mirror of
https://github.com/langgenius/dify-docs.git
synced 2026-03-26 13:18:34 +07:00
Add Japanese and English versions of gpt-oss deployment doc.
This commit is contained in:
@@ -0,0 +1,130 @@
|
||||
---
|
||||
title: " gpt-oss Local Deployment with Ollama and Dify "
|
||||
---
|
||||
# I. Introduction
|
||||
|
||||
The gpt-oss series is an open-source model first released by OpenAI in August 2025.
|
||||
|
||||
> gpt-oss:20b (fits systems with ~16 GB memory)
|
||||
>
|
||||
> gpt-oss:120b (designed for ≥ 60 GB memory)
|
||||
|
||||
You can run it locally with Ollama. No cloud calls. Data stays on your machine, which helps with privacy and latency.
|
||||
|
||||
Dify is an open-source platform for building AI Agents and Workflows. This guide shows how to run gpt-oss with Ollama and plug it into Dify for a private, high-performance setup.
|
||||
|
||||
* * *
|
||||
|
||||
# II. Environment Setup
|
||||
|
||||
## Step 1: Run gpt-oss with Ollama
|
||||
|
||||
1. Install Ollama
|
||||
|
||||
|
||||
[Download](https://ollama.com/) and install for macOS, Windows, or Linux. If anything is unclear, see the [official docs](https://docs.dify.ai/en/development/models-integration/ollama#integrate-local-models-deployed-by-ollama).
|
||||
|
||||
|
||||
|
||||
2. Pull a model
|
||||
|
||||
|
||||
```Bash
|
||||
# Recommended for most dev machines
|
||||
ollama pull gpt-oss:20b
|
||||
|
||||
# For large GPUs or multi-GPU hosts
|
||||
ollama pull gpt-oss:120b
|
||||
```
|
||||
|
||||
Both models are pre‑quantized in **MXFP4** , suitable for local deployment.
|
||||
|
||||
|
||||
|
||||
3. Start Ollama
|
||||
|
||||
|
||||
The default endpoint is http://localhost:11434.
|
||||
|
||||
## Step 2: Install Dify locally
|
||||
|
||||
See the [Dify docs](https://docs.dify.ai/en/getting-started/install-self-hosted/readme) for full instructions. Or follow the quick tutorial below.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Install [Docker](https://www.docker.com/products/docker-desktop/) and make sure Docker Engine is running.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### Install steps
|
||||
|
||||
```Bash
|
||||
git clone https://github.com/langgenius/Dify.git
|
||||
cd Dify/docker
|
||||
cp .env.example .env
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
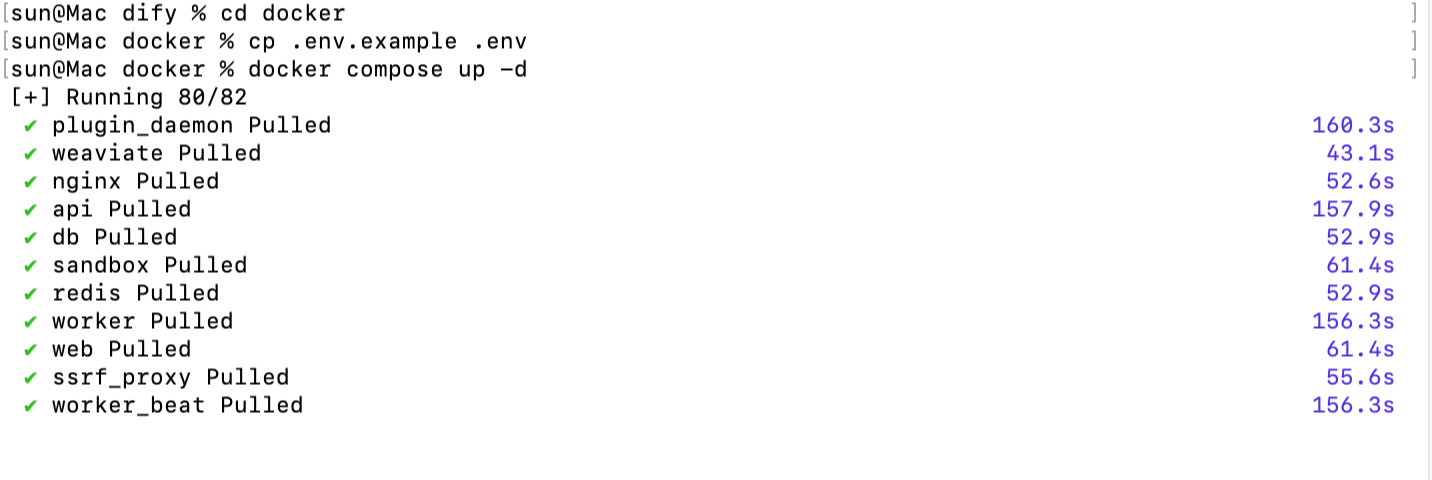
|
||||
|
||||
Open your local Dify instance and complete the initial setup.
|
||||
|
||||
|
||||
|
||||
# III. Add the model and test chat
|
||||
|
||||
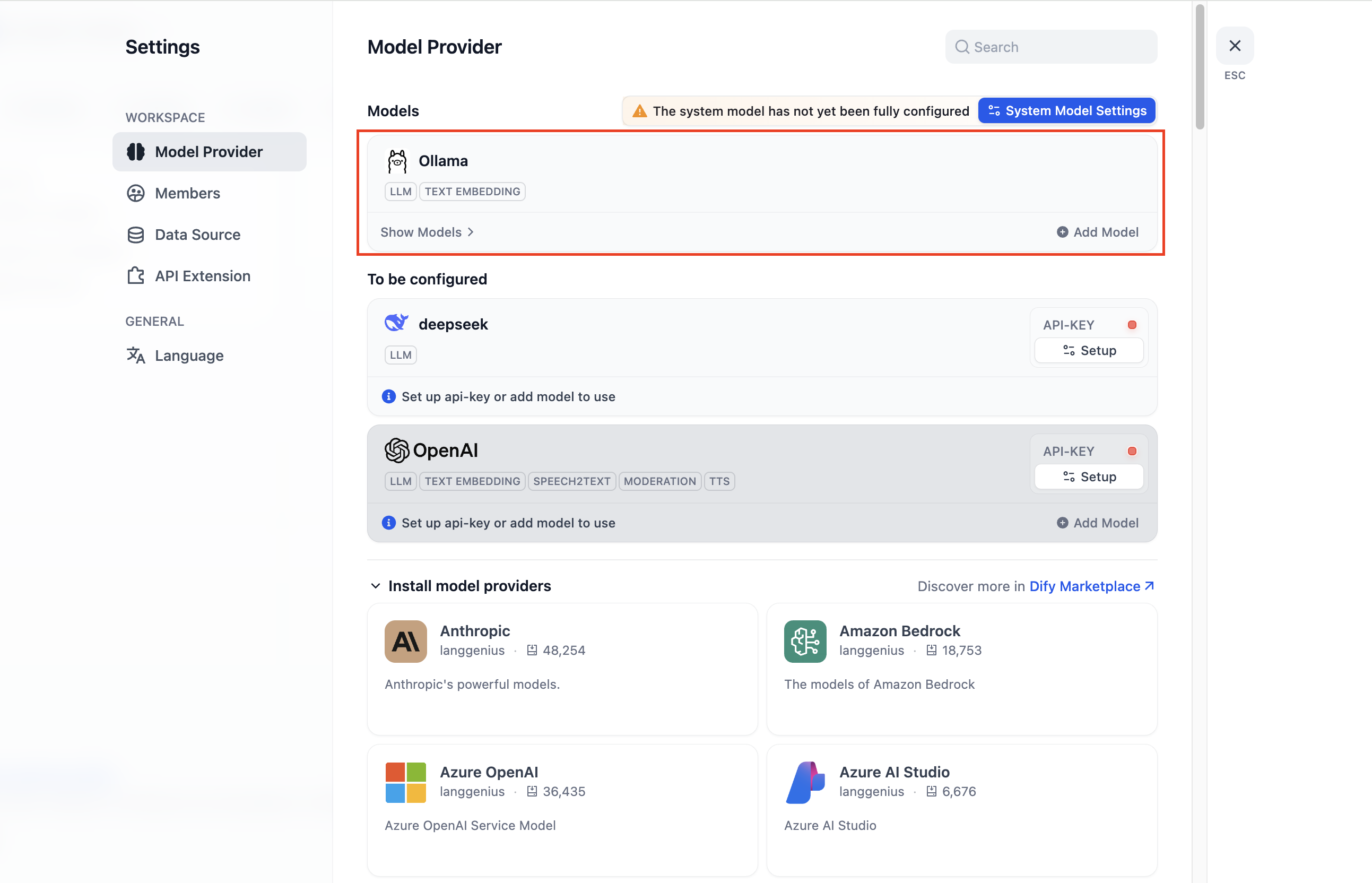
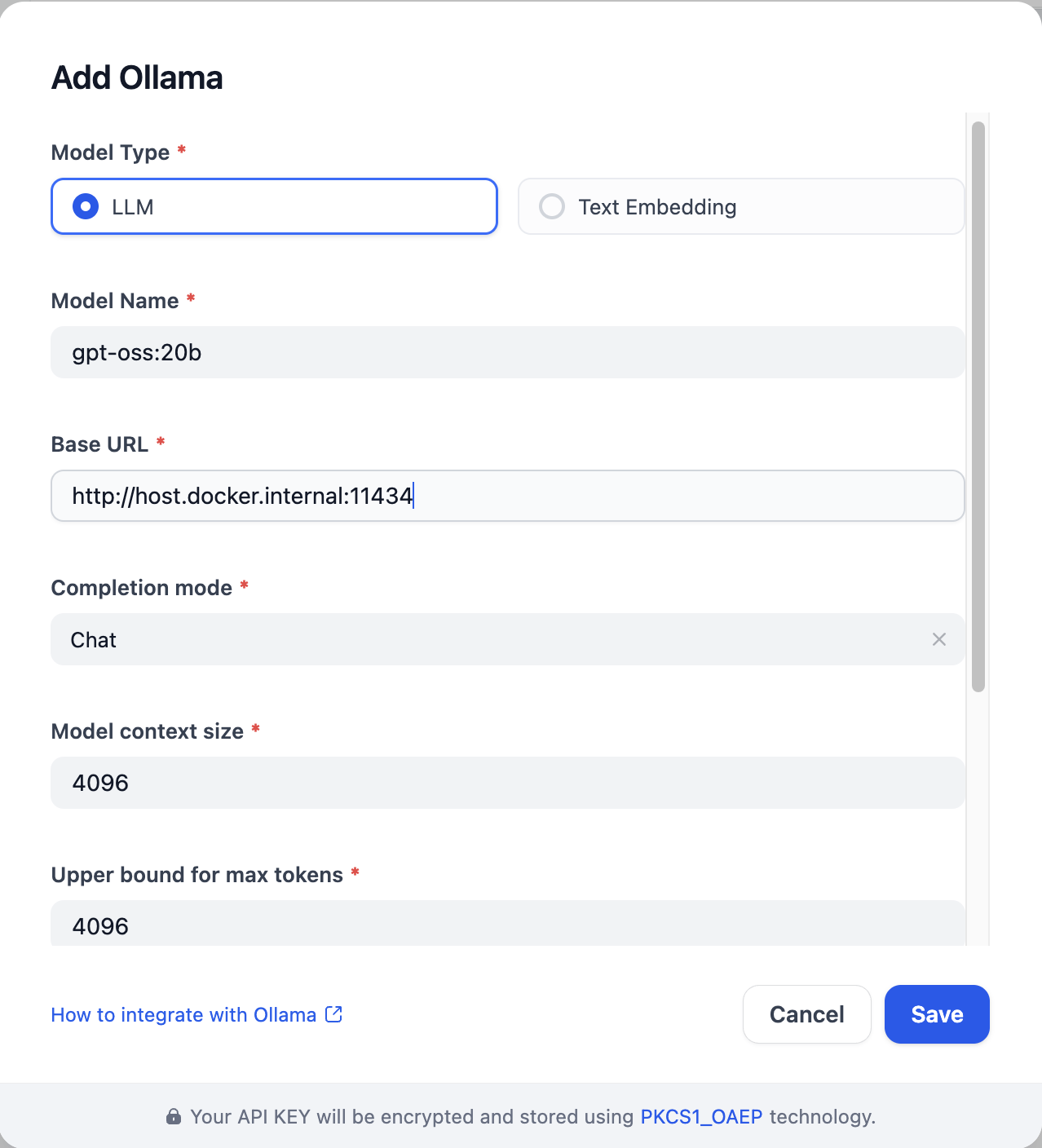
1. In **Settings → Model Providers → Ollama** , click **Add Ollama model type** .
|
||||
|
||||
|
||||
|
||||
|
||||
2. Set **Base URL** to `http://localhost:11434`, select **Model name** `gpt-oss:20b`, and fill in the required fields.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
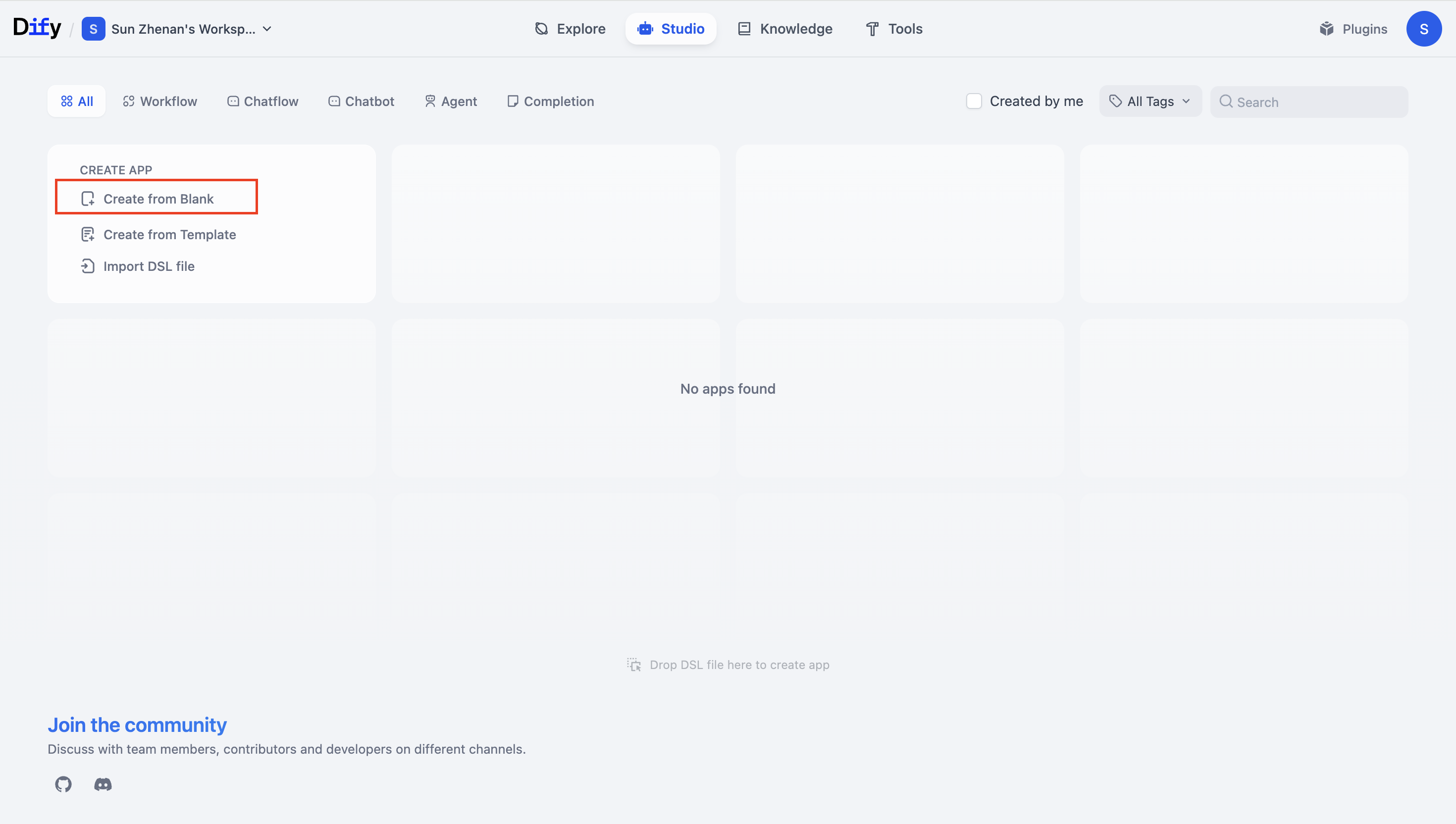
3. Create a blank template
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
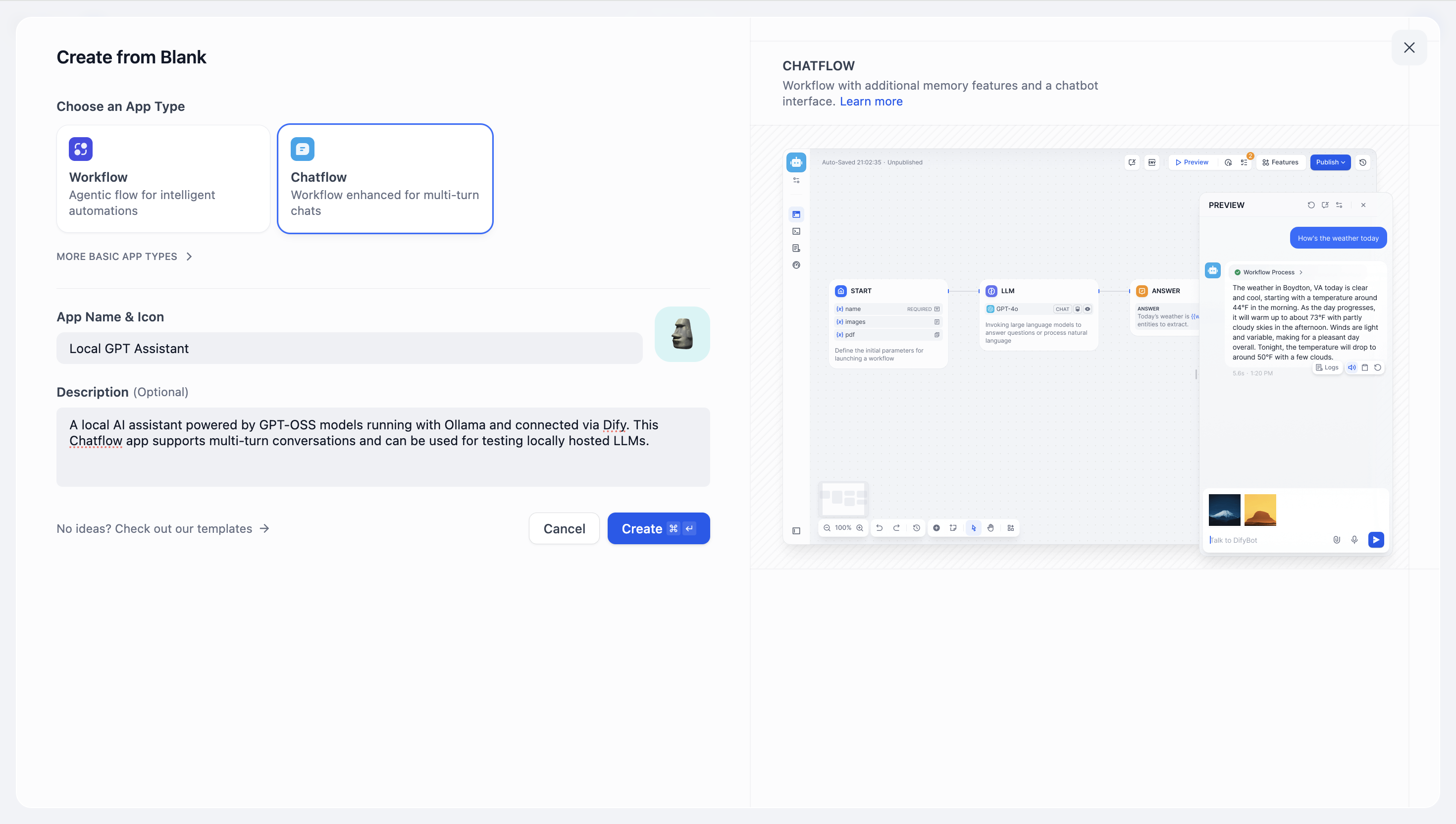
4. Select the app or workflow type you want to build.
|
||||
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
# IV. Verification and Usage
|
||||
|
||||
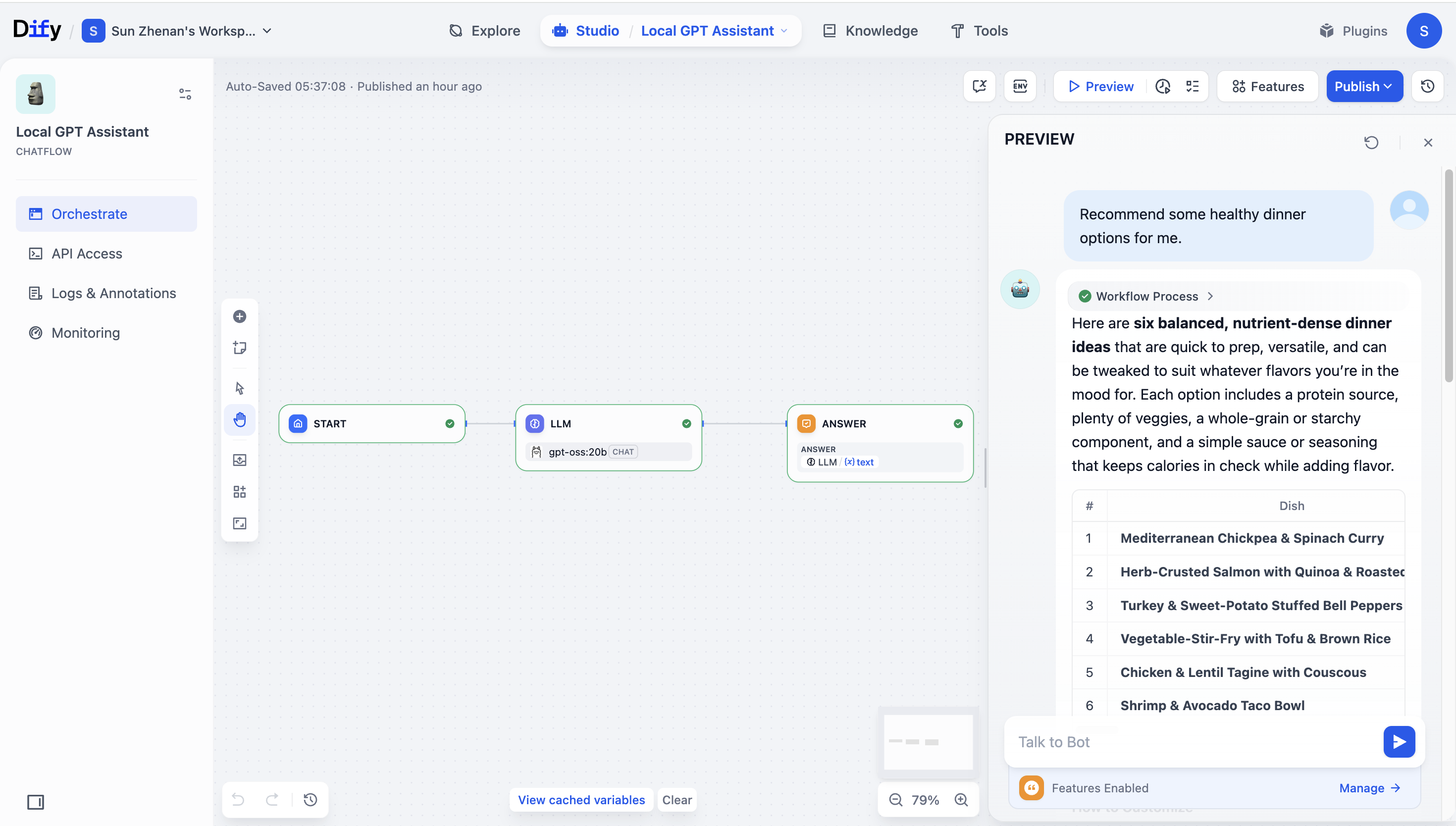
* On Dify’s **model testing** page, send a prompt and check that the response looks correct.
|
||||
|
||||
* In a workflow, add an **LLM** node, select `gpt-oss:20b`, and connect the nodes end to end.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
# V. Appendix — FAQ and tips
|
||||
|
||||
**Model Pull Is Slow**
|
||||
|
||||
* *Configure a Docker proxy or use an image mirror to speed up downloads.*
|
||||
|
||||
|
||||
**Insufficient GPU Memory**
|
||||
|
||||
* *Use* *`gpt-oss:20b`*. You can enable CPU offloading, but responses will be slower.*
|
||||
|
||||
**Port Access Issues**
|
||||
|
||||
* *Check firewall rules, port bindings, and Docker network settings to ensure connectivity.*
|
||||
Reference in New Issue
Block a user