diff --git a/docs.json b/docs.json
index 440f5982..5a74bb77 100644
--- a/docs.json
+++ b/docs.json
@@ -171,7 +171,7 @@
"en/guides/knowledge-base/knowledge-pipeline/authorize-data-source"]
},
{
- "group": "Connect External Knowledge",
+ "group": "Connect to External Knowledge",
"pages": [
"en/guides/knowledge-base/connect-external-knowledge-base",
"en/guides/knowledge-base/external-knowledge-api"]
@@ -1474,51 +1474,55 @@
]
},
{
- "group": "ナレッジベース",
+ "group": "ナレッジ",
"pages": [
"ja-jp/guides/knowledge-base/readme",
{
- "group": "ナレッジベース作成",
+ "group": "ナレッジの作成",
"pages": [
- "ja-jp/guides/knowledge-base/knowledge-base-creation/introduction",
- {
- "group": "1. オンラインデータソースの活用",
+ {"group": "クイック作成",
+ "pages": [
+ "ja-jp/guides/knowledge-base/knowledge-base-creation/introduction",
+ {
+ "group": "データのインポート",
"pages": [
"ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme",
"ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion",
- "ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website"
- ]
+ "ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website"]
+ },
+ "ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text",
+ "ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods"]
},
- "ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text",
- "ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods"
- ]
+ {
+ "group": "ナレッジパイプラインから作成",
+ "pages": [
+ "ja-jp/guides/knowledge-base/knowledge-pipeline/readme",
+ "ja-jp/guides/knowledge-base/knowledge-pipeline/create-knowledge-pipeline",
+ "ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration",
+ "ja-jp/guides/knowledge-base/knowledge-pipeline/publish-knowledge-pipeline",
+ "ja-jp/guides/knowledge-base/knowledge-pipeline/upload-files",
+ "ja-jp/guides/knowledge-base/knowledge-pipeline/manage-knowledge-base",
+ "ja-jp/guides/knowledge-base/knowledge-pipeline/authorize-data-source"]
+ },
+ {
+ "group": "外部ナレッジベースと連携",
+ "pages": [
+ "ja-jp/guides/knowledge-base/connect-external-knowledge-base",
+ "ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api-documentation"]
+ }]
},
{
- "group": "ナレッジパイプライン",
+ "group": "ナレッジの管理",
"pages": [
- "ja-jp/guides/knowledge-base/knowledge-pipeline/readme",
- "ja-jp/guides/knowledge-base/knowledge-pipeline/create-knowledge-pipeline",
- "ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration",
- "ja-jp/guides/knowledge-base/knowledge-pipeline/publish-knowledge-pipeline",
- "ja-jp/guides/knowledge-base/knowledge-pipeline/upload-files",
- "ja-jp/guides/knowledge-base/knowledge-pipeline/manage-knowledge-base",
- "ja-jp/guides/knowledge-base/knowledge-pipeline/authorize-data-source"
- ]
- },
- {
- "group": "ナレッジベースの管理",
- "pages": [
- "ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme",
"ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents",
+ "ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme",
+ "ja-jp/guides/knowledge-base/metadata",
"ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api"
]
},
- "ja-jp/guides/knowledge-base/metadata",
- "ja-jp/guides/knowledge-base/test-retrieval",
+ "ja-jp/guides/knowledge-base/test-retrieval",
"ja-jp/guides/knowledge-base/integrate-knowledge-within-application",
- "ja-jp/guides/knowledge-base/knowledge-request-rate-limit",
- "ja-jp/guides/knowledge-base/connect-external-knowledge-base",
- "ja-jp/guides/knowledge-base/api-documentation/external-knowledge-api-documentation"
+ "ja-jp/guides/knowledge-base/knowledge-request-rate-limit"
]
},
{
diff --git a/en/guides/knowledge-base/connect-external-knowledge-base.mdx b/en/guides/knowledge-base/connect-external-knowledge-base.mdx
index 0457a829..295b4289 100644
--- a/en/guides/knowledge-base/connect-external-knowledge-base.mdx
+++ b/en/guides/knowledge-base/connect-external-knowledge-base.mdx
@@ -1,5 +1,5 @@
---
-title: Connect External Knowledge
+title: Connect to External Knowledge Base
---
> To make a distinction, knowledge bases independent of the Dify platform are collectively referred to as **"external knowledge bases"** in this article.
diff --git a/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx b/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
index 805eb109..5aab1833 100644
--- a/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
+++ b/en/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
@@ -2,8 +2,6 @@
title: Upload Local Files
---
-Click on Knowledge in the main navigation bar of Dify. On this page, you can see your existing knowledge bases. Click **Create Knowledge** to enter the setup wizard. The Knowledge supports the import of the following two online data:
-
Click **Knowledge** in the top navigation bar of the Dify, then select **Create Knowledge** > **Import from file**.
Drag and drop or select files to upload. The number of files allowed for **batch upload** depends on your [subscription plan](https://dify.ai/pricing).
@@ -13,7 +11,7 @@ Drag and drop or select files to upload. The number of files allowed for **batch
* The upload size limit for a single document is 15MB;
* Different [subscription plans](https://dify.ai/pricing) for the SaaS version limit **batch upload numbers, total document uploads, and vector storage**
-
+
{/*
Contributing Section
diff --git a/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx b/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
index 676c07bb..fe22129b 100644
--- a/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
+++ b/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
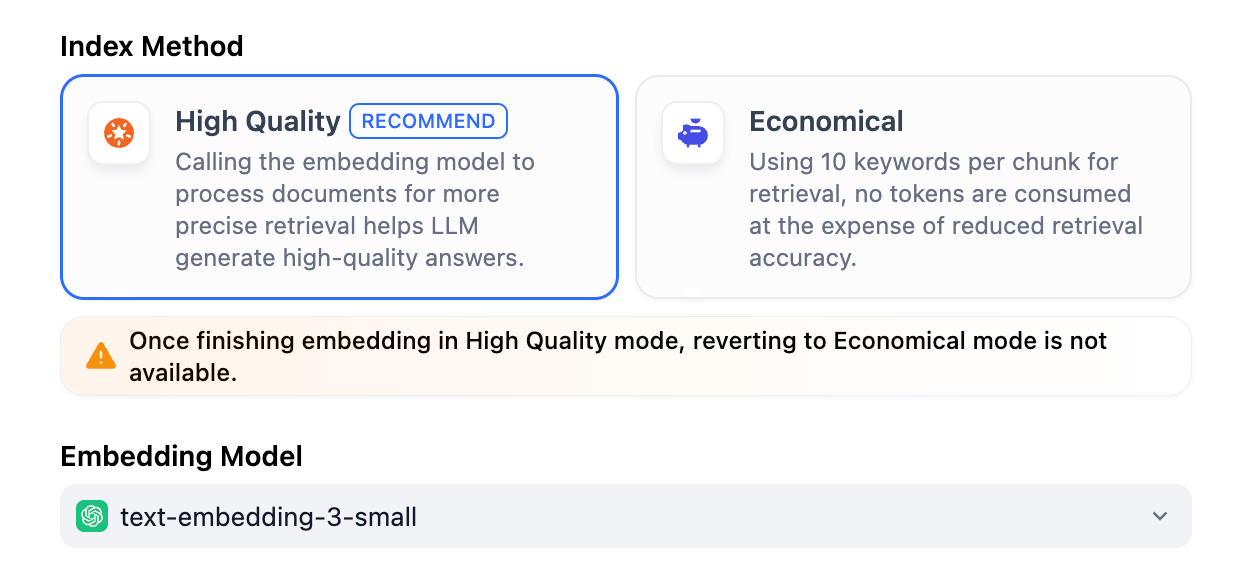
@@ -21,19 +21,19 @@ The knowledge base offers two index methods: **High-Quality** and **Economical**
Once a knowledge base is created in the High Quality index method, it cannot switch to Economical later.
- The High Quality index method uses an embedding model to convert content chunks into numeric vectors. This process is called embedding.
+ The High Quality index method uses an embedding model to convert content chunks into vector representations. This process is called embedding.
Think of these vectors as coordinates in a multi-dimensional space—the closer two points are, the more similar their meanings. This allows the system to find relevant information based on semantic similarity, not just exact keyword matches.
- Quick-created knowledge bases don't allow selecting embedding models that support image embedding (indicated by an **Image** icon) and thus they don't support image-based retrieval.
+ Quick-created knowledge bases don't allow selecting embedding models that support image embedding (indicated by a **Vision** icon) and thus they don't support image-based retrieval.
But don't worry—you can easily convert a quick-created knowledge base into a pipeline-created one to enable this feature.
 - Once chunked and vectorized, your content can be retrieved using one of three strategies: vector search, full-text search, or hybrid search. Learn more in [Retrieval Settings](#configure-the-retrieval-settings).
+ Once chunked and embed, your content can be retrieved using one of three strategies: vector search, full-text search, or hybrid search. Learn more in [Configure the Retrieval Settings](#configure-the-retrieval-settings).
### Enable Q&A Mode (Optional, Community Edition Only)
diff --git a/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx b/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
index 9992ff2f..3320608f 100644
--- a/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
+++ b/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
@@ -7,16 +7,16 @@ sidebarTitle: Manage Settings
Only the workspace owner, administrators, and editors can modify the knowledge base settings.
-In a knowledge base, click the **Settings** icon in the left sidebar to open its settings page.
+In a knowledge base, click the **Settings** icon in the left sidebar to enter its settings page.
| Settings | Description |
|:----------------------- |:---------------------|
| Name & Icon | The name and icon that identify the knowledge base.|
| Description | A brief description that indicates the knowledge base's purpose and content.|
| Permissions | Defines which workspace members can access the knowledge base.Members granted access to a knowledge base have all the permissions listed in [Manage Knowledge Content](/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents).|
-| Index Method | Defines how document chunks are processed and organized for retrieval. For more details, see [Specify the Index Method and Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods).|
+| Index Method | Defines how document chunks are processed and organized for retrieval. For more details, see [Select the Index Method](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#select-the-index-method).|
| Embedding Model | Specifies the embedding model used to convert document chunks into vector representations.Changing the embedding model will re-embed all chunks, regenerate the vector index, and discard the existing vectors.|
-| Retrieval Settings | Defines how the knowledge base retrieves relevant content. For more details, see [Specify the Index Method and Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods).|
+| Retrieval Settings | Defines how the knowledge base retrieves relevant content. For more details, see [Configure the Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#configure-the-retrieval-settings).|
Once a knowledge base is created, its chunk structure cannot be changed.
diff --git a/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx b/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
index f36e9fb0..10a16e94 100644
--- a/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
+++ b/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
@@ -16,7 +16,7 @@ In a knowledge base, each imported item—whether a local file, a Notion page, o
| Action | Description |
|:------------------- |:---------------------|
| Add | Import a new document.|
-| Modify Chunk Settings | Modify a document's chunking settings (excluding the chunk mode).
- Once chunked and vectorized, your content can be retrieved using one of three strategies: vector search, full-text search, or hybrid search. Learn more in [Retrieval Settings](#configure-the-retrieval-settings).
+ Once chunked and embed, your content can be retrieved using one of three strategies: vector search, full-text search, or hybrid search. Learn more in [Configure the Retrieval Settings](#configure-the-retrieval-settings).
### Enable Q&A Mode (Optional, Community Edition Only)
diff --git a/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx b/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
index 9992ff2f..3320608f 100644
--- a/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
+++ b/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
@@ -7,16 +7,16 @@ sidebarTitle: Manage Settings
Only the workspace owner, administrators, and editors can modify the knowledge base settings.
-In a knowledge base, click the **Settings** icon in the left sidebar to open its settings page.
+In a knowledge base, click the **Settings** icon in the left sidebar to enter its settings page.
| Settings | Description |
|:----------------------- |:---------------------|
| Name & Icon | The name and icon that identify the knowledge base.|
| Description | A brief description that indicates the knowledge base's purpose and content.|
| Permissions | Defines which workspace members can access the knowledge base.Members granted access to a knowledge base have all the permissions listed in [Manage Knowledge Content](/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents).|
-| Index Method | Defines how document chunks are processed and organized for retrieval. For more details, see [Specify the Index Method and Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods).|
+| Index Method | Defines how document chunks are processed and organized for retrieval. For more details, see [Select the Index Method](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#select-the-index-method).|
| Embedding Model | Specifies the embedding model used to convert document chunks into vector representations.Changing the embedding model will re-embed all chunks, regenerate the vector index, and discard the existing vectors.|
-| Retrieval Settings | Defines how the knowledge base retrieves relevant content. For more details, see [Specify the Index Method and Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods).|
+| Retrieval Settings | Defines how the knowledge base retrieves relevant content. For more details, see [Configure the Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#configure-the-retrieval-settings).|
Once a knowledge base is created, its chunk structure cannot be changed.
diff --git a/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx b/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
index f36e9fb0..10a16e94 100644
--- a/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
+++ b/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
@@ -16,7 +16,7 @@ In a knowledge base, each imported item—whether a local file, a Notion page, o
| Action | Description |
|:------------------- |:---------------------|
| Add | Import a new document.|
-| Modify Chunk Settings | Modify a document's chunking settings (excluding the chunk mode).
Each document can have its own chunking settings, while the chunk mode is shared across the knowledge base and cannot be changed once set.|
+| Modify Chunk Settings | Modify a document's chunking settings (excluding the chunk structure).Each document can have its own chunking settings, while the chunk structure is shared across the knowledge base and cannot be changed once set.|
| Delete | Permanently remove a document. **Deletion cannot be undone**.|
| Enable / Disable | Temporarily include or exclude a document from retrieval. On Dify Cloud, documents that have not been updated or retrieved for a certain period are automatically disabled to optimize performance.
The inactivity period varies by subscription plan:- Sandbox: 7 days
- Professional & Team: 30 days
Professional and Team users can re-enable these documents **with one click**.|
| Archive / Unarchive | Archive a document that you no longer need for retrieval but still want to keep. Archived documents are read-only and can be unarchived at any time.|
@@ -40,7 +40,7 @@ According to its chunk settings, every document is split into content chunks—t
| Enable / Disable | Temporarily include or exclude a chunk from retrieval. Disabled chunks cannot be edited.|
| Edit | Modify the content of a chunk. Edited chunks are marked **Edited**.
For documents chunked with Parent-child mode: - When editing a parent chunk, you can choose to regenerate its child chunks or keep them unchanged.
- Editing a child chunk does not update its parent chunk.
|
| Add / Edit / Delete Keywords | In knowledge bases using the Economical index method, you can add or modify keywords for each chunk to improve its retrievability. Each chunk can have up to 10 keywords.|
-| Upload / Delete Images | In knowledge bases with image-based retrieval enabled, you can delete imported images or upload new ones within the corresponding chunk. Choose an embedding model that supports image embedding (indicated by an **Image** icon) for the knowledge base to enable image-based retrieval.|
+| Upload / Delete Images | In knowledge bases with image-based retrieval enabled, you can delete imported images or upload new ones within the corresponding chunk. Choose an embedding model that supports image embedding (indicated by a **Vision** icon) for the knowledge base to enable image-based retrieval.|
## Best Practices
@@ -66,4 +66,14 @@ To do this, rewrite child chunks into **keywords**, **summaries**, or **common u
- *What's the refund period?*
-- *Are there any return shipping fees?*
\ No newline at end of file
+- *Are there any return shipping fees?*
+
+{/*
+Contributing Section
+DO NOT edit this section!
+It will be automatically generated by the script.
+*/}
+
+---
+
+[Edit this page](https://github.com/langgenius/dify-docs/edit/main/en/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx) | [Report an issue](https://github.com/langgenius/dify-docs/issues/new?template=docs.yml)
\ No newline at end of file
diff --git a/en/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx b/en/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
index abac44f8..86851a30 100644
--- a/en/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
+++ b/en/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
@@ -372,11 +372,11 @@ The High Quality method uses embedding models to convert chunks into numerical v
- To enable image-based retrieval, choose an embedding model that supports image embedding (indicated by an **Image** icon).
+ To enable image-based retrieval, choose an embedding model that supports image embedding (indicated by a **Vision** icon).
Knowledge bases with such embedding models are marked **Multimodal** on their cards.
-
- ![Knowledge Card]()
+
+  diff --git a/en/guides/knowledge-base/test-retrieval.mdx b/en/guides/knowledge-base/test-retrieval.mdx
index 4b8992b3..66e822de 100644
--- a/en/guides/knowledge-base/test-retrieval.mdx
+++ b/en/guides/knowledge-base/test-retrieval.mdx
@@ -2,7 +2,9 @@
title: Test Knowledge Retrieval
---
-In **Retrieval Testing**, you can simulate user queries to test how well the knowledge base retrieves relevant information and experiment with different retrieval settings for optimal performance.
+In a knowledge base, click the **Retrieval Testing** icon in the left sidebar to enter the testing page.
+
+Here, you can simulate user queries to test how well the knowledge base retrieves relevant information and experiment with different retrieval settings for optimal performance.
Retrieval settings adjusted here are temporary and only apply to the current test session.
@@ -12,8 +14,6 @@ In **Retrieval Testing**, you can simulate user queries to test how well the kno
For more on retrieval settings, see [Configure the Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#configure-the-retrieval-settings).
-![Retrieval Testing]()
-
The **Records** section logs all retrieval events associated with this knowledge base, including:
- Queries tested directly on the **Retrieval Testing** page
@@ -24,7 +24,6 @@ The **Records** section logs all retrieval events associated with this knowledge
-
{/*
Contributing Section
DO NOT edit this section!
diff --git a/en/guides/workflow/node/knowledge-retrieval.mdx b/en/guides/workflow/node/knowledge-retrieval.mdx
index 92070497..2dfc0bbf 100644
--- a/en/guides/workflow/node/knowledge-retrieval.mdx
+++ b/en/guides/workflow/node/knowledge-retrieval.mdx
@@ -19,12 +19,18 @@ Below is an example of using the Knowledge Retrieval node in a Chatflow:

- Before using a Knowledge Retrieval node, ensure that you have at least one available knowledge base. To learn about creating and managing knowledge bases, see [Knowledge](/en/guides/knowledge-base/readme).
+ Before using a Knowledge Retrieval node, ensure that you have at least one available knowledge base. To learn about creating knowledge bases, see [Knowledge](/en/guides/knowledge-base/readme#create-knowledge).
## Configure a Knowledge Retrieval Node
-To make the Knowledge Retrieval node work properly, you need to tell it *what* it should search for (the query), *where* it should search (the knowledge base), and *how* to process the retrieval results (the node-level retrieval settings). You can also use document metadata to enable filter-based searches and further improve retrieval precision.
+To make the Knowledge Retrieval node work properly, you need to tell it:
+
+- *What* it should search for (the query)
+- *Where* it should search (the knowledge base)
+- *How* to process the retrieval results (the node-level retrieval settings)
+
+You can also use document metadata to enable filter-based searches and further improve retrieval precision.
### Specify the Query
@@ -41,7 +47,7 @@ Provide the query content that the node should search for in the selected knowle
**Query Image** is available only when at least one added knowledge base supports image-based retrieval.
- Such knowledge bases are marked with an **Image** icon, indicating that they use an embedding model that supports image embedding.
+ Such knowledge bases are marked with a **Vision** icon, indicating that they use an embedding model that supports image embedding.
### Select Knowledge to Search
@@ -49,11 +55,11 @@ Provide the query content that the node should search for in the selected knowle
Add one or more existing knowledge bases for the node to search for content relevant to the query content.
- Knowledge bases marked with an **Image** icon support image-based retrieval, which means that you can use text and/or images as queries and retrieve both semantically related text and images.
+ Knowledge bases marked with a **Vision** icon support image-based retrieval, which means that you can use text and/or images as queries and retrieve both semantically related text and images.
- You can click the **Edit** icon next to any added knowledge base to modify its settings directly within the Knowledge Retrieval node. To learn more about these settings, see [Manage Knowledge](/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction) and [Specify the Index Method and Retrieval Setting](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods).
+ You can click the **Edit** icon next to any added knowledge base to modify its settings directly within the Knowledge Retrieval node. To learn more about these settings, see [Manage Knowledge Settings](/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction) and [Specify the Index Method and Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods).
### Configure Node-Level Retrieval Settings
diff --git a/images/multimodal_knowledge_base.png b/images/multimodal_knowledge_base.png
new file mode 100644
index 00000000..49e82c19
Binary files /dev/null and b/images/multimodal_knowledge_base.png differ
diff --git a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
index e71c8aff..73de5a82 100644
--- a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
+++ b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
@@ -1,5 +1,5 @@
---
-title: 外部ナレッジベースとの接続
+title: 外部ナレッジベースと連携
---
> この文書では、Difyプラットフォームとは独立したナレッジベースを総称して**「外部ナレッジベース」**と呼びます。
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx
index 3defde5b..7fd6433b 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx
@@ -1,5 +1,5 @@
---
-title: 2. チャンクモードの指定
+title: チャンクモードの指定
---
コンテンツをナレッジベースにアップロードした後、次に行うべき作業は、コンテンツの分割とデータのクリーニングです。この段階では、コンテンツの前処理と構造化を行い、長いテキストを複数の小さなブロックに分割します。
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
index 2574a4d6..67cfd2dc 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
@@ -1,41 +1,17 @@
---
-title: 1. テキストデータのインポート
+title: ローカルファイルをアップロード
---
-Difyプラットフォームの上部ナビゲーションにある**「ナレッジベース」**→**「ナレッジベースを作成」**をクリックします。ローカルファイルのアップロードやオンラインデータのインポートを通じて、ドキュメントをナレッジベースにアップロードできます。
+Dify の上部ナビゲーションバーで **ナレッジ** をクリックし、**ナレッジベースを作成** > **テキストファイルからインポート** を選択します。
-### **ローカルファイルのアップロード**
-
-ファイルをドラッグ&ドロップするか選択してアップロードします。**バッチアップロードに対応**していますが、一度にアップロードできるファイル数は[サブスクリプションプラン](https://dify.ai/pricing)によって制限されています。
+ファイルをドラッグ&ドロップするか選択してアップロードします。**バッチアップロードに対応**していますが、一度にアップロードできるファイル数は[サブスクリプションプラン](https://dify.ai/jp/pricing)によって制限されています。
**ローカルドキュメントのアップロードには以下の制限があります:**
* 単一ドキュメントのアップロードサイズは**15MB**に制限されています
-* 異なるSaaSバージョンの[サブスクリプションプラン](https://dify.ai/pricing)により**バッチアップロード数、ドキュメント総アップロード数、ベクトルストレージスペース**が制限されています
+* 異なるSaaSバージョンの[サブスクリプションプラン](https://dify.ai/jp/pricing)により**バッチアップロード数、ドキュメント総アップロード数、ベクトルストレージスペース**が制限されています
-
diff --git a/en/guides/knowledge-base/test-retrieval.mdx b/en/guides/knowledge-base/test-retrieval.mdx
index 4b8992b3..66e822de 100644
--- a/en/guides/knowledge-base/test-retrieval.mdx
+++ b/en/guides/knowledge-base/test-retrieval.mdx
@@ -2,7 +2,9 @@
title: Test Knowledge Retrieval
---
-In **Retrieval Testing**, you can simulate user queries to test how well the knowledge base retrieves relevant information and experiment with different retrieval settings for optimal performance.
+In a knowledge base, click the **Retrieval Testing** icon in the left sidebar to enter the testing page.
+
+Here, you can simulate user queries to test how well the knowledge base retrieves relevant information and experiment with different retrieval settings for optimal performance.
Retrieval settings adjusted here are temporary and only apply to the current test session.
@@ -12,8 +14,6 @@ In **Retrieval Testing**, you can simulate user queries to test how well the kno
For more on retrieval settings, see [Configure the Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#configure-the-retrieval-settings).
-![Retrieval Testing]()
-
The **Records** section logs all retrieval events associated with this knowledge base, including:
- Queries tested directly on the **Retrieval Testing** page
@@ -24,7 +24,6 @@ The **Records** section logs all retrieval events associated with this knowledge
-
{/*
Contributing Section
DO NOT edit this section!
diff --git a/en/guides/workflow/node/knowledge-retrieval.mdx b/en/guides/workflow/node/knowledge-retrieval.mdx
index 92070497..2dfc0bbf 100644
--- a/en/guides/workflow/node/knowledge-retrieval.mdx
+++ b/en/guides/workflow/node/knowledge-retrieval.mdx
@@ -19,12 +19,18 @@ Below is an example of using the Knowledge Retrieval node in a Chatflow:

- Before using a Knowledge Retrieval node, ensure that you have at least one available knowledge base. To learn about creating and managing knowledge bases, see [Knowledge](/en/guides/knowledge-base/readme).
+ Before using a Knowledge Retrieval node, ensure that you have at least one available knowledge base. To learn about creating knowledge bases, see [Knowledge](/en/guides/knowledge-base/readme#create-knowledge).
## Configure a Knowledge Retrieval Node
-To make the Knowledge Retrieval node work properly, you need to tell it *what* it should search for (the query), *where* it should search (the knowledge base), and *how* to process the retrieval results (the node-level retrieval settings). You can also use document metadata to enable filter-based searches and further improve retrieval precision.
+To make the Knowledge Retrieval node work properly, you need to tell it:
+
+- *What* it should search for (the query)
+- *Where* it should search (the knowledge base)
+- *How* to process the retrieval results (the node-level retrieval settings)
+
+You can also use document metadata to enable filter-based searches and further improve retrieval precision.
### Specify the Query
@@ -41,7 +47,7 @@ Provide the query content that the node should search for in the selected knowle
**Query Image** is available only when at least one added knowledge base supports image-based retrieval.
- Such knowledge bases are marked with an **Image** icon, indicating that they use an embedding model that supports image embedding.
+ Such knowledge bases are marked with a **Vision** icon, indicating that they use an embedding model that supports image embedding.
### Select Knowledge to Search
@@ -49,11 +55,11 @@ Provide the query content that the node should search for in the selected knowle
Add one or more existing knowledge bases for the node to search for content relevant to the query content.
- Knowledge bases marked with an **Image** icon support image-based retrieval, which means that you can use text and/or images as queries and retrieve both semantically related text and images.
+ Knowledge bases marked with a **Vision** icon support image-based retrieval, which means that you can use text and/or images as queries and retrieve both semantically related text and images.
- You can click the **Edit** icon next to any added knowledge base to modify its settings directly within the Knowledge Retrieval node. To learn more about these settings, see [Manage Knowledge](/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction) and [Specify the Index Method and Retrieval Setting](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods).
+ You can click the **Edit** icon next to any added knowledge base to modify its settings directly within the Knowledge Retrieval node. To learn more about these settings, see [Manage Knowledge Settings](/en/guides/knowledge-base/knowledge-and-documents-maintenance/introduction) and [Specify the Index Method and Retrieval Settings](/en/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods).
### Configure Node-Level Retrieval Settings
diff --git a/images/multimodal_knowledge_base.png b/images/multimodal_knowledge_base.png
new file mode 100644
index 00000000..49e82c19
Binary files /dev/null and b/images/multimodal_knowledge_base.png differ
diff --git a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
index e71c8aff..73de5a82 100644
--- a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
+++ b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
@@ -1,5 +1,5 @@
---
-title: 外部ナレッジベースとの接続
+title: 外部ナレッジベースと連携
---
> この文書では、Difyプラットフォームとは独立したナレッジベースを総称して**「外部ナレッジベース」**と呼びます。
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx
index 3defde5b..7fd6433b 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text.mdx
@@ -1,5 +1,5 @@
---
-title: 2. チャンクモードの指定
+title: チャンクモードの指定
---
コンテンツをナレッジベースにアップロードした後、次に行うべき作業は、コンテンツの分割とデータのクリーニングです。この段階では、コンテンツの前処理と構造化を行い、長いテキストを複数の小さなブロックに分割します。
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
index 2574a4d6..67cfd2dc 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
@@ -1,41 +1,17 @@
---
-title: 1. テキストデータのインポート
+title: ローカルファイルをアップロード
---
-Difyプラットフォームの上部ナビゲーションにある**「ナレッジベース」**→**「ナレッジベースを作成」**をクリックします。ローカルファイルのアップロードやオンラインデータのインポートを通じて、ドキュメントをナレッジベースにアップロードできます。
+Dify の上部ナビゲーションバーで **ナレッジ** をクリックし、**ナレッジベースを作成** > **テキストファイルからインポート** を選択します。
-### **ローカルファイルのアップロード**
-
-ファイルをドラッグ&ドロップするか選択してアップロードします。**バッチアップロードに対応**していますが、一度にアップロードできるファイル数は[サブスクリプションプラン](https://dify.ai/pricing)によって制限されています。
+ファイルをドラッグ&ドロップするか選択してアップロードします。**バッチアップロードに対応**していますが、一度にアップロードできるファイル数は[サブスクリプションプラン](https://dify.ai/jp/pricing)によって制限されています。
**ローカルドキュメントのアップロードには以下の制限があります:**
* 単一ドキュメントのアップロードサイズは**15MB**に制限されています
-* 異なるSaaSバージョンの[サブスクリプションプラン](https://dify.ai/pricing)により**バッチアップロード数、ドキュメント総アップロード数、ベクトルストレージスペース**が制限されています
+* 異なるSaaSバージョンの[サブスクリプションプラン](https://dify.ai/jp/pricing)により**バッチアップロード数、ドキュメント総アップロード数、ベクトルストレージスペース**が制限されています
- -
-### **オンラインデータのインポート**
-
-ナレッジベース作成時にオンラインデータからのインポートに対応しています。ナレッジベースでは以下の2種類のオンラインデータインポートをサポートしています:
-
-
- Notionからデータをインポートする方法について学ぶ
-
-
-
- ウェブサイトからデータをインポートする方法について学ぶ
-
-
-オンラインデータを参照するナレッジベースには、後からローカルドキュメントを追加することはできません。また、ローカルファイルタイプのナレッジベースに変更することもできません。これは、一つのナレッジベースに複数のデータソースが存在することで管理が困難になるのを防ぐためです。
-
-### 後からのインポート
-
-ドキュメントやその他のコンテンツデータの準備ができていない場合は、まず空のナレッジベースを作成し、後からローカルドキュメントをアップロードするか、オンラインデータをインポートすることができます。
+
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
index 1edeecf8..313efa4e 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
@@ -1,5 +1,5 @@
---
-title: 1.1 Notionデータをインポート
+title: Notionデータをインポート
---
DifyデータセットはNotionからのインポートをサポートし、**同期**を設定することで、Notionのデータが更新されると自動的にDifyに同期されます。
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
index 35ba3095..08c25ecc 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
@@ -1,5 +1,5 @@
---
-title: 1.2 Webサイトからデータをインポート
+title: Webサイトからデータをインポート
---
Dify のナレッジベースでは、[Jina Reader](https://jina.ai/reader)や[Firecrawl](https://www.firecrawl.dev/)を利用してウェブページをスクレイピングし、解析したデータをMarkdownの形式でナレッジベースに取り込むことができます。
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
index 6a4e300d..cbf333e2 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
@@ -1,5 +1,5 @@
---
-title: 3. インデックス方法と検索設定を指定
+title: インデックス方法と検索設定を指定
---
コンテンツの分割モードを選択した後、構造化されたコンテンツの**インデックス方法**と**検索設定**を行います。
@@ -16,21 +16,26 @@ title: 3. インデックス方法と検索設定を指定
- **高品質**
+
+
+ **高品質インデックス方式** で作成されたナレッジベースは、後から **経済的インデックス方式** に切り替えることはできません。
+
- 高品質モードでは、Embeddingモデルを使用して、分割されたテキストブロックを数値ベクトルに変換し、大量のテキスト情報をより効果的に圧縮・保存します。**これによりユーザーの質問とテキスト間のマッチングがより正確になります**。
+ **高品質インデックス方式** では、埋め込みモデル(Embedding モデル)を使ってコンテンツチャンクをベクトル表現に変換します。この処理を「**埋め込み(embedding)**」と呼びます。
- コンテンツブロックをベクトル化してデータベースに登録した後、ユーザーの質問にマッチするコンテンツブロックを効果的に取り出す検索方法が必要です。高品質モードでは、ベクトル検索、全文検索、ハイブリッド検索の3つの検索設定を提供しています。各設定の詳細については、[検索設定](#検索方法の指定)を参照してください。
+ これらのベクトルは、多次元空間上の座標のようなものです。2つの点の距離が近いほど、それらの意味が近いことを示しています。このしくみにより、システムは単なるキーワード一致ではなく、**意味的な類似性(セマンティック類似度)** に基づいて関連情報を検索できます。
- 高品質モードを選択した後、現在のナレッジベースのインデックス方法を後から**「エコノミー」インデックスモード**にダウングレードすることはできません。切り替えが必要な場合は、ナレッジベースを新しく作成し、インデックス方法を再選択することをお勧めします。
+
- > Embedding技術とベクトルについての詳細は、[「Embedding技術とDify」](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)を参照してください。
+ クイック作成されたナレッジベースでは、「**Vision**」アイコン付きの画像埋め込み対応モデルを選択することができないため、画像検索には対応していません。
-
-
-### **オンラインデータのインポート**
-
-ナレッジベース作成時にオンラインデータからのインポートに対応しています。ナレッジベースでは以下の2種類のオンラインデータインポートをサポートしています:
-
-
- Notionからデータをインポートする方法について学ぶ
-
-
-
- ウェブサイトからデータをインポートする方法について学ぶ
-
-
-オンラインデータを参照するナレッジベースには、後からローカルドキュメントを追加することはできません。また、ローカルファイルタイプのナレッジベースに変更することもできません。これは、一つのナレッジベースに複数のデータソースが存在することで管理が困難になるのを防ぐためです。
-
-### 後からのインポート
-
-ドキュメントやその他のコンテンツデータの準備ができていない場合は、まず空のナレッジベースを作成し、後からローカルドキュメントをアップロードするか、オンラインデータをインポートすることができます。
+
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
index 1edeecf8..313efa4e 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion.mdx
@@ -1,5 +1,5 @@
---
-title: 1.1 Notionデータをインポート
+title: Notionデータをインポート
---
DifyデータセットはNotionからのインポートをサポートし、**同期**を設定することで、Notionのデータが更新されると自動的にDifyに同期されます。
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
index 35ba3095..08c25ecc 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website.mdx
@@ -1,5 +1,5 @@
---
-title: 1.2 Webサイトからデータをインポート
+title: Webサイトからデータをインポート
---
Dify のナレッジベースでは、[Jina Reader](https://jina.ai/reader)や[Firecrawl](https://www.firecrawl.dev/)を利用してウェブページをスクレイピングし、解析したデータをMarkdownの形式でナレッジベースに取り込むことができます。
diff --git a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
index 6a4e300d..cbf333e2 100644
--- a/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
+++ b/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
@@ -1,5 +1,5 @@
---
-title: 3. インデックス方法と検索設定を指定
+title: インデックス方法と検索設定を指定
---
コンテンツの分割モードを選択した後、構造化されたコンテンツの**インデックス方法**と**検索設定**を行います。
@@ -16,21 +16,26 @@ title: 3. インデックス方法と検索設定を指定
- **高品質**
+
+
+ **高品質インデックス方式** で作成されたナレッジベースは、後から **経済的インデックス方式** に切り替えることはできません。
+
- 高品質モードでは、Embeddingモデルを使用して、分割されたテキストブロックを数値ベクトルに変換し、大量のテキスト情報をより効果的に圧縮・保存します。**これによりユーザーの質問とテキスト間のマッチングがより正確になります**。
+ **高品質インデックス方式** では、埋め込みモデル(Embedding モデル)を使ってコンテンツチャンクをベクトル表現に変換します。この処理を「**埋め込み(embedding)**」と呼びます。
- コンテンツブロックをベクトル化してデータベースに登録した後、ユーザーの質問にマッチするコンテンツブロックを効果的に取り出す検索方法が必要です。高品質モードでは、ベクトル検索、全文検索、ハイブリッド検索の3つの検索設定を提供しています。各設定の詳細については、[検索設定](#検索方法の指定)を参照してください。
+ これらのベクトルは、多次元空間上の座標のようなものです。2つの点の距離が近いほど、それらの意味が近いことを示しています。このしくみにより、システムは単なるキーワード一致ではなく、**意味的な類似性(セマンティック類似度)** に基づいて関連情報を検索できます。
- 高品質モードを選択した後、現在のナレッジベースのインデックス方法を後から**「エコノミー」インデックスモード**にダウングレードすることはできません。切り替えが必要な場合は、ナレッジベースを新しく作成し、インデックス方法を再選択することをお勧めします。
+
- > Embedding技術とベクトルについての詳細は、[「Embedding技術とDify」](https://mp.weixin.qq.com/s/vmY_CUmETo2IpEBf1nEGLQ)を参照してください。
+ クイック作成されたナレッジベースでは、「**Vision**」アイコン付きの画像埋め込み対応モデルを選択することができないため、画像検索には対応していません。
-  + ただし心配はいりません——クイック作成されたナレッジベースは、パイプライン経由で作成されたナレッジベースへ簡単に変換でき、この機能を有効にすることが可能です。
+
+
+
+
+
+ チャンク化と埋め込み処理が完了すると、コンテンツは **ベクトル検索**、**全文検索**、または **ハイブリッド検索** のいずれかの方法で検索できるようになります。詳細は [検索方法の指定](#検索方法の指定) を参照してください。
**Q\&Aモードの有効化(オプション、[コミュニティ版](/ja-jp/getting-started/install-self-hosted/faq)のみ)**
@@ -198,7 +203,7 @@ title: 3. インデックス方法と検索設定を指定
検索設定を指定した後、以下のドキュメントを参照して、実際のシナリオでのキーワードとコンテンツブロックのマッチング状況を確認できます。
-
+
実際のシナリオでのキーワードとコンテンツブロックのマッチング状況を確認する
diff --git a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
index d0c03a52..1ea414d4 100644
--- a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
@@ -1,243 +1,73 @@
---
-title: ナレッジベース内のドキュメントの管理
+title: ナレッジコンテンツの管理
+sidebarTitle: コンテンツの管理
---
-## ナレッジベース内のドキュメントの編集
+## ドキュメントの管理
-### ドキュメントの追加
+ナレッジベース内では、インポートされたすべてのアイテム(ローカルファイル、Notion ページ、またはウェブページなど)がドキュメントとして扱われます。ドキュメント一覧から、すべてのドキュメントを閲覧・管理し、ナレッジの正確性、関連性、最新性を維持できます。
-ナレッジベースは複数のドキュメントから構成されています。ドキュメントは、ローカルからのアップロードのほか、他のオンラインデータソースからのインポートにも対応しています。ナレッジベース内の各ドキュメントは、データソース上の “1ファイル” に相当し、たとえば Notion 内の1件のドキュメントや、Web上のオンラインドキュメントなどが該当します。
+
+ 画面上部のナレッジベース名をクリックすると、他のナレッジベースへ素早く切り替えできます。
+
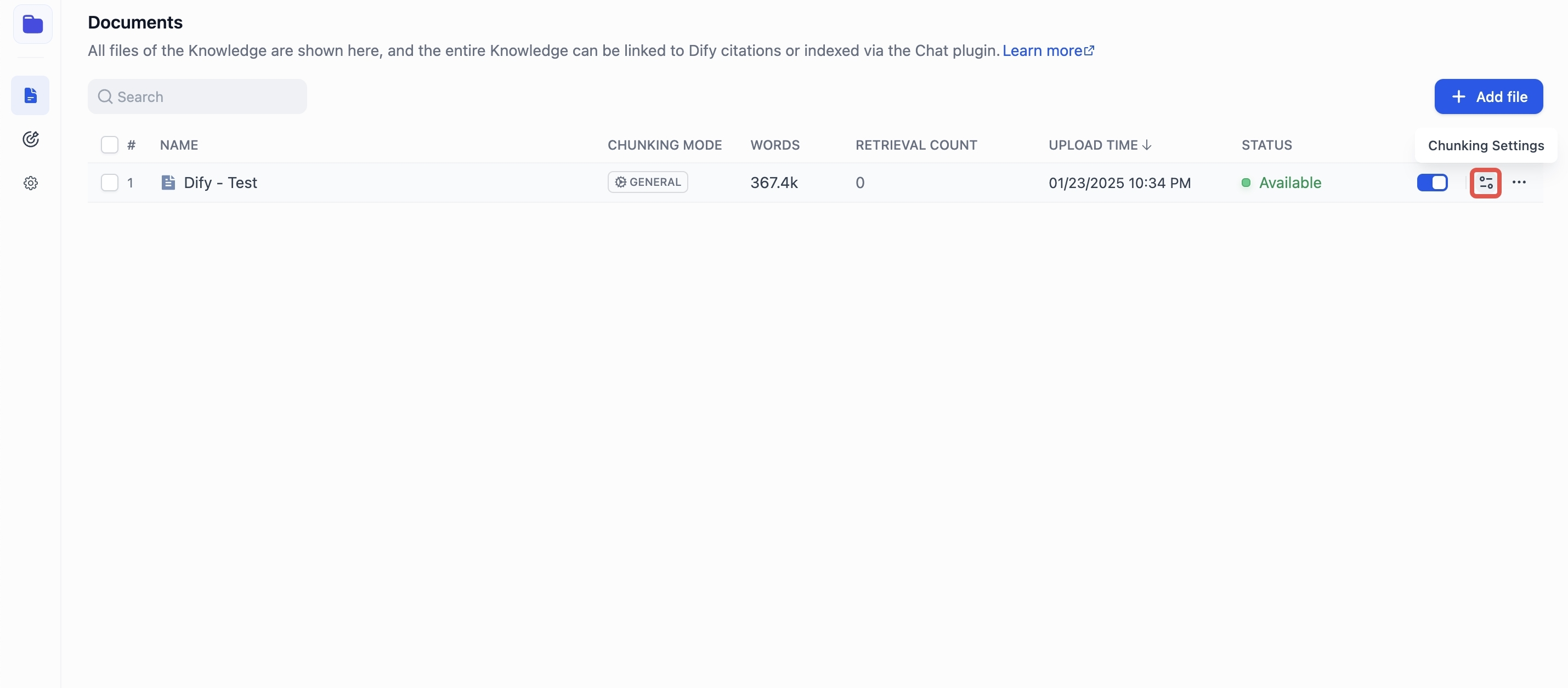
-既に作成済みのナレッジベースに新たなドキュメントを追加するには、「ナレッジベース」 → 「ドキュメント一覧」 → 「ファイル追加」をクリックしてください。
+
-
+| 操作 | 説明 |
+|:----------------------|:---------------------|
+| 追加 | 新しいドキュメントをインポートします。|
+| チャンク設定の変更 | ドキュメントのチャンク設定を変更します(チャンク構造を除く)。各ドキュメントには個別のチャンク設定を持たせることができますが、チャンク構造はナレッジベース全体で共通であり、一度設定すると変更できません。|
+| 削除 | ドキュメントを完全に削除します。**削除は元に戻せません。**|
+| 有効/無効 | 一時的にドキュメントを検索対象に含める/除外します。Dify Cloud では、一定期間更新または検索に使用されていないドキュメントは、自動的に無効化されパフォーマンスが最適化されます。
+ ただし心配はいりません——クイック作成されたナレッジベースは、パイプライン経由で作成されたナレッジベースへ簡単に変換でき、この機能を有効にすることが可能です。
+
+
+
+
+
+ チャンク化と埋め込み処理が完了すると、コンテンツは **ベクトル検索**、**全文検索**、または **ハイブリッド検索** のいずれかの方法で検索できるようになります。詳細は [検索方法の指定](#検索方法の指定) を参照してください。
**Q\&Aモードの有効化(オプション、[コミュニティ版](/ja-jp/getting-started/install-self-hosted/faq)のみ)**
@@ -198,7 +203,7 @@ title: 3. インデックス方法と検索設定を指定
検索設定を指定した後、以下のドキュメントを参照して、実際のシナリオでのキーワードとコンテンツブロックのマッチング状況を確認できます。
-
+
実際のシナリオでのキーワードとコンテンツブロックのマッチング状況を確認する
diff --git a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
index d0c03a52..1ea414d4 100644
--- a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
@@ -1,243 +1,73 @@
---
-title: ナレッジベース内のドキュメントの管理
+title: ナレッジコンテンツの管理
+sidebarTitle: コンテンツの管理
---
-## ナレッジベース内のドキュメントの編集
+## ドキュメントの管理
-### ドキュメントの追加
+ナレッジベース内では、インポートされたすべてのアイテム(ローカルファイル、Notion ページ、またはウェブページなど)がドキュメントとして扱われます。ドキュメント一覧から、すべてのドキュメントを閲覧・管理し、ナレッジの正確性、関連性、最新性を維持できます。
-ナレッジベースは複数のドキュメントから構成されています。ドキュメントは、ローカルからのアップロードのほか、他のオンラインデータソースからのインポートにも対応しています。ナレッジベース内の各ドキュメントは、データソース上の “1ファイル” に相当し、たとえば Notion 内の1件のドキュメントや、Web上のオンラインドキュメントなどが該当します。
+
+ 画面上部のナレッジベース名をクリックすると、他のナレッジベースへ素早く切り替えできます。
+
-既に作成済みのナレッジベースに新たなドキュメントを追加するには、「ナレッジベース」 → 「ドキュメント一覧」 → 「ファイル追加」をクリックしてください。
+
-
+| 操作 | 説明 |
+|:----------------------|:---------------------|
+| 追加 | 新しいドキュメントをインポートします。|
+| チャンク設定の変更 | ドキュメントのチャンク設定を変更します(チャンク構造を除く)。各ドキュメントには個別のチャンク設定を持たせることができますが、チャンク構造はナレッジベース全体で共通であり、一度設定すると変更できません。|
+| 削除 | ドキュメントを完全に削除します。**削除は元に戻せません。**|
+| 有効/無効 | 一時的にドキュメントを検索対象に含める/除外します。Dify Cloud では、一定期間更新または検索に使用されていないドキュメントは、自動的に無効化されパフォーマンスが最適化されます。
非アクティブ期間はプランごとに異なります:- Sandbox:7日
- Professional/Team:30日
Professional および Team プランのユーザーは、**ワンクリックで**これらのドキュメントを再有効化できます。 |
+| アーカイブ/アーカイブ解除 | 検索には不要だが保持しておきたいドキュメントをアーカイブします。アーカイブ済みドキュメントは読み取り専用で、いつでもアーカイブ解除可能です。|
+| 編集 | ドキュメント内のチャンクを編集して、コンテンツを修正します。詳細は [チャンクの管理](#チャンクの管理) を参照してください。|
+| 名前を変更 | ドキュメントの名前を変更します。|
-### ドキュメントの有効化/無効化/アーカイブ/削除
+## チャンクの管理
-**有効化**:通常使用可能な状態のドキュメントは、編集およびナレッジベース内での検索が可能です。無効化されたドキュメントは後から再び有効化できます。また、一度アーカイブされたドキュメントは、アーカイブ解除後にのみ再有効化が可能となります。
+チャンク設定に基づき、すべてのドキュメントは検索の基本単位であるコンテンツチャンクに分割されます。各ドキュメント内のチャンク一覧からそれらを閲覧・管理し、検索の効率と精度を最適化できます。
-**無効化**:AIアプリケーション利用時に検索対象から除外したいドキュメントについては、該当ドキュメント右側にある青いスイッチをオフにすることで無効化できます。なお、無効化後も内容の編集は可能です。
+
+ 左上のドキュメント名をクリックして、別のドキュメントに素早く切り替えられます。
+
-**アーカイブ**:今後削除せずに保存しておきたい古いドキュメントの場合、アーカイブ機能をご利用ください。アーカイブされたドキュメントは閲覧や削除は可能ですが、再編集はできません。アーカイブは、ナレッジベースのドキュメント一覧から該当ボタンをクリックするか、ドキュメント詳細画面から操作できます。**アーカイブ操作は後から取り消し可能です。**
+
-**削除**:⚠️ 削除は取り消し不可能なため、誤ったドキュメントや内容が曖昧なものについては、ドキュメント右側のメニューから削除してください。削除したドキュメントは復元できませんので、慎重に操作してください。
+| 操作 | 説明 |
+|:-------- |:---------------------|
+| 追加 | 新しいチャンクを1つまたは複数まとめて追加します。親子分割モード(階層分割モード)のドキュメントでは、親チャンクと子チャンクの両方を追加可能です。「チャンクを追加」は有料機能です。Dify Cloud で利用するには [Professional または Team プラン](https://dify.ai/jp/pricing) へのアップグレードが必要です。|
+| 削除 | チャンクを完全に削除します。**削除は元に戻せません。**|
+| 有効/無効 | 一時的にチャンクを検索対象に含める/除外します。無効化されたチャンクは編集できません。|
+| 編集 | チャンクの内容を修正します。編集されたチャンクは **「編集済み」** と表示されます。
親子分割モード(階層分割モード)のドキュメントでは:- 親チャンクを編集するとき、子チャンクを再生成するか保持するかを選択できます。
- 子チャンクを編集しても、親チャンクには影響しません。
|
+| キーワードの追加/編集/削除 | 経済的インデックス方式を使用するナレッジベースでは、各チャンクに対してキーワードを追加・編集して検索精度を向上させることができます。1つのチャンクにつき最大10個のキーワードを設定可能です。 |
+| 画像のアップロード/削除 | 画像検索機能が有効なナレッジベースでは、各チャンク内で画像を削除または新規アップロードできます。画像検索を有効にするには、「**Vision**」アイコン付きの埋め込みモデルを選択してください。 |
-> 上記の各操作は、複数のドキュメントを同時に選択した状態で一括実行することも可能です。
+## ベストプラクティス
-
+### チャンク品質の確認
-**注意:**
+ドキュメントをチャンク分割した後は、各チャンクを丁寧に確認し、意味的に完結し、検索精度と回答の関連性を最適化できるサイズであることを確認してください。
-ナレッジベース内で長期間更新がなく、または検索対象とならなかったドキュメントについては、システムの効率運用を考慮し、一時的に無効化される場合があります。
+注意すべき一般的な問題:
-- Sandbox/Free プランのユーザーでは、利用されていないナレッジベース内のドキュメントは **7日後** に自動で無効化されます。
-- Professional/Team プランのユーザーでは、同様のドキュメントが **30日後** に自動で無効化されます。
+- チャンクが **短すぎる**:文脈不足により意味情報が失われ、回答の精度が低下します。
-いつでもナレッジベースへアクセスし、再度有効化することで通常利用に戻すことが可能です。なお、料金プランをご利用のユーザーは **「一括復元」** 機能によって、無効化された全ドキュメントを迅速に有効化できます。
+- チャンクが **長すぎる**:不要情報を含み、意味的ノイズを引き起こして検索精度を下げます。
-
+- チャンクが **意味的に不完全**:文や段落の途中で強制的に区切られた結果、検索時に情報が欠落または誤解を招く場合があります。
----
+### 子チャンクを親チャンクの検索フックとして使用
-## テキスト分割の管理
+親子分割モード(階層分割モード)で分割されたドキュメントでは、システムは子チャンクを検索し、結果として親チャンクを返します。子チャンクを編集しても親チャンクは更新されないため、子チャンクを親チャンクの **セマンティックタグ(意味的タグ)** や **検索ヒント** として活用できます。
-### テキスト分割の表示
+そのためには、子チャンクを **キーワード**・**要約**・**ユーザーの一般的な質問** のいずれかに書き換えることを推奨します。
+たとえば、親チャンクが *返品ポリシー* 全体を扱う場合、子チャンクを次のように設定できます:
-ナレッジベースにアップロードされた各ドキュメントは、テキスト分割(Chunks)形式で格納されます。ドキュメントタイトルをクリックすると、詳細画面でそのドキュメントの分割リストが表示され、初期状態では1ページにつき10のブロックが表示されます。ページ下部の設定にて、1ページあたりの表示件数を調整可能です。
+- 「商品を返品するにはどうすればいいですか?」
-各ブロックは、先頭2行のプレビューを提示します。ブロック内の全内容を確認したい場合は、「分割を展開」ボタンをクリックしてください。
+- 「返金期間はどのくらいですか?」
-
-
-また、フィルター機能を利用することで、有効/無効状態のドキュメントをすばやく確認できます。
-
-
-
-なお、各種[テキスト分割モード](../create-knowledge-and-upload-documents/chunking-and-cleaning-text)により、分割表示の方法が異なります。
-
-
-
- **汎用モード**
-
- [汎用モード](../create-knowledge-and-upload-documents/#tong-yong)では、各テキスト分割は独立したブロックとして扱われます。ブロック内の全内容を確認する場合は、右上隅の全画面アイコンをクリックして全画面表示モードに切り替えてください。
-
- 
-
- また、上部のドキュメントタイトルをクリックすることで、ナレッジベース内の他ドキュメントへの迅速な切り替えが可能です。
-
- 
-
-
-
- **親子モード**
-
- [親子モード](../create-knowledge-and-upload-documents/#fu-zi-fen-duan)の場合、表示される内容は「親分割」と「子分割」に区分されます。
-
- • **親分割**
-
- ナレッジベース内の任意のドキュメントを選択すると、まず親分割が表示されます。親分割には、**「段落」** と **「全文」** の2種類の表示モードがあり、より豊富な文脈情報を提供します。下図は各モードにおけるテキストプレビューの違いを示しています。
-
- 
-
- • **子分割**
-
- 子分割は、通常、親分割内の1文などの小さなテキストブロックで、詳細情報を含みます。各ブロックには文字数および検索での召喚回数が表示されます。子分割ブロックをクリックすると、詳細内容が表示され、右上の全画面アイコンをクリックすれば全内容を表示できます。
-
- 
-
-
-
- **Q&A モード**
-
- Q&A モードでは、1つのブロック内に「質問」と「回答」が含まれます。任意のドキュメントタイトルをクリックすると、テキスト分割が表示されます。
-
- 
-
-
-
----
-
-### 分割品質の確認
-
-ドキュメントのテキスト分割は、ナレッジベースを利用した質疑応答システムの精度に大きく影響します。そのため、ナレッジベースとアプリケーションを連携する前に、分割品質を人の目でチェックすることを推奨します。
-
-自動化された文字長、識別子、あるいは NLP の意味解析に基づく分割方法は、大量のテキスト分割作業を大幅に軽減できますが、分割品質はドキュメントの形式や文脈の継続性に依存するため、機械的な処理だけでは十分でない場合があります。人力によるチェックと修正により、機械分割の弱点を補完することが可能です。
-
-分割品質を確認する際、主に以下の点に注意してください。
-
-- **短すぎるテキスト分割**:意味の一部が欠落する可能性があります。
-
-
-
-- **長すぎるテキスト分割**:文脈のノイズが生じ、検索精度に影響を与える場合があります。
-
-
-
-- **強制的な意味の切断**:最大分割長により、意味が途中で切れてしまう場合があり、検索時に情報が欠落する可能性があります。
-
-
-
----
-
-### テキスト分割の追加
-
-ナレッジベース内のドキュメントは、必要に応じて個別にテキスト分割を追加することが可能です。なお、分割追加の方法は選択している分割モードにより異なります。
-
-> テキスト分割の追加は有料機能となります。詳細は[こちら](https://dify.ai/pricing)をご確認ください。
-
-
-
- **汎用モード**
-
- 分割リスト上部の「分割を追加」ボタンをクリックすると、ドキュメント内に任意のテキストブロックを1つまたは複数追加できます。
-
- 
-
- 手動でテキスト分割を追加する際は、本文およびキーワードの入力が可能です。入力後、末尾の **「連続追加」** ボタンにチェックを入れると、引き続き新たな分割を追加できます。
-
- 
-
- また、一括で分割を追加する場合は、まず CSV 形式の分割アップロード用テンプレートをダウンロードします。Excelなどでテンプレートに沿って内容を編集し、CSVファイルとして保存後、アップロードしてください。
-
- 
-
-
-
- **父子モード**
-
- 分割リスト上部にある「分割を追加」ボタンをクリックすると、文書内に対して、1つまたは複数のカスタムな**親分割**を一括で追加できます。
-
- 
-
- 内容を入力後、下部にある **「連続追加」** ボタンにチェックを入れることで、引き続きテキストを追加できます。
-
- 
-
- また、親分割内において子分割を個別に追加することも可能です。親分割内の子分割右側にある「追加」ボタンをタップすると、子分割を単体で追加できます。
-
- 
-
-
-
- **Q&Aモード**
-
- 分割リスト上部にある「分割を追加」ボタンをクリックすると、文書内に質問と回答のペアによるコンテンツブロックを1つまたは複数追加できます。
-
-
-
----
-
-### テキスト分割の編集
-
-
-
- **汎用モード**
-
- 追加された分割の内容は、直接編集・変更が可能です。分割内のテキストやキーワードも自由に変更できます。
- また、重複して編集してしまわないよう、編集後のコンテンツブロックには「編集済み」ラベルが表示されます。
-
- 
-
-
-
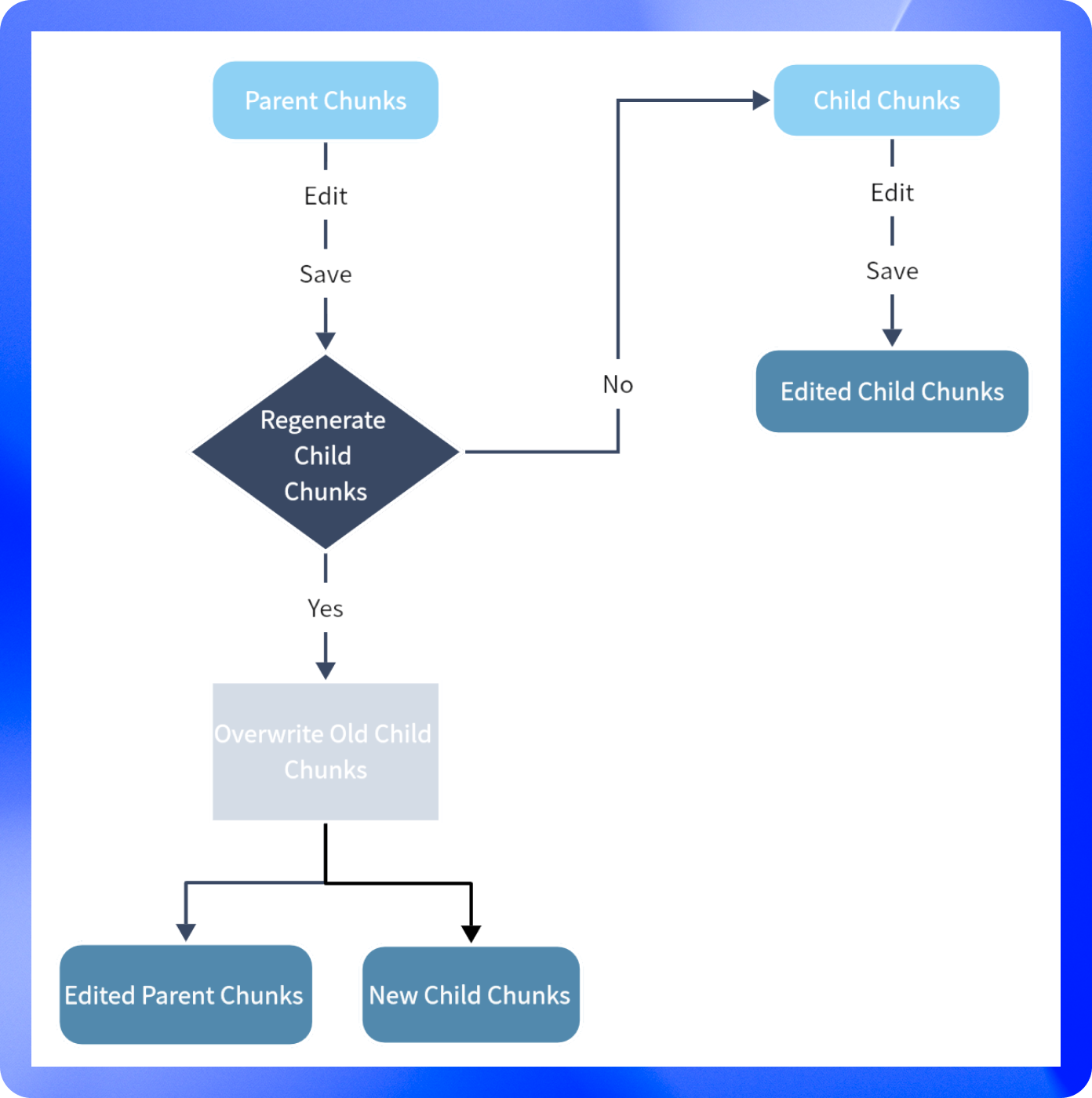
- **父子モード**
-
- 親分割は、内部に含む子分割の内容を保持していますが、双方は独立して編集可能です。つまり、親分割と子分割の内容はそれぞれ別々に変更できます。
- 下図は、親子分割間の編集フローを示しています。
-
- 
-
- **親分割の編集**:親分割右側の編集ボタンをクリックし、内容を入力してください。**「保存」**をクリックすると子分割の内容はそのままで、もし子分割の内容も再生成したい場合は **「保存して子分割を再生成」** をクリックしてください。
-
- 編集後、重複編集を防止するため、対象のコンテンツブロックには「編集済み」ラベルが表示されます。
-
- 
-
- **子分割の編集**:任意の子分割を選択し編集モードに入った後、変更が完了したら保存してください。なお、子分割の編集内容は親分割には影響しません。編集または新規追加された子分割には、`C-NUMBER-EDITED`という濃い青色のラベルが付与されます。
-
- また、子分割は現在の親分割のタグと見なすことも可能です。
-
- 
-
-
-
- **Q&Aモード**
-
- Q&Aモードでは、1つのコンテンツブロック内に質問と回答が含まれています。編集したいテキスト分割をクリックすると、質問と回答それぞれの内容を編集できるほか、現在のコンテンツブロックのキーワードも変更可能です。
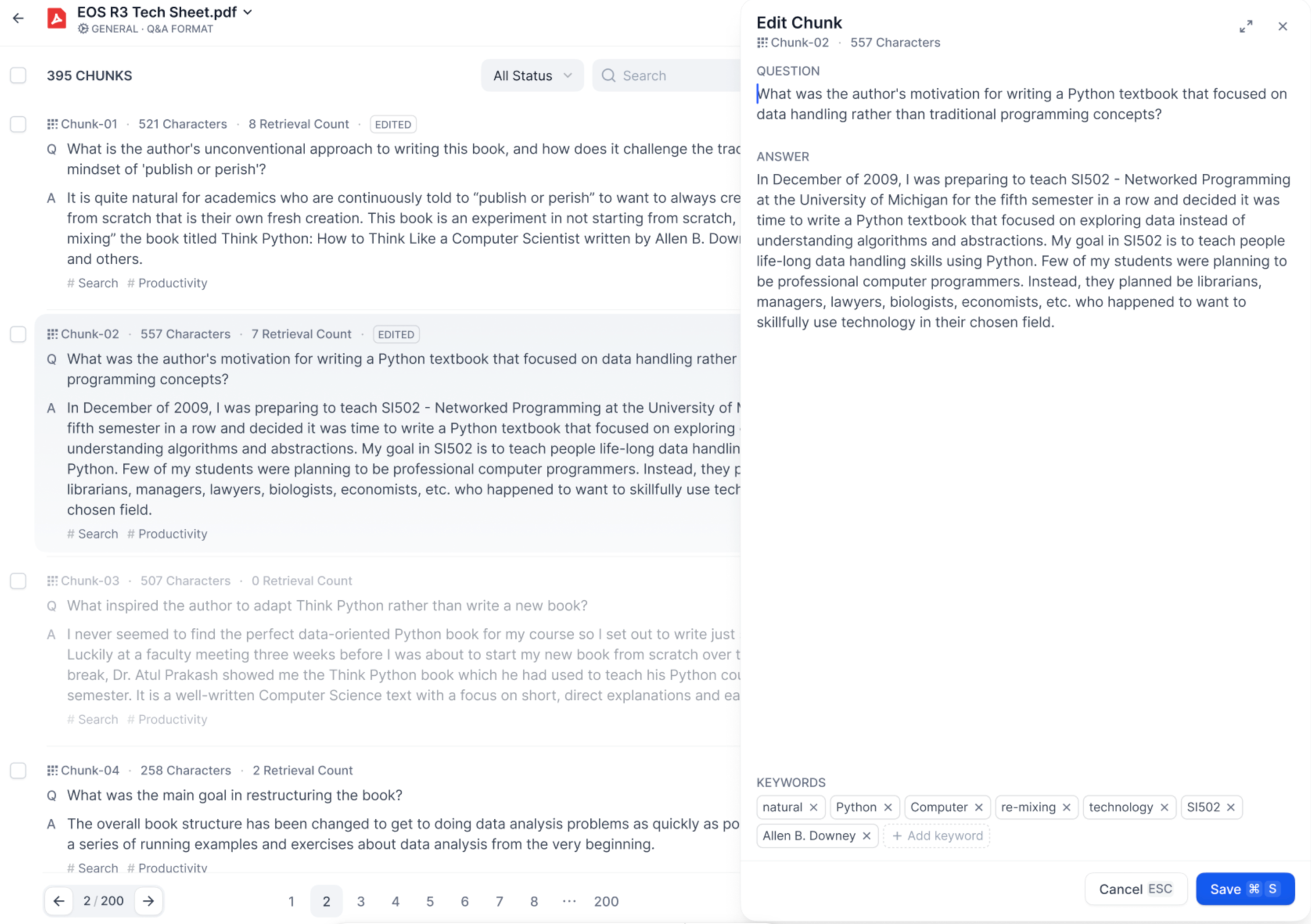
-
- 
-
-
-
-### アップロード済み文書のテキスト分割の変更
-
-既存のナレッジベースでは、文書の分割設定を再構成することができます。
-
-**大きい分割**
-- 1つの分割でより多くの文脈(コンテキスト)を保持できるため、複雑なタスクあるいは文脈に依存するタスクに適しています。
-- 分割数が減ることにより、処理時間およびストレージの必要量が削減されます。
-
-**小さい分割**
-- より細かい粒度でテキスト内容の正確な抽出や要約が可能です。
-- モデルのトークン制限を超えるリスクを軽減し、制約が厳しいモデルへの適応性も向上します。
-
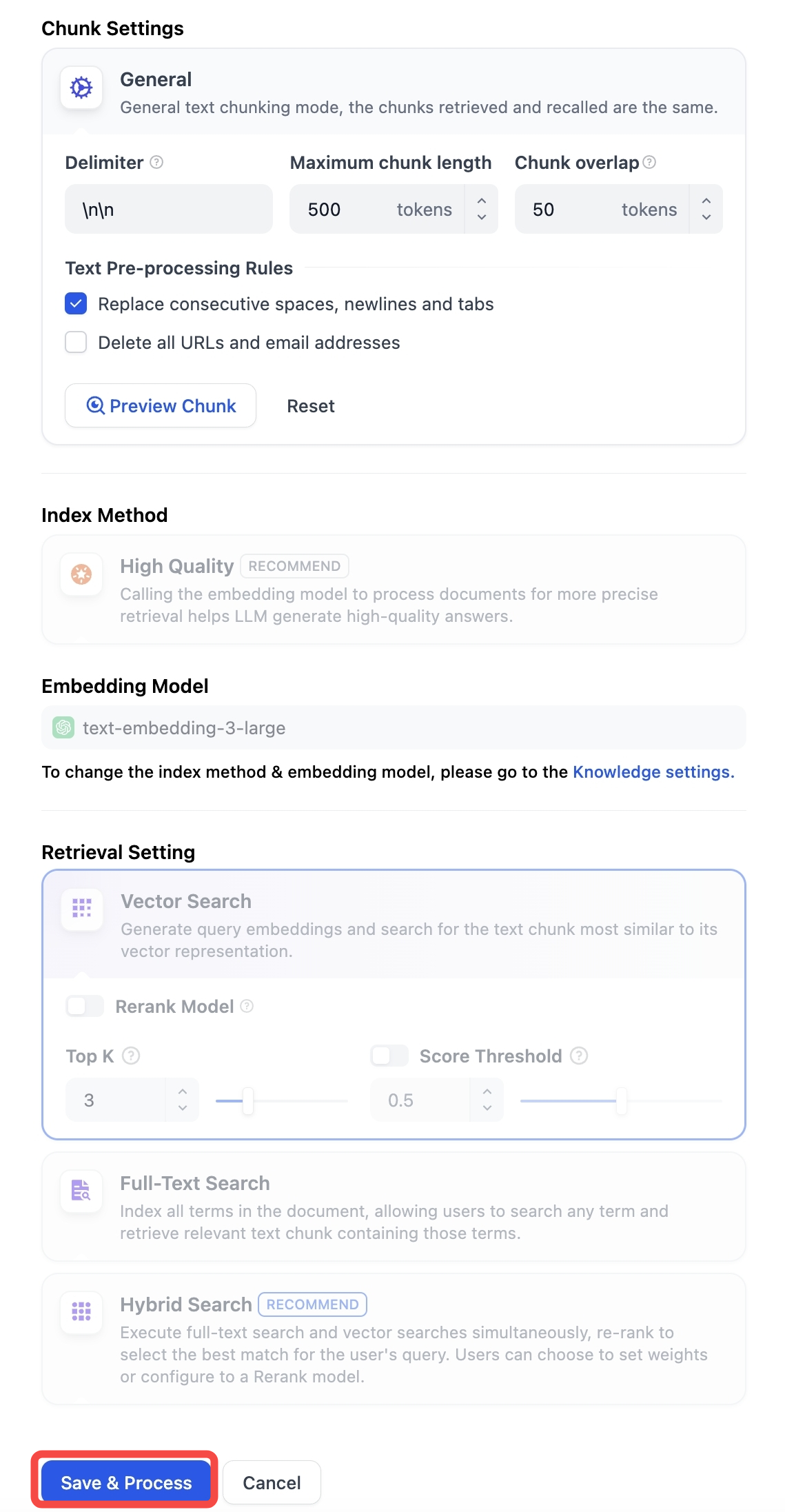
-「分割設定」にアクセス後、**保存して処理**ボタンをクリックすることで、分割設定の変更内容が保存され、現在の文書分割処理が再トリガーされます。
-設定保存と埋め込み処理が完了すると、文書の分割リストは自動的に更新され、ページの手動リロードは不要です。
-
-
-
- -
----
-
-### メタデータ管理
-
-メタデータの詳細については、[メタデータ](https://docs.dify.ai/ja-jp/guides/knowledge-base/metadata)を参照してください。
+- 「返品時の送料はかかりますか?」
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
index c1298c70..30fe6581 100644
--- a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
@@ -1,247 +1,26 @@
---
-title: ナレッジベースの管理
+title: ナレッジ設定の管理
+sidebarTitle: 設定の管理
---
-> ナレッジベースのページは、チームオーナー、チーム管理者、編集権限があるユーザーのみがアクセスできます。
-
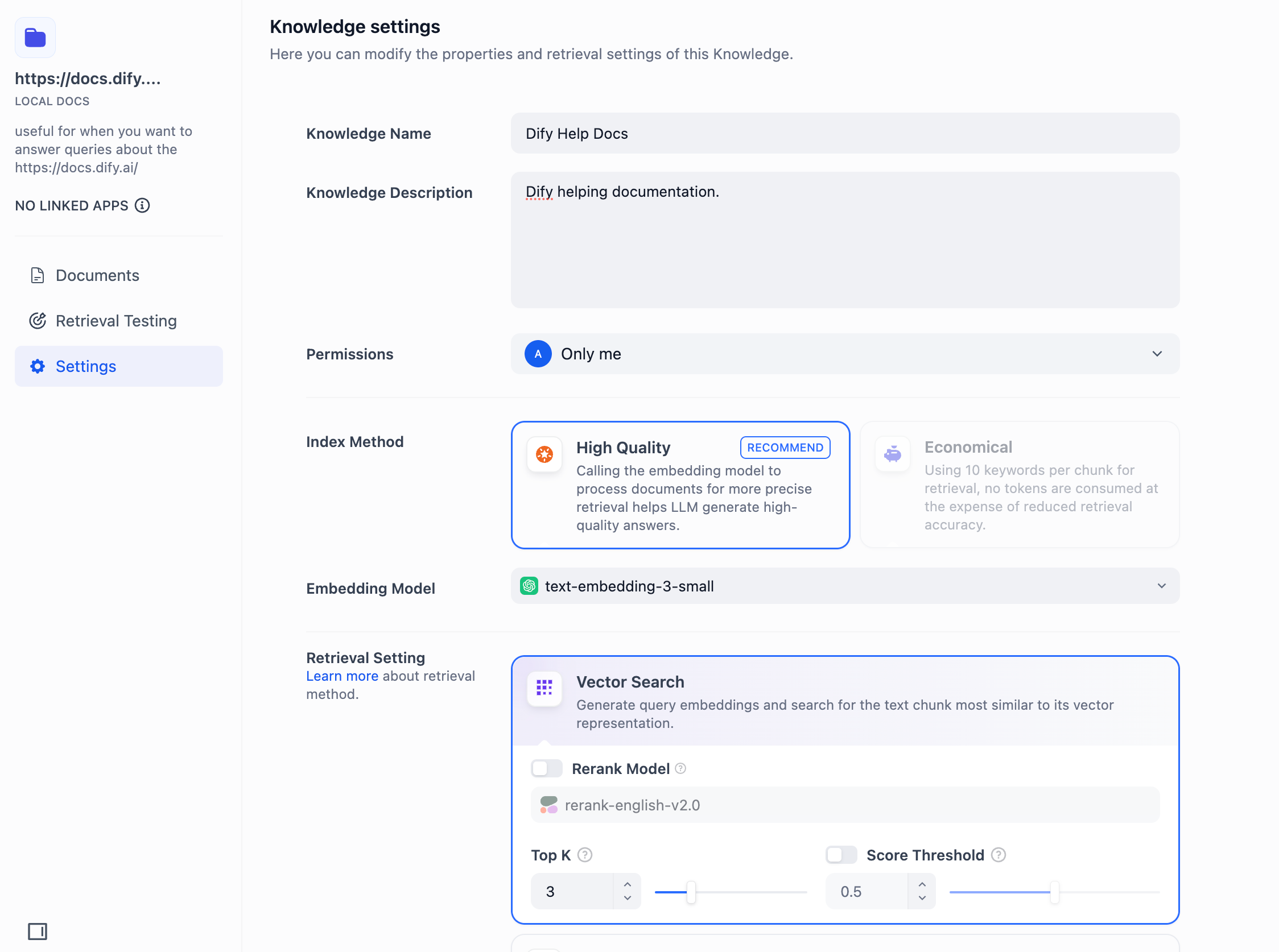
-Difyチームのホームページで、「ナレッジベース」ボタンをクリックし、管理したいナレッジベースを選択して、左のナビゲーションパネルで **設定** をクリックして調整を行います。
-
-ナレッジベースの名前、説明、表示権限、索引モード、埋め込みモデル、および検索設定を変更することができます。
-
-
-
-- **ナレッジベースの名前**:異なるナレッジベースを区別するために使用されます。
-- **ナレッジの説明**:ナレッジベースのドキュメントで表現される情報を説明するために使用されます。
-- **表示権限**:ナレッジベースへのアクセス制御を定義します。3つのレベルがあります:**「自分だけ」**、**「全チームメンバー」** と **「一部のチームメンバー」**。権限のない方はナレッジベースをアクセスできません。このナレッジベースを他のメンバーと共有すると、そのメンバーもこのナレッジベースに対する完全な権限を持ちます。
-- **索引方法**:詳細な説明については、[ドキュメント](./create-knowledge-and-upload-documents/setting-indexing-methods)を参照してください。
-- **埋め込みモデル**:ナレッジベースの埋め込みモデルを変更できます。埋め込みモデルを変更すると、ナレッジベース内のすべてのドキュメントが再埋め込みされ、元の埋め込みが削除されます。
-- **検索設定**:詳細な説明については、[ドキュメント](./create-knowledge-and-upload-documents/selecting-retrieval-settings)を参照してください。
-
----
-
-### 関連アプリの確認方法
-
-ナレッジベース内では、左側のサイドバーに紐づけられたアプリケーションの件数が表示されます。丸い情報アイコンにマウスカーソルを合わせると、紐付けられたアプリケーションの一覧がポップアップで現れます。さらに、右側にある「ジャンプ」ボタンをクリックすることで、それらのアプリケーションへ素早く移動して確認することが可能です。
-
-
-
----
-
-### ナレッジベースAPIの管理
-
-Difyのナレッジベースは、標準APIの完全なセットを提供しています。開発者はAPI呼び出しを行うことで、ナレッジベース内のドキュメントやチャンクの追加、削除、変更、クエリなどの日常的な管理およびメンテナンス操作を実行できます。詳細については、[ナレッジベースAPIドキュメント](maintain-dataset-via-api)を参照してください。
-
-
-
----
-
-## ナレッジベース内の文書管理
-
-### 文書の追加方法
-
-ナレッジベースは、さまざまな文書が集められたものです。これらの文書は、開発者や管理者によってアップロードされたり、他のデータソースから同期されたりすることがあります。ナレッジベース内の各文書は、データソースの中の1つのファイルに相当します。たとえば、Notionのライブラリにある文書や、新しいオンライン文書のページなどが該当します。
-
-「ナレッジベース」→「文書リスト」→「ファイルを追加」の順に進み、既に作成されているナレッジベースに新しい文書をアップロードできます。
-
-
-
-### 文書の有効化・無効化・アーカイブ・削除
-
-**有効化**:通常利用されている状態の文書で、内容の編集やナレッジベースでの検索が可能です。無効化された文書は再び有効化することができますが、アーカイブされた文書を再び有効化する前には、アーカイブを解除する必要があります。
-
-**無効化**:AIアプリケーションの利用時に検索結果に含まれたくない文書は、文書の横にある青いスイッチをオフにすることで無効化できます。無効化された後も、文書の編集は可能です。
-
-**アーカイブ**:もはや使用しないが削除したくない古い文書データは、アーカイブすることができます。アーカイブされたデータは閲覧や削除のみ可能で、編集はできません。ナレッジベースの文書リストからアーカイブボタンをクリックするか、文書の詳細ページでアーカイブ操作を行えます。アーカイブは後で取り消し可能です。
-
-**削除**:⚠️危険な操作です。誤りがある文書や誤解を招く内容の文書は、文書の横にあるメニューボタンから削除できます。削除された内容は復元できないため、慎重に操作してください。
-
-> 上記の操作は、複数の文書を選択して一括で行うことが可能です。
-
-
-
-**注意**:
-
-ナレッジベース内に長期間更新されていない、または検索されていない文書がある場合、ナレッジベースの効率的な運用を保つため、システムはこれらの非活動文書を一時的に無効化することがあります。
-
-- サンドボックス/無料版のユーザーは、ナレッジベースを利用していない場合、**7日**後に自動的に無効化されます。
-
-- プロフェッショナル/チーム版のユーザーは、ナレッジベースを利用していない場合、**30日**後に自動的に無効化されます。
-
-いつでもナレッジベースにアクセスして、無効化された文書を再び有効化し、通常の利用を再開できます。有料ユーザーは**ワンクリックで復活**機能を利用して、無効化されたすべての文書を迅速に有効化することができます。
-
-
+ナレッジベースの設定を変更できるのは、ワークスペースの所有者、管理者、および編集者のみです。
----
-
-## テキストチャンクの管理
-
-### テキストチャンクを確認
-
-ナレッジベースにアップロードされた文書は、テキストのチャンク(Chunk)として保存されています。文書の見出しをクリックして、詳細ページに移動すると、その文書に含まれるテキストチャンクのリストを見ることができます。デフォルトでは、各ページには10個のチャンクが表示され、ページ下部でこの表示数を変更することが可能です。
-
-チャンクは、先頭の2行がプレビューとして表示されます。チャンクの全内容を閲覧したい場合は、「チャンクを展開」ボタンを軽くタップします。
-
-
-
-[テキストチャンク](./create-knowledge-and-upload-documents/chunking-and-cleaning-text)を表示する方法にはいくつかのモードがあり、それぞれでテキストの見せ方が異なります:
-
-
-
- **汎用モード**
-
- [汎用モード](./create-knowledge-and-upload-documents/chunking-and-cleaning-text)では、各テキストチャンクが独立したブロックとして扱われます。全内容を表示したい場合は、右上にある全画面表示ボタンをタップしてください。
-
- 
-
- 文書の見出し部分をクリックすることで、ナレッジベース内の他の文書へ素早く移動が可能です。
-
- 
-
-
-
- **親子モード**
-
- [親子モード](./create-knowledge-and-upload-documents/chunking-and-cleaning-text)では、テキストが親チャンクと子チャンクに分かれて表示されます。
-
- * **親チャンク**
-
- ナレッジベース内の文書を選択すると、まず親チャンクの内容が表示されます。これには、**「段落」** 表示と **「全文」** 表示の2種類があり、文脈をより完全に提供します。以下は、異なる表示方法によるテキストプレビューの違いを説明します。
- 
-
- * **子チャンク**
-
- 子チャンクは通常、段落内の特定の文(より小さいテキストブロック)で、詳細な情報を含んでいます。各チャンクは、文字数と検索された回数を示します。詳細を見るには、子チャンクを軽くタップします。ブロックの全内容を見たい場合は、右上の全画面表示ボタンをタップしてください。
-
- 
-
-
-
- **Q&Aモード**
-
- Q&Aモードでは、各コンテンツブロックが一組の質問と答えを含んでいます。文書の見出しを軽くタップすることで、テキストチャンクを確認することができます。
-
- 
-
-
-
----
-
-### テキストチャンクの品質管理
-
-テキストをチャンクする作業は、ナレッジベースを用いたQ&Aアプリの性能に直接影響を及ぼします。ナレッジベースとアプリを結びつける前に、チャンクされたテキストの品質を手動で確認することを強く推奨します。
-
-文字数、特定の識別子、または自然言語処理(NLP)を用いた意味的なチャンクなど、自動化された方法で大量のテキストを効率的にチャンクすることが可能ですが、品質は文の構造や文脈による意味の流れに大きく左右されます。手動での確認と修正を行うことで、自動チャンクの限界を補い、より高い品質を保証することができます。
-
-チャンクの品質を検証する際には、以下の点に注意する必要があります:
-
-- **チャンクされたテキストが短すぎる**場合、意図した意味が途切れてしまう可能性があります;
-
-
-- **チャンクされたテキストが長すぎる**場合、不要な情報が混入し、検索結果の精度を低下させる原因となります;
-
-
-- **意味の流れが不自然に断ち切られている**場合、最大チャンク長を設定しても、内容の一部が失われることがあります;
-
-
----
-
-### テキストチャンクの追加
-
-ナレッジベースに含まれる文書は、テキストを追加的にチャンクすることが可能です。異なるチャンクモードはそれぞれ、特定のチャンク方法を提供します。
-
-> テキストチャンクの追加は有料機能です。この機能を利用するには、アカウントのアップグレードが必要です。
-
-
-
- **汎用モード**
-
- ドキュメントに「チャンク追加」ボタンがあり、これをクリックすることで任意の数のカスタマイズされたチャンクを追加することが可能です。
-
- 
-
- テキストチャンクを手動で追加する際には、テキスト本体とキーワードの入力が選択肢としてあります。入力完了後、画面下部の「追加を続ける」にチェックを入れると、さらにテキストの追加が行えます。
-
- 
-
- 複数のチャンクを一度に追加したい場合は、まずCSV形式のチャンクアップロード用テンプレートをダウンロードし、そのテンプレートに従ってExcelでチャンクの内容を編集します。編集後はCSVファイルを保存し、それをアップロードしてください。
-
- 
-
-
-
- **親子モード**
-
- 「チャンク追加」ボタンを使って、ドキュメント内に一つまたは複数のカスタム**親チャンク**を自由に追加できます。
-
- 
-
- 入力完了後、画面下部の **「追加を続ける」** にチェックを入れると、さらにテキストの追加が可能です。
-
- 
-
- 親チャンク内には、子チャンクを個別に追加することもできます。親チャンクに属する子チャンクの右側にある「追加」ボタンをクリックすることで、子チャンクを個別に追加できます。
-
- 
-
-
-
- **Q&Aモード**
-
- 「チャンク追加」ボタンをクリックすると、質問と回答のペアを形成するブロックを一つまたは複数、ドキュメント内に自由に追加することができます。
-
-
-
----
-
-### テキストチャンクの編集
-
-
-
- **汎用モード**
-
- 追加された段落は、直接内容の編集や修正が行えます。これには、文中のテキストやキーワードの変更が含まれます。
-
- 編集の重複を避けるため、編集完了後のコンテンツブロックには「編集済み」というマークが付けられます。
-
- 
-
-
-
- **親子モード**
-
- 親チャンクは、その中に含まれる子チャンクの内容を持っていますが、両者は独立しており、それぞれ個別に修正が可能です。以下の説明では、親子間の編集プロセスを解説します:
-
- 
-
- **親チャンクの編集**:親チャンクの右側にある編集ボタンをタップし、内容を入力します。**「保存」**をクリックすると、子チャンクには影響しません。**「保存して子チャンクを再生成」**を選択すると、子チャンクの内容も更新されます。
-
- 編集後のコンテンツブロックには「編集済み」というマークが付けられます。
-
- 
-
- **子チャンクの編集**:任意の子チャンクを選び、編集モードで修正します。保存後、親チャンクへの影響はありません。編集済みまたは追加された子チャンクブロックには、特定の編集状態を示すタグが表示されます。また、この子チャンクを現在の親テキストブロックのタグとして参照することも可能です。
-
- 
-
-
-
- **Q&Aモード**
-
- Q&Aモードでは、各コンテンツブロックが一つの質問とその答えを含んでいます。希望するテキストチャンクをクリックすることで、質問と答えを個別に修正できます。また、現在のブロック内のキーワードの編集もサポートされています。
-
- 
-
-
-
----
-
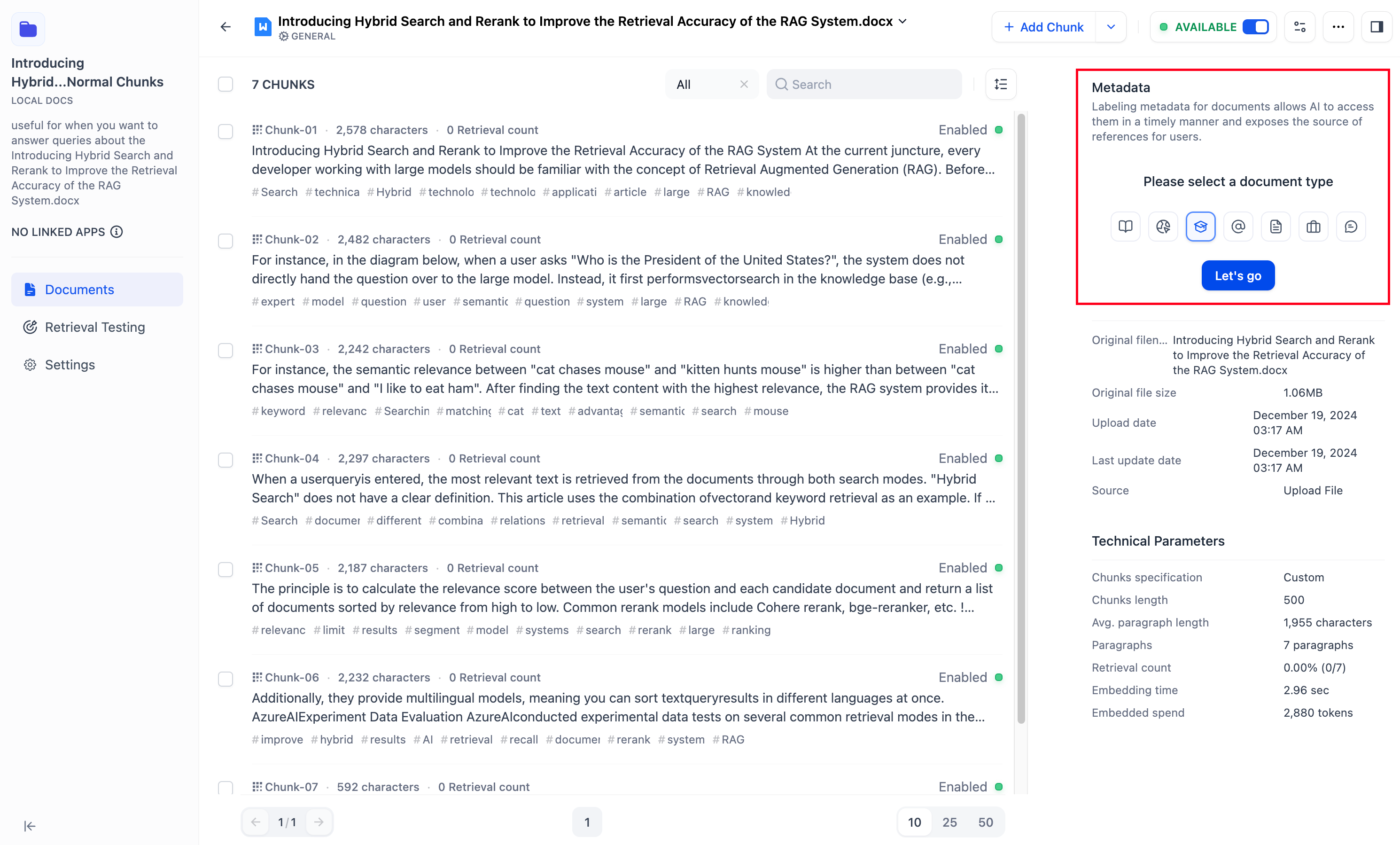
-## メタデータの管理
-
-メタデータは、ウェブページのタイトル、URL、キーワード、説明など、さまざまな情報源からの文書を区別するために用いられる情報です。これらは、ナレッジベースでのテキスト検索時に構造化されたフィールドとして利用されるほか、参照元の情報表示にも活用されます。
-
-
+ナレッジベース内の左サイドバーにある **設定** アイコンをクリックして、ナレッジベースの設定ページに移動します。
+
+| 設定項目 | 説明 |
+|:---------------- |:-------------|
+| 名前とアイコン | ナレッジベースを識別するための名前とアイコンを設定します。|
+| 説明 | ナレッジベースの目的と内容を示す簡潔な説明文です。|
+| 権限 | このナレッジベースへアクセスできるワークスペースメンバーを定義します。ナレッジベースへのアクセス権を付与されたメンバーは、[ナレッジコンテンツの管理](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents) に記載されたすべての操作権限を持ちます。 |
+| インデックス方法 | ドキュメントチャンクがどのように処理・整理され検索に使用されるかを定義します。詳細については、[インデックス方法の設定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#インデックス方法の設定) を参照してください。 |
+| 埋め込みモデル | ドキュメントチャンクをベクトル表現に変換する際に使用する埋め込みモデルを指定します。埋め込みモデルを変更すると、すべてのチャンクが再埋め込みされ、ベクトルインデックスが再生成され、既存のベクトルは破棄されます。 |
+| 検索設定 | ナレッジベースが関連するコンテンツをどのように検索するかを定義します。詳細については、[検索方法の指定 ](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#検索方法の指定) を参照してください。 |
+
+
+ ナレッジベースを作成した後は、チャンク構造を変更することはできません。
+
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx b/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx
index f56dd955..6054e720 100644
--- a/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx
@@ -1,64 +1,17 @@
---
-title: 作成手順
+title: ナレッジをクイック作成
+sidebarTitle: 概要
---
-ナレッジベースの作成とドキュメントのアップロードは、以下のステップに分かれています:
+1. **ナレッジ** > **ナレッジベースを作成** をクリックします。その後、[ローカルファイルをアップロード](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme)、[Notionデータをインポート](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion)、[Webサイトからデータをインポート](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website)、もしくは空のナレッジベースを作成します。
-1. ナレッジベースを作成します。ローカルファイルのアップロード、オンラインデータのインポート、または空のナレッジベースを作成することができます。
+2. [チャンクモードの指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)し、分割結果をプレビューします。この段階では、テキストの前処理と構造化が行われ、長文が複数の小さなチャンクに分割されます。
-
- ローカルファイルのアップロード、オンラインデータのインポート、または空のナレッジベースの作成について。
-
+3. [インデックス方法と検索設定を指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)します。ナレッジベースがユーザーのクエリを受け取ると、あらかじめ設定された検索方法に基づいて既存ドキュメントを検索し、関連性の高いコンテンツチャンクを抽出します。
-2. チャンキングモードを指定します。この段階では、コンテンツの前処理とデータ構造化を行い、長いテキストが複数のセグメントに分割されます。ここでは、テキストの分割効果をプレビューすることができます。
+4. データ処理が完了するまで待機します。
-
- テキスト分割とデータクリーニングのプロセスについて学ぶ
-
-
-3. インデックス方法と検索設定を設定します。ナレッジベースはユーザーからのクエリを受け取ると、事前設定された検索方法に従って既存のドキュメント内で関連コンテンツを検索し、言語モデルが高品質の回答を生成するために関連性の高い情報を抽出します。
-
-
- インデックス方法と検索パラメータの設定方法について学ぶ
-
-
-4. チャンクのエンベディング処理が完了するまで待ちます。
-5. アップロードが完了したら、アプリケーション内でナレッジベースを関連付けて使用します。[アプリケーション内でのナレッジベースの統合](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)を参照して、ナレッジベースに基づいて質問応答ができるLLMアプリケーションを構築できます。ナレッジベースの修正や管理が必要な場合は、[ナレッジベース管理とドキュメントメンテナンス](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)を参照してください。
-
-
-
-***
-
-### 参考資料
-
-#### ETL
-
-RAGの本番環境での応用では、より良いデータ検索結果を得るために、複数のソースからのデータに対して前処理とクリーニングを行う必要があります。これがETL(_extract, transform, load_)です。非構造化/半構造化データの前処理能力を強化するため、Difyでは**Dify ETL**と[**Unstructured ETL**](https://docs.unstructured.io/welcome)の2つのETLソリューションをサポートしています。Unstructuredは、後続のステップのためにデータを効率的に抽出し、クリーンなデータに変換します。Difyの各バージョンにおけるETLソリューションの選択:
-
-* SaaSバージョンでは選択できず、デフォルトでUnstructured ETLを使用します;
-* コミュニティバージョンでは選択可能で、デフォルトではDify ETLを使用し、[環境変数](/ja-jp/getting-started/install-self-hosted/environments)を通じてUnstructured ETLを有効にできます;
-
-ファイル解析でサポートされる形式の違い:
-
-| DIFY ETL | Unstructured ETL |
-| ---------------------------------------------- | ------------------------------------------------------------------------ |
-| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
-
-異なるETLソリューションはファイル抽出効果においても違いがあります。Unstructured ETLのデータ処理方法についてさらに詳しく知りたい場合は、[公式ドキュメント](https://docs.unstructured.io/open-source/core-functionality/partitioning)を参照してください。
-
-***
-
-#### **エンベディング**
-
-**エンベディング**は、離散変数(単語、短文、または文書全体など)を連続的なベクトル表現に変換する技術です。これにより、高次元データ(単語、フレーズ、画像など)を低次元空間にマッピングし、コンパクトで効果的な表現方法を提供します。このような表現は、データの次元を削減するだけでなく、重要な意味情報も保持するため、後続のコンテンツ検索がより効率的になります。
-
-**エンベディングモデル**は、テキストをベクトル化することに特化した大規模言語モデルで、テキストを密な数値ベクトルに変換し、意味情報を効果的に捉えることができます。
-
-***
-
-#### メタデータ
-
-メタデータ機能を使用してナレッジベースを管理する場合は、[メタデータ](/ja-jp/guides/knowledge-base/metadata)を参照してください。
+
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx b/ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
index a4727852..99d02d42 100644
--- a/ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
@@ -1,5 +1,5 @@
---
-title: ステップ2:ナレッジパイプラインのオーケストレーション
+title: ステップ2:ナレッジパイプラインをオーケストレーションする
---
# ナレッジパイプラインの構築
@@ -342,10 +342,20 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
**高品質モード**では、埋め込みモデル(Embedding)によりテキストをベクトル化し、意味的な関連性検索が可能です(完全一致でなくても適切な回答に辿り着けます)。
+
+
+ 画像検索を有効にするには、「**Vision**」アイコン付きの画像埋め込み対応モデルを選択してください。
+
+ このような埋め込みモデルを使用しているナレッジベースは、カード上で **Multimodal** と表示されます。
+
+
+
+
+
**コスト効率モード**では、各ブロックは10個のキーワードでインデックス化され、埋め込みモデルのコストは発生しません。
-詳細は[インデックス方法と検索設定の選択](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)もご参照ください。
+詳細は[インデックス方法と検索設定を指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)もご参照ください。
#### インデックス方法と検索設定概要
diff --git a/ja-jp/guides/knowledge-base/knowledge-pipeline/readme.mdx b/ja-jp/guides/knowledge-base/knowledge-pipeline/readme.mdx
index ab1585a4..920c1cbc 100644
--- a/ja-jp/guides/knowledge-base/knowledge-pipeline/readme.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-pipeline/readme.mdx
@@ -1,5 +1,6 @@
---
-title: ナレッジパイプラインの作成
+title: ナレッジパイプラインからナレッジを作成
+sidebarTitle: 概要
---
ナレッジパイプラインは、生データを検索可能なナレッジベースへと変換するためのドキュメント処理ワークフローです。ワークフローを組み立てるように、さまざまな処理ノードやツールを視覚的に組み合わせて設定し、データ処理の精度や関連性を最適化できます。
diff --git a/ja-jp/guides/knowledge-base/metadata.mdx b/ja-jp/guides/knowledge-base/metadata.mdx
index d8ec6654..795abdb9 100644
--- a/ja-jp/guides/knowledge-base/metadata.mdx
+++ b/ja-jp/guides/knowledge-base/metadata.mdx
@@ -1,5 +1,6 @@
---
-title: メタデータ
+title: ドキュメントのメタデータを管理
+sidebarTitle: メタデータの管理
---
## メタデータとは?
diff --git a/ja-jp/guides/knowledge-base/readme.mdx b/ja-jp/guides/knowledge-base/readme.mdx
index b92b605b..dc3e2059 100644
--- a/ja-jp/guides/knowledge-base/readme.mdx
+++ b/ja-jp/guides/knowledge-base/readme.mdx
@@ -1,42 +1,71 @@
---
-title: ナレッジベース
+title: ナレッジ
+sidebarTitle: 概要
---
-Difyプラットフォームでは、RAG(検索強化生成)ソリューションを通じて、ナレッジベースをよりアクセスしやすい形で提供します。開発者は企業の内部文書、FAQ、規格情報などをナレッジベースにアップロードし、整理することが可能で、これらはその後、大規模言語モデル(LLM)が問い合わせる際の情報源として利用されます。これにより、AIの大規模モデルが当初学習した静的なデータに依存する代わりに、ナレッジベースの内容をリアルタイムで更新し、情報が古くなることや欠けることによる問題を防ぐことができます。
+## はじめに
-ユーザーからの質問を受けたLLMは、まずナレッジベース内の内容をキーワードに基づいて検索します。これにより、関連性の高いコンテンツが選択され、LLMがより正確な答えを出すための重要な文脈を提供します。
+Dify の「ナレッジ」は、あなた自身のデータを統合し、AI アプリに活用できる仕組みです。これにより、LLM(大規模言語モデル)に特定分野の情報を文脈として提供し、より正確で関連性の高い、幻覚(誤情報)の少ない応答を実現します。
-この手法により、開発者はLLMが既存の訓練データに頼るだけでなく、リアルタイムの文書やデータベースからの最新情報を扱うことが可能となり、答えの正確性と関連性が向上します。
+この仕組みは **RAG(Retrieval-Augmented Generation/検索拡張生成)** によって支えられています。これは、モデルが事前学習された一般公開データだけに依存するのではなく、**あなたの独自ナレッジを追加の信頼ソースとして利用する**という意味です。
-**Difyの主な利点**:
+1. **(検索/Retrieval)** ユーザーが質問をすると、システムはまずナレッジから**最も関連性の高い情報を検索**します。
-* リアルタイム更新:ナレッジベースの内容はいつでも最新のものに更新することができ、モデルが最新情報を得られるようにします。
+2. **(拡張/Augmented)** 取得された情報はユーザーの質問文と組み合わせられ、**拡張文脈**として LLM に渡されます。
-* 高精度:関連する文書を検索することで、LLMは実際の内容に基づき高品質な回答を生み出すことができ、誤情報を減らします。
+3. **(生成/Generation)** LLM はその文脈をもとに、**より精度の高い**回答を生成します。
-* 柔軟性:開発者はナレッジベースの内容をカスタマイズでき、実際のニーズに合わせて知識の範囲を調整できます。
+
+ 詳細については [RAG](/ja-jp/learn-more/extended-reading/retrieval-augment/README) をご覧ください。
+
-ナレッジベース機能はRAGパイプラインの各段階を可視化し、ユーザーが個人またはチームのナレッジベースを管理しやすくするシンプルで使いやすいユーザーインターフェースを提供します。また、これを迅速にAIアプリケーションに統合することができます。準備するのは以下のようなテキストコンテンツだけです:
+ナレッジは「ナレッジベース」に保存・管理されます。用途やドメイン、データソースごとに複数のナレッジベースを作成でき、アプリケーションのニーズに応じて選択的に統合することが可能です。
-* 長文コンテンツ(TXT、Markdown、DOCX、HTML、JSON、さらにはPDF)
-* 構造化データ(CSV、Excelなど)
-* オンラインデータソース(ウェブサイトからの情報収集、Notionからのデータ取得など)
+ナレッジベースを構築するには、ローカルファイル(様々な形式)をアップロードしたり、Notion などのオンラインドキュメントのページを直接インポートしたり、ウェブサイトの内容を同期したり、または AWS Bedrock などの外部ナレッジベースと接続することができます。
-ファイルを「ナレッジベース」にアップロードすることで、データの自動処理が行われます。
+## ナレッジで構築する
-> もし既に独自のナレッジベースを持っている場合は、それをDifyに接続することで、外部のナレッジベースとの連携を確立できます。
+Dify のナレッジ機能を利用すれば、独自データや専門知識を基盤とした AI アプリを構築できます。代表的なユースケースは以下の通りです。
-
+1. **カスタマーサポートチャットボット**:製品ドキュメント、FAQ、トラブルシューティングガイド、サポート履歴などをもとに、より正確で最新の回答を行うスマートなサポートボットを構築。
-### 使用案例
+2. **社内ナレッジポータル**:従業員が会社のポリシーや手順を迅速にアクセスできる AI 検索・Q&A システムを構築。
-例えば、既存のナレッジベースや製品のドキュメントを利用してAIカスタマーサポートアシスタントを開発したい場合、Difyを用いると、ドキュメントをナレッジベースにアップロードし、対話型アプリケーションを簡単に作成できます。従来の手法では、テキストデータからAIカスタマーサポートアシスタントを開発するまで数週間を要し、継続的なメンテナンスや効果的な更新作業が難しいことがありました。しかし、Difyを使用すると、このプロセスをわずか3分で完了させ、ユーザーからのフィードバック収集を始めることができます。
+3. **コンテンツ生成ツール**:特定分野の資料やバックグラウンド情報をもとに、レポート、記事、メールなどを生成する知的ライティングツールを構築。
-### ナレッジベースとドキュメント
+4. **リサーチ・分析アプリケーション**:学術論文、市場レポート、法的文書などの特定の知識リポジトリから情報を検索・要約するリサーチ支援アプリを構築。
-Difyでのナレッジベースは、複数のドキュメント(Documents)から構成され、一つのドキュメントは複数のコンテンツブロック(Chunk)を含むことがあります。このナレッジベースは、アプリケーション全体で検索の対象として統合することが可能です。ドキュメントは、開発者や運営スタッフによってアップロードされるか、他のデータソースから同期されます。
+## ナレッジの作成
-独自のドキュメントライブラリを構築している場合、Difyの[外部ナレッジベース機能](./connect-external-knowledge-base)を利用して、自身のナレッジベースをDifyプラットフォームにリンクさせることができます。これにより、Difyプラットフォーム内で内容を再度アップロードすることなく、大規模な言語モデルがリアルタイムで独自のナレッジベースの内容を参照することが可能になります。
+- **[クイック作成](/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction)**:データをインポートし、処理ルールを定義して、あとは Dify に任せるだけ。迅速で初心者にも簡単。
+
+- **[ナレッジパイプラインから作成](/ja-jp/guides/knowledge-base/knowledge-pipeline/readme)**:独自ステップや各種プラグインを組み合わせ、柔軟で複雑なデータ処理ワークフローを構築。
+
+- **[外部ナレッジベースと連携](/ja-jp/guides/knowledge-base/connect-external-knowledge-base)**:API を介して外部ナレッジベースと直接同期し、既存データを移行せずに活用。
+
+## ナレッジの管理と最適化
+
+- **[コンテンツ管理](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents)**:ドキュメントやテキストチャンクの閲覧・追加・修正・削除を行い、最新かつ検索可能な状態を維持。
+
+- **[検索検証](/ja-jp/guides/knowledge-base/test-retrieval)**:ユーザーの質問をシミュレートして、ナレッジベースの検索精度を確認。
+
+- **[メタデータによる検索強化](/ja-jp/guides/knowledge-base/metadata)**:ドキュメントにメタデータを追加し、フィルタ検索を有効化して検索精度をさらに向上。
+
+- **[設定の調整](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme)**:インデックス方式、埋め込みモデル、検索戦略をいつでも変更可能。
+
+## ナレッジの利用
+
+- **[アプリケーションへの統合](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)**:AI アプリを自社データに基づかせることが可能。
+
+- **[ソースの引用表示](/ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属)**:ナレッジベースの情報に基づく回答時に、参照元をアプリ上で明示する機能を有効化。
+
+---
+
+**関連資料**
+
+- [InfraNodusでDify RAGを強化する:LLMのコンテキストを拡大](https://qiita.com/DifyJapan/items/44299efddc2e456a796f)
+
+- [Dify v1.1.0: カスタムメタデータによるナレッジベース検索の精密フィルタリング](https://qiita.com/DifyJapan/items/ee5445a1b010e4c362ec)
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/test-retrieval.mdx b/ja-jp/guides/knowledge-base/test-retrieval.mdx
index 62efa93c..df5e2dda 100644
--- a/ja-jp/guides/knowledge-base/test-retrieval.mdx
+++ b/ja-jp/guides/knowledge-base/test-retrieval.mdx
@@ -1,72 +1,27 @@
---
-title: リコールテスト/引用帰属
+title: ナレッジ検索テスト
---
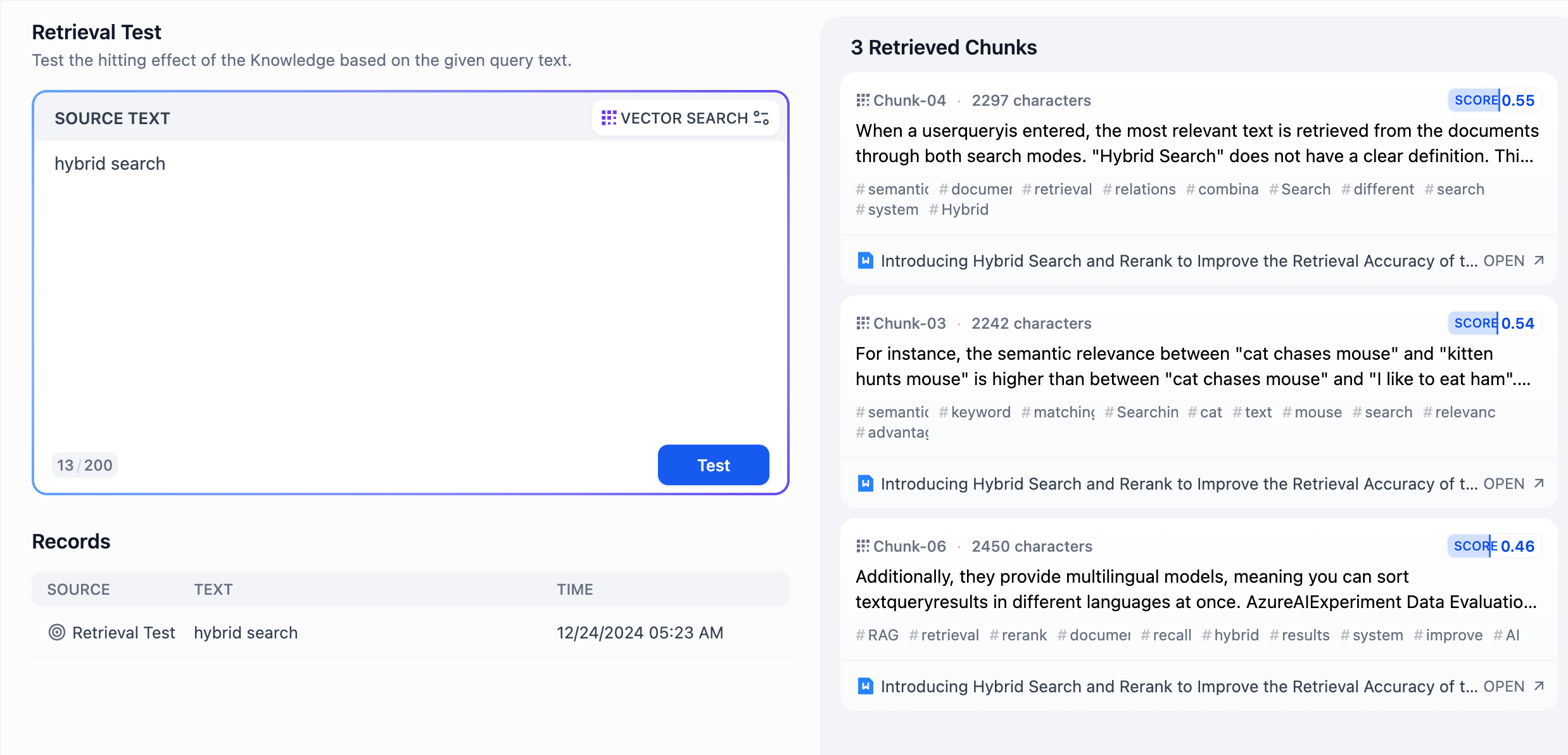
-### 1 リコールテスト
+ナレッジベース内の左サイドバーにある **検索テスト** アイコンをクリックして、テストページに移動します。
-Difyのナレッジベースでは、テキストによる検索テスト機能を提供しており、ユーザーがキーワードを入力すると、ナレッジベース内の関連コンテンツを呼び出すプロセスを模擬します。この際、検索されたコンテンツは関連度のスコアによって並べ替えられ、その後LLM(大規模言語モデル)に送られます。一般に、質問とコンテンツの一致度が高ければ高いほど、LLMによる回答の質も向上し、テキストの「学習効果」も高まります。
+このページでは、ユーザーのクエリをシミュレートして、ナレッジベースがどの程度関連情報を正しく検索できるかを確認し、最適なパフォーマンスを得るためにさまざまな検索設定を試すことができます。
-異なる検索手法や設定を試して、検索されたコンテンツの品質と効果を確認することが可能です。各ナレッジベースの分割方法には、それぞれ異なる検索テスト手法が対応しています。
+
+ ここで調整した検索設定は一時的なもので、現在のテストセッションにのみ適用されます。
+
-
-
- #### 一般モード
+
+ 検索設定の詳細については、[検索方法の指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#検索方法の指定) を参照してください。
+
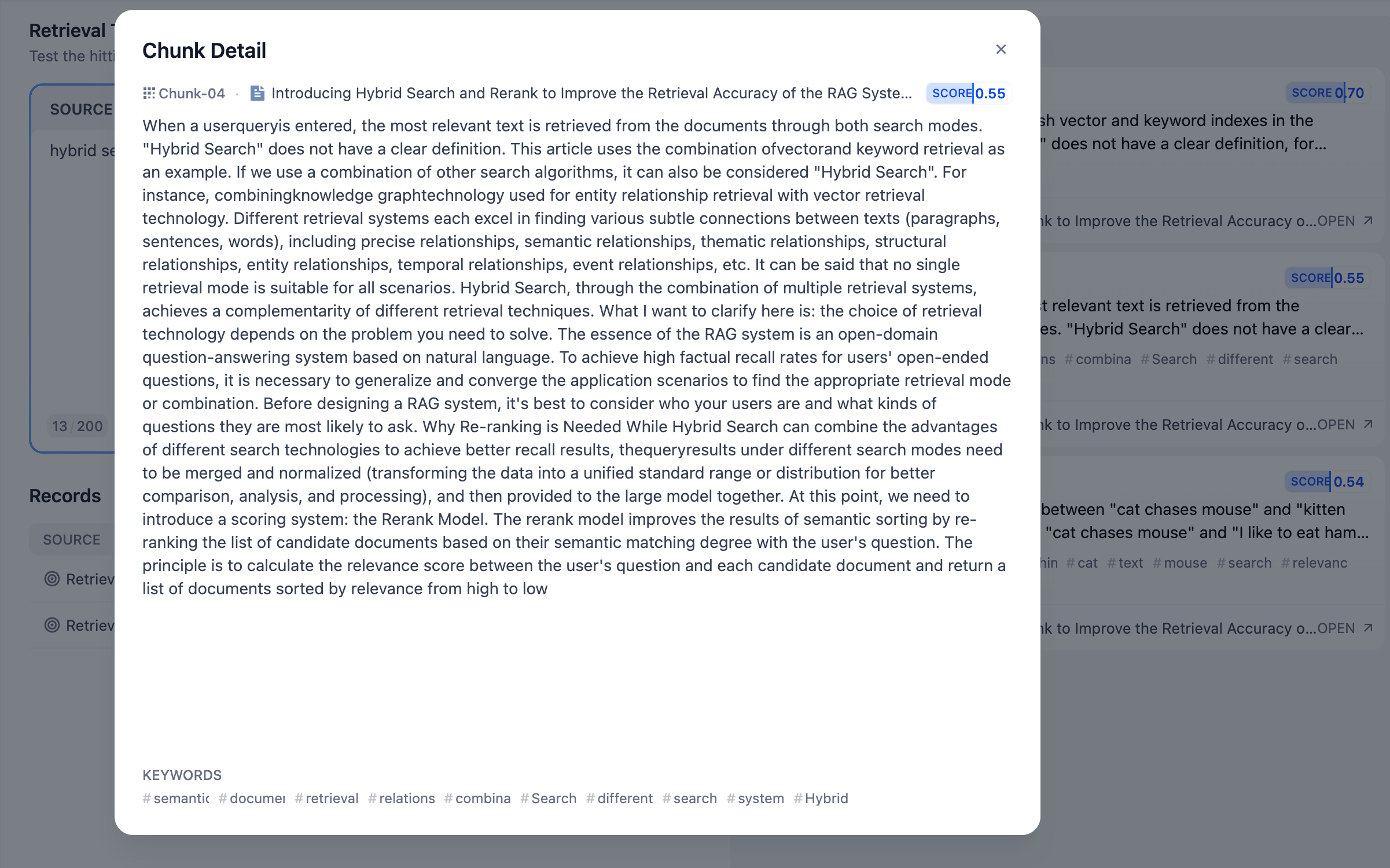
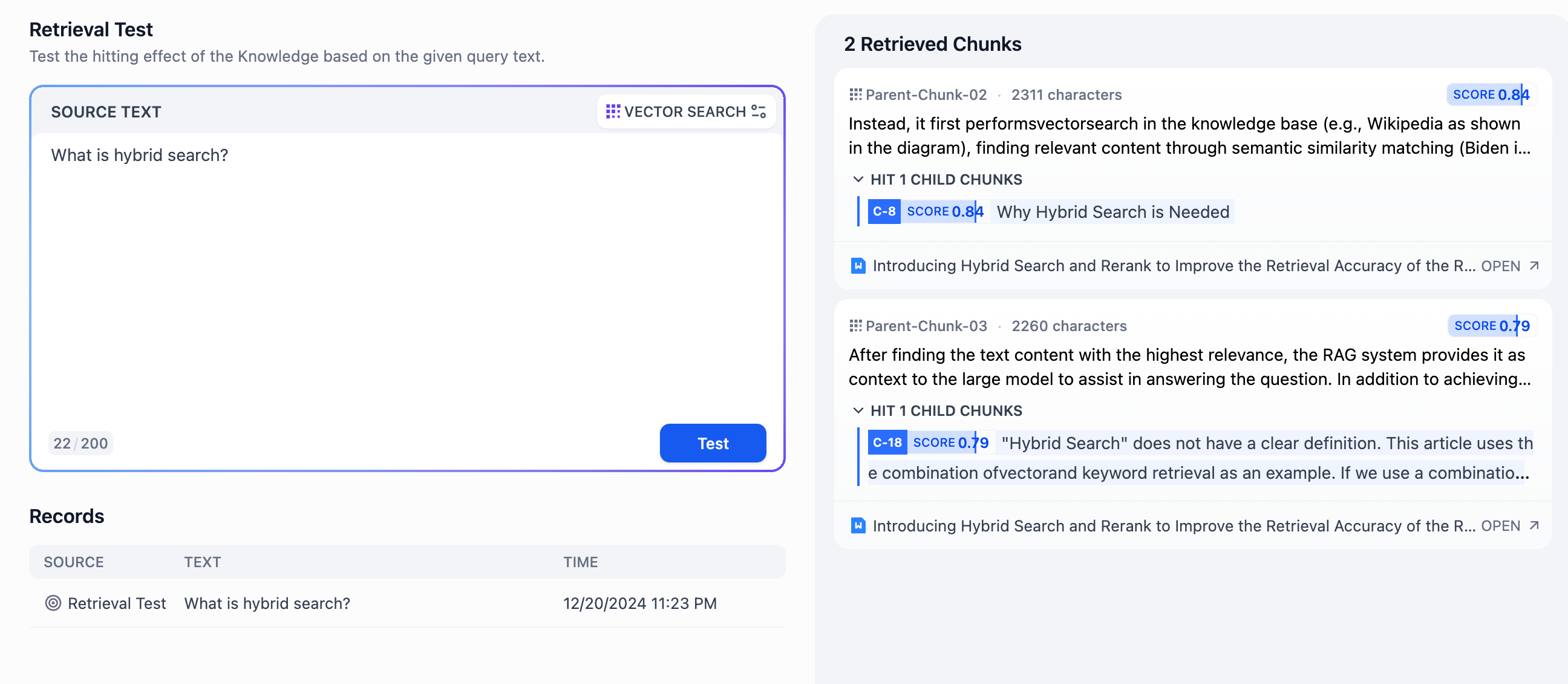
- **「ソーステキスト」** 入力欄に一般的なユーザー質問を入力し、**「テスト」** ボタンをクリックすることで、リコール結果を右側の **「リコール段落」** で確認できます。
+**記録** セクションには、このナレッジベースに関連するすべての検索イベントが記録されます。これには以下が含まれます。
- 一般モードでは、各コンテンツは独立しており、右上に表示されるスコアは、そのコンテンツがキーワードとどれだけマッチしているかを示します。高いスコアは、質問のキーワードとコンテンツがより密接に一致していることを意味します。
+- **検索テスト** ページ上で直接実行したクエリ
+- リンクされたアプリからの検索要求(テスト運用中または本番環境を問わず)
- 
-
- コンテンツをクリックすると、詳しい情報を確認できます。各コンテンツの下には、その情報源が表示され、その内容が信頼できるかどうかを判断できます。
-
- 
-
-
-
- #### 親子分割モード
-
- **「ソーステキスト」** 入力欄に質問を入力し、**「テスト」** をクリックすると、右側の「検索結果段落」で結果を確認できます。親子分割モードでは、質問のキーワードが子コンテンツにヒットし、より精度の高い一致を得られます。右上のスコアは、子コンテンツとキーワード間の一致度を示します。
-
- プレビューエリアでは、具体的にヒットした段落の内容を確認できます。一致後、子コンテンツが属する親コンテンツの全文脈を検索し、AIアプリケーションに完全な情報を提供します。
-
- 
-
- 各コンテンツの下にある情報源を参照することで、引用された内容を確認できます。詳細ページでは、左側に親コンテンツ、右側にヒットした子コンテンツの情報が表示されます。キーワードは複数の子コンテンツにヒットする可能性があり、一致度スコアも表示されます。これに基づき、現在のコンテンツが適切かどうかを判断できます。
-
- 
-
-
-
-**「履歴」** では、過去の検索記録を確認できます。ナレッジベースがアプリケーションに関連付けられている場合、そのアプリケーションでの検索履歴もここで見ることができます。
-
-**検索方法の変更**
-
-ソーステキスト入力欄の右上にあるアイコンをクリックすると、現在のナレッジベースの検索方法と具体的なパラメータを変更することができます。変更後は、現在の検索テストのデバッグプロセス中にのみ適用されます。異なる検索手法の効果を比較したい場合は、「ナレッジベース設定」>「検索設定」で設定してください。
-
-**リコールテストの推奨手順:**
-
-1. ユーザーの一般的な質問をカバーするテストケースやガイドラインの内容を設計・整理します。
-2. コンテンツの特徴や使用シーン(QAコンテンツか、多言語QAを含むかなど)に基づいて、適切な検索戦略を選択します。異なる検索手法の長所と短所については、拡張読み取り[検索強化生成(RAG)](/learn-more/extended-reading/retrieval-augment/)を参照してください。
-3. 検索するコンテンツの数(TopK)と検索スコアの閾値(Score)を調整し、実際のアプリケーションシナリオや文書の品質を考慮して、適切なパラメータの組み合わせを選択します。
-
-**TopK値と検索閾値(Score)の設定方法**
-
-* **TopKは、類似スコアの降順で検索されるコンテンツの最大数を指します。** TopK値を小さくすると、関連性の高いテキストが不足する可能性があります;TopK値を大きくすると、意味的に関連性の低いコンテンツが検索される可能性があり、LLMの応答品質が低下するかもしれません。
-
-* **検索閾値(Score)は、検索されるコンテンツの最低類似スコアを指します。** 閾値を下げると、関連性の低いコンテンツが検索される可能性があります;閾値を高く設定すると、関連するコンテンツが見逃される可能性があります。
-
----
-
-### 2 引用と帰属
-
-アプリケーション内でナレッジベースの効果をテストする際、**スタジオ -- 機能追加 -- 引用と帰属**に進み、引用と帰属機能を有効にします。
-
-
-
-機能を有効にすると、大規模言語モデルが質問に回答する際にナレッジベースからの内容を引用した場合、返信内容の下に具体的な引用段落情報を確認できます。これには**元のパラグラフテキスト、パラグラフ番号、マッチ度**などが含まれます。引用段落上部の**ナレッジベースにジャンプ**をクリックすると、開発者がデバッグ編集を行いやすいように、そのパラグラフが含まれるナレッジベースのパラグラフリストに簡単にアクセスできます。
-
-
+
+ テスト検索と通常の検索は同じ API エンドポイントを使用します。
+
{/*
Contributing Section
diff --git a/ja-jp/guides/workflow/node/knowledge-retrieval.mdx b/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
index 667d5fc2..8062641a 100644
--- a/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
+++ b/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
@@ -1,63 +1,133 @@
---
title: 知識検索
-version: '日本語'
---
-### 定義
+## はじめに
-ナレッジベースからユーザーの質問に関連するテキスト内容を検索し、それを下流のLLMノードのコンテキストとして使用することができます。
+知識検索ノードを使用すると、既存のナレッジベースを Chatflow や Workflow に統合できます。
-***
+このノードは指定されたナレッジからクエリに関連する情報を検索し、その結果を下流ノード(例:LLM)で利用できるコンテキスト情報として出力します。
-### シナリオ
+以下は Chatflow における 知識検索ノード の利用例です:
-一般的なシナリオ:外部データ/ナレッジに基づくAI質問応答システム(RAG)を構築。RAGの[基本概念](/ja-jp/learn-more/extended-reading/retrieval-augment/README)についてもっと知る。
+1. **ユーザー入力** ノードがユーザーの質問を収集します。
-下図は最も基本的なナレッジベース質問応答アプリケーションの例です。このプロセスの実行ロジックは、ユーザーの質問がLLMノードに渡される前に、ナレッジ検索ノードでユーザーの質問に最も関連するテキスト内容を検索し、召喚することです。その後、LLMノード内でユーザーの質問と検索されたコンテキストを一緒に入力し、LLMが検索内容に基づいて質問に答えるようにします。
+2. **知識検索** ノードが選択されたナレッジベースから関連情報を検索し、結果を出力します。
-
-
-
----
-
-### メタデータ管理
-
-メタデータの詳細については、[メタデータ](https://docs.dify.ai/ja-jp/guides/knowledge-base/metadata)を参照してください。
+- 「返品時の送料はかかりますか?」
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
index c1298c70..30fe6581 100644
--- a/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme.mdx
@@ -1,247 +1,26 @@
---
-title: ナレッジベースの管理
+title: ナレッジ設定の管理
+sidebarTitle: 設定の管理
---
-> ナレッジベースのページは、チームオーナー、チーム管理者、編集権限があるユーザーのみがアクセスできます。
-
-Difyチームのホームページで、「ナレッジベース」ボタンをクリックし、管理したいナレッジベースを選択して、左のナビゲーションパネルで **設定** をクリックして調整を行います。
-
-ナレッジベースの名前、説明、表示権限、索引モード、埋め込みモデル、および検索設定を変更することができます。
-
-
-
-- **ナレッジベースの名前**:異なるナレッジベースを区別するために使用されます。
-- **ナレッジの説明**:ナレッジベースのドキュメントで表現される情報を説明するために使用されます。
-- **表示権限**:ナレッジベースへのアクセス制御を定義します。3つのレベルがあります:**「自分だけ」**、**「全チームメンバー」** と **「一部のチームメンバー」**。権限のない方はナレッジベースをアクセスできません。このナレッジベースを他のメンバーと共有すると、そのメンバーもこのナレッジベースに対する完全な権限を持ちます。
-- **索引方法**:詳細な説明については、[ドキュメント](./create-knowledge-and-upload-documents/setting-indexing-methods)を参照してください。
-- **埋め込みモデル**:ナレッジベースの埋め込みモデルを変更できます。埋め込みモデルを変更すると、ナレッジベース内のすべてのドキュメントが再埋め込みされ、元の埋め込みが削除されます。
-- **検索設定**:詳細な説明については、[ドキュメント](./create-knowledge-and-upload-documents/selecting-retrieval-settings)を参照してください。
-
----
-
-### 関連アプリの確認方法
-
-ナレッジベース内では、左側のサイドバーに紐づけられたアプリケーションの件数が表示されます。丸い情報アイコンにマウスカーソルを合わせると、紐付けられたアプリケーションの一覧がポップアップで現れます。さらに、右側にある「ジャンプ」ボタンをクリックすることで、それらのアプリケーションへ素早く移動して確認することが可能です。
-
-
-
----
-
-### ナレッジベースAPIの管理
-
-Difyのナレッジベースは、標準APIの完全なセットを提供しています。開発者はAPI呼び出しを行うことで、ナレッジベース内のドキュメントやチャンクの追加、削除、変更、クエリなどの日常的な管理およびメンテナンス操作を実行できます。詳細については、[ナレッジベースAPIドキュメント](maintain-dataset-via-api)を参照してください。
-
-
-
----
-
-## ナレッジベース内の文書管理
-
-### 文書の追加方法
-
-ナレッジベースは、さまざまな文書が集められたものです。これらの文書は、開発者や管理者によってアップロードされたり、他のデータソースから同期されたりすることがあります。ナレッジベース内の各文書は、データソースの中の1つのファイルに相当します。たとえば、Notionのライブラリにある文書や、新しいオンライン文書のページなどが該当します。
-
-「ナレッジベース」→「文書リスト」→「ファイルを追加」の順に進み、既に作成されているナレッジベースに新しい文書をアップロードできます。
-
-
-
-### 文書の有効化・無効化・アーカイブ・削除
-
-**有効化**:通常利用されている状態の文書で、内容の編集やナレッジベースでの検索が可能です。無効化された文書は再び有効化することができますが、アーカイブされた文書を再び有効化する前には、アーカイブを解除する必要があります。
-
-**無効化**:AIアプリケーションの利用時に検索結果に含まれたくない文書は、文書の横にある青いスイッチをオフにすることで無効化できます。無効化された後も、文書の編集は可能です。
-
-**アーカイブ**:もはや使用しないが削除したくない古い文書データは、アーカイブすることができます。アーカイブされたデータは閲覧や削除のみ可能で、編集はできません。ナレッジベースの文書リストからアーカイブボタンをクリックするか、文書の詳細ページでアーカイブ操作を行えます。アーカイブは後で取り消し可能です。
-
-**削除**:⚠️危険な操作です。誤りがある文書や誤解を招く内容の文書は、文書の横にあるメニューボタンから削除できます。削除された内容は復元できないため、慎重に操作してください。
-
-> 上記の操作は、複数の文書を選択して一括で行うことが可能です。
-
-
-
-**注意**:
-
-ナレッジベース内に長期間更新されていない、または検索されていない文書がある場合、ナレッジベースの効率的な運用を保つため、システムはこれらの非活動文書を一時的に無効化することがあります。
-
-- サンドボックス/無料版のユーザーは、ナレッジベースを利用していない場合、**7日**後に自動的に無効化されます。
-
-- プロフェッショナル/チーム版のユーザーは、ナレッジベースを利用していない場合、**30日**後に自動的に無効化されます。
-
-いつでもナレッジベースにアクセスして、無効化された文書を再び有効化し、通常の利用を再開できます。有料ユーザーは**ワンクリックで復活**機能を利用して、無効化されたすべての文書を迅速に有効化することができます。
-
-
+ナレッジベースの設定を変更できるのは、ワークスペースの所有者、管理者、および編集者のみです。
----
-
-## テキストチャンクの管理
-
-### テキストチャンクを確認
-
-ナレッジベースにアップロードされた文書は、テキストのチャンク(Chunk)として保存されています。文書の見出しをクリックして、詳細ページに移動すると、その文書に含まれるテキストチャンクのリストを見ることができます。デフォルトでは、各ページには10個のチャンクが表示され、ページ下部でこの表示数を変更することが可能です。
-
-チャンクは、先頭の2行がプレビューとして表示されます。チャンクの全内容を閲覧したい場合は、「チャンクを展開」ボタンを軽くタップします。
-
-
-
-[テキストチャンク](./create-knowledge-and-upload-documents/chunking-and-cleaning-text)を表示する方法にはいくつかのモードがあり、それぞれでテキストの見せ方が異なります:
-
-
-
- **汎用モード**
-
- [汎用モード](./create-knowledge-and-upload-documents/chunking-and-cleaning-text)では、各テキストチャンクが独立したブロックとして扱われます。全内容を表示したい場合は、右上にある全画面表示ボタンをタップしてください。
-
- 
-
- 文書の見出し部分をクリックすることで、ナレッジベース内の他の文書へ素早く移動が可能です。
-
- 
-
-
-
- **親子モード**
-
- [親子モード](./create-knowledge-and-upload-documents/chunking-and-cleaning-text)では、テキストが親チャンクと子チャンクに分かれて表示されます。
-
- * **親チャンク**
-
- ナレッジベース内の文書を選択すると、まず親チャンクの内容が表示されます。これには、**「段落」** 表示と **「全文」** 表示の2種類があり、文脈をより完全に提供します。以下は、異なる表示方法によるテキストプレビューの違いを説明します。
- 
-
- * **子チャンク**
-
- 子チャンクは通常、段落内の特定の文(より小さいテキストブロック)で、詳細な情報を含んでいます。各チャンクは、文字数と検索された回数を示します。詳細を見るには、子チャンクを軽くタップします。ブロックの全内容を見たい場合は、右上の全画面表示ボタンをタップしてください。
-
- 
-
-
-
- **Q&Aモード**
-
- Q&Aモードでは、各コンテンツブロックが一組の質問と答えを含んでいます。文書の見出しを軽くタップすることで、テキストチャンクを確認することができます。
-
- 
-
-
-
----
-
-### テキストチャンクの品質管理
-
-テキストをチャンクする作業は、ナレッジベースを用いたQ&Aアプリの性能に直接影響を及ぼします。ナレッジベースとアプリを結びつける前に、チャンクされたテキストの品質を手動で確認することを強く推奨します。
-
-文字数、特定の識別子、または自然言語処理(NLP)を用いた意味的なチャンクなど、自動化された方法で大量のテキストを効率的にチャンクすることが可能ですが、品質は文の構造や文脈による意味の流れに大きく左右されます。手動での確認と修正を行うことで、自動チャンクの限界を補い、より高い品質を保証することができます。
-
-チャンクの品質を検証する際には、以下の点に注意する必要があります:
-
-- **チャンクされたテキストが短すぎる**場合、意図した意味が途切れてしまう可能性があります;
-
-
-- **チャンクされたテキストが長すぎる**場合、不要な情報が混入し、検索結果の精度を低下させる原因となります;
-
-
-- **意味の流れが不自然に断ち切られている**場合、最大チャンク長を設定しても、内容の一部が失われることがあります;
-
-
----
-
-### テキストチャンクの追加
-
-ナレッジベースに含まれる文書は、テキストを追加的にチャンクすることが可能です。異なるチャンクモードはそれぞれ、特定のチャンク方法を提供します。
-
-> テキストチャンクの追加は有料機能です。この機能を利用するには、アカウントのアップグレードが必要です。
-
-
-
- **汎用モード**
-
- ドキュメントに「チャンク追加」ボタンがあり、これをクリックすることで任意の数のカスタマイズされたチャンクを追加することが可能です。
-
- 
-
- テキストチャンクを手動で追加する際には、テキスト本体とキーワードの入力が選択肢としてあります。入力完了後、画面下部の「追加を続ける」にチェックを入れると、さらにテキストの追加が行えます。
-
- 
-
- 複数のチャンクを一度に追加したい場合は、まずCSV形式のチャンクアップロード用テンプレートをダウンロードし、そのテンプレートに従ってExcelでチャンクの内容を編集します。編集後はCSVファイルを保存し、それをアップロードしてください。
-
- 
-
-
-
- **親子モード**
-
- 「チャンク追加」ボタンを使って、ドキュメント内に一つまたは複数のカスタム**親チャンク**を自由に追加できます。
-
- 
-
- 入力完了後、画面下部の **「追加を続ける」** にチェックを入れると、さらにテキストの追加が可能です。
-
- 
-
- 親チャンク内には、子チャンクを個別に追加することもできます。親チャンクに属する子チャンクの右側にある「追加」ボタンをクリックすることで、子チャンクを個別に追加できます。
-
- 
-
-
-
- **Q&Aモード**
-
- 「チャンク追加」ボタンをクリックすると、質問と回答のペアを形成するブロックを一つまたは複数、ドキュメント内に自由に追加することができます。
-
-
-
----
-
-### テキストチャンクの編集
-
-
-
- **汎用モード**
-
- 追加された段落は、直接内容の編集や修正が行えます。これには、文中のテキストやキーワードの変更が含まれます。
-
- 編集の重複を避けるため、編集完了後のコンテンツブロックには「編集済み」というマークが付けられます。
-
- 
-
-
-
- **親子モード**
-
- 親チャンクは、その中に含まれる子チャンクの内容を持っていますが、両者は独立しており、それぞれ個別に修正が可能です。以下の説明では、親子間の編集プロセスを解説します:
-
- 
-
- **親チャンクの編集**:親チャンクの右側にある編集ボタンをタップし、内容を入力します。**「保存」**をクリックすると、子チャンクには影響しません。**「保存して子チャンクを再生成」**を選択すると、子チャンクの内容も更新されます。
-
- 編集後のコンテンツブロックには「編集済み」というマークが付けられます。
-
- 
-
- **子チャンクの編集**:任意の子チャンクを選び、編集モードで修正します。保存後、親チャンクへの影響はありません。編集済みまたは追加された子チャンクブロックには、特定の編集状態を示すタグが表示されます。また、この子チャンクを現在の親テキストブロックのタグとして参照することも可能です。
-
- 
-
-
-
- **Q&Aモード**
-
- Q&Aモードでは、各コンテンツブロックが一つの質問とその答えを含んでいます。希望するテキストチャンクをクリックすることで、質問と答えを個別に修正できます。また、現在のブロック内のキーワードの編集もサポートされています。
-
- 
-
-
-
----
-
-## メタデータの管理
-
-メタデータは、ウェブページのタイトル、URL、キーワード、説明など、さまざまな情報源からの文書を区別するために用いられる情報です。これらは、ナレッジベースでのテキスト検索時に構造化されたフィールドとして利用されるほか、参照元の情報表示にも活用されます。
-
-
+ナレッジベース内の左サイドバーにある **設定** アイコンをクリックして、ナレッジベースの設定ページに移動します。
+
+| 設定項目 | 説明 |
+|:---------------- |:-------------|
+| 名前とアイコン | ナレッジベースを識別するための名前とアイコンを設定します。|
+| 説明 | ナレッジベースの目的と内容を示す簡潔な説明文です。|
+| 権限 | このナレッジベースへアクセスできるワークスペースメンバーを定義します。ナレッジベースへのアクセス権を付与されたメンバーは、[ナレッジコンテンツの管理](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents) に記載されたすべての操作権限を持ちます。 |
+| インデックス方法 | ドキュメントチャンクがどのように処理・整理され検索に使用されるかを定義します。詳細については、[インデックス方法の設定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#インデックス方法の設定) を参照してください。 |
+| 埋め込みモデル | ドキュメントチャンクをベクトル表現に変換する際に使用する埋め込みモデルを指定します。埋め込みモデルを変更すると、すべてのチャンクが再埋め込みされ、ベクトルインデックスが再生成され、既存のベクトルは破棄されます。 |
+| 検索設定 | ナレッジベースが関連するコンテンツをどのように検索するかを定義します。詳細については、[検索方法の指定 ](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#検索方法の指定) を参照してください。 |
+
+
+ ナレッジベースを作成した後は、チャンク構造を変更することはできません。
+
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx b/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx
index f56dd955..6054e720 100644
--- a/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx
@@ -1,64 +1,17 @@
---
-title: 作成手順
+title: ナレッジをクイック作成
+sidebarTitle: 概要
---
-ナレッジベースの作成とドキュメントのアップロードは、以下のステップに分かれています:
+1. **ナレッジ** > **ナレッジベースを作成** をクリックします。その後、[ローカルファイルをアップロード](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme)、[Notionデータをインポート](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-notion)、[Webサイトからデータをインポート](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/sync-from-website)、もしくは空のナレッジベースを作成します。
-1. ナレッジベースを作成します。ローカルファイルのアップロード、オンラインデータのインポート、または空のナレッジベースを作成することができます。
+2. [チャンクモードの指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)し、分割結果をプレビューします。この段階では、テキストの前処理と構造化が行われ、長文が複数の小さなチャンクに分割されます。
-
- ローカルファイルのアップロード、オンラインデータのインポート、または空のナレッジベースの作成について。
-
+3. [インデックス方法と検索設定を指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)します。ナレッジベースがユーザーのクエリを受け取ると、あらかじめ設定された検索方法に基づいて既存ドキュメントを検索し、関連性の高いコンテンツチャンクを抽出します。
-2. チャンキングモードを指定します。この段階では、コンテンツの前処理とデータ構造化を行い、長いテキストが複数のセグメントに分割されます。ここでは、テキストの分割効果をプレビューすることができます。
+4. データ処理が完了するまで待機します。
-
- テキスト分割とデータクリーニングのプロセスについて学ぶ
-
-
-3. インデックス方法と検索設定を設定します。ナレッジベースはユーザーからのクエリを受け取ると、事前設定された検索方法に従って既存のドキュメント内で関連コンテンツを検索し、言語モデルが高品質の回答を生成するために関連性の高い情報を抽出します。
-
-
- インデックス方法と検索パラメータの設定方法について学ぶ
-
-
-4. チャンクのエンベディング処理が完了するまで待ちます。
-5. アップロードが完了したら、アプリケーション内でナレッジベースを関連付けて使用します。[アプリケーション内でのナレッジベースの統合](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)を参照して、ナレッジベースに基づいて質問応答ができるLLMアプリケーションを構築できます。ナレッジベースの修正や管理が必要な場合は、[ナレッジベース管理とドキュメントメンテナンス](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)を参照してください。
-
-
-
-***
-
-### 参考資料
-
-#### ETL
-
-RAGの本番環境での応用では、より良いデータ検索結果を得るために、複数のソースからのデータに対して前処理とクリーニングを行う必要があります。これがETL(_extract, transform, load_)です。非構造化/半構造化データの前処理能力を強化するため、Difyでは**Dify ETL**と[**Unstructured ETL**](https://docs.unstructured.io/welcome)の2つのETLソリューションをサポートしています。Unstructuredは、後続のステップのためにデータを効率的に抽出し、クリーンなデータに変換します。Difyの各バージョンにおけるETLソリューションの選択:
-
-* SaaSバージョンでは選択できず、デフォルトでUnstructured ETLを使用します;
-* コミュニティバージョンでは選択可能で、デフォルトではDify ETLを使用し、[環境変数](/ja-jp/getting-started/install-self-hosted/environments)を通じてUnstructured ETLを有効にできます;
-
-ファイル解析でサポートされる形式の違い:
-
-| DIFY ETL | Unstructured ETL |
-| ---------------------------------------------- | ------------------------------------------------------------------------ |
-| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
-
-異なるETLソリューションはファイル抽出効果においても違いがあります。Unstructured ETLのデータ処理方法についてさらに詳しく知りたい場合は、[公式ドキュメント](https://docs.unstructured.io/open-source/core-functionality/partitioning)を参照してください。
-
-***
-
-#### **エンベディング**
-
-**エンベディング**は、離散変数(単語、短文、または文書全体など)を連続的なベクトル表現に変換する技術です。これにより、高次元データ(単語、フレーズ、画像など)を低次元空間にマッピングし、コンパクトで効果的な表現方法を提供します。このような表現は、データの次元を削減するだけでなく、重要な意味情報も保持するため、後続のコンテンツ検索がより効率的になります。
-
-**エンベディングモデル**は、テキストをベクトル化することに特化した大規模言語モデルで、テキストを密な数値ベクトルに変換し、意味情報を効果的に捉えることができます。
-
-***
-
-#### メタデータ
-
-メタデータ機能を使用してナレッジベースを管理する場合は、[メタデータ](/ja-jp/guides/knowledge-base/metadata)を参照してください。
+
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx b/ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
index a4727852..99d02d42 100644
--- a/ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
@@ -1,5 +1,5 @@
---
-title: ステップ2:ナレッジパイプラインのオーケストレーション
+title: ステップ2:ナレッジパイプラインをオーケストレーションする
---
# ナレッジパイプラインの構築
@@ -342,10 +342,20 @@ Dify Extractorは、Difyが提供する内蔵ドキュメント解析ツール
**高品質モード**では、埋め込みモデル(Embedding)によりテキストをベクトル化し、意味的な関連性検索が可能です(完全一致でなくても適切な回答に辿り着けます)。
+
+
+ 画像検索を有効にするには、「**Vision**」アイコン付きの画像埋め込み対応モデルを選択してください。
+
+ このような埋め込みモデルを使用しているナレッジベースは、カード上で **Multimodal** と表示されます。
+
+
+
+
+
**コスト効率モード**では、各ブロックは10個のキーワードでインデックス化され、埋め込みモデルのコストは発生しません。
-詳細は[インデックス方法と検索設定の選択](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)もご参照ください。
+詳細は[インデックス方法と検索設定を指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods)もご参照ください。
#### インデックス方法と検索設定概要
diff --git a/ja-jp/guides/knowledge-base/knowledge-pipeline/readme.mdx b/ja-jp/guides/knowledge-base/knowledge-pipeline/readme.mdx
index ab1585a4..920c1cbc 100644
--- a/ja-jp/guides/knowledge-base/knowledge-pipeline/readme.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-pipeline/readme.mdx
@@ -1,5 +1,6 @@
---
-title: ナレッジパイプラインの作成
+title: ナレッジパイプラインからナレッジを作成
+sidebarTitle: 概要
---
ナレッジパイプラインは、生データを検索可能なナレッジベースへと変換するためのドキュメント処理ワークフローです。ワークフローを組み立てるように、さまざまな処理ノードやツールを視覚的に組み合わせて設定し、データ処理の精度や関連性を最適化できます。
diff --git a/ja-jp/guides/knowledge-base/metadata.mdx b/ja-jp/guides/knowledge-base/metadata.mdx
index d8ec6654..795abdb9 100644
--- a/ja-jp/guides/knowledge-base/metadata.mdx
+++ b/ja-jp/guides/knowledge-base/metadata.mdx
@@ -1,5 +1,6 @@
---
-title: メタデータ
+title: ドキュメントのメタデータを管理
+sidebarTitle: メタデータの管理
---
## メタデータとは?
diff --git a/ja-jp/guides/knowledge-base/readme.mdx b/ja-jp/guides/knowledge-base/readme.mdx
index b92b605b..dc3e2059 100644
--- a/ja-jp/guides/knowledge-base/readme.mdx
+++ b/ja-jp/guides/knowledge-base/readme.mdx
@@ -1,42 +1,71 @@
---
-title: ナレッジベース
+title: ナレッジ
+sidebarTitle: 概要
---
-Difyプラットフォームでは、RAG(検索強化生成)ソリューションを通じて、ナレッジベースをよりアクセスしやすい形で提供します。開発者は企業の内部文書、FAQ、規格情報などをナレッジベースにアップロードし、整理することが可能で、これらはその後、大規模言語モデル(LLM)が問い合わせる際の情報源として利用されます。これにより、AIの大規模モデルが当初学習した静的なデータに依存する代わりに、ナレッジベースの内容をリアルタイムで更新し、情報が古くなることや欠けることによる問題を防ぐことができます。
+## はじめに
-ユーザーからの質問を受けたLLMは、まずナレッジベース内の内容をキーワードに基づいて検索します。これにより、関連性の高いコンテンツが選択され、LLMがより正確な答えを出すための重要な文脈を提供します。
+Dify の「ナレッジ」は、あなた自身のデータを統合し、AI アプリに活用できる仕組みです。これにより、LLM(大規模言語モデル)に特定分野の情報を文脈として提供し、より正確で関連性の高い、幻覚(誤情報)の少ない応答を実現します。
-この手法により、開発者はLLMが既存の訓練データに頼るだけでなく、リアルタイムの文書やデータベースからの最新情報を扱うことが可能となり、答えの正確性と関連性が向上します。
+この仕組みは **RAG(Retrieval-Augmented Generation/検索拡張生成)** によって支えられています。これは、モデルが事前学習された一般公開データだけに依存するのではなく、**あなたの独自ナレッジを追加の信頼ソースとして利用する**という意味です。
-**Difyの主な利点**:
+1. **(検索/Retrieval)** ユーザーが質問をすると、システムはまずナレッジから**最も関連性の高い情報を検索**します。
-* リアルタイム更新:ナレッジベースの内容はいつでも最新のものに更新することができ、モデルが最新情報を得られるようにします。
+2. **(拡張/Augmented)** 取得された情報はユーザーの質問文と組み合わせられ、**拡張文脈**として LLM に渡されます。
-* 高精度:関連する文書を検索することで、LLMは実際の内容に基づき高品質な回答を生み出すことができ、誤情報を減らします。
+3. **(生成/Generation)** LLM はその文脈をもとに、**より精度の高い**回答を生成します。
-* 柔軟性:開発者はナレッジベースの内容をカスタマイズでき、実際のニーズに合わせて知識の範囲を調整できます。
+
+ 詳細については [RAG](/ja-jp/learn-more/extended-reading/retrieval-augment/README) をご覧ください。
+
-ナレッジベース機能はRAGパイプラインの各段階を可視化し、ユーザーが個人またはチームのナレッジベースを管理しやすくするシンプルで使いやすいユーザーインターフェースを提供します。また、これを迅速にAIアプリケーションに統合することができます。準備するのは以下のようなテキストコンテンツだけです:
+ナレッジは「ナレッジベース」に保存・管理されます。用途やドメイン、データソースごとに複数のナレッジベースを作成でき、アプリケーションのニーズに応じて選択的に統合することが可能です。
-* 長文コンテンツ(TXT、Markdown、DOCX、HTML、JSON、さらにはPDF)
-* 構造化データ(CSV、Excelなど)
-* オンラインデータソース(ウェブサイトからの情報収集、Notionからのデータ取得など)
+ナレッジベースを構築するには、ローカルファイル(様々な形式)をアップロードしたり、Notion などのオンラインドキュメントのページを直接インポートしたり、ウェブサイトの内容を同期したり、または AWS Bedrock などの外部ナレッジベースと接続することができます。
-ファイルを「ナレッジベース」にアップロードすることで、データの自動処理が行われます。
+## ナレッジで構築する
-> もし既に独自のナレッジベースを持っている場合は、それをDifyに接続することで、外部のナレッジベースとの連携を確立できます。
+Dify のナレッジ機能を利用すれば、独自データや専門知識を基盤とした AI アプリを構築できます。代表的なユースケースは以下の通りです。
-
+1. **カスタマーサポートチャットボット**:製品ドキュメント、FAQ、トラブルシューティングガイド、サポート履歴などをもとに、より正確で最新の回答を行うスマートなサポートボットを構築。
-### 使用案例
+2. **社内ナレッジポータル**:従業員が会社のポリシーや手順を迅速にアクセスできる AI 検索・Q&A システムを構築。
-例えば、既存のナレッジベースや製品のドキュメントを利用してAIカスタマーサポートアシスタントを開発したい場合、Difyを用いると、ドキュメントをナレッジベースにアップロードし、対話型アプリケーションを簡単に作成できます。従来の手法では、テキストデータからAIカスタマーサポートアシスタントを開発するまで数週間を要し、継続的なメンテナンスや効果的な更新作業が難しいことがありました。しかし、Difyを使用すると、このプロセスをわずか3分で完了させ、ユーザーからのフィードバック収集を始めることができます。
+3. **コンテンツ生成ツール**:特定分野の資料やバックグラウンド情報をもとに、レポート、記事、メールなどを生成する知的ライティングツールを構築。
-### ナレッジベースとドキュメント
+4. **リサーチ・分析アプリケーション**:学術論文、市場レポート、法的文書などの特定の知識リポジトリから情報を検索・要約するリサーチ支援アプリを構築。
-Difyでのナレッジベースは、複数のドキュメント(Documents)から構成され、一つのドキュメントは複数のコンテンツブロック(Chunk)を含むことがあります。このナレッジベースは、アプリケーション全体で検索の対象として統合することが可能です。ドキュメントは、開発者や運営スタッフによってアップロードされるか、他のデータソースから同期されます。
+## ナレッジの作成
-独自のドキュメントライブラリを構築している場合、Difyの[外部ナレッジベース機能](./connect-external-knowledge-base)を利用して、自身のナレッジベースをDifyプラットフォームにリンクさせることができます。これにより、Difyプラットフォーム内で内容を再度アップロードすることなく、大規模な言語モデルがリアルタイムで独自のナレッジベースの内容を参照することが可能になります。
+- **[クイック作成](/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction)**:データをインポートし、処理ルールを定義して、あとは Dify に任せるだけ。迅速で初心者にも簡単。
+
+- **[ナレッジパイプラインから作成](/ja-jp/guides/knowledge-base/knowledge-pipeline/readme)**:独自ステップや各種プラグインを組み合わせ、柔軟で複雑なデータ処理ワークフローを構築。
+
+- **[外部ナレッジベースと連携](/ja-jp/guides/knowledge-base/connect-external-knowledge-base)**:API を介して外部ナレッジベースと直接同期し、既存データを移行せずに活用。
+
+## ナレッジの管理と最適化
+
+- **[コンテンツ管理](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents)**:ドキュメントやテキストチャンクの閲覧・追加・修正・削除を行い、最新かつ検索可能な状態を維持。
+
+- **[検索検証](/ja-jp/guides/knowledge-base/test-retrieval)**:ユーザーの質問をシミュレートして、ナレッジベースの検索精度を確認。
+
+- **[メタデータによる検索強化](/ja-jp/guides/knowledge-base/metadata)**:ドキュメントにメタデータを追加し、フィルタ検索を有効化して検索精度をさらに向上。
+
+- **[設定の調整](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme)**:インデックス方式、埋め込みモデル、検索戦略をいつでも変更可能。
+
+## ナレッジの利用
+
+- **[アプリケーションへの統合](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)**:AI アプリを自社データに基づかせることが可能。
+
+- **[ソースの引用表示](/ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属)**:ナレッジベースの情報に基づく回答時に、参照元をアプリ上で明示する機能を有効化。
+
+---
+
+**関連資料**
+
+- [InfraNodusでDify RAGを強化する:LLMのコンテキストを拡大](https://qiita.com/DifyJapan/items/44299efddc2e456a796f)
+
+- [Dify v1.1.0: カスタムメタデータによるナレッジベース検索の精密フィルタリング](https://qiita.com/DifyJapan/items/ee5445a1b010e4c362ec)
{/*
Contributing Section
diff --git a/ja-jp/guides/knowledge-base/test-retrieval.mdx b/ja-jp/guides/knowledge-base/test-retrieval.mdx
index 62efa93c..df5e2dda 100644
--- a/ja-jp/guides/knowledge-base/test-retrieval.mdx
+++ b/ja-jp/guides/knowledge-base/test-retrieval.mdx
@@ -1,72 +1,27 @@
---
-title: リコールテスト/引用帰属
+title: ナレッジ検索テスト
---
-### 1 リコールテスト
+ナレッジベース内の左サイドバーにある **検索テスト** アイコンをクリックして、テストページに移動します。
-Difyのナレッジベースでは、テキストによる検索テスト機能を提供しており、ユーザーがキーワードを入力すると、ナレッジベース内の関連コンテンツを呼び出すプロセスを模擬します。この際、検索されたコンテンツは関連度のスコアによって並べ替えられ、その後LLM(大規模言語モデル)に送られます。一般に、質問とコンテンツの一致度が高ければ高いほど、LLMによる回答の質も向上し、テキストの「学習効果」も高まります。
+このページでは、ユーザーのクエリをシミュレートして、ナレッジベースがどの程度関連情報を正しく検索できるかを確認し、最適なパフォーマンスを得るためにさまざまな検索設定を試すことができます。
-異なる検索手法や設定を試して、検索されたコンテンツの品質と効果を確認することが可能です。各ナレッジベースの分割方法には、それぞれ異なる検索テスト手法が対応しています。
+
+ ここで調整した検索設定は一時的なもので、現在のテストセッションにのみ適用されます。
+
-
-
- #### 一般モード
+
+ 検索設定の詳細については、[検索方法の指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#検索方法の指定) を参照してください。
+
- **「ソーステキスト」** 入力欄に一般的なユーザー質問を入力し、**「テスト」** ボタンをクリックすることで、リコール結果を右側の **「リコール段落」** で確認できます。
+**記録** セクションには、このナレッジベースに関連するすべての検索イベントが記録されます。これには以下が含まれます。
- 一般モードでは、各コンテンツは独立しており、右上に表示されるスコアは、そのコンテンツがキーワードとどれだけマッチしているかを示します。高いスコアは、質問のキーワードとコンテンツがより密接に一致していることを意味します。
+- **検索テスト** ページ上で直接実行したクエリ
+- リンクされたアプリからの検索要求(テスト運用中または本番環境を問わず)
- 
-
- コンテンツをクリックすると、詳しい情報を確認できます。各コンテンツの下には、その情報源が表示され、その内容が信頼できるかどうかを判断できます。
-
- 
-
-
-
- #### 親子分割モード
-
- **「ソーステキスト」** 入力欄に質問を入力し、**「テスト」** をクリックすると、右側の「検索結果段落」で結果を確認できます。親子分割モードでは、質問のキーワードが子コンテンツにヒットし、より精度の高い一致を得られます。右上のスコアは、子コンテンツとキーワード間の一致度を示します。
-
- プレビューエリアでは、具体的にヒットした段落の内容を確認できます。一致後、子コンテンツが属する親コンテンツの全文脈を検索し、AIアプリケーションに完全な情報を提供します。
-
- 
-
- 各コンテンツの下にある情報源を参照することで、引用された内容を確認できます。詳細ページでは、左側に親コンテンツ、右側にヒットした子コンテンツの情報が表示されます。キーワードは複数の子コンテンツにヒットする可能性があり、一致度スコアも表示されます。これに基づき、現在のコンテンツが適切かどうかを判断できます。
-
- 
-
-
-
-**「履歴」** では、過去の検索記録を確認できます。ナレッジベースがアプリケーションに関連付けられている場合、そのアプリケーションでの検索履歴もここで見ることができます。
-
-**検索方法の変更**
-
-ソーステキスト入力欄の右上にあるアイコンをクリックすると、現在のナレッジベースの検索方法と具体的なパラメータを変更することができます。変更後は、現在の検索テストのデバッグプロセス中にのみ適用されます。異なる検索手法の効果を比較したい場合は、「ナレッジベース設定」>「検索設定」で設定してください。
-
-**リコールテストの推奨手順:**
-
-1. ユーザーの一般的な質問をカバーするテストケースやガイドラインの内容を設計・整理します。
-2. コンテンツの特徴や使用シーン(QAコンテンツか、多言語QAを含むかなど)に基づいて、適切な検索戦略を選択します。異なる検索手法の長所と短所については、拡張読み取り[検索強化生成(RAG)](/learn-more/extended-reading/retrieval-augment/)を参照してください。
-3. 検索するコンテンツの数(TopK)と検索スコアの閾値(Score)を調整し、実際のアプリケーションシナリオや文書の品質を考慮して、適切なパラメータの組み合わせを選択します。
-
-**TopK値と検索閾値(Score)の設定方法**
-
-* **TopKは、類似スコアの降順で検索されるコンテンツの最大数を指します。** TopK値を小さくすると、関連性の高いテキストが不足する可能性があります;TopK値を大きくすると、意味的に関連性の低いコンテンツが検索される可能性があり、LLMの応答品質が低下するかもしれません。
-
-* **検索閾値(Score)は、検索されるコンテンツの最低類似スコアを指します。** 閾値を下げると、関連性の低いコンテンツが検索される可能性があります;閾値を高く設定すると、関連するコンテンツが見逃される可能性があります。
-
----
-
-### 2 引用と帰属
-
-アプリケーション内でナレッジベースの効果をテストする際、**スタジオ -- 機能追加 -- 引用と帰属**に進み、引用と帰属機能を有効にします。
-
-
-
-機能を有効にすると、大規模言語モデルが質問に回答する際にナレッジベースからの内容を引用した場合、返信内容の下に具体的な引用段落情報を確認できます。これには**元のパラグラフテキスト、パラグラフ番号、マッチ度**などが含まれます。引用段落上部の**ナレッジベースにジャンプ**をクリックすると、開発者がデバッグ編集を行いやすいように、そのパラグラフが含まれるナレッジベースのパラグラフリストに簡単にアクセスできます。
-
-
+
+ テスト検索と通常の検索は同じ API エンドポイントを使用します。
+
{/*
Contributing Section
diff --git a/ja-jp/guides/workflow/node/knowledge-retrieval.mdx b/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
index 667d5fc2..8062641a 100644
--- a/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
+++ b/ja-jp/guides/workflow/node/knowledge-retrieval.mdx
@@ -1,63 +1,133 @@
---
title: 知識検索
-version: '日本語'
---
-### 定義
+## はじめに
-ナレッジベースからユーザーの質問に関連するテキスト内容を検索し、それを下流のLLMノードのコンテキストとして使用することができます。
+知識検索ノードを使用すると、既存のナレッジベースを Chatflow や Workflow に統合できます。
-***
+このノードは指定されたナレッジからクエリに関連する情報を検索し、その結果を下流ノード(例:LLM)で利用できるコンテキスト情報として出力します。
-### シナリオ
+以下は Chatflow における 知識検索ノード の利用例です:
-一般的なシナリオ:外部データ/ナレッジに基づくAI質問応答システム(RAG)を構築。RAGの[基本概念](/ja-jp/learn-more/extended-reading/retrieval-augment/README)についてもっと知る。
+1. **ユーザー入力** ノードがユーザーの質問を収集します。
-下図は最も基本的なナレッジベース質問応答アプリケーションの例です。このプロセスの実行ロジックは、ユーザーの質問がLLMノードに渡される前に、ナレッジ検索ノードでユーザーの質問に最も関連するテキスト内容を検索し、召喚することです。その後、LLMノード内でユーザーの質問と検索されたコンテキストを一緒に入力し、LLMが検索内容に基づいて質問に答えるようにします。
+2. **知識検索** ノードが選択されたナレッジベースから関連情報を検索し、結果を出力します。
-
-  -
+3. **LLM** ノードがユーザー質問と検索結果の両方をもとに回答を生成します。
-***
+4. **回答** ノードが LLM の出力をユーザーへ返します。
-### 設定方法
+
-**設定プロセス:**
+
+ 知識検索ノードを使用する前に、少なくとも1つの利用可能なナレッジベースが存在することを確認してください。
-1. クエリ変数を選択し、ナレッジベース内の関連するテキストセグメントを検索するための入力として使用します。一般的な対話型アプリケーションでは、開始ノードの`sys.query`をクエリ変数として使用します。ナレッジ ベースが受け入れることができる最大クエリ コンテンツは 200 文字です。
-2. 検索するナレッジベースを選択します。オプションとして選択可能なナレッジベースは、Difyナレッジベース内で事前に[作成](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)する必要があります。
-3. [リコールモード](/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval)と[ナレッジベース設定](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)を設定します。
-4. 下流ノードを接続し設定します。一般的にはLLMノードです。
+ ナレッジベースの作成方法については、[ナレッジ](/ja-jp/guides/knowledge-base/readme#ナレッジの作成) を参照してください。
+
-
-
-
+3. **LLM** ノードがユーザー質問と検索結果の両方をもとに回答を生成します。
-***
+4. **回答** ノードが LLM の出力をユーザーへ返します。
-### 設定方法
+
-**設定プロセス:**
+
+ 知識検索ノードを使用する前に、少なくとも1つの利用可能なナレッジベースが存在することを確認してください。
-1. クエリ変数を選択し、ナレッジベース内の関連するテキストセグメントを検索するための入力として使用します。一般的な対話型アプリケーションでは、開始ノードの`sys.query`をクエリ変数として使用します。ナレッジ ベースが受け入れることができる最大クエリ コンテンツは 200 文字です。
-2. 検索するナレッジベースを選択します。オプションとして選択可能なナレッジベースは、Difyナレッジベース内で事前に[作成](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/chunking-and-cleaning-text)する必要があります。
-3. [リコールモード](/ja-jp/learn-more/extended-reading/retrieval-augment/retrieval)と[ナレッジベース設定](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)を設定します。
-4. 下流ノードを接続し設定します。一般的にはLLMノードです。
+ ナレッジベースの作成方法については、[ナレッジ](/ja-jp/guides/knowledge-base/readme#ナレッジの作成) を参照してください。
+
-
-  -
+## 知識検索ノードの設定
-**出力変数**
+知識検索ノードを正常に機能させるには、次の3点を指定する必要があります:
-
-
-
+## 知識検索ノードの設定
-**出力変数**
+知識検索ノードを正常に機能させるには、次の3点を指定する必要があります:
-
-  -
+- **何を検索するか**(クエリ)
+- **どこを検索するか**(ナレッジベース)
+- **どのように検索結果を処理するか**(ノードレベルの検索設定)
-ナレッジ検索の出力変数`result`は、ナレッジベースから検索された関連テキストセグメントです。この変数のデータ構造には、セグメント内容、タイトル、リンク、アイコン、メタデータ情報が含まれています。
+また、ドキュメントのメタデータを利用してフィルタベースの検索を有効化し、検索精度をさらに向上させることもできます。
-**下流ノードの設定**
+### クエリの指定
-一般的な対話型アプリケーションでは、ナレッジベース検索の下流ノードは通常LLMノードであり、ナレッジ検索の**出力変数**`result`はLLMノード内の**コンテキスト変数**に関連付けられて設定されます。関連付け後、プロンプトの適切な位置に**コンテキスト変数**を挿入することができます。
+ノードが選択されたナレッジベースで検索する対象を指定します。
+
+- **クエリテキスト**:テキスト変数を選択します。たとえば、Chatflow では `userinput.query`(ユーザー入力ノードの入力)を指定できます。Workflow ではテキスト型のユーザー入力変数を利用します。
+
+- **クエリ画像**:画像変数を指定して画像検索を行います。ユーザーがアップロードした画像などを使用できます。最大サイズは 10 MB です。
+
+
+ 自己ホスティング環境では、環境変数 `UPLOAD_IMAGE_FILE_SIZE_LIMIT` を変更することで画像サイズ上限を調整できます(デフォルト値:10)。
+
+
+
+ **クエリ画像** は、画像検索対応のナレッジベースが少なくとも1つ存在する場合にのみ利用可能です。
+
+ 対応ナレッジベースは「**Vision**」アイコンで表示され、画像埋め込みに対応した埋め込みモデルを使用しています。
+
+
+### 検索対象ナレッジベースの選択
+
+ノードで検索対象とするナレッジベースを1つ以上追加します。
+
+
+ **Vision** アイコンが付いたナレッジベースは **画像検索** に対応しており、テキストおよび/または画像をクエリとして使用できます。これにより、意味的に関連するテキストと画像の両方を検索・取得することが可能です。
+
+
+
+ ノード内で任意のナレッジベースの **編集** アイコンをクリックすると、直接その設定を変更できます。
+
+ 設定項目の詳細は [ナレッジ設定の管理](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme) および [インデックス方法と検索設定を指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods) を参照してください。
+
+
+### ノードレベルの検索設定
+
+ナレッジベースから取得した検索結果を、ノード内でどのように絞り込み・再ランク付けするかを調整できます。
+
+
+ 検索設定には2つのレイヤー(階層)があります。
+
+ ナレッジベースレベルの設定が最初の検索プールを決定し、ノードレベルの設定がその結果を再スコアリングまたは絞り込みします。
+
+
+- **Rerank 設定**
+
+ - **ウェイト設定**: 再ランク付け時におけるセマンティック類似度(意味の近さ)とキーワード一致の比重を調整します。セマンティックの比重を高くすると意味的関連性を重視し、キーワードの比重を高くすると正確な一致を重視します。
+
+
+ **ウェイト設定** は、追加したナレッジベースがすべて「高品質」タイプである場合に利用できます。
+
+
+ - **Rerank モデル**: クエリとの関連度に基づいてすべての検索結果を再スコアリング・並べ替えします。
+
+- **トップ K**: 再ランク後に返す最大件数を指定します。 Rerank モデルを選択している場合、この値はモデルが処理可能な最大入力サイズ(トークン上限)に応じて自動的に調整されます。
+
+- **スコア閾値**: 結果を返す際の最低スコア(類似度)を指定します。この閾値未満の結果は除外されます。高めに設定すると関連性の厳密な検索が行われ、低めにするとより広範なマッチを含めることができます。
+
+
+ 複数のナレッジベースを追加した場合、まずそれぞれから同時に検索を行い、結果を統合して上記設定に基づいて再ランク付けが行われます。
+
+
+### メタデータフィルタの有効化
+
+ナレッジベース内のドキュメントメタデータを利用して、特定の条件に合致するドキュメントのみを検索対象とすることができます。これにより、大規模または多様なナレッジベース内での検索精度が向上します。
+
+
+ ドキュメントメタデータの作成と管理については、[メタデータ](/ja-jp/guides/knowledge-base/metadata) を参照してください。
+
+
+## 出力
+
+知識検索ノードの出力は `result` という変数として返されます。この変数は検索されたドキュメントチャンクの配列で、各チャンクには内容・メタデータ・タイトルなどの情報が含まれます。
+
+画像検索が有効で、関連する画像が取得された場合、`result` 変数には `files` フィールドが追加され、取得された画像情報が格納されます。
+
+![知識検索ノードの出力]()
+
+## LLM ノードとの連携
+
+検索結果を活用して LLM ノードで質問応答を行うには:
+
+1. **コンテキスト** フィールドで、知識検索ノードの `result` 変数を選択します。
+
+2. プロンプト入力欄で、`コンテキスト` 変数とユーザー入力変数(例:Chatflow の `userinput.query`)の両方を参照します。
+
+
-
+- **何を検索するか**(クエリ)
+- **どこを検索するか**(ナレッジベース)
+- **どのように検索結果を処理するか**(ノードレベルの検索設定)
-ナレッジ検索の出力変数`result`は、ナレッジベースから検索された関連テキストセグメントです。この変数のデータ構造には、セグメント内容、タイトル、リンク、アイコン、メタデータ情報が含まれています。
+また、ドキュメントのメタデータを利用してフィルタベースの検索を有効化し、検索精度をさらに向上させることもできます。
-**下流ノードの設定**
+### クエリの指定
-一般的な対話型アプリケーションでは、ナレッジベース検索の下流ノードは通常LLMノードであり、ナレッジ検索の**出力変数**`result`はLLMノード内の**コンテキスト変数**に関連付けられて設定されます。関連付け後、プロンプトの適切な位置に**コンテキスト変数**を挿入することができます。
+ノードが選択されたナレッジベースで検索する対象を指定します。
+
+- **クエリテキスト**:テキスト変数を選択します。たとえば、Chatflow では `userinput.query`(ユーザー入力ノードの入力)を指定できます。Workflow ではテキスト型のユーザー入力変数を利用します。
+
+- **クエリ画像**:画像変数を指定して画像検索を行います。ユーザーがアップロードした画像などを使用できます。最大サイズは 10 MB です。
+
+
+ 自己ホスティング環境では、環境変数 `UPLOAD_IMAGE_FILE_SIZE_LIMIT` を変更することで画像サイズ上限を調整できます(デフォルト値:10)。
+
+
+
+ **クエリ画像** は、画像検索対応のナレッジベースが少なくとも1つ存在する場合にのみ利用可能です。
+
+ 対応ナレッジベースは「**Vision**」アイコンで表示され、画像埋め込みに対応した埋め込みモデルを使用しています。
+
+
+### 検索対象ナレッジベースの選択
+
+ノードで検索対象とするナレッジベースを1つ以上追加します。
+
+
+ **Vision** アイコンが付いたナレッジベースは **画像検索** に対応しており、テキストおよび/または画像をクエリとして使用できます。これにより、意味的に関連するテキストと画像の両方を検索・取得することが可能です。
+
+
+
+ ノード内で任意のナレッジベースの **編集** アイコンをクリックすると、直接その設定を変更できます。
+
+ 設定項目の詳細は [ナレッジ設定の管理](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/readme) および [インデックス方法と検索設定を指定](/ja-jp/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods) を参照してください。
+
+
+### ノードレベルの検索設定
+
+ナレッジベースから取得した検索結果を、ノード内でどのように絞り込み・再ランク付けするかを調整できます。
+
+
+ 検索設定には2つのレイヤー(階層)があります。
+
+ ナレッジベースレベルの設定が最初の検索プールを決定し、ノードレベルの設定がその結果を再スコアリングまたは絞り込みします。
+
+
+- **Rerank 設定**
+
+ - **ウェイト設定**: 再ランク付け時におけるセマンティック類似度(意味の近さ)とキーワード一致の比重を調整します。セマンティックの比重を高くすると意味的関連性を重視し、キーワードの比重を高くすると正確な一致を重視します。
+
+
+ **ウェイト設定** は、追加したナレッジベースがすべて「高品質」タイプである場合に利用できます。
+
+
+ - **Rerank モデル**: クエリとの関連度に基づいてすべての検索結果を再スコアリング・並べ替えします。
+
+- **トップ K**: 再ランク後に返す最大件数を指定します。 Rerank モデルを選択している場合、この値はモデルが処理可能な最大入力サイズ(トークン上限)に応じて自動的に調整されます。
+
+- **スコア閾値**: 結果を返す際の最低スコア(類似度)を指定します。この閾値未満の結果は除外されます。高めに設定すると関連性の厳密な検索が行われ、低めにするとより広範なマッチを含めることができます。
+
+
+ 複数のナレッジベースを追加した場合、まずそれぞれから同時に検索を行い、結果を統合して上記設定に基づいて再ランク付けが行われます。
+
+
+### メタデータフィルタの有効化
+
+ナレッジベース内のドキュメントメタデータを利用して、特定の条件に合致するドキュメントのみを検索対象とすることができます。これにより、大規模または多様なナレッジベース内での検索精度が向上します。
+
+
+ ドキュメントメタデータの作成と管理については、[メタデータ](/ja-jp/guides/knowledge-base/metadata) を参照してください。
+
+
+## 出力
+
+知識検索ノードの出力は `result` という変数として返されます。この変数は検索されたドキュメントチャンクの配列で、各チャンクには内容・メタデータ・タイトルなどの情報が含まれます。
+
+画像検索が有効で、関連する画像が取得された場合、`result` 変数には `files` フィールドが追加され、取得された画像情報が格納されます。
+
+![知識検索ノードの出力]()
+
+## LLM ノードとの連携
+
+検索結果を活用して LLM ノードで質問応答を行うには:
+
+1. **コンテキスト** フィールドで、知識検索ノードの `result` 変数を選択します。
+
+2. プロンプト入力欄で、`コンテキスト` 変数とユーザー入力変数(例:Chatflow の `userinput.query`)の両方を参照します。
+
+ -コンテキスト変数は、LLMノード内で定義された特殊な変数タイプで、プロンプト内に外部検索されたテキスト内容を挿入するために使用されます。
+ 知識検索の呼び出しには、契約プランに応じたリクエスト上限(レートリミット)が適用されます。
+
+ 詳細は [ナレッジベースの要求頻度制限](/ja-jp/guides/knowledge-base/knowledge-request-rate-limit) を参照してください。
-ユーザーが質問すると、関連するテキストがナレッジ検索で召喚された場合、そのテキスト内容がコンテキスト変数の値としてプロンプトに挿入され、LLMが質問に答えます。関連するテキストが検索されなかった場合、コンテキスト変数の値は空となり、LLMは直接ユーザーの質問に答えます。
-
-
-
-コンテキスト変数は、LLMノード内で定義された特殊な変数タイプで、プロンプト内に外部検索されたテキスト内容を挿入するために使用されます。
+ 知識検索の呼び出しには、契約プランに応じたリクエスト上限(レートリミット)が適用されます。
+
+ 詳細は [ナレッジベースの要求頻度制限](/ja-jp/guides/knowledge-base/knowledge-request-rate-limit) を参照してください。
-ユーザーが質問すると、関連するテキストがナレッジ検索で召喚された場合、そのテキスト内容がコンテキスト変数の値としてプロンプトに挿入され、LLMが質問に答えます。関連するテキストが検索されなかった場合、コンテキスト変数の値は空となり、LLMは直接ユーザーの質問に答えます。
-
-
-  -
-
-この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](/ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属)機能もサポートします。
-
{/*
Contributing Section
DO NOT edit this section!
diff --git a/ja-jp/guides/workflow/node/llm.mdx b/ja-jp/guides/workflow/node/llm.mdx
index a9b110da..24dc914d 100644
--- a/ja-jp/guides/workflow/node/llm.mdx
+++ b/ja-jp/guides/workflow/node/llm.mdx
@@ -344,7 +344,7 @@ LLMノードの出力変数をクリックし、構造化スイッチの設定
.png)
-[知識検索ノード](knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](../ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属) 機能を使用して情報の出所を確認できます。
+[知識検索ノード](/ja-jp/guides/workflow/node/knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](/ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属) 機能を使用して情報の出所を確認できます。
通常のノードの変数もコンテキスト変数に入力可能ですが、例えば開始ノードの文字列型変数など、**引用と帰属** 機能は機能しません。
@@ -360,8 +360,6 @@ LLMノードの出力変数をクリックし、構造化スイッチの設定
さらなる情報は、[ファイルアップロード](../file-upload)を参照してください。
-.png)
-
* **エラー処理**
情報処理中に、LLMノードでは入力テキストがトークンの制限を超えたり、必要なパラメータが欠けているなどのエラーに遭遇することがあります。開発者は以下の手順に従い、エラー処理の枝を設定してノードエラーが発生した際の対処方針を構築することで、フローの中断を避けることができます:
diff --git a/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx b/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
index 480ec78e..bae13093 100644
--- a/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
+++ b/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
@@ -2,7 +2,7 @@
title: 上传本地文件
---
-点击 Dify 平台顶部导航中 **知识库** > **创建知识库** > **导入已有文本**。
+点击 Dify 平台顶部导航中的 **知识库** > **创建知识库** > **导入已有文本**。
拖拽或选中文件进行上传,**支持批量上传**,同时上传的文件数量限制取决于[订阅计划](https://dify.ai/pricing)。
diff --git a/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx b/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
index f92ce066..0c23aeb3 100644
--- a/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
+++ b/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
@@ -26,14 +26,14 @@ title: 指定索引方式与检索设置
这些向量可理解为多维空间中的坐标点——两个点越接近,它们的语义越相似。这使得系统能够基于语义相似度(而不仅仅是关键词匹配)找到相关信息。
- 快速创建的知识库无法选择支持图片向量化的嵌入模型(带有 **图片** 图标),因此不支持图片检索。
+ 快速创建的知识库无法选择支持图片向量化的嵌入模型(带有 **Vision** 图标),因此不支持图片检索。
不过,你可以轻松将快速创建的知识库转换为流水线创建的知识库,从而启用该功能。
- 对内容进行分段和嵌入后,可通过三种检索策略进行检索:向量检索、全文检索或混合检索。详见 [指定检索方式](#指定检索方式)。
+ 对内容进行分段和向量化后,可通过三种检索策略进行检索:向量检索、全文检索或混合检索。详见 [指定检索方式](#指定检索方式)。
**启用 Q\&A 模式(可选,仅适用于[社区版](/zh-hans/getting-started/install-self-hosted/faq))**
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
index b535b7e8..5ee48d17 100644
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
@@ -7,13 +7,13 @@ sidebarTitle: 调整设置
只有工作区所有者、管理员和编辑者可修改知识库设置。
-在知识库中,点击左侧边栏的 **设置** 图标即可进入设置页。
+在知识库中,点击左侧边栏的 **设置** 图标,进入设置页。
| 设置项 | 说明 |
|:----------------------- |:---------------------|
-| 名称和图标 | 用于标识知识库的名称和图标。|
-| 描述 | 简要说明知识库的用途和内容。|
-| 权限 | 定义哪些工作区成员可访问该知识库。被授予访问权限的成员将拥有 [维护知识库内容](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents) 中列出的全部权限。|
+| 名称和图标 | 标识知识库。|
+| 描述 | 简要说明知识库的用途和内容。|
+| 权限 | 定义哪些工作区成员可访问该知识库。被授予访问权限的成员将拥有 [维护知识库内容](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents) 中列出的全部权限。|
| 索引方式 | 决定文档分段的处理和组织方式。详见 [选择索引方式](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#选择索引方式)。|
| 嵌入模型 | 选择用于将文档分段转化为向量的嵌入模型。更换嵌入模型将对所有分段进行重新嵌入、重建向量索引,并删除原有向量。|
| 检索设置 | 决定知识库如何检索相关内容。详见 [指定检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#指定检索设置)。|
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
index 48ab77fa..9ebe4f09 100644
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
@@ -15,7 +15,7 @@ sidebarTitle: 维护内容
| 操作 | 说明 |
|:------------------- |:---------------------|
| 添加 | 导入新文档。|
-| 修改分段设置 | 修改文档的分段设置(不包括分段模式)。
-
-
-この変数は、LLMが質問に答える際のプロンプトコンテキストとして外部ナレッジの参照に使用されるだけでなく、そのデータ構造にセグメントの引用情報が含まれているため、アプリケーション側の[**引用と帰属**](/ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属)機能もサポートします。
-
{/*
Contributing Section
DO NOT edit this section!
diff --git a/ja-jp/guides/workflow/node/llm.mdx b/ja-jp/guides/workflow/node/llm.mdx
index a9b110da..24dc914d 100644
--- a/ja-jp/guides/workflow/node/llm.mdx
+++ b/ja-jp/guides/workflow/node/llm.mdx
@@ -344,7 +344,7 @@ LLMノードの出力変数をクリックし、構造化スイッチの設定
.png)
-[知識検索ノード](knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](../ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属) 機能を使用して情報の出所を確認できます。
+[知識検索ノード](/ja-jp/guides/workflow/node/knowledge-retrieval) の出力変数 `result` には引用情報も含まれており、[**引用と帰属**](/ja-jp/guides/application-orchestrate/app-toolkits/README#引用と帰属) 機能を使用して情報の出所を確認できます。
通常のノードの変数もコンテキスト変数に入力可能ですが、例えば開始ノードの文字列型変数など、**引用と帰属** 機能は機能しません。
@@ -360,8 +360,6 @@ LLMノードの出力変数をクリックし、構造化スイッチの設定
さらなる情報は、[ファイルアップロード](../file-upload)を参照してください。
-.png)
-
* **エラー処理**
情報処理中に、LLMノードでは入力テキストがトークンの制限を超えたり、必要なパラメータが欠けているなどのエラーに遭遇することがあります。開発者は以下の手順に従い、エラー処理の枝を設定してノードエラーが発生した際の対処方針を構築することで、フローの中断を避けることができます:
diff --git a/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx b/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
index 480ec78e..bae13093 100644
--- a/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
+++ b/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/import-content-data/readme.mdx
@@ -2,7 +2,7 @@
title: 上传本地文件
---
-点击 Dify 平台顶部导航中 **知识库** > **创建知识库** > **导入已有文本**。
+点击 Dify 平台顶部导航中的 **知识库** > **创建知识库** > **导入已有文本**。
拖拽或选中文件进行上传,**支持批量上传**,同时上传的文件数量限制取决于[订阅计划](https://dify.ai/pricing)。
diff --git a/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx b/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
index f92ce066..0c23aeb3 100644
--- a/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
+++ b/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods.mdx
@@ -26,14 +26,14 @@ title: 指定索引方式与检索设置
这些向量可理解为多维空间中的坐标点——两个点越接近,它们的语义越相似。这使得系统能够基于语义相似度(而不仅仅是关键词匹配)找到相关信息。
- 快速创建的知识库无法选择支持图片向量化的嵌入模型(带有 **图片** 图标),因此不支持图片检索。
+ 快速创建的知识库无法选择支持图片向量化的嵌入模型(带有 **Vision** 图标),因此不支持图片检索。
不过,你可以轻松将快速创建的知识库转换为流水线创建的知识库,从而启用该功能。
- 对内容进行分段和嵌入后,可通过三种检索策略进行检索:向量检索、全文检索或混合检索。详见 [指定检索方式](#指定检索方式)。
+ 对内容进行分段和向量化后,可通过三种检索策略进行检索:向量检索、全文检索或混合检索。详见 [指定检索方式](#指定检索方式)。
**启用 Q\&A 模式(可选,仅适用于[社区版](/zh-hans/getting-started/install-self-hosted/faq))**
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
index b535b7e8..5ee48d17 100644
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/introduction.mdx
@@ -7,13 +7,13 @@ sidebarTitle: 调整设置
只有工作区所有者、管理员和编辑者可修改知识库设置。
-在知识库中,点击左侧边栏的 **设置** 图标即可进入设置页。
+在知识库中,点击左侧边栏的 **设置** 图标,进入设置页。
| 设置项 | 说明 |
|:----------------------- |:---------------------|
-| 名称和图标 | 用于标识知识库的名称和图标。|
-| 描述 | 简要说明知识库的用途和内容。|
-| 权限 | 定义哪些工作区成员可访问该知识库。被授予访问权限的成员将拥有 [维护知识库内容](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents) 中列出的全部权限。|
+| 名称和图标 | 标识知识库。|
+| 描述 | 简要说明知识库的用途和内容。|
+| 权限 | 定义哪些工作区成员可访问该知识库。被授予访问权限的成员将拥有 [维护知识库内容](/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents) 中列出的全部权限。|
| 索引方式 | 决定文档分段的处理和组织方式。详见 [选择索引方式](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#选择索引方式)。|
| 嵌入模型 | 选择用于将文档分段转化为向量的嵌入模型。更换嵌入模型将对所有分段进行重新嵌入、重建向量索引,并删除原有向量。|
| 检索设置 | 决定知识库如何检索相关内容。详见 [指定检索设置](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#指定检索设置)。|
diff --git a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
index 48ab77fa..9ebe4f09 100644
--- a/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-knowledge-documents.mdx
@@ -15,7 +15,7 @@ sidebarTitle: 维护内容
| 操作 | 说明 |
|:------------------- |:---------------------|
| 添加 | 导入新文档。|
-| 修改分段设置 | 修改文档的分段设置(不包括分段模式)。
每个文档可拥有独立的分段设置,但分段模式在整个知识库中共享,且一旦设置无法更改。|
+| 修改分段设置 | 修改文档的分段设置(不包括分段结构)。每个文档可拥有独立的分段设置,但分段结构在整个知识库中共享,且一旦设置无法更改。|
| 删除 | 永久删除文档。**删除不可撤销**。|
| 启用 / 禁用 | 临时将文档纳入或排除检索。在 Dify Cloud 上,长时间未更新或未被检索的文档会自动禁用以优化性能。
不同订阅计划的未活跃时长如下:- Sandbox:7 天
- Professional & Team:30 天
Professional 和 Team 用户可一键重新启用这些文档。|
| 归档 / 取消归档 | 将不再需要检索但仍需保留的文档归档。归档文档为只读,可随时取消归档。|
@@ -39,13 +39,13 @@ sidebarTitle: 维护内容
| 启用 / 禁用 | 临时将分段纳入或排除检索。已禁用的分段不可编辑。|
| 编辑 | 修改分段内容。已编辑的分段将标记为 **已编辑**。
对于采用父子分段模式的文档:- 编辑父分段时,可选择重新生成其子分段或保持原有的子分段不变。
- 编辑子分段不会改变其父分段。
|
| 添加 / 编辑 / 删除关键词 | 在使用经济索引方式的知识库中,可为分段添加或修改关键词,以提升其可检索性。一个分段最多可添加 10 个关键词。|
-| 上传 / 删除图片 | 在启用图片检索的知识库中,可在对应分段中删除已导入的图片或上传新图片。为知识库选择支持图片向量化的嵌入模型(带有 **图片** 图标)即可启用图片检索。|
+| 上传 / 删除图片 | 在启用图片检索的知识库中,可在对应分段中删除已导入的图片或上传新图片。为知识库选择支持图片向量化的嵌入模型(带有 **Vision** 图标),即可启用图片检索。|
## 最佳实践
### 检查分段质量
-文档完成分段后,仔细检查每个分段,确保其语义完整、长度适中,以确保检索准确性和回复相关性。
+文档完成分段后,仔细检查每个分段,确保其语义完整、长度适中,以保证检索准确性和回复相关性。
常见问题包括:
diff --git a/zh-hans/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx b/zh-hans/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
index fe10976c..0e070039 100644
--- a/zh-hans/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-pipeline/knowledge-pipeline-orchestration.mdx
@@ -349,11 +349,11 @@ Unstructured 将文档转换为结构化的机器可读格式,具有高度可
- 若要启用图片检索,需选择支持图片向量化的嵌入模型(带有 **图片** 图标)。
+ 若要启用图片检索,需选择支持图片向量化的嵌入模型(带有 **Vision** 图标)。
采用此类嵌入模型的知识库,其卡片上将显示 **多模态** 图标。
- ![知识库卡片]()
+
diff --git a/zh-hans/guides/knowledge-base/test-retrieval.mdx b/zh-hans/guides/knowledge-base/test-retrieval.mdx
index 8f612773..b5bb4386 100644
--- a/zh-hans/guides/knowledge-base/test-retrieval.mdx
+++ b/zh-hans/guides/knowledge-base/test-retrieval.mdx
@@ -2,7 +2,7 @@
title: 测试召回效果
---
-在 **召回测试** 中,你可以模拟用户提问、测试知识库的召回效果,并尝试不同的检索设置以获得最佳结果。
+在知识库中,点击左侧边栏的 **召回测试** 图标,进入测试页面。在这里,你可以模拟用户提问、测试知识库的召回效果,并尝试不同的检索设置以获得最佳结果。
在召回测试中调整的检索设置,仅在当前测试会话中临时生效。
@@ -12,8 +12,6 @@ title: 测试召回效果
关于检索参数的更多说明,阅读 [指定检索方式](/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents/setting-indexing-methods#指定检索方式)。
-![召回测试]()
-
**记录** 板块记录与该知识库相关的所有检索事件,包括:
- 在 **召回测试** 页面进行的测试检索
diff --git a/zh-hans/guides/workflow/node/knowledge-retrieval.mdx b/zh-hans/guides/workflow/node/knowledge-retrieval.mdx
index 6edf06c3..220c4bbd 100644
--- a/zh-hans/guides/workflow/node/knowledge-retrieval.mdx
+++ b/zh-hans/guides/workflow/node/knowledge-retrieval.mdx
@@ -21,7 +21,13 @@ title: 知识检索
## 配置知识检索节点
-要使知识检索节点正常工作,你需要告诉它 *检索什么*(查询内容)、*在哪里检索*(知识库),以及 *如何处理检索结果*(节点级检索设置)。你还可以利用文档元数据实现基于筛选的检索,进一步提升检索精度。
+要使知识检索节点正常工作,你需要告诉它:
+
+- *检索什么*(查询内容)
+- *在哪里检索*(知识库)
+- *如何处理检索结果*(节点级检索设置)
+
+你还可以利用文档元数据实现基于筛选的检索,进一步提升检索精度。
### 指定查询内容
@@ -37,7 +43,7 @@ title: 知识检索
仅当至少有一个已添加的知识库支持图片检索时,才可使用 **图片查询**。
- 支持图片检索的知识库带有 **图片** 图标,表示其使用的嵌入模型支持图片向量化。
+ 支持图片检索的知识库带有 **Vision** 图标,表示其使用的嵌入模型支持图片向量化。
@@ -46,7 +52,7 @@ title: 知识检索
为节点添加一个或多个知识库,用于检索与查询内容相关的信息。
- 带有 **图片** 图标的知识库支持图片检索,可用文本和/或图片作为查询内容,同时检索语义相关的文本及图片。
+ 带有 **Vision** 图标的知识库支持图片检索,可用文本和/或图片作为查询内容,同时检索语义相关的文本及图片。