From a9d9ca80f80523a3fc1e16846198bb10602abbb7 Mon Sep 17 00:00:00 2001
From: RiskeyL <7a8y@163.com>
Date: Fri, 13 Feb 2026 00:30:16 +0800
Subject: [PATCH] Add jp docs
---
docs.json | 17 +-
ja/use-dify/build/collaboration.mdx | 20 +
ja/use-dify/build/file-system.mdx | 110 ++++
ja/use-dify/build/runtime.mdx | 72 +++
ja/use-dify/nodes/agent.mdx | 480 ++++++++++++++----
ja/use-dify/nodes/command.mdx | 15 +
ja/use-dify/nodes/knowledge-retrieval.mdx | 110 ++--
ja/use-dify/nodes/llm.mdx | 258 ++++++----
ja/use-dify/nodes/tools.mdx | 126 +++--
ja/use-dify/nodes/upload-file-to-sandbox.mdx | 38 ++
.../publish/publish-to-marketplace.mdx | 143 ++++++
ja/use-dify/workspace/app-management.mdx | 121 ++---
ja/use-dify/workspace/tools.mdx | 62 +++
13 files changed, 1193 insertions(+), 379 deletions(-)
create mode 100644 ja/use-dify/build/collaboration.mdx
create mode 100644 ja/use-dify/build/file-system.mdx
create mode 100644 ja/use-dify/build/runtime.mdx
create mode 100644 ja/use-dify/nodes/command.mdx
create mode 100644 ja/use-dify/nodes/upload-file-to-sandbox.mdx
create mode 100644 ja/use-dify/publish/publish-to-marketplace.mdx
create mode 100644 ja/use-dify/workspace/tools.mdx
diff --git a/docs.json b/docs.json
index b3571fce..1df82dae 100644
--- a/docs.json
+++ b/docs.json
@@ -840,11 +840,11 @@
"ja/use-dify/nodes/trigger/webhook-trigger"
]
},
+ "ja/use-dify/nodes/agent",
"ja/use-dify/nodes/llm",
"ja/use-dify/nodes/knowledge-retrieval",
"ja/use-dify/nodes/answer",
"ja/use-dify/nodes/output",
- "ja/use-dify/nodes/agent",
"ja/use-dify/nodes/question-classifier",
"ja/use-dify/nodes/ifelse",
"ja/use-dify/nodes/human-input",
@@ -857,7 +857,9 @@
"ja/use-dify/nodes/variable-assigner",
"ja/use-dify/nodes/parameter-extractor",
"ja/use-dify/nodes/http-request",
+ "ja/use-dify/nodes/command",
"ja/use-dify/nodes/list-operator",
+ "ja/use-dify/nodes/upload-file-to-sandbox",
"ja/use-dify/nodes/tools"
]
},
@@ -865,13 +867,16 @@
"group": "ビルド",
"expanded": false,
"pages": [
- "ja/use-dify/build/shortcut-key",
- "ja/use-dify/build/goto-anything",
+ "ja/use-dify/build/runtime",
"ja/use-dify/build/orchestrate-node",
+ "ja/use-dify/build/file-system",
+ "ja/use-dify/build/collaboration",
+ "ja/use-dify/build/goto-anything",
"ja/use-dify/build/predefined-error-handling-logic",
"ja/use-dify/build/mcp",
"ja/use-dify/build/version-control",
- "ja/use-dify/build/additional-features"
+ "ja/use-dify/build/additional-features",
+ "ja/use-dify/build/shortcut-key"
]
},
{
@@ -901,7 +906,8 @@
]
},
"ja/use-dify/publish/publish-mcp",
- "ja/use-dify/publish/developing-with-apis"
+ "ja/use-dify/publish/developing-with-apis",
+ "ja/use-dify/publish/publish-to-marketplace"
]
},
{
@@ -994,6 +1000,7 @@
"ja/use-dify/workspace/readme",
"ja/use-dify/workspace/model-providers",
"ja/use-dify/workspace/plugins",
+ "ja/use-dify/workspace/tools",
"ja/use-dify/workspace/app-management",
"ja/use-dify/workspace/team-members-management",
"ja/use-dify/workspace/personal-account-management",
diff --git a/ja/use-dify/build/collaboration.mdx b/ja/use-dify/build/collaboration.mdx
new file mode 100644
index 00000000..627142ec
--- /dev/null
+++ b/ja/use-dify/build/collaboration.mdx
@@ -0,0 +1,20 @@
+---
+title: ワークスペースメンバーとの共同作業
+sidebarTitle: コラボレーション
+icon: "users"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/build/collaboration)を参照してください。
+
+編集権限以上を持つワークスペースメンバーは、同じワークフローを同時に編集できます。キャンバスを右クリックして**コメントを追加**を選択し、アイデアを共有できます。
+
+より素早く複数のコメントを追加するには、`C` キーを押してコメントモードに入ります。コメント内で他のメンバーを `@` メンションすると、メールで通知されます。
+
+
+ セルフホスト環境では、コラボレーション機能はデフォルトで無効です。有効にするには、以下の環境変数を設定してください:
+
+ - `ENABLE_COLLABORATION_MODE` = `true`
+ - `SERVER_WORKER_CLASS` = `geventwebsocket.gunicorn.workers.GeventWebSocketWorker`
+
+ カスタムドメインでデプロイする場合は、`NEXT_PUBLIC_SOCKET_URL` に WebSocket サーバーの URL も設定してください。
+
diff --git a/ja/use-dify/build/file-system.mdx b/ja/use-dify/build/file-system.mdx
new file mode 100644
index 00000000..25be4211
--- /dev/null
+++ b/ja/use-dify/build/file-system.mdx
@@ -0,0 +1,110 @@
+---
+title: ファイルシステム
+icon: "folder-tree"
+keyword: skills, skill
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/build/file-system)を参照してください。
+
+[サンドボックスランタイム](/ja/use-dify/build/runtime#サンドボックスランタイム)を使用する各アプリケーションには、LLM が必要に応じてファイルの読み取り、書き込み、処理を行えるファイルシステムがあります。
+
+ファイルシステムには2種類のファイルが含まれます:
+
+- **リソース**:Skill など、アップロードまたは作成された永続ファイル。
+
+- **アーティファクト**:LLM が各実行時に生成する一時ファイル。
+
+ +
+## リソース
+
+リソースはワークフロー用に作成またはインポートしたファイルです。LLM は読み取りのみ可能で、変更はできません。リソースは実行間で永続し、アプリのエクスポート時に含まれます。
+
+### Skill
+
+[Skill](https://agentskills.io/home) は、指示、ナレッジ、スクリプト、その他の参考資料を特定のタスク用にバンドルします——一度定義すれば、ワークフロー間で再利用できます。
+
+たとえば、マーケティングコピーの生成のたびにスタイルガイドラインを繰り返し記述してブランド素材をアップロードする代わりに、すべてを含む `marketing-copy` Skill を作成し、必要なときに参照するだけで済みます。
+
+Skill は詳細な SOP(標準作業手順書)、LLM は能力のある新入社員と考えてください。新入社員は汎用的な能力を持っていますが、会社固有のプロセスは知りません。Skill は必要なすべて——手順、参考資料、使用するツール——を提供し、期待通りにタスクを完了できるようにします。
+
+#### Skill の作成またはインポート
+
+他で使用していた Skill のインポート、用意された Skill テンプレートの利用、またはファイルシステムでのカスタム Skill の直接作成が可能です。
+
+すべての Skill には `SKILL.md` ファイルが必要です。このファイルでタスクの内容、Skill の使用タイミング、実行手順を定義します。
+
+`SKILL.md` 内では、利用可能なリソース(スクリプト、テンプレート、コンテキスト資料、[Dify ツール](/ja/use-dify/workspace/tools))を参照し、いつどのように使用するかを指定できます。
+
+
+
+## リソース
+
+リソースはワークフロー用に作成またはインポートしたファイルです。LLM は読み取りのみ可能で、変更はできません。リソースは実行間で永続し、アプリのエクスポート時に含まれます。
+
+### Skill
+
+[Skill](https://agentskills.io/home) は、指示、ナレッジ、スクリプト、その他の参考資料を特定のタスク用にバンドルします——一度定義すれば、ワークフロー間で再利用できます。
+
+たとえば、マーケティングコピーの生成のたびにスタイルガイドラインを繰り返し記述してブランド素材をアップロードする代わりに、すべてを含む `marketing-copy` Skill を作成し、必要なときに参照するだけで済みます。
+
+Skill は詳細な SOP(標準作業手順書)、LLM は能力のある新入社員と考えてください。新入社員は汎用的な能力を持っていますが、会社固有のプロセスは知りません。Skill は必要なすべて——手順、参考資料、使用するツール——を提供し、期待通りにタスクを完了できるようにします。
+
+#### Skill の作成またはインポート
+
+他で使用していた Skill のインポート、用意された Skill テンプレートの利用、またはファイルシステムでのカスタム Skill の直接作成が可能です。
+
+すべての Skill には `SKILL.md` ファイルが必要です。このファイルでタスクの内容、Skill の使用タイミング、実行手順を定義します。
+
+`SKILL.md` 内では、利用可能なリソース(スクリプト、テンプレート、コンテキスト資料、[Dify ツール](/ja/use-dify/workspace/tools))を参照し、いつどのように使用するかを指定できます。
+
+ +
+#### プロンプトでの Skill の参照
+
+プロンプトエディターで `/` を入力し、**ファイル**タブから Skill フォルダーを選択します。
+
+LLM は最初に Skill のフロントマター(名前、説明、メタデータ)を読み取り、必要な場合にのみ全内容を読み込みます。これによりトークンが節約され、複数の Skill を使用する場合に特に効率的です。
+
+## アーティファクト
+
+アーティファクトは LLM が実行中に生成するファイル——レポート、画像、その他の出力です。LLM はアーティファクトに対して完全な読み書き権限を持ちます。
+
+**Skills** タブまたはキャンバス下部の**変数検査**パネルでアーティファクトのプレビューとダウンロードができます。
+
+### アーティファクトのライフサイクル
+
+アーティファクトはテスト環境と本番環境で異なるライフサイクルを持ちます。アプリのエクスポート時にはアーティファクトは含まれません。
+
+
+
+ アーティファクトはテスト実行間で保持されます。クリアするには、**変数検査**パネルの**すべてリセット**をクリックします。
+
+
+ アーティファクトは各実行にスコープされ、実行完了時に自動的にクリアされます。
+
+
+
+
+ **アーティファクト**の下に `.bashrc` や `.profile` などのシステムファイルが表示されることがあります。これらはサンドボックス環境の一部であり、実行間で保持されます。
+
+
+### エンドユーザーへのアーティファクトの出力
+
+アーティファクトはサンドボックス環境に保存されており、エンドユーザーに直接公開できません。出力するには、別の Agent ノードを通じて抽出する必要があります:
+
+1. ファイルを生成するノードの下流に Agent ノードを追加します。
+
+2. **Agent モード**をオフにし、**構造化出力**を有効にします。
+
+3. ファイル型の構造化出力変数を追加します。
+
+4. **対話履歴の追加**から上流 Agent ノードの対話履歴をインポートします。これにより LLM がファイルパスを特定できます。
+
+5. ユーザーメッセージで、モデルにファイルの抽出と出力を指示します(例:「生成された PDF ファイルを出力してください」)。
+
+6. 回答ノードまたは出力ノードで、Agent ノードのファイル出力変数を参照します。
+
+## サポートされるファイルタイプと操作
+
+ファイルシステム内のすべてのファイルはダウンロード可能です。一部はプレビューや編集も可能です。
+
+
+
+
+ リソースのみ編集可能です。
+
+ - **テキスト**: TXT, MD, MDX, HTML, HTM, XML, CSV
+ - **コード**: Python, JavaScript, JSON, YAML および [Monaco Editor](https://microsoft.github.io/monaco-editor/) がサポートするすべての言語
+ - **設定**: PROPERTIES, VTT
+
+
+ - **ドキュメント**: PDF, DOCX, DOC, XLSX, XLS, PPTX, PPT, EPUB
+ - **画像**: JPG, JPEG, PNG, GIF, WEBP, SVG
+ - **データ**: CSV, TSV, SQLite (.sqlite, .db) - テーブルプレビューのみ
+ - **メール**: EML, MSG
+
+
+ - **音声**: MP3, M4A, WAV, WEBM, AMR
+ - **動画**: MP4, MOV, MPEG, MPGA
+ - **その他**: カスタムファイル拡張子
+
+
diff --git a/ja/use-dify/build/runtime.mdx b/ja/use-dify/build/runtime.mdx
new file mode 100644
index 00000000..36c02a75
--- /dev/null
+++ b/ja/use-dify/build/runtime.mdx
@@ -0,0 +1,72 @@
+---
+title: ランタイム
+icon: "cube"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/build/runtime)を参照してください。
+
+ランタイムはワークフローが実行される環境で、LLM がアクセス・実行できる範囲を定めます。
+
+Dify は2種類のランタイム環境を提供しています:**サンドボックスランタイム**と**クラシックランタイム**。それぞれ異なるユースケースに最適化されています。
+
+## 概要
+
+
+
+
+ **適用シーン:** LLM が自律的に問題を解決する必要がある複雑なタスク。より強力ですが、速度は遅くトークン消費も多くなります。
+
+
+ サンドボックスランタイムでは、LLM が隔離環境で**コマンドラインを実行**できます。ターミナルでコマンドを使ってできることは、すべて LLM にもできます:
+
+ - **スクリプトやプログラムの実行** - コードを実行してデータを処理し、出力を生成し、あらゆる計算を行う
+
+ - **必要なツールのインストール** - pip やその他のパッケージマネージャーを使ってライブラリやツールをオンデマンドでダウンロード
+
+ - **外部リソースへのアクセス** - URL からファイルを取得、リポジトリのクローン、外部ソースからのデータ取得
+
+ - **ファイルの操作** - [ファイルシステム](/ja/use-dify/build/file-system)内のリソース([Skill](/ja/use-dify/build/file-system#skill) など)にアクセスし、さまざまな形式のファイルを処理し、スクリプトやツールを使ってマルチモーダルなアーティファクトを生成
+
+
+ サンドボックスランタイムでは、Agent ノードがクラシックランタイムにおける LLM ノードと Agent ノードの両方の役割を兼ねます。
+
+ これらの高度な機能が不要な簡単なタスクには、**[Agent モード](/ja/use-dify/nodes/agent#コマンド実行の有効化(agent-モード))** をオフにすることで、より高速なレスポンスと低いトークンコストを実現できます。
+
+
+ **LLM が真の Agent になります**。モデルが十分に強力なツール呼び出しと推論能力を持っている限り、どのコマンドを実行すべきかを自律的に判断し、タスクを完了できます。
+
+ LLM の能力が強力になったからこそ、サンドボックスでの実行が必要です。隔離環境は LLM に十分な自由度を与えつつ、安全な運用を保証します。
+
+
+ デフォルトのサンドボックスプロバイダー:
+
+ - Dify Cloud は E2B を使用。
+
+ - セルフホスト環境は SSH VM を使用。
+
+ **設定** > **サンドボックスプロバイダー**で他のプロバイダーを選択・設定できます。
+
+
+
+
+
+
+ **適用シーン:** シンプルで迅速なタスク。機能は限定的ですが、より高速で効率的です。
+
+
+ クラシックランタイムでは、LLM が最も得意とすることを行います:情報の分析、テキストの生成、問題の推論、そして事前設定されたツールの自律的な活用によるタスクの完了です。
+
+ 特定のツールキットを渡すイメージです——タスクは遂行できますが、**提供されたツールの範囲に限定されます**。
+
+
+
+
+## 比較表
+
+| 項目 | サンドボックスランタイム | クラシックランタイム |
+|:------------------------------|:-------------------------------------|:------------------------------------|
+| **適用シーン** | 複雑な自律的問題解決 | シンプルで明確なタスク |
+| **LLM の自律度** | 必要なコマンドを自由に実行 | 設定されたツールを使用 |
+| **ファイルシステム** | ✅ | ❌ |
+| **Skill** | ✅ | ❌ |
+| **アプリのエクスポート形式** | `.zip`(DSL + リソースファイル) | `.yml`(DSL ファイル) |
diff --git a/ja/use-dify/nodes/agent.mdx b/ja/use-dify/nodes/agent.mdx
index 7bdcfc3e..d3378fac 100644
--- a/ja/use-dify/nodes/agent.mdx
+++ b/ja/use-dify/nodes/agent.mdx
@@ -1,118 +1,382 @@
---
-title: "エージェント"
-description: "複雑なタスク実行のためにLLMにツールの自律制御を与える"
+title: "Agent"
+description: "LLM に複雑なタスクを自律的に完了させる"
icon: "robot"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/agent)を参照してください。
-
-エージェントノードは、LLMにツールの自律的な制御権を与え、どのツールをいつ使用するかを反復的に決定できるようにします。すべてのステップを事前に計画する代わりに、エージェントは問題を動的に推論し、複雑なタスクを完了するために必要に応じてツールを呼び出します。
-
-
-
+
+#### プロンプトでの Skill の参照
+
+プロンプトエディターで `/` を入力し、**ファイル**タブから Skill フォルダーを選択します。
+
+LLM は最初に Skill のフロントマター(名前、説明、メタデータ)を読み取り、必要な場合にのみ全内容を読み込みます。これによりトークンが節約され、複数の Skill を使用する場合に特に効率的です。
+
+## アーティファクト
+
+アーティファクトは LLM が実行中に生成するファイル——レポート、画像、その他の出力です。LLM はアーティファクトに対して完全な読み書き権限を持ちます。
+
+**Skills** タブまたはキャンバス下部の**変数検査**パネルでアーティファクトのプレビューとダウンロードができます。
+
+### アーティファクトのライフサイクル
+
+アーティファクトはテスト環境と本番環境で異なるライフサイクルを持ちます。アプリのエクスポート時にはアーティファクトは含まれません。
+
+
+
+ アーティファクトはテスト実行間で保持されます。クリアするには、**変数検査**パネルの**すべてリセット**をクリックします。
+
+
+ アーティファクトは各実行にスコープされ、実行完了時に自動的にクリアされます。
+
+
+
+
+ **アーティファクト**の下に `.bashrc` や `.profile` などのシステムファイルが表示されることがあります。これらはサンドボックス環境の一部であり、実行間で保持されます。
+
+
+### エンドユーザーへのアーティファクトの出力
+
+アーティファクトはサンドボックス環境に保存されており、エンドユーザーに直接公開できません。出力するには、別の Agent ノードを通じて抽出する必要があります:
+
+1. ファイルを生成するノードの下流に Agent ノードを追加します。
+
+2. **Agent モード**をオフにし、**構造化出力**を有効にします。
+
+3. ファイル型の構造化出力変数を追加します。
+
+4. **対話履歴の追加**から上流 Agent ノードの対話履歴をインポートします。これにより LLM がファイルパスを特定できます。
+
+5. ユーザーメッセージで、モデルにファイルの抽出と出力を指示します(例:「生成された PDF ファイルを出力してください」)。
+
+6. 回答ノードまたは出力ノードで、Agent ノードのファイル出力変数を参照します。
+
+## サポートされるファイルタイプと操作
+
+ファイルシステム内のすべてのファイルはダウンロード可能です。一部はプレビューや編集も可能です。
+
+
+
+
+ リソースのみ編集可能です。
+
+ - **テキスト**: TXT, MD, MDX, HTML, HTM, XML, CSV
+ - **コード**: Python, JavaScript, JSON, YAML および [Monaco Editor](https://microsoft.github.io/monaco-editor/) がサポートするすべての言語
+ - **設定**: PROPERTIES, VTT
+
+
+ - **ドキュメント**: PDF, DOCX, DOC, XLSX, XLS, PPTX, PPT, EPUB
+ - **画像**: JPG, JPEG, PNG, GIF, WEBP, SVG
+ - **データ**: CSV, TSV, SQLite (.sqlite, .db) - テーブルプレビューのみ
+ - **メール**: EML, MSG
+
+
+ - **音声**: MP3, M4A, WAV, WEBM, AMR
+ - **動画**: MP4, MOV, MPEG, MPGA
+ - **その他**: カスタムファイル拡張子
+
+
diff --git a/ja/use-dify/build/runtime.mdx b/ja/use-dify/build/runtime.mdx
new file mode 100644
index 00000000..36c02a75
--- /dev/null
+++ b/ja/use-dify/build/runtime.mdx
@@ -0,0 +1,72 @@
+---
+title: ランタイム
+icon: "cube"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/build/runtime)を参照してください。
+
+ランタイムはワークフローが実行される環境で、LLM がアクセス・実行できる範囲を定めます。
+
+Dify は2種類のランタイム環境を提供しています:**サンドボックスランタイム**と**クラシックランタイム**。それぞれ異なるユースケースに最適化されています。
+
+## 概要
+
+
+
+
+ **適用シーン:** LLM が自律的に問題を解決する必要がある複雑なタスク。より強力ですが、速度は遅くトークン消費も多くなります。
+
+
+ サンドボックスランタイムでは、LLM が隔離環境で**コマンドラインを実行**できます。ターミナルでコマンドを使ってできることは、すべて LLM にもできます:
+
+ - **スクリプトやプログラムの実行** - コードを実行してデータを処理し、出力を生成し、あらゆる計算を行う
+
+ - **必要なツールのインストール** - pip やその他のパッケージマネージャーを使ってライブラリやツールをオンデマンドでダウンロード
+
+ - **外部リソースへのアクセス** - URL からファイルを取得、リポジトリのクローン、外部ソースからのデータ取得
+
+ - **ファイルの操作** - [ファイルシステム](/ja/use-dify/build/file-system)内のリソース([Skill](/ja/use-dify/build/file-system#skill) など)にアクセスし、さまざまな形式のファイルを処理し、スクリプトやツールを使ってマルチモーダルなアーティファクトを生成
+
+
+ サンドボックスランタイムでは、Agent ノードがクラシックランタイムにおける LLM ノードと Agent ノードの両方の役割を兼ねます。
+
+ これらの高度な機能が不要な簡単なタスクには、**[Agent モード](/ja/use-dify/nodes/agent#コマンド実行の有効化(agent-モード))** をオフにすることで、より高速なレスポンスと低いトークンコストを実現できます。
+
+
+ **LLM が真の Agent になります**。モデルが十分に強力なツール呼び出しと推論能力を持っている限り、どのコマンドを実行すべきかを自律的に判断し、タスクを完了できます。
+
+ LLM の能力が強力になったからこそ、サンドボックスでの実行が必要です。隔離環境は LLM に十分な自由度を与えつつ、安全な運用を保証します。
+
+
+ デフォルトのサンドボックスプロバイダー:
+
+ - Dify Cloud は E2B を使用。
+
+ - セルフホスト環境は SSH VM を使用。
+
+ **設定** > **サンドボックスプロバイダー**で他のプロバイダーを選択・設定できます。
+
+
+
+
+
+
+ **適用シーン:** シンプルで迅速なタスク。機能は限定的ですが、より高速で効率的です。
+
+
+ クラシックランタイムでは、LLM が最も得意とすることを行います:情報の分析、テキストの生成、問題の推論、そして事前設定されたツールの自律的な活用によるタスクの完了です。
+
+ 特定のツールキットを渡すイメージです——タスクは遂行できますが、**提供されたツールの範囲に限定されます**。
+
+
+
+
+## 比較表
+
+| 項目 | サンドボックスランタイム | クラシックランタイム |
+|:------------------------------|:-------------------------------------|:------------------------------------|
+| **適用シーン** | 複雑な自律的問題解決 | シンプルで明確なタスク |
+| **LLM の自律度** | 必要なコマンドを自由に実行 | 設定されたツールを使用 |
+| **ファイルシステム** | ✅ | ❌ |
+| **Skill** | ✅ | ❌ |
+| **アプリのエクスポート形式** | `.zip`(DSL + リソースファイル) | `.yml`(DSL ファイル) |
diff --git a/ja/use-dify/nodes/agent.mdx b/ja/use-dify/nodes/agent.mdx
index 7bdcfc3e..d3378fac 100644
--- a/ja/use-dify/nodes/agent.mdx
+++ b/ja/use-dify/nodes/agent.mdx
@@ -1,118 +1,382 @@
---
-title: "エージェント"
-description: "複雑なタスク実行のためにLLMにツールの自律制御を与える"
+title: "Agent"
+description: "LLM に複雑なタスクを自律的に完了させる"
icon: "robot"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/agent)を参照してください。
-
-エージェントノードは、LLMにツールの自律的な制御権を与え、どのツールをいつ使用するかを反復的に決定できるようにします。すべてのステップを事前に計画する代わりに、エージェントは問題を動的に推論し、複雑なタスクを完了するために必要に応じてツールを呼び出します。
-
-
-  -
-
-## エージェント戦略
-
-エージェント戦略は、エージェントの思考と行動を定義します。モデルの能力とタスク要件に最も適したアプローチを選択してください。
-
-
-
-
-
-## エージェント戦略
-
-エージェント戦略は、エージェントの思考と行動を定義します。モデルの能力とタスク要件に最も適したアプローチを選択してください。
-
-
-  -
-
-
- 大規模言語モデルのネイティブな関数呼び出し機能を使用して、toolsパラメータを通じてツール定義を直接渡します。大規模言語モデルは、組み込まれたメカニズムを使用して、いつどのようにツールを呼び出すかを決定します。
-
- GPT-4、Claude 3.5、および関数呼び出しサポートが堅牢な他のモデルに最適です。
+
+
+ [サンドボックスランタイム](/ja/use-dify/build/runtime#サンドボックスランタイム)では、Agent ノードは LLM に自律的なコマンドライン実行能力を与えます。ツールの呼び出し、スクリプトの実行、外部リソースへのアクセス、[ファイルシステム](/ja/use-dify/build/file-system)の操作、マルチモーダル出力の生成が可能です。
+
+ これにはトレードオフがあります:レスポンス時間が長くなり、トークン消費も増えます。シンプルなタスクをより速く効率的に処理するには、**[Agent モード](#コマンド実行の有効化(agent-モード))** をオフにしてこれらの機能を無効にできます。
+
+ ## モデルの選択
+
+ 設定済みのプロバイダーからタスクに最適なモデルを選択します。
+
+ 選択後、モデルパラメータを調整してレスポンスの生成方法を制御できます。利用可能なパラメータとプリセットはモデルによって異なります。
+
+ ## プロンプトの作成
+
+ モデルに入力の処理方法とレスポンスの生成方法を指示します。`/` を入力して変数やファイルシステム内のリソースを挿入したり、`@` を入力して [Dify ツール](/ja/use-dify/workspace/tools)を参照したりできます。
+
+ どこから始めればよいかわからない場合や、既存のプロンプトを改善したい場合は、AI アシスト付きプロンプトジェネレーターをお試しください。
+
+
+
+
-
-
-
- 大規模言語モデルのネイティブな関数呼び出し機能を使用して、toolsパラメータを通じてツール定義を直接渡します。大規模言語モデルは、組み込まれたメカニズムを使用して、いつどのようにツールを呼び出すかを決定します。
-
- GPT-4、Claude 3.5、および関数呼び出しサポートが堅牢な他のモデルに最適です。
+
+
+ [サンドボックスランタイム](/ja/use-dify/build/runtime#サンドボックスランタイム)では、Agent ノードは LLM に自律的なコマンドライン実行能力を与えます。ツールの呼び出し、スクリプトの実行、外部リソースへのアクセス、[ファイルシステム](/ja/use-dify/build/file-system)の操作、マルチモーダル出力の生成が可能です。
+
+ これにはトレードオフがあります:レスポンス時間が長くなり、トークン消費も増えます。シンプルなタスクをより速く効率的に処理するには、**[Agent モード](#コマンド実行の有効化(agent-モード))** をオフにしてこれらの機能を無効にできます。
+
+ ## モデルの選択
+
+ 設定済みのプロバイダーからタスクに最適なモデルを選択します。
+
+ 選択後、モデルパラメータを調整してレスポンスの生成方法を制御できます。利用可能なパラメータとプリセットはモデルによって異なります。
+
+ ## プロンプトの作成
+
+ モデルに入力の処理方法とレスポンスの生成方法を指示します。`/` を入力して変数やファイルシステム内のリソースを挿入したり、`@` を入力して [Dify ツール](/ja/use-dify/workspace/tools)を参照したりできます。
+
+ どこから始めればよいかわからない場合や、既存のプロンプトを改善したい場合は、AI アシスト付きプロンプトジェネレーターをお試しください。
+
+
+
+  +
+
+
+
+
+  +
+
+
+ ### 指示とメッセージの指定
+
+ システム指示を定義し、**メッセージを追加**をクリックしてユーザー/アシスタントメッセージを追加します。すべて順番にプロンプトとしてモデルに送信されます。
+
+ モデルと直接会話するイメージです:
+
+ - **システム指示**はモデルのレスポンスルールを設定します——役割、トーン、行動ガイドライン。
+
+ - **ユーザーメッセージ**はモデルに送信する内容——質問、リクエスト、タスク。
+
+ - **アシスタントメッセージ**はモデルのレスポンスです。
+
+ ### 入力とルールの分離
+
+ システム指示で役割とルールを定義し、ユーザーメッセージで実際のタスク入力を渡します。例:
+
+ ```bash wrap
+ # システム指示
+ あなたは子ども向けの物語作家です。ユーザーの入力に基づいて物語を書いてください。簡単な言葉と温かいトーンを使ってください。
+
+ # ユーザーメッセージ
+ ウサギと恥ずかしがり屋のハリネズミが友達になる、おやすみ前のお話を書いてください。
+ ```
+
+ すべてをシステム指示にまとめる方が簡単に見えるかもしれませんが、役割定義とタスク入力を分離することで、モデルにとってより明確な構造になります。
+
+ ### 対話履歴のシミュレーション
+
+ アシスタントメッセージがモデルのレスポンスなら、なぜ手動で追加するのか疑問に思うかもしれません。
+
+ ユーザーメッセージとアシスタントメッセージを交互に追加することで、プロンプト内に対話履歴をシミュレーションできます。モデルはこれらを過去のやり取りとして扱い、動作の誘導に役立ちます。
+
+ ### 上流 LLM からの対話履歴のインポート
+
+ **対話履歴の追加**をクリックして、上流の Agent ノードから対話履歴をインポートします。これによりモデルは上流で何が起こったかを把握し、そのノードが中断したところから続けることができます。
+
+ 対話履歴には**ユーザー**メッセージ、**アシスタント**メッセージ、**ツール**メッセージが含まれます。Agent ノードの `context` 出力変数で確認できます。
+
+
+ システム指示はノード固有のため含まれません。
+
+
+ 複数の Agent ノードを連結する場合に有用です:
+
+ - 対話履歴をインポートしない場合、下流ノードは上流ノードの最終出力のみを受け取り、それがどのように導き出されたかはわかりません。
+
+ - 対話履歴をインポートすると、プロセス全体が見えます:ユーザーが何を質問したか、どのツールが呼び出されたか、どのような結果が返されたか、モデルがどのように推論したか。
+
+ **自動追加されるユーザーメッセージで新しいタスクを指定してください。** インポートされた履歴は現在のノードのメッセージの前に追加されるため、モデルはこれを1つの連続した会話として認識します。インポートされた履歴は通常アシスタントメッセージで終わるため、モデルは次に何をすべきかを知るためのフォローアップユーザーメッセージが必要です。
+
+
+
+ 2つの Agent ノードが順番に実行されるとします:Agent A はデータを分析してチャート画像を生成し、サンドボックスの出力フォルダーに保存します。Agent B はこれらのチャートを含む最終レポートを作成します。
+
+ Agent B が Agent A の最終テキスト出力のみを受け取る場合、分析結論はわかりますが、どのファイルが生成されどこに保存されているかはわかりません。
+
+ Agent A の対話履歴をインポートすることで、Agent B はツールメッセージから正確なファイルパスを確認でき、チャートをレポートに埋め込むことができます。
+
+ Agent A の対話履歴インポート後に Agent B が受け取る完全なメッセージシーケンス:
+
+ ```bash wrap
+ # Agent B のシステム指示
+ 1. System: "あなたはレポートデザイナーです。ビジュアルを埋め込んだプロフェッショナルなレポートを作成してください。"
+
+ # Agent A から
+ 2. User: "Q3 の売上データを分析し、可視化を作成してください。"
+
+ # Agent A から
+ 3. Tool: [bash] 棒グラフを作成:/output/q3_sales_by_region.png
+ 4. Tool: [bash] トレンドラインを作成:/output/q3_monthly_trend.png
+
+ # Agent A から
+ 5. Assistant: "Q3 の売上データを分析し、2つのチャートを作成しました..."
+
+ # Agent B のユーザーメッセージ
+ 6. User: "生成されたチャートを含む PDF レポートを作成してください。"
+ ```
+
+ Agent A の対話履歴をインポートすることで、Agent B はどのファイルが存在し、どこにあるかを正確に把握し、レポートに直接埋め込むことができます。
+
+
+
+
+
+ 例 1 の続きとして、生成された PDF レポートをエンドユーザーに提供したいとします。アーティファクトはエンドユーザーに直接公開できないため、3つ目の Agent ノードでファイルを抽出する必要があります。
+
+ Agent C の設定:
+
+ - **Agent モード**:オフ
+
+ - **構造化出力**:有効にし、ファイル型の出力変数を追加
+
+ - **対話履歴**:Agent B からインポート
+
+ - **ユーザーメッセージ**:「生成された PDF を出力してください。」
+
+ Agent B の対話履歴インポート後に Agent C が受け取る完全なメッセージシーケンス:
+ ```bash wrap
+ # Agent C のシステム指示(省略可)
+ 1. System:(なし)
+
+ # Agent A からのユーザーメッセージとツールメッセージ(簡潔にするため省略)
+ 2. ...
+
+ # Agent B から
+ 3. User: "生成されたチャートを含む PDF レポートを作成してください。"
+
+ # Agent B から
+ 4. Tool: [bash] レポートを作成:/output/q3_sales_report.pdf
+
+ # Agent B から
+ 5. Assistant: "チャートを埋め込んだ PDF レポートを作成しました..."
+
+ # Agent C のユーザーメッセージ
+ 6. User: "生成された PDF を出力してください。"
+ ```
+
+ Agent C はインポートされた対話履歴からファイルパスを特定し、ファイル変数として出力します。その後、回答ノードまたは出力ノードでこの変数を参照し、ファイルをエンドユーザーに提供できます。
+
+
+
+ ### Jinja2 を使った動的プロンプトの作成
+
+ [Jinja2](https://jinja.palletsprojects.com/en/stable/) テンプレートを使って、プロンプトに条件分岐、ループ、その他のロジックを追加できます。例えば、変数の値に応じて指示をカスタマイズできます。
+
+
+ ```jinja2 wrap
+ あなたは
+ {% if user_level == "beginner" %}忍耐強く親切な
+ {% elif user_level == "intermediate" %}プロフェッショナルで効率的な
+ {% else %}シニアエキスパートレベルの
+ {% endif %} アシスタントです。
+
+ {% if user_level == "beginner" %}
+ わかりやすい言葉で説明してください。必要に応じて例を示してください。専門用語は避けてください。
+ {% elif user_level == "intermediate" %} 一部の専門用語を使用できますが、適切な説明を付けてください。実践的なアドバイスとベストプラクティスを提供してください。
+ {% else %} 技術的な詳細に踏み込み、専門用語を使用してください。高度なユースケースと最適化ソリューションに焦点を当ててください。
+ {% endif %}
+ ```
+
+
+ デフォルトでは、すべての可能な指示をモデルに送信し、条件を説明し、どれに従うかをモデルに判断させる必要がありますが、この方法は必ずしも信頼できるとは限りません。
+
+ Jinja2 テンプレートを使えば、定義された条件に合致する指示のみが送信されるため、動作が予測可能になり、トークンの使用量も削減されます。
+
+ ## コマンド実行の有効化(Agent モード)
+
+ **Agent モード**をオンにすると、モデルが組み込みの bash ツールを使ってサンドボックスランタイムでコマンドラインを実行できるようになります。
+
+ これはすべての高度な機能の基盤です:モデルが他のツールを呼び出す、ファイル操作を行う、スクリプトを実行する、外部リソースにアクセスする——これらすべては bash ツールを呼び出して基盤となるコマンドラインを実行することで行われます。
+
+ これらの機能が不要なシンプルなタスクでは、**Agent モード**をオフにすることで、より高速なレスポンスと低いトークンコストを実現できます。
+
+ **最大イテレーション回数の調整**
+
+ **高度な設定**の**最大イテレーション回数**は、モデルが1つのリクエストに対して推論-行動サイクル(思考、ツール呼び出し、結果処理)を繰り返す回数を制限します。
+
+ 複数のツール呼び出しを必要とする複雑なマルチステップタスクでは、この値を増やしてください。値が大きいほどレイテンシとトークンコストが増加します。
+
+ ## 対話メモリの有効化(チャットフローのみ)
+
+
+ メモリはこのノード内でのみ有効です。異なる会話間では保持されません。
+
+
+ **メモリ**を有効にすると最近の対話が保持され、LLM がフォローアップの質問に一貫して回答できるようになります。
+
+ 現在のユーザークエリとアップロードされたファイルを渡すためのユーザーメッセージが自動的に追加されます。これはメモリが最近のユーザー-アシスタント間のやり取りを保存することで機能するためです。ユーザークエリがユーザーメッセージを通じて渡されないと、ユーザー側で記録するものがなくなります。
+
+ **ウィンドウサイズ**は保持する最近のやり取り数を制御します。例えば `5` は、直近の5組のユーザークエリと LLM レスポンスを保持します。
+
+ ## コンテキストの追加
+
+ **高度な設定** > **コンテキスト**で、LLM に追加の参照情報を提供し、ハルシネーションを減らしてレスポンスの精度を向上させます。
+
+ 一般的なパターン:ナレッジ検索ノードから[検索結果を渡す](/ja/use-dify/nodes/knowledge-retrieval#llm-ノードとの連携)ことで、検索拡張生成(RAG)を実現します。
+
+ ## マルチモーダル入力の処理
+
+ マルチモーダル対応モデルに画像、音声、動画、ドキュメントを処理させるには、以下のいずれかの方法を選択します:
+
+ - プロンプトでファイル変数を直接参照する。
+
+ - **高度な設定**で **Vision** を有効にし、ファイル変数を選択する。
+
+ **解像度**は画像処理の詳細レベルのみを制御します:
+
+ - **高**:複雑な画像でより高精度だが、より多くのトークンを使用
+
+ - **低**:シンプルな画像でより高速、より少ないトークンで処理
+
+ マルチモーダル機能を持たないモデルの場合は、[サンドボックスへのファイルアップロード](/ja/use-dify/nodes/upload-file-to-sandbox)ノードでファイルをサンドボックスにアップロードします。Agent ノードがコマンドラインを実行してツールのインストールやスクリプトの実行を行い、モデルがネイティブに処理できないファイル形式も処理できます。
+
+ ## 思考プロセスとツール呼び出しをレスポンスから分離
+
+ モデルの思考プロセスやツール呼び出しを含まないクリーンなレスポンスを取得するには、`generations.content` 出力変数を使用します。
+
+ `generations` 変数自体にはすべての中間ステップと最終レスポンスが含まれます。
+
+ ## 構造化出力の強制
+
+ 指示で出力形式を記述しても、一貫性のない結果が生じることがあります。より信頼性の高いフォーマットを実現するには、構造化出力を有効にして定義済みの JSON スキーマを強制します。
+
+
+ ネイティブ JSON をサポートしないモデルの場合、Dify はスキーマをプロンプトに含めますが、厳密な遵守は保証されません。
+
+
+
+
+
+
+ ### 指示とメッセージの指定
+
+ システム指示を定義し、**メッセージを追加**をクリックしてユーザー/アシスタントメッセージを追加します。すべて順番にプロンプトとしてモデルに送信されます。
+
+ モデルと直接会話するイメージです:
+
+ - **システム指示**はモデルのレスポンスルールを設定します——役割、トーン、行動ガイドライン。
+
+ - **ユーザーメッセージ**はモデルに送信する内容——質問、リクエスト、タスク。
+
+ - **アシスタントメッセージ**はモデルのレスポンスです。
+
+ ### 入力とルールの分離
+
+ システム指示で役割とルールを定義し、ユーザーメッセージで実際のタスク入力を渡します。例:
+
+ ```bash wrap
+ # システム指示
+ あなたは子ども向けの物語作家です。ユーザーの入力に基づいて物語を書いてください。簡単な言葉と温かいトーンを使ってください。
+
+ # ユーザーメッセージ
+ ウサギと恥ずかしがり屋のハリネズミが友達になる、おやすみ前のお話を書いてください。
+ ```
+
+ すべてをシステム指示にまとめる方が簡単に見えるかもしれませんが、役割定義とタスク入力を分離することで、モデルにとってより明確な構造になります。
+
+ ### 対話履歴のシミュレーション
+
+ アシスタントメッセージがモデルのレスポンスなら、なぜ手動で追加するのか疑問に思うかもしれません。
+
+ ユーザーメッセージとアシスタントメッセージを交互に追加することで、プロンプト内に対話履歴をシミュレーションできます。モデルはこれらを過去のやり取りとして扱い、動作の誘導に役立ちます。
+
+ ### 上流 LLM からの対話履歴のインポート
+
+ **対話履歴の追加**をクリックして、上流の Agent ノードから対話履歴をインポートします。これによりモデルは上流で何が起こったかを把握し、そのノードが中断したところから続けることができます。
+
+ 対話履歴には**ユーザー**メッセージ、**アシスタント**メッセージ、**ツール**メッセージが含まれます。Agent ノードの `context` 出力変数で確認できます。
+
+
+ システム指示はノード固有のため含まれません。
+
+
+ 複数の Agent ノードを連結する場合に有用です:
+
+ - 対話履歴をインポートしない場合、下流ノードは上流ノードの最終出力のみを受け取り、それがどのように導き出されたかはわかりません。
+
+ - 対話履歴をインポートすると、プロセス全体が見えます:ユーザーが何を質問したか、どのツールが呼び出されたか、どのような結果が返されたか、モデルがどのように推論したか。
+
+ **自動追加されるユーザーメッセージで新しいタスクを指定してください。** インポートされた履歴は現在のノードのメッセージの前に追加されるため、モデルはこれを1つの連続した会話として認識します。インポートされた履歴は通常アシスタントメッセージで終わるため、モデルは次に何をすべきかを知るためのフォローアップユーザーメッセージが必要です。
+
+
+
+ 2つの Agent ノードが順番に実行されるとします:Agent A はデータを分析してチャート画像を生成し、サンドボックスの出力フォルダーに保存します。Agent B はこれらのチャートを含む最終レポートを作成します。
+
+ Agent B が Agent A の最終テキスト出力のみを受け取る場合、分析結論はわかりますが、どのファイルが生成されどこに保存されているかはわかりません。
+
+ Agent A の対話履歴をインポートすることで、Agent B はツールメッセージから正確なファイルパスを確認でき、チャートをレポートに埋め込むことができます。
+
+ Agent A の対話履歴インポート後に Agent B が受け取る完全なメッセージシーケンス:
+
+ ```bash wrap
+ # Agent B のシステム指示
+ 1. System: "あなたはレポートデザイナーです。ビジュアルを埋め込んだプロフェッショナルなレポートを作成してください。"
+
+ # Agent A から
+ 2. User: "Q3 の売上データを分析し、可視化を作成してください。"
+
+ # Agent A から
+ 3. Tool: [bash] 棒グラフを作成:/output/q3_sales_by_region.png
+ 4. Tool: [bash] トレンドラインを作成:/output/q3_monthly_trend.png
+
+ # Agent A から
+ 5. Assistant: "Q3 の売上データを分析し、2つのチャートを作成しました..."
+
+ # Agent B のユーザーメッセージ
+ 6. User: "生成されたチャートを含む PDF レポートを作成してください。"
+ ```
+
+ Agent A の対話履歴をインポートすることで、Agent B はどのファイルが存在し、どこにあるかを正確に把握し、レポートに直接埋め込むことができます。
+
+
+
+
+
+ 例 1 の続きとして、生成された PDF レポートをエンドユーザーに提供したいとします。アーティファクトはエンドユーザーに直接公開できないため、3つ目の Agent ノードでファイルを抽出する必要があります。
+
+ Agent C の設定:
+
+ - **Agent モード**:オフ
+
+ - **構造化出力**:有効にし、ファイル型の出力変数を追加
+
+ - **対話履歴**:Agent B からインポート
+
+ - **ユーザーメッセージ**:「生成された PDF を出力してください。」
+
+ Agent B の対話履歴インポート後に Agent C が受け取る完全なメッセージシーケンス:
+ ```bash wrap
+ # Agent C のシステム指示(省略可)
+ 1. System:(なし)
+
+ # Agent A からのユーザーメッセージとツールメッセージ(簡潔にするため省略)
+ 2. ...
+
+ # Agent B から
+ 3. User: "生成されたチャートを含む PDF レポートを作成してください。"
+
+ # Agent B から
+ 4. Tool: [bash] レポートを作成:/output/q3_sales_report.pdf
+
+ # Agent B から
+ 5. Assistant: "チャートを埋め込んだ PDF レポートを作成しました..."
+
+ # Agent C のユーザーメッセージ
+ 6. User: "生成された PDF を出力してください。"
+ ```
+
+ Agent C はインポートされた対話履歴からファイルパスを特定し、ファイル変数として出力します。その後、回答ノードまたは出力ノードでこの変数を参照し、ファイルをエンドユーザーに提供できます。
+
+
+
+ ### Jinja2 を使った動的プロンプトの作成
+
+ [Jinja2](https://jinja.palletsprojects.com/en/stable/) テンプレートを使って、プロンプトに条件分岐、ループ、その他のロジックを追加できます。例えば、変数の値に応じて指示をカスタマイズできます。
+
+
+ ```jinja2 wrap
+ あなたは
+ {% if user_level == "beginner" %}忍耐強く親切な
+ {% elif user_level == "intermediate" %}プロフェッショナルで効率的な
+ {% else %}シニアエキスパートレベルの
+ {% endif %} アシスタントです。
+
+ {% if user_level == "beginner" %}
+ わかりやすい言葉で説明してください。必要に応じて例を示してください。専門用語は避けてください。
+ {% elif user_level == "intermediate" %} 一部の専門用語を使用できますが、適切な説明を付けてください。実践的なアドバイスとベストプラクティスを提供してください。
+ {% else %} 技術的な詳細に踏み込み、専門用語を使用してください。高度なユースケースと最適化ソリューションに焦点を当ててください。
+ {% endif %}
+ ```
+
+
+ デフォルトでは、すべての可能な指示をモデルに送信し、条件を説明し、どれに従うかをモデルに判断させる必要がありますが、この方法は必ずしも信頼できるとは限りません。
+
+ Jinja2 テンプレートを使えば、定義された条件に合致する指示のみが送信されるため、動作が予測可能になり、トークンの使用量も削減されます。
+
+ ## コマンド実行の有効化(Agent モード)
+
+ **Agent モード**をオンにすると、モデルが組み込みの bash ツールを使ってサンドボックスランタイムでコマンドラインを実行できるようになります。
+
+ これはすべての高度な機能の基盤です:モデルが他のツールを呼び出す、ファイル操作を行う、スクリプトを実行する、外部リソースにアクセスする——これらすべては bash ツールを呼び出して基盤となるコマンドラインを実行することで行われます。
+
+ これらの機能が不要なシンプルなタスクでは、**Agent モード**をオフにすることで、より高速なレスポンスと低いトークンコストを実現できます。
+
+ **最大イテレーション回数の調整**
+
+ **高度な設定**の**最大イテレーション回数**は、モデルが1つのリクエストに対して推論-行動サイクル(思考、ツール呼び出し、結果処理)を繰り返す回数を制限します。
+
+ 複数のツール呼び出しを必要とする複雑なマルチステップタスクでは、この値を増やしてください。値が大きいほどレイテンシとトークンコストが増加します。
+
+ ## 対話メモリの有効化(チャットフローのみ)
+
+
+ メモリはこのノード内でのみ有効です。異なる会話間では保持されません。
+
+
+ **メモリ**を有効にすると最近の対話が保持され、LLM がフォローアップの質問に一貫して回答できるようになります。
+
+ 現在のユーザークエリとアップロードされたファイルを渡すためのユーザーメッセージが自動的に追加されます。これはメモリが最近のユーザー-アシスタント間のやり取りを保存することで機能するためです。ユーザークエリがユーザーメッセージを通じて渡されないと、ユーザー側で記録するものがなくなります。
+
+ **ウィンドウサイズ**は保持する最近のやり取り数を制御します。例えば `5` は、直近の5組のユーザークエリと LLM レスポンスを保持します。
+
+ ## コンテキストの追加
+
+ **高度な設定** > **コンテキスト**で、LLM に追加の参照情報を提供し、ハルシネーションを減らしてレスポンスの精度を向上させます。
+
+ 一般的なパターン:ナレッジ検索ノードから[検索結果を渡す](/ja/use-dify/nodes/knowledge-retrieval#llm-ノードとの連携)ことで、検索拡張生成(RAG)を実現します。
+
+ ## マルチモーダル入力の処理
+
+ マルチモーダル対応モデルに画像、音声、動画、ドキュメントを処理させるには、以下のいずれかの方法を選択します:
+
+ - プロンプトでファイル変数を直接参照する。
+
+ - **高度な設定**で **Vision** を有効にし、ファイル変数を選択する。
+
+ **解像度**は画像処理の詳細レベルのみを制御します:
+
+ - **高**:複雑な画像でより高精度だが、より多くのトークンを使用
+
+ - **低**:シンプルな画像でより高速、より少ないトークンで処理
+
+ マルチモーダル機能を持たないモデルの場合は、[サンドボックスへのファイルアップロード](/ja/use-dify/nodes/upload-file-to-sandbox)ノードでファイルをサンドボックスにアップロードします。Agent ノードがコマンドラインを実行してツールのインストールやスクリプトの実行を行い、モデルがネイティブに処理できないファイル形式も処理できます。
+
+ ## 思考プロセスとツール呼び出しをレスポンスから分離
+
+ モデルの思考プロセスやツール呼び出しを含まないクリーンなレスポンスを取得するには、`generations.content` 出力変数を使用します。
+
+ `generations` 変数自体にはすべての中間ステップと最終レスポンスが含まれます。
+
+ ## 構造化出力の強制
+
+ 指示で出力形式を記述しても、一貫性のない結果が生じることがあります。より信頼性の高いフォーマットを実現するには、構造化出力を有効にして定義済みの JSON スキーマを強制します。
+
+
+ ネイティブ JSON をサポートしないモデルの場合、Dify はスキーマをプロンプトに含めますが、厳密な遵守は保証されません。
+
+
+  +
+ 1. **出力変数**の横で**構造化**をオンにします。出力変数リストの末尾に `structured_output` 変数が表示されます。
+
+ 2. **設定**をクリックし、以下のいずれかの方法で出力スキーマを定義します。
+
+ - **ビジュアルエディター**:ノーコードインターフェースでシンプルな構造を定義。対応する JSON スキーマが自動生成されます。
+
+ - **JSON Schema**:ネストされたオブジェクト、配列、バリデーションルールを含む複雑な構造のスキーマを直接記述。
+
+ - **AI 生成**:自然言語でニーズを記述し、AI にスキーマを生成させる。
+
+ - **JSON インポート**:既存の JSON オブジェクトを貼り付けて、対応するスキーマを自動生成。
+
+
+ ファイル型の構造化出力変数を使用して、サンドボックスからアーティファクトを抽出し、エンドユーザーに提供できます。詳細は[エンドユーザーへのアーティファクトの出力](/ja/use-dify/build/file-system#エンドユーザーへのアーティファクトの出力)を参照してください。
+
+
+ ## エラー処理
+
+ 一時的な問題(ネットワークの不具合など)に対する自動リトライ、またはエラーが続く場合にワークフローの実行を継続するための代替エラー処理戦略を設定します。
+
+
+
+ 1. **出力変数**の横で**構造化**をオンにします。出力変数リストの末尾に `structured_output` 変数が表示されます。
+
+ 2. **設定**をクリックし、以下のいずれかの方法で出力スキーマを定義します。
+
+ - **ビジュアルエディター**:ノーコードインターフェースでシンプルな構造を定義。対応する JSON スキーマが自動生成されます。
+
+ - **JSON Schema**:ネストされたオブジェクト、配列、バリデーションルールを含む複雑な構造のスキーマを直接記述。
+
+ - **AI 生成**:自然言語でニーズを記述し、AI にスキーマを生成させる。
+
+ - **JSON インポート**:既存の JSON オブジェクトを貼り付けて、対応するスキーマを自動生成。
+
+
+ ファイル型の構造化出力変数を使用して、サンドボックスからアーティファクトを抽出し、エンドユーザーに提供できます。詳細は[エンドユーザーへのアーティファクトの出力](/ja/use-dify/build/file-system#エンドユーザーへのアーティファクトの出力)を参照してください。
+
+
+ ## エラー処理
+
+ 一時的な問題(ネットワークの不具合など)に対する自動リトライ、またはエラーが続く場合にワークフローの実行を継続するための代替エラー処理戦略を設定します。
+
+  +
-
-
- 明示的な推論ステップを通じて大規模言語モデルを導く構造化されたプロンプトを使用します。透明な行動→観察**サイクルに従います。
-
- ネイティブな関数呼び出し機能を持たないモデルや、明示的な推論トレースが必要な場合によく機能します。
+
+
+ クラシックランタイムでは、Agent ノードは LLM にツールの自律的な制御権を与え、どのツールをいつ使用するかを反復的に判断できるようにします。Agent はすべてのステップを事前に計画するのではなく、問題を動的に推論し、必要に応じてツールを呼び出して複雑なタスクを完了します。
+
+
+
+
+
+ ## Agent 戦略
+
+ Agent 戦略は Agent の思考と行動の方法を定義します。モデルの能力とタスクの要件に最も適したアプローチを選択してください。
+
+
+
+
+
+
+
+ LLM のネイティブな Function Calling 機能を使用し、tools パラメータを通じてツール定義を直接渡します。LLM は組み込みメカニズムを使って、いつどのようにツールを呼び出すかを判断します。
+
+ GPT-4、Claude 3.5 など、強力な Function Calling サポートを持つモデルに最適です。
+
+
+
+ 構造化されたプロンプトを使い、LLM を明示的な推論ステップに導きます。**思考 → 行動 → 観察**のサイクルに従い、透明な意思決定を行います。
+
+ ネイティブな Function Calling 機能を持たないモデルや、明示的な推論トレースが必要な場合に適しています。
+
+
+
+
+ **マーケットプレイス → Agent 戦略**から追加の戦略をインストールするか、[コミュニティリポジトリ](https://github.com/langgenius/dify-plugins)にカスタム戦略を提供してください。
+
+
+
+
+
-
-
- 明示的な推論ステップを通じて大規模言語モデルを導く構造化されたプロンプトを使用します。透明な行動→観察**サイクルに従います。
-
- ネイティブな関数呼び出し機能を持たないモデルや、明示的な推論トレースが必要な場合によく機能します。
+
+
+ クラシックランタイムでは、Agent ノードは LLM にツールの自律的な制御権を与え、どのツールをいつ使用するかを反復的に判断できるようにします。Agent はすべてのステップを事前に計画するのではなく、問題を動的に推論し、必要に応じてツールを呼び出して複雑なタスクを完了します。
+
+
+
+
+
+ ## Agent 戦略
+
+ Agent 戦略は Agent の思考と行動の方法を定義します。モデルの能力とタスクの要件に最も適したアプローチを選択してください。
+
+
+
+
+
+
+
+ LLM のネイティブな Function Calling 機能を使用し、tools パラメータを通じてツール定義を直接渡します。LLM は組み込みメカニズムを使って、いつどのようにツールを呼び出すかを判断します。
+
+ GPT-4、Claude 3.5 など、強力な Function Calling サポートを持つモデルに最適です。
+
+
+
+ 構造化されたプロンプトを使い、LLM を明示的な推論ステップに導きます。**思考 → 行動 → 観察**のサイクルに従い、透明な意思決定を行います。
+
+ ネイティブな Function Calling 機能を持たないモデルや、明示的な推論トレースが必要な場合に適しています。
+
+
+
+
+ **マーケットプレイス → Agent 戦略**から追加の戦略をインストールするか、[コミュニティリポジトリ](https://github.com/langgenius/dify-plugins)にカスタム戦略を提供してください。
+
+
+
+  +
+
+ ## 設定
+
+ ### モデル選択
+
+ 選択した Agent 戦略をサポートする LLM を選択します。より高性能なモデルは複雑な推論をより良く処理しますが、イテレーションあたりのコストが高くなります。Function Calling 戦略を使用する場合は、モデルが Function Calling をサポートしていることを確認してください。
+
+ ### ツール設定
+
+ Agent がアクセスできるツールを設定します。各ツールには以下が必要です:
+
+ **認証** - ワークスペースで設定された外部サービスの API キーと認証情報
+
+ **説明** - ツールの機能と使用タイミングの明確な説明(これが Agent の意思決定を導きます)
+
+ **パラメータ** - 適切なバリデーションを伴う必須およびオプションの入力
+
+ ### 指示とコンテキスト
+
+ 自然言語の指示で Agent の役割、目標、コンテキストを定義します。上流のワークフローノードから変数を参照するには Jinja2 構文を使用します。
+
+ **クエリ**は Agent が処理すべきユーザー入力またはタスクを指定します。以前のワークフローノードからの動的コンテンツを使用できます。
+
+
+
+
+
+ ## 設定
+
+ ### モデル選択
+
+ 選択した Agent 戦略をサポートする LLM を選択します。より高性能なモデルは複雑な推論をより良く処理しますが、イテレーションあたりのコストが高くなります。Function Calling 戦略を使用する場合は、モデルが Function Calling をサポートしていることを確認してください。
+
+ ### ツール設定
+
+ Agent がアクセスできるツールを設定します。各ツールには以下が必要です:
+
+ **認証** - ワークスペースで設定された外部サービスの API キーと認証情報
+
+ **説明** - ツールの機能と使用タイミングの明確な説明(これが Agent の意思決定を導きます)
+
+ **パラメータ** - 適切なバリデーションを伴う必須およびオプションの入力
+
+ ### 指示とコンテキスト
+
+ 自然言語の指示で Agent の役割、目標、コンテキストを定義します。上流のワークフローノードから変数を参照するには Jinja2 構文を使用します。
+
+ **クエリ**は Agent が処理すべきユーザー入力またはタスクを指定します。以前のワークフローノードからの動的コンテンツを使用できます。
+
+
+  +
+
+ ### 実行制御
+
+ **最大イテレーション回数**は無限ループを防ぐための安全上限を設定します。タスクの複雑さに応じて設定してください——シンプルなタスクは3〜5回、複雑な調査は10〜15回が目安です。
+
+ **メモリ**は TokenBufferMemory を使って Agent が記憶する過去のメッセージ数を制御します。メモリウィンドウを大きくするとコンテキストが増えますが、トークンコストも増加します。これにより、ユーザーが以前のアクションを参照できる会話の連続性が実現します。
+
+ ### ツールパラメータの自動生成
+
+ ツールには**自動生成**または**手動入力**として設定されたパラメータがあります。自動生成パラメータ(`auto: false`)は Agent が自動的に設定し、手動入力パラメータはツールの永続設定の一部となる明示的な値が必要です。
+
+
+
+ ## 出力変数
+
+ Agent ノードは以下を含む包括的な出力を提供します:
+
+ **最終回答** - クエリに対する Agent の最終レスポンス
+
+ **ツール出力** - 実行中の各ツール呼び出しの結果
+
+ **推論トレース** - ステップごとの意思決定プロセス(特に ReAct 戦略で詳細)。JSON 出力で確認可能
+
+ **イテレーション回数** - 使用された推論サイクル数
+
+ **成功ステータス** - Agent がタスクを正常に完了したかどうか
+
+ **Agent ログ** - デバッグとモニタリングのためのメタデータを含む構造化ログイベント
+
+ ## ユースケース
+
+ **調査と分析** - Agent は複数のソースを自律的に検索し、情報を統合して包括的な回答を提供できます。
+
+ **トラブルシューティング** - 情報の収集、仮説のテスト、発見に基づくアプローチの調整が必要な診断タスク。
+
+ **マルチステップデータ処理** - 次のアクションが中間結果に依存する複雑なワークフロー。
+
+ **動的 API 統合** - API 呼び出しの順序が事前に決定できない応答と条件に依存するシナリオ。
+
+ ## ベストプラクティス
+
+ **明確なツール説明**は、Agent が各ツールをいつどのように効果的に使用するかを理解するのに役立ちます。
+
+ **適切なイテレーション制限**は、複雑なタスクに十分な柔軟性を確保しながらコストの暴走を防ぎます。
+
+ **詳細な指示**は、Agent の役割、目標、制約や優先事項に関するコンテキストを提供します。
+
+ **メモリ管理**は、ユースケースの要件に基づいてコンテキスト保持とトークン効率のバランスをとります。
+
-
-
- **マーケットプレイス → エージェント戦略**から追加戦略をインストールするか、[コミュニティリポジトリ](https://github.com/langgenius/dify-plugins)にカスタム戦略を貢献してください。
-
-
-
-
-
-
-## 設定
-
-### モデル選択
-
-選択したエージェント戦略をサポートする大規模言語モデルを選択してください。より高性能なモデルは複雑な推論をより良く処理しますが、反復あたりのコストが高くなります。その戦略を使用する場合は、モデルが関数呼び出しをサポートしていることを確認してください。
-
-### ツール設定
-
-エージェントがアクセスできるツールを設定します。各ツールには以下が必要です:
-
-**認証** - ワークスペースで設定された外部サービス用のAPIキーと認証情報
-
-**説明** - ツールの機能と使用タイミングの明確な説明(これがエージェントの意思決定を導きます)
-
-**パラメータ** - 適切な検証を伴うツールが受け入れる必須およびオプションの入力
-
-### 指示とコンテキスト
-
-自然言語の指示を使用してエージェントの役割、目標、コンテキストを定義します。上流のワークフローノードから変数を参照するには、Jinja2構文を使用します。
-
-**クエリ**は、エージェントが作業すべきユーザー入力またはタスクを指定します。これは以前のワークフローノードからの動的コンテンツにすることができます。
-
-
-
-
-
-### 実行制御
-
-**最大反復数**は、無限ループを防ぐための安全制限を設定します。タスクの複雑さに基づいて設定してください - 単純なタスクには3-5回の反復が必要ですが、複雑な調査には10-15回必要な場合があります。
-
-**メモリ**は、TokenBufferMemoryを使用してエージェントが記憶する過去のメッセージ数を制御します。より大きなメモリウィンドウはより多くのコンテキストを提供しますが、トークンコストが増加します。これにより、ユーザーが以前のアクションを参照できる会話の継続性が可能になります。
-
-### ツールパラメータ自動生成
-
-ツールには**自動生成**または**手動入力**として設定されたパラメータがあります。自動生成パラメータ(`auto: false`)はエージェントによって自動的に設定され、手動入力パラメータはツールの永続的な設定の一部となる明示的な値が必要です。
-
-
-
-## 出力変数
-
-エージェントノードは以下を含む包括的な出力を提供します:
-
-**最終回答** - クエリに対するエージェントの最終的な応答
-
-**ツール出力** - 実行中の各ツール呼び出しからの結果
-
-**推論トレース** - JSON出力で利用可能なステップバイステップの決定プロセス(特に推論と行動戦略で詳細)
-
-**反復回数** - 使用された推論サイクルの数
-
-**成功ステータス** - エージェントがタスクを正常に完了したかどうか
-
-**エージェントログ** - ツール呼び出しのデバッグと監視のためのメタデータを含む構造化されたログイベント
-
-## 使用例
-
-**調査と分析** - エージェントは複数のソースを自律的に検索し、情報を統合し、包括的。
-
-**トラブルシューティング** - エージェントが情報を収集し、仮説をテストし、発見に基づいてアプローチを適応させる必要がある診断タスク。
-
-**マルチステップデータ処理** - 次のアクションが中間結果に依存する複雑なワークフロー。
-
-**動的API統合** - API呼び出しの順序が事前に決定できない応答と条件に依存するシナリオ。
-
-## ベストプラクティス
-
-**明確なツール説明**は、エージェントが各ツールをいつどのように効果的に使用するかを理解するのに役立ちます。
-
-**適切な反復制限**は、複雑なタスクに対して十分な柔軟性を確保しながら、暴走コストを防ぎます。
-
-**詳細な指示**は、エージェントの役割、目標、制約や好みについてのコンテキストを提供します。
-
-**メモリ管理**は、使用例の要件に基づいて、コンテキスト保持とトークン効率のバランスを取ります。
diff --git a/ja/use-dify/nodes/command.mdx b/ja/use-dify/nodes/command.mdx
new file mode 100644
index 00000000..8ee66361
--- /dev/null
+++ b/ja/use-dify/nodes/command.mdx
@@ -0,0 +1,15 @@
+---
+title: コマンド実行
+description: ワークフロー内でシェルコマンドを直接実行
+icon: "rectangle-terminal"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/command)を参照してください。
+
+
+ このノードはサンドボックスランタイムを使用するアプリケーションでのみ利用可能です。
+
+
+Agent ノードはコマンドラインを自律的に実行できますが、実行するコマンドが明確で LLM の推論が不要な場合は、コマンド実行ノードの方が適しています。より高速で、トークンを消費しません。
+
+コマンドはデフォルトでルートディレクトリで実行されます。別の作業ディレクトリを使用するには、既存のパスまたは実行中に上流ノードによって作成されるパスを入力してください。
diff --git a/ja/use-dify/nodes/knowledge-retrieval.mdx b/ja/use-dify/nodes/knowledge-retrieval.mdx
index 3c73bd49..6b702f27 100644
--- a/ja/use-dify/nodes/knowledge-retrieval.mdx
+++ b/ja/use-dify/nodes/knowledge-retrieval.mdx
@@ -1,37 +1,33 @@
---
-title: 知識検索
+title: ナレッジ検索
icon: "database"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/knowledge-retrieval)を参照してください。
-## はじめに
+ナレッジ検索ノードを使用して、既存のナレッジベースをワークフローに統合します。このノードは特定のナレッジからクエリに関連する情報を検索し、下流ノード(LLM など)で使用するコンテキスト情報として結果を出力します。
-知識検索ノードを使用すると、既存のナレッジベースをChatflowやワークフローに統合できます。このノードは指定されたナレッジからクエリに関連する情報を検索し、その結果を下流ノード(例:LLM)で利用できるコンテキスト情報として出力します。
+以下はチャットフローでナレッジ検索ノードを使用する例です:
-以下はChatflowにおける知識検索ノードの利用例です:
+1. **ユーザー入力**ノードがユーザーのクエリを収集します。
-1. **ユーザー入力** ノードがユーザーの質問を収集します。
+2. **ナレッジ検索**ノードが選択されたナレッジベースからユーザーのクエリに関連するコンテンツを検索し、結果を出力します。
-2. **知識検索** ノードが選択されたナレッジベースからユーザーの質問に関連するコンテンツを検索し、検索結果を出力します。
+3. **LLM** ノードがユーザーのクエリと検索されたナレッジの両方に基づいてレスポンスを生成します。
-3. **LLM** ノードがユーザーの質問と検索されたナレッジの両方をもとに回答を生成します。
+4. **回答**ノードが LLM のレスポンスをユーザーに返します。
-4. **回答** ノードがLLMの応答をユーザーへ返します。
+
-
+ナレッジ検索ノードを使用する前に、少なくとも1つの利用可能なナレッジベースがあることを確認してください。ナレッジベースの作成方法については、[ナレッジ](/ja/use-dify/knowledge/readme#ナレッジの作成)を参照してください。
- 知識検索ノードを使用する前に、少なくとも1つのナレッジベースが利用可能であることを確認してください。ナレッジベースの作成方法については、[ナレッジ](/ja/use-dify/knowledge/readme#ナレッジの作成)を参照してください。
+ Dify Cloud では、ナレッジ検索の操作は契約プランに応じたレート制限が適用されます。詳細は[ナレッジリクエストレート制限](/ja/use-dify/knowledge/knowledge-request-rate-limit)を参照してください。
-
- Dify Cloudでは、知識検索の操作は契約プランに応じたレートリミットが適用されます。詳細は[ナレッジベースの要求頻度制限](/ja/use-dify/knowledge/knowledge-request-rate-limit)を参照してください。
-
+## ナレッジ検索ノードの設定
-## 設定
-
-知識検索ノードを正常に機能させるには、次の点を指定する必要があります:
+ナレッジ検索ノードを正しく機能させるには、以下を指定する必要があります:
- **何を**検索するか(クエリ)
@@ -39,98 +35,90 @@ icon: "database"
- **どのように**検索結果を処理するか(ノードレベルの検索設定)
-また、ドキュメントのメタデータを利用してフィルタベースの検索を有効化し、検索精度をさらに向上させることもできます。
+また、ドキュメントのメタデータを使用してフィルタベースの検索を有効にし、検索精度をさらに向上させることもできます。
### クエリの指定
-ノードが選択されたナレッジベースで検索するクエリ内容を指定します。
+選択したナレッジベースでノードが検索するクエリ内容を指定します。
-- **クエリテキスト**:テキスト変数を選択します。たとえば、Chatflowでは`userinput.query`を使用してユーザー入力を参照したり、ワークフローではカスタムのテキスト型ユーザー入力変数を使用したりできます。
+- **クエリテキスト**:テキスト変数を選択します。例えば、チャットフローでは `userinput.query` でユーザー入力を参照したり、ワークフローではカスタムのテキスト型ユーザー入力変数を使用したりできます。
-- **クエリ画像**:画像変数を選択します。例えば、ユーザー入力ノードを通じてユーザーがアップロードした画像を使用して画像検索を行います。画像サイズの上限は2 MBです。
+- **クエリ画像**:画像変数を選択します。例えば、ユーザー入力ノードを通じてユーザーがアップロードした画像を使用して画像検索を行います。画像サイズの上限は 2 MB です。
- セルフホスト環境では、環境変数`ATTACHMENT_IMAGE_FILE_SIZE_LIMIT`を変更することで画像サイズ上限を調整できます。
+ セルフホスト環境では、環境変数 `ATTACHMENT_IMAGE_FILE_SIZE_LIMIT` で画像サイズの上限を調整できます。
- **クエリ画像**オプションは、少なくとも1つのマルチモーダルナレッジベースが追加されている場合のみ利用できます。
+ **クエリ画像**オプションは、少なくとも1つのマルチモーダルナレッジベースが追加されている場合のみ利用可能です。
- そのようなナレッジベースには**Vision**アイコンが表示されており、マルチモーダル埋め込みモデルを使用していることを示しています。
+ そのようなナレッジベースには **Vision** タグが付いており、マルチモーダル埋め込みモデルを使用していることを示しています。
-### 検索対象ナレッジベースの選択
+### 検索対象のナレッジを選択
-ノードでクエリ内容に関連するコンテンツを検索するためのナレッジベースを1つ以上追加します。
+クエリに関連するコンテンツを検索するためのナレッジベースを1つ以上追加します。
-複数のナレッジベースを追加した場合、まずすべてのナレッジベースから同時に検索を行い、その後[ノードレベルの検索設定](#ノードレベルの検索設定)に従って結果を統合・処理します。
+複数のナレッジベースを追加した場合、まずすべてから同時に検索が行われ、その後[ノードレベルの検索設定](#ノードレベルの検索設定)に従って結果が統合・処理されます。
- **Vision**アイコンが付いたナレッジベースはクロスモーダル検索をサポートしており、セマンティックな関連性に基づいてテキストと画像の両方を検索できます。
+ **Vision** タグが付いたナレッジベースはクロスモーダル検索をサポートしており、セマンティックな関連性に基づいてテキストと画像の両方を検索できます。
-
- 追加したナレッジベースの横にある**編集**アイコンをクリックすると、知識検索ノード内で直接その設定を変更できます。
-
- これらの設定の詳細については、[ナレッジ設定の管理](/ja/use-dify/knowledge/manage-knowledge/introduction)をご覧ください。
-
+追加したナレッジベースの横にある**編集**アイコンをクリックすると、[設定](/ja/use-dify/knowledge/manage-knowledge/introduction)を変更できます。
### ノードレベルの検索設定
-ナレッジベースから取得した検索結果を、ノード内でどのように処理するかを微調整できます。
+ナレッジベースから取得された検索結果をノードでどのように処理するかを微調整します。
- 検索設定には2つのレイヤーがあります—ナレッジベースレベルと知識検索ノードレベルです。
-
- これらは2つの連続したフィルターと考えてください:ナレッジベースの設定が最初の結果プールを決定し、ノードの設定がさらに結果を再ランク付けまたは絞り込みます。
+ 検索設定には2つのレイヤーがあります——ナレッジベースレベルとナレッジ検索ノードレベルです。
+
+ 2つの連続したフィルターと考えてください:ナレッジベースの設定が最初の結果プールを決定し、ノードの設定がさらに結果を再ランク付けまたは絞り込みます。
-- **Rerank設定**
+- **Rerank 設定**
- - **ウェイト設定**:再ランク付け時におけるセマンティック類似度とキーワード一致の相対的な比重です。セマンティックの比重を高くすると意味的関連性を重視し、キーワードの比重を高くすると正確な一致を重視します。
+ - **加重スコア**:再ランク付け時のセマンティック類似度とキーワード一致の相対的な重み。セマンティックの重みを高くすると意味的な関連性が優先され、キーワードの重みを高くすると完全一致が優先されます。
- **ウェイト設定**は、追加したナレッジベースがすべて高品質タイプである場合のみ利用できます。
+ **加重スコア**は、追加されたすべてのナレッジベースが高品質タイプの場合にのみ利用可能です。
- - **Rerankモデル**:クエリとの関連度に基づいてすべての結果を再スコアリング・並べ替えするRerankモデルです。
+ - **Rerank モデル**:クエリとの関連度に基づいてすべての結果を再スコアリング・並べ替えする Rerank モデルです。
-
- マルチモーダルナレッジベースが追加されている場合は、マルチモーダルRerankモデル(**Vision**アイコン付き)も選択してください。そうでない場合、検索された画像は再ランク付けおよび最終出力から除外されます。
-
+
+ マルチモーダルナレッジベースが追加されている場合は、マルチモーダル Rerank モデル(**Vision** タグ付き)も選択してください。そうでないと、検索された画像が再ランク付けと最終出力から除外されます。
+
-- **トップK**:再ランク後に返す結果の最大件数です。Rerankモデルを選択している場合、この値はモデルの最大入力容量(モデルが一度に処理できるテキスト量)に基づいて自動的に調整されます。
+- **トップ K**:再ランク付け後に返す上位結果の最大数。Rerank モデルを選択している場合、この値はモデルの最大入力容量(一度に処理可能なテキスト量)に基づいて自動調整されます。
-- **スコア閾値**:返される結果の最低類似度スコアです。この閾値未満の結果は除外されます。高めに設定すると関連性の厳密な検索が行われ、低めにするとより広範なマッチを含めることができます。
+- **スコア閾値**:返される結果の最低類似度スコア。この閾値未満の結果は除外されます。高めの閾値は厳密な関連性を、低めの閾値はより広範なマッチを含めます。
-### メタデータフィルタの有効化
+### メタデータフィルタリングの有効化
-既存のドキュメントメタデータを使用して、ナレッジベース内の特定のドキュメントに検索を制限し、検索精度を向上させます。
+既存の[ドキュメントメタデータ](/ja/use-dify/knowledge/metadata)を使用して、ナレッジベース内の特定のドキュメントに検索を制限し、検索精度を向上させます。
-メタデータフィルタを有効にすると、知識検索ノードはナレッジベース全体を検索するのではなく、指定されたメタデータ条件に一致するドキュメントのみを検索します。これは、大規模で多様なナレッジベースでのターゲット検索に特に有用です。
-
-
- ドキュメントメタデータの作成と管理については、[メタデータ](/ja/use-dify/knowledge/metadata)を参照してください。
-
+メタデータフィルタリングを有効にすると、ナレッジ検索ノードはナレッジベース全体ではなく、指定されたメタデータ条件に一致するドキュメントのみを検索します。大規模で多様なナレッジベースでの絞り込み検索に特に有用です。
## 出力
-知識検索ノードの出力は`result`という変数として返されます。この変数は検索されたドキュメントチャンクの配列で、各チャンクにはコンテンツ、メタデータ、タイトル、その他の属性が含まれます。
+ナレッジ検索ノードは `result` という名前の変数として検索結果を出力します。これはドキュメントチャンクの配列で、各チャンクにはコンテンツ、メタデータ、タイトル、その他の属性が含まれます。
-検索結果に画像添付が含まれる場合、`result`変数には画像メタデータを含む`files`というフィールドも含まれます。
+検索結果に画像添付が含まれる場合、`result` 変数には画像の詳細を含む `files` フィールドも含まれます。
-## LLMノードとの連携
+## LLM ノードとの連携
-LLMノードでユーザーの質問に回答するためのコンテキストとして検索結果を使用するには:
+LLM ノードで検索結果をコンテキストとして使用するには:
-1. **コンテキスト**フィールドで、知識検索ノードの`result`変数を選択します。
+1. **高度な設定** > **コンテキスト**で、ナレッジ検索ノードの `result` 変数を選択します。
-2. プロンプトフィールドで、`Context`変数とユーザー入力変数(例:Chatflowの`userinput.query`)の両方を参照します。
+2. システム指示で `Context` 変数を参照します。
-3. (任意)LLMがVision機能に対応している場合(**Vision**アイコン付き)、**Vision**を有効にして検索された画像を解釈させることができます。
+3. 省略可:LLM が Vision 対応の場合、**Vision** を有効にして検索結果内の画像添付を処理させます。
- **Vision**を有効にすると、LLMは検索された画像を自動的に処理します。**Vision**入力フィールドで`Context`変数を再度手動で参照する必要はありません。
+ 検索結果を Vision の入力として指定する必要はありません。**Vision** を有効にすると、LLM は検索された画像を自動的に処理します。
-
+
+
+ ### 実行制御
+
+ **最大イテレーション回数**は無限ループを防ぐための安全上限を設定します。タスクの複雑さに応じて設定してください——シンプルなタスクは3〜5回、複雑な調査は10〜15回が目安です。
+
+ **メモリ**は TokenBufferMemory を使って Agent が記憶する過去のメッセージ数を制御します。メモリウィンドウを大きくするとコンテキストが増えますが、トークンコストも増加します。これにより、ユーザーが以前のアクションを参照できる会話の連続性が実現します。
+
+ ### ツールパラメータの自動生成
+
+ ツールには**自動生成**または**手動入力**として設定されたパラメータがあります。自動生成パラメータ(`auto: false`)は Agent が自動的に設定し、手動入力パラメータはツールの永続設定の一部となる明示的な値が必要です。
+
+
+
+ ## 出力変数
+
+ Agent ノードは以下を含む包括的な出力を提供します:
+
+ **最終回答** - クエリに対する Agent の最終レスポンス
+
+ **ツール出力** - 実行中の各ツール呼び出しの結果
+
+ **推論トレース** - ステップごとの意思決定プロセス(特に ReAct 戦略で詳細)。JSON 出力で確認可能
+
+ **イテレーション回数** - 使用された推論サイクル数
+
+ **成功ステータス** - Agent がタスクを正常に完了したかどうか
+
+ **Agent ログ** - デバッグとモニタリングのためのメタデータを含む構造化ログイベント
+
+ ## ユースケース
+
+ **調査と分析** - Agent は複数のソースを自律的に検索し、情報を統合して包括的な回答を提供できます。
+
+ **トラブルシューティング** - 情報の収集、仮説のテスト、発見に基づくアプローチの調整が必要な診断タスク。
+
+ **マルチステップデータ処理** - 次のアクションが中間結果に依存する複雑なワークフロー。
+
+ **動的 API 統合** - API 呼び出しの順序が事前に決定できない応答と条件に依存するシナリオ。
+
+ ## ベストプラクティス
+
+ **明確なツール説明**は、Agent が各ツールをいつどのように効果的に使用するかを理解するのに役立ちます。
+
+ **適切なイテレーション制限**は、複雑なタスクに十分な柔軟性を確保しながらコストの暴走を防ぎます。
+
+ **詳細な指示**は、Agent の役割、目標、制約や優先事項に関するコンテキストを提供します。
+
+ **メモリ管理**は、ユースケースの要件に基づいてコンテキスト保持とトークン効率のバランスをとります。
+
-
-
- **マーケットプレイス → エージェント戦略**から追加戦略をインストールするか、[コミュニティリポジトリ](https://github.com/langgenius/dify-plugins)にカスタム戦略を貢献してください。
-
-
-
-
-
-
-## 設定
-
-### モデル選択
-
-選択したエージェント戦略をサポートする大規模言語モデルを選択してください。より高性能なモデルは複雑な推論をより良く処理しますが、反復あたりのコストが高くなります。その戦略を使用する場合は、モデルが関数呼び出しをサポートしていることを確認してください。
-
-### ツール設定
-
-エージェントがアクセスできるツールを設定します。各ツールには以下が必要です:
-
-**認証** - ワークスペースで設定された外部サービス用のAPIキーと認証情報
-
-**説明** - ツールの機能と使用タイミングの明確な説明(これがエージェントの意思決定を導きます)
-
-**パラメータ** - 適切な検証を伴うツールが受け入れる必須およびオプションの入力
-
-### 指示とコンテキスト
-
-自然言語の指示を使用してエージェントの役割、目標、コンテキストを定義します。上流のワークフローノードから変数を参照するには、Jinja2構文を使用します。
-
-**クエリ**は、エージェントが作業すべきユーザー入力またはタスクを指定します。これは以前のワークフローノードからの動的コンテンツにすることができます。
-
-
-
-
-
-### 実行制御
-
-**最大反復数**は、無限ループを防ぐための安全制限を設定します。タスクの複雑さに基づいて設定してください - 単純なタスクには3-5回の反復が必要ですが、複雑な調査には10-15回必要な場合があります。
-
-**メモリ**は、TokenBufferMemoryを使用してエージェントが記憶する過去のメッセージ数を制御します。より大きなメモリウィンドウはより多くのコンテキストを提供しますが、トークンコストが増加します。これにより、ユーザーが以前のアクションを参照できる会話の継続性が可能になります。
-
-### ツールパラメータ自動生成
-
-ツールには**自動生成**または**手動入力**として設定されたパラメータがあります。自動生成パラメータ(`auto: false`)はエージェントによって自動的に設定され、手動入力パラメータはツールの永続的な設定の一部となる明示的な値が必要です。
-
-
-
-## 出力変数
-
-エージェントノードは以下を含む包括的な出力を提供します:
-
-**最終回答** - クエリに対するエージェントの最終的な応答
-
-**ツール出力** - 実行中の各ツール呼び出しからの結果
-
-**推論トレース** - JSON出力で利用可能なステップバイステップの決定プロセス(特に推論と行動戦略で詳細)
-
-**反復回数** - 使用された推論サイクルの数
-
-**成功ステータス** - エージェントがタスクを正常に完了したかどうか
-
-**エージェントログ** - ツール呼び出しのデバッグと監視のためのメタデータを含む構造化されたログイベント
-
-## 使用例
-
-**調査と分析** - エージェントは複数のソースを自律的に検索し、情報を統合し、包括的。
-
-**トラブルシューティング** - エージェントが情報を収集し、仮説をテストし、発見に基づいてアプローチを適応させる必要がある診断タスク。
-
-**マルチステップデータ処理** - 次のアクションが中間結果に依存する複雑なワークフロー。
-
-**動的API統合** - API呼び出しの順序が事前に決定できない応答と条件に依存するシナリオ。
-
-## ベストプラクティス
-
-**明確なツール説明**は、エージェントが各ツールをいつどのように効果的に使用するかを理解するのに役立ちます。
-
-**適切な反復制限**は、複雑なタスクに対して十分な柔軟性を確保しながら、暴走コストを防ぎます。
-
-**詳細な指示**は、エージェントの役割、目標、制約や好みについてのコンテキストを提供します。
-
-**メモリ管理**は、使用例の要件に基づいて、コンテキスト保持とトークン効率のバランスを取ります。
diff --git a/ja/use-dify/nodes/command.mdx b/ja/use-dify/nodes/command.mdx
new file mode 100644
index 00000000..8ee66361
--- /dev/null
+++ b/ja/use-dify/nodes/command.mdx
@@ -0,0 +1,15 @@
+---
+title: コマンド実行
+description: ワークフロー内でシェルコマンドを直接実行
+icon: "rectangle-terminal"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/command)を参照してください。
+
+
+ このノードはサンドボックスランタイムを使用するアプリケーションでのみ利用可能です。
+
+
+Agent ノードはコマンドラインを自律的に実行できますが、実行するコマンドが明確で LLM の推論が不要な場合は、コマンド実行ノードの方が適しています。より高速で、トークンを消費しません。
+
+コマンドはデフォルトでルートディレクトリで実行されます。別の作業ディレクトリを使用するには、既存のパスまたは実行中に上流ノードによって作成されるパスを入力してください。
diff --git a/ja/use-dify/nodes/knowledge-retrieval.mdx b/ja/use-dify/nodes/knowledge-retrieval.mdx
index 3c73bd49..6b702f27 100644
--- a/ja/use-dify/nodes/knowledge-retrieval.mdx
+++ b/ja/use-dify/nodes/knowledge-retrieval.mdx
@@ -1,37 +1,33 @@
---
-title: 知識検索
+title: ナレッジ検索
icon: "database"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/knowledge-retrieval)を参照してください。
-## はじめに
+ナレッジ検索ノードを使用して、既存のナレッジベースをワークフローに統合します。このノードは特定のナレッジからクエリに関連する情報を検索し、下流ノード(LLM など)で使用するコンテキスト情報として結果を出力します。
-知識検索ノードを使用すると、既存のナレッジベースをChatflowやワークフローに統合できます。このノードは指定されたナレッジからクエリに関連する情報を検索し、その結果を下流ノード(例:LLM)で利用できるコンテキスト情報として出力します。
+以下はチャットフローでナレッジ検索ノードを使用する例です:
-以下はChatflowにおける知識検索ノードの利用例です:
+1. **ユーザー入力**ノードがユーザーのクエリを収集します。
-1. **ユーザー入力** ノードがユーザーの質問を収集します。
+2. **ナレッジ検索**ノードが選択されたナレッジベースからユーザーのクエリに関連するコンテンツを検索し、結果を出力します。
-2. **知識検索** ノードが選択されたナレッジベースからユーザーの質問に関連するコンテンツを検索し、検索結果を出力します。
+3. **LLM** ノードがユーザーのクエリと検索されたナレッジの両方に基づいてレスポンスを生成します。
-3. **LLM** ノードがユーザーの質問と検索されたナレッジの両方をもとに回答を生成します。
+4. **回答**ノードが LLM のレスポンスをユーザーに返します。
-4. **回答** ノードがLLMの応答をユーザーへ返します。
+
-
+ナレッジ検索ノードを使用する前に、少なくとも1つの利用可能なナレッジベースがあることを確認してください。ナレッジベースの作成方法については、[ナレッジ](/ja/use-dify/knowledge/readme#ナレッジの作成)を参照してください。
- 知識検索ノードを使用する前に、少なくとも1つのナレッジベースが利用可能であることを確認してください。ナレッジベースの作成方法については、[ナレッジ](/ja/use-dify/knowledge/readme#ナレッジの作成)を参照してください。
+ Dify Cloud では、ナレッジ検索の操作は契約プランに応じたレート制限が適用されます。詳細は[ナレッジリクエストレート制限](/ja/use-dify/knowledge/knowledge-request-rate-limit)を参照してください。
-
- Dify Cloudでは、知識検索の操作は契約プランに応じたレートリミットが適用されます。詳細は[ナレッジベースの要求頻度制限](/ja/use-dify/knowledge/knowledge-request-rate-limit)を参照してください。
-
+## ナレッジ検索ノードの設定
-## 設定
-
-知識検索ノードを正常に機能させるには、次の点を指定する必要があります:
+ナレッジ検索ノードを正しく機能させるには、以下を指定する必要があります:
- **何を**検索するか(クエリ)
@@ -39,98 +35,90 @@ icon: "database"
- **どのように**検索結果を処理するか(ノードレベルの検索設定)
-また、ドキュメントのメタデータを利用してフィルタベースの検索を有効化し、検索精度をさらに向上させることもできます。
+また、ドキュメントのメタデータを使用してフィルタベースの検索を有効にし、検索精度をさらに向上させることもできます。
### クエリの指定
-ノードが選択されたナレッジベースで検索するクエリ内容を指定します。
+選択したナレッジベースでノードが検索するクエリ内容を指定します。
-- **クエリテキスト**:テキスト変数を選択します。たとえば、Chatflowでは`userinput.query`を使用してユーザー入力を参照したり、ワークフローではカスタムのテキスト型ユーザー入力変数を使用したりできます。
+- **クエリテキスト**:テキスト変数を選択します。例えば、チャットフローでは `userinput.query` でユーザー入力を参照したり、ワークフローではカスタムのテキスト型ユーザー入力変数を使用したりできます。
-- **クエリ画像**:画像変数を選択します。例えば、ユーザー入力ノードを通じてユーザーがアップロードした画像を使用して画像検索を行います。画像サイズの上限は2 MBです。
+- **クエリ画像**:画像変数を選択します。例えば、ユーザー入力ノードを通じてユーザーがアップロードした画像を使用して画像検索を行います。画像サイズの上限は 2 MB です。
- セルフホスト環境では、環境変数`ATTACHMENT_IMAGE_FILE_SIZE_LIMIT`を変更することで画像サイズ上限を調整できます。
+ セルフホスト環境では、環境変数 `ATTACHMENT_IMAGE_FILE_SIZE_LIMIT` で画像サイズの上限を調整できます。
- **クエリ画像**オプションは、少なくとも1つのマルチモーダルナレッジベースが追加されている場合のみ利用できます。
+ **クエリ画像**オプションは、少なくとも1つのマルチモーダルナレッジベースが追加されている場合のみ利用可能です。
- そのようなナレッジベースには**Vision**アイコンが表示されており、マルチモーダル埋め込みモデルを使用していることを示しています。
+ そのようなナレッジベースには **Vision** タグが付いており、マルチモーダル埋め込みモデルを使用していることを示しています。
-### 検索対象ナレッジベースの選択
+### 検索対象のナレッジを選択
-ノードでクエリ内容に関連するコンテンツを検索するためのナレッジベースを1つ以上追加します。
+クエリに関連するコンテンツを検索するためのナレッジベースを1つ以上追加します。
-複数のナレッジベースを追加した場合、まずすべてのナレッジベースから同時に検索を行い、その後[ノードレベルの検索設定](#ノードレベルの検索設定)に従って結果を統合・処理します。
+複数のナレッジベースを追加した場合、まずすべてから同時に検索が行われ、その後[ノードレベルの検索設定](#ノードレベルの検索設定)に従って結果が統合・処理されます。
- **Vision**アイコンが付いたナレッジベースはクロスモーダル検索をサポートしており、セマンティックな関連性に基づいてテキストと画像の両方を検索できます。
+ **Vision** タグが付いたナレッジベースはクロスモーダル検索をサポートしており、セマンティックな関連性に基づいてテキストと画像の両方を検索できます。
-
- 追加したナレッジベースの横にある**編集**アイコンをクリックすると、知識検索ノード内で直接その設定を変更できます。
-
- これらの設定の詳細については、[ナレッジ設定の管理](/ja/use-dify/knowledge/manage-knowledge/introduction)をご覧ください。
-
+追加したナレッジベースの横にある**編集**アイコンをクリックすると、[設定](/ja/use-dify/knowledge/manage-knowledge/introduction)を変更できます。
### ノードレベルの検索設定
-ナレッジベースから取得した検索結果を、ノード内でどのように処理するかを微調整できます。
+ナレッジベースから取得された検索結果をノードでどのように処理するかを微調整します。
- 検索設定には2つのレイヤーがあります—ナレッジベースレベルと知識検索ノードレベルです。
-
- これらは2つの連続したフィルターと考えてください:ナレッジベースの設定が最初の結果プールを決定し、ノードの設定がさらに結果を再ランク付けまたは絞り込みます。
+ 検索設定には2つのレイヤーがあります——ナレッジベースレベルとナレッジ検索ノードレベルです。
+
+ 2つの連続したフィルターと考えてください:ナレッジベースの設定が最初の結果プールを決定し、ノードの設定がさらに結果を再ランク付けまたは絞り込みます。
-- **Rerank設定**
+- **Rerank 設定**
- - **ウェイト設定**:再ランク付け時におけるセマンティック類似度とキーワード一致の相対的な比重です。セマンティックの比重を高くすると意味的関連性を重視し、キーワードの比重を高くすると正確な一致を重視します。
+ - **加重スコア**:再ランク付け時のセマンティック類似度とキーワード一致の相対的な重み。セマンティックの重みを高くすると意味的な関連性が優先され、キーワードの重みを高くすると完全一致が優先されます。
- **ウェイト設定**は、追加したナレッジベースがすべて高品質タイプである場合のみ利用できます。
+ **加重スコア**は、追加されたすべてのナレッジベースが高品質タイプの場合にのみ利用可能です。
- - **Rerankモデル**:クエリとの関連度に基づいてすべての結果を再スコアリング・並べ替えするRerankモデルです。
+ - **Rerank モデル**:クエリとの関連度に基づいてすべての結果を再スコアリング・並べ替えする Rerank モデルです。
-
- マルチモーダルナレッジベースが追加されている場合は、マルチモーダルRerankモデル(**Vision**アイコン付き)も選択してください。そうでない場合、検索された画像は再ランク付けおよび最終出力から除外されます。
-
+
+ マルチモーダルナレッジベースが追加されている場合は、マルチモーダル Rerank モデル(**Vision** タグ付き)も選択してください。そうでないと、検索された画像が再ランク付けと最終出力から除外されます。
+
-- **トップK**:再ランク後に返す結果の最大件数です。Rerankモデルを選択している場合、この値はモデルの最大入力容量(モデルが一度に処理できるテキスト量)に基づいて自動的に調整されます。
+- **トップ K**:再ランク付け後に返す上位結果の最大数。Rerank モデルを選択している場合、この値はモデルの最大入力容量(一度に処理可能なテキスト量)に基づいて自動調整されます。
-- **スコア閾値**:返される結果の最低類似度スコアです。この閾値未満の結果は除外されます。高めに設定すると関連性の厳密な検索が行われ、低めにするとより広範なマッチを含めることができます。
+- **スコア閾値**:返される結果の最低類似度スコア。この閾値未満の結果は除外されます。高めの閾値は厳密な関連性を、低めの閾値はより広範なマッチを含めます。
-### メタデータフィルタの有効化
+### メタデータフィルタリングの有効化
-既存のドキュメントメタデータを使用して、ナレッジベース内の特定のドキュメントに検索を制限し、検索精度を向上させます。
+既存の[ドキュメントメタデータ](/ja/use-dify/knowledge/metadata)を使用して、ナレッジベース内の特定のドキュメントに検索を制限し、検索精度を向上させます。
-メタデータフィルタを有効にすると、知識検索ノードはナレッジベース全体を検索するのではなく、指定されたメタデータ条件に一致するドキュメントのみを検索します。これは、大規模で多様なナレッジベースでのターゲット検索に特に有用です。
-
-
- ドキュメントメタデータの作成と管理については、[メタデータ](/ja/use-dify/knowledge/metadata)を参照してください。
-
+メタデータフィルタリングを有効にすると、ナレッジ検索ノードはナレッジベース全体ではなく、指定されたメタデータ条件に一致するドキュメントのみを検索します。大規模で多様なナレッジベースでの絞り込み検索に特に有用です。
## 出力
-知識検索ノードの出力は`result`という変数として返されます。この変数は検索されたドキュメントチャンクの配列で、各チャンクにはコンテンツ、メタデータ、タイトル、その他の属性が含まれます。
+ナレッジ検索ノードは `result` という名前の変数として検索結果を出力します。これはドキュメントチャンクの配列で、各チャンクにはコンテンツ、メタデータ、タイトル、その他の属性が含まれます。
-検索結果に画像添付が含まれる場合、`result`変数には画像メタデータを含む`files`というフィールドも含まれます。
+検索結果に画像添付が含まれる場合、`result` 変数には画像の詳細を含む `files` フィールドも含まれます。
-## LLMノードとの連携
+## LLM ノードとの連携
-LLMノードでユーザーの質問に回答するためのコンテキストとして検索結果を使用するには:
+LLM ノードで検索結果をコンテキストとして使用するには:
-1. **コンテキスト**フィールドで、知識検索ノードの`result`変数を選択します。
+1. **高度な設定** > **コンテキスト**で、ナレッジ検索ノードの `result` 変数を選択します。
-2. プロンプトフィールドで、`Context`変数とユーザー入力変数(例:Chatflowの`userinput.query`)の両方を参照します。
+2. システム指示で `Context` 変数を参照します。
-3. (任意)LLMがVision機能に対応している場合(**Vision**アイコン付き)、**Vision**を有効にして検索された画像を解釈させることができます。
+3. 省略可:LLM が Vision 対応の場合、**Vision** を有効にして検索結果内の画像添付を処理させます。
- **Vision**を有効にすると、LLMは検索された画像を自動的に処理します。**Vision**入力フィールドで`Context`変数を再度手動で参照する必要はありません。
+ 検索結果を Vision の入力として指定する必要はありません。**Vision** を有効にすると、LLM は検索された画像を自動的に処理します。
- +チャットフローでは、ナレッジを参照したレスポンスの横に引用がデフォルトで表示されます。キャンバス右上の**機能**で**引用と帰属**をオフにすることで無効にできます。
diff --git a/ja/use-dify/nodes/llm.mdx b/ja/use-dify/nodes/llm.mdx
index 5b00f589..d2c839e4 100644
--- a/ja/use-dify/nodes/llm.mdx
+++ b/ja/use-dify/nodes/llm.mdx
@@ -1,131 +1,219 @@
---
title: "LLM"
-description: "テキスト生成と分析のための言語モデルを起動"
+description: "大規模言語モデルを呼び出し、テキスト生成・分析、ツールによる複雑なタスクの実行を行う"
icon: "brain"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/llm)を参照してください。
-LLMノードは大規模言語モデルを呼び出してテキスト、画像、ドキュメントを処理します。設定されたモデルにプロンプトを送信し、その応答を取得します。構造化出力、コンテキスト管理、マルチモーダル入力をサポートしています。
+LLM ノードは大規模言語モデルを呼び出し、指示と上流ノードからの入力に基づいてレスポンスを生成します。
-
-
+チャットフローでは、ナレッジを参照したレスポンスの横に引用がデフォルトで表示されます。キャンバス右上の**機能**で**引用と帰属**をオフにすることで無効にできます。
diff --git a/ja/use-dify/nodes/llm.mdx b/ja/use-dify/nodes/llm.mdx
index 5b00f589..d2c839e4 100644
--- a/ja/use-dify/nodes/llm.mdx
+++ b/ja/use-dify/nodes/llm.mdx
@@ -1,131 +1,219 @@
---
title: "LLM"
-description: "テキスト生成と分析のための言語モデルを起動"
+description: "大規模言語モデルを呼び出し、テキスト生成・分析、ツールによる複雑なタスクの実行を行う"
icon: "brain"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/llm)を参照してください。
-LLMノードは大規模言語モデルを呼び出してテキスト、画像、ドキュメントを処理します。設定されたモデルにプロンプトを送信し、その応答を取得します。構造化出力、コンテキスト管理、マルチモーダル入力をサポートしています。
+LLM ノードは大規模言語モデルを呼び出し、指示と上流ノードからの入力に基づいてレスポンスを生成します。
-
-  -
+## モデルの選択
+
+設定済みのプロバイダーからタスクに最適なモデルを選択します。
+
+選択後、モデルパラメータを調整してレスポンスの生成方法を制御できます。利用可能なパラメータとプリセットはモデルによって異なります。
+
+## プロンプトの作成
+
+モデルに入力の処理方法とレスポンスの生成方法を指示します。`/` または `{` を入力して変数を参照できます。
+
+どこから始めればよいかわからない場合や、既存のプロンプトを改善したい場合は、AI アシスト付きプロンプトジェネレーターをお試しください。
+
+
+
+
+
+
+
+
+
+
+### 指示とメッセージの指定
+
+システム指示を定義し、**メッセージを追加**をクリックしてユーザー/アシスタントメッセージを追加します。すべて順番にプロンプトとしてモデルに送信されます。
+
+モデルと直接会話するイメージです:
+
+- **システム指示**はモデルのレスポンスルールを設定します——役割、トーン、行動ガイドライン。
+
+- **ユーザーメッセージ**はモデルに送信する内容——質問、リクエスト、タスク。
+
+- **アシスタントメッセージ**はモデルのレスポンスです。
+
+### 入力とルールの分離
+
+システム指示で役割とルールを定義し、ユーザーメッセージで実際のタスク入力を渡します。例:
+
+```bash wrap
+# システム指示
+あなたは子ども向けの物語作家です。ユーザーの入力に基づいて物語を書いてください。簡単な言葉と温かいトーンを使ってください。
+
+# ユーザーメッセージ
+ウサギと恥ずかしがり屋のハリネズミが友達になる、おやすみ前のお話を書いてください。
+```
+
+すべてをシステム指示にまとめる方が簡単に見えるかもしれませんが、役割定義とタスク入力を分離することで、モデルにとってより明確な構造になります。
+
+### 対話履歴のシミュレーション
+
+アシスタントメッセージがモデルのレスポンスなら、なぜ手動で追加するのか疑問に思うかもしれません。
+
+ユーザーメッセージとアシスタントメッセージを交互に追加することで、プロンプト内に対話履歴をシミュレーションできます。モデルはこれらを過去のやり取りとして扱い、動作の誘導に役立ちます。
+
+### 上流 LLM からの対話履歴のインポート
+
+**対話履歴の追加**をクリックして、上流の Agent または LLM ノードから対話履歴をインポートします。これによりモデルは上流で何が起こったかを把握し、そのノードが中断したところから続けることができます。
+
+対話履歴には**ユーザー**メッセージ、**アシスタント**メッセージ、**ツール**メッセージが含まれます。Agent または LLM ノードの `context` 出力変数で確認できます。
- LLMノードを使用する前に、**システム設定 → モデルプロバイダー**で少なくとも1つのモデルプロバイダーを設定してください。
+ システム指示はノード固有のため含まれません。
-## モデル選択とパラメータ
+複数の Agent または LLM ノードを連結する場合に有用です:
-設定したモデルプロバイダーから任意のモデルを選択できます。異なるモデルはそれぞれ異なるタスクに適しています。GPT-4とClaude 3.5は複雑な推論を得意としますがコストが高く、GPT-3.5 Turboは機能と価格のバランスが取れています。ローカル展開には、Ollama、LocalAI、Xinferenceを使用してください。
+- 対話履歴をインポートしない場合、下流ノードは上流ノードの最終出力のみを受け取り、それがどのように導き出されたかはわかりません。
-
-
-
+## モデルの選択
+
+設定済みのプロバイダーからタスクに最適なモデルを選択します。
+
+選択後、モデルパラメータを調整してレスポンスの生成方法を制御できます。利用可能なパラメータとプリセットはモデルによって異なります。
+
+## プロンプトの作成
+
+モデルに入力の処理方法とレスポンスの生成方法を指示します。`/` または `{` を入力して変数を参照できます。
+
+どこから始めればよいかわからない場合や、既存のプロンプトを改善したい場合は、AI アシスト付きプロンプトジェネレーターをお試しください。
+
+
+
+
+
+
+
+
+
+
+### 指示とメッセージの指定
+
+システム指示を定義し、**メッセージを追加**をクリックしてユーザー/アシスタントメッセージを追加します。すべて順番にプロンプトとしてモデルに送信されます。
+
+モデルと直接会話するイメージです:
+
+- **システム指示**はモデルのレスポンスルールを設定します——役割、トーン、行動ガイドライン。
+
+- **ユーザーメッセージ**はモデルに送信する内容——質問、リクエスト、タスク。
+
+- **アシスタントメッセージ**はモデルのレスポンスです。
+
+### 入力とルールの分離
+
+システム指示で役割とルールを定義し、ユーザーメッセージで実際のタスク入力を渡します。例:
+
+```bash wrap
+# システム指示
+あなたは子ども向けの物語作家です。ユーザーの入力に基づいて物語を書いてください。簡単な言葉と温かいトーンを使ってください。
+
+# ユーザーメッセージ
+ウサギと恥ずかしがり屋のハリネズミが友達になる、おやすみ前のお話を書いてください。
+```
+
+すべてをシステム指示にまとめる方が簡単に見えるかもしれませんが、役割定義とタスク入力を分離することで、モデルにとってより明確な構造になります。
+
+### 対話履歴のシミュレーション
+
+アシスタントメッセージがモデルのレスポンスなら、なぜ手動で追加するのか疑問に思うかもしれません。
+
+ユーザーメッセージとアシスタントメッセージを交互に追加することで、プロンプト内に対話履歴をシミュレーションできます。モデルはこれらを過去のやり取りとして扱い、動作の誘導に役立ちます。
+
+### 上流 LLM からの対話履歴のインポート
+
+**対話履歴の追加**をクリックして、上流の Agent または LLM ノードから対話履歴をインポートします。これによりモデルは上流で何が起こったかを把握し、そのノードが中断したところから続けることができます。
+
+対話履歴には**ユーザー**メッセージ、**アシスタント**メッセージ、**ツール**メッセージが含まれます。Agent または LLM ノードの `context` 出力変数で確認できます。
- LLMノードを使用する前に、**システム設定 → モデルプロバイダー**で少なくとも1つのモデルプロバイダーを設定してください。
+ システム指示はノード固有のため含まれません。
-## モデル選択とパラメータ
+複数の Agent または LLM ノードを連結する場合に有用です:
-設定したモデルプロバイダーから任意のモデルを選択できます。異なるモデルはそれぞれ異なるタスクに適しています。GPT-4とClaude 3.5は複雑な推論を得意としますがコストが高く、GPT-3.5 Turboは機能と価格のバランスが取れています。ローカル展開には、Ollama、LocalAI、Xinferenceを使用してください。
+- 対話履歴をインポートしない場合、下流ノードは上流ノードの最終出力のみを受け取り、それがどのように導き出されたかはわかりません。
-
-  -
+- 対話履歴をインポートすると、プロセス全体が見えます:ユーザーが何を質問したか、どのツールが呼び出されたか、どのような結果が返されたか、モデルがどのように推論したか。
-モデルパラメータは応答生成を制御します。**温度**は0(決定的)から1(創造的)の範囲です。**Top P**は確率によって単語選択を制限します。**頻度ペナルティ**は繰り返しを減らします。**存在ペナルティ**は新しいトピックを促進します。プリセットも使用できます:**精密**、**バランス**、**創造的**。
+**自動追加されるユーザーメッセージで新しいタスクを指定してください。** インポートされた履歴は現在のノードのメッセージの前に追加されるため、モデルはこれを1つの連続した会話として認識します。インポートされた履歴は通常アシスタントメッセージで終わるため、モデルは次に何をすべきかを知るためのフォローアップユーザーメッセージが必要です。
-## プロンプト設定
+
-インターフェースはモデルタイプに基づいて適応します。チャットモデルではメッセージロール(**システム**は動作用、**ユーザー**は入力用、**アシスタント**は例用)を使用し、補完モデルでは単純なテキスト継続を使用します。
+ 2つの LLM ノードが順番に実行されるとします:LLM A は検索ツールを呼び出してトピックを調査し、LLM B は調査結果に基づいてレポートを作成します。
-プロンプト内でワークフロー変数を二重中括弧で参照します:`{{variable_name}}`。変数はモデルに到達する前に実際の値で置き換えられます。
+ LLM B が LLM A の最終テキスト出力のみを受け取る場合、結論を要約できますが、検証や具体的なソースの引用はできません。LLM A の対話履歴をインポートすることで、LLM B は各ツール呼び出しの生データを確認し、レポートで直接参照できます。
-```text
-System: あなたは技術文書の専門家です。
-User: {{user_input}}
+ LLM A の対話履歴インポート後に LLM B が受け取る完全なメッセージシーケンス:
+
+ ```bash wrap
+ # LLM B のシステム指示
+ 1. System: "あなたはプロフェッショナルなレポートライターです..."
+
+ # LLM A から
+ 2. User: "EV 市場の新しいトレンドは何ですか?"
+
+ # LLM A から
+ 3. Tool: [URL と生データを含む検索結果]
+
+ # LLM A から
+ 4. Assistant: "検索結果に基づくと、主なトレンドは..."
+
+ # LLM B のユーザーメッセージ
+ 5. User: "500語の市場分析レポートを作成してください。"
+ ```
+
+ LLM B は次のことを理解します:調査プロセス(質問、検索、要約)を見た上で、テキスト出力だけでは得られない生データを含め、その情報に基づいてレポートを作成する必要があるということです。
+
+
+
+### Jinja2 を使った動的プロンプトの作成
+
+[Jinja2](https://jinja.palletsprojects.com/en/stable/) 構文で動的プロンプトを作成できます。例えば、条件分岐を使って変数の値に応じた指示をカスタマイズできます。
+
+
+```jinja2 wrap
+あなたは
+{% if user_level == "beginner" %}忍耐強く親切な
+{% elif user_level == "intermediate" %}プロフェッショナルで効率的な
+{% else %}シニアエキスパートレベルの
+{% endif %} アシスタントです。
+
+{% if user_level == "beginner" %}
+わかりやすい言葉で説明してください。必要に応じて例を示してください。専門用語は避けてください。
+{% elif user_level == "intermediate" %} 一部の専門用語を使用できますが、適切な説明を付けてください。実践的なアドバイスとベストプラクティスを提供してください。
+{% else %} 技術的な詳細に踏み込み、専門用語を使用してください。高度なユースケースと最適化ソリューションに焦点を当ててください。
+{% endif %}
```
+
-## コンテキスト変数
+デフォルトでは、すべての可能な指示をモデルに送信し、条件を説明し、どれに従うかをモデルに判断させる必要がありますが、この方法は必ずしも信頼できるとは限りません。
-コンテキスト変数はソース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答えるRAGアプリケーションが可能になります。
+Jinja2 テンプレートを使えば、定義された条件に合致する指示のみが送信されるため、動作が予測可能になり、トークンの使用量も削減されます。
-
-
-
+- 対話履歴をインポートすると、プロセス全体が見えます:ユーザーが何を質問したか、どのツールが呼び出されたか、どのような結果が返されたか、モデルがどのように推論したか。
-モデルパラメータは応答生成を制御します。**温度**は0(決定的)から1(創造的)の範囲です。**Top P**は確率によって単語選択を制限します。**頻度ペナルティ**は繰り返しを減らします。**存在ペナルティ**は新しいトピックを促進します。プリセットも使用できます:**精密**、**バランス**、**創造的**。
+**自動追加されるユーザーメッセージで新しいタスクを指定してください。** インポートされた履歴は現在のノードのメッセージの前に追加されるため、モデルはこれを1つの連続した会話として認識します。インポートされた履歴は通常アシスタントメッセージで終わるため、モデルは次に何をすべきかを知るためのフォローアップユーザーメッセージが必要です。
-## プロンプト設定
+
-インターフェースはモデルタイプに基づいて適応します。チャットモデルではメッセージロール(**システム**は動作用、**ユーザー**は入力用、**アシスタント**は例用)を使用し、補完モデルでは単純なテキスト継続を使用します。
+ 2つの LLM ノードが順番に実行されるとします:LLM A は検索ツールを呼び出してトピックを調査し、LLM B は調査結果に基づいてレポートを作成します。
-プロンプト内でワークフロー変数を二重中括弧で参照します:`{{variable_name}}`。変数はモデルに到達する前に実際の値で置き換えられます。
+ LLM B が LLM A の最終テキスト出力のみを受け取る場合、結論を要約できますが、検証や具体的なソースの引用はできません。LLM A の対話履歴をインポートすることで、LLM B は各ツール呼び出しの生データを確認し、レポートで直接参照できます。
-```text
-System: あなたは技術文書の専門家です。
-User: {{user_input}}
+ LLM A の対話履歴インポート後に LLM B が受け取る完全なメッセージシーケンス:
+
+ ```bash wrap
+ # LLM B のシステム指示
+ 1. System: "あなたはプロフェッショナルなレポートライターです..."
+
+ # LLM A から
+ 2. User: "EV 市場の新しいトレンドは何ですか?"
+
+ # LLM A から
+ 3. Tool: [URL と生データを含む検索結果]
+
+ # LLM A から
+ 4. Assistant: "検索結果に基づくと、主なトレンドは..."
+
+ # LLM B のユーザーメッセージ
+ 5. User: "500語の市場分析レポートを作成してください。"
+ ```
+
+ LLM B は次のことを理解します:調査プロセス(質問、検索、要約)を見た上で、テキスト出力だけでは得られない生データを含め、その情報に基づいてレポートを作成する必要があるということです。
+
+
+
+### Jinja2 を使った動的プロンプトの作成
+
+[Jinja2](https://jinja.palletsprojects.com/en/stable/) 構文で動的プロンプトを作成できます。例えば、条件分岐を使って変数の値に応じた指示をカスタマイズできます。
+
+
+```jinja2 wrap
+あなたは
+{% if user_level == "beginner" %}忍耐強く親切な
+{% elif user_level == "intermediate" %}プロフェッショナルで効率的な
+{% else %}シニアエキスパートレベルの
+{% endif %} アシスタントです。
+
+{% if user_level == "beginner" %}
+わかりやすい言葉で説明してください。必要に応じて例を示してください。専門用語は避けてください。
+{% elif user_level == "intermediate" %} 一部の専門用語を使用できますが、適切な説明を付けてください。実践的なアドバイスとベストプラクティスを提供してください。
+{% else %} 技術的な詳細に踏み込み、専門用語を使用してください。高度なユースケースと最適化ソリューションに焦点を当ててください。
+{% endif %}
```
+
-## コンテキスト変数
+デフォルトでは、すべての可能な指示をモデルに送信し、条件を説明し、どれに従うかをモデルに判断させる必要がありますが、この方法は必ずしも信頼できるとは限りません。
-コンテキスト変数はソース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答えるRAGアプリケーションが可能になります。
+Jinja2 テンプレートを使えば、定義された条件に合致する指示のみが送信されるため、動作が予測可能になり、トークンの使用量も削減されます。
-
-  -
+## コンテキストの追加
-知識検索ノードの出力をLLMノードのコンテキスト入力に接続し、次のように参照します:
+**高度な設定** > **コンテキスト**で、LLM に追加の参照情報を提供し、ハルシネーションを減らしてレスポンスの精度を向上させます。
-```text
-このコンテキストのみを使用して回答してください:
-{{knowledge_retrieval.result}}
+一般的なパターン:ナレッジ検索ノードから[検索結果を渡す](/ja/use-dify/nodes/knowledge-retrieval#llm-ノードとの連携)ことで、検索拡張生成(RAG)を実現します。
-質問:{{user_question}}
-```
+## 対話メモリの有効化(チャットフローのみ)
-知識検索からのコンテキスト変数を使用する場合、Difyは自動的に引用を追跡するため、ユーザーは情報源を確認できます。
+
+ メモリはこのノード内でのみ有効です。異なる会話間では保持されません。
+
-## 構造化出力
+**メモリ**を有効にすると最近の対話が保持され、LLM がフォローアップの質問に一貫して回答できるようになります。
-プログラムで使用するために、JSONなどの特定のデータ形式での応答をモデルに強制します。3つの方法で設定できます:
+現在のユーザークエリとアップロードされたファイルを渡すためのユーザーメッセージが自動的に追加されます。これはメモリが最近のユーザー-アシスタント間のやり取りを保存することで機能するためです。ユーザークエリがユーザーメッセージを通じて渡されないと、ユーザー側で記録するものがなくなります。
-
-
- シンプルな構造のためのユーザーフレンドリーなインターフェース。名前とタイプでフィールドを追加し、必須フィールドをマークし、説明を設定します。エディターは自動的にJSONスキーマを生成します。
-
-
-
- ネストされたオブジェクト、配列、検証ルールを含む複雑な構造のためにスキーマを直接記述します。
-
- ```json
- {
- "type": "object",
- "properties": {
- "sentiment": {
- "type": "string",
- "enum": ["positive", "negative", "neutral"]
- }
- },
- "required": ["sentiment"]
- }
- ```
-
-
-
- 平易な言語でニーズを説明し、AIにスキーマを生成させます。
-
-
+**ウィンドウサイズ**は保持する最近のやり取り数を制御します。例えば `5` は、直近の5組のユーザークエリと LLM レスポンスを保持します。
-
- ネイティブJSON対応のモデルは構造化出力を確実に処理します。その他のモデルについては、Difyがプロンプトにスキーマを含めますが、結果は異なる場合があります。
-
+## Dify ツールの利用
-## メモリとファイル処理
+
+ Tool Call タグが付いたモデルのみが Dify ツールを利用できます。
-
-メモリを有効にすると、チャットフロー会話内の複数のLLM呼び出しでコンテキストを維持できます。有効にすると、以前のインタラクションがフォーマットされたユーザー - アシスタント出力として後続のプロンプトに含まれます。`USER`テンプレートを編集することで、ユーザープロンプトに入力される内容をカスタマイズできます。メモリはノード固有であり、異なる会話間では持続しません。
+
+
-
+## コンテキストの追加
-知識検索ノードの出力をLLMノードのコンテキスト入力に接続し、次のように参照します:
+**高度な設定** > **コンテキスト**で、LLM に追加の参照情報を提供し、ハルシネーションを減らしてレスポンスの精度を向上させます。
-```text
-このコンテキストのみを使用して回答してください:
-{{knowledge_retrieval.result}}
+一般的なパターン:ナレッジ検索ノードから[検索結果を渡す](/ja/use-dify/nodes/knowledge-retrieval#llm-ノードとの連携)ことで、検索拡張生成(RAG)を実現します。
-質問:{{user_question}}
-```
+## 対話メモリの有効化(チャットフローのみ)
-知識検索からのコンテキスト変数を使用する場合、Difyは自動的に引用を追跡するため、ユーザーは情報源を確認できます。
+
+ メモリはこのノード内でのみ有効です。異なる会話間では保持されません。
+
-## 構造化出力
+**メモリ**を有効にすると最近の対話が保持され、LLM がフォローアップの質問に一貫して回答できるようになります。
-プログラムで使用するために、JSONなどの特定のデータ形式での応答をモデルに強制します。3つの方法で設定できます:
+現在のユーザークエリとアップロードされたファイルを渡すためのユーザーメッセージが自動的に追加されます。これはメモリが最近のユーザー-アシスタント間のやり取りを保存することで機能するためです。ユーザークエリがユーザーメッセージを通じて渡されないと、ユーザー側で記録するものがなくなります。
-
-
- シンプルな構造のためのユーザーフレンドリーなインターフェース。名前とタイプでフィールドを追加し、必須フィールドをマークし、説明を設定します。エディターは自動的にJSONスキーマを生成します。
-
-
-
- ネストされたオブジェクト、配列、検証ルールを含む複雑な構造のためにスキーマを直接記述します。
-
- ```json
- {
- "type": "object",
- "properties": {
- "sentiment": {
- "type": "string",
- "enum": ["positive", "negative", "neutral"]
- }
- },
- "required": ["sentiment"]
- }
- ```
-
-
-
- 平易な言語でニーズを説明し、AIにスキーマを生成させます。
-
-
+**ウィンドウサイズ**は保持する最近のやり取り数を制御します。例えば `5` は、直近の5組のユーザークエリと LLM レスポンスを保持します。
-
- ネイティブJSON対応のモデルは構造化出力を確実に処理します。その他のモデルについては、Difyがプロンプトにスキーマを含めますが、結果は異なる場合があります。
-
+## Dify ツールの利用
-## メモリとファイル処理
+
+ Tool Call タグが付いたモデルのみが Dify ツールを利用できます。
-
-メモリを有効にすると、チャットフロー会話内の複数のLLM呼び出しでコンテキストを維持できます。有効にすると、以前のインタラクションがフォーマットされたユーザー - アシスタント出力として後続のプロンプトに含まれます。`USER`テンプレートを編集することで、ユーザープロンプトに入力される内容をカスタマイズできます。メモリはノード固有であり、異なる会話間では持続しません。
+
+  +
+
-**ファイル処理**では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4Vは画像を、ClaudeはPDFを直接処理しますが、他のモデルでは前処理が必要な場合があります。
+[Dify ツール](/ja/use-dify/workspace/tools)を追加して、モデルが外部サービスや API と連携できるようにします。ウェブ検索やデータベースクエリなど、リアルタイムデータやテキスト生成を超えるアクションが必要なタスクに有用です。
-### ビジョン機能設定
+追加したツールは無効化・削除でき、設定も変更できます。より明確なツール説明により、モデルがツールの使用タイミングを適切に判断できます。
-画像を処理する際、詳細レベルを制御できます:
-- **高詳細** - 複雑な画像でより良い精度を提供しますが、より多くのトークンを使用します
-- **低詳細** - シンプルな画像でより少ないトークンでより高速な処理
+**最大イテレーション回数の調整**
-ビジョン機能のデフォルト変数セレクターは`userinput.files`で、ユーザー入力ノードからファイルを自動的に取得します。
+**高度な設定**の**最大イテレーション回数**は、モデルが1つのリクエストに対して推論-行動サイクル(思考、ツール呼び出し、結果処理)を繰り返す回数を制限します。
-
-
+
+
-**ファイル処理**では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4Vは画像を、ClaudeはPDFを直接処理しますが、他のモデルでは前処理が必要な場合があります。
+[Dify ツール](/ja/use-dify/workspace/tools)を追加して、モデルが外部サービスや API と連携できるようにします。ウェブ検索やデータベースクエリなど、リアルタイムデータやテキスト生成を超えるアクションが必要なタスクに有用です。
-### ビジョン機能設定
+追加したツールは無効化・削除でき、設定も変更できます。より明確なツール説明により、モデルがツールの使用タイミングを適切に判断できます。
-画像を処理する際、詳細レベルを制御できます:
-- **高詳細** - 複雑な画像でより良い精度を提供しますが、より多くのトークンを使用します
-- **低詳細** - シンプルな画像でより少ないトークンでより高速な処理
+**最大イテレーション回数の調整**
-ビジョン機能のデフォルト変数セレクターは`userinput.files`で、ユーザー入力ノードからファイルを自動的に取得します。
+**高度な設定**の**最大イテレーション回数**は、モデルが1つのリクエストに対して推論-行動サイクル(思考、ツール呼び出し、結果処理)を繰り返す回数を制限します。
-
-  -
+複数のツール呼び出しを必要とする複雑なマルチステップタスクでは、この値を増やしてください。値が大きいほどレイテンシとトークンコストが増加します。
-## Jinja2テンプレートサポート
+## マルチモーダル入力の処理
-LLMプロンプトは高度な変数処理のためにJinja2テンプレートをサポートしています。Jinja2モード(`edition_type: "jinja2"`)を使用すると、次のことができます:
+*マルチモーダル対応*モデルに画像、音声、動画、ドキュメントを処理させるには、以下のいずれかの方法を選択します:
-```jinja2
-{% for item in search_results %}
-{{ loop.index }}. {{ item.title }}: {{ item.content }}
-{% endfor %}
-```
+ - プロンプトでファイル変数を直接参照する。
-Jinja2変数は通常の変数置換とは別に処理され、プロンプト内でループ、条件文、複雑なデータ変換が可能になります。
+ - **高度な設定**で **Vision** を有効にし、ファイル変数を選択する。
-## ストリーミング出力
+ **解像度**は画像処理の詳細レベルのみを制御します:
-LLMノードはデフォルトでストリーミング出力をサポートしています。各テキストチャンクは`RunStreamChunkEvent`として生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。
+ - **高**:複雑な画像でより高精度だが、より多くのトークンを使用
-## エラーハンドリング
+ - **低**:シンプルな画像でより高速、より少ないトークンで処理
-失敗したLLM呼び出しのリトライ動作を設定します。最大リトライ回数、リトライ間隔、バックオフ乗数を設定します。リトライが十分でない場合のデフォルト値、エラールーティング、代替モデルなどのフォールバック戦略を定義します。
+## 思考プロセスとツール呼び出しをレスポンスから分離
+
+モデルの思考プロセスやツール呼び出し(もしあれば)を含まないクリーンなレスポンスを取得するには、`text` 出力変数(**推論タグ分離を有効化**をオンにした状態)または `generation.content` を参照します。
+
+`generations` 変数自体にはすべての中間ステップと最終レスポンスが含まれます。
+
+## 構造化出力の強制
+
+指示で出力形式を記述しても、一貫性のない結果が生じることがあります。より信頼性の高いフォーマットを実現するには、構造化出力を有効にして定義済みの JSON スキーマを強制します。
+
+
+ ネイティブ JSON をサポートしないモデルの場合、Dify はスキーマをプロンプトに含めますが、厳密な遵守は保証されません。
+
+
+
+
+1. **出力変数**の横で**構造化**をオンにします。出力変数リストの末尾に `structured_output` 変数が表示されます。
+
+2. **設定**をクリックし、以下のいずれかの方法で出力スキーマを定義します。
+
+ - **ビジュアルエディター**:ノーコードインターフェースでシンプルな構造を定義。対応する JSON スキーマが自動生成されます。
+
+ - **JSON Schema**:ネストされたオブジェクト、配列、バリデーションルールを含む複雑な構造のスキーマを直接記述。
+
+ - **AI 生成**:自然言語でニーズを記述し、AI にスキーマを生成させる。
+
+ - **JSON インポート**:既存の JSON オブジェクトを貼り付けて、対応するスキーマを自動生成。
+
+## エラー処理
+
+一時的な問題(ネットワークの不具合など)に対する自動リトライ、またはエラーが続く場合にワークフローの実行を継続するための代替エラー処理戦略を設定します。
+
+
diff --git a/ja/use-dify/nodes/tools.mdx b/ja/use-dify/nodes/tools.mdx
index 382dddac..b54884b4 100644
--- a/ja/use-dify/nodes/tools.mdx
+++ b/ja/use-dify/nodes/tools.mdx
@@ -1,92 +1,108 @@
---
title: "ツール"
-description: "事前構築された統合で外部サービスとAPIに接続"
+description: "外部サービスやAPIに接続"
icon: "wrench"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/tools)を参照してください。
+[Dify ツール](/ja/use-dify/workspace/tools)をワークフローに独立したノードとして追加します。
-ツールノードは、事前構築された統合を通じて、ワークフローを外部サービスやAPIに接続します。HTTPリクエストノードとは異なり、ツールは構造化されたインターフェース、組み込みエラーハンドリング、人気のサービス向けの簡素化された設定を提供します。
+これにより、ワークフローが外部サービスや API と連携し、リアルタイムデータへのアクセスやアクション(ウェブ検索、データベースクエリ、コンテンツ処理など)の実行が可能になります。
-
-
-
+複数のツール呼び出しを必要とする複雑なマルチステップタスクでは、この値を増やしてください。値が大きいほどレイテンシとトークンコストが増加します。
-## Jinja2テンプレートサポート
+## マルチモーダル入力の処理
-LLMプロンプトは高度な変数処理のためにJinja2テンプレートをサポートしています。Jinja2モード(`edition_type: "jinja2"`)を使用すると、次のことができます:
+*マルチモーダル対応*モデルに画像、音声、動画、ドキュメントを処理させるには、以下のいずれかの方法を選択します:
-```jinja2
-{% for item in search_results %}
-{{ loop.index }}. {{ item.title }}: {{ item.content }}
-{% endfor %}
-```
+ - プロンプトでファイル変数を直接参照する。
-Jinja2変数は通常の変数置換とは別に処理され、プロンプト内でループ、条件文、複雑なデータ変換が可能になります。
+ - **高度な設定**で **Vision** を有効にし、ファイル変数を選択する。
-## ストリーミング出力
+ **解像度**は画像処理の詳細レベルのみを制御します:
-LLMノードはデフォルトでストリーミング出力をサポートしています。各テキストチャンクは`RunStreamChunkEvent`として生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。
+ - **高**:複雑な画像でより高精度だが、より多くのトークンを使用
-## エラーハンドリング
+ - **低**:シンプルな画像でより高速、より少ないトークンで処理
-失敗したLLM呼び出しのリトライ動作を設定します。最大リトライ回数、リトライ間隔、バックオフ乗数を設定します。リトライが十分でない場合のデフォルト値、エラールーティング、代替モデルなどのフォールバック戦略を定義します。
+## 思考プロセスとツール呼び出しをレスポンスから分離
+
+モデルの思考プロセスやツール呼び出し(もしあれば)を含まないクリーンなレスポンスを取得するには、`text` 出力変数(**推論タグ分離を有効化**をオンにした状態)または `generation.content` を参照します。
+
+`generations` 変数自体にはすべての中間ステップと最終レスポンスが含まれます。
+
+## 構造化出力の強制
+
+指示で出力形式を記述しても、一貫性のない結果が生じることがあります。より信頼性の高いフォーマットを実現するには、構造化出力を有効にして定義済みの JSON スキーマを強制します。
+
+
+ ネイティブ JSON をサポートしないモデルの場合、Dify はスキーマをプロンプトに含めますが、厳密な遵守は保証されません。
+
+
+
+
+1. **出力変数**の横で**構造化**をオンにします。出力変数リストの末尾に `structured_output` 変数が表示されます。
+
+2. **設定**をクリックし、以下のいずれかの方法で出力スキーマを定義します。
+
+ - **ビジュアルエディター**:ノーコードインターフェースでシンプルな構造を定義。対応する JSON スキーマが自動生成されます。
+
+ - **JSON Schema**:ネストされたオブジェクト、配列、バリデーションルールを含む複雑な構造のスキーマを直接記述。
+
+ - **AI 生成**:自然言語でニーズを記述し、AI にスキーマを生成させる。
+
+ - **JSON インポート**:既存の JSON オブジェクトを貼り付けて、対応するスキーマを自動生成。
+
+## エラー処理
+
+一時的な問題(ネットワークの不具合など)に対する自動リトライ、またはエラーが続く場合にワークフローの実行を継続するための代替エラー処理戦略を設定します。
+
+
diff --git a/ja/use-dify/nodes/tools.mdx b/ja/use-dify/nodes/tools.mdx
index 382dddac..b54884b4 100644
--- a/ja/use-dify/nodes/tools.mdx
+++ b/ja/use-dify/nodes/tools.mdx
@@ -1,92 +1,108 @@
---
title: "ツール"
-description: "事前構築された統合で外部サービスとAPIに接続"
+description: "外部サービスやAPIに接続"
icon: "wrench"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/tools)を参照してください。
+[Dify ツール](/ja/use-dify/workspace/tools)をワークフローに独立したノードとして追加します。
-ツールノードは、事前構築された統合を通じて、ワークフローを外部サービスやAPIに接続します。HTTPリクエストノードとは異なり、ツールは構造化されたインターフェース、組み込みエラーハンドリング、人気のサービス向けの簡素化された設定を提供します。
+これにより、ワークフローが外部サービスや API と連携し、リアルタイムデータへのアクセスやアクション(ウェブ検索、データベースクエリ、コンテンツ処理など)の実行が可能になります。
-
-  -
+## ノードの追加と設定
-## ツールの種類
+1. キャンバスで**ノードを追加** > **ツール**をクリックし、利用可能なツールからアクションを選択します。
-Difyは、さまざまな統合ニーズに対応するため、複数のタイプのツールをサポートしています:
+2. 省略可:ツールが認証を必要とする場合、既存の認証情報を選択するか新しい認証情報を作成します。
-
-
-
+## ノードの追加と設定
-## ツールの種類
+1. キャンバスで**ノードを追加** > **ツール**をクリックし、利用可能なツールからアクションを選択します。
-Difyは、さまざまな統合ニーズに対応するため、複数のタイプのツールをサポートしています:
+2. 省略可:ツールが認証を必要とする場合、既存の認証情報を選択するか新しい認証情報を作成します。
-
- 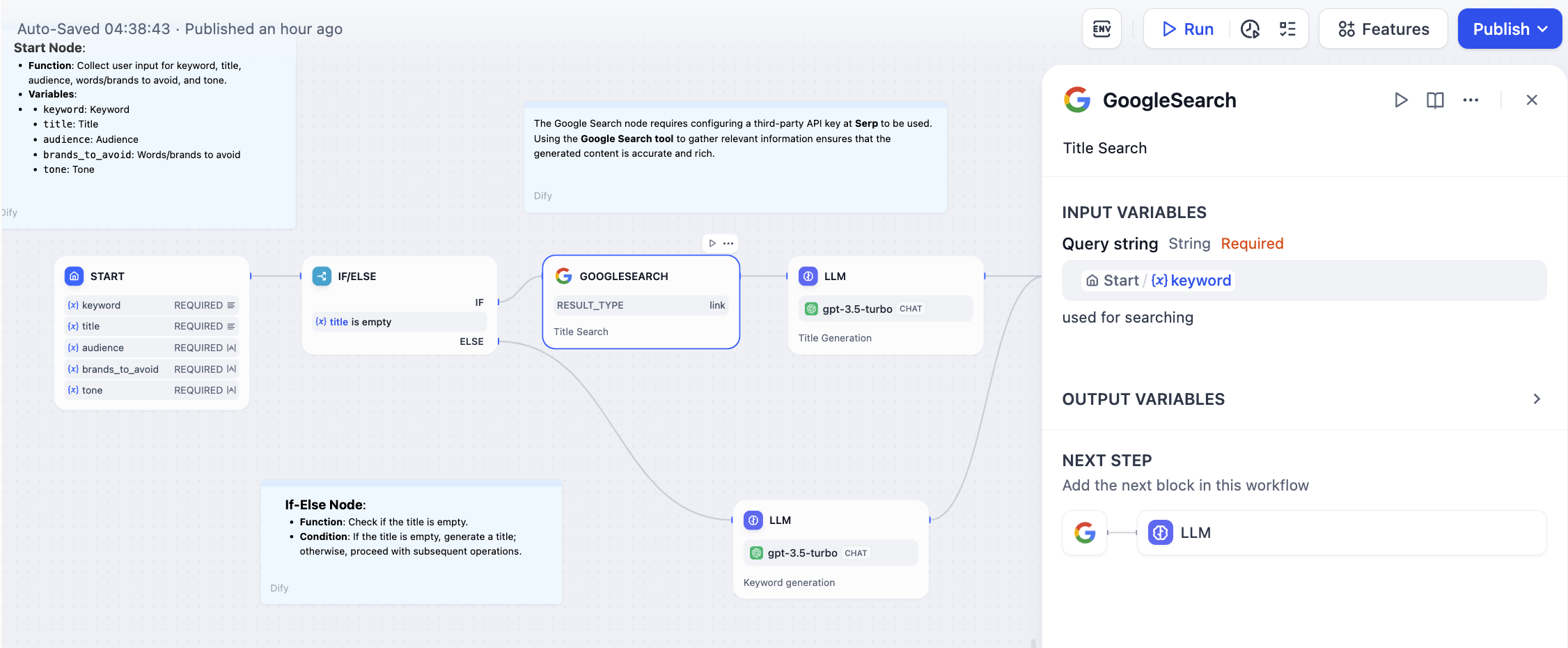 -
+
+ デフォルトの認証情報を変更するには、**ツール**または**プラグイン**に移動します。
+
-
-
- Google検索、天気API、生産性ツール、AIサービスなどの人気サービス向けに、Difyが管理する、すぐに使用できる統合。これらのツールは最小限の設定で、信頼性があり、テスト済みの統合を提供します。
-
-
-
- OpenAPI/Swagger仕様を使用して、独自のツールをインポート。内部API、専門サービス、または組み込みオプションでカバーされていないAPIに最適。一度設定すれば、複数のワークフローで再利用可能です。
-
-
-
- 複雑なワークフローを再利用可能なツールとして公開。これにより、異なるアプリケーション間で共有できるモジュラービルディングブロックが作成され、コードの再利用を促進し、メンテナンスを簡素化します。
-
-
-
- 専門機能を提供する外部MCP(Model Context Protocol)サーバーからのツール。拡張された機能のため、成長するMCPサーバーのエコシステムに接続します。
-
-
+3. その他の必須ツール設定を入力します。
-## 設定
+## ツール入力の準備
-### 認証
+ツールは上流ノードの出力と正確には一致しない特定の形式の入力を必要とする場合があります。データの再フォーマット、特定の情報の抽出、複数ノードからの出力の結合が必要になることがあります。
-多くのツールはAPIキーまたはOAuth認証を必要とします。ワークフローで使用する前に、ワークスペースの**ツール**セクションでこれらの認証情報を設定してください。認証は一度設定すれば自動的に処理されます。
+中間ノードを手動で追加したり上流の出力を変更する代わりに、**必要な場所で直接**入力を準備できます。
-### 入力パラメータ
+2つのアプローチが利用可能です:
-ツールは、入力設定のための検証付き構造化フォームを提供します。前のワークフローノードからの変数を使用してパラメータを設定します。インターフェースは自動的にデータタイプの検証を処理し、各パラメータに役立つ説明を提供します。
+| アプローチ | 適するケース | 仕組み |
+|:---------|:---------|:-------------------|
+| **変数の組み立て** | 上流の出力にデータが明確に構造化されて存在するが、再フォーマット、抽出、結合が必要な場合 |
-
+
+ デフォルトの認証情報を変更するには、**ツール**または**プラグイン**に移動します。
+
-
-
- Google検索、天気API、生産性ツール、AIサービスなどの人気サービス向けに、Difyが管理する、すぐに使用できる統合。これらのツールは最小限の設定で、信頼性があり、テスト済みの統合を提供します。
-
-
-
- OpenAPI/Swagger仕様を使用して、独自のツールをインポート。内部API、専門サービス、または組み込みオプションでカバーされていないAPIに最適。一度設定すれば、複数のワークフローで再利用可能です。
-
-
-
- 複雑なワークフローを再利用可能なツールとして公開。これにより、異なるアプリケーション間で共有できるモジュラービルディングブロックが作成され、コードの再利用を促進し、メンテナンスを簡素化します。
-
-
-
- 専門機能を提供する外部MCP(Model Context Protocol)サーバーからのツール。拡張された機能のため、成長するMCPサーバーのエコシステムに接続します。
-
-
+3. その他の必須ツール設定を入力します。
-## 設定
+## ツール入力の準備
-### 認証
+ツールは上流ノードの出力と正確には一致しない特定の形式の入力を必要とする場合があります。データの再フォーマット、特定の情報の抽出、複数ノードからの出力の結合が必要になることがあります。
-多くのツールはAPIキーまたはOAuth認証を必要とします。ワークフローで使用する前に、ワークスペースの**ツール**セクションでこれらの認証情報を設定してください。認証は一度設定すれば自動的に処理されます。
+中間ノードを手動で追加したり上流の出力を変更する代わりに、**必要な場所で直接**入力を準備できます。
-### 入力パラメータ
+2つのアプローチが利用可能です:
-ツールは、入力設定のための検証付き構造化フォームを提供します。前のワークフローノードからの変数を使用してパラメータを設定します。インターフェースは自動的にデータタイプの検証を処理し、各パラメータに役立つ説明を提供します。
+| アプローチ | 適するケース | 仕組み |
+|:---------|:---------|:-------------------|
+| **変数の組み立て** | 上流の出力にデータが明確に構造化されて存在するが、再フォーマット、抽出、結合が必要な場合 |- ニーズを記述します。
- 内部の**コード**ノードが自動的に作成され、変換を処理します。
|
+| **LLM の対話履歴から抽出** | データが LLM の対話履歴に埋め込まれており、LLM による解釈と抽出が必要な場合 | - ニーズを記述します。
- 内部の **LLM** ノードが自動的に作成され、選択した Agent または LLM ノードの対話履歴を読み取り、必要なデータを抽出します。
|
-### 出力処理
+### 変数の組み立て
-ツールは構造化されたデータを返し、これが下流のノードで変数として利用可能になります。出力スキーマは事前定義されており、互換性を確保し、統合の複雑さを軽減します。
+ -## HTTPリクエストに対する利点
+上流の出力にデータが明確に構造化されて存在するが、変換が必要な場合に使用します——部分文字列の抽出、複数出力の結合、データ型の変更など。
-**構造化されたインターフェース**は、組み込み検証を備えたフォームベースの設定を提供し、手動でのHTTPリクエスト設定よりもセットアップを簡単にします。
+
-**組み込みエラーハンドリング**には、自動リトライロジックとエラー管理が含まれ複雑さを軽減します。
+3つの上流 LLM ノードがそれぞれ商品説明を生成します。下流のツールは全説明を含む単一の配列を期待しています。
-**型安全性**により、入力および出力スキーマがワークフローノード間でのデータ互換性を維持することが保証されます。
+**変数の組み立て**を選択し、「LLM1、LLM2、LLM3 のテキスト出力を結合してください」と記述します。
-**ドキュメント**には、各ツールの使用例と詳細なパラメータ説明が含まれています。
+システムがコードを生成し、ツールが期待する配列形式で出力を結合します。
-## エラーハンドリングとリトライ
+
-外部サービスに依存するツールの堅牢なエラーハンドリングを設定します:
+
+ 変数を組み立てる前に、対象の上流ノードを実行して出力データを利用可能にしてください。
+
-
-
-## HTTPリクエストに対する利点
+上流の出力にデータが明確に構造化されて存在するが、変換が必要な場合に使用します——部分文字列の抽出、複数出力の結合、データ型の変更など。
-**構造化されたインターフェース**は、組み込み検証を備えたフォームベースの設定を提供し、手動でのHTTPリクエスト設定よりもセットアップを簡単にします。
+
-**組み込みエラーハンドリング**には、自動リトライロジックとエラー管理が含まれ複雑さを軽減します。
+3つの上流 LLM ノードがそれぞれ商品説明を生成します。下流のツールは全説明を含む単一の配列を期待しています。
-**型安全性**により、入力および出力スキーマがワークフローノード間でのデータ互換性を維持することが保証されます。
+**変数の組み立て**を選択し、「LLM1、LLM2、LLM3 のテキスト出力を結合してください」と記述します。
-**ドキュメント**には、各ツールの使用例と詳細なパラメータ説明が含まれています。
+システムがコードを生成し、ツールが期待する配列形式で出力を結合します。
-## エラーハンドリングとリトライ
+
-外部サービスに依存するツールの堅牢なエラーハンドリングを設定します:
+
+ 変数を組み立てる前に、対象の上流ノードを実行して出力データを利用可能にしてください。
+
-
-  -
+1. 変数を受け付けるツール入力フィールドで、`/` を入力しドロップダウンから**変数の組み立て**を選択します。
-**リトライ設定**は、失敗したツール実行を設定可能な間隔(最大5000ms)で最大10回まで自動的にリトライします。これは一時的なサービス問題やネットワークの問題を処理します。
+2. 自然言語でニーズを記述すると、AI がデータ変換用のコードを生成します。生成されたコードは入力フィールドの期待形式に自動的に適合します。
-
-
-
+1. 変数を受け付けるツール入力フィールドで、`/` を入力しドロップダウンから**変数の組み立て**を選択します。
-**リトライ設定**は、失敗したツール実行を設定可能な間隔(最大5000ms)で最大10回まで自動的にリトライします。これは一時的なサービス問題やネットワークの問題を処理します。
+2. 自然言語でニーズを記述すると、AI がデータ変換用のコードを生成します。生成されたコードは入力フィールドの期待形式に自動的に適合します。
-
-  -
+3. **実行**をクリックしてコードをテストします。内部のコードノードが開き、利用可能な上流データで実行されます。
-**エラーハンドリング**は、ツール実行が失敗した場合の代替ワークフローパスを定義し、外部サービスが利用できない場合でもワークフローが継続することを確保します。
+4. コードノードの出力を確認し、期待通りかを検証します:
-## カスタムツールの作成
+ - 問題なければ、そのまま終了します。コードは自動的に保存・適用されます。
-**OpenAPI統合**により、OpenAPI/Swagger仕様を持つ任意のサービスをインポートできます。インポートされると、そのサービスは組み込みオプションと同じ使いやすさでツールとして利用可能になります。
+ - 修正が必要な場合は、コードフィールドのコードジェネレーターアイコンをクリックして AI で引き続き改善するか、コードを直接編集します。
-**ワークフロー公開**は、マルチノードワークフローを、異なるアプリケーション間で再利用できるシングルノードツールに変換します。これはモジュール性を促進し、複雑なワークフロー管理を簡素化します。
+
+
-
+3. **実行**をクリックしてコードをテストします。内部のコードノードが開き、利用可能な上流データで実行されます。
-**エラーハンドリング**は、ツール実行が失敗した場合の代替ワークフローパスを定義し、外部サービスが利用できない場合でもワークフローが継続することを確保します。
+4. コードノードの出力を確認し、期待通りかを検証します:
-## カスタムツールの作成
+ - 問題なければ、そのまま終了します。コードは自動的に保存・適用されます。
-**OpenAPI統合**により、OpenAPI/Swagger仕様を持つ任意のサービスをインポートできます。インポートされると、そのサービスは組み込みオプションと同じ使いやすさでツールとして利用可能になります。
+ - 修正が必要な場合は、コードフィールドのコードジェネレーターアイコンをクリックして AI で引き続き改善するか、コードを直接編集します。
-**ワークフロー公開**は、マルチノードワークフローを、異なるアプリケーション間で再利用できるシングルノードツールに変換します。これはモジュール性を促進し、複雑なワークフロー管理を簡素化します。
+
+  +
-## ツール管理
+
+ 後から**変数の組み立て**インターフェースを再度開くには:
-ワークスペースナビゲーションの**ツール**を通じてツール設定にアクセスします。ここでは、認証認証情報の管理、カスタムツールのインポート、MCPサーバーの設定、ワークフローのツールとしての公開を行うことができます。
+ 1. 組み立て済み変数の横にある**内部を表示**をクリックします。
+ 2. 内部のコードノードを選択します。
+ 3. コードジェネレーターアイコンをクリックします。
+
-ツールの作成、管理、ワークフローのツールとしての公開に関する詳細なガイダンスについては、[ツール設定ガイド](/en/guides/tools)を参照してください。
+### LLM の対話履歴から抽出
+
+
+
-## ツール管理
+
+ 後から**変数の組み立て**インターフェースを再度開くには:
-ワークスペースナビゲーションの**ツール**を通じてツール設定にアクセスします。ここでは、認証認証情報の管理、カスタムツールのインポート、MCPサーバーの設定、ワークフローのツールとしての公開を行うことができます。
+ 1. 組み立て済み変数の横にある**内部を表示**をクリックします。
+ 2. 内部のコードノードを選択します。
+ 3. コードジェネレーターアイコンをクリックします。
+
-ツールの作成、管理、ワークフローのツールとしての公開に関する詳細なガイダンスについては、[ツール設定ガイド](/en/guides/tools)を参照してください。
+### LLM の対話履歴から抽出
+
+ +
+必要な情報が LLM の対話履歴——実行中に生成されたユーザー、アシスタント、ツールメッセージ——に埋め込まれている場合に使用します。LLM の対話履歴は `context` 出力変数で確認できます。
+
+
+
+上流の LLM ノードがコードを生成しますが、出力には自然言語の説明やコメントも含まれています。下流のコードインタープリターツールは純粋な実行可能コードを必要とします。
+
+上流 LLM を変更してコードのみを出力させる代わりに、コードインタープリターの入力フィールドで LLM ノードを `@` で指定し、「実行可能コードのみを抽出してください」と記述します。
+
+システムは選択した LLM ノードの対話履歴を読み取り、コードインタープリターが期待する形式でコード部分のみを抽出する内部 LLM ノードを作成します。
+
+
+
+
+ 対話履歴から抽出する前に、対象の上流 Agent または LLM ノードを実行して `context` データを利用可能にしてください。
+
+
+1. 変数を受け付ける入力フィールドで、`@` を入力し上流の Agent または LLM ノードを選択します。
+
+2. その対話履歴から何を抽出したいかを記述します。
+
+3. **内部を表示**をクリックし、内部の LLM ノードをテスト実行します。このノードは上流ノードの対話履歴を自動的にインポートし、構造化出力を使って要求された形式に合わせます。
+
+4. 出力を確認し、必要に応じて改善します。
diff --git a/ja/use-dify/nodes/upload-file-to-sandbox.mdx b/ja/use-dify/nodes/upload-file-to-sandbox.mdx
new file mode 100644
index 00000000..740795aa
--- /dev/null
+++ b/ja/use-dify/nodes/upload-file-to-sandbox.mdx
@@ -0,0 +1,38 @@
+---
+title: "サンドボックスへのファイルアップロード"
+description: "マルチモーダルファイルをサンドボックスにアップロードし、LLM がツールやスクリプトで処理できるようにする——モデルがネイティブに処理できないファイル形式にも対応"
+icon: "upload"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/upload-file-to-sandbox)を参照してください。
+
+
+ このノードはサンドボックスランタイムを使用するアプリケーションでのみ利用可能です。
+
+
+ファイルを LLM に直接渡す場合、処理能力はモデル自体のマルチモーダル機能に制限されます。[ドキュメント抽出](/ja/use-dify/nodes/doc-extractor)ノードでさまざまなファイル形式をテキストに変換して LLM に処理させることもできますが、サポートされる形式には限りがあります。
+
+ここでサンドボックスへのファイルアップロードノードが役立ちます。ファイルがアップロードされると、下流の [Agent ノード](/ja/use-dify/nodes/agent#サンドボックスランタイム)(**Agent モード**を有効にした状態)がコマンドラインを実行してツールのインストールやスクリプトの実行を行い、ファイルを LLM が処理可能な形式に変換できます。
+
+
+ - 処理結果はモデルの推論能力に依存します。
+ - 本番環境では、これらのアップロードファイルは各実行にスコープされ、サンドボックスに永続保存されません。
+
+
+**使い方:**
+
+1. サンドボックスへのファイルアップロードノードで、ファイル変数(ユーザー入力からのものなど)を選択します。`file` と `array[file]` の両方のデータ型がサポートされています。
+
+2. 下流の Agent ノードのプロンプトで、`sandbox_path` と `file_name` 変数を参照し、モデルがファイルの場所を特定して処理できるようにします。例:
+
+ ```bash wrap
+ # システム指示
+ あなたはデータアナリストです。アップロードされたデータファイルを分析し、インサイトを提供してください。
+
+ # ユーザーメッセージ
+ {{Upload File to Sandbox.sandbox_path}} にある "{{Upload File to Sandbox.file_name}}" のデータを分析してください。
+ ```
+
+
+ `file_name` 変数にはファイル拡張子が含まれます(例:`data.csv`)。
+
diff --git a/ja/use-dify/publish/publish-to-marketplace.mdx b/ja/use-dify/publish/publish-to-marketplace.mdx
new file mode 100644
index 00000000..7a99d52d
--- /dev/null
+++ b/ja/use-dify/publish/publish-to-marketplace.mdx
@@ -0,0 +1,143 @@
+---
+title: "マーケットプレイスに公開"
+sidebarTitle: "マーケットプレイス"
+description: "アプリを Dify マーケットプレイスに公開して世界中のユーザーと共有"
+icon: "store"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/publish/publish-to-marketplace)を参照してください。
+
+アプリをテンプレートとして Dify マーケットプレイスに公開すると、他の Dify ユーザーが発見して利用できるようになります。[アフィリエイトプログラム](https://dify.ai/affiliate-program)に参加している場合は、テンプレートから収益を得ることもできます。
+
+## テンプレートの提出
+
+テンプレートを公開するには、まず審査に提出します。承認されると、マーケットプレイスに掲載されます。
+
+提出方法は2つあります:
+
+
+
+ アプリ内で、**公開** > **マーケットプレイスに公開**をクリックします。
+
+ [クリエイターズプラットフォーム](https://creators.dify.dev/)に移動し、テンプレートの詳細を入力して審査に提出できます。
+
+
+ アプリをエクスポートし、[クリエイターズプラットフォーム](https://creators.dify.dev/)でエクスポートファイルをアップロードします。テンプレートの詳細を入力して審査に提出します。
+
+
+
+## テンプレート作成ガイドライン
+
+### 言語の要件
+
+テンプレートライブラリの一貫性と検索しやすさを保つため、以下に従ってください。
+
+**以下のフィールドは英語で記述する必要があります**:
+
+ - テンプレート名
+ - 概要
+ - セットアップ手順
+
+**アプリ内部では、任意の言語(日本語など)を使用できます**:
+
+ - ノード名
+ - プロンプト / システムメッセージ
+ - エンドユーザーに表示されるメッセージ
+
+テンプレートが主に英語以外のユーザーを対象とする場合は、タイトルにタグを追加できます。例:
+Stock Investment Analysis Copilot [JA]
+
+### テンプレート名とアイコン
+
+名前だけで、ユーザーがどこで動作し何をするかがわかるようにします。
+
+- 短い英語のフレーズを使い、通常3〜7語にします。
+- 推奨パターン:[チャネル / 対象] + [コアタスク]。例:
+ - WeChat Customer Support Bot
+ - CSV Data Analyzer with Natural Language
+ - Internal Docs Q&A Assistant
+ - GitHub Issue Triage Agent
+- ユーザーが検索しそうなキーワードを含めます:チャネル名(Slack、WeChat、Email、Notion)やタスク名(Summarizer、Assistant、Generator、Bot)。
+
+### カテゴリ
+
+ユーザーがブラウズやカテゴリフィルターでテンプレートを発見しやすくします。
+
+- テンプレートを最もよく表す1〜3つのカテゴリのみを選択してください。
+- 露出を増やすためにすべてのカテゴリを選択しないでください。
+
+### 言語
+
+ユーザーが言語フィルターでテンプレートを発見しやすくします。
+
+- テンプレートが実際の利用で対象とする言語を選択します。
+- これはテンプレートのユースケース、入力、または出力の言語を指します——タイトルや概要の言語(英語必須)では**ありません**。
+
+### 概要
+
+2〜4文の英語で、何をするか、誰向けかを説明します。
+
+前提条件、入力、出力をここに記載する必要はありません。
+
+**推奨構成**
+
+1. 第1文:何をするか
+ 主な機能を一文で要約。
+2. 第2〜3文:誰が、いつ
+ 典型的なユーザーの役割やシナリオ(サポートチーム、マーケター、創業者、個人のナレッジワーカーなど)。
+
+
+
+This template creates a stock investment analysis copilot that uses Yahoo Finance tools to fetch news, analytics, and ticker data for any listed company.
+
+It helps investors and analysts quickly generate structured research summaries, compare companies, and prepare reports without manually switching between multiple finance websites.
+
+
+
+### セットアップ手順
+
+セットアップ手順を Markdown の番号付きリスト(1., 2., 3.)で記述し、各ステップは動詞で始まる短い一文にします。
+
+新しいユーザーがこの手順に従うだけで、数分でテンプレートを動かせるようにします。
+
+**記述の原則**
+
+1. 実際のセットアップ順序に従います。通常:
+ 1. テンプレートの使用/インポート
+ 2. アカウントの接続 / API キーの追加
+ 3. データソースの接続(ドキュメント、データベース、スプレッドシートなど)
+ 4. オプションのカスタマイズ(アシスタント名、トーン、フィルターなど)
+ 5. ワークフローを有効化してテスト実行
+
+2. 各ステップで以下を明確にします:
+ - UI のどこをクリックするか
+ - 何を設定または入力するか
+
+3. 3〜8ステップが目安です。少なすぎると不完全に感じ、多すぎると負担になります。
+
+
+ 1. Click **Use template** to copy the "Investment Analysis Copilot (Yahoo Finance)" agent into your workspace.
+
+ 2. Go to **Settings → Model provider** and add your LLM API key. For example, OpenAI, Anthropic, or another supported provider.
+
+ 3. Open the agent's **Orchestrate** page and make sure the Yahoo Finance tools are enabled in the **Tools** section:
+ - `yahoo Analytics`
+ - `yahoo News`
+ - `yahoo Ticker`
+
+ 4. (Optional) Customize the analysis style:
+ - In the **INSTRUCTIONS** area, adjust the system prompt to match your target users. For example, tone, report length, preferred language, or risk preference.
+ - Update the suggested questions in the **Debug & Preview** panel if you want different example queries.
+
+ 5. Click **Publish** to make the agent available, then use the preview panel to test it:
+ - Enter a company name or ticker (e.g., `Nvidia`, `AAPL`, `TSLA`).
+ - Confirm that the copilot calls the Yahoo Finance tools and returns a structured investment analysis report.
+
+
+### 提出前クイックチェックリスト
+
+- タイトルが、どこで動作し何をするかを明確に示す短い英語フレーズであること。
+- 概要が2〜4文の英語で価値と典型的なユースケースを説明していること。
+- 関連するカテゴリが1〜3つのみ選択されていること。
+- セットアップ手順が明確な番号付きリストであること。
+- ワークフロー内部のテキストやプロンプトが、ターゲットユーザーに適した言語で記述されていること。
diff --git a/ja/use-dify/workspace/app-management.mdx b/ja/use-dify/workspace/app-management.mdx
index 7afe9e2a..71317a51 100644
--- a/ja/use-dify/workspace/app-management.mdx
+++ b/ja/use-dify/workspace/app-management.mdx
@@ -1,28 +1,27 @@
---
title: "アプリの管理"
-description: "強力な管理ツールとベストプラクティスでAIアプリケーションを整理、維持、共有"
+description: "AIアプリケーションの整理・保守・共有"
icon: "grid-2"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/workspace/app-management)を参照してください。
-
-アプリを適切に管理することは、生産性の高いAI開発にとって重要です。Difyは、アプリケーションのライフサイクル全体を通じて、整理、共有、保守を行うための包括的なツールを提供します。
+アプリを適切に管理することは、生産的な AI 開発にとって重要です。Dify は、アプリケーションのライフサイクル全体を通じて整理、共有、保守を行うための包括的なツールを提供します。
## アプリの整理
- より良い整理のために名前、説明、アイコン、ブランディングを更新します
+ 名前、説明、アイコン、ブランディングを更新してアプリを整理
- バリエーションを作成したり、既存のアプリを新しいプロジェクトのテンプレートとして使用します
+ バリエーションの作成や既存アプリを新規プロジェクトのテンプレートとして利用
- DifyのDSL形式を使用してワークスペース間でアプリを共有します
+ Dify の DSL 形式でワークスペース間のアプリ共有
- 不要になったアプリを安全に削除します
+ 不要なアプリの安全な削除
@@ -31,93 +30,103 @@ icon: "grid-2"
明確で説明的な情報でアプリを整理しましょう:
-
+
+必要な情報が LLM の対話履歴——実行中に生成されたユーザー、アシスタント、ツールメッセージ——に埋め込まれている場合に使用します。LLM の対話履歴は `context` 出力変数で確認できます。
+
+
+
+上流の LLM ノードがコードを生成しますが、出力には自然言語の説明やコメントも含まれています。下流のコードインタープリターツールは純粋な実行可能コードを必要とします。
+
+上流 LLM を変更してコードのみを出力させる代わりに、コードインタープリターの入力フィールドで LLM ノードを `@` で指定し、「実行可能コードのみを抽出してください」と記述します。
+
+システムは選択した LLM ノードの対話履歴を読み取り、コードインタープリターが期待する形式でコード部分のみを抽出する内部 LLM ノードを作成します。
+
+
+
+
+ 対話履歴から抽出する前に、対象の上流 Agent または LLM ノードを実行して `context` データを利用可能にしてください。
+
+
+1. 変数を受け付ける入力フィールドで、`@` を入力し上流の Agent または LLM ノードを選択します。
+
+2. その対話履歴から何を抽出したいかを記述します。
+
+3. **内部を表示**をクリックし、内部の LLM ノードをテスト実行します。このノードは上流ノードの対話履歴を自動的にインポートし、構造化出力を使って要求された形式に合わせます。
+
+4. 出力を確認し、必要に応じて改善します。
diff --git a/ja/use-dify/nodes/upload-file-to-sandbox.mdx b/ja/use-dify/nodes/upload-file-to-sandbox.mdx
new file mode 100644
index 00000000..740795aa
--- /dev/null
+++ b/ja/use-dify/nodes/upload-file-to-sandbox.mdx
@@ -0,0 +1,38 @@
+---
+title: "サンドボックスへのファイルアップロード"
+description: "マルチモーダルファイルをサンドボックスにアップロードし、LLM がツールやスクリプトで処理できるようにする——モデルがネイティブに処理できないファイル形式にも対応"
+icon: "upload"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/nodes/upload-file-to-sandbox)を参照してください。
+
+
+ このノードはサンドボックスランタイムを使用するアプリケーションでのみ利用可能です。
+
+
+ファイルを LLM に直接渡す場合、処理能力はモデル自体のマルチモーダル機能に制限されます。[ドキュメント抽出](/ja/use-dify/nodes/doc-extractor)ノードでさまざまなファイル形式をテキストに変換して LLM に処理させることもできますが、サポートされる形式には限りがあります。
+
+ここでサンドボックスへのファイルアップロードノードが役立ちます。ファイルがアップロードされると、下流の [Agent ノード](/ja/use-dify/nodes/agent#サンドボックスランタイム)(**Agent モード**を有効にした状態)がコマンドラインを実行してツールのインストールやスクリプトの実行を行い、ファイルを LLM が処理可能な形式に変換できます。
+
+
+ - 処理結果はモデルの推論能力に依存します。
+ - 本番環境では、これらのアップロードファイルは各実行にスコープされ、サンドボックスに永続保存されません。
+
+
+**使い方:**
+
+1. サンドボックスへのファイルアップロードノードで、ファイル変数(ユーザー入力からのものなど)を選択します。`file` と `array[file]` の両方のデータ型がサポートされています。
+
+2. 下流の Agent ノードのプロンプトで、`sandbox_path` と `file_name` 変数を参照し、モデルがファイルの場所を特定して処理できるようにします。例:
+
+ ```bash wrap
+ # システム指示
+ あなたはデータアナリストです。アップロードされたデータファイルを分析し、インサイトを提供してください。
+
+ # ユーザーメッセージ
+ {{Upload File to Sandbox.sandbox_path}} にある "{{Upload File to Sandbox.file_name}}" のデータを分析してください。
+ ```
+
+
+ `file_name` 変数にはファイル拡張子が含まれます(例:`data.csv`)。
+
diff --git a/ja/use-dify/publish/publish-to-marketplace.mdx b/ja/use-dify/publish/publish-to-marketplace.mdx
new file mode 100644
index 00000000..7a99d52d
--- /dev/null
+++ b/ja/use-dify/publish/publish-to-marketplace.mdx
@@ -0,0 +1,143 @@
+---
+title: "マーケットプレイスに公開"
+sidebarTitle: "マーケットプレイス"
+description: "アプリを Dify マーケットプレイスに公開して世界中のユーザーと共有"
+icon: "store"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/publish/publish-to-marketplace)を参照してください。
+
+アプリをテンプレートとして Dify マーケットプレイスに公開すると、他の Dify ユーザーが発見して利用できるようになります。[アフィリエイトプログラム](https://dify.ai/affiliate-program)に参加している場合は、テンプレートから収益を得ることもできます。
+
+## テンプレートの提出
+
+テンプレートを公開するには、まず審査に提出します。承認されると、マーケットプレイスに掲載されます。
+
+提出方法は2つあります:
+
+
+
+ アプリ内で、**公開** > **マーケットプレイスに公開**をクリックします。
+
+ [クリエイターズプラットフォーム](https://creators.dify.dev/)に移動し、テンプレートの詳細を入力して審査に提出できます。
+
+
+ アプリをエクスポートし、[クリエイターズプラットフォーム](https://creators.dify.dev/)でエクスポートファイルをアップロードします。テンプレートの詳細を入力して審査に提出します。
+
+
+
+## テンプレート作成ガイドライン
+
+### 言語の要件
+
+テンプレートライブラリの一貫性と検索しやすさを保つため、以下に従ってください。
+
+**以下のフィールドは英語で記述する必要があります**:
+
+ - テンプレート名
+ - 概要
+ - セットアップ手順
+
+**アプリ内部では、任意の言語(日本語など)を使用できます**:
+
+ - ノード名
+ - プロンプト / システムメッセージ
+ - エンドユーザーに表示されるメッセージ
+
+テンプレートが主に英語以外のユーザーを対象とする場合は、タイトルにタグを追加できます。例:
+Stock Investment Analysis Copilot [JA]
+
+### テンプレート名とアイコン
+
+名前だけで、ユーザーがどこで動作し何をするかがわかるようにします。
+
+- 短い英語のフレーズを使い、通常3〜7語にします。
+- 推奨パターン:[チャネル / 対象] + [コアタスク]。例:
+ - WeChat Customer Support Bot
+ - CSV Data Analyzer with Natural Language
+ - Internal Docs Q&A Assistant
+ - GitHub Issue Triage Agent
+- ユーザーが検索しそうなキーワードを含めます:チャネル名(Slack、WeChat、Email、Notion)やタスク名(Summarizer、Assistant、Generator、Bot)。
+
+### カテゴリ
+
+ユーザーがブラウズやカテゴリフィルターでテンプレートを発見しやすくします。
+
+- テンプレートを最もよく表す1〜3つのカテゴリのみを選択してください。
+- 露出を増やすためにすべてのカテゴリを選択しないでください。
+
+### 言語
+
+ユーザーが言語フィルターでテンプレートを発見しやすくします。
+
+- テンプレートが実際の利用で対象とする言語を選択します。
+- これはテンプレートのユースケース、入力、または出力の言語を指します——タイトルや概要の言語(英語必須)では**ありません**。
+
+### 概要
+
+2〜4文の英語で、何をするか、誰向けかを説明します。
+
+前提条件、入力、出力をここに記載する必要はありません。
+
+**推奨構成**
+
+1. 第1文:何をするか
+ 主な機能を一文で要約。
+2. 第2〜3文:誰が、いつ
+ 典型的なユーザーの役割やシナリオ(サポートチーム、マーケター、創業者、個人のナレッジワーカーなど)。
+
+
+
+This template creates a stock investment analysis copilot that uses Yahoo Finance tools to fetch news, analytics, and ticker data for any listed company.
+
+It helps investors and analysts quickly generate structured research summaries, compare companies, and prepare reports without manually switching between multiple finance websites.
+
+
+
+### セットアップ手順
+
+セットアップ手順を Markdown の番号付きリスト(1., 2., 3.)で記述し、各ステップは動詞で始まる短い一文にします。
+
+新しいユーザーがこの手順に従うだけで、数分でテンプレートを動かせるようにします。
+
+**記述の原則**
+
+1. 実際のセットアップ順序に従います。通常:
+ 1. テンプレートの使用/インポート
+ 2. アカウントの接続 / API キーの追加
+ 3. データソースの接続(ドキュメント、データベース、スプレッドシートなど)
+ 4. オプションのカスタマイズ(アシスタント名、トーン、フィルターなど)
+ 5. ワークフローを有効化してテスト実行
+
+2. 各ステップで以下を明確にします:
+ - UI のどこをクリックするか
+ - 何を設定または入力するか
+
+3. 3〜8ステップが目安です。少なすぎると不完全に感じ、多すぎると負担になります。
+
+
+ 1. Click **Use template** to copy the "Investment Analysis Copilot (Yahoo Finance)" agent into your workspace.
+
+ 2. Go to **Settings → Model provider** and add your LLM API key. For example, OpenAI, Anthropic, or another supported provider.
+
+ 3. Open the agent's **Orchestrate** page and make sure the Yahoo Finance tools are enabled in the **Tools** section:
+ - `yahoo Analytics`
+ - `yahoo News`
+ - `yahoo Ticker`
+
+ 4. (Optional) Customize the analysis style:
+ - In the **INSTRUCTIONS** area, adjust the system prompt to match your target users. For example, tone, report length, preferred language, or risk preference.
+ - Update the suggested questions in the **Debug & Preview** panel if you want different example queries.
+
+ 5. Click **Publish** to make the agent available, then use the preview panel to test it:
+ - Enter a company name or ticker (e.g., `Nvidia`, `AAPL`, `TSLA`).
+ - Confirm that the copilot calls the Yahoo Finance tools and returns a structured investment analysis report.
+
+
+### 提出前クイックチェックリスト
+
+- タイトルが、どこで動作し何をするかを明確に示す短い英語フレーズであること。
+- 概要が2〜4文の英語で価値と典型的なユースケースを説明していること。
+- 関連するカテゴリが1〜3つのみ選択されていること。
+- セットアップ手順が明確な番号付きリストであること。
+- ワークフロー内部のテキストやプロンプトが、ターゲットユーザーに適した言語で記述されていること。
diff --git a/ja/use-dify/workspace/app-management.mdx b/ja/use-dify/workspace/app-management.mdx
index 7afe9e2a..71317a51 100644
--- a/ja/use-dify/workspace/app-management.mdx
+++ b/ja/use-dify/workspace/app-management.mdx
@@ -1,28 +1,27 @@
---
title: "アプリの管理"
-description: "強力な管理ツールとベストプラクティスでAIアプリケーションを整理、維持、共有"
+description: "AIアプリケーションの整理・保守・共有"
icon: "grid-2"
---
⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/workspace/app-management)を参照してください。
-
-アプリを適切に管理することは、生産性の高いAI開発にとって重要です。Difyは、アプリケーションのライフサイクル全体を通じて、整理、共有、保守を行うための包括的なツールを提供します。
+アプリを適切に管理することは、生産的な AI 開発にとって重要です。Dify は、アプリケーションのライフサイクル全体を通じて整理、共有、保守を行うための包括的なツールを提供します。
## アプリの整理
- より良い整理のために名前、説明、アイコン、ブランディングを更新します
+ 名前、説明、アイコン、ブランディングを更新してアプリを整理
- バリエーションを作成したり、既存のアプリを新しいプロジェクトのテンプレートとして使用します
+ バリエーションの作成や既存アプリを新規プロジェクトのテンプレートとして利用
- DifyのDSL形式を使用してワークスペース間でアプリを共有します
+ Dify の DSL 形式でワークスペース間のアプリ共有
- 不要になったアプリを安全に削除します
+ 不要なアプリの安全な削除
@@ -31,93 +30,103 @@ icon: "grid-2"
明確で説明的な情報でアプリを整理しましょう:
-  +
アプリケーションの左上隅にある「情報を編集」をクリックします。
-
+
- アプリの目的をよりよく反映するためにアイコン、名前、または説明を変更します。
+ アプリの目的をよりよく反映するためにアイコン、名前、説明を変更します。
-
+
チームメンバーがアプリの機能を理解しやすい名前と説明を使用します。
-ワークスペース全体で一貫した命名規則を使用してください。アプリのステータスを示すために「Draft-」、「Test-」、「Prod-」などのプレフィックスを使用することを検討してください。
+ワークスペース全体で一貫した命名規則を使用してください。アプリのステータスを示すために「Draft-」、「Test-」、「Prod-」などのプレフィックスを検討してください。
## アプリのバリエーション作成
-複製は、バリエーションを作成したり、既存の作業から新しいプロジェクトを開始したりするのに最適です:
+複製は、バリエーションの作成や既存の作業から新しいプロジェクトを開始するのに最適です:
**複製すべき場合:**
-- 異なるプロンプトやモデルでA/Bテストバージョンを作成する
-- 異なるオーディエンスやユースケース向けにアプリを適応させる
-- 成功したパターンに基づいて新しいプロジェクトを開始する
-- 大きな変更を行う前にバックアップを作成する
+- 異なるプロンプトやモデルで A/B テストバージョンを作成
+- 異なるオーディエンスやユースケース向けにアプリを適応
+- 成功したパターンに基づいて新プロジェクトを開始
+- 大きな変更前にバックアップを作成
**複製の仕組み:**
-- すべての設定、プロンプト、ワークフローがコピーされます
-- 新しいアプリはカスタマイズ可能なデフォルト名を取得します
-- 元のアプリは変更されません
-- 両方のアプリは独立して動作します
+- すべての設定、プロンプト、ワークフローがコピーされる
+- 新しいアプリはカスタマイズ可能なデフォルト名を取得
+- 元のアプリは変更されない
+- 両方のアプリは独立して動作
## アプリのエクスポートとインポート
-DifyのDSL(ドメイン固有言語)形式により、ワークスペースやチーム間でアプリを共有できます:
+Dify の DSL(ドメイン固有言語)形式により、ワークスペースやチーム間でアプリを共有できます:
-
+
アプリケーションの左上隅にある「情報を編集」をクリックします。
-
+
- アプリの目的をよりよく反映するためにアイコン、名前、または説明を変更します。
+ アプリの目的をよりよく反映するためにアイコン、名前、説明を変更します。
-
+
チームメンバーがアプリの機能を理解しやすい名前と説明を使用します。
-ワークスペース全体で一貫した命名規則を使用してください。アプリのステータスを示すために「Draft-」、「Test-」、「Prod-」などのプレフィックスを使用することを検討してください。
+ワークスペース全体で一貫した命名規則を使用してください。アプリのステータスを示すために「Draft-」、「Test-」、「Prod-」などのプレフィックスを検討してください。
## アプリのバリエーション作成
-複製は、バリエーションを作成したり、既存の作業から新しいプロジェクトを開始したりするのに最適です:
+複製は、バリエーションの作成や既存の作業から新しいプロジェクトを開始するのに最適です:
**複製すべき場合:**
-- 異なるプロンプトやモデルでA/Bテストバージョンを作成する
-- 異なるオーディエンスやユースケース向けにアプリを適応させる
-- 成功したパターンに基づいて新しいプロジェクトを開始する
-- 大きな変更を行う前にバックアップを作成する
+- 異なるプロンプトやモデルで A/B テストバージョンを作成
+- 異なるオーディエンスやユースケース向けにアプリを適応
+- 成功したパターンに基づいて新プロジェクトを開始
+- 大きな変更前にバックアップを作成
**複製の仕組み:**
-- すべての設定、プロンプト、ワークフローがコピーされます
-- 新しいアプリはカスタマイズ可能なデフォルト名を取得します
-- 元のアプリは変更されません
-- 両方のアプリは独立して動作します
+- すべての設定、プロンプト、ワークフローがコピーされる
+- 新しいアプリはカスタマイズ可能なデフォルト名を取得
+- 元のアプリは変更されない
+- 両方のアプリは独立して動作
## アプリのエクスポートとインポート
-DifyのDSL(ドメイン固有言語)形式により、ワークスペースやチーム間でアプリを共有できます:
+Dify の DSL(ドメイン固有言語)形式により、ワークスペースやチーム間でアプリを共有できます:
- 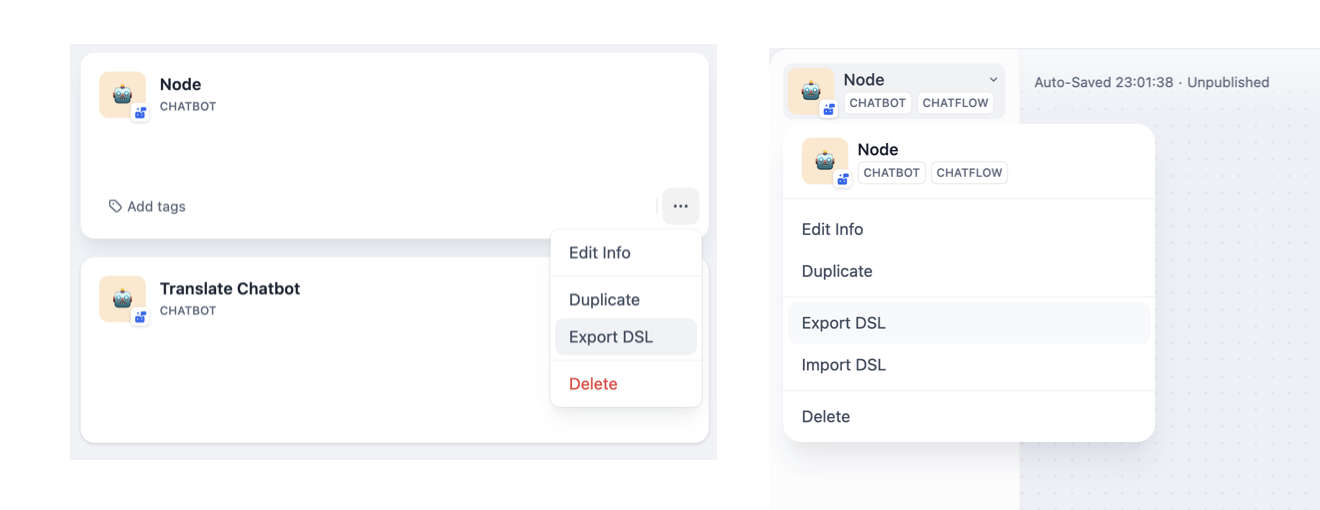 +
### アプリケーションのエクスポート
-**エクスポートする2つの方法:**
-1. **Studioページから** - アプリケーションメニューの「DSLエクスポート」をクリック
-2. **オーケストレーションから** - 左上隅の「DSLエクスポート」をクリック
+**エクスポート方法:**
+1. **Studio ページから** - アプリケーションメニューの「エクスポート」をクリック
+2. **オーケストレーションから** - 左上隅の「エクスポート」をクリック
+
+**エクスポート形式:**
+
+| ランタイム | 形式 | 内容 |
+|:--------|:-------|:---------|
+| サンドボックス | `.zip` | DSL ファイル + ファイルシステムのリソースファイル |
+| クラシック | `.yml` | DSL ファイルのみ |
**エクスポートされるもの:**
+- アプリの設定とメタデータ
- ワークフローオーケストレーションとノード設定
- モデルパラメータとプロンプトテンプレート
-- 知識ベース接続(データ自体ではない)
+- ナレッジベースの接続情報(データ自体は含まれない)
+- ファイルシステム内のリソースファイル(サンドボックスワークフローのみ)
**エクスポートされないもの:**
-- サードパーティツールのAPIキー(セキュリティ対策)
-- 実際の知識ベースコンテンツ
+- サードパーティツールの API キー(セキュリティ上の理由)
+- ナレッジベースの実コンテンツ
- 使用ログと分析データ
+- LLM が実行中に生成したアーティファクト(サンドボックスワークフロー)
-アプリでSecret型の環境変数を使用している場合、エクスポートに含めるかどうか尋ねられます。機密情報には注意してください。
+アプリで Secret 型の環境変数を使用している場合、エクスポートに含めるかどうか確認されます。機密情報の取り扱いにはご注意ください。
-
+
### アプリケーションのエクスポート
-**エクスポートする2つの方法:**
-1. **Studioページから** - アプリケーションメニューの「DSLエクスポート」をクリック
-2. **オーケストレーションから** - 左上隅の「DSLエクスポート」をクリック
+**エクスポート方法:**
+1. **Studio ページから** - アプリケーションメニューの「エクスポート」をクリック
+2. **オーケストレーションから** - 左上隅の「エクスポート」をクリック
+
+**エクスポート形式:**
+
+| ランタイム | 形式 | 内容 |
+|:--------|:-------|:---------|
+| サンドボックス | `.zip` | DSL ファイル + ファイルシステムのリソースファイル |
+| クラシック | `.yml` | DSL ファイルのみ |
**エクスポートされるもの:**
+- アプリの設定とメタデータ
- ワークフローオーケストレーションとノード設定
- モデルパラメータとプロンプトテンプレート
-- 知識ベース接続(データ自体ではない)
+- ナレッジベースの接続情報(データ自体は含まれない)
+- ファイルシステム内のリソースファイル(サンドボックスワークフローのみ)
**エクスポートされないもの:**
-- サードパーティツールのAPIキー(セキュリティ対策)
-- 実際の知識ベースコンテンツ
+- サードパーティツールの API キー(セキュリティ上の理由)
+- ナレッジベースの実コンテンツ
- 使用ログと分析データ
+- LLM が実行中に生成したアーティファクト(サンドボックスワークフロー)
-アプリでSecret型の環境変数を使用している場合、エクスポートに含めるかどうか尋ねられます。機密情報には注意してください。
+アプリで Secret 型の環境変数を使用している場合、エクスポートに含めるかどうか確認されます。機密情報の取り扱いにはご注意ください。
- 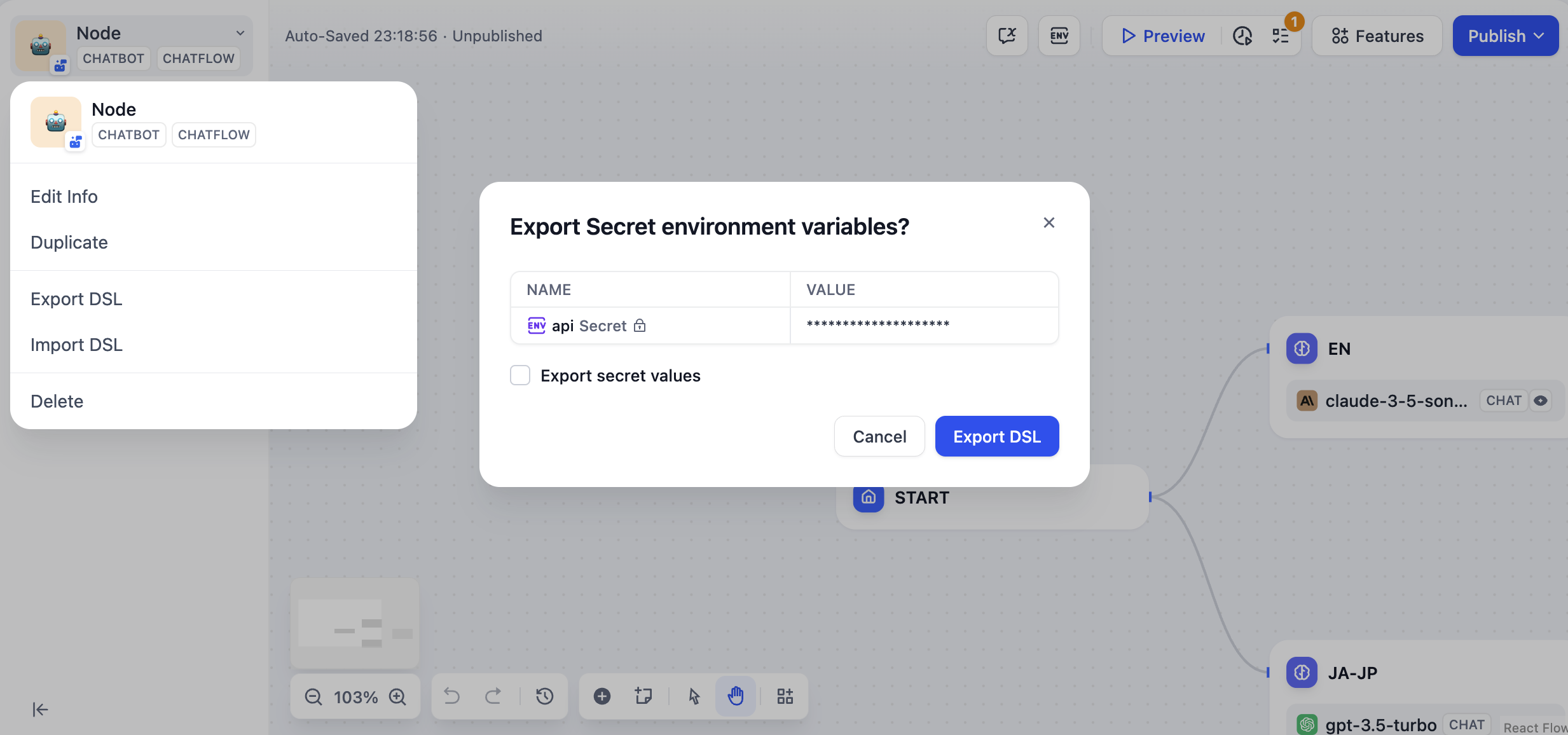 +
### アプリケーションのインポート
-
+
### アプリケーションのインポート
- 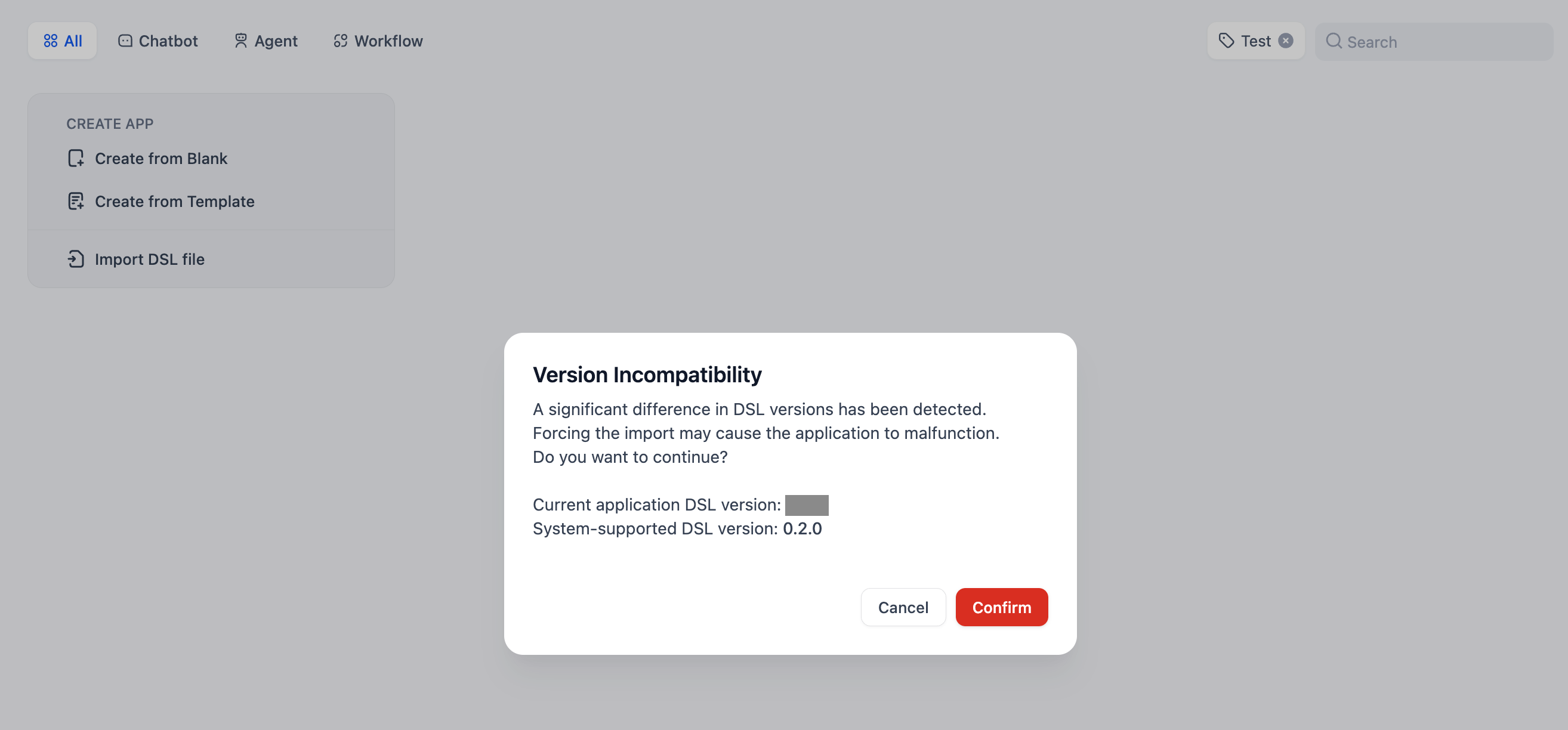 +
**インポートプロセス:**
-1. DSLファイル(YAML形式)をアップロード
+1. `.zip` ファイル(サンドボックスワークフロー)または `.yml` ファイル(その他のアプリ)をアップロード
2. システムがバージョン互換性をチェック
-3. DSLバージョンが現在のプラットフォームより古い場合、警告が表示される
+3. DSL バージョンが現在のプラットフォームより古い場合、警告が表示される
4. ファイルのすべての設定でアプリが作成される
**バージョン互換性:**
-- **SaaSユーザー**: DSLファイルは常に最新バージョンです
-- **コミュニティユーザー**: 互換性の問題を避けるためにアップグレードが必要な場合があります
+- **SaaS ユーザー**:DSL ファイルは常に最新バージョン
+- **コミュニティユーザー**:互換性の問題を避けるためにアップグレードが必要な場合がある
-Dify DSLは、YAML形式で完全なアプリ設定をキャプチャするAIアプリケーションエンジニアリング標準(v0.6+)です。
+Dify DSL は、YAML 形式で完全なアプリ設定をキャプチャする AI アプリケーションエンジニアリング標準(v0.6+)です。
## 安全なアプリ削除
@@ -127,51 +136,33 @@ Dify DSLは、YAML形式で完全なアプリ設定をキャプチャするAIア
**削除されるもの:**
- すべてのアプリ設定とプロンプト
- ワークフローオーケストレーションと設定
-- 使用ログと分析
-- 公開されたWebアプリとAPIアクセス
+- 使用ログと分析データ
+- 公開された Web アプリと API アクセス
- すべてのユーザー会話とデータ
**ユーザーへの影響:**
-- 公開されたWebアプリは即座に動作を停止します
-- API呼び出しはエラーを返し始めます
-- 既存のすべてのユーザーセッションが終了します
+- 公開された Web アプリは即座に動作停止
+- API 呼び出しはエラーを返すようになる
+- 既存のすべてのユーザーセッションが終了
バックアップ用にアプリを複製したり、削除する代わりに非公開にしたりできませんか?
-
+
計画された削除についてチームメンバーとユーザーに知らせます。
-
+
- 削除前に価値ある設定のDSLバックアップを作成します。
+ 削除前に価値ある設定の DSL バックアップを作成します。
-
+
- 「削除」をクリックして確認します—この操作は取り消すことができません。
+ 「削除」をクリックして確認します——この操作は取り消すことができません。
アプリの削除は永続的であり、取り消すことはできません。関連するすべてのデータ、ログ、ユーザーアクセスは即座に失われます。
-
-## ベストプラクティス
-
-**命名規則:**
-- アプリの目的を説明する分かりやすい名前を使用する
-- 関連する場合はバージョン番号やステータスインジケーターを含める
-- 一貫性のためにチーム全体の命名標準を検討する
-
-**整理のヒント:**
-- テスト用および未使用アプリの定期的な整理
-- 類似のアプリタイプには一貫したアイコンと説明を使用
-- 主要な設定変更を文書化
-- 本番アプリを実験的なアプリから分離して保管
-
-**コラボレーション:**
-- 知識移転のためにチームメンバーとDSLファイルを共有する
-- 複製を使用してチームテンプレ重要な設定をエクスポートする
-- アプリを共有する際はアクセス権限を考慮する
diff --git a/ja/use-dify/workspace/tools.mdx b/ja/use-dify/workspace/tools.mdx
new file mode 100644
index 00000000..254261f1
--- /dev/null
+++ b/ja/use-dify/workspace/tools.mdx
@@ -0,0 +1,62 @@
+---
+title: Dify ツール
+sidebarTitle: ツール
+icon: "wrench"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/workspace/tools)を参照してください。
+
+Dify ツールは LLM が外部サービスや API と連携できるようにし、リアルタイムデータへのアクセスやアクション(ウェブ検索、データベースクエリ、コンテンツ処理など)の実行を可能にします。
+
+各ツールには明確なインターフェースがあります:どのような入力を受け付け、どのようなアクションを実行し、どのような出力を返すか。これにより LLM はユーザーのリクエストに応じて、いつどのようにツールを呼び出すかを判断できます。
+
+ツールは以下で利用できます:
+
+- ワークフロー / チャットフローアプリ(独立したツールノードとして、または LLM / Agent ノード内で)
+
+- Agent アプリ
+
+すべてのツールは**ツール**ページで管理できます。
+
+
+
**インポートプロセス:**
-1. DSLファイル(YAML形式)をアップロード
+1. `.zip` ファイル(サンドボックスワークフロー)または `.yml` ファイル(その他のアプリ)をアップロード
2. システムがバージョン互換性をチェック
-3. DSLバージョンが現在のプラットフォームより古い場合、警告が表示される
+3. DSL バージョンが現在のプラットフォームより古い場合、警告が表示される
4. ファイルのすべての設定でアプリが作成される
**バージョン互換性:**
-- **SaaSユーザー**: DSLファイルは常に最新バージョンです
-- **コミュニティユーザー**: 互換性の問題を避けるためにアップグレードが必要な場合があります
+- **SaaS ユーザー**:DSL ファイルは常に最新バージョン
+- **コミュニティユーザー**:互換性の問題を避けるためにアップグレードが必要な場合がある
-Dify DSLは、YAML形式で完全なアプリ設定をキャプチャするAIアプリケーションエンジニアリング標準(v0.6+)です。
+Dify DSL は、YAML 形式で完全なアプリ設定をキャプチャする AI アプリケーションエンジニアリング標準(v0.6+)です。
## 安全なアプリ削除
@@ -127,51 +136,33 @@ Dify DSLは、YAML形式で完全なアプリ設定をキャプチャするAIア
**削除されるもの:**
- すべてのアプリ設定とプロンプト
- ワークフローオーケストレーションと設定
-- 使用ログと分析
-- 公開されたWebアプリとAPIアクセス
+- 使用ログと分析データ
+- 公開された Web アプリと API アクセス
- すべてのユーザー会話とデータ
**ユーザーへの影響:**
-- 公開されたWebアプリは即座に動作を停止します
-- API呼び出しはエラーを返し始めます
-- 既存のすべてのユーザーセッションが終了します
+- 公開された Web アプリは即座に動作停止
+- API 呼び出しはエラーを返すようになる
+- 既存のすべてのユーザーセッションが終了
バックアップ用にアプリを複製したり、削除する代わりに非公開にしたりできませんか?
-
+
計画された削除についてチームメンバーとユーザーに知らせます。
-
+
- 削除前に価値ある設定のDSLバックアップを作成します。
+ 削除前に価値ある設定の DSL バックアップを作成します。
-
+
- 「削除」をクリックして確認します—この操作は取り消すことができません。
+ 「削除」をクリックして確認します——この操作は取り消すことができません。
アプリの削除は永続的であり、取り消すことはできません。関連するすべてのデータ、ログ、ユーザーアクセスは即座に失われます。
-
-## ベストプラクティス
-
-**命名規則:**
-- アプリの目的を説明する分かりやすい名前を使用する
-- 関連する場合はバージョン番号やステータスインジケーターを含める
-- 一貫性のためにチーム全体の命名標準を検討する
-
-**整理のヒント:**
-- テスト用および未使用アプリの定期的な整理
-- 類似のアプリタイプには一貫したアイコンと説明を使用
-- 主要な設定変更を文書化
-- 本番アプリを実験的なアプリから分離して保管
-
-**コラボレーション:**
-- 知識移転のためにチームメンバーとDSLファイルを共有する
-- 複製を使用してチームテンプレ重要な設定をエクスポートする
-- アプリを共有する際はアクセス権限を考慮する
diff --git a/ja/use-dify/workspace/tools.mdx b/ja/use-dify/workspace/tools.mdx
new file mode 100644
index 00000000..254261f1
--- /dev/null
+++ b/ja/use-dify/workspace/tools.mdx
@@ -0,0 +1,62 @@
+---
+title: Dify ツール
+sidebarTitle: ツール
+icon: "wrench"
+---
+
+ ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/use-dify/workspace/tools)を参照してください。
+
+Dify ツールは LLM が外部サービスや API と連携できるようにし、リアルタイムデータへのアクセスやアクション(ウェブ検索、データベースクエリ、コンテンツ処理など)の実行を可能にします。
+
+各ツールには明確なインターフェースがあります:どのような入力を受け付け、どのようなアクションを実行し、どのような出力を返すか。これにより LLM はユーザーのリクエストに応じて、いつどのようにツールを呼び出すかを判断できます。
+
+ツールは以下で利用できます:
+
+- ワークフロー / チャットフローアプリ(独立したツールノードとして、または LLM / Agent ノード内で)
+
+- Agent アプリ
+
+すべてのツールは**ツール**ページで管理できます。
+
+ +
+## ツールの種類
+
+
+
+
+ [プラグイン](/ja/use-dify/workspace/plugins)ツールは、Dify とコミュニティが提供する一般的なユーティリティや人気サードパーティサービス向けのすぐに使える統合機能です。
+
+ すぐに使える組み込みプラグインツール(CurrentTime など)に加えて、[Dify マーケットプレイス](https://marketplace.dify.ai/)でさらに多くのツールを探してインストールできます。
+
+ **認証の管理**
+
+ 一部のプラグインツール(Google や GitHub など)は、使用前に API キーや OAuth などの認証が必要です。
+
+ これらのツールのワークスペースレベルの認証情報は、**ツール**ページや**プラグイン**ページから、またはアプリやノード内のツール設定から直接管理できます。
+
+
+
+
+ 標準的な OpenAPI(Swagger)仕様を使用して、外部サービスをカスタムツールとして統合します。プラグインとして提供されていない内部システムやサードパーティサービスに Dify を接続する場合に最適です。
+
+ OpenAPI スキーマを貼り付けるか、URL からインポートするか、提供されたサンプルから始めます。Dify が仕様を解析し、ツールインターフェースを自動生成します。
+
+
+
+
+ ユーザー入力ノードで始まるワークフローを再利用可能なツールに変換します。チャットフローはサポートされていません。
+
+ 複雑なマルチステップロジックを1つの機能にまとめることで、異なる Dify アプリ間で簡単に再利用できます。
+
+
+
+## ツールの種類
+
+
+
+
+ [プラグイン](/ja/use-dify/workspace/plugins)ツールは、Dify とコミュニティが提供する一般的なユーティリティや人気サードパーティサービス向けのすぐに使える統合機能です。
+
+ すぐに使える組み込みプラグインツール(CurrentTime など)に加えて、[Dify マーケットプレイス](https://marketplace.dify.ai/)でさらに多くのツールを探してインストールできます。
+
+ **認証の管理**
+
+ 一部のプラグインツール(Google や GitHub など)は、使用前に API キーや OAuth などの認証が必要です。
+
+ これらのツールのワークスペースレベルの認証情報は、**ツール**ページや**プラグイン**ページから、またはアプリやノード内のツール設定から直接管理できます。
+
+
+
+
+ 標準的な OpenAPI(Swagger)仕様を使用して、外部サービスをカスタムツールとして統合します。プラグインとして提供されていない内部システムやサードパーティサービスに Dify を接続する場合に最適です。
+
+ OpenAPI スキーマを貼り付けるか、URL からインポートするか、提供されたサンプルから始めます。Dify が仕様を解析し、ツールインターフェースを自動生成します。
+
+
+
+
+ ユーザー入力ノードで始まるワークフローを再利用可能なツールに変換します。チャットフローはサポートされていません。
+
+ 複雑なマルチステップロジックを1つの機能にまとめることで、異なる Dify アプリ間で簡単に再利用できます。
+
+  +
+
+
+
+ [Model Context Protocol(MCP)](https://modelcontextprotocol.io/) は、AI アプリが標準インターフェースを通じて外部データやツールに接続できるようにします。MCP サーバーは、データベース、ファイルシステム、API などの外部リソースをラップし、このプロトコルを通じて AI アプリからアクセスできるようにします。
+
+ MCP サーバーに接続すると、これらの外部リソースを Dify のツールとしてインポートでき、リストをいつでも更新して最新の変更を取得できます。
+
+
+
+
+
+
+
+ [Model Context Protocol(MCP)](https://modelcontextprotocol.io/) は、AI アプリが標準インターフェースを通じて外部データやツールに接続できるようにします。MCP サーバーは、データベース、ファイルシステム、API などの外部リソースをラップし、このプロトコルを通じて AI アプリからアクセスできるようにします。
+
+ MCP サーバーに接続すると、これらの外部リソースを Dify のツールとしてインポートでき、リストをいつでも更新して最新の変更を取得できます。
+
+
+