diff --git a/en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx b/en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx
index 8720f9cb..8b0a0170 100644
--- a/en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx
+++ b/en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx
@@ -1,5 +1,5 @@
---
-title: 2. Choose a Chunk Mode
+title: Choose a Chunk Mode
---
After uploading content to the knowledge base, the next step is chunking and data cleaning. **This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.**
diff --git a/en/guides/knowledge-base/create-knowledge-and-upload-documents/configure-retrieval-settings.mdx b/en/guides/knowledge-base/create-knowledge-and-upload-documents/configure-retrieval-settings.mdx
new file mode 100644
index 00000000..b883e410
--- /dev/null
+++ b/en/guides/knowledge-base/create-knowledge-and-upload-documents/configure-retrieval-settings.mdx
@@ -0,0 +1,3 @@
+---
+title: Configure Retrieval Settings
+---
\ No newline at end of file
diff --git a/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx b/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
index b1a580d3..dcf045e3 100644
--- a/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
+++ b/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
@@ -1,41 +1,25 @@
---
-title: 1. Import Text Data
+title: Use Local Files as Data Source to Quick Create Knowledge
+sidebarTitle: Upload Local Files
---
-Click on Knowledge in the main navigation bar of Dify. On this page, you can see your existing knowledge bases. Click **Create Knowledge** to enter the setup wizard. The Knowledge supports the import of the following two online data:
+When quick-creating a knowledge base, you can upload local files as its data source:
-Click **Knowledge** in the top navigation bar of the Dify, then select **Create Knowledge**. You can upload documents to the knowledge or importing online data to it.
+1. Click **Knowledge** > **Create Knowledge**.
-## Upload Local Files
-
-Drag and drop or select files to upload. The number of files allowed for **batch upload** depends on your [subscription plan](https://dify.ai/pricing).
-
-**Limitations for uploading documents:**
-
-* The upload size limit for a single document is 15MB;
-* Different [subscription plans](https://dify.ai/pricing) for the SaaS version limit **batch upload numbers, total document uploads, and vector storage**
-
-
-
-## Import From Online Data Source
-
-When creating a **Knowledge**, you can import data from online sources. The knowledge supports the following two types of online data:
-
-
- Learn how to import data from Notion
-
-
-
- Learn how to sync data from websites
-
+2. Select **Import from file** as the data source, then upload your files.
-If a knowledge base is set up to use online data, you won't be able to add local documents later or switch it to a local file-based mode. This prevents a single knowledge base from mixing multiple data sources, avoiding management complications.
+ - Maximum file size: 15 MB
+
+ - Maximum number of files per upload: 5
+
+ - On Dify Cloud, **batch uploading** is only available on [the **Professional** and **Team** plans](https://dify.ai/pricing).
-## Adding Data Later
-
-If you haven't prepared your documents or other content yet, simply create an empty knowledge first. You can then upload local files or import online data whenever you're ready.
+
+ Once a knowledge base is created, its data source cannot be changed later.
+
{/*
Contributing Section
diff --git a/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx b/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
index 4b3b820c..d6251348 100644
--- a/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
+++ b/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
@@ -1,80 +1,57 @@
---
-title: 1.1 Sync Data from Notion
+title: Use Notion as Data Source to Quick Create Knowledge
+sidebarTitle: Sync from Notion
---
-Dify datasets support importing from Notion and setting up **synchronization** so that data updates in Notion are automatically synced to Dify.
+When quick-creating a knowledge base, you can use Notion as its data source, importing specific pages and synchronizing them when their content is updated.
-### Authorization Verification
+## Import Notion Pages
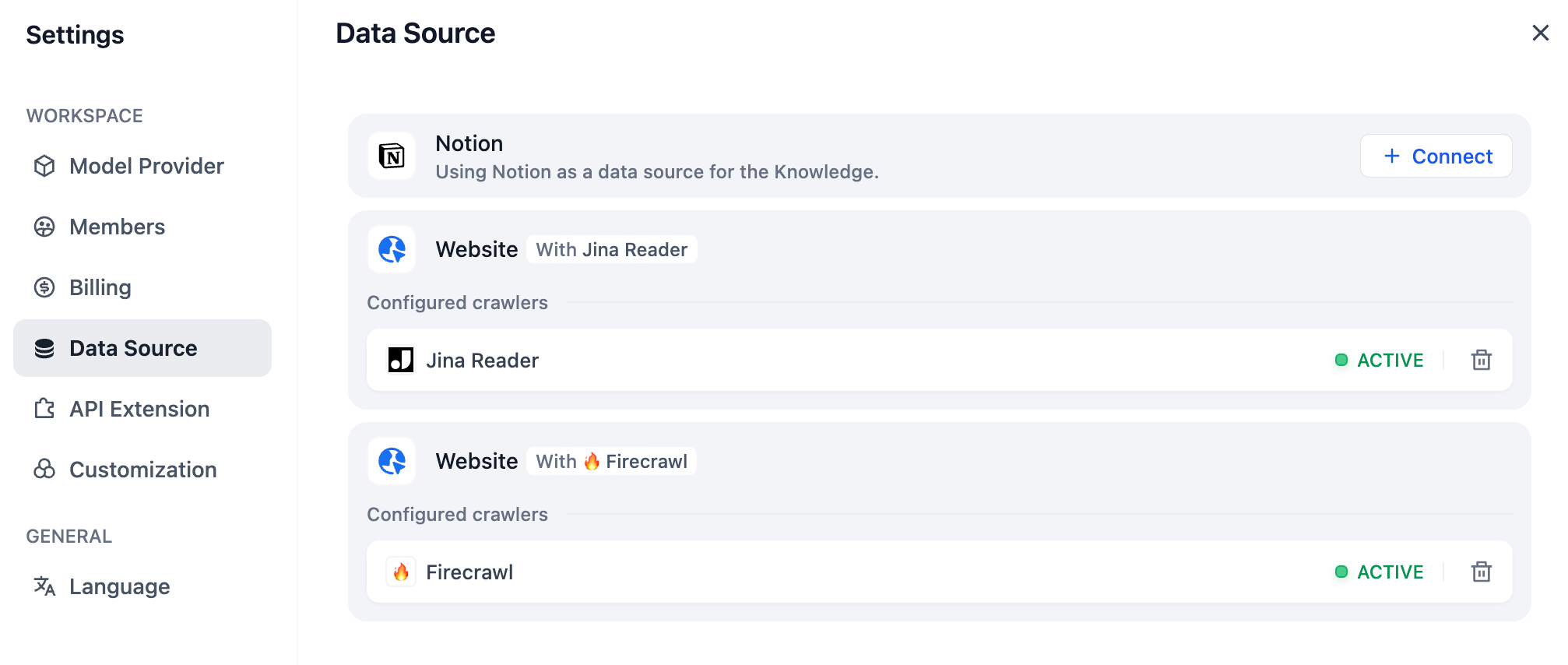
-1. When creating a dataset and selecting the data source, click **Sync from Notion Content -- Bind Now** and follow the prompts to complete the authorization verification.
-2. Alternatively, you can go to **Settings -- Data Sources -- Add Data Source**, click on the Notion source **Bind**, and complete the authorization verification.
+
+
+ Go to **Settings** > **Data Source**, then find and install the Notion data source plugin from the recommendation list.
+
+
+ Click **+ Configure** to authorize Dify to access your Notion workspace via OAuth or API key.
+
+
-
+
+ On Dify Cloud, the Notion data source plugin comes pre-configured with a default OAuth client that allows one-click authorization.
+
+
+
+ placeholder
+
+
-### Importing Notion Data
+
+ Once a workspace is connected, you can set it as the default import source, rename it, change which pages are authorized, or remove it from Dify.
+
+
+
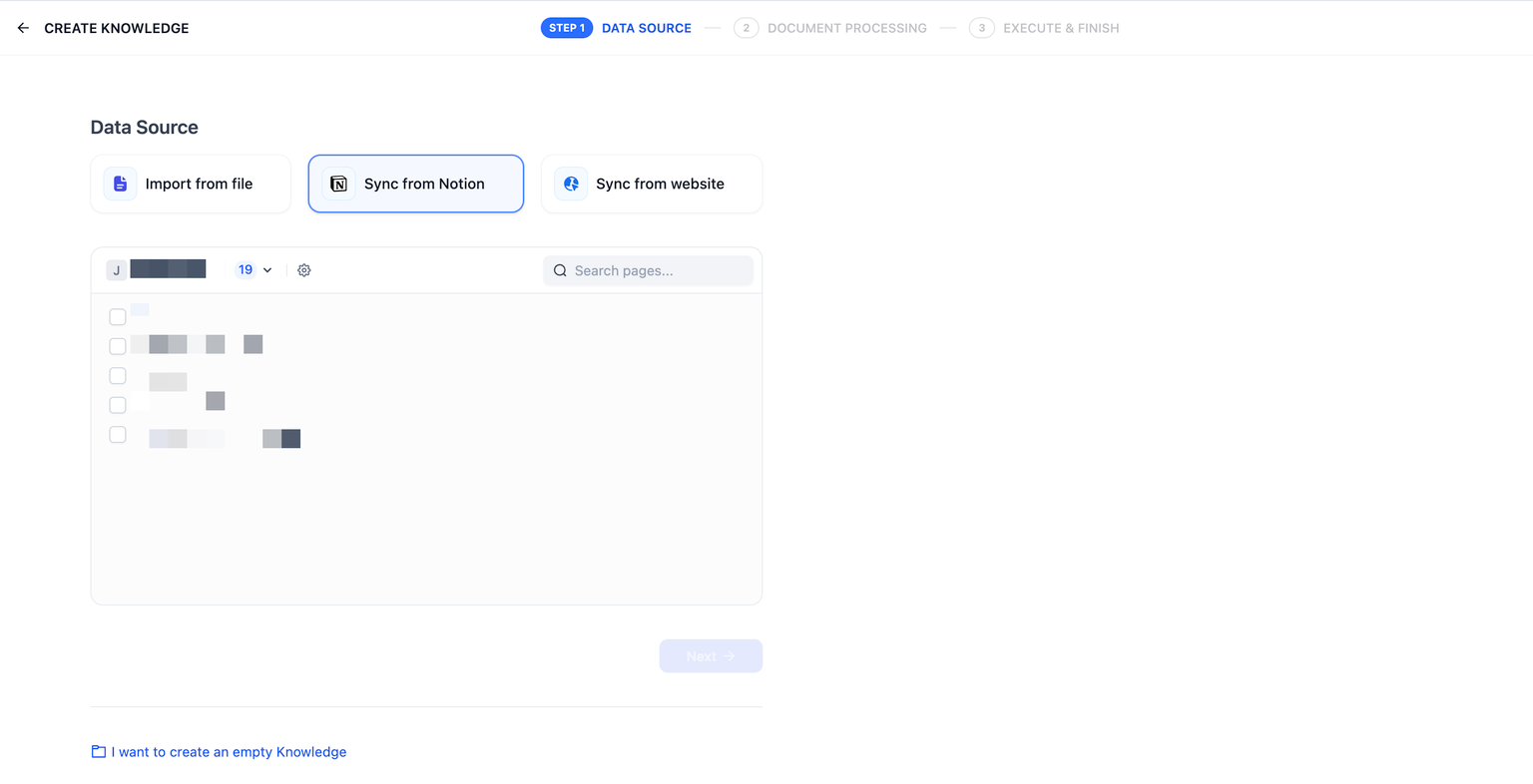
+ 1. Click **Create** > **Create Knowledge**, then select **Sync from Notion** as the data source.
-After completing the authorization verification, go to the create dataset page, click **Sync from Notion Content**, and select the authorized pages you need to import.
+ 2. Choose the target workspace and select the pages you want to import.
-
+
+ Images and files cannot be imported; data from tables will be converted to plain text.
+
+
+ Database pages can also be imported with their page properties preserved.
+
+
+
-### Chunking and Cleaning
+## Synchronize Imported Notion Pages
-Next, choose a [chunking mode](sync-from-notion.md#chunking-and-cleaning) and [indexing method](../setting-indexing-methods.md) for your knowledge base, then save it and wait for the automatically processing. Dify not only supports importing standard Notion pages but can also consolidate and save page attributes from database-type pages.
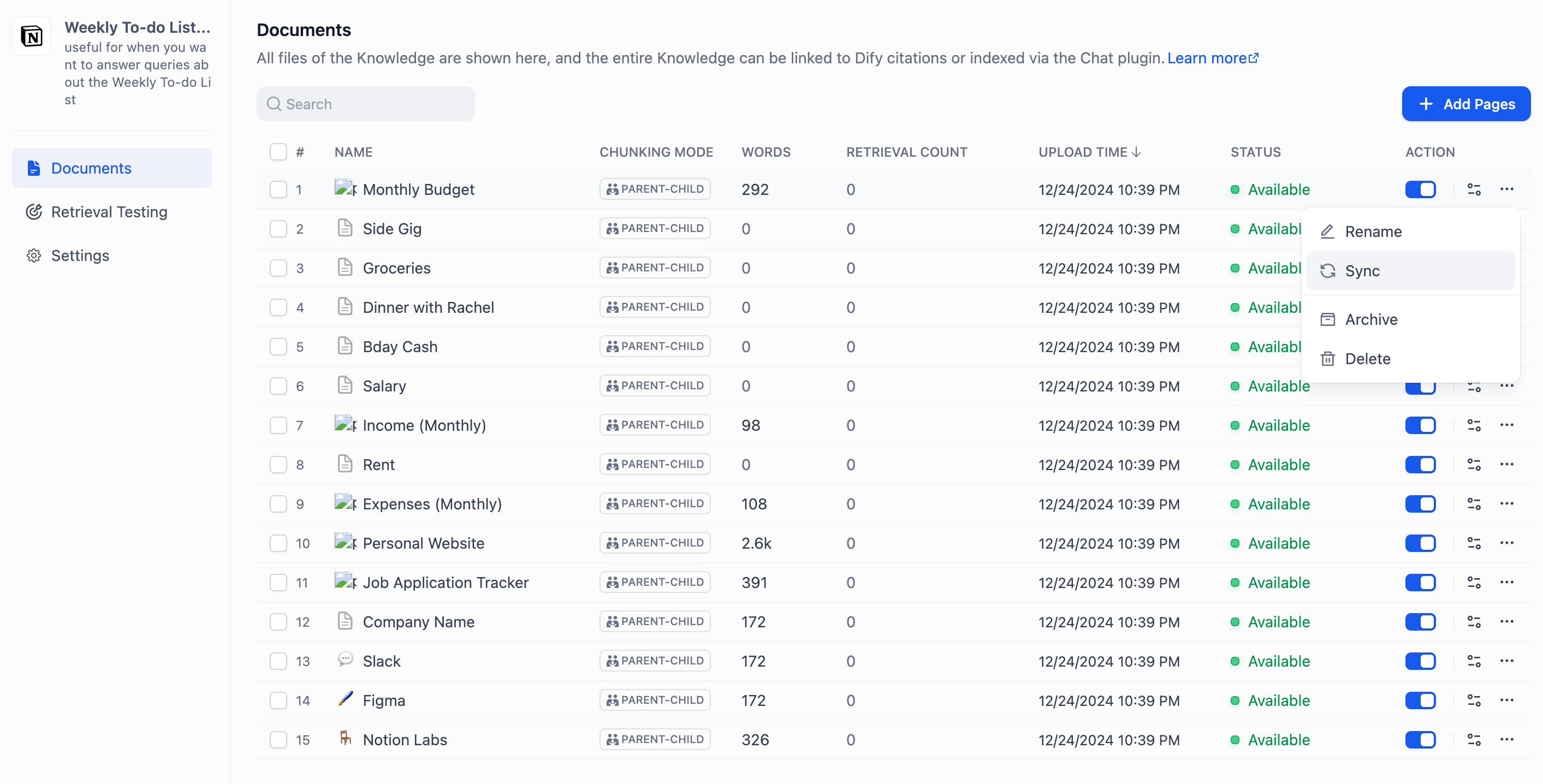
+If the content of an imported page is updated in Notion, you can synchronize the changes by clicking **Sync** for the corresponding page.
-_**Note: images and files cannot be imported, and data from tables will be converted to text.**_
+
+ For knowledge bases using the **High Quality** index method, synchronization requires re-embedding, which will consume tokens from the embedding model.
+
-
-
-### Synchronizing Notion Data
-
-If your Notion content has been updated, you can sync the changes by clicking the **Sync** button for the corresponding page in the document list of your knowledge base. Syncing involves an embedding process, which will consume tokens from your embedding model.
-
-
-
-### Integration Configuration Method for Community Edition Notion
-
-Notion offers two integration options: **internal integration** and **public integration**. For more details on the differences between these two methods, please refer to the [official Notion documentation](https://developers.notion.com/docs/authorization).
-
-#### 1. Using Internal Integration
-
-First, create an integration in the integration settings page [Create Integration](https://www.notion.so/my-integrations). By default, all integrations start as internal integrations; internal integrations will be associated with the workspace you choose, so you need to be the workspace owner to create an integration.
-
-Specific steps:
-
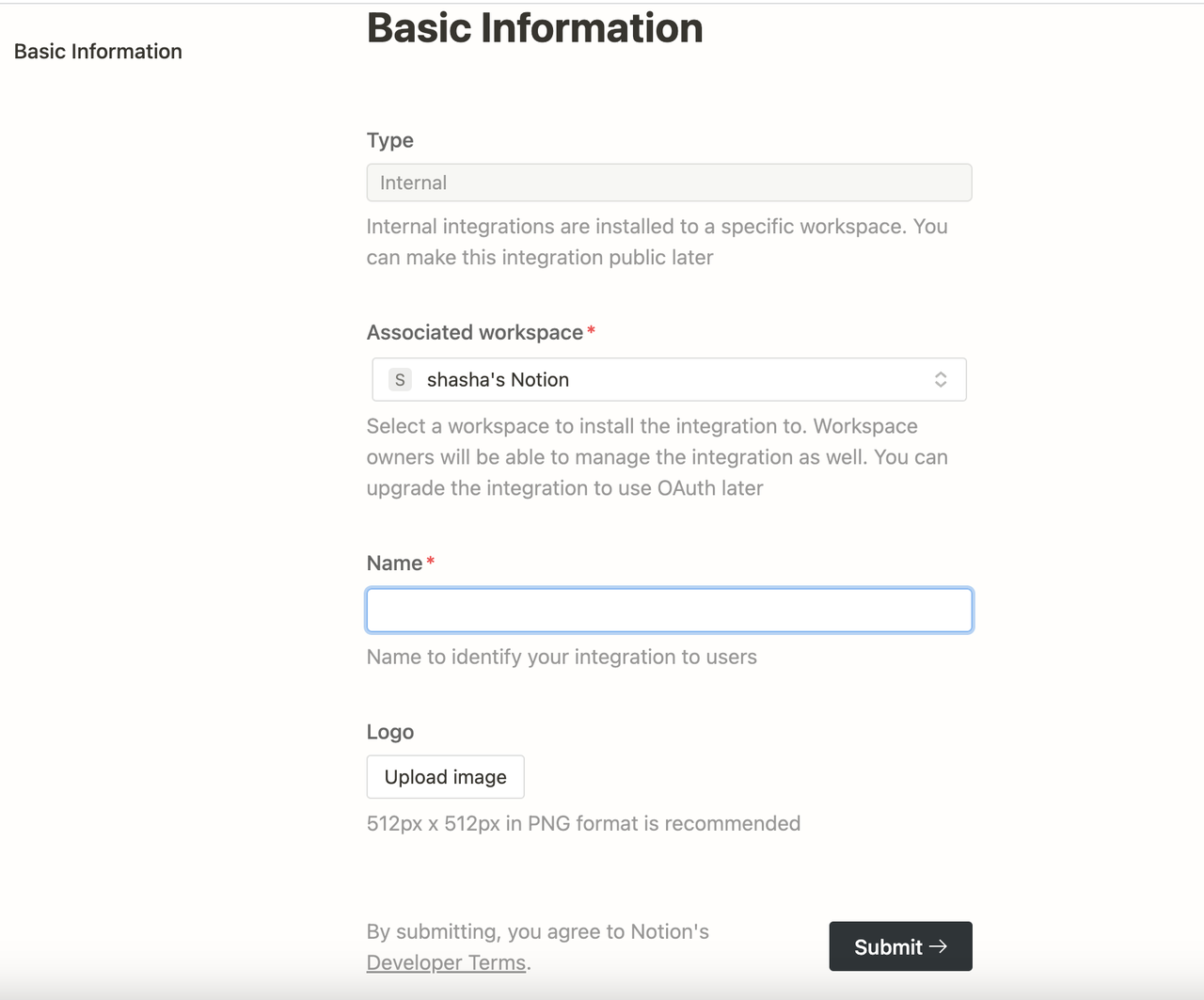
-Click the **New integration** button. The type is **Internal** by default (cannot be modified). Select the associated space, enter the integration name, upload a logo, and click **Submit** to create the integration successfully.
-
-
-
-After creating the integration, you can update its settings as needed under the Capabilities tab and click the **Show** button under Secrets to copy the secrets.
-
-
-
-After copying, go back to the Dify source code, and configure the relevant environment variables in the **.env** file. The environment variables are as follows:
-
-```
-NOTION_INTEGRATION_TYPE = internal or NOTION_INTEGRATION_TYPE = public
-NOTION_INTERNAL_SECRET=you-internal-secret
-```
-
-#### **Using Public Integration**
-
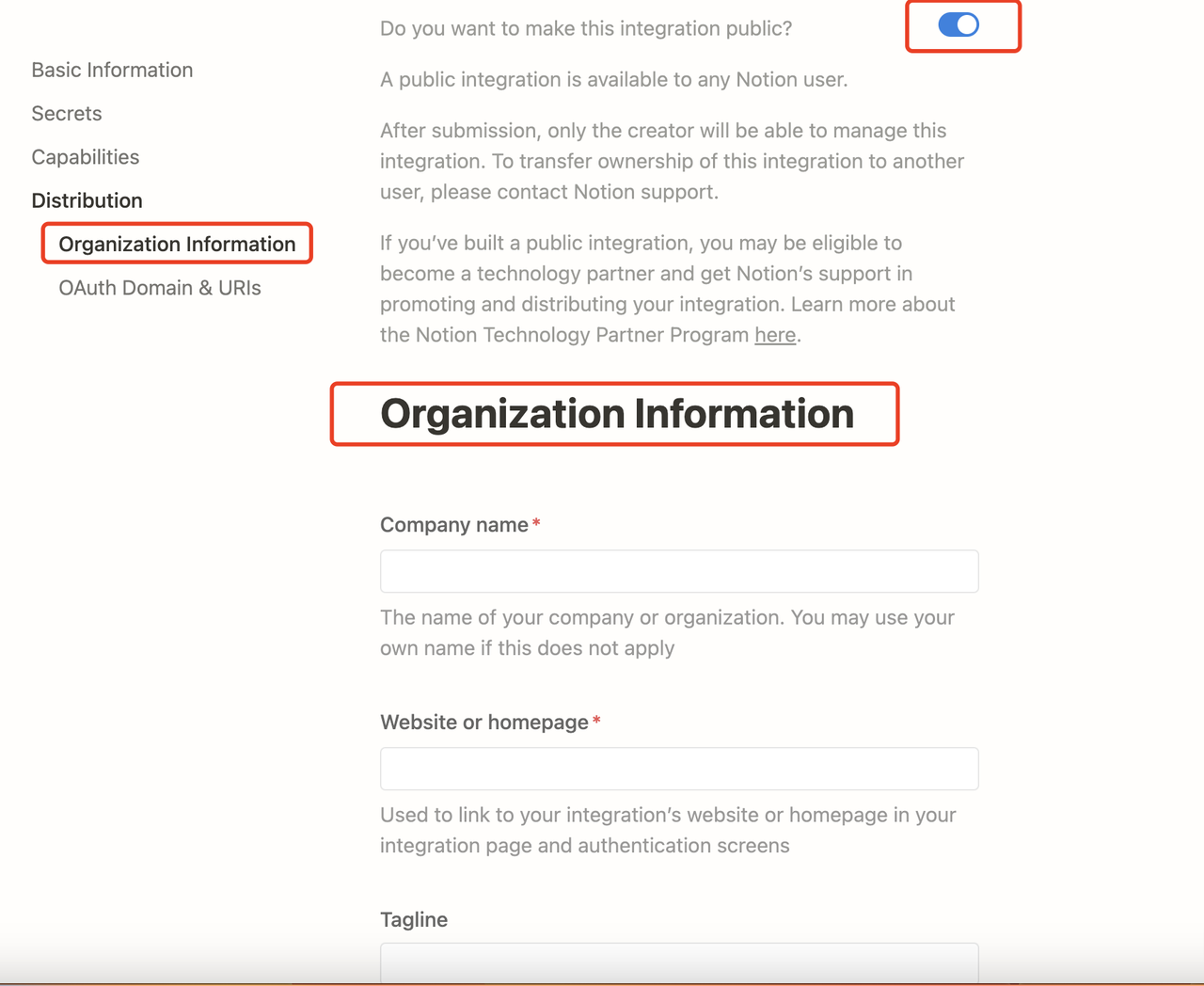
-**You need to upgrade the internal integration to a public integration.** Navigate to the Distribution page of the integration, and toggle the switch to make the integration public. When switching to the public setting, you need to fill in additional information in the Organization Information form below, including your company name, website, and redirect URL, then click the **Submit** button.
-
-
-
-After successfully making the integration public on the integration settings page, you will be able to access the integration key in the Keys tab:
-
-
-
-Go back to the Dify source code, and configure the relevant environment variables in the **.env** file. The environment variables are as follows:
-
-```
-NOTION_INTEGRATION_TYPE=public
-NOTION_CLIENT_SECRET=your-client-secret
-NOTION_CLIENT_ID=your-client-id
-```
-
-After configuration, you can operate the Notion data import and synchronization functions in the dataset.
+
{/*
Contributing Section
diff --git a/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx b/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
index da04afbe..54631ca1 100644
--- a/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
+++ b/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
@@ -1,66 +1,110 @@
---
-title: 1.2 Import Data from Website
+title: Use Websites as Data Source to Quick Create Knowledge
+sidebarTitle: Import from Websites
---
-The knowledge base supports crawling content from public web pages using third-party tools such as [Jina Reader](https://jina.ai/reader/) and [Firecrawl](https://www.firecrawl.dev/), parsing it into Markdown content, and importing it into the knowledge base.
+When quick-creating a knowledge base, you can use websites as its data source, importing specific webpages and synchronizing them when their content is updated.
-
-[Firecrawl](https://www.firecrawl.dev/) and [Jina Reader](https://jina.ai/reader/) are both open-source web parsing tools that can convert web pages into clean Markdown format text that is easy for LLMs to recognize, while providing easy-to-use API services.
-
+## Import Webpages
-The following sections will introduce the usage methods for Firecrawl and Jina Reader respectively.
+Choose from the available website crawler providers to fetch webpages from the target site and import them into a knowledge base.
-## Firecrawl
+
+
+
+
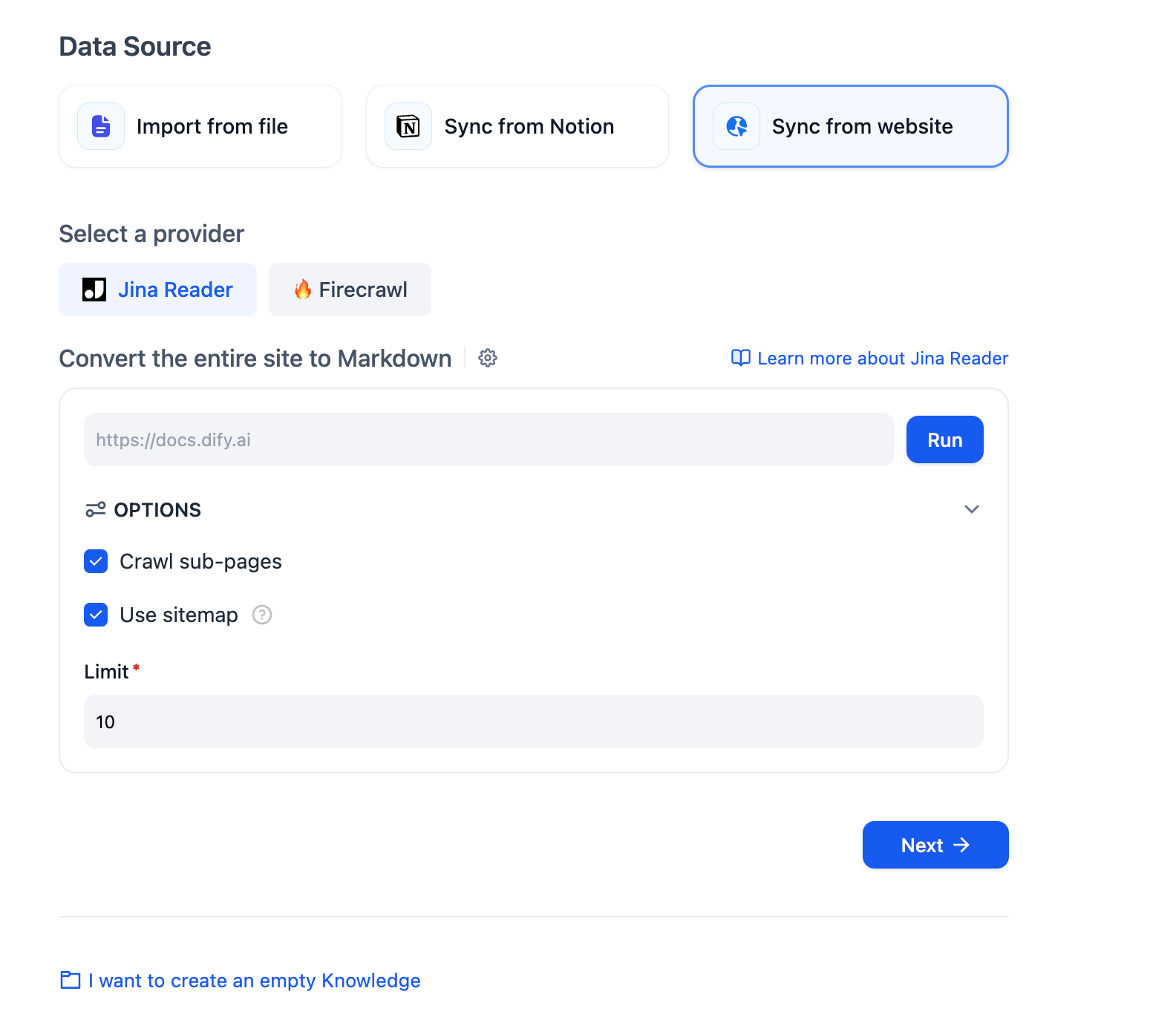
+ Go to **Settings** > **Data Source**, then find and install the Jina Reader data source plugin from the recommended list.
+
+
+ Click **+ Configure** to authorize Dify to access Jina Reader via API key.
+
+
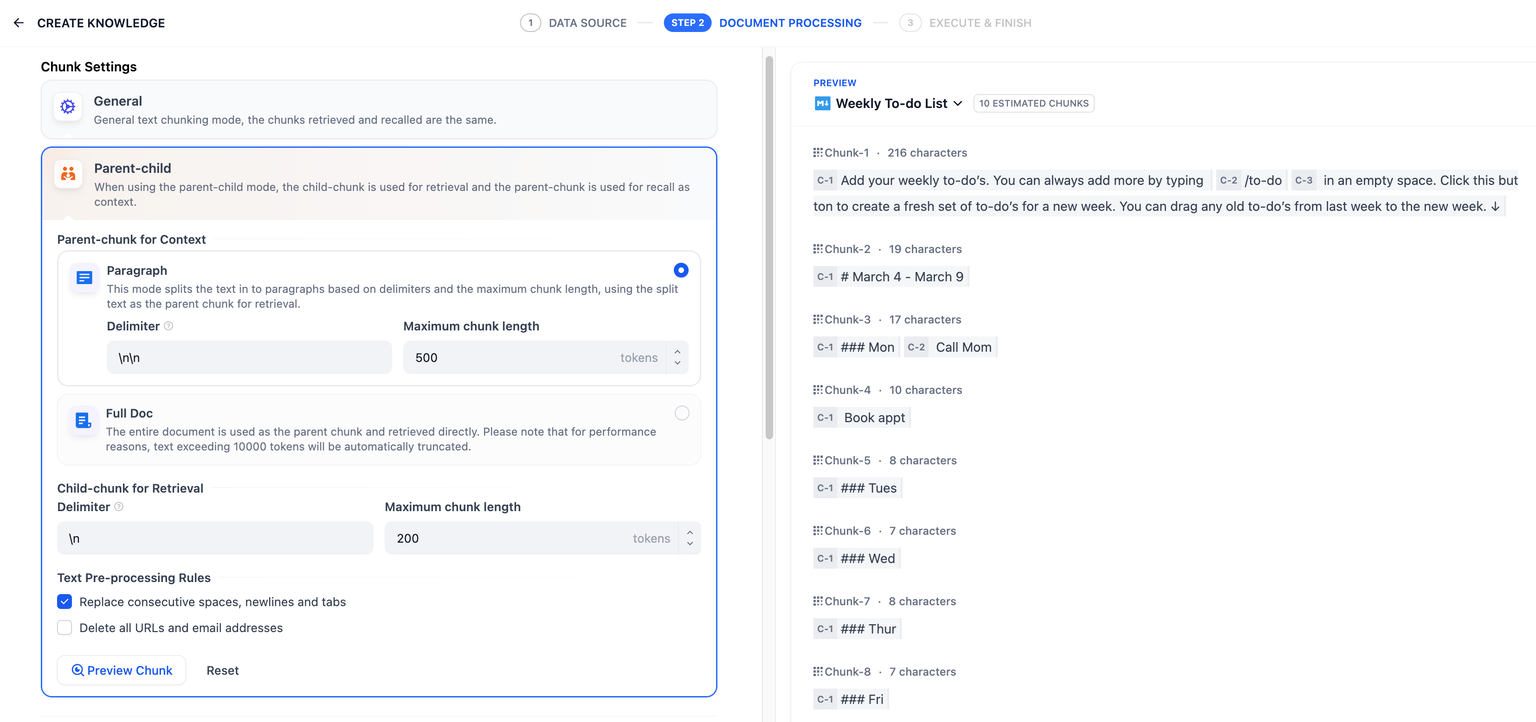
+ 1. Click **Create** > **Create Knowledge**, then select **Sync from website** as the data source.
-### **1. Configure Firecrawl API credentials**
+ 2. Choose Jina Reader as the provider, enter the target website URL, and configure the crawling options, including:
+
+ - Whether to crawl sub-pages
-Click on the avatar in the upper right corner, then go to the **DataSource** page, and click the **Configure** button next to Firecrawl.
+ - Whether to use a sitemap for crawling
+ > When enabled, if the target website has a sitemap at `https://example.com/sitemap.xml`, Jina Reader will crawl pages listed in the sitemap instead of following links from the target URL.
+
+ - The maximum number of pages to crawl
-
+ 3. Click **Run** to start crawling the website. After the crawl finishes, select the webpages you want to import.
+
+
+
+
+
+
+ Go to **Settings** > **Data Source**, then find and install the Firecrawl data source plugin from the recommended list.
+
+
+ Click **+ Configure** to authorize Dify to access Firecrawl via API key.
+
+
+ 1. Click **Create** > **Create Knowledge**, then select **Sync from website** as the data source.
-Log in to the [Firecrawl website](https://www.firecrawl.dev/) to complete registration, get your API Key, and then enter and save it in Dify.
+ 2. Choose Firecrawl as the provider, enter the target website URL, and configure the crawling options, including:
+
+ - Whether to crawl sub-pages
-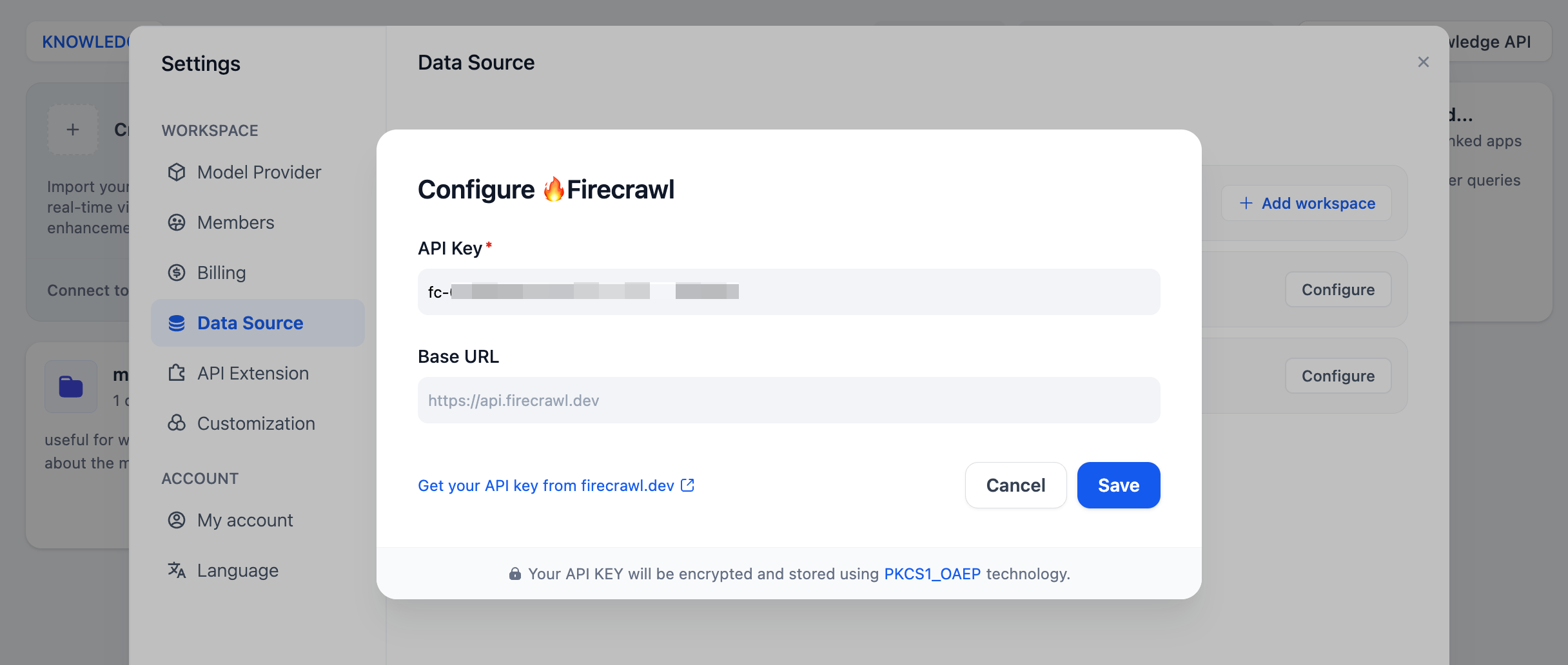
+ - The maximum number of pages to crawl
-### 2. Scrape target webpage
+ - The maximum crawl depth (how many levels of links Firecrawl will follow from the target URL)
+
+ > For example, if the target URL is `https://dify.ai/`:
+ > - Depth 0: Only crawl `https://dify.ai/` itself.
+ > - Depth 1: Crawl `https://dify.ai/` and the pages directly linked from it, such as `https://dify.ai/pricing` or `https://dify.ai/blog`.
+ > - Depth 2: Crawl all of the above, plus pages one level deeper, such as `https://dify.ai/blog/article-1`.
+
+ - Paths to exclude or include
+
+ > For example, if you set `Exclude paths` to `https://dify.ai/blog/*`, any pages whose URLs start with `https://dify.ai/blog/` will be skipped, such as:
+ > - `https://dify.ai/blog`
+ > - `https://dify.ai/blog/article-1`
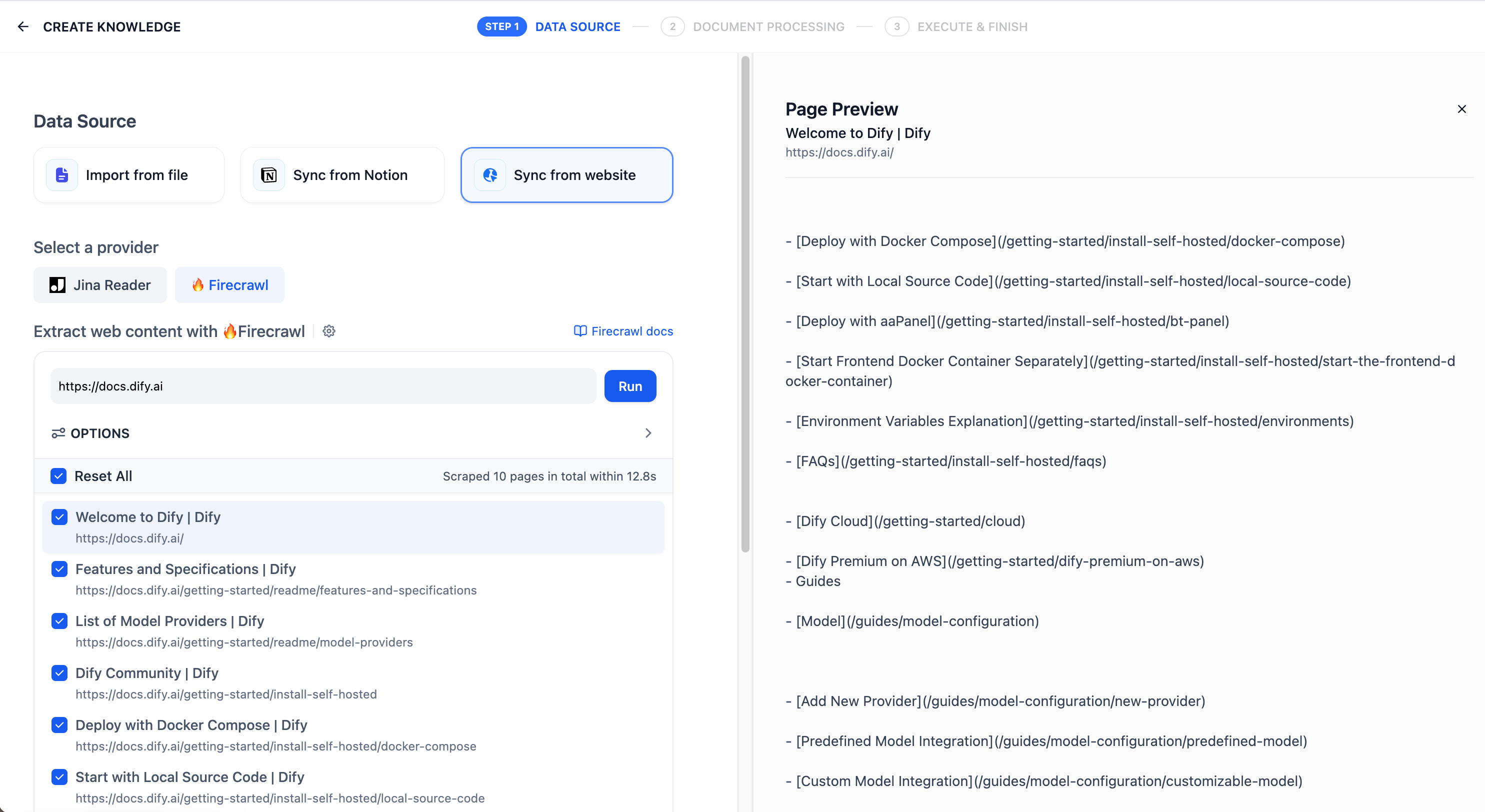
-On the knowledge base creation page, select **Sync from website**, choose Firecrawl as the provider, and enter the target URL to be crawled.
+ - Whether to extract only the main content (excluding headers, navigation, footers, and other layout elements)
-The configuration options include: Whether to crawl sub-pages, Page crawling limit, Page scraping max depth, Excluded paths, Include only paths, and Content extraction scope. After completing the configuration, click **Run** to preview the parsed pages.
+ 3. Click **Run** to start crawling the website. After the crawl finishes, select the webpages you want to import.
+
+
+
+
+
+
+ Go to **Settings** > **Data Source**, then find and install the WaterCrawl data source plugin from the recommended list.
+
+
+ Click **+ Configure** to authorize Dify to access WaterCrawl via API key.
+
+
+ 1. Click **Create** > **Create Knowledge**, then select **Sync from website** as the data source.
-
+ 2. Choose WaterCrawl as the provider, enter the target website URL, and configure the crawling options, including:
+
+ - Whether to crawl sub-pages
+
+ - The maximum number of pages to crawl
-### 3. Review import results
+ 3. Click **Run** to start crawling the website. After the crawl finishes, select the webpages you want to import.
+
+
+
+
+
+ After a knowledge base is created, you can add more webpages at any time from any website using any of the available providers.
+
-After importing the parsed text from the webpage, it is stored in the knowledge base documents. View the import results and click **Add URL** to continue importing new web pages.
+## Synchronize Imported Webpages
-***
+If the content of an imported webpage is updated, you can synchronize the changes by clicking **Sync** for the corresponding webpage.
-## Jina Reader
+
+ For knowledge bases using the **High Quality** index method, synchronization requires re-embedding, which consumes tokens from the embedding model.
+
-### 1. Configuring Jina Reader Credentials
-
-Click on the avatar in the upper right corner, then go to the **DataSource** page, and click the **Configure** button next to Jina Reader.
-
-
-
-Log in to the [Jina Reader website](https://jina.ai/reader/), complete registration, obtain the API Key, then fill it in and save.
-
-### 2. Using Jina Reader to Crawl Web Content
-
-On the knowledge base creation page, select **Sync from website**, choose Jina Reader as the provider, and enter the target URL to be crawled.
-
-
-
-Configuration options include: whether to crawl subpages, maximum number of pages to crawl, and whether to use sitemap for crawling. After completing the configuration, click the **Run** button to preview the page links to be crawled.
-
-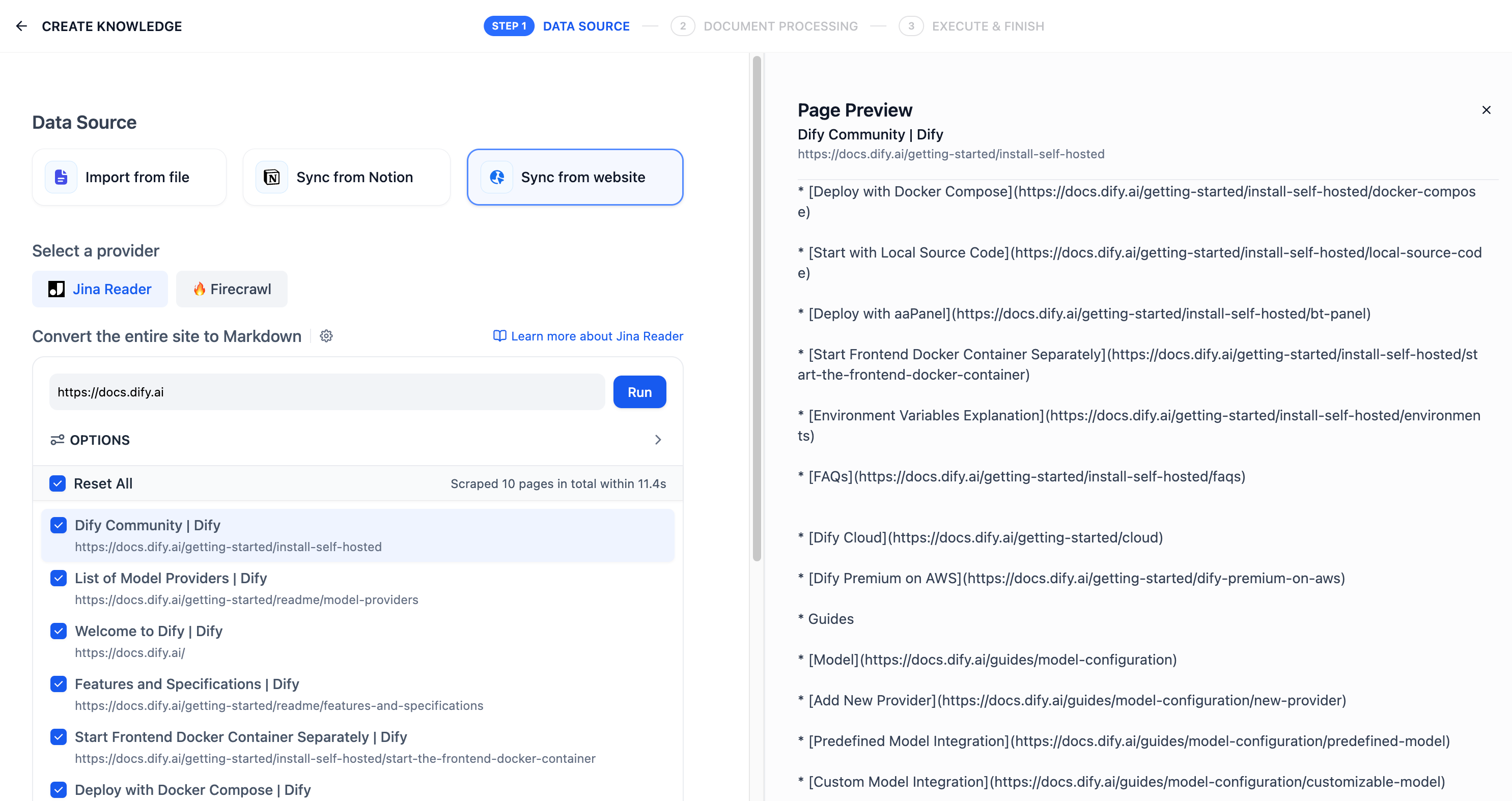
-
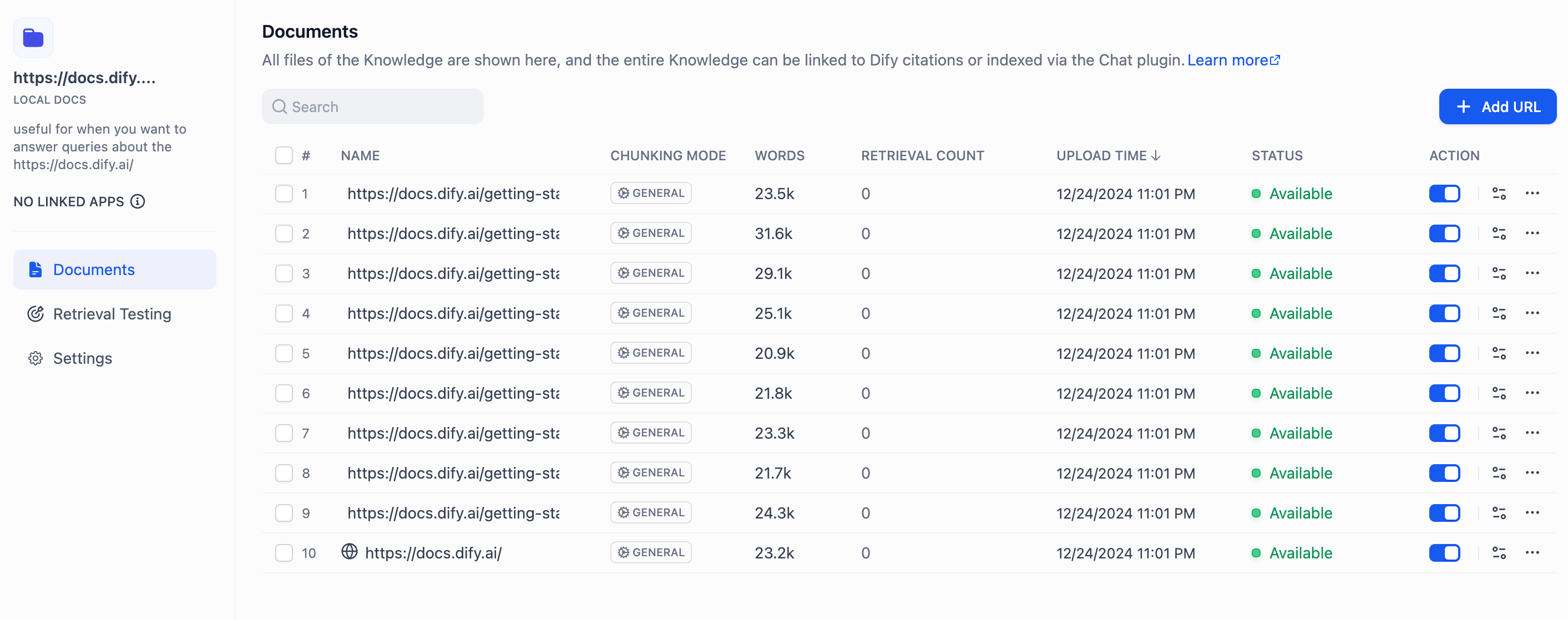
-After importing the parsed text from web pages into the knowledge base, you can review the imported results in the documents section. To add more web pages, click the **Add URL** button on the right to continue importing new pages.
-
-
-
-After crawling is complete, the content from the web pages will be incorporated into the knowledge base.
+
{/*
Contributing Section
diff --git a/en/guides/knowledge-base/knowledge-base-creation/introduction.mdx b/en/guides/knowledge-base/knowledge-base-creation/introduction.mdx
index 4c814119..00780702 100644
--- a/en/guides/knowledge-base/knowledge-base-creation/introduction.mdx
+++ b/en/guides/knowledge-base/knowledge-base-creation/introduction.mdx
@@ -1,67 +1,51 @@
---
-title: Create Knowledge Base
+title: Quick Create Knowledge
+sidebarTitle: Overview
---
-Steps to upload documents to create a knowledge base:
+To quick-create and configure a knowledge base:
-1. Create a knowledge base and import either local document file or online data.
+
+
-
-Create a knowledge base and import either local document file or online data.
-
+ 1. Click **Knowledge** > **Create Knowledge**.
-2. Choose a chunking mode and preview the spliting results. This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.
+ 2. [Upload local files](/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme), [sync content from Notion](/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion), or [import from websites](/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website). You can also start with an empty knowledge base and populate it later.
-
-Choose a chunking mode and preview the spliting results. This stage involves content preprocessing and structuring, where long texts are divided into multiple smaller chunks.
-
+
+ Once a knowledge base is created, its data source cannot be changed later.
+
+
+
+
-3. Configure the indexing method and retrieval setting. Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks.
+ 1. [Configure the chunk settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text) to define how raw data is pre-processed and split into smaller chunks, so each piece of content can be retrieved more efficiently and precisely within LLM context limits.
+
+ 2. [Choose an index method](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods) to control how chunks are represented and made searchable—either as vectors for high-quality semantic matching or as keywords for cost-efficient retrieval.
-
- Configure the indexing method and retrieval setting. Once the knowledge base receives a user query, it searches existing documents according to preset retrieval methods and extracts highly relevant content chunks.
-
+ 3. [Configure the retrieval settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/configure-retrieval-settings) to specify how the most relevant chunks are matched against user queries.
+
+
+
-4. Wait for the chunk embeddings to complete.
+After a knowledge base is successfully created, you can:
-5. Once finished, link the knowledge base to your application and start using it. You can then [integrate it into your application](../integrate-knowledge-within-application) to build an LLM that are capable of Q\&A based on knowledge-bases. If you want to modify and manage the knowledge base further, take refer to [Knowledge Base and Document Maintenance]([knowledge-and-documents-maintenance](/en/guides/knowledge-base/knowledge-and-documents-maintenance)).
+- [Review and modify the content chunks](/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents) to ensure they are appropriately chunked for retrieval.
-
+- [Simulate user queries](/en/guides/knowledge-base/retrieval-test-and-citation) to test and refine retrieval performance.
-***
+- [Add metadata to documents](/en/guides/knowledge-base/metadata) to enable filter-based retrieval.
-### Reference
+Once the knowledge is retrieval-ready, you can [integrate it into your apps](/en/guides/knowledge-base/integrate-knowledge-within-application).
-#### ETL
+As your data or requirements evolve, you can [adjust the knowledge base settings](/en/guides/knowledge-base/knowledge-base-creation/introduction) at any time.
-In production-level applications of RAG, to achieve better data retrieval, multi-source data needs to be preprocessed and cleaned, i.e., ETL (extract, transform, load). To enhance the preprocessing capabilities of unstructured/semi-structured data, Dify supports optional ETL solutions: **Dify ETL** and [**Unstructured ETL**](https://unstructured.io/).
+
+ You can always convert a quick-created knowledge base into a pipeline-created one for more advanced configurations and customizations.
+ 
+
-> Unstructured can efficiently extract and transform your data into clean data for subsequent steps.
-ETL solution choices in different versions of Dify:
-
-* The SaaS version defaults to using Unstructured ETL and cannot be changed;
-* The community version defaults to using Dify ETL but can enable Unstructured ETL through [environment variables](/en/getting-started/install-self-hosted/environments#zhi-shi-ku-pei-zhi);
-
-Differences in supported file formats for parsing:
-
-| DIFY ETL | Unstructured ETL |
-| ------------------------------------------------------- | --------------------------------------------------------------------------------------- |
-| txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv | txt, markdown, md, pdf, html, htm, xlsx, xls, docx, csv, eml, msg, pptx, ppt, xml, epub |
-
-
- Different ETL solutions may have differences in file extraction effects. For more information on Unstructured ETL’s data processing methods, please refer to the [official documentation](https://docs.unstructured.io/open-source/core-functionality/partitioning).
-
-
-#### **Embedding**
-
-**Embedding** transforms discrete variables (words, sentences, documents) into continuous vector representations, mapping high-dimensional data to lower-dimensional spaces. This technique preserves crucial semantic information while reducing dimensionality, enhancing content retrieval efficiency.
-
-**Embedding models**, specialized large language models, excel at converting text into dense numerical vectors, effectively capturing semantic nuances for improved data processing and analysis.
-
-#### **Metadata**
-
-For managing the knowledge base with metadata, see *[Metadata](../metadata)*.
{/*
Contributing Section
diff --git a/images/covert_to_pipeline_created_kb.png b/images/covert_to_pipeline_created_kb.png
new file mode 100644
index 00000000..8b58d6db
Binary files /dev/null and b/images/covert_to_pipeline_created_kb.png differ
diff --git a/images/sync_notion_pages.png b/images/sync_notion_pages.png
new file mode 100644
index 00000000..74c606d5
Binary files /dev/null and b/images/sync_notion_pages.png differ
diff --git a/images/sync_webpages.png b/images/sync_webpages.png
new file mode 100644
index 00000000..f324bdbe
Binary files /dev/null and b/images/sync_webpages.png differ