをサポートしており、**シリアル**および**パラレル**の2つのオーケストレーションデザインパターンがあります。
+
+
+
+
+
+**変数の設定:**
+
+代入られた変数:代入された変数を選択し、対象の会話変数を指定します
+
+設定する変数:変換する必要のあるソース変数を選択します
+
+上図の代入ロジック:`Language Recognition/text` を `language` に代入します。
+
+**書き込みモード:**
+
+* Overwrite (上書き): ソース変数の内容を対象の会話変数に上書きします
+* Append (追加):指定された変数が配列型の場合に使用します
+* Clear (クリア): 対象の会話変数内の内容をクリアします
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/orchestrate-node.mdx b/ja-jp/user-guide/build-app/flow-app/orchestrate-node.mdx
new file mode 100644
index 00000000..bbac1471
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/orchestrate-node.mdx
@@ -0,0 +1,141 @@
+---
+title: オーケストレートノード
+version: '日本語'
+---
+
+チャットフローおよびワークフローアプリケーションは、ビジュアルなドラッグアンドドロップ機能を通じてノードのオーケストレーションをサポートしており、**シリアル**および**パラレル**の2つのオーケストレーションデザインパターンがあります。
+
+
+  +
+
+## シリアルノードのデザインパターン
+
+このパターンでは、ノードはあらかじめ定義された順序で順次実行されます。各ノードは、前のノードがタスクを完了し、出力を生成した後にのみ操作を開始します。これにより、**タスクが論理的な順序で実行されることが保証されます**。
+
+シリアルパターンを実装した「小説生成」ワークフローアプリケーションを考えてみましょう。ユーザーが小説のスタイル、リズム、キャラクターを入力した後、LLMが順番に小説の概要、プロット、エンディングを完成させます。各ノードは前のノードの出力に基づいて動作し、小説のスタイルに一貫性をもたらします。
+
+### シリアル構造の作り方
+
+1. 2つのノードの間にある「+」アイコンをクリックして新しいシリアルノードを挿入します。
+2. ノードを順次リンクします。
+3. すべてのパスを「End」ノードに収束させて、ワークフローを最終承認します。
+
+
+
+
+
+## シリアルノードのデザインパターン
+
+このパターンでは、ノードはあらかじめ定義された順序で順次実行されます。各ノードは、前のノードがタスクを完了し、出力を生成した後にのみ操作を開始します。これにより、**タスクが論理的な順序で実行されることが保証されます**。
+
+シリアルパターンを実装した「小説生成」ワークフローアプリケーションを考えてみましょう。ユーザーが小説のスタイル、リズム、キャラクターを入力した後、LLMが順番に小説の概要、プロット、エンディングを完成させます。各ノードは前のノードの出力に基づいて動作し、小説のスタイルに一貫性をもたらします。
+
+### シリアル構造の作り方
+
+1. 2つのノードの間にある「+」アイコンをクリックして新しいシリアルノードを挿入します。
+2. ノードを順次リンクします。
+3. すべてのパスを「End」ノードに収束させて、ワークフローを最終承認します。
+
+
+  +
+
+### シリアル構造のアプリのログをチェックする
+
+シリアル構造のアプリは、ログが順次ノードの操作を表示します。会話ボックスの右上にある "View Logs - Tracing" を順にクリックすると、各ノードの入力、出力、トークン消費、実行時間を含む完全なワークフロープロセスが表示されます。
+
+
+
+
+
+### シリアル構造のアプリのログをチェックする
+
+シリアル構造のアプリは、ログが順次ノードの操作を表示します。会話ボックスの右上にある "View Logs - Tracing" を順にクリックすると、各ノードの入力、出力、トークン消費、実行時間を含む完全なワークフロープロセスが表示されます。
+
+
+  +
+
+## パラレルノードのデザインパターン
+
+このアーキテクチャパターンは、複数のノードを並行して実行することを可能にします。前のノードは、パラレル構造内の複数のノードを同時にトリガーできます。これらのパラレルノードは独立して動作し、タスクを同時に実行することで、全体のワークフロー効率を大幅に向上させます。
+
+パラレルアーキテクチャを実装した翻訳ワークフローアプリケーションを考えてみましょう。ユーザーがソーステキストを入力してワークフローをトリガーすると、パラレル構造内のすべてのノードが前のノードから同時に命令を受け取ります。これにより、複数の言語への同時翻訳が可能となり、全体の処理時間が大幅に短縮されます。
+
+
+
+
+
+## パラレルノードのデザインパターン
+
+このアーキテクチャパターンは、複数のノードを並行して実行することを可能にします。前のノードは、パラレル構造内の複数のノードを同時にトリガーできます。これらのパラレルノードは独立して動作し、タスクを同時に実行することで、全体のワークフロー効率を大幅に向上させます。
+
+パラレルアーキテクチャを実装した翻訳ワークフローアプリケーションを考えてみましょう。ユーザーがソーステキストを入力してワークフローをトリガーすると、パラレル構造内のすべてのノードが前のノードから同時に命令を受け取ります。これにより、複数の言語への同時翻訳が可能となり、全体の処理時間が大幅に短縮されます。
+
+
+ .png) +
+
+### パラレルノードのデザインパターン
+
+次の4つの方法は、ノードの追加やビジュアル操作を通じてパラレル構造を作成する方法を示しています:
+
+**方法1**
+
+ノードの上にカーソルを合わせると「+」ボタンが表示されます。クリックすると、複数のノードが追加され、自動的にパラレル構造が形成されます。
+
+
+
+
+
+### パラレルノードのデザインパターン
+
+次の4つの方法は、ノードの追加やビジュアル操作を通じてパラレル構造を作成する方法を示しています:
+
+**方法1**
+
+ノードの上にカーソルを合わせると「+」ボタンが表示されます。クリックすると、複数のノードが追加され、自動的にパラレル構造が形成されます。
+
+
+  +
+
+**方法2**
+
+ノードから接続を延長するには、ノードの「+」ボタンをドラッグしてパラレル構造を作成します。
+
+
+
+
+
+**方法2**
+
+ノードから接続を延長するには、ノードの「+」ボタンをドラッグしてパラレル構造を作成します。
+
+
+  +
+
+**方法3**
+
+キャンバス上に複数のノードがある場合は、ビジュアルにドラッグしてリンクし、パラレル構造を形成します。
+
+
+
+
+
+**方法3**
+
+キャンバス上に複数のノードがある場合は、ビジュアルにドラッグしてリンクし、パラレル構造を形成します。
+
+
+  +
+
+**方法4**
+
+キャンバスベースの方法に加えて、ノードの右側パネルの「Next Step」セクションからノードを追加することで、パラレル構造を生成することもできます。このアプローチにより、自動的にパラレル構成が作成されます。
+
+
+
+
+
+**方法4**
+
+キャンバスベースの方法に加えて、ノードの右側パネルの「Next Step」セクションからノードを追加することで、パラレル構造を生成することもできます。このアプローチにより、自動的にパラレル構成が作成されます。
+
+
+  +
+
+
+
+
+ +
+
+### パラレル構造の作り方
+
+以下の4つのパターンは、一般的なパラレル構造デザインを示しています:
+
+#### 1. 通常のパラレル
+
+通常のパラレルは、「開始 | パラレルノード | 終了」の3階層関係を指します。この構造は直感的で、ユーザー入力後に複数のタスクを同時に実行できます。
+
+> パラレルブランチの上限は10です。
+
+
+
+
+
+### パラレル構造の作り方
+
+以下の4つのパターンは、一般的なパラレル構造デザインを示しています:
+
+#### 1. 通常のパラレル
+
+通常のパラレルは、「開始 | パラレルノード | 終了」の3階層関係を指します。この構造は直感的で、ユーザー入力後に複数のタスクを同時に実行できます。
+
+> パラレルブランチの上限は10です。
+
+
+  +
+
+#### 2. ネストされたパラレル
+
+ネストされたパラレルは、「開始 | 複数のパラレル構造 | 終了」の多階層関係を指します。これは、外部APIを要求する必要があるノード内で同時に複数のタスクを処理し、結果を下流ノードに渡す必要があるような、より複雑なワークフローに適しています。
+
+ワークフローは、最大3層までのネスト関係をサポートします。
+
+
+
+
+
+#### 2. ネストされたパラレル
+
+ネストされたパラレルは、「開始 | 複数のパラレル構造 | 終了」の多階層関係を指します。これは、外部APIを要求する必要があるノード内で同時に複数のタスクを処理し、結果を下流ノードに渡す必要があるような、より複雑なワークフローに適しています。
+
+ワークフローは、最大3層までのネスト関係をサポートします。
+
+
+  +
+
+#### 3. 条件分岐 + パラレル
+
+パラレル構造は条件分岐と組み合わせて使用することもできます。
+
+
+
+
+
+#### 3. 条件分岐 + パラレル
+
+パラレル構造は条件分岐と組み合わせて使用することもできます。
+
+
+  +
+
+#### 4. イテレーション + パラレル
+
+このパターンは、イテレーションとパラレル構造を組み合わせたものです。
+
+
+
+
+
+#### 4. イテレーション + パラレル
+
+このパターンは、イテレーションとパラレル構造を組み合わせたものです。
+
+
+  +
+
+### パラレル構造のアプリのログをチェックする
+
+パラレル構造をもつアプリケーションは、ツリーのような形式でログを生成します。折りたたみ可能なパラレルノード グループにより、個々のノード ログを簡単に表示できます。
+
+
+
+
+
+### パラレル構造のアプリのログをチェックする
+
+パラレル構造をもつアプリケーションは、ツリーのような形式でログを生成します。折りたたみ可能なパラレルノード グループにより、個々のノード ログを簡単に表示できます。
+
+
+  +
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/variables.mdx b/ja-jp/user-guide/build-app/flow-app/variables.mdx
new file mode 100644
index 00000000..c0f39f8a
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/variables.mdx
@@ -0,0 +1,186 @@
+---
+title: 変数
+version: '日本語'
+---
+
+**ワークフロー**や**チャットフロー**は、単独ノードで構成されています。多くのノードは入力と出力のアイテムを持っていますが、各ノードの入力および出力情報は一貫性がなく、ダイナミックに変化します。
+
+**固定のシンボルを用いて、ダイナミックなコンテンツをどのように参照するのでしょうか?** 変数はダイナミックなデータコンテナとして、さまざまな内容を格納・送信し、異なるノードの間で相互に参照され、お互いに情報を移動することができます。
+
+### **システム変数**
+
+システム変数とは、チャットフロー/ワークフロー内でグローバルに使用される事前設定されたシステムレベルのパラメータです。すべてのシステムレベルの変数は`sys.`で始まります。
+
+#### ワークフロー
+
+ワークフローは、以下のシステム変数を提供します:
+
+
+
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/flow-app/variables.mdx b/ja-jp/user-guide/build-app/flow-app/variables.mdx
new file mode 100644
index 00000000..c0f39f8a
--- /dev/null
+++ b/ja-jp/user-guide/build-app/flow-app/variables.mdx
@@ -0,0 +1,186 @@
+---
+title: 変数
+version: '日本語'
+---
+
+**ワークフロー**や**チャットフロー**は、単独ノードで構成されています。多くのノードは入力と出力のアイテムを持っていますが、各ノードの入力および出力情報は一貫性がなく、ダイナミックに変化します。
+
+**固定のシンボルを用いて、ダイナミックなコンテンツをどのように参照するのでしょうか?** 変数はダイナミックなデータコンテナとして、さまざまな内容を格納・送信し、異なるノードの間で相互に参照され、お互いに情報を移動することができます。
+
+### **システム変数**
+
+システム変数とは、チャットフロー/ワークフロー内でグローバルに使用される事前設定されたシステムレベルのパラメータです。すべてのシステムレベルの変数は`sys.`で始まります。
+
+#### ワークフロー
+
+ワークフローは、以下のシステム変数を提供します:
+
+| 変数名 | +データタイプ | +说明 | +メモ | +
|---|---|---|---|
|
+ Array[File] | +ファイルパラメータで、ユーザーがアプリを初めて使用する際にアップロードした画像を保存します。 | +画像のアップロード機能は、アプリケーションの編成ページ右上の「機能」から開始する必要があります。 | +
sys.user_id |
+ String | +ユーザーIDです。ワークフローアプリを使用する際、システムが自動的にユーザーに一意の識別子を割り当て、異なるユーザーを区別するために使用します。 | ++ |
sys.app_id |
+ String | +アプリIDで、システムが各ワークフローアプリに一意の識別子を割り当て、異なるアプリを区別します。このパラメータは現在のアプリの基本情報を記録するために使用されます。 | +開発能力を持つユーザー向けで、このパラメータを使用して異なるワークフローアプリを区別し、特定できます。 | +
sys.workflow_id |
+ String | +ワークフローIDで、現在のワークフローアプリに含まれるすべてのノード情報を記録するために使用されます。 | +開発能力を持つユーザー向けで、このパラメータを使用してワークフロー内のノード情報を追跡および記録できます。 | +
sys.workflow_run_id |
+ String | +ワークフローアプリ実行IDで、ワークフローアプリ内の実行状況を記録するために使用されます。 | +開発能力を持つユーザー向けで、このパラメータを使用してアプリの過去の実行状況を追跡できます。 | +
 +
+
+#### チャットフロー
+
+チャットフローは、以下のシステム変数を提供します:
+
+
+
+
+#### チャットフロー
+
+チャットフローは、以下のシステム変数を提供します:
+
+| 変数名 | +データタイプ | +説明 | +メモ | +
|---|---|---|---|
sys.query |
+ String | +ユーザーが最初に入力したダイアログボックスの内容 | ++ |
sys.files |
+ Array[File] | +ユーザーがダイアログボックス内でアップロードした画像 | +画像のアップロード機能は、アプリケーションの構築ページ右上隅の「機能」で有効にする必要があります | +
sys.dialogue_count |
+ Number | +チャットフロー形式のアプリとの対話中にユーザーが持つ対話のラウンド数。各対話の後、自動的に1つのカウントが増加します。if-elseノードと組み合わせて豊富な分岐ロジックを作成できます。 例えば、Xラウンド目に到達したとき、対話履歴を振り返り分析を提供します。 |
+ + |
sys.conversation_id |
+ String | +対話ボックスのインタラクションセッションの一意の識別子で、すべての関連メッセージを同じ対話にグループ化し、LLMが同じトピックとコンテキストに対して持続的な対話を行うことを確認します。 | ++ |
sys.user_id |
+ String | +各アプリユーザーに割り当てられた一意の識別子で、異なる対話ユーザーを区別するために使用されます。 | ++ |
sys.app_id |
+ String | +アプリIDで、システムは各ワークフローアプリケーションに一意の識別子を割り当て、異なるアプリを区別し、このパラメータを使用して現在のアプリの基本情報を記録します。 | +開発能力を持つユーザー向けで、このパラメータを使用して異なるワークフローアプリを特定および位置付けることができます。 | +
sys.workflow_id |
+ String | +ワークフローIDで、現在のワークフローアプリ内に含まれるすべてのノード情報を記録するために使用されます。 | +開発能力を持つユーザー向けで、このパラメータを使用してワークフロー内のすべてのノード情報を追跡および記録できます。 | +
sys.workflow_run_id |
+ String | +ワークフローアプリケーションの実行IDで、ワークフローアプリケーション内の実行状況を記録するために使用されます。 | +開発能力を持つユーザー向けで、このパラメータを使用してアプリの過去の実行状況を追跡できます。 | +
 +
+
+### 環境変数
+
+**環境変数は、APIキーやデータベースのパスワードといった機密性の高い情報を保護する際に、ワークフロー実行時に活用されます。** これらはコードに直接書き込むのではなく、ワークフローに設定され、異なる環境間での共有が可能になっています。
+
+
+
+
+
+### 環境変数
+
+**環境変数は、APIキーやデータベースのパスワードといった機密性の高い情報を保護する際に、ワークフロー実行時に活用されます。** これらはコードに直接書き込むのではなく、ワークフローに設定され、異なる環境間での共有が可能になっています。
+
+
+  +
+
+サポートされるデータ型には以下の3つがあります:
+
+* String 文字列
+* Number 数値
+* Secret シークレット
+
+環境変数は以下の特徴を持ちます:
+
+* 多くのノードでグローバルに参照可能です;
+* 同一の環境変数名を複数設定することはできません;
+* ノードの出力変数は基本的に読み取り専用で、書き換えることはできません;
+
+### 会話変数
+
+> 会話変数は、マルチターンダイアログシナリオに適した機能ですが、ワークフロー型アプリケーションのインタラクションは線形かつ独立しており、複数回の対話が行われないため、会話変数は主にチャットフロー型アプリケーション(チャットボットからワークフローへの変換)にのみ適用されます。
+
+**会話変数は、同一のチャットフローセッション内でアプリ開発者が一時的に保存する特定の情報を定義し、現在のワークフロー内のマルチターンダイアログ全体でその情報を参照可能にします。** 具体例としては、コンテキスト、ダイアログボックスにアップロードされたファイル(近日公開予定)、ユーザーがダイアログ中に入力した好みなどが含まれます。これはLLMに随時参照できる「メモ帳」を提供し、LLMのメモリエラーによる情報のずれを防ぐためのものです。
+
+例えば、ユーザーが最初の対話で設定した言語を会話変数に保存すれば、LLMはその情報を参照し、続く対話で指定された言語でユーザーに返信することが可能です。
+
+
+
+
+
+サポートされるデータ型には以下の3つがあります:
+
+* String 文字列
+* Number 数値
+* Secret シークレット
+
+環境変数は以下の特徴を持ちます:
+
+* 多くのノードでグローバルに参照可能です;
+* 同一の環境変数名を複数設定することはできません;
+* ノードの出力変数は基本的に読み取り専用で、書き換えることはできません;
+
+### 会話変数
+
+> 会話変数は、マルチターンダイアログシナリオに適した機能ですが、ワークフロー型アプリケーションのインタラクションは線形かつ独立しており、複数回の対話が行われないため、会話変数は主にチャットフロー型アプリケーション(チャットボットからワークフローへの変換)にのみ適用されます。
+
+**会話変数は、同一のチャットフローセッション内でアプリ開発者が一時的に保存する特定の情報を定義し、現在のワークフロー内のマルチターンダイアログ全体でその情報を参照可能にします。** 具体例としては、コンテキスト、ダイアログボックスにアップロードされたファイル(近日公開予定)、ユーザーがダイアログ中に入力した好みなどが含まれます。これはLLMに随時参照できる「メモ帳」を提供し、LLMのメモリエラーによる情報のずれを防ぐためのものです。
+
+例えば、ユーザーが最初の対話で設定した言語を会話変数に保存すれば、LLMはその情報を参照し、続く対話で指定された言語でユーザーに返信することが可能です。
+
+
+  +
+
+**会話変数**は以下の6つのデータ型をサポートしています:
+
+* String 文字列
+* Number 数値
+* Object オブジェクト
+* Array\[string] 文字列の配列
+* Array\[number] 数値の配列
+* Array\[object] オブジェクトの配列
+
+**会话变量**具有以下特性:
+
+* 会話変数はほとんどのノード内でグローバルに参照可能です。
+* 会話変数の書き込みには[変数代入](./nodes/variable-assigner)ノードを使用する必要があります;
+* 会話変数は読み書き可能な変数です;
+
+会話変数と変数代入ノードの具体的な使用方法については、[変数代入](./nodes/variable-assigner)をご参照ください。
+
+### 注意事项
+
+* 変数名の重複を避けるため、ノードの命名は独自に設定してください。
+* ノードの出力変数は通常固定されており、編集することはできません。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/text-generator.mdx b/ja-jp/user-guide/build-app/text-generator.mdx
new file mode 100644
index 00000000..8b03235d
--- /dev/null
+++ b/ja-jp/user-guide/build-app/text-generator.mdx
@@ -0,0 +1,79 @@
+---
+title: テキスト生成アプリケーション
+version: '日本語'
+---
+
+テキスト生成アプリケーションは、特定の形式のコンテンツを生成することに特化したアプリの一種です。このアプリでは、ユーザーが具体的な要件やパラメータを入力すると、あらかじめ設定された形式に従ってテキストが自動的に出力されます。持続的な対話能力を持つチャットボットとは異なり、テキスト生成アプリは主に単発の入力に対して応答し、一度きりのコンテンツ生成を行います。その中で「プロンプトジェネレーター」は、代表的な例として挙げられます。
+
+## 適用シーン
+
+テキスト生成アプリケーションは、クリエイティブライティング、マーケティングコピー、技術文書など、標準化されたコンテンツを迅速に大量生成する必要がある場面に特に適しています。
+
+## 作成手順
+
+対話型アプリの構築方法を説明します。プロンプト、変数、コンテキスト、オープニングステートメント、次のステップの提案をサポートします。
+
+次に、「週報生成アプリケーター」の構築を例に、対話型アプリの作成手順を紹介します。
+
+### アプリの作成
+
+ホームページで「アプリの作成」ボタンをクリックして、アプリを作成します。アプリ名を入力し、アプリタイプとして**テキスト生成アプリ**を選択します。
+
+
+
+### アプリの構築
+
+アプリが作成されると、自動的にアプリの監視ページに移動します。ここで、チャットアプリに変数を設定したり、コンテキストを追加したり、追加のチャット機能を設定することができます。
+
+
+
+#### プロンプトの入力
+
+プロンプトは、AIに対して専門的な返答を促すためのもので、返答の精度を高めるためのヒントとして使用されます。組み込みのプロンプトジェネレーターを利用して、適切なプロンプトを作成することができます。プロンプトには、フォーム変数を挿入することも可能です。たとえば、`{{input}}`という変数をプロンプト内に挿入すると、ユーザーが入力した値に基づいてその変数の値が置換されます。
+
+例:
+1. 面接シーンのプロンプトを要求する指示を入力します。
+2. 右側のコンテンツボックスにプロンプトが自動生成されます。
+3. プロンプト内にカスタム変数を挿入することもできます。
+
+
+
+#### コンテキストの追加
+
+AIの対話範囲を特定のナレッジベースに制限したい場合、例えば企業内のカスタマーサービスのテンプレートを使用したいときは、"コンテキスト"でナレッジベースを参照できます。
+
+
+
+### デバッグ
+
+右側にユーザー入力項目を入力して、内容をデバッグします。
+
+
+
+回答が思わしくない場合は、プロンプトや基礎モデルを調整することができます。また、複数のモデルを同時に使用してデバッグすることも可能で、適切な設定を組み合わせて試すことができます。
+
+
+
+**複数のモデルでのデバッグ:**
+
+単一のモデルを使用することが効率的でない場合、**"複数のモデルでのデバッグ"**機能を使用して、複数のモデルの回答効果を一括で確認できます。
+
+
+
+最大で4つの大きなモデルを同時に追加できます。
+
+
+
+⚠️ 複数モデルデバッグ機能を使用する際に、一部の大きなモデルしか表示されない場合は、他の大きなモデルのキーがまだ追加されていないためです。「新しいプロバイダーを追加」を利用して、複数のモデルのキーを手動で追加できます。
+
+### アプリの公開
+
+アプリをデバッグしたら、右上の**"公開"**ボタンをクリックして独自のAIアプリを生成します。公開されたURLを通じてアプリを体験するだけでなく、APIベースの開発やWebサイトへの組み込みも行えます。詳細については、公開に関するセクションをご覧ください。
+
+公開済みのアプリをカスタマイズしたい場合は、当社のオープンソースのWebAppテンプレートをフォークしてください。テンプレートを基に、シナリオやスタイルに合わせてアプリをカスタマイズできます。
+
+## よくある質問
+
+**テキスト生成器にカスタムツールを追加する方法は?**
+
+チャットアシスタントタイプのアプリでは、サードパーティツールの追加はサポートされていません。カスタムツールを追加したい場合は、エージェントタイプのアプリ内で追加することが可能です。
diff --git a/zh-cn/management/app-management.mdx b/zh-cn/management/app-management.mdx
new file mode 100644
index 00000000..f26d3c70
--- /dev/null
+++ b/zh-cn/management/app-management.mdx
@@ -0,0 +1,41 @@
+---
+title: 应用管理
+version: '简体中文'
+---
+
+## [编辑应用信息](#edit-app-info)
+
+创建应用后,如果你想要修改应用名称或描述,可以点击应用左上角的 「编辑信息」 ,重新修改应用的图标、名称或描述。
+
+
+
+## [复制应用](#copy-app)
+
+应用均支持复制操作,点击应用左上角的 「复制」。
+
+## [导出应用](#export-app)
+
+在 Dify 内创建的应用均支持以 DSL 格式进行导出,你可以自由地将配置文件导入至任意 Dify 团队。
+
+通过以下两种方式导出 DSL 文件。
+
+* 在 “工作室” 页点击应用菜单按钮中 “导出 DSL”;
+* 进入应用的编排页后,点击左上角 “导出 DSL”。
+
+
+
+DSL 文件不包含自定义工具节点内已填写的授权信息,例如第三方服务的 API Key;如果环境变量中包含 `Secret`类型变量,导出文件时将提示是否允许导出该敏感信息。
+
+
+
+
+
+
+**会話変数**は以下の6つのデータ型をサポートしています:
+
+* String 文字列
+* Number 数値
+* Object オブジェクト
+* Array\[string] 文字列の配列
+* Array\[number] 数値の配列
+* Array\[object] オブジェクトの配列
+
+**会话变量**具有以下特性:
+
+* 会話変数はほとんどのノード内でグローバルに参照可能です。
+* 会話変数の書き込みには[変数代入](./nodes/variable-assigner)ノードを使用する必要があります;
+* 会話変数は読み書き可能な変数です;
+
+会話変数と変数代入ノードの具体的な使用方法については、[変数代入](./nodes/variable-assigner)をご参照ください。
+
+### 注意事项
+
+* 変数名の重複を避けるため、ノードの命名は独自に設定してください。
+* ノードの出力変数は通常固定されており、編集することはできません。
\ No newline at end of file
diff --git a/ja-jp/user-guide/build-app/text-generator.mdx b/ja-jp/user-guide/build-app/text-generator.mdx
new file mode 100644
index 00000000..8b03235d
--- /dev/null
+++ b/ja-jp/user-guide/build-app/text-generator.mdx
@@ -0,0 +1,79 @@
+---
+title: テキスト生成アプリケーション
+version: '日本語'
+---
+
+テキスト生成アプリケーションは、特定の形式のコンテンツを生成することに特化したアプリの一種です。このアプリでは、ユーザーが具体的な要件やパラメータを入力すると、あらかじめ設定された形式に従ってテキストが自動的に出力されます。持続的な対話能力を持つチャットボットとは異なり、テキスト生成アプリは主に単発の入力に対して応答し、一度きりのコンテンツ生成を行います。その中で「プロンプトジェネレーター」は、代表的な例として挙げられます。
+
+## 適用シーン
+
+テキスト生成アプリケーションは、クリエイティブライティング、マーケティングコピー、技術文書など、標準化されたコンテンツを迅速に大量生成する必要がある場面に特に適しています。
+
+## 作成手順
+
+対話型アプリの構築方法を説明します。プロンプト、変数、コンテキスト、オープニングステートメント、次のステップの提案をサポートします。
+
+次に、「週報生成アプリケーター」の構築を例に、対話型アプリの作成手順を紹介します。
+
+### アプリの作成
+
+ホームページで「アプリの作成」ボタンをクリックして、アプリを作成します。アプリ名を入力し、アプリタイプとして**テキスト生成アプリ**を選択します。
+
+
+
+### アプリの構築
+
+アプリが作成されると、自動的にアプリの監視ページに移動します。ここで、チャットアプリに変数を設定したり、コンテキストを追加したり、追加のチャット機能を設定することができます。
+
+
+
+#### プロンプトの入力
+
+プロンプトは、AIに対して専門的な返答を促すためのもので、返答の精度を高めるためのヒントとして使用されます。組み込みのプロンプトジェネレーターを利用して、適切なプロンプトを作成することができます。プロンプトには、フォーム変数を挿入することも可能です。たとえば、`{{input}}`という変数をプロンプト内に挿入すると、ユーザーが入力した値に基づいてその変数の値が置換されます。
+
+例:
+1. 面接シーンのプロンプトを要求する指示を入力します。
+2. 右側のコンテンツボックスにプロンプトが自動生成されます。
+3. プロンプト内にカスタム変数を挿入することもできます。
+
+
+
+#### コンテキストの追加
+
+AIの対話範囲を特定のナレッジベースに制限したい場合、例えば企業内のカスタマーサービスのテンプレートを使用したいときは、"コンテキスト"でナレッジベースを参照できます。
+
+
+
+### デバッグ
+
+右側にユーザー入力項目を入力して、内容をデバッグします。
+
+
+
+回答が思わしくない場合は、プロンプトや基礎モデルを調整することができます。また、複数のモデルを同時に使用してデバッグすることも可能で、適切な設定を組み合わせて試すことができます。
+
+
+
+**複数のモデルでのデバッグ:**
+
+単一のモデルを使用することが効率的でない場合、**"複数のモデルでのデバッグ"**機能を使用して、複数のモデルの回答効果を一括で確認できます。
+
+
+
+最大で4つの大きなモデルを同時に追加できます。
+
+
+
+⚠️ 複数モデルデバッグ機能を使用する際に、一部の大きなモデルしか表示されない場合は、他の大きなモデルのキーがまだ追加されていないためです。「新しいプロバイダーを追加」を利用して、複数のモデルのキーを手動で追加できます。
+
+### アプリの公開
+
+アプリをデバッグしたら、右上の**"公開"**ボタンをクリックして独自のAIアプリを生成します。公開されたURLを通じてアプリを体験するだけでなく、APIベースの開発やWebサイトへの組み込みも行えます。詳細については、公開に関するセクションをご覧ください。
+
+公開済みのアプリをカスタマイズしたい場合は、当社のオープンソースのWebAppテンプレートをフォークしてください。テンプレートを基に、シナリオやスタイルに合わせてアプリをカスタマイズできます。
+
+## よくある質問
+
+**テキスト生成器にカスタムツールを追加する方法は?**
+
+チャットアシスタントタイプのアプリでは、サードパーティツールの追加はサポートされていません。カスタムツールを追加したい場合は、エージェントタイプのアプリ内で追加することが可能です。
diff --git a/zh-cn/management/app-management.mdx b/zh-cn/management/app-management.mdx
new file mode 100644
index 00000000..f26d3c70
--- /dev/null
+++ b/zh-cn/management/app-management.mdx
@@ -0,0 +1,41 @@
+---
+title: 应用管理
+version: '简体中文'
+---
+
+## [编辑应用信息](#edit-app-info)
+
+创建应用后,如果你想要修改应用名称或描述,可以点击应用左上角的 「编辑信息」 ,重新修改应用的图标、名称或描述。
+
+
+
+## [复制应用](#copy-app)
+
+应用均支持复制操作,点击应用左上角的 「复制」。
+
+## [导出应用](#export-app)
+
+在 Dify 内创建的应用均支持以 DSL 格式进行导出,你可以自由地将配置文件导入至任意 Dify 团队。
+
+通过以下两种方式导出 DSL 文件。
+
+* 在 “工作室” 页点击应用菜单按钮中 “导出 DSL”;
+* 进入应用的编排页后,点击左上角 “导出 DSL”。
+
+
+
+DSL 文件不包含自定义工具节点内已填写的授权信息,例如第三方服务的 API Key;如果环境变量中包含 `Secret`类型变量,导出文件时将提示是否允许导出该敏感信息。
+
+
+
+ +
+- **已发布版本(Published Version)**: 用户发布到线上的所有版本,即最新发布版本和历史发布版本的统称。每一次发布操作都会生成一个新的已发布版本。
+
+- **最新发布版本(Latest Version)**: 用户最近一次发布到线上的版本。Dify 在版本管理界面中将其标记为 `Latest` ,以便与其他历史发布版本区分。
+
+
+
+- **已发布版本(Published Version)**: 用户发布到线上的所有版本,即最新发布版本和历史发布版本的统称。每一次发布操作都会生成一个新的已发布版本。
+
+- **最新发布版本(Latest Version)**: 用户最近一次发布到线上的版本。Dify 在版本管理界面中将其标记为 `Latest` ,以便与其他历史发布版本区分。
+
+ +
+- **历史发布版本(Previous Version)**: 用户曾经发布过,但现在已经不再处于当前线上状态的版本。
+
+
+
+- **历史发布版本(Previous Version)**: 用户曾经发布过,但现在已经不再处于当前线上状态的版本。
+
+ +
+- **版本回滚(Restore)**: 版本管理中的版本回滚功能允许用户将应用恢复到某个历史版本。
+
+
+
+- **版本回滚(Restore)**: 版本管理中的版本回滚功能允许用户将应用恢复到某个历史版本。
+
+ +
+## 功能
+
+- **查看所有版本**:在版本管理界面中,你可以查看所有已发布的版本,了解每个版本的详细信息。
+
+- **查找所需版本**: 你可以使用筛选功能快速查找所需的特定版本。
+
+- **发布新版本**: 你可以发布一个新的应用版本,并为该版本创建相应的版本名和版本描述。
+
+- **编辑已发布版本的信息**: 你可以编辑已发布版本的版本名和版本描述。
+
+- **删除历史版本**: 你可以删除不再需要的历史版本,清理版本列表。
+
+- **回滚到历史版本**: 通过版本回滚功能,你可以将历史版本的内容加载到草稿中并进行修改。
+
+## 如何查看所有版本?
+
+1. 点击右上角的 **版本管理功能** 按钮,进入版本管理界面。
+
+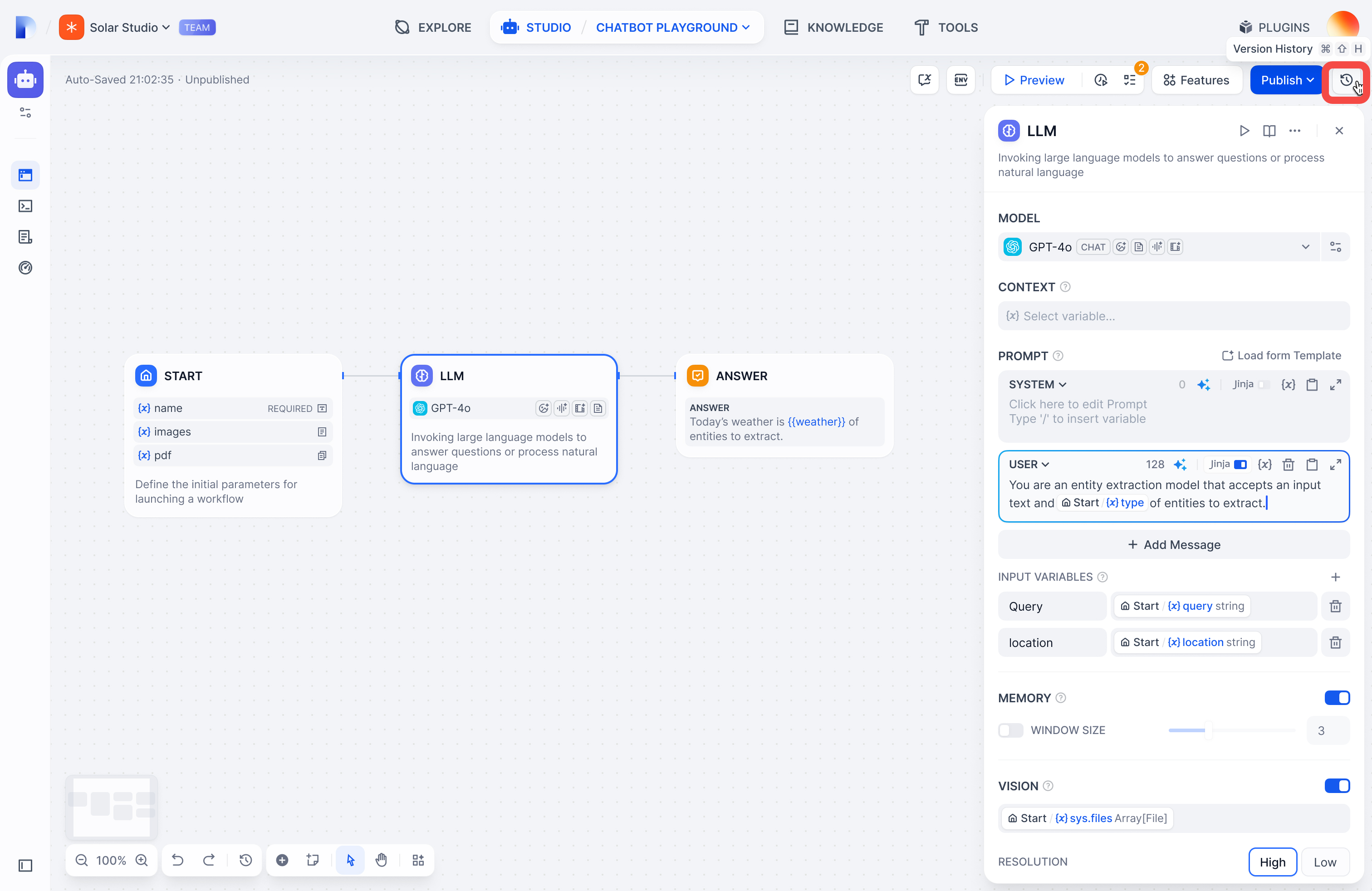
+
+2. 版本管理界面显示了一个按时间倒序排列的版本列表。你可以在列表内查看过往版本的 **版本名、版本信息、发布时间、发布者**。
+
+3. *(可选)* 如果版本列表超过当前可见的数量,你可以点击 **加载更多** 按钮,加载更多的版本记录。
+
+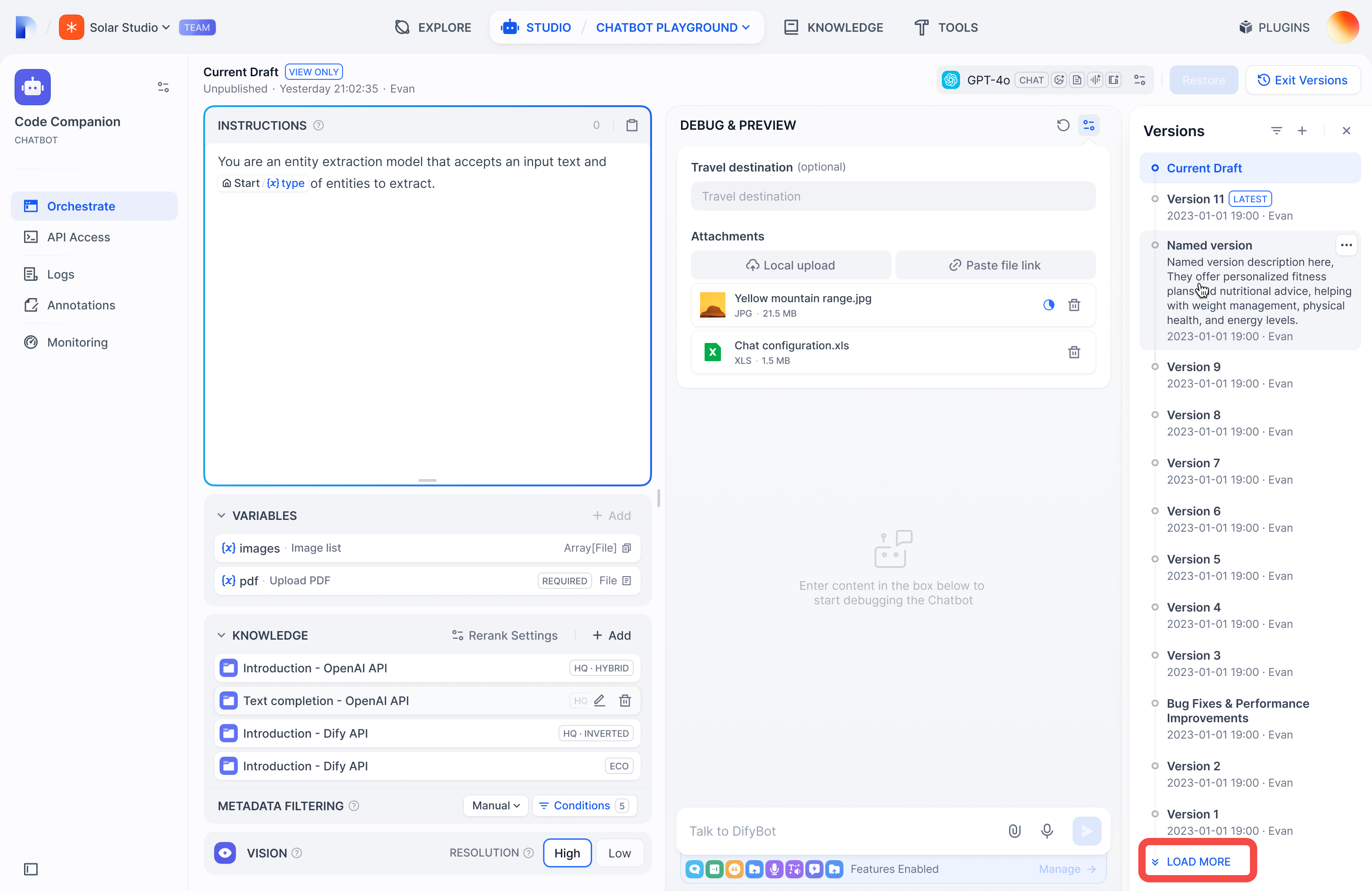
+
+## 如何查找我需要的版本?
+
+- **查找由我发布的版本**: 点击 **筛选** 按钮,弹出筛选框。该筛选框有两个选项:
+
+ - **所有版本**: 显示所有版本,包括你自己和其他用户发布的版本。
+ - **由我发布的版本**: 仅显示由你发布的版本。
+
+ 你可以根据需要选择合适的筛选项,以查看对应的版本。
+
+
+
+## 功能
+
+- **查看所有版本**:在版本管理界面中,你可以查看所有已发布的版本,了解每个版本的详细信息。
+
+- **查找所需版本**: 你可以使用筛选功能快速查找所需的特定版本。
+
+- **发布新版本**: 你可以发布一个新的应用版本,并为该版本创建相应的版本名和版本描述。
+
+- **编辑已发布版本的信息**: 你可以编辑已发布版本的版本名和版本描述。
+
+- **删除历史版本**: 你可以删除不再需要的历史版本,清理版本列表。
+
+- **回滚到历史版本**: 通过版本回滚功能,你可以将历史版本的内容加载到草稿中并进行修改。
+
+## 如何查看所有版本?
+
+1. 点击右上角的 **版本管理功能** 按钮,进入版本管理界面。
+
+
+
+2. 版本管理界面显示了一个按时间倒序排列的版本列表。你可以在列表内查看过往版本的 **版本名、版本信息、发布时间、发布者**。
+
+3. *(可选)* 如果版本列表超过当前可见的数量,你可以点击 **加载更多** 按钮,加载更多的版本记录。
+
+
+
+## 如何查找我需要的版本?
+
+- **查找由我发布的版本**: 点击 **筛选** 按钮,弹出筛选框。该筛选框有两个选项:
+
+ - **所有版本**: 显示所有版本,包括你自己和其他用户发布的版本。
+ - **由我发布的版本**: 仅显示由你发布的版本。
+
+ 你可以根据需要选择合适的筛选项,以查看对应的版本。
+
+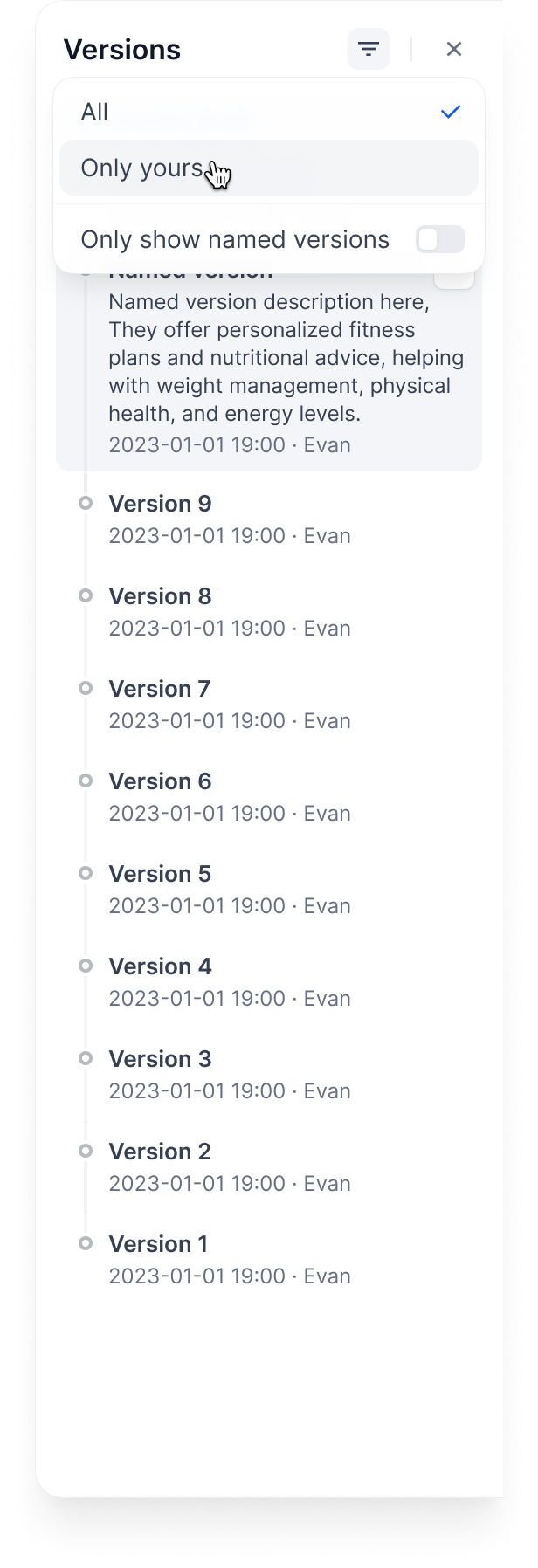 +
+- **查找已命名的版本**: 如果你只想查看已命名的版本,可以点击 **查找已命名的版本** 选项。启用该选项后,只有已命名版本会出现在版本列表中,其他未命名的版本将被隐藏。
+
+
+
+- **查找已命名的版本**: 如果你只想查看已命名的版本,可以点击 **查找已命名的版本** 选项。启用该选项后,只有已命名版本会出现在版本列表中,其他未命名的版本将被隐藏。
+
+ +
+## 如何发布新版本?
+
+1. 在 Dify 聊天流/工作流管理界面中完成聊天流/工作流创建后,点击面板的右上角的 **发布 > 发布更新** 按钮,即可直接发布当前版本。
+
+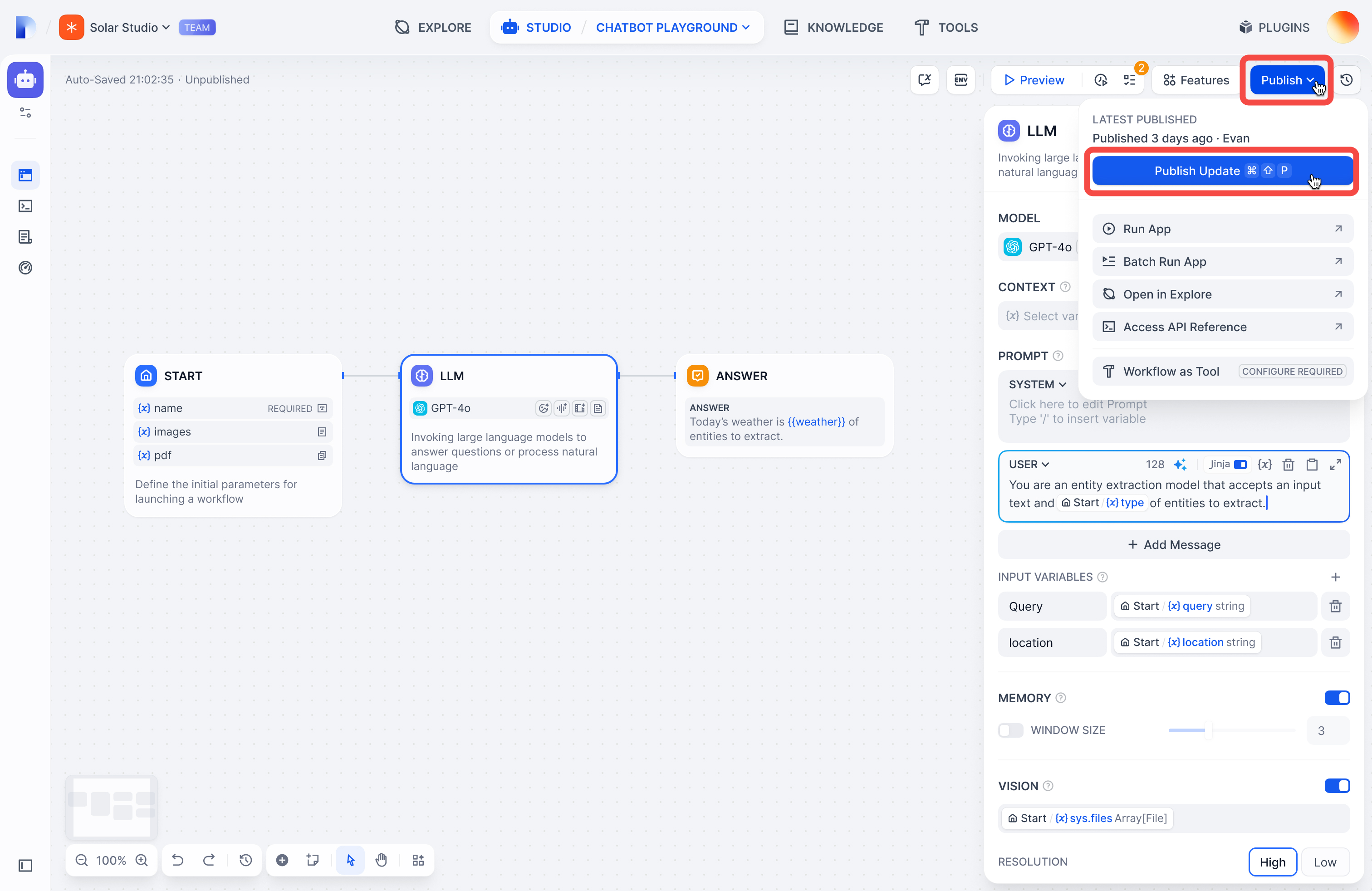
+
+2. 发布后,此最新发布版本将被标记为 `Latest` 。相关信息会显示在版本管理界面中。
+
+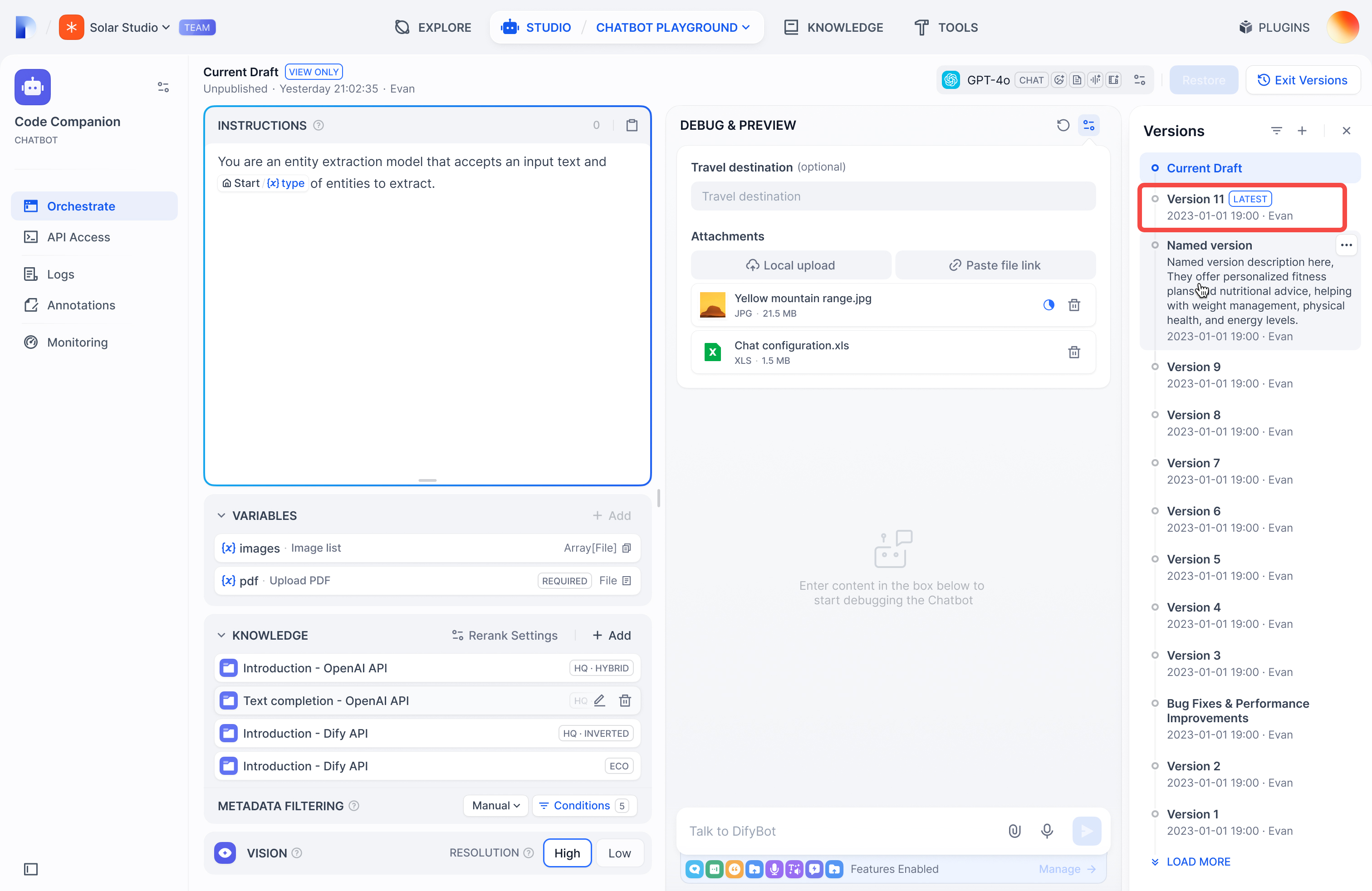
+
+## 如何编辑已发布版本的信息?
+
+1. 在版本管理界面,找到你需要编辑版本信息的版本,并点击该版本右上角的操作菜单。
+
+- 如果你之前以默认名称保存了该版本,可以点击 **命名此版本**,更新版本名与版本信息。
+
+
+
+## 如何发布新版本?
+
+1. 在 Dify 聊天流/工作流管理界面中完成聊天流/工作流创建后,点击面板的右上角的 **发布 > 发布更新** 按钮,即可直接发布当前版本。
+
+
+
+2. 发布后,此最新发布版本将被标记为 `Latest` 。相关信息会显示在版本管理界面中。
+
+
+
+## 如何编辑已发布版本的信息?
+
+1. 在版本管理界面,找到你需要编辑版本信息的版本,并点击该版本右上角的操作菜单。
+
+- 如果你之前以默认名称保存了该版本,可以点击 **命名此版本**,更新版本名与版本信息。
+
+ +
+- 如果你已经为该版本填写过版本名,可以点击 **编辑版本信息** 修改版本名与版本信息。
+
+
+
+2. 点击 **发布**,发布版本信息。
+
+
+
+## 如何删除历史版本?
+
+1. 在版本管理界面,找到你需要删除的已发布版本,点击该版本右上角的操作菜单。
+
+2. 选择 **删除**,弹出确认操作的弹窗。
+
+
+
+- 如果你已经为该版本填写过版本名,可以点击 **编辑版本信息** 修改版本名与版本信息。
+
+
+
+2. 点击 **发布**,发布版本信息。
+
+
+
+## 如何删除历史版本?
+
+1. 在版本管理界面,找到你需要删除的已发布版本,点击该版本右上角的操作菜单。
+
+2. 选择 **删除**,弹出确认操作的弹窗。
+
+ +
+3. 点击 **删除**,该版本将从版本管理界面中删除。
+
+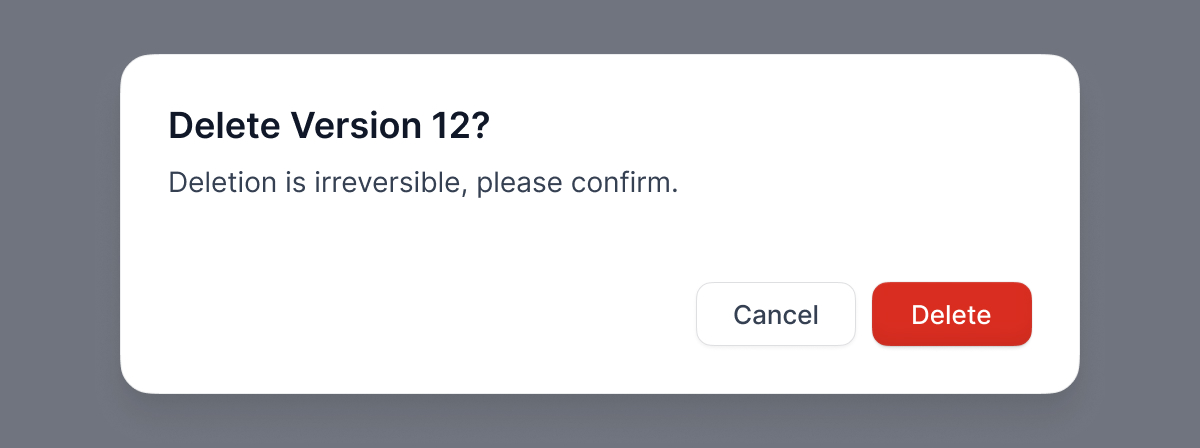
+
+
+
+3. 点击 **删除**,该版本将从版本管理界面中删除。
+
+
+
+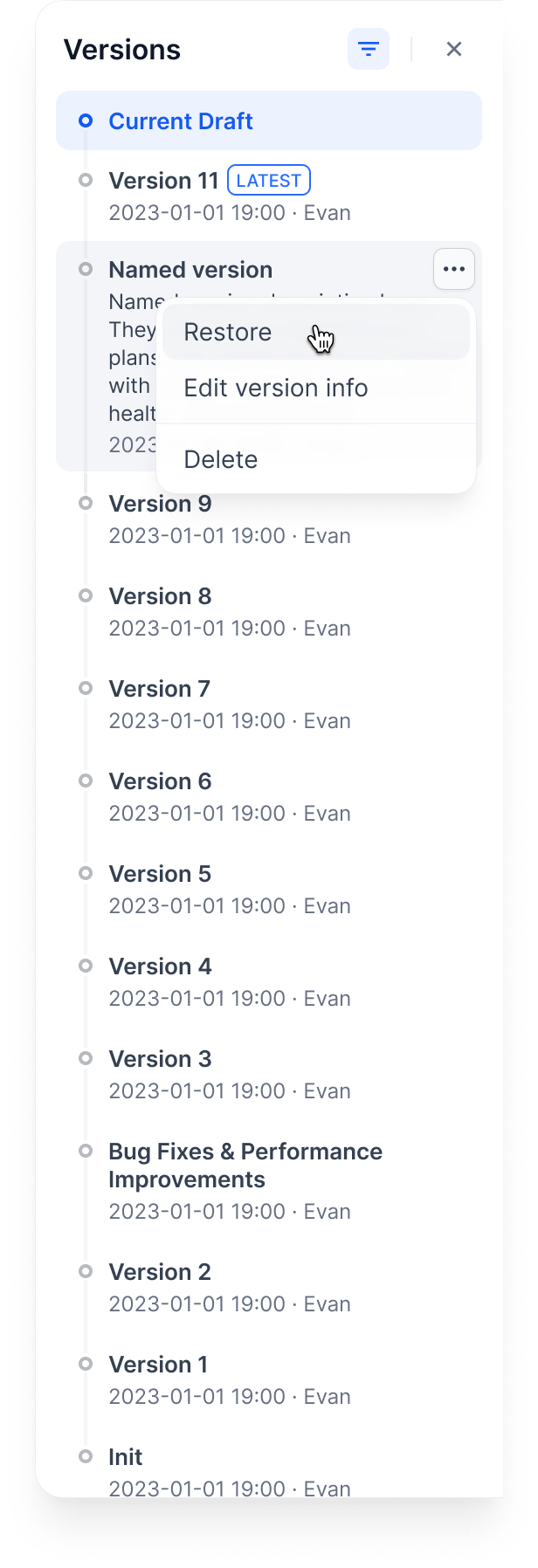 +
+3. 点击 **回滚**,当前的草稿版本将回滚为该历史版本。
+
+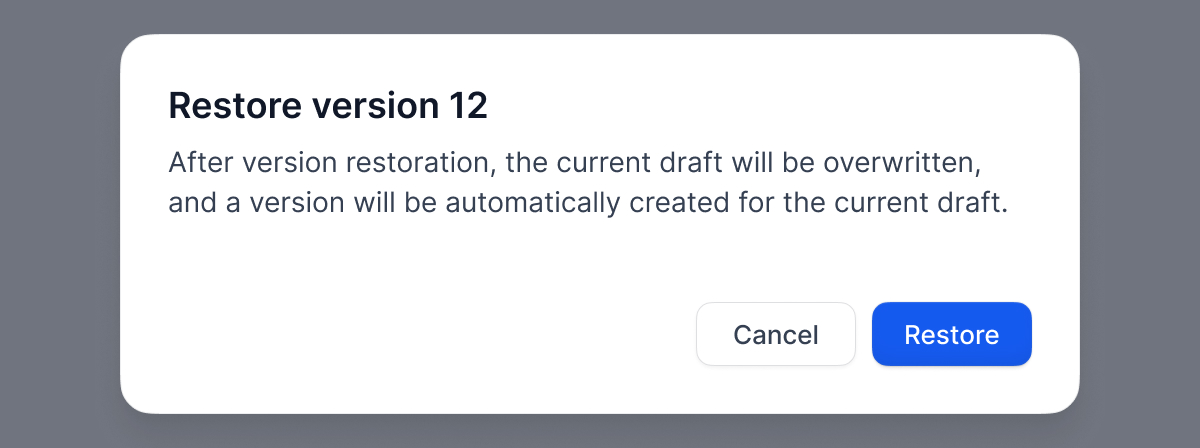
+
+## 使用场景
+
+以下用一个典型的用户使用场景来说明各版本之间的联系。
+
+> 相同颜色代表相同的版本内容。
+
+### 阶段一
+
+- 系统自动新建 **草稿版本** Version A。
+
+
+
+### 阶段二:首次发布
+
+- Version A 发布,成为 **最新发布版本**。
+- 系统自动新建 **草稿版本** Version B。
+
+
+
+### 阶段三:再次发布
+
+- Version B 发布,成为 **最新发布版本**。
+- Version A 成为 **历史发布版本**。
+- 系统自动新建 **草稿版本** Version C。
+
+
+
+### 阶段四:回滚操作
+
+- Version A 回滚至 **草稿版本**,覆盖 Version C。
+- Version B 仍为 **最新发布版本**。
+
+
+
+### 阶段五:发布回滚
+
+- Version A(回滚版)发布,成为 **最新发布版本**。
+- Version A 与 Version B 成为 **历史发布版本**。
+- 系统自动新建 **草稿版本** Version D。
+
+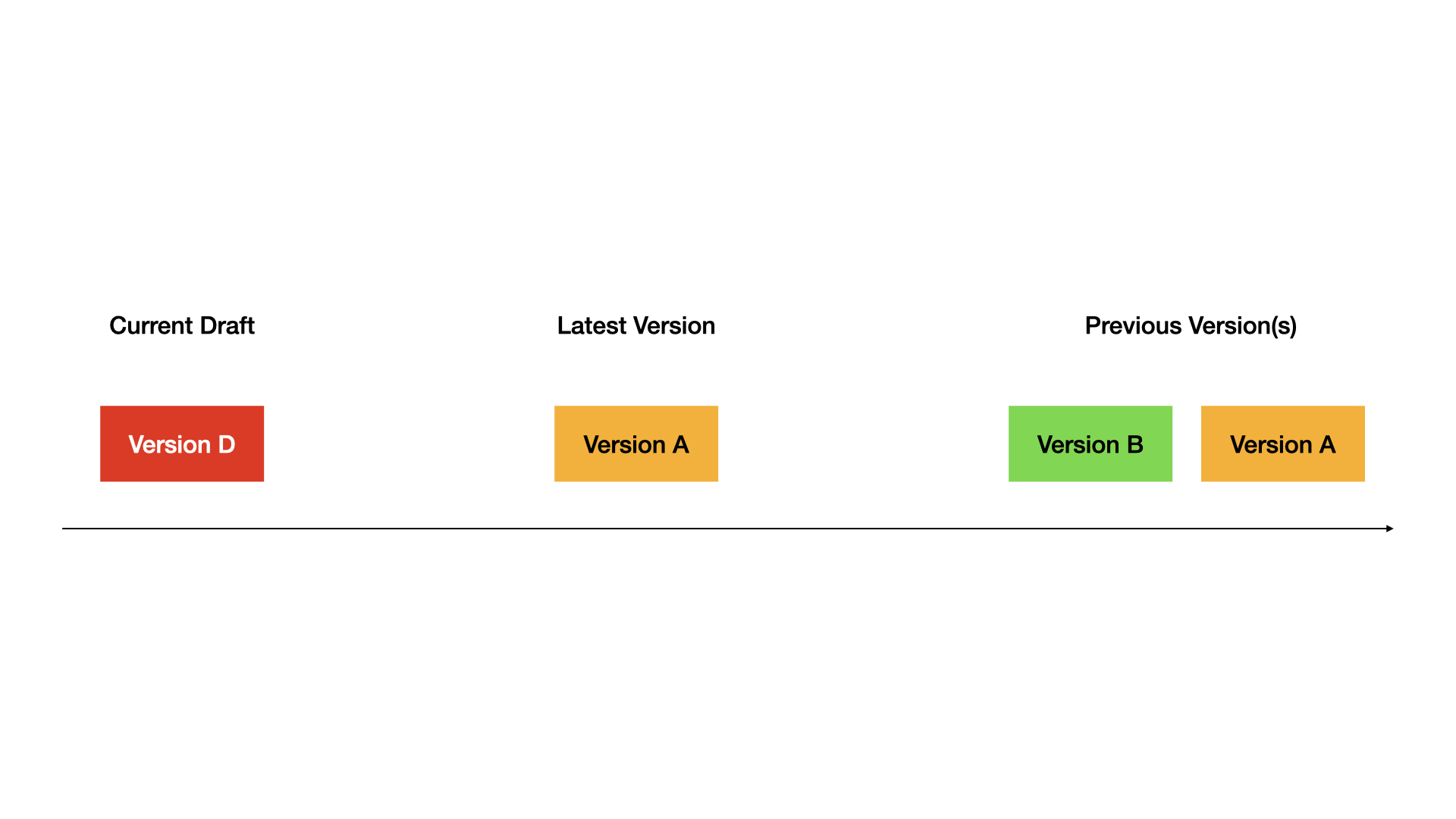
+
+### 全流程演示
+
+
+
+## FAQ
+
+- **草稿版本、已发布版本、最新发布版本和历史发布版本有什么区别?**
+
+| 定义 | 操作方式 | 是否可以从线上访问 | 是否可以删除 | 是否可以回滚 |
+|-----|---------|------------------|------------|------------|
+| 草稿版本 | 当前正在编辑和修改的版本,代表用户的最新工作进度。 | 只能通过 发布 (Publish) 操作推送至线上环境。 | 不可以从线上访问,必须通过发布操作将其推送为最新发布版本才可以从线上访问。 | 无法删除。 |
+| 最新发布版本 | 目前线上生效的版本,是最新的已发布版本。 | 是当前线上的版本,不能直接编辑,需通过发布新的草稿版本来更新。 | 可以从线上访问和使用。 | 可以通过回滚操作恢复到该版本内容。 |
+| 历史发布版本 | 过去已发布并保存的版本,用户可回滚使用,但不再对外生效。 | 可以通过 回滚 (Restore) 操作将历史版本加载到草稿版本中,再进行编辑和发布。 | 不可以从线上访问,仅保存在版本列表里。 | 可以通过回滚操作恢复到该版本内容。 |
+| 已发布版本 | 最新发布版本和历史发布版本的统称。 | / | / | / |
+
+- **回滚到历史版本后,当前的草稿版本会丢失吗?**
+
+当你选择回滚到历史版本后,系统会将你选择的历史版本的内容加载到新的草稿版本中。你可以继续在该草稿上进行修改并发布。
+
+因此,回滚到历史版本后,当前的草稿版本将会丢失。请谨慎操作。
+
+- **版本管理功能适用于哪些应用类型?**
+
+目前,版本管理功能仅适用于 **聊天流** 和 **工作流** 应用类型。**聊天助手**、**文本生成应用** 以及 **Agent** 暂不支持此功能。
diff --git a/zh-cn/user-guide/build-app/flow-app/publish.mdx b/zh-cn/user-guide/build-app/flow-app/application-publishing.mdx
similarity index 57%
rename from zh-cn/user-guide/build-app/flow-app/publish.mdx
rename to zh-cn/user-guide/build-app/flow-app/application-publishing.mdx
index f23775ed..f4b10356 100644
--- a/zh-cn/user-guide/build-app/flow-app/publish.mdx
+++ b/zh-cn/user-guide/build-app/flow-app/application-publishing.mdx
@@ -1,10 +1,11 @@
---
title: 应用发布
-version: '简体中文'
---
调试完成之后点击右上角的「发布」可以将该工作流保存并快速发布成为不同类型的应用。
+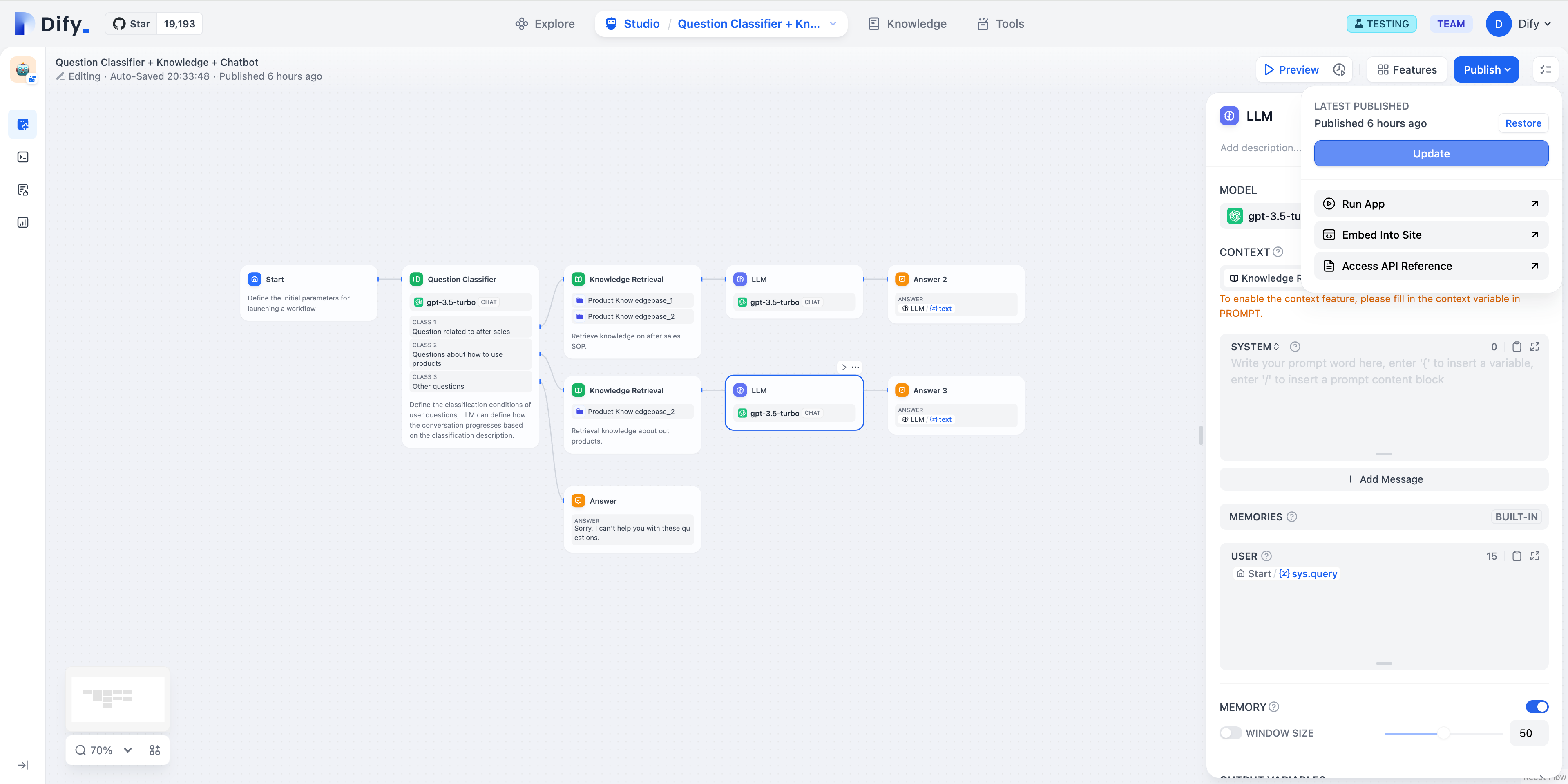
+
对话型应用支持发布为:
* 直接运行
@@ -18,4 +19,6 @@ version: '简体中文'
* 访问 API
* 发布为工具
-你也可以点击 **恢复** 预览上一次发布的应用版本,确认恢复将会使用上一次发布的工作流版本覆盖当前的工作流版本。
+
+
+3. 点击 **回滚**,当前的草稿版本将回滚为该历史版本。
+
+
+
+## 使用场景
+
+以下用一个典型的用户使用场景来说明各版本之间的联系。
+
+> 相同颜色代表相同的版本内容。
+
+### 阶段一
+
+- 系统自动新建 **草稿版本** Version A。
+
+
+
+### 阶段二:首次发布
+
+- Version A 发布,成为 **最新发布版本**。
+- 系统自动新建 **草稿版本** Version B。
+
+
+
+### 阶段三:再次发布
+
+- Version B 发布,成为 **最新发布版本**。
+- Version A 成为 **历史发布版本**。
+- 系统自动新建 **草稿版本** Version C。
+
+
+
+### 阶段四:回滚操作
+
+- Version A 回滚至 **草稿版本**,覆盖 Version C。
+- Version B 仍为 **最新发布版本**。
+
+
+
+### 阶段五:发布回滚
+
+- Version A(回滚版)发布,成为 **最新发布版本**。
+- Version A 与 Version B 成为 **历史发布版本**。
+- 系统自动新建 **草稿版本** Version D。
+
+
+
+### 全流程演示
+
+
+
+## FAQ
+
+- **草稿版本、已发布版本、最新发布版本和历史发布版本有什么区别?**
+
+| 定义 | 操作方式 | 是否可以从线上访问 | 是否可以删除 | 是否可以回滚 |
+|-----|---------|------------------|------------|------------|
+| 草稿版本 | 当前正在编辑和修改的版本,代表用户的最新工作进度。 | 只能通过 发布 (Publish) 操作推送至线上环境。 | 不可以从线上访问,必须通过发布操作将其推送为最新发布版本才可以从线上访问。 | 无法删除。 |
+| 最新发布版本 | 目前线上生效的版本,是最新的已发布版本。 | 是当前线上的版本,不能直接编辑,需通过发布新的草稿版本来更新。 | 可以从线上访问和使用。 | 可以通过回滚操作恢复到该版本内容。 |
+| 历史发布版本 | 过去已发布并保存的版本,用户可回滚使用,但不再对外生效。 | 可以通过 回滚 (Restore) 操作将历史版本加载到草稿版本中,再进行编辑和发布。 | 不可以从线上访问,仅保存在版本列表里。 | 可以通过回滚操作恢复到该版本内容。 |
+| 已发布版本 | 最新发布版本和历史发布版本的统称。 | / | / | / |
+
+- **回滚到历史版本后,当前的草稿版本会丢失吗?**
+
+当你选择回滚到历史版本后,系统会将你选择的历史版本的内容加载到新的草稿版本中。你可以继续在该草稿上进行修改并发布。
+
+因此,回滚到历史版本后,当前的草稿版本将会丢失。请谨慎操作。
+
+- **版本管理功能适用于哪些应用类型?**
+
+目前,版本管理功能仅适用于 **聊天流** 和 **工作流** 应用类型。**聊天助手**、**文本生成应用** 以及 **Agent** 暂不支持此功能。
diff --git a/zh-cn/user-guide/build-app/flow-app/publish.mdx b/zh-cn/user-guide/build-app/flow-app/application-publishing.mdx
similarity index 57%
rename from zh-cn/user-guide/build-app/flow-app/publish.mdx
rename to zh-cn/user-guide/build-app/flow-app/application-publishing.mdx
index f23775ed..f4b10356 100644
--- a/zh-cn/user-guide/build-app/flow-app/publish.mdx
+++ b/zh-cn/user-guide/build-app/flow-app/application-publishing.mdx
@@ -1,10 +1,11 @@
---
title: 应用发布
-version: '简体中文'
---
调试完成之后点击右上角的「发布」可以将该工作流保存并快速发布成为不同类型的应用。
+
+
对话型应用支持发布为:
* 直接运行
@@ -18,4 +19,6 @@ version: '简体中文'
* 访问 API
* 发布为工具
-你也可以点击 **恢复** 预览上一次发布的应用版本,确认恢复将会使用上一次发布的工作流版本覆盖当前的工作流版本。
+