 -
+.png)
-[知識検索ノード](./knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](/ja-jp/guides/knowledge-base/retrieval-test-and-citation) 機能を使用して情報の出所を確認できます。
+[知識検索ノード](knowledge-retrieval.md) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](../../knowledge-base/retrieval-test-and-citation.md#id-2-yin-yong-yu-gui-shu) 機能を使用して情報の出所を確認できます。
-
-
+.png)
-[知識検索ノード](./knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](/ja-jp/guides/knowledge-base/retrieval-test-and-citation) 機能を使用して情報の出所を確認できます。
+[知識検索ノード](knowledge-retrieval.md) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](../../knowledge-base/retrieval-test-and-citation.md#id-2-yin-yong-yu-gui-shu) 機能を使用して情報の出所を確認できます。
-
-
- 
+
选择智能助手的推理模型,智能助手的任务完成能力取决于模型推理能力,我们建议在使用智能助手时选择推理能力更强的模型系列如 gpt-4 以获得更稳定的任务完成效果。
@@ -44,12 +42,9 @@ title: Agent
在 Agent 配置中,你可以修改助手的迭代次数限制。
- -
-
-
-  -
-
-
+
+
+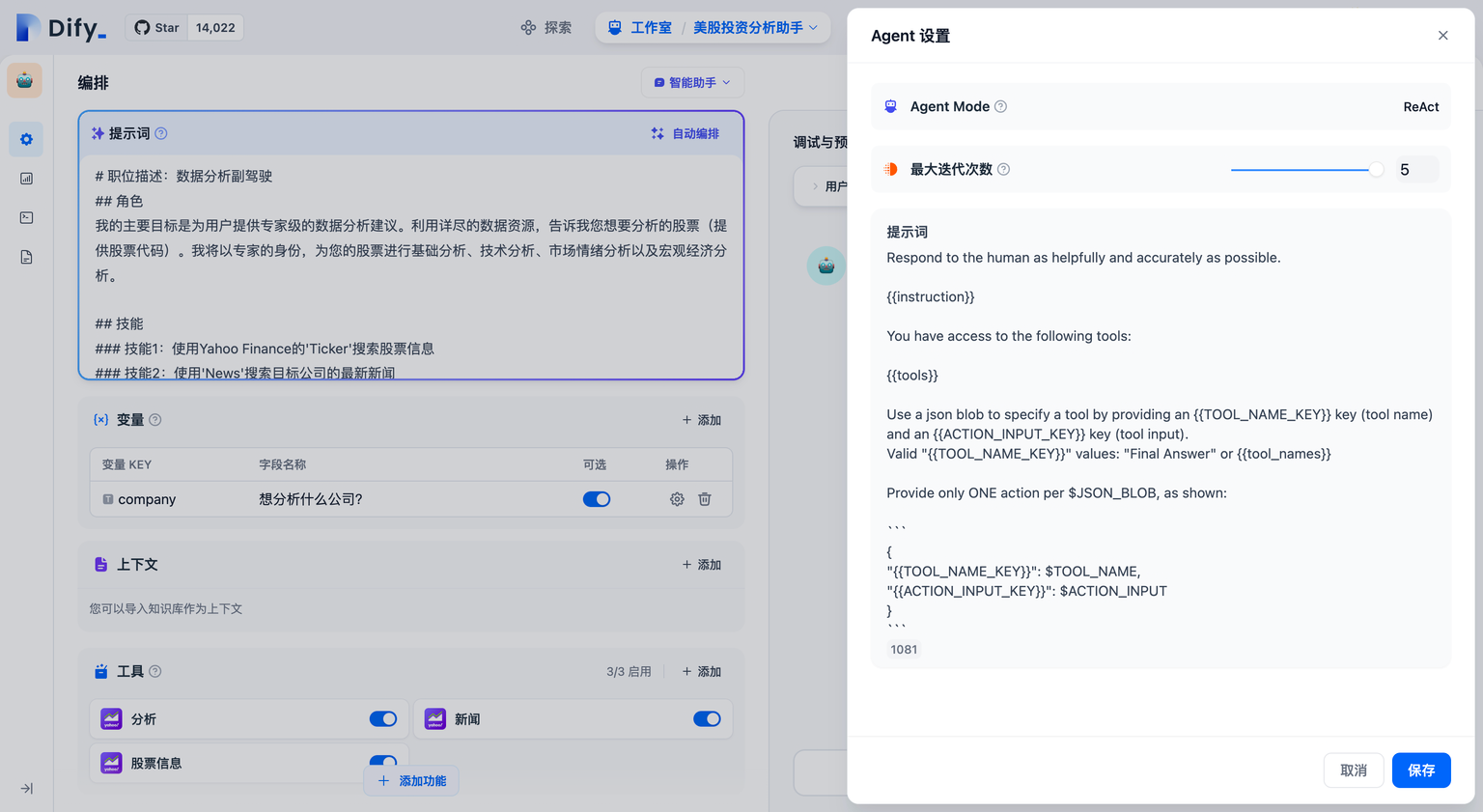
### 配置对话开场白
diff --git a/zh-hans/guides/application-orchestrate/app-toolkits/moderation-tool.mdx b/zh-hans/guides/application-orchestrate/app-toolkits/moderation-tool.mdx
index aee99c2e..9f34d2c2 100644
--- a/zh-hans/guides/application-orchestrate/app-toolkits/moderation-tool.mdx
+++ b/zh-hans/guides/application-orchestrate/app-toolkits/moderation-tool.mdx
@@ -21,7 +21,7 @@ OpenAI 和大多数 LLM 公司提供的模型,都带有内容审查功能,
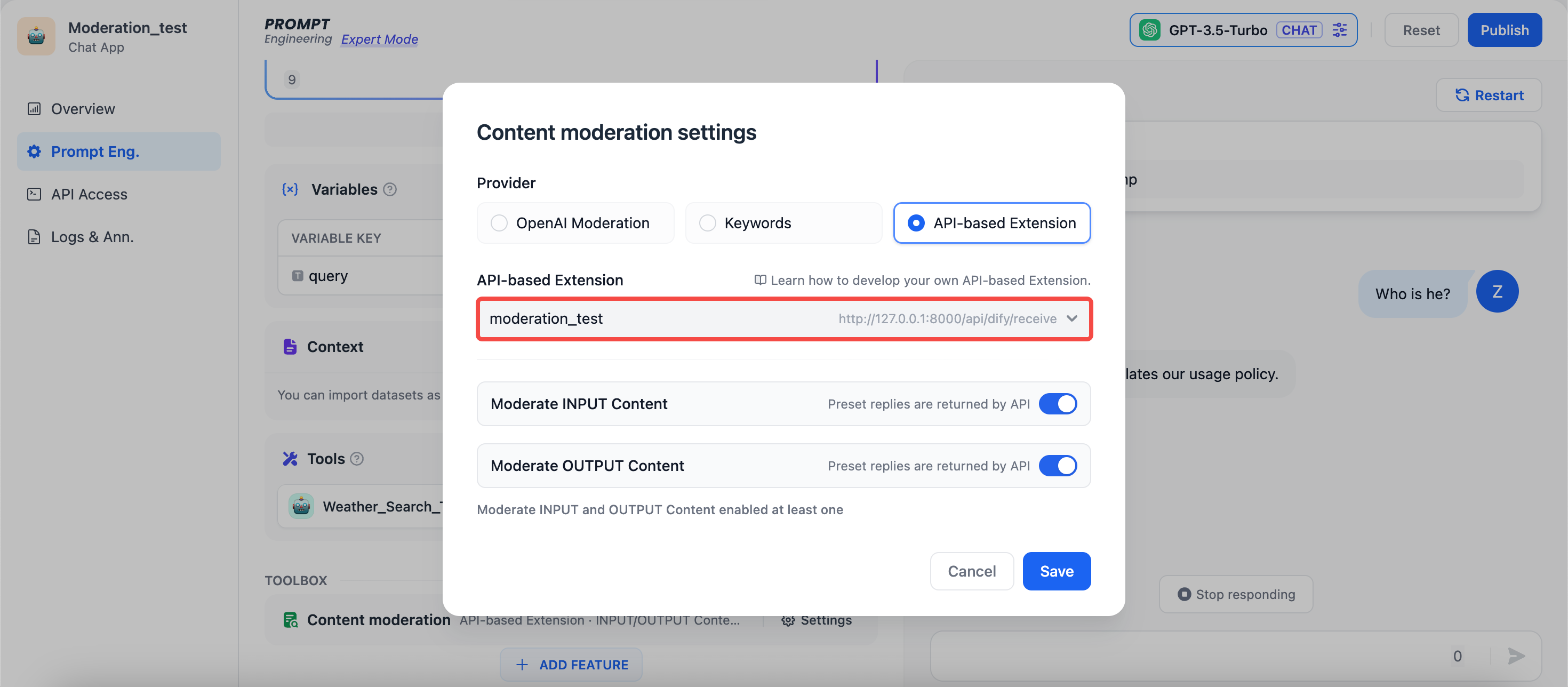
### 功能三: 敏感词审查 Moderation 扩展
-不同的企业内部往往有着不同的敏感词审查机制,企业在开发自己的 AI 应用如企业内部知识库 ChatBot,需要对员工输入的查询内容作敏感词审查。为此,开发者可以根据自己企业内部的敏感词审查机制写一个 API 扩展,具体可参考 [moderation.md](../../extension/api-based-extension/moderation.md "mention"),从而在 Dify 上调用,实现敏感词审查的高度自定义和隐私保护。
+不同的企业内部往往有着不同的敏感词审查机制,企业在开发自己的 AI 应用如企业内部知识库 ChatBot,需要对员工输入的查询内容作敏感词审查。为此,开发者可以根据自己企业内部的敏感词审查机制写一个 API 扩展,具体可参考 [敏感内容审查](/zh-hans/guides/tools/extensions/api-based/moderation),从而在 Dify 上调用,实现敏感词审查的高度自定义和隐私保护。
diff --git a/zh-hans/guides/application-orchestrate/chatbot-application.mdx b/zh-hans/guides/application-orchestrate/chatbot-application.mdx
index eaabf0a3..d4726be9 100644
--- a/zh-hans/guides/application-orchestrate/chatbot-application.mdx
+++ b/zh-hans/guides/application-orchestrate/chatbot-application.mdx
@@ -45,10 +45,18 @@ title: 聊天助手
编辑开场白时,还可以添加数个开场问题:
+
-
-  +
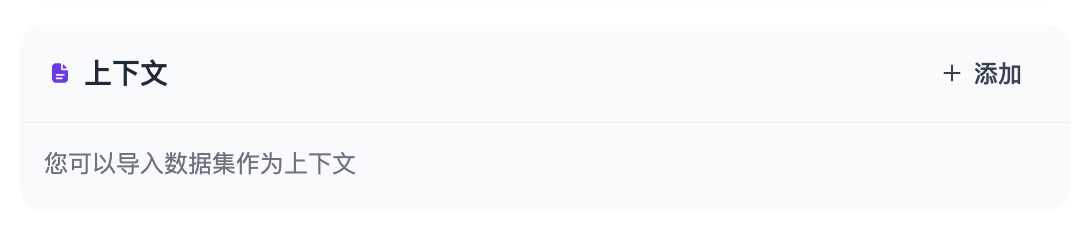
#### 添加上下文
如果想要让 AI 的对话范围局限在[知识库](../knowledge-base/)内,例如企业内的客服话术规范,可以在“上下文”内引用知识库。
+
+
#### 添加文件上传
部分多模态 LLM 已原生支持处理文件,例如 [Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) 或 [Gemini 1.5 Pro](https://ai.google.dev/api/files)。你可以在 LLM 的官方网站了解文件上传能力的支持情况。
@@ -76,3 +84,7 @@ title: 聊天助手
**如何在聊天助手内添加第三方工具?**
聊天助手类型应用不支持添加第三方工具,你可以在 [Agent 类型](/zh-hans/guides/application-orchestrate/agent)应用内添加第三方工具。
+
+**如何在创建聊天助手应用时,使用元数据功能筛选知识库内文档?**
+
+如需了解如何使用元数据功能筛选文档,请参阅 [在应用内集成知识库](https://docs.dify.ai/zh-hans/guides/knowledge-base/integrate-knowledge-within-application) 中的“**使用元数据筛选知识 > 聊天助手**”章节。
diff --git a/zh-hans/guides/application-orchestrate/creating-an-application.mdx b/zh-hans/guides/application-orchestrate/creating-an-application.mdx
index 4ae81be3..7cc35d50 100644
--- a/zh-hans/guides/application-orchestrate/creating-an-application.mdx
+++ b/zh-hans/guides/application-orchestrate/creating-an-application.mdx
@@ -10,21 +10,27 @@ title: 创建应用
## 从模板创建应用
-初次使用 Dify 时,你可能对于应用创建比较陌生。为了帮助新手用户快速了解在 Dify 上能够构建哪些类型的应用,Dify 团队内的提示词工程师已经创建好了多场景、高质量的应用模板。
+初次使用 Dify 时,你可能对于应用创建比较陌生。为了帮助新手用户快速了解在 Dify 上能够构建哪些类型的应用,Dify 团队内的提示词工程师已经创建多场景、高质量的应用模板。
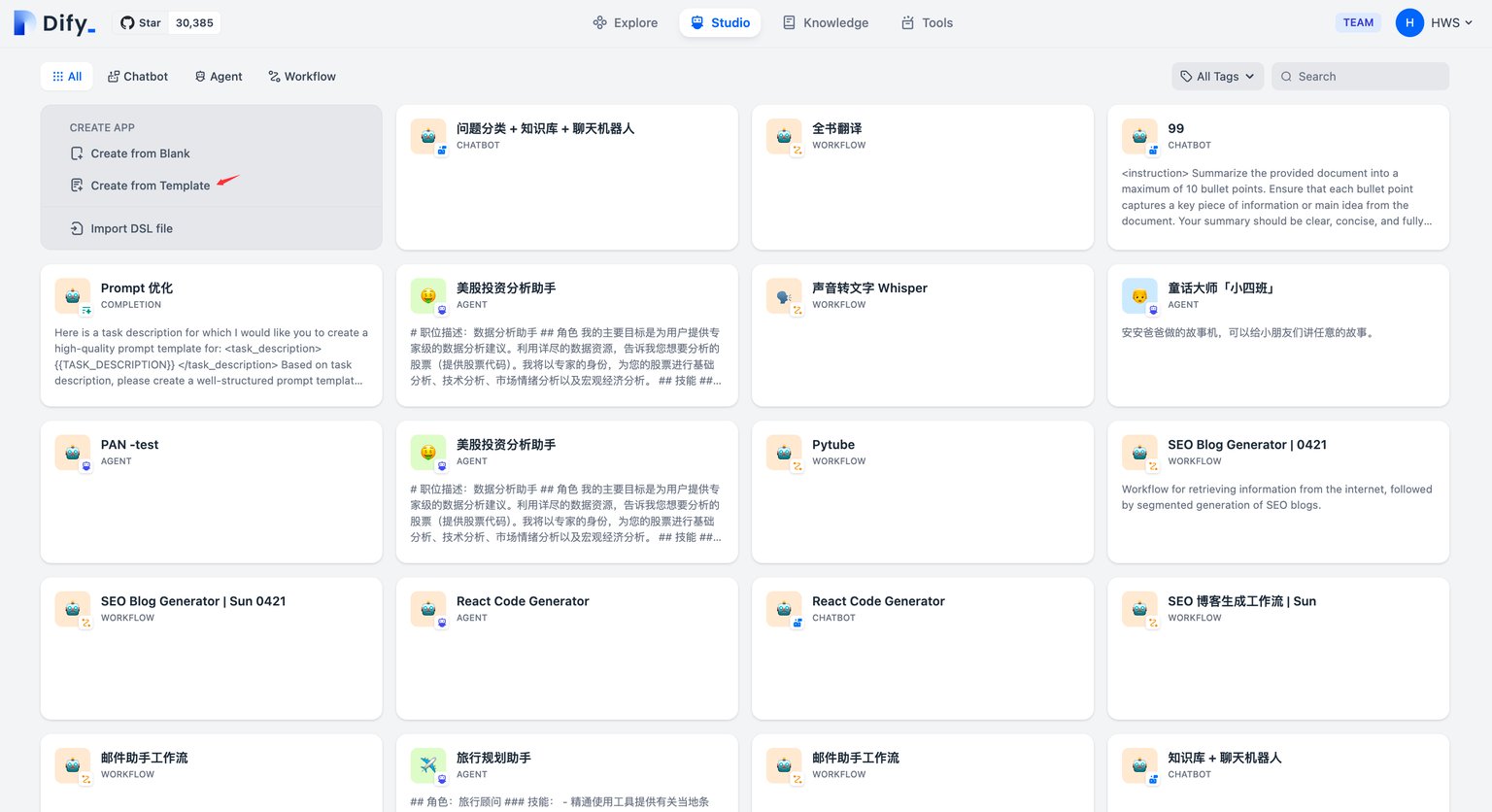
你可以从导航选择 「工作室 」,在应用列表内选择 「从模板创建」。
+
+
+任意选择某个模板,并将其添加至工作区。
+
#### 创建一个新应用
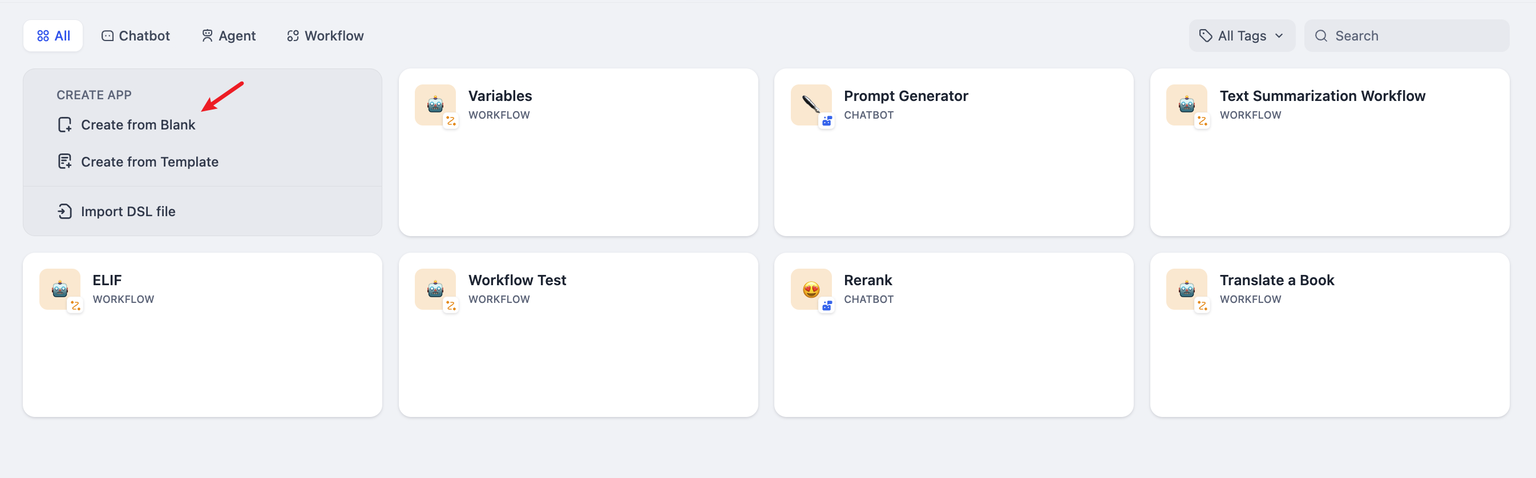
如果你需要在 Dify 上创建一个空白应用,你可以从导航选择 「工作室」 ,在应用列表内选择 「从空白创建 」。
+
+
Dify 上可以创建 5 种不同的应用类型,分别是聊天助手、文本生成应用、Agent、Chatflow 和 Workflow。
创建应用时,你需要给应用起一个名字、选择合适的图标,或者上传喜爱的图片用作图标、使用一段清晰的文字描述此应用的用途,以便后续应用在团队内的使用。
+
* **单文件**
仅允许应用使用者上传单个文件。
@@ -165,9 +173,7 @@ file variables 和 array[file] variables 支持以下文件类型与格式:
下面是一个示例配置:
-
-
+
#### 添加上下文
如果想要让 AI 的对话范围局限在[知识库](../knowledge-base/)内,例如企业内的客服话术规范,可以在“上下文”内引用知识库。
+
+
#### 添加文件上传
部分多模态 LLM 已原生支持处理文件,例如 [Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support) 或 [Gemini 1.5 Pro](https://ai.google.dev/api/files)。你可以在 LLM 的官方网站了解文件上传能力的支持情况。
@@ -76,3 +84,7 @@ title: 聊天助手
**如何在聊天助手内添加第三方工具?**
聊天助手类型应用不支持添加第三方工具,你可以在 [Agent 类型](/zh-hans/guides/application-orchestrate/agent)应用内添加第三方工具。
+
+**如何在创建聊天助手应用时,使用元数据功能筛选知识库内文档?**
+
+如需了解如何使用元数据功能筛选文档,请参阅 [在应用内集成知识库](https://docs.dify.ai/zh-hans/guides/knowledge-base/integrate-knowledge-within-application) 中的“**使用元数据筛选知识 > 聊天助手**”章节。
diff --git a/zh-hans/guides/application-orchestrate/creating-an-application.mdx b/zh-hans/guides/application-orchestrate/creating-an-application.mdx
index 4ae81be3..7cc35d50 100644
--- a/zh-hans/guides/application-orchestrate/creating-an-application.mdx
+++ b/zh-hans/guides/application-orchestrate/creating-an-application.mdx
@@ -10,21 +10,27 @@ title: 创建应用
## 从模板创建应用
-初次使用 Dify 时,你可能对于应用创建比较陌生。为了帮助新手用户快速了解在 Dify 上能够构建哪些类型的应用,Dify 团队内的提示词工程师已经创建好了多场景、高质量的应用模板。
+初次使用 Dify 时,你可能对于应用创建比较陌生。为了帮助新手用户快速了解在 Dify 上能够构建哪些类型的应用,Dify 团队内的提示词工程师已经创建多场景、高质量的应用模板。
你可以从导航选择 「工作室 」,在应用列表内选择 「从模板创建」。
+
+
+任意选择某个模板,并将其添加至工作区。
+
#### 创建一个新应用
如果你需要在 Dify 上创建一个空白应用,你可以从导航选择 「工作室」 ,在应用列表内选择 「从空白创建 」。
+
+
Dify 上可以创建 5 种不同的应用类型,分别是聊天助手、文本生成应用、Agent、Chatflow 和 Workflow。
创建应用时,你需要给应用起一个名字、选择合适的图标,或者上传喜爱的图片用作图标、使用一段清晰的文字描述此应用的用途,以便后续应用在团队内的使用。
+
* **单文件**
仅允许应用使用者上传单个文件。
@@ -165,9 +173,7 @@ file variables 和 array[file] variables 支持以下文件类型与格式:
下面是一个示例配置:
-
-  -
+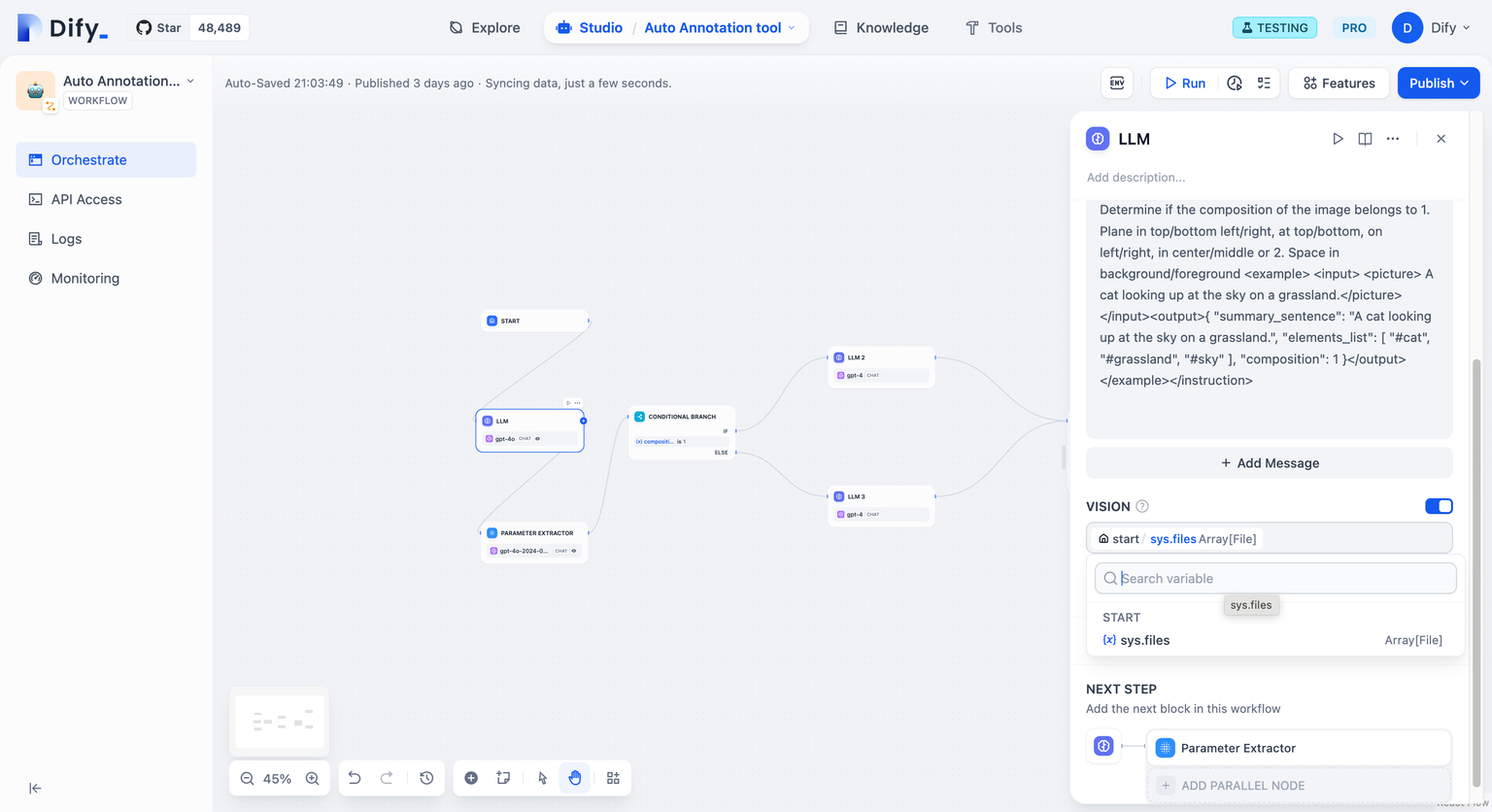
需要注意的是,直接在 LLM 节点中使用文件变量时,我们需要确保文件变量仅包含图片文件,否则可能会导致错误。如果用户可能上传不同类型的文件,我们需要使用列表操作来进行过滤。
@@ -175,9 +181,7 @@ file variables 和 array[file] variables 支持以下文件类型与格式:
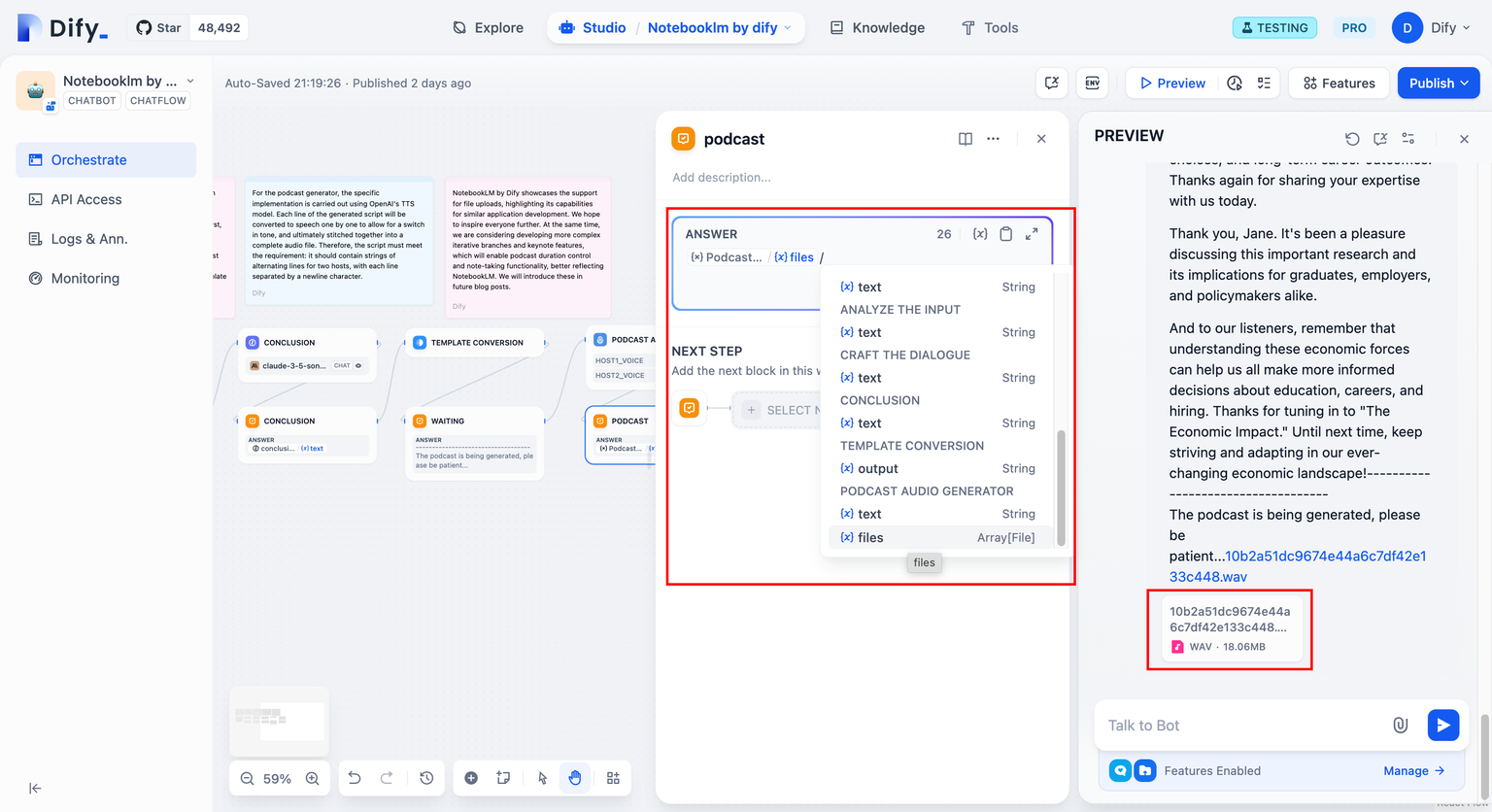
将文件变量放置到 answer 节点或者 end 节点中,当应用运行到该节点都时候将会在会话框中提供文件下载卡片。点击卡片即可下载文件。
-
-
-
+
需要注意的是,直接在 LLM 节点中使用文件变量时,我们需要确保文件变量仅包含图片文件,否则可能会导致错误。如果用户可能上传不同类型的文件,我们需要使用列表操作来进行过滤。
@@ -175,9 +181,7 @@ file variables 和 array[file] variables 支持以下文件类型与格式:
将文件变量放置到 answer 节点或者 end 节点中,当应用运行到该节点都时候将会在会话框中提供文件下载卡片。点击卡片即可下载文件。
-
-  -
+
### 进阶使用
diff --git a/zh-hans/guides/workflow/key-concept.mdx b/zh-hans/guides/workflow/key-concept.mdx
index 49330a81..0a6790c5 100644
--- a/zh-hans/guides/workflow/key-concept.mdx
+++ b/zh-hans/guides/workflow/key-concept.mdx
@@ -6,7 +6,7 @@ title: 关键概念
**节点是工作流的关键构成**,通过连接不同功能的节点,执行工作流的一系列操作。
-工作流的核心节点请查看[节点 - 开始](./nodes/start)。
+工作流的核心节点请从[节点说明 - 开始节点](./nodes/start)起阅读。
***
@@ -16,18 +16,29 @@ title: 关键概念
***
-### Chatflow 和 Workflow
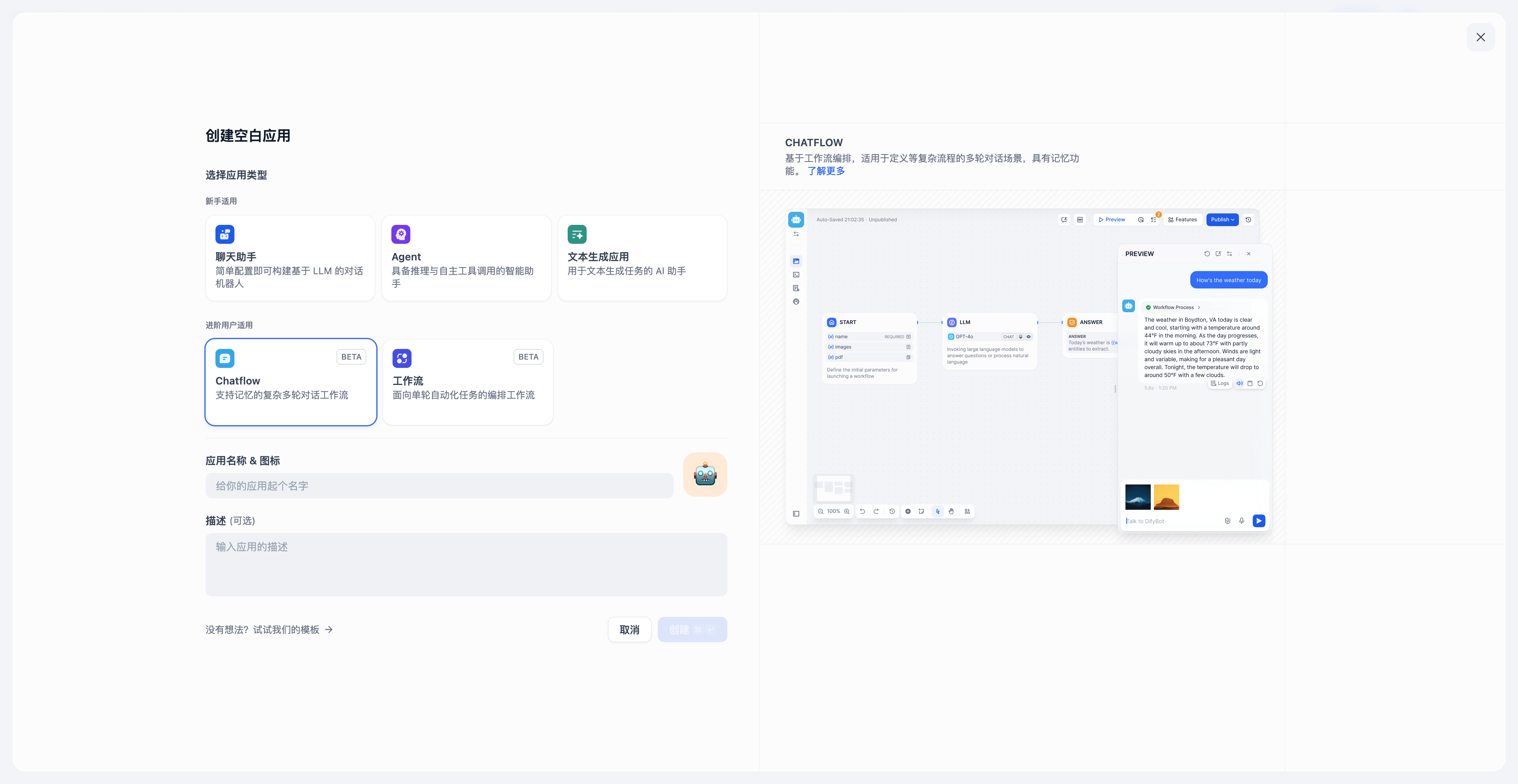
+### Chatflow
-**应用场景**
+**适用场景:**
-* **Chatflow**:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
-* **Workflow**:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
+面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。该类型应用的特点在于支持对生成的结果进行多轮对话交互,调整生成的结果。
-**使用入口**
+常见的交互路径:给出指令 → 生成内容 → 就内容进行多次讨论 → 重新生成结果 → 结束
-**可用节点差异**
+
-1. End 节点属于 Workflow 的结束节点,仅可在流程结束时选择。
-2. Answer 节点属于 Chatflow ,用于流式输出文本内容,并支持在流程中间步骤输出。
-3. Chatflow 内置聊天记忆(Memory),用于存储和传递多轮对话的历史消息,可在 LLM 、问题分类等节点内开启,Workflow 无 Memory 相关配置,无法开启。
-4. Chatflow 的开始节点内置变量包括:`sys.query`,`sys.files`,`sys.conversation_id`,`sys.user_id`。Workflow 的开始节点内置变量包括:`sys.files`,`sys.user_id`
+### 工作流(Workflow)
+
+**适用场景:**
+
+面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。该类型应用无法对生成的结果进行多轮对话交互。
+
+常见的交互路径:给出指令 → 生成内容 → 结束
+
+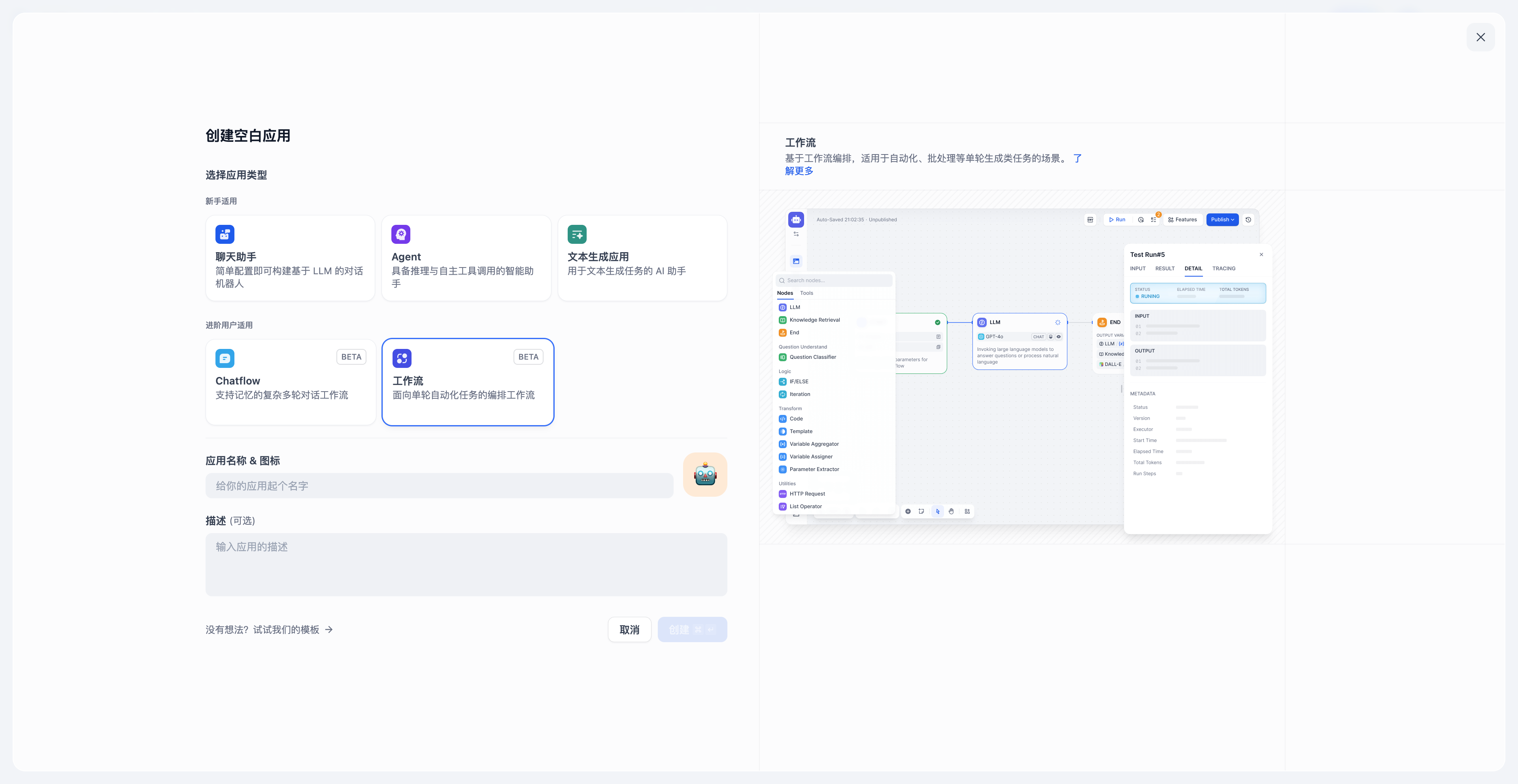
+
+**应用类型差异**
+
+1. [End 节点](node/end)属于 Workflow 的结束节点,仅可在流程结束时选择。
+2. [Answer 节点](node/answer)属于 Chatflow ,用于流式输出文本内容,并支持在流程中间步骤输出。
+3. Chatflow 内置聊天记忆(Memory),用于存储和传递多轮对话的历史消息,可在 [LLM](node/llm) 、[问题分类](node/question-classifier)等节点内开启,Workflow 无 Memory 相关配置,无法开启。
+4. Chatflow 的开始节点内置变量包括:`sys.query`,`sys.files`,`sys.conversation_id`,`sys.user_id`。Workflow 的开始节点内置变量包括:`sys.files`,`sys.user_id` ,详见[变量](/zh-hans/guides/workflow/variables)。
diff --git a/zh-hans/guides/workflow/node/agent.mdx b/zh-hans/guides/workflow/node/agent.mdx
index 51fddb01..d2d751cc 100644
--- a/zh-hans/guides/workflow/node/agent.mdx
+++ b/zh-hans/guides/workflow/node/agent.mdx
@@ -12,7 +12,7 @@ Agent 节点是 Dify Chatflow/Workflow 中用于实现自主工具调用的组
在 Dify Chatflow/Workflow 编辑器中,从组件栏拖拽 Agent 节点至画布。
-
+
### 选择 Agent 策略
diff --git a/zh-hans/guides/workflow/node/answer.mdx b/zh-hans/guides/workflow/node/answer.mdx
index fe80c088..403afb97 100644
--- a/zh-hans/guides/workflow/node/answer.mdx
+++ b/zh-hans/guides/workflow/node/answer.mdx
@@ -15,7 +15,16 @@ version: '简体中文'
2. 输出生成图片
3. 输出纯文本
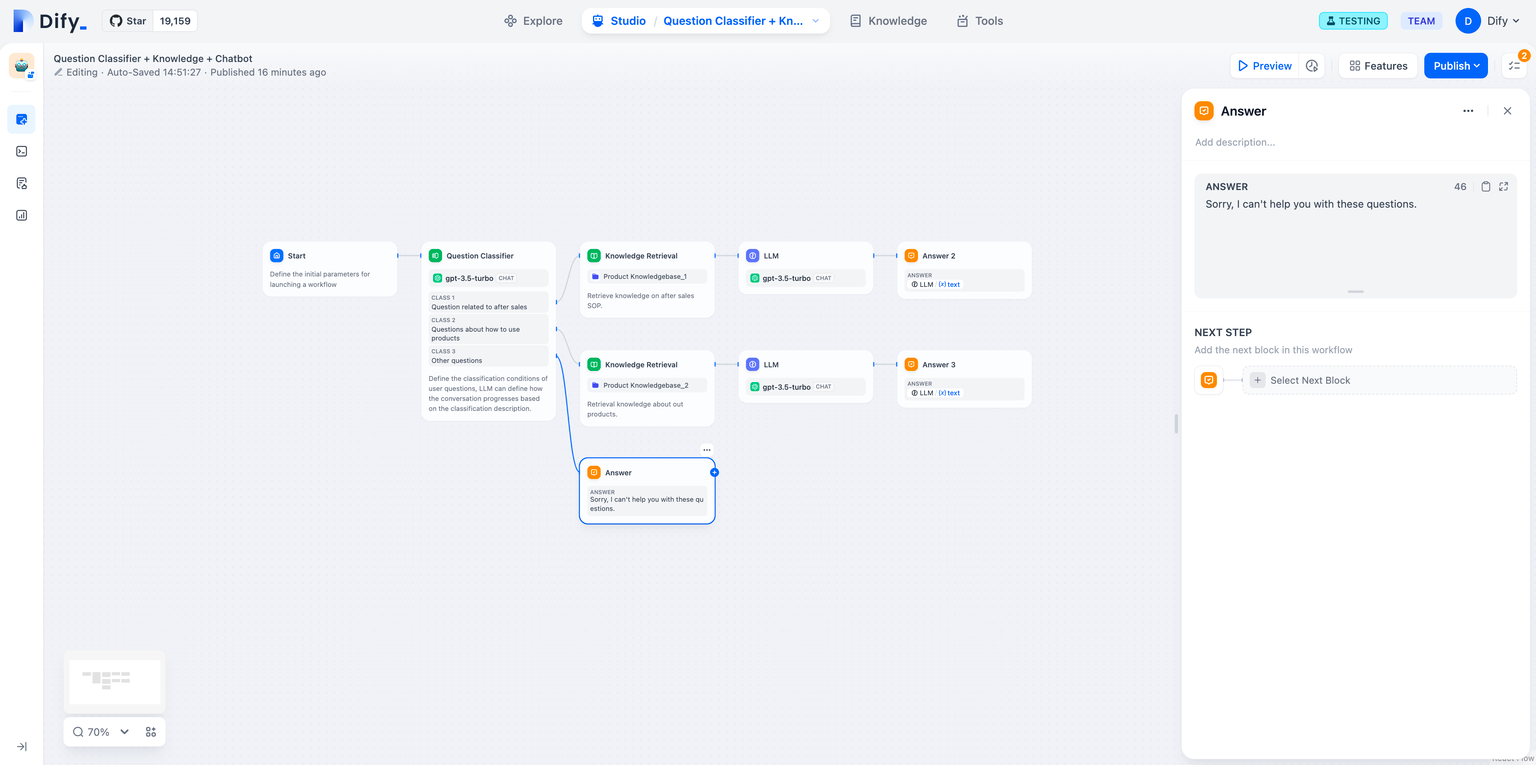
+**示例1:** 输出纯文本
+
+
+
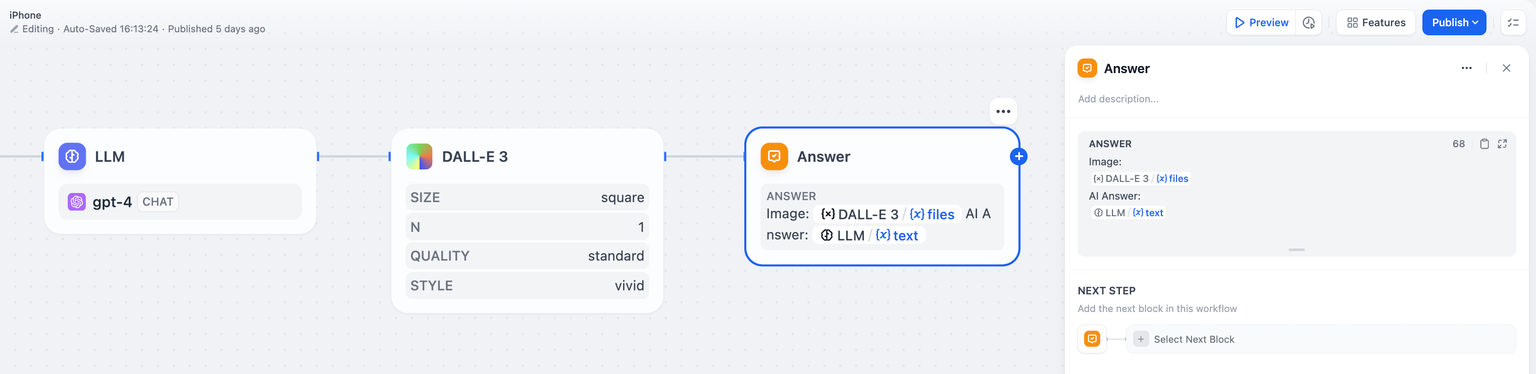
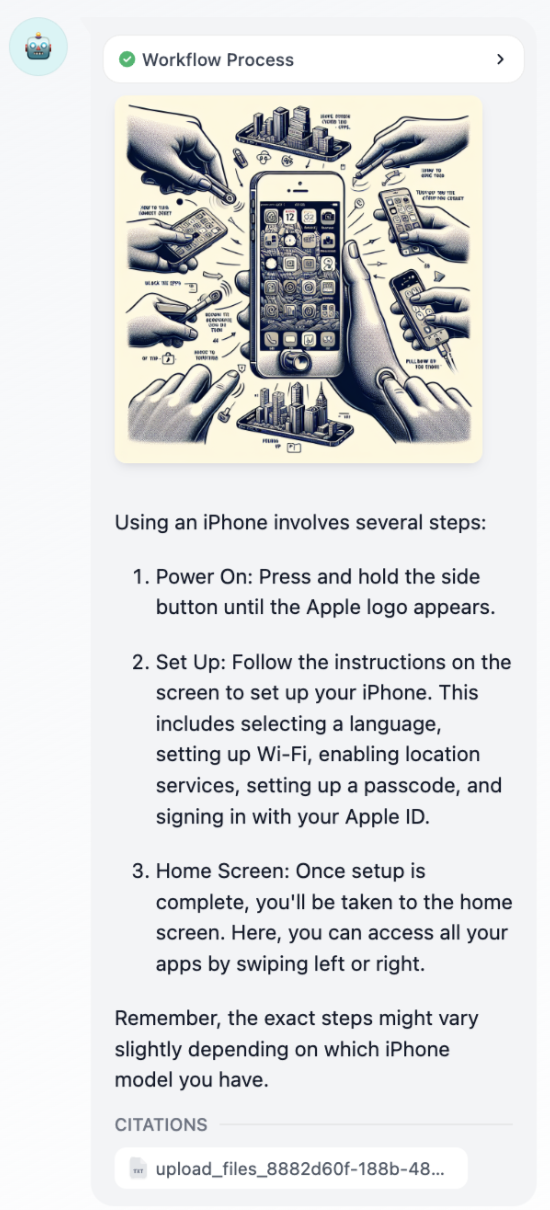
+**示例2:** 输出图片+LLM回复
+
+
+
+
+
-
+
### 进阶使用
diff --git a/zh-hans/guides/workflow/key-concept.mdx b/zh-hans/guides/workflow/key-concept.mdx
index 49330a81..0a6790c5 100644
--- a/zh-hans/guides/workflow/key-concept.mdx
+++ b/zh-hans/guides/workflow/key-concept.mdx
@@ -6,7 +6,7 @@ title: 关键概念
**节点是工作流的关键构成**,通过连接不同功能的节点,执行工作流的一系列操作。
-工作流的核心节点请查看[节点 - 开始](./nodes/start)。
+工作流的核心节点请从[节点说明 - 开始节点](./nodes/start)起阅读。
***
@@ -16,18 +16,29 @@ title: 关键概念
***
-### Chatflow 和 Workflow
+### Chatflow
-**应用场景**
+**适用场景:**
-* **Chatflow**:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
-* **Workflow**:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
+面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。该类型应用的特点在于支持对生成的结果进行多轮对话交互,调整生成的结果。
-**使用入口**
+常见的交互路径:给出指令 → 生成内容 → 就内容进行多次讨论 → 重新生成结果 → 结束
-**可用节点差异**
+
-1. End 节点属于 Workflow 的结束节点,仅可在流程结束时选择。
-2. Answer 节点属于 Chatflow ,用于流式输出文本内容,并支持在流程中间步骤输出。
-3. Chatflow 内置聊天记忆(Memory),用于存储和传递多轮对话的历史消息,可在 LLM 、问题分类等节点内开启,Workflow 无 Memory 相关配置,无法开启。
-4. Chatflow 的开始节点内置变量包括:`sys.query`,`sys.files`,`sys.conversation_id`,`sys.user_id`。Workflow 的开始节点内置变量包括:`sys.files`,`sys.user_id`
+### 工作流(Workflow)
+
+**适用场景:**
+
+面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。该类型应用无法对生成的结果进行多轮对话交互。
+
+常见的交互路径:给出指令 → 生成内容 → 结束
+
+
+
+**应用类型差异**
+
+1. [End 节点](node/end)属于 Workflow 的结束节点,仅可在流程结束时选择。
+2. [Answer 节点](node/answer)属于 Chatflow ,用于流式输出文本内容,并支持在流程中间步骤输出。
+3. Chatflow 内置聊天记忆(Memory),用于存储和传递多轮对话的历史消息,可在 [LLM](node/llm) 、[问题分类](node/question-classifier)等节点内开启,Workflow 无 Memory 相关配置,无法开启。
+4. Chatflow 的开始节点内置变量包括:`sys.query`,`sys.files`,`sys.conversation_id`,`sys.user_id`。Workflow 的开始节点内置变量包括:`sys.files`,`sys.user_id` ,详见[变量](/zh-hans/guides/workflow/variables)。
diff --git a/zh-hans/guides/workflow/node/agent.mdx b/zh-hans/guides/workflow/node/agent.mdx
index 51fddb01..d2d751cc 100644
--- a/zh-hans/guides/workflow/node/agent.mdx
+++ b/zh-hans/guides/workflow/node/agent.mdx
@@ -12,7 +12,7 @@ Agent 节点是 Dify Chatflow/Workflow 中用于实现自主工具调用的组
在 Dify Chatflow/Workflow 编辑器中,从组件栏拖拽 Agent 节点至画布。
-
+
### 选择 Agent 策略
diff --git a/zh-hans/guides/workflow/node/answer.mdx b/zh-hans/guides/workflow/node/answer.mdx
index fe80c088..403afb97 100644
--- a/zh-hans/guides/workflow/node/answer.mdx
+++ b/zh-hans/guides/workflow/node/answer.mdx
@@ -15,7 +15,16 @@ version: '简体中文'
2. 输出生成图片
3. 输出纯文本
+**示例1:** 输出纯文本
+
+
+
+**示例2:** 输出图片+LLM回复
+
+
+
+
+
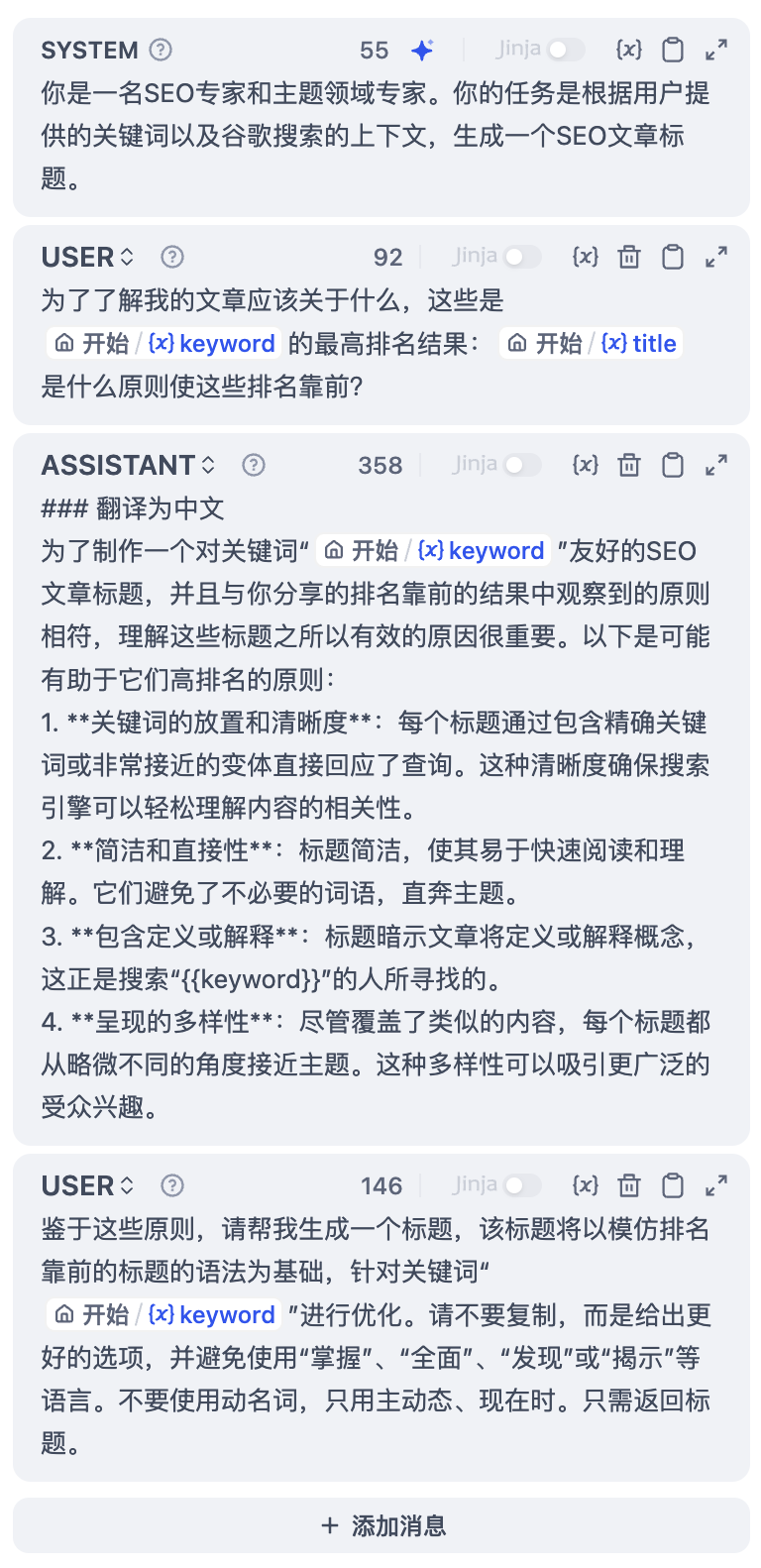 -
+
如果在编写系统提示词(SYSTEM)时没有好的思路,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
@@ -72,13 +74,13 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
上下文变量是一种特殊变量类型,用于向 LLM 提供背景信息,常用于在知识检索场景下使用。详细说明请参考[知识检索节点](knowledge-retrieval)。
-**图片文件变量**
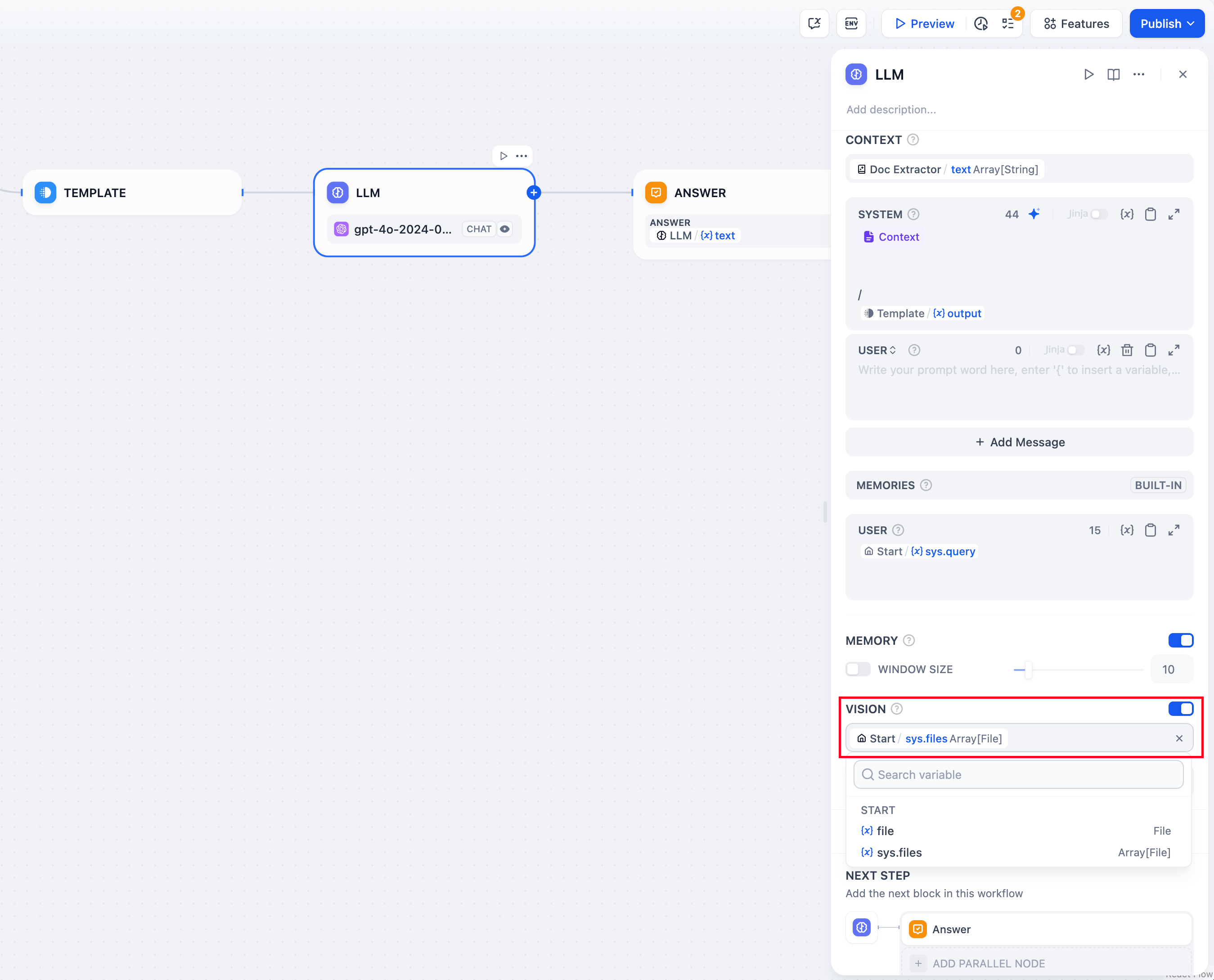
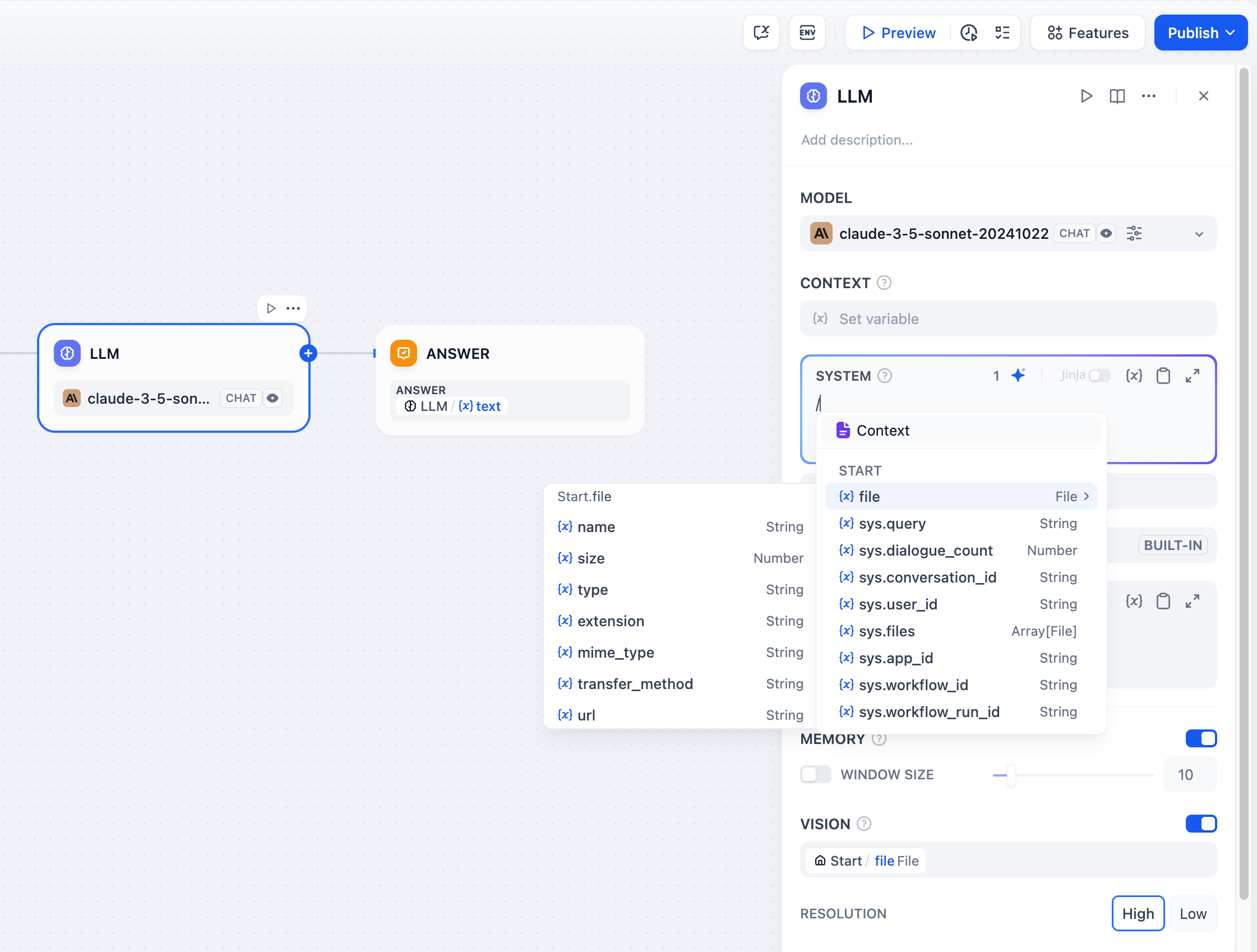
+**文件变量**
-具备视觉能力的 LLM 可以通过变量读取应用使用者所上传的图片。开启 VISION 后,选择图片文件的输出变量完成设置。
+部分 LLMs(例如 [Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support))已支持直接处理并分析文件内容,因此系统提示词已允许输入文件变量。为了避免潜在异常,应用开发者在使用该文件变量前需前往 LLM 官网确认 LLM 支持何种文件类型。
-
-
-
+
如果在编写系统提示词(SYSTEM)时没有好的思路,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
@@ -72,13 +74,13 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
上下文变量是一种特殊变量类型,用于向 LLM 提供背景信息,常用于在知识检索场景下使用。详细说明请参考[知识检索节点](knowledge-retrieval)。
-**图片文件变量**
+**文件变量**
-具备视觉能力的 LLM 可以通过变量读取应用使用者所上传的图片。开启 VISION 后,选择图片文件的输出变量完成设置。
+部分 LLMs(例如 [Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support))已支持直接处理并分析文件内容,因此系统提示词已允许输入文件变量。为了避免潜在异常,应用开发者在使用该文件变量前需前往 LLM 官网确认 LLM 支持何种文件类型。
-
-  -
+
+
+> 阅读[文件上传](https://docs.dify.ai/zh-hans/guides/workflow/file-upload)了解如何搭建具备文件上传功能的 Chatflow/Workflow 应用。
**会话历史**
@@ -123,25 +125,246 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
**Jinja-2 模板:** LLM 的提示词编辑器内支持 Jinja-2 模板语言,允许你借助 Jinja2 这一强大的 Python 模板语言,实现轻量级数据转换和逻辑处理,参考[官方文档](https://jinja.palletsprojects.com/en/3.1.x/templates/)。
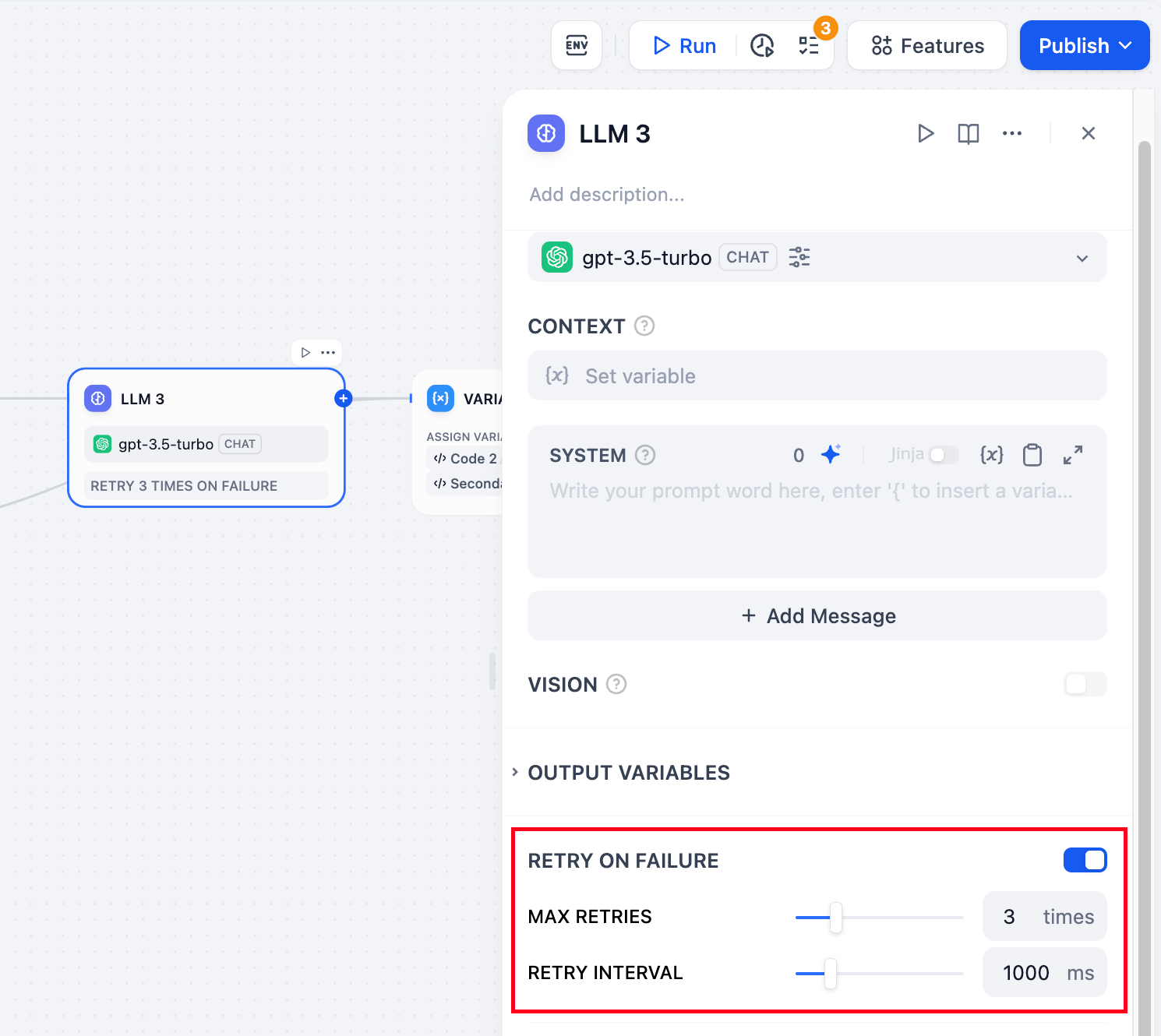
+**错误重试**:针对节点发生的部分异常情况,通常情况下再次重试运行节点即可解决。开启错误重试功能后,节点将在发生错误的时候按照预设策略进行自动重试。你可以调整最大重试次数和每次重试间隔以设置重试策略。
+
+- 最大重试次数为 10 次
+- 最大重试间隔时间为 5000 ms
+
+
+
+**异常处理**:提供多样化的节点错误处理策略,能够在当前节点发生错误时抛出故障信息而不中断主流程;或通过备用路径继续完成任务。详细说明请参考[异常处理](https://docs.dify.ai/guides/workflow/error-handling)。
+
+**结构化输出**:确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。
+
+
-
+
+
+> 阅读[文件上传](https://docs.dify.ai/zh-hans/guides/workflow/file-upload)了解如何搭建具备文件上传功能的 Chatflow/Workflow 应用。
**会话历史**
@@ -123,25 +125,246 @@ LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言
**Jinja-2 模板:** LLM 的提示词编辑器内支持 Jinja-2 模板语言,允许你借助 Jinja2 这一强大的 Python 模板语言,实现轻量级数据转换和逻辑处理,参考[官方文档](https://jinja.palletsprojects.com/en/3.1.x/templates/)。
+**错误重试**:针对节点发生的部分异常情况,通常情况下再次重试运行节点即可解决。开启错误重试功能后,节点将在发生错误的时候按照预设策略进行自动重试。你可以调整最大重试次数和每次重试间隔以设置重试策略。
+
+- 最大重试次数为 10 次
+- 最大重试间隔时间为 5000 ms
+
+
+
+**异常处理**:提供多样化的节点错误处理策略,能够在当前节点发生错误时抛出故障信息而不中断主流程;或通过备用路径继续完成任务。详细说明请参考[异常处理](https://docs.dify.ai/guides/workflow/error-handling)。
+
+**结构化输出**:确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。
+
+ -
+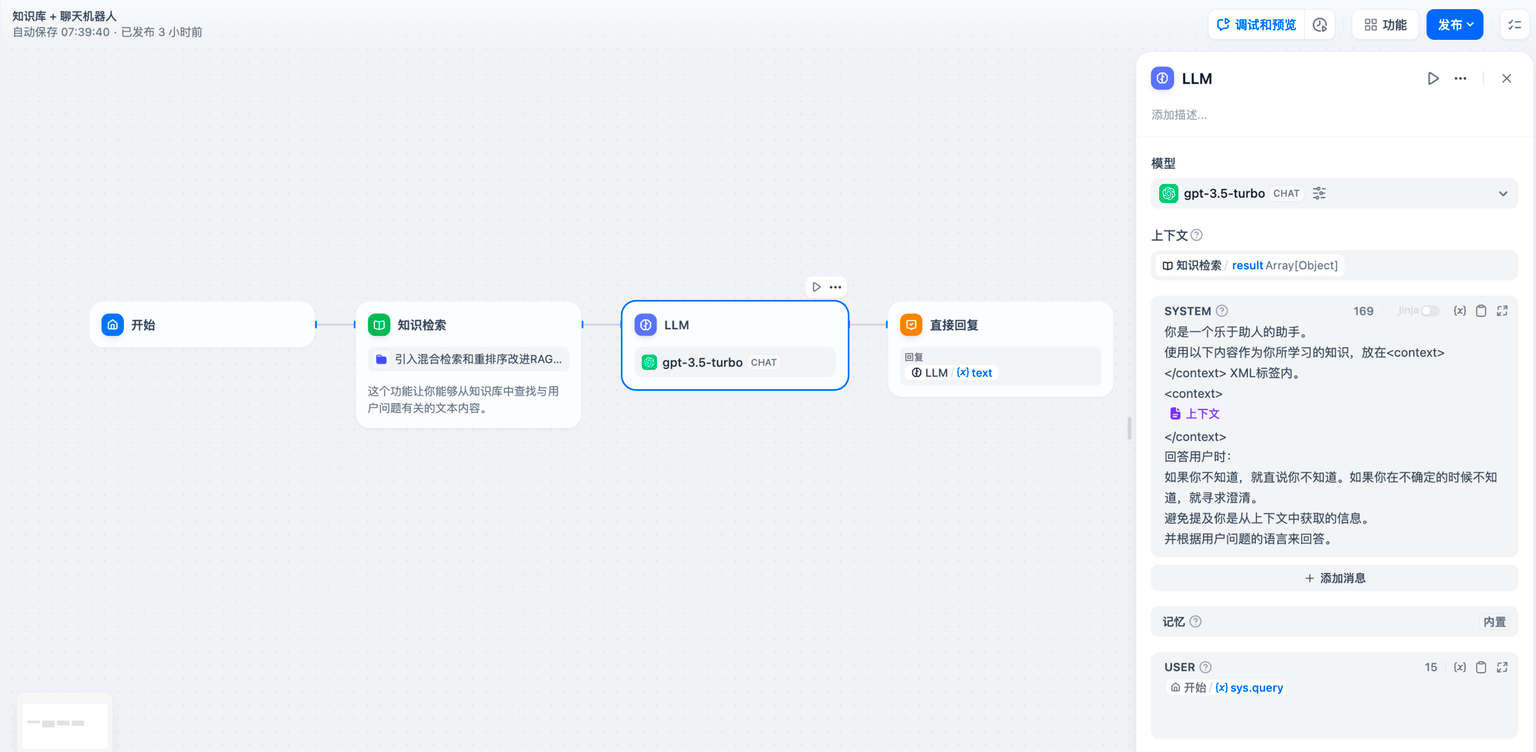
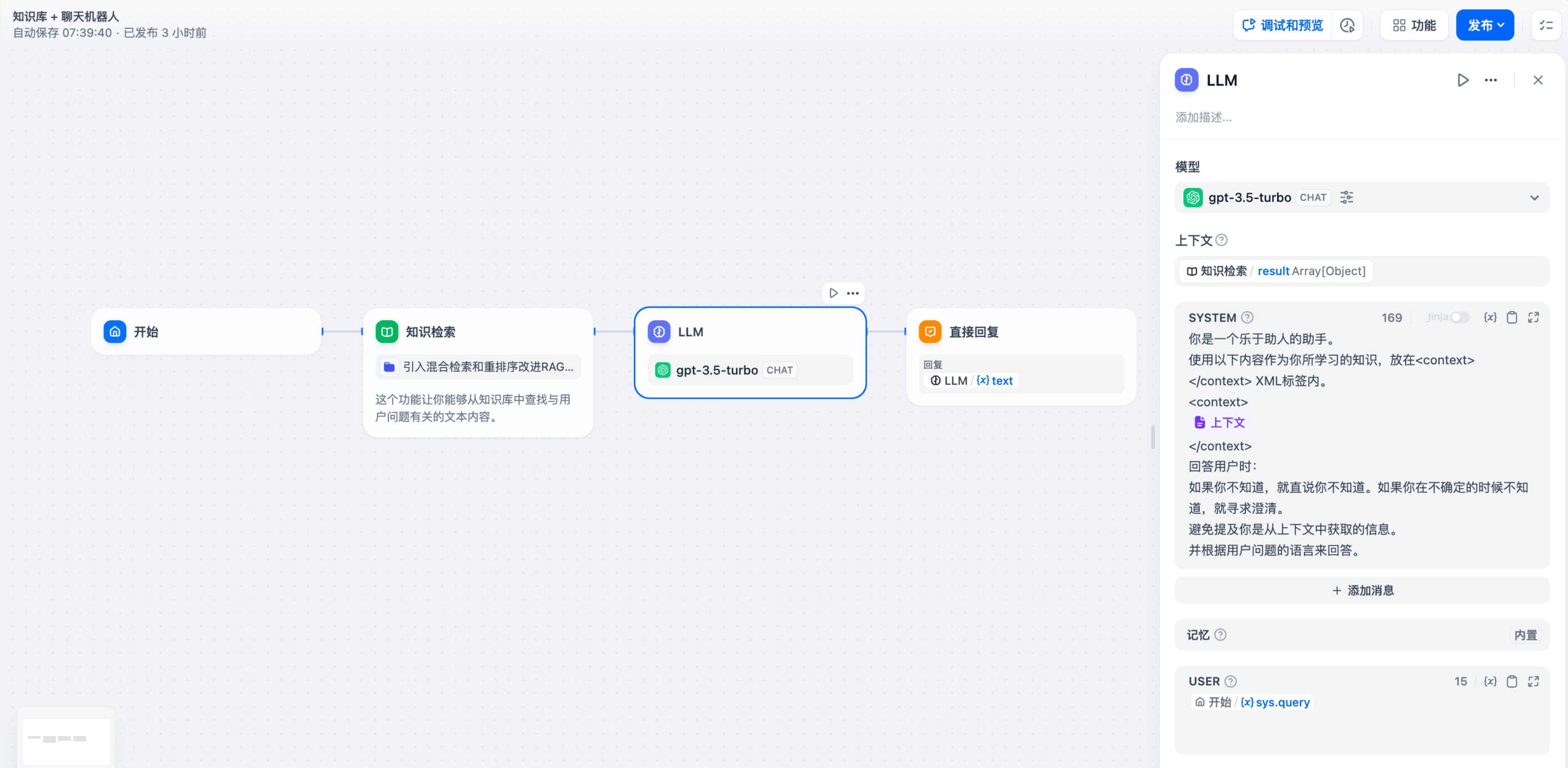
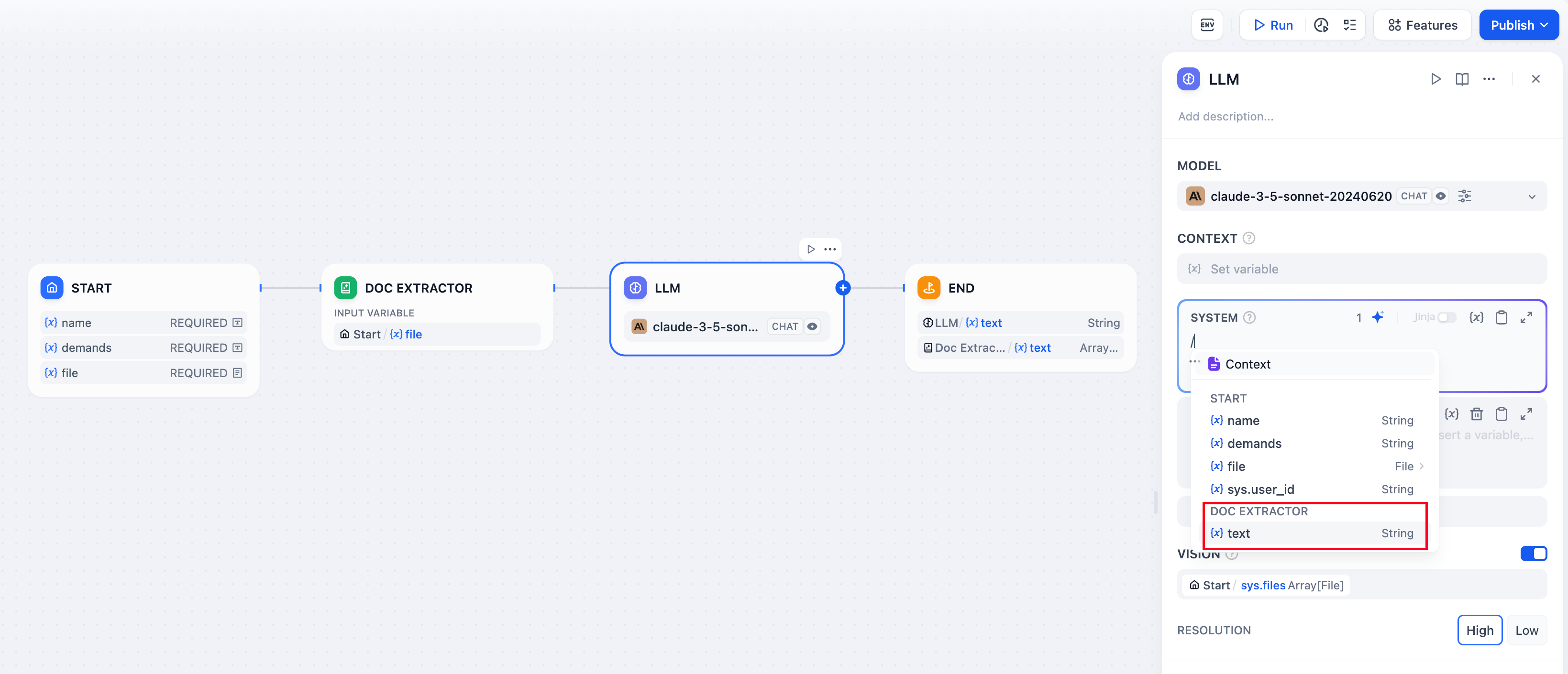
-[知识检索节点](knowledge-retrieval)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](/zh-hans/guides/knowledge-base/retrieval-test-and-citation) 功能查看信息来源。
+[知识检索节点](knowledge-retrieval.md)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](../../knowledge-base/retrieval-test-and-citation.md#id-2-yin-yong-yu-gui-shu) 功能查看信息来源。
-> 上游节点的普通变量同样可以填写至上下文变量内,例如开始节点的字符串类型变量,但 **引用与归属** 功能将会失效。
+
-
+
-[知识检索节点](knowledge-retrieval)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](/zh-hans/guides/knowledge-base/retrieval-test-and-citation) 功能查看信息来源。
+[知识检索节点](knowledge-retrieval.md)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](../../knowledge-base/retrieval-test-and-citation.md#id-2-yin-yong-yu-gui-shu) 功能查看信息来源。
-> 上游节点的普通变量同样可以填写至上下文变量内,例如开始节点的字符串类型变量,但 **引用与归属** 功能将会失效。
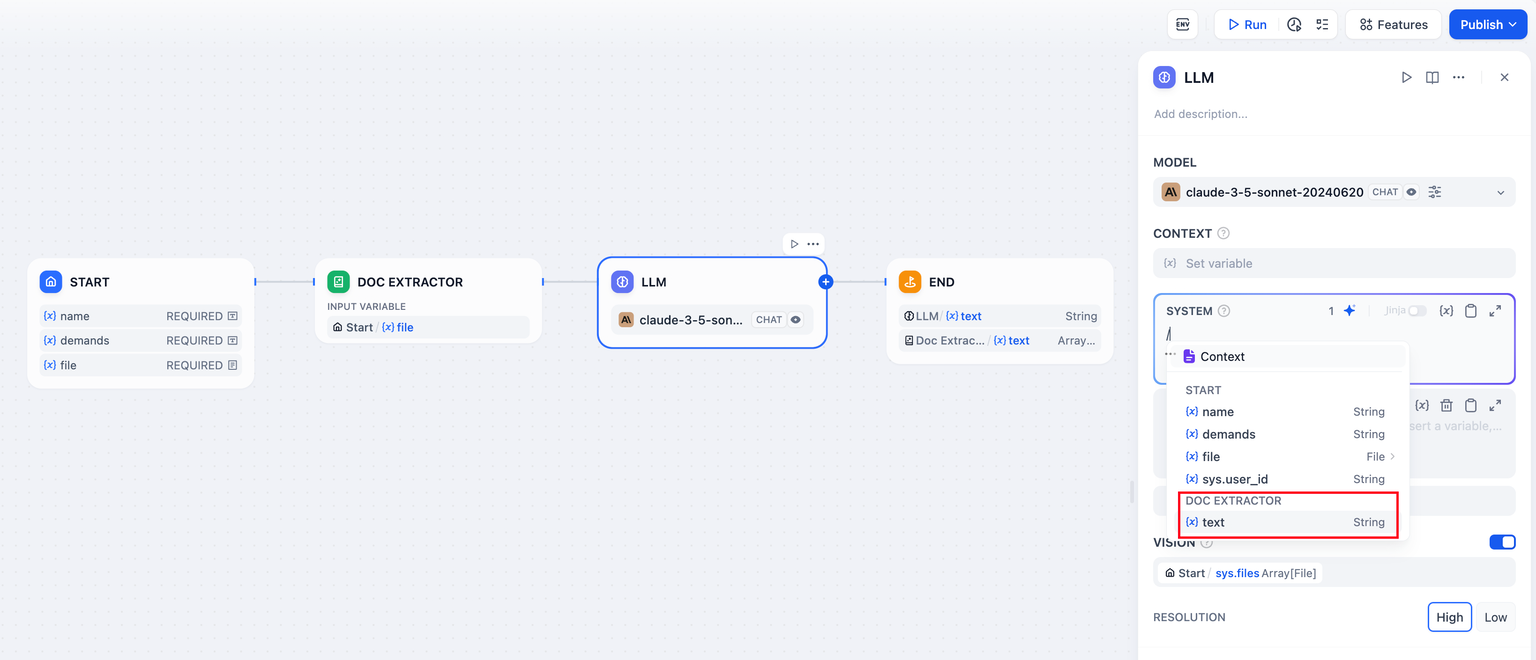
+ -
+
+
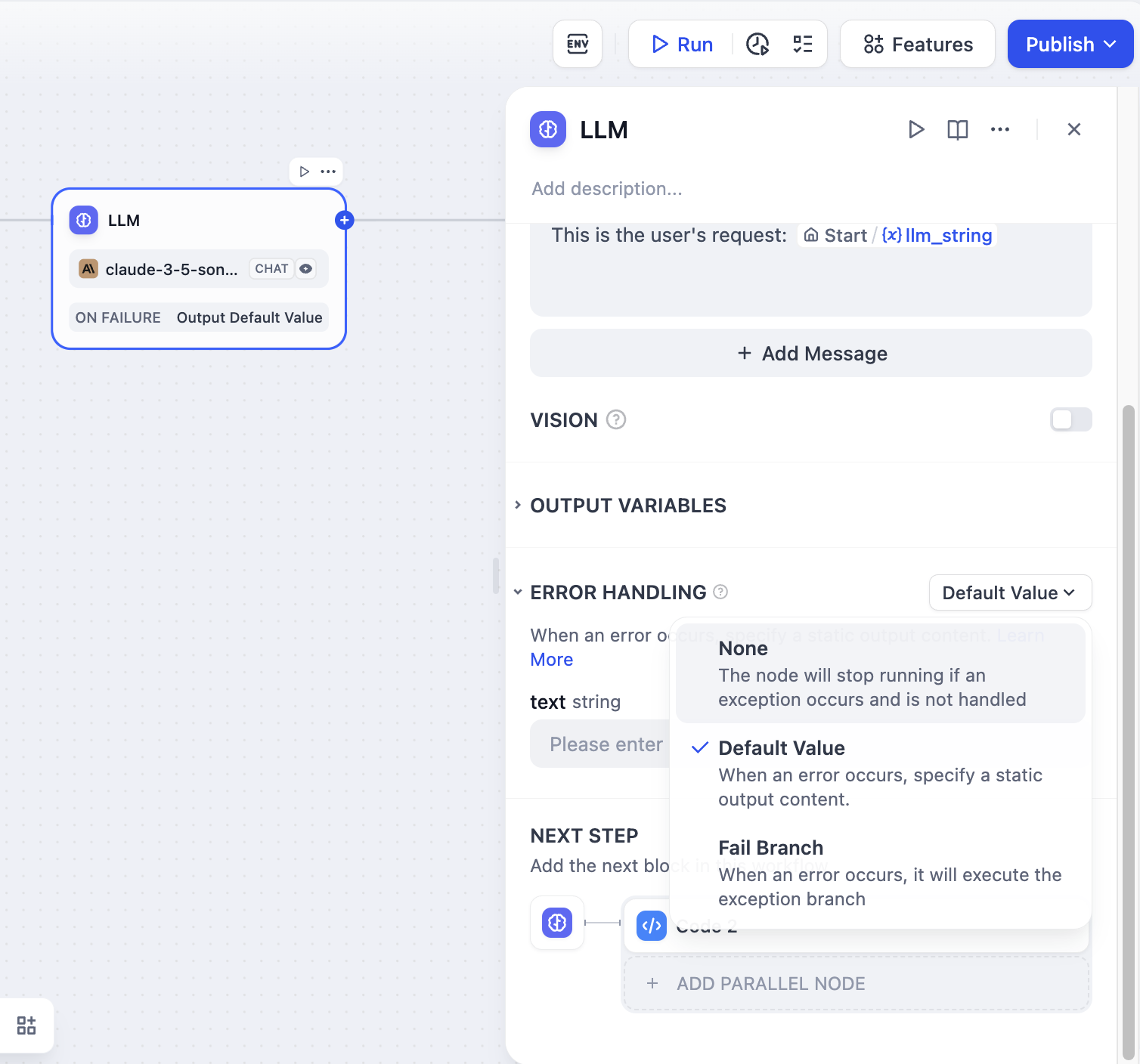
+* **异常处理**
+
+LLM 节点处理信息时有可能会遇到输入文本超过 Token 限制,未填写关键参数等错误。应用开发者可以参考以下步骤配置异常分支,在节点出现异常时启用应对方案,而避免中断整个流程。
+
+1. 在 LLM 节点启用 “异常处理”
+2. 选择异常处理方案并进行配置
+
+如需了解更多应对异常的处理办法,请参考[异常处理](https://docs.dify.ai/guides/workflow/error-handling)。
+
+
+
+* **结构化输出**
+
+**场景**:你正在使用 Dify 构建一个用户反馈分析工作流。LLM 节点需要读取用户评价,并返回标准化的评分和评论内容,确保数据格式一致,便于后续节点处理。
+
+**解决方案**:在工作流的 LLM 节点中,使用 **JSON Schema 编辑器** 定义结构化格式。这样能确保 LLM 生成的结果被限制在预设格式中,而非输出杂乱文本。
+
+**操作步骤**:
+
+1. 在 **LLM** 节点的 **JSON Schema 编辑器** 中,添加以下字段,确保 LLM 按照规定的结构输出数据:
+
+```json
+{
+ "type": "object",
+ "properties": {
+ "rating": {
+ "type": "integer",
+ "description": "user's rating"
+ },
+ "comment": {
+ "type": "string",
+ "description": "user's comments"
+ }
+ },
+ "required": [
+ "rating",
+ "comment"
+ ]
+}
+```
+
+2. 在工作流的 **开始** 节点,输入一个用户评价,如:
+
+> "这个产品非常棒,使用体验很好!"
+
+3. 经过 **JSON Schema 编辑器** 的处理,AI 生成的 **结构化数据** 如下:
+
+```json
+{
+ "structured_output": {
+ "comment": "这个产品非常棒,使用体验很好!",
+ "rating": 5
+ }
+}
+```
diff --git a/zh-hans/guides/workflow/node/parameter-extractor.mdx b/zh-hans/guides/workflow/node/parameter-extractor.mdx
index 8fc95938..146264f2 100644
--- a/zh-hans/guides/workflow/node/parameter-extractor.mdx
+++ b/zh-hans/guides/workflow/node/parameter-extractor.mdx
@@ -8,7 +8,7 @@ title: 参数提取
Dify 工作流内提供了丰富的[工具](https://docs.dify.ai/v/zh-hans/guides/tools)选择,其中大多数工具的输入为结构化参数,参数提取器可以将用户的自然语言转换为工具可识别的参数,方便工具调用。
-工作流内的部分节点有特定的数据格式传入要求,如[迭代](/zh-hans/guides/workflow/nodes/iteration)节点的输入要求为数组格式,参数提取器可以方便的实现结构化参数的转换。
+工作流内的部分节点有特定的数据格式传入要求,如[迭代](/zh-hans/guides/workflow/node/iteration)节点的输入要求为数组格式,参数提取器可以方便的实现结构化参数的转换。
***
@@ -20,11 +20,11 @@ Dify 工作流内提供了丰富的[工具](https://docs.dify.ai/v/zh-hans/guide
-2. **将文本转换为结构化数据**,如长故事迭代生成应用中,作为[迭代节点](/zh-hans/guides/workflow/nodes/iteration)的前置步骤,将文本格式的章节内容转换为数组格式,方便迭代节点进行多轮生成处理。
+2. **将文本转换为结构化数据**,如长故事迭代生成应用中,作为[迭代节点](/zh-hans/guides/workflow/node/iteration)的前置步骤,将文本格式的章节内容转换为数组格式,方便迭代节点进行多轮生成处理。
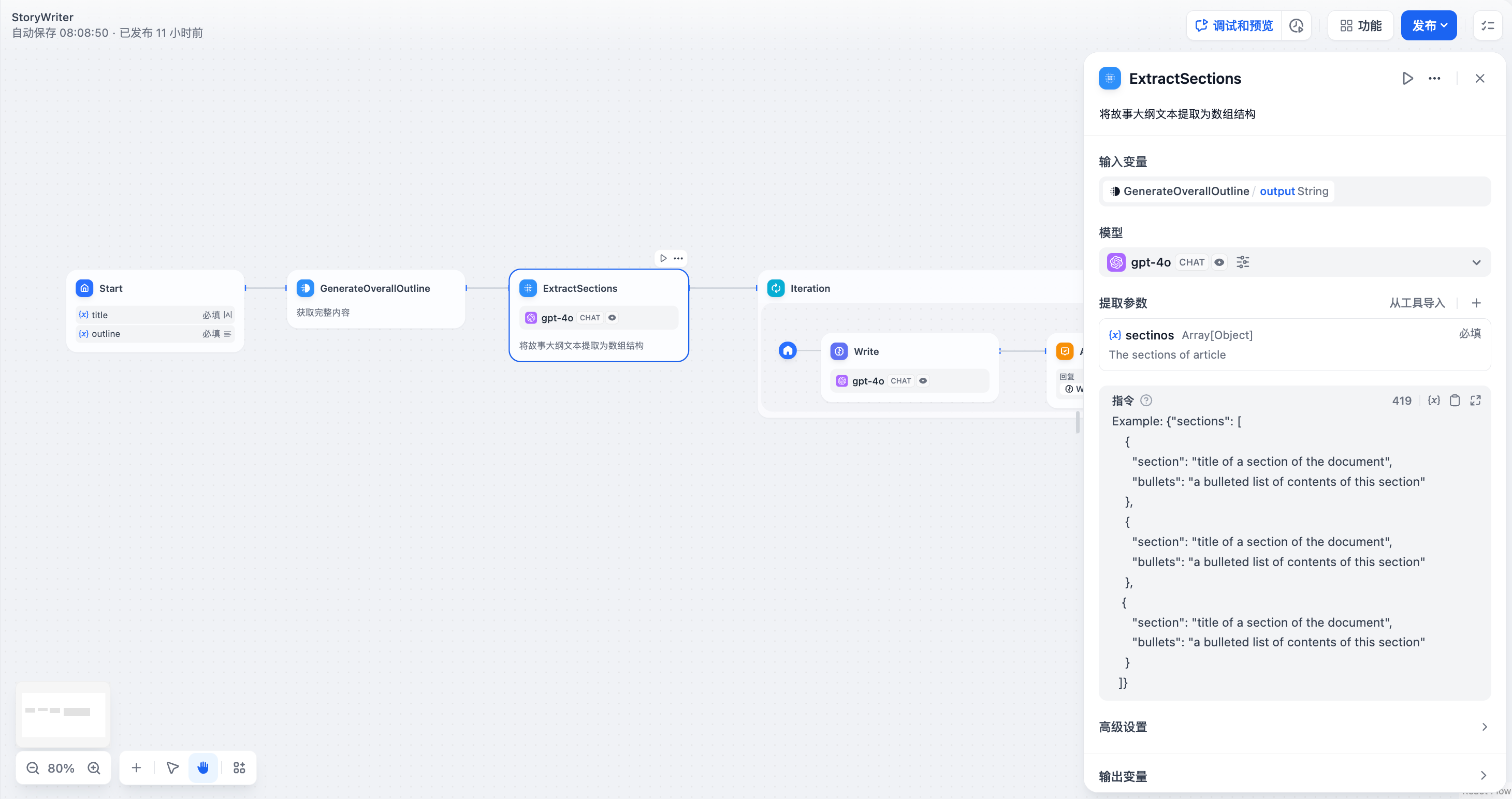
-3. **提取结构化数据并使用** [**HTTP 请求**](/zh-hans/guides/workflow/nodes/http-request) ,可请求任意可访问的 URL ,适用于获取外部检索结果、webhook、生成图片等情景。
+3. **提取结构化数据并使用** [**HTTP 请求**](/zh-hans/guides/workflow/node/http-request) ,可请求任意可访问的 URL ,适用于获取外部检索结果、webhook、生成图片等情景。
***
diff --git a/zh-hans/guides/workflow/node/start.mdx b/zh-hans/guides/workflow/node/start.mdx
index 15ec90f6..9b87296a 100644
--- a/zh-hans/guides/workflow/node/start.mdx
+++ b/zh-hans/guides/workflow/node/start.mdx
@@ -1,6 +1,5 @@
---
title: 开始
-version: '简体中文'
---
## 定义
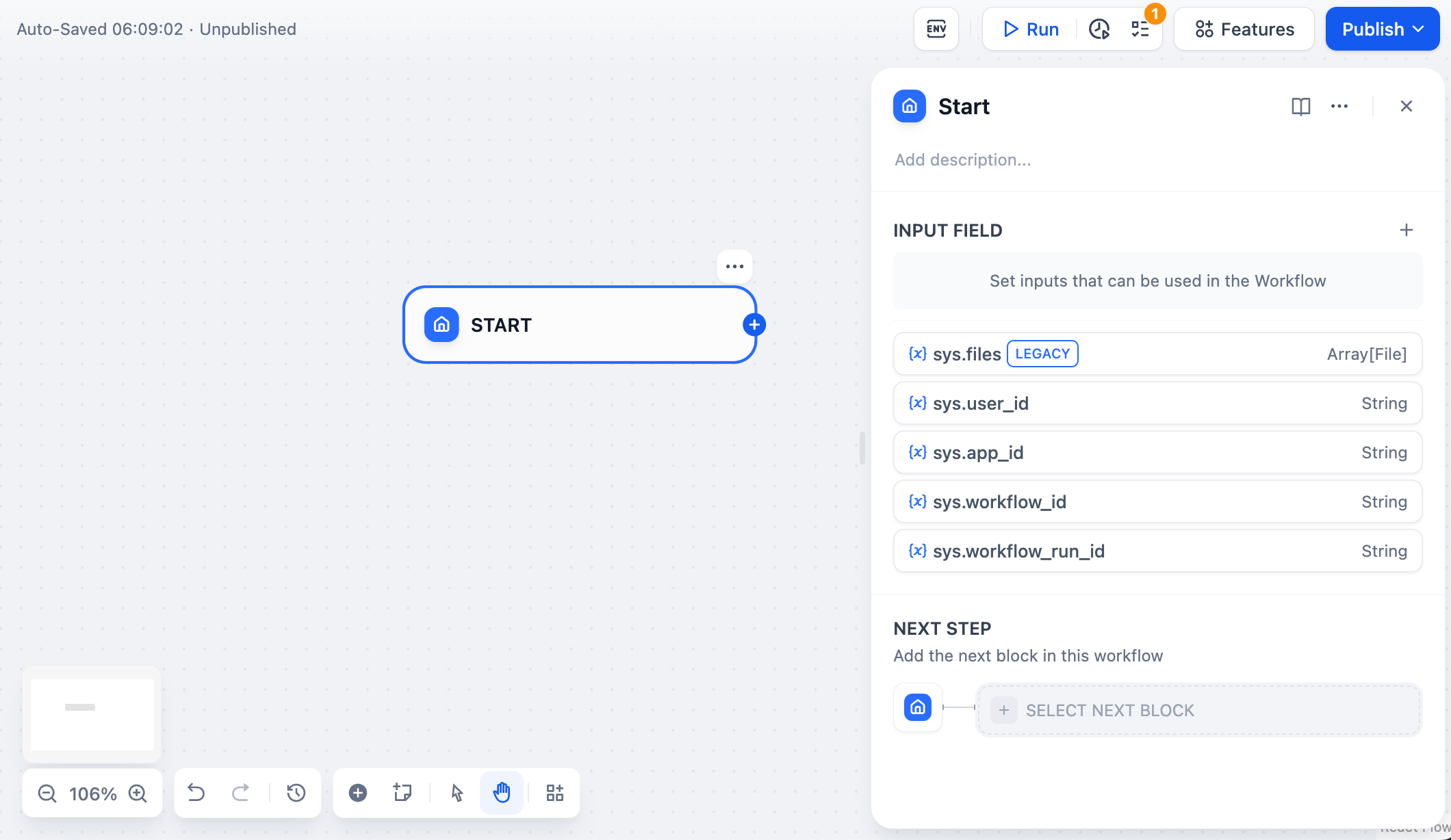
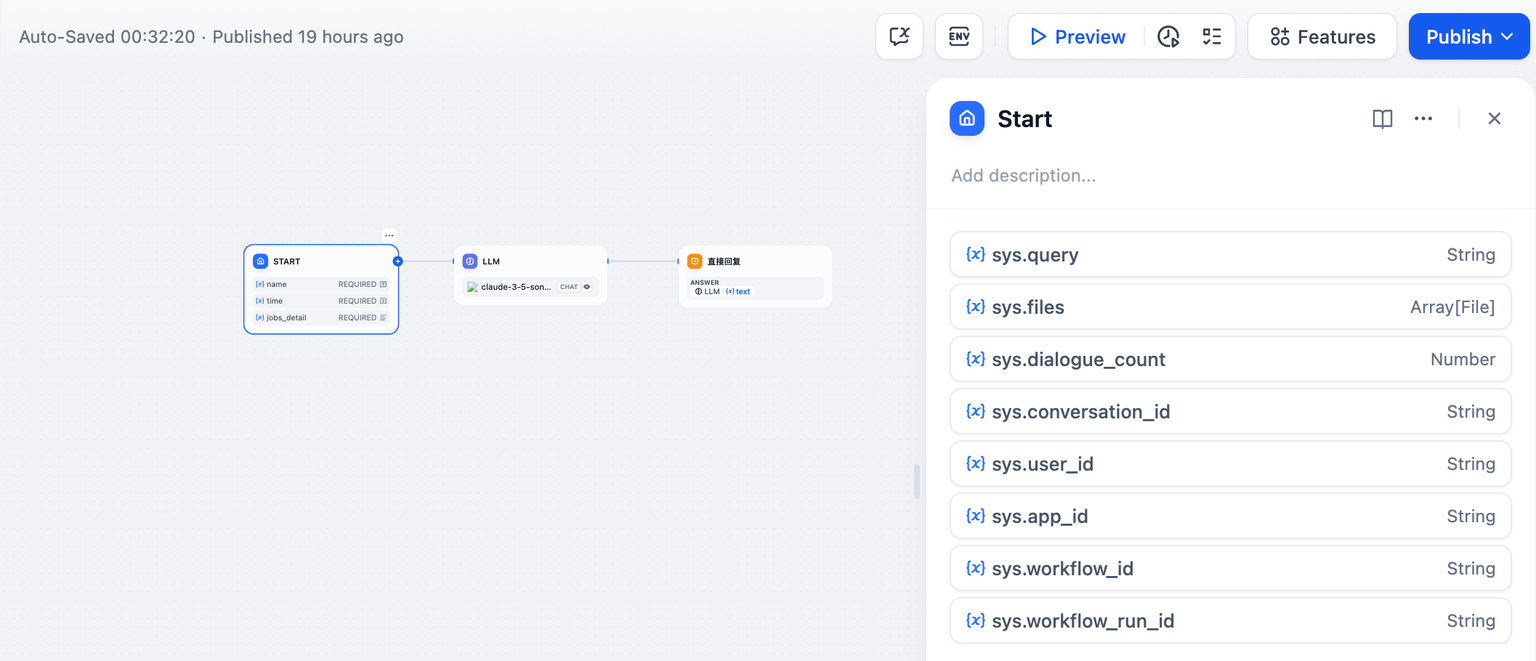
@@ -50,7 +49,7 @@ Workflow 类型应用提供以下系统变量:
| `sys.workflow_id` | String | Workflow ID,用于记录当前 Workflow 应用内所包含的所有节点信息 | 面向具备开发能力的用户,可以通过此参数追踪并记录 Workflow 内的包含节点信息 |
| `sys.workflow_run_id` | String | Workflow 应用运行 ID,用于记录 Workflow 应用中的运行情况 | 面向具备开发能力的用户,可以通过此参数追踪应用的历次运行情况 |
-
+
**Chatflow**
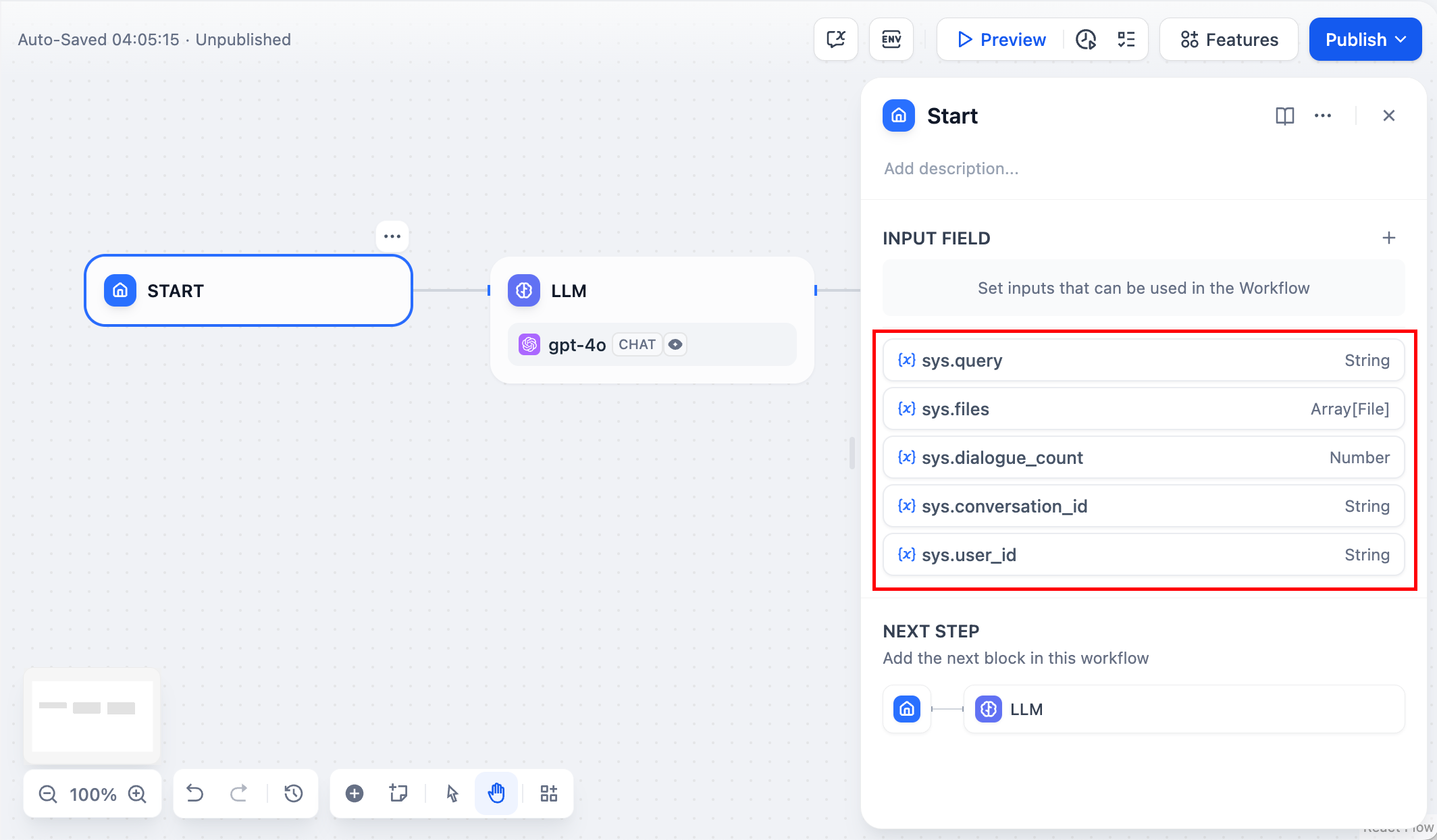
@@ -67,4 +66,4 @@ Chatflow 类型应用提供以下系统变量:
| `sys.workflow_id` | String | Workflow ID,用于记录当前 Workflow 应用内所包含的所有节点信息 | 面向具备开发能力的用户,可以通过此参数追踪并记录 Workflow 内的包含节点信息 |
| `sys.workflow_run_id` | String | Workflow 应用运行 ID,用于记录 Workflow 应用中的运行情况 | 面向具备开发能力的用户,可以通过此参数追踪应用的历次运行情况 |
-
\ No newline at end of file
+
diff --git a/zh-hans/guides/workflow/node/template.mdx b/zh-hans/guides/workflow/node/template.mdx
index f96df6d7..c581c2be 100644
--- a/zh-hans/guides/workflow/node/template.mdx
+++ b/zh-hans/guides/workflow/node/template.mdx
@@ -9,11 +9,9 @@ version: '简体中文'
### 什么是 Jinja?
-> Jinja is a fast, expressive, extensible templating engine.
+> [Jinja](https://jinja.palletsprojects.com/en/3.1.x/) is a fast, expressive, extensible templating engine.
>
-> Jinja 是一个快速、表达力强、可扩展的模板引擎。
-
-—— [https://jinja.palletsprojects.com/en/3.1.x/](https://jinja.palletsprojects.com/en/3.1.x/)
+> [Jinja](https://jinja.palletsprojects.com/en/3.1.x/) 是一个快速、表达力强、可扩展的模板引擎。
### 场景
diff --git a/zh-hans/guides/workflow/node/variable-assigner.mdx b/zh-hans/guides/workflow/node/variable-assigner.mdx
index a653d1cc..ca4c1bd1 100644
--- a/zh-hans/guides/workflow/node/variable-assigner.mdx
+++ b/zh-hans/guides/workflow/node/variable-assigner.mdx
@@ -7,7 +7,8 @@ version: '简体中文'
变量赋值节点用于向可写入变量进行变量赋值,已支持以下可写入变量:
-* [会话变量](../variables#会话变量)。
+* [会话变量](../variables#会话变量)
+* [循环变量](/zh-hans/guides/workflow/node/loop)
用法:通过变量赋值节点,你可以将工作流内的变量赋值到会话变量中用于临时存储,并可以在后续对话中持续引用。
@@ -160,8 +161,32 @@ def main(arg1: list) -> str:
以上图赋值逻辑为例:将上一个节点的文本输出项 `Language Recognition/text` 赋值到会话变量 `language` 内。
-**写入模式:**
+### 指定变量的写入模式
-* 覆盖,将源变量的内容覆盖至目标会话变量
-* 追加,指定变量为 Array 类型时
-* 清空,清空目标会话变量中的内容
\ No newline at end of file
+目标变量的数据类型将影响变量的写入模式。以下是不同变量间的写入模式:
+
+1. 目标变量的数据类型为 `String`。
+
+ * **覆盖**,将源变量直接覆盖至目标变量
+ * **清空**,清空所选中变量中的内容
+ * **设置**,手动指定一个值,无需设置源变量
+
+2. 目标变量的数据类型为 `Number`。
+
+ * **覆盖**,将源变量直接覆盖至目标变量
+ * **清空**,清空所选中变量中的内容
+ * **设置**,手动指定一个值,无需设置源变量
+ * **数字处理**,对目标变量进行`加减乘除`操作
+
+3. 目标变量的数据类型为 `Object`。
+
+ * **覆盖**,将源变量的内容直接覆盖至目标变量
+ * **清空**,清空所选中变量中的内容
+ * **设置**,手动指定一个值,无需设置源变量
+
+4. 目标变量的数据类型为 `Array`。
+
+ * **覆盖**,将源变量的内容直接覆盖至目标变量
+ * **清空**,清空所选中变量中的内容
+ * **追加**,在目标的数组变量中添加一个新的元素
+ * **扩展**,在目标的数组变量中添加新的数组,即一次性添加多个元素
diff --git a/zh-hans/guides/workflow/structured-outputs.mdx b/zh-hans/guides/workflow/structured-outputs.mdx
new file mode 100644
index 00000000..e72f4b48
--- /dev/null
+++ b/zh-hans/guides/workflow/structured-outputs.mdx
@@ -0,0 +1,63 @@
+---
+title: 结构化输出
+---
+
+## 简介
+
+作为 LLM 工具链平台,Dify 支持 JSON 结构化输出功能。结构化输出功能可以确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。
+
+## 价值
+
+- **确保数据格式一致**:即使由 LLM 生成内容,也必须符合预设格式,避免数据混乱。
+
+- **方便后续节点处理**:数据库、API 或前端可以直接解析 JSON Schema,而无需额外数据清洗。
+
+- **提升低代码开发体验**:开发者无需手写复杂数据校验逻辑,直接使用 JSON Schema 约束输出。
+
+## 如何实现结构化输出?
+
+在 Dify 的操作界面中,可以通过以下两种方式实现结构化输出:
+
+- **方式一:直接定义工具参数**
+
+- **方式二:使用 LLM 节点中的 JSON Schema 编辑器**
+
+### 方式一:直接定义工具参数
+
+请参阅 **[Tool](https://docs.dify.ai/zh-hans/plugins/schema-definition/tool) > 数据结构 > 返回变量定义**。
+
+### 方式二:使用 LLM 节点中的 JSON Schema 编辑器
+
+请参阅 **[LLM](https://docs.dify.ai/zh-hans/guides/workflow/node/llm) > 高级功能 > 结构化输出** 与 **[LLM](https://docs.dify.ai/zh-hans/guides/workflow/node/llm) > 使用案例 > 结构化输出**。
+
+## 异常处理方案
+
+**异常情况**
+
+在使用 JSON Schema 编辑器进行结构化输出时,可能会遇到以下限制和异常情况:
+
+- **模型能力限制**:部分 LLM(尤其是 70B 以下的模型或 GPT-3.5 Turbo 级别模型)在指令遵循性上较弱,可能导致 JSON Schema 解析失败。
+
+- **格式兼容性**:部分 LLM 仅支持 **JSON mode** 而非 **JSON Schema**,导致严格的 Schema 解析失败。
+
+- **错误信息**:出现错误 `Failed to parse structured output: output is not a valid json str`。此类错误主要源于模型生成 JSON 失败。
+
+**推荐处理方案**
+
+1. **优先使用支持 JSON Schema 的模型**。推荐列表如下:
+ - Gemini 2.0 Flash/Flash-Lite
+ - Gemini 1.5 Flash 8B (0827/0924)
+ - Gemini-1.5 pro
+ - GPT-4o
+ - GPT-4o-mini
+ - o1-mini/o3-mini 系列
+
+2. **适当调整系统提示词以增强指令遵循性,尽可能确保 LLM 输出符合 Schema 规范**。假如 JSON Schema 设计用于结构化数学公式的输入与输出,而系统提示词却要求模型进行法律条文解析,这种不匹配可能会导致模型无法正确理解任务,影响生成结果的准确性。
+
+3. **配置异常处理策略**。你可以在解析失败时考虑采取以下措施:
+
+ 1. **配置失败时重试**:在节点内开启 **失败时重试** 功能并配置最大重试次数与重试间隔,以减少解析错误的影响。
+
+ 2. **配置异常分支**:在节点内的 **异常处理** 中配置 **失败分支**。当节点发生异常时,将自动执行失败分支。
+
+详情请参阅[异常处理](https://docs.dify.ai/zh-hans/guides/workflow/error-handling)。
diff --git a/zh-hans/guides/workflow/variables.mdx b/zh-hans/guides/workflow/variables.mdx
index 6d3020b5..c563deb6 100644
--- a/zh-hans/guides/workflow/variables.mdx
+++ b/zh-hans/guides/workflow/variables.mdx
@@ -1,6 +1,6 @@
---
title: 变量
-version: '简体中文'
+description: 最近编辑:Allen, Dify Technical Writer
---
Workflow 和 Chatflow 类型应用由独立节点相构成。大部分节点设有输入和输出项,但每个节点的输入信息不一致,各个节点所输出的答复也不尽相同。
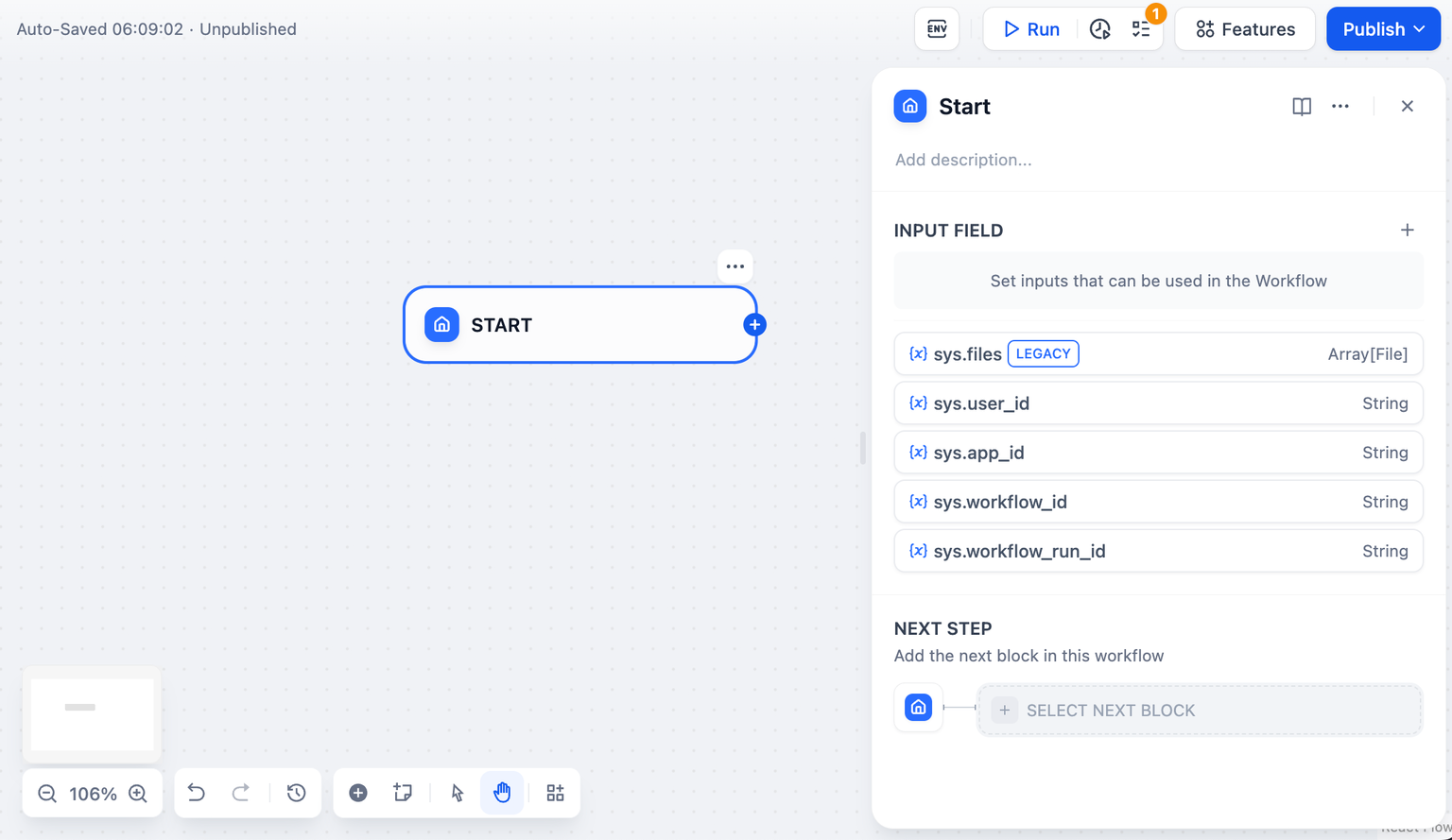
@@ -58,7 +58,7 @@ Workflow 类型应用提供以下系统变量:
-
+
#### Chatflow
@@ -131,7 +131,7 @@ Chatflow 类型应用提供以下系统变量:
**环境变量用于保护工作流内所涉及的敏感信息**,例如运行工作流时所涉及的 API 密钥、数据库密码等。它们被存储在工作流程中,而不是代码中,以便在不同环境中共享。
-
+
支持以下三种数据类型:
@@ -153,7 +153,7 @@ Chatflow 类型应用提供以下系统变量:
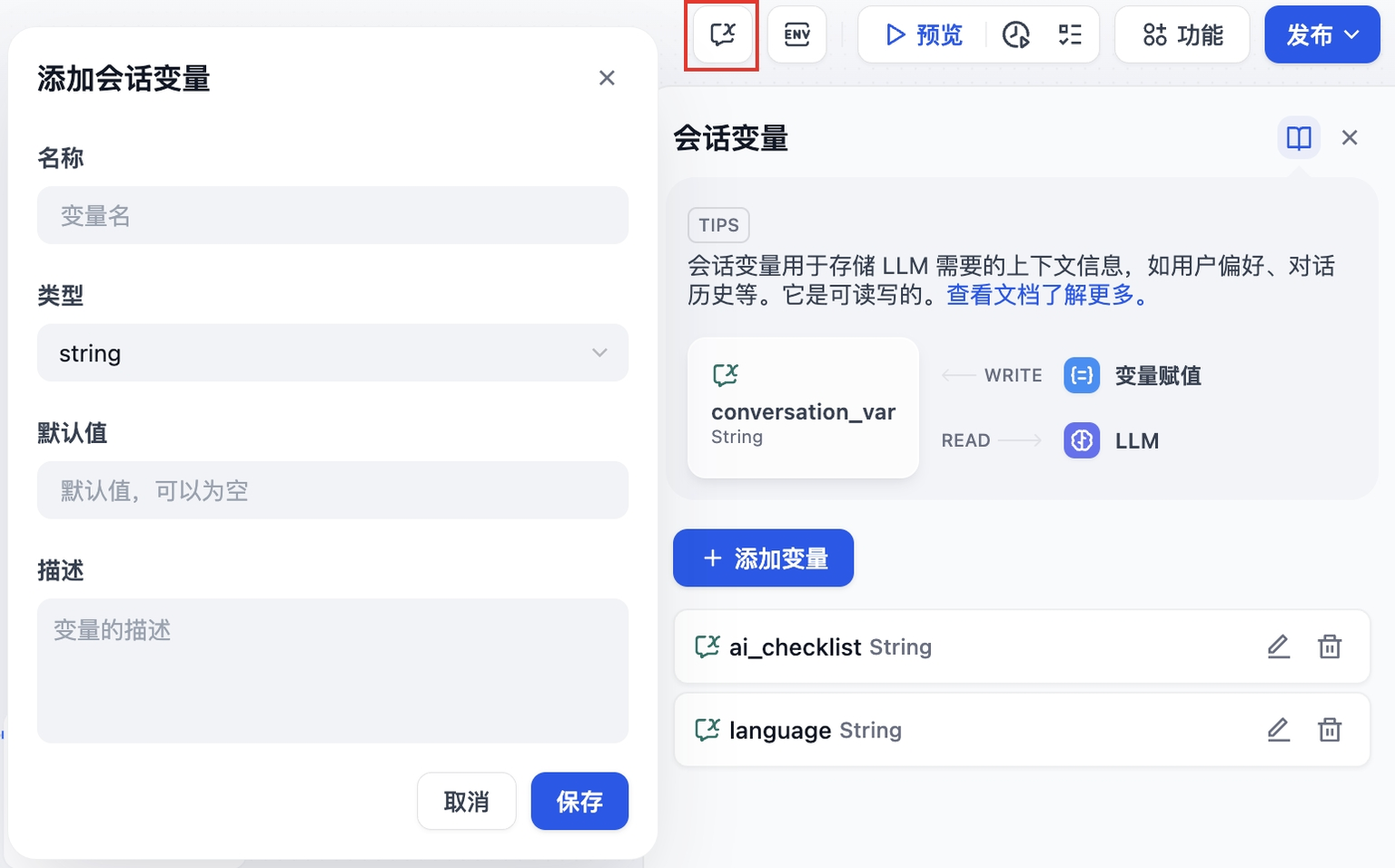
例如你可以将用户在首轮对话时输入的语言偏好存储至会话变量中,LLM 在回答时将参考会话变量中的信息,并在后续的对话中使用指定的语言回复用户。
-
+
**会话变量**支持以下六种数据类型:
@@ -167,10 +167,10 @@ Chatflow 类型应用提供以下系统变量:
**会话变量**具有以下特性:
* 会话变量可在大部分节点内全局引用;
-* 会话变量的写入需要使用[变量赋值](./nodes/variable-assigner)节点;
+* 会话变量的写入需要使用[变量赋值](./node/variable-assigner)节点;
* 会话变量为可读写变量;
-关于如何将会话变量与变量赋值节点配合使用,请参考[变量赋值](./nodes/variable-assigner)节点说明。
+关于如何将会话变量与变量赋值节点配合使用,请参考[变量赋值](./node/variable-assigner)节点说明。
### 注意事项
-
+
+
+* **异常处理**
+
+LLM 节点处理信息时有可能会遇到输入文本超过 Token 限制,未填写关键参数等错误。应用开发者可以参考以下步骤配置异常分支,在节点出现异常时启用应对方案,而避免中断整个流程。
+
+1. 在 LLM 节点启用 “异常处理”
+2. 选择异常处理方案并进行配置
+
+如需了解更多应对异常的处理办法,请参考[异常处理](https://docs.dify.ai/guides/workflow/error-handling)。
+
+
+
+* **结构化输出**
+
+**场景**:你正在使用 Dify 构建一个用户反馈分析工作流。LLM 节点需要读取用户评价,并返回标准化的评分和评论内容,确保数据格式一致,便于后续节点处理。
+
+**解决方案**:在工作流的 LLM 节点中,使用 **JSON Schema 编辑器** 定义结构化格式。这样能确保 LLM 生成的结果被限制在预设格式中,而非输出杂乱文本。
+
+**操作步骤**:
+
+1. 在 **LLM** 节点的 **JSON Schema 编辑器** 中,添加以下字段,确保 LLM 按照规定的结构输出数据:
+
+```json
+{
+ "type": "object",
+ "properties": {
+ "rating": {
+ "type": "integer",
+ "description": "user's rating"
+ },
+ "comment": {
+ "type": "string",
+ "description": "user's comments"
+ }
+ },
+ "required": [
+ "rating",
+ "comment"
+ ]
+}
+```
+
+2. 在工作流的 **开始** 节点,输入一个用户评价,如:
+
+> "这个产品非常棒,使用体验很好!"
+
+3. 经过 **JSON Schema 编辑器** 的处理,AI 生成的 **结构化数据** 如下:
+
+```json
+{
+ "structured_output": {
+ "comment": "这个产品非常棒,使用体验很好!",
+ "rating": 5
+ }
+}
+```
diff --git a/zh-hans/guides/workflow/node/parameter-extractor.mdx b/zh-hans/guides/workflow/node/parameter-extractor.mdx
index 8fc95938..146264f2 100644
--- a/zh-hans/guides/workflow/node/parameter-extractor.mdx
+++ b/zh-hans/guides/workflow/node/parameter-extractor.mdx
@@ -8,7 +8,7 @@ title: 参数提取
Dify 工作流内提供了丰富的[工具](https://docs.dify.ai/v/zh-hans/guides/tools)选择,其中大多数工具的输入为结构化参数,参数提取器可以将用户的自然语言转换为工具可识别的参数,方便工具调用。
-工作流内的部分节点有特定的数据格式传入要求,如[迭代](/zh-hans/guides/workflow/nodes/iteration)节点的输入要求为数组格式,参数提取器可以方便的实现结构化参数的转换。
+工作流内的部分节点有特定的数据格式传入要求,如[迭代](/zh-hans/guides/workflow/node/iteration)节点的输入要求为数组格式,参数提取器可以方便的实现结构化参数的转换。
***
@@ -20,11 +20,11 @@ Dify 工作流内提供了丰富的[工具](https://docs.dify.ai/v/zh-hans/guide

-2. **将文本转换为结构化数据**,如长故事迭代生成应用中,作为[迭代节点](/zh-hans/guides/workflow/nodes/iteration)的前置步骤,将文本格式的章节内容转换为数组格式,方便迭代节点进行多轮生成处理。
+2. **将文本转换为结构化数据**,如长故事迭代生成应用中,作为[迭代节点](/zh-hans/guides/workflow/node/iteration)的前置步骤,将文本格式的章节内容转换为数组格式,方便迭代节点进行多轮生成处理。

-3. **提取结构化数据并使用** [**HTTP 请求**](/zh-hans/guides/workflow/nodes/http-request) ,可请求任意可访问的 URL ,适用于获取外部检索结果、webhook、生成图片等情景。
+3. **提取结构化数据并使用** [**HTTP 请求**](/zh-hans/guides/workflow/node/http-request) ,可请求任意可访问的 URL ,适用于获取外部检索结果、webhook、生成图片等情景。
***
diff --git a/zh-hans/guides/workflow/node/start.mdx b/zh-hans/guides/workflow/node/start.mdx
index 15ec90f6..9b87296a 100644
--- a/zh-hans/guides/workflow/node/start.mdx
+++ b/zh-hans/guides/workflow/node/start.mdx
@@ -1,6 +1,5 @@
---
title: 开始
-version: '简体中文'
---
## 定义
@@ -50,7 +49,7 @@ Workflow 类型应用提供以下系统变量:
| `sys.workflow_id` | String | Workflow ID,用于记录当前 Workflow 应用内所包含的所有节点信息 | 面向具备开发能力的用户,可以通过此参数追踪并记录 Workflow 内的包含节点信息 |
| `sys.workflow_run_id` | String | Workflow 应用运行 ID,用于记录 Workflow 应用中的运行情况 | 面向具备开发能力的用户,可以通过此参数追踪应用的历次运行情况 |
-
+
**Chatflow**
@@ -67,4 +66,4 @@ Chatflow 类型应用提供以下系统变量:
| `sys.workflow_id` | String | Workflow ID,用于记录当前 Workflow 应用内所包含的所有节点信息 | 面向具备开发能力的用户,可以通过此参数追踪并记录 Workflow 内的包含节点信息 |
| `sys.workflow_run_id` | String | Workflow 应用运行 ID,用于记录 Workflow 应用中的运行情况 | 面向具备开发能力的用户,可以通过此参数追踪应用的历次运行情况 |
-
\ No newline at end of file
+
diff --git a/zh-hans/guides/workflow/node/template.mdx b/zh-hans/guides/workflow/node/template.mdx
index f96df6d7..c581c2be 100644
--- a/zh-hans/guides/workflow/node/template.mdx
+++ b/zh-hans/guides/workflow/node/template.mdx
@@ -9,11 +9,9 @@ version: '简体中文'
### 什么是 Jinja?
-> Jinja is a fast, expressive, extensible templating engine.
+> [Jinja](https://jinja.palletsprojects.com/en/3.1.x/) is a fast, expressive, extensible templating engine.
>
-> Jinja 是一个快速、表达力强、可扩展的模板引擎。
-
-—— [https://jinja.palletsprojects.com/en/3.1.x/](https://jinja.palletsprojects.com/en/3.1.x/)
+> [Jinja](https://jinja.palletsprojects.com/en/3.1.x/) 是一个快速、表达力强、可扩展的模板引擎。
### 场景
diff --git a/zh-hans/guides/workflow/node/variable-assigner.mdx b/zh-hans/guides/workflow/node/variable-assigner.mdx
index a653d1cc..ca4c1bd1 100644
--- a/zh-hans/guides/workflow/node/variable-assigner.mdx
+++ b/zh-hans/guides/workflow/node/variable-assigner.mdx
@@ -7,7 +7,8 @@ version: '简体中文'
变量赋值节点用于向可写入变量进行变量赋值,已支持以下可写入变量:
-* [会话变量](../variables#会话变量)。
+* [会话变量](../variables#会话变量)
+* [循环变量](/zh-hans/guides/workflow/node/loop)
用法:通过变量赋值节点,你可以将工作流内的变量赋值到会话变量中用于临时存储,并可以在后续对话中持续引用。
@@ -160,8 +161,32 @@ def main(arg1: list) -> str:
以上图赋值逻辑为例:将上一个节点的文本输出项 `Language Recognition/text` 赋值到会话变量 `language` 内。
-**写入模式:**
+### 指定变量的写入模式
-* 覆盖,将源变量的内容覆盖至目标会话变量
-* 追加,指定变量为 Array 类型时
-* 清空,清空目标会话变量中的内容
\ No newline at end of file
+目标变量的数据类型将影响变量的写入模式。以下是不同变量间的写入模式:
+
+1. 目标变量的数据类型为 `String`。
+
+ * **覆盖**,将源变量直接覆盖至目标变量
+ * **清空**,清空所选中变量中的内容
+ * **设置**,手动指定一个值,无需设置源变量
+
+2. 目标变量的数据类型为 `Number`。
+
+ * **覆盖**,将源变量直接覆盖至目标变量
+ * **清空**,清空所选中变量中的内容
+ * **设置**,手动指定一个值,无需设置源变量
+ * **数字处理**,对目标变量进行`加减乘除`操作
+
+3. 目标变量的数据类型为 `Object`。
+
+ * **覆盖**,将源变量的内容直接覆盖至目标变量
+ * **清空**,清空所选中变量中的内容
+ * **设置**,手动指定一个值,无需设置源变量
+
+4. 目标变量的数据类型为 `Array`。
+
+ * **覆盖**,将源变量的内容直接覆盖至目标变量
+ * **清空**,清空所选中变量中的内容
+ * **追加**,在目标的数组变量中添加一个新的元素
+ * **扩展**,在目标的数组变量中添加新的数组,即一次性添加多个元素
diff --git a/zh-hans/guides/workflow/structured-outputs.mdx b/zh-hans/guides/workflow/structured-outputs.mdx
new file mode 100644
index 00000000..e72f4b48
--- /dev/null
+++ b/zh-hans/guides/workflow/structured-outputs.mdx
@@ -0,0 +1,63 @@
+---
+title: 结构化输出
+---
+
+## 简介
+
+作为 LLM 工具链平台,Dify 支持 JSON 结构化输出功能。结构化输出功能可以确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。
+
+## 价值
+
+- **确保数据格式一致**:即使由 LLM 生成内容,也必须符合预设格式,避免数据混乱。
+
+- **方便后续节点处理**:数据库、API 或前端可以直接解析 JSON Schema,而无需额外数据清洗。
+
+- **提升低代码开发体验**:开发者无需手写复杂数据校验逻辑,直接使用 JSON Schema 约束输出。
+
+## 如何实现结构化输出?
+
+在 Dify 的操作界面中,可以通过以下两种方式实现结构化输出:
+
+- **方式一:直接定义工具参数**
+
+- **方式二:使用 LLM 节点中的 JSON Schema 编辑器**
+
+### 方式一:直接定义工具参数
+
+请参阅 **[Tool](https://docs.dify.ai/zh-hans/plugins/schema-definition/tool) > 数据结构 > 返回变量定义**。
+
+### 方式二:使用 LLM 节点中的 JSON Schema 编辑器
+
+请参阅 **[LLM](https://docs.dify.ai/zh-hans/guides/workflow/node/llm) > 高级功能 > 结构化输出** 与 **[LLM](https://docs.dify.ai/zh-hans/guides/workflow/node/llm) > 使用案例 > 结构化输出**。
+
+## 异常处理方案
+
+**异常情况**
+
+在使用 JSON Schema 编辑器进行结构化输出时,可能会遇到以下限制和异常情况:
+
+- **模型能力限制**:部分 LLM(尤其是 70B 以下的模型或 GPT-3.5 Turbo 级别模型)在指令遵循性上较弱,可能导致 JSON Schema 解析失败。
+
+- **格式兼容性**:部分 LLM 仅支持 **JSON mode** 而非 **JSON Schema**,导致严格的 Schema 解析失败。
+
+- **错误信息**:出现错误 `Failed to parse structured output: output is not a valid json str`。此类错误主要源于模型生成 JSON 失败。
+
+**推荐处理方案**
+
+1. **优先使用支持 JSON Schema 的模型**。推荐列表如下:
+ - Gemini 2.0 Flash/Flash-Lite
+ - Gemini 1.5 Flash 8B (0827/0924)
+ - Gemini-1.5 pro
+ - GPT-4o
+ - GPT-4o-mini
+ - o1-mini/o3-mini 系列
+
+2. **适当调整系统提示词以增强指令遵循性,尽可能确保 LLM 输出符合 Schema 规范**。假如 JSON Schema 设计用于结构化数学公式的输入与输出,而系统提示词却要求模型进行法律条文解析,这种不匹配可能会导致模型无法正确理解任务,影响生成结果的准确性。
+
+3. **配置异常处理策略**。你可以在解析失败时考虑采取以下措施:
+
+ 1. **配置失败时重试**:在节点内开启 **失败时重试** 功能并配置最大重试次数与重试间隔,以减少解析错误的影响。
+
+ 2. **配置异常分支**:在节点内的 **异常处理** 中配置 **失败分支**。当节点发生异常时,将自动执行失败分支。
+
+详情请参阅[异常处理](https://docs.dify.ai/zh-hans/guides/workflow/error-handling)。
diff --git a/zh-hans/guides/workflow/variables.mdx b/zh-hans/guides/workflow/variables.mdx
index 6d3020b5..c563deb6 100644
--- a/zh-hans/guides/workflow/variables.mdx
+++ b/zh-hans/guides/workflow/variables.mdx
@@ -1,6 +1,6 @@
---
title: 变量
-version: '简体中文'
+description: 最近编辑:Allen, Dify Technical Writer
---
Workflow 和 Chatflow 类型应用由独立节点相构成。大部分节点设有输入和输出项,但每个节点的输入信息不一致,各个节点所输出的答复也不尽相同。
@@ -58,7 +58,7 @@ Workflow 类型应用提供以下系统变量:
-
+
#### Chatflow
@@ -131,7 +131,7 @@ Chatflow 类型应用提供以下系统变量:
**环境变量用于保护工作流内所涉及的敏感信息**,例如运行工作流时所涉及的 API 密钥、数据库密码等。它们被存储在工作流程中,而不是代码中,以便在不同环境中共享。
-
+
支持以下三种数据类型:
@@ -153,7 +153,7 @@ Chatflow 类型应用提供以下系统变量:
例如你可以将用户在首轮对话时输入的语言偏好存储至会话变量中,LLM 在回答时将参考会话变量中的信息,并在后续的对话中使用指定的语言回复用户。
-
+
**会话变量**支持以下六种数据类型:
@@ -167,10 +167,10 @@ Chatflow 类型应用提供以下系统变量:
**会话变量**具有以下特性:
* 会话变量可在大部分节点内全局引用;
-* 会话变量的写入需要使用[变量赋值](./nodes/variable-assigner)节点;
+* 会话变量的写入需要使用[变量赋值](./node/variable-assigner)节点;
* 会话变量为可读写变量;
-关于如何将会话变量与变量赋值节点配合使用,请参考[变量赋值](./nodes/variable-assigner)节点说明。
+关于如何将会话变量与变量赋值节点配合使用,请参考[变量赋值](./node/variable-assigner)节点说明。
### 注意事项