diff --git a/docs.json b/docs.json
index c396510d..4bf68c5c 100644
--- a/docs.json
+++ b/docs.json
@@ -1336,7 +1336,7 @@
"group": "マニュアル",
"pages": [
{
- "group": "モデル",
+ "group": "モデルの設定",
"pages": [
"ja-jp/guides/model-configuration/README",
"ja-jp/guides/model-configuration/new-provider",
diff --git a/en/community/contribution.mdx b/en/community/contribution.mdx
index 55a3a037..4309428d 100644
--- a/en/community/contribution.mdx
+++ b/en/community/contribution.mdx
@@ -93,7 +93,9 @@ If you are adding a model provider,[this guide](https://github.com/langgenius/di
If you are adding tools used in Agent Assistants and Workflows, [this guide](https://github.com/langgenius/dify/blob/main/api/core/tools/README) is for you.
-> **Note** : If you want to contribute to a new tool, please make sure you've left your contact information on the tool's 'YAML' file, and submitted a corresponding docs PR in the [Dify-docs](https://github.com/langgenius/dify-docs/tree/main/en/guides/tools/tool-configuration) repository.
+
+**Note** : If you want to contribute to a new tool, please make sure you've left your contact information on the tool's 'YAML' file, and submitted a corresponding docs PR in the [Dify-docs](https://github.com/langgenius/dify-docs-mintlify) repository.
+
To help you quickly navigate where your contribution fits, a brief, annotated outline of Dify's backend & frontend is as follows:
diff --git a/en/getting-started/install-self-hosted/docker-compose.mdx b/en/getting-started/install-self-hosted/docker-compose.mdx
index 6ef75c35..0f7f9fc5 100644
--- a/en/getting-started/install-self-hosted/docker-compose.mdx
+++ b/en/getting-started/install-self-hosted/docker-compose.mdx
@@ -39,9 +39,6 @@ title: Deploy with Docker Compose
-> \[!IMPORTANT]
->
-> Dify 0.6.12 has introduced significant enhancements to Docker Compose deployment, designed to improve your setup and update experience. For more information, read the [README.md](https://github.com/langgenius/dify/blob/main/docker/README).
### Clone Dify
diff --git a/ja-jp/community/contribution.mdx b/ja-jp/community/contribution.mdx
index 80e3dfc4..920f822d 100644
--- a/ja-jp/community/contribution.mdx
+++ b/ja-jp/community/contribution.mdx
@@ -114,7 +114,9 @@ Difyはバックエンドとフロントエンドで構成されています。`
エージェントやワークフローにツールを追加提供する場合は、[このガイド](https://github.com/langgenius/dify/blob/main/api/core/tools/README)を参照してください。
-> 注意点:新しいツールを提供したい場合は、必ずツールの YAML 説明ページに連絡先を残し、ドキュメント[Dify-docs](https://github.com/langgenius/dify-docs/tree/main/en/guides/tools/tool-configuration) のコードリポジトリに対応するPRを提出してください。
+
+注意点:新しいツールを提供したい場合は、必ずツールの YAML 説明ページに連絡先を残し、ドキュメント[Dify-docs](https://github.com/langgenius/dify-docs-mintlify) のコードリポジトリに対応するPRを提出してください。
+
貢献する部分を迅速に理解できるように、以下にDifyのバックエンドとフロントエンドの簡単な注釈付きアウトラインを示します:
diff --git a/ja-jp/community/docs-contribution.mdx b/ja-jp/community/docs-contribution.mdx
index f836bc49..ad1cf39d 100644
--- a/ja-jp/community/docs-contribution.mdx
+++ b/ja-jp/community/docs-contribution.mdx
@@ -33,8 +33,9 @@ Dify のヘルプドキュメントは、[オープンソースプロジェク
git clone https://github.com//dify-docs.git
```
-> 注: GitHub のオンラインコードエディターを使用して、新しい md ファイルを適切なディレクトリに直接送信することもできます。
-
+
+注: GitHub のオンラインコードエディターを使用して、新しい md ファイルを適切なディレクトリに直接送信することもできます。
+
2. 関連するドキュメントディレクトリを見つけてファイルを追加する
たとえば、サードパーティツールの使用方法に関するドキュメントを追加したい場合は、`/guides/tools/tool-configuration/` ディレクトリに新しい md ファイルを追加してください。
diff --git a/ja-jp/development/models-integration/aws-bedrock-deepseek.mdx b/ja-jp/development/models-integration/aws-bedrock-deepseek.mdx
index f1267157..22bd43a4 100644
--- a/ja-jp/development/models-integration/aws-bedrock-deepseek.mdx
+++ b/ja-jp/development/models-integration/aws-bedrock-deepseek.mdx
@@ -30,7 +30,10 @@ title: AWS Bedrock からモデルを統合する
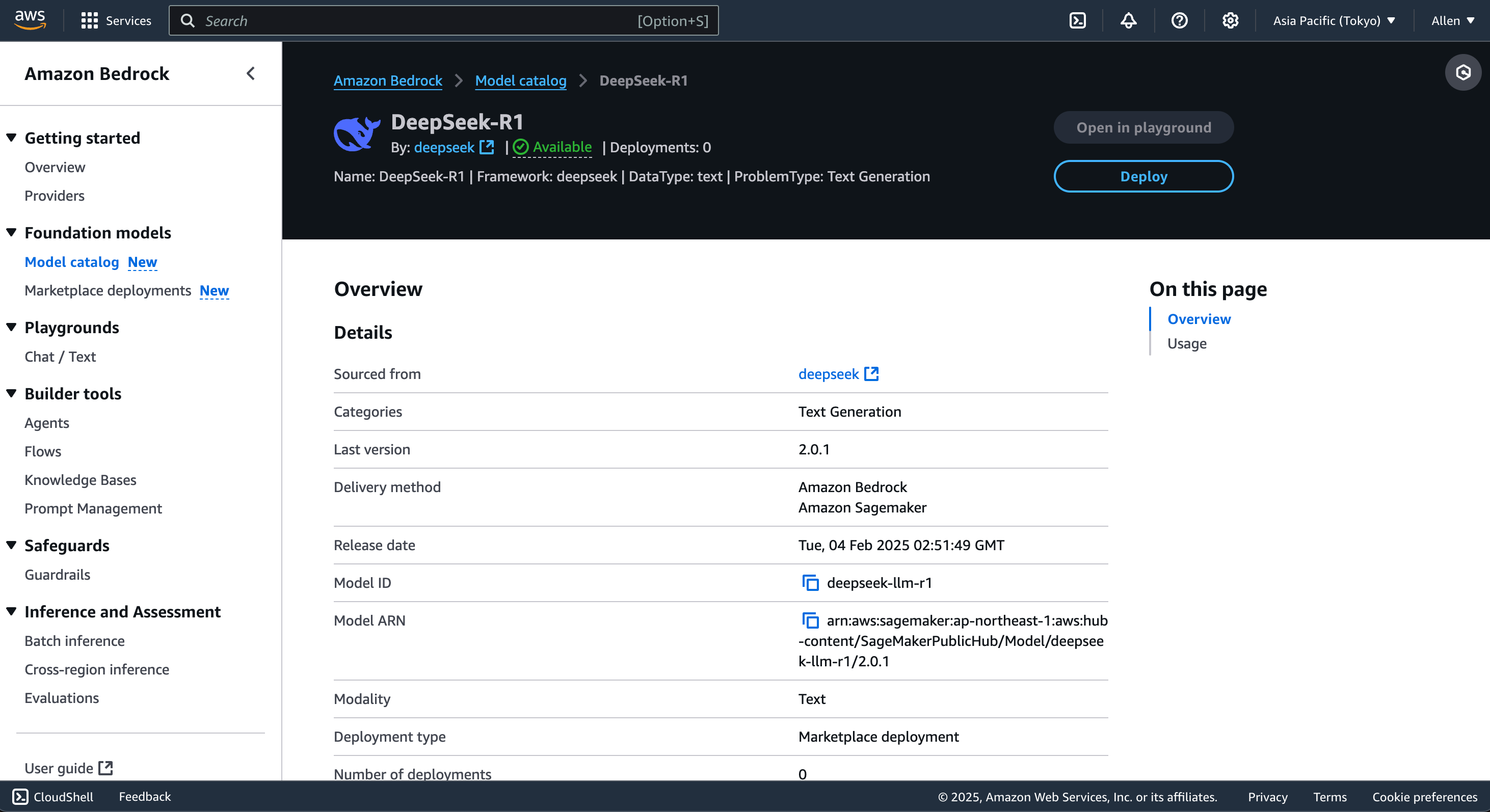
1. **モデル詳細** ページに移動し、**デプロイ** をクリックします。
2. デプロイ設定を構成するための指示に従います。
-> **注意:** モデルバージョンは異なるコンピューティング構成を必要とします。これはコストに影響します。
+
+**注意:**
+モデルバージョンは異なるコンピューティング構成を必要とします。これはコストに影響します。
+
@@ -68,8 +71,10 @@ title: AWS Bedrock からモデルを統合する
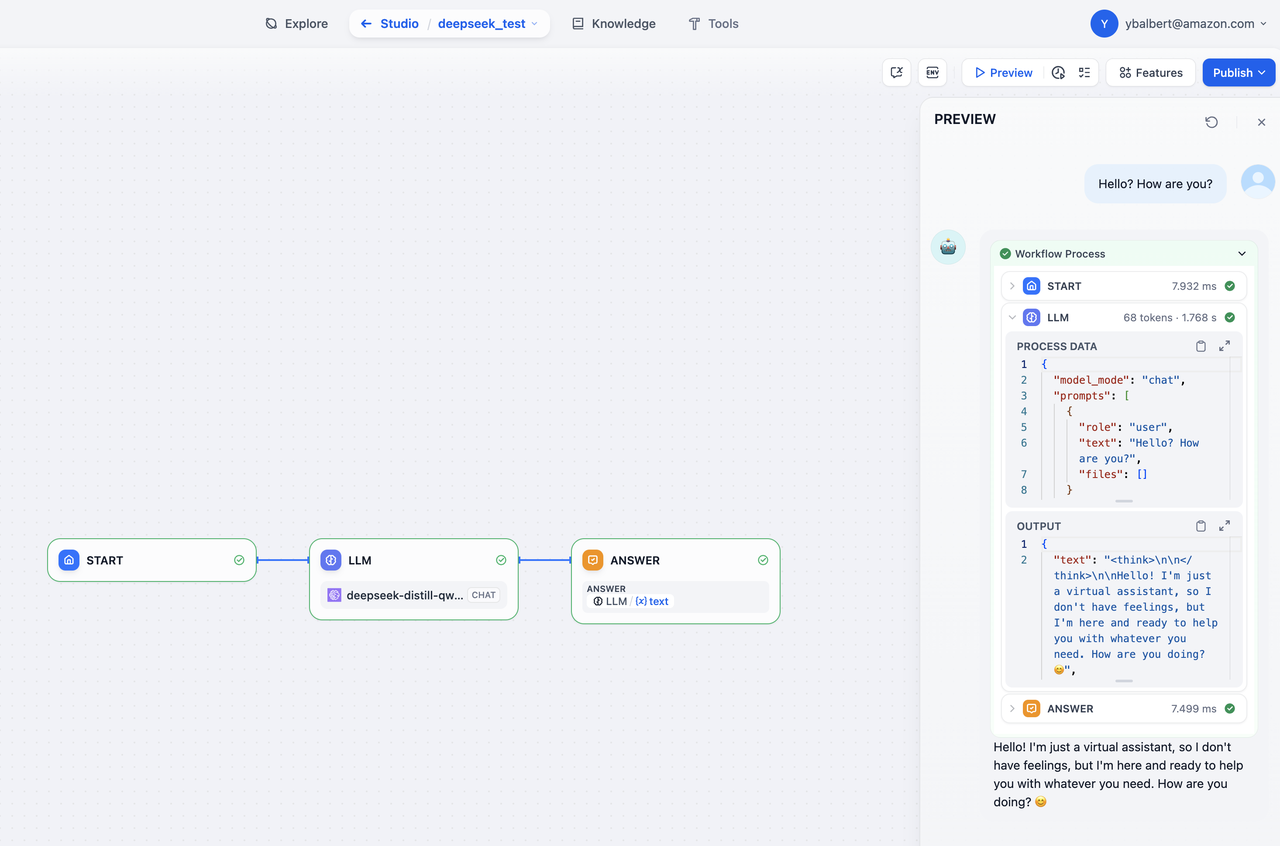
-> **注意:** 追加のテストとして、**チャットボット** アプリケーションを作成することもできます。
-
+
+**注意:**
+追加のテストとして、**チャットボット** アプリケーションを作成することもできます。
+
## FAQ
### 1. **デプロイ後にエンドポイント パラメータが表示されない**
diff --git a/ja-jp/development/models-integration/localai.mdx b/ja-jp/development/models-integration/localai.mdx
index 03d66e34..45876d6c 100644
--- a/ja-jp/development/models-integration/localai.mdx
+++ b/ja-jp/development/models-integration/localai.mdx
@@ -3,7 +3,8 @@ title: LocalAIでデプロイしたローカルモデルを統合
---
-[LocalAI](https://github.com/go-skynet/LocalAI) は、RESTFul APIを提供するローカル推論フレームワークで、OpenAI API仕様と互換性があります。これにより、消費者向けハードウェア上で、または自社サーバー上で、GPUを使用せずにLLM(大型言語モデル)や他のモデルを実行することが可能です。Difyは、LocalAIでデプロイされた大型言語モデルの推論および埋め込み機能をローカルで接続することをサポートしています。
+[LocalAI](https://github.com/go-skynet/LocalAI) は、RESTFul APIを提供するローカル推論フレームワークで、OpenAI API仕様と互換性があります。これにより、消費者向けハードウェア上で、または個人サーバー上で、GPUを使用せずにLLM(大型言語モデル)や他のモデルを実行することが可能です。
+Difyは、LocalAIでデプロイされた大型言語モデルの推論および埋め込み機能をローカルで接続することをサポートしています。
## LocalAIのデプロイ
diff --git a/ja-jp/getting-started/install-self-hosted/bt-panel.mdx b/ja-jp/getting-started/install-self-hosted/bt-panel.mdx
index 8a03ce34..61f534ad 100644
--- a/ja-jp/getting-started/install-self-hosted/bt-panel.mdx
+++ b/ja-jp/getting-started/install-self-hosted/bt-panel.mdx
@@ -13,7 +13,7 @@ Difyをインストールする前に、以下の最低システム要件を満
- | オペレーティングシステム |
+ OS |
ソフトウェア |
説明 |
@@ -37,9 +37,9 @@ Difyをインストールする前に、以下の最低システム要件を満
3. インストールが完了したら、`One-Click Install`から`Dify`を見つけて、`install`をクリックします。
4. ドメイン名やポートなどの基本情報を設定し、インストールを完了させます。
-> \[!重要]
->
-> ドメイン名はオプションです。ドメイン名を入力した場合は、[Website] --> [Proxy Project]から管理できます。ドメイン名を設定した後は、[Allow external access]のチェックを入れる必要はありません。それ以外の場合は、ポートを介してアクセスする前にチェックを入れる必要があります。
+
+ドメイン名はオプションです。ドメイン名を入力した場合は、[Website] --> [Proxy Project]から管理できます。ドメイン名を設定した後は、[Allow external access]のチェックを入れる必要はありません。それ以外の場合は、ポートを介してアクセスする前にチェックを入れる必要があります。
+
5. インストールが完了したら、前のステップで設定したドメイン名またはIPアドレスとポートをブラウザで入力してアクセスします。
- 名前(Name):アプリケーション名、デフォルトは`Dify-characters`
diff --git a/ja-jp/getting-started/install-self-hosted/docker-compose.mdx b/ja-jp/getting-started/install-self-hosted/docker-compose.mdx
index 836e4a1c..5339ac29 100644
--- a/ja-jp/getting-started/install-self-hosted/docker-compose.mdx
+++ b/ja-jp/getting-started/install-self-hosted/docker-compose.mdx
@@ -13,7 +13,7 @@ title: Docker Compose デプロイ
- | オペレーティング·システム |
+ OS |
ソフトウェア |
説明 |
@@ -42,6 +42,7 @@ title: Docker Compose デプロイ
+
### Difyのクローン
Difyのソースコードをローカルにクローンします
diff --git a/ja-jp/getting-started/install-self-hosted/local-source-code.mdx b/ja-jp/getting-started/install-self-hosted/local-source-code.mdx
index cd163b9f..3c063877 100644
--- a/ja-jp/getting-started/install-self-hosted/local-source-code.mdx
+++ b/ja-jp/getting-started/install-self-hosted/local-source-code.mdx
@@ -10,7 +10,7 @@ title: ローカルソースコードからの起動
> - CPU >= 2 コア
> - RAM >= 4 GiB
-| オペレーティングシステム | ソフトウェア | 説明 |
+| OS | ソフトウェア | 説明 |
| -------------------------- | -------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| macOS 10.14 以降 | Docker Desktop | Docker 仮想マシン(VM)が最低 2 つの仮想 CPU(vCPU)と 8 GB の初期メモリを使用するように設定してください。そうしないと、インストールが失敗する可能性があります。詳細については、[Mac 用 Docker Desktop インストールガイド](https://docs.docker.com/desktop/mac/install/)を参照してください。 |
| Linux プラットフォーム | Docker 19.03 以降 Docker Compose 1.25.1 以降 | Docker と Docker Compose のインストール方法については、それぞれ[Docker インストールガイド](https://docs.docker.com/engine/install/)と[Docker Compose インストールガイド](https://docs.docker.com/compose/install/)を参照してください。 |
diff --git a/ja-jp/getting-started/readme/model-providers.mdx b/ja-jp/getting-started/readme/model-providers.mdx
index f95a707d..2282a222 100644
--- a/ja-jp/getting-started/readme/model-providers.mdx
+++ b/ja-jp/getting-started/readme/model-providers.mdx
@@ -389,7 +389,7 @@ Difyは以下のモデルプロバイダーをサポートしています:
その中で (🛠️) は関数呼び出しをサポートすることを、(👓) は視覚能力を持つことを示します。
-この表は常に更新されています。また、コミュニティメンバーからのモデル供給者に関する様々な[リクエスト](https://github.com/langgenius/dify/discussions/categories/ideas)も注視しています。必要なモデル供給者がこのリストにない場合は、プルリクエストを提出して貢献することができます。詳しくは、[contribution](/ja-jp/community/contribution)ガイドをご覧ください。
+この表は常に更新されています。また、コミュニティメンバーからのモデル供給者に関する様々な[リクエスト](https://github.com/langgenius/dify/discussions/categories/ideas)も注視しています。必要なモデル供給者がこのリストにない場合は、プルリクエストを提出して貢献することができます。詳しくは、[貢献者ガイド](/ja-jp/community/contribution)をご覧ください。
{/*
Contributing Section
diff --git a/ja-jp/guides/application-publishing/developing-with-apis.mdx b/ja-jp/guides/application-publishing/developing-with-apis.mdx
index 508600ac..20cae39d 100644
--- a/ja-jp/guides/application-publishing/developing-with-apis.mdx
+++ b/ja-jp/guides/application-publishing/developing-with-apis.mdx
@@ -16,9 +16,7 @@ Difyは、「**後端即サービス(Backend as a Service)**」の理念に基
### 利用方法
-アプリケーションを選択し、アプリケーション(Apps)の左側ナビゲーションで**APIアクセス(API Access)**を見つけます。このページでDifyが提供するAPIドキュメントを確認し、APIにアクセスするための認証情報を管理できます。
-
-
+アプリケーションを選択し、アプリケーション(Apps)の左側ナビゲーションで **APIアクセス(API Access)** を見つけます。このページでDifyが提供するAPIドキュメントを確認し、APIにアクセスするための認証情報を管理できます。
例えば、あなたがコンサルティング会社の開発部門であれば、会社のプライベートデータベースに基づいてAI能力をエンドユーザーや開発者に提供できますが、開発者はあなたのデータやAIロジック設計を把握することはできません。これにより、サービスは安全かつ持続可能に提供され、商業目的を満たすことができます。
diff --git a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
index f1eac4f8..289fb2a0 100644
--- a/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
+++ b/ja-jp/guides/knowledge-base/connect-external-knowledge-base.mdx
@@ -8,7 +8,7 @@ title: 外部ナレッジベースとの接続
高度なコンテンツ検索の要件を持つ上級開発者にとって、Difyプラットフォームに組み込まれたナレッジベース機能とテキスト検索・取得メカニズムには**制約があり、検索結果を簡単に変更することができません。**
-テキスト検索と取得の精度に高い要求を持ち、内部資料の管理ニーズを満たすために、一部のチームは独自にRAGアルゴリズムを開発し、自社のテキスト取得システムを維持したり、コンテンツをクラウドプロバイダのナレッジベースサービス(例:[AWS Bedrock](https://aws.amazon.com/bedrock/))に統合したりしています。
+テキスト検索と取得の精度に高い要求を持ち、内部資料の管理ニーズを満たすために、一部のチームは独自にRAGアルゴリズムを開発し、個人のテキスト取得システムを維持したり、コンテンツをクラウドプロバイダのナレッジベースサービス(例:[AWS Bedrock](https://aws.amazon.com/bedrock/))に統合したりしています。
中立的なLLMアプリケーション開発プラットフォームであるDifyは、開発者にさまざまな選択肢を提供することを目指しています。
diff --git a/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx b/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx
index 5e6821eb..6b7978ef 100644
--- a/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx
+++ b/ja-jp/guides/knowledge-base/knowledge-base-creation/introduction.mdx
@@ -1,142 +1,60 @@
---
-title: ナレッジベース作成
+title: 作成手順
---
-ナレッジベースの作成および文書のアップロード手順は、主に以下のステップから成り立っています:
+ナレッジベースの作成とドキュメントのアップロードは、以下のステップに分かれています:
-1. ナレッジベースを新規作成し、ローカルの文書や[オンラインのデータ](./import-online-datasource/README)を取り込みます。
-2. 文書を分割する際のモードを選び、その効果をプレビューします。
-3. 検索機能のためのインデックス設定と検索オプションを構成します。
-4. 文書の分割処理が完了するまで待ちます。
-5. アップロードが完了したら、アプリ内でナレッジベースを利用開始します 🎉
+1. ナレッジベースを作成します。ローカルファイルのアップロード、オンラインデータのインポート、または空のナレッジベースを作成することができます。
-各ステップの詳細について説明します:
+
+ ローカルファイルのアップロード、オンラインデータのインポート、または空のナレッジベースの作成について。
+
-## 1. ナレッジベースの新規作成
+2. チャンキングモードを指定します。この段階では、コンテンツの前処理とデータ構造化を行い、長いテキストが複数のセグメントに分割されます。ここでは、テキストの分割効果をプレビューすることができます。
-Difyプラットフォームのトップメニューより **「ナレッジベース」→「新規作成」** を選択します。文書は、ローカルファイルのアップロードまたはオンラインデータの取り込みによってナレッジベースに追加できます。
+
+ テキスト分割とデータクリーニングのプロセスについて学ぶ
+
-* ローカルファイルのアップロード:ファイルをドラッグ&ドロップまたは選択してアップロードします。**一度に多数のファイルをアップロード**することが可能ですが、その上限は[サブスクリプションプラン](https://dify.ai/pricing)に依存します。
+3. インデックス方法と検索設定を設定します。ナレッジベースはユーザーからのクエリを受け取ると、事前設定された検索方法に従って既存のドキュメント内で関連コンテンツを検索し、言語モデルが高品質の回答を生成するために関連性の高い情報を抽出します。
- ローカルファイルのアップロードには以下の制約があります:
+
+ インデックス方法と検索パラメータの設定方法について学ぶ
+
- * 一度にアップロードできる最大サイズは**15MB**です;
+4. チャンクのエンベディング処理が完了するまで待ちます。
+5. アップロードが完了したら、アプリケーション内でナレッジベースを関連付けて使用します。[アプリケーション内でのナレッジベースの統合](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)を参照して、ナレッジベースに基づいて質問応答ができるLLMアプリケーションを構築できます。ナレッジベースの修正や管理が必要な場合は、[ナレッジベース管理とドキュメントメンテナンス](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)を参照してください。
- * 使用しているSaaS[サブスクリプションプラン](https://dify.ai/pricing)によって、**一括アップロード可能なファイル数、文書の総アップロード数、ベクトルストレージ**の利用可能容量が制限されます。
+
- 
+***
-* オンラインデータの取り込み:ナレッジベース作成時に[オンラインデータの取り込み](./import-online-datasource/README)が可能で、詳細はオンラインデータ取り込みのガイドを参照してください。オンラインデータソースを利用するナレッジベースには、後からローカルの文書を追加したり、ローカルファイルタイプのナレッジベースへ変更したりすることはできません。これは、複数のデータソースが混在すると管理が複雑になるためです。
+### 参考資料
-* 文書がまだ準備できていない場合でも、空のナレッジベースを先に作成し、後ほどローカル文書をアップロードしたり、オンラインデータを取り込んだりすることができます。
+#### ETL
-## 2. コンテンツ分割の指定方法
+RAGの本番環境での応用では、より良いデータ検索結果を得るために、複数のソースからのデータに対して前処理とクリーニングを行う必要があります。これがETL(_extract, transform, load_)です。非構造化/半構造化データの前処理能力を強化するため、Difyでは**Dify ETL**と[**Unstructured ETL**](https://docs.unstructured.io/welcome)の2つのETLソリューションをサポートしています。Unstructuredは、後続のステップのためにデータを効率的に抽出し、クリーンなデータに変換します。Difyの各バージョンにおけるETLソリューションの選択:
-コンテンツをナレッジベースにアップロードした後の次のステップは、コンテンツの分割とデータのクレンジングです。**このステップでは、コンテンツの前処理とデータの構造化が行われ、長いテキストは複数のセクションに分けられます。** LLMはユーザーからの質問を受け取った際、ナレッジベース内のセクションをどれだけ正確に検索し取り出せるかで、その質問に対する正確な回答が可能かどうかが決まります。詳細については、[コンテンツ分割の指定方法](./chunking-and-cleaning-text)をご参照ください。
+* SaaSバージョンでは選択できず、デフォルトでUnstructured ETLを使用します;
+* コミュニティバージョンでは選択可能で、デフォルトではDify ETLを使用し、[環境変数](/ja-jp/getting-started/install-self-hosted/environments)を通じてUnstructured ETLを有効にできます;
-以下の2つの分割モードがあります:
-
-* **汎用分割モード**
-
- このモードでは、システムがユーザーが定義したルールに従ってコンテンツを独立したセクションに分けます。質問が入力されると、システムはその質問のキーワードを自動で分析し、これらのキーワードとナレッジベース内のセクションとの関連度を計算します。そして、関連度に基づいてセクションをランキングし、最も関連性の高いセクションを選びLLMへ送り、処理して回答を得ます。
-
-
- **注意**:以前の **「自動分割とクリーニング」モード** は **汎用分割モード** に自動的に更新されました。何も変更する必要はなく、デフォルト設定をそのまま使用し続けることができます。
-
-
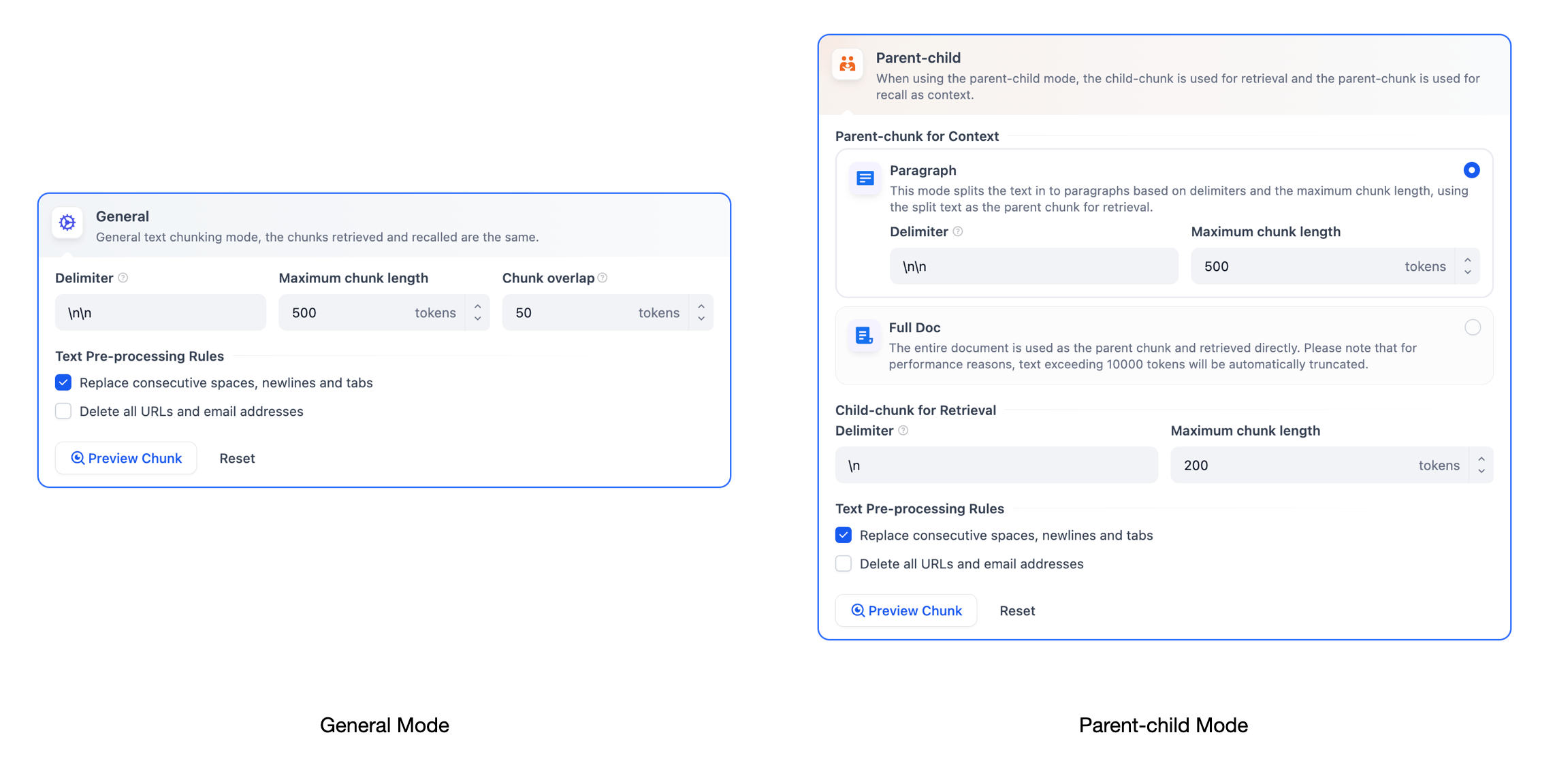
-* **親子分割モード(階層分割モード)**
-
- 二層の構造を採用し、検索精度とコンテキスト情報のバランスを取ります。このモードでは、親セクション(Parent-chunk)がより大きなテキスト単位(例えば段落)を包含し、豊富なコンテキスト情報を提供します。子セクション(Child-chunk)はより小さなテキスト単位(例えば文)で、精確な検索に利用されます。システムは最初に子セクションを通じて精確な検索を行い関連性を確保した後、対応する親セクションを取得しコンテキスト情報を補完し、レスポンスを生成する際に正確さを保ちながら完全な背景情報を提供します。セクションの分割方法は、区切り文字と最大長さの設定を通してカスタマイズできます。
-
-ナレッジベースを初めて作成する際は、[親子分割モード](./chunking-and-cleaning-text)を選択し、デフォルトのオプションを使用してナレッジベースの作成を行うことを推奨します。コンテンツセクションをカスタマイズしたい場合は、[分割ルール](./chunking-and-cleaning-text)を参照し、正規表現の文法に従って設定してください。
-
-
-
-
-**注意**:分割モードを選択し、ナレッジベースの作成を完了した後は、後からモードを変更することはできません。ナレッジベースにドキュメントを新たに追加する場合も、選択したコンテンツ分割戦略に従います。
-
-
-3. インデックス設定方法
-
-コンテンツを構造化する前処理(分割とクリーニング)を行った後、構造化されたコンテンツに対してどのように検索を行うかの設定が必要です。検索エンジンが効率的なインデックスアルゴリズムを用いて、ユーザーの問い合わせに最も関連性の高い検索結果を提供できるように、インデックスの設定方法が重要です。これは、LLMがナレッジベースから情報を検索する効率と回答の精度に直接影響します。
-
-以下に、三つのインデックス設定方法を紹介します。詳細は[インデックス設定方法](./setting-indexing-methods)をご覧ください。
-
-* **高品質**
-
- エンベッディングモデル(Embeddingモデル)を利用して、分割されたテキストブロックを数値ベクトルに変換し、大量のテキスト情報をより効率的に圧縮・保管します。これにより、ユーザーの問い合わせとテキストとのマッチングがより精密に行われます。
-
-* **経済的**
-
- 各テキストブロックごとに10個のキーワードを用いて検索を行います。精度は落ちますが、追加のコストはかかりません。
-
-* **Q&Aモード(コミュニティ版のみ対応)**
-
- ナレッジベースへの文書アップロード時に、システムがテキストを分割して要約し、各ブロックごとにQ&Aのペアを生成します。FAQ形式の文書に適しています。
-
-**高品質なインデックス設定方法**の利用を推奨します。
-
-
-
-## 4. 検索方法の選定
-
-ユーザーからの問い合わせを受けた後、ナレッジベースは関連する情報を既存のドキュメントから見つけ出すために検索方法を用いる。ビジネスの要求やデータの特徴に合わせて、検索方法を柔軟に組み合わせたり変更したりすることで、より効果的かつ正確な検索結果を提供できる。
-
-異なるインデックス作成方法によって、様々な検索オプションが提供される。詳細は[検索方法の選定](./selecting-retrieval-settings)セクションを参照。
-
-* **高品質インデックス**
-
- * **ベクトル検索**
-
- ユーザーの質問をベクトル化し、クエリテキストの数値ベクトルを作成。このクエリベクトルとナレッジベース内のテキストベクトルとの距離を比較し、最も近い内容を探索する。
-
- * **全文検索**
-
- キーワードによる検索で、ドキュメント内の全単語を索引付ける。ユーザーが質問を提出すると、そのキーワードでナレッジベース内の適切なテキスト部分を検索し、一致する内容を返す。これは検索エンジンにおける一般的な全文検索と似ている。
-
- * **ハイブリッド検索**(推奨)
-
- 全文検索とベクトル検索を同時に行い、リランクモデルを用いて両方の検索結果から最も適切な回答を選び出す。
-
-* **経済的安いインデックス**
-
- * **インバーテッド検索**
-
- インバーテッド検索は、ドキュメント内のキーワードを迅速に検索するための索引構造で、オンライン検索エンジンで広く使用されている。
-
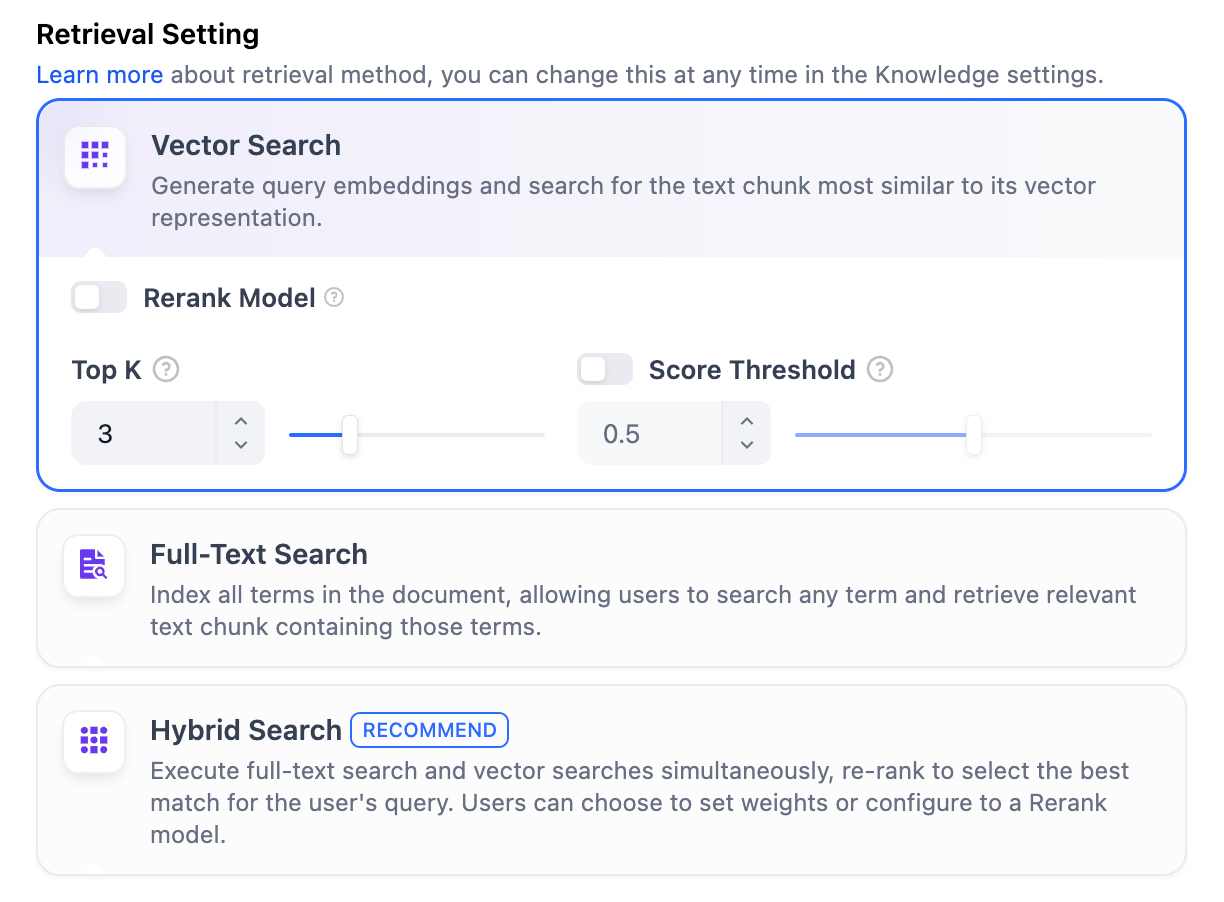
-
-
-選んだ検索方式に基づき、[リコールテスト/引用帰属](/ja-jp/guides/knowledge-base/retrieval-test-and-citation)セクションを参照し、キーワードとコンテンツの一致度をテストできる。
-
-## 5. アップロード完了
-
-上述した設定を終えて、「保存して処理」ボタンをクリックすることで、ナレッジベースの作成が完了する。アプリ内でナレッジベースを統合する方法については、[ナレッジベースの統合](/ja-jp/guides/knowledge-base/integrate-knowledge-within-application)セクションを参照。ナレッジベースの更新や管理が必要な場合は、[ナレッジベースの管理と文書のメンテナンス](/ja-jp/guides/knowledge-base/knowledge-and-documents-maintenance/introduction)セクションをご覧ください。
-
-
-
-
-## 参考文献
-
-### ETL
-
-RAGのプロダクションレベルのアプリケーションでは、データ召喚の効果を向上させるために、複数のデータソースを前処理およびクリーニングする必要があります。これをETL(抽出、変換、ロード)と呼びます。非構造化/半構造化データの前処理能力を強化するために、Difyは以下のオプションのETLソリューションをサポートしています:**Dify ETL** と[**Unstructured ETL**](https://unstructured.io/)。Unstructuredは、データを抽出してクリーンなデータに変換し、後続のステップに使用できるようにします。Difyの各バージョンでのETLソリューションの選択:
-
-* SaaS版では選択不可、デフォルトでUnstructured ETLを使用。
-* コミュニティ版では選択可能、デフォルトでDify ETLを使用、[環境変数](/ja-jp/getting-started/install-self-hosted/environments)を介してUnstructured ETLを有効にできます。
-
-ファイル解析のサポート形式の違い:
+ファイル解析でサポートされる形式の違い:
| DIFY ETL | Unstructured ETL |
| ---------------------------------------------- | ------------------------------------------------------------------------ |
| txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv | txt、markdown、md、pdf、html、htm、xlsx、xls、docx、csv、eml、msg、pptx、ppt、xml、epub |
-異なるETLソリューションではファイル抽出の効果にも違いがあります。Unstructured ETLのデータ処理方法について詳細を知りたい場合は、[公式ドキュメント](https://docs.unstructured.io/open-source/core-functionality/partitioning)を参照してください。
+異なるETLソリューションはファイル抽出効果においても違いがあります。Unstructured ETLのデータ処理方法についてさらに詳しく知りたい場合は、[公式ドキュメント](https://docs.unstructured.io/open-source/core-functionality/partitioning)を参照してください。
-### 埋め込み (Embedding)
+***
-**埋め込み(Embedding)**は、単語や文章、あるいはドキュメント全体のような離散変数を、連続ベクトル表現に変換する技術を指します。この技術を用いることで、単語やフレーズ、画像などの高次元データを、より小さな次元空間にマッピングし、データを簡潔かつ効率的に表現できます。この方法は、データの次元を減らすだけでなく、重要な意味の情報も保持し、コンテンツの検索を効率化します。
+#### **エンベディング**
-**埋め込みモデル**は、テキストデータを数値ベクトル化することに特化した言語モデルの一種で、テキストを密度の高い数値ベクトルに変換し、その意味内容を効果的に表現することに長けています。
+**エンベディング**は、離散変数(単語、短文、または文書全体など)を連続的なベクトル表現に変換する技術です。これにより、高次元データ(単語、フレーズ、画像など)を低次元空間にマッピングし、コンパクトで効果的な表現方法を提供します。このような表現は、データの次元を削減するだけでなく、重要な意味情報も保持するため、後続のコンテンツ検索がより効率的になります。
+
+**エンベディングモデル**は、テキストをベクトル化することに特化した大規模言語モデルで、テキストを密な数値ベクトルに変換し、意味情報を効果的に捉えることができます。
+
+***
#### メタデータ
diff --git a/ja-jp/guides/model-configuration/README.mdx b/ja-jp/guides/model-configuration/README.mdx
index 67509379..9eb566a9 100644
--- a/ja-jp/guides/model-configuration/README.mdx
+++ b/ja-jp/guides/model-configuration/README.mdx
@@ -16,7 +16,7 @@ Difyでは、モデルの使用シーンに応じて以下の4つのタイプに
1. **システム推論モデル**。アプリケーション内で使用されるのはこのタイプのモデルです。チャット、会話名生成、次の質問の提案でもこの推論モデルが使用されます。
> サポートされているシステム推論モデルプロバイダー:[OpenAI](https://platform.openai.com/account/api-keys)、[Azure OpenAIサービス](https://azure.microsoft.com/en-us/products/ai-services/openai-service/)、[Anthropic](https://console.anthropic.com/account/keys)、Hugging Faceハブ、Replicate、Xinference、OpenLLM、[讯飞星火](https://www.xfyun.cn/solutions/xinghuoAPI)、[文心一言](https://console.bce.baidu.com/qianfan/ais/console/applicationConsole/application)、[通义千问](https://dashscope.console.aliyun.com/api-key\_management?spm=a2c4g.11186623.0.0.3bbc424dxZms9k)、[Minimax](https://api.minimax.chat/user-center/basic-information/interface-key)、ZHIPU(ChatGLM)
-2. **埋め込みモデル**。データセット内の分割された文書の埋め込みに使用されるのはこのタイプのモデルです。データセットを使用するアプリケーションでは、ユーザーの質問を埋め込み処理する際にもこのタイプのモデルが使用されます。
+2. **Embeddingモデル**。データセット内の分割された文書の埋め込みに使用されるのはこのタイプのモデルです。データセットを使用するアプリケーションでは、ユーザーの質問を埋め込み処理する際にもこのタイプのモデルが使用されます。
> サポートされている埋め込みモデルプロバイダー:OpenAI、ZHIPU(ChatGLM)、Jina AI([Jina Embeddings](https://jina.ai/embeddings/))
3. [**Rerankモデル**](/ja-jp/learn-more/extended-reading/retrieval-augment/rerank)。**Rerankモデルは検索能力を強化し、LLMの検索結果を改善するために使用されます。**
@@ -50,14 +50,14 @@ Difyの`設定 > モデルプロバイダー`で接続するモデルを設定
モデルプロバイダーは2種類に分かれます:
-1. 自社モデル。このタイプのモデルプロバイダーは自社で開発したモデルを提供します。例としてOpenAI、Anthropicなどがあります。
+1. 個人モデル。このタイプのモデルプロバイダーは個人で開発したモデルを提供します。例としてOpenAI、Anthropicなどがあります。
2. ホストモデル。このタイプのモデルプロバイダーは第三者のモデルを提供します。例としてHugging Face、Replicateなどがあります。
Difyで異なるタイプのモデルプロバイダーを接続する方法は若干異なります。
-**自社モデルのモデルプロバイダーの接続**
+**個人モデルのモデルプロバイダーの接続**
-自社モデルのプロバイダーを接続すると、Difyはそのプロバイダーのすべてのモデルに自動的に接続します。
+個人モデルのプロバイダーを接続すると、Difyはそのプロバイダーのすべてのモデルに自動的に接続します。
Difyで対応するモデルプロバイダーのAPIキーを設定するだけで、そのモデルプロバイダーに接続できます。
diff --git a/ja-jp/guides/model-configuration/customizable-model.mdx b/ja-jp/guides/model-configuration/customizable-model.mdx
index 47e18eea..5eb7a4a3 100644
--- a/ja-jp/guides/model-configuration/customizable-model.mdx
+++ b/ja-jp/guides/model-configuration/customizable-model.mdx
@@ -42,6 +42,7 @@ help: # Help
title:
en_US: How to deploy Xinference
zh_Hans: 如何部署 Xinference
+ ja_JP: Xinferenceのデプロイ方法
url:
en_US: https://github.com/xorbitsai/inference
supported_model_types: # Supported model types. Xinference supports LLM/Text Embedding/Rerank
@@ -66,12 +67,14 @@ provider_credential_schema:
label:
en_US: Model type
zh_Hans: 模型类型
+ ja_JP: モデルタイプ
required: true
options:
- value: text-generation
label:
en_US: Language Model
- zh_Hans: 言語モデル
+ zh_Hans: 语言模型
+ ja_JP: 言語モデル
- value: embeddings
label:
en_US: Text Embedding
@@ -88,10 +91,12 @@ provider_credential_schema:
label:
en_US: Model name
zh_Hans: 模型名称
+ ja_JP: モデル名
required: true
placeholder:
- zh_Hans: 填写模型名称
en_US: Input model name
+ zh_Hans: 填写模型名称
+ ja_JP: モデル名を入力してください
```
* Xinferenceのローカルデプロイのアドレスを記入します。
@@ -99,13 +104,15 @@ provider_credential_schema:
```yaml
- variable: server_url
label:
- zh_Hans: 服务器URL
en_US: Server url
+ zh_Hans: 服务器URL
+ ja_JP: サーバーURL
type: text-input
required: true
placeholder:
- zh_Hans: 在此输入Xinference的服务器地址,如 https://example.com/xxx
en_US: Enter the url of your Xinference, for example https://example.com/xxx
+ zh_Hans: 在此输入Xinference的服务器地址,如 https://example.com/xxx
+ ja_JP: Xinferenceのサーバーアドレスをここに入力してください、例えば https://example.com/xxx
```
* 各モデルには一意の model\_uid があるため、ここで定義する必要があります。
@@ -113,13 +120,15 @@ provider_credential_schema:
```yaml
- variable: model_uid
label:
- zh_Hans: 模型 UID
en_US: Model uid
+ zh_Hans: 模型 UID
+ ja_JP: モデル UID
type: text-input
required: true
placeholder:
- zh_Hans: 在此输入你的 Model UID
en_US: Enter the model uid
+ zh_Hans: 在此输入你的 Model UID
+ ja_JP: モデルUIDを入力してください
```
これで、ベンダーの基本定義が完了しました。
diff --git a/ja-jp/guides/model-configuration/new-provider.mdx b/ja-jp/guides/model-configuration/new-provider.mdx
index 16108893..2bd8d2f2 100644
--- a/ja-jp/guides/model-configuration/new-provider.mdx
+++ b/ja-jp/guides/model-configuration/new-provider.mdx
@@ -33,7 +33,7 @@ title: 新しいプロバイダーの追加
新しいプロバイダーを追加するには主にいくつかのステップがあります。ここでは簡単に列挙し、具体的な手順は以下で詳しく説明します。
-* プロバイダーのYAMLファイルを作成し、[プロバイダースキーマ](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/en_US/schema)に基づいて記述します。
+* プロバイダーのYAMLファイルを作成し、[プロバイダースキーマ](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/en_US/schema.md)に基づいて記述します。
* プロバイダーのコードを作成し、`class`を実装します。
* モデルタイプに応じて、プロバイダーの`モジュール`内に対応するモデルタイプの`モジュール`を作成します。例えば`llm`や`text_embedding`。
* モデルタイプに応じて、対応するモデル`モジュール`内に同名のコードファイルを作成し、例えば`llm.py`、`class`を実装します。
@@ -42,9 +42,9 @@ title: 新しいプロバイダーの追加
#### 始めましょう
-新しいプロバイダーを追加するには、まずプロバイダーの英語識別子を決めます。例えば`anthropic`、この識別子を使って`model_providers`内に同名の`モジュール`を作成します。
+新しいプロバイダーを追加するには、まずプロバイダーの英語識別子を決めます。例えば`anthropic`、この識別子を使って`model_providers`内に同名の`module`を作成します。
-この`モジュール`内で、まずプロバイダーのYAML設定を準備する必要があります。
+この`module`内で、まずプロバイダーのYAML設定を準備する必要があります。
**プロバイダーYAMLの準備**
@@ -70,29 +70,33 @@ provider_credential_schema: # プロバイダーのクレデンシャルルー
type: secret-input # フォームタイプ、ここではsecret-inputは暗号化された情報入力フィールドを意味し、編集時にはマスクされた情報のみが表示されます。
required: true # 必須かどうか
placeholder: # プレースホルダー情報
- zh_Hans: 在此输入你的 API Key
en_US: Enter your API Key
+ zh_Hans: 在此输入你的 API Key
+ ja_JP: API Keyを入力してください
- variable: anthropic_api_url
label:
en_US: API URL
type: text-input # フォームタイプ、ここではtext-inputはテキスト入力フィールドを意味します
required: false
placeholder:
- zh_Hans: 在此输入你的 API URL
en_US: Enter your API URL
+ zh_Hans: 在此输入你的 API URL
+ ja_JP: API URLを入力してください
```
-カスタマイズ可能なモデルを提供するプロバイダー、例えば`OpenAI`が微調整モデルを提供する場合、[`モデルクレデンシャルスキーマ`](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/en_US/schema)を追加する必要があります。以下は`OpenAI`を例にしたものです:
+カスタマイズ可能なモデルを提供するプロバイダー、例えば`OpenAI`が微調整モデルを提供する場合、[`model_credential_schema`](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/en_US/schema.md)を追加する必要があります。以下は`OpenAI`を例にしたものです:
```yaml
model_credential_schema:
- model: # 微調整モデルの名称
+ model: # 微調整モデル名
label:
en_US: Model Name
zh_Hans: 模型名称
+ ja_JP: モデル名
placeholder:
en_US: Enter your model name
zh_Hans: 输入模型名称
+ ja_JP: モデル名を入力ください
credential_form_schemas:
- variable: openai_api_key
label:
@@ -100,29 +104,34 @@ model_credential_schema:
type: secret-input
required: true
placeholder:
- zh_Hans: 在此输入你的 API Key
en_US: Enter your API Key
+ zh_Hans: 在此输入你的 API Key
+ ja_JP: API keyを入力してください
- variable: openai_organization
label:
- zh_Hans: 组织 ID
en_US: Organization
+ zh_Hans: 组织 ID
+ ja_JP: 組織ID
type: text-input
required: false
placeholder:
- zh_Hans: 在此输入你的组织 ID
en_US: Enter your Organization ID
+ zh_Hans: 在此输入你的组织 ID
+ ja_JP: 組織IDを入力してください
- variable: openai_api_base
label:
- zh_Hans: API Base
en_US: API Base
+ zh_Hans: API Base
+ ja_JP: API Base
type: text-input
required: false
placeholder:
- zh_Hans: 在此输入你的 API Base
en_US: Enter your API Base
+ zh_Hans: 在此输入你的 API Base
+ ja_JP: API Baseを入力してください
```
-`model_providers`ディレクトリ内の他のプロバイダーディレクトリの[YAML設定情報](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/en_US/schema)も参考にできます。
+`model_providers`ディレクトリ内の他のプロバイダーディレクトリの[YAML設定情報](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/en_US/schema.md)も参考にできます。
**プロバイダーコードの実装**
@@ -181,7 +190,7 @@ def validate_provider_credentials(self, credentials: dict) -> None:
**テストコードの記述**
-`tests`ディレクトリ内にプロバイダーと同名の`モジュール`を作成します:`anthropic`。このモジュール内に`test_provider.py`および対応するモデルタイプのテストpyファイルを作成します。以下のようになります:
+`tests`ディレクトリ内にプロバイダーと同名の`module`を作成します:`anthropic`。このモジュール内に`test_provider.py`および対応するモデルタイプのtest pyファイルを作成します。以下のようになります:
```shell
.
diff --git a/ja-jp/guides/model-configuration/predefined-model.mdx b/ja-jp/guides/model-configuration/predefined-model.mdx
index aa0eedfa..1028e062 100644
--- a/ja-jp/guides/model-configuration/predefined-model.mdx
+++ b/ja-jp/guides/model-configuration/predefined-model.mdx
@@ -44,12 +44,14 @@ parameter_rules: # モデル呼び出しパラメータルール、LLMのみ提
use_template: top_p
- name: top_k
label: # 呼び出しパラメータ表示名
- zh_Hans: 取样数量
en_US: Top k
+ zh_Hans: 取样数量
+ ja_JP: サンプリング数
type: int # パラメータタイプ、float/int/string/booleanがサポートされています
help: # ヘルプ情報、パラメータの作用を説明
- zh_Hans: 仅从每个后续标记的前 K 个选项中采样。
en_US: Only sample from the top K options for each subsequent token.
+ zh_Hans: 仅从每个后续标记的前 K 个选项中采样。
+ ja_JP: 各後続マーカーの最初のKオプションからのみサンプリングする。
required: false # 必須かどうか、設定しない場合もあります
- name: max_tokens_to_sample
use_template: max_tokens
diff --git a/ja-jp/guides/model-configuration/schema.mdx b/ja-jp/guides/model-configuration/schema.mdx
index 69f5088b..78b3ec2a 100644
--- a/ja-jp/guides/model-configuration/schema.mdx
+++ b/ja-jp/guides/model-configuration/schema.mdx
@@ -3,9 +3,9 @@ title: 設定ルール
version: 'v1.0'
---
-- 供給業者のルールは [Provider](#Provider) エンティティに基づいています。
+- 供給業者のルールは [Provider](#provider) エンティティに基づいています。
-- モデルのルールは [AIModelEntity](#AIModelEntity) エンティティに基づいています。
+- モデルのルールは [AIModelEntity](#aimodelentity) エンティティに基づいています。
> 以下のすべてのエンティティは `Pydantic BaseModel` に基づいており、対応するエンティティは `entities` モジュールで見つけることができます。
@@ -32,10 +32,10 @@ version: 'v1.0'
- `url` (object) ヘルプリンク、i18n
- `zh_Hans` (string) [optional] 中国語のリンク
- `en_US` (string) 英語のリンク
-- `supported_model_types` (array[[ModelType](#ModelType)]) サポートされるモデルタイプ
-- `configurate_methods` (array[[ConfigurateMethod](#ConfigurateMethod)]) 設定方法
-- `provider_credential_schema` ([ProviderCredentialSchema](#ProviderCredentialSchema)) 供給業者の資格情報スキーマ
-- `model_credential_schema` ([ModelCredentialSchema](#ModelCredentialSchema)) モデルの資格情報スキーマ
+- `supported_model_types` (array[[ModelType](#modeltype)]) サポートされるモデルタイプ
+- `configurate_methods` (array[[ConfigurateMethod](#configuratemethod)]) 設定方法
+- `provider_credential_schema` ([ProviderCredentialSchema](#providercredentialschema)) 供給業者の資格情報スキーマ
+- `model_credential_schema` ([ModelCredentialSchema](#modelcredentialschema)) モデルの資格情報スキーマ
### AIModelEntity
@@ -43,10 +43,10 @@ version: 'v1.0'
- `label` (object) [optional] モデルの表示名、i18n、`en_US` 英語、`zh_Hans` 中国語の2種類の言語を設定できます
- `zh_Hans `(string) [optional] 中国語のラベル名
- `en_US` (string) 英語のラベル名
-- `model_type` ([ModelType](#ModelType)) モデルのタイプ
-- `features` (array[[ModelFeature](#ModelFeature)]) [optional] サポートされる機能のリスト
+- `model_type` ([ModelType](#modeltype)) モデルのタイプ
+- `features` (array[[ModelFeature](#modelfeature)]) [optional] サポートされる機能のリスト
- `model_properties` (object) モデルのプロパティ
- - `mode` ([LLMMode](#LLMMode)) モード (モデルタイプ `llm` で使用可能)
+ - `mode` ([LLMMode](#llmmode)) モード (モデルタイプ `llm` で使用可能)
- `context_size` (int) コンテキストサイズ (モデルタイプ `llm` `text-embedding` で使用可能)
- `max_chunks` (int) 最大チャンク数 (モデルタイプ `text-embedding` `moderation` で使用可能)
- `file_upload_limit` (int) ファイルの最大アップロード制限、単位:MB。(モデルタイプ `speech2text` で使用可能)
@@ -60,8 +60,8 @@ version: 'v1.0'
- `audio_type` (string) サポートされるオーディオファイルの拡張形式、例:mp3,wav(モデルタイプ `tts` で使用可能)
- `max_workers` (int) テキストオーディオ変換の並行タスク数をサポート(モデルタイプ `tts` で使用可能)
- `max_characters_per_chunk` (int) チャンクあたりの最大文字数(モデルタイプ `moderation` で使用可能)
-- `parameter_rules` (array[[ParameterRule](#ParameterRule)]) [optional] モデル呼び出しパラメータのルール
-- `pricing` ([PriceConfig](#PriceConfig)) [optional] 価格情報
+- `parameter_rules` (array[[ParameterRule](#parameterrule)]) [optional] モデル呼び出しパラメータのルール
+- `pricing` ([PriceConfig](#priceconfig)) [optional] 価格情報
- `deprecated` (bool) 廃止されていますか。廃止されると、モデルリストは表示されなくなりますが、すでに設定されているモデルは引き続き使用できます。デフォルトは False です。
### ModelType
@@ -161,7 +161,7 @@ version: 'v1.0'
### ProviderCredentialSchema
-- `credential_form_schemas` (array[[CredentialFormSchema](#CredentialFormSchema)]) 認証情報フォーム規範
+- `credential_form_schemas` (array[[CredentialFormSchema](#credentialformschema)]) 認証情報フォーム規範
### ModelCredentialSchema
@@ -172,7 +172,7 @@ version: 'v1.0'
- `placeholder` (object) モデルのヒント内容
- `en_US` (string) 英語
- `zh_Hans` (string) [optional] 中国語
-- `credential_form_schemas` (array[[CredentialFormSchema](#CredentialFormSchema)]) 認証情報フォーム規範
+- `credential_form_schemas` (array[[CredentialFormSchema](#credentialformschema)]) 認証情報フォーム規範
### CredentialFormSchema
@@ -180,15 +180,15 @@ version: 'v1.0'
- `label` (object) フォーム項目のラベル
- `en_US` (string) 英語のラベル
- `zh_Hans` (string) [optional] 中国語のラベル
-- `type` ([FormType](#FormType)) フォーム項目の種類
+- `type` ([FormType](#formtype)) フォーム項目の種類
- `required` (bool) この項目が必須かどうか
- `default` (string) デフォルト値
-- `options` (array[[FormOption](#FormOption)]) フォーム項目が `select` または `radio` の場合に使用するドロップダウンの選択肢を定義
+- `options` (array[[FormOption](#formoption)]) フォーム項目が `select` または `radio` の場合に使用するドロップダウンの選択肢を定義
- `placeholder` (object) フォーム項目が `text-input` の場合にのみ使用するプロパティ、入力フィールドに表示されるヒント
- `en_US` (string) 英語のプレースホルダー
- `zh_Hans` (string) [optional] 中国語のプレースホルダー
- `max_length` (int) フォーム項目が `text-input` の場合に使用するプロパティ、入力可能な最大文字数を定義。0 は制限なしを意味する。
-- `show_on` (array[[FormShowOnObject](#FormShowOnObject)]) 他のフォーム項目の値が条件に一致する場合に表示される。空の場合は常に表示される。
+- `show_on` (array[[FormShowOnObject](#formshowonobject)]) 他のフォーム項目の値が条件に一致する場合に表示される。空の場合は常に表示される。
### FormType
@@ -204,7 +204,7 @@ version: 'v1.0'
- `en_US` (string) 英語のラベル
- `zh_Hans` (string) [optional] 中国語のラベル
- `value` (string) ドロップダウンの選択肢の値
-- `show_on` (array[[FormShowOnObject](#FormShowOnObject)]) 他のフォーム項目の値が条件に一致する場合に表示される。空の場合は常に表示される。
+- `show_on` (array[[FormShowOnObject](#formshowonobject)]) 他のフォーム項目の値が条件に一致する場合に表示される。空の場合は常に表示される。
### FormShowOnObject
diff --git a/ja-jp/guides/workflow/node/loop.mdx b/ja-jp/guides/workflow/node/loop.mdx
index 5b31b6c8..72c4f5b4 100644
--- a/ja-jp/guides/workflow/node/loop.mdx
+++ b/ja-jp/guides/workflow/node/loop.mdx
@@ -1,10 +1,10 @@
---
-title: 繰り返し処理(ループ)
+title: ループ処理(繰り返し処理)
---
## 概要
-繰り返し処理(ループ)ノードは、前回の結果に依存する反復タスクを実行し、終了条件を満たすか最大繰り返し回数に達するまで継続します。
+ループノード(繰り返し処理)は、前回の結果に依存する反復タスクを実行し、終了条件を満たすか最大繰り返し回数に達するまで継続します。
## 繰り返し処理ノードと反復処理ノードの違い
@@ -18,7 +18,7 @@ title: 繰り返し処理(ループ)
- | 繰り返し処理(ループ) |
+ ループ(繰り返し処理) |
各回の処理が前回の結果に依存する。 |
前回の計算結果を必要とする処理に適している。 |
@@ -30,7 +30,7 @@ title: 繰り返し処理(ループ)
-## 繰り返し処理(ループ)ノードの設定方法
+## ループ(繰り返し処理)ノードの設定方法
@@ -47,7 +47,7 @@ title: 繰り返し処理(ループ)
x < 50、error_rate < 0.01 |
- | 最大繰り返し回数 |
+ 最大ループ回数 |
無限ループを防ぐための繰り返し回数の上限 |
10、100、1000 |
diff --git a/ja-jp/openapi-api-access-readme.mdx b/ja-jp/openapi-api-access-readme.mdx
index 2082cdd8..973257dd 100644
--- a/ja-jp/openapi-api-access-readme.mdx
+++ b/ja-jp/openapi-api-access-readme.mdx
@@ -27,7 +27,7 @@ APIを迅速に検証し理解していただくために、本文書のほと
- システムが自動入力試みる場合がありますが、Difyのデプロイ環境(クラウド版またはセルフホスト/オンプレミス版)に応じて正しいベースURLを選択または入力してください。詳細は下記の [サーバーアドレス (ベースURL)](#サーバーアドレス-base-url) セクションを参照してください。
+ システムが自動入力試みる場合がありますが、Difyのデプロイ環境(クラウド版またはセルフホスト/オンプレミス版)に応じて正しいベースURLを選択または入力してください。詳細は下記の [サーバーアドレス (ベースURL)](#サーバーアドレス-ベースurl) セクションを参照してください。
認証セクションに、Difyアプリケーションから取得した有効なAPIキーを入力する必要があります。詳細は [APIキー (API Key)](#apiキー-api-key) セクションを参照してください。
diff --git a/ja-jp/plugins/quick-start/develop-plugins/agent-strategy-plugin.mdx b/ja-jp/plugins/quick-start/develop-plugins/agent-strategy-plugin.mdx
index 396c6461..7c60953c 100644
--- a/ja-jp/plugins/quick-start/develop-plugins/agent-strategy-plugin.mdx
+++ b/ja-jp/plugins/quick-start/develop-plugins/agent-strategy-plugin.mdx
@@ -144,6 +144,7 @@ parameters:
label:
en_US: Model
zh_Hans: 模型
+ ja_JP: モデル
pt_BR: Model
- name: tools # toolsパラメータの名前
type: array[tools] # toolパラメータの型
@@ -151,6 +152,7 @@ parameters:
label:
en_US: Tools list
zh_Hans: 工具列表
+ ja_JP: ツールリスト
pt_BR: Tools list
- name: query # queryパラメータの名前
type: string # queryパラメータの型
@@ -158,6 +160,7 @@ parameters:
label:
en_US: Query
zh_Hans: 查询
+ ja_JP: クエリ
pt_BR: Query
- name: maximum_iterations
type: number
@@ -166,6 +169,7 @@ parameters:
label:
en_US: Maxium Iterations
zh_Hans: 最大迭代次数
+ ja_JP: 最大反復回数
pt_BR: Maxium Iterations
max: 50 # maxとminの値を設定すると、パラメータ表示がスライダーになります
min: 1
diff --git a/ja-jp/plugins/quick-start/develop-plugins/model-plugin/create-model-providers.mdx b/ja-jp/plugins/quick-start/develop-plugins/model-plugin/create-model-providers.mdx
index be22f42c..e5477d51 100644
--- a/ja-jp/plugins/quick-start/develop-plugins/model-plugin/create-model-providers.mdx
+++ b/ja-jp/plugins/quick-start/develop-plugins/model-plugin/create-model-providers.mdx
@@ -99,7 +99,8 @@ label:
en_US: Anthropic
description:
en_US: Anthropic's powerful models, such as Claude 3.
- zh_Hans: Anthropicの強力なモデル(例:Claude 3)。
+ zh_Hans: Anthropic 的强大模型,例如 Claude 3。
+ ja_JP: Anthropicの強力なモデル(例:Claude 3)。
icon_small:
en_US: icon_s_en.svg
icon_large:
@@ -108,7 +109,8 @@ background: "#F0F0EB"
help:
title:
en_US: Get your API Key from Anthropic
- zh_Hans: AnthropicからAPIキーを取得
+ zh_Hans: 从 Anthropic 获取 API Key
+ ja_JP: AnthropicからAPI Keyを取得
url:
en_US: https://console.anthropic.com/account/keys
supported_model_types:
@@ -123,16 +125,18 @@ provider_credential_schema:
type: secret-input
required: true
placeholder:
- zh_Hans: APIキーを入力してください
en_US: Enter your API Key
+ zh_Hans: 在此输入您的 API Key
+ ja_JP: API Keyを入力してください
- variable: anthropic_api_url
label:
en_US: API URL
type: text-input
required: false
placeholder:
- zh_Hans: API URLを入力してください
en_US: Enter your API URL
+ zh_Hans: 在此输入您的 API URL
+ ja_JP: API URLを入力してください
models:
llm:
predefined:
@@ -154,10 +158,12 @@ model_credential_schema:
model: # ファインチューニングモデル名
label:
en_US: Model Name
- zh_Hans: モデル名
+ zh_Hans: 模型名称
+ ja_JP: モデル名
placeholder:
en_US: Enter your model name
- zh_Hans: モデル名を入力
+ zh_Hans: 输入模型名称
+ ja_JP: モデル名を入力
credential_form_schemas:
- variable: openai_api_key
label:
@@ -165,26 +171,31 @@ model_credential_schema:
type: secret-input
required: true
placeholder:
- zh_Hans: APIキーを入力してください
en_US: Enter your API Key
+ zh_Hans: 在此输入您的 API Key
+ ja_JP: API Keyを入力してください
- variable: openai_organization
label:
- zh_Hans: 組織ID
en_US: Organization
+ zh_Hans: 组织 ID
+ ja_JP: 組織ID
type: text-input
required: false
placeholder:
- zh_Hans: 組織IDを入力してください
en_US: Enter your Organization ID
+ zh_Hans: 在此输入您的组织 ID
+ ja_JP: 組織IDを入力してください
- variable: openai_api_base
label:
- zh_Hans: API Base
en_US: API Base
+ zh_Hans: API Base
+ ja_JP: API Base
type: text-input
required: false
placeholder:
- zh_Hans: API Baseを入力してください
en_US: Enter your API Base
+ zh_Hans: 在此输入您的 API Base
+ ja_JP: API Baseを入力してください
```
より詳細なモデルプロバイダーYAMLの仕様については、[モデルインターフェースドキュメント](/ja-jp/plugins/schema-definition/model/model-schema)を参照してください。
diff --git a/ja-jp/plugins/quick-start/develop-plugins/model-plugin/customizable-model.mdx b/ja-jp/plugins/quick-start/develop-plugins/model-plugin/customizable-model.mdx
index c8b7d6e8..1f11721d 100644
--- a/ja-jp/plugins/quick-start/develop-plugins/model-plugin/customizable-model.mdx
+++ b/ja-jp/plugins/quick-start/develop-plugins/model-plugin/customizable-model.mdx
@@ -64,7 +64,8 @@ icon_large: # 大きいアイコン
help: # ヘルプ
title:
en_US: How to deploy Xinference
- zh_Hans: 如何部署 Xinference (Xinferenceのデプロイ方法)
+ zh_Hans: 如何部署 Xinference
+ ja_JP: Xinferenceのデプロイ方法
url:
en_US: https://github.com/xorbitsai/inference
supported_model_types: # サポートされているモデルタイプ。XinferenceはLLM/Text Embedding/Rerankをサポートしています。
@@ -86,13 +87,15 @@ provider_credential_schema:
type: select
label:
en_US: Model type
- zh_Hans: 模型类型 (モデルタイプ)
+ zh_Hans: 模型类型
+ ja_JP: モデルタイプ
required: true
options:
- value: text-generation
label:
en_US: Language Model
- zh_Hans: 语言模型 (言語モデル)
+ zh_Hans: 语言模型
+ ja_JP: 言語モデル
- value: embeddings
label:
en_US: Text Embedding
@@ -108,11 +111,13 @@ Xinferenceの各モデルでは、`model_name`という名前を定義する必
type: text-input
label:
en_US: Model name
- zh_Hans: 模型名称 (モデル名)
+ zh_Hans: 模型名称
+ ja_JP: モデル名
required: true
placeholder:
- zh_Hans: モデル名を入力してください
en_US: Input model name
+ zh_Hans: 填写模型名称
+ ja_JP: モデル名を入力してください
```
Xinferenceモデルでは、ユーザーがモデルのローカルデプロイアドレスを入力する必要があります。プラグイン内では、Xinferenceモデルのローカルデプロイアドレス(server\_url)とモデルUIDを入力できる場所を提供する必要があります。サンプルコードを以下に示します。
@@ -120,22 +125,26 @@ Xinferenceモデルでは、ユーザーがモデルのローカルデプロイ
```yaml
- variable: server_url
label:
- zh_Hans: サーバーURL
en_US: Server url
+ zh_Hans: 服务器URL
+ ja_JP: サーバーURL
type: text-input
required: true
placeholder:
- zh_Hans: Xinferenceのサーバーアドレスをここに入力してください(例:https://example.com/xxx)
en_US: Enter the url of your Xinference, for example https://example.com/xxx
+ zh_Hans: 在此输入Xinference的服务器地址,如 https://example.com/xxx
+ ja_JP: Xinferenceのサーバーアドレスをここに入力してください、例えば https://example.com/xxx
- variable: model_uid
label:
- zh_Hans: モデルUID
en_US: Model uid
+ zh_Hans: 模型 UID
+ ja_JP: モデル UID
type: text-input
required: true
placeholder:
- zh_Hans: モデルUIDを入力してください
en_US: Enter the model uid
+ zh_Hans: 在此输入你的 Model UID
+ ja_JP: モデルUIDを入力してください
```
すべてのパラメータを入力すると、カスタムモデルサプライヤのyaml設定ファイルの作成が完了します。次に、設定ファイルで定義されたモデルに具体的な機能コードファイルを追加する必要があります。
diff --git a/ja-jp/plugins/quick-start/develop-plugins/model-plugin/integrate-the-predefined-model.mdx b/ja-jp/plugins/quick-start/develop-plugins/model-plugin/integrate-the-predefined-model.mdx
index 793a01b2..885773a2 100644
--- a/ja-jp/plugins/quick-start/develop-plugins/model-plugin/integrate-the-predefined-model.mdx
+++ b/ja-jp/plugins/quick-start/develop-plugins/model-plugin/integrate-the-predefined-model.mdx
@@ -227,12 +227,14 @@ parameter_rules:
use_template: top_p
- name: top_k
label:
- zh_Hans: 取样数量
en_US: Top k
+ zh_Hans: 取样数量
+ ja_JP: サンプリング数
type: int
help:
- zh_Hans: 仅从每个后续标记的前 K 个选项中采样。
en_US: Only sample from the top K options for each subsequent token.
+ zh_Hans: 仅从每个后续标记的前 K 个选项中采样。
+ ja_JP: 各後続マーカーの最初のKオプションからのみサンプリングする。
required: false
- name: max_tokens
use_template: max_tokens
diff --git a/ja-jp/plugins/schema-definition/agent.mdx b/ja-jp/plugins/schema-definition/agent.mdx
index 23ac0721..57746e3a 100644
--- a/ja-jp/plugins/schema-definition/agent.mdx
+++ b/ja-jp/plugins/schema-definition/agent.mdx
@@ -51,10 +51,12 @@ identity:
label:
en_US: Agent
zh_Hans: Agent
+ ja_JP: Agent
pt_BR: Agent
description:
en_US: Agent
zh_Hans: Agent
+ ja_JP: Agent
pt_BR: Agent
icon: icon.svg
strategies:
@@ -74,6 +76,7 @@ identity:
label:
en_US: FunctionCalling
zh_Hans: FunctionCalling
+ ja_JP: FunctionCalling
pt_BR: FunctionCalling
description:
en_US: Function Calling is a basic strategy for agent, model will use the tools provided to perform the task.
diff --git a/ja-jp/plugins/schema-definition/reverse-invocation-of-the-dify-service/model.mdx b/ja-jp/plugins/schema-definition/reverse-invocation-of-the-dify-service/model.mdx
index 2423168d..0eacec07 100644
--- a/ja-jp/plugins/schema-definition/reverse-invocation-of-the-dify-service/model.mdx
+++ b/ja-jp/plugins/schema-definition/reverse-invocation-of-the-dify-service/model.mdx
@@ -103,12 +103,14 @@ identity:
label:
en_US: LLM
zh_Hans: LLM
+ ja_JP: LLM
pt_BR: LLM
description:
human:
en_US: A tool for invoking a large language model
zh_Hans: 用于调用大型语言模型的工具
- pt_BR: A tool for invoking a large language model
+ ja_JP: 大規模言語モデルを呼び出すためのツール
+ pt_BR: Ferramentas para chamar modelos de idiomas grandes
llm: A tool for invoking a large language model
parameters:
- name: prompt
@@ -117,11 +119,13 @@ parameters:
label:
en_US: Prompt string
zh_Hans: 提示字符串
- pt_BR: Prompt string
+ ja_JP: プロンプト文字列
+ pt_BR: Cadeia de prompt
human_description:
en_US: used for searching
zh_Hans: 用于搜索网页内容
- pt_BR: used for searching
+ ja_JP: Webコンテンツ検索用
+ pt_BR: Usado para pesquisar
llm_description: key words for searching
form: llm
- name: model
@@ -131,11 +135,13 @@ parameters:
label:
en_US: Model
zh_Hans: 使用的模型
- pt_BR: Model
+ ja_JP: モデル
+ pt_BR: Modelo
human_description:
en_US: Model
zh_Hans: 使用的模型
- pt_BR: Model
+ ja_JP: モデル
+ pt_BR: Modelo
llm_description: which Model to invoke
form: form
extra:
diff --git a/zh-hans/community/contribution.mdx b/zh-hans/community/contribution.mdx
index f371301e..0d90f04c 100644
--- a/zh-hans/community/contribution.mdx
+++ b/zh-hans/community/contribution.mdx
@@ -115,7 +115,9 @@ Dify 由后端和前端组成。通过 `cd api/` 导航到后端目录,然后
如果你要向 Agent 或 Workflow 添加工具提供程序,请参考 [工具开发](https://docs.dify.ai/plugins/quick-start/develop-plugins/tool-plugin)。
-> **注意**:如果你想要贡献新的工具,请确保已在工具的 `YAML` 文件内留下了你的联系方式,并且在 [Dify-docs](https://github.com/langgenius/dify-docs) 帮助文档代码仓库中提交了对应的文档 PR。
+
+**注意**:如果你想要贡献新的工具,请确保已在工具的 `YAML` 文件内留下了你的联系方式,并且在 [Dify-docs](https://github.com/langgenius/dify-docs-mintlify) 帮助文档代码仓库中提交了对应的文档 PR。
+
为了帮助你快速了解你的贡献在哪个部分,以下是 Dify 后端和前端的简要注释大纲:
diff --git a/zh-hans/guides/knowledge-base/knowledge-base-creation/introduction.mdx b/zh-hans/guides/knowledge-base/knowledge-base-creation/introduction.mdx
index 4a3981c5..7fbafffb 100644
--- a/zh-hans/guides/knowledge-base/knowledge-base-creation/introduction.mdx
+++ b/zh-hans/guides/knowledge-base/knowledge-base-creation/introduction.mdx
@@ -33,7 +33,7 @@ title: 创建步骤
#### ETL
-在 RAG 的生产级应用中,为了获得更好的数据召回效果,需要对多源数据进行预处理和清洗,即 ETL (_extract, transform, load_)。为了增强非结构化/半结构化数据的预处理能力,Dify 支持了可选的 ETL 方案:**Dify ETL** 和[ ](https://docs.unstructured.io/welcome)[**Unstructured ETL** ](https://unstructured.io/)。Unstructured 能够高效地提取并转换你的数据为干净的数据用于后续的步骤。Dify 各版本的 ETL 方案选择:
+在 RAG 的生产级应用中,为了获得更好的数据召回效果,需要对多源数据进行预处理和清洗,即 ETL (_extract, transform, load_)。为了增强非结构化/半结构化数据的预处理能力,Dify 支持了可选的 ETL 方案:**Dify ETL** 和[**Unstructured ETL**](https://docs.unstructured.io/welcome)[**Unstructured ETL** ](https://unstructured.io/)。Unstructured 能够高效地提取并转换你的数据为干净的数据用于后续的步骤。Dify 各版本的 ETL 方案选择:
* SaaS 版不可选,默认使用 Unstructured ETL;
* 社区版可选,默认使用 Dify ETL ,可通过[环境变量](/zh-hans/getting-started/install-self-hosted/environments)开启 Unstructured ETL;
diff --git a/zh-hans/guides/model-configuration/new-provider.mdx b/zh-hans/guides/model-configuration/new-provider.mdx
index 511fd544..848375d6 100644
--- a/zh-hans/guides/model-configuration/new-provider.mdx
+++ b/zh-hans/guides/model-configuration/new-provider.mdx
@@ -36,11 +36,11 @@ title: 增加新供应商
新增一个供应商主要分为几步,这里简单列出,帮助大家有一个大概的认识,具体的步骤会在下面详细介绍。
-* 创建供应商 yaml 文件,根据 [Provider Schema](https://github.com/langgenius/dify/blob/main/api/core/model\_runtime/docs/zh\_Hans/schema) 编写。
+* 创建供应商 yaml 文件,根据 [Provider Schema](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/zh_Hans/schema.md) 编写。
* 创建供应商代码,实现一个`class`。
* 根据模型类型,在供应商`module`下创建对应的模型类型 `module`,如`llm`或`text_embedding`。
* 根据模型类型,在对应的模型`module`下创建同名的代码文件,如`llm.py`,并实现一个`class`。
-* 如果有预定义模型,根据模型名称创建同名的yaml文件在模型`module`下,如`claude-2.1.yaml`,根据 [AI Model Entity](https://github.com/langgenius/dify/blob/main/api/core/model\_runtime/docs/zh\_Hans/schema.md#aimodelentity) 编写。
+* 如果有预定义模型,根据模型名称创建同名的yaml文件在模型`module`下,如`claude-2.1.yaml`,根据 [AI Model Entity](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/zh_Hans/schema.md#aimodelentity) 编写。
* 编写测试代码,确保功能可用。
#### 开始吧
@@ -85,7 +85,7 @@ provider_credential_schema: # 供应商凭据规则,由于 Anthropic 仅支
en_US: Enter your API URL
```
-如果接入的供应商提供自定义模型,比如`OpenAI`提供微调模型,那么我们就需要添加[`model_credential_schema`](https://github.com/langgenius/dify/blob/main/api/core/model\_runtime/docs/zh\_Hans/schema),以`OpenAI`为例:
+如果接入的供应商提供自定义模型,比如`OpenAI`提供微调模型,那么我们就需要添加[`model_credential_schema`](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/zh_Hans/schema.md),以`OpenAI`为例:
```yaml
model_credential_schema:
@@ -125,7 +125,7 @@ model_credential_schema:
en_US: Enter your API Base
```
-也可以参考`model_providers`目录下其他供应商目录下的 [YAML 配置信息](https://github.com/langgenius/dify/blob/main/api/core/model\_runtime/docs/zh\_Hans/schema)。
+也可以参考`model_providers`目录下其他供应商目录下的 [YAML 配置信息](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/docs/zh_Hans/schema.md)。
**实现供应商代码**
@@ -143,7 +143,7 @@ class XinferenceProvider(Provider):
**预定义模型供应商**
-供应商需要继承 `__base.model_provider.ModelProvider` 基类,实现 `validate_provider_credentials` 供应商统一凭据校验方法即可,可参考 [AnthropicProvider](https://github.com/langgenius/dify/blob/main/api/core/model\_runtime/model\_providers/anthropic/anthropic.py)。
+供应商需要继承 `__base.model_provider.ModelProvider` 基类,实现 `validate_provider_credentials` 供应商统一凭据校验方法即可,可参考 [AnthropicProvider](https://github.com/langgenius/dify/blob/main/api/core/model_runtime/model_providers/anthropic/anthropic.py)。
```python
def validate_provider_credentials(self, credentials: dict) -> None: