diff --git a/ja-jp/community/docs-contribution.mdx b/ja-jp/community/docs-contribution.mdx
index b627b917..3a696fcd 100644
--- a/ja-jp/community/docs-contribution.mdx
+++ b/ja-jp/community/docs-contribution.mdx
@@ -17,7 +17,7 @@ Dify のヘルプドキュメントは、[オープンソースプロジェク
ドキュメントを読んでいる際に内容の誤りを見つけたり、一部を修正したい場合は、文書ページの右側にある目次内の **“Github に編集”** ボタンをクリックしてください。これにより、GitHub のオンラインエディターを使用してファイルを修正できます。その後、修正内容を簡潔に説明した pull request を作成してください。タイトルは `Fix: Update xxx` の形式を使用してください。リクエストを受け取った後、レビューを行い、問題がなければ修正をマージします。
-
+
もちろん、[Issues ページ](https://github.com/langgenius/dify-docs/issues)にドキュメントのリンクを貼り付け、修正が必要な内容を簡単に説明していただくことも可能です。フィードバックを受け取った後、迅速に対応いたします。
diff --git a/ja-jp/development/models-integration/gpustack.mdx b/ja-jp/development/models-integration/gpustack.mdx
index 6fb1c465..9872439e 100644
--- a/ja-jp/development/models-integration/gpustack.mdx
+++ b/ja-jp/development/models-integration/gpustack.mdx
@@ -39,7 +39,7 @@ GPUStackにホストされたLLMを使用する方法の例です:
3. モデルを展開するために「Save」をクリックします。
-
+
## APIキーの作成方法
@@ -63,6 +63,6 @@ GPUStackにホストされたLLMを使用する方法の例です:
モデルをアプリケーションで使用するために、「Save」をクリックしてください。
-
+
GPUStackに関する詳細情報は、[Github Repo](https://github.com/gpustack/gpustack)を参照してください。
\ No newline at end of file
diff --git a/ja-jp/development/models-integration/hugging-face.mdx b/ja-jp/development/models-integration/hugging-face.mdx
index 4641e803..c5b3b1d1 100644
--- a/ja-jp/development/models-integration/hugging-face.mdx
+++ b/ja-jp/development/models-integration/hugging-face.mdx
@@ -15,7 +15,7 @@ Difyはテキスト生成(Text-Generation)と埋め込み(Embeddings)を
3. [Hugging Faceのモデル一覧ページ](https://huggingface.co/models)にアクセスし、対応するモデルの種類を選択します。
![]() @@ -32,7 +32,7 @@ DifyはHugging Face上のモデルを次の2つの方法で接続できます:
モデルの詳細ページの右側にHosted Inference APIのセクションがあるモデルのみがHosted Inference APIをサポートしています。以下の図のように表示されます:
@@ -32,7 +32,7 @@ DifyはHugging Face上のモデルを次の2つの方法で接続できます:
モデルの詳細ページの右側にHosted Inference APIのセクションがあるモデルのみがHosted Inference APIをサポートしています。以下の図のように表示されます:
![]() @@ -40,7 +40,7 @@ alt=""
モデルの詳細ページで、モデルの名前を取得できます。
@@ -40,7 +40,7 @@ alt=""
モデルの詳細ページで、モデルの名前を取得できます。
![]() @@ -50,7 +50,7 @@ alt=""
`設定 > モデルプロバイダー > Hugging Face > モデルタイプ`のエンドポイントタイプでHosted Inference APIを選択します。以下の図のように設定します:
@@ -50,7 +50,7 @@ alt=""
`設定 > モデルプロバイダー > Hugging Face > モデルタイプ`のエンドポイントタイプでHosted Inference APIを選択します。以下の図のように設定します:
![]() @@ -64,7 +64,7 @@ APIトークンは記事の冒頭で設定したAPIキーです。モデル名
モデルの詳細ページの右側にある`Deploy`ボタンの下にInference EndpointsオプションがあるモデルのみがInference Endpointをサポートしています。以下の図のように表示されます:
@@ -64,7 +64,7 @@ APIトークンは記事の冒頭で設定したAPIキーです。モデル名
モデルの詳細ページの右側にある`Deploy`ボタンの下にInference EndpointsオプションがあるモデルのみがInference Endpointをサポートしています。以下の図のように表示されます:
![]() @@ -74,7 +74,7 @@ alt=""
モデルのデプロイボタンをクリックし、Inference Endpointオプションを選択します。以前にクレジットカードを登録していない場合は、カードの登録が必要です。手順に従って進めてください。カードを登録した後、以下の画面が表示されます:必要に応じて設定を変更し、左下のCreate EndpointボタンをクリックしてInference Endpointを作成します。
@@ -74,7 +74,7 @@ alt=""
モデルのデプロイボタンをクリックし、Inference Endpointオプションを選択します。以前にクレジットカードを登録していない場合は、カードの登録が必要です。手順に従って進めてください。カードを登録した後、以下の画面が表示されます:必要に応じて設定を変更し、左下のCreate EndpointボタンをクリックしてInference Endpointを作成します。
![]() @@ -82,7 +82,7 @@ alt=""
モデルがデプロイされると、エンドポイントURLが表示されます。
@@ -82,7 +82,7 @@ alt=""
モデルがデプロイされると、エンドポイントURLが表示されます。
![]() @@ -92,7 +92,7 @@ alt=""
`設定 > モデルプロバイダー > Hugging Face > モデルタイプ`のエンドポイントタイプでInference Endpointsを選択します。以下の図のように設定します:
@@ -92,7 +92,7 @@ alt=""
`設定 > モデルプロバイダー > Hugging Face > モデルタイプ`のエンドポイントタイプでInference Endpointsを選択します。以下の図のように設定します:
![]() @@ -100,7 +100,7 @@ alt=""
APIトークンは記事の冒頭で設定したAPIキーです。`テキスト生成モデルの名前は任意に設定可能ですが、埋め込みモデルの名前はHugging Faceの名前と一致する必要があります。`エンドポイントURLは前のステップでデプロイしたモデルのエンドポイントURLを入力します。
@@ -100,7 +100,7 @@ alt=""
APIトークンは記事の冒頭で設定したAPIキーです。`テキスト生成モデルの名前は任意に設定可能ですが、埋め込みモデルの名前はHugging Faceの名前と一致する必要があります。`エンドポイントURLは前のステップでデプロイしたモデルのエンドポイントURLを入力します。
![]() diff --git a/ja-jp/development/models-integration/litellm.mdx b/ja-jp/development/models-integration/litellm.mdx
index caabffc9..d0326ce8 100644
--- a/ja-jp/development/models-integration/litellm.mdx
+++ b/ja-jp/development/models-integration/litellm.mdx
@@ -55,7 +55,7 @@ docker run \
`設定 > モデルプロバイダー > OpenAI-API互換` で、以下を入力してください:
diff --git a/ja-jp/development/models-integration/litellm.mdx b/ja-jp/development/models-integration/litellm.mdx
index caabffc9..d0326ce8 100644
--- a/ja-jp/development/models-integration/litellm.mdx
+++ b/ja-jp/development/models-integration/litellm.mdx
@@ -55,7 +55,7 @@ docker run \
`設定 > モデルプロバイダー > OpenAI-API互換` で、以下を入力してください:
![]() diff --git a/ja-jp/development/models-integration/ollama.mdx b/ja-jp/development/models-integration/ollama.mdx
index 8dc3f0a3..1ad6e5bd 100644
--- a/ja-jp/development/models-integration/ollama.mdx
+++ b/ja-jp/development/models-integration/ollama.mdx
@@ -3,7 +3,7 @@ title: Ollamaでデプロイしたローカルモデルを統合
---
-
+
[Ollama](https://github.com/jmorganca/ollama)は、Llama 2、Mistral、LlavaといったLLMを簡単にデプロイできるように設計された、クロスプラットフォーム対応の推論フレームワーククライアントです(MacOS、Windows、Linuxに対応)。ワンクリックでセットアップできるOllamaを利用すれば、LLMをローカル環境で実行でき、データを手元のマシンに保持することで、データプライバシーとセキュリティを強化できます。
@@ -29,8 +29,6 @@ title: Ollamaでデプロイしたローカルモデルを統合
Difyの設定画面で、「モデルプロバイダー」>「Ollama」を選択し、以下の情報を入力します。
- 
-
* モデル名: `llama3.2`
* ベースURL: `http://:11434`
@@ -57,7 +55,8 @@ title: Ollamaでデプロイしたローカルモデルを統合
4. Ollamaモデルの使用
- 
+ 
+
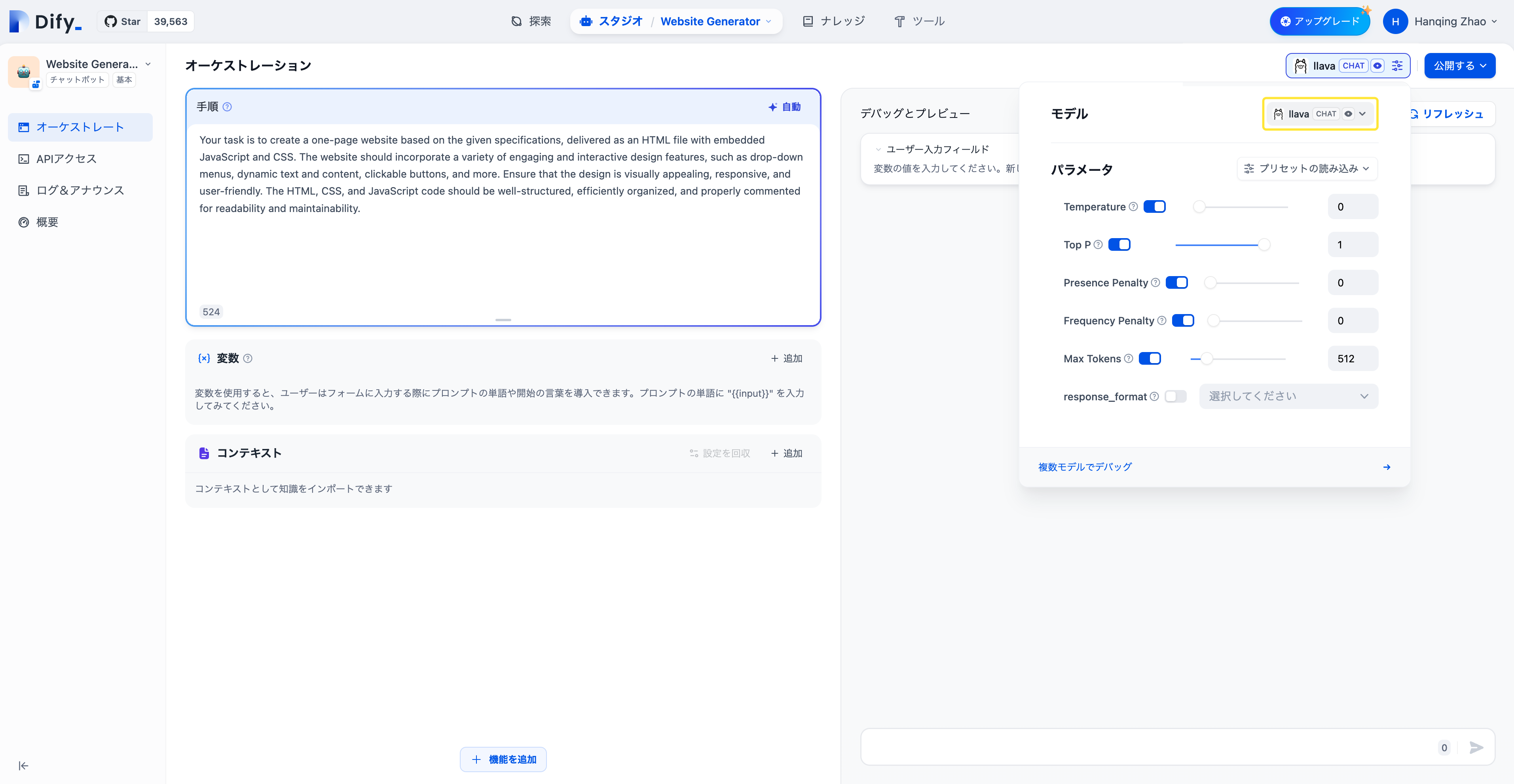
設定が必要なアプリの「プロンプトエンジニアリング」ページを開き、Ollamaプロバイダーの中から`llava`モデルを選択し、モデルパラメーターを設定して使用します。
diff --git a/ja-jp/development/models-integration/replicate.mdx b/ja-jp/development/models-integration/replicate.mdx
index f4201720..fdf38eb0 100644
--- a/ja-jp/development/models-integration/replicate.mdx
+++ b/ja-jp/development/models-integration/replicate.mdx
@@ -13,7 +13,7 @@ DifyはReplicate上の[言語モデル](https://replicate.com/collections/langua
4. Difyの`設定 > モデルプロバイダ > Replicate`にてモデルを追加します。
diff --git a/ja-jp/development/models-integration/ollama.mdx b/ja-jp/development/models-integration/ollama.mdx
index 8dc3f0a3..1ad6e5bd 100644
--- a/ja-jp/development/models-integration/ollama.mdx
+++ b/ja-jp/development/models-integration/ollama.mdx
@@ -3,7 +3,7 @@ title: Ollamaでデプロイしたローカルモデルを統合
---
-
+
[Ollama](https://github.com/jmorganca/ollama)は、Llama 2、Mistral、LlavaといったLLMを簡単にデプロイできるように設計された、クロスプラットフォーム対応の推論フレームワーククライアントです(MacOS、Windows、Linuxに対応)。ワンクリックでセットアップできるOllamaを利用すれば、LLMをローカル環境で実行でき、データを手元のマシンに保持することで、データプライバシーとセキュリティを強化できます。
@@ -29,8 +29,6 @@ title: Ollamaでデプロイしたローカルモデルを統合
Difyの設定画面で、「モデルプロバイダー」>「Ollama」を選択し、以下の情報を入力します。
- 
-
* モデル名: `llama3.2`
* ベースURL: `http://:11434`
@@ -57,7 +55,8 @@ title: Ollamaでデプロイしたローカルモデルを統合
4. Ollamaモデルの使用
- 
+ 
+
設定が必要なアプリの「プロンプトエンジニアリング」ページを開き、Ollamaプロバイダーの中から`llava`モデルを選択し、モデルパラメーターを設定して使用します。
diff --git a/ja-jp/development/models-integration/replicate.mdx b/ja-jp/development/models-integration/replicate.mdx
index f4201720..fdf38eb0 100644
--- a/ja-jp/development/models-integration/replicate.mdx
+++ b/ja-jp/development/models-integration/replicate.mdx
@@ -13,7 +13,7 @@ DifyはReplicate上の[言語モデル](https://replicate.com/collections/langua
4. Difyの`設定 > モデルプロバイダ > Replicate`にてモデルを追加します。
![]() @@ -21,7 +21,7 @@ alt=""
APIキーは第2ステップで設定したAPIキーです。モデル名とモデルバージョンはモデルの詳細ページで見つけることができます:
@@ -21,7 +21,7 @@ alt=""
APIキーは第2ステップで設定したAPIキーです。モデル名とモデルバージョンはモデルの詳細ページで見つけることができます:
![]() diff --git a/ja-jp/development/models-integration/xinference.mdx b/ja-jp/development/models-integration/xinference.mdx
index c8bc09a4..02ff69c3 100644
--- a/ja-jp/development/models-integration/xinference.mdx
+++ b/ja-jp/development/models-integration/xinference.mdx
@@ -33,7 +33,7 @@ Xinferenceのデプロイ方法は、[ローカルデプロイ](https://github.c
`http://127.0.0.1:9997`にアクセスし、デプロイするモデルとその仕様を選択します。以下の図を参照してください:
diff --git a/ja-jp/development/models-integration/xinference.mdx b/ja-jp/development/models-integration/xinference.mdx
index c8bc09a4..02ff69c3 100644
--- a/ja-jp/development/models-integration/xinference.mdx
+++ b/ja-jp/development/models-integration/xinference.mdx
@@ -33,7 +33,7 @@ Xinferenceのデプロイ方法は、[ローカルデプロイ](https://github.c
`http://127.0.0.1:9997`にアクセスし、デプロイするモデルとその仕様を選択します。以下の図を参照してください:
![]() diff --git a/ja-jp/guides/application-orchestrate/agent.mdx b/ja-jp/guides/application-orchestrate/agent.mdx
index 51be95ce..36f3504e 100644
--- a/ja-jp/guides/application-orchestrate/agent.mdx
+++ b/ja-jp/guides/application-orchestrate/agent.mdx
@@ -64,7 +64,7 @@ alt=""
### ファイルのアップロード
-Claude 3.5 Sonnet (https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) や Gemini 1.5 Pro (https://ai.google.dev/api/files) など、一部のLLMはファイル処理に標準対応しています。各LLMのウェブサイトで、ファイルのアップロード機能について詳しくご確認ください。
+[Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) や [Gemini 1.5 Pro](https://ai.google.dev/api/files) など、一部のLLMはファイル処理に標準対応しています。各LLMのウェブサイトで、ファイルのアップロード機能について詳しくご確認ください。
ファイルの読み込みに対応したLLMを選択し、「Document」を有効にしてください。これにより、チャットボットは複雑な設定なしでファイルの内容を理解し、利用できるようになります。
diff --git a/ja-jp/guides/application-orchestrate/agent.mdx.bak b/ja-jp/guides/application-orchestrate/agent.mdx.bak
index 51be95ce..36f3504e 100644
--- a/ja-jp/guides/application-orchestrate/agent.mdx.bak
+++ b/ja-jp/guides/application-orchestrate/agent.mdx.bak
@@ -64,7 +64,7 @@ alt=""
### ファイルのアップロード
-Claude 3.5 Sonnet (https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) や Gemini 1.5 Pro (https://ai.google.dev/api/files) など、一部のLLMはファイル処理に標準対応しています。各LLMのウェブサイトで、ファイルのアップロード機能について詳しくご確認ください。
+[Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) や [Gemini 1.5 Pro](https://ai.google.dev/api/files) など、一部のLLMはファイル処理に標準対応しています。各LLMのウェブサイトで、ファイルのアップロード機能について詳しくご確認ください。
ファイルの読み込みに対応したLLMを選択し、「Document」を有効にしてください。これにより、チャットボットは複雑な設定なしでファイルの内容を理解し、利用できるようになります。
diff --git a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
index 24fa4ff1..1e0a98c9 100644
--- a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
+++ b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
@@ -18,7 +18,7 @@ title: 外部ナレッジベースとの接続
- Difyプラットフォームは、独自に構築したナレッジベース内のアルゴリズムで処理されたテキストコンテンツを直接取得でき、開発者は独自のナレッジベースの情報検索メカニズムに焦点を当て、情報取得の精度を継続的に最適化できます。
-
diff --git a/ja-jp/guides/application-orchestrate/agent.mdx b/ja-jp/guides/application-orchestrate/agent.mdx
index 51be95ce..36f3504e 100644
--- a/ja-jp/guides/application-orchestrate/agent.mdx
+++ b/ja-jp/guides/application-orchestrate/agent.mdx
@@ -64,7 +64,7 @@ alt=""
### ファイルのアップロード
-Claude 3.5 Sonnet (https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) や Gemini 1.5 Pro (https://ai.google.dev/api/files) など、一部のLLMはファイル処理に標準対応しています。各LLMのウェブサイトで、ファイルのアップロード機能について詳しくご確認ください。
+[Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) や [Gemini 1.5 Pro](https://ai.google.dev/api/files) など、一部のLLMはファイル処理に標準対応しています。各LLMのウェブサイトで、ファイルのアップロード機能について詳しくご確認ください。
ファイルの読み込みに対応したLLMを選択し、「Document」を有効にしてください。これにより、チャットボットは複雑な設定なしでファイルの内容を理解し、利用できるようになります。
diff --git a/ja-jp/guides/application-orchestrate/agent.mdx.bak b/ja-jp/guides/application-orchestrate/agent.mdx.bak
index 51be95ce..36f3504e 100644
--- a/ja-jp/guides/application-orchestrate/agent.mdx.bak
+++ b/ja-jp/guides/application-orchestrate/agent.mdx.bak
@@ -64,7 +64,7 @@ alt=""
### ファイルのアップロード
-Claude 3.5 Sonnet (https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) や Gemini 1.5 Pro (https://ai.google.dev/api/files) など、一部のLLMはファイル処理に標準対応しています。各LLMのウェブサイトで、ファイルのアップロード機能について詳しくご確認ください。
+[Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) や [Gemini 1.5 Pro](https://ai.google.dev/api/files) など、一部のLLMはファイル処理に標準対応しています。各LLMのウェブサイトで、ファイルのアップロード機能について詳しくご確認ください。
ファイルの読み込みに対応したLLMを選択し、「Document」を有効にしてください。これにより、チャットボットは複雑な設定なしでファイルの内容を理解し、利用できるようになります。
diff --git a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
index 24fa4ff1..1e0a98c9 100644
--- a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
+++ b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
@@ -18,7 +18,7 @@ title: 外部ナレッジベースとの接続
- Difyプラットフォームは、独自に構築したナレッジベース内のアルゴリズムで処理されたテキストコンテンツを直接取得でき、開発者は独自のナレッジベースの情報検索メカニズムに焦点を当て、情報取得の精度を継続的に最適化できます。
-  (1).png) +
+  以下は外部ナレッジベースに接続するための詳細な手順です:
@@ -39,14 +39,14 @@ title: 外部ナレッジベースとの接続
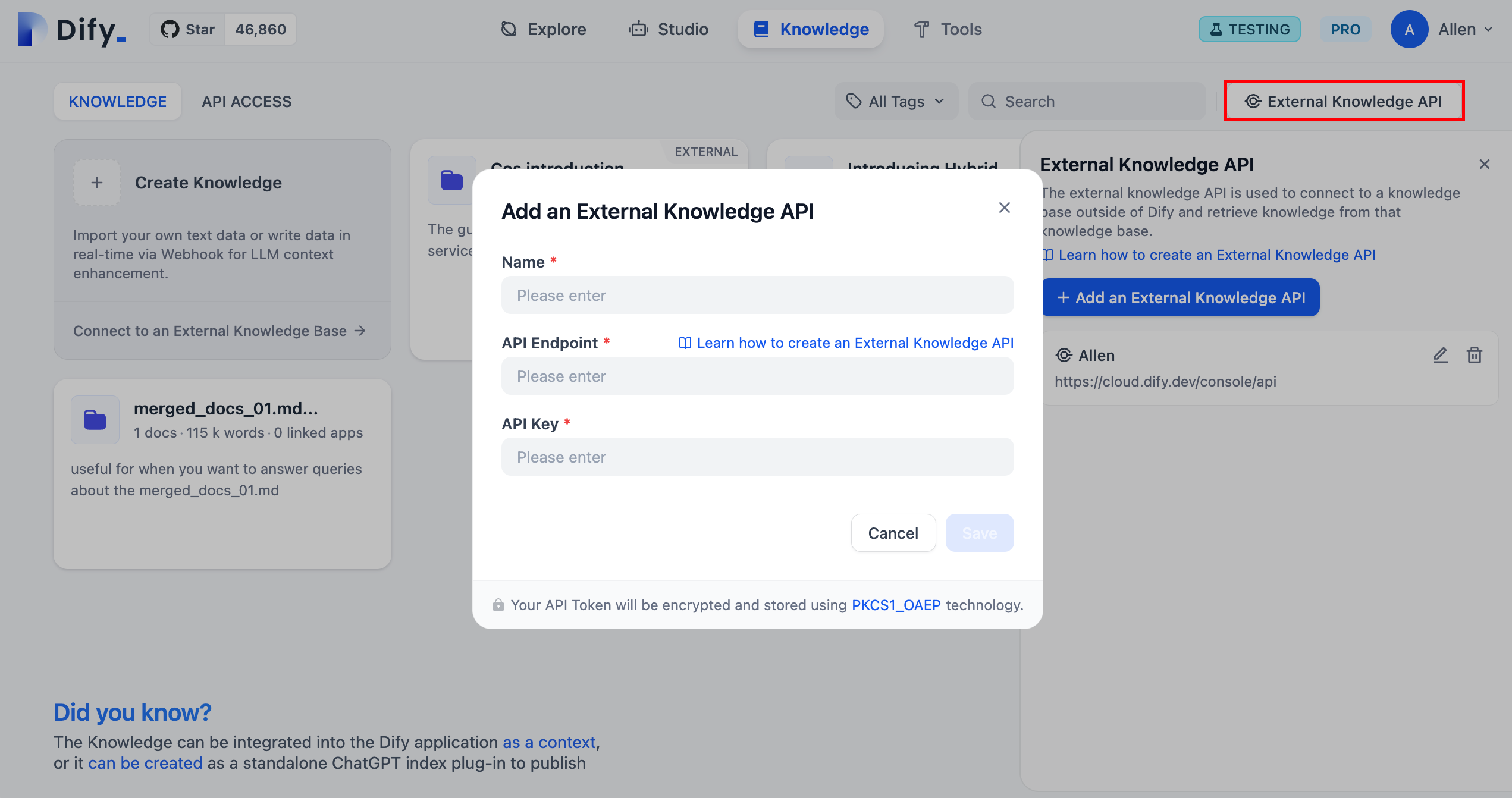
* APIキー:外部ナレッジベース接続のためのキー;詳細な説明は[外部ナレッジベースAPI](/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api-documentation)を参照してください。
-
以下は外部ナレッジベースに接続するための詳細な手順です:
@@ -39,14 +39,14 @@ title: 外部ナレッジベースとの接続
* APIキー:外部ナレッジベース接続のためのキー;詳細な説明は[外部ナレッジベースAPI](/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api-documentation)を参照してください。
-  +
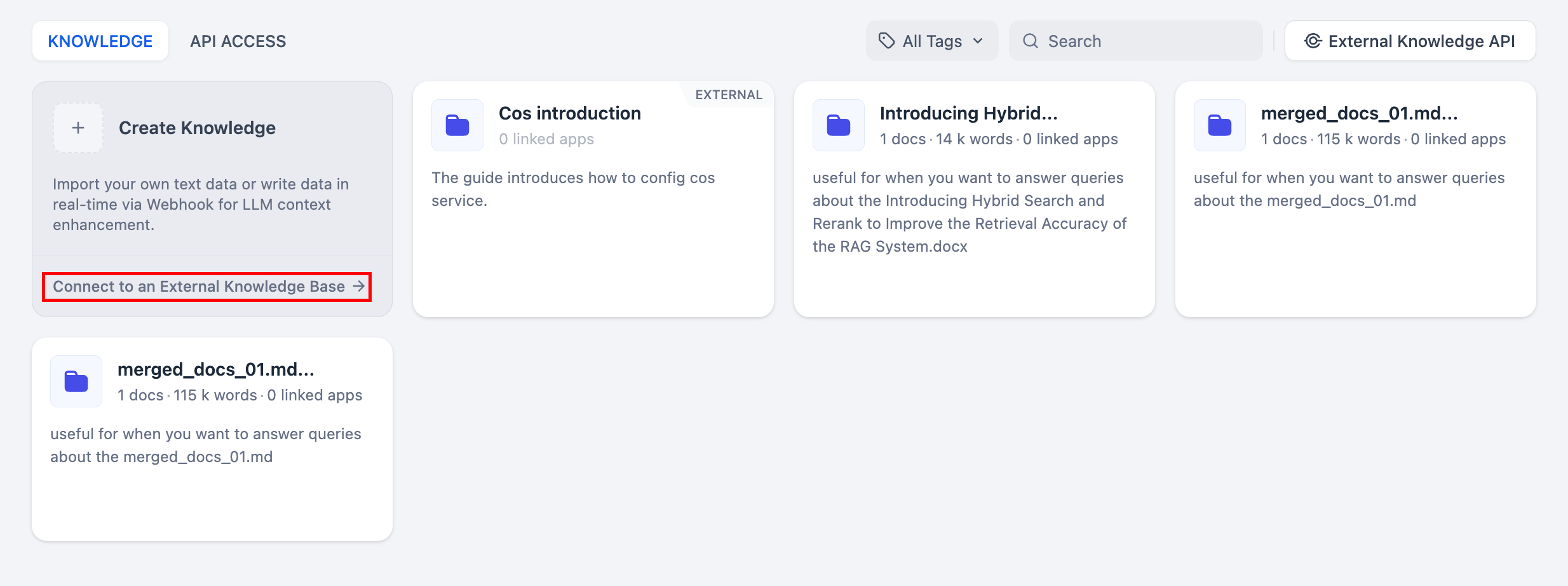
+  **"ナレッジベース"** ページに移動し、追加したナレッジベースカードの下にある **"外部ナレッジベースに接続"** をクリックして、パラメーター設定ページに移動します。
-
**"ナレッジベース"** ページに移動し、追加したナレッジベースカードの下にある **"外部ナレッジベースに接続"** をクリックして、パラメーター設定ページに移動します。
-  +
+  以下のパラメータを入力してください:
@@ -61,7 +61,7 @@ title: 外部ナレッジベースとの接続
**スコア閾値:** テキスト片フィルタリングの類似度閾値で、設定されたスコアを超えるテキスト片のみが召回されます。デフォルト値は0.5です。数値が高いほど、テキストと質問要求の類似度が高く、召回されるテキストの数が少なくなり、結果的により精度が高まります。
-
以下のパラメータを入力してください:
@@ -61,7 +61,7 @@ title: 外部ナレッジベースとの接続
**スコア閾値:** テキスト片フィルタリングの類似度閾値で、設定されたスコアを超えるテキスト片のみが召回されます。デフォルト値は0.5です。数値が高いほど、テキストと質問要求の類似度が高く、召回されるテキストの数が少なくなり、結果的により精度が高まります。
- .png) +
+ 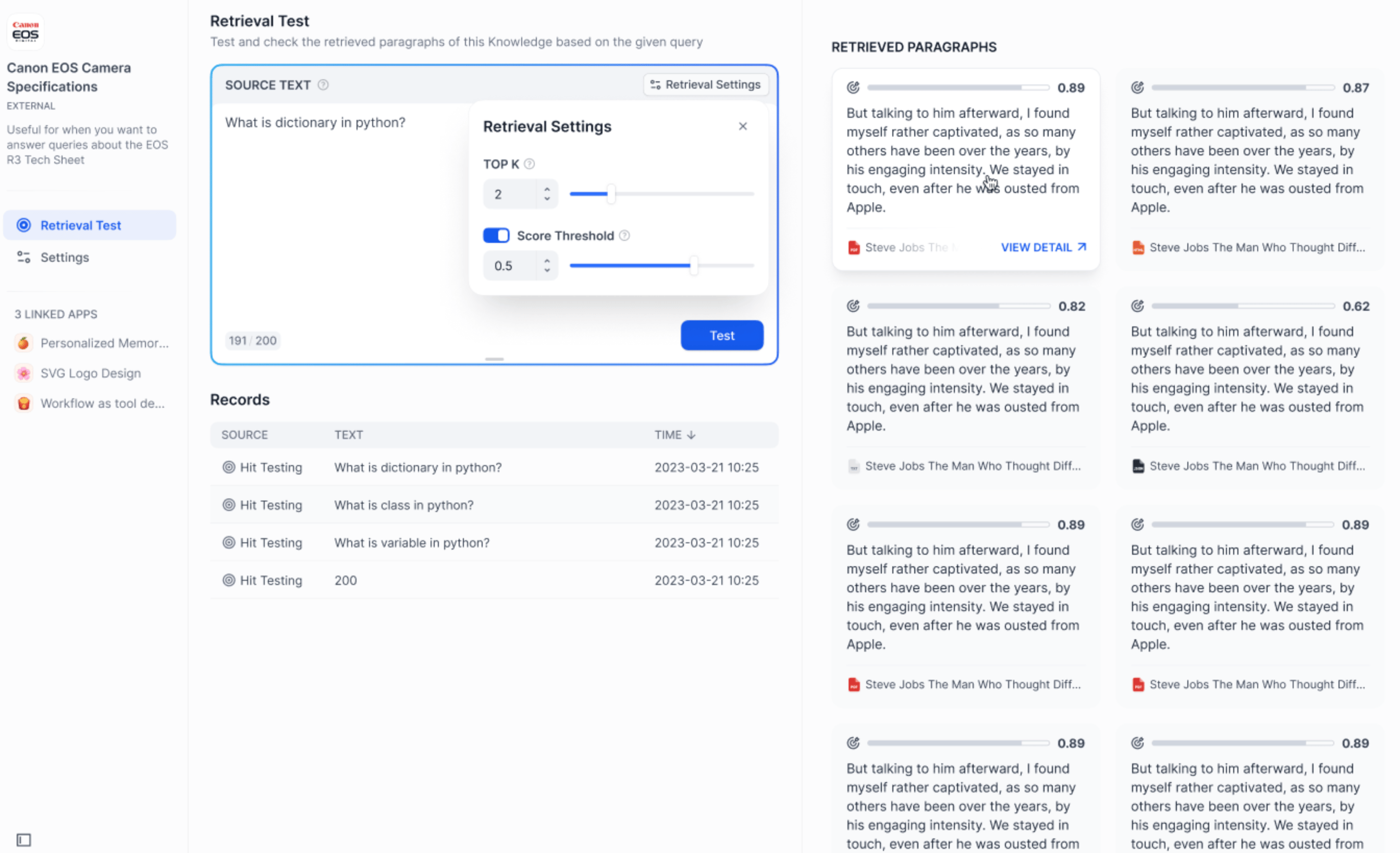 @@ -69,7 +69,7 @@ title: 外部ナレッジベースとの接続
接続が確立された後、開発者は **「召回テスト」** で可能な質問キーワードをシミュレーションし、外部ナレッジベースから召回されたテキスト片をプレビューできます。召回結果に満足できない場合は、召回パラメータの変更や外部ナレッジベースの検索設定の調整を試みてください。
-
@@ -69,7 +69,7 @@ title: 外部ナレッジベースとの接続
接続が確立された後、開発者は **「召回テスト」** で可能な質問キーワードをシミュレーションし、外部ナレッジベースから召回されたテキスト片をプレビューできます。召回結果に満足できない場合は、召回パラメータの変更や外部ナレッジベースの検索設定の調整を試みてください。
-  +
+ 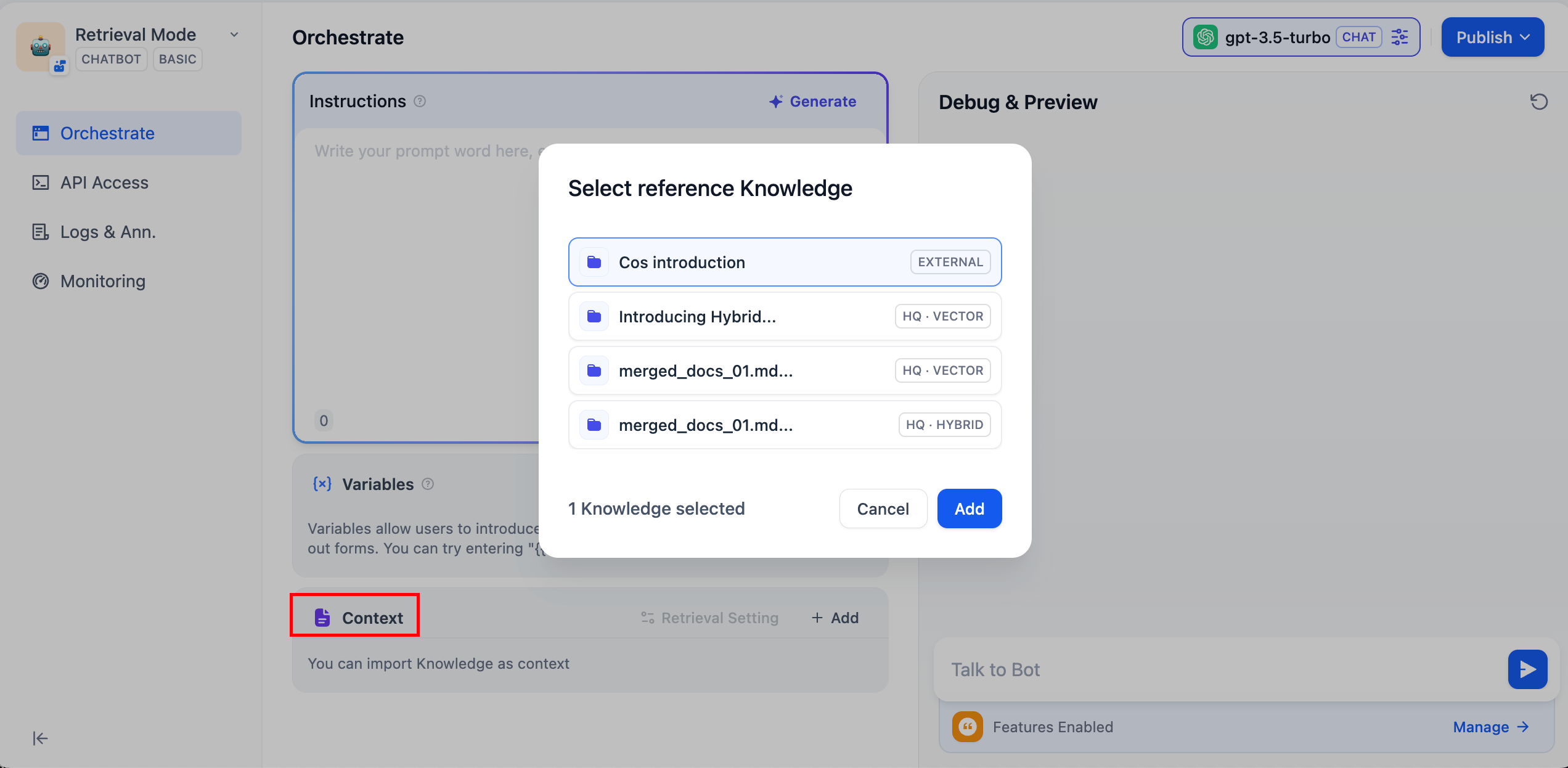 @@ -78,7 +78,7 @@ title: 外部ナレッジベースとの接続
Chatbot / エージェント型アプリの編成ページにある **「コンテキスト」** で、`EXTERNAL`ラベルの付いた外部ナレッジベースを選択します。
-
@@ -78,7 +78,7 @@ title: 外部ナレッジベースとの接続
Chatbot / エージェント型アプリの編成ページにある **「コンテキスト」** で、`EXTERNAL`ラベルの付いた外部ナレッジベースを選択します。
-  +
+ 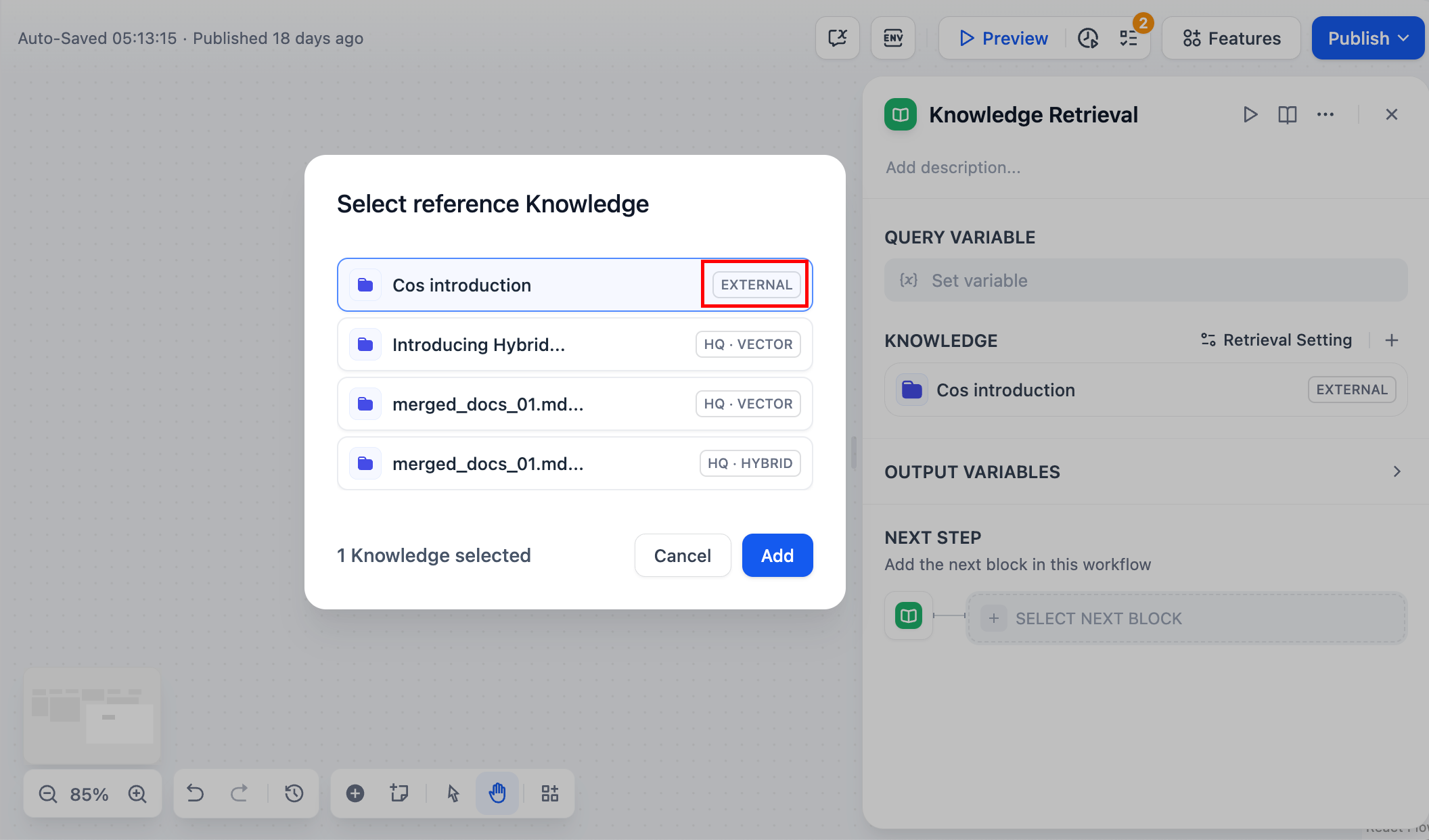 - **チャットフロー / ワークフロー型アプリ**
@@ -86,7 +86,7 @@ title: 外部ナレッジベースとの接続
チャットフロー / ワークフロー型アプリに **「知識検索」** ノードを追加し、`EXTERNAL`ラベルの付いた外部ナレッジベースを選択します。
-
- **チャットフロー / ワークフロー型アプリ**
@@ -86,7 +86,7 @@ title: 外部ナレッジベースとの接続
チャットフロー / ワークフロー型アプリに **「知識検索」** ノードを追加し、`EXTERNAL`ラベルの付いた外部ナレッジベースを選択します。
-  +
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
index 9d7a246f..ce2fb96f 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
@@ -62,7 +62,7 @@ Notionの統合は、**インターナル統合**(internal integration)と**
**New integration**ボタンをクリックし、タイプはデフォルトで**インターナル**(変更不可)です。関連付けるスペースを選択し、統合名を入力しロゴをアップロードした後、**Submit**をクリックして統合を作成します。
+
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
index 9d7a246f..ce2fb96f 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
@@ -62,7 +62,7 @@ Notionの統合は、**インターナル統合**(internal integration)と**
**New integration**ボタンをクリックし、タイプはデフォルトで**インターナル**(変更不可)です。関連付けるスペースを選択し、統合名を入力しロゴをアップロードした後、**Submit**をクリックして統合を作成します。
 @@ -70,7 +70,7 @@ Notionの統合は、**インターナル統合**(internal integration)と**
統合を作成したら、必要に応じてCapabilitiesタブで設定を更新し、Secretsタブで**Show**ボタンをクリックしてSecretsをコピーします。
@@ -70,7 +70,7 @@ Notionの統合は、**インターナル統合**(internal integration)と**
統合を作成したら、必要に応じてCapabilitiesタブで設定を更新し、Secretsタブで**Show**ボタンをクリックしてSecretsをコピーします。
 @@ -86,7 +86,7 @@ Notionの統合は、**インターナル統合**(internal integration)と**
**インターナル統合をパブリック統合にアップグレードする必要があります**。統合の配布ページに移動し、スイッチを切り替えて統合を公開します。スイッチをパブリック設定に切り替えるには、以下の組織情報フォームに会社名、Webサイト、リダイレクトURLなどの情報を入力し、**Submit**ボタンをクリックします。
@@ -86,7 +86,7 @@ Notionの統合は、**インターナル統合**(internal integration)と**
**インターナル統合をパブリック統合にアップグレードする必要があります**。統合の配布ページに移動し、スイッチを切り替えて統合を公開します。スイッチをパブリック設定に切り替えるには、以下の組織情報フォームに会社名、Webサイト、リダイレクトURLなどの情報を入力し、**Submit**ボタンをクリックします。
 @@ -94,7 +94,7 @@ Notionの統合は、**インターナル統合**(internal integration)と**
統合の設定ページで公開に成功すると、密鍵タブで統合の密鍵にアクセスできるようになります:
@@ -94,7 +94,7 @@ Notionの統合は、**インターナル統合**(internal integration)と**
統合の設定ページで公開に成功すると、密鍵タブで統合の密鍵にアクセスできるようになります:
 diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
index e3105acd..4530d17a 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
@@ -59,7 +59,7 @@ Dify のナレッジベースでは、[Jina Reader](https://jina.ai/reader)や[F
[Jina Readerの公式サイト](https://jina.ai/reader) にログインして登録を完了し、APIキーを取得してから入力し、保存します。
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
index e3105acd..4530d17a 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
@@ -59,7 +59,7 @@ Dify のナレッジベースでは、[Jina Reader](https://jina.ai/reader)や[F
[Jina Readerの公式サイト](https://jina.ai/reader) にログインして登録を完了し、APIキーを取得してから入力し、保存します。
.png) diff --git a/ja-jp/guides/workflow/file-upload.mdx b/ja-jp/guides/workflow/file-upload.mdx
index 119089e3..8075ed62 100644
--- a/ja-jp/guides/workflow/file-upload.mdx
+++ b/ja-jp/guides/workflow/file-upload.mdx
@@ -93,7 +93,7 @@ Difyは、[チャットフロー](/ja-jp/guides/workflow/concepts) と [ワー
この機能を有効にすると、アプリユーザーは対話中にいつでもファイルをアップロードおよび更新できます。最大10個のファイルを同時にアップロードでき、各ファイルのサイズ上限は15MBです。
-
diff --git a/ja-jp/guides/workflow/file-upload.mdx b/ja-jp/guides/workflow/file-upload.mdx
index 119089e3..8075ed62 100644
--- a/ja-jp/guides/workflow/file-upload.mdx
+++ b/ja-jp/guides/workflow/file-upload.mdx
@@ -93,7 +93,7 @@ Difyは、[チャットフロー](/ja-jp/guides/workflow/concepts) と [ワー
この機能を有効にすると、アプリユーザーは対話中にいつでもファイルをアップロードおよび更新できます。最大10個のファイルを同時にアップロードでき、各ファイルのサイズ上限は15MBです。
- .png) +
+ 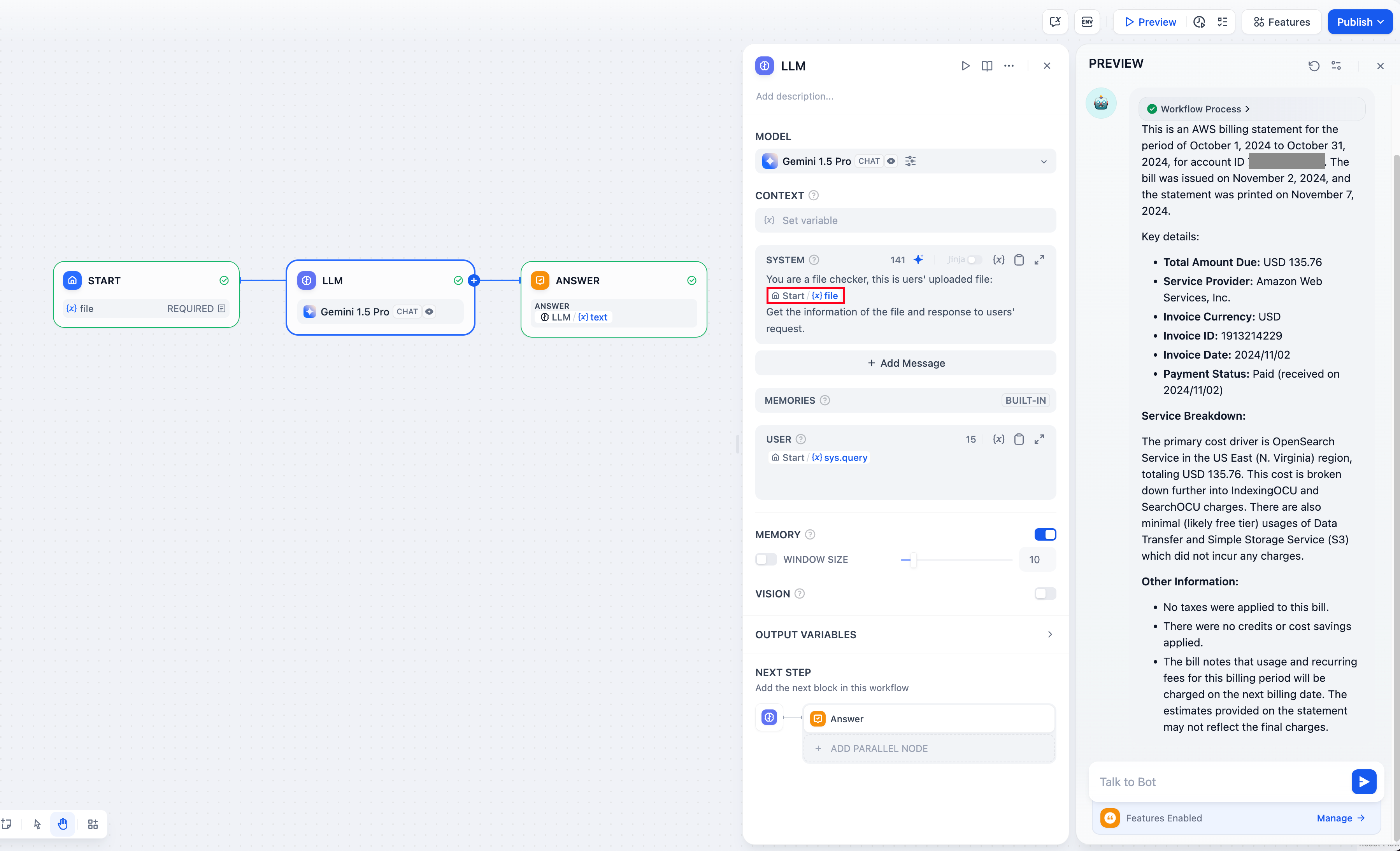 機能を有効にしても、LLM(大規模言語モデル)がファイルを直接読み取ることはできません。ファイルをLLMが理解できるテキスト形式に変換するには、が必要です。
@@ -106,13 +106,13 @@ Difyは、[チャットフロー](/ja-jp/guides/workflow/concepts) と [ワー
4. 最後に「直接応答」ノードを追加し、LLMノードの出力変数を入力します。
-
機能を有効にしても、LLM(大規模言語モデル)がファイルを直接読み取ることはできません。ファイルをLLMが理解できるテキスト形式に変換するには、が必要です。
@@ -106,13 +106,13 @@ Difyは、[チャットフロー](/ja-jp/guides/workflow/concepts) と [ワー
4. 最後に「直接応答」ノードを追加し、LLMノードの出力変数を入力します。
- .png) +
+  有効にすると、ユーザーは対話ボックスでファイルをアップロードして対話できます。ただし、この方法では、LLMアプリはファイルの内容を記憶する能力を持ちません。各対話ごとにファイルをアップロードする必要があります。
-
有効にすると、ユーザーは対話ボックスでファイルをアップロードして対話できます。ただし、この方法では、LLMアプリはファイルの内容を記憶する能力を持ちません。各対話ごとにファイルをアップロードする必要があります。
- .png) +
+  LLMが対話中にファイル内容を記憶する機能を追加したい場合は、方法2を参照してください。
@@ -153,19 +153,19 @@ LLMが対話中にファイル内容を記憶する機能を追加したい場
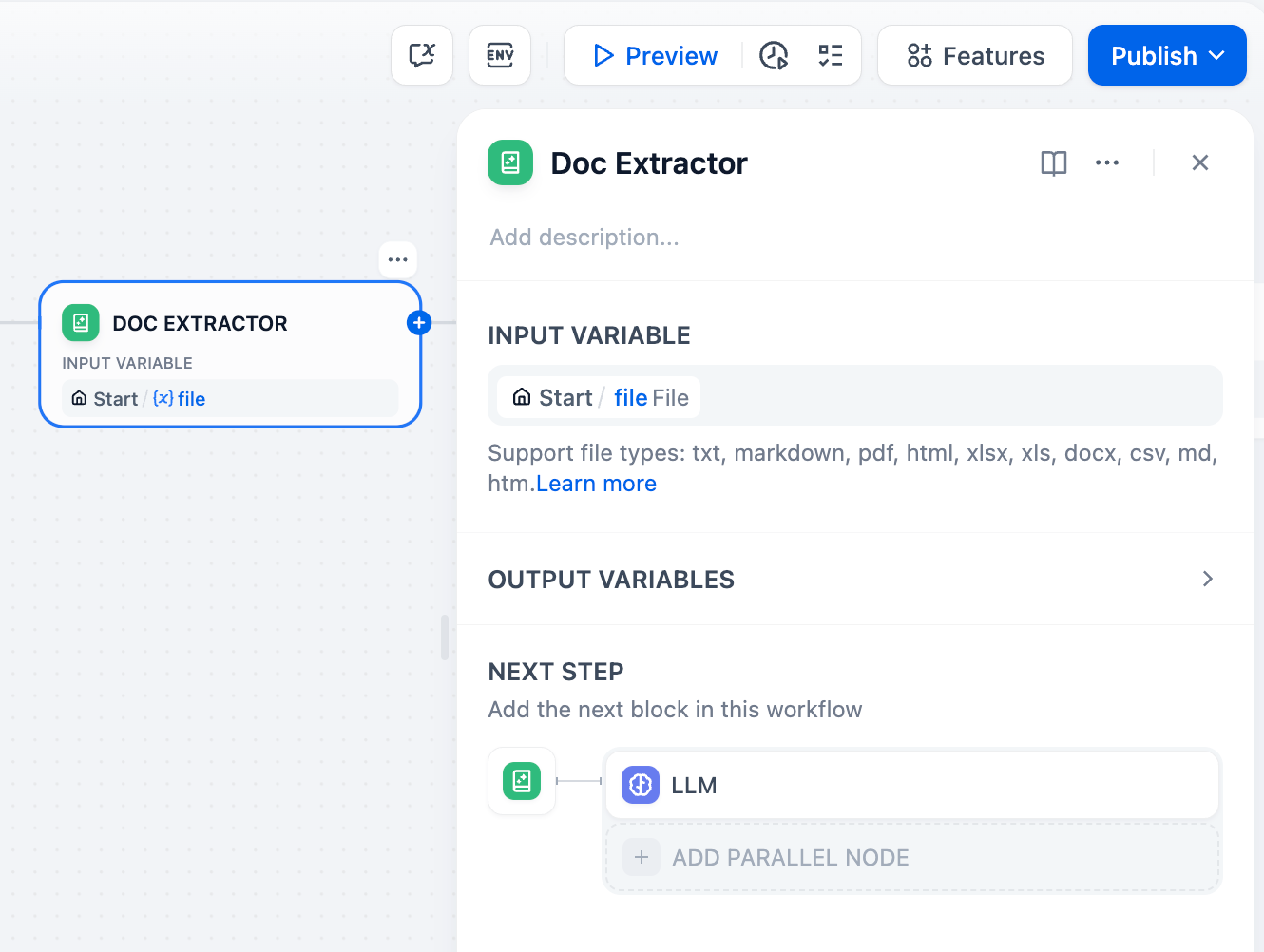
「開始」ノード内のファイル変数を **「テキスト抽出ツール」** ノードの入力変数として使用します。
-
LLMが対話中にファイル内容を記憶する機能を追加したい場合は、方法2を参照してください。
@@ -153,19 +153,19 @@ LLMが対話中にファイル内容を記憶する機能を追加したい場
「開始」ノード内のファイル変数を **「テキスト抽出ツール」** ノードの入力変数として使用します。
-  +
+  「テキスト抽出ツール」ノードの出力変数をLLMノードのシステムプロンプトに貼り付けます。
-
「テキスト抽出ツール」ノードの出力変数をLLMノードのシステムプロンプトに貼り付けます。
-  +
+  これらの設定が完了すると、ユーザーはWebApp内でファイルのURLを貼り付けるか、ローカルファイルをアップロードでき、その後、ドキュメントの内容に基づいてLLMとの対話が可能になります。ユーザーは対話の過程でいつでもファイルを置き換えることができ、LLMは常に最新のファイル内容を取得します。
-
これらの設定が完了すると、ユーザーはWebApp内でファイルのURLを貼り付けるか、ローカルファイルをアップロードでき、その後、ドキュメントの内容に基づいてLLMとの対話が可能になります。ユーザーは対話の過程でいつでもファイルを置き換えることができ、LLMは常に最新のファイル内容を取得します。
-  +
+  **LLMノードでファイル変数を参照する方法**
@@ -197,5 +197,5 @@ LLMノード内でファイル変数を直接使用する際は、そのファ
アプリが複数のファイル形式に対応できるようにしたい場合、例えば、ユーザーがドキュメントファイル、画像、音声、動画ファイルを同時にアップロードできるようにするには、「開始」ノードに「ファイルリスト」変数を追加し、「リスト操作」ノードを使用して異なるファイルタイプを処理する必要があります。詳細については、[リスト操作](/ja-jp/guides/workflow/nodes/list-operator)ノードを参照してください。
-
**LLMノードでファイル変数を参照する方法**
@@ -197,5 +197,5 @@ LLMノード内でファイル変数を直接使用する際は、そのファ
アプリが複数のファイル形式に対応できるようにしたい場合、例えば、ユーザーがドキュメントファイル、画像、音声、動画ファイルを同時にアップロードできるようにするには、「開始」ノードに「ファイルリスト」変数を追加し、「リスト操作」ノードを使用して異なるファイルタイプを処理する必要があります。詳細については、[リスト操作](/ja-jp/guides/workflow/nodes/list-operator)ノードを参照してください。
- .png) +
+  diff --git a/ja-jp/guides/workflow/node/doc-extractor.mdx b/ja-jp/guides/workflow/node/doc-extractor.mdx
index eb503828..5c2467c5 100644
--- a/ja-jp/guides/workflow/node/doc-extractor.mdx
+++ b/ja-jp/guides/workflow/node/doc-extractor.mdx
@@ -59,7 +59,7 @@ LLM(大規模言語モデル)は文書の内容を直接読み取ること
設定が完了すると、アプリケーションはファイルアップロード機能を持ち、ユーザーはPDFファイルをアップロードして対話を展開できるようになります。
-
diff --git a/ja-jp/guides/workflow/node/doc-extractor.mdx b/ja-jp/guides/workflow/node/doc-extractor.mdx
index eb503828..5c2467c5 100644
--- a/ja-jp/guides/workflow/node/doc-extractor.mdx
+++ b/ja-jp/guides/workflow/node/doc-extractor.mdx
@@ -59,7 +59,7 @@ LLM(大規模言語モデル)は文書の内容を直接読み取ること
設定が完了すると、アプリケーションはファイルアップロード機能を持ち、ユーザーはPDFファイルをアップロードして対話を展開できるようになります。
-  +
+  diff --git a/ja-jp/guides/workflow/node/http-request.mdx b/ja-jp/guides/workflow/node/http-request.mdx
index ca531db1..6ee814a2 100644
--- a/ja-jp/guides/workflow/node/http-request.mdx
+++ b/ja-jp/guides/workflow/node/http-request.mdx
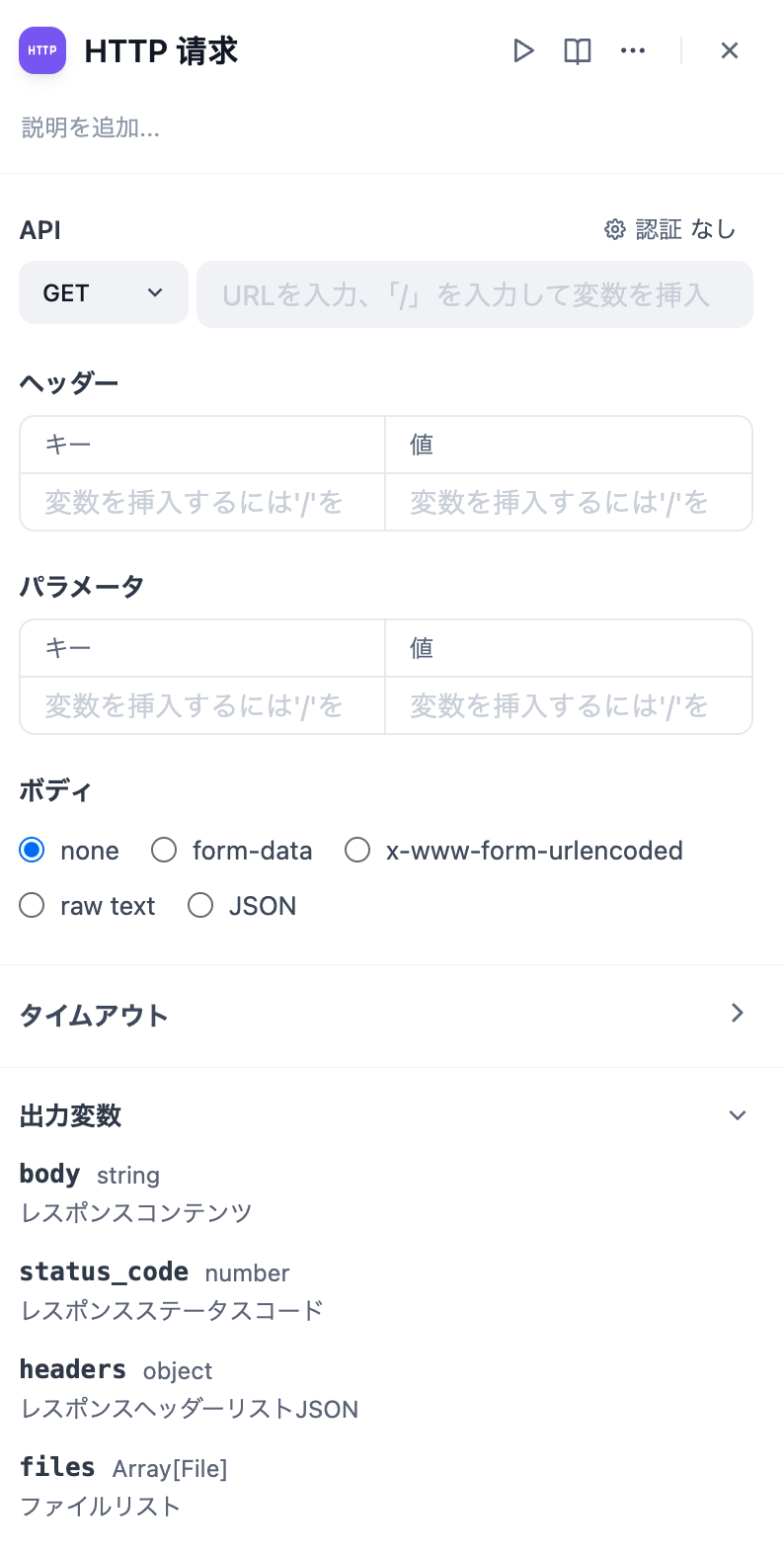
@@ -19,7 +19,7 @@ HTTP プロトコルを介してサーバーにリクエストを送信するこ
HTTPリクエストのURL、リクエストヘッダー、クエリパラメータ、リクエストボディの内容、および認証情報などを設定することができます。
-
diff --git a/ja-jp/guides/workflow/node/http-request.mdx b/ja-jp/guides/workflow/node/http-request.mdx
index ca531db1..6ee814a2 100644
--- a/ja-jp/guides/workflow/node/http-request.mdx
+++ b/ja-jp/guides/workflow/node/http-request.mdx
@@ -19,7 +19,7 @@ HTTP プロトコルを介してサーバーにリクエストを送信するこ
HTTPリクエストのURL、リクエストヘッダー、クエリパラメータ、リクエストボディの内容、および認証情報などを設定することができます。
-  +
+  @@ -30,7 +30,7 @@ HTTPリクエストのURL、リクエストヘッダー、クエリパラメー
このノードの便利な特性の一つは、シナリオに応じてリクエストの異なる部分に動的に変数を挿入できることです。例えば、カスタマーレビュープロセスを処理する際に、ユーザー名や顧客ID、レビュー内容などの変数をリクエストに埋め込むことで、カスタマイズされた自動返信情報を作成したり、特定の顧客情報を取得して関連リソースを特定のサーバーに送信したりすることができます。
-
@@ -30,7 +30,7 @@ HTTPリクエストのURL、リクエストヘッダー、クエリパラメー
このノードの便利な特性の一つは、シナリオに応じてリクエストの異なる部分に動的に変数を挿入できることです。例えば、カスタマーレビュープロセスを処理する際に、ユーザー名や顧客ID、レビュー内容などの変数をリクエストに埋め込むことで、カスタマイズされた自動返信情報を作成したり、特定の顧客情報を取得して関連リソースを特定のサーバーに送信したりすることができます。
-  +
+  HTTP HTTPリクエストの戻り値には、レスポンスボディ、ステータスコード、レスポンスヘッダー、ファイルが含まれます。特に、レスポンスにファイル(現在は画像タイプのみ)が含まれている場合、このノードはファイルを自動的に保存し、後続のプロセスで使用できるようにします。この設計により、処理効率が向上し、ファイルを含むレスポンスの処理がシンプルで直接的になります。
diff --git a/ja-jp/guides/workflow/node/ifelse.mdx b/ja-jp/guides/workflow/node/ifelse.mdx
index d18502af..d780eac2 100644
--- a/ja-jp/guides/workflow/node/ifelse.mdx
+++ b/ja-jp/guides/workflow/node/ifelse.mdx
@@ -35,7 +35,7 @@ if/else 条件に基づいてチャットフローとワークフローを2つ
### シナリオ
-
HTTP HTTPリクエストの戻り値には、レスポンスボディ、ステータスコード、レスポンスヘッダー、ファイルが含まれます。特に、レスポンスにファイル(現在は画像タイプのみ)が含まれている場合、このノードはファイルを自動的に保存し、後続のプロセスで使用できるようにします。この設計により、処理効率が向上し、ファイルを含むレスポンスの処理がシンプルで直接的になります。
diff --git a/ja-jp/guides/workflow/node/ifelse.mdx b/ja-jp/guides/workflow/node/ifelse.mdx
index d18502af..d780eac2 100644
--- a/ja-jp/guides/workflow/node/ifelse.mdx
+++ b/ja-jp/guides/workflow/node/ifelse.mdx
@@ -35,7 +35,7 @@ if/else 条件に基づいてチャットフローとワークフローを2つ
### シナリオ
-  +
+ 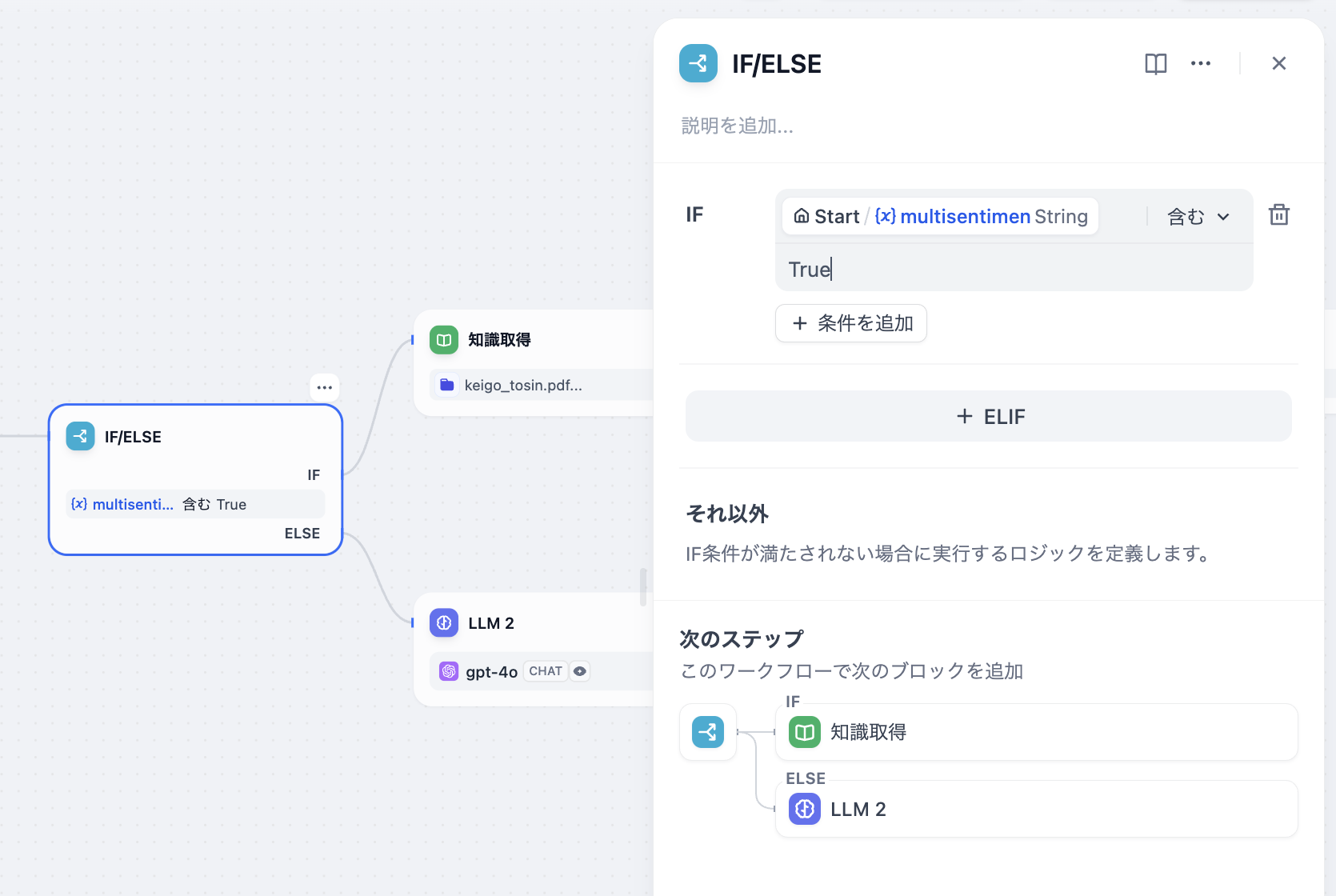 **テキスト要約ワークフロー**を例に、各条件を説明します。
@@ -51,5 +51,5 @@ if/else 条件に基づいてチャットフローとワークフローを2つ
複雑な条件判断が必要な場合、複数条件を設定し、条件間に **AND** または **OR** を設定することができます。これは条件間に**交集**または**并集**を取ることを意味します。
-
**テキスト要約ワークフロー**を例に、各条件を説明します。
@@ -51,5 +51,5 @@ if/else 条件に基づいてチャットフローとワークフローを2つ
複雑な条件判断が必要な場合、複数条件を設定し、条件間に **AND** または **OR** を設定することができます。これは条件間に**交集**または**并集**を取ることを意味します。
-  +
+ 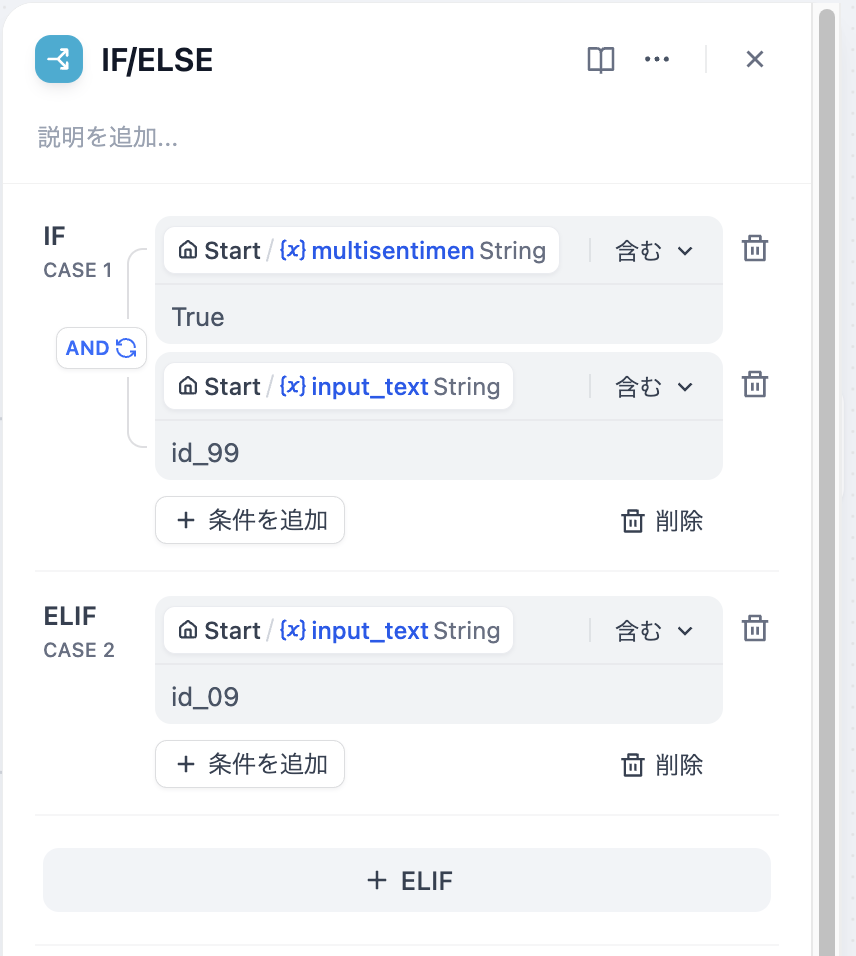 diff --git a/ja-jp/guides/workflow/node/iteration.mdx b/ja-jp/guides/workflow/node/iteration.mdx
index 16e2bb56..0e625dff 100644
--- a/ja-jp/guides/workflow/node/iteration.mdx
+++ b/ja-jp/guides/workflow/node/iteration.mdx
@@ -15,7 +15,7 @@ title: 反復処理(イテレーション)
#### **例1:長文イテレーション生成器**
-
diff --git a/ja-jp/guides/workflow/node/iteration.mdx b/ja-jp/guides/workflow/node/iteration.mdx
index 16e2bb56..0e625dff 100644
--- a/ja-jp/guides/workflow/node/iteration.mdx
+++ b/ja-jp/guides/workflow/node/iteration.mdx
@@ -15,7 +15,7 @@ title: 反復処理(イテレーション)
#### **例1:長文イテレーション生成器**
-  +
+ 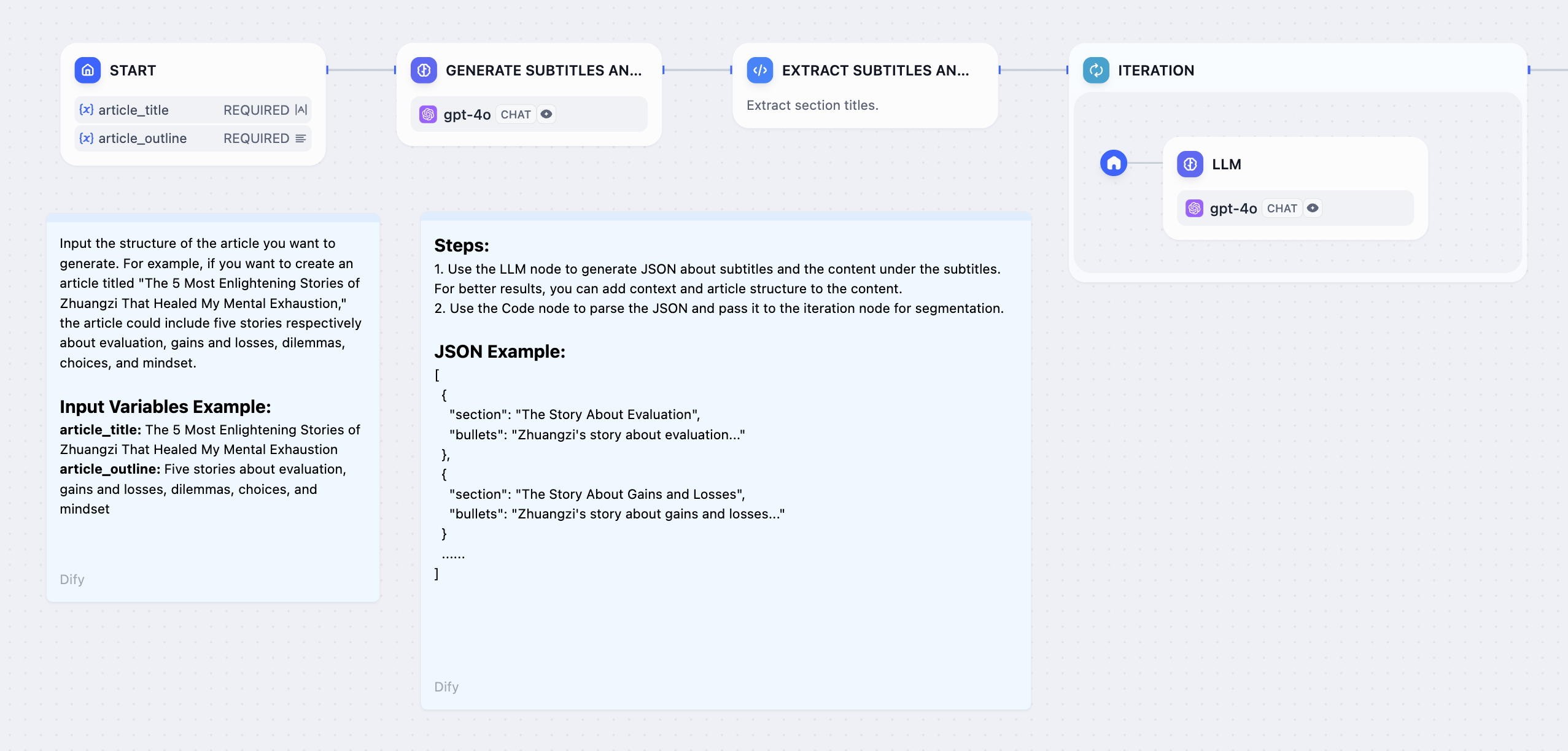 1. **開始ノード** 内にタイトルとアウトラインを入力
@@ -29,19 +29,19 @@ title: 反復処理(イテレーション)
1. **開始ノード** にタイトル(title)とアウトライン(outline)を設定;
-
1. **開始ノード** 内にタイトルとアウトラインを入力
@@ -29,19 +29,19 @@ title: 反復処理(イテレーション)
1. **開始ノード** にタイトル(title)とアウトライン(outline)を設定;
-  +
+  2. **Jinja-2 テンプレートノード** を使用してタイトルとアウトラインを完全なテキストに変換;
-
2. **Jinja-2 テンプレートノード** を使用してタイトルとアウトラインを完全なテキストに変換;
-  +
+  3. **パラメータ抽出ノード** を使用して、ストーリーテキストを配列(Array)構造に変換。抽出パラメータは `sections`、パラメータタイプは `Array[Object]`
-
3. **パラメータ抽出ノード** を使用して、ストーリーテキストを配列(Array)構造に変換。抽出パラメータは `sections`、パラメータタイプは `Array[Object]`
-  +
+  @@ -51,13 +51,13 @@ title: 反復処理(イテレーション)
4. ストーリーアウトラインの配列形式をイテレーションノードの入力として使用し、イテレーションノード内で **LLM ノード** を使用して処理
-
@@ -51,13 +51,13 @@ title: 反復処理(イテレーション)
4. ストーリーアウトラインの配列形式をイテレーションノードの入力として使用し、イテレーションノード内で **LLM ノード** を使用して処理
-  +
+  LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/item` を設定
-
LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/item` を設定
-  +
+  @@ -71,19 +71,19 @@ LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/i
5. イテレーションノード内に **直接応答ノード** を設定して、各イテレーション生成の後にストリーム出力を実現。
-
@@ -71,19 +71,19 @@ LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/i
5. イテレーションノード内に **直接応答ノード** を設定して、各イテレーション生成の後にストリーム出力を実現。
-  +
+ 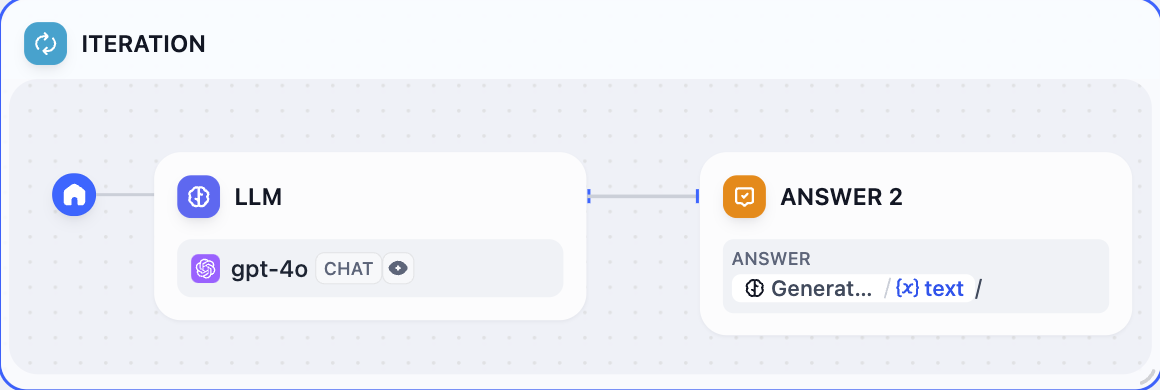 6. 完全なデバッグとプレビュー
-
6. 完全なデバッグとプレビュー
-  +
+ 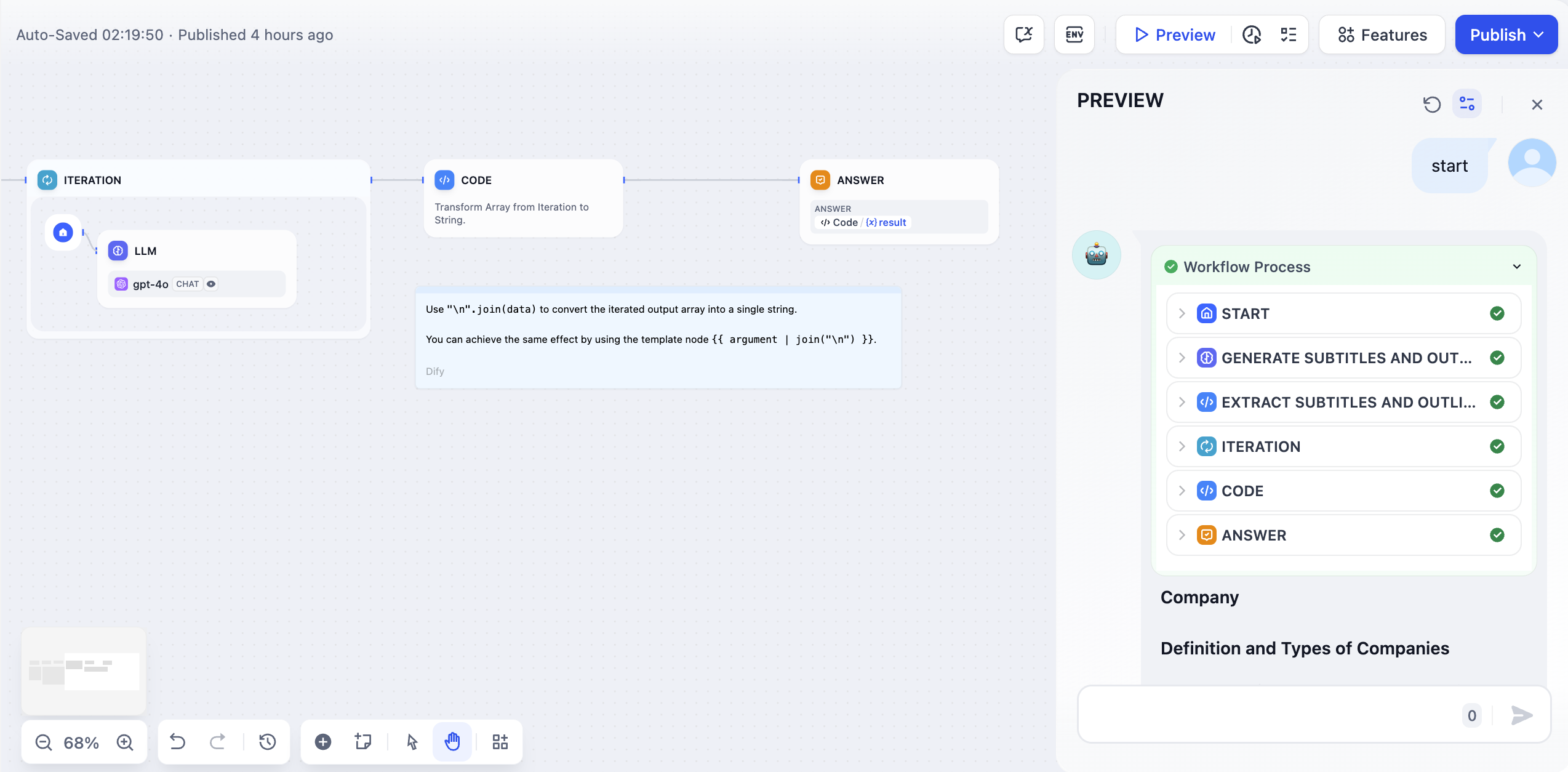 #### **例2:長文イテレーション生成器(別の編成方法)**
-
#### **例2:長文イテレーション生成器(別の編成方法)**
-  +
+ 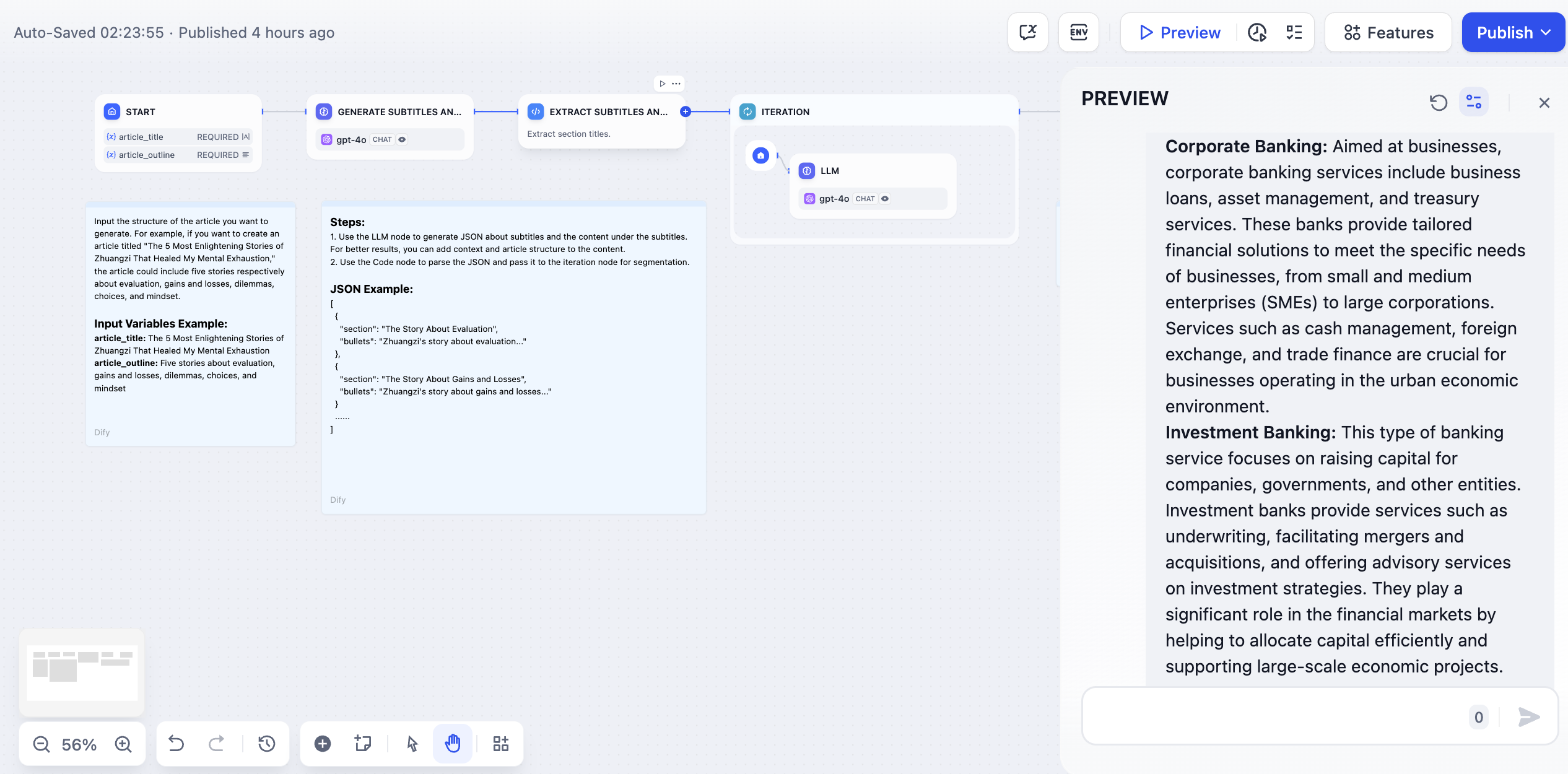 * **開始ノード** にタイトルとアウトラインを入力
@@ -147,13 +147,13 @@ LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/i
**CODE ノードを使用して返す**
-
+
**パラメータ抽出ノードを使用して返す**
-
* **開始ノード** にタイトルとアウトラインを入力
@@ -147,13 +147,13 @@ LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/i
**CODE ノードを使用して返す**
-
+
**パラメータ抽出ノードを使用して返す**
-  +
+ 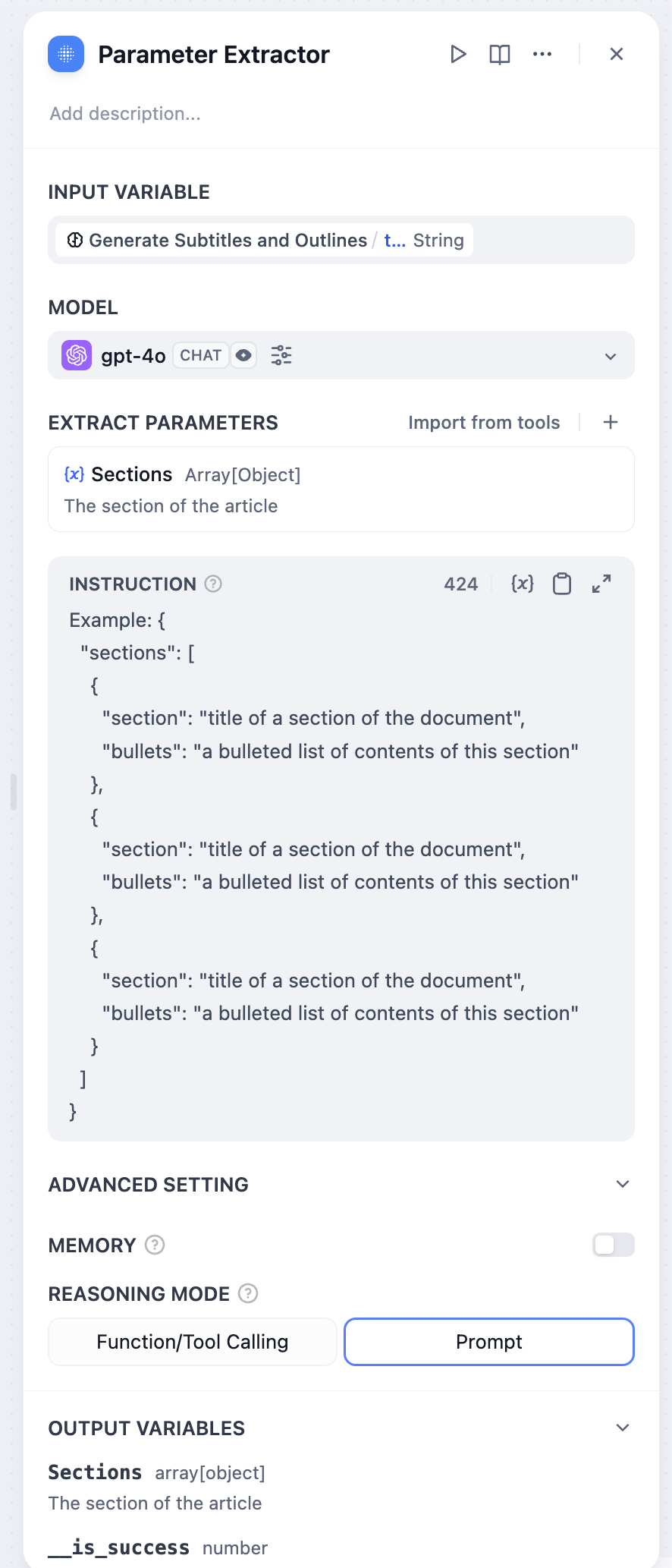 ### 配列をテキストに変換する方法
@@ -163,7 +163,7 @@ LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/i
**コードノードを使用した変換**
-
### 配列をテキストに変換する方法
@@ -163,7 +163,7 @@ LLM ノード内で入力変数 `GenerateOverallOutline/output` と `Iteration/i
**コードノードを使用した変換**
-  +
+ 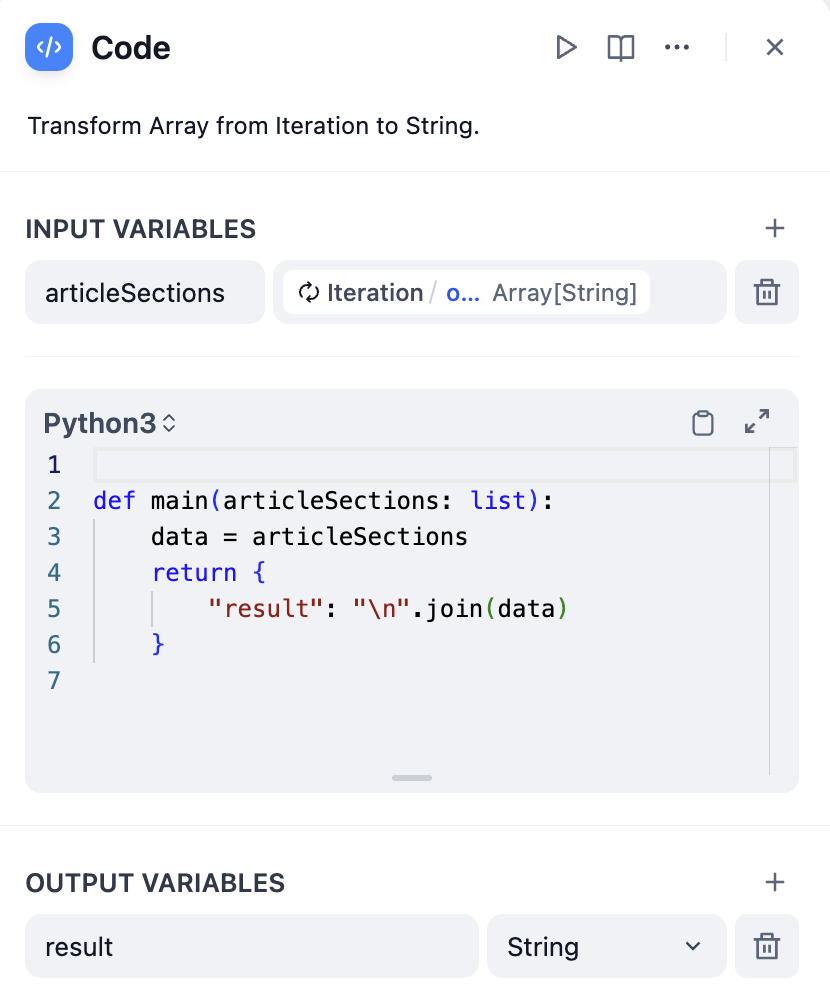 コード例:
@@ -179,7 +179,7 @@ def main(articleSections: list):
**テンプレートノードを使用した変換**
-
コード例:
@@ -179,7 +179,7 @@ def main(articleSections: list):
**テンプレートノードを使用した変換**
-  +
+ 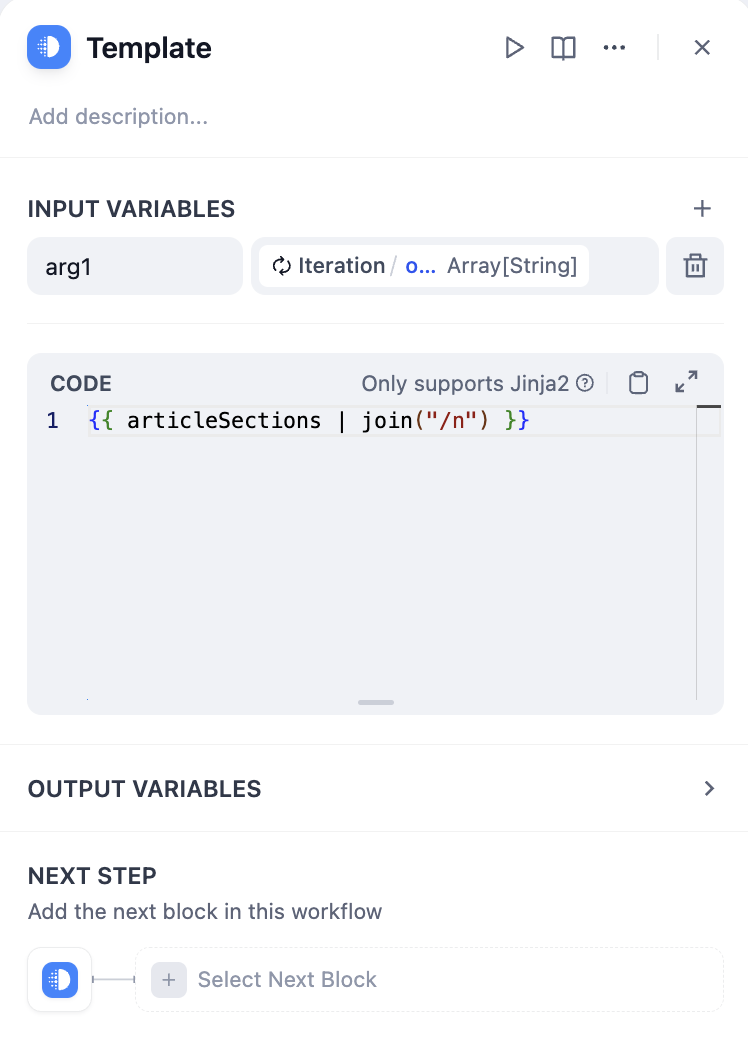 コード例:
diff --git a/ja-jp/guides/workflow/node/knowledge-retrieval.mdx b/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
index 2ce0d326..18645529 100644
--- a/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
+++ b/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
@@ -16,7 +16,7 @@ version: '日本語'
下図は最も基本的なナレッジベース質問応答アプリケーションの例です。このプロセスの実行ロジックは、ユーザーの質問がLLMノードに渡される前に、ナレッジ検索ノードでユーザーの質問に最も関連するテキスト内容を検索し、召喚することです。その後、LLMノード内でユーザーの質問と検索されたコンテキストを一緒に入力し、LLMが検索内容に基づいて質問に答えるようにします。
-
コード例:
diff --git a/ja-jp/guides/workflow/node/knowledge-retrieval.mdx b/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
index 2ce0d326..18645529 100644
--- a/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
+++ b/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
@@ -16,7 +16,7 @@ version: '日本語'
下図は最も基本的なナレッジベース質問応答アプリケーションの例です。このプロセスの実行ロジックは、ユーザーの質問がLLMノードに渡される前に、ナレッジ検索ノードでユーザーの質問に最も関連するテキスト内容を検索し、召喚することです。その後、LLMノード内でユーザーの質問と検索されたコンテキストを一緒に入力し、LLMが検索内容に基づいて質問に答えるようにします。
-  +
+ 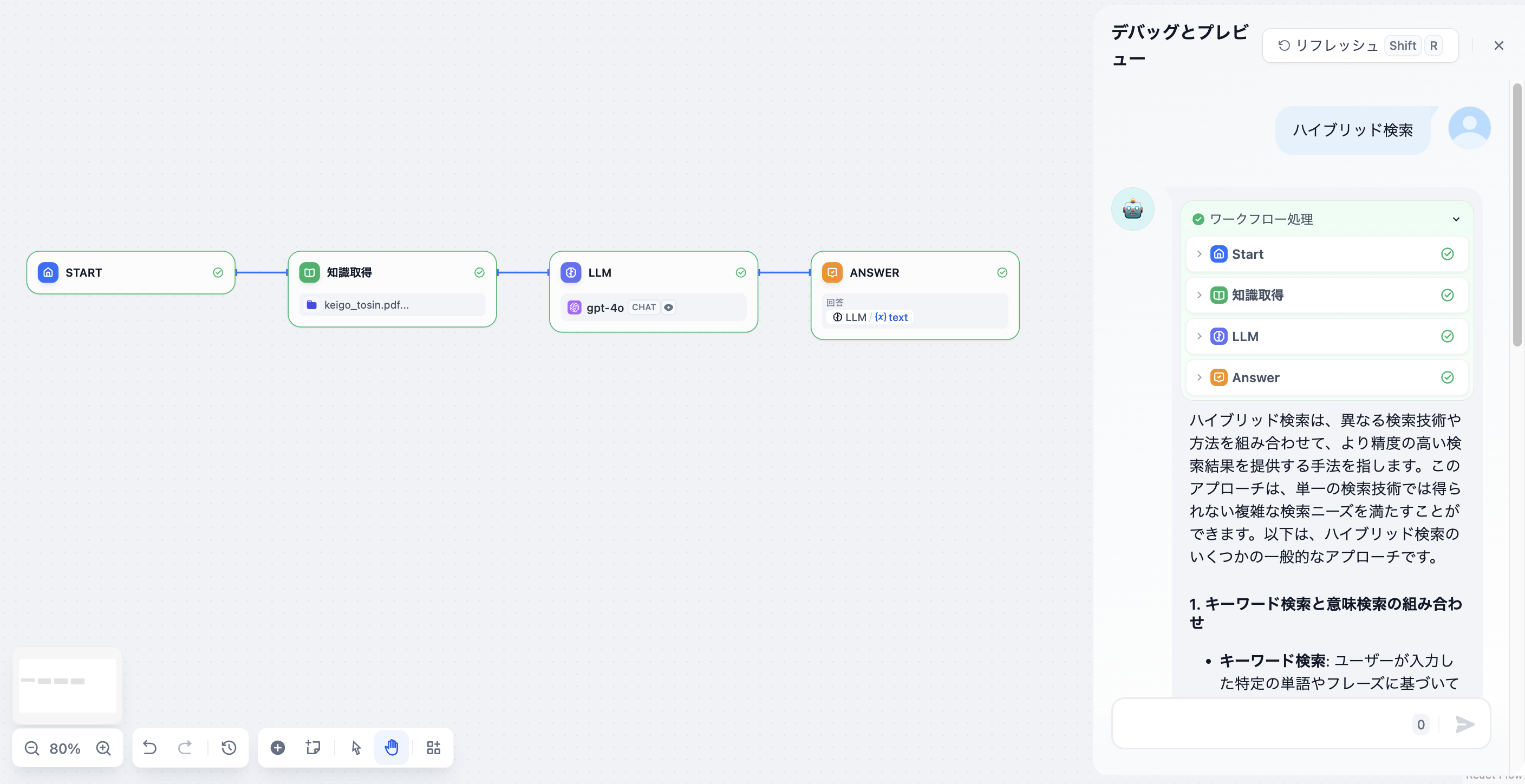 ***
@@ -31,13 +31,13 @@ version: '日本語'
4. 下流ノードを接続し設定します。一般的にはLLMノードです。
-
***
@@ -31,13 +31,13 @@ version: '日本語'
4. 下流ノードを接続し設定します。一般的にはLLMノードです。
-  +
+ 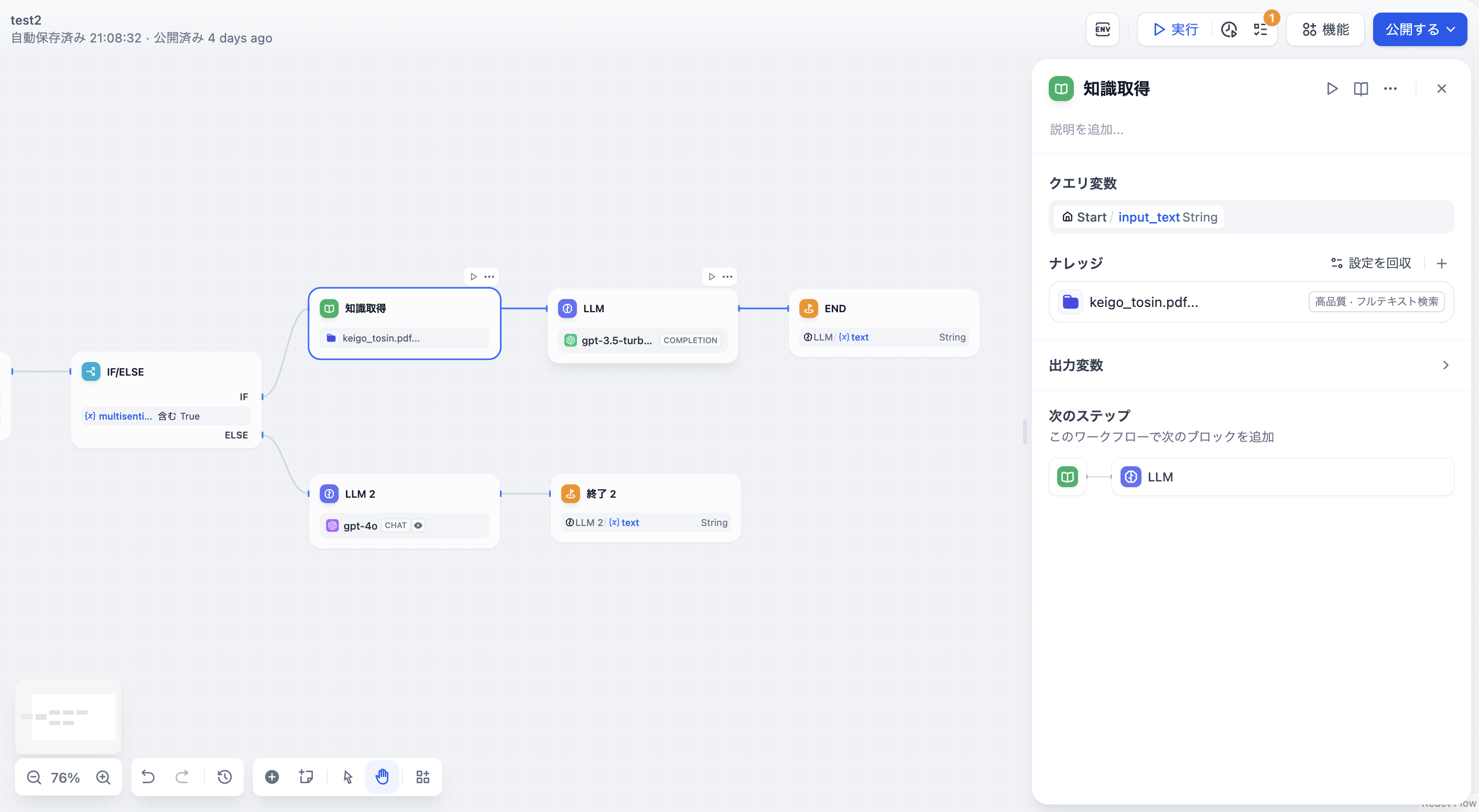 **出力変数**
-
**出力変数**
-  +
+  ナレッジ検索の出力変数`result`は、ナレッジベースから検索された関連テキストセグメントです。この変数のデータ構造には、セグメント内容、タイトル、リンク、アイコン、メタデータ情報が含まれています。
@@ -53,7 +53,7 @@ version: '日本語'
ユーザーが質問すると、関連するテキストがナレッジ検索で召喚された場合、そのテキスト内容がコンテキスト変数の値としてプロンプトに挿入され、LLMが質問に答えます。関連するテキストが検索されなかった場合、コンテキスト変数の値は空となり、LLMは直接ユーザーの質問に答えます。
-
ナレッジ検索の出力変数`result`は、ナレッジベースから検索された関連テキストセグメントです。この変数のデータ構造には、セグメント内容、タイトル、リンク、アイコン、メタデータ情報が含まれています。
@@ -53,7 +53,7 @@ version: '日本語'
ユーザーが質問すると、関連するテキストがナレッジ検索で召喚された場合、そのテキスト内容がコンテキスト変数の値としてプロンプトに挿入され、LLMが質問に答えます。関連するテキストが検索されなかった場合、コンテキスト変数の値は空となり、LLMは直接ユーザーの質問に答えます。
-  +
+ 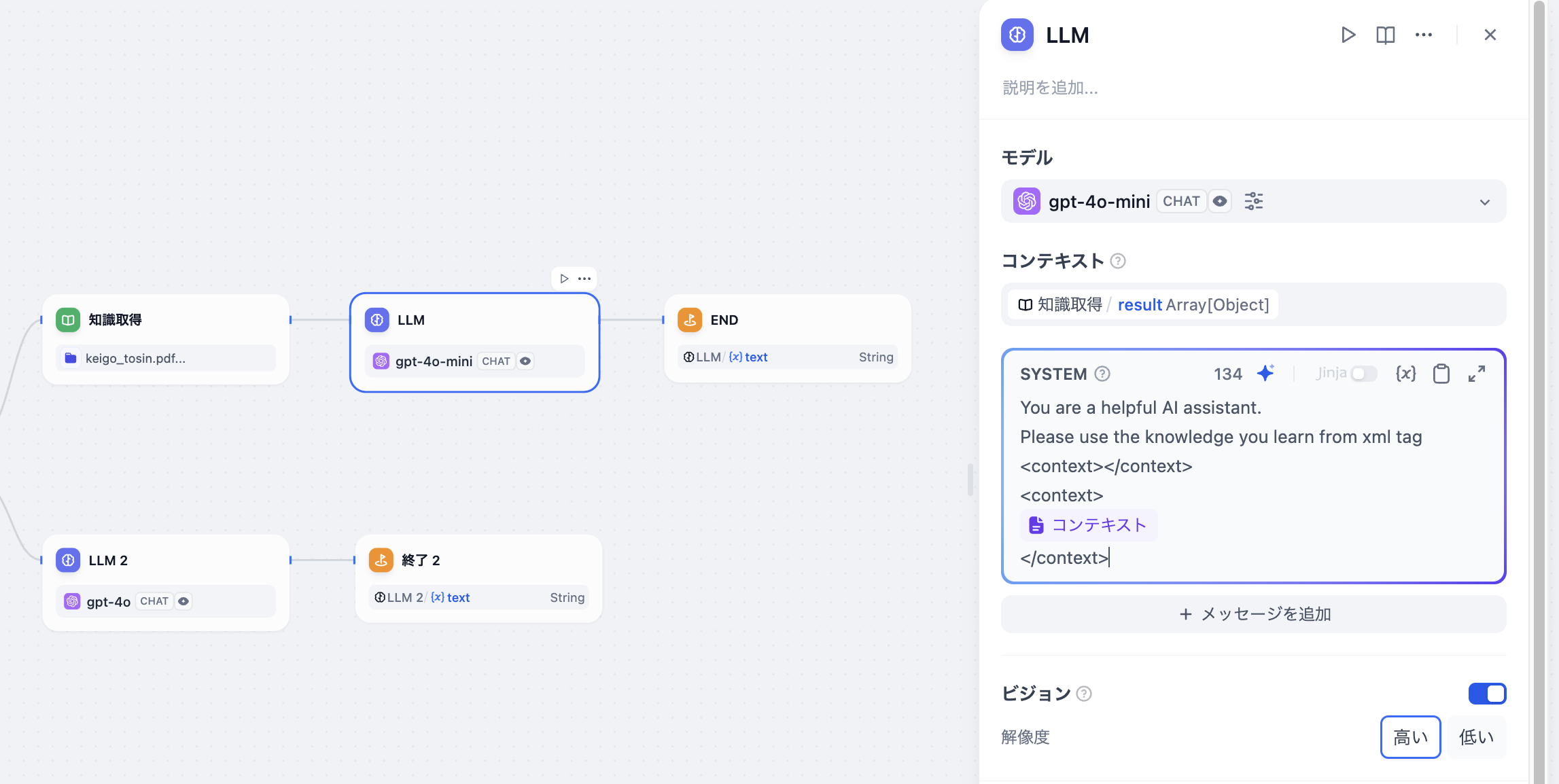 この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)機能もサポートします。
\ No newline at end of file
diff --git a/ja-jp/guides/workflow/node/llm.mdx b/ja-jp/guides/workflow/node/llm.mdx
index 493aa3a0..ab2f731c 100644
--- a/ja-jp/guides/workflow/node/llm.mdx
+++ b/ja-jp/guides/workflow/node/llm.mdx
@@ -8,7 +8,7 @@ version: '日本語'
大規模言語モデルを活用して質問に回答したり、自然言語を処理したりします。
-
この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)機能もサポートします。
\ No newline at end of file
diff --git a/ja-jp/guides/workflow/node/llm.mdx b/ja-jp/guides/workflow/node/llm.mdx
index 493aa3a0..ab2f731c 100644
--- a/ja-jp/guides/workflow/node/llm.mdx
+++ b/ja-jp/guides/workflow/node/llm.mdx
@@ -8,7 +8,7 @@ version: '日本語'
大規模言語モデルを活用して質問に回答したり、自然言語を処理したりします。
-  +
+  ***
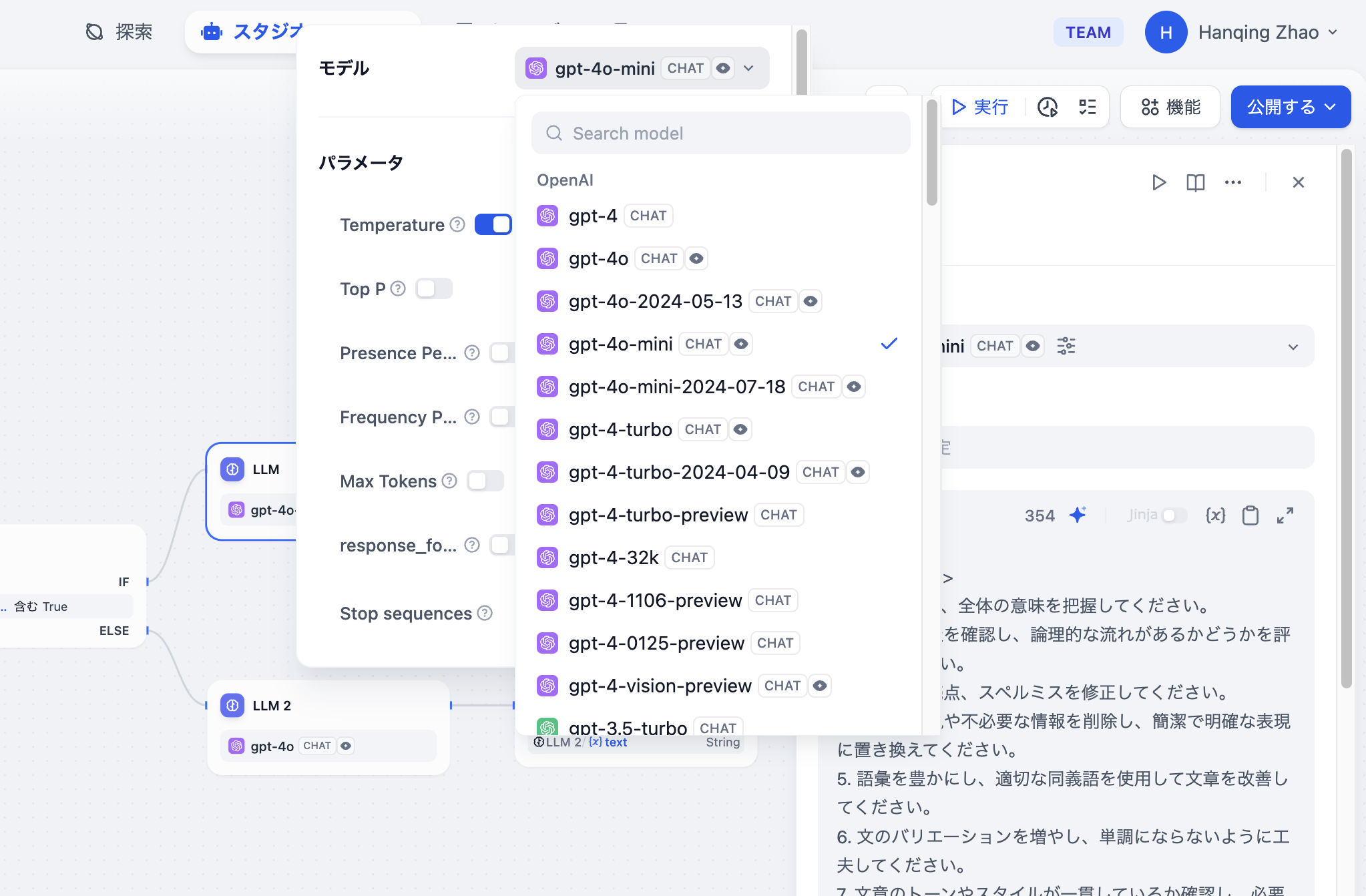
@@ -34,7 +34,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
エディットページで、前のノードの末尾を右クリックするか、+ボタンを軽くタップして新しいノードを追加し、LLM(大規模言語モデル)を選択します。
-
***
@@ -34,7 +34,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
エディットページで、前のノードの末尾を右クリックするか、+ボタンを軽くタップして新しいノードを追加し、LLM(大規模言語モデル)を選択します。
-  +
+  **設定手順:**
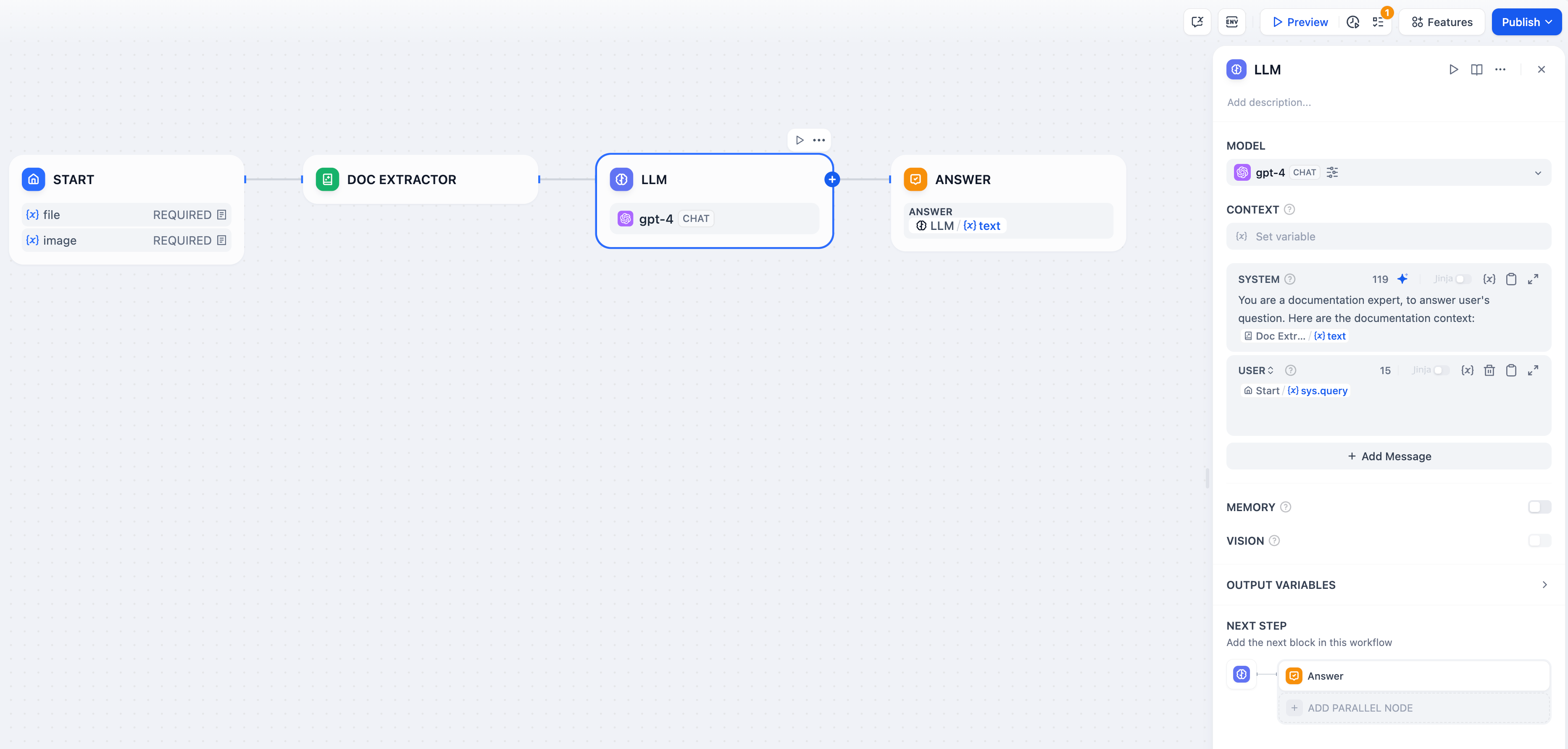
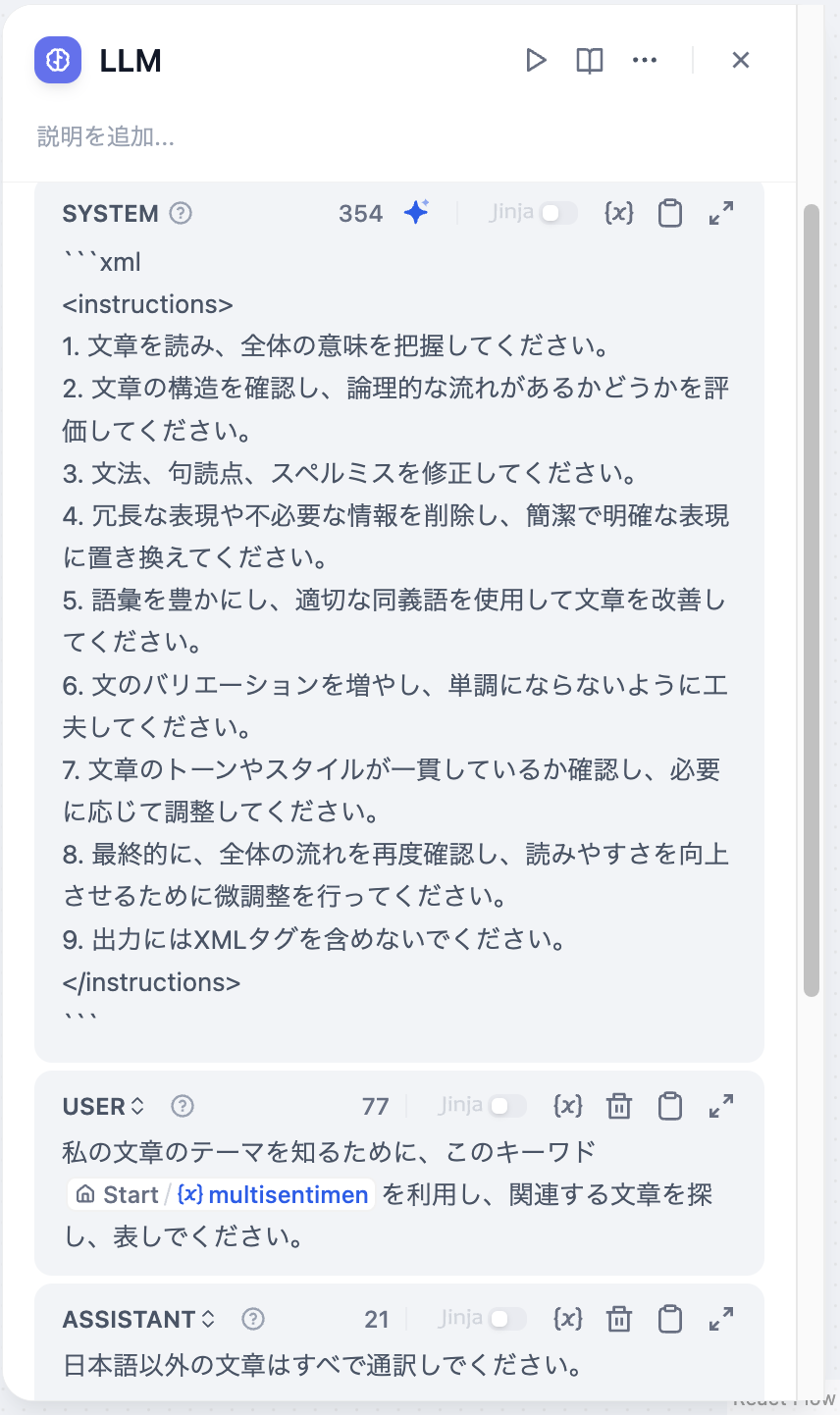
@@ -50,19 +50,19 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
4. **プロンプトの作成**:LLMノードには使いやすいプロンプト編集ページがあり、チャットモデルまたはコンプリートモデルを選択することで異なるプロンプト編集構造が表示されます。チャットモデル(Chat model)を選択した場合、システムプロンプト(SYSTEM)、ユーザー(USER)、アシスタント(ASSISTANT)の3つのセクションをカスタマイズできます。
-
**設定手順:**
@@ -50,19 +50,19 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
4. **プロンプトの作成**:LLMノードには使いやすいプロンプト編集ページがあり、チャットモデルまたはコンプリートモデルを選択することで異なるプロンプト編集構造が表示されます。チャットモデル(Chat model)を選択した場合、システムプロンプト(SYSTEM)、ユーザー(USER)、アシスタント(ASSISTANT)の3つのセクションをカスタマイズできます。
-  +
+  システムプロンプト(SYSTEM)を作成する際にアイデアが浮かばない場合は、プロンプトジェネレーター機能を使用して、実際のビジネスシナリオに適したプロンプトを迅速に生成することができます。
-
システムプロンプト(SYSTEM)を作成する際にアイデアが浮かばない場合は、プロンプトジェネレーター機能を使用して、実際のビジネスシナリオに適したプロンプトを迅速に生成することができます。
-  +
+ 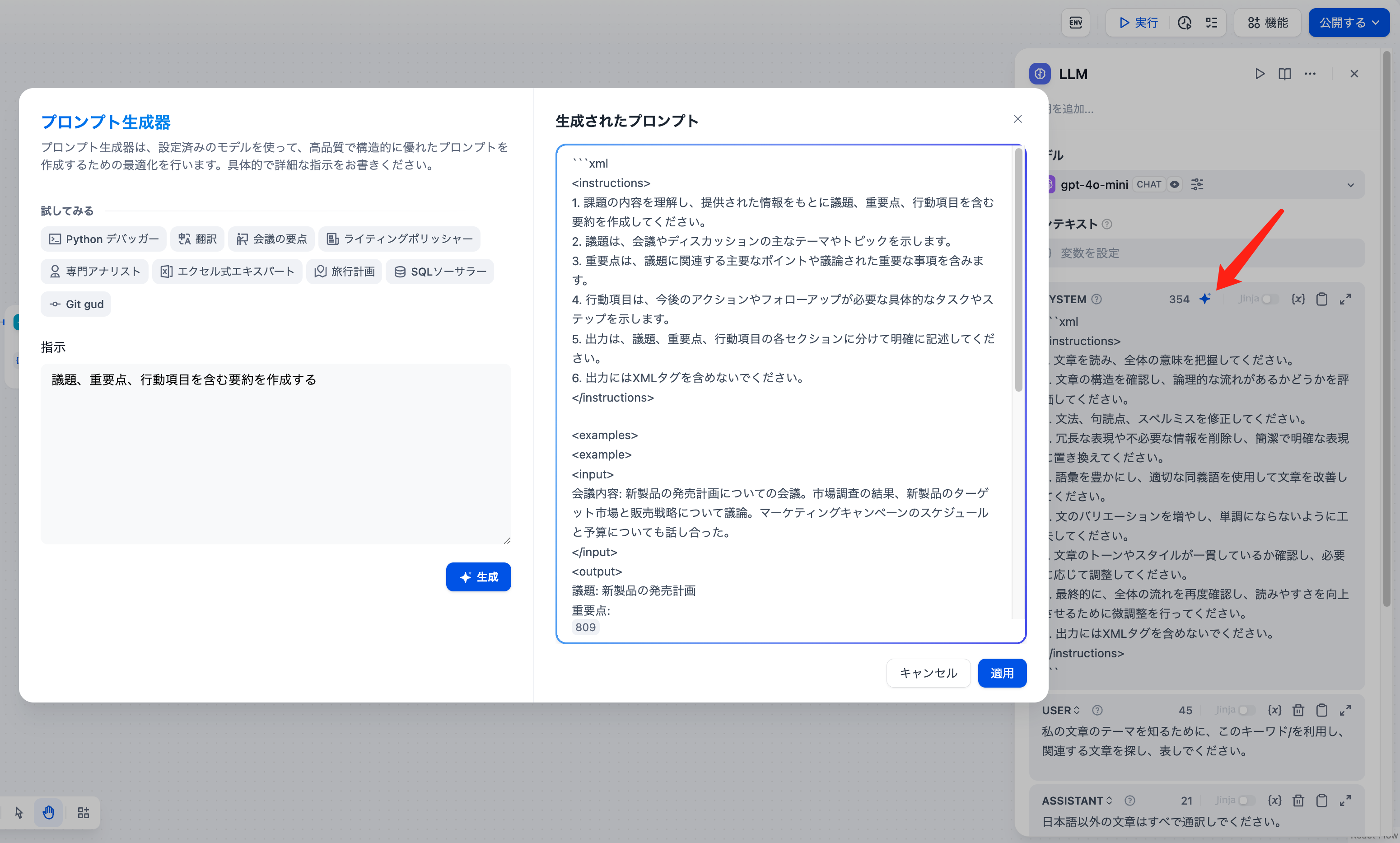 プロンプトエディターでは、**“/”** を入力することで **変数挿入メニュー** を呼び出し、**特殊変数ブロック**や **上流ノードの変数**をプロンプトに挿入してコンテキスト内容として使用できます。
-
プロンプトエディターでは、**“/”** を入力することで **変数挿入メニュー** を呼び出し、**特殊変数ブロック**や **上流ノードの変数**をプロンプトに挿入してコンテキスト内容として使用できます。
-  +
+ 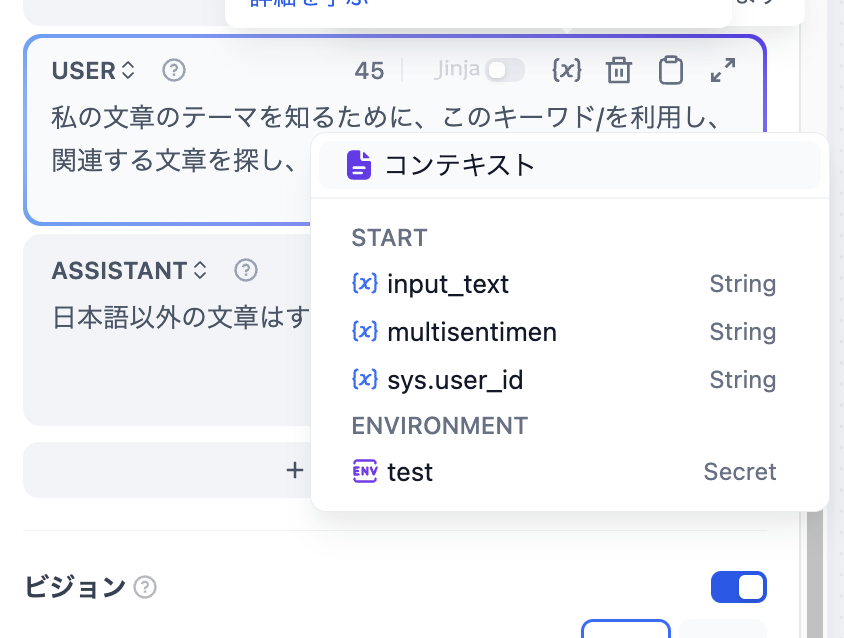 5. **上級的な設定**:メモリ機能をオンにしたり、メモリウィンドウを設定したり、ビジョン機能を有効にしたり、Jinja-2テンプレート言語を使ってより複雑なプロンプトを作成したりできます。
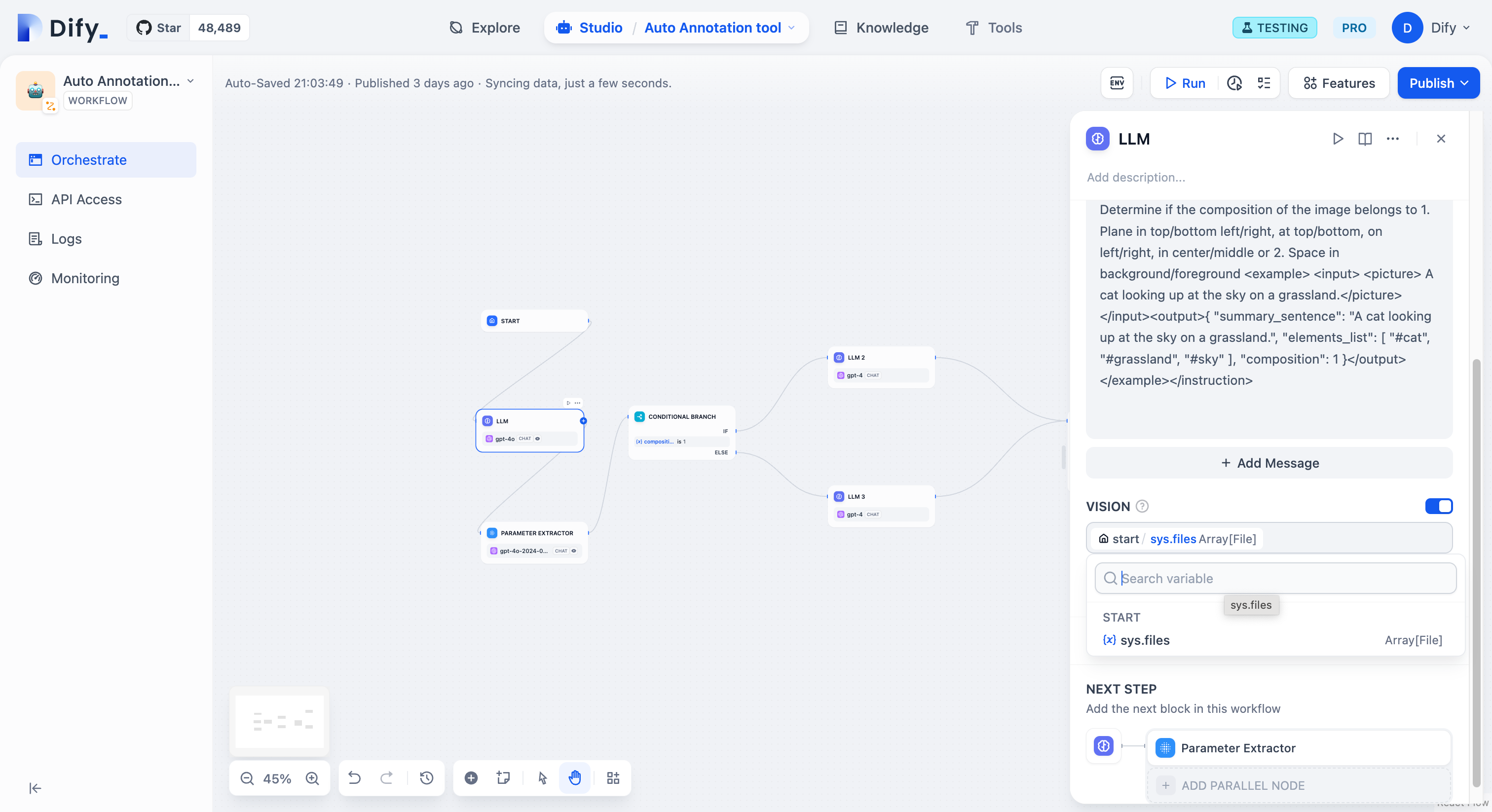
@@ -80,7 +80,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
視覚機能を備えた言語モデル(LLM)は、アプリケーションユーザーがアップロードした画像をこの変数を通じて読み取ることができます。VISION機能を有効にした後、画像ファイルの出力変数を選択して設定を完了させてください。
- {/*
5. **上級的な設定**:メモリ機能をオンにしたり、メモリウィンドウを設定したり、ビジョン機能を有効にしたり、Jinja-2テンプレート言語を使ってより複雑なプロンプトを作成したりできます。
@@ -80,7 +80,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
視覚機能を備えた言語モデル(LLM)は、アプリケーションユーザーがアップロードした画像をこの変数を通じて読み取ることができます。VISION機能を有効にした後、画像ファイルの出力変数を選択して設定を完了させてください。
- {/* .png) */}
+ {/*
*/}
+ {/* 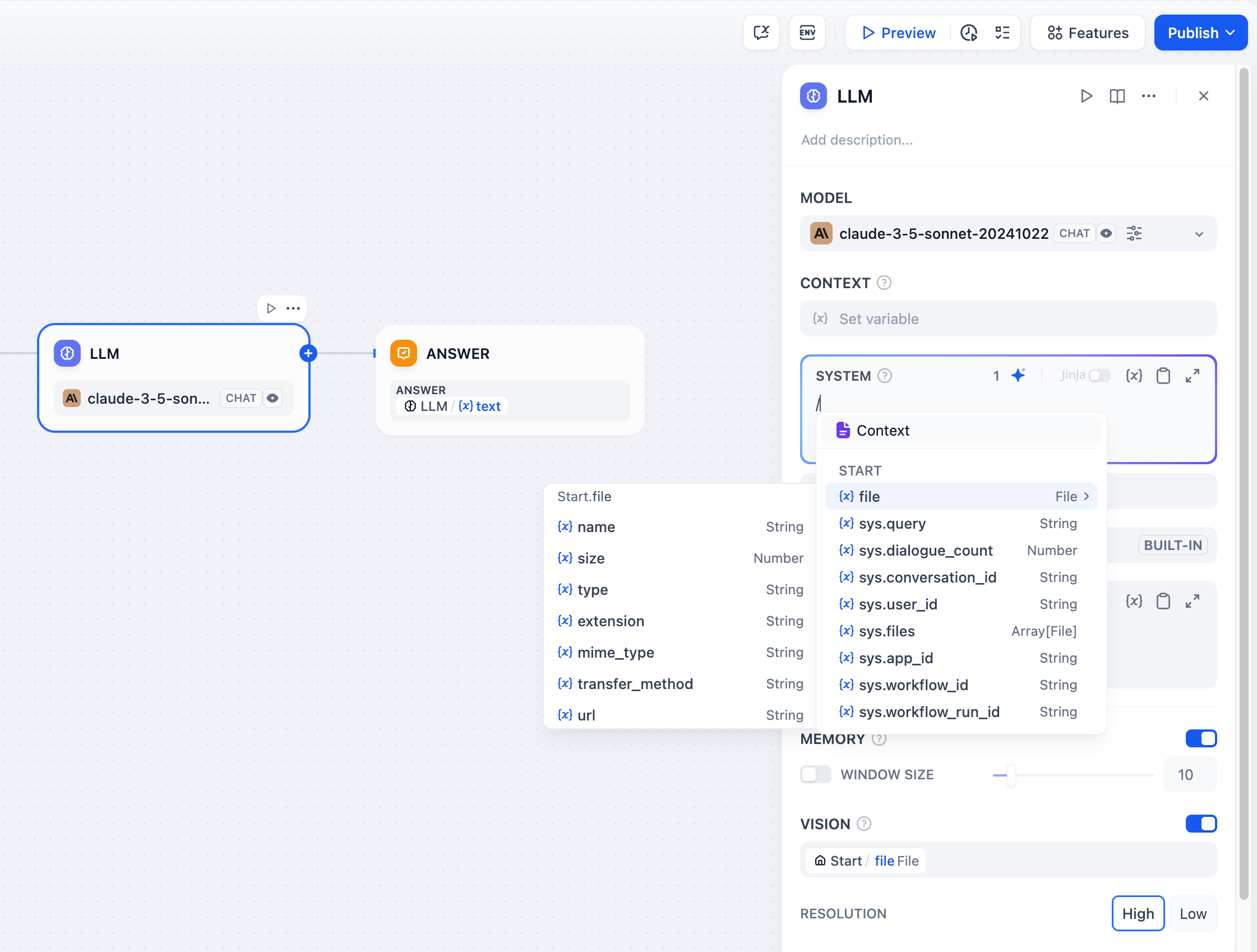 */}

@@ -93,7 +93,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
-
*/}

@@ -93,7 +93,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
-  +
+  **モデルパラメーター**
@@ -101,7 +101,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
モデルのパラメータはモデルの出力に影響を与えます。異なるモデルには異なるパラメータがあります。以下の図は`gpt-4`のパラメータリストです。
-
**モデルパラメーター**
@@ -101,7 +101,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
モデルのパラメータはモデルの出力に影響を与えます。異なるモデルには異なるパラメータがあります。以下の図は`gpt-4`のパラメータリストです。
-  +
+ 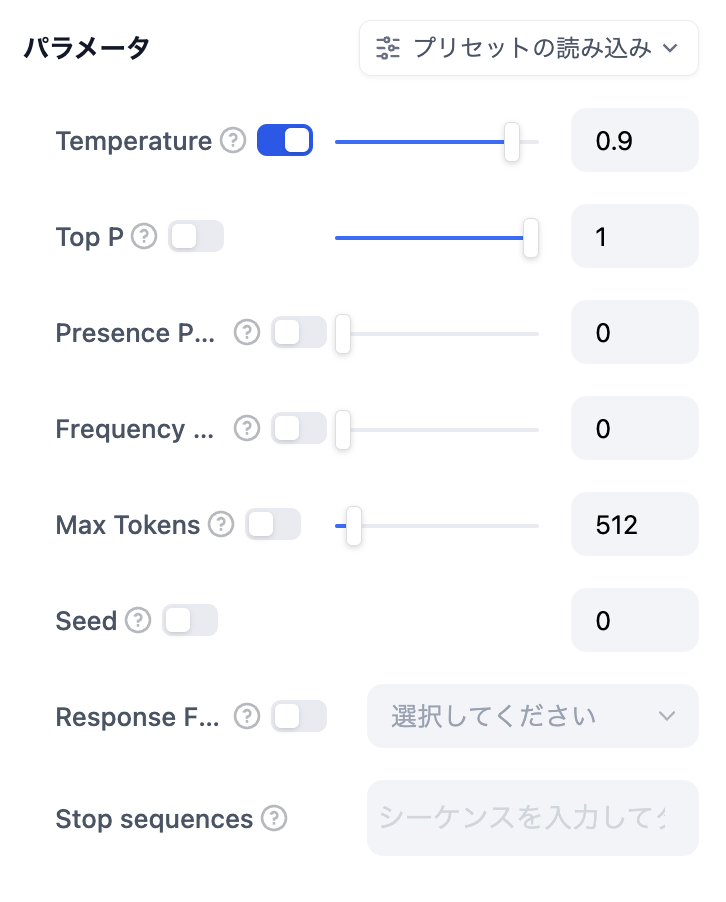 主要なパラメータ用語は以下のように説明されています:
@@ -114,7 +114,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
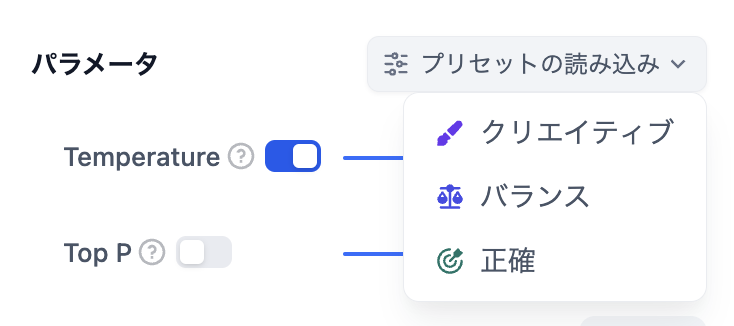
これらのパラメータが何であるか理解できない場合は、プリセットを読み込んで、「クリエイティブ」、「バランス」、「正確」の3つのプリセットから選択することができます。
-
主要なパラメータ用語は以下のように説明されています:
@@ -114,7 +114,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
これらのパラメータが何であるか理解できない場合は、プリセットを読み込んで、「クリエイティブ」、「バランス」、「正確」の3つのプリセットから選択することができます。
-  +
+  ***
@@ -142,7 +142,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
3. **コンテキスト変数** をアプリケーションのプロンプトに挿入し、LLMがナレッジベース内のテキスト内容を読み取れるようにします。
-
***
@@ -142,7 +142,7 @@ LLM は チャットフロー/ワークフロー の中心的なノードであ
3. **コンテキスト変数** をアプリケーションのプロンプトに挿入し、LLMがナレッジベース内のテキスト内容を読み取れるようにします。
-  +
+  [知識検索ノード](./knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](/ja-jp/guides/knowledge-base/retrieval-test-and-citation) 機能を使用して情報の出所を確認できます。
diff --git a/ja-jp/guides/workflow/node/parameter-extractor.mdx b/ja-jp/guides/workflow/node/parameter-extractor.mdx
index 059aab86..01683723 100644
--- a/ja-jp/guides/workflow/node/parameter-extractor.mdx
+++ b/ja-jp/guides/workflow/node/parameter-extractor.mdx
@@ -20,13 +20,13 @@ Difyワークフロー内には豊富な[ツール](/ja-jp/introduction)が用
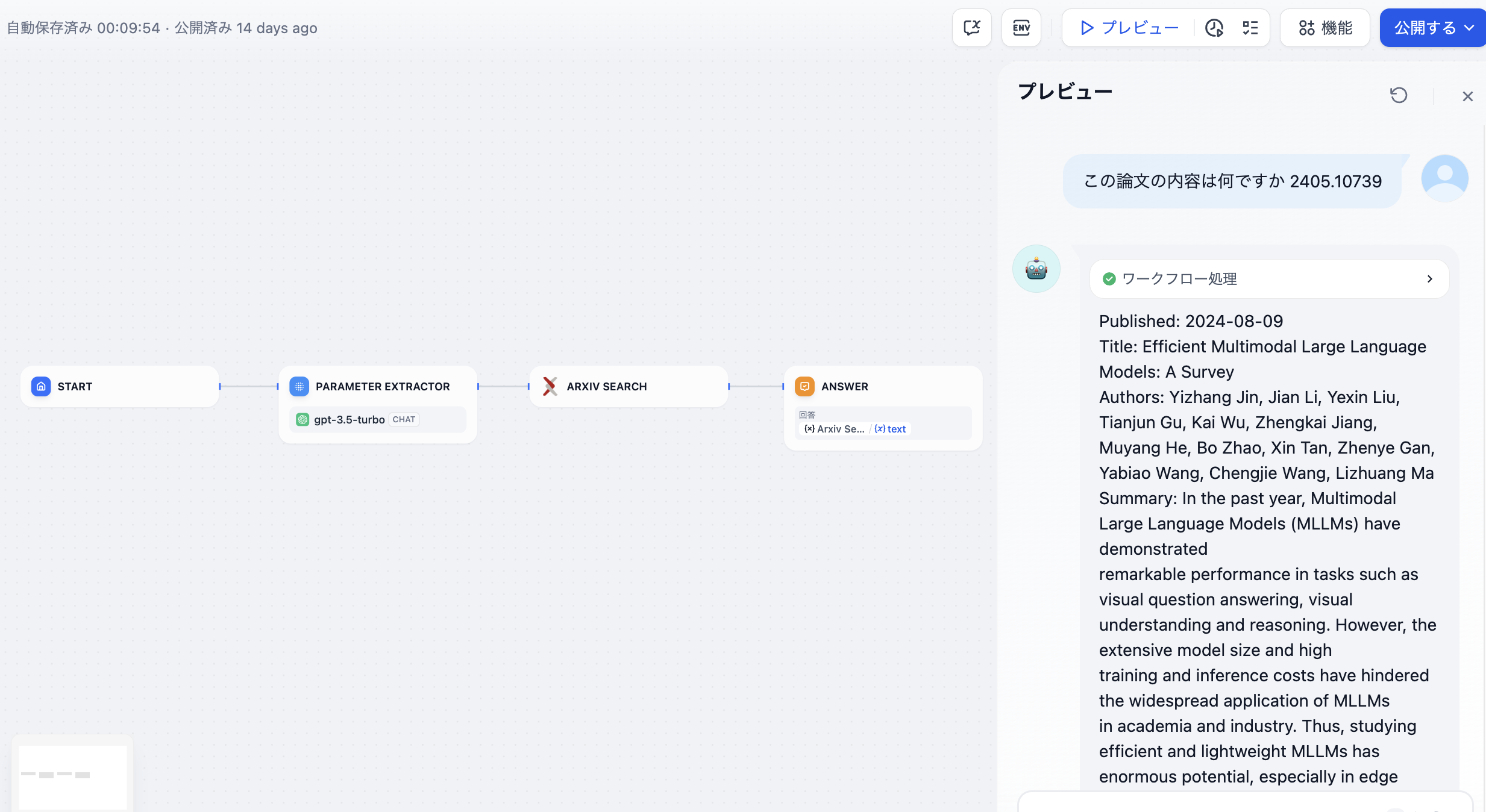
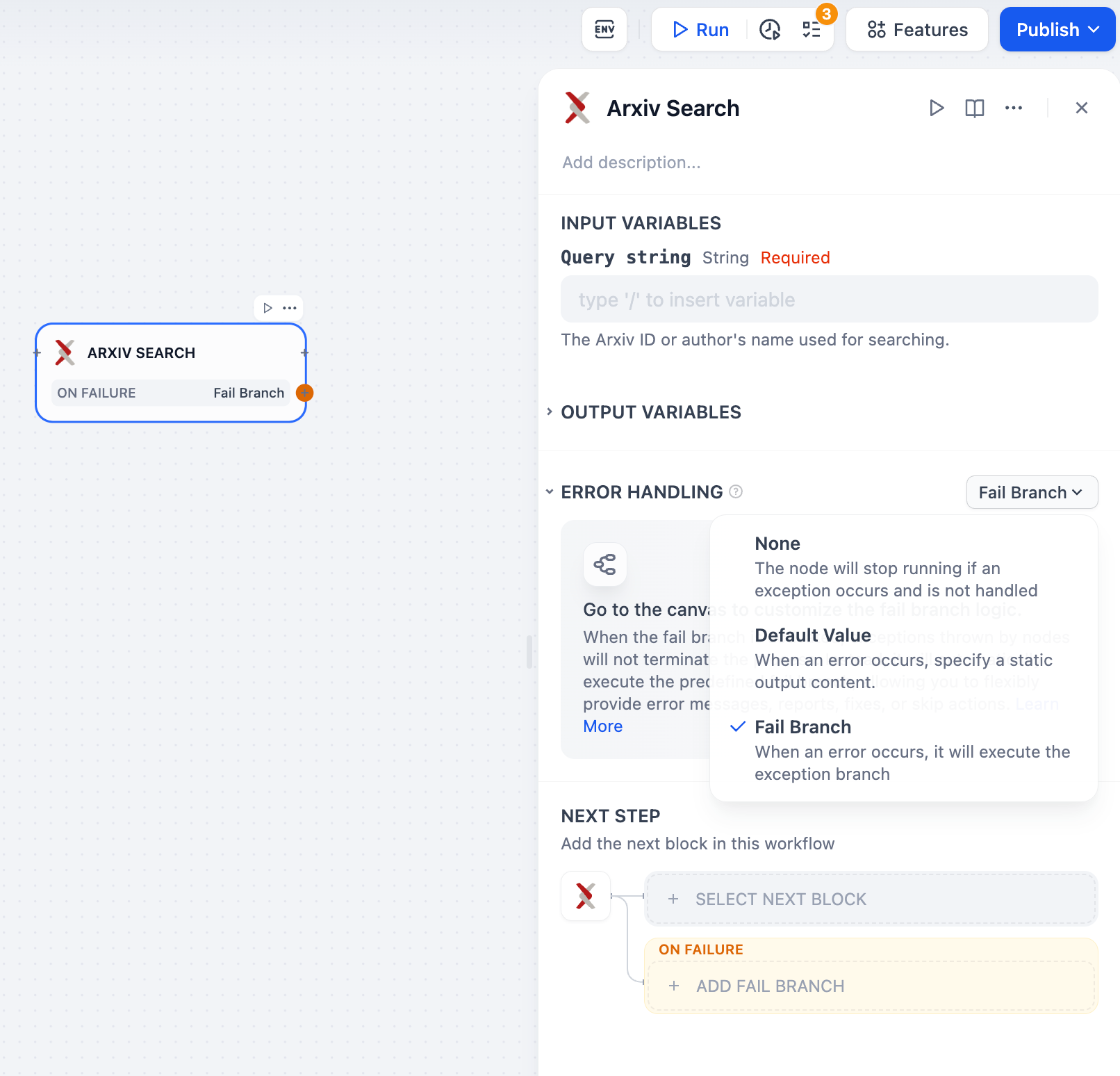
この例では、Arxiv論文検索ツールの入力パラメータとして「論文の著者」または「論文番号」が要求されます。パラメータ抽出器は「この論文の内容は何ですか:2405.10739」という質問から論文番号**2405.10739**を抽出し、ツールのパラメータとして正確に検索します。
-
[知識検索ノード](./knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](/ja-jp/guides/knowledge-base/retrieval-test-and-citation) 機能を使用して情報の出所を確認できます。
diff --git a/ja-jp/guides/workflow/node/parameter-extractor.mdx b/ja-jp/guides/workflow/node/parameter-extractor.mdx
index 059aab86..01683723 100644
--- a/ja-jp/guides/workflow/node/parameter-extractor.mdx
+++ b/ja-jp/guides/workflow/node/parameter-extractor.mdx
@@ -20,13 +20,13 @@ Difyワークフロー内には豊富な[ツール](/ja-jp/introduction)が用
この例では、Arxiv論文検索ツールの入力パラメータとして「論文の著者」または「論文番号」が要求されます。パラメータ抽出器は「この論文の内容は何ですか:2405.10739」という質問から論文番号**2405.10739**を抽出し、ツールのパラメータとして正確に検索します。
-  +
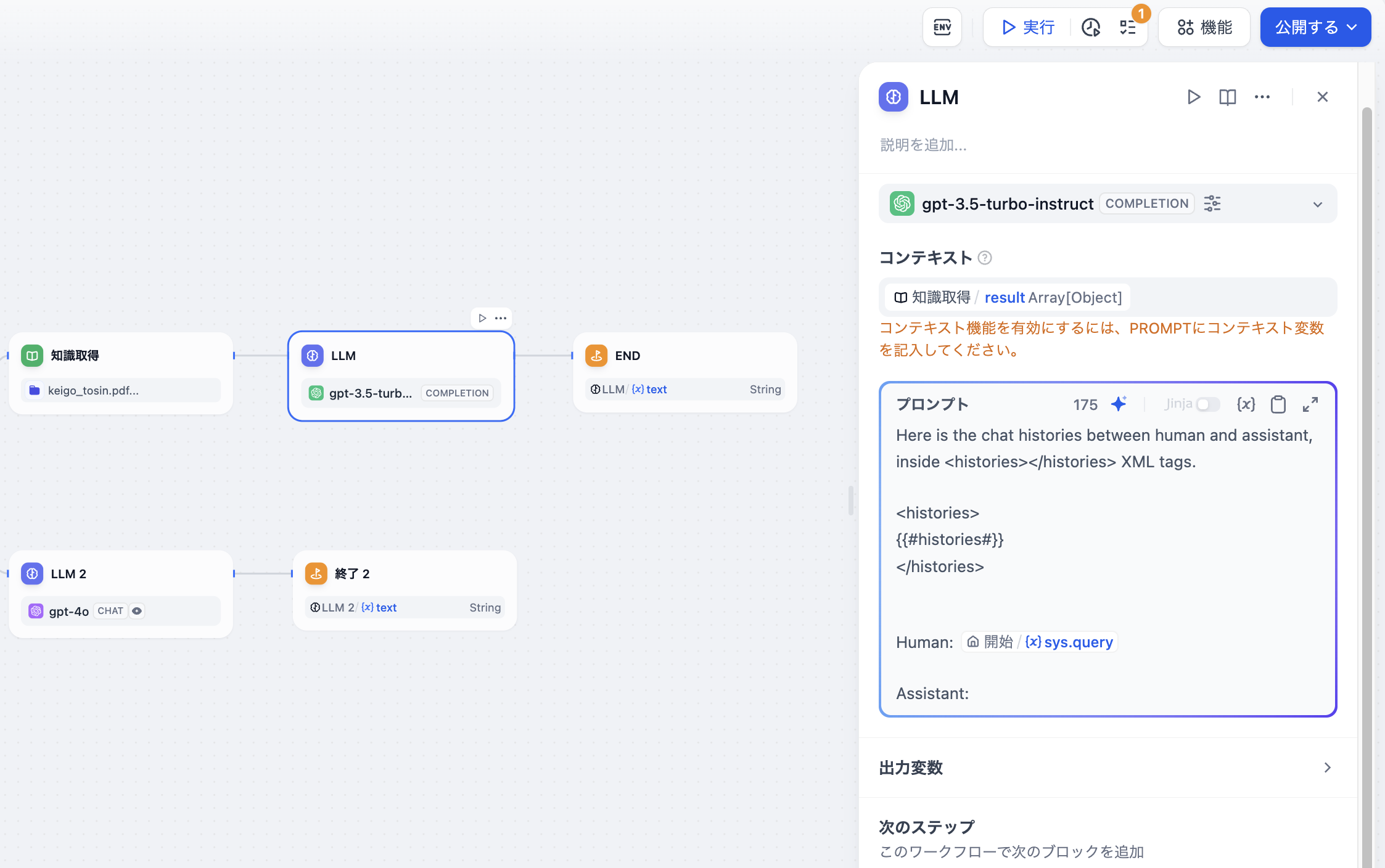
+  2. **テキストを構造化データに変換する**例として、長い物語のイテレーション生成アプリの前工程として、テキスト形式の章内容を配列形式に変換し、[イテレーションノード](./iteration)でのマルチラウンド生成処理を容易にします。
-
2. **テキストを構造化データに変換する**例として、長い物語のイテレーション生成アプリの前工程として、テキスト形式の章内容を配列形式に変換し、[イテレーションノード](./iteration)でのマルチラウンド生成処理を容易にします。
-  +
+ 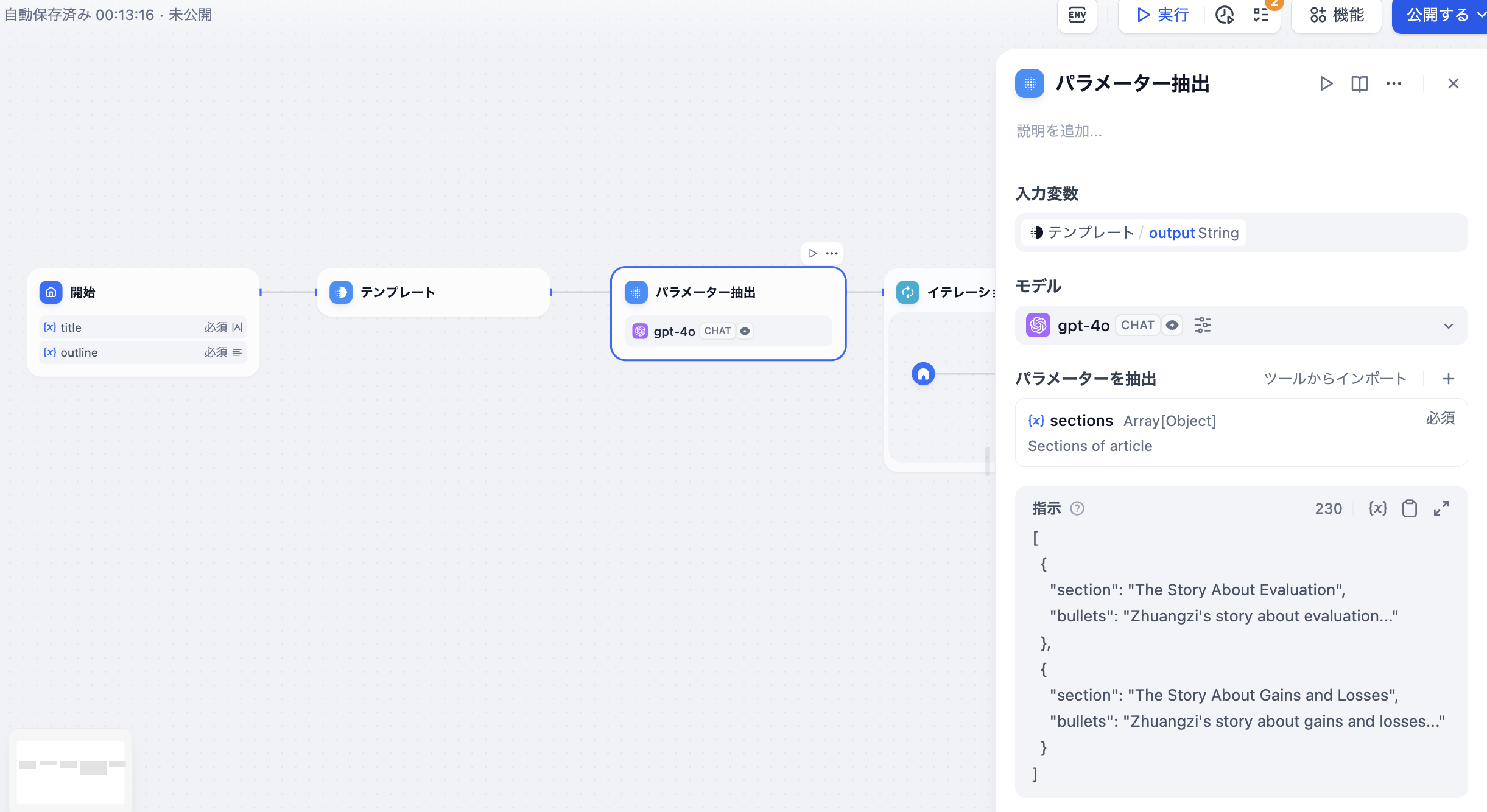 3. **構造化データを抽出して**[**HTTPリクエスト**](./http-request)**を使用する**ことで、任意のアクセス可能なURLにリクエストを送信し、外部検索結果の取得やウェブフック、画像生成などのシナリオに適用できます。
@@ -36,7 +36,7 @@ Difyワークフロー内には豊富な[ツール](/ja-jp/introduction)が用
### 設定方法
-
3. **構造化データを抽出して**[**HTTPリクエスト**](./http-request)**を使用する**ことで、任意のアクセス可能なURLにリクエストを送信し、外部検索結果の取得やウェブフック、画像生成などのシナリオに適用できます。
@@ -36,7 +36,7 @@ Difyワークフロー内には豊富な[ツール](/ja-jp/introduction)が用
### 設定方法
-  +
+ 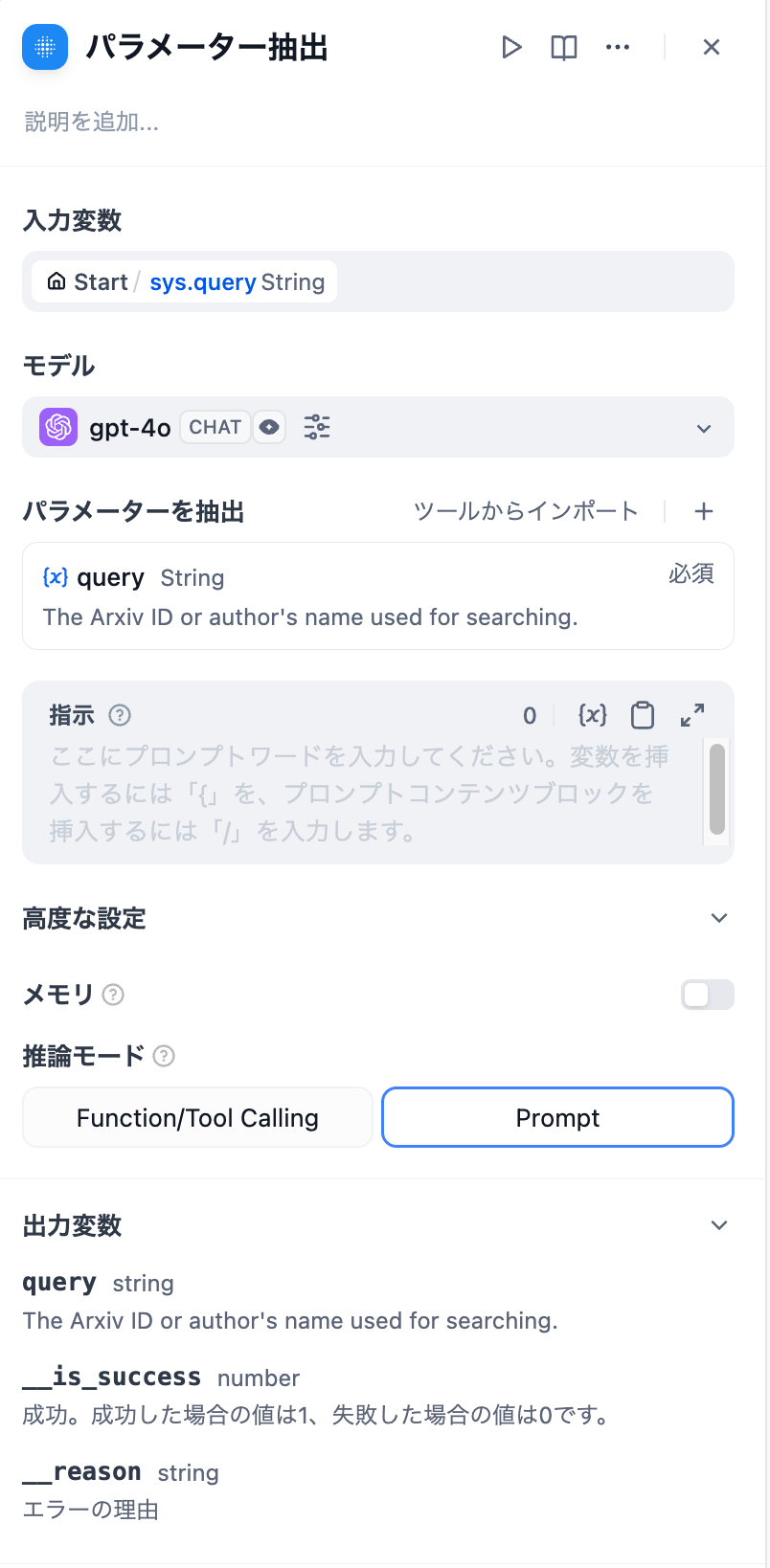 **設定手順**
diff --git a/ja-jp/guides/workflow/node/question-classifier.mdx b/ja-jp/guides/workflow/node/question-classifier.mdx
index a5d60551..acff7b02 100644
--- a/ja-jp/guides/workflow/node/question-classifier.mdx
+++ b/ja-jp/guides/workflow/node/question-classifier.mdx
@@ -18,7 +18,7 @@ version: '日本語'
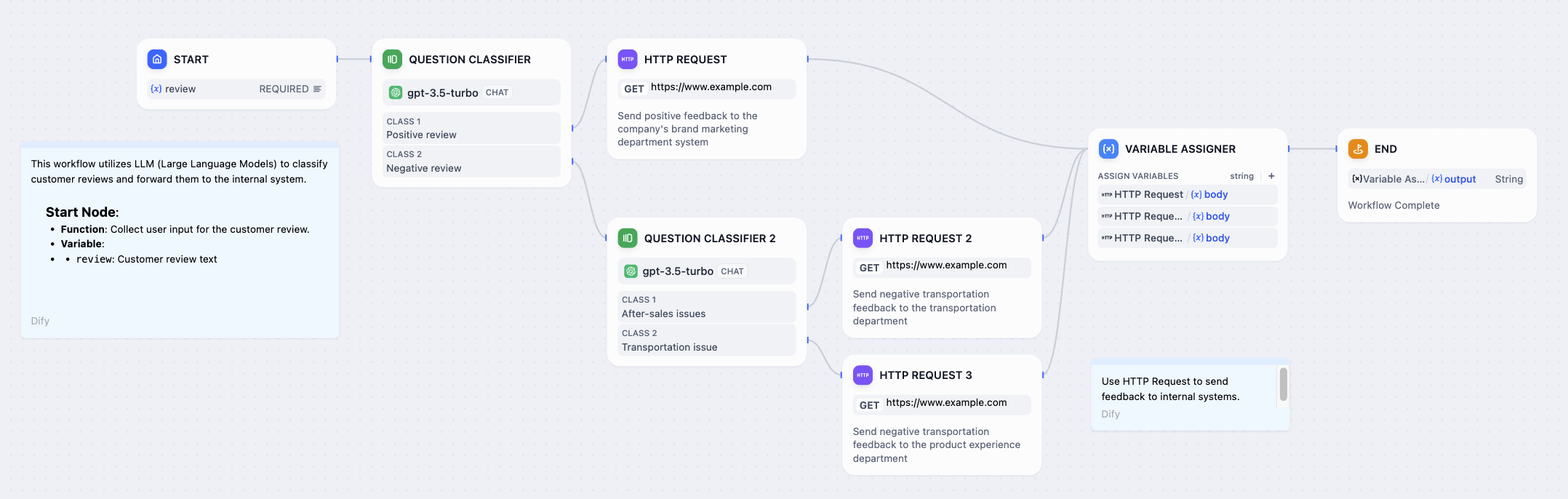
以下の図は製品カスタマーサービスシナリオのサンプルワークフローテンプレートです:
-
**設定手順**
diff --git a/ja-jp/guides/workflow/node/question-classifier.mdx b/ja-jp/guides/workflow/node/question-classifier.mdx
index a5d60551..acff7b02 100644
--- a/ja-jp/guides/workflow/node/question-classifier.mdx
+++ b/ja-jp/guides/workflow/node/question-classifier.mdx
@@ -18,7 +18,7 @@ version: '日本語'
以下の図は製品カスタマーサービスシナリオのサンプルワークフローテンプレートです:
-  +
+ 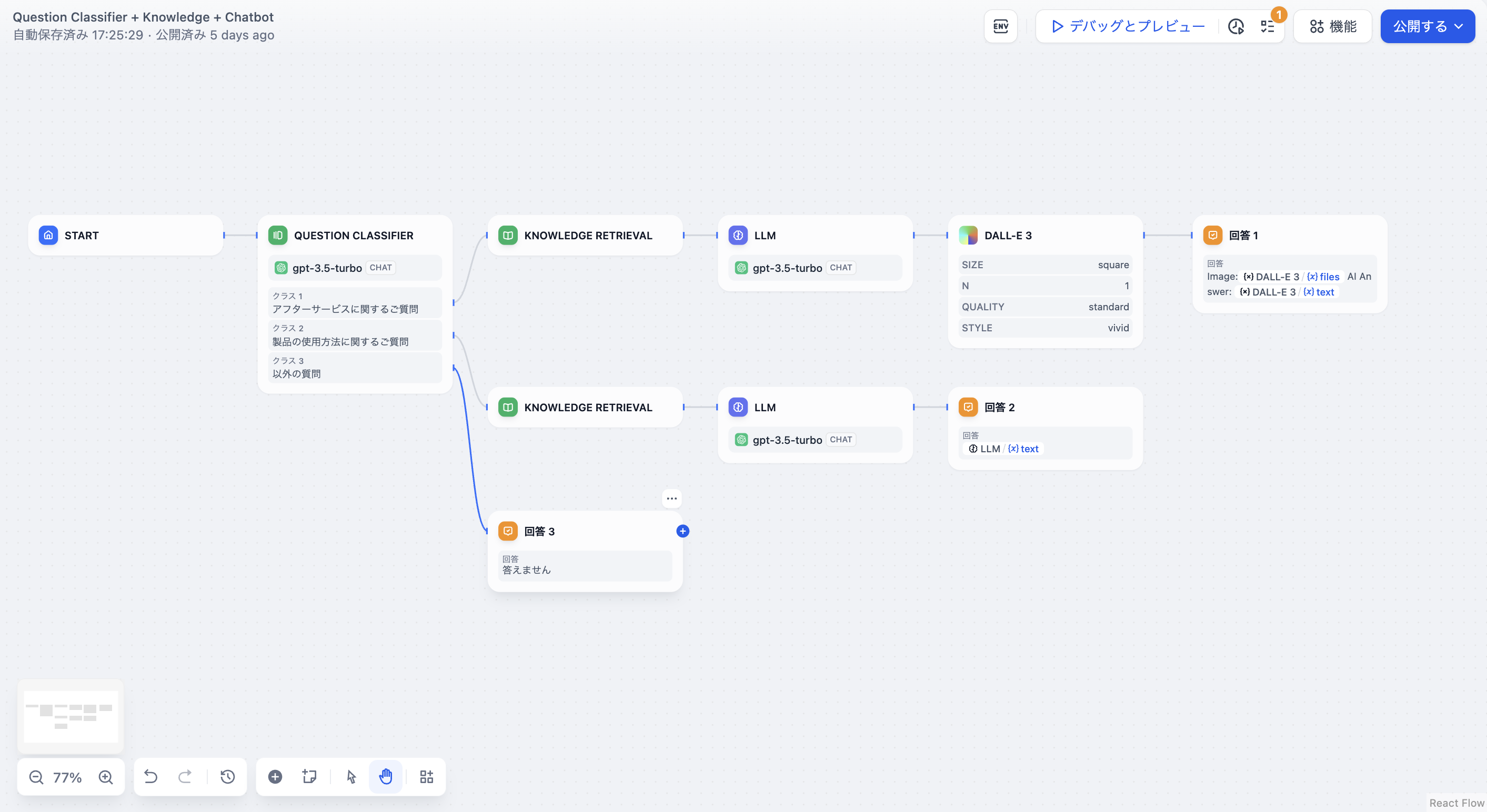 このシナリオでは、3つの分類ラベル/説明を設定しています:
@@ -38,7 +38,7 @@ version: '日本語'
### 設定方法
-
このシナリオでは、3つの分類ラベル/説明を設定しています:
@@ -38,7 +38,7 @@ version: '日本語'
### 設定方法
-  +
+ 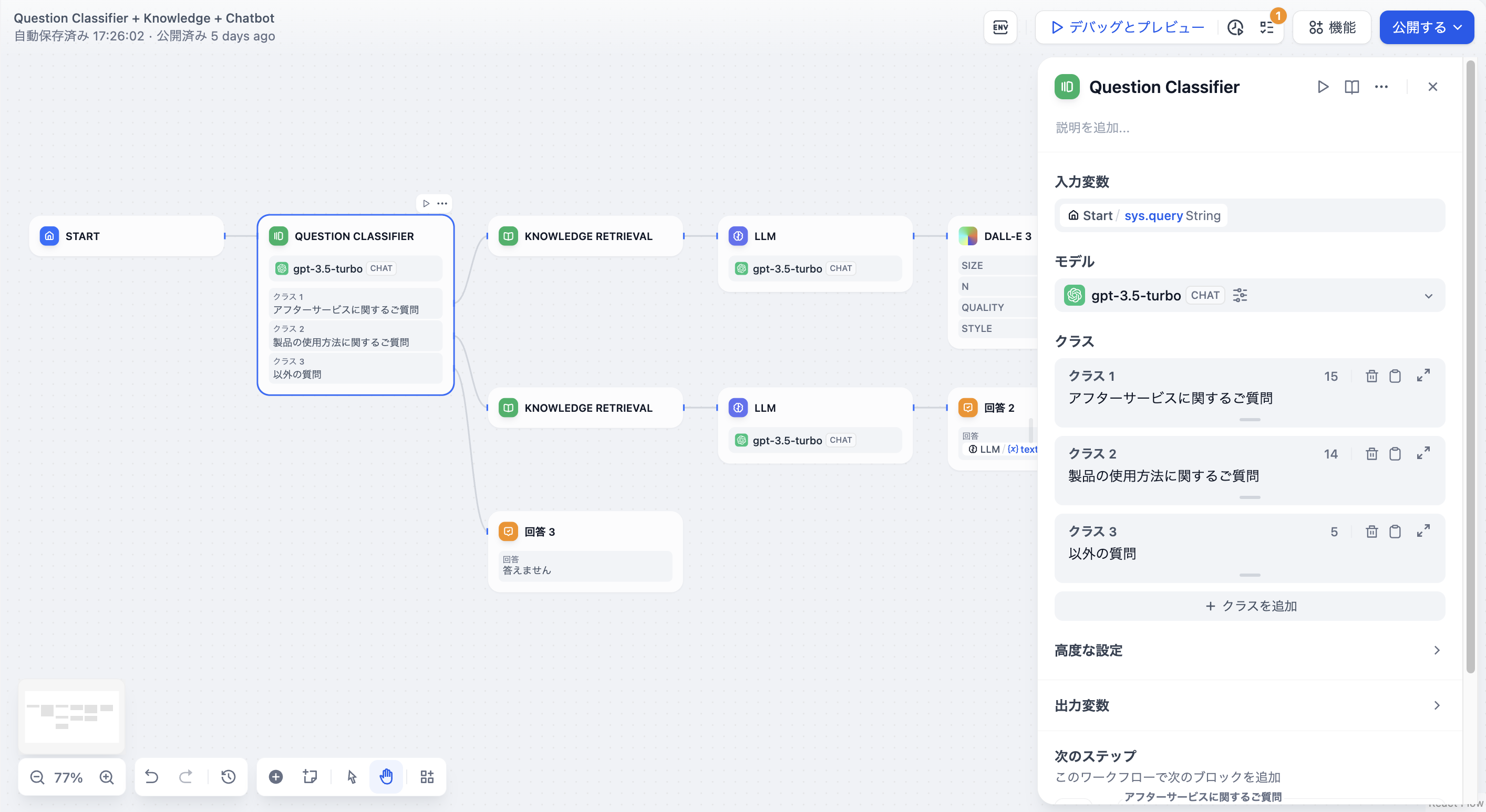 **設定手順:**
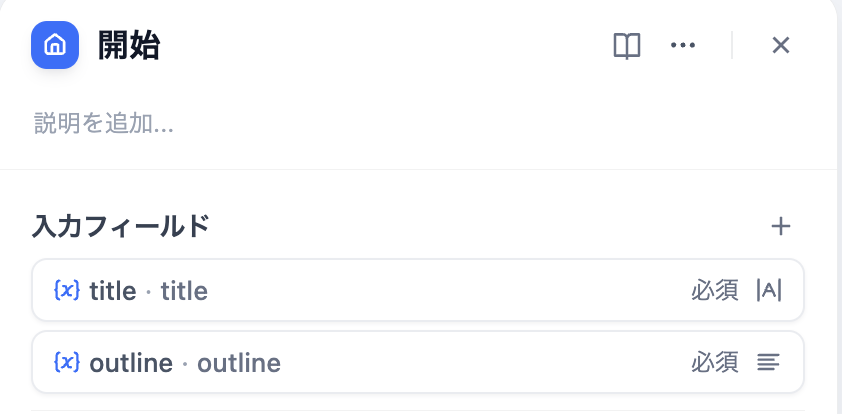
diff --git a/ja-jp/guides/workflow/node/start.mdx b/ja-jp/guides/workflow/node/start.mdx
index c9783b43..b19edb33 100644
--- a/ja-jp/guides/workflow/node/start.mdx
+++ b/ja-jp/guides/workflow/node/start.mdx
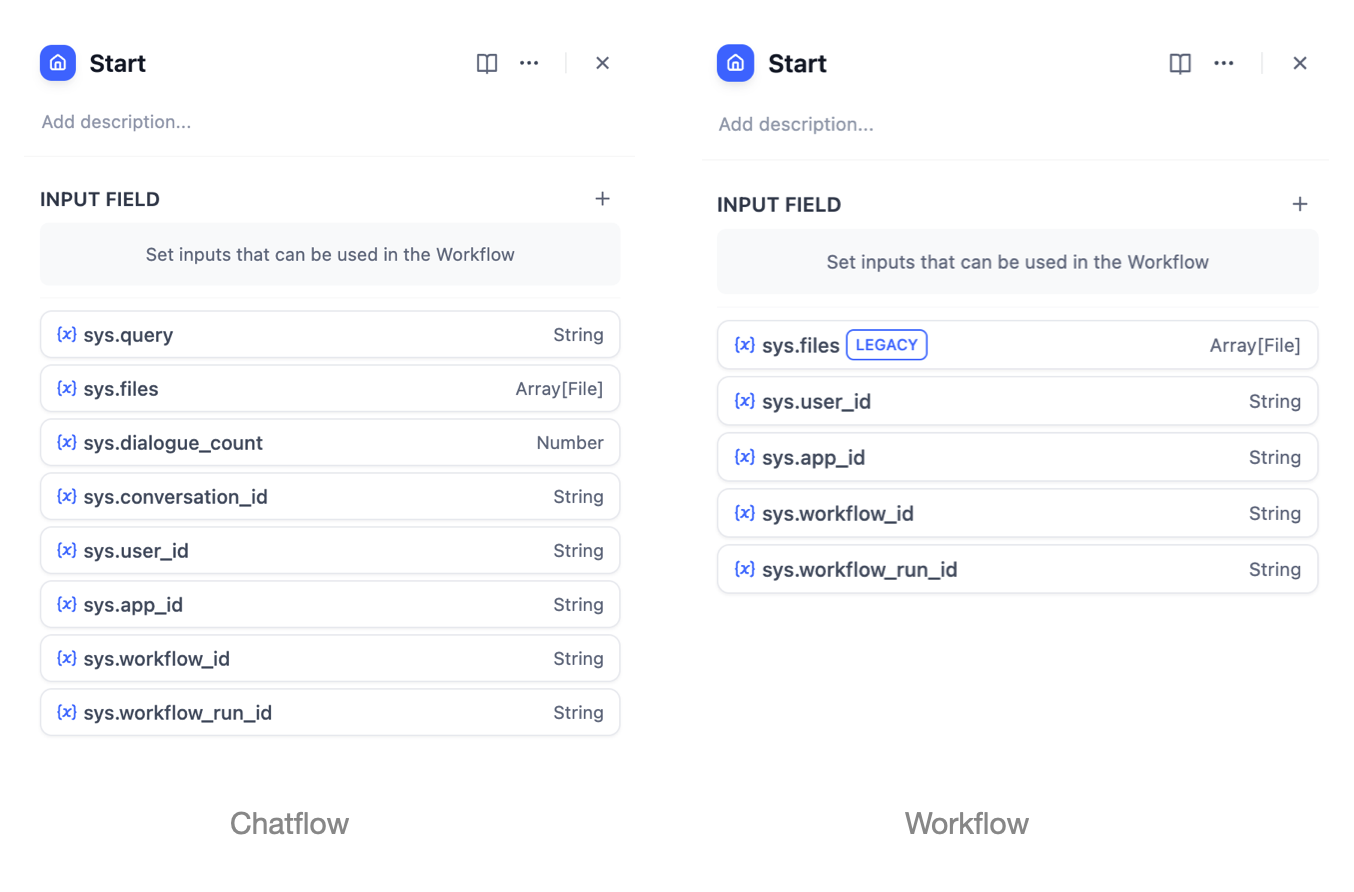
@@ -12,7 +12,7 @@ version: '日本語'
開始ノードの設定ページでは、**“入力フィールド”**とデフォルトの[**システム変数**](/ja-jp/guides/workflow/variables)という二つの設定部分が見られます。
-
**設定手順:**
diff --git a/ja-jp/guides/workflow/node/start.mdx b/ja-jp/guides/workflow/node/start.mdx
index c9783b43..b19edb33 100644
--- a/ja-jp/guides/workflow/node/start.mdx
+++ b/ja-jp/guides/workflow/node/start.mdx
@@ -12,7 +12,7 @@ version: '日本語'
開始ノードの設定ページでは、**“入力フィールド”**とデフォルトの[**システム変数**](/ja-jp/guides/workflow/variables)という二つの設定部分が見られます。
-  +
+  ### 入力フィールド
@@ -47,7 +47,7 @@ version: '日本語'
設定が完了した後、使用者はアプリを使用する前に、入力項目に従ってLLMに必要な情報を提供します。より多くの情報がLLMの質問応答効率を向上させるのに役立ちます。
-
### 入力フィールド
@@ -47,7 +47,7 @@ version: '日本語'
設定が完了した後、使用者はアプリを使用する前に、入力項目に従ってLLMに必要な情報を提供します。より多くの情報がLLMの質問応答効率を向上させるのに役立ちます。
- .png) +
+  ### システム変数
diff --git a/ja-jp/guides/workflow/node/template.mdx b/ja-jp/guides/workflow/node/template.mdx
index 8b5a40e9..f3d8cde3 100644
--- a/ja-jp/guides/workflow/node/template.mdx
+++ b/ja-jp/guides/workflow/node/template.mdx
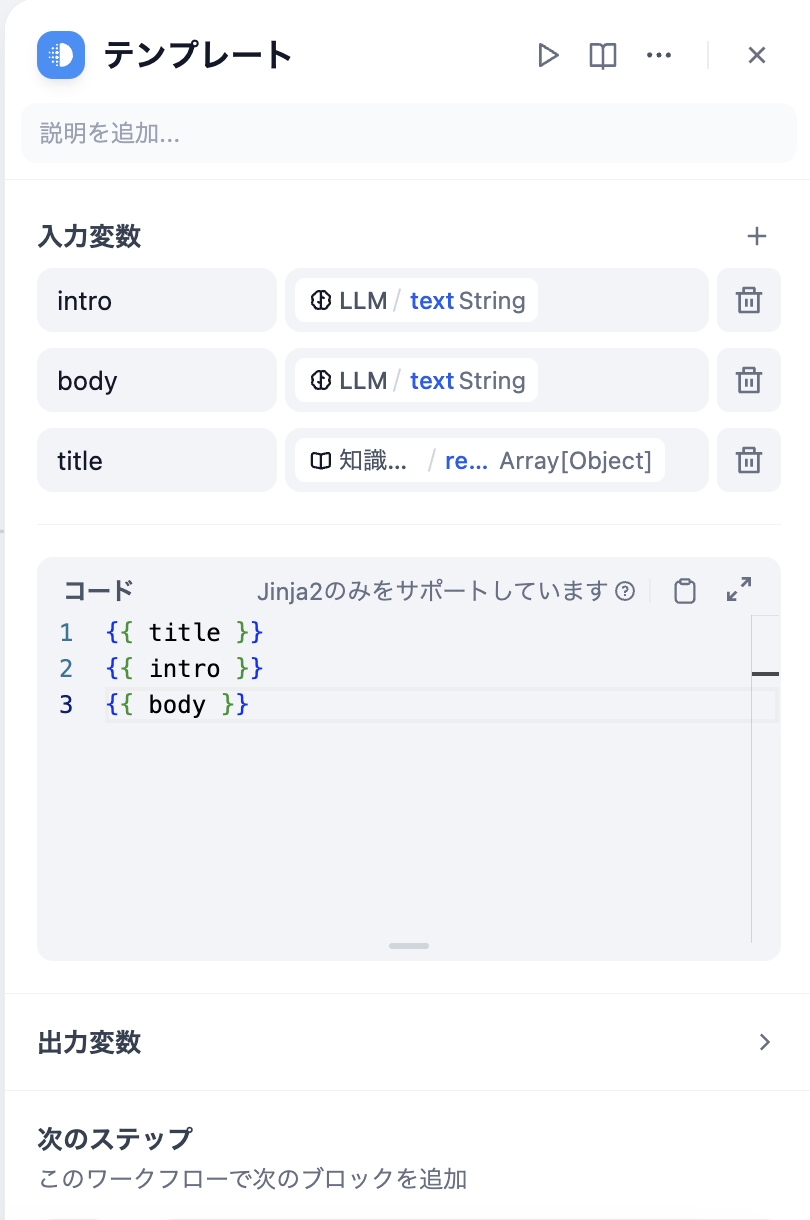
@@ -22,7 +22,7 @@ Jinja2のPythonテンプレート言語を使って、データ変換やテキ
**例1:** 複数の入力(記事のタイトル、紹介、内容)を一つの完全なテキストに結合する
-
### システム変数
diff --git a/ja-jp/guides/workflow/node/template.mdx b/ja-jp/guides/workflow/node/template.mdx
index 8b5a40e9..f3d8cde3 100644
--- a/ja-jp/guides/workflow/node/template.mdx
+++ b/ja-jp/guides/workflow/node/template.mdx
@@ -22,7 +22,7 @@ Jinja2のPythonテンプレート言語を使って、データ変換やテキ
**例1:** 複数の入力(記事のタイトル、紹介、内容)を一つの完全なテキストに結合する
-  +
+  **例2:** ナレッジリトリーバルノードで取得した情報およびその関連メタデータを、構造化されたMarkdown形式にまとめる
@@ -42,7 +42,7 @@ Jinja2のPythonテンプレート言語を使って、データ変換やテキ
```
-
**例2:** ナレッジリトリーバルノードで取得した情報およびその関連メタデータを、構造化されたMarkdown形式にまとめる
@@ -42,7 +42,7 @@ Jinja2のPythonテンプレート言語を使って、データ変換やテキ
```
- .png) +
Jinjaの[公式ドキュメント](https://jinja.palletsprojects.com/en/3.1.x/templates/)を参考にして、さまざまなタスクを実行するためのより複雑なテンプレートを作成することができます。
\ No newline at end of file
diff --git a/ja-jp/guides/workflow/node/tools.mdx b/ja-jp/guides/workflow/node/tools.mdx
index 5f818ade..0d8eb5d5 100644
--- a/ja-jp/guides/workflow/node/tools.mdx
+++ b/ja-jp/guides/workflow/node/tools.mdx
@@ -18,13 +18,13 @@ version: '日本語'
また、より複雑なワークフローを編成し、それをツールとして公開することもできます。
-
+
Jinjaの[公式ドキュメント](https://jinja.palletsprojects.com/en/3.1.x/templates/)を参考にして、さまざまなタスクを実行するためのより複雑なテンプレートを作成することができます。
\ No newline at end of file
diff --git a/ja-jp/guides/workflow/node/tools.mdx b/ja-jp/guides/workflow/node/tools.mdx
index 5f818ade..0d8eb5d5 100644
--- a/ja-jp/guides/workflow/node/tools.mdx
+++ b/ja-jp/guides/workflow/node/tools.mdx
@@ -18,13 +18,13 @@ version: '日本語'
また、より複雑なワークフローを編成し、それをツールとして公開することもできます。
-  +
+  ツールノードは他のノードと接続でき、[変数](/ja-jp/guides/workflow/variables)を通じてデータを処理および受け渡しすることができます。
-
ツールノードは他のノードと接続でき、[変数](/ja-jp/guides/workflow/variables)を通じてデータを処理および受け渡しすることができます。
-  +
+  ### 将工作流应用发布为工具
diff --git a/ja-jp/guides/workflow/node/variable-aggregator.mdx b/ja-jp/guides/workflow/node/variable-aggregator.mdx
index 57f6f355..b8a563dd 100644
--- a/ja-jp/guides/workflow/node/variable-aggregator.mdx
+++ b/ja-jp/guides/workflow/node/variable-aggregator.mdx
@@ -19,19 +19,19 @@ title: 変数集約
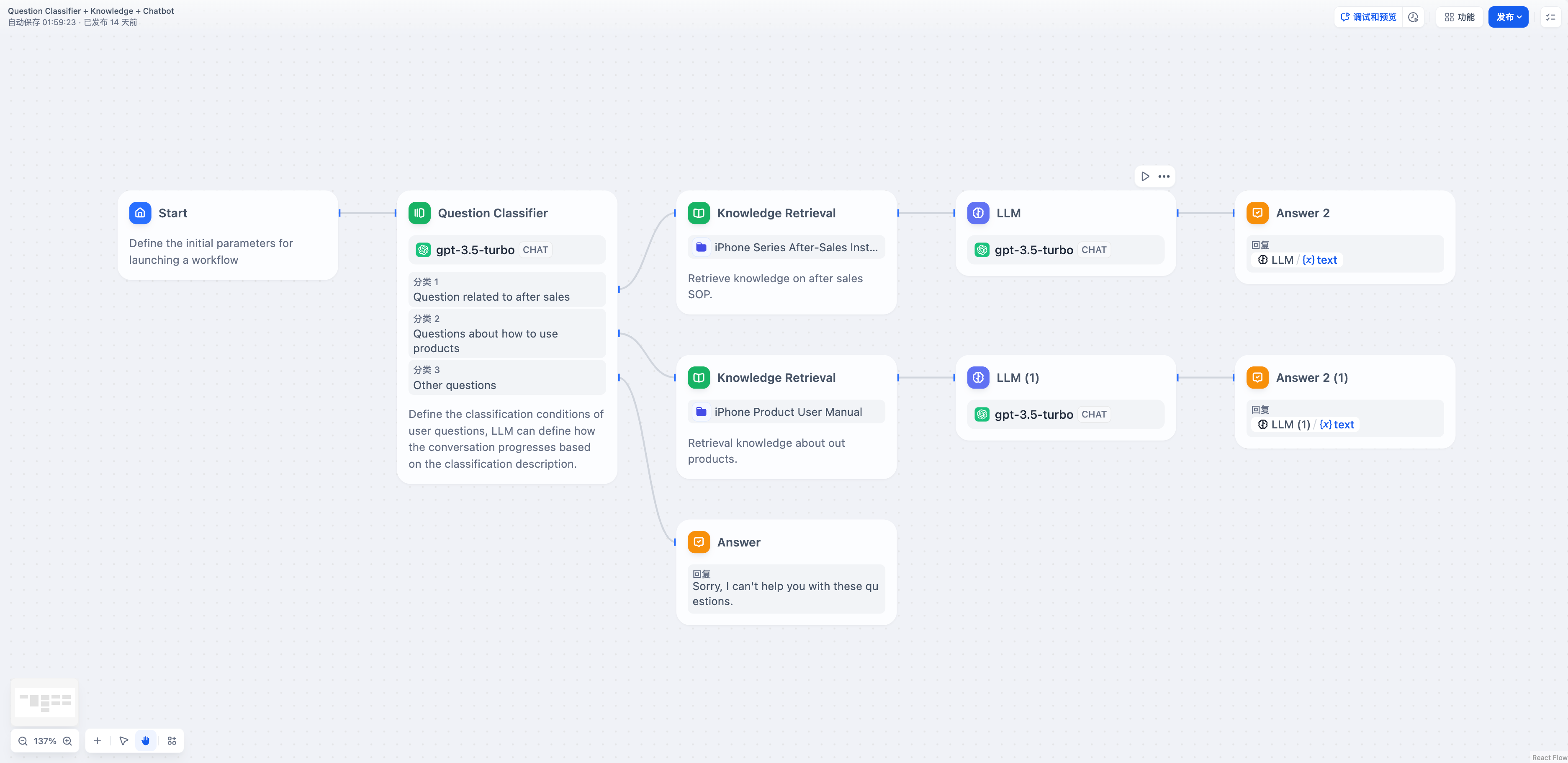
変数集約を追加しない場合、分類1と分類2のブランチは異なるナレッジベース検索を経て、ダウンズトリームの大規模言語モデルおよび直接返信ノードを繰り返し定義する必要があります。
-
### 将工作流应用发布为工具
diff --git a/ja-jp/guides/workflow/node/variable-aggregator.mdx b/ja-jp/guides/workflow/node/variable-aggregator.mdx
index 57f6f355..b8a563dd 100644
--- a/ja-jp/guides/workflow/node/variable-aggregator.mdx
+++ b/ja-jp/guides/workflow/node/variable-aggregator.mdx
@@ -19,19 +19,19 @@ title: 変数集約
変数集約を追加しない場合、分類1と分類2のブランチは異なるナレッジベース検索を経て、ダウンズトリームの大規模言語モデルおよび直接返信ノードを繰り返し定義する必要があります。
- .png) +
+  変数集約を追加することで、二つのナレッジベース検索ノードの出力を一つの変数に集約できます。
-
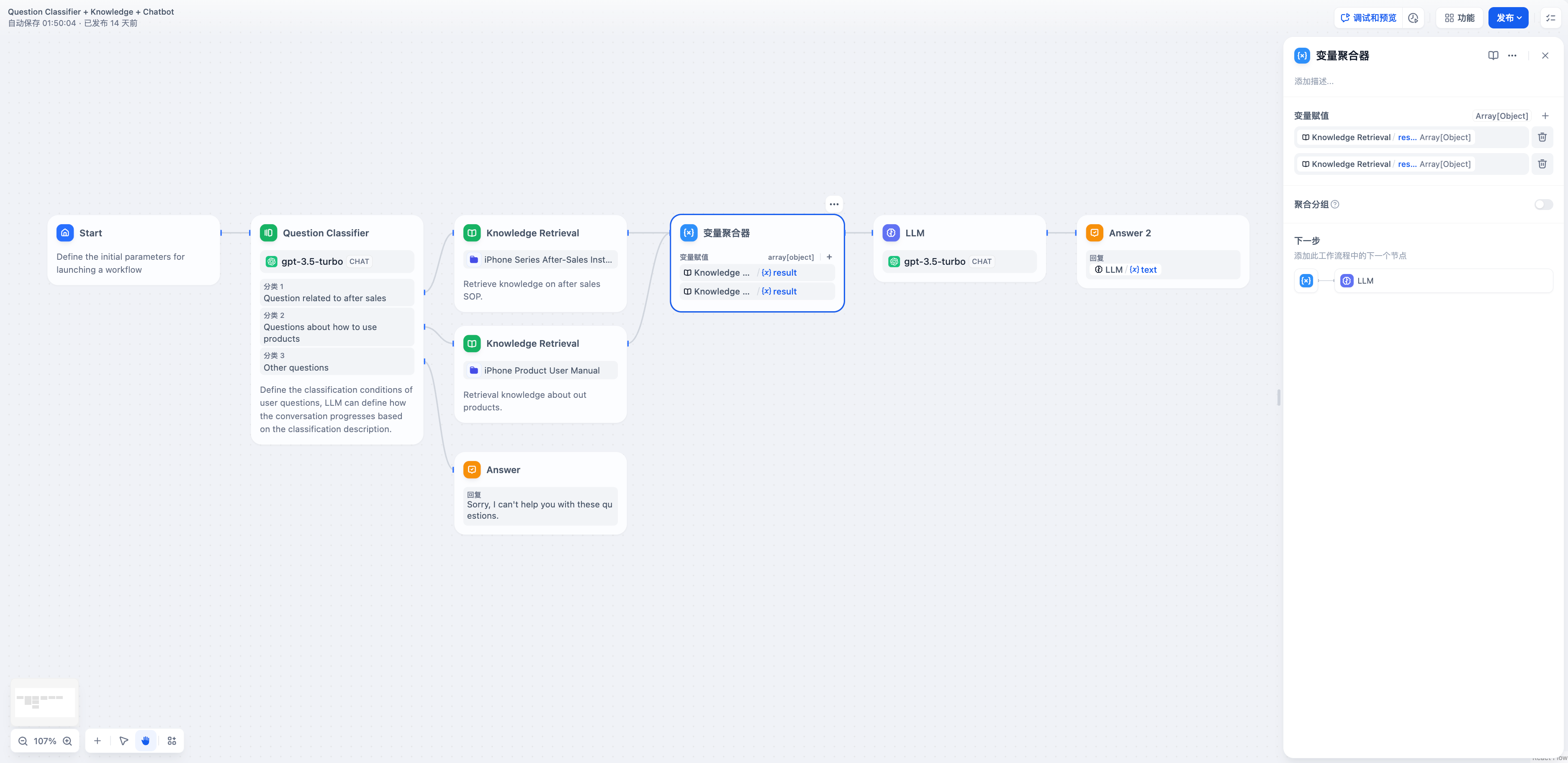
変数集約を追加することで、二つのナレッジベース検索ノードの出力を一つの変数に集約できます。
-  +
+  **IF/ELSE 条件ブランチ後のマルチ集約**
-
**IF/ELSE 条件ブランチ後のマルチ集約**
-  +
+  ### フォーマットに要求
diff --git a/ja-jp/guides/workflow/node/variable-assigner.mdx b/ja-jp/guides/workflow/node/variable-assigner.mdx
index adbee970..e147a16a 100644
--- a/ja-jp/guides/workflow/node/variable-assigner.mdx
+++ b/ja-jp/guides/workflow/node/variable-assigner.mdx
@@ -12,7 +12,7 @@ version: '日本語'
使用方法:このノードを使用することで、ワークフローの中で変数の値を会話変数に一時的に保存し、後続の会話でその値を参照することができます。
-
### フォーマットに要求
diff --git a/ja-jp/guides/workflow/node/variable-assigner.mdx b/ja-jp/guides/workflow/node/variable-assigner.mdx
index adbee970..e147a16a 100644
--- a/ja-jp/guides/workflow/node/variable-assigner.mdx
+++ b/ja-jp/guides/workflow/node/variable-assigner.mdx
@@ -12,7 +12,7 @@ version: '日本語'
使用方法:このノードを使用することで、ワークフローの中で変数の値を会話変数に一時的に保存し、後続の会話でその値を参照することができます。
-  +
+ 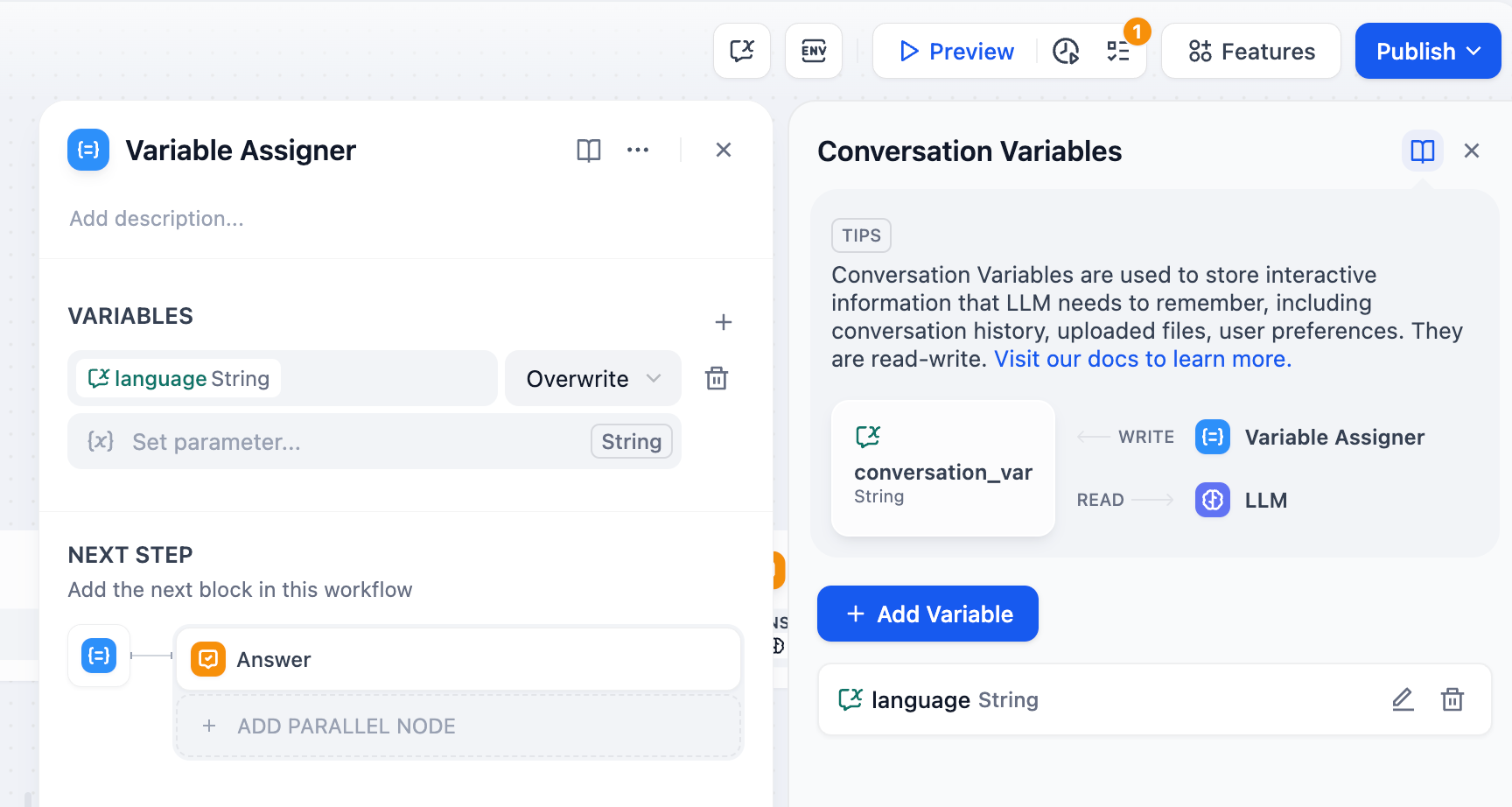 ***
@@ -28,7 +28,7 @@ version: '日本語'
例えば:会話が始まると、LLMはユーザーの入力に必要な情報や好み、またはチャット履歴が含まれているかを自動的に判断します。情報が存在する場合、LLMはそれを先に抽出して保存し、コンテキストとして利用して応答します。もし新しい情報を覚える必要がない場合、LLMは以前の関連する記録を用いて個性化な応答を出します。
-
***
@@ -28,7 +28,7 @@ version: '日本語'
例えば:会話が始まると、LLMはユーザーの入力に必要な情報や好み、またはチャット履歴が含まれているかを自動的に判断します。情報が存在する場合、LLMはそれを先に抽出して保存し、コンテキストとして利用して応答します。もし新しい情報を覚える必要がない場合、LLMは以前の関連する記録を用いて個性化な応答を出します。
-  +
+  **設定手順:**
@@ -115,7 +115,7 @@ def main(arg1: list) -> str:
例:ユーザーが会話を始める前に、`language`入力欄に「日本語」と指定した場合、その言語は会話変数に書き込まれ、LLMは後続の返信時に会話変数の情報を参照し、継続的に「日本語」を使用して返信します。
-
**設定手順:**
@@ -115,7 +115,7 @@ def main(arg1: list) -> str:
例:ユーザーが会話を始める前に、`language`入力欄に「日本語」と指定した場合、その言語は会話変数に書き込まれ、LLMは後続の返信時に会話変数の情報を参照し、継続的に「日本語」を使用して返信します。
-  +
+  **設定手順:**
@@ -133,7 +133,7 @@ def main(arg1: list) -> str:
例:会話を始める際、LLMはユーザーにチェックリストに関連するアイテムの入力を求めます。ユーザーがチェックリストの内容を一度述べると、その内容は会話変数に更新され、及び保存されます。LLMは各会話の後に、ユーザーに不足しているアイテムの追加を促します。
-
**設定手順:**
@@ -133,7 +133,7 @@ def main(arg1: list) -> str:
例:会話を始める際、LLMはユーザーにチェックリストに関連するアイテムの入力を求めます。ユーザーがチェックリストの内容を一度述べると、その内容は会話変数に更新され、及び保存されます。LLMは各会話の後に、ユーザーに不足しているアイテムの追加を促します。
-  +
+  **配置流程:**
@@ -151,7 +151,7 @@ def main(arg1: list) -> str:
ノードの右側の `+` マークをクリックし、「変数代入」 ノードを選択し、「代入られた変数」 と 「設定する変数」 を入力します。
-
**配置流程:**
@@ -151,7 +151,7 @@ def main(arg1: list) -> str:
ノードの右側の `+` マークをクリックし、「変数代入」 ノードを選択し、「代入られた変数」 と 「設定する変数」 を入力します。
-  +
+ 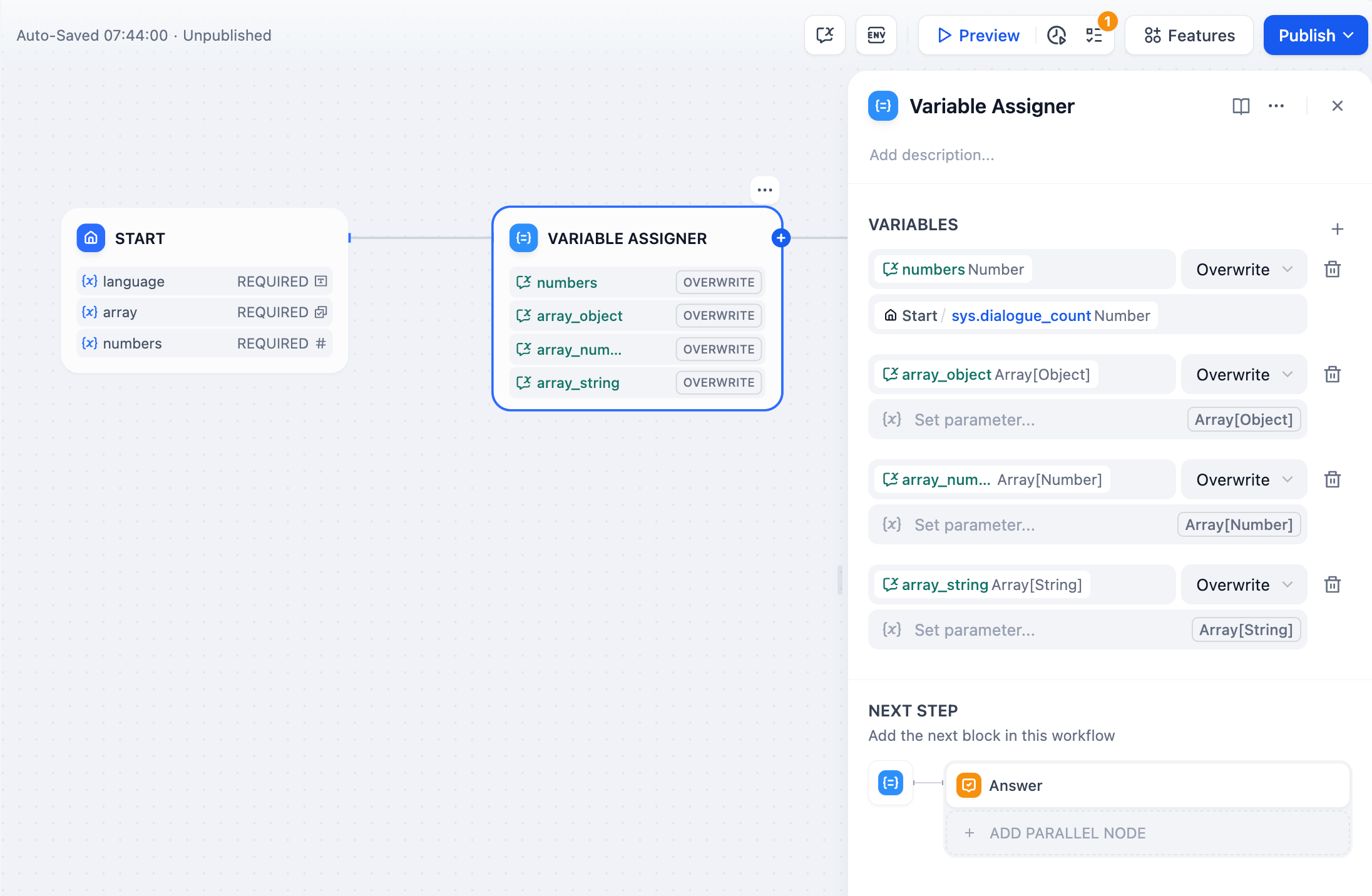 **変数の設定:**
diff --git a/ja-jp/guides/workflow/variables.mdx b/ja-jp/guides/workflow/variables.mdx
index c0f39f8a..c9d53e01 100644
--- a/ja-jp/guides/workflow/variables.mdx
+++ b/ja-jp/guides/workflow/variables.mdx
@@ -59,7 +59,7 @@ version: '日本語'
-
**変数の設定:**
diff --git a/ja-jp/guides/workflow/variables.mdx b/ja-jp/guides/workflow/variables.mdx
index c0f39f8a..c9d53e01 100644
--- a/ja-jp/guides/workflow/variables.mdx
+++ b/ja-jp/guides/workflow/variables.mdx
@@ -59,7 +59,7 @@ version: '日本語'
-  +
+  #### チャットフロー
@@ -128,7 +128,7 @@ version: '日本語'
-
#### チャットフロー
@@ -128,7 +128,7 @@ version: '日本語'
-  +
+  ### 環境変数
@@ -136,7 +136,7 @@ version: '日本語'
**環境変数は、APIキーやデータベースのパスワードといった機密性の高い情報を保護する際に、ワークフロー実行時に活用されます。** これらはコードに直接書き込むのではなく、ワークフローに設定され、異なる環境間での共有が可能になっています。
-
### 環境変数
@@ -136,7 +136,7 @@ version: '日本語'
**環境変数は、APIキーやデータベースのパスワードといった機密性の高い情報を保護する際に、ワークフロー実行時に活用されます。** これらはコードに直接書き込むのではなく、ワークフローに設定され、異なる環境間での共有が可能になっています。
-  +
+  サポートされるデータ型には以下の3つがあります:
@@ -160,7 +160,7 @@ version: '日本語'
例えば、ユーザーが最初の対話で設定した言語を会話変数に保存すれば、LLMはその情報を参照し、続く対話で指定された言語でユーザーに返信することが可能です。
-
サポートされるデータ型には以下の3つがあります:
@@ -160,7 +160,7 @@ version: '日本語'
例えば、ユーザーが最初の対話で設定した言語を会話変数に保存すれば、LLMはその情報を参照し、続く対話で指定された言語でユーザーに返信することが可能です。
-  +
+  **会話変数**は以下の6つのデータ型をサポートしています:
diff --git a/ja-jp/learn-more/extended-reading/how-to-use-json-schema-in-dify.mdx b/ja-jp/learn-more/extended-reading/how-to-use-json-schema-in-dify.mdx
index 94c55bea..d0d408d5 100644
--- a/ja-jp/learn-more/extended-reading/how-to-use-json-schema-in-dify.mdx
+++ b/ja-jp/learn-more/extended-reading/how-to-use-json-schema-in-dify.mdx
@@ -16,7 +16,7 @@ JSON Schemaは、JSONデータ構造を記述するための仕様です。開
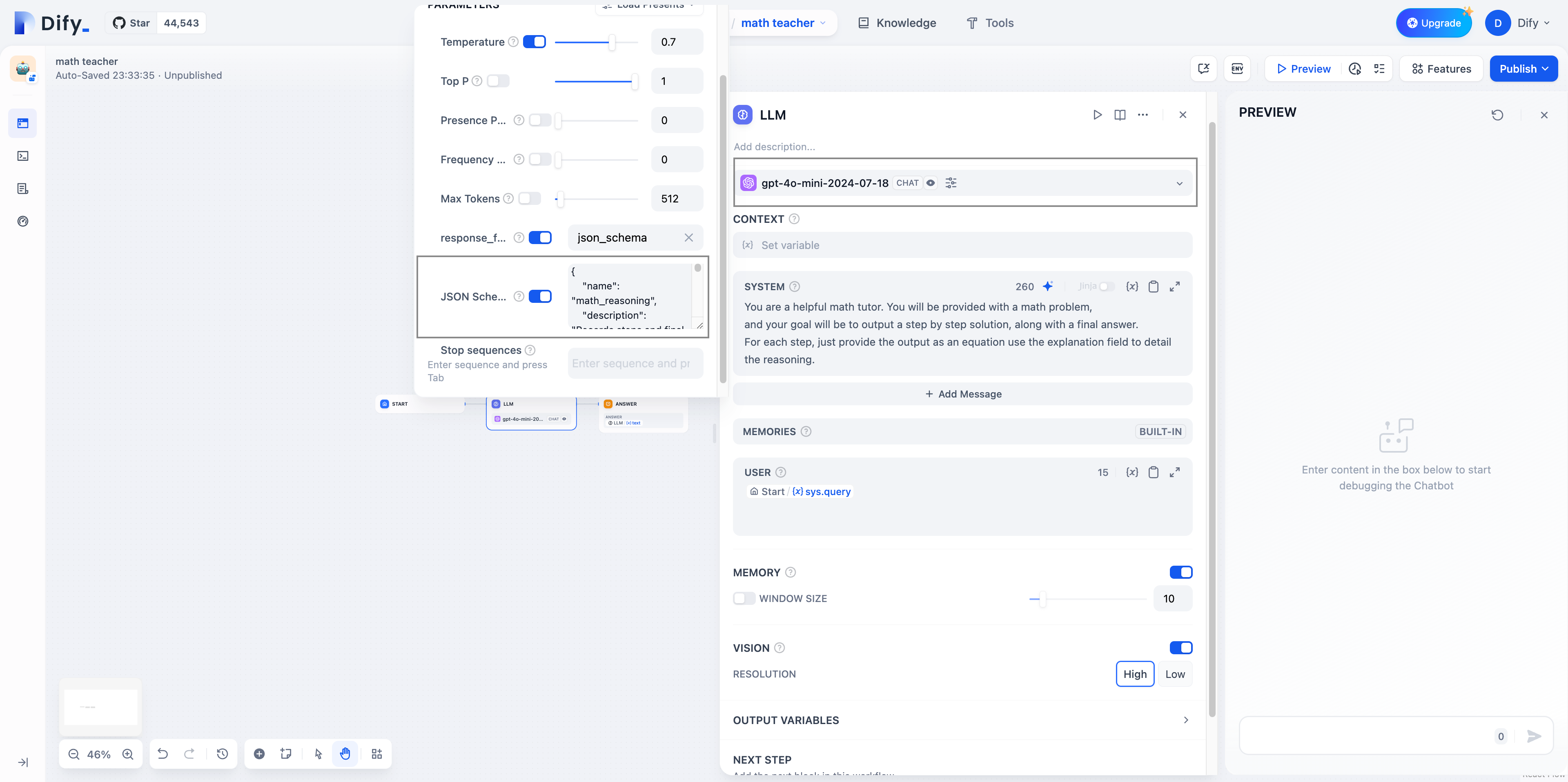
アプリケーション内のLLMを、上記で言及したJSON Schema出力をサポートするモデルのいずれかに切り替えます。次に、設定フォームで`JSON Schema`を有効にし、JSON Schemaテンプレートを入力します。同時に、`response_format`列を有効にし、`json_schema`形式に切り替えます。
-
+
LLMによって生成されたコンテンツは、次の形式で出力をサポートします:
@@ -201,7 +201,7 @@ LLMによって生成されたコンテンツは、次の形式で出力をサ
**例の出力:**
-
+
## ヒント
diff --git a/ja-jp/learn-more/extended-reading/retrieval-augment/README.mdx b/ja-jp/learn-more/extended-reading/retrieval-augment/README.mdx
index ebaf7fa5..e36d5874 100644
--- a/ja-jp/learn-more/extended-reading/retrieval-augment/README.mdx
+++ b/ja-jp/learn-more/extended-reading/retrieval-augment/README.mdx
@@ -12,7 +12,7 @@ RAGアーキテクチャは、ベクトル検索を中核としで、大規模
次の図では、ユーザーが「アメリカ合衆国の大統領は誰ですか?」と尋ねた場合、システムはその質問を直接大規模モデルに渡して回答を得るのではなく、まずナレッジベース(図に示されているWikipediaなど)でベクトル検索を行います。意味的類似性マッチングを通じて関連コンテンツ(例:「ジョー・バイデンはアメリカ合衆国の第46代および現職大統領である…」)を見つけ出します。その後、システムはユーザーの質問と収集した関連知識を大規模モデルに提供し、十分な情報を基に信頼性のある回答を得ることができます。
**会話変数**は以下の6つのデータ型をサポートしています:
diff --git a/ja-jp/learn-more/extended-reading/how-to-use-json-schema-in-dify.mdx b/ja-jp/learn-more/extended-reading/how-to-use-json-schema-in-dify.mdx
index 94c55bea..d0d408d5 100644
--- a/ja-jp/learn-more/extended-reading/how-to-use-json-schema-in-dify.mdx
+++ b/ja-jp/learn-more/extended-reading/how-to-use-json-schema-in-dify.mdx
@@ -16,7 +16,7 @@ JSON Schemaは、JSONデータ構造を記述するための仕様です。開
アプリケーション内のLLMを、上記で言及したJSON Schema出力をサポートするモデルのいずれかに切り替えます。次に、設定フォームで`JSON Schema`を有効にし、JSON Schemaテンプレートを入力します。同時に、`response_format`列を有効にし、`json_schema`形式に切り替えます。
-
+
LLMによって生成されたコンテンツは、次の形式で出力をサポートします:
@@ -201,7 +201,7 @@ LLMによって生成されたコンテンツは、次の形式で出力をサ
**例の出力:**
-
+
## ヒント
diff --git a/ja-jp/learn-more/extended-reading/retrieval-augment/README.mdx b/ja-jp/learn-more/extended-reading/retrieval-augment/README.mdx
index ebaf7fa5..e36d5874 100644
--- a/ja-jp/learn-more/extended-reading/retrieval-augment/README.mdx
+++ b/ja-jp/learn-more/extended-reading/retrieval-augment/README.mdx
@@ -12,7 +12,7 @@ RAGアーキテクチャは、ベクトル検索を中核としで、大規模
次の図では、ユーザーが「アメリカ合衆国の大統領は誰ですか?」と尋ねた場合、システムはその質問を直接大規模モデルに渡して回答を得るのではなく、まずナレッジベース(図に示されているWikipediaなど)でベクトル検索を行います。意味的類似性マッチングを通じて関連コンテンツ(例:「ジョー・バイデンはアメリカ合衆国の第46代および現職大統領である…」)を見つけ出します。その後、システムはユーザーの質問と収集した関連知識を大規模モデルに提供し、十分な情報を基に信頼性のある回答を得ることができます。
![]() diff --git a/ja-jp/learn-more/extended-reading/retrieval-augment/hybrid-search.mdx b/ja-jp/learn-more/extended-reading/retrieval-augment/hybrid-search.mdx
index 4c1deede..a7518296 100644
--- a/ja-jp/learn-more/extended-reading/retrieval-augment/hybrid-search.mdx
+++ b/ja-jp/learn-more/extended-reading/retrieval-augment/hybrid-search.mdx
@@ -33,7 +33,7 @@ RAG(Retrieval-Augmented Generation)の検索フェーズにおける主要
ハイブリッド検索では、データベースに事前にベクトルインデックスとキーワードインデックスを構築しておく必要があります。ユーザーのクエリが入力されると、両方の検索手法を使用して文書から最も関連性の高いテキストが取得されます。
diff --git a/ja-jp/learn-more/extended-reading/retrieval-augment/hybrid-search.mdx b/ja-jp/learn-more/extended-reading/retrieval-augment/hybrid-search.mdx
index 4c1deede..a7518296 100644
--- a/ja-jp/learn-more/extended-reading/retrieval-augment/hybrid-search.mdx
+++ b/ja-jp/learn-more/extended-reading/retrieval-augment/hybrid-search.mdx
@@ -33,7 +33,7 @@ RAG(Retrieval-Augmented Generation)の検索フェーズにおける主要
ハイブリッド検索では、データベースに事前にベクトルインデックスとキーワードインデックスを構築しておく必要があります。ユーザーのクエリが入力されると、両方の検索手法を使用して文書から最も関連性の高いテキストが取得されます。
![]() @@ -47,7 +47,7 @@ alt=""
定義:クエリ埋め込みを生成し、そのベクトル表現に最も類似したテキストセグメントを取得します。
@@ -47,7 +47,7 @@ alt=""
定義:クエリ埋め込みを生成し、そのベクトル表現に最も類似したテキストセグメントを取得します。
![]() diff --git a/ja-jp/learn-more/extended-reading/retrieval-augment/rerank.mdx b/ja-jp/learn-more/extended-reading/retrieval-augment/rerank.mdx
index 3ed6b683..0befe389 100644
--- a/ja-jp/learn-more/extended-reading/retrieval-augment/rerank.mdx
+++ b/ja-jp/learn-more/extended-reading/retrieval-augment/rerank.mdx
@@ -10,7 +10,7 @@ title: Rerank
**再順位付けモデルは、候補ドキュメントのリストとユーザーのクエリの意味的な一致度を計算し、その一致度に基づいて再並べ替えを行うことで、意味的な順位付け結果を向上させます**。その基本的な原理は、ユーザーのクエリと各候補ドキュメントとの関連スコアを算出し、関連性の高い順に並べ替えたドキュメントリストを返すことです。一般的な再順位付けモデルには、Cohere RerankやBGE Rerankerなどがあります。
diff --git a/ja-jp/learn-more/extended-reading/retrieval-augment/rerank.mdx b/ja-jp/learn-more/extended-reading/retrieval-augment/rerank.mdx
index 3ed6b683..0befe389 100644
--- a/ja-jp/learn-more/extended-reading/retrieval-augment/rerank.mdx
+++ b/ja-jp/learn-more/extended-reading/retrieval-augment/rerank.mdx
@@ -10,7 +10,7 @@ title: Rerank
**再順位付けモデルは、候補ドキュメントのリストとユーザーのクエリの意味的な一致度を計算し、その一致度に基づいて再並べ替えを行うことで、意味的な順位付け結果を向上させます**。その基本的な原理は、ユーザーのクエリと各候補ドキュメントとの関連スコアを算出し、関連性の高い順に並べ替えたドキュメントリストを返すことです。一般的な再順位付けモデルには、Cohere RerankやBGE Rerankerなどがあります。
![]() @@ -32,7 +32,7 @@ Cohere Rerankの例を挙げると、アカウントを登録し、APIを申請
Difyは現在、Cohere Rerankモデルをサポートしており、「モデルプロバイダー-> Cohere」ページに進んで、RerankモデルのAPIキーを入力してください。
@@ -32,7 +32,7 @@ Cohere Rerankの例を挙げると、アカウントを登録し、APIを申請
Difyは現在、Cohere Rerankモデルをサポートしており、「モデルプロバイダー-> Cohere」ページに進んで、RerankモデルのAPIキーを入力してください。
![]() @@ -46,7 +46,7 @@ alt=""
「データセット->データセットの作成->検索設定」ページに進み、Rerank設定を追加してください。データセットの作成時だけでなく、既存のデータセットの設定内でもRerankの構成を変更し、適用されたデータセットのリコールモード設定でRerankの構成を調整することができます。
@@ -46,7 +46,7 @@ alt=""
「データセット->データセットの作成->検索設定」ページに進み、Rerank設定を追加してください。データセットの作成時だけでなく、既存のデータセットの設定内でもRerankの構成を変更し、適用されたデータセットのリコールモード設定でRerankの構成を調整することができます。
![]() @@ -62,7 +62,7 @@ alt=""
複数のリコールモードについての詳細は、[複数リコール](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)を参照してください。
@@ -62,7 +62,7 @@ alt=""
複数のリコールモードについての詳細は、[複数リコール](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)を参照してください。
![]() diff --git a/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval.mdx b/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval.mdx
index 52388458..ab92d1b0 100644
--- a/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval.mdx
+++ b/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval.mdx
@@ -6,7 +6,7 @@ title: リトリーバルモード
ユーザーがナレッジベースのQ\&A用AIアプリケーションを構築する際に、Difyはアプリケーション内で複数のデータセットが関連付けられている場合に、検索時に2つの検索モードをサポートします:N-of-1検索モードとMulti-Path検索モードです。
diff --git a/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval.mdx b/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval.mdx
index 52388458..ab92d1b0 100644
--- a/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval.mdx
+++ b/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval.mdx
@@ -6,7 +6,7 @@ title: リトリーバルモード
ユーザーがナレッジベースのQ\&A用AIアプリケーションを構築する際に、Difyはアプリケーション内で複数のデータセットが関連付けられている場合に、検索時に2つの検索モードをサポートします:N-of-1検索モードとMulti-Path検索モードです。
![]() @@ -20,7 +20,7 @@ alt=""
以下は、マルチパス検索モードの技術フローチャートです:
@@ -20,7 +20,7 @@ alt=""
以下は、マルチパス検索モードの技術フローチャートです:
![]() diff --git a/ja-jp/learn-more/how-to-use-json-schema-in-dify.mdx b/ja-jp/learn-more/how-to-use-json-schema-in-dify.mdx
index 2df01723..749455b1 100644
--- a/ja-jp/learn-more/how-to-use-json-schema-in-dify.mdx
+++ b/ja-jp/learn-more/how-to-use-json-schema-in-dify.mdx
@@ -205,7 +205,7 @@ LLMによって生成されたコンテンツは、次の形式で出力をサ
**例の出力:**
-
+
## ヒント
diff --git a/ja-jp/learn-more/use-cases/build-an-notion-ai-assistant.mdx b/ja-jp/learn-more/use-cases/build-an-notion-ai-assistant.mdx
index ff5dc636..7bdf9d08 100644
--- a/ja-jp/learn-more/use-cases/build-an-notion-ai-assistant.mdx
+++ b/ja-jp/learn-more/use-cases/build-an-notion-ai-assistant.mdx
@@ -83,7 +83,7 @@ AIアプリケーションに「プリセットプロンプト」を追加する
> 私のNotionワークスペース内でITの専門家として振る舞い、コンピュータサイエンス、ネットワークインフラ、Notionノート、ITセキュリティに関する知識を活用して問題を解決してほしい。
diff --git a/ja-jp/learn-more/how-to-use-json-schema-in-dify.mdx b/ja-jp/learn-more/how-to-use-json-schema-in-dify.mdx
index 2df01723..749455b1 100644
--- a/ja-jp/learn-more/how-to-use-json-schema-in-dify.mdx
+++ b/ja-jp/learn-more/how-to-use-json-schema-in-dify.mdx
@@ -205,7 +205,7 @@ LLMによって生成されたコンテンツは、次の形式で出力をサ
**例の出力:**
-
+
## ヒント
diff --git a/ja-jp/learn-more/use-cases/build-an-notion-ai-assistant.mdx b/ja-jp/learn-more/use-cases/build-an-notion-ai-assistant.mdx
index ff5dc636..7bdf9d08 100644
--- a/ja-jp/learn-more/use-cases/build-an-notion-ai-assistant.mdx
+++ b/ja-jp/learn-more/use-cases/build-an-notion-ai-assistant.mdx
@@ -83,7 +83,7 @@ AIアプリケーションに「プリセットプロンプト」を追加する
> 私のNotionワークスペース内でITの専門家として振る舞い、コンピュータサイエンス、ネットワークインフラ、Notionノート、ITセキュリティに関する知識を活用して問題を解決してほしい。
![]() @@ -91,7 +91,7 @@ alt=""
初期設定では、AIがユーザーに開始文を提供し、質問の手がかりを与えるようにすることをお勧めします。また、「音声からテキストへの変換」機能を有効にして、ユーザーがAIアシスタントと音声でやり取りできるようにします。
@@ -91,7 +91,7 @@ alt=""
初期設定では、AIがユーザーに開始文を提供し、質問の手がかりを与えるようにすることをお勧めします。また、「音声からテキストへの変換」機能を有効にして、ユーザーがAIアシスタントと音声でやり取りできるようにします。
![]() @@ -99,7 +99,7 @@ alt=""
今や「概要」で公開URLをクリックして、自分のAIアシスタントとチャットできるようになりました!
@@ -99,7 +99,7 @@ alt=""
今や「概要」で公開URLをクリックして、自分のAIアシスタントとチャットできるようになりました!
![]() diff --git a/ja-jp/learn-more/use-cases/create-a-midjoureny-prompt-word-robot-with-zero-code.mdx b/ja-jp/learn-more/use-cases/create-a-midjoureny-prompt-word-robot-with-zero-code.mdx
index 575a5c2a..f06136db 100644
--- a/ja-jp/learn-more/use-cases/create-a-midjoureny-prompt-word-robot-with-zero-code.mdx
+++ b/ja-jp/learn-more/use-cases/create-a-midjoureny-prompt-word-robot-with-zero-code.mdx
@@ -13,7 +13,7 @@ Dify には、ChatGPT のような対話型アプリケーションと、ボタ
Dify はこちらでアクセスできます:https://dify.ai/
diff --git a/ja-jp/learn-more/use-cases/create-a-midjoureny-prompt-word-robot-with-zero-code.mdx b/ja-jp/learn-more/use-cases/create-a-midjoureny-prompt-word-robot-with-zero-code.mdx
index 575a5c2a..f06136db 100644
--- a/ja-jp/learn-more/use-cases/create-a-midjoureny-prompt-word-robot-with-zero-code.mdx
+++ b/ja-jp/learn-more/use-cases/create-a-midjoureny-prompt-word-robot-with-zero-code.mdx
@@ -13,7 +13,7 @@ Dify には、ChatGPT のような対話型アプリケーションと、ボタ
Dify はこちらでアクセスできます:https://dify.ai/
![]() @@ -21,7 +21,7 @@ alt=""
名前を入力して作成が完了すると、ダッシュボードページが表示され、データモニタリングやアプリケーション設定が行えます。まずは左側のプロンプトオーケストレーションをクリックします。ここが主な作業ページです。
@@ -21,7 +21,7 @@ alt=""
名前を入力して作成が完了すると、ダッシュボードページが表示され、データモニタリングやアプリケーション設定が行えます。まずは左側のプロンプトオーケストレーションをクリックします。ここが主な作業ページです。
![]() @@ -37,7 +37,7 @@ alt=""
私のプレフィックスプロンプトの構造を見てみましょう。主に2つの部分から成り立っています。最初は、GPT に以下の英語の構造に従って写真の説明を出力するよう指示する部分です。英語の構造はプロンプトのテンプレートで、主に「テーマのカラフルな写真、複雑なパターン、鮮明なコントラスト、環境の説明、カメラモデル、入力内容に関連するレンズ焦点距離の説明、入力内容に関連する構図の説明、4人の写真家の名前」となります。これがプロンプトの主な内容です。理論的には、右側のプレビュー領域に保存して、生成したいテーマを入力すると、対応するプロンプトが生成されるはずです。
@@ -37,7 +37,7 @@ alt=""
私のプレフィックスプロンプトの構造を見てみましょう。主に2つの部分から成り立っています。最初は、GPT に以下の英語の構造に従って写真の説明を出力するよう指示する部分です。英語の構造はプロンプトのテンプレートで、主に「テーマのカラフルな写真、複雑なパターン、鮮明なコントラスト、環境の説明、カメラモデル、入力内容に関連するレンズ焦点距離の説明、入力内容に関連する構図の説明、4人の写真家の名前」となります。これがプロンプトの主な内容です。理論的には、右側のプレビュー領域に保存して、生成したいテーマを入力すると、対応するプロンプトが生成されるはずです。
![]() @@ -45,7 +45,7 @@ alt=""
さて、後ろにある `{{proportion}}` と `{{version}}` は何でしょうか。右側を見ると、ユーザーが画像比率とモデルバージョンを選択する必要があります。これらの変数はユーザーの選択情報を伝達するためのものです。設定方法を見てみましょう。
@@ -45,7 +45,7 @@ alt=""
さて、後ろにある `{{proportion}}` と `{{version}}` は何でしょうか。右側を見ると、ユーザーが画像比率とモデルバージョンを選択する必要があります。これらの変数はユーザーの選択情報を伝達するためのものです。設定方法を見てみましょう。
![]() @@ -71,7 +71,7 @@ alt=""
変数には2種類あり、テキスト変数とドロップダウンオプションがあります。テキスト変数はユーザーが手動で入力するもので、ドロップダウンオプションは選択するものです。ここではユーザーにコマンドを手打ちさせたくないので、ドロップダウンオプションを選択します。必要なオプションを追加します。
@@ -71,7 +71,7 @@ alt=""
変数には2種類あり、テキスト変数とドロップダウンオプションがあります。テキスト変数はユーザーが手動で入力するもので、ドロップダウンオプションは選択するものです。ここではユーザーにコマンドを手打ちさせたくないので、ドロップダウンオプションを選択します。必要なオプションを追加します。
![]() @@ -87,7 +87,7 @@ alt=""
しかし、GPT が変数内容を変更してしまう可能性があります。その対策として、右側のモデル選択で多様性を低く設定します。これにより創造的な出力が減り、変数内容が変更されにくくなります。他のパラメータの意味は小さな感嘆符をクリックして確認できます。
@@ -87,7 +87,7 @@ alt=""
しかし、GPT が変数内容を変更してしまう可能性があります。その対策として、右側のモデル選択で多様性を低く設定します。これにより創造的な出力が減り、変数内容が変更されにくくなります。他のパラメータの意味は小さな感嘆符をクリックして確認できます。
![]() @@ -95,7 +95,7 @@ alt=""
これでアプリケーションが完成し、テスト出力に問題がなければ、右上の公開ボタンをクリックしてアプリケーションを公開します。公開アクセス URL からアプリケーションにアクセスできます。設定でアプリケーション名や概要、アイコンなどの内容を設定することもできます。
@@ -95,7 +95,7 @@ alt=""
これでアプリケーションが完成し、テスト出力に問題がなければ、右上の公開ボタンをクリックしてアプリケーションを公開します。公開アクセス URL からアプリケーションにアクセスできます。設定でアプリケーション名や概要、アイコンなどの内容を設定することもできます。
![]() diff --git a/ja-jp/learn-more/use-cases/create-an-ai-chatbot-with-business-data-in-minutes.mdx b/ja-jp/learn-more/use-cases/create-an-ai-chatbot-with-business-data-in-minutes.mdx
index bcf4939e..94954a63 100644
--- a/ja-jp/learn-more/use-cases/create-an-ai-chatbot-with-business-data-in-minutes.mdx
+++ b/ja-jp/learn-more/use-cases/create-an-ai-chatbot-with-business-data-in-minutes.mdx
@@ -10,7 +10,7 @@ title: 数分でビジネスデータを用いた公式サイトのAIインテ
Difyは、オープンソースで非常に簡単に使えるLLMOpsプラットフォームであり、視覚的に迅速にAIアプリケーションを作成および運営するためのツールプラットフォームです。Difyは、視覚的なプロンプトの編成、運営、データセット管理などの機能を提供します。AIに関する技術的な研究や難解な概念の理解は不要です。Difyは、OpenAI、Azure OpenAI、Antropicなどの優れた大規模言語モデル提供者と連携しており、GPTシリーズ、Claudeシリーズのモデルを提供しています。将来的には優れたオープンソースモデルも接続される予定です。これらはすべて設定で切り替えて使用できます。これにより、アプリケーションを作成およびデバッグする際に、異なるモデルの効果を比較して、最適なモデルを選択できます。**Difyを基にすれば、AIインテリジェントカスタマーサービスを簡単に開発できるだけでなく、自分の使用習慣やニーズに合ったテキスト執筆アシスタント、バーチャルリクルートメントHRエキスパート、会議まとめアシスタント、翻訳アシスタントなどのさまざまなテキスト生成型アプリケーションも作成できます。**
diff --git a/ja-jp/learn-more/use-cases/create-an-ai-chatbot-with-business-data-in-minutes.mdx b/ja-jp/learn-more/use-cases/create-an-ai-chatbot-with-business-data-in-minutes.mdx
index bcf4939e..94954a63 100644
--- a/ja-jp/learn-more/use-cases/create-an-ai-chatbot-with-business-data-in-minutes.mdx
+++ b/ja-jp/learn-more/use-cases/create-an-ai-chatbot-with-business-data-in-minutes.mdx
@@ -10,7 +10,7 @@ title: 数分でビジネスデータを用いた公式サイトのAIインテ
Difyは、オープンソースで非常に簡単に使えるLLMOpsプラットフォームであり、視覚的に迅速にAIアプリケーションを作成および運営するためのツールプラットフォームです。Difyは、視覚的なプロンプトの編成、運営、データセット管理などの機能を提供します。AIに関する技術的な研究や難解な概念の理解は不要です。Difyは、OpenAI、Azure OpenAI、Antropicなどの優れた大規模言語モデル提供者と連携しており、GPTシリーズ、Claudeシリーズのモデルを提供しています。将来的には優れたオープンソースモデルも接続される予定です。これらはすべて設定で切り替えて使用できます。これにより、アプリケーションを作成およびデバッグする際に、異なるモデルの効果を比較して、最適なモデルを選択できます。**Difyを基にすれば、AIインテリジェントカスタマーサービスを簡単に開発できるだけでなく、自分の使用習慣やニーズに合ったテキスト執筆アシスタント、バーチャルリクルートメントHRエキスパート、会議まとめアシスタント、翻訳アシスタントなどのさまざまなテキスト生成型アプリケーションも作成できます。**
![]() @@ -30,7 +30,7 @@ AIモデルのメッセージコールにはトークンが消費されます。
会社の既存のナレッジベースや製品ドキュメントに基づいてAIカスタマーサービスを構築し、ユーザーと交流したい場合、製品に関するドキュメントをできるだけ多くDifyのデータセットにアップロードする必要があります。Difyはデータの**セグメント処理とクレンジング**を行います。Difyデータセットは、高品質と経済的な二つのインデックスモードをサポートしており、高品質モードを使用することをお勧めします。トークンを消費しますが、より高い精度を提供します。操作手順: 【データセット】ページで新しいデータセットを作成し、ビジネスデータをアップロードします(複数のテキストの一括アップロードをサポート)。クレンジング方法を選択し、【保存して処理】をクリックするだけで、数秒で処理が完了します。
@@ -30,7 +30,7 @@ AIモデルのメッセージコールにはトークンが消費されます。
会社の既存のナレッジベースや製品ドキュメントに基づいてAIカスタマーサービスを構築し、ユーザーと交流したい場合、製品に関するドキュメントをできるだけ多くDifyのデータセットにアップロードする必要があります。Difyはデータの**セグメント処理とクレンジング**を行います。Difyデータセットは、高品質と経済的な二つのインデックスモードをサポートしており、高品質モードを使用することをお勧めします。トークンを消費しますが、より高い精度を提供します。操作手順: 【データセット】ページで新しいデータセットを作成し、ビジネスデータをアップロードします(複数のテキストの一括アップロードをサポート)。クレンジング方法を選択し、【保存して処理】をクリックするだけで、数秒で処理が完了します。
![]() @@ -52,7 +52,7 @@ alt=""
> オープニング:こんにちは、私はBob☀️、Difyの最初のAIメンバーです。Dify製品、チーム、さらにはLLMOpsに関する質問について何でも話し合うことができます。
@@ -52,7 +52,7 @@ alt=""
> オープニング:こんにちは、私はBob☀️、Difyの最初のAIメンバーです。Dify製品、チーム、さらにはLLMOpsに関する質問について何でも話し合うことができます。
![]() @@ -62,7 +62,7 @@ alt=""
以上の設定が完了したら、現在のページ右側でメッセージを送信してパフォーマンスが期待通りかどうかをデバッグできます。その後、【公開】をクリックします。この時点で、AIインテリジェントカスタマーサービスが完成しています。
@@ -62,7 +62,7 @@ alt=""
以上の設定が完了したら、現在のページ右側でメッセージを送信してパフォーマンスが期待通りかどうかをデバッグできます。その後、【公開】をクリックします。この時点で、AIインテリジェントカスタマーサービスが完成しています。
![]() @@ -72,7 +72,7 @@ alt=""
このステップでは、準備が整ったAIインテリジェントカスタマーサービスを公式サイトのページに埋め込みます。順に【概観】->【埋め込み】をクリックし、**scriptタグ方式を選択し、**scriptコードを公式サイトの``または``タグにコピーします。技術的な知識がない場合は、公式サイトの開発担当者にコードの貼り付けとページの更新を頼んでください。
@@ -72,7 +72,7 @@ alt=""
このステップでは、準備が整ったAIインテリジェントカスタマーサービスを公式サイトのページに埋め込みます。順に【概観】->【埋め込み】をクリックし、**scriptタグ方式を選択し、**scriptコードを公式サイトの``または``タグにコピーします。技術的な知識がない場合は、公式サイトの開発担当者にコードの貼り付けとページの更新を頼んでください。
![]() @@ -80,7 +80,7 @@ alt=""
1. コピーしたコードを公式サイトの目標位置に貼り付けます:
@@ -80,7 +80,7 @@ alt=""
1. コピーしたコードを公式サイトの目標位置に貼り付けます:
![]() @@ -88,7 +88,7 @@ alt=""
1. 公式サイトを更新すると、ビジネスデータを持つ公式サイトのAIインテリジェントカスタマーサービスが完成します。効果を試してみてください:
@@ -88,7 +88,7 @@ alt=""
1. 公式サイトを更新すると、ビジネスデータを持つ公式サイトのAIインテリジェントカスタマーサービスが完成します。効果を試してみてください:
![]() @@ -96,7 +96,7 @@ alt=""
以上は、Dify公式サイトのAIカスタマーサービスBobの例を通じて、Difyアプリケーションを公式サイトに埋め込む具体的な手順を示しました。もちろん、Difyが提供するさらに多くの機能を使用してAIカスタマーサービスのパフォーマンスを向上させることも可能です。たとえば、変数設定を追加して、ユーザーがインタラクションを開始する前に名前や使用している具体的な製品などの必要な情報を入力させることができます。ぜひ一緒に探求し、企業のAIインテリジェントカスタマーサービスをカスタマイズしてみてください。
@@ -96,7 +96,7 @@ alt=""
以上は、Dify公式サイトのAIカスタマーサービスBobの例を通じて、Difyアプリケーションを公式サイトに埋め込む具体的な手順を示しました。もちろん、Difyが提供するさらに多くの機能を使用してAIカスタマーサービスのパフォーマンスを向上させることも可能です。たとえば、変数設定を追加して、ユーザーがインタラクションを開始する前に名前や使用している具体的な製品などの必要な情報を入力させることができます。ぜひ一緒に探求し、企業のAIインテリジェントカスタマーサービスをカスタマイズしてみてください。
![]() \ No newline at end of file
diff --git a/ja-jp/learn-more/use-cases/dify-on-whatsapp.mdx b/ja-jp/learn-more/use-cases/dify-on-whatsapp.mdx
index 92c6e531..ffabd264 100644
--- a/ja-jp/learn-more/use-cases/dify-on-whatsapp.mdx
+++ b/ja-jp/learn-more/use-cases/dify-on-whatsapp.mdx
@@ -86,7 +86,7 @@ alt=""
[Twilioコンソール]に移動し、Account SIDとAuth Tokenを取得して保存します。
\ No newline at end of file
diff --git a/ja-jp/learn-more/use-cases/dify-on-whatsapp.mdx b/ja-jp/learn-more/use-cases/dify-on-whatsapp.mdx
index 92c6e531..ffabd264 100644
--- a/ja-jp/learn-more/use-cases/dify-on-whatsapp.mdx
+++ b/ja-jp/learn-more/use-cases/dify-on-whatsapp.mdx
@@ -86,7 +86,7 @@ alt=""
[Twilioコンソール]に移動し、Account SIDとAuth Tokenを取得して保存します。
![]() @@ -142,7 +142,7 @@ npx localtunnel --port 9000
このコマンドは、ローカルサーバー(9000ポートで実行中)とlocaltunnelが作成するパブリックドメイン間に接続を確立します。localtunnel転送URLを取得すると、クライアントからそのURLへのリクエストはすべて自動的にFastAPIのバックエンドに転送されます。
@@ -142,7 +142,7 @@ npx localtunnel --port 9000
このコマンドは、ローカルサーバー(9000ポートで実行中)とlocaltunnelが作成するパブリックドメイン間に接続を確立します。localtunnel転送URLを取得すると、クライアントからそのURLへのリクエストはすべて自動的にFastAPIのバックエンドに転送されます。
![]() @@ -220,7 +220,7 @@ TwilioのメッセージAPIを使用して、チャットボットがWhatsAppユ
「試してみる」セクションで「WhatsAppメッセージを送信」をクリックします。デフォルトでサンドボックスタブに移動し、「+14155238886」という電話番号と、隣に参加コード、右側にQRコードが表示されます。
@@ -220,7 +220,7 @@ TwilioのメッセージAPIを使用して、チャットボットがWhatsAppユ
「試してみる」セクションで「WhatsAppメッセージを送信」をクリックします。デフォルトでサンドボックスタブに移動し、「+14155238886」という電話番号と、隣に参加コード、右側にQRコードが表示されます。
![]() @@ -241,7 +241,7 @@ FastAPIアプリケーションで設定したエンドポイントは/message
設定が完了したら、「保存」ボタンを押します。
@@ -241,7 +241,7 @@ FastAPIアプリケーションで設定したエンドポイントは/message
設定が完了したら、「保存」ボタンを押します。
![]() diff --git a/ja-jp/learn-more/use-cases/how-to-connect-aws-bedrock.mdx b/ja-jp/learn-more/use-cases/how-to-connect-aws-bedrock.mdx
index 9f79912a..e86e704a 100644
--- a/ja-jp/learn-more/use-cases/how-to-connect-aws-bedrock.mdx
+++ b/ja-jp/learn-more/use-cases/how-to-connect-aws-bedrock.mdx
@@ -16,7 +16,7 @@ title: AWS Bedrock Knowledge Baseに統合する方法
[AWS Bedrock](https://aws.amazon.com/bedrock/)にアクセスし、ナレッジベースサービスを作成してください。
diff --git a/ja-jp/learn-more/use-cases/how-to-connect-aws-bedrock.mdx b/ja-jp/learn-more/use-cases/how-to-connect-aws-bedrock.mdx
index 9f79912a..e86e704a 100644
--- a/ja-jp/learn-more/use-cases/how-to-connect-aws-bedrock.mdx
+++ b/ja-jp/learn-more/use-cases/how-to-connect-aws-bedrock.mdx
@@ -16,7 +16,7 @@ title: AWS Bedrock Knowledge Baseに統合する方法
[AWS Bedrock](https://aws.amazon.com/bedrock/)にアクセスし、ナレッジベースサービスを作成してください。
![]() @@ -26,7 +26,7 @@ alt=""
Difyプラットフォームは、直接的にAWS Bedrock Knowledge Baseに接続することができません。開発チームは、Difyの外部ナレッジベース接続に関する[API定義](/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api-documentation)を参照し、バックエンドAPIサービスを手動で構築してAWS Bedrockと接続する必要があります。具体的なアーキテクチャの概要は以下の通りです:
@@ -26,7 +26,7 @@ alt=""
Difyプラットフォームは、直接的にAWS Bedrock Knowledge Baseに接続することができません。開発チームは、Difyの外部ナレッジベース接続に関する[API定義](/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api-documentation)を参照し、バックエンドAPIサービスを手動で構築してAWS Bedrockと接続する必要があります。具体的なアーキテクチャの概要は以下の通りです:
![]() @@ -129,7 +129,7 @@ class ExternalDatasetService:
AWS Bedrockの管理画面にログインし、作成したナレッジベースのIDを取得します。このパラメータは、Difyプラットフォームとの接続に使用されます。
@@ -129,7 +129,7 @@ class ExternalDatasetService:
AWS Bedrockの管理画面にログインし、作成したナレッジベースのIDを取得します。このパラメータは、Difyプラットフォームとの接続に使用されます。
![]() @@ -145,7 +145,7 @@ Difyプラットフォームの**"ナレッジベース"**ページに移動し
- API Key(外部ナレッジベースへの接続キー、ステップ2でカスタマイズ可能)
@@ -145,7 +145,7 @@ Difyプラットフォームの**"ナレッジベース"**ページに移動し
- API Key(外部ナレッジベースへの接続キー、ステップ2でカスタマイズ可能)
![]() @@ -155,7 +155,7 @@ alt=""
**"ナレッジベース"**ページに移動し、ナレッジベースのカードの下にある **"外部ナレッジベースを接続"** をクリックして、パラメータ設定ページに移動します。
@@ -155,7 +155,7 @@ alt=""
**"ナレッジベース"**ページに移動し、ナレッジベースのカードの下にある **"外部ナレッジベースを接続"** をクリックして、パラメータ設定ページに移動します。
![]() @@ -178,7 +178,7 @@ alt=""
**スコア閾値:** テキストセグメントの選択に使用される類似度の閾値です。設定されたスコアを超えるテキストセグメントのみが取得され、デフォルト値は0.5です。数値が高くなるほど、テキストと質問の類似度が高く、取得されるテキストの数は減少し、結果もより精度が高くなります。
@@ -178,7 +178,7 @@ alt=""
**スコア閾値:** テキストセグメントの選択に使用される類似度の閾値です。設定されたスコアを超えるテキストセグメントのみが取得され、デフォルト値は0.5です。数値が高くなるほど、テキストと質問の類似度が高く、取得されるテキストの数は減少し、結果もより精度が高くなります。
![]() @@ -190,7 +190,7 @@ alt=""
外部ナレッジベースとの接続が確立された後、開発者は**"テスト取得"**で可能な質問のキーワードをシミュレートし、AWS Bedrock Knowledge Baseから取得したテキストセグメントをプレビューできます。
@@ -190,7 +190,7 @@ alt=""
外部ナレッジベースとの接続が確立された後、開発者は**"テスト取得"**で可能な質問のキーワードをシミュレートし、AWS Bedrock Knowledge Baseから取得したテキストセグメントをプレビューできます。
![]() @@ -198,7 +198,7 @@ alt=""
検索結果に満足できない場合は、検索設定を変更したり、AWS Bedrock Knowledge Baseの検索設定を調整したりすることができます。
@@ -198,7 +198,7 @@ alt=""
検索結果に満足できない場合は、検索設定を変更したり、AWS Bedrock Knowledge Baseの検索設定を調整したりすることができます。
![]() diff --git a/ja-jp/learn-more/use-cases/how-to-integrate-dify-chatbot-to-your-wix-website.mdx b/ja-jp/learn-more/use-cases/how-to-integrate-dify-chatbot-to-your-wix-website.mdx
index 5bc718a9..aa96f820 100644
--- a/ja-jp/learn-more/use-cases/how-to-integrate-dify-chatbot-to-your-wix-website.mdx
+++ b/ja-jp/learn-more/use-cases/how-to-integrate-dify-chatbot-to-your-wix-website.mdx
@@ -18,10 +18,10 @@ Wixは人気のWebサイト作成プラットフォームです。ドラッグ
3. ページ右上の「公開」ボタンをクリックします。
4. 公開ページで「サイトに埋め込む」のオプションを選択します。
- 
+ 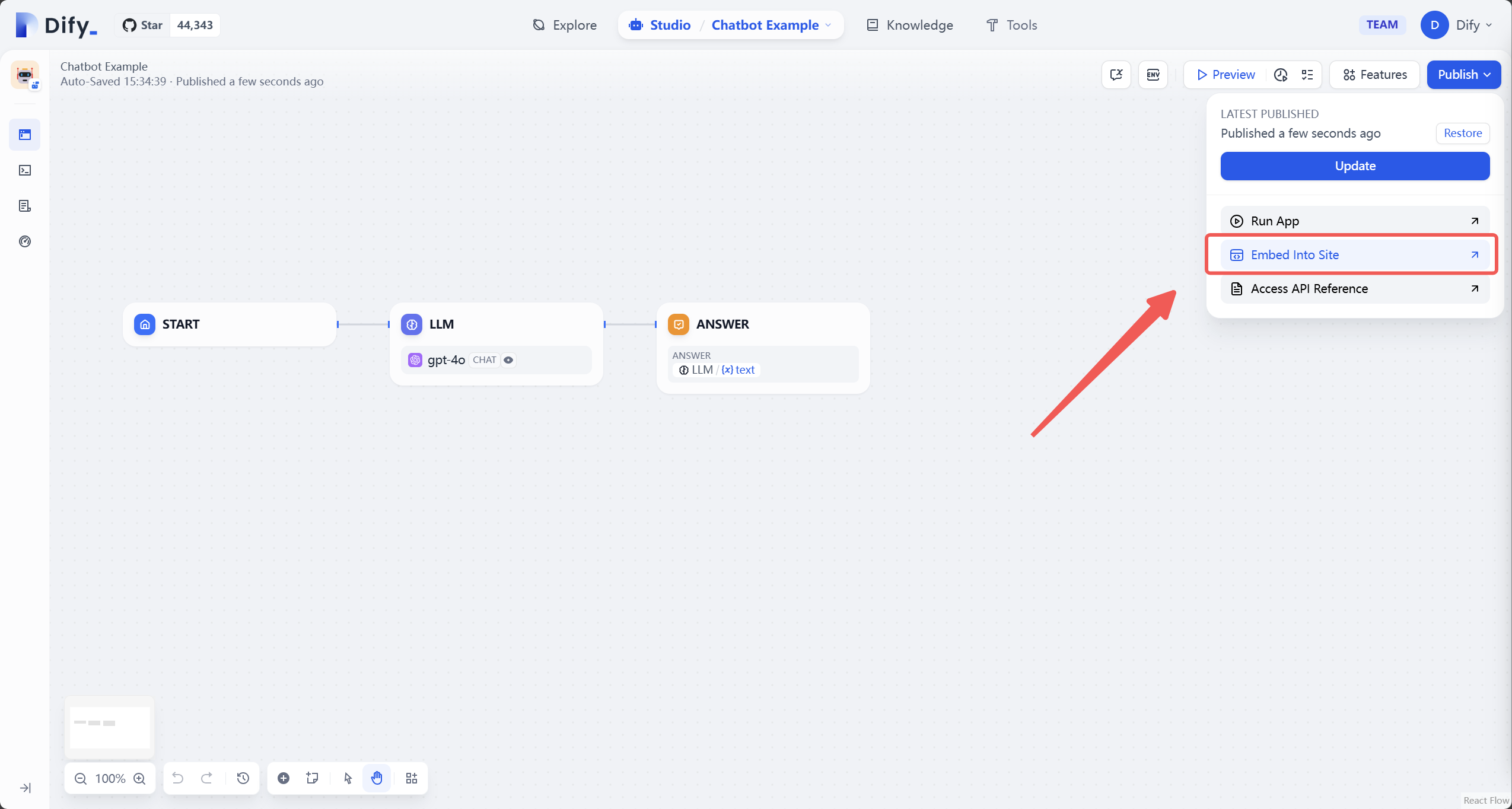
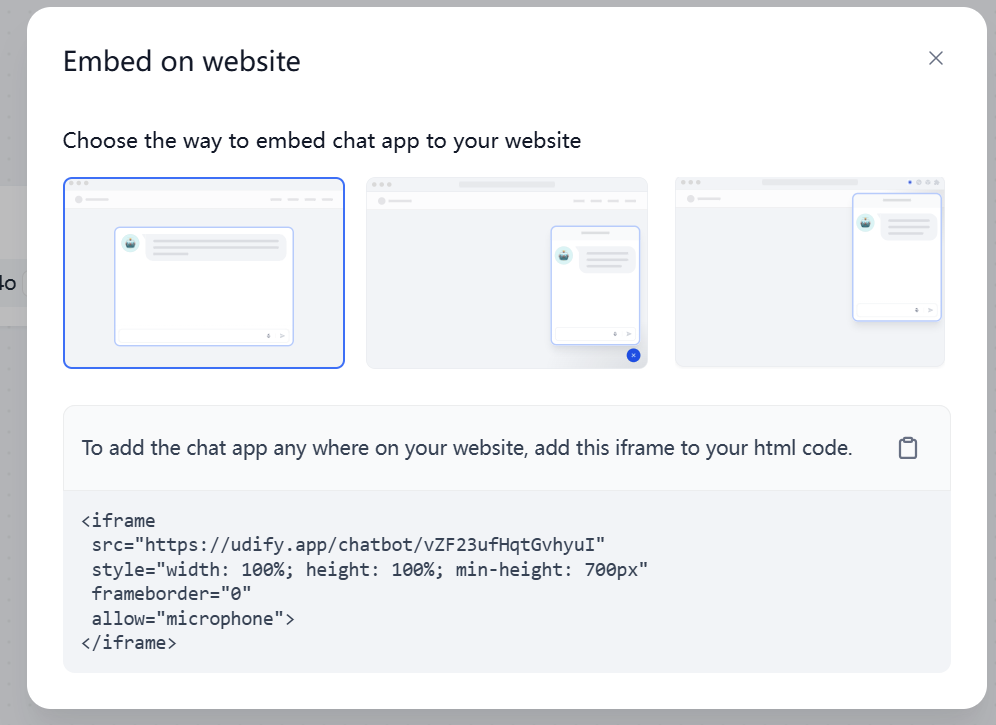
5. 適切なスタイルを選択し、表示されるiFrameコードをコピーします。例:
- 
+ 
## 2. iFrameコードスニペットをWixサイトに埋め込む
@@ -29,7 +29,7 @@ Wixは人気のWebサイト作成プラットフォームです。ドラッグ
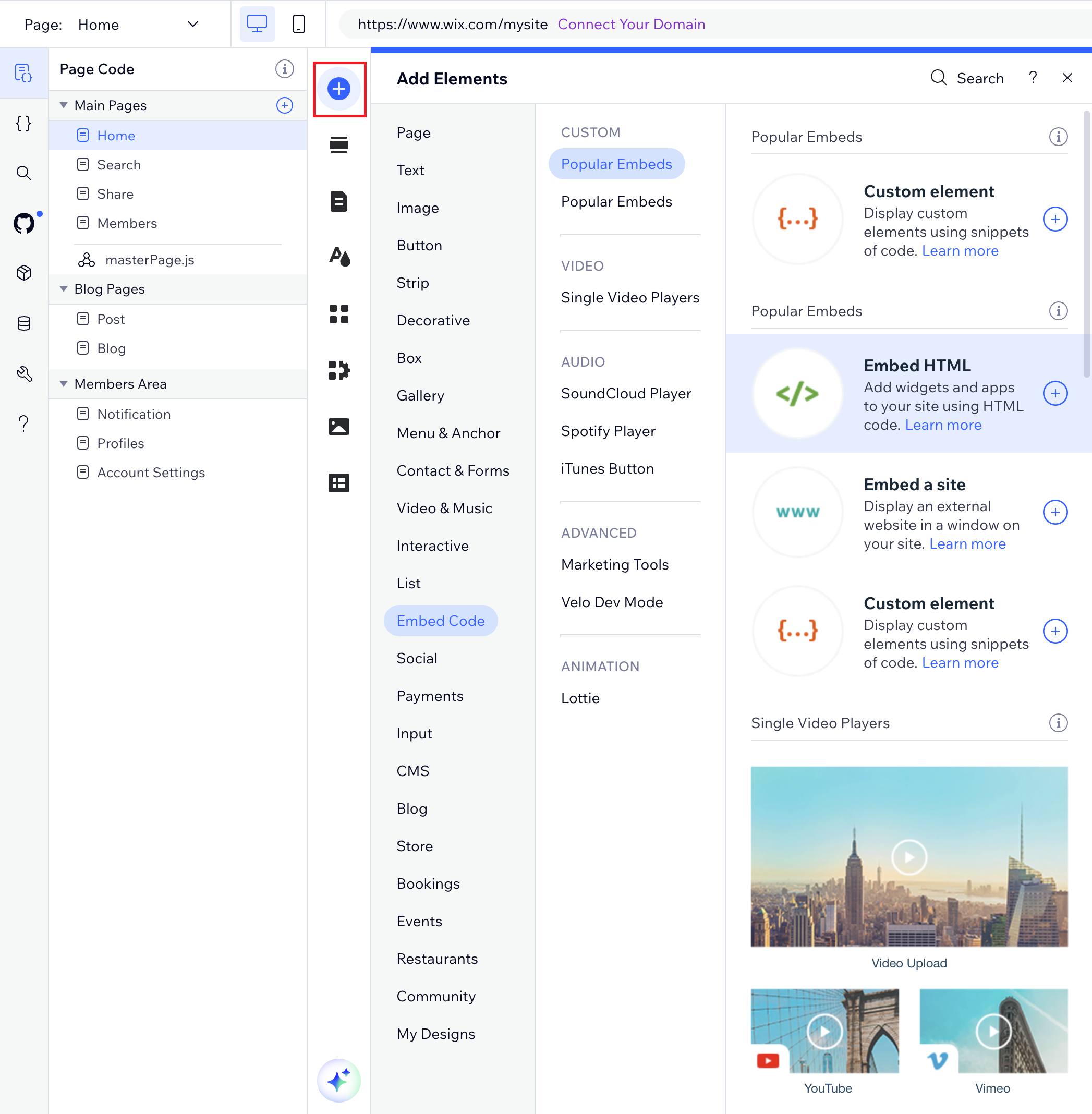
2. ページの左側にある青い`+`(要素の追加)ボタンをクリックします。
3. **埋め込みコード**を選択し、**HTMLを埋め込む**をクリックして、ページにHTML iFrame要素を追加します。
- 
+ 
4. `HTML設定`ボックスで、`コード`オプションを選択します。
5. Difyアプリケーションから取得したiFrameコードスニペットを貼り付けます。
6. **更新**ボタンをクリックして変更内容を保存し、プレビューします。
@@ -40,7 +40,7 @@ Wixは人気のWebサイト作成プラットフォームです。ドラッグ
```
-
+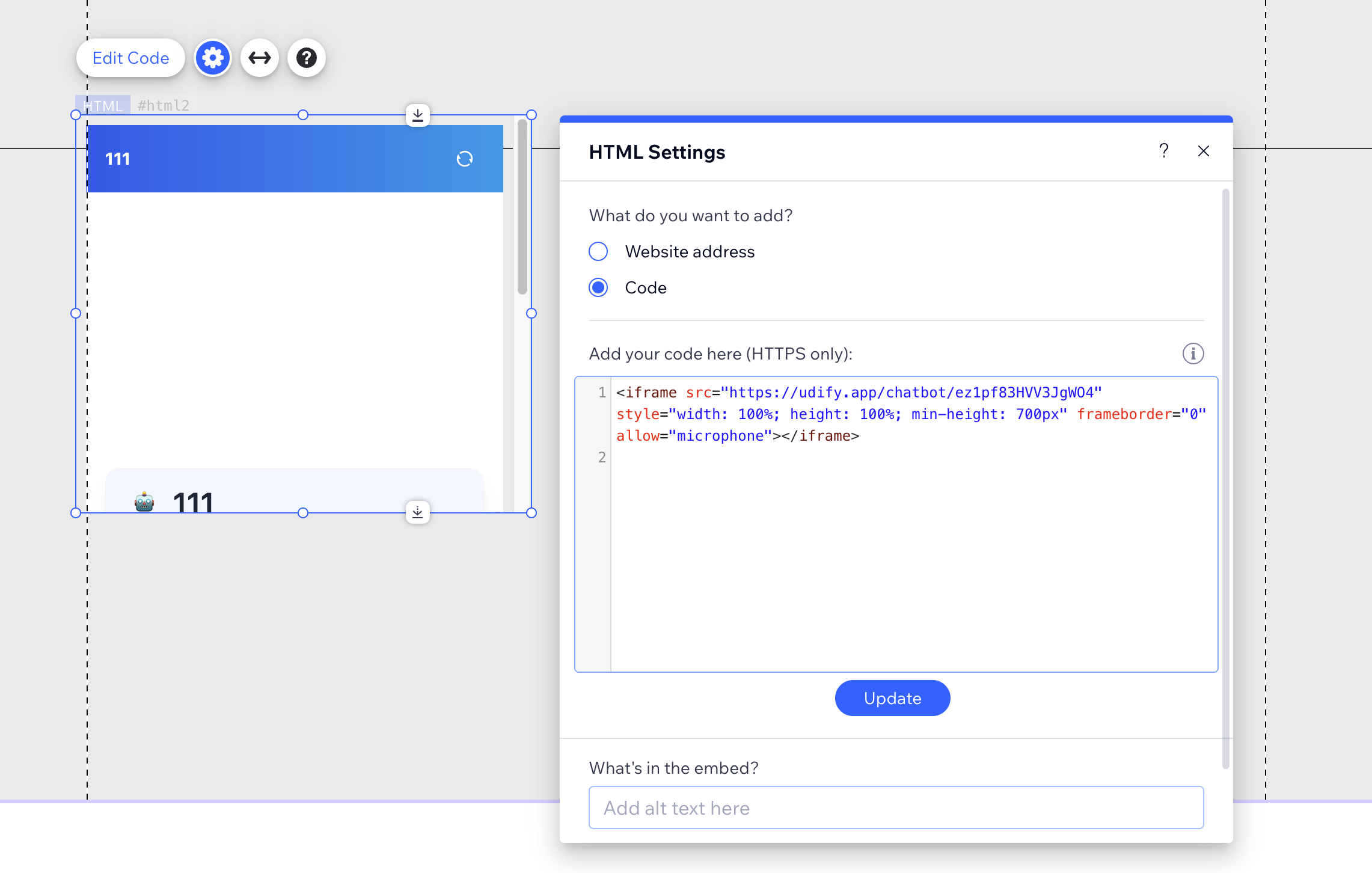
> ⚠️ iFrameコード内のアドレスがHTTPSで始まることを確認してください。HTTPアドレスは正しく表示されません。
diff --git a/scripts/interactive_image_path_fixer.py b/scripts/interactive_image_path_fixer.py
new file mode 100644
index 00000000..ab8d27fa
--- /dev/null
+++ b/scripts/interactive_image_path_fixer.py
@@ -0,0 +1,640 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+
+"""
+交互式图片路径修复工具
+
+该脚本可以交互式地查找并修复 .mdx 文件中的相对图片路径,
+将它们替换为原始 dify-docs 仓库中对应的在线 URL。
+
+每次找到一个问题时,会显示详细信息并等待用户确认后再进行修改。
+
+目录映射关系:
+ dify-docs-mintlify -> dify-docs
+ zh-hans -> zh_CN
+ en -> en
+ ja-jp -> jp
+"""
+
+import os
+import re
+import sys
+from pathlib import Path
+import argparse
+from colorama import init, Fore, Style
+import difflib
+
+# 初始化 colorama
+init(autoreset=True)
+
+# 查找图片的正则表达式
+MD_IMAGE_RE = re.compile(r'!\[(.*?)\]\(((?!https?://|/).+?\.(png|jpe?g|gif|svg))\)')
+HTML_IMAGE_RE = re.compile(r']*src=["\']([^"\']+\.(png|jpe?g|gif|svg))["\'][^>]*>')
+FRAME_IMAGE_RE = re.compile(r']*src=["\'](/[^"\']+\.(png|jpe?g|gif|svg))["\'][^>]*>')
+
+# 查找在线URL的正则表达式
+MD_ONLINE_URL_RE = re.compile(r'!\[[^\]]*\]\((https://[^\s\)]+\.(png|jpe?g|gif|svg|jpeg))\)')
+HTML_ONLINE_URL_RE = re.compile(r']*src=["\'](https://[^\s"\']+\.(png|jpe?g|gif|svg|jpeg))["\'][^>]*>')
+
+# 语言目录映射
+LANGUAGE_MAPPING = {
+ 'zh-hans': 'zh_CN',
+ 'en': 'en',
+ 'ja-jp': 'jp'
+}
+
+REVERSE_LANGUAGE_MAPPING = {v: k for k, v in LANGUAGE_MAPPING.items()}
+
+def find_relative_images(file_path):
+ """
+ 在 .mdx 文件中查找所有相对路径的图片。
+ 返回一个包含 (匹配文本, 图片路径, 行号, 位置) 的列表
+ """
+ relative_images = []
+
+ with open(file_path, 'r', encoding='utf-8') as f:
+ content = f.read()
+
+ # 检查 Markdown 图片语法
+ for match in MD_IMAGE_RE.finditer(content):
+ image_path = match.group(2)
+ if not image_path.startswith(('http://', 'https://', '/')):
+ # 记录行号和位置
+ line_no = content[:match.start()].count('\n') + 1
+ position = match.start()
+ relative_images.append((match.group(0), image_path, line_no, position))
+
+ # 检查 HTML img 标签
+ for match in HTML_IMAGE_RE.finditer(content):
+ image_path = match.group(1)
+ if not image_path.startswith(('http://', 'https://', '/')):
+ line_no = content[:match.start()].count('\n') + 1
+ position = match.start()
+ relative_images.append((match.group(0), image_path, line_no, position))
+
+ # 检查 Frame 组件中的相对路径
+ for match in FRAME_IMAGE_RE.finditer(content):
+ image_path = match.group(1)
+ # 如 /ja-jp/img/... 或 /en-us/img/... 或 /zh-cn/... 这样的路径
+ if image_path.startswith('/'):
+ line_no = content[:match.start()].count('\n') + 1
+ position = match.start()
+ relative_images.append((match.group(0), image_path, line_no, position))
+
+ # 按位置排序,确保按照文档中的顺序处理
+ relative_images.sort(key=lambda x: x[3])
+
+ # 返回时去掉位置信息
+ return [(match, path, line) for match, path, line, _ in relative_images]
+
+def parse_md_file_for_urls(file_path):
+ """仔细解析Markdown文件以提取在线URL和它们的位置"""
+ urls = []
+
+ try:
+ with open(file_path, 'r', encoding='utf-8') as f:
+ content = f.read()
+ lines = content.split('\n')
+
+ # 查找图片URLs
+ for i, line in enumerate(lines):
+ # 查找Markdown风格的图片
+ for match in MD_ONLINE_URL_RE.finditer(line):
+ url = match.group(1)
+ position = sum(len(l) + 1 for l in lines[:i]) + match.start()
+ urls.append((url, i+1, position))
+
+ # 查找HTML风格的图片
+ for match in HTML_ONLINE_URL_RE.finditer(line):
+ url = match.group(1)
+ position = sum(len(l) + 1 for l in lines[:i]) + match.start()
+ urls.append((url, i+1, position))
+
+ # 按文档中的位置排序
+ urls.sort(key=lambda x: x[2])
+
+ return urls
+ except Exception as e:
+ print(f"{Fore.RED}读取文件 {file_path} 时出错: {e}")
+ return []
+
+def find_corresponding_file(mintlify_file, mintlify_base, dify_base):
+ """查找 dify-docs 仓库中对应的文件"""
+
+ # 获取从 mintlify_base 到文件的相对路径
+ rel_path = os.path.relpath(mintlify_file, mintlify_base)
+
+ # 提取语言文件夹(路径的第一个组件)
+ parts = rel_path.split(os.sep)
+ if len(parts) > 0 and parts[0] in LANGUAGE_MAPPING:
+ lang_folder = parts[0]
+ mapped_lang = LANGUAGE_MAPPING[lang_folder]
+ parts[0] = mapped_lang
+
+ # 用映射后的语言重建路径
+ rel_path = os.path.join(*parts)
+
+ # 将扩展名从 .mdx 改为 .md
+ if rel_path.endswith('.mdx'):
+ rel_path = rel_path[:-4] + '.md'
+
+ # 构建在 dify-docs 中的完整路径
+ dify_file = os.path.join(dify_base, rel_path)
+
+ return dify_file if os.path.exists(dify_file) else None
+
+def extract_img_basename(path):
+ """从图片路径中提取基本文件名"""
+ # 处理常规和语言前缀路径
+ # 如 /ja-jp/img/jp-env-variable.png 或 /en-us/img/image.png
+ if path.startswith('/'):
+ parts = path.split('/')
+ if len(parts) > 1:
+ return parts[-1] # 获取最后一部分(文件名)
+ return os.path.basename(path)
+
+def get_file_extension(path):
+ """获取文件扩展名"""
+ basename = extract_img_basename(path)
+ if '.' in basename:
+ return basename.split('.')[-1].lower()
+ return None
+
+def debug_print_file_comparison(mintlify_file, dify_file):
+ """打印两个文件的内容对比,用于调试"""
+ print(f"\n{Fore.CYAN}======= 文件内容对比 =======")
+
+ # 读取mintlify文件内容
+ try:
+ with open(mintlify_file, 'r', encoding='utf-8') as f:
+ mintlify_content = f.read()
+ print(f"\n{Fore.GREEN}Mintlify文件({mintlify_file}):")
+ print(mintlify_content[:500] + "..." if len(mintlify_content) > 500 else mintlify_content)
+ except Exception as e:
+ print(f"{Fore.RED}读取 {mintlify_file} 错误: {e}")
+
+ # 读取dify文件内容
+ try:
+ with open(dify_file, 'r', encoding='utf-8') as f:
+ dify_content = f.read()
+ print(f"\n{Fore.YELLOW}Dify文件({dify_file}):")
+ print(dify_content[:500] + "..." if len(dify_content) > 500 else dify_content)
+ except Exception as e:
+ print(f"{Fore.RED}读取 {dify_file} 错误: {e}")
+
+ # 提取并比较图片URLs
+ mintlify_images = find_relative_images(mintlify_file)
+ dify_urls = parse_md_file_for_urls(dify_file)
+
+ print(f"\n{Fore.CYAN}Mintlify图片({len(mintlify_images)}):")
+ for i, (_, img_path, _) in enumerate(mintlify_images):
+ print(f"{i+1}. {img_path}")
+
+ print(f"\n{Fore.CYAN}Dify URLs({len(dify_urls)}):")
+ for i, (url, _, _) in enumerate(dify_urls):
+ print(f"{i+1}. {url}")
+
+def match_images_precisely(mintlify_images, dify_file):
+ """精确匹配图片,按照文档位置和上下文"""
+ results = []
+ dify_urls = parse_md_file_for_urls(dify_file)
+
+ # 按照位置对应匹配图片和URL
+ for i, (match_text, img_path, line_no) in enumerate(mintlify_images):
+ img_ext = get_file_extension(img_path)
+
+ # 检查是否有足够的URLs
+ if i < len(dify_urls):
+ # 检查扩展名是否匹配
+ url_ext = get_file_extension(dify_urls[i][0])
+ if img_ext and url_ext and img_ext.lower() == url_ext.lower():
+ results.append((match_text, img_path, line_no, dify_urls[i][0], dify_file))
+ else:
+ # 尝试在剩余URL中找到匹配的扩展名
+ found_match = False
+ for j, (url, _, _) in enumerate(dify_urls):
+ if j != i: # 避免重复使用当前位置
+ j_ext = get_file_extension(url)
+ if img_ext and j_ext and img_ext.lower() == j_ext.lower():
+ results.append((match_text, img_path, line_no, url, dify_file))
+ found_match = True
+ break
+
+ if not found_match:
+ results.append((match_text, img_path, line_no, None, None))
+ else:
+ results.append((match_text, img_path, line_no, None, None))
+
+ return results
+
+def get_all_content_after_image(content, image_path):
+ """获取图片后的所有文本内容"""
+ # 查找相对路径的位置
+ index = content.find(image_path)
+ if index == -1:
+ return ""
+
+ # 返回图片后的所有内容
+ return content[index + len(image_path):]
+
+def match_images_by_name_and_context(mintlify_file, dify_file):
+ """通过图片名称和上下文匹配图片"""
+ try:
+ # 读取文件内容
+ with open(mintlify_file, 'r', encoding='utf-8') as f:
+ mintlify_content = f.read()
+
+ with open(dify_file, 'r', encoding='utf-8') as f:
+ dify_content = f.read()
+
+ # 获取mintlify文件中的相对图片
+ mintlify_images = find_relative_images(mintlify_file)
+
+ # 提取dify文件中的在线URLs
+ dify_urls = parse_md_file_for_urls(dify_file)
+
+ # 按顺序匹配每个图片
+ results = []
+ for match_text, img_path, line_no in mintlify_images:
+ # 提取图片名称和后缀
+ img_base = extract_img_basename(img_path)
+ img_ext = get_file_extension(img_path)
+
+ # 获取图片在mintlify文件中的实际位置
+ img_index = mintlify_content.find(img_path)
+ if img_index == -1:
+ img_index = mintlify_content.find(match_text)
+
+ # 获取图片后的文本上下文(用于更精确的匹配)
+ after_text = mintlify_content[img_index + len(match_text):img_index + len(match_text) + 200]
+ after_text = re.sub(r'[\n\r\s]+', ' ', after_text).strip()
+
+ # 尝试通过图片在文档中的位置和顺序匹配
+ # 首先,确定当前图片是这种类型的第几个图片
+ same_ext_images = [i for i, (_, p, _) in enumerate(mintlify_images)
+ if get_file_extension(p) == img_ext]
+ current_index = same_ext_images.index(mintlify_images.index((match_text, img_path, line_no)))
+
+ # 获取对应索引的相同类型URL
+ same_ext_urls = [(i, u) for i, (u, _, _) in enumerate(dify_urls)
+ if get_file_extension(u) == img_ext]
+
+ if current_index < len(same_ext_urls):
+ # 按顺序匹配
+ url_index, url = same_ext_urls[current_index]
+ results.append((match_text, img_path, line_no, url, dify_file))
+ else:
+ # 如果顺序匹配失败,尝试上下文相似度匹配
+ best_match = None
+ best_score = 0
+
+ for _, (url, url_line, _) in enumerate(dify_urls):
+ # 检查扩展名是否匹配
+ url_ext = get_file_extension(url)
+ if img_ext != url_ext:
+ continue
+
+ # 获取URL在dify文件中的实际位置
+ url_index = dify_content.find(url)
+
+ # 获取URL后的文本上下文
+ url_after_text = dify_content[url_index + len(url):url_index + len(url) + 200]
+ url_after_text = re.sub(r'[\n\r\s]+', ' ', url_after_text).strip()
+
+ # 计算上下文相似度
+ matcher = difflib.SequenceMatcher(None, after_text, url_after_text)
+ score = matcher.ratio()
+
+ if score > best_score:
+ best_score = score
+ best_match = url
+
+ if best_match:
+ results.append((match_text, img_path, line_no, best_match, dify_file))
+ else:
+ results.append((match_text, img_path, line_no, None, None))
+
+ return results
+
+ except Exception as e:
+ print(f"{Fore.RED}匹配图片时出错: {e}")
+ return []
+
+def find_matching_image_url(mintlify_file, dify_file, img_path, order_index=0):
+ """查找匹配的图片URL,考虑多种策略"""
+ # 策略1: 按顺序匹配
+ # 策略2: 按扩展名匹配
+ # 策略3: 按上下文匹配
+
+ try:
+ # 获取图片扩展名
+ img_ext = get_file_extension(img_path)
+ if not img_ext:
+ return None
+
+ # 解析dify文件中的URLs
+ urls = parse_md_file_for_urls(dify_file)
+
+ # 按顺序和扩展名匹配
+ # 找出所有扩展名匹配的URLs
+ matching_urls = []
+ for url, _, _ in urls:
+ url_ext = get_file_extension(url)
+ if url_ext == img_ext:
+ matching_urls.append(url)
+
+ # 如果没有匹配的URL,返回None
+ if not matching_urls:
+ return None
+
+ # 如果图片序号在有效范围内,按序号匹配
+ if order_index < len(matching_urls):
+ return matching_urls[order_index]
+
+ # 否则返回第一个匹配的URL
+ return matching_urls[0]
+
+ except Exception as e:
+ print(f"{Fore.RED}查找匹配URL时出错: {e}")
+ return None
+
+def validate_content_alignment(mintlify_file, dify_file, img_path, url, check_text_length=200):
+ """验证内容对齐情况,确保图片周围的内容相似"""
+ try:
+ with open(mintlify_file, 'r', encoding='utf-8') as f:
+ mintlify_content = f.read()
+
+ with open(dify_file, 'r', encoding='utf-8') as f:
+ dify_content = f.read()
+
+ # 在原始文件中找到图片位置
+ img_index = mintlify_content.find(img_path)
+ if img_index == -1:
+ return False
+
+ # 在目标文件中找到URL位置
+ url_index = dify_content.find(url)
+ if url_index == -1:
+ return False
+
+ # 获取图片后的文本
+ img_after = mintlify_content[img_index + len(img_path):img_index + len(img_path) + check_text_length]
+ img_after = re.sub(r'[\n\r\s]+', ' ', img_after).strip()
+
+ # 获取URL后的文本
+ url_after = dify_content[url_index + len(url):url_index + len(url) + check_text_length]
+ url_after = re.sub(r'[\n\r\s]+', ' ', url_after).strip()
+
+ # 计算相似度
+ matcher = difflib.SequenceMatcher(None, img_after, url_after)
+ ratio = matcher.ratio()
+
+ # 返回相似度是否超过阈值
+ return ratio > 0.5
+
+ except Exception as e:
+ print(f"{Fore.RED}验证内容对齐时出错: {e}")
+ return False
+
+def replace_image_in_file(file_path, match_text, online_url):
+ """在文件中将单个相对图片路径替换为在线 URL"""
+ try:
+ with open(file_path, 'r', encoding='utf-8') as f:
+ content = f.read()
+
+ new_content = content
+ if '
diff --git a/ja-jp/learn-more/use-cases/how-to-integrate-dify-chatbot-to-your-wix-website.mdx b/ja-jp/learn-more/use-cases/how-to-integrate-dify-chatbot-to-your-wix-website.mdx
index 5bc718a9..aa96f820 100644
--- a/ja-jp/learn-more/use-cases/how-to-integrate-dify-chatbot-to-your-wix-website.mdx
+++ b/ja-jp/learn-more/use-cases/how-to-integrate-dify-chatbot-to-your-wix-website.mdx
@@ -18,10 +18,10 @@ Wixは人気のWebサイト作成プラットフォームです。ドラッグ
3. ページ右上の「公開」ボタンをクリックします。
4. 公開ページで「サイトに埋め込む」のオプションを選択します。
- 
+ 
5. 適切なスタイルを選択し、表示されるiFrameコードをコピーします。例:
- 
+ 
## 2. iFrameコードスニペットをWixサイトに埋め込む
@@ -29,7 +29,7 @@ Wixは人気のWebサイト作成プラットフォームです。ドラッグ
2. ページの左側にある青い`+`(要素の追加)ボタンをクリックします。
3. **埋め込みコード**を選択し、**HTMLを埋め込む**をクリックして、ページにHTML iFrame要素を追加します。
- 
+ 
4. `HTML設定`ボックスで、`コード`オプションを選択します。
5. Difyアプリケーションから取得したiFrameコードスニペットを貼り付けます。
6. **更新**ボタンをクリックして変更内容を保存し、プレビューします。
@@ -40,7 +40,7 @@ Wixは人気のWebサイト作成プラットフォームです。ドラッグ
```
-
+
> ⚠️ iFrameコード内のアドレスがHTTPSで始まることを確認してください。HTTPアドレスは正しく表示されません。
diff --git a/scripts/interactive_image_path_fixer.py b/scripts/interactive_image_path_fixer.py
new file mode 100644
index 00000000..ab8d27fa
--- /dev/null
+++ b/scripts/interactive_image_path_fixer.py
@@ -0,0 +1,640 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+
+"""
+交互式图片路径修复工具
+
+该脚本可以交互式地查找并修复 .mdx 文件中的相对图片路径,
+将它们替换为原始 dify-docs 仓库中对应的在线 URL。
+
+每次找到一个问题时,会显示详细信息并等待用户确认后再进行修改。
+
+目录映射关系:
+ dify-docs-mintlify -> dify-docs
+ zh-hans -> zh_CN
+ en -> en
+ ja-jp -> jp
+"""
+
+import os
+import re
+import sys
+from pathlib import Path
+import argparse
+from colorama import init, Fore, Style
+import difflib
+
+# 初始化 colorama
+init(autoreset=True)
+
+# 查找图片的正则表达式
+MD_IMAGE_RE = re.compile(r'!\[(.*?)\]\(((?!https?://|/).+?\.(png|jpe?g|gif|svg))\)')
+HTML_IMAGE_RE = re.compile(r']*src=["\']([^"\']+\.(png|jpe?g|gif|svg))["\'][^>]*>')
+FRAME_IMAGE_RE = re.compile(r']*src=["\'](/[^"\']+\.(png|jpe?g|gif|svg))["\'][^>]*>')
+
+# 查找在线URL的正则表达式
+MD_ONLINE_URL_RE = re.compile(r'!\[[^\]]*\]\((https://[^\s\)]+\.(png|jpe?g|gif|svg|jpeg))\)')
+HTML_ONLINE_URL_RE = re.compile(r']*src=["\'](https://[^\s"\']+\.(png|jpe?g|gif|svg|jpeg))["\'][^>]*>')
+
+# 语言目录映射
+LANGUAGE_MAPPING = {
+ 'zh-hans': 'zh_CN',
+ 'en': 'en',
+ 'ja-jp': 'jp'
+}
+
+REVERSE_LANGUAGE_MAPPING = {v: k for k, v in LANGUAGE_MAPPING.items()}
+
+def find_relative_images(file_path):
+ """
+ 在 .mdx 文件中查找所有相对路径的图片。
+ 返回一个包含 (匹配文本, 图片路径, 行号, 位置) 的列表
+ """
+ relative_images = []
+
+ with open(file_path, 'r', encoding='utf-8') as f:
+ content = f.read()
+
+ # 检查 Markdown 图片语法
+ for match in MD_IMAGE_RE.finditer(content):
+ image_path = match.group(2)
+ if not image_path.startswith(('http://', 'https://', '/')):
+ # 记录行号和位置
+ line_no = content[:match.start()].count('\n') + 1
+ position = match.start()
+ relative_images.append((match.group(0), image_path, line_no, position))
+
+ # 检查 HTML img 标签
+ for match in HTML_IMAGE_RE.finditer(content):
+ image_path = match.group(1)
+ if not image_path.startswith(('http://', 'https://', '/')):
+ line_no = content[:match.start()].count('\n') + 1
+ position = match.start()
+ relative_images.append((match.group(0), image_path, line_no, position))
+
+ # 检查 Frame 组件中的相对路径
+ for match in FRAME_IMAGE_RE.finditer(content):
+ image_path = match.group(1)
+ # 如 /ja-jp/img/... 或 /en-us/img/... 或 /zh-cn/... 这样的路径
+ if image_path.startswith('/'):
+ line_no = content[:match.start()].count('\n') + 1
+ position = match.start()
+ relative_images.append((match.group(0), image_path, line_no, position))
+
+ # 按位置排序,确保按照文档中的顺序处理
+ relative_images.sort(key=lambda x: x[3])
+
+ # 返回时去掉位置信息
+ return [(match, path, line) for match, path, line, _ in relative_images]
+
+def parse_md_file_for_urls(file_path):
+ """仔细解析Markdown文件以提取在线URL和它们的位置"""
+ urls = []
+
+ try:
+ with open(file_path, 'r', encoding='utf-8') as f:
+ content = f.read()
+ lines = content.split('\n')
+
+ # 查找图片URLs
+ for i, line in enumerate(lines):
+ # 查找Markdown风格的图片
+ for match in MD_ONLINE_URL_RE.finditer(line):
+ url = match.group(1)
+ position = sum(len(l) + 1 for l in lines[:i]) + match.start()
+ urls.append((url, i+1, position))
+
+ # 查找HTML风格的图片
+ for match in HTML_ONLINE_URL_RE.finditer(line):
+ url = match.group(1)
+ position = sum(len(l) + 1 for l in lines[:i]) + match.start()
+ urls.append((url, i+1, position))
+
+ # 按文档中的位置排序
+ urls.sort(key=lambda x: x[2])
+
+ return urls
+ except Exception as e:
+ print(f"{Fore.RED}读取文件 {file_path} 时出错: {e}")
+ return []
+
+def find_corresponding_file(mintlify_file, mintlify_base, dify_base):
+ """查找 dify-docs 仓库中对应的文件"""
+
+ # 获取从 mintlify_base 到文件的相对路径
+ rel_path = os.path.relpath(mintlify_file, mintlify_base)
+
+ # 提取语言文件夹(路径的第一个组件)
+ parts = rel_path.split(os.sep)
+ if len(parts) > 0 and parts[0] in LANGUAGE_MAPPING:
+ lang_folder = parts[0]
+ mapped_lang = LANGUAGE_MAPPING[lang_folder]
+ parts[0] = mapped_lang
+
+ # 用映射后的语言重建路径
+ rel_path = os.path.join(*parts)
+
+ # 将扩展名从 .mdx 改为 .md
+ if rel_path.endswith('.mdx'):
+ rel_path = rel_path[:-4] + '.md'
+
+ # 构建在 dify-docs 中的完整路径
+ dify_file = os.path.join(dify_base, rel_path)
+
+ return dify_file if os.path.exists(dify_file) else None
+
+def extract_img_basename(path):
+ """从图片路径中提取基本文件名"""
+ # 处理常规和语言前缀路径
+ # 如 /ja-jp/img/jp-env-variable.png 或 /en-us/img/image.png
+ if path.startswith('/'):
+ parts = path.split('/')
+ if len(parts) > 1:
+ return parts[-1] # 获取最后一部分(文件名)
+ return os.path.basename(path)
+
+def get_file_extension(path):
+ """获取文件扩展名"""
+ basename = extract_img_basename(path)
+ if '.' in basename:
+ return basename.split('.')[-1].lower()
+ return None
+
+def debug_print_file_comparison(mintlify_file, dify_file):
+ """打印两个文件的内容对比,用于调试"""
+ print(f"\n{Fore.CYAN}======= 文件内容对比 =======")
+
+ # 读取mintlify文件内容
+ try:
+ with open(mintlify_file, 'r', encoding='utf-8') as f:
+ mintlify_content = f.read()
+ print(f"\n{Fore.GREEN}Mintlify文件({mintlify_file}):")
+ print(mintlify_content[:500] + "..." if len(mintlify_content) > 500 else mintlify_content)
+ except Exception as e:
+ print(f"{Fore.RED}读取 {mintlify_file} 错误: {e}")
+
+ # 读取dify文件内容
+ try:
+ with open(dify_file, 'r', encoding='utf-8') as f:
+ dify_content = f.read()
+ print(f"\n{Fore.YELLOW}Dify文件({dify_file}):")
+ print(dify_content[:500] + "..." if len(dify_content) > 500 else dify_content)
+ except Exception as e:
+ print(f"{Fore.RED}读取 {dify_file} 错误: {e}")
+
+ # 提取并比较图片URLs
+ mintlify_images = find_relative_images(mintlify_file)
+ dify_urls = parse_md_file_for_urls(dify_file)
+
+ print(f"\n{Fore.CYAN}Mintlify图片({len(mintlify_images)}):")
+ for i, (_, img_path, _) in enumerate(mintlify_images):
+ print(f"{i+1}. {img_path}")
+
+ print(f"\n{Fore.CYAN}Dify URLs({len(dify_urls)}):")
+ for i, (url, _, _) in enumerate(dify_urls):
+ print(f"{i+1}. {url}")
+
+def match_images_precisely(mintlify_images, dify_file):
+ """精确匹配图片,按照文档位置和上下文"""
+ results = []
+ dify_urls = parse_md_file_for_urls(dify_file)
+
+ # 按照位置对应匹配图片和URL
+ for i, (match_text, img_path, line_no) in enumerate(mintlify_images):
+ img_ext = get_file_extension(img_path)
+
+ # 检查是否有足够的URLs
+ if i < len(dify_urls):
+ # 检查扩展名是否匹配
+ url_ext = get_file_extension(dify_urls[i][0])
+ if img_ext and url_ext and img_ext.lower() == url_ext.lower():
+ results.append((match_text, img_path, line_no, dify_urls[i][0], dify_file))
+ else:
+ # 尝试在剩余URL中找到匹配的扩展名
+ found_match = False
+ for j, (url, _, _) in enumerate(dify_urls):
+ if j != i: # 避免重复使用当前位置
+ j_ext = get_file_extension(url)
+ if img_ext and j_ext and img_ext.lower() == j_ext.lower():
+ results.append((match_text, img_path, line_no, url, dify_file))
+ found_match = True
+ break
+
+ if not found_match:
+ results.append((match_text, img_path, line_no, None, None))
+ else:
+ results.append((match_text, img_path, line_no, None, None))
+
+ return results
+
+def get_all_content_after_image(content, image_path):
+ """获取图片后的所有文本内容"""
+ # 查找相对路径的位置
+ index = content.find(image_path)
+ if index == -1:
+ return ""
+
+ # 返回图片后的所有内容
+ return content[index + len(image_path):]
+
+def match_images_by_name_and_context(mintlify_file, dify_file):
+ """通过图片名称和上下文匹配图片"""
+ try:
+ # 读取文件内容
+ with open(mintlify_file, 'r', encoding='utf-8') as f:
+ mintlify_content = f.read()
+
+ with open(dify_file, 'r', encoding='utf-8') as f:
+ dify_content = f.read()
+
+ # 获取mintlify文件中的相对图片
+ mintlify_images = find_relative_images(mintlify_file)
+
+ # 提取dify文件中的在线URLs
+ dify_urls = parse_md_file_for_urls(dify_file)
+
+ # 按顺序匹配每个图片
+ results = []
+ for match_text, img_path, line_no in mintlify_images:
+ # 提取图片名称和后缀
+ img_base = extract_img_basename(img_path)
+ img_ext = get_file_extension(img_path)
+
+ # 获取图片在mintlify文件中的实际位置
+ img_index = mintlify_content.find(img_path)
+ if img_index == -1:
+ img_index = mintlify_content.find(match_text)
+
+ # 获取图片后的文本上下文(用于更精确的匹配)
+ after_text = mintlify_content[img_index + len(match_text):img_index + len(match_text) + 200]
+ after_text = re.sub(r'[\n\r\s]+', ' ', after_text).strip()
+
+ # 尝试通过图片在文档中的位置和顺序匹配
+ # 首先,确定当前图片是这种类型的第几个图片
+ same_ext_images = [i for i, (_, p, _) in enumerate(mintlify_images)
+ if get_file_extension(p) == img_ext]
+ current_index = same_ext_images.index(mintlify_images.index((match_text, img_path, line_no)))
+
+ # 获取对应索引的相同类型URL
+ same_ext_urls = [(i, u) for i, (u, _, _) in enumerate(dify_urls)
+ if get_file_extension(u) == img_ext]
+
+ if current_index < len(same_ext_urls):
+ # 按顺序匹配
+ url_index, url = same_ext_urls[current_index]
+ results.append((match_text, img_path, line_no, url, dify_file))
+ else:
+ # 如果顺序匹配失败,尝试上下文相似度匹配
+ best_match = None
+ best_score = 0
+
+ for _, (url, url_line, _) in enumerate(dify_urls):
+ # 检查扩展名是否匹配
+ url_ext = get_file_extension(url)
+ if img_ext != url_ext:
+ continue
+
+ # 获取URL在dify文件中的实际位置
+ url_index = dify_content.find(url)
+
+ # 获取URL后的文本上下文
+ url_after_text = dify_content[url_index + len(url):url_index + len(url) + 200]
+ url_after_text = re.sub(r'[\n\r\s]+', ' ', url_after_text).strip()
+
+ # 计算上下文相似度
+ matcher = difflib.SequenceMatcher(None, after_text, url_after_text)
+ score = matcher.ratio()
+
+ if score > best_score:
+ best_score = score
+ best_match = url
+
+ if best_match:
+ results.append((match_text, img_path, line_no, best_match, dify_file))
+ else:
+ results.append((match_text, img_path, line_no, None, None))
+
+ return results
+
+ except Exception as e:
+ print(f"{Fore.RED}匹配图片时出错: {e}")
+ return []
+
+def find_matching_image_url(mintlify_file, dify_file, img_path, order_index=0):
+ """查找匹配的图片URL,考虑多种策略"""
+ # 策略1: 按顺序匹配
+ # 策略2: 按扩展名匹配
+ # 策略3: 按上下文匹配
+
+ try:
+ # 获取图片扩展名
+ img_ext = get_file_extension(img_path)
+ if not img_ext:
+ return None
+
+ # 解析dify文件中的URLs
+ urls = parse_md_file_for_urls(dify_file)
+
+ # 按顺序和扩展名匹配
+ # 找出所有扩展名匹配的URLs
+ matching_urls = []
+ for url, _, _ in urls:
+ url_ext = get_file_extension(url)
+ if url_ext == img_ext:
+ matching_urls.append(url)
+
+ # 如果没有匹配的URL,返回None
+ if not matching_urls:
+ return None
+
+ # 如果图片序号在有效范围内,按序号匹配
+ if order_index < len(matching_urls):
+ return matching_urls[order_index]
+
+ # 否则返回第一个匹配的URL
+ return matching_urls[0]
+
+ except Exception as e:
+ print(f"{Fore.RED}查找匹配URL时出错: {e}")
+ return None
+
+def validate_content_alignment(mintlify_file, dify_file, img_path, url, check_text_length=200):
+ """验证内容对齐情况,确保图片周围的内容相似"""
+ try:
+ with open(mintlify_file, 'r', encoding='utf-8') as f:
+ mintlify_content = f.read()
+
+ with open(dify_file, 'r', encoding='utf-8') as f:
+ dify_content = f.read()
+
+ # 在原始文件中找到图片位置
+ img_index = mintlify_content.find(img_path)
+ if img_index == -1:
+ return False
+
+ # 在目标文件中找到URL位置
+ url_index = dify_content.find(url)
+ if url_index == -1:
+ return False
+
+ # 获取图片后的文本
+ img_after = mintlify_content[img_index + len(img_path):img_index + len(img_path) + check_text_length]
+ img_after = re.sub(r'[\n\r\s]+', ' ', img_after).strip()
+
+ # 获取URL后的文本
+ url_after = dify_content[url_index + len(url):url_index + len(url) + check_text_length]
+ url_after = re.sub(r'[\n\r\s]+', ' ', url_after).strip()
+
+ # 计算相似度
+ matcher = difflib.SequenceMatcher(None, img_after, url_after)
+ ratio = matcher.ratio()
+
+ # 返回相似度是否超过阈值
+ return ratio > 0.5
+
+ except Exception as e:
+ print(f"{Fore.RED}验证内容对齐时出错: {e}")
+ return False
+
+def replace_image_in_file(file_path, match_text, online_url):
+ """在文件中将单个相对图片路径替换为在线 URL"""
+ try:
+ with open(file_path, 'r', encoding='utf-8') as f:
+ content = f.read()
+
+ new_content = content
+ if ' +
+ 点击部署按钮后,你需要输入一个生成的域名,以便将域名绑定到你的 Dify 实例并注入到其他服务中作为环境变量。
然后选择你喜欢的区域,点击部署按钮,你的 Dify 实例将在几分钟内部署完成。
-
点击部署按钮后,你需要输入一个生成的域名,以便将域名绑定到你的 Dify 实例并注入到其他服务中作为环境变量。
然后选择你喜欢的区域,点击部署按钮,你的 Dify 实例将在几分钟内部署完成。
- +
+ 部署完成后,你可以在 Zeabur 控制台中看到一个项目页面,如下图所示,你在部署过程中输入的域名将自动绑定到 NGINX 服务,你可以通过该域名访问你的 Dify 实例。
-
部署完成后,你可以在 Zeabur 控制台中看到一个项目页面,如下图所示,你在部署过程中输入的域名将自动绑定到 NGINX 服务,你可以通过该域名访问你的 Dify 实例。
- +
你也可以在 NGINX 服务页面的 Networking 选项卡中更改域名。你可以参考 [Zeabur 文档](https://zeabur.com/docs/deploy/domain-binding) 了解更多信息。
\ No newline at end of file
diff --git a/zh-hans/guides/tools/quick-tool-integration.mdx b/zh-hans/guides/tools/quick-tool-integration.mdx
index 3927576a..4a207f11 100644
--- a/zh-hans/guides/tools/quick-tool-integration.mdx
+++ b/zh-hans/guides/tools/quick-tool-integration.mdx
@@ -247,5 +247,5 @@ class GoogleProvider(BuiltinToolProviderController):
当然,因为 google\_search 需要一个凭据,在使用之前,还需要在前端配置它的凭据。
-
+
你也可以在 NGINX 服务页面的 Networking 选项卡中更改域名。你可以参考 [Zeabur 文档](https://zeabur.com/docs/deploy/domain-binding) 了解更多信息。
\ No newline at end of file
diff --git a/zh-hans/guides/tools/quick-tool-integration.mdx b/zh-hans/guides/tools/quick-tool-integration.mdx
index 3927576a..4a207f11 100644
--- a/zh-hans/guides/tools/quick-tool-integration.mdx
+++ b/zh-hans/guides/tools/quick-tool-integration.mdx
@@ -247,5 +247,5 @@ class GoogleProvider(BuiltinToolProviderController):
当然,因为 google\_search 需要一个凭据,在使用之前,还需要在前端配置它的凭据。
-  +
+  diff --git a/zh-hans/learn-more/how-to-use-json-schema-in-dify.mdx b/zh-hans/learn-more/how-to-use-json-schema-in-dify.mdx
index 13b8ebb2..c0764dc0 100644
--- a/zh-hans/learn-more/how-to-use-json-schema-in-dify.mdx
+++ b/zh-hans/learn-more/how-to-use-json-schema-in-dify.mdx
@@ -22,7 +22,7 @@ JSON Schema 是一种用于描述 JSON 数据结构的规范,开发者可以
将应用中的 LLM 切换至上述支持 JSON Schema 输出的模型,然后在设置表单开启 `JSON Schema` 并填写 JSON Schema 模板;同时开启 `response_format` 栏并切换至 `json_schema` 格式。
-
+
LLM 生成的内容支持以下格式输出:
diff --git a/zh-hans/learn-more/use-cases/dify-on-dingtalk.mdx b/zh-hans/learn-more/use-cases/dify-on-dingtalk.mdx
index e8f2c87a..8e344edc 100644
--- a/zh-hans/learn-more/use-cases/dify-on-dingtalk.mdx
+++ b/zh-hans/learn-more/use-cases/dify-on-dingtalk.mdx
@@ -13,33 +13,7 @@ IM 是天然的智能聊天机器人应用场景,校企用户有不少是使
diff --git a/zh-hans/learn-more/how-to-use-json-schema-in-dify.mdx b/zh-hans/learn-more/how-to-use-json-schema-in-dify.mdx
index 13b8ebb2..c0764dc0 100644
--- a/zh-hans/learn-more/how-to-use-json-schema-in-dify.mdx
+++ b/zh-hans/learn-more/how-to-use-json-schema-in-dify.mdx
@@ -22,7 +22,7 @@ JSON Schema 是一种用于描述 JSON 数据结构的规范,开发者可以
将应用中的 LLM 切换至上述支持 JSON Schema 输出的模型,然后在设置表单开启 `JSON Schema` 并填写 JSON Schema 模板;同时开启 `response_format` 栏并切换至 `json_schema` 格式。
-
+
LLM 生成的内容支持以下格式输出:
diff --git a/zh-hans/learn-more/use-cases/dify-on-dingtalk.mdx b/zh-hans/learn-more/use-cases/dify-on-dingtalk.mdx
index e8f2c87a..8e344edc 100644
--- a/zh-hans/learn-more/use-cases/dify-on-dingtalk.mdx
+++ b/zh-hans/learn-more/use-cases/dify-on-dingtalk.mdx
@@ -13,33 +13,7 @@ IM 是天然的智能聊天机器人应用场景,校企用户有不少是使

-
-## 1. 准备工作
-
-1. 安装好 Git、Docker、Docker Compose
-2. 一个有企业应用开发者权限的钉钉账号
-3. 可使用的 Dify 平台(自部署和官方 SaaS 服务都可以)
-4. 一个你是群主的钉钉群,用作测试
-
-然后我们一步一步详细介绍如何操作。
-
-## 2. 详细步骤
-
-### 2.1. 创建 Dify 应用
-
-创建 Dify 应用在本文就不赘述了,可以参考非常详实的 [Dify 官方文档](/zh-hans/guides/application-orchestrate/creating-an-application)。这里你需要知道的是,本文介绍的方法支持接入的 Dify 应用包含了 Dify 目前所有类型。
-
-下图是一个简易方法让你快速识别自己应用的类型,**后续配置时需要明确写明接入应用的类型**。
-
-
-
-另外需要说明的是,虽然所有类型的应用都可以接入,但是根据类型不同也有些限制和区别:
-
-* AGENT 也属于 CHATBOT,聊天助手应用在接入钉钉机器人后是可以保持聊天上下文的(即支持多轮对话),只有本身在 Dify 中支持会话的才可以
-* COMPLETION(文本生成)、WORKFLOW(纯工作流)应用在创建的时候有限制,接收的用户输入 **只能有一个且变量名为 `query`**,因为钉钉对话场景下用户输入是单条消息,所以这里只能设置一个变量。
-
- +
+