From 51ff31e56d02364021cbe87357c8763c9f5fced9 Mon Sep 17 00:00:00 2001
From: "mintlify[bot]" <109931778+mintlify[bot]@users.noreply.github.com>
Date: Mon, 11 Aug 2025 08:49:35 +0000
Subject: [PATCH] Documentation edits made through Mintlify web editor
---
zh-hans/guides/workflow/node/llm.mdx | 463 ++++++++++++++++++++++++++-
1 file changed, 462 insertions(+), 1 deletion(-)
diff --git a/zh-hans/guides/workflow/node/llm.mdx b/zh-hans/guides/workflow/node/llm.mdx
index f5a0dcbd..bf5b6edd 100644
--- a/zh-hans/guides/workflow/node/llm.mdx
+++ b/zh-hans/guides/workflow/node/llm.mdx
@@ -1,3 +1,464 @@
---
title: "LLM"
----
\ No newline at end of file
+---
+
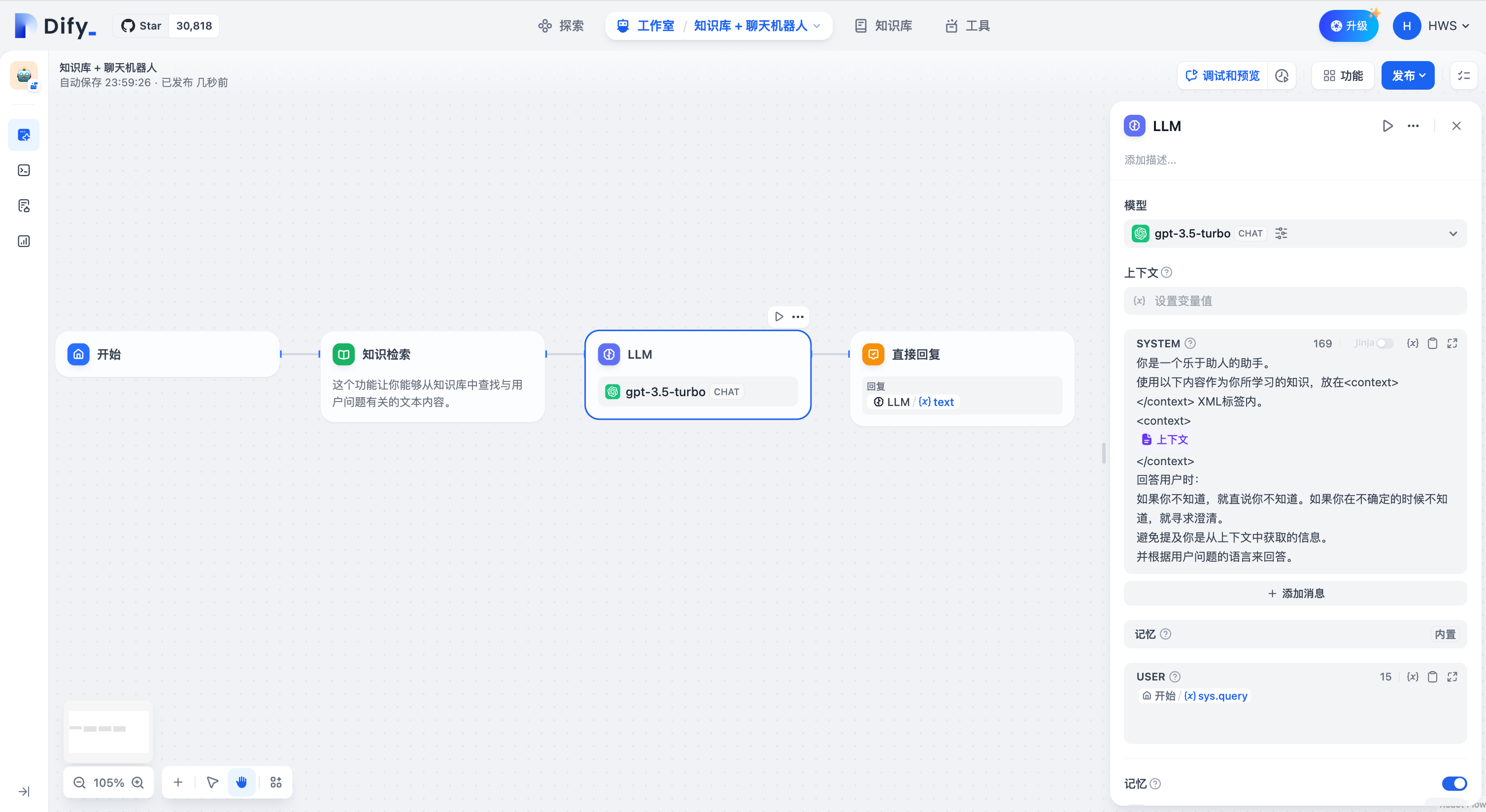
+### 定义
+
+调用大语言模型的能力,处理用户在 "开始" 节点中输入的信息(自然语言、上传的文件或图片),给出有效的回应信息。
+
+
+ 
+
+
+---
+
+### 应用场景
+
+LLM 节点是 Chatflow/Workflow 的核心节点。该节点能够利用大语言模型的对话/生成/分类/处理等能力,根据给定的提示词处理广泛的任务类型,并能够在工作流的不同环节使用。
+
+- **意图识别**,在客服对话情景中,对用户问题进行意图识别和分类,导向下游不同的流程。
+- **文本生成**,在文章生成情景中,作为内容生成的节点,根据主题、关键词生成符合的文本内容。
+- **内容分类**,在邮件批处理情景中,对邮件的类型进行自动化分类,如咨询/投诉/垃圾邮件。
+- **文本转换**,在文本翻译情景中,将用户提供的文本内容翻译成指定语言。
+- **代码生成**,在辅助编程情景中,根据用户的要求生成指定的业务代码,编写测试用例。
+- **RAG**,在知识库问答情景中,将检索到的相关知识和用户问题重新组织回复问题。
+- **图片理解**,使用 vision 能力的多模态模型,能对图像内的信息进行理解和问答。
+
+选择合适的模型,编写提示词,你可以在 Chatflow/Workflow 中构建出强大、可靠的解决方案。
+
+---
+
+### 配置示例
+
+在应用编辑页中,点击鼠标右键或轻点上一节点末尾的 \+ 号,添加节点并选择 LLM。
+
+
+ 
+
+
+**配置步骤:**
+
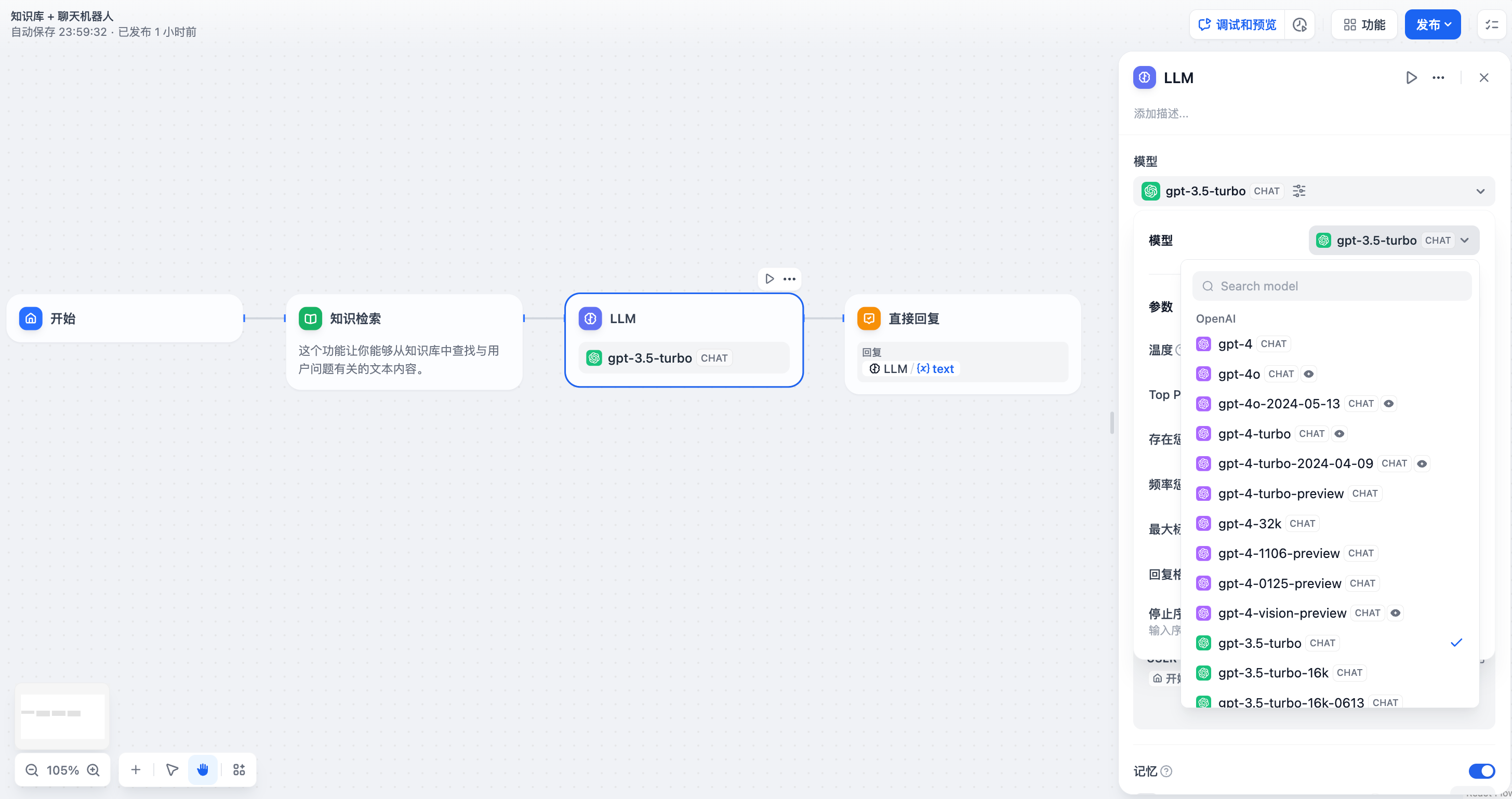
+1. **选择模型**,Dify 提供了全球主流模型的[支持](/zh-hans/getting-started/readme/model-providers),包括 OpenAI 的 GPT 系列、Anthropic 的 Claude 系列、Google 的 Gemini 系列等,选择一个模型取决于其推理能力、成本、响应速度、上下文窗口等因素,你需要根据场景需求和任务类型选择合适的模型。
+
+> 如果你是初次使用 Dify ,在 LLM 节点选择模型之前,需要在 **系统设置—模型供应商** 内提前完成[模型配置](../../model-configuration/)。
+
+2. **配置模型参数**,模型参数用于控制模型的生成结果,例如温度、TopP,最大标记、回复格式等,为了方便选择系统同时提供了 3 套预设参数:创意,平衡和精确。如果你对以上参数并不熟悉,建议选择默认设置。若希望应用具备图片分析能力,请选择具备视觉能力的模型。
+3. **填写上下文(可选)**,上下文可以理解为向 LLM 提供的背景信息,常用于填写[知识检索](knowledge-retrieval)的输出变量。
+4. **编写提示词**,LLM 节点提供了一个易用的提示词编排页面,选择聊天模型或补全模型,会显示不同的提示词编排结构。如果选择聊天模型(Chat model),你可以自定义系统提示词(SYSTEM)/用户(USER)/ 助手(ASSISTANT)三部分内容。
+
+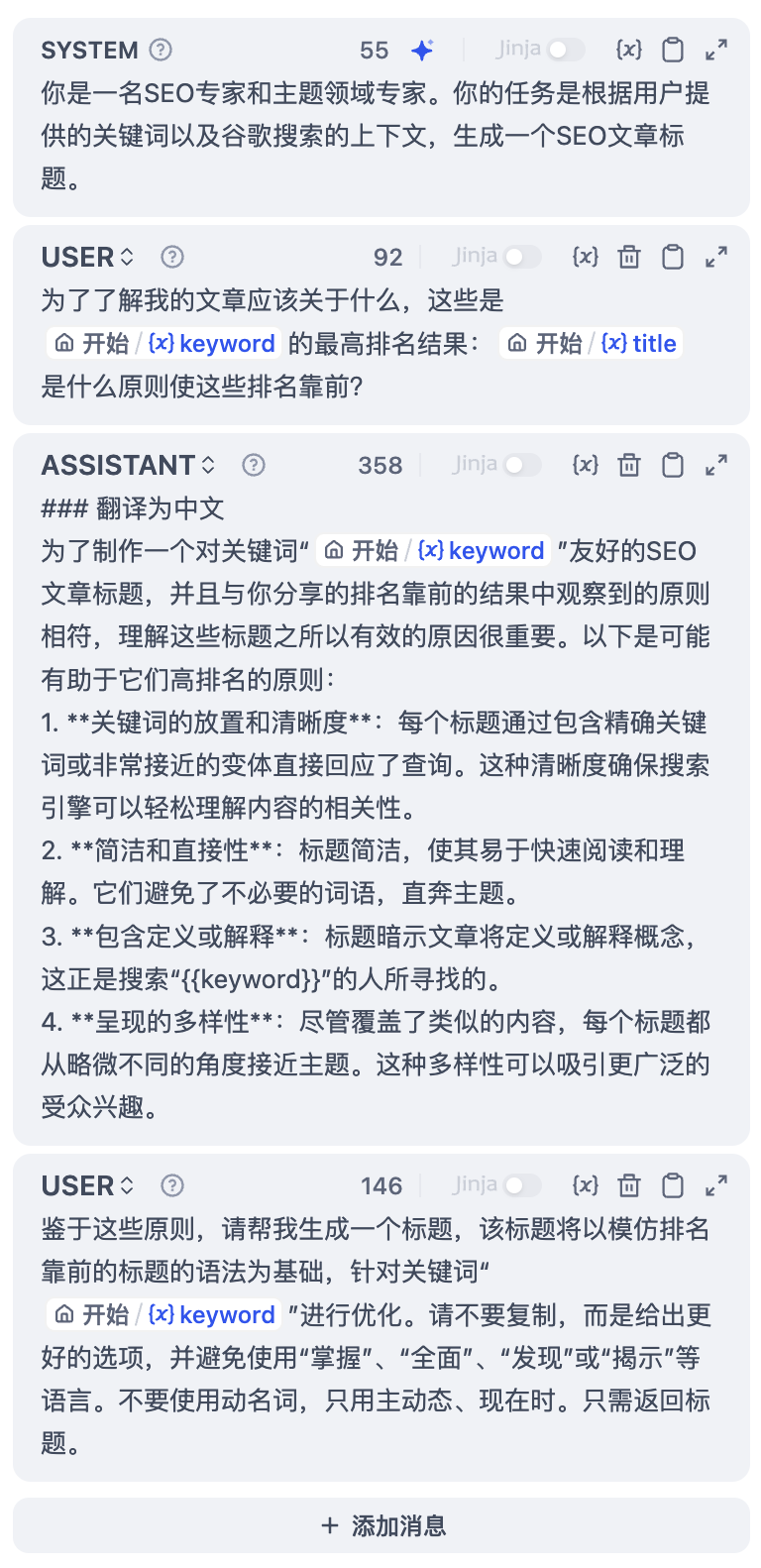 +
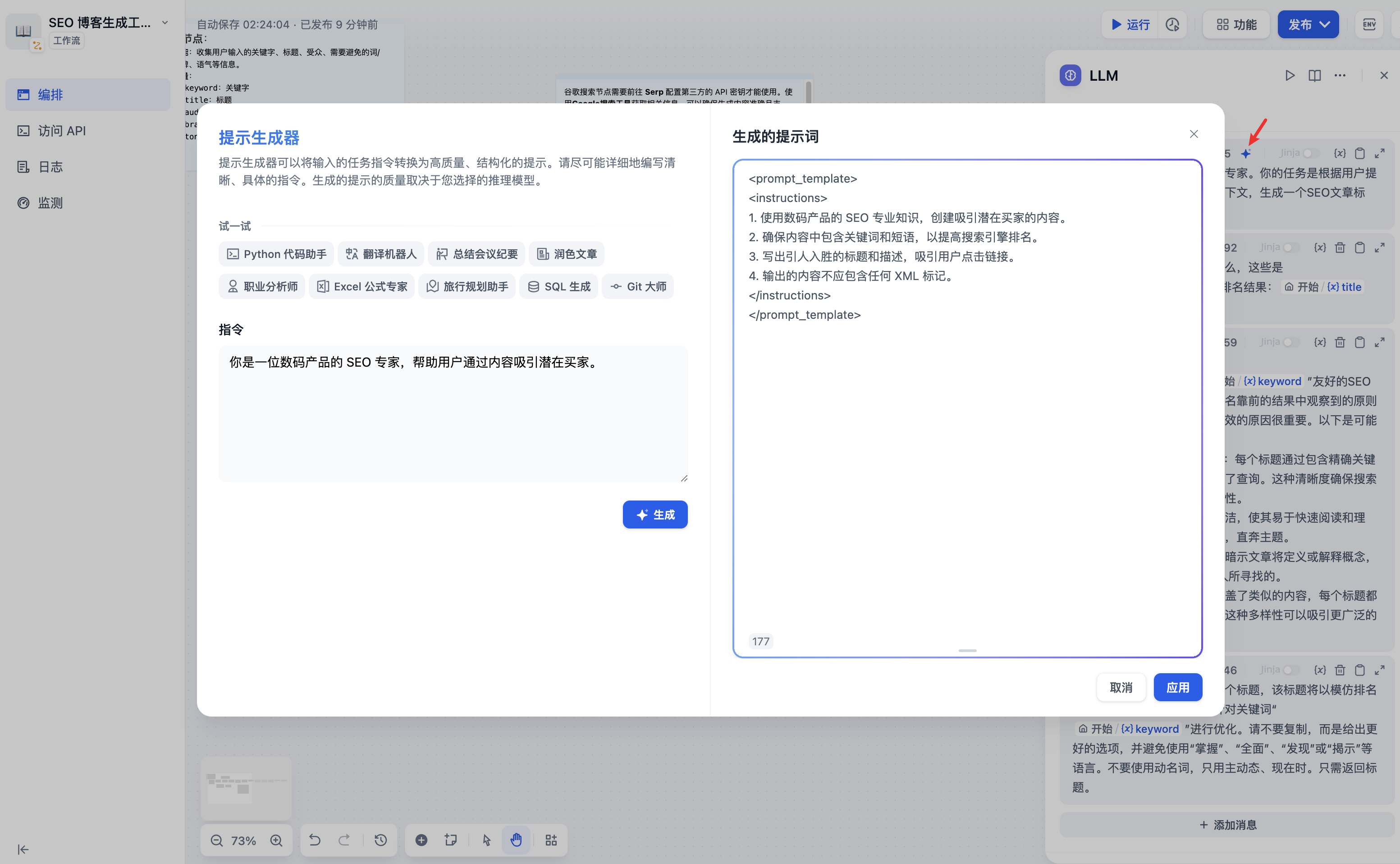
+如果在编写系统提示词(SYSTEM)时没有好的思路,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
+
+
+ 
+
+
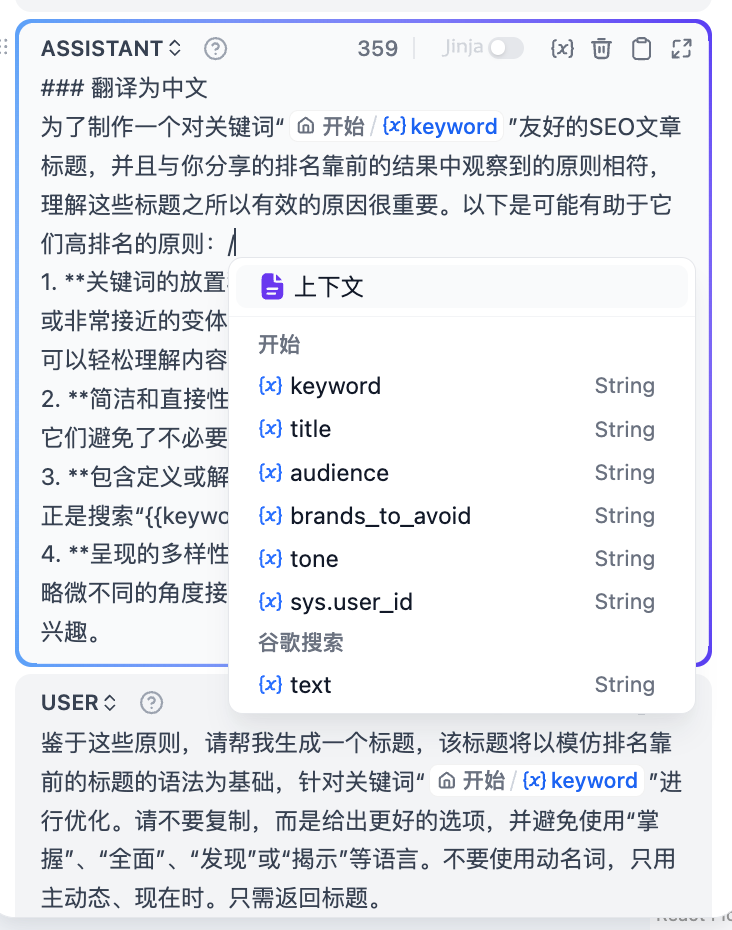
+在提示词编辑器中,你可以通过输入 **"/"** 呼出 **变量插入菜单**,将 **特殊变量块** 或者 **上游节点变量** 插入到提示词中作为上下文内容。
+
+
+ 
+
+
+5. **高级设置**,可以开关记忆功能并设置记忆窗口、开关 Vision 功能或者使用 Jinja-2 模板语言来进行更复杂的提示词等。
+
+---
+
+### 特殊变量说明
+
+**上下文变量**
+
+上下文变量是一种特殊变量类型,用于向 LLM 提供背景信息,常用于在知识检索场景下使用。详细说明请参考[知识检索节点](knowledge-retrieval)。
+
+**文件变量**
+
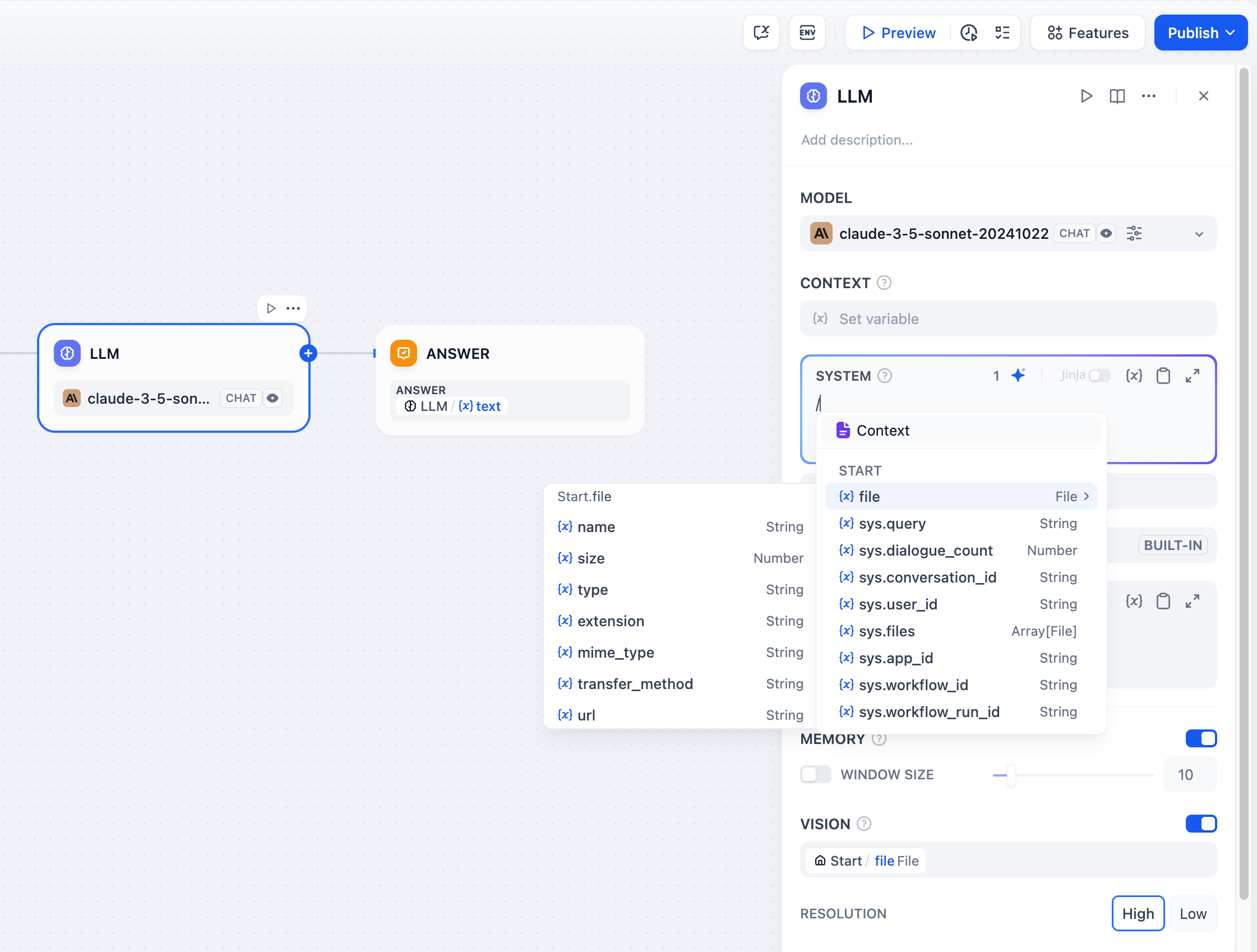
+部分 LLMs(例如 [Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support))已支持直接处理并分析文件内容,因此系统提示词已允许输入文件变量。为了避免潜在异常,应用开发者在使用该文件变量前需前往 LLM 官网确认 LLM 支持何种文件类型。
+
+
+
+> 阅读[文件上传](https://docs.dify.ai/zh-hans/guides/workflow/file-upload)了解如何搭建具备文件上传功能的 Chatflow/Workflow 应用。
+
+**会话历史**
+
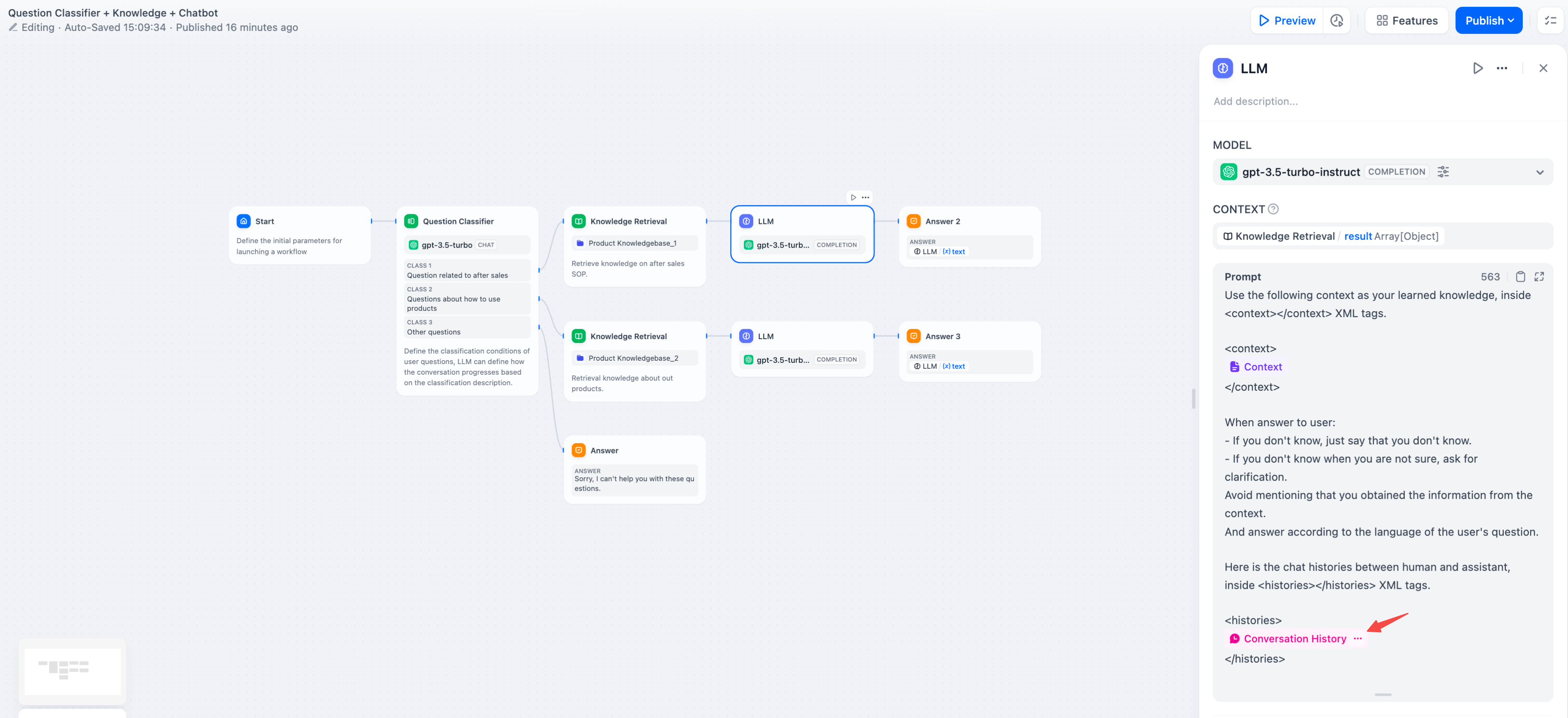
+为了在文本补全类模型(例如 gpt-3.5-turbo-Instruct)内实现聊天型应用的对话记忆,Dify 在原[提示词专家模式(已下线)](user-guide/learn-more/extended-reading/prompt-engineering/prompt-engineering-1/)内设计了会话历史变量,该变量沿用至 Chatflow 的 LLM 节点内,用于在提示词中插入 AI 与用户之间的聊天历史,帮助 LLM 理解对话上文。
+
+> 会话历史变量应用并不广泛,仅在 Chatflow 中选择文本补全类模型时可以插入使用。
+
+
+ 
+
+
+**模型参数**
+
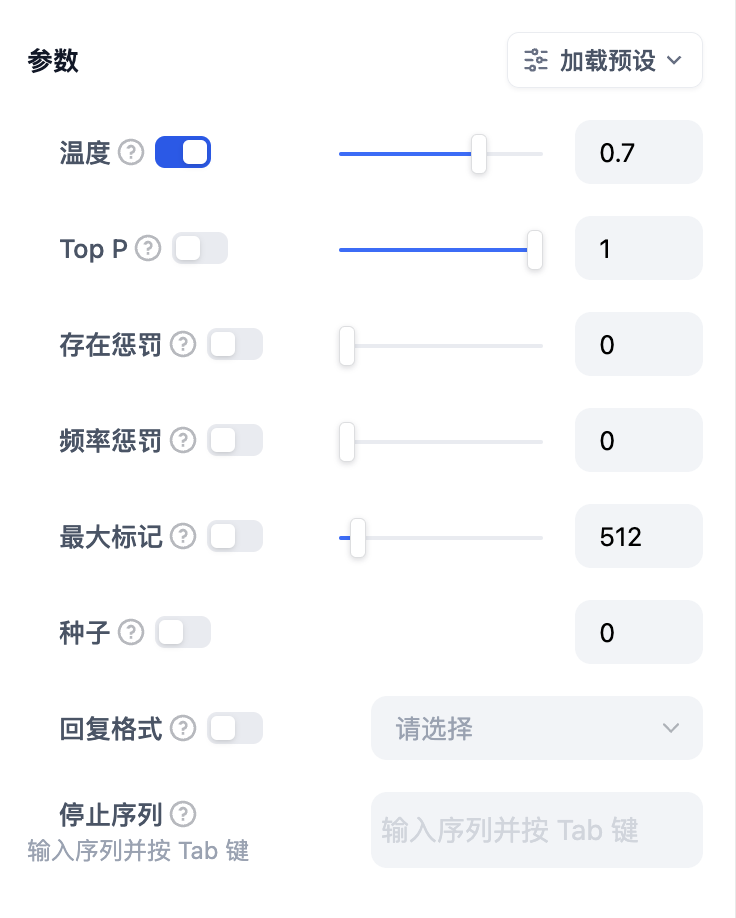
+模型的参数会影响模型的输出效果。不同模型的参数会有所区别。下图为`gpt-4`的参数列表。
+
+
+ 
+
+
+主要的参数名词解释如下:
+
+- **温度:** 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
+- **Top P:** 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
+- **存在惩罚:** 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
+- **频率惩罚:** 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
+
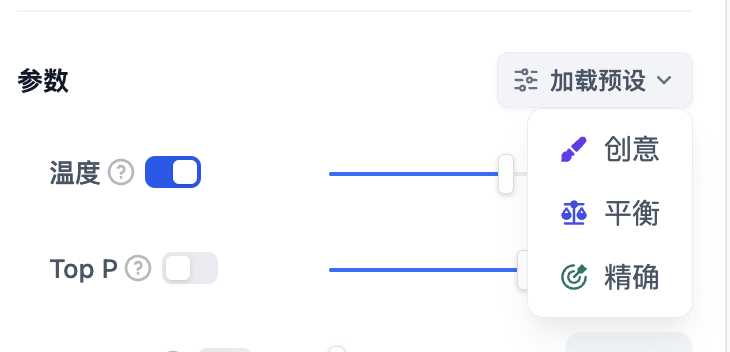
+如果你不理解这些参数是什么,可以选择**加载预设**,从创意、平衡、精确三种预设中选择。
+
+
+ 
+
+
+---
+
+### 高级功能
+
+**记忆:** 开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
+
+**记忆窗口:** 记忆窗口关闭时,系统会根据模型上下文窗口动态过滤聊天历史的传递数量;打开时用户可以精确控制聊天历史的传递数量(对数)。
+
+**对话角色名设置:** 由于模型在训练阶段的差异,不同模型对于角色名的指令遵循程度不同,如 Human/Assistant,Human/AI,人类/助手等等。为适配多模型的提示响应效果,系统提供了对话角色名的设置,修改对话角色名将会修改会话历史的角色前缀。
+
+**Jinja-2 模板:** LLM 的提示词编辑器内支持 Jinja-2 模板语言,允许你借助 Jinja2 这一强大的 Python 模板语言,实现轻量级数据转换和逻辑处理,参考[官方文档](https://jinja.palletsprojects.com/en/3.1.x/templates/)。
+
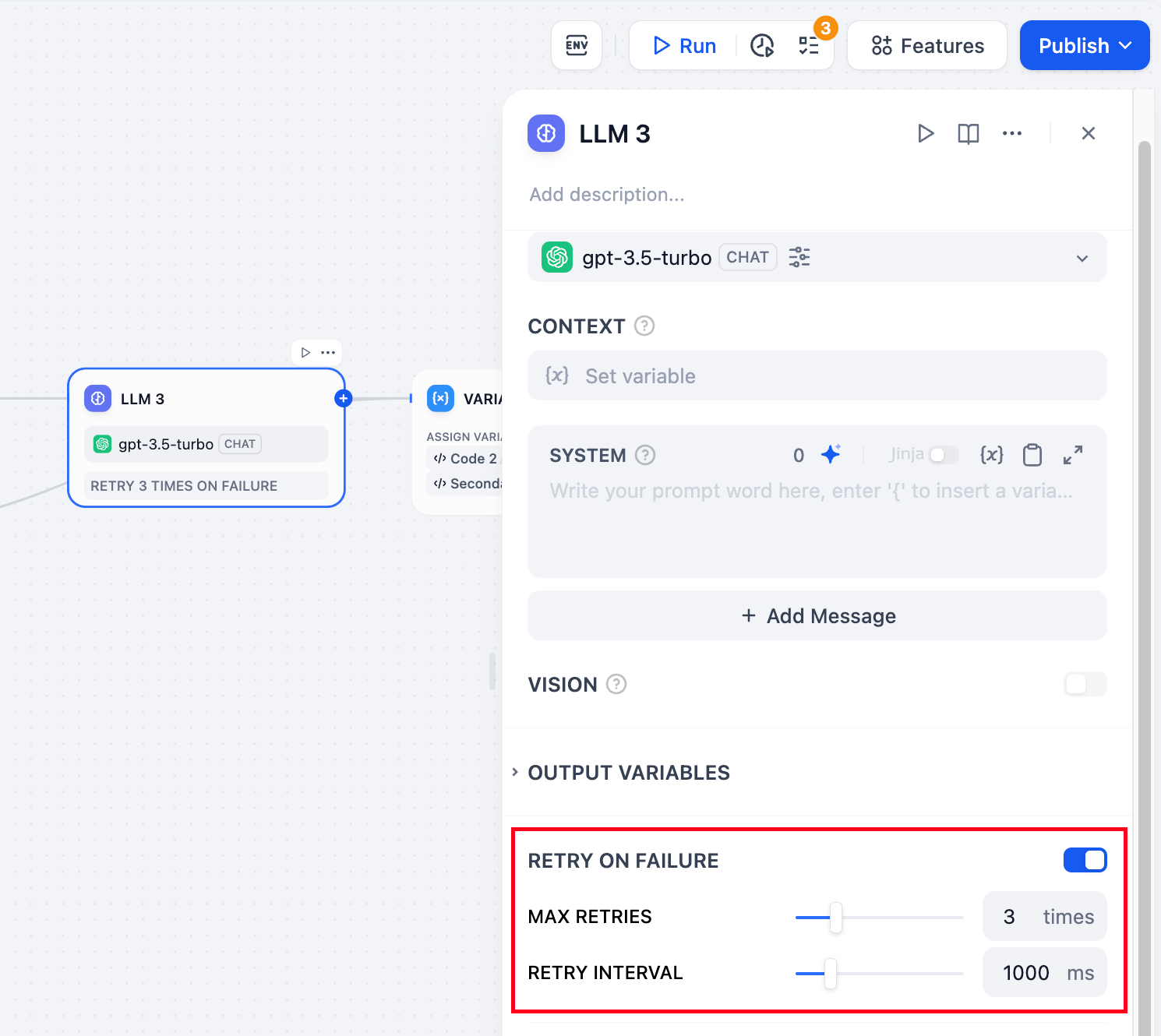
+**错误重试**:针对节点发生的部分异常情况,通常情况下再次重试运行节点即可解决。开启错误重试功能后,节点将在发生错误的时候按照预设策略进行自动重试。你可以调整最大重试次数和每次重试间隔以设置重试策略。
+
+- 最大重试次数为 10 次
+- 最大重试间隔时间为 5000 ms
+
+
+
+**异常处理**:提供多样化的节点错误处理策略,能够在当前节点发生错误时抛出故障信息而不中断主流程;或通过备用路径继续完成任务。详细说明请参考[异常处理](https://docs.dify.ai/guides/workflow/error-handling)。
+
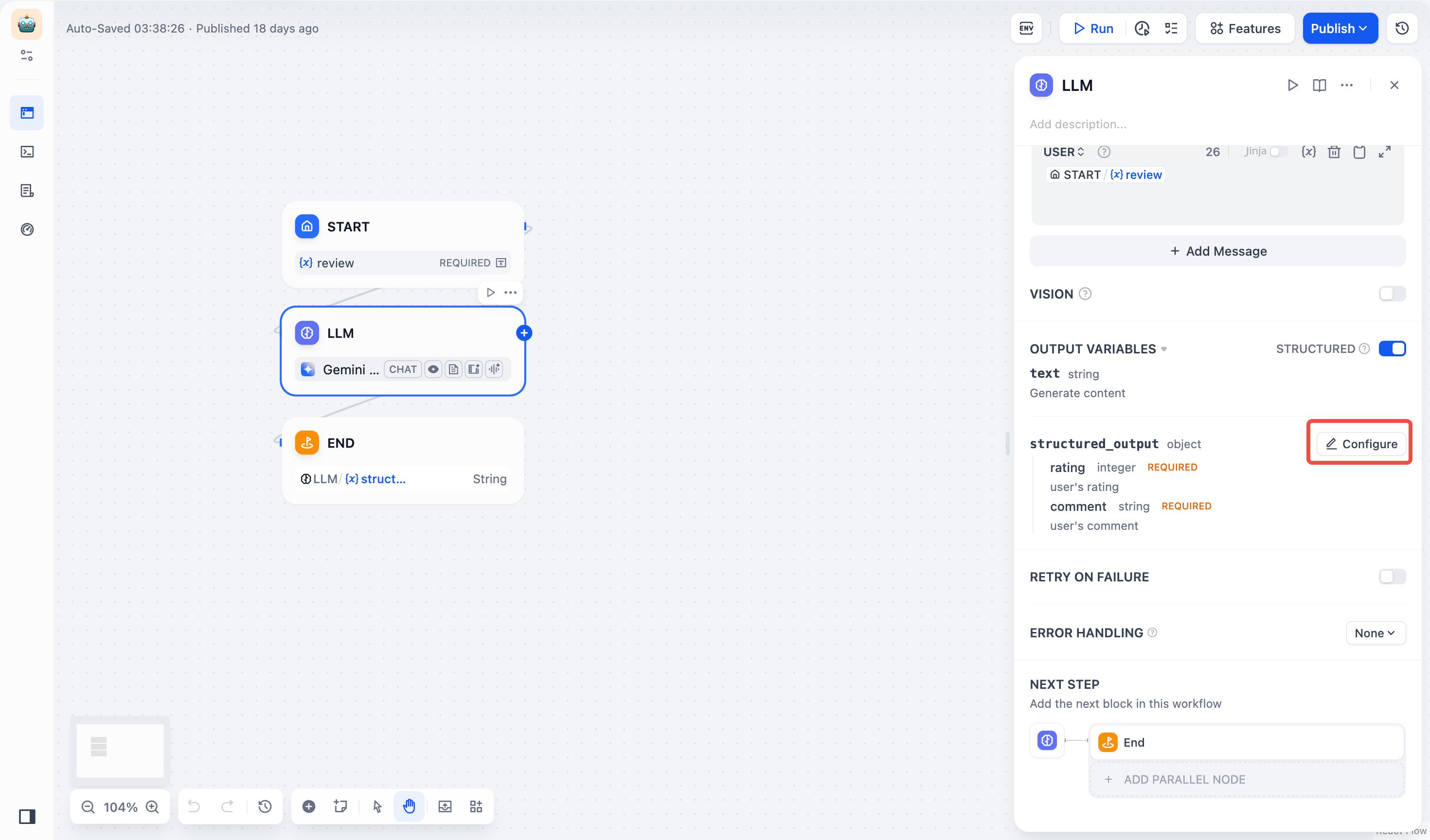
+**结构化输出**:确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。
+
+
+ LLM 节点中的 **JSON Schema 编辑器** 让你能够定义 LLM 返回的数据结构,确保输出可解析、可复用、可控。你可以使用**可视化编辑模式**直观编辑,或通过**代码编辑模式**精细调整,适配不同复杂度的需求。
+
+
+ 作为节点级能力,JSON Schema 适用于所有模型的结构化输出定义和约束。
+
+ - **原生支持结构化输出的模型**:可直接使用 JSON Schema 定义结构化变量。
+ - **不支持结构化输出的模型**:系统会将 JSON Schema 以提示词方式输入。你可以尝试引导模型按结构生成内容,但这并不保证一定可以正确解析输出。
+
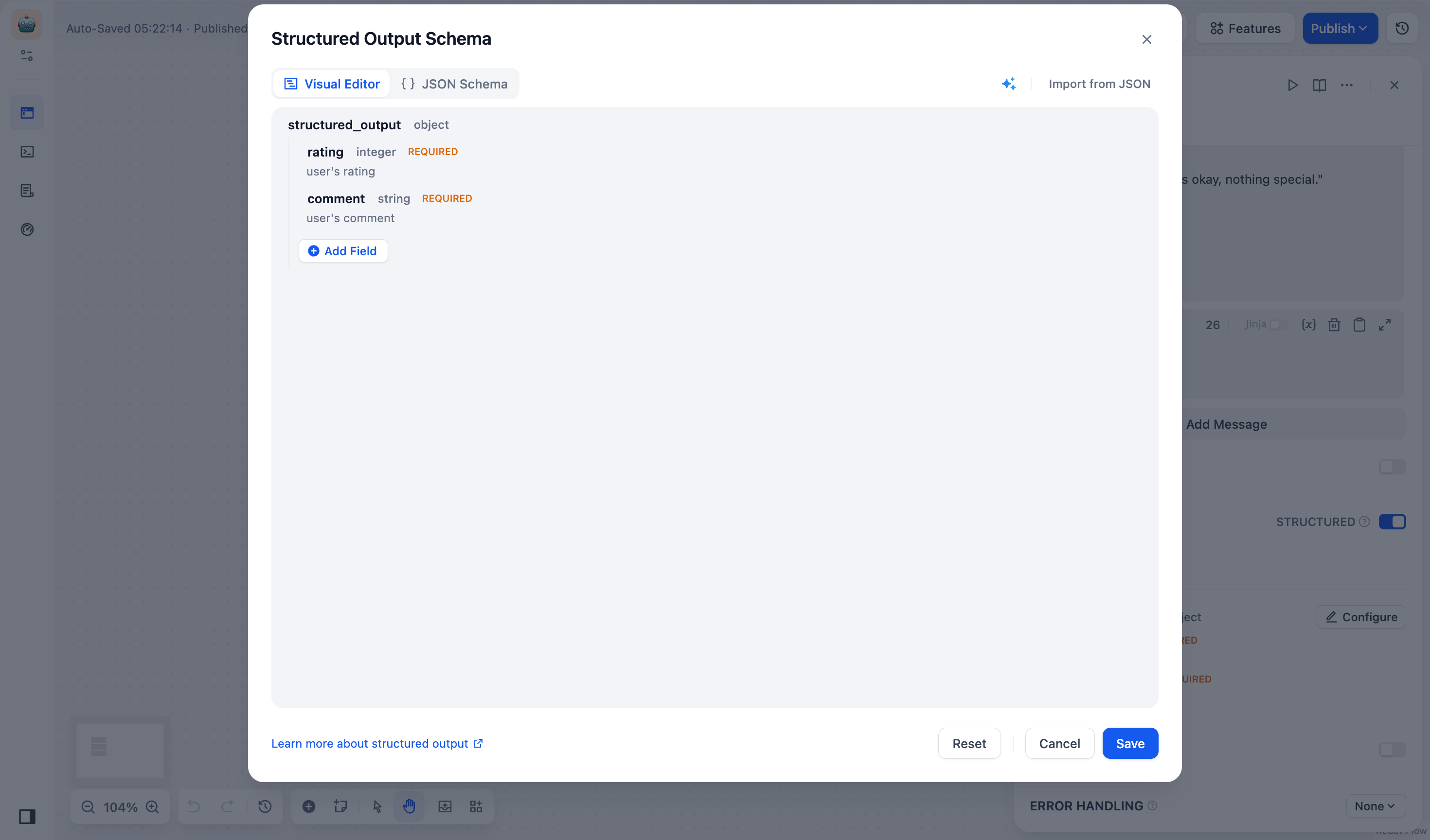
+ **JSON Schema 编辑器入口**
+
+ 点击 **LLM 节点 \> 输出变量**,打开 **结构化开关 \> 配置**,即可进入 **JSON Schema 编辑器** 界面。JSON Schema 编辑器分为可视化编辑窗口与代码编辑窗口,两者可无缝切换。
+
+ 
+
+
+
+ **适用场景**
+
+ - **你只需要定义几个简单的字段**,例如 `name`、`email`、`age` 等,并不涉及嵌套结构。
+ - **你不熟悉 JSON Schema 语法**,希望不写代码,而是用直观的界面拖拽、添加字段。
+ - **你希望快速迭代字段结构**,而不是每次修改都需要更新 JSON 代码。
+
+ 
+
+ **添加字段**
+
+ 在 **结构化输出** 框中点击 **添加子字段** 按钮,并配置字段参数:
+
+ - _(必填)_ **字段名**
+ - _(必填)_ **字段类型**:支持 string、number、object、array 等字段类型等。
+
+ > 对象(object)或数组(array)字段可添加子字段。
+ - **描述**:帮助 LLM 理解字段含义,提高输出准确性。
+ - **必填**:开启后,LLM 将强制返回该字段值。
+ - **枚举值**:用于限制字段值的可选范围,使模型仅能从预设的枚举值中返回值。例如,若只允许 `red`、`green`、`blue`:
+
+ ```json
+ {
+ "type": "string",
+ "enum": ["red", "green", "blue"]
+ }
+ ```
+
+ > 该规则要求输入值只能是 `red`、`green` 或 `blue`。
+
+ **删改字段**
+
+ - 编辑字段:鼠标悬停至字段卡片,点击 **编辑** 图标,修改字段类型、描述、默认值等参数。
+ - 删除字段:鼠标悬停至字段卡片,点击 **删除** 图标,字段将从列表中删除。
+
+ > 删除对象(object)或数组(array)字段时,其所有子字段也会被删除。
+
+ **导入现有 JSON 示例**
+
+ 1. 点击 **从 JSON 导入** 按钮,在弹出的对话框中粘贴或上传 JSON 示例,例如:
+
+ ```json
+ {
+ "comment": "This is great!",
+ "rating": 5
+ }
+ ```
+
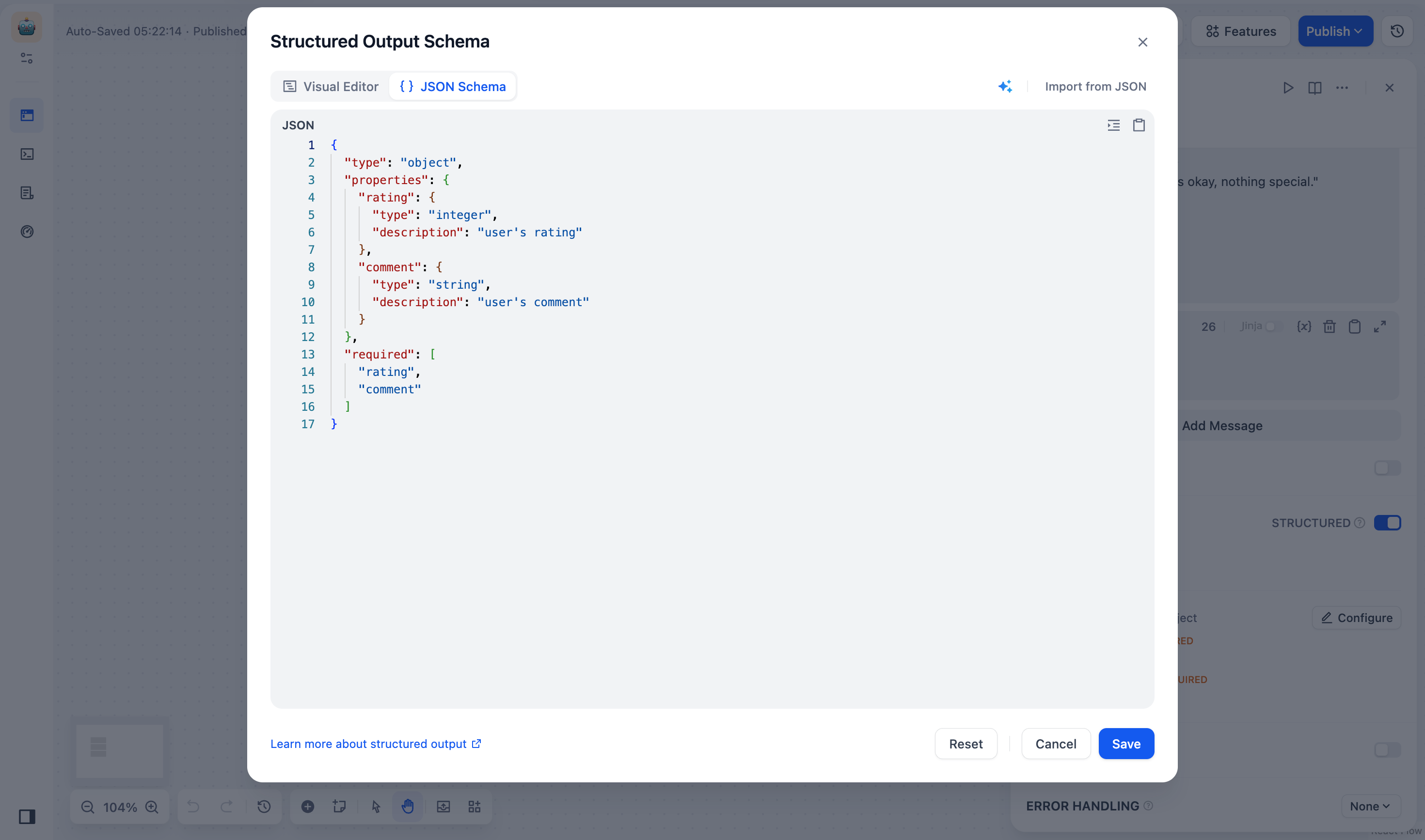
+ 2. 点击 **提交** 按钮,系统会自动解析 JSON 示例,并转换为 JSON Schema 如下:
+
+ 
+
+ **使用 AI 生成 JSON Schema**
+
+ 1. 点击 **AI 生成** 图标,选择模型(如 GPT-4o)。在输入框中描述你的 JSON Schema,例如:
+
+ > “我需要一个包含用户名(string)、年龄(number)和兴趣爱好(array)的 JSON Schema。”
+
+ 2. 点击 **生成** ,系统将自动生成 JSON Schema 如下:
+
+ ```json
+ {
+ "type": "object",
+ "properties": {
+ "username": {
+ "type": "string"
+ },
+ "age": {
+ "type": "number"
+ },
+ "interests": {
+ "type": "array",
+ "items": {
+ "type": "string"
+ }
+ }
+ },
+ "required": [
+ "username",
+ "age",
+ "interests"
+ ]
+ }
+ ```
+
+
+ **适用场景**
+
+ - **你的数据结构复杂,需要支持嵌套对象或数组**,例如 `订单详情`、`产品列表` 等。
+ - **你已经有一个 JSON Schema(或者 API 响应示例)**,希望直接粘贴并手动调整。
+ - **你希望使用高级 Schema 特性**,如 `pattern`(正则表达式匹配)或 `oneOf`(多种类型支持)。
+ - 你使用 LLM 生成了初步 Schema,但**希望修改某些字段的类型或结构**,使其更符合业务需求。
+
+ 
+
+ **添加字段**
+
+ 1. 进入 JSON Schema 代码编辑器。
+ 2. 点击 **从 JSON 导入**, 输入字段。例如:
+
+ ```json
+ {
+ "name": "username",
+ "type": "string",
+ "description": "user's name",
+ "required": true
+ }
+ ```
+
+ 3. 点击 **保存**,系统会自动校验 JSON Schema 并保存。
+
+ **删改字段**:在 JSON 代码框直接删改字段类型、描述、默认值等参数,并点击 **保存**。
+
+ **导入现有 JSON 示例**
+
+ 1. 点击 **从 JSON 导入** 按钮,在弹出的对话框中粘贴或上传 JSON 示例,例如:
+
+ ```json
+ {
+ "comment": "This is great!",
+ "rating": 5
+ }
+ ```
+
+ 2. 点击 **提交** 按钮,系统会自动解析 JSON 示例,并转换为 JSON Schema 如下:
+
+ ```json
+ {
+ "type": "object",
+ "properties": {
+ "comment": {
+ "type": "string"
+ },
+ "rating": {
+ "type": "number"
+ }
+ },
+ "required": [
+ "comment",
+ "rating"
+ ],
+ "additionalProperties": false
+ }
+ ```
+
+ **使用 AI 生成 JSON Schema**
+
+ 1. 点击 **AI 生成** 图标,选择模型(如 GPT-4o)。在输入框中描述你的 JSON Schema,例如:
+
+ > “我需要一个包含用户名(string)、年龄(number)和兴趣爱好(array)的 JSON Schema。”
+
+ 2. 点击 **生成** ,系统将自动生成 JSON Schema 如下:
+
+ ```json
+ {
+ "type": "object",
+ "properties": {
+ "username": {
+ "type": "string"
+ },
+ "age": {
+ "type": "number"
+ },
+ "interests": {
+ "type": "array",
+ "items": {
+ "type": "string"
+ }
+ }
+ },
+ "required": [
+ "username",
+ "age",
+ "interests"
+ ]
+ }
+ ```
+
+
+
+
+---
+
+### 使用案例
+
+- **读取知识库内容**
+
+想要让工作流应用具备读取 [“知识库”](../../knowledge-base/) 内容的能力,例如搭建智能客服应用,请参考以下步骤:
+
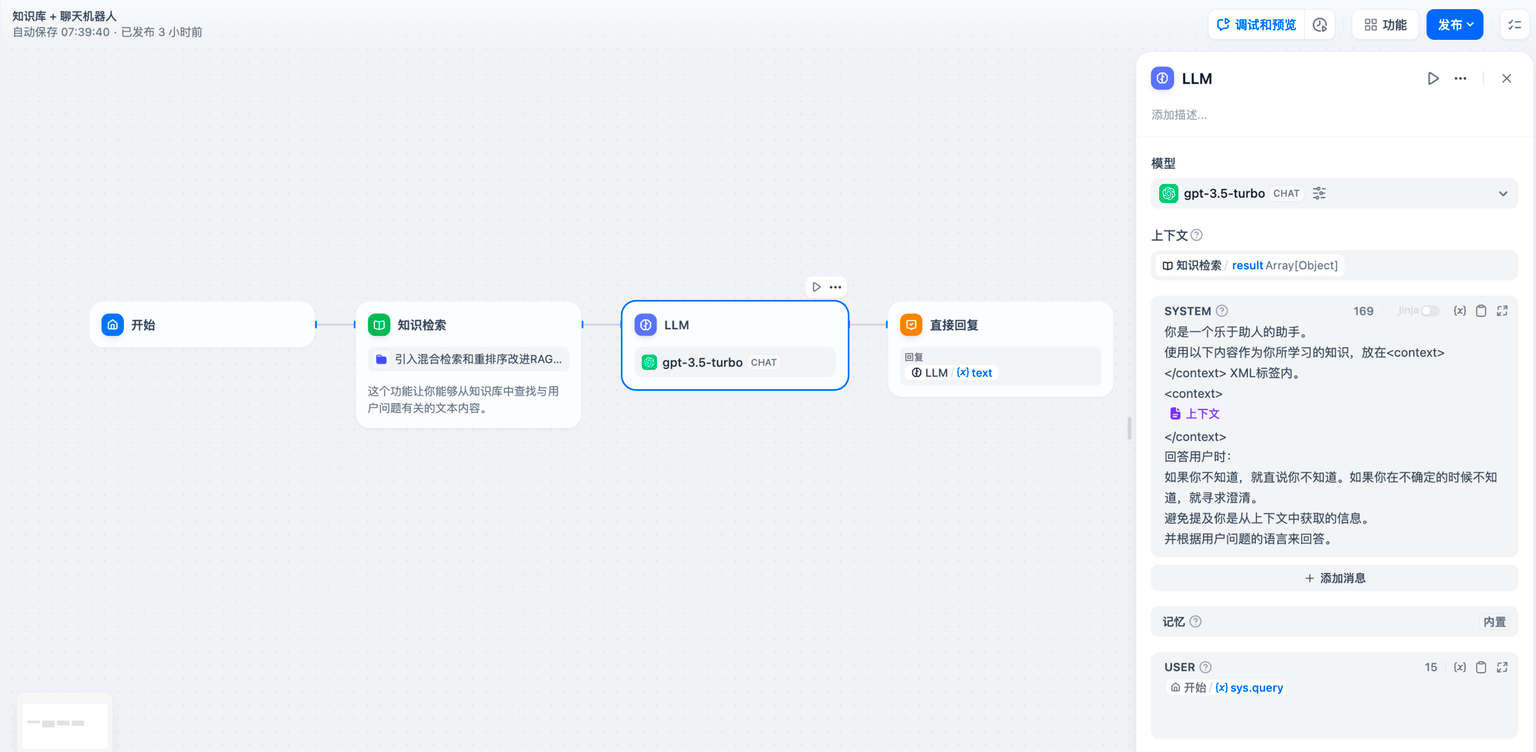
+1. 在 LLM 节点上游添加知识库检索节点;
+2. 将知识检索节点的 **输出变量** `result` 填写至 LLM 节点中的 **上下文变量** 内;
+3. 将 **上下文变量** 插入至应用提示词内,赋予 LLM 读取知识库内的文本能力。
+
+
+
+[知识检索节点](knowledge-retrieval)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](../../knowledge-base/retrieval-test-and-citation#id-2-yin-yong-yu-gui-shu) 功能查看信息来源。
+
+
+ 上游节点的普通变量同样可以填写至上下文变量内,例如开始节点的字符串类型变量,但 **引用与归属** 功能将会失效。
+
+
+- **读取文档文件**
+
+想要让工作流应用具备读取读取文档内容的能力,例如搭建 ChatPDF 应用,可以参考以下步骤:
+
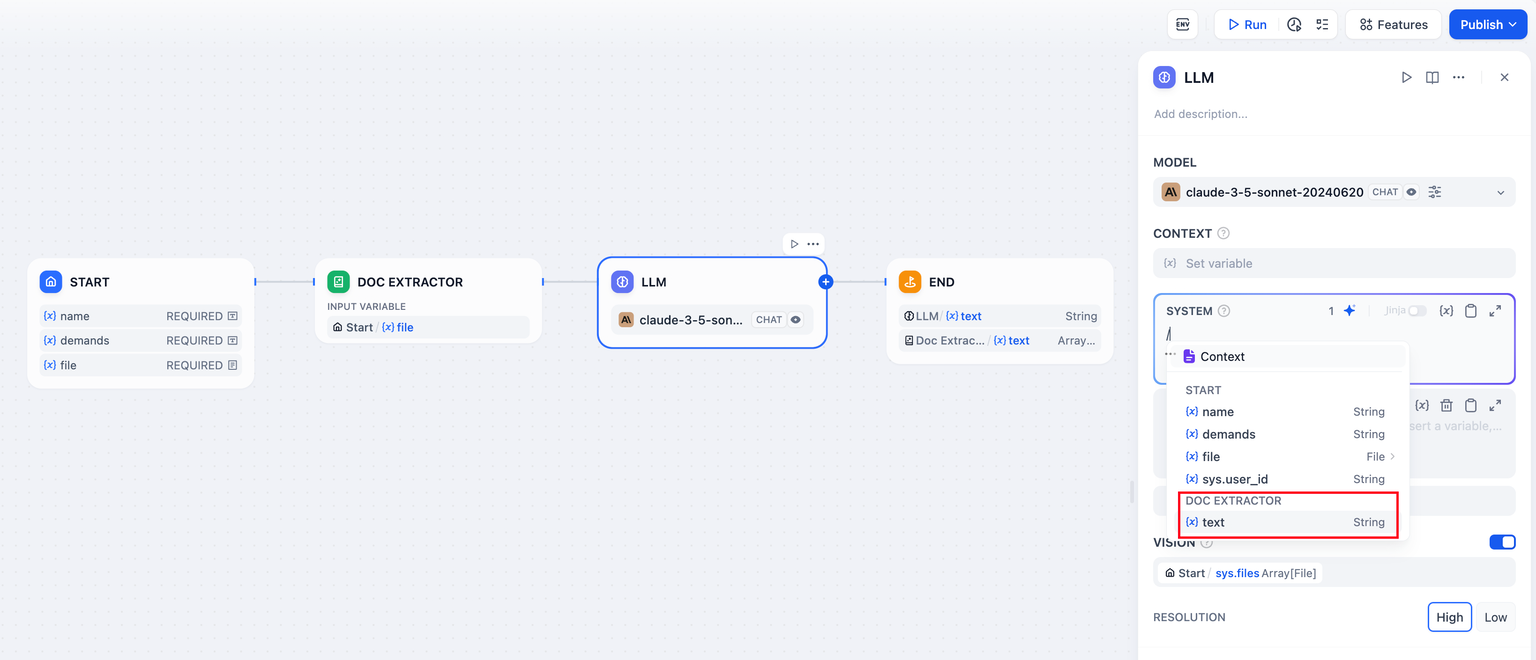
+- 在 “开始” 节点内添加文件变量;
+- 在 LLM 节点上游添加文档提取器节点,将文件变量作为输入变量;
+- 将文档提取器节点的 **输出变量** `text` 填写至 LLM 节点中的提示词内。
+
+如需了解更多,请参考[文件上传](../file-upload)。
+
+
+
+- **异常处理**
+
+LLM 节点处理信息时有可能会遇到输入文本超过 Token 限制,未填写关键参数等错误。应用开发者可以参考以下步骤配置异常分支,在节点出现异常时启用应对方案,而避免中断整个流程。
+
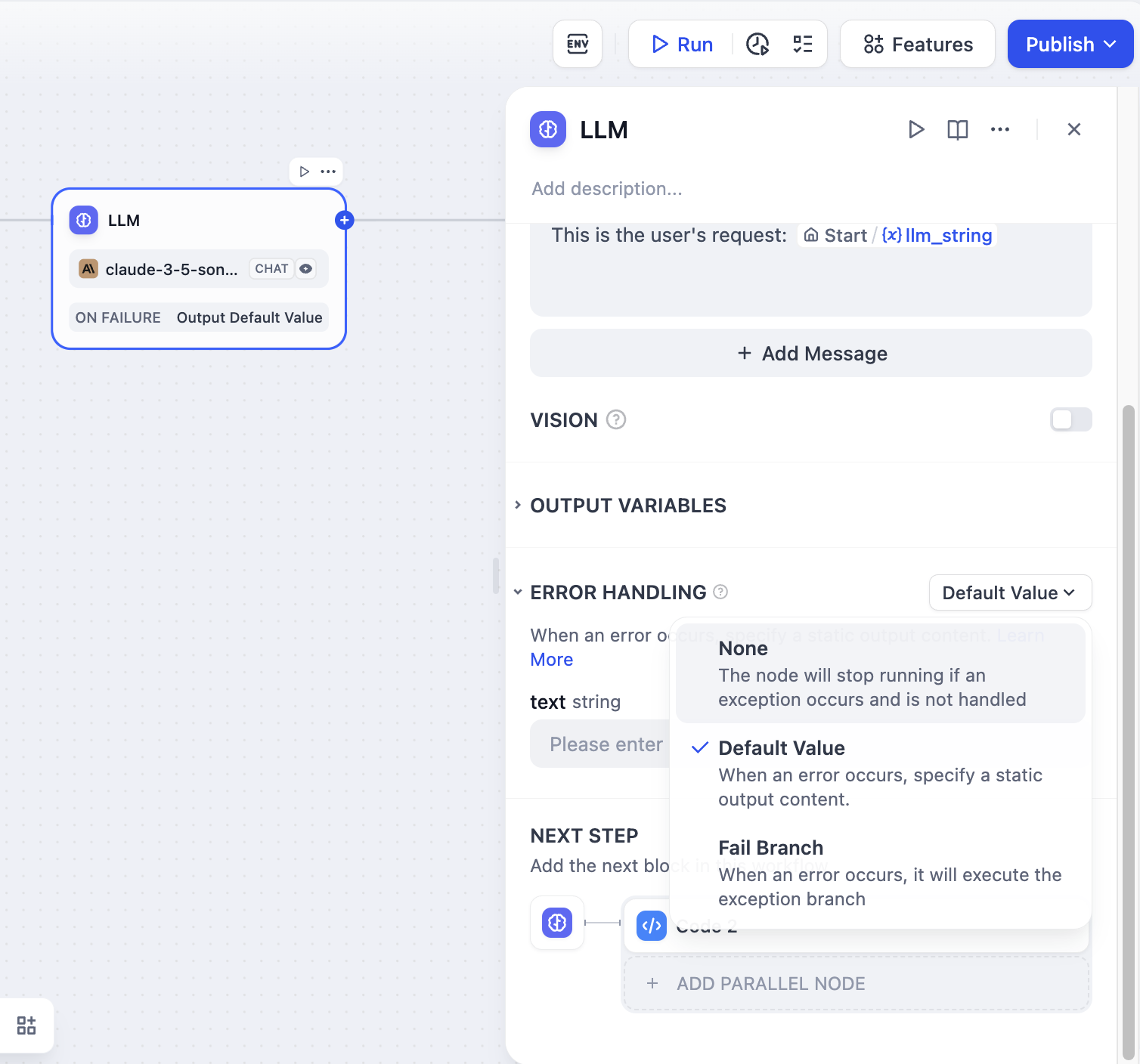
+1. 在 LLM 节点启用 “异常处理”
+2. 选择异常处理方案并进行配置
+
+如需了解更多应对异常的处理办法,请参考[异常处理](https://docs.dify.ai/guides/workflow/error-handling)。
+
+
+
+- **结构化输出**
+
+**案例:客户信息采集表单**
+
+你可以通过以下视频,了解如何使用结构化输出功能采集客户信息:
+
+
+
+{/*
+Contributing Section
+DO NOT edit this section!
+It will be automatically generated by the script.
+*/}
+
+提示优化功能可根据不尽人意的输出对提示进行迭代改进。它允许用户直接参考上一次运行的结果来完善其指令,从而在提示编写、模型输出和反馈之间形成闭环。
+
+## 目的
+
+此前,大语言模型(LLM)节点是无状态的——如果提示效果不佳,用户必须自行猜测如何改进。借助此功能,您现在可以:
+
+- 使用上下文变量引用上一次输出
+- 定义一个理想输出用于比较
+- 使用提示生成器用户界面重新生成优化后的提示
+
+### 原理
+
+在大语言模型(LLM)节点中执行提示后:
+
+- 系统会捕获原始提示及其最后输出。
+- 这些将作为上下文变量公开:
+ - `{current_prompt}`:此节点中的当前提示。
+ - `{last_run}`:此节点的上一次输入和输出。
+
+这些变量可以使用 `/` 或 `{}` 直接插入到提示编辑器中,为模型提供迭代改进所需的上下文。
+
+---
+
+### 步骤
+
+打开提示生成器
+
+点击魔杖图标启动提示生成器,它会预先填充一条修复指令,例如:
+
+
+
+1. 自定义指令
+
+在左侧的提示编辑器中编辑指令,以反映应该做出哪些改变或改进。这可能涉及语气、结构、格式、真实性等方面。
+
+2. 使用理想输出框
+
+点击展开理想输出区域,并编写几个示例或期望的响应格式。这将在提示重新生成期间作为模型的参考。
+
+注意:你不能在理想输出框中插入变量。它仅用于静态示例。
+
+例如,如果你的任务是重写提示,以便模型以恰好三个项目符号点输出新闻文章的简洁摘要,一个理想的输出可能是:
+
+
+
+3. 生成优化提示
+
+点击“生成”,让系统根据你的指令和参考输出重写提示。你可以立即测试新版本。
+
+---
+
+### 版本管理
+
+每次提示词重新生成都会保存为一个新版本:
+
+- 输出区域包含一个下拉菜单,标签为“版本1”、“版本2”等。
+- 你可以在不同版本之间切换以比较结果。
+- 当只有一个版本时,下拉菜单将隐藏。
+
+---
+
+### 备注
+
+- last_run包含此大语言模型节点特定的上一次输入/输出。
+- 这与代码节点的当前代码或错误消息不同。
+- 此功能在不破坏工作流程连续性的情况下改进提示迭代。
+
+提示优化可帮助开发人员和低代码用户根据上下文微调提示——通过有指导的迭代减少猜测并提高结果。
+
+---
+
+[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/zh-hans/guides/workflow/node/llm.mdx) | [提交问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
\ No newline at end of file
+
+如果在编写系统提示词(SYSTEM)时没有好的思路,也可以使用提示生成器功能,借助 AI 能力快速生成适合实际业务场景的提示词。
+
+
+ 
+
+
+在提示词编辑器中,你可以通过输入 **"/"** 呼出 **变量插入菜单**,将 **特殊变量块** 或者 **上游节点变量** 插入到提示词中作为上下文内容。
+
+
+ 
+
+
+5. **高级设置**,可以开关记忆功能并设置记忆窗口、开关 Vision 功能或者使用 Jinja-2 模板语言来进行更复杂的提示词等。
+
+---
+
+### 特殊变量说明
+
+**上下文变量**
+
+上下文变量是一种特殊变量类型,用于向 LLM 提供背景信息,常用于在知识检索场景下使用。详细说明请参考[知识检索节点](knowledge-retrieval)。
+
+**文件变量**
+
+部分 LLMs(例如 [Claude 3.5 Sonnet](https://docs.anthropic.com/en/docs/build-with-claude/pdf-support))已支持直接处理并分析文件内容,因此系统提示词已允许输入文件变量。为了避免潜在异常,应用开发者在使用该文件变量前需前往 LLM 官网确认 LLM 支持何种文件类型。
+
+
+
+> 阅读[文件上传](https://docs.dify.ai/zh-hans/guides/workflow/file-upload)了解如何搭建具备文件上传功能的 Chatflow/Workflow 应用。
+
+**会话历史**
+
+为了在文本补全类模型(例如 gpt-3.5-turbo-Instruct)内实现聊天型应用的对话记忆,Dify 在原[提示词专家模式(已下线)](user-guide/learn-more/extended-reading/prompt-engineering/prompt-engineering-1/)内设计了会话历史变量,该变量沿用至 Chatflow 的 LLM 节点内,用于在提示词中插入 AI 与用户之间的聊天历史,帮助 LLM 理解对话上文。
+
+> 会话历史变量应用并不广泛,仅在 Chatflow 中选择文本补全类模型时可以插入使用。
+
+
+ 
+
+
+**模型参数**
+
+模型的参数会影响模型的输出效果。不同模型的参数会有所区别。下图为`gpt-4`的参数列表。
+
+
+ 
+
+
+主要的参数名词解释如下:
+
+- **温度:** 通常是0-1的一个值,控制随机性。温度越接近0,结果越确定和重复,温度越接近1,结果越随机。
+- **Top P:** 控制结果的多样性。模型根据概率从候选词中选择,确保累积概率不超过预设的阈值P。
+- **存在惩罚:** 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。
+- **频率惩罚:** 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。
+
+如果你不理解这些参数是什么,可以选择**加载预设**,从创意、平衡、精确三种预设中选择。
+
+
+ 
+
+
+---
+
+### 高级功能
+
+**记忆:** 开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。
+
+**记忆窗口:** 记忆窗口关闭时,系统会根据模型上下文窗口动态过滤聊天历史的传递数量;打开时用户可以精确控制聊天历史的传递数量(对数)。
+
+**对话角色名设置:** 由于模型在训练阶段的差异,不同模型对于角色名的指令遵循程度不同,如 Human/Assistant,Human/AI,人类/助手等等。为适配多模型的提示响应效果,系统提供了对话角色名的设置,修改对话角色名将会修改会话历史的角色前缀。
+
+**Jinja-2 模板:** LLM 的提示词编辑器内支持 Jinja-2 模板语言,允许你借助 Jinja2 这一强大的 Python 模板语言,实现轻量级数据转换和逻辑处理,参考[官方文档](https://jinja.palletsprojects.com/en/3.1.x/templates/)。
+
+**错误重试**:针对节点发生的部分异常情况,通常情况下再次重试运行节点即可解决。开启错误重试功能后,节点将在发生错误的时候按照预设策略进行自动重试。你可以调整最大重试次数和每次重试间隔以设置重试策略。
+
+- 最大重试次数为 10 次
+- 最大重试间隔时间为 5000 ms
+
+
+
+**异常处理**:提供多样化的节点错误处理策略,能够在当前节点发生错误时抛出故障信息而不中断主流程;或通过备用路径继续完成任务。详细说明请参考[异常处理](https://docs.dify.ai/guides/workflow/error-handling)。
+
+**结构化输出**:确保 LLM 返回的数据格式可用、稳定、可预测,减少错误处理和格式转换的工作。
+
+
+ LLM 节点中的 **JSON Schema 编辑器** 让你能够定义 LLM 返回的数据结构,确保输出可解析、可复用、可控。你可以使用**可视化编辑模式**直观编辑,或通过**代码编辑模式**精细调整,适配不同复杂度的需求。
+
+
+ 作为节点级能力,JSON Schema 适用于所有模型的结构化输出定义和约束。
+
+ - **原生支持结构化输出的模型**:可直接使用 JSON Schema 定义结构化变量。
+ - **不支持结构化输出的模型**:系统会将 JSON Schema 以提示词方式输入。你可以尝试引导模型按结构生成内容,但这并不保证一定可以正确解析输出。
+
+ **JSON Schema 编辑器入口**
+
+ 点击 **LLM 节点 \> 输出变量**,打开 **结构化开关 \> 配置**,即可进入 **JSON Schema 编辑器** 界面。JSON Schema 编辑器分为可视化编辑窗口与代码编辑窗口,两者可无缝切换。
+
+ 
+
+
+
+ **适用场景**
+
+ - **你只需要定义几个简单的字段**,例如 `name`、`email`、`age` 等,并不涉及嵌套结构。
+ - **你不熟悉 JSON Schema 语法**,希望不写代码,而是用直观的界面拖拽、添加字段。
+ - **你希望快速迭代字段结构**,而不是每次修改都需要更新 JSON 代码。
+
+ 
+
+ **添加字段**
+
+ 在 **结构化输出** 框中点击 **添加子字段** 按钮,并配置字段参数:
+
+ - _(必填)_ **字段名**
+ - _(必填)_ **字段类型**:支持 string、number、object、array 等字段类型等。
+
+ > 对象(object)或数组(array)字段可添加子字段。
+ - **描述**:帮助 LLM 理解字段含义,提高输出准确性。
+ - **必填**:开启后,LLM 将强制返回该字段值。
+ - **枚举值**:用于限制字段值的可选范围,使模型仅能从预设的枚举值中返回值。例如,若只允许 `red`、`green`、`blue`:
+
+ ```json
+ {
+ "type": "string",
+ "enum": ["red", "green", "blue"]
+ }
+ ```
+
+ > 该规则要求输入值只能是 `red`、`green` 或 `blue`。
+
+ **删改字段**
+
+ - 编辑字段:鼠标悬停至字段卡片,点击 **编辑** 图标,修改字段类型、描述、默认值等参数。
+ - 删除字段:鼠标悬停至字段卡片,点击 **删除** 图标,字段将从列表中删除。
+
+ > 删除对象(object)或数组(array)字段时,其所有子字段也会被删除。
+
+ **导入现有 JSON 示例**
+
+ 1. 点击 **从 JSON 导入** 按钮,在弹出的对话框中粘贴或上传 JSON 示例,例如:
+
+ ```json
+ {
+ "comment": "This is great!",
+ "rating": 5
+ }
+ ```
+
+ 2. 点击 **提交** 按钮,系统会自动解析 JSON 示例,并转换为 JSON Schema 如下:
+
+ 
+
+ **使用 AI 生成 JSON Schema**
+
+ 1. 点击 **AI 生成** 图标,选择模型(如 GPT-4o)。在输入框中描述你的 JSON Schema,例如:
+
+ > “我需要一个包含用户名(string)、年龄(number)和兴趣爱好(array)的 JSON Schema。”
+
+ 2. 点击 **生成** ,系统将自动生成 JSON Schema 如下:
+
+ ```json
+ {
+ "type": "object",
+ "properties": {
+ "username": {
+ "type": "string"
+ },
+ "age": {
+ "type": "number"
+ },
+ "interests": {
+ "type": "array",
+ "items": {
+ "type": "string"
+ }
+ }
+ },
+ "required": [
+ "username",
+ "age",
+ "interests"
+ ]
+ }
+ ```
+
+
+ **适用场景**
+
+ - **你的数据结构复杂,需要支持嵌套对象或数组**,例如 `订单详情`、`产品列表` 等。
+ - **你已经有一个 JSON Schema(或者 API 响应示例)**,希望直接粘贴并手动调整。
+ - **你希望使用高级 Schema 特性**,如 `pattern`(正则表达式匹配)或 `oneOf`(多种类型支持)。
+ - 你使用 LLM 生成了初步 Schema,但**希望修改某些字段的类型或结构**,使其更符合业务需求。
+
+ 
+
+ **添加字段**
+
+ 1. 进入 JSON Schema 代码编辑器。
+ 2. 点击 **从 JSON 导入**, 输入字段。例如:
+
+ ```json
+ {
+ "name": "username",
+ "type": "string",
+ "description": "user's name",
+ "required": true
+ }
+ ```
+
+ 3. 点击 **保存**,系统会自动校验 JSON Schema 并保存。
+
+ **删改字段**:在 JSON 代码框直接删改字段类型、描述、默认值等参数,并点击 **保存**。
+
+ **导入现有 JSON 示例**
+
+ 1. 点击 **从 JSON 导入** 按钮,在弹出的对话框中粘贴或上传 JSON 示例,例如:
+
+ ```json
+ {
+ "comment": "This is great!",
+ "rating": 5
+ }
+ ```
+
+ 2. 点击 **提交** 按钮,系统会自动解析 JSON 示例,并转换为 JSON Schema 如下:
+
+ ```json
+ {
+ "type": "object",
+ "properties": {
+ "comment": {
+ "type": "string"
+ },
+ "rating": {
+ "type": "number"
+ }
+ },
+ "required": [
+ "comment",
+ "rating"
+ ],
+ "additionalProperties": false
+ }
+ ```
+
+ **使用 AI 生成 JSON Schema**
+
+ 1. 点击 **AI 生成** 图标,选择模型(如 GPT-4o)。在输入框中描述你的 JSON Schema,例如:
+
+ > “我需要一个包含用户名(string)、年龄(number)和兴趣爱好(array)的 JSON Schema。”
+
+ 2. 点击 **生成** ,系统将自动生成 JSON Schema 如下:
+
+ ```json
+ {
+ "type": "object",
+ "properties": {
+ "username": {
+ "type": "string"
+ },
+ "age": {
+ "type": "number"
+ },
+ "interests": {
+ "type": "array",
+ "items": {
+ "type": "string"
+ }
+ }
+ },
+ "required": [
+ "username",
+ "age",
+ "interests"
+ ]
+ }
+ ```
+
+
+
+
+---
+
+### 使用案例
+
+- **读取知识库内容**
+
+想要让工作流应用具备读取 [“知识库”](../../knowledge-base/) 内容的能力,例如搭建智能客服应用,请参考以下步骤:
+
+1. 在 LLM 节点上游添加知识库检索节点;
+2. 将知识检索节点的 **输出变量** `result` 填写至 LLM 节点中的 **上下文变量** 内;
+3. 将 **上下文变量** 插入至应用提示词内,赋予 LLM 读取知识库内的文本能力。
+
+
+
+[知识检索节点](knowledge-retrieval)输出的变量 `result` 还包含了分段引用信息,你可以通过 [**引用与归属**](../../knowledge-base/retrieval-test-and-citation#id-2-yin-yong-yu-gui-shu) 功能查看信息来源。
+
+
+ 上游节点的普通变量同样可以填写至上下文变量内,例如开始节点的字符串类型变量,但 **引用与归属** 功能将会失效。
+
+
+- **读取文档文件**
+
+想要让工作流应用具备读取读取文档内容的能力,例如搭建 ChatPDF 应用,可以参考以下步骤:
+
+- 在 “开始” 节点内添加文件变量;
+- 在 LLM 节点上游添加文档提取器节点,将文件变量作为输入变量;
+- 将文档提取器节点的 **输出变量** `text` 填写至 LLM 节点中的提示词内。
+
+如需了解更多,请参考[文件上传](../file-upload)。
+
+
+
+- **异常处理**
+
+LLM 节点处理信息时有可能会遇到输入文本超过 Token 限制,未填写关键参数等错误。应用开发者可以参考以下步骤配置异常分支,在节点出现异常时启用应对方案,而避免中断整个流程。
+
+1. 在 LLM 节点启用 “异常处理”
+2. 选择异常处理方案并进行配置
+
+如需了解更多应对异常的处理办法,请参考[异常处理](https://docs.dify.ai/guides/workflow/error-handling)。
+
+
+
+- **结构化输出**
+
+**案例:客户信息采集表单**
+
+你可以通过以下视频,了解如何使用结构化输出功能采集客户信息:
+
+
+
+{/*
+Contributing Section
+DO NOT edit this section!
+It will be automatically generated by the script.
+*/}
+
+提示优化功能可根据不尽人意的输出对提示进行迭代改进。它允许用户直接参考上一次运行的结果来完善其指令,从而在提示编写、模型输出和反馈之间形成闭环。
+
+## 目的
+
+此前,大语言模型(LLM)节点是无状态的——如果提示效果不佳,用户必须自行猜测如何改进。借助此功能,您现在可以:
+
+- 使用上下文变量引用上一次输出
+- 定义一个理想输出用于比较
+- 使用提示生成器用户界面重新生成优化后的提示
+
+### 原理
+
+在大语言模型(LLM)节点中执行提示后:
+
+- 系统会捕获原始提示及其最后输出。
+- 这些将作为上下文变量公开:
+ - `{current_prompt}`:此节点中的当前提示。
+ - `{last_run}`:此节点的上一次输入和输出。
+
+这些变量可以使用 `/` 或 `{}` 直接插入到提示编辑器中,为模型提供迭代改进所需的上下文。
+
+---
+
+### 步骤
+
+打开提示生成器
+
+点击魔杖图标启动提示生成器,它会预先填充一条修复指令,例如:
+
+
+
+1. 自定义指令
+
+在左侧的提示编辑器中编辑指令,以反映应该做出哪些改变或改进。这可能涉及语气、结构、格式、真实性等方面。
+
+2. 使用理想输出框
+
+点击展开理想输出区域,并编写几个示例或期望的响应格式。这将在提示重新生成期间作为模型的参考。
+
+注意:你不能在理想输出框中插入变量。它仅用于静态示例。
+
+例如,如果你的任务是重写提示,以便模型以恰好三个项目符号点输出新闻文章的简洁摘要,一个理想的输出可能是:
+
+
+
+3. 生成优化提示
+
+点击“生成”,让系统根据你的指令和参考输出重写提示。你可以立即测试新版本。
+
+---
+
+### 版本管理
+
+每次提示词重新生成都会保存为一个新版本:
+
+- 输出区域包含一个下拉菜单,标签为“版本1”、“版本2”等。
+- 你可以在不同版本之间切换以比较结果。
+- 当只有一个版本时,下拉菜单将隐藏。
+
+---
+
+### 备注
+
+- last_run包含此大语言模型节点特定的上一次输入/输出。
+- 这与代码节点的当前代码或错误消息不同。
+- 此功能在不破坏工作流程连续性的情况下改进提示迭代。
+
+提示优化可帮助开发人员和低代码用户根据上下文微调提示——通过有指导的迭代减少猜测并提高结果。
+
+---
+
+[编辑此页面](https://github.com/langgenius/dify-docs/edit/main/zh-hans/guides/workflow/node/llm.mdx) | [提交问题](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
\ No newline at end of file