 +
+ 
.png) +
+ .png) 在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
@@ -30,7 +30,7 @@ version: 'English'
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
-
在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
@@ -30,7 +30,7 @@ version: 'English'
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
- .png) +
+ .png) ###
@@ -46,7 +46,7 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
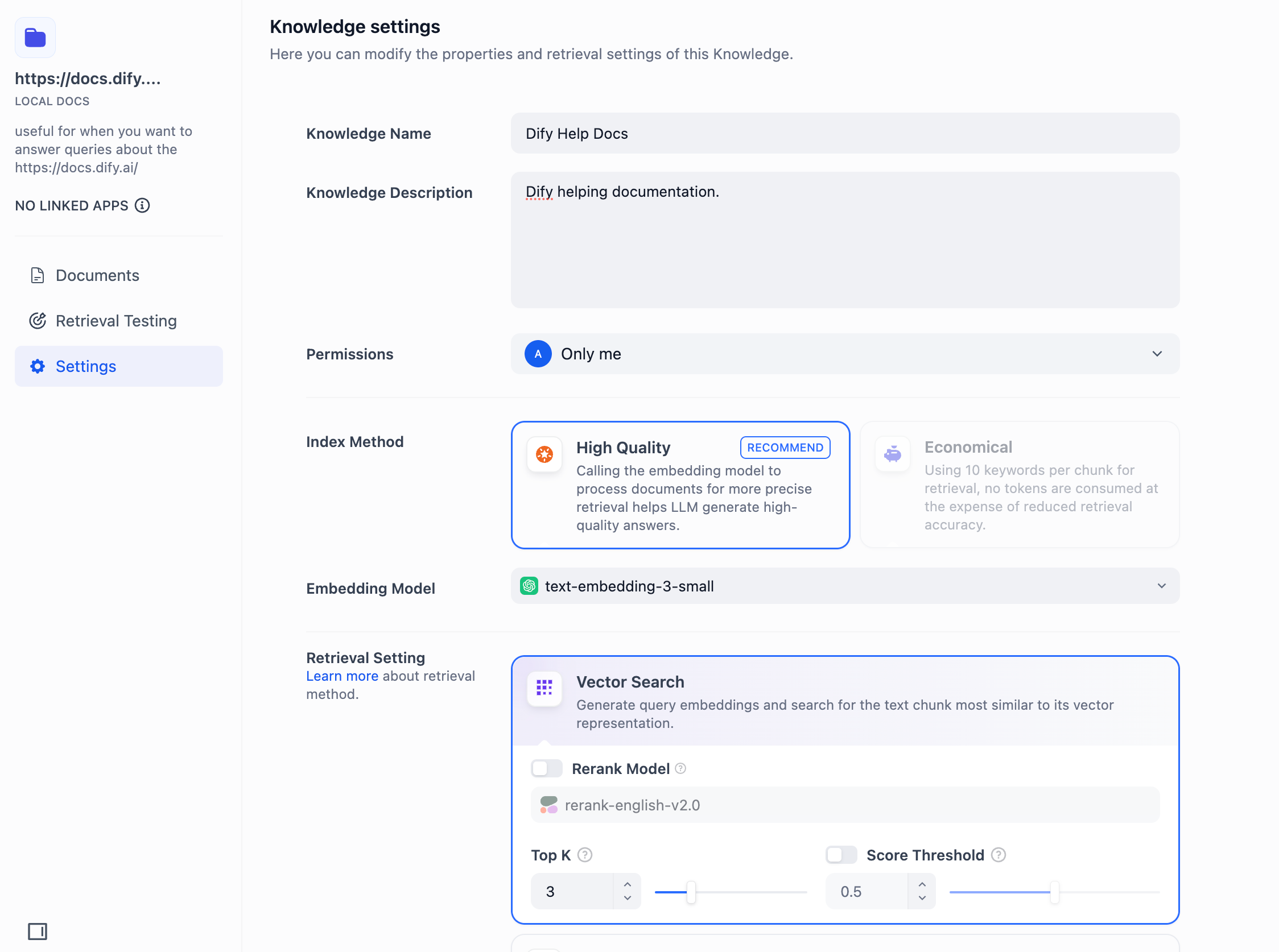
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
-
###
@@ -46,7 +46,7 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
- .png) +
+ .png) **TopK:** 用于设置 Rerank 后返回相关文档的数量。
@@ -57,8 +57,8 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“提示词编排->上下文->设置”页面中设置为多路召回模式时需开启 Rerank 模型。
-查看更多关于多路召回模式的说明,[《多路召回》](/zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application)。
+查看更多关于多路召回模式的说明,[《多路召回》](/zh-hans/user-guide/knowledge-base/integrate-knowledge-within-application)。
-
**TopK:** 用于设置 Rerank 后返回相关文档的数量。
@@ -57,8 +57,8 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“提示词编排->上下文->设置”页面中设置为多路召回模式时需开启 Rerank 模型。
-查看更多关于多路召回模式的说明,[《多路召回》](/zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application)。
+查看更多关于多路召回模式的说明,[《多路召回》](/zh-hans/user-guide/knowledge-base/integrate-knowledge-within-application)。
- .png) +
+ .png) diff --git a/en/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx b/en/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
index 1479ca26..1543cb1b 100644
--- a/en/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
+++ b/en/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
@@ -12,7 +12,7 @@ version: 'English'
在下图中,当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统…),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
-
diff --git a/en/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx b/en/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
index 1479ca26..1543cb1b 100644
--- a/en/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
+++ b/en/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
@@ -12,7 +12,7 @@ version: 'English'
在下图中,当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统…),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
- .png) +
+ .png) **为什么需要这样做呢?**
diff --git a/en/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx b/en/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
index 7cc3d174..600d3f49 100644
--- a/en/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
+++ b/en/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
@@ -6,19 +6,19 @@ version: 'English'
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-
**为什么需要这样做呢?**
diff --git a/en/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx b/en/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
index 7cc3d174..600d3f49 100644
--- a/en/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
+++ b/en/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
@@ -6,19 +6,19 @@ version: 'English'
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-  +
+  ### 召回设置
根据用户意图同时匹配所有知识库,从多路知识库查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
-在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
+在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-hans/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
以下是多路召回模式的技术流程图:
-
### 召回设置
根据用户意图同时匹配所有知识库,从多路知识库查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
-在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
+在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-hans/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
以下是多路召回模式的技术流程图:
- .png) +
+ .png) 由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/en/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx b/en/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
index a418df0a..6acd7b70 100644
--- a/en/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
+++ b/en/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
@@ -24,7 +24,7 @@ Click on Knowledge in the main navigation bar of Dify. On this page, you can see
* The upload size limit for a single document is 15MB;
-
由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/en/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx b/en/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
index a418df0a..6acd7b70 100644
--- a/en/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
+++ b/en/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
@@ -24,7 +24,7 @@ Click on Knowledge in the main navigation bar of Dify. On this page, you can see
* The upload size limit for a single document is 15MB;
-  +
+  ***
@@ -59,7 +59,7 @@ Two strategies are supported:
The Automated mode is designed for users unfamiliar with segmentation and preprocessing techniques. In this mode, Dify automatically segments and sanitizes content files, streamlining the document preparation process.
-
***
@@ -59,7 +59,7 @@ Two strategies are supported:
The Automated mode is designed for users unfamiliar with segmentation and preprocessing techniques. In this mode, Dify automatically segments and sanitizes content files, streamlining the document preparation process.
-  +
+  @@ -81,7 +81,7 @@ Two strategies are supported:
* Delete all URLs and email addresses.
-
@@ -81,7 +81,7 @@ Two strategies are supported:
* Delete all URLs and email addresses.
-  +
+  @@ -99,14 +99,14 @@ You need to choose the **indexing method** for the text to specify the data matc
The High-Quality indexing method offers three retrieval settings: vector retrieval, full-text retrieval, and hybrid retrieval. For more details on retrieval settings, please check ["Retrieval Settings"](#4-retrieval-settings).
-
@@ -99,14 +99,14 @@ You need to choose the **indexing method** for the text to specify the data matc
The High-Quality indexing method offers three retrieval settings: vector retrieval, full-text retrieval, and hybrid retrieval. For more details on retrieval settings, please check ["Retrieval Settings"](#4-retrieval-settings).
-  +
+  +
+
 +
+  **Vector Search Settings:**
@@ -149,7 +149,7 @@ In high-quality indexing mode, Dify offers three retrieval settings:
**Definition:** Indexing all terms in the document, allowing users to query any terms and return text fragments containing those terms.
-
**Vector Search Settings:**
@@ -149,7 +149,7 @@ In high-quality indexing mode, Dify offers three retrieval settings:
**Definition:** Indexing all terms in the document, allowing users to query any terms and return text fragments containing those terms.
-  +
+  **Rerank Model**: After configuring the API key for the Rerank model on the "Model Provider" page, you can enable the “Rerank Model” in the retrieval settings. The system will then perform semantic reordering of the retrieved document results after hybrid retrieval, optimizing the ranking results. Once the Rerank model is established, the TopK and Score Threshold settings will only take effect during the reranking step.
@@ -166,7 +166,7 @@ In high-quality indexing mode, Dify offers three retrieval settings:
**Definition:** This process performs both full-text search and vector search simultaneously, incorporating a reordering step to select the best results that match the user's query from both types of search outcomes. In this mode, users can specify "weight settings" without needing to configure the Rerank model API, or they can opt for a Rerank model for retrieval.
-
**Rerank Model**: After configuring the API key for the Rerank model on the "Model Provider" page, you can enable the “Rerank Model” in the retrieval settings. The system will then perform semantic reordering of the retrieved document results after hybrid retrieval, optimizing the ranking results. Once the Rerank model is established, the TopK and Score Threshold settings will only take effect during the reranking step.
@@ -166,7 +166,7 @@ In high-quality indexing mode, Dify offers three retrieval settings:
**Definition:** This process performs both full-text search and vector search simultaneously, incorporating a reordering step to select the best results that match the user's query from both types of search outcomes. In this mode, users can specify "weight settings" without needing to configure the Rerank model API, or they can opt for a Rerank model for retrieval.
-  +
+  **Weight Settings:** This feature enables users to set custom weights for semantic priority and keyword priority. Keyword search refers to performing a full-text search within the knowledge base, while semantic search involves vector search within the knowledge base.
@@ -210,7 +210,7 @@ An inverted index is an index structure designed for rapid keyword retrieval in
**TopK:** This parameter filters the text chucks that are most similar to the user's question. The system dynamically adjusts the number of snippets based on the context window size of the selected model. The default value is 3, meaning a higher value results in more text segments being retrieved.
-
+
After specifying the retrieval settings, you can refer to [Retrieval Test/Citation Attribution](/en/guides/knowledge-base/retrieval-test-and-citation) to check the matching between keywords and content chunks.
diff --git a/invalid_links_report.md b/invalid_links_report.md
index 9ade9175..09edf2ad 100644
--- a/invalid_links_report.md
+++ b/invalid_links_report.md
@@ -841,7 +841,7 @@
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 6 | 快速接入 | /zh-cn/user-guide/tools/quick-tool-integration |
+| 6 | 快速接入 | /zh-hans/user-guide/tools/quick-tool-integration |
### 文件: zh-hans/guides/tools/extensions/code-based/moderation.mdx
@@ -853,33 +853,33 @@
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 6 | API 扩展 | /zh-cn/user-guide/tools/extensions/api-based/api-based-extension |
-| 6 | API 扩展 | /zh-cn/user-guide/tools/extensions/api-based/api-based-extension |
+| 6 | API 扩展 | /zh-hans/user-guide/tools/extensions/api-based/api-based-extension |
+| 6 | API 扩展 | /zh-hans/user-guide/tools/extensions/api-based/api-based-extension |
### 文件: zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
| 266 | 外部数据工具 | ../../knowledge-base/external-data-tool.md "mention" |
-| 272 | 使用 Cloudflare Workers 部署 API Tools | /zh-cn/user-guide/tools/extensions/api-based/cloudflare-workers |
+| 272 | 使用 Cloudflare Workers 部署 API Tools | /zh-hans/user-guide/tools/extensions/api-based/cloudflare-workers |
### 文件: zh-hans/guides/tools/community/alphavantage.mdx
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 22 | 变量 | /zh-cn/user-guide/build-app/flow-app/variables |
+| 22 | 变量 | /zh-hans/user-guide/build-app/flow-app/variables |
### 文件: zh-hans/guides/tools/dify/dall-e.mdx
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 24 | 变量 | /zh-cn/user-guide/build-app/flow-app/variables |
+| 24 | 变量 | /zh-hans/user-guide/build-app/flow-app/variables |
### 文件: zh-hans/guides/tools/dify/stable-diffusion.mdx
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 76 | 变量 | /zh-cn/user-guide/build-app/flow-app/variables |
+| 76 | 变量 | /zh-hans/user-guide/build-app/flow-app/variables |
### 文件: zh-hans/guides/management/app-management.mdx
@@ -987,7 +987,7 @@
|------|----------|----------|
| 41 | 支持 | user-guide/getting-started/readme/model-providers |
| 85 | 提示词专家模式(已下线) | user-guide/learn-more/extended-reading/prompt-engineering/prompt-engineering-1/ |
-| 132 | "知识库" | /zh-cn/user-guide/knowledge-base/ |
+| 132 | "知识库" | /zh-hans/user-guide/knowledge-base/ |
### 文件: zh-hans/guides/workflow/nodes/variable-assigner.mdx
diff --git a/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api.json b/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api.json
index 82a9653a..24430268 100644
--- a/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api.json
+++ b/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api.json
@@ -7,7 +7,7 @@
"post": {
"summary": "知识召回 API",
"deprecated": false,
- "description": "该 API 用于连接团队内独立维护的知识库,如需了解更多操作指引,请参考阅读[连接外部知识库](/zh-cn/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge-base)。你可以在 Authorization HTTP 头部中使用 API-Key 来验证权限,认证逻辑由开发者在检索 API 中定义,如下所示:\n\n```text\nAuthorization: Bearer {API_KEY}\n```",
+ "description": "该 API 用于连接团队内独立维护的知识库,如需了解更多操作指引,请参考阅读[连接外部知识库](/zh-hans/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge-base)。你可以在 Authorization HTTP 头部中使用 API-Key 来验证权限,认证逻辑由开发者在检索 API 中定义,如下所示:\n\n```text\nAuthorization: Bearer {API_KEY}\n```",
"tags": [],
"requestBody": {
"content": {
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/hybrid-search.mdx b/ja-jp/guides/knowledge-base/indexing-and-retrieval/hybrid-search.mdx
index c0553edf..4432ddfa 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/hybrid-search.mdx
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/hybrid-search.mdx
@@ -33,7 +33,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
在混合检索中,你需要在数据库中提前建立向量索引和关键词索引,在用户问题输入时,分别通过两种检索器在文档中检索出最相关的文本。
-
**Weight Settings:** This feature enables users to set custom weights for semantic priority and keyword priority. Keyword search refers to performing a full-text search within the knowledge base, while semantic search involves vector search within the knowledge base.
@@ -210,7 +210,7 @@ An inverted index is an index structure designed for rapid keyword retrieval in
**TopK:** This parameter filters the text chucks that are most similar to the user's question. The system dynamically adjusts the number of snippets based on the context window size of the selected model. The default value is 3, meaning a higher value results in more text segments being retrieved.
-
+
After specifying the retrieval settings, you can refer to [Retrieval Test/Citation Attribution](/en/guides/knowledge-base/retrieval-test-and-citation) to check the matching between keywords and content chunks.
diff --git a/invalid_links_report.md b/invalid_links_report.md
index 9ade9175..09edf2ad 100644
--- a/invalid_links_report.md
+++ b/invalid_links_report.md
@@ -841,7 +841,7 @@
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 6 | 快速接入 | /zh-cn/user-guide/tools/quick-tool-integration |
+| 6 | 快速接入 | /zh-hans/user-guide/tools/quick-tool-integration |
### 文件: zh-hans/guides/tools/extensions/code-based/moderation.mdx
@@ -853,33 +853,33 @@
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 6 | API 扩展 | /zh-cn/user-guide/tools/extensions/api-based/api-based-extension |
-| 6 | API 扩展 | /zh-cn/user-guide/tools/extensions/api-based/api-based-extension |
+| 6 | API 扩展 | /zh-hans/user-guide/tools/extensions/api-based/api-based-extension |
+| 6 | API 扩展 | /zh-hans/user-guide/tools/extensions/api-based/api-based-extension |
### 文件: zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
| 266 | 外部数据工具 | ../../knowledge-base/external-data-tool.md "mention" |
-| 272 | 使用 Cloudflare Workers 部署 API Tools | /zh-cn/user-guide/tools/extensions/api-based/cloudflare-workers |
+| 272 | 使用 Cloudflare Workers 部署 API Tools | /zh-hans/user-guide/tools/extensions/api-based/cloudflare-workers |
### 文件: zh-hans/guides/tools/community/alphavantage.mdx
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 22 | 变量 | /zh-cn/user-guide/build-app/flow-app/variables |
+| 22 | 变量 | /zh-hans/user-guide/build-app/flow-app/variables |
### 文件: zh-hans/guides/tools/dify/dall-e.mdx
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 24 | 变量 | /zh-cn/user-guide/build-app/flow-app/variables |
+| 24 | 变量 | /zh-hans/user-guide/build-app/flow-app/variables |
### 文件: zh-hans/guides/tools/dify/stable-diffusion.mdx
| 行号 | 链接文本 | 链接 URL |
|------|----------|----------|
-| 76 | 变量 | /zh-cn/user-guide/build-app/flow-app/variables |
+| 76 | 变量 | /zh-hans/user-guide/build-app/flow-app/variables |
### 文件: zh-hans/guides/management/app-management.mdx
@@ -987,7 +987,7 @@
|------|----------|----------|
| 41 | 支持 | user-guide/getting-started/readme/model-providers |
| 85 | 提示词专家模式(已下线) | user-guide/learn-more/extended-reading/prompt-engineering/prompt-engineering-1/ |
-| 132 | "知识库" | /zh-cn/user-guide/knowledge-base/ |
+| 132 | "知识库" | /zh-hans/user-guide/knowledge-base/ |
### 文件: zh-hans/guides/workflow/nodes/variable-assigner.mdx
diff --git a/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api.json b/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api.json
index 82a9653a..24430268 100644
--- a/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api.json
+++ b/ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api.json
@@ -7,7 +7,7 @@
"post": {
"summary": "知识召回 API",
"deprecated": false,
- "description": "该 API 用于连接团队内独立维护的知识库,如需了解更多操作指引,请参考阅读[连接外部知识库](/zh-cn/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge-base)。你可以在 Authorization HTTP 头部中使用 API-Key 来验证权限,认证逻辑由开发者在检索 API 中定义,如下所示:\n\n```text\nAuthorization: Bearer {API_KEY}\n```",
+ "description": "该 API 用于连接团队内独立维护的知识库,如需了解更多操作指引,请参考阅读[连接外部知识库](/zh-hans/user-guide/knowledge-base/knowledge-base-creation/connect-external-knowledge-base)。你可以在 Authorization HTTP 头部中使用 API-Key 来验证权限,认证逻辑由开发者在检索 API 中定义,如下所示:\n\n```text\nAuthorization: Bearer {API_KEY}\n```",
"tags": [],
"requestBody": {
"content": {
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/hybrid-search.mdx b/ja-jp/guides/knowledge-base/indexing-and-retrieval/hybrid-search.mdx
index c0553edf..4432ddfa 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/hybrid-search.mdx
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/hybrid-search.mdx
@@ -33,7 +33,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
在混合检索中,你需要在数据库中提前建立向量索引和关键词索引,在用户问题输入时,分别通过两种检索器在文档中检索出最相关的文本。
- .png) +
+ .png) “混合检索”实际上并没有明确的定义,本文以向量检索和关键词检索的组合为示例。如果我们使用其他搜索算法的组合,也可以被称为“混合检索”。比如,我们可以将用于检索实体关系的知识图谱技术与向量检索技术结合。
@@ -45,7 +45,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
定义:通过生成查询嵌入并查询与其向量表示最相似的文本分段。
-
“混合检索”实际上并没有明确的定义,本文以向量检索和关键词检索的组合为示例。如果我们使用其他搜索算法的组合,也可以被称为“混合检索”。比如,我们可以将用于检索实体关系的知识图谱技术与向量检索技术结合。
@@ -45,7 +45,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
定义:通过生成查询嵌入并查询与其向量表示最相似的文本分段。
- .png) +
+ .png) **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -59,7 +59,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
定义:索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。
-
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -59,7 +59,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
定义:索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。
- .png) +
+ .png) **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -71,7 +71,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。
-
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -71,7 +71,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。
- .png) +
+ .png) **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -83,7 +83,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“数据集->创建数据集”页面并在检索设置中设置不同的检索模式:
-
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -83,7 +83,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“数据集->创建数据集”页面并在检索设置中设置不同的检索模式:
- .png) +
+ .png) ### 数据集设置中修改检索模式
@@ -91,7 +91,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“数据集->选择数据集->设置”页面中可以对已创建的数据集修改不同的检索模式。
-
### 数据集设置中修改检索模式
@@ -91,7 +91,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“数据集->选择数据集->设置”页面中可以对已创建的数据集修改不同的检索模式。
- .png) +
+ .png) ### 提示词编排中修改检索模式
@@ -99,5 +99,5 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“提示词编排->上下文->选择数据集->设置”页面中可以在创建应用时修改不同的检索模式。
-
### 提示词编排中修改检索模式
@@ -99,5 +99,5 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“提示词编排->上下文->选择数据集->设置”页面中可以在创建应用时修改不同的检索模式。
- .png) +
+ .png) diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx b/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
index f102548f..1f85bb37 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
-
+
在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
@@ -30,7 +30,7 @@ version: '简体中文'
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
-
+
###
@@ -46,7 +46,7 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
-
+
**TopK:** 用于设置 Rerank 后返回相关文档的数量。
@@ -60,5 +60,5 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
查看更多关于多路召回模式的说明,[《多路召回》](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)。
-
+
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak b/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
index 0f0bab5a..71e40b50 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
@@ -10,7 +10,7 @@ version: '简体中文'
**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
-
+
在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
@@ -30,7 +30,7 @@ version: '简体中文'
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
-
+
###
@@ -46,7 +46,7 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
-
+
**TopK:** 用于设置 Rerank 后返回相关文档的数量。
@@ -57,8 +57,8 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“提示词编排->上下文->设置”页面中设置为多路召回模式时需开启 Rerank 模型。
-查看更多关于多路召回模式的说明,[《多路召回》](/zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application)。
+查看更多关于多路召回模式的说明,[《多路召回》](/zh-hans/user-guide/knowledge-base/integrate-knowledge-within-application)。
-
+
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
index 7c503941..c92291ba 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
@@ -12,7 +12,7 @@ version: '简体中文'
在下图中,当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统…),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
-
+
**为什么需要这样做呢?**
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
index 1e80fedc..bb96708c 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
@@ -6,7 +6,7 @@ version: '简体中文'
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-
+
### 召回设置
@@ -18,7 +18,7 @@ version: '简体中文'
以下是多路召回模式的技术流程图:
-
+
由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
index 97e68f5a..036035a5 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
@@ -6,19 +6,19 @@ version: '简体中文'
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-
+
### 召回设置
根据用户意图同时匹配所有知识库,从多路知识库查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
-在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
+在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-hans/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
以下是多路召回模式的技术流程图:
-
+
由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance.mdx b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
index 3d88e0fb..ecd98235 100644
--- a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
在 Dify 团队首页中,点击顶部的 “知识库” tab 页,选择需要管理的知识库,轻点左侧导航中的**设置**进行调整。你可以调整知识库名称、描述、可见权限、索引模式、Embedding 模型和检索设置。
-
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx b/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
index f102548f..1f85bb37 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
-
+
在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
@@ -30,7 +30,7 @@ version: '简体中文'
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
-
+
###
@@ -46,7 +46,7 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
-
+
**TopK:** 用于设置 Rerank 后返回相关文档的数量。
@@ -60,5 +60,5 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
查看更多关于多路召回模式的说明,[《多路召回》](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)。
-
+
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak b/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
index 0f0bab5a..71e40b50 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
@@ -10,7 +10,7 @@ version: '简体中文'
**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
-
+
在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
@@ -30,7 +30,7 @@ version: '简体中文'
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
-
+
###
@@ -46,7 +46,7 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
-
+
**TopK:** 用于设置 Rerank 后返回相关文档的数量。
@@ -57,8 +57,8 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“提示词编排->上下文->设置”页面中设置为多路召回模式时需开启 Rerank 模型。
-查看更多关于多路召回模式的说明,[《多路召回》](/zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application)。
+查看更多关于多路召回模式的说明,[《多路召回》](/zh-hans/user-guide/knowledge-base/integrate-knowledge-within-application)。
-
+
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
index 7c503941..c92291ba 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
@@ -12,7 +12,7 @@ version: '简体中文'
在下图中,当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统…),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
-
+
**为什么需要这样做呢?**
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
index 1e80fedc..bb96708c 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
@@ -6,7 +6,7 @@ version: '简体中文'
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-
+
### 召回设置
@@ -18,7 +18,7 @@ version: '简体中文'
以下是多路召回模式的技术流程图:
-
+
由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
index 97e68f5a..036035a5 100644
--- a/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
+++ b/ja-jp/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
@@ -6,19 +6,19 @@ version: '简体中文'
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-
+
### 召回设置
根据用户意图同时匹配所有知识库,从多路知识库查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
-在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
+在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-hans/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
以下是多路召回模式的技术流程图:
-
+
由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance.mdx b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
index 3d88e0fb..ecd98235 100644
--- a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
在 Dify 团队首页中,点击顶部的 “知识库” tab 页,选择需要管理的知识库,轻点左侧导航中的**设置**进行调整。你可以调整知识库名称、描述、可见权限、索引模式、Embedding 模型和检索设置。
- .png) +
+ .png) **知识库名称**,用于区分不同的知识库。
@@ -32,7 +32,7 @@ version: '简体中文'
Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库内的文档、分段进行增删改查等日常管理维护操作,请参考[知识库 API 文档](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api)。
-
**知识库名称**,用于区分不同的知识库。
@@ -32,7 +32,7 @@ version: '简体中文'
Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库内的文档、分段进行增删改查等日常管理维护操作,请参考[知识库 API 文档](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api)。
- .png) +
+ .png) ## 维护知识库中的文本
@@ -44,7 +44,7 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
点击 「知识库」 > 「文档列表 ,然后轻点 「 添加文件 」,即可在已创建的知识库内上传新的文档。
-
## 维护知识库中的文本
@@ -44,7 +44,7 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
点击 「知识库」 > 「文档列表 ,然后轻点 「 添加文件 」,即可在已创建的知识库内上传新的文档。
- .png) +
+ .png) ***
@@ -62,7 +62,7 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
知识库内已上传的每个文档都会以文本分段(Chunks)的形式进行存储,你可以在分段列表内查看每一个分段的具体文本内容。
-
***
@@ -62,7 +62,7 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
知识库内已上传的每个文档都会以文本分段(Chunks)的形式进行存储,你可以在分段列表内查看每一个分段的具体文本内容。
- .png) +
+ .png) ***
@@ -78,19 +78,19 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
* **过短的文本分段**,导致语义缺失;
-
***
@@ -78,19 +78,19 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
* **过短的文本分段**,导致语义缺失;
- .png) +
+ .png) * **过长的文本分段**,导致语义噪音影响匹配准确性;
-
* **过长的文本分段**,导致语义噪音影响匹配准确性;
- .png) +
+ .png) * **明显的语义截断**,在使用最大分段长度限制时会出现强制性的语义截断,导致召回时缺失内容;
-
* **明显的语义截断**,在使用最大分段长度限制时会出现强制性的语义截断,导致召回时缺失内容;
- .png) +
+ .png) ***
@@ -100,23 +100,23 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
在分段列表内点击 「 添加分段 」 ,可以在文档内自行添加一个或批量添加多个自定义分段。
-
***
@@ -100,23 +100,23 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
在分段列表内点击 「 添加分段 」 ,可以在文档内自行添加一个或批量添加多个自定义分段。
- .png) +
+ .png) 批量添加分段时,你需要先下载 CSV 格式的分段上传模板,并按照模板格式在 Excel 内编辑所有的分段内容,再将 CSV 文件保存后上传。
-
批量添加分段时,你需要先下载 CSV 格式的分段上传模板,并按照模板格式在 Excel 内编辑所有的分段内容,再将 CSV 文件保存后上传。
- .png) +
+ .png) ***
-### ![]()编辑文本分段
+### ![]()编辑文本分段
在分段列表内,你可以对已添加的分段内容直接进行编辑修改。包括分段的文本内容和关键词。
-
***
-### ![]()编辑文本分段
+### ![]()编辑文本分段
在分段列表内,你可以对已添加的分段内容直接进行编辑修改。包括分段的文本内容和关键词。
- .png) +
+ .png) ***
@@ -130,5 +130,5 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
-
***
@@ -130,5 +130,5 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
- .png) +
+ .png) diff --git a/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx b/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
index b1f2d79f..cedd6b40 100644
--- a/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
@@ -26,7 +26,7 @@ version: '简体中文'
- 单文档的上传大小限制为 15MB;
-
+
***
@@ -61,7 +61,7 @@ version: '简体中文'
自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,Dify 将为你自动分段与清洗内容文件。
-
+
@@ -83,7 +83,7 @@ version: '简体中文'
* 删除所有 URL 和电子邮件地址;
-
+
@@ -103,14 +103,14 @@ version: '简体中文'
> 如需了解更多,请参考[《Embedding 技术与 Dify》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
高质量索引方式提供向量检索、全文检索和混合检索三种检索设置。关于更多检索设置的说明,请阅读 [检索设置](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)。
-
+
+
+
**向量检索设置:**
@@ -153,7 +153,7 @@ version: '简体中文'
**定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
-
+
**Rerank 模型:** 使用第三方 Rerank 模型对全文检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
@@ -170,7 +170,7 @@ version: '简体中文'
**定义:** 同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。在此模式下可以指定“权重设置”(无需配置 Rerank 模型 API)或选择 Rerank 模型进行检索。
-
+
在混合检索设置内可以选择启用**“权重设置”**或**“Rerank 模型”**。
@@ -218,7 +218,7 @@ version: '简体中文'
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
+
指定检索设置后,你可以参考[召回测试/引用归属](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
diff --git a/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak b/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
index b4d9941d..4b9e2d9e 100644
--- a/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
+++ b/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
@@ -19,14 +19,14 @@ version: '简体中文'
- 拖拽或选中文件进行上传,批量上传的文件数量取决于[订阅计划](https://dify.ai/pricing);
- 如果还没有准备好文档,可以先创建一个空知识库;
-- 如果你在创建知识库时选择了使用外部数据源(Notion 或同步 Web 站点),该知识库的类型不可更改;此举是为了防止单一知识库存在多数据源而造成的管理困难。如果你需要使用多个数据源,建议创建多个知识库并使用 [多路召回](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 模式在同一个应用内引用多个知识库。
+- 如果你在创建知识库时选择了使用外部数据源(Notion 或同步 Web 站点),该知识库的类型不可更改;此举是为了防止单一知识库存在多数据源而造成的管理困难。如果你需要使用多个数据源,建议创建多个知识库并使用 [多路召回](/zh-hans/user-guide/knowledge-base/indexing-and-retrieval/rerank) 模式在同一个应用内引用多个知识库。
**上传文档存在以下限制:**
- 单文档的上传大小限制为 15MB;
-
+
***
@@ -61,7 +61,7 @@ version: '简体中文'
自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,Dify 将为你自动分段与清洗内容文件。
-
+
@@ -83,7 +83,7 @@ version: '简体中文'
* 删除所有 URL 和电子邮件地址;
-
+
@@ -103,14 +103,14 @@ version: '简体中文'
> 如需了解更多,请参考[《Embedding 技术与 Dify》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
高质量索引方式提供向量检索、全文检索和混合检索三种检索设置。关于更多检索设置的说明,请阅读 [检索设置](create-knowledge-and-upload-documents.md#id-4-jian-suo-she-zhi)。
-
+
+
+
**向量检索设置:**
@@ -153,7 +153,7 @@ version: '简体中文'
**定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
-
+
**Rerank 模型:** 使用第三方 Rerank 模型对全文检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
@@ -170,7 +170,7 @@ version: '简体中文'
**定义:** 同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。在此模式下可以指定“权重设置”(无需配置 Rerank 模型 API)或选择 Rerank 模型进行检索。
-
+
在混合检索设置内可以选择启用**“权重设置”**或**“Rerank 模型”**。
@@ -218,10 +218,10 @@ version: '简体中文'
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
+
-指定检索设置后,你可以参考[召回测试/引用归属](/zh-cn/user-guide/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
+指定检索设置后,你可以参考[召回测试/引用归属](/zh-hans/user-guide/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
## 5 完成上传
diff --git a/scripts/check_links-backup.py b/scripts/check_links-backup.py
new file mode 100644
index 00000000..d5abb6af
--- /dev/null
+++ b/scripts/check_links-backup.py
@@ -0,0 +1,228 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+"""
+Link Checker for Markdown/MDX files
+
+This script checks both online links and relative file paths in markdown files.
+It verifies that online links are accessible and that relative paths exist in the filesystem.
+"""
+
+import re
+import requests
+import os
+from pathlib import Path
+import concurrent.futures
+import argparse
+import sys
+from colorama import init, Fore, Style
+
+# Initialize colorama for cross-platform colored terminal output
+init()
+
+class LinkChecker:
+ def __init__(self, base_dir, timeout=10, max_workers=10):
+ self.base_dir = Path(base_dir)
+ self.timeout = timeout
+ self.max_workers = max_workers
+ self.results = {"valid": [], "invalid": [], "skipped": []}
+ self.headers = {
+ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
+ }
+
+ def extract_links_from_markdown(self, file_path):
+ """Extract all links from a Markdown/MDX file, with line and column info"""
+ with open(file_path, 'r', encoding='utf-8') as file:
+ content = file.read()
+
+ link_infos = []
+ # Markdown links [text](url)
+ for match in re.finditer(r'\[.*?\]\((.*?)\)', content):
+ url = match.group(1)
+ start = match.start(1)
+ line = content.count('\n', 0, start) + 1
+ col = start - content.rfind('\n', 0, start)
+ link_infos.append((url, line, col))
+ # HTML links
+ for match in re.finditer(r'
diff --git a/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx b/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
index b1f2d79f..cedd6b40 100644
--- a/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx
@@ -26,7 +26,7 @@ version: '简体中文'
- 单文档的上传大小限制为 15MB;
-
+
***
@@ -61,7 +61,7 @@ version: '简体中文'
自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,Dify 将为你自动分段与清洗内容文件。
-
+
@@ -83,7 +83,7 @@ version: '简体中文'
* 删除所有 URL 和电子邮件地址;
-
+
@@ -103,14 +103,14 @@ version: '简体中文'
> 如需了解更多,请参考[《Embedding 技术与 Dify》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
高质量索引方式提供向量检索、全文检索和混合检索三种检索设置。关于更多检索设置的说明,请阅读 [检索设置](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)。
-
+
+
+
**向量检索设置:**
@@ -153,7 +153,7 @@ version: '简体中文'
**定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
-
+
**Rerank 模型:** 使用第三方 Rerank 模型对全文检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
@@ -170,7 +170,7 @@ version: '简体中文'
**定义:** 同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。在此模式下可以指定“权重设置”(无需配置 Rerank 模型 API)或选择 Rerank 模型进行检索。
-
+
在混合检索设置内可以选择启用**“权重设置”**或**“Rerank 模型”**。
@@ -218,7 +218,7 @@ version: '简体中文'
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
+
指定检索设置后,你可以参考[召回测试/引用归属](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
diff --git a/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak b/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
index b4d9941d..4b9e2d9e 100644
--- a/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
+++ b/ja-jp/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
@@ -19,14 +19,14 @@ version: '简体中文'
- 拖拽或选中文件进行上传,批量上传的文件数量取决于[订阅计划](https://dify.ai/pricing);
- 如果还没有准备好文档,可以先创建一个空知识库;
-- 如果你在创建知识库时选择了使用外部数据源(Notion 或同步 Web 站点),该知识库的类型不可更改;此举是为了防止单一知识库存在多数据源而造成的管理困难。如果你需要使用多个数据源,建议创建多个知识库并使用 [多路召回](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 模式在同一个应用内引用多个知识库。
+- 如果你在创建知识库时选择了使用外部数据源(Notion 或同步 Web 站点),该知识库的类型不可更改;此举是为了防止单一知识库存在多数据源而造成的管理困难。如果你需要使用多个数据源,建议创建多个知识库并使用 [多路召回](/zh-hans/user-guide/knowledge-base/indexing-and-retrieval/rerank) 模式在同一个应用内引用多个知识库。
**上传文档存在以下限制:**
- 单文档的上传大小限制为 15MB;
-
+
***
@@ -61,7 +61,7 @@ version: '简体中文'
自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,Dify 将为你自动分段与清洗内容文件。
-
+
@@ -83,7 +83,7 @@ version: '简体中文'
* 删除所有 URL 和电子邮件地址;
-
+
@@ -103,14 +103,14 @@ version: '简体中文'
> 如需了解更多,请参考[《Embedding 技术与 Dify》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
高质量索引方式提供向量检索、全文检索和混合检索三种检索设置。关于更多检索设置的说明,请阅读 [检索设置](create-knowledge-and-upload-documents.md#id-4-jian-suo-she-zhi)。
-
+
+
+
**向量检索设置:**
@@ -153,7 +153,7 @@ version: '简体中文'
**定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
-
+
**Rerank 模型:** 使用第三方 Rerank 模型对全文检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
@@ -170,7 +170,7 @@ version: '简体中文'
**定义:** 同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。在此模式下可以指定“权重设置”(无需配置 Rerank 模型 API)或选择 Rerank 模型进行检索。
-
+
在混合检索设置内可以选择启用**“权重设置”**或**“Rerank 模型”**。
@@ -218,10 +218,10 @@ version: '简体中文'
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
+
-指定检索设置后,你可以参考[召回测试/引用归属](/zh-cn/user-guide/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
+指定检索设置后,你可以参考[召回测试/引用归属](/zh-hans/user-guide/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
## 5 完成上传
diff --git a/scripts/check_links-backup.py b/scripts/check_links-backup.py
new file mode 100644
index 00000000..d5abb6af
--- /dev/null
+++ b/scripts/check_links-backup.py
@@ -0,0 +1,228 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+"""
+Link Checker for Markdown/MDX files
+
+This script checks both online links and relative file paths in markdown files.
+It verifies that online links are accessible and that relative paths exist in the filesystem.
+"""
+
+import re
+import requests
+import os
+from pathlib import Path
+import concurrent.futures
+import argparse
+import sys
+from colorama import init, Fore, Style
+
+# Initialize colorama for cross-platform colored terminal output
+init()
+
+class LinkChecker:
+ def __init__(self, base_dir, timeout=10, max_workers=10):
+ self.base_dir = Path(base_dir)
+ self.timeout = timeout
+ self.max_workers = max_workers
+ self.results = {"valid": [], "invalid": [], "skipped": []}
+ self.headers = {
+ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
+ }
+
+ def extract_links_from_markdown(self, file_path):
+ """Extract all links from a Markdown/MDX file, with line and column info"""
+ with open(file_path, 'r', encoding='utf-8') as file:
+ content = file.read()
+
+ link_infos = []
+ # Markdown links [text](url)
+ for match in re.finditer(r'\[.*?\]\((.*?)\)', content):
+ url = match.group(1)
+ start = match.start(1)
+ line = content.count('\n', 0, start) + 1
+ col = start - content.rfind('\n', 0, start)
+ link_infos.append((url, line, col))
+ # HTML links
+ for match in re.finditer(r' # 3. Frame标签中的图片: ......
-# 4. 相对路径图片: 
+# 4. 相对路径图片: 
# Markdown格式图片
MD_IMG_PATTERN = re.compile(r'!\[(.*?)\]\((https?://[^)]+|/[^)]+)\)')
@@ -49,7 +49,7 @@ HTML_IMG_PATTERN = re.compile(r'
# 3. Frame标签中的图片: ......
-# 4. 相对路径图片: 
+# 4. 相对路径图片: 
# Markdown格式图片
MD_IMG_PATTERN = re.compile(r'!\[(.*?)\]\((https?://[^)]+|/[^)]+)\)')
@@ -49,7 +49,7 @@ HTML_IMG_PATTERN = re.compile(r' (3).png) +
+  (3).png) 对话型应用支持发布为:
diff --git a/zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation.mdx.bak b/zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation.mdx.bak
index 08efeaf9..bae29688 100644
--- a/zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation.mdx.bak
+++ b/zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation.mdx.bak
@@ -11,7 +11,7 @@ POST
+
“混合检索”实际上并没有明确的定义,本文以向量检索和关键词检索的组合为示例。如果我们使用其他搜索算法的组合,也可以被称为“混合检索”。比如,我们可以将用于检索实体关系的知识图谱技术与向量检索技术结合。
@@ -45,7 +45,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
定义:通过生成查询嵌入并查询与其向量表示最相似的文本分段。
-
+
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -59,7 +59,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
定义:索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。
-
+
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -71,7 +71,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。
-
+
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -83,7 +83,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“数据集->创建数据集”页面并在检索设置中设置不同的检索模式:
-
+
### 数据集设置中修改检索模式
@@ -91,7 +91,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“数据集->选择数据集->设置”页面中可以对已创建的数据集修改不同的检索模式。
-
+
### 提示词编排中修改检索模式
@@ -99,5 +99,5 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“提示词编排->上下文->选择数据集->设置”页面中可以在创建应用时修改不同的检索模式。
-
+
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx b/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
index 8c3b0797..34e38a4d 100644
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
+++ b/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
-
+
在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
@@ -30,7 +30,7 @@ version: '简体中文'
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
-
+
###
@@ -46,7 +46,7 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
-
+
**TopK:** 用于设置 Rerank 后返回相关文档的数量。
@@ -60,5 +60,5 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
查看更多关于多路召回模式的说明,[《多路召回》](/zh-hans/guides/knowledge-base/integrate-knowledge-within-application)。
-
+
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak b/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
deleted file mode 100644
index 0f0bab5a..00000000
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
+++ /dev/null
@@ -1,64 +0,0 @@
----
-title: 重排序
-version: '简体中文'
----
-
-### 为什么需要重排序?
-
-混合检索能够结合不同检索技术的优势获得更好的召回结果,但在不同检索模式下的查询结果需要进行合并和归一化(将数据转换为统一的标准范围或分布,以便更好地进行比较、分析和处理),然后再一起提供给大模型。这时候我们需要引入一个评分系统:重排序模型(Rerank Model)。
-
-**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
-
-
-
-
-
-在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
-
-不过,重排序并不是只适用于不同检索系统的结果合并,即使是在单一检索模式下,引入重排序步骤也能有效帮助改进文档的召回效果,比如我们可以在关键词检索之后加入语义重排序。
-
-在具体实践过程中,除了将多路查询结果进行归一化之外,在将相关的文本分段交给大模型之前,我们一般会限制传递给大模型的分段个数(即 TopK,可以在重排序模型参数中设置),这样做的原因是大模型的输入窗口存在大小限制(一般为 4K、8K、16K、128K 的 Token 数量),你需要根据选用的模型输入窗口的大小限制,选择合适的分段策略和 TopK 值。
-
-需要注意的是,即使模型上下文窗口很足够大,过多的召回分段会可能会引入相关度较低的内容,导致回答的质量降低,所以重排序的 TopK 参数并不是越大越好。
-
-重排序并不是搜索技术的替代品,而是一种用于增强现有检索系统的辅助工具。**它最大的优势是不仅提供了一种简单且低复杂度的方法来改善搜索结果,允许用户将语义相关性纳入现有的搜索系统中,而且无需进行重大的基础设施修改。**
-
-以 Cohere Rerank 为例,你只需要注册账户和申请 API ,接入只需要两行代码。另外,他们也提供了多语言模型,也就是说你可以将不同语言的文本查询结果进行一次性排序。
-
-### 如何配置 Rerank 模型?
-
-Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
-
-
-
-
-
-###
-
-### 如何获取 Cohere Rerank 模型?
-
-登录:[https://cohere.com/rerank](https://cohere.com/rerank),在页内注册并申请 Rerank 模型的使用资格,获取 API 秘钥。
-
-###
-
-### 数据集检索模式中设置 Rerank 模型
-
-进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
-
-
-
-
-
-**TopK:** 用于设置 Rerank 后返回相关文档的数量。
-
-**Score 阈值:** 用于设置 Rerank 后返回相关文档的最低分值。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
-
-### 数据集多路召回模式中设置 Rerank 模型
-
-进入“提示词编排->上下文->设置”页面中设置为多路召回模式时需开启 Rerank 模型。
-
-查看更多关于多路召回模式的说明,[《多路召回》](/zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application)。
-
-
-
-
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
index 7c503941..c92291ba 100644
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
+++ b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
@@ -12,7 +12,7 @@ version: '简体中文'
在下图中,当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统…),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
-
+
**为什么需要这样做呢?**
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
index 6edd2274..440f1a9a 100644
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
+++ b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
@@ -6,7 +6,7 @@ version: '简体中文'
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-
+
### 召回设置
@@ -18,7 +18,7 @@ version: '简体中文'
以下是多路召回模式的技术流程图:
-
+
由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
deleted file mode 100644
index 97e68f5a..00000000
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
+++ /dev/null
@@ -1,24 +0,0 @@
----
-title: 召回模式
-version: '简体中文'
----
-
-当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-
-
-
-
-
-### 召回设置
-
-根据用户意图同时匹配所有知识库,从多路知识库查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
-
-在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
-
-以下是多路召回模式的技术流程图:
-
-
-
-
-
-由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance.mdx b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
index eca1117c..97f9548e 100644
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
在 Dify 团队首页中,点击顶部的 “知识库” tab 页,选择需要管理的知识库,轻点左侧导航中的**设置**进行调整。你可以调整知识库名称、描述、可见权限、索引模式、Embedding 模型和检索设置。
-
+
**知识库名称**,用于区分不同的知识库。
@@ -32,7 +32,7 @@ version: '简体中文'
Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库内的文档、分段进行增删改查等日常管理维护操作,请参考[知识库 API 文档](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api)。
-
+
## 维护知识库中的文本
@@ -44,7 +44,7 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
点击 「知识库」 > 「文档列表 ,然后轻点 「 添加文件 」,即可在已创建的知识库内上传新的文档。
-
+
***
@@ -62,7 +62,7 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
知识库内已上传的每个文档都会以文本分段(Chunks)的形式进行存储,你可以在分段列表内查看每一个分段的具体文本内容。
-
+
***
@@ -78,19 +78,19 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
* **过短的文本分段**,导致语义缺失;
-
+
* **过长的文本分段**,导致语义噪音影响匹配准确性;
-
+
* **明显的语义截断**,在使用最大分段长度限制时会出现强制性的语义截断,导致召回时缺失内容;
-
+
***
@@ -100,23 +100,23 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
在分段列表内点击 「 添加分段 」 ,可以在文档内自行添加一个或批量添加多个自定义分段。
-
+
批量添加分段时,你需要先下载 CSV 格式的分段上传模板,并按照模板格式在 Excel 内编辑所有的分段内容,再将 CSV 文件保存后上传。
-
+
***
-### ![]()编辑文本分段
+### 编辑文本分段
在分段列表内,你可以对已添加的分段内容直接进行编辑修改。包括分段的文本内容和关键词。
-
+
***
@@ -130,5 +130,5 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
-
+
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx.bak b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx.bak
deleted file mode 100644
index 06de5e21..00000000
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx.bak
+++ /dev/null
@@ -1,48 +0,0 @@
----
-title: 管理知识库
----
-
-> 知识库管理页仅面向团队所有者、团队管理员、拥有编辑权限的角色开放。
-
-点击 Dify 平台顶部的“知识库”按钮,选择需要管理的知识库。轻点左侧导航中的**设置**进行调整。
-
-你可以在此处调整知识库名称、描述、可见权限、索引模式、Embedding 模型和检索设置。
-
-
-
-* **知识库名称**,用于区分不同的知识库。
-* **知识库描述**,用于描述知识库内文档代表的信息。
-* **可见权限**,提供 **“只有我”** 、**“所有团队成员”** 和 **“部分团队成员”** 三种权限范围。不具有权限的人将无法访问该知识库。若选择将知识库公开至其它成员,则意味着其它成员同样具备该知识库的查看、编辑和删除权限。
-* **索引方法**,详细说明请参考[索引方法文档](../create-knowledge-and-upload-documents/setting-indexing-methods)。
-* **Embedding 模型**, 修改知识库的嵌入模型,修改 Embedding 模型将对知识库内的所有文档重新嵌入,原先的嵌入将会被删除。
-* **检索设置**,详细说明请参考[检索设置文档](../create-knowledge-and-upload-documents/setting-indexing-methods)。
-
-***
-
-### 查看知识库内已关联的应用
-
-知识库将会在左侧信息栏中显示已关联的应用数量。将鼠标悬停至圆形信息图标时将显示所有已关联的 Apps 列表,点击右侧的跳转按钮即可快速查看对应的应用。
-
-
-
-***
-
-你可以通过网页维护或 API 两种方式维护知识库内的文档。
-
-#### 维护知识库内文档
-
-支持管理知识库内的文档和对应的文档分段。详细说明请参考以下文档:
-
-
+
***
@@ -61,7 +61,7 @@ version: '简体中文'
自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,Dify 将为你自动分段与清洗内容文件。
-
+
@@ -83,7 +83,7 @@ version: '简体中文'
* 删除所有 URL 和电子邮件地址;
-
+
@@ -103,14 +103,14 @@ version: '简体中文'
> 如需了解更多,请参考[《Embedding 技术与 Dify》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
高质量索引方式提供向量检索、全文检索和混合检索三种检索设置。关于更多检索设置的说明,请阅读 [检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)。
-
+
+
+
**向量检索设置:**
@@ -153,7 +153,7 @@ version: '简体中文'
**定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
-
+
**Rerank 模型:** 使用第三方 Rerank 模型对全文检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
@@ -170,7 +170,7 @@ version: '简体中文'
**定义:** 同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。在此模式下可以指定“权重设置”(无需配置 Rerank 模型 API)或选择 Rerank 模型进行检索。
-
+
在混合检索设置内可以选择启用**“权重设置”**或**“Rerank 模型”**。
@@ -218,7 +218,7 @@ version: '简体中文'
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
+
指定检索设置后,你可以参考[召回测试/引用归属](/zh-hans/guides/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
diff --git a/zh-hans/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak b/zh-hans/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
deleted file mode 100644
index b4d9941d..00000000
--- a/zh-hans/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
+++ /dev/null
@@ -1,254 +0,0 @@
----
-title: 创建知识库 & 上传文档
-version: '简体中文'
----
-
-创建知识库并上传文档大致分为以下步骤:
-
-1. 在 Dify 团队内创建知识库,从本地选择你需要上传的文档;
-2. 选择分段与清洗模式,预览效果;
-3. 配置索引方式和检索设置;
-4. 等待分段嵌入;
-5. 完成上传,在应用内关联并使用 🎉
-
-以下是各个步骤的详细说明:
-
-## 1 创建知识库
-
-在 Dify 主导航栏中点击知识库,在该页面你可以看到团队内的知识库,点击“**创建知识库”** 进入创建向导。
-
-- 拖拽或选中文件进行上传,批量上传的文件数量取决于[订阅计划](https://dify.ai/pricing);
-- 如果还没有准备好文档,可以先创建一个空知识库;
-- 如果你在创建知识库时选择了使用外部数据源(Notion 或同步 Web 站点),该知识库的类型不可更改;此举是为了防止单一知识库存在多数据源而造成的管理困难。如果你需要使用多个数据源,建议创建多个知识库并使用 [多路召回](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 模式在同一个应用内引用多个知识库。
-
-**上传文档存在以下限制:**
-
-- 单文档的上传大小限制为 15MB;
-
-
-
-
-
-***
-
-## 2 选择分段与清洗策略
-
-将内容上传至知识库后,需要先对内容进行分段与数据清洗,该阶段可以被理解为是对内容预处理与结构化。
-
-
-
-
-
-
-
-
-
-
-
-
-
- **向量检索设置:**
-
- **Rerank 模型:** 使用第三方 Rerank 模型对向量检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
-
- **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
-
- **Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
-
- > TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置。
-
-
-
-
- **Rerank 模型:** 使用第三方 Rerank 模型对全文检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
-
- **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
- **Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
-
- > TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置。
-
-
-
-
- 在混合检索设置内可以选择启用**“权重设置”**或**“Rerank 模型”**。
-
- **权重设置:** 允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。
-
- * **语义值为 1**
-
- 仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
-
- > 语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:[《Dify:Embedding 技术与 Dify 数据集设计/规划》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
-
- * **关键词值为 1**
-
- 仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
-
- * **自定义关键词和语义权重**
-
- 除了仅启用语义检索或关键词检索模式,我们还提供了灵活的自定义权重设置。你可以通过不断调试二者的权重,找到符合业务场景的最佳权重比例。
-
- ***
-
- **Rerank 模型:** 你可以在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”,系统会在混合检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。
-
- ***
-
- **“权重设置”** 和 **“Rerank 模型”** 设置内支持启用以下选项:
-
- **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
- **Score 阈值:**用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5。数值越高,预期被召回的文本数量越少。
-
-
-
-
-指定检索设置后,你可以参考[召回测试/引用归属](/zh-cn/user-guide/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
-
-## 5 完成上传
-
-配置完上文所述的各项配置后,轻点“保存并处理”即可完成知识库的创建。你可以参考 [在应用内集成知识库](integrate-knowledge-within-application),搭建出能够基于知识库进行问答的 LLM 应用。
-
-***
-
-## 参考阅读
-
-#### ETL
-
-在 RAG 的生产级应用中,为了获得更好的数据召回效果,需要对多源数据进行预处理和清洗,即 ETL (_extract, transform, load_)。为了增强非结构化/半结构化数据的预处理能力,Dify 支持了可选的 ETL 方案:**Dify ETL** 和[ ](https://docs.unstructured.io/welcome)[**Unstructured ETL** ](https://unstructured.io/)。
-
-> Unstructured 能够高效地提取并转换您的数据为干净的数据用于后续的步骤。Dify 各版本的 ETL 方案选择:
-
-文件解析支持格式的差异:
-
-| DIFY ETL | Unstructured ETL |
-| ---------------------------------------------- | ------------------------------------------------------------------------ |
-| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
-
-
对话型应用支持发布为:
diff --git a/zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation.mdx.bak b/zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation.mdx.bak
index 08efeaf9..bae29688 100644
--- a/zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation.mdx.bak
+++ b/zh-hans/guides/knowledge-base/api-documentation/external-knowledge-api-documentation.mdx.bak
@@ -11,7 +11,7 @@ POST
+
“混合检索”实际上并没有明确的定义,本文以向量检索和关键词检索的组合为示例。如果我们使用其他搜索算法的组合,也可以被称为“混合检索”。比如,我们可以将用于检索实体关系的知识图谱技术与向量检索技术结合。
@@ -45,7 +45,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
定义:通过生成查询嵌入并查询与其向量表示最相似的文本分段。
-
+
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -59,7 +59,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
定义:索引文档中的所有词汇,从而允许用户查询任意词汇,并返回包含这些词汇的文本片段。
-
+
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -71,7 +71,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。
-
+
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。
@@ -83,7 +83,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“数据集->创建数据集”页面并在检索设置中设置不同的检索模式:
-
+
### 数据集设置中修改检索模式
@@ -91,7 +91,7 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“数据集->选择数据集->设置”页面中可以对已创建的数据集修改不同的检索模式。
-
+
### 提示词编排中修改检索模式
@@ -99,5 +99,5 @@ RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的
进入“提示词编排->上下文->选择数据集->设置”页面中可以在创建应用时修改不同的检索模式。
-
+
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx b/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
index 8c3b0797..34e38a4d 100644
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
+++ b/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
-
+
在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
@@ -30,7 +30,7 @@ version: '简体中文'
Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
-
+
###
@@ -46,7 +46,7 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
-
+
**TopK:** 用于设置 Rerank 后返回相关文档的数量。
@@ -60,5 +60,5 @@ Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”
查看更多关于多路召回模式的说明,[《多路召回》](/zh-hans/guides/knowledge-base/integrate-knowledge-within-application)。
-
+
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak b/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
deleted file mode 100644
index 0f0bab5a..00000000
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/rerank.mdx.bak
+++ /dev/null
@@ -1,64 +0,0 @@
----
-title: 重排序
-version: '简体中文'
----
-
-### 为什么需要重排序?
-
-混合检索能够结合不同检索技术的优势获得更好的召回结果,但在不同检索模式下的查询结果需要进行合并和归一化(将数据转换为统一的标准范围或分布,以便更好地进行比较、分析和处理),然后再一起提供给大模型。这时候我们需要引入一个评分系统:重排序模型(Rerank Model)。
-
-**重排序模型会计算候选文档列表与用户问题的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果**。其原理是计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低排序的文档列表。常见的 Rerank 模型如:Cohere rerank、bge-reranker 等。
-
-
-
-
-
-在大多数情况下,在重排序之前会有一次前置检索,这是由于计算查询与数百万个文档之间的相关性得分将会非常低效。所以,**重排序一般都放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果**。
-
-不过,重排序并不是只适用于不同检索系统的结果合并,即使是在单一检索模式下,引入重排序步骤也能有效帮助改进文档的召回效果,比如我们可以在关键词检索之后加入语义重排序。
-
-在具体实践过程中,除了将多路查询结果进行归一化之外,在将相关的文本分段交给大模型之前,我们一般会限制传递给大模型的分段个数(即 TopK,可以在重排序模型参数中设置),这样做的原因是大模型的输入窗口存在大小限制(一般为 4K、8K、16K、128K 的 Token 数量),你需要根据选用的模型输入窗口的大小限制,选择合适的分段策略和 TopK 值。
-
-需要注意的是,即使模型上下文窗口很足够大,过多的召回分段会可能会引入相关度较低的内容,导致回答的质量降低,所以重排序的 TopK 参数并不是越大越好。
-
-重排序并不是搜索技术的替代品,而是一种用于增强现有检索系统的辅助工具。**它最大的优势是不仅提供了一种简单且低复杂度的方法来改善搜索结果,允许用户将语义相关性纳入现有的搜索系统中,而且无需进行重大的基础设施修改。**
-
-以 Cohere Rerank 为例,你只需要注册账户和申请 API ,接入只需要两行代码。另外,他们也提供了多语言模型,也就是说你可以将不同语言的文本查询结果进行一次性排序。
-
-### 如何配置 Rerank 模型?
-
-Dify 目前已支持 Cohere Rerank 模型,进入“模型供应商-> Cohere”页面填入 Rerank 模型的 API 秘钥:
-
-
-
-
-
-###
-
-### 如何获取 Cohere Rerank 模型?
-
-登录:[https://cohere.com/rerank](https://cohere.com/rerank),在页内注册并申请 Rerank 模型的使用资格,获取 API 秘钥。
-
-###
-
-### 数据集检索模式中设置 Rerank 模型
-
-进入“数据集->创建数据集->检索设置”页面并在添加 Rerank 设置。除了在创建数据集可以设置 Rerank ,你也可以在已创建的数据集设置内更改 Rerank 配置,在应用编排的数据集召回模式设置中更改 Rerank 配置。
-
-
-
-
-
-**TopK:** 用于设置 Rerank 后返回相关文档的数量。
-
-**Score 阈值:** 用于设置 Rerank 后返回相关文档的最低分值。设置 Rerank 模型后,TopK 和 Score 阈值设置仅在 Rerank 步骤生效。
-
-### 数据集多路召回模式中设置 Rerank 模型
-
-进入“提示词编排->上下文->设置”页面中设置为多路召回模式时需开启 Rerank 模型。
-
-查看更多关于多路召回模式的说明,[《多路召回》](/zh-cn/user-guide/knowledge-base/integrate-knowledge-within-application)。
-
-
-
-
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
index 7c503941..c92291ba 100644
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
+++ b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval-augment.mdx
@@ -12,7 +12,7 @@ version: '简体中文'
在下图中,当用户提问时 “美国总统是谁?” 时,系统并不是将问题直接交给大模型来回答,而是先将用户问题在知识库中(如下图中的维基百科)进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第46届总统…),然后再将用户问题和搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
-
+
**为什么需要这样做呢?**
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
index 6edd2274..440f1a9a 100644
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
+++ b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx
@@ -6,7 +6,7 @@ version: '简体中文'
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-
+
### 召回设置
@@ -18,7 +18,7 @@ version: '简体中文'
以下是多路召回模式的技术流程图:
-
+
由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak b/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
deleted file mode 100644
index 97e68f5a..00000000
--- a/zh-hans/guides/knowledge-base/indexing-and-retrieval/retrieval.mdx.bak
+++ /dev/null
@@ -1,24 +0,0 @@
----
-title: 召回模式
-version: '简体中文'
----
-
-当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个知识库,此时需要应用 Dify 的召回策略决定从哪些知识库中检索内容。
-
-
-
-
-
-### 召回设置
-
-根据用户意图同时匹配所有知识库,从多路知识库查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。
-
-在多路召回模式下,建议配置 Rerank 模型。你可以阅读 [重排序](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 了解更多。
-
-以下是多路召回模式的技术流程图:
-
-
-
-
-
-由于多路召回模式不依赖于模型的推理能力或知识库描述,该模式在多知识库检索时能够获得质量更高的召回效果,除此之外加入 Rerank 步骤也能有效改进文档召回效果。因此,当创建的知识库问答应用关联了多个知识库时,我们更推荐将召回模式配置为多路召回。
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance.mdx b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
index eca1117c..97f9548e 100644
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
在 Dify 团队首页中,点击顶部的 “知识库” tab 页,选择需要管理的知识库,轻点左侧导航中的**设置**进行调整。你可以调整知识库名称、描述、可见权限、索引模式、Embedding 模型和检索设置。
-
+
**知识库名称**,用于区分不同的知识库。
@@ -32,7 +32,7 @@ version: '简体中文'
Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库内的文档、分段进行增删改查等日常管理维护操作,请参考[知识库 API 文档](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api)。
-
+
## 维护知识库中的文本
@@ -44,7 +44,7 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
点击 「知识库」 > 「文档列表 ,然后轻点 「 添加文件 」,即可在已创建的知识库内上传新的文档。
-
+
***
@@ -62,7 +62,7 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
知识库内已上传的每个文档都会以文本分段(Chunks)的形式进行存储,你可以在分段列表内查看每一个分段的具体文本内容。
-
+
***
@@ -78,19 +78,19 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
* **过短的文本分段**,导致语义缺失;
-
+
* **过长的文本分段**,导致语义噪音影响匹配准确性;
-
+
* **明显的语义截断**,在使用最大分段长度限制时会出现强制性的语义截断,导致召回时缺失内容;
-
+
***
@@ -100,23 +100,23 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
在分段列表内点击 「 添加分段 」 ,可以在文档内自行添加一个或批量添加多个自定义分段。
-
+
批量添加分段时,你需要先下载 CSV 格式的分段上传模板,并按照模板格式在 Excel 内编辑所有的分段内容,再将 CSV 文件保存后上传。
-
+
***
-### ![]()编辑文本分段
+### 编辑文本分段
在分段列表内,你可以对已添加的分段内容直接进行编辑修改。包括分段的文本内容和关键词。
-
+
***
@@ -130,5 +130,5 @@ Dify 知识库提供整套标准 API ,开发者通过 API 调用对知识库
-
+
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx.bak b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx.bak
deleted file mode 100644
index 06de5e21..00000000
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx.bak
+++ /dev/null
@@ -1,48 +0,0 @@
----
-title: 管理知识库
----
-
-> 知识库管理页仅面向团队所有者、团队管理员、拥有编辑权限的角色开放。
-
-点击 Dify 平台顶部的“知识库”按钮,选择需要管理的知识库。轻点左侧导航中的**设置**进行调整。
-
-你可以在此处调整知识库名称、描述、可见权限、索引模式、Embedding 模型和检索设置。
-
-
-
-* **知识库名称**,用于区分不同的知识库。
-* **知识库描述**,用于描述知识库内文档代表的信息。
-* **可见权限**,提供 **“只有我”** 、**“所有团队成员”** 和 **“部分团队成员”** 三种权限范围。不具有权限的人将无法访问该知识库。若选择将知识库公开至其它成员,则意味着其它成员同样具备该知识库的查看、编辑和删除权限。
-* **索引方法**,详细说明请参考[索引方法文档](../create-knowledge-and-upload-documents/setting-indexing-methods)。
-* **Embedding 模型**, 修改知识库的嵌入模型,修改 Embedding 模型将对知识库内的所有文档重新嵌入,原先的嵌入将会被删除。
-* **检索设置**,详细说明请参考[检索设置文档](../create-knowledge-and-upload-documents/setting-indexing-methods)。
-
-***
-
-### 查看知识库内已关联的应用
-
-知识库将会在左侧信息栏中显示已关联的应用数量。将鼠标悬停至圆形信息图标时将显示所有已关联的 Apps 列表,点击右侧的跳转按钮即可快速查看对应的应用。
-
-
-
-***
-
-你可以通过网页维护或 API 两种方式维护知识库内的文档。
-
-#### 维护知识库内文档
-
-支持管理知识库内的文档和对应的文档分段。详细说明请参考以下文档:
-
-
+
***
@@ -61,7 +61,7 @@ version: '简体中文'
自动模式适合对分段规则与预处理规则尚不熟悉的初级用户。在该模式下,Dify 将为你自动分段与清洗内容文件。
-
+
@@ -83,7 +83,7 @@ version: '简体中文'
* 删除所有 URL 和电子邮件地址;
-
+
@@ -103,14 +103,14 @@ version: '简体中文'
> 如需了解更多,请参考[《Embedding 技术与 Dify》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
高质量索引方式提供向量检索、全文检索和混合检索三种检索设置。关于更多检索设置的说明,请阅读 [检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)。
-
+
+
+
**向量检索设置:**
@@ -153,7 +153,7 @@ version: '简体中文'
**定义:** 关键词检索,即索引文档中的所有词汇。用户输入问题后,通过明文关键词匹配知识库内对应的文本片段,返回符合关键词的文本片段;类似搜索引擎中的明文检索。
-
+
**Rerank 模型:** 使用第三方 Rerank 模型对全文检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
@@ -170,7 +170,7 @@ version: '简体中文'
**定义:** 同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果。在此模式下可以指定“权重设置”(无需配置 Rerank 模型 API)或选择 Rerank 模型进行检索。
-
+
在混合检索设置内可以选择启用**“权重设置”**或**“Rerank 模型”**。
@@ -218,7 +218,7 @@ version: '简体中文'
**TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
+
指定检索设置后,你可以参考[召回测试/引用归属](/zh-hans/guides/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
diff --git a/zh-hans/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak b/zh-hans/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
deleted file mode 100644
index b4d9941d..00000000
--- a/zh-hans/guides/knowledge-base/knowledge-base-creation/upload-documents.mdx.bak
+++ /dev/null
@@ -1,254 +0,0 @@
----
-title: 创建知识库 & 上传文档
-version: '简体中文'
----
-
-创建知识库并上传文档大致分为以下步骤:
-
-1. 在 Dify 团队内创建知识库,从本地选择你需要上传的文档;
-2. 选择分段与清洗模式,预览效果;
-3. 配置索引方式和检索设置;
-4. 等待分段嵌入;
-5. 完成上传,在应用内关联并使用 🎉
-
-以下是各个步骤的详细说明:
-
-## 1 创建知识库
-
-在 Dify 主导航栏中点击知识库,在该页面你可以看到团队内的知识库,点击“**创建知识库”** 进入创建向导。
-
-- 拖拽或选中文件进行上传,批量上传的文件数量取决于[订阅计划](https://dify.ai/pricing);
-- 如果还没有准备好文档,可以先创建一个空知识库;
-- 如果你在创建知识库时选择了使用外部数据源(Notion 或同步 Web 站点),该知识库的类型不可更改;此举是为了防止单一知识库存在多数据源而造成的管理困难。如果你需要使用多个数据源,建议创建多个知识库并使用 [多路召回](/zh-cn/user-guide/knowledge-base/indexing-and-retrieval/rerank) 模式在同一个应用内引用多个知识库。
-
-**上传文档存在以下限制:**
-
-- 单文档的上传大小限制为 15MB;
-
-
-
-
-
-***
-
-## 2 选择分段与清洗策略
-
-将内容上传至知识库后,需要先对内容进行分段与数据清洗,该阶段可以被理解为是对内容预处理与结构化。
-
-
-
-
-
-
-
-
-
-
-
-
-
- **向量检索设置:**
-
- **Rerank 模型:** 使用第三方 Rerank 模型对向量检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
-
- **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。默认值为 3,数值越高,预期被召回的文本分段数量越多。
-
- **Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
-
- > TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置。
-
-
-
-
- **Rerank 模型:** 使用第三方 Rerank 模型对全文检索召回后的分段再一次进行语义重排序,优化排序结果。在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”。
-
- **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
- **Score 阈值:** 用于设置文本片段筛选的相似度阈值,只召回超过设置分数的文本片段,默认值为 0.5。数值越高说明对于文本与问题要求的相似度越高,预期被召回的文本数量也越少。
-
- > TopK 和 Score 设置仅在 Rerank 步骤生效,因此需要添加并开启 Rerank 模型才能应用两者中的设置。
-
-
-
-
- 在混合检索设置内可以选择启用**“权重设置”**或**“Rerank 模型”**。
-
- **权重设置:** 允许用户赋予语义优先和关键词优先自定义的权重。关键词检索指的是在知识库内进行全文检索(Full Text Search),语义检索指的是在知识库内进行向量检索(Vector Search)。
-
- * **语义值为 1**
-
- 仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
-
- > 语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:[《Dify:Embedding 技术与 Dify 数据集设计/规划》](https://mp.weixin.qq.com/s/vmY\_CUmETo2IpEBf1nEGLQ)。
-
- * **关键词值为 1**
-
- 仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
-
- * **自定义关键词和语义权重**
-
- 除了仅启用语义检索或关键词检索模式,我们还提供了灵活的自定义权重设置。你可以通过不断调试二者的权重,找到符合业务场景的最佳权重比例。
-
- ***
-
- **Rerank 模型:** 你可以在“模型供应商”页面配置 Rerank 模型的 API 秘钥之后,在检索设置中打开“Rerank 模型”,系统会在混合检索后对已召回的文档结果再一次进行语义重排序,优化排序结果。
-
- ***
-
- **“权重设置”** 和 **“Rerank 模型”** 设置内支持启用以下选项:
-
- **TopK:** 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 3 。数值越高,预期被召回的文本分段数量越多。
-
- **Score 阈值:**用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.5。数值越高,预期被召回的文本数量越少。
-
-
-
-
-指定检索设置后,你可以参考[召回测试/引用归属](/zh-cn/user-guide/knowledge-base/retrieval-test-and-citation)查看关键词与内容块的匹配情况。
-
-## 5 完成上传
-
-配置完上文所述的各项配置后,轻点“保存并处理”即可完成知识库的创建。你可以参考 [在应用内集成知识库](integrate-knowledge-within-application),搭建出能够基于知识库进行问答的 LLM 应用。
-
-***
-
-## 参考阅读
-
-#### ETL
-
-在 RAG 的生产级应用中,为了获得更好的数据召回效果,需要对多源数据进行预处理和清洗,即 ETL (_extract, transform, load_)。为了增强非结构化/半结构化数据的预处理能力,Dify 支持了可选的 ETL 方案:**Dify ETL** 和[ ](https://docs.unstructured.io/welcome)[**Unstructured ETL** ](https://unstructured.io/)。
-
-> Unstructured 能够高效地提取并转换您的数据为干净的数据用于后续的步骤。Dify 各版本的 ETL 方案选择:
-
-文件解析支持格式的差异:
-
-| DIFY ETL | Unstructured ETL |
-| ---------------------------------------------- | ------------------------------------------------------------------------ |
-| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
-
-.png) +
+ .png) ### 提示词编排中开启标注回复
@@ -29,7 +29,7 @@ version: '简体中文'
进入"应用构建->添加功能"开启标注回复开关:
-
### 提示词编排中开启标注回复
@@ -29,7 +29,7 @@ version: '简体中文'
进入"应用构建->添加功能"开启标注回复开关:
- .png) +
+ .png) 开启时需要先设置标注回复的参数,可设置参数包括:Score 阈值 和 Embedding 模型
@@ -41,7 +41,7 @@ version: '简体中文'
点击保存并启用时,该设置会立即生效,系统将对所有已保存的标注利用 Embedding 模型生成嵌入保存。
-
开启时需要先设置标注回复的参数,可设置参数包括:Score 阈值 和 Embedding 模型
@@ -41,7 +41,7 @@ version: '简体中文'
点击保存并启用时,该设置会立即生效,系统将对所有已保存的标注利用 Embedding 模型生成嵌入保存。
- .png) +
+ .png) ### 在会话调试页添加标注
@@ -49,19 +49,19 @@ version: '简体中文'
你可以在调试与预览页面直接在模型回复信息上添加或编辑标注。
-
### 在会话调试页添加标注
@@ -49,19 +49,19 @@ version: '简体中文'
你可以在调试与预览页面直接在模型回复信息上添加或编辑标注。
- .png) +
+ .png) 编辑成你需要的高质量回复并保存。
-
编辑成你需要的高质量回复并保存。
- .png) +
+ .png) 再次输入同样的用户问题,系统将使用已保存的标注直接回复用户问题。
-
再次输入同样的用户问题,系统将使用已保存的标注直接回复用户问题。
- .png) +
+ .png) ### 日志与标注中开启标注回复
@@ -69,7 +69,7 @@ version: '简体中文'
进入"应用构建->日志与标注->标注"开启标注回复开关:
-
### 日志与标注中开启标注回复
@@ -69,7 +69,7 @@ version: '简体中文'
进入"应用构建->日志与标注->标注"开启标注回复开关:
- .png) +
+ .png) ### 在标注后台设置标注回复参数
@@ -81,7 +81,7 @@ version: '简体中文'
**Embedding 模型**:用于对标注文本进行向量化,切换模型时会重新生成嵌入。
-
### 在标注后台设置标注回复参数
@@ -81,7 +81,7 @@ version: '简体中文'
**Embedding 模型**:用于对标注文本进行向量化,切换模型时会重新生成嵌入。
- .png) +
+ .png) ### 批量导入标注问答对
@@ -89,7 +89,7 @@ version: '简体中文'
在批量导入功能内,你可以下载标注导入模板,按模板格式编辑标注问答对,编辑好后在此批量导入。
-
### 批量导入标注问答对
@@ -89,7 +89,7 @@ version: '简体中文'
在批量导入功能内,你可以下载标注导入模板,按模板格式编辑标注问答对,编辑好后在此批量导入。
- .png) +
+ .png) ### 批量导出标注问答对
@@ -97,7 +97,7 @@ version: '简体中文'
通过标注批量导出功能,你可以一次性导出系统内已保存的所有标注问答对。
-
### 批量导出标注问答对
@@ -97,7 +97,7 @@ version: '简体中文'
通过标注批量导出功能,你可以一次性导出系统内已保存的所有标注问答对。
- .png) +
+ .png) ### 查看标注回复命中历史
@@ -105,5 +105,5 @@ version: '简体中文'
在标注命中历史功能内,你可以查看所有命中该条标注的编辑历史、命中的用户问题、回复答案、命中来源、匹配相似分数、命中时间等信息,你可以根据这些系统信息持续改进你的标注内容。
-
### 查看标注回复命中历史
@@ -105,5 +105,5 @@ version: '简体中文'
在标注命中历史功能内,你可以查看所有命中该条标注的编辑历史、命中的用户问题、回复答案、命中来源、匹配相似分数、命中时间等信息,你可以根据这些系统信息持续改进你的标注内容。
- .png) +
+ .png) diff --git a/zh-hans/guides/monitoring/logs.mdx b/zh-hans/guides/monitoring/logs.mdx
index 17cec412..6311aac5 100644
--- a/zh-hans/guides/monitoring/logs.mdx
+++ b/zh-hans/guides/monitoring/logs.mdx
@@ -26,7 +26,7 @@ version: '简体中文'
-
diff --git a/zh-hans/guides/monitoring/logs.mdx b/zh-hans/guides/monitoring/logs.mdx
index 17cec412..6311aac5 100644
--- a/zh-hans/guides/monitoring/logs.mdx
+++ b/zh-hans/guides/monitoring/logs.mdx
@@ -26,7 +26,7 @@ version: '简体中文'
-  +
+  点击一条日志会在界面右侧打开日志详情面板,在该面板中运营人员可以对一次互动进行标注:
diff --git a/zh-hans/guides/tools/advanced-tool-integration.mdx b/zh-hans/guides/tools/advanced-tool-integration.mdx
index 30760cd5..a8966814 100644
--- a/zh-hans/guides/tools/advanced-tool-integration.mdx
+++ b/zh-hans/guides/tools/advanced-tool-integration.mdx
@@ -2,7 +2,7 @@
title: 高级接入工具
---
-在开始接入工具之前,请确保你已经阅读过[快速接入](/zh-cn/user-guide/tools/quick-tool-integration),并对 Dify 的工具接入流程有了基本的了解。
+在开始接入工具之前,请确保你已经阅读过[快速接入](/zh-hans/user-guide/tools/quick-tool-integration),并对 Dify 的工具接入流程有了基本的了解。
### 工具接口
diff --git a/zh-hans/guides/tools/community/alphavantage.mdx b/zh-hans/guides/tools/community/alphavantage.mdx
index 9400371d..ef707fd7 100644
--- a/zh-hans/guides/tools/community/alphavantage.mdx
+++ b/zh-hans/guides/tools/community/alphavantage.mdx
@@ -19,7 +19,7 @@ AlphaVantage 一个在线平台,它提供金融市场数据和API,便于个
- **Chatflow / Workflow 应用**
-Chatflow 和 Workflow 应用均支持添加 `AlphaVantage` 工具节点。添加后,需要在节点内的 “输入变量 → 股票代码” 通过[变量](/zh-cn/user-guide/build-app/flow-app/variables)引用用户输入的查询内容。最后在 “结束” 节点内使用变量引用 `AlphaVantage` 节点输出的内容。
+Chatflow 和 Workflow 应用均支持添加 `AlphaVantage` 工具节点。添加后,需要在节点内的 “输入变量 → 股票代码” 通过[变量](/zh-hans/user-guide/build-app/flow-app/variables)引用用户输入的查询内容。最后在 “结束” 节点内使用变量引用 `AlphaVantage` 节点输出的内容。
- **Agent 应用**
diff --git a/zh-hans/guides/tools/community/comfyui.mdx b/zh-hans/guides/tools/community/comfyui.mdx
index 1b642444..24188bc2 100644
--- a/zh-hans/guides/tools/community/comfyui.mdx
+++ b/zh-hans/guides/tools/community/comfyui.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
## 2. 导出工作流的 API 文件。
-
+
如图所示,在工具栏中选择 `Save(API Format)`,如果没有该选择,则需要在设置中开启 `Dev Mode`。
diff --git a/zh-hans/guides/tools/community/searchapi.mdx b/zh-hans/guides/tools/community/searchapi.mdx
index c7d896d5..d8b18372 100644
--- a/zh-hans/guides/tools/community/searchapi.mdx
+++ b/zh-hans/guides/tools/community/searchapi.mdx
@@ -15,7 +15,7 @@ SearchApi 是一个强大的实时 SERP API,可提供来自 Google 搜索、Go
在 Dify 导航页内轻点 `工具 > SearchApi > 去授权` 填写 API Key。
-
+
## 3. 使用工具
@@ -25,7 +25,7 @@ SearchApi 是一个强大的实时 SERP API,可提供来自 Google 搜索、Go
Chatflow 和 Workflow 应用均支持添加 `SearchApi` 系列工具节点,提供 Google Jobs API,Google News API,Google Search API,YouTube 脚本 API 四种工具。
-
+
* **Agent 应用**
diff --git a/zh-hans/guides/tools/community/serper.mdx b/zh-hans/guides/tools/community/serper.mdx
index 4dd16792..1ca083b7 100644
--- a/zh-hans/guides/tools/community/serper.mdx
+++ b/zh-hans/guides/tools/community/serper.mdx
@@ -15,7 +15,7 @@ Serper 是一个强大的实时搜索引擎工具API,可提供来自 Google
在 Dify 导航页内轻点 `工具 > Serper > 去授权` 填写 API Key。
-
+
## 3. 使用工具
diff --git a/zh-hans/guides/tools/community/siliconflow.mdx b/zh-hans/guides/tools/community/siliconflow.mdx
index 6b9f1564..a656bbd2 100644
--- a/zh-hans/guides/tools/community/siliconflow.mdx
+++ b/zh-hans/guides/tools/community/siliconflow.mdx
@@ -16,7 +16,7 @@ SiliconCloud 基于优秀的开源基础模型,提供高性价比的 GenAI 服
在 Dify 的工具页中点击 `SiliconCloud > 去授权` 填写 API Key。
-
点击一条日志会在界面右侧打开日志详情面板,在该面板中运营人员可以对一次互动进行标注:
diff --git a/zh-hans/guides/tools/advanced-tool-integration.mdx b/zh-hans/guides/tools/advanced-tool-integration.mdx
index 30760cd5..a8966814 100644
--- a/zh-hans/guides/tools/advanced-tool-integration.mdx
+++ b/zh-hans/guides/tools/advanced-tool-integration.mdx
@@ -2,7 +2,7 @@
title: 高级接入工具
---
-在开始接入工具之前,请确保你已经阅读过[快速接入](/zh-cn/user-guide/tools/quick-tool-integration),并对 Dify 的工具接入流程有了基本的了解。
+在开始接入工具之前,请确保你已经阅读过[快速接入](/zh-hans/user-guide/tools/quick-tool-integration),并对 Dify 的工具接入流程有了基本的了解。
### 工具接口
diff --git a/zh-hans/guides/tools/community/alphavantage.mdx b/zh-hans/guides/tools/community/alphavantage.mdx
index 9400371d..ef707fd7 100644
--- a/zh-hans/guides/tools/community/alphavantage.mdx
+++ b/zh-hans/guides/tools/community/alphavantage.mdx
@@ -19,7 +19,7 @@ AlphaVantage 一个在线平台,它提供金融市场数据和API,便于个
- **Chatflow / Workflow 应用**
-Chatflow 和 Workflow 应用均支持添加 `AlphaVantage` 工具节点。添加后,需要在节点内的 “输入变量 → 股票代码” 通过[变量](/zh-cn/user-guide/build-app/flow-app/variables)引用用户输入的查询内容。最后在 “结束” 节点内使用变量引用 `AlphaVantage` 节点输出的内容。
+Chatflow 和 Workflow 应用均支持添加 `AlphaVantage` 工具节点。添加后,需要在节点内的 “输入变量 → 股票代码” 通过[变量](/zh-hans/user-guide/build-app/flow-app/variables)引用用户输入的查询内容。最后在 “结束” 节点内使用变量引用 `AlphaVantage` 节点输出的内容。
- **Agent 应用**
diff --git a/zh-hans/guides/tools/community/comfyui.mdx b/zh-hans/guides/tools/community/comfyui.mdx
index 1b642444..24188bc2 100644
--- a/zh-hans/guides/tools/community/comfyui.mdx
+++ b/zh-hans/guides/tools/community/comfyui.mdx
@@ -10,7 +10,7 @@ version: '简体中文'
## 2. 导出工作流的 API 文件。
-
+
如图所示,在工具栏中选择 `Save(API Format)`,如果没有该选择,则需要在设置中开启 `Dev Mode`。
diff --git a/zh-hans/guides/tools/community/searchapi.mdx b/zh-hans/guides/tools/community/searchapi.mdx
index c7d896d5..d8b18372 100644
--- a/zh-hans/guides/tools/community/searchapi.mdx
+++ b/zh-hans/guides/tools/community/searchapi.mdx
@@ -15,7 +15,7 @@ SearchApi 是一个强大的实时 SERP API,可提供来自 Google 搜索、Go
在 Dify 导航页内轻点 `工具 > SearchApi > 去授权` 填写 API Key。
-
+
## 3. 使用工具
@@ -25,7 +25,7 @@ SearchApi 是一个强大的实时 SERP API,可提供来自 Google 搜索、Go
Chatflow 和 Workflow 应用均支持添加 `SearchApi` 系列工具节点,提供 Google Jobs API,Google News API,Google Search API,YouTube 脚本 API 四种工具。
-
+
* **Agent 应用**
diff --git a/zh-hans/guides/tools/community/serper.mdx b/zh-hans/guides/tools/community/serper.mdx
index 4dd16792..1ca083b7 100644
--- a/zh-hans/guides/tools/community/serper.mdx
+++ b/zh-hans/guides/tools/community/serper.mdx
@@ -15,7 +15,7 @@ Serper 是一个强大的实时搜索引擎工具API,可提供来自 Google
在 Dify 导航页内轻点 `工具 > Serper > 去授权` 填写 API Key。
-
+
## 3. 使用工具
diff --git a/zh-hans/guides/tools/community/siliconflow.mdx b/zh-hans/guides/tools/community/siliconflow.mdx
index 6b9f1564..a656bbd2 100644
--- a/zh-hans/guides/tools/community/siliconflow.mdx
+++ b/zh-hans/guides/tools/community/siliconflow.mdx
@@ -16,7 +16,7 @@ SiliconCloud 基于优秀的开源基础模型,提供高性价比的 GenAI 服
在 Dify 的工具页中点击 `SiliconCloud > 去授权` 填写 API Key。
-  +
+  ### 3. 使用工具
@@ -28,7 +28,7 @@ Chatflow 和 Workflow 应用均支持添加 `SiliconFlow` 工具节点。
将用户输入的内容通过[变量](../../workflow/variables)传递至 Siliconflow 工具的 Flux 或 Stable Diffusion 节点内的“提示词”“负面提示词”框中,按照需求调整内置参数,最后在“结束”节点的回复框中选中 Siliconflow 工具节点的输出内容(文本、图片等)。
-
### 3. 使用工具
@@ -28,7 +28,7 @@ Chatflow 和 Workflow 应用均支持添加 `SiliconFlow` 工具节点。
将用户输入的内容通过[变量](../../workflow/variables)传递至 Siliconflow 工具的 Flux 或 Stable Diffusion 节点内的“提示词”“负面提示词”框中,按照需求调整内置参数,最后在“结束”节点的回复框中选中 Siliconflow 工具节点的输出内容(文本、图片等)。
-  +
+  * **Agent 应用**
@@ -36,9 +36,9 @@ Chatflow 和 Workflow 应用均支持添加 `SiliconFlow` 工具节点。
在 Agent 应用内添加 `Stable Diffusion` 或 `Flux` 工具,然后在对话框内发送图片描述,调用工具生成 AI 图像。
-
* **Agent 应用**
@@ -36,9 +36,9 @@ Chatflow 和 Workflow 应用均支持添加 `SiliconFlow` 工具节点。
在 Agent 应用内添加 `Stable Diffusion` 或 `Flux` 工具,然后在对话框内发送图片描述,调用工具生成 AI 图像。
-  +
+  -
-  +
+  diff --git a/zh-hans/guides/tools/dify/bing.mdx b/zh-hans/guides/tools/dify/bing.mdx
index bf7f9737..86782c95 100644
--- a/zh-hans/guides/tools/dify/bing.mdx
+++ b/zh-hans/guides/tools/dify/bing.mdx
@@ -15,7 +15,7 @@ Bing 搜索工具能够帮助你在使用 LLM 应用的时候,获取联网搜
在 Dify 导航页内轻点 `工具 > Azure > 去授权` 填写 API Key。
-
+
## 3. 使用工具
diff --git a/zh-hans/guides/tools/dify/dall-e.mdx b/zh-hans/guides/tools/dify/dall-e.mdx
index b5fd6502..fabef17b 100644
--- a/zh-hans/guides/tools/dify/dall-e.mdx
+++ b/zh-hans/guides/tools/dify/dall-e.mdx
@@ -15,18 +15,18 @@ DALL-E 是由 OpenAI 开发的一种基于文本提示生成图像的工具。Di
在 Dify 导航页内轻点 `工具 > DALL-E > 去授权` 填写 API Key。
-
+
## 3. 使用工具
* **Chatflow / Workflow 应用**
-Chatflow 和 Workflow 应用均支持添加 `DALL-E 绘图` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-cn/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `DALL-E 绘图` 输出的图像。
+Chatflow 和 Workflow 应用均支持添加 `DALL-E 绘图` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-hans/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `DALL-E 绘图` 输出的图像。
-
+
* **Agent 应用**
在 Agent 应用内添加 `DALL-E` 工具,然后在对话框内发送图片描述,调用工具生成 AI 图像。
-
+
diff --git a/zh-hans/guides/tools/dify/google.mdx b/zh-hans/guides/tools/dify/google.mdx
index d82da634..d2489ab8 100644
--- a/zh-hans/guides/tools/dify/google.mdx
+++ b/zh-hans/guides/tools/dify/google.mdx
@@ -15,7 +15,7 @@ Google 搜索工具能够帮助你在使用 LLM 应用的时候,获取联网
在 Dify 导航页内轻点 `工具 > Google > 去授权` 填写 API Key。
-
+
## 3. 使用工具
diff --git a/zh-hans/guides/tools/dify/perplexity.mdx b/zh-hans/guides/tools/dify/perplexity.mdx
index de985210..f9a5e94f 100644
--- a/zh-hans/guides/tools/dify/perplexity.mdx
+++ b/zh-hans/guides/tools/dify/perplexity.mdx
@@ -15,7 +15,7 @@ Perplexity 是一个基于 AI 的搜索引擎,能够理解复杂的查询并
在 Dify 导航页内轻点 `工具 > Perplexity > 去授权` 填写 API Key。
-
+
## 3. 使用工具
@@ -25,10 +25,10 @@ Perplexity 是一个基于 AI 的搜索引擎,能够理解复杂的查询并
Chatflow 和 Workflow 应用均支持添加 Perplexity 工具节点。将用户输入的内容通过变量传递至 Perplexity 工具节点内的“查询”框中,按照需求调整 Perplexity 工具的内置参数,最后在“结束”节点的回复框中选中 Perplexity 工具节点的输出内容。
-
+
* **Agent 应用**
在 Agent 应用内添加 `Perplexity Search` 工具,然后输入相关指令即可调用此工具。
-
+
diff --git a/zh-hans/guides/tools/dify/stable-diffusion.mdx b/zh-hans/guides/tools/dify/stable-diffusion.mdx
index d9169761..077b4e51 100644
--- a/zh-hans/guides/tools/dify/stable-diffusion.mdx
+++ b/zh-hans/guides/tools/dify/stable-diffusion.mdx
@@ -73,7 +73,7 @@ git clone https://huggingface.co/JamesFlare/pastel-mix
- **Chatflow / Workflow 应用**
-Chatflow 和 Workflow 应用均支持添加 `Stable Diffusion` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-cn/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `Stable Diffusion` 输出的图像。
+Chatflow 和 Workflow 应用均支持添加 `Stable Diffusion` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-hans/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `Stable Diffusion` 输出的图像。
- **Agent 应用**
diff --git a/zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx b/zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx
index 0bc4b4b6..3e96cc63 100644
--- a/zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx
+++ b/zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx
@@ -263,10 +263,10 @@ API 返回为:
* 按照上述的范例,我们把本地已经启动的服务端点暴露出去,将代码范例接口:`http://127.0.0.1:8000/api/dify/receive` 替换为 `https://177e-159-223-41-52.ngrok-free.app/api/dify/receive`
-此 API 端点即可公网访问。至此,我们即可在 Dify 配置该 API 端点进行本地调试代码,配置步骤请参考 [外部数据工具](../../knowledge-base/external-data-tool.md "mention")。
+此 API 端点即可公网访问。至此,我们即可在 Dify 配置该 API 端点进行本地调试代码,配置步骤请参考 [外部数据工具](./external-data-tool)。
### 使用 Cloudflare Workers 部署 API 扩展
我们推荐你使用 Cloudflare Workers 来部署你的 API 扩展,因为 Cloudflare Workers 可以方便的提供一个公网地址,而且可以免费使用。
-详细说明请参考 [使用 Cloudflare Workers 部署 API Tools](/zh-cn/user-guide/tools/extensions/api-based/cloudflare-workers)。
+详细说明请参考 [使用 Cloudflare Workers 部署 API Tools](/zh-hans/user-guide/tools/extensions/api-based/cloudflare-workers)。
diff --git a/zh-hans/guides/tools/extensions/api-based/external-data-tool.mdx b/zh-hans/guides/tools/extensions/api-based/external-data-tool.mdx
index 23f28c4a..cc3aa583 100644
--- a/zh-hans/guides/tools/extensions/api-based/external-data-tool.mdx
+++ b/zh-hans/guides/tools/extensions/api-based/external-data-tool.mdx
@@ -3,11 +3,11 @@ title: 外部数据工具
version: '简体中文'
---
-在创建 AI 应用时,开发者可以通过 API 扩展的方式实现使用外部工具获取额外数据组装至 Prompt 中作为 LLM 额外信息。具体的实操过程可以参考 [API 扩展](/zh-cn/user-guide/tools/extensions/api-based/api-based-extension)。
+在创建 AI 应用时,开发者可以通过 API 扩展的方式实现使用外部工具获取额外数据组装至 Prompt 中作为 LLM 额外信息。具体的实操过程可以参考 [API 扩展](/zh-hans/user-guide/tools/extensions/api-based/api-based-extension)。
### 前置条件
-请先阅读 [API 扩展](/zh-cn/user-guide/tools/extensions/api-based/api-based-extension) 完成 API 服务基础能力的开发和接入。
+请先阅读 [API 扩展](/zh-hans/user-guide/tools/extensions/api-based/api-based-extension) 完成 API 服务基础能力的开发和接入。
### 扩展点
diff --git a/zh-hans/guides/tools/extensions/code-based/moderation.mdx b/zh-hans/guides/tools/extensions/code-based/moderation.mdx
index 76a4e815..da5f71d4 100644
--- a/zh-hans/guides/tools/extensions/code-based/moderation.mdx
+++ b/zh-hans/guides/tools/extensions/code-based/moderation.mdx
@@ -1,6 +1,5 @@
---
title: 敏感内容审查
-version: '简体中文'
---
除了系统内置的内容审查类型,Dify 也支持用户扩展自定义的内容审查规则,该方法适用于私有部署的开发者定制开发。比如企业内部客服,规定用户在查询的时候以及客服回复的时候,除了不可以输入暴力,性和非法行为等相关词语,也不能出现企业自己规定的禁词或违反内部制定的审查逻辑,那么开发者可以在私有部署的 Dify 代码层扩展自定义内容审查规则。
@@ -32,7 +31,7 @@ version: '简体中文'
### 2.添加前端组件规范
-* `schema.json`,这里定义了前端组件规范,详细见 [Broken link](broken-reference "mention") 。
+* `schema.json`,这里定义了前端组件规范,详细见 [Broken link](/zh-hans/guides/extension/code-based-extension) 。
```json
{
diff --git a/zh-hans/guides/tools/introduction.mdx b/zh-hans/guides/tools/introduction.mdx
index e1d02256..04d06cad 100644
--- a/zh-hans/guides/tools/introduction.mdx
+++ b/zh-hans/guides/tools/introduction.mdx
@@ -17,7 +17,7 @@ version: '简体中文'
### 如何配置第一方工具
-
diff --git a/zh-hans/guides/tools/dify/bing.mdx b/zh-hans/guides/tools/dify/bing.mdx
index bf7f9737..86782c95 100644
--- a/zh-hans/guides/tools/dify/bing.mdx
+++ b/zh-hans/guides/tools/dify/bing.mdx
@@ -15,7 +15,7 @@ Bing 搜索工具能够帮助你在使用 LLM 应用的时候,获取联网搜
在 Dify 导航页内轻点 `工具 > Azure > 去授权` 填写 API Key。
-
+
## 3. 使用工具
diff --git a/zh-hans/guides/tools/dify/dall-e.mdx b/zh-hans/guides/tools/dify/dall-e.mdx
index b5fd6502..fabef17b 100644
--- a/zh-hans/guides/tools/dify/dall-e.mdx
+++ b/zh-hans/guides/tools/dify/dall-e.mdx
@@ -15,18 +15,18 @@ DALL-E 是由 OpenAI 开发的一种基于文本提示生成图像的工具。Di
在 Dify 导航页内轻点 `工具 > DALL-E > 去授权` 填写 API Key。
-
+
## 3. 使用工具
* **Chatflow / Workflow 应用**
-Chatflow 和 Workflow 应用均支持添加 `DALL-E 绘图` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-cn/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `DALL-E 绘图` 输出的图像。
+Chatflow 和 Workflow 应用均支持添加 `DALL-E 绘图` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-hans/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `DALL-E 绘图` 输出的图像。
-
+
* **Agent 应用**
在 Agent 应用内添加 `DALL-E` 工具,然后在对话框内发送图片描述,调用工具生成 AI 图像。
-
+
diff --git a/zh-hans/guides/tools/dify/google.mdx b/zh-hans/guides/tools/dify/google.mdx
index d82da634..d2489ab8 100644
--- a/zh-hans/guides/tools/dify/google.mdx
+++ b/zh-hans/guides/tools/dify/google.mdx
@@ -15,7 +15,7 @@ Google 搜索工具能够帮助你在使用 LLM 应用的时候,获取联网
在 Dify 导航页内轻点 `工具 > Google > 去授权` 填写 API Key。
-
+
## 3. 使用工具
diff --git a/zh-hans/guides/tools/dify/perplexity.mdx b/zh-hans/guides/tools/dify/perplexity.mdx
index de985210..f9a5e94f 100644
--- a/zh-hans/guides/tools/dify/perplexity.mdx
+++ b/zh-hans/guides/tools/dify/perplexity.mdx
@@ -15,7 +15,7 @@ Perplexity 是一个基于 AI 的搜索引擎,能够理解复杂的查询并
在 Dify 导航页内轻点 `工具 > Perplexity > 去授权` 填写 API Key。
-
+
## 3. 使用工具
@@ -25,10 +25,10 @@ Perplexity 是一个基于 AI 的搜索引擎,能够理解复杂的查询并
Chatflow 和 Workflow 应用均支持添加 Perplexity 工具节点。将用户输入的内容通过变量传递至 Perplexity 工具节点内的“查询”框中,按照需求调整 Perplexity 工具的内置参数,最后在“结束”节点的回复框中选中 Perplexity 工具节点的输出内容。
-
+
* **Agent 应用**
在 Agent 应用内添加 `Perplexity Search` 工具,然后输入相关指令即可调用此工具。
-
+
diff --git a/zh-hans/guides/tools/dify/stable-diffusion.mdx b/zh-hans/guides/tools/dify/stable-diffusion.mdx
index d9169761..077b4e51 100644
--- a/zh-hans/guides/tools/dify/stable-diffusion.mdx
+++ b/zh-hans/guides/tools/dify/stable-diffusion.mdx
@@ -73,7 +73,7 @@ git clone https://huggingface.co/JamesFlare/pastel-mix
- **Chatflow / Workflow 应用**
-Chatflow 和 Workflow 应用均支持添加 `Stable Diffusion` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-cn/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `Stable Diffusion` 输出的图像。
+Chatflow 和 Workflow 应用均支持添加 `Stable Diffusion` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-hans/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `Stable Diffusion` 输出的图像。
- **Agent 应用**
diff --git a/zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx b/zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx
index 0bc4b4b6..3e96cc63 100644
--- a/zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx
+++ b/zh-hans/guides/tools/extensions/api-based/api-based-extension.mdx
@@ -263,10 +263,10 @@ API 返回为:
* 按照上述的范例,我们把本地已经启动的服务端点暴露出去,将代码范例接口:`http://127.0.0.1:8000/api/dify/receive` 替换为 `https://177e-159-223-41-52.ngrok-free.app/api/dify/receive`
-此 API 端点即可公网访问。至此,我们即可在 Dify 配置该 API 端点进行本地调试代码,配置步骤请参考 [外部数据工具](../../knowledge-base/external-data-tool.md "mention")。
+此 API 端点即可公网访问。至此,我们即可在 Dify 配置该 API 端点进行本地调试代码,配置步骤请参考 [外部数据工具](./external-data-tool)。
### 使用 Cloudflare Workers 部署 API 扩展
我们推荐你使用 Cloudflare Workers 来部署你的 API 扩展,因为 Cloudflare Workers 可以方便的提供一个公网地址,而且可以免费使用。
-详细说明请参考 [使用 Cloudflare Workers 部署 API Tools](/zh-cn/user-guide/tools/extensions/api-based/cloudflare-workers)。
+详细说明请参考 [使用 Cloudflare Workers 部署 API Tools](/zh-hans/user-guide/tools/extensions/api-based/cloudflare-workers)。
diff --git a/zh-hans/guides/tools/extensions/api-based/external-data-tool.mdx b/zh-hans/guides/tools/extensions/api-based/external-data-tool.mdx
index 23f28c4a..cc3aa583 100644
--- a/zh-hans/guides/tools/extensions/api-based/external-data-tool.mdx
+++ b/zh-hans/guides/tools/extensions/api-based/external-data-tool.mdx
@@ -3,11 +3,11 @@ title: 外部数据工具
version: '简体中文'
---
-在创建 AI 应用时,开发者可以通过 API 扩展的方式实现使用外部工具获取额外数据组装至 Prompt 中作为 LLM 额外信息。具体的实操过程可以参考 [API 扩展](/zh-cn/user-guide/tools/extensions/api-based/api-based-extension)。
+在创建 AI 应用时,开发者可以通过 API 扩展的方式实现使用外部工具获取额外数据组装至 Prompt 中作为 LLM 额外信息。具体的实操过程可以参考 [API 扩展](/zh-hans/user-guide/tools/extensions/api-based/api-based-extension)。
### 前置条件
-请先阅读 [API 扩展](/zh-cn/user-guide/tools/extensions/api-based/api-based-extension) 完成 API 服务基础能力的开发和接入。
+请先阅读 [API 扩展](/zh-hans/user-guide/tools/extensions/api-based/api-based-extension) 完成 API 服务基础能力的开发和接入。
### 扩展点
diff --git a/zh-hans/guides/tools/extensions/code-based/moderation.mdx b/zh-hans/guides/tools/extensions/code-based/moderation.mdx
index 76a4e815..da5f71d4 100644
--- a/zh-hans/guides/tools/extensions/code-based/moderation.mdx
+++ b/zh-hans/guides/tools/extensions/code-based/moderation.mdx
@@ -1,6 +1,5 @@
---
title: 敏感内容审查
-version: '简体中文'
---
除了系统内置的内容审查类型,Dify 也支持用户扩展自定义的内容审查规则,该方法适用于私有部署的开发者定制开发。比如企业内部客服,规定用户在查询的时候以及客服回复的时候,除了不可以输入暴力,性和非法行为等相关词语,也不能出现企业自己规定的禁词或违反内部制定的审查逻辑,那么开发者可以在私有部署的 Dify 代码层扩展自定义内容审查规则。
@@ -32,7 +31,7 @@ version: '简体中文'
### 2.添加前端组件规范
-* `schema.json`,这里定义了前端组件规范,详细见 [Broken link](broken-reference "mention") 。
+* `schema.json`,这里定义了前端组件规范,详细见 [Broken link](/zh-hans/guides/extension/code-based-extension) 。
```json
{
diff --git a/zh-hans/guides/tools/introduction.mdx b/zh-hans/guides/tools/introduction.mdx
index e1d02256..04d06cad 100644
--- a/zh-hans/guides/tools/introduction.mdx
+++ b/zh-hans/guides/tools/introduction.mdx
@@ -17,7 +17,7 @@ version: '简体中文'
### 如何配置第一方工具
- .png) +
+ .png) Dify 目前已支持:
@@ -25,7 +25,7 @@ Dify 目前已支持:
Dify 目前已支持:
@@ -25,7 +25,7 @@ Dify 目前已支持:
| 工具 | 工具描述 |
|---|---|
| 谷歌搜索 | 用于执行 Google SERP 搜索并提取片段和网页的工具,输入应该是一个搜索查询 |
| 维基百科 | 用于执行维基百科搜索并提取片段和网页的工具 |
| DALL-E 绘画 | 用于通过自然语言输入生成高质量图片 |
| 网页抓取 | 用于爬取网页数据的工具 |
| WolframAlpha | 一个强大的计算知识引擎,能根据问题直接给出标准化答案,同时具有强大的数学计算功能 |
| 图表生成 | 用于生成可视化图表的工具,你可以通过它来生成柱状图、折线图、饼图等各类图表 |
| 当前时间 | 用于查询当前时间的工具 |
| 雅虎财经 | 获取并整理出最新的新闻、股票报价等一切你想要的财经信息 |
| Stable Diffusion | 一个可以在本地部署的图片生成的工具,您可以使用 stable-diffusion-webui 来部署它 |
| Vectorizer | 一个将 PNG 和 JPG 图像快速轻松地转换为 SVG 矢量图的工具 |
| YouTube | 一个用于获取油管频道视频统计数据的工具 |
.png) +
+ .png) 凭据校验成功后工具会显示"已授权"状态。配置凭据后,工作区中的所有成员都可以在编排应用程序时使用此工具。
-
凭据校验成功后工具会显示"已授权"状态。配置凭据后,工作区中的所有成员都可以在编排应用程序时使用此工具。
- .png) +
+ .png) ### 如何创建自定义工具
@@ -50,19 +50,19 @@ Dify 目前已支持:
工具目前支持两种鉴权方式:无鉴权 和 API Key。
-
### 如何创建自定义工具
@@ -50,19 +50,19 @@ Dify 目前已支持:
工具目前支持两种鉴权方式:无鉴权 和 API Key。
- .png) +
+ .png) 在导入 Schema 内容后系统会主动解析文件内的参数,并可预览工具具体的参数、 方法、路径。您也可以在此对工具参数进行测试。
-
在导入 Schema 内容后系统会主动解析文件内的参数,并可预览工具具体的参数、 方法、路径。您也可以在此对工具参数进行测试。
- .png) +
+ .png) 完成自定义工具创建之后,工作区中的所有成员都可以在"工作室"内编排应用程序时使用此工具。
-
完成自定义工具创建之后,工作区中的所有成员都可以在"工作室"内编排应用程序时使用此工具。
- .png) +
+ .png) #### Cloudflare Workers
@@ -77,11 +77,11 @@ Dify 目前已支持:
目前,您可以在"工作室"中创建**智能助手型应用**时,将已配置好凭据的工具在其中使用。
-
#### Cloudflare Workers
@@ -77,11 +77,11 @@ Dify 目前已支持:
目前,您可以在"工作室"中创建**智能助手型应用**时,将已配置好凭据的工具在其中使用。
- .png) +
+ .png) 以下图为例,在财务分析应用内添加工具后,智能助手将在需要时自主调用工具,从工具中查询财务报告数据,并将数据分析后完成与用户之间的对话。
-
以下图为例,在财务分析应用内添加工具后,智能助手将在需要时自主调用工具,从工具中查询财务报告数据,并将数据分析后完成与用户之间的对话。
- .png) +
+ .png) diff --git a/zh-hans/guides/tools/readme.mdx b/zh-hans/guides/tools/readme.mdx
index 6c316d31..3c3a798f 100644
--- a/zh-hans/guides/tools/readme.mdx
+++ b/zh-hans/guides/tools/readme.mdx
@@ -44,7 +44,7 @@ Dify 目前已支持:
| YouTube | 一个用于获取油管频道视频统计数据的工具 |
+
### 3. 使用工具
@@ -28,7 +28,7 @@ Chatflow 和 Workflow 应用均支持添加 `SiliconFlow` 工具节点。
将用户输入的内容通过[变量](../../workflow/variables)传递至 Siliconflow 工具的 Flux 或 Stable Diffusion 节点内的“提示词”“负面提示词”框中,按照需求调整内置参数,最后在“结束”节点的回复框中选中 Siliconflow 工具节点的输出内容(文本、图片等)。
-
+
* **Agent 应用**
@@ -36,9 +36,9 @@ Chatflow 和 Workflow 应用均支持添加 `SiliconFlow` 工具节点。
在 Agent 应用内添加 `Stable Diffusion` 或 `Flux` 工具,然后在对话框内发送图片描述,调用工具生成 AI 图像。
-
+
-
+
diff --git a/zh-hans/guides/tools/tool-configuration/stable-diffusion.mdx b/zh-hans/guides/tools/tool-configuration/stable-diffusion.mdx
index d9169761..077b4e51 100644
--- a/zh-hans/guides/tools/tool-configuration/stable-diffusion.mdx
+++ b/zh-hans/guides/tools/tool-configuration/stable-diffusion.mdx
@@ -73,7 +73,7 @@ git clone https://huggingface.co/JamesFlare/pastel-mix
- **Chatflow / Workflow 应用**
-Chatflow 和 Workflow 应用均支持添加 `Stable Diffusion` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-cn/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `Stable Diffusion` 输出的图像。
+Chatflow 和 Workflow 应用均支持添加 `Stable Diffusion` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-hans/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `Stable Diffusion` 输出的图像。
- **Agent 应用**
diff --git a/zh-hans/guides/workflow/additional-feature.mdx b/zh-hans/guides/workflow/additional-feature.mdx
index 41c3e20a..a6b548f7 100644
--- a/zh-hans/guides/workflow/additional-feature.mdx
+++ b/zh-hans/guides/workflow/additional-feature.mdx
@@ -1,6 +1,5 @@
---
title: 附加功能
-version: '简体中文'
---
Workflow 和 Chatflow 应用均支持开启附加功能以增强使用者的交互体验。例如添加文件上传入口、给 LLM 应用添加一段自我介绍或使用欢迎语,让应用使用者获得更加丰富的交互体验。
@@ -96,7 +95,7 @@ LLM 并不具备直接读取文档文件的能力,因此需要使用 [文档
3. 添加 LLM 节点,在系统提示词中选中文档提取器节点的输出变量。
4. 在末尾添加 "直接回复" 节点,填写 LLM 节点的输出变量。
-使用此方法搭建出的 Chatflow 应用无法记忆已上传的文件内容。应用使用者每次对话时都需要在聊天框中上传文档文件。如果你希望应用能够记忆已上传的文件,请参考 [《文件上传:在开始节点添加变量》](file-upload.md#fang-fa-er-zai-tian-jia-wen-jian-bian-liang)。
+使用此方法搭建出的 Chatflow 应用无法记忆已上传的文件内容。应用使用者每次对话时都需要在聊天框中上传文档文件。如果你希望应用能够记忆已上传的文件,请参考 [《文件上传:在开始节点添加变量》](file-upload#fang-fa-er-zai-tian-jia-wen-jian-bian-liang)。
diff --git a/zh-hans/guides/workflow/bulletin.mdx b/zh-hans/guides/workflow/bulletin.mdx
index 4b070c8c..dcab5787 100644
--- a/zh-hans/guides/workflow/bulletin.mdx
+++ b/zh-hans/guides/workflow/bulletin.mdx
@@ -4,7 +4,7 @@ description: 作者:Evanchen,Allen。
---
-图片上传功能已被纳入至更加综合的[文件上传](file-upload)功能中,为了避免出现功能重复,我们决定对 Workflow 和 Chatflow 应用的“[附加功能](additional-features)”进行升级和调整:
+图片上传功能已被纳入至更加综合的[文件上传](file-upload)功能中,为了避免出现功能重复,我们决定对 Workflow 和 Chatflow 应用的“[附加功能](./additional-feature)”进行升级和调整:
* 移除 Chatflow 应用“功能”中的图片上传选项,取而代之的是新的“文件上传”功能。你可以在“文件上传”功能内选择图片文件类型。同时,应用对话框中的图片上传 icon 也被替换为文件上传 icon。
@@ -41,7 +41,7 @@ Dify 此前仅支持上传图片文件。而在最新的版本中,已提供更
-如果你希望在 Chatflow 应用中添加“图片上传”功能,请在功能中开启“文件上传”,仅勾选“图片”类型。然后在 LLM 节点中启用 Vision 功能,并在其中填写 `sys.files` 变量。此时输入框将出现“回形针”的上传入口,详细说明请参考 [附加功能](additional-features)。
+如果你希望在 Chatflow 应用中添加“图片上传”功能,请在功能中开启“文件上传”,仅勾选“图片”类型。然后在 LLM 节点中启用 Vision 功能,并在其中填写 `sys.files` 变量。此时输入框将出现“回形针”的上传入口,详细说明请参考 [附加功能](./additional-feature)。
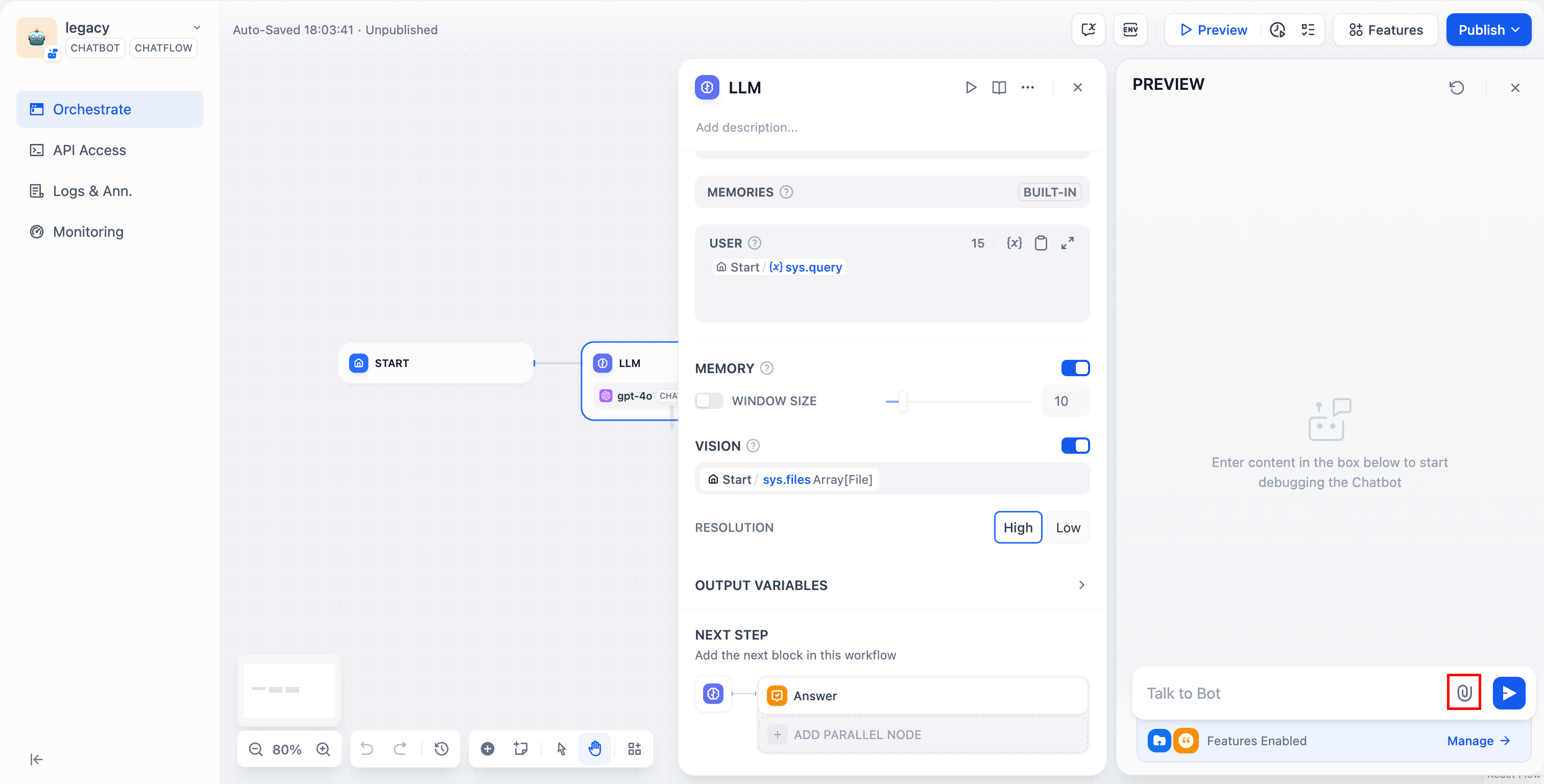
@@ -59,7 +59,7 @@ Dify 此前仅支持上传图片文件。而在最新的版本中,已提供更
已启用“图片上传”功能的 Chatflow 应用将自动完成切换,无需变更。
-如果你希望在 Chatflow 应用中添加“图片上传”功能,详细说明请参考[附加功能](additional-features)。
+如果你希望在 Chatflow 应用中添加“图片上传”功能,详细说明请参考[附加功能](./additional-feature)。
* Workflow 应用
diff --git a/zh-hans/guides/workflow/create-flow-app.mdx b/zh-hans/guides/workflow/create-flow-app.mdx
index db3db99d..6b65a68d 100644
--- a/zh-hans/guides/workflow/create-flow-app.mdx
+++ b/zh-hans/guides/workflow/create-flow-app.mdx
@@ -1,6 +1,5 @@
---
title: 创建应用
-version: '简体中文'
---
## Chatflow
@@ -13,7 +12,7 @@ version: '简体中文'
在 "工作室" 页,轻点左侧 “创建空白应用”,然后选择 “聊天助手” 中的 “工作流编排”。
-
+
## Workflow
@@ -25,7 +24,7 @@ version: '简体中文'
在 "工作室" 页,轻点左侧 “创建空白应用”,然后选择 “工作流” 完成创建。
-
+
## 两者之间的差异
diff --git a/zh-hans/guides/workflow/file-upload.mdx b/zh-hans/guides/workflow/file-upload.mdx
index 449843d0..78be85d4 100644
--- a/zh-hans/guides/workflow/file-upload.mdx
+++ b/zh-hans/guides/workflow/file-upload.mdx
@@ -35,13 +35,13 @@ title: 文件上传
### 快速开始
-Dify 支持在 [ChatFlow](/zh-hans/guides/workflow/concepts#chatflow-和-workflow) 和 [WorkFlow](/zh-hans/guides/workflow/concepts#chatflow-和-workflow) 类型应用中上传文件,并通过[变量](/zh-hans/guides/workflow/variables)交由 LLM 处理。应用开发者可以参考以下方法为应用开启文件上传功能:
+Dify 支持在 [ChatFlow](/zh-hans/guides/workflow/key-concepts#chatflow-和-workflow) 和 [WorkFlow](/zh-hans/guides/workflow/concepts#chatflow-和-workflow) 类型应用中上传文件,并通过[变量](/zh-hans/guides/workflow/variables)交由 LLM 处理。应用开发者可以参考以下方法为应用开启文件上传功能:
* 在 Workflow 应用中:
- * 在 ["开始节点"](/zh-hans/guides/workflow/nodes/start) 添加文件变量
+ * 在 ["开始节点"](/zh-hans/guides/workflow/node/start) 添加文件变量
* 在 ChatFlow 应用中:
* 在 ["附加功能"](/zh-hans/guides/workflow/additional-feature) 中开启文件上传,允许在聊天窗中直接上传文件
- * 在 ["开始节点"](/zh-hans/guides/workflow/nodes/start) 添加文件变量
+ * 在 ["开始节点"](/zh-hans/guides/workflow/node/start) 添加文件变量
* 注意:这两种方法可以同时配置,它们是彼此独立的。附加功能中的文件上传设置(包括上传方式和数量限制)不会影响开始节点中的文件变量。例如只想通过开始节点创建文件变量,则无需开启附加功能中的文件上传功能。
这两种方法为应用提供了灵活的文件上传选项,以满足不同场景的需求。
@@ -84,12 +84,12 @@ file variables 和 array[file] variables 支持以下文件类型与格式:
diff --git a/zh-hans/guides/tools/readme.mdx b/zh-hans/guides/tools/readme.mdx
index 6c316d31..3c3a798f 100644
--- a/zh-hans/guides/tools/readme.mdx
+++ b/zh-hans/guides/tools/readme.mdx
@@ -44,7 +44,7 @@ Dify 目前已支持:
| YouTube | 一个用于获取油管频道视频统计数据的工具 |
+
### 3. 使用工具
@@ -28,7 +28,7 @@ Chatflow 和 Workflow 应用均支持添加 `SiliconFlow` 工具节点。
将用户输入的内容通过[变量](../../workflow/variables)传递至 Siliconflow 工具的 Flux 或 Stable Diffusion 节点内的“提示词”“负面提示词”框中,按照需求调整内置参数,最后在“结束”节点的回复框中选中 Siliconflow 工具节点的输出内容(文本、图片等)。
-
+
* **Agent 应用**
@@ -36,9 +36,9 @@ Chatflow 和 Workflow 应用均支持添加 `SiliconFlow` 工具节点。
在 Agent 应用内添加 `Stable Diffusion` 或 `Flux` 工具,然后在对话框内发送图片描述,调用工具生成 AI 图像。
-
+
-
+
diff --git a/zh-hans/guides/tools/tool-configuration/stable-diffusion.mdx b/zh-hans/guides/tools/tool-configuration/stable-diffusion.mdx
index d9169761..077b4e51 100644
--- a/zh-hans/guides/tools/tool-configuration/stable-diffusion.mdx
+++ b/zh-hans/guides/tools/tool-configuration/stable-diffusion.mdx
@@ -73,7 +73,7 @@ git clone https://huggingface.co/JamesFlare/pastel-mix
- **Chatflow / Workflow 应用**
-Chatflow 和 Workflow 应用均支持添加 `Stable Diffusion` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-cn/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `Stable Diffusion` 输出的图像。
+Chatflow 和 Workflow 应用均支持添加 `Stable Diffusion` 工具节点。添加后,需要在节点内的 “输入变量 → 提示词” 内填写[变量](/zh-hans/user-guide/build-app/flow-app/variables)引用用户输入的提示词,或者是上一节点生成的内容。最后在 “结束” 节点内使用变量引用 `Stable Diffusion` 输出的图像。
- **Agent 应用**
diff --git a/zh-hans/guides/workflow/additional-feature.mdx b/zh-hans/guides/workflow/additional-feature.mdx
index 41c3e20a..a6b548f7 100644
--- a/zh-hans/guides/workflow/additional-feature.mdx
+++ b/zh-hans/guides/workflow/additional-feature.mdx
@@ -1,6 +1,5 @@
---
title: 附加功能
-version: '简体中文'
---
Workflow 和 Chatflow 应用均支持开启附加功能以增强使用者的交互体验。例如添加文件上传入口、给 LLM 应用添加一段自我介绍或使用欢迎语,让应用使用者获得更加丰富的交互体验。
@@ -96,7 +95,7 @@ LLM 并不具备直接读取文档文件的能力,因此需要使用 [文档
3. 添加 LLM 节点,在系统提示词中选中文档提取器节点的输出变量。
4. 在末尾添加 "直接回复" 节点,填写 LLM 节点的输出变量。
-使用此方法搭建出的 Chatflow 应用无法记忆已上传的文件内容。应用使用者每次对话时都需要在聊天框中上传文档文件。如果你希望应用能够记忆已上传的文件,请参考 [《文件上传:在开始节点添加变量》](file-upload.md#fang-fa-er-zai-tian-jia-wen-jian-bian-liang)。
+使用此方法搭建出的 Chatflow 应用无法记忆已上传的文件内容。应用使用者每次对话时都需要在聊天框中上传文档文件。如果你希望应用能够记忆已上传的文件,请参考 [《文件上传:在开始节点添加变量》](file-upload#fang-fa-er-zai-tian-jia-wen-jian-bian-liang)。

diff --git a/zh-hans/guides/workflow/bulletin.mdx b/zh-hans/guides/workflow/bulletin.mdx
index 4b070c8c..dcab5787 100644
--- a/zh-hans/guides/workflow/bulletin.mdx
+++ b/zh-hans/guides/workflow/bulletin.mdx
@@ -4,7 +4,7 @@ description: 作者:Evanchen,Allen。
---
-图片上传功能已被纳入至更加综合的[文件上传](file-upload)功能中,为了避免出现功能重复,我们决定对 Workflow 和 Chatflow 应用的“[附加功能](additional-features)”进行升级和调整:
+图片上传功能已被纳入至更加综合的[文件上传](file-upload)功能中,为了避免出现功能重复,我们决定对 Workflow 和 Chatflow 应用的“[附加功能](./additional-feature)”进行升级和调整:
* 移除 Chatflow 应用“功能”中的图片上传选项,取而代之的是新的“文件上传”功能。你可以在“文件上传”功能内选择图片文件类型。同时,应用对话框中的图片上传 icon 也被替换为文件上传 icon。
@@ -41,7 +41,7 @@ Dify 此前仅支持上传图片文件。而在最新的版本中,已提供更

-如果你希望在 Chatflow 应用中添加“图片上传”功能,请在功能中开启“文件上传”,仅勾选“图片”类型。然后在 LLM 节点中启用 Vision 功能,并在其中填写 `sys.files` 变量。此时输入框将出现“回形针”的上传入口,详细说明请参考 [附加功能](additional-features)。
+如果你希望在 Chatflow 应用中添加“图片上传”功能,请在功能中开启“文件上传”,仅勾选“图片”类型。然后在 LLM 节点中启用 Vision 功能,并在其中填写 `sys.files` 变量。此时输入框将出现“回形针”的上传入口,详细说明请参考 [附加功能](./additional-feature)。

@@ -59,7 +59,7 @@ Dify 此前仅支持上传图片文件。而在最新的版本中,已提供更
已启用“图片上传”功能的 Chatflow 应用将自动完成切换,无需变更。
-如果你希望在 Chatflow 应用中添加“图片上传”功能,详细说明请参考[附加功能](additional-features)。
+如果你希望在 Chatflow 应用中添加“图片上传”功能,详细说明请参考[附加功能](./additional-feature)。
* Workflow 应用
diff --git a/zh-hans/guides/workflow/create-flow-app.mdx b/zh-hans/guides/workflow/create-flow-app.mdx
index db3db99d..6b65a68d 100644
--- a/zh-hans/guides/workflow/create-flow-app.mdx
+++ b/zh-hans/guides/workflow/create-flow-app.mdx
@@ -1,6 +1,5 @@
---
title: 创建应用
-version: '简体中文'
---
## Chatflow
@@ -13,7 +12,7 @@ version: '简体中文'
在 "工作室" 页,轻点左侧 “创建空白应用”,然后选择 “聊天助手” 中的 “工作流编排”。
-
+
## Workflow
@@ -25,7 +24,7 @@ version: '简体中文'
在 "工作室" 页,轻点左侧 “创建空白应用”,然后选择 “工作流” 完成创建。
-
+
## 两者之间的差异
diff --git a/zh-hans/guides/workflow/file-upload.mdx b/zh-hans/guides/workflow/file-upload.mdx
index 449843d0..78be85d4 100644
--- a/zh-hans/guides/workflow/file-upload.mdx
+++ b/zh-hans/guides/workflow/file-upload.mdx
@@ -35,13 +35,13 @@ title: 文件上传
### 快速开始
-Dify 支持在 [ChatFlow](/zh-hans/guides/workflow/concepts#chatflow-和-workflow) 和 [WorkFlow](/zh-hans/guides/workflow/concepts#chatflow-和-workflow) 类型应用中上传文件,并通过[变量](/zh-hans/guides/workflow/variables)交由 LLM 处理。应用开发者可以参考以下方法为应用开启文件上传功能:
+Dify 支持在 [ChatFlow](/zh-hans/guides/workflow/key-concepts#chatflow-和-workflow) 和 [WorkFlow](/zh-hans/guides/workflow/concepts#chatflow-和-workflow) 类型应用中上传文件,并通过[变量](/zh-hans/guides/workflow/variables)交由 LLM 处理。应用开发者可以参考以下方法为应用开启文件上传功能:
* 在 Workflow 应用中:
- * 在 ["开始节点"](/zh-hans/guides/workflow/nodes/start) 添加文件变量
+ * 在 ["开始节点"](/zh-hans/guides/workflow/node/start) 添加文件变量
* 在 ChatFlow 应用中:
* 在 ["附加功能"](/zh-hans/guides/workflow/additional-feature) 中开启文件上传,允许在聊天窗中直接上传文件
- * 在 ["开始节点"](/zh-hans/guides/workflow/nodes/start) 添加文件变量
+ * 在 ["开始节点"](/zh-hans/guides/workflow/node/start) 添加文件变量
* 注意:这两种方法可以同时配置,它们是彼此独立的。附加功能中的文件上传设置(包括上传方式和数量限制)不会影响开始节点中的文件变量。例如只想通过开始节点创建文件变量,则无需开启附加功能中的文件上传功能。
这两种方法为应用提供了灵活的文件上传选项,以满足不同场景的需求。
@@ -84,12 +84,12 @@ file variables 和 array[file] variables 支持以下文件类型与格式:
 -开启该功能并不意味着赋予 LLM 直接读取文件的能力,还需要配备[**文档提取器**](/zh-hans/guides/workflow/nodes/doc-extractor)将文档解析为文本供 LLM 理解。
+开启该功能并不意味着赋予 LLM 直接读取文件的能力,还需要配备[**文档提取器**](/zh-hans/guides/workflow/node/doc-extractor)将文档解析为文本供 LLM 理解。
* 对于音频文件,可以使用 `gpt-4o-audio-preview` 等支持多模态输入的模型直接处理音频,无需额外的提取器。
* 对于视频和其他文件类型,暂无对应的提取器,需要应用开发者接入[外部工具](/zh-hans/guides/tools/extensions/api-based/api-based-extension)进行处理
-2. 添加[文档提取器](/zh-hans/guides/workflow/nodes/doc-extractor)节点,在输入变量中选中 `sys.files` 变量。
+2. 添加[文档提取器](/zh-hans/guides/workflow/node/doc-extractor)节点,在输入变量中选中 `sys.files` 变量。
3. 添加 LLM 节点,在系统提示词中选中文档提取器节点的输出变量。
4. 在末尾添加 "直接回复" 节点,填写 LLM 节点的输出变量。
@@ -109,7 +109,7 @@ file variables 和 array[file] variables 支持以下文件类型与格式:
#### 1. 在"开始"节点添加文件变量
-在应用的["开始"](/zh-hans/guides/workflow/nodes/start)节点内添加输入字段,选择 **"单文件"** 或 **"文件列表"** 字段类型的变量。
+在应用的["开始"](/zh-hans/guides/workflow/node/start)节点内添加输入字段,选择 **"单文件"** 或 **"文件列表"** 字段类型的变量。
-开启该功能并不意味着赋予 LLM 直接读取文件的能力,还需要配备[**文档提取器**](/zh-hans/guides/workflow/nodes/doc-extractor)将文档解析为文本供 LLM 理解。
+开启该功能并不意味着赋予 LLM 直接读取文件的能力,还需要配备[**文档提取器**](/zh-hans/guides/workflow/node/doc-extractor)将文档解析为文本供 LLM 理解。
* 对于音频文件,可以使用 `gpt-4o-audio-preview` 等支持多模态输入的模型直接处理音频,无需额外的提取器。
* 对于视频和其他文件类型,暂无对应的提取器,需要应用开发者接入[外部工具](/zh-hans/guides/tools/extensions/api-based/api-based-extension)进行处理
-2. 添加[文档提取器](/zh-hans/guides/workflow/nodes/doc-extractor)节点,在输入变量中选中 `sys.files` 变量。
+2. 添加[文档提取器](/zh-hans/guides/workflow/node/doc-extractor)节点,在输入变量中选中 `sys.files` 变量。
3. 添加 LLM 节点,在系统提示词中选中文档提取器节点的输出变量。
4. 在末尾添加 "直接回复" 节点,填写 LLM 节点的输出变量。
@@ -109,7 +109,7 @@ file variables 和 array[file] variables 支持以下文件类型与格式:
#### 1. 在"开始"节点添加文件变量
-在应用的["开始"](/zh-hans/guides/workflow/nodes/start)节点内添加输入字段,选择 **"单文件"** 或 **"文件列表"** 字段类型的变量。
+在应用的["开始"](/zh-hans/guides/workflow/node/start)节点内添加输入字段,选择 **"单文件"** 或 **"文件列表"** 字段类型的变量。