 -
+
-**可调参数**
+**調整可能なパラメータ**
* **TopK**
- 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小,动态调整分段数量。数值越高,预期被召回的文本分段数量越多。
-* **Score 阈值**
+ ユーザーの質問に最も類似したテキストセグメントを選択するために使用されます。システムはモデルの選択に基づいてコンテキストウィンドウサイズを動的に調整し、セグメントの数を増やします。数値が高いほど、リコールされるテキストセグメントの数が増加します。
+* **スコアの閾値**
- 用于设置文本片段筛选的相似度阈值。向量检索的相似度分数需要超过设置的分数后才会被召回,数值越高,预期被召回的文本数量越少。
+ テキストセグメントの選択に使用される類似性の閾値を設定します。ベクトル検索の類似性スコアは、設定したスコアを超える必要があり、数値が高いほどリコールされるテキストの数が減少します。
-### 使用元数据筛选知识
+複数のリコールモードを利用することで、高品質なリコール効果を得ることができるため、リコールモードを複数のリコールモードに設定することを強くお勧めします。
-#### 聊天流/工作流
+### メタデータを使用して知識をフィルタリングする
-在 **聊天流/工作流** 的 **知识检索** 节点中,你可以使用 **元数据筛选** 功能精确检索文档。该功能有助于你根据文档的元数据字段(如标签、类别或访问权限)优化检索结果。
+#### チャットフロー/ワークフロー
-##### 配置步骤
+**チャットフロー/ワークフロー**の**知識検索**ノードでは、**メタデータフィルタリング**機能を使用して文書を正確に検索できます。この機能は、文書のメタデータフィールド(タグ、カテゴリ、アクセス権限など)に基づいて検索結果を最適化するのに役立ちます。
-1. 选择筛选模式
+**設定手順**
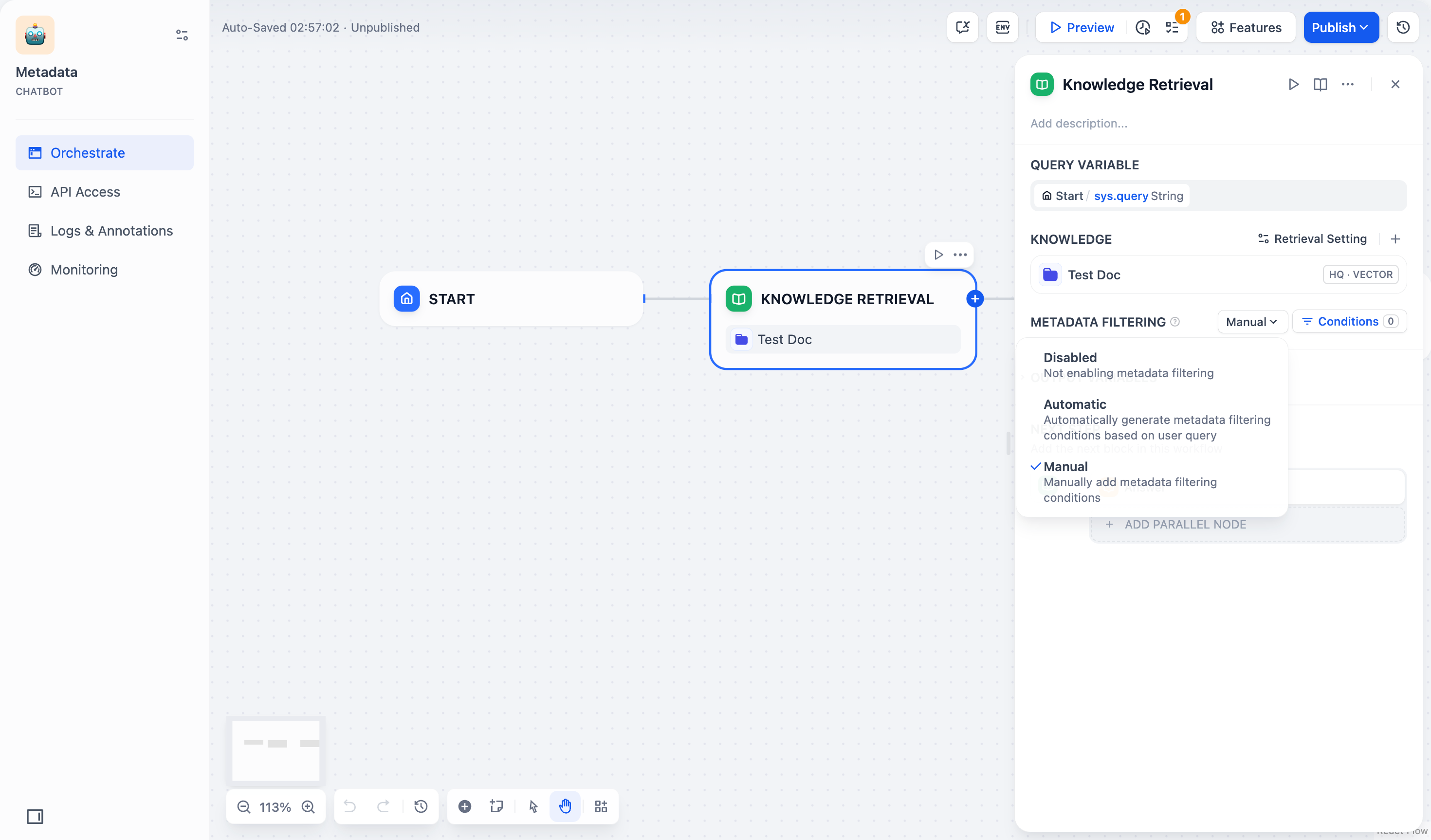
- - **禁用模式**(默认):禁用 **元数据筛选** 功能,不配置任何筛选条件。
+1. フィルタリングモードを選択する
- - **自动模式**:系统会根据传输给该 **知识检索** 节点的 **查询变量** 自动配置筛选条件,适用于简单的筛选需求。
+ * **無効モード**(デフォルト):**メタデータフィルタリング**機能を無効にし、フィルタリング条件を設定しません。
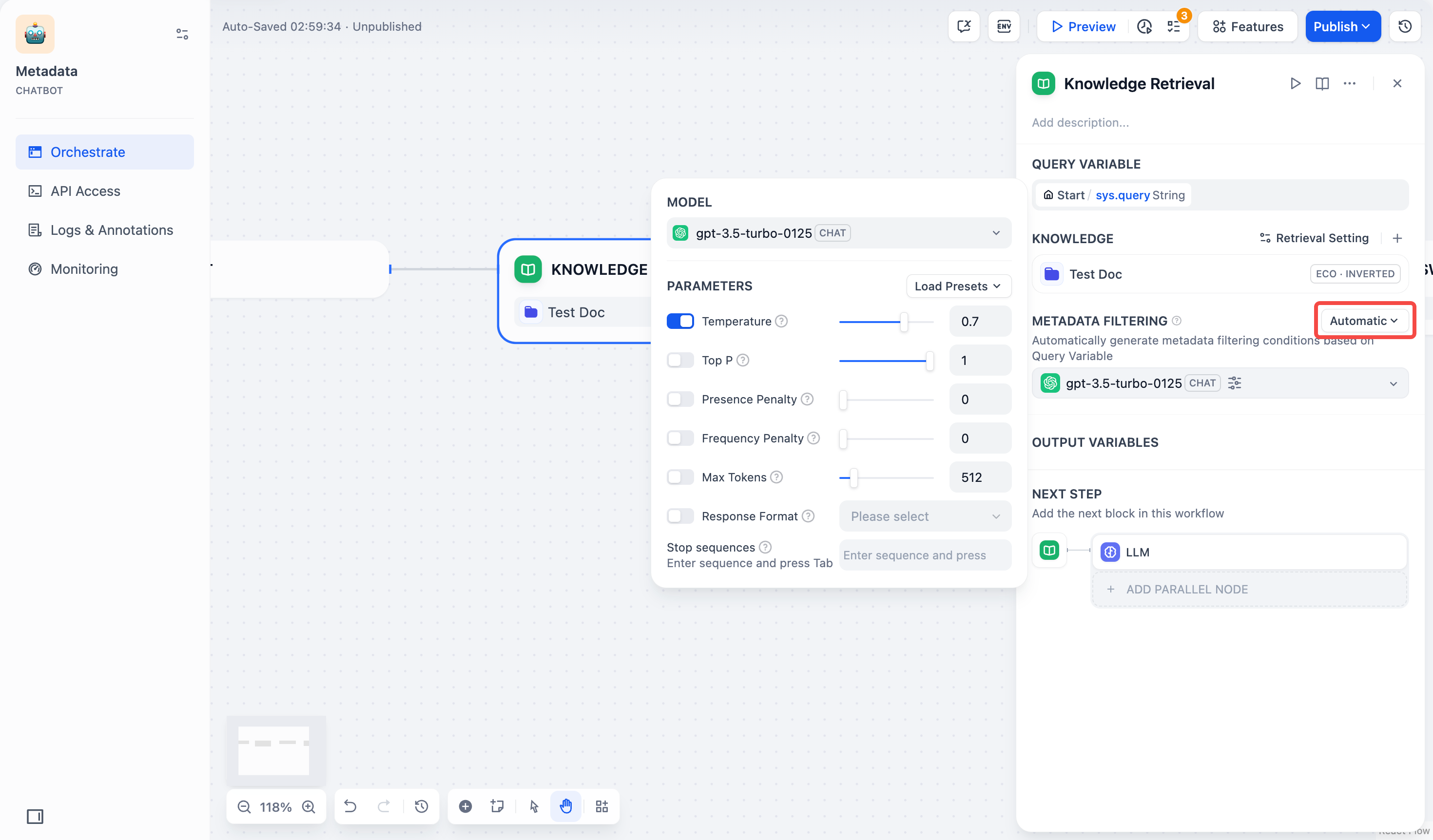
+ * **自動モード**:システムは**知識検索**ノードに渡される**クエリ変数**に基づいてフィルタリング条件を自動的に設定します。簡単なフィルタリング要件に適しています。
- > 启用自动模式后,你依然需要在 **模型** 栏中选择合适的大模型以执行文档检索任务。
+ > 自動モードを有効にした後も、**モデル**欄で文書検索タスクを実行するための適切な大規模モデルを選択する必要があります。
- 
+ 
- - **手动模式**:用户可以手动配置筛选条件,自由设置筛选规则,适用于复杂的筛选需求。
+ * **手動モード**:ユーザーが手動でフィルタリング条件を設定し、フィルタリングルールを自由に設定できます。複雑なフィルタリング要件に適しています。
-
+
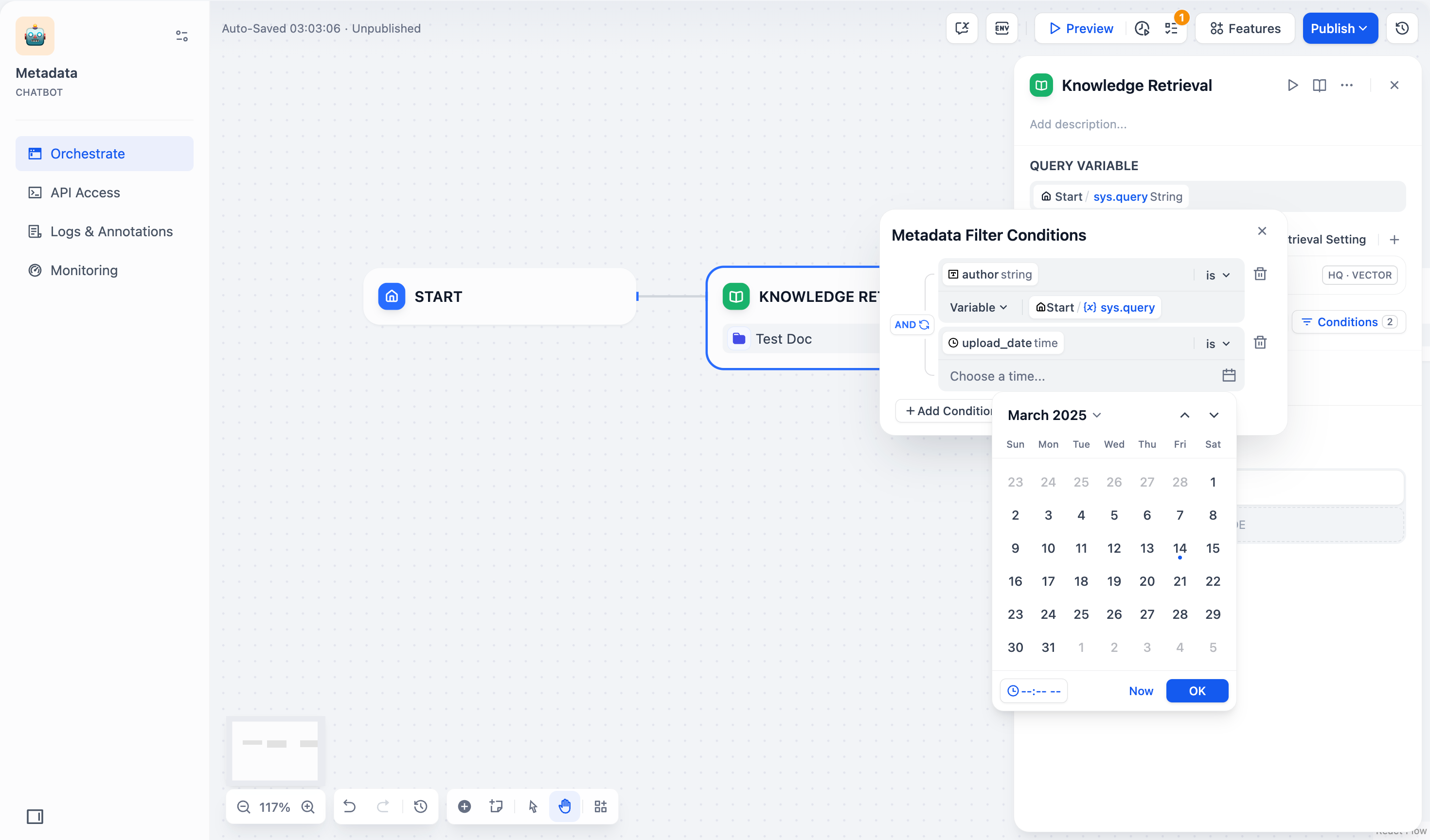
-2. 如果你选择了 **手动模式**,请参照以下步骤配置筛选条件:
+2. **手動モード**を選択した場合は、以下の手順でフィルタリング条件を設定してください:
- 1. 点击 **条件** 按钮,弹出配置框。
-
- 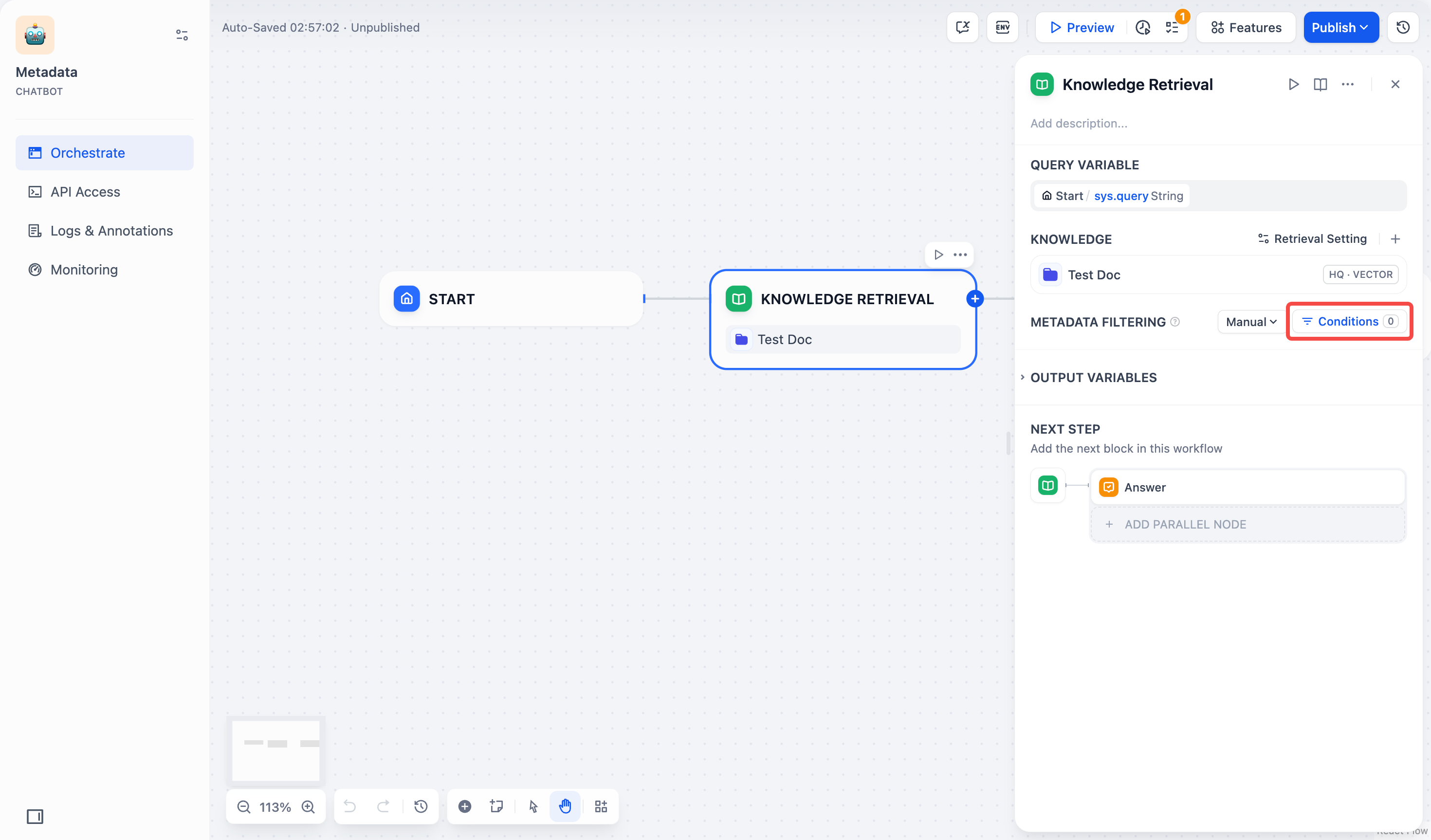
+ 1. **条件**ボタンをクリックすると、設定ボックスが表示されます。
- 2. 点击配置框中的 **+添加条件** 按钮:
+ 
- - 可以从下拉列表中选择一个已选中知识库内的元数据字段,添加到筛选条件列表中。
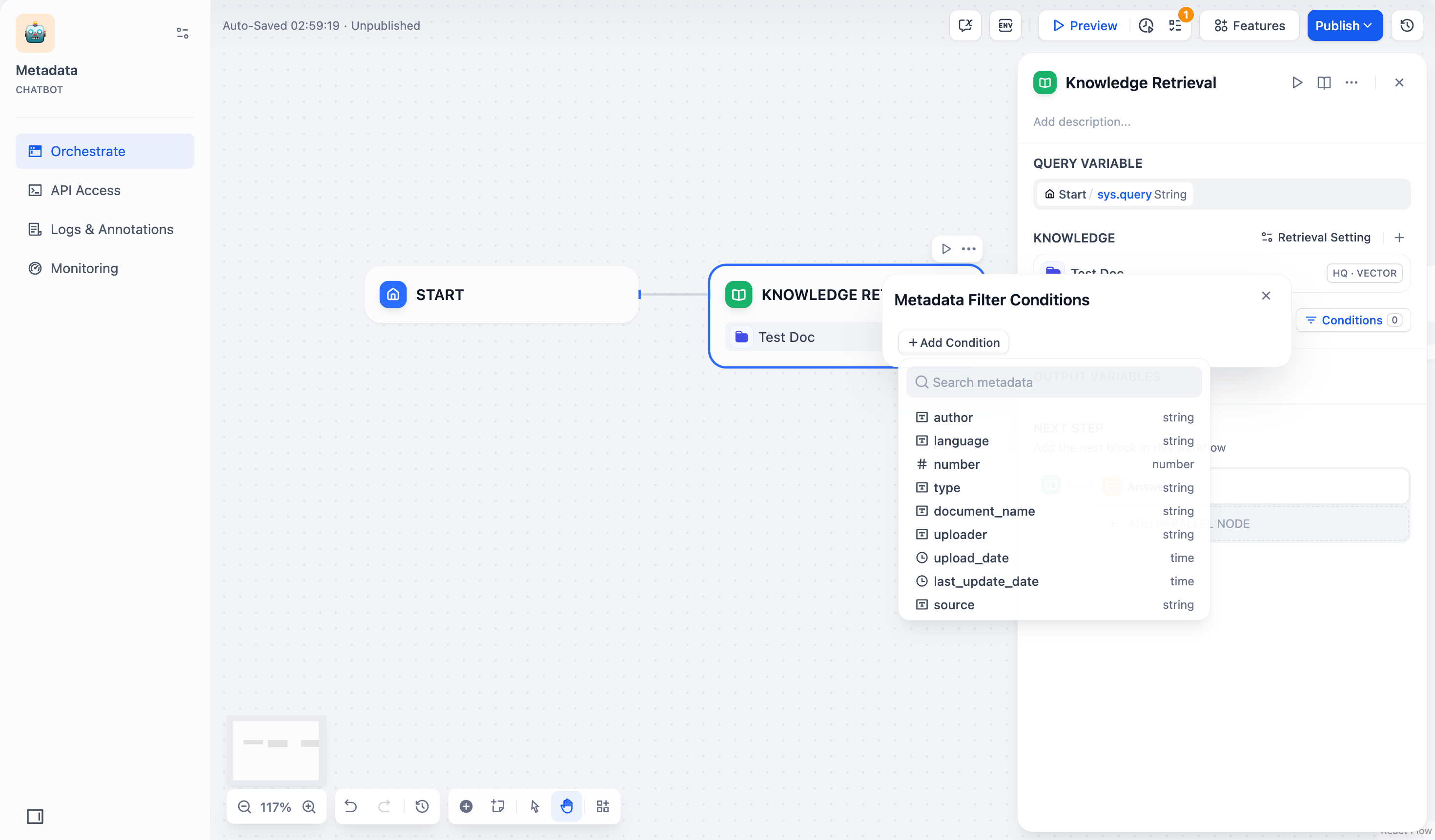
+ 2. 設定ボックスの**+条件を追加**ボタンをクリックします:
- > 如果你同时选择了多个知识库,下拉列表只会显示这些知识库共有的元数据字段。
+ * ドロップダウンリストから選択したナレッジベース内の既存のメタデータフィールドを選択し、フィルタリング条件リストに追加できます。
- - 可以在 **搜索元数据** 搜索框中搜索你需要的字段,添加到筛选条件列表中。
-
- 
+ > 複数のナレッジベースを同時に選択した場合、ドロップダウンリストにはこれらのナレッジベースに共通するメタデータフィールドのみが表示されます。
- 3. 如果需要添加多条字段,可以重复点击 **+添加条件** 按钮。
+ * **メタデータを検索**検索ボックスで必要なフィールドを検索し、フィルタリング条件リストに追加することもできます。
- 
+ 
- 4. 配置字段类型的筛选条件:
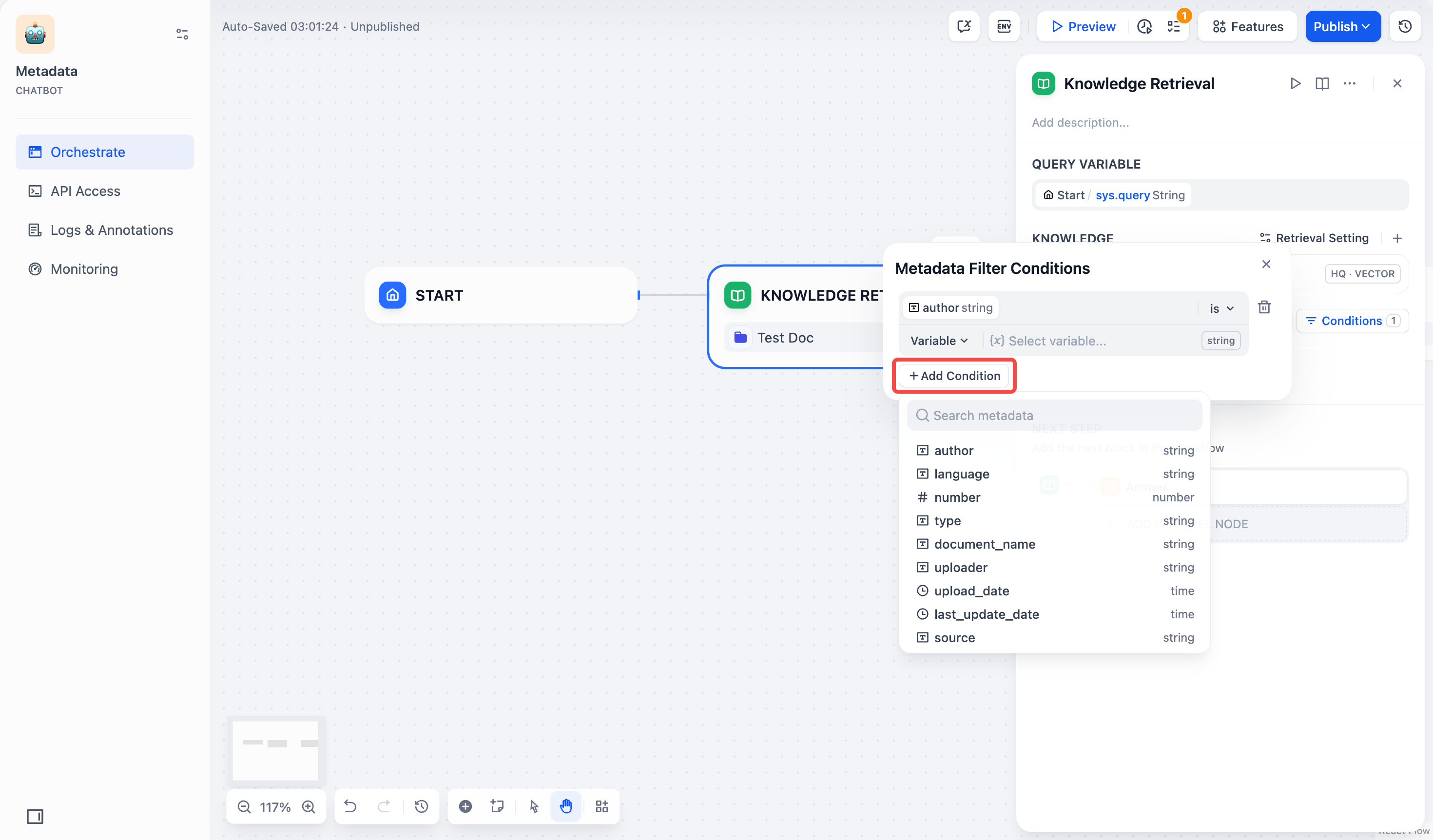
+ 3. 複数のフィールドを追加する必要がある場合は、**+条件を追加**ボタンを繰り返しクリックします。
- | 字段类型 | 筛选条件 | 筛选条件说明与示例 |
- | --- | --- | --- |
- | 字符串 | is | 字段的值必须与你输入的值完全匹配。例如,如果你设置筛选条件为 `is "Published"`,则只会返回标记为 "Published" 的文档。 |
- | | is not | 字段的值不能与你输入的值匹配。例如,如果你设置筛选条件为 `is not "Draft"`,则会返回所有未标记为 "Draft" 的文档。 |
- | | is empty | 字段的值为空。如果你配置了此条件,可以检索到未标记该字符串的文档。 |
- | | is not empty | 字段的值不为空。如果你配置了此条件,可以检索到标记了该字符串的文档。 |
- | | contains | 字段的值包含你输入的文本。例如,如果你设置筛选条件为 `contains "Report"`,则会返回所有包含"Report"的文档,如"Monthly Report" 或 "Annual Report"。 |
- | | not contains | 字段的值不包含你输入的文本。例如,如果你设置筛选条件为 `not contains "Draft"`,则会返回所有不包含 "Draft" 的文档。 |
- | | starts with | 字段的值以你输入的文本开头。例如,如果你设置筛选条件为 `starts with "Doc"`,则会返回所有以"Doc"开头的文档,如 "Doc1"、"Document"等。 |
- | | ends with | 字段的值以你输入的文本结尾。例如,如果你设置筛选条件为 `ends with "2024"`,则会返回所有以"2024"结尾的文档,如"Report 2024"、"Summary 2024"等。 |
- | 数字 | = | 字段的值必须等于你输入的数字。例如,`= 10` 会匹配所有数字标记为 10 的文档。 |
- | | ≠ | 字段的值不能等于你输入的数字。例如,`≠ 5` 会返回所有数字未标记为 5 的文档。 |
- | | > | 字段的值必须大于你输入的数字。例如,`100` 会返回所有数字标记为大于 100 的文档。 |
- | | < | 字段的值必须小于你输入的数字。例如,`< 50` 会返回所有数字标记为小于 50 的文档。 |
- | | ≥ | 字段的值必须大于或等于你输入的数字。例如,`≥ 20` 会返回所有数字标记为大于或等于 20 的文档。 |
- | | ≤ | 字段的值必须小于或等于你输入的数字。例如,`≤ 200` 会返回所有数字标记为小于或等于 200 的文档。 |
- | | is empty | 字段未设置值。例如,`is empty` 会返回所有该字段未标记数字的文档。 |
- | | is not empty | 字段已设置值。例如,`is not empty` 会返回所有该字段已标记数字的文档。 |
- | 时间 | is | 字段的时间值必须与你选择的时间完全匹配。例如,`is "2024-01-01"` 只会返回标记为 2024 年 1 月 1 日的文档。 |
- | | before | 字段的时间值必须早于你选择的时间。例如,`before "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之前的文档。 |
- | | after | 字段的时间值必须晚于你选择的时间。例如,`after "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之后的文档。 |
- | | is empty | 字段的时间值为空。如果你配置了此条件,可以检索到未标记该时间信息的文档。 |
- | | is not empty | 字段的时间值不为空。如果你配置了此条件,可以检索到标记了该时间信息的文档。 |
+ 
- 5. 选择并添加元数据筛选值:
- - **变量**:选择 **变量(Variable)**,并选择该**聊天流/工作流**中需要用于筛选文档的变量。
+ 4. フィールドタイプごとのフィルタリング条件を設定します:
- 
+ | フィールドタイプ | フィルタリング条件 | フィルタリング条件の説明と例 |
+ | ------------ | ---------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------- |
+ | 文字列 | is | フィールドの値は入力した値と完全に一致する必要があります。例えば、フィルタリング条件を is `"公開済み"` に設定した場合、「公開済み」とマークされた文書のみが返されます。 |
+ | is not | フィールドの値は入力した値と一致してはいけません。例えば、フィルタリング条件を `is not "下書き"` に設定した場合、「下書き」とマークされていないすべての文書が返されます。 | |
+ | is empty | フィールドの値が空です。この条件を設定すると、その文字列がマークされていない文書を検索できます。 | |
+ | is not empty | フィールドの値が空ではありません。この条件を設定すると、その文字列がマークされている文書を検索できます。 | |
+ | contains | フィールドの値に入力したテキストが含まれています。例えば、フィルタリング条件を `contains "レポート"` に設定した場合、「月次レポート」や「年次レポート」など、「レポート」を含むすべての文書が返されます。 | |
+ | not contains | フィールドの値に入力したテキストが含まれていません。例えば、フィルタリング条件を `not contains "下書き"` に設定した場合、「下書き」を含まないすべての文書が返されます。 | |
+ | starts with | フィールドの値が入力したテキストで始まります。例えば、フィルタリング条件を `starts with "Doc"` に設定した場合、「Doc1」や「Document」など、「Doc」で始まるすべての文書が返されます。 | |
+ | ends with | フィールドの値が入力したテキストで終わります。例えば、フィルタリング条件を `ends with "2024"` に設定した場合、「レポート 2024」や「概要 2024」など、「2024」で終わるすべての文書が返されます。 | |
+ | 数値 | = | フィールドの値は入力した数値と等しい必要があります。例えば、`= 10` は数値が10とマークされているすべての文書に一致します。 |
+ | ≠ | フィールドの値は入力した数値と等しくてはいけません。例えば、`≠ 5` は数値が5とマークされていないすべての文書を返します。 | |
+ | > | フィールドの値は入力した数値より大きい必要があります。例えば、`> 100` は数値が100より大きいとマークされているすべての文書を返します。 | |
+ | < | フィールドの値は入力した数値より小さい必要があります。例えば、`< 50` は数値が50より小さいとマークされているすべての文書を返します。 | |
+ | ≥ | フィールドの値は入力した数値以上である必要があります。例えば、`≥ 20` は数値が20以上とマークされているすべての文書を返します。 | |
+ | ≤ | フィールドの値は入力した数値以下である必要があります。例えば、`≤ 200` は数値が200以下とマークされているすべての文書を返します。 | |
+ | is empty | フィールドに値が設定されていません。例えば、`is empty` はそのフィールドに数値がマークされていないすべての文書を返します。 | |
+ | is not empty | フィールドに値が設定されています。例えば、`is not empty` はそのフィールドに数値がマークされているすべての文書を返します。 | |
+ | 時間 | is | フィールドの時間値は選択した時間と完全に一致する必要があります。例えば、`is "2024-01-01"` は2024年1月1日とマークされている文書のみを返します。 |
+ | before | フィールドの時間値は選択した時間より前でなければなりません。例えば、`before "2024-01-01"` は2024年1月1日より前とマークされているすべての文書を返します。 | |
+ | after | フィールドの時間値は選択した時間より後でなければなりません。例えば、`after "2024-01-01"` は2024年1月1日より後とマークされているすべての文書を返します。 | |
+ | is empty | フィールドの時間値が空です。この条件を設定すると、その時間情報がマークされていない文书を検索できます。 | |
+ | is not empty | フィールドの時間値が空ではありません。この条件を設定すると、その时间信息がマークされている文书を検索できます。 | |
- - **常量**:选择 **常量(Constant)**,并手动输入你需要的常量值。
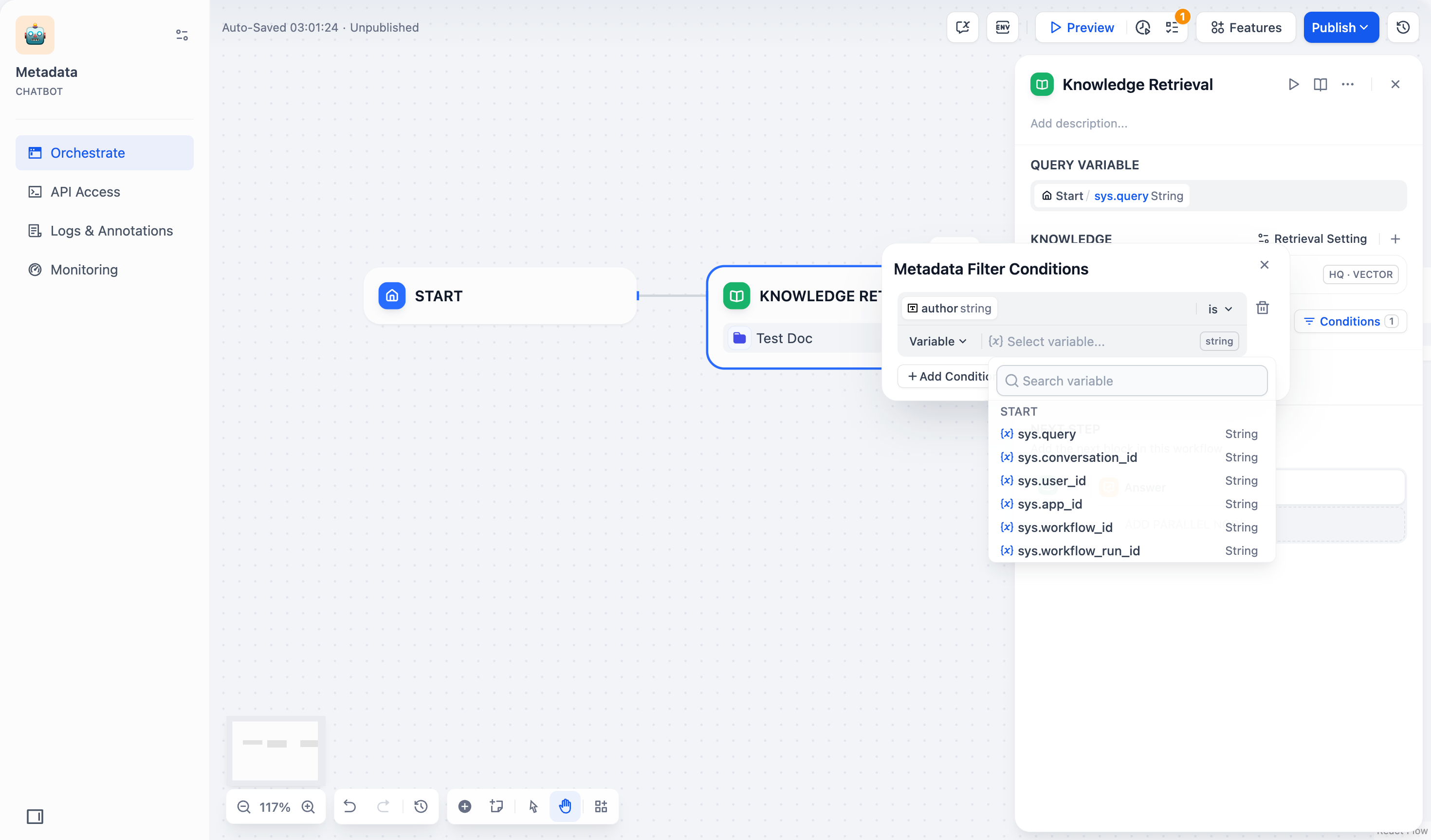
+ 5. メタデータフィルタリング値を選択して追加します:
- > **时间** 字段类型仅支持使用常量筛选文档。如果你选用时间字段筛选文档,系统会弹出时间选择器,供你选择具体的时间节点。
+ * **変数**:**変数(Variable)を選択し、そのチャットフロー/ワークフロー**内で文書のフィルタリングに使用する変数を選択します。
- 
+ 
-
-
+
-**可调参数**
+**調整可能なパラメータ**
* **TopK**
- 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小,动态调整分段数量。数值越高,预期被召回的文本分段数量越多。
-* **Score 阈值**
+ ユーザーの質問に最も類似したテキストセグメントを選択するために使用されます。システムはモデルの選択に基づいてコンテキストウィンドウサイズを動的に調整し、セグメントの数を増やします。数値が高いほど、リコールされるテキストセグメントの数が増加します。
+* **スコアの閾値**
- 用于设置文本片段筛选的相似度阈值。向量检索的相似度分数需要超过设置的分数后才会被召回,数值越高,预期被召回的文本数量越少。
+ テキストセグメントの選択に使用される類似性の閾値を設定します。ベクトル検索の類似性スコアは、設定したスコアを超える必要があり、数値が高いほどリコールされるテキストの数が減少します。
-### 使用元数据筛选知识
+複数のリコールモードを利用することで、高品質なリコール効果を得ることができるため、リコールモードを複数のリコールモードに設定することを強くお勧めします。
-#### 聊天流/工作流
+### メタデータを使用して知識をフィルタリングする
-在 **聊天流/工作流** 的 **知识检索** 节点中,你可以使用 **元数据筛选** 功能精确检索文档。该功能有助于你根据文档的元数据字段(如标签、类别或访问权限)优化检索结果。
+#### チャットフロー/ワークフロー
-##### 配置步骤
+**チャットフロー/ワークフロー**の**知識検索**ノードでは、**メタデータフィルタリング**機能を使用して文書を正確に検索できます。この機能は、文書のメタデータフィールド(タグ、カテゴリ、アクセス権限など)に基づいて検索結果を最適化するのに役立ちます。
-1. 选择筛选模式
+**設定手順**
- - **禁用模式**(默认):禁用 **元数据筛选** 功能,不配置任何筛选条件。
+1. フィルタリングモードを選択する
- - **自动模式**:系统会根据传输给该 **知识检索** 节点的 **查询变量** 自动配置筛选条件,适用于简单的筛选需求。
+ * **無効モード**(デフォルト):**メタデータフィルタリング**機能を無効にし、フィルタリング条件を設定しません。
+ * **自動モード**:システムは**知識検索**ノードに渡される**クエリ変数**に基づいてフィルタリング条件を自動的に設定します。簡単なフィルタリング要件に適しています。
- > 启用自动模式后,你依然需要在 **模型** 栏中选择合适的大模型以执行文档检索任务。
+ > 自動モードを有効にした後も、**モデル**欄で文書検索タスクを実行するための適切な大規模モデルを選択する必要があります。
- 
+ 
- - **手动模式**:用户可以手动配置筛选条件,自由设置筛选规则,适用于复杂的筛选需求。
+ * **手動モード**:ユーザーが手動でフィルタリング条件を設定し、フィルタリングルールを自由に設定できます。複雑なフィルタリング要件に適しています。
-
+
-2. 如果你选择了 **手动模式**,请参照以下步骤配置筛选条件:
+2. **手動モード**を選択した場合は、以下の手順でフィルタリング条件を設定してください:
- 1. 点击 **条件** 按钮,弹出配置框。
-
- 
+ 1. **条件**ボタンをクリックすると、設定ボックスが表示されます。
- 2. 点击配置框中的 **+添加条件** 按钮:
+ 
- - 可以从下拉列表中选择一个已选中知识库内的元数据字段,添加到筛选条件列表中。
+ 2. 設定ボックスの**+条件を追加**ボタンをクリックします:
- > 如果你同时选择了多个知识库,下拉列表只会显示这些知识库共有的元数据字段。
+ * ドロップダウンリストから選択したナレッジベース内の既存のメタデータフィールドを選択し、フィルタリング条件リストに追加できます。
- - 可以在 **搜索元数据** 搜索框中搜索你需要的字段,添加到筛选条件列表中。
-
- 
+ > 複数のナレッジベースを同時に選択した場合、ドロップダウンリストにはこれらのナレッジベースに共通するメタデータフィールドのみが表示されます。
- 3. 如果需要添加多条字段,可以重复点击 **+添加条件** 按钮。
+ * **メタデータを検索**検索ボックスで必要なフィールドを検索し、フィルタリング条件リストに追加することもできます。
- 
+ 
- 4. 配置字段类型的筛选条件:
+ 3. 複数のフィールドを追加する必要がある場合は、**+条件を追加**ボタンを繰り返しクリックします。
- | 字段类型 | 筛选条件 | 筛选条件说明与示例 |
- | --- | --- | --- |
- | 字符串 | is | 字段的值必须与你输入的值完全匹配。例如,如果你设置筛选条件为 `is "Published"`,则只会返回标记为 "Published" 的文档。 |
- | | is not | 字段的值不能与你输入的值匹配。例如,如果你设置筛选条件为 `is not "Draft"`,则会返回所有未标记为 "Draft" 的文档。 |
- | | is empty | 字段的值为空。如果你配置了此条件,可以检索到未标记该字符串的文档。 |
- | | is not empty | 字段的值不为空。如果你配置了此条件,可以检索到标记了该字符串的文档。 |
- | | contains | 字段的值包含你输入的文本。例如,如果你设置筛选条件为 `contains "Report"`,则会返回所有包含"Report"的文档,如"Monthly Report" 或 "Annual Report"。 |
- | | not contains | 字段的值不包含你输入的文本。例如,如果你设置筛选条件为 `not contains "Draft"`,则会返回所有不包含 "Draft" 的文档。 |
- | | starts with | 字段的值以你输入的文本开头。例如,如果你设置筛选条件为 `starts with "Doc"`,则会返回所有以"Doc"开头的文档,如 "Doc1"、"Document"等。 |
- | | ends with | 字段的值以你输入的文本结尾。例如,如果你设置筛选条件为 `ends with "2024"`,则会返回所有以"2024"结尾的文档,如"Report 2024"、"Summary 2024"等。 |
- | 数字 | = | 字段的值必须等于你输入的数字。例如,`= 10` 会匹配所有数字标记为 10 的文档。 |
- | | ≠ | 字段的值不能等于你输入的数字。例如,`≠ 5` 会返回所有数字未标记为 5 的文档。 |
- | | > | 字段的值必须大于你输入的数字。例如,`100` 会返回所有数字标记为大于 100 的文档。 |
- | | < | 字段的值必须小于你输入的数字。例如,`< 50` 会返回所有数字标记为小于 50 的文档。 |
- | | ≥ | 字段的值必须大于或等于你输入的数字。例如,`≥ 20` 会返回所有数字标记为大于或等于 20 的文档。 |
- | | ≤ | 字段的值必须小于或等于你输入的数字。例如,`≤ 200` 会返回所有数字标记为小于或等于 200 的文档。 |
- | | is empty | 字段未设置值。例如,`is empty` 会返回所有该字段未标记数字的文档。 |
- | | is not empty | 字段已设置值。例如,`is not empty` 会返回所有该字段已标记数字的文档。 |
- | 时间 | is | 字段的时间值必须与你选择的时间完全匹配。例如,`is "2024-01-01"` 只会返回标记为 2024 年 1 月 1 日的文档。 |
- | | before | 字段的时间值必须早于你选择的时间。例如,`before "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之前的文档。 |
- | | after | 字段的时间值必须晚于你选择的时间。例如,`after "2024-01-01"` 会返回所有标记为 2024 年 1 月 1 日之后的文档。 |
- | | is empty | 字段的时间值为空。如果你配置了此条件,可以检索到未标记该时间信息的文档。 |
- | | is not empty | 字段的时间值不为空。如果你配置了此条件,可以检索到标记了该时间信息的文档。 |
+ 
- 5. 选择并添加元数据筛选值:
- - **变量**:选择 **变量(Variable)**,并选择该**聊天流/工作流**中需要用于筛选文档的变量。
+ 4. フィールドタイプごとのフィルタリング条件を設定します:
- 
+ | フィールドタイプ | フィルタリング条件 | フィルタリング条件の説明と例 |
+ | ------------ | ---------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------- |
+ | 文字列 | is | フィールドの値は入力した値と完全に一致する必要があります。例えば、フィルタリング条件を is `"公開済み"` に設定した場合、「公開済み」とマークされた文書のみが返されます。 |
+ | is not | フィールドの値は入力した値と一致してはいけません。例えば、フィルタリング条件を `is not "下書き"` に設定した場合、「下書き」とマークされていないすべての文書が返されます。 | |
+ | is empty | フィールドの値が空です。この条件を設定すると、その文字列がマークされていない文書を検索できます。 | |
+ | is not empty | フィールドの値が空ではありません。この条件を設定すると、その文字列がマークされている文書を検索できます。 | |
+ | contains | フィールドの値に入力したテキストが含まれています。例えば、フィルタリング条件を `contains "レポート"` に設定した場合、「月次レポート」や「年次レポート」など、「レポート」を含むすべての文書が返されます。 | |
+ | not contains | フィールドの値に入力したテキストが含まれていません。例えば、フィルタリング条件を `not contains "下書き"` に設定した場合、「下書き」を含まないすべての文書が返されます。 | |
+ | starts with | フィールドの値が入力したテキストで始まります。例えば、フィルタリング条件を `starts with "Doc"` に設定した場合、「Doc1」や「Document」など、「Doc」で始まるすべての文書が返されます。 | |
+ | ends with | フィールドの値が入力したテキストで終わります。例えば、フィルタリング条件を `ends with "2024"` に設定した場合、「レポート 2024」や「概要 2024」など、「2024」で終わるすべての文書が返されます。 | |
+ | 数値 | = | フィールドの値は入力した数値と等しい必要があります。例えば、`= 10` は数値が10とマークされているすべての文書に一致します。 |
+ | ≠ | フィールドの値は入力した数値と等しくてはいけません。例えば、`≠ 5` は数値が5とマークされていないすべての文書を返します。 | |
+ | > | フィールドの値は入力した数値より大きい必要があります。例えば、`> 100` は数値が100より大きいとマークされているすべての文書を返します。 | |
+ | < | フィールドの値は入力した数値より小さい必要があります。例えば、`< 50` は数値が50より小さいとマークされているすべての文書を返します。 | |
+ | ≥ | フィールドの値は入力した数値以上である必要があります。例えば、`≥ 20` は数値が20以上とマークされているすべての文書を返します。 | |
+ | ≤ | フィールドの値は入力した数値以下である必要があります。例えば、`≤ 200` は数値が200以下とマークされているすべての文書を返します。 | |
+ | is empty | フィールドに値が設定されていません。例えば、`is empty` はそのフィールドに数値がマークされていないすべての文書を返します。 | |
+ | is not empty | フィールドに値が設定されています。例えば、`is not empty` はそのフィールドに数値がマークされているすべての文書を返します。 | |
+ | 時間 | is | フィールドの時間値は選択した時間と完全に一致する必要があります。例えば、`is "2024-01-01"` は2024年1月1日とマークされている文書のみを返します。 |
+ | before | フィールドの時間値は選択した時間より前でなければなりません。例えば、`before "2024-01-01"` は2024年1月1日より前とマークされているすべての文書を返します。 | |
+ | after | フィールドの時間値は選択した時間より後でなければなりません。例えば、`after "2024-01-01"` は2024年1月1日より後とマークされているすべての文書を返します。 | |
+ | is empty | フィールドの時間値が空です。この条件を設定すると、その時間情報がマークされていない文书を検索できます。 | |
+ | is not empty | フィールドの時間値が空ではありません。この条件を設定すると、その时间信息がマークされている文书を検索できます。 | |
- - **常量**:选择 **常量(Constant)**,并手动输入你需要的常量值。
+ 5. メタデータフィルタリング値を選択して追加します:
- > **时间** 字段类型仅支持使用常量筛选文档。如果你选用时间字段筛选文档,系统会弹出时间选择器,供你选择具体的时间节点。
+ * **変数**:**変数(Variable)を選択し、そのチャットフロー/ワークフロー**内で文書のフィルタリングに使用する変数を選択します。
- 
+ 
-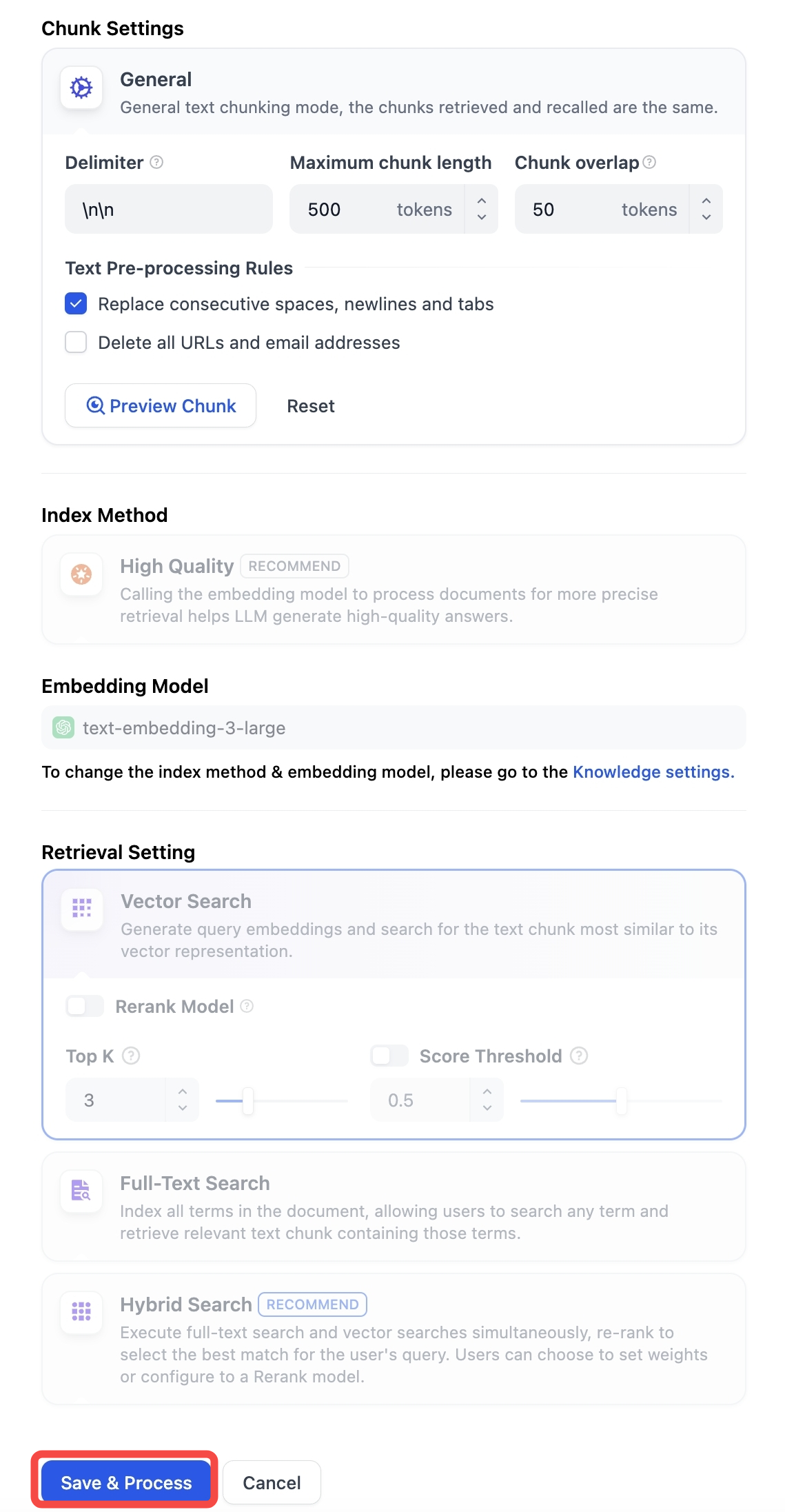 -### 元数据管理
+---
+
+### メタデータ管理
+
+メタデータの詳細については、[メタデータ](https://docs.dify.ai/ja-jp/guides/knowledge-base/metadata)を参照してください。
-如需了解元数据的相关信息,请参阅 [元数据](/ja-jp/guides/knowledge-base/metadata)。
diff --git a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
index 7f36c341..e43cc5b5 100644
--- a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
@@ -1,5 +1,5 @@
---
-title: ナレッジベースの管理(待处理)
+title: ナレッジベースの管理
---
> ナレッジベースのページは、チームオーナー、チーム管理者、編集権限があるユーザーのみがアクセスできます。
@@ -8,44 +8,32 @@ Difyチームのホームページで、「ナレッジベース」ボタンを
ナレッジベースの名前、説明、表示権限、索引モード、埋め込みモデル、および検索設定を変更することができます。
-
-### 元数据管理
+---
+
+### メタデータ管理
+
+メタデータの詳細については、[メタデータ](https://docs.dify.ai/ja-jp/guides/knowledge-base/metadata)を参照してください。
-如需了解元数据的相关信息,请参阅 [元数据](/ja-jp/guides/knowledge-base/metadata)。
diff --git a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
index 7f36c341..e43cc5b5 100644
--- a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
@@ -1,5 +1,5 @@
---
-title: ナレッジベースの管理(待处理)
+title: ナレッジベースの管理
---
> ナレッジベースのページは、チームオーナー、チーム管理者、編集権限があるユーザーのみがアクセスできます。
@@ -8,44 +8,32 @@ Difyチームのホームページで、「ナレッジベース」ボタンを
ナレッジベースの名前、説明、表示権限、索引モード、埋め込みモデル、および検索設定を変更することができます。
-
-  -
-
-  -
-
-  -
-
| - | ビルトインメタデータ(Built-in) | -カスタムメタデータ | +Feature | +ビルトインメタデータ(Built-in) | +カスタムメタデータ | +
|---|---|---|---|---|---|
| 表示位置 | +ナレッジベースインターフェースのメタデータ欄の下半分。 | +ナレッジベースインターフェースのメタデータ欄の上半分。 | |||
| 表示位置 | -ナレッジベースインターフェースのメタデータ欄の下半分。 | -ナレッジベースインターフェースのメタデータ欄の上半分。 | +有効化方法 | +デフォルトでは無効で、手動で有効にする必要があります。 | +ユーザーが必要に応じて自由に追加できます。 |
| 有効化方法 | -デフォルトでは無効で、手動で有効にする必要があります。 | -ユーザーが必要に応じて自由に追加できます。 | +生成方法 | +有効化後、システムが自動的に関連情報を抽出してフィールド値を生成します。 | +ユーザーが手動で追加し、完全にユーザー定義です。 |
| 生成方法 | -有効化後、システムが自動的に関連情報を抽出してフィールド値を生成します。 | -ユーザーが手動で追加し、完全にユーザー定義です。 | +修正権限 | +一度生成されると、フィールドとフィールド値は修正できません。 | +フィールド名の削除や編集が可能で、フィールド値も修正できます。 |
| 修正権限 | -一度生成されると、フィールドとフィールド値は修正できません。 | -フィールド名の削除や編集が可能で、フィールド値も修正できます。 | +適用範囲 | +有効化後、既にアップロードされた文書と新たにアップロードされるすべての文書に適用されます。 | +メタデータフィールドを追加した後、フィールドはナレッジベースのメタデータリストに保存されます。具体的な文書にそのフィールドを適用するには手動設定が必要です。 |
| 適用範囲 | -有効化後、既にアップロードされた文書と新たにアップロードされるすべての文書に適用されます。 | -メタデータフィールドを追加した後、フィールドはナレッジベースのメタデータリストに保存されます。具体的な文書にそのフィールドを適用するには手動設定が必要です。 | +フィールド | +
+ システムによって事前定義され、以下を含みます:
+
|
+ 初期状態では、ナレッジベースにカスタムメタデータフィールドはなく、ユーザーが手動で追加する必要があります。 |
| フィールド | -
- システムによって事前定義され、以下を含みます: - • document_name (string):ファイル名 - • uploader (string):アップローダー - • upload_date (time):アップロード日 - • last_update_date (time):最終更新時間 - • source (string):ファイルソース - |
- 初期状態では、ナレッジベースにカスタムメタデータフィールドはなく、ユーザーが手動で追加する必要があります。 | -|||
| フィールド値タイプ | -
- • 文字列 (string):テキスト値 - • 数値 (number):数値 - • 時間 (time):日付と時間 - |
-
- • 文字列 (string):テキスト値 - • 数値 (number):数値 - • 時間 (time):日付と時間 - |
+ フィールド値タイプ | +
+
|
+
+
|
-
-
-  -
-
 - 選択した文書に既に作成されたフィールドを追加する場合:
- ドロップダウンリストから既存のフィールドを選択して、フィールドリストに追加できます。
- **メタデータを検索** 検索ボックスで必要なフィールドを検索し、その文書のフィールドリストに追加できます。
-
-
- 選択した文書に既に作成されたフィールドを追加する場合:
- ドロップダウンリストから既存のフィールドを選択して、フィールドリストに追加できます。
- **メタデータを検索** 検索ボックスで必要なフィールドを検索し、その文書のフィールドリストに追加できます。
-
-  - 選択した文書に新しいフィールドを作成する場合は、ポップアップの左下にある **+メタデータを新規作成** ボタンをクリックし、前述の **メタデータフィールドの新規作成** セクションを参照してフィールドを作成できます。
-
- > **+メタデータを新規作成** ポップアップで作成したメタデータフィールドは、自動的にナレッジベースのフィールドリストに同期されます。
-
- 選択した文書に新しいフィールドを作成する場合は、ポップアップの左下にある **+メタデータを新規作成** ボタンをクリックし、前述の **メタデータフィールドの新規作成** セクションを参照してフィールドを作成できます。
-
- > **+メタデータを新規作成** ポップアップで作成したメタデータフィールドは、自動的にナレッジベースのフィールドリストに同期されます。
-  +
- 既に作成されたフィールドを管理する場合は、そのポップアップの右下にある **管理** ボタンをクリックすると、ナレッジベースの管理インターフェースに移動します。
-
+
- 既に作成されたフィールドを管理する場合は、そのポップアップの右下にある **管理** ボタンをクリックすると、ナレッジベースの管理インターフェースに移動します。
-  2. *(オプション)* フィールドを追加した後、フィールド値ボックスにそのフィールドに対応するフィールド値を入力します。
-
2. *(オプション)* フィールドを追加した後、フィールド値ボックスにそのフィールドに対応するフィールド値を入力します。
- - 値タイプが **時間** の場合、フィールド値を入力する際に時間選択ツールが表示され、具体的な時間を選択できます。
-
- 値タイプが **時間** の場合、フィールド値を入力する際に時間選択ツールが表示され、具体的な時間を選択できます。
- 3. **保存** ボタンをクリックして、操作を保存します。
@@ -275,11 +276,12 @@ alt=""
- **フィールド値のリセット**: カーソルをフィールド名の左側にある青い点の上に置くと、青い点は **リセット** ボタンに変わります。青い点をクリックすると、フィールドボックス内の修正された内容が元のメタデータ値にリセットされます。
-
3. **保存** ボタンをクリックして、操作を保存します。
@@ -275,11 +276,12 @@ alt=""
- **フィールド値のリセット**: カーソルをフィールド名の左側にある青い点の上に置くと、青い点は **リセット** ボタンに変わります。青い点をクリックすると、フィールドボックス内の修正された内容が元のメタデータ値にリセットされます。
-  - **フィールド値の削除**:
@@ -287,21 +289,23 @@ alt=""
- 複数のフィールド値を削除する:**複数の値** カードの削除アイコンをクリックして、選択したすべての文書のそのメタデータフィールドの値を消去します。
-
- **フィールド値の削除**:
@@ -287,21 +289,23 @@ alt=""
- 複数のフィールド値を削除する:**複数の値** カードの削除アイコンをクリックして、選択したすべての文書のそのメタデータフィールドの値を消去します。
-  - **単一メタデータフィールドの削除**: フィールドの最右側にある削除記号をクリックして、そのフィールドを削除します。削除後、そのフィールドは横線で消され、グレーアウトします。
-
- > この操作は選択した文書のそのフィールドとフィールド値のみを削除し、フィールド自体はナレッジベースに保持されます。
-
- **単一メタデータフィールドの削除**: フィールドの最右側にある削除記号をクリックして、そのフィールドを削除します。削除後、そのフィールドは横線で消され、グレーアウトします。
-
- > この操作は選択した文書のそのフィールドとフィールド値のみを削除し、フィールド自体はナレッジベースに保持されます。
-  2. **保存** ボタンをクリックして、操作を保存します。
@@ -313,11 +317,12 @@ alt=""
- **はい**: このオプションをチェックする場合、編集モードでの変更はすべての選択された文書に適用されます。元々そのフィールドを持っていなかった文書には、自動的にそのフィールドが追加されます。
-
2. **保存** ボタンをクリックして、操作を保存します。
@@ -313,11 +317,12 @@ alt=""
- **はい**: このオプションをチェックする場合、編集モードでの変更はすべての選択された文書に適用されます。元々そのフィールドを持っていなかった文書には、自動的にそのフィールドが追加されます。
- #### 単一文書のメタデータ情報の編集
@@ -341,7 +346,7 @@ alt=""
- 新しいフィールドを作成してその文書にフィールド値をマークしたい場合は、ポップアップの左下にある**+ メタデータを新規作成**ボタンをクリックし、前述の**メタデータフィールドの新規作成**セクションを参照してフィールドを作成できます。
> 文書ページで作成された新しいメタデータフィールドは、自動的にナレッジベースのフィールドリストに同期されます。
-
+

- ナレッジベースに既存のフィールドを使用してその文書にフィールド値をマークしたい場合は、以下のいずれかの方法で既存のフィールドを使用できます:
@@ -349,7 +354,7 @@ alt=""
- ドロップダウンリストからナレッジベースの既存のフィールドを選択し、その文書のフィールドリストに追加します。
- **メタデータを検索**検索ボックスで必要なフィールドを検索し、その文書のフィールドリストに追加します。
-
+

- ナレッジベースの既存のフィールドを管理したい場合は、ポップアップの右下にある**管理**ボタンをクリックして、ナレッジベースの管理インターフェースに移動します。
@@ -376,3 +381,88 @@ alt=""
- **フィールドの削除**:フィールド値ボックスの右側にある削除ボタンをクリックして、フィールドを削除します。
> この操作はその文書のそのフィールドとフィールド値のみを削除し、フィールド自体はナレッジベースに保持されます。
+
+
+
+3. 右上の**保存**ボタンをクリックして、修正後のフィールド情報を保存します。
+
+## メタデータ機能を使用してナレッジベース内の文書をフィルタリングする方法は?
+
+[アプリケーション内でナレッジベースを統合する](https://docs.dify.ai/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)の**メタデータを使用して知識をフィルタリングする**セクションを参照してください。
+
+## API情報
+
+[APIを通じてナレッジベースを維持する](https://docs.dify.ai/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api)を参照してください。
+
+## FAQ
+
+- **メタデータの役割は何ですか?**
+
+ - 検索効率の向上:ユーザーはメタデータタグを使用して関連情報を素早くフィルタリングして検索でき、時間を節約し作業効率を高めます。
+
+ - データセキュリティの強化:メタデータを通じてアクセス権限を設定し、許可されたユーザーのみが機密情報にアクセスできるようにすることで、データのセキュリティを確保します。
+
+ - データ管理能力の最適化:メタデータは企業や組織が効果的にデータを分類・保存するのを助け、データの管理と検索能力を向上させ、データの可用性と一貫性を強化します。
+
+ - 自動化プロセスのサポート:メタデータは文書管理やデータ分析などのシナリオでタスクや操作を自動的にトリガーし、プロセスを簡素化して全体の効率を高めます。
+
+- **ナレッジベースメタデータ管理リスト内のメタデータフィールドと特定の文書内のメタデータ値には、どのような違いがありますか?**
+
+
#### 単一文書のメタデータ情報の編集
@@ -341,7 +346,7 @@ alt=""
- 新しいフィールドを作成してその文書にフィールド値をマークしたい場合は、ポップアップの左下にある**+ メタデータを新規作成**ボタンをクリックし、前述の**メタデータフィールドの新規作成**セクションを参照してフィールドを作成できます。
> 文書ページで作成された新しいメタデータフィールドは、自動的にナレッジベースのフィールドリストに同期されます。
-
+

- ナレッジベースに既存のフィールドを使用してその文書にフィールド値をマークしたい場合は、以下のいずれかの方法で既存のフィールドを使用できます:
@@ -349,7 +354,7 @@ alt=""
- ドロップダウンリストからナレッジベースの既存のフィールドを選択し、その文書のフィールドリストに追加します。
- **メタデータを検索**検索ボックスで必要なフィールドを検索し、その文書のフィールドリストに追加します。
-
+

- ナレッジベースの既存のフィールドを管理したい場合は、ポップアップの右下にある**管理**ボタンをクリックして、ナレッジベースの管理インターフェースに移動します。
@@ -376,3 +381,88 @@ alt=""
- **フィールドの削除**:フィールド値ボックスの右側にある削除ボタンをクリックして、フィールドを削除します。
> この操作はその文書のそのフィールドとフィールド値のみを削除し、フィールド自体はナレッジベースに保持されます。
+
+
+
+3. 右上の**保存**ボタンをクリックして、修正後のフィールド情報を保存します。
+
+## メタデータ機能を使用してナレッジベース内の文書をフィルタリングする方法は?
+
+[アプリケーション内でナレッジベースを統合する](https://docs.dify.ai/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)の**メタデータを使用して知識をフィルタリングする**セクションを参照してください。
+
+## API情報
+
+[APIを通じてナレッジベースを維持する](https://docs.dify.ai/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api)を参照してください。
+
+## FAQ
+
+- **メタデータの役割は何ですか?**
+
+ - 検索効率の向上:ユーザーはメタデータタグを使用して関連情報を素早くフィルタリングして検索でき、時間を節約し作業効率を高めます。
+
+ - データセキュリティの強化:メタデータを通じてアクセス権限を設定し、許可されたユーザーのみが機密情報にアクセスできるようにすることで、データのセキュリティを確保します。
+
+ - データ管理能力の最適化:メタデータは企業や組織が効果的にデータを分類・保存するのを助け、データの管理と検索能力を向上させ、データの可用性と一貫性を強化します。
+
+ - 自動化プロセスのサポート:メタデータは文書管理やデータ分析などのシナリオでタスクや操作を自動的にトリガーし、プロセスを簡素化して全体の効率を高めます。
+
+- **ナレッジベースメタデータ管理リスト内のメタデータフィールドと特定の文書内のメタデータ値には、どのような違いがありますか?**
+
+| / | +定義 | +性質 | +例 | +
|---|---|---|---|
| メタデータ管理リスト内のメタデータフィールド | +文書の特定の属性を説明するための事前定義されたフィールド。 | +グローバルフィールド。すべての文書がこれらのフィールドを使用できます。 | +著者、文書タイプ、アップロード日。 | +
| 特定の文書内のメタデータ値 | +各文書が必要に応じてマークする特定の文書に関する情報。 | +文書固有の値。各文書はその内容に応じて異なるメタデータ値をマークします。 | +文書Aの「著者」フィールド値は「張三」、文書Bの「著者」フィールド値は「李四」。 | +
| 操作方法 | +操作手順 | +影響範囲 | +結果 | +
|---|---|---|---|
| ナレッジベース管理インターフェースでメタデータフィールドを削除 | +ナレッジベース管理インターフェースで、特定のメタデータフィールドの右側にある削除アイコンをクリックして、そのフィールドを削除します。 | +ナレッジベース管理リストからそのメタデータフィールドとそのすべてのフィールド値を完全に削除します。 | +そのフィールドはナレッジベースから削除され、すべての文書内のそのフィールドとすべてのフィールド値も消えます。 | +
| メタデータ編集ポップアップで選択された文書のメタデータフィールドを削除 | +メタデータ編集ポップアップで、特定のメタデータフィールドの右側にある削除アイコンをクリックして、そのフィールドを削除します。 | +選択された文書のそのフィールドとフィールド値のみを削除し、フィールド自体はナレッジベース管理リストに保持されます。 | +選択された文書内のフィールドとフィールド値は削除されますが、フィールドはナレッジベース内に保持され、フィールド値カウントは数値上の変化が発生します。 | +
| 文書詳細インターフェースでメタデータフィールドを削除 | +文書詳細インターフェースのメタデータ編集モードで、特定のメタデータフィールドの右側にある削除アイコンをクリックして、そのフィールドを削除します。 | +その文書のそのフィールドとフィールド値のみを削除し、フィールド自体はナレッジベース管理リストに保持されます。 | +その文書内のフィールドとフィールド値は削除されますが、フィールドはナレッジベース内に保持され、フィールド値カウントは数値上の変化が発生します。 | +
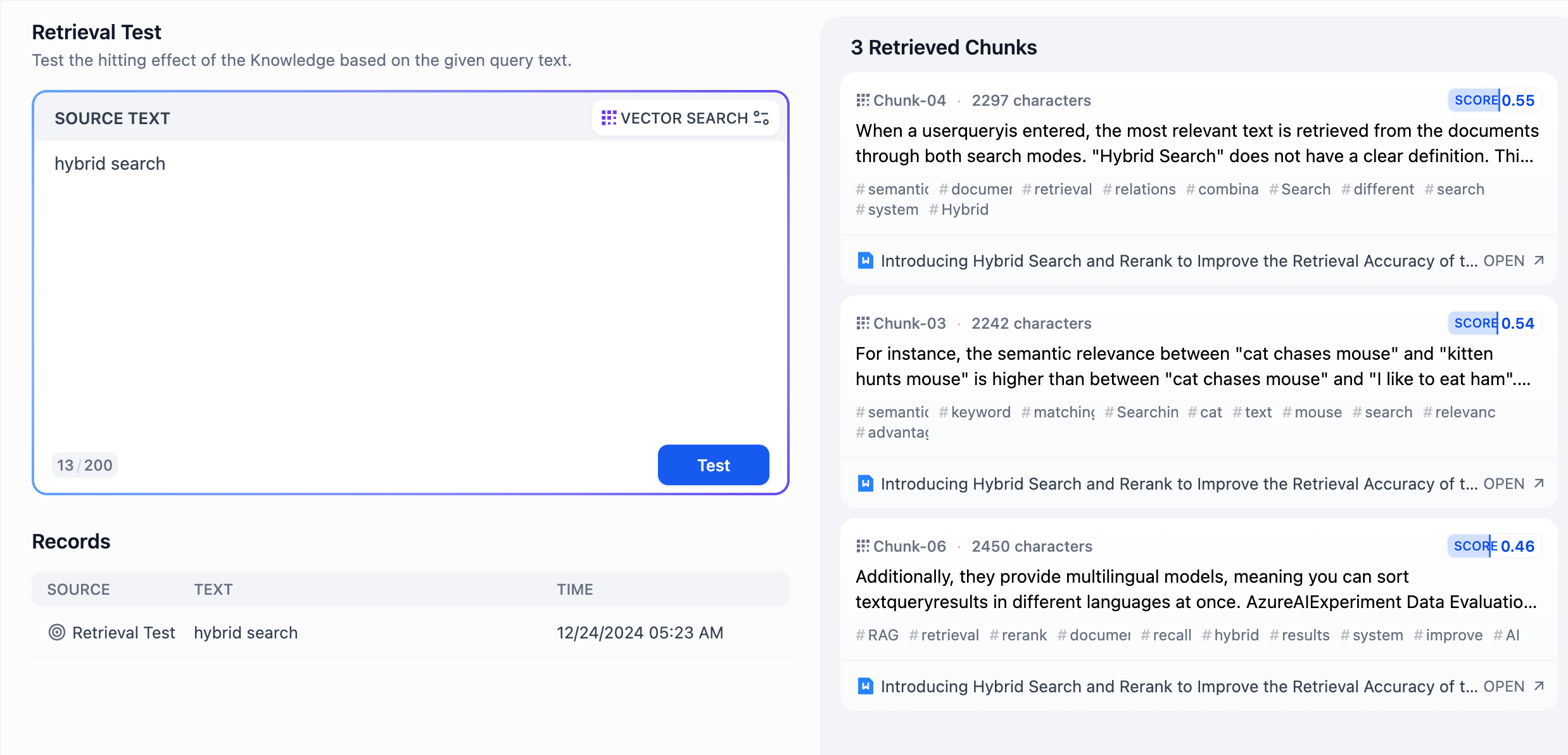
一般モード - レコール内容チョック
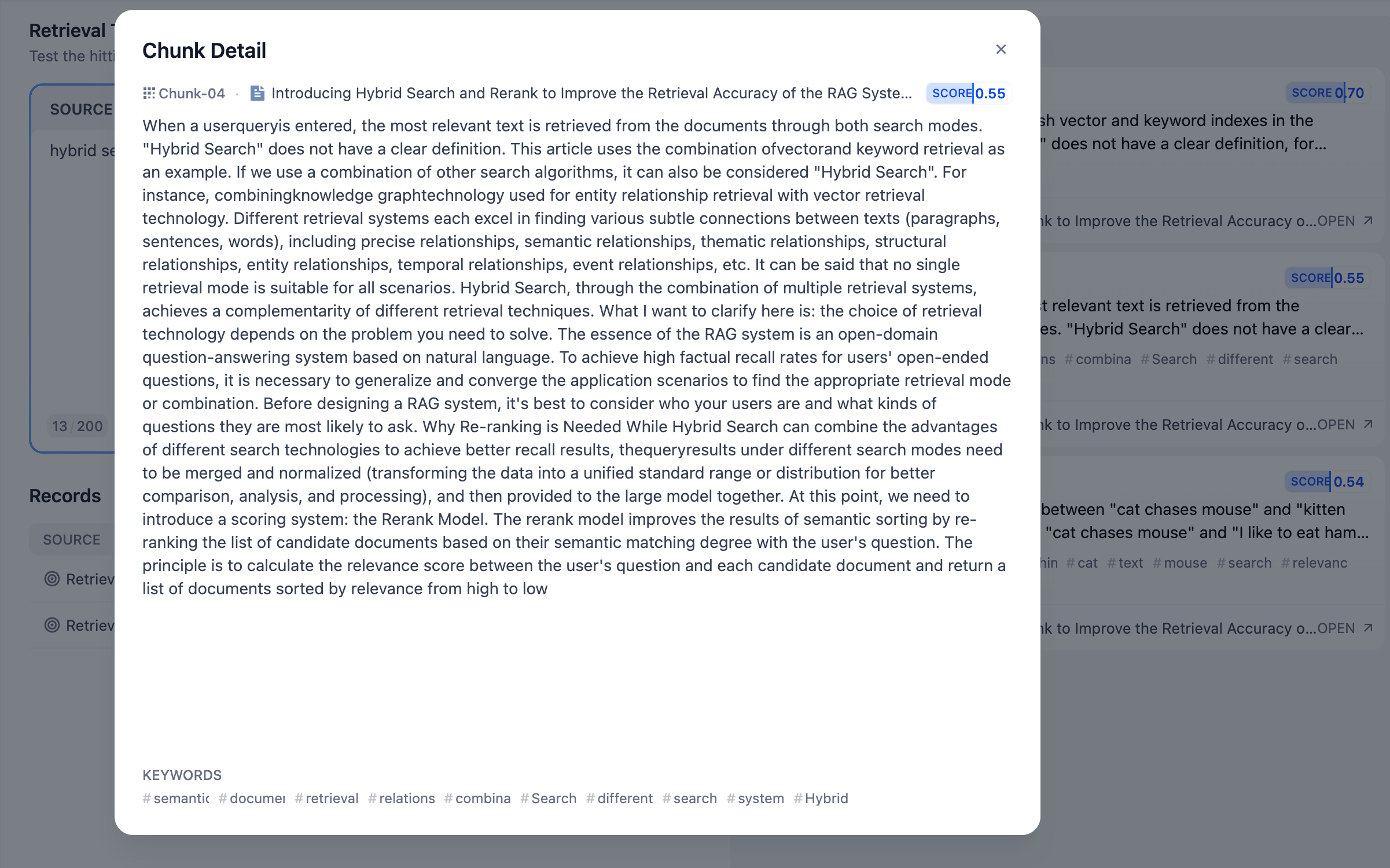
レコール内容の詳細
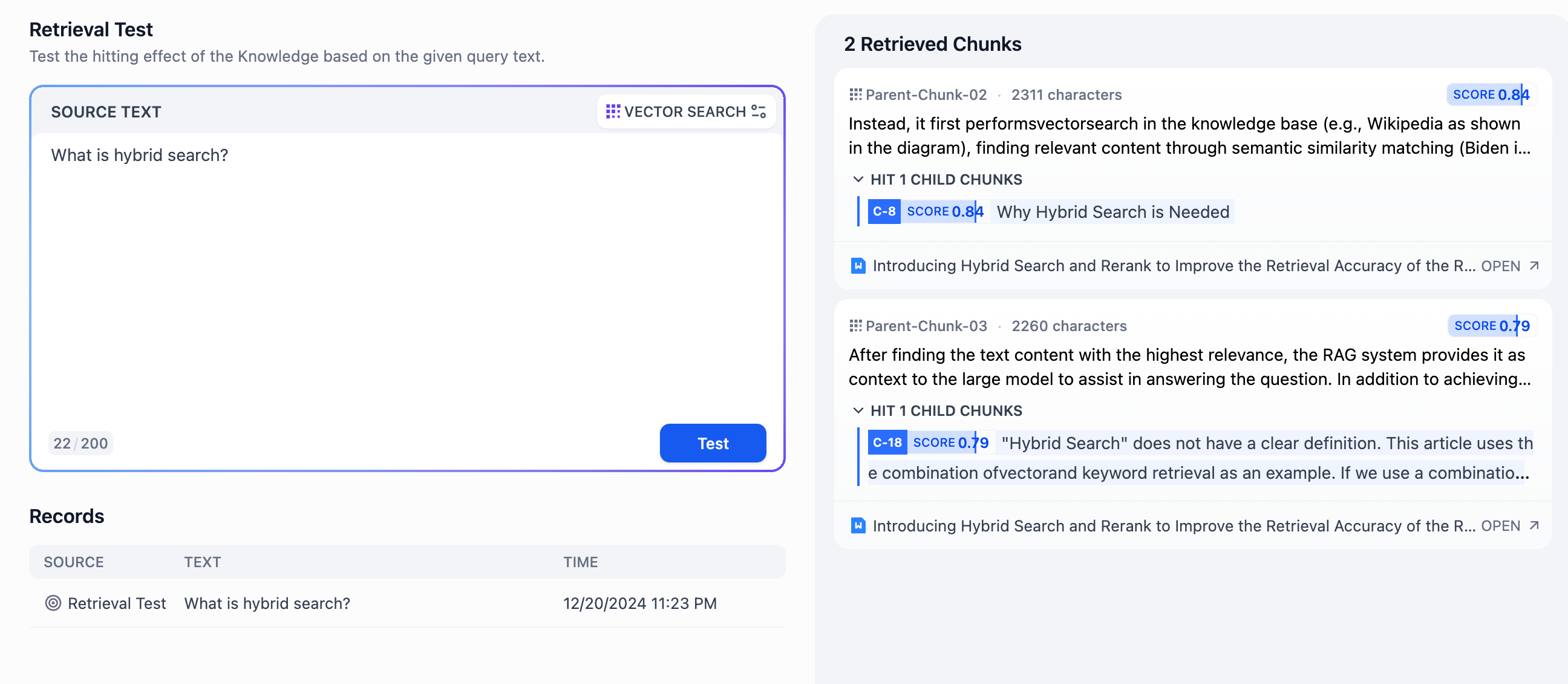
レコールテスト - 親子分割モード

レコール内容の詳細

引用と帰属機能を有効にする

返信内容の引用情報を確認する